Robustine
Description
This compound has been reported in Zanthoxylum simulans, Zanthoxylum wutaiense, and other organisms with data available.
Properties
IUPAC Name |
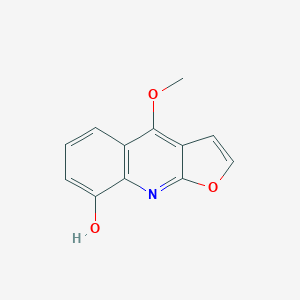
4-methoxyfuro[2,3-b]quinolin-8-ol |
Source


|
|---|---|---|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI |
InChI=1S/C12H9NO3/c1-15-11-7-3-2-4-9(14)10(7)13-12-8(11)5-6-16-12/h2-6,14H,1H3 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI Key |
VGVNNMLKTSWBAR-UHFFFAOYSA-N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Canonical SMILES |
COC1=C2C=COC2=NC3=C1C=CC=C3O |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Formula |
C12H9NO3 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
DSSTOX Substance ID |
DTXSID20177086 |
Source
|
| Record name | Furo(2,3-b)quinolin-8-ol, 4-methoxy- | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID20177086 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
Molecular Weight |
215.20 g/mol |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
CAS No. |
2255-50-7 |
Source
|
| Record name | 8-Hydroxydictamnine | |
| Source | CAS Common Chemistry | |
| URL | https://commonchemistry.cas.org/detail?cas_rn=2255-50-7 | |
| Description | CAS Common Chemistry is an open community resource for accessing chemical information. Nearly 500,000 chemical substances from CAS REGISTRY cover areas of community interest, including common and frequently regulated chemicals, and those relevant to high school and undergraduate chemistry classes. This chemical information, curated by our expert scientists, is provided in alignment with our mission as a division of the American Chemical Society. | |
| Explanation | The data from CAS Common Chemistry is provided under a CC-BY-NC 4.0 license, unless otherwise stated. | |
| Record name | Furo(2,3-b)quinolin-8-ol, 4-methoxy- | |
| Source | ChemIDplus | |
| URL | https://pubchem.ncbi.nlm.nih.gov/substance/?source=chemidplus&sourceid=0002255507 | |
| Description | ChemIDplus is a free, web search system that provides access to the structure and nomenclature authority files used for the identification of chemical substances cited in National Library of Medicine (NLM) databases, including the TOXNET system. | |
| Record name | Furo(2,3-b)quinolin-8-ol, 4-methoxy- | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID20177086 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
Foundational & Exploratory
The Bedrock of Discovery: A Technical Guide to Research Robustness in Drug Development
For Immediate Release
In the high-stakes world of drug development, where the path from a promising molecule to a life-saving therapy is long and fraught with peril, the concept of research robustness stands as the bedrock upon which all progress is built. This in-depth guide, intended for researchers, scientists, and drug development professionals, will dissect the core tenets of research robustness, explore its critical importance, and provide actionable insights into ensuring its implementation in the laboratory and beyond.
Defining Research Robustness: More Than Just a Single Result
Research robustness is the quality of a scientific finding to hold true under a variety of conditions.[1][2] It is the manifestation of reliability and dependability in experimental outcomes.[1][3] A robust finding is not a fleeting observation tied to a specific, highly controlled setting but rather a consistent and reproducible effect that can withstand scrutiny and variations in experimental parameters.[1][2]
At its core, research robustness is a composite of several key concepts:
-
Reproducibility : This refers to the ability to obtain the same or very similar results when re-analyzing the original data using the same computational steps, methods, and code.[4][5][6] It is a test of the transparency and integrity of the data analysis process.
-
Replicability : This is the ability to achieve consistent results when an entire experiment is repeated, including the collection of new data.[4][5][6] It validates the original findings and demonstrates that they were not due to chance or specific, unrecorded experimental conditions.
-
Generalizability : This concept extends replicability further, assessing whether the findings hold true in different contexts, such as with different populations, in different settings, or with slight variations in the experimental model.[4][5][7]
A failure in any of these areas can have profound consequences, particularly in the drug development pipeline, where decisions worth millions of dollars and impacting countless lives are based on preclinical research findings.
The Imperative of Robustness in Drug Development
The journey of a drug from the lab bench to the patient's bedside is a multi-stage process, with preclinical research forming the foundation for clinical trials. A lack of robustness in these early stages can lead to a cascade of costly and ultimately fruitless efforts.
The consequences of non-robust preclinical research are stark:
-
Wasted Resources : Companies may invest heavily in developing a drug candidate based on promising preclinical data, only to find that the initial results cannot be replicated, leading to the termination of the project.
-
Ethical Concerns : Flawed research can lead to unnecessary clinical trials, exposing patients to potentially ineffective or even harmful treatments.
-
Erosion of Public Trust : The inability to replicate high-profile scientific findings can undermine public confidence in the scientific enterprise as a whole.
Landmark internal reviews by pharmaceutical companies have highlighted the severity of this issue. Famously, researchers at Amgen were able to replicate only 6 out of 53 "landmark" cancer research studies.[8][9] Similarly, a team at Bayer HealthCare reported that they could not validate the findings of approximately two-thirds of 67 published preclinical studies.[8]
These sobering statistics underscore the urgent need for a renewed focus on research robustness.
The Reproducibility Project: Cancer Biology - A Case Study
The "Reproducibility Project: Cancer Biology," a major initiative to systematically replicate key findings in preclinical cancer research, has provided invaluable quantitative data on the challenges of ensuring robustness. The project aimed to replicate 193 experiments from 53 high-impact cancer papers published between 2010 and 2012.[3][10][11]
The results of this ambitious project highlight several critical areas of concern:
| Metric | Finding | Source |
| Replication Success Rate | Of the 50 experiments that could be replicated, the median effect size was 85% smaller than the original finding. | [3][11] |
| Direction of Effect | While 79% of replications showed an effect in the same direction as the original positive findings, the magnitude was often substantially lower. | [3] |
| Statistical Significance | Only 43% of replication effects for original positive findings were statistically significant and in the same direction. | [3] |
| Protocol Availability | A significant challenge was the lack of detailed experimental protocols in the original publications, necessitating extensive communication with the original authors. | [7][10] |
These findings do not necessarily imply misconduct or flawed science in the original studies. Instead, they point to systemic issues such as publication bias towards novel and positive results, and a lack of emphasis on detailed methods reporting.
Experimental Protocols: The Blueprint for Robustness
The single most critical factor in ensuring the reproducibility and replicability of research is a detailed and transparent experimental protocol. Without a clear and comprehensive description of the methods used, other researchers cannot hope to replicate the findings.
A robust experimental protocol should include, but not be limited to:
-
Reagents : Specific details of all reagents used, including manufacturer, catalog number, and lot number.
-
Cell Lines and Animal Models : Source, authentication, and health status of all biological materials.
-
Experimental Procedures : Step-by-step instructions for all procedures, including incubation times, temperatures, and concentrations.
-
Data Collection : A clear description of how data was collected and what instruments were used.
-
Statistical Analysis Plan : The statistical methods to be used for data analysis should be predefined to avoid p-hacking and other questionable research practices.
The "Registered Reports" format, where the experimental protocol and analysis plan are peer-reviewed and accepted for publication before the research is conducted, is a powerful tool for promoting transparency and robustness. The Reproducibility Project: Cancer Biology utilized this format, and their published Registered Reports in journals like eLife serve as excellent examples of detailed protocols.
Visualizing Complexity: Workflows and Signaling Pathways
To further aid in the understanding and implementation of robust research practices, visual representations of experimental workflows and biological pathways are invaluable.
A Generalized Workflow for Preclinical Drug Discovery
The following diagram illustrates a typical, albeit simplified, workflow for preclinical drug discovery, highlighting key stages where robustness is critical.
Key Signaling Pathways in Cancer Biology
Understanding the intricate signaling pathways that drive cancer is fundamental to developing targeted therapies. The robustness of research into these pathways is paramount. Below are diagrams of several key pathways frequently implicated in cancer.
This pathway is crucial for regulating the cell cycle and is often overactive in cancer, promoting cell survival and proliferation.
The Ras/MAPK pathway is a critical signaling cascade that transmits signals from cell surface receptors to the nucleus, influencing gene expression and cell proliferation. Dysregulation of this pathway is a common feature of many cancers.
Best Practices for Fostering Research Robustness
Achieving research robustness requires a concerted effort from individual researchers, institutions, and funding agencies. Key best practices include:
-
Rigorous Experimental Design : This includes appropriate controls, randomization, and blinding to minimize bias.
-
Transparent Reporting : Detailed and transparent reporting of all methods, data, and analysis code is essential for reproducibility.
-
Data Sharing : Making raw data publicly available allows for independent verification of analyses.
-
Pre-registration of Studies : Pre-registering study protocols and analysis plans before data collection helps to prevent p-hacking and HARKing (hypothesizing after the results are known).
-
Embracing Null Results : The publication of null or negative findings is crucial for a complete and unbiased scientific record.
Conclusion: A Call for a Culture of Robustness
The challenges to research robustness are significant, but they are not insurmountable. By fostering a culture that values rigor, transparency, and collaboration, the scientific community can enhance the reliability of preclinical research. For the drug development industry, a commitment to robust research is not just good scientific practice; it is a fundamental requirement for success. By building on a foundation of robust and reproducible findings, we can accelerate the discovery of new medicines and deliver on the promise of improving human health.
References
- 1. Reproducibility in Cancer Biology: The challenges of replication | eLife [elifesciences.org]
- 2. cos.io [cos.io]
- 3. Culturing Suspension Cancer Cell Lines | Springer Nature Experiments [experiments.springernature.com]
- 4. Reproducibility Project: Cancer Biology | Collections | eLife [elifesciences.org]
- 5. osf.io [osf.io]
- 6. opticalcore.wisc.edu [opticalcore.wisc.edu]
- 7. Registered Reports | eLife [elifesciences.org]
- 8. azurebiosystems.com [azurebiosystems.com]
- 9. osf.io [osf.io]
- 10. Western Blotting: Products, Protocols, & Applications | Thermo Fisher Scientific - HK [thermofisher.com]
- 11. miltenyibiotec.com [miltenyibiotec.com]
A Technical Guide to Reproducible Research in Drug Development
For Researchers, Scientists, and Drug Development Professionals
This in-depth technical guide provides a comprehensive overview of the core principles and practices of reproducible research, tailored for professionals in the drug development pipeline. By adhering to the methodologies outlined below, researchers can enhance the reliability, transparency, and impact of their work. This guide will walk through a practical example of a reproducible bioinformatics workflow to identify markers of drug sensitivity in cancer cell lines.
The Core Principles of Reproducible Research
Reproducible research is the foundation of robust scientific discovery, ensuring that findings can be independently verified and built upon.[1] In the context of drug development, where the stakes are exceptionally high, a commitment to reproducibility is paramount for both scientific integrity and efficient translation of preclinical discoveries.[2] The core tenets of reproducible research include:
-
Transparent and Detailed Reporting: All methods, materials, and analytical procedures must be documented with sufficient detail to allow other researchers to replicate the work.[3]
-
Data and Code Accessibility: The raw and processed data, along with the code used for analysis, should be made available to the broader scientific community.[4]
-
Version Control: A systematic approach to managing changes to code and documents over time is essential for tracking the evolution of an analysis and ensuring that specific results can be regenerated.[5]
-
Environment Consistency: The computational environment, including software versions and dependencies, should be captured and shared to prevent discrepancies arising from different system configurations.
A Reproducible Workflow for Cancer Drug Sensitivity Analysis
To illustrate the practical application of these principles, this guide will outline a reproducible workflow for analyzing publicly available cancer drug sensitivity data. The goal of this analysis is to identify genomic features that are associated with a cancer cell line's response to a particular drug.
Datasets
This workflow utilizes two of the largest publicly available pharmacogenomics datasets:
-
Genomics of Drug Sensitivity in Cancer (GDSC): A comprehensive resource of drug sensitivity data for a wide range of cancer cell lines, along with their genomic characterization.[4]
-
Cancer Cell Line Encyclopedia (CCLE): A collaborative project that has characterized a large panel of human cancer cell lines at the genetic and pharmacologic levels.[6]
For this example, we will focus on a subset of the data, specifically the response of breast cancer cell lines to the MEK inhibitor, Trametinib.
Experimental Protocol: Data Acquisition and Preprocessing
The following protocol details the steps for acquiring and preparing the data for analysis.
-
Data Acquisition:
-
Download the drug sensitivity data (IC50 values) and the genomic data (gene expression and mutation data) from the GDSC and CCLE portals.
-
-
Data Integration:
-
Merge the drug sensitivity and genomic datasets for the cell lines that are common to both the GDSC and CCLE projects. This step is crucial for increasing the statistical power of the analysis.
-
-
Data Cleaning and Normalization:
-
Handle missing values in the datasets. For this protocol, cell lines with missing drug sensitivity values for Trametinib will be excluded.
-
Normalize the gene expression data to account for technical variations between experiments. A common method is to use a log2 transformation.
-
-
Feature Selection:
-
For this analysis, we will focus on the association between the expression of genes in the MAPK signaling pathway and sensitivity to Trametinib, a MEK inhibitor. A list of genes in this pathway can be obtained from publicly available pathway databases such as KEGG or Reactome.
-
The following diagram illustrates the data acquisition and preprocessing workflow:
References
- 1. GitHub - SmritiChawla/Precily [github.com]
- 2. Tutorial 2a: Digging Deeper with Cell Line and Drug Subgroups [pkimes.com]
- 3. researchgate.net [researchgate.net]
- 4. google.com [google.com]
- 5. researchgate.net [researchgate.net]
- 6. Enhancing Reproducibility in Cancer Drug Screening: How Do We Move Forward? - PMC [pmc.ncbi.nlm.nih.gov]
Foundational Concepts of Validity in Scientific Experiments: An In-depth Technical Guide
For Researchers, Scientists, and Drug Development Professionals
The Four Pillars of Experimental Validity
Internal Validity: Establishing a True Cause-and-Effect Relationship
Threats to Internal Validity:
A variety of factors can jeopardize the internal validity of an experiment. Researchers must be vigilant in identifying and mitigating these threats:
-
Confounding Variables: These are unmeasured third variables that influence both the cause and the effect.[1][6][7] For instance, in a study examining the link between a new cardiovascular drug and reduced heart attack risk, a confounding variable could be the participants' diet, which independently affects heart health.
-
History: External events that occur during the course of a study can influence the outcome.[2][8][9][10]
-
Maturation: Natural changes in the participants over time, such as aging or spontaneous remission of a condition, can be mistaken for a treatment effect.[2][8][9][10]
-
Instrumentation: Changes in the measurement instruments or their administration can lead to apparent changes in the outcome.[8][9][10]
-
Testing: The act of taking a pre-test can influence the results of a post-test, independent of the treatment.[8][9]
-
Selection Bias: If groups are not comparable at the start of the study, any observed differences in outcome may be due to pre-existing differences rather than the treatment.[1][2][8][9]
-
Attrition (Experimental Mortality): If participants drop out of a study at different rates across groups, the remaining samples may no longer be comparable.[1][2][8]
Strategies to Enhance Internal Validity:
-
Randomization: Randomly assigning participants to treatment and control groups helps to ensure that confounding variables are evenly distributed, reducing their potential to bias the results.[7][11]
-
Control Groups: A well-defined control group provides a baseline against which the effects of the treatment can be compared.
-
Blinding: Masking the treatment allocation from participants (single-blind) or from both participants and researchers (double-blind) minimizes placebo effects and observer bias.
-
Standardized Protocols: Ensuring that the experimental procedures are consistent for all participants reduces variability and the influence of extraneous factors.
External Validity: Generalizing Findings to the Real World
External validity refers to the extent to which the results of a study can be generalized to other settings, populations, and times.[1][4][12][13] In drug development, high external validity is critical for predicting a drug's effectiveness in the broader patient population beyond the controlled environment of a clinical trial.[14][15]
Threats to External Validity:
-
Sample Features: If the study sample is not representative of the target population, the findings may not be generalizable.[1] For example, a drug tested only on a specific age group may have different effects in other age groups.
-
Situational Factors: The specific setting and conditions of the experiment, such as the time of day or the characteristics of the researchers, can limit the generalizability of the findings.[1][16]
-
Pre- and Post-test Effects: The use of a pre-test can sensitize participants to the treatment, making the results not generalizable to a population that has not been pre-tested.[1]
-
Hawthorne Effect: Participants may alter their behavior simply because they are aware of being observed, leading to results that may not be replicated in a real-world setting.[17][18]
Strategies to Enhance External Validity:
-
Representative Sampling: Using random sampling techniques to select participants that accurately reflect the characteristics of the target population.
-
Replication: Conducting the study in different settings and with different populations to see if the results are consistent.[1]
-
Field Experiments: Conducting studies in real-world settings rather than highly controlled laboratory environments.[16]
-
Ecological Validity: Ensuring that the experimental conditions mimic the real-world situations to which the findings are intended to apply.[19]
Construct Validity: Measuring the Intended Concept
Construct validity is the degree to which a test or measurement tool accurately assesses the theoretical concept it is intended to measure.[10][20][21][22] In drug development, this means ensuring that the chosen endpoints and biomarkers truly reflect the underlying disease process or the drug's mechanism of action.
Threats to Construct Validity:
-
Inadequate Preoperational Explication of Constructs: A failure to clearly and comprehensively define the construct of interest before developing the measurement tool.
-
Mono-operation Bias: Using only one method to measure a construct, which may not capture all of its facets.
-
Mono-method Bias: Using only one type of measurement (e.g., self-report), which may be influenced by method-specific biases.
-
Confounding Constructs and Levels of Constructs: The measurement may inadvertently capture other related constructs.
Strategies to Enhance Construct Validity:
-
Clear Operational Definitions: Providing a precise and detailed definition of the construct and how it will be measured.[23]
-
Convergent and Discriminant Validity: Demonstrating that the measure correlates with other measures of the same construct (convergent validity) and does not correlate with measures of unrelated constructs (discriminant validity).[10][24]
-
Expert Review: Having experts in the field evaluate the relevance and appropriateness of the measurement tool.[23]
-
Pilot Testing: Conducting a small-scale trial of the measurement tool to identify any potential issues before the main study.[23][25]
Statistical Conclusion Validity: The Accuracy of Inferences
-
Fishing and the Error Rate Problem: Conducting multiple statistical tests on the same data increases the probability of finding a significant result by chance (Type I error).[7]
-
Unreliability of Measures: Inconsistent or error-prone measurement tools can obscure a true relationship between variables.[26]
-
Power Analysis: Conducting a power analysis before the study to determine the appropriate sample size.[6]
-
Appropriate Statistical Tests: Selecting and using statistical tests that are suitable for the research design and the type of data collected.[23]
-
Controlling for Multiple Comparisons: Using statistical methods to adjust for the increased risk of Type I errors when conducting multiple tests.
-
Using Reliable Measures: Employing measurement tools with established reliability.[26]
Experimental Protocol: In Vitro Efficacy of a Novel Anti-Cancer Compound (NACC-1)
To illustrate the practical application of these validity concepts, a hypothetical experimental protocol for assessing the in vitro efficacy of a novel anti-cancer compound is presented below.
2.1 Objective: To determine the dose-dependent cytotoxic effect of a novel anti-cancer compound (NACC-1) on a human breast cancer cell line (MCF-7).
2.2 Materials and Methods:
-
Cell Line: MCF-7 human breast cancer cell line.
-
Compound: Novel Anti-Cancer Compound 1 (NACC-1), dissolved in DMSO.
-
Reagents: Dulbecco's Modified Eagle Medium (DMEM), Fetal Bovine Serum (FBS), Penicillin-Streptomycin, Trypsin-EDTA, MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) reagent, DMSO.
-
Equipment: 96-well plates, incubator (37°C, 5% CO2), microplate reader.
2.3 Experimental Procedure:
-
Cell Culture: MCF-7 cells are cultured in DMEM supplemented with 10% FBS and 1% Penicillin-Streptomycin in a humidified incubator at 37°C with 5% CO2.
-
Cell Seeding: Cells are seeded into 96-well plates at a density of 5,000 cells per well and allowed to adhere overnight.
-
Compound Treatment: NACC-1 is serially diluted in culture medium to final concentrations of 0.1, 1, 10, 50, and 100 µM. The vehicle control group receives medium with the same concentration of DMSO as the highest NACC-1 concentration. A negative control group receives only fresh medium. Each treatment is performed in triplicate.
-
Incubation: The treated cells are incubated for 48 hours.
-
MTT Assay: After 48 hours, the medium is removed, and MTT reagent is added to each well. The plates are incubated for 4 hours, allowing viable cells to convert MTT into formazan crystals.
-
Data Collection: The formazan crystals are dissolved in DMSO, and the absorbance is measured at 570 nm using a microplate reader.
2.4 Data Analysis:
Cell viability is calculated as a percentage relative to the vehicle control. The IC50 (half-maximal inhibitory concentration) value is determined by plotting the percentage of cell viability against the log of the compound concentration and fitting the data to a sigmoidal dose-response curve.
Data Presentation
The quantitative data from the hypothetical experiment is summarized in the table below.
| NACC-1 Concentration (µM) | Mean Absorbance (570 nm) | Standard Deviation | % Cell Viability |
| Vehicle Control (0) | 1.25 | 0.08 | 100 |
| 0.1 | 1.22 | 0.07 | 97.6 |
| 1 | 1.05 | 0.06 | 84.0 |
| 10 | 0.63 | 0.05 | 50.4 |
| 50 | 0.25 | 0.03 | 20.0 |
| 100 | 0.10 | 0.02 | 8.0 |
Mandatory Visualizations
Signaling Pathway: Hypothetical Mechanism of NACC-1 Action
This diagram illustrates a plausible signaling pathway through which NACC-1 might exert its anti-cancer effects.
Caption: Hypothetical signaling pathway of NACC-1 action.
Experimental Workflow: In Vitro Efficacy Assessment
This diagram outlines the logical flow of the experimental protocol described above.
Caption: Workflow for in vitro efficacy assessment of NACC-1.
Conclusion
References
- 1. Confounding Variables | Definition, Examples & Controls [enago.com]
- 2. researchgate.net [researchgate.net]
- 3. toolify.ai [toolify.ai]
- 4. General Principles of Preclinical Study Design - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Cell signaling pathways step-by-step [mindthegraph.com]
- 6. communitymedicine4asses.wordpress.com [communitymedicine4asses.wordpress.com]
- 7. viares.com [viares.com]
- 8. What is a confounding variable? [dovetail.com]
- 9. Threats to validity of Research Design [web.pdx.edu]
- 10. quillbot.com [quillbot.com]
- 11. stats.libretexts.org [stats.libretexts.org]
- 12. Pre-Clinical Testing → Example of In Vitro Study for Efficacy | Developing Medicines [drugdevelopment.web.unc.edu]
- 13. DOT Language | Graphviz [graphviz.org]
- 14. researchgate.net [researchgate.net]
- 15. Assessing the validity of clinical trials - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. Introduction - Assuring Data Quality and Validity in Clinical Trials for Regulatory Decision Making - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 17. Statistical Considerations for Preclinical Studies - PMC [pmc.ncbi.nlm.nih.gov]
- 18. 21 Top Threats to External Validity (2025) [helpfulprofessor.com]
- 19. Single-Case Design, Analysis, and Quality Assessment for Intervention Research - PMC [pmc.ncbi.nlm.nih.gov]
- 20. youtube.com [youtube.com]
- 21. The role of a statistician in drug development: Pre-clinical studies | by IDEAS ESRs | IDEAS Blog | Medium [medium.com]
- 22. sketchviz.com [sketchviz.com]
- 23. Addressing Methodologic Challenges and Minimizing Threats to Validity in Synthesizing Findings from Individual Level Data Across Longitudinal Randomized Trials - PMC [pmc.ncbi.nlm.nih.gov]
- 24. Construct Validity | Definition, Types, & Examples [scribbr.com]
- 25. Statistical Analysis of Preclinical Data – Pharma.Tips [pharma.tips]
- 26. researchgate.net [researchgate.net]
- 27. Confounding - PMC [pmc.ncbi.nlm.nih.gov]
A Technical Guide to Ensuring Robustness in Qualitative Research for Scientific and Drug Development Contexts
In the realms of scientific inquiry and drug development, the rigor and validity of research methodologies are paramount. While quantitative studies have long-established metrics for robustness, qualitative research employs a distinct set of principles to ensure the trustworthiness and credibility of its findings. This guide provides an in-depth exploration of the core dimensions of robustness in qualitative research, offering detailed methodologies and practical applications for researchers, scientists, and drug development professionals. Understanding and implementing these dimensions are critical for generating high-quality, dependable insights that can confidently inform subsequent research and development phases.
The trustworthiness of qualitative research is generally assessed through four key dimensions: credibility, transferability, dependability, and confirmability. These pillars ensure that the research findings are believable, applicable to other contexts, consistent over time, and free from researcher bias.
Credibility: Ensuring the "Truth" of the Findings
Methodologies for Enhancing Credibility:
-
Prolonged Engagement: This involves spending sufficient time with participants in their natural setting to build trust and gain a deep understanding of the context. The extended period allows the researcher to move beyond initial impressions and uncover more nuanced insights.
-
Triangulation: This technique involves using multiple data sources, methods, investigators, or theories to corroborate findings. For instance, a researcher might use interviews, observations, and document analysis to study a phenomenon (data triangulation) or have multiple researchers analyze the same data independently (investigator triangulation).
-
Peer Debriefing: This involves regular meetings with a disinterested peer who is familiar with the research methodology but not directly involved in the study. This process allows for an external check on the research process, challenging the researcher's assumptions and interpretations.
-
Member Checking: This is the process of sharing research findings with the participants from whom the data were originally collected. It allows them to validate the researcher's interpretations and correct any inaccuracies, ensuring the findings are grounded in their experiences.
A typical workflow for ensuring credibility through these methods can be visualized as an iterative process of data collection, analysis, and validation.
Transferability: Applicability in Other Contexts
Transferability, akin to external validity, refers to the extent to which the findings of a qualitative study can be applied to other contexts or with other participants. Unlike quantitative research, the goal is not to generalize findings to a population but to provide a rich and detailed description so that other researchers can assess the applicability to their own settings.
Methodology for Enhancing Transferability:
-
Thick Description: This is the cornerstone of ensuring transferability. The researcher must provide a detailed and vivid account of the research context, participants, and the phenomenon under investigation. This allows readers to have a comprehensive understanding of the setting and to make an informed judgment about whether the findings could be relevant to their own situations.
To demonstrate the context for a study on the adoption of a new medical device, a researcher might provide the following demographic and contextual data.
| Parameter | Description |
| Setting | Two tertiary care hospitals (one urban, one rural) |
| Participant Roles | Surgeons, surgical nurses, and hospital administrators |
| Number of Participants | 15 (8 surgeons, 5 nurses, 2 administrators) |
| Years of Experience | Range: 3-25 years; Mean: 12.5 years |
| Prior Experience with Similar Devices | 60% of clinicians had prior experience with a previous generation of the device |
Dependability: Consistency of Findings
Dependability, analogous to reliability in quantitative research, addresses the consistency and stability of the research findings over time. It seeks to ensure that if the study were to be repeated with the same participants in the same context, the findings would be similar.
Methodology for Enhancing Dependability:
-
Audit Trail: This involves creating a detailed and transparent record of the entire research process. This documentation should include all raw data, notes on data collection and analysis, and records of methodological decisions. An external auditor can then examine this trail to assess the rigor and consistency of the research process.
The logical relationship between the components of an audit trail for dependability is illustrated below.
Confirmability: Objectivity of Findings
Confirmability refers to the degree to which the research findings are a result of the participants' experiences and not the researcher's biases, motivations, or interests. It is concerned with the objectivity of the data interpretation.
Methodology for Enhancing Confirmability:
-
Reflexivity Journal: The researcher maintains a journal throughout the study, documenting their personal thoughts, feelings, assumptions, and biases. This practice helps the researcher to be aware of their own influence on the research process and to actively mitigate it.
-
Confirmability Audit: Similar to the dependability audit, a confirmability audit involves an external reviewer examining the audit trail. However, the focus here is on assessing whether the data and interpretations are logically connected and not skewed by the researcher's perspective. The auditor would trace the data from collection through analysis to the final findings to ensure a clear and unbiased path.
The interconnectedness of the four dimensions of trustworthiness is crucial. A study cannot be considered robust if it meets the criteria for one dimension but fails on another. The following diagram illustrates the supportive relationship between these dimensions.
By systematically addressing these four dimensions, researchers in scientific and drug development fields can significantly enhance the robustness and impact of their qualitative work. The detailed methodologies provided serve as a practical toolkit for designing and executing qualitative studies that are not only insightful but also stand up to rigorous scrutiny. This commitment to robustness ensures that qualitative findings can be a valuable and trusted component of the evidence base in any scientific endeavor.
Defining and Demonstrating Robustness in a Research Proposal: A Technical Guide
In the landscape of scientific research and drug development, a "robust" finding is one that is reliable, reproducible, and resilient to minor variations in experimental conditions.[1][2] For researchers, scientists, and drug development professionals, articulating a clear strategy for ensuring robustness is no longer a subsidiary component of a research proposal but a cornerstone of its credibility. A robust proposal convinces reviewers and stakeholders that the planned research has been meticulously designed to yield results that are not only statistically significant but also scientifically meaningful and translatable.[3][4]
This guide provides an in-depth framework for defining, designing, and presenting a robust research plan. It covers the conceptual pillars of robustness, details key experimental and statistical methodologies, and offers a clear visual language for representing these complex strategies.
The Pillars of a Robust Research Proposal
Robustness is a multifaceted concept built on three core pillars: conceptual strength, methodological rigor, and statistical validity. A compelling proposal must address all three.
-
Conceptual Robustness: This is the foundation of the entire project. It refers to the strength and clarity of the research question and hypothesis.[5] A conceptually robust proposal is grounded in a thorough literature review that identifies a clear gap in knowledge and presents a well-reasoned hypothesis.[6]
-
Methodological Robustness: This pillar addresses the quality and rigor of the experimental design.[7][8] It ensures that the methods are not only appropriate for the research question but are also designed to minimize bias and maximize reproducibility.[4][9] Key elements include transparent reporting, randomization, blinding, and the use of appropriate controls.[8][9]
-
Statistical Robustness: This involves the use of statistical methods that yield reliable results, even when underlying assumptions are not perfectly met.[10][11] It is about ensuring that the findings are not statistical artifacts, unduly influenced by outliers, or dependent on a single analytical approach.[10][12]
The logical relationship between these pillars forms the overall strength of the proposal.
Methodologies for Demonstrating Robustness
To move from theory to practice, a proposal must detail the specific experiments and analyses that will be used to establish robustness. This involves a proactive approach to identifying and testing potential sources of variability.
A robust experimental design anticipates challenges and incorporates strategies to mitigate them.[13] This includes validation, replication, and the use of controls to ensure that results are dependable.[14][15] The goal is to demonstrate that the findings are not an artifact of a specific model, reagent batch, or experimental condition.[4][16]
References
- 1. Robustness in Science → Term [pollution.sustainability-directory.com]
- 2. Replication Of Studies: Advancing Scientific Rigor & Reliability - Mind the Graph Blog [mindthegraph.com]
- 3. Adding robustness to rigor and reproducibility for the three Rs of improving translational medical research - PMC [pmc.ncbi.nlm.nih.gov]
- 4. How to design robust preclinical efficacy studies that make a difference [jax.org]
- 5. scholar.place [scholar.place]
- 6. writelerco.com [writelerco.com]
- 7. scholar.place [scholar.place]
- 8. Methodology Matters: Designing Robust Research Methods [falconediting.com]
- 9. Methodological Rigor in Preclinical Cardiovascular Studies: Targets to Enhance Reproducibility and Promote Research Translation - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Robust statistics - Wikipedia [en.wikipedia.org]
- 11. academic.oup.com [academic.oup.com]
- 12. regression - How do Measure "Robustness" in Statistics? - Cross Validated [stats.stackexchange.com]
- 13. Mastering Research: The Principles of Experimental Design [servicescape.com]
- 14. Importance of Replication Studies - Enago Academy [enago.com]
- 15. longdom.org [longdom.org]
- 16. Robustness in experimental design: A study on the reliability of selection approaches - PMC [pmc.ncbi.nlm.nih.gov]
An In-Depth Technical Guide to the Core Principles of Reproducibility and Replicability in Scientific Research
In the realms of scientific inquiry and drug development, the concepts of reproducibility and replicability serve as the bedrock of evidentiary support.[1][2] Though often used interchangeably, they represent distinct, yet interconnected, pillars of the scientific method.[3][4][5] This guide delineates the critical differences between these two concepts, providing researchers, scientists, and drug development professionals with a comprehensive framework for ensuring the validity and reliability of their work.
Defining the Core Concepts: Reproducibility vs. Replicability
At its core, the distinction between reproducibility and replicability lies in the origin of the data being analyzed.
-
Reproducibility , in its modern, computationally focused definition, is the ability to obtain consistent results using the same input data, computational steps, methods, and code as the original study.[4][6][7][8] This is often referred to as "computational reproducibility."[4][6] A successful reproduction demonstrates that the data analysis was conducted transparently, fairly, and correctly.[3] It is a minimum necessary condition for trusting the analytical findings from a given dataset.[3]
-
Replicability is the ability to obtain consistent results across studies aimed at answering the same scientific question, each of which has obtained its own new data.[4][6][7][8] This process involves conducting the entire research process anew, from data collection to analysis.[3] A successful replication shows that the original study's findings are reliable and not just an artifact of a specific dataset or experimental condition.[3]
It is important to note that terminology can vary across different scientific communities.[4][9] However, the distinction between re-analyzing original data (reproducibility) and collecting new data (replicability) is the most widely accepted framework.[4][7]
Core Differences Summarized
The following table provides a structured comparison of the key attributes distinguishing reproducibility from replicability.
| Attribute | Reproducibility | Replicability |
| Primary Goal | To validate the correctness and transparency of the data analysis.[3] | To assess the reliability and generalizability of a scientific finding.[2] |
| Starting Materials | Original researcher's data, code, and computational methods.[4][6][7] | Original study's experimental protocol and methods. |
| Data Source | Same data as the original study.[4][6][8] | New data collected in an independent experiment.[4][6][7] |
| Expected Outcome | The same or very similar numerical results, figures, and tables. | Consistent findings and conclusions, given the inherent uncertainty.[4][6] |
| Inference from Success | The original analysis is computationally sound and was reported honestly.[3] | The scientific claim is robust and likely not due to chance or artifact. |
| Inference from Failure | Potential issues with the original analysis, code, or data handling. | The original finding may not be reliable or generalizable. |
| Synonymous Term | Computational Reproducibility.[4] | Experimental Replicability.[5] |
The "Reproducibility Crisis" in Scientific Research
The distinction between these concepts is not merely academic; it is at the heart of the "reproducibility crisis" affecting many scientific fields.[10] A 2016 survey published in Nature revealed that over 70% of researchers have tried and failed to reproduce another scientist's experiments, and more than half have failed to reproduce their own.[11]
| Metric | Finding | Source |
| Failed Replication of Another's Work | >70% of researchers reported failure to reproduce another scientist's experiments.[11] | Nature survey of 1,576 researchers.[11] |
| Failed Replication of Own Work | >50% of researchers reported failure to reproduce their own experiments.[11][12] | Nature survey of 1,576 researchers.[11] |
| Belief in a "Crisis" | 52% of surveyed researchers agree there is a significant "reproducibility crisis."[10][11] | Nature survey of 1,576 researchers.[11] |
| Replication Rates in Preclinical Research | Low replication rates found in biomedical research, with one study in cancer biology finding a rate as low as 10%.[11] | Amgen study (Begley and Ellis, 2012).[13] |
| Replication in Psychology | The Reproducibility Project: Psychology replicated 100 studies and found that only 36% had statistically significant results. | Open Science Collaboration (2015).[13] |
This lack of reproducibility and replicability can lead to wasted resources, delays in scientific progress, and an erosion of public trust in science.[14] In drug development, the inability to replicate preclinical studies can have severe consequences, contributing to the failure of clinical trials.[12]
Visualizing the Workflows and Logical Relationships
To further clarify the distinction, the following diagrams illustrate the workflows for achieving reproducibility and replicability, as well as their logical relationship.
A study can be reproducible but not replicable.[3] For example, the analysis of a dataset might be perfectly sound (reproducible), but the results might not hold up when a new experiment is conducted due to previously unrecognized variables or random chance in the original experiment.[3] This highlights that reproducibility is a necessary, but not sufficient, condition for replicability.
Detailed Methodologies for Ensuring Reproducibility and Replicability
Achieving reproducibility and replicability requires meticulous planning and documentation.[15][16][17] Below are illustrative protocols for both a computational (reproducibility) and a wet-lab (replicability) experiment.
This protocol details the steps to reproduce an analysis identifying differentially expressed genes from a public dataset.
-
1.0 Data Source & Acquisition
-
1.1 Dataset: The raw and processed RNA-seq data are available from the Gene Expression Omnibus (GEO) under accession number GSE00000.
-
1.2 Download: Data was downloaded on 2025-10-27 using the GEOquery R package (v2.74.0).
-
-
2.0 Computational Environment
-
2.1 Operating System: Ubuntu 22.04.1 LTS
-
2.2 Language: R version 4.3.1
-
2.3 Key R Packages:
-
DESeq2 (v1.42.0) for differential expression analysis.
-
ggplot2 (v3.4.4) for visualization.
-
dplyr (v1.1.3) for data manipulation.
-
-
2.4 Environment Management: A Docker container definition file (Dockerfile) is provided in the supplementary materials to reconstruct the exact computational environment.
-
-
3.0 Analysis Script
-
3.1 Script Name: run_differential_expression.R (available at GitHub: [link-to-repo]).
-
3.2 Script Execution: The entire analysis can be run from the command line using Rscript run_differential_expression.R.
-
3.3 Seed: The random seed is set to 12345 at the beginning of the script for stochastic processes to ensure identical results.
-
-
4.0 Analysis Steps
-
4.1 Data Loading: Raw count data and metadata are loaded from the downloaded GEO files.
-
4.2 Pre-processing: Genes with a total count of less than 10 across all samples are removed.
-
4.3 Differential Expression: The DESeq() function from the DESeq2 package is used with the design formula ~ condition.
-
4.4 Results Extraction: Results are extracted using the results() function with an adjusted p-value (padj) threshold of 0.05.
-
4.5 Visualization: A volcano plot is generated using ggplot2 and saved as volcano_plot.png.
-
This protocol details the steps to replicate an experiment measuring the IC50 of a novel kinase inhibitor.
-
1.0 Materials & Reagents
-
1.1 Cell Line: A549 (ATCC, Cat# CCL-185, Lot# 70000001). Cells were used between passages 5 and 10.
-
1.2 Culture Medium: F-12K Medium (Gibco, Cat# 21127022, Lot# 00001) supplemented with 10% Fetal Bovine Serum (FBS) (Sigma-Aldrich, Cat# F0926, Lot# 00002) and 1% Penicillin-Streptomycin (Thermo Fisher, Cat# 15140122, Lot# 00003).
-
1.3 Kinase Inhibitor: Compound XYZ (synthesis protocol provided in supplementary materials), dissolved in DMSO (Sigma-Aldrich, Cat# D2650, Lot# 00004) to a 10 mM stock.
-
1.4 Assay Reagent: CellTiter-Glo® Luminescent Cell Viability Assay (Promega, Cat# G7570, Lot# 00005).
-
-
2.0 Equipment
-
2.1 Plate Reader: Tecan Spark 10M with luminescence module.
-
2.2 Incubator: Heracell VIOS 160i, set to 37°C, 5% CO2.
-
2.3 Liquid Handler: Eppendorf epMotion 5075.
-
-
3.0 Experimental Procedure
-
3.1 Cell Seeding: A549 cells were seeded into a 96-well white, clear-bottom plate (Corning, Cat# 3610) at a density of 5,000 cells/well in 100 µL of culture medium. Plates were incubated for 24 hours.
-
3.2 Compound Treatment: Compound XYZ was serially diluted in culture medium to create a 10-point, 3-fold dilution series. 10 µL of each dilution was added to the respective wells. The final DMSO concentration was maintained at 0.1% across all wells.
-
3.3 Incubation: Plates were incubated for 72 hours at 37°C, 5% CO2.
-
3.4 Viability Measurement: Plates were equilibrated to room temperature for 30 minutes. 100 µL of CellTiter-Glo® reagent was added to each well. The plate was placed on an orbital shaker for 2 minutes and then incubated at room temperature for 10 minutes to stabilize the luminescent signal.
-
3.5 Data Acquisition: Luminescence was read on the Tecan Spark 10M with an integration time of 1 second.
-
-
4.0 Data Analysis
-
4.1 Normalization: Data was normalized to vehicle (0.1% DMSO) controls (100% viability) and no-cell controls (0% viability).
-
4.2 Curve Fitting: The normalized data was fitted to a four-parameter logistic (4PL) curve using GraphPad Prism (v9.5.1) to determine the IC50 value.
-
Conclusion
References
- 1. online225.psych.wisc.edu [online225.psych.wisc.edu]
- 2. fiveable.me [fiveable.me]
- 3. Reproducibility vs Replicability | Difference & Examples [scribbr.com]
- 4. Understanding Reproducibility and Replicability - Reproducibility and Replicability in Science - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 5. Reproducibility | NNLM [nnlm.gov]
- 6. Summary - Reproducibility and Replicability in Science - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 7. quora.com [quora.com]
- 8. gesis.org [gesis.org]
- 9. khinsen.wordpress.com [khinsen.wordpress.com]
- 10. Replication crisis - Wikipedia [en.wikipedia.org]
- 11. rr.gklab.org [rr.gklab.org]
- 12. mindwalkai.com [mindwalkai.com]
- 13. Replicability - Reproducibility and Replicability in Science - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 14. Reproducibility and Replicability in Research: Challenges and Way Forward | Researcher.Life [researcher.life]
- 15. bitesizebio.com [bitesizebio.com]
- 16. Ensuring Reproducibility and Transparency in Experimental Research [statology.org]
- 17. bitesizebio.com [bitesizebio.com]
Methodological & Application
Application Notes and Protocols for Ensuring Robustness in Clinical Trial Design
For Researchers, Scientists, and Drug Development Professionals
These application notes and protocols provide a comprehensive guide to designing robust clinical trials, ensuring the reliability, validity, and reproducibility of study outcomes. Adherence to these principles is critical for generating high-quality evidence to support regulatory approval and inform clinical practice.
Core Principles of Robust Clinical Trial Design
A robust clinical trial is designed to minimize bias and produce results that are both reliable and generalizable.[1] The foundation of such a trial rests on several key principles that must be meticulously planned and executed.
A well-designed clinical trial protocol should clearly outline the study's objectives, design, ethical considerations, and regulatory requirements.[2] The research question should be well-defined, forming the basis of a successful trial.[3]
Key Principles:
-
Randomization: The random allocation of participants to different treatment groups is a cornerstone of robust trial design.[4][5] It aims to create comparable groups, minimizing selection bias and confounding.[6]
-
Blinding (or Masking): This practice prevents bias in the reporting and assessment of outcomes by ensuring that participants, investigators, and/or assessors are unaware of the treatment assignments.[5][6]
-
Well-Defined Endpoints: The selection of appropriate primary and secondary endpoints is crucial for a trial's success.[7][8] Endpoints should be clinically relevant, measurable, and sensitive to the effects of the intervention.[8][9]
-
Adequate Sample Size and Power: The trial must be planned with a sufficient number of participants to detect a clinically meaningful treatment effect with high probability (power) while controlling for the risk of false-positive results.[10][11]
-
Handling of Missing Data: Strategies for preventing and managing missing data should be established during the design phase to avoid biased results and a reduction in statistical power.[12][13]
-
Adaptive Designs: These designs allow for pre-planned modifications to the trial based on accumulating data, which can increase efficiency and the likelihood of success.[14][15][16]
Experimental Protocols
Protocol for Randomization and Blinding
Objective: To minimize selection and assessment bias through the implementation of robust randomization and blinding procedures.
Methodologies:
-
Selection of Randomization Method: Choose a randomization technique appropriate for the trial's specific needs.[17]
-
Simple Randomization: Assigns participants to treatment groups with a known probability, similar to a coin toss. Best suited for large trials.[17]
-
Block Randomization: Ensures a balance in the number of participants in each group at specific points during enrollment.[17]
-
Stratified Randomization: Used to ensure balance of important baseline characteristics (e.g., age, disease severity) across treatment groups.[17][18]
-
Adaptive Randomization: Adjusts the probability of assignment to different treatment arms based on accumulating data.[14][17]
-
-
Allocation Concealment: The process of hiding the treatment allocation sequence from those involved in participant recruitment and enrollment. This is crucial to prevent selection bias.[5] Methods include central randomization (e.g., via a telephone or web-based system) or the use of sequentially numbered, opaque, sealed envelopes.
-
Implementation of Blinding:
-
Single-Blind: The participant is unaware of the treatment assignment.[19]
-
Double-Blind: Both the participant and the investigators/assessors are unaware of the treatment assignment.[19][20] This is the "gold standard" for reducing bias.[6]
-
Triple-Blind: Participants, investigators, and data analysts are all blinded to the treatment allocation.
-
-
Maintaining the Blind: Use of identical-appearing placebo or active comparator treatments is essential. Procedures should be in place to manage situations where unblinding is necessary for patient safety.
Protocol for Sample Size Calculation
Objective: To determine the minimum number of participants required to achieve the study's objectives with adequate statistical power.
Methodologies:
-
Define Study Parameters:
-
Primary Endpoint: The main outcome used to evaluate the treatment effect.[21]
-
Clinically Meaningful Difference: The smallest treatment effect that is considered clinically important.[21]
-
Statistical Power (1-β): The probability of detecting a true treatment effect, typically set at 80% or 90%.[11][21]
-
Significance Level (α): The probability of a Type I error (false positive), usually set at 5% (0.05).[11][21]
-
Variability of the Outcome: The expected standard deviation of the primary endpoint, often estimated from previous studies.[10]
-
-
Select the Appropriate Formula: The formula for sample size calculation varies depending on the study design (e.g., superiority, non-inferiority) and the type of endpoint (e.g., continuous, binary, time-to-event).[10][22]
-
Calculate the Sample Size: Use statistical software or online calculators to perform the calculation based on the defined parameters.[10]
-
Adjust for Attrition: Account for potential dropouts by increasing the calculated sample size. A common approach is to divide the initial sample size by (1 - expected dropout rate).[10]
Protocol for Handling Missing Data
Objective: To minimize the impact of missing data on the validity and integrity of the trial results.
Methodologies:
-
Prevention of Missing Data:
-
Design a protocol that is feasible and minimizes participant burden.
-
Implement robust data collection and management systems.[3]
-
Maintain regular contact with participants to encourage retention.
-
-
Define the Missing Data Mechanism:
-
Missing Completely at Random (MCAR): The probability of data being missing is unrelated to both observed and unobserved data.[13]
-
Missing at Random (MAR): The probability of data being missing depends only on the observed data.[13]
-
Missing Not at Random (MNAR): The probability of data being missing depends on the unobserved data.[13]
-
-
Select an Appropriate Analysis Method: The choice of method depends on the assumed missing data mechanism.
-
Complete Case Analysis: Only includes participants with complete data. This can lead to biased results if data are not MCAR.[13]
-
Last Observation Carried Forward (LOCF): Imputes missing values with the last observed value. This method is generally discouraged as it can introduce bias.[12]
-
Multiple Imputation (MI): A robust method that creates multiple complete datasets by imputing missing values based on the observed data. This approach accounts for the uncertainty associated with the imputed values.[23][24]
-
Mixed Models for Repeated Measures (MMRM): A model-based approach that can handle missing data under the MAR assumption without imputation.[23]
-
Data Presentation: Summary Tables
Table 1: Comparison of Randomization Techniques
| Randomization Technique | Description | Advantages | Disadvantages | Best Suited For |
| Simple Randomization | Each participant has an equal chance of being assigned to any group.[17] | Easy to implement. | Can lead to unequal group sizes, especially in small trials.[17] | Large clinical trials. |
| Block Randomization | Participants are randomized in blocks to ensure balance between groups at the end of each block.[17] | Maintains balance in group sizes throughout the trial.[17] | Can be predictable if the block size is known. | Most clinical trials. |
| Stratified Randomization | Participants are first divided into strata based on important prognostic factors, then randomized within each stratum.[17] | Ensures balance of key prognostic factors across groups.[17] | Can be complex to implement with many strata. | Trials where specific baseline characteristics are known to influence the outcome. |
| Adaptive Randomization | The probability of assigning a participant to a particular group changes as data from the trial accumulate.[17] | Can increase the number of participants assigned to the more effective treatment.[14] | Can be complex to design and implement; potential for operational bias.[15] | Early phase or exploratory trials. |
Table 2: Key Parameters for Sample Size Calculation
| Parameter | Definition | Typical Value(s) | Impact on Sample Size |
| Significance Level (α) | Probability of a Type I error (false positive).[11] | 0.05 (two-sided)[11] | Decreasing α increases sample size. |
| Power (1-β) | Probability of detecting a true effect.[11] | 80% or 90%[11] | Increasing power increases sample size.[21] |
| Clinically Meaningful Difference (Effect Size) | The smallest difference in outcome between treatment groups that is considered clinically relevant.[21] | Varies by disease and intervention. | Detecting a smaller difference requires a larger sample size.[21] |
| Variability (Standard Deviation) | The spread of the data for the primary outcome. | Estimated from prior studies. | Higher variability increases sample size. |
| Dropout Rate | The proportion of participants expected to leave the study before completion.[10] | Varies by study duration and population. | Higher anticipated dropout rate increases the required sample size.[10] |
Mandatory Visualizations
Workflow for a Robust Randomized Controlled Trial (RCT)
Caption: Workflow of a robust randomized controlled trial.
Logical Relationships in Blinding
Caption: Levels of blinding in a clinical trial.
Decision Pathway for Handling Missing Data
Caption: Decision pathway for handling missing data.
References
- 1. Optimizing Clinical Trials with Robust Design [clinicaltrialsolutions.org]
- 2. lindushealth.com [lindushealth.com]
- 3. Best Practices for Designing Effective Clinical Drug Trials [raptimresearch.com]
- 4. Practical aspects of randomization and blinding in randomized clinical trials - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Randomization and blinding: Significance and symbolism [wisdomlib.org]
- 6. Purpose of Randomization and Blinding in Research Studies - Academy [pubrica.com]
- 7. clinilaunchresearch.in [clinilaunchresearch.in]
- 8. bioaccessla.com [bioaccessla.com]
- 9. memoinoncology.com [memoinoncology.com]
- 10. riskcalc.org [riskcalc.org]
- 11. intuitionlabs.ai [intuitionlabs.ai]
- 12. scispace.com [scispace.com]
- 13. Strategies for Dealing with Missing Data in Clinical Trials: From Design to Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 14. veristat.com [veristat.com]
- 15. Benefits, challenges and obstacles of adaptive clinical trial designs - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Key design considerations for adaptive clinical trials: a primer for clinicians | The BMJ [bmj.com]
- 17. Top Five Tips for Clinical Trial Design - Biotech at Scale [thermofisher.com]
- 18. pure.johnshopkins.edu [pure.johnshopkins.edu]
- 19. Chapter 6 Randomization and allocation, blinding and placebos | Clinical Biostatistics [bookdown.org]
- 20. clinicalpursuit.com [clinicalpursuit.com]
- 21. Sample Size Estimation in Clinical Trial - PMC [pmc.ncbi.nlm.nih.gov]
- 22. researchgate.net [researchgate.net]
- 23. quanticate.com [quanticate.com]
- 24. Robust analyzes for longitudinal clinical trials with missing and non-normal continuous outcomes - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for Assessing the Robustness of Statistical Models
Introduction
In statistical analysis, particularly within research, drug development, and scientific studies, the robustness of a statistical model refers to its ability to remain effective and provide reliable results even when its underlying assumptions are not perfectly met.[1] Robust statistics are resistant to outliers or minor deviations from model assumptions.[1] Assessing model robustness is a critical practice to ensure the soundness, reliability, and generalizability of research findings.[2][3] This document provides detailed application notes and protocols for key methods used to evaluate the robustness of statistical models.
Cross-Validation
Application Note
Cross-validation is a powerful statistical technique for evaluating how the results of a statistical analysis will generalize to an independent dataset.[3] It is essential for assessing a model's performance on unseen data, thereby preventing issues like overfitting, where a model learns the training data too well, including its noise, and fails to generalize to new data.[3][4] The core idea is to partition the data into complementary subsets, train the model on one subset, and validate it on the other.[3] This process is repeated multiple times to obtain a more reliable estimate of the model's predictive performance.[3][4] Common types of cross-validation include K-Fold, Stratified K-Fold, and Leave-One-Out Cross-Validation (LOOCV).[5][6]
Key Applications:
-
Model Performance Estimation: Provides a more accurate measure of how a model will perform on new, unseen data.[4]
-
Model Selection: Helps in comparing the performance of different models to select the best one.[5]
-
Hyperparameter Tuning: Aids in optimizing model parameters for the best performance.[5]
-
Overfitting Prevention: Ensures the model is not just memorizing the training data but can generalize well.[4]
Experimental Protocol: K-Fold Cross-Validation
This protocol describes the steps to perform a K-Fold cross-validation to assess model robustness.
-
Data Partitioning: 1.1. Choose an integer 'K' (e.g., 5 or 10). This value represents the number of folds or subsets the data will be divided into. 1.2. Randomly shuffle the dataset. 1.3. Split the dataset into K equal-sized folds.[5]
-
Iterative Model Training and Validation: 2.1. For each of the K folds: a. Select the current fold as the validation set. b. Use the remaining K-1 folds as the training set. c. Train the statistical model on the training set. d. Evaluate the model's performance on the validation set using a chosen metric (e.g., Mean Squared Error for regression, Accuracy for classification). e. Store the performance score.
-
Performance Aggregation: 3.1. After iterating through all K folds, calculate the average of the K performance scores.[4] 3.2. This average score represents the overall performance of the model. The standard deviation of the scores can also be calculated to understand the variability of the model's performance across different data subsets.
Caption: Workflow for K-Fold Cross-Validation.
Data Presentation: Comparison of Cross-Validation Techniques
| Technique | Description | Pros | Cons |
| Hold-Out | The dataset is split into two parts: a training set and a testing set (e.g., 80%/20%).[4] | Simple and fast to implement.[4] | High variance due to a single split; performance can depend heavily on the specific split.[4] |
| K-Fold | The data is divided into K folds. The model is trained on K-1 folds and tested on the remaining one, repeated K times.[4] | Provides a more accurate performance estimate as every data point is used for testing.[4] | Can be computationally expensive for large K. |
| Leave-One-Out (LOOCV) | A special case of K-Fold where K equals the number of data points (n). Each data point is used once as a test set.[6][7] | Provides an unbiased estimate of the test error. | Computationally very expensive for large datasets.[5][7] |
| Stratified K-Fold | A variation of K-Fold that ensures each fold has the same proportion of class labels as the original dataset.[5] | Particularly useful for imbalanced datasets to ensure representative splits. | Can be complex to implement for multi-label classification. |
| Time Series | Special methods like Forward Chaining are used where the training set consists of past data and the test set consists of future data.[4] | Maintains the temporal order of data, which is crucial for time-dependent datasets. | Reduces the amount of available training data in early folds. |
Bootstrapping
Application Note
Bootstrapping is a resampling technique used to estimate the distribution of a statistic by repeatedly drawing samples from the original dataset with replacement.[8][9] In the context of model validation, bootstrapping helps assess the stability and variability of a model's performance estimates.[9][10] By creating multiple "bootstrap samples," training the model on each, and evaluating its performance, one can obtain a robust estimate of performance metrics and their confidence intervals.[8] This method is particularly useful when the underlying distribution of the data is unknown or when the sample size is limited.[8][9]
Key Applications:
-
Estimating Model Performance: Provides a robust estimate of metrics like accuracy, precision, and recall.[8]
-
Assessing Stability: Evaluates how much the model's performance varies with different training data.[10]
-
Confidence Interval Estimation: Constructs confidence intervals for model parameters and performance metrics.[9]
-
Reducing Variance: Helps in reducing the variance of performance estimates by averaging over many samples.[8]
Experimental Protocol: Bootstrap Validation
This protocol outlines the steps for performing bootstrap validation of a statistical model.
-
Bootstrap Sampling: 1.1. From the original dataset of size 'n', create a large number (B) of bootstrap samples (e.g., B=1000). 1.2. Each bootstrap sample is created by randomly selecting 'n' instances from the original dataset with replacement.[8] This means some instances may appear multiple times in a sample, while others may not appear at all.
-
Model Training and Evaluation: 2.1. For each of the B bootstrap samples: a. Train the statistical model on the bootstrap sample. b. The instances from the original dataset that were not included in the bootstrap sample form the "out-of-bag" (OOB) sample.[8] c. Evaluate the trained model on the OOB sample to get an unbiased performance estimate.[8] d. Store the performance score.
-
Result Aggregation and Analysis: 3.1. After iterating through all B bootstrap samples, you will have a distribution of B performance scores. 3.2. Calculate the mean of these scores to get the bootstrap-estimated model performance. 3.3. Calculate the standard deviation of the scores to estimate the standard error of the model's performance. 3.4. Construct a confidence interval (e.g., a 95% confidence interval) for the performance metric from the distribution of scores.
Caption: Workflow for Bootstrap Validation.
Data Presentation: Summary of Bootstrap Analysis Results
| Performance Metric | Bootstrap Mean | Standard Error | 95% Confidence Interval |
| Accuracy | 0.852 | 0.021 | [0.811, 0.893] |
| Precision | 0.789 | 0.035 | [0.720, 0.858] |
| Recall | 0.881 | 0.028 | [0.826, 0.936] |
| AUC | 0.915 | 0.015 | [0.886, 0.944] |
Sensitivity Analysis
Application Note
Key Applications:
-
Identifying Influential Variables: Determines which input variables have the greatest effect on the model's output.[11]
-
Assessing Robustness of Findings: Helps understand how sensitive the results are to changes in assumptions.[12]
-
Uncertainty Quantification: Quantifies how uncertainty in the inputs translates to uncertainty in the output.[13][14]
-
Model Simplification: Can help in identifying and potentially eliminating non-sensitive parameters.[11]
Experimental Protocol: One-at-a-Time (OAT) Sensitivity Analysis
This protocol describes a basic method for conducting a sensitivity analysis.
-
Define Baseline: 1.1. Establish a baseline scenario by setting all input variables to their central or most likely values. 1.2. Run the model with these baseline values and record the output.
-
Vary Inputs Systematically: 2.1. For each input variable, define a plausible range of values (e.g., based on confidence intervals or expert opinion). 2.2. One at a time, vary each input variable across its defined range while keeping all other variables at their baseline values.[11] 2.3. For each variation, run the model and record the output.
-
Analyze and Quantify Sensitivity: 3.1. For each input variable, analyze how the model output changes in response to the variations. 3.2. Quantify the sensitivity. This can be done by calculating the partial derivative, standardized regression coefficients, or simply the range of output change for a given input change.[12][14] 3.3. Rank the input variables based on their influence on the output to identify the most critical factors.
Caption: Conceptual flow of Sensitivity Analysis.
Data Presentation: Results of a Sensitivity Analysis
| Input Variable | Range of Variation | Baseline Output | Output Range | Sensitivity Index |
| Drug Dosage (mg) | 50 - 150 | 0.75 | 0.60 - 0.85 | 0.45 |
| Patient Age (years) | 40 - 70 | 0.75 | 0.72 - 0.78 | 0.15 |
| Biomarker X Level | 0.5 - 1.5 | 0.75 | 0.74 - 0.76 | 0.08 |
| Sensitivity Index can be a normalized measure of the output change. |
Simulation Studies
Application Note
Simulation studies are computer experiments that involve generating data through pseudo-random sampling to evaluate the performance of statistical methods.[15] They are essential for assessing the robustness of a model when its underlying assumptions are violated.[16] By creating simulated datasets where the "true" relationships are known, researchers can see how well a model performs under various conditions, including misspecification of the model, presence of outliers, or different data distributions.[15][16] This provides empirical evidence about a method's performance and helps in making informed modeling decisions.[15]
Key Applications:
-
Evaluating Method Performance: Gauges the performance of new or existing statistical methods.[15]
-
Comparing Methods: Compares how different methods perform under specific scenarios.[15]
-
Assessing Robustness to Misspecification: Tests how a model behaves when its assumptions (e.g., normality, linearity) are not met.[16]
-
Sample Size and Power Calculation: Can be used to determine the required sample size for a study.[15]
Experimental Protocol: Designing a Simulation Study
This protocol provides a framework for conducting a simulation study to test model robustness.
-
Define Objectives and Scenarios: 1.1. Clearly state the goal of the simulation. For example, to assess the robustness of a linear regression model to non-normally distributed errors. 1.2. Define the different scenarios to be tested. This includes the "correctly specified" scenario where model assumptions are met, and one or more "misspecified" scenarios where assumptions are violated.[16]
-
Data Generating Mechanism: 2.1. For each scenario, define the process for generating the simulated datasets. This involves specifying the true underlying model, the distribution of variables, and the sample size. 2.2. Generate a large number of datasets (e.g., 1000) for each scenario.
-
Model Fitting and Evaluation: 3.1. For each generated dataset, fit the statistical model being tested. 3.2. Calculate relevant performance metrics. For example, the bias and variance of parameter estimates, or the mean squared error of predictions.[15]
-
Summarize and Compare Results: 4.1. Aggregate the performance metrics across all simulated datasets for each scenario. 4.2. Compare the model's performance in the misspecified scenarios to its performance in the correctly specified scenario.[16] 4.3. A model is considered robust to a particular assumption violation if its performance does not degrade significantly in the misspecified scenario.
Caption: Workflow for a Simulation Study.
Data Presentation: Summary of Simulation Study Results
| Scenario | Assumed Error Distribution | True Error Distribution | Parameter Estimate Bias | Mean Squared Error (MSE) |
| 1 (Correctly Specified) | Normal | Normal | 0.002 | 1.05 |
| 2 (Misspecified) | Normal | Skewed (Chi-squared) | 0.150 | 2.54 |
| 3 (Misspecified) | Normal | Heavy-tailed (t-dist) | 0.005 | 1.88 |
References
- 1. What Is Robustness in Statistics? [thoughtco.com]
- 2. Robustness Checking in Regression: Ensuring Stability and Validity in Supervised Learning | by Macro Pulse - Daily 3 Miniute Brief | Medium [medium.com]
- 3. Cross-validation (statistics) - Wikipedia [en.wikipedia.org]
- 4. Cross-Validation and Its Types: A Comprehensive Guide - Data Science Courses in Edmonton, Canada [saidatascience.com]
- 5. medium.com [medium.com]
- 6. analyticsvidhya.com [analyticsvidhya.com]
- 7. 10.6 - Cross-validation | STAT 501 [online.stat.psu.edu]
- 8. bugfree.ai [bugfree.ai]
- 9. Bootstrap Method - GeeksforGeeks [geeksforgeeks.org]
- 10. Bootstrap validation [causalwizard.app]
- 11. statisticshowto.com [statisticshowto.com]
- 12. Julius AI | AI for Data Analysis | What Is Sensitivity Analysis in Statistics & How Is It Used? [julius.ai]
- 13. youtube.com [youtube.com]
- 14. Sensitivity analysis - Wikipedia [en.wikipedia.org]
- 15. towardsdatascience.com [towardsdatascience.com]
- 16. regression - How do Measure "Robustness" in Statistics? - Cross Validated [stats.stackexchange.com]
Applying Sensitivity Analysis to Test Research Robustness: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
Introduction to Sensitivity Analysis
Key Objectives of Sensitivity Analysis:
-
Identify Influential Parameters: Pinpoint which model inputs or assumptions have the most significant impact on the output.[5]
-
Enhance Credibility: Increase confidence in the research findings by demonstrating their stability across a range of plausible scenarios.[4]
-
Guide Future Research: Highlight areas where more precise data is needed to reduce uncertainty.[6]
Methodologies for Sensitivity Analysis
Several methods can be employed for sensitivity analysis, ranging from simple one-at-a-time approaches to more complex global methods. The choice of method depends on the complexity of the model, the number of parameters, and the specific research question.
One-at-a-Time (OAT) Sensitivity Analysis
OAT is the most straightforward approach, where one input parameter is varied at a time while keeping all others constant at their baseline values.[7][8] This method is easy to implement and interpret, making it a good starting point for sensitivity analysis.[9]
Partial Rank Correlation Coefficient (PRCC)
PRCC is a global sensitivity analysis method that measures the correlation between ranked input parameters and ranked output variables, while accounting for the linear effects of other parameters.[10][11] It is particularly useful for identifying monotonic, non-linear relationships in complex models.[12]
Sobol Indices
The Sobol method is a variance-based global sensitivity analysis technique that decomposes the variance of the model output into contributions from individual input parameters and their interactions.[4][13] It provides a comprehensive understanding of how each parameter and its interactions with others contribute to the output uncertainty.[14]
Experimental Protocols
The following protocols provide detailed, step-by-step guidance for implementing the described sensitivity analysis methods.
Protocol for One-at-a-Time (OAT) Sensitivity Analysis
Objective: To assess the impact of individual parameter changes on a model output.
Materials:
-
A defined mathematical or computational model.
-
Baseline values for all input parameters.
-
Defined range of variation for each parameter to be tested.
Procedure:
-
Establish the Baseline: Run the model with all input parameters set to their baseline (nominal) values to obtain the baseline output.
-
Define Parameter Ranges: For each parameter of interest, define a plausible range of variation (e.g., ±10%, ±20% from the baseline).[9]
-
Vary Parameters Individually:
-
Select one parameter and vary its value across its defined range, while keeping all other parameters fixed at their baseline values.[8]
-
Run the model for each new value of the selected parameter and record the corresponding output.
-
-
Repeat for All Parameters: Repeat step 3 for each parameter of interest, one at a time.
-
Analyze and Visualize Results: Compare the outputs obtained from the varied parameter values to the baseline output. Visualize the results using tornado plots or spider charts to rank the parameters by their influence.[2][15]
Protocol for Partial Rank Correlation Coefficient (PRCC) Analysis
Objective: To quantify the monotonic relationship between input parameters and model output in a complex, non-linear model.
Materials:
-
A defined mathematical or computational model.
-
Probability distributions for each input parameter.
-
Software capable of performing Latin Hypercube Sampling (LHS) and calculating PRCC (e.g., R with the sensitivity package, Python with SALib).[16][17]
Procedure:
-
Define Parameter Distributions: Assign a probability distribution (e.g., uniform, normal) to each input parameter based on existing knowledge or uncertainty.
-
Generate Parameter Samples: Use Latin Hypercube Sampling (LHS) to generate a set of input parameter samples from their defined distributions. LHS ensures a more efficient and uniform sampling of the parameter space compared to simple random sampling.[10]
-
Run the Model: Execute the model for each set of parameter samples generated in the previous step and record the corresponding output values.
-
Rank Transformation: Rank-transform both the input parameter samples and the corresponding output values.
-
Calculate PRCC: Compute the partial rank correlation coefficient for each input parameter with respect to the output, controlling for the linear effects of the other parameters.[18]
-
Assess Statistical Significance: Determine the statistical significance of the calculated PRCC values to identify parameters that have a significant monotonic relationship with the output.[18]
Protocol for Sobol Indices Analysis
Objective: To apportion the output variance to individual input parameters and their interactions.
Materials:
-
A defined mathematical or computational model.
-
Probability distributions for each input parameter.
-
Software capable of performing Sobol analysis (e.g., R with the sensitivity package, Python with SALib, MATLAB).[19]
Procedure:
-
Define Parameter Distributions: As with PRCC, assign a probability distribution to each input parameter.
-
Generate Input Samples: Generate two independent sets of input parameter samples (matrices A and B) using a quasi-random sampling method like the Sobol sequence.[4]
-
Create Additional Sample Matrices: Generate additional sample matrices for each input parameter by taking all columns from matrix A and the i-th column from matrix B (for the i-th parameter).
-
Run the Model: Run the model for all generated sample matrices to obtain the corresponding outputs.
-
Calculate Sobol Indices:
-
Interpret the Results: A high first-order index indicates that the parameter itself has a strong influence on the output. A large difference between the total-order and first-order indices for a parameter suggests strong interaction effects with other parameters.
Data Presentation
Clear and concise presentation of sensitivity analysis results is crucial for effective communication. Tables are an excellent way to summarize quantitative data for easy comparison.[1]
Table 1: Example of One-at-a-Time (OAT) Sensitivity Analysis Results
| Parameter | Variation | Output Value | Change from Baseline (%) |
| Baseline | - | 100.0 | - |
| Drug Efficacy | -20% | 85.0 | -15.0% |
| +20% | 115.0 | +15.0% | |
| Patient Adherence | -10% | 92.0 | -8.0% |
| +10% | 108.0 | +8.0% | |
| Drug Clearance | -15% | 105.0 | +5.0% |
| +15% | 95.0 | -5.0% |
Table 2: Example of PRCC and Sobol Indices Results
| Parameter | PRCC Value | p-value | First-Order Sobol Index (Si) | Total-Order Sobol Index (STi) |
| Drug Efficacy | 0.85 | <0.001 | 0.62 | 0.65 |
| Patient Adherence | 0.42 | 0.012 | 0.18 | 0.25 |
| Drug Clearance | -0.68 | <0.001 | 0.35 | 0.38 |
| Initial Dose | 0.15 | 0.250 | 0.02 | 0.05 |
Mandatory Visualizations
Visual representations are essential for conveying the complex relationships identified through sensitivity analysis.
Signaling Pathway Diagram
The following diagram illustrates a hypothetical signaling pathway that could be the subject of a sensitivity analysis to identify key drug targets.
Caption: A hypothetical signaling pathway illustrating ligand binding, kinase activation, and gene expression.
Experimental Workflow Diagram
This diagram outlines the general workflow for conducting a sensitivity analysis.
Caption: A generalized workflow for performing a sensitivity analysis to assess research robustness.
Logical Relationship Diagram
This diagram illustrates the logical relationship between different types of sensitivity analysis and their primary outputs.
Caption: Relationship between sensitivity analysis methods and their respective primary outputs.
References
- 1. wallstreetprep.com [wallstreetprep.com]
- 2. What is a Sensitivity Analysis? Definition, Examples & How to [chartexpo.com]
- 3. DOT Language | Graphviz [graphviz.org]
- 4. Sobol Sensitivity Analysis: A Tool to Guide the Development and Evaluation of Systems Pharmacology Models - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Use of a Local Sensitivity Analysis to Inform Study Design Based on a Mechanistic Toxicokinetic Model for γ-Hydroxybutyric Acid - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Global sensitivity analysis of Open Systems Pharmacology Suite physiologically based pharmacokinetic models - PMC [pmc.ncbi.nlm.nih.gov]
- 7. vizule.io [vizule.io]
- 8. Building diagrams using graphviz | Chad’s Blog [chadbaldwin.net]
- 9. researchgate.net [researchgate.net]
- 10. A Methodology For Performing Global Uncertainty And Sensitivity Analysis In Systems Biology - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Partial Rank Correlation Coefficients - File Exchange - MATLAB Central [mathworks.com]
- 12. Performing a Sensitivity Analysis UQ Study [comsol.fr]
- 13. researchgate.net [researchgate.net]
- 14. docs.sciml.ai [docs.sciml.ai]
- 15. Choosing a method for sensitivity analysis - Analytica Docs [docs.analytica.com]
- 16. FBA-PRCC. Partial Rank Correlation Coefficient (PRCC) Global Sensitivity Analysis (GSA) in Application to Constraint-Based Models [mdpi.com]
- 17. GitHub - scmassey/model-sensitivity-analysis: Latin hypercube sampling and partial rank correlation coefficients [github.com]
- 18. FBA-PRCC. Partial Rank Correlation Coefficient (PRCC) Global Sensitivity Analysis (GSA) in Application to Constraint-Based Models - PMC [pmc.ncbi.nlm.nih.gov]
- 19. sbiosobol - Perform global sensitivity analysis by computing first- and total-order Sobol indices (requires Statistics and Machine Learning Toolbox) - MATLAB [mathworks.com]
Application Notes and Protocols for Robust Data Collection and Management
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive guide to establishing robust data collection and management practices essential for the integrity and success of research, particularly in the context of drug development. Adherence to these protocols will enhance data quality, ensure regulatory compliance, and facilitate effective collaboration.
Section 1: Core Principles of Robust Data Management
Effective data management is foundational to reproducible and high-quality research. It encompasses the entire lifecycle of data, from initial planning to final archiving. The core principles are outlined in a Data Management Plan (DMP), a living document that details the strategies for data handling throughout a research project.[1][2][3][4][5][6]
A well-structured DMP addresses several key areas to ensure data integrity and usability.[1][5][7] This includes defining the types of data to be collected, the standards for metadata, and the procedures for data storage and preservation.[1][3] A clear plan for data sharing and publication should also be established from the outset.
The Data Management Plan (DMP)
A DMP is a formal document that outlines how data will be handled during a research project and after its completion.[3] Many funding agencies now mandate a DMP as part of the grant application process.[1]
Key Components of a Data Management Plan:
| Component | Description | Key Considerations |
| Data Description | The types and formats of data to be collected (e.g., quantitative, qualitative, imaging).[3] | What is the source and expected size of the data?[3] Who will be responsible for managing the data?[3] |
| Metadata Standards | The "data about the data," including variable names, definitions, and experimental context. | Adherence to existing standards like the Data Documentation Initiative (DDI) is recommended.[1] |
| Data Storage & Backup | Procedures for storing, backing up, and securing the data. | A common best practice is the 3-2-1 rule: three copies of the data on two different media, with one copy offsite.[1] |
| Data Security | Measures to protect data, especially sensitive or confidential information.[2][8] | This includes encryption, access controls, and compliance with regulations like HIPAA.[2][9][10][11] |
| Data Sharing & Archiving | Plans for sharing data with collaborators and the wider scientific community, and long-term preservation.[1] | This involves cleaning and documenting datasets for reuse.[1] |
| Roles & Responsibilities | Clearly defined roles for data collection, quality control, and management.[3][7][8] | This fosters a shared understanding of the project's data management procedures.[8] |
The ALCOA+ Principles for Data Integrity
The ALCOA+ principles are a set of guidelines developed to ensure data integrity, particularly in regulated environments like the pharmaceutical industry. These principles help maintain the quality and reliability of data throughout its lifecycle.
| Principle | Description |
| Attributable | Data should be traceable to the individual who generated it and when.[12] |
| Legible | Data must be readable and permanent.[12] |
| Contemporaneous | Data should be recorded at the time the work is performed.[12] |
| Original | The first recording of the data, or a certified true copy.[12] |
| Accurate | Data should be free from errors and reflect the actual observation.[12] |
| Complete | All data, including any repeat or re-analysis, should be available. |
| Consistent | Data should be presented in a consistent and chronological sequence. |
| Enduring | Data should be maintained in a durable and accessible format for the required retention period. |
| Available | Data must be accessible for review, audit, or inspection. |
Section 2: Data Collection Techniques
The method of data collection significantly impacts data quality. The choice of technique should align with the research objectives and the nature of the data.
Electronic Data Capture (EDC) Systems
EDC systems are computerized systems designed for the collection of clinical data in an electronic format, replacing traditional paper-based methods.[13][14] They are widely used in clinical trials to streamline data collection and improve data quality.[13][15][16]
Advantages of EDC Systems:
| Feature | Benefit |
| Real-time Data Entry | Reduces delays between data collection and analysis.[16] |
| Automated Validation Checks | Improves data accuracy by identifying errors at the point of entry.[13][17] |
| Centralized Database | Facilitates secure and efficient data management and access for authorized users.[18] |
| Audit Trails | Provides a secure, computer-generated, time-stamped record of all data changes.[15] |
| Standardized Data Formats | Ensures consistency across different study sites and trials.[16] |
Laboratory Data Collection
In a laboratory setting, robust data collection relies on controlled conditions, reproducibility, and the use of specialized equipment.[19]
Best Practices for Laboratory Data Collection:
| Practice | Description |
| Standard Operating Procedures (SOPs) | Adherence to detailed SOPs standardizes methods and reduces variability in data collection.[19][20] |
| Instrument Calibration | Regular calibration of instruments ensures the accuracy and precision of measurements.[21][22] |
| Replicate Measurements | Performing multiple measurements of the same sample provides insight into experimental variability.[19] |
| Use of Controls | Including control samples helps to validate the accuracy of the methodology.[19] |
| Comprehensive Documentation | Meticulous record-keeping of all experimental conditions and any deviations is crucial for reproducibility.[19] |
Section 3: Experimental Protocols
Protocol for Data Validation
Objective: To ensure that collected data is accurate, complete, and consistent.
Methodology:
-
Define Validation Rules: Before data collection begins, establish a clear set of validation rules. These rules should be based on the expected data types, ranges, and formats.[23][24]
-
Implement Automated Checks: Whenever possible, use an EDC system or other software to perform automated validation checks at the time of data entry.[17]
-
Data Type Check: Confirms that the data is of the correct type (e.g., numeric, text, date).[24][25]
-
Range Check: Ensures that numerical data falls within a predefined range.[24][25]
-
Format Check: Verifies that data conforms to a specific format (e.g., YYYY-MM-DD).[23][25]
-
Consistency Check: Ensures logical consistency between related data points.[23][25]
-
Uniqueness Check: Verifies that a value is unique within a dataset (e.g., subject ID).[23][25]
-
Presence Check: Confirms that required fields are not left empty.[23]
-
-
Manual Review: For data that cannot be validated automatically, implement a process for manual review by a trained data manager or researcher.
-
Query Management: Establish a system for raising and resolving data queries. This should involve clear communication between the data entry personnel and the data manager.
-
Source Data Verification (SDV): In clinical trials, perform SDV to compare the data in the EDC system with the original source documents.
Protocol for Data Security
Objective: To protect research data from unauthorized access, alteration, or destruction.
Methodology:
-
Access Control:
-
Implement role-based access control to ensure that users can only access the data necessary for their roles.
-
Use strong, unique passwords and multi-factor authentication where possible.[11]
-
-
Encryption:
-
Secure Storage:
-
Data Backup:
-
Physical Security:
Section 4: Visualizing Workflows and Pathways
Data Management Lifecycle
Caption: The lifecycle of research data from initial planning to final sharing and archiving.
Data Quality Control Workflow
Caption: A workflow for ensuring data quality through automated and manual validation checks.
References
- 1. mylaminin.net [mylaminin.net]
- 2. Rising Scholars - Best Practices for Managing Research Data [risingscholars.net]
- 3. How to create an efficient Data Management Plan? - Drugdesigntech SA [drugdesigntech.com]
- 4. FDA Explains How to Craft a Data Management Plan | RAPS [raps.org]
- 5. A guide to creating a clinical trial data management plan | Clinical Trials Hub [clinicaltrialshub.htq.org.au]
- 6. fda.gov [fda.gov]
- 7. cytel.com [cytel.com]
- 8. Foundational Practices of Research Data Management [riojournal.com]
- 9. k3techs.com [k3techs.com]
- 10. osp.uccs.edu [osp.uccs.edu]
- 11. Protect Your Field Research: 5 Best Practices for Data Security - SurveyCTO [surveycto.com]
- 12. SOP for Data Integrity | Pharmaguideline [pharmaguideline.com]
- 13. Electronic data capture - Wikipedia [en.wikipedia.org]
- 14. collectiveminds.health [collectiveminds.health]
- 15. clinion.com [clinion.com]
- 16. lindushealth.com [lindushealth.com]
- 17. llri.in [llri.in]
- 18. Best Practices and Tools for Laboratory Data Management [1lims.com]
- 19. solubilityofthings.com [solubilityofthings.com]
- 20. GMP Batch Record Design: SOPs & Recordkeeping for Pharma Compliance – Pharma GMP [pharmagmp.in]
- 21. Monitoring Quality Control: Can We Get Better Data? - PMC [pmc.ncbi.nlm.nih.gov]
- 22. srpcontrol.com [srpcontrol.com]
- 23. future-processing.com [future-processing.com]
- 24. Data validation - Wikipedia [en.wikipedia.org]
- 25. corporatefinanceinstitute.com [corporatefinanceinstitute.com]
- 26. Data Security Guidelines for Research | Ohio University [ohio.edu]
- 27. An Overview of Data Management in Human Subjects Research - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for Implementing Version Control in Reproducible Data Analysis
Audience: Researchers, scientists, and drug development professionals.
Introduction: The Imperative for Reproducibility in Data Analysis
In the realms of scientific research and drug development, the ability to reproduce analyses and results is a cornerstone of scientific rigor and regulatory compliance.[1][2][3] Version control systems (VCS) are powerful tools that track changes to files over time, enabling researchers to revisit specific versions of their work, collaborate effectively, and ensure the long-term reproducibility of their findings.[4][5] By recording the entire evolution of a project—from code and data to results and documentation—version control provides a transparent and auditable history.[1][6] This document provides detailed application notes and protocols for implementing version control, with a focus on tools and practices relevant to data-intensive research environments.
Core Concepts in Version Control
A foundational understanding of version control terminology is essential for its effective implementation. The most widely used version control system is Git, which forms the basis of many collaborative platforms like GitHub and GitLab.[6]
Key Terminology:
-
Repository (Repo): A digital directory where your project's files and their entire history of changes are stored.
-
Commit: A snapshot of your repository at a specific point in time. Each commit has a unique ID and a descriptive message.[4]
-
Branch: A parallel version of your repository, allowing you to develop new features or conduct experiments without altering the main project.[5]
-
Merge: The process of integrating changes from one branch into another.
-
Pull Request (PR): A request to merge your changes from a feature branch into the main branch, often used for code review and collaboration.[5]
Application Notes: Best Practices for Version Control in Research
Adhering to best practices ensures that version control enhances, rather than complicates, your research workflow.
-
Commit Early and Often: Make small, logical commits with clear and descriptive messages. This creates a granular history that is easy to navigate and understand.
-
Use Branches for New Analyses: Isolate new experiments, analyses, or feature development in separate branches. This protects the stability of your main branch and facilitates parallel work.
-
Leverage .gitignore: Create a .gitignore file in your repository to exclude unnecessary files from version control, such as temporary files, large raw data files (see section on large data), and sensitive information.
-
Document Everything: Use a README.md file to provide a comprehensive overview of the project, its structure, and instructions for reproducing the analysis.[3]
-
Consistent Project Structure: Organize your project with a clear and logical directory structure, separating raw data, processed data, analysis scripts, and results.[3]
Protocols for Reproducible Data Analysis Workflows
Protocol 1: Setting Up a Version-Controlled Research Project
This protocol outlines the initial steps for creating a new research project with version control using Git and GitHub.
Materials:
-
A computer with Git installed.
-
A GitHub account.
Procedure:
-
Create a New Repository on GitHub:
-
Log in to your GitHub account.
-
Click the "+" icon in the top-right corner and select "New repository."
-
Provide a descriptive name for your repository (e.g., project-drugx-analysis).
-
Add a brief description.
-
Initialize the repository with a README file, a .gitignore template (e.g., for Python or R), and a license (e.g., MIT or GPL).
-
Click "Create repository."
-
-
Clone the Repository to Your Local Machine:
-
On the GitHub repository page, click the "Code" button and copy the HTTPS or SSH URL.
-
Open a terminal or command prompt on your local machine.
-
Navigate to the directory where you want to store your project.
-
Execute the command: git clone
-
-
Establish Project Structure:
-
Navigate into the newly created project directory.
-
Create subdirectories to organize your project, for example:
-
data/raw/
-
data/processed/
-
scripts/
-
results/
-
docs/
-
-
-
Initial Commit and Push:
-
Add your project structure to the repository: git add .
-
Commit the changes with a descriptive message: git commit -m "Initial project structure"
-
Push the changes to your remote GitHub repository: git push origin main
-
Protocol 2: A Feature Branch Workflow for Data Analysis
This protocol describes a standard workflow for conducting a new analysis in a separate branch to ensure the integrity of the main branch.
Procedure:
-
Create a New Branch:
-
From your project's main branch, create a new branch for your analysis: git checkout -b feature/new-analysis
-
-
Conduct Your Analysis:
-
Add your raw data to the data/raw/ directory (if not already present).
-
Develop your analysis scripts in the scripts/ directory.
-
As you work, make regular commits to save your progress:
-
git add scripts/my_analysis.R
-
git commit -m "Add initial data processing steps"
-
-
-
Push Your Branch to GitHub:
-
Periodically push your feature branch to the remote repository to back up your work and facilitate collaboration: git push -u origin feature/new-analysis
-
-
Open a Pull Request:
-
When your analysis is complete and ready for review, navigate to your repository on GitHub.
-
GitHub will typically detect the new branch and prompt you to create a pull request.
-
Provide a clear title and description for your pull request, outlining the purpose and findings of your analysis.
-
-
Review and Merge:
-
Collaborators can now review your code and analysis, providing feedback directly within the pull request.
-
Once approved, the feature branch can be merged into the main branch, incorporating your new analysis into the project's primary record.
-
Handling Large Data in Version Control
Standard Git is not designed to handle large binary files, which are common in scientific research and drug development.[7] Versioning large datasets directly in Git can lead to a bloated and slow repository.[7] Specialized tools are available to address this challenge.
Tools for Large Data Versioning:
-
Git Large File Storage (LFS): An extension for Git that replaces large files with text pointers inside Git, while storing the file contents on a remote server.[7]
Protocol 3: Versioning Large Data with DVC
This protocol provides a basic workflow for tracking a large data file using DVC.
Materials:
-
A Git repository.
-
DVC installed (pip install dvc).
-
A remote storage location (e.g., an S3 bucket).
Procedure:
-
Initialize DVC:
-
In your Git repository, initialize DVC: dvc init
-
This creates a .dvc directory to store DVC's internal files.
-
-
Configure Remote Storage:
-
Set up your remote storage location: dvc remote add -d myremote s3://my-bucket/project-data
-
-
Track a Large Data File:
-
Add your large data file to DVC tracking: dvc add data/raw/large_dataset.csv
-
This creates a .dvc file that contains metadata about the original file.
-
-
Commit to Git:
-
Add the .dvc file to Git's staging area: git add data/raw/large_dataset.csv.dvc .gitignore
-
Commit the change: git commit -m "Add and track large_dataset.csv with DVC"
-
-
Push Data to Remote Storage:
-
Upload the data file to your configured remote storage: dvc push
-
-
Push Git Changes:
-
Push the Git commit to your remote repository: git push
-
Data Presentation: Comparison of Data Versioning Tools
The choice of a data versioning tool can impact performance and storage efficiency. The following table summarizes a performance comparison between S3, DVC, and Git LFS.
| Tool | Initial Upload (s) | Subsequent Upload (s) | Download (s) | Storage Approach |
| S3 | 59.51 | 50.83 | 238.90 | Stores every version of every file without deduplication.[10] |
| DVC | 111.73 | 11.79 | 8.88 | Uses pointers in Git and stores files in remote storage with file-level deduplication.[8][10] |
| Git LFS | 15.89 | 4.28 | 8.90 | Uses pointers in Git and stores files on an LFS server with file-level deduplication.[10] |
Data adapted from a benchmark study. Performance can vary based on project characteristics and infrastructure.[10]
Visualizing Workflows and Concepts
Basic Git Workflow
Caption: A diagram illustrating the basic workflow of moving changes between the workspace, staging area, local repository, and remote repository in Git.
Feature Branch Workflow
Caption: The feature branch workflow, showing the creation of a feature branch, a pull request for review, and the final merge into the main branch.
DVC and Git Integration for Large Data
References
- 1. The Top 7 Data Version Control Tools for 2023 | by Amy Devs Editor | Towards Dev [towardsdev.com]
- 2. blog.hrbopenresearch.org [blog.hrbopenresearch.org]
- 3. fiveable.me [fiveable.me]
- 4. A Reproducible Data Analysis Workflow With R Markdown, Git, Make, and Docker| Quantitative and Computational Methods in Behavioral Sciences [qcmb.psychopen.eu]
- 5. Chapter 8 Using GitHub in a workflow | Tools for Reproducible Workflows in R [hutchdatascience.org]
- 6. Research in progress blog Version control for scientific research [blogs.biomedcentral.com]
- 7. Git LFS and DVC: The Ultimate Guide to Managing Large Artifacts in MLOps | by Pablo jusue | Medium [medium.com]
- 8. Why Git LFS Is Not Good Practice for AI Model Weights and Why You Should Use DVC Instead (Demo with Azure Data Lake Storage 2) | by Neel Shah | Medium [medium.com]
- 9. ai.devtheworld.jp [ai.devtheworld.jp]
- 10. xethub.com [xethub.com]
Application Notes and Protocols for Enhancing Research Robustness Through Pre-registration
For Researchers, Scientists, and Drug Development Professionals
Application Notes: The Role of Pre-registration in Bolstering Research Integrity
Pre-registration is the practice of formally documenting a study's hypotheses, methodology, and analysis plan before the research begins.[1] This time-stamped, unalterable record is typically lodged in a public registry, serving as a transparent blueprint of the intended research. The primary aim of pre-registration is to enhance the credibility and robustness of research findings by mitigating biases that can arise during the research lifecycle.
In the context of drug development, where the stakes are exceptionally high, pre-registration provides a framework for rigorous, transparent, and reproducible science. It is a powerful tool to combat issues such as publication bias, p-hacking, and Hypothesizing After the Results are Known (HARKing), thereby fostering greater trust in research outcomes.[2][3]
Key Benefits of Pre-registration
-
Reduces Publication Bias: By creating a public record of planned studies, pre-registration helps to counter the "file drawer problem," where studies with null or negative findings are less likely to be published.[4] This ensures that the scientific literature provides a more complete and unbiased representation of the evidence.
-
Minimizes Questionable Research Practices: Pre-registration discourages practices like p-hacking (data dredging to find statistically significant results) and HARKing (presenting post-hoc hypotheses as if they were a priori).[1] By committing to an analysis plan in advance, researchers are less likely to be influenced by the data they collect.
-
Enhances Methodological Rigor: The process of creating a detailed pre-registration plan encourages researchers to think critically about their experimental design, sample size, and analysis methods before embarking on the study.[5] This can lead to more robust and well-powered studies.
-
Increases Transparency and Reproducibility: Publicly available pre-registration documents allow for greater transparency in the research process. Other researchers can compare the final publication with the original plan to assess the fidelity of the study and to aid in replication efforts.
Quantitative Impact of Pre-registration on Research Outcomes
The implementation of pre-registration has demonstrated a tangible impact on research findings, particularly in reducing the prevalence of positive results, which is often indicative of publication bias.
| Metric | Pre-Pre-registration Era | Post-Pre-registration Era | Key Finding |
| Publication of Positive Results in NHLBI-funded Clinical Trials | 57% of studies published before 2000 reported a significant benefit. | Only 8% of studies published after 2000 (when pre-registration was required) reported a significant benefit. | A dramatic decrease in the proportion of studies reporting positive primary outcomes after the mandate for pre-registration. |
| Discrepancies between Registered and Published Primary Outcomes | A meta-epidemiological study found that outcome switching occurred in 47% of observational studies.[3] | A systematic review identified discrepancies in the primary outcome in a median of 31% of clinical trials. | Outcome switching is a common issue, and pre-registration helps to identify and quantify these discrepancies. |
| Effect Sizes in Psychological Research | Meta-analyses of non-preregistered studies often show larger effect sizes. | A meta-analysis using a method to account for publication bias in non-preregistered studies found that the average effect size estimate is substantially closer to zero.[4] | Pre-registration can lead to more realistic and less inflated effect size estimates by mitigating publication bias. |
| Presence of a Pre-Analysis Plan (PAP) | Pre-registration without a detailed PAP showed no meaningful difference in the distribution of test statistics compared to non-pre-registered studies.[1][6] | Pre-registered studies with a complete PAP were found to be significantly less p-hacked.[1][6] | The inclusion of a detailed and specific Pre-Analysis Plan is crucial for pre-registration to be effective in reducing p-hacking. |
Protocols for Implementing Pre-registration
Step-by-Step Guide to Creating a Pre-registration Plan
A comprehensive pre-registration plan should be detailed enough for another researcher to replicate the study and the analysis without further information. The following steps, adapted from established guidelines and templates, provide a framework for creating a robust pre-registration document.[5][7][8]
-
Define the Study Information:
-
Title: A descriptive title of the study.
-
Authors and Affiliations: List all individuals who have contributed to the study design.
-
Research Questions: State the primary and secondary questions the study aims to answer.
-
Hypotheses: Clearly state all hypotheses to be tested, specifying whether they are directional or non-directional.
-
-
Detail the Experimental Design:
-
Study Type: Specify the type of study (e.g., randomized controlled trial, cohort study, in vitro experiment).
-
Blinding: Describe the level of blinding (e.g., double-blind, single-blind, not blinded) and who will be blinded.
-
Independent Variables: Define the variables that will be manipulated or observed.
-
Dependent Variables: Define the primary and secondary outcome variables.
-
Controls: Describe the control conditions or groups.
-
-
Outline the Sampling Plan:
-
Population: Describe the target population from which the sample will be drawn.
-
Inclusion and Exclusion Criteria: List the specific criteria for including and excluding participants or samples.
-
Sample Size: State the target sample size and provide a power analysis or justification for this size.
-
Sampling Method: Describe the method of sampling (e.g., random sampling, convenience sampling).
-
-
Specify the Experimental Procedures:
-
Materials and Instruments: List all materials, reagents, and instruments to be used.
-
Step-by-Step Procedures: Provide a detailed, sequential description of all experimental procedures. This should be comprehensive enough for another researcher to follow.
-
-
Develop a Detailed Analysis Plan (Pre-Analysis Plan - PAP):
-
Data Preprocessing: Describe how the raw data will be cleaned and prepared for analysis (e.g., handling of outliers, data transformations).
-
Statistical Models: Specify the statistical models that will be used to test each hypothesis.
-
Inference Criteria: Define the criteria for statistical significance (e.g., p-value threshold, confidence intervals).
-
Handling of Missing Data: Describe the strategy for dealing with missing data.
-
Subgroup and Sensitivity Analyses: If planned, specify any subgroup or sensitivity analyses that will be conducted.
-
Example Pre-registration Protocol for a Preclinical Drug Development Study
This is a synthesized, representative protocol for a preclinical study evaluating the efficacy of a novel compound in a mouse model of Alzheimer's disease.
Title: Efficacy of Compound XYZ on Cognitive Deficits and Amyloid-beta Pathology in the 5XFAD Mouse Model of Alzheimer's Disease.
1. Research Questions and Hypotheses:
-
Primary Research Question: Does chronic administration of Compound XYZ improve cognitive function in 5XFAD mice?
-
Secondary Research Question: Does chronic administration of Compound XYZ reduce amyloid-beta plaque burden in the hippocampus and cortex of 5XFAD mice?
-
Primary Hypothesis (directional): 5XFAD mice treated with Compound XYZ will show improved performance in the Morris Water Maze test compared to vehicle-treated 5XFAD mice.
-
Secondary Hypothesis (directional): 5XFAD mice treated with Compound XYZ will have a lower amyloid-beta plaque load in the hippocampus and cortex compared to vehicle-treated 5XFAD mice.
2. Experimental Design:
-
Study Type: In vivo, randomized, placebo-controlled, double-blind study.
-
Animals: 40 male 5XFAD transgenic mice and 20 male wild-type littermates, aged 3 months at the start of the experiment.
-
Groups:
-
Wild-type + Vehicle (n=10)
-
5XFAD + Vehicle (n=10)
-
5XFAD + Compound XYZ (10 mg/kg) (n=10)
-
5XFAD + Compound XYZ (30 mg/kg) (n=10)
-
-
Blinding: The experimenter conducting the behavioral tests and the pathologist analyzing the brain tissue will be blinded to the treatment groups.
-
Independent Variable: Treatment with Compound XYZ (0, 10, or 30 mg/kg).
-
Dependent Variables:
-
Primary: Escape latency and time spent in the target quadrant in the Morris Water Maze.
-
Secondary: Amyloid-beta plaque number and area in the hippocampus and cortex, measured by immunohistochemistry.
-
3. Experimental Procedures:
-
Drug Administration: Compound XYZ or vehicle will be administered daily via oral gavage for 3 months.
-
Morris Water Maze Protocol:
-
Acquisition Phase (5 days): Four trials per day. Mice will be trained to find a hidden platform in a circular pool of water. Escape latency will be recorded.
-
Probe Trial (Day 6): The platform will be removed, and mice will be allowed to swim for 60 seconds. The time spent in the target quadrant will be recorded.
-
-
Tissue Collection and Processing:
-
At the end of the treatment period, mice will be euthanized by transcardial perfusion with saline followed by 4% paraformaldehyde.
-
Brains will be removed, post-fixed, and cryoprotected.
-
Coronal sections (40 µm) will be cut using a cryostat.
-
-
Immunohistochemistry:
-
Free-floating sections will be stained with an anti-amyloid-beta antibody (6E10).
-
Sections will be incubated with a biotinylated secondary antibody and visualized using an avidin-biotin-peroxidase complex and diaminobenzidine.
-
-
Image Analysis:
-
Images of the hippocampus and cortex will be captured using a light microscope.
-
Plaque number and the percentage of area covered by plaques will be quantified using ImageJ software.
-
4. Analysis Plan:
-
Morris Water Maze Data:
-
Acquisition Phase: A two-way repeated-measures ANOVA will be used to analyze escape latency, with treatment group as the between-subjects factor and training day as the within-subjects factor.
-
Probe Trial: A one-way ANOVA followed by Tukey's post-hoc test will be used to compare the time spent in the target quadrant between the groups.
-
-
Immunohistochemistry Data:
-
A one-way ANOVA followed by Tukey's post-hoc test will be used to compare plaque number and plaque area between the treatment groups for each brain region (hippocampus and cortex).
-
-
Statistical Significance: A p-value of < 0.05 will be considered statistically significant.
-
Missing Data: If a mouse dies during the study, its data will be excluded from the analysis.
Visualizing Pre-registration Concepts with Graphviz
The Pre-registration Workflow
References
- 1. journals.uchicago.edu [journals.uchicago.edu]
- 2. researchgate.net [researchgate.net]
- 3. peerreviewcongress.org [peerreviewcongress.org]
- 4. Meta-analyzing nonpreregistered and preregistered studies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. cos.io [cos.io]
- 6. Do Pre-Registration and Pre-analysis Plans Reduce p-Hacking and Publication Bias? | Stanford Institute for Economic Policy Research (SIEPR) [siepr.stanford.edu]
- 7. Welcome to Registrations & Preregistrations! - OSF Support [help.osf.io]
- 8. osf.io [osf.io]
Application Notes and Protocols for Ensuring Robustness in Computational Simulations
Audience: Researchers, scientists, and drug development professionals.
Introduction
Computational simulations are integral to modern drug discovery and development, offering cost-effective and rapid methods for screening compounds, predicting toxicity, and understanding complex biological systems.[1] However, the predictive power of these in silico models is contingent upon their robustness and reproducibility.[1][2] Robustness, in this context, is the ability of a system or component to function correctly in the presence of invalid inputs or stressful environmental conditions.[3] These application notes and protocols provide a comprehensive framework for ensuring the robustness of computational simulations through rigorous validation, sensitivity analysis, and uncertainty quantification.
Core Principles of Robust Computational Modeling
To ensure the reliability of computational models, several core principles must be upheld throughout the modeling lifecycle. These include meticulous documentation, version control, and the use of standardized formats and workflows.
Key Recommendations:
-
Comprehensive Documentation: Fully document the model development process, including all simulation inputs, algorithms, and software versions used.[4]
-
Code and Data Sharing: Share model code and associated documentation in public repositories to enhance transparency and reproducibility.[4]
-
Standardized Formats: Utilize widely adopted standards for model representation, such as Systems Biology Markup Language (SBML) for systems biology models.
-
Reproducible Workflows: Employ workflow management systems like Nextflow or the Common Workflow Language (CWL) to automate and document computational experiments, ensuring they can be reproduced by others.[5][6][7][8]
A generalized workflow for ensuring the reproducibility of computational research is depicted below.
Methodologies for Ensuring Robustness
Three key methodologies are central to establishing the robustness of computational simulations: Sensitivity Analysis, Uncertainty Quantification, and Experimental Validation.
Sensitivity Analysis
Sensitivity analysis assesses how the uncertainty in the output of a model can be attributed to different sources of uncertainty in its inputs.[9] This helps identify the parameters that have the most significant impact on the simulation results.
This protocol outlines the steps for performing a Sobol sensitivity analysis, a variance-based method suitable for complex, non-linear models.[10][11][12][13]
-
Define Model Inputs and Outputs:
-
Inputs: Identify all model parameters (e.g., absorption rate, clearance, Emax, EC50).
-
Outputs: Define the key model outputs of interest (e.g., Cmax, AUC, tumor volume at a specific time point).
-
-
Specify Parameter Distributions:
-
For each input parameter, define a probability distribution (e.g., uniform, normal) that reflects its uncertainty. This can be based on literature values, experimental data, or expert opinion.
-
-
Generate Parameter Sets:
-
Use a quasi-random sampling method (e.g., Sobol sequences) to generate a set of parameter combinations that uniformly sample the parameter space.[10]
-
-
Run Model Simulations:
-
Execute the PK/PD model for each parameter set generated in the previous step.
-
-
Calculate Sobol Indices:
-
First-order indices (Si): Quantify the contribution of each individual parameter to the output variance.
-
Total-order indices (STi): Measure the total effect of a parameter, including its interactions with other parameters.
-
-
Analyze and Interpret Results:
-
Rank parameters based on their Sobol indices to identify the most influential ones.
-
A high Si indicates that the parameter has a strong direct effect on the output.
-
A large difference between STi and Si for a parameter suggests significant interaction effects with other parameters.
-
Uncertainty Quantification
Uncertainty quantification (UQ) aims to determine the uncertainty in model inputs and estimate the resultant uncertainty in model outputs.[14] This provides a probabilistic understanding of the model's predictions.
This protocol describes a general workflow for UQ using a sampling-based approach.
-
Identify Sources of Uncertainty:
-
Parameter Uncertainty: Arises from variability in experimental measurements used to determine model parameters.
-
Model Inadequacy: Stems from the simplifying assumptions made during model development.
-
-
Characterize Input Uncertainties:
-
Assign probability distributions to uncertain input parameters based on available data or expert knowledge.
-
-
Propagate Uncertainty:
-
Use a sampling method, such as Monte Carlo simulation, to propagate the input uncertainties through the model. This involves running the simulation numerous times with parameter values sampled from their respective distributions.
-
-
Quantify Output Uncertainty:
-
Analyze the distribution of the model outputs to quantify their uncertainty. This can be expressed as confidence intervals, prediction intervals, or probability density functions.
-
-
Model Validation and Discrepancy Quantification:
-
Compare the uncertain model predictions with experimental data to assess the model's validity.
-
Quantify the model discrepancy, which is the difference between the model predictions and the real-world system.
-
Experimental Validation
Experimental validation is crucial for building confidence in a computational model's predictive capabilities.[1] This involves comparing the model's predictions with real-world experimental data.
This protocol details a standard in vitro assay to determine the half-maximal inhibitory concentration (IC50) of a compound, a key metric for validating predictions of drug efficacy.[4][15]
-
Materials and Reagents:
-
Recombinant kinase
-
Kinase substrate (e.g., a peptide or protein)
-
ATP (Adenosine triphosphate)
-
Test compound (kinase inhibitor)
-
Assay buffer (e.g., Tris-HCl, MgCl2, DTT)
-
Detection reagent (e.g., ADP-Glo™ Kinase Assay kit)
-
384-well plates
-
Plate reader (luminometer)
-
-
Procedure:
-
Compound Preparation: Prepare a serial dilution of the test compound in the assay buffer.
-
Kinase Reaction:
-
Add the kinase and substrate to the wells of a 384-well plate.
-
Add the serially diluted test compound to the wells.
-
Initiate the kinase reaction by adding ATP.
-
Incubate the plate at the optimal temperature for the kinase for a specified time (e.g., 60 minutes).
-
-
Detection:
-
Stop the kinase reaction and add the detection reagent according to the manufacturer's instructions.
-
Incubate to allow the detection signal to develop.
-
-
Data Acquisition: Measure the luminescence of each well using a plate reader.
-
-
Data Analysis:
-
Subtract the background luminescence (no enzyme control) from all readings.
-
Calculate the percentage of kinase inhibition for each compound concentration relative to the vehicle control.
-
Plot the percentage of inhibition against the logarithm of the compound concentration and fit a sigmoidal dose-response curve to determine the IC50 value.
-
A hypothetical signaling pathway where a drug's predicted inhibition can be experimentally verified is shown below.
Western blotting can be used to measure changes in protein levels and phosphorylation states, providing experimental validation for computational models of signaling pathways.[9][16][17][18]
-
Cell Culture and Treatment:
-
Culture cells to the desired confluency.
-
Treat cells with the drug or stimulus as predicted by the computational model.
-
Include appropriate controls (e.g., untreated, vehicle control).
-
-
Protein Extraction:
-
Lyse the cells to extract total protein.
-
Determine the protein concentration of the lysates.
-
-
SDS-PAGE and Protein Transfer:
-
Separate the protein lysates by size using sodium dodecyl sulfate-polyacrylamide gel electrophoresis (SDS-PAGE).
-
Transfer the separated proteins to a membrane (e.g., nitrocellulose or PVDF).
-
-
Immunoblotting:
-
Block the membrane to prevent non-specific antibody binding.
-
Incubate the membrane with a primary antibody specific to the target protein (e.g., a phosphorylated form of a kinase).
-
Wash the membrane and incubate with a secondary antibody conjugated to an enzyme (e.g., horseradish peroxidase).
-
-
Detection:
-
Add a chemiluminescent substrate and detect the signal using an imaging system.
-
-
Analysis:
-
Quantify the band intensities to determine the relative changes in protein levels or phosphorylation.
-
Compare the experimental results with the predictions of the computational model.
-
Quantitative Data Summary
Summarizing quantitative data in a structured format is essential for comparing the performance of different models and methodologies.
Table 1: Comparison of Machine Learning Models for Drug Efficacy Prediction
| Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score | AUC |
| Random Forest | 85.2 | 88.1 | 81.5 | 84.7 | 0.92 |
| Support Vector Machine | 82.5 | 85.3 | 78.9 | 82.0 | 0.90 |
| Gradient Boosting | 87.1 | 90.2 | 83.6 | 86.8 | 0.94 |
| Deep Neural Network | 88.4 | 91.5 | 85.0 | 88.1 | 0.95 |
Data is hypothetical and for illustrative purposes.
Table 2: In Vitro IC50 Values for Kinase Inhibitors
| Inhibitor | Target Kinase | IC50 (nM) - Experimental | IC50 (nM) - Predicted | Fold Difference |
| Gefitinib | EGFR | 25 | 30 | 1.2 |
| Erlotinib | EGFR | 2 | 3 | 1.5 |
| Lapatinib | EGFR/HER2 | 10 / 12 | 15 / 18 | 1.5 / 1.5 |
| Sorafenib | VEGFR/PDGFR | 90 / 57 | 110 / 70 | 1.2 / 1.2 |
Data adapted from various sources for illustrative purposes.[15]
Conclusion
Ensuring the robustness of computational simulations is paramount for their effective application in drug discovery and development. By implementing rigorous methodologies for sensitivity analysis, uncertainty quantification, and experimental validation, researchers can build greater confidence in their in silico models. The protocols and guidelines presented in these application notes provide a framework for achieving robust and reproducible computational research, ultimately accelerating the discovery of new and effective therapeutics.
References
- 1. academic.oup.com [academic.oup.com]
- 2. Parameter Estimation and Uncertainty Quantification for Systems Biology Models - PMC [pmc.ncbi.nlm.nih.gov]
- 3. rtg.math.ncsu.edu [rtg.math.ncsu.edu]
- 4. benchchem.com [benchchem.com]
- 5. tcoffee.org [tcoffee.org]
- 6. [PDF] Nextflow enables reproducible computational workflows | Semantic Scholar [semanticscholar.org]
- 7. biorxiv.org [biorxiv.org]
- 8. researchgate.net [researchgate.net]
- 9. Dissect Signaling Pathways with Multiplex Western Blots | Thermo Fisher Scientific - JP [thermofisher.com]
- 10. researchgate.net [researchgate.net]
- 11. researchgate.net [researchgate.net]
- 12. mooseframework.inl.gov [mooseframework.inl.gov]
- 13. scilit.com [scilit.com]
- 14. Complete Sample Protocol for Measuring IC50 of Inhibitor PD168393 in A431 Cells Responding to Epidermal Gro... [protocols.io]
- 15. Assessing the Inhibitory Potential of Kinase Inhibitors In Vitro: Major Pitfalls and Suggestions for Improving Comparability of Data Using CK1 Inhibitors as an Example - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Western Blot Procedure | Cell Signaling Technology [cellsignal.com]
- 17. youtube.com [youtube.com]
- 18. origene.com [origene.com]
Troubleshooting & Optimization
How to identify and mitigate sources of bias in research
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals identify and mitigate sources of bias in their experiments.
Frequently Asked Questions (FAQs)
Q1: What are the main types of bias I should be concerned about in my research?
A1: Research bias is a systematic error that can lead to inaccurate results. The three primary types of bias are:
-
Selection Bias: Occurs when the study population is not representative of the target population you want to generalize your findings to.[1] This can happen through non-random sampling methods, high rates of non-response from specific groups, or significant loss of participants during follow-up.[1]
-
Information (or Classification) Bias: Arises from systematic errors in how data is measured or classified.[1] This can be due to faulty equipment, inconsistent data collection procedures, or inaccurate recall of past events by participants (recall bias).[1] Observer bias, where a researcher's expectations influence data recording, is another form of information bias.[1]
-
Confounding Bias: Occurs when a third, external variable is associated with both the exposure and the outcome, distorting the true relationship between them.[1][2] For example, if a study finds a link between coffee drinking and lung cancer, smoking could be a confounding variable as it's associated with both coffee drinking and an increased risk of lung cancer.[2]
Q2: How can I identify potential sources of bias in my experimental design?
A2: Critically evaluating your study plan is crucial for identifying potential biases before they occur. Here are some key areas to examine:
-
Sampling Method: Is your method for selecting participants truly random and representative of the population you are studying? Be wary of convenience sampling, which can introduce selection bias.
-
Blinding: Will participants, investigators, and outcome assessors be aware of the treatment allocations? A lack of blinding can introduce performance and detection bias.
-
Data Collection Tools: Are your measurement instruments validated and standardized? Inconsistent data collection can lead to information bias.
-
Reporting: Have you pre-specified your primary and secondary outcomes? Selectively reporting only favorable results leads to reporting bias.[3]
Q3: What is publication bias and how can I avoid contributing to it?
A3: Publication bias is the tendency for studies with positive or statistically significant results to be more likely to be published than those with negative or null results.[4][5] This can create a skewed perception of the evidence for a particular intervention or hypothesis.[4]
To mitigate publication bias, you can:
-
Pre-register your study protocol: This creates a public record of your study's objectives and methods before data collection begins.
-
Publish all results: Commit to publishing your findings regardless of the outcome. Journals are increasingly willing to publish high-quality studies with null or negative results.[6]
-
Share your data: Making your data available to other researchers promotes transparency and allows for more comprehensive meta-analyses.[4]
Troubleshooting Guides
Issue: I'm concerned about selection bias in my clinical trial.
This guide provides steps to mitigate selection bias during the design and execution of your research.
Experimental Protocol: Randomization Techniques
Randomization is a key method to reduce selection bias by ensuring that each participant has an equal chance of being assigned to any study group.[7][8]
1. Simple Randomization:
- Methodology: Each participant is assigned to a group using a random number generator or a similar method.
- Use Case: Best suited for large clinical trials.
- Limitation: In smaller trials, it can lead to an unequal number of participants in each group by chance.
2. Block Randomization:
- Methodology: Participants are divided into blocks of a predetermined size (e.g., 4, 6, 8). Within each block, a random sequence of treatment assignments is created to ensure an equal number of participants in each group within that block. For a block size of 4 and two treatments (A and B), possible sequences are AABB, ABAB, ABBA, BAAB, BABA, BBAA. A block is randomly chosen to assign treatments to the incoming participants.[9][10]
- Use Case: Useful for ensuring a balance between groups throughout the recruitment period, especially in smaller trials.[9]
- To Enhance Unpredictability: Use multiple block sizes and randomly select a new block size after each block is filled.[11]
3. Stratified Randomization:
- Methodology:
- Identify Strata: Define key baseline characteristics (strata) that could influence the outcome (e.g., age, disease severity).[2][12]
- Separate Randomization: Create separate block randomization lists for each stratum.[2]
- Assign Participants: When a new participant is enrolled, determine their stratum and then assign them to a treatment group using the randomization list for that specific stratum.[2]
- Use Case: Ensures that important prognostic factors are evenly distributed among the treatment groups.[2]
DOT Script for Randomization Workflow
Caption: Workflow for Stratified Randomization.
Issue: My results might be influenced by observer or participant expectations.
This guide outlines how to implement blinding to reduce information bias.
Experimental Protocol: Blinding Techniques
Blinding, or masking, prevents participants, clinicians, and outcome assessors from knowing which treatment a participant is receiving, thus reducing bias.[7]
-
Single-Blind: The participants are unaware of their treatment assignment.[13]
-
Double-Blind: Both the participants and the investigators/clinicians are unaware of the treatment assignments.[13][14][15] This is considered the gold standard for reducing bias.[16]
-
Triple-Blind: The participants, investigators, and the data analysts are all unaware of the treatment assignments until the study is completed.[13]
Methodology for Implementing a Double-Blind Study:
-
Identical Placebo: Create a placebo that is identical in appearance, taste, and smell to the active treatment.[13]
-
Third-Party Randomization and Coding: A third party, not involved in the study's conduct, should generate the randomization sequence and code the treatments (e.g., with unique numbers).[17]
-
Masked Treatment Administration: The coded treatments are given to the investigators, who administer them to participants according to the randomization schedule.
-
Blinded Outcome Assessment: The individuals assessing the outcomes should also be unaware of the treatment allocations.
-
Unblinding: The treatment codes are only revealed after the study is complete and the data has been analyzed.[17]
DOT Script for Blinding in a Clinical Trial
Caption: Triple-Blinding in a Clinical Trial.
Issue: I'm worried that a confounding variable is affecting my results.
This guide provides analytical approaches to mitigate confounding bias after data collection.
Analytical Protocol: Statistical Techniques to Control for Confounding
If potential confounders were measured during the study, you can use statistical methods to adjust for their effects.[2]
1. Stratification:
- Methodology: Analyze the relationship between the exposure and outcome separately within different levels (strata) of the confounding variable. For example, if smoking is a confounder, you would analyze the data for smokers and non-smokers separately.
- Benefit: It's a straightforward way to see if the association between exposure and outcome is consistent across different subgroups.
2. Multivariate Analysis:
- Methodology: Use statistical models that can account for multiple variables simultaneously. Common models include:
- Multiple Linear Regression: Used when the outcome variable is continuous.
- Logistic Regression: Used when the outcome variable is binary (e.g., yes/no, diseased/healthy).
- Analysis of Covariance (ANCOVA): Combines analysis of variance (ANOVA) and regression to control for the effects of confounding variables (covariates).[2]
- Benefit: Allows you to estimate the effect of the exposure on the outcome while statistically controlling for the influence of one or more confounding variables.[18]
3. Sensitivity Analysis:
- Methodology: Test how sensitive your study results are to the presence of an unmeasured confounder. This involves making assumptions about the strength of the relationship between the unmeasured confounder, the exposure, and the outcome, and then calculating how the results would change under these assumptions.
- Benefit: Helps you assess the robustness of your findings to potential unmeasured confounding.
DOT Script for Confounding Variable Relationship
References
- 1. Step-by-Step Guide to Stratified Random Sampling in Research - Insight7 - Call Analytics & AI Coaching for Customer Teams [insight7.io]
- 2. Unlocking Stratified Randomization: A Comprehensive Guide for Phase III Clinical Trials [cloudbyz.com]
- 3. Stratified Randomization Explained: A Complete Guide! [upgrad.com]
- 4. CONSORT 2025 statement: updated guideline for reporting randomised trials | The BMJ [bmj.com]
- 5. researchgate.net [researchgate.net]
- 6. d-nb.info [d-nb.info]
- 7. Sensitivity Analysis - Developing a Protocol for Observational Comparative Effectiveness Research: A User's Guide - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 8. editverse.com [editverse.com]
- 9. Blocked Randomization with Randomly Selected Block Sizes - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Sealed Envelope | Randomisation protocols [sealedenvelope.com]
- 11. quanticate.com [quanticate.com]
- 12. Stratified Random Sampling: A Full Guide [dovetail.com]
- 13. evidentiq.com [evidentiq.com]
- 14. Implementing the Double Blind Procedure for Research Studies [clinicaltrialsolutions.org]
- 15. verywellmind.com [verywellmind.com]
- 16. simplypsychology.org [simplypsychology.org]
- 17. viares.com [viares.com]
- 18. The PRISMA 2020 statement: an updated guideline for reporting systematic reviews - PubMed [pubmed.ncbi.nlm.nih.gov]
Technical Support Center: Troubleshooting Non-Reproducible Experimental Outcomes
This technical support center is designed to assist researchers, scientists, and drug development professionals in troubleshooting and resolving non-reproducible experimental outcomes. By addressing common issues encountered in key laboratory techniques, this guide aims to enhance experimental reliability and accelerate scientific discovery.
Frequently Asked Questions (FAQs)
Q1: What are the most common causes of non-reproducible experimental results?
Non-reproducible research is a significant issue, with studies suggesting that over 50% of preclinical research is not reproducible, costing an estimated $28 billion annually in the U.S. alone.[1][2] The primary causes can be broadly categorized into four main areas:
-
Faulty biological reagents and reference materials: This is considered the largest contributor, accounting for over a third of irreproducible preclinical studies.[1][3] This includes issues with cell line contamination or misidentification, and variability in reagent quality.[1][2]
-
Poor study design and data analysis: Flaws in experimental design, inadequate controls, small sample sizes, and the misuse of statistical analyses are major contributors to false-positive results.[1][2]
-
Lack of standardization in protocols: Variations in experimental protocols and analytical methods across different laboratories or even between individuals within the same lab can lead to inconsistent findings.[2]
-
Biological variability: Inherent differences in cell lines, primary tissues, and animal models can contribute to varied experimental outcomes.[2]
Q2: How can I minimize the impact of reagent variability on my experiments?
Reagent quality and consistency are critical for reproducible results.[4][5] Lot-to-lot variations in reagents, especially antibodies and cytokines, can significantly impact assay performance.[6][7]
-
Qualify new reagent lots: Before using a new batch of a critical reagent in a large-scale experiment, perform a small-scale validation experiment to compare its performance against the previous lot.
-
Standardize reagent preparation: Document and adhere to strict protocols for reagent reconstitution, storage, and handling.
-
Purchase from reputable suppliers: Source reagents from manufacturers with robust quality control and quality assurance procedures.[4]
-
Aliquot reagents: To avoid repeated freeze-thaw cycles that can degrade sensitive reagents, aliquot them into single-use volumes upon receipt.
Q3: My cell cultures are behaving inconsistently. What could be the problem?
Inconsistent cell culture behavior is a frequent source of experimental variability. Several factors can contribute to this issue:
-
Contamination: Mycoplasma, bacteria, and fungi are common contaminants that can alter cellular physiology and experimental outcomes.[8] Regular testing for mycoplasma is crucial as it is often not visible by standard microscopy.[8]
-
Temperature fluctuations: Mammalian cells are sensitive to temperature changes. Deviations from the optimal 37°C can affect growth rates, gene expression, and overall cell health.[8] Even brief periods outside the incubator can impact reproducibility.[8]
-
Inconsistent passaging: Variations in cell density at seeding, passage number, and the duration of enzymatic digestion can lead to divergent cell populations over time.
-
Media and supplement variability: Different lots of serum and media can have varying compositions, affecting cell growth and behavior.
Troubleshooting Guides
Cell Culture Contamination
Problem: Sudden cell death, cloudy media, or a rapid change in media pH.
Possible Cause & Solution:
| Possible Cause | How to Identify | Recommended Action |
| Bacterial Contamination | Media appears cloudy (turbid), rapid drop in pH (media turns yellow), visible small, motile particles between cells under a microscope.[8] | Discard the contaminated culture and decontaminate the incubator and biosafety cabinet. Review aseptic technique. |
| Yeast Contamination | Media becomes cloudy, small, budding, oval-shaped particles visible under a microscope. | Discard the contaminated culture and thoroughly clean the work area. |
| Fungal (Mold) Contamination | Visible filamentous structures (mycelia) or clumps of spores in the culture. The pH may be stable initially. | Immediately remove and discard the contaminated flask. Decontaminate all affected surfaces and equipment. |
| Mycoplasma Contamination | Often no visible signs. May cause changes in cell growth, morphology, or metabolism, leading to inconsistent results. | Regularly test cultures for mycoplasma using PCR-based or culture-based methods. If positive, discard the culture or treat with specific anti-mycoplasma agents if the cell line is irreplaceable. |
Western Blotting
Problem: No bands or weak signal on the western blot.
Possible Cause & Solution:
| Possible Cause | Recommended Troubleshooting Step |
| Inefficient Protein Transfer | Stain the membrane with Ponceau S after transfer to visualize protein bands. Also, stain the gel with Coomassie Blue after transfer to check for remaining protein. |
| Low Protein Concentration | Quantify protein concentration in your lysate using a protein assay (e.g., BCA or Bradford). |
| Inactive Antibody | Use a positive control known to express the target protein to validate antibody activity. |
| Suboptimal Antibody Concentration | The signal is very faint even with a positive control. |
| Insufficient Incubation Time | Short incubation times may not allow for adequate antibody binding. |
Enzyme-Linked Immunosorbent Assay (ELISA)
Problem: High background signal in an ELISA experiment.
Possible Cause & Solution:
| Possible Cause | Recommended Troubleshooting Step |
| Insufficient Washing | High signal in negative control wells. |
| Non-specific Antibody Binding | High signal across the entire plate. |
| Excessive Antibody Concentration | The entire plate develops color too quickly and intensely. |
| Contaminated Reagents | Random high-signal wells. |
| Prolonged Incubation Times | High signal in all wells, including blanks. |
Polymerase Chain Reaction (PCR)
Problem: Non-specific bands or no product in a PCR experiment.
Possible Cause & Solution:
| Possible Cause | Recommended Troubleshooting Step |
| Incorrect Annealing Temperature | Multiple bands or a smear is visible on the gel. |
| Primer-Dimers | A low molecular weight band (typically <100 bp) is observed, especially in the no-template control. |
| Poor Template Quality | No amplification or a smear. |
| Presence of PCR Inhibitors | No amplification in the sample but the positive control works. |
| Incorrect Magnesium Concentration | No product or non-specific products. |
Experimental Protocols
Western Blotting Protocol
This protocol provides a general guideline for performing a western blot. Optimization of specific steps may be required.
-
Sample Preparation:
-
Lyse cells or tissues in an appropriate lysis buffer containing protease and phosphatase inhibitors.
-
Determine the protein concentration of the lysate using a standard protein assay.
-
Mix the desired amount of protein (e.g., 20-30 µg) with Laemmli sample buffer and heat at 95-100°C for 5 minutes.[9]
-
-
Gel Electrophoresis:
-
Load samples into the wells of an SDS-PAGE gel.
-
Run the gel at a constant voltage until the dye front reaches the bottom.
-
-
Protein Transfer:
-
Blocking:
-
Incubate the membrane in a blocking buffer (e.g., 5% non-fat dry milk or BSA in TBST) for 1 hour at room temperature to prevent non-specific antibody binding.[1]
-
-
Antibody Incubation:
-
Incubate the membrane with the primary antibody diluted in blocking buffer, typically overnight at 4°C with gentle agitation.[10]
-
Wash the membrane three times with TBST for 5-10 minutes each.
-
Incubate the membrane with the appropriate HRP-conjugated secondary antibody diluted in blocking buffer for 1 hour at room temperature.[11]
-
Wash the membrane again as described above.
-
-
Detection:
-
Incubate the membrane with a chemiluminescent substrate (ECL) and detect the signal using an imaging system or X-ray film.[11]
-
Sandwich ELISA Protocol
This is a general protocol for a sandwich ELISA. Specific antibody concentrations and incubation times should be optimized.
-
Plate Coating:
-
Coat a 96-well microplate with the capture antibody diluted in a coating buffer (e.g., PBS).
-
Incubate overnight at 4°C.[12]
-
Wash the plate three times with wash buffer (e.g., PBS with 0.05% Tween-20).
-
-
Blocking:
-
Block the plate by adding a blocking buffer (e.g., 1% BSA in PBS) to each well.
-
Incubate for 1-2 hours at room temperature.[12]
-
Wash the plate as described above.
-
-
Sample Incubation:
-
Add standards and samples to the appropriate wells.
-
Incubate for 2 hours at room temperature.
-
Wash the plate four times.
-
-
Detection Antibody Incubation:
-
Add the biotinylated detection antibody diluted in blocking buffer to each well.
-
Incubate for 1-2 hours at room temperature.
-
Wash the plate four times.
-
-
Enzyme Conjugate Incubation:
-
Add streptavidin-HRP conjugate diluted in blocking buffer to each well.
-
Incubate for 20-30 minutes at room temperature in the dark.
-
Wash the plate four times.
-
-
Substrate Development and Measurement:
-
Add the TMB substrate solution to each well.
-
Incubate for 15-30 minutes at room temperature in the dark.
-
Stop the reaction by adding a stop solution (e.g., 2N H2SO4).
-
Read the absorbance at 450 nm using a microplate reader.
-
PCR Protocol for Gene Expression Analysis (RT-qPCR)
This protocol outlines the steps for a two-step RT-qPCR.
-
RNA Extraction and Quantification:
-
Extract total RNA from cells or tissues using a suitable method.
-
Assess RNA quality and quantity using a spectrophotometer and gel electrophoresis.
-
-
Reverse Transcription (cDNA Synthesis):
-
Synthesize cDNA from the RNA template using a reverse transcriptase enzyme and a mix of random primers or oligo(dT) primers.
-
Incubate the reaction according to the manufacturer's protocol (e.g., 25°C for 10 min, 50°C for 50 min, 85°C for 5 min).
-
-
Quantitative PCR (qPCR):
-
Prepare a qPCR master mix containing SYBR Green or a TaqMan probe, forward and reverse primers, and the synthesized cDNA template.
-
Run the qPCR reaction in a real-time PCR cycler using a typical program:
-
Initial denaturation: 95°C for 2-10 minutes.
-
Cycling (40 cycles):
-
Denaturation: 95°C for 15 seconds.
-
Annealing/Extension: 60°C for 1 minute.[13]
-
-
Melt curve analysis (for SYBR Green).
-
-
-
Data Analysis:
-
Determine the cycle threshold (Ct) values for your gene of interest and a reference (housekeeping) gene.
-
Calculate the relative gene expression using the ΔΔCt method.
-
Visualizations
Experimental Workflow: Troubleshooting Inconsistent Western Blot Results
References
- 1. ELISA - Wikipedia [en.wikipedia.org]
- 2. A comprehensive pathway map of epidermal growth factor receptor signaling - PMC [pmc.ncbi.nlm.nih.gov]
- 3. addgene.org [addgene.org]
- 4. chem.libretexts.org [chem.libretexts.org]
- 5. tandfonline.com [tandfonline.com]
- 6. reddit.com [reddit.com]
- 7. researchgate.net [researchgate.net]
- 8. Temperature in cell culture - Cellculture2 [cellculture2.altervista.org]
- 9. bio-rad.com [bio-rad.com]
- 10. bosterbio.com [bosterbio.com]
- 11. york.ac.uk [york.ac.uk]
- 12. praxilabs.com [praxilabs.com]
- 13. quora.com [quora.com]
How to handle outliers for more robust data analysis
Technical Support Center: Robust Data Analysis
This guide provides researchers, scientists, and drug development professionals with a comprehensive resource for identifying and handling outliers to ensure more robust and accurate data analysis.
Frequently Asked Questions (FAQs)
Q1: What is an outlier and why is it a concern in data analysis?
Q2: How can I identify potential outliers in my dataset?
There are several methods for identifying outliers, which can be broadly categorized into visual and statistical techniques.[4]
-
Visual Inspection: This is often the first step. Plotting your data using box plots, scatterplots, and histograms can provide an intuitive way to spot points that lie far from the main data cluster.[4][7][8]
-
Statistical Methods: These provide more objective, mathematical approaches. Common methods include:
-
Z-Score: This method measures how many standard deviations a data point is from the mean.[9] A common rule of thumb is to consider points with a Z-score greater than 3 or less than -3 as outliers.[9]
-
Interquartile Range (IQR): This method is robust for data that isn't normally distributed.[7] Outliers are typically defined as values that fall below Q1 - 1.5IQR or above Q3 + 1.5IQR.[7][9]
-
Dixon's Q Test: A suitable test for smaller datasets (under 10 observations) that does not require assumptions about the data's distribution.[10]
-
Grubbs' Test: This test checks if an extreme value is a statistically significant outlier.[11]
-
Q3: Should I always remove outliers from my data?
No, removing outliers is not always the correct approach and should be done with caution. The decision depends on the cause of the outlier.[12]
-
Legitimate Removal: It is appropriate to remove an outlier if you can confirm it resulted from a data entry or measurement error that cannot be corrected, or if the data point does not belong to the population you are studying.[12]
-
Inappropriate Removal: You should not remove an outlier simply because it weakens your hypothesis or makes your results less statistically significant.[12][13] Genuine extreme values can be very informative and may represent natural variation or a novel discovery within your study population.[3][12] Resisting the temptation to remove outliers inappropriately is crucial for maintaining the integrity of your research.[12]
Q4: What are the primary methods for handling outliers?
Once an outlier is identified, you can choose from several handling strategies depending on its nature and the goals of your analysis.
-
Correction: If the outlier is a confirmed data entry or measurement error, the best approach is to correct it if possible.[12]
-
Removal (Trimming): Involves deleting the outlier data point(s) from the dataset. This is only recommended for confirmed errors that cannot be corrected.[2][7]
-
Transformation: Applying a mathematical function (e.g., taking the logarithm) to your data can reduce the influence of extreme values.[7][14] This technique compresses the range of values, making the data more suitable for certain parametric tests.[7]
-
Imputation (Replacement): This involves replacing the outlier with an estimated value, such as the mean, median, or mode of the variable.[2][7] More advanced methods can use regression or machine learning models to predict a more reasonable value.[7]
-
Winsorization (Capping): This method involves replacing the most extreme values with less extreme ones, specifically the nearest value that is not an outlier.[15] For instance, the top 5% of data might be replaced by the value at the 95th percentile.
-
Using Robust Methods: Instead of altering the data, you can use statistical methods that are naturally less sensitive to outliers.[7][12]
Q5: How should I report the handling of outliers in my research?
Transparency is critical.[14] You must document all decisions and actions taken regarding outliers to ensure your analysis is reproducible.[7] If you remove or modify any data points, you should state this clearly in your methodology section, including a footnote explaining which points were removed and how the results changed.[5] Always report your rationale for the chosen handling method.[14]
Troubleshooting Guides
Issue: My data is not normally distributed. Are Z-scores still appropriate for outlier detection?
Solution:
For skewed or non-normally distributed data, the Z-score method is not ideal because it relies on the mean and standard deviation, which are themselves sensitive to outliers.[16] A more robust alternative is the Interquartile Range (IQR) method , as it is based on the median and is less affected by extreme values.[7][10] Non-parametric tests, which do not assume a normal distribution, are also robust to outliers.[12]
Issue: I have found an extreme data point, but I can't determine if it's an error or a true biological variant.
Solution:
This is a common challenge in experimental sciences. The first step is to investigate the underlying cause.[12]
-
Review Experimental Records: Check lab notebooks, instrument logs, and sample handling records for any documented anomalies or deviations from protocol.
-
Re-measure if Possible: If the sample is available and stable, re-running the measurement can help confirm or refute the original value.[12]
Issue: Removing an outlier makes my results statistically significant. Is this practice acceptable?
Solution:
This practice is generally considered unethical and scientifically unsound.[12][13] Removing data points solely to achieve a desired outcome is a form of data manipulation.[12] An outlier should only be removed for legitimate reasons, such as a confirmed error.[12] If an outlier is a genuine part of your dataset's natural variation, it must be kept.[12] If its presence violates the assumptions of your chosen statistical test, you should use a more robust statistical method that can handle the outlier rather than removing the data point itself.[12]
Data Presentation: Comparison of Outlier Handling Techniques
| Method | Description | Best For | Considerations |
| Correction | Fixing typos or re-measuring to correct an erroneous data point. | Confirmed measurement or data entry errors. | The original source of the error must be identifiable and correctable.[12] |
| Removal (Trimming) | Deleting the outlier observation from the dataset.[2] | Data points known to be incorrect or not part of the study population.[12] | Can reduce statistical power, especially in small datasets. Should be used sparingly. |
| Transformation | Applying a mathematical function (e.g., log, square root) to the data.[7] | Skewed data where extreme values distort the distribution. | Can make the interpretation of results less intuitive as the original scale is lost.[7] |
| Imputation | Replacing the outlier with a statistical estimate like the mean, median, or a predicted value.[7] | Situations where removing the data point would result in significant loss of information. | Simple imputation (mean/median) can reduce variance; advanced methods are more complex.[7] |
| Winsorization | Replacing extreme values with the highest and lowest non-outlier values.[2] | Reducing the influence of outliers while retaining the data point in the dataset. | The choice of percentile for capping is subjective and can influence results.[15] |
| Robust Statistics | Using analytical methods that are inherently less sensitive to outliers.[7][12] | Datasets with legitimate extreme values that should not be removed or altered. | Includes methods like non-parametric tests, robust regression, and median-based measures.[12] |
Experimental Protocols
Methodology: Outlier Identification using the Interquartile Range (IQR)
This protocol describes a robust method for identifying outliers that does not require the data to be normally distributed.[7][10]
Objective: To identify data points that lie an abnormal distance from the central tendency of the data.
Procedure:
-
Sort the Data: Arrange all data points in the variable of interest in ascending order.[9]
-
Calculate Quartiles:
-
Compute the IQR: Calculate the interquartile range by subtracting the first quartile from the third quartile (IQR = Q3 - Q1). The IQR represents the range of the middle 50% of your data.[9]
-
Define Outlier Fences:
-
Identify Outliers: Any data point that falls below the lower fence or above the upper fence is classified as a potential outlier.[9]
Visualizations
Workflow Diagrams
Caption: A workflow for identifying potential outliers in a dataset.
References
- 1. simplilearn.com [simplilearn.com]
- 2. Mastering Outlier Detection and Treatment: A Comprehensive Guide | by Rahul Sharma | Medium [nachi-keta.medium.com]
- 3. Why Detecting Outliers is Crucial for Accurate Data Analysis? [dasca.org]
- 4. machinelearningmastery.com [machinelearningmastery.com]
- 5. Outliers in Statistical Analysis: How Serious They Are and What To Do | by M. Reza Roshandel | Medium [medium.com]
- 6. Evaluating Outlier Impact on Time Series Data Analysis - Magnimind Academy [magnimindacademy.com]
- 7. kdnuggets.com [kdnuggets.com]
- 8. bigdataelearning.com [bigdataelearning.com]
- 9. How to Find Outliers | 4 Ways with Examples & Explanation [scribbr.com]
- 10. pharmtech.com [pharmtech.com]
- 11. editverse.com [editverse.com]
- 12. statisticsbyjim.com [statisticsbyjim.com]
- 13. publications - Do I have to report all data and how should I deal with outliers if there are too many? - Academia Stack Exchange [academia.stackexchange.com]
- 14. Taming outliers in biomedical research: A handy guide | Editage Insights [editage.com]
- 15. Mastering Outlier Management: Techniques to Improve Data Quality | by FATIMA EL MOUEDDANE | Medium [medium.com]
- 16. thedocs.worldbank.org [thedocs.worldbank.org]
Technical Support Center: Refining Experimental Protocols for Enhanced Result Stability
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals enhance the stability and reproducibility of their experimental results. The guides are presented in a question-and-answer format to directly address specific issues encountered during common laboratory procedures.
General Laboratory Practices
Q1: How can I improve the overall reproducibility of my experiments?
A1: Ensuring day-to-day reproducibility requires a multi-faceted approach focusing on detailed documentation, consistent execution, and robust data analysis. Implementing standardized protocols and data management plans is crucial for minimizing variability.[1][2][3] Senior investigators should actively oversee experimental details and encourage a culture of transparency and rigor within the lab.[1][2]
Key Recommendations for Enhancing Reproducibility:
-
Detailed Protocols: Document every step of your experimental procedure with explicit details, including reagent concentrations, incubation times, and specific equipment used.[1]
-
Data Management Plan: Specify your data analysis plan before starting the experiment to reduce selective reporting.[1]
-
Active Oversight: Senior lab members should periodically audit raw data and oversee experiments to ensure adherence to protocols.[1]
-
Open Communication: Foster an environment where all team members feel empowered to voice concerns about potential issues or deviations.[1]
Western Blot Troubleshooting
Q2: I'm observing high background on my Western blots. What are the common causes and how can I fix it?
A2: High background on a Western blot can obscure the signal from your protein of interest and manifests as a uniform dark haze or non-specific bands.[4] This issue can arise from several factors throughout the Western blot workflow.[5][6]
Troubleshooting High Background in Western Blotting
| Potential Cause | Recommended Solution |
| Insufficient Blocking | Increase blocking time (e.g., 2 hours at room temperature or overnight at 4°C). Increase the concentration of the blocking agent (e.g., 3-5% BSA or non-fat dry milk).[6][7] Add 0.05% Tween-20 to the blocking buffer.[6] |
| High Antibody Concentration | Titrate the primary and secondary antibodies to determine the optimal concentration that provides a strong signal with low background.[8] |
| Inadequate Washing | Increase the number of wash steps (e.g., 4-5 washes for 5 minutes each).[6] Ensure the membrane is fully submerged and agitated during washes.[6] Increase the Tween-20 concentration in the wash buffer to 0.1%.[6] |
| Membrane Drying Out | Ensure the membrane remains covered in buffer at all times during incubations and washes.[8][9] |
| Contaminated Buffers | Prepare fresh buffers and filter them before use to remove any microbial or particulate contamination.[9] |
| Overexposure | Reduce the exposure time during signal detection.[6][7] |
Q3: My Western blot shows weak or no signal. What should I check?
A3: A weak or absent signal can be frustrating and may stem from issues in sample preparation, protein transfer, or antibody incubation steps.[5][7]
Troubleshooting Weak or No Signal in Western Blotting
| Potential Cause | Recommended Solution |
| Inefficient Protein Transfer | Verify transfer efficiency by staining the membrane with Ponceau S after transfer.[5] Ensure good contact between the gel and the membrane, and that the transfer sandwich is assembled correctly.[5] Optimize transfer time and voltage/current.[5] |
| Low Protein Loading | Increase the amount of protein loaded onto the gel, especially for low-abundance proteins. |
| Suboptimal Antibody Concentration | Increase the concentration of the primary antibody.[7] Extend the primary antibody incubation time (e.g., overnight at 4°C).[7] Ensure the secondary antibody is appropriate for the primary antibody and used at the correct dilution. |
| Inactive Antibody | Check the antibody's expiration date and storage conditions.[7] Avoid repeated freeze-thaw cycles. |
| Issues with Detection Reagents | Ensure that the substrate has not expired and is prepared correctly. |
ELISA Troubleshooting
Q4: I am experiencing high background in my ELISA assay. What are the likely causes and solutions?
A4: High background in an ELISA, characterized by high optical density (OD) readings in negative control wells, can reduce the assay's sensitivity and lead to inaccurate results.[10][11][12]
Troubleshooting High Background in ELISA
| Potential Cause | Recommended Solution |
| Insufficient Washing | Increase the number of wash cycles and ensure complete aspiration of wash buffer from the wells.[10][11][12] Verify the performance of the plate washer.[10] |
| High Antibody Concentration | Titrate the detection antibody to find the optimal concentration. |
| Prolonged Incubation Time | Strictly adhere to the incubation times specified in the protocol.[12] |
| Contaminated Reagents or Water | Use high-quality, sterile water for preparing buffers.[10] Ensure reagents are not contaminated with microbes or other substances.[10][11] |
| Substrate Deterioration | Ensure the substrate solution is colorless before adding it to the plate.[10] |
| Cross-Contamination | Use fresh pipette tips for each reagent and sample to avoid cross-well contamination.[10] |
Q5: My ELISA standard curve is poor or non-linear. How can I improve it?
A5: A reliable standard curve is essential for accurate quantification in ELISA.[13] A poor standard curve can result from several issues, including incorrect dilutions and pipetting errors.
Acceptable Parameters for ELISA Standard Curve
| Parameter | Acceptable Range/Criteria |
| Coefficient of Determination (R²) | ≥ 0.99 indicates a good fit for the curve. |
| Optical Density (OD) of Blank | Should be low, typically < 0.2. |
| OD Range of Standards | The linear portion of the curve is most reliable for quantification.[7] Some sources suggest an optimal maximum OD of 1.0-2.0.[14][15] |
| Coefficient of Variation (%CV) for Replicates | Should be ≤ 20%. |
PCR/qPCR Troubleshooting
Q6: I'm getting low or no yield of my PCR product. What are the possible reasons?
A6: Low or no amplification in PCR can be due to a variety of factors, from suboptimal reaction components to incorrect cycling conditions.[14][16]
Troubleshooting Low or No PCR Product Yield
| Potential Cause | Recommended Solution |
| Poor Template Quality or Quantity | Assess DNA/RNA purity (A260/280 ratio should be ~1.8 for DNA and ~2.0 for RNA).[17] Increase the amount of template in the reaction.[13] |
| Suboptimal Primer Design or Concentration | Verify primer specificity and check for secondary structures.[16][18] Optimize primer concentration (typically 0.1-0.5 µM). |
| Incorrect Annealing Temperature | Optimize the annealing temperature using a gradient PCR. A good starting point is 5°C below the lowest primer Tm.[17] |
| Issues with PCR Reagents | Ensure all components were added to the reaction mix.[16] Use fresh dNTPs and ensure the polymerase is active.[16] |
| Insufficient Number of Cycles | Increase the number of PCR cycles (typically 25-35 cycles).[13][18] |
Q7: My qPCR results show high variability between technical replicates. What could be the cause?
Acceptable Variation in qPCR Technical Replicates
| Parameter | Acceptable Range |
| Standard Deviation of Cq values | Should be < 0.25 for triplicate technical replicates.[21] |
| Difference in Cq values | Replicates with Cq values differing by more than 0.5 cycles should be re-evaluated.[22] |
Cell Culture Troubleshooting
Q8: I suspect my cell culture is contaminated. What are the signs and how can I prevent it?
A8: Cell culture contamination is a common problem that can lead to unreliable experimental results and loss of valuable cell lines.[23][24][25] Contaminants can be biological (bacteria, fungi, mycoplasma, other cell lines) or chemical.[26][27]
Identifying and Preventing Cell Culture Contamination
| Type of Contamination | Signs of Contamination | Prevention Strategies |
| Bacterial | Sudden drop in pH (media turns yellow), cloudy media, visible moving particles under the microscope.[24][25] | Strict aseptic technique, regular sterilization of equipment, use of sterile reagents.[23][24] |
| Fungal (Yeast/Mold) | Visible filamentous structures (mold) or small, budding particles (yeast) in the media. Media may become cloudy.[25] | Maintain a clean and dry incubator, filter all media and solutions. |
| Mycoplasma | Often no visible signs, but can alter cell growth, metabolism, and morphology.[3][22] | Regular testing for mycoplasma, quarantine new cell lines. |
| Cross-Contamination | Unexpected cell morphology, changes in growth rate. | Handle only one cell line at a time in the biosafety cabinet, clearly label all flasks and plates, and practice good aseptic technique.[23] |
Experimental Protocols
Detailed Western Blot Protocol
-
Sample Preparation:
-
Lyse cells or tissues in RIPA buffer supplemented with protease and phosphatase inhibitors.
-
Determine protein concentration using a BCA assay.
-
Mix protein lysates with 4x Laemmli sample buffer and heat at 95-100°C for 5 minutes.
-
-
Gel Electrophoresis:
-
Load 20-30 µg of protein per well onto an SDS-PAGE gel.
-
Run the gel in 1x Tris-Glycine-SDS running buffer at 100-150V until the dye front reaches the bottom.
-
-
Protein Transfer:
-
Blocking and Antibody Incubation:
-
Block the membrane in 5% non-fat dry milk or BSA in TBST (Tris-buffered saline with 0.1% Tween-20) for 1 hour at room temperature.[6]
-
Incubate the membrane with the primary antibody (diluted in blocking buffer) overnight at 4°C with gentle agitation.[6]
-
Wash the membrane three times for 5-10 minutes each with TBST.
-
Incubate with the HRP-conjugated secondary antibody (diluted in blocking buffer) for 1 hour at room temperature.[5]
-
Wash the membrane three times for 10 minutes each with TBST.
-
-
Detection:
-
Incubate the membrane with a chemiluminescent substrate.
-
Detect the signal using an imaging system.
-
Standard Sandwich ELISA Protocol
-
Plate Coating:
-
Coat a 96-well plate with 100 µL/well of capture antibody diluted in coating buffer (e.g., 1-10 µg/mL in PBS).
-
Incubate overnight at 4°C.[23]
-
-
Blocking:
-
Wash the plate three times with wash buffer (PBST).
-
Block the plate with 200 µL/well of blocking buffer (e.g., 1% BSA in PBST) for 1-2 hours at room temperature.[9]
-
-
Sample and Standard Incubation:
-
Wash the plate three times with wash buffer.
-
Add 100 µL/well of standards and samples (in duplicate or triplicate) to the plate.
-
Incubate for 2 hours at room temperature.[29]
-
-
Detection Antibody Incubation:
-
Wash the plate three times with wash buffer.
-
Add 100 µL/well of biotinylated detection antibody diluted in blocking buffer.
-
Incubate for 1-2 hours at room temperature.[29]
-
-
Enzyme Conjugate Incubation:
-
Substrate Development and Measurement:
Visualizations
MAPK/ERK Signaling Pathway
Caption: Simplified MAPK/ERK signaling cascade from cell surface to nucleus.
Experimental Workflow for High-Throughput Drug Screening
Caption: Workflow for a typical high-throughput drug screening campaign.
References
- 1. licorbio.com [licorbio.com]
- 2. polytechnique-insights.com [polytechnique-insights.com]
- 3. Contamination [qiagen.com]
- 4. protocols.io [protocols.io]
- 5. Western blot normalization - Wikipedia [en.wikipedia.org]
- 6. bioscience.co.uk [bioscience.co.uk]
- 7. betalifesci.com [betalifesci.com]
- 8. eag.com [eag.com]
- 9. sciencedaily.com [sciencedaily.com]
- 10. licorbio.com [licorbio.com]
- 11. Guide to western blot quantification | Abcam [abcam.com]
- 12. Western Blot Band Quantification | MtoZ Biolabs [mtoz-biolabs.com]
- 13. Data analysis for ELISA | Abcam [abcam.com]
- 14. researchgate.net [researchgate.net]
- 15. Recommended maximum OD values in ELISA optimization. What's the reason? - ELISA and Immunoassay [protocol-online.org]
- 16. Replication crisis - Wikipedia [en.wikipedia.org]
- 17. Troubleshooting ELISA | U-CyTech [ucytech.com]
- 18. quantics.co.uk [quantics.co.uk]
- 19. drugtargetreview.com [drugtargetreview.com]
- 20. cephamls.com [cephamls.com]
- 21. genomique.iric.ca [genomique.iric.ca]
- 22. Use and Misuse of Cq in qPCR Data Analysis and Reporting - PMC [pmc.ncbi.nlm.nih.gov]
- 23. bioradiations.com [bioradiations.com]
- 24. researchgate.net [researchgate.net]
- 25. ELISA Troubleshooting Guide | Sino Biological [sinobiological.com]
- 26. bio-rad.com [bio-rad.com]
- 27. A Beginner’s Guide to Cell Culture: Practical Advice for Preventing Needless Problems - PMC [pmc.ncbi.nlm.nih.gov]
- 28. researchgate.net [researchgate.net]
- 29. nas.org [nas.org]
Technical Support Center: Enhancing Transparency and Openness in Research
Welcome to the Technical Support Center for Improving the Transparency and Openness of Research Methods. This resource is designed for researchers, scientists, and drug development professionals to navigate the practical challenges of implementing open science principles in their daily experimental work. Here you will find troubleshooting guides and frequently asked questions (FAQs) in a user-friendly question-and-answer format to directly address specific issues you may encounter.
FAQs and Troubleshooting Guides
This section provides answers to common questions and solutions to problems you might face during your research lifecycle, from initial study design to publication and data sharing.
Preregistration
Q: My preregistration was rejected. What are the common reasons and how can I fix them?
A: Preregistration rejection can be disheartening, but it's often a fixable issue. Common rejection reasons include:
-
Lack of a clear distinction between confirmatory and exploratory analyses: Your preregistration should explicitly state which hypotheses are being tested confirmatory (with pre-specified analyses) and which analyses are exploratory.
-
Vague or ambiguous analysis plans: Phrases like "we will explore the relationship between X and Y" are too general. Specify the exact statistical tests you will use.[1]
-
Incomplete information: Ensure all sections of the preregistration form are filled out with sufficient detail.[2] This includes defining all variables, outlining the sampling plan, and specifying the criteria for data exclusion.
-
Mismatched information: Ensure consistency across all documents. For example, the information in your preregistration should match your ethics approval.
Troubleshooting Steps:
-
Review the feedback carefully: The reviewers will typically provide specific reasons for rejection.
-
Revise your plan: Address each of the reviewer's points directly. If you need to add more detail to your analysis plan, do so.
-
Use a template: Many repositories like the Open Science Framework (OSF) provide detailed templates to guide you.[1]
-
Seek clarification: If the feedback is unclear, don't hesitate to contact the editors or the preregistration platform for clarification.
Q: Can I deviate from my preregistered plan?
A: Yes, deviations are permissible, but they must be transparently reported in your final research paper.[3] Unforeseen circumstances, such as issues with data collection or the need for a more appropriate statistical test, can necessitate changes to your original plan.[3] The key is to document the deviation and provide a clear justification for the change.[3]
Data Sharing and Management
Q: How do I choose the right data repository for my research?
A: Selecting an appropriate data repository is crucial for long-term data preservation and accessibility. Consider the following factors:
-
Discipline-specific vs. generalist repositories: Discipline-specific repositories are often preferred as they cater to the data standards and needs of a particular research community.
-
Funder and journal requirements: Many funding agencies and journals recommend or mandate the use of specific repositories.
-
Repository features: Look for repositories that provide persistent identifiers (like DOIs), support data citation, and have clear policies on data preservation and access.
Here is a comparison of some popular generalist data repositories:
| Feature | Dryad | Figshare | Zenodo | Open Science Framework (OSF) |
| Primary Focus | Curation and preservation of scientific and medical research data | Universal repository for all research outputs | General-purpose open-access repository | Project management and collaboration platform |
| Storage Limits (Free Tier) | 20 GB per dataset | 20 GB total | 50 GB per dataset | 5 GB per private project, 50 GB per public project |
| Cost | Data Publication Charge (DPC) per submission | Freemium model with paid options for more storage | Free | Free |
| Persistent Identifiers | DOIs | DOIs | DOIs | DOIs |
| Licensing | Creative Commons licenses | Various open licenses | Various open licenses | Various open licenses |
| Versioning | Yes | Yes | Yes | Yes |
Q: How do I anonymize sensitive data for sharing?
A: Anonymizing data is a critical step when sharing information about human participants. The goal is to remove or alter personally identifiable information (PII) to protect participant privacy.
Troubleshooting Common Anonymization Errors:
-
Incomplete anonymization: Simply removing names is often not enough. Other "indirect identifiers" like location, dates, or unique demographic combinations can be used to re-identify individuals.
-
Using weak anonymization methods: For example, replacing names with initials is not a robust method.
-
Not considering the risk of re-identification: Datasets can sometimes be linked with other publicly available information to re-identify participants.
Best Practices for Anonymization:
-
Identify all direct and indirect identifiers: Direct identifiers include names, addresses, and social security numbers. Indirect identifiers can include age, gender, occupation, and location.
-
Apply appropriate anonymization techniques:
-
Suppression: Removing an identifier completely.
-
Generalization: Replacing a specific value with a more general one (e.g., replacing an exact age with an age range).
-
Pseudonymization: Replacing an identifier with a randomly generated one.
-
-
Assess the risk of re-identification: After anonymization, evaluate the dataset to ensure that the risk of re-identifying individuals is minimized.
Peer Review
Q: How should I respond to a reviewer who requests additional experiments that are beyond the scope of my study?
A: This is a common and often challenging situation. Here's a step-by-step guide to formulating a professional and effective response:
-
Acknowledge and thank the reviewer: Begin by thanking the reviewer for their thoughtful suggestion.
-
Politely and respectfully disagree: Clearly state that you believe the suggested experiments are outside the scope of the current study.
-
Provide a clear and concise justification: Explain why the experiments are out of scope. For example, they might address a different research question, require a different set of methodologies, or be a substantial project in their own right.[4][5]
-
Suggest it as a direction for future research: Frame the reviewer's suggestion as a valuable idea for a future study. This shows that you have considered their input seriously.[5][6]
-
Offer to add a limitation to your manuscript: If appropriate, you can offer to add a sentence to the limitations section of your discussion, acknowledging that the requested experiment was not performed and could be an area for future investigation.
Example Response:
Q: A reviewer has criticized my statistical methods. How should I respond?
A: Critiques of statistical methods are common and should be addressed carefully and thoroughly.
Troubleshooting Steps:
-
Understand the criticism: Make sure you fully understand the reviewer's concern. If their comment is unclear, you can politely ask for clarification in your response.[7]
-
Re-evaluate your analysis: Objectively assess whether the reviewer's point is valid. It's possible that a different statistical approach would be more appropriate.
-
Consult a statistician: If you are unsure about the best course of action, consider consulting with a statistician.
-
Formulate your response:
-
If you agree with the reviewer: Thank them for their feedback, explain that you have re-analyzed the data using the suggested method, and present the new results.
-
If you disagree with the reviewer: Thank them for their suggestion, but politely explain why you believe your original statistical approach is appropriate for your data and research question. Provide a clear and well-supported justification, citing relevant statistical literature if possible.
-
Detailed Experimental Protocols
To enhance reproducibility, it is essential to provide detailed experimental protocols. Below are key components to include when documenting your methods.
Key Components of a Reproducible Protocol
A well-written protocol should be a standalone document that allows another researcher to replicate your experiment with minimal ambiguity.[4]
-
Introduction/Background: Briefly explain the purpose of the protocol and any relevant background information.
-
Materials and Reagents:
-
List all reagents, including the manufacturer, catalog number, and lot number.
-
Specify all equipment used, including the model and manufacturer.
-
Detail the preparation of all solutions and media.
-
-
Step-by-Step Procedure:
-
Provide a clear, chronological sequence of steps.[4]
-
Use precise language and avoid jargon.
-
Specify exact quantities, concentrations, incubation times, and temperatures.
-
-
Data Collection and Analysis:
-
Describe how data will be collected and recorded.
-
Specify the statistical methods that will be used for analysis.
-
-
Troubleshooting and Notes:
-
Include a section with tips and tricks for avoiding common pitfalls.[4]
-
Provide guidance on what to do if something goes wrong.
-
Mandatory Visualizations
The following diagrams illustrate key workflows and relationships in the research process. They are created using the Graphviz DOT language to ensure clarity and reproducibility.
The Peer Review Process
Caption: A flowchart of the typical academic peer review process.
Data Sharing Workflow
Caption: A workflow for preparing and sharing research data.
Decision Tree for Open Access Publishing
Caption: A decision tree to guide researchers in choosing an open access publishing route.
References
- 1. researchgate.net [researchgate.net]
- 2. lornajane.net [lornajane.net]
- 3. online.ucpress.edu [online.ucpress.edu]
- 4. How can I reply to peer review comments requesting additional experiments? | Editage Insights [editage.com]
- 5. researchgate.net [researchgate.net]
- 6. internationalscienceediting.com [internationalscienceediting.com]
- 7. How I respond to peer reviewer comments - PMC [pmc.ncbi.nlm.nih.gov]
Validation & Comparative
A Comparative Guide to Validating the Robustness of a New Analytical Method
In the rigorous landscape of pharmaceutical development and scientific research, ensuring the reliability of a new analytical method is paramount. Robustness testing is a critical component of method validation that demonstrates the method's capacity to remain unaffected by small, deliberate variations in its parameters. This guide provides a comprehensive comparison of two principal strategies for robustness testing: the traditional "One Factor at a Time" (OFAT) approach and the more modern "Design of Experiments" (DoE) methodology. This comparison is supported by experimental data, detailed protocols, and visualizations to aid researchers, scientists, and drug development professionals in selecting and implementing the most appropriate strategy for their needs.
Comparison of Robustness Testing Strategies: OFAT vs. DoE
The choice between OFAT and DoE for robustness testing has significant implications for the efficiency and comprehensiveness of the validation process. While OFAT is straightforward in its approach, DoE offers a more holistic understanding of the method's performance.
Key Differences:
| Feature | One Factor at a Time (OFAT) | Design of Experiments (DoE) |
| Experimental Approach | Varies one factor while keeping others constant. | Systematically varies multiple factors simultaneously. |
| Efficiency | Can be time-consuming and require a large number of experiments, especially with many factors.[1] | More efficient, requiring fewer experimental runs to assess multiple factors and their interactions.[1][2] |
| Data Quality | Provides limited information on the individual effects of each factor. | Reveals not only the main effects of each factor but also their interactions, providing a more complete picture of the method's robustness.[2] |
| Predictive Power | Limited predictive capability for conditions not explicitly tested. | Allows for the development of predictive models to understand the method's performance within a defined design space. |
| Regulatory Acceptance | Historically accepted but may be viewed as less rigorous. | Increasingly preferred by regulatory bodies like the FDA and EMA due to its scientific rigor and alignment with Quality by Design (QbD) principles.[3][4] |
Quantitative Comparison of Experimental Runs
To illustrate the efficiency of DoE, consider a hypothetical robustness study for an HPLC method with seven factors.
| Experimental Design | Number of Factors | Number of Experimental Runs |
| OFAT | 7 | 15 (1 nominal + 2 for each of the 7 factors) |
| Plackett-Burman (DoE) | 7 | 8 to 12 |
| Full Factorial (DoE) | 7 | 128 (2^7) |
As the table demonstrates, a Plackett-Burman design, a type of fractional factorial DoE, significantly reduces the number of required experiments compared to both OFAT and a full factorial design, making it a highly efficient screening tool for identifying critical factors.[5][6]
Experimental Protocols
Detailed methodologies are crucial for the successful implementation of robustness testing. Below are protocols for both the OFAT and a Plackett-Burman DoE approach for a typical HPLC method.
Protocol 1: Robustness Testing using OFAT
Objective: To assess the impact of individual variations in HPLC method parameters on the assay results.
Method Parameters and Variations:
| Parameter | Nominal Value | Lower Level (-) | Upper Level (+) |
| Flow Rate (mL/min) | 1.0 | 0.9 | 1.1 |
| Column Temperature (°C) | 30 | 28 | 32 |
| Mobile Phase pH | 6.8 | 6.6 | 7.0 |
| % Organic in Mobile Phase | 50 | 48 | 52 |
| Wavelength (nm) | 254 | 252 | 256 |
| Injection Volume (µL) | 10 | 9 | 11 |
| Column Lot | Lot A | Lot B | Lot C |
Procedure:
-
Prepare a standard solution of the analyte at a known concentration.
-
Perform an initial set of injections (n=3) using the nominal method parameters to establish a baseline.
-
Vary the first parameter (e.g., Flow Rate) to its lower level (0.9 mL/min) while keeping all other parameters at their nominal values. Perform a set of injections (n=3).
-
Vary the same parameter to its upper level (1.1 mL/min) and perform another set of injections (n=3).
-
Return the first parameter to its nominal value.
-
Repeat steps 3-5 for each of the remaining parameters, one at a time.
-
Analyze the data for key responses such as peak area, retention time, tailing factor, and resolution.
-
Calculate the mean and relative standard deviation (RSD) for each condition and compare them to the nominal condition.
Protocol 2: Robustness Testing using a Plackett-Burman Design (DoE)
Objective: To efficiently screen for critical HPLC method parameters that significantly impact the assay results.
Experimental Design: A 12-run Plackett-Burman design will be used to study the seven factors from the previous example. The design matrix is as follows:
| Run | Flow Rate | Temp. | pH | % Organic | Wavelength | Inj. Vol. | Column Lot |
| 1 | + | + | - | + | + | + | - |
| 2 | - | + | + | - | + | + | + |
| 3 | + | - | + | + | - | + | + |
| 4 | - | + | - | + | + | - | + |
| 5 | + | - | + | - | + | + | - |
| 6 | - | + | + | + | - | + | - |
| 7 | + | + | + | - | + | - | + |
| 8 | - | - | - | - | - | - | - |
| 9 | + | + | - | - | - | + | + |
| 10 | - | - | + | + | + | - | - |
| 11 | + | - | - | + | - | - | + |
| 12 | - | + | - | - | + | - | - |
(Note: "+" represents the high level and "-" represents the low level of the factor)
Procedure:
-
Prepare a standard solution of the analyte at a known concentration.
-
For each of the 12 experimental runs, set the HPLC parameters according to the design matrix.
-
Perform a set of injections (n=3) for each run.
-
Record the key responses (peak area, retention time, tailing factor, resolution) for each run.
-
Analyze the results using statistical software to determine the main effect of each factor on the responses.
-
Generate Pareto charts and normal probability plots to visualize the significance of each factor.
Data Presentation
The following tables present illustrative data from a hypothetical robustness study of an HPLC method for the assay of a drug substance.
Table 1: OFAT Robustness Study Results
| Parameter Varied | Level | Peak Area (mAU*s) | Retention Time (min) | Tailing Factor | Resolution |
| Nominal | - | 1250 ± 10 | 5.00 ± 0.02 | 1.10 ± 0.01 | 2.5 ± 0.1 |
| Flow Rate | 0.9 mL/min | 1388 ± 12 | 5.55 ± 0.03 | 1.12 ± 0.02 | 2.6 ± 0.1 |
| 1.1 mL/min | 1136 ± 9 | 4.55 ± 0.02 | 1.08 ± 0.01 | 2.4 ± 0.1 | |
| Temperature | 28 °C | 1255 ± 11 | 5.10 ± 0.02 | 1.11 ± 0.01 | 2.5 ± 0.1 |
| 32 °C | 1245 ± 10 | 4.90 ± 0.02 | 1.09 ± 0.01 | 2.5 ± 0.1 | |
| pH | 6.6 | 1248 ± 13 | 5.25 ± 0.03 | 1.15 ± 0.02 | 2.2 ± 0.1 |
| 7.0 | 1252 ± 11 | 4.75 ± 0.02 | 1.05 ± 0.01 | 2.8 ± 0.1 | |
| % Organic | 48% | 1247 ± 12 | 5.80 ± 0.03 | 1.13 ± 0.02 | 2.7 ± 0.1 |
| 52% | 1253 ± 10 | 4.20 ± 0.02 | 1.07 ± 0.01 | 2.3 ± 0.1 |
Table 2: DoE (Plackett-Burman) Main Effects on Peak Area
| Factor | Main Effect Estimate | p-value | Significance |
| Flow Rate | -125.5 | < 0.01 | Significant |
| Temperature | -5.2 | 0.65 | Not Significant |
| pH | 15.8 | 0.23 | Not Significant |
| % Organic | -89.3 | < 0.05 | Significant |
| Wavelength | 2.1 | 0.89 | Not Significant |
| Injection Volume | 110.7 | < 0.01 | Significant |
| Column Lot | 8.5 | 0.52 | Not Significant |
The DoE results clearly identify Flow Rate, % Organic, and Injection Volume as the most critical parameters affecting the peak area.
Mandatory Visualization
Diagrams are essential for visualizing complex processes and relationships in analytical method validation.
Caption: Workflow for conducting a robustness study of an analytical method.
Caption: Conceptual comparison of OFAT and DoE experimental approaches.
Conclusion
Validating the robustness of a new analytical method is a non-negotiable step in ensuring data quality and regulatory compliance. While the OFAT approach is simple to implement, the Design of Experiments (DoE) methodology offers a more efficient, comprehensive, and scientifically sound strategy. By understanding the interactions between method parameters, DoE provides a deeper understanding of the method's capabilities and limitations, ultimately leading to more robust and reliable analytical procedures. This guide provides the necessary framework for researchers to make an informed decision on the most suitable robustness testing strategy for their specific needs.
References
Parametric vs. Non-parametric Tests: A Fundamental Divide
A Guide to the Robustness of Common Statistical Tests
For researchers, scientists, and professionals in drug development, selecting the appropriate statistical test is a critical step in ensuring the validity and reliability of experimental findings. While many are familiar with standard statistical tests, a deeper understanding of their "robustness" is essential for handling real-world data that may not meet ideal assumptions. A robust statistical test is one that performs well and provides reliable results even when its underlying assumptions are not fully met.[1][2][3][4] This guide provides a comparative overview of the robustness of several common statistical tests, supported by experimental data and methodological insights.
Statistical tests are broadly categorized into parametric and non-parametric tests.
-
Parametric tests , such as the t-test and Analysis of Variance (ANOVA), assume that the data are drawn from a population with a specific distribution, often a normal distribution.[5][6] They also frequently assume homogeneity of variances (i.e., the variance is equal across groups) and that the data are independent.[3][7]
-
Non-parametric tests , like the Mann-Whitney U test and the Kruskal-Wallis test, make fewer assumptions about the data's distribution.[1][8] They are often used when the assumptions of parametric tests are violated, particularly the normality assumption.[8][9][10]
Comparing Robustness: t-test vs. Mann-Whitney U and ANOVA vs. Kruskal-Wallis
The choice between a parametric test and its non-parametric counterpart often hinges on the robustness of the parametric test to violations of its assumptions.
Student's t-test vs. Mann-Whitney U Test
The Student's t-test is used to compare the means of two groups, while the Mann-Whitney U test (also known as the Wilcoxon rank-sum test) compares the distributions of two groups by analyzing the ranks of the data.[11]
-
Violation of Normality: The t-test is remarkably robust to deviations from normality, especially with larger sample sizes (typically n ≥ 30 for each group).[9] This robustness is attributed to the Central Limit Theorem, which states that the distribution of sample means will tend to be normal as the sample size increases, regardless of the population's distribution.[8] For smaller sample sizes or when the data is heavily skewed or contains significant outliers, the Mann-Whitney U test is often more powerful and appropriate.[7][8][9]
-
Violation of Homogeneity of Variances: The t-test is less robust to the violation of the assumption of equal variances, especially when the sample sizes of the two groups are unequal.[12][13] When variances are unequal, Welch's t-test, a modification of the Student's t-test, is a more reliable alternative as it does not assume equal variances.[12][14] While the Mann-Whitney U test does not assume normality, it does assume that the shape of the distributions in the two groups is similar.
ANOVA vs. Kruskal-Wallis Test
ANOVA is an extension of the t-test used to compare the means of three or more groups.[5] The Kruskal-Wallis test is its non-parametric alternative.[10]
-
Violation of Normality: Similar to the t-test, ANOVA is considered robust to violations of the normality assumption, particularly with large sample sizes.[2][15] However, with small sample sizes or highly skewed data, the Kruskal-Wallis test is a more suitable choice.[10]
-
Violation of Homogeneity of Variances: ANOVA's robustness to heterogeneity of variance is compromised when group sample sizes are unequal.[16][17] If the larger sample size is paired with the larger variance, the ANOVA F-test can be too liberal (increasing the Type I error rate). Conversely, if the smaller sample size is paired with the larger variance, the test can be too conservative. When variances are unequal, Welch's ANOVA or other robust methods are recommended.[18] Studies have shown that while the Kruskal-Wallis test is competitive with ANOVA in terms of controlling for Type I error, its statistical power can be significantly affected by unequal variances.[19][20]
Data Summary
The following tables summarize the key characteristics and robustness of these statistical tests.
Table 1: Characteristics of Common Statistical Tests
| Test | Type | Purpose | Key Assumptions |
| Student's t-test | Parametric | Compares the means of two independent groups. | 1. Data are normally distributed within each group.2. Variances of the two groups are equal.3. Observations are independent. |
| Mann-Whitney U Test | Non-parametric | Compares the distributions of two independent groups. | 1. Observations are independent.2. Data are at least ordinal.3. The distributions of the two groups have the same shape. |
| ANOVA | Parametric | Compares the means of three or more independent groups. | 1. Data are normally distributed within each group.2. Variances of the groups are equal.3. Observations are independent. |
| Kruskal-Wallis Test | Non-parametric | Compares the distributions of three or more independent groups. | 1. Observations are independent.2. Data are at least ordinal.3. The distributions of the groups have the same shape. |
Table 2: Robustness to Assumption Violations
| Test | Violation of Normality | Violation of Homogeneity of Variances |
| Student's t-test | Robust, especially with larger sample sizes (n ≥ 30).[9] | Not robust, especially with unequal sample sizes. Welch's t-test is a better alternative.[12][13] |
| Mann-Whitney U Test | Not applicable as it does not assume normality. Can be more powerful than the t-test when data is non-normal.[7][21] | Assumes similar distribution shapes, which includes variance. Performance can be affected. |
| ANOVA | Robust, especially with larger sample sizes.[2][15] | Not robust, especially with unequal sample sizes.[16][17] |
| Kruskal-Wallis Test | Not applicable as it does not assume normality. A good alternative to ANOVA for non-normal data.[10][22] | Power can be negatively impacted by unequal variances.[19][20] |
Experimental Protocols
The robustness of statistical tests is often evaluated through Monte Carlo simulation studies . A typical protocol for such a study is as follows:
-
Data Generation:
-
Define a set of population distributions to sample from. This typically includes the normal distribution as a baseline and various non-normal distributions (e.g., skewed, heavy-tailed).
-
Specify the population parameters, including the means and variances for each group being compared.
-
Generate a large number of random samples (e.g., 10,000) from these defined populations under different conditions:
-
Normality: Data drawn from normal vs. non-normal distributions.
-
Homogeneity of Variance: Equal vs. unequal population variances.
-
Sample Size: Equal vs. unequal sample sizes across groups.
-
-
-
Application of Statistical Tests:
-
For each generated sample, apply the statistical tests being compared (e.g., t-test and Mann-Whitney U test).
-
Record the p-value for each test.
-
-
Performance Evaluation:
-
Type I Error Rate: When the null hypothesis is true (e.g., no difference in population means), the Type I error rate is the proportion of simulations where the p-value is less than the significance level (e.g., α = 0.05). A robust test should have a Type I error rate close to the specified alpha level.
-
Statistical Power: When the null hypothesis is false (e.g., there is a true difference in population means), the power is the proportion of simulations where the p-value is less than the significance level. A robust test should maintain high power to detect a true effect under various conditions.
-
-
Analysis of Results:
-
Compare the Type I error rates and power of the different tests across the various simulated conditions.
-
Summarize the findings in tables and charts to illustrate the relative robustness of each test.
-
Visualization of Test Selection Logic
The following diagram illustrates a decision-making workflow for selecting an appropriate statistical test based on data characteristics.
Caption: A flowchart for selecting an appropriate statistical test.
References
- 1. m.youtube.com [m.youtube.com]
- 2. hypothesis testing - What does it mean for a statistical test to be "robust"? - Cross Validated [stats.stackexchange.com]
- 3. Robustness & robust tests – PSYCTC.org [psyctc.org]
- 4. statisticsbyjim.com [statisticsbyjim.com]
- 5. 6sigma.us [6sigma.us]
- 6. What to do when data is not normally distributed in statistics [statsig.com]
- 7. Normality, and when to use t-test vs. Mann-Whitney U-test? - Cross Validated [stats.stackexchange.com]
- 8. What to do with nonnormal data - Minitab [support.minitab.com]
- 9. researchgate.net [researchgate.net]
- 10. isixsigma.com [isixsigma.com]
- 11. campus.datacamp.com [campus.datacamp.com]
- 12. statisticshowto.com [statisticshowto.com]
- 13. Influence of highly unequal sample sizes on statistical tests and data visualization - Cross Validated [stats.stackexchange.com]
- 14. t Test: unequal variances | Real Statistics Using Excel [real-statistics.com]
- 15. hypothesis testing - Should I use Kruskal-Wallis or Anova? - Cross Validated [stats.stackexchange.com]
- 16. Understanding test for equal variances - Minitab [support.minitab.com]
- 17. researchgate.net [researchgate.net]
- 18. researchgate.net [researchgate.net]
- 19. ERIC - ED091423 - The ANOVA F-Test Versus The Kruskal-Wallis Test: A Robustness Study., 1974-Apr [eric.ed.gov]
- 20. A COMPARISON OF THE KRUSKAL-WALLIS TEST WITH ANOVA UNDER VIOLATIONS OF HOMOGENEITY OF VARIANCE - ProQuest [proquest.com]
- 21. anova - Power of a Mann Whitney test compared to a t test - Cross Validated [stats.stackexchange.com]
- 22. researchgate.net [researchgate.net]
A Researcher's Guide to Cross-Validation Techniques for Assessing Model Robustness
In the realms of scientific research and drug development, the ability to build robust and generalizable predictive models is paramount. A model that performs exceptionally well on the data it was trained on, but fails to predict outcomes on new, unseen data is of little practical use. To this end, cross-validation is an indispensable set of techniques for rigorously assessing a model's performance and its ability to generalize to independent datasets. This guide provides a comparative overview of common cross-validation methods, their experimental application, and quantitative performance data to aid researchers in selecting the most appropriate technique for their needs.
Comparison of Cross-Validation Techniques
The choice of a cross-validation strategy depends on several factors, including the size and nature of the dataset, the computational resources available, and the specific goals of the modeling task. Below is a summary of key cross-validation techniques and their characteristics.
| Technique | Description | Advantages | Disadvantages | Best Suited For |
| K-Fold Cross-Validation | The dataset is randomly partitioned into 'k' equal-sized subsets or "folds". The model is trained on k-1 folds and validated on the remaining fold. This process is repeated k times, with each fold used exactly once as the validation set.[1][2] | - Simple to understand and implement.[1] - Generally provides a less biased estimate of model performance than a simple train/test split.[1] - Computationally efficient for most datasets.[3] | - Performance estimate can have high variance, especially for small k. - May not be suitable for imbalanced datasets as folds may not have a representative distribution of classes. | General-purpose model evaluation, particularly with balanced datasets.[4] |
| Stratified K-Fold Cross-Validation | A variation of k-fold cross-validation where each fold contains approximately the same percentage of samples of each target class as the complete set.[5] | - Ensures that each fold is representative of the overall class distribution.[4] - Provides a more reliable and less biased estimate of model performance on imbalanced datasets. | - Can be slightly more computationally expensive than standard k-fold. | Classification problems with imbalanced datasets.[4] |
| Leave-One-Out Cross-Validation (LOOCV) | An extreme case of k-fold cross-validation where k is equal to the number of samples in the dataset. For a dataset with 'n' samples, the model is trained on n-1 samples and tested on the single remaining sample, repeated n times.[5] | - Provides a nearly unbiased estimate of model performance as it uses almost the entire dataset for training in each iteration.[6] | - Computationally very expensive, especially for large datasets.[3] - The estimate of the test error can have high variance because the training sets are highly correlated.[6][7] | Small datasets where maximizing the training data in each fold is critical. |
| Monte Carlo Cross-Validation (Repeated Random Sub-sampling) | The dataset is randomly split into training and validation sets multiple times. The proportion of the split (e.g., 80% training, 20% validation) is fixed, and the process is repeated for a specified number of iterations. | - The number of iterations and the training/validation split size are not dependent on the number of folds. - Can provide a smoother estimate of the model performance. | - Some data points may be selected multiple times in the validation set, while others may never be selected. - The results can have some variability due to the random sampling. | Situations where a flexible number of iterations and split proportions are desired. |
| Nested Cross-Validation | This method involves two nested loops of cross-validation. The outer loop splits the data to evaluate the final model's performance, while the inner loop is used for hyperparameter tuning. | - Provides a less biased estimate of the model's generalization error when hyperparameter tuning is performed. - Helps to prevent overfitting during the model selection and tuning process. | - Computationally very expensive due to the nested loops. | When hyperparameter tuning is a critical part of the modeling pipeline and a robust estimate of the final model's performance is required. |
Experimental Protocols
To objectively compare the performance of different cross-validation techniques, a well-defined experimental protocol is essential. The following outlines a general methodology that can be adapted for specific research questions.
Objective:
To compare the performance and computational cost of K-Fold, Stratified K-Fold, and Leave-One-Out Cross-Validation on a given dataset and machine learning model.
Materials:
-
Dataset: A well-characterized dataset relevant to the research domain (e.g., a public benchmark dataset from UCI or a proprietary drug discovery dataset). The dataset should be pre-processed to handle missing values and normalize features.
-
Machine Learning Models: A selection of classification or regression models (e.g., Support Vector Machine (SVM), Random Forest (RF)).
-
Computational Resources: A computing environment with sufficient processing power and memory to handle the computational demands of the different cross-validation techniques.
-
Software: A programming language and libraries for machine learning (e.g., Python with scikit-learn).
Methodology:
-
Dataset Preparation:
-
Load the dataset and perform initial exploratory data analysis to understand its characteristics (e.g., number of samples, features, class distribution).
-
If comparing performance on imbalanced vs. balanced data, create two versions of the dataset. The imbalanced version will be the original dataset (if applicable), and a balanced version can be created using techniques like random undersampling of the majority class or oversampling of the minority class (e.g., using SMOTE).
-
-
Model Selection and Hyperparameter Tuning (Optional but Recommended):
-
For each machine learning model (e.g., SVM, RF), define a grid of hyperparameters to be evaluated.
-
For a fair comparison, it is recommended to perform hyperparameter tuning within each training fold of the cross-validation loop (nested cross-validation approach) to avoid data leakage.
-
-
Cross-Validation Implementation:
-
For each machine learning model:
-
Implement K-Fold Cross-Validation:
-
Set the number of folds (k), typically 5 or 10.
-
For each fold, train the model on the k-1 training folds and evaluate it on the held-out validation fold.
-
Record the performance metrics for each fold.
-
-
Implement Stratified K-Fold Cross-Validation:
-
Set the number of folds (k), typically 5 or 10.
-
The process is the same as K-Fold, but the data is split in a stratified manner.
-
Record the performance metrics for each fold.
-
-
Implement Leave-One-Out Cross-Validation:
-
For each sample in the dataset, train the model on all other samples and test on the single held-out sample.
-
Record the performance metric for each iteration.
-
-
-
-
Performance Evaluation:
-
For each cross-validation technique and model combination, calculate the average and standard deviation of the following performance metrics across all folds/iterations:
-
For classification tasks: Accuracy, Precision, Recall, F1-Score, and Area Under the Receiver Operating Characteristic Curve (AUC-ROC).
-
For regression tasks: Mean Squared Error (MSE), Root Mean Squared Error (RMSE), and R-squared.
-
-
Measure and record the total computational time taken to execute each cross-validation procedure for each model.
-
-
Data Analysis and Comparison:
-
Summarize the averaged performance metrics and computational times in a structured table for easy comparison.
-
Analyze the results to identify which cross-validation technique provides the most robust and reliable performance estimate for the given dataset and models, considering the trade-off between bias, variance, and computational cost.
-
Quantitative Data Summary
The following tables present a summary of experimental data from a comparative study evaluating different cross-validation techniques on both imbalanced and balanced datasets using Support Vector Machine (SVM) and Random Forest (RF) models.[3][8]
Table 1: Performance on Imbalanced Dataset (without parameter tuning)
| Cross-Validation Technique | Machine Learning Model | Sensitivity | Balanced Accuracy |
| Repeated K-Folds | SVM | 0.541 | 0.764 |
| K-Folds | RF | 0.784 | 0.884 |
| LOOCV | RF | 0.787 | - |
| LOOCV | Bagging | 0.784 | - |
Table 2: Performance on Balanced Dataset (with parameter tuning)
| Cross-Validation Technique | Machine Learning Model | Sensitivity | Balanced Accuracy | Precision | F1-Score |
| LOOCV | SVM | 0.893 | - | - | - |
| - | Bagging | - | 0.895 | - | - |
| Stratified K-Folds | SVM | - | - | Enhanced | Enhanced |
| Stratified K-Folds | RF | - | - | Enhanced | Enhanced |
Table 3: Computational Processing Time
| Cross-Validation Technique | Machine Learning Model | Processing Time (seconds) |
| K-Folds | SVM | 21.480 |
| Repeated K-Folds | RF | 1986.570 |
Note: A '-' indicates that the specific metric was not reported in the cited study for that combination.
Visualizing Cross-Validation Workflows
The following diagrams, generated using the DOT language, illustrate the logical flow of the described cross-validation techniques.
Caption: Workflow of K-Fold Cross-Validation (k=5).
Caption: Stratified K-Fold maintains class proportions in each fold.
Caption: LOOCV uses each sample as a test set once.
Caption: Nested CV for hyperparameter tuning and model evaluation.
References
- 1. machinelearningmastery.com [machinelearningmastery.com]
- 2. simplilearn.com [simplilearn.com]
- 3. Comparative Analysis of Cross-Validation Techniques: LOOCV, K-folds Cross-Validation, and Repeated K-folds Cross-Validation in Machine Learning Models , American Journal of Theoretical and Applied Statistics, Science Publishing Group [sciencepublishinggroup.com]
- 4. 5.7 Advantages of k-fold Cross-Validation over LOOCV | Introduction to Statistical Learning Using R Book Club [r4ds.github.io]
- 5. neptune.ai [neptune.ai]
- 6. A Comprehensive Guide to Cross-Validation in Machine Learning | by Mirko Peters | Mirko Peters — Data & Analytics Blog [blog.mirkopeters.com]
- 7. article.sciencepublishinggroup.com [article.sciencepublishinggroup.com]
- 8. researchgate.net [researchgate.net]
The Critical Role of Independent Verification in Scientific Discovery
In the realm of scientific advancement, particularly within the fast-paced and high-stakes field of drug development, the reproducibility of experimental findings is paramount. Independent verification serves as the bedrock of scientific integrity, ensuring that published results are not only robust and reliable but can also form a solid foundation for future research and clinical applications. The inability to reproduce preclinical studies can have profound negative impacts, leading to wasted resources, stalled drug development pipelines, and ultimately, delays in delivering potentially life-saving therapies to patients.[1] This guide provides a framework for researchers, scientists, and drug development professionals to understand the importance of independent verification and offers practical guidance on how to approach and present verification studies.
The "Reproducibility Crisis": A Call for Rigor
A significant challenge facing the scientific community is the "reproducibility crisis," where a startlingly high number of published findings cannot be replicated by other researchers.[2][3] This issue is particularly acute in preclinical research, with some studies indicating that only a small fraction of findings can be successfully reproduced.[3] The reasons for this are multifaceted and complex, ranging from inadequate reporting of experimental details and the use of unvalidated reagents to flawed study design and statistical analysis.[3][4] The consequences of this crisis are far-reaching, eroding public trust in science and hindering the translation of basic research into tangible clinical benefits.
To address this challenge, a renewed emphasis on rigorous experimental design, detailed and transparent reporting of methodologies, and the independent verification of key findings is essential.
Data Presentation: A Comparative Approach
Clear and concise presentation of data is crucial for comparing the results of an original study with those of an independent verification effort. Structured tables are an effective way to summarize quantitative data, allowing for a direct and objective comparison.
Table 1: Comparative Analysis of Protein Expression via Western Blot
| Target Protein | Original Study (Relative Densitometry Units) | Verification Study (Relative Densitometry Units) | Fold Change (Original) | Fold Change (Verification) | Conclusion |
| Protein X | |||||
| Control | 1.00 ± 0.12 | 1.00 ± 0.15 | - | - | - |
| Treatment A | 2.50 ± 0.25 | 2.35 ± 0.30 | 2.5 | 2.35 | Consistent |
| Treatment B | 0.40 ± 0.08 | 0.45 ± 0.09 | 0.4 | 0.45 | Consistent |
| Loading Control (e.g., GAPDH) | 1.05 ± 0.09 | 1.02 ± 0.08 | - | - | Consistent |
Table 2: Comparative Analysis of Cell Viability via MTT Assay
| Treatment Group | Original Study (% Viability ± SD) | Verification Study (% Viability ± SD) | IC50 (Original) | IC50 (Verification) | Conclusion |
| Vehicle Control | 100 ± 5.2 | 100 ± 6.1 | - | - | - |
| Compound Y (1 µM) | 85.3 ± 4.1 | 82.1 ± 5.5 | Consistent | ||
| Compound Y (10 µM) | 52.7 ± 3.8 | 49.9 ± 4.7 | 9.5 µM | 10.2 µM | Consistent |
| Compound Y (50 µM) | 21.4 ± 2.9 | 24.0 ± 3.3 | Consistent | ||
| Positive Control (e.g., Staurosporine) | 15.8 ± 2.1 | 18.2 ± 2.5 | Consistent |
Experimental Protocols: Ensuring Methodological Fidelity
Detailed and transparent experimental protocols are the cornerstone of reproducible research. The following sections provide methodologies for two common assays often used in drug development research.
Western Blot for Protein Expression Analysis
Objective: To quantitatively compare the expression levels of a target protein between an original and a verification study.
Methodology:
-
Sample Preparation: Cells or tissues are lysed in RIPA buffer supplemented with protease and phosphatase inhibitors. Protein concentration is determined using a BCA assay.
-
SDS-PAGE: Equal amounts of protein (20-30 µg) are loaded onto a 4-20% Tris-glycine gel and separated by electrophoresis.
-
Protein Transfer: Proteins are transferred from the gel to a PVDF membrane.
-
Blocking: The membrane is blocked for 1 hour at room temperature in 5% non-fat dry milk in Tris-buffered saline with 0.1% Tween 20 (TBST).
-
Primary Antibody Incubation: The membrane is incubated overnight at 4°C with the primary antibody diluted in the blocking buffer.
-
Secondary Antibody Incubation: The membrane is washed three times with TBST and then incubated for 1 hour at room temperature with a horseradish peroxidase (HRP)-conjugated secondary antibody.
-
Detection: After further washing, the signal is detected using an enhanced chemiluminescence (ECL) substrate and imaged using a chemiluminescence detection system.
-
Densitometry Analysis: Band intensities are quantified using image analysis software. The target protein signal is normalized to a loading control (e.g., GAPDH or β-actin).
MTT Assay for Cell Viability
Objective: To assess the effect of a compound on cell viability and compare the results between an original and a verification study.
Methodology:
-
Cell Seeding: Cells are seeded in a 96-well plate at a density of 5,000-10,000 cells per well and allowed to adhere overnight.
-
Compound Treatment: The cells are treated with various concentrations of the test compound or vehicle control for a specified period (e.g., 24, 48, or 72 hours).
-
MTT Addition: MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) solution is added to each well and incubated for 2-4 hours at 37°C.
-
Formazan Solubilization: The medium is removed, and the formazan crystals are dissolved in dimethyl sulfoxide (DMSO).
-
Absorbance Measurement: The absorbance is measured at 570 nm using a microplate reader.
-
Data Analysis: Cell viability is calculated as a percentage of the vehicle-treated control. The half-maximal inhibitory concentration (IC50) is determined by non-linear regression analysis.
Visualizing the Path to Verified Findings
Diagrams are powerful tools for illustrating complex biological pathways, experimental processes, and the logical flow of scientific inquiry.
References
Ensuring Scientific Rigor: A Guide to Robustness Checks in Statistical Analysis
In the realms of research, drug development, and clinical trials, the credibility of statistical findings is paramount. A statistical analysis, no matter how sophisticated, rests on a foundation of assumptions. Robustness checks are a critical component of the analytical process, designed to test the stability and reliability of results when these underlying assumptions are altered. This guide provides a comparative overview of common robustness check methodologies, offering detailed protocols and insights to help researchers, scientists, and drug development professionals validate their statistical claims.
Comparing Methods for Robustness Checks
The choice of a robustness check depends on the specific assumptions of the statistical model and the nature of the research question. Below is a comparison of four widely used methods:
| Method | Description | Key Advantages | Key Limitations | Typical Application |
| Simulation Studies | Involves creating artificial datasets to test how a statistical method performs under various known conditions. By manipulating parameters like sample size, effect size, and error distribution, researchers can assess the method's resilience to violations of its assumptions. | Allows for a controlled evaluation of a method's performance across a wide range of scenarios. Can reveal biases and inefficiencies that may not be apparent in a single dataset. | The relevance of the findings depends on how well the simulated data reflects real-world complexities. Can be computationally intensive. | Evaluating the performance of a new statistical estimator or comparing different analytical approaches before applying them to real data. |
| Sensitivity Analysis | Examines how sensitive the output of a statistical model is to changes in its input assumptions. This can involve systematically varying the values of influential observations, changing the definition of a key variable, or altering the time window of the analysis. | Provides a direct assessment of how much the results depend on specific assumptions. Helps to identify influential data points or parameters that have a large impact on the conclusions. | Can be challenging to explore the full range of plausible variations in assumptions. The interpretation of results can sometimes be subjective. | Assessing the impact of outliers or influential data points on regression results. Testing the stability of findings to different definitions of the primary outcome. |
| Placebo Tests | Involves re-running the primary analysis on a "placebo" condition where the expected effect is zero. For example, testing for an effect in a time period before the intervention occurred or on an outcome that should not be affected. | Provides a powerful way to check for spurious findings that may arise from unobserved confounding factors or model misspecification. A significant result in a placebo test raises doubts about the validity of the original finding. | The design of a credible placebo test can be challenging and is not always feasible. A null result in a placebo test does not definitively prove the original finding is correct. | In quasi-experimental studies, testing for pre-treatment trends to ensure the treatment and control groups were comparable before the intervention. |
| Varying Model Specifications | Entails re-estimating the main statistical model using different functional forms, including or excluding different sets of control variables, or using alternative estimation techniques. | Helps to assess whether the main findings are dependent on a specific set of modeling choices. Can reveal whether the results are consistent across different plausible analytical approaches. | There can be a very large number of alternative specifications to test, leading to concerns about "p-hacking" if not done systematically and transparently. | In regression analysis, adding or removing covariates to see if the coefficient of interest remains stable. Using different link functions in a generalized linear model. |
Experimental Protocols
To ensure transparency and reproducibility, the methodologies for conducting robustness checks should be clearly documented.
Protocol for a Simulation-Based Robustness Check
-
Define the Objective: Clearly state the assumption being tested (e.g., normality of errors, absence of outliers).
-
Specify the Data-Generating Process: Define the true underlying model that will be used to generate the simulated datasets. This includes specifying the functional form, the true parameter values, and the distribution of the error term.
-
Introduce Deviations: Systematically introduce violations of the assumption being tested. For example, generate data with errors drawn from a skewed distribution or add a certain percentage of outliers.
-
Apply the Statistical Method: Apply the statistical method of interest to each of the simulated datasets.
-
Evaluate Performance: Compare the estimates from the statistical method to the true parameter values. Common performance metrics include bias, variance, and mean squared error.
-
Summarize and Conclude: Summarize the results across all simulations to assess how the performance of the method changes as the assumption is increasingly violated.
Protocol for a Sensitivity Analysis
-
Identify Key Assumptions: List the critical assumptions of the primary statistical analysis.
-
Define a Range of Plausible Deviations: For each assumption, specify a credible range of alternative values or scenarios. For instance, if assessing the impact of an influential data point, the deviation would be its exclusion from the analysis.
-
Re-run the Analysis: Re-perform the statistical analysis under each of the alternative scenarios.
-
Compare Results: Compare the key results (e.g., coefficient estimates, p-values) from the sensitivity analyses to the results of the primary analysis.
Protocol for a Placebo Test
-
Identify a Placebo Condition: Determine a context where the true effect of the intervention or variable of interest is known to be zero.
-
Define the Placebo Analysis: Specify the statistical model and data to be used for the placebo test. This should mirror the primary analysis as closely as possible.
-
Conduct the Placebo Test: Execute the statistical analysis on the placebo condition.
-
Interpret the Results: A statistically significant finding in the placebo test suggests that the primary analysis may be biased. A non-significant result provides greater confidence in the original findings.
Protocol for Varying Model Specifications
-
Identify Alternative Specifications: Enumerate a set of plausible alternative model specifications. This should be guided by theory and prior research.
-
Pre-specify the Set of Models: To avoid data dredging, the set of models to be tested should be defined before the analysis is conducted.
-
Estimate the Models: Fit each of the pre-specified models to the data.
-
Compare Key Parameters: Focus on the stability of the coefficient of interest and its statistical significance across the different models.
-
Summarize the Evidence: Report the range of estimates and discuss the overall consistency of the findings.
Visualizing the Robustness Check Workflow
A systematic approach is crucial for conducting and interpreting robustness checks. The following diagram illustrates a typical workflow.
Enhancing the Predictive Power of Preclinical Research: A Guide to Assessing and Improving External Validity
For researchers, scientists, and drug development professionals, the ultimate goal of preclinical research is to generate findings that translate into effective clinical therapies. However, a significant gap persists between promising preclinical results and successful clinical trials. A key factor contributing to this translational failure is insufficient external validity—the extent to which experimental findings can be generalized to different populations, settings, and conditions. This guide provides a comprehensive comparison of strategies to assess and enhance the external validity of preclinical experimental findings, supported by experimental data and detailed protocols.
A major challenge in drug development is that highly controlled and standardized preclinical studies often fail to capture the heterogeneity of human populations and the complexities of real-world clinical practice.[1][2] This guide explores robust methodologies designed to bridge this gap, including systematic heterogenization, multi-batch and multicenter studies, and rigorous assessment of a model's predictive validity.
Comparing Strategies to Bolster External Validity
Different approaches can be employed during the preclinical phase to increase the likelihood that experimental findings will be replicable and predictive of clinical outcomes. The following table summarizes key strategies, their impact on experimental design, and their potential benefits for improving translational success.
| Strategy | Description | Key Experimental Considerations | Potential Impact on External Validity |
| Systematic Heterogenization | Intentionally introducing controlled sources of variation into the experimental design. This can include factors like age, sex, and housing conditions of animal models.[3][4] | - A factorial design is often employed to systematically vary multiple factors. - Requires larger sample sizes to ensure sufficient statistical power for each subgroup. - Statistical analysis must account for the introduced sources of variation. | Increases the generalizability of findings to a more diverse population by demonstrating the robustness of an effect across different conditions. |
| Multi-Batch Experiments | Conducting the same experiment in multiple batches over time within the same laboratory. | - Each batch serves as a replicate, allowing for the assessment of temporal variability. - Important to standardize core experimental procedures across batches. - Statistical analysis should assess both within-batch and between-batch consistency of results. | Helps to identify and control for subtle, often unnoticed, variations in experimental conditions that can occur over time, thereby improving the reproducibility of the findings. |
| Multi-Center Studies | A collaborative effort where the same experimental protocol is conducted in multiple independent laboratories.[5] | - Requires a highly detailed and standardized protocol to ensure consistency across centers. - A central coordinating body is essential for data management and analysis. - Can be logistically complex and resource-intensive. | Provides the most robust assessment of generalizability by testing the reproducibility of findings across different research environments, personnel, and subtle variations in methodology. |
| Assessing Predictive Validity | Evaluating how well an animal model can predict the efficacy of treatments that are already known to be effective or ineffective in humans.[6][7][8] | - Requires the use of well-characterized positive and negative control compounds. - The model should demonstrate a dose-response relationship to effective treatments that mirrors clinical observations. - Endpoints in the animal model should be translationally relevant to clinical outcomes. | Directly evaluates the translational relevance of an animal model, providing confidence that the model can differentiate between effective and ineffective therapeutic interventions. |
Experimental Protocols
To facilitate the implementation of these strategies, detailed experimental protocols are essential. Below are examples of how to structure such studies.
Protocol 1: Systematic Heterogenization in a Preclinical Oncology Study
Objective: To assess the efficacy of a novel anti-cancer agent in a mouse model of melanoma while systematically varying the age and sex of the animals.
Methodology:
-
Animal Model: C57BL/6 mice subcutaneously implanted with B16-F10 melanoma cells.
-
Experimental Groups:
-
Young (8-10 weeks) male mice + Vehicle
-
Young (8-10 weeks) male mice + Drug X
-
Young (8-10 weeks) female mice + Vehicle
-
Young (8-10 weeks) female mice + Drug X
-
Aged (18-20 months) male mice + Vehicle
-
Aged (18-20 months) male mice + Drug X
-
Aged (18-20 months) female mice + Vehicle
-
Aged (18-20 months) female mice + Drug X
-
-
Treatment: Drug X (or vehicle) administered daily via oral gavage for 14 days, starting when tumors reach a volume of approximately 100 mm³.
-
Endpoints:
-
Primary: Tumor growth inhibition, measured by caliper every two days.
-
Secondary: Overall survival, body weight changes.
-
-
Statistical Analysis: A three-way ANOVA will be used to analyze the effects of drug treatment, age, and sex on tumor growth. Survival data will be analyzed using the Kaplan-Meier method and log-rank test.
Protocol 2: Multi-Center Preclinical Trial in Oncology
Objective: To validate the efficacy of a promising drug candidate in a multi-center setting to ensure the robustness of the findings before advancing to clinical trials.
Methodology:
-
Study Coordination: A central coordinating center will be responsible for protocol distribution, data collection, and statistical analysis.
-
Participating Centers: Three independent research laboratories with expertise in preclinical oncology models.
-
Standardized Protocol: A detailed protocol will be provided to all centers, specifying:
-
Animal strain, age, and supplier.
-
Cell line and passage number for tumor implantation.
-
Detailed procedures for tumor implantation, randomization, and blinding.
-
Drug formulation, dose, and administration schedule.
-
Standardized methods for tumor measurement and data recording.
-
-
Data Submission: All raw data will be submitted to the coordinating center for centralized analysis.
-
Statistical Analysis: A mixed-effects model will be used to analyze the data, with "center" included as a random effect to assess inter-laboratory variability.
Visualizing Complex Biological and Experimental Processes
To further clarify the logical relationships and workflows involved in assessing external validity, the following diagrams are provided in the DOT language for use with Graphviz.
Caption: A typical workflow for preclinical drug discovery.
The diagram above illustrates a simplified workflow of the drug discovery and development process, highlighting where strategies to enhance external validity are incorporated.
Caption: The PI3K/Akt signaling pathway in Alzheimer's disease.
This diagram depicts the PI3K/Akt signaling pathway, which is implicated in the pathogenesis of Alzheimer's disease.[9][10][11][12][13] Dysregulation of this pathway can lead to increased tau hyperphosphorylation, a hallmark of the disease. Animal models used to study Alzheimer's disease should accurately recapitulate the key components and dysregulation of such critical signaling pathways to have strong predictive validity.
By proactively incorporating strategies to assess and improve external validity, researchers can increase the robustness and generalizability of their preclinical findings, ultimately enhancing the probability of successful clinical translation and the development of new medicines.
References
- 1. Systematic heterogenisation to improve reproducibility in animal studies - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Systematic heterogenisation to improve reproducibility in animal studies | PLOS Biology [journals.plos.org]
- 4. Systematic heterogenization revisited: Increasing variation in animal experiments to improve reproducibility? - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. biorxiv.org [biorxiv.org]
- 6. Editorial: Preclinical Animal Models and Measures of Pain: Improving Predictive Validity for Analgesic Drug Development - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Frontiers | Editorial: Preclinical animal models and measures of pain: improving predictive validity for analgesic drug development - volume II [frontiersin.org]
- 8. Predictive validity of behavioural animal models for chronic pain - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Frontiers | The role of PI3K signaling pathway in Alzheimer’s disease [frontiersin.org]
- 10. biointerfaceresearch.com [biointerfaceresearch.com]
- 11. researchgate.net [researchgate.net]
- 12. researchgate.net [researchgate.net]
- 13. The PI3K/Akt signaling axis in Alzheimer’s disease: a valuable target to stimulate or suppress? - PMC [pmc.ncbi.nlm.nih.gov]
A Comparative Analysis of Robust Versus Traditional Statistical Approaches in Scientific Research
A Guide for Researchers, Scientists, and Drug Development Professionals
Key Differences at a Glance
Data Presentation: A Quantitative Comparison
The following tables summarize the performance of various traditional and robust statistical estimators in the presence of outliers, based on simulation studies. Performance is typically evaluated using metrics such as Bias (the difference between the estimator's expected value and the true value) and Mean Squared Error (MSE), which measures the average squared difference between the estimated values and the actual value.
Table 1: Comparison of Estimators for Central Tendency
| Estimator Type | Estimator | Performance with No Outliers | Performance with 10% Outliers |
| Traditional | Mean | Low Bias, Low MSE | High Bias, High MSE |
| Robust | Median | Low Bias, Slightly Higher MSE | Low Bias, Low MSE |
| Robust | 10% Trimmed Mean | Low Bias, Slightly Higher MSE | Low Bias, Low MSE |
| Robust | Huber's M-estimator | Low Bias, Low MSE | Low Bias, Low MSE |
Table 2: Comparison of Estimators for Regression (Ordinary Least Squares vs. Robust Regression)
| Estimator | Metric | No Outliers | 5% Outlier Contamination | 10% Outlier Contamination | 20% Outlier Contamination | 30% Outlier Contamination |
| OLS | Bias | -0.000815 | Fluctuates | Increases | Increases | Increases |
| RMSE | 0.0124 | 0.0554 | 0.0783 | High | 0.116 | |
| R² | 0.971 | 0.611 | Decreases | Decreases | 0.266 | |
| Robust | Bias | -0.000727 | Stable | Stable | Stable | Stable |
| RMSE | 0.0125 | 0.0140 | 0.0150 | Lower than OLS | 0.0910 | |
| R² | 0.971 | 0.595 | Decreases | Decreases | 0.207 |
Note: OLS stands for Ordinary Least Squares, a common traditional regression method. RMSE is the Root Mean Square Error. R² is the coefficient of determination. Data is based on simulated studies investigating the effect of outliers.[1][2][3]
Experimental Protocols
The comparative data presented above is typically generated through Monte Carlo simulation studies. A detailed methodology for such a study is outlined below.
Objective: To compare the performance of traditional and robust estimators of central tendency and regression in the presence of varying levels of data contamination.
Protocol:
-
Data Generation:
-
Generate a primary dataset of a specified size (e.g., n=100) from a known distribution (e.g., a normal distribution with a specified mean and variance).
-
Introduce a controlled percentage of outliers (e.g., 0%, 5%, 10%, 20%) into the dataset. Outliers can be generated from a different distribution with a larger variance or by adding a significant shift to a subset of the original data points.
-
-
Estimation:
-
Apply both traditional (e.g., sample mean, Ordinary Least Squares regression) and robust (e.g., median, trimmed mean, M-estimators, robust regression) estimators to the generated datasets (both clean and contaminated).
-
-
Performance Evaluation:
-
For each estimator and each level of contamination, calculate performance metrics. Common metrics include:
-
Bias: The average difference between the estimated value and the true population parameter over a large number of simulations.
-
Mean Squared Error (MSE): The average of the squares of the errors (the difference between the estimator and the true value). This metric penalizes larger errors more heavily.
-
Root Mean Squared Error (RMSE): The square root of the MSE, providing an error metric in the same units as the parameter.
-
-
-
Iteration:
-
Repeat steps 1-3 a large number of times (e.g., 10,000 iterations) to obtain a stable distribution of the performance metrics.
-
-
Analysis:
-
Summarize the results in tables and plots to visually and quantitatively compare the performance of the different estimators under each condition.
-
Mandatory Visualization
The following diagrams illustrate key concepts and workflows relevant to the application of these statistical methods in a drug development context.
Caption: PI3K/AKT/mTOR signaling pathway, a key regulator of cell growth, is a common target in cancer drug development.
Caption: A simplified workflow of a clinical trial, highlighting the statistical analysis phase.
Conclusion
References
- 1. researchgate.net [researchgate.net]
- 2. Statistical Approaches to Analysis of Small Clinical Trials - Small Clinical Trials - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 3. Chapter 10 Protocol and Statistical Analysis Plan Considerations | Covariate Adjustment in Randomized Trials [covariateadjustment.github.io]
- 4. journals.tubitak.gov.tr [journals.tubitak.gov.tr]
Peer Review: A Gatekeeper Under Scrutiny in the Validation of Research Robustness
In the rigorous world of scientific and drug development research, the validation of findings is paramount. Peer review has long stood as the primary gatekeeper, a critical process designed to ensure the quality, validity, and significance of published research.[1][2][3] This guide provides a comprehensive comparison of different peer review models and emerging alternatives, offering an objective analysis of their roles in upholding research robustness. Through a detailed examination of experimental data and methodologies, we aim to equip researchers, scientists, and drug development professionals with a clearer understanding of the strengths and limitations inherent in these validation processes.
The Role and Mechanism of Traditional Peer Review
At its core, peer review is a system of self-regulation by qualified members of a profession.[4] It subjects a researcher's scholarly work to the scrutiny of other experts in the same field.[4] This process is intended to act as a filter, ensuring that only high-quality research is published, and to improve the quality of manuscripts deemed suitable for publication.[5]
The traditional peer review process generally follows a structured workflow:
Comparison of Peer Review Models
Different models of peer review have been developed to address potential biases and limitations in the traditional system. The most common types are single-blind, double-blind, and open peer review.
| Feature | Single-Blind Review | Double-Blind Review | Open Peer Review |
| Anonymity | Reviewers are anonymous to the author. | Both author and reviewers are anonymous to each other. | Identities of both author and reviewers are known to all parties. |
| Prevalence | Most common method, especially in science journals.[6] | Common in social sciences and humanities.[6] | A growing minority of journals are adopting this model.[6] |
| Reported Acceptance Rate | ~19.0% | ~14.2% (significantly lower than single-blind)[7] | Varies, but transparency may influence review quality. |
| Error Detection Rate | Studies show reviewers miss a significant number of major errors (on average, only detecting about 3 out of 9).[6] | No conclusive evidence of superior error detection compared to single-blind. Blinding success is estimated at around 52%.[7] | Transparency may encourage more thorough reviews, but data is limited. |
| Potential for Bias | Reviewer bias can be based on author's reputation, institution, gender, or nationality.[3][4] | Aims to reduce bias, but reviewers may still deduce author identity. Studies show it may not significantly benefit female authors in some fields.[8] | Aims to increase accountability and reduce harshness, but may lead to less critical reviews due to politeness or fear of retribution. |
Alternatives to Traditional Peer Review
In response to the limitations of traditional peer review, several alternative models have emerged, leveraging technology and a more collaborative approach.
| Alternative Model | Description | Advantages | Disadvantages |
| Post-Publication Review | Review and discussion of a paper occur after it has been published, often on platforms like preprint servers or in journal comment sections.[3] | Accelerates dissemination of research; allows for a wider range of feedback; reflects the evolving nature of scientific knowledge.[7] | Potentially misleading or flawed research can be disseminated before thorough vetting; lacks a formal, structured review process. |
| Collaborative Review | Reviewers and sometimes the author work together to improve the manuscript.[9] | Can be more constructive and less adversarial; may lead to a higher quality final manuscript.[9] | Can be time-consuming; may dilute the independence of individual reviewer assessments.[9] |
| Decoupled (Portable) Review | Peer review is conducted independently of a specific journal. Reviews can then be submitted to different journals along with the manuscript.[10] | Reduces redundant review efforts if a paper is rejected and resubmitted; can speed up the publication process. | Requires a centralized platform and standardized review criteria; acceptance by journals may vary. |
Experimental Protocols for Assessing Peer Review Efficacy
The robustness of the peer review process itself is a subject of ongoing research. Several experimental protocols have been employed to evaluate its effectiveness and identify areas for improvement.
Error Detection Studies
A common methodology to assess the rigor of peer review involves intentionally introducing errors into a manuscript and then tracking their detection by reviewers.
One notable study using this method found that, on average, reviewers detected only about a quarter of the major errors inserted into a paper, with some reviewers not spotting any at all.[11]
Bias Assessment Protocols
To investigate bias in peer review, researchers have employed protocols that manipulate author characteristics while keeping the manuscript content the same.
Methodology:
-
Selection of a published paper: A paper from a prestigious institution is chosen.
-
Manipulation of author identity: The authors' names and affiliations are changed to suggest a less prestigious background.
-
Resubmission: The altered manuscript is resubmitted to the same journal that originally published it.
-
Analysis of outcomes: The editorial and reviewer decisions for the resubmitted manuscript are compared to the original publication decision.
A well-known study using this protocol found that only a small fraction of the altered papers were identified as resubmissions, and the majority were rejected, suggesting a strong bias in favor of authors from prestigious institutions.[11]
Research Robustness and Validity Assessment
Beyond peer review, several methodologies exist to assess the intrinsic robustness of research findings.
-
Replication Studies: These involve independently repeating a study's methodology to determine if the original findings can be reproduced. A lack of reproducibility can indicate issues with the original study's design, execution, or analysis.
-
Fragility Index: This metric is used to assess the robustness of statistically significant findings in clinical trials. It calculates the minimum number of patients whose outcome would need to change to turn a statistically significant result into a non-significant one.[12] A low fragility index suggests that the findings are not robust and could be easily overturned by a small change in the data.[12]
-
Sensitivity Analysis: This involves systematically changing key assumptions or parameters in a statistical model to see how sensitive the results are to those changes. Robust findings should remain stable across a range of plausible assumptions.
The Path Forward: Towards a More Robust System
While peer review remains a cornerstone of scholarly communication, it is not without its flaws.[11] The evidence suggests that it can be a slow, biased, and sometimes ineffective process for detecting errors.[11] The emergence of alternative models and the use of rigorous protocols to study the review process itself are crucial steps towards a more transparent, efficient, and reliable system for validating research. For researchers, scientists, and drug development professionals, a critical understanding of these processes is essential for both contributing to and evaluating the body of scientific knowledge.
References
- 1. Alternatives to Peer Review: Novel Approaches for Research Evaluation - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Open versus blind peer review: is anonymity better than transparency? | BJPsych Advances | Cambridge Core [cambridge.org]
- 3. exordo.com [exordo.com]
- 4. Single-Blind Vs. Double-Blind Peer Review - Simple Guide [fourwaves.com]
- 5. Evaluating research protocols - HealthSense [healthsense-uk.org]
- 6. What errors do peer reviewers detect, and does training improve their ability to detect them? - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. Single-Blind vs. Double-Blind vs. Open Peer Review: Medicine & Healthcare Book Chapter | IGI Global Scientific Publishing [igi-global.com]
- 9. authorservices.wiley.com [authorservices.wiley.com]
- 10. youtube.com [youtube.com]
- 11. Peer review: a flawed process at the heart of science and journals - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Assessing the robustness of results from clinical trials and meta-analyses with the fragility index - PMC [pmc.ncbi.nlm.nih.gov]
How to write a strong rebuttal to critiques of a study's robustness
In the rigorous landscape of scientific and drug development research, critiques of a study's robustness are not just common; they are a cornerstone of the validation process. A well-crafted rebuttal not only addresses these criticisms but also strengthens the credibility and impact of your work. This guide provides a framework for researchers, scientists, and drug development professionals to construct compelling responses to critiques, ensuring your findings are accurately represented and understood.
The Art of the Scientific Rebuttal: A Strategic Approach
A strong rebuttal is built on a foundation of respect, clarity, and robust evidence. The goal is not to be defensive but to engage in a constructive dialogue that ultimately improves the scientific record.[1][2][3] Acknowledge the time and effort reviewers have invested and view their feedback as an opportunity to refine and clarify your research.[1]
Key Principles for an Effective Rebuttal:
-
Maintain a Professional and Respectful Tone: Your response should be objective and focused on the scientific merits of the critiques.[2][3][4] Avoid emotional language and address comments in a courteous manner.
-
Be Systematic and Thorough: Address every point raised by the critics.[1][2][4] A point-by-point response, quoting the original comment before your reply, is a clear and effective format.[1]
-
Acknowledge and Concede When Appropriate: If a criticism is valid, acknowledge it and explain the corrective actions taken. This demonstrates a commitment to scientific rigor.
-
Provide Evidence for Disagreements: When you disagree with a critique, provide a clear and well-reasoned argument supported by data or citations.[3]
Data Presentation: The Foundation of a Strong Rebuttal
Clear and concise data presentation is paramount in a rebuttal. Summarizing quantitative data in well-structured tables allows for easy comparison and reinforces your arguments.
Table 1: Comparative Analysis of Compound X Efficacy in Original vs. Rebuttal Studies
| Parameter | Original Study (n=10) | Rebuttal Study - Dose 1 (n=15) | Rebuttal Study - Dose 2 (n=15) | Alternative Compound Y (n=15) |
| Tumor Growth Inhibition (%) | 65 ± 5.2 | 68 ± 4.9 | 75 ± 5.1 | 55 ± 6.3 |
| IC50 (nM) | 150 ± 12 | 145 ± 10 | 110 ± 9 | 250 ± 20 |
| Apoptosis Rate (%) | 40 ± 3.5 | 42 ± 3.1 | 55 ± 4.2 | 30 ± 2.8 |
| p-value (vs. Control) | < 0.01 | < 0.01 | < 0.001 | < 0.05 |
Data are presented as mean ± standard deviation.
Experimental Protocols: Ensuring Reproducibility
Providing detailed methodologies for key experiments is crucial for transparency and allows other researchers to replicate your findings.[5][6]
Detailed Protocol: Western Blot Analysis of Protein Expression
This protocol outlines the steps for assessing the expression levels of key proteins in response to treatment with Compound X.
1. Materials and Reagents:
- Cell Lysis Buffer (RIPA Buffer)
- Protease and Phosphatase Inhibitor Cocktails
- BCA Protein Assay Kit
- 4-12% Bis-Tris Gels
- PVDF Membranes
- Blocking Buffer (5% non-fat milk in TBST)
- Primary Antibodies (specific to target proteins)
- HRP-conjugated Secondary Antibodies
- Enhanced Chemiluminescence (ECL) Substrate
- Imaging System
2. Cell Lysis and Protein Quantification:
- Treat cells with Compound X or vehicle control for the specified duration.
- Wash cells with ice-cold PBS and lyse with RIPA buffer containing protease and phosphatase inhibitors.
- Centrifuge lysates at 14,000 rpm for 15 minutes at 4°C.
- Collect the supernatant and determine protein concentration using the BCA Protein Assay Kit.
3. Gel Electrophoresis and Transfer:
- Normalize protein samples to a concentration of 1-2 µg/µL.
- Separate 20-30 µg of protein per lane on a 4-12% Bis-Tris gel.
- Transfer proteins to a PVDF membrane at 100V for 90 minutes.
4. Immunoblotting:
- Block the membrane with Blocking Buffer for 1 hour at room temperature.
- Incubate the membrane with primary antibodies overnight at 4°C with gentle agitation.
- Wash the membrane three times with TBST for 10 minutes each.
- Incubate with HRP-conjugated secondary antibodies for 1 hour at room temperature.
- Wash the membrane three times with TBST for 10 minutes each.
5. Detection and Analysis:
- Apply ECL substrate to the membrane.
- Capture chemiluminescent signals using an imaging system.
- Quantify band intensities using densitometry software and normalize to a loading control (e.g., GAPDH or β-actin).
Mandatory Visualizations: Illustrating Your Points with Clarity
Visual diagrams are powerful tools for conveying complex information in a rebuttal. The following diagrams are generated using Graphviz (DOT language) to illustrate a signaling pathway, an experimental workflow, and a logical argument.
Signaling Pathway: Mechanism of Action of Compound X
References
Safety Operating Guide
Navigating the Disposal of Robustine: A Procedural Guide for Laboratory Safety
This guide provides essential safety and logistical information for the proper disposal of Robustine. Given the absence of a specific Safety Data Sheet (SDS) for this compound, these procedures are based on its classification as a furoquinoline alkaloid and established best practices for hazardous chemical waste management. Furoquinoline alkaloids are recognized for a range of biological activities, and some have demonstrated cytotoxic and mutagenic properties, necessitating that they be handled as potentially hazardous materials.[1][2]
Researchers, scientists, and drug development professionals must always consult with their institution's Environmental Health and Safety (EHS) department to ensure full compliance with local, state, and federal regulations.
Hazard Assessment and Classification
Due to its chemical class, this compound should be treated as a toxic chemical waste . Alkaloids are a class of compounds known for their significant physiological effects and are often subject to regulation as hazardous waste.[3][4] In the absence of specific toxicity data for this compound, a cautious approach requires assuming it may be harmful if ingested, inhaled, or absorbed through the skin.
Proper Disposal Protocol for this compound
The following step-by-step procedure outlines the safe handling and disposal of this compound waste from the point of generation to its final collection.
Step 1: Personal Protective Equipment (PPE) Before handling this compound in any form (pure, in solution, or as waste), it is mandatory to wear appropriate PPE. This includes:
-
Gloves: Chemical-resistant nitrile gloves.
-
Eye Protection: Safety glasses with side shields or chemical splash goggles.
-
Lab Coat: A standard laboratory coat to protect clothing and skin.
Step 2: Waste Segregation and Collection Proper segregation is critical to prevent dangerous chemical reactions and ensure compliant disposal.[5] Never mix incompatible waste streams.
-
Solid Waste: Collect all solid materials contaminated with this compound, such as unused powder, gloves, weigh papers, and pipette tips, in a dedicated, leak-proof hazardous waste container.[6]
-
Liquid Waste: Collect all solutions containing this compound in a separate, leak-proof, and clearly labeled hazardous waste container. Do not pour any this compound solution down the drain.[6][7]
-
Sharps Waste: Any sharps, including needles, syringes, or glass pipettes contaminated with this compound, must be placed in a designated, puncture-proof sharps container for hazardous chemical waste.[6]
Step 3: Container Labeling All waste containers must be clearly and accurately labeled as soon as waste is added. The label must include:
-
The words "Hazardous Waste "[6]
-
The full chemical name: This compound
-
The primary hazard: Toxic
-
An accurate list of all chemical constituents and their approximate percentages.[5]
-
The accumulation start date.[7]
Step 4: Storage Store all this compound hazardous waste containers in a designated and secure Satellite Accumulation Area (SAA) within the laboratory.[5][8] This area should be at or near the point of generation and away from sinks or floor drains.[1]
Step 5: Scheduling Disposal Contact your institution's Environmental Health and Safety (EHS) department or a licensed hazardous waste contractor to schedule a pickup for the waste containers.[9] Do not attempt to transport or dispose of the waste yourself.
Quantitative Data Summary
The known chemical and physical properties of this compound are summarized in the table below.
| Property | Value | Reference(s) |
| Chemical Family | Furoquinoline Alkaloid | [7][10] |
| Molecular Formula | C₁₂H₉NO₃ | [5][7][10] |
| Molecular Weight | 215.2 g/mol | [10] |
| IUPAC Name | 4-methoxyfuro[2,3-b]quinolin-8-ol | [5][7] |
| CAS Number | 2255-50-7 | [5][10] |
| Solubility | Soluble in DMSO (50 mg/mL) | [10] |
| Storage (as product) | 4°C, protect from light | [10] |
Experimental Protocols
No experimental protocols for the specific disposal or neutralization of this compound were found in the reviewed literature. The standard and required protocol is to manage this compound waste through a certified hazardous waste program, as detailed in the steps above. Any attempt to neutralize or treat the chemical waste in the lab without a validated and approved protocol is strongly discouraged and may be non-compliant with regulations.[11]
This compound Disposal Workflow
The logical workflow for the proper management and disposal of this compound waste is illustrated in the diagram below.
Caption: Decision workflow for the safe disposal of this compound waste.
References
- 1. Cytotoxicity of a naturally occurring furoquinoline alkaloid and four acridone alkaloids towards multi-factorial drug-resistant cancer cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Furoquinoline alkaloid - Wikipedia [en.wikipedia.org]
- 3. britannica.com [britannica.com]
- 4. Alkaloid - Wikipedia [en.wikipedia.org]
- 5. 8-Hydroxydictamnine | C12H9NO3 | CID 164950 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 6. benchchem.com [benchchem.com]
- 7. biorlab.com [biorlab.com]
- 8. 8-Hydroxydictamnine | 2255-50-7 | Benchchem [benchchem.com]
- 9. Robustin | C22H18O7 | CID 54708253 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 10. glpbio.com [glpbio.com]
- 11. researchgate.net [researchgate.net]
Personal protective equipment for handling Robustine
For researchers, scientists, and drug development professionals, ensuring a safe laboratory environment is paramount when handling chemical compounds. This document provides essential, immediate safety and logistical information for the handling of Robustine, with a focus on personal protective equipment (PPE), operational plans, and disposal.
Hazard Identification and Risk Assessment
This compound (CAS 2255-50-7) presents specific hazards that necessitate careful handling procedures. According to the Safety Data Sheet (SDS), this compound is harmful if swallowed and causes serious eye irritation[1]. The primary routes of exposure are ingestion and eye contact. A thorough risk assessment should be conducted before any handling of this substance.
Personal Protective Equipment (PPE)
The selection and proper use of PPE is the most critical line of defense to minimize exposure to this compound. The following table summarizes the required and recommended PPE for various handling scenarios.
| Operation | Required PPE | Recommended Additional PPE |
| Weighing and Aliquoting (Solid Form) | - Nitrile gloves (double-gloving recommended)- Laboratory coat- Safety glasses with side shields or chemical splash goggles | - Face shield- Respiratory protection (N95 or higher) if dust is generated |
| Solution Preparation and Handling | - Nitrile gloves (double-gloving recommended)- Laboratory coat- Chemical splash goggles | - Face shield- Chemical-resistant apron |
| Spill Cleanup | - Nitrile gloves (double-gloving)- Chemical-resistant disposable gown- Chemical splash goggles- Face shield | - Respiratory protection (based on spill size and ventilation)- Chemical-resistant boot covers |
| Waste Disposal | - Nitrile gloves- Laboratory coat- Safety glasses | - |
Note: Always inspect PPE for integrity before use. Damaged gloves or other equipment should be replaced immediately.
Experimental Protocols: Donning and Doffing PPE
Proper procedure for putting on (donning) and taking off (doffing) PPE is crucial to prevent cross-contamination.
Donning Sequence:
-
Gown/Lab Coat: Put on a clean laboratory coat or gown.
-
Gloves (First Pair): Don the first pair of nitrile gloves, ensuring the cuffs are tucked under the sleeves of the gown.
-
Goggles/Face Shield: Put on safety goggles or a face shield.
-
Gloves (Second Pair): Don a second pair of nitrile gloves over the first pair, ensuring the cuffs of the second pair go over the sleeves of the gown.
Doffing Sequence (to be performed in a designated area):
-
Outer Gloves: Remove the outer pair of gloves by peeling them off from the cuff, turning them inside out. Dispose of them in the appropriate chemical waste container.
-
Gown/Lab Coat: Untie or unbutton the gown and peel it away from your body, turning it inside out. Fold it with the contaminated side inward and dispose of it.
-
Goggles/Face Shield: Remove eye and face protection from the back to the front and place it in a designated area for decontamination.
-
Inner Gloves: Remove the inner pair of gloves using the same technique as the outer pair.
-
Hand Hygiene: Wash hands thoroughly with soap and water.
Logical Workflow for Handling this compound
The following diagram illustrates the decision-making process and workflow for safely handling this compound in a laboratory setting.
Caption: Workflow for the safe handling of this compound, from preparation to disposal.
Disposal Plan
All waste contaminated with this compound, including empty containers, used PPE, and spill cleanup materials, must be disposed of as hazardous chemical waste.
-
Solid Waste: Collect in a designated, labeled, and sealed container.
-
Liquid Waste: Collect in a labeled, sealed, and appropriate chemical waste container.
-
Follow all local, state, and federal regulations for hazardous waste disposal. Do not dispose of this compound down the drain[1].
By adhering to these safety protocols, researchers can minimize their risk of exposure and ensure a safe working environment when handling this compound.
References
Retrosynthesis Analysis
AI-Powered Synthesis Planning: Our tool employs the Template_relevance Pistachio, Template_relevance Bkms_metabolic, Template_relevance Pistachio_ringbreaker, Template_relevance Reaxys, Template_relevance Reaxys_biocatalysis model, leveraging a vast database of chemical reactions to predict feasible synthetic routes.
One-Step Synthesis Focus: Specifically designed for one-step synthesis, it provides concise and direct routes for your target compounds, streamlining the synthesis process.
Accurate Predictions: Utilizing the extensive PISTACHIO, BKMS_METABOLIC, PISTACHIO_RINGBREAKER, REAXYS, REAXYS_BIOCATALYSIS database, our tool offers high-accuracy predictions, reflecting the latest in chemical research and data.
Strategy Settings
| Precursor scoring | Relevance Heuristic |
|---|---|
| Min. plausibility | 0.01 |
| Model | Template_relevance |
| Template Set | Pistachio/Bkms_metabolic/Pistachio_ringbreaker/Reaxys/Reaxys_biocatalysis |
| Top-N result to add to graph | 6 |
Feasible Synthetic Routes




Featured Recommendations
| Most viewed |
|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
