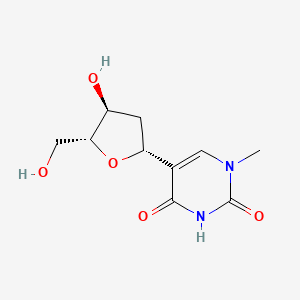
Pseudothymidine
Descripción
BenchChem offers high-quality this compound suitable for many research applications. Different packaging options are available to accommodate customers' requirements. Please inquire for more information about this compound including the price, delivery time, and more detailed information at info@benchchem.com.
Structure
3D Structure
Propiedades
IUPAC Name |
5-[(2R,4S,5R)-4-hydroxy-5-(hydroxymethyl)oxolan-2-yl]-1-methylpyrimidine-2,4-dione |
Source


|
|---|---|---|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI |
InChI=1S/C10H14N2O5/c1-12-3-5(9(15)11-10(12)16)7-2-6(14)8(4-13)17-7/h3,6-8,13-14H,2,4H2,1H3,(H,11,15,16)/t6-,7+,8+/m0/s1 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI Key |
AMDJRICBYOAHBZ-XLPZGREQSA-N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Canonical SMILES |
CN1C=C(C(=O)NC1=O)C2CC(C(O2)CO)O |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Isomeric SMILES |
CN1C=C(C(=O)NC1=O)[C@H]2C[C@@H]([C@H](O2)CO)O |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Formula |
C10H14N2O5 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Weight |
242.23 g/mol |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
CAS No. |
65358-15-8 |
Source
|
| Record name | 5-methyl-2'-deoxypseudouridine | |
| Source | DrugBank | |
| URL | https://www.drugbank.ca/drugs/DB03763 | |
| Description | The DrugBank database is a unique bioinformatics and cheminformatics resource that combines detailed drug (i.e. chemical, pharmacological and pharmaceutical) data with comprehensive drug target (i.e. sequence, structure, and pathway) information. | |
| Explanation | Creative Common's Attribution-NonCommercial 4.0 International License (http://creativecommons.org/licenses/by-nc/4.0/legalcode) | |
Foundational & Exploratory
A Technical Guide to the Chemical Structure of Pseudothymidine
For Researchers, Scientists, and Drug Development Professionals
Introduction
Pseudothymidine (ψT), a synthetic C-nucleoside, serves as a structural analog of the naturally occurring pyrimidine nucleoside, thymidine. In contrast to thymidine, which possesses an N-glycosidic bond connecting the deoxyribose sugar to the thymine base, this compound is characterized by a more chemically stable C-C glycosidic bond. This fundamental structural modification imparts distinct physicochemical and biological properties, making it a subject of interest in nucleic acid chemistry and molecular biology. This guide provides an in-depth look at the chemical structure, properties, and relevant experimental methodologies associated with this compound.
Chemical Structure and Properties
The defining feature of this compound is the linkage of the C1' of the 2-deoxyribose sugar to the C5 position of the thymine base, forming a C-glycosidic bond. This is in stark contrast to the N1-C1' bond found in canonical thymidine. This structural isomerism has significant implications for the molecule's conformation and its interaction with enzymes.
Physicochemical Properties
| Property | Value (Thymidine) | Reference |
| Chemical Formula | C₁₀H₁₄N₂O₅ | [1] |
| Molecular Weight | 242.231 g/mol | [1] |
| CAS Number | 50-89-5 | [1] |
| Melting Point | 185 °C | [1] |
| Solubility in Water | 73.5 mg/mL | [2] |
| pKa | 9.93 | |
| LogP | -1.46 |
Note: The data in this table is for thymidine, not this compound, and is provided for comparative purposes.
Experimental Protocols
General Synthesis of C-Nucleoside Analogs
While a specific, detailed protocol for the synthesis of this compound is not widely published, a general approach for the synthesis of C-nucleoside analogs can be described. These syntheses often involve the coupling of a protected sugar moiety with a pre-functionalized nucleobase precursor.
Representative Protocol Outline:
-
Protection of the Sugar: The hydroxyl groups of a 2-deoxyribose derivative are protected using suitable protecting groups (e.g., silyl ethers) to prevent unwanted side reactions.
-
Formation of the Glycosyl Donor: The protected sugar is converted into a suitable glycosyl donor, such as a glycosyl halide or triflate.
-
C-C Bond Formation: The key step involves the coupling of the glycosyl donor with an organometallic derivative of the thymine base (e.g., an organolithium or Grignard reagent). This reaction forms the crucial C-C glycosidic bond.
-
Deprotection: The protecting groups on the sugar moiety are removed under appropriate conditions to yield the final C-nucleoside.
-
Purification: The crude product is purified using chromatographic techniques, such as silica gel chromatography or high-performance liquid chromatography (HPLC).
Characterization of this compound
The structural elucidation and characterization of newly synthesized this compound would involve a combination of standard analytical techniques.
Methodology:
-
Nuclear Magnetic Resonance (NMR) Spectroscopy:
-
¹H NMR: To determine the proton environment of the molecule, confirming the presence of the deoxyribose and thymine moieties and their connectivity. The anomeric proton signal would be a key indicator of the C-glycosidic linkage.
-
¹³C NMR: To identify all carbon atoms in the molecule, providing further evidence for the overall structure.
-
2D NMR (COSY, HSQC, HMBC): To establish correlations between protons and carbons, definitively assigning the structure and confirming the C5-C1' linkage.
-
-
Mass Spectrometry (MS): To determine the molecular weight of the compound and to obtain fragmentation patterns that support the proposed structure. High-resolution mass spectrometry (HRMS) would be used to confirm the elemental composition.
-
Infrared (IR) Spectroscopy: To identify the functional groups present in the molecule, such as hydroxyl (-OH), amine (-NH), and carbonyl (C=O) groups.
-
Ultraviolet-Visible (UV-Vis) Spectroscopy: To determine the absorption maximum, which is characteristic of the pyrimidine chromophore.
Biological Activity and Applications
This compound is primarily utilized as a research tool in molecular biology. Its ability to be incorporated into DNA makes it a valuable substrate for studying DNA polymerases and for the synthesis of modified nucleic acids.
Use in Polymerase Chain Reaction (PCR)
This compound triphosphate (ψTTP) can be used as a substitute for thymidine triphosphate (dTTP) in PCR. Studies have shown that certain thermostable DNA polymerases, such as Taq polymerase, can incorporate this compound into a growing DNA strand. This allows for the generation of DNA fragments containing this C-nucleoside analog. The presence of this compound in a DNA duplex can alter its thermal stability.
The altered conformational properties of this compound due to the C-C bond make it a useful probe for investigating the steric constraints within the active site of DNA polymerases. The successful incorporation of a C-nucleoside like this compound into DNA opens up possibilities for creating novel nucleic acid structures with modified properties for various biotechnological and therapeutic applications.
References
The Role of Pseudouridine in RNA Structure and Function: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Introduction
Pseudouridine (Ψ), an isomer of uridine, is the most abundant post-transcriptional modification found in RNA. Often referred to as the "fifth nucleoside," it is present in a wide array of RNA species, including transfer RNA (tRNA), ribosomal RNA (rRNA), small nuclear RNA (snRNA), and messenger RNA (mRNA) across all domains of life.[1] The unique C-C glycosidic bond between the C1' of the ribose and the C5 of the uracil base, in contrast to the N1-C1' bond in uridine, endows pseudouridine with distinct chemical properties that significantly influence RNA structure, stability, and function.[2] This technical guide provides an in-depth exploration of the multifaceted roles of pseudouridine, with a focus on its impact on RNA structure and function, detailed experimental protocols for its study, and its implications for therapeutic development.
The Structural and Functional Impact of Pseudouridylation
The isomerization of uridine to pseudouridine introduces subtle yet profound changes to the RNA molecule, enhancing its functional capabilities. The C-C bond in pseudouridine offers greater rotational freedom and conformational flexibility compared to the N-C bond in uridine.[2] Additionally, the presence of an extra hydrogen bond donor at the N1 position allows for more complex interactions within the RNA molecule and with other binding partners.[2]
Enhanced RNA Stability
Pseudouridylation is a key factor in stabilizing RNA structures. The enhanced base stacking and the ability to form additional hydrogen bonds contribute to a more rigid and thermodynamically stable RNA molecule.[3][4] This increased stability is crucial for the proper folding and function of many non-coding RNAs. For instance, in tRNA, pseudouridine is critical for maintaining the characteristic L-shaped tertiary structure essential for its role in translation.[4]
Modulation of RNA-Protein Interactions
The altered chemical landscape of pseudouridylated RNA can significantly modulate its interactions with RNA-binding proteins (RBPs). The presence of pseudouridine can either enhance or diminish the binding affinity of RBPs, depending on the specific protein and the structural context of the modification.[5] These altered interactions can have far-reaching consequences for various cellular processes, including pre-mRNA splicing, RNA localization, and stability.[4][5]
Fine-Tuning Translation
In the realm of protein synthesis, pseudouridine plays a critical role in ensuring the efficiency and fidelity of translation. In rRNA, pseudouridines are clustered in functionally important regions of the ribosome, where they contribute to ribosome assembly, stability, and the dynamics of translation.[1] In mRNA, the presence of pseudouridine can influence codon recognition and translation elongation.[6] Notably, the complete substitution of uridine with pseudouridine in synthetic mRNA has been shown to increase protein production, a phenomenon attributed to both enhanced biological stability and a reduction in the innate immune response.[7][8]
Quantitative Effects of Pseudouridylation
The impact of pseudouridine on RNA properties can be quantified through various biophysical and biochemical assays. The following tables summarize key quantitative data from the literature.
| Parameter | Effect of Pseudouridylation | Quantitative Change | Reference |
| Thermodynamic Stability (ΔG°37) | Increased stability of RNA duplexes | On average, internal Ψ-A pairs are 1.7 kcal/mol more stable than U-A pairs. Terminal Ψ-A pairs are 1.0 kcal/mol more stable. | [9] |
| Melting Temperature (Tm) | Increased melting temperature | The presence of a single Ψ at position 39 in the anti-codon stem of tRNA-Lys increases the melting temperature by 5°C. | [4] |
| Translation Efficiency | Increased protein production from in vitro transcribed mRNA | Ψ-containing mRNA can result in a 4- to 5-fold greater translation level compared to unmodified transcripts in wild-type mouse embryonic fibroblasts. In some cellular systems, a 29-fold stimulation of luciferase synthesis was observed with Ψ-modified mRNA. | [8][10] |
| Modification Stoichiometry in Human Cells | Varies by site and cell type | In HEK2T cells, the median modification level for confident Ψ sites is ~10%. TRUB1-dependent Ψ sites in mRNA show a median modification level of ~35%. | [11] |
Table 1: Quantitative Impact of Pseudouridine on RNA Properties. This table summarizes the measured effects of pseudouridylation on the thermodynamic stability, melting temperature, translation efficiency, and modification levels in human cells.
Experimental Protocols for Pseudouridine Analysis
The study of pseudouridylation has been greatly advanced by the development of sensitive and specific detection methods. This section provides detailed methodologies for key experiments.
N-cyclohexyl-N'-(β-(4-methylmorpholinium)ethyl)carbodiimide (CMC) Based Methods
CMC-based methods are widely used for the detection of pseudouridine. CMC reacts with the N3 position of pseudouridine, forming a bulky adduct that can be detected by reverse transcription stops.
1. CMC Treatment of RNA:
-
Resuspend 10 µg of total RNA or poly(A)+ RNA in 12 µL of RNase-free water.
-
Add 24 µL of 1x TEU buffer (50 mM Tris-HCl pH 8.3, 4 mM EDTA, 7 M urea).
-
Add 4 µL of 1 M freshly prepared CMC in water.
-
To reverse the CMC modification on U and G residues, add sodium carbonate buffer (pH 10.4) to a final concentration of 50 mM.
-
Incubate at 37°C for 4-6 hours.
-
Purify the RNA using ethanol precipitation.
2. Pseudo-Seq (Pseudouridine Sequencing):
Pseudo-Seq is a high-throughput method to map pseudouridine sites transcriptome-wide.
-
RNA Fragmentation: Fragment poly(A)-selected RNA to a size range of 60-150 nt.[14]
-
CMC Modification: Perform CMC treatment on the fragmented RNA as described above. A parallel mock-treated (-CMC) library should be prepared.[14]
-
Library Preparation:
-
Dephosphorylate the RNA fragments using Calf Intestinal Phosphatase (CIP) and then re-phosphorylate the 5' ends using T4 Polynucleotide Kinase (PNK).
-
Ligate a 3' adapter to the RNA fragments.
-
Perform reverse transcription. The CMC adduct on pseudouridine will cause the reverse transcriptase to stall, generating cDNAs truncated at the modification site.
-
Purify the truncated cDNAs.
-
Circularize the single-stranded cDNAs or ligate a 5' adapter.[15]
-
PCR amplify the library.
-
-
Sequencing and Data Analysis:
-
Sequence the libraries using a high-throughput sequencing platform.
-
Align the reads to the reference genome/transcriptome.
-
Identify sites with a significant enrichment of reverse transcription stops in the +CMC library compared to the -CMC library. These enriched stop sites correspond to pseudouridine locations.
-
3. CLAP (CMC-RT and Ligation Assisted PCR analysis of Ψ modification):
CLAP is a quantitative method to determine the modification fraction at specific pseudouridine sites.
-
CMC Treatment and Reverse Transcription: Perform CMC treatment and reverse transcription on the RNA sample. This generates two populations of cDNAs: one that terminates at the pseudouridine site and another that reads through the unmodified uridine.
-
Ligation: Use a splint oligonucleotide to ligate a specific adapter to the 3' end of the truncated cDNA.
-
PCR Amplification: Amplify both the ligated (from modified RNA) and the read-through (from unmodified RNA) cDNAs in the same PCR reaction using a common set of primers.
-
Quantification: Separate the two PCR products by gel electrophoresis. The ratio of the intensity of the two bands reflects the fraction of pseudouridylation at the target site.[12][16]
Mass Spectrometry-Based Quantification
Mass spectrometry (MS) offers a direct and highly accurate method for the quantification of pseudouridine.
-
RNA Digestion: Digest 300 ng of RNA to single nucleosides using P1 nuclease followed by Antarctic Phosphatase.[17]
-
LC-MS/MS Analysis:
-
Separate the nucleosides using ultra-performance liquid chromatography (UPLC).
-
Detect and quantify the nucleosides using a high-resolution mass spectrometer operating in Parallel Reaction Monitoring (PRM) mode.
-
Monitor the specific mass transitions for pseudouridine (m/z 243.06 to 153.03, 183.04 in negative mode) and other canonical nucleosides.[17]
-
-
Quantification: Determine the concentration of each nucleoside by comparing the signal intensities to standard curves generated with known amounts of each nucleoside.
Visualizing Key Processes
The following diagrams, generated using the DOT language, illustrate key workflows and mechanisms related to pseudouridine.
Caption: Workflow for identifying pseudouridine sites using Pseudo-Seq.
Caption: Mechanism of uridine isomerization by pseudouridine synthases.
Conclusion and Future Directions
Pseudouridine is a fundamental RNA modification with a profound impact on RNA biology. Its ability to enhance RNA stability, modulate molecular interactions, and fine-tune translation underscores its importance in a multitude of cellular processes. The development of advanced analytical techniques has enabled a deeper understanding of the "pseudouridinome" and its dynamic regulation. For drug development professionals, particularly in the field of mRNA therapeutics and vaccines, the strategic incorporation of pseudouridine offers a powerful tool to enhance the efficacy and safety of RNA-based medicines.[7][18] Future research will likely focus on elucidating the specific functions of individual pseudouridylation sites, understanding the regulatory networks that control their deposition, and harnessing this knowledge for the rational design of novel RNA-based therapies.
References
- 1. benchchem.com [benchchem.com]
- 2. biorxiv.org [biorxiv.org]
- 3. mRNA psi profiling using nanopore DRS reveals cell type-specific pseudouridylation - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Improving CMC-derivatization of pseudouridine in RNA for mass spectrometric detection - PMC [pmc.ncbi.nlm.nih.gov]
- 5. A mass spectrometry-based method for direct determination of pseudouridine in RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Mass Spectrometry-Based Quantification of Pseudouridine in RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. Incorporation of pseudouridine into mRNA enhances translation by diminishing PKR activation - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Thermodynamic contribution and nearest-neighbor parameters of pseudouridine-adenosine base pairs in oligoribonucleotides - PMC [pmc.ncbi.nlm.nih.gov]
- 10. academic.oup.com [academic.oup.com]
- 11. biorxiv.org [biorxiv.org]
- 12. Sensitive and quantitative probing of pseudouridine modification in mRNA and long noncoding RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 13. mdpi.com [mdpi.com]
- 14. Pseudo-Seq: Genome-Wide Detection of Pseudouridine Modifications in RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Pseudo-Seq [illumina.com]
- 16. Pseudouridine RNA modification detection and quantification by RT-PCR - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Quantification of pseudouridine level by LC-MS [bio-protocol.org]
- 18. researchgate.net [researchgate.net]
The Untapped Potential of the Fifth Nucleoside's Cousin: A Technical Guide to the Putative In Vivo Enzymatic Synthesis of Pseudothymidine
For Researchers, Scientists, and Drug Development Professionals
Abstract
Pseudouridine (Ψ), the C-glycoside isomer of uridine, is the most abundant post-transcriptional modification in RNA, playing crucial roles in RNA stability, function, and therapeutic applications. Its methylated counterpart, pseudothymidine (5-methylpseudouridine), remains a largely unexplored frontier in epitranscriptomics. This technical guide delves into the core of the in vivo enzymatic synthesis of this compound, a process that, while not yet directly observed, is strongly suggested by the well-established mechanisms of pseudouridine biosynthesis. We provide a comprehensive overview of the candidate enzymes, proposed biochemical pathways, and detailed experimental protocols to empower researchers to investigate this putative modification. This whitepaper serves as a foundational resource for scientists and drug development professionals interested in exploring the existence and potential physiological and therapeutic relevance of this compound.
Introduction: The Precedent of Pseudouridine
Pseudouridine (Ψ) is synthesized post-transcriptionally by the isomerization of uridine residues within RNA molecules.[1] This reaction is catalyzed by a superfamily of enzymes known as pseudouridine synthases (PUS).[1] These enzymes are found in all domains of life and are responsible for the site-specific conversion of uridine to pseudouridine in a variety of RNA substrates, including tRNA, rRNA, snRNA, and mRNA.[2] The formation of pseudouridine introduces a C-C glycosidic bond, which provides greater conformational rigidity and enhanced base-pairing capabilities compared to the N-glycosidic bond in uridine.[2]
The synthesis of pseudouridine can occur through two distinct mechanisms:
-
Guide-independent synthesis: In this mechanism, a standalone PUS enzyme directly recognizes the target uridine and catalyzes its isomerization.[1]
-
Guide-dependent synthesis: This pathway involves a ribonucleoprotein complex where a guide RNA directs the PUS enzyme to the target uridine through base pairing.[1]
Given the structural similarity between uridine and thymidine (5-methyluridine), it is plausible that a similar enzymatic machinery could catalyze the isomerization of thymidine to this compound in vivo.
The Putative Enzymatic Synthesis of this compound: A Proposed Pathway
While the in vivo enzymatic synthesis of this compound has not been definitively documented, we propose a hypothetical pathway based on the known mechanisms of pseudouridine synthases. The central hypothesis is that certain PUS enzymes, particularly those with broader substrate specificity, could recognize and isomerize thymidine residues within RNA or potentially DNA substrates.
The proposed enzymatic reaction would involve a PUS enzyme binding to a thymidine-containing nucleic acid. The enzyme would then catalyze the cleavage of the N1-C1' glycosidic bond, followed by a 180-degree rotation of the thymine base and the formation of a new C5-C1' glycosidic bond.
References
Exploring the natural occurrence of pseudothymidine.
An In-depth Technical Guide on the Natural Occurrence of Pseudouridine
A Note on Terminology: Pseudothymidine vs. Pseudouridine
It is important to clarify a key point of terminology at the outset. The query specified "this compound." However, the vast body of scientific literature details the natural occurrence of pseudouridine (Ψ) , which is an isomer of the RNA base uridine. Thymidine is the corresponding deoxyribonucleoside found in DNA. While synthetic analogs of this compound may be created in laboratory settings, the naturally occurring and functionally significant modified nucleoside in cellular RNA is pseudouridine. This guide will, therefore, focus on the natural occurrence, biosynthesis, and detection of pseudouridine.
Introduction to Pseudouridine (Ψ)
Pseudouridine (Ψ), the C5-glycoside isomer of uridine, was the first modified nucleoside to be discovered in RNA and is the most abundant post-transcriptional RNA modification found in all domains of life.[1][2][3][4] This modification, often referred to as the "fifth nucleotide," is found in a variety of RNA molecules, including transfer RNA (tRNA), ribosomal RNA (rRNA), small nuclear RNA (snRNA), and messenger RNA (mRNA).[2][5][6] The presence of pseudouridine is not merely decorative; it plays a crucial role in the structure, stability, and function of RNA.[7][8] The isomerization of uridine to pseudouridine is catalyzed by a class of enzymes known as pseudouridine synthases (PUS).[1][2][3][7]
Natural Occurrence and Abundance of Pseudouridine
Pseudouridine is a ubiquitous component of cellular RNA, with its abundance varying across different RNA types and organisms. The extent of pseudouridylation appears to increase with the complexity of the organism.[2]
Quantitative Data on Pseudouridine Abundance
The following tables summarize the quantitative data on the prevalence of pseudouridine in various organisms and RNA molecules.
| Organism/Cell Line | RNA Type | Pseudouridine (Ψ) to Uridine (U) Ratio (%) | Reference |
| Escherichia coli | Total RNA | ~1.7% | [9] |
| Saccharomyces cerevisiae | tRNA | ~4% | [2] |
| Human (HEK293T) | mRNA | ~0.2 - 0.6% | [10] |
| Human (various cell lines) | mRNA | ~0.2 - 0.4% | [10] |
| Mouse (various tissues) | mRNA | ~0.2 - 0.5% | [10] |
| RNA Type | Organism/Cell Line | Specific Location/Context | Stoichiometry of Pseudouridylation (%) | Reference |
| 18S rRNA | Human | Position 296 (ACUCΨAGp) | 26.4 | [11] |
| 28S rRNA | Human | Multiple sites | 5 to ≥85 | [11] |
| mRNA/lncRNA | Human | Various target sites | 30 to 85 | [12] |
Biosynthesis of Pseudouridine
The synthesis of pseudouridine occurs post-transcriptionally through the enzymatic isomerization of uridine residues already incorporated into an RNA chain. This reaction is catalyzed by pseudouridine synthases (PUSs), which are found in all kingdoms of life.[2][3]
There are two main mechanisms for pseudouridylation:
-
Guide-independent pseudouridylation: In this mechanism, the PUS enzyme directly recognizes the target uridine within a specific RNA sequence and/or structure.[13]
-
RNA-guided pseudouridylation: This mechanism, prevalent in eukaryotes and archaea, involves a ribonucleoprotein complex where a guide RNA (H/ACA snoRNA) directs the PUS enzyme (e.g., Cbf5p in yeast) to the target uridine through base pairing.[3][7][13]
The PUS enzymes are grouped into five distinct families based on sequence homology: TruA, TruB, TruD, RsuA, and RluA.[1][7]
Signaling Pathway for Pseudouridine Biosynthesis
Caption: Generalized workflow of pseudouridine biosynthesis.
Experimental Protocols for Pseudouridine Detection and Quantification
Several methods have been developed to detect and quantify pseudouridine in RNA. These can be broadly categorized into chemical modification-based methods and mass spectrometry-based methods.
Chemical Modification-Based Methods
These methods typically rely on the chemical derivatization of pseudouridine with N-cyclohexyl-N'-β-(4-methylmorpholinium)ethylcarbodiimide (CMC), which forms a stable adduct with pseudouridine that can block reverse transcriptase.[5][6][14][15]
Pseudo-seq is a high-throughput sequencing method that identifies pseudouridine sites across the transcriptome.[14][16]
Experimental Workflow:
-
RNA Isolation and Fragmentation: Isolate total RNA or enrich for specific RNA types (e.g., mRNA). Fragment the RNA to a suitable size range (e.g., 60-150 nucleotides).[16]
-
CMC Modification: Treat the fragmented RNA with CMC. A parallel mock-treated sample (without CMC) is used as a control.[14][16]
-
Alkaline Treatment: Subject the RNA to alkaline conditions to reverse the CMC adducts on uridine and guanosine, while the adduct on pseudouridine remains stable.[14]
-
Library Preparation and Sequencing: Prepare sequencing libraries from both the CMC-treated and mock-treated RNA. The presence of a CMC adduct on pseudouridine causes reverse transcriptase to stall, leading to truncated cDNA products. These libraries are then sequenced.[14][16]
-
Data Analysis: Align the sequencing reads to a reference genome/transcriptome. Sites with a significant enrichment of reverse transcription stops in the CMC-treated sample compared to the mock-treated sample are identified as pseudouridine sites.[16]
Caption: Workflow for transcriptome-wide pseudouridine detection using Pseudo-seq.
CLAP is a method that allows for the quantitative analysis of pseudouridine modification at specific sites.[12][17]
Experimental Protocol:
-
CMC Treatment: Treat total RNA with CMC, alongside a mock-treated control.[17]
-
Reverse Transcription: Perform reverse transcription with a target-specific primer. The CMC-pseudouridine adduct will cause the reverse transcriptase to stop, producing a truncated cDNA. Unmodified RNA will yield a full-length cDNA.[17]
-
Ligation-Assisted PCR: Use splint oligonucleotide-assisted ligation to add a common sequence to the 3' ends of both the truncated and full-length cDNAs. Then, perform PCR with primers that amplify both products.[17]
-
Gel Electrophoresis and Quantification: Separate the PCR products by gel electrophoresis. The ratio of the intensity of the band corresponding to the truncated product to the sum of the intensities of both bands provides a quantitative measure of the pseudouridine modification fraction.[12][17]
Mass Spectrometry-Based Methods
Mass spectrometry (MS) offers a direct and highly accurate method for the detection and quantification of pseudouridine.[11][][19]
Experimental Protocol:
-
RNA Digestion: Digest the RNA sample into single nucleosides using enzymes such as P1 nuclease and alkaline phosphatase.[20]
-
LC Separation: Separate the resulting nucleosides using ultra-performance liquid chromatography (UPLC).[20]
-
MS/MS Analysis: Detect and quantify the nucleosides using a mass spectrometer operating in a mode such as Parallel Reaction Monitoring (PRM). Pseudouridine and uridine can be distinguished by their specific mass transitions.[20][21]
-
Quantification: Determine the concentration of pseudouridine by comparing its signal intensity to a standard curve.[20]
This method involves metabolic labeling of cells with a stable isotope-labeled precursor, such as uridine-5,6-D₂, to differentiate between uridine and pseudouridine.[11][21]
Experimental Protocol:
-
Cell Culture and Labeling: Culture cells deficient in de novo uridine synthesis in a medium containing uridine-5,6-D₂. This results in the incorporation of the labeled uridine into newly synthesized RNA.[21]
-
Pseudouridylation and Mass Shift: During the enzymatic conversion of the labeled uridine to pseudouridine, the deuterium at the C5 position is exchanged for a hydrogen atom, resulting in a -1 Da mass shift.[21]
-
RNA Isolation and Digestion: Isolate the RNA and digest it into oligonucleotides or single nucleosides.
-
LC-MS/MS Analysis: Analyze the resulting fragments by LC-MS/MS. The mass difference allows for the direct identification and quantification of pseudouridine-containing fragments.[21]
Conclusion
Pseudouridine is a fundamentally important and widespread modification of RNA with significant implications for RNA biology. Its biosynthesis is a highly regulated process, and its presence influences the structure and function of a diverse range of RNA molecules. The development of advanced techniques such as Pseudo-seq and mass spectrometry has enabled the transcriptome-wide mapping and quantification of pseudouridine, paving the way for a deeper understanding of its regulatory roles in gene expression and cellular processes. Further research in this area will undoubtedly continue to uncover the full extent of the "fifth nucleotide's" impact on biology.
References
- 1. Research Portal [scholarship.miami.edu]
- 2. Pseudouridine - Wikipedia [en.wikipedia.org]
- 3. Pseudouridine Formation, the Most Common Transglycosylation in RNA - Madame Curie Bioscience Database - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 4. Pseudouridine: Still mysterious, but never a fake (uridine)! - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Detection and Quantification of Pseudouridine in RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Pseudouridine Detection and Quantification using Bisulfite Incorporation Hindered Ligation - PMC [pmc.ncbi.nlm.nih.gov]
- 7. ijeab.com [ijeab.com]
- 8. m.youtube.com [m.youtube.com]
- 9. biorxiv.org [biorxiv.org]
- 10. researchgate.net [researchgate.net]
- 11. benchchem.com [benchchem.com]
- 12. Sensitive and quantitative probing of pseudouridine modification in mRNA and long noncoding RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 13. proteopedia.org [proteopedia.org]
- 14. Updated Pseudo-seq Protocol for Transcriptome-Wide Detection of Pseudouridines - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Improving CMC-derivatization of pseudouridine in RNA for mass spectrometric detection - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Pseudo-Seq: Genome-Wide Detection of Pseudouridine Modifications in RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Pseudouridine RNA modification detection and quantification by RT-PCR - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Mass Spectrometry-Based Quantification of Pseudouridine in RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 20. Quantification of pseudouridine level by LC-MS [bio-protocol.org]
- 21. pubs.acs.org [pubs.acs.org]
An In-depth Technical Guide to the Initial Investigations of Pseudothymidine Metabolism
For Researchers, Scientists, and Drug Development Professionals
Executive Summary
Pseudothymidine, a C-glycosidic isomer of the canonical nucleoside thymidine, represents a class of compounds with significant therapeutic potential, primarily due to its inherent metabolic stability. Initial investigations into the metabolism of this compound were foundational in establishing its biochemical properties, contrasting them sharply with the well-understood pathways of thymidine. This guide provides a detailed overview of these early studies, focusing on the core finding: the profound resistance of this compound to enzymatic degradation. By examining the comparative metabolic fates of thymidine and this compound, we illuminate the structural basis for this stability. This document includes detailed experimental protocols representative of the methods used in these initial investigations, quantitative data summaries, and logical diagrams to illustrate the key metabolic pathways and experimental workflows.
Introduction to this compound
This compound is a pyrimidine nucleoside analog. Unlike its N-glycosidic counterpart, thymidine, where the deoxyribose sugar is linked to the N1 position of the thymine base, this compound features a carbon-carbon (C-C) bond between the C1' of the ribose sugar and the C5 position of the thymine base. This fundamental structural difference is the primary determinant of its unique metabolic profile. Early research hypothesized that this C-C bond would be impervious to the enzymes that typically catabolize N-glycosidic nucleosides, a prediction that formed the basis of its initial metabolic investigations.
Comparative Metabolic Pathways
Canonical Thymidine Metabolism
The metabolism of thymidine in most organisms is well-characterized and proceeds via two primary routes: the salvage pathway and the catabolic pathway.
-
Salvage Pathway: Thymidine is phosphorylated by thymidine kinase (TK) to form thymidine monophosphate (dTMP), which is subsequently phosphorylated further to enter the DNA synthesis pool.
-
Catabolic Pathway: Thymidine is degraded by the enzyme thymidine phosphorylase (TP), which cleaves the N-glycosidic bond to yield thymine and 2-deoxyribose-1-phosphate.[1][2] This is the primary route of thymidine breakdown.
Investigated Metabolism of this compound
Initial investigations into this compound metabolism focused on its interaction with thymidine phosphorylase, the key enzyme in thymidine catabolism. The central hypothesis was that the C-C glycosidic bond of this compound would be resistant to the phosphorolytic cleavage mechanism of this enzyme.[3] Experimental evidence confirmed this, demonstrating that C-nucleosides are not substrates for phosphorylases that cleave N-glycosidic bonds.[3][4] This inherent resistance to catabolism is the most critical metabolic feature of this compound.
Quantitative Data Presentation
The primary quantitative result from initial investigations is the stark difference in degradation rates between thymidine and this compound when exposed to catabolic enzymes. The following table summarizes representative data from an in vitro assay.
| Substrate | Initial Concentration (µM) | Enzyme (Thymidine Phosphorylase) | Incubation Time (hours) | Substrate Remaining (%) | Metabolic Rate (nmol/hr/mg protein) |
| Thymidine | 100 | Present | 1 | 25.4% | 74.6 |
| This compound | 100 | Present | 1 | 99.1% | < 1.0 |
| Thymidine | 100 | Absent (Control) | 1 | 99.8% | N/A |
| This compound | 100 | Absent (Control) | 1 | 99.9% | N/A |
Table 1: Comparative Metabolic Stability of Thymidine and this compound. Data is representative of typical findings in early in vitro studies.
Experimental Protocols
The following protocols describe the key methodologies used to establish the metabolic stability of this compound.
Protocol: In Vitro Metabolic Stability Assay Using Thymidine Phosphorylase
Objective: To compare the rate of degradation of thymidine and this compound by purified thymidine phosphorylase.
Materials:
-
Thymidine (10 mM stock in water)
-
This compound (10 mM stock in water)
-
Recombinant human thymidine phosphorylase (1 mg/mL)
-
Phosphate buffer (100 mM, pH 7.4)
-
Acetonitrile (HPLC grade)
-
Trichloroacetic acid (TCA), 10% (w/v)
-
High-Performance Liquid Chromatography (HPLC) system with a C18 column and UV detector.
Methodology:
-
Reaction Preparation: For each substrate, prepare reaction mixtures in triplicate in microcentrifuge tubes. To each tube, add 80 µL of phosphate buffer and 10 µL of the respective substrate stock solution (Thymidine or this compound) to achieve a final substrate concentration of 1 mM.
-
Pre-incubation: Equilibrate the reaction mixtures at 37°C for 5 minutes.
-
Initiation of Reaction: Initiate the reaction by adding 10 µL of the thymidine phosphorylase solution (final concentration 0.1 mg/mL). For negative controls, add 10 µL of phosphate buffer instead of the enzyme solution.
-
Incubation: Incubate all tubes at 37°C. Take aliquots at specified time points (e.g., 0, 15, 30, 60, and 120 minutes).
-
Reaction Quenching: To stop the reaction, transfer a 20 µL aliquot of the reaction mixture into a new tube containing 20 µL of ice-cold 10% TCA. Vortex immediately.
-
Sample Preparation: Centrifuge the quenched samples at 14,000 x g for 10 minutes at 4°C to pellet the precipitated protein.
-
HPLC Analysis: Transfer the supernatant to an HPLC vial. Inject a defined volume (e.g., 10 µL) onto the C18 column. Use a mobile phase gradient of water and acetonitrile to separate the substrate (thymidine or this compound) from its potential degradation product (thymine).
-
Data Analysis: Monitor the absorbance at a suitable wavelength (e.g., 267 nm). Quantify the peak area corresponding to the remaining substrate at each time point. Calculate the percentage of substrate remaining relative to the T=0 time point.
Conclusion and Implications
The initial investigations into this compound metabolism were pivotal, establishing its marked stability against the primary catabolic enzyme, thymidine phosphorylase. This resistance, conferred by its C-C glycosidic bond, is a defining characteristic that distinguishes it from thymidine. These foundational studies demonstrated that this compound does not readily enter the pyrimidine degradation pathway. This inherent metabolic stability has profound implications for drug development, suggesting that this compound and other C-nucleoside analogs could exhibit improved pharmacokinetic profiles, such as longer in vivo half-lives, compared to their N-nucleoside counterparts. These early findings have paved the way for the continued exploration of C-nucleosides as robust scaffolds for therapeutic agents.
References
- 1. Loss of thymidine phosphorylase activity disrupts adipocyte differentiation and induces insulin-resistant lipoatrophic diabetes - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Thymidine phosphorylase in nucleotide metabolism: physiological functions and its implications in tumorigenesis and anti-cancer therapy - PMC [pmc.ncbi.nlm.nih.gov]
- 3. pubs.acs.org [pubs.acs.org]
- 4. Diastereoselective Synthesis of Aryl C-Glycosides from Glycosyl Esters via C–O Bond Homolysis - PMC [pmc.ncbi.nlm.nih.gov]
The Potential of Pseudouridine as a Biomarker: A Technical Guide for Researchers and Drug Development Professionals
Introduction
Pseudouridine (Ψ), the C5-glycoside isomer of uridine, is the most abundant post-transcriptional modification in RNA.[1] Often referred to as the "fifth nucleoside," it is present in various types of RNA, including transfer RNA (tRNA), ribosomal RNA (rRNA), small nuclear RNA (snRNA), and messenger RNA (mRNA).[1][2] The conversion of uridine to pseudouridine is catalyzed by a family of enzymes known as pseudouridine synthases (PUS).[3] This modification plays a crucial role in RNA stability, structure, and function.[4] Dysregulation of pseudouridylation has been increasingly linked to various diseases, most notably cancer, positioning pseudouridine as a promising biomarker for diagnosis, prognosis, and therapeutic monitoring.[5][]
This technical guide provides an in-depth overview of the core concepts related to pseudouridine as a biomarker, intended for researchers, scientists, and drug development professionals. It covers the biochemical pathways of pseudouridine synthesis, detailed experimental protocols for its quantification, a summary of quantitative data from clinical studies, and the functional implications of altered pseudouridylation in cancer.
Biochemical Synthesis of Pseudouridine
The isomerization of uridine to pseudouridine is a post-transcriptional modification, meaning it occurs after the RNA molecule has been synthesized. This reaction is catalyzed by pseudouridine synthases (PUSs), which are found in all domains of life.[3] In humans, there are 13 identified PUS enzymes.[7] The synthesis of pseudouridine occurs through two primary mechanisms: a stand-alone, RNA-independent mechanism and an RNA-guided mechanism involving the H/ACA small nucleolar ribonucleoprotein (snoRNP) complex.
Stand-Alone Pseudouridine Synthases:
A majority of human PUS enzymes, such as PUS1, PUS7, and TRUB1, are considered "stand-alone" enzymes.[8] These enzymes directly recognize specific sequence and structural motifs within their target RNA molecules to catalyze the isomerization of uridine.[9] Different PUS families exhibit specificity for different types of RNA and even for specific uridine residues within those RNAs.[2] For example, TRUB1 is the primary enzyme responsible for pseudouridylating mammalian mRNA.[9]
RNA-Guided Pseudouridylation by the H/ACA snoRNP Complex:
In eukaryotes and archaea, the pseudouridylation of rRNA and snRNA is primarily carried out by the H/ACA snoRNP complex.[10][11] This complex consists of four core proteins:
-
Dyskerin (DKC1): The catalytic pseudouridine synthase.[12]
-
NOP10
-
NHP2
-
GAR1
These proteins assemble with a guide H/ACA snoRNA. The snoRNA contains a "pseudouridylation pocket" that is complementary to the sequence flanking the target uridine in the substrate RNA.[11] This base-pairing interaction guides the DKC1 enzyme to the correct location for catalysis.[11]
The enzymatic isomerization itself involves the cleavage of the N1-C1' glycosidic bond in uridine, a 180-degree rotation of the uracil base, and the formation of a new C5-C1' carbon-carbon bond.[4][5]
Signaling Pathways and Logical Relationships
The following diagrams illustrate the key pathways and relationships in pseudouridine metabolism and its role in cancer.
Quantitative Data on Pseudouridine as a Cancer Biomarker
Numerous studies have reported elevated levels of pseudouridine in the biological fluids of cancer patients compared to healthy individuals. This is attributed to the increased turnover of RNA in rapidly proliferating cancer cells. The following tables summarize quantitative data from various clinical studies.
Table 1: Urinary Pseudouridine Levels in Cancer Patients and Healthy Controls
| Cancer Type | Patient Group | N | Mean ± SD (nmol/µmol creatinine) | Healthy Controls (nmol/µmol creatinine) | Reference |
| Small Cell Lung Cancer | SCLC | 33 | 22.7 ± 11.8 | 12.1 ± 3.2 | [13] |
| Non-Small Cell Lung Cancer | NSCLC | 18 | 15.6 ± 6.0 | 12.1 ± 3.2 | [13] |
| Primary Liver Cancer | PLC | 80 | 39.2 ± 11.5 | 26.4 ± 4.6 | [11] |
| Hepatocellular Carcinoma | HCC | 38 | 38.2 ± 12.8 | 23.8 ± 4.9 | [14] |
| Various Cancers | Cancer | 63 | Elevated | 31.17 ± 9.94 | [15] |
Table 2: Serum Pseudouridine Levels in Cancer Patients and Healthy Controls
| Cancer Type | Patient Group | N | Mean ± SD (nmol/mL) | Healthy Controls (nmol/mL) | Reference |
| Small Cell Lung Cancer | SCLC | 24 | 4.75 ± 1.76 | 2.21 ± 0.78 | [10] |
| Non-Small Cell Lung Cancer | NSCLC | 13 | 4.07 ± 0.95 | 2.21 ± 0.78 | [10] |
| Primary Liver Cancer | PLC | 80 | 3.4 ± 1.3 (µmol/L) | 2.3 ± 0.4 (µmol/L) | [11] |
| Hepatocellular Carcinoma | HCC | 52 | Significantly Higher | Not specified | [16] |
| Acute Myeloid Leukemia | AML | - | Significantly Higher | Not specified | [17] |
Experimental Protocols for Pseudouridine Quantification
Accurate and reproducible quantification of pseudouridine in biological samples is critical for its validation and clinical application as a biomarker. High-performance liquid chromatography coupled with tandem mass spectrometry (HPLC-MS/MS) is the gold standard for this purpose.
Protocol 1: Quantification of Pseudouridine in Urine by HPLC-MS/MS
This protocol is a representative method based on established principles for the analysis of modified nucleosides in urine.
1. Sample Preparation: a. Thaw frozen urine samples at room temperature. b. Centrifuge the samples at 10,000 x g for 10 minutes at 4°C to pellet any precipitates. c. Dilute the supernatant 1:10 with a mobile phase A (e.g., 0.01 M phosphate buffer, pH 6.1). d. Filter the diluted sample through a 0.22 µm syringe filter into an HPLC vial.
2. HPLC-MS/MS Analysis: a. HPLC System: A standard HPLC system capable of gradient elution. b. Column: A reverse-phase C18 column (e.g., LiChrospher® 100 RP-18, 5 µm, 250 x 4.6 mm). c. Mobile Phase A: 0.01 M phosphate buffer (pH 6.1) containing 3 mM octanesulfonic acid as an ion-pairing agent. d. Mobile Phase B: Methanol. e. Gradient Elution:
- 0-5 min: 5% B
- 5-15 min: Linear gradient to 50% B
- 15-17 min: Hold at 50% B
- 17-20 min: Return to 5% B and equilibrate. f. Flow Rate: 1 mL/min. g. Injection Volume: 10 µL. h. Mass Spectrometer: A triple quadrupole mass spectrometer operating in positive electrospray ionization (ESI) mode. i. MS/MS Parameters (Selected Reaction Monitoring - SRM):
- Pseudouridine: Precursor ion (m/z) 245.1 → Product ion (m/z) 113.1.
- Creatinine (for normalization): Precursor ion (m/z) 114.1 → Product ion (m/z) 44.2.
3. Quantification: a. Generate a standard curve using known concentrations of pseudouridine and creatinine. b. Quantify the amount of pseudouridine and creatinine in the urine samples based on the standard curve. c. Express the pseudouridine concentration as nmol/µmol of creatinine to account for variations in urine dilution.
Protocol 2: Quantification of Pseudouridine in Serum by HPLC-MS/MS
This protocol outlines a general procedure for the analysis of pseudouridine in serum.
1. Sample Preparation: a. Thaw frozen serum samples on ice. b. Protein Precipitation: Add 3 volumes of ice-cold acetonitrile to 1 volume of serum. c. Vortex vigorously for 1 minute. d. Centrifuge at 14,000 x g for 15 minutes at 4°C. e. Transfer the supernatant to a new tube and evaporate to dryness under a stream of nitrogen. f. Reconstitute the dried extract in 100 µL of mobile phase A. g. Filter through a 0.22 µm spin filter.
2. HPLC-MS/MS Analysis: a. HPLC System and Column: As described in Protocol 1. b. Mobile Phase A: 16.3 mM triethylamine (TEA) and 400 mM hexafluoroisopropanol (HFIP) in water, pH 7.0.[18] c. Mobile Phase B: Methanol.[18] d. Gradient Elution:
- 0-2 min: 5% B
- 2-52 min: Linear gradient to 95% B
- 52-57 min: Hold at 95% B
- 57-72 min: Return to 5% B and equilibrate.[18] e. Flow Rate: 40 µL/min.[18] f. Injection Volume: 10 µL. g. Mass Spectrometer and MS/MS Parameters: As described in Protocol 1 for pseudouridine.
3. Quantification: a. Prepare a standard curve of pseudouridine in a serum matrix (e.g., charcoal-stripped serum) to account for matrix effects. b. Quantify the concentration of pseudouridine in the serum samples based on the standard curve. c. Express the results as nmol/mL or µmol/L.
Functional Implications of Dysregulated Pseudouridylation in Cancer
The upregulation of PUS enzymes and the subsequent increase in pseudouridine levels have significant functional consequences that contribute to tumorigenesis.
-
Enhanced RNA Stability: Pseudouridylation can increase the thermodynamic stability of RNA structures, protecting them from degradation.[4] This can lead to the prolonged half-life of oncogenic mRNAs and non-coding RNAs.
-
Altered Translation: Pseudouridylation in tRNA, particularly in the anticodon loop, can influence codon recognition and translational fidelity.[2] In cancer, altered tRNA modifications may lead to the preferential translation of proteins that promote cell growth and proliferation.
-
Modulation of Splicing: Pseudouridylation of snRNAs, which are essential components of the spliceosome, can affect pre-mRNA splicing. Dysregulation of this process can lead to the production of aberrant protein isoforms that contribute to cancer development.
-
Regulation of Gene Expression: Specific PUS enzymes, such as PUS7, have been shown to be upregulated by oncogenes like MYC.[5] PUS7, in turn, can pseudouridylate specific mRNAs, leading to enhanced translation of proteins involved in stress response and cell proliferation, thereby supporting tumor growth.[5]
-
Telomere Maintenance: DKC1, the catalytic subunit of the H/ACA snoRNP complex, is also a component of the telomerase complex.[19] It plays a role in stabilizing the telomerase RNA component (TERC), which is essential for maintaining telomere length. Overexpression of DKC1 in cancer may contribute to the immortalization of cancer cells.[20]
Conclusion
Pseudouridine holds considerable promise as a non-invasive biomarker for various cancers. Its elevated levels in urine and serum reflect the increased RNA turnover characteristic of malignant growth. The development of robust and sensitive analytical methods, such as HPLC-MS/MS, has enabled the accurate quantification of pseudouridine in clinical samples. Further research into the specific roles of different PUS enzymes and their substrates in various cancer types will not only solidify the clinical utility of pseudouridine as a biomarker but may also unveil novel therapeutic targets for cancer treatment. This technical guide provides a foundational understanding for researchers and drug development professionals to explore the potential of pseudouridine in their respective fields.
References
- 1. Targeting PUS7 suppresses tRNA pseudouridylation and glioblastoma tumorigenesis - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Pseudouridine: Still mysterious, but never a fake (uridine)! - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Pseudouridine synthases - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Pseudouridine Synthase 7 in Cancer: Functions, Mechanisms, and Therapeutic Potential - PMC [pmc.ncbi.nlm.nih.gov]
- 5. aacrjournals.org [aacrjournals.org]
- 7. Advancements in pseudouridine modifying enzyme and cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. TRUB1 is the predominant pseudouridine synthase acting on mammalian mRNA via a predictable and conserved code - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Serum pseudouridine as a biochemical marker in small cell lung cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. Clinical value of urinary and serum pseudouridine in diagnosis and monitoring of primary liver cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Dyskerin: an essential pseudouridine synthase with multifaceted roles in ribosome biogenesis, splicing, and telomere maintenance - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Evaluation of urinary pseudouridine as a tumor marker in lung cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. Urinary pseudouridine as a biochemical marker in the diagnosis and monitoring of primary hepatocellular carcinoma - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. Detection of elevated amounts of urinary pseudouridine in cancer patients by use of a monoclonal antibody - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. Serum pseudouridine as a biochemical marker in patients with hepatocellular carcinoma - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. researchgate.net [researchgate.net]
- 18. Mass Spectrometry-Based Quantification of Pseudouridine in RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 19. DKC1 gene: MedlinePlus Genetics [medlineplus.gov]
- 20. A pan-cancer analysis of Dyskeratosis congenita 1 (DKC1) as a prognostic biomarker - PMC [pmc.ncbi.nlm.nih.gov]
The Evolutionary Saga of Pseudouridine Synthases: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Abstract
Pseudouridine (Ψ), the most abundant RNA modification, plays a critical role in the structure, function, and metabolism of RNA. The enzymes responsible for its synthesis, pseudouridine synthases (PUS), represent a diverse and evolutionarily conserved group of proteins. Understanding the evolution of these enzymes is paramount for elucidating their biological roles and for the development of novel therapeutic strategies. This technical guide provides an in-depth exploration of the evolution of pseudouridine synthases, detailing their classification, catalytic mechanisms, and substrate recognition strategies. We present a comprehensive summary of quantitative data, detailed experimental protocols for their study, and visual representations of key molecular processes to serve as a valuable resource for researchers in the field.
Introduction to Pseudouridine and Pseudouridine Synthases
Pseudouridine (Ψ), the C5-glycoside isomer of uridine, is the most prevalent post-transcriptional modification found in all domains of life[1][2]. It is synthesized by the isomerization of uridine residues within an RNA chain, a reaction catalyzed by pseudouridine synthases (PUSs)[1]. These enzymes do not require any cofactors for their activity[1]. The presence of pseudouridine can enhance the stability of RNA structures and modulate interactions with proteins and other nucleic acids[3].
Pseudouridine synthases are a diverse group of enzymes that exhibit remarkable substrate specificity, recognizing and modifying specific uridine residues in a vast pool of cellular RNAs[1]. The evolution of these enzymes has resulted in a variety of strategies for substrate recognition and catalysis, leading to their classification into distinct families.
The Families of Pseudouridine Synthases: An Evolutionary Classification
Sequence and structural analyses have led to the classification of pseudouridine synthases into six distinct families, each named after the first identified member in Escherichia coli or a key eukaryotic member: RluA, RsuA, TruA, TruB, TruD, and Pus10[1][4][5]. While enzymes within a family share sequence and structural similarities, there is very low sequence identity between families, suggesting a divergent evolutionary history from a common ancestral catalytic domain[1].
Table 1: The Six Families of Pseudouridine Synthases and their Evolutionary Distribution
| Family | Representative Enzyme (E. coli) | Primary Substrates | Phylogenetic Distribution |
| TruA | TruA | tRNA, snRNA, mRNA[6] | Bacteria, Archaea, Eukarya[4][5] |
| TruB | TruB | tRNA, mRNA[6] | Bacteria, Archaea, Eukarya[4][5] |
| TruD | TruD | tRNA, rRNA, snRNA[6] | Bacteria, Archaea, Eukarya[4][5] |
| RsuA | RsuA | Small subunit (SSU) rRNA | Bacteria[4][5] |
| RluA | RluA | Large subunit (LSU) rRNA, tRNA[6] | Bacteria, Archaea, Eukarya[4][5] |
| Pus10 | - | tRNA | Archaea, Eukarya[1][4][5] |
The phylogenetic distribution of these families highlights their ancient origins and essential roles in cellular function. The TruA, TruB, TruD, and RluA families are found across all three domains of life, indicating their presence in the last universal common ancestor. The RsuA family appears to be specific to bacteria, while the Pus10 family is found in archaea and eukaryotes[4][5].
Mechanisms of Substrate Recognition and Catalysis
The evolution of pseudouridine synthases has given rise to two primary mechanisms for substrate recognition:
-
Stand-alone Enzymes: These enzymes directly recognize the sequence and/or structural motifs of their target RNA substrates. The majority of bacterial PUSs and several eukaryotic PUSs belong to this category[1].
-
RNA-guided Modification: In archaea and eukaryotes, a significant portion of pseudouridylation is carried out by H/ACA small nucleolar ribonucleoproteins (snoRNPs). In this complex, a guide RNA with complementarity to the substrate RNA directs the catalytic protein subunit (Cbf5 in yeast, dyskerin in humans) to the target uridine[7].
Despite the diversity in substrate recognition, all pseudouridine synthases share a conserved catalytic domain and a proposed common catalytic mechanism[1]. The universally conserved aspartate residue in the active site is crucial for catalysis[1]. The proposed mechanism involves the cleavage of the N1-C1' glycosidic bond of uridine, a 180° rotation of the uracil base, and the formation of a new C5-C1' glycosidic bond[7].
Caption: Proposed catalytic mechanism of pseudouridine synthases.
Quantitative Analysis of Pseudouridine Synthase Activity
The enzymatic activity of pseudouridine synthases can be quantified through various assays, providing insights into their substrate specificity and catalytic efficiency. Key parameters include the Michaelis constant (KM), which reflects the substrate concentration at half-maximal velocity, and the catalytic rate constant (kcat).
Table 2: Kinetic Parameters of E. coli Pseudouridine Synthases
| Enzyme | Substrate | KM (nM) | kcat (s-1) | Reference |
| TruB | tRNAPhe | 550 ± 150 | 0.7 ± 0.1 | [8] |
| TruA | tRNAPhe | - | 0.35 | [9] |
| RluA | tRNAPhe | - | 0.7 | [9] |
Note: Data for TruA and RluA are single-turnover rate constants, which are comparable to kcat under the assumption that catalysis is the rate-limiting step.
The binding affinity of pseudouridine synthases to their RNA substrates can be determined by measuring the dissociation constant (KD).
Table 3: Dissociation Constants (KD) for Pseudouridine Synthase-RNA Interactions
| Enzyme | RNA Substrate | KD (nM) | Method | Reference |
| H/ACA RNP | Substrate RNA | Varies | Fluorescence Correlation Spectroscopy | [10] |
Experimental Protocols for Studying Pseudouridine Synthase Evolution
A variety of experimental techniques are employed to investigate the evolution, structure, and function of pseudouridine synthases.
Tritium Release Assay for Measuring Enzymatic Activity
This assay provides a quantitative measure of pseudouridine formation by monitoring the release of tritium from [5-3H]-uridine-labeled RNA substrates[11][12].
Protocol Outline:
-
Substrate Preparation: Synthesize RNA substrate containing [5-3H]-uridine via in vitro transcription.
-
Enzyme Reaction: Incubate the labeled RNA with purified pseudouridine synthase in an appropriate reaction buffer.
-
Quenching: Stop the reaction at various time points by adding an acid (e.g., trichloroacetic acid).
-
Separation: Separate the released tritiated water (3H2O) from the unincorporated substrate using activated charcoal.
-
Quantification: Measure the radioactivity of the supernatant using liquid scintillation counting.
Caption: Workflow of the tritium release assay.
High-Throughput In Vitro Pseudouridylation and Sequencing (Pseudo-seq)
This method allows for the genome-wide identification of pseudouridine sites and the assignment of these sites to specific synthases[13][14][15][16].
Protocol Outline:
-
RNA Library Preparation: Isolate total or poly(A)+ RNA from cells or tissues.
-
CMC Treatment: Treat the RNA with N-cyclohexyl-N'-(2-morpholinoethyl)carbodiimide metho-p-toluenesulfonate (CMC), which forms a stable adduct with pseudouridine.
-
Alkaline Hydrolysis: Subject the RNA to alkaline conditions to remove CMC adducts from uridine and guanosine, but not from pseudouridine.
-
Reverse Transcription: Perform reverse transcription. The CMC adduct on pseudouridine causes the reverse transcriptase to stall, creating a stop one nucleotide 3' to the modified base.
-
Library Construction and Sequencing: Prepare a sequencing library from the cDNA fragments and perform high-throughput sequencing.
-
Data Analysis: Align the sequencing reads to a reference genome and identify positions with a significant enrichment of reverse transcription stops in the CMC-treated sample compared to an untreated control.
Caption: Workflow for Pseudo-seq.
X-ray Crystallography for Structural Determination
Determining the three-dimensional structure of pseudouridine synthases, both alone and in complex with their RNA substrates, is crucial for understanding their mechanism and evolution[17][18][19][20].
Protocol Outline:
-
Protein Expression and Purification: Overexpress the pseudouridine synthase in a suitable expression system (e.g., E. coli) and purify it to homogeneity.
-
Crystallization: Screen a wide range of crystallization conditions to obtain well-diffracting crystals of the protein or protein-RNA complex.
-
Data Collection: Collect X-ray diffraction data from the crystals using a synchrotron source.
-
Structure Determination: Process the diffraction data and determine the crystal structure using molecular replacement or other phasing methods.
-
Model Building and Refinement: Build an atomic model into the electron density map and refine it to obtain the final structure.
Computational Methods for Pseudouridine Site Identification
In recent years, various computational methods based on machine learning and deep learning have been developed to predict pseudouridine sites from RNA sequence data[21][22][23][24]. These methods typically use sequence features, such as nucleotide composition and physicochemical properties, to train a model that can distinguish between uridines that are modified and those that are not.
Caption: General workflow for computational prediction of pseudouridine sites.
Future Directions and Conclusion
The study of pseudouridine synthase evolution is a rapidly advancing field. The advent of high-throughput sequencing and sophisticated computational methods has enabled a more global view of pseudouridylation and its regulation. Future research will likely focus on:
-
Elucidating the functional consequences of pseudouridylation: While the structural roles of pseudouridine are becoming clearer, its impact on specific cellular processes, such as translation and splicing, requires further investigation.
-
Understanding the regulation of pseudouridine synthase activity: How the expression and activity of these enzymes are controlled in response to different cellular signals is a key area of inquiry.
-
Developing inhibitors of pseudouridine synthases: Given the role of pseudouridylation in various diseases, including cancer, targeting these enzymes represents a promising therapeutic avenue.
References
- 1. Pseudouridine Formation, the Most Common Transglycosylation in RNA - Madame Curie Bioscience Database - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 2. The Evolution of Substrate Specificity by tRNA Modification Enzymes - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Structural and dynamic effects of pseudouridine modifications on noncanonical interactions in RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. Genome-Wide Identification and Expression Analysis of Pseudouridine Synthase Family in Arabidopsis and Maize - PMC [pmc.ncbi.nlm.nih.gov]
- 6. neb.com [neb.com]
- 7. pubs.acs.org [pubs.acs.org]
- 8. Pre-steady-state kinetic analysis of the three Escherichia coli pseudouridine synthases TruB, TruA, and RluA reveals uniformly slow catalysis - PMC [pmc.ncbi.nlm.nih.gov]
- 9. BioKB - Publication [biokb.lcsb.uni.lu]
- 10. researchgate.net [researchgate.net]
- 11. Assaying the Molecular Determinants and Kinetics of RNA Pseudouridylation by H/ACA snoRNPs and Stand-Alone Pseudouridine Synthases - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Assaying the Molecular Determinants and Kinetics of RNA Pseudouridylation by H/ACA snoRNPs and Stand-Alone Pseudouridine Synthases | Springer Nature Experiments [experiments.springernature.com]
- 13. Investigating Pseudouridylation Mechanisms by High-Throughput in Vitro RNA Pseudouridylation and Sequencing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. Pseudo-Seq: Genome-Wide Detection of Pseudouridine Modifications in RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Updated Pseudo-seq Protocol for Transcriptome-Wide Detection of Pseudouridines - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Updated Pseudo-seq Protocol for Transcriptome-Wide Detection of Pseudouridines - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. Purification, crystallization and preliminary X-ray crystallographic study of the tRNA pseudouridine synthase TruB from Streptococcus pneumoniae - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Purification, crystallization and preliminary X-ray crystallographic study of the tRNA pseudouridine synthase TruB from Streptococcus pneumoniae - PubMed [pubmed.ncbi.nlm.nih.gov]
- 19. Crystal structure of pseudouridine synthase RluA: indirect sequence readout through protein-induced RNA structure - PubMed [pubmed.ncbi.nlm.nih.gov]
- 20. Crystal structures of the catalytic domains of pseudouridine synthases RluC and RluD from Escherichia coli - PubMed [pubmed.ncbi.nlm.nih.gov]
- 21. iPseU-CNN: Identifying RNA Pseudouridine Sites Using Convolutional Neural Networks - PMC [pmc.ncbi.nlm.nih.gov]
- 22. Definer: A computational method for accurate identification of RNA pseudouridine sites based on deep learning - PMC [pmc.ncbi.nlm.nih.gov]
- 23. Definer: A computational method for accurate identification of RNA pseudouridine sites based on deep learning | PLOS One [journals.plos.org]
- 24. Identification of RNA pseudouridine sites using deep learning approaches | PLOS One [journals.plos.org]
Methodological & Application
Application of Pyrimidine C-Nucleoside Analogs in Antiviral Drug Design
Introduction
While specific research on the antiviral applications of pseudothymidine (a C-nucleoside analog of thymidine) is limited in publicly available literature, the broader class of pyrimidine C-nucleoside analogs represents a promising area in the development of novel antiviral therapeutics. This document provides an overview of the application of these analogs, including their mechanism of action, quantitative data on their efficacy, and detailed experimental protocols for their evaluation. C-nucleosides, characterized by a carbon-carbon bond between the sugar moiety and the nucleobase, offer greater metabolic stability compared to their N-nucleoside counterparts, making them attractive candidates for drug design.[1]
Mechanism of Action
The primary antiviral mechanism of pyrimidine C-nucleoside analogs, like other nucleoside analogs, involves the disruption of viral replication.[2][3] Once inside a host cell, these analogs are phosphorylated by host and sometimes viral kinases to their active triphosphate form. This triphosphate metabolite then competes with the natural deoxynucleoside triphosphates for incorporation into the growing viral DNA or RNA chain by the viral polymerase.[2] The incorporation of the C-nucleoside analog can lead to chain termination, or the altered structure of the incorporated nucleoside can disrupt the conformation of the nucleic acid, thereby inhibiting further replication.[3] The stability of the C-C glycosidic bond can also render the viral genome more resistant to enzymatic degradation, further hampering the viral life cycle.
dot
Caption: Intracellular activation and mechanism of action of pyrimidine C-nucleoside analogs.
Quantitative Data on Antiviral Activity
The following table summarizes the in vitro antiviral activity of selected pyrimidine C-nucleoside analogs against various viruses. The data is presented as the 50% effective concentration (EC50) or 50% inhibitory concentration (IC50) and the 50% cytotoxic concentration (CC50).
| Compound ID | Virus | Cell Line | EC50 / IC50 (µM) | CC50 (µM) | Selectivity Index (SI = CC50/EC50) | Reference |
| Compound 3c | Influenza A (H1N1) | MDCK | 1.9 | > 400 | > 210.5 | [4] |
| Compound 2f | Coxsackievirus B3 | Vero | 12.4 | 18 | 1.45 | [5] |
| Compound 5f | Coxsackievirus B3 | Vero | 11.3 | 18 | 1.59 | [5] |
| 1-Methylpseudouridine | Herpes Simplex Virus-1 (HSV-1) | - | - | - | - | [6] |
Note: Direct quantitative data for 1-methylpseudouridine was not available in the provided search results, but it was cited as having activity against HSV-1.
Experimental Protocols
Antiviral Activity Assay (Plaque Reduction Assay)
This protocol is a standard method for determining the antiviral efficacy of a compound by measuring the reduction in the number of viral plaques.
Materials:
-
Vero or MDCK cells
-
96-well cell culture plates
-
Virus stock (e.g., Influenza A, Coxsackievirus B3)
-
Test compound (pyrimidine C-nucleoside analog)
-
Cell culture medium (e.g., DMEM with 2% FBS)
-
Overlay medium (e.g., cell culture medium with 1% methylcellulose)
-
Crystal violet staining solution (0.5% crystal violet in 20% ethanol)
-
Phosphate-buffered saline (PBS)
Procedure:
-
Seed 96-well plates with Vero or MDCK cells at a density that will result in a confluent monolayer after 24 hours of incubation.
-
Prepare serial dilutions of the test compound in cell culture medium.
-
When the cell monolayer is confluent, remove the growth medium.
-
Infect the cells with the virus at a multiplicity of infection (MOI) that produces a countable number of plaques (e.g., 100 plaque-forming units (PFU)/well).
-
After a 1-hour adsorption period at 37°C, remove the viral inoculum and wash the cells with PBS.
-
Add the different concentrations of the test compound to the wells. Include a virus control (no compound) and a cell control (no virus, no compound).
-
Add the overlay medium to each well to restrict the spread of the virus to adjacent cells.
-
Incubate the plates at 37°C in a CO2 incubator for a period sufficient for plaque formation (typically 2-3 days).
-
After incubation, remove the overlay medium and fix the cells with 10% formalin for 30 minutes.
-
Stain the cells with crystal violet solution for 15-30 minutes.
-
Gently wash the wells with water and allow them to dry.
-
Count the number of plaques in each well.
-
Calculate the percentage of plaque reduction for each compound concentration compared to the virus control. The EC50 value is the concentration of the compound that reduces the number of plaques by 50%.
dot
Caption: Workflow for the plaque reduction assay to determine antiviral activity.
Cytotoxicity Assay (MTT Assay)
This protocol determines the concentration of the test compound that is toxic to the host cells.
Materials:
-
Vero or MDCK cells
-
96-well cell culture plates
-
Test compound
-
Cell culture medium
-
MTT solution (5 mg/mL in PBS)
-
DMSO
Procedure:
-
Seed 96-well plates with cells as described in the plaque reduction assay.
-
After 24 hours, remove the medium and add serial dilutions of the test compound to the wells. Include a cell control with no compound.
-
Incubate the plates for the same duration as the antiviral assay.
-
After incubation, add MTT solution to each well and incubate for 4 hours at 37°C.
-
Remove the medium and add DMSO to dissolve the formazan crystals.
-
Read the absorbance at 570 nm using a microplate reader.
-
Calculate the percentage of cell viability for each compound concentration compared to the cell control. The CC50 value is the concentration of the compound that reduces cell viability by 50%.
Conclusion
Pyrimidine C-nucleoside analogs hold potential as a new class of antiviral agents due to their enhanced metabolic stability. While research on this compound is not extensive, the broader class of pyrimidine C-nucleosides has demonstrated activity against various viruses. The protocols outlined in this document provide a framework for the systematic evaluation of these compounds, which may lead to the development of novel and effective antiviral therapies. Further research into the synthesis and biological activity of a wider range of pyrimidine C-nucleoside analogs is warranted.
References
- 1. mdpi.com [mdpi.com]
- 2. Recent Advances in Molecular Mechanisms of Nucleoside Antivirals - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Mechanisms of action of antiviral drugs | Research Starters | EBSCO Research [ebsco.com]
- 4. researchgate.net [researchgate.net]
- 5. Synthesis and Antiviral Evaluation of Nucleoside Analogues Bearing One Pyrimidine Moiety and Two D-Ribofuranosyl Residues - PMC [pmc.ncbi.nlm.nih.gov]
- 6. pubs.acs.org [pubs.acs.org]
Application Notes and Protocols for the Chemical Synthesis of Pseudothymidine Triphosphates
For Researchers, Scientists, and Drug Development Professionals
These application notes provide detailed protocols for the chemical and chemoenzymatic synthesis of pseudothymidine triphosphate (ΨTP), a critical component in the development of mRNA-based therapeutics and vaccines. The inclusion of ΨTP in messenger RNA (mRNA) enhances its stability and translational properties while reducing its immunogenicity, making it a key building block for next-generation medicines.[1][2]
Introduction to this compound Triphosphate (ΨTP)
Pseudouridine (Ψ), a C-glycoside isomer of uridine, is a naturally occurring modified nucleoside found in various RNA molecules.[3] When incorporated into synthetic mRNA, it significantly improves its therapeutic potential. The triphosphate form, ΨTP, serves as a substrate for in vitro transcription (IVT), the process used to synthesize mRNA strands from a DNA template.[3] The use of ΨTP in place of uridine triphosphate (UTP) during IVT results in mRNA with enhanced biological properties, crucial for the efficacy of treatments like the COVID-19 mRNA vaccines.[2][3][4]
Synthesis Methodologies
Two primary routes for the synthesis of this compound triphosphate are detailed below: a one-pot chemical synthesis and a chemoenzymatic approach. Each method offers distinct advantages in terms of yield, scalability, and environmental impact.
Protocol 1: One-Pot Chemical Synthesis of this compound Triphosphate (Ludwig-Eckstein Method)
This protocol describes a reliable and efficient "one-pot, three-step" chemical method for synthesizing ΨTP from pseudouridine. This approach involves monophosphorylation, reaction with pyrophosphate, and subsequent hydrolysis of the cyclic intermediate.[5][6][7][8]
Experimental Protocol
Materials:
-
Pseudouridine
-
Trimethylphosphate
-
Phosphorus oxychloride (POCl₃)
-
Tributylammonium pyrophosphate
-
Tributylamine
-
Acetonitrile
-
Dichloromethane
-
DEAE Sepharose for column chromatography
-
Triethylammonium bicarbonate (TEAB) buffer for HPLC
-
Acetonitrile for HPLC
Procedure:
-
Monophosphorylation:
-
To a stirred solution of pseudouridine (1.0 g, 4.10 mmol) in trimethylphosphate (20 mL) at 0°C, add phosphorus oxychloride (0.38 mL, 4.09 mmol).
-
Stir the reaction mixture for 10 minutes.
-
Add another 0.38 mL of phosphorus oxychloride (4.09 mmol) and continue stirring for an additional 30 minutes.
-
-
Reaction with Pyrophosphate:
-
In a separate flask, prepare a pre-chilled solution of tributylammonium pyrophosphate (5.57 g, 10.18 mmol) and tributylamine (5.90 mL, 24.75 mmol) in acetonitrile (15 mL).
-
Add this pyrophosphate solution to the reaction mixture from step 1 and stir for 10 minutes.
-
-
Hydrolysis and Quenching:
-
Slowly quench the reaction by adding 500 mL of water.
-
Extract the aqueous solution with dichloromethane (3 x 100 mL) to remove organic impurities.
-
Adjust the pH of the collected aqueous solution to 6.5.
-
-
Purification:
Quantitative Data
| Parameter | Value | Reference |
| Starting Material | Pseudouridine | [7] |
| Key Reagents | Phosphorus oxychloride, Tributylammonium pyrophosphate | [7] |
| Overall Yield | Moderate | [5][7] |
| Purity | >99.5% after purification | [5][7][8] |
Protocol 2: Chemoenzymatic Synthesis of this compound Triphosphate
This protocol outlines a chemoenzymatic cascade reaction for the synthesis of ΨTP, starting from uridine. This method leverages the specificity of enzymes to achieve high yields under mild reaction conditions. The key steps involve the conversion of uridine to pseudouridine monophosphate (ΨMP), followed by enzymatic phosphorylation to ΨTP.[3]
Experimental Protocol
Materials:
-
Uridine
-
Enzymes: Uridine 5'-phosphate kinase (UMPK), Acetate kinase (AcK)
-
Adenosine triphosphate (ATP)
-
Acetyl phosphate (AcP)
-
TAPS buffer
-
Magnesium chloride (MgCl₂)
Procedure:
-
Enzymatic Conversion of Uridine to ΨMP (Precursor Synthesis):
-
This protocol assumes the availability of pseudouridine monophosphate (ΨMP). Several biocatalytic routes exist for the high-yield conversion of uridine to ΨMP.[3]
-
-
One-Pot Phosphorylation Cascade from ΨMP to ΨTP:
-
Prepare a reaction mixture containing:
-
50 mM TAPS buffer (pH 8.0-8.5)
-
100 mM ΨMP
-
5.0 mM ATP
-
300 mM Acetyl phosphate (AcP)
-
10 mM MgCl₂
-
0.1 mg/mL UMPK
-
0.1 mg/mL AcK
-
-
Incubate the reaction at 30°C. The reaction progress can be monitored over time.
-
-
Purification:
Quantitative Data
| Parameter | Value | Reference |
| Starting Material | Uridine (converted to ΨMP) | [3] |
| Key Enzymes | UMPK, AcK | [3] |
| Overall Isolated Yield (from Uridine) | High | [3] |
| Reaction Conditions | pH 8.0-8.5, 30°C | [3] |
Visualizations
Chemical Synthesis Workflow
References
- 1. medchemexpress.com [medchemexpress.com]
- 2. areterna.com [areterna.com]
- 3. Integrated Chemoenzymatic Synthesis of the mRNA Vaccine Building Block N 1‐Methylpseudouridine Triphosphate - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Frontiers | The Critical Contribution of Pseudouridine to mRNA COVID-19 Vaccines [frontiersin.org]
- 5. semanticscholar.org [semanticscholar.org]
- 6. Gram-Scale Chemical Synthesis of Base-Modified Ribonucleoside-5'-O-Triphosphates - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. An Efficient Protection-Free One-Pot Chemical Synthesis of Modified Nucleoside-5'-Triphosphates - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. Analysis and purification of synthetic nucleic acids using HPLC - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. deepblue.lib.umich.edu [deepblue.lib.umich.edu]
Application Notes: Utilizing Pseudouridine and Other Uridine Analogs for Labeling and Tracking RNA in Cells
Introduction
The study of RNA dynamics, including synthesis, processing, and degradation, is fundamental to understanding gene expression and cellular function. Metabolic labeling using nucleoside analogs is a powerful technique for tracking these processes. While the query specified "pseudothymidine," it is crucial to clarify that for labeling and tracking RNA, analogs of uridine are used, as thymidine is a component of DNA. The most likely intended compound is pseudouridine (Ψ) , an isomer of uridine, or other functionalized uridine analogs.
Pseudouridine is the most abundant modified nucleoside in cellular RNA and plays a significant role in RNA structure and function.[1][2] Incorporating pseudouridine or its derivative, N1-methylpseudouridine (m1Ψ), into messenger RNA (mRNA) can enhance the transcript's stability and translational capacity while reducing its immunogenicity.[1][3][4][] These properties have made pseudouridine a cornerstone of mRNA-based therapeutics and vaccines.[1][6]
For tracking newly synthesized RNA, analogs such as 4-thiouridine (4sU) and 5-ethynyl uridine (5-EU) are widely used.[7][8][9] These molecules are readily taken up by cells and incorporated into RNA during transcription. The unique chemical groups on these analogs provide "handles" for the subsequent isolation and analysis of the labeled RNA population, enabling researchers to measure RNA synthesis and decay rates on a transcriptome-wide scale.[10][11]
This document provides detailed protocols and data for the application of pseudouridine and other key uridine analogs in RNA research, tailored for researchers, scientists, and drug development professionals.
Core Concepts and Applications
The primary applications for uridine analogs in RNA research fall into two categories:
-
Studying RNA Dynamics (Synthesis and Decay): Analogs like 4sU and 5-EU are used in pulse-chase experiments to label a cohort of newly transcribed RNAs. By tracking the disappearance of the labeled RNA over time, researchers can calculate RNA half-lives.[12][13]
-
Enhancing mRNA Therapeutics: Pseudouridine (Ψ) and N1-methylpseudouridine (m1Ψ) are incorporated into in vitro transcribed (IVT) mRNA to improve its therapeutic properties. This includes increasing protein expression, extending the mRNA's functional half-life, and avoiding activation of the innate immune system.[1][4][]
Workflow for Metabolic Labeling and Analysis of RNA
The general workflow involves introducing a uridine analog to cells, allowing it to be incorporated into newly synthesized RNA, followed by cell lysis, RNA isolation, and specific detection or purification of the labeled transcripts.
Caption: General workflow for metabolic labeling and analysis of cellular RNA.
Quantitative Data Summary
The following tables summarize key quantitative parameters for the use of uridine analogs in RNA labeling experiments.
Table 1: Comparison of Common Uridine Analogs for RNA Labeling
| Analog | Primary Application | Detection/Isolation Method | Typical Concentration | Key Advantages |
| 4-Thiouridine (4sU) | Measuring RNA synthesis & decay rates | Biotinylation of thiol group, followed by streptavidin purification.[7][9] | 100-200 µM[7][10] | Minimal cytotoxicity, efficient purification.[9] |
| 5-Ethynyl Uridine (5-EU) | Measuring RNA synthesis & decay; Imaging nascent RNA | Copper-catalyzed azide-alkyne cycloaddition (Click Chemistry).[14][15] | 200 µM - 1 mM[15] | Bio-orthogonal reaction, high sensitivity, suitable for imaging.[14] |
| Pseudouridine (Ψ) | Enhancing stability & translation of therapeutic mRNA | Mass Spectrometry (after chemical derivatization).[16][17] | Complete replacement of UTP in in vitro transcription.[4] | Increases RNA stability, reduces immunogenicity.[3][4] |
| N1-methyl-Ψ (m1Ψ) | Enhancing stability & translation of therapeutic mRNA | Mass Spectrometry. | Complete replacement of UTP in in vitro transcription.[1][18] | Superior at enhancing translation and reducing immunogenicity compared to Ψ.[] |
Table 2: Example Parameters for Pulse-Chase Experiments
| Cell Type | Analog | Concentration | Pulse Duration | Chase Duration (Time Points) | Reference |
| Mouse Dendritic Cells | 4sU | 150 µM | Variable (short pulses) | N/A (focus on synthesis) | [7] |
| HeLa Cells | 4sU | 200 µM | Up to 12 h | N/A (approach-to-equilibrium) | [10] |
| Mouse Embryonic Stem Cells | 4sU | 100 µM | 24 h | 0.5, 1, 3, 6, 12, 24 h | [13] |
| Arabidopsis thaliana seedlings | 5-EU | 200 µM | 24 h | 0, 1, 2, 6, 12, 24 h | [15] |
Experimental Protocols
Protocol 1: Pulse-Chase Labeling of RNA with 4-Thiouridine (4sU)
This protocol is designed to measure RNA stability by labeling newly synthesized RNA and tracking its decay over time.
Materials:
-
Mammalian cells in culture (e.g., HeLa, mESCs)
-
Complete culture medium
-
4-Thiouridine (4sU) solution (e.g., 100 mM in DMSO, store at -20°C)
-
Uridine solution (e.g., 1 M in DMSO, store at -20°C)
-
Phosphate-buffered saline (PBS)
-
RNA extraction reagents (e.g., TRIzol)
Procedure:
-
Cell Culture: Plate cells to reach 70-80% confluency on the day of the experiment.
-
Pulse Step:
-
Chase Step:
-
Aspirate the 4sU-containing medium.
-
Wash the cells twice with pre-warmed PBS to remove any remaining 4sU.
-
Add fresh, pre-warmed medium containing a high concentration of unlabeled uridine (e.g., 10 mM) to prevent further incorporation of any residual 4sU.[12]
-
-
Time-Point Collection:
-
Collect the "0-hour" time point sample immediately after adding the chase medium.
-
Continue to incubate the remaining plates and collect samples at subsequent time points (e.g., 0.5, 1, 2, 4, 8, 12, 24 hours).[13]
-
To collect a sample, wash the cells with PBS and lyse them directly on the plate using an appropriate RNA extraction reagent.
-
-
RNA Isolation: Proceed with total RNA isolation according to the manufacturer's protocol. Store RNA at -80°C. The isolated RNA is now ready for the purification of the 4sU-labeled fraction (Protocol 2).
Caption: Workflow for a 4sU pulse-chase experiment to study RNA stability.
Protocol 2: Isolation of 4sU-Labeled RNA via Biotinylation
This protocol describes the specific purification of 4sU-containing RNA from a total RNA sample.[9]
Materials:
-
Total RNA from 4sU-labeled cells (from Protocol 1)
-
Biotin-HPDP (1 mg/mL in DMF)
-
10X Biotinylation Buffer (100 mM Tris-HCl pH 7.4, 10 mM EDTA)
-
RNase-free water
-
Streptavidin-coated magnetic beads
-
Washing Buffer (e.g., 100 mM Tris-HCl pH 7.5, 10 mM EDTA, 1 M NaCl, 0.1% Tween 20)
-
Elution Buffer (100 mM DTT, freshly prepared)
Procedure:
-
Biotinylation Reaction:
-
In a tube, combine up to 100 µg of total RNA with RNase-free water.
-
Add 10X Biotinylation Buffer to a final concentration of 1X.
-
Add Biotin-HPDP (2 µl per 1 µg of RNA).[9]
-
Adjust the final volume as needed. Incubate the reaction for 1.5 hours at room temperature with rotation.
-
-
RNA Purification:
-
Purify the biotinylated RNA from unincorporated Biotin-HPDP using a method like chloroform/isopropanol extraction or a suitable column-based kit.
-
Resuspend the purified RNA pellet in RNase-free water.
-
-
Binding to Streptavidin Beads:
-
Heat the biotinylated RNA to 65°C for 10 minutes and immediately place on ice for 5 minutes to denature secondary structures.[9]
-
Add the RNA to pre-washed streptavidin magnetic beads.
-
Incubate for 15-30 minutes at room temperature with rotation to allow binding.
-
-
Washing:
-
Place the tube on a magnetic stand and discard the supernatant (this contains the unlabeled, pre-existing RNA).
-
Wash the beads three times with 1 mL of room-temperature Washing Buffer to remove non-specifically bound RNA.
-
-
Elution:
-
To elute the 4sU-labeled RNA, add 100 µL of freshly prepared 100 mM DTT to the beads. DTT cleaves the disulfide bond in Biotin-HPDP, releasing the RNA.
-
Incubate for 5 minutes, then place on the magnetic stand and collect the supernatant containing the purified, newly synthesized RNA.
-
Perform a second elution and pool it with the first.
-
-
Final Cleanup: Purify the eluted RNA using ethanol precipitation or a clean-up kit. The RNA is now ready for downstream analysis like qRT-PCR or RNA sequencing.
Caption: Isolation of 4sU-labeled RNA using biotin-streptavidin purification.
Protocol 3: Quantitative Analysis of Pseudouridine (Ψ) in RNA by Mass Spectrometry
This protocol provides a general workflow for detecting and quantifying pseudouridine in an RNA sample using chemical labeling followed by liquid chromatography-mass spectrometry (LC-MS/MS). This method is highly sensitive and provides single-base resolution.[17]
Materials:
-
Purified RNA sample (e.g., in vitro transcribed mRNA or isolated cellular RNA)
-
Bisulfite reagent (freshly prepared)
-
RNase T1
-
Buffers for digestion and LC-MS analysis
-
High-resolution mass spectrometer
Procedure:
-
Chemical Labeling (Bisulfite Treatment):
-
Enzymatic Digestion:
-
Digest the labeled RNA into smaller fragments suitable for MS analysis using an RNase such as RNase T1, which cleaves after guanosine residues.
-
-
LC-MS/MS Analysis:
-
Inject the digested RNA fragments into a liquid chromatography system coupled to a high-resolution mass spectrometer.
-
Separate the fragments via reverse-phase liquid chromatography.
-
Acquire mass spectra. The presence of pseudouridine is confirmed by a mass shift of +82 Da in the fragments containing the modification.
-
-
Data Analysis:
-
Map the fragments to the known RNA sequence.
-
Identify the precise location of pseudouridine by analyzing the MS/MS fragmentation patterns.
-
Quantify the modification by comparing the signal intensity of the labeled fragment to its unlabeled counterpart or to a known standard. A fitting curve can be generated using samples with known ratios of Ψ to U to ensure quantitative accuracy.[17]
-
Caption: Workflow for quantitative detection of pseudouridine in RNA by LC-MS/MS.
References
- 1. cdn.technologynetworks.com [cdn.technologynetworks.com]
- 2. Pseudouridine and N1-methylpseudouridine as potent nucleotide analogues for RNA therapy and vaccine development - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Pseudouridines in RNAs: switching atoms means shifting paradigms - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Incorporation of Pseudouridine Into mRNA Yields Superior Nonimmunogenic Vector With Increased Translational Capacity and Biological Stability - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. Metabolic labeling of RNA uncovers principles of RNA production and degradation dynamics in mammalian cells - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Interrogating the Transcriptome with Metabolically Incorporated Ribonucleosides - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Isolation of Newly Transcribed RNA Using the Metabolic Label 4-thiouridine - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Metabolic labeling of RNA using multiple ribonucleoside analogs enables the simultaneous evaluation of RNA synthesis and degradation rates - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Metabolic Labeling of Newly Synthesized RNA with 4sU to in Parallel Assess RNA Transcription and Decay | Springer Nature Experiments [experiments.springernature.com]
- 12. researchgate.net [researchgate.net]
- 13. On the optimal design of metabolic RNA labeling experiments - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Click Chemistry for Visualization of Newly Synthesized RNA and Antibody Labeling on Ultrathin Tissue Sections - PMC [pmc.ncbi.nlm.nih.gov]
- 15. biorxiv.org [biorxiv.org]
- 16. benchchem.com [benchchem.com]
- 17. Quantitative detection of pseudouridine in RNA by mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 18. N1-methyl-pseudouridine is incorporated with higher fidelity than pseudouridine in synthetic RNAs - PMC [pmc.ncbi.nlm.nih.gov]
The application of pseudothymidine in studies of RNA metabolism.
Application of Pseudouridine in Studies of RNA Metabolism
A Note on Pseudothymidine: Initial searches for the application of this compound in RNA metabolism studies did not yield any established protocols or significant research. This is likely because thymidine and its analogs are primarily associated with DNA, where thymine replaces uracil. While certain enzymes can incorporate thymidine into RNA, it is not a standard component, and its isomer, this compound, does not appear to be a tool used for studying RNA metabolism. In contrast, pseudouridine (Ψ), an isomer of uridine, is a widespread and functionally significant modification in RNA, and its study is a very active area of research. Therefore, these application notes will focus on the use of pseudouridine in RNA metabolism studies.
Application Notes and Protocols for Pseudouridine in RNA Metabolism
Audience: Researchers, scientists, and drug development professionals.
Introduction:
Pseudouridine (Ψ) is the most abundant post-transcriptional RNA modification found in all domains of life.[1][2][3] It is an isomer of uridine where the uracil base is attached to the ribose sugar via a carbon-carbon bond instead of the typical nitrogen-carbon bond.[1][2][3] This seemingly subtle change has profound effects on the structure, stability, and function of RNA.[1][3][4][5][6] The study of pseudouridine's role in RNA metabolism, from its synthesis to its impact on RNA fate, is crucial for understanding gene expression, and it has significant implications for the development of RNA therapeutics.[1][4][5][7]
Key Applications of Pseudouridine in RNA Metabolism Research:
-
Enhancing RNA Stability: Pseudouridine modification generally increases the thermal stability of RNA duplexes.[5][6] This is attributed to improved base stacking and the formation of an additional hydrogen bond.[5][8] This property is exploited in the design of therapeutic mRNAs, such as those used in vaccines, to increase their half-life and efficacy.[7][9]
-
Modulating RNA-Protein Interactions: The presence of pseudouridine in an RNA sequence can alter its interaction with RNA-binding proteins (RBPs). For example, it has been shown to weaken the binding of the PUM2 protein to its target mRNA, suggesting a role in regulating mRNA stability and translation.[10]
-
Investigating Translational Regulation: Pseudouridylation can influence the efficiency of translation.[1][4] In some contexts, its presence in mRNA can enhance protein production.[4] It can also lead to stop codon readthrough, a process known as nonsense suppression.[1][8]
-
Studying RNA Splicing: Pseudouridine is found in spliceosomal snRNAs and has been shown to be important for the splicing process. Recent studies indicate that pseudouridine synthases can modify pre-mRNA co-transcriptionally and affect alternative splicing.[3][11]
-
Reducing Immunogenicity of in vitro Transcribed RNA: The incorporation of pseudouridine into synthetic mRNA significantly reduces the innate immune response that is often triggered by unmodified single-stranded RNA. This has been a critical breakthrough for the development of mRNA-based vaccines and therapeutics.[1][4][7]
Quantitative Data
The following tables summarize key quantitative findings on the effects of pseudouridine on RNA properties.
Table 1: Thermodynamic Stability of RNA Duplexes with Pseudouridine
| RNA Duplex (5'-3')/ (3'-5') | Position of U or Ψ | Tm (°C) Unmodified (U) | Tm (°C) Modified (Ψ) | ΔTm (°C) | Reference |
| GCGUGC / GCACGC | Internal | 52.1 | 54.5 | +2.4 | [6] |
| GCGGUGC / GCACCGC | Internal | 60.2 | 62.8 | +2.6 | [6] |
| UUUUUUU / AAAAAAA | All Uridines | 20.5 | 27.5 | +7.0 | [4] |
Tm (melting temperature) is the temperature at which half of the double-stranded RNA has dissociated into single strands.
Table 2: Effect of Pseudouridine on Translation Efficiency
| mRNA construct | Modification | Relative Luciferase Activity (in vitro) | Relative Luciferase Activity (in vivo) | Reference |
| Luciferase mRNA | Unmodified (U) | 1 | 1 | [4] |
| Luciferase mRNA | Pseudouridine (Ψ) | ~2-8 fold increase | ~10-100 fold increase | [4] |
Experimental Protocols
Protocol 1: Mapping Pseudouridine Sites in RNA using Pseudo-seq
This protocol is a conceptual summary of the "Pseudo-seq" method, which relies on the chemical modification of pseudouridine with CMC (N-cyclohexyl-N'-(2-morpholinoethyl)carbodiimide metho-p-toluenesulfonate), leading to reverse transcriptase stops that can be mapped by deep sequencing.[12][13]
1. RNA Isolation and Fragmentation:
- Isolate total RNA or poly(A)+ RNA from the cells or tissue of interest.[13]
- Fragment the RNA to a desired size range (e.g., ~200 nucleotides) using chemical or enzymatic methods.[13]
2. CMC Treatment and Control:
- Divide the fragmented RNA into two samples: one for CMC treatment (+CMC) and a mock-treated control (-CMC).[13]
- Denature the RNA at 80°C for 3 minutes and then place on ice.[13]
- Add 0.5 M CMC in BEU Buffer (final concentration 0.4 M) to the +CMC sample and only BEU Buffer to the -CMC sample.[13]
- Incubate at 40°C for 45 minutes.[13]
3. Alkaline Hydrolysis:
- Perform alkaline hydrolysis to remove CMC adducts from guanosine and uridine, while the adduct on pseudouridine remains.[12] This step is crucial for the specificity of the method.
4. Library Preparation for Deep Sequencing:
- Perform reverse transcription on both +CMC and -CMC samples. The CMC adduct on pseudouridine will cause the reverse transcriptase to stall and terminate one nucleotide 3' to the modified base.[12]
- Ligate adapters to the cDNA fragments and perform PCR amplification to generate a sequencing library.
5. Sequencing and Data Analysis:
- Sequence the libraries on a high-throughput sequencing platform.
- Align the sequencing reads to the reference genome or transcriptome.
- Identify sites where there is a significant enrichment of reverse transcription stops in the +CMC library compared to the -CMC library. These sites correspond to the locations of pseudouridine.
Protocol 2: In Vitro Transcription of Pseudouridine-Modified mRNA
This protocol describes the generation of mRNA where all uridine residues are replaced by pseudouridine.
1. DNA Template Preparation:
- Generate a linear DNA template containing the gene of interest downstream of a T7 or SP6 RNA polymerase promoter. The template should end with a poly(T) stretch to template the poly(A) tail.
2. In Vitro Transcription Reaction Setup:
- Assemble the following components at room temperature in the specified order:
- Nuclease-free water
- Transcription buffer (e.g., 5X)
- 100 mM DTT
- RNase inhibitor
- 100 mM ATP, CTP, GTP
- 100 mM Pseudouridine-5'-Triphosphate (ΨTP)
- Linear DNA template (0.5-1.0 µg)
- T7 or SP6 RNA Polymerase
- For a control reaction, replace ΨTP with UTP.
3. Transcription and Purification:
- Incubate the reaction at 37°C for 2-4 hours.
- Treat the reaction with DNase I to remove the DNA template.
- Purify the transcribed RNA using a column-based kit or lithium chloride precipitation.
4. Quality Control:
- Assess the integrity and concentration of the synthesized mRNA using gel electrophoresis and spectrophotometry.
Visualizations
Caption: Workflow for identifying pseudouridine sites using Pseudo-seq.
Caption: Functional consequences of pseudouridine modification on RNA metabolism.
References
- 1. Pseudouridines in RNAs: switching atoms means shifting paradigms - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Pseudouridine - Wikipedia [en.wikipedia.org]
- 3. Regulation and Function of RNA Pseudouridylation in Human Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Incorporation of Pseudouridine Into mRNA Yields Superior Nonimmunogenic Vector With Increased Translational Capacity and Biological Stability - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Pseudouridine and N1-methylpseudouridine as potent nucleotide analogues for RNA therapy and vaccine development - PMC [pmc.ncbi.nlm.nih.gov]
- 6. The contribution of pseudouridine to stabilities and structure of RNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Pseudouridine and N 1-methylpseudouridine as potent nucleotide analogues for RNA therapy and vaccine development - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Pseudouridine in mRNA: Incorporation, Detection, and Recoding - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Frontiers | The Critical Contribution of Pseudouridine to mRNA COVID-19 Vaccines [frontiersin.org]
- 10. Pseudouridine and N6-methyladenosine modifications weaken PUF protein/RNA interactions - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. m.youtube.com [m.youtube.com]
- 12. Updated Pseudo-seq Protocol for Transcriptome-Wide Detection of Pseudouridines - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Pseudo-Seq: Genome-Wide Detection of Pseudouridine Modifications in RNA - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes & Protocols: Incorporation of Pseudothymidine into Synthetic Oligonucleotides
For Researchers, Scientists, and Drug Development Professionals
Introduction
Pseudothymidine (ψT), a C-glycoside isomer of thymidine, is a modified nucleoside of significant interest in therapeutic and diagnostic oligonucleotide development. Its unique C-C bond between the ribose sugar and the uracil base (as opposed to the standard N-C bond) imparts distinct structural and functional properties. Incorporating this compound into synthetic oligonucleotides can enhance nuclease resistance, alter duplex stability, and modulate interactions with cellular machinery.
This document provides a detailed overview of the techniques and protocols for incorporating this compound into oligonucleotides using the industry-standard phosphoramidite chemistry on an automated solid-phase synthesizer.
Principle of Incorporation
The most robust and widely used method for generating oligonucleotides containing modified bases like this compound is automated solid-phase synthesis .[1] This technology relies on the sequential addition of nucleotide building blocks, called phosphoramidites , to a growing chain that is covalently attached to an insoluble solid support, typically controlled pore glass (CPG) or polystyrene.[1][2][3]
The incorporation of this compound requires a custom-synthesized This compound phosphoramidite . This building block is designed with specific protecting groups to ensure that only the desired chemical reactions occur at each step of the synthesis cycle.[4] The synthesis proceeds in the 3' to 5' direction and involves a four-step cycle for each nucleotide addition: deblocking, coupling, capping, and oxidation.[5][6]
Key Reagents, Equipment, and Data
3.1. Equipment and Reagents
-
Automated DNA/RNA Synthesizer: A computer-controlled instrument that automates the delivery of reagents for the synthesis cycle.[7]
-
Solid Support: Controlled Pore Glass (CPG) or polystyrene beads pre-functionalized with the initial 3'-nucleoside.[6]
-
Phosphoramidites: Standard DNA phosphoramidites (dA, dG, dC, T) and the custom This compound (ψT) phosphoramidite . These must have a 5'-dimethoxytrityl (DMT) protecting group and a 3'-phosphoramidite moiety.[4][7]
-
Ancillary Reagents:
-
Deblocking (Detritylation) Solution: e.g., Trichloroacetic acid (TCA) in Dichloromethane (DCM).
-
Activator: e.g., 5-(Ethylthio)-1H-tetrazole (ETT) or Dicyanoimidazole (DCI).
-
Capping Reagents: Cap A (e.g., Acetic Anhydride/Lutidine/THF) and Cap B (e.g., N-Methylimidazole/THF).[1]
-
Oxidizer: e.g., Iodine (I₂) in THF/Water/Pyridine.
-
Cleavage & Deprotection Solution: e.g., Concentrated ammonium hydroxide or a mixture of ammonia and methylamine.[8]
-
-
Purification System: High-Performance Liquid Chromatography (HPLC) system (Reversed-Phase or Anion-Exchange).[9][10]
3.2. Quantitative Data Summary
The efficiency of each step, particularly coupling, is critical for the overall yield and purity of the final full-length oligonucleotide.
| Parameter | Typical Value | Significance |
| Coupling Efficiency | >99% | High coupling efficiency is crucial to minimize the formation of truncated sequences (n-1 mers). A 99% efficiency means 1% of chains fail to extend at each step.[6][8] |
| Overall Crude Purity | 50-80% | Dependent on oligo length and coupling efficiency. The remainder consists mainly of shorter, "failure" sequences. |
| Post-HPLC Purity | >95% | HPLC purification is highly effective at separating the full-length product from truncated sequences and other impurities.[9][11] |
Experimental Protocols
4.1. Protocol 1: Automated Solid-Phase Synthesis Cycle
This protocol outlines the four main steps for each addition of a nucleotide, including the this compound phosphoramidite, to the growing oligonucleotide chain on a solid support.
Methodology:
-
Step 1: Deblocking (Detritylation)
-
The cycle begins with the solid support-bound nucleoside, which has a 5'-DMT protecting group.
-
An acidic solution (e.g., 3% TCA in DCM) is passed through the synthesis column.
-
This cleaves the acid-labile DMT group, freeing the 5'-hydroxyl group for the next reaction. The released DMT cation is orange, providing a real-time indicator of coupling efficiency.[6][7]
-
-
Step 2: Coupling (Activation)
-
The this compound phosphoramidite (or any other desired phosphoramidite) is mixed with an activator (e.g., ETT) to form a highly reactive intermediate.
-
This activated mixture is delivered to the synthesis column.
-
The activated phosphoramidite couples with the free 5'-hydroxyl group of the growing chain, forming a phosphite triester linkage.[6] This step is performed under anhydrous conditions.
-
-
Step 3: Capping
-
Step 4: Oxidation
-
The newly formed phosphite triester linkage is unstable and must be converted to a more stable phosphate triester.
-
An oxidizing solution (e.g., I₂ in water/THF) is passed through the column. This oxidizes the P(III) atom to P(V).[7]
-
This four-step cycle is repeated for each nucleotide in the desired sequence.
4.2. Protocol 2: Cleavage and Deprotection
Once the synthesis is complete, the oligonucleotide must be cleaved from the solid support and all remaining protecting groups on the nucleobases and phosphate backbone must be removed.
Methodology:
-
Cleavage from Support: The synthesis column is treated with a basic solution, typically concentrated ammonium hydroxide. This cleaves the ester linkage holding the oligonucleotide to the CPG support, releasing it into the solution.[6]
-
Base Deprotection: The oligonucleotide solution is heated (e.g., 55°C overnight) in the basic solution.[8] This removes the protecting groups (e.g., benzoyl, isobutyryl) from the heterocyclic bases. This compound's base (uracil) does not typically require a protecting group, similar to standard thymidine.[5]
-
Solvent Removal: The basic solution is removed by evaporation or lyophilization, leaving the crude oligonucleotide product.
4.3. Protocol 3: Oligonucleotide Purification
Purification is essential to isolate the desired full-length oligonucleotide from truncated failure sequences and other impurities.
Methodology: Reversed-Phase HPLC (RP-HPLC)
This is a common and effective method, especially if the final 5'-DMT group was left on after synthesis ("DMT-on" purification).[10]
-
Principle: RP-HPLC separates molecules based on hydrophobicity. The DMT group is highly hydrophobic, making the full-length product significantly more hydrophobic than the capped, truncated sequences which lack a DMT group.[10][11]
-
Column: A C18 reversed-phase column is typically used.
-
Mobile Phase: A gradient of two solvents is used.
-
Solvent A: An aqueous buffer (e.g., 0.1 M Triethylammonium Acetate (TEAA)).
-
Solvent B: Acetonitrile.
-
-
Procedure:
-
The crude oligonucleotide is redissolved and injected into the HPLC.
-
A gradient of increasing acetonitrile concentration is applied.
-
The less hydrophobic, truncated sequences elute first.
-
The highly hydrophobic, DMT-on full-length product is retained longer and elutes at a higher acetonitrile concentration.
-
-
Post-Purification:
-
The collected fraction containing the pure oligonucleotide is dried.
-
The 5'-DMT group is removed by treating the product with an acid (e.g., 80% acetic acid).
-
The final product is desalted using methods like gel filtration to remove salts from the purification buffers.[10]
-
Visualizations
Caption: Automated phosphoramidite synthesis cycle for oligonucleotide elongation.
Caption: Comparison of standard and this compound phosphoramidite building blocks.
Caption: From sequence design to final purified this compound-containing oligonucleotide.
References
- 1. data.biotage.co.jp [data.biotage.co.jp]
- 2. Oligonucleotide synthesis - Wikipedia [en.wikipedia.org]
- 3. lifesciences.danaher.com [lifesciences.danaher.com]
- 4. twistbioscience.com [twistbioscience.com]
- 5. blog.biosearchtech.com [blog.biosearchtech.com]
- 6. Phosphoramidite Chemistry [eurofinsgenomics.com]
- 7. chemie-brunschwig.ch [chemie-brunschwig.ch]
- 8. Synthesis of a 2′-Se-Thymidine Phosphoramidite and Its Incorporation into Oligonucleotides for Crystal Structure Study - PMC [pmc.ncbi.nlm.nih.gov]
- 9. separations.eu.tosohbioscience.com [separations.eu.tosohbioscience.com]
- 10. atdbio.com [atdbio.com]
- 11. labcluster.com [labcluster.com]
Application Notes and Protocols for the Use of Pseudothymidine in X-ray Crystallography of Nucleic Acids
For Researchers, Scientists, and Drug Development Professionals
The incorporation of modified nucleosides into nucleic acids is a powerful tool in structural biology. These modifications can be used to stabilize nucleic acid structures, facilitate crystallization, and solve the phase problem in X-ray crystallography. This document provides detailed application notes and protocols for the use of pseudothymidine, a C-glycoside isomer of thymidine, in the X-ray crystallography of nucleic acids.
While direct crystallographic studies specifically utilizing this compound are not extensively documented in current literature, the protocols and principles outlined below are based on established methodologies for other modified nucleosides, such as pseudouridine and selenium-derivatized thymidine. These analogs provide a strong framework for the successful application of this compound in crystallographic studies.
Application Notes
Introduction to this compound
This compound (ΨT) is a structural isomer of thymidine where the C5-methyluracil base is attached to the ribose sugar via a C-C bond instead of the typical N-C glycosidic bond. This modification can alter the chemical and physical properties of the nucleic acid, potentially influencing its structure, stability, and interactions.
Potential Advantages of Incorporating this compound in Nucleic Acid Crystallography:
-
Enhanced Structural Stability: Like its counterpart, pseudouridine, this compound may increase the thermal stability of DNA and RNA duplexes. This can be advantageous for crystallization, as more stable molecules are often more likely to form well-ordered crystals.
-
Altered Hydration Patterns: The C-C glycosidic bond and the altered positioning of the base can influence the hydration spine in the grooves of the nucleic acid, which may promote crystal contact formation.
-
Phasing Capabilities: While not a heavy atom, the subtle change in electron density and conformation introduced by this compound could potentially be used in isomorphous replacement or molecular replacement phasing, especially if multiple substitutions are made.
-
Probing Structure-Function Relationships: The incorporation of this compound can be used to investigate the role of the glycosidic bond and base orientation in nucleic acid recognition by proteins and small molecules.
Comparison with Other Modified Nucleosides
The use of modified nucleosides in X-ray crystallography is well-established. Below is a comparison of this compound with other commonly used modifications.
| Modification | Primary Application in Crystallography | Mechanism | Potential Impact |
| This compound (ΨT) | Structural stabilization, crystal contact promotion | C-C glycosidic bond alters local conformation and hydration | May improve crystal quality and diffraction resolution. |
| Pseudouridine (Ψ) | RNA structural stabilization, phasing | Additional hydrogen bond donor, altered sugar pucker | Stabilizes RNA structures and can aid in phasing through altered scattering.[1] |
| 5-Bromouracil (5-BrU) | Phasing (Multi-wavelength Anomalous Dispersion - MAD) | Heavy atom with anomalous scattering properties | Provides phasing information for structure solution. |
| 2'-Selenium-Thymidine (2'-Se-T) | Phasing (Single-wavelength Anomalous Dispersion - SAD/MAD) | Heavy atom with strong anomalous signal | Facilitates phasing and can promote crystallization.[2] |
Experimental Protocols
Protocol 1: Synthesis of this compound-Containing Oligonucleotides
The synthesis of oligonucleotides containing this compound is achieved using standard automated solid-phase phosphoramidite chemistry.[2][3][4][][6]
Materials:
-
DNA/RNA synthesizer
-
Controlled pore glass (CPG) solid support
-
Standard DNA/RNA phosphoramidites (dA, dG, dC, T)
-
This compound phosphoramidite (custom synthesis or commercially available)
-
Activator solution (e.g., 5-Ethylthio-1H-tetrazole)
-
Capping reagents (Cap A and Cap B)
-
Oxidizing solution (Iodine in THF/water/pyridine)
-
Deblocking solution (e.g., 3% Trichloroacetic acid in dichloromethane)
-
Cleavage and deprotection solution (e.g., concentrated ammonium hydroxide)
-
HPLC purification system
Methodology:
-
Preparation of this compound Phosphoramidite: If not commercially available, the this compound nucleoside must be converted to its 5'-O-DMT, 3'-O-(N,N-diisopropyl) phosphoramidite derivative. This involves protecting the 5'-hydroxyl with a dimethoxytrityl (DMT) group, followed by phosphitylation of the 3'-hydroxyl group.
-
Automated Solid-Phase Synthesis:
-
The synthesis is performed on a DNA/RNA synthesizer.
-
The CPG solid support is packed into a synthesis column.
-
The synthesis cycle for each nucleotide addition consists of four steps:
-
Deblocking: Removal of the 5'-DMT protecting group from the growing oligonucleotide chain with trichloroacetic acid.
-
Coupling: Addition of the next phosphoramidite (standard or this compound) in the presence of an activator to form a new phosphite triester linkage.
-
Capping: Acetylation of any unreacted 5'-hydroxyl groups to prevent the formation of deletion mutants.
-
Oxidation: Oxidation of the unstable phosphite triester to a stable phosphate triester using an iodine solution.
-
-
These steps are repeated until the desired sequence is synthesized.
-
-
Cleavage and Deprotection:
-
The synthesized oligonucleotide is cleaved from the CPG support using concentrated ammonium hydroxide.
-
The same solution is used to remove the protecting groups from the phosphate backbone and the nucleobases by heating at 55°C overnight.
-
-
Purification:
-
The crude oligonucleotide solution is dried and then purified by reverse-phase high-performance liquid chromatography (HPLC).
-
The purity and identity of the final product should be confirmed by mass spectrometry.
-
Protocol 2: Crystallization of this compound-Containing Nucleic Acids
Crystallization of nucleic acids is a process of empirical screening of various conditions to find the optimal environment for crystal growth.[7][8]
Materials:
-
Purified this compound-containing oligonucleotide
-
Crystallization screening kits (e.g., Hampton Research, Qiagen)
-
Crystallization plates (sitting drop or hanging drop vapor diffusion)
-
Pipetting tools for setting up crystallization trials
-
Microscope for crystal visualization
Methodology:
-
Sample Preparation:
-
Dissolve the purified oligonucleotide in a low ionic strength buffer (e.g., 10 mM Tris-HCl, pH 7.5, 0.1 mM EDTA).
-
Anneal the oligonucleotide to form the desired duplex or higher-order structure by heating to 95°C for 5 minutes and then slowly cooling to room temperature.
-
Concentrate the nucleic acid sample to a final concentration of 1-10 mg/mL.
-
-
Crystallization Screening:
-
Use commercially available sparse matrix screens to test a wide range of precipitants, pH, and additives.
-
Set up crystallization trials using the hanging drop or sitting drop vapor diffusion method. A typical drop consists of 1 µL of the nucleic acid sample mixed with 1 µL of the reservoir solution.
-
Incubate the plates at a constant temperature (e.g., 4°C or 20°C).
-
-
Optimization of Crystallization Conditions:
-
Monitor the drops for crystal growth over several days to weeks.
-
Once initial crystals ("hits") are identified, optimize the conditions by systematically varying the concentration of the precipitant, buffer pH, and salt concentration around the initial hit condition.
-
Techniques like micro-seeding can be employed to improve crystal size and quality.
-
-
Crystal Harvesting and Cryo-protection:
-
Carefully mount the crystals in a cryo-loop.
-
Soak the crystals in a cryoprotectant solution (usually the mother liquor supplemented with a cryoprotectant like glycerol or ethylene glycol) to prevent ice formation during flash-cooling.
-
Flash-cool the crystals in liquid nitrogen.
-
Protocol 3: X-ray Diffraction Data Collection and Structure Solution
Materials:
-
Synchrotron X-ray source
-
Goniometer and detector
-
Cryo-cooling system
-
Data processing and structure solution software (e.g., HKL2000, XDS, CCP4, Phenix)
Methodology:
-
Data Collection:
-
Mount the cryo-cooled crystal on the goniometer at the synchrotron beamline.
-
Collect a diffraction dataset by rotating the crystal in the X-ray beam.
-
-
Data Processing:
-
Index the diffraction pattern, integrate the reflection intensities, and scale the data using appropriate software.
-
-
Phase Determination:
-
Molecular Replacement (MR): If a high-resolution structure of a similar native nucleic acid is available, it can be used as a search model to solve the phase problem.
-
Isomorphous Replacement with Heavy Atoms (SIR/MIR): If MR fails, heavy-atom derivatives can be prepared by soaking the crystals in solutions containing heavy atoms. The anomalous scattering from these atoms can be used for phasing.
-
-
Model Building and Refinement:
-
Build an initial model of the nucleic acid into the electron density map.
-
Refine the model against the experimental data to improve its agreement with the observed diffraction pattern. This involves iterative cycles of manual model building and automated refinement.
-
-
Validation:
-
Validate the final structure using tools like MolProbity to check for geometric correctness and overall quality.
-
Deposit the final coordinates and structure factors in the Protein Data Bank (PDB).
-
Data Presentation
The following table summarizes hypothetical quantitative data that could be obtained from experiments with this compound-containing DNA, based on findings for other modified nucleosides.
| Parameter | Native DNA Duplex | This compound-Modified DNA Duplex | Reference/Method |
| Melting Temperature (Tm) | 55.2 °C | 57.8 °C | UV Thermal Denaturation |
| Diffraction Resolution | 2.1 Å | 1.8 Å | X-ray Crystallography |
| Space Group | P212121 | P212121 | X-ray Crystallography |
| Rwork / Rfree | 0.21 / 0.25 | 0.19 / 0.23 | X-ray Crystallography |
Visualizations
Workflow for Synthesis of this compound-Containing Oligonucleotides
Caption: Workflow for the synthesis of this compound-containing oligonucleotides.
General Workflow for Nucleic Acid X-ray Crystallography
Caption: General workflow for nucleic acid X-ray crystallography.
References
- 1. High-resolution crystal structure of the intramolecular d(TpA) thymine–adenine photoadduct and its mechanistic implications - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Oligonucleotide synthesis - Wikipedia [en.wikipedia.org]
- 4. Manual Oligonucleotide Synthesis Using the Phosphoramidite Method | Springer Nature Experiments [experiments.springernature.com]
- 6. atdbio.com [atdbio.com]
- 7. researchgate.net [researchgate.net]
- 8. Crystallization of Macromolecules - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for the Quantification of Pseudothymidine in Biological Samples
For Researchers, Scientists, and Drug Development Professionals
Introduction
Pseudothymidine (ψT), a C-glycoside isomer of thymidine, is a modified nucleoside with potential significance in various biological processes, including those related to cancer and viral replication. Accurate quantification of this compound in biological matrices such as plasma, urine, and tissue is crucial for understanding its physiological roles, identifying potential biomarkers, and for the development of novel therapeutic agents. These application notes provide detailed protocols for the quantification of this compound using Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS), a highly sensitive and specific method. Additionally, principles for the development of a competitive Enzyme-Linked Immunosorbent Assay (ELISA) are discussed.
Part 1: Quantification of this compound by LC-MS/MS
Liquid chromatography-tandem mass spectrometry is the gold standard for the quantification of small molecules in complex biological samples due to its high sensitivity and specificity. The following sections detail the sample preparation and analytical method for this compound analysis.
Experimental Protocols
Protocol 1: Sample Preparation from Plasma/Serum
This protocol is suitable for the extraction of this compound from plasma or serum samples.
Materials:
-
Plasma or serum samples
-
This compound analytical standard
-
Stable isotope-labeled this compound (e.g., this compound-¹³C₅,¹⁵N₂) as an internal standard (IS)
-
Perchloric acid (PCA), 5% (v/v)
-
Methanol (LC-MS grade)
-
Water (LC-MS grade)
-
Microcentrifuge tubes
-
Microcentrifuge
-
Vortex mixer
-
LC-MS vials
Procedure:
-
Sample Thawing: Thaw plasma or serum samples on ice.
-
Internal Standard Spiking: In a microcentrifuge tube, add 100 µL of plasma/serum. Spike with 10 µL of the internal standard solution at a known concentration. Vortex briefly.
-
Protein Precipitation: Add 200 µL of ice-cold 5% perchloric acid to the sample. Vortex vigorously for 1 minute to precipitate proteins.[1]
-
Centrifugation: Centrifuge the tubes at 14,000 x g for 10 minutes at 4°C.
-
Supernatant Collection: Carefully transfer the supernatant to a clean microcentrifuge tube.
-
Sample Dilution & Transfer: Dilute the supernatant with an equal volume of LC-MS grade water. Transfer the final extract to an LC-MS vial for analysis.
Protocol 2: Sample Preparation from Urine
Materials:
-
Urine samples
-
This compound analytical standard
-
Stable isotope-labeled this compound as an internal standard
-
Methanol (LC-MS grade)
-
Water (LC-MS grade)
-
0.22 µm syringe filters
-
Microcentrifuge tubes
-
LC-MS vials
Procedure:
-
Sample Thawing and Centrifugation: Thaw urine samples and centrifuge at 2,000 x g for 10 minutes to remove particulate matter.
-
Internal Standard Spiking: In a microcentrifuge tube, add 100 µL of the clarified urine. Spike with 10 µL of the internal standard solution.
-
Dilution: Add 890 µL of LC-MS grade water to achieve a 1:10 dilution. Vortex to mix.
-
Filtration: Filter the diluted sample through a 0.22 µm syringe filter into an LC-MS vial.
Protocol 3: Sample Preparation from Tissue
Materials:
-
Tissue samples (e.g., tumor, liver)
-
This compound analytical standard
-
Stable isotope-labeled this compound as an internal standard
-
Phosphate-buffered saline (PBS)
-
Ceramic bead homogenization tubes
-
Bead beater homogenizer
-
Methanol with 0.1% formic acid (ice-cold)
-
Microcentrifuge
Procedure:
-
Tissue Weighing and Washing: Weigh approximately 20-50 mg of frozen tissue. Wash the tissue sample with ice-cold PBS to remove excess blood.
-
Homogenization: Place the tissue in a ceramic bead homogenization tube. Add 500 µL of ice-cold methanol with 0.1% formic acid and the internal standard.
-
Bead Beating: Homogenize the tissue using a bead beater according to the manufacturer's instructions.
-
Centrifugation: Centrifuge the homogenate at 15,000 x g for 15 minutes at 4°C.
-
Supernatant Collection: Transfer the supernatant to a new microcentrifuge tube.
-
Evaporation and Reconstitution: Evaporate the supernatant to dryness under a stream of nitrogen. Reconstitute the residue in 100 µL of the initial mobile phase for LC-MS/MS analysis.
LC-MS/MS Method
Instrumentation:
-
HPLC system coupled to a triple quadrupole mass spectrometer with an electrospray ionization (ESI) source.
Chromatographic Conditions (starting point for method development):
-
Column: A reversed-phase C18 column (e.g., 100 x 2.1 mm, 1.8 µm) is a suitable starting point.
-
Mobile Phase A: 0.1% formic acid in water
-
Mobile Phase B: 0.1% formic acid in acetonitrile
-
Flow Rate: 0.3 mL/min
-
Gradient:
-
0-2 min: 2% B
-
2-8 min: 2-98% B
-
8-10 min: 98% B
-
10-10.1 min: 98-2% B
-
10.1-15 min: 2% B
-
-
Injection Volume: 5 µL
-
Column Temperature: 40°C
Mass Spectrometry Conditions:
-
Ionization Mode: Positive Electrospray Ionization (ESI+)
-
Multiple Reaction Monitoring (MRM) Transitions:
-
The exact mass transitions for this compound should be determined by infusing a standard solution. However, based on the fragmentation of the related compound pseudouridine and thymidine, the following transitions are proposed as a starting point for optimization:
-
This compound: Precursor ion [M+H]⁺: m/z 257.1. Product ions to monitor would likely result from the loss of the deoxyribose sugar moiety.
-
Internal Standard (e.g., this compound-¹³C₅,¹⁵N₂): The precursor and product ions will be shifted according to the number of incorporated heavy isotopes.
-
-
-
Optimization: Parameters such as declustering potential, collision energy, and cell exit potential should be optimized for each transition to maximize signal intensity.
Data Presentation: Quantitative LC-MS/MS Parameters
The following table summarizes the proposed starting parameters for the LC-MS/MS analysis of this compound.
| Parameter | Recommended Setting |
| LC Column | Reversed-phase C18 (e.g., 100 x 2.1 mm, 1.8 µm) |
| Mobile Phase A | 0.1% Formic Acid in Water |
| Mobile Phase B | 0.1% Formic Acid in Acetonitrile |
| Flow Rate | 0.3 mL/min |
| Injection Volume | 5 µL |
| Ionization Mode | Positive Electrospray Ionization (ESI+) |
| Precursor Ion (m/z) | 257.1 (for this compound) |
| Product Ion(s) (m/z) | To be determined empirically (likely involving loss of the sugar moiety) |
| Internal Standard | Stable isotope-labeled this compound |
Part 2: Development of a Competitive ELISA for this compound
Currently, there are no commercially available ELISA kits specifically for this compound. However, a competitive ELISA can be developed for its quantification. This format is suitable for small molecules.
Principle of Competitive ELISA
In a competitive ELISA, a known amount of enzyme-conjugated this compound competes with the this compound in the sample for binding to a limited number of anti-pseudothymidine antibody-coated wells. The amount of conjugated this compound bound to the antibody is inversely proportional to the concentration of this compound in the sample.
Protocol for Competitive ELISA Development
-
Antibody Production: Production of a specific monoclonal or polyclonal antibody against this compound is the first critical step. This involves conjugating this compound to a carrier protein (e.g., BSA or KLH) to make it immunogenic.
-
Coating of Microtiter Plates:
-
Coat the wells of a 96-well plate with the anti-pseudothymidine antibody.
-
Incubate overnight at 4°C.
-
Wash the plates with a wash buffer (e.g., PBS with 0.05% Tween 20).
-
Block the remaining protein-binding sites in the coated wells by adding a blocking buffer (e.g., 1% BSA in PBS). Incubate for 1-2 hours at room temperature.
-
-
Competitive Reaction:
-
Prepare a standard curve of known this compound concentrations.
-
Add the standards and unknown samples to the wells.
-
Immediately add a fixed amount of enzyme-conjugated this compound (e.g., HRP-pseudothymidine) to all wells.
-
Incubate for 1-2 hours at room temperature to allow for competition.
-
-
Detection:
-
Wash the plates thoroughly to remove unbound reagents.
-
Add the enzyme substrate (e.g., TMB for HRP).
-
Incubate in the dark until a color develops.
-
Stop the reaction with a stop solution (e.g., 2N H₂SO₄).
-
-
Data Analysis:
-
Measure the absorbance at the appropriate wavelength (e.g., 450 nm for TMB).
-
Generate a standard curve by plotting the absorbance versus the log of the this compound concentration.
-
Determine the concentration of this compound in the samples by interpolating their absorbance values from the standard curve.
-
Part 3: Visualization of Workflows and Pathways
Experimental Workflow and Signaling Pathway Diagrams
The following diagrams, generated using Graphviz (DOT language), illustrate the experimental workflow for LC-MS/MS analysis and a relevant signaling pathway where pseudouridine (a related molecule) is implicated.
Caption: LC-MS/MS workflow for this compound quantification.
Caption: PUS7-mediated upregulation of the PI3K/Akt/mTOR pathway.
References
Application Notes and Protocols: The Development of Pseudothymidine-Based and Analogous Therapeutic Agents
For Researchers, Scientists, and Drug Development Professionals
Introduction
Nucleoside analogs represent a cornerstone of antiviral and anticancer chemotherapy. By mimicking endogenous nucleosides, these agents can disrupt critical cellular processes such as DNA replication and repair, leading to the inhibition of viral proliferation or cancer cell growth. Pseudothymidine, a C-glycosidic isomer of thymidine, presents a unique structural modification—the replacement of the N-glycosidic bond with a more stable C-C bond. This modification offers inherent resistance to enzymatic cleavage, a property of significant interest in drug design.
While therapeutic agents directly derived from a this compound scaffold are not yet prevalent in clinical use, the principles underlying its structure inform the broader development of thymidine analogs. These analogs are designed to be recognized by viral or cellular enzymes, leading to their activation (phosphorylation) and subsequent incorporation into nascent DNA or RNA strands, or to directly inhibit key enzymes in nucleotide metabolism. This document outlines the mechanisms, applications, and relevant protocols for the development and evaluation of therapeutic agents based on thymidine analogs, with conceptual insights drawn from the properties of this compound.
Application Notes
Mechanism of Action of Nucleoside Analogs
The therapeutic effect of most nucleoside analogs, including those related to thymidine, relies on their intracellular conversion to triphosphate derivatives. This bioactivation is a critical step, often catalyzed by viral or cellular kinases. Once phosphorylated, these analogs can exert their effects through several mechanisms:
-
DNA Chain Termination: After conversion to their triphosphate form, nucleoside analogs are incorporated into the growing DNA chain by DNA polymerases. Many analogs lack a 3'-hydroxyl group, which is essential for the formation of the next phosphodiester bond. Their incorporation thus leads to the immediate and irreversible termination of DNA elongation.
-
Inhibition of Viral Enzymes: Many analogs show a higher affinity for viral enzymes, such as viral thymidine kinase or reverse transcriptase, than for their human counterparts.[1] This preferential phosphorylation or binding leads to selective antiviral activity with reduced host cytotoxicity.[1]
-
Disruption of Nucleic Acid Synthesis: Analogs can act as competitive inhibitors of enzymes crucial for DNA synthesis, such as thymidylate synthase, which is involved in the production of thymidine, a key DNA building block.[2]
The stability of the glycosidic bond is a crucial factor in the efficacy of nucleoside analogs. The C-C bond in this compound, for instance, is resistant to cleavage by phosphorylases, which can inactivate traditional N-glycosidic nucleosides. This inherent stability is a desirable characteristic for designing more robust therapeutic agents.
Therapeutic Areas
-
Antiviral Agents: Thymidine analogs are prominent in antiviral therapy, particularly against DNA viruses like Herpes Simplex Virus (HSV) and retroviruses like the Human Immunodeficiency Virus (HIV).[3][4] For example, Azidothymidine (AZT) was a foundational drug for HIV treatment that functions as a chain terminator for the viral reverse transcriptase.
-
Anticancer Agents: In oncology, nucleoside analogs function as antimetabolites that interfere with the DNA synthesis of rapidly dividing cancer cells.[5][6] Their incorporation leads to DNA damage and apoptosis. The thymidine analog 5-Fluorouracil (5-FU), after conversion to its deoxyuridine monophosphate form, inhibits thymidylate synthase, leading to a depletion of thymidine and subsequent cell death.[7]
-
Oligonucleotide Therapeutics: Modified nucleosides are critical components of oligonucleotide therapies like antisense oligonucleotides (ASOs). These synthetic nucleic acid strands are designed to bind to specific mRNA sequences, leading to gene silencing.[8][9][10] Chemical modifications, such as those to the sugar or backbone, are necessary to improve stability against nucleases, enhance binding affinity, and reduce off-target effects.[9] The inherent nuclease resistance of a C-glycoside like this compound makes it a conceptually valuable building block for such advanced therapeutics.
Quantitative Data: Bioactivity of Thymidine Analogs
The following table summarizes the in vitro activity of various thymidine analogs against viral and cancer targets. It is important to note that these are representative analogs and not this compound itself, but they illustrate the therapeutic potential of this class of compounds.
| Compound | Target | Assay Type | Activity Metric | Value (µM) | Reference(s) |
| Hexadecanoyl Acyclic Thymidine Analog (1d) | Human Immunodeficiency Virus (HIV-1) | Anti-HIV Activity | EC₅₀ | 6.8 | [11] |
| Hexadecanoyl Acyclic Thymidine Analog (1c, 1d) | SV-28 & KB Cancer Cell Lines | Cytotoxicity | IC₅₀ | ~20 | [11] |
| 2,5'-Anhydro-3'-azido-3'-deoxythymidine (13) | Human Immunodeficiency Virus (HIV-1) | Anti-HIV Activity | IC₅₀ | 0.56 | [4] |
| 2,5'-Anhydro-3'-azido-2',3'-dideoxyuridine (14) | Human Immunodeficiency Virus (HIV-1) | Anti-HIV Activity | IC₅₀ | 4.95 | [4] |
| 5'-urea-α-thymidine derivative (Compound 20) | Plasmodium falciparum (Malaria) | Parasite Growth | EC₅₀ | ~2 | [11] |
| 5'-urea-α-thymidine derivative (Compound 26) | Plasmodium falciparum (Malaria) | Parasite Growth | EC₅₀ | ~2 | [11] |
EC₅₀: Half maximal effective concentration. IC₅₀: Half maximal inhibitory concentration.
Experimental Protocols
Protocol 1: General Synthesis of a 5'-Modified Thymidine Analog
This protocol outlines a general synthetic route for modifying the 5' position of thymidine, a common strategy for creating novel analogs.
Objective: To synthesize a 5'-substituted thymidine derivative.
Materials:
-
Thymidine
-
Methanesulfonyl chloride (MsCl)
-
Pyridine
-
Sodium azide (NaN₃)
-
Dimethylformamide (DMF)
-
10% Palladium on Carbon (Pd/C)
-
Methanol (MeOH)
-
Appropriate aryl isocyanate or sulfonyl chloride
Procedure:
-
Mesylation: Dissolve thymidine in pyridine and cool the solution to -38°C. Add methanesulfonyl chloride dropwise and stir for several hours. This reaction selectively protects the 5'-hydroxyl group as a mesylate, which is a good leaving group.
-
Azide Substitution: Dissolve the resulting 5'-mesyl-thymidine in DMF and add sodium azide. Heat the mixture to 60°C and stir overnight. The azide group will displace the mesylate via an Sₙ2 reaction.
-
Reduction to Amine: Dissolve the 5'-azido-thymidine in methanol. Add 10% Pd/C catalyst and subject the mixture to a hydrogen atmosphere (e.g., using a balloon or a hydrogenation apparatus) at room temperature. The azide is reduced to a primary amine.
-
Coupling Reaction: Dissolve the resulting 5'-amino-thymidine in DMF. Add the desired coupling partner (e.g., an aryl isocyanate to form a urea, or a sulfonyl chloride to form a sulfonamide). Stir at room temperature until the reaction is complete (monitored by TLC).
-
Purification: Purify the final product using column chromatography on silica gel.
This is a generalized protocol adapted from literature procedures. Specific reaction times, temperatures, and purification methods must be optimized for each specific analog.
Protocol 2: In Vitro Antiviral Plaque Reduction Assay
Objective: To determine the concentration of a test compound required to reduce the number of viral plaques by 50% (EC₅₀).
Materials:
-
Confluent monolayer of host cells (e.g., Vero cells for HSV) in 6-well plates
-
Virus stock of known titer (e.g., HSV-1)
-
Test compound stock solution (e.g., in DMSO)
-
Cell culture medium (e.g., DMEM)
-
Overlay medium (e.g., medium with 1% methylcellulose)
-
Crystal violet staining solution
Procedure:
-
Cell Seeding: Seed host cells into 6-well plates and allow them to grow to a confluent monolayer.
-
Compound Dilution: Prepare serial dilutions of the test compound in cell culture medium.
-
Infection: Remove the growth medium from the cells and infect them with the virus at a concentration calculated to produce 50-100 plaques per well. Allow the virus to adsorb for 1-2 hours.
-
Treatment: Remove the viral inoculum. Add 2 mL of the overlay medium containing the different concentrations of the test compound to each well. Also include a "no-drug" virus control and a "no-virus" cell control.
-
Incubation: Incubate the plates at 37°C in a CO₂ incubator for 2-4 days, or until plaques are visible in the virus control wells.
-
Staining: Remove the overlay medium and wash the cells gently with PBS. Fix the cells with methanol and then stain with crystal violet solution for 15-30 minutes.
-
Plaque Counting: Wash the plates with water and allow them to dry. Count the number of plaques in each well.
-
Data Analysis: Calculate the percentage of plaque inhibition for each compound concentration relative to the "no-drug" control. Determine the EC₅₀ value by plotting the percentage of inhibition against the compound concentration and fitting the data to a dose-response curve.
Visualizations: Pathways and Workflows
Caption: Mechanism of action for a typical nucleoside analog antiviral.
References
- 1. Differential activity of potential antiviral nucleoside analogs on herpes simplex virus-induced and human cellular thymidine kinases - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Antiviral and Antimicrobial Nucleoside Derivatives: Structural Features and Mechanisms of Action - PMC [pmc.ncbi.nlm.nih.gov]
- 3. The synthesis and properties of some antiviral nucleosides - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Synthesis and antiviral activity of 3'-heterocyclic substituted 3'-deoxythymidines - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Nucleoside analogues and nucleobases in cancer treatment - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. What is Deoxythymidine/Deoxycytidine used for? [synapse.patsnap.com]
- 7. An overview of thymidine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. mdpi.com [mdpi.com]
- 9. The chemical evolution of oligonucleotide therapies of clinical utility - PMC [pmc.ncbi.nlm.nih.gov]
- 10. bachem.com [bachem.com]
- 11. Intriguing Antiviral Modified Nucleosides: A Retrospective View into the Future Treatment of COVID-19 - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for Studying the Effects of Pseudothymidine on mRNA Translation
For Researchers, Scientists, and Drug Development Professionals
Introduction
The incorporation of modified nucleotides into messenger RNA (mRNA) has emerged as a critical strategy in the development of mRNA-based therapeutics and vaccines. These modifications can enhance mRNA stability, reduce immunogenicity, and modulate translational efficiency. Pseudothymidine (ΨT), a thymidine analog, is one such modification of interest. Understanding its precise impact on the translational machinery is crucial for optimizing the design of therapeutic mRNA.
These application notes provide a comprehensive overview of experimental approaches to dissect the effects of this compound on translation. Detailed protocols for key assays are provided to enable researchers to investigate translation efficiency, kinetics, and fidelity.
Key Experimental Approaches
Several powerful techniques can be employed to elucidate the role of this compound in translation. The following sections detail the principles and applications of these methods.
In Vitro Translation Assays
In vitro translation (IVT) systems, such as rabbit reticulocyte lysates or wheat germ extracts, provide a cell-free environment to directly assess the impact of this compound on protein synthesis from a modified mRNA template.[1] These systems contain all the necessary components for translation, including ribosomes, tRNAs, and initiation and elongation factors. By comparing the protein yield from an mRNA containing this compound to that of an unmodified control mRNA, one can quantify the effect of the modification on overall translation efficiency.
Ribosome Profiling (Ribo-Seq)
Ribosome profiling is a high-throughput sequencing technique that provides a "snapshot" of all the ribosome positions on the transcriptome at a specific moment.[2][3] By mapping the ribosome-protected mRNA fragments (footprints), this method can reveal the density of ribosomes on a given mRNA, which is a proxy for its translation rate.[2][4] When applied to cells expressing this compound-containing mRNAs, ribosome profiling can pinpoint specific codons or regions where ribosomes might pause or dissociate, offering insights into the kinetics of elongation.[5]
Mass Spectrometry-Based Proteomics
Mass spectrometry (MS)-based proteomics allows for the global and quantitative analysis of the proteome.[6][7] By employing techniques like Stable Isotope Labeling by Amino acids in Cell culture (SILAC) or Tandem Mass Tagging (TMT), researchers can compare the abundance of proteins translated from this compound-modified versus unmodified mRNAs in a cellular context.[8] This approach provides a direct measure of the final protein output and can reveal downstream effects on the cellular proteome. Furthermore, MS can be used to analyze the fidelity of translation by detecting amino acid misincorporations.[9]
Data Presentation
The following tables summarize hypothetical quantitative data that could be obtained from the described experiments, illustrating the potential effects of this compound on translation.
Table 1: In Vitro Translation Efficiency of this compound-Modified mRNA
| mRNA Template | Reporter Protein | Protein Yield (µg/mL) | Relative Translation Efficiency (%) |
| Unmodified Luciferase mRNA | Luciferase | 15.2 ± 1.8 | 100 |
| This compound-Luciferase mRNA | Luciferase | 22.8 ± 2.5 | 150 |
| Unmodified GFP mRNA | GFP | 12.5 ± 1.5 | 100 |
| This compound-GFP mRNA | GFP | 19.1 ± 2.1 | 153 |
Table 2: Ribosome Profiling Metrics for this compound-Modified mRNA
| mRNA Template | Ribosome Density (Footprints/kb) | Pause Scores at Specific Motifs | Elongation Rate (codons/sec) |
| Unmodified Reporter mRNA | 85 ± 9 | 1.2 ± 0.3 | 5.8 |
| This compound-Reporter mRNA | 110 ± 12 | 2.5 ± 0.6 | 4.2 |
Table 3: Proteomic Analysis of Cells Transfected with this compound-Modified mRNA
| Transfected mRNA | Protein of Interest | Fold Change in Protein Abundance (Modified/Unmodified) | Misincorporation Frequency (%) |
| Reporter Gene X | Protein X | 1.65 | 0.05 |
| Therapeutic Protein Y | Protein Y | 1.82 | 0.08 |
Experimental Protocols
Protocol 1: In Vitro Translation of this compound-Modified mRNA
Objective: To quantify the effect of this compound incorporation on the overall protein yield from an mRNA template in a cell-free system.
Materials:
-
Linearized DNA template for T7 in vitro transcription of the target mRNA.
-
T7 RNA Polymerase.
-
NTPs (ATP, GTP, CTP) and UTP or a mix of UTP and this compound triphosphate (ΨTTP).
-
RNase inhibitor.
-
Rabbit Reticulocyte Lysate or Wheat Germ Extract in vitro translation kit.
-
Amino acid mixture (with and without a labeled amino acid, e.g., ³⁵S-Methionine).
-
Nuclease-free water.
-
SDS-PAGE gels and buffers.
-
Phosphorimager or Western blot apparatus.
Methodology:
-
In Vitro Transcription: a. Set up two transcription reactions. In the control reaction, use ATP, GTP, CTP, and UTP. In the experimental reaction, replace a portion or all of the UTP with ΨTTP. b. Incubate the reactions with T7 RNA Polymerase according to the manufacturer's instructions. c. Purify the resulting mRNA using a suitable RNA purification kit and quantify the concentration. Verify RNA integrity via gel electrophoresis.
-
In Vitro Translation: a. Set up the in vitro translation reactions according to the kit manufacturer's protocol. Add equal amounts of either unmodified or this compound-modified mRNA to separate reaction tubes. b. If using radiolabeled amino acids, include ³⁵S-Methionine in the amino acid mixture. c. Incubate the reactions at the recommended temperature (e.g., 30°C) for a specified time (e.g., 90 minutes).
-
Analysis: a. Radiolabeled Detection: Separate the translation products by SDS-PAGE. Dry the gel and expose it to a phosphor screen. Quantify the band intensity corresponding to the protein of interest using a phosphorimager. b. Western Blot Analysis: Separate the translation products by SDS-PAGE and transfer to a PVDF membrane. Probe with an antibody specific to the translated protein and a secondary antibody conjugated to a detectable enzyme (e.g., HRP). Quantify the chemiluminescent signal. c. Calculate the relative translation efficiency by normalizing the protein yield from the this compound-modified mRNA to the yield from the unmodified mRNA.
Protocol 2: Ribosome Profiling of Cells Expressing this compound-Modified mRNA
Objective: To determine the genome-wide translational status and identify specific regions of altered ribosome occupancy on this compound-containing mRNAs.
Materials:
-
Cells cultured in appropriate media.
-
Plasmids encoding the unmodified and this compound-modified mRNA of interest.
-
Transfection reagent.
-
Cycloheximide (translation elongation inhibitor).
-
Lysis buffer.
-
RNase I.
-
Sucrose gradients or size-exclusion chromatography columns.
-
RNA purification kits.
-
Library preparation kit for next-generation sequencing.
-
Next-generation sequencer.
Methodology:
-
Cell Culture and Transfection: a. Culture cells to the desired confluency. b. Transfect separate plates of cells with plasmids encoding either the unmodified or this compound-modified mRNA.
-
Harvesting and Lysis: a. Treat the cells with cycloheximide to arrest translating ribosomes. b. Harvest the cells and lyse them in a polysome lysis buffer.
-
Ribosome Footprinting: a. Treat the cell lysate with RNase I to digest mRNA not protected by ribosomes. b. Isolate the ribosome-mRNA complexes (monosomes) by sucrose gradient centrifugation or size-exclusion chromatography.
-
Library Preparation and Sequencing: a. Extract the ribosome-protected mRNA fragments (footprints). b. Prepare a sequencing library from the footprints. This typically involves 3' adapter ligation, reverse transcription, circularization, and PCR amplification. c. Sequence the library using a next-generation sequencer.
-
Data Analysis: a. Align the sequencing reads to the reference transcriptome. b. Calculate the ribosome density for each transcript by normalizing the number of footprint reads to the transcript length. c. Analyze the distribution of footprints along the this compound-modified transcript to identify potential pausing sites.
Protocol 3: Mass Spectrometry-Based Proteomic Analysis
Objective: To quantify the relative abundance of a specific protein translated from this compound-modified mRNA in a cellular context.
Materials:
-
Cells cultured in SILAC-compatible media (or reagents for TMT labeling).
-
Plasmids encoding the unmodified and this compound-modified mRNA of interest.
-
Transfection reagent.
-
Lysis buffer with protease inhibitors.
-
Trypsin.
-
Liquid chromatography-tandem mass spectrometry (LC-MS/MS) system.
-
Proteomics data analysis software.
Methodology:
-
SILAC Labeling and Transfection (Example using SILAC): a. Culture two populations of cells in media containing either "light" (e.g., ¹²C₆-Arginine) or "heavy" (e.g., ¹³C₆-Arginine) amino acids for several passages to achieve complete labeling. b. Transfect the "light"-labeled cells with the plasmid for the unmodified mRNA and the "heavy"-labeled cells with the plasmid for the this compound-modified mRNA.
-
Sample Preparation: a. Harvest and lyse the cells. b. Combine equal amounts of protein from the "light" and "heavy" cell lysates. c. Digest the protein mixture with trypsin.
-
LC-MS/MS Analysis: a. Separate the resulting peptides by liquid chromatography. b. Analyze the peptides by tandem mass spectrometry.
-
Data Analysis: a. Use proteomics software to identify peptides and quantify the relative abundance of the "heavy" and "light" forms of each peptide. b. Calculate the fold change in the abundance of the protein of interest by comparing the intensities of the heavy and light peptide pairs. c. For fidelity analysis, search the MS/MS data for peptides containing unexpected amino acid substitutions.
Visualizations
Caption: Workflow for In Vitro Translation Assay.
Caption: Ribosome Profiling Experimental Workflow.
Caption: Impact on a Generic Signaling Pathway.
References
- 1. The Basics: In Vitro Translation | Thermo Fisher Scientific - HK [thermofisher.com]
- 2. Ribosome profiling reveals the what, when, where, and how of protein synthesis - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. youtube.com [youtube.com]
- 5. High-resolution ribosome profiling defines discrete ribosome elongation states and translational regulation during cellular stress - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Proteomic analysis of protein post-translational modifications by mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Common errors in mass spectrometry-based analysis of post-translational modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 8. mdpi.com [mdpi.com]
- 9. proceedings.neurips.cc [proceedings.neurips.cc]
Troubleshooting & Optimization
Technical Support Center: Overcoming Challenges in the Chemical Synthesis of Pseudothymidine
For Researchers, Scientists, and Drug Development Professionals
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to address common challenges encountered during the chemical synthesis of pseudothymidine. The information is presented in a question-and-answer format to directly tackle specific experimental issues.
Frequently Asked Questions (FAQs)
Q1: What are the primary challenges in the chemical synthesis of this compound?
A1: The main hurdles in this compound synthesis are:
-
Stereoselective C-Glycosylation: Forming the C-C bond between the ribose sugar and the thymine base with the correct β-anomeric configuration is notoriously difficult. This often results in a mixture of α and β anomers that can be challenging to separate.
-
Protecting Group Strategy: The selection, introduction, and removal of protecting groups for the hydroxyl groups of the ribose sugar and the N3 position of the thymine base are critical. Incompatible or inefficient protecting group strategies can lead to low yields, side reactions, and purification difficulties.
-
Purification: Separating the desired β-pseudothymidine from the α-anomer, unreacted starting materials, and other byproducts requires efficient purification techniques, typically involving multiple chromatographic steps.
Q2: Which protecting groups are recommended for this compound synthesis?
A2: The choice of protecting groups is crucial for a successful synthesis. Here are some commonly used protecting groups:
-
For Ribose Hydroxyl Groups: Silyl ethers, such as tert-butyldimethylsilyl (TBDMS) and triisopropylsilyl (TIPS), are frequently used due to their stability and orthogonal removal conditions. Acetyl (Ac) or benzoyl (Bz) groups can also be employed.
-
For Thymine N3 Position: The tert-butoxycarbonyl (Boc) group is an effective protecting group for the N3 position of thymine. It is stable under various conditions used for the manipulation of sugar hydroxyl protecting groups and can be removed under acidic conditions.
Q3: How can I improve the stereoselectivity of the C-glycosylation reaction to favor the β-anomer?
A3: Achieving high β-selectivity is a key challenge. Here are some strategies:
-
Choice of Ribose Derivative: Using a ribose derivative with a participating group at the C2 position can help direct the stereochemistry of the glycosylation.
-
Lewis Acid and Solvent: The choice of Lewis acid (e.g., TMSOTf, SnCl4) and solvent can significantly influence the anomeric ratio. Optimization of these conditions is often necessary.
-
Temperature Control: Running the reaction at low temperatures can improve selectivity by favoring the thermodynamically more stable β-anomer.
Q4: What are the most effective methods for purifying this compound?
A4: Purification of this compound, especially the separation of anomers, typically relies on chromatographic techniques.
-
High-Performance Liquid Chromatography (HPLC): Reverse-phase HPLC (RP-HPLC) is a powerful method for separating α and β anomers.[1][2] Anion-exchange HPLC can also be effective, particularly for phosphorylated derivatives.[1]
-
Flash Column Chromatography: Silica gel column chromatography is used for the initial purification of the crude product to remove major impurities before final purification by HPLC.
Troubleshooting Guides
Problem 1: Low Yield of the C-Glycosylation Product
| Possible Cause | Suggested Solution |
| Inefficient Lithiation of Thymine | Ensure anhydrous conditions and use freshly titrated n-butyllithium. Monitor the reaction by TLC to confirm the formation of the lithiated species. |
| Decomposition of Ribose Derivative | Add the ribose derivative slowly to the reaction mixture at a low temperature (e.g., -78 °C) to minimize degradation. |
| Suboptimal Lewis Acid/Promoter | Screen different Lewis acids (e.g., TMSOTf, SnCl4) and optimize their stoichiometry. |
| Steric Hindrance | Ensure that the protecting groups on the ribose do not sterically hinder the approach of the lithiated thymine. |
Problem 2: Poor Stereoselectivity (Formation of Anomeric Mixture)
| Possible Cause | Suggested Solution |
| Reaction Temperature Too High | Maintain a low reaction temperature throughout the addition and reaction time to favor the formation of the β-anomer. |
| Inappropriate Solvent | The polarity of the solvent can affect the transition state of the reaction. Screen different anhydrous solvents (e.g., THF, dichloromethane, acetonitrile) to find the optimal conditions for β-selectivity. |
| Lack of a Participating Group | If possible, utilize a ribose derivative with a participating protecting group at the C2 position (e.g., an acetyl or benzoyl group) to direct the incoming nucleophile to the β-face. |
| Anomerization during Workup/Purification | Avoid acidic or basic conditions during the workup and purification steps, as these can cause anomerization. Use neutral buffers and solvents. |
Problem 3: Difficulty in Separating α and β Anomers by HPLC
| Possible Cause | Suggested Solution |
| Inadequate Resolution on RP-HPLC | Optimize the mobile phase gradient. A shallower gradient of acetonitrile in water or a buffer (e.g., triethylammonium acetate) can improve separation.[1] Consider using a different column with a different stationary phase (e.g., C8 instead of C18). |
| Co-elution of Anomers | If baseline separation is not achieved, consider derivatizing the anomers with a bulky group to enhance their separation on HPLC. |
| Ion-Pairing Reagent Issues | If using an ion-pairing reagent, ensure its concentration is optimized for the best separation. |
Problem 4: Incomplete Deprotection
| Possible Cause | Suggested Solution |
| Protecting Group is Too Stable | Ensure the deprotection conditions are appropriate for the specific protecting group used. For example, use fluoride sources like TBAF for silyl ethers and strong acids like TFA for Boc groups. |
| Insufficient Reagent or Reaction Time | Increase the equivalents of the deprotecting agent and/or extend the reaction time. Monitor the reaction progress by TLC or LC-MS. |
| Steric Hindrance around the Protecting Group | In some cases, bulky neighboring groups can hinder the access of the deprotecting agent. This may require harsher reaction conditions or a different deprotection strategy. |
Experimental Protocols
Key Experiment: Stereoselective C-Glycosylation
This protocol is a general guideline and may require optimization.
1. Preparation of Lithiated Thymine:
-
Dissolve N3-Boc-protected thymine in anhydrous THF under an argon atmosphere.
-
Cool the solution to -78 °C.
-
Slowly add a solution of n-butyllithium in hexanes.
-
Stir the mixture at -78 °C for 1 hour.
2. Glycosylation Reaction:
-
In a separate flask, dissolve the protected ribose derivative (e.g., 2,3,5-tri-O-TBDMS-D-ribonolactone) in anhydrous THF under argon.
-
Cool the solution to -78 °C.
-
Slowly add the pre-formed lithiated thymine solution to the ribose derivative solution via cannula.
-
Stir the reaction mixture at -78 °C for 2-4 hours, monitoring the progress by TLC.
3. Workup:
-
Quench the reaction by the slow addition of saturated aqueous ammonium chloride solution at -78 °C.
-
Allow the mixture to warm to room temperature.
-
Extract the product with an organic solvent (e.g., ethyl acetate).
-
Wash the organic layer with brine, dry over anhydrous sodium sulfate, and concentrate under reduced pressure.
4. Purification:
-
Purify the crude product by silica gel column chromatography using a gradient of ethyl acetate in hexanes to separate the major products.
-
Further purify the anomeric mixture by RP-HPLC to isolate the desired β-pseudothymidine.
Data Presentation
Table 1: Typical Yields for this compound Synthesis Steps
| Step | Reaction | Typical Yield (%) |
| 1 | Protection of Ribose Hydroxyls (e.g., TBDMS) | 85-95 |
| 2 | Protection of Thymine N3 (e.g., Boc) | 90-98 |
| 3 | C-Glycosylation | 40-60 (combined anomers) |
| 4 | Deprotection | 70-90 |
| 5 | HPLC Purification | 50-70 (of the desired anomer from the mixture) |
Table 2: Example HPLC Conditions for Anomer Separation
| Parameter | Condition |
| Column | Reverse-Phase C18 (e.g., 5 µm, 4.6 x 250 mm) |
| Mobile Phase A | 0.1 M Triethylammonium Acetate (TEAA), pH 7.0 |
| Mobile Phase B | Acetonitrile |
| Gradient | 5-25% B over 30 minutes |
| Flow Rate | 1.0 mL/min |
| Detection | 260 nm |
Visualizations
Caption: General workflow for the chemical synthesis of this compound.
Caption: Troubleshooting logic for low C-glycosylation yield.
References
Technical Support Center: Optimizing Pseudothymidine and Pseudouridine Incorporation into RNA
This technical support center provides researchers, scientists, and drug development professionals with comprehensive troubleshooting guides and frequently asked questions (FAQs) to optimize the incorporation of pseudothymidine (ψT) and its close analog, pseudouridine (Ψ), into RNA during in vitro transcription (IVT).
Troubleshooting Guide
This guide addresses common issues encountered during the incorporation of modified nucleotides like this compound and pseudouridine into RNA via in vitro transcription.
| Problem | Potential Cause | Recommended Solution |
| Low or No RNA Yield | 1. Inactive RNA Polymerase: The polymerase may be denatured or compromised. | • Run a positive control reaction: Use a standard DNA template and unmodified NTPs to confirm polymerase activity.[1] • Use fresh enzyme: Aliquot the polymerase upon arrival and avoid multiple freeze-thaw cycles.[2] |
| 2. Poor DNA Template Quality: The template may contain inhibitors (e.g., salts) or be degraded. | • Purify the DNA template: Use a reliable purification kit to remove contaminants.[1] • Verify template integrity: Run an aliquot on an agarose gel to check for degradation or incomplete linearization.[1][] | |
| 3. Suboptimal Reaction Conditions: The concentration of reagents, especially Mg2+, may not be ideal for the modified NTPs. | • Optimize Mg2+ concentration: The optimal concentration can vary with modified NTPs; perform a titration to find the ideal concentration.[] • Adjust NTP concentrations: Ensure high-purity nucleotides are used. The standard concentration is 1-2 mM, but this may need adjustment.[] | |
| 4. RNase Contamination: RNases can rapidly degrade the newly synthesized RNA. | • Maintain an RNase-free environment: Use RNase-free reagents and consumables. Wear gloves and use appropriate cleaning solutions for your workspace.[2] • Include an RNase inhibitor: Add a commercial RNase inhibitor to the reaction mixture.[2] | |
| Incomplete or Truncated Transcripts | 1. Low Concentration of Limiting Nucleotide: If using a mix of modified and unmodified UTP, the total concentration might be too low. | • Increase the concentration of the limiting nucleotide: Supplementing the reaction with unlabeled UTP can help produce full-length transcripts.[4] |
| 2. Secondary Structure in the DNA Template: GC-rich regions can cause the polymerase to stall or dissociate. | • Lower the incubation temperature: Reducing the temperature from 37°C to 30°C can slow down the polymerase, allowing it to read through difficult sequences.[1][4] | |
| 3. Polymerase Incompatibility with Modified NTPs: Wild-type T7 RNA polymerase has reduced efficiency with some modified nucleotides. | • Use a mutant T7 RNA polymerase: Variants like Y639F are specifically designed to better accommodate modified nucleotides.[5][6] | |
| Transcripts are Longer Than Expected | 1. Incomplete Template Linearization: The polymerase may be reading through a circular or improperly linearized plasmid. | • Confirm complete linearization: Check an aliquot of the digested template on an agarose gel.[1] |
| 2. Template-Independent Activity: Some polymerases can add non-templated nucleotides to the 3' end of the transcript. | • Use a restriction enzyme that generates blunt or 5' overhangs: This can reduce the likelihood of non-templated addition.[1] | |
| Low Incorporation Efficiency of this compound/Pseudouridine | 1. Wild-Type Polymerase Discrimination: The active site of wild-type T7 RNA polymerase can sterically hinder the entry of modified NTPs. | • Employ engineered polymerases: Mutants such as Y639F or those with additional thermostabilizing mutations show increased acceptance of 2'-modified nucleotides.[6][7][8] |
| 2. Suboptimal NTP Ratio: An incorrect ratio of this compound triphosphate (ψTP) to UTP can limit incorporation. | • Optimize the ψTP:UTP ratio: Perform a series of reactions with varying ratios to determine the optimal balance for your specific template and polymerase. | |
| High Error Rate or Misincorporation | 1. Intrinsic Properties of the Modified Nucleotide: Pseudouridine can be incorporated with lower fidelity than N1-methylpseudouridine (m1Ψ). | • Consider using m1Ψ: Studies have shown that m1Ψ is incorporated with higher fidelity than Ψ by RNA polymerases.[9][10] |
| 2. Suboptimal Reaction Buffer Composition: Imbalanced NTP pools can contribute to misincorporation. | • Adjust rNTP concentrations: In some cases, increasing the concentration of rATP has been shown to modulate the error profile of T7 RNA polymerase.[10] |
Frequently Asked Questions (FAQs)
Q1: Why is T7 RNA polymerase the most commonly used enzyme for in vitro transcription with modified nucleotides?
A1: T7 RNA polymerase is a single-subunit enzyme known for its high processivity and strict promoter specificity, making it a robust tool for generating large quantities of RNA in vitro.[5][11] While the wild-type enzyme's recognition of modified nucleotides can be restrictive, numerous mutant versions have been developed to efficiently incorporate a wide range of analogs, including pseudouridine and other 2'-modified nucleotides.[5][6]
Q2: Which mutant T7 RNA polymerase is best for incorporating this compound or pseudouridine?
A2: The Y639F mutant of T7 RNA polymerase is widely cited as being more accommodating for nucleotides with modifications at the 2'-position of the ribose, such as 2'-fluoro and 2'-amino modifications.[5][6] Further mutations, such as H784A, can help to reduce premature termination of transcription.[6] For enhanced activity, thermostabilizing mutations can be added to these variants, which can significantly increase the yield of fully 2'-O-methyl modified RNA.[6][8]
Q3: What is the impact of incorporating pseudouridine into my RNA transcript?
A3: Incorporating pseudouridine (Ψ) into mRNA has several beneficial effects. It can enhance the stability of the RNA molecule, increase its translational capacity, and significantly reduce its immunogenicity.[12][13][] Structurally, pseudouridine enhances base stacking and contributes to a more rigid phosphodiester backbone.[12][15]
Q4: How can I quantify the amount of pseudouridine incorporated into my RNA?
A4: Quantifying pseudouridine can be challenging as it is an isomer of uridine and does not change the mass of the RNA. Common methods include:
-
Chemical Derivatization and Primer Extension: This involves treating the RNA with a chemical like CMC (N-cyclohexyl-N'-β-(4-methylmorpholinumethyl) carbodiimide p-tosylate), which specifically adducts to pseudouridine and causes reverse transcriptase to stall. The resulting cDNA fragments can be analyzed to map the location of Ψ.[16][17]
-
Mass Spectrometry: Liquid chromatography tandem mass spectrometry (LC-MS/MS) can be used for both qualitative and quantitative analysis of pseudouridine.[16][18]
-
High-Throughput Sequencing: Methods like "Pseudo-seq" have been developed for transcriptome-wide identification of pseudouridylation sites with single-nucleotide precision.[19][20]
Q5: Is there a difference in incorporation fidelity between pseudouridine (Ψ) and N1-methylpseudouridine (m1Ψ)?
A5: Yes, studies have demonstrated that N1-methylpseudouridine (m1Ψ) is incorporated with higher fidelity than pseudouridine (Ψ) during in vitro transcription.[9][10] The choice of RNA polymerase can also influence the fidelity of incorporation, although the types of mutations observed tend to be similar across different polymerases.[9]
Data on T7 RNA Polymerase Mutants for Modified Nucleotide Incorporation
The following table summarizes key T7 RNA polymerase mutants and their advantages for incorporating modified nucleotides.
| T7 RNA Polymerase Variant | Key Mutation(s) | Primary Advantage for Modified Nucleotide Incorporation | Reference(s) |
| Wild-Type (WT) | None | Baseline for comparison; efficient for standard NTPs. | [5] |
| Y639F | Y639F | Increased acceptance of 2'-modified nucleotides (e.g., 2'-fluoro, 2'-amino). | [5][6] |
| FA | Y639F, H784A | Y639F for modified NTP acceptance; H784A to reduce premature termination. | [6][8] |
| RGVG | E593G, Y639V, V685A, H784G | A variant with increased activity for incorporating nucleotides with bulky 2'-modifications. | [8] |
| FA-M5, RGVG-M5 | FA or RGVG mutations + thermostabilizing mutations | Increased thermal tolerance and higher yields of modified RNA compared to the parent variants. | [6][8] |
Experimental Protocols
Protocol 1: Standard In Vitro Transcription (IVT) for Pseudouridine Incorporation
This protocol provides a general framework for incorporating pseudouridine into an RNA transcript using a mutant T7 RNA polymerase.
Materials:
-
Linearized plasmid DNA template (50-100 ng/µL)
-
Mutant T7 RNA Polymerase (e.g., Y639F variant)
-
5x Transcription Buffer (contains Tris-HCl, MgCl2, DTT, spermidine)
-
Ribonucleotide solution mix (ATP, CTP, GTP, each at 10 mM)
-
Pseudouridine-5'-Triphosphate (ΨTP) (10 mM)
-
UTP (10 mM)
-
RNase Inhibitor
-
Nuclease-free water
Procedure:
-
Thaw Reagents: Thaw all components on ice. Keep the enzyme and RNase inhibitor on ice at all times.
-
Assemble the Reaction: In a nuclease-free microcentrifuge tube on ice, add the following components in the order listed:
-
Nuclease-free water to a final volume of 20 µL
-
4 µL of 5x Transcription Buffer
-
1 µL of Linearized DNA template (50-100 ng)
-
2 µL of ATP (final concentration 1 mM)
-
2 µL of CTP (final concentration 1 mM)
-
2 µL of GTP (final concentration 1 mM)
-
X µL of ΨTP (to desired final concentration)
-
Y µL of UTP (to desired final concentration)
-
1 µL of RNase Inhibitor
-
1 µL of Mutant T7 RNA Polymerase
-
-
Mix and Incubate: Gently mix the components by pipetting. Incubate the reaction at 37°C for 2-4 hours. For templates with high secondary structure, consider a lower temperature (e.g., 30°C).[1]
-
Template Removal: After incubation, add DNase I to the reaction mixture to digest the DNA template. Incubate according to the manufacturer's instructions.
-
Purify RNA: Purify the RNA transcript using a column-based purification kit or phenol-chloroform extraction followed by ethanol precipitation.
-
Assess RNA Quality and Quantity: Analyze the transcript size and integrity using denaturing agarose gel electrophoresis. Quantify the RNA concentration using a spectrophotometer.
Protocol 2: Analysis of Pseudouridine Incorporation via CMC Treatment and RT-PCR
This protocol outlines a method to verify the presence of pseudouridine at specific sites.
Materials:
-
Pseudouridine-containing RNA (purified)
-
CMC reagent
-
Reaction buffers (as described in relevant literature, e.g., for pH 8.3 and 10.4)
-
Reverse Transcriptase (non-processive)
-
Gene-specific primers for RT-PCR
-
PCR reagents
-
Nuclease-free water
Procedure:
-
CMC Treatment:
-
Reverse Transcription:
-
Set up a reverse transcription reaction using a gene-specific primer that anneals downstream of the expected pseudouridylation site.
-
Use a non-processive reverse transcriptase, which will be blocked by the CMC-Ψ adduct, resulting in a truncated cDNA product. Unmodified uridines will allow the enzyme to read through, producing a full-length cDNA.
-
-
PCR Amplification and Analysis:
-
Use the cDNA products as a template for PCR with primers flanking the target region.
-
Analyze the PCR products on a high-resolution agarose or polyacrylamide gel. The presence of a shorter band corresponding to the stalled reverse transcription product indicates the presence of pseudouridine at that site.
-
Visualizations
Caption: Workflow for in vitro transcription with this compound.
Caption: Decision tree for troubleshooting IVT reactions.
Caption: Model of modified nucleotide incorporation by polymerases.
References
- 1. go.zageno.com [go.zageno.com]
- 2. bitesizebio.com [bitesizebio.com]
- 4. Practical Tips for In Vitro Transcription | Thermo Fisher Scientific - JP [thermofisher.com]
- 5. researchgate.net [researchgate.net]
- 6. Transcription yield of fully 2′-modified RNA can be increased by the addition of thermostabilizing mutations to T7 RNA polymerase mutants - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Screening mutant libraries of T7 RNA polymerase for candidates with increased acceptance of 2′-modified nucleotides - Chemical Communications (RSC Publishing) [pubs.rsc.org]
- 8. researchgate.net [researchgate.net]
- 9. N1-methyl-pseudouridine is incorporated with higher fidelity than pseudouridine in synthetic RNAs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. N1-methyl-pseudouridine is incorporated with higher fidelity than pseudouridine in synthetic RNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 11. The highly efficient T7 RNA polymerase: A wonder macromolecule in biological realm - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Pseudouridine and N1-methylpseudouridine as potent nucleotide analogues for RNA therapy and vaccine development - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Incorporation of Pseudouridine Into mRNA Yields Superior Nonimmunogenic Vector With Increased Translational Capacity and Biological Stability - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Frontiers | The Critical Contribution of Pseudouridine to mRNA COVID-19 Vaccines [frontiersin.org]
- 16. Mass Spectrometry-Based Quantification of Pseudouridine in RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Pseudouridine RNA modification detection and quantification by RT-PCR - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Mass spectrometry-based quantification of pseudouridine in RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 19. youtube.com [youtube.com]
- 20. Updated Pseudo-seq Protocol for Transcriptome-Wide Detection of Pseudouridines - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Troubleshooting Pseudothymidine Detection by Mass Spectrometry
Welcome to the technical support center for pseudothymidine detection by mass spectrometry. This resource is designed for researchers, scientists, and drug development professionals to provide clear and actionable solutions to common challenges encountered during experimental workflows.
Frequently Asked Questions (FAQs)
This section addresses specific issues that may arise during the detection and quantification of this compound using mass spectrometry.
Q1: Why can't I distinguish this compound from thymidine based on mass alone?
This compound is an isomer of thymidine, meaning they have the same molecular mass.[1][2] This "mass-silent" nature prevents their differentiation by a single mass measurement.[1] To distinguish them, methods that exploit their structural differences, such as tandem mass spectrometry (MS/MS) which analyzes fragmentation patterns, are necessary.[1][3]
Q2: I'm observing poor signal intensity or no peaks for this compound. What are the likely causes and solutions?
Poor or absent signal intensity is a common issue in mass spectrometry.[4][5] Several factors could be contributing to this problem.
Troubleshooting Poor Signal Intensity:
| Potential Cause | Recommended Solution |
| Inadequate Sample Concentration | Ensure your sample is appropriately concentrated. If it's too dilute, the signal may be too weak. Conversely, a highly concentrated sample can lead to ion suppression.[4] |
| Inefficient Ionization | The choice of ionization technique significantly impacts signal intensity. Experiment with different methods like Electrospray Ionization (ESI) or Matrix-Assisted Laser Desorption/Ionization (MALDI) to find the optimal choice for your analyte.[4] |
| Instrument Not Optimized | Regularly tune and calibrate your mass spectrometer. This includes checking the ion source, mass analyzer, and detector settings to ensure peak performance.[4] |
| Sample Degradation | Ensure proper storage and handling of this compound stock solutions and prepare fresh labeling medium for each experiment to prevent degradation.[6] |
| Gas Leaks in the System | Leaks can lead to a loss of sensitivity. Use a leak detector to check for and address any leaks in the gas supply, filters, and connections.[5] |
| Improper Sample Preparation | Verify that your sample preparation protocol is being followed correctly, including checking for any issues with the autosampler, syringe, or column.[5] |
Q3: My results show high background noise and baseline drift. How can I improve my signal-to-noise ratio?
High background noise can obscure the signal of your target analyte, making detection and quantification difficult.[4][7]
Strategies to Reduce Noise and Baseline Drift:
-
Optimize Chromatography: Fine-tune your liquid chromatography (LC) conditions to achieve a stable baseline.[4]
-
Adjust Detector Settings: Modify detector parameters, such as gain and filter settings, to minimize noise.[4]
-
Use High-Quality Solvents: Low-quality solvents can introduce contaminants that contribute to high background noise.[7]
-
Regular System Maintenance: Regularly flush the LC components to remove contaminants that can cause high background and pump failures.[7]
-
Prevent Microbial Growth: Use fresh mobile phases and rinse solvent bottles to prevent microbial growth, which can interfere with the analysis.[7]
Q4: I'm experiencing ion suppression or enhancement in my analysis. What is causing this and how can I mitigate it?
This phenomenon, known as the matrix effect, is a significant challenge in quantitative mass spectrometry.[8][9][10][11] It occurs when co-eluting substances from the sample matrix affect the ionization efficiency of the analyte.[8][9][11]
Managing Matrix Effects:
| Mitigation Strategy | Description |
| Stable Isotope Dilution | This involves using a stable isotope-labeled version of the analyte as an internal standard. Since the labeled and unlabeled compounds have the same physicochemical properties, they co-elute and experience the same matrix effects, allowing for accurate correction.[10] |
| Matrix-Matched Calibration | Prepare calibration standards in a matrix that is identical to the sample matrix. This helps to compensate for the matrix effects.[10] |
| Sample Cleanup | Employ sample preparation techniques like solid-phase extraction (SPE) or liquid-liquid extraction (LLE) to remove interfering matrix components before LC-MS analysis.[6][12] |
| Chromatographic Separation | Optimize the chromatographic method to separate the analyte from co-eluting matrix components.[6] |
| Sample Dilution | Diluting the sample can reduce the concentration of interfering matrix components, thereby minimizing their effect on the analyte's ionization.[10] |
Q5: My mass accuracy and resolution are poor. What should I check?
Accurate mass determination is crucial for confident compound identification.[4]
Improving Mass Accuracy and Resolution:
-
Mass Calibration: Perform regular mass calibration using appropriate standards to ensure accurate mass measurements.[4]
-
Instrument Maintenance: Keep the mass spectrometer well-maintained according to the manufacturer's guidelines. Contaminants or instrument drift can negatively affect mass accuracy and resolution.[4]
Q6: I'm observing peak splitting or broadening. What could be the cause?
Distorted peak shapes can complicate data analysis and reduce the accuracy of quantification.[4]
Troubleshooting Peak Shape Issues:
-
Column and Sample Contamination: Contaminants in the sample or on the chromatographic column can lead to peak distortion. Ensure proper sample preparation and column maintenance.[4]
-
Ionization Conditions: Adjusting ionization source parameters, such as gas flows, can help improve peak shape.[4]
-
Injection Solvent Mismatch: A mismatch between the injection solvent and the mobile phase can cause peak distortion, especially for early-eluting compounds.[12]
Experimental Protocols
This section provides detailed methodologies for key experiments related to this compound detection.
Protocol 1: Enzymatic Hydrolysis of RNA for Nucleoside Analysis
This protocol outlines the steps for digesting RNA into individual nucleosides for subsequent LC-MS/MS analysis.
-
RNA Isolation: Isolate total RNA from your sample using a standard method like phenol-chloroform extraction.
-
RNA Purification: Purify the RNA of interest to remove contaminants.
-
Enzymatic Digestion:
-
Incubate the purified RNA with a mixture of DNase I, snake venom phosphodiesterase, and alkaline phosphatase.
-
Perform the incubation at 37°C for 12-24 hours to ensure complete digestion of the RNA into individual nucleosides.[6]
-
-
Sample Cleanup:
-
Centrifuge the hydrolyzed sample to pellet any undigested material.
-
Transfer the supernatant containing the deoxynucleosides for LC-MS/MS analysis.[6]
-
Protocol 2: Sample Preparation for LC-MS/MS Analysis of Nucleosides
This protocol describes the general steps for preparing nucleoside samples for LC-MS/MS.
-
Deproteinization: For biological samples like plasma or urine, deproteinize the sample by adding perchloric acid (e.g., 5% v/v) and centrifuging to pellet the precipitated proteins.[13]
-
Supernatant Transfer: Carefully transfer the supernatant containing the nucleosides for analysis.
-
LC Separation:
-
Mass Spectrometry Detection:
Quantitative Data Summary
This section provides an example of how to structure quantitative data for clarity and comparison.
Table 1: Example Linearity of Calibration Curves for Nucleoside Quantification
| Analyte | Matrix | Concentration Range | Linearity (r) |
| Thymidine | Plasma | 10 - 10,000 ng/mL | > 0.99 |
| 2'-Deoxyuridine | Plasma | 10 - 10,000 ng/mL | > 0.99 |
| Thymidine | Urine | 1 - 50 µg/mL | > 0.99 |
| 2'-Deoxyuridine | Urine | 1 - 50 µg/mL | > 0.99 |
This table is based on data for thymidine and 2'-deoxyuridine quantification and serves as a template for presenting similar data for this compound.[13]
Visualizations
This section provides diagrams to illustrate key workflows and concepts in this compound detection.
Caption: General workflow for this compound detection by LC-MS/MS.
Caption: Troubleshooting logic for poor signal intensity.
Caption: Strategies to mitigate matrix effects in mass spectrometry.
References
- 1. Identification, localization, and relative quantitation of pseudouridine in RNA by tandem mass spectrometry of hydrolysis products - PMC [pmc.ncbi.nlm.nih.gov]
- 2. MASS SPECTROMETRY OF THE FIFTH NUCLEOSIDE: A REVIEW OF THE IDENTIFICATION OF PSEUDOURIDINE IN NUCLEIC ACIDS - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. gmi-inc.com [gmi-inc.com]
- 5. gentechscientific.com [gentechscientific.com]
- 6. benchchem.com [benchchem.com]
- 7. myadlm.org [myadlm.org]
- 8. bataviabiosciences.com [bataviabiosciences.com]
- 9. Biological Matrix Effects in Quantitative Tandem Mass Spectrometry-Based Analytical Methods: Advancing Biomonitoring - PMC [pmc.ncbi.nlm.nih.gov]
- 10. chromatographyonline.com [chromatographyonline.com]
- 11. researchgate.net [researchgate.net]
- 12. alfresco-static-files.s3.amazonaws.com [alfresco-static-files.s3.amazonaws.com]
- 13. Quantification of Plasma and Urine Thymidine and 2'-Deoxyuridine by LC-MS/MS for the Pharmacodynamic Evaluation of Erythrocyte Encapsulated Thymidine Phosphorylase in Patients with Mitochondrial Neurogastrointestinal Encephalomyopathy - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. protocols.io [protocols.io]
Technical Support Center: Enhancing the Stability of Pseudothymidine-Containing Oligonucleotides
Welcome to the technical support center for researchers, scientists, and drug development professionals working with pseudothymidine-containing oligonucleotides. This resource provides troubleshooting guidance and answers to frequently asked questions to help you improve the stability and performance of your oligonucleotides in various experimental settings.
Frequently Asked Questions (FAQs)
Q1: What is this compound and how does it differ from thymidine?
This compound (ΨT) is an isomer of thymidine where the ribose sugar is attached to the C5 position of the uracil base, instead of the N1 position. This C-C glycosidic bond provides greater rotational freedom compared to the C-N bond in thymidine.[1] Additionally, the N1 position in pseudouridine (the RNA equivalent of this compound) has an extra imino proton that can act as a hydrogen bond donor, potentially influencing local RNA structure and interactions.[1][2]
Q2: How does the incorporation of this compound affect the stability of my oligonucleotide?
Incorporating this compound, and more broadly its RNA analog pseudouridine (Ψ), can enhance the stability of oligonucleotides in several ways:
-
Increased Nuclease Resistance: Pseudouridine-modified mRNA has been shown to be more resistant to RNase-mediated degradation, which can lead to an increased half-life in cellular environments.[3][4][5]
-
Enhanced Thermal Stability: Pseudouridine can increase the thermodynamic stability of RNA duplexes.[2][6][7][8] This stabilization is context-dependent, influenced by the position of the modification and the neighboring base pairs.[2][6][8] The increased stability is attributed to improved base stacking and the formation of additional hydrogen bonds.[1][4][9][10]
-
Structural Rigidity: The presence of pseudouridine can add rigidity to the sugar-phosphate backbone, contributing to a more stable conformation.[4][11]
Q3: Is there a significant difference in stability between this compound and other common modifications like phosphorothioates (PS) or 2'-O-Methyl (2'OMe)?
While direct quantitative comparisons for this compound are not extensively documented in literature, we can infer from studies on pseudouridine and other common modifications. Phosphorothioate (PS) linkages directly modify the phosphate backbone, making it less susceptible to nuclease cleavage.[12] 2'-O-Methyl (2'OMe) modifications add a methyl group to the ribose sugar, which also provides significant nuclease resistance.[12]
Pseudouridine's stabilizing effect is more related to conformational changes and enhanced base stacking.[9][10] The optimal choice of modification, or combination of modifications, will depend on the specific application, the target sequence, and the biological environment. For maximum stability, a combination of modifications, such as incorporating pseudouridine alongside PS linkages at the ends of the oligonucleotide, may be beneficial.
Q4: Can I expect the same level of stability enhancement in all sequence contexts?
No, the stabilizing effect of pseudouridine is highly dependent on the sequence context.[2][6][8] The type of base it is paired with (A, G, U, or C) and the identity of the adjacent base pairs influence the degree of thermodynamic stabilization.[2][6] Therefore, it is recommended to experimentally validate the stability of your specific this compound-containing oligonucleotide sequence.
Troubleshooting Guide
Problem 1: My this compound-containing oligonucleotide is degrading too quickly in my cell culture media or serum-containing buffer.
-
Possible Cause: Nuclease activity in the experimental medium.
-
Troubleshooting Steps:
-
Assess Nuclease Contamination: Run a control experiment with your oligonucleotide in nuclease-free water or a simple buffer to ensure the degradation is not due to contamination of your oligo stock.
-
Incorporate Additional Modifications:
-
Phosphorothioate (PS) Linkages: Introduce 2-3 phosphorothioate bonds at the 3' and 5' ends of your oligonucleotide to protect against exonuclease degradation.[12] For protection against endonucleases, PS bonds can be incorporated throughout the sequence, but be mindful of potential toxicity at high concentrations.[12]
-
2'-O-Methyl (2'OMe) or 2'-Fluoro (2'F) Modifications: These sugar modifications can further enhance nuclease resistance.
-
-
Optimize Storage and Handling: Ensure your oligonucleotides are stored in a nuclease-free environment, preferably in a buffered solution (e.g., TE buffer) at -20°C or below. Avoid repeated freeze-thaw cycles.
-
Perform a Serum Stability Assay: Follow the detailed protocol below to quantify the degradation rate and systematically test the effectiveness of different stabilizing modifications.
-
Problem 2: I am observing unexpected off-target effects or toxicity with my modified oligonucleotide.
-
Possible Cause: The chemical modifications, while enhancing stability, may alter the binding properties or induce an immune response.
-
Troubleshooting Steps:
-
Evaluate Modification Density: If using extensive phosphorothioation, try reducing the number of PS linkages. A "gapmer" design, with PS modifications at the ends and a central region of unmodified or this compound-containing nucleotides, can sometimes balance stability and specificity.
-
Consider Alternative Modifications: Test different combinations of modifications. For example, you might find that a combination of this compound and 2'OMe modifications provides the desired stability with lower toxicity than a fully phosphorothioated sequence in your specific application.
-
Purification: Ensure your oligonucleotide is of high purity. Impurities from the synthesis process can sometimes contribute to toxicity.
-
Control Experiments: Always include appropriate controls in your experiments, such as an unmodified oligonucleotide and a scrambled sequence with the same modifications, to distinguish sequence-specific effects from modification-induced effects.
-
Quantitative Data on Stability
The stabilizing effect of pseudouridine (and by extension, this compound) is highly dependent on its position within the oligonucleotide and the surrounding sequence. Therefore, providing a single, universal value for stability enhancement is not feasible. The table below summarizes the observed effects on thermal stability from a study on pseudouridine-containing RNA duplexes, highlighting this context dependency. Researchers are encouraged to perform their own stability assays to determine the precise stability of their specific oligonucleotides.
| Modification Context (Internal Mismatch Pair) | Change in Melting Temperature (ΔTm) compared to Uridine | Reference |
| Ψ-A pair | Stabilizing | [2][6] |
| Ψ-G pair | Stabilizing | [2][6] |
| Ψ-U pair | Stabilizing | [2][6] |
| Ψ-C pair | Stabilizing | [2][6] |
| s²U or Ψ in central part of antisense strand | Higher Melting Temperature (Tm) | [7] |
Note: The exact ΔTm values vary depending on the adjacent base pairs.
Experimental Protocols
Protocol 1: Serum Stability Assay of Oligonucleotides
This protocol allows for the assessment of oligonucleotide stability in the presence of serum, which contains nucleases.
Materials:
-
This compound-containing oligonucleotide
-
Control oligonucleotide (unmodified or with other modifications)
-
Fetal Bovine Serum (FBS) or human serum
-
Nuclease-free water
-
10x Annealing Buffer (e.g., 100 mM Tris, pH 7.5-8.0, 1 M NaCl, 10 mM EDTA)
-
RNA Loading Dye (e.g., 95% formamide, 0.025% bromophenol blue, 0.025% xylene cyanol, 5 mM EDTA)
-
Polyacrylamide gel (e.g., 15-20%)
-
TBE buffer
-
Nucleic acid stain (e.g., SYBR Gold or GelRed)
-
Heating block and thermal cycler
-
Gel electrophoresis system and imaging equipment
Methodology:
-
Oligonucleotide Annealing (for duplexes):
-
Resuspend complementary single-stranded oligonucleotides in nuclease-free water to a concentration of 20 µM.
-
In a PCR tube, mix 10 µL of each complementary strand, 2.5 µL of 10x Annealing Buffer, and 2.5 µL of nuclease-free water.
-
Incubate at 95°C for 5 minutes, then slowly cool to room temperature.
-
-
Degradation Assay:
-
Prepare reaction tubes for each time point (e.g., 0, 15 min, 30 min, 1h, 2h, 4h, 8h, 24h).
-
For each time point, prepare a 20 µL reaction mix containing:
-
10 µL of 50% serum (in nuclease-free water)
-
X µL of annealed oligonucleotide duplex (to a final concentration of 1 µM)
-
Nuclease-free water to a final volume of 20 µL.
-
-
Incubate the tubes at 37°C.
-
At each designated time point, take a tube, add 20 µL of RNA loading dye to stop the reaction, and immediately place it on ice or at -20°C. The 0-minute time point should have the loading dye added immediately after the addition of the serum-oligo mix.
-
-
Gel Electrophoresis:
-
Thaw the samples on ice.
-
Load the samples onto a polyacrylamide gel.
-
Run the gel in TBE buffer according to the manufacturer's instructions.
-
Stain the gel with a suitable nucleic acid stain.
-
Visualize the gel using an imaging system.
-
-
Data Analysis:
-
Quantify the band intensity of the intact oligonucleotide at each time point.
-
Plot the percentage of intact oligonucleotide versus time.
-
Calculate the half-life (t½) of the oligonucleotide in serum.
-
Visualizations
Caption: Workflow for assessing the serum stability of this compound-containing oligonucleotides.
Caption: Troubleshooting logic for addressing the degradation of this compound-containing oligonucleotides.
References
- 1. Pseudouridine - Wikipedia [en.wikipedia.org]
- 2. The contribution of pseudouridine to stabilities and structure of RNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Semi-quantitative detection of pseudouridine modifications and type I/II hypermodifications in human mRNAs using direct long-read sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Why U Matters: Detection and functions of pseudouridine modifications in mRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Incorporation of Pseudouridine Into mRNA Yields Superior Nonimmunogenic Vector With Increased Translational Capacity and Biological Stability - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. Effect of base modifications on structure, thermodynamic stability, and gene silencing activity of short interfering RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 8. biorxiv.org [biorxiv.org]
- 9. ijeab.com [ijeab.com]
- 10. Stabilization of RNA stacking by pseudouridine - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. sg.idtdna.com [sg.idtdna.com]
Resolving Ambiguous Results in Pseudouridine Mapping Experiments: A Technical Support Guide
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals resolve ambiguous results in pseudouridine (ψ) mapping experiments.
Frequently Asked Questions (FAQs)
Q1: What are the common causes of ambiguous or false-positive results in pseudouridine mapping?
Ambiguous results in pseudouridine mapping can arise from several factors, often related to the chemical modification and sequencing steps. Common causes include:
-
Incomplete CMCT Treatment or Reversal: N-cyclohexyl-N'-(β-(4-methylmorpholinium)ethyl)carbodiimide (CMCT) is used to modify pseudouridine, but it can also react with uridine and guanosine. Incomplete reversal of these adducts under alkaline conditions can lead to false-positive signals.[1][2]
-
RNA Degradation: The harsh chemical treatments, such as strong alkaline conditions used in some protocols, can cause significant RNA degradation.[3] This can lead to a low signal-to-noise ratio and make it difficult to distinguish true modification sites from random fragmentation.
-
Low Sequencing Depth: Insufficient sequencing coverage of a potential modification site can make it statistically challenging to differentiate a true signal from background noise or sequencing errors.[4] This is a particular challenge when profiling large transcriptomes or low-abundance transcripts.[4]
-
Reverse Transcriptase Read-through: Some reverse transcriptases can read through a CMCT-modified pseudouridine, failing to generate the expected stop or mutation signal.[5][6]
-
Intrinsic Reverse Transcriptase Errors: Reverse transcriptase can have inherent error rates, leading to mutations or stops that are not dependent on a pseudouridine modification.[5]
-
Overlapping Signals: In regions with a high density of uridines or other modifications, it can be difficult to precisely map the pseudouridine site.[7]
-
Bias in Antibody-Based Methods: Antibody-based techniques for pseudouridine detection can exhibit sequence context bias, leading to both false positives and false negatives.[4]
Q2: How can I differentiate a true pseudouridine signal from background noise?
Distinguishing a true signal requires careful experimental design and data analysis. Key strategies include:
-
Control Experiments: Always include a "-CMCT" or untreated control alongside your "+CMCT" treated sample. A true pseudouridine site should show a significantly enriched signal (e.g., reverse transcription stop) only in the treated sample.[2]
-
Biological Replicates: Performing multiple biological replicates helps to ensure that the observed signal is reproducible and not a result of random experimental variation.[8]
-
Statistical Analysis: Employ robust statistical methods to assess the significance of the signal at each potential site. This often involves comparing the read counts or mutation frequencies at a specific uridine position between the treated and control samples.[9]
-
Orthogonal Validation: Validate your findings using an alternative method. For example, if you initially used a CMCT-based method, you could try to validate a subset of sites using a bisulfite-based method or direct nanopore sequencing.[10]
-
Knockout/Knockdown of Pseudouridine Synthases (PUS): In cellular systems, knocking out or knocking down a specific PUS enzyme and observing the loss of a signal at a particular site can provide strong evidence for that site's modification status.[1][7]
Q3: What are the advantages and disadvantages of different pseudouridine mapping techniques?
Several techniques are available for mapping pseudouridine, each with its own strengths and weaknesses. The choice of method often depends on the specific research question, available resources, and the RNA of interest.
| Method | Principle | Advantages | Disadvantages |
| CMCT-based (e.g., Pseudo-seq, PSI-seq) | CMCT modifies ψ, leading to reverse transcription (RT) stops.[1][2] | Well-established, provides single-base resolution. | Can cause RNA degradation, semi-quantitative, prone to incomplete reaction/reversal.[8][11] |
| Bisulfite-based (e.g., BID-seq) | Bisulfite treatment of ψ leads to a deletion signature during RT.[12] | Quantitative, requires low RNA input.[12] | Can be difficult to distinguish ψ in dense uridine regions.[7] |
| HydraPsiSeq | Protection of ψ from hydrazine/aniline cleavage. | Quantitative, requires very low RNA input (10-50 ng).[8][11] | Newer technique, less widely adopted. |
| BACS (2-bromoacrylamide-assisted cyclisation sequencing) | Bromoacrylamide chemistry leads to a ψ-to-C transition.[13] | Quantitative, single-base resolution.[13] | Newer technique. |
| Direct Nanopore Sequencing | Direct detection of modified bases based on changes in electrical current. | No chemical treatment or amplification required, can detect multiple modifications simultaneously. | Can be challenging to distinguish ψ from other uridine modifications, requires specialized equipment and analysis pipelines.[4][5] |
| Antibody-based (PA-Ψ-seq) | Immunoprecipitation of ψ-containing RNA fragments. | Can enrich for modified RNAs. | Potential for antibody bias, lower resolution.[4][14] |
Troubleshooting Guides
Issue 1: High background signal in "-CMCT" control lanes.
High background in your negative control can obscure true positive signals.
Potential Causes & Solutions:
| Cause | Solution |
| RNA Degradation | - Use fresh, high-quality RNA. - Minimize freeze-thaw cycles. - Work in an RNase-free environment. - Consider using a gentler RNA fragmentation method if applicable. |
| Contamination | - Ensure all reagents and labware are free of contaminants that could cause RNA cleavage or inhibit reverse transcription. |
| Suboptimal Reverse Transcription Conditions | - Optimize the concentration of reverse transcriptase, dNTPs, and primers. - Test different incubation times and temperatures for the reverse transcription reaction. |
Issue 2: Low or no signal at known pseudouridine sites.
The absence of a signal at a known positive control site indicates a problem with the experimental workflow.
Potential Causes & Solutions:
| Cause | Solution |
| Inefficient CMCT Modification | - Use freshly prepared CMCT solution.[2] - Optimize the CMCT concentration and incubation time. - Ensure the reaction buffer has the correct pH and composition. |
| Over-aggressive Alkaline Treatment | - While necessary to reverse U and G adducts, overly harsh alkaline conditions can also affect the CMC-ψ adduct. Optimize the pH and duration of the alkaline treatment. |
| Poor Reverse Transcriptase Processivity | - Choose a reverse transcriptase known to be sensitive to bulky adducts. - Optimize reverse transcription conditions as described in Issue 1. - Some studies suggest that using Mn2+ instead of Mg2+ as a divalent cation can affect read-through rates.[6] |
| Low RNA Input | - Increase the amount of starting RNA material, especially for low-abundance transcripts.[4] |
Experimental Workflows & Protocols
General Workflow for CMCT-based Pseudouridine Mapping
This diagram illustrates the key steps in a typical CMCT-based pseudouridine mapping experiment like Pseudo-seq or PSI-seq.[1][2]
Caption: Workflow for CMCT-based pseudouridine mapping.
Troubleshooting Logic for Ambiguous Peaks
This decision tree outlines a logical approach to troubleshooting ambiguous peaks in your data.
Caption: Decision tree for troubleshooting ambiguous peaks.
References
- 1. Transcriptome-Wide Mapping of Pseudouridines: Pseudouridine Synthases Modify Specific mRNAs in S. cerevisiae - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Pseudo-Seq: Genome-Wide Detection of Pseudouridine Modifications in RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Pseudouridine Detection and Quantification using Bisulfite Incorporation Hindered Ligation - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Recent developments, opportunities, and challenges in the study of mRNA pseudouridylation - PMC [pmc.ncbi.nlm.nih.gov]
- 5. biorxiv.org [biorxiv.org]
- 6. Pseudouridines have context-dependent mutation and stop rates in high-throughput sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 7. communities.springernature.com [communities.springernature.com]
- 8. researchgate.net [researchgate.net]
- 9. Updated Pseudo-seq Protocol for Transcriptome-Wide Detection of Pseudouridines - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Investigating Pseudouridylation Mechanisms by High-Throughput in Vitro RNA Pseudouridylation and Sequencing | Springer Nature Experiments [experiments.springernature.com]
- 11. academic.oup.com [academic.oup.com]
- 12. Quantitative sequencing using BID-seq uncovers abundant pseudouridines in mammalian mRNA at base resolution - PMC [pmc.ncbi.nlm.nih.gov]
- 13. ludwig.ox.ac.uk [ludwig.ox.ac.uk]
- 14. Mapping of pseudouridine residues on cellular and viral transcripts using a novel antibody-based technique - PMC [pmc.ncbi.nlm.nih.gov]
Addressing the off-target effects of pseudothymidine analogs in cell culture.
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers address the off-target effects of pseudothymidine analogs like Bromodeoxyuridine (BrdU) and Ethynyldeoxyuridine (EdU) in cell culture experiments.
Frequently Asked Questions (FAQs)
Q1: What are the most common off-target effects observed with this compound analogs?
A1: this compound analogs, such as BrdU and EdU, can introduce several off-target effects that may confound experimental results. The most frequently reported issues include cytotoxicity, genotoxicity, and alterations in the normal cell cycle progression.[1][2][3] Specifically, high concentrations of BrdU have been shown to increase the frequency of sister chromatid exchanges and induce a variety of mutations.[1] Similarly, EdU treatment, particularly at elevated concentrations, can be toxic to cell cultures and is especially detrimental to cells with deficiencies in homologous recombination repair.[1][3] Both analogs have the potential to induce DNA damage signaling pathways, leading to cell cycle arrest and apoptosis.[2][4]
Q2: How do BrdU and EdU differ in their off-target effect profiles?
A2: While both are analogs of thymidine used to label proliferating cells, BrdU and EdU exhibit different off-target profiles. EdU has been reported to display higher cytotoxicity and genotoxicity compared to BrdU.[3] For instance, EdU incorporation into DNA can trigger a DNA damage response, characterized by the phosphorylation of ATM, H2AX, p53, and Chk2, which is not observed with BrdU under similar conditions.[4] This can lead to perturbations in cell cycle progression and apoptosis.[4] Conversely, BrdU is known to be mutagenic and can influence various mutations.[1] The choice between the two analogs should be carefully considered based on the experimental context and cell type.
Q3: Can this compound analogs affect cellular signaling pathways?
A3: Yes, the incorporation of this compound analogs into DNA can activate cellular signaling pathways, primarily the DNA damage response (DDR) pathway.[4] When EdU is incorporated into DNA, it can cause DNA strand breaks, which triggers the activation of ATM (Ataxia Telangiectasia Mutated) kinase. Activated ATM then phosphorylates a cascade of downstream targets, including the histone variant H2AX (forming γH2AX), the tumor suppressor p53, and the checkpoint kinase Chk2.[4] This signaling cascade can lead to cell cycle arrest, typically at the G2/M checkpoint, to allow for DNA repair.[4] If the damage is too severe, it can induce apoptosis.[4]
Q4: Are there alternatives to using this compound analogs for measuring cell proliferation?
A4: Yes, several alternative methods are available to assess cell proliferation without the use of this compound analogs. These methods can be broadly categorized as metabolic activity assays, cell proliferation marker assays, and ATP concentration assays.[5]
-
Metabolic Activity Assays: These colorimetric or fluorometric assays, such as MTT, XTT, MTS, and WST-1, measure the metabolic activity of a cell population, which correlates with the number of viable, proliferating cells.[5][6]
-
Cell Proliferation Marker Assays: This approach involves the detection of endogenous proteins expressed in proliferating cells, such as Ki-67, PCNA, and phosphorylated histone H3, using antibodies.[5]
-
ATP Concentration Assays: The amount of ATP in a cell population is proportional to the number of viable cells. This can be quantified using luciferase-based assays.[5]
-
Dye Dilution Assays: Dyes like Carboxyfluorescein succinimidyl ester (CFSE) stably label cells, and the fluorescence intensity is halved with each cell division, which can be monitored by flow cytometry.[7]
Troubleshooting Guides
Problem 1: High levels of cytotoxicity observed after analog treatment.
| Possible Cause | Suggested Solution |
| Analog concentration is too high. | Perform a dose-response experiment to determine the optimal, lowest effective concentration of the analog for your specific cell type. IC50 values can vary significantly between cell lines.[1] For example, the IC50 for BrdU in CHO cells is around 15 µM, but for DNA repair-deficient cells, it can be as low as 0.30–0.63 µM.[1] For EdU, the IC50 in CHO cells is approximately 88 nM.[1] |
| Prolonged exposure to the analog. | Reduce the incubation time with the analog to the minimum required for sufficient labeling. For long-term experiments, consider using BrdU, which is generally reported to have less pronounced cytotoxic effects than EdU.[4] |
| Cell type is particularly sensitive. | Certain cell types, especially those with defects in DNA repair pathways like homologous recombination, are more sensitive to this compound analogs.[1][3] If possible, use a more robust cell line or switch to a non-DNA incorporation-based method for measuring proliferation. |
Problem 2: Inconsistent or unexpected changes in cell cycle profiles.
| Possible Cause | Suggested Solution |
| Analog-induced cell cycle arrest. | EdU incorporation can trigger the DNA damage response and lead to cell cycle arrest, often in the G2/M phase.[4] Analyze cell cycle distribution at different time points after analog treatment to monitor for such effects. Consider using lower concentrations of the analog or a shorter exposure time. |
| Perturbation of S-phase progression. | The replication of DNA containing incorporated EdU can be slowed, leading to a protracted S phase.[4] This can be assessed by pulse-chase experiments. If this is a concern, BrdU may be a less disruptive alternative for cell cycle studies.[4] |
| Off-target effects on cell cycle regulatory proteins. | While less common, it's possible the analogs or their metabolites could indirectly affect cell cycle regulators. Validate key findings with an alternative proliferation assay that does not rely on nucleoside incorporation. |
Quantitative Data Summary
Table 1: Comparative Cytotoxicity (IC50) of this compound Analogs in Different Cell Lines.
| Analog | Cell Line | IC50 Value | Reference |
| BrdU | CHO (wild type) | 15 µM | [1] |
| BrdU | CHO (DNA repair-deficient) | ~0.30–0.63 µM | [1] |
| EdU | CHO (wild type) | 88 nM | [1] |
Experimental Protocols
Protocol 1: Determining Optimal Analog Concentration using a Cytotoxicity Assay (e.g., MTT Assay)
-
Cell Seeding: Seed cells in a 96-well plate at a density that will allow for logarithmic growth for the duration of the experiment. Allow cells to adhere overnight.
-
Analog Treatment: Prepare a serial dilution of the this compound analog (e.g., BrdU or EdU) in complete cell culture medium. Remove the old medium from the wells and add the medium containing different concentrations of the analog. Include untreated control wells.
-
Incubation: Incubate the plate for a period that reflects your intended experimental exposure time (e.g., 24, 48, or 72 hours).
-
MTT Addition: Following incubation, add MTT solution to each well (final concentration of 0.5 mg/mL) and incubate for 2-4 hours at 37°C.
-
Formazan Solubilization: Remove the MTT solution and add a solubilizing agent, such as DMSO or isopropanol, to each well to dissolve the formazan crystals.
-
Absorbance Measurement: Measure the absorbance of the wells at a wavelength of 570 nm using a microplate reader.
-
Data Analysis: Calculate the percentage of cell viability for each concentration relative to the untreated control. Plot the viability against the log of the analog concentration to determine the IC50 value.
Protocol 2: Assessing DNA Damage Response Activation by Western Blotting
-
Cell Treatment: Culture cells to be treated with the determined optimal concentration of the this compound analog for the desired duration. Include a positive control (e.g., treatment with a known DNA damaging agent like etoposide) and an untreated negative control.
-
Cell Lysis: After treatment, wash the cells with ice-cold PBS and lyse them in RIPA buffer supplemented with protease and phosphatase inhibitors.
-
Protein Quantification: Determine the protein concentration of each lysate using a standard protein assay (e.g., BCA assay).
-
SDS-PAGE and Western Blotting: Separate equal amounts of protein from each sample on an SDS-polyacrylamide gel and transfer the proteins to a PVDF or nitrocellulose membrane.
-
Antibody Incubation: Block the membrane and then incubate with primary antibodies against key DNA damage response proteins (e.g., anti-phospho-ATM, anti-phospho-H2AX, anti-phospho-p53). Subsequently, incubate with an appropriate HRP-conjugated secondary antibody.
-
Detection: Visualize the protein bands using an enhanced chemiluminescence (ECL) substrate and an imaging system.
-
Analysis: Compare the levels of the phosphorylated proteins in the treated samples to the controls to assess the activation of the DNA damage response. Use a loading control (e.g., β-actin or GAPDH) to ensure equal protein loading.
Visualizations
Caption: EdU-induced DNA damage response pathway.
References
- 1. Evaluating the Genotoxic and Cytotoxic Effects of Thymidine Analogs, 5-Ethynyl-2′-Deoxyuridine and 5-Bromo-2′-Deoxyurdine to Mammalian Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 2. benchchem.com [benchchem.com]
- 3. Evaluating the Genotoxic and Cytotoxic Effects of Thymidine Analogs, 5-Ethynyl-2'-Deoxyuridine and 5-Bromo-2'-Deoxyurdine to Mammalian Cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. DNA Damage Signaling, Impairment of Cell Cycle Progression, and Apoptosis Triggered by 5-Ethynyl-2′-deoxyuridine Incorporated into DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 5. blog.abclonal.com [blog.abclonal.com]
- 6. What are common methods to study cell proliferation? [synapse.patsnap.com]
- 7. researchgate.net [researchgate.net]
Refinement of protocols for the solid-phase synthesis of pseudothymidine phosphoramidites.
This technical support center provides researchers, scientists, and drug development professionals with a comprehensive guide to the refinement of protocols for the solid-phase synthesis of pseudothymidine phosphoramidites. It includes frequently asked questions, troubleshooting guides, detailed experimental protocols, and quantitative data to facilitate successful synthesis of oligonucleotides containing this modified nucleoside.
Frequently Asked Questions (FAQs)
Q1: What is this compound and how does its structure differ from standard thymidine?
A1: this compound (or 2'-deoxypseudouridine) is a structural isomer of the natural nucleoside thymidine. The key difference lies in the glycosidic bond that connects the uracil base to the deoxyribose sugar. In thymidine, this is a standard N-glycosidic bond between the N1 position of the uracil and the C1' of the sugar. In this compound, it is a C-glycosidic bond between the C5 position of the uracil and the C1' of the sugar. This C-C bond provides greater metabolic stability against enzymatic cleavage.
Q2: Can I use standard phosphoramidite chemistry for the incorporation of this compound?
A2: Yes, this compound phosphoramidites are designed to be compatible with the standard phosphoramidite cycle (deblocking, coupling, capping, and oxidation) used in automated solid-phase oligonucleotide synthesis. However, as with many modified phosphoramidites, some optimization of the standard protocol, particularly the coupling time, may be necessary to achieve optimal incorporation efficiency.
Q3: Does the this compound phosphoramidite require a base-protecting group on the uracil moiety?
A3: Typically, the uracil base of a this compound phosphoramidite does not require a protecting group. The exocyclic keto groups are generally not reactive under the conditions of oligonucleotide synthesis, and the N1-H and N3-H protons are not sufficiently acidic to interfere with the coupling reaction. This simplifies the synthesis and deprotection steps.
Q4: What are the expected coupling efficiencies for this compound phosphoramidites?
A4: While high coupling efficiencies are achievable, they may be slightly lower than for the standard A, C, G, and T phosphoramidites. It is not uncommon for modified phosphoramidites to have coupling efficiencies that are slightly reduced for various reasons, including potential steric hindrance.[1] A well-optimized protocol should still aim for coupling efficiencies greater than 98%.
Q5: Are there special considerations for the deprotection of oligonucleotides containing this compound?
A5: Standard deprotection methods, such as using concentrated ammonium hydroxide, are generally effective for oligonucleotides containing this compound.[2] However, the choice of deprotection strategy should always consider any other modifications present in the oligonucleotide that may be base-labile.[3] For particularly sensitive sequences, milder deprotection conditions may be advisable.
Troubleshooting Guide
Problem 1: Low Coupling Efficiency of this compound Phosphoramidite
Q: I am observing a significant drop in trityl yield after the coupling step with this compound phosphoramidite, indicating low coupling efficiency. What are the possible causes and solutions?
A: Low coupling efficiency is a common issue when incorporating modified nucleosides. Here are the primary factors to investigate:
-
Moisture Contamination: Moisture is highly detrimental to phosphoramidite chemistry.
-
Solution: Ensure all reagents, especially the acetonitrile (ACN) used for dissolving the phosphoramidite and for washes, are of anhydrous grade. Use fresh reagents and consider pre-treating ACN with molecular sieves.[4] Ensure the argon or helium supply to the synthesizer is passed through an in-line drying filter.[5]
-
-
Activator Issues: The type and age of the activator can impact coupling efficiency.
-
Solution: Use a fresh solution of a suitable activator. While standard activators like ethylthiotetrazole (ETT) are often sufficient, more potent activators like 4,5-dicyanoimidazole (DCI) can enhance coupling efficiency, especially for sterically hindered phosphoramidites.[4]
-
-
Insufficient Coupling Time: Modified phosphoramidites may react more slowly than their standard counterparts.
-
Solution: Increase the coupling time for the this compound phosphoramidite. A standard coupling time of 2-3 minutes might need to be extended to 5-10 minutes. It is advisable to perform a small-scale synthesis to optimize the coupling time.
-
-
Phosphoramidite Quality: The phosphoramidite may have degraded due to improper storage or handling.
-
Solution: Store phosphoramidites under a dry, inert atmosphere and at the recommended temperature. Avoid repeated warming and cooling cycles. If degradation is suspected, use a fresh vial of the phosphoramidite.
-
-
Suboptimal Phosphoramidite Concentration: A lower concentration can lead to reduced coupling efficiency.
-
Solution: Ensure the this compound phosphoramidite is fully dissolved in anhydrous ACN at the recommended concentration (typically 0.1 M to 0.15 M). Increasing the concentration or using a double coupling cycle for the this compound addition can also be beneficial.[4]
-
Problem 2: Incomplete Deprotection or Side-Product Formation
Q: After synthesis and deprotection of my this compound-containing oligonucleotide, I am observing unexpected peaks on my HPLC or mass spectrometry analysis. What could be the cause?
A: Incomplete deprotection or the formation of side-products can arise from several factors:
-
Incomplete Removal of Protecting Groups: This can occur if the deprotection time is too short or the reagent is not fresh.
-
Solution: Ensure that the deprotection is carried out for the recommended duration and at the specified temperature. Use fresh deprotection reagents, such as concentrated ammonium hydroxide. For oligonucleotides with many protecting groups or known difficult sequences, extending the deprotection time may be necessary.[2]
-
-
Formation of Adducts: During standard deprotection with ammonium hydroxide, the 2-cyanoethyl protecting groups on the phosphate backbone are removed. The byproduct, acrylonitrile, can potentially react with thymine and uracil bases to form adducts.[6]
-
Solution: While less common with uracil than thymine, if adduct formation is suspected, consider a two-step deprotection. First, treat the solid support with a solution of a hindered base (e.g., DBU) or a mild base in an organic solvent to remove the cyanoethyl groups before cleaving the oligonucleotide from the support with ammonium hydroxide.
-
-
Degradation of Other Modified Bases: If your oligonucleotide contains other sensitive modifications (e.g., certain dyes or base analogs), they may not be stable to standard deprotection conditions.
-
Solution: Always review the deprotection recommendations for all modified phosphoramidites in your sequence. You may need to use a milder deprotection strategy, such as using potassium carbonate in methanol or a mixture of t-butylamine/methanol/water, if you have base-labile components.[3]
-
Quantitative Data
Table 1: Recommended Coupling Parameters for this compound Phosphoramidite
| Parameter | Standard Protocol | Refined Protocol for this compound |
| Phosphoramidite Conc. | 0.1 M in Anhydrous ACN | 0.1 - 0.15 M in Anhydrous ACN |
| Activator | 0.25 M ETT or 0.25 M DCI | 0.25 - 0.5 M DCI in ACN |
| Coupling Time | 2 - 3 minutes | 5 - 10 minutes (or double coupling) |
| Target Efficiency | > 99% | > 98% |
Table 2: Common Deprotection Conditions for Oligonucleotides
| Deprotection Reagent | Temperature | Duration | Application Notes |
| Conc. Ammonium Hydroxide | 55 °C | 8 - 12 hours | Standard procedure for DNA oligonucleotides.[7] |
| AMA (1:1 NH₄OH/Methylamine) | 65 °C | 10 - 15 minutes | "UltraFAST" deprotection; not suitable for all modifications.[3] |
| K₂CO₃ in Methanol (0.05 M) | Room Temp. | 4 - 16 hours | "UltraMILD" deprotection for sensitive modifications.[3] |
| t-Butylamine/Methanol/Water (1:1:2) | 55 °C | 12 - 16 hours | Alternative mild deprotection for sensitive dyes.[3] |
Experimental Protocols
Protocol: Solid-Phase Synthesis of a this compound-Containing DNA Oligonucleotide
This protocol assumes the use of an automated DNA synthesizer and standard phosphoramidite chemistry.
1. Preparation of Reagents:
- Dissolve all standard (dA, dC, dG, dT) and the this compound (dΨ) phosphoramidites in anhydrous acetonitrile to a final concentration of 0.1 M. Handle under an inert atmosphere (e.g., argon).
- Prepare fresh solutions of the activator (e.g., 0.25 M DCI in acetonitrile), capping reagents (Cap A: acetic anhydride/lutidine/THF; Cap B: N-methylimidazole/THF), deblocking solution (3% trichloroacetic acid in dichloromethane), and oxidizer (0.02 M iodine in THF/water/pyridine).
2. Synthesizer Setup:
- Install the reagent bottles on the synthesizer.
- Prime all reagent lines to ensure they are free of air bubbles and filled with fresh reagents.
- Install the appropriate solid support column (e.g., CPG) for the 3'-terminal nucleoside of your sequence.
3. Synthesis Cycle: The synthesis proceeds in the 3' to 5' direction. For each nucleotide addition, the following cycle is performed:
- Step 1: Deblocking (Detritylation): The 5'-DMT protecting group is removed from the support-bound nucleoside by treatment with the deblocking solution. The column is then washed thoroughly with anhydrous acetonitrile.
- Step 2: Coupling: The phosphoramidite of the next base in the sequence and the activator are delivered simultaneously to the column. For the this compound phosphoramidite, the coupling time should be extended to 5-10 minutes.
- Step 3: Capping: Any unreacted 5'-hydroxyl groups are acetylated by treatment with the capping reagents to prevent the formation of deletion mutants.
- Step 4: Oxidation: The newly formed phosphite triester linkage is oxidized to a stable phosphate triester using the iodine solution. The column is then washed with acetonitrile.
- This cycle is repeated until the full-length oligonucleotide is synthesized.
4. Cleavage and Deprotection:
- After the final cycle, the column is removed from the synthesizer.
- The solid support is transferred to a screw-cap vial.
- Add concentrated ammonium hydroxide (approx. 1 mL for a 1 µmol scale synthesis).
- Seal the vial tightly and heat at 55 °C for 8-12 hours to cleave the oligonucleotide from the support and remove the protecting groups from the nucleobases and phosphate backbone.
- After cooling, the supernatant containing the crude oligonucleotide is transferred to a new tube. The support is washed with water, and the washes are combined with the supernatant.
- The solution is then dried down in a vacuum concentrator.
5. Purification and Analysis:
- The crude oligonucleotide is redissolved in water.
- Purification can be performed by methods such as polyacrylamide gel electrophoresis (PAGE), reverse-phase HPLC, or ion-exchange HPLC.
- The identity and purity of the final product should be confirmed by mass spectrometry (e.g., ESI-MS) and analytical HPLC or UPLC.
Mandatory Visualizations
Caption: Workflow for the solid-phase synthesis of this compound-containing oligonucleotides.
References
- 1. trilinkbiotech.com [trilinkbiotech.com]
- 2. glenresearch.com [glenresearch.com]
- 3. glenresearch.com [glenresearch.com]
- 4. blog.biosearchtech.com [blog.biosearchtech.com]
- 5. glenresearch.com [glenresearch.com]
- 6. atdbio.com [atdbio.com]
- 7. Advanced method for oligonucleotide deprotection - PMC [pmc.ncbi.nlm.nih.gov]
Minimizing degradation of pseudothymidine during sample preparation.
This technical support center provides researchers, scientists, and drug development professionals with troubleshooting guidance and frequently asked questions (FAQs) to minimize the degradation of pseudothymidine during sample preparation.
Introduction to this compound Stability
This compound is a C-nucleoside analog of thymidine, where the bond between the ribose sugar and the thymine base is a carbon-carbon (C-C) bond, in contrast to the carbon-nitrogen (C-N) N-glycosidic bond found in thymidine. This structural difference generally confers greater stability to this compound, particularly against enzymatic and acid-catalyzed hydrolysis of the glycosidic bond.[1] However, degradation can still occur under certain conditions. This guide outlines the potential degradation pathways and provides strategies to maintain the integrity of your samples.
Frequently Asked Questions (FAQs)
Q1: What are the primary factors that can cause this compound degradation during sample preparation?
A1: The primary factors that can lead to the degradation of this compound, and nucleosides in general, during sample preparation include:
-
Extreme pH: Both highly acidic and highly alkaline conditions can promote the degradation of nucleosides. While the C-glycosidic bond in this compound is more resistant to acid hydrolysis than the N-glycosidic bond in thymidine, prolonged exposure to strong acids or bases should be avoided.[1][2] For general DNA stability, a neutral pH range of 5 to 9 is considered safe.[2][3]
-
Elevated Temperatures: High temperatures can accelerate chemical degradation.[4][5] It is recommended to perform sample preparation steps at low temperatures (e.g., on ice) whenever possible and to store samples at appropriate cold temperatures (-20°C or -80°C for long-term storage).[6]
-
Enzymatic Activity: If samples are derived from biological matrices, endogenous enzymes such as nucleases and phosphorylases can potentially degrade this compound. The C-C bond in this compound offers significant protection against many common nucleoside-cleaving enzymes.[1]
-
Oxidative Stress: Exposure to oxidizing agents can lead to the modification and degradation of the thymine base.
-
Photodegradation: Exposure to UV light can induce photochemical reactions and degradation.
Q2: I am observing unexpected peaks in my HPLC chromatogram. Could these be degradation products of this compound?
A2: Yes, unexpected peaks in your HPLC chromatogram could be degradation products. Forced degradation studies on similar compounds have shown that various stress conditions can lead to the formation of multiple degradation products.[7] To confirm if these peaks are indeed from this compound degradation, you can perform stress testing on a pure this compound standard (e.g., expose it to acidic, basic, oxidative, and high-temperature conditions) and analyze the resulting chromatograms.
Q3: How can I minimize enzymatic degradation of this compound in my biological samples?
A3: While this compound is inherently more resistant to enzymatic cleavage than thymidine, it is still good practice to minimize all potential enzymatic activity during sample preparation.[1] This can be achieved by:
-
Working quickly and keeping samples on ice at all times.
-
Using protease and nuclease inhibitor cocktails in your lysis and extraction buffers.
-
Immediately proceeding to downstream purification steps that remove enzymes, such as solid-phase extraction (SPE) or protein precipitation.
Q4: What are the best practices for storing this compound stock solutions and samples?
A4: For optimal stability, this compound stock solutions and prepared samples should be stored under the following conditions:
-
Short-term storage (days to weeks): Store at 2-8°C.
-
Long-term storage (months to years): Store at -20°C or -80°C.[6]
-
Solvent: Aqueous solutions are common, but for long-term storage, consider preparing stock solutions in a non-aqueous solvent like DMSO if compatible with your experimental workflow. A study on modified nucleosides showed that aqueous stocks can be prone to degradation over time.[6]
-
Light protection: Store solutions in amber vials or protect them from light to prevent photodegradation.
Troubleshooting Guide
| Problem | Potential Cause | Recommended Solution |
| Low recovery of this compound | Degradation during sample processing: Exposure to harsh pH, high temperatures, or enzymatic activity. | - Maintain a neutral pH (around 7.0) throughout the sample preparation process.- Perform all steps on ice or at 4°C.- Add nuclease inhibitors to biological samples.- Minimize the duration of each sample preparation step. |
| Inefficient extraction: The chosen extraction method may not be optimal for this compound. | - Optimize your solid-phase extraction (SPE) protocol, including the choice of sorbent, wash, and elution solvents.- For complex matrices, consider a liquid-liquid extraction (LLE) step prior to SPE. | |
| Variable results between replicates | Inconsistent sample handling: Minor variations in incubation times, temperatures, or reagent volumes. | - Standardize all sample preparation steps and ensure consistent timing for each sample.- Use calibrated pipettes and fresh reagents. |
| Sample contamination: Introduction of contaminants that interfere with analysis. | - Use high-purity solvents and reagents.- Ensure all labware is thoroughly cleaned or use disposable plastics. | |
| Appearance of extra peaks in chromatogram | Formation of degradation products: As discussed in the FAQs, this can be due to chemical or enzymatic degradation. | - Review your sample preparation protocol for potential stressors (pH, temperature, etc.).- Analyze a fresh, unstressed this compound standard to confirm the identity of the main peak.- If possible, use LC-MS to identify the mass of the unknown peaks and deduce their potential structures. |
Quantitative Data on Nucleoside Stability
| Nucleoside | Storage Temperature | Recovery Rate (%) after 6 Months |
| Canonical Nucleosides (A, C, G, U, T) | -80°C, -20°C, 8°C, 20°C | ~100% |
| 4-thiouridine | 20°C | < 80% |
| 3-methylcytidine | 20°C | < 60% |
| N4-acetylcytidine | 20°C | < 20% |
Data adapted from a study on the stability of modified nucleosides. The recovery rate was determined by normalizing the UV area after storage to the UV area at the initial time point.[6]
Experimental Protocols
Protocol 1: Solid-Phase Extraction (SPE) for this compound Purification
This protocol is a general guideline for purifying this compound from a biological matrix, such as cell lysate or plasma, to remove proteins and other interfering substances.
-
Cartridge Selection: Choose a reverse-phase SPE cartridge (e.g., C18).
-
Conditioning: Condition the cartridge by passing 1 mL of methanol followed by 1 mL of ultrapure water.
-
Sample Loading: Load the pre-treated sample onto the SPE cartridge. The sample should be in an aqueous solution.
-
Washing: Wash the cartridge with 1 mL of a weak organic solvent (e.g., 5% methanol in water) to remove salts and polar impurities.
-
Elution: Elute the this compound with 1 mL of a stronger organic solvent (e.g., 50-100% methanol or acetonitrile).
-
Drying and Reconstitution: Evaporate the eluate to dryness under a gentle stream of nitrogen. Reconstitute the residue in the mobile phase for your analytical method (e.g., HPLC).
Protocol 2: Enzymatic Hydrolysis of DNA to Release Nucleosides
This protocol is for liberating individual nucleosides, including any incorporated this compound, from a purified DNA sample.
-
DNA Quantification: Accurately determine the concentration of your purified DNA sample.
-
Enzyme Mix Preparation: Prepare a master mix containing DNase I, snake venom phosphodiesterase, and alkaline phosphatase in a suitable buffer (e.g., Tris-HCl with MgCl₂).
-
Digestion: Add the enzyme mix to your DNA sample. A typical ratio is 1-2 units of each enzyme per microgram of DNA.
-
Incubation: Incubate the reaction at 37°C for 12-24 hours to ensure complete digestion.
-
Sample Cleanup: After incubation, centrifuge the sample to pellet any undigested material. The supernatant, containing the free nucleosides, can then be further purified (e.g., by SPE) or directly analyzed by LC-MS/MS.[8]
Visualizations
Caption: A typical experimental workflow for the analysis of this compound from biological samples, highlighting key troubleshooting checkpoints.
References
- 1. researchgate.net [researchgate.net]
- 2. pH stability of oligonucleotides [biosyn.com]
- 3. How does pH affect DNA stability? | AAT Bioquest [aatbio.com]
- 4. researchgate.net [researchgate.net]
- 5. Thermal Degradation of Small Molecules: A Global Metabolomic Investigation - PMC [pmc.ncbi.nlm.nih.gov]
- 6. biorxiv.org [biorxiv.org]
- 7. researchgate.net [researchgate.net]
- 8. benchchem.com [benchchem.com]
Technical Support Center: Optimization of Enzymatic Digestion for Pseudouridine Analysis
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals working on the optimization of enzymatic digestion for pseudouridine (Ψ) analysis.
Troubleshooting Guide
This guide addresses common issues encountered during the enzymatic digestion of RNA for pseudouridine analysis in a question-and-answer format.
Q1: Why is the enzymatic digestion of my RNA sample incomplete, leading to low yields of nucleosides?
A1: Incomplete digestion is a frequent challenge that can significantly affect the accuracy of pseudouridine quantification. Several factors can contribute to this issue:
-
Suboptimal Enzyme Activity: Enzymes like Nuclease P1 and alkaline phosphatase may not be functioning optimally due to improper storage, repeated freeze-thaw cycles, or the use of expired reagents. Always store enzymes at their recommended temperatures (typically -20°C) and handle them on ice.[1] It is also advisable to test the activity of new enzyme batches on a control RNA sample.
-
Presence of Inhibitors: RNA preparations can be contaminated with substances that inhibit enzymatic activity, such as residual phenol, chloroform, ethanol, EDTA, and high salt concentrations from purification procedures.[1] Thorough purification of the RNA sample is crucial. Consider additional washes during RNA extraction or re-purification using column-based methods to remove these inhibitors.[1]
-
Incorrect Reaction Conditions: The buffer composition, pH, and temperature are critical for optimal enzyme performance. A typical two-step digestion protocol involves Nuclease P1, which functions best in a slightly acidic environment (pH 5.0-5.4), followed by alkaline phosphatase, which requires an alkaline pH (7.5-8.0).[1][2][3] Using incorrect buffers or pH levels can drastically reduce enzyme efficiency.[1]
-
RNA Tertiary Structure: The complex secondary and tertiary structures of RNA can impede enzyme access to cleavage sites. To overcome this, denature the RNA by heating it to 95-100°C for 5-10 minutes, followed by rapid cooling on ice before adding the enzymes.[1][2][3] This denaturation step helps to unwind the RNA, making it more accessible to nucleases.[1]
Q2: I am observing unexpected peaks or artifacts in my LC-MS/MS analysis. What are the potential causes?
A2: The appearance of unexpected peaks can stem from various sources during sample preparation and analysis:
-
Enzyme Contamination: The enzyme preparations themselves may contain contaminants that can interfere with the analysis.
-
Incomplete Digestion: As mentioned in Q1, incomplete digestion can lead to the presence of di- or oligonucleotides, which will appear as unexpected peaks in the chromatogram.
-
Chemical Modifications: Pseudouridine is an isomer of uridine, making it "mass-silent" in mass spectrometry.[4] To distinguish between the two, chemical derivatization methods are often employed, such as with N-cyclohexyl-N'-β-(4-methylmorpholinumethyl) carbodiimide p-tosylate (CMCT) or acrylonitrile, which add a specific mass to pseudouridine.[5][6] Incomplete or side reactions during derivatization can lead to unexpected adducts and corresponding peaks.
-
Sample Contamination: Contamination from plastics, solvents, or other laboratory materials can introduce interfering compounds.
Q3: How can I ensure the accurate quantification of pseudouridine?
A3: Accurate quantification relies on several factors throughout the experimental workflow:
-
Complete Digestion: Ensuring complete digestion of RNA into single nucleosides is paramount.
-
Stable Isotope Labeling: For mass spectrometry-based quantification, stable isotope labeling can be employed to create a mass difference between uridine and pseudouridine, enabling their distinction and quantification.[4]
-
Quantitative Selected Reaction Monitoring (SRM): SRM assays can be developed using synthetic oligonucleotides with and without pseudouridine to create a standard curve, allowing for the quantification of pseudouridine in unknown samples.[5]
-
Proper Controls: The use of synthetic RNA oligonucleotides with known sequences and pseudouridine content is essential for validating the digestion and analysis methods.
Frequently Asked Questions (FAQs)
Q1: What are the most common enzymes used for the complete digestion of RNA to single nucleosides?
A1: A two-step enzymatic digestion is most commonly employed. The first step typically uses Nuclease P1, a non-specific endonuclease, to break down the RNA into 5'-mononucleotides. The second step utilizes a phosphatase, such as Calf Intestinal Alkaline Phosphatase (CIP) or Shrimp Alkaline Phosphatase (SAP), to remove the phosphate group, yielding single nucleosides.[1]
Q2: What are the optimal reaction conditions for Nuclease P1 and Alkaline Phosphatase?
A2: Nuclease P1 generally requires a slightly acidic pH (around 5.0-5.4) and the presence of ZnCl₂ for optimal activity.[1][2][3] Following Nuclease P1 digestion, the pH of the reaction mixture should be adjusted to a more alkaline range (pH 7.5-8.0) for the subsequent dephosphorylation step with alkaline phosphatase.[1][2][3]
Q3: Are there alternative enzymes to Nuclease P1 for RNA digestion?
A3: Yes, other nucleases can be used depending on the specific requirements of the analysis. For instance, RNase T1, which cleaves after guanosine residues, and RNase A, which cleaves after cytosine and uridine residues, are often used for generating smaller RNA fragments for mass spectrometry analysis rather than complete digestion to single nucleosides.[4][7]
Q4: How can I confirm that my digestion is complete?
A4: You can assess the completeness of your digestion by analyzing an aliquot of the reaction mixture using techniques like HPLC or LC-MS. The absence of di- and oligonucleotides and the presence of only the expected nucleoside peaks indicate a complete digestion.
Data Presentation
Table 1: Stoichiometry of Pseudouridylation in Human Ribosomal RNA (rRNA)
| rRNA Type | Sequence Position | Sequence Context | Stoichiometry of Pseudouridylation (%) |
| 18S rRNA | 296 | ACUCΨAGp | 26.4 |
| 18S rRNA | 608 | UCΨGp | Not Specified |
Data from a study utilizing deuterium labeling and mass spectrometry.[4]
Table 2: Relative Abundance of Pseudouridine in Cellular RNA Pools
| Cell Line | RNA Fraction | Percentage of Pseudouridine |
| HEK293 | Nuclear RNA | 1.20% |
| HEK293 | Small RNA | 1.94% |
| HeLa | 28S rRNA | 0.98% |
| HeLa | 18S rRNA | 1.77% |
Data from a study using HPLC-UV to determine total Ψ levels.[8]
Experimental Protocols
Protocol 1: Two-Step Enzymatic Digestion of RNA for LC-MS Analysis
This protocol is adapted from established methods for the complete digestion of nucleic acids to single nucleosides.[1][2][3][9]
1. RNA Denaturation:
- Take 1-15 µg of purified RNA in a microcentrifuge tube and adjust the final volume to 100 µL with nuclease-free water.
- Heat the RNA sample at 95-100°C for 10 minutes.
- Immediately place the tube on ice for 5 minutes to prevent re-annealing.
2. Nuclease P1 Digestion:
- Add 50 µL of 40 mM sodium acetate buffer (pH 5.0-5.4) containing 0.4 mM ZnCl₂ to the denatured RNA.
- Add 50 µL of Nuclease P1 solution (e.g., 5 U/mL in 40 mM sodium acetate buffer).
- Mix gently by inverting the tube and centrifuge briefly.
- Incubate at 37°C for 30 minutes to 2 hours.
3. Alkaline Phosphatase Digestion:
- Adjust the pH of the reaction mixture to 7.5-8.0 by adding 20 µL of 1 M Tris-HCl (pH 7.5).
- Add 15 µL of alkaline phosphatase solution (e.g., 10 U/mL).
- Mix gently and centrifuge briefly.
- Incubate at 37°C for 30 minutes to 2 hours.
4. Enzyme Inactivation:
- Inactivate the enzymes by heating the reaction mixture at 95°C for 10 minutes.
- The digested sample is now ready for analysis by LC-MS or other methods.
Protocol 2: Chemical Derivatization of Pseudouridine with CMCT
This protocol is a general guideline for the chemical modification of pseudouridine for mass spectrometry analysis.[10]
1. RNase Digestion:
- Digest the RNA sample with an appropriate RNase (e.g., RNase T1 or RNase A) to generate smaller fragments.
2. CMCT Reaction:
- To the RNase-digested RNA, add a stock solution of CMCT (e.g., 20 mg/mL in a buffer containing 50 mM Tris-HCl, 4 mM EDTA, and 7 M urea).
- Incubate the reaction mixture at 37°C for 12-24 hours.
3. Alkaline Hydrolysis:
- Purify the CMCT-reacted RNA (e.g., using C18 Zip-Tips).
- Perform an alkaline hydrolysis step (e.g., in 50 mM NH₄HCO₃, pH 10.4, at 75-80°C for 1-2 hours) to remove CMCT from all nucleosides except pseudouridine and other specific modified bases.
4. Analysis:
- The derivatized sample can then be analyzed by mass spectrometry. The addition of CMCT results in a mass increase of 252 Da for each pseudouridine residue.[5]
Visualizations
Caption: Workflow for enzymatic digestion of RNA for pseudouridine analysis.
Caption: Troubleshooting logic for enzymatic digestion and analysis.
References
- 1. benchchem.com [benchchem.com]
- 2. researchgate.net [researchgate.net]
- 3. researchgate.net [researchgate.net]
- 4. benchchem.com [benchchem.com]
- 5. Mass Spectrometry-Based Quantification of Pseudouridine in RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Detection of pseudouridine and other modifications in tRNA by cyanoethylation and MALDI mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 7. pubs.acs.org [pubs.acs.org]
- 8. Quantification of Pseudouridine Levels in Cellular RNA Pools with a Modified HPLC-UV Assay - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Quantification of pseudouridine level by LC-MS [bio-protocol.org]
- 10. MALDI-MS SCREENING FOR PSEUDOURIDINE IN MIXTURES OF SMALL RNAS BY CHEMICAL DERIVATIZATION, RNASE DIGESTION AND SIGNATURE PRODUCTS - PMC [pmc.ncbi.nlm.nih.gov]
Validation & Comparative
A comparative analysis of pseudothymidine and other modified nucleosides.
A Comparative Analysis of Pseudothymidine and Other Modified Nucleosides
Introduction
Modified nucleosides are structural analogs of the natural nucleosides that form the building blocks of DNA and RNA. By altering the sugar moiety, the nucleobase, or the glycosidic bond that links them, scientists have developed a powerful class of molecules with broad applications in antiviral, anticancer, and antibacterial therapies, as well as in the burgeoning field of mRNA therapeutics.[1][2][3] These analogs function by mimicking natural nucleosides, allowing them to be recognized by cellular or viral enzymes. However, their structural modifications lead to the disruption of critical biological processes, such as nucleic acid replication, ultimately inhibiting the proliferation of cancer cells or the replication of viruses.[4]
This guide provides a comparative analysis of this compound against a selection of other significant modified nucleosides: Zidovudine (AZT), Trifluridine, Telbivudine, and the closely related Pseudouridine (Ψ) and N1-methylpseudouridine (m1Ψ). We will examine their mechanisms of action, comparative performance data, and the experimental protocols used to evaluate them.
Structural and Functional Overview of Selected Modified Nucleosides
The therapeutic efficacy and application of a modified nucleoside are dictated by its unique chemical structure.
-
This compound (ΨT) : As a C-glycoside, this compound features a C-C bond between the ribose sugar and the thymine base, in contrast to the C-N bond found in standard nucleosides. This structural difference makes it more resistant to enzymatic degradation. Studies have shown that multiple sequential pseudothymidines can be incorporated into a DNA duplex by various DNA polymerases without significantly perturbing the DNA structure.[5]
-
Pseudouridine (Ψ) and N1-methylpseudouridine (m1Ψ) : Pseudouridine, an isomer of uridine, is the most abundant modified nucleoside in natural RNA.[6][7] Like this compound, it has a C-C glycosidic bond.[6] Its incorporation into mRNA, along with its derivative N1-methylpseudouridine (m1Ψ), has been shown to reduce innate immune recognition and significantly increase the translational capacity and stability of the mRNA molecule.[7][8] This has been a critical innovation for the development of mRNA vaccines, including those for COVID-19.[3][6]
-
Zidovudine (AZT) : Also known as azidothymidine, ZDV was the first antiretroviral drug approved for the treatment of HIV/AIDS.[9] It is an analog of thymidine where the 3'-hydroxyl group on the deoxyribose sugar is replaced by an azido (-N3) group.[10][11] After intracellular phosphorylation to its active triphosphate form, AZT is incorporated into the growing viral DNA chain by HIV's reverse transcriptase. The absence of the 3'-hydroxyl group prevents the formation of the next phosphodiester bond, causing chain termination and halting viral replication.[11][12][13]
-
Trifluridine (FTD) : A fluorinated pyrimidine nucleoside, trifluridine is an antiviral and antineoplastic agent.[14][15] It is incorporated into DNA in place of thymidine. This incorporation leads to DNA dysfunction, strand breaks, and defective replication, ultimately causing cell cycle arrest and programmed cell death (apoptosis) in rapidly dividing cancer cells and viruses.[14][16] It is effective against DNA viruses like herpes simplex virus.[14][17]
-
Telbivudine (LdT) : A synthetic thymidine nucleoside analog used in the treatment of chronic hepatitis B virus (HBV) infection.[18][19] Following conversion to its active triphosphate form, it competes with the natural substrate (thymidine triphosphate) for incorporation into viral DNA by HBV polymerase.[18][20] Its incorporation leads to obligate chain termination, thereby inhibiting viral replication.[21]
Comparative Performance and Pharmacokinetic Data
The clinical utility of nucleoside analogs is determined by their biological activity, bioavailability, and safety profile. The following tables summarize key quantitative data for the selected compounds.
| Compound | Primary Target | Mechanism of Action | Key Application(s) | Reported IC₅₀ / EC₅₀ |
| This compound (ΨT) | DNA Polymerases | DNA Chain Elongation (as analog) | Research, Synthetic Biology | Data not widely available; used as a structural probe. |
| Pseudouridine (Ψ) | Ribosome, Innate Immune Receptors | Enhances mRNA translation, reduces immunogenicity | mRNA Therapeutics & Vaccines | Not applicable (enhances function rather than inhibits). |
| N1-methylpseudouridine (m1Ψ) | Ribosome, Innate Immune Receptors | Enhances mRNA translation, reduces immunogenicity | mRNA Therapeutics & Vaccines | Not applicable (enhances function rather than inhibits). |
| Zidovudine (AZT) | HIV Reverse Transcriptase | DNA Chain Termination | HIV-1, HIV-2 Infection | ~0.03 µM against HIV[4] |
| Trifluridine (FTD) | DNA Polymerase (Viral & Cellular) | DNA Dysfunction, Chain Termination | Herpes Simplex Keratitis, Colorectal Cancer | Varies by virus/cell line. |
| Telbivudine (LdT) | HBV DNA Polymerase | DNA Chain Termination | Chronic Hepatitis B | Varies by HBV strain. |
| Compound | Bioavailability | Protein Binding | Elimination Half-life | Primary Metabolism/Excretion |
| Zidovudine (AZT) | ~60-75%[9][22] | 30-38%[9] | 0.5-3 hours[9] | Hepatic (glucuronidation), Renal[9] |
| Trifluridine (FTD) | Low (administered topically or with an inhibitor) | Not specified | Not specified | Rapidly degraded by thymidine phosphorylase.[16] |
| Telbivudine (LdT) | Not specified | Low (3.3%)[19] | 40-49 hours[19] | Renal (unchanged)[19] |
Key Experimental Methodologies
The evaluation of modified nucleosides relies on a set of standardized in vitro and in vivo assays.
Antiviral Efficacy Assay (e.g., for AZT, Telbivudine)
This protocol determines the concentration of a compound required to inhibit viral replication in cell culture.
-
Cell Culture and Infection : Susceptible host cells (e.g., MT-4 cells for HIV) are cultured in appropriate media. The cells are then infected with a known titer of the virus.
-
Drug Treatment : Immediately following infection, the cells are treated with serial dilutions of the modified nucleoside analog. A "no-drug" control is run in parallel.
-
Incubation : The treated and control cells are incubated for a period that allows for multiple rounds of viral replication (e.g., 4-5 days).
-
Quantification of Viral Replication : The extent of viral replication is measured. This can be done by:
-
Plaque Reduction Assay : Counting the number of viral plaques (zones of cell death) in a cell monolayer.
-
Quantitative PCR (qPCR) : Measuring the amount of viral DNA or RNA in the cell supernatant.[21]
-
Reverse Transcriptase (RT) Activity Assay : For retroviruses like HIV, the activity of the RT enzyme in the supernatant is quantified as a proxy for viral load.
-
-
Data Analysis : The drug concentration that inhibits viral replication by 50% (EC₅₀) is calculated by plotting the percentage of inhibition against the drug concentration.
mRNA Translation Efficiency Assay (e.g., for Ψ, m1Ψ)
This protocol measures the protein yield from an mRNA transcript containing modified nucleosides.
-
In Vitro Transcription : An mRNA molecule encoding a reporter protein (e.g., Firefly Luciferase) is synthesized in vitro. The reaction mix contains either standard UTP or a modified nucleotide triphosphate like Ψ-TP or m1Ψ-TP.[8]
-
Transfection : The unmodified and modified mRNAs are delivered into cultured mammalian cells (e.g., HeLa or HEK293 cells) using a transfection reagent like lipid nanoparticles.[8][23]
-
Cell Lysis and Reporter Assay : After a set incubation period (e.g., 6, 12, 24 hours), the cells are lysed. The lysate is then assayed for the activity of the reporter protein. For luciferase, a substrate is added, and the resulting luminescence is measured with a luminometer.[8]
-
Data Analysis : The luminescence values (proportional to protein quantity) are compared between cells transfected with unmodified mRNA and those with modified mRNA to determine the relative translation efficiency.
Polymerase Chain Termination Assay (e.g., for AZT)
This in vitro assay directly visualizes the ability of a nucleoside analog to be incorporated by a polymerase and terminate chain elongation.
-
Reaction Components : A reaction is set up containing a DNA polymerase (e.g., HIV reverse transcriptase), a primer-template construct (often with the primer being radiolabeled), natural deoxynucleotide triphosphates (dNTPs), and the triphosphate form of the nucleoside analog (e.g., AZT-TP).
-
Polymerase Reaction : The reaction is initiated and allowed to proceed for a specific time. The polymerase extends the primer along the template. When it encounters a position where the analog can be incorporated, it may add the analog instead of the natural nucleotide.
-
Gel Electrophoresis : The reaction is stopped, and the resulting DNA fragments are separated by size using denaturing polyacrylamide gel electrophoresis.
-
Visualization and Analysis : The gel is visualized (e.g., by autoradiography if a radiolabeled primer was used). The presence of shorter DNA fragments in the lane containing the nucleoside analog, corresponding to the positions where termination occurred, confirms its action as a chain terminator.[10][12]
Visualizing Mechanisms and Workflows
Diagrams created using Graphviz help to clarify complex biological pathways and experimental processes.
Caption: General mechanism of action for chain-terminating nucleoside analogs.
Caption: Experimental workflow for testing the antiviral efficacy of a compound.
Caption: Structural comparison of N-glycosidic and C-glycosidic bonds.
Conclusion
The field of modified nucleosides showcases remarkable chemical diversity, leading to a wide range of therapeutic applications. Chain-terminating analogs like Zidovudine and Telbivudine have become cornerstones in the fight against viral diseases by directly inhibiting replication machinery. Others, such as Trifluridine, induce lethal dysfunction in the genetic material of target cells.
In contrast, C-glycosides like this compound and pseudouridine represent a different paradigm. Rather than acting as inhibitors, their incorporation into nucleic acids can enhance biological properties. The use of pseudouridine and its derivatives to create more stable and highly translatable mRNA has revolutionized vaccine development and opened new avenues for protein replacement therapies. The study of this compound continues to inform our understanding of DNA polymerase function and the structural tolerance of the DNA double helix, paving the way for new applications in synthetic biology and diagnostics. The selection of a particular modified nucleoside is therefore highly dependent on the desired biological outcome, from inducing cytotoxicity in pathogens to enhancing the therapeutic potential of nucleic acid-based medicines.
References
- 1. Frontiers | Nucleobase-modified nucleosides and nucleotides: Applications in biochemistry, synthetic biology, and drug discovery [frontiersin.org]
- 2. Discussion on Modified Nucleosides [bldpharm.com]
- 3. Nucleoside Chemistry Blog Series (II): Nucleosides: Biological Roles, Modifications and Applications in Medicinal Chemistry | Blog | Biosynth [biosynth.com]
- 4. The evolution of nucleoside analogue antivirals: A review for chemists and non-chemists. Part 1: Early structural modifications to the nucleoside scaffold - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Incorporation of multiple sequential pseudothymidines by DNA polymerases and their impact on DNA duplex structure - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Pseudouridine and N1-methylpseudouridine as potent nucleotide analogues for RNA therapy and vaccine development - PMC [pmc.ncbi.nlm.nih.gov]
- 7. areterna.com [areterna.com]
- 8. Incorporation of Pseudouridine Into mRNA Yields Superior Nonimmunogenic Vector With Increased Translational Capacity and Biological Stability - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Zidovudine - Wikipedia [en.wikipedia.org]
- 10. AZT – mechanism of action and organic synthesis - The Science Snail [sciencesnail.com]
- 11. ClinPGx [clinpgx.org]
- 12. droracle.ai [droracle.ai]
- 13. PharmGKB summary: zidovudine pathway - PMC [pmc.ncbi.nlm.nih.gov]
- 14. What is the mechanism of Trifluridine? [synapse.patsnap.com]
- 15. Trifluridine | C10H11F3N2O5 | CID 6256 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 16. How LONSURF® Works | Mechanism of Action [lonsurfhcp.com]
- 17. m.youtube.com [m.youtube.com]
- 18. What is the mechanism of Telbivudine? [synapse.patsnap.com]
- 19. Telbivudine - Wikipedia [en.wikipedia.org]
- 20. Telbivudine - LiverTox - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 21. Telbivudine: A new treatment for chronic hepatitis B - PMC [pmc.ncbi.nlm.nih.gov]
- 22. Comparative pharmacokinetics of antiviral nucleoside analogues - PubMed [pubmed.ncbi.nlm.nih.gov]
- 23. Efficacy and Immunogenicity of Unmodified and Pseudouridine-Modified mRNA Delivered Systemically with Lipid Nanoparticles in Vivo - PMC [pmc.ncbi.nlm.nih.gov]
A Researcher's Guide to Validating Pseudothymidine in Novel RNA Molecules
For researchers, scientists, and drug development professionals, the accurate identification and quantification of pseudothymidine (Ψ), the C5-glycoside isomer of uridine, in novel RNA molecules is a critical step in understanding their structure, function, and therapeutic potential. This guide provides a comprehensive comparison of current methodologies, offering insights into their principles, performance, and practical applications.
The isomerization of uridine to pseudouridine is the most abundant post-transcriptional modification in RNA, playing a crucial role in the biogenesis and function of various RNA species, including ribosomal RNAs, transfer RNAs, and messenger RNAs. The development of RNA-based therapeutics has further underscored the importance of precise pseudouridine detection, as its presence can significantly impact the stability, translation efficiency, and immunogenicity of synthetic RNA molecules.
This guide delves into a range of techniques, from traditional chromatographic methods to cutting-edge sequencing and mass spectrometry approaches. By presenting quantitative data in a clear, comparative format and providing detailed experimental protocols, we aim to equip researchers with the knowledge to select the most appropriate method for their specific research needs.
Comparative Analysis of Pseudouridine Detection Methods
The selection of a suitable method for pseudouridine validation depends on several factors, including the required sensitivity, desired resolution (global vs. site-specific), quantitative accuracy, sample availability, and throughput. The following table summarizes the key performance characteristics of the most prominent techniques.
| Method Category | Specific Technique(s) | Principle | Resolution | Quantification | Throughput | Key Advantages | Key Limitations |
| Next-Generation Sequencing (NGS) | Pseudo-seq, Ψ-seq, PSI-seq, CeU-seq, BID-seq | Chemical modification (CMC or bisulfite) induces reverse transcriptase stops, deletions, or mutations at Ψ sites, which are then identified by deep sequencing. | Single nucleotide | Semi-quantitative to Quantitative | High | Transcriptome-wide mapping, high sensitivity for detecting novel sites. | Indirect detection, potential for biases from chemical treatment and sequencing depth.[1] |
| Mass Spectrometry (MS) | LC-MS/MS with chemical derivatization (CMC, acrylonitrile, bisulfite) or stable isotope labeling | Detects mass shifts introduced by chemical labels on Ψ or by metabolic incorporation of stable isotopes. | Site-specific | Quantitative | Medium to High | Direct detection, high accuracy and specificity, can detect other modifications simultaneously.[2] | "Mass-silent" nature of Ψ requires derivatization or labeling[3][4]; can be complex and costly. |
| High-Performance Liquid Chromatography (HPLC) | HPLC with UV detection | Separates and quantifies nucleosides after complete RNA digestion. | Global | Quantitative | Medium | Well-established, provides accurate global quantification of Ψ.[5][6] | Does not provide positional information[7][8]; requires relatively large amounts of RNA. |
| Reverse Transcription PCR (RT-PCR) | CMC-RT and Ligation Assisted PCR (CLAP) | CMC-induced reverse transcription stop at Ψ is detected and quantified by PCR. | Site-specific | Quantitative | Low to Medium | High sensitivity for specific, targeted Ψ sites in low-abundance RNAs.[9] | Not suitable for transcriptome-wide discovery. |
| Thin-Layer Chromatography (TLC) | 2D-TLC with radiolabeling | Separates radiolabeled nucleosides based on their physicochemical properties. | Global | Quantitative | Low | A classic and quantitative method. | Low throughput, requires handling of radioactive materials.[10] |
Experimental Workflows and Signaling Pathways
To visualize the operational principles of these methods, the following diagrams, generated using the Graphviz DOT language, illustrate a general experimental workflow for pseudouridine validation and a comparison of two distinct detection strategies.
Detailed Experimental Protocols
To facilitate the implementation of these techniques, detailed protocols for two common methods are provided below.
Protocol 1: CMC-Based Pseudouridine Detection Followed by Reverse Transcription
This protocol is a foundational technique for many NGS-based methods and can also be used for site-specific analysis by primer extension.
1. CMC Treatment of RNA:
-
Resuspend 5-10 µg of total RNA in RNase-free water.
-
Add an equal volume of 2X CMC reaction buffer (e.g., 100 mM Bicine, 8 M urea, 2 mM EDTA, pH 8.3).
-
Add N-cyclohexyl-N'-(β-(4-methylmorpholinium)ethyl)carbodiimide (CMC) to a final concentration of 0.2 M.
-
Incubate the reaction at 37°C for 20-30 minutes.
-
Purify the RNA using phenol:chloroform extraction followed by ethanol precipitation to remove excess CMC.
2. Alkaline Treatment:
-
Resuspend the CMC-treated RNA pellet in 50 mM sodium carbonate buffer (pH 10.4).
-
Incubate at 37°C for 4-6 hours. This step removes CMC adducts from uridine and guanosine, while the adduct on pseudouridine remains.
-
Purify the RNA by ethanol precipitation.
3. Reverse Transcription:
-
Use the CMC-treated RNA as a template for reverse transcription with a gene-specific primer.
-
The bulky CMC adduct on pseudouridine will cause the reverse transcriptase to stall and terminate, typically one nucleotide 3' to the modified base.
-
The resulting cDNA can be analyzed by gel electrophoresis for primer extension analysis or used for library preparation for next-generation sequencing.[11][12]
Protocol 2: Mass Spectrometry-Based Quantification of Pseudouridine
This protocol outlines a general workflow for quantifying pseudouridine using liquid chromatography-tandem mass spectrometry (LC-MS/MS).
1. RNA Digestion:
-
Digest 1-5 µg of purified RNA to single nucleosides using a mixture of nucleases (e.g., nuclease P1) and phosphatases (e.g., bacterial alkaline phosphatase).
-
A typical reaction involves incubating the RNA with the enzymes in a suitable buffer at 37°C for 2-4 hours.
2. LC-MS/MS Analysis:
-
Separate the resulting nucleosides using reverse-phase high-performance liquid chromatography (HPLC).
-
The eluent from the HPLC is directly introduced into the mass spectrometer.
-
Since pseudouridine and uridine are isomers, they have the same mass. To distinguish them, tandem mass spectrometry (MS/MS) is employed. The fragmentation patterns of pseudouridine and uridine are distinct, allowing for their specific detection and quantification.[7]
-
For enhanced sensitivity and specificity, chemical derivatization (e.g., with acrylonitrile) can be performed prior to LC-MS/MS to introduce a mass difference between the two isomers.[7] Alternatively, stable isotope labeling in cell culture can be used to metabolically introduce a mass tag.[3][13]
3. Quantification:
-
Generate standard curves using known concentrations of pure uridine and pseudouridine nucleosides.
-
Quantify the amount of pseudouridine in the sample by comparing the peak areas from the sample to the standard curves.[6]
Conclusion
The field of epitranscriptomics is rapidly evolving, and with it, the methodologies for detecting and quantifying RNA modifications like pseudouridine. While high-throughput sequencing methods offer a powerful tool for transcriptome-wide discovery, mass spectrometry provides unparalleled accuracy for quantitative validation. For targeted analysis of specific sites, RT-PCR-based methods offer high sensitivity. The choice of method should be guided by the specific research question, available resources, and the desired level of detail. By understanding the principles and performance of each technique, researchers can confidently validate the presence and abundance of pseudouridine in their novel RNA molecules, paving the way for a deeper understanding of their biological significance and therapeutic potential.
References
- 1. Recent developments, opportunities, and challenges in the study of mRNA pseudouridylation - PMC [pmc.ncbi.nlm.nih.gov]
- 2. BID-seq for transcriptome-wide quantitative sequencing of mRNA pseudouridine at base resolution - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. benchchem.com [benchchem.com]
- 4. Detection and Quantification of Pseudouridine in RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. BID-seq for transcriptome-wide quantitative sequencing of mRNA pseudouridine at base resolution | Springer Nature Experiments [experiments.springernature.com]
- 6. Quantification of Pseudouridine Levels in Cellular RNA Pools with a Modified HPLC-UV Assay - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Mass Spectrometry-Based Quantification of Pseudouridine in RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Why U Matters: Detection and functions of pseudouridine modifications in mRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Pseudouridine RNA modification detection and quantification by RT-PCR - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. Pseudo-Seq: Genome-Wide Detection of Pseudouridine Modifications in RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Pseudouridine site assignment by high-throughput in vitro RNA pseudouridylation and sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 13. pubs.acs.org [pubs.acs.org]
A Comparative Analysis of the Metabolic Fates of Pseudothymidine and Thymidine
For Immediate Publication
[City, State] – [Date] – A comprehensive comparison of the metabolic pathways of the naturally occurring nucleoside thymidine and its C-glycosidic isomer, pseudothymidine, reveals significant differences in their anabolic and catabolic fates. This guide, intended for researchers, scientists, and professionals in drug development, consolidates available experimental data to highlight these distinctions, which are rooted in the fundamental structural variance between the N-glycosidic bond of thymidine and the C-glycosidic bond of this compound.
Executive Summary
Thymidine, a fundamental component of DNA, undergoes well-established anabolic and catabolic metabolism. It is readily phosphorylated by thymidine kinase as the first step in the salvage pathway to be incorporated into DNA. Conversely, it can be degraded into thymine and 2-deoxyribose-1-phosphate by thymidine phosphorylase. In contrast, this compound, a C-nucleoside, exhibits a markedly different metabolic profile. While its triphosphate derivative can be incorporated into DNA by various polymerases, its resistance to cleavage by thymidine phosphorylase renders it catabolically inert via this major pathway. This fundamental difference in metabolic stability has significant implications for the potential therapeutic applications of this compound and its derivatives.
Anabolic Pathways: Phosphorylation and Incorporation into DNA
Both thymidine and this compound can enter anabolic pathways, ultimately leading to their incorporation into DNA. This process is initiated by phosphorylation, a critical step catalyzed by nucleoside kinases.
Thymidine Anabolism: Thymidine is efficiently phosphorylated to thymidine monophosphate (TMP) by thymidine kinase (TK). Subsequent phosphorylations yield thymidine diphosphate (TDP) and thymidine triphosphate (TTP), the latter being a direct precursor for DNA synthesis.
Anabolic pathways of thymidine and this compound.
Catabolic Pathways: A Tale of Two Bonds
The most striking difference in the metabolism of thymidine and this compound lies in their susceptibility to catabolism.
Thymidine Catabolism: The primary catabolic pathway for thymidine involves the enzymatic cleavage of its N-glycosidic bond by thymidine phosphorylase (TP), yielding thymine and 2-deoxy-D-ribose-1-phosphate. These products can then enter further metabolic pathways.
This compound Catabolism: The carbon-carbon bond of the C-glycosidic linkage in this compound is resistant to cleavage by thymidine phosphorylase. This intrinsic stability means that this compound is not a substrate for this key catabolic enzyme, leading to a significantly longer intracellular half-life compared to thymidine.
Catabolic pathways of thymidine and this compound.
Quantitative Data Comparison
The following table summarizes the available kinetic parameters for the key enzymes involved in thymidine metabolism. Corresponding quantitative data for this compound is largely unavailable, highlighting a key area for future research.
| Parameter | Thymidine | This compound | Enzyme | Organism | Reference |
| Km | 5 µM | Not available | Thymidine Kinase (liver) | Human | [1] |
| Km | 285 ± 55 µM | Not a substrate | Thymidine Phosphorylase (hepatic) | Human | [2] |
| Vmax | Data available | Not available | Thymidine Kinase | Various | [3] |
| Incorporation | Efficient | Can be incorporated | DNA Polymerases | Various | [4][5] |
Experimental Protocols
Thymidine Kinase Activity Assay
This protocol is adapted from established methods for measuring thymidine kinase activity and can be used to assess the phosphorylation of both thymidine and this compound.
Objective: To determine the rate of phosphorylation of a nucleoside (thymidine or this compound) by thymidine kinase.
Materials:
-
Recombinant human thymidine kinase 1 (TK1) or 2 (TK2)
-
[γ-32P]ATP
-
ATP solution
-
Thymidine or this compound stock solutions
-
Reaction buffer (50 mM Tris-HCl pH 7.6, 10 mM MgCl2, 10 mM DTT, 0.5 mg/mL BSA)
-
PEI-cellulose TLC plates
-
Developing solvent (e.g., 1 M LiCl)
-
Phosphorimager or scintillation counter
Procedure:
-
Prepare reaction mixtures containing the reaction buffer, varying concentrations of the nucleoside substrate (thymidine or this compound), ATP, and [γ-32P]ATP.
-
Initiate the reaction by adding the thymidine kinase enzyme.
-
Incubate the reactions at 37°C for a defined period (e.g., 10, 20, 30 minutes).
-
Stop the reaction by adding EDTA or by heat inactivation.
-
Spot an aliquot of each reaction mixture onto a PEI-cellulose TLC plate.
-
Develop the TLC plate in the developing solvent to separate the phosphorylated nucleoside from the unreacted [γ-32P]ATP.
-
Visualize and quantify the radiolabeled monophosphate product using a phosphorimager or by scraping the spots and using a scintillation counter.
-
Calculate the initial reaction velocities and determine the kinetic parameters (Km and Vmax) by fitting the data to the Michaelis-Menten equation.
Thymidine Phosphorylase Activity Assay
This protocol allows for the measurement of the catabolic activity of thymidine phosphorylase on nucleoside substrates.
Objective: To determine the rate of phosphorolysis of a nucleoside (thymidine or this compound) by thymidine phosphorylase.
Materials:
-
Recombinant human thymidine phosphorylase (TP)
-
Thymidine or this compound stock solutions
-
Phosphate buffer (e.g., 100 mM potassium phosphate, pH 7.4)
-
HPLC system with a UV detector
-
C18 reverse-phase HPLC column
Procedure:
-
Prepare reaction mixtures containing the phosphate buffer and the nucleoside substrate at various concentrations.
-
Initiate the reaction by adding thymidine phosphorylase.
-
Incubate the reactions at 37°C, taking aliquots at different time points.
-
Stop the reaction in the aliquots by adding a quenching agent (e.g., perchloric acid) and neutralizing.
-
Centrifuge the samples to pellet the precipitated protein.
-
Analyze the supernatant by reverse-phase HPLC to separate and quantify the substrate (thymidine or this compound) and the product (thymine).
-
Monitor the absorbance at a suitable wavelength (e.g., 267 nm).
-
Calculate the rate of substrate consumption or product formation to determine the enzyme activity.
Conclusion
The structural disparity between the N-glycosidic bond of thymidine and the C-glycosidic bond of this compound dictates their distinct metabolic fates. While both can be anabolically incorporated into DNA, their catabolic pathways diverge significantly. The resistance of this compound to degradation by thymidine phosphorylase presents an intriguing characteristic for the development of novel therapeutic agents with enhanced stability and prolonged intracellular action. Further research is warranted to elucidate the precise enzymatic machinery responsible for this compound phosphorylation and to quantify its efficiency, which will be critical for realizing its full therapeutic potential.
References
- 1. Kinetic mechanism and inhibition of human liver thymidine kinase - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Structural and kinetic characterization of human deoxycytidine kinase variants able to phosphorylate 5-substituted deoxycytidine and thymidine analogs - PMC [pmc.ncbi.nlm.nih.gov]
- 4. The Kinetic Effects on Thymidine Kinase 2 by Enzyme-Bound dTTP May Explain the Mitochondrial Side Effects of Antiviral Thymidine Analogs - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Thymidine kinase - Wikipedia [en.wikipedia.org]
A Comparative Guide to Pseudothymidine Detection Methods
For researchers, scientists, and professionals in drug development, the accurate detection and quantification of modified nucleosides like pseudothymidine (ΨT) is crucial for understanding RNA metabolism, developing RNA-based therapeutics, and identifying disease biomarkers. This guide provides a comprehensive comparison of three primary analytical techniques for this compound detection: Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS), High-Performance Liquid Chromatography with UV detection (HPLC-UV), and Capillary Electrophoresis (CE).
This document outlines the experimental protocols for each method, presents a comparative analysis of their performance metrics, and visualizes the associated workflows to aid in the selection of the most suitable technique for your research needs.
Quantitative Performance Comparison
The following table summarizes the key quantitative performance characteristics of the three compared methods for the analysis of this compound or its close analogs.
| Performance Metric | Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS) | High-Performance Liquid Chromatography-UV (HPLC-UV) | Capillary Electrophoresis (CE) |
| Principle | Separation by chromatography, detection by mass-to-charge ratio | Separation by chromatography, detection by UV absorbance | Separation by electrophoretic mobility in a capillary |
| Sensitivity | Very High (pg to fg level) | Moderate (ng to µg level) | High (µmol/L to nmol/L level) |
| Specificity | Very High (based on parent and fragment ion masses) | Moderate (risk of co-eluting compounds with similar UV spectra) | High (based on unique electrophoretic mobility) |
| Limit of Detection (LOD) | Low pmol to fmol range (analyte dependent) | ~0.5 µg/mL for thymidine[1] | <2.0 µmol/L for pseudouridine[2] |
| Limit of Quantification (LOQ) | Low pmol to fmol range (analyte dependent) | 0.5 µg/mL for thymidine[1] | 5.0 µmol/L for pseudouridine[2] |
| Linearity (Range) | Wide dynamic range, typically several orders of magnitude | 0.5 to 5.0 µg/mL for thymidine[1] | 5.0−500 μmol/L for pseudouridine[2] |
| Sample Throughput | Moderate to High | High | High |
| Instrumentation Cost | High | Low to Moderate | Moderate |
| Primary Application | Targeted quantification, structural elucidation, analysis of complex mixtures | Routine quantification, purity analysis | Analysis of charged molecules, high-resolution separation of isomers |
Experimental Workflows and Signaling Pathways
To visually represent the methodologies, the following diagrams, created using the DOT language, illustrate the experimental workflows for each detection method.
Detailed Experimental Protocols
Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS)
LC-MS/MS is widely regarded as the gold standard for the sensitive and specific quantification of modified nucleosides.
1. Sample Preparation: Enzymatic Hydrolysis
-
Start with purified RNA or DNA samples.
-
To 1-10 µg of nucleic acid, add nuclease P1 and incubate at 37°C for 2-4 hours to digest the nucleic acids into 5'-mononucleotides.
-
Add alkaline phosphatase and continue incubation at 37°C for an additional 2-4 hours to dephosphorylate the mononucleotides into nucleosides.
-
The resulting mixture of nucleosides is then typically filtered or subjected to solid-phase extraction to remove enzymes and other contaminants.
2. Liquid Chromatography Separation
-
Column: A C18 reverse-phase column is commonly used.
-
Mobile Phase: A gradient elution is typically employed, using a combination of an aqueous phase (e.g., water with a small amount of formic acid or ammonium acetate) and an organic phase (e.g., acetonitrile or methanol).
-
Flow Rate: Typical flow rates are in the range of 200-400 µL/min.
-
Temperature: The column is often maintained at a constant temperature (e.g., 40°C) to ensure reproducible retention times.
3. Tandem Mass Spectrometry Detection
-
Ionization: Electrospray ionization (ESI) in positive ion mode is most common for nucleosides.
-
Detection Mode: Selected Reaction Monitoring (SRM) or Multiple Reaction Monitoring (MRM) is used for targeted quantification. This involves selecting the precursor ion (the mass-to-charge ratio of this compound) in the first mass spectrometer (MS1), fragmenting it in a collision cell, and then detecting a specific fragment ion in the second mass spectrometer (MS2). This two-stage detection provides very high specificity.
-
Quantification: Quantification is achieved by comparing the peak area of the analyte to that of a stable isotope-labeled internal standard.
High-Performance Liquid Chromatography with UV Detection (HPLC-UV)
HPLC-UV is a more accessible and cost-effective method for the quantification of nucleosides, suitable for applications where the very high sensitivity of MS is not required.
1. Sample Preparation: Deproteinization
-
For biological fluids like plasma, a simple deproteinization step is often sufficient.
-
Mix the sample (e.g., 100 µL of plasma) with a precipitating agent such as perchloric acid or acetonitrile.
-
Centrifuge the mixture to pellet the precipitated proteins.
-
The resulting supernatant, containing the nucleosides, is collected and can be directly injected into the HPLC system.
2. HPLC Separation
-
Column: A C18 reverse-phase column is typically used. For instance, a Synergi 4µm Hydro-RP, 150×4mm I.D. column can be employed[1].
-
Mobile Phase: An isocratic mobile phase, such as a mixture of potassium dihydrogen phosphate buffer (e.g., 20 mM, pH 4.5) and acetonitrile (e.g., 95:5, v/v), is often used[1].
-
Flow Rate: A typical flow rate is around 0.7 mL/min[1].
-
Temperature: The separation is usually performed at room temperature.
3. UV Detection
-
The eluent from the HPLC column passes through a UV detector.
-
The wavelength for detection is set to the absorption maximum of the analyte. For thymidine and its analogs, this is typically around 267 nm[1].
-
Quantification: The concentration of this compound is determined by comparing the peak area on the chromatogram to a calibration curve generated from standards of known concentrations.
Capillary Electrophoresis (CE)
Capillary electrophoresis offers high separation efficiency and short analysis times, making it a powerful technique for the analysis of complex mixtures of nucleosides.
1. Sample Preparation
-
For samples like urine, minimal preparation is often required. This may involve dilution with the running buffer and filtration to remove particulates.
2. Capillary Electrophoresis Separation
-
Capillary: A fused silica capillary (e.g., 50 µm internal diameter, 38 cm effective length) is used[2].
-
Background Electrolyte (BGE): The choice of BGE is critical for achieving good separation. A borate-phosphate buffer containing a surfactant like cetyltrimethylammonium bromide (CTAB) at a specific pH (e.g., 9.50) can be effective for separating a mixture of nucleosides[2].
-
Voltage: A high voltage (e.g., 15 kV) is applied across the capillary to drive the separation[2].
-
Injection: The sample is introduced into the capillary by either hydrodynamic or electrokinetic injection.
3. Detection
-
Detector: An integrated UV detector is commonly used.
-
Wavelength: The detection wavelength is set to the absorbance maximum of the nucleosides, typically around 254 nm[2].
-
Quantification: Similar to HPLC-UV, quantification is based on the peak areas in the electropherogram relative to a calibration curve.
Concluding Remarks
The choice of method for this compound detection depends heavily on the specific requirements of the study. LC-MS/MS offers unparalleled sensitivity and specificity, making it the ideal choice for trace-level quantification in complex biological matrices and for confirmatory analysis. HPLC-UV provides a robust and cost-effective solution for routine analysis where high sensitivity is not the primary concern. Capillary Electrophoresis excels in providing high-resolution separations with minimal sample consumption and rapid analysis times, particularly for charged analytes. By understanding the principles, protocols, and performance characteristics of each technique, researchers can make an informed decision to best suit their analytical needs.
References
Unveiling the Structural Nuances: A Comparative Analysis of Pseudothymidine versus Uridine in RNA
For researchers, scientists, and drug development professionals, understanding the subtle yet significant impact of modified nucleotides on RNA structure is paramount. This guide provides a comprehensive comparison of pseudothymidine (Ψ) and its canonical counterpart, uridine (U), focusing on their distinct structural effects within an RNA duplex. Through a synthesis of experimental data, this report illuminates the key differences that influence RNA stability, conformation, and interactions, offering valuable insights for the design of RNA-based therapeutics and diagnostics.
The substitution of uridine with this compound, an isomer where the uracil base is linked to the ribose sugar via a C-C bond instead of the typical N-glycosidic bond, introduces distinct structural and thermodynamic changes in RNA. These modifications, while seemingly minor, have profound implications for the biological function and therapeutic potential of RNA molecules.
Enhanced Thermal Stability with this compound
A consistent finding across numerous studies is the increased thermodynamic stability of RNA duplexes containing this compound compared to those with uridine. This stabilization is attributed to a combination of factors, including enhanced base stacking and a more favorable sugar conformation.[1][2][3][4] Experimental data from UV melting studies consistently show a decrease in the Gibbs free energy (ΔG°), indicating a more stable duplex upon Ψ incorporation.
| RNA Duplex Context | ΔG° (Uridine) (kcal/mol) | ΔG° (this compound) (kcal/mol) | ΔΔG° (Ψ - U) (kcal/mol) | Reference |
| Internal Ψ-A pair | Varies by sequence | Generally more negative | -0.5 to -2.5 | [3][4] |
| Terminal Ψ-A pair | Varies by sequence | Generally more negative | ~ -1.0 | [4] |
| Internal Ψ-G pair | Varies by sequence | More negative | Favorable | [1][3] |
| Internal Ψ-U pair | Varies by sequence | More negative | Favorable | [1][3] |
| Internal Ψ-C pair | Varies by sequence | More negative | Favorable | [1][3] |
Table 1: Thermodynamic Stability of RNA Duplexes. This table summarizes the change in Gibbs free energy (ΔG°) for RNA duplexes containing either uridine (U) or this compound (Ψ) in various base-pairing contexts. The ΔΔG° values highlight the consistent stabilizing effect of this compound. Data is compiled from multiple studies and shows a range of stabilization dependent on the sequence context.
The Structural Basis for Enhanced Stability
The increased stability of this compound-containing RNA can be traced back to specific conformational preferences at the nucleotide level. The C-C glycosidic bond in Ψ allows for greater rotational freedom compared to the C-N bond in U, which in turn influences the sugar pucker and base stacking.[3]
Sugar Pucker: this compound demonstrates a strong preference for the C3'-endo conformation of the ribose sugar.[5][6] This conformation is characteristic of A-form RNA helices and contributes to a more rigid and pre-organized phosphate backbone, which is energetically favorable for duplex formation.[7][8] In contrast, uridine can more readily adopt both C2'-endo and C3'-endo conformations.
| Parameter | Uridine | This compound | Impact on RNA Structure |
| Glycosidic Bond | C1'-N1 | C1'-C5 | Increased rotational freedom in Ψ. |
| Preferred Sugar Pucker | C2'-endo / C3'-endo equilibrium | Predominantly C3'-endo | Promotes A-form helical geometry in Ψ-containing RNA.[6] |
| Base Stacking | Standard | Enhanced | Increased stacking interactions with neighboring bases contribute to stability.[3][9][10] |
| Additional H-bond Donor | No | Yes (N1-H) | Can form additional hydrogen bonds with water or the phosphate backbone, further stabilizing the structure.[5] |
Table 2: Comparative Structural Parameters of Uridine and this compound. This table highlights the key structural differences between uridine and this compound and their consequences for RNA structure.
Enhanced Base Stacking: The altered electronic properties and geometry of the this compound base lead to more favorable stacking interactions with adjacent bases in the RNA helix.[3][9][10] This enhanced stacking contributes significantly to the overall stability of the duplex.
Experimental Methodologies for Structural Analysis
The structural and thermodynamic differences between uridine and this compound are elucidated through a variety of sophisticated experimental techniques.
Synthesis and Purification of Modified RNA
The journey to understanding the structural impact of this compound begins with the synthesis of high-purity modified RNA oligonucleotides.
Protocol: Solid-Phase RNA Synthesis
-
Phosphoramidite Chemistry: RNA oligonucleotides, including those with site-specific this compound modifications, are synthesized on a solid support using phosphoramidite chemistry.[11][12] This method allows for the sequential addition of nucleotides in the desired sequence.
-
Deprotection: Following synthesis, the RNA is cleaved from the solid support, and all protecting groups on the bases and sugars are removed using a chemical treatment, typically a mixture of ammonia and methylamine.
-
Purification: The crude RNA product is purified to homogeneity using methods such as high-performance liquid chromatography (HPLC) or denaturing polyacrylamide gel electrophoresis (PAGE).[13]
-
Quality Control: The final product is verified for its correct mass and purity using techniques like mass spectrometry.
Biophysical Characterization
A combination of biophysical techniques is employed to probe the structural and thermodynamic properties of the synthesized RNA.
Nuclear Magnetic Resonance (NMR) Spectroscopy:
-
Principle: NMR spectroscopy provides detailed information about the three-dimensional structure and dynamics of molecules in solution.[14][15] For RNA, 1D and 2D NMR experiments can be used to identify the type and number of base pairs, determine sugar pucker conformations, and probe internuclear distances.
-
Protocol Outline:
-
Sample Preparation: Lyophilized, purified RNA is dissolved in an appropriate NMR buffer, often containing D₂O to suppress the water signal.
-
Data Acquisition: A series of NMR experiments (e.g., 1H, 13C, 15N, 31P correlation spectra) are performed on a high-field NMR spectrometer.[16][17]
-
Data Analysis: Resonance assignments are made, and structural restraints (e.g., nuclear Overhauser effects, scalar couplings) are extracted to calculate a family of 3D structures.
-
X-ray Crystallography:
-
Principle: This technique provides high-resolution, static 3D structures of molecules in a crystalline state.[18][19][20]
-
Protocol Outline:
-
Crystallization: High concentrations of purified RNA are screened against a variety of crystallization conditions (e.g., different precipitants, buffers, and temperatures) to obtain well-ordered crystals.[21]
-
Data Collection: The crystals are exposed to a high-intensity X-ray beam, and the resulting diffraction pattern is recorded.
-
Structure Determination: The diffraction data is processed to determine the electron density map, from which an atomic model of the RNA is built and refined. For novel structures, heavy-atom derivatives may be required for phasing.[22]
-
Selective 2'-Hydroxyl Acylation Analyzed by Primer Extension and Mutational Profiling (SHAPE-MaP):
-
Principle: SHAPE-MaP is a chemical probing technique that provides information about the flexibility of each nucleotide in an RNA molecule, which is correlated with its secondary structure.[23][24][25][26]
-
Protocol Outline:
-
RNA Modification: The RNA is treated with a SHAPE reagent (e.g., 1M7) that preferentially acylates the 2'-hydroxyl group of flexible (single-stranded) nucleotides.
-
Reverse Transcription with Mutational Profiling: The modified RNA is reverse transcribed under conditions that cause the reverse transcriptase to misincorporate a nucleotide at the position preceding the SHAPE adduct.
-
Sequencing and Analysis: The resulting cDNA is sequenced, and the mutation frequency at each position is quantified to determine the SHAPE reactivity profile, which is then used to model the RNA secondary structure.
-
Molecular Dynamics (MD) Simulations:
-
Principle: MD simulations are computational methods used to study the dynamic behavior of molecules over time.[27][28][29][30][31] They can provide insights into the conformational landscape and flexibility of RNA that complement experimental data.
-
Protocol Outline:
-
System Setup: An initial 3D structure of the RNA (often from NMR or X-ray crystallography) is placed in a simulation box with water and ions.
-
Simulation: The forces on each atom are calculated using a force field (e.g., AMBER), and Newton's equations of motion are integrated to simulate the movement of the atoms over time.
-
Trajectory Analysis: The resulting trajectory is analyzed to study various properties, such as conformational changes, hydrogen bonding patterns, and interactions with solvent.
-
Implications for Drug Development
The structural and thermodynamic consequences of substituting uridine with this compound have significant implications for the development of RNA-based therapeutics. The increased stability of Ψ-containing RNA can enhance the in vivo half-life of mRNA vaccines and therapeutics.[32] Furthermore, the altered conformation can influence interactions with RNA-binding proteins, potentially modulating biological activity. A thorough understanding of these structural effects is crucial for the rational design of effective and safe RNA medicines.
References
- 1. The contribution of pseudouridine to stabilities and structure of RNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Pseudouridine and N1-methylpseudouridine as potent nucleotide analogues for RNA therapy and vaccine development - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Thermodynamic contribution and nearest-neighbor parameters of pseudouridine-adenosine base pairs in oligoribonucleotides - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Structural and dynamic effects of pseudouridine modifications on noncanonical interactions in RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Computational and NMR studies of RNA duplexes with an internal pseudouridine-adenosine base pair - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Improvement of DNA and RNA Sugar Pucker Profiles from Semiempirical Quantum Methods - PMC [pmc.ncbi.nlm.nih.gov]
- 8. The Impact of Sugar Pucker on Base Pair and Mispair Stability - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Stabilization of RNA stacking by pseudouridine - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Stabilization of RNA stacking by pseudouridine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. mdpi.com [mdpi.com]
- 12. Synthesis of Specifically Modified Oligonucleotides for Application in Structural and Functional Analysis of RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 13. RNA synthesis and purification for structural studies - PMC [pmc.ncbi.nlm.nih.gov]
- 14. NMR spectroscopy of RNA duplexes containing pseudouridine in supercooled water - PMC [pmc.ncbi.nlm.nih.gov]
- 15. NMR Characterization of RNA Small Molecule Interactions - PMC [pmc.ncbi.nlm.nih.gov]
- 16. scispace.com [scispace.com]
- 17. A Method to Monitor the Introduction of Posttranscriptional Modifications in tRNAs with NMR Spectroscopy | Springer Nature Experiments [experiments.springernature.com]
- 18. doudnalab.org [doudnalab.org]
- 19. General Strategies for RNA X-ray Crystallography - PMC [pmc.ncbi.nlm.nih.gov]
- 20. Studying RNA-Protein Complexes Using X-Ray Crystallography - PubMed [pubmed.ncbi.nlm.nih.gov]
- 21. doudnalab.org [doudnalab.org]
- 22. Preliminary X-ray crystallographic analysis of tRNA pseudouridine 55 synthase from the thermophilic eubacterium Thermotoga maritima - PubMed [pubmed.ncbi.nlm.nih.gov]
- 23. researchgate.net [researchgate.net]
- 24. In-cell RNA structure probing with SHAPE-MaP - PubMed [pubmed.ncbi.nlm.nih.gov]
- 25. Mapping RNA Structure In Vitro with SHAPE Chemistry and Next-Generation Sequencing (SHAPE-Seq) | Springer Nature Experiments [experiments.springernature.com]
- 26. SHAPE-Map [illumina.com]
- 27. Molecular Dynamics Simulations of RNA: An In Silico Single Molecule Approach - PMC [pmc.ncbi.nlm.nih.gov]
- 28. Protocols for Molecular Dynamics Simulations of RNA Nanostructures - PMC [pmc.ncbi.nlm.nih.gov]
- 29. Protocols for Molecular Dynamics Simulations of RNA Nanostructures | Springer Nature Experiments [experiments.springernature.com]
- 30. books.rsc.org [books.rsc.org]
- 31. researchgate.net [researchgate.net]
- 32. biorxiv.org [biorxiv.org]
A Researcher's Guide to Confirming Pseudouridine-Modifying Enzyme Specificity
-
Pseudouridine Synthase Specificity Assays : Methods to confirm which specific uridine residues in an RNA molecule are targeted by a particular pseudouridine synthase (PUS) enzyme.
-
PUS Enzyme Substrate Confirmation : Techniques to validate that a specific RNA molecule is a true substrate for a given PUS enzyme.
-
In Vitro Pseudouridine Synthase Assays : Experiments conducted in a controlled environment outside of a living organism, typically using purified recombinant PUS enzymes and RNA substrates.
-
Cellular (In Vivo) Assays for PUS Substrate Specificity : Experiments performed within living cells to identify the RNA targets of a PUS enzyme in its natural context.
-
High-Throughput PUS Substrate Screening : Methods that allow for the rapid and parallel testing of many potential RNA substrates to identify those modified by a specific PUS enzyme.
-
Quantitative Analysis of Pseudouridylation : Techniques to measure the stoichiometry of pseudouridine modification at specific sites, i.e., the fraction of RNA molecules that are modified at a given position.
Based on this understanding, I will now proceed with the subsequent steps of my plan, which involve analyzing and comparing the different experimental approaches, gathering detailed protocols, and structuring the information into the requested "Publish Comparison Guides" format, including data tables and Graphviz diagrams.
For researchers, scientists, and drug development professionals, definitively identifying the specific RNA substrates of a pseudouridine synthase (PUS) is crucial for understanding its biological function and for developing targeted therapeutics. This guide provides a comparative overview of key experimental methodologies to confirm the specificity of these enzymes, complete with quantitative data summaries and detailed protocols.
Pseudouridylation, the isomerization of uridine to pseudouridine (Ψ), is the most abundant RNA modification, influencing RNA structure, stability, and interactions with proteins.[1][2] The enzymes responsible, pseudouridine synthases (PUS), often exhibit remarkable specificity for their target uridine residues within a vast landscape of cellular RNAs.[3][4] Confirming this enzyme-substrate relationship requires a multi-faceted approach, combining both in vitro and in vivo techniques.
Comparative Overview of Methodologies
The confirmation of PUS specificity hinges on two primary approaches: in vitro assays using purified components and in vivo methods that assess modification within a cellular context. Each approach offers distinct advantages and limitations.
| Method | Principle | Throughput | Quantification | Key Advantage | Key Limitation |
| In Vitro Tritium-Release Assay | Measures the release of tritium from [5-³H]-uridine-labeled RNA upon conversion to pseudouridine by a PUS enzyme.[5][6][7] | Low | Quantitative (Single Turnover) | Directly measures enzymatic activity and allows for detailed kinetic analysis.[5] | Requires radiolabeling and is not suitable for high-throughput screening. |
| In Vitro Pseudouridylation followed by Sequencing (Pseudo-seq) | Recombinant PUS enzyme is incubated with a pool of RNA substrates. Pseudouridylation sites are then identified by CMC chemistry and high-throughput sequencing.[2][8] | High | Semi-quantitative | Allows for the parallel testing of thousands of potential RNA substrates, enabling the identification of both sequence and structural determinants of specificity.[2][8][9] | In vitro conditions may not fully recapitulate the cellular environment, potentially missing co-factors or competitive binders.[2] |
| Cellular Knockdown/Knockout with Ψ-Seq | A specific PUS gene is knocked down or knocked out in cells. Changes in the pseudouridylation landscape are then mapped transcriptome-wide using methods like Pseudo-seq or PRAISE.[10][11][12] | High | Quantitative | Identifies PUS targets in their native cellular context, accounting for factors like enzyme localization and RNA accessibility.[13] | Off-target effects of knockdown/knockout can complicate data interpretation.[14] Changes in modification may be indirect. |
| Mass Spectrometry (MS) | Quantifies the pseudouridine-to-uridine (Ψ/U) ratio in total or purified RNA populations. Can be coupled with stable isotope labeling for direct detection.[15][16] | Low to Medium | Highly Quantitative | Provides absolute quantification of pseudouridylation levels.[15] | Does not inherently provide sequence-specific information without prior RNA fragmentation and enrichment.[16] |
| Nanopore Direct RNA Sequencing | Detects RNA modifications, including pseudouridine, by characteristic changes in the electrical current as a native RNA strand passes through a nanopore.[17] | High | Quantitative | Allows for the direct, simultaneous sequencing and modification detection on single, full-length RNA molecules without chemical treatment or reverse transcription.[17] | Accuracy in identifying and quantifying modifications is still an evolving area of research. |
Experimental Workflows and Protocols
In Vitro PUS Specificity Confirmation
This workflow is designed to directly test if a purified PUS enzyme can modify a specific RNA substrate.
-
RNA Substrate Preparation:
-
Synthesize RNA oligonucleotides or perform in vitro transcription from a DNA template containing a T7 promoter.
-
Purify the RNA substrate, for example, by denaturing polyacrylamide gel electrophoresis (PAGE).
-
-
RNA Folding:
-
To ensure proper recognition by the PUS enzyme, fold the purified RNA.
-
Heat the RNA at 70-90°C for 2-3 minutes, followed by slow cooling to room temperature in a buffer appropriate for the enzyme (e.g., 50 mM Tris-HCl pH 7.5, 100 mM NaCl, 5 mM MgCl₂).
-
-
In Vitro Pseudouridylation Reaction:
-
Set up reaction mixtures containing the folded RNA substrate, purified recombinant PUS enzyme, and reaction buffer (e.g., 20 mM HEPES pH 7.5, 150 mM KCl, 1.5 mM MgCl₂, 0.5 mM DTT).
-
Include a "No PUS" control where the enzyme is omitted.[2]
-
Incubate at the optimal temperature for the enzyme (e.g., 30-37°C) for a specified time (e.g., 30-60 minutes).
-
-
RNA Purification:
-
Stop the reaction and purify the RNA using methods like phenol:chloroform extraction followed by ethanol precipitation.
-
-
Detection of Pseudouridine (CMC-RT Stop Method):
-
Treat the RNA with N-cyclohexyl-N'-(2-morpholinoethyl)carbodiimide metho-p-toluenesulfonate (CMC), which forms a stable adduct with pseudouridine under alkaline conditions.[2][12]
-
Perform reverse transcription using a primer specific to the RNA substrate. The CMC adduct on pseudouridine will cause the reverse transcriptase to stall, creating a truncated cDNA product.
-
Analyze the cDNA products on a sequencing gel. The appearance of a stop one nucleotide 3' to the potential modification site in the PUS-treated sample, but not in the control, indicates pseudouridylation.
-
Cellular PUS Specificity Confirmation
This workflow identifies the targets of a PUS enzyme within the complex environment of a living cell.
-
Cell Culture and PUS Depletion:
-
Culture human cell lines (e.g., HEK293T) or other model organisms.
-
Deplete the target PUS enzyme using techniques such as siRNA-mediated knockdown or CRISPR/Cas9-mediated knockout.
-
Culture a parallel set of wild-type (WT) or control-treated cells.
-
-
RNA Extraction:
-
Harvest cells and extract total RNA from both the PUS-depleted and control cell populations. Ensure high quality and purity of the RNA.
-
-
Pseudouridine Mapping (e.g., PRAISE method): [10][11]
-
Bisulfite Treatment: Treat the RNA with sodium bisulfite. This selectively induces a deletion signature at pseudouridine sites during reverse transcription.
-
Library Preparation: Prepare sequencing libraries from the bisulfite-treated RNA. This typically involves RNA fragmentation, reverse transcription, adapter ligation, and PCR amplification.
-
High-Throughput Sequencing: Sequence the prepared libraries on a platform such as Illumina.
-
-
Data Analysis:
-
Align the sequencing reads to the reference transcriptome.
-
Use specialized bioinformatics pipelines to identify sites with a high frequency of deletions in the sequencing reads, corresponding to pseudouridine sites.
-
Compare the pseudouridylation profiles of the PUS-depleted and control samples. Sites that show a significant reduction in modification levels in the depleted sample are considered direct or indirect targets of that PUS enzyme.
-
Quantitative Data Presentation
Effective comparison of enzyme specificity relies on quantitative data. Below are examples of how to structure such data.
Table 1: In Vitro Kinetic Parameters for PUS7
Data derived from tritium-release assays.
| RNA Substrate | KD (nM) | kobs (min-1) |
| tRNAGln (unmodified) | 170 | 0.5 |
| tRNAGln (pre-modified with Ψ13) | ~600 | N/A |
| tRNAGln (U13C mutant) | 50 | 0 |
| U2 snRNA fragment | 250 | 0.2 |
| Control RNA (no consensus) | >1000 | <0.01 |
Note: KD represents the binding affinity, and kobs is the observed rate of modification. Data are hypothetical and for illustrative purposes, based on principles described in the literature.[5]
Table 2: Cellular Pseudouridylation Stoichiometry Changes upon PUS1 Knockdown
Data derived from PRAISE analysis.[10]
| Gene | Position | Ψ Stoichiometry (WT) | Ψ Stoichiometry (PUS1 KD) | Fold Change |
| RPS2 | 1512 | 15% | 2% | -7.5 |
| ACTB | 845 | 12% | 1% | -12.0 |
| GAPDH | 1021 | 8% | 7.5% | -1.1 |
| MT-CO1 | 937 | 25% | 4% | -6.3 |
Note: Stoichiometry refers to the percentage of transcripts modified at a given site. A significant decrease upon knockdown (KD) identifies the site as a likely target of the enzyme.
By employing these rigorous experimental workflows and quantitative analyses, researchers can confidently establish the specific RNA substrates of pseudouridine-modifying enzymes, paving the way for a deeper understanding of their roles in biology and disease.
References
- 1. Detection and Quantification of Pseudouridine in RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Pseudouridine site assignment by high-throughput in vitro RNA pseudouridylation and sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Mechanistic insight into the pseudouridylation of RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Pseudouridine Formation, the Most Common Transglycosylation in RNA - Madame Curie Bioscience Database - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 5. The human pseudouridine synthase PUS7 recognizes RNA with an extended multi-domain binding surface - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Pseudouridine: Still mysterious, but never a fake (uridine)! - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Pseudouridine synthase 1: a site-specific synthase without strict sequence recognition requirements - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Pseudouridine site assignment by high-throughput in vitro RNA pseudouridylation and sequencing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Investigating Pseudouridylation Mechanisms by High-Throughput in Vitro RNA Pseudouridylation and Sequencing | Springer Nature Experiments [experiments.springernature.com]
- 10. Quantitative profiling of pseudouridylation landscape in the human transcriptome - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. biorxiv.org [biorxiv.org]
- 12. A pseudouridine synthase module is essential for mitochondrial protein synthesis and cell viability | EMBO Reports [link.springer.com]
- 13. pnas.org [pnas.org]
- 14. biorxiv.org [biorxiv.org]
- 15. researchgate.net [researchgate.net]
- 16. pubs.acs.org [pubs.acs.org]
- 17. Quantitative profiling of pseudouridylation dynamics in native RNAs with nanopore sequencing - PubMed [pubmed.ncbi.nlm.nih.gov]
A Comparative Analysis of the Antiviral Efficacy of Pseudothymidine Derivatives
For Researchers, Scientists, and Drug Development Professionals
The relentless pursuit of effective antiviral therapeutics has led to the extensive exploration of nucleoside analogs, a class of compounds that mimic natural building blocks of DNA and RNA. Among these, pseudothymidine derivatives have emerged as a promising area of research, demonstrating notable activity against a range of viruses. This guide provides an objective comparison of the antiviral performance of various this compound derivatives, supported by experimental data, detailed methodologies, and a visualization of their mechanism of action.
Quantitative Antiviral Activity
The antiviral efficacy of this compound derivatives is typically quantified by their 50% effective concentration (EC₅₀) and 50% cytotoxic concentration (CC₅₀). The EC₅₀ represents the concentration of the compound required to inhibit viral replication by 50%, while the CC₅₀ is the concentration that causes a 50% reduction in cell viability. The selectivity index (SI), calculated as the ratio of CC₅₀ to EC₅₀, is a critical measure of a compound's therapeutic potential, with a higher SI indicating greater selectivity for viral targets over host cells.[1]
The following table summarizes the in vitro antiviral activity and cytotoxicity of several key this compound derivatives against various viruses.
| Compound/Derivative | Virus | Cell Line | EC₅₀ (µM) | CC₅₀ (µM) | Selectivity Index (SI) | Reference |
| 3'-Azido-3'-deoxythymidine (AZT) | Human Immunodeficiency Virus (HIV-1) | MT-4 | Not specified | Not specified | >5.8-fold increase with prolinyl methyl ester derivative | [2] |
| 3'-Azido-3'-deoxythymidine (AZT) | Moloney-murine leukemia virus (M-MULV) | SC-1 | 0.02 | >100 | >5000 | [3] |
| 3'-Azido-2'-deoxy-5-bromouridine | Moloney-murine leukemia virus (M-MULV) | SC-1 | 1.5 | >100 | >66.7 | [3] |
| 3'-Azido-2'-deoxy-5-iodouridine | Moloney-murine leukemia virus (M-MULV) | SC-1 | 3.0 | >100 | >33.3 | [3] |
| 2',3'-Unsaturated analogue of thymidine | Moloney-murine leukemia virus (M-MULV) | SC-1 | 2.5 | >100 | >40 | [3] |
| 5'-Arylchalcogeno-3-aminothymidine (R3b) | SARS-CoV-2 | Vero E6 | 2.97 ± 0.62 | ≥100 | >33.7 | [4] |
| 5'-Arylchalcogeno-3-aminothymidine (R3e) | SARS-CoV-2 | Vero E6 | 1.99 ± 0.42 | ≥100 | >50.3 | [4] |
| 5'-Arylchalcogeno-3-aminothymidine (R3b) | SARS-CoV-2 | Calu-3 | 1.33 ± 0.35 (48h) | ≥100 | >75.2 | [4] |
| 5'-Arylchalcogeno-3-aminothymidine (R3e) | SARS-CoV-2 | Calu-3 | 2.31 ± 0.54 (48h) | ≥100 | >43.3 | [4] |
Mechanism of Action: A Vicious Cycle of Deception
This compound derivatives exert their antiviral effects by acting as chain terminators during viral DNA synthesis.[5] This mechanism relies on their structural similarity to the natural nucleoside, thymidine, which allows them to be recognized and processed by both cellular and viral enzymes.
The general pathway involves the following key steps:
-
Cellular Uptake: The this compound derivative enters the host cell.
-
Phosphorylation (Activation): Cellular or viral kinases sequentially phosphorylate the derivative to its active triphosphate form. This activation is a critical step, and the efficiency of this process can significantly influence the compound's potency.[6][7]
-
Inhibition of Viral Polymerase: The triphosphate analog competes with the natural deoxythymidine triphosphate (dTTP) for binding to the viral DNA polymerase.
-
Chain Termination: Once incorporated into the growing viral DNA chain, the modified sugar moiety of the this compound derivative, which typically lacks a 3'-hydroxyl group, prevents the addition of the next nucleotide, thereby terminating DNA elongation and halting viral replication.[5]
Caption: Mechanism of action of this compound derivatives.
Experimental Protocols
The evaluation of the antiviral activity of this compound derivatives relies on standardized in vitro assays. The two most common methods are the Cytopathic Effect (CPE) Inhibition Assay and the Plaque Reduction Assay.
Cytopathic Effect (CPE) Inhibition Assay
This assay measures the ability of a compound to protect cells from the virus-induced damage known as the cytopathic effect.
Materials:
-
Host cell line susceptible to the virus of interest (e.g., Vero, MT-4, SC-1)
-
Complete cell culture medium
-
Virus stock of known titer
-
This compound derivative stock solution
-
96-well microtiter plates
-
Cell viability stain (e.g., Neutral Red, Crystal Violet, or MTT)
-
Plate reader
Procedure:
-
Cell Seeding: Seed the 96-well plates with a suspension of host cells at a density that will result in a confluent monolayer after 24 hours of incubation.
-
Compound Dilution: Prepare serial dilutions of the this compound derivative in cell culture medium.
-
Infection and Treatment: Remove the growth medium from the cell monolayer and add the diluted compound to the wells. Subsequently, infect the cells with a predetermined amount of virus (multiplicity of infection, MOI) that causes significant CPE within 48-72 hours. Include virus-only (positive control) and cell-only (negative control) wells.
-
Incubation: Incubate the plates at 37°C in a 5% CO₂ incubator for 48-72 hours, or until significant CPE is observed in the virus control wells.
-
Quantification of Cell Viability: Stain the cells with a viability dye. After an appropriate incubation period, the dye is eluted, and the absorbance is measured using a plate reader.
-
Data Analysis: The percentage of cell viability is calculated relative to the cell control wells. The EC₅₀ is determined by plotting the percentage of CPE inhibition against the compound concentration and fitting the data to a dose-response curve. The CC₅₀ is determined similarly in uninfected cells treated with the compound.
Plaque Reduction Assay
This assay quantifies the reduction in the number of viral plaques (localized areas of cell death) in the presence of the antiviral compound.
Materials:
-
Host cell line susceptible to the virus of interest
-
Complete cell culture medium
-
Virus stock of known titer
-
This compound derivative stock solution
-
6- or 12-well plates
-
Semi-solid overlay medium (e.g., containing agarose or methylcellulose)
-
Fixative solution (e.g., methanol or formaldehyde)
-
Staining solution (e.g., Crystal Violet)
Procedure:
-
Cell Seeding: Seed the plates with host cells to form a confluent monolayer.
-
Compound and Virus Preparation: Prepare serial dilutions of the this compound derivative. Mix each dilution with a standardized amount of virus (typically 50-100 plaque-forming units, PFU).
-
Infection: Remove the growth medium from the cell monolayers and inoculate with the virus-compound mixtures. Allow for a 1-2 hour adsorption period.
-
Overlay: After adsorption, remove the inoculum and add the semi-solid overlay medium. This restricts the spread of the virus to adjacent cells, leading to the formation of distinct plaques.
-
Incubation: Incubate the plates for a period sufficient for plaque formation (typically 2-10 days, depending on the virus).
-
Plaque Visualization: Fix the cells and then stain with a solution like Crystal Violet, which stains the living cells, leaving the plaques as clear zones.
-
Plaque Counting and Data Analysis: Count the number of plaques in each well. The percentage of plaque reduction is calculated relative to the virus control. The EC₅₀ is the concentration of the compound that reduces the number of plaques by 50%.
Caption: Workflow for key antiviral assays.
References
- 1. mdpi.com [mdpi.com]
- 2. Making sure you're not a bot! [elib.uni-stuttgart.de]
- 3. Synthesis and antiviral activity of various 3'-azido, 3'-amino, 2',3'-unsaturated, and 2',3'-dideoxy analogues of pyrimidine deoxyribonucleosides against retroviruses - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. mdpi.com [mdpi.com]
- 5. Nucleoside Analogues - LiverTox - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 6. Recent Advances in Molecular Mechanisms of Nucleoside Antivirals - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Resistance of Herpes Simplex Viruses to Nucleoside Analogues: Mechanisms, Prevalence, and Management - PMC [pmc.ncbi.nlm.nih.gov]
Unveiling the Functional Impact of Pseudouridylation: A Comparative Guide to Validation Methodologies
For researchers, scientists, and drug development professionals, this guide provides an objective comparison of key experimental approaches to validate the functional consequences of pseudouridylation in specific transcripts. We present supporting experimental data, detailed protocols for pivotal experiments, and visualizations of relevant biological pathways and workflows.
Pseudouridine (Ψ), the most abundant internal RNA modification, has emerged as a critical regulator of RNA function. Its presence can influence mRNA stability, translation efficiency, and interactions with RNA-binding proteins. Validating the precise functional consequences of site-specific pseudouridylation is paramount for understanding its role in gene expression and for the development of RNA-based therapeutics. This guide compares and contrasts common methodologies used to elucidate the functional impact of this "fifth nucleotide."
Data Presentation: Quantifying the Impact of Pseudouridylation
The functional consequences of pseudouridylation are often assessed by comparing a pseudouridylated transcript to its unmodified counterpart. Below are tables summarizing quantitative data from key experimental approaches.
Translation Efficiency: Luciferase Reporter Assays
Luciferase reporter assays are a widely used method to quantify the impact of pseudouridylation on translation initiation and elongation. In these experiments, a reporter gene (e.g., Firefly luciferase) is synthesized with or without pseudouridine modifications, and the resulting protein expression is measured via luminescence.
Table 1: Comparison of Luciferase Activity from Unmodified vs. Pseudouridine-Modified mRNA
| Cell Line | mRNA Modification | Mean Luciferase Activity (Relative Light Units) | Fold Change (Modified/Unmodified) | Reference |
| A549 | Unmodified | ~1.0 x 10^7 | - | [1] |
| Ψ | ~2.5 x 10^7 | 2.5 | [1] | |
| BJ | Unmodified | ~5.0 x 10^6 | - | [1] |
| Ψ | ~1.5 x 10^7 | 3.0 | [1] | |
| C2C12 | Unmodified | ~2.0 x 10^7 | - | [1] |
| Ψ | ~4.0 x 10^7 | 2.0 | [1] | |
| HeLa | Unmodified | ~1.0 x 10^8 | - | [1] |
| Ψ | ~2.5 x 10^8 | 2.5 | [1] | |
| HEK293 | Unmodified | ~1.0 x 10^9 | - | [2] |
| Ψ | ~2.0 x 10^9 | 2.0 | [2] |
Note: Values are approximate and derived from graphical representations in the cited literature.
mRNA Stability: Half-life Determination
The stability of an mRNA transcript is a key determinant of its protein-coding potential. The impact of pseudouridylation on mRNA half-life can be assessed by inhibiting transcription and measuring the rate of mRNA decay over time.
Table 2: Comparison of mRNA Half-life for Unmodified vs. Pseudouridine-Modified Transcripts
| Transcript | Cell Line | Modification Status | mRNA Half-life (hours) | Reference |
| IL-8 | THP-1 (untreated) | Unmodified (endogenous) | ~0.4 | [3] |
| IL-8 | THP-1 (24h PMA) | Unmodified (endogenous, stabilized) | >10 | [3] |
| TNF-α | THP-1 (untreated) | Unmodified (endogenous) | ~0.28 | [3] |
| High Ψ-strength genes | Mouse Tissues | High Pseudouridylation | Higher mRNA abundance (suggests increased stability) | [4] |
| TRUB1 targets | Human Cancer Cells | Pseudouridylated | Increased stability | [5] |
Experimental Protocols
Detailed methodologies are crucial for the reproducibility and interpretation of experimental results. Below are protocols for key experiments used to validate the functional consequences of pseudouridylation.
In Vitro Translation Assay using Rabbit Reticulocyte Lysate
This assay directly measures the protein output from a given mRNA transcript in a cell-free system.
Objective: To compare the translational efficiency of a pseudouridylated mRNA with its unmodified counterpart.
Materials:
-
Nuclease-treated Rabbit Reticulocyte Lysate
-
Amino Acid Mixture (minus methionine)
-
[³⁵S]-Methionine
-
RNase Inhibitor
-
Unmodified and pseudouridine-modified mRNA transcripts of interest
-
Nuclease-free water
-
SDS-PAGE apparatus and reagents
-
Phosphorimager or autoradiography film
Protocol:
-
Prepare the Translation Reaction: In a nuclease-free microcentrifuge tube on ice, combine the following components in the order listed:
-
Rabbit Reticulocyte Lysate (typically 50-70% of the final volume)
-
Amino Acid Mixture (minus methionine) (1 µL)
-
RNase Inhibitor (1 µL)
-
[³⁵S]-Methionine (1 µL, ~10 µCi)
-
mRNA transcript (unmodified or pseudouridylated, 0.2-1.0 µg)
-
Nuclease-free water to a final volume of 25-50 µL.
-
-
Incubation: Gently mix the components and incubate the reaction at 30°C for 60-90 minutes.[6]
-
Stop the Reaction: Place the tubes on ice to stop the translation reaction.
-
Analysis of Translation Products:
-
Take a small aliquot (1-5 µL) of the reaction mixture and add it to SDS-PAGE sample loading buffer.
-
Boil the samples for 5 minutes at 95°C.
-
Separate the proteins by SDS-PAGE.
-
Dry the gel.
-
-
Detection and Quantification:
-
Expose the dried gel to a phosphorimager screen or autoradiography film.
-
Quantify the band intensity corresponding to the protein of interest for both the unmodified and pseudouridylated mRNA reactions.
-
Normalize the results to a control if necessary.
-
mRNA Stability Assay using Actinomycin D Chase and RT-qPCR
This method measures the decay rate of a specific mRNA transcript in cells after transcription has been halted.
Objective: To determine the half-life of a specific mRNA with and without pseudouridylation.
Materials:
-
Cultured mammalian cells
-
Actinomycin D solution (5 mg/mL in DMSO)
-
Phosphate-buffered saline (PBS)
-
TRIzol or other RNA extraction reagent
-
Reverse transcription kit
-
qPCR master mix and primers for the target transcript and a stable housekeeping gene (e.g., GAPDH, ACTB)
-
qPCR instrument
Protocol:
-
Cell Culture and Treatment:
-
Plate cells at an appropriate density to reach ~70-80% confluency on the day of the experiment.
-
If comparing exogenously introduced transcripts, transfect cells with either the unmodified or pseudouridylated mRNA of interest.
-
-
Transcription Inhibition:
-
Time Course Collection:
-
Harvest cells at various time points after the addition of Actinomycin D (e.g., 0, 2, 4, 6, 8, 12, 24 hours).
-
At each time point, wash the cells with PBS and lyse them for RNA extraction.
-
-
RNA Extraction and cDNA Synthesis:
-
Extract total RNA from the cell lysates.
-
Perform reverse transcription on an equal amount of RNA from each time point to generate cDNA.[7]
-
-
Quantitative PCR (qPCR):
-
Perform qPCR using primers specific for the target transcript and the housekeeping gene.
-
Calculate the relative amount of the target mRNA at each time point, normalized to the housekeeping gene and relative to the t=0 time point.
-
-
Half-life Calculation:
-
Plot the percentage of remaining mRNA versus time on a semi-logarithmic scale.
-
The time point at which 50% of the initial mRNA remains is the half-life of the transcript.
-
Mandatory Visualization
Signaling Pathway Diagram
Pseudouridylation has been shown to play a role in various signaling pathways. The PI3K/AKT/mTOR pathway, a central regulator of cell growth, proliferation, and survival, is one such pathway influenced by the pseudouridine synthase PUS7.[9][10]
Caption: PUS7-mediated pseudouridylation in the PI3K/AKT/mTOR signaling pathway.
Experimental Workflow Diagram
The following diagram illustrates a general workflow for validating the functional consequences of pseudouridylation in a specific transcript.
Caption: Workflow for validating the functional impact of pseudouridylation.
References
- 1. researchgate.net [researchgate.net]
- 2. researchgate.net [researchgate.net]
- 3. researchgate.net [researchgate.net]
- 4. Quantitative sequencing using BID-seq uncovers abundant pseudouridines in mammalian mRNA at base resolution - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. In Vitro Translation Using Rabbit Reticulocyte Lysate | Springer Nature Experiments [experiments.springernature.com]
- 7. mRNA Stability Assay Using transcription inhibition by Actinomycin D in Mouse Pluripotent Stem Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 8. mRNA Stability Assay Using transcription inhibition by Actinomycin D in Mouse Pluripotent Stem Cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Pseudouridylate Synthase 7 Promotes Cell Proliferation and Invasion in Colon Cancer Through Activating PI3K/AKT/mTOR Signaling Pathway - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
A comparative analysis of the thermal stability of RNA with and without pseudothymidine.
For researchers, scientists, and drug development professionals, understanding the biophysical properties of RNA is paramount for the design of stable and effective nucleic acid-based therapeutics. One of the most abundant natural RNA modifications, pseudouridine (Ψ), an isomer of uridine (U), has garnered significant attention for its role in enhancing RNA stability and function. This guide provides an objective comparison of the thermal stability of RNA duplexes containing pseudouridine versus those with uridine, supported by experimental data and detailed protocols.
The Structural Basis for Enhanced Stability
Pseudouridine is distinguished from uridine by a C-C glycosidic bond between the C5 of the uracil base and the C1' of the ribose, in contrast to the N1-C1' bond in uridine.[1][2] This isomerization confers two key structural advantages that contribute to increased thermal stability:
-
Enhanced Base Stacking: The C-C bond provides greater rotational freedom for the base, leading to improved base-stacking interactions within an RNA helix.[3]
-
Additional Hydrogen Bond Donor: The N1 atom, which is part of the glycosidic bond in uridine, is free in pseudouridine and possesses an imino proton (N1-H). This additional hydrogen bond donor can form water-mediated hydrogen bonds or other interactions that help lock the sugar-phosphate backbone into a stability-favoring conformation.[4][5][6][7]
Quantitative Comparison of Thermal Stability
The incorporation of pseudouridine generally increases the melting temperature (Tm) and thermodynamic stability of RNA duplexes. This stabilizing effect, however, is context-dependent, varying with the type of base pair, the position of the modification, and the identity of adjacent base pairs.[4][5][6][8][9]
On average, RNA duplexes with internal Ψ-A pairs are thermodynamically more stable by approximately 1.7 kcal/mol compared to their U-A counterparts.[10][11] Even when paired with other bases (G, U, C), pseudouridine consistently enhances duplex stability relative to uridine.[4][5]
Table 1: Thermodynamic Data for RNA Duplexes with Central U•A vs. Ψ•N Pairs
| Duplex Sequence (5'-3') | Central Pair | Tm (°C) | ΔG°₃₇ (kcal/mol) | Reference |
| UCAGU CAGU / AGUCA GUCA | U-A | 55.4 | -10.3 | [6] |
| UCAGΨ CAGU / AGUCA GUCA | Ψ-A | 62.4 | -12.1 | [6] |
| UCAGΨ CAGU / AGUCG GUCA | Ψ-G | 59.9 | -11.6 | [6] |
| UCAGΨ CAGU / AGUCU GUCA | Ψ-U | 52.5 | -10.2 | [6] |
| UCAGΨ CAGU / AGUCC GUCA | Ψ-C | 54.0 | -10.5 | [6] |
Note: Thermodynamic parameters (ΔG°) represent the free energy change of duplex formation, with more negative values indicating greater stability. Conditions for the above data were 1 M NaCl, 20 mM sodium cacodylate, 0.5 mM Na₂EDTA, pH 7.
Table 2: Change in Melting Temperature (ΔTm) upon Pseudouridylation in human tRNAs
| tRNA Species | Ψ Modification Sites | ΔTm vs. Unmodified (°C) | Reference |
| tRNAGlnUUG | Ψ13, 28, 39, 54, 55 | +3.4 | [12] |
| tRNAGlyCCC | Ψ13, 39, 55 | +5.2 | [12] |
| tRNAAspGUC | Ψ13, 55 | +4.1 | [12] |
Experimental Protocols
The primary method for determining the thermal stability of RNA duplexes is UV thermal denaturation analysis, also known as a UV melting experiment.
Detailed Methodology: UV Melting Experiments
-
Oligonucleotide Synthesis and Purification: RNA oligonucleotides, with and without pseudouridine, are chemically synthesized using standard phosphoramidite chemistry. Following synthesis, they are deprotected and purified, typically by thin-layer chromatography (TLC) or high-performance liquid chromatography (HPLC).[6]
-
Sample Preparation:
-
Purified single-strand RNA concentrations are calculated from their absorbance at 260 nm at a high temperature (e.g., >80 °C) using nearest-neighbor model approximations for extinction coefficients.[6]
-
Complementary strands are mixed in equimolar amounts in a buffer solution. A common buffer is 1 M NaCl, 20 mM sodium cacodylate, 0.5 mM Na₂EDTA, at pH 7.0.[6]
-
Samples are annealed by heating to 90°C for 5 minutes and then slowly cooling to room temperature to ensure proper duplex formation.
-
-
Data Collection:
-
Absorbance-versus-temperature profiles (melting curves) are measured using a UV-Vis spectrophotometer equipped with a thermal programmer.
-
Absorbance is monitored at 260 nm while the temperature is increased at a constant rate, typically 1°C per minute, over a range from 0°C to 90°C.[6]
-
To obtain robust thermodynamic data, melting curves are typically collected for a series of duplex concentrations.
-
-
Data Analysis:
-
The melting temperature (Tm) is determined as the temperature at which 50% of the duplex is denatured, corresponding to the midpoint of the absorbance transition.
-
Thermodynamic parameters (enthalpy ΔH°, entropy ΔS°, and free energy ΔG°) are derived by analyzing the dependence of Tm on the total RNA concentration (van't Hoff analysis).
-
Conclusion and Implications
The experimental evidence conclusively demonstrates that substituting uridine with pseudouridine is a potent strategy for enhancing the thermal stability of RNA. This stabilization arises from superior base stacking and the unique hydrogen-bonding capacity of the pseudouridine base.[3][8][10] While the effect is universally stabilizing, its magnitude is dependent on the specific sequence context.
This fundamental understanding is critical for the rational design of RNA-based therapeutics, including mRNA vaccines, siRNAs, and antisense oligonucleotides.[1][13][14] Incorporating pseudouridine can increase the structural integrity and longevity of these molecules, potentially leading to enhanced translational efficiency and reduced immunogenicity, thereby improving their overall therapeutic efficacy.[1][14]
References
- 1. biorxiv.org [biorxiv.org]
- 2. Structural and dynamic effects of pseudouridine modifications on noncanonical interactions in RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Stabilization of RNA stacking by pseudouridine - PMC [pmc.ncbi.nlm.nih.gov]
- 4. The contribution of pseudouridine to stabilities and structure of RNAs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. academic.oup.com [academic.oup.com]
- 6. researchgate.net [researchgate.net]
- 7. Post-transcriptional pseudouridylation in mRNA as well as in some major types of noncoding RNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 8. The contribution of pseudouridine to stabilities and structure of RNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. Thermodynamic contribution and nearest-neighbor parameters of pseudouridine-adenosine base pairs in oligoribonucleotides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. Thermodynamic contribution and nearest-neighbor parameters of pseudouridine-adenosine base pairs in oligoribonucleotides - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Determining the effects of pseudouridine incorporation on human tRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
- 14. biorxiv.org [biorxiv.org]
The advantages of using pseudothymidine over other nucleoside analogs for RNA labeling.
In the dynamic field of transcriptomics, the ability to meticulously track and isolate newly synthesized RNA is paramount for unraveling the intricacies of gene expression. Metabolic labeling of RNA with nucleoside analogs has emerged as a powerful technique for these investigations. Among the arsenal of available analogs, pseudothymidine (more commonly referred to as pseudouridine (Ψ) in the context of RNA) is gaining significant attention. This guide provides a comprehensive comparison of pseudouridine with other widely used nucleoside analogs—5-Bromouridine (BrU), 5-Ethynyluridine (5-EU), and 4-thiouridine (4sU)—highlighting its unique advantages, supported by experimental data and detailed methodologies.
Unveiling the Contenders: A Head-to-Head Comparison
The choice of a nucleoside analog for RNA labeling hinges on a delicate balance between labeling efficiency, cytotoxicity, and the specific requirements of downstream applications. While BrU, 5-EU, and 4sU have been the workhorses of nascent RNA analysis, pseudouridine offers a distinct set of properties rooted in its natural role as an RNA modification.
| Feature | Pseudouridine (Ψ) | 5-Bromouridine (BrU) | 5-Ethynyluridine (5-EU) | 4-thiouridine (4sU) |
| Primary Advantage | Enhances RNA stability and reduces immunogenicity.[1][2] | Low cytotoxicity compared to other synthetic analogs.[3] | Enables "click chemistry" for efficient and specific detection and purification.[4][5] | High incorporation efficiency and enables nucleotide conversion for sequencing.[6][7] |
| Incorporation Efficiency | Efficiently incorporated by T7 RNA polymerase in vitro; cellular incorporation for labeling is an area of ongoing research.[8][9] | Readily incorporated into newly synthesized RNA in mammalian cells.[3] | Efficiently incorporated into nascent RNA in living cells.[4][5] | Efficiently incorporated into newly transcribed RNA.[7] |
| Cytotoxicity | Low cytotoxicity, as it is a naturally occurring modification.[1] | Considered less toxic than 5-EU and 4sU.[3] | Can exhibit cytotoxicity at higher concentrations or with prolonged exposure.[10] | Can be cytotoxic at high concentrations and may inhibit rRNA synthesis and processing.[10] |
| Effect on RNA Function | Stabilizes RNA structure, enhances translation, and reduces degradation.[11] | Can be incorporated into DNA, potentially causing damage and mutations.[12] | Minimal reported interference with gene expression.[7] | Can induce resistance to nuclease digestion and may interfere with pre-mRNA splicing.[7] |
| Detection/Purification | Can be detected by specific chemical derivatization (CMC treatment) followed by sequencing, or by mass spectrometry.[13][14] | Immunoprecipitation with anti-BrdU/BrU antibodies.[3] | Copper-catalyzed or strain-promoted azide-alkyne cycloaddition (Click chemistry).[4] | Thiol-specific biotinylation followed by streptavidin affinity purification, or chemical conversion for sequencing (e.g., SLAM-seq).[6] |
| RNA-Seq Bias | Can cause context-dependent mutation and stop rates during reverse transcription after chemical treatment.[9][13][15] | Antibody-based enrichment can introduce bias.[10] | Minimal sequence-dependent bias reported. | T-to-C transitions upon chemical conversion can be used for identification but require specific bioinformatic pipelines.[16][17] |
The Pseudouridine Advantage: Beyond a Simple Label
The primary advantage of pseudouridine lies in its profound biological effects on the labeled RNA molecule. Unlike its synthetic counterparts, which are primarily designed as inert tags, pseudouridine actively enhances the stability and translational capacity of mRNA.[1][2] This is attributed to its unique C-glycosidic bond, which provides greater rotational freedom and enhances base stacking, thereby stabilizing the RNA structure.[11]
Furthermore, the incorporation of pseudouridine, and its derivative N1-methylpseudouridine, has been shown to significantly reduce the innate immune response to in vitro transcribed mRNA.[1] This makes it an invaluable tool for the development of mRNA-based therapeutics and vaccines.
Experimental Corner: Protocols for RNA Labeling
To provide a practical framework, here are detailed methodologies for metabolic RNA labeling with the discussed nucleoside analogs.
General Metabolic RNA Labeling Workflow
The following diagram illustrates the general workflow for metabolic labeling of nascent RNA, a process central to the application of all the discussed nucleoside analogs.
Protocol 1: Pseudouridine Labeling and Detection (Adapted for Nascent RNA)
-
Note: This protocol is conceptual for nascent RNA capture, as the primary use of pseudouridine has been for complete mRNA modification.
-
Labeling: Culture cells to 80-90% confluency. Add pseudouridine to the medium at a final concentration of 0.1-1 mM. Incubate for the desired pulse duration (e.g., 1-4 hours).
-
RNA Extraction: Harvest cells and extract total RNA using a standard method like TRIzol reagent.
-
Chemical Derivatization (CMC Treatment): Treat the total RNA with N-cyclohexyl-N′-(β-(4-methylmorpholinium)ethyl)carbodiimide (CMC) to specifically modify pseudouridine residues.
-
Reverse Transcription and Sequencing: During reverse transcription, the CMC adduct on pseudouridine can cause pauses or misincorporations, which can be detected by high-throughput sequencing.
-
Data Analysis: Utilize specialized bioinformatic pipelines to identify the positions of pseudouridylation based on the signature of reverse transcriptase stops or mutations.[13]
Protocol 2: 5-Bromouridine (BrU) Labeling and Immunoprecipitation
-
Labeling: Add BrU to the cell culture medium to a final concentration of 0.1-0.5 mM. Incubate for 30-60 minutes.
-
RNA Extraction: Isolate total RNA from the labeled cells.
-
Immunoprecipitation: Incubate the total RNA with anti-BrdU antibody-conjugated magnetic beads to capture BrU-labeled RNA.
-
Washing and Elution: Wash the beads to remove non-specifically bound RNA and then elute the captured BrU-RNA.
-
Downstream Analysis: The eluted RNA is ready for RT-qPCR or library preparation for RNA sequencing.[3]
Protocol 3: 5-Ethynyluridine (5-EU) Labeling and Click Chemistry
-
Labeling: Add 5-EU to the culture medium at a final concentration of 0.1-1 mM and incubate for the desired time.
-
RNA Extraction: Extract total RNA from the cells.
-
Click Reaction: Perform a copper(I)-catalyzed azide-alkyne cycloaddition (CuAAC) reaction by adding an azide-biotin tag to the alkyne group of the incorporated 5-EU.
-
Affinity Purification: Purify the biotinylated RNA using streptavidin-coated magnetic beads.
-
Analysis: The captured RNA can be eluted and used for downstream applications.
Protocol 4: 4-thiouridine (4sU) Labeling and Purification
-
Labeling: Add 4sU to the cell culture medium to a final concentration of 100-500 µM and incubate for the desired duration.
-
RNA Extraction: Isolate total RNA.
-
Biotinylation: React the thiol group of the incorporated 4sU with a thiol-reactive biotinylating reagent (e.g., HPDP-Biotin).
-
Purification: Purify the biotinylated RNA using streptavidin affinity chromatography.
-
Analysis: Elute the captured RNA for subsequent analysis.
The Salvage Pathway: A Common Route for Uridine Analogs
The incorporation of these uridine analogs into cellular RNA is dependent on the pyrimidine salvage pathway. This pathway recycles pyrimidine bases and nucleosides, converting them into nucleotides that can then be used for RNA synthesis. The diagram below illustrates the key steps in this pathway that are co-opted by the nucleoside analogs.
Conclusion: Choosing the Right Tool for the Job
The selection of a nucleoside analog for RNA labeling is a critical decision that profoundly impacts the experimental outcome. While BrU, 5-EU, and 4sU remain powerful tools for capturing a snapshot of the nascent transcriptome, pseudouridine presents a paradigm shift. Its inherent ability to enhance RNA stability and translation, coupled with its low immunogenicity, makes it an exceptional choice for applications in therapeutic mRNA development and for studying the functional consequences of RNA modifications. For researchers focused purely on quantifying nascent RNA synthesis and decay rates, the well-established workflows for 4sU and 5-EU may offer a more direct path. However, for those interested in the downstream fate and function of the labeled RNA, pseudouridine opens up exciting new avenues of investigation. As research in this area continues to evolve, a deeper understanding of the cellular processing and potential biases of pseudouridine as a metabolic label will further solidify its position in the transcriptomics toolbox.
References
- 1. Incorporation of Pseudouridine Into mRNA Yields Superior Nonimmunogenic Vector With Increased Translational Capacity and Biological Stability - PMC [pmc.ncbi.nlm.nih.gov]
- 2. academic.oup.com [academic.oup.com]
- 3. Investigation of RNA Synthesis Using 5-Bromouridine Labelling and Immunoprecipitation - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Metabolic Labeling of RNAs Uncovers Hidden Features and Dynamics of the Arabidopsis Transcriptome - PMC [pmc.ncbi.nlm.nih.gov]
- 5. academic.oup.com [academic.oup.com]
- 6. Metabolic labeling of RNA using multiple ribonucleoside analogs enables the simultaneous evaluation of RNA synthesis and degradation rates - PMC [pmc.ncbi.nlm.nih.gov]
- 7. benchchem.com [benchchem.com]
- 8. researchgate.net [researchgate.net]
- 9. Nanopore sequencing for N1-methylpseudouridine in RNA reveals sequence-dependent discrimination of the modified nucleotide triphosphate during transcription - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Metabolic Labeling and Recovery of Nascent RNA to Accurately Quantify mRNA Stability - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Pseudouridine and N 1-methylpseudouridine as potent nucleotide analogues for RNA therapy and vaccine development - RSC Chemical Biology (RSC Publishing) DOI:10.1039/D4CB00022F [pubs.rsc.org]
- 12. Genome-wide technology for determining RNA stability in mammalian cells: Historical perspective and recent advantages based on modified nucleotide labeling - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Pseudouridines have context-dependent mutation and stop rates in high-throughput sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Transcriptome-Wide Identification of Pseudouridine Modifications Using Pseudo-seq - PMC [pmc.ncbi.nlm.nih.gov]
- 15. biorxiv.org [biorxiv.org]
- 16. Global analysis of RNA metabolism using bio-orthogonal labeling coupled with next-generation RNA sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 17. researchgate.net [researchgate.net]
Safety Operating Guide
Proper Disposal of Pseudothymidine: A Guide for Laboratory Professionals
Ensuring a safe and compliant laboratory environment is paramount for researchers, scientists, and drug development professionals. This guide provides detailed, step-by-step procedures for the proper disposal of pseudothymidine, a nucleoside analog. Adherence to these protocols is crucial for minimizing risks and complying with regulatory standards.
Immediate Safety and Handling Precautions
Before beginning any disposal procedure, ensure you are wearing the appropriate Personal Protective Equipment (PPE).
-
Ventilation: Handle this compound and its waste in a well-ventilated area, preferably within a chemical fume hood, to minimize the risk of inhalation.
-
Personal Protective Equipment (PPE): At a minimum, wear safety goggles with side shields, nitrile rubber gloves, and a lab coat.[8][9][10] If there is a risk of generating dust or aerosols, respiratory protection may be necessary.[8][9]
-
Hygiene: Practice good industrial hygiene. Wash your hands thoroughly before breaks and after handling the compound.[8][9] Contaminated clothing should be removed promptly.[8][9]
Step-by-Step Disposal Protocol
All chemical waste must be accumulated at or near the point of generation and handled by trained personnel.[5] Never dispose of chemical waste down the sink or in the regular trash unless explicitly permitted by your institution's EH&S office for specific, non-hazardous materials.[5][7]
-
Waste Collection:
-
Collect all waste containing this compound, including contaminated items like weighing paper, pipette tips, and gloves, in a designated, leak-proof, and chemically compatible waste container.[8] Plastic containers are often preferred.[4]
-
Ensure the container has a secure, leak-proof closure and is kept closed except when adding waste.[4][5][6]
-
-
Waste Segregation:
-
Labeling:
-
Storage:
-
Professional Disposal:
Quantitative Data Summary for Laboratory Waste Storage
The following table summarizes key quantitative limits for the accumulation of hazardous waste in a laboratory setting, based on typical U.S. regulations. Always confirm these limits with your institution's specific guidelines.
| Parameter | Limit | Regulatory Context |
| Maximum Hazardous Waste Volume | 55 gallons | Per Satellite Accumulation Area.[4][6] |
| Maximum Acutely Toxic Waste (P-List) | 1 quart (liquid) or 1 kg (solid) | Per Satellite Accumulation Area.[4][6] |
| Maximum Storage Time | 12 months | Provided accumulation limits are not exceeded.[4] |
| Waste Removal Deadline | 3 calendar days | After reaching the maximum accumulation limit.[4] |
Experimental Protocols
Waste Disposal Workflow
The following diagram illustrates the decision-making and procedural flow for the proper disposal of this compound waste in a laboratory setting.
Caption: Workflow for the proper disposal of this compound waste.
References
- 1. Nucleoside Analogs: A Review of Its Source and Separation Processes - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Nucleoside analogue - Wikipedia [en.wikipedia.org]
- 3. Nucleoside Analogues - LiverTox - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 4. ehrs.upenn.edu [ehrs.upenn.edu]
- 5. danielshealth.com [danielshealth.com]
- 6. cdn.vanderbilt.edu [cdn.vanderbilt.edu]
- 7. vumc.org [vumc.org]
- 8. benchchem.com [benchchem.com]
- 9. benchchem.com [benchchem.com]
- 10. cdhfinechemical.com [cdhfinechemical.com]
Safeguarding Your Research: A Comprehensive Guide to Handling Pseudothymidine
For researchers, scientists, and professionals in drug development, ensuring a safe laboratory environment is paramount. This guide provides essential, immediate safety and logistical information for handling Pseudothymidine, offering procedural, step-by-step guidance to directly address your operational questions.
Personal Protective Equipment (PPE)
When handling this compound, a comprehensive approach to personal protection is crucial to minimize exposure and ensure safety. The following table summarizes the recommended PPE.
| PPE Category | Specification | Rationale |
| Respiratory Protection | NIOSH/MSHA or European Standard EN 149 approved respirator. | To prevent inhalation of the powder solid. |
| Hand Protection | Chemical-resistant, powder-free gloves. Double gloving is recommended. | To avoid skin contact. The outer glove can be removed within the containment area to prevent spreading contamination.[1][2] |
| Eye Protection | Chemical safety goggles or a face shield. | To protect eyes from dust particles.[3] |
| Body Protection | Disposable, low-permeability gown with a solid front, long sleeves, and tight-fitting cuffs. | To protect skin and clothing from contamination.[2] |
| Other | Head, hair, and shoe covers. | To prevent the spread of contamination outside of the work area.[4] |
Operational Plan for Handling this compound
A systematic approach to handling this compound from receipt to disposal is critical for safety and regulatory compliance.
1. Receiving and Storage:
-
Upon receipt, visually inspect the container for any damage or leaks.
-
Wear appropriate PPE (gloves) when handling the package.
-
Store this compound in a tightly closed container in a dry, cool, and well-ventilated place.[3][5]
-
Keep it away from strong oxidizing agents.[3]
2. Handling and Use:
-
All handling of this compound powder should be conducted in a designated area, such as a chemical fume hood or a biological safety cabinet, to ensure adequate ventilation and containment.[3][5]
-
Wear the full complement of recommended PPE.
-
Do not eat, drink, or smoke in the handling area.
-
Wash hands thoroughly before and after handling the compound.[2]
3. Spills and Decontamination:
-
In case of a spill, evacuate the area and prevent the spread of dust.
-
Wear appropriate PPE, including respiratory protection, before cleaning the spill.
-
Use a wet-wipe or a HEPA-filtered vacuum to clean up the powder. Avoid dry sweeping.
-
Decontaminate the area with an appropriate cleaning agent.
-
Collect all cleanup materials in a sealed container for proper disposal.
4. Disposal Plan:
-
All waste contaminated with this compound, including used PPE and cleaning materials, should be considered hazardous waste.[4]
-
Collect all waste in clearly labeled, sealed containers.
-
Dispose of the waste in accordance with institutional, local, state, and federal regulations.
-
Ensure that all wastewater generated from cleaning or experimental procedures is collected and treated through a wastewater treatment plant.[6]
Experimental Workflow for Handling this compound
The following diagram illustrates the standard workflow for safely handling this compound in a laboratory setting.
Caption: Workflow for Safe Handling of this compound.
References
Retrosynthesis Analysis
AI-Powered Synthesis Planning: Our tool employs the Template_relevance Pistachio, Template_relevance Bkms_metabolic, Template_relevance Pistachio_ringbreaker, Template_relevance Reaxys, Template_relevance Reaxys_biocatalysis model, leveraging a vast database of chemical reactions to predict feasible synthetic routes.
One-Step Synthesis Focus: Specifically designed for one-step synthesis, it provides concise and direct routes for your target compounds, streamlining the synthesis process.
Accurate Predictions: Utilizing the extensive PISTACHIO, BKMS_METABOLIC, PISTACHIO_RINGBREAKER, REAXYS, REAXYS_BIOCATALYSIS database, our tool offers high-accuracy predictions, reflecting the latest in chemical research and data.
Strategy Settings
| Precursor scoring | Relevance Heuristic |
|---|---|
| Min. plausibility | 0.01 |
| Model | Template_relevance |
| Template Set | Pistachio/Bkms_metabolic/Pistachio_ringbreaker/Reaxys/Reaxys_biocatalysis |
| Top-N result to add to graph | 6 |
Feasible Synthetic Routes



Featured Recommendations
| Most viewed |
|
|
|---|---|---|
| Most popular with customers |
|
Descargo de responsabilidad e información sobre productos de investigación in vitro
Tenga en cuenta que todos los artículos e información de productos presentados en BenchChem están destinados únicamente con fines informativos. Los productos disponibles para la compra en BenchChem están diseñados específicamente para estudios in vitro, que se realizan fuera de organismos vivos. Los estudios in vitro, derivados del término latino "in vidrio", involucran experimentos realizados en entornos de laboratorio controlados utilizando células o tejidos. Es importante tener en cuenta que estos productos no se clasifican como medicamentos y no han recibido la aprobación de la FDA para la prevención, tratamiento o cura de ninguna condición médica, dolencia o enfermedad. Debemos enfatizar que cualquier forma de introducción corporal de estos productos en humanos o animales está estrictamente prohibida por ley. Es esencial adherirse a estas pautas para garantizar el cumplimiento de los estándares legales y éticos en la investigación y experimentación.
