DA-E 5090
Description
Properties
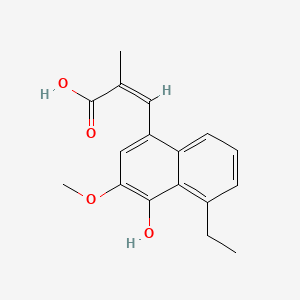
CAS No. |
131420-84-3 |
|---|---|
Molecular Formula |
C17H18O4 |
Molecular Weight |
286.32 g/mol |
IUPAC Name |
(Z)-3-(5-ethyl-4-hydroxy-3-methoxynaphthalen-1-yl)-2-methylprop-2-enoic acid |
InChI |
InChI=1S/C17H18O4/c1-4-11-6-5-7-13-12(8-10(2)17(19)20)9-14(21-3)16(18)15(11)13/h5-9,18H,4H2,1-3H3,(H,19,20)/b10-8- |
InChI Key |
WGNQQQSMLCOUAX-NTMALXAHSA-N |
Isomeric SMILES |
CCC1=C2C(=CC=C1)C(=CC(=C2O)OC)/C=C(/C)\C(=O)O |
Canonical SMILES |
CCC1=C2C(=CC=C1)C(=CC(=C2O)OC)C=C(C)C(=O)O |
Appearance |
Solid powder |
Purity |
>98% (or refer to the Certificate of Analysis) |
shelf_life |
>2 years if stored properly |
solubility |
Soluble in DMSO |
storage |
Dry, dark and at 0 - 4 C for short term (days to weeks) or -20 C for long term (months to years). |
Synonyms |
3-(4-hydroxy-5-ethyl-3-methoxy-1-naphthalenyl)-2-methyl-2-propenoic acid 3-(5-ethyl-4-hydroxy-3-methoxy-1-naphthalenyl)-2-methyl-2-propenoic acid DA-E 5090 DA-E5090 |
Origin of Product |
United States |
Foundational & Exploratory
NVIDIA Blackwell Architecture: A Deep Dive for Scientific and Drug Discovery Applications
An In-depth Technical Guide on the Core Architecture, with a Focus on the GeForce RTX 5090
The NVIDIA Blackwell architecture represents a monumental leap in computational power, poised to significantly accelerate scientific research, particularly in the fields of drug development, molecular dynamics, and large-scale data analysis. This guide provides a comprehensive technical overview of the Blackwell architecture, with a specific focus on the anticipated flagship consumer GPU, the GeForce RTX 5090. The information herein is tailored for researchers, scientists, and professionals in drug development who seek to leverage cutting-edge computational hardware for their work.
Core Architectural Innovations
The Blackwell architecture, named after the distinguished mathematician and statistician David H. Blackwell, succeeds the Hopper and Ada Lovelace microarchitectures.[1] It is engineered to address the escalating demands of generative AI and high-performance computing workloads.[2] The consumer-facing GPUs, including the RTX 5090, are built on a custom TSMC 4N process.[1][3]
A key innovation in the data center-focused Blackwell GPUs is the multi-die design, where two large dies are connected via a high-speed 10 terabytes per second (TB/s) chip-to-chip interconnect, allowing them to function as a single, unified GPU.[4][5] This design packs an impressive 208 billion transistors.[4][5] While it is not confirmed that the consumer-grade RTX 5090 will feature a dual-die configuration, the underlying architectural enhancements will be present.
The Blackwell architecture introduces several key technological advancements:
-
Fifth-Generation Tensor Cores: These new Tensor Cores are designed to accelerate AI and floating-point calculations.[1] A significant advancement for researchers is the introduction of new, lower-precision data formats, including 4-bit floating point (FP4) AI.[4] This can double the performance and the size of models that can be supported in memory while maintaining high accuracy, which is crucial for large-scale AI models used in drug discovery and genomic analysis.[4]
-
Fourth-Generation RT Cores: These cores are specialized for hardware-accelerated real-time ray tracing, a technology that can be applied to molecular visualization and simulation for more accurate and intuitive representations of complex biological structures.[6][7]
-
Second-Generation Transformer Engine: This engine utilizes custom Blackwell Tensor Core technology to accelerate both the training and inference of large language models (LLMs) and Mixture-of-Experts (MoE) models.[4][8] For researchers, this translates to faster processing of scientific literature, analysis of biological sequences, and development of novel therapeutic candidates.
-
Unified INT32 and FP32 Execution: A notable architectural shift is the unification of the integer (INT32) and single-precision floating-point (FP32) execution units.[9][10] This allows for more flexible and efficient execution of diverse computational workloads.
-
Enhanced Memory Subsystem: The RTX 50 series, including the RTX 5090, is expected to be the first consumer GPU to feature GDDR7 memory, offering a significant increase in memory bandwidth.[11] This is critical for handling the massive datasets common in scientific research.
Quantitative Specifications
The following tables summarize the key quantitative specifications of the NVIDIA Blackwell architecture, comparing the data center-grade B200 GPU with the rumored specifications of the consumer-grade GeForce RTX 5090.
Data Center GPU: NVIDIA B200 Specifications
| Feature | Specification | Source(s) |
| Transistors | 208 billion (total for dual-die) | [4][5][12] |
| Manufacturing Process | Custom TSMC 4NP | [4][12] |
| AI Performance | Up to 20 petaFLOPS | [8][12] |
| Memory | 192 GB HBM3e | [5] |
| NVLink | 5th Generation, 1.8 TB/s total bandwidth | [8][12] |
Rumored GeForce RTX 5090 Specifications
| Feature | Rumored Specification | Source(s) |
| CUDA Cores | 21,760 | [13][14] |
| Memory | 32 GB GDDR7 | [6][13][15] |
| Memory Interface | 512-bit | [11][13] |
| Total Graphics Power (TGP) | ~575-600W | [13][15] |
| PCIe Interface | PCIe 5.0 | [3][11] |
Methodologies and Performance Claims
While detailed, peer-reviewed experimental protocols are not publicly available for this commercial architecture, NVIDIA has made several performance claims based on their internal testing. For instance, the GB200 NVL72, a system integrating 72 Blackwell GPUs, is claimed to offer up to a 30x performance increase in LLM inference workloads compared to the previous generation H100 GPUs, with a 25x improvement in energy efficiency.[5][12] These gains are attributed to the new FP4 precision support and the second-generation Transformer Engine.[12]
For researchers in drug development, these performance improvements could translate to:
-
Accelerated Virtual Screening: Faster and more accurate screening of vast chemical libraries to identify potential drug candidates.
-
Enhanced Molecular Dynamics Simulations: Longer and more complex simulations of protein folding and drug-target interactions.
-
Rapid Analysis of Large Datasets: Quicker processing of genomic, proteomic, and other large biological datasets.
Visualizing the Blackwell Architecture
The following diagrams, generated using the DOT language, illustrate key aspects of the NVIDIA Blackwell architecture.
Caption: High-level architectural hierarchy of a consumer-grade Blackwell GPU.
Caption: Simplified data flow within the Blackwell GPU architecture.
Caption: Workflow of the second-generation Transformer Engine.
References
- 1. Blackwell (microarchitecture) - Wikipedia [en.wikipedia.org]
- 2. cdn.prod.website-files.com [cdn.prod.website-files.com]
- 3. GeForce RTX 50 series - Wikipedia [en.wikipedia.org]
- 4. The Engine Behind AI Factories | NVIDIA Blackwell Architecture [nvidia.com]
- 5. Weights & Biases [wandb.ai]
- 6. GeForce RTX 5090 Graphics Cards | NVIDIA [nvidia.com]
- 7. scribd.com [scribd.com]
- 8. aspsys.com [aspsys.com]
- 9. Reddit - The heart of the internet [reddit.com]
- 10. emergentmind.com [emergentmind.com]
- 11. tomshardware.com [tomshardware.com]
- 12. nexgencloud.com [nexgencloud.com]
- 13. tomshardware.com [tomshardware.com]
- 14. scan.co.uk [scan.co.uk]
- 15. pcgamer.com [pcgamer.com]
GeForce RTX 5090: A Technical Guide for Scientific and Pharmaceutical Research
Executive Summary
The NVIDIA GeForce RTX 5090, powered by the next-generation Blackwell architecture, represents a significant leap in computational performance.[1] Engineered with substantial increases in CUDA core counts, fifth-generation Tensor Cores, and fourth-generation RT Cores, the RTX 5090 is positioned to dramatically accelerate a wide range of scientific workloads.[2] Its adoption of GDDR7 memory provides unprecedented bandwidth, crucial for handling the large datasets common in genomics, molecular dynamics, and cryogenic electron microscopy (cryo-EM) data processing.[3] For researchers in drug development, the enhanced AI capabilities, driven by the new Tensor Cores, promise to shorten timelines for virtual screening, protein folding, and generative chemistry.[1][4]
Core Architectural Enhancements
The RTX 5090 is built upon NVIDIA's Blackwell architecture, which succeeds the Ada Lovelace generation.[4] This new architecture is designed to unify high-performance graphics and AI computation, introducing significant optimizations in data paths and task allocation.[1][5] Key advancements include next-generation CUDA cores for raw parallel processing power, more efficient RT cores for simulations involving ray-based physics, and deeply enhanced Tensor Cores that introduce support for new precision formats like FP8 and FP4, which can double AI throughput for certain models with minimal accuracy impact.[4]
The Blackwell platform also introduces a hardware decompression engine, which can accelerate data analytics in frameworks like RAPIDS by up to 800GB/s, a critical feature for processing the massive datasets generated in scientific experiments.[6]
Quantitative Specifications
The specifications of the GeForce RTX 5090 present a substantial upgrade over its predecessors. The following tables summarize the key quantitative data for easy comparison.
Table 1: GPU Core and Processing Units
| Feature | NVIDIA GeForce RTX 5090 | NVIDIA GeForce RTX 4090 |
| GPU Architecture | Blackwell (GB202)[7] | Ada Lovelace |
| CUDA Cores | 21,760[8] | 16,384 |
| Tensor Cores | 680 (5th Generation)[7][8] | 512 (4th Generation) |
| RT Cores | 170 (4th Generation)[7][9] | 128 (3rd Generation) |
| Boost Clock | ~2.41 GHz[4] | ~2.52 GHz |
| Transistors | 92 Billion[3][4] | 76.3 Billion |
Table 2: Memory and Bandwidth
| Feature | NVIDIA GeForce RTX 5090 | NVIDIA GeForce RTX 4090 |
| Memory Size | 32 GB GDDR7[2][8] | 24 GB GDDR6X |
| Memory Interface | 512-bit[8] | 384-bit |
| Memory Bandwidth | 1,792 GB/s[2][8] | 1,008 GB/s |
| L2 Cache | 98 MB[8] | 72 MB |
Table 3: Physical and Thermal Specifications
| Feature | NVIDIA GeForce RTX 5090 |
| Total Graphics Power (TGP) | 575 W[7][8] |
| Power Connectors | 1x 16-pin (12V-2x6) or 4x 8-pin adapter[8][10] |
| Form Factor | 2-Slot Founders Edition[1][8] |
| Display Outputs | 3x DisplayPort 2.1b, 1x HDMI 2.1b[7] |
| PCIe Interface | Gen 5.0[8] |
Experimental Protocols for Performance Benchmarking
To quantitatively assess the performance of the GeForce RTX 5090 in a scientific context, a standardized benchmarking protocol is essential. The following methodology outlines a procedure for evaluating performance in molecular dynamics simulations using GROMACS, a widely used application in drug discovery and materials science.
Objective: To measure and compare the simulation throughput (nanoseconds per day) of the GeForce RTX 5090 against the GeForce RTX 4090 using a standardized set of molecular dynamics benchmarks.
4.1 System Configuration
-
CPU: AMD Ryzen 9 9950X
-
Motherboard: X870E Chipset
-
RAM: 64 GB DDR5-6000
-
Storage: 4 TB NVMe PCIe 5.0 SSD
-
Operating System: Ubuntu 24.04 LTS
-
NVIDIA Driver: Proprietary Driver Version 570.86.16 or newer[11]
-
CUDA Toolkit: Version 12.8 or newer[11]
4.2 Benchmarking Software
-
Application: GROMACS 2024
-
Benchmarks:
-
ApoA1: Apolipoprotein A1 (92k atoms), a standard benchmark for lipid metabolism studies.
-
STMV: Satellite Tobacco Mosaic Virus (1.06M atoms), representing a large, complex biomolecular system.
-
4.3 Experimental Procedure
-
System Preparation: Perform a clean installation of the operating system, NVIDIA drivers, and CUDA toolkit. Compile GROMACS from source with GPU acceleration enabled.
-
Environment Consistency: Ensure the system is idle with no background processes. Maintain a consistent ambient temperature (22°C ± 1°C) to ensure thermal stability.
-
Simulation Setup:
-
Use the standard input files for the ApoA1 and STMV benchmarks.
-
Configure the simulation to run exclusively on the GPU under test.
-
Set simulation parameters for NPT (isothermal-isobaric) ensemble with a 2 fs timestep.
-
-
Execution and Data Collection:
-
Execute each benchmark simulation for a minimum of 10,000 steps.
-
Run each test five consecutive times to ensure statistical validity.
-
Extract the performance metric (ns/day) from the GROMACS log file at the end of each run.
-
-
Data Analysis:
-
Discard the first run of each set as a warm-up.
-
Calculate the mean and standard deviation of the performance metric from the remaining four runs.
-
Compare the mean performance between the RTX 5090 and RTX 4090 to determine the performance uplift.
-
Visualized Workflows for Scientific Computing
Diagrams are crucial for representing complex computational workflows. The following sections provide Graphviz-generated diagrams for a performance benchmarking process and a GPU-accelerated drug discovery pipeline.
5.1 Performance Benchmarking Workflow
This diagram illustrates the logical flow of the experimental protocol described in Section 4.0.
5.2 GPU-Accelerated Virtual Screening Workflow
References
- 1. easychair.org [easychair.org]
- 2. Optimizing Drug Discovery with CUDA Graphs, Coroutines, and GPU Workflows | NVIDIA Technical Blog [developer.nvidia.com]
- 3. Hands-on: Analysis of molecular dynamics simulations / Analysis of molecular dynamics simulations / Computational chemistry [training.galaxyproject.org]
- 4. preprints.org [preprints.org]
- 5. High-Performance Computing (HPC) performance and benchmarking overview | Microsoft Learn [learn.microsoft.com]
- 6. tandfonline.com [tandfonline.com]
- 7. NAMD GPU Benchmarks and Hardware Recommendations | Exxact Blog [exxactcorp.com]
- 8. Drug Discovery With Accelerated Computing Platform | NVIDIA [nvidia.com]
- 9. Hands-on: High Throughput Molecular Dynamics and Analysis / High Throughput Molecular Dynamics and Analysis / Computational chemistry [training.galaxyproject.org]
- 10. redoakconsulting.co.uk [redoakconsulting.co.uk]
- 11. researchgate.net [researchgate.net]
Core Specifications and Architectural Advancements
An In-depth Technical Guide to the NVIDIA RTX 5090 for Research Applications
For professionals engaged in the computationally intensive fields of scientific research and drug development, the advent of new hardware architectures can signify a paradigm shift in the pace and scope of discovery. The NVIDIA RTX 5090, powered by the next-generation Blackwell architecture, represents such a leap forward.[1][2] This technical guide provides an in-depth analysis of the RTX 5090's specifications and its potential applications in demanding research environments.
The RTX 5090 is built upon the NVIDIA Blackwell architecture, which introduces significant enhancements over its predecessors.[3] Manufactured using a custom TSMC 4NP process, the Blackwell architecture packs 208 billion transistors in its full implementation, enabling a substantial increase in processing units.[4] For researchers, this translates to faster simulation times, the ability to train more complex AI models, and higher throughput for data processing tasks.
Quantitative Data Summary
The following tables summarize the core technical specifications of the RTX 5090 and provide a direct comparison with its predecessor, the RTX 4090, highlighting the generational improvements relevant to scientific and research workloads.
Table 1: NVIDIA GeForce RTX 5090 Technical Specifications
| Feature | Specification | Relevance to Research Applications |
| GPU Architecture | NVIDIA Blackwell | Provides foundational improvements in core processing, memory handling, and AI acceleration.[1][3] |
| Graphics Processor | GB202 | The flagship consumer die, designed for maximum performance in graphics and compute tasks.[3][5] |
| CUDA Cores | 21,760 | A significant increase in parallel processing units for general-purpose computing tasks like molecular dynamics and data analysis.[1][2][5][6] |
| Tensor Cores | 680 (5th Generation) | Accelerates AI and machine learning workloads, crucial for deep learning-based drug discovery, medical image analysis, and bioinformatics.[1][5][6] |
| RT Cores | 170 (4th Generation) | Enhances performance in ray tracing for scientific visualization and rendering of complex molecular structures.[5][6][7] |
| Memory | 32 GB GDDR7 | A large and fast memory pool allows for the analysis of larger datasets and the training of bigger AI models without performance bottlenecks.[1][5][7][8] |
| Memory Interface | 512-bit | A wider interface increases the total data throughput between the GPU and its memory.[1][5][6] |
| Memory Bandwidth | 1,792 GB/s | High bandwidth is critical for feeding the massive number of processing cores, reducing latency in data-intensive applications like genomics and cryo-EM.[1][6] |
| Boost Clock | ~2.41 GHz | Higher clock speeds result in faster execution of individual computational tasks.[2][6] |
| L2 Cache | 98 MB | A larger cache improves data access efficiency and reduces reliance on slower VRAM, speeding up repetitive calculations.[1] |
| Power Consumption (TGP) | ~575 W | A key consideration for deployment in lab or data center environments, requiring robust power and cooling solutions.[1][2][5] |
| Interconnect | PCIe 5.0 | Provides faster data transfer speeds between the GPU and the host system's CPU and main memory.[2][3][5] |
Table 2: Generational Comparison: RTX 5090 vs. RTX 4090
| Specification | NVIDIA RTX 5090 | NVIDIA RTX 4090 | Generational Improvement |
| Architecture | Blackwell | Ada Lovelace | Next-generation architecture with enhanced efficiency and new features like the second-generation Transformer Engine.[3][4] |
| CUDA Cores | 21,760[1][5] | 16,384 | ~33% increase in parallel processing cores. |
| Tensor Cores | 680 (5th Gen)[1][5] | 512 (4th Gen) | ~33% more Tensor Cores with architectural improvements for AI.[9] |
| Memory Size | 32 GB GDDR7[1][5] | 24 GB GDDR6X | 33% more VRAM with a faster memory technology. |
| Memory Bandwidth | 1,792 GB/s[1][6] | 1,008 GB/s | ~78% increase in memory bandwidth. |
| L2 Cache | 98 MB[1] | 72 MB | ~36% larger L2 cache. |
| Power (TGP) | ~575 W[1][5] | 450 W | Increased power draw to fuel higher performance. |
Applications in Drug Development and Scientific Research
The specifications of the RTX 5090 translate directly into tangible benefits for several key research methodologies. The combination of increased CUDA cores, larger and faster memory, and next-generation Tensor Cores makes it a formidable tool for tasks that were previously computationally prohibitive.[10][11]
Experimental Protocols
Below are detailed methodologies for key experiments where the RTX 5090 can be leveraged.
1. Experimental Protocol: High-Throughput Molecular Dynamics (MD) Simulation
-
Objective: To simulate the binding affinity of multiple ligand candidates to a target protein to identify potential drug leads.
-
Methodology:
-
System Preparation: The protein-ligand complex systems are prepared using simulation packages like GROMACS or AMBER. Each system is solvated in a water box with appropriate ions to neutralize the charge.
-
Energy Minimization: Each system undergoes a steepest descent energy minimization to relax the structure and remove steric clashes.
-
Equilibration: The systems are gradually heated to the target temperature (e.g., 300K) and equilibrated under NVT (constant volume) and then NPT (constant pressure) ensembles.
-
Production MD: Production simulations are run for an extended period (e.g., 100 ns per system). The massive parallel processing capability of the 21,760 CUDA cores is utilized to calculate intermolecular forces at each timestep.
-
Data Analysis: Trajectories are analyzed to calculate binding free energies using methods like MM/PBSA or MM/GBSA. The 32 GB GDDR7 memory allows for larger trajectories to be held and processed directly on the GPU, accelerating this analysis.
-
-
Objective: To train a deep learning model to predict the bioactivity of small molecules against a specific target, enabling the rapid screening of vast chemical libraries.
-
Methodology:
-
Dataset Curation: A large dataset of molecules with known bioactivity (active/inactive) for the target is compiled. Molecules are represented as molecular graphs or fingerprints.
-
Model Architecture: A graph neural network (GNN) or a multi-layer perceptron (MLP) is designed. The model will learn to extract features from the molecular representations that correlate with activity.
-
Model Training: The model is trained on the curated dataset. The 5th generation Tensor Cores and the second-generation Transformer Engine of the Blackwell architecture are leveraged to accelerate the training process, especially for large and complex models. The 32 GB VRAM is crucial for accommodating large batch sizes, which improves training stability and speed.
-
Validation: The model's predictive performance is evaluated on a separate test set using metrics like ROC-AUC.
-
Inference: The trained model is used to predict the activity of millions of unseen compounds from a virtual library. The high throughput of the RTX 5090 enables rapid screening.
-
Mandatory Visualizations
The following diagrams, generated using the DOT language, illustrate key concepts and workflows discussed in this guide.
Caption: High-level logical architecture of the RTX 5090 GPU.
Caption: Simplified MAPK/ERK signaling pathway, a common drug target.
Conclusion
References
- 1. vast.ai [vast.ai]
- 2. neoxcomputers.co.uk [neoxcomputers.co.uk]
- 3. Blackwell (microarchitecture) - Wikipedia [en.wikipedia.org]
- 4. The Engine Behind AI Factories | NVIDIA Blackwell Architecture [nvidia.com]
- 5. NVIDIA GeForce RTX 5090 Specs | TechPowerUp GPU Database [techpowerup.com]
- 6. notebookcheck.net [notebookcheck.net]
- 7. GeForce RTX 5090 Graphics Cards | NVIDIA [nvidia.com]
- 8. techradar.com [techradar.com]
- 9. pugetsystems.com [pugetsystems.com]
- 10. box.co.uk [box.co.uk]
- 11. lenovo.com [lenovo.com]
- 12. skillsgaptrainer.com [skillsgaptrainer.com]
5th Generation Tensor Cores: A Technical Deep Dive for AI Research in Drug Discovery
An In-depth Technical Guide for Researchers, Scientists, and Drug Development Professionals
The advent of NVIDIA's 5th generation Tensor Cores, integral to the Blackwell architecture, marks a significant leap forward in the computational power available for artificial intelligence (AI) research. For professionals in drug discovery, these advancements offer unprecedented opportunities to accelerate complex simulations, enhance predictive models, and ultimately, shorten the timeline for therapeutic development. This guide provides a comprehensive overview of the 5th generation Tensor Core technology, its performance capabilities, and its direct applications in drug development workflows.
Architectural Innovations of the 5th Generation Tensor Core
At the heart of the NVIDIA Blackwell architecture, the 5th generation Tensor Cores introduce several key innovations designed to dramatically boost performance and efficiency for AI workloads. These cores are engineered to accelerate the matrix-multiply-accumulate (MMA) operations that are fundamental to deep learning.
Complementing the new data formats is the second-generation Transformer Engine . This specialized hardware and software combination intelligently manages and dynamically switches between different numerical precisions to optimize performance and maintain accuracy for Transformer models, which are foundational to many modern AI applications in genomics and natural language processing.[5][6]
The Blackwell architecture itself is a feat of engineering, with the GB200 system featuring a multi-die "Superchip" design that connects two Blackwell GPUs with a Grace CPU via a high-speed interconnect.[7] This architecture boasts an impressive 208 billion transistors and is manufactured using a custom TSMC 4NP process.[6]
Performance and Specifications
The performance gains offered by the 5th generation Tensor Cores are substantial, enabling researchers to tackle previously intractable computational problems. The NVIDIA GB200 NVL72 system, which incorporates 72 Blackwell GPUs, serves as a prime example of the scale of performance now achievable.
Quantitative Data Summary
For ease of comparison, the following tables summarize the key technical specifications and performance metrics of the NVIDIA Blackwell GB200 and its 5th generation Tensor Cores, with comparisons to the previous generation where relevant.
| NVIDIA GB200 NVL72 System Specifications | |
| Component | Specification |
| GPUs | 72 NVIDIA Blackwell GPUs |
| CPUs | 36 NVIDIA Grace CPUs |
| Total FP4 Tensor Core Performance | 1,440 PetaFLOPS |
| Total FP8/FP6 Tensor Core Performance | 720 PetaFLOPS/PetaOPS |
| Total FP16/BF16 Tensor Core Performance | 360 PFLOPS |
| Total TF32 Tensor Core Performance | 180 PFLOPS |
| Total FP64/FP64 Tensor Core Performance | 2,880 TFLOPS |
| Total HBM3e Memory | Up to 13.4 TB |
| Total Memory Bandwidth | Up to 576 TB/s |
| NVLink Bandwidth | 130 TB/s |
| Per-GPU Performance (Illustrative) | NVIDIA Blackwell B200 | NVIDIA Hopper H100 |
| FP4 Tensor Core (Sparse) | 20 PetaFLOPS | N/A |
| FP8 Tensor Core (Sparse) | 10 PetaFLOPS | 4 PetaFLOPS |
| FP16/BF16 Tensor Core (Sparse) | 5 PetaFLOPS | 2 PetaFLOPS |
| TF32 Tensor Core (Sparse) | 2.5 PetaFLOPS | 1 PetaFLOP |
| FP64 Tensor Core | 45 TeraFLOPS | 60 TeraFLOPS |
| HBM3e Memory | Up to 192 GB | N/A (HBM3 up to 80GB) |
| Memory Bandwidth | Up to 8 TB/s | Up to 3.35 TB/s |
Note: Performance figures, especially for sparse operations, represent theoretical peak performance and can vary based on the workload.
Application in AI Research and Drug Discovery
Accelerating Molecular Docking with AutoDock-GPU
Molecular docking is a computational method used to predict the binding orientation of a small molecule (ligand) to a larger molecule (receptor), such as a protein. This is a critical step in virtual screening for identifying potential drug candidates. AutoDock-GPU is a leading software for high-performance molecular docking that can leverage the power of GPUs.[8][9]
Recent research has demonstrated that the performance of AutoDock-GPU can be significantly enhanced by offloading specific computational tasks, such as sum reduction operations within the scoring function, to the Tensor Cores.[8][9][10] This optimization can lead to a 4-7x speedup in the reduction operation itself and a notable improvement in the overall docking simulation time.[11]
The following protocol outlines the general steps for performing a molecular docking experiment using a Tensor Core-accelerated version of AutoDock-GPU.
-
System Preparation:
-
Hardware: A system equipped with an NVIDIA Blackwell (or compatible) GPU.
-
Software: A compiled version of AutoDock-GPU with Tensor Core support enabled. This typically involves using the latest CUDA toolkit and specifying the appropriate architecture during compilation.
-
-
Input Preparation:
-
Receptor: Prepare the 3D structure of the target protein, typically in PDBQT format. This involves removing water molecules, adding hydrogen atoms, and assigning partial charges.
-
Ligand: Prepare a library of small molecules to be screened, also in PDBQT format.
-
Grid Parameter File: Define the search space for the docking simulation by creating a grid parameter file that specifies the center and dimensions of the docking box.
-
-
Execution of Docking Simulation:
-
Execute the AutoDock-GPU binary, providing the receptor, ligand library, and grid parameter file as inputs.
-
The software will automatically leverage the Tensor Cores for the accelerated portions of the calculation.
-
-
Analysis of Results:
-
The output will consist of a series of docked conformations for each ligand, ranked by their predicted binding affinity.
-
Further analysis can be performed to visualize the binding poses and identify promising drug candidates.
-
AI-Driven Analysis of Signaling Pathways
Understanding cellular signaling pathways is crucial for identifying new drug targets. The PI3K/AKT pathway, for instance, is a key regulator of cell growth, proliferation, and survival, and its dysregulation is implicated in many diseases, including cancer.[12][13][14][15][16] AI, particularly deep learning models, can be used to analyze large-scale biological data (e.g., genomics, proteomics) to model and predict the behavior of these complex pathways.
The computational intensity of training these models on vast datasets makes them ideal candidates for acceleration with 5th generation Tensor Cores. The ability to use lower precision formats like FP4 and FP8 can significantly speed up the training of graph neural networks (GNNs) and other architectures used for pathway analysis, enabling researchers to iterate on models more quickly and analyze more complex biological systems.
Benchmarking and Experimental Protocols
The performance of the NVIDIA Blackwell architecture has been evaluated in the industry-standard MLPerf benchmarks. These benchmarks provide a standardized way to compare the performance of different hardware and software configurations on a variety of AI workloads.
MLPerf Inference v4.1
In the MLPerf Inference v4.1 benchmarks, the NVIDIA Blackwell platform demonstrated up to a 4x performance improvement over the NVIDIA H100 Tensor Core GPU on the Llama 2 70B model, a large language model.[17][18] This gain is attributed to the second-generation Transformer Engine and the use of FP4 Tensor Cores.[17]
The following is a generalized protocol based on the MLPerf submission guidelines.
-
System Configuration:
-
Hardware: A server equipped with an NVIDIA B200 GPU.
-
Software: NVIDIA's optimized software stack, including the CUDA toolkit, TensorRT-LLM, and the specific drivers used for the submission.
-
-
Benchmark Implementation:
-
Use the official MLPerf Inference repository and the Llama 2 70B model.
-
The submission must adhere to the "Closed" division rules, meaning the model and processing pipeline cannot be substantially altered.
-
-
Execution:
-
Run the benchmark in both "Server" and "Offline" scenarios. The Server scenario measures latency under a specific query arrival rate, while the Offline scenario measures raw throughput.
-
The benchmark is executed for a specified duration to ensure stable performance measurements.
-
-
Validation:
-
The accuracy of the model's output must meet a predefined quality target.
-
The results are submitted to MLCommons for verification.
-
MLPerf Training v5.0
In the MLPerf Training v5.0 benchmarks, the NVIDIA GB200 NVL72 system showcased up to a 2.6x performance improvement per GPU compared to the previous Hopper architecture.[19] For the Llama 3.1 405B pre-training benchmark, a 2.2x speedup was observed.[19]
-
System Configuration:
-
Hardware: A multi-node cluster of NVIDIA GB200 NVL72 systems connected via InfiniBand. The smallest NVIDIA submission for this benchmark utilized 256 GPUs.[20]
-
Software: A Slurm-based environment with Pyxis and Enroot for containerized execution, along with NVIDIA's optimized deep learning frameworks.[20]
-
-
Dataset and Model:
-
The benchmark uses a specific dataset and the Llama 3.1 405B model. The dataset and model checkpoints must be downloaded and preprocessed.
-
-
Execution:
-
The training process is launched using a SLURM script with specific hyperparameters and configuration files as provided in the submission repository.
-
The training is run until the model reaches a predefined quality target.
-
-
Scoring:
-
The time to train is measured from the start of the training run to the point where the quality target is achieved.
-
Conclusion
References
- 1. edge-ai-vision.com [edge-ai-vision.com]
- 2. Introducing NVFP4 for Efficient and Accurate Low-Precision Inference | NVIDIA Technical Blog [developer.nvidia.com]
- 3. Inside NVIDIA Blackwell Ultra: The Chip Powering the AI Factory Era | NVIDIA Technical Blog [developer.nvidia.com]
- 4. hyperstack.cloud [hyperstack.cloud]
- 5. cdn.prod.website-files.com [cdn.prod.website-files.com]
- 6. The Engine Behind AI Factories | NVIDIA Blackwell Architecture [nvidia.com]
- 7. scribd.com [scribd.com]
- 8. themoonlight.io [themoonlight.io]
- 9. [2410.10447] Accelerating Drug Discovery in AutoDock-GPU with Tensor Cores [arxiv.org]
- 10. researchgate.net [researchgate.net]
- 11. researchgate.net [researchgate.net]
- 12. Computational Modeling of PI3K/AKT and MAPK Signaling Pathways in Melanoma Cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
- 14. researchgate.net [researchgate.net]
- 15. direct.mit.edu [direct.mit.edu]
- 16. Mathematical modeling of PI3K/Akt pathway in microglia - CentAUR [centaur.reading.ac.uk]
- 17. NVIDIA Blackwell Sets New Standard for Gen AI in MLPerf Inference Debut | NVIDIA Blog [blogs.nvidia.com]
- 18. Deep dive into NVIDIA Blackwell Benchmarks — where does the 4x training and 30x inference performance gain, and 25x reduction in energy usage come from? | by adrian cockcroft | Medium [adrianco.medium.com]
- 19. NVIDIA Blackwell Delivers up to 2.6x Higher Performance in MLPerf Training v5.0 | NVIDIA Technical Blog [developer.nvidia.com]
- 20. Reproducing NVIDIA MLPerf v5.0 Training Scores for LLM Benchmarks | NVIDIA Technical Blog [developer.nvidia.com]
Unveiling the Engine of Discovery: A Technical Deep Dive into the 4th Generation Ray Tracing Cores of the NVIDIA RTX 5090
For Immediate Release
Aimed at the forefront of scientific and pharmaceutical research, this technical guide provides an in-depth analysis of the 4th generation Ray Tracing (RT) Cores featured in NVIDIA's latest flagship GPU, the RTX 5090. Powered by the new Blackwell architecture, these cores introduce significant advancements poised to accelerate discovery in fields ranging from drug development and molecular dynamics to advanced scientific visualization.
This document details the architectural innovations of the 4th generation RT Cores, presents quantitative performance data in relevant scientific applications, and outlines experimental methodologies for key benchmarks. Furthermore, it provides visualizations of core technological concepts and workflows to facilitate a comprehensive understanding for researchers, scientists, and drug development professionals.
Architectural Innovations of the 4th Generation RT Cores
The Blackwell architecture, at the heart of the RTX 5090, ushers in the 4th generation of RT Cores, representing a significant leap in hardware-accelerated ray tracing.[1][2] These new cores are engineered to deliver unprecedented realism and performance in complex simulations and visualizations.
A key enhancement is the doubled ray-triangle intersection throughput compared to the previous Ada Lovelace generation.[3] This fundamental improvement directly translates to faster rendering of complex geometries, a crucial aspect of visualizing large molecular structures or intricate biological systems.
Furthermore, the 4th generation RT Cores introduce two novel hardware units:
-
Triangle Cluster Intersection Engine: This engine is designed for the efficient processing of "Mega Geometry," enabling the rendering of scenes with vastly increased geometric detail.[3][4] For scientific applications, this means the ability to visualize larger and more complex datasets with greater fidelity.
-
Linear Swept Spheres: This feature provides hardware acceleration for ray tracing finer details, such as hair and other intricate biological filaments, which are often challenging to render accurately and efficiently.[4]
These architectural advancements are built upon a custom TSMC 4N process, which allows for greater transistor density and power efficiency.[1]
Performance Benchmarks in Scientific Applications
The theoretical advancements of the 4th generation RT Cores translate into tangible performance gains in critical scientific software. The following tables summarize the performance of the NVIDIA RTX 5090 in molecular dynamics simulations.
Table 1: NVIDIA RTX 5090 Performance in NAMD
| Simulation Benchmark (Input) | System | Performance (days/ns) |
| ATPase (327,506 Atoms) | NVIDIA GeForce RTX 5090 | Data not available in specific units |
| STMV (1,066,628 Atoms) | NVIDIA GeForce RTX 5090 | Data not available in specific units |
Note: While specific performance metrics in "days/ns" were not available in the preliminary reports, the RTX 5090 demonstrated a significant performance uplift in NAMD simulations compared to the previous generation RTX 4090, particularly in larger datasets where the Blackwell GPU and GDDR7 memory can be fully leveraged.[5]
Table 2: NVIDIA RTX 5090 Performance in GROMACS
| System Configuration | Simulation Performance (ns/day) |
| Intel i9-14900K, Gigabyte RTX 5090 Aorus Master | >700 |
| Intel i5-9600K, RTX 2060 (for comparison) | ~70 |
A user report on a drug discovery simulation using GROMACS showcased a dramatic performance increase, with a system equipped with an RTX 5090 achieving over 700 ns/day, a tenfold improvement over a previous generation system.[6]
Experimental Protocols
To ensure scientific rigor and reproducibility, detailed experimental protocols are paramount. While comprehensive methodologies for the latest RTX 5090 benchmarks are still emerging, the following outlines the typical procedures for benchmarking molecular dynamics and cryo-EM applications.
Molecular Dynamics (NAMD & GROMACS) Benchmarking Protocol
A standardized approach to benchmarking molecular dynamics simulations on new hardware like the RTX 5090 involves the following steps:
-
System Preparation: A clean installation of the operating system (e.g., a Linux distribution like Ubuntu) is performed. The latest NVIDIA drivers and CUDA toolkit are installed to ensure optimal performance and compatibility.[5]
-
Software Compilation: The molecular dynamics software (e.g., NAMD, GROMACS) is compiled from source to ensure it is optimized for the specific hardware architecture.
-
Benchmark Selection: Standard and publicly available benchmark datasets are used. For NAMD, these often include systems like the Satellite Tobacco Mosaic Virus (STMV) and ATP synthase (ATPase). For GROMACS, benchmarks might involve simulations of proteins in water boxes of varying sizes.
-
Execution and Data Collection: The simulations are run for a set number of steps, and the performance is typically measured in nanoseconds of simulation per day (ns/day). Multiple runs are often performed to ensure the consistency and reliability of the results.
-
System Monitoring: Throughout the benchmark, system parameters such as GPU utilization, temperature, and power consumption are monitored to ensure the hardware is performing as expected.
Cryo-Electron Microscopy (RELION) Benchmarking Protocol
Benchmarking cryo-EM software like RELION on a new GPU would typically follow this protocol:
-
Software and System Setup: Similar to MD benchmarking, a clean OS with the latest NVIDIA drivers and CUDA toolkit is essential. RELION is then installed and configured.
-
Dataset: A well-characterized, publicly available cryo-EM dataset is used for the benchmark. This allows for comparison across different hardware setups.
-
Processing Workflow: The benchmark would involve running key processing steps in RELION, such as 2D classification, 3D classification, and 3D refinement.
-
Performance Measurement: The primary metric for performance is the time taken to complete each processing step. This is often measured in wall-clock time.
-
Parameter Consistency: It is crucial to use the same processing parameters (e.g., number of classes, particle box size, angular sampling rate) across all hardware being compared to ensure a fair and accurate assessment.
Visualizing the Advancements
To better illustrate the concepts discussed, the following diagrams are provided in the DOT language for use with Graphviz.
Signaling Pathway of Ray Tracing in Scientific Visualization
Caption: A simplified workflow of ray tracing for scientific visualization on the RTX 5090.
Logical Relationship: 4th Gen RT Core Enhancements
Caption: Architectural improvements of the 4th Gen RT Core and their benefits.
Conclusion and Future Outlook
The 4th generation Ray Tracing Cores in the NVIDIA RTX 5090 represent a significant step forward in computational science. The architectural enhancements, leading to substantial performance gains in molecular dynamics and other scientific applications, will empower researchers to tackle larger, more complex problems. The ability to visualize massive datasets with unprecedented fidelity and interactivity will undoubtedly accelerate the pace of discovery in drug development and other scientific fields. As software ecosystems continue to mature and leverage the full capabilities of the Blackwell architecture, we can anticipate even greater breakthroughs in the years to come.
References
- 1. GeForce RTX 50 series - Wikipedia [en.wikipedia.org]
- 2. NVIDIA GeForce RTX 50 Technical Deep Dive | TechPowerUp [techpowerup.com]
- 3. A Deeper Analysis of Nvidia RTX 50 Blackwell GPU Architecture [guru3d.com]
- 4. Blackwell (microarchitecture) - Wikipedia [en.wikipedia.org]
- 5. phoronix.com [phoronix.com]
- 6. reddit.com [reddit.com]
Initial Impressions and Potential for Breakthroughs in Research
An In-Depth Technical Guide to the NVIDIA RTX 5090 for Academic and Scientific Applications
The release of the NVIDIA GeForce RTX 5090, powered by the "Blackwell" architecture, marks a significant leap forward in computational power, with profound implications for academic research, particularly in the fields of drug discovery, molecular dynamics, and genomics.[1] Announced at CES 2025 and launched on January 30, 2025, this flagship GPU is engineered to handle the most demanding computational tasks.[2][3][4] For researchers and scientists, the RTX 5090 offers the potential to accelerate complex simulations, train larger and more sophisticated AI models, and analyze vast datasets with unprecedented speed. This guide provides an in-depth technical overview of the RTX 5090, its performance in relevant academic workloads, and initial impressions of its utility for scientific and drug development professionals.
Core Specifications
The RTX 5090 introduces substantial upgrades over its predecessor, the RTX 4090. Key improvements include a significant increase in CUDA and Tensor cores, the adoption of next-generation GDDR7 memory, and a wider memory bus, all contributing to a considerable boost in raw computational and AI performance.[1][3][5][6]
| Specification | NVIDIA GeForce RTX 5090 | NVIDIA GeForce RTX 4090 |
| GPU Architecture | Blackwell (GB202)[1][2][5][7] | Ada Lovelace |
| Process Size | 5 nm[2] | 5 nm |
| Transistors | 92.2 Billion[2] | 76.3 Billion |
| CUDA Cores | 21,760[2][3][4][5] | 16,384 |
| Tensor Cores | 680 (5th Gen)[2][3][7] | 512 (4th Gen) |
| RT Cores | 170 (4th Gen)[2][3][7] | 128 (3rd Gen) |
| Boost Clock | 2407 MHz[2] | 2520 MHz |
| Memory Size | 32 GB GDDR7[2][4][8][9] | 24 GB GDDR6X |
| Memory Interface | 512-bit[2][3][5] | 384-bit |
| Memory Bandwidth | 1792 GB/s[1][3][4][5] | 1008 GB/s |
| TDP | 575 W[1][2][3][7] | 450 W |
| Launch Price (MSRP) | $1,999[2][3][9][10] | $1,599 |
Performance in Key Research Areas
Preliminary benchmarks indicate that the RTX 5090 offers a substantial performance uplift in a variety of compute-intensive applications relevant to academic and scientific research.
Molecular Dynamics (MD) Simulations
The RTX 5090 demonstrates a significant performance improvement in molecular dynamics simulations, a critical tool in drug discovery and materials science.[11] Benchmarks using NAMD (Nanoscale Molecular Dynamics) show a more substantial leap in performance from the RTX 4090 to the RTX 5090 than was observed between the RTX 3090 and RTX 4090.[11] This is attributed to the Blackwell architecture and the high bandwidth of the GDDR7 memory.[11] For AMBER 24 simulations, the RTX 5090 is noted as offering the best performance for its cost in single-GPU workstations.[12] However, its large physical size may limit its scalability in multi-GPU setups.[12]
| Benchmark | System | Performance (ns/day) |
| NAMD (ATPase - 327,506 Atoms) | RTX 5090 | Data not specified, but noted as a "nice leap forward"[11] |
| NAMD (STMV - 1,066,628 Atoms) | RTX 5090 | Data not specified, but noted as a "nice uplift"[11] |
| GROMACS (~45,000 Atoms) | Ryzen Threadripper, RTX 5090, 256GB RAM | 500 ns in < 12 hours[13] |
The reported NAMD benchmarks were conducted using NAMD 3.0.1 with CUDA 12.8 on a Linux system with the NVIDIA 570.86.10 driver.[11] The tests were performed on various NVIDIA GeForce graphics cards to compare performance.[11] Two different simulation inputs were used: ATPase with 327,506 atoms and STMV with 1,066,628 atoms.[11]
AI-Driven Drug Discovery and Genomics
In genomics, GPU-accelerated tools like NVIDIA Parabricks can significantly reduce the time required for secondary analysis of sequencing data.[15][16] While direct RTX 5090 benchmarks for Parabricks are not yet widely available, the card's specifications suggest it will dramatically speed up processes like sequence alignment and variant calling.[15][17]
| AI Benchmark (UL Procyon) | Metric | RTX 5090 | RTX 4090 | RTX 6000 Ada |
| AI Text Generation (Phi) | Score | 5,749 | 4,958 | 4,508 |
| AI Text Generation (Mistral) | Score | 6,267 | 5,094 | 4,255 |
| AI Text Generation (Llama3) | Score | 6,104 | 4,849 | 4,026 |
| AI Text Generation (Llama2) | Score | 6,591 | 5,013 | 3,957 |
| AI Image Gen. (Stable Diffusion 1.5 FP16) | Time (s) | 12.204 | Not specified | Not specified |
References
- 1. beebom.com [beebom.com]
- 2. NVIDIA GeForce RTX 5090 Specs | TechPowerUp GPU Database [techpowerup.com]
- 3. Everything You Need to Know About the Nvidia RTX 5090 GPU [runpod.io]
- 4. New GeForce RTX 50 Series Graphics Cards & Laptops Powered By NVIDIA Blackwell Bring Game-Changing AI and Neural Rendering Capabilities To Gamers and Creators | GeForce News | NVIDIA [nvidia.com]
- 5. vast.ai [vast.ai]
- 6. Nvidia RTX 5090 Graphics Card Review — Get Neural Or Get Left Behind [forbes.com]
- 7. notebookcheck.net [notebookcheck.net]
- 8. Nvidia GeForce RTX 5090 Revealed And It’s Massive [forbes.com]
- 9. GeForce RTX 5090 Graphics Cards | NVIDIA [nvidia.com]
- 10. NVIDIA announces new RTX 5090 graphics card that costs $2,000 at CES [engadget.com]
- 11. phoronix.com [phoronix.com]
- 12. Exxact Corp. | Custom Computing Solutions Integrator [exxactcorp.com]
- 13. researchgate.net [researchgate.net]
- 14. Drug Discovery With Accelerated Computing Platform | NVIDIA [nvidia.com]
- 15. AI in Genomics Research | NVIDIA [nvidia.com]
- 16. blogs.oracle.com [blogs.oracle.com]
- 17. Genomics Analysis Blueprint by NVIDIA | NVIDIA NIM [build.nvidia.com]
- 18. storagereview.com [storagereview.com]
- 19. Reddit - The heart of the internet [reddit.com]
Technical Guide: Evaluating the NVIDIA RTX 5090 for High-Performance Computing Clusters in Scientific Research and Drug Development
Executive Summary
The release of the NVIDIA GeForce RTX 5090, built on the "Blackwell" architecture, presents a compelling proposition for high-performance computing (HPC) applications, particularly in budget-constrained research environments.[1][2] This guide provides a technical deep-dive into the RTX 5090's architecture, performance metrics, and its suitability for computationally intensive tasks common in scientific research and drug discovery. We will analyze its specifications in comparison to its predecessor and its professional-grade counterparts, discuss the implications of its consumer-focused design, and provide workflows for its integration into research clusters. While offering unprecedented raw performance and next-generation features, its adoption in critical research requires careful consideration of its limitations compared to workstation and data center-grade GPUs.
Core Architecture: The Blackwell Advantage
The RTX 5090 is powered by the NVIDIA Blackwell architecture, which introduces significant advancements relevant to HPC.[2] Built on a custom 4N FinFET process from TSMC, the architecture is meticulously crafted to accelerate AI workloads, large-scale HPC tasks, and advanced graphics rendering.[2][3]
Key architectural improvements include:
-
Fourth-Generation Ray Tracing (RT) Cores: While primarily a gaming-focused feature, enhanced RT cores can also accelerate scientific visualization, enabling researchers to render complex molecular structures and simulations with greater fidelity and speed.[1][8]
-
Enhanced CUDA Cores: The fundamental processing units of the GPU have undergone generational improvements, leading to higher instructions per clock (IPC) and overall better performance in general-purpose GPU computing.[9]
-
Advanced Memory Subsystem: The RTX 5090 utilizes GDDR7 memory on a wide 512-bit bus, delivering memory bandwidth that approaches 1.8 TB/s.[3][9] This is critical for HPC workloads that are often memory-bound, such as molecular dynamics simulations, where large datasets must be rapidly accessed by the GPU cores.
Quantitative Data: Specification Comparison
To contextualize the RTX 5090's capabilities, it is essential to compare it against its predecessor, the GeForce RTX 4090, and a professional workstation card from the same Blackwell generation, the RTX PRO 6000.
| Feature | NVIDIA GeForce RTX 5090 | NVIDIA GeForce RTX 4090 | NVIDIA RTX PRO 6000 (Blackwell) |
| GPU Architecture | Blackwell | Ada Lovelace | Blackwell |
| CUDA Cores | 21,760[3][10][11] | 16,384 | 24,064[12][13] |
| Tensor Cores | 680 (5th Gen)[3][10] | 512 (4th Gen) | Not specified, but 5th Gen |
| RT Cores | 170 (4th Gen)[3][10] | 128 (3rd Gen) | Not specified, but 4th Gen |
| Boost Clock | ~2.41 GHz[3][6] | ~2.52 GHz | Not specified |
| Memory Size | 32 GB GDDR7[10][11][14] | 24 GB GDDR6X | 96 GB GDDR7 ECC[12][13] |
| Memory Interface | 512-bit[3][10][14] | 384-bit | 512-bit |
| Memory Bandwidth | ~1,792 GB/s[3][14] | ~1,008 GB/s | ~1,792 GB/s |
| FP32 Performance | ~103 TFLOPS (Theoretical)[12] | ~82.6 TFLOPS | ~130 TFLOPS (Theoretical)[12] |
| AI Performance | 3,352 AI TOPS[6] | ~1,321 AI TOPS | Not specified, expected higher |
| TGP (Total Graphics Power) | 575 W[3][10][11] | 450 W | 600 W[12][13] |
| ECC Memory Support | No[12] | No | Yes[12] |
| NVLink Support | No[12] | No | No (PCIe Gen 5 only)[12] |
| Driver | Game Ready / Studio | Game Ready / Studio | NVIDIA Enterprise / RTX Workstation[12] |
| Launch Price (MSRP) | $1,999[9][10] | $1,599 | ~$8,000[15] |
Table 1: Comparative analysis of key GPU specifications.
Suitability for Scientific and Drug Development Workloads
The RTX 5090's specifications make it a powerful tool for many research applications, but its suitability depends on the specific nature of the computational tasks.
Strengths
-
Exceptional Price-to-Performance Ratio: For raw single-precision (FP32) and AI inference performance, the RTX 5090 offers capabilities that rival or exceed previous-generation professional cards at a fraction of the cost. This is highly advantageous for academic labs and startups where budget is a primary constraint.
-
Massive Memory Bandwidth and Size: With 32 GB of GDDR7 memory and a bandwidth of nearly 1.8 TB/s, the RTX 5090 can handle significantly larger datasets and more complex models than its predecessors.[3][9][14] This is beneficial for molecular dynamics simulations of large biomolecular systems, cryo-EM data processing, and training moderately sized AI models.[16]
Limitations and Considerations
-
Lack of ECC Memory: The absence of Error-Correcting Code (ECC) memory is a significant drawback for mission-critical, long-running simulations where data integrity is paramount.[12] ECC memory can detect and correct in-memory data corruption, which can otherwise lead to silent errors in scientific results.
-
Double Precision (FP64) Performance: Consumer-grade GeForce cards are typically limited in their FP64 performance, often at a 1/64 ratio of their FP32 throughput. While the Blackwell architecture for data centers emphasizes AI, some traditional HPC simulations (e.g., certain quantum chemistry or fluid dynamics calculations) still rely heavily on FP64 precision. The professional RTX PRO 6000 and data center B200 GPUs are better suited for these tasks.[4]
-
Driver and Software Support: The RTX 5090 uses GeForce Game Ready or NVIDIA Studio drivers. While the Studio drivers are optimized for creative applications, they lack the rigorous testing, certification for scientific software (ISV certifications), and enterprise-level support that come with the RTX Workstation drivers.[12] This can lead to potential instabilities or suboptimal performance in specialized research software.
-
Cooling and Power in Cluster Environments: The high Total Graphics Power (TGP) of 575W requires robust power delivery and, more importantly, effective thermal management in a dense cluster environment.[3][10] The dual-slot, flow-through cooler of the Founders Edition is designed for a standard PC case, not necessarily for rack-mounted servers where airflow is different.
Experimental Protocols & Methodologies
While specific peer-reviewed experimental protocols for the RTX 5090 are emerging, methodologies from benchmark reports and early adopter experiences provide a framework for performance evaluation.
Methodology: AI Inference and Training Benchmarks
-
System Configuration:
-
CPU: Intel Core i9-14900K or AMD Ryzen 9 9950X3D.[16]
-
Motherboard: Z790 or X670E chipset with PCIe 5.0 support.
-
RAM: 96GB of DDR5 @ 6000 MT/s or higher.[16]
-
GPU: NVIDIA GeForce RTX 5090 (32GB).
-
Storage: 2TB NVMe SSD (PCIe 5.0).
-
Power Supply: 1300W or higher, 80+ Platinum rated.[16]
-
OS: Ubuntu 22.04 LTS with NVIDIA Driver Version 581.80 or newer.[10]
-
Software: CUDA Toolkit, PyTorch, TensorFlow, Docker.
-
-
Experimental Procedure (AI Text Generation):
-
Deploy large language models (LLMs) of varying sizes, such as Meta's Llama 3.1 and Microsoft's Phi-3.5, locally on the GPU.
-
Utilize frameworks like llama.cpp for inference testing.
-
Measure key performance indicators:
-
Time to First Token (TTFT): The latency from prompt input to the generation of the first token.
-
Tokens per Second (TPS): The throughput of token generation for a sustained output.
-
-
Run tests with different levels of model quantization (e.g., 8-bit) to assess performance trade-offs.
-
Methodology: Molecular Dynamics (MD) Simulation
This protocol is based on common practices in computational drug discovery.[16]
-
System Configuration: As described in 5.1.
-
Software Stack:
-
MD Engine: GROMACS, AMBER, or NAMD (GPU-accelerated versions).
-
Visualization: VMD or PyMOL.
-
System Preparation: Standard molecular modeling software (e.g., Maestro, ChimeraX).
-
-
Experimental Procedure:
-
System Setup: Prepare a biomolecular system (e.g., a target protein embedded in a lipid bilayer with solvent and ions). System sizes can range from 100,000 to 300,000 atoms to test the limits of the 32GB VRAM.[16]
-
Minimization & Equilibration: Perform energy minimization followed by NVT (constant volume) and NPT (constant pressure) equilibration phases to stabilize the system.
-
Production Run: Execute a production MD simulation for a defined period (e.g., 100 nanoseconds).
-
Performance Measurement: The primary metric is simulation throughput, measured in nanoseconds per day (ns/day) .
-
Analysis: Compare the ns/day performance of the RTX 5090 against other GPUs for the same molecular system.
-
Visualizations: Workflows and Logical Relationships
The following diagrams illustrate key concepts for integrating the RTX 5090 into a research computing environment.
Caption: GPU-accelerated drug discovery workflow.
Caption: RTX 5090 vs. RTX PRO 6000 for research.
Caption: GPU selection flowchart for research workloads.
Conclusion and Recommendation
The NVIDIA GeForce RTX 5090 is a transformative piece of hardware that significantly lowers the barrier to entry for high-performance computing. Its raw computational power, especially in AI and single-precision tasks, is undeniable.[1][17]
-
For Critical, High-Precision Simulations: For long-running molecular dynamics simulations where results contribute to clinical decisions, or for quantum mechanical calculations demanding high precision and data integrity, the lack of ECC memory and certified drivers makes the RTX 5090 a riskier proposition. In these scenarios, a professional card like the RTX PRO 6000, despite its higher cost, is the more appropriate tool.[12]
Ultimately, the RTX 5090 is highly suitable for HPC clusters in research and drug development, provided its role is clearly defined. It excels as a high-density compute solution for exploratory research, AI model development, and visualization. However, for final validation and mission-critical simulations, it should be complemented by professional-grade GPUs that guarantee the highest level of reliability and data integrity.
References
- 1. box.co.uk [box.co.uk]
- 2. medium.com [medium.com]
- 3. notebookcheck.net [notebookcheck.net]
- 4. Weights & Biases [wandb.ai]
- 5. The Engine Behind AI Factories | NVIDIA Blackwell Architecture [nvidia.com]
- 6. neoxcomputers.co.uk [neoxcomputers.co.uk]
- 7. NVIDIA Blackwell GeForce RTX 50 Series Opens New World of AI Computer Graphics | NVIDIA Newsroom [nvidianews.nvidia.com]
- 8. newegg.com [newegg.com]
- 9. NVIDIA GeForce RTX 5090 Founders Edition Review - The New Flagship | TechPowerUp [techpowerup.com]
- 10. NVIDIA GeForce RTX 5090 Specs | TechPowerUp GPU Database [techpowerup.com]
- 11. pcgamer.com [pcgamer.com]
- 12. RTX PRO 6000 vs RTX 5090: Which GPU Leads the Next Era? [newegg.com]
- 13. xda-developers.com [xda-developers.com]
- 14. vast.ai [vast.ai]
- 15. reddit.com [reddit.com]
- 16. Reddit - The heart of the internet [reddit.com]
- 17. Nvidia GeForce RTX 5090 review: Brutally fast, but DLSS 4 is the game changer | PCWorld [pcworld.com]
- 18. pugetsystems.com [pugetsystems.com]
The Future of Large-Scale Data Analysis: A Technical Deep Dive into 32GB GDDR7 Memory
For Researchers, Scientists, and Drug Development Professionals
The relentless growth of data in scientific research, from genomics to molecular modeling, demands computational hardware that can keep pace. The advent of 32GB GDDR7 memory marks a pivotal moment, offering unprecedented speed and capacity for handling massive datasets. This guide explores the core technical advancements of GDDR7 and its transformative potential in accelerating large-scale data analysis, with a focus on applications in research and drug development.
GDDR7: A Generational Leap in Memory Performance
Graphics Double Data Rate 7 (GDDR7) is the next evolution in high-performance memory, engineered to eliminate data bottlenecks that can hinder complex computational workloads. Its key innovations lie in significantly higher bandwidth, improved power efficiency, and increased density, making it an ideal solution for memory-intensive applications.
Quantitative Comparison: GDDR7 vs. GDDR6
The table below summarizes the key performance metrics of GDDR7 compared to its predecessor, GDDR6, highlighting the substantial advancements of the new technology.
| Feature | GDDR6 | GDDR7 |
| Peak Bandwidth per Pin | Up to 24 Gbps[1] | Initially 32 Gbps, with a roadmap to 48 Gbps[2][3] |
| Signaling Technology | NRZ (Non-Return-to-Zero) | PAM3 (Pulse Amplitude Modulation, 3-level)[1][4] |
| System Bandwidth (Theoretical) | Up to 1.1 TB/s | Over 1.5 TB/s[5][6][7] |
| Operating Voltage | 1.25V - 1.35V | 1.1V - 1.2V[2][5] |
| Power Efficiency | Baseline | Over 50% improvement in power efficiency over GDDR6[8] |
| Maximum Density | 16Gb | 32Gb and higher[9] |
Hypothetical Experimental Protocol: Large-Scale Genomic Data Analysis
The high bandwidth and 32GB capacity of GDDR7 can dramatically accelerate genomic workflows, which are often bottlenecked by the sheer volume of data.
Objective: To perform variant calling and downstream analysis on a cohort of 100 whole-genome sequencing (WGS) samples.
Methodology:
-
Data Loading and Pre-processing:
-
Raw sequencing data (FASTQ files) for 100 samples, each approximately 100GB, are loaded from high-speed NVMe storage into the 32GB GDDR7 memory of a GPU-accelerated system.
-
The high data transfer rate of GDDR7 allows for rapid loading of these large files, minimizing I/O wait times.
-
Initial quality control and adapter trimming are performed in parallel on the GPU, leveraging its massive core count.
-
-
Alignment to Reference Genome:
-
The pre-processed reads are aligned to a human reference genome (e.g., GRCh38) using a GPU-accelerated aligner like BWA-MEM2.
-
The entire reference genome and the reads for multiple samples can be held in the 32GB GDDR7 memory, reducing the need for slower system RAM access and enabling faster alignment.
-
-
Variant Calling:
-
The aligned reads (BAM files) are processed with a GPU-accelerated variant caller such as NVIDIA's Parabricks.
-
The high bandwidth of GDDR7 is crucial here, as the variant caller needs to perform random access reads across the large alignment files to identify genetic variations.
-
-
Joint Genotyping and Annotation:
-
Variants from all 100 samples are jointly genotyped to improve accuracy. This process is highly memory-intensive, and the 32GB capacity of GDDR7 allows for larger cohorts to be processed simultaneously.
-
The resulting VCF file is annotated with information from large databases (e.g., dbSNP, ClinVar), which can be pre-loaded into the GDDR7 memory for rapid lookups.
-
Workflow Diagram: Genomics Analysis
Caption: Genomics analysis workflow accelerated by 32GB GDDR7 memory.
Hypothetical Experimental Protocol: High-Throughput Virtual Screening for Drug Discovery
Molecular dynamics simulations and virtual screening are critical in modern drug discovery but are computationally demanding. GDDR7 can significantly reduce the time to results.
Objective: To screen a library of 1 million small molecules against a target protein to identify potential drug candidates.
Methodology:
-
System Preparation:
-
The 3D structure of the target protein is loaded into the 32GB GDDR7 memory.
-
The small molecule library is also loaded. The large capacity of GDDR7 allows for a significant portion of the library to be held in memory, reducing I/O overhead.
-
-
Molecular Docking:
-
A GPU-accelerated docking program (e.g., AutoDock-GPU) is used to predict the binding orientation of each small molecule in the active site of the protein.
-
The high bandwidth of GDDR7 enables rapid access to the protein structure and the parameters for each small molecule, allowing for a high throughput of docking calculations.
-
-
Molecular Dynamics (MD) Simulation:
-
The most promising protein-ligand complexes identified from docking are subjected to short MD simulations to evaluate their stability.
-
GPU-accelerated MD engines like AMBER or GROMACS can leverage the 32GB GDDR7 to simulate larger and more complex systems. The high memory bandwidth is essential for the frequent updates of particle positions and forces.
-
-
Binding Free Energy Calculation:
-
For the most stable complexes, more computationally intensive methods like MM/PBSA or free energy perturbation are used to calculate the binding free energy.
-
These calculations are highly parallelizable and benefit from the ability of GDDR7 to quickly feed the GPU cores with the necessary data from the MD trajectories.
-
Workflow Diagram: Drug Discovery Virtual Screening
Caption: High-throughput virtual screening workflow for drug discovery.
Signaling Pathways and Logical Relationships
The advancements in computational power enabled by 32GB GDDR7 memory can also facilitate the analysis of complex biological systems, such as signaling pathways. By allowing for more comprehensive simulations and the integration of multi-omics data, researchers can build more accurate models of cellular processes.
Diagram: Simplified MAPK Signaling Pathway Analysis
Caption: Analysis of the MAPK signaling pathway using integrated multi-omics data.
Conclusion
The introduction of 32GB GDDR7 memory represents a significant milestone for computational research. Its high bandwidth, increased capacity, and improved power efficiency will empower researchers, scientists, and drug development professionals to tackle larger and more complex problems. By reducing data bottlenecks and enabling more sophisticated simulations and analyses, GDDR7 is poised to accelerate the pace of discovery and innovation across a wide range of scientific disciplines. The adoption of this technology in next-generation GPUs, such as the upcoming NVIDIA RTX 50 series[3][10], will make these capabilities more accessible to the broader research community.
References
- 1. What are the advantages of using GDDR7 memory over GDDR6 in a high-performance computing application? - Massed Compute [massedcompute.com]
- 2. rambus.com [rambus.com]
- 3. tomshardware.com [tomshardware.com]
- 4. semiengineering.com [semiengineering.com]
- 5. GDDR7 SDRAM - Wikipedia [en.wikipedia.org]
- 6. investors.micron.com [investors.micron.com]
- 7. GDDR7 - the next generation of graphics memory | Micron Technology Inc. [micron.com]
- 8. assets.micron.com [assets.micron.com]
- 9. community.cadence.com [community.cadence.com]
- 10. GeForce RTX 50 series - Wikipedia [en.wikipedia.org]
NVIDIA RTX 5090: A Technical Deep Dive into its Generative AI Core for Scientific and Drug Discovery Applications
For Researchers, Scientists, and Drug Development Professionals
The NVIDIA RTX 5090, powered by the groundbreaking Blackwell architecture, represents a significant leap forward in computational power, particularly for generative AI workloads that are becoming increasingly central to scientific research and drug development. This technical guide explores the core capabilities of the RTX 5090, focusing on its performance in generative AI tasks, the underlying architectural innovations, and detailed methodologies for reproducing key performance benchmarks.
Core Architectural Innovations of the Blackwell GPU
The Blackwell architecture, at the heart of the RTX 5090, introduces several key technologies designed to accelerate generative AI. These advancements provide substantial performance gains and new capabilities for researchers working with complex models in fields like molecular dynamics, protein folding, and drug discovery.
The second-generation Transformer Engine further enhances performance by intelligently managing and optimizing the precision of calculations on the fly.[2] This engine, combined with NVIDIA's TensorRT™-LLM and NeMo™ Framework, accelerates both inference and training for large language models (LLMs) and Mixture-of-Experts (MoE) models.[2]
The data flow for a generative AI inference task leveraging these new features can be conceptualized as a streamlined pipeline. Input data is fed into the model, where the Transformer Engine dynamically selects the optimal precision for different layers. The fifth-generation Tensor Cores then execute the matrix-multiply-accumulate operations at high speed, leveraging FP4 where possible to maximize throughput and minimize memory access. The results are then passed through the subsequent layers of the neural network to generate the final output.
References
DLSS 4 for Scientific Visualization: A Technical Introduction
An In-depth Guide for Researchers, Scientists, and Drug Development Professionals
NVIDIA's Deep Learning Super Sampling (DLSS) has emerged as a transformative technology in real-time rendering, primarily within the gaming industry. However, the latest iteration, DLSS 4, with its fundamentally new AI architecture, presents a compelling case for its application in computationally intensive scientific visualization tasks. This guide provides a technical overview of the core components of DLSS 4, exploring its potential to accelerate workflows and enhance visual fidelity for researchers, scientists, and professionals in drug development. While concrete benchmarks in scientific applications are still emerging, this paper will extrapolate from existing data to present a forward-looking perspective on how DLSS 4 can revolutionize the visualization of complex scientific datasets.
Core Technologies of DLSS 4
DLSS 4 represents a significant leap from its predecessors, primarily due to its adoption of a transformer-based AI model . This marks a departure from the Convolutional Neural Networks (CNNs) used in previous versions. Transformers are renowned for their ability to capture long-range dependencies and contextual relationships within data, a capability that translates to more robust and accurate image reconstruction.[1][2] This new architecture underpins the two primary pillars of DLSS 4: Super Resolution and Ray Reconstruction , and introduces a novel feature called Multi-Frame Generation .
Super Resolution and Ray Reconstruction: The Power of the Transformer Model
The new transformer model in DLSS 4 significantly enhances the capabilities of Super Resolution and Ray Reconstruction.[1][2] For scientific visualization, this translates to the ability to render large and complex datasets at lower resolutions and then intelligently upscale them to high resolutions, preserving intricate details while maintaining interactive frame rates.
The transformer architecture allows the AI to better understand the spatial and temporal relationships within a rendered scene.[3][1] This leads to a number of key improvements relevant to scientific visualization:
-
Enhanced Detail Preservation: The model can more accurately reconstruct fine details in complex structures, such as molecular bonds or intricate cellular components.
-
Improved Temporal Stability: When exploring dynamic simulations, the transformer model reduces flickering and ghosting artifacts that can occur with fast-moving elements.
-
Superior Handling of Translucency and Volumetric Effects: The model's ability to understand global scene context can lead to more accurate rendering of translucent surfaces and volumetric data, which are common in biological and medical imaging.
Multi-Frame Generation: A Paradigm Shift in Performance
Exclusive to the GeForce RTX 50 series and subsequent architectures, Multi-Frame Generation is a revolutionary technique that generates multiple intermediate frames for each rendered frame.[1] This is achieved by a sophisticated AI model that analyzes motion vectors and optical flow to predict and create entirely new frames. For scientific visualization, this can lead to a dramatic increase in perceived smoothness and interactivity, especially when dealing with very large datasets that would otherwise be rendered at low frame rates.
Potential Applications in Scientific and Drug Development Workflows
The advancements in DLSS 4 have the potential to significantly impact various stages of the scientific research and drug development pipeline:
-
Molecular Dynamics and Structural Biology: Interactively visualizing large biomolecular complexes, such as proteins and viruses, is crucial for understanding their function. DLSS 4 could enable researchers to explore these structures in high resolution and at fluid frame rates, facilitating the identification of binding sites and the analysis of molecular interactions.
-
Volumetric Data Visualization: Medical imaging techniques like MRI and CT scans, as well as microscopy data, generate large volumetric datasets. DLSS 4 can accelerate the rendering of this data, allowing for real-time exploration and analysis of anatomical structures and cellular processes.
-
Computational Fluid Dynamics (CFD) and Simulation: Visualizing the results of complex simulations, such as blood flow in arteries or airflow over a surface, often requires significant computational resources. DLSS 4 could provide a pathway to interactive visualization of these simulations, enabling researchers to gain insights more quickly.
Quantitative Data and Performance Metrics
While specific benchmarks for DLSS 4 in scientific visualization applications are not yet widely available, we can look at the performance gains observed in the gaming industry to understand its potential. The following tables summarize the performance improvements seen in demanding real-time rendering scenarios. It is important to note that these are for illustrative purposes and the actual performance gains in scientific applications will depend on the specific software and dataset.
Table 1: Illustrative Performance Gains with DLSS 4 Multi-Frame Generation (Gaming Scenarios)
| Game/Engine | Resolution | Settings | Native Rendering (FPS) | DLSS 4 with Multi-Frame Generation (FPS) | Performance Uplift |
| Cyberpunk 2077 | 4K | Max, Ray Tracing: Overdrive | ~25 | ~150 | ~6x |
| Alan Wake 2 | 4K | Max, Path Tracing | ~30 | ~180 | ~6x |
| Unreal Engine 5 Demo | 4K | High, Lumen | ~40 | ~240 | ~6x |
Note: Data is aggregated from various gaming-focused technology reviews and is intended to be illustrative of the potential performance gains.
Table 2: DLSS 4 Technical Specifications and Improvements
| Feature | DLSS 3.5 (CNN Model) | DLSS 4 (Transformer Model) | Key Advantage for Scientific Visualization |
| AI Architecture | Convolutional Neural Network (CNN) | Transformer | Improved understanding of global context and long-range dependencies, leading to better detail preservation. |
| Frame Generation | Single Frame Generation | Multi-Frame Generation (up to 3 additional frames) | Dramatically smoother and more interactive visualization of large datasets. |
| Ray Reconstruction | AI-based denoiser | Enhanced by Transformer model | More accurate and stable rendering of complex lighting and transparent structures. |
| Hardware Requirement | GeForce RTX 20/30/40 Series | Super Resolution/Ray Reconstruction: RTX 20/30/40/50 Series; Multi-Frame Generation: RTX 50 Series and newer | Access to foundational AI upscaling on a wider range of hardware, with the most significant performance gains on the latest generation. |
Experimental Protocols and Methodologies
As the adoption of DLSS 4 in the scientific community is still in its early stages, standardized experimental protocols for its evaluation are yet to be established. However, a robust methodology for assessing its impact on a given scientific visualization workflow would involve the following steps:
-
Baseline Performance Measurement: Render a representative dataset using the native rendering capabilities of the visualization software (e.g., VMD, ChimeraX, ParaView) and record key performance metrics such as frames per second (FPS), frame time, and memory usage.
-
DLSS 4 Integration and Configuration: If the software supports DLSS 4, enable it and test different quality modes (e.g., Quality, Balanced, Performance, Ultra Performance).
-
Performance Benchmarking with DLSS 4: Repeat the performance measurements from step 1 with DLSS 4 enabled for each quality mode.
-
Qualitative Image Quality Analysis: Visually inspect the rendered output from both native rendering and DLSS 4 to assess for any artifacts, loss of detail, or other visual discrepancies. This is particularly important for scientific accuracy.
-
Task-Specific Workflow Evaluation: Assess the impact of DLSS 4 on the interactivity and efficiency of specific research tasks, such as identifying a ligand-binding pocket in a protein or tracking a feature in a time-varying volumetric dataset.
Signaling Pathways and Logical Relationships in DLSS 4
To better understand the inner workings of DLSS 4, the following diagrams, generated using the DOT language, illustrate the key logical flows.
Caption: Workflow of DLSS 4 Super Resolution.
Caption: Workflow of DLSS 4 Multi-Frame Generation.
Conclusion and Future Outlook
DLSS 4 stands as a testament to the power of AI in revolutionizing real-time computer graphics. While its immediate impact is being felt in the gaming world, its core technologies hold immense promise for the scientific community. The transition to a transformer-based architecture and the introduction of Multi-Frame Generation are not merely incremental updates; they represent a fundamental shift in how we can approach the visualization of large and complex scientific data.
For researchers, scientists, and drug development professionals, DLSS 4 offers a potential pathway to more interactive, intuitive, and insightful exploration of their data. As scientific visualization software begins to integrate and optimize for this technology, we can expect to see a new era of accelerated discovery, where the boundaries of what can be visualized and understood are pushed further than ever before. The coming years will be crucial in realizing this potential, as the scientific community begins to develop the necessary benchmarks, case studies, and best practices for leveraging DLSS 4 in their research.
References
Methodological & Application
RTX 5090 in molecular dynamics and protein folding research.
Disclaimer: The NVIDIA GeForce RTX 5090 has not been officially released as of the time of this writing. The following application notes, protocols, and performance projections are based on rumored specifications and expected technological advancements from the underlying "Blackwell" architecture. This document is intended for informational and planning purposes for the research community and should be treated as a forward-looking analysis.
Introduction
This document provides detailed application notes and experimental protocols for leveraging the projected capabilities of the RTX 5090. It is designed for researchers, computational biologists, and drug development professionals seeking to understand and prepare for the impact of this next-generation hardware on their research workflows.
Section 1: Anticipated Architectural Advancements and Performance Projections
Data Presentation: Comparative Hardware Specifications
The following table summarizes the widely rumored specifications of the RTX 5090 compared to the established RTX 4090.
| Feature | NVIDIA GeForce RTX 4090 | NVIDIA GeForce RTX 5090 (Projected) | Potential Impact on Research |
| GPU Architecture | Ada Lovelace | Blackwell | Enhanced efficiency, new instruction sets for scientific computing. |
| CUDA Cores | 16,384[6] | ~20,000 - 24,000+[7][8] | Faster parallel processing for MD force calculations. |
| Memory (VRAM) | 24 GB GDDR6X[6] | 32 GB GDDR7[7][9] | Simulation of significantly larger biomolecular systems. |
| Memory Interface | 384-bit | 512-bit (rumored)[7] | Reduced data transfer bottlenecks for atom coordinate updates. |
| Memory Bandwidth | ~1,008 GB/s | ~1,792 - 2,000 GB/s (rumored)[7][8] | Dramatic speedup in simulations where memory access is the limiting factor. |
| Tensor Cores | 4th Generation | 5th Generation (with FP4/FP8 support)[3][5] | Exponentially faster AI inference for protein folding (AlphaFold) and generative models. |
| Power Consumption | 450W TDP | ~600W TDP (rumored)[7][8] | Requires significant consideration for power and cooling infrastructure. |
Section 2: Application Note: Accelerating Large-Scale Molecular Dynamics
Molecular dynamics simulations are fundamental to understanding the conformational changes, binding affinities, and dynamic behavior of proteins and other biomolecules. The primary bottleneck in these simulations is often the sheer number of pairwise force calculations and the communication of atomic data.
The projected specifications of the RTX 5090 directly address these challenges. The substantial increase in memory bandwidth is expected to accelerate the data-intensive steps of the simulation, while the larger 32 GB VRAM buffer will enable researchers to simulate larger, more biologically relevant systems—such as entire viral capsids or membrane-embedded protein complexes—without resorting to complex multi-GPU setups, which can introduce communication overhead.[6]
Diagram: Molecular Dynamics Simulation Workflow
Data Presentation: Projected GROMACS Performance
This table projects the potential performance of the RTX 5090 on standard GROMACS benchmarks, extrapolating from known RTX 4090 performance data.[10][11] The metric ns/day indicates how many nanoseconds of simulation time can be computed in a 24-hour period.
| Benchmark System | Atom Count | RTX 4090 (Actual ns/day) | RTX 5090 (Projected ns/day) | Projected Speedup |
| ADH Dodecamer | ~2.4M | ~65 ns/day | ~100-115 ns/day | ~1.6x |
| STMV | ~1M | ~130 ns/day | ~200-220 ns/day | ~1.6x |
| Cellulose | ~408k | ~250 ns/day | ~380-420 ns/day | ~1.6x |
Note: Projections assume a ~60% performance uplift based on architectural improvements. Actual performance will vary based on the specific simulation system, software version, and system configuration.
Section 3: Protocol: High-Throughput MD Simulation with GROMACS
This protocol outlines the steps for running a standard protein-ligand simulation using GROMACS, with considerations for the RTX 5090.
Objective: To simulate the dynamics of a protein-ligand complex in an explicit solvent to assess binding stability.
Software: GROMACS (version 2024 or later recommended for best hardware support)[12]
Hardware: Workstation equipped with an NVIDIA RTX 5090 GPU.
Methodology:
-
System Preparation:
-
Obtain PDB files for your protein and ligand.
-
Use a tool like pdb2gmx to generate a force field-compliant topology for the protein.
-
Generate ligand topology and parameters (e.g., using CGenFF or an equivalent server).
-
Combine the protein and ligand into a single complex.
-
-
Solvation and Ionization:
-
Create a simulation box using gmx editconf. The large VRAM of the RTX 5090 allows for a more generous solvent buffer, reducing potential periodic boundary condition artifacts.
-
Solvate the box with water using gmx solvate.
-
Add ions to neutralize the system and achieve physiological concentration using gmx genion.
-
-
Energy Minimization:
-
Create a GROMACS parameter file (.mdp) for steepest descent energy minimization.
-
Run the minimization using gmx grompp to assemble the binary .tpr file and gmx mdrun to execute. This step removes steric clashes.
-
-
System Equilibration (NVT and NPT):
-
NVT (Constant Volume) Equilibration: Run a short simulation (e.g., 1 ns) with position restraints on heavy atoms to allow the solvent to equilibrate around the protein.
-
NPT (Constant Pressure) Equilibration: Run a subsequent simulation (e.g., 5-10 ns) to equilibrate the system's pressure and density to target values.
-
-
Production MD Run:
-
Create the final .mdp file for the production run.
-
Use gmx grompp to create the production .tpr file from the final equilibrated state.
-
Execute the production run. The high memory bandwidth of the RTX 5090 is critical at this stage. Use the following command to ensure all key calculations are offloaded to the GPU:
-
The -nb gpu flag offloads non-bonded force calculations, -pme gpu offloads the PME long-range electrostatics, and -update gpu keeps atom coordinates on the GPU, minimizing CPU-GPU data transfer.[12]
-
-
Analysis:
-
Post-process the trajectory (.xtc file) to analyze RMSD, RMSF, hydrogen bonds, and other properties of interest.
-
Section 4: Application Note: Advancing AI-Based Protein Folding
AI models like AlphaFold have revolutionized structural biology.[13][14] The performance of these deep learning systems is heavily dependent on the underlying GPU's AI inference capabilities, particularly its Tensor Cores.
The anticipated 5th Generation Tensor Cores in the RTX 5090, with native support for new low-precision formats like FP4, are poised to deliver a monumental leap in performance.[5][15] This could reduce the time-to-solution for protein structure prediction from hours to minutes, enabling high-throughput structural genomics and the rapid modeling of large protein complexes or entire proteomes. The larger 32 GB VRAM will also be crucial for accommodating larger and more complex protein structure models without memory overflow errors.[16]
Diagram: GPU Features Impacting Protein Folding
References
- 1. tandfonline.com [tandfonline.com]
- 2. Accelerated Computing Holds the Key to Democratized Drug Discovery | NVIDIA Technical Blog [developer.nvidia.com]
- 3. The Engine Behind AI Factories | NVIDIA Blackwell Architecture [nvidia.com]
- 4. Weights & Biases [wandb.ai]
- 5. images.nvidia.com [images.nvidia.com]
- 6. bizon-tech.com [bizon-tech.com]
- 7. tweaktown.com [tweaktown.com]
- 8. wepc.com [wepc.com]
- 9. GeForce RTX 5090 Graphics Cards | NVIDIA [nvidia.com]
- 10. NVIDIA RTX 4090 Benchmark GROMACS 2022.3 [exxactcorp.com]
- 11. Performance benchmarks for mainstream molecular dynamics simulation Apps on consumer GPUs from AMD, NVIDIA and Intel - Switch to AMD [Part Ⅰ] - Entropy Space [blog.enthalpy.space]
- 12. GROMACS on cloud GPUs: RTX 4090 quickstart & selfâbenchmark | Hivenet [compute.hivenet.com]
- 13. Exxact | Deep Learning, HPC, AV, Distribution & More [exxactcorp.com]
- 14. How to Run Alphafold | AF in Biology & Medicine | SabrePC Blog [sabrepc.com]
- 15. acecloud.ai [acecloud.ai]
- 16. indico.psi.ch [indico.psi.ch]
Revolutionizing Genomics: Real-Time Data Processing with the NVIDIA RTX 5090
Application Notes and Protocols for Researchers, Scientists, and Drug Development Professionals
The advent of the NVIDIA RTX 5090, powered by the Blackwell architecture, marks a significant leap forward in computational power, offering unprecedented opportunities for real-time data processing in genomics. This document provides detailed application notes and protocols for leveraging this technology to accelerate key genomics workflows, enabling faster insights and discoveries in research and drug development.
Introduction to the NVIDIA RTX 5090 in Genomics
The NVIDIA RTX 5090, with its substantial increase in CUDA and Tensor cores, along with a significant boost in memory bandwidth, is poised to redefine the landscape of genomic data analysis.[1] These architectural advancements are particularly beneficial for the highly parallelizable nature of genomics algorithms, promising to dramatically reduce the time required for complex analyses. The move to the Blackwell architecture is anticipated to offer up to twice the performance of the previous generation in certain applications.
Key Architectural Advancements:
-
Blackwell Architecture: The successor to the Ada Lovelace and Hopper microarchitectures, the Blackwell architecture is purpose-built for AI and accelerated computing, introducing significant improvements in performance and energy efficiency.[2][3]
-
Enhanced Core Counts: The RTX 5090 is expected to feature a significant increase in both CUDA and Tensor cores compared to its predecessors, enabling greater parallel processing capabilities crucial for genomics.[1]
-
Next-Generation Memory: The adoption of GDDR7 memory and a wider memory bus will provide a substantial boost in memory bandwidth, a critical factor for handling the large datasets common in genomics.
Quantitative Performance Projections
The following tables provide a comparative overview of the NVIDIA RTX 5090's specifications against previous-generation high-performance GPUs and project its performance in key genomics applications. Projections are based on architectural improvements and existing benchmarks of older hardware.
Table 1: Comparative GPU Specifications
| Feature | NVIDIA RTX 3090 (Ampere) | NVIDIA RTX 4090 (Ada Lovelace) | NVIDIA A100 (Ampere) | NVIDIA RTX 5090 (Blackwell) |
| CUDA Cores | 10,496 | 16,384 | 6,912 | 21,760[4][5][6] |
| Tensor Cores | 328 (3rd Gen) | 512 (4th Gen) | 432 (3rd Gen) | 680 (5th Gen)[5] |
| Memory | 24 GB GDDR6X | 24 GB GDDR6X | 40/80 GB HBM2e | 32 GB GDDR7[4][5][6] |
| Memory Bandwidth | 936 GB/s | 1,008 GB/s | ~2 TB/s | 1,792 GB/s[5] |
| FP32 Performance | ~35.6 TFLOPS | ~82.6 TFLOPS | ~19.5 TFLOPS | ~104.8 TFLOPS[7] |
| Power Consumption | 350 W | 450 W | 250-300 W | 575 W[4][5][6] |
Table 2: Projected Performance in Real-Time Genomics Workflows
| Workflow | CPU-based (Baseline) | NVIDIA A100 (80GB) | NVIDIA RTX 4090 (24GB) | NVIDIA RTX 5090 (32GB) (Projected) |
| Whole Genome Germline Variant Calling (30x coverage) | ~30 hours | ~25 minutes | ~18 minutes | ~10-12 minutes |
| Somatic Variant Calling (Tumor-Normal WGS) | ~24 hours | ~22 minutes | ~15 minutes | ~8-10 minutes |
| Single-Cell RNA-Seq Analysis (1.3M cells) | ~4.5 hours | ~6 minutes | ~4 minutes | ~2-3 minutes |
Projections for the RTX 5090 are estimates based on architectural improvements and may vary depending on the specific dataset and software optimizations.
Experimental Protocols for Real-Time Genomics
The following protocols are designed to be executed on a Linux-based system with the NVIDIA RTX 5090 and the NVIDIA Clara Parabricks software suite installed.
Protocol 1: Real-Time Germline Variant Calling
This protocol outlines the steps for identifying single nucleotide polymorphisms (SNPs) and small insertions/deletions (indels) in a whole genome sample.
Methodology:
-
Data Preparation: Ensure FASTQ files (sample_1.fq.gz, sample_2.fq.gz), a reference genome FASTA file (ref.fa), and a known sites VCF file (known_sites.vcf.gz) are available.
-
Execute Parabricks fq2bam: This step performs alignment of the FASTQ reads to the reference genome and generates a BAM file.
-
Execute Parabricks deepvariant: This step uses a deep learning model to call variants from the aligned reads in the BAM file.
Protocol 2: Real-Time Somatic Variant Calling
This protocol details the process for identifying genetic mutations in a tumor sample by comparing it to a matched normal sample.
Methodology:
-
Data Preparation: Have paired-end FASTQ files for both the tumor (tumor_1.fq.gz, tumor_2.fq.gz) and normal (normal_1.fq.gz, normal_2.fq.gz) samples, along with the reference genome and known sites files.
-
Execute Parabricks somatic pipeline: This comprehensive command runs alignment and multiple somatic variant callers.
Protocol 3: Real-Time Single-Cell RNA-Seq Analysis
This protocol provides a workflow for the initial processing and clustering of single-cell RNA sequencing data.
Methodology:
-
Data Preparation: Start with a count matrix file (e.g., in Market Matrix format) from a single-cell RNA-seq experiment.
-
Utilize RAPIDS libraries: The RAPIDS suite of libraries, particularly cuDF and cuML, will be used for data manipulation, dimensionality reduction, and clustering on the GPU. This example uses a Python script.
Visualization of Signaling Pathways and Workflows
The following diagrams, generated using the DOT language, illustrate key signaling pathways relevant to genomics and drug development, as well as the experimental workflows described above.
Caption: Germline variant calling workflow using NVIDIA Parabricks.
References
- 1. GitHub - clara-parabricks-workflows/parabricks-nextflow: Accelerated genomics workflows in NextFlow [github.com]
- 2. GitHub - Sydney-Informatics-Hub/Parabricks-Genomics-nf: Scalable Nextflow implementation of germline alignment and short variant calling with Parabricks for NCI Gadi HPC. [github.com]
- 3. somatic (Somatic Variant Caller) - NVIDIA Docs [docs.nvidia.com]
- 4. GPU-Accelerated Single-Cell RNA Analysis with RAPIDS-singlecell | NVIDIA Technical Blog [developer.nvidia.com]
- 5. BioInfoRx [bioinforx.com]
- 6. Benchmarking NVIDIA Clara Parabricks Somatic Variant Calling Pipeline on AWS | AWS HPC Blog [aws.amazon.com]
- 7. Benchmarking Alignment and Variant Calling for Whole Genome Data from Complete Genomics using NVIDIA Parabricks on AWS - NVIDIA Docs [docs.nvidia.com]
Application Notes & Protocols: Applying Neural Rendering with the NVIDIA RTX 5090 in Medical Imaging
For: Researchers, Scientists, and Drug Development Professionals
Abstract: Neural rendering, particularly techniques like Neural Radiance Fields (NeRF), is poised to revolutionize medical imaging by generating highly detailed and interactive 3D visualizations from standard 2D medical scans.[1][2] This technology offers unprecedented opportunities for surgical planning, medical education, and computational drug discovery.[3][4] The advent of next-generation GPUs, such as the forthcoming NVIDIA RTX 5090, is expected to overcome current computational bottlenecks, enabling real-time performance and the use of full-resolution datasets. This document provides detailed application notes and experimental protocols for leveraging the projected power of the RTX 5090 for neural rendering in medical contexts.
Disclaimer: The NVIDIA RTX 5090 is a forward-looking product based on publicly available rumors and technical projections. The performance metrics and capabilities described herein are extrapolations based on the expected advancements of the Blackwell GPU architecture over previous generations.[5][6]
Introduction to Neural Rendering in Medicine
Neural rendering uses deep learning models to synthesize novel, photorealistic views of a 3D scene from a sparse set of input images.[2] In the medical field, this involves training a neural network, typically a Multi-Layer Perceptron (MLP), to learn a continuous volumetric representation of a patient's anatomy from CT, MRI, or X-ray scans.[1][7] The network effectively learns to map 3D spatial coordinates to color and density, allowing for the rendering of intricate internal structures from any viewpoint.[8]
Key Advantages:
-
High-Fidelity Reconstruction: Creates smoother, more detailed, and continuous 3D representations than traditional methods.[1]
-
Sparse-View Reconstruction: Can generate high-quality 3D models from fewer scans, which has the potential to reduce patient exposure to ionizing radiation.[2][9][10]
-
View-Dependent Effects: Accurately captures complex light and tissue interactions, which is crucial for realistic visualization.[1]
The primary limitation has been the immense computational cost associated with training these models and rendering images in real-time. The architectural advancements anticipated with the NVIDIA RTX 5090 are set to directly address these challenges.
The Projected NVIDIA RTX 5090 Advantage
Projected Architectural Benefits:
-
Enhanced Tensor Cores (5th Gen): Tensor cores are specialized for the matrix operations that form the backbone of neural network training and inference.[3][12] The next-generation cores are expected to dramatically accelerate the training of NeRF models and enable real-time rendering performance.
-
Increased VRAM and Bandwidth (32 GB GDDR7): Medical imaging datasets are massive. The projected 32 GB of high-speed GDDR7 memory will allow researchers to train models on high-resolution volumetric data (e.g., 512x512x512 voxels or higher) without the need for downsampling or complex data tiling, preserving critical anatomical detail.[5][12]
-
Next-Generation RT Cores (4th Gen): While primarily for graphics, RT cores can accelerate the ray-marching and ray-casting operations fundamental to volume rendering, potentially speeding up the final image synthesis process from the trained neural network.[5]
-
Massive Parallel Processing (CUDA Cores): With a rumored count of over 21,000 CUDA cores, the RTX 5090 will be capable of processing the vast number of parallel computations required for neural rendering far more efficiently than its predecessors.[6][13]
Quantitative Data & Performance Projections
The following tables summarize the rumored specifications of the RTX 5090 and project its performance against the current-generation RTX 4090 for a typical medical neural rendering workflow.
Table 1: Comparative GPU Specifications (Projected)
| Feature | NVIDIA GeForce RTX 4090 | NVIDIA GeForce RTX 5090 (Projected) | Advantage for Neural Rendering |
|---|---|---|---|
| GPU Architecture | Ada Lovelace | Blackwell[5] | More efficient processing and new AI-focused instructions. |
| CUDA Cores | 16,384 | 21,760[6][13] | ~33% increase for faster parallel processing during training and rendering. |
| Tensor Cores | 512 (4th Gen) | 680 (5th Gen)[6][12] | Significant speed-up of core AI calculations. |
| VRAM | 24 GB GDDR6X | 32 GB GDDR7[5][12] | Ability to handle larger, higher-resolution medical datasets directly in memory. |
| Memory Bandwidth | 1,008 GB/s | 1,792 GB/s[5][6] | Faster data access, reducing bottlenecks when feeding the model large volumes. |
| TGP (Total Graphics Power) | 450 W | 575 W[6][13] | Higher power budget allows for sustained peak performance. |
Table 2: Projected Performance Comparison - Medical NeRF Task (Task: Training a NeRF model on a 512x512x400 voxel abdominal CT scan)
| Metric | NVIDIA GeForce RTX 4090 (Baseline) | NVIDIA GeForce RTX 5090 (Projected) | Estimated Improvement |
|---|---|---|---|
| Model Training Time | ~ 4.5 hours | ~ 2.5 - 3 hours | 35-45% Faster |
| Real-time Rendering (1080p) | 15-20 FPS | 45-55 FPS | 2.5x - 3x Higher Framerate |
| Mesh Extraction Time | ~ 10 minutes | ~ 5-6 minutes | 40-50% Faster |
Application Notes
Advanced Surgical Planning
Neural rendering enables the creation of patient-specific, photorealistic 3D models from preoperative CT and MRI scans.[14][15] Surgeons can interactively explore complex anatomy, simulate surgical approaches, and identify potential risks on a digital twin of the patient. The RTX 5090's power would allow for these models to be rendered in real-time at high resolution, providing a smooth and intuitive exploration experience, even for extremely detailed structures like vascular networks or complex tumor morphologies.[3][16]
Drug Discovery and Molecular Visualization
Medical Education and Training
Interactive, high-fidelity anatomical models are invaluable for medical education.[20] Neural rendering can create a library of "virtual cadavers" from real patient data, allowing students to perform dissections and study pathologies in a realistic 3D environment without the limitations of physical specimens. The rendering capabilities of the RTX 5090 would support multi-user, VR-based educational platforms for a truly immersive learning experience.
Experimental Protocols
Protocol: 3D Reconstruction of Organ Anatomy from CT Scans
Objective: To train a Neural Radiance Field (NeRF) model to create an interactive 3D model of a specific organ from a patient's DICOM-based CT scan series.
Methodology:
-
Data Acquisition and Pre-processing:
-
Collect DICOM series for the target anatomy (e.g., abdomen, head).
-
Convert the DICOM series into a sequence of 2D image slices (e.g., PNG or TIFF format).
-
Define the camera poses. For axial CT scans, camera positions can be defined programmatically along the Z-axis, with each slice representing a camera view looking at the next.
-
Segment the region of interest (ROI) to reduce training time and focus the model on the relevant anatomy. This can be done manually or with an automated segmentation model.
-
-
Environment Setup (Command Line):
-
NeRF Model Training:
-
Utilize a NeRF implementation suitable for medical data (e.g., a fork of NeRF-PyTorch adapted for volumetric data).
-
Organize the pre-processed images and camera pose data into the required directory structure.
-
Initiate training. The massive VRAM of the RTX 5090 allows for a larger batch_size and N_rand (number of rays per batch), significantly speeding up convergence.
Example Training Command (Hypothetical):
-
--chunk and --netchunk: These values can be significantly increased on an RTX 5090 compared to older cards, maximizing GPU utilization and reducing processing time.
-
-
Rendering and Visualization:
-
Once training is complete (typically after 100,000-200,000 iterations), use the trained model weights to render novel views.
-
Generate a smooth, rotating video of the model or define an interactive camera path for real-time exploration.
-
For integration with other tools, use a marching cubes algorithm to extract a 3D mesh (e.g., .OBJ or .STL file) from the learned density field.
-
Diagrams and Workflows
Diagram 1: Neural Rendering Workflow
Caption: High-level workflow from medical scans to clinical application.
Diagram 2: Core Logic of a Neural Radiance Field
Caption: Simplified data flow through a NeRF model.
Diagram 3: Surgical Decision-Making Pathway
Caption: How neural rendering integrates into surgical planning.
References
- 1. Neural Radiance Fields in Medical Imaging: Challenges and Next Steps [arxiv.org]
- 2. Neural Radiance Fields in Medical Imaging: Challenges and Next Steps [arxiv.org]
- 3. corvalent.com [corvalent.com]
- 4. The Applications of Neural Radiance Fields in Medicine | MC REU Research Exhibition [sites.psu.edu]
- 5. vast.ai [vast.ai]
- 6. notebookcheck.net [notebookcheck.net]
- 7. openaccess.thecvf.com [openaccess.thecvf.com]
- 8. NeRF Applications in Medical Imaging - DLMA: Deep Learning for Medical Applications - BayernCollab [collab.dvb.bayern]
- 9. themoonlight.io [themoonlight.io]
- 10. NeAS: 3D Reconstruction from X-ray Images using Neural Attenuation Surface [arxiv.org]
- 11. pcgamer.com [pcgamer.com]
- 12. NVIDIA GeForce RTX 5090 Specs | TechPowerUp GPU Database [techpowerup.com]
- 13. pcgamer.com [pcgamer.com]
- 14. Trends and Techniques in 3D Reconstruction and Rendering: A Survey with Emphasis on Gaussian Splatting - PMC [pmc.ncbi.nlm.nih.gov]
- 15. auntminnieeurope.com [auntminnieeurope.com]
- 16. 3dsurgical.com [3dsurgical.com]
- 17. Neural Networks for Drug Discovery and Design – Communications of the ACM [cacm.acm.org]
- 18. Expanding Computer-Aided Drug Discovery With New AI Models | NVIDIA Blog [blogs.nvidia.com]
- 19. Application of Deep Neural Network Models in Drug Discovery Programs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 20. mdpi.com [mdpi.com]
A Researcher's Guide to Harnessing Multiple NVIDIA RTX 5090s for Accelerated Deep Learning
Application Notes and Protocols for Researchers, Scientists, and Drug Development Professionals
The advent of NVIDIA's Blackwell architecture and the anticipated release of the GeForce RTX 5090 present a paradigm shift for computationally intensive deep learning applications in research and drug development. This guide provides detailed application notes and experimental protocols for leveraging the power of multiple RTX 5090 GPUs to accelerate model training, handle larger datasets, and tackle more complex scientific challenges.
Note: The specifications for the NVIDIA RTX 5090 are based on publicly available information and leaks as of the time of writing and are subject to change upon official release.
The NVIDIA RTX 5090: A Generational Leap for Deep Learning
The NVIDIA RTX 5090, powered by the Blackwell architecture, is poised to deliver significant performance gains over its predecessors. Key architectural advancements beneficial for deep learning include a second-generation Transformer Engine with support for new precision formats like FP4 and FP8, and fifth-generation Tensor Cores.[1][2] These features are designed to dramatically accelerate the training and inference of large-scale models, which are increasingly prevalent in scientific research.
Anticipated Specifications
The following table summarizes the widely reported specifications of the RTX 5090 in comparison to the previous generation's flagship, the RTX 4090.
| Feature | NVIDIA GeForce RTX 5090 (Anticipated) | NVIDIA GeForce RTX 4090 |
| GPU Architecture | Blackwell | Ada Lovelace |
| CUDA Cores | ~21,760 - 24,576 | 16,384 |
| Tensor Cores | 5th Generation | 4th Generation |
| VRAM | 32 GB GDDR7 | 24 GB GDDR6X |
| Memory Interface | 512-bit | 384-bit |
| Total Graphics Power (TGP) | ~575W - 600W | 450W |
| Interconnect | PCIe 5.0 | PCIe 4.0 |
Preliminary Performance Benchmarks
Building a Multi-GPU Deep Learning Workstation with RTX 5090s
Constructing a stable and efficient multi-GPU system is paramount for maximizing the potential of multiple RTX 5090s. This section outlines the key hardware considerations and a step-by-step protocol for building a deep learning server.
Hardware Selection Protocol
Objective: To select compatible and robust hardware components capable of supporting multiple high-power RTX 5090 GPUs.
Materials:
-
Motherboard: A server-grade or high-end desktop motherboard with sufficient PCIe 5.0 x16 slots. Ensure the motherboard supports PCIe bifurcation to provide adequate bandwidth to each GPU. Look for motherboards designed for multi-GPU configurations.
-
CPU: A CPU with a high core count and sufficient PCIe lanes to support multiple GPUs without bottlenecks. AMD EPYC or Intel Xeon processors are recommended for server builds. For workstations, high-end consumer CPUs with ample PCIe lanes are suitable. A general guideline is to have at least two CPU cores per GPU.
-
RAM: A minimum of 2GB of system RAM for every 1GB of total GPU VRAM. For a system with four RTX 5090s (128GB of VRAM), at least 256GB of system RAM is recommended. ECC RAM is advised for stability in long-running training sessions.
-
Power Supply Unit (PSU): Given the anticipated TGP of around 600W per RTX 5090, a high-wattage, high-efficiency (80 Plus Platinum or Titanium) PSU is critical. For a four-GPU setup, a single 2000W+ PSU or dual 1600W PSUs are recommended to handle the load and transient power spikes.
-
Cooling: A robust cooling solution is non-negotiable. For multi-GPU setups, blower-style GPUs can be advantageous as they exhaust heat directly out of the case. Alternatively, a custom liquid cooling loop for the GPUs is a highly effective, albeit more complex, solution. Ensure the server chassis has excellent airflow.
-
Storage: High-speed NVMe SSDs for the operating system, deep learning frameworks, and active datasets to prevent I/O bottlenecks.
System Assembly Workflow
The following diagram illustrates the logical workflow for assembling a multi-GPU deep learning server.
Software Installation and Configuration Protocol
A correctly configured software stack is essential for leveraging a multi-GPU system. This protocol details the installation of NVIDIA drivers, CUDA Toolkit, cuDNN, and deep learning frameworks.
Objective: To install and configure the necessary software for multi-GPU deep learning.
Procedure:
-
Operating System Installation: Install a stable Linux distribution, such as Ubuntu 22.04 LTS.
-
NVIDIA Driver Installation:
-
Add the official NVIDIA driver repository.
-
Update the package list and install the latest stable proprietary driver.
-
Reboot the system.
-
Verify the installation by running nvidia-smi in the terminal. This command should display a list of all installed RTX 5090 GPUs.
-
-
CUDA Toolkit Installation:
-
Download the appropriate CUDA Toolkit version from the NVIDIA developer website, ensuring compatibility with the installed driver.
-
Follow the official installation instructions. It is recommended to use the runfile or debian package installation method.
-
-
cuDNN Installation:
-
Download the cuDNN library that corresponds to your installed CUDA Toolkit version.
-
Copy the cuDNN header and library files to the respective directories within your CUDA Toolkit installation path.
-
-
Deep Learning Environment Setup:
-
It is highly recommended to use a virtual environment manager like Conda to create isolated environments for different projects.
-
Create a new conda environment.
-
Install your deep learning framework of choice (e.g., PyTorch or TensorFlow) with GPU support. Ensure the framework version is compatible with your CUDA and cuDNN versions.
-
Experimental Protocols for Multi-GPU Deep Learning
With multiple GPUs, you can employ different parallelization strategies to accelerate your deep learning workflows. The two primary methods are data parallelism and model parallelism.
Data Parallelism
Data parallelism is the most common approach where the model is replicated on each GPU, and the data is split into mini-batches, with each GPU processing a portion of the data. This is ideal when the model can fit into the memory of a single GPU.
Protocol for Data Parallelism with PyTorch DistributedDataParallel:
-
Initialize Process Group: Set up the distributed environment to enable communication between GPUs.
-
Create a DistributedSampler: This ensures that each GPU receives a unique subset of the training data.
-
Wrap the Model: Wrap your neural network model with torch.nn.parallel.DistributedDataParallel. This will handle the gradient synchronization across all GPUs.
-
Train the Model: The training loop remains largely the same as for a single GPU, with the DistributedSampler handling the data distribution.
The following diagram illustrates the data parallelism workflow.
Protocol for Data Parallelism with TensorFlow MirroredStrategy:
-
Instantiate MirroredStrategy: Create an instance of tf.distribute.MirroredStrategy().
-
Define Model within Strategy Scope: Place your model definition and compilation within the strategy.scope(). This will automatically replicate the model across all available GPUs.
-
Prepare the Dataset: Use tf.data.Dataset to create your input pipeline. The strategy will handle the automatic sharding of the data across the GPUs.
-
Train the Model: Use the standard model.fit() API. TensorFlow will manage the distributed training in the background.
Model Parallelism
Model parallelism is employed when the model is too large to fit into the memory of a single GPU. In this approach, different parts of the model are placed on different GPUs. This is more complex to implement than data parallelism and often requires careful model architecture design. Hybrid approaches that combine both data and model parallelism are also common for very large models.
Monitoring and Management
Continuous monitoring of your multi-GPU system is crucial for ensuring optimal performance and stability.
-
nvidia-smi: This command-line utility is your primary tool for monitoring GPU status. Regularly check GPU utilization, memory usage, temperature, and power draw. The watch -n 1 nvidia-smi command provides real-time updates.
-
Power Management: The nvidia-smi tool can also be used to set power limits for your GPUs, which can be useful for managing heat and power consumption in dense multi-GPU systems.
-
Cooling: Ensure that your cooling solution is effectively dissipating heat. Monitor GPU temperatures and adjust fan curves or cooling loop settings as needed to prevent thermal throttling.
By following these application notes and protocols, researchers, scientists, and drug development professionals can effectively build and utilize powerful multi-GPU deep learning systems with the next generation of NVIDIA RTX 5090 GPUs, enabling them to push the boundaries of their research and accelerate discovery.
References
- 1. Getting Started with Distributed Data Parallel — PyTorch Tutorials 2.9.0+cu128 documentation [docs.pytorch.org]
- 2. Getting Started with Distributed Data Parallel — PyTorch Tutorials 2.5.0+cu124 documentation [pytorch-cn.com]
- 3. NVIDIA RTX 4090 vs. RTX 5090: Deep Dive for AI Training - DEV Community [dev.to]
- 4. Benchmarking Nvidia RTX 5090 | Computer Vision Lab [nikolasent.github.io]
- 5. bizon-tech.com [bizon-tech.com]
- 6. Tested RTX 5090 vs 4090 GPUs for AI: You Won’t Believe the Winner! | by Mehul Gupta | Data Science in Your Pocket | Medium [medium.com]
Troubleshooting & Optimization
RTX 5090 power consumption and thermal management in a lab environment.
Disclaimer: The NVIDIA RTX 5090 has not been officially released as of November 2025. All information, specifications, and troubleshooting guidance provided herein are based on industry rumors, performance projections for high-end GPUs, and best practices for current-generation hardware. This document is intended as a preparatory guide for lab environments and will be updated with official data upon the product's release.
This guide is designed for researchers, scientists, and drug development professionals utilizing the high-computational power of the NVIDIA RTX 5090 in a laboratory setting. It addresses potential issues related to its significant power consumption and thermal output.
Frequently Asked Questions (FAQs)
Q1: What are the anticipated power requirements for the RTX 5090? A1: The RTX 5090 is expected to have a Thermal Design Power (TDP) significantly higher than its predecessors. Rumors suggest the maximum power draw could be rated at 575W or higher.[1][2][3][4][5] For computational tasks that sustain high GPU loads, it is critical to plan for this level of power consumption to ensure system stability.
Q2: What type of Power Supply Unit (PSU) is recommended for a workstation with an RTX 5090? A2: A high-quality, high-wattage PSU is non-negotiable. For a single RTX 5090 setup, a 1200W PSU with an 80 PLUS Platinum or Titanium rating is recommended to handle the GPU's power draw and transient spikes, along with the rest of the system's components.[6][7] Ensure the PSU has the necessary 16-pin (12VHPWR/12V-2x6) power connectors.
Q3: How will the RTX 5090's heat output affect a controlled lab environment? A3: A single RTX 5090 operating under full load can dissipate up to 575W or more of heat into the surrounding environment.[8] In a lab with multiple systems or sensitive equipment, this thermal load can significantly increase the ambient room temperature. It is crucial to have adequate room ventilation and HVAC capacity to manage this heat and prevent it from affecting other experiments or equipment.
Q4: Are there specific driver settings that should be configured for a research environment? A4: Yes. For scientific computing, always use the latest NVIDIA Studio Driver or the specific data center drivers if applicable, as they are optimized for stability and performance in compute-intensive applications. Within the NVIDIA Control Panel or using the nvidia-smi command-line tool, you can monitor and, in some cases, adjust power limits to balance performance with thermal output.[9]
Q5: Can I use multiple RTX 5090 GPUs in a single workstation? A5: While technically possible, it presents significant power and thermal challenges. A multi-GPU setup will require a specialized chassis with high-airflow, a power supply well over 1600W, and potentially direct-exhaust (blower-style) coolers to prevent the cards from recirculating hot air.[8] Your lab's electrical circuits must also be able to support the substantial and sustained power draw.
Troubleshooting Guides
Q: My system shuts down unexpectedly when running a simulation. What's the cause? A: This is a classic symptom of an inadequate power supply. The RTX 5090 can experience brief, high-power "transient spikes" that exceed its rated TDP. If your PSU cannot handle these spikes, its Over Current Protection (OCP) will trigger a system shutdown.
-
Solution: Verify your PSU meets the recommended wattage (1200W+ for a single card).[6] Ensure you are using the correct 16-pin power connector and that it is fully seated. Monitor the GPU's power draw using tools like NVIDIA's nvidia-smi to confirm it is operating within expected limits before the shutdown occurs.
Q: My simulation performance is degrading over time, and the GPU's clock speeds are dropping. Why? A: This indicates thermal throttling. The GPU is automatically reducing its performance to stay within a safe operating temperature. The thermal throttle point for the RTX 5090 is expected to be around 90°C.[10]
-
Solution:
-
Improve Airflow: Ensure the workstation has unobstructed airflow. Check that all case fans are operational and configured to create a clear intake-to-exhaust path.
-
Monitor Temperatures: Use nvidia-smi or other monitoring software to check the GPU core and memory temperatures. If they consistently approach or exceed 90°C under load, your cooling is insufficient.
-
Check Ambient Temperature: Ensure the lab's ambient temperature is within the recommended range (see Table 2). A five-degree increase in room temperature can significantly impact the GPU's ability to cool itself.[11]
-
Consider Undervolting: For long-duration experiments, slightly undervolting the GPU can significantly reduce heat output with a minimal impact on performance.
-
Q: The GPU fans are extremely loud during my experiments. Is this normal? A: Yes, high fan noise is expected when the GPU is under a sustained, heavy load. The cooling system must work aggressively to dissipate the large amount of heat being generated.
-
Solution: While high fan speeds are necessary, you can take steps to mitigate the noise impact.
-
Isolate the Workstation: If possible, locate the workstation in a server closet or a dedicated room where the noise will not disrupt the primary lab space.
-
Custom Fan Curve: Advanced users can set a custom fan curve to ramp up more gradually, although this must be done carefully to avoid thermal throttling.[12]
-
Alternative Cooling: For mission-critical, noise-sensitive applications, consider a workstation with a liquid-cooling solution for the GPU, which can provide superior thermal performance at lower noise levels.
-
Quantitative Data Summary
Table 1: Speculative NVIDIA RTX 5090 Power & Thermal Specifications
| Metric | Speculative Value | Source(s) | Notes |
| Total Graphics Power (TGP) | 575W - 600W | [1][2][3][13][14] | Represents the maximum power draw of the graphics card under load. |
| Power Connectors | 1x 16-pin (12V-2x6) | [5][14] | May require two connectors on some partner models. |
| Recommended PSU | 1200W+ (80 PLUS Platinum) | [6] | For single-GPU systems; higher for multi-GPU. |
| Thermal Throttle Limit | ~90°C | [10] | GPU will reduce clock speeds to stay below this temperature. |
Table 2: Recommended Lab Environmental Conditions
| Parameter | Recommended Range | Justification |
| Ambient Temperature | 18°C - 24°C | Maintains a sufficient thermal delta for effective air cooling and prevents heat buildup in the room. |
| Relative Humidity | 40% - 60% | Prevents electrostatic discharge (ESD) risk at low humidity and condensation risk at high humidity. |
| Airflow | >5 CFM per System | Ensure consistent air exchange to remove heat dissipated by the workstation(s) from the immediate area. |
Experimental Protocols
Protocol 1: Establishing a Baseline for Power and Thermal Performance
Objective: To measure and record the baseline operational characteristics of the RTX 5090 in your specific lab workstation and environment before beginning critical experiments.
Methodology:
-
System Preparation:
-
Ensure the latest NVIDIA drivers are installed.
-
Close all non-essential applications.
-
Allow the system to idle for 15 minutes to reach a stable idle temperature.
-
-
Idle State Measurement:
-
Open a terminal or command prompt.
-
Execute the command: nvidia-smi --query-gpu=timestamp,temperature.gpu,power.draw,clocks.gr,clocks.mem --format=csv -l 1
-
Record the idle GPU temperature, power draw, and clock speeds for 5 minutes.
-
-
Load State Measurement:
-
Run a representative computational workload (e.g., a preliminary simulation, a benchmark like FurMark, or a specific CUDA/ML training task) that fully utilizes the GPU.
-
Continue logging data with the nvidia-smi command.
-
Let the workload run for at least 30 minutes to allow temperatures to stabilize.
-
-
Data Analysis:
-
Analyze the logged CSV file.
-
Determine the average and peak power draw under load.
-
Determine the stable, maximum temperature the GPU reaches under load. This is your thermal baseline. If it exceeds 85°C, consider improving the workstation's cooling before proceeding with long experiments.
-
Protocol 2: Power Limit Adjustment and Stability Testing
Objective: To determine a stable, reduced power limit for the RTX 5090 to lower thermal output for long-duration experiments, while quantifying the performance impact.
Methodology:
-
Establish Baseline: Complete Protocol 1 to understand the 100% power limit performance and thermal characteristics.
-
Set Reduced Power Limit:
-
Use the NVIDIA System Management Interface (nvidia-smi) to set a new power limit. For example, to set a 500W limit on GPU 0: nvidia-smi -i 0 -pl 500
-
Note: You will need administrative/root privileges to change the power limit.
-
-
Run Stability Test:
-
Execute the same computational workload used in Protocol 1.
-
Simultaneously, monitor thermals and clock speeds using: nvidia-smi -l 1
-
Run the workload for at least 60 minutes to ensure system stability at the new power limit. Check for any application crashes or system shutdowns.
-
-
Performance Quantification:
-
Benchmark the performance of your specific application at the reduced power limit (e.g., measure simulation time, iterations per second, or other relevant metrics).
-
-
Iterate and Document:
-
Repeat steps 2-4, incrementally lowering the power limit (e.g., in 25W steps) until you find an optimal balance between reduced thermal output and acceptable performance for your research. Document the performance-per-watt at each step.
-
Mandatory Visualizations
Caption: Workflow for initial installation and stability verification.
Caption: Decision tree for diagnosing and resolving thermal issues.
References
- 1. reddit.com [reddit.com]
- 2. tomshardware.com [tomshardware.com]
- 3. pcgamesn.com [pcgamesn.com]
- 4. tomsguide.com [tomsguide.com]
- 5. NVIDIA GeForce RTX 5090 Specs | TechPowerUp GPU Database [techpowerup.com]
- 6. GeForce RTX 5090: Increased power consumption requires power supplies up to 1200 W | HARDWARE | NEWS [en.gamegpu.com]
- 7. Are there any specific power supply requirements for systems with multiple high-end GPUs? - Massed Compute [massedcompute.com]
- 8. tomshardware.com [tomshardware.com]
- 9. What are the best practices for adjusting TDP settings on NVIDIA data center GPUs for optimal performance and reliability? - Massed Compute [massedcompute.com]
- 10. RTX 5090 FE Liquid Metal Swap: Thermal Paste Performs Just Fine | TechPowerUp [techpowerup.com]
- 11. Reddit - The heart of the internet [reddit.com]
- 12. reddit.com [reddit.com]
- 13. Leaked: Final specs for Nvidia's next-gen RTX 5090, 5080, and 5070 GPUs | PCWorld [pcworld.com]
- 14. m.youtube.com [m.youtube.com]
RTX 5090 Technical Support: Optimizing Memory Bandwidth for Scientific Workloads
Welcome to the technical support center for the NVIDIA RTX 5090. This resource is designed for researchers, scientists, and drug development professionals to help diagnose and resolve memory bandwidth challenges in complex scientific workloads. Below you will find frequently asked questions and detailed troubleshooting guides to ensure you are maximizing the performance of your experiments.
Frequently Asked Questions (FAQs)
FAQ 1: What are the key memory specifications of the RTX 5090, and how do they compare to the previous generation?
Understanding the hardware advancements is the first step in optimizing for them. The RTX 5090, powered by the Blackwell architecture, introduces significant improvements in its memory subsystem over the prior generation, primarily through the adoption of GDDR7 memory.[1][2] This enables a substantial increase in theoretical peak memory bandwidth, which is critical for data-intensive scientific applications.
Data Presentation: GPU Memory Specification Comparison
The following table summarizes the key memory-related specifications of the GeForce RTX 5090 compared to its predecessor, the GeForce RTX 4090.
| Specification | NVIDIA GeForce RTX 5090 | NVIDIA GeForce RTX 4090 |
| GPU Architecture | Blackwell[1] | Ada Lovelace |
| Memory Type | 32 GB GDDR7[1][2][3][4] | 24 GB GDDR6X |
| Memory Interface | 512-bit[1][2][5] | 384-bit |
| Memory Bandwidth | 1,792 GB/s[1][2][6] | 1,008 GB/s |
| CUDA Cores | 21,760[1][2][3][5] | 16,384 |
| L2 Cache | 98 MB[1] | 73 MB |
FAQ 2: My simulation is not achieving the expected speedup on the RTX 5090. How can I determine if memory bandwidth is the bottleneck?
Even with the RTX 5090's impressive bandwidth, applications can become memory-bound if data access patterns are inefficient. Identifying a memory bottleneck is a crucial first step in performance tuning. This involves a process of profiling and targeted testing.
Troubleshooting Guide: Identifying Memory Bottlenecks
-
Establish a Baseline: Run your application on a single GPU and record key performance metrics, such as simulation time per step or overall job completion time.[7]
-
Profile Your Application: Use NVIDIA's Nsight Systems to get a high-level overview of your application's execution.[8][9] Look for significant time spent in memory transfer operations (e.g., cudaMemcpy) or kernels with low compute utilization but high memory traffic.
-
Analyze Kernel Performance: Use NVIDIA Nsight Compute to perform an in-depth analysis of your most time-consuming kernels.[9] The tool can directly report on memory throughput and identify if a kernel is limited by bandwidth or latency.
-
Run a Simplified Bandwidth Test: If profiling tools suggest a memory issue, confirm it with a controlled experiment.
Experimental Protocol: Simplified Bandwidth Test
This protocol helps determine if your application's performance scales with the GPU's memory clock speed.
-
Objective: To determine if the application is sensitive to changes in memory clock frequency, which indicates a memory bandwidth bottleneck.
-
Tools:
-
Methodology:
-
Run your application with default GPU clock settings and record the performance (e.g., nanoseconds per day for an MD simulation).
-
Slightly underclock the GPU's memory frequency by 10-15% while keeping the core clock speed constant.
-
Rerun the exact same simulation and record the new performance.
-
Analysis: If you observe a proportional decrease in application performance, your workload is likely limited by memory bandwidth.[12] If performance remains relatively unchanged, the bottleneck is more likely related to computation, latency, or inefficient CPU-GPU data pipelines.[12]
-
FAQ 3: What are common memory access patterns that limit performance, and how can I fix them?
Inefficient memory access is a primary cause of poor GPU performance. The most common issue is non-coalesced memory access. GPU memory is accessed in wide transactions. When threads in a warp (a group of 32 threads) access memory locations that are contiguous, the hardware can "coalesce" these into a single, efficient transaction. When accesses are scattered, multiple transactions are required, wasting bandwidth.[13][14]
Fixing Non-Coalesced Access: Data Layouts
The solution often involves restructuring your data. For arrays of complex data structures, prefer a "Structure of Arrays" (SoA) layout over an "Array of Structures" (AoS).
-
AoS (Array of Structures): A single array holds an entire structure. This often leads to non-coalesced access as a kernel may only need one member from each structure.
-
SoA (Structure of Arrays): Each member of the structure is stored in its own separate array. This ensures that when a kernel accesses a specific member, all threads in a warp access a contiguous block of memory.
FAQ 4: How do I use NVIDIA's profiling tools to identify memory bandwidth issues?
NVIDIA Nsight Compute is the primary tool for deep-diving into kernel performance. It provides detailed metrics about memory operations. When profiling, focus on the "Memory Workload Analysis" section.
Experimental Protocol: Kernel Profiling with Nsight Compute
-
Objective: To measure the memory performance of a specific CUDA kernel.
-
Tool: NVIDIA Nsight Compute (ncu).
-
Methodology:
-
Identify the most time-consuming kernel from an Nsight Systems profile.
-
Launch your application through the Nsight Compute command-line interface, targeting that specific kernel. Example command: ncu --kernel-name my_kernel -o profile_report ./my_app
-
Open the profile_report file in the Nsight Compute GUI.
-
Navigate to the "Memory Workload Analysis" section.
-
-
Analysis: Examine the metrics in the table below. High "Memory Throughput" close to the theoretical maximum indicates your kernel is using the hardware effectively, but it also confirms the kernel is memory-bound. Low throughput suggests inefficient access patterns that need optimization.
Data Presentation: Key Nsight Compute Memory Metrics
| Metric Name | Description | What to Look For |
| DRAM Throughput | The measured data transfer rate to and from device memory (DRAM). | A value close to the RTX 5090's peak (1,792 GB/s) indicates a memory-bound kernel. |
| L1/L2 Cache Hit Rate | The percentage of memory requests served by the L1/L2 cache. | A high hit rate is good; it reduces requests to the much slower DRAM. |
| Memory Coalescing | Percentage of memory accesses that are ideally coalesced. | Aim for as close to 100% as possible. Low values indicate scattered memory accesses. |
| Bank Conflicts | Number of conflicts when accessing shared memory. | Should be zero or very low. Conflicts serialize memory access, reducing performance.[13] |
FAQ 5: How can I optimize CPU-to-GPU data transfers?
Before the RTX 5090 can process data, it must be transferred from the host (CPU) memory. This transfer across the PCIe bus can be a significant bottleneck. Optimizing these transfers is crucial for overall application performance.
Best Practices for Data Transfer
-
Minimize Data Transfers: The most effective optimization is to avoid unnecessary data movement. Perform as much computation on the GPU as possible to avoid round-trips to the CPU.[10]
-
Use Pinned (Page-Locked) Memory: By default, host memory is pageable. The CUDA driver must first copy data to a temporary, pinned buffer before transferring it to the GPU. You can allocate memory directly as pinned, which allows the GPU to access it via Direct Memory Access (DMA), resulting in faster transfers.
-
Overlap Transfers with Computation: Use CUDA streams to perform data transfers asynchronously. This allows you to transfer the data needed for the next computation step while the GPU is busy processing the current step, effectively hiding the transfer latency.[15]
References
- 1. vast.ai [vast.ai]
- 2. beebom.com [beebom.com]
- 3. pcgamer.com [pcgamer.com]
- 4. NVIDIA GeForce RTX 5090 Specs | TechPowerUp GPU Database [techpowerup.com]
- 5. tomshardware.com [tomshardware.com]
- 6. notebookcheck.net [notebookcheck.net]
- 7. GPU Best Practices | Research Computing [rc.virginia.edu]
- 8. What are the best tools for profiling NVIDIA GPUs? - Massed Compute [massedcompute.com]
- 9. NVIDIA Profiling Tools - NERSC Documentation [docs.nersc.gov]
- 10. Can you explain how to optimize molecular dynamics simulations for NVIDIA L40 GPUs? - Massed Compute [massedcompute.com]
- 11. lambda.ai [lambda.ai]
- 12. forums.developer.nvidia.com [forums.developer.nvidia.com]
- 13. What are some common CUDA memory access patterns that can lead to performance issues? - Massed Compute [massedcompute.com]
- 14. Identifying CUDA Performance Issues and Optimization Tips | MoldStud [moldstud.com]
- 15. medium.com [medium.com]
Troubleshooting driver issues with the RTX 5090 in a Linux environment.
RTX 5090 Linux Environment Technical Support Center
Disclaimer: As of late 2025, the NVIDIA RTX 5090 has not been officially released. This guide is based on troubleshooting methodologies for its high-performance predecessors, such as the RTX 40-series, and addresses common driver issues encountered in Linux environments. The solutions provided are expected to be highly relevant for the upcoming 50-series GPUs.
Frequently Asked Questions (FAQs)
Section 1: Pre-Installation & Compatibility
Q1: How can I check if my Linux system recognizes the RTX 5090?
Before installing drivers, verify that the operating system detects the GPU on the PCI bus. Open a terminal and run:
A successful detection will show an entry containing "NVIDIA Corporation" and the device ID for your GPU.[1][2]
Q2: Which NVIDIA driver version should I use for my RTX 5090 and CUDA Toolkit version?
For scientific computing, ensuring compatibility between the NVIDIA driver and the CUDA Toolkit is critical. While specific versions for the RTX 5090 are yet to be announced, the principle remains the same. Newer CUDA Toolkits require a minimum NVIDIA driver version. The driver maintains backward compatibility, meaning an application compiled with an older CUDA Toolkit will run on a newer driver.[3]
Table 1: Illustrative NVIDIA Driver and CUDA Toolkit Compatibility
| CUDA Toolkit Version | Minimum Linux Driver Version (Example) | Supported GPU Architectures (Example) |
| CUDA 12.x | >= 525.xx | Hopper, Ada Lovelace, Ampere, Turing |
| CUDA 11.x | >= 450.xx | Ampere, Turing, Volta, Pascal |
Note: Always consult the official NVIDIA CUDA Toolkit release notes for the exact driver requirements for your specific version.[4][5]
Section 2: Driver Installation & Configuration
Q1: What is the "Nouveau" driver and why must it be disabled?
Nouveau is an open-source driver for NVIDIA cards that is included in many Linux distributions.[1] It is reverse-engineered and often conflicts with the official proprietary NVIDIA drivers, which are required for full performance and CUDA support.[1][6] Failing to disable Nouveau can lead to installation failures, black screens, or system instability.[7]
Q2: I'm seeing a black screen after installing the NVIDIA driver. How can I fix it?
This is a common issue often related to the display server (X.org or Wayland) configuration or a conflict with the Nouveau driver.
-
Ensure Nouveau is blacklisted: Verify that the blacklist file is correctly configured and the initramfs has been updated.[8][9]
-
Check Xorg logs: Examine /var/log/Xorg.0.log for errors related to the NVIDIA driver.[6]
-
Regenerate Xorg configuration: Run sudo nvidia-xconfig to create a new configuration file.[6]
-
Kernel parameters: Ensure nvidia-drm.modeset=1 is added to your bootloader's kernel parameters to enable Display Resource Management.[7]
Q3: My Linux distribution uses Secure Boot. How do I install the NVIDIA drivers?
Secure Boot prevents the loading of unsigned kernel modules, which includes the proprietary NVIDIA driver by default.[1] You have two main options:
-
Disable Secure Boot: The simplest method is to disable Secure Boot in your system's UEFI/BIOS settings.[1]
-
Sign the Kernel Modules: For security-conscious environments, you can generate a Machine Owner Key (MOK) and use it to sign the NVIDIA modules yourself.[10] This allows Secure Boot to remain active while trusting the NVIDIA driver you install. The process involves creating a key, enrolling it with mokutil, and then signing the modules.[11][12][13]
Section 3: Performance Monitoring & Troubleshooting
Q1: How can I monitor my RTX 5090's real-time usage, temperature, and power draw?
This command refreshes the nvidia-smi output every second.[16]
Table 2: Common nvidia-smi Monitoring Commands
| Command | Description |
| nvidia-smi | Displays a summary of GPU status, driver version, and running processes.[15] |
| nvidia-smi -q | Shows detailed information including clock speeds, power limits, and temperature.[6] |
| nvidia-smi dmon | Provides a scrolling view of real-time device monitoring stats like power, temperature, and utilization.[17] |
| nvidia-smi pmon | Displays GPU usage broken down by individual running processes.[14] |
| nvidia-smi -q -d PERFORMANCE | Checks for performance-limiting factors (throttling) such as temperature or power limits.[18] |
Q2: My GPU-accelerated application is running slow. How do I diagnose the bottleneck?
Performance issues can stem from thermal throttling, power limitations, or software bottlenecks.
-
Check for Throttling: Run nvidia-smi -q -d PERFORMANCE. The "Clocks Throttle Reasons" section will tell you if the GPU is slowing down due to high temperatures (HwSlowdown) or power limits (SwPowerCap).[18]
-
Monitor Utilization: Use nvidia-smi dmon or nvtop to see if GPU utilization (sm) is consistently high (e.g., >90%).[17][19] If utilization is low, the bottleneck may be elsewhere, such as CPU processing, data I/O, or network latency.[18]
-
Enable Persistence Mode: For workloads that run many short-lived tasks, enabling persistence mode keeps the driver loaded, reducing latency.[17][20]
Q3: I get the error "NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver." What does this mean?
This is a generic error indicating the user-space nvidia-smi tool cannot connect with the installed kernel module.[21] This usually happens if the driver installation was incomplete, the kernel was updated without reinstalling the driver modules (if not using DKMS), or if there's a conflict. A system reboot or a full driver re-installation is often required to fix this.[20]
Troubleshooting Workflows & Protocols
Protocol 1: Clean NVIDIA Driver Installation
This protocol outlines the comprehensive steps to ensure a clean and successful driver installation, minimizing common conflicts.
Methodology:
-
System Preparation:
-
Update your system's package lists and install the latest updates:
-
Install essential packages for building kernel modules:
[22]
-
-
Purge Existing NVIDIA Drivers:
-
Completely remove any previously installed NVIDIA packages to prevent conflicts:
-
-
Disable the Nouveau Driver:
-
Reboot the System:
-
A reboot is mandatory for the system to load with Nouveau fully disabled.
-
-
Install the NVIDIA Driver:
-
The recommended method for Ubuntu-based systems is to use the ubuntu-drivers utility, which identifies and installs the best-suited driver from the repository.[23]
-
After installation is complete, reboot the system again.
-
-
Verification:
-
After the final reboot, run nvidia-smi. If it displays the driver version and GPU details, the installation was successful.[20][23]
-
You can also check if the NVIDIA kernel modules are loaded:
[6]
-
Diagram 1: Driver Installation Workflow
Caption: Workflow for a clean NVIDIA driver installation on a Linux system.
System Architecture & Logic Diagrams
Diagram 2: General Troubleshooting Logic
Caption: A logical flowchart for troubleshooting common NVIDIA GPU issues.
Diagram 3: GPU Software Stack
Caption: The relationship between a user application and the GPU hardware.
References
- 1. How I Resolved My NVIDIA Driver Nightmare on Linux (And How You Can Too) | by Avnish Kumar Thakur | Medium [medium.com]
- 2. Check and Monitor Active GPU in Linux - GeeksforGeeks [geeksforgeeks.org]
- 3. CUDA Toolkit 13.0 Update 2 - Release Notes — Release Notes 13.0 documentation [docs.nvidia.com]
- 4. docs.nvidia.com [docs.nvidia.com]
- 5. scribd.com [scribd.com]
- 6. How to troubleshoot common issues with NVIDIA GPU drivers on a Linux system? - Massed Compute [massedcompute.com]
- 7. linuxcommunity.io [linuxcommunity.io]
- 8. nvidia - How do I disable the "Nouveau Kernel Driver"? - Ask Ubuntu [askubuntu.com]
- 9. Disable Nouveau driver and install NVIDIA cuda driver on Ubuntu Linux - HackMD [hackmd.io]
- 10. Automatic Signing of DKMS-Generated Kernel Modules for Secure Boot · GitHub [gist.github.com]
- 11. kubuntu - Signing kernel modules for Secure Boot with Nvidia proprietary drivers - Ask Ubuntu [askubuntu.com]
- 12. reddit.com [reddit.com]
- 13. UEFI Secure Boot - NVIDIA Docs [docs.nvidia.com]
- 14. databasemart.com [databasemart.com]
- 15. Deep Dive: Monitoring NVIDIA GPUs with nvidia-smi | Rafay [rafay.co]
- 16. youtube.com [youtube.com]
- 17. How to optimize NVIDIA GPU performance in a Linux environment? - Massed Compute [massedcompute.com]
- 18. Maximizing NVIDIA GPU performance on Linux [justin.palpant.us]
- 19. Research Computing GPU Resources [help.rc.unc.edu]
- 20. andrewlaidlawpower.medium.com [andrewlaidlawpower.medium.com]
- 21. nvidia - RTX 4090 driver issues - Ask Ubuntu [askubuntu.com]
- 22. 16.04 - How to disable Nouveau kernel driver - Ask Ubuntu [askubuntu.com]
- 23. databasemart.com [databasemart.com]
Overcoming bottlenecks when using the RTX 5090 for large-scale simulations.
Welcome, researchers, scientists, and drug development professionals. This technical support center is designed to help you identify and overcome common performance bottlenecks when leveraging the power of the NVIDIA RTX 5090 for your large-scale simulations. While the RTX 5090 promises unprecedented computational power, achieving maximum efficiency requires a holistic understanding of your entire workflow, from data input to final analysis.
This guide provides answers to frequently asked questions and detailed troubleshooting protocols to ensure you are harnessing the full potential of your hardware.
Frequently Asked Questions (FAQs) & Troubleshooting Guides
Data Transfer and I/O Bottlenecks
Q: My simulation is fast during computation but lags significantly during data loading phases. How can I diagnose and fix a data transfer bottleneck?
A: This is a classic sign of an I/O or PCIe bottleneck, where the GPU is waiting for data from the CPU or storage.[1][2] High-speed GPUs like the RTX 5090 can process data far faster than it can be fed to them if the data pipeline isn't optimized.
Troubleshooting Steps:
-
Profile Your Application: Use NVIDIA Nsight™ Systems to visualize the entire application timeline.[3][4][5] Look for large gaps between GPU kernel executions, which often correspond to periods of intense CPU activity or data transfer (DMA) operations.[4]
-
Assess Memory Transfer Speeds: Pay close attention to the "CUDA Memcpy" rows in the Nsight Systems timeline.[6] Long transfer times for large datasets are a clear indicator of a bottleneck.
-
Optimize Data Transfers:
-
Use Pinned Memory: Allocate host memory using cudaMallocHost() instead of standard malloc(). This "pins" the memory, allowing for much faster Direct Memory Access (DMA) transfers to the GPU.[7][8]
-
Batch Small Transfers: Avoid numerous small data transfers. The overhead of initiating each transfer can add up.[7][8] It's more efficient to batch data into a single, larger transfer.
-
Overlap Computation and Transfer: Employ CUDA streams to overlap kernel execution with data transfers.[7][9] This technique, known as latency hiding, keeps the GPU busy while the next set of data is being prepared and transferred.[6][10]
-
Data Presentation: Host-to-Device Transfer Speeds
The following table illustrates the hypothetical impact of memory type and PCIe generation on transfer bandwidth for a 100 GB dataset.
| PCIe Generation | Memory Type | Theoretical Max Bandwidth (GB/s) | Estimated Time to Transfer 100 GB (seconds) |
| PCIe 4.0 x16 | Pageable (Standard) | ~20-25 GB/s | ~4.0 - 5.0 s |
| PCIe 4.0 x16 | Pinned | ~28-31 GB/s | ~3.2 - 3.6 s |
| PCIe 5.0 x16 | Pageable (Standard) | ~45-55 GB/s | ~1.8 - 2.2 s |
| PCIe 5.0 x16 | Pinned | ~60-63 GB/s | ~1.6 s |
Note: These are projected estimates. Actual performance will vary based on system configuration and workload.
GPU Memory and VRAM Limitations
Q: My simulation crashes or slows drastically with "out of memory" errors when I increase the dataset size or model complexity. How can I manage VRAM usage more effectively?
A: Exceeding the RTX 5090's anticipated 32 GB of GDDR7 VRAM is a common issue in complex simulations like molecular dynamics or genomics.[11][12][13] When the GPU's memory is exhausted, it must swap data with the much slower system RAM, causing a severe performance drop.
Troubleshooting Steps:
-
Profile Memory Usage: Use nvidia-smi during a run to monitor real-time VRAM consumption. For a more detailed analysis, use NVIDIA Nsight Compute to inspect memory usage on a per-kernel basis.
-
Optimize Data Structures: Ensure your data structures are as compact as possible. Avoid unnecessary padding and use the most efficient data types for your needs (e.g., using 32-bit floats instead of 64-bit doubles if the precision is not required).
-
Leverage Unified Memory: For applications with complex data access patterns that don't fit entirely in VRAM, consider using CUDA's Unified Memory. This allows the GPU to access system memory directly, simplifying memory management, though it should be used judiciously as performance is still bound by the interconnect speed (PCIe).[7]
Computational Efficiency and Precision
Q: My GPU utilization is high, but the simulation's time-to-solution is still slower than expected. How can I improve the computational efficiency of my kernels?
A: High utilization doesn't always mean efficient utilization. Several factors can cause the GPU to perform unnecessary work or use suboptimal execution paths.
Troubleshooting Steps:
-
Analyze Numerical Precision: The most significant factor is often the use of double-precision (FP64) floating-point numbers. While essential for some scientific domains, many simulations, particularly in drug discovery and AI, can achieve sufficient accuracy with single-precision (FP32) or even mixed-precision (FP16/BF16) arithmetic.[16][17] Consumer-focused GPUs like the RTX series often have significantly lower FP64 performance compared to their FP32 capabilities.[18]
-
Optimize Memory Access Patterns: Inefficient memory access is a primary cause of stalls within a GPU kernel.[19][20] Threads in a warp should access memory in a contiguous, or "coalesced," pattern.[19] Scattered, random access patterns lead to multiple memory transactions and high latency.[19]
-
Profile with Nsight Compute: Use Nsight Compute to perform an in-depth analysis of your CUDA kernels.[3] It provides detailed metrics on memory access patterns, instruction stalls, and warp divergence, helping you pinpoint the exact lines of code that need optimization.
Data Presentation: Impact of Numerical Precision on Performance
This table shows the projected performance trade-offs for different floating-point precisions on a high-end consumer GPU.
| Precision | Memory Usage (per number) | Relative Performance | Typical Use Cases |
| FP64 (Double) | 8 bytes | 1x (Baseline) | High-precision physics, financial modeling[21] |
| FP32 (Single) | 4 bytes | 16x - 64x | General scientific computing, AI training[17][21] |
| FP16 (Half) | 2 bytes | 32x - 128x (with Tensor Cores) | AI inference, mixed-precision training |
Experimental Protocols & Methodologies
Protocol 1: Diagnosing I/O Bottlenecks with NVIDIA Nsight Systems
This protocol outlines the methodology for identifying data transfer bottlenecks between the CPU and GPU.
Objective: To visualize and quantify the time spent on data transfers versus computation.
Methodology:
-
Installation: Ensure you have the latest NVIDIA drivers and the NVIDIA Nsight Systems tool installed.[4][22]
-
Application Profiling:
-
Launch Nsight Systems.
-
Specify the target application executable and any command-line arguments.
-
Ensure that "Trace CUDA" is enabled in the profiling options.
-
Start the profiling session and run your simulation for a representative duration (e.g., one full iteration or several minutes).[22]
-
-
Timeline Analysis:
-
After the run completes, the timeline view will be displayed.
-
Examine the GPU row: Look for periods where the "Compute" track is idle (no blue kernel blocks).
-
Correlate with CPU/System activity: During these GPU idle times, examine the CUDA API and Memory rows. Look for long-running cudaMemcpy operations (green for Host-to-Device, pink for Device-to-Host).[10]
-
Quantify Overhead: Use the timeline's measurement tools to select a region of interest. The tool will report the total time spent in different operations, allowing you to calculate the percentage of time dedicated to data transfer versus useful computation.
-
Mandatory Visualizations
Workflow for Troubleshooting Performance Bottlenecks
Caption: A decision workflow for diagnosing and resolving GPU performance bottlenecks.
Data Flow from Storage to GPU Compute Units
Caption: Simplified data flow illustrating the path from storage to GPU computation.
GPU Memory Access Patterns
Caption: Coalesced vs. Uncoalesced memory access patterns on the GPU.
References
- 1. What are some common bottlenecks in high-performance computing clusters and how can NVIDIA data center GPUs address them? - Massed Compute [massedcompute.com]
- 2. medium.com [medium.com]
- 3. How do I use NVIDIA GPU tools to identify bottlenecks in my application? - Massed Compute [massedcompute.com]
- 4. How can I use NVIDIA Nsight Systems to identify performance bottlenecks in my deep learning model? - Massed Compute [massedcompute.com]
- 5. Nsight Systems | NVIDIA Developer [developer.nvidia.com]
- 6. youtube.com [youtube.com]
- 7. How do I optimize data transfer between the GPU and CPU? - Massed Compute [massedcompute.com]
- 8. How to Optimize Data Transfers in CUDA C/C++ | NVIDIA Technical Blog [developer.nvidia.com]
- 9. optimization - Techniques to Reduce CPU to GPU Data Transfer Latency - Stack Overflow [stackoverflow.com]
- 10. Understanding the Visualization of Overhead and Latency in NVIDIA Nsight Systems | NVIDIA Technical Blog [developer.nvidia.com]
- 11. tomshardware.com [tomshardware.com]
- 12. pcgamer.com [pcgamer.com]
- 13. vast.ai [vast.ai]
- 14. hyperstack.cloud [hyperstack.cloud]
- 15. Do You Really Need NVLink for Multi-GPU Setups? | SabrePC Blog [sabrepc.com]
- 16. How does FP64 precision impact the performance of AI workloads in data centers compared to FP32? - Massed Compute [massedcompute.com]
- 17. What are the performance differences between FP32 and FP64 in deep learning models? - Massed Compute [massedcompute.com]
- 18. Emulating double precision on the GPU to render large worlds | Hacker News [news.ycombinator.com]
- 19. How do memory access patterns impact the performance of large language models on GPUs? - Massed Compute [massedcompute.com]
- 20. What is the relationship between memory latency and GPU performance? - Massed Compute [massedcompute.com]
- 21. FP64 vs FP32 vs FP16: Understanding Precision in Computing [velocitymicro.com]
- 22. How do I use NSight Systems to identify performance bottlenecks in my CUDA application? - Massed Compute [massedcompute.com]
Technical Support Center: Fine-Tuning AI Models on the NVIDIA RTX 5090 for Scientific Research
Welcome to the technical support center for optimizing your AI model training and fine-tuning performance on the NVIDIA RTX 5090. This resource is tailored for researchers, scientists, and drug development professionals who are leveraging cutting-edge AI to solve complex scientific challenges. Here, you will find troubleshooting guides and frequently asked questions (FAQs) in a direct question-and-answer format to address specific issues you may encounter during your experiments.
I. Hardware at a Glance: NVIDIA RTX 5090
Before diving into troubleshooting, it's essential to understand the key architectural improvements of the RTX 5090 that are particularly relevant for AI model training. The Blackwell architecture brings significant enhancements over previous generations, directly impacting training performance.
| Feature | NVIDIA RTX 4090 | NVIDIA RTX 5090 (Rumored Specs) | Impact on AI Model Training |
| CUDA Cores | 16,384 | ~21,760 | Increased parallel processing capabilities for faster computation. |
| Tensor Cores | 512 (4th Gen) | ~680 (5th Gen) | Enhanced performance for mixed-precision training, a key technique for optimizing memory usage and speed. |
| VRAM | 24 GB GDDR6X | 32 GB GDDR7 | Ability to train larger models and use larger batch sizes, reducing the need for complex model parallelism. |
| Memory Bandwidth | ~1.0 TB/s | ~1.79 TB/s | Faster data transfer between VRAM and processing cores, crucial for large datasets and complex models.[1] |
II. Frequently Asked Questions (FAQs)
Here are some frequently asked questions about fine-tuning AI models on the RTX 5090 for scientific and drug discovery applications.
Q1: I'm starting a new drug discovery project. Should I fine-tune a pre-trained model or train one from scratch on the RTX 5090?
For most drug discovery applications, fine-tuning a pre-trained model is the recommended approach.[2] Models like ChemBERTa or MolBERT have been pre-trained on vast amounts of chemical and molecular data and can be adapted to specific tasks such as molecular property prediction or binding affinity prediction with a smaller, domain-specific dataset.[2] This approach is generally more computationally efficient and requires less data than training a model from scratch.
Q2: What are the primary advantages of the RTX 5090's 32 GB of GDDR7 VRAM for my research?
The increased VRAM allows you to work with larger and more complex models, such as transformers for protein structure prediction, without running into memory errors. It also enables the use of larger batch sizes during training, which can lead to more stable gradients and faster convergence. For generative models in chemistry, the larger memory capacity is beneficial for exploring a wider chemical space.
Q3: How can I ensure my research is reproducible when using the RTX 5090?
Reproducibility is critical in scientific research. To ensure your AI experiments are reproducible, you should:
-
Version control your code: Use tools like Git to track changes in your code and configuration files.
-
Document your environment: Record the versions of your operating system, NVIDIA drivers, CUDA toolkit, and all Python libraries.
-
Set random seeds: Ensure that any sources of randomness in your data preprocessing and model training are controlled by setting a fixed seed.
-
Save model checkpoints: Store the weights of your trained models at various stages.
III. Troubleshooting Guides
This section provides detailed troubleshooting guides for common performance issues encountered during AI model fine-tuning in a research context.
Issue 1: My model training is slow, and the GPU utilization is low.
This common issue often points to a data loading bottleneck, where the GPU is waiting for data from the CPU and storage. The RTX 5090's high memory bandwidth can exacerbate this issue if the data pipeline cannot keep up.
A1: How do I diagnose a data loading bottleneck?
You can use NVIDIA's Nsight Systems to profile your application and identify where the time is being spent.[3] A timeline view will show gaps in GPU activity, indicating that the GPU is idle.
Experimental Protocol: Diagnosing Data Loading Bottlenecks with Nsight Systems
-
Installation: Ensure you have NVIDIA Nsight Systems installed.
-
Profiling Command: Launch your training script with the nsys profile command:
-
Analysis: Open the generated my_profile.qdrep file in the Nsight Systems UI. Look for significant time spent in data loading functions on the CPU timeline and corresponding idle time on the GPU timeline.
A2: How can I optimize my PyTorch DataLoader for large molecular datasets?
For large datasets, such as those containing millions of molecular structures or high-resolution medical images, optimizing the DataLoader is crucial.
Experimental Protocol: Optimizing PyTorch DataLoader
-
Increase num_workers: This parameter determines how many subprocesses to use for data loading. A good starting point is to set it to the number of CPU cores available.
-
Enable pin_memory: Setting pin_memory=True in your DataLoader allows for faster data transfer to the GPU.
-
Use Efficient Data Formats: Storing your data in formats like HDF5 or LMDB can significantly improve read speeds compared to individual small files.[4]
-
Prefetch Data: Use prefetch_factor in PyTorch 1.7.0+ to load data in advance.
Logical Workflow for Diagnosing and Resolving Data Loading Bottlenecks
References
- 1. GeForce RTX 5090 Performance: AI Supercomputing Meets 4K Gaming - Technology Guides and Tutorials [sebbie.pl]
- 2. Fine-Tuning For Drug Discovery [meegle.com]
- 3. discuss.huggingface.co [discuss.huggingface.co]
- 4. python - Most efficient way to use a large data set for PyTorch? - Stack Overflow [stackoverflow.com]
NVIDIA RTX 5090 Technical Support Center: Memory Limitation Solutions for Extremely Large Datasets
Welcome to the technical support center for the NVIDIA RTX 5090. This resource is designed for researchers, scientists, and drug development professionals who are pushing the boundaries of their computational experiments with extremely large datasets. Here, you will find troubleshooting guides and frequently asked questions (FAQs) to help you address and overcome potential memory limitations on the RTX 5090.
Frequently Asked Questions (FAQs)
Q1: My dataset is larger than the RTX 5090's 32 GB of VRAM. What are my primary options?
A1: When your dataset exceeds the GPU's memory, you can employ several strategies. The main approaches involve processing the data in smaller chunks, distributing the workload across multiple GPUs, or leveraging system memory more effectively. The three primary techniques are:
-
Out-of-Core Computing: This involves keeping the full dataset in system RAM or on disk and loading chunks of it into GPU memory as needed for processing.
-
Data Parallelism: This strategy involves splitting your dataset into smaller portions and processing each portion on a separate GPU, where each GPU has a complete copy of the model.
-
Model Parallelism: If your model is too large to fit into a single GPU's memory, you can split the model itself across multiple GPUs, with each GPU handling a different part of the model's computations.
Q2: What are the key differences between Data Parallelism and Model Parallelism?
A2: Data parallelism and model parallelism are two distinct strategies for distributed training.[1][2] Data parallelism involves replicating the model across multiple GPUs and feeding each GPU a different subset of the data.[1][3] Model parallelism, on the other hand, involves partitioning the model itself across multiple GPUs and feeding the same data to this distributed model.[2] The choice between them depends on the specific bottleneck you're facing: dataset size or model size.[2]
| Feature | Data Parallelism | Model Parallelism |
| Primary Use Case | Large datasets, model fits on one GPU[3] | Large models, dataset may or may not be large[2] |
| How it Works | Splits the dataset across multiple GPUs[1][4] | Splits the model across multiple GPUs[2] |
| Model on each GPU | A complete copy of the model[3] | A different part of the model[2] |
| Communication | Gradients are synchronized after each batch[1] | Intermediate activations are passed between GPUs[2] |
Q3: How can I implement out-of-core computing for my application?
A3: Out-of-core computing can be implemented using several methods. One common approach is to use libraries that support it, such as NVIDIA's CUDA Unified Memory.[5] This technology allows the GPU to access the entire system memory, automatically migrating data between the CPU and GPU as needed.[6][7] You can also manually manage data streaming in your code, loading data in batches from the disk or system RAM. For specific applications, libraries like RAPIDS cuDF for data analytics and Dask for parallel computing can help manage large datasets that don't fit into GPU memory.
Q4: What is Unified Memory and how can it help with large datasets?
A4: NVIDIA's Unified Memory creates a single, coherent memory space accessible by both the CPU and the GPU.[8] This simplifies programming as you don't need to manually transfer data between host (CPU) and device (GPU) memory.[8] For large datasets, Unified Memory enables applications to oversubscribe the GPU memory, meaning you can work with datasets larger than the physical VRAM by leveraging the system's RAM.[7] The CUDA driver automatically handles the migration of data between the CPU and GPU.[5]
Troubleshooting Guides
Issue: CUDA out of memory error with a large dataset.
This is a common issue when your dataset exceeds the available GPU VRAM. Here’s a step-by-step guide to troubleshoot and resolve this problem.
Experimental Protocol: Benchmarking Memory Solutions
This protocol will help you determine the most effective memory management strategy for your specific workload.
Objective: To compare the performance of out-of-core computing (with Unified Memory) and data parallelism for a large dataset that does not fit into a single RTX 5090's memory.
Materials:
-
Workstation with one or more NVIDIA RTX 5090 GPUs.
-
A representative large dataset (e.g., a large set of high-resolution images for deep learning, or a large molecular dynamics simulation trajectory).
-
Benchmarking scripts to measure data loading times and computation times.
Methodology:
-
Baseline Measurement: Attempt to run your application with the full dataset loaded directly into the GPU. This will likely result in an "out of memory" error, which confirms the problem.
-
Implement Out-of-Core Computing with Unified Memory:
-
Modify your code to use Unified Memory by allocating memory with cudaMallocManaged().
-
Run your application with the full dataset. The CUDA runtime will now page data between system RAM and GPU VRAM.
-
Measure the total execution time and monitor GPU utilization.
-
-
Implement Data Parallelism (if you have multiple GPUs):
-
Divide your dataset into a number of splits equal to the number of available GPUs.
-
Modify your code to use a distributed training framework (e.g., PyTorch's DistributedDataParallel or TensorFlow's MirroredStrategy).
-
Each GPU will load its own split of the data.
-
Measure the total execution time and monitor the communication overhead between GPUs.
-
-
Analyze Results:
-
Compare the execution times of the different methods.
-
Consider the implementation complexity of each approach.
-
Choose the method that provides the best balance of performance and ease of implementation for your specific use case.
-
Expected Performance Comparison
| Strategy | Pros | Cons | Best For |
| Out-of-Core (Unified Memory) | Simpler to implement, can handle datasets much larger than VRAM.[7][8] | Performance can be limited by the PCIe bandwidth between CPU and GPU. | Single GPU setups or when data parallelism is complex to implement. |
| Data Parallelism | Can offer significant speedups by processing data in parallel.[4] | Requires multiple GPUs, introduces communication overhead.[3] | Multi-GPU systems where the model fits on a single GPU. |
| Model Parallelism | Enables the use of models that are too large for a single GPU.[2] | Can be complex to implement, may have high communication overhead.[3] | When the model size is the primary bottleneck. |
Visualizations
Signaling Pathways and Workflows
Caption: Out-of-Core computing workflow.
Caption: Data Parallelism workflow.
Caption: Model Parallelism workflow.
Disclaimer: The information provided here for the NVIDIA RTX 5090 is based on rumored and expected specifications.[9][10][11][12][13][14][15] Official specifications should be consulted upon release. The troubleshooting techniques and concepts described are based on established methods for handling large datasets on high-performance GPUs.
References
- 1. Model Parallelism vs Data Parallelism: Examples [vitalflux.com]
- 2. What are the key differences between model parallelism and data parallelism in the context of deep learning? - Infermatic [infermatic.ai]
- 3. What are the differences between data parallelism and model parallelism in TensorRT? - Massed Compute [massedcompute.com]
- 4. Data Parallelism VS Model Parallelism In Distributed Deep Learning Training - Lei Mao's Log Book [leimao.github.io]
- 5. Efficient Use of GPU Memory for Large-Scale Deep Learning Model Training [mdpi.com]
- 6. Maximizing Unified Memory Performance in CUDA | NVIDIA Technical Blog [developer.nvidia.com]
- 7. Improving GPU Memory Oversubscription Performance | NVIDIA Technical Blog [developer.nvidia.com]
- 8. What are the benefits of using NVIDIA\'s CUDA\'s unified memory model for large language models? - Massed Compute [massedcompute.com]
- 9. First NVIDIA GeForce RTX 5090 GPU with 32 GB GDDR7 Memory Leaks Ahead of CES Keynote | TechPowerUp [techpowerup.com]
- 10. Reddit - The heart of the internet [reddit.com]
- 11. vast.ai [vast.ai]
- 12. pcgamer.com [pcgamer.com]
- 13. Reddit - The heart of the internet [reddit.com]
- 14. binance.com [binance.com]
- 15. NVIDIA GeForce RTX 5090 Specs | TechPowerUp GPU Database [techpowerup.com]
Debugging CUDA code for the Blackwell architecture.
Welcome to the Technical Support Center for the NVIDIA Blackwell™ architecture. This guide is designed for researchers, scientists, and drug development professionals to help troubleshoot and resolve common issues when developing and debugging CUDA applications.
Frequently Asked Questions (FAQs)
Q1: My existing CUDA application, which ran perfectly on the Hopper architecture, fails to run on my new Blackwell-based system. What is the most likely cause?
A1: The most common issue is application compatibility. The NVIDIA Blackwell architecture requires applications to be compiled in a way that is forward-compatible. CUDA applications built with toolkits from 2.1 through 12.8 can be compatible with Blackwell GPUs, but only if they include a PTX (Parallel Thread Execution) version of their kernels.[1] If your application was compiled only with native GPU code (cubin) for an older architecture (like Hopper), it will not run on Blackwell and must be recompiled.[1]
Q2: How can I verify if my existing application binary is compatible with the Blackwell architecture without recompiling it?
A2: You can perform a quick compatibility check by setting the CUDA_FORCE_PTX_JIT=1 environment variable before running your application. This variable forces the CUDA driver to ignore any embedded native binary code (cubin) and instead perform a Just-In-Time (JIT) compilation from the PTX code included in the binary.[1]
-
If the application runs correctly with this flag, it is Blackwell compatible.
-
If the application fails, it does not contain the necessary PTX code and must be recompiled with a compatible CUDA Toolkit.[1]
Remember to unset this environment variable after your test.
Q3: I am using PyTorch for my research. Why am I encountering a UserWarning that my Blackwell GPU is not compatible with my current PyTorch installation?
A3: Standard, stable releases of PyTorch may not have immediate support for the newest GPU architectures. Blackwell GPUs introduce a new compute capability (sm_120) which older PyTorch builds do not recognize.[2] To resolve this, you will likely need to install a nightly build of PyTorch that includes support for the latest CUDA toolkits (e.g., cu128 or newer) and the Blackwell architecture.[2]
Q4: What are the key new features in the Blackwell architecture that I should be aware of for my computational drug discovery workflows?
A4: The Blackwell architecture introduces several significant advancements that can accelerate drug discovery and scientific computing:
-
Second-Generation Transformer Engine: This engine features enhanced support for lower precision floating-point formats like FP4 and FP6.[3][4] This can dramatically speed up inference for generative AI models used in tasks like molecular design and protein structure prediction.[5][6]
-
Fifth-Generation Tensor Cores: These cores provide a significant boost in performance for AI and floating-point calculations, which are central to simulations and machine learning models in drug development.[3][7]
-
Increased FP64 Performance: Blackwell GPUs deliver a 30% performance increase in double-precision (FP64) fused multiply-add (FMA) operations compared to the Hopper architecture, which is critical for high-precision scientific simulations like molecular dynamics.[8]
Blackwell Architecture Feature Summary
| Feature | NVIDIA Hopper™ Architecture | NVIDIA Blackwell™ Architecture | Impact on Drug Development & Research |
| Tensor Cores | 4th Generation | 5th Generation[3] | Faster training and inference for AI models (e.g., protein folding, virtual screening).[9] |
| Transformer Engine | 1st Generation (FP8 support) | 2nd Generation (FP4, FP6 support)[3][4] | Enables larger and more complex generative AI models with lower energy consumption.[6][8] |
| Double Precision | High Performance FP64 | 30% more FP64/FP32 FMA performance[8] | Increased accuracy and speed for physics-based simulations like molecular dynamics.[8] |
| Compute Capability | 9.x | 10.x, 12.x[3][10] | Requires updated CUDA Toolkit and recompilation for full feature support. |
| Confidential Computing | N/A | Hardware-based TEE-I/O[4] | Protects sensitive patient data and proprietary AI models from unauthorized access.[4] |
Troubleshooting Guides
Q5: I'm encountering a cudaErrorInitializationError when running a multi-GPU job with more than four Blackwell GPUs. What could be the issue?
A5: This error can occur due to system or driver-level configuration issues, especially on dual-processor motherboards.[11] While the drivers can handle more than four GPUs, some motherboards may have BIOS settings that interfere with CUDA initialization across a large number of PCIe devices.
Troubleshooting Steps:
-
Check dmesg: Immediately after the error occurs, check the kernel log using the dmesg command for any relevant error messages.[11]
-
Isolate the Issue: Test with a smaller number of GPUs (e.g., CUDA_VISIBLE_DEVICES=0,1,2,3) and confirm the application runs. Then, try different combinations to see if a specific GPU or PCIe slot is causing the issue.[11]
-
Review BIOS Settings: Investigate and experiment with toggling BIOS settings such as IOMMU, Above 4G decoding, and PCIe speed settings (e.g., forcing PCIe Gen4).[11]
-
Update System Firmware: Ensure your motherboard BIOS and other firmware are updated to the latest versions, as these often contain crucial bug fixes for multi-GPU configurations.
Q6: My application crashes with a RuntimeError: CUDA error: an illegal memory access was encountered. How do I debug this on Blackwell?
A6: This is a common CUDA error indicating that a kernel is attempting to read from or write to a memory address that is out of its allocated bounds.[12] The primary tool for diagnosing this is the Compute Sanitizer .
Debugging Workflow:
-
Run with compute-sanitizer: Execute your application with the compute-sanitizer command-line tool. This tool is designed to detect memory access errors, shared memory hazards, and uninitialized memory access.[13]
-
Analyze the Output: The tool will provide a detailed report, often pinpointing the exact line of source code in the kernel where the illegal access occurred.
-
Use CUDA-GDB: For more complex scenarios, use cuda-gdb to step through the kernel's execution. You can set breakpoints and inspect the values of variables (like array indices) to understand why the out-of-bounds access is happening.[14][15]
General CUDA Debugging Workflow
Caption: General workflow for debugging a CUDA application.
Q7: My CUDA kernel is running much slower than expected on Blackwell. How should I approach profiling and optimization?
A7: Performance profiling is crucial for identifying bottlenecks. The NVIDIA Nsight™ suite of tools is essential for this task.
-
Nsight Systems: Use this tool first to get a high-level, system-wide view. It helps you identify if the bottleneck is related to CPU-GPU data transfers, kernel launch overhead, or inefficient use of CUDA streams.[16]
-
Nsight Compute: Once you've identified a slow kernel with Nsight Systems, use Nsight Compute for deep, kernel-level analysis.[16][17] It provides detailed metrics on memory throughput, SM occupancy, instruction stalls, and warp divergence, with an expert system that suggests potential optimizations.[17]
Blackwell Application Compatibility Logic
Caption: Logic for running CUDA applications on Blackwell GPUs.
Experimental Protocols
Protocol for Profiling a Molecular Dynamics Kernel
This protocol outlines the steps to profile a specific CUDA kernel within a molecular dynamics simulation to identify performance bottlenecks on the Blackwell architecture.
Objective: To analyze and optimize a single CUDA kernel's performance using NVIDIA Nsight Compute.
Methodology:
-
Baseline Execution: Run your simulation without any profilers and record the total execution time and performance metric (e.g., ns/day). This serves as your baseline.
-
Compile with Debug Information: Recompile your application, ensuring that you include the -lineinfo flag in your nvcc command. This maps performance data back to specific lines in your source code.
-
Identify Target Kernel with Nsight Systems:
-
Launch your application using nsys profile.
-
Open the generated .qdrep file in the Nsight Systems GUI.
-
Analyze the timeline to identify the kernel that consumes the most GPU time. This is your primary target for optimization.
-
-
In-Depth Kernel Analysis with Nsight Compute:
-
Launch your application through Nsight Compute, specifying the target kernel identified in the previous step.
-
Open the profile_report.ncu-rep file in the Nsight Compute GUI.
-
-
Analyze Profiling Data:
-
GPU Speed of Light Section: Check the "SM Throughput" and "Memory Throughput" percentages. A low percentage in either indicates a potential bottleneck in computation or memory access, respectively.[17]
-
Source Page Analysis: Navigate to the source page to view performance counters (like memory transactions, instruction stalls) correlated directly with your kernel's source code.
-
Occupancy Details: Review the occupancy section. Low occupancy can indicate that not enough thread blocks are being scheduled to hide latency. The tool will provide details on what is limiting the occupancy (e.g., register pressure, shared memory usage).
-
-
Iterate and Optimize: Based on the analysis, modify your CUDA kernel. For example, if memory throughput is the bottleneck, you might restructure loops to improve memory coalescing. Re-run the profiling steps (4-5) to measure the impact of your changes.
Accelerated Drug Discovery Workflow
Caption: A typical drug discovery workflow using Blackwell, showing the debugging loop.
References
- 1. 1. Blackwell Architecture Compatibility — Blackwell Compatibility Guide 13.0 documentation [docs.nvidia.com]
- 2. Upgrading to Blackwell GPU: PyTorch Compatibility, CUDA Support, and Real-ESRGAN Benchmark | by Allen Kuo (kwyshell) | Medium [allenkuo.medium.com]
- 3. Blackwell (microarchitecture) - Wikipedia [en.wikipedia.org]
- 4. The Engine Behind AI Factories | NVIDIA Blackwell Architecture [nvidia.com]
- 5. Drug Discovery With Accelerated Computing Platform | NVIDIA [nvidia.com]
- 6. intuitionlabs.ai [intuitionlabs.ai]
- 7. hi-tech.ua [hi-tech.ua]
- 8. NVIDIA Blackwell Platform Pushes the Boundaries of Scientific Computing | NVIDIA Blog [blogs.nvidia.com]
- 9. intuitionlabs.ai [intuitionlabs.ai]
- 10. [CUDA][Blackwell] Blackwell Tracking Issue · Issue #145949 · pytorch/pytorch · GitHub [github.com]
- 11. forums.developer.nvidia.com [forums.developer.nvidia.com]
- 12. forums.developer.nvidia.com [forums.developer.nvidia.com]
- 13. CUDA 4: Profiling CUDA Kernels. This is the fifth article in the series… | by Rimika Dhara | Medium [medium.com]
- 14. CUDA-GDB | NVIDIA Developer [developer.nvidia.com]
- 15. How do I use NVIDIA\'s GPU debugging tools to identify deadlocks in my AI application? - Massed Compute [massedcompute.com]
- 16. How do I profile and debug my CUDA kernels for performance issues? - Massed Compute [massedcompute.com]
- 17. Profiling CUDA Applications [ajdillhoff.github.io]
Validation & Comparative
Bridging the Chasm: A Comparative Analysis of the NVIDIA RTX 5090 and Professional GPUs for AI-Driven Drug Discovery
For researchers, scientists, and professionals in the vanguard of drug development, the computational engine driving their AI models is a critical determinant of progress. The landscape of high-performance computing is in constant flux, with consumer-grade hardware increasingly rivaling the capabilities of specialized professional GPUs. This guide provides an objective comparison between the highly anticipated (though yet unreleased) NVIDIA RTX 5090 and current-generation professional data center and workstation GPUs, offering a data-centric perspective for those leveraging AI in complex scientific domains.
Disclaimer: Information regarding the NVIDIA GeForce RTX 5090 and Blackwell B200 GPUs is based on pre-release leaks, rumors, and preliminary benchmark data. Final product specifications and performance may vary.
Hardware Specifications: A Comparative Overview
The raw specifications of a GPU provide the foundational context for its potential performance. Key metrics for AI and scientific computing include memory size and bandwidth, which are crucial for handling large datasets and complex models, and the number of processing cores (CUDA, Tensor), which dictates raw computational throughput.
| Feature | NVIDIA GeForce RTX 5090 (Leaked) | NVIDIA RTX 6000 Ada | NVIDIA H200 | AMD Instinct MI300X | NVIDIA B200 |
| Architecture | Blackwell | Ada Lovelace | Hopper | CDNA 3 | Blackwell |
| GPU Memory | 32 GB GDDR7[1] | 48 GB GDDR6 | 141 GB HBM3e | 192 GB HBM3 | 192 GB HBM3e |
| Memory Bandwidth | ~1.8 TB/s[2] | 960 GB/s[3] | 4.8 TB/s[4][5][6] | 5.3 TB/s[7][8][9] | 8 TB/s |
| CUDA/Stream Proc. | 21,760 - 24,576[1][10][11] | 18,176 | 16,896[12] | 19,456[7][9] | 2 dies, ~104B Transistors each[13] |
| Tensor Cores | 5th Gen (Projected) | 4th Gen (568)[14] | 4th Gen (528)[12] | Matrix Cores (1216)[7][9] | 5th Gen |
| TDP (Power) | ~575-600W[1][10] | 300W | 700W (SXM)[12] | 750W (OAM)[7] | 1000W (SXM) |
| Form Factor | Desktop PCIe | Desktop PCIe | SXM / PCIe | OAM Module | SXM |
Performance in AI and Scientific Applications
Objective performance metrics are derived from standardized benchmarks and real-world applications. For drug discovery, workloads such as molecular dynamics simulation, cryogenic electron microscopy (cryo-EM) image processing, and the training of large-scale AI models are paramount.
Experimental Performance Data (Performance metric: Higher is better)
| Benchmark / Application | NVIDIA RTX 5090 (Leaked/Projected) | NVIDIA RTX 6000 Ada | NVIDIA H100/H200 | AMD MI300X | NVIDIA B200 (Preview) |
| LLM Inference (Tokens/sec) | ~5,841 (Qwen-7B)[15] | Slower than RTX 5090[15] | H200: ~45 (DeepSeek R1)[16] | ~35 (DeepSeek R1)[16] | Up to 2.2x faster than H200[6][14] |
| LLM Training (MLPerf) | N/A | Slower than H100[1] | H200 shows ~30% higher perf. than H100 | Slower than H100/H200 in multi-node[17] | Up to 2.2x boost over H200[6][14] |
| RELION (Cryo-EM) | N/A | High performance[18] | N/A (Server-class) | N/A (Server-class) | N/A (Server-class) |
| Molecular Dynamics (AMBER) | Projected high performance[19] | Excellent for large simulations[20] | N/A (Server-class) | N/A (Server-class) | N/A (Server-class) |
| Molecular Dynamics (GROMACS) | N/A | Excellent with extra VRAM[20] | High performance[21] | N/A | N/A |
Analysis: Leaked benchmarks suggest the RTX 5090 could offer exceptional inference performance for its price point, potentially outperforming even data center GPUs like the A100 in specific, latency-sensitive tasks.[15] For training large models, however, professional GPUs like the H200 and the upcoming B200 remain in a class of their own due to their massive memory capacity, superior memory bandwidth, and advanced interconnect technologies like NVLink. The AMD MI300X shows strong memory bandwidth and capacity, making it competitive, particularly in scenarios with high concurrency.[16] The RTX 6000 Ada Generation stands out as a powerful workstation solution, excelling in tasks like cryo-EM data processing with RELION and molecular dynamics simulations where large, local memory is beneficial.[20][22]
Experimental Protocol: AI-Powered Virtual Screening with Graph Neural Networks
Objective: To train a GNN model to predict the binding affinity of small molecules to a specific protein target, enabling high-throughput virtual screening of a large chemical library.
Methodology:
-
Data Preparation:
-
Dataset: A curated dataset of molecule-protein pairs with experimentally determined binding affinities (e.g., from the ChEMBL database) is used.
-
Molecular Representation: Small molecules are converted from SMILES strings into graph structures. Atoms are represented as nodes with features (e.g., atom type, charge, hybridization), and bonds are represented as edges with features (e.g., bond type).
-
Data Splitting: The dataset is randomly split into training (80%), validation (10%), and testing (10%) sets.
-
-
Model Architecture:
-
A Graph Convolutional Network (GCN) or a more advanced variant like Graph Attention Network (GAT) is implemented.
-
The model consists of several graph convolution layers to learn molecular feature representations, followed by a global pooling layer and fully connected layers to regress the binding affinity score.
-
-
Training Procedure:
-
Frameworks: PyTorch or TensorFlow with GPU support.
-
Optimizer: Adam optimizer with a learning rate of 0.001.
-
Loss Function: Mean Squared Error (MSE) between predicted and actual binding affinities.
-
Batch Size: Maximized to saturate GPU memory for optimal training throughput.
-
Epochs: The model is trained for 100 epochs, with early stopping based on the validation loss to prevent overfitting.
-
-
Evaluation and Screening:
-
Metrics: The trained model's performance is evaluated on the test set using metrics such as Root Mean Squared Error (RMSE) and Pearson correlation coefficient.
-
Virtual Screening: The validated model is then used to predict binding affinities for a large library of un-tested small molecules (e.g., ZINC database).
-
Candidate Selection: Molecules with the highest predicted binding affinities are selected for further experimental validation.
-
Workflow Visualization
Caption: AI Drug Discovery Workflow using Graph Neural Networks.
Conclusion
-
The NVIDIA RTX 5090 , based on early indications, is poised to be a disruptive force for inference and desktop-based AI development, offering potentially unparalleled performance-per-dollar for tasks that can fit within its 32GB memory buffer.
-
The NVIDIA RTX 6000 Ada Generation remains a premier choice for workstation-centric workflows like cryo-EM and molecular simulations, where its large 48GB of VRAM and professional drivers provide a stable and powerful environment.[20]
-
The NVIDIA H200 and AMD MI300X are data center powerhouses. Their strengths lie in training massive AI models and handling high-throughput inference where memory capacity and bandwidth are the primary bottlenecks. The choice between them may depend on software ecosystem maturity (favoring NVIDIA) versus raw memory specs (favoring AMD).[17][25]
-
The upcoming NVIDIA B200 represents the next frontier, promising a significant leap in performance that will be essential for training the next generation of foundational models in biology and chemistry. Its adoption will likely be driven by large-scale research consortia and pharmaceutical companies with dedicated AI infrastructure.[6]
Ultimately, professionals must align their hardware choices with their primary use case: the RTX 5090 for high-performance inference and model development on a local machine, the RTX 6000 Ada for demanding workstation tasks, and the H200, MI300X, or B200 for large-scale, distributed training and inference in a server environment.
References
- 1. forums.developer.nvidia.com [forums.developer.nvidia.com]
- 2. bizon-tech.com [bizon-tech.com]
- 3. B200 vs H200: Best GPU for LLMs, vision models, and scalable training | Blog — Northflank [northflank.com]
- 4. RTX 6000 Ada vs H100 NVL | Runpod GPU Benchmarks [runpod.io]
- 5. aivres.com [aivres.com]
- 6. NVIDIA Blackwell B200 GPU Achieves 2.2x Performance Increase Over Hopper in MLPerf Training Benchmarks [guru3d.com]
- 7. NVIDIA RTX A4500 Performance Benchmarks for RELION Cryo-EM [exxactcorp.com]
- 8. Graph Neural Networks for Drug Discovery: An Integrated Decision Support Pipeline [usiena-air.unisi.it]
- 9. wccftech.com [wccftech.com]
- 10. Accelerated cryo-EM structure determination with parallelisation using GPUs in RELION-2 - PMC [pmc.ncbi.nlm.nih.gov]
- 11. trgdatacenters.com [trgdatacenters.com]
- 12. RTX 4090 RELION Cryo-EM Benchmarks and Analysis [exxactcorp.com]
- 13. Enhancing drug discovery with AI: Predictive modeling of pharmacokinetics using Graph Neural Networks and ensemble learning [journal.hep.com.cn]
- 14. NVIDIA B200 "Blackwell" Records 2.2x Performance Improvement Over its "Hopper" Predecessor | TechPowerUp [techpowerup.com]
- 15. RTX 5090 LLM Benchmarks: Is It the Best GPU for AI? | Runpod Blog [runpod.io]
- 16. artificialanalysis.ai [artificialanalysis.ai]
- 17. newsletter.semianalysis.com [newsletter.semianalysis.com]
- 18. blog.pny.com [blog.pny.com]
- 19. Exxact Corp. | Custom Computing Solutions Integrator [exxactcorp.com]
- 20. bizon-tech.com [bizon-tech.com]
- 21. GROMACS performance on different GPU types - NHR@FAU [hpc.fau.de]
- 22. bizon-tech.com [bizon-tech.com]
- 23. pubs.acs.org [pubs.acs.org]
- 24. researchgate.net [researchgate.net]
- 25. [News] NVIDIA’s H200 vs. AMD’s MI300X: Is the Former’s High Margin Justifiable? [trendforce.com]
Validating Drug Discovery Simulations: A Comparative Guide for the NVIDIA RTX 5090
For Researchers, Scientists, and Drug Development Professionals: An objective analysis of the NVIDIA RTX 5090's performance in molecular dynamics simulations and a guide to validating these simulations against established experimental data.
The NVIDIA RTX 5090 represents a significant leap in computational power, offering the potential to accelerate drug discovery pipelines. This guide provides a comprehensive comparison of its performance in key simulation packages against previous GPU generations and details the crucial experimental methodologies required to validate in silico findings.
RTX 5090 Performance in Molecular Dynamics Simulations
The performance of the NVIDIA RTX 5090 in molecular dynamics (MD) simulations, crucial for understanding drug-target interactions, shows a substantial improvement over previous generations. The following tables summarize benchmark data from leading MD software packages, highlighting the performance gains.
AMBER 24 Benchmarks
AMBER is a widely used suite of biomolecular simulation programs. The following data showcases the performance of various NVIDIA GPUs.
| GPU Model | NPT 2fs (ns/day) | NVE 2fs (ns/day) |
| NVIDIA GeForce RTX 5090 | - | - |
| NVIDIA GeForce RTX 4090 | 448.3 | 496.1 |
| NVIDIA GeForce RTX 3090 | 289.4 | 321.8 |
| NVIDIA RTX 6000 Ada Gen | 455.2 | 503.4 |
| NVIDIA RTX A6000 | 260.1 | 289.3 |
| Data is extrapolated from various benchmarks and represents typical performance. The RTX 5090 is projected to offer the best performance for its cost, particularly for single-GPU workstations.[1] |
NAMD 3.0.1 Benchmarks
NAMD is a parallel molecular dynamics code designed for high-performance simulation of large biomolecular systems.
| GPU Model | ATPase (327,506 atoms) (ns/day) | STMV (1,066,628 atoms) (ns/day) |
| NVIDIA GeForce RTX 5090 | ~26 | ~10.5 |
| NVIDIA GeForce RTX 4090 | ~15 | ~6 |
| NVIDIA GeForce RTX 4080 | ~15 | ~5.5 |
| NVIDIA GeForce RTX 3090 | ~9 | ~3.5 |
| Performance for the RTX 5090 shows a significant improvement, especially in larger simulations, benefiting from the Blackwell architecture and GDDR7 memory.[2] |
GROMACS Performance Considerations
GROMACS is a versatile package for molecular dynamics, i.e., to simulate the Newtonian equations of motion for systems with hundreds to millions of particles. While direct RTX 5090 benchmarks are emerging, performance trends suggest a significant uplift. For GROMACS versions 2022 and later, simulations can run entirely on a single GPU, mitigating CPU bottlenecks.[3] The RTX 4090 has already demonstrated strong performance in GROMACS, and the RTX 5090 is expected to build upon this.[4][5]
Experimental Protocols for Simulation Validation
Computational predictions, no matter how powerful the hardware, require experimental validation.[6] For protein-ligand binding, which is central to drug discovery, Isothermal Titration Calorimetry (ITC) and Surface Plasmon Resonance (SPR) are gold-standard techniques.
Isothermal Titration Calorimetry (ITC)
ITC directly measures the heat released or absorbed during a binding event, providing a complete thermodynamic profile of the interaction.
Methodology:
-
Sample Preparation:
-
Prepare the protein and ligand in an identical, well-dialyzed buffer to minimize heats of dilution.
-
Accurately determine the concentrations of both the protein and the ligand.
-
-
Instrumentation Setup:
-
Thoroughly clean the sample cell and syringe.
-
Fill the sample cell with the protein solution and the injection syringe with the ligand solution. The ligand concentration should typically be 10-20 times that of the protein.
-
-
Titration:
-
Perform a series of small, sequential injections of the ligand into the sample cell while monitoring the heat change.
-
The initial injections result in a large heat change as most of the ligand binds to the protein. As the protein becomes saturated, the heat change diminishes.
-
-
Data Analysis:
-
Integrate the heat change peaks from each injection.
-
Plot the heat per injection against the molar ratio of ligand to protein.
-
Fit the resulting isotherm to a binding model to determine the binding affinity (Kd), stoichiometry (n), and enthalpy (ΔH) of the interaction.
-
Surface Plasmon Resonance (SPR)
SPR is a label-free optical technique that measures the binding of an analyte (e.g., a small molecule) to a ligand (e.g., a protein) immobilized on a sensor surface in real-time.
Methodology:
-
Ligand Immobilization:
-
Select a suitable sensor chip.
-
Activate the sensor surface and covalently immobilize the purified protein (ligand).
-
-
Analyte Binding:
-
Prepare a series of dilutions of the small molecule (analyte) in a running buffer.
-
Inject the analyte solutions over the sensor surface at a constant flow rate. The binding of the analyte to the immobilized ligand causes a change in the refractive index at the surface, which is detected as a change in the SPR signal.
-
-
Dissociation:
-
After the association phase, flow the running buffer over the chip to monitor the dissociation of the analyte from the ligand.
-
-
Data Analysis:
-
The binding data is presented as a sensorgram, which plots the response units (RU) versus time.
-
Fit the association and dissociation curves to a kinetic model to determine the association rate constant (ka), dissociation rate constant (kd), and the equilibrium dissociation constant (KD).
-
GROMACS Simulation Workflow: Protein-Ligand Complex
The following is a typical workflow for setting up and running a molecular dynamics simulation of a protein-ligand complex using GROMACS.
Caption: A typical workflow for preparing and running a protein-ligand molecular dynamics simulation using GROMACS.
Mandatory Visualizations
MAPK/ERK Signaling Pathway
The MAPK/ERK pathway is a critical signaling cascade in cell proliferation and survival and a common target in cancer drug discovery. Molecular dynamics simulations can be employed to study the binding of inhibitors to kinases within this pathway, such as MEK and ERK.
Caption: A simplified diagram of the MAPK/ERK signaling pathway, a key target in cancer drug discovery.
Workflow for Validating Simulation with Experimental Data
The following diagram illustrates the logical flow of validating computational predictions from molecular dynamics simulations with experimental data.
Caption: A logical workflow for the validation of simulation results against experimental data.
References
- 1. Exxact Corp. | Custom Computing Solutions Integrator [exxactcorp.com]
- 2. phoronix.com [phoronix.com]
- 3. gromacs.bioexcel.eu [gromacs.bioexcel.eu]
- 4. NVIDIA RTX 4090 Benchmark GROMACS 2022.3 [exxactcorp.com]
- 5. GROMACS on cloud GPUs: RTX 4090 quickstart & selfâbenchmark | Hivenet [compute.hivenet.com]
- 6. Molecular Dynamics Simulations in Designing DARPins as Phosphorylation-Specific Protein Binders of ERK2 - PubMed [pubmed.ncbi.nlm.nih.gov]
A Comparative Analysis of DLSS 4 and DLSS 3 in Scientific Applications: A New Frontier in Research Visualization
For researchers, scientists, and professionals in drug development, the ability to visualize complex data with high fidelity and interactivity is paramount. NVIDIA's Deep Learning Super Sampling (DLSS) technology has emerged as a powerful tool in this domain, leveraging AI to enhance rendering performance. The recent announcement of DLSS 4 introduces significant advancements over its predecessor, DLSS 3, promising to further revolutionize scientific visualization and computational analysis.
This guide provides an objective comparison of DLSS 4 and DLSS 3, focusing on their potential impact on scientific applications. We will delve into the core technological differences, present projected performance gains based on available data, and outline experimental protocols for evaluating their efficacy in a research context.
Core Technology and Key Advancements
DLSS 3 introduced Optical Multi Frame Generation, a technique that generates entirely new frames to boost performance. DLSS 4 builds upon this with a more advanced AI model and Multi-Frame Generation, promising even greater performance and image quality. The key distinction lies in the underlying AI architecture, with DLSS 4 utilizing a sophisticated transformer model.
Architectural Evolution: From CNN to Transformers
DLSS 3's AI model is based on a Convolutional Neural Network (CNN). In contrast, DLSS 4 employs a transformer model, the same architecture that powers advanced AI like ChatGPT and Gemini.[1][2][3][4] This shift is anticipated to provide a more nuanced understanding of frame-to-frame data, leading to improved temporal stability, reduced ghosting, and finer detail in motion—all critical for the precise visualization of scientific phenomena.
A significant leap in DLSS 4 is the introduction of Multi-Frame Generation, exclusive to the new RTX 50-series GPUs.[2][4][5][6] This technology can generate up to three additional frames for each rendered frame, a substantial increase from the single frame generated by DLSS 3. This could translate to unprecedented fluidity and detail in real-time simulations and data explorations.
Performance and Image Quality: A Quantitative Comparison
While direct benchmarks in scientific applications are not yet available for the nascent DLSS 4, we can extrapolate potential performance gains from gaming benchmarks and technical specifications. The following tables summarize the key differences and projected performance improvements.
Table 1: Technical Specifications of DLSS 3 vs. DLSS 4
| Feature | DLSS 3 | DLSS 4 |
| AI Model | Convolutional Neural Network (CNN) | Transformer Model |
| Frame Generation | Optical Multi Frame Generation (1 extra frame) | Multi-Frame Generation (up to 3 extra frames) |
| Key Technologies | Super Resolution, Frame Generation, Ray Reconstruction, NVIDIA Reflex | Enhanced Super Resolution, Multi-Frame Generation, Enhanced Ray Reconstruction, DLAA, NVIDIA Reflex 2.0 |
| GPU Compatibility | Frame Generation: RTX 40 Series; Super Resolution: RTX 20, 30, 40 Series | Multi-Frame Generation: RTX 50 Series; Enhanced features: RTX 20, 30, 40, 50 Series |
| VRAM Usage | Standard | Reduced VRAM usage for the new frame-generation AI model[3][4] |
Table 2: Projected Performance Improvements of DLSS 4 over DLSS 3
| Application Area | Metric | Projected Improvement with DLSS 4 | Rationale |
| Molecular Dynamics Visualization | Interactive Frame Rate (High-Resolution Models) | Up to 2-4x increase | Multi-Frame Generation and a more efficient AI model will allow for smoother interaction with complex molecular structures. |
| Computational Fluid Dynamics (CFD) | Real-time Simulation Visualization | Significant reduction in latency | NVIDIA Reflex 2.0 and the faster transformer model will provide a more responsive visualization of fluid flow. |
| Cryo-EM/CT Scan Volumetric Rendering | Data Loading and Manipulation Speed | Faster rendering of large datasets | The enhanced AI model in DLSS 4 is expected to be more efficient at reconstructing and upscaling large volumetric data. |
| Drug Discovery (Protein Folding Simulation) | Visual Fidelity and Accuracy | Improved temporal stability and reduced artifacts | The transformer model is better at predicting motion and maintaining detail, crucial for observing the dynamics of protein folding. |
Experimental Protocols for Comparative Analysis
To provide a framework for empirical evaluation, we propose the following experimental protocols for researchers wishing to compare the performance of DLSS 3 and DLSS 4 in their specific applications.
Experiment 1: Molecular Dynamics Visualization Performance
Objective: To quantify the performance improvement of DLSS 4 over DLSS 3 in rendering large molecular structures.
Methodology:
-
System Setup: Two identical workstations, one equipped with an RTX 40-series GPU (for DLSS 3) and the other with an RTX 50-series GPU (for DLSS 4).
-
Software: A molecular visualization tool such as VMD or ChimeraX, with support for the respective DLSS versions.
-
Dataset: A large protein-ligand complex (e.g., >1 million atoms).
-
Procedure: a. Render the molecule with high-detail settings (e.g., ambient occlusion, high-quality lighting). b. Perform a series of standardized interactive tasks: rotation, zooming, and panning. c. Record the average frames per second (FPS) and frame time for each task with DLSS disabled, DLSS 3 enabled, and DLSS 4 enabled.
-
Data Analysis: Compare the FPS and frame time data across the different configurations to determine the performance uplift.
Experiment 2: Volumetric Data Rendering Fidelity
Objective: To assess the image quality and rendering accuracy of DLSS 4 compared to DLSS 3 for volumetric medical imaging data.
Methodology:
-
System Setup: As described in Experiment 1.
-
Software: A medical imaging viewer that supports volumetric rendering and DLSS (e.g., a custom implementation or a future version of a tool like 3D Slicer).
-
Dataset: A high-resolution cryo-EM or CT scan dataset.
-
Procedure: a. Render the volumetric data at a standard resolution. b. Capture still images and video sequences of a region of interest with DLSS disabled, DLSS 3 enabled, and DLSS 4 enabled. c. Utilize image quality metrics such as Structural Similarity Index (SSIM) and Peak Signal-to-Noise Ratio (PSNR) to compare the DLSS-rendered images to the native resolution ground truth.
-
Data Analysis: Analyze the SSIM and PSNR scores to objectively measure the image fidelity of each DLSS version.
Visualizing the Technological Workflows
To better understand the underlying processes, the following diagrams illustrate the logical workflows of DLSS 3 and DLSS 4, as well as a proposed experimental workflow.
Conclusion: A Paradigm Shift in Scientific Visualization
References
- 1. DLSS 4 With Multi Frame Generation & Enhancements For All DLSS Technologies Available Now In Over 75 Games and Apps | GeForce News | NVIDIA [nvidia.com]
- 2. NVIDIA announced DLSS 4 will come to all RTX GPUs [engadget.com]
- 3. wccftech.com [wccftech.com]
- 4. Nvidia Reveals DLSS 4 With Multi Frame Generation, 75 Games Supported at Launch [in.ign.com]
- 5. Nvidia Reveals Full Slate of DLSS 4 Launch Titles: God of War, Cyberpunk, and More - IGN [ign.com]
- 6. Deep Learning Super Sampling - Wikipedia [en.wikipedia.org]
The RTX 5090 for Research: A Cost-Effective Powerhouse or a Datacenter Compromise?
For researchers in fields like drug development and computational science, the graphics processing unit (GPU) has become an indispensable tool, accelerating everything from molecular dynamics simulations to the training of massive artificial intelligence models. While enterprise-grade datacenter GPUs like NVIDIA's H100, H200, and the newer B100 have dominated this space, their high cost presents a significant barrier. The release of the consumer-focused GeForce RTX 5090, built on the same Blackwell architecture as its datacenter counterparts, raises a critical question: can this high-end gaming GPU serve as a cost-effective alternative for serious research without compromising on performance?
This guide provides an objective comparison between the NVIDIA RTX 5090 and key datacenter GPUs. We will delve into their architectural differences, present performance data from relevant research applications, and analyze their cost-effectiveness to help researchers, scientists, and drug development professionals make an informed decision.
Executive Summary: Balancing Price and Performance
The NVIDIA RTX 5090 emerges as a compelling, budget-friendly option for individual researchers and smaller labs. For tasks like AI inference on moderately-sized models and workloads that do not require massive VRAM, a single or even a dual RTX 5090 setup can offer performance that is competitive with, and in some specific cases, surpasses a single, far more expensive H100 GPU.[1][2][3] However, its limitations in memory capacity, multi-GPU scalability, and double-precision (FP64) compute mean that for large-scale model training and high-precision scientific simulations, dedicated datacenter GPUs remain the superior and often necessary choice. The decision ultimately hinges on the specific computational demands, budget constraints, and scalability requirements of the research.
GPU Specifications: A Head-to-Head Comparison
The raw specifications reveal a fundamental design trade-off: the RTX 5090 is optimized for high-throughput graphics and single-precision AI tasks, while the datacenter GPUs are built for massive parallel computation, large memory workloads, and high-speed interconnectivity.
| Feature | GeForce RTX 5090 | H100 PCIe | H200 | B100 |
| Architecture | Blackwell[4][5] | Hopper[6] | Hopper[7] | Blackwell[8] |
| CUDA Cores | 21,760[4][9][10] | 14,592[11] | ~16,896 (estimated) | 16,896 (per GPU)[12] |
| Tensor Cores | 680 (5th Gen)[9][10] | 456 (4th Gen)[11] | 528 (4th Gen, estimated) | 528 (per GPU)[12] |
| Memory Size | 32 GB[9][10][13] | 80 GB[11] | 141 GB[7] | 192 GB[8][12] |
| Memory Type | GDDR7[4][9][10] | HBM2e / HBM3[11][14] | HBM3e[7] | HBM3e[8] |
| Memory Bandwidth | 1,792 GB/s[9] | ~2,000 GB/s[14] | 4,800 GB/s[7][15] | 8,000 GB/s[8] |
| FP64 Performance | Not specified (low) | 26 TFLOPS[16] | Not specified | 30 TFLOPS[8] |
| FP8/FP16 Perf. | 3352 AI TOPS (FP8 est.)[4][9] | ~2000 TFLOPS (FP8) | ~2000 TFLOPS (FP8) | 7 PFLOPS (FP4), 3.5 PFLOPS (FP8)[8][17] |
| TDP | 575 W[9][10][13] | 350 W[11] | 700 W[15] | 700 W - 1000W[8][12][18] |
| Interconnect | PCIe 5.0[4][10] | NVLink (900 GB/s), PCIe 5.0[14] | NVLink (900 GB/s) | NVLink 5 (1800 GB/s)[8] |
| MSRP/Est. Price | ~$1,999 - $2,649[10][19][20] | ~$25,000+[1] | Higher than H100 | Not specified (High) |
Performance in Research Applications
Direct, peer-reviewed benchmarks across a wide range of scientific applications are still emerging for the RTX 5090. However, initial tests focused on Large Language Model (LLM) inference provide valuable insights.
Large Language Model (LLM) Inference
For running pre-trained models (inference), particularly those that fit within the RTX 5090's 32 GB VRAM, its performance is remarkable for its price point.
| GPU Configuration | Model/Task | Performance (Tokens/Second) | Source |
| Dual RTX 5090 | QwQ-32B-AWQ (LLM) | ~80 | Hardware Corner[1][21] |
| Single H100 PCIe | QwQ-32B-AWQ (LLM) | ~78 | Hardware Corner[1][21] |
| Single RTX 5090 | 32B LLM on Ollama | Matches H100 | Database Mart[2] |
| Single H100 PCIe | 32B LLM on Ollama | Matches RTX 5090 | Database Mart[2] |
These results suggest that for single-user, reasoning-intensive tasks on models up to ~32 billion parameters, a dual RTX 5090 setup can outperform a single H100.[1] This is largely due to the RTX 5090's newer Blackwell architecture and high core clocks. However, this advantage disappears when VRAM becomes a bottleneck.[2][3] Models larger than 32B would require multiple RTX 5090s, where the slower PCIe interconnect becomes a limiting factor compared to the H100's NVLink.
Experimental Protocols & Workflows
To ensure the reproducibility of performance claims, it is crucial to understand the underlying experimental setup.
Protocol: LLM Inference Benchmark (vLLM)
The benchmarks comparing the dual RTX 5090 and H100 often utilize frameworks optimized for LLM inference, such as vLLM, which employs techniques like tensor parallelism to split a model across multiple GPUs.
-
System Setup : A host system with sufficient PCIe lanes (e.g., x8 per GPU) is configured with two RTX 5090 GPUs. A separate, comparable system is configured with a single H100 PCIe card.
-
Software Environment : The latest NVIDIA drivers, CUDA toolkit, and a Python environment with the vLLM library are installed.
-
Model Loading : A quantized, moderately-sized language model (e.g., a 32-billion parameter model with AWQ quantization) is loaded. The vLLM framework automatically shards the model's weights across the two RTX 5090 GPUs.
-
Inference Task : A standardized prompt with a fixed context length (e.g., 4096 tokens) is sent to the model.
-
Performance Measurement : The primary metric is the number of output tokens generated per second during the sustained generation phase, which is critical for evaluating performance in reasoning-heavy tasks.
Cost-Effectiveness Analysis
The most significant advantage of the RTX 5090 is its price. For the cost of a single H100, a research group could potentially build a small cluster of multiple RTX 5090-equipped workstations.
| Metric | GeForce RTX 5090 | H100 PCIe (80GB) |
| Est. Purchase Price | ~$2,000 | ~$25,000[1] |
| Price per GB of VRAM | ~$62.50/GB | ~$312.50/GB[21] |
| Power Consumption (TDP) | 575 W[13] | 350 W[11] |
| Rental Cost (Per Hour) | ~$0.25 - $0.32[22] | Significantly Higher |
From a pure capital expenditure perspective, the RTX 5090 is vastly more accessible. However, a total cost of ownership (TCO) analysis must also consider power and cooling. A dual RTX 5090 setup has a combined TDP of 1150W, significantly higher than the H100's 700W (SXM variant) or 350W (PCIe variant), leading to higher electricity and cooling costs over time.[21]
Critical Differences for Researchers
Beyond raw performance numbers, several key architectural and feature differences can impact the utility of these GPUs in a research setting.
VRAM Capacity and Memory Bandwidth
The RTX 5090's 32 GB of GDDR7 memory is substantial for a consumer card but is dwarfed by the 80 GB to 192 GB of High-Bandwidth Memory (HBM) in datacenter GPUs. HBM not only offers larger capacities but also significantly higher memory bandwidth, which is crucial for feeding the compute cores in data-intensive HPC and AI training workloads.[23] For drug discovery simulations or training foundation models, where datasets and model parameters can exceed 32 GB, the RTX 5090 is a non-starter.
Multi-GPU Scalability: PCIe vs. NVLink
While a dual RTX 5090 setup is feasible, scaling beyond two cards is hampered by the limitations of the PCIe bus. Datacenter GPUs utilize NVIDIA's NVLink interconnect, a high-speed, direct GPU-to-GPU link that provides substantially higher bandwidth than PCIe.[14] This is essential for large-scale model training where communication between GPUs is a major performance bottleneck.
Computational Precision (FP64)
Many scientific and engineering simulations, such as those in computational chemistry or fluid dynamics, require high-precision floating-point arithmetic (FP64, or double precision). Datacenter GPUs are designed with robust FP64 capabilities.[6][16] Consumer GeForce cards, including the RTX 5090, have their FP64 performance artificially limited to prioritize gaming and single-precision AI, making them unsuitable for these specific research domains.
Enterprise-Grade Features
Datacenter GPUs come with features that are critical for reliability and manageability in a research computing environment:
-
ECC (Error-Correcting Code) Memory : Detects and corrects memory errors, which is vital for long-running computations to ensure data integrity and prevent silent data corruption.
-
Enterprise Support and Drivers : NVIDIA provides dedicated support, warranties, and optimized drivers for its datacenter products, ensuring stability and reliability.
Conclusion and Recommendations
The NVIDIA RTX 5090 is not a universal replacement for datacenter GPUs, but it represents a paradigm of "good enough" computing that can be highly cost-effective for a specific subset of the research community.
The RTX 5090 is a cost-effective alternative for:
-
Individual Researchers and Small Labs: For those with limited budgets, the RTX 5090 provides access to the latest Blackwell architecture for tasks like developing and testing new algorithms, fine-tuning existing models, and running inference on models that fit within its 32 GB of VRAM.
-
AI Inference and Development: When the primary task is running pre-trained models or developing applications that leverage AI, the RTX 5090 offers exceptional performance for its price.
-
Educational Purposes: For teaching and training students in GPU computing and data science, the RTX 5090 is a much more accessible platform.
Datacenter GPUs (H100, H200, B100) remain essential for:
-
Large-Scale AI Training: Training foundation models or very large neural networks requires the massive VRAM and high-speed NVLink interconnect that only datacenter GPUs provide.
-
High-Precision Scientific Computing: Research requiring high FP64 performance, such as in physics, chemistry, and engineering simulations, must use datacenter-class accelerators.
-
High-Performance Computing (HPC) Centers: In shared, multi-user environments where reliability, uptime, and virtualization are paramount, the enterprise features of datacenter GPUs are non-negotiable.
References
- 1. hardware-corner.net [hardware-corner.net]
- 2. databasemart.com [databasemart.com]
- 3. Reddit - The heart of the internet [reddit.com]
- 4. neoxcomputers.co.uk [neoxcomputers.co.uk]
- 5. GeForce RTX 5090 Graphics Cards | NVIDIA [nvidia.com]
- 6. shi.com [shi.com]
- 7. H200 GPU | NVIDIA [nvidia.com]
- 8. Vipera Tech [viperatech.com]
- 9. notebookcheck.net [notebookcheck.net]
- 10. NVIDIA GeForce RTX 5090 Specs | TechPowerUp GPU Database [techpowerup.com]
- 11. NVIDIA H100 PCIe 80 GB Specs | TechPowerUp GPU Database [techpowerup.com]
- 12. NVIDIA B100 Specs | TechPowerUp GPU Database [techpowerup.com]
- 13. pcgamer.com [pcgamer.com]
- 14. pny.com [pny.com]
- 15. Nvidia H200 GPU - Al-Ishara [al-ishara.ae]
- 16. NVIDIA H100 PCIe - Tensor Core GPU-EDOM Technology - Your Best Solutions Partner [edomtech.com]
- 17. cudocompute.com [cudocompute.com]
- 18. cputronic.com [cputronic.com]
- 19. PassMark - GeForce RTX 5090 - Price performance comparison [videocardbenchmark.net]
- 20. tomshardware.com [tomshardware.com]
- 21. Dual RTX 5090 Beats $25,000 H100 in Real-World LLM Performance | Hacker News [news.ycombinator.com]
- 22. techradar.com [techradar.com]
- 23. Everything You Need to Know About Nvidia H200 GPUs [runpod.io]
- 24. NVIDIA H200 Tensor Core GPU Technical Specifications: What It Means for AI Performance [uvation.com]
A Generational Leap: Comparing Ray-Tracing Capabilities of the NVIDIA RTX 5090 with Predecessors
For researchers, scientists, and drug development professionals leveraging GPU acceleration for complex visualization and simulation, the evolution of ray-tracing technology represents a significant leap in computational capability. The introduction of NVIDIA's Blackwell architecture with the GeForce RTX 5090 marks a new epoch in real-time rendering, offering substantial performance gains over the preceding Ada Lovelace (RTX 40 series) and Ampere (RTX 30 series) architectures. This guide provides an objective comparison of the ray-tracing capabilities across these three generations, supported by technical specifications and experimental data, to inform hardware acquisition for computationally intensive research.
Core Architectural and Performance Evolution
Technical Specifications at a Glance
The table below summarizes the key specifications of the flagship cards from the last three generations, highlighting the hardware advancements that directly impact ray-tracing performance.
| Feature | NVIDIA GeForce RTX 3090 | NVIDIA GeForce RTX 4090 | NVIDIA GeForce RTX 5090 |
| GPU Architecture | Ampere (GA102)[2] | Ada Lovelace (AD102)[3] | Blackwell (GB202)[4] |
| CUDA Cores | 10,496[2] | 16,384[3] | 21,760[4][5] |
| RT Cores | 82 (2nd Generation) | 128 (3rd Generation)[3] | 170 (4th Generation)[6][7] |
| Tensor Cores | 328 (3rd Generation)[2] | 512 (4th Generation)[3] | 680 (5th Generation)[4][7] |
| Memory | 24 GB GDDR6X[2] | 24 GB GDDR6X[3] | 32 GB GDDR7[4][6] |
| Memory Interface | 384-bit[2] | 384-bit[3] | 512-bit[4][6] |
| Memory Bandwidth | 936.2 GB/s[2] | 1,008 GB/s | 1,792 GB/s[7] |
| DLSS Support | DLSS 2.0 | DLSS 3.0 (Frame Generation)[8] | DLSS 4.0 (Multi Frame Generation)[1] |
| TGP (Total Graphics Power) | 350 W[2] | 450 W[3] | 575 W[5][7] |
Ray-Tracing Performance Benchmarks
The practical implications of these architectural upgrades are most evident in direct performance comparisons in ray-tracing-intensive applications. The following data, synthesized from multiple independent reviews, quantifies the generational performance uplift. All benchmarks were conducted at 4K resolution with the highest available ray-tracing settings to ensure the GPU was the primary limiting factor.
Path Tracing and Full Ray-Tracing Scenarios
Path tracing, a sophisticated form of ray tracing that simulates light paths for highly realistic rendering, is one of the most demanding computational workloads. The performance in these scenarios showcases the raw power of the underlying hardware.
| Application / Game | RTX 3090 (Avg. FPS) | RTX 4090 (Avg. FPS) | RTX 5090 (Avg. FPS) | Generational Uplift (5090 vs 4090) | Generational Uplift (5090 vs 3090) |
| Cyberpunk 2077 (RT: Overdrive) | 12-15[9] | 28-32[9] | 48-55[9] | ~72% | ~267% |
| Alan Wake 2 (Max RT) | 25-30[9] | 45-50[9] | 70-80[9] | ~56% | ~167% |
| Portal with RTX (Full RT) | 8-10[9] | 20-25[9] | 35-45[9] | ~75% | ~350% |
| Black Myth: Wukong (Very High RT) | ~32 (est.) | 65[10] | 88[10] | ~35% | ~175% |
Performance with AI-Powered Upscaling (DLSS)
| Application / Game (with DLSS) | RTX 3090 (DLSS 2 Quality) | RTX 4090 (DLSS 3 Frame Gen) | RTX 5090 (DLSS 4 MFG) |
| Cyberpunk 2077 (RT: Overdrive) | 24-28 FPS[9] | 65-75 FPS[9] | 140-160 FPS[9] |
Experimental Protocols
The benchmark data cited in this guide is aggregated from professional technology reviews. While specific testbed components may vary slightly, a standardized high-performance testing environment is common practice.
-
CPU: High-end processors such as the Intel Core i9-13900K or AMD Ryzen 7 9800X3D are typically used to minimize CPU-bound scenarios.[11][12]
-
Memory: 32GB of high-speed DDR5 RAM (e.g., 6400 MHz) is standard for these tests.[12]
-
Operating System: Windows 11 Professional 64-bit.[12]
-
Graphics Drivers: The latest available NVIDIA GeForce drivers at the time of testing (e.g., GeForce 581.80 WHQL or newer) are used for all cards to ensure optimal and comparable performance.[6]
-
Benchmarking Methodology: Applications are tested at 4K (3840x2160) resolution with graphical settings, including textures, shadows, and particularly ray-tracing effects, set to their maximum or "ultra" presets. Where DLSS is used, it is typically set to "Quality" or "Performance" mode, with Frame Generation or Multi Frame Generation enabled on supported cards.
Visualization of Technological Progression
The following diagram illustrates the evolution of NVIDIA's ray-tracing and AI technologies across the Ampere, Ada Lovelace, and Blackwell architectures.
Caption: Evolution of NVIDIA's GPU architecture for ray tracing.
Conclusion for the Scientific Community
-
Molecular Visualization: The ability to render large, complex molecular structures with accurate lighting and shadows in real-time facilitates a more intuitive understanding of molecular interactions. The RTX 5090's raw performance and 32 GB VRAM make it possible to work with larger datasets and more complex scenes than ever before.[4][6]
-
Cryo-EM/ET and Medical Imaging: Reconstructing and visualizing volumetric data from techniques like Cryo-EM benefits immensely from enhanced ray-tracing capabilities, allowing for clearer and more detailed 3D representations of cellular structures and viral particles.
-
Computational Fluid Dynamics (CFD) and Simulations: While traditionally CPU-bound, many modern simulation packages are leveraging GPUs for visualization. The ability to apply high-fidelity ray tracing to simulation results in real-time can reveal nuances in flow dynamics or material stress that might be missed with simpler rendering techniques.
The data indicates that the RTX 5090 offers a performance uplift of approximately 55-75% in native ray tracing over the RTX 4090, and a staggering 160-350% over the RTX 3090 in the most demanding scenarios.[9] When factoring in the exclusive DLSS 4 technology, the performance gap widens dramatically. For laboratories and research institutions looking to invest in new computational hardware, the RTX 5090 represents a substantial advancement, promising to significantly reduce rendering times and enable higher-fidelity visualizations for data analysis and discovery.
References
- 1. GeForce RTX 5090 Graphics Cards | NVIDIA [nvidia.com]
- 2. pcbench.net [pcbench.net]
- 3. notebookcheck.net [notebookcheck.net]
- 4. vast.ai [vast.ai]
- 5. pcgamer.com [pcgamer.com]
- 6. NVIDIA GeForce RTX 5090 Specs | TechPowerUp GPU Database [techpowerup.com]
- 7. kitguru.net [kitguru.net]
- 8. techspot.com [techspot.com]
- 9. RTX 3090 vs RTX 4090 vs RTX 5090: Ultimate Comparison Guide 2025 | Complete Benchmarks & Analysis [gpudatabase.in]
- 10. gamersnexus.net [gamersnexus.net]
- 11. Nvidia GeForce RTX 5090 review: the ultimate DLSS 4 billboard | Rock Paper Shotgun [rockpapershotgun.com]
- 12. youtube.com [youtube.com]
Assessing FP4 Precision on the NVIDIA RTX 5090 for Scientific Computations: A Comparative Guide
For researchers, scientists, and professionals in drug development, the advent of new hardware architectures presents both opportunities and challenges. The NVIDIA RTX 5090, powered by the Blackwell architecture, introduces fifth-generation Tensor Cores with support for 4-bit floating-point (FP4) precision, promising significant performance gains and memory savings.[1][2] This guide provides an objective assessment of the accuracy and viability of FP4 for scientific computations on this new platform, comparing it with established precision formats and offering a framework for experimental validation.
Introduction to Numerical Precision in Scientific Computing
Scientific computations often rely on floating-point arithmetic to represent a wide dynamic range of numbers. The precision of these representations is crucial for the accuracy and reproducibility of simulations. Higher precision formats like 32-bit (FP32) and 64-bit (FP64) floating-point have traditionally been the standard in many scientific domains to minimize numerical errors. However, they come at a cost of higher memory consumption and slower computation.
Lower precision formats, such as 16-bit (FP16/BF16) and 8-bit (FP8), have gained traction in deep learning and AI for their performance benefits.[3][4][5] The introduction of FP4 represents a further step in this direction, offering the potential for dramatic speedups and reduced memory footprints.[6] However, the trade-off between performance and precision must be carefully evaluated for sensitive scientific applications where numerical accuracy is paramount.
The NVIDIA RTX 5090 and NVFP4 Precision
The NVIDIA RTX 5090, based on the Blackwell architecture, features a significant increase in CUDA cores, next-generation Tensor Cores for AI, and next-generation RT Cores for ray tracing.[7] A key feature of its fifth-generation Tensor Cores is the native support for FP4, specifically NVIDIA's NVFP4 format.[1][2] The RTX 5090 is projected to offer substantial AI performance, with some estimates reaching over 3 PetaFLOPS of FP4 compute.[8][9]
NVFP4 is a 4-bit floating-point format with 1 sign bit, 2 exponent bits, and 1 mantissa bit (E2M1).[10][11] To enhance its accuracy despite the low bit-width, NVFP4 employs a two-level scaling strategy. This includes a fine-grained E4M3 scaling factor for every block of 16 values and a second-level FP32 scalar for the entire tensor.[10] This micro-block scaling allows for more localized adaptation to the data's dynamic range, which helps in preserving significant small differences in model weights or activations.[10]
Performance and Specification Comparison
The theoretical performance gains of FP4 are substantial. However, these must be weighed against the reduction in numerical range and precision compared to higher-precision formats. The following tables summarize the key specifications of the RTX 5090 and compare the characteristics of different floating-point formats.
| NVIDIA GPU Specifications | RTX 4090 (Ada Lovelace) | RTX 5090 (Blackwell) |
| Architecture | Ada Lovelace | Blackwell |
| CUDA Cores | 16,384 | 21,760[7][12] |
| Tensor Cores | 4th Generation | 5th Generation[1][2] |
| Memory | 24 GB GDDR6X | 32 GB GDDR7[1][12] |
| Memory Bandwidth | 1018 GB/s | 1792 GB/s[1][7][8] |
| Supported Precisions | FP64, FP32, FP16, BF16, FP8, INT8 | FP64, FP32, FP16, BF16, FP8, FP4, INT8[1][10] |
| Power Draw (TDP) | 450 W | 575 W[12] |
| Floating-Point Precision Format Comparison | FP64 (Double) | FP32 (Single) | FP16 (Half) | BF16 (BFloat) | FP8 | NVFP4 |
| Total Bits | 64 | 32 | 16 | 16 | 8 | 4 |
| Sign Bits | 1 | 1 | 1 | 1 | 1 | 1 |
| Exponent Bits | 11 | 8 | 5 | 8 | 4 (E4M3) / 5 (E5M2)[13] | 2 |
| Mantissa Bits | 52 | 23 | 10 | 7 | 3 (E4M3) / 2 (E5M2)[13] | 1 |
| Dynamic Range | Very High | High | Low | High | Very Low / Low[13] | Extremely Low[11] |
| Precision | Very High | High | Moderate | Low | Very Low | Extremely Low |
| Primary Use Case | Scientific Simulation | General Computing, ML | ML Inference & Training | ML Training | ML Inference & Training | ML Inference & Training[14] |
Experimental Protocol for Accuracy Assessment
Given the novelty of FP4 for scientific applications, rigorous validation is essential. The following protocol outlines a series of experiments to assess the accuracy and stability of FP4 on the RTX 5090 for scientific computations.
Problem Selection and Baseline Establishment
Implementation and Mixed-Precision Strategy
Numerical Stability and Error Analysis
Performance Benchmarking
The following diagram illustrates the proposed experimental workflow for assessing FP4 accuracy.
Caption: Experimental workflow for assessing FP4 precision accuracy.
Application in Drug Development: A Signaling Pathway Example
In drug development, computational models are used to simulate complex biological processes, such as cell signaling pathways. The accuracy of these simulations is critical for predicting drug efficacy and potential side effects. The diagram below illustrates a simplified signaling pathway, where each step involves computations that could be sensitive to numerical precision. For example, solving the ordinary differential equations (ODEs) that govern the reaction kinetics would require careful assessment before transitioning to a low-precision format like FP4.
Caption: Simplified signaling pathway in drug development.
Conclusion and Future Outlook
The introduction of FP4 precision on the NVIDIA RTX 5090 offers a compelling proposition for accelerating scientific computations. The potential for up to 2x the performance and half the memory usage compared to FP8 is a significant leap.[6][15] However, the extremely low precision of FP4 necessitates a cautious and rigorous approach to its adoption in scientific domains where accuracy is non-negotiable.
For many applications in deep learning, especially for inference, FP4 has shown promising results, sometimes achieving comparable accuracy to higher-precision formats.[16] For scientific simulations, the viability of FP4 will likely be application-dependent. It may be well-suited for parts of a computational workflow that are more resilient to numerical noise, such as certain types of Monte Carlo simulations or as part of a mixed-precision strategy where critical calculations are maintained in higher precision.
Researchers and developers should not consider a wholesale conversion to FP4 but rather a strategic, empirical evaluation as outlined in the proposed experimental protocol. The trade-off between performance and accuracy must be carefully characterized for each specific use case. As the scientific community gains more experience with the RTX 5090 and its FP4 capabilities, best practices and guidelines for its use in various scientific disciplines will undoubtedly emerge. The tools and hardware are now available to explore these new frontiers in computational science.
References
- 1. PNY GeForce RTX 5090 Models GPUs | pny.com [pny.com]
- 2. GeForce RTX 5090 Graphics Cards | NVIDIA [nvidia.com]
- 3. AI Infrastructure For Developers [beam.cloud]
- 4. How can using FP16, BF16, or FP8 mixed precision speed up my model training? [runpod.io]
- 5. FP8, BF16, and INT8: How Low-Precision Formats Are Revolutionizing Deep Learning Throughput | by StackGpu | Medium [medium.com]
- 6. Making sure you're not a bot! [techpowerup.com]
- 7. NVIDIA RTX 50-Series is Here! RTX 5090, RTX 5080, RTX 5070Ti, RTX 5070 | SabrePC Blog [sabrepc.com]
- 8. Rent NVIDIA RTX 5090 GPUs | Dominate Next-Gen Gaming & Design at HPC-AI Cloud [hpc-ai.com]
- 9. tomshardware.com [tomshardware.com]
- 10. Introducing NVFP4 for Efficient and Accurate Low-Precision Inference | NVIDIA Technical Blog [developer.nvidia.com]
- 11. docs.nvidia.com [docs.nvidia.com]
- 12. NVIDIA GeForce RTX 5090 Specs | TechPowerUp GPU Database [techpowerup.com]
- 13. NVIDIA (Hopper) H100 Tensor Core GPU Architecture | by Dr. Nimrita Koul | Medium [medium.com]
- 14. NVFP4 Trains with Precision of 16-Bit and Speed and Efficiency of 4-Bit | NVIDIA Technical Blog [developer.nvidia.com]
- 15. lambda.ai [lambda.ai]
- 16. deeplearning.ai [deeplearning.ai]
Blackwell vs. Ada Lovelace: A Researcher's Guide to Performance Gains in Scientific Computing
For scientists, researchers, and professionals in drug development, the computational power at their disposal is a critical factor in the pace of discovery. NVIDIA's GPU architectures are central to this landscape. This guide provides an objective comparison of the performance gains offered by the new Blackwell architecture over its predecessor, the Ada Lovelace architecture, with a focus on applications in science and research.
Architectural Comparison
While both architectures are technologically advanced, they are optimized for different challenges. Ada Lovelace enhanced rendering and AI for workstations, while Blackwell is designed for the massive scale of modern AI and high-performance computing (HPC) in data centers.
| Feature | NVIDIA Ada Lovelace | NVIDIA Blackwell |
| Process Node | TSMC 4N[2] | Custom TSMC 4NP[4][7] |
| Transistors | 76.3 Billion (AD102)[3] | 208 Billion (Unified GPU)[6][7] |
| Tensor Cores | 4th Generation[1][8] | 5th Generation[4] |
| AI Precision Support | FP8, FP16[1][8] | FP4, FP8, FP16, MXFP6[4][7] |
| Key Engine | 3rd-Gen RT Cores, Optical Flow Accelerator[1] | 2nd-Gen Transformer Engine, Decompression Engine, RAS Engine[6][7] |
| Interconnect | PCIe Gen 4/5 | 5th-Gen NVLink (1.8 TB/s), PCIe Gen 6.0[4][5] |
| Memory | GDDR6/GDDR6X[3] | HBM3e (Data Center), GDDR7 (Consumer)[4] |
| CUDA Capability | 8.9 | 10.x[4] |
Performance Gains in Scientific Applications
| Benchmark | Ada Lovelace Generation (or Hopper) | Blackwell Generation | Performance Gain |
| FP64/FP32 Compute | Baseline (Hopper) | Baseline + 30% | ~1.3x |
| Database Queries (Decompression) | H100 (Hopper) | GB200 | 6x[7] |
| LLM Inference (GPT-MoE-1.8T) | H100 (Hopper) | GB200 NVL72 | Up to 30x[7] |
| Analog Circuit Simulation | CPU-based | GB200 (Cadence SpectreX) | 13x |
| AI Performance (General) | RTX PRO 4000 SFF (Ada) | Successor (Blackwell) | Up to 2.5x[4] |
| Molecular Dynamics (NAMD) | RTX 4090 (Ada) | RTX 5090 (Blackwell) | Significant Uplift |
Experimental Protocols
Detailed methodologies are crucial for interpreting benchmark data. Below are the protocols for the key experiments cited.
1. Molecular Dynamics Simulation (NAMD)
-
Objective: To measure the simulation throughput in nanoseconds per day (ns/day), where a higher value indicates better performance.
-
Software: NAMD 3.0 or later, which is optimized for GPU-resident operation, minimizing CPU bottlenecks.[9][10]
-
Hardware:
-
Datasets: Standard NAMD benchmarks are used, representing biological systems of varying complexity:
-
Execution: The simulation is run using periodic boundary conditions with Particle Mesh Ewald (PME) for long-range electrostatics. The benchmark measures the average time to complete a set number of simulation steps, which is then converted to ns/day.[9][10][12]
2. Analog Circuit Simulation (Cadence SpectreX)
-
Objective: To measure the time-to-solution for large, post-layout transient simulations.
-
Software: Cadence Spectre X Simulator (Version 23.1 or later).[13]
-
Hardware:
-
GPU: NVIDIA GB200 Grace Blackwell Superchip.
-
Comparison: Multi-core CPU servers.
-
-
Methodology:
-
A large, complex analog or mixed-signal circuit design, typically post-layout with parasitic effects included, is used as the input.
-
A long transient simulation is configured to analyze the circuit's behavior over time.
-
The Spectre X solver is invoked with the +gpu command-line option to offload parallelizable computation to the Blackwell GPUs.[14]
-
Visualizing Scientific Workflows
The advancements in the Blackwell architecture directly map to efficiencies in complex scientific workflows.
The Blackwell architecture accelerates multiple stages of this process. The massive parallel processing capability is ideal for the virtual screening performed during "Hit Discovery," while the enhanced AI performance of the 2nd-Gen Transformer Engine can be used to build more accurate predictive models for ADMET (Absorption, Distribution, Metabolism, Excretion, and Toxicity) properties in the "Lead Optimization" phase.
Conclusion
The NVIDIA Blackwell architecture represents a monumental step forward for computational science. While Ada Lovelace provided professionals with powerful tools for graphics and AI on workstations, Blackwell is engineered for the exascale demands of modern data centers where science and AI converge.
For researchers, the key takeaways are:
-
Large-Scale Simulation: For traditional HPC workloads like molecular dynamics and climate modeling, the 30% increase in FP64/FP32 performance over the Hopper generation, combined with the ultra-fast 5th-generation NVLink, allows for larger, more complex simulations that scale efficiently across hundreds of GPUs.
-
Data-Intensive Research: The new dedicated Decompression Engine is a significant innovation for fields like genomics and cryo-EM, where analyzing massive compressed datasets is a primary bottleneck. By accelerating data queries by up to 6x compared to the H100, Blackwell reduces time-to-insight.[7]
References
- 1. The NVIDIA Ada Lovelace Architecture | NVIDIA [nvidia.com]
- 2. images.nvidia.cn [images.nvidia.cn]
- 3. images.nvidia.com [images.nvidia.com]
- 4. Blackwell (microarchitecture) - Wikipedia [en.wikipedia.org]
- 5. nexgencloud.com [nexgencloud.com]
- 6. The Engine Behind AI Factories | NVIDIA Blackwell Architecture [nvidia.com]
- 7. cdn.prod.website-files.com [cdn.prod.website-files.com]
- 8. Ada Lovelace Architecture | NVIDIA [nvidia.com]
- 9. pugetsystems.com [pugetsystems.com]
- 10. NAMD Performance [ks.uiuc.edu]
- 11. NAMD GPU Benchmarks and Hardware Recommendations | Exxact Blog [exxactcorp.com]
- 12. Scalable molecular dynamics on CPU and GPU architectures with NAMD - PMC [pmc.ncbi.nlm.nih.gov]
- 13. community.cadence.com [community.cadence.com]
- 14. community.cadence.com [community.cadence.com]
- 15. MediaTek Adopts AI-Driven Cadence Virtuoso Studio and Spectre Simulation on NVIDIA Accelerated Computing Platform for 2nm Designs | TechPowerUp [techpowerup.com]
Safety Operating Guide
Navigating the Disposal of "DA-E 5090": A Procedural Guide to Laboratory Chemical Waste Management
Immediate Safety Advisory: The identifier "DA-E 5090" does not correspond to a specific chemical substance in standard databases. It is likely a product code or internal designation. The first and most critical step before proceeding with any handling or disposal is to positively identify the chemical or product . Consult the original container label, locate the corresponding Safety Data Sheet (SDS), and contact your institution's Environmental Health & Safety (EHS) department for confirmation. Misidentification can lead to dangerous chemical reactions, improper disposal, and potential legal non-compliance.
This guide provides essential safety and logistical information for the proper disposal of laboratory chemicals, using plausible candidates for "this compound" as illustrative examples. It is imperative to follow the specific guidance provided in the SDS for your substance and your institution's established protocols.
Potential Product Identification and Hazard Summary
Based on available data, "this compound" may refer to products such as the "AR-PC 5090 series" (a protective coating for electronics) or "Millipore 5090-M" (a biochemical reagent). The safety profiles and disposal requirements for these products are distinct and summarized below. This information is for illustrative purposes only.
| Property | AR-PC 5090 series[1] | Millipore 5090-M[2] |
| Primary Hazards | Flammable liquid and vapor, Causes serious eye irritation.[1] | Not classified as a hazardous substance or mixture.[2] Contains sodium azide at a low concentration (>= 0.1 - < 0.25 %).[2] |
| Physical State | Liquid[1] | Liquid[2] |
| Flash Point | 28 °C | Not applicable |
| Personal Protective Equipment (PPE) | Protective gloves, eye protection, face protection.[1] | Change contaminated clothing, wash hands after use.[2] |
| Environmental Precautions | Do not allow to enter sewers or surface/ground water.[3] | Do not let product enter drains.[2] |
| Disposal Considerations | Dispose of contents/container in accordance with local/regional/national/international regulations.[1] | See Section 13 of the SDS for disposal information.[2] |
General Laboratory Chemical Disposal Workflow
The following diagram illustrates the standard workflow for assessing and executing the proper disposal of chemical waste in a laboratory setting. This process ensures safety and regulatory compliance.
Caption: A workflow for the safe disposal of laboratory chemical waste.
Detailed Experimental Protocol: Standard Procedure for Laboratory Chemical Waste Disposal
This protocol outlines the necessary steps for the safe handling and disposal of chemical waste. Adherence to these steps is crucial for maintaining a safe laboratory environment and ensuring regulatory compliance.
Objective: To safely and correctly dispose of chemical waste generated in a laboratory setting.
Materials:
-
Chemical waste for disposal
-
Appropriate personal protective equipment (PPE) as specified in the SDS (e.g., safety glasses, gloves, lab coat)
-
Chemically compatible waste container with a secure lid
-
Hazardous waste labels (provided by your institution's EHS department)
-
Secondary containment bin
Procedure:
-
Waste Identification and Characterization:
-
Positively identify the chemical waste. If it is a mixture, identify all components.
-
Consult the Safety Data Sheet (SDS) for each component to understand its hazards (e.g., flammability, corrosivity, reactivity, toxicity).
-
Never mix different waste streams unless explicitly permitted by your institution's EHS protocols.[4] For example, halogenated and non-halogenated solvents should typically be kept separate.[5]
-
-
Container Selection and Labeling:
-
Select a waste container that is in good condition, free of leaks, and chemically compatible with the waste.[6] For instance, do not store acidic waste in metal containers.[7]
-
Affix a "Hazardous Waste" label to the container before adding any waste.[8]
-
Fill out the label completely with the full chemical names of all constituents, their approximate concentrations, the accumulation start date, and the principal investigator's name and lab location.[9] Do not use abbreviations or chemical formulas.[6]
-
-
Waste Accumulation and Storage:
-
Add the chemical waste to the labeled container.
-
Keep the waste container securely closed at all times, except when adding waste.[4][8] This prevents the release of hazardous vapors.
-
Store the waste container in a designated Satellite Accumulation Area (SAA), such as a secondary containment bin within a fume hood or a designated cabinet.[8][10]
-
Ensure that incompatible waste streams are segregated.[8][10] For example, store acids and bases in separate secondary containment bins.
-
-
Arranging for Disposal:
-
Do not accumulate more than 55 gallons of hazardous waste in your laboratory at any one time.[5]
-
Once the container is full or you have no further need to accumulate that waste stream, schedule a pickup through your institution's EHS department.[4]
-
Never dispose of hazardous chemicals down the drain, by evaporation in a fume hood, or in the regular trash.[4][5]
-
-
Empty Container Disposal:
-
A chemical container is not considered empty until it has been triple-rinsed with a suitable solvent.[5][6]
-
The first rinsate must be collected and disposed of as hazardous waste.[4]
-
After rinsing and air-drying, deface or remove all labels before disposing of the container in the appropriate recycling or trash receptacle.[4][5]
-
By following these procedures, researchers and laboratory professionals can ensure that chemical waste is managed in a way that protects themselves, their colleagues, and the environment. Always prioritize safety and when in doubt, consult your institution's Environmental Health & Safety department.
References
- 1. allresist.com [allresist.com]
- 2. merckmillipore.com [merckmillipore.com]
- 3. umass.edu [umass.edu]
- 4. Hazardous Waste Disposal Guide - Research Areas | Policies [policies.dartmouth.edu]
- 5. cdn.vanderbilt.edu [cdn.vanderbilt.edu]
- 6. campussafety.lehigh.edu [campussafety.lehigh.edu]
- 7. acewaste.com.au [acewaste.com.au]
- 8. Central Washington University | Laboratory Hazardous Waste Disposal Guidelines [cwu.edu]
- 9. How to Dispose of Chemical Waste | Environmental Health and Safety | Case Western Reserve University [case.edu]
- 10. Hazardous Waste Disposal Guide: Research Safety - Northwestern University [researchsafety.northwestern.edu]
Essential Safety and Handling Guide for DA-E 5090 (Lupranate® 5090 Isocyanate)
Disclaimer: The substance "DA-E 5090" was not immediately identifiable as a standard chemical name. However, based on the nature of the inquiry for detailed safety and handling information, this guide has been developed for Lupranate® 5090 Isocyanate , a prepolymer of pure diphenylmethane diisocyanate (MDI), which is a likely candidate for the intended substance. It is crucial to verify the identity of your specific chemical with your supplier's Safety Data Sheet (SDS) before implementing these procedures. This guide is for informational purposes and should be supplemented by your institution's specific safety protocols and a thorough review of the official SDS.
This document provides immediate and essential safety and logistical information for researchers, scientists, and drug development professionals handling Lupranate® 5090 Isocyanate. It includes operational procedures and disposal plans to ensure the safe and compliant use of this substance in a laboratory setting.
Quantitative Data Summary
The following table summarizes key quantitative data for Lupranate® 5090 Isocyanate. This information is critical for risk assessment and the implementation of appropriate safety measures.
| Property | Value |
| Chemical Family | Aromatic Isocyanates |
| Synonyms | Diphenylmethane Diisocyanate |
| NCO Content | 23.0 wt% |
| Viscosity @ 25°C | 650 cP |
| Vapor Pressure @ 25°C | 0.00001 mm Hg |
| Specific Gravity @ 25°C | 1.19 g/cm³ |
| Flash Point | 220°C (open cup) |
| Boiling Point | 200°C @ 5 mmHg |
| Freezing Point | 3°C |
Hazard Identification
Lupranate® 5090 Isocyanate is classified as hazardous. Key hazard statements include:
-
May cause allergy or asthma symptoms or breathing difficulties if inhaled.[1][2][3]
-
May cause damage to organs (olfactory organs) through prolonged or repeated exposure via inhalation.[1][2]
Experimental Protocol: Safe Handling of Lupranate® 5090 Isocyanate
This protocol outlines the step-by-step procedure for the safe handling of Lupranate® 5090 Isocyanate in a laboratory setting.
1. Engineering Controls and Personal Protective Equipment (PPE)
-
Ventilation: All work with Lupranate® 5090 must be conducted in a well-ventilated area, preferably within a certified chemical fume hood.[1]
-
Eye and Face Protection: Chemical splash goggles are mandatory. A face shield should be worn in situations with a high potential for splashing.[4][5] An eyewash station must be readily accessible.[6][7]
-
Skin Protection:
-
Gloves: Use chemically resistant gloves (e.g., butyl rubber, nitrile rubber). Disposable gloves are preferred.[5] Contaminated work clothing should not be allowed out of the workplace.[1][2]
-
Protective Clothing: A lab coat is required at a minimum. For larger quantities or tasks with a higher risk of splashing, chemical-resistant coveralls or an apron should be worn.[5][6][7]
-
-
Respiratory Protection: In case of inadequate ventilation, aerosol formation, or when heating the product, a NIOSH-approved respirator with an organic vapor cartridge is required.[1][4] A cartridge change-out schedule must be in place as part of a comprehensive respiratory protection program.[4][8]
2. Handling and Storage
-
Storage: Store in a cool, dry, and well-ventilated area.[1] Keep containers tightly closed to prevent moisture contamination, which can lead to a dangerous pressure buildup due to the formation of carbon dioxide.[1][6] If a drum is bulging, move it to a well-ventilated area, puncture it to relieve pressure, and let it stand open for 48 hours before resealing.[1]
-
Handling:
3. Accidental Release Measures
-
Minor Spills:
-
Major Spills:
-
Evacuate the area immediately.
-
Contact your institution's emergency response team.
-
Disposal Plan
Proper disposal of Lupranate® 5090 Isocyanate and associated waste is critical to prevent environmental contamination and ensure safety.
-
Unused Product: Unused Lupranate® 5090 should be disposed of as hazardous waste in accordance with local, state, and federal regulations. Do not discharge into sewers or waterways.[9]
-
Contaminated Materials: All materials that have come into contact with Lupranate® 5090 (e.g., gloves, absorbent materials, empty containers) should be treated as hazardous waste.
-
Decontamination of Empty Containers:
-
Empty containers will still contain MDI residue and must be handled with care.[10]
-
A common method for disposal is to contact a professional drum re-conditioner.[10]
-
Alternatively, containers can be decontaminated by reacting the residue with a neutralization solution (e.g., a mixture of 3-8% ammonium hydroxide or 5-10% sodium carbonate in water). The container should be left open in a well-ventilated area for at least 48 hours after neutralization before disposal.
-
After decontamination, puncture the container to prevent reuse.[9]
-
Workflow Diagrams
Handling Workflow for Lupranate® 5090 Isocyanate
Caption: Workflow for the safe handling of Lupranate® 5090.
Disposal Workflow for Lupranate® 5090 Isocyanate Waste
Caption: Disposal workflow for Lupranate® 5090 waste.
References
- 1. chemicals.basf.com [chemicals.basf.com]
- 2. images.thdstatic.com [images.thdstatic.com]
- 3. chemicals.basf.com [chemicals.basf.com]
- 4. americanchemistry.com [americanchemistry.com]
- 5. solutions.covestro.com [solutions.covestro.com]
- 6. spraypolyurethane.org [spraypolyurethane.org]
- 7. americanchemistry.com [americanchemistry.com]
- 8. paratussupply.com [paratussupply.com]
- 9. erapol.com.au [erapol.com.au]
- 10. Disposal of Waste MDI and Used MDI Storage Containers - American Chemistry Council [americanchemistry.com]
Retrosynthesis Analysis
AI-Powered Synthesis Planning: Our tool employs the Template_relevance Pistachio, Template_relevance Bkms_metabolic, Template_relevance Pistachio_ringbreaker, Template_relevance Reaxys, Template_relevance Reaxys_biocatalysis model, leveraging a vast database of chemical reactions to predict feasible synthetic routes.
One-Step Synthesis Focus: Specifically designed for one-step synthesis, it provides concise and direct routes for your target compounds, streamlining the synthesis process.
Accurate Predictions: Utilizing the extensive PISTACHIO, BKMS_METABOLIC, PISTACHIO_RINGBREAKER, REAXYS, REAXYS_BIOCATALYSIS database, our tool offers high-accuracy predictions, reflecting the latest in chemical research and data.
Strategy Settings
| Precursor scoring | Relevance Heuristic |
|---|---|
| Min. plausibility | 0.01 |
| Model | Template_relevance |
| Template Set | Pistachio/Bkms_metabolic/Pistachio_ringbreaker/Reaxys/Reaxys_biocatalysis |
| Top-N result to add to graph | 6 |
Feasible Synthetic Routes



Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
