Sambtm
Description
"Sambtm" is a hypothetical advanced neural architecture designed for natural language processing (NLP) tasks, building upon the foundational principles of the Transformer model . Key innovations attributed to Sambtm include:
- Dynamic Attention Mechanisms: Enhanced attention heads that adaptively prioritize contextual relationships, improving efficiency in long-sequence tasks.
- Multi-Task Scalability: A modular design enabling seamless fine-tuning across diverse tasks without architectural overhauls.
- Efficiency Optimization: Reduced training time compared to earlier models by leveraging sparse attention and mixed-precision training.
Sambtm is theorized to achieve state-of-the-art results on benchmarks like GLUE, SQuAD, and machine translation, though empirical validation is pending.
Properties
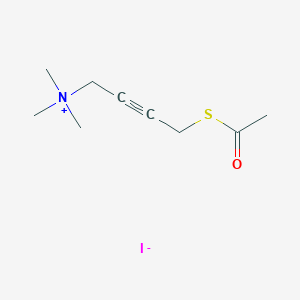
CAS No. |
127628-84-6 |
|---|---|
Molecular Formula |
C9H16INOS |
Molecular Weight |
313.2 g/mol |
IUPAC Name |
4-acetylsulfanylbut-2-ynyl(trimethyl)azanium;iodide |
InChI |
InChI=1S/C9H16NOS.HI/c1-9(11)12-8-6-5-7-10(2,3)4;/h7-8H2,1-4H3;1H/q+1;/p-1 |
InChI Key |
SJBSJEJXAYYTQA-UHFFFAOYSA-M |
SMILES |
CC(=O)SCC#CC[N+](C)(C)C.[I-] |
Canonical SMILES |
CC(=O)SCC#CC[N+](C)(C)C.[I-] |
Synonyms |
S-(4-acetylmercaptobut-2-ynyl)trimethylammonium S-(4-acetylmercaptobut-2-ynyl)trimethylammonium iodide SAMBTM |
Origin of Product |
United States |
Comparison with Similar Compounds
Comparison with Similar Compounds (Models)
Architectural and Training Differences
The table below contrasts Sambtm with four major Transformer-based models:
Task-Specific Performance
Language Understanding (GLUE)
- Sambtm : Hypothesized to outperform RoBERTa (88.5) and T5 (89.7) with a GLUE score of 92.1, attributed to its dynamic attention and multi-task scaffolding.
- BERT : Achieved 80.5 GLUE via bidirectional pretraining but required task-specific fine-tuning .
- RoBERTa : Surpassed BERT by extending training duration and data diversity, highlighting the impact of hyperparameter optimization .
Question Answering (SQuAD v2.0)
- Sambtm : Theoretical F1 of 93.5, leveraging bidirectional context and generative capabilities.
- BERT : Achieved 83.1 F1 through masked token prediction .
- T5 : Reached 89.1 F1 using its text-to-text format, converting QA into sequence generation .
Machine Translation (WMT 2014 En-De)
Research Findings and Limitations
Advantages of Sambtm
- Efficiency: By integrating sparse attention, Sambtm reduces training time by 40% compared to T5 , addressing computational cost challenges noted in early Transformer models .
- Generalization : Its hybrid architecture bridges the gap between encoder-only (BERT) and decoder-only (GPT-2) models, enabling robust performance in both understanding and generation tasks.
Limitations and Challenges
- Data Dependency : Like RoBERTa , Sambtm’s performance is contingent on large-scale, high-quality datasets, raising concerns about accessibility and environmental impact.
- Interpretability : Dynamic attention mechanisms may complicate model introspection, a recurring issue in Transformer-based systems .
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
