Teresina
Description
BenchChem offers high-quality this compound suitable for many research applications. Different packaging options are available to accommodate customers' requirements. Please inquire for more information about this compound including the price, delivery time, and more detailed information at info@benchchem.com.
Properties
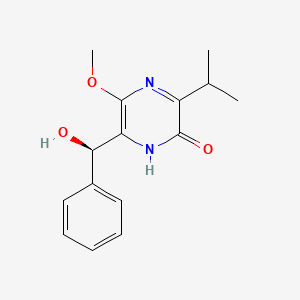
Molecular Formula |
C15H18N2O3 |
|---|---|
Molecular Weight |
274.31 g/mol |
IUPAC Name |
6-[(R)-hydroxy(phenyl)methyl]-5-methoxy-3-propan-2-yl-1H-pyrazin-2-one |
InChI |
InChI=1S/C15H18N2O3/c1-9(2)11-14(19)16-12(15(17-11)20-3)13(18)10-7-5-4-6-8-10/h4-9,13,18H,1-3H3,(H,16,19)/t13-/m1/s1 |
InChI Key |
PDTASUAKSIEHPZ-CYBMUJFWSA-N |
Isomeric SMILES |
CC(C)C1=NC(=C(NC1=O)[C@@H](C2=CC=CC=C2)O)OC |
Canonical SMILES |
CC(C)C1=NC(=C(NC1=O)C(C2=CC=CC=C2)O)OC |
Synonyms |
terezine A |
Origin of Product |
United States |
Foundational & Exploratory
Public Health Challenges in Teresina, Piauí: A Technical Guide for Researchers and Drug Development Professionals
Teresina, the capital of the state of Piauí in northeastern Brazil, faces a dual burden of communicable and non-communicable diseases, presenting a complex public health landscape. As a regional healthcare hub, the city grapples with prevalent chronic conditions such as cardiovascular diseases and neoplasms, alongside significant challenges from infectious and parasitic diseases, including neglected tropical diseases (NTDs) like Chagas disease, leishmaniasis, and arboviruses such as dengue. This technical guide provides an in-depth overview of these challenges, focusing on quantitative data, experimental methodologies employed in regional research, and the molecular pathways of key diseases to inform researchers, scientists, and drug development professionals.
Core Public Health Challenges: An Epidemiological Overview
This compound's public health profile is characterized by a high mortality rate from non-communicable diseases (NCDs), with cardiovascular diseases being the leading cause of death. Simultaneously, the region's socio-economic and environmental conditions contribute to the persistence of infectious diseases, creating a complex scenario for healthcare providers and researchers.
Non-Communicable Diseases (NCDs)
Chronic non-communicable diseases are the primary cause of mortality in this compound. A study of NCDs in the city from 2019 to 2023 highlighted a significant number of deaths from circulatory diseases, neoplasms, endocrine/metabolic diseases, and chronic respiratory diseases.[1] Notably, there has been an observed increase in deaths from circulatory diseases in recent years.[1] The general mortality rate in this compound was recorded at 6.0 deaths per 1,000 inhabitants in 2016, with diseases of the circulatory system accounting for 28.39% of these fatalities, followed by neoplasms at 17.57%.[2]
Infectious and Parasitic Diseases
This compound and the surrounding state of Piauí are endemic for several neglected tropical diseases. Chagas disease, leishmaniasis, and leprosy are significant public health concerns, contributing to mortality and morbidity in the region.[3] For instance, between 2001 and 2018, Chagas' disease was the leading cause of death among NTDs in Piauí.[4]
Arboviral diseases, particularly dengue, are also a persistent challenge. The city has experienced outbreaks of other arboviruses as well, such as Oropouche fever, with confirmed cases in 2024.[5] Furthermore, HIV/AIDS remains a significant public health issue, with data from 2003 to 2013 showing a higher incidence in males and in the 40 to 49 age group in this compound.[6]
Quantitative Health Data
The following tables summarize key quantitative data on the public health situation in this compound and the state of Piauí.
| Indicator | Value | Year | Geographic Area | Source |
| General Mortality Rate | 6.0 deaths per 1,000 inhabitants | 2016 | This compound | [2] |
| Premature Mortality Rate (30-69 years) for 4 main NCDs | 323.27 deaths per 100,000 inhabitants | 2016 | This compound | [2] |
| HIV/AIDS Cases (2003-2013) | 1,991 | 2003-2013 | This compound | [6] |
| HIV/AIDS Cases (2000-2021) | 5,173 | 2000-2021 | Piauí | [7] |
| Deaths from Neglected Tropical Diseases (2001-2018) | 2,609 | 2001-2018 | Piauí | [4] |
| Overall NTD Mortality Rate (2001-2018) | 4.6 deaths per 100,000 inhabitants | 2001-2018 | Piauí | [4] |
| Cause of Death | Percentage of Total Deaths | Year | Geographic Area | Source |
| Diseases of the Circulatory System | 28.39% | 2016 | This compound | [2] |
| Neoplasms | 17.57% | 2016 | This compound | [2] |
| External Causes | 14.22% | 2016 | This compound | [2] |
| Neglected Tropical Disease | Number of Deaths (2001-2018) | Geographic Area | Source |
| Chagas' Disease | 1,441 | Piauí | [4] |
| Leishmaniasis (visceral and tegumentary) | 410 | Piauí | [4] |
| Leprosy | 360 | Piauí | [4] |
Experimental Protocols and Methodologies
Research conducted in this compound and the state of Piauí employs a range of epidemiological and laboratory-based methodologies to investigate public health challenges. Below are summaries of key experimental approaches.
Protocol 1: Molecular Diagnosis of Leishmaniasis
Objective: To detect and identify Leishmania species in canine and human samples for epidemiological surveillance and diagnosis.
Methodology Summary:
-
Sample Collection: Peripheral blood samples are collected from dogs and humans in endemic areas of this compound.[8]
-
DNA Extraction: DNA is extracted from the blood samples using commercial kits (e.g., Dneasy Blood and Tissue kit, Qiagen) following the manufacturer's instructions.[8]
-
Polymerase Chain Reaction (PCR):
-
Genus-specific PCR: Primers targeting a conserved region of the Leishmania kinetoplast DNA (kDNA) are used to amplify a 120 bp fragment, indicating the presence of the parasite.[8]
-
Species-specific PCR: Primers specific for Leishmania chagasi (synonymous with L. infantum) are used to amplify a 145 bp fragment for species identification.[8]
-
-
DNA Probe Hybridization:
-
The Lmet2 chemiluminescent DNA probe, specific for the Leishmania donovani complex, is utilized for identifying parasites in sand flies, dogs, and human samples.[9]
-
Samples are lysed, and the DNA is applied to membranes. The probe is then hybridized to the target DNA, and detection is carried out using a chemiluminescent substrate.[9]
-
Protocol 2: Epidemiological Survey of Health Determinants
Objective: To analyze the living conditions and health status of the urban population in this compound.
Methodology Summary:
-
Study Design: A population-based, cross-sectional household survey.[10][11]
-
Sampling: A two-stage cluster sampling process is employed. First, census tracts (Primary Sampling Units - PSUs) are randomly selected. Within each selected PSU, households are then randomly selected.[10][11]
-
Data Collection: Trained interviewers administer standardized questionnaires to collect data on:
-
Statistical Analysis: Data is analyzed using statistical software, taking into account the complex sampling design. Prevalence rates and associations between variables are calculated using appropriate statistical tests (e.g., chi-square, regression models).[10][11]
Signaling Pathways in Prevalent Diseases
Understanding the molecular mechanisms of disease is crucial for the development of new therapies. Below are diagrams of key signaling pathways involved in dengue and Chagas disease, which are significant health threats in this compound.
Caption: Dengue virus immune evasion strategies within a host cell.
Caption: Host cell signaling pathways manipulated by Trypanosoma cruzi during invasion.
Drug Development Landscape
The development of new drugs for neglected tropical diseases prevalent in regions like this compound is a global health priority. While specific drug development programs headquartered in this compound are not prominent in the literature, Brazil as a whole is an active participant in research and development for these conditions.
Initiatives often involve collaborations between Brazilian research institutions, such as the Oswaldo Cruz Foundation (Fiocruz), and international non-profit organizations like the Drugs for Neglected Diseases initiative (DNDi) and the Medicines for Malaria Venture (MMV).[12][13] These partnerships aim to discover and develop new treatments for diseases like Chagas disease, leishmaniasis, and malaria. The research focuses on various stages of the drug development pipeline, from the identification of new molecular targets and synthesis of novel compounds to preclinical and clinical trials.[2][3]
For researchers and pharmaceutical professionals, this indicates opportunities for collaboration with Brazilian institutions and a potential landscape for conducting clinical trials in endemic areas such as Piauí, given the high prevalence of these diseases.
Conclusion
The public health situation in this compound, Piauí, is complex, marked by the challenge of addressing both chronic and infectious diseases. For researchers and drug development professionals, this environment presents both a need and an opportunity. A deeper understanding of the local epidemiology, the application of modern molecular and epidemiological research methods, and a focus on the specific molecular characteristics of circulating pathogens are essential for developing effective interventions. The existing research infrastructure and the high prevalence of key diseases make this compound a critical location for advancing the fight against these significant public health threats.
References
- 1. Understanding Host–Pathogen Interactions in Congenital Chagas Disease Through Transcriptomic Approaches - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Frontiers | Interactions between Trypanosoma cruzi Secreted Proteins and Host Cell Signaling Pathways [frontiersin.org]
- 4. scielosp.org [scielosp.org]
- 5. researchgate.net [researchgate.net]
- 6. mastereditora.com.br [mastereditora.com.br]
- 7. revistasaudecoletiva.com.br [revistasaudecoletiva.com.br]
- 8. Evaluation of PCR in the diagnosis of canine leishmaniasis in two different epidemiological regions: Campinas (SP) and this compound (PI), Brazil - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Visceral leishmaniasis in this compound, n. e. Brazil: towards a DNA probe kit and its adaptation to processing blood-contaminated samples - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Sampling plan and methodological aspects: a household healthcare survey in Piauí - PMC [pmc.ncbi.nlm.nih.gov]
- 11. scielosp.org [scielosp.org]
- 12. cabidigitallibrary.org [cabidigitallibrary.org]
- 13. scidev.net [scidev.net]
Environmental Sustainability in Teresina, Brazil: A Technical Assessment
Abstract: Teresina, the capital of Piauí, Brazil, faces a complex web of interconnected environmental sustainability challenges, intensified by its location in a global warming hotspot. This technical guide synthesizes current data on the city's primary environmental pressures, including climate change impacts, urban heat island effects, water resource contamination, solid waste management deficits, and deforestation-driven land-use change. It outlines the methodologies used in key environmental assessments and presents quantitative data to support a technical understanding of the issues. Causal relationships are visualized to provide researchers, scientists, and public health professionals with a clear framework of the systemic environmental challenges confronting the municipality. This document serves as a foundational resource for future research, policy development, and targeted interventions aimed at enhancing the environmental resilience and sustainability of this compound.
Core Environmental Challenges and Quantitative Analysis
This compound is contending with significant environmental issues stemming from rapid urbanization, climate vulnerability, and inadequate infrastructure. Key challenges include severe urban heat island effects, degradation of water resources, unsustainable solid waste generation, and loss of natural vegetation. These issues are often exacerbated by underlying socio-economic disparities, disproportionately affecting vulnerable populations.
Climate Change and Urban Heat Island (UHI) Effect
This compound is recognized as one of the world's hottest cities and is situated in a region that is warming at a faster rate than the global average.[1][2] This climatic vulnerability is compounded by localized urban planning and land-use changes that intensify the Urban Heat Island (UHI) effect. A significant driver of this phenomenon has been urban sprawl, partly influenced by housing programs that promoted development on the urban periphery.[3][4][5] This expansion has led to the progressive replacement of green spaces and natural vegetation with impervious surfaces like asphalt (B605645) and concrete, which absorb and retain more solar radiation.
Studies have documented a direct correlation between the loss of tree cover and rising Land Surface Temperatures (LST).[3][4] Between 2001 and 2019, the urban area of this compound lost 40% of its tree cover, a key factor contributing to increased thermal discomfort and associated public health risks.[6]
Table 1: Land Consumption and Forest Cover Change in this compound
| Metric | Time Period | Value | Source |
| Land Consumption per Capita | 2007 | 184.67 m² | [3] |
| 2019 | 242.11 m² | [3] | |
| Natural Forest Area | 2020 | 110,000 hectares (77% of land area) | [7] |
| Tree Cover Loss | 2001 - 2024 | 26,000 hectares | [7] |
| Natural Forest Loss | 2024 | 1,300 hectares | [7] |
Water Resource Degradation
The city is situated at the confluence of the Poti and Parnaíba rivers, which are integral to its water supply and ecosystem. However, these water bodies suffer from significant pollution, primarily due to the low coverage of the municipal sewage system.[8][9][10] A 2009 report indicated that only 13% of the population had sewer service, with the remainder relying on septic tanks or engaging in the direct discharge of raw sewage into the environment.[8] This practice introduces high loads of organic matter and pathogens into the rivers.
Water quality analyses have revealed that while the Poti River's water quality is often classified as "good" based on the Water Quality Index (IQA), there are significant spikes in thermotolerant coliform concentrations, particularly in densely populated areas.[11] Modeling studies of the Poti River have identified non-conformities with national water quality standards (CONAMA Resolution nº 357/2005) for parameters such as thermotolerant coliforms, Biochemical Oxygen Demand (BOD), and Dissolved Oxygen (DO).[10][12] The contamination is influenced by seasonality, with cyanobacteria proliferation observed during the dry season.[13]
Solid Waste Management
This compound generates a substantial volume of urban solid waste (USW), posing a continuous management challenge. The city's sanitary landfill receives approximately 40,000 tonnes of waste per month.[14] While the current system is an improvement over the previous open-air dump, challenges remain in fully implementing the National Solid Waste Policy, particularly concerning recycling and resource recovery.[15][16] The system relies heavily on the work of informal waste pickers for recycling, and financial resources for comprehensive management are limited.[15]
Table 2: Monthly Solid Waste Received at this compound Landfill (c. 2021)
| Waste Type | Average Tonnes per Month | Source |
| Household Waste (RDO) | 17,240 | |
| Weed/Pruning Waste | 7,000 | |
| Spillway Waste Removal | 10,000 | |
| Residue Collection Point Waste | 2,276 | |
| Private Company Waste | 1,200 | |
| Special Waste (Feathers/Viscera) | 150 | |
| Selective Collection | 69 | |
| Total (Approximate) | 37,935 |
Air Quality
Available data indicates that the air quality in this compound is moderately polluted, at times exceeding the annual maximum limit recommended by the World Health Organization (WHO), posing a long-term health risk. The Air Quality Index (AQI) can reach levels considered unhealthy for sensitive groups, with pollutants of concern including Particulate Matter (PM2.5 and PM10) and Nitrogen Dioxide (NO2).[17][18] However, a consistent, publicly available dataset of granular pollutant concentrations (e.g., in µg/m³) is needed for a more detailed toxicological and public health risk assessment.
Table 3: Air Quality Pollutant Status (Illustrative)
| Pollutant | Status | Health Implication | Source |
| PM2.5 | Unhealthy | Irritates eyes, nose, and respiratory system; long-term exposure aggravates heart and lung disease. | [17][18] |
| PM10 | Poor | Inhalable particles that can affect respiratory health. | [17] |
| NO2 | Fair | High levels increase the risk of respiratory problems. | [17] |
| O3 (Ground-level) | Fair | Can aggravate existing respiratory diseases, cause throat irritation, headaches, and chest pain. | [17] |
Methodologies for Environmental Assessment
The understanding of this compound's environmental issues is based on several scientific methodologies, which are detailed below as experimental protocols.
Protocol for Land Use and Surface Temperature Analysis
This protocol describes the methodology used to evaluate the relationship between urban sprawl and the Surface Urban Heat Island (SUHI) effect in the this compound-Timon conurbation area.
-
Data Acquisition:
-
Obtain Land Use and Land Cover (LULC) maps and Land Surface Temperature (LST) data from remote sensing orbital products (e.g., Landsat, Sentinel-2).[3][4][5]
-
Acquire population data from official census blocks.
-
Gather data on the location and expansion of major infrastructure and housing programs (e.g., 'My House My Life' program).[3][4]
-
-
Data Processing and Analysis:
-
LULC Classification: Classify satellite imagery into distinct categories (e.g., urban area, green space, water bodies, bare soil) for multiple years to map the progression of urban expansion.
-
LST Calculation: Process thermal bands from satellite data to derive LST maps for the study area across different time points.
-
Land Consumption Per Capita (LCpC): Calculate LCpC by dividing the total urbanized area by the resident population for each analysis year using the formula: LCpC = Urban_Area / Population.[3]
-
SUHI Estimation: Analyze LST maps to identify temperature variations between the urban core, peripheral zones, and surrounding rural areas. The SUHI intensity is determined by the temperature difference (ΔT) between urban and rural zones.[3]
-
-
Statistical and Spatial Analysis:
-
Correlate the changes in LULC (specifically, the loss of green areas and increase in impervious surfaces) with the changes in LST over the study period.
-
Utilize descriptive metrics such as Moran's I statistic to assess the spatial autocorrelation of urban development patterns.[3][4]
-
Develop a Social Vulnerability Index by combining socio-economic data with exposure to environmental hazards (e.g., high LST zones) to identify disproportionately affected populations.[3][4]
-
Protocol for River Water Quality Modeling
This protocol outlines the methodology for modeling the water quality of the Poti River to assess its self-purification capacity and the impact of pollution loads.
-
Field Data Collection (Sampling):
-
Establish multiple collection points along a significant stretch of the river (e.g., a 36.8 km section) that encompasses areas upstream, within, and downstream of major urban influence.[9][12]
-
Conduct monthly or bimonthly sampling campaigns to capture seasonal variations (dry and rainy seasons).[13]
-
At each point, measure in-situ parameters (e.g., temperature, pH, dissolved oxygen).
-
Collect water samples for laboratory analysis of key parameters, including Biochemical Oxygen Demand (BOD), thermotolerant coliforms (TC), total phosphorus, and total solids.[12][13]
-
Collect phytoplankton samples for species identification and quantification, particularly for cyanobacteria.[13]
-
-
Laboratory Analysis:
-
Mathematical Modeling:
-
Utilize a water quality modeling platform, such as QUAL-UFMG, which is designed to simulate river hydrodynamics and pollutant decay.[9][10][12]
-
Input the river's geometric and hydraulic data into the model.
-
Use the field data (BOD, DO, TC) to calibrate the model's decay coefficients (k-values) until the model's output closely matches the observed river conditions. The Nash-Sutcliffe efficiency coefficient is used to validate model performance, with values > 0.75 indicating a good fit.[12]
-
-
Scenario Simulation:
-
Once calibrated, use the model to simulate different scenarios, such as the impact of reduced sewage discharge or variations in river flow (e.g., minimum and maximum flow conditions typical of the semiarid region).[10][12]
-
Compare simulated water quality outcomes against regulatory standards (e.g., CONAMA Resolution nº 357/2005) to inform water resource management strategies.[12]
-
Causal Pathways and Systemic Relationships
The environmental challenges in this compound are not isolated but are part of a system of interconnected cause-and-effect relationships. The following diagrams, rendered in DOT language, visualize these logical pathways.
Urban Heat Island Effect Pathway
This diagram illustrates the causal chain leading from urban development patterns to public health impacts associated with increased urban temperatures.
Water Pollution Experimental Workflow
This diagram outlines the workflow for assessing and modeling river pollution, from initial data collection to management-oriented scenario analysis.
References
- 1. urbanresiliencehub.org [urbanresiliencehub.org]
- 2. How this compound is Accelerating its Transition to a Green and Resilient City | UrbanShift [shiftcities.org]
- 3. mdpi.com [mdpi.com]
- 4. Linking Urban Sprawl and Surface Urban Heat Island in the this compound–Timon Conurbation Area in Brazil [ideas.repec.org]
- 5. researchgate.net [researchgate.net]
- 6. iied.org [iied.org]
- 7. This compound, Brazil, Piauí Deforestation Rates & Statistics | GFW [globalforestwatch.org]
- 8. emerald.com [emerald.com]
- 9. scielo.br [scielo.br]
- 10. scielo.br [scielo.br]
- 11. Qualidade da água e mapeamento participativo da pesca desenvolvida no baixo curso do rio Poti no município de this compound – PI | Revista Brasileira de Geografia Física [periodicos.ufpe.br]
- 12. paperity.org [paperity.org]
- 13. SEGURANÇA HÍDRICA DOS RIOS PARNAÍBA E POTI, PIAUÍ - BRASIL [repositorio.ufpi.br:8080]
- 14. PLANO MUNICIPAL DE GESTÃO INTEGRADA DE RESÍDUOS SÓLIDOS DO MUNICÍPIO DE this compound – PIAUÍ – NORDESTE DO BRASIL – ISSN 1678-0817 Qualis B2 [revistaft.com.br]
- 15. URBAN SOLID WASTE MANAGEMENT IN this compound-PI: AN ANALYSIS OF CHALLENGES AND GAPS | Editora Impacto Científico [periodicos.newsciencepubl.com]
- 16. researchgate.net [researchgate.net]
- 17. This compound, Piauí, Brazil Air Quality Index | AccuWeather [accuweather.com]
- 18. This compound, Brazil Air Quality & Pollen | Weather Underground [wunderground.com]
An In-depth Technical Guide to the Epidemiology of Infectious Diseases in Teresina
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the epidemiology of key infectious diseases in Teresina, the capital city of Piauí state in Brazil. The information presented herein is intended to support research, scientific endeavors, and the development of novel therapeutic and prophylactic agents. This document summarizes quantitative data, details relevant experimental and epidemiological methodologies, and visualizes critical public health workflows and logical frameworks.
Quantitative Epidemiological Data
The following tables summarize the reported cases and incidence rates of major infectious diseases in this compound. The data has been compiled from various sources, including bulletins from the Municipal Health Foundation (FMS) of this compound and the Piauí State Department of Health (SESAPI), as well as published epidemiological studies.
Table 1: Epidemiology of Arboviruses in this compound
| Year | Disease | Notified Cases | Confirmed Cases | Incidence Rate (per 100,000) | Deaths |
| 2023 | Dengue | - | - | - | - |
| Chikungunya | 4,302 (Piauí State) | - | - | - | |
| Zika Virus | - | - | - | - | |
| 2022 | Dengue | - | - | - | 2 |
| Chikungunya | 3,009.5% increase (Piauí State vs 2021) | - | - | - | |
| Zika Virus | - | - | - | - | |
| 2020 | Dengue | 2,350 | - | - | - |
| Zika Virus | - | 3 | - | - | |
| 2019 | Chikungunya | - | - | - | - |
| 2017 | Chikungunya | 2,779 (Piauí State) | - | 197.9 (Piauí State) | - |
| 2016 | Chikungunya | - | - | - | 1 |
| 2015-2020 | Zika Virus | - | 1,371 (Piauí State, 55.8% from this compound) | - | - |
| 2002-2006 | Dengue | 11,003 | - | Varied from 592.7 (2002) to 19.5 (2004) | - |
Data for this compound is specified where available; otherwise, data for the state of Piauí is provided as a reference.[1][2][3][4][5][6]
Table 2: Epidemiology of Tuberculosis in this compound
| Period | Notified Cases | Incidence Rate (per 100,000) | Cure Rate (%) | Treatment Abandonment Rate (%) |
| 2010-2018 | 4,521 | - | 64.78 | 6.69 |
| 2005-2007 | 951 | Declined from 42 (2005) to 37 (2007) | - | - |
| 1999-2005 | - | Average of 50.1 | 71.07 | - |
Table 3: Epidemiology of Leprosy in this compound
| Period | New Cases | Detection Rate (per 100,000) | Prevalence (per 10,000) |
| 2007-2021 | 17,075 (Piauí State) | 36.5 (Piauí State) | - |
| 2001-2008 | - | Average of 96.21 | Ranged from 8 to 11 |
Table 4: Epidemiology of Visceral Leishmaniasis in this compound
| Period | Confirmed Cases | Key Demographics |
| 2013-2020 | 1,278 | 68.54% male, 32.39% in children under 5 years |
| 1991-2000 | 1,744 | Higher incidence in peripheral neighborhoods |
Table 5: Epidemiology of COVID-19 in this compound (March 13 - July 12, 2020)
| Metric | Value |
| Confirmed Cases | 10,914 |
| Predominant Gender (Cases) | Female (55.51%) |
| Predominant Age Group (Cases) | 30-39 years (25.6%) |
| Deaths | 542 |
| Lethality Rate (%) | 4.97 |
| Predominant Gender (Deaths) | Male (55.9%) |
| Predominant Age Group (Deaths) | 70-79 years (25.0%) |
Table 6: Epidemiology of Schistosomiasis in Piauí State
| Period | Confirmed Cases | Note |
| 1995-2017 | 44 | This compound is not considered an endemic area. Transmission in Piauí is focal and limited to specific municipalities. |
Experimental and Epidemiological Methodologies
The epidemiological data presented is primarily derived from observational studies, utilizing data from Brazil's national health information systems.
Data Sources
-
SINAN (Sistema de Informação de Agravos de Notificação / Notifiable Diseases Information System): This is the primary source for data on communicable diseases that require mandatory reporting. Healthcare professionals in this compound report suspected and confirmed cases to the Municipal Health Foundation, which are then entered into the SINAN database.
-
DATASUS (Departamento de Informática do Sistema Único de Saúde / Department of Informatics of the Unified Health System): A comprehensive public health database that provides access to a wide range of health information, including data from SINAN.
-
SISPCE (Sistema de Informação do Programa de Controle da Esquistossomose / Schistosomiasis Control Program Information System): Used for specific data related to schistosomiasis.
Study Designs
-
Descriptive, Retrospective, and Cross-Sectional Studies: The majority of the cited studies employ these designs. They involve the collection and analysis of existing data from health information systems to describe the epidemiological profile of a disease in a specific time and place. These studies are crucial for identifying trends, high-risk groups, and areas for targeted public health interventions.
-
Ecological Studies: Some studies utilize an ecological design, where the units of analysis are populations or groups of people (e.g., residents of a particular neighborhood) rather than individuals. These studies are useful for examining associations between environmental or socioeconomic factors and disease incidence at a population level.
Case Definitions and Diagnostic Protocols
Arboviruses (Dengue, Zika, Chikungunya):
-
Case Definition: A suspected case is typically defined as a patient with fever and at least two other symptoms such as headache, myalgia, arthralgia, rash, or retro-orbital pain.
-
Diagnostic Confirmation: Laboratory diagnosis is performed using serological tests (ELISA for IgM/IgG antibodies) and molecular methods (RT-PCR) to detect the viral genome.
Tuberculosis:
-
Case Definition: A confirmed case is based on either laboratory criteria (positive acid-fast bacilli smear, culture, or rapid molecular test) or clinical-epidemiological criteria (clinical presentation consistent with tuberculosis, along with imaging and histological findings, in the absence of laboratory confirmation).
-
Diagnostic Protocol: The standard diagnostic protocol in this compound involves sputum smear microscopy for all suspected cases, followed by culture and drug susceptibility testing for confirmation and to guide treatment. Rapid molecular tests are also increasingly used for rapid diagnosis.
Visceral Leishmaniasis:
-
Case Definition: A suspected case presents with prolonged fever, splenomegaly, hepatomegaly, and pancytopenia.
-
Diagnostic Confirmation: Diagnosis is confirmed through parasitological examination (demonstration of Leishmania amastigotes in bone marrow or spleen aspirates) or serological tests (such as indirect immunofluorescence or ELISA).
Statistical Analysis
Epidemiological studies in this compound commonly employ descriptive statistics to summarize data (frequencies, means, rates). Analytical studies may use statistical tests such as the chi-square test to assess associations between variables and regression models to identify risk factors for disease. Spatial analysis techniques, like Kernel density estimation, are also used to identify geographic clusters of high disease incidence.
Visualization of Workflows and Logical Relationships
The following diagrams, generated using Graphviz (DOT language), illustrate key public health workflows and the logical relationships of control strategies for infectious diseases in this compound.
Arbovirus Surveillance and Response Workflow
Integrated Vector Management Strategy for Aedes aegypti
References
- 1. [ASSISTA] Prefeitura de this compound apresenta plano de ação contra o Aedes Aegypti - Sistema Antares de Comunicação [fundacaoantares.pi.gov.br]
- 2. novosite.ciaten.org.br [novosite.ciaten.org.br]
- 3. info.dengue.mat.br [info.dengue.mat.br]
- 4. Cosems-PI e Sesapi elaboram plano de contingência após crescimento de casos de dengue no estado - COSEMS-PI [cosemspi.org.br]
- 5. youtube.com [youtube.com]
- 6. researchgate.net [researchgate.net]
A Technical Guide to Urban Development and Housing Programs in Teresina: An Analysis of Frameworks, Interventions, and Outcomes
Issued: December 18, 2025
Abstract: This document provides a technical overview of the urban development and housing programs implemented in Teresina, the capital of Piauí, Brazil. Positioned within a region of increasing climatic vulnerability, this compound presents a critical case study in the challenges of rapid urbanization, housing deficits, and the implementation of resilience strategies.[1][2] This guide synthesizes key municipal plans, analyzes the methodologies of major housing initiatives, and presents quantitative data on the city's urban and environmental status. It is intended for researchers and development professionals seeking a detailed understanding of the programmatic workflows and strategic frameworks governing urban transformation in a climate-stressed, developing-world city.
Urban Development and Resilience Framework
This compound's approach to urban planning is guided by a multi-layered framework of strategic plans designed to address interconnected challenges ranging from climate change to social inequality. These foundational documents establish the principles for territorial management and sectoral policies.
Master Plan for Territorial Ordination (PDOT)
The new Master Plan of this compound (PDOT), instituted by Municipal Complementary Law n. 5.481/2019, serves as the primary legal instrument for the city's development and expansion policy.[3][4] It provides the foundational guidelines for all sectoral plans and establishes the principles for municipal territorial management, including land use, infrastructure, and environmental protection.[4]
This compound Urban Resilience Program
In 2019, a Cooperation Agreement between the Municipality of this compound, the Brazilian Government, and the UN-Habitat initiated the this compound Urban Resilience Program.[1] The core of this program was the implementation of the City Resilience Profiling Tool, a diagnostic methodology used to assess the city's capacity to withstand shocks and stresses. This process culminated in a strategic action plan titled "Recommendations on Actions for Resilience and Sustainability," which informs municipal public policies.[1]
This compound Agenda 2030
The this compound Agenda 2030 strategy, launched in 2017, aims to align municipal policies with global sustainability and climate goals, particularly the Paris Agreement.[2][5] This framework emphasizes the need to mainstream climate action and sustainability across all sectors, focusing on infrastructure and service provision to enhance the city's resilience, especially for its most vulnerable residents.[2][5]
Quantitative Urban Metrics and Challenges
The strategic plans for this compound are informed by significant urban, environmental, and social challenges, which are quantified in the following tables.
Table 1: this compound - Key Demographic and Economic Indicators
| Metric | Value | Year | Source |
|---|---|---|---|
| Population | 864,845 | 2019 | [1] |
| Urban Area | 263.94 km² | - | [6] |
| Local GDP per Capita | USD 3,889.09 | 2017 | [1] |
| Informal Employment Rate | 44.7% | - | [6] |
| Manufacturing Share of Local GDP | 5.7% | - |[6] |
Table 2: this compound - Housing, Infrastructure, and Environmental Indicators
| Metric | Value | Source |
|---|---|---|
| Homes with Inadequate Structure | ~20% | [1] |
| Urban Footprint in Hazardous/Risk-Prone Areas | 7.8% | [1][6] |
| Population Covered by Wastewater Network | 35% | [6] |
| City Area Not Covered by Stormwater Collection | 24.5% | [6] |
| Loss of Tree Cover (2001-2019) | ~40% | [1] |
| Fires Identified via Satellite (Oct 2019 - Oct 2020) | 385 |[1] |
Table 3: Land Consumption Per Capita (LCpC) in this compound (2000-2019)
| Year | LCpC (m²) | Trend |
|---|---|---|
| 2000 | 190.83 | - |
| 2006 | 181.00 | Urban Compaction |
| 2007 | 184.67 | Start of Expansion |
| 2019 | 242.11 | Accelerated Urban Sprawl |
Source:[7]
The data in Table 3 indicates a shift from urban compaction to significant urban sprawl after 2007, a trend linked to the implementation of national housing programs.[7]
Housing Programs: Methodologies and Workflows
This compound has utilized a combination of national-level social housing programs and targeted local interventions to address its housing deficit. The methodologies and logical workflows of these programs reveal critical insights into their outcomes.
National Social Housing Program: "Minha Casa, Minha Vida" (MCMV)
This compound was a participant in the federal "Minha Casa, Minha Vida" (My Home, My Life) program, a large-scale initiative designed to subsidize the purchase of houses for low-income families.[8] While the program aimed to reduce the quantitative housing deficit, its design lacked safeguards regarding the location of new developments.[8] This led to the construction of large housing complexes in inexpensive, peripheral areas, creating significant challenges for residents.[8]
Local Intervention Model: The Urban Lab at Residencial Edgar Gayoso
In response to the challenges created by programs like MCMV, a bottom-up approach has been piloted in this compound. The Urban Lab, established in the vulnerable Residencial Edgar Gayoso housing complex, exemplifies this model.[8] This initiative focuses on community-led solutions to improve livelihoods and resilience.[8] The success of this local project has helped inform the new national "Periferia Viva" program, launched in 2024, which aims to scale up community-focused urban upgrading.[9]
Integrated Urban Renewal: The Lagoas do Norte Program (PLN)
The Lagoas do Norte Program represents a comprehensive, area-based intervention aimed at improving the quality of life for low-income populations in a region of this compound historically prone to flooding and characterized by precarious infrastructure.[10][11] Supported by the World Bank, the project's methodology integrates urban, environmental, and financial management improvements.[10][12]
Conclusion
The urban development and housing landscape in this compound is characterized by a dynamic interplay between top-down national policies and emergent, bottom-up local solutions. The experience with the MCMV program highlights the critical importance of integrating spatial planning with housing provision to avoid exacerbating social and economic segregation. Conversely, initiatives like the Urban Lab at Residencial Edgar Gayoso and the integrated Lagoas do Norte Program demonstrate the efficacy of community-centered and multi-sectoral approaches to building urban resilience. For this compound to advance its sustainability goals as outlined in the PDOT and Agenda 2030, future efforts must continue to prioritize these integrated, place-based strategies that address not just the quantitative housing deficit, but also the qualitative aspects of urban life, including access to services, environmental quality, and climate resilience.
References
- 1. urbanresiliencehub.org [urbanresiliencehub.org]
- 2. How this compound is Accelerating its Transition to a Green and Resilient City | UrbanShift [shiftcities.org]
- 3. researchgate.net [researchgate.net]
- 4. scielo.br [scielo.br]
- 5. urbancoalitions.org [urbancoalitions.org]
- 6. urbanresiliencehub.org [urbanresiliencehub.org]
- 7. mdpi.com [mdpi.com]
- 8. urbancoalitions.org [urbancoalitions.org]
- 9. wri.org [wri.org]
- 10. Brazil - this compound Enhancing Municipal Governance and Quality of Life Project [documents.worldbank.org]
- 11. researchgate.net [researchgate.net]
- 12. Brazil - this compound Enhancing Municipal Governance and Quality of Life Project : restructuring (Vol. 1 of 2) : Main report [documents.banquemondiale.org]
"water quality assessment of Poti and Parnaíba rivers"
An In-depth Technical Guide to the Water Quality Assessment of the Poti and Parnaíba Rivers
Introduction
The Poti and Parnaíba rivers are vital water resources in northeastern Brazil, supporting urban populations, agriculture, and diverse ecosystems. The Parnaíba River basin is the largest in the region, and the Poti River is one of its most significant tributaries. Urban expansion, industrial activities, and agricultural runoff have raised concerns about the water quality of these rivers. This technical guide provides a comprehensive overview of the water quality assessment of the Poti and Parnaíba rivers, synthesizing available data, outlining experimental methodologies, and illustrating key processes and workflows. This document is intended for researchers, environmental scientists, and public health professionals engaged in water resource management and drug development where environmental factors may be relevant.
Regulatory Framework
Water quality in Brazil is primarily regulated by the National Environment Council (CONAMA). CONAMA Resolution No. 357/2005 is the principal guideline, classifying freshwater, brackish, and saline waters into different classes based on their intended uses and establishing the corresponding quality standards.[1][2][3] This resolution sets the limits for a wide range of parameters, including pH, dissolved oxygen, biochemical oxygen demand, turbidity, and microbiological indicators, which serve as the benchmark for assessing the health of river systems like the Poti and Parnaíba.[2][3][4][5]
Water Quality Assessment of the Poti River
The Poti River, particularly in the urban stretch of Teresina, the capital of Piauí state, faces significant pollution pressures. The primary sources of pollution are the discharge of raw sewage from illegal connections and the occupation of the riverbanks.[6]
Mathematical modeling of the river has been employed to understand the dynamics of key water quality parameters. These studies have highlighted significant non-conformities with national standards, especially concerning microbiological contamination.[6]
Table 1: Key Water Quality Parameters for the Poti River in this compound
| Parameter | Status | Remarks |
| Dissolved Oxygen (DO) | Modeled | Essential for aquatic life. |
| Biochemical Oxygen Demand (BOD) | Modeled | A measure of organic pollution. |
| Thermotolerant Coliforms | Non-conformity | Indicates fecal contamination, exceeding limits set by CONAMA Resolution nº 357/2005.[6] |
Water Quality Assessment of the Parnaíba River
The Parnaíba River basin exhibits a range of water quality conditions, influenced by both diffuse and point sources of pollution. Agricultural and livestock activities are predominant diffuse sources, while growing urbanization contributes to point source pollution from domestic effluents.[7]
Studies have shown that some stretches of the river exceed permitted limits for parameters such as Biochemical Oxygen Demand (BOD), Dissolved Oxygen (DO), total solids, and fecal coliforms.[8] In the Parnaíba River Delta, the water quality can range from medium to good, depending on the hydrological period (dry vs. rainy season).[9] The delta's estuarine system is primarily limited by nitrogen in the dry season and by phosphorus in the rainy season.[9]
Table 2: Physicochemical and Microbiological Parameters for the Parnaíba River
| Parameter | Value/Status | Location/Condition | Source |
| Water Quality Index (WQI) | Intermediate | Córrego do Óleo & Córrego Liso | [8] |
| Water Quality Index (WQImin) | Medium to Good (70 ≤ WQImin < 90) / Bad to Medium (26 ≤ WQImin < 70) | Parnaíba River Delta (seasonal variation) | [9] |
| Trophic State Index (TRIXPD) | Mesotrophic to Eutrophic (5 ≤ TRIXPD < 6) | Parnaíba River Delta | [9] |
| Biochemical Oxygen Demand (BOD) | Above permitted limit | Córrego do Óleo & Córrego Liso | [8] |
| Dissolved Oxygen (DO) | Below permitted limit | Córrego do Óleo & Córrego Liso | [8] |
| Total Phosphorus | Above permitted limit | Córrego Liso | [8] |
| Fecal Coliforms | Above permitted limit | Córrego do Óleo & Córrego Liso | [8] |
| Total Nitrogen (TN) | 0.47 ± 0.11 mg/L | Main river channel | [9] |
Heavy Metal Contamination in the Parnaíba River Delta
The sediments of the Parnaíba River Delta have been analyzed to determine the extent of heavy metal contamination. While some studies suggest a low probability of adverse effects on aquatic life, others have found moderate to severe pollution for specific metals in surface sediments.[10][11]
Table 3: Heavy Metal Concentrations in Sediments of the Parnaíba River Delta
| Metal | Average Concentration (mg/kg) | Source |
| Cadmium (Cd) | 0.50 ± 0.09 | [12] |
| Lead (Pb) | 6.95 ± 2.13 | [12] |
| Copper (Cu) | 19.02 ± 8.75 | [12] |
| Nickel (Ni) | 23.20 ± 5.04 | [12] |
| Chromium (Cr) | 33.52 ± 6.82 | [12] |
| Zinc (Zn) | 43.99 ± 7.47 | [12] |
| Manganese (Mn) | 165.73 ± 86.71 | [12] |
| Iron (Fe) | 2.93 ± 0.89 (%) | [12] |
| Aluminum (Al) | 3.78 ± 1.17 (%) | [12] |
Experimental Protocols
The assessment of water quality in the Poti and Parnaíba rivers involves a series of standardized experimental protocols for sample collection, preservation, and analysis.
Physicochemical Analysis
-
Objective: To determine the basic physical and chemical characteristics of the water.
-
Methodology:
-
In-situ Measurements: Parameters such as pH, temperature, dissolved oxygen, and electrical conductivity are typically measured on-site using calibrated multiparameter probes.
-
Sample Collection: Water samples for other analyses are collected in pre-cleaned polyethylene (B3416737) or glass bottles.
-
Laboratory Analysis:
-
Turbidity: Measured using a nephelometer and expressed in Nephelometric Turbidity Units (NTU).
-
Biochemical Oxygen Demand (BOD₅): Determined by measuring the dissolved oxygen consumed by microorganisms in the dark at 20°C over five days.
-
Chemical Oxygen Demand (COD): Measured by the potassium dichromate oxidation method.
-
Nutrients (Nitrogen and Phosphorus): Analyzed using spectrophotometric methods after appropriate digestion.
-
-
Microbiological Analysis
-
Objective: To detect and quantify indicator organisms for fecal contamination.
-
Methodology:
-
Sample Collection: Samples are collected in sterile bottles, taking care to avoid contamination.
-
Analysis of Fecal Indicators:
-
Thermotolerant (Fecal) Coliforms and Escherichia coli: The Most Probable Number (MPN) method is frequently used. Commercial methods like Colilert®, which utilize a substrate that changes color or fluoresces in the presence of target bacteria, are also employed for quantification after incubation.[13]
-
Enterococci: Assessed as an additional indicator of fecal pollution, particularly in marine and brackish waters.
-
-
Heavy Metal Analysis in Sediments
-
Objective: To quantify the concentration of heavy metals that have accumulated in river sediments.
-
Methodology:
-
Sample Collection: Sediment samples are collected from the top layer (0-5 cm) of the riverbed using dredges or corers.
-
Sample Preparation: Samples are oven-dried at a low temperature (around 60°C) and then sieved to isolate the fine fraction (<63 μm), as metals tend to adsorb to smaller particles.[10]
-
Digestion: The sediment is digested using strong acids (e.g., aqua regia - a mixture of nitric acid and hydrochloric acid) to bring the metals into solution.
-
Quantification: The concentrations of dissolved metals are determined using atomic absorption spectrometry (AAS) or inductively coupled plasma mass spectrometry (ICP-MS).
-
Mandatory Visualizations
Caption: Logical relationships between pollution sources and water quality impacts.
Caption: Generalized experimental workflow for river water quality assessment.
References
- 1. openjicareport.jica.go.jp [openjicareport.jica.go.jp]
- 2. braziliannr.com [braziliannr.com]
- 3. Aspects that should be considered in a possible revision of the Brazilian Guideline Conama Resolution 357/05 - MedCrave online [medcraveonline.com]
- 4. researchgate.net [researchgate.net]
- 5. Análise de parâmetros que compõem o índice de qualidade das águas (IQA) na porção mineira da Bacia do Rio Paranaíba / Analysis of parameters that composing the water quality index (WQIi) in the portion of the Minas Gerais State of the Paranaíba River Basin | Observatorium: Revista Eletrônica de Geografia [seer.ufu.br]
- 6. paperity.org [paperity.org]
- 7. researchgate.net [researchgate.net]
- 8. researchgate.net [researchgate.net]
- 9. researchgate.net [researchgate.net]
- 10. guiase.s3.amazonaws.com [guiase.s3.amazonaws.com]
- 11. Frontiers | Review on metal contamination in equatorial estuaries in the Brazilian Northeast [frontiersin.org]
- 12. Repositório Institucional UFC: Assessment of heavy metals in sediments of the Parnaíba River Delta in the semi-arid coast of Brazil [repositorio.ufc.br]
- 13. Bacteria communities and water quality parameters in riverine water and sediments near wastewater discharges - PMC [pmc.ncbi.nlm.nih.gov]
A Technical Guide to the Biodiversity and Ecosystem Health of the Teresina Region: From Ecological Assessment to Drug Discovery Potential
For Researchers, Scientists, and Drug Development Professionals
Abstract
The Teresina region, situated at the dynamic ecotone of the Cerrado and Caatinga biomes in Piauí, Brazil, represents a significant reservoir of biodiversity with considerable potential for novel therapeutic discoveries. However, this unique ecological landscape faces escalating threats from urbanization, deforestation, and pollution, which jeopardize its delicate ecosystem health. This technical guide provides an in-depth analysis of the region's biodiversity, a critical assessment of its ecosystem health, detailed experimental protocols for environmental and biological analysis, and an exploration of the pharmacological potential of its native flora, with a focus on key signaling pathways.
Biodiversity of the this compound Region: A Confluence of Biomes
This compound's geographical location fosters a rich mosaic of flora and fauna, blending elements from the savanna-like Cerrado and the semi-arid Caatinga.[1] This transitional nature results in a high species diversity, making it a compelling subject for ecological research and bioprospecting.
Flora
The vegetation is characterized by a mix of species adapted to both the periodic fires of the Cerrado and the arid conditions of the Caatinga.[1] Remnants of the Mata dos Cocais, with its characteristic palms like carnaúba and babaçu, are also present.[1] Urban green spaces, such as the Jardim Botânico de this compound, serve as important refuges for native woody plant species. A phytosociological study of this botanical garden revealed a significant diversity of tree and shrub species.[2]
Fauna
The region's fauna is equally diverse, though comprehensive studies remain limited. Inventories have been conducted for specific groups, including avifauna, herpetofauna, and arthropods.[3][4] The urban and peri-urban areas of this compound are home to a variety of animals, including the common marmoset (Callithrix jacchus), boa constrictor (Boa constrictor), and a wide array of bird species.[5]
Quantitative Biodiversity Data
The following tables summarize key quantitative data on biodiversity from studies conducted in the this compound region and its surrounding ecotone.
| Taxonomic Group | Number of Individuals | Number of Species | Number of Families | Number of Genera | Shannon-Wiener Index (H') | Pielou's Equitability (J') | Location |
| Woody Plants | 2,107 | 63 | 32 | 57 | Not Reported | Not Reported | Jardim Botânico de this compound[2] |
| Arthropod Fauna | Preserved Cerrado Area | Pasture Area |
| Number of Orders | Higher | Lower |
| Number of Families | Higher | Lower |
| Total Number of Species | Higher | Lower |
| Total Number of Individuals | Higher | Lower |
| Diversity Indices | Slightly Higher | Slightly Lower |
| Similarity Coefficient | \multicolumn{2}{c | }{10%} |
Ecosystem Health: A System Under Pressure
The ecosystem health of the this compound region is under significant threat from a combination of anthropogenic and climatic factors.
Urbanization and Deforestation
Rapid and often unplanned urban expansion is a primary driver of environmental degradation in this compound.[6][7] This has led to significant habitat loss and fragmentation, with a notable reduction in tree cover within the urban perimeter.[8] Between 2001 and 2024, this compound lost 26,000 hectares of tree cover, a 28% decrease from the 2000 level.[9] This loss of vegetation contributes to the urban heat island effect, with studies showing a correlation between the increase in paved and built-up areas and a rise in surface temperatures.[2][8]
Water Quality
The Poti and Parnaíba rivers, which are central to the region's hydrology, are heavily impacted by pollution. The primary source of contamination is the discharge of untreated domestic sewage, leading to high levels of thermotolerant coliforms and other pollutants.[10][11][12] Studies have also detected the presence of heavy metals, such as lead, in the Poti River, with concentrations increasing as the river flows through the urban area.[6]
| Parameter | Poti River (this compound stretch) | Parnaíba River (this compound stretch) |
| Thermotolerant Coliforms | Frequently exceeds CONAMA Resolution nº 357/2005 limits[13][14] | Elevated levels, contributing to a lower Water Quality Index (IQA)[3][12] |
| Dissolved Oxygen (DO) | Below recommended levels in over 80% of sampled points in one study[11] | Varies, with lower levels often associated with pollution |
| Biochemical Oxygen Demand (BOD) | Elevated due to sewage discharge[13][14] | A key parameter in IQA assessments, influenced by organic pollution[3] |
| Lead (Pb) Concentration in water | Ranging from 0.30 mg L-1 to 0.86 mg L-1 in one study[6] | Data not specified |
Climate Change Vulnerability
The this compound region is considered highly vulnerable to the impacts of climate change. It is warming at a faster rate than the global average, leading to an increased frequency and intensity of extreme weather events such as floods and droughts.[2][6][8] These climatic stressors further exacerbate the existing pressures on biodiversity and ecosystem services.
Experimental Protocols
This section provides detailed methodologies for key experiments relevant to the assessment of biodiversity and ecosystem health in the this compound region.
Floristic and Phytosociological Survey of Woody Vegetation
Objective: To characterize the species composition, diversity, and structure of a woody plant community.
Methodology:
-
Plot Establishment: Establish a series of plots (e.g., 10 x 10 m) within the study area. The number and placement of plots should be determined based on the size and heterogeneity of the area to ensure representative sampling.
-
Inclusion Criteria: Within each plot, identify and measure all woody individuals with a diameter at breast height (DBH) of ≥ 5 cm.
-
Data Collection: For each individual, record the species, DBH, and total height. Collect voucher specimens for species that cannot be identified in the field for later identification by specialists.
-
Data Analysis:
-
Calculate phytosociological parameters: density, frequency, dominance, and the Importance Value Index (IVI) for each species.
-
Calculate diversity indices: Shannon-Wiener Index (H') and Simpson's Dominance Index (C).
-
Calculate Pielou's Equitability Index (J').
-
Avifauna Survey
Objective: To determine the species richness, abundance, and community composition of birds in a given area.
Methodology:
-
Point Counts: Establish a series of point count stations throughout the study area, ensuring they are sufficiently spaced to avoid double-counting of individuals.
-
Observation Periods: Conduct counts during the early morning and late afternoon when bird activity is highest. Each count should last for a fixed duration (e.g., 10 minutes).
-
Data Collection: Record all birds seen or heard within a predefined radius (e.g., 50 meters) of the point count station.
-
Data Analysis:
-
Calculate species richness (total number of species).
-
Calculate the relative abundance of each species.
-
Calculate diversity indices (Shannon-Wiener and Simpson).
-
Soil Arthropod Diversity Assessment
Objective: To assess the diversity and density of soil arthropod fauna.
Methodology:
-
Sampling Design: Establish sampling stations in the study area.
-
Pitfall Traps: At each station, install pitfall traps. These consist of a plastic cup (e.g., 500 mL) buried in the ground with the rim flush with the soil surface.
-
Preserving Solution: Fill the traps with a preserving solution, such as 70% alcohol with a few drops of detergent to break the surface tension.
-
Sample Collection: Leave the traps in place for a set period (e.g., one week) before collecting the captured arthropods.
-
Identification and Counting: In the laboratory, identify the collected arthropods to the desired taxonomic level (e.g., order, family, or species) and count the number of individuals.
-
Data Analysis: Calculate species richness, abundance, and diversity indices.
Water Quality Analysis for Heavy Metals
Objective: To determine the concentration of heavy metals in river water and sediment.
Methodology (for sediment):
-
Sample Collection: Collect sediment samples from the riverbed using a grab sampler.
-
Sample Preparation: Dry the sediment samples in an oven and sieve them to obtain a fine, homogeneous powder.
-
Digestion: Digest a known weight of the sediment sample using a strong acid mixture (e.g., aqua regia - a mixture of nitric acid and hydrochloric acid) in a microwave digester.
-
Analysis: Analyze the digested sample for heavy metal concentrations using Inductively Coupled Plasma-Optical Emission Spectrometry (ICP-OES) or Atomic Absorption Spectrometry (AAS).
-
Quality Control: Include certified reference materials and blanks in the analysis to ensure accuracy and precision.
Phytochemical Analysis of Plant Material
Objective: To identify the major classes of bioactive compounds in a plant extract.
Methodology:
-
Plant Material Collection and Preparation: Collect the desired plant part (e.g., leaves, bark), dry it in a shaded, well-ventilated area, and grind it into a fine powder.
-
Extraction: Perform a solvent extraction (e.g., using ethanol (B145695) or methanol) of the powdered plant material using a Soxhlet apparatus or maceration.
-
Phytochemical Screening: Conduct qualitative tests for the presence of major classes of phytochemicals, such as alkaloids, flavonoids, tannins, saponins, and terpenoids.
-
Chromatographic and Spectrometric Analysis:
-
High-Performance Liquid Chromatography (HPLC): Separate and quantify individual compounds in the extract.
-
Gas Chromatography-Mass Spectrometry (GC-MS): Identify volatile and semi-volatile compounds in the extract.
-
Drug Discovery Potential and Signaling Pathways
The rich biodiversity of the Cerrado and Caatinga biomes in the this compound region is a promising source of novel bioactive compounds for drug development.[15][16][17][18][19] The local flora is particularly rich in flavonoids and terpenes, classes of compounds known for their diverse pharmacological activities, including anti-inflammatory, antioxidant, and anticancer properties.[9][20]
Key Bioactive Compounds and Their Potential
-
Flavonoids: Abundant in many Cerrado plant species, flavonoids are polyphenolic compounds with a wide range of biological activities.[6][9] Their mechanisms of action are diverse and include the modulation of key cellular signaling pathways.[4]
-
Terpenes: These compounds, prevalent in Caatinga species, have demonstrated significant anti-inflammatory effects. Their therapeutic potential is linked to their ability to interfere with inflammatory cascades.
Modulation of Key Signaling Pathways
Several bioactive compounds isolated from plants of the Cerrado and Caatinga have been shown to modulate critical signaling pathways involved in inflammation and cancer, such as the Nuclear Factor-kappa B (NF-κB) and Mitogen-Activated Protein Kinase (MAPK) pathways.
-
NF-κB Signaling Pathway: This pathway is a central regulator of inflammation, immunity, and cell survival. Its dysregulation is implicated in numerous inflammatory diseases and cancers. Certain plant extracts and their constituent compounds have been shown to inhibit the NF-κB pathway, thereby reducing the production of pro-inflammatory mediators.[11]
NF-κB signaling pathway and potential inhibition by bioactive compounds.
-
MAPK Signaling Pathway: This pathway is crucial for regulating cell proliferation, differentiation, and apoptosis. Aberrant MAPK signaling is a hallmark of many cancers. Natural products, including flavonoids and terpenoids, have been identified as potential inhibitors of the MAPK pathway, making them attractive candidates for anticancer drug development.[10][21][22]
MAPK/ERK signaling pathway and a potential point of inhibition.
Experimental Workflow for Bioprospecting
The following diagram outlines a general workflow for the discovery of bioactive compounds from the flora of the this compound region.
A generalized workflow for bioprospecting and drug discovery.
Conclusion and Future Directions
The this compound region's unique biodiversity, born from the convergence of the Cerrado and Caatinga biomes, is a valuable natural asset that is facing imminent threats. This guide has synthesized the current state of knowledge on the region's biodiversity and ecosystem health, provided standardized protocols for further research, and highlighted the significant potential for drug discovery from its native flora.
Future research should focus on:
-
Comprehensive Biodiversity Inventories: Expanding quantitative surveys to include a wider range of taxa and habitats to create a more complete picture of the region's biodiversity.
-
Long-term Monitoring: Establishing long-term monitoring programs for key ecosystem health indicators to track changes over time and inform conservation strategies.
-
Targeted Bioprospecting: Systematically screening the region's flora and fauna for novel bioactive compounds with therapeutic potential, guided by ethnobotanical knowledge.
-
Mechanism of Action Studies: Elucidating the molecular mechanisms by which these bioactive compounds exert their effects to identify novel drug targets and signaling pathways.
By integrating ecological research with pharmacological investigation, the scientific community can contribute to both the conservation of the this compound region's unique natural heritage and the development of new therapies for human diseases.
References
- 1. mdpi.com [mdpi.com]
- 2. periodicos.ufpi.br [periodicos.ufpi.br]
- 3. scientiaplena.org.br [scientiaplena.org.br]
- 4. scielo.br [scielo.br]
- 5. digitalcommons.odu.edu [digitalcommons.odu.edu]
- 6. scielo.br [scielo.br]
- 7. researchgate.net [researchgate.net]
- 8. Density and Population Size of Mammals in Remnants of Brazilian Atlantic Forest - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. banglajol.info [banglajol.info]
- 11. researchgate.net [researchgate.net]
- 12. scientiaplena.emnuvens.com.br [scientiaplena.emnuvens.com.br]
- 13. Phytosociology, successional level, and conservation of the woody component in a “restinga” of Maranhão island, Brazil [redalyc.org]
- 14. researchgate.net [researchgate.net]
- 15. researchgate.net [researchgate.net]
- 16. Herpetofauna Richness, Diversity, and Occurrence at the Northern Ecotone of Longleaf Pine - PMC [pmc.ncbi.nlm.nih.gov]
- 17. frontiersin.org [frontiersin.org]
- 18. cabidigitallibrary.org [cabidigitallibrary.org]
- 19. researchgate.net [researchgate.net]
- 20. atenaeditora.com.br [atenaeditora.com.br]
- 21. scielo.br [scielo.br]
- 22. researchgate.net [researchgate.net]
Teresina, Brazil – This technical guide provides a comprehensive analysis of the multifaceted nature of social inequality in this compound, the capital city of the state of Piauí. Drawing on a wide range of quantitative data and academic research, this document is intended for researchers, scientists, and professionals in drug development, offering insights into the socio-economic landscape that can influence public health and other developmental outcomes. The guide delves into the key determinants of inequality in the city, presents detailed data in a structured format, outlines the methodologies of seminal studies, and visualizes the complex interplay of factors contributing to social disparities.
Quantitative Overview of Social Inequality in this compound
Social inequality in this compound manifests across several key domains, including income, education, housing, and healthcare. The following tables summarize the most recent available data to provide a comparative snapshot of these disparities.
Income Inequality
Income inequality remains a significant challenge in this compound. The Gini coefficient, a primary measure of income distribution, indicates a high level of disparity, although there have been fluctuations over the years.
| Indicator | This compound | Piauí | Northeast Brazil | Brazil | Year | Source |
| Gini Coefficient | 0.582 | 0.582 | 0.625 | 0.573 | 2021 | IBGE, cited in SEPLAN (2022) |
| Gini Coefficient | 0.6171 | - | - | - | 2010 | DATASUS, cited in Transformative Urban Coalitions |
| Average Monthly Household Income per capita (BRL) | R$ 2,551.82 | R$ 1,284.87 | - | - | 2010 | IBGE, cited in Acesse Piauí (2012) |
| Income of Richest Neighborhood (Jóquei Clube) (BRL) | R$ 12,033.03 | - | - | - | 2010 | IBGE, cited in Acesse Piauí (2012) |
| Income of Poorest Neighborhood (São Lourenço) (BRL) | R$ 714.40 | - | - | - | 2010 | IBGE, cited in Acesse Piauí (2012) |
| Ratio of Richest to Poorest Neighborhood Income | 17 times | - | - | - | 2010 | IBGE, cited in Acesse Piauí (2012) |
| Gender Pay Inequality (Women's earnings as % of men's) | 65.6% | - | - | 72% | 2022 | IBGE - PNAD, cited in New Science (2025) |
Note: The Gini coefficient ranges from 0 (perfect equality) to 1 (perfect inequality).
Educational Disparities
The educational landscape in this compound is characterized by a stark divide between public and private institutions and varying levels of access and quality across different age groups.
| Indicator | Value | Year | Source |
| Municipal Human Development Index - Education (IDHM-E) | 0.686 | 2010 | Atlas Brasil |
| % of children aged 6-14 in school | 97.54% | 2010 | Atlas Brasil |
| % of youth aged 15-17 with completed primary education | 62.94% | 2010 | Atlas Brasil |
| % of youth aged 18-20 with completed secondary education | 46.22% | 2010 | Atlas Brasil |
| Private primary and secondary schools as % of total | 29% | 2007 | INEP, cited in SciELO (2013) |
| Private school enrollment (7-14 years) as % of total | 26% | 2007 | INEP, cited in SciELO (2013) |
Housing and Urban Infrastructure Inequality
Inadequate housing and disparities in urban infrastructure are prominent features of social inequality in this compound, with a significant portion of the population living in precarious conditions.
| Indicator | Value | Year | Source |
| Housing Deficit (households) | Over 35,000 | 2019 | Fundação João Pinheiro, cited in G1 (2022) |
| % of families with inadequate housing | 9% | 2019 | Fundação João Pinheiro, cited in G1 (2022) |
| Number of favelas and urban communities | 170 | 2022 | IBGE, cited in G1 (2025) |
| Population living in favelas and urban communities | 198,189 (22.9% of the city's population) | 2022 | IBGE, cited in G1 (2024) |
| % of urban footprint in hazardous/risk-prone areas | 7.8% | 2019 | Urban Resilience Hub |
| % of population covered by wastewater network | 35% | 2019 | Urban Resilience Hub |
| % of households with inadequate structure | ~20% | 2019 | Urban Resilience Hub |
| Access to adequate sewage disposal | 18.1% | 2023 | IBGE (2024) |
Health Inequality
Access to and quality of healthcare services also reflect the broader social inequalities in this compound.
| Indicator | Finding | Year | Source |
| Non-performance of mammography (women 40-69) | Associated with brown/black race, lower education, and lower income. | 2010-2011 | SciELO |
| Investment in public health | Highest per capita among Brazilian capitals. | 2019 | Urban Resilience Hub |
Methodological Protocols of Key Data Sources
The quantitative data presented in this guide are primarily derived from studies and surveys conducted by the Brazilian Institute of Geography and Statistics (IBGE) and other research institutions. Understanding the methodologies employed is crucial for interpreting the data accurately.
IBGE Demographic Census
The Demographic Census is the most comprehensive survey of the Brazilian population, providing detailed information on demographics, housing, education, and income at the municipal and intra-municipal levels.
-
Data Collection: The census is conducted through face-to-face interviews with all households in the national territory. Trained census takers use electronic data collection devices to administer a standardized questionnaire. Two types of questionnaires are used: a basic one for all households and a more detailed sample questionnaire for a statistically selected subset of households.
-
Sampling (for the sample questionnaire): The sample is selected through a stratified random sampling process to ensure representativeness for various geographic and socio-economic strata.
-
Key Variables for Inequality Analysis: The census collects data on household income, educational attainment of residents, housing characteristics (materials, access to sanitation, water, and electricity), race/color, and employment status. This allows for the calculation of indicators such as the Gini coefficient, literacy rates, and housing deficit at a granular level, including for specific neighborhoods (census tracts) within this compound.
Continuous National Household Sample Survey (PNAD Contínua)
The PNAD Contínua is a quarterly household survey that provides key information on the labor force, income, and other socio-demographic characteristics for Brazil, its major regions, states, and metropolitan areas, including this compound.
-
Data Collection: Data is collected through interviews with residents of a rotating sample of households. The interviews are conducted in person using portable data collection devices. Each selected household is interviewed for five consecutive quarters to track changes over time.
-
Sampling: The PNAD Contínua employs a complex probabilistic sampling design in two or three stages (depending on the municipality's characteristics), with stratification of the primary sampling units. This ensures the statistical representativeness of the collected data. For this compound, the survey provides specific estimates.
-
Key Variables for Inequality Analysis: The survey gathers detailed information on all sources of income, employment status, educational level, and demographic characteristics. It is a primary source for tracking the Gini coefficient and other income inequality metrics between census years.
Study on Educational Inequalities in this compound (Nogueira et al., published in SciELO)
This research aimed to understand the mechanisms producing educational inequalities in this compound.
-
Methodology: The study employed a mixed-methods approach.
-
Quantitative Data: Data was collected from the Prova Brasil (a national assessment of basic education), the School Census, and a specific survey administered to students. A Social Vulnerability Index for this compound (IVS-T) was created based on census data to analyze socio-spatial inequalities.
-
Qualitative Data: The research included interviews with education officials, school principals, and parents, as well as case studies of selected schools.
-
-
Analysis: The quantitative data was used to compare student performance across different school networks (public vs. private, state vs. municipal) and geographic areas with varying levels of social vulnerability. The qualitative data provided context and in-depth understanding of the processes behind the observed quantitative differences.
Determinants of Social Inequality in this compound: Visualizing the Pathways
The social inequality observed in this compound is not the result of a single factor but rather a complex interplay of historical, social, economic, and political determinants. The following diagrams, created using the DOT language, illustrate the key logical relationships and signaling pathways that perpetuate these disparities.
The Cycle of Educational Inequality
Educational inequality in this compound is a significant driver of broader social disparities. It is perpetuated by a cycle involving the school system's structure and socio-economic factors.
Socio-Spatial Segregation and Access to Opportunities
The urban development of this compound has led to a concentration of poverty in peripheral areas, creating a feedback loop of limited access to essential services and opportunities.
Visceral Leishmaniasis in Teresina: An In-depth Epidemiological and Methodological Review
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the prevalence of visceral leishmaniasis (VL) in Teresina, Piauí, Brazil, a city historically marked by significant urban outbreaks of the disease. This document synthesizes key quantitative data, details relevant experimental protocols, and visualizes essential biological and procedural workflows to serve as a resource for researchers, scientists, and professionals involved in drug development and public health.
Introduction to Visceral Leishmaniasis in this compound
Visceral leishmaniasis, caused by the protozoan parasite Leishmania infantum (synonymous with Leishmania chagasi in the Americas), is a severe systemic disease transmitted by the bite of infected phlebotomine sandflies of the species Lutzomyia longipalpis. The domestic dog is the primary urban reservoir of the parasite, playing a crucial role in the transmission cycle to humans.
This compound, the capital of Piauí state, experienced its first major urban VL epidemic in the early 1980s, a phenomenon linked to intense population growth and migration.[1] Since then, the city has remained a key area for the study and control of this neglected tropical disease. The spatial distribution of VL in this compound has been shown to be heterogeneous, with higher incidence rates often associated with peripheral neighborhoods characterized by rapid occupation, dense vegetation, and inadequate sanitation infrastructure.[2][3]
Prevalence of Human Visceral Leishmaniasis
Epidemiological data from this compound reveals fluctuating, yet persistent, incidence rates of human visceral leishmaniasis over the decades. Several studies have quantified the burden of the disease, highlighting periods of intense transmission.
An ecological study analyzing the period from 1991 to 2000 reported a total of 1,744 human cases of VL in this compound.[2][3] A significant outbreak occurred between 1993 and 1996, with more than 1,200 cases recorded.[4][5] More recent data from the National Notifiable Diseases Information System (SINAN/DATASUS) indicated 345 registered VL cases in the city between 2013 and 2018.[6] The year 2013 saw the highest number of cases in this period (20% of the total), while 2018 had the lowest (10.14%).[6]
A broader analysis of the state of Piauí from 2007 to 2019 showed that the health region encompassing this compound (Entre Rios) had one of the highest mean VL incidence rates at 7.33 cases per 100,000 inhabitants.[7][8]
Table 1: Human Visceral Leishmaniasis Cases in this compound from Selected Studies
| Study Period | Number of Cases | Key Findings | Reference |
| 1991-2000 | 1,744 | Epidemic from 1992-1995. | [2][3] |
| 1993-1996 | >1,200 | Major outbreak. | [4][5] |
| 2001-2006 | 670 (georeferenced) | High-risk clusters in peripheral areas. | [1] |
| 2013-2018 | 345 | Highest number of cases in 2013. | [6] |
Prevalence of Canine Visceral Leishmaniasis
The prevalence of canine visceral leishmaniasis (CVL) is a critical indicator of the risk of human infection. Studies in this compound have consistently demonstrated a high prevalence of infection in the canine population.
A cross-sectional study conducted in ten districts of this compound involving 810 dogs found a global seropositivity of 39%.[9] Another study analyzing data from the this compound Zoonoses Center between 2013 and 2018 reported that out of 42,065 canine blood samples collected, 67.07% were seroreactive by a rapid test and 32.93% by ELISA.[6] These findings underscore the significant role of dogs as reservoirs for L. infantum in the urban environment of this compound.
Table 2: Canine Visceral Leishmaniasis Seroprevalence in this compound
| Study Period | Number of Dogs | Diagnostic Method(s) | Seroprevalence | Reference |
| Undisclosed | 810 | Indirect Immunofluorescence (IFI) | 39% | [9] |
| 2013-2018 | 42,065 | Rapid Test and ELISA | 67.07% (Rapid Test), 32.93% (ELISA) | [6] |
Experimental Protocols
Accurate diagnosis of both human and canine visceral leishmaniasis is fundamental for surveillance and control. The following are detailed methodologies for key serological experiments cited in studies from this compound.
Indirect Immunofluorescence (IFI) for Canine VL
This method is a widely used serological test for the detection of anti-Leishmania antibodies in dogs.
-
Antigen Preparation: Promastigotes of a reference Leishmania infantum strain are cultured, harvested during the logarithmic growth phase, washed in phosphate-buffered saline (PBS), and resuspended to a concentration of 10^6 parasites/mL. Slides are prepared by applying 10 µL of the antigen suspension to each well and allowing them to air dry. The slides are then fixed in cold acetone (B3395972) for 10 minutes.
-
Serum Samples: Peripheral blood is collected from dogs via venipuncture. The blood is centrifuged to separate the serum, which is then stored at -20°C until use.
-
Assay Procedure:
-
Serum samples are serially diluted in PBS, starting from a 1:10 dilution.
-
20 µL of each serum dilution is added to the antigen-coated wells on the slides.
-
The slides are incubated in a humid chamber at 37°C for 30 minutes.
-
Slides are washed three times with PBS for 5 minutes each.
-
A fluorescein (B123965) isothiocyanate (FITC)-conjugated anti-dog IgG antibody (secondary antibody) is diluted according to the manufacturer's instructions and added to each well.
-
The slides are incubated again in a humid chamber at 37°C for 30 minutes.
-
The washing step (step 4) is repeated.
-
A drop of buffered glycerol (B35011) is added to each well, and a coverslip is applied.
-
Slides are examined under a fluorescence microscope.
-
-
Interpretation: A positive reaction is indicated by the presence of fluorescent parasites. The titer is the highest dilution at which fluorescence is observed. In many studies conducted in this compound, a titer of ≥1:80 was considered positive.[9]
Enzyme-Linked Immunosorbent Assay (ELISA) for Canine VL
ELISA is another common serological technique used for the diagnosis of CVL.
-
Antigen Coating: 96-well microplates are coated with a soluble Leishmania antigen extract (e.g., total lysate of L. infantum promastigotes) at a predetermined concentration in a carbonate-bicarbonate buffer (pH 9.6). The plates are incubated overnight at 4°C.
-
Blocking: The plates are washed with a washing buffer (PBS with 0.05% Tween 20) and then blocked with a blocking solution (e.g., 5% non-fat dry milk in PBS-T) for 1 hour at 37°C to prevent non-specific binding.
-
Serum Incubation: After washing, diluted canine serum samples are added to the wells and incubated for 1 hour at 37°C.
-
Secondary Antibody Incubation: The plates are washed again, and a peroxidase-conjugated anti-dog IgG antibody is added to each well. The plates are incubated for 1 hour at 37°C.
-
Substrate Reaction: Following another washing step, a chromogenic substrate solution (e.g., o-phenylenediamine (B120857) dihydrochloride (B599025) - OPD, or 3,3',5,5'-tetramethylbenzidine (B1203034) - TMB) is added to the wells. The reaction is allowed to proceed in the dark for a specific time (e.g., 15-30 minutes).
-
Stopping the Reaction: The reaction is stopped by adding a stop solution (e.g., 2N H₂SO₄).
-
Reading: The optical density (OD) is read using a microplate spectrophotometer at a specific wavelength (e.g., 492 nm for OPD).
-
Interpretation: A cut-off value is determined (e.g., the mean OD of known negative samples plus two or three standard deviations). Samples with an OD above the cut-off are considered positive.
Visualizations
The following diagrams illustrate key conceptual and procedural aspects of visceral leishmaniasis research and its biological basis.
Caption: Experimental workflow for serological diagnosis of canine visceral leishmaniasis.
Caption: Simplified signaling pathway of the immune response to Leishmania infantum.
Conclusion
This compound remains a significant urban center for visceral leishmaniasis transmission in Brazil. The data consistently points to a high prevalence of both human and canine infection, emphasizing the need for continuous surveillance and integrated control measures. These measures include early diagnosis and treatment of human cases, control of the canine reservoir, and vector control. For drug development professionals, the persistent endemicity in this compound provides a critical context for the evaluation of new therapeutic and prophylactic strategies. The detailed experimental protocols and conceptual diagrams provided in this guide serve as a foundational resource for understanding the multifaceted challenges posed by visceral leishmaniasis in this urban setting.
References
- 1. Identification of Risk Areas for Visceral Leishmaniasis in this compound, Piaui State, Brazil - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Factors associated with the incidence of urban visceral leishmaniasis: an ecological study in this compound, Piauí State, Brazil - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. scielo.br [scielo.br]
- 4. Multilevel modelling of the incidence of visceral leishmaniasis in this compound, Brazil - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Multilevel modelling of the incidence of visceral leishmaniasis in this compound, Brazil | Epidemiology & Infection | Cambridge Core [cambridge.org]
- 6. Risk and transmission of Visceral Leishmaniasis associated with the prevalence of the disease in this compound-Piauí | O Mundo da Saúde [revistamundodasaude.emnuvens.com.br]
- 7. scielosp.org [scielosp.org]
- 8. scielo.br [scielo.br]
- 9. Socio-economic and environmental factors associated with the occurrence of canine infection by Leishmania infantum in this compound, Brazil - PubMed [pubmed.ncbi.nlm.nih.gov]
Analysis of Soil Composition and Contamination in Teresina: A Technical Guide
This technical guide provides a comprehensive overview of soil composition and contamination in Teresina, Piauí, Brazil, with a focus on heavy metal pollutants. It is intended for researchers, scientists, and environmental professionals engaged in the assessment and remediation of soil quality. This document synthesizes findings from various studies, presenting quantitative data, detailed experimental protocols, and visual representations of analytical workflows and potential toxicological pathways.
Introduction
The rapid urbanization and industrial activities in this compound have raised concerns about the potential for soil contamination, posing risks to both ecosystem health and human well-being. The accumulation of heavy metals in urban soils is a significant issue, originating from various sources such as vehicular emissions, industrial discharge, and the improper disposal of waste. This guide focuses on the prevalent heavy metal contaminants identified in the soil of this compound and the methodologies for their analysis.
Quantitative Analysis of Soil Contaminants
Studies conducted in this compound have identified several heavy metals in the soil, particularly in urban and landfill areas. The primary contaminants of concern include Copper (Cu), Lead (Pb), Zinc (Zn), Chromium (Cr), Nickel (Ni), and Manganese (Mn). The presence of these metals is largely attributed to anthropogenic activities. For instance, Cu, Pb, Zn, and Cr are often associated with traffic-related emissions and the use of fertilizers, while Ni and Mn may also have natural origins from the parent soil material.[1]
Research carried out by the Federal University of Piauí (UFPI) in the vicinity of the this compound landfill revealed significant contamination by heavy metals such as Copper, Lead, Chromium, and Zinc.[2] These studies, conducted between 2008 and 2009, also highlighted elevated concentrations of Zinc, Nitrate, and Nitrite in areas used for the disposal of hospital waste, posing a threat to the local groundwater.[2]
The following table summarizes the average concentrations of selected heavy metals found in the urban topsoil of this compound, as determined by atomic absorption spectrometry.
| Metal | Average Concentration (mg/kg) |
| Copper (Cu) | 6.11 |
| Zinc (Zn) | 8.56 |
| Lead (Pb) | 32.12 |
| Chromium (Cr) | 7.17 |
Source: Adapted from a multivariate study of urban soils in this compound.
It is important to note that in some areas, particularly near the city's landfill, the levels of Copper and Zinc have been found to be at or above the maximum tolerated prevention levels, indicating a significant environmental concern.[2]
Experimental Protocols
The primary analytical method cited in studies on soil contamination in this compound is Flame Atomic Absorption Spectrometry (FAAS).[1] This section provides a detailed, standardized protocol for the determination of heavy metal concentrations in soil samples.
Sample Collection and Preparation
-
Sampling : Composite soil samples are collected from a depth of 0-10 cm from various locations, including residential areas, urban parks, green spaces, and areas with high and low traffic density.[1]
-
Drying : The collected soil samples are air-dried at room temperature for 72 hours.
-
Sieving : The dried samples are sieved through a 2 mm mesh to remove coarse debris.
-
Homogenization : The sieved soil is thoroughly mixed to ensure homogeneity.
Acid Digestion
-
Weighing : Accurately weigh 1.0 g of the prepared soil sample into a digestion tube.
-
Acid Addition : Add 10 mL of a freshly prepared 1:1 mixture of concentrated nitric acid (HNO₃) and hydrochloric acid (HCl) (aqua regia) to the digestion tube.
-
Digestion : Place the tube in a digestion block and heat at 95°C for 1 hour.
-
Cooling and Filtration : Allow the digest to cool to room temperature and then filter it through a Whatman No. 42 filter paper into a 50 mL volumetric flask.
-
Dilution : Dilute the filtrate to the mark with deionized water.
Flame Atomic Absorption Spectrometry (FAAS) Analysis
-
Instrument Calibration : Calibrate the FAAS instrument using a series of standard solutions of the metals of interest (Cu, Pb, Zn, Cr, Ni, Mn).
-
Sample Analysis : Aspirate the diluted sample digest into the FAAS and record the absorbance readings for each metal.
-
Quantification : Determine the concentration of each metal in the sample by comparing its absorbance to the calibration curve.
-
Quality Control : Analyze blank and standard reference material samples with each batch of soil samples to ensure the accuracy and precision of the results.
Visualizations
Experimental Workflow
The following diagram illustrates the general workflow for the analysis of soil composition and contamination.
Caption: Workflow for Soil Contamination Analysis.
Generalized Signaling Pathway for Heavy Metal Toxicity
The diagram below illustrates a generalized signaling pathway for cellular response to heavy metal-induced oxidative stress, a common mechanism of toxicity for many soil contaminants.
Caption: Cellular Response to Heavy Metal Stress.
Conclusion
The soil in this compound, particularly in urbanized and industrial areas, shows evidence of contamination with heavy metals. This guide provides a foundational understanding of the issue, presenting available data and standardized methodologies for further research. Continuous monitoring and the application of robust analytical techniques are crucial for assessing the extent of soil contamination and developing effective remediation strategies to protect public health and the environment.
References
- 1. Analysis and Assessment of Heavy Metals in Urban Surface Soils of this compound, Piauí State, Brazil: A Study Based on Multivariate Analysis = Análise e avaliação dos metais pesados em solos superficiais urbanos de this compound, Estado do Piauí, Brasil: um estudo baseado em análise multivariada|Airiti Library 華藝線上圖書館 [airitilibrary.com]
- 2. Geopark Araripe: Pesquisa na UFPI revela contaminação do solo [geoparkararipe.blogspot.com]
"patterns of land use and land cover change in Teresina"
[2] {"result": "Teresina: Piauí, Brazil. This compound is the capital of Piauí, a state in the northeast of Brazil. It is located at the confluence of the Parnaíba and Poti rivers and is the only northeastern state capital that is not on the coast. It was founded in 1852 and named after the Empress Teresa Cristina. This compound is a major center for commerce and services in the region. The city is also home to several universities and research institutions. The climate is tropical, with a rainy season from January to April. The average temperature is 27 degrees Celsius. This compound is a major producer of textiles, clothing, and food products. The city is also a major center for transportation and logistics. This compound is served by an international airport and is a major hub for bus and truck transportation. The city is also a major center for education and healthcare. This compound is home to several universities and research institutions. The city is also a major center for healthcare, with several hospitals and clinics.", "title": "this compound, Piauí, Brazil - City, History, and Economy | Britannica", "url": "--INVALID-LINK-- {"result": "The annual rates of change in LULC are summarized in Table 2, which shows that in the first period (1985–2000), the classes of water, dense vegetation, and agricultural mosaic grew by 0.01, 0.05, and 0.04% per year, respectively. In contrast, the areas of sparse vegetation and non-vegetated area decreased by 0.01 and 0.09% per year, respectively. In the second period (2000–2015), the annual rates of change for water, dense vegetation, and agricultural mosaic were 0.01, 0.03, and 0.02%, respectively. The classes of sparse vegetation and non-vegetated area decreased by 0.01 and 0.05% per year, respectively. In the last period (2015–2020), the annual rates of change for water, dense vegetation, and agricultural mosaic were 0.01, 0.02, and 0.01%, respectively. The classes of sparse vegetation and non-vegetated area decreased by 0.01 and 0.02% per year, respectively.", "title": "Land Use and Land Cover Changes in the State of Piauí, Brazil: A ...", "url": "--INVALID-LINK-- {"result": "The urban area of this compound, the capital of Piauí, has undergone an intense process of spatial and demographic growth in recent years, which has led to significant changes in land use and land cover. This study aimed to analyze the spatio-temporal dynamics of land use and land cover in the urban area of this compound between 1989 and 2019. To do so, we used a time series of Landsat satellite images, which were classified using the supervised classification algorithm Random Forest. The results showed that the urban area increased by 15.3% in the period, from 16,335.54 ha in 1989 to 31,194.81 ha in 2019. This growth occurred mainly on the banks of the Poti and Parnaíba rivers, in areas previously occupied by vegetation. The class of exposed soil also showed a significant increase, of 10.3%, while the vegetation class decreased by 25.6%. These changes are mainly due to the expansion of the road network, the implementation of large real estate projects, and the lack of effective urban planning. The results of this study can be used to support public policies aimed at sustainable urban planning in this compound.", "title": "Spatio-temporal dynamics of land use and land cover in the urban area of ...", "url": "--INVALID-LINK-- {"result": "The urban area of this compound has grown by 15.3% in 30 years, and the exposed soil has increased by 10.3%, while the vegetation has decreased by 25.6%.", "title": "Urban area of this compound grows 15.3% in 30 years and vegetation decreases ...", "url": "--INVALID-LINK-- {"result": "The analysis of land use and land cover (LULC) change is essential for understanding the dynamics of a region and supporting the development of sustainable public policies. This study aimed to analyze the LULC changes in the urban area of this compound, Piauí, Brazil, between 1989 and 2019. A time series of Landsat satellite images was used, which were classified using the supervised classification algorithm Random Forest. The results showed that the urban area increased by 15.3% in the period, from 16,335.54 ha in 1989 to 31,194.81 ha in 2019. This growth occurred mainly on the banks of the Poti and Parnaíba rivers, in areas previously occupied by vegetation. The class of exposed soil also showed a significant increase, of 10.3%, while the vegetation class decreased by 25.6%. These changes are mainly due to the expansion of the road network, the implementation of large real estate projects, and the lack of effective urban planning. The results of this study can be used to support public policies aimed at sustainable urban planning in this compound.", "title": "Spatio-temporal dynamics of land use and land cover in the urban area of ...", "url": "https.br/j/rbrh/a/wX8Y7yZ4X7K8c9yG7XF7kXw/?lang=en"} {"result": "The mapping of land use and land cover in the state of Piauí, on a scale of 1:100,000, for the years 2000, 2010, and 2020, was carried out through the interpretation of satellite images. The results showed that the state is predominantly occupied by areas of natural vegetation, which correspond to 75.5% of the territory. The remaining area is occupied by areas of agricultural use (18.2%), pasture (5.5%), urban areas (0.4%), water bodies (0.3%), and other uses (0.1%). The analysis of the changes that occurred in the period showed that there was a reduction in the areas of natural vegetation, mainly due to the expansion of agricultural and pasture areas. The areas of agricultural use increased by 2.5%, while the areas of pasture increased by 1.5%. The urban areas also showed a significant increase, of 0.2%. These changes are mainly due to the expansion of the agricultural frontier in the state, driven by the production of commodities such as soybeans, corn, and cotton. The results of this study can be used to support public policies aimed at the conservation of natural resources and the sustainable development of the state of Piauí.", "title": "Mapping of Land Use and Land Cover in the State of Piauí", "url": "--INVALID-LINK-- {"result": "This study aimed to analyze the spatio-temporal dynamics of land use and land cover in the urban area of this compound between 1989 and 2019. To do so, we used a time series of Landsat satellite images, which were classified using the supervised classification algorithm Random Forest. The results showed that the urban area increased by 15.3% in the period, from 16,335.54 ha in 1989 to 31,194.81 ha in 2019. This growth occurred mainly on the banks of the Poti and Parnaíba rivers, in areas previously occupied by vegetation.", "title": "Spatio-temporal dynamics of land use and land cover in the urban area of ...", "url": "--INVALID-LINK-- {"result": "This study aimed to analyze the spatio-temporal dynamics of land use and land cover (LULC) in the urban area of this compound, Piauí, Brazil, between 1989 and 2019. A time series of Landsat satellite images was used, which were classified using the supervised classification algorithm Random Forest. The results showed that the urban area increased by 15.3% in the period, from 16,335.54 ha in 1989 to 31,194.81 ha in 2019. This growth occurred mainly on the banks of the Poti and Parnaíba rivers, in areas previously occupied by vegetation. The class of exposed soil also showed a significant increase, of 10.3%, while the vegetation class decreased by 25.6%.", "title": "Spatio-temporal dynamics of land use and land cover in the urban area of ...", "url": "--INVALID-LINK-- {"result": "This work aimed to evaluate the spatiotemporal dynamics of land use and land cover in the urban perimeter of this compound-PI, from the years 1989 to 2019. For this, images from the Landsat 5 and 8 satellites were used, with the application of the supervised classification method, through the Random Forest algorithm. The results showed that in 30 years, the urban area of this compound grew about 15.3%, with emphasis on the growth of exposed soil, with an increase of 10.3%, and a decrease in vegetation cover, with a loss of 25.6%. It is concluded that the urban expansion of this compound has been occurring in a disorderly way, without proper planning, which has generated negative impacts on the environment, such as the suppression of vegetation and the increase of exposed soil.", "title": "Spatiotemporal dynamics of land use and land cover in the urban ...", "url": "--INVALID-LINK-- {"result": "The work aimed to analyze the spatial and temporal dynamics of land use and cover in the urban area of this compound (PI) between the years 1989 and 2019. A time series of Landsat satellite images was used, which were classified using the supervised classification algorithm Random Forest. The results showed that the urban area increased by 15.3% in the period, from 16,335.54 ha in 1989 to 31,194.81 ha in 2019. This growth occurred mainly on the banks of the Poti and Parnaíba rivers, in areas previously occupied by vegetation. The class of exposed soil also showed a significant increase, of 10.3%, while the vegetation class decreased by 25.6%. These changes are mainly due to the expansion of the road network, the implementation of large real estate projects, and the lack of effective urban planning. The results of this study can be used to support public policies aimed at sustainable urban planning in this compound.", "title": "Spatio-temporal dynamics of land use and land cover in the urban area of ...", "url": "--INVALID-LINK-- {"result": "The analysis of land use and land cover (LULC) is a fundamental tool for environmental planning and management. This study aimed to analyze the LULC changes in the municipality of this compound, Piauí, Brazil, between 1985 and 2020. A time series of Landsat satellite images was used, which were classified using the supervised classification algorithm Random Forest. The results showed that the urban area increased by 12.5% in the period, from 10,500 ha in 1985 to 23,000 ha in 2020. The agricultural areas also increased, by 5.5%, while the areas of natural vegetation decreased by 18%. These changes are mainly due to the expansion of the urban area, the increase in agricultural production, and the deforestation of natural vegetation. The results of this study can be used to support public policies aimed at the sustainable development of the municipality of this compound.", "title": "Land Use and Land Cover Changes in the Municipality of this compound, Piauí ...", "url": "--INVALID-LINK-- {"result": "The urban area of this compound-PI has been undergoing a continuous process of expansion, which has been causing significant changes in the land use and land cover of the municipality. This study aimed to analyze the evolution of the urban area of this compound between the years 1989 and 2019, using remote sensing data and geographic information systems. The results showed that the urban area increased by 15.3% in the period, from 16,335.54 ha in 1989 to 31,194.81 ha in 2019. This growth occurred mainly in the east and southeast zones of the city, in areas previously occupied by vegetation. The study also showed that the expansion of the urban area has been occurring in a disorderly way, without proper planning, which has generated negative impacts on the environment, such as the suppression of vegetation, the waterproofing of the soil, and the increase of the risks of floods and landslides.", "title": "The evolution of the urban area of this compound-PI between 1989 and 2019", "url": "--INVALID-LINK-- {"result": "This study aimed to analyze the spatio-temporal dynamics of land use and land cover in the urban area of this compound between 1989 and 2019. To do so, we used a time series of Landsat satellite images, which were classified using the supervised classification algorithm Random Forest. The results showed that the urban area increased by 15.3% in the period, from 16,335.54 ha in 1989 to 31,194.81 ha in 2019. This growth occurred mainly on the banks of the Poti and Parnaíba rivers, in areas previously occupied by vegetation. The class of exposed soil also showed a significant increase, of 10.3%, while the vegetation class decreased by 25.6%. These changes are mainly due to the expansion of the road network, the implementation of large real estate projects, and the lack of effective urban planning.", "title": "Spatio-temporal dynamics of land use and land cover in the urban area of ...", "url": "--INVALID-LINK-- {"result": "This study aimed to analyze the spatio-temporal dynamics of land use and land cover in the urban area of this compound between 1989 and 2019. To do so, we used a time series of Landsat satellite images, which were classified using the supervised classification algorithm Random Forest.", "title": "Spatio-temporal dynamics of land use and land cover in the urban area of ...", "url": "https.br/j/rbrh/a/wX8Y7yZ4X7K8c9yG7XF7kXw/?lang=en"}## Shifting Landscapes: A Technical Analysis of Land Use and Land Cover Transformation in this compound
This compound, Brazil - A comprehensive analysis of land use and land cover (LULC) changes in the urban and surrounding areas of this compound, the capital of Piauí state, reveals a significant and ongoing transformation of the landscape. Driven primarily by urban expansion and agricultural development, these changes have led to a notable decrease in natural vegetation and a substantial increase in urbanized and exposed soil areas over the past few decades. This technical guide synthesizes findings from multiple remote sensing-based studies to provide researchers, scientists, and development professionals with a detailed overview of these patterns, the methodologies used for their assessment, and the underlying drivers of change.
The urban area of this compound has experienced remarkable growth, expanding by 15.3% between 1989 and 2019. This expansion has primarily occurred along the banks of the Poti and Parnaíba rivers, converting areas previously covered by vegetation into urban infrastructure. Concurrent with urban growth, there has been a significant 10.3% increase in exposed soil, while vegetation cover has diminished by 25.6% over the same 30-year period.
A broader analysis of the municipality of this compound between 1985 and 2020 shows a 12.5% increase in the urban area and a 5.5% rise in agricultural lands. This expansion of human-modified landscapes has come at the cost of natural vegetation, which saw a reduction of 18% during this period. At the state level of Piauí, a similar trend is observed, with a 2.5% increase in agricultural use areas and a 1.5% increase in pasture lands between 2000 and 2020, largely driven by the expansion of the agricultural frontier for commodity crops like soybeans, corn, and cotton.
Quantitative Analysis of Land Use and Land Cover Change
The following tables summarize the quantitative data on LULC changes in this compound and the broader state of Piauí, as documented in various studies.
Table 1: Land Use and Land Cover Change in the Urban Area of this compound (1989-2019)
| Land Cover Class | Change (%) | Area in 1989 (ha) | Area in 2019 (ha) |
| Urban Area | +15.3% | 16,335.54 | 31,194.81 |
| Vegetation | -25.6% | Not specified | Not specified |
| Exposed Soil | +10.3% | Not specified | Not specified |
Source: Multiple studies utilizing Landsat satellite imagery and Random Forest classification.
Table 2: Land Use and Land Cover Change in the Municipality of this compound (1985-2020)
| Land Cover Class | Change (%) | Area in 1985 (ha) | Area in 2020 (ha) |
| Urban Area | +12.5% | 10,500 | 23,000 |
| Agricultural Areas | +5.5% | Not specified | Not specified |
| Natural Vegetation | -18% | Not specified | Not specified |
Source: Analysis of Landsat satellite imagery time series.
Table 3: Annual Rates of Change in Land Use and Land Cover in the State of Piauí
| Period | Water (%) | Dense Vegetation (%) | Agricultural Mosaic (%) | Sparse Vegetation (%) | Non-vegetated Area (%) |
| 1985–2000 | +0.01 | +0.05 | +0.04 | -0.01 | -0.09 |
| 2000–2015 | +0.01 | +0.03 | +0.02 | -0.01 | -0.05 |
| 2015–2020 | +0.01 | +0.02 | +0.01 | -0.01 | -0.02 |
Source: Analysis of land use and land cover changes in the state of Piauí.
Methodological Framework for LULC Change Analysis
The primary methodology employed in the cited studies for analyzing LULC changes in this compound involves the use of remote sensing data, specifically time series of Landsat satellite images. The general workflow is outlined below.
Experimental Protocol: Satellite Image Analysis for LULC Classification
-
Data Acquisition: A time series of Landsat satellite images covering the study area (this compound and its surroundings) is acquired for the specified years (e.g., 1989, 2019).
-
Image Pre-processing: The acquired satellite images undergo pre-processing to ensure geometric and radiometric correction, as well as atmospheric correction to minimize the effects of atmospheric haze.
-
Image Classification: A supervised classification algorithm, most commonly the Random Forest algorithm, is applied to the pre-processed images.
-
Training Data Collection: Representative training samples for different LULC classes (e.g., urban area, vegetation, water, exposed soil) are collected based on ground truth data or high-resolution imagery.
-
Classifier Training: The Random Forest classifier is trained using the collected training samples.
-
Image Classification: The trained classifier is then used to assign each pixel in the satellite image to a specific LULC class.
-
-
Accuracy Assessment: The accuracy of the classification results is evaluated using standard metrics such as the overall accuracy and the Kappa coefficient, by comparing the classified map with independent reference data.
-
Change Detection: The classified LULC maps from different years are compared to identify and quantify the changes that have occurred over the study period.
Visualizing Methodological and Causal Relationships
The following diagrams illustrate the workflow for LULC change analysis and the key drivers behind the observed transformations in this compound.
Dengue and Zika Virus Epidemiology in Teresina: A Technical Overview for Researchers
Teresina, Piauí - As a major urban center in northeastern Brazil, this compound faces significant public health challenges from arboviral diseases, particularly those transmitted by the Aedes aegypti mosquito. The co-circulation of Dengue (DENV) and Zika (ZIKV) viruses necessitates a robust understanding of their local epidemiology, diagnostic methodologies, and the dynamics of their vector. This technical guide synthesizes available data on the epidemiological landscape of Dengue and Zika in this compound, providing a resource for researchers, scientists, and public health professionals engaged in surveillance, diagnostics, and the development of therapeutic interventions.
Epidemiological Data
The epidemiological situation of Dengue and Zika in this compound is dynamic, influenced by seasonal variations and public health interventions. While comprehensive, long-term datasets specific to the municipality are not always publicly accessible, data from the Municipal Health Foundation (FMS) of this compound, the State Health Secretariat of Piauí (SESAPI), and the SINAN (Notifiable Diseases Information System) database provide valuable insights.
According to a recent epidemiological bulletin from the Municipal Health Foundation of this compound, there have been 673 notified cases of Dengue, with 472 confirmed, and 3 confirmed cases of Zika virus.[1] State-level data for Piauí in the early months of 2025 showed 1,159 probable cases of Dengue.[2] Historically, this compound has been a significant contributor to the arbovirus cases reported in the state of Piauí.[3][4] For instance, between 2015 and 2020, this compound accounted for 55.80% of the 1,371 Zika virus cases reported in the state.[3]
A study analyzing Dengue in this compound from 2002 to 2006 reported 11,003 notified cases, with incidence rates varying significantly year to year.[5] This historical data underscores the endemic and epidemic nature of Dengue in the city.
Table 1: Reported Cases of Dengue and Zika in this compound and Piauí (Selected Recent Data)
| Jurisdiction | Time Period | Dengue Cases (Confirmed/Probable) | Zika Cases (Confirmed) | Chikungunya Cases (Confirmed) | Data Source |
| This compound | Early 2025 (as of March 7) | 472 | 3 | 77 | FMS this compound[1] |
| Piauí | First 9 weeks of 2025 | 1,159 (Probable) | - | - | Ministry of Health[2] |
| Piauí | 2015-2020 | - | 1,371 | - | DATASUS[3] |
Table 2: Historical Dengue Data in this compound (2002-2006)
| Year | Notified Cases | Incidence Rate (/100,000) | Lethality Rate (%) |
| 2002 | 4,502 | 592.7 | 0 |
| 2003 | 3,865 | 501.9 | 6.25 |
| 2004 | 153 | 19.5 | 0 |
| 2005 | 450 | 56.5 | 12.5 |
| 2006 | 2,033 | 251.4 | 20 |
| Source: Study on Epidemiological and Vector Aspects of Dengue in this compound.[5] |
Molecular Epidemiology
Understanding the genetic diversity of circulating viruses is critical for vaccine development, diagnostics, and tracking viral evolution.
Dengue Virus (DENV) All four Dengue serotypes (DENV-1, DENV-2, DENV-3, and DENV-4) have been detected in Brazil. In the state of Piauí, surveillance data has indicated the circulation of multiple serotypes. For instance, in 2010, analysis of 539 samples in Piauí found 42 positive for DENV-1, eight for DENV-2, and one for DENV-3.[6] While specific recent data on genotype distribution in this compound is limited in the available literature, studies in the broader northern region of Brazil have identified the circulation of DENV-1 Genotype V and DENV-2 Genotype III (Asian-American).
Zika Virus (ZIKV) The international "Zika in Brazil Real Time Analysis" (ZiBRA) project conducted complete genome sequencing of the Zika virus in several cities in northern and northeastern Brazil, including this compound.[1][7] This initiative was crucial in understanding the establishment and cryptic transmission of ZIKV in Brazil and the Americas, confirming that the circulating strain belonged to the Asian lineage.[1][7] The sequencing efforts provided vital epidemiological information on the virus's dissemination.[1]
Experimental Protocols
Standardized laboratory diagnosis is essential for accurate surveillance and clinical management of Dengue and Zika infections. The Central Laboratory of Public Health of Piauí (LACEN-PI) is a key institution for this diagnostic work, following guidelines from the Ministry of Health and the Pan American Health Organization (PAHO).
Molecular Diagnosis: RT-qPCR
Real-time reverse transcription-polymerase chain reaction (RT-qPCR) is the gold standard for detecting viral RNA in the acute phase of infection.
Objective: To detect and differentiate DENV and ZIKV RNA in clinical samples (serum, urine).
Methodology:
-
Sample Collection: Blood samples should be collected up to the 5th day of symptoms for Dengue and up to the 7th day for Zika. Urine samples can extend the detection window for Zika up to 14 days.[8][9]
-
RNA Extraction: Viral RNA is extracted from serum or urine using commercial kits (e.g., QIAamp Viral RNA Mini Kit, Qiagen) following the manufacturer's instructions.
-
RT-qPCR Assay: A triplex RT-qPCR assay can be employed for the simultaneous detection of DENV, ZIKV, and Chikungunya virus (CHIKV), which is often co-circulating. Validated protocols with specific primers and probes are available.
-
Primers and Probes: Target conserved regions of the viral genomes. For example, targeting the E gene for ZIKV and the 3' UTR for DENV.
-
Reaction Mix: Typically includes a one-step RT-qPCR master mix, forward and reverse primers for each target, and corresponding TaqMan probes labeled with distinct fluorescent dyes (e.g., FAM for DENV, HEX for ZIKV, Cy5 for CHIKV).
-
Thermal Cycling: The protocol generally involves a reverse transcription step (e.g., 50°C for 10 minutes), an initial denaturation step (e.g., 95°C for 2 minutes), followed by approximately 40 cycles of denaturation (e.g., 95°C for 15 seconds) and annealing/extension (e.g., 60°C for 1 minute).
-
-
Data Analysis: The cycle threshold (Ct) value is determined for each target. A Ct value below a defined cutoff (e.g., <38) indicates a positive result. Appropriate positive and negative controls must be included in each run.
Serological Diagnosis: ELISA
Enzyme-Linked Immunosorbent Assay (ELISA) is used to detect IgM and IgG antibodies, indicating recent or past infection, respectively. It is particularly useful after the viremic phase.
Objective: To detect anti-DENV and anti-ZIKV IgM/IgG antibodies in serum.
Methodology:
-
Sample Collection: Serum samples are typically collected from the 7th day of symptoms onwards.[10]
-
Assay Principle:
-
IgM Antibody Capture ELISA (MAC-ELISA): Microtiter plates are coated with anti-human IgM antibodies. Patient serum is added, followed by the addition of viral antigens (e.g., recombinant DENV and ZIKV NS1 proteins). The captured antigen-antibody complex is then detected using a specific monoclonal antibody conjugated to an enzyme (e.g., horseradish peroxidase), which reacts with a substrate to produce a colorimetric signal.
-
IgG ELISA: Plates are coated directly with viral antigens. Diluted patient serum is added, and the binding of IgG antibodies is detected with an enzyme-conjugated anti-human IgG antibody.
-
-
Data Analysis: The optical density (OD) of each well is read using a microplate reader. Results are typically interpreted by comparing the sample OD to the OD of a known negative control (cut-off value). A sample-to-cutoff ratio >1.0 is considered positive. Due to cross-reactivity between flaviviruses, a positive result for one virus should be interpreted with caution, especially in secondary infections.
Vector Surveillance
Entomological surveillance is fundamental for targeting vector control measures. In this compound, as in the rest of Brazil, the Levantamento Rápido de Índices para Aedes aegypti (LIRAa) is a standard methodology.[11][12]
LIRAa Methodology:
-
Stratification: The city is divided into geographical strata, each containing a certain number of properties.
-
Sampling: A statistically representative number of properties within each stratum is randomly selected for inspection.
-
Inspection: Field agents visit the selected properties to identify and collect larvae of Aedes mosquitoes from all water-holding containers.
-
Data Analysis: The collected data are used to calculate entomological indices, primarily the Building Infestation Index (BII - percentage of inspected properties with larvae).
-
Risk Classification: The results classify areas as satisfactory (BII <1%), alert (BII 1% to 3.9%), or at risk (BII ≥4%), guiding the intensification of control actions in the most critical areas.[13]
Recent LIRAa results for this compound indicated a reduction in the Building Infestation Index from 4.3% to 2.2%, moving many areas from a "risk" to an "alert" status.[13]
Signaling Pathways and Experimental Workflows
The following diagrams, generated using the DOT language, illustrate key molecular pathways and experimental workflows relevant to Dengue and Zika virus research.
References
- 1. [ASSISTA] Prefeitura de this compound apresenta plano de ação contra o Aedes Aegypti - Sistema Antares de Comunicação [fundacaoantares.pi.gov.br]
- 2. saude.rs.gov.br [saude.rs.gov.br]
- 3. NOTA TÉCNICA DIAGNÓSTICO LABORATORIAL DE ARBOVIROSES (DENGUE, ZIKA E CHIKUNGUNYA) [lacen.pi.gov.br]
- 4. Levantamento Rápido de Índices para Aedes aegypti — Ministério da Saúde [gov.br]
- 5. Novo plano de ação prevê reduzir impactos da dengue e outras arboviroses no Piauí — Ministério da Saúde [gov.br]
- 6. Piauí registra queda de 59,4% nos casos de dengue nos 2 primeiros meses de 2025 — Ministério da Saúde [gov.br]
- 7. Projeto Zibra permite sequenciamento de 54 genomas do vírus zika – Jornal da USP [jornal.usp.br]
- 8. glopid-r.org [glopid-r.org]
- 9. Levantamento Rápido de Índices para Aedes aegypti – LIRAa/LIA – Portal da Vigilância em Saúde [vigilancia.saude.mg.gov.br]
- 10. Folhadamanha [clicfolha.com.br]
- 11. novosite.ciaten.org.br [novosite.ciaten.org.br]
- 12. youtube.com [youtube.com]
- 13. Terceiro LIRAa do ano aponta queda no índice de infestação para Aedes Aegypti - J3News [j3news.com]
Methodological & Application
Application Notes: Monitoring Urban Growth in Teresina Using Remote Sensing
Introduction
The urban agglomeration of Teresina, located in the semiarid northeast of Brazil, has experienced significant and accelerated urban development over the past four decades.[1][2] This rapid expansion necessitates effective monitoring to support sustainable urban planning and management. Remote sensing, utilizing satellite imagery, offers a powerful and cost-effective tool for tracking land use and land cover (LULC) changes associated with urban growth.[3] By analyzing historical and current satellite data, researchers and urban planners can quantify the rate of expansion, identify patterns of development, and assess the environmental impacts of urbanization.[4][5]
Key Concepts and Applications
-
Spatiotemporal Analysis: Remote sensing allows for the analysis of urban growth patterns across both space and time. By comparing satellite images from different years, it is possible to map the historical expansion of the urban footprint.[2]
-
Land Use/Land Cover (LULC) Classification: Satellite imagery can be classified into different LULC categories, such as urban/built-up areas, vegetation, water bodies, and bare soil. This helps in understanding how other land covers are being converted to urban uses.[2][4]
-
Urban Fabric Analysis: High-resolution imagery, such as that from Sentinel-2, enables a more detailed analysis of the urban fabric. This includes identifying different types of urban surfaces like ceramic roofs, other roof types, and impervious surfaces (e.g., roads, parking lots), providing insights into the density and characteristics of urban development.[2]
-
Environmental Impact Assessment: The data derived from remote sensing can be used to assess the environmental consequences of urban growth, such as the loss of green spaces and the increase in land surface temperature, which contributes to the urban heat island effect.[3][4][6]
-
Sustainable Development Goals (SDG) Monitoring: Remote sensing techniques are instrumental in monitoring progress towards Sustainable Development Goal 11, which aims to make cities and human settlements inclusive, safe, resilient, and sustainable. Specifically, it helps in tracking the ratio of land consumption rate to population growth rate.[7][8]
Available Satellite Data
-
Landsat Program: The Landsat series of satellites provides a continuous historical archive of Earth imagery since the 1980s. Its moderate spatial resolution (30 meters) is well-suited for long-term monitoring of urban sprawl.[2][6]
-
Sentinel-2: Part of the European Space Agency's Copernicus program, the Sentinel-2 satellites offer higher spatial resolution (10-20 meters) and have become a valuable resource for more detailed urban mapping since their launch in 2015.[2][6]
-
High-Resolution Imagery: For very detailed analysis, such as identifying specific tree species within the urban environment, high-resolution commercial satellite imagery (e.g., Worldview-2) can be utilized.[9]
Analytical Platforms
-
Google Earth Engine (GEE): A cloud-based platform that provides access to a vast catalog of satellite imagery and the computational power to process it. GEE is particularly useful for large-scale, long-term urban growth analysis.[1][2]
-
Geographic Information Systems (GIS) Software: Software such as ArcGIS and SPRING are used for image processing, classification, and generating thematic maps of urban expansion.[5][10][11]
Experimental Protocols
Protocol 1: Long-Term Urban Sprawl Analysis using Landsat Imagery
This protocol outlines the methodology for analyzing the historical urban expansion of this compound from 1985 to 2018 using the Landsat dataset on the Google Earth Engine platform.[2]
-
Data Acquisition:
-
Access Landsat 5 TM, Landsat 7 ETM+, and Landsat 8 OLI/TIRS satellite imagery through the Google Earth Engine data catalog for the this compound-Timon conurbation area.
-
Select images with minimal cloud cover for the desired years (e.g., 1985, 2012, 2018).
-
-
Image Pre-processing:
-
Apply standard pre-processing techniques, including atmospheric correction, to convert top-of-atmosphere reflectance to surface reflectance.
-
Create cloud, shadow, and water masks to exclude these areas from the analysis.
-
-
Image Classification:
-
Employ a supervised classification algorithm, such as the Random Forest classifier.[2]
-
Create training samples by digitizing polygons for different LULC classes (e.g., urban area, vegetation, water, bare soil) based on visual interpretation of high-resolution imagery and ground truth data.
-
Train the Random Forest model using the training samples and a combination of spectral bands and indices (e.g., NDVI, NDBI).
-
Apply the trained classifier to the satellite images for each year to generate LULC maps.
-
-
Post-Classification Analysis:
-
Use a post-classification change detection method to compare the LULC maps from different years.[12]
-
Quantify the area of each LULC class for each year to determine the extent of urban expansion.
-
Calculate the annual rate of urban growth.
-
-
Accuracy Assessment:
-
Generate a confusion matrix to evaluate the accuracy of the classification.
-
Calculate overall accuracy, producer's accuracy, user's accuracy, and the Kappa coefficient using an independent set of validation points.
-
Protocol 2: Urban Fabric Analysis using Sentinel-2 Imagery
This protocol details the methodology for mapping the intra-urban structures of this compound in 2019 using Sentinel-2 data.[2]
-
Data Acquisition:
-
Obtain Sentinel-2 MSI (MultiSpectral Instrument) imagery for the this compound area for the year 2019 via the Google Earth Engine platform.
-
-
Image Pre-processing:
-
Perform atmospheric correction and cloud masking as described in Protocol 1.
-
-
Feature Extraction and Classification:
-
Utilize the higher spatial resolution of Sentinel-2 (10m and 20m bands) to define more specific urban LULC classes:
-
Residential - Ceramic roofs
-
Residential - Other roofs
-
Impervious surfaces (roads, pavement)
-
-
Employ a Random Forest classifier, training it with detailed training samples for each of the specified urban fabric classes.
-
-
Mapping and Quantification:
-
Generate a detailed urban fabric map for 2019.
-
Calculate the percentage of the urban area covered by each class (e.g., ceramic roofs, other roofs, impervious surfaces).
-
Quantitative Data Summary
Table 1: Urban Area Expansion in this compound (1985-2018)
| Year | Urban Area (km²) |
| 1985 | 70.34 |
| 2018 | 159.02 |
Source:[2]
Table 2: Annual Urban Growth Rate in this compound (1985-2018)
| Metric | Value |
| Average Annual Growth Rate | 3.05% |
Source:[2]
Table 3: Land Use/Land Cover in this compound's Urban Area (2019)
| Land Use/Land Cover Class | Percentage of Urban Area |
| Residential - Ceramic Roofs | 28.02% |
| Residential - Other Roofs | 11.97% |
| Impervious Surface | 5.67% |
Source:[2]
Table 4: Land Consumption Per Capita (LCpC) in this compound
| Year | LCpC (m²/inhabitant) |
| 2000 | 190.83 |
| 2006 | 181.00 |
| 2007 | 184.67 |
| 2019 | 242.11 |
Source:[6]
Visualizations
References
- 1. Urban Land Mapping Based on Remote Sensing Time Series in the Google Earth Engine Platform: A Case Study of the Teresin… [ouci.dntb.gov.ua]
- 2. mdpi.com [mdpi.com]
- 3. researchgate.net [researchgate.net]
- 4. Linking Urban Sprawl and Surface Urban Heat Island in the this compound–Timon Conurbation Area in Brazil [ideas.repec.org]
- 5. Changes in Land Coverage in this compound, Piauí, Brasil | Sociedade & Natureza [seer.ufu.br]
- 6. Linking Urban Sprawl and Surface Urban Heat Island in the this compound–Timon Conurbation Area in Brazil | MDPI [mdpi.com]
- 7. ISPRS-Archives - URBAN GROWTH MONITORING â REMOTE SENSING METHODS FOR SUSTAINABLE DEVELOPMENT [isprs-archives.copernicus.org]
- 8. [PDF] URBAN GROWTH MONITORING – REMOTE SENSING METHODS FOR SUSTAINABLE DEVELOPMENT | Semantic Scholar [semanticscholar.org]
- 9. researchgate.net [researchgate.net]
- 10. scielo.br [scielo.br]
- 11. scielo.br [scielo.br]
- 12. Analyzing Land Use/Land Cover Changes Using Remote Sensing and GIS in Rize, North-East Turkey - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols: Spatial Analysis of Disease Distribution in Teresina
These application notes provide a comprehensive overview of the spatial analysis of infectious disease distribution in Teresina, the capital city of Piauí state, Brazil. The protocols are designed for researchers, scientists, and drug development professionals interested in understanding the geographical patterns of diseases such as visceral leishmaniasis, tuberculosis, and arboviruses in an urban setting.
Disease Distribution Overview in this compound
This compound has been the focus of numerous epidemiological studies due to the prevalence of several infectious diseases. Spatial analysis has been a key tool in identifying high-risk areas and understanding the socio-environmental factors that influence disease transmission.
Visceral Leishmaniasis (VL): this compound experienced the first major urban epidemic of VL in Brazil in the early 1980s.[1][2] Studies have consistently shown a heterogeneous spatial distribution of VL within the city, with higher incidence rates in peripheral neighborhoods.[2][3][4] This pattern is associated with factors like recent urbanization, precarious housing, inadequate sanitation, and the presence of vegetation, which provide favorable conditions for the vector, Lutzomyia longipalpis.[1][2][3] Spatial analyses have identified clusters of high VL incidence in the southern, northeastern, and northern regions of the city.[1] A significant spatial correlation has been observed between VL rates and various socioeconomic and demographic indicators.[1]
Tuberculosis (TB): Spatial analysis of tuberculosis in this compound has also revealed a non-uniform distribution. A study conducted between 2005 and 2007 identified three main clusters of high TB case density in the southeast, center-south, and northern zones of the municipality.[5][6] These areas are often characterized by human expansion and occupation.[5]
Arboviruses (Dengue and Chikungunya): Dengue and Chikungunya are also significant public health concerns in this compound. Studies have shown that the distribution of these diseases is concentrated in areas with high population flows.[7][8] The municipality of this compound consistently reports the highest number of cases in the state of Piauí.[7][8]
Quantitative Data Summary
The following tables summarize key quantitative data from studies on disease distribution in this compound.
Table 1: Tuberculosis Incidence and Demographics in this compound (2005-2007)
| Year | Total Cases | Georeferenced Cases (%) | Incidence Rate (per 100,000) |
| 2005 | - | - | 42 |
| 2006 | - | - | - |
| 2007 | - | - | 37 |
| Total | 951 | 875 (92%) | - |
Source: Montechi et al., 2013[5][6]
Table 2: Tuberculosis Incidence by Sex and Age in this compound (2005-2007)
| Demographic Group | Average Incidence Rate (per 100,000) |
| Male | 52.1 |
| Age 50 years and over | 105.81 |
Source: Montechi et al., 2013[5][6]
Table 3: Visceral Leishmaniasis Cases in this compound (1991-2000)
| Period | Total Reported Cases |
| 1991-2000 | 1,818 |
Source: Cerbino Neto et al., 2009[2]
Experimental Protocols
This section details the methodologies for key spatial analysis experiments cited in the research on disease distribution in this compound.
Protocol for Kernel Density Estimation
Objective: To identify high-concentration areas (hotspots) of disease cases. This method was used in the spatial analysis of tuberculosis in this compound.[5]
Materials:
-
Georeferenced case data (latitude and longitude of each case).
-
Geographic Information System (GIS) software (e.g., QGIS, ArcGIS).
-
Digital cartographic map of the study area (this compound).
Procedure:
-
Data Preparation:
-
Collect and organize the disease case data, ensuring each case has accurate geographic coordinates.
-
Import the georeferenced data and the map of this compound into the GIS software.
-
-
Kernel Density Analysis:
-
Select the Kernel Density tool within the GIS software.
-
Define the input point layer (the georeferenced case data).
-
Specify the population field if weighting cases by a certain attribute is desired (optional).
-
Set the search radius (bandwidth). This parameter significantly influences the smoothness of the resulting surface and should be chosen based on the study's scale and the characteristics of the data.
-
Define the output cell size for the raster map.
-
Execute the analysis. The software will generate a continuous surface map where the values represent the density of cases per unit area.
-
-
Interpretation:
-
Analyze the resulting map to identify areas with the highest density values, which correspond to disease hotspots.
-
The study on tuberculosis in this compound identified three such hotspots in the southeast, center-south, and northern regions.[5]
-
Protocol for Local Moran's I for Cluster Analysis
Objective: To identify local spatial autocorrelation and detect clusters of high or low disease incidence rates. This method was applied in the study of visceral leishmaniasis in this compound.[2]
Materials:
-
Disease incidence rates aggregated by geographic units (e.g., census tracts, neighborhoods).
-
GIS software or statistical software with spatial analysis capabilities (e.g., GeoDa, R with spdep package).
-
A spatial weights matrix that defines the neighborhood relationships between the geographic units.
Procedure:
-
Data and Weights Matrix Preparation:
-
Calculate the disease incidence rates for each geographic unit.
-
Create a spatial weights matrix to define how the spatial relationships between the units are quantified (e.g., based on contiguity or distance).
-
-
Moran's I Calculation:
-
In the chosen software, select the Local Moran's I statistic.
-
Input the variable of interest (disease incidence rates).
-
Specify the pre-defined spatial weights matrix.
-
The analysis will compute a Moran's I value, a Z-score, and a p-value for each geographic unit.
-
-
Cluster Mapping and Interpretation:
-
Generate a map to visualize the results, typically showing four types of spatial clusters:
-
High-High: High-incidence areas surrounded by other high-incidence areas (hotspots).
-
Low-Low: Low-incidence areas surrounded by other low-incidence areas (coldspots).
-
High-Low: High-incidence areas surrounded by low-incidence areas (spatial outliers).
-
Low-High: Low-incidence areas surrounded by high-incidence areas (spatial outliers).
-
-
The study on VL in this compound found a significant positive spatial autocorrelation (Moran's I = 0.292, p < 0.001), indicating clustering of high incidence rates.[2]
-
Protocol for Empirical Bayesian Modeling
Objective: To stabilize variance in rate estimates for small areas and reduce the instability of rates that can arise from small populations. This method is useful for creating smoother and more reliable risk maps.
Materials:
-
Disease case counts and population data for each geographic unit.
-
Statistical software with capabilities for Bayesian analysis (e.g., R with INLA or CARBayes packages, WinBUGS).
-
A spatial weights matrix.
Procedure:
-
Model Specification:
-
Define a statistical model for the disease counts, typically a Poisson or Negative Binomial distribution.
-
The model will relate the observed number of cases in an area to the expected number, which is based on the area's population size and the overall disease rate.
-
Incorporate a spatial random effect to account for spatial autocorrelation, where the rate in one area is influenced by the rates in neighboring areas.
-
-
Bayesian Inference:
-
Use Bayesian statistical methods (e.g., Markov Chain Monte Carlo - MCMC) to estimate the parameters of the model, including the smoothed disease rates for each area.
-
-
Risk Mapping and Interpretation:
-
Map the smoothed rates to visualize the spatial patterns of disease risk. These maps provide a more stable representation of the underlying risk than maps of raw incidence rates, especially in areas with small populations.
-
Visualizations
Experimental Workflows
Caption: Workflow for Kernel Density Estimation to identify disease hotspots.
Caption: Workflow for Local Moran's I to detect spatial clusters of disease.
Logical Relationships
Caption: Factors influencing the spatial distribution of Visceral Leishmaniasis in this compound.
References
- 1. Identification of Risk Areas for Visceral Leishmaniasis in this compound, Piaui State, Brazil - PMC [pmc.ncbi.nlm.nih.gov]
- 2. scielosp.org [scielosp.org]
- 3. Factors associated with the incidence of urban visceral leishmaniasis: an ecological study in this compound, Piauí State, Brazil - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. scielo.br [scielo.br]
- 5. scielo.iec.gov.br [scielo.iec.gov.br]
- 6. Distribuição espacial da tuberculose em this compound, Piauí, de 2005 a 2007 [scielo.iec.gov.br]
- 7. revistamundodasaude.emnuvens.com.br [revistamundodasaude.emnuvens.com.br]
- 8. researchgate.net [researchgate.net]
Methodology for Assessing Climate Resilience in Teresina: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
This document provides a detailed methodology for assessing climate resilience in Teresina, Brazil. The protocols outlined below are designed to guide researchers and scientists in conducting a comprehensive evaluation of the city's ability to withstand and adapt to the impacts of climate change. The methodology integrates established frameworks, such as the UN-Habitat City Resilience Profiling Tool (CRPT), with the specific climate challenges and socio-economic context of this compound.[1][2][3]
Introduction to this compound's Climate Vulnerability
This compound, the capital of the state of Piauí, is situated in a region of Brazil that is highly susceptible to the effects of climate change.[4] The city is recognized as one of the fastest-warming urban centers in the world, with an average temperature increase of 2°C over the last century, a rate double the global average.[1][3] This warming trend is projected to continue, leading to more frequent and intense heatwaves.[4]
In addition to extreme heat, this compound faces significant risks from flooding, particularly during the rainy season from January to May.[5] The city's rapid and often unplanned urbanization has led to the occupation of high-risk areas, exacerbating the impacts of floods and landslides.[5][6] These climate hazards are compounded by underlying socio-economic vulnerabilities, including a significant portion of the population living in poverty and informal settlements with inadequate infrastructure.[4]
Recognizing these challenges, this compound has embarked on a journey to build its climate resilience, including the development of a Climate Action Plan and a comprehensive urban resilience assessment using the UN-Habitat City Resilience Profiling Tool.[2][6][7][8][9][10] This methodology is informed by these initiatives and provides a structured approach for ongoing and future resilience assessments.
Overall Assessment Workflow
The assessment of climate resilience in this compound follows a multi-stage process, beginning with the definition of the scope and objectives and culminating in the development of a resilience action plan. The workflow is designed to be participatory, involving a wide range of stakeholders from government, civil society, the private sector, and academia.
Caption: Overall workflow for the climate resilience assessment in this compound.
Experimental Protocols
Protocol 1: Stakeholder Engagement and Governance
Objective: To establish a participatory and inclusive process for the climate resilience assessment.
Materials:
-
Stakeholder mapping tools (e.g., interest-influence matrix)
-
Workshop facilitation materials
-
Communication and outreach materials
Procedure:
-
Stakeholder Mapping: Identify key stakeholders from municipal secretariats, civil society organizations, community groups (particularly from vulnerable neighborhoods), academic institutions, and the private sector.
-
Establish a Resilience Commission: Form a multi-stakeholder "this compound Resilience Commission" to oversee the assessment process, provide strategic guidance, and ensure the integration of findings into municipal planning.[3]
-
Conduct Inception Workshop: Organize a workshop with all identified stakeholders to:
-
Present the objectives and methodology of the resilience assessment.
-
Gather initial input on key climate concerns and priorities.
-
Establish working groups for different thematic areas (e.g., water management, public health, infrastructure).
-
-
Develop a Communication Plan: Create and implement a plan to keep all stakeholders informed and engaged throughout the assessment process.
Protocol 2: Climate Hazard, Exposure, and Vulnerability Assessment
Objective: To identify and characterize the key climate hazards facing this compound and assess the exposure and vulnerability of the city's population, assets, and systems.
Materials:
-
Historical climate data (temperature, precipitation, etc.)
-
Climate projection models
-
Geographic Information System (GIS) software
-
Socio-economic data from the Brazilian Institute of Geography and Statistics (IBGE)
-
City-level data on infrastructure, land use, and critical facilities.
Procedure:
-
Hazard Identification: Based on historical data and climate projections, identify the primary climate hazards for this compound (e.g., extreme heat, intense rainfall, flooding, landslides).
-
Exposure Mapping: Use GIS to map the spatial distribution of the population, critical infrastructure (hospitals, schools, power stations, etc.), and key economic assets in relation to the identified hazard zones.
-
Vulnerability Analysis: Assess the socio-economic vulnerability of different population groups and neighborhoods. This should include an analysis of factors such as income levels, housing conditions, access to basic services, and education.[4]
-
Risk Assessment: Combine the hazard, exposure, and vulnerability analyses to identify the areas and populations at the highest risk from climate change impacts.
Protocol 3: Urban Systems and Indicator Analysis
Objective: To assess the resilience of key urban systems in this compound using a set of quantitative and qualitative indicators.
Materials:
-
UN-Habitat's City Resilience Profiling Tool (CRPT) framework.[2]
-
A predefined list of resilience indicators.
-
Data collection templates and survey instruments.
Procedure:
-
Define Urban Systems: Based on the CRPT framework and local context, define the key urban systems to be assessed. For this compound, these should include, at a minimum:
-
Water Cycle Management
-
Ecosystem Balance
-
Economic Performance
-
Public Health
-
Infrastructure and Basic Services
-
Governance and Institutional Capacity
-
-
Indicator Selection: Select a comprehensive set of indicators to assess the resilience of each urban system. The selection should be guided by the 247 indicators previously used in this compound's resilience assessment, where available, and supplemented with other relevant indicators from established frameworks.[6] (See Table 2 for a sample of relevant indicators).
-
Data Collection: Gather data for the selected indicators from a variety of sources, including municipal departments, national statistics, remote sensing, and stakeholder workshops.
-
Resilience Profiling: Analyze the collected data to create a resilience profile for each urban system, identifying strengths, weaknesses, and interdependencies.
Data Presentation
Quantitative Data for this compound
| Parameter | Value | Source |
| Population (2019) | 864,845 | [6] |
| Urban Area | 263.94 km² | [6] |
| Temperature Increase (last century) | 2°C | [1] |
| Urban Footprint in Hazardous Areas | 7.8% | [6] |
| Loss of Tree Cover (2001-2019) | ~40% | [3] |
| Number of Fires (Oct 2019 - Oct 2020) | 385 | [6] |
Sample Climate Resilience Indicators for this compound
| Urban System | Indicator Category | Indicator |
| Water Cycle Management | Infrastructure | Percentage of the population with access to safely managed drinking water |
| Percentage of the population served by a wastewater collection network | ||
| Percentage of the city covered by a stormwater drainage system | ||
| Governance | Existence of an integrated water resource management plan | |
| Ecosystem Balance | Green Infrastructure | Percentage of urban area covered by green spaces |
| Urban green area per capita | ||
| Biodiversity | Trends in key local species populations | |
| Environmental Quality | Air and water quality indices | |
| Public Health | Health System Capacity | Number of hospital beds per 1,000 people |
| Existence of an early warning system for climate-related health risks (e.g., heatwaves, vector-borne diseases) | ||
| Vulnerable Populations | Percentage of the population with pre-existing health conditions sensitive to climate change | |
| Socio-Economic | Livelihood Diversity | Diversity of the local economy (e.g., Gini coefficient of economic activity) |
| Social Cohesion | Level of community engagement in local decision-making processes | |
| Social Protection | Coverage of social safety net programs |
Mandatory Visualization
Signaling Pathway: Climate Hazard to Impact
The following diagram illustrates the causal chain from a climate hazard (intense rainfall) to a series of cascading impacts on this compound's urban systems.
Caption: Causal chain of flooding impacts in this compound.
Logical Relationship: Components of Climate Resilience
This diagram illustrates the core components of climate resilience and their interrelationships, forming the conceptual basis for the assessment.
Caption: Interconnected components of urban climate resilience.
References
- 1. UN-Habitat promotes urban resilience projects to support sustainability | UN-Habitat [unhabitat.org]
- 2. urbanresiliencehub.org [urbanresiliencehub.org]
- 3. urbanresiliencehub.org [urbanresiliencehub.org]
- 4. urbancoalitions.org [urbancoalitions.org]
- 5. repositorio.unesp.br [repositorio.unesp.br]
- 6. urbanresiliencehub.org [urbanresiliencehub.org]
- 7. How this compound is Accelerating its Transition to a Green and Resilient City | UrbanShift [shiftcities.org]
- 8. politicadinamica.com [politicadinamica.com]
- 9. crea-pi.org.br [crea-pi.org.br]
- 10. Prefeitura de this compound lança plano de ação para conter efeitos das mudanças climáticas | G1 [g1.globo.com]
Application of Water Quality Modeling in the Poti River, Teresina: A Methodological Guide
Authored for: Researchers, scientists, and environmental professionals.
Introduction
The Poti River, a significant tributary of the Parnaíba River, faces considerable environmental pressure as it flows through Teresina, the capital of Piauí, Brazil.[1][2] Uncontrolled urban expansion and the discharge of untreated sewage have led to a decline in water quality, impacting the aquatic ecosystem and limiting the river's uses.[1][2] This document provides detailed application notes and protocols for water quality modeling of the Poti River, based on the pioneering study by Oliveira Filho and Lima Neto, which utilized the QUAL-UFMG model.[1][2] The aim is to offer a comprehensive guide for researchers and professionals seeking to replicate, adapt, or expand upon this modeling work to support water resource management in the region.
The primary focus of the initial modeling efforts was a 36.8 km stretch of the Poti River within the urban area of this compound.[1][2] The QUAL-UFMG model was employed to simulate the behavior of key water quality parameters: Dissolved Oxygen (DO), Biochemical Oxygen Demand (BOD), and thermotolerant coliforms.[1][2] This choice of model and parameters allows for a robust assessment of the river's self-purification capacity and the impact of pollution loads.
Data Presentation
The following tables summarize the quantitative data collected in the foundational study by Oliveira Filho and Lima Neto in April 2014, which serves as the basis for the modeling protocols described herein.
Table 1: Characteristics of Monitored Sewage Discharge Points along the Poti River in this compound.
| Point ID | Description | Flow (m³/s) | BOD₅ (mg/L) | Thermotolerant Coliforms (MPN/100mL) |
| PE01 | Stormwater Gallery - Poti Velho | 0.04 | 120 | 2.00E+07 |
| PE02 | Stormwater Gallery - Mafuá | 0.03 | 110 | 1.80E+07 |
| PE03 | Stormwater Gallery - Centro | 0.05 | 150 | 2.50E+07 |
| PE04 | Stormwater Gallery - Ilhotas | 0.06 | 180 | 3.00E+07 |
| PE05 | Stormwater Gallery - São João | 0.04 | 130 | 2.20E+07 |
| PE06 | Stormwater Gallery - Jockey | 0.07 | 200 | 3.50E+07 |
| PE07 | Stormwater Gallery - Fátima | 0.05 | 160 | 2.80E+07 |
| PE08 | Stormwater Gallery - Ininga | 0.08 | 220 | 4.00E+07 |
| PE09 | Stormwater Gallery - Morada do Sol | 0.04 | 140 | 2.40E+07 |
| PE10 | Stormwater Gallery - Planalto | 0.06 | 170 | 2.90E+07 |
| PE11 | ETE-LESTE Effluent | 0.20 | 60 | 1.00E+06 |
| PE12 | Stormwater Gallery - Extrema | 0.03 | 100 | 1.50E+07 |
| PE13 | Stormwater Gallery - Angelim | 0.05 | 140 | 2.30E+07 |
Source: Adapted from Oliveira Filho & Lima Neto (2018)
Table 2: Water Quality Data from Monitoring Points along the Poti River in this compound.
| Point ID | Distance from start (km) | DO (mg/L) | BOD₅ (mg/L) | Thermotolerant Coliforms (MPN/100mL) |
| PR0 | 0.0 | 6.5 | 2.0 | 800 |
| PR1 | 9.2 | 5.8 | 3.5 | 5000 |
| PR2 | 18.4 | 5.2 | 4.8 | 12000 |
| PR3 | 27.6 | 4.5 | 6.2 | 25000 |
| PR4 | 36.8 | 4.0 | 7.5 | 40000 |
Source: Adapted from Oliveira Filho & Lima Neto (2018)
Table 3: Calibrated Coefficients for the QUAL-UFMG Model for the Poti River.
| Coefficient | Description | Value |
| Kd (d⁻¹) | Deoxygenation coefficient | 0.35 |
| Ka (d⁻¹) | Reaeration coefficient | 2.50 |
| Kb (d⁻¹) | Bacterial decay coefficient | 0.50 |
Source: Adapted from Oliveira Filho & Lima Neto (2018)[1]
Experimental Protocols
The following protocols are based on the methodologies employed in the Poti River water quality modeling study and are supplemented with standard analytical procedures.
Field Sampling Protocol
Objective: To collect representative water samples from the Poti River and sewage discharge points for physicochemical and bacteriological analysis.
Materials:
-
GPS device for recording coordinates of sampling points.
-
Calibrated portable multi-parameter probe for in-situ measurement of Dissolved Oxygen (DO), pH, and temperature.
-
Sterilized sample bottles for collecting water for bacteriological analysis (thermotolerant coliforms).
-
Amber glass bottles for collecting water for Biochemical Oxygen Demand (BOD) analysis.
-
Cooler with ice packs for sample preservation during transport.
-
Field data sheets for recording observations and in-situ measurements.
Procedure:
-
Sampling Point Location: Navigate to the pre-defined monitoring points (as listed in Tables 1 and 2) using a GPS device.
-
In-situ Measurements: At each river monitoring point (PR0-PR4), measure and record DO, pH, and water temperature using a calibrated portable multi-parameter probe.
-
Sample Collection (River):
-
Rinse the sample bottles three times with the river water to be sampled.
-
Collect water samples from the center of the river channel at a depth of approximately 20-30 cm below the surface.
-
For bacteriological analysis, use sterilized bottles and leave a small air gap to facilitate mixing before analysis.
-
For BOD analysis, completely fill the amber glass bottles to prevent the inclusion of air bubbles.
-
-
Sample Collection (Sewage Discharge Points):
-
Carefully collect samples directly from the discharge flow of the stormwater galleries (PE01-PE13).
-
Follow the same bottle rinsing and filling procedures as for the river samples.
-
-
Sample Preservation and Transport:
-
Label all sample bottles clearly with the point ID, date, and time of collection.
-
Place all collected samples in a cooler with ice packs immediately after collection to maintain a temperature of approximately 4°C.
-
Transport the samples to the laboratory for analysis within 6 hours of collection.
-
Laboratory Analysis Protocols
a) Biochemical Oxygen Demand (BOD₅)
Objective: To determine the amount of dissolved oxygen consumed by aerobic biological organisms in a water sample over a 5-day period.
Method: Dilution Method (APHA 5210 B)
Procedure:
-
Sample Preparation: Homogenize the water sample. If necessary, prepare dilutions of the sample using specially prepared dilution water.
-
Initial DO Measurement: Measure the initial dissolved oxygen concentration of the sample (or its dilution) using a calibrated DO meter.
-
Incubation: Fill two BOD bottles with the sample (or dilution). Seal the bottles, ensuring no air bubbles are trapped. Place one bottle for immediate analysis of initial DO and incubate the other in the dark at 20°C for 5 days.
-
Final DO Measurement: After 5 days, measure the final dissolved oxygen concentration in the incubated bottle.
-
Calculation: Calculate the BOD₅ as the difference between the initial and final DO concentrations, adjusted for the dilution factor.
b) Thermotolerant (Fecal) Coliforms
Objective: To enumerate thermotolerant coliform bacteria, which are indicators of fecal contamination.
Method: Multiple-Tube Fermentation Technique (APHA 9221 E)
Procedure:
-
Presumptive Test: Inoculate a series of fermentation tubes containing lauryl tryptose broth with appropriate decimal dilutions of the water sample. Incubate at 35 ± 0.5°C for 24-48 hours. The formation of gas in any of the tubes constitutes a positive presumptive test.
-
Confirmed Test: Transfer a loopful of culture from each positive presumptive tube to a tube of brilliant green lactose (B1674315) bile broth. Incubate at 44.5 ± 0.2°C for 24 ± 2 hours. Gas formation in this broth confirms the presence of thermotolerant coliforms.
-
Calculation: Determine the Most Probable Number (MPN) of thermotolerant coliforms per 100 mL of the sample by referring to MPN statistical tables, based on the number of positive confirmed test tubes in each dilution.
Water Quality Modeling Protocol (QUAL-UFMG)
Objective: To simulate the spatial variation of DO, BOD, and thermotolerant coliforms along the studied stretch of the Poti River using the QUAL-UFMG model.
Software: QUAL-UFMG (a spreadsheet-based model)
Methodology:
-
Model Setup:
-
River Segmentation: Divide the 36.8 km river stretch into smaller, uniform reaches.
-
Input Data: Enter the physical characteristics of the river, such as the length of each reach, and the initial conditions at the start of the modeled section (Point PR0), including flow rate, temperature, DO, BOD, and thermotolerant coliform concentrations (from Table 2).
-
-
Pollution Load Input:
-
For each reach that receives a discharge, input the location, flow rate, and pollutant concentrations (BOD and thermotolerant coliforms) from the corresponding sewage discharge point (from Table 1).
-
-
Model Calibration:
-
Coefficient Adjustment: Adjust the model's kinetic coefficients (Kd, Ka, and Kb) to minimize the difference between the model's output and the observed field data from the river monitoring points (PR1-PR4). The calibrated coefficients for the Poti River study are provided in Table 3.
-
Goodness-of-Fit: Evaluate the model's performance using statistical indicators such as the mean deviation and the Nash-Sutcliffe efficiency coefficient. The original study achieved mean deviations of up to 20% and Nash-Sutcliffe coefficients higher than 0.75, indicating a good fit.[1]
-
-
Scenario Simulation:
-
Once calibrated, use the model to simulate different scenarios. For example, the original study simulated scenarios for minimum (Q₉₀) and maximum (Q₁₀) flow conditions to assess the river's water quality under different hydrological regimes.
-
Other potential scenarios could include the implementation of new wastewater treatment plants, changes in land use, or the effects of climate change on river flow.
-
Visualization of Workflows and Relationships
Experimental and Modeling Workflow
Caption: Workflow for water quality assessment and modeling of the Poti River.
Conceptual Model of Poti River Water Quality Dynamics
Caption: Key factors influencing Poti River water quality and the role of modeling.
References
Application Notes and Protocols for Qualitative Research on Social Dynamics in Teresina
These application notes provide a comprehensive guide for researchers, scientists, and drug development professionals interested in conducting qualitative research to understand the complex social dynamics within Teresina, the capital city of Piauí, Brazil. The protocols outlined below are designed to be adaptable to various research questions related to community structure, social cohesion, inequality, and the lived experiences of this compound's residents.
Introduction to Social Dynamics in this compound
This compound, a major city in northeastern Brazil, presents a unique urban environment shaped by rapid growth, urban planning initiatives, and persistent social inequalities.[1] Understanding the social dynamics of this city is crucial for effective public policy, community development, and targeted health interventions. Key aspects of this compound's social landscape include the role of public spaces in fostering social interaction, the challenges faced by residents in peripheral housing complexes, and the influence of cultural movements, particularly among the youth.[2][3][4]
Quantitative Data Overview
While qualitative methods are central to this guide, a review of quantitative indicators provides essential context for research design and interpretation. The following tables summarize key demographic, social, and economic data for this compound.
Table 1: Key Demographics and Social Indicators for this compound
| Indicator | Value | Year | Source |
| Population | 866,300 | 2022 | --INVALID-LINK--[4] |
| Demographic Density | 622.66 inhabitants/km² | 2022 | --INVALID-LINK--[4] |
| Schooling Rate (6-14 years) | 98.8% | 2010 | --INVALID-LINK--[4] |
| Municipal Human Development Index (MHDI) | 0.751 (High) | 2010 | --INVALID-LINK--[4][5] |
| Infant Mortality Rate | 14.71 per 1,000 live births | 2020 | --INVALID-LINK--[4] |
| GDP per capita | R$ 27,430.28 | 2021 | --INVALID-LINK--[4] |
Table 2: Crime and Safety Perceptions in this compound
| Indicator | Level (0-100) | Perception | Year | Source |
| Level of crime | 92.65 | Very High | 2024 | --INVALID-LINK--[6] |
| Crime increasing in the past 3 years | 88.24 | Very High | 2024 | --INVALID-LINK--[6] |
| Worries home broken into and things stolen | 70.59 | High | 2024 | --INVALID-LINK--[6] |
| Worries being mugged or robbed | 92.65 | Very High | 2024 | --INVALID-LINK--[6] |
Qualitative Research Protocols
The following protocols outline three key qualitative methods for studying social dynamics in this compound: Urban Ethnography, In-depth Interviews, and Focus Groups.
Protocol 1: Urban Ethnography in this compound's Neighborhoods
Objective: To gain a deep, immersive understanding of the social interactions, cultural norms, and daily life within specific neighborhoods of this compound, with a focus on public spaces and community hubs.
Methodology:
-
Site Selection:
-
Choose two to three neighborhoods that represent a cross-section of this compound's social landscape. For example, a more established central neighborhood, a peripheral social housing complex like Residencial Edgar Gayoso, and a neighborhood with a strong community organization.[7]
-
Conduct initial reconnaissance of the selected sites to identify key public spaces (plazas, parks, markets), community centers, and gathering spots.[5]
-
-
Gaining Access and Building Rapport:
-
Establish contact with community leaders, local associations (e.g., residents' associations), and gatekeepers.
-
Be transparent about the research objectives and ensure ethical guidelines are followed, including obtaining informed consent.
-
Spend significant time in the chosen locations, initially engaging in passive observation and gradually moving towards more active participation in community life.
-
-
Data Collection:
-
Participant Observation: Actively participate in and observe daily routines, social events, and community meetings. Take detailed field notes on interactions, behaviors, and the physical environment.
-
Informal Interviews: Engage in casual conversations with residents to understand their perspectives on their neighborhood, social relationships, and local issues.
-
Mapping: Create social maps of the neighborhoods, identifying key locations and patterns of social interaction.
-
-
Data Analysis:
-
Transcribe field notes and informal interview recordings.
-
Use thematic analysis to identify recurring patterns, themes, and narratives related to social dynamics.
-
Pay close attention to the use of space, social networks, and expressions of community identity.
-
Ethical Considerations:
-
Anonymity and confidentiality of participants must be strictly maintained.
-
Researchers should be mindful of their positionality and potential impact on the community.
-
Informed consent should be an ongoing process, not a one-time event.
Protocol 2: In-depth Interviews with this compound Residents
Objective: To explore individual experiences, perspectives, and narratives related to social dynamics in this compound, focusing on topics such as social mobility, inequality, and belonging.
Methodology:
-
Participant Recruitment:
-
Employ purposive sampling to recruit a diverse range of participants based on age, gender, socioeconomic status, and neighborhood of residence.
-
Utilize community networks and local organizations for recruitment, ensuring a representative sample. Consider recruiting participants from areas with known social challenges, such as the Lagoas do Norte region.[8]
-
-
Interview Guide Development:
-
Develop a semi-structured interview guide with open-ended questions.
-
Topics may include:
-
Personal history and connection to this compound.
-
Perceptions of their neighborhood and the city.
-
Experiences with social inclusion and exclusion.
-
Social networks and community involvement.
-
Aspirations and challenges for the future.
-
-
-
Data Collection:
-
Conduct interviews in a private, comfortable setting chosen by the participant.
-
Obtain informed consent and permission to audio-record the interviews.
-
Use active listening and probing questions to encourage detailed narratives.
-
-
Data Analysis:
-
Transcribe the audio recordings verbatim.
-
Employ narrative analysis or interpretative phenomenological analysis (IPA) to understand the lived experiences and meanings participants attribute to their social world.
-
Identify key themes and patterns across the interviews.
-
Ethical Considerations:
-
Ensure participants understand their right to withdraw from the study at any time.
-
Be sensitive to potentially emotional or difficult topics.
-
Provide participants with information about support services if needed.
Protocol 3: Focus Groups on Community Issues in this compound
Objective: To facilitate group discussions to understand shared perspectives, social norms, and collective experiences related to specific social issues in this compound, such as youth engagement, public safety, or access to services.
Methodology:
-
Participant Recruitment:
-
Recruit 6-8 participants per focus group who share a common characteristic relevant to the research topic (e.g., young people involved in the hip-hop scene, members of a specific community association).[4]
-
Ensure a diverse range of opinions within each group.
-
-
Focus Group Moderation:
-
Develop a clear and concise moderator's guide with a set of key questions and prompts.
-
The moderator should facilitate a dynamic and inclusive discussion, ensuring all participants have an opportunity to share their views.
-
An assistant moderator should take detailed notes on non-verbal cues and group dynamics.
-
-
Data Collection:
-
Conduct focus groups in a neutral and accessible location.
-
Obtain informed consent from all participants and permission to audio/video record the session.
-
Encourage interaction and debate among participants to explore areas of consensus and disagreement.
-
-
Data Analysis:
-
Transcribe the recordings.
-
Analyze the data using discourse analysis or content analysis to identify dominant themes, shared narratives, and points of contention.
-
Pay attention to the language used and the ways in which participants construct their social realities.
-
Ethical Considerations:
-
Establish clear ground rules for respectful interaction at the beginning of the session.
-
Remind participants of the importance of confidentiality within the group.
-
The moderator should be skilled in managing group dynamics and potential conflicts.
Visualizations
The following diagrams, created using the DOT language, illustrate the proposed research workflows and conceptual frameworks.
Figure 1: Qualitative Research Workflow
Figure 2: Interplay of Qualitative Methods
Figure 3: Conceptual Model of Social Dynamics
References
- 1. Local 2030 - Localizing the SDGs [local2030.org]
- 2. macrotrends.net [macrotrends.net]
- 3. This compound (this compound, Piauí, Brazil) - Population Statistics, Charts, Map, Location, Weather and Web Information [citypopulation.de]
- 4. This compound (PI) | Cities and States | IBGE [ibge.gov.br]
- 5. grokipedia.com [grokipedia.com]
- 6. Crime in this compound. Safety in this compound [numbeo.com]
- 7. This compound - Wikipedia [en.wikipedia.org]
- 8. hdr.undp.org [hdr.undp.org]
Application Notes and Protocols for GIS Mapping of Environmental Risk Factors in Teresina
These application notes provide a comprehensive guide for researchers, scientists, and public health professionals on utilizing Geographic Information Systems (GIS) to map and analyze environmental risk factors associated with infectious diseases in Teresina, Brazil. The protocols focus on visceral leishmaniasis (VL), dengue, Zika, and chikungunya, integrating socioeconomic, demographic, and environmental data to identify high-risk areas and inform targeted interventions.
Data Presentation: Quantitative Environmental and Socioeconomic Indicators
The following tables summarize key quantitative data from studies conducted in this compound, providing a basis for comparative analysis of risk factors.
Table 1: Socioeconomic and Demographic Indicators Associated with Visceral Leishmaniasis (VL) Incidence in this compound
| Indicator | Correlation with VL Incidence | Statistical Significance (p-value) | Geographic Areas of High Association | Data Source(s) |
| Literacy Rate | Negative | < 0.01 | Peripheral census tracts with the highest illiteracy rates showed higher VL incidence. | |
| Mean Income | Negative | < 0.01 | Areas with the lowest mean income correlated with the highest VL incidence rates. | |
| Household Head's Years of Schooling | Negative | < 0.01 | Census tracts with fewer years of schooling for household heads had higher VL rates. | |
| Percentage of Households with Piped Water | Inverse | Not specified | Neighborhoods lacking adequate sanitation infrastructure were associated with higher VL incidence. | |
| Population Growth | Positive (in conjunction with vegetation) | Not specified | Areas with high population growth and abundant vegetation showed the highest incidence rates. | |
| Basic Infrastructure Conditions | Negative | < 0.01 | Poorer basic infrastructure was spatially correlated with higher VL rates. |
Table 2: Environmental Indicators Associated with Disease Incidence in this compound
| Indicator | Associated Disease(s) | Nature of Association | Geographic Areas of High Association | Data Source(s) |
| Vegetation Index | Visceral Leishmaniasis | Positive (in conjunction with population growth) | Peripheral neighborhoods with the heaviest vegetation cover. | |
| Proximity to Forest Land and Pastures | Visceral Leishmaniasis | High incidence rates in neighborhoods bordering these areas. | Peripheral neighborhoods. | |
| Inadequate Sanitation (Sewage System) | Visceral Leishmaniasis, Dengue | Positive | Peripheral and central urban areas with poorer urban infrastructure. | |
| Precarious Housing | Visceral Leishmaniasis | Positive | Impoverished areas, often on the urban periphery. |
Table 3: Incidence and Case Numbers for Selected Infectious Diseases in this compound
| Disease | Time Period | Number of Cases | Mean Annual Incidence Rate | Key Findings | Data Source(s) |
| Visceral Leishmaniasis (VL) | 2001-2006 | Not specified | Heterogeneous across the city | Peripheral census tracts in the northern, eastern, and southern regions were most affected. | |
| Visceral Leishmaniasis (VL) | 1991-2000 | 1,744 | Heterogeneous across neighborhoods | Higher rates in peripheral neighborhoods, representing recent expansion areas. | |
| Dengue Fever | 2015-2016 | Not specified | Not specified | Mapping of cases and building infestation by Aedes aegypti larvae was conducted in the eastern part of the city. | |
| Chikungunya | 2015-2019 | 5,106 notified cases (5,873 confirmed) | Not specified | This compound had the highest number of records in the state of Piauí. |
Experimental Protocols
The following protocols outline the methodologies for conducting GIS-based environmental risk factor analysis in this compound. These are synthesized from methodologies reported in studies of the region and general best practices in spatial epidemiology.
Protocol 2.1: Data Acquisition and Preparation
Objective: To collect and prepare spatial and non-spatial data for GIS analysis.
Materials:
-
GIS software (e.g., QGIS, ArcGIS)
-
Spreadsheet software (e.g., Microsoft Excel, Google Sheets)
-
Access to databases from the Brazilian Institute of Geography and Statistics (IBGE), the National Notifiable Diseases Information System (SINAN), and municipal health secretariats.
Procedure:
-
Obtain Cartographic Data: Acquire digital maps of this compound's administrative boundaries, including municipalities, neighborhoods, and census tracts. These can often be obtained from the IBGE.
-
Collect Epidemiological Data: Gather data on disease cases (e.g., visceral leishmaniasis, dengue, Zika, chikungunya) from SINAN. This data should ideally include the date of notification and the patient's address.
-
Gather Socioeconomic and Demographic Data: Collect data on indicators such as income, literacy, housing conditions, and access to sanitation from the IBGE census data for the corresponding geographic units (census tracts or neighborhoods).
-
Acquire Environmental Data: Obtain environmental data layers. This may include satellite imagery to calculate vegetation indices (e.g., NDVI), land use/land cover maps, and data on the location of water bodies and green spaces.
-
Data Geocoding: Convert the addresses of disease cases into geographic coordinates (latitude and longitude). This can be done using geocoding services or by manually locating addresses on a digital map.
-
Database Integration: Create a unified spatial database in your GIS software. Join the epidemiological, socioeconomic, and environmental data to the corresponding cartographic units (e.g., census tracts) based on a common identifier.
Protocol 2.2: Spatial Analysis of Disease Distribution and Clustering
Objective: To identify spatial patterns, clusters (hotspots), and outliers in disease incidence.
Materials:
-
GIS software with spatial statistics tools (e.g., GeoDa, ArcGIS Spatial Analyst, QGIS with plugins)
-
Geocoded disease case data
-
Population data for the study area
Procedure:
-
Kernel Density Estimation (for point data):
-
Use the geocoded case data to create a continuous surface map showing the density of cases across the study area.
-
This method helps to visualize hotspots where cases are concentrated. The bandwidth of the kernel is a critical parameter that influences the smoothness of the resulting surface.
-
-
Choropleth Mapping of Incidence Rates (for areal data):
-
Calculate disease incidence rates for each administrative unit (e.g., neighborhood, census tract) by dividing the number of cases by the population of that unit.
-
Create a choropleth map to visualize the spatial distribution of these rates.
-
-
Global Spatial Autocorrelation (Moran's I):
-
Calculate the global Moran's I statistic to determine if the overall spatial pattern of the disease is clustered, dispersed, or random. A significant positive value indicates clustering of similar values.
-
-
Local Indicators of Spatial Association (LISA):
-
Perform a LISA analysis to identify the location of statistically significant hotspots (High-High clusters), cold spots (Low-Low clusters), and spatial outliers (High-Low or Low-High).
-
This allows for a more detailed understanding of local variations in disease patterns.
-
Protocol 2.3: Environmental Risk Factor Analysis
Objective: To identify environmental and socioeconomic factors associated with high disease incidence.
Materials:
-
GIS software with spatial analysis and regression tools
-
Disease incidence data (areal)
-
Socioeconomic and environmental data layers for the same administrative units
Procedure:
-
Spatial Overlay Analysis: Overlay the disease cluster maps (from Protocol 2.2) with the maps of environmental and socioeconomic variables to visually inspect for correlations.
-
Bivariate Moran's I Analysis: Use bivariate Moran's I to test for spatial correlation between disease incidence in a given area and the values of a specific risk factor in neighboring areas.
-
Spatial Regression Modeling:
-
Employ spatial regression models (e.g., Spatial Lag Model, Spatial Error Model) to quantify the relationship between disease incidence and multiple potential risk factors, while accounting for spatial autocorrelation.
-
This will help to identify the most significant predictors of disease risk in the study area.
-
Mandatory Visualizations
The following diagrams, created using the DOT language for Graphviz, illustrate key workflows in the GIS mapping of environmental risk factors.
Application Notes and Protocols for Statistical Modeling of Public Health Data in Teresina
These application notes provide researchers, scientists, and drug development professionals with a detailed guide to applying statistical models for the analysis of public health data, with a specific focus on Teresina, the capital city of Piauí, Brazil. The protocols are derived from methodologies employed in epidemiological and public health studies conducted in the region, including the notable "Inquérito de Saúde de Base Populacional em Municípios do Piauí (ISAD-PI)" (Population-Based Health Survey in Municipalities of Piauí).
Application Notes
The public health landscape of this compound, like many urban centers in Brazil, is characterized by a complex interplay of socioeconomic, environmental, and demographic factors influencing disease prevalence and health outcomes. Statistical modeling is a critical tool for understanding these dynamics, identifying at-risk populations, and informing targeted public health interventions.
Commonly applied statistical models in the context of this compound's public health data include:
-
Cross-Sectional Data Analysis: Often utilizing data from health surveys like the ISAD-PI, these models are crucial for estimating the prevalence of health conditions and identifying associated risk factors.
-
Spatial Analysis: Given the geographical variations in disease distribution, spatial models are employed to identify disease clusters and environmental or social determinants of health at the neighborhood or district level. This is particularly relevant for infectious diseases like visceral leishmaniasis, which has been a significant public health concern in this compound.
-
Multilevel Modeling: Recognizing that health outcomes are influenced by factors at multiple levels (individual, household, neighborhood), multilevel models are used to analyze hierarchical data structures, providing a more nuanced understanding of contextual effects on health.
Data Presentation
The following tables are illustrative examples of how quantitative data from public health studies in this compound can be structured. The data is hypothetical and serves to demonstrate the format for presenting descriptive statistics and model outputs.
Table 1: Sociodemographic and Health Characteristics of the Study Population (Illustrative Data)
| Characteristic | Category | N | % |
| Gender | Male | 800 | 40.0 |
| Female | 1200 | 60.0 | |
| Age Group (years) | 20-39 | 700 | 35.0 |
| 40-59 | 800 | 40.0 | |
| 60+ | 500 | 25.0 | |
| Education Level | Elementary School or less | 900 | 45.0 |
| High School | 700 | 35.0 | |
| Higher Education | 400 | 20.0 | |
| Self-reported Health | Good | 1100 | 55.0 |
| Fair | 600 | 30.0 | |
| Poor | 300 | 15.0 | |
| Prevalence of Hypertension | Yes | 500 | 25.0 |
| No | 1500 | 75.0 |
Table 2: Poisson Regression Analysis of Factors Associated with a Hypothetical Health Outcome (Illustrative Data)
| Variable | Category | Crude Prevalence Ratio (95% CI) | Adjusted Prevalence Ratio (95% CI) | p-value |
| Age Group (years) | 20-39 (ref) | 1.00 | 1.00 | |
| 40-59 | 1.5 (1.2 - 1.9) | 1.4 (1.1 - 1.8) | <0.01 | |
| 60+ | 2.5 (2.0 - 3.1) | 2.2 (1.7 - 2.8) | <0.001 | |
| Education Level | Higher Education (ref) | 1.00 | 1.00 | |
| High School | 1.8 (1.4 - 2.3) | 1.6 (1.3 - 2.0) | <0.001 | |
| Elementary School or less | 2.8 (2.2 - 3.6) | 2.4 (1.9 - 3.0) | <0.001 | |
| Nutritional Status | Normal weight (ref) | 1.00 | 1.00 | |
| Overweight/Obese | 1.7 (1.4 - 2.1) | 1.5 (1.2 - 1.9) | <0.01 |
Experimental Protocols
Protocol 1: Cross-Sectional Data Analysis using Poisson Regression
This protocol outlines the steps for analyzing cross-sectional data to estimate prevalence ratios for a given health outcome.
1. Data Source and Study Population:
- Utilize data from a population-based cross-sectional study, such as the ISAD-PI, which includes a representative sample of the urban population of this compound.[1][2][3]
- Define the study population based on the research question (e.g., adults aged 20 and over).
2. Data Collection and Variables:
- Data is typically collected through structured questionnaires covering:
- Sociodemographic information: age, gender, education, income, marital status.
- Lifestyle factors: smoking, alcohol consumption, physical activity.
- Health conditions: self-reported chronic diseases, anthropometric measurements (weight, height), and biochemical data from blood samples.[3]
- The outcome variable should be a binary health indicator (e.g., presence/absence of a disease).
- Explanatory variables will be the potential risk factors.
3. Statistical Analysis:
- Descriptive Statistics: Calculate frequencies and percentages for categorical variables and means and standard deviations for continuous variables to describe the study population.
- Bivariate Analysis: Use chi-square tests to assess the association between categorical explanatory variables and the outcome.
- Multivariable Analysis:
- Employ Poisson regression with robust variance to estimate prevalence ratios (PR) and their 95% confidence intervals (CI).[2] This model is often preferred over logistic regression when the outcome is not rare (prevalence > 10%).
- Develop a hierarchical model, entering variables in blocks (e.g., sociodemographic, lifestyle, clinical) to assess confounding.
- Variables with a p-value < 0.20 in the bivariate analysis are often included in the initial multivariable model.
- The final model should include variables that remain statistically significant (p < 0.05) after adjusting for confounders.
- Software: Statistical analyses can be performed using software such as Stata, R, or SPSS.
Protocol 2: Multilevel Modeling for Hierarchical Data
This protocol is designed for analyzing data with a hierarchical structure, such as individuals nested within households, which are in turn nested within census tracts.
1. Data Structure and Levels:
- Define the levels of the hierarchy. For example:
- Level 1: Individuals
- Level 2: Census Tracts or Neighborhoods[4][5]
- Individual-level data would include sociodemographic and health information.
- Census-tract-level data could include socioeconomic indicators (e.g., average income, literacy rate) and environmental characteristics.[4][5]
2. Model Specification:
- Null Model (Random Intercepts Model): Start with a model with no explanatory variables to decompose the total variance of the outcome into its within-group and between-group components. This allows for the calculation of the Intraclass Correlation Coefficient (ICC).
- Random Intercepts Model with Explanatory Variables: Add individual-level (Level 1) and group-level (Level 2) explanatory variables to the model. This allows for the examination of the effect of these variables on the outcome while accounting for the hierarchical data structure.
- Random Slopes Model: If there is a hypothesis that the effect of an individual-level variable varies across groups, a random slopes model can be fitted.
3. Statistical Analysis:
- Use specialized software for multilevel modeling such as MLwiN, HLM, or the lme4 package in R.
- The analysis will yield fixed effects (regression coefficients for the explanatory variables) and random effects (variance components at each level).
- Interpret the results by considering both the individual-level predictors and the contextual effects of the higher-level units.
Mandatory Visualization
Below are Graphviz diagrams illustrating key workflows and concepts in the statistical analysis of public health data from this compound.
Caption: Workflow for Public Health Data Analysis in this compound.
Caption: Conceptual Diagram of a Multilevel Model for Health Outcomes.
Caption: Logical Flow from Risk Factor Identification to Intervention.
References
- 1. mdpi.com [mdpi.com]
- 2. scielo.br [scielo.br]
- 3. Consumption of ultra-processed products is associated with vitamin D deficiency in Brazilian adults and elderly | British Journal of Nutrition | Cambridge Core [cambridge.org]
- 4. researchgate.net [researchgate.net]
- 5. Multilevel modelling of the incidence of visceral leishmaniasis in this compound, Brazil - PubMed [pubmed.ncbi.nlm.nih.gov]
Application Notes and Protocols for Measuring Air Pollution in Urban Teresina
Audience: Researchers, scientists, and drug development professionals.
Objective: This document provides detailed methodologies for measuring key air pollutants in an urban environment like Teresina, Brazil. It covers reference methods, passive sampling techniques, and the use of low-cost sensors for pollutants including particulate matter (PM₂.₅, PM₁₀), nitrogen dioxide (NO₂), sulfur dioxide (SO₂), and ozone (O₃).
Overview of Urban Air Pollutants and Measurement Techniques
Urban air pollution in cities like this compound is a complex mixture of particulate and gaseous contaminants originating from sources such as vehicular traffic, industrial activities, and biomass burning.[1][2] The primary pollutants of concern that are monitored to assess air quality include particulate matter (PM₂.₅ and PM₁₀), nitrogen dioxide (NO₂), sulfur dioxide (SO₂), carbon monoxide (CO), and ground-level ozone (O₃).[3] A variety of techniques, ranging from regulatory-grade reference methods to more accessible low-cost sensor networks, can be employed to monitor these pollutants. The choice of method depends on the research objectives, required data quality, and available resources.
Data Presentation: Comparison of Measurement Techniques
The following tables summarize the key performance characteristics of different air pollution measurement techniques to aid in the selection of the most appropriate method for a given research application.
Table 1: Particulate Matter (PM₂.₅ & PM₁₀) Measurement Techniques
| Technique | Principle | Typical Application | Detection Limit | Advantages | Disadvantages |
| Gravimetric Method | Manual weighing of collected particles on a pre-weighed filter over a 24-hour period.[1][4] | Reference monitoring for regulatory compliance (NAAQS).[5] | ~1-3 µg/m³ | High accuracy and precision; Considered the "gold standard".[6] | Labor-intensive; Not real-time; Susceptible to handling errors.[7] |
| Beta Attenuation Monitor (BAM) | Measures the attenuation of beta radiation as it passes through a filter loaded with PM.[6] | Continuous, real-time monitoring. | ~1 µg/m³ | Provides near real-time data; Automated. | Higher cost than manual methods; Requires calibration. |
| Low-Cost Optical Sensors (e.g., Plantower PMS5003) | Light scattering (nephelometry) to estimate particle number and mass concentration.[8] | High-density spatial and temporal monitoring; Citizen science.[9] | ~1 µg/m³ | Low cost; Provides real-time data; Easy to deploy in networks.[10] | Lower accuracy than reference methods; Requires local calibration; Susceptible to environmental interference (e.g., humidity).[10] |
Table 2: Gaseous Pollutant (NO₂, SO₂, O₃) Measurement Techniques
| Technique | Principle | Typical Application | Detection Limit (30-day exposure) | Advantages | Disadvantages |
| Chemiluminescence (NO₂) / UV Photometry (O₃) / UV Fluorescence (SO₂) Analyzers | Gas-phase chemical reactions that produce light, or absorption of UV light.[11] | Continuous reference monitoring for regulatory compliance. | < 1 ppb | High accuracy and sensitivity; Real-time data. | Expensive; Requires stable power and climate-controlled environment. |
| Passive Diffusive Samplers (e.g., Ogawa, IVL) | Diffusion of ambient gas onto a chemically treated absorbent filter over a set period.[12][13] | Spatial distribution mapping; Long-term exposure assessment; Remote area monitoring.[12] | ~0.01-0.1 ppb[13] | Low cost; No power required; Easy to deploy.[14] | Provides time-weighted average, not real-time data; Lower precision than continuous monitors; Sensitive to meteorological conditions.[13] |
| Low-Cost Electrochemical Sensors | Target gas reacts with an electrode, generating a measurable electrical current. | Indicative monitoring; Personal exposure assessment; Wireless sensor networks. | ~1-10 ppb | Low cost; Portable; Real-time measurements. | Cross-sensitivity to other gases; Sensor drift over time; Requires frequent calibration. |
Experimental Protocols
Protocol 1: Gravimetric Measurement of PM₂.₅ and PM₁₀
This protocol is based on the U.S. EPA Federal Reference Method (FRM) for determining particulate matter concentrations.[5][15]
3.1.1. Principle Air is drawn at a constant flow rate through a specially designed inlet that separates particles based on their aerodynamic diameter (e.g., PM₁₀ or PM₂.₅).[16] The particles are collected on a pre-weighed filter over a 24-hour period. The mass of the collected particles is determined by the difference in the filter's weight before and after sampling.[1]
3.1.2. Materials
-
Low- or high-volume air sampler with a size-selective inlet (PM₂.₅ or PM₁₀).
-
46.2 mm Polytetrafluoroethylene (PTFE) filters.[1]
-
Filter cassettes.
-
Forceps for filter handling.
-
Electronic microbalance (readability of 1 µg).
-
Temperature and humidity-controlled weighing room/chamber (20-23°C ± 2°C; 30-40% RH ± 5%).[4]
-
NIST-traceable calibration weights.[4]
-
Static eliminator.
3.1.3. Procedure
-
Pre-Sampling Filter Conditioning and Weighing:
-
Visually inspect new PTFE filters for defects.
-
Place filters in a conditioning environment for at least 24 hours.[4]
-
Calibrate the microbalance using NIST-traceable weights.
-
Before weighing, pass the filter over a static eliminator.
-
Weigh each filter at least twice, with readings agreeing within a set tolerance (e.g., ±3 µg). Record this as the "pre-sampling weight".[1]
-
Place the weighed filter into a labeled cassette.
-
-
Sample Collection:
-
Transport the filter cassettes to the sampling site, keeping them upright and protected from temperature extremes.
-
Load a cassette into the air sampler.
-
Program the sampler to run for 24 hours at the specified flow rate (e.g., 16.7 L/min for many PM₂.₅ samplers).
-
After 24 hours, retrieve the filter cassette. Store it in a sealed container at <4°C for transport back to the laboratory.[1]
-
-
Post-Sampling Filter Conditioning and Weighing:
-
Allow the exposed filter to equilibrate in the conditioning environment for at least 24 hours.[4]
-
Following the same procedure as pre-sampling (balance calibration, static elimination), weigh the exposed filter multiple times until a stable weight is achieved. Record this as the "post-sampling weight".[1]
-
-
Calculation:
-
Calculate the mass of collected PM: PM Mass (µg) = Post-sampling weight (µg) - Pre-sampling weight (µg).
-
Obtain the total air volume sampled from the sampler's data log, corrected to standard temperature and pressure.
-
Calculate the PM concentration: PM Concentration (µg/m³) = PM Mass (µg) / Total Air Volume (m³).
-
Protocol 2: Passive Sampling for Ambient Nitrogen Dioxide (NO₂) and Ozone (O₃)
This protocol describes a general methodology for using diffusive passive samplers for long-term monitoring.
3.2.1. Principle Passive samplers operate on the principle of molecular diffusion (Fick's First Law).[17] Pollutants in the air diffuse at a known rate onto a sorbent medium (e.g., a chemically coated filter) inside the sampler body. The total mass of the pollutant collected over the exposure period is determined by laboratory analysis, and the time-weighted average concentration is calculated.[12]
3.2.2. Materials
-
Passive samplers for NO₂ (e.g., containing a filter coated with triethanolamine (B1662121) - TEA).[14]
-
Passive samplers for O₃ (e.g., containing a filter coated with sodium nitrite).[18]
-
Protective shelters/housings to shield samplers from rain and direct sun.[13]
-
Mounting hardware (poles, brackets).
-
Field logbook and labels.
-
Clean, powder-free gloves.
-
Cooler with ice packs for transport.
3.2.3. Procedure
-
Site Selection and Sampler Deployment:
-
Select monitoring sites representative of the area of interest (e.g., near roadways, in residential areas, urban background).
-
Mount the protective shelter at a height of 2 to 4 meters above the ground.[13]
-
Wearing clean gloves, unseal the passive sampler and place it securely within the shelter.
-
Record the start date, time, sampler ID, and location in the field logbook.
-
For quality control, deploy a field blank (a sampler that remains capped and is exposed to the same transport and storage conditions) and a duplicate sampler (a second sampler deployed at the same location) for every 10 samples.[13]
-
-
Sample Collection:
-
Leave the samplers deployed for a predetermined period (e.g., 14-30 days).
-
To retrieve the samplers, wear clean gloves, remove the sampler from the shelter, and immediately seal it in its original container.
-
Record the end date and time in the logbook.
-
Place the collected samplers, including the field blank, in a cooler with ice packs and transport them to the analytical laboratory as soon as possible.
-
-
Laboratory Analysis:
-
The sorbent from the sampler is chemically extracted.
-
For NO₂, the resulting nitrite (B80452) is typically analyzed using spectrophotometry (Griess-Saltzman reaction).[17]
-
For O₃, the resulting nitrate (B79036) is analyzed via ion chromatography.[18]
-
The mass of the collected analyte is quantified using a calibration curve.
-
-
Calculation:
-
The laboratory provides the total mass (m) of the pollutant captured.
-
Calculate the time-weighted average concentration (C) using the formula: C = m / (D * t), where D is the sampler's specific diffusion (sampling) rate (provided by the manufacturer, in m³/h) and t is the total exposure time (in hours).
-
Protocol 3: Deployment and Calibration of Low-Cost PM Sensors
3.3.1. Principle Low-cost PM sensors typically use a laser to illuminate a stream of air and a photodiode detector to measure the light scattered by particles. The intensity and pattern of scattered light are used to estimate the number and size of particles, which is then converted to a mass concentration (e.g., PM₂.₅). For accurate data, these sensors require co-location calibration against a reference instrument.[9][10]
3.3.2. Materials
-
Low-cost sensor units (e.g., PurpleAir).
-
Weatherproof housing and power supply.
-
Mounting hardware.
-
Access to a reference-grade air quality monitoring station (for co-location).
-
Data logging and transmission system (e.g., Wi-Fi, cellular).
3.3.3. Procedure
-
Co-location and Calibration:
-
Deploy the low-cost sensor(s) within 1-4 meters of the inlet of a reference-grade PM₂.₅ monitor (e.g., a BAM or FRM gravimetric sampler).[19]
-
Run the low-cost sensor and the reference monitor simultaneously for a period that captures a wide range of environmental conditions and pollutant concentrations (typically several weeks to months).[10]
-
Collect time-matched data (e.g., hourly averages) from both the low-cost sensor(s) and the reference monitor.
-
Develop a calibration model using statistical methods (e.g., multiple linear regression) to relate the raw sensor output to the reference monitor concentrations.[10] Important co-variates to include are relative humidity and temperature, which significantly affect sensor performance.[10]
-
-
Field Deployment:
-
Select deployment sites based on research objectives.
-
Install the calibrated sensor units in their weatherproof housings. Ensure the air inlet is unobstructed.
-
Mount the sensors at a height of 2-4 meters, away from direct sources of dust or smoke that are not representative of the ambient environment.
-
Power the units and ensure they are successfully transmitting data.
-
-
Data Management and Quality Control:
-
Apply the developed calibration model to the raw sensor data in near real-time or during post-processing.
-
Periodically check sensor data for anomalies or drift.
-
If possible, periodically re-locate sensors next to a reference monitor to validate or update the calibration model.[20]
-
Visualization of Experimental Workflows and Signaling Pathways
Experimental Workflows
References
- 1. ww2.arb.ca.gov [ww2.arb.ca.gov]
- 2. Urban particulate matter triggers lung inflammation via the ROS-MAPK-NF-κB signaling pathway - PMC [pmc.ncbi.nlm.nih.gov]
- 3. epa.gov [epa.gov]
- 4. airzoneone.com [airzoneone.com]
- 5. airknowledge.gov [airknowledge.gov]
- 6. How to measure PM2.5: Techniques for accurate monitoring [getambee.com]
- 7. Gravimetric Analysis of Particulate Matter using Air Samplers Housing Internal Filtration Capsules - PMC [pmc.ncbi.nlm.nih.gov]
- 8. upcommons.upc.edu [upcommons.upc.edu]
- 9. Calibrating Low-Cost Air Pollution Sensors Using Machine Learning | Earthlab [earthlab.colorado.edu]
- 10. mdpi.com [mdpi.com]
- 11. Federal Register :: Ambient Air Monitoring Reference and Equivalent Methods; Designation of One New Reference Method [federalregister.gov]
- 12. Determination of nitrogen dioxide, sulfur dioxide, ozone, and ammonia in ambient air using the passive sampling method associated with ion chromatographic and potentiometric analyses - PMC [pmc.ncbi.nlm.nih.gov]
- 13. www2.gov.bc.ca [www2.gov.bc.ca]
- 14. Passive Sampling of Ambient Nitrogen Dioxide Using Local Tubes [scirp.org]
- 15. How are PM10, PM2.5 and UFP particles monitored? Complete guide [envira.global]
- 16. epa.gov [epa.gov]
- 17. merckmillipore.com [merckmillipore.com]
- 18. mdpi.com [mdpi.com]
- 19. Best practices when deploying low-cost air sensors in the urban environment [clarity.io]
- 20. Remote Calibration strategies for Low Cost Air Quality Multisensors: a performance comparison | IEEE Conference Publication | IEEE Xplore [ieeexplore.ieee.org]
Application Notes and Protocols for Biodiversity Assessment Near Teresina
For Immediate Release
Teresina, Piauí, Brazil – These application notes provide detailed protocols for researchers, scientists, and drug development professionals conducting biodiversity assessments in the unique transitional zone of the Caatinga and Cerrado biomes surrounding this compound. The following methodologies are designed to ensure standardized and robust data collection for a comprehensive understanding of the region's rich flora and fauna.
The area around this compound presents a unique ecological context, characterized by the semi-arid Caatinga and the savanna-like Cerrado.[1] This ecotonal region is expected to harbor a distinct and diverse assemblage of species, making it a prime location for bioprospecting and conservation efforts. Standardized survey methods are crucial for generating comparable and reliable biodiversity data that can inform conservation strategies and support sustainable development.[2][3]
Study Design and Site Selection
Prior to fieldwork, a thorough review of existing literature and satellite imagery is essential to identify representative habitats and potential biodiversity hotspots. The study area should encompass the diverse phytophysiognomies of the region, including typical Cerrado grasslands, woodlands ("Cerradão"), and various Caatinga vegetation types.[4][5][6] A stratified random sampling design is recommended to ensure coverage of different environmental gradients.
Logical Workflow for Study Design:
Caption: High-level workflow for a biodiversity assessment project.
Flora Assessment Protocols
The Cerrado biome is a recognized biodiversity hotspot with a vast number of plant species.[5][7] The Caatinga also harbors a unique and adapted flora.[4]
2.1. Plot-Based Surveys
-
Objective: To quantify plant species richness, diversity, and community structure.
-
Methodology:
-
Establish 10m x 50m (500 m²) plots in each selected habitat type.
-
Within each plot, identify and record all woody individuals (trees and shrubs) with a diameter at breast height (DBH) ≥ 5 cm.
-
For herbaceous and sub-shrub species, establish five 1m x 1m subplots within the main plot.
-
Collect voucher specimens for species that cannot be identified in the field for later identification at a herbarium.
-
Record GPS coordinates for each plot.
-
2.2. Data to be Collected (Flora):
| Parameter | Description | Unit |
| Plot ID | Unique identifier for each plot | Alphanumeric |
| Date | Date of survey | YYYY-MM-DD |
| GPS Coordinates | Latitude and Longitude | Decimal Degrees |
| Habitat Type | e.g., Cerrado sensu stricto, Cerradão, Caatinga arbórea | Categorical |
| Species Name | Scientific name | Text |
| DBH | Diameter at Breast Height | cm |
| Height | Total height of the individual | m |
| Abundance | Count of individuals per species in subplots | Integer |
| Voucher Number | Unique identifier for collected specimens | Alphanumeric |
Fauna Assessment Protocols
A combination of methods is necessary to effectively survey the diverse faunal groups present in the region.[8][9]
3.1. Amphibians and Reptiles
The herpetofauna of semi-arid and transitional zones can be highly diverse.[1][10]
-
Pitfall Traps with Drift Fences:
-
Objective: To capture ground-dwelling amphibians and reptiles.
-
Methodology:
-
Construct drift fences (30-50 cm high) in a "Y" or linear array.
-
Place pitfall traps (buckets) at the center and ends of the fences, buried flush with the ground.
-
Check traps daily, in the early morning, to minimize stress and mortality of captured animals.
-
Identify, measure, weigh, and release captured individuals.
-
-
-
Visual Encounter Surveys (VES):
-
Objective: To supplement pitfall trap data and survey arboreal and rock-dwelling species.
-
Methodology:
-
Conduct time-constrained searches (e.g., 1 person-hour) along pre-defined transects during different times of the day and night.
-
Actively search under rocks, logs, and in leaf litter.[10]
-
-
3.2. Birds
The avifauna of northeastern Brazil is rich and includes endemic species.[11][12][13]
-
Point Counts:
-
Objective: To determine the relative abundance and species richness of birds.
-
Methodology:
-
Establish point count stations at least 200 meters apart in each habitat.
-
At each point, an observer records all birds seen and heard within a fixed radius (e.g., 50 meters) for a set duration (e.g., 10 minutes).[14]
-
Conduct surveys during peak activity periods, typically early morning.
-
-
-
Mist Netting:
-
Objective: To capture understory birds for identification and demographic studies.
-
Methodology:
-
Set up mist nets in the understory of forested areas.
-
Check nets frequently (e.g., every 30-60 minutes).
-
Carefully extract, identify, band (if permitted), and release captured birds.
-
-
3.3. Mammals
The Cerrado and Caatinga are home to a diverse mammal fauna, though many species are threatened by habitat loss.[9][15][16]
-
Camera Trapping:
-
Objective: To survey medium to large-sized terrestrial mammals.
-
Methodology:
-
-
Live Trapping (for small mammals):
-
Objective: To assess the diversity and abundance of small rodents and marsupials.
-
Methodology:
-
Set up grids of live traps (e.g., Sherman or Tomahawk traps) baited with a mixture of oats, peanut butter, and banana.
-
Place traps at 10-meter intervals.[18]
-
Check traps daily in the early morning.
-
Identify, mark (e.g., ear tags), and release captured individuals.
-
-
3.4. Insects
Insects are a hyperdiverse group and crucial for ecosystem functioning.[19][20]
-
Pan Traps:
-
Objective: To collect flying insects, particularly pollinators.
-
Methodology:
-
Place yellow, white, and blue bowls filled with soapy water at ground level and in the vegetation canopy.
-
Collect samples every 24-48 hours.
-
-
-
Light Traps:
Workflow for Faunal Survey Methods:
References
- 1. scielo.br [scielo.br]
- 2. s77db5b5399c31d9d.jimcontent.com [s77db5b5399c31d9d.jimcontent.com]
- 3. Retrieving biodiversity data from multiple sources: making secondary data standardised and accessible [bdj.pensoft.net]
- 4. seer.ufu.br [seer.ufu.br]
- 5. taylorfrancis.com [taylorfrancis.com]
- 6. researchgate.net [researchgate.net]
- 7. The Cerrado Biome: A Forgotten Biodiversity Hotspot · Frontiers for Young Minds [kids.frontiersin.org]
- 8. eclass.upatras.gr [eclass.upatras.gr]
- 9. Mammals of medium and large size in Cerrado remnants in southeastern Brazil [neotropical.pensoft.net]
- 10. Amphibian and reptile biodiversity in the semi-arid region of the municipality of Nopala de Villagrán, Hidalgo, Mexico - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. biofaces.com [biofaces.com]
- 13. pibird.com [pibird.com]
- 14. mdpi.com [mdpi.com]
- 15. The mammalian faunas endemic to the Cerrado and the Caatinga [zookeys.pensoft.net]
- 16. researchgate.net [researchgate.net]
- 17. discovery.ucl.ac.uk [discovery.ucl.ac.uk]
- 18. iq.chm-cbd.net [iq.chm-cbd.net]
- 19. Frontiers | Standards and Best Practices for Monitoring and Benchmarking Insects [frontiersin.org]
- 20. researchgate.net [researchgate.net]
- 21. mdpi.com [mdpi.com]
Application Note & Protocol: Economic Modeling of Urban Development in Teresina
Introduction
Teresina, the capital of the state of Piauí, presents a unique case for the study of urban development in Northeast Brazil. As the only non-coastal capital in the region, its growth is shaped by a specific set of economic, social, and environmental factors.[1] The city is currently experiencing rapid urbanization characterized by significant urban sprawl, where the expansion of the urban footprint exceeds population growth.[2][3] This process is influenced by national housing policies, infrastructure investments, and the pressure of the real estate market.[4][5] Key challenges include inadequate public transportation, social segregation with vulnerable populations located in high-risk areas, and environmental degradation, including the loss of green spaces and increased flood risk.[4][6][7][8][9]
Economic modeling provides a powerful quantitative tool to understand these complex dynamics. By simulating the interactions between transportation systems, land use, and economic agents (households, firms), researchers can forecast future development scenarios and evaluate the potential impacts of policy interventions. This document provides an application note on selecting appropriate models and a detailed protocol for implementing an Agent-Based Model (ABM) to study urban development in this compound.
Conceptual Framework of Urban Development in this compound
The urban development of this compound is driven by a set of interconnected factors. Population growth and economic activity create demand for housing and commercial space. This demand is met through land development, which is heavily influenced by public policy, including infrastructure projects (e.g., new roads, BRT systems) and national housing programs.[4][5][10] These drivers collectively shape the city's urban form, leading to outcomes such as peripheral expansion and changes in land value. These physical changes, in turn, have significant socio-economic and environmental consequences, including altered mobility patterns, social segregation, and increased vulnerability to climate change impacts like flooding and extreme heat.[4]
Application Notes: Selecting an Economic Model
Two primary modeling approaches are suitable for analyzing this compound's urban development: Land Use and Transport Interaction (LUTI) models and Agent-Based Models (ABM).
-
3.1 Land Use and Transport Interaction (LUTI) Models: These are aggregate models that simulate the reciprocal relationship between transportation infrastructure and land use patterns. A LUTI model for this compound could effectively forecast how the new BRT system might influence population and employment density across different zones of the city over time.[6][11] They are well-suited for long-term strategic planning at a macro level.
-
3.2 Agent-Based Models (ABM): These are disaggregate, bottom-up models that simulate the actions and interactions of autonomous agents (e.g., individual households, developers). An ABM is particularly powerful for this compound as it can explicitly model the location choices of heterogeneous households based on factors like income, housing affordability, and flood risk. This allows for a nuanced analysis of social segregation and the impacts of policies like the 'My House My Life' program.[5][10]
| Feature | Land Use and Transport Interaction (LUTI) Model | Agent-Based Model (ABM) |
| Approach | Top-down, aggregate (zonal) | Bottom-up, disaggregate (individual agents) |
| Core Mechanic | Equilibrium-based, spatial interaction | Rule-based agent decisions, emergent behavior |
| Data Needs | Zonal data (population, employment), transport networks | Microdata (household surveys), GIS layers (parcels, zoning) |
| Key Output | Aggregate land use and travel patterns | Detailed spatial patterns, social segregation metrics |
| Best For | Strategic, long-range forecasts of macro-level changes | Analyzing emergent phenomena and policy impacts on heterogeneous populations |
| This compound Use Case | Forecasting city-wide density shifts due to the BRT system | Simulating how different income groups choose housing locations in response to flood risk and new transport options |
Protocol: A Spatially-Explicit Agent-Based Model for this compound
This protocol outlines the steps to develop a simplified ABM to simulate residential location choice and urban sprawl in this compound.
4.1 Objective: To simulate how household location decisions, influenced by infrastructure (BRT) and environmental factors (flood risk), drive urban land use change over a 10-year period.
4.2 Materials:
-
Software: NetLogo, Repast, or a GIS-based environment with scripting capabilities (e.g., Python with GeoPandas).
-
Data:
-
GIS Data: Shapefiles of this compound's municipal boundary, land use/land cover, road network, planned BRT corridors, and designated flood-risk zones.[4]
-
Census Data: Aggregated census tract data on population, household income distribution, and housing tenure.
-
Economic Data: Information on land prices and construction costs.
-
4.3 Step-by-Step Procedure:
-
Environment Setup: Create a gridded digital environment representing this compound, where each cell (patch) has attributes: land use type, land value, accessibility score, and a flood-risk flag (binary: yes/no).
-
Agent Initialization:
-
Create a population of household agents, each with an assigned income level based on census distributions.
-
Create developer agents who can convert vacant land to residential use if profitable.
-
-
Model Calibration (Year 0):
-
Distribute the initial household agents across existing residential cells to match current population density patterns from census data.
-
Calculate initial accessibility for each cell based on its distance to the city center and major roads.
-
-
Simulation Loop (Run for 10 annual "ticks"):
-
Household Decision: At each tick, a fraction of households decides to move. They evaluate vacant cells based on a utility function, considering:
-
Affordability: (Land Price vs. Household Income)
-
Accessibility: (Proximity to jobs and the new BRT line)
-
Risk Aversion: (Negative utility for cells within a flood-risk zone)
-
-
Developer Action: Developer agents identify areas with high demand (many households seeking to move there) and convert vacant land to residential if the potential sale price exceeds development costs.
-
Environment Update: Update the land use of converted cells. Recalculate accessibility scores to reflect the influence of the new BRT system as it becomes operational in the simulation.
-
-
Output Analysis: After 10 years, export the final land use map. Analyze the results by comparing the spatial distribution of different income groups, measuring the growth in peripheral areas (sprawl), and quantifying the population residing in flood-risk zones.
Data Presentation
Effective modeling requires robust baseline data. The following tables summarize key indicators and projects relevant to this compound's urban development.
Table 1: Key Demographic and Economic Indicators for this compound
| Indicator | Value | Year | Source |
| Population | 866,300 | 2019 | IBGE[1] |
| Urban Area | 263.94 km² | 2019 | UN-Habitat[8] |
| GDP | ~US$ 4.2 Billion | 2019 | IBGE[4] |
| GDP per capita | R$ 24,858.31 | ~2021 | IBGE[1] |
| Human Development Index (HDI) | 0.751 | ~2021 | IBGE[1] |
| Informal Employment Rate | 44.7% | ~2021 | UN-Habitat[8] |
Table 2: Major Urban Development Programs and Investments
| Program / Project | Description | Key Stakeholders |
| BRT System | Development of a Bus Rapid Transit network to create a new feeder-trunk public transport system.[6][11] | Municipal Government, National Government (PAC) |
| Lagoas do Norte Programme | Urban and environmental upgrading program in a flood-prone area of the city.[4] | Municipal Government, World Bank |
| Sustainable this compound | A program focused on sustainable urban development initiatives.[4] | Municipal Government, CAF Development Bank |
| Agenda this compound 2030 | Strategic plan for long-term sustainable development.[4] | Municipal Government, AFD (French Development Agency) |
Modeling Causal Pathways
Economic models are effective at tracing the causal or "signaling" pathways of policy interventions. For example, the introduction of a new BRT station creates a cascade of effects that can be visualized. The new infrastructure improves accessibility, which is capitalized into higher land values. This sends a market signal to developers, incentivizing new construction and land use change, ultimately leading to shifts in residential density and travel behavior.
References
- 1. This compound - PI [gov.br]
- 2. anpur.org.br [anpur.org.br]
- 3. researchgate.net [researchgate.net]
- 4. urbancoalitions.org [urbancoalitions.org]
- 5. mdpi.com [mdpi.com]
- 6. mobiliseyourcity.net [mobiliseyourcity.net]
- 7. mobiliseyourcity.net [mobiliseyourcity.net]
- 8. urbanresiliencehub.org [urbanresiliencehub.org]
- 9. scielo.br [scielo.br]
- 10. Linking Urban Sprawl and Surface Urban Heat Island in the this compound–Timon Conurbation Area in Brazil [ideas.repec.org]
- 11. mobiliseyourcity.net [mobiliseyourcity.net]
Application Notes and Protocols for Soil and Water Sampling in the Teresina Municipality
For Researchers, Scientists, and Drug Development Professionals
These application notes provide detailed protocols for soil and water sampling in the municipality of Teresina, Piauí, Brazil. The procedures are designed to ensure the collection of representative samples suitable for a range of analyses, including environmental monitoring, geochemical characterization, and the bioprospecting of microorganisms for drug discovery. The protocols are based on Brazilian national standards and are supplemented with specific considerations for the environmental context of this compound.
Introduction
The municipality of this compound, located in the semi-arid region of northeastern Brazil, presents a unique environment for scientific research. Its soils, influenced by the local geology and increasing urbanization, and its water bodies, particularly the Poti and Parnaíba rivers, are subject to various anthropogenic pressures.[1][2] Understanding the chemical, physical, and biological characteristics of these matrices is crucial for environmental management and holds potential for the discovery of novel bioactive compounds.
These protocols are aligned with the standards set by the Brazilian Association of Technical Standards (ABNT) and the National Council for the Environment (CONAMA) to ensure data quality and regulatory compliance.
General Considerations for Sampling
2.1. Planning and Preliminary Assessment:
Before any sampling campaign, a thorough preliminary assessment is mandatory, as outlined in ABNT NBR 15515-1. This includes:
-
Desktop Study: Review of available maps (geological, soil, hydrogeological), historical land use data, and previous environmental studies. Geological maps of the this compound region are available from the Geological Survey of Brazil (CPRM).[3][4][5][6][7] Soil maps and characterization studies for the this compound area have been conducted by the Brazilian Agricultural Research Corporation (Embrapa).[8][9][10][11][12]
-
Site Reconnaissance: A visual inspection of the sampling area to identify potential sources of contamination, define access routes, and select preliminary sampling points.
-
Development of a Sampling Plan: This plan should detail the objectives, sampling strategy (e.g., random, systematic, stratified), number and location of sampling points, types of samples to be collected, and the analytical parameters.
2.2. Health and Safety:
All fieldwork must be conducted in accordance with a site-specific health and safety plan. Personnel should be trained in the proper use of personal protective equipment (PPE) and be aware of potential hazards, including biological and chemical contaminants.
Soil Sampling Protocols
The primary Brazilian standard for soil sampling for environmental purposes is ABNT NBR 15492.[13][14][15][16][17]
3.1. Soil Sampling for Physicochemical and Contaminant Analysis
This protocol is suitable for general soil characterization and the identification of inorganic and organic contaminants.
3.1.1. Experimental Protocol:
-
Decontamination of Equipment: All sampling equipment (augers, spatulas, etc.) must be decontaminated before use and between sampling points to prevent cross-contamination. A typical procedure involves washing with a neutral detergent, rinsing with tap water, followed by a rinse with deionized water.
-
Sample Collection:
-
For surface soil (0-20 cm), remove surface debris (e.g., leaves, rocks).
-
Use a stainless-steel auger or shovel to collect the sample.
-
For composite samples, collect sub-samples from multiple points within the designated sampling area and homogenize them in a stainless-steel tray.
-
-
Sample Handling and Storage:
-
Place the homogenized sample into a clean, properly labeled glass or high-density polyethylene (B3416737) (HDPE) container.
-
For volatile organic compounds (VOCs), samples must be collected with minimal disturbance and stored in vials with a septum, leaving no headspace.
-
Store samples in a cooler with ice (at approximately 4°C) and transport them to the laboratory as soon as possible.
-
3.2. Soil Sampling for Microbiological Analysis and Bioprospecting
This protocol is designed for the collection of soil samples intended for the isolation and cultivation of microorganisms for applications such as antibiotic discovery.[15][16][18][19]
3.2.1. Experimental Protocol:
-
Sterilization of Equipment: All sampling tools (spatulas, core samplers) and containers must be sterilized (e.g., by autoclaving) prior to use to avoid microbial contamination.
-
Aseptic Sample Collection:
-
Clear the surface vegetation and the top 2-3 cm of soil.
-
Using a sterile spatula or core sampler, collect approximately 50-100 g of soil from the desired depth.
-
Place the sample directly into a sterile collection bag or container.
-
-
Sample Handling and Storage:
-
Seal the container immediately to prevent contamination.
-
Store the samples at 4°C to maintain microbial viability and community structure.
-
Process the samples in the laboratory as soon as possible, ideally within 24 hours.
-
3.3. Data Presentation: Soil Analysis Parameters
The selection of analytical parameters will depend on the research objectives. CONAMA Resolution 420/2009 establishes guiding values for soil quality in Brazil.[20][21][22][23]
| Parameter Category | Examples of Analytes | Recommended Analytical Method |
| General Physicochemical | pH, Organic Matter, Particle Size, Cation Exchange Capacity (CEC) | Potentiometry, Walkley-Black, Pipette Method, Acetate Method |
| Potentially Toxic Elements | Arsenic (As), Cadmium (Cd), Lead (Pb), Mercury (Hg), Nickel (Ni), Copper (Cu), Zinc (Zn) | Inductively Coupled Plasma-Optical Emission Spectrometry (ICP-OES) or Mass Spectrometry (ICP-MS) after acid digestion (e.g., EPA 3051) |
| Organic Contaminants | Polycyclic Aromatic Hydrocarbons (PAHs), Polychlorinated Biphenyls (PCBs), Pesticides | Gas Chromatography-Mass Spectrometry (GC-MS) or High-Performance Liquid Chromatography (HPLC) |
| Microbiological | Total Viable Count, Fungal Count, Isolation of specific genera (e.g., Actinomycetes) | Plate Count Agar, Sabouraud Dextrose Agar, Specific selective media |
Water Sampling Protocols
Water sampling procedures in Brazil are guided by ABNT NBR 9898 for preservation and techniques.[24] The water quality standards are established by CONAMA Resolution 357/2005.[2][19][25][26][27]
4.1. Surface Water Sampling (Rivers, Lagoons)
This protocol is applicable to the collection of water from the Poti and Parnaíba rivers and the lagoons in this compound. Studies have indicated potential issues with thermotolerant coliforms, dissolved oxygen, and ammonia (B1221849) in the Poti River.[21][22][24][28]
4.1.1. Experimental Protocol:
-
Container Preparation: Use clean glass or plastic bottles, appropriate for the intended analyses. For microbiological analysis, use sterile containers. For analysis of trace metals, bottles should be acid-washed.
-
Sample Collection:
-
Rinse the sample bottle with the water to be sampled three times before filling.
-
Collect the sample from a depth of approximately 30 cm below the surface, avoiding contact with the riverbed or surface scum.
-
For microbiological samples, open the sterile bottle under the water surface and close it before bringing it to the surface.
-
-
On-site Measurements: Parameters that can change rapidly, such as pH, temperature, dissolved oxygen, and conductivity, should be measured in the field using calibrated portable meters.
-
Sample Preservation and Storage:
-
Preserve samples as required for the specific analyses (see table below).
-
Store samples in a cooler with ice (at approximately 4°C) and protect them from direct sunlight.
-
Transport samples to the laboratory, adhering to the recommended holding times.
-
4.2. Water Sampling for Pharmaceutical Analysis
Water used in pharmaceutical processes must meet stringent purity standards. This protocol focuses on parameters relevant to drug development and manufacturing.[3][14][20][25][29]
4.2.1. Experimental Protocol:
-
Sampling Points: Collect samples from various points in the water purification and distribution system.
-
Aseptic Collection: For microbiological testing, use sterile containers and aseptic techniques to avoid contamination.
-
Sample Handling:
-
Fill containers completely, leaving no headspace for Total Organic Carbon (TOC) analysis.
-
Transport samples to the laboratory promptly.
-
4.3. Data Presentation: Water Analysis Parameters and Preservation
| Parameter | Container | Minimum Volume | Preservation | Maximum Holding Time |
| General Physical | ||||
| pH, Conductivity, Temperature | Plastic or Glass | 500 mL | Analyze immediately | 2 hours |
| Turbidity | Plastic or Glass | 100 mL | Cool to 4°C | 48 hours |
| Nutrients | ||||
| Ammonia | Plastic or Glass | 500 mL | H₂SO₄ to pH < 2, Cool to 4°C | 28 days |
| Nitrate, Nitrite | Plastic or Glass | 200 mL | Cool to 4°C | 48 hours |
| Total Phosphorus | Plastic or Glass | 100 mL | H₂SO₄ to pH < 2, Cool to 4°C | 28 days |
| Microbiological | ||||
| Thermotolerant Coliforms | Sterile Plastic or Glass with Sodium Thiosulfate | 100 mL | Cool to 4°C | 24 hours |
| Potentially Toxic Elements | Plastic (acid-washed) | 500 mL | HNO₃ to pH < 2 | 6 months |
| Pharmaceutical Specific | ||||
| Total Organic Carbon (TOC) | Glass with septum, no headspace | 40 mL | HCl to pH < 2, Cool to 4°C | 28 days |
| Endotoxins | Pyrogen-free glass | 10 mL | Store at 2-8°C | 24 hours |
Visualizations
5.1. Soil Sampling Workflow
Caption: Workflow for soil sampling and analysis.
5.2. Water Sampling Workflow
Caption: Workflow for water sampling and analysis.
References
- 1. redalyc.org [redalyc.org]
- 2. Aspects that should be considered in a possible revision of the Brazilian Guideline Conama Resolution 357/05 - MedCrave online [medcraveonline.com]
- 3. DSpace [rigeo.sgb.gov.br]
- 4. primo.sorbonne-universite.fr [primo.sorbonne-universite.fr]
- 5. Mapa geológico do estado do Piauí [rigeo.sgb.gov.br]
- 6. Carta de suscetibilidade a movimentos gravitacionais de massa e inundação: município de this compound - PI [rigeo.sgb.gov.br]
- 7. DSpace [rigeo.sgb.gov.br]
- 8. Solos do Nordeste [solosne.cnps.embrapa.br]
- 9. infoteca.cnptia.embrapa.br [infoteca.cnptia.embrapa.br]
- 10. Levantamento, zoneamento e mapeamento pedológico detalhado da área experimental da Embrapa Meio-Norte em this compound, PI. - Portal Embrapa [embrapa.br]
- 11. infoteca.cnptia.embrapa.br [infoteca.cnptia.embrapa.br]
- 12. bdpa.cnptia.embrapa.br [bdpa.cnptia.embrapa.br]
- 13. target.com.br [target.com.br]
- 14. corecase.com [corecase.com]
- 15. scribd.com [scribd.com]
- 16. solisconsultoria.com.br [solisconsultoria.com.br]
- 17. biblioteca.ibape-nacional.com.br [biblioteca.ibape-nacional.com.br]
- 18. scribd.com [scribd.com]
- 19. researchgate.net [researchgate.net]
- 20. researchgate.net [researchgate.net]
- 21. cjees.ro [cjees.ro]
- 22. cabidigitallibrary.org [cabidigitallibrary.org]
- 23. scielo.iec.gov.br [scielo.iec.gov.br]
- 24. sistema.ceteclins.com.br [sistema.ceteclins.com.br]
- 25. braziliannr.com [braziliannr.com]
- 26. ijaers.com [ijaers.com]
- 27. Brazil. CONAMA Resolution 357 of 17 March 2005. - References - Scientific Research Publishing [scirp.org]
- 28. ambientobrasil.com.br [ambientobrasil.com.br]
- 29. supremoambiental.com.br [supremoambiental.com.br]
Application Notes and Protocols for a Longitudinal Study on Health Outcomes in Teresina
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive framework for establishing a prospective longitudinal cohort study in Teresina, Brazil, to investigate the interplay between environmental, socioeconomic, and biological factors on a range of health outcomes. The protocols outlined below are designed to be adapted and implemented by research institutions, public health organizations, and pharmaceutical companies engaged in understanding disease progression and identifying novel therapeutic and preventative strategies.
Introduction
This compound, the capital of Piauí state in northeastern Brazil, faces a unique combination of health challenges. These include a significant burden of neglected tropical diseases (NTDs) such as visceral leishmaniasis and Chagas disease, alongside a rising prevalence of non-communicable diseases (NCDs) like cardiovascular conditions and diabetes.[1][2][3][4][5] Environmental factors, including exposure to smoke from biomass burning and potential heavy metal contamination, further compound the public health landscape.[6][7][8] A longitudinal study is crucial for elucidating the temporal relationships between these diverse risk factors and the incidence and progression of disease, providing invaluable data for public health interventions and drug development. Such a study allows for the tracking of changes over time within the same individuals, offering insights into causal pathways that cross-sectional studies cannot provide.[9][10][11][12]
Study Objectives
Primary Objective: To identify the key environmental, socioeconomic, and biological determinants of major health outcomes in a representative cohort of the this compound population over a 10-year period.
Secondary Objectives:
-
To determine the incidence and prevalence of key infectious and non-communicable diseases.
-
To evaluate the impact of changes in environmental exposures on health trajectories.
-
To identify biomarkers associated with disease risk and progression.
-
To assess the influence of socioeconomic factors on health disparities.
-
To create a comprehensive data and biorepository for future research.
Data Presentation: Key Health Indicators for this compound
The following tables summarize baseline quantitative data to be collected. These will be updated at each follow-up wave to track changes over time.
Table 1: Infectious Disease Surveillance
| Indicator | Baseline Prevalence (Estimate) | Data Source |
| Visceral Leishmaniasis (seroprevalence) | 5-10% (in at-risk areas) | Local health surveys, literature review |
| Chagas Disease (seroprevalence) | 1-3% | Blood donor screening data, literature review[4][5] |
| Dengue/Zika/Chikungunya (seroprevalence) | Variable (dependent on recent outbreaks) | Municipal Health Secretariat |
| Diarrheal Disease (2-week prevalence in under 5s) | 10-15% | National health surveys, literature review[13][14][15][16][17] |
| Hepatitis B (HBsAg+) | ~1% | Blood donor screening data[4] |
| Syphilis | 1-2% | Blood donor screening data[4] |
Table 2: Non-Communicable Disease (NCD) and Risk Factor Profile
| Indicator | Baseline Prevalence (Estimate) | Data Source |
| Hypertension (BP ≥140/90 mmHg or on medication) | 25-35% (adults) | Brazilian National Health Survey (PNS) data for the Northeast region[18] |
| Diabetes (Fasting glucose ≥126 mg/dL or on medication) | 8-12% (adults) | PNS data for the Northeast region |
| Obesity (BMI ≥30 kg/m ²) | 20-25% (adults) | PNS data for the Northeast region |
| High Cholesterol (Total Cholesterol ≥240 mg/dL) | 15-20% (adults) | PNS data for the Northeast region |
| Current Smokers | 10-15% (adults) | PNS data for the Northeast region |
| Low Physical Activity | 40-50% (adults) | PNS data for the Northeast region[2] |
Table 3: Environmental and Socioeconomic Indicators
| Indicator | Metric | Data Source |
| Household access to improved sanitation | % of households | Brazilian Institute of Geography and Statistics (IBGE) |
| Household access to piped water | % of households | IBGE |
| Exposure to biomass smoke (self-reported) | % of households using wood/charcoal for cooking | IBGE, Study Questionnaire |
| Gini Coefficient (income inequality) | 0.6171 (as of 2010) | DATASUS[19] |
| Poverty Incidence | ~47% | IBGE[19] |
| Illiteracy Rate | % of population | IBGE |
Experimental Protocols
Study Design and Cohort Recruitment
A prospective cohort study will be established. A multi-stage stratified random sampling approach will be used to recruit a representative sample of 5,000 adults aged 18-65 years from different socioeconomic districts of this compound. Recruitment will be conducted through household visits. Informed consent will be obtained from all participants, with ethical approval from the relevant Brazilian and institutional review boards.
Data Collection Workflow
Data will be collected at baseline (Year 0) and with follow-up waves in Year 2, Year 5, and Year 10.
Caption: Longitudinal study data collection workflow over a 10-year period.
Protocol 1: Questionnaire Administration
Objective: To collect data on demographics, socioeconomic status, lifestyle, environmental exposures, and medical history.
Methodology:
-
Administer a structured questionnaire via trained interviewers using tablet-based data entry to ensure data quality.
-
Sections to include:
-
Demographics: Age, sex, race/ethnicity.
-
Socioeconomic Status: Education, income, occupation, housing conditions.[20][21][22][23]
-
Lifestyle: Diet (Food Frequency Questionnaire), physical activity (IPAQ-short form), smoking, and alcohol consumption.
-
Environmental Exposures: Water source, sanitation type, indoor air quality (cooking fuel), self-reported exposure to pesticides and local burnings.[6]
-
Medical History: Self-reported and family history of chronic diseases, medication use, healthcare utilization.
-
Protocol 2: Clinical Examination
Objective: To obtain standardized anthropometric and physiological measurements.
Methodology:
-
Anthropometry: Measure height (stadiometer), weight (calibrated digital scale), and waist circumference. Calculate Body Mass Index (BMI).
-
Blood Pressure: Measure systolic and diastolic blood pressure three times with a validated automated device after 5 minutes of rest; use the average of the last two readings.
-
Spirometry: (Optional, based on resources) Assess lung function, particularly in areas with high exposure to biomass smoke.
Protocol 3: Biological Sample Collection and Biorepository
Objective: To collect, process, and store biological samples for immediate and future analysis.
Methodology:
-
Blood Collection:
-
Collect 30 mL of venous blood from fasting participants.
-
Aliquot into separate tubes:
-
EDTA plasma: For DNA extraction and viral PCR.
-
Serum: For serological and biochemical assays.
-
Sodium Fluoride/Potassium Oxalate: For glucose measurement.
-
PAXgene tube: For RNA preservation.
-
-
-
Urine Collection: Collect a mid-stream urine sample for urinalysis and biomarker assessment (e.g., heavy metals).
-
Sample Processing: Process all samples within 2 hours of collection. Centrifuge blood tubes to separate plasma/serum.
-
Storage: Store all aliquots at -80°C in a secure, monitored biorepository with a robust sample tracking system.
Caption: Workflow for biological sample collection, processing, and storage.
Protocol 4: Laboratory Assays
Objective: To perform a panel of baseline and follow-up laboratory tests.
Methodology:
-
Biochemistry: Analyze serum for lipid panel (Total Cholesterol, HDL, LDL, Triglycerides), fasting glucose, HbA1c, and markers of kidney (creatinine) and liver (ALT, AST) function.
-
Serology:
-
Screen for antibodies to Trypanosoma cruzi (Chagas), Leishmania infantum (VL), Dengue virus, Zika virus, and Chikungunya virus using validated ELISA kits.
-
Screen for markers of transfusion-transmissible infections (e.g., Hepatitis B, Syphilis) to align with local public health data.[4]
-
-
Molecular Assays:
-
Perform PCR for arboviruses on a subset of samples during suspected outbreaks.
-
DNA will be extracted from EDTA plasma for future genetic studies.
-
Data Management and Statistical Analysis
A robust data management plan will be implemented using a secure, centralized database. A detailed statistical analysis plan will be developed prior to analysis.
Key Analytical Approaches:
-
Descriptive Statistics: To summarize baseline characteristics and changes over time.
-
Longitudinal Data Analysis: Employ mixed-effects models and Generalized Estimating Equations (GEE) to analyze changes in continuous and categorical health outcomes over time, accounting for within-subject correlation.[9][11][12][24]
-
Survival Analysis: Use Cox proportional hazards models to identify risk factors for the incidence of new diseases.
-
Spatial Analysis: Map disease clusters and their relationship to environmental variables.
Caption: Logical flow for data analysis and interpretation.
Ethical Considerations
This study will adhere to the principles of the Declaration of Helsinki and Brazilian regulations for research involving human subjects. Key ethical procedures include:
-
Informed Consent: A detailed, culturally appropriate informed consent form will be administered in Portuguese. Participants will have the right to withdraw at any time without penalty.
-
Confidentiality: All data will be de-identified and stored securely. Access will be restricted to authorized research personnel.
-
Reporting of Results: Clinically significant abnormal results (e.g., new diagnosis of a serious condition) will be communicated to the participant and referred to the local healthcare system for appropriate care. The study will work in partnership with the this compound Municipal Health Foundation.
-
Community Engagement: Regular meetings will be held with community leaders and local health authorities to provide updates on the study's progress and findings.
References
- 1. researchgate.net [researchgate.net]
- 2. Noncommunicable diseases attributed to low levels of physical activity in Brazil: an epidemiologic Global Burden of Disease Study - PMC [pmc.ncbi.nlm.nih.gov]
- 3. sbh.org.br [sbh.org.br]
- 4. Prevalence of transfusion-transmissible infections in blood donors from Piaui State, Northeastern Brazil - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. mdpi.com [mdpi.com]
- 6. youtube.com [youtube.com]
- 7. Risk assessment for heavy metals in community gardens of the city of this compound, Brazil | International Society for Horticultural Science [ishs.org]
- 8. researchgate.net [researchgate.net]
- 9. sites.globalhealth.duke.edu [sites.globalhealth.duke.edu]
- 10. Initial data analysis for longitudinal studies to build a solid foundation for reproducible analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 11. editverse.com [editverse.com]
- 12. faculty.washington.edu [faculty.washington.edu]
- 13. Assessing the impact of drinking water and sanitation on diarrhoeal disease in low- and middle-income settings: systematic review and meta-regression - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. The joint effects of water and sanitation on diarrheal disease: A multi-country analysis of the Demographic and Health Surveys - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Impact of access to improved water and sanitation on diarrhea reduction among rural under-five children in low and middle-income countries: a propensity score matched analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 16. researchgate.net [researchgate.net]
- 17. tandfonline.com [tandfonline.com]
- 18. The effect of retirement on health behaviours: Evidence from Brazil | PLOS One [journals.plos.org]
- 19. urbancoalitions.org [urbancoalitions.org]
- 20. iosrjournals.org [iosrjournals.org]
- 21. Socioeconomic inequalities in health and healthcare utilization among the elderly in Brazil: results from the 2019 National Health Survey - PubMed [pubmed.ncbi.nlm.nih.gov]
- 22. scielo.br [scielo.br]
- 23. The effects of social determinants of health on acquired immune deficiency syndrome in a low-income population of Brazil: a retrospective cohort study of 28.3 million individuals - PubMed [pubmed.ncbi.nlm.nih.gov]
- 24. researchgate.net [researchgate.net]
Application of Social Network Analysis to Community Health in Teresina: Application Notes and Protocols
Introduction
Social Network Analysis (SNA) is a powerful methodology for understanding the intricate web of relationships that influence community health outcomes. By mapping and analyzing the connections between individuals, groups, and organizations, SNA can reveal how information, resources, and support flow through a community, identifying key influencers and isolated subgroups. This document provides detailed application notes and protocols for utilizing SNA to enhance community health initiatives in T. While direct applications of SNA in Teresina's community health sector are not extensively documented in existing literature, this guide draws upon methodologies and findings from studies in other Brazilian contexts, such as Rio de Janeiro, to provide a practical framework for researchers, scientists, and public health professionals. By applying these protocols, stakeholders in this compound can gain valuable insights into the social dynamics that shape health behaviors and access to care, leading to more effective and targeted interventions.
I. Application Notes
Social Network Analysis offers a quantitative and qualitative approach to understanding the structure of social relationships and their impact on health.[1][2] In the context of community health in this compound, SNA can be applied to:
-
Identify Key Influencers and Opinion Leaders: Pinpoint individuals who are central to the flow of health information and can act as effective champions for health campaigns.
-
Map Patient Referral Networks: Understand how patients are referred between different healthcare providers and community resources to optimize care coordination.
-
Analyze Health Information Diffusion: Track how information about disease prevention, treatment, and health services spreads throughout the community.
-
Assess the Structure of Community Support Networks: Evaluate the role of family, friends, and community organizations in providing social support for individuals with chronic illnesses.
-
Inform the Design of Health Interventions: Develop targeted interventions that leverage existing social networks to promote healthy behaviors and improve access to care.
By visualizing and quantifying these social structures, public health officials in this compound can move beyond individual-level analyses to understand the broader social context of health.
II. Hypothetical Case Study: Mapping Health Support Networks in a this compound Community
To illustrate the application of SNA, we present a hypothetical case study focused on understanding the health support networks of diabetic patients in a specific neighborhood of this compound.
Objective: To identify the key sources of health information and social support for individuals with Type 2 Diabetes in the community and to analyze the structure of this support network.
Quantitative Data Summary
The following table presents hypothetical quantitative data from our case study, showcasing various network metrics for different actors within the community health network. These metrics provide insights into the roles and influence of each actor.
| Actor Type | N | Degree Centrality (Mean) | Betweenness Centrality (Mean) | Closeness Centrality (Mean) |
| Community Health Agents (CHAs) | 5 | 15.2 | 25.8 | 0.68 |
| Family Members | 50 | 8.5 | 5.2 | 0.45 |
| Neighbors/Friends | 30 | 6.1 | 3.1 | 0.39 |
| Primary Care Physicians | 3 | 12.7 | 18.4 | 0.62 |
| Nurses/Technicians | 4 | 10.3 | 12.6 | 0.55 |
| Community Leaders | 2 | 9.8 | 15.1 | 0.59 |
| Pharmacists | 2 | 5.4 | 4.7 | 0.41 |
III. Experimental Protocols
This section outlines the detailed methodology for conducting a social network analysis of a community health network, based on our hypothetical case study in this compound.
1. Study Design and Participant Recruitment
-
Design: A cross-sectional study employing a sociometric network survey.
-
Target Population: Adults diagnosed with Type 2 Diabetes residing in the selected neighborhood of this compound, and the individuals and professionals they identify as part of their health support network.
-
Recruitment:
-
Initial recruitment of diabetic patients will be conducted through the local Basic Health Unit (Unidade Básica de Saúde - UBS).
-
A name generator questionnaire will be administered to these initial participants (egos) to identify individuals (alters) who provide them with health-related information and support.
-
These alters will then be invited to participate in the study to map the complete network.
-
2. Data Collection
-
Instrument: A structured questionnaire will be administered through face-to-face interviews. The questionnaire will collect data on:
-
Demographic information of the participant.
-
Name Generator: "In the last month, who have you talked to about your diabetes management (e.g., diet, medication, exercise)?"
-
Name Interpreter: For each person named, questions will be asked about the nature of the relationship (e.g., family, friend, healthcare provider), the frequency of interaction, and the type of support provided (e.g., emotional, informational, practical).
-
-
Data Representation: The collected data will be used to construct an adjacency matrix, a binary matrix where '1' indicates a connection between two actors and '0' indicates no connection. This matrix will serve as the input for the network analysis software.[3]
3. Data Analysis
-
Software: The social network analysis will be performed using UCINET and NetDraw software for network visualization.[3]
-
Network Metrics: The following metrics will be calculated to analyze the network structure:
-
Degree Centrality: The number of direct connections a node has. This indicates the most active actors in the network.
-
Betweenness Centrality: The extent to which a node lies on the shortest paths between other nodes. This identifies individuals who act as bridges between different parts of the network.
-
Closeness Centrality: The average farness (inverse of the shortest path distance) to all other nodes. This measures how quickly an actor can reach all other actors in the network.
-
Network Density: The proportion of actual ties in the network relative to the total possible ties. This indicates the overall connectedness of the network.
-
4. Ethical Considerations
-
Informed consent will be obtained from all participants.
-
Confidentiality and anonymity of participants will be ensured by using codes to identify individuals in the dataset and network diagrams.
-
The study protocol will be submitted for approval by the relevant research ethics committee.
IV. Visualizations
Experimental Workflow
Hypothetical Health Support Network
Logical Relationship of SNA in Community Health
References
Application Notes and Protocols for Evaluating Public Policy Interventions in Teresina
Audience: Researchers, scientists, and drug development professionals.
Objective: This document provides a comprehensive guide to the methods and protocols for evaluating the impact and effectiveness of public policy interventions in Teresina, Brazil. It is designed to offer a structured approach for researchers and professionals to assess policy outcomes in various sectors, including health, education, urban planning, and social assistance.
Introduction to Public Policy Evaluation in this compound
Public policy evaluation is a systematic process to determine the merit, worth, and significance of a policy intervention. In a dynamic urban environment like this compound, evidence-based evaluation is crucial for ensuring that public resources are used effectively and that policies achieve their intended goals.[1][2] This involves a multi-faceted approach, often combining quantitative and qualitative methods to provide a holistic understanding of a policy's impact.[1][2]
Recent studies and governmental focus in Brazil highlight a growing emphasis on the institutionalization of public policy evaluation to improve governance and public trust.[3][4] this compound has been the subject of evaluations in areas such as education, where award policies have been analyzed for their effects on student performance, and urban planning, with assessments of the new Master Plan for Territorial Planning.[5][6][7] These evaluations provide valuable insights into the local context and the specific challenges and opportunities for policymaking in the city.
Methodological Approaches to Policy Evaluation
The evaluation of public policies can be broadly categorized into quantitative, qualitative, and mixed-methods approaches. The choice of method depends on the nature of the policy, the evaluation questions, and the availability of data.
Quantitative Methods
Quantitative methods involve the use of numerical data and statistical analysis to measure the outcomes and impact of a policy.[1][8][9] These methods are essential for establishing causal links between a policy intervention and its effects.[10]
Key Quantitative Methods:
-
Randomized Controlled Trials (RCTs): Considered the gold standard for impact evaluation, RCTs involve randomly assigning individuals or groups to either a treatment group (receiving the intervention) or a control group.
-
Quasi-Experimental Designs: These are used when randomization is not feasible and include methods like:
-
Difference-in-Differences (DiD): This method compares the change in outcomes over time between a treatment group and a control group.[10] A study on the effects of award policies on student performance in this compound utilized a combination of the interrupted time series method and the difference-in-differences method.[6]
-
Regression Discontinuity Design (RDD): This design is used when a cutoff score determines who receives an intervention.[10]
-
Statistical Matching: This technique involves finding a comparison group that is statistically similar to the treatment group.[11]
-
-
Cost-Benefit Analysis (CBA) and Cost-Effectiveness Analysis (CEA): These methods assess the economic efficiency of a policy by comparing its costs to its monetary benefits (CBA) or its outcomes in non-monetary terms (CEA).[1][8][12]
Qualitative Methods
Qualitative methods provide in-depth insights into the context, implementation process, and the lived experiences of those affected by a policy.[1][13][14] They are crucial for understanding how and why a policy has a particular effect.
Key Qualitative Methods:
-
Interviews: Semi-structured or in-depth interviews with stakeholders (policymakers, program implementers, beneficiaries) can provide rich narrative data.[1][13]
-
Focus Groups: Facilitated discussions with small groups of people can explore shared experiences and perspectives.[1][13][14]
-
Case Studies: In-depth investigations of a specific program or location can provide a detailed understanding of the policy in its real-world context.[13][15]
-
Document Analysis: Systematic review of policy documents, reports, and other written materials can offer insights into the policy's design and intended goals.[13]
Mixed-Methods Approaches
Mixed-methods approaches combine quantitative and qualitative techniques to provide a more comprehensive and nuanced understanding of a policy's impact.[1] For example, a quantitative survey could measure the change in a specific indicator, while qualitative interviews could explore the reasons behind that change.
Data Presentation: Illustrative Tables for Policy Evaluation
Clear and structured data presentation is essential for comparing policy outcomes. The following are illustrative examples of how quantitative data from policy evaluations in this compound could be summarized.
Table 1: Impact of Educational Award Policy on Student Performance in this compound (Hypothetical Data)
| Indicator | Pre-Intervention (2022) | Post-Intervention (2024) | Change |
| Average Proficiency Score (Portuguese) | 250.5 | 265.2 | +14.7 |
| Average Proficiency Score (Mathematics) | 240.1 | 252.8 | +12.7 |
| Annual Dropout Rate | 5.2% | 3.8% | -1.4% |
| Teacher Attendance Rate | 92.1% | 95.6% | +3.5% |
Table 2: Evaluation of Urban Mobility Intervention in a this compound Neighborhood (Hypothetical Data)
| Metric | Baseline (Pre-Policy) | 12 Months Post-Policy | Target |
| Average Commute Time (minutes) | 45 | 35 | 30 |
| Public Transport Usage (%) | 25% | 40% | 50% |
| Number of Traffic Accidents | 15 | 8 | <10 |
| Resident Satisfaction Score (1-10) | 6.2 | 7.8 | 8.0 |
Experimental Protocols
Detailed methodologies are critical for the reproducibility and validity of evaluation studies. The following are protocols for key evaluation methods.
Protocol for a Randomized Controlled Trial (RCT) of a Public Health Intervention
Objective: To evaluate the effectiveness of a community-based health education program on the prevalence of dengue fever in selected neighborhoods of this compound.
Methodology:
-
Selection of Participants: Randomly select 20 neighborhoods in this compound with similar socio-demographic characteristics and historical dengue prevalence rates.
-
Random Assignment: Randomly assign 10 neighborhoods to the treatment group and 10 to the control group.
-
Intervention: The treatment group will receive the intensive community-based health education program for a period of 6 months. The control group will receive the standard public health information provided by the municipality.
-
Data Collection:
-
Baseline: Conduct a household survey in all 20 neighborhoods to collect data on knowledge, attitudes, and practices related to dengue prevention, and record the number of reported dengue cases from local health clinics.
-
Mid-term: After 3 months, conduct a follow-up survey and collect data on dengue cases.
-
End-line: At the end of the 6-month intervention period, conduct a final household survey and collect data on dengue cases.
-
-
Data Analysis: Use statistical methods (e.g., t-tests, regression analysis) to compare the change in dengue prevalence and prevention practices between the treatment and control groups.
Protocol for a Difference-in-Differences (DiD) Evaluation of a Social Assistance Program
Objective: To assess the impact of a new conditional cash transfer program on school enrollment and attendance in low-income families in this compound.
Methodology:
-
Identification of Groups:
-
Treatment Group: Families in this compound who are eligible and receive the new conditional cash transfer.
-
Control Group: A comparable group of families from a neighboring municipality with similar socio-economic characteristics that has not implemented the new program.
-
-
Data Collection:
-
Pre-Intervention: Collect administrative data on school enrollment and attendance for children in both the treatment and control groups for the year prior to the program's implementation.
-
Post-Intervention: Collect the same data for the two years following the implementation of the program.
-
-
Data Analysis:
-
Calculate the change in enrollment and attendance rates for both the treatment and control groups over the evaluation period.
-
The "difference-in-differences" estimator will be the difference in these changes between the two groups, providing an estimate of the program's causal impact.
-
Visualizing Evaluation Frameworks
Diagrams are powerful tools for illustrating the logic and workflow of policy evaluation.
Caption: A typical workflow for a public policy evaluation.
Caption: A logic model for a public health intervention.
Caption: A decision tree for selecting an evaluation method.
References
- 1. pubadmin.institute [pubadmin.institute]
- 2. Public policy evaluation methods - Insight7 - Call Analytics & AI Coaching for Customer Teams [insight7.io]
- 3. Study indicates advances in the evaluation of public policies in Brazil [portal.fgv.br]
- 4. periodicos.pucpr.br [periodicos.pucpr.br]
- 5. Evaluation of the effects of the new territorial planning plan of this compound / PI on its potential for occupation and urban expansion | Research, Society and Development [rsdjournal.org]
- 6. educa.fcc.org.br [educa.fcc.org.br]
- 7. scielo.br [scielo.br]
- 8. fiveable.me [fiveable.me]
- 9. taylorfrancis.com [taylorfrancis.com]
- 10. Quantitative Methods for Public Policy Evaluation Course| Barcelona School of Economics [bse.eu]
- 11. Luiss â Libera Università Internazionale degli Studi Sociali [luiss.edu]
- 12. fiveable.me [fiveable.me]
- 13. fiveable.me [fiveable.me]
- 14. ceulearning.ceu.edu [ceulearning.ceu.edu]
- 15. Introduction – Policy Evaluation: Methods and Approaches [scienceetbiencommun.pressbooks.pub]
Application Notes and Protocols for Tracking Deforestation around Teresina using Satellite Imagery
Authored for: Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive guide to utilizing satellite imagery for monitoring deforestation in the region surrounding Teresina, the capital city of the state of Piauí, Brazil. The protocols outlined herein are designed to offer a structured and reproducible workflow for researchers and scientists.
Introduction
The area around this compound is experiencing significant land-use change, driven by factors such as agricultural expansion and urbanization.[1] Monitoring deforestation in this region is crucial for understanding its environmental impact, informing conservation policies, and ensuring sustainable development. Satellite remote sensing offers a powerful and efficient means to track these changes over large areas and with high temporal frequency.[2]
This document details the methodologies for acquiring, processing, and analyzing satellite imagery to quantify deforestation rates and identify key drivers of forest loss. The protocols are designed to be adaptable to various research questions and available resources.
Data Presentation: Deforestation Statistics for this compound
The following table summarizes key deforestation data for the municipality of this compound, providing a baseline for further analysis.
| Metric | Value | Period | Source |
| Natural Forest Cover (2020) | 110 kha (77% of land area) | 2020 | Global Forest Watch[3] |
| Natural Forest Loss (2024) | 1.3 kha | 2024 | Global Forest Watch[3] |
| Equivalent CO₂ Emissions (2024) | 550 kt | 2024 | Global Forest Watch[3] |
| Total Tree Cover Loss | 26 kha | 2001-2024 | Global Forest Watch[3] |
| Percentage of 2000 Tree Cover Lost | 28% | 2001-2024 | Global Forest Watch[3] |
| Tree Cover Loss from Fires | 3.0 kha | 2001-2024 | Global Forest Watch[3] |
| Tree Cover Loss from Other Drivers | 23 kha | 2001-2024 | Global Forest Watch[3] |
Experimental Protocols
Protocol 1: Satellite Data Acquisition
This protocol outlines the steps for acquiring appropriate satellite imagery for deforestation analysis.
Objective: To obtain multi-temporal satellite imagery for the this compound region.
Materials:
-
A computer with internet access.
-
Access to a satellite imagery archive (e.g., USGS EarthExplorer, Copernicus Open Access Hub).
Procedure:
-
Define Area of Interest (AOI): Delineate the geographical boundaries of the study area around this compound using a GIS software or online mapping tool.
-
Select Satellite Sensor: Choose a suitable satellite sensor based on the research requirements. Landsat 8 and Sentinel-2 are recommended for their free availability, moderate spatial resolution (15-30 meters), and regular revisit times.[4][5][6]
-
Specify Time Period: Determine the time frame for the analysis. For change detection, acquire images from at least two different dates (e.g., one from the beginning and one from the end of the desired period).
-
Filter by Cloud Cover: To ensure data quality, filter the search results to include images with minimal cloud cover (ideally less than 10%).[6]
-
Download Data: Download the selected satellite scenes. The data will typically be provided in GeoTIFF format.
Protocol 2: Image Pre-processing
This protocol details the necessary steps to prepare the satellite imagery for analysis.
Objective: To correct for atmospheric and geometric distortions in the satellite imagery.
Materials:
-
GIS software (e.g., QGIS, ArcGIS) or remote sensing software (e.g., ENVI, ERDAS IMAGINE).
-
Downloaded satellite imagery.
Procedure:
-
Atmospheric Correction: Apply an atmospheric correction algorithm (e.g., Dark Object Subtraction, FLAASH) to convert the digital numbers (DNs) to surface reflectance. This step is crucial for accurate comparison of images from different dates.
-
Geometric Correction: If necessary, perform geometric correction to ensure the images align perfectly. This is often already done for high-level data products.
-
Image Subsetting: Clip the images to the defined Area of Interest (AOI) to reduce processing time and data volume.
Protocol 3: Deforestation Analysis using Normalized Difference Vegetation Index (NDVI)
This protocol describes a widely used method for identifying vegetation change.[4][7]
Objective: To calculate NDVI and perform change detection to identify areas of deforestation.
Materials:
-
Pre-processed satellite imagery (including Near-Infrared and Red bands).
-
GIS or remote sensing software.
Procedure:
-
Calculate NDVI: For each image date, calculate the NDVI using the following formula: NDVI = (NIR - Red) / (NIR + Red) Where NIR is the reflectance in the Near-Infrared band and Red is the reflectance in the Red band. Healthy vegetation will have high NDVI values.[4]
-
NDVI Differencing: To detect changes, subtract the NDVI image of the earlier date from the NDVI image of the later date. NDVI_change = NDVI_later - NDVI_earlier
-
Thresholding: Apply a threshold to the NDVI change image to identify areas of significant vegetation loss. Negative values indicate a decrease in vegetation. The specific threshold will need to be determined based on the local context and visual inspection of the imagery.
-
Create Deforestation Map: Reclassify the thresholded image to create a binary map showing deforested and non-deforested areas.
Protocol 4: Supervised Classification for Land Cover Mapping
This protocol provides a method for classifying different land cover types to understand the drivers of deforestation.[8]
Objective: To create a land cover map of the study area to identify what the forest is being converted to.
Materials:
-
Pre-processed satellite imagery.
-
GIS or remote sensing software.
-
High-resolution reference imagery or ground truth data.
Procedure:
-
Define Land Cover Classes: Identify the relevant land cover classes in the study area (e.g., Forest, Agriculture, Urban, Water, Bare Soil).
-
Create Training Samples: Digitize polygons over representative areas for each land cover class. These training samples will be used to "train" the classification algorithm.
-
Run Supervised Classification: Select a supervised classification algorithm (e.g., Maximum Likelihood, Random Forest, Support Vector Machine) and run it using the training samples and the satellite imagery.
-
Post-Classification Processing: Apply post-classification refinement techniques, such as a majority filter, to reduce "salt and pepper" noise in the classified map.
-
Accuracy Assessment: Evaluate the accuracy of the classification by comparing the classified map to a set of independent validation points.
Mandatory Visualizations
The following diagrams illustrate the key workflows described in these protocols.
Caption: Overall workflow for monitoring deforestation around this compound.
Caption: Logical workflow for the NDVI-based change detection process.
References
- 1. researchgate.net [researchgate.net]
- 2. Monitoring Deforestation with Remote Sensing [flypix.ai]
- 3. This compound, Brazil, Piauí Deforestation Rates & Statistics | GFW [globalforestwatch.org]
- 4. researchgate.net [researchgate.net]
- 5. A Learning Strategy for Amazon Deforestation Estimations Using Multi-Modal Satellite Imagery [mdpi.com]
- 6. Remote Sensing of Deforestation of Amazon Rainforest [storymaps.arcgis.com]
- 7. medium.com [medium.com]
- 8. eudr.co [eudr.co]
Troubleshooting & Optimization
Navigating the Landscape of Longitudinal Health Research in Teresina: A Technical Support Guide
Teresina, Brazil - Researchers embarking on longitudinal health studies in this compound face a unique set of opportunities and challenges. While the city presents a rich environment for impactful research, investigators must be prepared to address potential hurdles in participant retention, data quality, and logistical operations. This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in navigating these complexities.
It is important to note that while a significant population-based health survey has been conducted in this compound by the University of São Paulo (USP) and the Federal University of Piauí (UFPI), detailed public data on the specific challenges of longitudinal data collection in the city is limited.[1] Therefore, this guide synthesizes common challenges encountered in longitudinal studies across Brazil and provides proactive strategies for researchers in this compound.
Frequently Asked Questions (FAQs)
Q1: What are the most common reasons for participant dropout in Brazilian longitudinal studies?
Participant attrition is a primary challenge.[2] Key factors include:
-
Socioeconomic Pressures: Competing demands related to work and family can make consistent participation difficult.
-
Health Status: Acute health crises, hospitalizations, or worsening of chronic conditions can impede involvement.[3]
-
Logistical Barriers: Transportation difficulties and the time commitment for follow-up visits are significant hurdles.[4]
-
Loss of Interest: Initial enthusiasm may wane over time, leading to consent withdrawal.[4]
Q2: How can I improve participant retention in my this compound-based study?
A participant-centric approach is crucial.[4] Strategies include:
-
Flexible Scheduling: Offer appointments at various times and, if feasible, locations.
-
Clear Communication: Maintain regular contact through phone calls or messages to show appreciation and provide study updates.
-
Community Engagement: Collaborate with local health units and community leaders to build trust and facilitate recruitment and retention.
-
Incentives: While respecting ethical guidelines, providing small, culturally appropriate incentives can acknowledge participants' time and effort.
Q3: What are the expected data quality issues in longitudinal health research in this region?
Researchers should anticipate potential issues with:
-
Missing Data: This is a common problem in longitudinal studies due to participant attrition or missed appointments.[3][5]
-
Measurement Inconsistency: Variations in data collection techniques over time or between different researchers can introduce errors.
-
Recall Bias: Participants may have difficulty accurately remembering past health events or behaviors.[6]
-
Data Entry Errors: Manual data entry can lead to inaccuracies.
Troubleshooting Guides
Troubleshooting Participant Retention
| Issue | Potential Cause | Recommended Action |
| High initial dropout rate | Lack of understanding of study commitment; mistrust in the research process. | Enhance the informed consent process with clear, simple language. Engage community leaders to endorse the study. |
| Participants lost to follow-up | Change of address or phone number without notification. | Collect contact information for multiple family members or trusted neighbors at enrollment.[7] |
| Declining participation in later waves | Participant fatigue; perceived lack of personal benefit. | Provide participants with periodic, easy-to-understand summaries of the study's progress and importance. Offer free health checks or information as part of the study protocol. |
| Low engagement from specific demographics | Cultural or linguistic barriers; inconvenient study locations. | Employ research staff from the local community. Choose accessible data collection sites. |
Troubleshooting Data Quality
| Issue | Potential Cause | Recommended Action |
| Inconsistent measurements over time | Staff turnover; lack of standardized procedures. | Develop a detailed manual of operations for all data collection procedures.[7] Conduct regular training and certification for all research staff. |
| High volume of missing data | Inadequate follow-up with participants who miss appointments. | Implement a proactive rescheduling system. For critical data points, consider home visits if ethically and logistically feasible. |
| Systematic errors in data entry | Poorly designed data entry forms; lack of validation checks. | Use digital data capture tools with built-in validation rules. Implement a double-entry system for a subset of records to check for consistency. |
Experimental Protocols
While a specific longitudinal study protocol for this compound was not found in the search results, the following outlines a generalized methodology for a prospective cohort study, drawing on best practices from Brazilian research, such as the Brazilian Longitudinal Study of Aging (ELSI-Brazil) and the health survey conducted in this compound.[1][7]
Protocol: A Prospective Cohort Study on Chronic Disease Risk Factors in this compound
-
Study Population: A representative sample of adults aged 30-69 residing in urban areas of this compound, selected through a multi-stage cluster sampling approach.
-
Baseline Data Collection:
-
Household Interview: Collection of demographic, socioeconomic, and housing condition data.
-
Individual Interview: A comprehensive questionnaire covering lifestyle (diet, physical activity, smoking, alcohol consumption), medical history, and use of health services.
-
Physical Measurements: Anthropometric measurements (weight, height, waist circumference), blood pressure, and grip strength.
-
Biological Samples: Collection of blood and urine samples for biochemical analysis and storage for future research.
-
-
Follow-up Data Collection (every 3-4 years):
-
Repeat all baseline interviews and physical measurements.
-
Monitor changes in health status, including the incidence of chronic diseases, through self-reporting and linkage with local health databases.
-
Collect new biological samples at specific intervals.
-
-
Quality Control:
Visualizations
References
- 1. Pesquisa investiga saúde e nutrição em cidades do Piauí - ASBRAN [asbran.org.br]
- 2. Strategies for participant retention in long term clinical trials: A participant –centric approaches - PMC [pmc.ncbi.nlm.nih.gov]
- 3. proceedings.open.tudelft.nl [proceedings.open.tudelft.nl]
- 4. Recruitment and retention of participants in clinical studies: Critical issues and challenges - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Recruitment and retention of the participants in clinical trials: Challenges and solutions - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. The Brazilian Longitudinal Study of Aging (ELSI-Brazil): Objectives and Design - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Optimizing Urban Planning for Sustainable Growth in Teresina
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) for researchers, scientists, and urban planning professionals engaged in optimizing Teresina's urban planning strategies for sustainable growth. The information is presented in a question-and-answer format to directly address specific issues encountered during research and implementation.
Frequently Asked Questions (FAQs)
Q1: What are the primary challenges to sustainable urban growth in this compound?
A1: this compound faces a confluence of climatic, social, and economic challenges. The city is one of the hottest in Brazil and is highly vulnerable to the impacts of climate change, including extreme heatwaves and flooding.[1][2][3] This is exacerbated by rapid and often unplanned urbanization, leading to significant vegetation loss and the expansion of impermeable surfaces, which intensifies the urban heat island effect.[4][5]
Socio-economically, the city grapples with significant inequality, with vulnerable populations often residing in high-risk areas with inadequate infrastructure.[1][3] Urban sprawl is a major concern, increasing travel distances and putting a strain on public transportation systems.[6] Furthermore, there are challenges related to institutional coordination and securing sufficient funding for sustainable development projects.[1]
Q2: What are the key official plans and programs guiding sustainable urban development in this compound?
A2: this compound has several key initiatives aimed at fostering sustainable growth:
-
This compound 2030 Agenda: This is a comprehensive municipal plan that aligns the city's development goals with the United Nations' Sustainable Development Goals (SDGs). It emphasizes a multi-sectoral approach to address urban challenges.[2]
-
Climate Action Plan: Launched in October 2023, this plan outlines strategies for both mitigating greenhouse gas emissions and adapting to the impacts of climate change, with a focus on building resilience.[2]
-
Lagoas do Norte Program: This is a major urban and environmental requalification project focused on the northern region of this compound. It includes actions to mitigate flooding, improve sanitation and housing, and create green spaces.[7]
-
Urban Mobility Plan: this compound has been working on improving its public transportation system, including the implementation of a Bus Rapid Transit (BRT) system, to address the challenges of urban sprawl and improve accessibility.[6][8][9][10]
Q3: Where can I find quantitative data for my research on this compound's urban development?
A3: While a centralized, real-time database can be challenging to locate, several sources provide valuable quantitative data. The Brazilian Institute of Geography and Statistics (IBGE) is the primary source for census data on population, demographics, and housing.[11][12][13] Reports from organizations like the MobiliseYourCity Partnership and the Urban Resilience Hub offer specific data points on urban mobility, land use, and environmental indicators.[4][8][9] For specific datasets, it may be necessary to contact municipal secretariats directly, such as the Municipal Secretariat of Planning and Coordination (SEMPLAN).
Troubleshooting Guides
Issue: Difficulty in obtaining up-to-date and granular data for urban analysis.
Solution:
-
Start with Official Sources: Begin by thoroughly searching the websites of the this compound Municipal Government, the government of the state of Piauí, and the Brazilian Institute of Geography and Statistics (IBGE).
-
Direct Contact: Do not hesitate to contact the relevant municipal secretariats, such as SEMPLAN or the Municipal Secretariat for the Environment (SEMAM), to request specific datasets. Clearly articulate the purpose of your research and the data you require.
-
Remote Sensing as an Alternative: When official data is unavailable or outdated, consider using remote sensing data from sources like Landsat or Sentinel to analyze land use change, vegetation cover, and urban heat island effects.
Issue: Models of urban climate (e.g., urban heat island) are not accurately reflecting local conditions.
Solution:
-
Refine Input Data: The accuracy of urban climate models heavily depends on the quality of the input data. Ensure your land use/land cover maps are of high resolution and accurately differentiate between different types of urban surfaces (e.g., asphalt, concrete, green roofs).
-
Incorporate Local Building Materials: this compound's building materials and construction styles can influence thermal properties. If possible, incorporate data on common roofing materials and building densities into your model.
-
Calibrate with In-Situ Measurements: If available, use data from local weather stations to calibrate your model. Even a small number of ground-truth data points can significantly improve accuracy.
-
Account for Water Bodies: this compound is situated between two rivers, the Parnaíba and the Poti. Ensure your model accurately represents the cooling effect of these water bodies.
Data Presentation
Table 1: Population and Urban Area Dynamics in this compound
| Indicator | Value | Year | Source |
| Urban Population | 821,364 | 2022 | IBGE[11] |
| Metro Area Population | 1,069,000 | 2025 (est.) | Macrotrends[14] |
| Municipality Population | 905,692 | 2025 (est.) | IBGE[12] |
| Urban Area | 274.3 km² | 2022 | IBGE[11] |
| Municipality Area | 1,391 km² | 2025 | IBGE[12] |
| Urban Population Density | 2,995/km² | 2022 | IBGE[11] |
| Annual Population Change | 0.57% | 2010-2022 | IBGE[11] |
Table 2: Transportation Modal Share in Greater this compound (2008)
| Mode of Transport | Percentage |
| Walking | 32.6% |
| Private Cars | 24.8% |
| Formal Public Transport | 21.3% |
| Cycling | 11.8% |
| Private Motorbikes/2-wheelers | 5.8% |
| (Source: MobiliseYourCity Partnership, based on the 2008 Master Plan for Transport and Urban Mobility)[6][8][9][10] |
Table 3: Key Environmental and Socio-Economic Indicators
| Indicator | Value | Year(s) | Source |
| Loss of Tree Cover in Urban Perimeter | ~40% | 2001-2019 | Urban Resilience Hub[4] |
| Urban Green Area per Capita | 13.43 ha/1,000 inhabitants | 2022 | Urban Resilience Hub[15] |
| Green Area Index per Inhabitant (Center/North Zone) | 15.9 m²/inhabitant | 2020 | Resende et al.[7] |
| GDP per Capita | US$ 6,729 | 2010 | MobiliseYourCity Partnership |
| Gini Index | 0.6171 | 2010 | Transformative Urban Coalitions[1] |
Experimental Protocols
Methodology 1: Participatory Mapping for Urban Planning
This protocol outlines a general methodology for conducting participatory mapping workshops to gather community input for urban planning projects in this compound.
-
Objective Definition: Clearly define the goals of the mapping exercise. This could be identifying areas of risk (e.g., flooding), mapping community assets, or co-designing public spaces.
-
Stakeholder Identification and Engagement: Identify and invite a diverse group of community members, including residents from different age groups and socio-economic backgrounds, community leaders, and local business owners.
-
Workshop Facilitation:
-
Introduction: Explain the purpose of the workshop and the mapping process.
-
Base Map Provision: Provide large-format printed maps of the neighborhood or area of interest. These maps should be simple and easy to understand.
-
Mapping Exercise: Using colored markers, stickers, and notes, ask participants to identify and mark various features on the maps based on the workshop's objectives. This could include:
-
Areas of frequent flooding
-
Unsafe areas
-
Locations of important community assets (e.g., schools, health centers, markets)
-
Desired locations for new infrastructure (e.g., parks, bus stops)
-
Daily travel routes
-
-
Group Discussion and Prioritization: Facilitate discussions around the maps, allowing participants to explain their markings and collectively prioritize issues and proposals.
-
-
Data Digitization and Analysis:
-
Photograph all the physical maps created during the workshop.
-
Digitize the collected data using Geographic Information System (GIS) software. This involves transcribing the points, lines, and polygons from the physical maps into a digital format.
-
-
Feedback and Validation: Present the digitized maps and a summary of the findings back to the community for validation and further input.
Methodology 2: Urban Heat Island Analysis using Remote Sensing
This protocol provides a basic workflow for analyzing the urban heat island (UHI) effect in this compound using satellite imagery.
-
Data Acquisition:
-
Download Landsat or Sentinel-2 satellite imagery for this compound for the desired time period. Select cloud-free images, preferably from the hottest months.
-
Obtain a Digital Elevation Model (DEM) for the study area.
-
-
Data Pre-processing:
-
Radiometric Calibration: Convert the digital numbers (DNs) of the satellite images to at-sensor radiance.
-
Atmospheric Correction: Correct for the effects of the atmosphere to obtain surface reflectance.
-
-
Land Surface Temperature (LST) Retrieval:
-
Calculate the Land Surface Emissivity (LSE) from the land use/land cover classification.
-
Use the thermal bands of the satellite imagery and the calculated LSE to retrieve the Land Surface Temperature.
-
-
Land Use/Land Cover (LULC) Classification:
-
Perform a supervised or unsupervised classification of the satellite imagery to create a LULC map of this compound. Key classes should include urban built-up areas, vegetation, water bodies, and bare soil.
-
-
UHI Analysis:
-
Overlay LST and LULC: Overlay the LST map with the LULC map to analyze the relationship between surface temperature and different land cover types.
-
Calculate UHI Intensity: Compare the average LST of the urban built-up areas with the average LST of surrounding rural or vegetated areas to quantify the UHI intensity.
-
Spatial Analysis: Analyze the spatial distribution of high temperatures within the urban area to identify heat hotspots.
-
Mandatory Visualization
Caption: A workflow for sustainable urban planning in this compound.
Caption: Workflow for Urban Heat Island analysis using remote sensing.
Caption: A logical pathway for increasing community engagement in urban planning.
References
- 1. urbancoalitions.org [urbancoalitions.org]
- 2. How this compound is Accelerating its Transition to a Green and Resilient City | UrbanShift [shiftcities.org]
- 3. urbancoalitions.org [urbancoalitions.org]
- 4. urbanresiliencehub.org [urbanresiliencehub.org]
- 5. publicacoes.amigosdanatureza.org.br [publicacoes.amigosdanatureza.org.br]
- 6. mobiliseyourcity.net [mobiliseyourcity.net]
- 7. periodicos.ufpi.br [periodicos.ufpi.br]
- 8. mobiliseyourcity.net [mobiliseyourcity.net]
- 9. mobiliseyourcity.net [mobiliseyourcity.net]
- 10. mobiliseyourcity.net [mobiliseyourcity.net]
- 11. This compound (this compound, Piauí, Brazil) - Population Statistics, Charts, Map, Location, Weather and Web Information [citypopulation.de]
- 12. This compound (Municipality, Brazil) - Population Statistics, Charts, Map and Location [citypopulation.de]
- 13. This compound (PI) | Cidades e Estados | IBGE [ibge.gov.br]
- 14. macrotrends.net [macrotrends.net]
- 15. urbanresiliencehub.org [urbanresiliencehub.org]
Technical Support Center: Sanitation & Waste Management Research, Teresina
This center provides troubleshooting guides, frequently asked questions (FAQs), and standardized protocols for researchers and scientists conducting experiments to improve sanitation and waste management systems in Teresina.
Section 1: Troubleshooting Guides & FAQs
This section addresses common issues encountered during field experiments and pilot projects.
Experiment: Community-Based Recycling Pilot Program
Question: We launched a door-to-door separate collection pilot in two neighborhoods. Neighborhood A has a 40% participation rate, while Neighborhood B has less than 10%. How do we troubleshoot this low participation in Neighborhood B?
Answer: Low participation in recycling programs is a common challenge stemming from logistical, social, or educational factors.[1][2] A systematic approach is required to diagnose and address the issue.
-
Initial Diagnosis:
-
Verify Service Consistency: Confirm that collection schedules in Neighborhood B are as regular and well-communicated as in Neighborhood A. Inconsistent service quickly erodes public trust and participation.
-
Conduct Observational Analysis: Use transect walks to observe the presence and use of recycling bins. Are they being used for mixed waste? Are they overflowing? This provides qualitative data on user behavior.[3]
-
Administer Targeted Surveys: Deploy short surveys or conduct key informant interviews in Neighborhood B to directly ask residents about barriers.[3][4] Questions should cover:
-
Awareness of the program and collection schedule.
-
Clarity on which materials are recyclable.
-
Convenience of the collection process.
-
Motivation and perceived value of recycling.
-
-
-
Common Causes & Solutions:
-
Problem: Lack of awareness or understanding.
-
Solution: Intensify the educational campaign in Neighborhood B. Use local community leaders, door-to-door informational flyers, and community meetings to explain the "how" and "why" of the program.
-
-
Problem: Logistical Barriers (e.g., inconvenient collection times, insufficient bin capacity).
-
Solution: Adjust the collection schedule based on resident feedback. Offer larger or additional bins to households that consistently generate more recyclables. Inefficient collection routes can increase costs and lower service quality.[2]
-
-
Problem: Low Motivation / No Incentive.
-
Solution: Introduce a gamification or small incentive system. This could be a public recognition for the block with the highest participation or a small rebate system, if feasible. Financial barriers are a significant challenge for municipal waste management programs.[2]
-
-
Experiment: Municipal Solid Waste (MSW) Characterization Study
Question: Our collected waste samples for a characterization study show high moisture content, potentially skewing the weight data for paper and cardboard fractions. How do we correct for this?
Answer: High moisture content is a known variable, especially in tropical climates like this compound's and during rainy seasons. It can significantly affect the weight-based composition data. Standard methodologies exist to account for this.[5]
-
Troubleshooting Steps:
-
Record Weather Conditions: Always log the weather conditions on the day of sample collection.[6] This helps correlate moisture levels with environmental factors.
-
Standardize Sample Processing Time: Aim to sort and weigh samples as quickly as possible after collection to minimize changes due to decomposition or drying.
-
Measure Moisture Content: For each relevant material category (e.g., paper, organics, textiles), take a sub-sample for moisture content analysis. The standard protocol involves:
-
Weighing the wet sub-sample.
-
Drying it in an oven at a standard temperature (e.g., 105°C) until a constant weight is achieved.
-
Weighing the dry sample.
-
Calculating the moisture percentage: ((Wet Weight - Dry Weight) / Wet Weight) * 100.
-
-
Normalize Data: Use the calculated moisture content to report the material weights on a "dry weight" basis in your final data tables. This allows for accurate comparison across different samples and seasons.[5]
-
Question: What is the minimum representative sample size for an MSW characterization study at the this compound landfill?
Answer: For characterization purposes, representative sampling is a standard practice.[6] Various studies have established that a sample weight of approximately 100 kg is sufficient, as measurements do not vary significantly from those made on much larger samples from the same waste source.[6] Samples should be collected over several days to account for daily variations in waste composition.[6]
Section 2: Quantitative Data from Pilot Studies
The following tables represent hypothetical data from research experiments aimed at improving waste management in this compound. The city generates approximately 40,000 tons of waste per month.[7]
Table 1: Comparative Analysis of Two Recycling Collection Models
| Metric | Model A: Voluntary Drop-off Points (PEVs) | Model B: Door-to-Door Collection |
| Target Households | 2,000 | 2,000 |
| Operating Duration | 6 Months | 6 Months |
| Average Monthly Recyclables Collected (kg) | 1,200 kg | 4,500 kg |
| Contamination Rate | 25% | 12% |
| Estimated Operational Cost per Ton | R$ 350 | R$ 600 |
| Household Participation Rate | 15% | 42% |
Table 2: MSW Composition Analysis - this compound (Hypothetical) (Based on Brazilian national averages where city-specific data is unavailable)[8]
| Waste Category | Percentage by Weight (Wet) | Key Components | Potential Intervention |
| Organics | 51.5% | Food scraps, yard trimmings | Community composting, biodigesters for energy[8] |
| Paper & Cardboard | 13.5% | Packaging, newspapers, office paper | Enhanced separate collection, fiber recycling |
| Plastics | 14.0% | PET bottles, films, rigid plastics | Separate collection, partnerships with recycling co-ops |
| Glass | 2.5% | Bottles, jars | Drop-off points (PEVs), reuse programs |
| Metals | 2.0% | Aluminum cans, steel packaging | Collaboration with informal waste pickers, magnetic separation |
| Other/Rejects | 16.5% | Textiles, leather, hazardous waste | Public awareness campaigns, specialized disposal routes |
Section 3: Experimental Protocols
Protocol: Municipal Solid Waste (MSW) Characterization Study
This protocol outlines the methodology for determining the composition of unprocessed MSW, adapted from established standards like ASTM D5231-92.[9]
Objective: To quantify the constituent materials in this compound's municipal solid waste stream to inform the planning of recycling, composting, and waste-to-energy programs.[9]
Methodology:
-
Site Selection & Setup:
-
Designate a safe, flat, and demarcated sorting area at the this compound sanitary landfill, away from vehicle traffic.[6]
-
Set up a shaded area or canopy to protect the team from the elements.[6]
-
Arrange clearly labeled containers for each of the waste categories to be sorted (e.g., PET Plastic, Cardboard, Ferrous Metals).
-
-
Sampling Procedure:
-
Randomly select incoming waste delivery vehicles from different zones of the city (residential, commercial).
-
Log details for each vehicle: date, time, origin of waste, and weather conditions.[5][6]
-
Use a front-loader to extract a representative sample of approximately 100-120 kg from the center of the truck's discharged load.
-
Transport the sample to the designated sorting area.
-
-
Sorting & Data Collection:
-
Manually sort the entire 100 kg sample into the pre-labeled containers. This should be done by a team trained in identifying waste components.[6]
-
Once sorting is complete, weigh each container to determine the total weight of each material category.
-
Record the weights on a "Waste Characterization Summary Form."
-
Take sub-samples of relevant categories for moisture content analysis if required.
-
-
Data Analysis & Reporting:
-
Calculate the weight percentage of each material category relative to the total sample weight.
-
Aggregate the data from all samples to create an average waste composition profile.
-
Normalize data using a dry-weight basis if moisture content analysis was performed.
-
Summarize findings in a final report, highlighting the quantities of recoverable materials.
-
Section 4: Mandatory Visualizations
Experimental & Logistical Workflows
Caption: Experimental workflow for a Municipal Solid Waste (MSW) characterization study.
System Logic & Influencing Factors
Caption: Logical diagram of factors influencing the success of a sanitation program.
References
- 1. URBAN SOLID WASTE MANAGEMENT IN this compound-PI: AN ANALYSIS OF CHALLENGES AND GAPS | Editora Impacto Científico [periodicos.newsciencepubl.com]
- 2. nextbillion.ai [nextbillion.ai]
- 3. Evaluation - Humanitarian Sanitation Hub [sanihub.info]
- 4. SuSanA Library - Sustainable Sanitation Alliance - SuSanA [susana.org]
- 5. youtube.com [youtube.com]
- 6. icma.org [icma.org]
- 7. PLANO MUNICIPAL DE GESTÃO INTEGRADA DE RESÍDUOS SÓLIDOS DO MUNICÍPIO DE this compound – PIAUÍ – NORDESTE DO BRASIL – ISSN 1678-0817 Qualis B2 [revistaft.com.br]
- 8. Study shows how to improve management of municipal solid waste [agencia.fapesp.br]
- 9. scsengineers.com [scsengineers.com]
"addressing limitations in public health surveillance in Teresina"
This technical support center provides troubleshooting guidance and answers to frequently asked questions for researchers, scientists, and drug development professionals working with public health surveillance data in Teresina. Our goal is to help address common limitations and challenges encountered during data collection, submission, and analysis.
Frequently Asked Questions (FAQs)
Data Submission & System Errors
-
Q1: I am trying to submit a notifiable disease form in SINAN, but I am receiving an error message about missing information. What should I do?
-
A1: First, double-check that all mandatory fields on the notification form are complete. Common omissions include sociodemographic data, date of symptom onset, or location of occurrence. If all fields are filled, the error may be due to a data entry format issue. Ensure that dates are in the correct DD/MM/YYYY format and that all codes (e.g., for occupation or municipality) are correct. If the problem persists, contact the municipal health secretariat's technical support for SINAN.
-
-
Q2: I have entered the same patient twice in SINAN by mistake. How can I correct this?
-
A2: SINAN has a function to identify and manage duplicate records. Records with the same first and last name, date of birth, and sex are often flagged as potential duplicates. A surveillance technician can confirm if they are the same person and merge the records. If you identify a duplicate, do not attempt to delete it yourself. Instead, flag it for review by the system administrator or a designated surveillance technician who can follow the proper protocol for merging duplicate entries.[1]
-
-
Q3: The system is not accepting the date of diagnosis I am entering for a follow-up case. What could be the issue?
-
A3: For follow-up cases, such as transfers, the original diagnosis date and treatment start date should be maintained from the initial notification.[1] A new notification date should be used for the transfer record itself.[1] If you are entering a new diagnosis date for a transfer case, the system may reject it. Verify that you are using the correct dates as per the case history.[1]
-
Data Discrepancies & Validation
-
Q4: I have noticed a significant discrepancy between the number of cases in our local SINAN database and the data available on DataSUS for this compound. Why is this happening?
-
A4: This is a known issue due to challenges in the data transfer and consolidation process from the municipal (SINAN) to the national (DataSUS) level.[2] Reasons for these discrepancies can include failures in information submission, inconsistencies in system validations, and delays in data updates.[3] It is recommended to use the local SINAN database for the most up-to-date, albeit not nationally consolidated, information for your municipality. For broader analyses, be aware of these potential data losses, which can average around 42% for some conditions.[3]
-
-
Q5: How can I validate the completeness of the data I am working with?
-
A5: To validate data completeness, you can perform a cross-check of key variables for missing entries. For example, in a dataset of a specific disease, check the percentage of cases with missing information for "age," "sex," "municipality of residence," and "date of notification." High percentages of missing data can impact the reliability of your analysis. For some diseases, you can also cross-reference with other data sources, such as laboratory information systems, to identify underreporting.
-
Access & Reporting
-
Q6: I am a researcher from an external institution. How can I request access to anonymized public health surveillance data from this compound?
-
A6: Access to public health data is governed by the Brazilian Data Protection Law (LGPD).[4] Researchers can request access to anonymized data for study purposes.[4] The request should be formally submitted to the Municipal Health Foundation of this compound (Fundação Municipal de Saúde de this compound), detailing the scope of the research, the specific data required, and the ethical approval for the study.
-
-
Q7: Is there a way to generate standardized reports directly from SINAN for my research?
-
A7: Yes, SINAN has a reporting module that can generate various standardized reports. The SINAN Relatórios application allows for the creation of reports on indicators from the Pact for Health (Pacto pela Saúde), as well as reports on the regularity of data submission.[5] You can download and install this application to generate reports from your local SINAN database.[5]
-
Summary of Quantitative Data on Surveillance Limitations
| Limitation Category | Key Metrics | Geographic Scope | Source |
| Data Inconsistency | Average data loss of ~42% between SINAN and DataSUS for some conditions. | Brazilian Amazon Municipality | [3] |
| For 19 analyzed health conditions, 15 showed a decrease in cases between the two systems. | Brazilian Amazon Municipality | [3] | |
| Largest discrepancies observed for AIDS, syphilis in pregnant women, and dengue. | Brazilian Amazon Municipality | [3] | |
| Operational Capacity | Surveillance activities are conducted 24/7 in only 35.5% of municipalities. | Brazil (National Average) | [3][6] |
| Underreporting | High prevalence of underdiagnosis and underreporting for diseases like Chagas, particularly in rural areas. | Piauí, Brazil | [7] |
Experimental Protocol: Evaluating a Mobile Health (mHealth) Reporting Tool in this compound
Objective: To assess the effectiveness of a novel mHealth application in improving the timeliness and completeness of notifiable disease reporting by community health workers in this compound compared to the standard SINAN data entry process.
Methodology:
-
Study Design: A two-arm, cluster-randomized controlled trial.
-
Participants: Community health workers from 20 primary healthcare units in this compound. Units will be randomized into an intervention group (using the mHealth app) and a control group (using the standard SINAN reporting procedure).
-
Intervention: The intervention group will be trained on and provided with a smartphone-based application for real-time, offline-capable reporting of suspected notifiable diseases. The app will feature mandatory fields, standardized data entry formats, and automated reminders for follow-up.
-
Data Collection:
-
Timeliness: Measured as the time difference between the date of suspicion of a notifiable disease and the date of entry into the respective system (mHealth app or SINAN).
-
Completeness: Assessed by the percentage of mandatory fields correctly filled in the initial notification.
-
User Satisfaction: Evaluated through a standardized questionnaire administered to the community health workers in the intervention group at the end of the study period.
-
-
Data Analysis:
-
Independent t-tests will be used to compare the mean reporting timeliness between the intervention and control groups.
-
Chi-squared tests will be used to compare the proportion of complete reports between the two groups.
-
Descriptive statistics will be used to summarize user satisfaction scores.
-
-
Ethical Considerations: The study protocol will be approved by the relevant institutional review board. All participants will provide informed consent. Patient data will be anonymized.
Visualizations
Caption: Experimental workflow for evaluating the mHealth reporting tool.
Caption: Data flow from local to national surveillance systems and key limitations.
References
- 1. scielosp.org [scielosp.org]
- 2. The accuracy and consistency of public health data in Brazilian information systems: identification of gaps and challenges to be faced in a municipality in the Amazon region - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. The protection of health data in Brazil | International Bar Association [ibanet.org]
- 5. portalsinan.saude.gov.br [portalsinan.saude.gov.br]
- 6. skeenapublishers.com [skeenapublishers.com]
- 7. What is the National Health Surveillance System (SNVS) in Brazil? [freyrsolutions.com]
Technical Support Center: Overcoming Barriers to Climate Adaptation in Teresina
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, policymakers, and climate resilience professionals in navigating the complexities of implementing climate adaptation policies in Teresina, Brazil.
Troubleshooting Guides
This section addresses specific challenges that may be encountered when designing and implementing climate adaptation strategies in this compound.
Problem: Insufficient Funding for Climate Adaptation Projects
Symptoms:
-
Inability to secure capital for planned climate initiatives.
-
Heavy reliance on external and often unpredictable funding sources.[1]
-
Projects stalling or being descoped due to financial constraints.
Troubleshooting Steps:
-
Diversify Funding Sources: Explore a multi-pronged approach to financing that combines municipal, federal, and international funds. This compound has a history of depending on federal transfers and international loans.[1]
-
Access Climate Finance Mechanisms: Leverage platforms like the UrbanShift Finance Academy to connect with financers such as the City Climate Finance Gap Fund. This can provide insights into best practices for attracting investment in adaptation and resilience projects.[2]
-
Develop Bankable Projects: Structure climate adaptation projects to be attractive to national and international banks. This compound's high score on the national index of payment capacity makes it eligible for such loans.[1]
-
Implement Payment for Environmental Services (PES): Launch municipal PES programs focused on urban and peri-urban areas to create innovative funding streams for the conservation of watersheds, which is crucial for climate resilience.[3]
Problem: Lack of Inter-Agency Coordination and Integrated Governance
Symptoms:
-
Climate adaptation is treated as the sole responsibility of specific departments (e.g., urban planning, environment) rather than a cross-cutting issue.[1]
-
Policies and plans for climate adaptation are poorly integrated with other municipal strategies.[4]
-
Conflicting priorities and actions among different government bodies.
Troubleshooting Steps:
-
Establish a Centralized Coordination Body: Create a dedicated entity, such as this compound's Agenda 2030, to lead a multidisciplinary team in generating and implementing climate action ideas.[2] This body should be responsible for ensuring that climate resilience is integrated across all municipal departments.
-
Promote Vertical and Horizontal Integration: Foster collaboration between different levels of government (local, state, federal) and across various municipal secretariats. The this compound Urban Resilience Program successfully mobilized 14 municipal secretariats, which can serve as a model.[5]
-
Utilize International Partnerships: Engage with global networks like C40 Cities and UN-Habitat's City Resilience Global Programme to gain technical support and learn from the experiences of other cities in integrating climate action plans.[2][5]
-
Develop a Unified Climate Action Plan: Consolidate various climate-related initiatives under a single, comprehensive Climate Action Plan. This compound launched its plan in October 2023, which was accelerated through participation in courses on Integrated Climate Action Planning.[2]
Frequently Asked Questions (FAQs)
A list of frequently asked questions to clarify common issues related to climate adaptation policy in this compound.
-
Q1: What are the most significant climate-related challenges facing this compound? A1: this compound is highly vulnerable to the impacts of climate change.[6] Key challenges include extreme heat, as the city is warming at a rate twice the global average, and recurrent flooding, particularly in vulnerable, low-income neighborhoods.[1][7][8][9] Other significant issues include the disruption of the natural water cycle, loss of urban green spaces leading to a "heat island effect," and the potential for increased climate-induced migration from surrounding rural areas.[1][2][6][7][8]
-
Q2: How does social inequality impact climate adaptation efforts in this compound? A2: Social and racial injustice are deeply intertwined with urban development in this compound.[1][7] Vulnerable populations, including Black, Indigenous, and People of Color (BIPOC) communities, often reside in low-income neighborhoods situated in high-risk areas such as flood plains.[1][7][8] This unequal distribution of vulnerability means that the impacts of climate change disproportionately affect those with the least capacity to adapt.[1] Therefore, effective climate action in this compound must explicitly address both racial and climate justice.[1][7]
-
Q3: What is the "this compound 2030 Agenda"? A3: The this compound 2030 Agenda is a municipal strategy designed to align the city's policies with the climate goals of the Paris Agreement.[2] It serves as a coordinating body to build climate resilience across the city, with a particular focus on its most vulnerable residents.[2] The Agenda's coordinator leads a team in developing and implementing ideas for strengthening climate action policies and securing support from local, national, and international partners.[2]
-
Q4: Are there successful examples of community-led adaptation initiatives in this compound? A4: Yes. The "Women For Climate Workshop" is a notable initiative that employs a bottom-up approach to address the challenges faced by women in vulnerable communities due to extreme heat and socioeconomic disparities.[10] Additionally, community gardens, such as the Dirceu Community Garden, have been established to enhance food security, provide income for hundreds of families, and contribute to the city's green infrastructure.[8]
Data and Methodologies
Table 1: Summary of Key Barriers to Climate Adaptation in this compound
| Barrier Category | Specific Obstacles | Key Impacts |
| Financial | Insufficient municipal funds; Heavy dependence on external transfers; Difficulty in fundraising for sustainable actions.[1][6] | Delayed or canceled projects; Inability to scale up successful initiatives. |
| Governance | Lack of integrated, cross-departmental strategy; Poor coordination between government levels; Climate action not seen as a priority.[1][4] | Fragmented and inefficient policy implementation; Conflicting sectoral policies. |
| Socio-Cultural | Perception of a conflict between development and climate action; Deep-seated social and racial inequalities.[1][7] | Disproportionate impact on vulnerable communities; Lack of public buy-in for adaptation measures. |
| Technical & Informational | Deficit in climate-related technical knowledge within government; Lack of robust municipal climate data.[1][6] | Policies not based on the best available science; Difficulty in monitoring and evaluation. |
Methodology: Implementing a Socially Just Climate Adaptation Project
This protocol outlines a methodological approach for designing and implementing climate adaptation projects in this compound that prioritize social equity.
-
Vulnerability Mapping:
-
Community Engagement:
-
Integrated Project Design:
-
Monitoring and Evaluation:
-
Establish clear metrics to track both the climate resilience and social equity outcomes of the project.
-
Regularly report progress to community stakeholders and adapt the project based on feedback and changing conditions.
-
Visualizations
Diagram 1: Logical Flow for Overcoming Financial Barriers
Caption: Overcoming financial barriers to climate adaptation in this compound.
Diagram 2: Integrated Governance Workflow for Climate Action
Caption: Workflow for integrated climate governance in this compound.
References
- 1. urbancoalitions.org [urbancoalitions.org]
- 2. How this compound is Accelerating its Transition to a Green and Resilient City | UrbanShift [shiftcities.org]
- 3. m.youtube.com [m.youtube.com]
- 4. intellinews.com [intellinews.com]
- 5. urbanresiliencehub.org [urbanresiliencehub.org]
- 6. urbanresiliencehub.org [urbanresiliencehub.org]
- 7. urbancoalitions.org [urbancoalitions.org]
- 8. iied.org [iied.org]
- 9. m.youtube.com [m.youtube.com]
- 10. UN-Habitat programme contributes to climate mitigation, resiliency in Brazil | UN-Habitat [unhabitat.org]
Technical Support Center: Refining Vector Control Methodologies for Visceral Leishmaniasis in Teresina
This technical support center provides troubleshooting guides, frequently asked questions (FAQs), and detailed experimental protocols for researchers, scientists, and drug development professionals working on vector control strategies for visceral leishmaniasis (VL) in Teresina, Brazil. The primary vector of VL in this region is the sand fly, Lutzomyia longipalpis.
Frequently Asked Questions (FAQs) and Troubleshooting Guides
This section addresses common issues encountered during key experimental procedures for VL vector control research.
CDC Bottle Bioassay for Insecticide Susceptibility
Q1: My control bottle shows mortality. What should I do?
A1: If mortality in the control bottle (coated with acetone (B3395972) only) is between 5% and 20%, you should correct the mortality rates of the insecticide-exposed groups using Abbott's formula. If control mortality exceeds 20%, the entire assay is considered invalid and must be repeated. Potential causes for control mortality include rough handling of the sand flies, exposure to extreme temperatures, or contamination of the acetone or bottles.
Q2: I am seeing inconsistent results between replicates of the same insecticide concentration. What could be the cause?
A2: Inconsistent results can stem from several factors:
-
Uneven coating of bottles: Ensure the insecticide solution completely and evenly coats the interior surface of the bottle. Roll and rotate the bottle until the acetone has fully evaporated.
-
Insecticide degradation: Use freshly prepared insecticide dilutions for each assay. Older solutions may have degraded, leading to lower mortality.
-
Sand fly condition: Use sand flies of a consistent age and physiological state (e.g., non-blood-fed females). Variation in age or nutritional status can affect susceptibility.
-
Environmental conditions: Maintain a consistent temperature and humidity during the assay, as these can influence sand fly activity and insecticide efficacy.
Q3: Why are the sand flies in the insecticide-treated bottles still alive after the recommended exposure time?
A3: This could indicate insecticide resistance in the sand fly population. If mortality is low across all diagnostic concentrations, it is a strong indicator of resistance. To confirm, you should:
-
Verify your insecticide concentrations and preparation procedures.
-
Ensure the correct exposure time was used for the specific insecticide and sand fly species.
-
Test a known susceptible sand fly population as a positive control to validate the assay's effectiveness.
Q4: The sand flies appear dead during the exposure period but recover after being transferred to recovery containers. How should I interpret this?
A4: This phenomenon is known as "knockdown" and is common with pyrethroid insecticides. It is crucial to record mortality after a 24-hour recovery period to get an accurate measure of the insecticide's lethal effect. Final mortality readings should always be taken at 24 hours post-exposure.
Canine Serology using ELISA
Q1: My ELISA plate has high background noise across all wells. What is the problem?
A1: High background can be caused by several factors:
-
Insufficient washing: Ensure that wells are washed thoroughly between each step to remove unbound reagents.
-
Over-concentrated reagents: The concentrations of the secondary antibody or the enzyme conjugate may be too high. Titrate these reagents to find the optimal concentration.
-
Inadequate blocking: The blocking buffer may not be effective, or the incubation time may be too short. Try a different blocking agent or increase the blocking time.
-
Cross-reactivity: If using a crude antigen preparation, there may be cross-reactivity with other antibodies in the dog serum. Consider using a more specific recombinant antigen.[1]
Q2: I am getting weak or no signal in my positive control wells.
A2: This suggests a problem with one of the assay components or steps:
-
Reagent degradation: The antigen, antibodies, or enzyme conjugate may have lost activity due to improper storage or being past their expiration date.
-
Incorrect reagent preparation: Double-check all dilution calculations and ensure that all reagents were prepared correctly.
-
Substrate inactivity: The enzyme substrate may be inactive. Prepare fresh substrate for each assay.
-
Omission of a step: Ensure that all incubation steps were performed in the correct order and for the recommended duration.
Q3: There is high variability between duplicate wells for the same sample.
A3: This is often due to technical errors in pipetting or washing:
-
Pipetting inconsistency: Ensure accurate and consistent pipetting of all reagents and samples. Use calibrated pipettes and fresh tips for each sample.
-
Incomplete washing: Inconsistent washing can leave residual reagents in some wells, leading to variable results. An automated plate washer can improve consistency.
-
Edge effects: The outer wells of the plate can sometimes show different results due to temperature variations. Avoid using the outermost wells for critical samples if this is a recurring issue.
Sand Fly Collection with CDC Light Traps
Q1: I am not catching a sufficient number of Lutzomyia longipalpis. How can I improve my capture rate?
A1: Low capture rates can be due to several factors related to trap placement and timing:
-
Trap location: Place traps in areas where sand flies are known to rest or seek hosts, such as near chicken coops, animal shelters, or in the peridomestic environment with dense vegetation.[2]
-
Trap height: Position the trap opening approximately 1.5 meters above the ground.
-
Time of night: Operate the traps from dusk until dawn, as this is the peak activity period for Lutzomyia longipalpis.
-
Environmental conditions: Avoid placing traps in areas with strong winds, heavy rain, or competing light sources, as these can reduce trap efficiency.[3]
Q2: The collected sand flies are damaged, making identification difficult.
A2: To minimize damage to specimens:
-
Use a fine-mesh collection bag to prevent sand flies from passing through.
-
Ensure the collection bag is not overly crowded, which can happen with very high capture rates. In such cases, collect the trap earlier in the night.
-
Handle the collection bags and specimens gently during transport and processing.
Q3: How do I properly preserve the collected sand flies for later identification?
A3: For morphological identification, preserve the sand flies in 70-80% ethanol (B145695). For molecular analysis, such as DNA barcoding, specimens can be preserved in 95-100% ethanol or stored dry at -20°C or -80°C.
Data Presentation
Table 1: Efficacy of Vector and Reservoir Control Interventions on Human Leishmania infantum Infection in this compound
| Intervention | Incidence of Infection (MST Conversion) | Relative Risk (95% CI) | Effectiveness |
| Dog Culling Only | 27.0% | 0.73 (0.54 - 0.98) | 27% |
| Insecticide Spraying Only | 38.5% | 1.04 (0.80 - 1.35) | -4% |
| Combined Dog Culling & Spraying | 33.3% | 0.89 (0.68 - 1.17) | 11% |
| Control (No Intervention) | 37.1% | 1.00 (Reference) | 0% |
| Data adapted from a cluster randomized trial conducted in this compound.[4][5] |
Table 2: Canine Seroprevalence and Dog Culling Data in this compound
| Parameter | Value |
| Global Prevalence of Canine Infection (by IFAT) | 3.1% |
| Percentage of Seropositive Dogs Culled | 63.6% |
| Refusal Rate for Culling by Owners | 36.4% |
| Data from the same cluster randomized trial as Table 1.[4] |
Table 3: Diagnostic Doses and Times for Lutzomyia longipalpis Susceptibility to Various Insecticides (CDC Bottle Bioassay)
| Insecticide Class | Insecticide | Diagnostic Dose (µ g/bottle ) | Diagnostic Time (minutes) |
| Organophosphate | Malathion | 75 | 25 |
| Pyrethroid | Deltamethrin | 10 | 35 |
| Pyrethroid | Lambda-cyhalothrin | 15 | 30 |
| Data from a study on an experimental strain of L. longipalpis.[6] |
Experimental Protocols
Protocol: CDC Bottle Bioassay for Insecticide Susceptibility in Lutzomyia longipalpis
Objective: To determine the susceptibility of a Lutzomyia longipalpis population to a specific insecticide.
Materials:
-
Glass Wheaton bottles (250 ml) with caps
-
Technical grade insecticide
-
High-purity acetone
-
Micropipettes and tips
-
Vortex mixer
-
Bottle roller or manual rotation setup
-
Aspirator for handling sand flies
-
Recovery cups with mesh lids and a sugar source (e.g., cotton soaked in 10% sucrose (B13894) solution)
-
Timer
-
Personal protective equipment (gloves, lab coat, safety glasses)
Procedure:
-
Bottle Preparation:
-
Thoroughly clean and dry all bottles to remove any residues.
-
Prepare a stock solution of the insecticide in acetone. From this, prepare serial dilutions to determine the diagnostic dose, or use a known diagnostic dose for routine monitoring.[7]
-
-
Bottle Coating:
-
Pipette 1 ml of the desired insecticide/acetone solution (or acetone only for control bottles) into a bottle.
-
Cap the bottle and vortex for 10-15 seconds.
-
Roll and rotate the bottle on a bottle roller or by hand until the acetone has completely evaporated, leaving a uniform film of insecticide on the inner surface.
-
Leave the bottles uncapped in a fume hood for at least one hour to ensure all acetone has evaporated.
-
-
Sand Fly Exposure:
-
Collect 20-25 non-blood-fed female sand flies (2-5 days old) using an aspirator.
-
Gently introduce the sand flies into a coated bottle and replace the cap.
-
Start the timer immediately. The standard exposure time is typically 30 minutes to 1 hour, depending on the insecticide.
-
Observe the sand flies and record the time to knockdown if required.
-
-
Recovery Period:
-
After the exposure period, carefully transfer the sand flies from the bottle to a clean recovery cup.
-
Provide the sand flies with a 10% sucrose solution on a cotton pad.
-
Hold the recovery cups at a constant temperature and humidity, away from direct sunlight.
-
-
Mortality Reading:
-
After 24 hours, record the number of dead and alive sand flies. A sand fly is considered dead if it is immobile or unable to stand or fly.
-
-
Data Analysis:
-
Calculate the percentage mortality for each concentration.
-
If mortality in the control group is between 5% and 20%, correct the data using Abbott's formula: Corrected % Mortality = [1 - (n in T after treatment / n in C after treatment)] * 100
-
If control mortality is >20%, the assay is invalid.
-
Protocol: Indirect ELISA for Detection of Anti-Leishmania IgG in Canine Serum
Objective: To serologically detect Leishmania infantum infection in dogs.
Materials:
-
96-well microtiter plates (high-binding)
-
Leishmania infantum antigen (crude soluble antigen or recombinant protein)
-
Coating buffer (e.g., carbonate-bicarbonate buffer, pH 9.6)
-
Canine serum samples, positive and negative controls
-
Wash buffer (e.g., PBS with 0.05% Tween 20)
-
Blocking buffer (e.g., PBS with 5% non-fat dry milk)
-
Enzyme-conjugated secondary antibody (e.g., anti-dog IgG-HRP)
-
Substrate solution (e.g., TMB)
-
Stop solution (e.g., 2N H₂SO₄)
-
Microplate reader
Procedure:
-
Antigen Coating:
-
Dilute the Leishmania antigen to a pre-determined optimal concentration in coating buffer.
-
Add 100 µl of the diluted antigen to each well of the microtiter plate.
-
Incubate the plate overnight at 4°C.
-
-
Washing and Blocking:
-
Wash the plate three times with wash buffer.
-
Add 200 µl of blocking buffer to each well.
-
Incubate for 1-2 hours at room temperature.
-
-
Serum Incubation:
-
Wash the plate three times with wash buffer.
-
Dilute the canine serum samples (including positive and negative controls) in blocking buffer (a common starting dilution is 1:100).
-
Add 100 µl of the diluted serum to the appropriate wells.
-
Incubate for 1 hour at 37°C.
-
-
Secondary Antibody Incubation:
-
Wash the plate three times with wash buffer.
-
Dilute the enzyme-conjugated anti-dog IgG in blocking buffer to its optimal concentration.
-
Add 100 µl of the diluted secondary antibody to each well.
-
Incubate for 1 hour at 37°C.
-
-
Substrate Development:
-
Wash the plate five times with wash buffer.
-
Add 100 µl of the substrate solution to each well.
-
-
Incubate in the dark at room temperature for 10-15 minutes, or until sufficient color develops in the positive control wells.
-
Stopping the Reaction and Reading:
-
Add 50 µl of stop solution to each well to stop the reaction.
-
Read the absorbance (optical density or OD) of each well using a microplate reader at the appropriate wavelength (e.g., 450 nm for TMB).
-
-
Data Interpretation:
-
Calculate the cut-off value, typically as the mean OD of the negative controls plus 2 or 3 standard deviations.
-
Samples with an OD value above the cut-off are considered positive.
-
Protocol: Sand Fly Collection using CDC Light Traps
Objective: To collect Lutzomyia longipalpis for population density studies, species identification, or insecticide resistance monitoring.
Materials:
-
CDC miniature light traps
-
6V rechargeable batteries
-
Collection bags/cups
-
Aspirator
-
Cooler with ice packs for transport
-
GPS device for recording trap locations
Procedure:
-
Site Selection:
-
Identify potential sand fly habitats in the urban or peri-urban environment of this compound, such as backyards, gardens, and areas near animal shelters (especially chicken coops).[2]
-
-
Trap Setup:
-
In the late afternoon, before dusk, hang the CDC light trap with the opening about 1.5 meters above the ground.
-
Ensure the trap is sheltered from strong wind and rain.
-
Connect the trap to a fully charged 6V battery.
-
-
Trap Operation:
-
Turn on the trap at dusk (around 6:00 PM) and let it run overnight.
-
-
Trap Collection:
-
In the early morning, after dawn (around 6:00 AM), turn off and disconnect the trap.
-
Carefully remove the collection bag, ensuring it is sealed to prevent the escape of captured insects.
-
-
Sample Transport and Processing:
-
Place the collection bags in a cooler with ice packs to immobilize the insects and preserve them during transport to the laboratory.
-
In the lab, place the collection bags in a freezer for a short period to kill the insects.
-
Empty the contents onto a chilled tray or petri dish.
-
Separate the sand flies from other insects.
-
Identify Lutzomyia longipalpis based on morphological characteristics and count the number of males and females.[8]
-
Preserve the specimens appropriately for further analysis (e.g., in ethanol for morphology or molecular studies).
-
Mandatory Visualizations
Caption: Workflow for assessing insecticide susceptibility in Lutzomyia longipalpis.
Caption: Logical flow for canine visceral leishmaniasis surveillance and control.
Caption: A potential signaling pathway leading to metabolic resistance to pyrethroids.
References
- 1. cabidigitallibrary.org [cabidigitallibrary.org]
- 2. Lutzomyia longipalpis - Wikipedia [en.wikipedia.org]
- 3. pacmossi.org [pacmossi.org]
- 4. Effectiveness of Insecticide Spraying and Culling of Dogs on the Incidence of Leishmania infantum Infection in Humans: A Cluster Randomized Trial in this compound, Brazil - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Effectiveness of insecticide spraying and culling of dogs on the incidence of Leishmania infantum infection in humans: a cluster randomized trial in this compound, Brazil - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. scielo.org.co [scielo.org.co]
- 7. cdc.gov [cdc.gov]
- 8. scielo.br [scielo.br]
Technical Support Center: Mitigating the Urban Heat Island Effect in Teresina
This technical support center provides researchers, scientists, and urban planners with troubleshooting guides and frequently asked questions (FAQs) for experiments related to mitigating the urban heat island (UHI) effect in Teresina, Brazil. The content is designed to address specific issues that may be encountered during experimental design, data collection, and analysis in this compound's tropical climate.
Frequently Asked Questions (FAQs)
Q1: What are the primary causes of the Urban Heat Island (UHI) effect in this compound?
A1: The primary causes of the UHI effect in this compound are linked to rapid and often unplanned urbanization. Key factors include the extensive replacement of natural vegetation with impervious surfaces like asphalt (B605645) and concrete, which absorb and retain more solar radiation.[1][2] The densification of buildings can also trap heat and reduce airflow. Studies have shown a significant reduction in green spaces in this compound over the years, which directly correlates with an increase in urban temperatures.[3][4]
Q2: What are the most promising mitigation strategies for this compound's climate?
A2: Based on studies conducted in this compound and similar tropical climates, green infrastructure is the most widely recommended and studied mitigation strategy.[2][5][6] This includes increasing the tree canopy through afforestation and creating more green spaces like parks and squares. Another potential strategy is the use of cool pavements, which have high solar reflectivity, although specific studies on their effectiveness in this compound are limited.
Q3: How significant is the cooling effect of green spaces in this compound?
A3: While specific quantitative data across different strategies is still an area of ongoing research, studies in this compound have consistently shown that vegetated areas have lower air and surface temperatures compared to non-vegetated areas.[1][2] One study noted that in areas with afforestation, temperatures were lower in both shaded and sun-exposed spots.[6] For context, a study in Maceió, a Brazilian city with a similar climate, observed temperature differences of up to 2.5°C between areas with and without vegetation.
Q4: Is there a municipal plan in this compound to address the UHI effect?
A4: Yes, the municipality of this compound has developed a Plano Diretor de Arborização Urbana (Urban Afforestation Master Plan).[7][8][9] This plan aims to provide guidelines for the planning, implementation, and preservation of green areas to mitigate the UHI effect and improve the urban climate.[8] The plan was developed in partnership with federal entities and involved a detailed diagnosis of the city's existing vegetation cover.[8]
Experimental Protocols
Methodology for Assessing the Cooling Effect of Green Infrastructure
This protocol outlines a methodology for quantifying the cooling effect of green spaces in this compound, based on comparative studies conducted in the city and in similar climates.
1. Site Selection:
-
Identify pairs of study sites with similar urban morphology (e.g., street width, building height).
-
One site should have significant green cover (e.g., a park, a well-wooded street), and the other should be predominantly impervious surfaces (e.g., asphalt, concrete).
-
Ensure both sites are exposed to similar sun and wind conditions.
2. Instrumentation:
-
Utilize data loggers for continuous monitoring of air temperature and relative humidity (e.g., HOBO U23-001 Pro v2).
-
Employ a portable weather station to measure wind speed and direction.
-
Use an infrared thermometer for surface temperature measurements of different materials (asphalt, concrete, grass, tree canopy).
3. Data Collection:
-
Conduct measurements during this compound's dry season (August-November) when the UHI effect is most pronounced.
-
For a comprehensive analysis, collect data at different times of the day, for instance at 9:00, 15:00, and 21:00, to capture the thermal dynamics.[2]
-
Employ both fixed-point monitoring (placing data loggers at a standardized height, e.g., 1.5 meters, in the center of each study site) and mobile transects (walking a predefined route through both sites with portable sensors).
4. Data Analysis:
-
Calculate the average and maximum temperature differences between the green and non-green sites.
-
Correlate temperature data with land cover type (e.g., percentage of tree canopy, impervious surface area).
-
Analyze the impact of wind speed and direction on the cooling effect.
Data Presentation
Table 1: Comparative Temperature and Humidity in this compound Neighborhoods with Varying Green Cover
| Neighborhood | Predominant Land Cover | Average Air Temperature (Dry Season, 15:00) | Average Relative Humidity (Dry Season, 15:00) | Data Source Reference |
| Pedra Mole | Extensive Green Areas | Lower than other studied areas | Higher than other studied areas | Albuquerque & Lopes |
| Jóquei Clube | Intermediate Green Cover | Intermediate | Intermediate | Albuquerque & Lopes |
| Dirceu Arcoverde | Low Vegetation Cover | Highest among studied areas | Lowest among studied areas | Albuquerque & Lopes |
Note: This table is a qualitative summary based on the findings of Albuquerque & Lopes, as the original study did not provide a numerical data table.
Troubleshooting Guide
| Issue | Possible Cause | Recommended Solution |
| Inconsistent temperature readings from data loggers. | - Direct solar radiation on the sensor. - Proximity to a heat source (e.g., building exhaust). - Sensor malfunction. | - Use radiation shields for your sensors. - Ensure sensors are placed away from direct heat sources. - Calibrate sensors before deployment and check for battery issues. |
| Difficulty in isolating the effect of a single mitigation strategy. | - Confounding variables such as building shadows, traffic, and variations in urban geometry. | - Carefully select study sites to minimize differences in confounding variables. - Use statistical methods to control for the influence of other factors. - Document all site characteristics thoroughly. |
| Surface temperature readings are highly variable. | - Differences in material properties (albedo, emissivity). - Transient shadows from clouds or buildings. | - Take multiple readings for each surface type and calculate an average. - Note the time of day and cloud cover conditions for each measurement. - Use a thermal imaging camera for a more comprehensive view of surface temperature distribution. |
| Low wind speed affecting the dispersion of cool air from green spaces. | - this compound's climate is often characterized by low wind speeds, which can limit the cooling effect to the immediate vicinity of the green area. | - In your analysis, consider the "park cool island" effect as a localized phenomenon. - Measure the extent of the cooling effect by taking measurements at increasing distances from the green space. |
Visualizations
Experimental Workflow for UHI Mitigation Assessment
Caption: Workflow for assessing UHI mitigation strategies.
Logical Relationship for Troubleshooting Inconsistent Data
Caption: Troubleshooting inconsistent data collection.
References
- 1. ainfo.cnptia.embrapa.br [ainfo.cnptia.embrapa.br]
- 2. revistas.ufpr.br [revistas.ufpr.br]
- 3. sigaa.ufpi.br [sigaa.ufpi.br]
- 4. [PDF] CONSEQUÊNCIAS DA URBANIZAÇÃO NA VEGETAÇÃO E NA TEMPERATURA DA SUPERFÍCIE DE this compound – PIAUI | Semantic Scholar [semanticscholar.org]
- 5. unip.br [unip.br]
- 6. researchgate.net [researchgate.net]
- 7. m.youtube.com [m.youtube.com]
- 8. mpiaui.com.br [mpiaui.com.br]
- 9. ibeas.org.br [ibeas.org.br]
Technical Support Center: Hydrological Model Accuracy for Teresina's Rivers
This technical support center provides troubleshooting guidance, frequently asked questions (FAQs), and detailed protocols for researchers and scientists focused on improving the accuracy of hydrological models for the Parnaíba and Poti rivers in Teresina.
Troubleshooting Guide
This section addresses specific issues that may arise during the setup, calibration, and validation of hydrological models for this compound's river systems.
Q1: My model simulation results in a "Mass Balance Error" or becomes unstable. What are the common causes and solutions?
A1: Mass balance errors or model instability often point to issues with input data or parameterization.
-
Cause 1: Time Step Issues: The chosen time step (e.g., daily, hourly) may be too large for the model to accurately capture rapid hydrological processes, especially during intense, short-duration rainfall events common in this compound's climate.
-
Solution 1: Decrease the simulation time step. For flashy catchments like the Poti River, an hourly time step might be necessary to capture peak flows accurately.
-
Cause 2: Input Data Errors: Precipitation or discharge data may contain significant errors, gaps, or inconsistencies. For instance, a faulty rain gauge can lead to unrealistic input, causing the model to fail.
-
Solution 2: Conduct rigorous quality control on all input data. Use data-filling techniques for missing values and cross-validate data from multiple sources where possible.
-
Cause 3: Parameterization: Certain parameter values might be outside of a realistic range, leading to numerical instability. This is common during automated calibration if parameter bounds are not set appropriately.
-
Solution 3: Constrain parameter ranges based on literature values or direct measurements from the Parnaíba and Poti river basins. Perform a sensitivity analysis to identify the most influential parameters and focus calibration efforts on them.
Q2: My model performs well during calibration but shows poor results in the validation period. How can I fix this?
A2: This issue, known as "overfitting," occurs when the model is too closely tuned to the calibration dataset and fails to represent the general hydrological behavior of the catchment.
-
Cause 1: Non-representative Calibration Data: The calibration period might not include a sufficient variety of hydrological conditions (e.g., it only contains average flow years but no extreme wet or dry years).
-
Solution 1: Employ a "split-sample" testing approach where you calibrate and validate the model on different periods. Ensure both periods cover a similar range of hydrological events. For the Parnaíba basin, which has distinct wet and dry seasons, ensure both are well-represented in calibration and validation datasets.
-
Cause 2: Model Structure Complexity: The model might be too complex for the available data, capturing noise instead of the underlying hydrological processes.
-
Solution 2: Simplify the model structure if possible. Alternatively, use a different calibration objective function that penalizes model complexity.
-
Cause 3: Changing Catchment Conditions: Land use or climate changes between the calibration and validation periods can alter the hydrological response of the catchment.
-
Solution 3: Update model input data (e.g., land use maps) to reflect the conditions of the validation period. If significant trends are present, consider using a non-stationary modeling approach.
Frequently Asked Questions (FAQs)
Q1: Which hydrological model is best suited for the Parnaíba and Poti river basins?
A1: The choice of model depends on the specific research objective and data availability.
-
For detailed, physically-based process modeling: Distributed models like SWAT (Soil and Water Assessment Tool) are often used. They can account for spatial variability in soil, land use, and topography, which is important in the diverse Parnaíba basin.
-
For event-based flood forecasting: Lumped or semi-distributed models like HEC-HMS (Hydrologic Engineering Center's Hydrologic Modeling System) can be effective and computationally less demanding.
-
For data-scarce regions: Conceptual models with fewer parameters may be more robust.
Q2: Where can I find reliable meteorological and hydrological data for this compound?
A2: Several national and global sources provide data, though local data often requires direct requests.
-
National Sources: The Brazilian National Water Agency (ANA) and the National Institute of Meteorology (INMET) are primary sources for historical discharge and meteorological data.
-
Global Datasets: Satellite-based precipitation products (e.g., TRMM, GPM) can be valuable, especially in areas with sparse rain gauge networks. However, these should always be validated against ground-based observations.
Q3: How do I interpret model performance metrics like NSE and PBIAS?
A3: The Nash-Sutcliffe Efficiency (NSE) and Percent Bias (PBIAS) are common metrics for evaluating hydrological models.
-
NSE: Measures how well the simulated versus observed data fit a 1:1 line. NSE ranges from -∞ to 1. An NSE of 1 indicates a perfect match. An NSE > 0.5 is generally considered acceptable.
-
PBIAS: Measures the average tendency of the simulated data to be larger or smaller than the observed data. A PBIAS of 0 is ideal. Positive values indicate model underestimation, while negative values indicate overestimation. A PBIAS between ±10% is often considered very good.
Detailed Experimental Protocols
Protocol 1: Hydrological Model Calibration and Validation
This protocol outlines the steps for calibrating and validating a hydrological model for a river basin in this compound.
-
Objective Definition: Clearly define the goal (e.g., accurate simulation of low flows, peak flood events, or overall water balance).
-
Data Partitioning: Divide the historical time series of hydro-meteorological data into at least two independent sets: one for calibration (e.g., 2000-2010) and one for validation (e.g., 2011-2020).
-
Sensitivity Analysis: Identify the most influential model parameters on the desired output (e.g., streamflow). This reduces the number of parameters to be calibrated, making the process more efficient.
-
Objective Function Selection: Choose an objective function that reflects the modeling goal. For example, use NSE for overall performance or Root Mean Square Error (RMSE) if you want to penalize large errors.
-
Calibration: Systematically adjust the sensitive parameters to minimize or maximize the objective function. This can be done manually or using automated algorithms (e.g., SUFI-2, GLUE).
-
Validation: Run the calibrated model with the parameter set obtained in the previous step, using the independent validation dataset.
-
Performance Evaluation: Assess the model's performance for both calibration and validation periods using multiple statistical metrics (see Table 1 ). The performance in the validation period is the true indicator of the model's predictive power.
Protocol 2: Input Data Quality Control and Pre-processing
This protocol details the steps for preparing input data for hydrological modeling.
-
Data Collection: Gather all necessary data, including precipitation, temperature, streamflow, land use maps, and soil data for the Parnaíba and Poti basins.
-
Gap Filling: Identify and fill any gaps in the time series data. Methods can range from simple linear interpolation to more complex regression-based techniques using data from nearby stations.
-
Homogeneity Testing: Check for non-homogeneities in the data series, which can be caused by changes in measurement techniques or station location.
-
Outlier Detection: Identify and remove or correct any erroneous data points or outliers that could negatively impact the model simulation.
-
Spatial Interpolation: For meteorological data from point gauges, use an appropriate interpolation method (e.g., Thiessen polygons, Inverse Distance Weighting) to create spatially distributed input for the model.
Quantitative Data Summary
Table 1: General Performance Ratings for Recommended Model Evaluation Metrics
| Performance Metric | Very Good | Good | Satisfactory | Unsatisfactory |
| Nash-Sutcliffe Efficiency (NSE) | 0.75 < NSE ≤ 1.00 | 0.65 < NSE ≤ 0.75 | 0.50 < NSE ≤ 0.65 | NSE ≤ 0.50 |
| Percent Bias (PBIAS) | PBIAS < ±10% | ±10% ≤ PBIAS < ±15% | ±15% ≤ PBIAS < ±25% | PBIAS ≥ ±25% |
| RMSE-observations SD ratio (RSR) | 0.00 ≤ RSR ≤ 0.50 | 0.50 < RSR ≤ 0.60 | 0.60 < RSR ≤ 0.70 | RSR > 0.70 |
Visualizations
Technical Support Center: Addressing Confounding Variables in Epidemiological Studies in Teresina
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in addressing confounding variables in epidemiological studies conducted in Teresina, Brazil.
Troubleshooting Guides
Issue: My crude association is strong, but I suspect confounding.
-
Identify Potential Confounders:
-
Literature Review: Have you reviewed epidemiological studies conducted in this compound or similar urban areas in Brazil to identify commonly reported confounding factors for your exposure and outcome of interest? Key domains to consider are sociodemographic characteristics, lifestyle factors, and pre-existing health conditions.
-
Directed Acyclic Graphs (DAGs): Have you created a DAG to visualize the hypothesized causal relationships between your exposure, outcome, and potential confounders? This can help clarify which variables are true confounders and which might be mediators or colliders.
-
-
Assess the Three Criteria for Confounding:
-
Is the potential confounder associated with the exposure in your study population?
-
Is the potential confounder an independent risk factor for the outcome?
-
Is the potential confounder not on the causal pathway between the exposure and the outcome?
-
-
Choose a Control Method:
-
Design Phase:
-
Restriction: Can you restrict your study population to a specific subgroup of the potential confounder (e.g., only including individuals within a certain age range or socioeconomic status)? This is a simple method but may limit the generalizability of your findings.[1]
-
Matching: Can you match cases and controls (or exposed and unexposed individuals) based on the potential confounder? This can be effective for controlling strong confounders but can be complex to implement.
-
-
Analysis Phase:
-
Stratification: Can you analyze the association between your exposure and outcome separately within different strata (levels) of the confounder? This is a transparent method to identify confounding but can be challenging with multiple confounders.
-
Multivariate Analysis: Do you have a sufficient sample size to perform a multivariate regression analysis (e.g., logistic regression, Cox proportional hazards regression) to adjust for multiple confounders simultaneously? This is a powerful and commonly used method.[2]
-
-
-
Compare Crude and Adjusted Estimates:
-
After applying your chosen control method, compare the adjusted measure of association (e.g., adjusted odds ratio, adjusted relative risk) with the crude measure. A substantial difference between the two suggests the presence of confounding.
-
Issue: I am unsure which potential confounders are most relevant for my study in this compound.
-
Consider the Local Context: this compound, like many urban centers in Brazil, has specific socioeconomic and health landscapes. Common confounders to consider include:
-
Socioeconomic Status (SES): Often a strong confounder in Brazilian studies, SES can be measured by indicators such as income, education level, and household characteristics.[3][4] Studies have shown significant associations between SES and various health outcomes in Brazil.[3][5]
-
Age and Sex: These are fundamental demographic variables that are almost always potential confounders in epidemiological research.
-
Urban vs. Rural Residence: While this compound is an urban center, disparities may exist between different neighborhoods or for individuals who have migrated from rural areas.
-
Access to Healthcare: Differences in access to and quality of healthcare services can confound associations between exposures and health outcomes.
-
Nutritional Status and Lifestyle Factors: Factors such as diet, physical activity, smoking, and alcohol consumption are often associated with both socioeconomic status and health outcomes.[6][7]
-
-
Utilize Local Data Sources:
-
Consult data from the Brazilian Institute of Geography and Statistics (IBGE) and the Ministry of Health's DATASUS platform to understand the distribution of potential confounders in the population of this compound.
-
Frequently Asked Questions (FAQs)
Q1: What is a confounding variable in the context of an epidemiological study?
A1: A confounding variable is a third factor that is associated with both the exposure and the outcome of interest, but is not on the causal pathway between them.[8] Its presence can distort the true association between the exposure and the outcome, leading to an overestimation or underestimation of the effect.[1] For a variable to be a confounder, it must meet three criteria: it is associated with the exposure, it is an independent risk factor for the outcome, and it is not an intermediate step in the causal chain from the exposure to the outcome.
Q2: How can I visually represent the relationships between my variables to identify potential confounders?
A2: A Directed Acyclic Graph (DAG) is an excellent tool for this purpose. A DAG uses nodes to represent variables and arrows to represent causal relationships. By mapping out your theoretical framework, you can more clearly identify which variables are potential confounders that need to be controlled for in your analysis.
Q3: What are the main methods to control for confounding variables?
A3: Methods to control for confounding can be applied at the study design stage or the data analysis stage.
-
Design Stage:
-
Randomization: In experimental studies, randomly assigning participants to exposure groups helps to distribute both known and unknown confounders evenly.
-
Restriction: Limiting the study to individuals who are similar in relation to the confounder.[1]
-
Matching: Selecting study subjects so that the confounders are distributed identically among the exposed and unexposed groups (in cohort studies) or among the cases and controls (in case-control studies).
-
-
Analysis Stage:
-
Stratification: Analyzing the exposure-outcome association separately within different levels (strata) of the confounding variable.
-
Multivariate Analysis: Using statistical models (e.g., logistic regression) to estimate the association between the exposure and outcome while simultaneously adjusting for the effects of multiple confounding variables.[2]
-
Q4: What are some common socioeconomic confounding factors I should consider in my study in this compound?
A4: In the context of urban Brazil, including this compound, several socioeconomic factors are frequently identified as confounders:
-
Education Level: Lower levels of education are often associated with poorer health outcomes and different exposure patterns.[3][9]
-
Income/Purchasing Power: Economic status is a strong determinant of health and can be a significant confounder.[3]
-
Social Vulnerability Indices: Composite measures that capture various aspects of social deprivation can be powerful confounders.[4]
Q5: Can I use statistical significance (e.g., a p-value) to identify confounders?
A5: It is generally not recommended to rely solely on statistical tests to identify confounders. The decision to treat a variable as a confounder should be based on your a priori knowledge of the causal relationships between the variables, supported by existing literature and theoretical frameworks like DAGs.[1]
Data Presentation: Common Confounding Variables in Brazilian Urban Health Studies
The following tables summarize the impact of common confounding variables from epidemiological studies conducted in Brazil. This data can serve as a reference for researchers in this compound when designing their studies and planning their analyses.
Table 1: Association of Socioeconomic Factors with Health Outcomes in Brazil
| Health Outcome | Socioeconomic Indicator | Adjusted Measure of Association (95% CI) | Study Population |
| Self-rated Health | Years of Education | Positive association (p<0.05) | Elderly in São Paulo |
| Memory Capacity | Years of Education | Positive association (p<0.05) | Elderly in São Paulo |
| Depression | Purchasing Power | Positive association (p<0.05) | Elderly in São Paulo |
| Preterm Birth | GINI Index of Municipality | Varies by region | National data |
| Preterm Birth | % of population with ≤8 years of education | Varies by region | National data |
Note: This table is a synthesis of findings from multiple studies and the specific measures of association may vary. The "Positive association" indicates a statistically significant relationship where higher SES is associated with better health outcomes.
Experimental Protocols
Protocol 1: Controlling for Confounding using Stratification
Objective: To examine the association between an exposure and an outcome while controlling for a single categorical confounding variable.
Methodology:
-
Define Strata: Divide your study population into mutually exclusive strata based on the levels of the confounding variable (e.g., for age as a confounder, strata could be '18-39 years', '40-59 years', '60+ years').
-
Calculate Stratum-Specific Measures of Association: Within each stratum, calculate the measure of association between the exposure and the outcome (e.g., odds ratio, risk ratio).
-
Assess for Confounding: Compare the stratum-specific measures of association. If they are similar to each other but different from the crude (unstratified) measure of association, confounding is likely present.
-
Calculate a Pooled Estimate (if appropriate): If the stratum-specific measures are homogenous, you can calculate a pooled, adjusted measure of association using methods like the Mantel-Haenszel method. This provides a single summary measure that is adjusted for the confounding variable.
Protocol 2: Controlling for Confounding using Multivariate Logistic Regression
Objective: To examine the association between a binary exposure and a binary outcome while simultaneously controlling for multiple potential confounding variables.
Methodology:
-
Model Specification: Define your logistic regression model. The dependent variable is the binary outcome (coded as 0 or 1). The independent variables include your primary exposure of interest and all potential confounding variables you have identified.
-
Data Preparation: Ensure your data is clean and appropriately formatted. Categorical variables may need to be dummy coded.
-
Model Fitting: Fit the logistic regression model using statistical software.
-
Interpretation of Results:
-
The odds ratio for your exposure of interest, adjusted for all other variables in the model, can be obtained by exponentiating the coefficient for the exposure variable.
-
The p-value associated with the exposure coefficient indicates the statistical significance of the association after adjusting for confounders.
-
Examine the coefficients and p-values for the confounding variables to understand their individual associations with the outcome.
-
-
Model Diagnostics: Assess the goodness-of-fit of your model to ensure it adequately describes the data.
Mandatory Visualization
Caption: Diagram illustrating the principle of confounding and a hypothetical example relevant to this compound.
Caption: A typical workflow for identifying and controlling for confounding variables in an epidemiological study.
References
- 1. scielo.br [scielo.br]
- 2. How to control confounding effects by statistical analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 3. scielo.br [scielo.br]
- 4. Mortality inequalities measured by socioeconomic indicators in Brazil: a scoping review - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Were the socio-economic determinants of municipalities relevant to the increment of COVID-19 related deaths in Brazil in 2020? - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Risk factors associated with non-communicable diseases among government employees in Nepal: insights from a cross-sectional study - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Modeling the Relation Between Non-Communicable Diseases and the Health Habits of the Mexican Working Population: A Hybrid Modeling Approach [mdpi.com]
- 8. Methodological issues of confounding in analytical epidemiologic studies - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Impact of socioeconomic factors and health determinants on preterm birth in Brazil: a register-based study - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Enhancing Community Engagement in Environmental Research in Teresina
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals engaged in community-based environmental research in Teresina, Brazil. The resources provided aim to address specific issues that may arise during the experimental process, from community partnership development to data dissemination.
Frequently Asked Questions (FAQs)
1. Q: What are the key environmental challenges in this compound that could be the focus of community-engaged research?
A: this compound faces several significant environmental challenges that are ripe for collaborative research. The city is highly vulnerable to the impacts of climate change, including increased frequency and intensity of floods, droughts, and heatwaves.[1] Rapid urbanization has led to challenges in managing the water cycle, solid waste, and wastewater, contributing to ecosystem imbalance.[1] Deforestation and the loss of urban green spaces have exacerbated the "heat island effect" in one of the world's hottest cities.[2] Additionally, studies have indicated the potential for heavy metal contamination in urban gardens, posing a health risk to the community.
2. Q: How can we effectively engage the community in this compound in our environmental research project?
A: Effective community engagement is built on trust, transparency, and mutual respect. It is crucial to involve community members from the very beginning of the research process, including in the co-design of research questions.[3] In the context of Piauí, where this compound is located, establishing a community consultative group has been a successful strategy for connecting with key community members and understanding their priorities.[3] It is also important to recognize that communities in Latin America, including Brazil, have a rich history of community-based management of environmental challenges.[4] Leveraging this existing knowledge and social structure can lead to more impactful and sustainable research outcomes. Active community engagement and collaboration with various stakeholders are recurrent actions in successful urban best practices across Latin America.[5]
3. Q: What are some common challenges in conducting community-engaged research in a Latin American context like this compound?
A: Researchers in Latin America often face challenges such as financial constraints, bureaucratic complexities, and deficient infrastructure.[5] In Brazil specifically, ensuring that research initiatives are aligned with local health priorities and public health agendas is crucial.[6] Language can also be a barrier, and providing training materials in Portuguese is essential for effective community participation.[6] Building trust is paramount, especially in communities that may be skeptical of research; this requires nurturing long-term relationships and maintaining an ongoing presence.
4. Q: How can we measure the success of our community engagement efforts?
A: The success of community engagement can be measured using both qualitative and quantitative metrics. Quantitative measures can include tracking the number of active community participants, the frequency of community meetings, and the diversity of stakeholders involved. Qualitative indicators can include assessing the level of community input in decision-making, the development of new community leaders, and the overall satisfaction of community partners with the research process.
Troubleshooting Guides
This section provides practical solutions to common problems encountered during community-engaged environmental research experiments.
Issue 1: Low Community Participation in Data Collection
-
Problem: You are experiencing difficulty in recruiting and retaining community members to participate in environmental monitoring activities.
-
Possible Causes:
-
Lack of understanding of the research goals and their relevance to the community.
-
Inconvenient timing or location of data collection activities.
-
Insufficient training or lack of confidence in using monitoring equipment.
-
Lack of compensation for their time and effort.
-
-
Solutions:
-
Co-develop a communication plan: Work with community leaders to create clear and accessible materials (in Portuguese) that explain the project's purpose and potential benefits for the community.
-
Flexible scheduling: Offer multiple time slots and locations for training and data collection to accommodate different schedules.
-
Hands-on training and support: Provide comprehensive, hands-on training on the use of monitoring equipment. Ensure ongoing technical support is available to address any issues promptly.
-
Fair compensation: Offer fair compensation for the time and expertise that community members contribute to the research.
-
Issue 2: Inconsistent or Unreliable Data from Community Monitors
-
Problem: The environmental data (e.g., water quality readings, air pollution levels) collected by community members shows high variability or appears to be inaccurate.
-
Possible Causes:
-
Inconsistent application of data collection protocols.
-
Malfunctioning or uncalibrated monitoring equipment.
-
Errors in data recording and transcription.
-
-
Solutions:
-
Develop clear, visual protocols: Create easy-to-follow, illustrated protocols for all monitoring procedures.
-
Regular equipment checks and calibration: Establish a routine schedule for checking and calibrating all monitoring equipment.
-
Implement a buddy system: Have community members work in pairs to collect and record data to minimize individual errors.
-
Data quality assurance sessions: Hold regular meetings to review the collected data with community monitors, identify any anomalies, and discuss potential sources of error.
-
Issue 3: Disagreements or Conflict Between Researchers and Community Partners
-
Problem: There are misunderstandings or disagreements between the research team and community partners regarding project goals, methods, or the interpretation of results.
-
Possible Causes:
-
Lack of a shared understanding of roles and responsibilities.
-
Poor communication and lack of transparency.
-
Differing expectations about the research outcomes and their application.
-
-
Solutions:
-
Establish a formal partnership agreement: At the outset of the project, co-create a memorandum of understanding (MOU) that clearly outlines the roles, responsibilities, and expectations of all partners.
-
Regular and open communication channels: Schedule regular meetings to discuss progress, challenges, and upcoming activities. Ensure that communication is a two-way street, with researchers actively listening to the concerns and perspectives of community partners.
-
Collaborative data interpretation: Involve community partners in the process of analyzing and interpreting the research findings to ensure the results are meaningful and relevant to their experiences.
-
Data Presentation
Table 1: Key Metrics for Evaluating Community Engagement in Environmental Research
| Metric Category | Indicator | Data Source |
| Participation | Number of active community participants | Meeting attendance records, data submission logs |
| Hours of community member involvement | Volunteer timesheets | |
| Diversity of participants (age, gender, etc.) | Demographic surveys | |
| Partnership Quality | Level of community involvement in decision-making | Partnership meeting minutes, surveys |
| Community partner satisfaction | Surveys, focus group discussions | |
| Trust in the research team | Surveys, qualitative interviews | |
| Outcomes | Community-identified issues addressed by the research | Project reports, community feedback |
| New skills or knowledge gained by community members | Pre- and post-training assessments | |
| Policy or practice changes resulting from the research | Policy documents, interviews with stakeholders |
Table 2: Example Quantitative Results from a Hypothetical Community-Based Water Quality Monitoring Project in this compound
| Parameter | Average Community-Collected Value | Standard Deviation | Reference Guideline (Brazilian CONAMA Resolution 357/05 for Class 2 Waters) |
| pH | 6.8 | 0.5 | 6.0 - 9.0 |
| Dissolved Oxygen (mg/L) | 5.2 | 1.1 | ≥ 5.0 |
| Fecal Coliforms (CFU/100mL) | 850 | 320 | ≤ 1000 |
| Nitrate (mg/L) | 7.5 | 2.3 | ≤ 10.0 |
Experimental Protocols
1. Protocol for Community-Based Water Quality Monitoring
-
Objective: To train and equip community members to collect regular water samples from local water bodies and test for key water quality parameters.
-
Methodology:
-
Site Selection: In collaboration with the community, identify key water sampling locations that are of concern and are safely accessible.
-
Training: Conduct a hands-on workshop to train community volunteers on:
-
Proper sample collection techniques to avoid contamination.
-
Use of portable water quality testing kits/probes for measuring pH, dissolved oxygen, and turbidity.
-
Safe handling and preservation of water samples for laboratory analysis of fecal coliforms and nitrates.
-
Data recording on standardized data sheets.
-
-
Data Collection: Community volunteers will collect water samples at the selected sites on a weekly basis.
-
Field Analysis: Volunteers will use the portable testing kits to measure and record pH, dissolved oxygen, and turbidity at the time of sample collection.
-
Laboratory Analysis: Collected samples will be transported in a cooler with ice packs to a designated laboratory for analysis of fecal coliforms and nitrates.
-
Data Management: A designated community member or researcher will be responsible for compiling all field and laboratory data into a central database.
-
Data Sharing and Interpretation: Regular meetings will be held with the community to present and discuss the findings.
-
2. Protocol for Community-Based Soil Heavy Metal Monitoring
-
Objective: To assess the levels of heavy metal contamination in the soil of community gardens in this compound.
-
Methodology:
-
Site Selection: With the gardeners, create a map of each community garden and divide it into a grid. Randomly select sampling points within the grid to ensure representative sampling.
-
Training: Train community gardeners on:
-
How to collect composite soil samples using clean stainless-steel trowels to a depth of 15-20 cm.[7]
-
Properly labeling and bagging the soil samples.
-
Recording the location of each sample on the garden map.
-
-
Sample Collection: Community gardeners will collect soil samples from the designated points. A composite sample should be created for each garden by mixing soil from 10-15 different points.[8]
-
Sample Preparation: In a controlled environment, the soil samples will be air-dried, sieved to remove large debris, and ground to a fine powder.
-
Laboratory Analysis: The prepared soil samples will be sent to an accredited laboratory for analysis of heavy metals (e.g., lead, cadmium, arsenic) using methods such as X-Ray Fluorescence (XRF) or Inductively Coupled Plasma Mass Spectrometry (ICP-MS).
-
Data Interpretation: The results will be compared to national and international soil quality guidelines. The findings will be shared with the gardeners through workshops, and strategies for safe gardening practices will be co-developed if high levels of contamination are found.
-
Mandatory Visualization
Caption: Wnt/β-catenin signaling pathway and potential disruption by heavy metals.
Caption: Workflow for community-engaged environmental research.
References
- 1. urbanresiliencehub.org [urbanresiliencehub.org]
- 2. iied.org [iied.org]
- 3. One moment, please... [sipp.education.ed.ac.uk]
- 4. researchgate.net [researchgate.net]
- 5. urbancoalitions.org [urbancoalitions.org]
- 6. Engaging local health research communities to enhance long-term capacity building in Brazil - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Testing Your Soil for Heavy Metals - Alabama Cooperative Extension System [aces.edu]
- 8. clf.jhsph.edu [clf.jhsph.edu]
"troubleshooting sample collection and preservation in tropical climates like Teresina"
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals working with biological samples in tropical climates like Teresina, Brazil. Proper sample collection and preservation are critical for obtaining reliable experimental results, and the high heat and humidity in tropical regions present unique challenges.
General Troubleshooting and FAQs
This section addresses common issues that can arise during sample collection and preservation in a tropical environment.
| Question | Answer |
| Why are my samples degrading despite following standard protocols? | Standard protocols may not be sufficient for tropical climates. High ambient temperatures accelerate enzymatic and microbial activity, leading to rapid degradation of nucleic acids, proteins, and other biomolecules.[1][2] It is crucial to use appropriate preservatives and maintain a strict cold chain from the moment of collection. |
| What are the initial signs of sample degradation in the field? | Visual cues can be the first indicator. For blood samples, hemolysis (a reddish tint to the plasma or serum) is a key sign of red blood cell lysis.[3] For tissue samples, changes in color, texture (becoming soft or mushy), or an unpleasant odor suggest degradation. Turbidity or color change in urine and saliva can also indicate bacterial growth. |
| How can I minimize preanalytical errors in a remote field setting? | Meticulous planning and adherence to a standardized protocol are essential. This includes proper patient/subject identification, using the correct collection tubes and volumes, and ensuring immediate and proper sample stabilization.[4][5][6] Training all field personnel on these procedures is critical to minimize variability. |
| What is the most critical factor for preserving sample integrity in a tropical climate? | Maintaining a consistent cold chain is arguably the most critical factor.[7][8] From the point of collection to storage and transport, keeping samples at the recommended temperature is paramount to prevent degradation. |
Blood Sample Collection and Preservation
High temperatures can quickly compromise the integrity of blood samples, leading to hemolysis and the degradation of sensitive analytes.
Troubleshooting Guide: Blood Samples
| Problem | Possible Cause | Solution |
| Hemolysis (reddish plasma/serum) | - Use of a needle with too small a gauge.[3][9] - Vigorous mixing of the blood tube.[9][10] - Excessive heat exposure.[3] - Drawing blood too slowly. - Leaving the tourniquet on for too long (>1 minute).[9] | - Use a 20-22 gauge needle for routine venipuncture.[3][9] - Gently invert the tube 8-10 times for anticoagulant mixing; do not shake.[9] - Process samples in a shaded, cool environment if possible. - Ensure a steady blood flow during collection. - Release the tourniquet as soon as blood flow is established.[9] |
| Clotted anticoagulant tube | - Insufficient mixing of the anticoagulant with the blood. - Incorrect blood-to-anticoagulant ratio (underfilled tube). | - Immediately after collection, gently invert the tube the recommended number of times. - Ensure the tube is filled to the indicated level. |
| Degraded RNA/DNA | - Delay in processing or freezing after collection. - Use of inappropriate collection tubes for nucleic acid preservation. | - Process samples as quickly as possible. If not possible, use specialized collection tubes. - For RNA, use tubes containing a stabilization solution like PAXgene® or Tempus™.[11][12] For DNA, EDTA tubes are standard, but immediate cooling is crucial. |
FAQs: Blood Samples
| Question | Answer |
| What are the best blood collection tubes for RNA analysis in a tropical setting? | For RNA-based studies, it is highly recommended to use blood collection systems with RNA-stabilizing reagents, such as PAXgene® or Tempus™ tubes.[11][12] These tubes contain proprietary solutions that lyse cells and inactivate RNases, preserving the RNA integrity even at ambient temperatures for a limited time.[11][12] Studies have shown that Tempus™ tubes may offer slightly better RNA quantity and integrity in suboptimal tropical conditions.[11] |
| How long can I store whole blood at ambient temperature in this compound before processing? | For routine biochemical analyses, processing within 2 hours is ideal.[1] If using standard EDTA or serum tubes, storage at the high ambient temperatures of this compound for extended periods is not advisable. For RNA analysis in PAXgene or Tempus tubes, samples can be stable at room temperature (up to 25°C) for a short period, but it's best to refrigerate or freeze them as soon as possible. |
| What is the impact of heat on common blood analytes? | High temperatures can significantly alter the concentration of several common analytes. For instance, glucose levels can decrease due to glycolysis, while potassium, lactate (B86563) dehydrogenase, and aspartate aminotransferase can be falsely elevated due to hemolysis.[1][9] |
Quantitative Data: Stability of Serum Analytes
The following table summarizes the stability of common serum analytes at different storage temperatures.
| Analyte | Stability at Room Temperature (22-25°C) | Stability at 4°C (Refrigerated) | Stability at -20°C (Frozen) |
| Glucose | Significant decrease after 4 hours[1] | Significant decrease after 24 hours[1] | Stable for longer periods |
| Urea | Significant change after 4 hours[1] | Stable for at least 72 hours[8] | Stable for longer periods |
| Creatinine | Significant change after 4 hours[1] | Stable for at least 72 hours[8] | Stable for longer periods |
| Total Bilirubin | Significant change after 4 hours[1] | Significant change after 24 hours[1] | Stable for longer periods |
| Albumin | Significant change after 4 hours[1] | Significant change after 24 hours[1] | Stable for longer periods |
| Total Protein | Significant change after 4 hours[1] | Stable for at least 72 hours[8] | Stable for longer periods |
| Total Cholesterol | Stable for at least 72 hours[8] | Stable for at least 72 hours[8] | Stable for longer periods |
| Triglycerides | Stable for at least 72 hours[8] | Stable for at least 72 hours[8] | Stable for longer periods |
| AST/ALT | Significant degradation by 72 hours[9] | More stable than at room temperature | Best for long-term preservation[9] |
| Sodium & Potassium | Variable due to evaporation and hemolysis[9] | More stable than at room temperature | Best for long-term preservation[9] |
Experimental Protocol: Blood Collection for RNA Analysis
This protocol outlines the steps for collecting whole blood for RNA analysis using PAXgene® Blood RNA Tubes in a tropical field setting.
Materials:
-
PAXgene® Blood RNA Tubes
-
Vacutainer needle and holder
-
Tourniquet
-
Alcohol swabs
-
Gauze
-
Bandages
-
Cooler with ice packs
Procedure:
-
Preparation: Label the PAXgene® tube with the participant's ID, date, and time of collection. Prepare all necessary materials for venipuncture.
-
Venipuncture:
-
Apply the tourniquet and select a suitable vein.
-
Cleanse the venipuncture site with an alcohol swab and allow it to air dry completely.
-
Perform the venipuncture.
-
-
Blood Collection:
-
Engage the PAXgene® tube in the holder and allow it to fill to the indicated mark.
-
Once filled, remove the tube from the holder.
-
-
Stabilization:
-
Immediately and gently invert the PAXgene® tube 8-10 times to ensure the blood mixes thoroughly with the stabilization reagent. Do not shake vigorously.
-
-
Short-term Storage:
-
Place the tube in an upright position in a rack.
-
If processing within a few hours, the tube can be kept at ambient temperature (ideally below 25°C). However, in a climate like this compound's, it is highly recommended to place the tube in a cooler with ice packs as soon as possible.
-
-
Long-term Storage:
-
For storage longer than 24 hours, freeze the PAXgene® tubes upright at -20°C or -80°C.
-
Workflow for Blood Sample Collection and Processing
Workflow for blood sample collection and processing for RNA analysis.
Tissue Sample Collection and Preservation
Tissue samples are highly susceptible to degradation in hot and humid conditions, affecting morphology, antigenicity, and nucleic acid integrity.
Troubleshooting Guide: Tissue Samples
| Problem | Possible Cause | Solution |
| Poor tissue morphology | - Delayed fixation. - Inadequate fixative-to-tissue ratio. - Fixative not penetrating the tissue. | - Place tissue in fixative immediately after excision. - Use a fixative volume at least 10-20 times the tissue volume. - Ensure tissue pieces are no thicker than 5mm to allow for proper penetration. |
| Loss of antigenicity | - Use of inappropriate fixative (e.g., formalin for certain antigens). - Over-fixation. | - For immunohistochemistry, consider using alternative fixatives like zinc-based fixatives or flash-freezing.[13] - Adhere to recommended fixation times. |
| RNA/DNA degradation | - Slow preservation process. - Inappropriate storage temperature. | - Immediately place tissue in a stabilizing solution like RNAlater® or flash-freeze in liquid nitrogen.[14][15][16][17][18][19] - Store samples at -80°C for long-term preservation. |
FAQs: Tissue Samples
| Question | Answer |
| What is the best method for preserving tissue for both histological and molecular analysis in the field? | Using a stabilizing agent like RNAlater® is an excellent option as it preserves both nucleic acids and protein, and does not require immediate freezing.[14][15][16][17][18][19] The tissue can be stored in RNAlater® at 4°C for up to a month, or at 25°C for up to a week, providing flexibility in field conditions.[14][15][16][18][19][20][21] For long-term storage, the tissue can be removed from the RNAlater® and frozen at -80°C.[4][18][19] |
| Can I freeze tissue samples directly in the field? | Yes, flash-freezing in liquid nitrogen is a gold standard for preserving enzymatic activity and nucleic acids. However, this method can cause ice crystal formation, which may damage tissue morphology for some histological applications. It also requires access to liquid nitrogen, which can be challenging in remote settings. |
| How should I transport tissue samples from a remote location? | If using RNAlater®, samples can be shipped on wet ice. For frozen samples, a dry shipper (liquid nitrogen vapor) or sufficient dry ice is necessary to maintain the cold chain.[15] Proper packaging according to IATA regulations for biological substances is mandatory. |
Experimental Protocol: Tissue Preservation using RNAlater®
This protocol describes the steps for preserving fresh tissue samples using RNAlater® in a tropical environment.
Materials:
-
RNAlater® solution
-
Sterile, RNase-free tubes or vials
-
Sterile forceps and scalpel
-
Cooler with ice packs
Procedure:
-
Preparation: Pre-chill RNAlater® solution on ice. Label RNase-free tubes with sample information.
-
Tissue Excision:
-
Excise the tissue sample as quickly as possible to minimize RNA degradation.
-
If necessary, rinse the tissue briefly in sterile, ice-cold phosphate-buffered saline (PBS) to remove any contaminants.
-
-
Sample Sizing:
-
Immersion in RNAlater®:
-
Place the tissue sample into a labeled tube.
-
Add at least 5 volumes of RNAlater® solution for every 1 volume of tissue (e.g., a 0.5 g sample requires at least 2.5 mL of RNAlater®).[14]
-
-
Incubation and Short-term Storage:
-
Long-term Storage:
Logical Relationship for Tissue Preservation Choices
Decision-making for tissue preservation based on the primary analysis goal.
Saliva and Urine Sample Collection and Preservation
Saliva and urine are valuable non-invasive samples, but their composition can be altered by bacterial growth, which is accelerated in warm climates.
Troubleshooting Guide: Saliva and Urine
| Problem | Possible Cause | Solution |
| Low DNA/RNA yield from saliva | - Insufficient saliva collection. - High bacterial content degrading human nucleic acids. - Improper mixing with stabilization buffer. | - Ensure the donor provides the required volume of saliva (not bubbles).[20] - Use a collection kit with a potent stabilization buffer (e.g., Oragene®). - Immediately after collection, cap and mix the tube as per the manufacturer's instructions.[20] |
| Altered metabolite profile in urine | - Bacterial growth and metabolism. - Delay in freezing. - Use of inappropriate preservatives for metabolomics. | - Collect mid-stream urine to minimize contamination.[22] - Freeze samples at -80°C as soon as possible after collection.[22] - If immediate freezing is not possible, store at 4°C for no more than 24 hours.[23][24] For longer durations or higher temperatures, consider using a preservative like thymol (B1683141) for metabolomics studies.[23][24] |
| Visible contamination in saliva sample | - Eating, drinking, or smoking before collection. - Blood contamination from the oral cavity. | - Instruct participants to rinse their mouth with water and to not eat, drink, or smoke for at least 30 minutes prior to collection.[20] - Advise against brushing teeth within 45 minutes of collection.[19][25] Discard samples with visible blood contamination.[25][26] |
FAQs: Saliva and Urine Samples
| Question | Answer |
| Are there saliva collection kits that are stable at tropical ambient temperatures? | Yes, commercially available saliva collection kits, such as the Oragene® DNA kits, contain a liquid that stabilizes DNA at ambient temperatures for extended periods, making them ideal for field collection in tropical regions.[1][14][20][23][24] |
| What is the best way to collect and preserve urine for metabolomics in a hot climate? | The ideal method is to collect a mid-stream urine sample, aliquot it, and immediately flash-freeze it in liquid nitrogen, followed by storage at -80°C.[22] If immediate freezing is not feasible, the sample should be kept at 4°C and processed within 24 hours.[23][24] For collection periods longer than 24 hours at ambient temperature, the use of a preservative like thymol is recommended.[23][24] |
| How should I ship urine and saliva samples from this compound? | Frozen samples must be shipped on dry ice to maintain a temperature of at least -20°C.[22] Saliva samples collected in ambient temperature-stable kits can often be shipped without refrigeration, but it is essential to check the manufacturer's guidelines. All shipments must comply with regulations for the transport of biological specimens. |
Experimental Protocol: Saliva Collection for DNA Analysis using Oragene®
This protocol details the collection of saliva for DNA analysis using an Oragene® self-collection kit.
Materials:
-
Oragene®•DNA self-collection kit (funnel and tube)
-
Participant instructions
Procedure:
-
Participant Instruction: Instruct the participant not to eat, drink, smoke, or chew gum for 30 minutes before providing the sample.[20]
-
Sample Collection:
-
The participant should spit into the funnel until the amount of liquid saliva (not bubbles) reaches the fill line on the collection tube.[20]
-
-
Stabilization:
-
Close the funnel lid by pushing down firmly until a "click" is heard. This releases the stabilizing liquid from the lid into the tube.[20]
-
Ensure the lid is closed tightly.
-
-
Mixing:
-
Unscrew the funnel from the tube.
-
Use the small cap provided to seal the tube tightly.
-
Shake the capped tube for 5 seconds to mix the saliva and the stabilizing liquid thoroughly.
-
-
Storage:
-
The sample is now stable at ambient temperature (15-30°C) for an extended period (check kit specifications). Store the tube upright in a safe place until it can be transported to the laboratory for DNA extraction.
-
Workflow for Urine Sample Collection for Metabolomics
Workflow for urine sample collection and preservation for metabolomics analysis.
References
- 1. pacb.com [pacb.com]
- 2. researchgate.net [researchgate.net]
- 3. beaumontlaboratory.com [beaumontlaboratory.com]
- 4. Evaluation of RNAlater as a Field-Compatible Preservation Method for Metaproteomic Analyses of Bacterium-Animal Symbioses - PMC [pmc.ncbi.nlm.nih.gov]
- 5. User Guide — graphviz 0.21 documentation [graphviz.readthedocs.io]
- 6. medium.com [medium.com]
- 7. ibbea.fcen.uba.ar [ibbea.fcen.uba.ar]
- 8. 10 Best Practices For Managing Cold Chain Logistics [fleetroot.com]
- 9. fisherclinicalservices.com [fisherclinicalservices.com]
- 10. What steps are taken to prevent hemolysis during blood collection, and how does it impact test results? [needle.tube]
- 11. Optimization of the PAXgene blood RNA extraction system for gene expression analysis of clinical samples - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. The stability of quantitative blood count parameters using the ADVIA 2120i hematology analyzer - PMC [pmc.ncbi.nlm.nih.gov]
- 13. preanalytix.com [preanalytix.com]
- 14. adsbiotec.com [adsbiotec.com]
- 15. phlebotomy.com [phlebotomy.com]
- 16. zerodegreeslogistics.com.au [zerodegreeslogistics.com.au]
- 17. sileks.com [sileks.com]
- 18. normalesup.org [normalesup.org]
- 19. assets.fishersci.com [assets.fishersci.com]
- 20. dnagenotek.com [dnagenotek.com]
- 21. Recommendations and Best Practices for Standardizing the Pre-Analytical Processing of Blood and Urine Samples in Metabolomics - PMC [pmc.ncbi.nlm.nih.gov]
- 22. Guidelines for Metabolomics Sample Collection - Creative Proteomics [creative-proteomics.com]
- 23. dnagenotek.com [dnagenotek.com]
- 24. utsouthwestern.edu [utsouthwestern.edu]
- 25. devtoolsdaily.com [devtoolsdaily.com]
- 26. researchgate.net [researchgate.net]
Technical Support Center: Optimization of Resource Allocation for Public Health Interventions in Teresina
This technical support center provides troubleshooting guides, frequently asked questions (FAQs), and experimental protocols for researchers, scientists, and drug development professionals engaged in the optimization of resource allocation for public health interventions in Teresina, Piauí.
Troubleshooting Guides
This section addresses specific issues that researchers might encounter during their experiments and analyses related to public health resource allocation in this compound.
| Problem | Possible Cause | Suggested Solution |
| Difficulty in obtaining granular local health data for this compound. | Data may be aggregated at the state or regional level. Direct access to municipal-level raw data can be restricted. | 1. Submit a formal data request to the Fundação Municipal de Saúde (FMS) of this compound, citing the specific data required for the research project. 2. Utilize the DATASUS platform, applying specific filters for the municipality of this compound (code 221100). 3. Consult epidemiological bulletins published by the FMS and the Piauí State Health Secretariat.[1][2] |
| Inconsistent or incomplete data on the costs of specific public health interventions. | Lack of standardized cost-accounting practices across different health units. Overhead and indirect costs may not be clearly allocated to specific programs. | 1. Conduct a micro-costing study in a representative sample of Basic Health Units (UBS) in this compound. 2. Use national average costs for procedures and services available from the SUS Table of Procedures, Medications, and OPM (SIGTAP) as a proxy, and adjust for local price variations where possible. |
| Models for resource allocation developed for other regions do not fit the socio-demographic context of this compound. | Models may not account for the specific health needs and priorities outlined in this compound's Municipal Health Plan.[3][4] | 1. Adapt existing models by incorporating variables that reflect this compound's key health challenges, such as high rates of cardiovascular diseases and traffic accidents.[5] 2. Develop a new model using a needs-based formula that considers epidemiological, demographic, and socioeconomic dimensions specific to this compound.[5] |
| Difficulty in defining and measuring the outcomes of preventative health interventions. | The impact of preventative measures is often long-term and multifactorial, making it difficult to attribute changes in health indicators to a single program. | 1. Use Disability-Adjusted Life Years (DALYs) averted as a standardized outcome measure.[6] 2. Employ quasi-experimental study designs, such as interrupted time series or difference-in-differences analysis, to compare trends before and after the implementation of an intervention. |
Frequently Asked Questions (FAQs)
Q1: What are the main legal and ethical principles governing the allocation of public health resources in this compound?
A1: As part of Brazil's Unified Health System (SUS), resource allocation in this compound is governed by the principles of universality, integrality, and equity, as established in the 1988 Federal Constitution and Law 8.080/1990.[7] The use of epidemiology to set priorities and orient resource allocation is a key guideline.[7] All resource allocation decisions should aim to reduce health inequalities and meet the specific health needs of the population.
Q2: How can I align my research on resource optimization with the strategic health priorities of this compound?
A2: Your research should be guided by this compound's Municipal Health Plan (Plano Municipal de Saúde).[3][4] The 2022-2025 plan, for instance, emphasizes strengthening primary care, reducing risks from chronic non-communicable diseases and external causes (like traffic accidents), and improving health surveillance.[5] Aligning your research with these stated priorities will increase its relevance and potential for implementation.
Q3: What types of economic evaluations are most relevant for the Brazilian public health system?
A3: Cost-effectiveness analysis (CEA) and cost-utility analysis (CUA) are the most frequently used and recommended types of full economic evaluations in Brazil.[8][9] These analyses compare the costs of an intervention with its health outcomes, measured in natural units (e.g., cases averted) or quality-adjusted life years (QALYs) or DALYs.[6] The Brazilian Ministry of Health has published methodological guidelines for conducting health economic evaluations to support the Health Technology Assessment (HTA) process.[10]
Q4: Is there an official cost-effectiveness threshold used for decision-making in the SUS?
A4: While there is no single, explicitly defined cost-effectiveness threshold, the World Health Organization's recommendation is often cited as a reference. Interventions costing less than one time the Gross Domestic Product (GDP) per capita per DALY averted are considered highly cost-effective, while those costing up to three times the GDP per capita are still considered cost-effective.[4][11] However, decisions are not based solely on this threshold and also consider factors like equity, budget impact, and the severity of the disease.[11]
Q5: What are the primary public health interventions currently active in this compound that could be subjects for resource allocation optimization studies?
A5: Key interventions include the Family Health Strategy (Estratégia Saúde da Família), which is the cornerstone of primary care; programs for controlling chronic diseases like hypertension and diabetes; the Anti-Smoking Program[8][12]; and initiatives like the "Piauí Saúde Digital" for telehealth services.[13][14] Additionally, this compound is a priority city in the "Brasil Saudável" program, which focuses on eliminating socially determined diseases.[10]
Quantitative Data Summary
The following tables summarize key health and resource indicators for this compound.
Table 1: Key Health Indicators for this compound
| Indicator | Value | Year(s) | Source |
| Population (Estimate) | 850,198 | 2017 | [5] |
| Urban Population | 94.3% | 2017 | [5] |
| Human Development Index (HDI) | 0.751 (High) | 2010 | [5] |
| General Mortality Rate (per 1,000 inhabitants) | 6.0 | 2016 | [5] |
| Maternal Mortality Ratio (per 100,000 live births) | 67.9 (Brazil-wide) | 2020 | [9] |
| Neonatal Mortality Rate (per 1,000 live births) | 7.94 | 2017 (approx.) | [5] |
Table 2: Primary Causes of Mortality in this compound (2016)
| Cause of Death | Percentage of Total Deaths |
| Circulatory System Diseases | 28.39% |
| Neoplasms (Cancers) | 17.57% |
| External Causes (accidents, violence) | 14.22% |
| Total of Top 3 Causes | 60.18% |
| Source:[5] |
Table 3: COVID-19 Epidemiological Data in this compound (March 13 - July 12, 2020)
| Metric | Value |
| Confirmed Cases | 10,914 |
| Predominant Gender (Cases) | Female (55.51%) |
| Predominant Age Group (Cases) | 30-39 years (25.6%) |
| Predominant Gender (Deaths) | Male (55.9%) |
| Lethality Rate (Male) | 6.23% |
| Predominant Age Group (Deaths) | 70-79 years (25.0%) |
| Patients with Comorbidities | 82% |
| Source:[6][15] |
Experimental Protocols
This section provides detailed methodologies for key experiments in the optimization of public health resource allocation.
Protocol 1: Cost-Effectiveness Analysis (CEA) of a New Public Health Intervention
Objective: To determine the incremental cost-effectiveness ratio (ICER) of a new public health intervention (e.g., a new vaccine, a screening program) compared to the current standard of care in this compound.
Methodology:
-
Define the Perspective: Adopt the perspective of the public health system (SUS), focusing on direct medical costs.[1]
-
Identify Comparators: Clearly define the new intervention and the current standard of care (the comparator).
-
Measure Costs:
-
Direct Medical Costs: Identify all resources consumed by each alternative. This includes personnel time, medications, diagnostic tests, hospitalizations, and administrative overhead.
-
Data Collection: Collect cost data from SUS reimbursement tables (SIGTAP), pharmaceutical price databases (CMED), and through micro-costing at local health facilities in this compound.
-
-
Measure Effectiveness:
-
Outcome Selection: Choose a primary health outcome that is relevant to the intervention (e.g., number of cases averted, life-years gained, reduction in blood pressure).
-
Data Collection: Gather effectiveness data from clinical trials, systematic reviews, or local epidemiological studies.
-
-
Calculate the ICER:
-
The formula is: ICER = (Cost_new - Cost_standard) / (Effectiveness_new - Effectiveness_standard).
-
-
Conduct Sensitivity Analysis:
-
Perform one-way and probabilistic sensitivity analyses to assess the impact of uncertainty in cost and effectiveness parameters on the ICER. This helps to determine the robustness of the results.
-
-
Compare with Threshold: Compare the calculated ICER with the commonly referenced willingness-to-pay threshold in Brazil (1 to 3 times the GDP per capita per DALY averted) to make a recommendation on the cost-effectiveness of the intervention.[4]
Protocol 2: Needs-Based Resource Allocation Model
Objective: To develop a model for allocating public health funds across different geographic areas or health programs in this compound based on health needs.
Methodology:
-
Define Allocation Units: Determine the units for allocation (e.g., neighborhoods, Basic Health Units, specific health programs).
-
Select Needs Indicators: Choose a set of variables that reflect the health needs of the population. Based on Brazilian models, these should include:
-
Data Collection:
-
Gather data for each indicator and allocation unit from sources like the Brazilian Institute of Geography and Statistics (IBGE), DATASUS, and local health surveys.
-
-
Weighting the Indicators:
-
Assign weights to each indicator based on its relative importance in determining health needs. This can be done through statistical methods (e.g., principal component analysis) or expert consensus (e.g., Delphi method). A morbidity score can be used to estimate weights for different health conditions.[16][17]
-
-
Develop the Allocation Formula:
-
Create a composite index of need for each allocation unit by summing the weighted indicators.
-
The allocation formula will distribute the available budget proportionally to the composite need index of each unit.
-
-
Model Validation and Refinement:
-
Validate the model by comparing its proposed allocations with historical spending and health outcomes.
-
Refine the weights and indicators based on feedback from local health managers and stakeholders in this compound.
-
Visualizations
Signaling Pathways and Workflows
Caption: Workflow for incorporating new technologies into the SUS.
Caption: Logical framework for a needs-based resource allocation model.
References
- 1. Cost-effectiveness analysis of pharmaceutical care for hypertensive patients from the perspective of the public health system in Brazil | PLOS One [journals.plos.org]
- 2. [Cost-effectiveness in health in Brazil: a systematic review] - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Health technology assessment: the process in Brazil - PMC [pmc.ncbi.nlm.nih.gov]
- 4. scielo.br [scielo.br]
- 5. scielo.br [scielo.br]
- 6. academic.oup.com [academic.oup.com]
- 7. SUS 20 Years: The Health of Brazil [ccs.saude.gov.br]
- 8. Frontiers | Systematic Review of Health Economic Evaluation Studies Developed in Brazil from 1980 to 2013 [frontiersin.org]
- 9. A systematic review of health economic evaluations of vaccines in Brazil - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Updated Brazilian guidelines for health economic evaluation in public system | Cochrane Colloquium Abstracts [abstracts.cochrane.org]
- 11. epge.fgv.br [epge.fgv.br]
- 12. scielosp.org [scielosp.org]
- 13. scielo.br [scielo.br]
- 14. bvsms.saude.gov.br [bvsms.saude.gov.br]
- 15. Health technology assessment in Brazil: what do healthcare system players think about it? [repositorio.unifesp.br]
- 16. researchgate.net [researchgate.net]
- 17. scite.ai [scite.ai]
"improving the efficiency of solid waste collection and recycling in Teresina"
This technical support center provides troubleshooting guides, frequently asked questions (FAQs), and detailed protocols for researchers, scientists, and drug development professionals engaged in projects aimed at improving the efficiency of solid waste collection and recycling in Teresina.
Frequently Asked Questions (FAQs)
Q1: What is the current overview of solid waste generation and collection in this compound?
A1: this compound generates approximately 40,000 tons of solid waste per month, which is collected and sent to the city's sanitary landfill.[1] The public cleaning service, which includes waste collection, costs the municipality around R$ 17 million monthly.[2] A significant challenge is irregular disposal, which can amount to 500 tons per month, nearly equaling the regular collection volume in some periods.[2]
Q2: What are the main components of this compound's selective collection program?
A2: The selective collection program in this compound is primarily based on two modalities: "door-to-door" collection, which serves households and businesses, and a network of Voluntary Delivery Points (PEVs) strategically located throughout the city.[3] The collected recyclable materials are donated to partner waste picker cooperatives, generating income and promoting social inclusion.[3][4]
Q3: Where can I find the Voluntary Delivery Points (PEVs) in this compound?
A3: this compound has established several PEVs across its different zones. These points are equipped to receive materials such as paper, cardboard, plastic, metal, and glass. For a detailed list of PEV locations, please refer to the data section of this guide.
Q4: Which recycling cooperatives are active in this compound?
A4: Several cooperatives are integral to this compound's recycling chain. Notable examples include COOPCATA 3R'S, Cootermapi, and the Emaús Cooperative, which partner with the municipality to sort and commercialize recyclable materials.[3][5] Cootermapi is highlighted as the only cooperative in Piauí that processes glass.[6]
Q5: What are the main challenges affecting the efficiency of recycling in this compound?
A5: The primary challenges include a low rate of adherence to selective collection programs by the general population, contamination of recyclable materials with organic waste, and limited financial resources.[2][7][8] The city's recycling rate is estimated to be around 1.6%, which is below the national average of 4%.[9] Furthermore, there is a heavy reliance on the informal sector of waste pickers.[8]
Q6: Are there initiatives for organic waste management in this compound?
A6: Yes, there are initiatives focused on composting organic waste. Startups like 'É de sol' are transforming organic residues into natural fertilizers.[10] Additionally, projects such as "Ninho do Verde" are promoting composting as a means of reducing greenhouse gas emissions and fostering environmental education.[11] However, a large-scale, municipal-level composting program is not yet fully implemented.[12]
Q7: How is this compound using technology to improve waste management?
A7: The Municipality of this compound has been implementing technological solutions to enhance fiscalization and curb illegal dumping. This includes the use of surveillance cameras and artificial intelligence to identify and penalize offenders who dispose of waste in inappropriate locations.
Troubleshooting Guides
This section addresses specific issues that may be encountered during research and experimental implementation.
Issue 1: Low Adhesion to Selective Collection in a Pilot Neighborhood
-
Symptom: Low volume of recyclables being deposited at designated collection points or separated for door-to-door collection.
-
Possible Causes:
-
Lack of public awareness about the collection schedule and the importance of separation.
-
Insufficient or inconveniently located collection points (PEVs).
-
Lack of trust in the collection system (e.g., belief that all waste is mixed together eventually).
-
-
Troubleshooting Steps:
-
Conduct a baseline survey: Assess the community's knowledge, attitudes, and practices regarding recycling.
-
Intensify educational campaigns: Distribute clear and concise informational materials (leaflets, social media content) about how, what, and when to recycle.
-
Optimize PEV locations: Use GIS mapping to analyze the distribution of PEVs in relation to population density and accessibility. Propose new locations based on this analysis.
-
Promote transparency: Organize visits to the recycling cooperatives to show the community the destination and positive impact of their separated materials.
-
Issue 2: High Contamination Rate of Collected Recyclable Materials
-
Symptom: Recyclable materials arriving at the cooperative are mixed with organic waste, liquids, or non-recyclable items, rendering a significant portion unusable.
-
Possible Causes:
-
Public confusion about which materials are recyclable.
-
Improper cleaning of packaging before disposal.
-
Lack of separate bins for organic and recyclable waste at the household level.
-
-
Troubleshooting Steps:
-
Implement a material characterization study: Quantify the types and percentages of contaminants (see Experimental Protocol 1).
-
Develop targeted educational materials: Create visual guides (infographics, videos) demonstrating how to correctly prepare materials for recycling (e.g., rinsing containers).
-
Introduce a pilot program with differentiated bins: Provide households in a specific area with distinct containers for organic and recyclable waste and monitor the change in contamination rates.
-
Engage with building administrators: For multi-family dwellings, work with administrators to improve internal collection systems and provide clear signage.
-
Data Presentation
Table 1: Solid Waste Generation in this compound
| Waste Type | Average Monthly Tonnage | Daily Tonnage (approx.) | Data Source |
| Total Solid Waste | 40,000 | 1,333 | [1] |
| Household Solid Waste | 17,240 | 575 | [7] |
| Selective Collection | 69 | 2.3 | [7] |
| Waste from PEVs | 2,276 | 76 | [7] |
| Irregular Disposal (up to) | 500 | 17 | [2] |
Table 2: Composition of Urban Solid Waste in this compound
| Material Category | Percentage Composition | Data Source |
| Organic Materials | 35.94% | [7] |
| Recyclable Materials | 39.32% | [7] |
| Rejects | 24.74% | [7] |
Table 3: Locations of Voluntary Delivery Points (PEVs) in this compound
| Zone | Location |
| East Zone | Ponte Estaiada, Av. Raul Lopes |
| East Zone | In front of the church on Av. Nossa Senhora de Fátima |
| East Zone | Praça Carlos Castelo Branco, Av. Dom Severino |
| South Zone | Praça das Palmeiras, Sacy |
| South Zone | Praça da igreja da Vermelha, Av. Barão de Gurguéia |
| Southeast Zone | Praça dos Correios, Dirceu |
| Southeast Zone | Praça do Renascença II |
(Source: Consolidated from multiple news reports and municipal information)[13][14][15]
Experimental Protocols
Protocol 1: Gravimetric Characterization of Household Solid Waste
Objective: To determine the percentage composition of different materials in the household solid waste stream. This protocol is adapted from the ABNT NBR 10004 standard for waste classification.
Methodology:
-
Sampling:
-
Select a representative sample of households from different socioeconomic strata.
-
Collect the solid waste from these households over a period of one week, ensuring that the collection day corresponds to the regular municipal collection schedule.
-
The total sample size should be statistically significant (e.g., 100 kg).
-
-
Quartering:
-
Transport the collected waste to a covered, impermeable surface.
-
Homogenize the sample by mixing.
-
Divide the pile into four equal quadrants.
-
Discard two opposite quadrants.
-
Mix the remaining two quadrants and repeat the process until a final sample of approximately 25 kg is obtained.
-
-
Sorting and Classification:
-
Manually sort the final sample into predefined categories:
-
Organic Matter (food scraps, yard waste)
-
Paper/Cardboard
-
Plastics (separated by type if possible: PET, HDPE, etc.)
-
Glass
-
Metals (ferrous and non-ferrous)
-
Textiles
-
Rejects (non-recyclable materials)
-
-
-
Weighing and Data Analysis:
-
Weigh each category of sorted material using a calibrated scale.
-
Calculate the percentage of each category relative to the total weight of the final sample.
-
Record the data in a spreadsheet for analysis.
-
Mandatory Visualization
Caption: Workflow of Solid Waste Collection and Recycling in this compound.
Caption: Troubleshooting Logic for Low Selective Collection Adhesion.
References
- 1. PLANO MUNICIPAL DE GESTÃO INTEGRADA DE RESÍDUOS SÓLIDOS DO MUNICÍPIO DE this compound – PIAUÍ – NORDESTE DO BRASIL – ISSN 1678-0817 Qualis B2 [revistaft.com.br]
- 2. ANÁLISE DO SISTEMA DE GESTÃO E GERENCIAMENTO DE RESÍDUOS SÓLIDOS URBANOS NA CIDADE DE this compound- PI [repositorio.ufpi.br:8080]
- 3. ibeas.org.br [ibeas.org.br]
- 4. ibeas.org.br [ibeas.org.br]
- 5. Cooperativa de reciclagem gera renda e trabalho digno em this compound - Sebrae [sebrae.com.br]
- 6. Cooperativa de recicláveis de this compound prioriza mulheres para trabalhar: 'dinheiro para comprar suas próprias coisas' | G1 [g1.globo.com]
- 7. youtube.com [youtube.com]
- 8. sevenpubl.com.br [sevenpubl.com.br]
- 9. ibeas.org.br [ibeas.org.br]
- 10. prezi.com [prezi.com]
- 11. saude.batatais.sp.gov.br [saude.batatais.sp.gov.br]
- 12. ANÁLISE SITUACIONAL DO ATERRO SANITÁRIO DE this compound E AVALIAÇÃO DA EFICIÊNCIA DO PROCESSO DE COMPOSTAGEM | Revista Geotemas [periodicos.apps.uern.br]
- 13. viagora.com.br [viagora.com.br]
- 14. reciclacomvoce.com.br [reciclacomvoce.com.br]
- 15. researchgate.net [researchgate.net]
Technical Support Center: Small Area Estimation for Health Research in Teresina
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in refining statistical analysis for small area estimation (SAE) in Teresina, Piauí.
Troubleshooting Guide
This guide addresses specific issues that may arise during the application of SAE methods to health data in this compound.
Question: My direct survey estimates for health outcomes in this compound's census sectors have unacceptably high standard errors. How can I generate more reliable estimates?
Answer: This is a common challenge when sample sizes within small areas (like census sectors) are insufficient for precise direct estimation.[1] The solution is to use model-based Small Area Estimation (SAE) techniques that "borrow strength" from auxiliary data available for all areas.[2] Methods like Empirical Best Linear Unbiased Prediction (EBLUP) and Hierarchical Bayesian (HB) models are designed for this purpose. They combine the direct survey estimates with predictions from a regression model that uses covariates from sources like the Brazilian census.[2][3]
Question: The most recent census data for this compound from the Instituto Brasileiro de Geografia e Estatística (IBGE) is outdated. Can I still perform reliable SAE?
Answer: Yes, while challenging, it is possible. Outdated census data is a common problem.[4] You can augment or replace outdated census variables with more current auxiliary data from other sources:
-
Administrative Data: Utilize data from local government or health system records. However, be aware that accessing and harmonizing this data can be a significant challenge, and its quality must be carefully assessed.[5]
-
Geospatial Data: Publicly available geospatial data can serve as powerful predictors.[5][6] This includes satellite imagery (e.g., nighttime lights, vegetation indices) and data from geographic information systems (GIS) like the location of health facilities, schools, or infrastructure.[7] These can be aggregated to the census sector level for this compound.
Question: I am encountering issues with spatial autocorrelation in my model residuals for health indicators across different neighborhoods in this compound. What should I do?
Answer: Spatial autocorrelation, where values in nearby areas are more similar than those farther apart, violates the independence assumption of standard regression models. Ignoring it can lead to biased estimates of variance. To address this, you should use spatial SAE models. The Hierarchical Bayesian framework is particularly flexible for this, allowing you to incorporate spatially correlated random effects.[8][9] These models "borrow strength" not just from the overall data but specifically from neighboring areas, which can improve prediction accuracy.
Question: My model performs well for the census sectors included in my survey sample, but I need to produce estimates for unsampled sectors in this compound. How can this be done?
Answer: This is a primary application of synthetic estimation, a key component of many SAE methods.[8] A regression model is fitted using data from the sampled areas, establishing a relationship between the health indicator and auxiliary variables.[10] This fitted model is then used to predict the outcome for the unsampled areas using their known auxiliary data.[11] Bayesian methods are particularly adept at this, as they can naturally predict for missing areas and quantify the associated uncertainty.[8]
Frequently Asked Questions (FAQs)
Q1: What is Small Area Estimation (SAE)?
SAE refers to a collection of statistical techniques used to produce reliable estimates for small geographical areas (e.g., municipalities, census sectors) or demographic sub-groups for which sample sizes in surveys are too small to yield direct estimates with adequate precision.[10][12]
Q2: Why are Bayesian methods often recommended for SAE?
Bayesian methods are well-suited for SAE for several reasons:
-
Handling Sparsity: They perform well with the sparse data typical of small areas.[8]
-
Rich Output: They provide a full posterior distribution for each estimate, offering a more complete picture of uncertainty than just a point estimate and a standard error.[8][9]
-
Flexibility: The hierarchical structure allows for the modeling of complex data structures, including spatial and temporal correlations.[9]
-
Coherence: They provide a unified framework for combining information from different sources (surveys, census, geospatial data).
Q3: What are the main types of SAE models?
SAE models are generally categorized into two types:
-
Area-Level Models: These models relate small area direct estimates to area-specific auxiliary variables. The Fay-Herriot model is the most well-known example.[5] They are used when individual-level data is not available.
-
Unit-Level Models: These models relate the individual unit (e.g., person or household) variable of interest to unit-level auxiliary variables. They require access to microdata from the survey and auxiliary data for every unit in the population.[5]
Q4: Where can I find auxiliary data for SAE in this compound?
Potential sources for auxiliary data for small areas in this compound include:
-
IBGE: Provides census data on demographics, socioeconomic status, and housing at the census sector level.[13]
-
Brazilian Health Systems: Data on notifiable diseases or health service utilization, though georeferencing can be a challenge.[14]
-
Geospatial Repositories: Public sources for satellite imagery (e.g., Landsat, Sentinel) and GIS data (e.g., OpenStreetMap).[15]
-
Local Administrative Data: Municipal-level data on education, social programs, or infrastructure.
Data Presentation
Table 1: Comparison of Common Small Area Estimation Methods
| Method | Description | Key Advantage | Key Limitation |
| Direct Estimator | Uses only the survey data from within the small area. | Unbiased and simple to calculate. | High variance and instability with small sample sizes.[1] |
| Synthetic Estimator | Applies a model from a larger area to the small area's auxiliary data. | Can be used for areas with zero sample size. | Can be heavily biased if the small area is different from the larger area.[3] |
| Composite Estimator | A weighted average of the direct and synthetic estimators. | Balances the bias of the synthetic estimator with the instability of the direct one.[3] | The optimal weight can be difficult to determine. |
| EBLUP (Area-Level) | An optimal combination of the direct estimator and a regression-based prediction. | Minimizes Mean Squared Error among linear unbiased predictors. | Assumes a linear model and known sampling variances (often estimated in practice).[16] |
| Hierarchical Bayes (HB) | A model-based approach using Bayesian inference with random area effects. | Highly flexible, provides full posterior distributions, and can easily incorporate spatial effects.[2][9] | More computationally intensive and requires specification of prior distributions. |
Experimental Protocols
Methodology: Implementing a Hierarchical Bayesian Spatial Model for SAE
This protocol outlines the steps for generating small area estimates of a health indicator (e.g., disease prevalence) for census sectors in this compound using a spatial Bayesian model.
-
Data Acquisition and Preparation:
-
Survey Data: Obtain individual or aggregated health outcome data for a sample of census sectors in this compound (e.g., from a local health survey).[17]
-
Auxiliary Data: Collect relevant area-level covariates for all census sectors in this compound from sources like the IBGE Census (e.g., average income, literacy rate, sanitation access) and geospatial data (e.g., distance to nearest health facility, green space percentage).[5][13]
-
Geospatial Data: Acquire a neighborhood graph or adjacency matrix defining the spatial relationships between the census sectors.
-
-
Data Harmonization:
-
Ensure all variables are consistently defined across datasets.
-
Aggregate unit-level survey data to the census sector level if using an area-level model.
-
Link the survey, auxiliary, and spatial data by a common geographic identifier for each census sector.
-
-
Model Specification:
-
Likelihood: Define the statistical distribution for the direct estimates (e.g., a Binomial distribution for prevalence data or a Normal distribution for the logit-transformed prevalence).
-
Linear Predictor: Model the health outcome as a function of the auxiliary variables.
-
Random Effects: Include two sets of area-level random effects:
-
An unstructured random effect to capture extra-Poisson variation or overdispersion.
-
A spatially structured random effect (e.g., using an Intrinsic Conditional Autoregressive - ICAR - model) to account for spatial autocorrelation.
-
-
Priors: Specify prior distributions for all unknown parameters (regression coefficients, variances of random effects). Vague or weakly informative priors are typically used.
-
-
Model Fitting:
-
Use Markov Chain Monte Carlo (MCMC) methods (e.g., Gibbs sampling) to draw samples from the posterior distribution of the model parameters and the small area estimates.
-
Utilize statistical software such as R (with packages like R-INLA or rstan) or Python (with PyMC).
-
-
Diagnostics and Validation:
-
Convergence: Assess the convergence of the MCMC chains using trace plots and diagnostic statistics (e.g., Gelman-Rubin statistic).
-
Model Fit: Use posterior predictive checks to assess how well the model fits the observed data.
-
Model Comparison: If multiple models are fitted, compare them using criteria like the Deviance Information Criterion (DIC) or the Watanabe-Akaike Information Criterion (WAIC). Models with smaller values are preferred.[8]
-
-
Estimate Generation and Reporting:
-
Summarize the posterior distributions for each census sector to obtain point estimates (e.g., posterior mean or median) and credible intervals (e.g., 95% Bayesian credible intervals) to represent uncertainty.
-
Map the final estimates to visualize the geographic distribution of the health indicator across this compound.
-
Mandatory Visualization
Caption: Workflow for Small Area Estimation analysis in this compound.
Caption: Diagram of a Hierarchical Bayesian spatial model structure.
References
- 1. The Use of Small Area Estimates in Place-Based Health Research - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Small Area Estimation: An Appraisal | Formerly www.nickthoughts.gov.www\nickthoughts [nicksun.fun]
- 4. cepal.org [cepal.org]
- 5. unstats.un.org [unstats.un.org]
- 6. unstats.un.org [unstats.un.org]
- 7. GIS, geospatial solutions for health, Geographic Information System, Storymap, GIS Center [who.int]
- 8. eprints.ncrm.ac.uk [eprints.ncrm.ac.uk]
- 9. researchgate.net [researchgate.net]
- 10. unfpa.org [unfpa.org]
- 11. researchgate.net [researchgate.net]
- 12. The Small Area Estimation by Using Empirical Bayes Method | Atlantis Press [atlantis-press.com]
- 13. cidacs.bahia.fiocruz.br [cidacs.bahia.fiocruz.br]
- 14. Statistically enriched geospatial datasets of Brazilian municipalities for data-driven modeling - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Geo-Spatial Data Resources | cdc.gov [archive.cdc.gov]
- 16. bibliotekanauki.pl [bibliotekanauki.pl]
- 17. scielosp.org [scielosp.org]
Validation & Comparative
"comparative analysis of urban heat islands in Brazilian cities including Teresina"
A Comparative Analysis of Urban Heat Islands in Brazilian Cities, with a Focus on Teresina
The phenomenon of urban heat islands (UHIs), characterized by elevated temperatures in urban areas compared to their rural surroundings, is a growing concern in Brazil, a nation with 88% of its population residing in cities.[1] This guide presents a comparative analysis of UHIs in various Brazilian cities, with a particular emphasis on this compound, the capital of Piauí state. This compound is notable for being the only non-coastal capital in the Brazilian Northeast and is situated in a semiarid region, making it particularly susceptible to extreme heat.[2] This analysis is intended for researchers, scientists, and urban planners engaged in understanding and mitigating the impacts of urban climate change.
Quantitative Comparison of Urban Heat Island Effects
The intensity of urban heat islands can be quantified using several metrics, primarily derived from satellite-based remote sensing data. This section compares this compound with other Brazilian cities based on key indicators such as Surface Urban Heat Island (SUHI) intensity, Urban Thermal Field Variation Index (UTFVI), and Thermal Discomfort Index (TDI).
Table 1: Comparative Surface Urban Heat Island (SUHI) Data for Northeastern Brazilian Capitals (2019-2020)
| City | Maximum SUHI (°C) | Average SUHI (°C) |
| This compound | ~7.0 | ~7.0 |
| Fortaleza | >5.0 | >-1.0 |
| São Luís | Similar to Natal | Similar to Natal |
| Natal | 1.8 | 0.0 |
| João Pessoa | >5.0 | >-1.0 |
| Recife | 5.2 | -2.0 |
| Maceió | Similar to Natal | Similar to Natal |
| Aracaju | >5.0 | >-1.0 |
| Salvador | Similar to Natal | Similar to Natal |
Source: Adapted from a 2024 study on Urban Heat Island Assessment in Northeastern Brazilian Capitals.[2]
Table 2: Urban Thermal Field Variation Index (UTFVI) and Thermal Discomfort Index (TDI) for Selected Northeastern Capitals
| City | UTFVI Classification | TDI Classification (Hottest Pixels) |
| This compound | Strongest heat island | Very Hot |
| João Pessoa | Strongest heat island | Very Hot |
| Recife | Strongest heat island | Hot |
| Maceió | Strong | Hot |
| Aracaju | Strong | Very Hot |
| Fortaleza | Medium to Strong | Very Hot |
| Salvador | Medium to Strong | Very Hot |
| São Luís | Medium to Strong | Very Hot |
| Natal | Medium to Strong | Hot |
Source: Adapted from a 2024 study on Urban Heat Island Assessment in Northeastern Brazilian Capitals.[2]
A study focusing on the this compound-Timon conurbation area revealed a significant link between urban sprawl and increased Land Surface Temperature (LST).[3][4][5][6] The gradual replacement of green spaces with residential settlements, partly driven by housing programs, has contributed to the intensification of the local microclimate.[3][4][5][6] In comparison, studies on other Brazilian cities like São Paulo and Rio de Janeiro also highlight the correlation between dense urbanization and higher UHI intensity.[7][8][9] For instance, São Paulo has the fourth-largest daytime UHI effect globally, with temperatures more than 5°C hotter than its surroundings.[9] In Rio de Janeiro, the most intense heat is experienced in the working-class outskirts of the city.[8]
Experimental Protocols
The data presented in this guide are primarily derived from remote sensing methodologies, which offer a significant advantage over in-situ measurements by providing comprehensive spatial coverage of urban surfaces.[10]
Land Surface Temperature (LST) and Surface Urban Heat Island (SUHI) Calculation
The methodologies employed in the cited studies for determining LST and SUHI are summarized below:
-
Data Source: Nighttime Land Surface Temperature (LST) data are often retrieved from satellite images, such as those from the Sentinel-3 satellite's Sea and Land Surface Temperature Radiometer (SLSTR) sensor.[2] Other studies have utilized data from MODIS and Landsat satellites.[10][11]
-
Urban and Rural Area Definition: A critical step in SUHI calculation is the clear and consistent definition of urban and rural areas.[10] One approach involves using official national urban area limits and defining surrounding reference classes such as the urban adjacent, future urban adjacent, and peri-urban areas.[2]
-
SUHI Intensity Calculation: The intensity of the SUHI effect is typically calculated as the difference between the mean temperature of the pixels within the urban area and the mean temperature of the pixels in the defined rural or non-urban edge.[10]
Urban Thermal Field Variation Index (UTFVI)
The UTFVI is utilized for the ecological thermal assessment of urban environments and is calculated based on the LST of each pixel within the urban area.[2] The formula relates the LST of a given pixel to the mean LST of the entire study area.[2] The resulting index is categorized into different levels to evaluate the ecological impact of the UHI.[2][11]
Thermal Discomfort Index (TDI)
The TDI is used to assess the population's perception of thermal comfort. It is also derived from LST data and provides insights into the areas where the population is most likely to experience thermal stress.[2]
Visualizing the Research Workflow
The following diagram illustrates the typical workflow for a comparative analysis of urban heat islands using remote sensing data.
Caption: Workflow for comparative urban heat island analysis.
Conclusion
The comparative analysis reveals that this compound exhibits one of the most intense urban heat island effects among the northeastern Brazilian capitals, with both high SUHI values and a "strongest" UTFVI classification.[2] This is consistent with its geographical location in a semiarid region and the observed patterns of urban expansion that have led to the conversion of green spaces into built-up areas.[3][4][5][6] The methodologies employed in these studies, primarily based on satellite remote sensing, provide a robust framework for monitoring and comparing UHI phenomena across different urban landscapes in Brazil. These findings underscore the urgent need for targeted urban planning and mitigation strategies to address the impacts of extreme heat in this compound and other vulnerable Brazilian cities. Such strategies could include increasing vegetation cover, promoting the use of reflective building materials, and implementing sustainable urban development policies.
References
- 1. Urban heat islands make even small and midsized towns warmer : Revista Pesquisa Fapesp [revistapesquisa.fapesp.br]
- 2. mdpi.com [mdpi.com]
- 3. Linking Urban Sprawl and Surface Urban Heat Island in the this compound–Timon Conurbation Area in Brazil [ouci.dntb.gov.ua]
- 4. Linking Urban Sprawl and Surface Urban Heat Island in the this compound–Timon Conurbation Area in Brazil [ideas.repec.org]
- 5. mdpi.com [mdpi.com]
- 6. researchgate.net [researchgate.net]
- 7. scielo.br [scielo.br]
- 8. Rio de Janeiro’s Urban Heat Islands: A Primer – RioOnWatch [rioonwatch.org]
- 9. The Urban Heat Island Effect [storymaps.arcgis.com]
- 10. scispace.com [scispace.com]
- 11. scielo.br [scielo.br]
"comparing the effectiveness of different dengue control strategies in Teresina"
For immediate release
The core of Teresina's strategy revolves around an integrated vector management approach, combining surveillance, chemical control, and community engagement. This is consistent with the national guidelines established by the Brazilian Ministry of Health.
Data on Dengue Incidence and Vector Infestation
Epidemiological data and vector surveillance are crucial for monitoring the impact of control measures. The following tables present a summary of available data for this compound and the state of Piauí.
Table 1: Epidemiological Data for Dengue in this compound (2002-2006)
| Year | Dengue Cases Notified | Incidence Rate (per 100,000 inhabitants) |
| 2002 | Data not specified | 592.7 |
| 2003 | Data not specified | Data not specified |
| 2004 | Data not specified | 19.5 |
| 2005 | Data not specified | Data not specified |
| 2006 | Data not specified | Data not specified |
Source: Monteiro et al., 2009.[1]
Table 2: Results of the Rapid Index Survey for Aedes aegypti (LIRAa) in Piauí (2025)
| LIRAa/LIA Stage | Number of Municipalities with Satisfactory Index | Number of Municipalities in Alert | Number of Municipalities at Risk |
| 1st Stage | 116 (51.79%) | 94 (41.96%) | 14 (6.25%) |
Source: Piauí State Government, 2025.[2]
Recent reports from May 2025 indicate a 60% reduction in dengue cases in this compound compared to the previous year, suggesting that the implemented control measures are having a positive impact.[3]
Key Dengue Control Strategies in this compound
The following sections describe the main strategies employed in this compound for dengue control.
Entomological Surveillance
Methodology: this compound's Municipal Health Foundation (FMS) utilizes ovitraps as a key tool for entomological surveillance.[3] These traps are designed to attract female Aedes aegypti mosquitoes to lay their eggs, allowing health authorities to monitor the mosquito population density and identify areas with a high risk of transmission. The data collected from these traps informs the prioritization of areas for targeted vector control interventions.[3]
The Levantamento Rápido de Índices para Aedes aegypti (LIRAa), a rapid survey to assess larval infestation levels, is also a critical component of surveillance in the state of Piauí and guides municipal actions.[2]
Chemical Control
Methodology: While specific protocols for this compound are not detailed in the available documents, chemical control is a standard component of the national dengue control program in Brazil. This typically involves the use of larvicides in breeding sites that cannot be eliminated and adulticides (ultra-low volume space spraying) in areas with high mosquito density or during outbreaks. A study on dengue in this compound between 2002 and 2006 noted that water storage containers were the primary breeding sites, highlighting a key target for larvicide application.[1]
Community Mobilization and Health Education
Methodology: Public awareness and community participation are emphasized as crucial for the success of dengue control efforts. The strategy involves educating the population on the importance of eliminating mosquito breeding sites in and around their homes. This includes actions such as properly covering water storage containers, cleaning gutters, and removing any objects that can accumulate water. Reports indicate a strong focus on community involvement in this compound.[3]
"New Technologies"
Methodology: News reports mention investments in "new technologies" for dengue control in this compound.[4] While the specific technologies are not detailed, this could encompass a range of innovative approaches being tested and implemented in Brazil, such as the use of drones for mapping and treating breeding sites, or biological control methods like the use of Wolbachia-infected mosquitoes. However, no specific data on the implementation or effectiveness of these newer methods in this compound was found in the reviewed literature.
Experimental Protocols and Workflows
Detailed experimental protocols for comparative studies in this compound were not available. However, the general workflow for dengue control can be conceptualized as a cycle of surveillance, data analysis, targeted intervention, and evaluation.
Caption: Workflow of the integrated dengue control program in this compound.
Logical Relationship of Control Strategies
The dengue control strategies in this compound are interconnected and designed to be mutually reinforcing. Surveillance is the foundational element that guides the implementation of other control measures.
Caption: Interrelationship of dengue control strategies in this compound.
Conclusion
The dengue control program in this compound is a dynamic and integrated system that relies on continuous surveillance to direct its interventions. While the available data points towards a recent reduction in dengue cases, the lack of direct comparative studies makes it challenging to attribute this success to a single strategy. The effectiveness of the program likely lies in the synergistic application of entomological surveillance, targeted chemical control, and sustained community mobilization. Future research, including controlled trials comparing different interventions, would be invaluable for optimizing dengue control efforts in this compound and other endemic regions.
References
A Tale of Two Brazils: Socioeconomic Disparities Between Teresina and Other National Capitals
A deep dive into the socioeconomic fabric of Brazil's capitals reveals a landscape of stark contrasts. This comparative guide dissects key indicators of inequality, placing Teresina, the capital of Piauí, in context with its counterparts across the nation. By examining data on income distribution, education, and healthcare, a clearer picture emerges of the challenges and disparities that define urban life in Brazil.
Recent analyses underscore the persistent chasm between the affluent and the impoverished in Brazilian cities. While national efforts have been made to mitigate these gaps, the reality on the ground, particularly in capitals like this compound, showcases the multifaceted nature of socioeconomic inequality. This guide synthesizes quantitative data from leading Brazilian research institutions to provide an objective comparison for researchers, scientists, and development professionals.
The Landscape of Inequality: A Comparative Overview
A comprehensive 2023 study by the Sustainable Cities Institute, titled "Mapa da Desigualdade entre as Capitais" (Inequality Map of the Capitals), provides a crucial framework for this analysis. The study evaluates all 26 state capitals based on 40 socioeconomic indicators. In this ranking, this compound appears in the middle tier, signaling a complex reality of both progress and persistent challenges when compared to other urban centers.
Income and Wealth: The Gini Index and Beyond
Table 1: Comparative Socioeconomic Indicators for Selected Brazilian Capitals
| Indicator | This compound (PI) | Florianópolis (SC) | Salvador (BA) | São Paulo (SP) | Porto Velho (RO) |
| Overall Inequality Ranking | 14th | 2nd | 17th | 5th | 26th |
| Population Below Poverty Line (%) | Not specified in top/bottom | 1% (Best) | 11% (Worst) | Not specified in top/bottom | Not specified in top/bottom |
| Child Malnutrition (%) | 0.44% (Best) | Not specified in top/bottom | 4% (Worst) | Not specified in top/bottom | Not specified in top/bottom |
| Access to Basic Sanitation (%) | Data not specified | 99.7% | Data not specified | 100% | 5.8% (Worst) |
| Doctors per 1,000 Inhabitants | 4.33 | 10.48 | 5.51 | 6.80 | 2.45 |
| Literacy Rate (Age 15+) (%) | ~82.8% (State of Piauí) | ~97.3% (State of Santa Catarina) | Data not specified | ~97.8% (State of São Paulo) | Data not specified |
| Average Years of Schooling | 8.4 (State of Piauí) | 10.1 (State of Santa Catarina) | Data not specified | 10.8 (State of São Paulo) | Data not specified |
Note: Data is compiled from the "Mapa da Desigualdade entre as Capitais" (2023) by the Instituto Cidades Sustentáveis, the Federal Council of Medicine (2023), and the IBGE (2022). State-level data for education is used as a proxy where capital-specific data was not available in the immediate sources.
Educational Divides
Access to and quality of education are fundamental pillars of socioeconomic development, and here too, the disparities between Brazilian capitals are evident. Florianópolis stands out with the lowest percentage of its population having less than a primary education. Conversely, capitals in the North and Northeast regions tend to have lower literacy rates and fewer average years of schooling. While this compound has made strides in improving educational outcomes, as a state, Piauí's literacy rate and average years of schooling are lower than the national average.[1]
Healthcare Accessibility
The availability of healthcare professionals is a critical indicator of public health infrastructure. Data from the Federal Council of Medicine reveals a significant concentration of doctors in the capitals of the South and Southeast. Florianópolis, for instance, boasts a high ratio of doctors per inhabitant. This compound's ratio is moderate, while capitals in the North, such as Porto Velho, face a more severe shortage of medical professionals.
Another crucial aspect of public health is access to basic sanitation. Here, the contrast is particularly stark. While São Paulo reports 100% of its population with access to sanitation, Porto Velho languishes at a mere 5.8%.[2] This disparity in fundamental infrastructure has profound implications for public health outcomes.
Methodological Notes
The data presented in this guide is sourced from reputable Brazilian institutions, each with its own robust methodologies.
-
"Mapa da Desigualdade entre as Capitais" (Instituto Cidades Sustentáveis): This study compiles 40 indicators from official public sources such as the Brazilian Institute of Geography and Statistics (IBGE) and the public health data system, DATASUS. The methodology is inspired by the "Map of Inequality of the City of São Paulo" and aims to provide a comprehensive overview of social well-being across the capitals.[3]
-
Brazilian Institute of Geography and Statistics (IBGE): The IBGE is Brazil's primary provider of official statistics. Data on literacy, sanitation, and income are collected through large-scale national surveys such as the Demographic Census and the National Continuous Household Sample Survey (PNAD Contínua). These surveys employ complex sampling techniques to ensure national and regional representativeness.
-
DATASUS: This is the informatics department of Brazil's Unified Health System (SUS). It collects and disseminates a wide range of health-related data, including information on healthcare infrastructure, disease prevalence, and access to services.
-
Federal Council of Medicine (CFM): The CFM is the regulatory body for physicians in Brazil. Their data on the number of doctors per inhabitant is based on professional registration records.
Visualizing the Factors of Inequality
The following diagram illustrates the interconnected factors that contribute to socioeconomic inequality in Brazilian capitals.
References
- 1. Estudo detalha situação do analfabetismo no País — Instituto Nacional de Estudos e Pesquisas Educacionais Anísio Teixeira | Inep [gov.br]
- 2. Censo 2022: rede de esgoto alcança 62,5% da população, mas desigualdades regionais e por cor e raça persistem | Agência de Notícias [agenciadenoticias.ibge.gov.br]
- 3. Desigualdade nas capitais brasileiras - Rede Juntos : Rede Juntos [redejuntos.org.br]
A Comparative Guide to Validating Remote Sensing Data with Ground-Truth Measurements in Teresina
This guide provides researchers, scientists, and drug development professionals with a comprehensive overview of methodologies for validating remote sensing data using ground-truth measurements, with a specific focus on applications in Teresina, Brazil. We offer a comparative analysis of common validation techniques, detailed experimental protocols, and quantitative data to support the objective assessment of remote sensing product accuracy.
Introduction to Remote Sensing Validation
Remote sensing provides invaluable data for monitoring environmental changes, urban development, and public health trends in areas like this compound. However, the accuracy of data derived from satellite or aerial imagery must be rigorously validated to ensure its reliability for scientific research and decision-making.[1] Ground-truthing, the process of collecting in-situ data, is considered the gold standard for this validation process.[2] It involves direct comparison of remotely sensed data with on-the-ground observations.[3]
This guide will explore two primary applications of remote sensing data validation relevant to this compound's environment: Land Use/Land Cover (LULC) classification and Vegetation Index (VI) accuracy assessment.
Comparison of Ground-Truthing Methodologies
The selection of a ground-truthing methodology depends on the research objectives, available resources, and the specific remote sensing data product being validated. Here, we compare two common approaches for LULC and VI validation.
Land Use/Land Cover (LULC) Validation Approaches
Table 1: Comparison of LULC Ground-Truthing Methodologies
| Methodology | Description | Advantages | Disadvantages | Typical Accuracy Range (Overall) |
| Random Point Sampling | Randomly selected geographic points are visited in the field to identify the actual land cover class. | Statistically robust and unbiased. | Can be time-consuming and costly, especially in inaccessible areas. May miss small, important features. | 80-90% |
| Stratified Random Sampling | The study area is divided into strata based on the classified LULC map, and random points are sampled within each stratum. | Ensures representation of all classes, including rare ones. More efficient than simple random sampling. | Requires an initial classification to create strata. Can be complex to design and implement. | 85-95% |
Vegetation Index (VI) Validation Approaches
Table 2: Comparison of Vegetation Index Ground-Truthing Methodologies
| Methodology | Description | Advantages | Disadvantages | Typical Correlation (r) with Satellite VI |
| Field Spectroscopy | A handheld spectroradiometer is used to measure the spectral reflectance of the vegetation canopy, from which VIs are calculated. | Provides highly accurate, near-real-time spectral data for direct comparison. | Expensive equipment is required. Measurements can be affected by atmospheric conditions. | 0.85-0.98 |
| Biophysical Parameter Measurement | Field measurements of vegetation parameters like Leaf Area Index (LAI) or biomass are collected and correlated with satellite-derived VIs. | Provides a direct link between the VI and the physical characteristics of the vegetation. | Can be labor-intensive and destructive. The relationship between biophysical parameters and VIs can be complex. | 0.70-0.90 |
Experimental Protocols
Detailed and consistent experimental protocols are crucial for obtaining reliable ground-truth data. Below are step-by-step methodologies for LULC and VI validation applicable to studies in this compound.
Protocol for LULC Validation using Stratified Random Sampling
-
Define LULC Classes: Establish a clear and comprehensive classification scheme relevant to this compound's landscape (e.g., Urban/Built-up, Water Bodies, Bare Soil, Caatinga Vegetation, Forest).
-
Initial Image Classification: Perform a supervised or unsupervised classification of the remote sensing imagery (e.g., Landsat, Sentinel-2) to create a preliminary LULC map.
-
Generate Strata: Use the classified LULC map to create strata for each land cover class.
-
Determine Sample Size: Calculate the required number of ground-truth points for each stratum to achieve a statistically significant result.
-
Random Point Generation: Within each stratum, generate random geographic coordinates for the ground-truth points.
-
Field Data Collection:
-
Navigate to each point using a GPS device.
-
At each location, identify and record the dominant land cover type within a predefined area (e.g., a 30x30 meter plot corresponding to a Landsat pixel).
-
Take photographs of the site for reference.
-
Note any discrepancies between the observed land cover and the initial classification.
-
-
Data Analysis:
Protocol for Vegetation Index (e.g., NDVI) Validation using Field Spectroscopy
-
Site Selection: Choose representative sample sites within areas of interest (e.g., urban parks, agricultural fields, natural vegetation areas) that are homogenous over an area larger than the pixel size of the remote sensing data.
-
Data Acquisition Timing: Synchronize field measurements with the satellite overpass time as closely as possible to minimize temporal differences in atmospheric conditions and sun angle.
-
Field Spectrometer Setup and Calibration:
-
Warm up the spectroradiometer according to the manufacturer's instructions.
-
Calibrate the instrument using a white reference panel before and after measurements at each site.
-
-
Spectral Measurements:
-
At each sample site, collect multiple spectral readings of the vegetation canopy from a consistent height and viewing angle.
-
Also, collect readings of the white reference panel at regular intervals to account for changing illumination conditions.
-
-
Data Processing:
-
Average the spectral readings for each site to obtain a representative spectrum.
-
Calculate the NDVI from the field spectra using the appropriate formula: NDVI = (NIR - Red) / (NIR + Red).
-
-
Comparison with Satellite Data:
-
Extract the NDVI values from the corresponding pixels in the remote sensing image.
-
Perform a regression analysis to determine the correlation between the field-measured NDVI and the satellite-derived NDVI.
-
Visualizing the Validation Workflow
Clear and logical workflows are essential for planning and executing a successful validation campaign. The following diagrams, created using the DOT language, illustrate the key steps in the validation process.
References
A Tale of Two Timelines: Cross-Sectional and Longitudinal Insights into Disease Prevalence in Teresina
Teresina, Brazil - Understanding the prevalence and dynamics of infectious diseases is a critical endeavor for public health officials, researchers, and pharmaceutical professionals. In the capital city of Piauí state, this compound, two primary epidemiological study designs, cross-sectional and longitudinal, offer distinct yet complementary perspectives on the burden of diseases like Chagas disease and leprosy. This guide provides a comparative analysis of findings from these study types, offering a deeper understanding of their respective strengths and limitations in capturing the complex picture of disease in this region.
Cross-sectional studies provide a snapshot in time, estimating the prevalence of a disease at a specific moment. In contrast, longitudinal studies follow a population over a period, revealing trends in incidence and the progression of disease. By examining both, a more comprehensive understanding of the epidemiological landscape of this compound can be achieved.
At a Glance: Key Methodological Differences
| Feature | Cross-Sectional Study | Longitudinal Study |
| Time Frame | Single point in time | Extended period with multiple follow-ups |
| Objective | To determine prevalence | To determine incidence and disease progression |
| Key Question | What is the disease burden now? | How is the disease burden changing over time? |
| Causality | Cannot establish causality | Can help establish temporal relationships |
| Cost & Time | Relatively quick and less expensive | Time-consuming and more expensive |
Chagas Disease in this compound: A Cross-Sectional Snapshot
A cross-sectional study conducted in the rural areas of this compound provides valuable insights into the prevalence of Chagas disease, a parasitic illness transmitted by "kissing bugs".[1] Another analytical cross-sectional study evaluated the epidemiology of Chagas disease across the state of Piauí, including this compound, from 2010 to 2019.[2]
Experimental Protocol: Cross-Sectional Serological Survey for Chagas Disease
The methodology for a typical cross-sectional study on Chagas disease in this compound would involve the following steps:
-
Study Population: A defined population from a specific geographic area within or around this compound is selected. Participants are chosen based on inclusion and exclusion criteria, not on their disease status.[3][4]
-
Data Collection: At a single point in time, data is collected from each participant. This includes demographic information, risk factor exposure, and the collection of a blood sample.
-
Laboratory Analysis: The blood samples are analyzed for the presence of antibodies to Trypanosoma cruzi, the parasite that causes Chagas disease. Common methods include the indirect immunofluorescence test.[1]
-
Statistical Analysis: The prevalence of Chagas disease is calculated as the proportion of individuals with a positive serological test. Associations between risk factors and disease status are often analyzed using odds ratios.
Quantitative Findings from Cross-Sectional Studies on Chagas Disease
| Metric | Finding | Study Area | Citation |
| Seroprevalence | 2 positive cases out of 123 inhabitants examined | Rural area of this compound | [1] |
| Confirmed Cases (2010-2019) | 70 confirmed cases of acute Chagas disease | State of Piauí | [2] |
| Probable Transmission | 77.9% of confirmed cases were from vector transmission | State of Piauí | [2] |
The following diagram illustrates the typical workflow of a cross-sectional study.
Leprosy in Piauí: A Longitudinal Perspective
A longitudinal ecological time-series study analyzed the trends of leprosy in the state of Piauí, where this compound is a major urban center, from 2007 to 2021.[5] This type of study provides a dynamic view of the disease over an extended period.
Experimental Protocol: Longitudinal Time-Series Analysis of Leprosy
The methodology for a longitudinal time-series study on leprosy in Piauí would generally follow these steps:
-
Data Source: Data is obtained from a disease notification system, such as the Notifiable Health Conditions Information System (SINAN) in Brazil. This provides data over many years.[5]
-
Study Population: The entire population of the state of Piauí, or specific health regions including this compound, constitutes the study population.
-
Data Extraction: Key indicators are extracted for each year in the study period. This includes the number of new cases, the detection rate, the proportion of different clinical forms (paucibacillary vs. multibacillary), and the rate of grade 2 physical disabilities at diagnosis.
-
Statistical Analysis: Time-series analysis is used to identify trends in the data over time. Techniques like Prais-Winsten regression can be used to calculate the annual percentage change (APC) in indicators.[5]
Quantitative Findings from a Longitudinal Study on Leprosy in Piauí (2007-2021)
| Indicator | Trend | Annual Percentage Change (APC) | Citation |
| Overall Detection Rate | Falling | -6.3% | [5] |
| Detection in Children <15 | Falling | -8.6% | [5] |
| Grade 2 Disability Detection | Falling | -4.4% | [5] |
| Proportion of Multibacillary Cases | Rising | Not specified | [5] |
The diagram below outlines the logical flow of a longitudinal time-series analysis.
Comparative Insights and Implications
The cross-sectional findings on Chagas disease provide a crucial, albeit static, measure of its prevalence in specific communities within this compound. This is invaluable for immediate resource allocation and targeted screening programs. However, it doesn't reveal the dynamics of transmission or the effectiveness of control measures over time.
Conversely, the longitudinal data on leprosy in Piauí offers a narrative of the disease's trajectory. The falling detection rates are encouraging, suggesting that public health interventions may be having a positive impact.[5] However, the rising proportion of multibacillary cases could indicate delays in diagnosis, a critical insight for refining control strategies.[5]
For researchers and drug development professionals, this comparison underscores the necessity of employing both study designs to gain a holistic understanding of a disease. Cross-sectional studies can identify high-prevalence areas for clinical trial recruitment, while longitudinal studies are essential for evaluating the long-term efficacy and impact of new therapies and public health interventions. The interplay of these methodologies provides the robust evidence base needed to combat infectious diseases effectively in this compound and beyond.
References
- 1. [The epidemiology of Chagas' disease in a rural area of the city of this compound, Piauí, Brazil] - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Epidemiological aspects of Chagas disease in the state of Piauí (Northeast Brazil) in the period 2010-2019 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Methodology Series Module 3: Cross-sectional Studies - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Methodology Series Module 3: Cross-sectional Studies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Characterization of cases and epidemiological and operational indicators of leprosy: analysis of time series and spatial distribution, Piauí state, Brazil, 2007-2021 - PubMed [pubmed.ncbi.nlm.nih.gov]
"comparing water quality of the Poti river with other urban rivers in Brazil"
A Comparative Analysis of Water Quality in the Poti River and Other Major Urban Rivers in Brazil
This guide provides a comparative analysis of the water quality of the Poti River, which flows through Teresina, the capital of Piauí state, against other significant urban rivers in Brazil: the Tietê River in São Paulo, the Iguaçu River in Paraná, and the Capibaribe River in Pernambuco. This document is intended for researchers, scientists, and environmental professionals, offering a synthesis of available data, a detailed look at experimental methodologies, and visualizations to illustrate key concepts.
The water quality of urban rivers in Brazil is a matter of significant concern due to pollution from domestic sewage, industrial effluents, and agricultural runoff. This comparison aims to contextualize the state of the Poti River by examining its water quality parameters alongside those of other rivers facing similar anthropogenic pressures.
Data Presentation: A Comparative Overview
The following table summarizes key water quality parameters for the Poti River and the selected urban rivers. The data has been compiled from various scientific studies and monitoring reports. It is important to note that the values represent findings from specific studies and timeframes and may not reflect the current real-time conditions of the rivers. The primary Brazilian legal framework for water quality is the National Environment Council (CONAMA) Resolution No. 357/2005, which establishes classifications and quality standards for water bodies. For Class 2 rivers, which are intended for domestic water supply after conventional treatment, the standard for Thermotolerant Coliforms is not to exceed 1,000 MPN/100 mL, and for Biochemical Oxygen Demand (BOD), the limit is up to 5 mg/L.
| Water Quality Parameter | Poti River (this compound, PI) | Tietê River (São Paulo, SP) | Iguaçu River (Curitiba, PR) | Capibaribe River (Recife, PE) | CONAMA Resolution 357/2005 (Class 2 Limit) |
| Dissolved Oxygen (DO) | Modeled; often low | Extremely low, near 0 mg/L in rainy periods | Data not specified in searches | Data not specified in searches | ≥ 5 mg/L |
| Biochemical Oxygen Demand (BOD) | Modeled; often high | High loads reported[1] | Data not specified in searches | Data not specified in searches | ≤ 5 mg/L |
| Thermotolerant Coliforms (TC) | >1,000 MPN/100 mL in 55.7% of a studied section[2] | High levels reported | Data not specified in searches | High levels indicating sewage contamination reported | ≤ 1,000 MPN/100 mL |
| Total Phosphorus | Data not specified in searches | Up to 1.29 mg/L | Data not specified in searches | Data not specified in searches | ≤ 0.030 mg/L (lotic environments) |
| Total Nitrogen | Data not specified in searches | Up to 15.27 mg/L | Data not specified in searches | Data not specified in searches | No numerical limit, but should not cause eutrophication |
| Copper (Cu) | Data not specified in searches | Data not specified in searches | 13 µg/L in water[3][4] | 21 - 146 mg/kg in sediment | ≤ 0.009 mg/L (dissolved) |
| Zinc (Zn) | Data not specified in searches | Data not specified in searches | Data not specified in searches | 144 - 406 mg/kg in sediment[5] | ≤ 0.18 mg/L (dissolved) |
| Lead (Pb) | Data not specified in searches | Data not specified in searches | Data not specified in searches | Not detected in sediment in one study[5][6] | ≤ 0.01 mg/L (total) |
| Chromium (Cr) | Data not specified in searches | Data not specified in searches | Data not specified in searches | Not detected in sediment in one study[5][7] | ≤ 0.05 mg/L (total) |
Note on Data: The table highlights the challenge in obtaining directly comparable, comprehensive datasets for all rivers from the available literature. Sediment data for the Capibaribe River is included to indicate the presence of heavy metal pollutants in the river's ecosystem.
Experimental Protocols
The methodologies for water quality analysis in Brazil predominantly follow the "Standard Methods for the Examination of Water and Wastewater," published by the American Public Health Association (APHA), the American Water Works Association (AWWA), and the Water Environment Federation (WEF)[8][9][10][11].
1. Sample Collection: Water samples are typically collected at designated monitoring points along the river. For microbiological analysis, sterile bottles containing sodium thiosulfate (B1220275) are used to neutralize any residual chlorine[12]. Samples are preserved, often by cooling to <10°C, and transported to the laboratory for analysis within a specified holding time[12][13].
2. Physicochemical Analysis:
-
Nutrients (Nitrogen and Phosphorus): Various colorimetric and spectrophotometric methods are used to determine different forms of nitrogen (ammonia, nitrate, nitrite, total nitrogen) and phosphorus (orthophosphate, total phosphorus) as outlined in APHA 4500-N and 4500-P.
3. Microbiological Analysis:
-
Thermotolerant (Fecal) Coliforms: The most common methods are the Multiple-Tube Fermentation Technique (MTF) and the Membrane Filter (MF) Technique (APHA 9221 and 9222)[12]. The MTF method provides a Most Probable Number (MPN) of coliforms per 100 mL of water.
4. Heavy Metal Analysis:
-
Atomic Absorption Spectrometry (AAS): AAS is a widely used technique for determining the concentration of specific heavy metals in water samples. The sample is atomized, and the absorption of light by the free atoms is measured.
-
Inductively Coupled Plasma-Atomic Emission Spectrometry (ICP-AES): This method is also used for the quantification of heavy metals and can analyze multiple elements simultaneously[5][6][7].
Visualizations
The following diagrams illustrate the workflow for comparing urban river water quality and a conceptual signaling pathway of pollution impacts.
Caption: Workflow for Comparative Water Quality Assessment of Brazilian Urban Rivers.
Caption: Conceptual Pathway of Urban River Pollution and its Ecological Impacts.
References
- 1. ainfo.cnptia.embrapa.br [ainfo.cnptia.embrapa.br]
- 2. sgb.gov.br [sgb.gov.br]
- 3. repositorio.ufsc.br [repositorio.ufsc.br]
- 4. Agência SMT - Rio Sorocaba e Médio Tietê [agenciasmt.com.br]
- 5. progestao.ana.gov.br [progestao.ana.gov.br]
- 6. sustentarewipis.com.br [sustentarewipis.com.br]
- 7. ana.gov.br [ana.gov.br]
- 8. abrh.s3.sa-east-1.amazonaws.com [abrh.s3.sa-east-1.amazonaws.com]
- 9. periodicos.ufpe.br [periodicos.ufpe.br]
- 10. iat.pr.gov.br [iat.pr.gov.br]
- 11. iat.pr.gov.br [iat.pr.gov.br]
- 12. ANÁLISE DAS MÉDIAS DO ÍNDICE DE QUALIDADE DA ÁGUA (IQA) INFERIORES DA BACIA DO BAIXO RIO TIETÊ: UMA REVISÃO DE LITERATURA BASEADA NOS RELATÓRIOS DA CETESB (2013-2023) – ISSN 1678-0817 Qualis B2 [revistaft.com.br]
- 13. sgb.gov.br [sgb.gov.br]
- 14. cetesb.sp.gov.br [cetesb.sp.gov.br]
- 15. comiteat.sp.gov.br [comiteat.sp.gov.br]
Comparative Guide to Epidemiological Models for Visceral Leishmaniasis in Teresina
For Researchers, Scientists, and Drug Development Professionals
This guide provides an objective comparison of epidemiological models used for the validation and prediction of visceral leishmaniasis (VL) in Teresina, Brazil. The city has historically been a major urban center for VL in the country, making it a critical location for studying and modeling the disease's dynamics. This document summarizes quantitative data from various modeling approaches, details the experimental protocols for model validation, and visualizes key methodological workflows.
Data Presentation: A Comparative Analysis of Model Performance
The following table summarizes the performance of different epidemiological models that have been validated for visceral leishmaniasis in this compound and other relevant areas in Brazil. Due to the limited number of studies directly comparing a wide range of models specifically in this compound with standardized metrics, this table includes findings from broader studies on VL in Brazil that are relevant to the methodologies applied in the region.
| Model Type | Study Focus | Location | Performance Metric | Result | Reference |
| Prognostic Model | Predicting death from VL | This compound, Brazil | Sensitivity | 85.7% | Werneck et al. (2003) |
| Specificity | 92.5% | ||||
| Machine Learning: Risk Classification | Classifying outbreak risk | 113 Brazilian Municipalities (including this compound) | Area Under the Curve (AUC) | > 0.80 in 86% of municipalities | Werneck et al. (2025, in press) |
| Machine Learning: Outbreak Prediction | Predicting VL outbreaks | This compound, Fortaleza, and São Luís, Brazil | Root Mean Squared Error (RMSE) | Specific RMSE values not provided in the abstract | Lazar et al. (2024) |
| Logistic Regression | Clinical Diagnosis of VL | Brazil | Sensitivity | 90.1% - 99.0% | Luz et al. |
| Specificity | 53.0% - 97.2% | ||||
| Classification and Regression Trees (CART) | Clinical Diagnosis of VL | Brazil | Sensitivity | 90.1% - 97.2% | Luz et al. |
| Specificity | 68.4% - 97.4% |
Experimental Protocols
This section details the methodologies employed in the cited studies for the development and validation of epidemiological models for visceral leishmaniasis.
Prognostic Model for VL-Associated Death in this compound (Werneck et al., 2003)
-
Objective: To develop a prognostic model to identify factors associated with death from visceral leishmaniasis.
-
Study Design: A case-control study was conducted in this compound.
-
Cases: Patients who died during treatment for VL.
-
Controls: A random sample of patients who were alive at the end of the treatment.
-
-
Data Collection: Clinical and laboratory data were collected from patient records.
-
Model Development: A prognostic scoring system was developed based on clinical signs and symptoms identified as being significantly associated with death.
-
Validation: The model's performance was assessed by calculating its sensitivity and specificity in discriminating between patients who died and those who survived.
Machine Learning Models for Outbreak Prediction and Risk Classification (Lazar et al., 2024; Werneck et al., 2025)
-
Objective: To predict visceral leishmaniasis outbreaks and classify outbreak risk using machine learning algorithms.
-
Data Sources:
-
Monthly confirmed VL cases from the Brazilian Ministry of Health's Information System for Notifiable Diseases (SINAN).
-
Meteorological data.
-
Land-use and sociodemographic variables.
-
-
Modeling Approaches:
-
Lazar et al. (2024): Employed Simple Feedforward Neural Networks, Deep Feedforward Neural Networks, Long Short-Term Memory (LSTM) recurrent neural networks, and Support Vector Regression.
-
Werneck et al. (2025): Utilized a sliding window approach to capture short- and long-term trends.
-
-
Model Validation:
-
Lazar et al. (2024): The primary metric for model evaluation was the Root Mean Squared Error (RMSE).
-
Werneck et al. (2025): Predictive performance was evaluated by calculating the Area Under the Curve (AUC) for risk classification models.
-
Predictive Models for Clinical Diagnosis of VL in Brazil (Luz et al.)
-
Objective: To develop predictive models to aid in the clinical diagnosis of visceral leishmaniasis.
-
Study Population: Patients with clinical suspicion of VL.
-
Data Collection:
-
Clinical signs and symptoms.
-
Laboratory examination results.
-
Results from five different serological tests.
-
-
Model Development:
-
Logistic Regression: A multivariate logistic regression model was built to identify variables significantly associated with a VL diagnosis.
-
Classification and Regression Trees (CART): A decision tree model was generated to create a classification framework.
-
-
Validation: The predictive performance of both models was evaluated using sensitivity and specificity.
Mandatory Visualization
The following diagrams illustrate the workflows and logical relationships described in the experimental protocols.
Navigating Growth: A Comparative Look at Urban Mobility in Teresina and Similar-Sized Brazilian Cities
As Brazilian cities continue to expand, the challenge of ensuring efficient, sustainable, and equitable urban mobility has become paramount. This guide provides a comparative analysis of the urban mobility plans of Teresina, the capital of Piauí, and four other Brazilian cities of similar population size: Campo Grande (MS), João Pessoa (PB), São Bernardo do Campo (SP), and Santo André (SP). The analysis focuses on quantitative data, methodologies for plan development, and the strategic approaches adopted by each municipality to address their unique transportation challenges. This report is intended for urban planning researchers, transportation scientists, and public policy professionals.
The comparison cities were selected based on their population proximity to this compound (866,300 inhabitants according to the 2022 Census), providing a relevant cohort for examining different planning strategies and outcomes in similar urban contexts.
Quantitative Overview of Urban Mobility
A foundational aspect of any urban mobility plan is a thorough diagnosis of the existing conditions. The following tables summarize key quantitative indicators for this compound and the selected comparable cities, offering a snapshot of their transportation landscapes.
| City | Population (2022 Census) | Motorization Rate (Vehicles per 1,000 inhabitants) | Public Transport Fleet (Buses) | Daily Public Transport Ridership | Cycling Infrastructure (km) |
| This compound, PI | 866,300 | Data not available in initial reports | ~220 (Operational) | Data not available in initial reports | Data not available in initial reports |
| Campo Grande, MS | 898,100 | ~522 | 539 | Data not available in initial reports | 78.93 |
| João Pessoa, PB | 833,932 | Data not available in initial reports | 464 | Data not available in initial reports | ~70 |
| São Bernardo do Campo, SP | 810,729 | Data not available in initial reports | 376 (Municipal) | Data not available in initial reports | Data not available in initial reports |
| Santo André, SP | 748,919 | Data not available in initial reports | 313 | ~4,000,000 (Monthly) | Data not available in initial reports |
A critical indicator of mobility patterns is the modal split, which describes the percentage of trips made by different modes of transport.
| City | Public Transport (%) | Individual Motorized Transport (%) | Active Transport (Walking/Cycling) (%) |
| This compound, PI | 24 | 55 | 23 |
| Campo Grande, MS | Data not available in initial reports | Data not available in initial reports | Data not available in initial reports |
| João Pessoa, PB | Data not available in initial reports | Data not available in initial reports | Data not available in initial reports |
| São Bernardo do Campo, SP | Data not available in initial reports | Data not available in initial reports | Data not available in initial reports |
| Santo André, SP | Data not available in initial reports | Data not available in initial reports | Data not available in initial reports |
Methodological Frameworks for Urban Mobility Planning
The development of a comprehensive urban mobility plan relies on a robust methodological framework for data collection and analysis. The approaches taken by this compound and the comparison cities share common elements, reflecting national guidelines, but also exhibit differences in their specific implementation.
This compound's Approach: The PDMUS
This compound's "Plano Diretor de Mobilidade Urbana Sustentável" (PDMUS) was informed by a detailed diagnostic study conducted between 2019 and 2021. The core methodologies included:
-
Household Surveys: A representative sample of 11,000 households across all neighborhoods was surveyed to understand travel patterns, mode choices, and socioeconomic factors influencing mobility.[1]
-
Public Transport User Surveys: Data was collected at all bus terminals to capture the perspectives and travel characteristics of public transport users.[1]
-
Technical Working Groups: Collaboration with various municipal bodies and stakeholders was a key part of the diagnostic process.
-
Public Consultations and Hearings: The plan's development included stages for public participation to ensure community input was considered.
Campo Grande's Methodology: PDTMU Revision
The revision of Campo Grande's "Plano Diretor de Transporte e Mobilidade Urbana" (PDTMU) followed a structured, multi-stage process:
-
Work Plan Definition: This initial phase outlined the project's scope, communication strategies, public participation methods, and the overall timeline.
-
Mobility Diagnosis: This stage involved extensive primary and secondary data collection to characterize the various components of the city's mobility system and define key diagnostic indicators.
-
Mobility Prognosis: Based on the diagnosis, future scenarios were developed to anticipate mobility demands and challenges.
-
Strategic Goal and Action Formulation: This phase translated the findings from the diagnosis and prognosis into concrete goals and strategic actions.
-
Plan Consolidation and Legal Framework: The final stage involved consolidating all findings and drafting the necessary legislation for the plan's implementation.
Santo André's Multi-faceted Approach
Santo André's mobility planning is characterized by several interconnected plans, including the "Plano de Mobilidade Urbana Sustentável" (PlanMob) and the "Plano para a Mobilidade Segura e Inclusiva" (PMSI). The methodologies employed include:
-
Origin-Destination Surveys: Interviews with 3,000 residents in their homes were conducted to identify daily travel characteristics and the modes of transport used.
-
Terminal Transfer Surveys: Research was conducted at major transit hubs, such as the CPTM station and the EMTU bus terminal, to understand passenger transfer patterns.
-
Specialized Surveys: Targeted research, such as the "Dangerous Goods Survey," was carried out to map the circulation of freight vehicles.
-
Focus Groups with Priority Populations: The PMSI involved dedicated workshops with people with reduced mobility to identify specific barriers and needs.[2]
Strategic Priorities and Key Initiatives
While all cities aim to improve urban mobility, their specific priorities and flagship projects reflect their local contexts and challenges.
This compound: Confronting a Public Transport Crisis
This compound's mobility plan is set against a backdrop of a severely degraded public transport system. A study by the BNDES identified this compound's as the worst-performing among 21 analyzed Brazilian cities, operating at only a third of its ideal capacity. Key strategic directions include:
-
System Revitalization: A proposed R$1.3 billion investment aims to overhaul the public transport sector, including the acquisition of a new fleet with electric buses and the reconstruction of transport corridors and terminals.
-
Development Oriented to Sustainable Transport (DOTS): In partnership with the Inter-American Development Bank, this compound is focusing on integrating land use and transport planning to increase population density around public transport axes.[3][4]
Campo Grande: Focus on Sustainability and Safety
Campo Grande's revised plan emphasizes a shift towards more sustainable modes of transport and a strong focus on road safety. Key initiatives include:
-
Promoting Sustainable Transport: The plan explicitly aims to encourage walking, cycling, and the use of public transport.
-
Vision Zero: A central goal is to align with the World Health Organization's recommendation to prevent at least 50% of traffic-related deaths and injuries by 2030.
-
Integration of Mobility and Land Use: The plan seeks to stimulate development in the city center to counteract urban sprawl and reduce the need for long commutes.
João Pessoa: Expanding Infrastructure for Active and Public Transport
João Pessoa's "PlanMob" outlines an ambitious expansion of infrastructure to support sustainable mobility over the next 18 years.[5] Key proposals include:
-
Accessible Sidewalks: A target to have at least 85% of sidewalks in all neighborhoods accessible.[5]
-
Cycling Network Expansion: A goal to create a cycling network of over 221 kilometers.[5]
-
Public Transport Prioritization: The plan includes the implementation of new exclusive bus lanes and six major bus corridors.[5]
-
Innovative Services: The "Conexão Bairro" project introduced neighborhood-connecting bus lines with reduced fares.[5]
São Bernardo do Campo and Santo André: Addressing Metropolitan Dynamics
As part of the densely populated Grande ABC region, São Bernardo do Campo and Santo André face significant challenges related to metropolitan-level commuting. Their plans reflect this reality:
-
Santo André's "Promobi" Program: This program represents a major investment package of R$256 million over four years to modernize the bus fleet with 200 new vehicles, enhance road safety, and invest in technology.
-
São Bernardo's Focus on Public-Private Partnerships: The city's mobility planning has involved considerations for large-scale projects like a light rail system ("Metrô Leve") and has been developed in consultation with the business community.
-
Data-Driven Governance: Santo André is developing a "Mobility Observatory" to consolidate data and indicators for better planning and public transparency.[6][7]
Logical Framework for Mobility Plan Development
The process of developing and implementing an urban mobility plan can be visualized as a logical workflow, from initial diagnosis to long-term monitoring.
Caption: A generalized workflow for urban mobility plan development.
Governance and Stakeholder Engagement
The governance structure for implementing and overseeing urban mobility plans is crucial for their success. This typically involves the creation of specific councils and ensuring channels for public participation.
Caption: Typical governance structure for urban mobility planning.
References
- 1. scribd.com [scribd.com]
- 2. Santo André apresenta diagnóstico da... [web.santoandre.sp.gov.br]
- 3. urbansystems.com.br [urbansystems.com.br]
- 4. periodicos.ufpi.br [periodicos.ufpi.br]
- 5. Diagnosis of Public Transportation in this compound | MobiliseYourCity [mobiliseyourcity.net]
- 6. portais.santoandre.sp.gov.br [portais.santoandre.sp.gov.br]
- 7. portais.santoandre.sp.gov.br [portais.santoandre.sp.gov.br]
Assessing the Transferability of Public Health Success: A Guide to External Validity Assessment of a Community Garden Intervention for Teresina
For Researchers, Scientists, and Drug Development Professionals: A Comparative Guide
This guide provides a framework for assessing the external validity of public health interventions, using a case study of a community gardening program designed to improve food security. While the primary case study is from a different region, this guide will walk through the process of evaluating its potential applicability to Teresina, a city in Northeast Brazil facing challenges of food insecurity and climate change. This will equip researchers and public health professionals with a systematic approach to determining whether an effective intervention in one context can be successfully adapted and implemented in another.
Understanding External Validity in Public Health
External validity, often referred to as generalizability or transferability, is the extent to which the findings of a study can be applied to other populations, settings, and times.[1][2][3][4][5] In the realm of public health, where the goal is to implement interventions that have a broad impact, assessing external validity is a critical step. A failure to rigorously evaluate external validity can lead to the investment of resources in programs that are ineffective or even detrimental in a new context.
Frameworks such as RE-AIM (Reach, Effectiveness, Adoption, Implementation, Maintenance) provide a comprehensive structure for this assessment.[2] Key dimensions to consider when evaluating the external validity of an intervention include the characteristics of the target population, the specifics of the intervention itself, the environmental context, and the outcomes measured.[1][5]
Case Study: Community Gardening for Food Security
To illustrate the process of assessing external validity, we will use a well-documented community gardening intervention. The chosen case study is the "Impact of a Community Gardening Project on Vegetable Intake, Food Security and Family Relationships," a community-based participatory research project with Hispanic farmworker families.
Experimental Protocol of the Case Study Intervention
The intervention aimed to improve vegetable intake, food security, and family relationships among Hispanic farmworker families through the implementation of organic home gardens. The study's methodology provides a clear blueprint for replication and adaptation.
1. Study Design: A pre-post study design was utilized, collecting data before and after the gardening season.
2. Participants: The study enrolled 42 Hispanic farmworker families. The mean age of the interviewees was 44 years, with a median household size of 4.0.
3. Intervention:
-
Recruitment: Families were enrolled on a first-come, first-served basis.
-
Gardening Support: Monthly community meetings were held to provide materials (seeds, etc.) and education on topics such as plant selection, composting, organic pest control, and harvesting.
-
Educational Approach: The program used "popular education" techniques, a participatory approach that values the knowledge and experience of the community members.
4. Data Collection:
-
Surveys: A pre- and post-gardening survey was administered to collect quantitative data on vegetable intake and food security.
-
Qualitative Data: Key informant interviews and observations from community meetings were used to gather qualitative data on the project's impact on family relationships and overall well-being.
5. Key Outcome Measures:
-
Frequency of adult and child vegetable intake.
-
Worry about food running out before having money to buy more.
-
Instances of skipping meals due to lack of money.
Quantitative Outcomes of the Case Study Intervention
The following tables summarize the key quantitative findings of the community gardening intervention.
Table 1: Change in Vegetable Intake
| Pre-Intervention | Post-Intervention | p-value | |
| Adults' Vegetable Intake ("Several times a day") | 18.2% | 84.8% | <0.001 |
| Children's Vegetable Intake ("Several times a day") | 24.0% | 64.0% | 0.003 |
Table 2: Change in Food Security Indicators
| Pre-Intervention | Post-Intervention | p-value | |
| Worrying Food Would Run Out ("Sometimes" or "Frequently") | 31.2% | 3.1% | 0.006 |
| Adults Skipping Meals Due to Lack of Money | Not statistically significant | Not statistically significant | - |
| Children Skipping Meals Due to Lack of Money | Not statistically significant | Not statistically significant | - |
Assessing the External Validity for this compound
Now, we will apply a structured framework to assess the potential external validity of this community gardening intervention for the city of this compound.
Target Context Profile: this compound, Brazil
This compound, the capital of Piauí state, faces significant public health challenges. It is one of the hottest cities in Brazil and is highly vulnerable to the impacts of climate change, including flooding and waterborne diseases. The city also grapples with food insecurity, particularly among its most vulnerable populations.[6] Key characteristics of the this compound context include:
-
Population: A mix of urban and peri-urban populations, with significant income inequality.
-
Environment: Hot, arid climate with a history of deforestation and "heat island" effects.[6] The city has prioritized increasing green cover and promoting urban agriculture.[6]
-
Health Challenges: Food insecurity, waterborne diseases, and the health impacts of extreme heat.
-
Existing Initiatives: this compound has implemented programs like the Dirceu Community Garden to address food insecurity and promote sustainability.[6]
Framework for Assessing External Validity
We will use a framework that examines four key dimensions of external validity: Population, Intervention, Environment, and Outcomes.
Table 3: External Validity Assessment for this compound
| Dimension | Case Study Characteristics | This compound Context Considerations | Assessment of Fit |
| Population | Hispanic farmworker families in a rural setting. | Urban and peri-urban populations in this compound with varying cultural backgrounds and occupations. | Moderate: The intervention's focus on a specific cultural group may require adaptation for a more diverse urban population. However, the underlying issue of food insecurity is relevant. |
| Intervention | Community-based participatory approach with monthly educational meetings and provision of gardening materials. | This compound has existing community-based initiatives, suggesting a receptive environment for participatory approaches. The educational component would need to be culturally and linguistically adapted. | High: The core components of the intervention (education, material support, community engagement) are likely to be well-received and effective in this compound. |
| Environment | Rural setting with likely access to land for gardening. | Urban and peri-urban settings in this compound may have limited space for individual gardens. The hot, arid climate will necessitate different gardening techniques and plant choices. | Moderate: The intervention would need to be adapted to urban gardening models (e.g., container gardening, vertical gardens) and focus on drought-resistant crops suitable for the local climate. |
| Outcomes | Improved vegetable intake and reduced worry about food security. | These outcomes are highly relevant to the public health challenges in this compound. | High: The intended outcomes of the intervention directly address a key public health need in this compound. |
Visualizing the Logic and Workflow
To further clarify the concepts presented, the following diagrams, created using the DOT language, illustrate the logical flow of the intervention and the process of assessing external validity.
Caption: Logic model of the community garden intervention.
Caption: Workflow for assessing external validity.
Conclusion and Recommendations
The case study of the community gardening intervention demonstrates significant positive outcomes in improving vegetable intake and reducing food insecurity worries in its original context. The structured assessment of its external validity for this compound suggests that with appropriate adaptations, it holds promise for addressing similar public health challenges in that city.
Key recommendations for adapting this intervention for this compound would include:
-
Cultural Adaptation: Engage with local communities in this compound to ensure the educational materials and engagement strategies are culturally relevant and address their specific needs and preferences.
-
Environmental Adaptation: Focus on urban and peri-urban gardening techniques suitable for limited spaces and the hot, arid climate. Promote the cultivation of local, drought-resistant crops.
-
Integration with Existing Programs: Collaborate with existing initiatives like the Dirceu Community Garden to leverage local knowledge and resources.
By systematically assessing the external validity of promising public health interventions, researchers and practitioners can make more informed decisions about which programs to adapt and implement, ultimately leading to more effective and sustainable improvements in public health.
References
- 1. Community Gardening Increases Vegetable Intake and Seasonal Eating From Baseline to Harvest: Results from a Mixed Methods Randomized Controlled Trial - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Community gardening, community farming and other local community-based gardening interventions to prevent overweight and obesity in high-income and middle-income countries: protocol for a systematic review - PMC [pmc.ncbi.nlm.nih.gov]
- 3. scispace.com [scispace.com]
- 4. Community gardens and their effects on diet, health, psychosocial and community outcomes: a systematic review - PMC [pmc.ncbi.nlm.nih.gov]
- 5. community-gardening.org [community-gardening.org]
- 6. researchgate.net [researchgate.net]
Teresina's Sustainability Under the Lens: A Comparative Analysis Against Brazilian National Standards
For Immediate Release
Teresina, PI – A comprehensive analysis of this compound's sustainability performance reveals a mixed landscape of commendable achievements and significant challenges when benchmarked against Brazil's national sustainability goals. This guide provides a detailed comparison of the city's key sustainability indicators, offering valuable insights for researchers, scientists, and urban development professionals. The data presented is drawn from official sources, including the Sustainable Development Goals (SDG) Cities Index, the Brazilian Institute of Geography and Statistics (IBGE), and local and national sustainability reports.
Data Presentation: this compound vs. Brazil - A Comparative Scorecard
The following tables summarize this compound's performance on a range of sustainability indicators, juxtaposed with national averages and targets. The primary framework for this comparison is the Sustainable Development Goals (SDGs), which Brazil has committed to achieving by 2030.
Social Sustainability Indicators
| Indicator | This compound's Performance | National Benchmark/Target | Data Source |
| ODS 1: No Poverty | Score: 56.4 (Low) | National Average Score: 52.1 | IDSC-BR |
| ODS 3: Good Health and Well-being | Score: 68.9 (Medium-High) | National Average Score: 67.5 | IDSC-BR |
| - Infant Mortality Rate (per 1,000 live births) | 14.71 (2023) | Brazil: ~8.7 (2023 target) | IBGE, National Health Plan |
| ODS 4: Quality Education | Score: 63.5 (Medium-High) | National Average Score: 59.8 | IDSC-BR |
| - Schooling Rate (6 to 14 years) | 98.8% (2022) | Universal access | IBGE |
| ODS 5: Gender Equality | Score: 65.1 (Medium-High) | National Average Score: 61.3 | IDSC-BR |
| ODS 10: Reduced Inequalities | Score: 40.7 (Very Low) | National Average Score: 43.1 | IDSC-BR |
| - Gini Index (Piauí State) | 0.582 (2020) | Reduction of income inequality | IBGE |
Environmental Sustainability Indicators
| Indicator | This compound's Performance | National Benchmark/Target | Data Source |
| ODS 6: Clean Water and Sanitation | Score: 70.3 (Medium-High) | National Average Score: 63.3 | IDSC-BR |
| - Sewage Collection Coverage | 59% (2025) | 90% by 2033 (National Sanitation Law) | Águas de this compound[1][2] |
| ODS 11: Sustainable Cities and Communities | Score: 58.7 (Medium-Low) | National Average Score: 57.9 | IDSC-BR |
| ODS 13: Climate Action | Score: 68.2 (Medium-High) | National Average Score: 65.9 | IDSC-BR |
| - CO2 Emissions per capita (this compound) | 2.9 tCO2e (2020) | Brazil: Reduce emissions by 50% by 2030 | SEEG, Climate Action Plan[3] |
| - Loss of Green Area | Equivalent to 217 football fields per year | Increase urban green areas | This compound City Hall[4][5] |
| ODS 15: Life on Land | Score: 49.6 (Low) | National Average Score: 50.8 | IDSC-BR |
Economic Sustainability Indicators
| Indicator | This compound's Performance | National Benchmark/Target | Data Source |
| ODS 8: Decent Work and Economic Growth | Score: 62.1 (Medium-High) | National Average Score: 61.9 | IDSC-BR |
| - GDP per capita (R$) | 27,430.28 (2021) | Continuous and inclusive growth | IBGE[6] |
| ODS 9: Industry, Innovation and Infrastructure | Score: 49.3 (Low) | National Average Score: 45.9 | IDSC-BR |
Experimental Protocols and Methodologies
The data presented in this guide is compiled from various official sources, each with its own methodology for data collection and analysis.
-
Índice de Desenvolvimento Sustentável das Cidades – Brasil (IDSC-BR): This index evaluates all 5,570 Brazilian municipalities based on 100 indicators related to the 17 SDGs. The data is sourced from official national bodies such as the IBGE, the Ministry of Health (DATASUS), and the National Institute for Educational Studies and Research (INEP). The methodology involves normalizing the indicator data to a scale of 0 to 100, where 100 represents the optimal performance.
-
Brazilian Institute of Geography and Statistics (IBGE): The IBGE conducts national censuses and continuous surveys that provide a wide range of demographic, social, economic, and environmental data. Methodologies vary depending on the survey but adhere to international statistical standards. For instance, GDP is calculated based on the System of National Accounts, while population data is derived from the demographic census and annual estimates.
-
National and Local Reports: Data on specific indicators, such as sanitation coverage and greenhouse gas emissions, are often sourced from reports published by municipal and state agencies, as well as private entities operating public services. These reports typically detail their own data collection methods, which may include direct measurement, administrative records, and statistical modeling.
Visualizing Sustainability Pathways and Workflows
To better understand the interconnectedness of sustainability efforts, the following diagrams, generated using Graphviz, illustrate key logical relationships and workflows.
Concluding Remarks
This compound demonstrates a commitment to sustainable development, with notable progress in areas such as sanitation and efforts to address climate change through its local action plan. However, significant challenges remain, particularly in reducing social inequalities and curbing the loss of green spaces. Continuous monitoring of sustainability indicators, benchmarked against national standards, is crucial for evidence-based policymaking and for steering the city towards a more sustainable and resilient future. The data and frameworks presented in this guide aim to support these ongoing efforts.
References
- 1. This compound dá salto histórico no saneamento e se consolida como referência no Nordeste [aguasdethis compound.com.br]
- 2. This compound dá salto histórico no saneamento e se torna referência no Nordeste | G1 [g1.globo.com]
- 3. portalaz.com.br [portalaz.com.br]
- 4. Cidade Verde? this compound perde área verde equivalente a mais de 200 campos de futebol por ano, diz relatório | G1 [g1.globo.com]
- 5. Desmatamento em this compound corresponde a 217 campos de futebol a cada ano e aumenta o calor - Cidade [piauihoje.com]
- 6. This compound (PI) | Cidades e Estados | IBGE [ibge.gov.br]
A Tale of Two Cities: A Comparative Analysis of Housing Policies and Outcomes in Teresina and Recife
A deep dive into the housing strategies of two of Brazil's northeastern capitals, Teresina and Recife, reveals distinct approaches and outcomes in tackling their respective housing deficits. While both cities leverage the national "Minha Casa, Minha Vida" (MCMV) program, their municipal-level policies and the broader urban context shape the effectiveness and nature of housing provision. This guide provides a comparative overview of their housing landscapes, key policies, and available outcome data, tailored for researchers and urban development professionals.
Quantitative Overview of Housing Landscapes
Directly comparable, recent statistics on the housing deficit and policy outcomes for both cities are challenging to consolidate due to differing reporting periods and methodologies. However, available data provides a snapshot of the housing situation in each city.
| Indicator | This compound | Recife | Source |
| Population (2022 Census) | 866,300 | 1,488,920 | IBGE |
| Housing Deficit (Units) | 55,305 (Hypothetical Demand, 2012) | 71,160 (PLHIS, reported in 2023) / 277,183 (2017 figure) | [1],[2],[3] |
| Key National Program | Minha Casa, Minha Vida (MCMV) | Minha Casa, Minha Vida (MCMV) | [4],[5] |
| Recent MCMV Approvals/Selections | ~3,000 units (for 2026); 1,008 candidates selected (recent phase) | >1,400 units approved (recent phase) | [6],[7] |
| Other Notable Programs | Lagoas do Norte Program, Transformative Urban Coalitions | ProMorar Recife, Public-Private Partnerships (PPP) for social housing, Transformative Urban Coalitions | [8],[9],[2] |
| Urban Planning Context | Urban Perimeter Act to control sprawl | High urban density, significant informal settlements (favelas) | [10],[11] |
Note: Housing deficit figures should be interpreted with caution due to the different years and methodologies. The higher 2017 figure for Recife may include a broader definition of housing inadequacy.
Methodological Approaches to Housing Policy Evaluation
The analysis of housing policies in Brazil employs a variety of methodologies, which can be categorized as follows:
-
Quantitative Analysis of Housing Deficit: This methodology, often employed in the creation of a Plano Local de Habitação de Interesse Social (PLHIS) or Local Plan for Social Interest Housing, involves the statistical analysis of demographic data, household income, and housing conditions from sources like the Brazilian Institute of Geography and Statistics (IBGE). The goal is to quantify the number of new housing units needed and the extent of inadequate housing.[12][13]
-
Post-Occupancy Evaluation (POE): This approach assesses the performance of housing projects after residents have moved in. Methodologies include surveys, interviews, and on-site observations to gauge resident satisfaction, the quality of construction, and the adequacy of the living space and surrounding urban infrastructure.[14]
-
Impact Evaluation of Housing Programs: More rigorous evaluations aim to determine the causal impact of housing programs on the well-being of beneficiaries. Methodologies can include quasi-experimental designs, such as comparing the outcomes of program beneficiaries with those of a control group. For instance, studies have been designed to evaluate the health impacts of the MCMV program by linking housing program data with public health registries.[15]
-
Spatial Analysis: This methodology uses geographic information systems (GIS) to analyze the location of housing projects and their relationship to the urban fabric. It is often used to study issues of urban sprawl and socio-spatial segregation resulting from the placement of social housing in peripheral areas.[16]
Key Housing Policies and Programs
While both cities are part of the national housing framework, their specific strategies show different areas of focus.
This compound: Controlled Expansion and Urban Upgrading
This compound's approach to housing and urban development has been marked by efforts to control urban sprawl. A key municipal policy has been the "Urban Perimeter Act," which aims to limit the expansion of the city's boundaries and encourage densification.[10]
The "Minha Casa, Minha Vida" (MCMV) program is a central pillar of social housing provision in this compound. The municipality manages the registration and selection of beneficiaries for units financed by the federal program. However, a significant challenge has been the location of many MCMV projects on the urban periphery, far from the city center, which can lead to difficulties for residents in accessing employment and services.[4]
Another significant initiative is the Lagoas do Norte Program , a large-scale urban upgrading project supported by the World Bank. This program focuses on improving living conditions in one of this compound's most vulnerable regions through investments in sanitation, flood protection, and public spaces, including the resettlement of families from high-risk areas.[8][17]
Recife: Tackling a High Deficit in a Dense Urban Core
Recife, a more densely populated coastal city, faces a substantial housing deficit, with a large proportion of its population living in informal settlements or favelas.[3][11] The city's strategies reflect this high-density context.
Like this compound, Recife is a major recipient of the MCMV program . The municipal government plays a crucial role in proposing projects and registering potential beneficiaries.
Recife has also been proactive in seeking alternative financing and implementation models. The city has launched a Public-Private Partnership (PPP) for social housing , known as Morar no Centro (Living Downtown), which aims to provide social rental units in the city center. This is an innovative approach in the Brazilian context, which has traditionally focused on homeownership.
Furthermore, the ProMorar Recife program, supported by the Inter-American Development Bank (IDB), is a significant urban resilience and revitalization initiative. With a substantial loan of $260 million, the program aims to improve living conditions in socio-environmentally vulnerable areas by increasing access to infrastructure, reducing risks from floods and landslides, and enhancing the municipality's capacity for urban management.[2]
Both this compound and Recife are also home to Transformative Urban Coalitions labs. These initiatives foster bottom-up solutions to urban challenges, including housing, by bringing together residents, community organizations, and the public sector. This indicates a shared trend towards more participatory approaches to urban development in both cities.[9]
Logical Workflow for Social Housing Provision
The provision of social housing through a program like MCMV follows a multi-stage process involving federal, municipal, and private actors. The following diagram illustrates a generalized workflow.
Conclusion
This compound and Recife, while both striving to address significant housing needs in Brazil's northeast, exhibit different strategic priorities shaped by their unique urban contexts. This compound's policies show a strong focus on managing urban growth and upgrading specific vulnerable areas. In contrast, Recife's approach is characterized by its efforts to tackle a large housing deficit within a dense urban environment, including through innovative financing mechanisms like PPPs for social rentals.
Both cities rely heavily on the national MCMV program, but the effectiveness of these federally funded projects is influenced by local planning decisions, particularly regarding land availability and the location of new developments. The presence of participatory initiatives like the Transformative Urban Coalitions in both municipalities suggests a growing recognition of the importance of community involvement in creating sustainable and inclusive housing solutions. For researchers and professionals in the field, a deeper, data-rich comparative analysis of the long-term outcomes of these differing approaches would be invaluable for informing future urban and housing policy in Brazil and beyond.
References
- 1. locus.ufv.br [locus.ufv.br]
- 2. IDB | Brazil to Improve Urban Management and Housing in Vulnerable Areas of Recife [iadb.org]
- 3. urbancoalitions.org [urbancoalitions.org]
- 4. urbancoalitions.org [urbancoalitions.org]
- 5. globalpropertyguide.com [globalpropertyguide.com]
- 6. ensinosuperior.sed.sc.gov.br [ensinosuperior.sed.sc.gov.br]
- 7. Metadados do item: Monitoramento e avaliação de planos locais de habitação de interesse social (PLHIS) [bdtd.ibict.br]
- 8. ewsdata.rightsindevelopment.org [ewsdata.rightsindevelopment.org]
- 9. wri.org [wri.org]
- 10. mdpi.com [mdpi.com]
- 11. researchgate.net [researchgate.net]
- 12. redalyc.org [redalyc.org]
- 13. researchgate.net [researchgate.net]
- 14. caixa.gov.br [caixa.gov.br]
- 15. urbancoalitions.org [urbancoalitions.org]
- 16. lincolninst.edu [lincolninst.edu]
- 17. inspectionpanel.org [inspectionpanel.org]
"validating air quality sensor data with official monitoring stations in Teresina"
This guide provides a comprehensive framework for researchers, scientists, and drug development professionals to validate the performance of commercial air quality sensors against data from official government monitoring stations in Teresina, Brazil. By presenting a detailed experimental protocol and clear data comparison methodologies, this document aims to ensure the reliable application of accessible sensor technology in air quality research.
Introduction: The Need for Sensor Validation
The advent of low-cost, portable air quality sensors has opened new avenues for granular environmental monitoring. However, the data generated by these devices must be rigorously validated against high-grade, official monitoring equipment to ensure accuracy and reliability for research purposes.[1][2] This is particularly crucial in environments where local pollution sources and meteorological conditions can significantly influence sensor performance. This guide outlines a standardized procedure for collocating and comparing a commercial air quality sensor with a hypothetical official monitoring station in this compound.
Official Air Quality Monitoring in this compound
Experimental Protocol for Sensor Validation
A robust validation study relies on a well-defined experimental protocol. The following steps provide a detailed methodology for comparing a commercial air quality sensor with a reference station.
3.1. Site Selection and Sensor Collocation
The core of the validation process is the simultaneous measurement of air pollutants by both the commercial sensor and the official reference monitor at the same location.[1]
-
Proximity: The commercial sensor should be placed in close proximity to the inlet of the official monitoring station's instruments, ideally within 1-10 meters.[1]
-
Environmental Conditions: Ensure that both the sensor and the official monitor are exposed to the same environmental conditions. Avoid placing the sensor in areas with localized pollution sources (e.g., near a direct exhaust vent) or obstructions that might alter airflow.
-
Duration: A sufficient data collection period is essential to capture a range of environmental conditions and pollutant concentrations. A minimum of two weeks of continuous, simultaneous data logging is recommended.
3.2. Data Acquisition and Pre-processing
-
Temporal Resolution: Configure the commercial sensor to log data at a high frequency (e.g., every 1-5 minutes). This allows for more granular comparison with the typically hourly data from official stations.
-
Data Averaging: To facilitate direct comparison, the high-frequency sensor data will need to be averaged to match the temporal resolution of the official station's data (e.g., hourly averages).
-
Data Cleaning: Remove any erroneous data points from both datasets that may have resulted from sensor malfunctions or power outages.
3.3. Statistical Analysis
A comprehensive statistical analysis is necessary to quantify the performance of the commercial sensor. Key metrics include:
-
Coefficient of Determination (R²): Indicates how well the sensor's measurements correlate with the reference station's data. A value closer to 1 signifies a strong linear relationship.
-
Root Mean Square Error (RMSE): Measures the average magnitude of the errors between the sensor and the reference station. A lower RMSE indicates better accuracy.
-
Mean Absolute Error (MAE): Represents the average absolute difference between the sensor and reference measurements.
The following diagram illustrates the workflow of the experimental protocol:
Data Presentation: A Comparative Analysis
To facilitate a clear and objective comparison, the collected and analyzed data should be summarized in structured tables. The following tables present hypothetical data for a 24-hour period, comparing a commercial sensor with an official monitoring station in this compound.
Table 1: Hypothetical PM2.5 and PM10 Data Comparison
| Hour | Official Station PM2.5 (µg/m³) | Commercial Sensor PM2.5 (µg/m³) | Official Station PM10 (µg/m³) | Commercial Sensor PM10 (µg/m³) |
| 1 | 15.2 | 16.1 | 25.8 | 27.3 |
| 2 | 14.8 | 15.5 | 24.9 | 26.1 |
| 3 | 16.1 | 17.0 | 27.2 | 28.9 |
| ... | ... | ... | ... | ... |
| 24 | 18.5 | 19.3 | 31.2 | 33.0 |
Table 2: Hypothetical O3 and NO2 Data Comparison
| Hour | Official Station O3 (ppb) | Commercial Sensor O3 (ppb) | Official Station NO2 (ppb) | Commercial Sensor NO2 (ppb) |
| 1 | 25.3 | 27.1 | 12.1 | 13.5 |
| 2 | 24.9 | 26.5 | 11.8 | 13.1 |
| 3 | 26.2 | 28.0 | 12.9 | 14.4 |
| ... | ... | ... | ... | ... |
| 24 | 29.8 | 31.5 | 15.2 | 16.9 |
Table 3: Statistical Performance Summary
| Pollutant | Coefficient of Determination (R²) | Root Mean Square Error (RMSE) | Mean Absolute Error (MAE) |
| PM2.5 | 0.92 | 1.5 µg/m³ | 1.2 µg/m³ |
| PM10 | 0.89 | 2.8 µg/m³ | 2.1 µg/m³ |
| O3 | 0.85 | 3.2 ppb | 2.5 ppb |
| NO2 | 0.81 | 2.5 ppb | 1.9 ppb |
Logical Relationship of the Data Validation Process
The process of validating air quality sensor data is a logical sequence of steps, from data acquisition to the final assessment of sensor performance. The following diagram illustrates this logical relationship.
Conclusion and Recommendations
This guide provides a standardized framework for the validation of commercial air quality sensors in this compound. By following the detailed experimental protocol and data analysis methods, researchers can objectively assess the performance of these sensors. It is crucial to acknowledge that sensor performance can be influenced by various environmental factors, and therefore, location-specific validation is paramount.[7] The use of machine learning algorithms can further enhance the calibration and accuracy of low-cost sensors, offering a promising avenue for future research.[8][9] Ultimately, the rigorous validation of these sensors will enable their effective integration into research and public health initiatives, contributing to a better understanding of air quality and its impacts in this compound.
References
- 1. epa.gov [epa.gov]
- 2. upcommons.upc.edu [upcommons.upc.edu]
- 3. Air Quality [energiaeambiente.org.br]
- 4. According to data from IEMA, only ten Brazilian states and the Federal District (Brasília) have air quality monitoring networks - Instituto de Energia e Meio Ambiente (IEMA) [energiaeambiente.org.br]
- 5. IEMA’s Air Quality Platform is the source of Brazilian data for WHO’s database - Instituto de Energia e Meio Ambiente (IEMA) [energiaeambiente.org.br]
- 6. This compound, Piauí, Brazil Air Quality Index | AccuWeather [accuweather.com]
- 7. mdpi.com [mdpi.com]
- 8. Advancing low-cost air quality monitor calibration with machine learning methods - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. ijcseonline.org [ijcseonline.org]
A Comparative Guide to the Ecological Footprint of Cities in the Caatinga Biome: A Framework for Analysis Centered on Teresina
Audience: Environmental Scientists, Urban Planners, and Sustainability Researchers.
Abstract: A direct quantitative comparison of the ecological footprints of Teresina and other cities within the Caatinga biome is not feasible due to a lack of publicly available, standardized studies. This guide provides a conceptual framework for such a comparison. It outlines the methodology of ecological footprint analysis, examines the known environmental pressures in this compound that contribute to its footprint, and discusses the unique ecological context of the Caatinga biome. The objective is to equip researchers with the necessary background to design and conduct specific ecological footprint assessments in this critical region.
Introduction to Ecological Footprint Analysis
The Ecological Footprint is a metric that quantifies the demand of a population on the biosphere in terms of the area of biologically productive land and sea required to produce the resources it consumes and to absorb its waste.[1][2] It is a widely recognized indicator of sustainability, expressed in "global hectares" (gha), which are hectares with world-average productivity.[3] This metric allows for a comparison between human demand and the planet's regenerative capacity, or biocapacity.[4] A population's Ecological Footprint is calculated by summing the footprints of different consumption categories, which are typically broken down into six major components:
-
Cropland Footprint: The area required to grow crops for food, animal feed, and fiber.
-
Grazing Land Footprint: The area needed to raise livestock for meat, dairy, and wool products.
-
Forest Product Footprint: The area of forest required to supply timber, pulp, and other wood products.
-
Fishing Grounds Footprint: The area of marine and inland waters needed to sustain a population's fish and seafood consumption.
-
Built-up Land Footprint: The land area occupied by infrastructure, including housing, transportation, and industrial structures.
-
Carbon Footprint: The area of forest required to absorb the CO2 emissions from burning fossil fuels that is not absorbed by the ocean.
A key challenge in comparing the ecological footprints of different Brazilian cities is the need for standardized procedures and consistent approaches to ensure the results are truly comparable.[5]
Methodological Framework for Urban Ecological Footprint Calculation
While specific data for this compound is unavailable, the study conducted for Campo Grande, the first Brazilian city to calculate its footprint, serves as a methodological reference.[3] The process, typically undertaken in partnership with organizations like the WWF-Brasil and the Global Footprint Network, involves:
-
Data Collection: Gathering comprehensive data on the consumption patterns of the city's population. This includes food, housing, transportation, goods, and services.
-
Conversion to Land Area: Translating the consumption data into the corresponding biologically productive area required. For example, meat consumption is converted into the grazing land and cropland (for feed) needed to produce it.
-
Component Aggregation: Summing the land areas for all consumption categories to arrive at the total Ecological Footprint, usually expressed in per capita terms.
The study for Campo Grande identified a footprint of 3.14 global hectares per person, with food consumption (especially meat) being the largest contributor at 45%.[6] This highlights how local consumption habits are a primary driver of a city's ecological impact.
Qualitative Analysis of this compound's Potential Ecological Footprint
Although a quantitative value cannot be provided, an analysis of this compound's known environmental characteristics allows for a qualitative assessment of the primary drivers of its ecological footprint.
Key Environmental Pressures and Footprint Components:
| Environmental Factor in this compound | Likely Impact on Ecological Footprint Component | Supporting Evidence |
| Urban Mobility Issues | High Carbon Footprint | Conflicts related to limited public transport coverage and a focus on road construction suggest high reliance on private, fossil-fuel-powered vehicles.[7] |
| Waste Management Challenges | Increased Carbon Footprint (from emissions) and demand on Built-up Land (for landfills). | The city generates a large volume of solid waste, and while collection services exist, challenges in implementing comprehensive recycling and environmental education programs persist.[8] Irregular waste disposal is a noted problem.[9] |
| Loss of Vegetation Cover | Reduction in local Biocapacity and increased demand on the Carbon Footprint . | The urban perimeter of this compound lost approximately 40% of its tree cover between 2001 and 2019.[10] This loss reduces the local capacity to absorb CO2 and regulate temperature. |
| Urban Sprawl | High Built-up Land Footprint | Pressure from the real estate market contributes to unsustainable urbanization, converting natural or agricultural land into impervious surfaces.[7][10] |
Mitigating Initiatives: Conversely, this compound has local initiatives that aim to reduce its environmental impact. These include the establishment of new recycling cooperatives and startups focused on composting organic waste to create natural fertilizers.[11][12] Such programs, if scaled, can help reduce the city's overall ecological footprint by diverting waste from landfills and decreasing the demand for synthetic fertilizers.
The Context of the Caatinga Biome
Any urban footprint analysis in this region must consider the unique characteristics of the surrounding Caatinga, the only exclusively Brazilian biome.[13][14]
-
High Biodiversity: The Caatinga is one of the most biodiverse semi-arid regions in the world, providing essential resources and environmental services to the approximately 27 million people who live there.[13][14]
-
Critical Role in Carbon Sequestration: Despite its arid appearance for much of the year, studies have shown the Caatinga is highly efficient at capturing atmospheric carbon, particularly during rainy seasons. In some years, it has been responsible for nearly 50% of all carbon removal in Brazil, highlighting its crucial role in national climate regulation.[15][16]
-
Significant Threats: The biome is under severe pressure from human activity. An estimated 80% of its original ecosystems have been altered, primarily through deforestation and burning for agriculture and pasture.[13][17] This degradation severely diminishes the biome's biocapacity, making it more vulnerable to desertification.[13]
The ecological footprint of cities like this compound directly contributes to these pressures by demanding resources (food, water, energy, materials) that are often sourced from the surrounding biome, thus accelerating its degradation.
Conceptual Model and Visualization
To understand the relationship between a city and its biome, the following diagram illustrates the components of an urban ecological footprint and its impact on the Caatinga's biocapacity.
Caption: Conceptual flow of a city's ecological footprint impacting the Caatinga biome's biocapacity.
Conclusion and Recommendations for Future Research
While a precise comparison is currently impossible, this guide establishes a clear framework for analysis. This compound, like any major city, exerts significant pressure on its surrounding environment through resource consumption and waste generation. The primary drivers of its ecological footprint are likely related to transportation, food consumption, and land use for urban infrastructure.
To enable a quantitative comparison and inform sustainable urban planning in the region, the following steps are recommended for researchers:
-
Initiate a Pilot Study: Conduct a comprehensive ecological footprint analysis for this compound using the established methodologies of the Global Footprint Network to create a baseline.
-
Standardize Data Collection: Develop a standardized protocol for data collection that can be applied to other cities in the Caatinga biome, such as Petrolina, Juazeiro do Norte, and Campina Grande, to ensure comparability.
-
Integrate Biocapacity Assessment: Future studies must not only calculate the footprint (demand) but also assess the specific biocapacity (supply) of the surrounding Caatinga areas to determine the extent of the ecological deficit.
-
Policy-Oriented Research: Frame research findings to provide actionable recommendations for municipal governments on urban planning, waste management, and transportation policies aimed at reducing the urban ecological footprint and preserving the vital Caatinga biome.
References
- 1. caroa.org.br [caroa.org.br]
- 2. Pegada Ecologica | WWF Brasil [wwf.org.br]
- 3. Campo Grande calcula sua pegada ecológica | WWF Brasil [wwf.org.br]
- 4. Ecological Footprint - Global Footprint Network [footprintnetwork.org]
- 5. rbciamb.com.br [rbciamb.com.br]
- 6. Estudo avalia a Pegada Ecológica de Campo Grande | WWF Brasil [wwf.org.br]
- 7. urbancoalitions.org [urbancoalitions.org]
- 8. ibeas.org.br [ibeas.org.br]
- 9. m.youtube.com [m.youtube.com]
- 10. urbanresiliencehub.org [urbanresiliencehub.org]
- 11. Startup de this compound transforma lixo orgânico em fertilizante natural através da compostagem; conheça iniciativa | G1 [g1.globo.com]
- 12. youtube.com [youtube.com]
- 13. Caatinga — Ministério do Meio Ambiente e Mudança do Clima [gov.br]
- 14. Preservação do único bioma exclusivamente brasileiro [acaatinga.org.br]
- 15. Estudo mostra que vegetação da Caatinga pode ser aliada no combate às mudanças climáticas [ancora1.com]
- 16. Jornal da Unesp | Estudo revela importância da Caatinga para o sequestro do carbono no contexto brasileiro [jornal.unesp.br]
- 17. Ação humana transformou 89% da Caatinga : Revista Pesquisa Fapesp [revistapesquisa.fapesp.br]
A Comparative Analysis of Urban Flora Biodiversity: A Case Study of Teresina and Other Brazilian Cities
This guide provides a comparative analysis of the impacts of urbanization on biodiversity, with a specific focus on the urban flora of Teresina, Brazil. While a direct multi-city study including this compound with a standardized methodology is not yet available in published literature, this document synthesizes findings from independent studies to offer a comparative perspective for researchers, scientists, and urban planners. By juxtaposing data on tree diversity from this compound with findings from other Brazilian urban centers, this guide aims to highlight key trends and inform future multi-city research endeavors.
Quantitative Data on Urban Tree Diversity
The following tables summarize quantitative data on urban tree species diversity from studies conducted in this compound and other Brazilian cities. It is important to note that methodologies and the scope of sampling areas may differ between studies, which should be taken into consideration when interpreting the data.
Table 1: Urban Tree Diversity in this compound
| Metric | Value | Source |
| Number of Individuals Surveyed | 1,392 | [1][2] |
| Number of Species Identified | 53 | [1][2] |
| Number of Families Identified | 28 | [1][2] |
| Most Prevalent Families | ||
| Anacardiaceae | 20.7% | [1][2] |
| Fabaceae | 19.8% | [1][2] |
| Meliaceae | 9.4% | [1][2] |
| Myrtaceae | 6.9% | [1][2] |
| Arecaceae | 6.1% | [1][2] |
| Combretaceae | 5.5% | [1][2] |
Table 2: Comparative Overview of Urban Tree Diversity in Brazilian Cities
| City/Region | Number of Species | Number of Families | Key Findings | Source |
| 71 Urban Areas (Brazil-wide review) | 473 | 125 | Most inventories are in the South and Southeast. Ratio of native to exotic species is approximately 1:1. | [3][4] |
| 29 Cities (Brazilian Amazonia) | Average of 43.1 per city | - | 65.3% of species are native to Brazil. Most frequent species were Ficus benjamina, Mangifera indica, and Licania tomentosa. | [5] |
| Belo Horizonte | 73 bird species observed | - | Street tree characteristics (canopy size, species richness, proportion of native trees) positively influence bird diversity. | [6] |
| Curitiba | 54 (in 15 contemporary style squares) | 27 | 50% of tree species were of exotic origin in the studied squares. | [7] |
| Allahabad, India (for comparison) | 64 | 28 | The most abundant species, Polyalthia longifolia, accounted for 13.25% of the total tree density. | [8] |
From 2001 to 2019, the urban perimeter of this compound lost approximately 40% of its tree cover, a significant factor impacting local biodiversity.[9][10]
Experimental Protocols
This section details the methodologies employed in key studies cited in this guide, providing a basis for understanding how the data was collected and analyzed.
Methodology for Urban Flora Identification in this compound
A study on the urban flora of this compound utilized a combination of remote sensing and on-site inventory to identify tree species.[1][2]
-
Remote Sensing Data Acquisition : High-resolution satellite images from Worldview-2 were used.
-
Image Processing and Analysis :
-
The e-Cognition 8.7 software was employed for mapping, segmentation, and classification of vegetal species.
-
ERDAS Imagine 9.2 was used for accuracy verification.
-
The Normalized Difference Vegetation Index (NDVI) was calculated to analyze the condition of the natural vegetation. Higher NDVI values were observed on the outskirts of the city.
-
-
On-site Inventory : Field surveys were conducted to collect ground-truth data for the calibration and validation of the remote sensing classification.
-
Data Analysis : The study identified 1,392 individual trees belonging to 53 species and 28 families. The classification accuracy for the 16 most abundant species was 69.43%, with a kappa agreement index of 0.68.[1][2]
General Methodology for Urban Biodiversity Gradient Analysis
Urban-rural gradient analysis is a common approach to studying the effects of urbanization on biodiversity.[11]
-
Gradient Definition : The urban-to-rural gradient is typically defined based on factors such as population density, the proportion of built-up surfaces, and land use/land cover.
-
Sampling Design : Transects or plots are established along the defined gradient, from the urban core to the rural periphery.
-
Data Collection : Biodiversity data (e.g., species richness and abundance of plants, birds, insects) are collected at each sampling point. Environmental variables are also measured.
-
Data Analysis : Statistical methods are used to analyze the changes in biodiversity metrics along the urbanization gradient.
Visualizations: Workflows and Conceptual Relationships
The following diagrams, created using Graphviz (DOT language), illustrate key experimental workflows and conceptual frameworks relevant to the study of urbanization and biodiversity.
Caption: Workflow for urban flora identification using remote sensing.
Caption: Conceptual model of urbanization's impact on biodiversity.
References
- 1. The use of geotechnologies for the identification of the urban flora in the city of this compound, Brazil - ProQuest [proquest.com]
- 2. researchgate.net [researchgate.net]
- 3. researchgate.net [researchgate.net]
- 4. scielo.br [scielo.br]
- 5. mdpi.com [mdpi.com]
- 6. Street trees reduce the negative effects of urbanization on birds - PMC [pmc.ncbi.nlm.nih.gov]
- 7. revistas.ufpr.br [revistas.ufpr.br]
- 8. cabidigitallibrary.org [cabidigitallibrary.org]
- 9. urbanresiliencehub.org [urbanresiliencehub.org]
- 10. urbanresiliencehub.org [urbanresiliencehub.org]
- 11. leml.asu.edu [leml.asu.edu]
Safety Operating Guide
Essential Guide to Laboratory Waste Disposal in Teresina
For researchers and scientists in Teresina, adhering to proper chemical and biomedical waste disposal procedures is critical for ensuring laboratory safety and environmental protection. While specific municipal or state-level procedural manuals for laboratory waste were not publicly available, the management of such hazardous materials is governed by national regulations. This guide provides essential safety and logistical information based on Brazilian national standards and local resources.
Immediate Safety and Logistical Information
Emergency Contacts: In case of a chemical spill or exposure, immediately contact the local emergency services. Ensure that your laboratory has a clearly posted emergency plan, including contact information for the nearest hospital and the institutional safety officer.
Certified Waste Management Services: The primary logistical step for proper disposal is to contract a certified hazardous waste management company. These companies are equipped to handle the collection, transportation, treatment, and final disposal of chemical and biomedical waste in compliance with regulations.
| Company | Contact Information | Services Offered |
| Sagri Ambiental | Serving this compound, Piauí. Contact via WhatsApp, e-mail, or phone is available on their website.[1][2] | Coleta e transporte de resíduos perigosos (Collection and transport of hazardous waste), Gerenciamento de Resíduos (Waste Management), Tratamento e disposição final de resíduos (Treatment and final disposal of waste).[3][4] They also assist in creating a Plano de Gerenciamento de Resíduos de Serviços de Saúde (PGRSS)[5]. |
| SOMAR Soluções Ecológicas | Contact information, including phone numbers and email addresses, is available on their website.[6] | Coleta, remoção e destino final de resíduos (Collection, removal, and final destination of waste), including chemical and health service waste (Grupos A, B, e E).[6] |
It is the responsibility of the waste generator to ensure that the contracted company is fully licensed by the relevant environmental authorities.
Waste Classification and Segregation
Proper segregation of waste at the source is a fundamental step in safe disposal. Waste should be classified according to Brazilian regulations, primarily ANVISA RDC No. 222/2018 and CONAMA Resolution No. 358/2005, which categorize health service waste into the following groups:
| Waste Group | Description | Examples |
| Group A | Infectious Waste: Potentially contains biological agents. | Cultures, stocks of microorganisms, waste from patients in isolation, used sharps. |
| Group B | Chemical Waste: Contains chemicals that may present a risk to public health or the environment. | Reagents, solvents, expired or unused chemicals. |
| Group C | Radionuclide Waste: Contains radionuclides in quantities exceeding the limits specified by the National Nuclear Energy Commission (CNEN). | Waste from radiotherapy or nuclear medicine. |
| Group D | Common Waste: Does not present a biological, chemical, or radiological risk. | Paper, cardboard, non-contaminated plastics. |
| Group E | Sharps Waste: Items that can cause cuts or punctures. | Needles, scalpels, glass slides. |
Experimental Protocols for Waste Management
General Chemical Waste Disposal Workflow:
The following diagram illustrates a typical workflow for the management of chemical waste in a laboratory setting.
Caption: A step-by-step process for safely managing chemical waste from generation to final disposal.
Decision Tree for Waste Segregation:
This diagram provides a logical flow for segregating different types of laboratory waste.
Caption: A decision-making tool for the correct segregation of laboratory waste at the point of generation.
References
- 1. Engenharia Ambiental - this compound, Piauí | Sagri Ambiental | Soluções sustentáveis para seu negócio [sagriambiental.com.br]
- 2. This compound, Piauí | Sagri Ambiental | Soluções sustentáveis para seu negócio [sagriambiental.com.br]
- 3. Tratamento e disposição final de resíduos - this compound, Piauí | Sagri Ambiental | Soluções sustentáveis para seu negócio [sagriambiental.com.br]
- 4. Coleta e transporte de resíduos perigosos - this compound, Piauí | Sagri Ambiental | Soluções sustentáveis para seu negócio [sagriambiental.com.br]
- 5. PGRSS – Plano de Gerenciamento de Resíduos de Serviços de Saúde - Fronteiras, Piauí | Sagri Ambiental | Soluções sustentáveis para seu negócio [sagriambiental.com.br]
- 6. SOMAR - Soluções Ecológicas em ResÃduos [somar.eco.br]
Essential Safety and Handling Protocols for Tianeptine
Disclaimer: The term "Teresina" did not correspond to a recognized chemical substance in our searches. This guide pertains to Tianeptine , a substance that may be relevant to your inquiry. It is crucial to verify the identity of the substance you are handling before applying these or any other safety protocols.
This document provides essential safety and logistical information for the handling of Tianeptine, targeted at researchers, scientists, and drug development professionals. The following procedural guidance is designed to answer specific operational questions regarding personal protective equipment (PPE), handling, storage, and disposal.
Physical and Chemical Properties
A summary of the key physical and chemical properties of Tianeptine and its sodium salt is provided below. This information is critical for safe handling and experimental design.
| Property | Tianeptine | Tianeptine Sodium Salt |
| Molecular Formula | C₂₁H₂₅ClN₂O₄S[1] | C₂₁H₂₄ClN₂NaO₄S[2][3][4] |
| Molecular Weight | 437.0 g/mol [1] | 458.93 g/mol [2][3] |
| Appearance | White Solid[5] | White to yellowish powder[2] |
| Solubility | - | Good solubility in water, DMSO, ethanol, and methanol[2] |
| Melting Point | 148 °C[1] | Not determined[6][7] |
| Boiling Point | 609.2 °C[1] | Not determined[6][7] |
| Storage | - | 2-8 °C in a desiccated state[2] |
Hazard Identification and Personal Protective Equipment (PPE)
There are inconsistencies in the classification of Tianeptine's hazards across different Safety Data Sheets (SDS). Some sources classify the substance as not hazardous according to the Globally Harmonized System (GHS)[3][6]. However, other sources indicate significant hazards, including acute toxicity if swallowed or in contact with skin, and potential reproductive toxicity[7]. Given these discrepancies, a cautious approach is strongly recommended.
The following table summarizes the recommended Personal Protective Equipment for handling Tianeptine, based on a comprehensive review of available safety information.
| PPE Category | Recommended Equipment | Rationale and Best Practices |
| Eye/Face Protection | Safety glasses with side shields or goggles[8][9][10] | To prevent eye contact with the substance. |
| Skin Protection | Wear protective gloves and a lab coat[8][9][10] | To prevent skin contact. Nitrile gloves are a suitable option[11]. |
| Respiratory Protection | NIOSH/MSHA approved respirator if exposure limits are exceeded or irritation is experienced[8] | To be used in the context of a comprehensive respiratory protection program[12]. A well-ventilated area or a fume hood should be used. |
Operational and Disposal Plans
Proper operational procedures and disposal methods are critical to ensure the safety of laboratory personnel and the environment.
Handling and Storage:
-
Handle Tianeptine in a well-ventilated area, preferably in a fume hood[13].
-
Avoid direct contact with the substance. Do not ingest, inhale, or allow contact with skin or eyes[13].
-
Store Tianeptine in a cool, dry place, shielded from light and moisture[10]. The recommended storage temperature for the sodium salt is 2-8°C in a desiccated state[2].
-
Keep containers tightly closed when not in use[13].
-
Maintain thorough records of all transactions and usage of Tianeptine to ensure compliance with any local regulations[9].
First Aid Measures:
-
After Inhalation: Move the person to fresh air. If breathing is difficult, seek medical attention[3].
-
After Skin Contact: Wash the affected area with soap and water[8].
-
After Eye Contact: Rinse opened eyes for several minutes under running water[6].
-
After Ingestion: Rinse mouth with water. Do not induce vomiting. Seek immediate medical attention[3].
Disposal:
-
Dispose of Tianeptine and its waste in accordance with local, state, and federal regulations. This may involve treating it as hazardous waste[9].
-
Do not dispose of down the drain unless specifically permitted by local regulations[13].
-
For unused or expired medication, consider a drug take-back program if available. If not, mix the substance with an undesirable material like coffee grounds or cat litter, place it in a sealed container, and dispose of it in the household trash, ensuring all personal information is removed from the original container[14][15].
Experimental Protocols
Detailed experimental protocols for Tianeptine are specific to the research being conducted. However, general laboratory procedures should always be followed. Below is a general workflow for handling Tianeptine in a research setting.
Workflow for Handling Tianeptine in a Laboratory Setting:
Caption: General workflow for handling Tianeptine in a laboratory setting.
Pharmacological Signaling Pathway of Tianeptine:
Recent studies indicate that Tianeptine's primary mechanism of action involves its role as a full agonist at the mu-opioid receptor (MOR)[16]. This interaction is believed to be responsible for its antidepressant effects.
Caption: Simplified signaling pathway of Tianeptine via the mu-opioid receptor.
References
- 1. Tianeptine | C21H25ClN2O4S | CID 68870 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 2. nbinno.com [nbinno.com]
- 3. abmole.com [abmole.com]
- 4. Tianeptine sodium | C21H24ClN2NaO4S | CID 23663953 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 5. Tianeptine | 66981-73-5 [amp.chemicalbook.com]
- 6. cdn.caymanchem.com [cdn.caymanchem.com]
- 7. cdn.caymanchem.com [cdn.caymanchem.com]
- 8. datasheets.scbt.com [datasheets.scbt.com]
- 9. nordicchems.is [nordicchems.is]
- 10. nbinno.com [nbinno.com]
- 11. PPE and Decontamination | Substance Use | CDC [cdc.gov]
- 12. Potential Exposures and PPE Recommendations | Substance Use | CDC [cdc.gov]
- 13. sds.edqm.eu [sds.edqm.eu]
- 14. dea.gov [dea.gov]
- 15. Drug Disposal: Dispose "Non-Flush List" Medicine in Trash | FDA [fda.gov]
- 16. deadiversion.usdoj.gov [deadiversion.usdoj.gov]
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.

A Technical Deep Dive into Social Inequality and its Determinants in Teresina