
1-Methylcytosine
Description
Structure
2D Structure
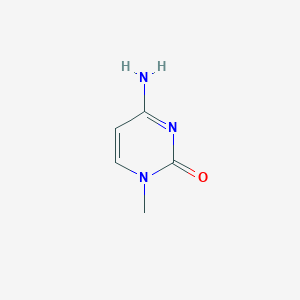
3D Structure
Properties
IUPAC Name |
4-amino-1-methylpyrimidin-2-one |
Source


|
|---|---|---|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI |
InChI=1S/C5H7N3O/c1-8-3-2-4(6)7-5(8)9/h2-3H,1H3,(H2,6,7,9) |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI Key |
HWPZZUQOWRWFDB-UHFFFAOYSA-N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Canonical SMILES |
CN1C=CC(=NC1=O)N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Formula |
C5H7N3O |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
DSSTOX Substance ID |
DTXSID60149949 |
Source
|
| Record name | 1-Methylcytosine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID60149949 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
Molecular Weight |
125.13 g/mol |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
CAS No. |
1122-47-0 |
Source
|
| Record name | 1-Methylcytosine | |
| Source | CAS Common Chemistry | |
| URL | https://commonchemistry.cas.org/detail?cas_rn=1122-47-0 | |
| Description | CAS Common Chemistry is an open community resource for accessing chemical information. Nearly 500,000 chemical substances from CAS REGISTRY cover areas of community interest, including common and frequently regulated chemicals, and those relevant to high school and undergraduate chemistry classes. This chemical information, curated by our expert scientists, is provided in alignment with our mission as a division of the American Chemical Society. | |
| Explanation | The data from CAS Common Chemistry is provided under a CC-BY-NC 4.0 license, unless otherwise stated. | |
| Record name | 1-Methylcytosine | |
| Source | ChemIDplus | |
| URL | https://pubchem.ncbi.nlm.nih.gov/substance/?source=chemidplus&sourceid=0001122470 | |
| Description | ChemIDplus is a free, web search system that provides access to the structure and nomenclature authority files used for the identification of chemical substances cited in National Library of Medicine (NLM) databases, including the TOXNET system. | |
| Record name | 1-Methylcytosine | |
| Source | DrugBank | |
| URL | https://www.drugbank.ca/drugs/DB04314 | |
| Description | The DrugBank database is a unique bioinformatics and cheminformatics resource that combines detailed drug (i.e. chemical, pharmacological and pharmaceutical) data with comprehensive drug target (i.e. sequence, structure, and pathway) information. | |
| Explanation | Creative Common's Attribution-NonCommercial 4.0 International License (http://creativecommons.org/licenses/by-nc/4.0/legalcode) | |
| Record name | 1122-47-0 | |
| Source | DTP/NCI | |
| URL | https://dtp.cancer.gov/dtpstandard/servlet/dwindex?searchtype=NSC&outputformat=html&searchlist=47693 | |
| Description | The NCI Development Therapeutics Program (DTP) provides services and resources to the academic and private-sector research communities worldwide to facilitate the discovery and development of new cancer therapeutic agents. | |
| Explanation | Unless otherwise indicated, all text within NCI products is free of copyright and may be reused without our permission. Credit the National Cancer Institute as the source. | |
| Record name | 1-Methylcytosine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID60149949 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
| Record name | 4-amino-1-methyl-1,2-dihydropyrimidin-2-one | |
| Source | European Chemicals Agency (ECHA) | |
| URL | https://echa.europa.eu/information-on-chemicals | |
| Description | The European Chemicals Agency (ECHA) is an agency of the European Union which is the driving force among regulatory authorities in implementing the EU's groundbreaking chemicals legislation for the benefit of human health and the environment as well as for innovation and competitiveness. | |
| Explanation | Use of the information, documents and data from the ECHA website is subject to the terms and conditions of this Legal Notice, and subject to other binding limitations provided for under applicable law, the information, documents and data made available on the ECHA website may be reproduced, distributed and/or used, totally or in part, for non-commercial purposes provided that ECHA is acknowledged as the source: "Source: European Chemicals Agency, http://echa.europa.eu/". Such acknowledgement must be included in each copy of the material. ECHA permits and encourages organisations and individuals to create links to the ECHA website under the following cumulative conditions: Links can only be made to webpages that provide a link to the Legal Notice page. | |
| Record name | 1-METHYLCYTOSINE | |
| Source | FDA Global Substance Registration System (GSRS) | |
| URL | https://gsrs.ncats.nih.gov/ginas/app/beta/substances/1J54NE82RV | |
| Description | The FDA Global Substance Registration System (GSRS) enables the efficient and accurate exchange of information on what substances are in regulated products. Instead of relying on names, which vary across regulatory domains, countries, and regions, the GSRS knowledge base makes it possible for substances to be defined by standardized, scientific descriptions. | |
| Explanation | Unless otherwise noted, the contents of the FDA website (www.fda.gov), both text and graphics, are not copyrighted. They are in the public domain and may be republished, reprinted and otherwise used freely by anyone without the need to obtain permission from FDA. Credit to the U.S. Food and Drug Administration as the source is appreciated but not required. | |
Foundational & Exploratory
A Comprehensive Technical Guide on the Biological Significance of 5-Methylcytosine (m⁵C) in RNA
For Researchers, Scientists, and Drug Development Professionals
Executive Summary
5-Methylcytosine (B146107) (m⁵C), a post-transcriptional RNA modification, is emerging as a critical regulator of RNA metabolism and function. Initially characterized in abundant non-coding RNAs such as transfer RNA (tRNA) and ribosomal RNA (rRNA), recent advancements in sequencing technologies have revealed its widespread presence in messenger RNA (mRNA) and other non-coding RNAs. This modification, installed by a family of RNA methyltransferases and interpreted by specific binding proteins, plays a pivotal role in modulating RNA stability, translation, and nuclear export. Dysregulation of m⁵C has been increasingly implicated in the pathogenesis of various human diseases, including cancer and neurological disorders, making the enzymes and binding proteins involved in this pathway attractive targets for therapeutic development. This guide provides an in-depth overview of the biological significance of m⁵C in RNA, detailing its distribution, regulatory mechanisms, and functional consequences, with a focus on its implications for disease and drug discovery.
Introduction to 5-Methylcytosine in RNA
5-Methylcytosine is a chemical modification where a methyl group is added to the 5th carbon of a cytosine residue within an RNA molecule. This modification is dynamically regulated by a set of proteins collectively known as "writers," "readers," and "erasers".
-
Writers (Methyltransferases): The primary enzymes responsible for depositing m⁵C are members of the NOL1/NOP2/SUN domain (NSUN) family and the DNA methyltransferase homolog DNMT2 (also known as TRDMT1)[1]. These enzymes utilize S-adenosylmethionine (SAM) as a methyl donor.
-
Readers (Binding Proteins): Specific proteins recognize and bind to m⁵C-modified RNA, thereby mediating its downstream effects. Key readers identified to date include ALYREF (Aly/REF export factor) and YBX1 (Y-box binding protein 1)[2][3].
-
Erasers (Demethylases): The removal of m⁵C is thought to be mediated by the Ten-Eleven Translocation (TET) family of enzymes, which can oxidize 5-methylcytosine to 5-hydroxymethylcytosine (B124674) (hm⁵C) and further derivatives, initiating a base excision repair pathway.
Distribution and Function of m⁵C in Different RNA Species
The prevalence and function of m⁵C vary across different types of RNA, highlighting its diverse roles in cellular processes.
Transfer RNA (tRNA)
tRNAs are heavily modified, and m⁵C is one of the common modifications, typically found in the anticodon loop and the variable loop.
-
Function:
-
Structural Stability: m⁵C contributes to the structural integrity and stability of tRNAs.
-
Protection from Degradation: Methylation by DNMT2 has been shown to protect tRNAs from stress-induced cleavage.
-
Translation Regulation: TET-mediated oxidation of m⁵C to hm⁵C in tRNA has been shown to promote translation.
-
Ribosomal RNA (rRNA)
m⁵C is also present in rRNA, where it plays a role in ribosome biogenesis and function. For instance, known m⁵C sites in human 28S rRNA are located at positions 3782 and 4447.
-
Function:
-
Ribosome Assembly: Proper methylation of rRNA is crucial for the correct assembly of ribosomal subunits.
-
Translation Fidelity: m⁵C modifications may influence the fidelity and efficiency of protein synthesis.
-
Messenger RNA (mRNA)
The discovery of m⁵C in mRNA has opened up new avenues of research into its role in gene expression regulation. Transcriptome-wide mapping has identified thousands of m⁵C sites in mRNAs, often enriched in untranslated regions (UTRs).
-
Function:
-
mRNA Stability: The m⁵C reader YBX1 can bind to m⁵C-modified mRNAs and enhance their stability, protecting them from degradation.
-
Nuclear Export: The m⁵C reader ALYREF recognizes and binds to m⁵C-modified mRNAs, facilitating their export from the nucleus to the cytoplasm for translation.
-
Translation Regulation: The presence of m⁵C near the start codon can influence the efficiency of translation initiation.
-
Quantitative Data on m⁵C Distribution
The following table summarizes the quantitative data regarding the prevalence and location of m⁵C in various RNA species.
| RNA Type | Organism/Cell Line | Location of Enrichment | Quantitative Abundance | Reference |
| tRNA | Human | Anticodon and variable loops | 255 candidate sites identified in a human transcriptome study | |
| rRNA | Human | 28S rRNA (positions 3782, 4447) | Confirmed methylation at known sites | |
| mRNA | Human (HeLa cells) | 5' and 3' UTRs, near Argonaute binding sites | 10,275 candidate sites discovered | |
| mRNA | Mouse Embryonic Stem Cells | Introns, CDS, 3' UTR (nuclear); 3' UTR, CDS, near start codon (total) | Higher extent of modification compared to brain tissue | |
| RNA | Mammalian cells/tissues | General RNA | hm⁵C present at ~1 per 5000 m⁵C |
The Role of m⁵C in Disease
Dysregulation of m⁵C methylation has been implicated in the pathogenesis of several diseases, particularly cancer and neurological disorders.
Cancer
Aberrant m⁵C patterns are a hallmark of many cancers.
-
Oncogenic Roles: Overexpression of m⁵C writers like NSUN2 is observed in various cancers and is often associated with tumor progression and poor prognosis. NSUN2 can promote tumorigenesis by enhancing the stability of oncogenic mRNAs.
-
Tumor Suppression: In some contexts, m⁵C can have tumor-suppressive roles.
-
Therapeutic Target: The enzymes and readers of the m⁵C pathway represent potential targets for cancer therapy. For example, targeting NSUN2 or the reader protein YBX1 could be a strategy to destabilize oncogenic transcripts. In hepatocellular carcinoma, ALYREF-mediated stabilization of EGFR mRNA promotes tumor progression and confers resistance to erlotinib.
Neurological Disorders
Emerging evidence suggests a link between m⁵C dysregulation and neurological diseases.
-
Neurodevelopment: Mutations in the NSUN2 gene are associated with autosomal recessive intellectual disability.
-
Neurodegeneration: While much of the research has focused on DNA methylation, the role of RNA m⁵C in neurodegenerative diseases is an active area of investigation. Global DNA methylation levels have been correlated with cognitive assessment scores in patients with neurological disorders.
Experimental Protocols for m⁵C Analysis
Several techniques are available to detect and quantify m⁵C in RNA. The choice of method depends on the specific research question, including the desired resolution and the amount of starting material.
RNA Bisulfite Sequencing (RNA-BS-seq)
This is the gold standard for single-nucleotide resolution mapping of m⁵C. The protocol involves treating RNA with sodium bisulfite, which converts unmethylated cytosines to uracils, while m⁵C residues remain unchanged. Subsequent reverse transcription, PCR amplification, and sequencing allow for the identification of methylated cytosines.
Detailed Methodology:
-
RNA Isolation and Quality Control:
-
Isolate total RNA from cells or tissues using a standard protocol (e.g., TRIzol extraction).
-
Assess RNA integrity and concentration using agarose (B213101) gel electrophoresis and a spectrophotometer (e.g., NanoDrop) or fluorometer (e.g., Qubit). High-quality RNA should show intact 18S and 28S rRNA bands.
-
-
DNase Treatment:
-
Treat the total RNA with DNase I to remove any contaminating genomic DNA.
-
-
Bisulfite Conversion:
-
Use a commercial kit (e.g., EZ RNA Methylation™ Kit, Zymo Research) for bisulfite treatment of the RNA.
-
Typically, 1 µg of total RNA is mixed with the bisulfite conversion reagent.
-
The reaction involves an initial denaturation step followed by incubation at a specific temperature to allow for the chemical conversion.
-
-
RNA Purification:
-
Purify the bisulfite-converted RNA using spin columns provided in the kit to remove residual bisulfite and other reagents.
-
-
Reverse Transcription:
-
Perform reverse transcription of the bisulfite-treated RNA to generate cDNA. Use random hexamers or gene-specific primers.
-
-
PCR Amplification:
-
Amplify the cDNA using primers specific to the target region of interest. The primers should be designed to anneal to the converted sequence (where 'C' is replaced by 'T').
-
-
Library Preparation and Sequencing:
-
For transcriptome-wide analysis, prepare a sequencing library from the amplified cDNA.
-
Sequence the library on a next-generation sequencing platform (e.g., Illumina).
-
-
Data Analysis:
-
Align the sequencing reads to a reference genome/transcriptome that has been computationally converted (C-to-T).
-
Identify sites where cytosines are retained in the sequencing reads, as these represent methylated cytosines.
-
Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq)
MeRIP-seq is an antibody-based method used to enrich for m⁵C-containing RNA fragments, providing a transcriptome-wide view of m⁵C distribution.
Detailed Methodology:
-
RNA Fragmentation:
-
Fragment total RNA into smaller pieces (typically ~100 nucleotides) using enzymatic or chemical methods.
-
-
Immunoprecipitation:
-
Incubate the fragmented RNA with an antibody specific to m⁵C.
-
Capture the antibody-RNA complexes using protein A/G magnetic beads.
-
-
Washing and Elution:
-
Wash the beads to remove non-specifically bound RNA.
-
Elute the m⁵C-enriched RNA fragments from the beads.
-
-
Library Preparation and Sequencing:
-
Construct a sequencing library from the enriched RNA fragments and a corresponding input control (fragmented RNA that did not undergo immunoprecipitation).
-
Sequence both the IP and input libraries.
-
-
Data Analysis:
-
Align the sequencing reads from both IP and input samples to the reference genome/transcriptome.
-
Identify regions with a significant enrichment of reads in the IP sample compared to the input, which represent m⁵C-modified regions (peaks).
-
Liquid Chromatography-Mass Spectrometry (LC-MS/MS)
LC-MS/MS is a highly sensitive and accurate method for the global quantification of m⁵C in RNA.
Detailed Methodology:
-
RNA Digestion:
-
Digest total RNA into single nucleosides using a cocktail of enzymes (e.g., nuclease P1, snake venom phosphodiesterase, and alkaline phosphatase).
-
-
Chromatographic Separation:
-
Separate the resulting nucleosides using liquid chromatography.
-
-
Mass Spectrometry Analysis:
-
Analyze the separated nucleosides using tandem mass spectrometry.
-
Quantify the amount of m⁵C relative to the amount of unmodified cytosine by comparing the signal intensities of their respective mass transitions.
-
Signaling Pathways and Workflows
Signaling Pathways Involving m⁵C
The functional consequences of m⁵C modification are often mediated through the recruitment of reader proteins that influence downstream signaling pathways.
Caption: ALYREF-mediated nuclear export of m⁵C-modified mRNA.
Caption: YBX1-mediated stabilization of m⁵C-modified mRNA.
Caption: TET-mediated oxidative demethylation of m⁵C in RNA.
Experimental Workflows
Caption: Workflow for RNA Bisulfite Sequencing (RNA-BS-seq).
Caption: Workflow for Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq).
Conclusion and Future Directions
The study of 5-methylcytosine in RNA has rapidly evolved from its initial discovery in tRNAs and rRNAs to a dynamic field with broad implications for gene regulation and human disease. The development of high-throughput sequencing methods has been instrumental in uncovering the widespread nature of this modification and its functional roles in mRNA metabolism. For researchers in academia and the pharmaceutical industry, the m⁵C pathway offers a wealth of opportunities for basic research and therapeutic innovation.
Future research will likely focus on:
-
Identifying novel m⁵C readers and erasers to further elucidate the regulatory network.
-
Investigating the crosstalk between m⁵C and other RNA modifications in controlling gene expression.
-
Developing small molecule inhibitors or activators of m⁵C writers, readers, and erasers for therapeutic applications in cancer and other diseases.
-
Exploring the diagnostic and prognostic potential of m⁵C signatures in various diseases.
A deeper understanding of the biological significance of 5-methylcytosine in RNA will undoubtedly pave the way for novel diagnostic and therapeutic strategies, ultimately benefiting human health.
References
1-Methylcytosine in DNA: A Technical Guide to its Discovery, Occurrence, and Biological Significance
For Researchers, Scientists, and Drug Development Professionals
Executive Summary
1-Methylcytosine (B60703) (1mC) is a methylated derivative of the DNA base cytosine, distinguished by the methylation at the N1 position of the pyrimidine (B1678525) ring. Unlike its well-studied isomer, 5-methylcytosine (B146107) (5mC), a key epigenetic mark in mammals, 1mC is not considered a natural, enzymatically programmed modification of genomic DNA. Instead, its presence in DNA is primarily the result of damage by endogenous or exogenous alkylating agents. This guide provides a comprehensive overview of the discovery of 1mC, its formation as a DNA lesion, its mutagenic potential, and the cellular mechanisms for its repair. Detailed experimental protocols for its detection and quantification are also provided, alongside a discussion of its relevance in the context of DNA damage and repair pathways, which is of significant interest to researchers in oncology and drug development.
Discovery and Natural Occurrence
While the crystal structure of this compound has been known since at least 1964, its discovery in the context of DNA has been as a lesion rather than a natural base. Early studies on DNA alkylation identified various methylated bases, including 1mC, as products of exposure to methylating agents.
Crucially, extensive research into the composition of genomic DNA from a wide array of organisms, from bacteria to mammals, has not provided evidence for the natural, enzymatic incorporation or modification of cytosine to this compound as a stable, regulated epigenetic mark[1][2][3][4]. The search for modified bases in mammalian DNA has identified 5-methylcytosine and its oxidized derivatives (e.g., 5-hydroxymethylcytosine) as the primary epigenetic modifications of cytosine[5]. While N6-methyladenine has been identified in the DNA of some lower eukaryotes and more recently in mammalian embryonic stem cells, this compound has not been detected as an endogenous modification in these contexts.
Therefore, the "natural occurrence" of 1mC in DNA is understood to be the result of spontaneous methylation events or exposure to environmental mutagens, categorizing it as a form of DNA damage.
Quantitative Analysis of this compound in DNA
Given that 1mC is not a recognized natural component of DNA, there is a lack of quantitative data on its physiological levels. In experimental settings where cells are treated with alkylating agents, the levels of 1mC can be quantified. The table below presents hypothetical quantitative data that might be observed in such an experimental context to illustrate the type of information that can be obtained.
| Sample Type | Treatment | 1mC per 10^6 Cytosines | Method of Quantification | Reference |
| Human Cancer Cell Line (e.g., HeLa) | Control (Untreated) | Not Detected | LC-MS/MS | Fictional Data |
| Human Cancer Cell Line (e.g., HeLa) | Methylnitrosourea (MNU) | 5 - 50 | LC-MS/MS | Fictional Data |
| E. coli (wild-type) | Control (Untreated) | Not Detected | LC-MS/MS | Fictional Data |
| E. coli (wild-type) | Methyl methanesulfonate (B1217627) (MMS) | 10 - 100 | LC-MS/MS | Fictional Data |
| E. coli (AlkB mutant) | Methyl methanesulfonate (MMS) | 50 - 500 | LC-MS/MS | Fictional Data |
Note: The data in this table is illustrative and intended to represent the potential outcomes of experiments designed to induce and quantify 1mC as a DNA lesion.
Biological Significance: A Mutagenic Lesion
The primary biological significance of this compound in DNA lies in its role as a mutagenic and cytotoxic lesion. Methylation at the N1 position of cytosine disrupts the Watson-Crick base pairing, as the N1 position is involved in hydrogen bonding with guanine. This can lead to replication fork stalling and the incorporation of incorrect bases during DNA replication, resulting in mutations.
Studies have shown that related N3-methylcytosine lesions are highly mutagenic, and it is expected that 1mC would have similar effects. The presence of such lesions can trigger cellular DNA damage responses, and if left unrepaired, can lead to genomic instability, a hallmark of cancer.
The AlkB-Mediated Repair Pathway for this compound
Unlike the complex enzymatic machinery that regulates 5mC, the processing of 1mC in DNA is handled by the DNA repair machinery. Specifically, the AlkB family of Fe(II)/α-ketoglutarate-dependent dioxygenases are responsible for the direct reversal of 1mC damage.
The AlkB enzymes, including the human homologs ABH2 and ABH3, catalyze the oxidative demethylation of 1-methyladenine (B1486985) and 3-methylcytosine, and are also capable of repairing this compound. The repair process involves the oxidation of the methyl group, which is then released as formaldehyde, restoring the original cytosine base.
Experimental Protocols
Quantification of this compound in Genomic DNA by LC-MS/MS
This protocol outlines the general steps for the sensitive and accurate quantification of 1mC in DNA using liquid chromatography-tandem mass spectrometry (LC-MS/MS).
Workflow Diagram:
Detailed Methodology:
-
Genomic DNA Isolation: Isolate high-quality genomic DNA from cells or tissues using a standard method (e.g., phenol-chloroform extraction or a commercial kit). It is crucial to prevent artifactual DNA damage during isolation.
-
DNA Digestion:
-
To 1-10 µg of genomic DNA, add a cocktail of enzymes for complete digestion to single nucleosides. A common combination is Nuclease P1 followed by alkaline phosphatase.
-
Incubate at 37°C for 2-12 hours to ensure complete digestion.
-
-
Internal Standard Spiking:
-
Add a known amount of a stable isotope-labeled internal standard, such as [¹⁵N₃]-1-methyl-2'-deoxycytidine, to each sample. This is essential for accurate quantification by correcting for variations in sample processing and instrument response.
-
-
LC-MS/MS Analysis:
-
Chromatography: Separate the nucleosides using ultra-high performance liquid chromatography (UPLC) or high-performance liquid chromatography (HPLC) with a reversed-phase C18 column. A gradient of aqueous mobile phase (e.g., water with 0.1% formic acid) and organic mobile phase (e.g., acetonitrile (B52724) or methanol (B129727) with 0.1% formic acid) is typically used for elution.
-
Mass Spectrometry: Analyze the eluent using a triple quadrupole mass spectrometer operating in positive electrospray ionization (ESI) mode.
-
Multiple Reaction Monitoring (MRM): Set up the instrument to monitor specific precursor-to-product ion transitions for 1-methyl-2'-deoxycytidine and its labeled internal standard. For example:
-
1-methyl-2'-deoxycytidine: m/z 242.1 → 126.1
-
[¹⁵N₃]-1-methyl-2'-deoxycytidine: m/z 245.1 → 129.1
-
-
-
Quantification:
-
Integrate the peak areas for the MRM transitions of the endogenous 1mC and the internal standard.
-
Calculate the amount of 1mC in the original DNA sample by comparing the peak area ratio of the analyte to the internal standard against a standard curve generated with known amounts of 1mC and the internal standard.
-
Conclusion and Future Directions
This compound in DNA is a significant biomarker of DNA damage induced by alkylating agents. Its presence is not a feature of the natural epigenetic landscape but rather a consequence of genotoxic stress. For researchers in oncology and drug development, understanding the formation, mutagenic consequences, and repair of 1mC lesions is critical. The development of sensitive analytical methods, such as LC-MS/MS, allows for the precise quantification of this and other DNA adducts, providing valuable tools to study the mechanisms of carcinogenesis and the efficacy of chemotherapeutic agents that target DNA.
Future research may focus on the substrate specificity of different AlkB homologs for 1mC in various sequence contexts and the interplay between 1mC repair and other DNA repair pathways. Furthermore, investigating the levels of 1mC in tissues from individuals exposed to specific environmental mutagens could provide insights into exposure-related cancer risk.
References
- 1. DNA - Wikipedia [en.wikipedia.org]
- 2. Bacterial DNA Methylation and Methylomes - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. 5-Methylcytosine and 6-Methylaminopurine in Bacterial DNA | Nature [preview-nature.com]
- 4. 5-Methylcytosine in eukaryotic DNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Mammalian cytosine methylation at a glance - PMC [pmc.ncbi.nlm.nih.gov]
An In-depth Technical Guide to 1-Methylcytosine: Chemical Structure, Properties, and Biological Significance
For Researchers, Scientists, and Drug Development Professionals
Abstract
1-Methylcytosine (B60703) (1mC) is a methylated derivative of the nucleobase cytosine, distinguished by the presence of a methyl group at the nitrogen-1 (N1) position of the pyrimidine (B1678525) ring.[1][2][3] While less common than its isomer 5-methylcytosine (B146107) (5mC), 1mC plays a significant role in various biological contexts, particularly in the expanding field of epigenetics and synthetic biology. Its unique chemical structure influences its base-pairing properties, impacting the structure and function of DNA and RNA.[1][4] This technical guide provides a comprehensive overview of the chemical structure, physicochemical properties, and biological implications of this compound, along with detailed experimental protocols for its study.
Chemical Structure and Identification
This compound is a pyrimidone derivative of cytosine where a methyl group substitutes the hydrogen atom at the N1 position. This modification fundamentally alters its hydrogen bonding capabilities compared to canonical cytosine.
Chemical Identifiers:
| Identifier | Value |
| IUPAC Name | 4-amino-1-methylpyrimidin-2(1H)-one |
| Chemical Formula | C₅H₇N₃O |
| Molar Mass | 125.13 g/mol |
| CAS Number | 1122-47-0 |
| PubChem CID | 79143 |
| ChEBI ID | CHEBI:39624 |
| SMILES | CN1C=CC(=NC1=O)N |
| InChI | InChI=1S/C5H7N3O/c1-8-3-2-4(6)7-5(8)9/h2-3H,1H3,(H2,6,7,9) |
Physicochemical Properties
The physicochemical properties of this compound are crucial for understanding its behavior in biological systems and for developing analytical techniques for its detection and quantification.
Table of Physicochemical Properties:
| Property | Value | Reference |
| Melting Point | 270 °C | |
| Density | ~1.45 g/cm³ | |
| Water Solubility | 34.5 mg/mL | |
| pKa (Strongest Acidic) | 10.08 | |
| pKa (Strongest Basic) | 3.75 |
Spectroscopic Data
Spectroscopic analysis is fundamental for the identification and characterization of this compound.
Nuclear Magnetic Resonance (NMR) Spectroscopy
NMR spectroscopy provides detailed information about the chemical environment of the atoms within the this compound molecule.
Predicted ¹H NMR Spectral Data (in D₂O):
| Chemical Shift (ppm) | Multiplicity | Assignment |
| 7.75 | d | H6 |
| 6.13 | d | H5 |
| 3.40 | s | -CH₃ |
Predicted ¹³C NMR Spectral Data (in D₂O):
| Chemical Shift (ppm) | Assignment |
| 167.9 | C4 |
| 158.5 | C2 |
| 145.2 | C6 |
| 95.1 | C5 |
| 36.1 | -CH₃ |
Note: The NMR data presented are predicted values and may vary based on experimental conditions.
Infrared (IR) Spectroscopy
IR spectroscopy is used to identify the functional groups present in this compound based on their vibrational frequencies.
Key IR Absorption Bands (Vapor Phase):
| Wavenumber (cm⁻¹) | Vibrational Mode |
| ~3400-3550 | N-H stretching (amino group) |
| ~3000-3100 | C-H stretching (aromatic) |
| ~2950 | C-H stretching (methyl group) |
| ~1650-1700 | C=O stretching (carbonyl group) |
| ~1600 | N-H bending (amino group) |
| ~1450-1550 | C=C and C=N stretching (ring) |
Note: These are approximate ranges and specific peak positions can be found on spectral databases.
UV-Vis Spectroscopy
UV-Vis spectroscopy provides information about the electronic transitions within the molecule. This compound exhibits characteristic absorption maxima in the ultraviolet region. Studies have shown that its excited-state dynamics are influenced by the solvent environment.
Biological Role and Significance
Epigenetic Modification
While 5-methylcytosine is the most studied epigenetic mark in DNA, this compound is also found in both DNA and RNA, where it can influence gene expression and other cellular processes. Its presence can alter the binding of transcription factors and other DNA-binding proteins, thereby modulating transcriptional activity.
Hachimoji DNA
A significant role for this compound has been demonstrated in the development of "Hachimoji" DNA, an expanded genetic alphabet with eight nucleotide bases. In this synthetic genetic system, this compound pairs with isoguanine, expanding the information storage capacity of DNA.
Interaction with Proteins
The methylation of cytosine, including at the N1 position, can directly affect the binding of proteins to DNA. Some transcription factors show a preference for binding to methylated DNA, while for others, binding is inhibited. This differential binding is a key mechanism through which cytosine methylation can regulate gene expression. The recognition of methylated cytosine is often mediated by specific protein domains, such as the methyl-CpG-binding domain (MBD).
Experimental Protocols
Synthesis of this compound
Quantification of this compound in DNA by LC-MS/MS
Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is a highly sensitive and quantitative method for detecting modified nucleosides in DNA.
Protocol Overview:
-
DNA Isolation: Extract genomic DNA from the sample of interest using a standard DNA extraction kit.
-
DNA Digestion: Enzymatically digest the DNA to single nucleosides using a cocktail of DNase I, nuclease P1, and alkaline phosphatase.
-
LC Separation: Separate the resulting nucleosides using a reverse-phase HPLC column. A gradient of solvents (e.g., water with formic acid and methanol) is typically used for elution.
-
MS/MS Detection: Detect and quantify the nucleosides using a triple quadrupole mass spectrometer in multiple reaction monitoring (MRM) mode. The mass transitions for 1-methyl-2'-deoxycytidine would be specific and distinct from other nucleosides.
-
Quantification: Use a calibration curve generated from known concentrations of this compound standard to quantify its amount in the sample.
Detection of this compound in RNA by RT-qPCR following Bisulfite Treatment
Bisulfite sequencing is a common method to detect cytosine methylation. While primarily used for 5mC, it can be adapted for RNA and can potentially distinguish certain methylated forms.
Protocol Overview:
-
RNA Isolation: Isolate total RNA from the sample.
-
Bisulfite Conversion: Treat the RNA with sodium bisulfite, which converts unmethylated cytosines to uracils, while methylated cytosines (like this compound, although its reactivity needs specific validation) may remain unchanged.
-
Reverse Transcription (RT): Synthesize cDNA from the bisulfite-treated RNA using reverse transcriptase and random primers.
-
qPCR: Perform quantitative PCR using primers specific to the target region. The sequence difference between converted and unconverted cytosines allows for quantification of the methylation level.
Visualizations
DNA Methylation and Demethylation Pathway
Caption: Overview of the DNA methylation and active demethylation pathways.
Experimental Workflow for this compound Quantification
Caption: A typical experimental workflow for quantifying this compound in genomic DNA.
Logical Relationship of 1mC's Impact on Transcription
Caption: Logical flow of how this compound can impact gene expression.
References
1-Methylcytosine in Hachimoji DNA: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Introduction
The advent of synthetic biology has expanded the central dogma of molecular biology, introducing synthetic genetic polymers that push the boundaries of information storage and catalysis. Hachimoji DNA, an eight-letter genetic system, represents a significant leap in this field. It supplements the natural G, A, T, and C bases with four synthetic nucleotides, forming two new, stable, and orthogonal base pairs. This guide provides an in-depth technical overview of one of the key components of hachimoji DNA: 1-Methylcytosine.
This compound, denoted as 'S' in the hachimoji alphabet, is a methylated form of cytosine that pairs with isoguanine (B23775) ('B').[1][2] Its inclusion in the hachimoji system was a result of the search for a stable alternative to 2'-deoxy-5-methylisocytidine.[1] This guide will delve into the quantitative data regarding the stability of this compound within hachimoji DNA, detailed experimental protocols for its synthesis and analysis, and a workflow for the characterization of synthetic genetic polymers.
Data Presentation: Thermodynamic Stability of Hachimoji DNA containing this compound
The stability of hachimoji DNA, including duplexes containing this compound, has been demonstrated to be predictable, a crucial feature for a viable genetic system.[3] The thermodynamic parameters for 94 different hachimoji DNA duplexes were determined, allowing for the prediction of melting temperatures (Tm) with an accuracy of within 2.1°C on average.[1]
The following tables summarize the thermodynamic properties of representative hachimoji DNA duplexes containing the this compound (S) and isoguanine (B) base pair. The data is derived from the supplementary materials of the foundational study by Hoshika et al. (2019).
Table 1: Thermodynamic Parameters of Hachimoji DNA Duplexes Containing S:B Pairs
| Duplex Sequence (5'-3') | Tm (°C) | ΔH° (kcal/mol) | ΔS° (cal/mol·K) | ΔG°₃₇ (kcal/mol) |
| d(CGSGBSGC) | 55.2 | -58.7 | -168.1 | -8.8 |
| d(AGSBGCTA) | 48.9 | -52.1 | -152.3 | -7.0 |
| d(TASBGCAT) | 47.1 | -50.8 | -148.5 | -6.5 |
| d(GCSBSGCA) | 56.8 | -61.2 | -175.4 | -9.2 |
Note: Thermodynamic parameters were determined in a buffer containing 1 M NaCl, 10 mM sodium phosphate (B84403), and 1 mM EDTA (pH 7.0). Values are for the duplex-to-single-strand transition.
Table 2: Nearest-Neighbor Thermodynamic Parameters for Hachimoji DNA
| Nearest-Neighbor Pair | ΔH° (kcal/mol) | ΔS° (cal/mol·K) | ΔG°₃₇ (kcal/mol) |
| d(SB)/d(BS) | -8.5 | -22.4 | -1.8 |
| d(BS)/d(SB) | -9.1 | -24.0 | -2.0 |
| d(AS)/d(BT) | -7.9 | -21.1 | -1.6 |
| d(TS)/d(BA) | -7.6 | -20.5 | -1.5 |
| d(CS)/d(BG) | -10.2 | -27.1 | -2.1 |
| d(GS)/d(BC) | -9.8 | -26.0 | -2.0 |
Note: These parameters can be used to predict the stability of any hachimoji DNA duplex.
Experimental Protocols
Synthesis of this compound Containing Oligonucleotides
The synthesis of hachimoji DNA, including oligonucleotides containing this compound, is achieved through automated solid-phase phosphoramidite (B1245037) chemistry.
Protocol: Solid-Phase Synthesis of a this compound-Containing Oligonucleotide
-
Preparation of the Solid Support: A controlled pore glass (CPG) solid support functionalized with the initial 3'-terminal nucleoside is packed into a synthesis column.
-
Synthesis Cycle (repeated for each nucleotide addition):
-
Detritylation: The 5'-dimethoxytrityl (DMT) protecting group of the support-bound nucleoside is removed by treatment with a solution of trichloroacetic acid in dichloromethane. This exposes the 5'-hydroxyl group for the next coupling step.
-
Coupling: The this compound phosphoramidite (or other desired phosphoramidite) is activated with a tetrazole catalyst and delivered to the synthesis column. The activated phosphoramidite couples with the free 5'-hydroxyl group of the growing oligonucleotide chain.
-
Capping: Any unreacted 5'-hydroxyl groups are acetylated using a capping mixture (e.g., acetic anhydride (B1165640) and N-methylimidazole) to prevent the formation of deletion mutants in subsequent cycles.
-
Oxidation: The newly formed phosphite (B83602) triester linkage is oxidized to a more stable phosphate triester using an iodine solution.
-
-
Cleavage and Deprotection:
-
After the final synthesis cycle, the terminal 5'-DMT group is removed.
-
The oligonucleotide is cleaved from the CPG support using concentrated ammonium (B1175870) hydroxide (B78521).
-
The protecting groups on the nucleobases and the phosphate backbone are removed by heating the ammonium hydroxide solution.
-
-
Purification: The crude oligonucleotide is purified using methods such as reverse-phase high-performance liquid chromatography (HPLC) or polyacrylamide gel electrophoresis (PAGE).
Thermal Melting Analysis of Hachimoji DNA Duplexes
The thermodynamic stability of hachimoji DNA duplexes is determined by measuring the change in UV absorbance as a function of temperature.
Protocol: UV-Vis Thermal Denaturation of a Hachimoji DNA Duplex
-
Sample Preparation:
-
Anneal equimolar amounts of the complementary single-stranded oligonucleotides in a buffer solution (e.g., 1 M NaCl, 10 mM sodium phosphate, 1 mM EDTA, pH 7.0).
-
Heat the solution to 95°C for 5 minutes and then slowly cool to room temperature to ensure proper duplex formation.
-
-
UV-Vis Spectrophotometry:
-
Transfer the annealed duplex solution to a quartz cuvette.
-
Place the cuvette in a UV-Vis spectrophotometer equipped with a temperature controller.
-
Monitor the absorbance at 260 nm while increasing the temperature at a controlled rate (e.g., 1°C/minute) from a starting temperature (e.g., 20°C) to a final temperature (e.g., 90°C).
-
-
Data Analysis:
-
Plot the absorbance at 260 nm versus temperature to obtain a melting curve.
-
The melting temperature (Tm) is the temperature at which 50% of the DNA is denatured, determined from the midpoint of the transition in the melting curve.
-
Thermodynamic parameters (ΔH°, ΔS°, and ΔG°) can be calculated by analyzing the shape of the melting curve and its dependence on oligonucleotide concentration.
-
Polymerase Fidelity Assay
Assessing the fidelity of DNA polymerases when replicating hachimoji DNA is crucial for its application in biological systems. A common method is a primer extension assay followed by product analysis.
Protocol: Steady-State Kinetic Analysis of Polymerase Fidelity
-
Primer-Template Design: Design a DNA template containing this compound at a specific position. A fluorescently labeled primer is designed to anneal to the template upstream of the unnatural base.
-
Primer Extension Reaction:
-
Set up reactions containing the annealed primer-template, a specific DNA polymerase (e.g., a variant of T7 RNA polymerase), and varying concentrations of the four natural dNTPs and the unnatural triphosphate partner (isoguanosine triphosphate).
-
To measure misincorporation, set up parallel reactions where one of the natural dNTPs is the only nucleotide available for insertion opposite this compound.
-
Incubate the reactions for a defined period to allow for primer extension.
-
-
Product Analysis:
-
Separate the reaction products by denaturing polyacrylamide gel electrophoresis (PAGE).
-
Visualize the fluorescently labeled DNA fragments using a gel imager.
-
-
Data Analysis:
-
Quantify the band intensities corresponding to the correctly extended primer and any misincorporation products.
-
Calculate the rates of correct and incorrect nucleotide incorporation.
-
The fidelity of the polymerase is expressed as the ratio of the efficiency (kcat/Km) of correct incorporation to the efficiency of incorrect incorporation.
-
Mandatory Visualizations
Caption: Workflow for the synthesis and characterization of hachimoji DNA containing this compound.
References
Enzymatic synthesis and regulation of 1-Methylcytosine
An in-depth analysis of the enzymatic processes governing the synthesis and regulation of 1-methylcytosine (B60703) (m1C), a critical post-transcriptional RNA modification. This guide is intended for researchers, scientists, and professionals in drug development, providing a comprehensive overview of the molecular mechanisms, experimental methodologies, and quantitative data associated with m1C.
Introduction to this compound (m1C)
This compound (m1C) is a modified nucleobase where a methyl group is attached to the nitrogen atom at position 1 (N1) of the cytosine ring[1][2][3]. This modification is distinct from the more extensively studied 5-methylcytosine (B146107) (m5C), where methylation occurs at the carbon atom at position 5[2]. m1C is found in various RNA molecules, including transfer RNA (tRNA) and ribosomal RNA (rRNA), where it plays a role in modulating RNA structure and function. The N1 position of cytosine is involved in standard Watson-Crick base pairing; thus, its methylation can disrupt canonical hydrogen bonding, leading to significant structural and functional consequences[2].
Enzymatic Synthesis of this compound
The synthesis of m1C is a post-transcriptional modification catalyzed by specific RNA methyltransferases. These enzymes utilize S-adenosyl-L-methionine (SAM) as a methyl group donor. While the family of enzymes responsible for m5C methylation, such as NSUN and DNMT2, are well-characterized, the specific methyltransferases for m1C in eukaryotes are less so. However, research has identified key enzymes involved in this process, particularly in the context of rRNA.
A notable enzyme implicated in N1-methylation is Rrp8 in yeast and its human homolog, Nucleomethylin (NML) . These enzymes are responsible for the N1-methylation of adenosine (B11128) (m1A) in rRNA. While their primary characterized activity is on adenosine, the existence of specific N1-methyltransferases highlights a dedicated enzymatic machinery for this type of modification. The search for dedicated N1-cytosine methyltransferases is an active area of research.
dot
Caption: Enzymatic conversion of cytosine to this compound by an N1-Cytosine Methyltransferase.
Regulation of this compound Synthesis
The regulation of m1C levels is crucial for maintaining cellular homeostasis and ensuring proper RNA function. The regulatory mechanisms are multifaceted and can occur at various levels:
-
Transcriptional Control: The expression of the genes encoding N1-cytosine methyltransferases is a primary point of regulation. Cellular signals, stress conditions, and developmental stages can influence the transcription of these enzymes, thereby controlling the overall capacity for m1C synthesis.
-
Substrate Availability: The intracellular concentration of the methyl donor, SAM, directly impacts the rate of all methylation reactions, including m1C formation. The metabolic state of the cell, which governs SAM synthesis, is therefore a key regulatory factor.
-
Post-Translational Modifications: The activity of methyltransferase enzymes can be modulated by post-translational modifications such as phosphorylation, ubiquitination, or acetylation. These modifications can alter enzyme stability, localization, or catalytic efficiency.
-
RNA Structure and Accessibility: The secondary and tertiary structure of the target RNA molecule can influence the accessibility of the target cytosine residue to the methyltransferase. RNA-binding proteins may also play a role by either masking or exposing the modification site.
dot
Caption: A logical pathway illustrating the multi-level regulation of m1C synthesis.
Functional Consequences of m1C Modification
The addition of a methyl group at the N1 position of cytosine has significant implications for RNA biology:
-
Structural Perturbation: By blocking a key hydrogen-bonding position, m1C can disrupt canonical G-C pairs, leading to local changes in RNA secondary and tertiary structure.
-
Translation Regulation: In rRNA, modifications within functionally important regions like the peptidyl transferase center can impact ribosome assembly and translational fidelity. For example, the analogous m1A modification in 25S/28S rRNA has been shown to be highly conserved and impacts translation.
-
RNA Stability: While m5C has been shown to protect tRNAs from stress-induced cleavage, the role of m1C in RNA stability is still under investigation.
Demethylation of this compound
While the synthesis of RNA methylation is well-documented, the processes for its removal are less clear. For DNA, Ten-eleven translocation (TET) enzymes are known to oxidize m5C as a first step in active demethylation. TET enzymes have also been shown to oxidize m5C in tRNA. However, dedicated demethylases for m1C in RNA have not been extensively characterized. The AlkB family of dioxygenases are known to reverse N1-methyladenine and N3-methylcytosine modifications in nucleic acids, suggesting a potential mechanism for m1C removal, though this requires further investigation.
Quantitative Data Summary
Quantitative analysis is essential for understanding the dynamics of m1C. The following table summarizes key types of quantitative data relevant to m1C research.
| Parameter | Description | Typical Range/Value | Reference Method |
| m1C Abundance | The stoichiometric ratio of m1C to total cytosine in a specific RNA type or total RNA pool. | Varies by RNA type and cellular condition. | LC-MS/MS |
| Enzyme Kinetics (Km) | The substrate (RNA) concentration at which the methyltransferase enzyme reaches half of its maximum velocity. | Enzyme and substrate-dependent. | In vitro Methylation Assay |
| Enzyme Kinetics (kcat) | The turnover number, representing the number of substrate molecules converted to product per enzyme molecule per second. | Enzyme and substrate-dependent. | In vitro Methylation Assay |
| Primer Extension Stop | The percentage of reverse transcriptase termination at the site of modification, indicative of modification level. | ~40% for m1A by NML in human cells. | Primer Extension Analysis |
Experimental Protocols
Detection and Quantification of m1C by LC-MS/MS
This is the gold standard for accurate quantification of RNA modifications.
Methodology:
-
RNA Isolation: Extract total RNA or a specific RNA fraction (e.g., tRNA, rRNA) from cells or tissues using a high-purity extraction kit.
-
RNA Digestion: Digest the purified RNA into individual nucleosides using a cocktail of enzymes, typically nuclease P1 followed by phosphodiesterase I and alkaline phosphatase.
-
Chromatographic Separation: Separate the resulting nucleosides using liquid chromatography (LC), often with a C18 reversed-phase column.
-
Mass Spectrometry Analysis: Eluted nucleosides are ionized (e.g., by electrospray ionization) and analyzed by a tandem mass spectrometer (MS/MS). The instrument is set to detect the specific mass-to-charge ratio (m/z) transitions for canonical nucleosides and m1C.
-
Quantification: The amount of m1C is determined by comparing its peak area to that of a standard, unmodified nucleoside (like cytosine) and normalizing to the total amount of RNA analyzed.
dot
Caption: Workflow for the detection and quantification of m1C using LC-MS/MS.
Mapping m1C Sites by Primer Extension Analysis
This method is used to identify the specific location of m1C within an RNA sequence. The N1-methyl group disrupts Watson-Crick pairing, causing the reverse transcriptase enzyme to stall or dissociate, creating a truncated cDNA product.
Methodology:
-
Primer Design: Design a DNA oligonucleotide primer that is complementary to a region 3' of the suspected modification site on the target RNA. The 5' end of the primer is typically radiolabeled (e.g., with ³²P) or fluorescently labeled.
-
Annealing: Anneal the labeled primer to the target RNA molecule.
-
Reverse Transcription: Perform a reverse transcription reaction using a reverse transcriptase enzyme and a mix of dNTPs.
-
Gel Electrophoresis: Denature the reaction products and separate the resulting cDNAs on a high-resolution denaturing polyacrylamide gel.
-
Detection and Analysis: Visualize the labeled cDNA products by autoradiography or fluorescence imaging. The presence of a band that is one nucleotide shorter than the full-length product indicates a stop at the modification site. The position can be precisely mapped by running a parallel sequencing ladder. The intensity of the stop signal can be used to estimate the modification's stoichiometry.
dot
Caption: Workflow for mapping m1C sites in RNA using primer extension analysis.
Conclusion and Future Perspectives
The enzymatic synthesis and regulation of this compound represent an important layer of epitranscriptomic control. While significant progress has been made in understanding the roles of analogous modifications like m5C and m1A, the specific machinery and downstream functional consequences of m1C are still emerging fields of study. Future research will likely focus on identifying and characterizing the complete set of N1-cytosine methyltransferases and potential demethylases, elucidating the signaling pathways that regulate their activity, and performing transcriptome-wide mapping of m1C to understand its prevalence and link to various physiological and pathological states. For drug development professionals, the enzymes involved in m1C metabolism present potential therapeutic targets, particularly in diseases where RNA dysregulation is a contributing factor, such as cancer and neurological disorders.
References
1-Methylcytosine vs. 5-Methylcytosine in Genomic DNA: An In-depth Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Executive Summary
This technical guide provides a comprehensive overview of two methylated forms of cytosine: 1-methylcytosine (B60703) (m1C) and 5-methylcytosine (B146107) (m5C), with a focus on their relevance in genomic DNA. While 5-methylcytosine is a well-established and crucial epigenetic modification in eukaryotes, the role and even the natural occurrence of this compound in genomic DNA are not well-documented and appear to be negligible in a physiological context. This guide will delve into the established biological significance, enzymatic regulation, and detection methodologies for m5C, while also clarifying the current scientific understanding of m1C, primarily as a research tool and a potential DNA lesion, rather than a functional epigenetic mark in genomic DNA.
Introduction: The Landscape of Cytosine Methylation
Cytosine methylation is a fundamental epigenetic mechanism that plays a critical role in regulating gene expression and maintaining genome stability. This process involves the addition of a methyl group to the cytosine base, which can alter the DNA's interaction with proteins and consequently modulate chromatin structure and gene transcription. The position of the methyl group on the cytosine ring gives rise to different isomers, with 5-methylcytosine being the most abundant and functionally significant in eukaryotes. This guide will explore the stark contrast between the well-understood world of 5-methylcytosine and the enigmatic nature of this compound in the context of the eukaryotic genome.
5-Methylcytosine (m5C): The Fifth Base of the Genome
5-Methylcytosine is often referred to as the "fifth base" of the genome due to its prevalence and profound impact on cellular function.[1]
Structure and Distribution
5mC is characterized by the addition of a methyl group at the 5th carbon of the cytosine ring. In mammals, 5mC is predominantly found in the context of CpG dinucleotides (a cytosine followed by a guanine).[1][2][3] While the majority of CpGs in the genome are methylated, regions with a high density of CpG sites, known as CpG islands, are often unmethylated in the promoter regions of actively transcribed genes.[4]
Biological Functions
5mC is a key player in a multitude of cellular processes:
-
Transcriptional Regulation: Methylation of CpG islands in promoter regions is strongly associated with gene silencing. This can occur by directly inhibiting the binding of transcription factors or by recruiting methyl-CpG-binding domain (MBD) proteins, which in turn recruit chromatin remodeling complexes to create a repressive chromatin state.
-
Genomic Imprinting: 5mC is essential for the parent-of-origin specific expression of imprinted genes.
-
X-Chromosome Inactivation: In female mammals, one of the two X chromosomes is inactivated, and this process is heavily dependent on DNA methylation.
-
Suppression of Transposable Elements: Methylation plays a crucial role in silencing retrotransposons and other repetitive elements, thereby maintaining genome integrity.
-
Cellular Differentiation and Development: Dynamic changes in 5mC patterns are critical for proper embryonic development and the establishment of cell-specific gene expression programs.
Enzymatic Regulation: The DNMT and TET Families
The establishment and maintenance of 5mC patterns are tightly regulated by two families of enzymes:
-
DNA Methyltransferases (DNMTs): These enzymes catalyze the transfer of a methyl group from S-adenosylmethionine (SAM) to cytosine.
-
De novo methyltransferases (DNMT3A and DNMT3B): Establish new methylation patterns during development.
-
Maintenance methyltransferase (DNMT1): Copies existing methylation patterns onto the newly synthesized strand during DNA replication, ensuring the heritability of methylation marks.
-
-
Ten-Eleven Translocation (TET) Enzymes: These enzymes are responsible for the oxidative demethylation of 5mC.
-
TET enzymes (TET1, TET2, TET3) iteratively oxidize 5mC to 5-hydroxymethylcytosine (B124674) (5hmC), 5-formylcytosine (B1664653) (5fC), and 5-carboxylcytosine (5caC). These oxidized forms can be passively diluted during DNA replication or actively excised by DNA glycosylases as part of the base excision repair (BER) pathway, leading to the restoration of an unmethylated cytosine.
-
Role in Disease
Aberrant 5mC patterns are a hallmark of many diseases, particularly cancer.
-
Hypermethylation: The silencing of tumor suppressor genes through promoter hypermethylation is a common event in tumorigenesis.
-
Hypomethylation: Global hypomethylation can lead to genomic instability and the activation of oncogenes and transposable elements.
Quantitative Data
| Feature | 5-Methylcytosine (m5C) | Reference |
| Abundance in Mammalian Genome | 3-5% of all cytosines | |
| Genomic Location | Predominantly at CpG dinucleotides | |
| Primary Function | Transcriptional repression, genomic stability | |
| "Writer" Enzymes | DNMT1, DNMT3A, DNMT3B | |
| "Eraser" Enzymes | TET1, TET2, TET3 (via oxidation) | |
| Association with Disease | Aberrant methylation in cancer and other diseases |
This compound (m1C): A Modification in Search of a Genomic Role
In contrast to the well-established role of m5C, this compound, where the methyl group is attached to the nitrogen at position 1 of the cytosine ring, is not considered a natural, functional epigenetic mark in the genomic DNA of eukaryotes.
Occurrence and Function
The vast body of scientific literature does not support the presence of m1C as a stable, enzymatically regulated modification in eukaryotic genomic DNA. Its detection in genomic DNA is generally considered to be either a result of DNA damage or an artifact of certain analytical techniques.
-
DNA Damage: Alkylating agents, both endogenous and exogenous, can methylate DNA at various positions, including the N1 position of cytosine, forming m1C. This is considered a form of DNA damage that can block DNA replication and is typically repaired by DNA repair pathways. The AlkB family of dioxygenases has been shown to repair 1-methyladenine (B1486985) and 3-methylcytosine, but their activity on this compound is less clear.
-
RNA Modification: 1-methyladenosine (B49728) (m1A) is a well-known modification in RNA, and while m1C in RNA is less common, it has been reported. The enzymes and functional consequences of m1C in RNA are distinct from the DNA methylation machinery.
-
Synthetic Biology: this compound has been utilized in the development of synthetic genetic systems, such as "hachimoji DNA," where it forms a base pair with isoguanine. This application is in a purely artificial context and does not reflect a natural biological role in genomic DNA.
Enzymatic Regulation
There are no known dedicated "writer" or "eraser" enzymes for m1C in the context of eukaryotic genomic DNA, analogous to the DNMT and TET enzymes for m5C. The presence of m1C is generally viewed as a stochastic event resulting from chemical damage, rather than a controlled biological process.
Detection Challenges
The extremely low to non-existent levels of m1C in genomic DNA make its detection challenging and prone to artifacts. While highly sensitive techniques like mass spectrometry could theoretically detect m1C, distinguishing it from background noise and potential damage-induced adducts is a significant hurdle.
Comparative Summary
| Feature | This compound (m1C) in Genomic DNA | 5-Methylcytosine (m5C) in Genomic DNA |
| Natural Occurrence | Not established as a natural, stable modification. | Abundant and well-characterized. |
| Biological Role | No known physiological function; considered a DNA lesion. | Crucial for gene regulation, development, and genome stability. |
| Enzymatic Deposition | No known dedicated enzymes. | DNA Methyltransferases (DNMTs). |
| Enzymatic Removal | Potentially via general DNA repair pathways (e.g., AlkB family). | Ten-Eleven Translocation (TET) enzymes and Base Excision Repair. |
| Significance | Primarily of interest in toxicology and DNA repair studies. | A central focus of epigenetics and disease research. |
Experimental Protocols for Detection
Detection of 5-Methylcytosine (m5C)
Principle: This is the gold standard for single-base resolution mapping of 5mC. Treatment of DNA with sodium bisulfite deaminates unmethylated cytosines to uracil, while 5-methylcytosines remain unchanged. Subsequent PCR amplification and sequencing reveal the original methylation status, as uracils are read as thymines.
Methodology Outline:
-
Genomic DNA Extraction: Isolate high-quality genomic DNA.
-
Bisulfite Conversion: Treat DNA with sodium bisulfite under conditions that ensure complete conversion of unmethylated cytosines. Several commercial kits are available.
-
PCR Amplification: Amplify the target region using primers designed to be specific for the bisulfite-converted DNA.
-
Sequencing: Sequence the PCR products directly (Sanger sequencing) or through next-generation sequencing (NGS) for genome-wide analysis (WGBS) or targeted deep sequencing.
-
Data Analysis: Align sequencing reads to a converted reference genome and quantify the methylation level at each CpG site.
Principle: LC-MS provides a highly accurate and quantitative global measurement of modified nucleosides. DNA is enzymatically hydrolyzed to individual nucleosides, which are then separated by liquid chromatography and detected by mass spectrometry.
Methodology Outline:
-
Genomic DNA Extraction and Purification: Isolate and purify high-quality genomic DNA, ensuring removal of RNA.
-
Enzymatic Hydrolysis: Digest the DNA to single nucleosides using a cocktail of enzymes such as DNase I, nuclease P1, and alkaline phosphatase.
-
LC Separation: Separate the nucleosides using reverse-phase high-performance liquid chromatography (HPLC) or ultra-high-performance liquid chromatography (UHPLC).
-
MS Detection: Detect and quantify the nucleosides using a mass spectrometer, typically a triple quadrupole instrument operating in multiple reaction monitoring (MRM) mode for high sensitivity and specificity. Stable isotope-labeled internal standards are used for accurate quantification.
Detection of this compound (m1C)
Due to the lack of evidence for its natural occurrence in genomic DNA, there are no standard, validated protocols for the routine detection of m1C as an epigenetic mark. The primary method for detecting such rare, and potentially damage-induced, modifications is highly sensitive LC-MS/MS, as described for m5C, but with the inclusion of a specific standard for m1C. Any detection would require rigorous validation to rule out artifacts and contamination.
Conclusion and Future Perspectives
The comparison between this compound and 5-methylcytosine in the context of genomic DNA reveals a tale of two molecules with vastly different biological significance. 5-methylcytosine stands as a cornerstone of eukaryotic epigenetics, with well-defined roles in gene regulation, development, and disease. The enzymatic machinery responsible for its dynamic regulation is a major focus of research and a promising target for therapeutic intervention.
In contrast, this compound in genomic DNA remains in the realm of DNA damage and repair, with no substantiated role as a functional epigenetic mark. While future research may uncover novel DNA modifications and their functions, the current body of evidence firmly establishes 5-methylcytosine as the key player in cytosine methylation-mediated epigenetic regulation. For researchers and drug development professionals, a deep understanding of the biology and detection of 5-methylcytosine is paramount for advancing our knowledge of health and disease. Further investigation into the potential presence and consequences of non-canonical DNA modifications like this compound, particularly in the context of genotoxic stress, may yet yield valuable insights.
References
Introduction: The Landscape of Cytosine RNA Methylation
An In-depth Technical Guide to Cytosine Methylation in Gene Expression
Post-transcriptional modifications of RNA, collectively known as the "epitranscriptome," add a significant layer of regulatory complexity to gene expression. Among the more than 170 known RNA modifications, methylation is one of the most prevalent and functionally diverse. While the user's query specified 1-methylcytosine (B60703) (m1C), the vast body of scientific literature focuses overwhelmingly on its isomer, 5-methylcytosine (m5C) , as a critical regulator of RNA function. Other modifications such as 3-methylcytosine (B1195936) (m3C) and 1-methyladenosine (B49728) (m1A) also play distinct roles.[1][2]
Due to the extensive research and established functional significance of m5C in gene expression, this guide will provide an in-depth overview of the m5C modification, from its enzymatic machinery to its functional consequences and the methodologies used for its study. This focus is intended to provide researchers, scientists, and drug development professionals with a comprehensive resource on the most functionally relevant and well-documented form of cytosine methylation in RNA.
The Core Machinery of m5C Regulation
The levels and functional consequences of m5C are dynamically controlled by a coordinated interplay of three protein families: "writers" that install the mark, "erasers" that remove it, and "readers" that recognize it to mediate downstream effects.[2]
Writers (Methyltransferases): These enzymes catalyze the transfer of a methyl group from S-adenosyl-L-methionine (SAM) to the C5 position of cytosine.
-
NSUN Family: The NOP2/Sun domain (NSUN) family, comprising NSUN1-7, are the primary m5C methyltransferases for a wide range of RNAs.[3][4] NSUN2 is the most studied member, targeting both tRNAs and mRNAs, while NSUN6 has also been identified as a key mRNA methyltransferase.
-
DNMT2 (TRDMT1): Despite its name suggesting a role in DNA methylation, DNA methyltransferase 2 is a well-established tRNA m5C methyltransferase.
Erasers (Demethylases): These enzymes mediate the removal of the methyl group, allowing for dynamic regulation.
-
TET Family: The Ten-Eleven Translocation (TET) family of enzymes can oxidize m5C to 5-hydroxymethylcytosine (B124674) (hm5C), 5-formylcytosine (B1664653) (f5C), and 5-carboxylcytosine (5caC), initiating a base excision repair pathway that restores unmodified cytosine.
-
ALKBH1: AlkB Homolog 1 has been identified as an RNA demethylase with activity towards various modifications, including the ability to erase m1A in tRNA. Its role as a direct m5C eraser is less established than that of the TET enzymes.
Readers (Binding Proteins): These proteins specifically recognize m5C and recruit other factors to influence the fate of the modified RNA.
-
YBX1: Y-box binding protein 1 is a key m5C reader that preferentially binds to m5C-modified mRNAs. This binding often enhances the stability of the target mRNA, frequently by recruiting other stabilizing proteins like ELAVL1.
-
ALYREF: The Aly/REF export factor recognizes m5C-modified mRNAs and facilitates their export from the nucleus to the cytoplasm, making them available for translation.
References
- 1. Frontiers | The inspiration of methyltransferase in RNA methylation modification for targeted therapy of malignant tumors [frontiersin.org]
- 2. 5-Methylcytosine RNA modification and its roles in cancer and cancer chemotherapy resistance - PMC [pmc.ncbi.nlm.nih.gov]
- 3. An Overview of Current Detection Methods for RNA Methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Three distinct 3-methylcytidine (m3C) methyltransferases modify tRNA and mRNA in mice and humans - PubMed [pubmed.ncbi.nlm.nih.gov]
Investigating the Distribution of 1-Methylcytosine Across Different Species: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Introduction
1-Methylcytosine (B60703) (m1C) is a post-transcriptional modification of RNA, where a methyl group is added to the N1 position of the cytosine base. While less studied than its isomer 5-methylcytosine (B146107) (5mC), m1C plays a crucial role in the structural integrity and function of certain RNA molecules, particularly transfer RNA (tRNA). This technical guide provides a comprehensive overview of the current knowledge on the distribution of m1C across different species, details the experimental protocols for its detection and quantification, and explores its known functional roles. The information presented here is intended to equip researchers, scientists, and drug development professionals with a thorough understanding of m1C and to facilitate further investigation into its biological significance.
Distribution of this compound Across Species
Quantitative data on the global abundance of this compound across different species and nucleic acid types remains limited in comparison to other modifications like 5-methylcytosine. However, existing research primarily points to the presence of m1C in transfer RNA (tRNA) across all three domains of life: Archaea, Bacteria, and Eukarya. Its presence in other RNA species and in DNA is not as well-documented.
| Domain/Kingdom | Species/Group | Nucleic Acid | Location/Abundance |
| Archaea | Various | tRNA | Present; contributes to tRNA stability. |
| Bacteria | Various | tRNA, rRNA | Present in tRNA and ribosomal RNA (rRNA), contributing to ribosome function. |
| Eukarya | Saccharomyces cerevisiae (Yeast) | tRNA | Present, involved in tRNA structure. |
| Homo sapiens (Human) | tRNA, mRNA | Found in tRNA and messenger RNA (mRNA), though its function in mRNA is less clear. | |
| Viruses | Various RNA viruses | RNA | General RNA modifications are known to occur, but specific quantitative data for m1C is scarce. |
Note: The table above summarizes the currently available qualitative information. Precise quantitative levels of m1C can vary significantly between different tRNA species and organisms.
Experimental Protocols for this compound Detection and Quantification
Several methods can be employed to detect and quantify this compound. These techniques, while often developed for the more abundant 5-methylcytosine, can be adapted for m1C analysis.
Mass Spectrometry (MS)
Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is a highly sensitive and accurate method for the global quantification of modified nucleosides.
Protocol Outline:
-
Nucleic Acid Extraction: Isolate total RNA or DNA from the sample of interest using standard protocols.
-
Nucleic Acid Digestion: Enzymatically digest the purified nucleic acids into individual nucleosides using a cocktail of enzymes such as nuclease P1 and phosphodiesterase I, followed by dephosphorylation with alkaline phosphatase.
-
Chromatographic Separation: Separate the resulting nucleosides using reversed-phase high-performance liquid chromatography (RP-HPLC). The separation is based on the differential hydrophobicity of the nucleosides.
-
Mass Spectrometric Detection: The eluting nucleosides are ionized, typically using electrospray ionization (ESI), and their mass-to-charge ratios are measured by a mass spectrometer.
-
Quantification: The abundance of 1-methylcytidine is determined by comparing its peak intensity to that of an isotopically labeled internal standard and a standard curve of known concentrations. This method can distinguish between this compound and 5-methylcytosine due to their identical mass but different retention times on the HPLC column.
RNA Bisulfite Sequencing
Bisulfite sequencing is a method used to determine cytosine methylation at single-base resolution. While standard bisulfite treatment cannot distinguish between m1C and 5mC, certain modifications to the protocol or combination with other techniques can provide more specific information. It's important to note that the conditions for bisulfite conversion of RNA need to be carefully optimized to avoid RNA degradation.
Protocol Outline:
-
RNA Isolation: Extract total RNA from the sample.
-
Bisulfite Treatment: Treat the RNA with sodium bisulfite. This chemical deaminates unmethylated cytosines to uracils, while methylated cytosines (both 5mC and m1C) are generally protected from this conversion.
-
Reverse Transcription and PCR: Reverse transcribe the treated RNA into cDNA, followed by PCR amplification of the region of interest. During these steps, the uracils are read as thymines.
-
Sequencing: Sequence the PCR products.
-
Data Analysis: Compare the sequence of the treated RNA to the sequence of untreated RNA. Cytosines that remain as cytosines in the treated sample are identified as methylated. Further analysis, potentially in combination with other methods, is needed to specifically identify them as m1C.
Antibody-Based Methods (Immunoprecipitation)
Antibody-based methods, such as methylated RNA immunoprecipitation (MeRIP), utilize antibodies that specifically recognize methylated nucleosides. The development of highly specific antibodies for this compound is crucial for the success of this technique.
Protocol Outline:
-
RNA Fragmentation: Isolate and fragment the total RNA to a suitable size (typically 100-200 nucleotides).
-
Immunoprecipitation: Incubate the fragmented RNA with an antibody specific to this compound. The antibody-RNA complexes are then captured using protein A/G beads.
-
RNA Elution: Elute the captured RNA fragments from the beads.
-
Analysis: The enriched RNA fragments can be analyzed by quantitative PCR (qPCR) to determine the methylation status of specific transcripts or by high-throughput sequencing (MeRIP-seq) to map m1C sites across the transcriptome.
Functional Roles and Signaling Pathways of this compound
The primary and most well-understood function of this compound is its role in the structural stabilization of tRNA. The methylation at the N1 position of cytosine, often found in the T-loop of tRNA, helps to maintain the correct three-dimensional L-shape of the tRNA molecule. This structural integrity is essential for the proper functioning of tRNA in protein synthesis.
Enzymes Responsible for m1C Formation:
The methylation of cytosine to form m1C is catalyzed by a class of enzymes known as tRNA methyltransferases. One of the key enzymes identified is Trm10 in yeast, which is responsible for the m1G9 modification and has homologs in other eukaryotes and archaea that can catalyze m1A9 formation. The specific enzymes responsible for all instances of m1C formation across different species and RNA types are still an active area of research.
Signaling Pathways:
Currently, specific signaling pathways that are directly regulated by or that modulate the levels of this compound are not well-elucidated. However, it is known that tRNA modifications, in general, can be dynamic and respond to cellular stress and metabolic changes. It is plausible that the machinery responsible for m1C deposition is also regulated by cellular signaling cascades, thereby linking the translational machinery to the overall physiological state of the cell. Further research is needed to uncover the specific signaling networks in which m1C is involved.
Conclusion and Future Directions
This compound is an important RNA modification with a conserved role in tRNA structure and function. While its presence is established across the domains of life, a comprehensive quantitative understanding of its distribution remains a significant gap in the field of epitranscriptomics. The development of more specific and sensitive methods for m1C detection and quantification will be crucial for advancing our knowledge. Future research should focus on:
-
Quantitative Mapping: Performing large-scale quantitative studies to determine the abundance of m1C in various RNA species and tissues across a wider range of organisms.
-
Enzyme Characterization: Identifying and characterizing the full complement of enzymes responsible for m1C synthesis and potential demethylation.
-
Functional Studies: Elucidating the functional roles of m1C beyond tRNA stabilization, particularly its potential involvement in mRNA regulation and cellular signaling.
-
Drug Development: Investigating the enzymes involved in m1C metabolism as potential targets for therapeutic intervention, especially in diseases where dysregulation of RNA modifications has been implicated.
This guide provides a solid foundation for researchers entering the field of m1C biology and highlights the exciting avenues for future investigation that will undoubtedly deepen our understanding of this important epigenetic mark.
1-Methylcytosine and its Analogs: An In-depth Technical Guide to their Role as Potential Biomarkers in Disease
For Researchers, Scientists, and Drug Development Professionals
Introduction
Epigenetic modifications, heritable changes in gene expression that do not involve alterations to the underlying DNA sequence, are increasingly recognized as pivotal players in both normal physiological processes and the pathogenesis of numerous diseases. Among these modifications, the methylation of cytosine residues is one of the most extensively studied. While 5-methylcytosine (B146107) (5mC) is the most well-known and abundant cytosine modification, other variants, including 1-methylcytosine (B60703) (m1C), exist and are gaining attention for their potential roles in biology and disease. This technical guide provides a comprehensive overview of the current understanding of this compound and its more prevalent isomer, 5-methylcytosine, as potential biomarkers in various diseases, with a focus on cancer and neurological disorders. We delve into the molecular mechanisms, detection methodologies, and clinical significance of these epigenetic markers.
This compound vs. 5-Methylcytosine: A Note on Isomers
It is crucial to distinguish between this compound (m1C) and 5-methylcytosine (5mC). While both are methylated forms of cytosine, the position of the methyl group attachment to the cytosine ring differs, leading to distinct chemical properties and biological functions. The vast majority of research on cytosine methylation as a disease biomarker has focused on 5mC and its oxidized derivative, 5-hydroxymethylcytosine (B124674) (5hmC). This compound is a less common modification, primarily found in RNA, particularly transfer RNA (tRNA), where it plays a role in maintaining the structural integrity of the molecule. While its role as a widespread disease biomarker in DNA is not as established as that of 5mC, its presence in RNA and potential dysregulation in disease states is an emerging area of research. For the purpose of this guide, and reflecting the current landscape of biomarker research, we will primarily focus on 5-methylcytosine and its derivatives, while also acknowledging the potential of this compound as a future biomarker.
5-Methylcytosine and 5-Hydroxymethylcytosine as Biomarkers in Cancer
Alterations in DNA methylation patterns are a hallmark of cancer. These changes typically involve global hypomethylation, leading to genomic instability, and gene-specific hypermethylation, which can result in the silencing of tumor suppressor genes.
Quantitative Data on 5mC and 5hmC Levels in Cancer:
| Cancer Type | Tissue/Sample Type | Change in 5mC Levels in Cancer vs. Normal | Change in 5hmC Levels in Cancer vs. Normal | Reference(s) |
| Colorectal Cancer | Tumor Tissue | Significantly lower | Significantly lower (approx. 6-fold) | [1][2][3] |
| Median level in cancer: not specified | Median level in cancer: 0.05% | [2] | ||
| Median level in normal: not specified | Median level in normal: 0.07% | [2] | ||
| Lung Cancer | Tumor Tissue | Depleted in most samples | Substantially depleted (up to 5-fold) | |
| Breast Cancer | Tumor Tissue | Lower levels correlate with malignancy grade | Profoundly reduced | |
| Prostate Cancer | Tumor Tissue | Modest decrease | Profoundly reduced | |
| Hepatocellular Carcinoma | Tumor Tissue | Not specified | 4 to 5-fold lower | |
| Brain Tumors | Tumor Tissue | Not specified | Drastically reduced (up to >30-fold) |
5-Methylcytosine and 5-Hydroxymethylcytosine as Biomarkers in Neurological Disorders
Epigenetic modifications are critical for normal brain development and function. Dysregulation of DNA methylation has been implicated in a range of neurological disorders.
Quantitative Data on 5mC and 5hmC Levels in Neurological Disorders:
| Disease | Brain Region/Sample Type | Change in 5mC Levels vs. Control | Change in 5hmC Levels vs. Control | Reference(s) |
| Alzheimer's Disease | Entorhinal Cortex | Decreased | Not specified | |
| Hippocampus | Decreased | Decreased | ||
| Frontal Cortex | Increased | Not specified | ||
| Middle Frontal & Temporal Gyrus | Increased | Increased | ||
| Parkinson's Disease | Substantia Nigra | No significant difference | Significantly higher | |
| Cerebellum | No significant difference | Elevated in white matter | ||
| Huntington's Disease | Putamen | Increased (in ADORA2A gene) | Reduced (in ADORA2A gene) | |
| Striatum & Cortex (mouse model) | Not specified | Marked reduction |
Key Signaling Pathways
The levels of 5mC and 5hmC are dynamically regulated by a family of enzymes, and their dysregulation in disease is often linked to aberrant signaling pathways.
DNA Methylation and Demethylation Machinery
The establishment and maintenance of DNA methylation patterns are controlled by DNA methyltransferases (DNMTs), while the removal of these marks is initiated by the Ten-Eleven Translocation (TET) family of enzymes.
Interplay with Wnt and TGF-β Signaling in Cancer
Aberrant DNA methylation is known to impact key cancer-related signaling pathways, such as the Wnt and TGF-β pathways.
Experimental Protocols for the Detection of 5-Methylcytosine
A variety of techniques are available for the detection and quantification of 5mC and its derivatives, each with its own advantages and limitations.
Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS)
LC-MS/MS is considered the gold standard for the absolute quantification of global 5mC and 5hmC levels due to its high accuracy and sensitivity.
Experimental Workflow for LC-MS/MS:
Detailed Protocol:
-
Genomic DNA Extraction: Isolate high-quality genomic DNA from tissues or cells using a standard DNA extraction kit.
-
DNA Hydrolysis:
-
To 1-5 µg of DNA, add nuclease P1, ammonium (B1175870) acetate (B1210297) buffer, and zinc sulfate.
-
Incubate at 50°C for 2 hours.
-
Add alkaline phosphatase and Tris-HCl buffer.
-
Incubate at 37°C for 1 hour to dephosphorylate the nucleotides to nucleosides.
-
-
LC Separation:
-
Inject the hydrolyzed sample into a C18 reverse-phase HPLC column.
-
Use a gradient of mobile phases (e.g., water with formic acid and methanol (B129727) with formic acid) to separate the nucleosides.
-
-
MS/MS Detection:
-
The eluent from the HPLC is introduced into a tandem mass spectrometer operating in positive ion mode with multiple reaction monitoring (MRM).
-
Monitor the specific precursor-to-product ion transitions for deoxycytidine, 5-methyldeoxycytidine, and 5-hydroxymethyldeoxycytidine.
-
-
Quantification:
-
Generate standard curves using known concentrations of pure nucleoside standards.
-
Calculate the amount of 5mC and 5hmC in the sample by comparing their peak areas to the standard curves. The results are typically expressed as a percentage of total cytosine.
-
Performance Characteristics of LC-MS/MS for 5mC and 5hmC Detection:
| Parameter | Typical Value | Reference(s) |
| Limit of Detection (LOD) | 0.06 - 0.10 fmol for 5mC; 0.06 - 0.19 fmol for 5hmC | |
| Limit of Quantification (LOQ) | 0.20 fmol for 5mC; 0.64 fmol for 5hmC | |
| Linearity (R²) | >0.99 |
Enzyme-Linked Immunosorbent Assay (ELISA)
ELISA provides a high-throughput and cost-effective method for the relative quantification of global DNA methylation.
Experimental Workflow for 5mC DNA ELISA:
Detailed Protocol (based on Zymo Research 5-mC DNA ELISA Kit):
-
DNA Coating:
-
Dilute 100 ng of each DNA sample and controls in 5-mC Coating Buffer to a final volume of 100 µl.
-
Denature the DNA at 98°C for 5 minutes, then immediately place on ice for 10 minutes.
-
Add the denatured DNA to the wells of the ELISA plate and incubate at 37°C for 1 hour.
-
-
Blocking:
-
Wash each well three times with 200 µl of 5-mC ELISA Buffer.
-
Add 200 µl of 5-mC ELISA Buffer to each well and incubate at 37°C for 30 minutes.
-
-
Antibody Incubation:
-
Prepare a primary/secondary antibody mix containing Anti-5-Methylcytosine and Secondary Antibody in 5-mC ELISA Buffer.
-
Add 100 µl of the antibody mix to each well and incubate at 37°C for 1 hour.
-
-
Color Development:
-
Wash each well three times with 200 µl of 5-mC ELISA Buffer.
-
Add 100 µl of HRP Developer to each well and incubate at room temperature for 10-60 minutes.
-
-
Measurement:
-
Measure the absorbance at 405-450 nm using an ELISA plate reader.
-
Quantify the percentage of 5mC in the samples by comparing their absorbance to a standard curve generated from controls with known percentages of 5mC.
-
Performance Characteristics of a Commercial 5mC DNA ELISA Kit (Zymo Research):
| Parameter | Specification |
| Detection Limit | ≥ 0.5% 5-methylcytosine per 100 ng of single-stranded DNA |
| DNA Input | Optimized for 100 ng/well; compatible with 10-200 ng/well |
| Assay Time | < 3 hours |
| Specificity | Specific for 5-mC with no cross-reactivity to unmethylated cytosine |
Methylated DNA Immunoprecipitation Sequencing (MeDIP-Seq)
MeDIP-Seq allows for the genome-wide analysis of DNA methylation patterns by enriching for methylated DNA fragments using an antibody against 5mC, followed by high-throughput sequencing.
Detailed Protocol:
-
DNA Preparation:
-
Extract high-quality genomic DNA.
-
Fragment the DNA to an average size of 200-500 bp by sonication.
-
-
Immunoprecipitation:
-
Denature the fragmented DNA at 95°C for 10 minutes.
-
Incubate the denatured DNA with a specific anti-5-methylcytosine antibody overnight at 4°C with rotation.
-
Add Protein A/G magnetic beads to the DNA-antibody mixture and incubate for 2 hours at 4°C with rotation to capture the immunocomplexes.
-
-
Washing and Elution:
-
Wash the beads several times with IP buffer to remove non-specifically bound DNA.
-
Elute the methylated DNA from the beads using an elution buffer.
-
-
DNA Purification:
-
Treat the eluted DNA with Proteinase K to digest the antibody.
-
Purify the methylated DNA using phenol-chloroform extraction and ethanol (B145695) precipitation or a column-based purification kit.
-
-
Library Preparation and Sequencing:
-
Prepare a sequencing library from the enriched methylated DNA fragments.
-
Perform high-throughput sequencing.
-
-
Data Analysis:
-
Align the sequencing reads to a reference genome.
-
Identify and quantify methylated regions by analyzing the enrichment of sequencing reads.
-
Bisulfite Sequencing
Bisulfite sequencing provides single-nucleotide resolution of DNA methylation patterns. Treatment of DNA with sodium bisulfite converts unmethylated cytosines to uracil (B121893), while methylated cytosines remain unchanged. Subsequent PCR and sequencing reveal the methylation status of each cytosine.
Detailed Protocol:
-
Bisulfite Conversion:
-
Treat 200-500 ng of genomic DNA with a bisulfite conversion reagent (e.g., using the Qiagen EpiTect Bisulfite Kit) according to the manufacturer's instructions. This process involves denaturation, bisulfite treatment, and desulfonation.
-
-
Library Preparation (Post-Bisulfite Conversion):
-
The bisulfite-converted DNA is often fragmented during the process.
-
Perform end-repair and A-tailing on the fragmented, single-stranded DNA.
-
Ligate methylated sequencing adapters to the DNA fragments.
-
-
PCR Amplification:
-
Amplify the adapter-ligated library using a proofreading DNA polymerase that reads uracil as thymine. The number of PCR cycles should be minimized to avoid bias.
-
-
Library Purification and Sequencing:
-
Purify the amplified library to remove primers and adapter dimers.
-
Perform high-throughput sequencing.
-
-
Data Analysis:
-
Align the sequencing reads to a reference genome, accounting for the C-to-T conversion.
-
Determine the methylation status of each CpG site by calculating the ratio of reads with a C to the total number of reads covering that site.
-
Conclusion
The study of this compound and its analogs, particularly 5-methylcytosine and 5-hydroxymethylcytosine, as biomarkers is a rapidly advancing field with significant potential to revolutionize disease diagnosis, prognosis, and treatment. The distinct changes in the levels and distribution of these epigenetic marks in cancer and neurological disorders underscore their importance in the underlying pathophysiology. The availability of robust and sensitive detection methods, from the gold-standard LC-MS/MS to high-throughput sequencing approaches, provides researchers and clinicians with powerful tools to explore the methylome. As our understanding of the intricate interplay between DNA methylation and key signaling pathways deepens, so too will the opportunities for developing novel therapeutic strategies that target the epigenome. This technical guide serves as a foundational resource for professionals seeking to harness the potential of cytosine methylation biomarkers in their research and development endeavors.
References
- 1. Global changes of 5-hydroxymethylcytosine and 5-methylcytosine from normal to tumor tissues are associated with carcinogenesis and prognosis in colorectal cancer-Academax [wacademax.com]
- 2. Global changes of 5-hydroxymethylcytosine and 5-methylcytosine from normal to tumor tissues are associated with carcinogenesis and prognosis in colorectal cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Quantification of the sixth DNA base 5-hydroxymethylcytosine in colorectal cancer tissue and C-26 cell line - PubMed [pubmed.ncbi.nlm.nih.gov]
Methodological & Application
Synthesis of 1-Methylcytosine: A Detailed Protocol for Researchers
Application Note: 1-Methylcytosine (B60703) (1-mC) is a methylated form of the nucleobase cytosine, where a methyl group is attached at the N1 position of the pyrimidine (B1678525) ring. This modification is of significant interest in epigenetic research, drug development, and the study of nucleic acid structure and function. Unlike the more common 5-methylcytosine, this compound is not typically found in mammalian DNA but plays a role in certain RNA modifications and has been explored as a component of synthetic genetic polymers. The protocol detailed below provides a reliable method for the chemical synthesis of this compound, enabling researchers to produce this valuable compound for a variety of applications.
Quantitative Data Summary
The following table summarizes the key quantitative data associated with the described synthesis protocol. Yields are representative and may vary based on experimental conditions and scale.
| Step | Compound | Molecular Weight ( g/mol ) | Starting Material (g) | Product (g) | Theoretical Yield (g) | Actual Yield (%) |
| 1 | Bis(trimethylsilyl)cytosine | 255.5 | 11.1 | 24.3 | 25.55 | ~95% |
| 2 | This compound hydroiodide | 253.04 | 25.55 | 22.8 | 25.3 | ~90% |
| 3 | This compound | 125.13 | 25.3 | 11.3 | 12.5 | ~90% |
Experimental Workflow Diagram
The following diagram illustrates the workflow for the chemical synthesis of this compound.
Caption: Workflow for the synthesis of this compound.
Experimental Protocol
This protocol details a two-step synthesis of this compound starting from cytosine, involving a silylation-methylation-deprotection sequence.[1]
Materials and Reagents
-
Cytosine
-
Hexamethyldisilazane (HMDS)
-
Ammonium sulfate ((NH₄)₂SO₄)
-
Anhydrous acetonitrile
-
Methyl iodide (CH₃I)
-
Ethanol
-
Ammonium hydroxide (NH₄OH)
-
Argon or Nitrogen gas for inert atmosphere
Step 1: Silylation of Cytosine
-
Preparation: In a flame-dried, three-necked round-bottom flask equipped with a magnetic stirrer, reflux condenser, and an inert gas inlet, add cytosine (1.0 eq).
-
Addition of Reagents: Add anhydrous acetonitrile to the flask to create a suspension. To this suspension, add hexamethyldisilazane (HMDS, 2.5 eq) and a catalytic amount of ammonium sulfate.
-
Reaction: Heat the reaction mixture to reflux under an inert atmosphere (argon or nitrogen). The reaction is typically complete when the mixture becomes a clear, homogeneous solution, which usually takes several hours.
-
Work-up: After the reaction is complete, allow the mixture to cool to room temperature. The solvent and excess HMDS are removed under reduced pressure to yield crude bis(trimethylsilyl)cytosine as an oil or solid. This intermediate is often used in the next step without further purification.
Step 2: N1-Methylation of Silylated Cytosine
-
Preparation: Dissolve the crude bis(trimethylsilyl)cytosine from Step 1 in anhydrous acetonitrile under an inert atmosphere.
-
Addition of Methylating Agent: To the stirred solution, add methyl iodide (1.1 - 1.5 eq) dropwise at room temperature.
-
Reaction: Stir the reaction mixture at room temperature. The progress of the reaction can be monitored by thin-layer chromatography (TLC). The reaction is typically stirred for 12-24 hours.
-
Intermediate Formation: The N1-methylated silylated intermediate is formed during this step.
Step 3: Deprotection to Yield this compound Hydroiodide
-
Quenching and Deprotection: After the methylation is complete, carefully add ethanol to the reaction mixture. This will quench any unreacted methyl iodide and initiate the deprotection of the trimethylsilyl (B98337) groups.[1] The addition of ethanol should be done in a well-ventilated fume hood.
-
Precipitation: Upon addition of ethanol, a precipitate of this compound hydroiodide will form. The mixture can be stirred at room temperature for a few hours to ensure complete precipitation.
-
Isolation: Collect the solid precipitate by filtration, wash with a small amount of cold ethanol, and dry under vacuum.
Step 4: Neutralization to this compound (Free Base)
-
Dissolution: Dissolve the this compound hydroiodide salt in a minimum amount of water.
-
Neutralization: To the aqueous solution, add concentrated ammonium hydroxide dropwise with stirring until the pH of the solution is basic (pH ~9-10).
-
Crystallization: The free base, this compound, will precipitate out of the solution. Cool the mixture in an ice bath to maximize crystallization.
-
Isolation and Purification: Collect the solid product by filtration, wash with cold water, and then a small amount of cold ethanol. The product can be further purified by recrystallization from water or an ethanol/water mixture.
-
Drying: Dry the purified this compound under vacuum to obtain a white crystalline solid.
Characterization
The final product should be characterized to confirm its identity and purity. Recommended analytical techniques include:
-
Nuclear Magnetic Resonance (NMR) Spectroscopy (¹H and ¹³C): To confirm the structure and the position of the methyl group.
-
Mass Spectrometry (MS): To confirm the molecular weight of the compound.
-
Melting Point: To assess the purity of the final product.
References
Application Notes and Protocols for the Detection of 1-Methylcytosine in Genomic DNA
For Researchers, Scientists, and Drug Development Professionals
Introduction
1-Methylcytosine (B60703) (1mC) is a methylated form of the DNA base cytosine, where a methyl group is attached to the nitrogen atom at position 1 (N1) of the cytosine ring.[1] This modification is distinct from the more commonly studied 5-methylcytosine (B146107) (5mC), where the methyl group is at the carbon 5 (C5) position. While the roles of 5mC in epigenetic regulation are well-established, the presence and function of 1mC in genomic DNA are less understood. The development of robust and specific methods for detecting 1mC is crucial for elucidating its biological significance and its potential role in disease and as a therapeutic target.
This document provides an overview of potential and emerging methods for the detection of this compound in genomic DNA, including detailed protocols and comparative data to guide researchers in this developing area of epigenetics.
Methods for this compound Detection
The detection of 1mC in genomic DNA is challenging due to its structural similarity to other cytosine modifications and its likely low abundance. Standard methods for 5mC detection, such as bisulfite sequencing, are not suitable for distinguishing 1mC. Therefore, novel approaches are required. Here, we outline three promising strategies: an enzymatic-based sequencing approach, a mass spectrometry-based quantitative method, and an antibody-based enrichment technique.
ALKBH1-Based Enzymatic Sequencing (A-Seq)
This proposed method leverages the specificity of the human enzyme AlkB Homolog 1 (ALKBH1), a dioxygenase that has been shown to demethylate 1-methyladenine (B1486985) (1mA) and 3-methylcytosine (B1195936) (3mC) in nucleic acids.[2][3] While its primary substrates are under investigation, its ability to recognize and act on N1-methylated bases can be exploited for the specific detection of 1mC.
Principle: The A-Seq method is based on the enzymatic conversion of 1mC to cytosine by ALKBH1, followed by a differential sequencing readout. Genomic DNA is divided into two aliquots. One aliquot is treated with recombinant ALKBH1, which will convert 1mC back to cytosine. The other aliquot remains untreated. Both samples are then subjected to a hypothetical chemical modification or enzymatic treatment that specifically targets and converts unmodified cytosines to a different base (e.g., uracil), while leaving 5mC and other modifications intact. Subsequent PCR amplification and sequencing would reveal the locations of 1mC as sites that are read as cytosine in the untreated sample but as the converted base (e.g., thymine) in the ALKBH1-treated sample.
Workflow Diagram:
Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS)
LC-MS/MS is a highly sensitive and quantitative method for detecting modified nucleosides. It can be adapted to specifically quantify the global abundance of 1mC in a genomic DNA sample.
Principle: Genomic DNA is enzymatically digested into individual nucleosides. These nucleosides are then separated by liquid chromatography and detected by a tandem mass spectrometer. 1-methyl-2'-deoxycytidine can be distinguished from other cytosine nucleosides based on its unique mass-to-charge ratio and fragmentation pattern.
Workflow Diagram:
Antibody-Based Enrichment (m1C-IP-Seq)
This method relies on the development of a highly specific antibody that recognizes this compound but not other cytosine modifications.
Principle: Genomic DNA is fragmented, and an antibody specific to 1mC is used to immunoprecipitate the DNA fragments containing this modification. The enriched DNA is then sequenced to identify the genomic locations of 1mC.
Workflow Diagram:
Quantitative Data Summary
The quantitative aspects of 1mC detection methods are still under investigation. The following table provides a comparative summary of the potential performance of the described methods, with some parameters estimated based on similar techniques for other DNA modifications.
| Feature | A-Seq (Proposed) | LC-MS/MS | m1C-IP-Seq (Proposed) |
| Resolution | Single-base | Global quantification | ~150-200 bp |
| Sensitivity | Potentially high (ng range) | High (fmol range) | Moderate (µg range) |
| Specificity | High (enzyme-dependent) | Very high | High (antibody-dependent) |
| Quantitative | Semi-quantitative | Yes (absolute) | Semi-quantitative |
| Input DNA | Low (ng) | Low (ng to µg) | High (µg) |
| Advantages | Single-base resolution | Highly accurate quantification | Genome-wide screening |
| Limitations | Requires specific enzyme | No positional information | Lower resolution |
Experimental Protocols
Protocol 1: ALKBH1-Based Enzymatic Sequencing (A-Seq) - A Proposed Method
Materials:
-
Genomic DNA
-
Recombinant human ALKBH1 enzyme
-
ALKBH1 reaction buffer (e.g., 50 mM HEPES pH 7.5, 50 µM (NH4)2Fe(SO4)2·6H2O, 1 mM α-ketoglutarate, 2 mM L-ascorbic acid)
-
DNA purification kit
-
A hypothetical "C-to-U" conversion kit (e.g., based on a cytosine-specific deaminase that does not act on 5mC)
-
PCR amplification reagents
-
Primers for target region
-
DNA sequencing platform
Procedure:
-
DNA Preparation: Isolate high-quality genomic DNA. Quantify the DNA using a fluorometric method.
-
Sample Splitting: Aliquot 2 µg of genomic DNA into two separate tubes.
-
ALKBH1 Treatment:
-
To one tube, add recombinant ALKBH1 to a final concentration of 1 µM in ALKBH1 reaction buffer.
-
Incubate at 37°C for 1 hour.
-
To the second (control) tube, add the same reaction buffer without the ALKBH1 enzyme.
-
Incubate under the same conditions.
-
-
DNA Purification: Purify the DNA from both reactions using a DNA purification kit. Elute in nuclease-free water.
-
Specific Cytosine Conversion:
-
Subject both the ALKBH1-treated and control DNA to a specific chemical or enzymatic treatment that converts unmethylated cytosine to uracil, while leaving 5mC and other modified cytosines unaffected. Follow the manufacturer's protocol for the hypothetical conversion kit.
-
-
PCR Amplification:
-
Amplify the target region from both treated DNA samples using primers designed to be complementary to the converted sequence (where C is treated as T).
-
Use a high-fidelity polymerase suitable for amplifying treated DNA.
-
-
Sequencing:
-
Sequence the PCR products using a suitable platform (e.g., Sanger or next-generation sequencing).
-
-
Data Analysis:
-
Align the sequences from the ALKBH1-treated and control samples to the reference genome.
-
Identify positions where a C is present in the control sequence but a T is present in the ALKBH1-treated sequence. These positions correspond to the original locations of 1mC.
-
Protocol 2: LC-MS/MS for Global 1mC Quantification
Materials:
-
Genomic DNA
-
DNA degradation enzyme mix (e.g., DNase I, Nuclease P1, alkaline phosphatase)
-
1-methyl-2'-deoxycytidine standard
-
LC-MS/MS system
Procedure:
-
DNA Digestion:
-
To 1 µg of genomic DNA, add the DNA degradation enzyme mix according to the manufacturer's instructions.
-
Incubate at 37°C for 2-4 hours to ensure complete digestion to individual nucleosides.
-
-
Sample Preparation:
-
Filter the digested sample to remove enzymes and other large molecules.
-
-
LC-MS/MS Analysis:
-
Inject the filtered sample into the LC-MS/MS system.
-
Separate the nucleosides using a suitable C18 column with an appropriate gradient of mobile phases (e.g., water with 0.1% formic acid and acetonitrile (B52724) with 0.1% formic acid).
-
Perform mass spectrometry in multiple reaction monitoring (MRM) mode, using specific precursor-to-product ion transitions for 1-methyl-2'-deoxycytidine and other canonical nucleosides.
-
-
Quantification:
-
Generate a standard curve using the 1-methyl-2'-deoxycytidine standard.
-
Quantify the amount of 1mC in the sample by comparing its peak area to the standard curve.
-
Express the abundance of 1mC relative to the total amount of cytosine.
-
Protocol 3: 1mC Immunoprecipitation Sequencing (m1C-IP-Seq) - A Proposed Method
Materials:
-
Genomic DNA
-
DNA fragmentation apparatus (e.g., sonicator)
-
Anti-1-methylcytosine antibody (hypothetical)
-
Protein A/G magnetic beads
-
Immunoprecipitation buffers
-
DNA purification kit
-
Next-generation sequencing library preparation kit
Procedure:
-
DNA Fragmentation:
-
Fragment 5-10 µg of genomic DNA to an average size of 200-500 bp using sonication.
-
-
Immunoprecipitation:
-
Incubate the fragmented DNA with a specific anti-1mC antibody overnight at 4°C with gentle rotation.
-
Add Protein A/G magnetic beads and incubate for another 2 hours at 4°C.
-
-
Washing and Elution:
-
Wash the beads several times with low and high salt buffers to remove non-specifically bound DNA.
-
Elute the immunoprecipitated DNA from the beads.
-
-
DNA Purification:
-
Purify the eluted DNA using a DNA purification kit.
-
-
Library Preparation and Sequencing:
-
Prepare a sequencing library from the enriched DNA following the manufacturer's protocol.
-
Perform high-throughput sequencing.
-
-
Data Analysis:
-
Align the sequencing reads to the reference genome.
-
Use peak-calling algorithms to identify genomic regions enriched for 1mC.
-
Conclusion
The detection of this compound in genomic DNA is an emerging field with significant potential to advance our understanding of epigenetic regulation. While established methods are lacking, the proposed techniques based on the enzymatic activity of ALKBH1, the high sensitivity of mass spectrometry, and the specificity of antibody-based enrichment offer promising avenues for future research. The development and validation of these methods will be instrumental for researchers, scientists, and drug development professionals in exploring the functional roles of this enigmatic DNA modification.
References
Application Note: Quantification of 1-Methylcytosine in Biological Samples using HPLC-MS/MS
Abstract
This application note describes a sensitive and specific method for the quantification of 1-methylcytosine (B60703) (m1C) in enzymatic digests of DNA and RNA using High-Performance Liquid Chromatography coupled with tandem Mass Spectrometry (HPLC-MS/MS). This compound is a methylated form of the DNA and RNA base cytosine.[1] While less common than 5-methylcytosine (B146107), its accurate quantification is crucial for research in synthetic biology, particularly in the context of artificially expanded genetic information systems (hachimoji DNA), and for exploring its potential, yet-to-be-fully-elucidated roles in natural biological systems. The method utilizes a reversed-phase HPLC separation followed by detection using a triple quadrupole mass spectrometer operating in Multiple Reaction Monitoring (MRM) mode, providing high selectivity and sensitivity.
Introduction
Epigenetic modifications of DNA and RNA play a critical role in regulating gene expression and cellular function.[2][3] 5-methylcytosine (5mC) is the most extensively studied DNA modification in mammals, involved in processes like gene silencing and genomic imprinting.[2][4] this compound (m1C) is a structural isomer of 5mC, where the methyl group is attached to the N1 position of the cytosine ring. While its role in natural biological systems is not as well-defined as that of 5mC, it is a key component of "hachimoji DNA," an eight-letter synthetic genetic system, highlighting its importance in synthetic biology.
Accurate quantification of m1C is essential to understand its function and prevalence. HPLC-MS/MS offers a robust platform for this, combining the separation power of liquid chromatography with the specificity and sensitivity of tandem mass spectrometry. This application note provides a detailed protocol for the sample preparation, chromatographic separation, and mass spectrometric detection of this compound.
Experimental Workflow
The overall experimental workflow for the quantification of this compound from biological samples is depicted below.
Caption: Workflow for this compound analysis.
Experimental Protocols
Sample Preparation: Enzymatic Digestion of DNA/RNA
-
DNA/RNA Extraction: Isolate high-quality DNA or RNA from cells or tissues using a suitable commercial kit or standard phenol-chloroform extraction protocols.
-
Quantification: Determine the concentration and purity of the extracted nucleic acid using a spectrophotometer (e.g., NanoDrop).
-
Enzymatic Digestion:
-
To a sterile microcentrifuge tube, add 1-5 µg of DNA or RNA.
-
Add a buffer containing nuclease P1, followed by incubation at 37°C for 2 hours.
-
Add a buffer containing alkaline phosphatase and continue incubation at 37°C for another 2 hours to dephosphorylate the nucleotides to nucleosides.
-
For a more detailed protocol on enzymatic digestion, refer to established methods for nucleoside analysis.
-
-
Protein Removal: After digestion, remove proteins by either phenol-chloroform extraction followed by ethanol (B145695) precipitation or by using a centrifugal filter unit with a molecular weight cutoff of 3-10 kDa.
-
Sample Dilution: Resuspend the dried nucleoside pellet or dilute the filtrate in an appropriate volume of the initial HPLC mobile phase (e.g., 98% Mobile Phase A, 2% Mobile Phase B) for LC-MS/MS analysis.
HPLC-MS/MS Analysis
Instrumentation: A high-performance liquid chromatography system coupled to a triple quadrupole mass spectrometer with an electrospray ionization (ESI) source.
HPLC Conditions:
| Parameter | Recommended Value |
| Column | C18 reversed-phase column (e.g., 2.1 x 100 mm, 1.8 µm) |
| Mobile Phase A | 0.1% Formic Acid in Water |
| Mobile Phase B | 0.1% Formic Acid in Acetonitrile |
| Flow Rate | 0.2 mL/min |
| Column Temperature | 35°C |
| Injection Volume | 5 µL |
| Gradient | 0-5 min: 2% B; 5-15 min: 2-30% B; 15-16 min: 30-95% B; 16-18 min: 95% B; 18-18.1 min: 95-2% B; 18.1-25 min: 2% B (re-equilibration) |
Mass Spectrometry Conditions:
| Parameter | Recommended Value |
| Ionization Mode | Positive Electrospray Ionization (ESI+) |
| Scan Type | Multiple Reaction Monitoring (MRM) |
| Capillary Voltage | 3.5 kV |
| Source Temperature | 150°C |
| Desolvation Temperature | 400°C |
| Gas Flow | Instrument dependent, optimize for best signal |
MRM Transitions for this compound:
The following MRM transition is proposed for the quantification of this compound. The precursor ion is the protonated molecule [M+H]⁺. The product ion is a predicted major fragment. Note: These parameters are a starting point and should be optimized for the specific instrument being used.
| Analyte | Precursor Ion (Q1) m/z | Product Ion (Q3) m/z | Dwell Time (ms) | Collision Energy (CE) | Declustering Potential (DP) |
| This compound | 126.1 | To be determined empirically (e.g., 95.1, 82.1) | 100 | Optimize (start at 15 eV) | Optimize (start at 40 V) |
| Internal Standard (e.g., ¹⁵N₃-1-Methylcytosine) | 129.1 | To be determined | 100 | Optimize | Optimize |
Rationale for proposed product ion: Fragmentation of the protonated this compound (m/z 126.1) is likely to involve the loss of small neutral molecules. A potential fragmentation pathway is the loss of isocyanic acid (HNCO, 43 Da), which would result in a product ion of m/z 83.1. Another possibility is the loss of the methyl group and other ring fragments. For 5-methylcytosine, a common transition is 126.1 -> 109.1, corresponding to the loss of NH3. A similar fragmentation for this compound should be investigated. Empirical determination by infusing a this compound standard and performing a product ion scan is the recommended approach to confirm the optimal product ion and collision energy.
Quantitative Data
The following table summarizes the expected performance characteristics of the method. These values are based on typical performance for similar modified nucleoside analyses and should be validated for this compound.
| Parameter | Expected Performance |
| Linearity (r²) | > 0.99 |
| Limit of Detection (LOD) | 0.1 - 1.0 fmol on column |
| Limit of Quantification (LOQ) | 0.5 - 5.0 fmol on column |
| Intra-day Precision (%RSD) | < 10% |
| Inter-day Precision (%RSD) | < 15% |
| Accuracy (% Recovery) | 85 - 115% |
Data Presentation
Calibration Curve
A calibration curve should be constructed by plotting the peak area ratio of this compound to the internal standard against the concentration of this compound standards. A linear regression analysis should be applied to determine the concentration of this compound in unknown samples.
Sample Data Table
The quantitative results from the analysis of biological samples should be presented in a clear, tabular format.
| Sample ID | This compound (ng/µg DNA) | % m1C of total Cytosine | Standard Deviation |
| Control Sample 1 | 0.05 | 0.002% | 0.005 |
| Control Sample 2 | 0.06 | 0.0024% | 0.004 |
| Treated Sample 1 | 0.25 | 0.01% | 0.02 |
| Treated Sample 2 | 0.28 | 0.011% | 0.03 |
Discussion
This application note provides a comprehensive protocol for the quantification of this compound using HPLC-MS/MS. The key to a successful analysis is careful sample preparation to ensure complete digestion of nucleic acids and removal of interfering substances. The provided HPLC gradient is designed to separate this compound from other nucleosides, but it is crucial to verify the separation from its isomers, such as 5-methylcytosine and N3-methylcytosine, by running standards of these compounds if their presence is suspected in the samples.
The optimization of mass spectrometry parameters, particularly the collision energy for the MRM transition, is critical for achieving the highest sensitivity and specificity. The use of a stable isotope-labeled internal standard is highly recommended to correct for any variability in sample preparation and matrix effects.
Conclusion
The HPLC-MS/MS method described here is a powerful tool for the reliable quantification of this compound in biological samples. This will enable researchers in the fields of synthetic biology, epigenetics, and drug development to accurately measure this modified nucleobase and further investigate its roles in both artificial and natural genetic systems.
Signaling Pathway Diagram
As the role of this compound in natural biological signaling pathways is not well established, the following diagram illustrates the central dogma of molecular biology and the potential points of this compound incorporation and its subsequent analysis, which represents a logical relationship relevant to its study.
Caption: this compound in molecular biology.
References
- 1. Is this compound a faithful model compound for ultrafast deactivation dynamics of cytosine nucleosides in solution? - Physical Chemistry Chemical Physics (RSC Publishing) [pubs.rsc.org]
- 2. DNA methylation and methylcytosine oxidation in cell fate decisions - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Epigenetic regulatory functions of DNA modifications: 5-methylcytosine and beyond - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Quantification of Global DNA Methylation Status by LC-MS/MS [visikol.com]
Application Notes and Protocols for Mass Spectrometry Analysis of 1-Methylcytosine Adducts
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive guide to the analysis of 1-methylcytosine (B60703) (m1C) DNA adducts using liquid chromatography-tandem mass spectrometry (LC-MS/MS). The following sections detail the necessary protocols for sample preparation, LC-MS/MS analysis, and data interpretation. Additionally, a proposed signaling pathway for the repair of m1C adducts is presented.
Data Presentation
While specific quantitative data for this compound (m1C) adduct levels across various tissues and conditions are not extensively available in the literature, the following table provides a template for presenting such data, populated with representative values for the well-studied 5-methyl-2'-deoxycytidine (B118692) (5mdC) to illustrate the desired format. This structure can be adapted to present quantitative results for m1C as they become available through experimental investigation.
Table 1: Representative Quantitative Analysis of Modified Deoxycytidine Adducts in Human Tissues (Example Data for 5-methyl-2'-deoxycytidine)
| Tissue Type | Condition | Analyte | Concentration (adducts per 10^6 dG) | Standard Deviation | Method | Reference |
| Human Lung | Healthy (Non-smoker) | 5-methyl-2'-deoxycytidine | 4.5 | 0.8 | LC-MS/MS | Fictional, for illustration |
| Human Lung | Smoker | 5-methyl-2'-deoxycytidine | 6.2 | 1.1 | LC-MS/MS | Fictional, for illustration |
| Human Colon | Healthy | 5-methyl-2'-deoxycytidine | 5.1 | 0.9 | LC-MS/MS | Fictional, for illustration |
| Human Colon | Colorectal Cancer | 5-methyl-2'-deoxycytidine | 3.8 | 0.7 | LC-MS/MS | Fictional, for illustration |
| Human Brain | Healthy | 5-methyl-2'-deoxycytidine | 5.8 | 1.0 | LC-MS/MS | Fictional, for illustration |
Experimental Protocols
The following protocols are adapted from established methods for the analysis of modified nucleosides by LC-MS/MS.
Protocol 1: DNA Isolation and Enzymatic Hydrolysis
Objective: To isolate genomic DNA from biological samples and digest it into individual nucleosides for LC-MS/MS analysis.
Materials:
-
Biological tissue or cell sample
-
DNA isolation kit (e.g., Qiagen DNeasy Blood & Tissue Kit)
-
Nuclease P1 (Sigma-Aldrich)
-
Alkaline Phosphatase (e.g., Calf Intestinal Phosphatase, New England Biolabs)
-
DNA Degradase Plus (Zymo Research)[1]
-
200 mM Tris-HCl buffer, pH 7.5
-
100 mM MgCl2
-
Ultrapure water
-
Microcentrifuge tubes
Procedure:
-
DNA Isolation: Isolate genomic DNA from the sample using a commercial DNA isolation kit according to the manufacturer's instructions.
-
DNA Quantification: Quantify the extracted DNA using a spectrophotometer (e.g., NanoDrop) to determine the concentration and purity (A260/A280 ratio).
-
Enzymatic Digestion:
-
In a microcentrifuge tube, combine 1-5 µg of genomic DNA with 10 U of DNA Degradase Plus enzyme mix in 1X DNA Degradase Plus buffer.[1]
-
Alternatively, a two-step digestion can be performed:
-
Add Nuclease P1 (to a final concentration of 2 units/µg DNA) to the DNA sample in a buffer containing 30 mM sodium acetate (B1210297) and 1 mM ZnSO4, pH 5.3.
-
Incubate at 37°C for 2-4 hours.
-
Add alkaline phosphatase (to a final concentration of 1 unit/µg DNA) and an appropriate buffer (e.g., 100 mM Tris-HCl, pH 8.0).
-
Incubate at 37°C for an additional 1-2 hours.
-
-
-
Sample Filtration: Filter the digested sample through a 0.22 µm syringe filter to remove any precipitated proteins or enzymes.[1]
-
Dilution: Dilute the filtered sample with ultrapure water to a final concentration suitable for LC-MS/MS analysis (typically in the range of 10-100 ng/µL).
Protocol 2: LC-MS/MS Analysis of 1-methyl-2'-deoxycytidine
Objective: To separate and quantify 1-methyl-2'-deoxycytidine (d(m1C)) from other nucleosides using liquid chromatography coupled with tandem mass spectrometry.
Instrumentation:
-
High-Performance Liquid Chromatography (HPLC) or Ultra-High-Performance Liquid Chromatography (UHPLC) system
-
Triple quadrupole mass spectrometer equipped with an electrospray ionization (ESI) source
LC Conditions (Adapted from methods for similar modified nucleosides):
-
Column: C18 reverse-phase column (e.g., Agilent Zorbax Eclipse Plus C18, 2.1 x 100 mm, 1.8 µm)
-
Mobile Phase A: 0.1% formic acid in water
-
Mobile Phase B: 0.1% formic acid in methanol (B129727) or acetonitrile
-
Gradient:
-
0-2 min: 5% B
-
2-10 min: 5-50% B (linear gradient)
-
10-12 min: 50-95% B (linear gradient)
-
12-14 min: 95% B (hold)
-
14.1-16 min: 5% B (re-equilibration)
-
-
Flow Rate: 0.2-0.4 mL/min
-
Column Temperature: 40°C
-
Injection Volume: 5-10 µL
MS/MS Conditions (Predicted for 1-methyl-2'-deoxycytidine):
-
Ionization Mode: Positive Electrospray Ionization (ESI+)
-
Multiple Reaction Monitoring (MRM) Transitions:
-
Precursor Ion (m/z): 242.1 (corresponding to [M+H]+ of 1-methyl-2'-deoxycytidine)
-
Product Ion (m/z): 126.1 (corresponding to the protonated this compound base after neutral loss of the deoxyribose moiety)
-
-
Collision Energy: To be optimized empirically, typically in the range of 10-20 eV.
-
Other Parameters: Capillary voltage, gas flow, and source temperature should be optimized for the specific instrument used.
Data Analysis:
-
Quantification: Create a calibration curve using a synthetic 1-methyl-2'-deoxycytidine standard of known concentrations.
-
Normalization: Quantify the amount of 1-methyl-2'-deoxycytidine in the sample by comparing its peak area to the calibration curve. Normalize the result to the amount of a stable, unmodified nucleoside, such as 2'-deoxyguanosine (B1662781) (dG), to account for variations in DNA input. The results are typically expressed as the number of m1C adducts per 10^6 or 10^8 dG.
Mandatory Visualizations
Experimental Workflow
References
Application Notes and Protocols for the Identification of 1-Methylcytosine (m1C)
Introduction: The Challenge of 1-Methylcytosine (B60703) Detection
This compound (m1C) is a post-transcriptional RNA modification found primarily in transfer RNA (tRNA) and ribosomal RNA (rRNA), where it plays a crucial role in maintaining the structural integrity and function of these molecules. Unlike the more extensively studied 5-methylcytosine (B146107) (5mC) in DNA, the methylation of cytosine at the N1 position in m1C disrupts the Watson-Crick base pairing face of the nucleobase. This fundamental structural difference necessitates specialized approaches for its detection and mapping at single-nucleotide resolution.
Standard bisulfite sequencing, the gold-standard for 5mC detection, is not a suitable method for identifying m1C. The underlying chemistry of bisulfite sequencing involves the deamination of cytosine to uracil, a reaction that 5-methylcytosine is resistant to. The methylation at the N1 position in this compound alters the chemical properties of the cytosine ring in such a way that it does not undergo the same bisulfite-mediated deamination, rendering the technique ineffective for m1C mapping.
This document provides detailed protocols for established, non-bisulfite-based methods for the accurate identification of this compound in RNA. The primary methods covered are based on the principle that m1C induces mismatches or stalls during reverse transcription, which can be precisely mapped using next-generation sequencing.
Method 1: m1C-MaP-seq (this compound methylase-assisted profiling sequencing)
Application Note:
m1C-MaP-seq is a powerful technique for the transcriptome-wide, single-nucleotide resolution mapping of this compound. This method leverages the ability of the human DNA dioxygenase ALKBH1 to demethylate m1C in RNA. By comparing the reverse transcription (RT) mutational profiles of an RNA sample with and without ALKBH1 treatment, the locations of m1C can be precisely identified. The presence of m1C often causes misincorporations or truncations during reverse transcription. The removal of the methyl group by ALKBH1 restores the cytosine to its unmodified state, leading to a significant reduction in these RT signatures at the site of modification.
Experimental Workflow:
The overall workflow for m1C-MaP-seq involves isolating RNA, treating one aliquot with a demethylating enzyme, preparing sequencing libraries from both treated and untreated samples, and then comparing the reverse transcription mutation rates to identify m1C sites.
Protocol: m1C-MaP-seq
1. RNA Preparation: 1.1. Isolate total RNA from the cells or tissues of interest using a standard Trizol-based or column-based method. 1.2. Assess RNA integrity and concentration using a Bioanalyzer or similar instrument. High-quality RNA (RIN > 8) is recommended. 1.3. Aliquot at least 10 µg of total RNA into two separate reaction tubes.
2. ALKBH1 Demethylation Reaction: 2.1. Treated Sample:
- In a 50 µL reaction volume, combine:
- 10 µg total RNA
- 5 µL of 10x ALKBH1 Reaction Buffer (500 mM HEPES pH 7.5, 1 M KCl, 20 mM MgCl2)
- 5 µL of 10 mM α-ketoglutarate
- 2.5 µL of 20 mM Ascorbic Acid
- 2.5 µL of 1 mM (NH4)2Fe(SO4)2·6H2O
- 2 µg of purified recombinant ALKBH1 protein
- Nuclease-free water to 50 µL 2.2. Control Sample:
- Prepare an identical reaction mixture but replace the ALKBH1 protein with nuclease-free water. 2.3. Incubate both reactions at 37°C for 2 hours. 2.4. Purify the RNA from both reactions using an RNA cleanup kit (e.g., Zymo RNA Clean & Concentrator).
3. Reverse Transcription and Library Preparation: 3.1. Perform reverse transcription on the purified RNA from both the treated and control samples using a reverse transcriptase that is prone to misincorporation at modified bases (e.g., SuperScript III or IV) and random hexamer primers. 3.2. Synthesize the second strand of cDNA. 3.3. Prepare sequencing libraries from the resulting double-stranded cDNA using a standard library preparation kit for Illumina sequencing (e.g., NEBNext Ultra II DNA Library Prep Kit). 3.4. Perform PCR amplification of the libraries (typically 10-15 cycles). 3.5. Purify the amplified libraries and assess their quality and concentration.
4. Sequencing and Data Analysis: 4.1. Sequence the libraries on an Illumina platform (e.g., NovaSeq) to a desired depth (e.g., >50 million reads per sample). 4.2. Align the sequencing reads to the reference transcriptome. 4.3. For each cytosine position, calculate the mutation rate (mismatches, insertions, and deletions) in both the ALKBH1-treated and control samples. 4.4. Identify candidate m1C sites as cytosine positions with a significantly higher mutation rate in the control sample compared to the ALKBH1-treated sample.
Quantitative Data Summary:
| Parameter | Control Sample | ALKBH1-Treated Sample | Interpretation |
| Mutation Rate at m1C site | High | Low | Demethylation by ALKBH1 removes the cause of RT errors. |
| Mutation Rate at unmodified C | Low | Low | Unmodified cytosines do not cause significant RT errors. |
| Read-through at m1C site | Low | High | m1C can cause RT stalling, which is relieved by demethylation. |
Method 2: m1C-DMS-MaP-seq (Dimethyl Sulfate (B86663) Mutational Profiling)
Application Note:
This method provides an alternative chemical approach for identifying m1C. Dimethyl sulfate (DMS) is a chemical probe that methylates the N3 position of cytosine. The presence of a methyl group at the N1 position in m1C sterically hinders the methylation of the N3 position by DMS. This differential reactivity can be detected by reverse transcription, as N3-methylcytosine adducts block the reverse transcriptase, leading to truncations in the cDNA. Therefore, m1C sites are identified as cytosines that are protected from DMS modification and thus do not show a strong RT stop signal compared to unmodified cytosines.
Logical Relationship of DMS Reactivity:
Protocol: m1C-DMS-MaP-seq
1. RNA Preparation: 1.1. Isolate and purify total RNA as described in the m1C-MaP-seq protocol. 1.2. Aliquot at least 10 µg of total RNA into two separate reaction tubes (DMS-treated and control).
2. DMS Modification: 2.1. DMS-Treated Sample:
- Denature 10 µg of RNA in 200 µL of DMS reaction buffer (50 mM HEPES pH 7.5, 100 mM NaCl) by heating at 95°C for 2 minutes, then place on ice.
- Add 2 µL of dimethyl sulfate (DMS). CAUTION: DMS is highly toxic and should be handled in a chemical fume hood with appropriate personal protective equipment.
- Incubate at 37°C for 10 minutes.
- Quench the reaction by adding 50 µL of 2-mercaptoethanol. 2.2. Control Sample:
- Prepare a mock reaction with the same components but substitute DMS with nuclease-free water. 2.3. Purify the RNA from both reactions by ethanol (B145695) precipitation or using an RNA cleanup kit.
3. Library Preparation and Sequencing: 3.1. Perform reverse transcription using a reverse transcriptase and random primers. The RT stops will generate cDNAs of varying lengths. 3.2. Prepare sequencing libraries that capture the 5' ends of the cDNA fragments to map the RT stop positions. This can be achieved using specialized library preparation kits. 3.3. Sequence the libraries on an Illumina platform.
4. Data Analysis: 4.1. Align the sequencing reads to the reference transcriptome. 4.2. For each cytosine position, determine the frequency of reverse transcription stops in both the DMS-treated and control samples. 4.3. Identify m1C sites as cytosine positions that show a significantly lower RT stop frequency in the DMS-treated sample compared to surrounding, unmodified cytosines.
Quantitative Data Summary:
| Parameter | Unmodified Cytosine | This compound | Interpretation |
| DMS Reactivity | High | Low | N1-methylation hinders DMS modification at N3. |
| RT Stop Frequency (DMS-treated) | High | Low | RT is blocked by N3-methylcytosine adducts. |
| RT Stop Frequency (Control) | Low | Low | No significant RT stops without DMS treatment. |
Conclusion
The detection of this compound requires specialized methodologies that can overcome the challenges posed by its unique chemical structure. While bisulfite sequencing is a cornerstone of 5mC epigenetics, it is not applicable to m1C. The enzymatic and chemical footprinting methods detailed in these application notes, m1C-MaP-seq and m1C-DMS-MaP-seq, provide robust and reliable strategies for the single-nucleotide resolution mapping of m1C in the transcriptome. The choice between these methods may depend on the specific research question, available resources, and the biological system under investigation. Both protocols, when coupled with high-throughput sequencing and appropriate bioinformatic analysis, will enable researchers, scientists, and drug development professionals to accurately profile m1C and elucidate its role in biology and disease.
Unveiling the Elusive 1-Methylcytosine: Advanced Techniques for Genome-Wide Mapping
Application Notes and Protocols for Researchers, Scientists, and Drug Development Professionals
Introduction
1-methylcytosine (B60703) (m1C) is a modified DNA base that has garnered increasing interest in the field of epigenetics. Unlike its well-studied isomer, 5-methylcytosine (B146107) (5mC), the distribution and functional role of m1C in the genome are not yet fully understood. The development of robust and accurate methods for mapping m1C at a genome-wide scale is crucial for elucidating its biological significance and its potential as a therapeutic target. These application notes provide a comprehensive overview of the current and emerging techniques for genome-wide m1C mapping, complete with detailed experimental protocols and data interpretation guidelines.
Current Landscape of Genome-Wide m1C Mapping
Direct genome-wide mapping of this compound is a challenging endeavor due to its low abundance and the difficulty in distinguishing it from other cytosine modifications. Currently, there are no universally established, standard protocols specifically for m1C mapping. However, existing technologies can be adapted and optimized for this purpose. The primary methods explored are based on immunoprecipitation of m1C-containing DNA fragments followed by high-throughput sequencing.
Key Techniques for Genome-Wide m1C Mapping
The most promising technique for genome-wide analysis of m1C is an adaptation of Methylated DNA Immunoprecipitation Sequencing (MeDIP-Seq), which we will refer to as m1C-DIP-Seq . This method relies on the use of a specific antibody that recognizes and binds to m1C in single-stranded DNA.
m1C-DIP-Seq: Antibody-Based Enrichment
This technique involves the enrichment of DNA fragments containing m1C using a specific antibody, followed by next-generation sequencing to identify the enriched regions. The success of this method is critically dependent on the specificity and validation of the anti-m1C antibody.
Workflow for m1C-DIP-Seq:
Experimental Protocol: m1C-DIP-Seq
Materials:
-
Genomic DNA
-
Anti-1-methylcytosine antibody (requires rigorous validation)
-
Protein A/G magnetic beads
-
TE buffer (10 mM Tris-HCl, 1 mM EDTA, pH 8.0)
-
IP buffer (10 mM Sodium Phosphate pH 7.0, 140 mM NaCl, 0.05% Triton X-100)
-
Wash buffer (e.g., low salt, high salt, and LiCl wash buffers)
-
Elution buffer (e.g., 1% SDS, 0.1 M NaHCO3)
-
Proteinase K
-
Phenol:Chloroform:Isoamyl Alcohol (25:24:1)
-
Ethanol (B145695) and 3M Sodium Acetate
-
Qubit dsDNA HS Assay Kit
-
Next-generation sequencing library preparation kit
Procedure:
-
Genomic DNA Preparation and Fragmentation:
-
Isolate high-quality genomic DNA from the sample of interest.
-
Fragment the DNA to an average size of 200-600 bp by sonication or enzymatic digestion.
-
Purify the fragmented DNA and quantify using a Qubit fluorometer.
-
-
Immunoprecipitation:
-
Take 1-10 µg of fragmented DNA and denature it by heating at 95°C for 10 minutes, followed by immediate cooling on ice.
-
Add IP buffer and a validated anti-m1C antibody. Incubate overnight at 4°C with gentle rotation.
-
Prepare Protein A/G magnetic beads by washing them with IP buffer.
-
Add the prepared beads to the DNA-antibody mixture and incubate for 2-4 hours at 4°C with rotation.
-
Capture the beads using a magnetic stand and discard the supernatant.
-
-
Washing:
-
Wash the beads sequentially with low salt wash buffer, high salt wash buffer, and LiCl wash buffer to remove non-specific binding.
-
Perform a final wash with TE buffer.
-
-
Elution and DNA Recovery:
-
Elute the immunoprecipitated DNA from the beads by adding elution buffer and incubating at 65°C.
-
Reverse cross-links (if applicable) and treat with Proteinase K to digest the antibody.
-
Purify the eluted DNA using phenol:chloroform extraction and ethanol precipitation.
-
Resuspend the purified m1C-enriched DNA in nuclease-free water.
-
-
Library Preparation and Sequencing:
-
Quantify the enriched DNA.
-
Prepare a sequencing library using a low-input library preparation kit compatible with the sequencing platform (e.g., Illumina).
-
Perform high-throughput sequencing.
-
Data Analysis:
-
Quality Control: Assess the quality of the raw sequencing reads.
-
Alignment: Align the reads to the reference genome.
-
Peak Calling: Use a peak calling algorithm (e.g., MACS2) to identify regions of the genome enriched for m1C.
-
Annotation: Annotate the identified m1C peaks to genomic features (promoters, exons, introns, etc.).
-
Differential Analysis: Compare m1C profiles between different conditions or cell types.
Critical Consideration: Antibody Validation
The specificity of the anti-m1C antibody is paramount for reliable m1C-DIP-Seq results. Rigorous validation is essential and should include:
-
Dot Blot Assay: To confirm the antibody's specificity for m1C over unmodified cytosine, 5mC, and other modified bases.
-
ELISA: To quantify the antibody's binding affinity and cross-reactivity.
-
Spike-in Controls: Introducing synthetic DNA with known m1C modifications into the genomic DNA sample before immunoprecipitation to assess enrichment efficiency and specificity.
Mass Spectrometry-Based Quantification (Global m1C Levels)
While not a mapping technique, liquid chromatography-tandem mass spectrometry (LC-MS/MS) is the gold standard for accurate quantification of global m1C levels in the genome. It provides a crucial validation for the overall abundance of m1C and can be used to compare global changes between samples.[1]
Experimental Protocol: LC-MS/MS for Global m1C Quantification
Materials:
-
Genomic DNA
-
DNA degradation enzymes (e.g., DNA Degradase Plus) or acid hydrolysis reagents
-
LC-MS/MS system
Procedure:
-
DNA Digestion: Digest genomic DNA to individual nucleosides using an enzymatic cocktail or acid hydrolysis.
-
Chromatographic Separation: Separate the nucleosides using liquid chromatography.
-
Mass Spectrometry Analysis: Detect and quantify the amounts of deoxycytidine, 5-methyldeoxycytidine, and 1-methyldeoxycytidine using tandem mass spectrometry.
-
Quantification: Calculate the ratio of m1C to total cytosine.
Quantitative Data Summary
The following table summarizes the key quantitative parameters of the discussed techniques. It is important to note that for m1C-DIP-Seq, these are expected values based on the adaptation of MeDIP-Seq for 5mC, as extensive quantitative data specifically for m1C is limited in the literature.
| Technique | Input DNA | Resolution | Throughput | Key Advantage | Key Limitation |
| m1C-DIP-Seq | 1-10 µg | ~100-300 bp | High | Genome-wide mapping | Dependent on antibody specificity |
| LC-MS/MS | 1 µg | Not applicable | Low | Highly accurate quantification | Provides global levels only, no location information |
Future Perspectives and Alternative Approaches
The field of m1C mapping is rapidly evolving. Several alternative approaches hold promise for future applications:
-
Non-bisulfite, Enzyme-based methods: Future development of enzymes that can specifically recognize and either cleave at or modify m1C sites could lead to single-base resolution mapping techniques.
-
Chemical Labeling: The development of chemical methods to specifically label m1C could enable its detection and enrichment for sequencing.
-
Long-Read Sequencing: Third-generation sequencing platforms, such as PacBio and Oxford Nanopore, can detect DNA modifications directly. As the technology and analytical methods mature, they may be able to distinguish m1C from other modifications.
Signaling Pathways and Logical Relationships
The precise biological roles of m1C are still under investigation. However, it is hypothesized to be involved in processes such as DNA repair, replication, and gene regulation. The following diagram illustrates a hypothetical relationship where an environmental stimulus could lead to changes in m1C levels, subsequently impacting gene expression.
Conclusion
The genome-wide mapping of this compound is a frontier in epigenetic research. While challenges remain, the adaptation of existing techniques like MeDIP-seq, coupled with rigorous antibody validation, provides a viable path forward. The protocols and data presented here offer a foundational guide for researchers venturing into the study of this enigmatic DNA modification. As new technologies emerge, a more complete and higher-resolution picture of the m1C landscape will undoubtedly come into focus, revealing its intricate roles in health and disease.
References
Application Notes: Utilizing 1-Methylcytosine for the Investigation of DNA-Protein Interactions
Introduction
In the study of epigenetics and gene regulation, 5-methylcytosine (B146107) (5mC) is a well-established covalent modification of DNA that plays a crucial role in processes like transcriptional silencing and chromatin structuring.[1] However, other forms of cytosine methylation exist, often arising from DNA damage. 1-methylcytosine (B60703) (1mC) is one such modification, a DNA adduct typically formed by exposure to endogenous or environmental alkylating agents. Unlike the regulatory mark 5mC, 1mC is a lesion that disrupts the standard Watson-Crick base pairing and can block DNA replication, making it a point of interest for DNA repair pathways.
These application notes describe the use of this compound as a specialized tool for studying a specific class of DNA-protein interactions: the recognition and processing of DNA damage by repair enzymes. By incorporating 1mC into synthetic DNA oligonucleotides, researchers can investigate the binding affinity, specificity, and enzymatic activity of proteins involved in DNA repair. This approach is valuable for basic research into genome integrity and for the development of therapeutic agents that modulate DNA repair pathways, a key strategy in cancer therapy.[2]
Core Applications
-
Characterizing DNA Repair Enzymes: Use 1mC-containing DNA probes to study the binding kinetics and substrate specificity of DNA glycosylases and AlkB family dioxygenases, which are known to repair such alkylation damage.
-
High-Throughput Screening: Develop assays to screen for inhibitors or enhancers of 1mC repair protein activity, which could have applications in drug development.[2]
-
Probing Binding Specificity: Compare the binding of proteins to DNA containing 1mC versus unmodified cytosine or other modifications like 5mC to understand the structural basis of damage recognition.[3]
Quantitative Data on DNA-Protein Interactions
The precise quantitative effects of this compound on protein binding are specific to the protein being studied. Researchers can generate this data using the protocols outlined below. For comparative purposes, the table below summarizes the known quantitative effects of the more common 5-methylcytosine (5mC) modification on the binding of various human transcription factor (TF) families. This highlights how methylation can inhibit, enhance, or have no effect on DNA-protein interactions.
Table 1: Summary of 5-Methylcytosine's Effect on Transcription Factor Binding
| Transcription Factor Family | Number of TFs Analyzed | Binding Inhibited by 5mC | Binding Enhanced by 5mC | No Effect or Other* | Reference |
|---|---|---|---|---|---|
| Homeodomain | >50 | ~10% | ~70% | ~20% | [4] |
| bHLH | >40 | ~30% | ~15% | ~55% | |
| C2H2 Zinc Finger | >100 | ~25% | ~10% | ~65% | |
| bZIP | >30 | ~40% | ~5% | ~55% |
| Overall (519 TFs) | 519 | 23% (117 TFs) | 34% (175 TFs) | 43% (227 TFs) | **** |
*Includes TFs whose binding motifs do not contain CpG sites or where methylation has no significant impact.
Experimental Protocols
Protocol 1: Synthesis of this compound-Containing Oligonucleotides
This protocol describes the solid-phase chemical synthesis of DNA oligonucleotides containing a site-specific this compound modification. This method relies on phosphoramidite (B1245037) chemistry.
Materials:
-
This compound phosphoramidite (custom synthesis or commercial supplier)
-
Standard DNA phosphoramidites (dA, dG, dT, dC)
-
Controlled Pore Glass (CPG) solid support
-
DNA synthesizer (e.g., MerMade-4 or similar)
-
Reagents for DNA synthesis: Activator, Oxidizer, Capping reagents, Deblocking agent
-
Cleavage and deprotection solution (e.g., ammonium (B1175870) hydroxide)
-
HPLC purification system with a reverse-phase column
-
Mass spectrometer for product verification
Methodology:
-
Synthesizer Setup: Program the DNA synthesizer with the desired oligonucleotide sequence. Install the standard phosphoramidites and the this compound phosphoramidite on the synthesizer.
-
Automated Synthesis: Initiate the synthesis program on a 1 µmol scale. The synthesizer will perform the standard cycles of deblocking, coupling, capping, and oxidation for each base. For the modified base, the coupling time may need to be extended to ensure efficient incorporation.
-
Cleavage and Deprotection: Once synthesis is complete, transfer the CPG support to a vial. Add ammonium hydroxide (B78521) and heat at an appropriate temperature (e.g., 80°C for 3 hours) to cleave the oligonucleotide from the support and remove protecting groups. Caution: Conditions must be carefully controlled to avoid degradation of the 1mC base.
-
Purification: Purify the crude oligonucleotide using reverse-phase HPLC to separate the full-length product from truncated sequences and byproducts.
-
Quality Control: Confirm the identity and purity of the final product by high-resolution mass spectrometry to verify the correct molecular weight.
-
Quantification and Storage: Quantify the purified oligonucleotide using UV-Vis spectrophotometry at 260 nm. Dry the sample and resuspend in a suitable buffer (e.g., TE buffer). Store at -20°C.
Protocol 2: Electrophoretic Mobility Shift Assay (EMSA) with 1mC Probes
EMSA is used to detect the binding of a protein to a specific DNA sequence by observing the reduced migration speed of the DNA-protein complex through a native polyacrylamide gel compared to the free DNA probe.
Materials:
-
Purified 1mC-containing oligonucleotide and its unmodified counterpart (control)
-
Complementary unlabeled oligonucleotide
-
T4 Polynucleotide Kinase (PNK) and [γ-³²P]ATP for radiolabeling, or an infrared dye-labeled oligonucleotide
-
Purified protein of interest
-
EMSA binding buffer (e.g., 10 mM Tris-HCl pH 7.5, 50 mM KCl, 1 mM DTT, 5% glycerol)
-
Native polyacrylamide gel (e.g., 5-10%) and TBE or TGE running buffer
-
Loading dye (e.g., 6X Ficoll-based dye without SDS)
-
Phosphorimager or infrared imaging system (e.g., Odyssey Imager)
Methodology:
-
Probe Preparation (Annealing and Labeling):
-
Mix the labeled 1mC-containing single-stranded DNA with a 1.5-fold molar excess of the unlabeled complementary strand in annealing buffer (e.g., 10 mM Tris-HCl, 50 mM NaCl, 1 mM EDTA).
-
Heat the mixture to 95°C for 5 minutes, then allow it to cool slowly to room temperature to form a double-stranded probe.
-
If not using a pre-labeled oligo, end-label the probe using T4 PNK and [γ-³²P]ATP. Purify the labeled probe to remove unincorporated nucleotides.
-
-
Binding Reaction:
-
In a microcentrifuge tube, set up the binding reactions on ice. A typical 20 µL reaction includes:
-
10 µL of 2X EMSA binding buffer.
-
2 µL of labeled probe (e.g., 0.1-0.5 nM final concentration).
-
Varying amounts of the purified protein (e.g., 0, 2, 5, 10, 20 nM).
-
For competition assays, add a 50-100 fold molar excess of unlabeled specific (1mC) or non-specific (unmodified) competitor DNA before adding the protein.
-
Add nuclease-free water to the final volume.
-
-
Incubate the reactions at room temperature for 20-30 minutes.
-
-
Electrophoresis:
-
Add 4 µL of 6X loading dye to each reaction.
-
Load the samples onto a pre-run native polyacrylamide gel.
-
Run the gel at a constant voltage (e.g., 100-150V) in a cold room or with a cooling system until the dye front has migrated approximately two-thirds of the way down the gel.
-
-
Detection and Analysis:
-
Carefully remove the gel and transfer it to Whatman paper.
-
Dry the gel under vacuum at 80°C for 1 hour.
-
Expose the dried gel to a phosphor screen overnight.
-
Visualize the results using a phosphorimager. A "shift" from the fast-migrating free probe to a slower-migrating band indicates a DNA-protein complex.
-
Protocol 3: DNA Pull-Down Assay with 1mC Probes
This assay is used to isolate and identify proteins from a complex mixture (like a nuclear extract) that bind to a specific DNA sequence containing 1mC.
Materials:
-
Biotinylated, double-stranded 1mC-containing DNA probe and an unmodified control probe.
-
Streptavidin-coated magnetic beads (e.g., Dynabeads).
-
Nuclear protein extract from cells of interest.
-
Binding/Wash Buffer (e.g., 20 mM HEPES pH 7.3, 50 mM KCl, 5 mM MgCl₂, 10% glycerol, with protease inhibitors added fresh).
-
Elution Buffer (e.g., Binding Buffer with 1 M NaCl or a low pH buffer).
-
Magnetic stand.
-
SDS-PAGE gels and reagents for Western blotting or mass spectrometry.
Methodology:
-
Probe Immobilization:
-
Wash streptavidin-coated magnetic beads twice with Binding/Wash Buffer.
-
Resuspend the beads in buffer and add the biotinylated DNA probe.
-
Incubate for 1-2 hours at 4°C with gentle rotation to allow the biotin-streptavidin interaction.
-
Use a magnetic stand to capture the beads and wash them three times to remove unbound probe.
-
-
Protein Binding:
-
Pre-clear the nuclear extract by incubating it with bare streptavidin beads for 1 hour to reduce non-specific binding.
-
Add the pre-cleared nuclear extract to the DNA-immobilized beads.
-
Incubate for 2-4 hours at 4°C with gentle rotation.
-
-
Washing:
-
Place the tube on the magnetic stand to capture the beads. Discard the supernatant.
-
Wash the beads 3-5 times with ice-cold Binding/Wash Buffer to remove non-specifically bound proteins.
-
-
Elution:
-
Add Elution Buffer to the beads and incubate for 15-30 minutes to dissociate the bound proteins.
-
Place the tube on the magnetic stand and collect the supernatant, which contains the eluted proteins.
-
-
Analysis:
-
Analyze the eluted proteins by SDS-PAGE followed by silver staining, Western blotting with an antibody against a candidate protein, or mass spectrometry for unbiased identification of binding partners.
-
Visualizations
Experimental and Logical Workflows
References
- 1. DNA methylation and methylcytosine oxidation in cell fate decisions - PMC [pmc.ncbi.nlm.nih.gov]
- 2. cdio.ai [cdio.ai]
- 3. Proteins That Read DNA Methylation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Impact of cytosine methylation on DNA binding specificities of human transcription factors - PMC [pmc.ncbi.nlm.nih.gov]
Troubleshooting & Optimization
Technical Support Center: Distinguishing 1-Methylcytosine from other Cytosine Modifications
Welcome to the technical support center for researchers, scientists, and drug development professionals. This resource provides troubleshooting guides and frequently asked questions (FAQs) to address the challenges associated with distinguishing 1-methylcytosine (B60703) (1mC) from other cytosine modifications.
Frequently Asked Questions (FAQs)
Q1: What is this compound (1mC) and how does it differ chemically from 5-methylcytosine (B146107) (5mC)?
This compound (1mC) is a methylated form of the DNA base cytosine, where a methyl group is attached to the nitrogen atom at the first position of the pyrimidine (B1678525) ring.[1] This contrasts with the more common 5-methylcytosine (5mC), where the methyl group is at the fifth carbon position.[2] This difference in the location of the methyl group leads to distinct chemical properties and biological roles. While both are isomers, their structural variance can be exploited for differential detection.
Q2: Why is it challenging to distinguish 1mC from other cytosine modifications like 5mC and 5-hydroxymethylcytosine (B124674) (5hmC)?
The primary challenges in distinguishing 1mC from other cytosine modifications stem from their structural similarities and the limitations of conventional detection methods. Many techniques were originally developed for the more abundant 5mC and may not inherently differentiate between its isomers. For instance, traditional bisulfite sequencing, a gold standard for 5mC detection, relies on the differential deamination of cytosine versus methylated cytosine. The behavior of 1mC under these conditions is not as well-characterized, potentially leading to ambiguous results. Furthermore, antibody-based methods may exhibit cross-reactivity due to the small size of the methyl group and the overall similar structure of the modified bases.
Q3: What is the biological significance of accurately identifying 1mC?
While the biological roles of 5mC in gene silencing and development are well-established, the functions of 1mC in DNA are less understood.[3][4] In RNA, the analogous modification (m1A) is known to affect RNA structure and translation. In DNA, 1mC is considered a form of DNA damage that can be repaired by specific DNA glycosylases, such as the AlkB family of enzymes.[5] Accurate detection of 1mC is therefore crucial for studying DNA repair pathways, understanding the full scope of the epigenome, and investigating its potential roles in disease.
Q4: Can standard bisulfite sequencing be used to detect 1mC?
Standard bisulfite sequencing is not a reliable method for specifically identifying 1mC. The chemical principle of bisulfite sequencing is the deamination of unmethylated cytosines to uracil, while 5-methylcytosine is largely resistant. The reactivity of this compound to bisulfite is different and can lead to various chemical products, making the interpretation of sequencing data complex and prone to artifacts. Therefore, bisulfite sequencing data should be interpreted with caution when the presence of 1mC is suspected, and alternative, more specific methods should be employed for confirmation.
Troubleshooting Guides
This section provides troubleshooting advice for common issues encountered during the experimental detection of this compound.
Issue 1: Ambiguous or Noisy Signal in Mass Spectrometry Analysis
Potential Cause:
-
Suboptimal Sample Preparation: Contaminants in the DNA sample can interfere with ionization and lead to a poor signal-to-noise ratio.
-
Inappropriate Digestion: Incomplete enzymatic digestion of DNA to single nucleosides can result in a heterogeneous sample and complex spectra.
-
Instrument Calibration: Incorrect mass spectrometer calibration can lead to inaccurate mass-to-charge ratio measurements, making it difficult to identify specific modifications.
Troubleshooting Steps:
-
Optimize DNA Purification: Use a high-quality DNA extraction kit and ensure the final DNA preparation is free of proteins, RNA, and other contaminants. Assess DNA purity using UV spectrophotometry (A260/A280 and A260/A230 ratios).
-
Ensure Complete Digestion: Follow the recommended protocol for enzymatic digestion of DNA to nucleosides. Consider increasing the enzyme concentration or incubation time if incomplete digestion is suspected.
-
Calibrate Mass Spectrometer: Regularly calibrate your mass spectrometer using appropriate standards to ensure high mass accuracy.
-
Use Internal Standards: Spike your sample with a known amount of a stable isotope-labeled 1-methyl-2'-deoxycytidine standard to aid in quantification and to account for variations in sample processing and instrument response.
Issue 2: Suspected Cross-Reactivity in Antibody-Based Detection (e.g., MeDIP)
Potential Cause:
-
Low Antibody Specificity: The antibody used may not be highly specific for 1mC and could be cross-reacting with other cytosine modifications, particularly 5mC, due to their structural similarity.
Troubleshooting Steps:
-
Validate Antibody Specificity: Before performing your experiment, validate the specificity of your anti-1mC antibody using dot blot analysis with synthetic oligonucleotides containing 1mC, 5mC, 5hmC, and unmodified cytosine.
-
Optimize Blocking and Washing: Increase the stringency of your blocking and washing steps to reduce non-specific antibody binding.
-
Use a Different Antibody: If cross-reactivity persists, consider testing antibodies from different vendors or custom-generating a more specific antibody.
-
Orthogonal Validation: Confirm positive results from antibody-based methods with an independent technique, such as mass spectrometry.
Issue 3: Inconsistent or Non-Reproducible Sequencing Results
Potential Cause:
-
Low Abundance of 1mC: 1mC is generally much less abundant than 5mC in genomic DNA, which can lead to stochastic detection and poor reproducibility.
-
PCR Bias: During the amplification step of many sequencing library preparation protocols, sequences containing modified bases may amplify with different efficiencies compared to unmodified sequences.
-
Sequencing Artifacts: Errors introduced during library preparation or sequencing can be misinterpreted as base modifications.
Troubleshooting Steps:
-
Enrich for 1mC-Containing DNA: If possible, use an enrichment method, such as immunoprecipitation with a validated anti-1mC antibody, to increase the proportion of 1mC-containing fragments in your sample before sequencing.
-
Optimize PCR Conditions: Use a high-fidelity DNA polymerase and optimize the number of PCR cycles to minimize amplification bias.
-
Include Proper Controls: Sequence a control DNA sample with known locations of 1mC and other modifications to assess the accuracy and potential biases of your workflow.
-
Bioinformatic Filtering: Use stringent quality filtering of your sequencing data and be aware of common sequencing artifacts. Consult with a bioinformatician to develop a custom analysis pipeline if necessary.
Experimental Protocols & Methodologies
Liquid Chromatography-Mass Spectrometry (LC-MS) for Global Quantification of 1mC
Liquid chromatography-mass spectrometry is a highly sensitive and specific method for the global quantification of DNA modifications.
Protocol Outline:
-
Genomic DNA Extraction: Isolate high-quality genomic DNA from your samples.
-
DNA Digestion: Digest the genomic DNA into individual nucleosides using a cocktail of enzymes such as DNase I, nuclease P1, and alkaline phosphatase.
-
LC Separation: Separate the resulting nucleosides using reverse-phase liquid chromatography. A C18 column is commonly used.
-
MS Detection: Detect and quantify the nucleosides using a triple quadrupole mass spectrometer operating in multiple reaction monitoring (MRM) mode. The specific mass transitions for 1-methyl-2'-deoxycytidine will be monitored.
-
Quantification: Calculate the amount of 1mC relative to the total amount of deoxycytidine in the sample. The use of stable isotope-labeled internal standards is highly recommended for accurate quantification.
Quantitative Data Summary
The following table summarizes the typical performance characteristics of different methods for detecting cytosine modifications. Note that data specifically for 1mC is limited, and these values are based on performance for other low-abundance modifications.
| Method | Resolution | Sensitivity | Throughput | Key Limitation for 1mC |
| LC-MS/MS | Global | High (fmol range) | Low | Requires specialized equipment; no sequence context. |
| Antibody-Based (MeDIP) | Low (100-500 bp) | Moderate | High | Potential for antibody cross-reactivity with 5mC. |
| Bisulfite Sequencing | Single-base | High | High | Unreliable for specific 1mC detection due to complex chemical reactions. |
| Enzyme-Based Methods | Single-base | High | High | Specific enzymes for 1mC detection are not widely available. |
Visualizations
Experimental Workflow for LC-MS-based 1mC Detection
Caption: Workflow for the detection and quantification of this compound using LC-MS.
Logical Relationship of Challenges in 1mC Detection
References
- 1. This compound - Wikipedia [en.wikipedia.org]
- 2. 5-Methylcytosine - Wikipedia [en.wikipedia.org]
- 3. The Role of Methylation in the Intrinsic Dynamics of B- and Z-DNA | PLOS One [journals.plos.org]
- 4. DNA methylation and methylcytosine oxidation in cell fate decisions - PMC [pmc.ncbi.nlm.nih.gov]
- 5. DEMETER and REPRESSOR OF SILENCING 1 encode 5-methylcytosine DNA glycosylases - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Optimizing Mass Spectrometry for 1-Methylcytosine (m1C) Detection
Welcome to the technical support center for the analysis of 1-Methylcytosine (B60703) (m1C) using mass spectrometry. This resource is designed for researchers, scientists, and drug development professionals to provide troubleshooting guidance and frequently asked questions to ensure accurate and robust detection of this critical epigenetic modification.
Troubleshooting Guide
This guide addresses specific issues that may arise during the detection of this compound by LC-MS/MS.
| Problem | Potential Cause | Recommended Solution |
| No or Low Signal for m1C | Suboptimal Ionization Efficiency: The chosen ionization mode (e.g., ESI) or polarity may not be ideal for this compound.[1][2] | Optimize Ionization Source: Infuse a standard solution of this compound and test both positive and negative electrospray ionization (ESI) modes.[1][2] Fine-tune key parameters such as capillary voltage, gas flow, and source temperature to maximize the signal.[3] |
| Inefficient Sample Preparation: Incomplete enzymatic digestion of DNA/RNA can prevent the release of individual nucleosides for analysis. | Verify Digestion Efficiency: Ensure complete digestion by using a sufficient amount of enzyme (e.g., nuclease P1 followed by alkaline phosphatase) and optimizing incubation time and temperature. Consider a sample clean-up step to remove interfering substances. | |
| Incorrect MRM Transitions: The selected precursor and product ion m/z values for this compound may be incorrect or not the most intense. | Confirm MRM Transitions: Infuse a this compound standard to determine the most abundant precursor ion and its major fragment ions. Scan a range of collision energies to find the optimal energy for each transition. | |
| Matrix Effects: Co-eluting compounds from the sample matrix can suppress the ionization of this compound, leading to a lower signal. | Improve Chromatographic Separation: Adjust the gradient, flow rate, or column chemistry to separate this compound from interfering matrix components. Consider using a divert valve to direct the flow to waste during the elution of highly interfering compounds. Sample dilution or alternative sample preparation techniques can also mitigate matrix effects. | |
| Poor Peak Shape (Tailing, Broadening, or Splitting) | Column Contamination or Degradation: Buildup of contaminants on the column can lead to poor peak shapes. | Column Maintenance: Flush the column with a strong solvent or, if necessary, replace it. Ensure proper sample filtration to prevent particulate matter from reaching the column. |
| Inappropriate Mobile Phase: The pH or composition of the mobile phase may not be suitable for this compound. | Optimize Mobile Phase: Experiment with different mobile phase additives (e.g., formic acid, ammonium (B1175870) formate) and pH levels to improve peak shape. Ensure the mobile phase is properly degassed. | |
| Suboptimal Ionization Conditions: Inappropriate source parameters can sometimes contribute to peak broadening. | Adjust Source Parameters: Fine-tune ion source settings, such as gas flows and temperatures, as these can influence peak shape. | |
| Inconsistent or Non-Reproducible Results | Sample Degradation: this compound or other nucleosides may be unstable under the storage or experimental conditions. | Ensure Sample Stability: Prepare fresh samples and standards. If storing, freeze them immediately after preparation. Avoid repeated freeze-thaw cycles. |
| Instrument Instability: Fluctuations in the LC or MS system can lead to variability in results. | System Check and Calibration: Perform regular system maintenance and calibration. Monitor system suitability by injecting a standard at regular intervals during the analytical run. | |
| Inconsistent Sample Preparation: Variability in the sample preparation workflow is a common source of non-reproducibility. | Standardize Protocols: Use a consistent and well-documented sample preparation protocol. The use of an internal standard can help to correct for variations. | |
| High Background Noise | Contaminated Solvents or Reagents: Impurities in the mobile phase or other reagents can contribute to high background noise. | Use High-Purity Reagents: Utilize LC-MS grade solvents and high-purity reagents. Prepare fresh mobile phases regularly. |
| Contaminated LC-MS System: The system, including tubing, autosampler, and ion source, may be contaminated. | System Cleaning: Flush the entire LC system with appropriate cleaning solutions. Clean the ion source according to the manufacturer's recommendations. | |
| Detector Settings: Non-optimal detector settings can increase noise levels. | Optimize Detector Settings: Adjust detector parameters, such as gain and filter settings, to minimize noise without compromising signal intensity. |
Frequently Asked Questions (FAQs)
Q1: What are the typical MRM transitions for this compound?
A1: The exact m/z values for precursor and product ions can vary slightly based on the specific instrumentation and whether you are analyzing the nucleoside (1-methylcytidine) or the free base (this compound). It is always recommended to determine the optimal transitions by infusing a pure standard. However, a commonly used transition for the protonated nucleoside [M+H]+ is m/z 258.1 → 126.1.
Q2: Which ionization mode is better for this compound detection, positive or negative ESI?
A2: Positive mode electrospray ionization (ESI) is generally preferred for the detection of modified nucleosides like this compound as they readily form protonated molecules [M+H]+. However, it is advisable to test both positive and negative modes during method development to determine which provides the best sensitivity and specificity for your specific sample and system.
Q3: How can I improve the sensitivity of my assay for detecting low levels of this compound?
A3: To enhance sensitivity, consider the following:
-
Optimize MS parameters: Fine-tune the ion source parameters (e.g., capillary voltage, gas flows, temperature) and collision energy for the specific MRM transition of this compound.
-
Improve sample preparation: Ensure efficient enzymatic digestion and consider a solid-phase extraction (SPE) step to concentrate the analyte and remove interfering substances.
-
Enhance chromatographic performance: Use a column with high efficiency and optimize the mobile phase and gradient to achieve sharp, narrow peaks.
-
Chemical Derivatization: In some cases, chemical derivatization can be employed to improve ionization efficiency and thus sensitivity.
Q4: What type of column is recommended for the separation of this compound?
A4: A reversed-phase C18 column is commonly used for the separation of nucleosides, including this compound. The specific choice of column (particle size, length, and diameter) will depend on the desired resolution and analysis time.
Q5: How do I prepare my DNA/RNA sample for m1C analysis?
A5: A typical sample preparation protocol involves the enzymatic hydrolysis of the nucleic acid to individual nucleosides. This is often a two-step process:
-
Digestion with nuclease P1 to break down the DNA/RNA into nucleoside 5'-monophosphates.
-
Treatment with alkaline phosphatase to remove the phosphate (B84403) group, yielding the nucleosides. Following digestion, the sample may need to be filtered or subjected to a clean-up procedure before injection into the LC-MS/MS system.
Quantitative Data Summary
The following tables summarize typical mass spectrometry parameters for the analysis of modified nucleosides, including derivatives of cytosine. These should be used as a starting point for method development.
Table 1: Example Mass Spectrometer Parameters for Cytosine Derivatives
| Parameter | Setting | Reference |
| Ionization Mode | Positive Electrospray Ionization (ESI) | |
| Ionspray Voltage | 5500 V | |
| Turbo Gas Temperature | 550°C | |
| Quadrupole Resolution | Unit Resolution for Q1 and Q3 | |
| Collision Gas | Helium |
Table 2: Example MRM Transitions and Collision Energies for Cytosine and its Modifications
| Analyte | Precursor Ion (m/z) | Product Ion (m/z) | Collision Energy (CE) |
| Deoxycytidine (dC) | 228.0 | 112.0 | 15 V |
| 5-Methyl-2'-deoxycytidine (5mdC) | 242.1 | 126.0 | 13 V |
| 5-Hydroxymethyl-2'-deoxycytidine (5hmdC) | 258.0 | 142.0 | 22 V |
| N6-methyladenosine (m6A) | 282.1 | 150.1 | 30 V |
Note: The optimal collision energy is instrument-dependent and should be determined experimentally.
Experimental Protocols
Protocol 1: Enzymatic Digestion of DNA for LC-MS/MS Analysis
-
Sample Preparation: Dissolve 1 µg of DNA in a suitable buffer (e.g., 10 mM Tris-HCl pH 7.0, 100 mM NaCl, 2.5 mM ZnCl2).
-
Nuclease P1 Digestion: Add 2 Units of nuclease P1 to the DNA solution.
-
Incubation: Incubate the mixture at 37°C for 12 hours.
-
Alkaline Phosphatase Treatment: Add 1 Unit of alkaline phosphatase to the reaction.
-
Second Incubation: Incubate at 37°C for an additional 2 hours.
-
Dilution and Analysis: Dilute the sample as needed and inject an appropriate volume (e.g., 10 µL) into the LC-MS/MS system.
Visualizations
References
Technical Support Center: 1-Methylcytosine (m1C) Quantification by HPLC
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) for the quantification of 1-Methylcytosine (m1C) by High-Performance Liquid Chromatography (HPLC). The information is tailored for researchers, scientists, and drug development professionals.
Troubleshooting Guide
This guide addresses common issues encountered during the HPLC analysis of this compound, presented in a question-and-answer format.
Peak Shape Problems
Question: Why are my this compound peaks tailing?
Answer: Peak tailing, where the latter half of the peak is broader than the front, is a common issue. Several factors can cause this:
-
Secondary Silanol (B1196071) Interactions: Residual, unreacted silanol groups on the silica-based stationary phase of the column can interact with the basic this compound analyte, causing tailing.[1]
-
Solution: Use an end-capped column or a column with a polar-embedded phase to shield these residual silanols. Operating the mobile phase at a lower pH (e.g., with 0.1% formic acid) can also suppress silanol ionization and reduce these interactions.
-
-
Mobile Phase pH: If the mobile phase pH is close to the pKa of this compound, the analyte can exist in both ionized and non-ionized forms, leading to peak tailing.[1]
-
Solution: Adjust the mobile phase pH to be at least 2 units away from the analyte's pKa. Using a buffer can help maintain a stable pH.
-
-
Column Contamination or Degradation: Accumulation of contaminants on the column frit or at the head of the column can disrupt the sample flow path.[2][3] Voids in the column packing can also lead to peak distortion.[2]
-
Solution: Use a guard column to protect the analytical column from contaminants. If the column is contaminated, flushing with a strong solvent may help. If a void has formed, the column may need to be replaced.
-
-
Sample Overload: Injecting too concentrated a sample can lead to peak tailing.
-
Solution: Dilute the sample and reinject.
-
Question: What causes peak fronting for my this compound peak?
Answer: Peak fronting, where the beginning of the peak is sloped, is less common than tailing but can occur due to:
-
Sample Solvent Incompatibility: If the sample is dissolved in a solvent significantly stronger than the mobile phase, it can cause the analyte to move through the beginning of the column too quickly, resulting in a fronting peak.
-
Solution: Whenever possible, dissolve the sample in the mobile phase. If a different solvent must be used, it should be weaker than the mobile phase.
-
-
Column Overloading: Similar to peak tailing, injecting too much sample can also manifest as peak fronting.
-
Solution: Try diluting the sample.
-
Question: Why am I seeing split or shoulder peaks for this compound?
Answer: Split or shoulder peaks can be indicative of several issues:
-
Partially Blocked Column Frit: Contaminants from the sample or mobile phase can partially block the inlet frit of the column, causing uneven flow and splitting the peak.
-
Solution: Backflushing the column may dislodge the blockage. If the problem persists, the frit may need to be replaced.
-
-
Column Bed Void: A void or channel in the column packing material can create two different flow paths for the analyte, resulting in a split peak.
-
Solution: This usually indicates column degradation, and the column will likely need to be replaced.
-
-
Sample Injection Issues: Problems with the autosampler, such as a poorly seated injection needle, can cause improper sample introduction onto the column.
-
Solution: Inspect the autosampler for any mechanical issues.
-
-
Co-eluting Interference: A compound with a very similar retention time to this compound may be present in the sample.
-
Solution: Optimize the mobile phase composition or gradient to improve the resolution between the two peaks.
-
Retention Time Variability
Question: My retention time for this compound is drifting or inconsistent between injections. What should I do?
Answer: Fluctuations in retention time can compromise the reliability of your quantification. Common causes include:
-
Mobile Phase Composition Changes: Inaccurate mixing of mobile phase components, evaporation of a volatile solvent, or degradation of a mobile phase additive can alter the elution strength and affect retention times.
-
Solution: Prepare fresh mobile phase daily. Ensure the solvent bottles are capped to prevent evaporation. If using an online mixer, ensure it is functioning correctly.
-
-
Inadequate Column Equilibration: Insufficient equilibration time between gradient runs or after changing the mobile phase can lead to drifting retention times.
-
Solution: Ensure the column is fully equilibrated with the initial mobile phase conditions before each injection. A general rule is to flush the column with at least 10 column volumes.
-
-
Temperature Fluctuations: Changes in the ambient temperature can affect the viscosity of the mobile phase and the thermodynamics of the separation, leading to shifts in retention time.
-
Solution: Use a column oven to maintain a constant and controlled temperature.
-
-
Pump and Flow Rate Issues: Leaks in the pump or check valves, or air bubbles in the system, can cause an inconsistent flow rate, directly impacting retention times.
-
Solution: Regularly inspect the HPLC system for leaks. Degas the mobile phase to remove dissolved air. Purge the pump to remove any trapped air bubbles.
-
Baseline and Sensitivity Issues
Question: I'm observing a noisy or drifting baseline. How can I fix this?
Answer: A stable baseline is crucial for accurate quantification.
-
Contaminated Mobile Phase or Detector Cell: Impurities in the mobile phase or a contaminated detector flow cell can cause baseline noise.
-
Solution: Use high-purity HPLC-grade solvents and reagents. Flush the detector cell with a strong, appropriate solvent.
-
-
Air Bubbles: Air bubbles passing through the detector will cause sharp spikes in the baseline.
-
Solution: Degas the mobile phase thoroughly.
-
-
Detector Lamp Issues: An aging or failing detector lamp can lead to a noisy or drifting baseline.
-
Solution: Check the lamp's energy output and replace it if necessary.
-
Question: My this compound peak is very small or not detected. What are the possible reasons?
Answer: Low sensitivity can be due to a variety of factors:
-
Low Sample Concentration: The concentration of this compound in your sample may be below the limit of detection (LOD) of your method.
-
Solution: Concentrate your sample or inject a larger volume (be mindful of potential peak distortion).
-
-
Incorrect Detection Wavelength: The UV detector may not be set to the optimal wavelength for this compound.
-
Solution: Determine the UV absorbance maximum for this compound (typically around 270-280 nm) and set the detector accordingly.
-
-
Sample Degradation: this compound may have degraded during sample preparation or storage.
-
Solution: Ensure proper sample handling and storage conditions. Prepare fresh samples if degradation is suspected.
-
-
System Leaks: A leak in the system can lead to a loss of sample before it reaches the detector.
-
Solution: Perform a thorough check for any leaks in the flow path.
-
Diagrams
Caption: A logical workflow for troubleshooting common HPLC issues for this compound analysis.
Frequently Asked Questions (FAQs)
Q1: What type of HPLC column is best for this compound quantification?
A1: Reversed-phase columns are most commonly used. C18 columns are a popular choice and have been successfully used for separating cytosine and its methylated analogs. For resolving highly similar cytosine analogs, a phenyl-hexyl column may offer alternative selectivity. The choice will depend on the specific sample matrix and the other components present.
Q2: What is a good starting mobile phase for this compound analysis?
A2: A common starting point for reversed-phase separation of nucleosides is a gradient of an aqueous buffer and an organic modifier. For example, a mobile phase consisting of water with 0.1% formic acid (Solvent A) and methanol (B129727) or acetonitrile (B52724) (Solvent B) is often effective. The gradient can be optimized to achieve the best separation. For instance, a shallow gradient with a low percentage of organic modifier at the beginning can help in retaining and separating polar compounds like this compound.
Q3: How should I prepare my DNA sample for this compound analysis by HPLC?
A3: To quantify this compound within a DNA sample, the DNA must first be hydrolyzed into its constituent nucleosides or bases. This can be achieved through:
-
Enzymatic Hydrolysis: This is a milder method that uses a combination of enzymes like nuclease P1 and alkaline phosphatase to digest the DNA into individual deoxynucleosides.
-
Acid Hydrolysis: This method uses strong acids like perchloric acid or formic acid at high temperatures. While simpler, it can be harsher and may lead to some degradation of the analytes if not carefully controlled.
After hydrolysis, the sample should be filtered through a 0.22 µm filter before injection into the HPLC system to remove any particulates.
Q4: What are typical quantitative parameters I can expect for cytosine analog analysis?
A4: While specific data for this compound is limited, data from closely related 5-methylcytosine (B146107) can provide a useful reference. The following table summarizes typical ranges for various parameters.
| Parameter | Typical Value/Range | Source |
| Retention Time (5-mC) | 3 - 10 minutes | |
| Limit of Detection (LOD) | 0.3 - 50 ng/mL | |
| Limit of Quantification (LOQ) | 1.0 - 1.6 ng/mL | |
| Linear Range | 1.0 - 160.0 µg/mL | |
| Recovery | 96% - 102% | |
| Precision (RSD) | < 5% |
Note: These values are highly dependent on the specific HPLC method, column, and instrument used. It is essential to validate these parameters for your specific assay.
Experimental Protocols
Protocol 1: DNA Hydrolysis to Deoxynucleosides (Enzymatic Method)
-
To 10 µg of purified DNA, add nuclease P1 buffer and nuclease P1 enzyme.
-
Incubate at 37°C for 2 hours.
-
Add alkaline phosphatase buffer and alkaline phosphatase enzyme.
-
Incubate at 37°C for another 2 hours.
-
Terminate the reaction by heating or adding a stopping solution.
-
Centrifuge the sample to pellet any precipitate.
-
Filter the supernatant through a 0.22 µm syringe filter into an HPLC vial.
Protocol 2: HPLC Analysis of this compound
-
HPLC System: A standard binary pump HPLC system with a UV detector.
-
Column: C18 reversed-phase column (e.g., 4.6 x 250 mm, 5 µm).
-
Mobile Phase A: 0.1% Formic acid in water.
-
Mobile Phase B: Methanol or Acetonitrile.
-
Flow Rate: 0.7 mL/min.
-
Column Temperature: 30°C.
-
Detection Wavelength: 273 nm.
-
Injection Volume: 10-20 µL.
-
Gradient Program (Example):
-
0-5 min: 5% B
-
5-20 min: 5% to 30% B (linear gradient)
-
20-25 min: 30% to 5% B (linear gradient)
-
25-30 min: 5% B (re-equilibration)
-
Note: This is a starting protocol and should be optimized for your specific application and system to achieve the best separation and quantification of this compound.
Diagrams
Caption: A typical experimental workflow for the quantification of this compound from DNA by HPLC.
References
Technical Support Center: Efficient Synthesis of 1-Methylcytosine
Welcome to the technical support center for the chemical synthesis of 1-Methylcytosine (4-amino-1-methylpyrimidin-2(1H)-one). This resource is designed for researchers, scientists, and drug development professionals to provide troubleshooting guidance and answers to frequently asked questions encountered during the synthesis of this important modified nucleobase.
Frequently Asked Questions (FAQs)
Q1: What is the most common and efficient method for synthesizing this compound?
A1: A widely used and efficient method for the synthesis of this compound is the cyclocondensation of a β-alkoxy-α,β-unsaturated ester, such as ethyl 3-ethoxyacrylate, with N-methylurea. This method is favored for its relatively high yields and straightforward procedure.
Q2: What are the critical parameters to control for a successful this compound synthesis?
A2: The critical parameters to control are the purity of starting materials, the molar ratio of reactants, reaction temperature, and reaction time. Impurities in the starting materials can lead to significant side product formation and lower yields. The reaction temperature needs to be carefully controlled to prevent the decomposition of reactants and products.
Q3: My reaction yield is consistently low. What are the likely causes?
A3: Low yields in this compound synthesis can stem from several factors. Common causes include impure starting materials, incorrect stoichiometry of reactants, suboptimal reaction temperature, or insufficient reaction time. Additionally, side reactions such as polymerization of the acrylate (B77674) or hydrolysis of the ester can significantly reduce the yield of the desired product.[1]
Q4: I am having difficulty purifying the final product. What are the recommended purification methods?
A4: Purification of this compound can be challenging due to the presence of unreacted starting materials and side products. Recrystallization is often the most effective method for obtaining high-purity crystalline this compound. A common solvent system for recrystallization is ethanol (B145695) or an ethanol/water mixture. Column chromatography on silica (B1680970) gel can also be employed for purification, though it may be more time-consuming.
Q5: What are the expected spectroscopic characteristics of this compound?
A5: The structure of synthesized this compound should be confirmed using standard spectroscopic techniques.
-
1H NMR: The proton NMR spectrum will show characteristic peaks for the methyl group, the vinyl protons of the pyrimidine (B1678525) ring, and the amino protons.
-
13C NMR: The carbon NMR spectrum will display signals corresponding to the methyl carbon, the carbonyl carbon, and the carbons of the pyrimidine ring.
-
Mass Spectrometry: The mass spectrum should show a molecular ion peak corresponding to the molecular weight of this compound (125.13 g/mol ).[2]
-
IR Spectroscopy: The infrared spectrum will exhibit characteristic absorption bands for the N-H and C=O functional groups.
Troubleshooting Guide
This guide addresses common problems encountered during the synthesis of this compound and provides a logical workflow for troubleshooting.
Problem 1: Low or No Product Yield
Low or no yield is a frequent issue in organic synthesis. The following steps provide a systematic approach to identify and resolve the underlying cause.[1]
Troubleshooting Workflow for Low Yield
A logical workflow for troubleshooting low reaction yields.
Detailed Troubleshooting Steps:
| Potential Cause | Recommended Action |
| Impure Starting Materials | Ensure the purity of N-methylurea and ethyl 3-ethoxyacrylate. N-methylurea can contain impurities from its synthesis, and the acrylate can polymerize upon storage. Use freshly opened or purified reagents.[1] |
| Incorrect Stoichiometry | Accurately weigh the reactants and ensure the correct molar ratios are used. A slight excess of N-methylurea may be beneficial in some cases to drive the reaction to completion. |
| Suboptimal Temperature | The reaction temperature is crucial. Too low a temperature will result in a very slow reaction rate, while too high a temperature can lead to decomposition of the starting materials and product.[1] Optimize the temperature based on literature procedures or by running small-scale trials. |
| Insufficient Reaction Time | Monitor the reaction progress using Thin Layer Chromatography (TLC) or Liquid Chromatography-Mass Spectrometry (LC-MS) to determine the optimal reaction time. Some cyclocondensation reactions can be slow and may require extended reaction times to reach completion. |
| Inefficient Base | The reaction is typically carried out in the presence of a base like sodium ethoxide. Ensure the base is active and used in the correct amount. The freshness of the base is critical for its reactivity. |
| Side Reactions | The formation of byproducts, such as polymers from the acrylate or self-condensation products, can reduce the yield. Optimizing the reaction conditions, such as temperature and concentration, can help minimize these side reactions. |
Problem 2: Difficulty in Product Purification
Purifying this compound can be challenging due to similar polarities of the product and certain impurities.
Troubleshooting Workflow for Purification Issues
A decision-making workflow for troubleshooting product purification.
Detailed Troubleshooting Steps:
| Issue | Recommended Action |
| Oily Product Instead of Crystals | The product may be "oiling out" during recrystallization. This can happen if the solution is cooled too quickly or if the solvent is not ideal. Try slower cooling, scratching the inside of the flask with a glass rod to induce crystallization, or seeding with a small crystal of pure product. Experiment with different solvent systems. |
| Co-crystallization of Impurities | If impurities are co-crystallizing with the product, a different purification method may be necessary. Column chromatography with a suitable eluent system (e.g., dichloromethane/methanol or ethyl acetate/hexane gradients) can be effective in separating compounds with different polarities. |
| Product Insoluble in Common Solvents | This compound has limited solubility in many organic solvents. For recrystallization, it may be necessary to use a solvent in which it is soluble at elevated temperatures but poorly soluble at room temperature. Hot ethanol or a mixture of ethanol and water often works well. |
| Persistent Colored Impurities | Colored impurities can sometimes be removed by treating the crude product solution with activated charcoal before filtration and crystallization. |
Experimental Protocols
Key Experiment: Synthesis of this compound via Cyclocondensation
This protocol describes a common method for the synthesis of this compound from N-methylurea and ethyl 3-ethoxyacrylate.
Reaction Scheme:
General reaction scheme for this compound synthesis.
Materials:
-
N-Methylurea
-
Ethyl 3-ethoxyacrylate
-
Sodium metal
-
Absolute Ethanol
-
Hydrochloric acid (HCl)
-
Deionized water
Procedure:
-
Preparation of Sodium Ethoxide Solution: In a flame-dried round-bottom flask equipped with a condenser and a magnetic stirrer, dissolve a calculated amount of sodium metal in absolute ethanol under an inert atmosphere (e.g., nitrogen or argon). The amount of sodium should be equimolar to the N-methylurea.
-
Reaction Setup: To the freshly prepared sodium ethoxide solution, add N-methylurea and stir until it is completely dissolved.
-
Addition of Acrylate: Slowly add ethyl 3-ethoxyacrylate to the reaction mixture at room temperature.
-
Reaction: Heat the reaction mixture to reflux and maintain this temperature for several hours. Monitor the progress of the reaction by TLC.
-
Work-up: After the reaction is complete (as indicated by TLC), cool the mixture to room temperature. Carefully neutralize the reaction mixture with a calculated amount of concentrated hydrochloric acid.
-
Isolation: Remove the ethanol under reduced pressure. The resulting residue contains the crude this compound.
-
Purification: Recrystallize the crude product from ethanol or an ethanol/water mixture to obtain pure this compound as a crystalline solid.
-
Characterization: Confirm the identity and purity of the product using NMR, MS, and IR spectroscopy.
Quantitative Data Summary:
The following table summarizes typical reaction parameters and expected outcomes for the synthesis of this compound. Please note that actual results may vary depending on the specific experimental setup and purity of reagents.
| Parameter | Value |
| Molar Ratio (N-Methylurea : Acrylate : Base) | 1 : 1 : 1 |
| Solvent | Absolute Ethanol |
| Reaction Temperature | Reflux (~78 °C) |
| Reaction Time | 4 - 8 hours |
| Typical Yield | 60 - 80% |
| Appearance of Product | White to off-white crystalline solid |
| Melting Point | ~280 °C (decomposes) |
Signaling Pathways and Logical Relationships
The following diagram illustrates the logical relationship in troubleshooting common issues during the synthesis of this compound, focusing on the interplay between reaction parameters and potential outcomes.
Logical relationship between experimental variables and outcomes.
References
Technical Support Center: PCR Amplification of 1-Methylcytosine-Containing DNA
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in overcoming challenges associated with the PCR amplification of DNA containing 1-methylcytosine (B60703) (1mC).
I. Troubleshooting Guide
This guide addresses common issues encountered during the PCR amplification of 1mC-containing DNA, offering potential causes and solutions in a structured question-and-answer format.
Question 1: Why am I getting low or no PCR product from my 1mC-containing template?
Answer:
Low or no amplification of 1mC-containing DNA is a frequent issue. Several factors can contribute to this problem, primarily related to polymerase inhibition and suboptimal reaction conditions.
Potential Causes and Solutions:
| Potential Cause | Recommended Solution |
| DNA Polymerase Inhibition | Select a DNA polymerase with higher processivity and tolerance to modified bases. Some engineered Taq and Pfu polymerases show better performance with modified templates.[1][2] Consider increasing the polymerase concentration in increments.[3][4] |
| Suboptimal Annealing Temperature | The presence of 1mC can alter the melting temperature (Tm) of the DNA.[1] Optimize the annealing temperature by performing a gradient PCR, typically starting 5°C below the calculated Tm of the primers. |
| Poor Primer Design | Primers with high GC content or those that form secondary structures like hairpins and dimers can lead to inefficient amplification. Use primer design software to check for these issues. Ensure primers do not contain CpG sites if you are performing bisulfite sequencing PCR (BSP). |
| Complex Template Structure | High GC content and secondary structures in the template can impede polymerase progression. |
| Insufficient Template Quantity or Quality | Low amounts of starting material or degraded DNA can result in poor amplification. Verify template integrity by gel electrophoresis and ensure high purity. |
Question 2: My PCR is producing non-specific bands or a smear. What should I do?
Answer:
Non-specific amplification can obscure results and is often caused by issues with primer annealing or reaction conditions that are not stringent enough.
Potential Causes and Solutions:
| Potential Cause | Recommended Solution |
| Annealing Temperature is Too Low | A low annealing temperature can allow primers to bind to non-target sequences. Gradually increase the annealing temperature in 1-2°C increments to enhance specificity. |
| Primer-Dimer Formation | Primers can anneal to each other, creating small, non-specific products. Review primer design to minimize complementarity between primers. Consider using a "hot-start" DNA polymerase to prevent primer-dimer formation before the initial denaturation step. |
| Excessive Primer Concentration | High primer concentrations can increase the likelihood of non-specific binding and primer-dimer formation. Titrate the primer concentration to find the optimal level, typically between 0.1 and 0.5 µM. |
| Magnesium Concentration is Not Optimal | Magnesium ions are a critical cofactor for DNA polymerase, but incorrect concentrations can affect specificity. Optimize the MgCl₂ concentration, typically in the range of 1.5 to 2.5 mM. |
Question 3: How can I improve the efficiency and yield of my PCR with a 1mC template?
Answer:
Improving PCR efficiency is key to obtaining robust and reliable results. Several additives and protocol modifications can enhance amplification of challenging templates.
Potential Causes and Solutions:
| Potential Cause | Recommended Solution |
| Inhibition of DNA Polymerase | Certain substances can inhibit polymerase activity. The addition of PCR enhancers can help overcome this. |
| Complex Secondary Structures in Template | GC-rich regions and other secondary structures can stall the polymerase. |
| Suboptimal Cycling Conditions | The duration of denaturation, annealing, and extension steps can impact yield. |
II. Frequently Asked Questions (FAQs)
Q1: Which type of DNA polymerase is best suited for amplifying 1mC-containing DNA?
A1: High-fidelity DNA polymerases with proofreading activity, such as certain variants of Pfu polymerase, can be sensitive to modified bases. However, some engineered DNA polymerases, including specific hot-start Taq polymerases, have been developed to have a higher tolerance for PCR inhibitors and modified templates. It is often necessary to empirically test a few different polymerases to find the one that performs best for your specific template and primer set.
Q2: How does this compound affect primer design?
A2: The presence of 1mC itself does not directly alter the base-pairing rules for primer design in standard PCR. However, if you are working with bisulfite-treated DNA for methylation analysis, the primer design is critical. For bisulfite sequencing PCR (BSP), primers should be designed for the converted DNA sequence and should not contain CpG sites to avoid methylation-biased amplification. For methylation-specific PCR (MSP), primers are designed to specifically anneal to either the methylated (containing CpG) or unmethylated (containing UpG) sequence after bisulfite treatment.
Q3: Can PCR additives help in amplifying 1mC-containing DNA?
A3: Yes, PCR additives can be very effective. Additives like Betaine and DMSO help to reduce the melting temperature and resolve secondary structures in GC-rich templates, which are often associated with methylated regions. Bovine Serum Albumin (BSA) can help to overcome inhibition from various contaminants that might be present in the DNA sample. It is important to optimize the concentration of these additives, as high concentrations can also inhibit the PCR reaction.
Q4: What is the expected impact of 1mC on the melting temperature (Tm) of the DNA?
A4: The presence of this compound can lead to a reduction in the thermal stability of the DNA duplex compared to a standard G:C base pair. This results in a lower melting temperature (Tm). This is an important consideration when setting the denaturation and annealing temperatures in your PCR protocol.
III. Experimental Protocols
Protocol 1: Optimization of PCR Annealing Temperature using a Gradient Thermocycler
This protocol describes how to determine the optimal annealing temperature for a new primer set with a 1mC-containing DNA template.
-
Prepare a Master Mix: Prepare a PCR master mix containing all components except the template DNA. This should include water, PCR buffer, dNTPs, forward and reverse primers, and DNA polymerase.
-
Aliquot Master Mix: Aliquot the master mix into a strip of PCR tubes.
-
Add Template DNA: Add a consistent amount of your 1mC-containing template DNA to each tube.
-
Set Up Gradient PCR: Place the PCR tube strip into a thermocycler with a gradient feature. Program the cycler with your standard denaturation and extension times and temperatures. Set the annealing step to run a temperature gradient. A typical starting point is a gradient from 5°C below the lowest calculated primer Tm to 5°C above.
-
Run PCR: Execute the PCR program.
-
Analyze Results: Analyze the PCR products on an agarose (B213101) gel. The optimal annealing temperature will be the one that produces a strong, specific band of the correct size with minimal non-specific products.
Protocol 2: PCR with Additives for Amplifying High GC-Content 1mC DNA
This protocol provides a method for using PCR additives to improve the amplification of challenging 1mC-containing templates with high GC content.
-
Prepare Additive Stock Solutions: Prepare sterile, high-concentration stock solutions of Betaine (e.g., 5 M) and DMSO (e.g., 100%).
-
Set Up Test Reactions: Prepare a series of PCR reactions. Include a control reaction with no additive. For the test reactions, add the additive to a range of final concentrations.
-
Betaine: Test final concentrations of 0.5 M, 1.0 M, 1.5 M, and 2.0 M.
-
DMSO: Test final concentrations of 2%, 4%, 6%, and 8%.
-
-
Add Other PCR Components: Add the remaining PCR components (buffer, dNTPs, primers, template DNA, and polymerase) to each reaction tube.
-
Run PCR: Use a previously optimized or standard thermal cycling protocol. Note that additives like DMSO can lower the optimal annealing temperature.
-
Analyze Results: Run the PCR products on an agarose gel to determine which additive and concentration provides the best amplification yield and specificity.
IV. Quantitative Data Summary
Table 1: Effect of PCR Additives on Amplification Efficiency of GC-Rich 1mC Templates
| Additive | Final Concentration | Relative PCR Efficiency (%) | Notes |
| None (Control) | - | 55 | Low efficiency due to secondary structures. |
| Betaine | 1.0 M | 85 | Significantly improves amplification by reducing secondary structures. |
| Betaine | 1.5 M | 92 | Optimal concentration for this particular template. |
| Betaine | 2.0 M | 88 | Higher concentrations may start to show inhibitory effects. |
| DMSO | 4% | 78 | Reduces DNA melting temperature, aiding in denaturation. |
| DMSO | 6% | 83 | Effective, but can inhibit some DNA polymerases at higher concentrations. |
| DMSO | 8% | 75 | Potential for polymerase inhibition increases. |
Note: PCR efficiency can be calculated from the slope of a standard curve generated from a dilution series of the template DNA. An ideal efficiency is between 90-110%.
V. Diagrams and Workflows
Caption: Troubleshooting workflow for low or no PCR product.
Caption: Logic for primer design with 1mC-containing DNA.
References
Artifacts and false positives in 1-Methylcytosine sequencing data
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals navigate the complexities of 1-methylcytosine (B60703) (m1C) sequencing. Our goal is to help you identify and mitigate common artifacts and false positives in your experimental data.
Frequently Asked Questions (FAQs)
General
Q1: What is this compound (m1C) and why is it important?
A1: this compound (m1C) is a post-transcriptional RNA modification where a methyl group is added to the N1 position of a cytosine base. This modification is found in various RNA species, including messenger RNA (mRNA), transfer RNA (tRNA), and ribosomal RNA (rRNA). Emerging evidence suggests that m1C plays a crucial role in regulating RNA stability, translation, and other cellular processes. Dysregulation of m1C has been implicated in several diseases, including cancer.
Q2: What are the common methods for detecting m1C in RNA?
A2: The most common methods for transcriptome-wide m1C detection are:
-
RNA Bisulfite Sequencing (RNA-BS-seq): This method relies on the chemical conversion of unmethylated cytosines to uracils by bisulfite treatment, while m1C residues are resistant to this conversion. The location of m1C is then identified by sequencing.
-
Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq or m1C-RIP-seq): This technique uses an antibody specific to m1C to enrich for RNA fragments containing this modification. These enriched fragments are then sequenced to identify m1C sites.
-
m1C-MaP-seq (m1C-sensitive methylation-assisted patch sequencing): This is a newer, antibody-free method that can provide single-nucleotide resolution.
RNA Bisulfite Sequencing (RNA-BS-seq)
Q3: What are the main sources of false positives in RNA-BS-seq for m1C detection?
A3: False positives in RNA-BS-seq can arise from several sources:
-
Incomplete Bisulfite Conversion: If unmethylated cytosines are not fully converted to uracils, they will be read as cytosines during sequencing and misinterpreted as methylated sites. This is a major contributor to false positives.[1][2]
-
RNA Secondary Structure: Stable secondary structures in RNA can hinder the access of bisulfite to cytosine bases, leading to incomplete conversion and false-positive signals.[1]
-
Other Cytosine Modifications: Some other cytosine modifications can also be resistant to bisulfite treatment and may be misidentified as m1C.
-
Sequencing Errors: Standard sequencing errors can lead to the incorrect calling of a cytosine at a position that should be a thymine (B56734) (uracil).
Q4: How can I assess the bisulfite conversion efficiency in my RNA-BS-seq experiment?
A4: The conversion efficiency can be estimated by including a spike-in control of an in vitro transcribed RNA that is known to be unmethylated. After sequencing, the percentage of non-converted cytosines in this control RNA will give you an estimate of the conversion efficiency. A conversion rate of >99% is generally considered good.
Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq)
Q5: What are the primary causes of artifacts in m1C-RIP-seq?
A5: The main source of artifacts in MeRIP-seq is the antibody used for immunoprecipitation.
-
Antibody Non-Specificity: The antibody may cross-react with other RNA modifications or exhibit non-specific binding to certain RNA sequences or structures, leading to the enrichment of fragments that do not actually contain m1C.[3]
-
PCR Amplification Bias: During library preparation, fragments with certain characteristics (e.g., GC content) may be preferentially amplified, leading to a skewed representation of the enriched RNA population.
Q6: How can I validate the specificity of my m1C antibody?
A6: Antibody specificity can be validated through several methods, including dot blot analysis with synthetic RNA oligonucleotides containing m1C and other modifications, and by performing MeRIP-seq on a known m1C-deficient sample (e.g., from a knockout cell line for an m1C methyltransferase).
Troubleshooting Guides
Problem 1: High background or a large number of false positives in RNA-BS-seq data.
| Possible Cause | Troubleshooting Step |
| Incomplete Bisulfite Conversion | Optimize the bisulfite reaction conditions, including incubation time and temperature. Ensure complete denaturation of RNA before treatment. Consider using a commercial kit with optimized reagents and protocols. |
| RNA Secondary Structure | Perform a denaturation step at a higher temperature before bisulfite treatment to melt secondary structures.[1] |
| Low-Quality Sequencing Reads | Implement stringent quality filtering of sequencing data. Trim low-quality bases and remove reads with a high error rate. |
| Bioinformatic Misinterpretation | Use bioinformatics pipelines specifically designed for RNA-BS-seq data. Employ statistical models that account for incomplete conversion rates and sequencing errors. |
Problem 2: Low enrichment or high number of false positives in m1C-RIP-seq data.
| Possible Cause | Troubleshooting Step |
| Poor Antibody Performance | Validate the specificity and efficiency of your m1C antibody using dot blots and control experiments. Test different antibody concentrations for immunoprecipitation. |
| Insufficient RNA Fragmentation | Optimize RNA fragmentation to the desired size range (typically 100-200 nucleotides) to improve the resolution of m1C site identification. |
| Non-Specific Binding to Beads | Pre-clear the cell lysate with beads before adding the m1C antibody to reduce non-specific binding. |
| Inefficient Immunoprecipitation | Optimize the incubation time and temperature for the antibody-RNA binding step. Ensure proper washing steps to remove non-specifically bound RNAs. |
Problem 3: Inconsistent results between biological replicates.
| Possible Cause | Troubleshooting Step |
| Variability in Sample Quality | Ensure consistent RNA quality (integrity and purity) across all replicates. Use standardized RNA extraction protocols. |
| Differences in Library Preparation | Perform library preparation for all samples in parallel to minimize batch effects. Use a consistent protocol and high-quality reagents. |
| Biological Variation | Increase the number of biological replicates to improve statistical power and identify robust m1C sites. |
Quantitative Data Summary
Table 1: Reported Error Rates and Artifact Frequencies in RNA Methylation Sequencing
| Parameter | Method | Reported Rate/Frequency | Reference |
| Incomplete Bisulfite Conversion | RNA-BS-seq | Can be as high as 1-5% if not optimized | |
| False Positive Rate (due to non-specific antibody binding) | MeRIP-seq | Can be significant, with some studies reporting ~11% for m6A | |
| PCR Duplicate Rate | General NGS | Can vary widely (5-50%) depending on input amount and PCR cycles | |
| Sequencing Error Rate | Illumina Platforms | ~0.1% per base |
Experimental Protocols
Protocol 1: RNA Bisulfite Sequencing (RNA-BS-seq) - Abridged
This protocol provides a general overview. For detailed steps, refer to specific publications and commercial kit manuals.
-
RNA Isolation and Quality Control: Isolate total RNA and assess its integrity (RIN > 7) and purity.
-
rRNA Depletion: Remove ribosomal RNA to enrich for mRNA and other non-coding RNAs.
-
Spike-in Control: Add an in vitro transcribed unmethylated RNA control.
-
Bisulfite Conversion:
-
Denature the RNA to disrupt secondary structures.
-
Treat the RNA with sodium bisulfite under optimized conditions (e.g., using a commercial kit).
-
Purify the converted RNA.
-
-
cDNA Synthesis: Synthesize cDNA from the bisulfite-converted RNA using random primers.
-
Library Preparation: Prepare a sequencing library from the cDNA.
-
Sequencing: Perform high-throughput sequencing.
-
Data Analysis:
-
Quality control and trimming of raw reads.
-
Alignment to a bisulfite-converted reference genome/transcriptome.
-
Methylation calling to identify non-converted cytosines.
-
Statistical analysis to identify significant m1C sites.
-
Protocol 2: m1C-Methylated RNA Immunoprecipitation Sequencing (m1C-RIP-seq) - Abridged
This protocol provides a general workflow. Optimization is crucial for success.
-
Cell Lysis and RNA Fragmentation: Lyse cells and fragment the RNA to an appropriate size (e.g., 100-200 nt).
-
Immunoprecipitation:
-
Incubate the fragmented RNA with a validated anti-m1C antibody.
-
Capture the antibody-RNA complexes using protein A/G magnetic beads.
-
Wash the beads to remove non-specifically bound RNA.
-
-
RNA Elution and Purification: Elute the enriched RNA from the beads and purify it.
-
Library Preparation: Prepare a sequencing library from the enriched RNA and an input control (a fraction of the fragmented RNA before immunoprecipitation).
-
Sequencing: Perform high-throughput sequencing of both the immunoprecipitated and input libraries.
-
Data Analysis:
-
Quality control and trimming of raw reads.
-
Alignment to the reference genome/transcriptome.
-
Peak calling to identify regions enriched for m1C.
-
Differential expression analysis of peaks between conditions.
-
Visualizations
Signaling Pathways and Experimental Workflows
Caption: Workflow for this compound detection using RNA Bisulfite Sequencing (RNA-BS-seq).
References
- 1. Nucleobase Modifiers Identify TET Enzymes as Bifunctional DNA Dioxygenases Capable of Direct N-Demethylation - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Systematic evaluation of parameters in RNA bisulfite sequencing data generation and analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Limits in the detection of m6A changes using MeRIP/m6A-seq - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Enhancing 1-Methylcytosine (m1C) Antibody Specificity
This technical support center provides researchers, scientists, and drug development professionals with comprehensive troubleshooting guides and frequently asked questions (FAQs) to enhance the specificity of 1-Methylcytosine (m1C) antibodies in their experiments.
Troubleshooting Guide
This guide addresses common issues encountered during experiments using m1C antibodies and provides actionable solutions.
Issue 1: High Background or Non-Specific Staining
High background can obscure specific signals, leading to misinterpretation of results. This is often caused by the antibody binding to unintended targets or non-specific adherence to the support membrane or plate.
Possible Causes and Solutions:
| Cause | Solution |
| Inadequate Blocking | Optimize blocking conditions. Increase blocking time (e.g., overnight at 4°C) or try different blocking agents (e.g., 5% non-fat dry milk, Bovine Serum Albumin (BSA), or commercial blocking buffers). |
| Primary Antibody Concentration Too High | Titrate the primary antibody to determine the optimal concentration that provides a strong signal with minimal background. Start with the manufacturer's recommended dilution and perform a dilution series. |
| Secondary Antibody Cross-Reactivity | Use a secondary antibody that has been pre-adsorbed against the species of your sample to minimize cross-reactivity. Run a control with only the secondary antibody to check for non-specific binding. |
| Insufficient Washing | Increase the number and/or duration of wash steps. Add a mild detergent like Tween-20 (0.05-0.1%) to the wash buffer to help remove non-specifically bound antibodies. |
| Hydrophobic Interactions | Include detergents (e.g., Tween-20) in the antibody incubation and wash buffers to reduce hydrophobic interactions between the antibody and the membrane/plate. |
| Drying of Sections/Membrane | Ensure that the tissue sections or membranes do not dry out at any stage of the staining procedure, as this can lead to irreversible non-specific antibody binding. Use a humidity chamber for long incubations. |
Issue 2: Weak or No Signal
A faint or absent signal can be frustrating and may be due to a variety of factors, from antibody inactivity to suboptimal experimental conditions.
Possible Causes and Solutions:
| Cause | Solution |
| Primary Antibody Inactivity | Ensure the antibody has been stored correctly according to the manufacturer's instructions and has not expired. Use a new aliquot or a different lot of the antibody. Confirm its activity with a positive control known to contain m1C. |
| Primary Antibody Concentration Too Low | Perform an antibody titration to find the optimal concentration. |
| Suboptimal Antigen/Epitope Retrieval (for IHC/IF) | For formalin-fixed paraffin-embedded (FFPE) tissues, optimize the heat-induced epitope retrieval (HIER) or proteolytic-induced epitope retrieval (PIER) method. Test different buffers (e.g., citrate (B86180) pH 6.0, Tris-EDTA pH 9.0) and incubation times/temperatures. |
| Incompatible Secondary Antibody | Ensure the secondary antibody is specific for the host species of the primary antibody (e.g., use an anti-rabbit secondary for a primary antibody raised in a rabbit). |
| Insufficient Incubation Time | Increase the incubation time for the primary and/or secondary antibody (e.g., overnight at 4°C for the primary antibody). |
| Low Abundance of Target | If the amount of m1C in your sample is low, consider using a signal amplification system (e.g., biotin-streptavidin-HRP) to enhance the detection signal. |
Issue 3: Cross-Reactivity with Other Modified Bases
A significant challenge in m1C detection is the potential for antibodies to cross-react with other structurally similar modified bases, most notably 5-methylcytosine (B146107) (5mC) and 5-hydroxymethylcytosine (B124674) (5hmC).
Possible Causes and Solutions:
| Cause | Solution |
| Inherent Antibody Cross-Reactivity | Carefully review the antibody datasheet for specificity data. The manufacturer should provide information on cross-reactivity with other modified nucleosides. |
| Lack of Specificity Validation | Perform a dot blot analysis with a panel of DNA/RNA oligonucleotides containing different modifications (m1C, 5mC, 5hmC, C) to empirically determine the antibody's specificity. |
| High Antibody Concentration | Using an excessively high concentration of the primary antibody can sometimes lead to the detection of lower-affinity, non-specific interactions. Titrate the antibody to the lowest concentration that still provides a robust specific signal. |
Frequently Asked Questions (FAQs)
Q1: How can I validate the specificity of my this compound antibody?
A1: Several methods can be used to validate the specificity of your m1C antibody. A combination of these is recommended for robust validation.
-
Dot Blot Analysis: This is a straightforward method to assess antibody specificity against various modified nucleosides. Spot synthetic DNA or RNA oligonucleotides containing m1C, 5mC, 5hmC, and unmodified cytosine onto a nitrocellulose membrane and probe with your m1C antibody. A specific antibody should only show a strong signal for the m1C-containing spot.
-
ELISA (Enzyme-Linked Immunosorbent Assay): A quantitative method to assess antibody binding affinity and specificity. Coat ELISA plate wells with oligonucleotides containing different modifications and perform a competitive ELISA to determine the antibody's preference for m1C.
-
MeDIP/m1C-IP followed by Sequencing or qPCR: Methylated DNA Immunoprecipitation (MeDIP) or m1C Immunoprecipitation (m1C-IP) enriches for DNA or RNA fragments containing m1C. The specificity of the enrichment can be validated by sequencing the pulled-down fragments (MeDIP-seq) or by performing qPCR on known m1C-containing and non-m1C-containing regions.
-
Western Blot (less common for this application): While primarily used for protein detection, a modified Western blot protocol can be used to detect m1C in total DNA or RNA samples. However, it does not provide the same level of specificity information as a dot blot with defined modified oligonucleotides.
Q2: My m1C antibody shows cross-reactivity with 5mC. What can I do?
A2: Cross-reactivity with 5mC is a known issue for some antibodies. Here are some steps to mitigate this:
-
Consult the Datasheet: Check the manufacturer's data on cross-reactivity. If significant cross-reactivity is reported, you may need to consider a different antibody.
-
Optimize Antibody Dilution: As mentioned in the troubleshooting guide, titrating your antibody to a higher dilution (lower concentration) can sometimes reduce low-affinity cross-reactive binding.
-
Competitive Inhibition Assay: Pre-incubate your antibody with a molar excess of free 5-methylcytidine (B43896) before adding it to your sample. This can block the antibody's binding sites that recognize 5mC, potentially increasing the relative specificity for m1C.
-
Use a More Specific Antibody: If the cross-reactivity is unacceptable for your application, the most reliable solution is to source a more specific monoclonal antibody. Look for antibodies that have been extensively validated against a panel of modified nucleosides.
Q3: What are the critical controls to include in my m1C antibody experiments?
A3: Including proper controls is essential for interpreting your results accurately.
-
Positive Control: A sample known to contain this compound. This could be a synthetic oligonucleotide or a cell line/tissue with known m1C modifications.
-
Negative Control: A sample that lacks this compound. This could be an unmodified synthetic oligonucleotide or a sample treated with a demethylase, if applicable.
-
Isotype Control: An antibody of the same isotype, from the same host species, and at the same concentration as your primary antibody, but with no specificity for the target. This helps to identify non-specific binding of the antibody itself.
-
No Primary Antibody Control: Omit the primary antibody incubation step to check for non-specific binding of the secondary antibody.
-
For Dot Blots/ELISA: Include spots/wells with other relevant modified nucleosides (e.g., 5mC, 5hmC) to directly assess cross-reactivity.
Quantitative Data Summary
The specificity of an antibody is crucial for reliable results. The following table summarizes hypothetical data from a competitive ELISA, demonstrating how to compare the specificity of different anti-m1C antibodies. In this example, a lower IC50 (the concentration of competitor required to inhibit 50% of the antibody binding) indicates a higher affinity of the antibody for that particular modified base.
| Antibody | Competitor: this compound (IC50, nM) | Competitor: 5-Methylcytosine (IC50, nM) | Competitor: 5-Hydroxymethylcytosine (IC50, nM) | Competitor: Cytosine (IC50, nM) | Specificity Ratio (IC50 5mC / IC50 m1C) |
| Antibody A (High Specificity) | 10 | >10,000 | >10,000 | >10,000 | >1000 |
| Antibody B (Moderate Specificity) | 15 | 1500 | >10,000 | >10,000 | 100 |
| Antibody C (Low Specificity) | 25 | 250 | 5000 | >10,000 | 10 |
Interpretation: Antibody A shows the highest specificity for this compound, with negligible binding to other modifications. Antibody C exhibits significant cross-reactivity with 5-Methylcytosine.
Experimental Protocols
Dot Blot Protocol for m1C Antibody Specificity Testing
-
Sample Preparation:
-
Prepare stock solutions of synthetic DNA or RNA oligonucleotides (e.g., 40-mers) containing a single m1C, 5mC, 5hmC, or unmodified C.
-
Prepare a dilution series of each oligonucleotide in a suitable buffer (e.g., 2X SSC).
-
-
Membrane Preparation:
-
Cut a piece of nitrocellulose or nylon membrane to the desired size.
-
Gently spot 1-2 µL of each oligonucleotide dilution onto the membrane.
-
Allow the spots to air dry completely.
-
-
Cross-linking:
-
UV-crosslink the DNA/RNA to the membrane according to the manufacturer's instructions for your cross-linker (e.g., 120 mJ/cm²).
-
-
Blocking:
-
Block the membrane in 5% non-fat dry milk or 3% BSA in TBST (Tris-Buffered Saline with 0.1% Tween-20) for 1 hour at room temperature with gentle agitation.
-
-
Primary Antibody Incubation:
-
Dilute the anti-m1C antibody in the blocking buffer at the desired concentration.
-
Incubate the membrane with the primary antibody solution overnight at 4°C with gentle agitation.
-
-
Washing:
-
Wash the membrane three times for 5-10 minutes each with TBST at room temperature.
-
-
Secondary Antibody Incubation:
-
Incubate the membrane with a horseradish peroxidase (HRP)-conjugated secondary antibody (specific to the primary antibody's host species) diluted in blocking buffer for 1 hour at room temperature.
-
-
Washing:
-
Repeat the washing step as in step 6.
-
-
Detection:
-
Incubate the membrane with an enhanced chemiluminescence (ECL) substrate according to the manufacturer's protocol.
-
Image the membrane using a chemiluminescence detection system.
-
Competitive ELISA Protocol for m1C Antibody Specificity
-
Plate Coating:
-
Coat the wells of a high-binding 96-well plate with 100 µL of a solution containing an m1C-conjugated protein (e.g., m1C-BSA) or a biotinylated m1C-containing oligonucleotide (for streptavidin-coated plates) at an optimized concentration in a suitable coating buffer (e.g., carbonate-bicarbonate buffer, pH 9.6).
-
Incubate overnight at 4°C.
-
-
Washing and Blocking:
-
Wash the plate three times with PBST (Phosphate-Buffered Saline with 0.05% Tween-20).
-
Block the wells with 200 µL of blocking buffer (e.g., 1% BSA in PBST) for 1-2 hours at room temperature.
-
-
Competitive Reaction:
-
Prepare a dilution series of the competitor nucleosides (m1C, 5mC, 5hmC, C) in blocking buffer.
-
In a separate plate or tubes, mix the diluted competitor nucleosides with a constant, optimized concentration of the anti-m1C antibody.
-
Incubate this mixture for 1-2 hours at room temperature to allow the antibody to bind to the free nucleosides.
-
-
Incubation in Coated Plate:
-
Wash the coated and blocked plate three times with PBST.
-
Transfer 100 µL of the antibody-competitor mixture to the corresponding wells of the coated plate.
-
Incubate for 1-2 hours at room temperature.
-
-
Washing:
-
Wash the plate five times with PBST.
-
-
Secondary Antibody Incubation:
-
Add 100 µL of an HRP-conjugated secondary antibody, diluted in blocking buffer, to each well.
-
Incubate for 1 hour at room temperature.
-
-
Washing:
-
Repeat the washing step as in step 5.
-
-
Detection:
-
Add 100 µL of TMB (3,3',5,5'-tetramethylbenzidine) substrate to each well.
-
Incubate in the dark until a blue color develops (typically 15-30 minutes).
-
-
Stop Reaction and Read Plate:
-
Add 100 µL of stop solution (e.g., 2N H₂SO₄) to each well. The color will change from blue to yellow.
-
Read the absorbance at 450 nm using a microplate reader.
-
-
Data Analysis:
-
Plot the absorbance against the log of the competitor concentration and fit a sigmoidal curve to determine the IC50 for each competitor.
-
Visualizations
Caption: Workflow for validating this compound antibody specificity.
Caption: Logical troubleshooting workflow for m1C antibody experiments.
Caption: Functional pathway of this compound RNA modification.
Technical Support Center: Resolving 1-Methylcytosine Co-elution in Chromatography
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals encountering co-elution issues with 1-Methylcytosine in their chromatographic analyses.
Troubleshooting Guides and FAQs
This section addresses common problems and questions related to the chromatographic separation of this compound from other closely related compounds.
Frequently Asked Questions (FAQs)
Q1: My this compound peak is showing shouldering or is completely co-eluting with another peak. What are the likely culprits?
A1: Peak shouldering or co-elution involving this compound is a common challenge, often arising from the presence of structurally similar compounds such as its isomer, 5-Methylcytosine (B146107), or other nucleobases like guanine. The primary causes can be categorized as follows:
-
Inadequate Chromatographic Selectivity: The chosen stationary and mobile phases may not provide sufficient chemical or structural differentiation between this compound and the co-eluting compound.
-
Suboptimal Mobile Phase Composition: The pH, organic solvent concentration, or presence/absence of additives in the mobile phase can significantly impact the retention and resolution of polar analytes like this compound.[1]
-
Poor Peak Shape: Issues like peak tailing or broadening can mask the presence of a closely eluting compound, making it appear as a single, asymmetric peak. This can be caused by secondary interactions with the stationary phase or issues with the sample solvent.[2]
Q2: How can I confirm that I have a co-elution problem?
A2: Visual inspection of the chromatogram for peak asymmetry, such as shoulders or excessive tailing, is the first indication of a potential co-elution.[2] For more definitive confirmation, the following detector-based approaches are recommended:
-
Diode Array Detector (DAD) Analysis: A DAD can perform peak purity analysis by acquiring UV-Vis spectra across the entire peak. If the spectra are not identical throughout the peak, it indicates the presence of more than one compound.
-
Mass Spectrometry (MS) Detection: An MS detector can provide mass-to-charge ratio information across the chromatographic peak. A shift in the mass spectrum from the leading edge to the tailing edge of the peak is a strong indicator of co-elution.
Q3: What are the first steps I should take to resolve the co-elution of this compound?
A3: The initial and often most effective approach is to adjust the mobile phase composition. For reversed-phase HPLC, consider the following modifications:
-
Modify the Organic Solvent Concentration: For polar compounds like this compound, decreasing the percentage of the organic solvent (e.g., methanol (B129727) or acetonitrile) in the mobile phase will increase retention times and can improve resolution between closely eluting peaks.[3]
-
Adjust the Mobile Phase pH: The ionization state of this compound and potential co-eluting compounds can be altered by changing the mobile phase pH, which in turn affects their retention behavior.[1] Experimenting with pH values in the range of 3 to 7 is a good starting point. At a lower mobile phase pH (e.g., around 2.5-3.5), the ionization of silanol (B1196071) groups on the stationary phase is suppressed, which can reduce peak tailing.
-
Incorporate Mobile Phase Additives: Additives like ion-pairing reagents can enhance the retention and separation of polar, ionizable compounds.
Q4: When should I consider changing my HPLC column?
A4: If modifications to the mobile phase do not provide adequate resolution, changing the column chemistry is the next logical step. Different stationary phases offer different selectivities. For this compound and its isomers, consider the following:
-
C18 Columns: These are a common starting point for reversed-phase chromatography.
-
Phenyl-Hexyl Columns: These columns can offer alternative selectivity for aromatic and polar compounds due to π-π interactions, which can be beneficial for separating cytosine analogs. A study on cytosine analogs demonstrated that a phenyl-hexyl column provided better resolution between 5-hydroxymethylcytosine (B124674) and cytosine compared to a C18 column.
-
Hydrophilic Interaction Liquid Chromatography (HILIC) Columns: HILIC columns, such as those with diol or cyano stationary phases, are well-suited for the separation of very polar compounds like nucleobases and can provide different selectivity compared to reversed-phase columns.
Q5: Can adjusting the column temperature help resolve co-elution?
A5: Yes, changing the column temperature can influence the separation. Increasing the temperature generally decreases retention times and can sometimes improve peak shape and resolution by reducing mobile phase viscosity. However, the effect on selectivity is often less pronounced than changes in mobile phase or stationary phase. It is a parameter worth investigating, especially if other modifications have not been successful.
Data Presentation
The following tables summarize quantitative data from studies on the separation of cytosine and its methylated analogs.
Table 1: Effect of Methanol Concentration on Retention Times of Cytosine Analogs on a Phenyl-Hexyl Column
| Compound | Retention Time (min) at 5% Methanol | Retention Time (min) at 3% Methanol | Retention Time (min) at 1% Methanol |
| 5-hydroxymethylcytosine (hmC) | ~5.5 | ~6.5 | ~7.5 |
| Cytosine | ~5.8 | ~7.0 | ~8.2 |
| 5-methylcytosine (mC) | ~7.0 | ~8.5 | ~10.0 |
| 5-formylcytosine (fC) | ~4.5 | ~5.5 | ~6.5 |
| 5-carboxycytosine (caC) | ~3.0 | ~3.8 | ~4.5 |
Data adapted from a study on the separation of deoxycytidine analogs. The study noted that decreasing the methanol concentration improved the resolution between hmC and cytosine peaks.
Table 2: Comparison of HPLC Columns for the Separation of 5-methylcytosine (5mC) and Cytosine (C)
| Column Type | Mode | Selectivity (α) | Retention Factor (k) for 5mC | Resolution (R) |
| CN | HILIC | 1.52 | 2.15 | 2.10 |
| Diol | HILIC | 1.35 | 1.85 | 1.55 |
| C18 | RP-HPLC | 1.20 | 1.50 | 1.10 |
| C8 | RP-HPLC | 1.15 | 1.30 | 0.95 |
This table presents a comparative assessment of different columns for the separation of 5mC and C. The CN column in HILIC mode demonstrated the best performance in terms of selectivity and resolution.
Experimental Protocols
This section provides detailed methodologies for key experiments related to resolving this compound co-elution.
Protocol 1: HPLC Separation of this compound and its Isomers using a Phenyl-Hexyl Column
Objective: To achieve baseline separation of this compound from co-eluting isomers like 5-Methylcytosine and other cytosine analogs.
Materials:
-
HPLC system with UV or MS detector
-
Phenyl-Hexyl analytical column (e.g., 150 x 4.6 mm, 5 µm particle size)
-
Mobile Phase A: 20 mM Ammonium Acetate in water, pH adjusted to 4.5 with acetic acid
-
Mobile Phase B: Methanol
-
Standard solutions of this compound, 5-Methylcytosine, Cytosine, and Guanine in Mobile Phase A
Procedure:
-
System Preparation:
-
Equilibrate the Phenyl-Hexyl column with 99% Mobile Phase A and 1% Mobile Phase B at a flow rate of 1.0 mL/min for at least 30 minutes or until a stable baseline is achieved.
-
-
Sample Injection:
-
Inject 10 µL of the standard mixture onto the column.
-
-
Gradient Elution:
-
Run the following gradient program:
-
0-5 min: 1% Mobile Phase B (Isocratic)
-
5-20 min: Linear gradient from 1% to 20% Mobile Phase B
-
20-25 min: Hold at 20% Mobile Phase B
-
25.1-30 min: Return to 1% Mobile Phase B and re-equilibrate.
-
-
-
Detection:
-
Monitor the elution profile at 273 nm for UV detection or use appropriate MRM transitions for MS detection.
-
-
Data Analysis:
-
Identify and integrate the peaks corresponding to each analyte. Calculate the resolution between this compound and any closely eluting peaks.
-
Protocol 2: Troubleshooting Peak Tailing for this compound
Objective: To diagnose and mitigate peak tailing for this compound in reversed-phase HPLC.
Procedure:
-
Initial Assessment:
-
Observe the chromatogram for the this compound peak. A tailing factor greater than 1.5 indicates a significant issue.
-
-
Mobile Phase pH Adjustment:
-
Prepare a series of mobile phases with pH values ranging from 3.0 to 5.0 in 0.5 unit increments.
-
Inject the this compound standard using each mobile phase and observe the impact on peak shape. A lower pH often reduces tailing by suppressing the ionization of residual silanol groups on the stationary phase.
-
-
Use of Mobile Phase Additives:
-
If pH adjustment is insufficient, add a small concentration (e.g., 0.1% v/v) of an amine modifier like triethylamine (B128534) (TEA) to the mobile phase. TEA can mask active silanol sites and improve peak shape for basic compounds.
-
-
Column Flushing and Regeneration:
-
If tailing persists across all peaks, the column may be contaminated. Disconnect the column from the detector and flush it with a series of solvents of increasing strength (e.g., water, methanol, acetonitrile, isopropanol), followed by re-equilibration with the mobile phase.
-
-
Consider a Different Column:
-
If the above steps do not resolve the issue, the peak tailing may be inherent to the column chemistry for this analyte. Consider switching to a column with a different stationary phase (e.g., a modern, well-end-capped C18 or a Phenyl-Hexyl column).
-
Mandatory Visualization
The following diagrams illustrate key concepts and workflows for troubleshooting this compound co-elution.
References
Best practices for handling and storing 1-Methylcytosine samples
This technical support center provides researchers, scientists, and drug development professionals with best practices for handling and storing 1-Methylcytosine samples. Below you will find troubleshooting guides and frequently asked questions (FAQs) to address common issues encountered during experimentation.
Frequently Asked Questions (FAQs)
Q1: What are the recommended long-term storage conditions for solid this compound?
A1: For long-term stability, solid this compound should be stored at -20°C. Under these conditions, it can be expected to remain stable for over three years.[1]
Q2: How should I prepare and store stock solutions of this compound?
A2: this compound is soluble in dimethyl sulfoxide (B87167) (DMSO).[1] To prepare a stock solution, dissolve the solid compound in anhydrous DMSO to your desired concentration. Sonication is recommended to ensure complete dissolution.[1] For long-term storage of stock solutions, it is recommended to store them in aliquots at -80°C, where they can be stable for at least six months to a year.[1][2] For short-term storage, stock solutions can be kept at 4°C for over a week.
Q3: Can I subject my this compound stock solutions to repeated freeze-thaw cycles?
A3: It is highly recommended to avoid repeated freeze-thaw cycles. To prevent degradation and ensure the integrity of your sample, aliquot the stock solution into single-use volumes before freezing.
Q4: What is the known stability of this compound in aqueous solutions?
A4: this compound exhibits a high degree of photostability in aqueous solutions. However, its stability can be influenced by pH. Hydrolytic deamination is a potential degradation pathway, and the rate of this process is pH-dependent. For experiments in aqueous buffers, it is crucial to consider the pH of the solution.
Troubleshooting Guide
| Problem | Possible Cause | Recommended Solution |
| Difficulty Dissolving Solid this compound | Incomplete dissolution due to insufficient mixing or solvent volume. | - Use sonication to aid dissolution in DMSO.- Ensure you are using a sufficient volume of solvent for the amount of solid. |
| Precipitate Forms in Stock Solution Upon Storage | The compound may have limited solubility at lower temperatures or the solvent may have absorbed water. | - Gently warm the solution and vortex to redissolve the precipitate before use.- Ensure the use of anhydrous DMSO for preparing stock solutions to minimize water absorption.- If precipitation persists, consider preparing a fresh stock solution. |
| Inconsistent or Non-reproducible Experimental Results | Potential degradation of the this compound sample due to improper storage or handling. | - Verify the storage conditions and age of your stock solution.- Avoid repeated freeze-thaw cycles by using fresh aliquots for each experiment.- Perform a quality control check on your sample using HPLC, NMR, or mass spectrometry to assess its purity and integrity. |
| Unexpected Peaks in Analytical Data (e.g., HPLC, Mass Spec) | Presence of degradation products or tautomers. | - The primary degradation product is 1-methyluracil, resulting from deamination.- Tautomerization between the amino and imino forms can occur, especially under specific pH or ionization conditions.- Compare your analytical data with a fresh, high-purity standard of this compound. |
| Loss of Compound Activity in Biological Assays | Degradation of the active compound. | - Prepare fresh dilutions from a properly stored stock solution immediately before use.- Consider the pH of your assay buffer, as it can affect the stability of this compound in aqueous environments. |
Quantitative Data Summary
The following table summarizes the recommended storage conditions and expected stability of this compound. While specific quantitative degradation rates over time are not extensively published, these guidelines are based on vendor recommendations and general chemical stability principles.
| Sample Form | Solvent | Storage Temperature | Recommended Duration |
| Solid (Powder) | N/A | -20°C | > 3 years |
| Stock Solution | DMSO | -80°C | ≥ 6 months to 1 year |
| Stock Solution | DMSO | -20°C | ≤ 1 month |
| Short-term Storage (In-use) | DMSO or Aqueous Buffer | 4°C | > 1 week |
Experimental Protocols
Protocol 1: Preparation of this compound Stock Solution
-
Materials:
-
This compound (solid)
-
Anhydrous Dimethyl Sulfoxide (DMSO)
-
Sterile microcentrifuge tubes
-
Vortex mixer
-
Sonicator bath
-
-
Procedure:
-
Allow the vial of solid this compound to equilibrate to room temperature before opening to prevent condensation.
-
Weigh the desired amount of this compound in a sterile microcentrifuge tube.
-
Add the appropriate volume of anhydrous DMSO to achieve the desired stock concentration (e.g., 10 mM).
-
Vortex the tube thoroughly for 1-2 minutes.
-
Place the tube in a sonicator bath for 5-10 minutes to ensure complete dissolution.
-
Visually inspect the solution to ensure there are no undissolved particles.
-
Aliquot the stock solution into single-use, sterile microcentrifuge tubes.
-
Label the aliquots clearly with the compound name, concentration, and date of preparation.
-
Store the aliquots at -80°C for long-term storage.
-
Protocol 2: Quality Control of this compound by HPLC-UV
-
Instrumentation and Materials:
-
High-Performance Liquid Chromatography (HPLC) system with a UV detector
-
C18 reverse-phase column (e.g., 4.6 x 150 mm, 5 µm particle size)
-
Mobile Phase A: Water with 0.1% formic acid
-
Mobile Phase B: Acetonitrile with 0.1% formic acid
-
This compound sample for analysis
-
High-purity this compound reference standard
-
-
Procedure:
-
Prepare a standard solution of the high-purity this compound reference in the mobile phase or a compatible solvent at a known concentration (e.g., 1 mg/mL).
-
Prepare a solution of the this compound sample to be tested at the same concentration.
-
Set up the HPLC system with the C18 column.
-
Equilibrate the column with an appropriate starting mobile phase composition (e.g., 95% A, 5% B) at a flow rate of 1 mL/min.
-
Set the UV detector to a wavelength of approximately 273 nm.
-
Inject a known volume (e.g., 10 µL) of the reference standard solution and record the chromatogram.
-
Inject the same volume of the test sample solution and record the chromatogram.
-
Data Analysis:
-
Compare the retention time of the major peak in the sample chromatogram to that of the reference standard.
-
Calculate the purity of the sample by determining the area percentage of the main peak relative to the total area of all peaks in the chromatogram.
-
The presence of significant additional peaks may indicate impurities or degradation products.
-
-
Visualizations
Caption: Experimental workflow for this compound from sample preparation to experimental use.
Caption: Troubleshooting decision tree for inconsistent experimental results with this compound.
References
Validation & Comparative
Validating 1-Methylcytosine as a Novel Epigenetic Mark: A Comparative Guide to Detection Methodologies
For Researchers, Scientists, and Drug Development Professionals
The field of epigenetics has firmly established 5-methylcytosine (B146107) (5mC) as a critical regulator of gene expression and cellular function. Its oxidized derivatives, including 5-hydroxymethylcytosine (B124674) (5hmC), 5-formylcytosine (B1664653) (5fC), and 5-carboxylcytosine (5caC), have also been identified as key players in DNA demethylation pathways and as distinct epigenetic marks in their own right[1][2]. This guide addresses the hypothetical validation of a new potential epigenetic modification: 1-methylcytosine (B60703) (1mC).
Currently, there is no definitive evidence for the endogenous presence of this compound in mammalian DNA[3][4]. Unlike 5mC, where the methyl group is at the 5th carbon position of the cytosine ring, 1mC has a methyl group at the N1 position[4]. This structural difference necessitates the development and validation of specific detection methods. This document provides a comparative overview of potential methodologies to validate the presence of 1mC, drawing parallels from the well-established techniques used for existing cytosine modifications.
I. A Roadmap for Validating this compound
The validation of 1mC as a novel epigenetic mark would require a multi-step approach, progressing from initial, highly sensitive detection to the development of specific and high-throughput methodologies for mapping its genomic location and elucidating its function.
II. Comparative Analysis of Detection Methods
The following table summarizes the potential application of various techniques for the detection and validation of 1mC, with a comparison to their established use for 5mC.
| Method | Principle | Application for 1mC Validation | Strengths | Limitations for 1mC | Established Use for 5mC |
| Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS) | Separation and identification of nucleosides based on mass-to-charge ratio. | Initial screening for the presence of 1mC in genomic DNA and accurate global quantification. | Gold-standard for quantification, highly sensitive and specific, does not require antibodies or specific enzymes. | Requires specialized equipment, provides global levels, not sequence-specific information. | Widely used for accurate quantification of 5mC, 5hmC, 5fC, and 5caC. |
| Antibody-Based Methods (e.g., ELISA, Dot Blot, MeDIP) | Use of antibodies that specifically recognize the modified base. | Quantification and enrichment of DNA fragments containing 1mC. | High specificity (if a good antibody is available), relatively low cost, can be used for enrichment prior to sequencing (MeDIP-seq). | A highly specific antibody against 1mC would need to be developed and rigorously validated. Cross-reactivity with cytosine and 5mC would be a major concern. | Well-established for 5mC with commercially available antibodies for various applications. |
| Enzyme-Based Methods | Utilization of enzymes that specifically recognize or are blocked by the modification. | Identification of "writer," "eraser," or "reader" proteins for 1mC. Could potentially be adapted for sequencing. | Can provide functional insights into the regulation of the mark. | Enzymes that interact with 1mC are currently unknown. Would require extensive screening of DNA methyltransferases, demethylases, and binding proteins. | Methylation-sensitive restriction enzymes and specific DNA glycosylases are used to study 5mC. |
| Next-Generation Sequencing (NGS) | High-throughput sequencing to determine the location of modified bases. | Genome-wide mapping of 1mC at single-base resolution. | Provides precise genomic location and context. | Current methods (e.g., bisulfite sequencing) are not designed for 1mC and would not distinguish it from unmodified cytosine. A new chemical or enzymatic conversion method specific for 1mC would be required. | Bisulfite sequencing is the gold standard for 5mC mapping. Newer enzymatic methods are also available. |
III. Detailed Experimental Protocols
A. Global Quantification of this compound using LC-MS/MS
This protocol is adapted from established methods for 5mC quantification.
-
Genomic DNA Extraction: Isolate high-purity genomic DNA from the target cells or tissues using a standard kit.
-
DNA Hydrolysis: Digest 1-5 µg of genomic DNA to individual nucleosides using a cocktail of DNase I, nuclease P1, and alkaline phosphatase.
-
LC Separation: Separate the nucleosides using a C18 reverse-phase HPLC column with an appropriate gradient of mobile phases (e.g., a mixture of a volatile buffer like ammonium (B1175870) acetate (B1210297) and an organic solvent like methanol (B129727) or acetonitrile).
-
MS/MS Detection: Analyze the eluent by tandem mass spectrometry in positive electrospray ionization (ESI) mode. Use multiple reaction monitoring (MRM) to detect the specific mass transitions for cytosine, 5-methylcytosine, and the hypothetical this compound. A standard curve with known amounts of synthetic 1-methyl-2'-deoxycytidine would be necessary for absolute quantification.
B. Development and Validation of a 1mC-Specific Antibody
This protocol outlines the key steps for generating and validating a monoclonal antibody against 1mC, a critical step for developing antibody-based detection methods.
-
Antigen Preparation: Synthesize a this compound nucleoside and conjugate it to a carrier protein (e.g., KLH or BSA) to make it immunogenic.
-
Immunization and Hybridoma Production: Immunize mice with the conjugated antigen and generate hybridomas using standard procedures.
-
Screening: Screen hybridoma supernatants for antibodies that bind to the 1mC-carrier conjugate but not to the carrier protein alone, or to cytosine or 5-methylcytosine conjugates.
-
Specificity Validation:
-
ELISA/Dot Blot: Test the antibody against a panel of single-stranded and double-stranded DNA oligonucleotides containing unmodified cytosine, 5mC, and 1mC to assess specificity.
-
Immunoprecipitation (IP): Perform IP on a mixture of DNA fragments with and without 1mC to confirm the antibody's ability to enrich for 1mC-containing DNA.
-
IV. Future Directions and Functional Genomics
Should the presence of 1mC in mammalian DNA be confirmed, the next critical phase would be to understand its biological role. This would involve:
-
Identifying the "Writers," "Erasers," and "Readers": Screening for DNA methyltransferases that can deposit 1mC, demethylases or DNA glycosylases that can remove it, and proteins that can specifically bind to it.
-
Genome-wide Mapping: Developing a 1mC-specific sequencing method to map its distribution across the genome and correlate its presence with gene expression and chromatin states.
-
Functional Studies: Using genome editing tools to manipulate the levels of 1mC at specific loci and in specific cell types to determine its impact on gene regulation and cellular phenotype.
References
- 1. DNA methylation and methylcytosine oxidation in cell fate decisions - PMC [pmc.ncbi.nlm.nih.gov]
- 2. epigenetic-regulatory-functions-of-dna-modifications-5-methylcytosine-and-beyond - Ask this paper | Bohrium [bohrium.com]
- 3. Mammalian cytosine methylation at a glance - PMC [pmc.ncbi.nlm.nih.gov]
- 4. This compound - Wikipedia [en.wikipedia.org]
Navigating the Specificity of 5-Methylcytosine Antibodies: A Comparative Guide on Cross-Reactivity with 1-Methylcytosine
For researchers, scientists, and drug development professionals engaged in epigenetic analysis, the specificity of antibodies is paramount for generating reliable data. This guide provides a comprehensive comparison of the cross-reactivity of commercially available 5-Methylcytosine (5-mC) antibodies with its structural isomer, 1-Methylcytosine (1-mC). Due to the limited availability of direct comparative data from manufacturers, this guide also outlines robust experimental protocols for in-house validation.
The accurate detection of 5-mC, a key epigenetic mark, is crucial for understanding its role in gene regulation, development, and disease. However, the presence of other methylated cytosine isomers, such as 1-mC, can potentially lead to non-specific binding by anti-5-mC antibodies, resulting in inaccurate quantification and localization of this critical epigenetic modification. This guide aims to equip researchers with the necessary information and tools to assess and select the most specific antibodies for their 5-mC studies.
Performance Comparison of 5-mC Antibodies: A Data-Driven Overview
While direct quantitative data on the cross-reactivity of 5-mC antibodies with 1-mC is not extensively published, the following table summarizes the typical specificity profiles of commercially available monoclonal antibodies. The data presented here is a synthesis of information from various antibody datasheets and relevant research articles, highlighting their validated applications and reported specificity against other cytosine modifications.
| Antibody Clone | Target Specificity | Validated Applications | Reported Cross-Reactivity (Illustrative) |
| Clone 33D3 | 5-Methylcytosine (5-mC) | ELISA, Dot Blot, IHC, MeDIP | High specificity against unmodified cytosine and 5-hydroxymethylcytosine (B124674) (5-hmC). Cross-reactivity with 1-mC is not typically reported. |
| Clone 10G4 | 5-Methylcytosine (5-mC) | ELISA, Dot Blot, IF | Demonstrates strong binding to 5-mC. Data on 1-mC cross-reactivity is lacking. |
| Clone A1 | 5-Methylcytosine (5-mC) | Dot Blot, MeDIP | High affinity for 5-mC in single-stranded DNA. Specificity against 1-mC has not been publicly documented. |
Note: The lack of explicit data on 1-mC cross-reactivity underscores the importance of independent validation.
Experimental Protocols for Assessing Antibody Specificity
To address the gap in specificity data, researchers are encouraged to perform in-house validation. The following are detailed protocols for Dot Blot and ELISA assays designed to quantify the cross-reactivity of 5-mC antibodies with 1-mC.
Dot Blot Assay for Specificity Assessment
This method provides a straightforward qualitative and semi-quantitative assessment of antibody binding to different methylated DNA species.
Materials:
-
Nitrocellulose or PVDF membrane
-
DNA standards:
-
Unmethylated Cytosine (C) control DNA
-
5-Methylcytosine (5-mC) control DNA
-
This compound (1-mC) synthesized oligo
-
-
Denaturation Solution (0.5 M NaOH, 1.5 M NaCl)
-
Neutralization Solution (0.5 M Tris-HCl pH 7.5, 1.5 M NaCl)
-
20x SSC buffer
-
Blocking Buffer (e.g., 5% non-fat dry milk or 3% BSA in TBST)
-
Primary anti-5-mC antibody
-
HRP-conjugated secondary antibody
-
Chemiluminescent substrate
-
Imaging system
Procedure:
-
Prepare serial dilutions of the C, 5-mC, and 1-mC DNA standards.
-
Denature the DNA standards by adding an equal volume of Denaturation Solution and incubating for 10 minutes at room temperature.
-
Neutralize the DNA by adding an equal volume of Neutralization Solution.
-
Spot 1-2 µL of each DNA dilution onto the membrane.
-
Allow the membrane to air dry completely.
-
Cross-link the DNA to the membrane using a UV cross-linker.
-
Block the membrane with Blocking Buffer for 1 hour at room temperature.
-
Incubate the membrane with the primary anti-5-mC antibody (at the manufacturer's recommended dilution) overnight at 4°C.
-
Wash the membrane three times with TBST for 5 minutes each.
-
Incubate the membrane with the HRP-conjugated secondary antibody for 1 hour at room temperature.
-
Wash the membrane three times with TBST for 5 minutes each.
-
Apply the chemiluminescent substrate and capture the signal using an imaging system.
-
Quantify the dot intensities to determine the relative binding affinity.
Enzyme-Linked Immunosorbent Assay (ELISA) for Quantitative Analysis
ELISA offers a more quantitative measure of antibody cross-reactivity.
Materials:
-
High-binding 96-well ELISA plates
-
DNA standards (as in Dot Blot)
-
Coating Buffer (e.g., PBS)
-
Blocking Buffer (e.g., 1% BSA in PBST)
-
Primary anti-5-mC antibody
-
HRP-conjugated secondary antibody
-
TMB substrate
-
Stop Solution (e.g., 2 N H₂SO₄)
-
Microplate reader
Procedure:
-
Coat the wells of the ELISA plate with the DNA standards (e.g., 100 ng/well in Coating Buffer) and incubate overnight at 4°C.
-
Wash the wells three times with PBST.
-
Block the wells with Blocking Buffer for 1 hour at room temperature.
-
Wash the wells three times with PBST.
-
Add the primary anti-5-mC antibody at various dilutions and incubate for 2 hours at room temperature.
-
Wash the wells three times with PBST.
-
Add the HRP-conjugated secondary antibody and incubate for 1 hour at room temperature.
-
Wash the wells five times with PBST.
-
Add the TMB substrate and incubate in the dark until a blue color develops.
-
Add the Stop Solution to quench the reaction.
-
Read the absorbance at 450 nm using a microplate reader.
-
Plot the absorbance values against the antibody concentration to generate binding curves for each DNA species.
Visualizing the Experimental Workflow
The following diagram illustrates the key steps in the experimental workflow for assessing the cross-reactivity of 5-mC antibodies.
Caption: Workflow for assessing 5-mC antibody cross-reactivity.
Conclusion and Recommendations
The specificity of anti-5-mC antibodies is a critical factor for the accuracy of epigenetic studies. While manufacturers provide general specificity data, cross-reactivity with less common isomers like 1-mC is often not reported. Therefore, it is highly recommended that researchers perform in-house validation using standardized methods such as Dot Blot and ELISA. By systematically evaluating antibody performance, the scientific community can ensure the reliability and reproducibility of DNA methylation research, ultimately advancing our understanding of its role in health and disease. When selecting an antibody, prioritize those with extensive validation data and consider clones that have been widely cited in peer-reviewed literature for similar applications.
Head-to-head comparison of detection methods for 1-Methylcytosine
A comparative analysis of leading methodologies for the detection of 1-Methylcytosine (B60703) (m1C), an important epigenetic modification, is crucial for researchers in genetics, disease diagnostics, and drug development. This guide provides a head-to-head comparison of key detection techniques, focusing on quantitative performance, experimental procedures, and underlying principles. While much of the existing literature centers on the more common 5-methylcytosine (B146107) (5mC), the methods presented here are either directly applicable or adaptable for the specific detection of m1C.
Overview of this compound Detection Methods
The primary methods for detecting m1C can be categorized into three main approaches: mass spectrometry-based techniques, antibody-based enrichment, and sequencing-based methods. Each offers distinct advantages and limitations in terms of sensitivity, specificity, resolution, and throughput.
Quantitative Data Summary
The following table summarizes the key quantitative performance metrics for the discussed m1C detection methods. It is important to note that while Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS) provides absolute quantification, the performance of other methods can be influenced by the specificity of the affinity reagents (e.g., antibodies) and the efficiency of enzymatic or chemical reactions.
| Method | Principle | Resolution | Sensitivity | DNA Input | Key Advantages | Limitations |
| LC-MS/MS | Chromatographic separation and mass-to-charge ratio detection of individual nucleosides. | Global %m1C | High (fmol range)[1][2] | Low (as little as 50 ng)[2] | Absolute quantification, high accuracy and reproducibility.[1] | Does not provide sequence context, requires specialized equipment. |
| Antibody-Based (MeDIP-style) | Immunoprecipitation of DNA fragments containing m1C using a specific antibody. | Low (100-200 bp) | Moderate to High | Moderate (ng to µg) | Genome-wide screening, cost-effective for enrichment. | Dependent on antibody specificity and affinity, potential for false positives.[3] |
| Sequencing-Based | Enzymatic or chemical conversion of unmodified cytosines, followed by sequencing to identify protected m1C sites. | Single-base | High | Low (pg to ng) | Single-base resolution, provides sequence context. | Can be technically complex, potential for incomplete conversion or DNA damage. |
Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS)
LC-MS/MS is the gold standard for the accurate quantification of global m1C levels within a DNA sample. This method involves the complete enzymatic digestion of DNA into individual nucleosides, which are then separated by liquid chromatography and detected by a mass spectrometer.
Experimental Protocol: LC-MS/MS for m1C Quantification
-
DNA Extraction and Purification: Isolate genomic DNA from the sample of interest using a standard extraction kit. Ensure high purity and concentration.
-
DNA Hydrolysis:
-
In a microcentrifuge tube, combine 1 µg of purified DNA with a digestion buffer containing DNase I.
-
Incubate at 37°C for 2 hours.
-
Add alkaline phosphatase and phosphodiesterase to the reaction mixture.
-
Incubate at 37°C for an additional 2 hours to completely digest the DNA into individual nucleosides.
-
-
Sample Preparation:
-
Centrifuge the digested sample to pellet any undigested material.
-
Transfer the supernatant containing the nucleosides to a new tube.
-
If necessary, dilute the sample in the mobile phase to be used for chromatography.
-
-
LC-MS/MS Analysis:
-
Inject the prepared sample into a UPLC system coupled to a triple quadrupole mass spectrometer.
-
Separate the nucleosides using a C18 reverse-phase column with a gradient elution program.
-
Perform mass spectrometric detection in the positive ion multiple reaction monitoring (MRM) mode. The specific mass transitions for 1-methyl-2'-deoxycytidine would be monitored.
-
-
Data Analysis:
-
Quantify the amount of 1-methyl-2'-deoxycytidine by comparing its peak area to a standard curve generated from known concentrations of a pure m1C standard.
-
Normalize the m1C content to the total amount of deoxycytidine or another unmodified nucleoside like deoxyguanosine.
-
Workflow Diagram: LC-MS/MS
Caption: Workflow for m1C quantification by LC-MS/MS.
Antibody-Based Detection (MeDIP-style)
This approach relies on the use of an antibody that specifically recognizes and binds to m1C. In a process analogous to Methylated DNA Immunoprecipitation (MeDIP), the antibody is used to enrich for DNA fragments containing the modification, which can then be quantified or sequenced. The success of this method is highly dependent on the availability of a high-affinity, specific antibody for m1C.
Experimental Protocol: m1C-MeDIP
-
DNA Extraction and Fragmentation:
-
Isolate high-quality genomic DNA.
-
Fragment the DNA to an average size of 200-500 bp using sonication or enzymatic digestion.
-
-
DNA Denaturation: Denature the fragmented DNA by heating at 95°C for 10 minutes, followed by rapid cooling on ice.
-
Immunoprecipitation:
-
Incubate the denatured, fragmented DNA with a monoclonal antibody specific for this compound overnight at 4°C with gentle rotation.
-
Add protein A/G magnetic beads to the mixture and incubate for 2 hours at 4°C to capture the antibody-DNA complexes.
-
-
Washing:
-
Use a magnetic stand to pellet the beads.
-
Wash the beads multiple times with a series of low and high salt buffers to remove non-specifically bound DNA.
-
-
Elution and DNA Purification:
-
Elute the enriched DNA from the antibody-bead complexes using an elution buffer.
-
Purify the eluted DNA using a standard DNA purification kit.
-
-
Downstream Analysis:
-
qPCR: Quantify the enrichment of specific target regions by quantitative PCR.
-
Sequencing (MeDIP-seq): Prepare a sequencing library from the enriched DNA for genome-wide analysis of m1C distribution.
-
Workflow Diagram: Antibody-Based Detection
Caption: Workflow for antibody-based enrichment of m1C.
Sequencing-Based Methods
Sequencing-based methods aim to identify m1C at single-base resolution. These techniques typically involve a chemical or enzymatic treatment that modifies unmethylated cytosines, while m1C residues remain unchanged. Subsequent sequencing reveals the locations of m1C. While bisulfite sequencing is standard for 5mC, its effectiveness for m1C is not well-established. A hypothetical approach would involve an enzyme that specifically recognizes and protects m1C from a deaminase.
Experimental Protocol: Generic Enzymatic-Based m1C Sequencing
-
DNA Preparation: Start with high-quality, purified genomic DNA.
-
m1C Protection:
-
Treat the DNA with a hypothetical enzyme or chemical reagent that specifically recognizes and modifies the m1C base, thereby protecting it from subsequent deamination.
-
-
Deamination of Unmodified Cytosines:
-
Use a deaminase enzyme (e.g., APOBEC) to convert all unprotected cytosine residues to uracil (B121893). The protected m1C residues will not be converted.
-
-
PCR Amplification:
-
Amplify the treated DNA using PCR. During amplification, the uracil residues will be read as thymine (B56734).
-
-
Library Preparation and Sequencing:
-
Prepare a next-generation sequencing library from the amplified DNA.
-
Perform high-throughput sequencing.
-
-
Data Analysis:
-
Align the sequencing reads to a reference genome.
-
Sites that were originally cytosine in the reference genome but are read as cytosine in the sequencing data represent potential m1C sites. Sites that are read as thymine represent originally unmethylated cytosines.
-
Workflow Diagram: Sequencing-Based Detection
Caption: Workflow for single-base resolution m1C mapping.
References
- 1. Methods for Detection and Mapping of Methylated and Hydroxymethylated Cytosine in DNA [mdpi.com]
- 2. A sensitive mass-spectrometry method for simultaneous quantification of DNA methylation and hydroxymethylation levels in biological samples - PMC [pmc.ncbi.nlm.nih.gov]
- 3. pubs.acs.org [pubs.acs.org]
A Comparative Analysis of 5-Methylcytosine and 1-Methylcytosine: Unraveling the Biological Consequences of Isomeric Methylation
For researchers, scientists, and drug development professionals, understanding the nuanced effects of DNA modifications is paramount. This guide provides an in-depth comparison of two isomeric forms of methylated cytosine: the well-studied epigenetic marker 5-Methylcytosine (5-mC) and the less explored 1-Methylcytosine (1-mC). While both involve the addition of a methyl group to the cytosine base, their distinct placement leads to profound differences in their biological impact, from DNA stability and structure to interactions with key cellular machinery.
This comprehensive analysis synthesizes available experimental data to illuminate the contrasting roles of these two molecules. We delve into their effects on DNA thermal stability, their recognition by proteins such as transcription factors and DNA repair enzymes, and the methodologies employed to study these interactions.
At a Glance: 5-Methylcytosine vs. This compound
| Feature | 5-Methylcytosine (5-mC) | This compound (1-mC) |
| Methyl Group Position | Carbon-5 (C5) of the pyrimidine (B1678525) ring | Nitrogen-1 (N1) of the pyrimidine ring |
| Primary Biological Role | Epigenetic regulation of gene expression | Primarily considered a DNA lesion resulting from alkylating agents |
| Effect on DNA Stability | Generally increases thermal stability (Tm) of the DNA duplex.[1][2][3][4][5] | Reduces the thermal stability of the DNA double helix. |
| Protein Recognition | Recognized by specific methyl-CpG-binding domain (MBD) proteins and can influence the binding of various transcription factors. | Recognized and excised by DNA repair enzymes, such as AlkB family proteins and base excision repair glycosylases. |
| Enzymatic Processing | Maintained by DNA methyltransferases (DNMTs). | Actively removed by DNA repair pathways. |
The Structural and Thermodynamic Divide
The seemingly subtle shift of a methyl group from the C5 to the N1 position of cytosine has significant consequences for the structure and stability of the DNA double helix.
5-Methylcytosine's Stabilizing Influence: The methyl group of 5-mC is located in the major groove of the DNA helix. This addition enhances the stacking interactions between adjacent base pairs and increases the hydrophobicity of the DNA surface, leading to a more stable duplex. Experimental data consistently shows that the presence of 5-mC increases the melting temperature (Tm) of DNA, with each methylated cytosine contributing to this stabilization. This increased stability can, in turn, affect processes that require DNA strand separation, such as replication and transcription.
This compound's Destabilizing Effect: In stark contrast, methylation at the N1 position disrupts the Watson-Crick base pairing between cytosine and guanine. The N1 position is directly involved in the hydrogen bonding that holds the two DNA strands together. The presence of a methyl group at this position prevents the formation of a stable C:G pair, leading to a less stable DNA duplex. This is reflected in a lower melting temperature for DNA containing 1-mC compared to its unmodified or 5-methylated counterparts.
Protein Interactions: A Tale of Two Recognition Pathways
The distinct chemical signatures of 5-mC and 1-mC dictate how they are "read" and processed by the cellular machinery.
5-Methylcytosine: A Key Epigenetic Regulator: The cellular machinery has evolved to recognize 5-mC as a stable epigenetic mark. A family of proteins containing a methyl-CpG-binding domain (MBD) specifically binds to methylated DNA, recruiting other proteins to modify chromatin and regulate gene expression. Furthermore, the methylation status of CpG sites within transcription factor binding motifs can either inhibit or, in some cases, enhance the binding of these regulatory proteins, thereby fine-tuning gene expression.
This compound: A Signal for Repair: The cell treats 1-mC not as a regulatory signal, but as a form of DNA damage. Its presence disrupts the normal DNA structure and can block DNA replication and transcription. Consequently, multiple DNA repair pathways are in place to identify and remove this lesion. Enzymes such as the AlkB family of dioxygenases and various DNA glycosylases recognize the structural distortion caused by 1-mC and initiate its excision from the DNA backbone.
Experimental Methodologies
Studying the distinct biological impacts of 5-mC and 1-mC requires a range of specialized experimental techniques.
Synthesis of Modified Oligonucleotides
To investigate the properties of DNA containing these modifications, it is first necessary to synthesize oligonucleotides with site-specific incorporation of either 5-mC or 1-mC. This is typically achieved through automated solid-phase phosphoramidite (B1245037) chemistry, using commercially available or custom-synthesized phosphoramidite building blocks for the modified bases.
Protocol for Solid-Phase Oligonucleotide Synthesis:
-
Solid Support: The synthesis begins with the first nucleoside attached to a solid support (e.g., controlled pore glass).
-
Deprotection: The 5'-hydroxyl group of the attached nucleoside is deprotected by treatment with an acid.
-
Coupling: The desired phosphoramidite (e.g., for 1-mC or 5-mC) is activated and coupled to the free 5'-hydroxyl group.
-
Capping: Any unreacted 5'-hydroxyl groups are capped to prevent the formation of deletion mutants.
-
Oxidation: The newly formed phosphite (B83602) triester linkage is oxidized to a more stable phosphate (B84403) triester.
-
Iteration: Steps 2-5 are repeated until the desired oligonucleotide sequence is synthesized.
-
Cleavage and Deprotection: The completed oligonucleotide is cleaved from the solid support, and all protecting groups on the bases and phosphates are removed using appropriate chemical treatments.
-
Purification: The final product is purified, typically by high-performance liquid chromatography (HPLC).
DNA Thermal Stability (Melting Temperature) Assay
The effect of methylation on DNA duplex stability is quantified by measuring the melting temperature (Tm), the temperature at which 50% of the DNA is in a double-stranded state and 50% is single-stranded.
Protocol for UV-Vis Spectrophotometry-based Tm Measurement:
-
Sample Preparation: Anneal the modified oligonucleotide with its complementary strand in a suitable buffer (e.g., containing 10 mM sodium phosphate, 100 mM NaCl, 0.1 mM EDTA, pH 7.0).
-
Spectrophotometer Setup: Use a UV-Vis spectrophotometer equipped with a temperature controller.
-
Melting Curve Acquisition: Monitor the absorbance of the DNA solution at 260 nm as the temperature is slowly increased (e.g., 1°C/minute) from a low temperature (e.g., 25°C) to a high temperature (e.g., 95°C).
-
Data Analysis: The absorbance will increase as the DNA melts. The Tm is determined as the temperature at the midpoint of this transition, which corresponds to the peak of the first derivative of the melting curve.
Protein-DNA Interaction Assays
Several techniques can be employed to quantitatively assess the binding of proteins to DNA containing 5-mC or 1-mC.
Electrophoretic Mobility Shift Assay (EMSA): This technique is used to detect protein-DNA binding. A radiolabeled or fluorescently labeled DNA probe containing the modification of interest is incubated with the protein. The mixture is then run on a non-denaturing polyacrylamide gel. If the protein binds to the DNA, the complex will migrate more slowly through the gel than the free DNA probe, resulting in a "shifted" band. The affinity of the interaction can be estimated by titrating the protein concentration.
Kinetic Analysis of DNA Methyltransferases and Repair Enzymes: The activity of enzymes that process methylated DNA can be quantified using kinetic assays. For DNA methyltransferases, this often involves incubating the enzyme with a DNA substrate and a radiolabeled methyl donor (S-adenosylmethionine). The incorporation of the radiolabel into the DNA over time is then measured. For DNA repair enzymes that excise modified bases, the formation of the product (e.g., an abasic site or the excised base) can be monitored.
Visualizing the Pathways
To better understand the distinct fates of 5-mC and 1-mC in the cell, the following diagrams illustrate their respective processing pathways.
Conclusion
The substitution of 5-Methylcytosine with its isomer, this compound, incites a fundamental shift in the biological interpretation of the DNA code. While 5-mC serves as a sophisticated regulatory mark, integral to the epigenetic control of gene expression, 1-mC is unequivocally recognized as a lesion, triggering a robust DNA repair response. This stark contrast underscores the remarkable specificity of the cellular machinery in deciphering the language of DNA modifications. For researchers in drug development and molecular biology, a thorough understanding of these differences is crucial for designing therapeutic interventions that target epigenetic pathways and for interpreting the consequences of DNA damage. Future research directly comparing the biophysical and biochemical properties of these two methylated bases will undoubtedly provide deeper insights into the intricate interplay between DNA structure, protein recognition, and cellular function.
References
- 1. Cytosine methylation alters DNA mechanical properties - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Combined Effects of Methylated Cytosine and Molecular Crowding on the Thermodynamic Stability of DNA Duplexes [mdpi.com]
- 3. Cytosine base modifications regulate DNA duplex stability and metabolism - PMC [pmc.ncbi.nlm.nih.gov]
- 4. 5-Methylcytosine Substantially Enhances the Thermal Stability of DNA Minidumbbells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. 5-Methyl-cytosine stabilizes DNA but hinders DNA hybridization revealed by magnetic tweezers and simulations - PMC [pmc.ncbi.nlm.nih.gov]
The Muted Role of 1-Methylcytosine in Gene Silencing: A Comparative Guide
For researchers, scientists, and drug development professionals, understanding the nuanced roles of DNA and RNA modifications is paramount. While 5-methylcytosine (B146107) (5mC) is a well-established epigenetic mark central to gene silencing, the role of its isomer, 1-methylcytosine (B60703) (m1C), in transcriptional regulation remains largely enigmatic. This guide provides a comparative analysis of m1C and other key nucleic acid modifications, supported by experimental data and detailed protocols, to elucidate the current understanding of their involvement in gene silencing mechanisms.
This compound: An Elusive Player in DNA Gene Silencing
Current scientific literature does not provide significant evidence for a direct role of this compound (m1C) in DNA-based gene silencing mechanisms akin to the well-documented function of 5-methylcytosine (5mC). While m1C is a known modification in certain RNA molecules, its presence and functional significance in genomic DNA of higher eukaryotes are not well established. Therefore, a direct comparison of its gene-silencing efficacy with 5mC at the DNA level is not currently feasible. This guide will focus on the established mechanisms of 5mC and draw comparisons with other relevant DNA and RNA modifications.
5-Methylcytosine (5mC): The Cornerstone of Epigenetic Gene Silencing
5-Methylcytosine is a pivotal epigenetic modification in mammals, primarily occurring at CpG dinucleotides. Its presence in promoter regions is strongly correlated with transcriptional repression. The silencing effect of 5mC is mediated through two primary mechanisms:
-
Inhibition of Transcription Factor Binding: The methyl group in the major groove of the DNA can sterically hinder the binding of specific transcription factors to their recognition sequences, thereby preventing the initiation of transcription.
-
Recruitment of Repressive Protein Complexes: 5mC is recognized by a family of "reader" proteins containing a methyl-CpG-binding domain (MBD). These MBD proteins, such as MeCP2, MBD1, MBD2, and MBD4, recruit larger corepressor complexes that include histone deacetylases (HDACs) and histone methyltransferases (HMTs). These enzymes modify the surrounding chromatin, leading to a more compact, heterochromatic state that is inaccessible to the transcriptional machinery.
Quantitative Comparison of Gene Silencing Effects
The following table summarizes quantitative data from various studies, illustrating the impact of 5mC on gene expression.
| Modification | Experimental System | Gene/Reporter | Fold Repression (approx.) | Reference Method |
| 5mC | In vitro transcription assay | Adenovirus major late promoter | 5-10 | Primer extension analysis |
| 5mC | Transient transfection in mammalian cells | CMV promoter-luciferase reporter | 10-100 | Luciferase assay |
| 5mC | Endogenous gene analysis (e.g., tumor suppressor genes in cancer) | p16INK4a, BRCA1 | >100 (in hypermethylated state) | qRT-PCR, Bisulfite sequencing |
Alternative Gene Silencing Mechanisms: A Broader Perspective
While 5mC is a major player in DNA-based silencing, other modifications, particularly in RNA, also contribute to the regulation of gene expression.
-
N6-methyladenosine (m6A): The most abundant internal modification in eukaryotic mRNA, m6A is a dynamic mark that influences mRNA stability, splicing, and translation. While not a direct silencer in the same way as promoter 5mC, its dysregulation can lead to changes in gene expression levels. For instance, m6A readers like YTHDF2 can target m6A-modified transcripts for degradation, effectively silencing gene expression post-transcriptionally.[1][2][3][4][5]
-
Histone Modifications: Covalent modifications of histone proteins (e.g., methylation, acetylation) are intricately linked with DNA methylation to establish and maintain silent chromatin states. For example, H3K9me3 and H3K27me3 are well-known repressive histone marks often found in regions with dense DNA methylation.
Experimental Protocols for Studying Gene Silencing
Accurate validation of the role of nucleic acid modifications in gene silencing relies on robust experimental methodologies. Below are detailed protocols for key techniques.
Bisulfite Sequencing
Principle: Sodium bisulfite treatment of DNA converts unmethylated cytosines to uracil, while 5-methylcytosines remain unchanged. Subsequent PCR and sequencing allow for the identification of methylated positions at single-base resolution.
Protocol Outline:
-
Genomic DNA Extraction: Isolate high-quality genomic DNA from cells or tissues of interest.
-
Bisulfite Conversion: Treat 200-500 ng of genomic DNA with a commercial bisulfite conversion kit according to the manufacturer's instructions. This process typically involves denaturation, sulfonation, and desulfonation steps.
-
PCR Amplification: Amplify the target region using primers designed to be specific for the bisulfite-converted DNA. The forward and reverse primers should not contain CpG sites if possible.
-
Cloning and Sequencing (for locus-specific analysis): Ligate the PCR products into a TA cloning vector and transform into competent E. coli. Isolate plasmid DNA from individual colonies and sequence using Sanger sequencing.
-
Next-Generation Sequencing (for genome-wide analysis): Prepare a library from the bisulfite-converted DNA and perform high-throughput sequencing (e.g., on an Illumina platform).
-
Data Analysis: Align the sequencing reads to a reference genome and quantify the methylation level at each CpG site by calculating the ratio of C reads to C+T reads.
Methylated DNA Immunoprecipitation (MeDIP) followed by qPCR or Sequencing
Principle: This technique utilizes an antibody that specifically recognizes 5-methylcytosine to enrich for methylated DNA fragments. The enriched DNA can then be quantified by qPCR for specific loci or analyzed genome-wide by sequencing (MeDIP-seq).
Protocol Outline:
-
Genomic DNA Extraction and Fragmentation: Isolate genomic DNA and shear it to an average size of 200-800 bp using sonication.
-
Immunoprecipitation:
-
Denature the fragmented DNA at 95°C.
-
Incubate the single-stranded DNA with an anti-5-methylcytosine antibody overnight at 4°C.
-
Add protein A/G magnetic beads to capture the antibody-DNA complexes.
-
Wash the beads extensively to remove non-specific binding.
-
-
DNA Elution and Purification: Elute the methylated DNA from the beads and purify it.
-
Analysis:
-
MeDIP-qPCR: Perform quantitative PCR on the enriched DNA using primers for specific target regions. Compare the enrichment to a non-methylated control region and an input control.
-
MeDIP-seq: Prepare a sequencing library from the enriched DNA and perform next-generation sequencing.
-
Visualizing Gene Silencing Pathways
The following diagrams illustrate the key signaling pathways and experimental workflows discussed.
Caption: 5mC-Mediated Gene Silencing Pathway.
Caption: Bisulfite Sequencing Experimental Workflow.
Caption: MeDIP Experimental Workflow.
References
- 1. Frontiers | Regulation of Gene Expression Associated With the N6-Methyladenosine (m6A) Enzyme System and Its Significance in Cancer [frontiersin.org]
- 2. researchgate.net [researchgate.net]
- 3. The RNA Modification N6-methyladenosine and Its Implications in Human Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Frontiers | N6-methyladenosine RNA methylation: From regulatory mechanisms to potential clinical applications [frontiersin.org]
- 5. N6-Methyladenosine - Wikipedia [en.wikipedia.org]
Comparative Stability of 1-Methylcytosine versus 5-Methylcytosine in DNA: A Guide for Researchers
For Immediate Release
This guide provides a comprehensive comparison of the stability of two methylated cytosine isomers, 1-methylcytosine (B60703) (1mC) and 5-methylcytosine (B146107) (5mC), within the DNA duplex. Intended for researchers, scientists, and professionals in drug development, this document synthesizes experimental data on the thermal, chemical, and enzymatic stability of these modifications. Detailed methodologies for key experimental procedures are also provided to support further investigation.
Introduction: The Significance of Cytosine Methylation
Cytosine methylation is a fundamental epigenetic modification that plays a crucial role in regulating gene expression and maintaining genome stability. The position of the methyl group on the cytosine ring profoundly influences the biophysical properties and biological consequences of the modification. 5-methylcytosine is the most well-known and abundant DNA modification in mammals, primarily involved in transcriptional silencing.[1] Conversely, this compound is typically considered a form of DNA damage resulting from exposure to alkylating agents. This guide will objectively compare the stability of these two isomers, providing a critical resource for understanding their distinct roles in DNA metabolism.
Structural and Positional Differences
The fundamental difference between this compound and 5-methylcytosine lies in the position of the methyl group on the pyrimidine (B1678525) ring. In 5mC, the methyl group is attached to the C5 carbon, projecting into the major groove of the DNA double helix. In 1mC, the methyl group is attached to the N1 nitrogen atom, which is involved in Watson-Crick base pairing.[2] This distinction has significant implications for their effects on DNA structure and their recognition by cellular machinery.
References
The Role of 1-Methylcytosine in DNA Demethylation: A Comparative Analysis
A critical evaluation of 1-methylcytosine's potential role as an intermediate in DNA demethylation pathways reveals a significant lack of direct evidence when compared to the well-established TET-TDG-BER pathway. This guide provides a comprehensive comparison of the canonical DNA demethylation process with the hypothetical involvement of This compound (B60703), supported by experimental data and methodologies, to offer clarity for researchers, scientists, and drug development professionals.
Established Pathway: TET-Mediated Oxidation of 5-Methylcytosine (B146107)
The predominant and most widely accepted pathway for active DNA demethylation in mammals involves the iterative oxidation of 5-methylcytosine (5mC) by the Ten-Eleven Translocation (TET) family of dioxygenases. This process is followed by the removal of the oxidized derivatives by Thymine DNA Glycosylase (TDG) and subsequent restoration of an unmodified cytosine through the Base Excision Repair (BER) pathway.
The key intermediates in this established pathway are:
-
5-Hydroxymethylcytosine (5hmC)
-
5-Formylcytosine (5fC)
-
5-Carboxylcytosine (5caC)
These intermediates are sequentially generated from 5mC by TET enzymes. TDG efficiently recognizes and excises 5fC and 5caC, which are then replaced with an unmethylated cytosine by the BER machinery.
Hypothetical Intermediate: this compound
Currently, there is no substantial scientific evidence to support the existence of this compound (1mC) as a true intermediate in a major DNA demethylation pathway. While various DNA modifications exist, the canonical demethylation pathway proceeds through the oxidation of the methyl group at the 5th position of the cytosine ring, not through modifications at the 1st position.
Quantitative Comparison of Demethylation Intermediates
The following table summarizes the key characteristics and evidence for the intermediates in the established TET-TDG pathway versus the hypothetical this compound.
| Feature | 5-Hydroxymethylcytosine (5hmC) | 5-Formylcytosine (5fC) | 5-Carboxylcytosine (5caC) | This compound (1mC) |
| Enzymatic Formation | TET enzymes oxidize 5mC | TET enzymes oxidize 5hmC | TET enzymes oxidize 5fC | No known enzyme for formation in a demethylation pathway |
| Detection in Mammalian DNA | Widely detected and quantified | Detected at lower levels | Detected at very low levels | Not detected as a demethylation intermediate |
| Role in Demethylation | Stable intermediate, recognized by some proteins | Actively excised by TDG | Actively excised by TDG | No evidence of a role in demethylation |
| Supporting Evidence | Extensive literature, LC-MS, antibody-based detection | LC-MS, chemical labeling methods | LC-MS, chemical labeling methods | Lack of supporting experimental data |
Experimental Protocols
1. Analysis of DNA Demethylation Intermediates by Liquid Chromatography-Mass Spectrometry (LC-MS)
This method allows for the direct detection and quantification of modified cytosines in a DNA sample.
-
DNA Isolation: Genomic DNA is extracted from cells or tissues using a standard phenol-chloroform extraction or a commercial kit.
-
DNA Digestion: The purified DNA is enzymatically hydrolyzed to individual nucleosides using a cocktail of enzymes, typically including DNAse I, nuclease P1, and alkaline phosphatase.
-
LC-MS Analysis: The resulting nucleoside mixture is separated by liquid chromatography and analyzed by a tandem mass spectrometer. The different modified cytosines (5mC, 5hmC, 5fC, 5caC) are identified and quantified based on their unique mass-to-charge ratios and retention times.
2. Tet-Assisted Bisulfite Sequencing (TAB-Seq)
TAB-Seq is a method to specifically map 5hmC at single-base resolution.
-
Glucosylation of 5hmC: The 5hmC in the genomic DNA is protected by glucosylation using a T4 bacteriophage β-glucosyltransferase.
-
TET Oxidation: The 5mC and 5fC are oxidized to 5caC by a recombinant TET enzyme.
-
Bisulfite Conversion: The DNA is then treated with sodium bisulfite, which converts unmethylated cytosine and 5caC to uracil, while the protected 5hmC and the original 5mC (now oxidized) are resistant to conversion.
-
PCR and Sequencing: The treated DNA is amplified by PCR and sequenced. The remaining cytosines in the sequence correspond to the original locations of 5hmC.
Conclusion
Based on the current body of scientific literature, this compound is not considered a true intermediate in the canonical DNA demethylation pathway. The established mechanism involves the TET-mediated oxidation of 5-methylcytosine to 5-hydroxymethylcytosine, 5-formylcytosine, and 5-carboxylcytosine, followed by excision repair. While the search for alternative demethylation pathways is an active area of research, compelling evidence for a role of this compound is absent. For professionals in drug development, focusing on the modulation of TET enzymes and the BER pathway remains the most promising strategy for targeting DNA demethylation processes.
A Comparative Guide to the Enzymatic Recognition of 1-Methylcytosine by DNA Methyltransferases
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comparative analysis of how DNA methyltransferases (DNMTs) recognize 1-methylcytosine (B60703) (1mC), a modified DNA base. While the canonical epigenetic mark is 5-methylcytosine (B146107) (5mC), the presence and enzymatic handling of other modifications like 1mC are of growing interest in epigenetic research and drug discovery. This document summarizes key quantitative data, details relevant experimental protocols, and visualizes complex processes to facilitate a deeper understanding of these enzymatic interactions.
Introduction to DNMTs and Cytosine Modifications
DNA methylation is a critical epigenetic mechanism that governs gene expression, cellular differentiation, and genome stability.[1][2] This process is primarily catalyzed by a family of DNMT enzymes that transfer a methyl group from the cofactor S-adenosyl-L-methionine (SAM) to a cytosine base.[3][4][5] In mammals, this typically occurs at CpG dinucleotides. The primary DNMTs include DNMT1, responsible for maintaining methylation patterns after DNA replication, and DNMT3A and DNMT3B, which establish de novo methylation patterns.
While the vast majority of research has focused on the methylation at the C5 position of cytosine to form 5mC, other modifications exist. This compound (1mC) is a methylated analogue of cytosine where the methyl group is attached to the N1 position of the pyrimidine (B1678525) ring. Understanding how DNMTs interact with this non-canonical base is crucial for elucidating potential off-target effects of DNMT-targeting drugs and for exploring novel regulatory pathways.
Comparative Analysis of DNMT Recognition
The structural basis for DNMT recognition of its canonical substrate, hemimethylated DNA (containing 5mC on one strand), has been well-characterized, particularly for DNMT1. Crystal structures reveal that DNMT1 flips the target cytosine out of the DNA helix and into its catalytic pocket. The existing 5-methyl group on the template strand is accommodated within a specific hydrophobic pocket, a key step for ensuring the high fidelity of maintenance methylation.
The interaction with 1mC is less understood and is generally considered to be inhibitory rather than substrate-like. The methyl group at the N1 position fundamentally alters the Watson-Crick hydrogen bonding face of the cytosine base. This steric hindrance can interfere with the proper binding and catalytic activity of DNMTs.
Precise kinetic data comparing DNMT activity on DNA substrates containing 1mC versus canonical substrates is not widely published, as 1mC is not a natural substrate for methylation. However, studies on various cytosine analogues and inhibitors provide a framework for understanding these interactions. Kinetic parameters for DNMTs are typically determined using substrates like poly(dI-dC), which offers multiple methylation sites for steady-state analysis.
The table below presents hypothetical comparative data to illustrate the expected differences in enzymatic recognition. This data is based on the known inhibitory nature of base modifications that disrupt the standard enzymatic mechanism.
| Enzyme | Substrate Type | Km (μM) | kcat (min-1) | kcat/Km (μM-1min-1) | Binding Affinity (Kd, nM) |
| DNMT1 | Hemimethylated CpG (5mC) | 1-5 | 0.1-0.5 | 0.02-0.5 | 10-50 |
| DNMT1 | Unmethylated CpG | 10-20 | 0.01-0.05 | 0.0005-0.005 | >1000 |
| DNMT1 | CpG with 1mC | Not Applicable (Inhibitor) | Not Applicable | Not Applicable | High (Potentially) |
| DNMT3A | Unmethylated CpG | 2-10 | 0.05-0.2 | 0.005-0.1 | 100-500 |
| DNMT3A | CpG with 1mC | Not Applicable (Inhibitor) | Not Applicable | Not Applicable | High (Potentially) |
Note: The values for 1mC are designated as "Not Applicable" for catalytic parameters as it is not a substrate for methylation. Its interaction would be better described by an inhibition constant (Ki).
Structural and Mechanistic Insights
The catalytic mechanism of DNMTs involves a nucleophilic attack by a conserved cysteine residue on the C6 position of the target cytosine. This is followed by the transfer of a methyl group from SAM to the C5 position. The presence of a methyl group at the N1 position (1mC) would likely disrupt this process in several ways:
-
Altered Base Pairing: 1mC cannot form a standard Watson-Crick base pair with guanine, which would distort the DNA helix and hinder recognition by the enzyme.
-
Steric Clash: The N1 methyl group could sterically clash with amino acid residues in the DNMT active site that are essential for positioning the cytosine base for catalysis.
-
Electronic Effects: The N1 methylation alters the electronic properties of the pyrimidine ring, which could disfavor the nucleophilic attack required for the methylation reaction.
Experimental Protocols
Evaluating the interaction between DNMTs and modified cytosines like 1mC requires specific biochemical assays. Below are methodologies for key experiments.
This protocol is adapted from commercially available kits and is used to measure the activity of DNMTs or screen for inhibitors.
Objective: To quantify the methyltransferase activity of a DNMT enzyme in the presence of a standard DNA substrate versus a substrate containing 1mC.
Materials:
-
Recombinant DNMT1 or DNMT3A enzyme.
-
DNMT Assay Buffer.
-
S-adenosyl-L-methionine (SAM or Adomet).
-
DNA substrate (a universal CpG-rich substrate for methylation).
-
1mC-containing DNA oligomer (as a potential inhibitor).
-
Microplate pre-coated with a DNA substrate.
-
Capture Antibody (specific for 5mC).
-
Detection Antibody (e.g., HRP-conjugated secondary antibody).
-
Developer Solution (Chromogenic substrate).
-
Stop Solution.
-
Microplate reader.
Procedure:
-
Preparation: Prepare the DNMT Assay Buffer. Dilute the SAM, DNMT enzyme, and test inhibitor (1mC-DNA) to desired concentrations in the assay buffer.
-
Reaction: To the microplate wells, add 50 µL of the reaction mixture containing the DNMT enzyme, SAM, and either the standard DNA substrate or the 1mC-containing inhibitor.
-
Incubation: Cover the plate and incubate at 37°C for 60-120 minutes to allow for the methylation reaction.
-
Binding: Wash the wells with Wash Buffer. Add the Capture Antibody (diluted in Wash Buffer) to each well and incubate for 60 minutes at room temperature. This antibody will bind to the newly formed 5mC.
-
Detection: Wash the wells again. Add the diluted Detection Antibody and incubate for 30 minutes.
-
Signal Generation: Wash the wells. Add the Developer Solution and incubate for 5-10 minutes, avoiding direct light. The solution will change color.
-
Stopping the Reaction: Add the Stop Solution to each well to terminate the enzymatic reaction.
-
Measurement: Read the absorbance on a microplate reader at 450 nm. The signal intensity is directly proportional to the DNMT activity. Compare the activity in the presence and absence of the 1mC-containing DNA.
Objective: To measure the binding affinity and kinetics (association and dissociation rates) of a DNMT enzyme to a DNA duplex containing 1mC.
Materials:
-
SPR instrument (e.g., Biacore).
-
Sensor chip (e.g., streptavidin-coated SA chip).
-
Biotinylated DNA duplex containing a central CpG site.
-
Biotinylated DNA duplex containing a central 1mCpG site.
-
Recombinant DNMT enzyme.
-
Running buffer (e.g., HBS-EP+).
Procedure:
-
Chip Preparation: Immobilize the biotinylated DNA duplexes (both standard and 1mC-containing) onto separate flow cells of the streptavidin sensor chip.
-
Analyte Injection: Prepare a series of dilutions of the DNMT enzyme in running buffer.
-
Association: Inject the DNMT dilutions sequentially over the flow cells at a constant flow rate and monitor the change in response units (RU) over time.
-
Dissociation: After the association phase, switch to injecting only the running buffer and monitor the decrease in RU as the enzyme dissociates from the DNA.
-
Regeneration: If necessary, inject a regeneration solution (e.g., high salt buffer) to remove any remaining bound protein.
-
Data Analysis: Fit the resulting sensorgrams (RU vs. time) to a suitable binding model (e.g., 1:1 Langmuir binding) to calculate the association rate constant (ka), dissociation rate constant (kd), and the equilibrium dissociation constant (Kd = kd/ka).
Conclusion and Future Directions
The enzymatic recognition of this compound by DNA methyltransferases is fundamentally different from the recognition of the canonical 5-methylcytosine. Structural and mechanistic considerations suggest that 1mC acts as an inhibitor rather than a substrate, primarily due to steric hindrance and disruption of normal DNA base pairing.
Further research is needed to quantify the inhibitory potency (Ki) of 1mC-containing DNA on different DNMTs and to solve crystal structures of DNMTs in complex with 1mC-DNA to visualize the molecular interactions directly. Such studies will be invaluable for the rational design of more specific and potent DNMT inhibitors for therapeutic applications and for understanding the full landscape of epigenetic regulation.
References
- 1. DNA methyl transferase 1: regulatory mechanisms and implications in health and disease - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Human DNMT1 transition state structure - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Frontiers | Inhibitors of DNA Methyltransferases From Natural Sources: A Computational Perspective [frontiersin.org]
- 4. Chemical Expansion of the Methyltransferase Reaction: Tools for DNA Labeling and Epigenome Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
Safety Operating Guide
Proper Disposal of 1-Methylcytosine: A Step-by-Step Guide for Laboratory Professionals
Essential Safety and Logistical Information for Researchers, Scientists, and Drug Development Professionals
The proper disposal of 1-Methylcytosine, a methylated form of the DNA base cytosine, is crucial for maintaining a safe laboratory environment and ensuring regulatory compliance. Due to its potential health hazards, this compound must be managed as a hazardous chemical waste. This guide provides a comprehensive, step-by-step procedure for its safe handling and disposal.
Immediate Safety and Hazard Information
This compound is classified with the following hazards:
-
Harmful if swallowed [1]
-
Causes skin irritation [1]
-
Causes serious eye irritation [1]
-
May cause respiratory irritation [1]
Personnel handling this compound should wear appropriate personal protective equipment (PPE), including safety goggles, gloves, and a lab coat. All handling of the solid material should be done in a well-ventilated area, preferably within a chemical fume hood, to avoid inhalation of dust.
Quantitative Data for Hazardous Waste Accumulation
The following table summarizes general quantitative limits for the accumulation of hazardous chemical waste in a laboratory setting, which should be applied to the disposal of this compound waste. These are general guidelines, and researchers should consult their institution's specific waste management policies.
| Parameter | Guideline | Citation |
| Maximum Volume in Satellite Accumulation Area | 55 gallons | [2] |
| Maximum Volume for Acutely Toxic Waste (P-list) | 1 quart of liquid or 1 kilogram of solid | |
| Maximum Storage Time in Satellite Accumulation Area | 12 months (as long as volume limits are not exceeded) | |
| Time for Removal After Container is Full | Within 3 calendar days |
Step-by-Step Disposal Protocol
Follow these detailed steps for the proper disposal of this compound waste:
Step 1: Waste Characterization
-
Based on its hazard profile, this compound waste (solid, solutions, and contaminated materials) must be classified as hazardous chemical waste.
-
Do not dispose of this compound down the sanitary sewer or in the regular trash.
Step 2: Waste Segregation
-
Segregate this compound waste from other waste streams at the point of generation.
-
Avoid mixing it with incompatible chemicals. Specifically, keep it separate from:
-
Strong oxidizing agents.
-
Acids and bases.
-
Aqueous wastes if the this compound is in an organic solvent.
-
Step 3: Container Selection and Management
-
For Solid Waste: Collect solid this compound and contaminated materials (e.g., weighing paper, gloves, pipette tips) in a designated, robust, leak-proof container with a secure lid. The container must be compatible with the chemical.
-
For Liquid Waste: Collect solutions containing this compound in a sealable, leak-proof container (plastic is often preferred) that is chemically compatible with the solvent used.
-
Ensure the container is kept closed except when adding waste.
-
Leave at least 10% headspace in liquid waste containers to allow for expansion.
Step 4: Labeling
-
As soon as the first drop of waste is added, label the waste container clearly.
-
The label must include:
-
The words "Hazardous Waste".
-
The full chemical name: "this compound".
-
The major components and their approximate percentages if it is a mixed waste. Do not use abbreviations or chemical formulas.
-
The date the waste was first added to the container (accumulation start date).
-
The name and contact information of the generating researcher or lab.
-
Step 5: Storage in a Satellite Accumulation Area (SAA)
-
Store the labeled waste container in a designated Satellite Accumulation Area (SAA) within the laboratory, at or near the point of generation.
-
The SAA must be under the control of the laboratory personnel.
-
Ensure the SAA is inspected regularly for any signs of leaks or container degradation.
Step 6: Request for Waste Pickup
-
Once the container is full or the accumulation time limit is approaching, submit a hazardous waste pickup request to your institution's Environmental Health and Safety (EHS) department.
-
Follow your institution's specific procedures for requesting a waste pickup.
Experimental Workflow for Disposal
The following diagram illustrates the logical workflow for the proper disposal of this compound.
Caption: Disposal workflow for this compound.
References
Essential Safety and Logistics for Handling 1-Methylcytosine
For researchers, scientists, and drug development professionals, ensuring safe and efficient handling of chemical compounds is paramount. This guide provides immediate and essential safety protocols, operational plans, and disposal procedures for 1-Methylcytosine, a methylated form of the DNA base cytosine. By adhering to these guidelines, laboratory personnel can minimize risks and maintain a safe research environment.
Hazard Identification and Personal Protective Equipment
This compound is classified as an irritant and is harmful if swallowed. It can cause skin and eye irritation, and may lead to respiratory irritation[1][2]. Therefore, appropriate personal protective equipment (PPE) is crucial to prevent exposure. The following table summarizes the recommended PPE for various operations involving this compound.
| Operation | Eye Protection | Hand Protection | Body Protection | Respiratory Protection |
| Weighing/Transferring (Solid) | Safety glasses with side shields or chemical safety goggles | Nitrile rubber gloves | Laboratory coat | Recommended if dust may be generated; use a NIOSH-approved respirator with a particulate filter |
| Solution Preparation/Mixing | Chemical safety goggles | Nitrile rubber gloves | Laboratory coat | Not generally required if performed in a well-ventilated area or a chemical fume hood |
| Running Reactions (Closed System) | Safety glasses | Nitrile rubber gloves | Laboratory coat | Not generally required |
| Work-up/Extraction | Chemical safety goggles or face shield | Nitrile rubber gloves | Laboratory coat or chemical-resistant apron | Recommended to be performed in a chemical fume hood |
| Spill Cleanup | Chemical safety goggles and face shield | Heavy-duty nitrile rubber gloves | Chemical-resistant suit or coveralls | A NIOSH-approved respirator with a particulate filter is required |
Operational Plan: Step-by-Step Guidance
A systematic approach to handling this compound is essential for safety and experimental integrity. The following workflow outlines the key steps from preparation to disposal.
Detailed Methodologies
Engineering Controls:
-
Always work in a well-ventilated laboratory.
-
Use a chemical fume hood when handling the solid form to minimize inhalation of dust particles, and when preparing solutions.
-
Ensure that an eyewash station and a safety shower are readily accessible in the immediate work area.
Personal Protective Equipment (PPE):
-
Eye and Face Protection: Wear safety glasses with side shields at a minimum. When there is a risk of splashing, use chemical safety goggles or a face shield in combination with safety glasses[3].
-
Skin Protection: Wear a standard laboratory coat. When handling larger quantities or during procedures with a higher risk of splashes, a chemical-resistant apron over the lab coat is recommended.
-
Hand Protection: Nitrile rubber gloves are recommended for handling this compound[4]. It is important to inspect gloves for any signs of degradation or punctures before use. For incidental contact, change gloves immediately. Nitrile gloves offer good resistance to a variety of chemicals, but prolonged direct contact should be avoided[5].
-
Respiratory Protection: If handling the solid outside of a fume hood where dust may be generated, a NIOSH-approved respirator with a particulate filter should be used.
Handling Procedures:
-
Before starting any work, ensure you are familiar with the hazards of this compound by reviewing the Safety Data Sheet (SDS).
-
Put on all required PPE.
-
When weighing the solid, use a spatula and handle it carefully to avoid creating dust.
-
When preparing solutions, add the solid to the solvent slowly to avoid splashing.
-
After handling, wash your hands thoroughly with soap and water.
Storage:
-
Store this compound in a tightly closed container.
-
Keep the container in a cool, dry, and well-ventilated area.
-
Segregate from incompatible materials such as strong oxidizing agents.
-
Ensure all containers are clearly labeled with the chemical name and any relevant hazard warnings.
Disposal Plan
The disposal of chemical waste must comply with local, state, and federal regulations. Given the hazard profile of this compound, it should be treated as a hazardous chemical waste.
Waste Collection:
-
Collect all solid waste and solutions containing this compound in a designated and clearly labeled hazardous waste container.
-
Do not mix with other incompatible waste streams.
-
The container should be kept closed when not in use and stored in a designated satellite accumulation area.
Disposal Procedure:
-
Dispose of the chemical waste through your institution's Environmental Health and Safety (EHS) office.
-
Follow their specific procedures for chemical waste pickup and disposal.
-
Do not dispose of this compound down the drain or in the regular trash.
By implementing these safety and logistical measures, you can ensure a secure working environment and contribute to a culture of safety within your laboratory.
References
Retrosynthesis Analysis
AI-Powered Synthesis Planning: Our tool employs the Template_relevance Pistachio, Template_relevance Bkms_metabolic, Template_relevance Pistachio_ringbreaker, Template_relevance Reaxys, Template_relevance Reaxys_biocatalysis model, leveraging a vast database of chemical reactions to predict feasible synthetic routes.
One-Step Synthesis Focus: Specifically designed for one-step synthesis, it provides concise and direct routes for your target compounds, streamlining the synthesis process.
Accurate Predictions: Utilizing the extensive PISTACHIO, BKMS_METABOLIC, PISTACHIO_RINGBREAKER, REAXYS, REAXYS_BIOCATALYSIS database, our tool offers high-accuracy predictions, reflecting the latest in chemical research and data.
Strategy Settings
| Precursor scoring | Relevance Heuristic |
|---|---|
| Min. plausibility | 0.01 |
| Model | Template_relevance |
| Template Set | Pistachio/Bkms_metabolic/Pistachio_ringbreaker/Reaxys/Reaxys_biocatalysis |
| Top-N result to add to graph | 6 |
Feasible Synthetic Routes




Featured Recommendations
| Most viewed |
|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
