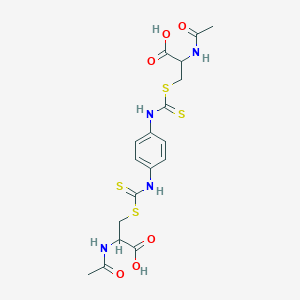
Not found
描述
BenchChem offers high-quality this compound suitable for many research applications. Different packaging options are available to accommodate customers' requirements. Please inquire for more information about this compound including the price, delivery time, and more detailed information at info@benchchem.com.
属性
分子式 |
C18H22N4O6S4 |
|---|---|
分子量 |
518.7 g/mol |
IUPAC 名称 |
2-acetamido-3-[[4-[(2-acetamido-2-carboxyethyl)sulfanylcarbothioylamino]phenyl]carbamothioylsulfanyl]propanoic acid |
InChI |
InChI=1S/C18H22N4O6S4/c1-9(23)19-13(15(25)26)7-31-17(29)21-11-3-5-12(6-4-11)22-18(30)32-8-14(16(27)28)20-10(2)24/h3-6,13-14H,7-8H2,1-2H3,(H,19,23)(H,20,24)(H,21,29)(H,22,30)(H,25,26)(H,27,28) |
InChI 键 |
HTRJZMPLPYYXIN-UHFFFAOYSA-N |
规范 SMILES |
CC(=O)NC(CSC(=S)NC1=CC=C(C=C1)NC(=S)SCC(C(=O)O)NC(=O)C)C(=O)O |
同义词 |
2-AAPA cpd 2-acetylamino-3-(4-(2-acetylamino-2-carboxyethylsulfanylthiocarbonylamino)phenylthiocarbamoylsulfanyl)propionic acid |
产品来源 |
United States |
Foundational & Exploratory
Whitepaper: Strategies for Identification and Characterization of Proteins with No Apparent Homologs in Existing Databases
A Technical Guide for Researchers in Life Sciences and Drug Discovery
Introduction
The identification of protein homologs is a cornerstone of modern biological research, enabling functional annotation, evolutionary analysis, and the identification of potential drug targets. However, it is not uncommon for researchers to encounter proteins with no readily identifiable homologs in public or proprietary databases. This situation can arise from a multitude of factors, ranging from the limitations of sequence-based search algorithms to the genuine novelty of the protein .
This technical guide provides an in-depth exploration of the reasons why a protein homolog may not be found and presents a comprehensive overview of advanced computational and experimental strategies to address this challenge. We will delve into the nuances of sequence and profile-based search methods, detail experimental workflows for de novo protein identification and sequencing, and provide structured data and visualizations to aid in understanding these complex processes.
Why Homologs Go Undetected: The Limitations of Sequence-Based Searches
The most common starting point for finding protein homologs is a sequence similarity search using tools like BLAST (Basic Local Alignment Search Tool). While powerful, these methods have inherent limitations, particularly when dealing with distantly related proteins.
The "Twilight Zone" of Sequence Similarity
Evolutionary divergence can lead to sequences that share a common ancestor and three-dimensional structure but have very low sequence identity. For protein pairs with less than 25-35% sequence identity, it becomes statistically challenging to distinguish true homologs from random alignments, a concept often referred to as the "twilight zone" of sequence alignment. Standard BLAST searches may fail to detect these remote homologs.[1][2]
Limitations of Standard Search Algorithms
Standard search algorithms like BLAST are not always sensitive enough to detect distant evolutionary relationships.[1][3] Sequences can degrade significantly over evolutionary time, yet the proteins can still fold into similar 3D structures and perform similar functions.[1] More advanced methods are often required to uncover these remote homologies.
Rapid Evolution and Novel Protein Functions
In some biological contexts, such as viral evolution, proteins can evolve so rapidly that their sequences diverge beyond the point of easy recognition by standard tools.[3] Furthermore, a protein may have a genuinely novel function or belong to a newly evolved protein family that is not yet represented in the databases.
Advanced Computational Strategies for Detecting Remote Homologs
When standard searches fail, more sensitive computational methods can be employed to detect distant evolutionary relationships. These methods often build statistical models or profiles from multiple sequences to enhance search sensitivity.
Position-Specific Iterated BLAST (PSI-BLAST)
PSI-BLAST is an iterative search method that builds a position-specific scoring matrix (PSSM) from an initial BLAST search.[4][5][6][7] This PSSM captures the sequence variability at each position in a multiple sequence alignment of the top hits. In subsequent iterations, the PSSM is used to search the database, which can uncover more distant homologs.[4][5][6][7] This iterative refinement of the profile significantly increases the sensitivity of the search.
-
Initial BLASTp: Start with a standard protein-protein BLAST (BLASTp) search against a protein database (e.g., NCBI's non-redundant protein database).[4]
-
First Iteration: Review the initial results. PSI-BLAST will automatically generate a multiple sequence alignment of significant hits and create a PSSM.[5]
-
Subsequent Iterations: Use the PSSM to search the database again. New sequences found in this iteration are added to the alignment, and the PSSM is refined.[4]
-
Convergence: Repeat the iterations until no new significant hits are found.
-
Analysis: Carefully examine the results for conserved domains and functional motifs that may indicate homology.
Profile Hidden Markov Models (HMMs)
Profile HMMs are statistical models that represent the consensus sequence of a protein family.[8] Tools like HMMER use profile HMMs to search for remote homologs with high sensitivity.[9] They are particularly effective because they model not only conserved residues but also insertions and deletions within the protein family.[10] For sequences with less than 30% identity, profile-based methods can detect up to three times more homologs than pairwise alignments.[10]
-
Obtain a Multiple Sequence Alignment (MSA): If you have a set of related sequences, create an MSA using tools like ClustalW.
-
Build the Profile HMM: Use the hmmbuild program from the HMMER package to create a profile HMM from your MSA.
-
Calibrate the HMM (Optional but Recommended): Use hmmcalibrate to improve the sensitivity of the database search by determining appropriate statistical significance parameters.
-
Search the Database: Use hmmsearch to search a sequence database with your profile HMM.
-
Analyze the Results: Examine the E-values and bit scores to identify potential homologs.
Comparison of Search Method Sensitivities
The choice of search method can significantly impact the ability to detect remote homologs. The following table summarizes the relative sensitivities of different methods.
| Method | Principle | Relative Sensitivity | Typical Use Case |
| BLASTp | Local sequence alignment | Low to Moderate | Finding closely related homologs. |
| PSI-BLAST | Iterative profile-based search | High | Finding moderately to distantly related homologs.[4] |
| HMMER | Profile Hidden Markov Models | Very High | Detecting remote homologs and classifying proteins into families.[9][10] |
| HHblits/HHpred | HMM-HMM comparison | Very High | Finding very distant homologs by comparing profiles.[3] |
Experimental Approaches for Novel Protein Discovery and Sequencing
When computational methods fail to identify homologs, it may be necessary to turn to experimental techniques to characterize the protein. Mass spectrometry-based proteomics is a powerful tool for identifying and sequencing unknown proteins.
"Bottom-Up" Proteomics for Protein Identification
The most common approach for protein identification is "bottom-up" proteomics.[11] In this workflow, proteins are enzymatically digested into smaller peptides, which are then analyzed by tandem mass spectrometry (LC-MS/MS).[11][12] The resulting peptide fragmentation spectra are then matched against a sequence database to identify the protein.
-
Sample Preparation: Isolate and purify the protein of interest. This can involve techniques like gel electrophoresis.[11][12]
-
Enzymatic Digestion: Digest the protein into peptides using a protease such as trypsin.[11][12]
-
Liquid Chromatography (LC) Separation: Separate the complex mixture of peptides using high-performance liquid chromatography (HPLC).[12]
-
Tandem Mass Spectrometry (MS/MS): Analyze the separated peptides using a mass spectrometer.[13] The instrument first measures the mass-to-charge ratio (m/z) of the intact peptides (MS1 scan) and then selects and fragments individual peptides to generate fragmentation spectra (MS2 scan).[12]
-
Database Searching: Use a search algorithm (e.g., SEQUEST, Mascot) to compare the experimental fragmentation spectra to theoretical spectra generated from a protein sequence database.
De Novo Protein Sequencing
When a protein is not present in any database, de novo sequencing is required.[14][15][16] This technique determines the amino acid sequence of a peptide directly from its fragmentation spectrum without relying on a database.[14][15][16] Algorithms for de novo sequencing analyze the mass differences between peaks in the MS/MS spectrum to deduce the amino acid sequence.[14]
-
Sample Preparation and MS/MS Analysis: Follow the same initial steps as in bottom-up proteomics to generate high-quality fragmentation spectra.
-
Spectral Interpretation: Use de novo sequencing software (e.g., PEAKS, Novor) to analyze the MS/MS spectra. The software identifies ion series (typically b- and y-ions) and calculates the mass differences between adjacent peaks to determine the amino acid sequence.[15]
-
Sequence Assembly: The sequences of multiple overlapping peptides are assembled to reconstruct the full-length protein sequence.
| Sequencing Approach | Principle | Advantages | Limitations |
| Database-Dependent | Matches experimental spectra to theoretical spectra from a database. | High-throughput and computationally efficient. | Cannot identify proteins not in the database.[17] |
| De Novo Sequencing | Deduces peptide sequence directly from fragmentation spectra. | Enables sequencing of novel proteins and those from unsequenced organisms.[15][16] | Computationally intensive and can be less accurate than database searches.[15] |
Integrating Genomics, Transcriptomics, and Proteomics
A comprehensive approach to identifying and characterizing novel proteins involves the integration of data from genomics, transcriptomics, and proteomics. This "proteogenomics" workflow can provide strong evidence for the existence and function of a novel protein.
By creating a custom protein database from genomic and transcriptomic data, it is possible to identify peptides that map to previously unannotated open reading frames (ORFs).[18][19] This provides strong evidence that a predicted gene is indeed expressed as a protein.
Conclusion
The inability to find a protein homolog in a database is not a dead end but rather an entry point into a deeper investigation of a potentially novel protein. By employing advanced computational search strategies and leveraging powerful experimental techniques like mass spectrometry and de novo sequencing, researchers can overcome the limitations of standard homology-based annotation. The integrated approach of proteogenomics offers a robust framework for the discovery and validation of novel proteins, paving the way for new insights into biological function and the identification of new therapeutic targets.
References
- 1. Is Protein BLAST a thing of the past? - PMC [pmc.ncbi.nlm.nih.gov]
- 2. The limits of protein sequence comparison? - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Powerful Sequence Similarity Search Methods and In-Depth Manual Analyses Can Identify Remote Homologs in Many Apparently “Orphan” Viral Proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Understanding PSI-BLAST: A Comprehensive Guide - Omics tutorials [omicstutorials.com]
- 5. PSI-BLAST Tutorial - Comparative Genomics - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 6. PSI-BLAST tutorial - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. PSI-BLAST tutorial - PMC [pmc.ncbi.nlm.nih.gov]
- 8. stat.purdue.edu [stat.purdue.edu]
- 9. HMMER [hmmer.org]
- 10. Rational Design of Profile HMMs for Sensitive and Specific Sequence Detection with Case Studies Applied to Viruses, Bacteriophages, and Casposons - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Protein Mass Spectrometry Made Simple - PMC [pmc.ncbi.nlm.nih.gov]
- 12. allumiqs.com [allumiqs.com]
- 13. Protein Identification by Tandem Mass Spectrometry - Creative Proteomics [creative-proteomics.com]
- 14. creative-biolabs.com [creative-biolabs.com]
- 15. De Novo Protein Sequencing: How to Improve Accuracy and Data Analysis Efficiency | MtoZ Biolabs [mtoz-biolabs.com]
- 16. medium.com [medium.com]
- 17. De novo sequencing methods in proteomics - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. A workflow to identify novel proteins based on the direct mapping of peptide-spectrum-matches to genomic locations - PMC [pmc.ncbi.nlm.nih.gov]
- 19. researchgate.net [researchgate.net]
Technical Guide: Establishing a Foundational Identity and History for Cell Lines with Missing Data
Audience: Researchers, scientists, and drug development professionals.
This document outlines a systematic approach to rectify this situation by establishing a new, verified historical record through rigorous authentication, characterization, and documentation.
The Core Problem: Consequences of an Unknown History
When historical data for a cell line is unavailable, it is impossible to ensure the two most critical attributes of a reliable in vitro model: its identity and its stability. The consequences are significant:
-
Misidentification and Cross-Contamination: A staggering number of cell lines are misidentified. The International Cell Line Authentication Committee (ICLAC) maintains a register of hundreds of misidentified cell lines, with HeLa being a common contaminant.[1][3] Using the wrong cell line renders all experimental data irrelevant to the intended biological model.
-
Genetic and Phenotypic Drift: Continuous passaging exerts selective pressure on cell populations, leading to changes in growth rate, morphology, gene expression, and response to stimuli.[4][5][6][7] Data from a low-passage culture may not be comparable to that from a high-passage culture, even if the line is "correct".[2][5]
-
Irreproducible Research: The use of unauthenticated or overly passaged cell lines is a major contributor to the reproducibility crisis in biomedical research.[2][8] Without a baseline, results cannot be reliably reproduced within or between labs.
-
Wasted Resources: Experiments conducted on poorly characterized cell lines can lead to incorrect theories and derail scientific progress, wasting significant time, funding, and effort.[1]
The logical workflow upon discovering a lack of historical data is not to search for lost records, but to assume the current cell stock is unverified and initiate a process of re-authentication and characterization.
References
- 1. biocompare.com [biocompare.com]
- 2. The costs of using unauthenticated, over-passaged cell lines: how much more data do we need? - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. The repercussions of using misidentified cell lines | Culture Collections [culturecollections.org.uk]
- 4. Passage number of cancer cell lines: Importance, intricacies, and way-forward - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. cellculturecompany.com [cellculturecompany.com]
- 7. Impact of Passage Number on Cell Line Phenotypes [cytion.com]
- 8. Incorrect cell line validation and verification - PMC [pmc.ncbi.nlm.nih.gov]
A Researcher's Guide to Elucidating the Mechanism of Action for a Novel Compound
For Researchers, Scientists, and Drug Development Professionals
Introduction
The identification of a novel compound with promising therapeutic activity is a significant milestone in drug discovery. However, a critical subsequent step is the elucidation of its mechanism of action (MoA). A thorough understanding of how a compound exerts its effects at the molecular, cellular, and organismal levels is paramount for its optimization, preclinical development, and ultimately, its clinical success. A well-defined MoA can help predict potential side effects, identify patient populations who are most likely to respond, and uncover new therapeutic indications.
This guide provides an in-depth overview of the core experimental strategies and computational approaches employed to unravel the MoA of a novel compound. It is designed to be a technical resource for researchers, scientists, and drug development professionals, offering detailed experimental protocols, structured data presentation, and visualizations of key concepts and workflows.
Phase 1: Target Identification and Engagement
The initial phase of MoA elucidation focuses on identifying the direct molecular target(s) of the novel compound and confirming physical engagement in a relevant biological context.
Experimental Protocols
1. Affinity Chromatography coupled with Mass Spectrometry (AC-MS)
This technique is a cornerstone for identifying the protein targets of a small molecule.
-
Principle: The novel compound is immobilized on a solid support (e.g., beads) to create an affinity matrix. This matrix is then incubated with a complex protein mixture, such as a cell lysate. Proteins that bind to the compound are "captured" and subsequently eluted and identified by mass spectrometry.
-
Protocol Outline:
-
Compound Immobilization: Covalently attach the novel compound to a solid support (e.g., NHS-activated sepharose beads) via a functional group on the compound. A linker may be used to minimize steric hindrance.
-
Cell Lysis: Prepare a cell lysate from a relevant cell line or tissue under non-denaturing conditions to preserve protein structure and interactions.
-
Affinity Purification: Incubate the cell lysate with the compound-immobilized beads. Include a control with beads that have been treated with a blocking agent but without the compound to identify non-specific binders.
-
Washing: Wash the beads extensively with a series of buffers of increasing stringency to remove non-specifically bound proteins.
-
Elution: Elute the specifically bound proteins from the beads. This can be achieved by changing the pH, increasing the ionic strength, or by competitive elution with an excess of the free compound.
-
Sample Preparation for Mass Spectrometry: The eluted proteins are typically separated by SDS-PAGE, followed by in-gel digestion with trypsin.
-
LC-MS/MS Analysis: The resulting peptides are analyzed by liquid chromatography-tandem mass spectrometry (LC-MS/MS) to determine their amino acid sequences.
-
Data Analysis: The identified proteins are cross-referenced with protein databases to identify the potential targets. Candidates are prioritized based on their enrichment in the compound-treated sample compared to the control.[1][2]
-
2. Cellular Thermal Shift Assay (CETSA)
CETSA is a powerful method to confirm target engagement in intact cells or tissue samples.[3][4]
-
Principle: The binding of a ligand (the novel compound) to its target protein often increases the thermal stability of the protein. CETSA measures this change in thermal stability.[4]
-
Protocol Outline:
-
Cell Treatment: Treat intact cells with the novel compound at various concentrations. A vehicle-treated control is essential.
-
Heating: Heat the cell suspensions at a range of temperatures in a thermocycler.
-
Cell Lysis and Fractionation: Lyse the cells and separate the soluble protein fraction (containing folded, non-denatured proteins) from the precipitated fraction by centrifugation.
-
Protein Quantification: Quantify the amount of the putative target protein remaining in the soluble fraction at each temperature using techniques like Western blotting or ELISA.
-
Data Analysis: Plot the amount of soluble protein as a function of temperature to generate a melting curve. A shift in the melting curve to a higher temperature in the presence of the compound indicates target engagement.[4] An isothermal dose-response fingerprint can also be generated by heating all samples at a single, optimized temperature and varying the compound concentration to determine the cellular EC50.[5]
-
Data Presentation
Table 1: Summary of Target Identification and Engagement Data
| Parameter | Experimental Method | Result | Interpretation |
| Putative Target(s) | Affinity Chromatography-Mass Spectrometry | Protein X, Protein Y | The compound directly binds to these proteins in a cellular context. |
| Binding Affinity (Kd) | Surface Plasmon Resonance (SPR) | 50 nM (for Protein X) | High-affinity interaction with Protein X. |
| Thermal Shift (ΔTm) | Cellular Thermal Shift Assay (CETSA) | +4.2 °C (for Protein X) | The compound stabilizes Protein X in intact cells, confirming engagement. |
| Cellular EC50 | Isothermal Dose-Response CETSA | 200 nM (for Protein X) | Concentration of the compound required for 50% of maximal target engagement in cells. |
Phase 2: Elucidation of Cellular and Pathway Effects
Once the direct target is identified and engagement is confirmed, the next phase is to understand the downstream consequences of this interaction on cellular signaling pathways and phenotypes.
Experimental Protocols
1. Luciferase Reporter Gene Assay
This is a widely used method to investigate the effect of a compound on the activity of a specific signaling pathway.[6][7][8]
-
Principle: A reporter gene (e.g., luciferase) is placed under the control of a promoter that is regulated by a transcription factor of interest. The activity of the luciferase enzyme, which produces a luminescent signal in the presence of its substrate, serves as a readout for the activity of the signaling pathway.[6][7]
-
Protocol Outline:
-
Cell Transfection: Transfect a suitable cell line with a plasmid containing the luciferase reporter construct. A control plasmid with a constitutively active promoter (e.g., CMV) can be co-transfected to normalize for transfection efficiency.
-
Compound Treatment: Treat the transfected cells with the novel compound at various concentrations.
-
Cell Lysis: After an appropriate incubation period, lyse the cells to release the luciferase enzyme.[6][9]
-
Luminescence Measurement: Add the luciferase substrate (luciferin) to the cell lysate and measure the resulting luminescence using a luminometer.[6][10]
-
Data Analysis: Normalize the luciferase activity of the experimental reporter to that of the control reporter. A change in luminescence in response to the compound indicates modulation of the signaling pathway.
-
2. High-Content Imaging and Analysis
This technique allows for the quantitative analysis of multiple cellular parameters in response to compound treatment.
-
Principle: Automated microscopy and image analysis are used to measure changes in cell morphology, protein localization, and the expression of specific biomarkers.
-
Protocol Outline:
-
Cell Plating and Treatment: Plate cells in multi-well plates and treat with the novel compound.
-
Staining: Stain the cells with fluorescent dyes or antibodies to visualize specific cellular components (e.g., nucleus, cytoskeleton, target protein).
-
Image Acquisition: Acquire images using a high-content imaging system.
-
Image Analysis: Use image analysis software to quantify various cellular features, such as nuclear translocation of a transcription factor, changes in cell shape, or the intensity of a fluorescently labeled protein.
-
Data Presentation
Table 2: Summary of Cellular and Pathway Effects
| Parameter | Experimental Method | Result | Interpretation |
| Pathway Activity (IC50) | Luciferase Reporter Assay (NF-κB) | 150 nM | The compound inhibits the NF-κB signaling pathway. |
| Protein Phosphorylation | Western Blot (p-ERK) | Decreased by 80% at 1 µM | The compound inhibits the MAPK/ERK signaling pathway. |
| Transcription Factor Localization | High-Content Imaging (NFAT) | 90% nuclear exclusion at 500 nM | The compound prevents the activation and nuclear translocation of NFAT. |
| Cell Viability (GI50) | CellTiter-Glo Assay | 5 µM (in cancer cell line A) | The compound has a growth-inhibitory effect on cancer cells. |
Phase 3: In Vivo Validation
The final phase involves validating the MoA in a living organism to understand the compound's physiological effects.
Experimental Protocols
1. Animal Models of Disease
-
Principle: Use an appropriate animal model that recapitulates key aspects of the human disease to evaluate the in vivo efficacy and MoA of the novel compound.
-
Protocol Outline:
-
Model Selection: Choose a relevant animal model (e.g., a xenograft model for cancer, a transgenic model for a genetic disease).
-
Compound Administration: Administer the novel compound to the animals via a clinically relevant route.
-
Efficacy Assessment: Monitor disease progression and assess the therapeutic effect of the compound.
-
Pharmacodynamic (PD) Biomarker Analysis: Collect tissue or blood samples to measure biomarkers that reflect the engagement of the target and modulation of the downstream pathway in vivo.
-
Data Presentation
Table 3: Summary of In Vivo Validation Data
| Parameter | Experimental Model | Result | Interpretation |
| Tumor Growth Inhibition | Mouse Xenograft Model | 75% reduction in tumor volume | The compound has significant anti-tumor efficacy in vivo. |
| Target Engagement (in vivo) | In vivo CETSA on tumor tissue | Significant thermal stabilization of Protein X | The compound engages its target in the tumor tissue. |
| Pathway Modulation (in vivo) | Immunohistochemistry (p-STAT3) | 85% decrease in p-STAT3 staining in tumors | The compound inhibits the target pathway in the in vivo setting. |
Mandatory Visualizations
Signaling Pathway Diagram
References
- 1. researchgate.net [researchgate.net]
- 2. wp.unil.ch [wp.unil.ch]
- 3. Screening for Target Engagement using the Cellular Thermal Shift Assay - CETSA - Assay Guidance Manual - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 4. benchchem.com [benchchem.com]
- 5. bio-protocol.org [bio-protocol.org]
- 6. indigobiosciences.com [indigobiosciences.com]
- 7. bitesizebio.com [bitesizebio.com]
- 8. bioagilytix.com [bioagilytix.com]
- 9. assaygenie.com [assaygenie.com]
- 10. youtube.com [youtube.com]
Unraveling a Novel Inborn Error of Metabolism: A Technical Guide to the ACAA2 Gain-of-Function Variant
A Whitepaper for Researchers, Scientists, and Drug Development Professionals
Abstract
The landscape of rare diseases is continually expanding with the advent of advanced genomic sequencing technologies. A recently identified autosomal dominant disorder, stemming from a recurrent gain-of-function variant in the ACAA2 gene, presents a novel challenge in the field of inborn errors of metabolism. This technical guide provides a comprehensive overview of the current, albeit limited, understanding of this emerging disease, characterized by a complex phenotype including familial partial lipodystrophy, lipomatosis, infantile steatohepatitis, and hypoglycemia. We consolidate the sparse existing data, propose a pathogenic mechanism, and offer a detailed compendium of experimental protocols to facilitate further research. This document is intended to serve as a foundational resource for researchers, clinicians, and industry professionals dedicated to elucidating the pathophysiology of this rare condition and developing potential therapeutic interventions.
Introduction to the ACAA2-Related Metabolic Disorder
Acetyl-CoA Acyltransferase 2 (ACAA2) is a mitochondrial enzyme that catalyzes the final step of the fatty acid β-oxidation spiral, the thiolytic cleavage of 3-ketoacyl-CoA into acetyl-CoA and a shortened acyl-CoA. This process is fundamental for energy production from fatty acids, particularly during periods of fasting.
A newly described rare genetic disorder has been linked to a recurrent heterozygous missense variant in the ACAA2 gene (c.688G>A; p.Glu230Lys).[1] Unlike typical inborn errors of metabolism that arise from loss-of-function mutations, this disorder is hypothesized to be caused by a pathological gain-of-function in the ACAA2 enzyme.[1] The precise molecular consequences of this enhanced enzymatic activity are still under investigation, but it is speculated to disrupt the delicate balance of mitochondrial lipid and energy metabolism.
Clinically, affected individuals present with a multisystemic phenotype that emerges from infancy to adulthood. Key features include:
-
Familial Partial Lipodystrophy (FPL): Characterized by the loss of subcutaneous adipose tissue from the limbs and gluteal region, with variable accumulation of fat in the face, neck, and intra-abdominal areas.[1][2]
-
Lipomatosis: The formation of benign tumors composed of adipose tissue.[1]
-
Infantile Steatohepatitis: Fatty infiltration and inflammation of the liver occurring in infancy.[1]
-
Hypoglycemia: Episodes of abnormally low blood sugar, which can be severe enough to cause neurological damage, particularly in infants.[1]
A critical diagnostic marker for this condition is the presence of elevated levels of long-chain acylcarnitines in plasma, which is paradoxical for a disorder involving an enzyme at the end of the beta-oxidation pathway and points towards a complex disruption of mitochondrial acyl-CoA metabolism.[1]
Summarized Patient Data
The following table summarizes the key clinical and biochemical findings from the initial reported cohort of individuals with the ACAA2 p.Glu230Lys variant. This data is compiled from the limited existing literature.[1]
| Parameter | Finding |
| Genetics | |
| Gene | ACAA2 |
| Variant | c.688G>A; p.Glu230Lys |
| Inheritance | Autosomal Dominant (including de novo cases) |
| Clinical Phenotype | |
| Adipose Tissue | Familial Partial Lipodystrophy, Pubic and Dorsocervical Lipomatosis |
| Hepatic | Infantile Steatohepatitis, Hepatomegaly, Steatosis, Fibrosis |
| Metabolic | Hypoglycemia (especially in infancy) |
| Biochemical Markers | |
| Plasma Acylcarnitines | Elevated long-chain species (e.g., C14, C16, C18) |
| Liver Function Tests | Elevated transaminases (in infancy) |
| Histopathology (Liver) | Micro- and macrovesicular steatosis, periportal fibrosis, damaged mitochondria |
Hypothesized Pathogenic Mechanism and Signaling Pathway
The ACAA2 enzyme catalyzes the conversion of 3-ketoacyl-CoA to acetyl-CoA and a shortened acyl-CoA. The p.Glu230Lys gain-of-function variant is thought to enhance this catalytic activity. The precise downstream consequences are yet to be fully elucidated, but a plausible hypothesis is that the overactive enzyme rapidly depletes the pool of 3-ketoacyl-CoA, leading to an increased "pull" on the entire β-oxidation pathway. This could paradoxically lead to an accumulation of upstream long-chain acyl-CoAs that cannot be processed efficiently, which are then shunted into acylcarnitine formation. This disruption in mitochondrial fatty acid homeostasis could lead to lipotoxicity in hepatocytes, impaired adipocyte function and storage, and dysregulated energy balance leading to hypoglycemia.
Caption: Hypothesized pathogenic mechanism of the ACAA2 gain-of-function variant.
Experimental Protocols
To facilitate research into this novel disorder, we provide detailed methodologies for key experiments. These protocols are adapted from established procedures for related metabolic diseases.
Patient-Derived Fibroblast Culture
-
Objective: To establish a renewable source of patient cells for biochemical and functional studies.
-
Methodology: Adapted from primary human fibroblast culture protocols.[3][4]
-
Biopsy Collection: Obtain a 3-4 mm skin punch biopsy from the patient under sterile conditions. Place the biopsy in a sterile tube containing transport medium (e.g., DMEM with 10% FBS and antibiotics).
-
Explant Preparation: In a biosafety cabinet, wash the biopsy with sterile PBS. Mince the tissue into 1-2 mm pieces using sterile scalpels.
-
Culture Initiation: Place the tissue pieces into a 6-well plate, ensuring they adhere to the bottom. Add a minimal amount of complete DMEM (high glucose, 20% FBS, penicillin/streptomycin) to just cover the tissue.
-
Cell Outgrowth: Incubate at 37°C in a 5% CO₂ incubator. Fibroblasts will begin to migrate from the explants within 7-14 days.
-
Expansion: Once a sufficient number of fibroblasts have emerged, trypsinize the cells and transfer them to a larger flask for expansion. Subsequent passages can be performed in DMEM with 10% FBS.
-
Acylcarnitine Profiling by Tandem Mass Spectrometry
-
Objective: To quantify the levels of long-chain acylcarnitines, the key diagnostic biomarker.
-
Methodology: Based on established LC-MS/MS protocols for acylcarnitine analysis.[5]
-
Sample Preparation (Plasma):
-
To 50 µL of patient plasma, add an internal standard solution containing stable isotope-labeled acylcarnitines.
-
Precipitate proteins by adding 200 µL of cold acetonitrile. Vortex and centrifuge.
-
Transfer the supernatant to a new tube and evaporate to dryness under a nitrogen stream.
-
-
Derivatization (Butylation):
-
Reconstitute the dried extract in 100 µL of 3N HCl in n-butanol.
-
Incubate at 65°C for 15 minutes.
-
Evaporate the butanolic HCl to dryness and reconstitute in the initial mobile phase.
-
-
LC-MS/MS Analysis:
-
Chromatography: Use a C18 column with a gradient elution of water and acetonitrile, both containing 0.1% formic acid.
-
Mass Spectrometry: Operate in positive electrospray ionization (ESI) mode with multiple reaction monitoring (MRM) to detect specific acylcarnitine species.
-
Quantification: Calculate the concentration of each acylcarnitine species by comparing its peak area to that of the corresponding internal standard.
-
-
ACAA2 (3-Ketoacyl-CoA Thiolase) Enzymatic Assay
-
Objective: To measure the enzymatic activity of ACAA2 in patient-derived cells and to characterize the kinetic properties of the gain-of-function variant.
-
Methodology: A coupled spectrophotometric assay adapted from protocols for thiolase activity.[6][7] This assay measures the thiolytic cleavage of a substrate (e.g., acetoacetyl-CoA) in the reverse (condensation) direction, which is then coupled to a reaction that produces a detectable change in absorbance. For the forward reaction (cleavage), the decrease in the 3-ketoacyl-CoA substrate can be monitored. A more direct forward assay is described below.
-
Principle (Forward Reaction): The cleavage of the 3-ketoacyl-CoA substrate by ACAA2 results in the disappearance of the enolate form of the substrate, which can be monitored by a decrease in absorbance at ~305-310 nm.
-
Reaction Mixture:
-
50 mM Tris-HCl buffer, pH 8.0
-
20 mM MgCl₂
-
50 µM Coenzyme A (CoA)
-
50 µM 3-ketoacyl-CoA substrate (e.g., acetoacetyl-CoA or a longer-chain substrate)
-
Cell or mitochondrial lysate (containing the ACAA2 enzyme)
-
-
Procedure:
-
Prepare cell or mitochondrial lysates from patient-derived fibroblasts and control cell lines.
-
In a quartz cuvette, combine the buffer, MgCl₂, and CoA.
-
Add the cell lysate and equilibrate to 37°C.
-
Initiate the reaction by adding the 3-ketoacyl-CoA substrate.
-
Immediately monitor the decrease in absorbance at 305 nm using a spectrophotometer.
-
-
Data Analysis:
-
Calculate the rate of reaction (enzyme activity) from the linear portion of the absorbance vs. time plot, using the molar extinction coefficient of the substrate.
-
To determine kinetic parameters (Vmax and Km) for the wild-type and mutant enzymes, repeat the assay with varying substrate concentrations and fit the data to the Michaelis-Menten equation.[8][9] A higher Vmax would be indicative of a gain-of-function.
-
-
Cellular Model Generation using CRISPR-Cas9
-
Objective: To create isogenic cell lines (e.g., in HEK293 or HepG2 cells) with the ACAA2 p.Glu230Lys variant to study the disease mechanism in a controlled genetic background.
-
Methodology: A CRISPR-Cas9 knock-in strategy.[9]
-
Component Design:
-
sgRNA: Design a single guide RNA that directs the Cas9 nuclease to a site as close as possible to the target mutation site (c.688) in the ACAA2 gene.
-
Cas9: Utilize a high-fidelity Cas9 nuclease to minimize off-target effects.
-
Donor Template: Synthesize a single-stranded oligodeoxynucleotide (ssODN) donor template containing the desired G-to-A point mutation. The ssODN should have 40-60 base pair homology arms flanking the mutation site. Introduce a silent mutation in the PAM sequence within the donor template to prevent re-cutting by Cas9 after successful editing.
-
-
Delivery: Co-transfect the sgRNA, Cas9 (as plasmid or RNP complex), and the ssODN donor template into the target cells using electroporation or a lipid-based transfection reagent.
-
Clonal Selection: After transfection, seed the cells at a low density to allow for the growth of single-cell-derived colonies.
-
Screening and Validation:
-
Expand individual clones and extract genomic DNA.
-
Screen for the desired knock-in mutation using PCR followed by Sanger sequencing or restriction fragment length polymorphism (RFLP) analysis if the mutation creates or destroys a restriction site.
-
Confirm the expression of the mutant ACAA2 protein by Western blot and validate the functional consequences using the enzymatic and mitochondrial function assays described herein.
-
-
Caption: Workflow for generating an ACAA2 gain-of-function cellular model.
Analysis of Mitochondrial Respiration
-
Objective: To assess the impact of the ACAA2 gain-of-function mutation on mitochondrial function.
-
Methodology: The Seahorse XF Cell Mito Stress Test.[10]
-
Cell Seeding: Seed control and patient-derived fibroblasts (or CRISPR-edited cells) in a Seahorse XF cell culture microplate. Allow cells to adhere and form a monolayer.
-
Assay Preparation: The day before the assay, hydrate the sensor cartridge. On the day of the assay, replace the culture medium with Seahorse XF assay medium supplemented with glucose, pyruvate, and glutamine, and incubate in a non-CO₂ incubator at 37°C.
-
Mito Stress Test: Load the sensor cartridge with compounds that modulate mitochondrial respiration (oligomycin, FCCP, and a mixture of rotenone/antimycin A). The Seahorse XF Analyzer will sequentially inject these compounds and measure the oxygen consumption rate (OCR) in real-time.
-
Data Analysis: The assay provides key parameters of mitochondrial function:
-
Basal Respiration: The baseline oxygen consumption of the cells.
-
ATP Production: The portion of basal respiration used to generate ATP.
-
Maximal Respiration: The maximum OCR the cells can achieve.
-
Spare Respiratory Capacity: The ability of the cell to respond to an energetic demand. An increase in basal and maximal respiration might be expected in cells with an ACAA2 gain-of-function, reflecting an increased flux through the β-oxidation pathway.
-
-
Future Directions and Conclusion
The discovery of the ACAA2 gain-of-function disorder opens up a new area of research in metabolic diseases. The immediate priorities should be to further characterize the clinical spectrum of the disease, understand the precise molecular consequences of the enhanced enzyme activity, and develop robust cellular and animal models. The experimental protocols detailed in this guide provide a roadmap for the scientific community to begin addressing these critical questions.
Key future research should focus on:
-
Developing a mouse model with the p.Glu230Lys knock-in mutation to study the systemic effects of the disorder and test therapeutic strategies.
-
Performing detailed lipidomic and metabolomic analyses on patient samples and model systems to understand the full scope of metabolic dysregulation.
-
Investigating potential therapeutic approaches, such as small molecule inhibitors that could normalize ACAA2 activity or strategies to mitigate the downstream effects of metabolic dysregulation.
This technical guide serves as a starting point for a collaborative effort to unravel the complexities of this rare disease. By providing a consolidated resource of current knowledge and actionable experimental plans, we hope to accelerate the pace of discovery and ultimately improve the lives of individuals affected by this novel ACAA2-related disorder.
References
- 1. A spectrophotometric assay for measuring acetyl-coenzyme A carboxylase. | Semantic Scholar [semanticscholar.org]
- 2. researchgate.net [researchgate.net]
- 3. A spectrophotometric assay for measuring acetyl-coenzyme A carboxylase - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Peroxisomal Plant 3-Ketoacyl-CoA Thiolase Structure and Activity Are Regulated by a Sensitive Redox Switch - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Practical assay method of cytosolic acetoacetyl-CoA thiolase by rapid release of cytosolic enzymes from cultured lymphocytes using digitonin - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Impairment of mitochondrial acetoacetyl CoA thiolase activity in the colonic mucosa of patients with ulcerative colitis - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Cloning, Expression and Purification of an Acetoacetyl CoA Thiolase from Sunflower Cotyledon - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Basics of Enzymatic Assays for HTS - Assay Guidance Manual - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 9. chem.libretexts.org [chem.libretexts.org]
- 10. youtube.com [youtube.com]
Navigating the Terra Incognita of Metabolism: A Technical Guide to Characterizing the Methylaspartate Cycle
For Researchers, Scientists, and Drug Development Professionals
Abstract: The landscape of microbial metabolism is vast and continues to reveal novel pathways with significant implications for biotechnology and drug development. The methylaspartate cycle, a recently elucidated anaplerotic pathway for acetate assimilation, stands as a prime example of metabolic diversity.[1][2] This stands in contrast to the more well-known glyoxylate cycle.[2][3] This technical guide provides an in-depth exploration of the methylaspartate cycle, a pathway notably absent in most model organisms but crucial for the survival of certain extremophiles, particularly haloarchaea.[1][4][5] We present a comprehensive overview of the cycle's enzymatic steps, quantitative data from key studies, detailed experimental protocols for its characterization, and visual diagrams to illuminate its intricate network. This document serves as a critical resource for researchers aiming to understand, engineer, or target this unique metabolic route.
Introduction: The Methylaspartate Cycle, a Novel Anaplerotic Pathway
Growth on two-carbon compounds like acetate requires a metabolic strategy to replenish the intermediates of the central carbon metabolism, a process known as anaplerosis. While the glyoxylate cycle is a well-established anaplerotic pathway in many organisms, it is not universally conserved.[6] Haloarchaea, a group of extremophilic archaea, have evolved a distinct solution: the methylaspartate cycle.[1][2][3] This pathway allows for the net conversion of acetyl-CoA to malate, a key precursor for biosynthesis.[1][2]
The discovery of the methylaspartate cycle in organisms like Haloarcula marismortui highlights the remarkable adaptability of microbial metabolism.[2][3] Unlike the glyoxylate cycle, the methylaspartate cycle involves a unique set of enzymatic reactions, including the key intermediate for which it is named, methylaspartate.[1][3] Understanding this pathway is not only fundamental to comprehending the metabolic capabilities of these organisms but also opens avenues for novel biotechnological applications and the development of targeted antimicrobial strategies.
Organisms: The methylaspartate cycle has been experimentally confirmed in haloarchaea such as Haloarcula marismortui and Haloarcula hispanica.[4] Bioinformatic analyses suggest its presence in approximately 40% of sequenced haloarchaea.[4][5] Notably, this pathway is absent in commonly studied model organisms like Escherichia coli and Saccharomyces cerevisiae, which typically utilize the glyoxylate cycle for growth on acetate.
The Methylaspartate Cycle: A Step-by-Step Enzymatic Journey
The methylaspartate cycle is intricately linked with the tricarboxylic acid (TCA) cycle. It effectively converts two molecules of acetyl-CoA into one molecule of malate.[4] The core of the pathway begins with the conversion of glutamate to methylaspartate and proceeds through a series of unique enzymatic transformations.
The key enzymatic steps of the methylaspartate cycle are:
-
Glutamate Mutase (MamAB): Glutamate is isomerized to (2S,3S)-3-methylaspartate.
-
Methylaspartate Ammonia-Lyase (Mal): This enzyme catalyzes the elimination of ammonia from methylaspartate to form mesaconate.
-
Succinyl-CoA:Mesaconate CoA-Transferase (Mct): Mesaconate is activated to mesaconyl-CoA.[5]
-
Mesaconyl-CoA Hydratase (Mch): Mesaconyl-CoA is hydrated to form β-methylmalyl-CoA.[5]
-
β-Methylmalyl-CoA Lyase (Mcl): This enzyme cleaves β-methylmalyl-CoA into glyoxylate and propionyl-CoA.
-
Propionyl-CoA Carboxylase: Propionyl-CoA is carboxylated to methylmalonyl-CoA.
-
Methylmalonyl-CoA Mutase: Methylmalonyl-CoA is isomerized to succinyl-CoA, which then enters the TCA cycle to regenerate the initial acceptor molecule.
-
Malate Synthase (Ms): Glyoxylate condenses with a second molecule of acetyl-CoA to form malate, the net product of the cycle.
// Nodes Glutamate [label="Glutamate", fillcolor="#F1F3F4"]; Methylaspartate [label="(2S,3S)-3-Methylaspartate", fillcolor="#F1F3F4"]; Mesaconate [label="Mesaconate", fillcolor="#F1F3F4"]; Mesaconyl_CoA [label="Mesaconyl-CoA", fillcolor="#F1F3F4"]; beta_Methylmalyl_CoA [label="β-Methylmalyl-CoA", fillcolor="#F1F3F4"]; Glyoxylate [label="Glyoxylate", fillcolor="#FBBC05"]; Propionyl_CoA [label="Propionyl-CoA", fillcolor="#F1F3F4"]; Methylmalonyl_CoA [label="Methylmalonyl-CoA", fillcolor="#F1F3F4"]; Succinyl_CoA [label="Succinyl-CoA", fillcolor="#F1F3F4"]; Malate [label="Malate", fillcolor="#34A853"]; Acetyl_CoA_in [label="Acetyl-CoA", fillcolor="#EA4335"]; Acetyl_CoA_in2 [label="Acetyl-CoA", fillcolor="#EA4335"]; TCA_Cycle [label="TCA Cycle", shape=ellipse, fillcolor="#4285F4", fontcolor="#FFFFFF"];
// Edges Glutamate -> Methylaspartate [label="Glutamate Mutase (MamAB)"]; Methylaspartate -> Mesaconate [label="Methylaspartate Ammonia-Lyase (Mal)"]; Mesaconate -> Mesaconyl_CoA [label="Succinyl-CoA:Mesaconate\nCoA-Transferase (Mct)"]; Mesaconyl_CoA -> beta_Methylmalyl_CoA [label="Mesaconyl-CoA Hydratase (Mch)"]; beta_Methylmalyl_CoA -> Glyoxylate [label="β-Methylmalyl-CoA Lyase (Mcl)"]; beta_Methylmalyl_CoA -> Propionyl_CoA [label="β-Methylmalyl-CoA Lyase (Mcl)"]; Propionyl_CoA -> Methylmalonyl_CoA [label="Propionyl-CoA Carboxylase"]; Methylmalonyl_CoA -> Succinyl_CoA [label="Methylmalonyl-CoA Mutase"]; Succinyl_CoA -> TCA_Cycle [label="To TCA Cycle"]; TCA_Cycle -> Glutamate [label="From TCA Cycle"]; Acetyl_CoA_in -> TCA_Cycle; Acetyl_CoA_in2 -> Malate; Glyoxylate -> Malate [label="Malate Synthase (Ms)"]; } The Methylaspartate Cycle
Quantitative Data
The characterization of the methylaspartate cycle has been supported by quantitative measurements of enzyme activities and metabolite concentrations. The following tables summarize key data from studies on Haloarcula hispanica.
Table 1: Specific Activities of Key Enzymes in the Methylaspartate Cycle in Haloarcula hispanica
| Enzyme | Substrate | Specific Activity (nmol min⁻¹ mg⁻¹ protein) |
| Methylaspartate ammonia-lyase | (2S,3S)-3-Methylaspartate | 130 ± 10 |
| Mesaconate CoA-transferase | Mesaconate | 50 ± 5 |
| Mesaconyl-CoA hydratase | Mesaconyl-CoA | 250 ± 20 |
| β-Methylmalyl-CoA lyase | β-Methylmalyl-CoA | 180 ± 15 |
| Malate synthase | Glyoxylate + Acetyl-CoA | 70 ± 8 |
Data are representative values from published studies and may vary based on experimental conditions.
Table 2: Intracellular Metabolite Concentrations in Acetate-Grown Haloarcula hispanica
| Metabolite | Concentration (mM) |
| Glutamate | 150 - 200 |
| Mesaconate | 0.5 - 1.0 |
These high concentrations of glutamate are a notable feature of haloarchaea utilizing this pathway.[2][3]
Experimental Protocols
The elucidation of the methylaspartate cycle has relied on a combination of proteomics, enzyme assays, and metabolite analysis. Below are detailed methodologies for key experiments.
Proteomic Analysis of Acetate-Grown vs. Succinate-Grown Cells
Objective: To identify proteins that are upregulated during growth on acetate, a substrate that necessitates an anaplerotic pathway.
Methodology:
-
Cell Culture: Grow Haloarcula marismortui in a defined medium with either acetate or succinate as the sole carbon source.
-
Protein Extraction: Harvest cells in the exponential growth phase, lyse them by sonication in a suitable buffer, and centrifuge to remove cell debris.
-
Two-Dimensional Gel Electrophoresis (2D-PAGE):
-
Separate proteins in the first dimension by isoelectric focusing (IEF).
-
Separate proteins in the second dimension by SDS-polyacrylamide gel electrophoresis (SDS-PAGE).
-
-
Protein Identification:
-
Excise protein spots that are significantly upregulated in acetate-grown cells.
-
Perform in-gel digestion with trypsin.
-
Analyze the resulting peptides by matrix-assisted laser desorption/ionization-time of flight (MALDI-TOF) mass spectrometry.
-
Identify the proteins by comparing the peptide mass fingerprints to a protein database.
-
Enzyme Assays
Objective: To measure the specific activities of the enzymes involved in the methylaspartate cycle.
General Considerations: Assays are typically performed spectrophotometrically by monitoring the change in absorbance of a substrate or product.
Example: β-Methylmalyl-CoA Lyase Assay
-
Reaction Mixture: Prepare a reaction mixture containing buffer, β-methylmalyl-CoA, and cell-free extract or purified enzyme.
-
Detection: The cleavage of β-methylmalyl-CoA to glyoxylate and propionyl-CoA can be coupled to the reduction of NAD⁺ by lactate dehydrogenase in the presence of glyoxylate, or the formation of propionyl-CoA can be monitored by HPLC.
-
Measurement: Monitor the change in absorbance at 340 nm (for the coupled assay) or quantify the peak corresponding to propionyl-CoA by HPLC.
-
Calculation: Calculate the specific activity based on the rate of product formation, the amount of protein in the assay, and the molar extinction coefficient of NADH.
Metabolite Analysis by High-Performance Liquid Chromatography (HPLC)
Objective: To identify and quantify the intermediates of the methylaspartate cycle.
Methodology:
-
Metabolite Extraction: Quench the metabolism of cell cultures rapidly (e.g., with cold methanol) and extract metabolites using a suitable solvent (e.g., a chloroform/methanol/water mixture).
-
HPLC Separation:
-
Use a reversed-phase C18 column.
-
Employ a gradient of a suitable mobile phase (e.g., acetonitrile and a buffered aqueous solution) to separate the metabolites.
-
-
Detection:
-
Detect CoA esters by their UV absorbance at 260 nm.
-
Detect organic acids by UV absorbance at a lower wavelength (e.g., 210 nm) or by mass spectrometry.
-
-
Quantification: Quantify the metabolites by comparing their peak areas to those of known standards.
// Nodes Start [label="Hypothesis:\nNovel Acetate Assimilation Pathway", shape=ellipse, fillcolor="#4285F4", fontcolor="#FFFFFF"]; Proteomics [label="Comparative Proteomics\n(Acetate vs. Succinate)", fillcolor="#F1F3F4"]; Upregulated_Proteins [label="Identification of\nUpregulated Proteins", fillcolor="#FBBC05"]; Gene_Identification [label="Gene Identification and\nOperon Analysis", fillcolor="#F1F3F4"]; Enzyme_Assays [label="Enzyme Assays", fillcolor="#F1F3F4"]; Metabolite_Analysis [label="Metabolite Analysis (HPLC)", fillcolor="#F1F3F4"]; Pathway_Reconstruction [label="Pathway Reconstruction", fillcolor="#34A853", fontcolor="#FFFFFF"];
// Edges Start -> Proteomics; Proteomics -> Upregulated_Proteins; Upregulated_Proteins -> Gene_Identification; Gene_Identification -> Enzyme_Assays; Gene_Identification -> Metabolite_Analysis; Enzyme_Assays -> Pathway_Reconstruction; Metabolite_Analysis -> Pathway_Reconstruction; } Experimental Workflow for Pathway Elucidation
Logical Relationships and Regulation
The methylaspartate cycle is not an isolated pathway but is integrated with the broader metabolic network of the cell.
-
Link to TCA Cycle: The cycle is dependent on the TCA cycle for the initial conversion of acetyl-CoA to glutamate and for the regeneration of succinyl-CoA.[6]
-
Nitrogen Metabolism: The involvement of glutamate and the release of ammonia by methylaspartate ammonia-lyase create a direct link to nitrogen metabolism.[2][3]
-
Regulation: The genes encoding the key enzymes of the methylaspartate cycle in Haloarcula marismortui are organized in an operon, suggesting coordinate regulation at the transcriptional level.[3] Their expression is induced by acetate and repressed by other carbon sources like succinate.
// Nodes Acetate [label="Acetate", fillcolor="#EA4335"]; TCA_Cycle [label="TCA Cycle", shape=ellipse, fillcolor="#4285F4", fontcolor="#FFFFFF"]; Methylaspartate_Cycle [label="Methylaspartate Cycle", shape=ellipse, fillcolor="#FBBC05"]; Biosynthesis [label="Biosynthesis", shape=ellipse, fillcolor="#34A853", fontcolor="#FFFFFF"]; Nitrogen_Metabolism [label="Nitrogen Metabolism", shape=ellipse, fillcolor="#5F6368", fontcolor="#FFFFFF"];
// Edges Acetate -> TCA_Cycle [label="Acetyl-CoA"]; TCA_Cycle -> Methylaspartate_Cycle [label="Glutamate"]; Methylaspartate_Cycle -> TCA_Cycle [label="Succinyl-CoA"]; Methylaspartate_Cycle -> Biosynthesis [label="Malate"]; Methylaspartate_Cycle -> Nitrogen_Metabolism [label="NH₃"]; Nitrogen_Metabolism -> Methylaspartate_Cycle [label="Glutamate"]; } Metabolic Network Integration
Implications for Drug Development
The unique nature of the methylaspartate cycle and its presence in specific groups of microorganisms make it a potential target for novel antimicrobial agents. Enzymes that are essential for the cycle and are absent in humans and other non-target organisms could be attractive targets for inhibitor screening and design. For instance, methylaspartate ammonia-lyase and β-methylmalyl-CoA lyase represent promising candidates for the development of drugs against pathogenic haloarchaea or other organisms that may harbor this pathway.
Conclusion
The methylaspartate cycle is a testament to the metabolic ingenuity of life in extreme environments. Its elucidation has not only expanded our fundamental understanding of carbon metabolism but also provided a new set of tools and targets for biotechnological and pharmaceutical research. This technical guide offers a comprehensive resource for scientists and researchers to delve into the intricacies of this fascinating pathway, from its molecular mechanisms to its broader physiological and evolutionary context. The continued exploration of such unique metabolic pathways will undoubtedly uncover further opportunities for innovation in science and medicine.
References
- 1. The methylaspartate cycle in haloarchaea and its possible role in carbon metabolism - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. A methylaspartate cycle in haloarchaea - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. researchgate.net [researchgate.net]
- 5. Frontiers | Succinyl-CoA:Mesaconate CoA-Transferase and Mesaconyl-CoA Hydratase, Enzymes of the Methylaspartate Cycle in Haloarcula hispanica [frontiersin.org]
- 6. The methylaspartate cycle in haloarchaea and its possible role in carbon metabolism - PMC [pmc.ncbi.nlm.nih.gov]
Overcoming the Crystallization Barrier: A Technical Guide to the Structure and Function of the Cav1.1 Channel Complex
A Whitepaper for Researchers, Scientists, and Drug Development Professionals
Abstract: For decades, the atomic-resolution structure of the voltage-gated calcium channel Cav1.1, a cornerstone of skeletal muscle excitation-contraction coupling, remained elusive to X-ray crystallography. This guide explores the profound challenges inherent in crystallizing large, multi-subunit membrane proteins and details the revolutionary impact of single-particle cryo-electron microscopy (cryo-EM) in finally elucidating its architecture. We provide an in-depth overview of the Cav1.1 signaling pathway, a detailed cryo-EM workflow, and quantitative data derived from these breakthrough structural studies, offering a blueprint for tackling similarly challenging macromolecular complexes.
Introduction to the Cav1.1 Channel
The voltage-gated calcium channel Cav1.1 (also known as the dihydropyridine receptor, DHPR) is a heteromultimeric protein complex essential for life.[1] Located in the transverse tubules of skeletal muscle, its primary role is to convert the electrical signal of a neuronal action potential into an intracellular calcium release, the direct trigger for muscle contraction.[2][3][4] This process, known as excitation-contraction (EC) coupling, makes Cav1.1 a critical component of all voluntary movement.[2][5]
The complex consists of a central pore-forming α1-subunit and auxiliary α2δ, β, and γ subunits, each contributing to its function and regulation.[6][7] Beyond its physiological role, mutations in the gene encoding Cav1.1 are linked to debilitating channelopathies such as hypokalemic periodic paralysis and malignant hyperthermia, making it a significant target for drug development.[1][8] Despite its importance, the complete, high-resolution crystal structure of the Cav1.1 complex proved unattainable for many years.
The Crystallization Challenge
The journey to determine the structure of Cav1.1 highlights the significant hurdles faced when studying complex membrane proteins via X-ray crystallography.[9][10]
Core Challenges Include:
-
Inherent Flexibility: Membrane proteins like Cav1.1 are dynamic and adopt multiple conformations, which impedes the formation of the highly ordered, rigid crystal lattice required for X-ray diffraction.[9][11]
-
Hydrophobicity and Stability: Cav1.1 is embedded within a lipid bilayer.[11] Extracting it requires detergents that can disrupt its native structure and lead to aggregation or misfolding.[9][12] Maintaining stability outside the membrane environment is a major bottleneck.[9]
-
Size and Complexity: The Cav1.1 complex is large and composed of multiple subunits, adding layers of complexity to expression, purification, and crystallization.[6] Eukaryotic expression systems are often necessary to ensure proper folding and post-translational modifications.[9]
-
Crystal Quality: Even when crystals are obtained, they are often small, thin, or poorly ordered, making it difficult to collect high-quality diffraction data.[12]
These combined difficulties meant that for a long time, our understanding of Cav1.1 was based on lower-resolution data and homology models.[13]
Methodological Breakthrough: Cryo-Electron Microscopy (Cryo-EM)
The "resolution revolution" in cryo-EM provided the breakthrough needed to overcome the crystallization barrier for membrane proteins.[14] Cryo-EM does not require crystallization; instead, it involves flash-freezing purified protein complexes in a thin layer of vitreous ice and imaging millions of individual particles with an electron microscope.[15] This approach is exceptionally well-suited for large, flexible complexes like Cav1.1.[16]
Cryo-EM Experimental Workflow
The general workflow for determining the structure of a membrane protein complex like Cav1.1 using single-particle cryo-EM involves several key stages, from protein production to final 3D model.[14][16]
Experimental Protocol: Membrane Protein Purification & Grid Preparation
This protocol provides a generalized methodology for preparing a large membrane protein complex for cryo-EM analysis.
-
Expression and Harvest: The target protein (e.g., rabbit Cav1.1) is overexpressed in a suitable eukaryotic cell line (e.g., HEK293 cells). Cells are harvested and cell pellets are flash-frozen and stored at -80°C.
-
Membrane Preparation: Cell pellets are resuspended in a hypotonic lysis buffer containing protease inhibitors. Cells are lysed via dounce homogenization, and the lysate is centrifuged to pellet nuclei and debris. The supernatant is then ultracentrifuged to pellet the cell membranes.
-
Solubilization: The membrane pellet is resuspended in a solubilization buffer containing a mild detergent (e.g., DDM or LMNG), cholesterol analogue (e.g., CHS), and protease inhibitors.[17] The mixture is stirred for 1-2 hours at 4°C to extract the protein from the lipid bilayer.
-
Affinity Chromatography: The solubilized extract is clarified by ultracentrifugation, and the supernatant is incubated with an affinity resin (e.g., Strep-Tactin for a Strep-tagged protein). The resin is washed extensively with a buffer containing a lower concentration of detergent to remove non-specific binders. The protein is then eluted.
-
Size Exclusion Chromatography (SEC): The eluate from the affinity step is concentrated and injected onto a size exclusion chromatography column. This step is crucial for separating the intact complex from aggregates and smaller contaminants, ensuring sample homogeneity.[16] The buffer for SEC contains a detergent suitable for cryo-EM (e.g., DDM/CHS).
-
Quality Control: Fractions from the SEC peak corresponding to the complex are analyzed by SDS-PAGE to verify the presence of all subunits and by negative-stain EM to assess particle integrity and homogeneity.
-
Cryo-EM Grid Preparation: The purified, concentrated protein (typically 1-5 mg/mL) is applied to a glow-discharged cryo-EM grid (e.g., Quantifoil R1.2/1.3). Using a vitrification robot (e.g., Vitrobot), the grid is blotted to create a thin film of the sample, which is then plunge-frozen into liquid ethane. This rapid freezing traps the protein complexes in a layer of non-crystalline (vitreous) ice.
The Cav1.1 Signaling Pathway in Skeletal Muscle
Cav1.1 is the voltage sensor in skeletal muscle EC coupling.[4][5] It physically interacts with the ryanodine receptor (RyR1), a calcium release channel on the sarcoplasmic reticulum (SR), to trigger muscle contraction in a process that does not strictly require calcium influx through the Cav1.1 pore itself.[1][5][8]
Pathway Steps:
-
A nerve impulse triggers an action potential that travels down the neuron and depolarizes the muscle cell membrane (sarcolemma).[2][18]
-
This depolarization propagates into the T-tubules, where Cav1.1 resides.[19] The voltage-sensing domains of Cav1.1 detect this change.[20]
-
The voltage-induced conformational change in Cav1.1 is mechanically transmitted to the RyR1 channel on the SR.[1][3]
-
This allosteric activation opens the RyR1 channel, causing a massive release of stored Ca²⁺ ions from the SR into the cytosol.[2][19]
-
The sharp increase in cytosolic Ca²⁺ concentration allows calcium to bind to the regulatory protein troponin.[18][21]
-
This binding event moves another protein, tropomyosin, exposing myosin-binding sites on actin filaments and initiating the cross-bridge cycling that results in muscle contraction.[21]
Quantitative Data Summary
The cryo-EM structures of the Cav1.1 complex have provided unprecedented, near-atomic detail.[6][13][22] This has allowed for precise measurements and a deeper understanding of its architecture and drug interactions.
Table 1: Cryo-EM Structural Data for Rabbit Cav1.1 Complex
| PDB ID | Publication Year | Resolution (Å) | Ligand/State | Key Findings | Reference |
| 5GJW | 2016 | 3.6 | Apo (putative inactivated) | Revealed overall architecture, subunit arrangement, and interactions. The inner gate is closed. | [13][22] |
| 5GJV | 2015 | 4.2 | Apo | First overall structure of the Cav1.1 complex, showing the arrangement of α1, α2δ, β, and γ subunits. | [6][7] |
| 6JP8 | 2021 | 2.9 | Amlodipine (Antagonist) | High-resolution view of a DHP drug binding site, explaining its inhibitory mechanism. | [23] |
| 6JPA | 2021 | 3.2 | (R)-(+)-Bay K8644 (Antagonist) | Shows binding mode of a chiral antagonist, contributing to understanding of drug stereospecificity. | [23] |
| 6JPB | 2021 | 3.4 | (S)-(-)-Bay K8644 (Agonist) | Structure in the presence of an agonist, which surprisingly still showed an inactivated conformation. | [23] |
Conclusion and Future Directions
The successful determination of the Cav1.1 structure via cryo-EM marks a pivotal moment in the study of voltage-gated ion channels. It provides a definitive atomic framework for understanding the molecular basis of excitation-contraction coupling and the pathology of related diseases.[6][13] For drug development professionals, these structures offer a precise template for the rational design of novel therapeutics targeting Cav channels with higher specificity and efficacy.
Future research will likely focus on capturing the Cav1.1 complex in different functional states (e.g., open/activated) to create a dynamic "movie" of its action. Further investigation into its interaction with regulatory proteins and lipids will continue to refine our understanding of this essential molecular machine. The workflows and protocols established during the study of Cav1.1 now serve as a valuable guide for researchers tackling other large, challenging protein complexes that have long resisted crystallographic approaches.
References
- 1. Cav1.1 - Wikipedia [en.wikipedia.org]
- 2. bio.libretexts.org [bio.libretexts.org]
- 3. Voltage-gated calcium channel Cav1.1 complex - Proteopedia, life in 3D [proteopedia.org]
- 4. researchgate.net [researchgate.net]
- 5. CaV1.1: The atypical prototypical voltage-gated Ca2+ channel - PMC [pmc.ncbi.nlm.nih.gov]
- 6. molbio.princeton.edu [molbio.princeton.edu]
- 7. Structure of the voltage-gated calcium channel Cav1.1 complex - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Skeletal muscle CaV1.1 channelopathies - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Overcoming the challenges of membrane protein crystallography - PMC [pmc.ncbi.nlm.nih.gov]
- 10. sciencedaily.com [sciencedaily.com]
- 11. Membrane Protein Research: Challenges & New Solutions - Creative Proteomics [creative-proteomics.com]
- 12. biology.stackexchange.com [biology.stackexchange.com]
- 13. researchgate.net [researchgate.net]
- 14. pubs.acs.org [pubs.acs.org]
- 15. encyclopedia.pub [encyclopedia.pub]
- 16. cytivalifesciences.com [cytivalifesciences.com]
- 17. Overview of Membrane Protein Sample Preparation for Single-Particle Cryo-Electron Microscopy Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 18. study.com [study.com]
- 19. derangedphysiology.com [derangedphysiology.com]
- 20. Voltage sensor movements of CaV1.1 during an action potential in skeletal muscle fibers - PMC [pmc.ncbi.nlm.nih.gov]
- 21. Excitation-Contraction Coupling | Definition, Purpose & Diagram - Video | Study.com [study.com]
- 22. discovery.researcher.life [discovery.researcher.life]
- 23. Structural Basis of the Modulation of the Voltage-Gated Calcium Ion Channel Cav 1.1 by Dihydropyridine Compounds* - PubMed [pubmed.ncbi.nlm.nih.gov]
Whitepaper: A Strategic Approach to the Synthesis of Novel Chemical Entities
Audience: Researchers, scientists, and drug development professionals.
Abstract: The design and synthesis of novel chemical entities for which no established protocols exist is a cornerstone of modern drug discovery and materials science. This guide outlines a systematic, multi-phase approach for navigating the complex process of planning, executing, and validating the synthesis of a new molecule. We will use the hypothetical target molecule "Targesyn-1," a novel kinase inhibitor, as a case study to illustrate key principles, from initial retrosynthetic analysis to final biological evaluation. This document provides detailed experimental frameworks, data presentation standards, and logical workflow diagrams to support researchers in this endeavor.
Phase 1: Design and Retrosynthetic Analysis
The journey to a new molecule begins not in the lab, but in conceptual design and strategic planning. Before any reaction is attempted, a viable synthetic pathway must be developed. Retrosynthetic analysis is a technique used to deconstruct the target molecule into simpler, commercially available precursors. This process involves breaking key chemical bonds and applying known chemical transformations in reverse.
The primary goal is to identify a logical and efficient sequence of reactions that will allow for the construction of the target molecule from simple starting materials. This analysis forms the blueprint for the entire synthesis.
Caption: Retrosynthetic analysis of the hypothetical molecule Targesyn-1.
Phase 2: Forward Synthesis Workflow
With a retrosynthetic plan in place, the forward synthesis can be executed. This phase involves the stepwise construction of the target molecule from the identified precursors. Each step must be carefully optimized to maximize yield and purity. This is often an iterative process, requiring adjustments to reaction conditions, catalysts, and reagents based on the experimental outcomes.
A typical workflow involves performing a reaction, followed by workup (quenching the reaction and initial separation), purification of the intermediate product, and finally, characterization to confirm its identity and purity before proceeding to the next step.
Caption: General workflow for a multi-step chemical synthesis.
Experimental Protocols: A Template
Detailed and reproducible protocols are essential. Below is a hypothetical protocol for a key Suzuki coupling step in the synthesis of Targesyn-1, illustrating the necessary level of detail.
Protocol: Synthesis of Intermediate B via Suzuki Coupling
-
Materials & Reagents:
-
Precursor 2 (1.0 eq, 2.5 mmol, 500 mg)
-
Precursor 3 (1.1 eq, 2.75 mmol, 680 mg)
-
Palladium(II) Acetate (Pd(OAc)₂, 0.02 eq, 0.05 mmol, 11.2 mg)
-
SPhos (ligand, 0.04 eq, 0.10 mmol, 41.0 mg)
-
Potassium Carbonate (K₂CO₃, 3.0 eq, 7.5 mmol, 1.04 g)
-
1,4-Dioxane (15 mL)
-
Water (5 mL)
-
Nitrogen (inert gas)
-
-
Procedure:
-
To a 100 mL round-bottom flask equipped with a magnetic stir bar, add Precursor 2, Precursor 3, and Potassium Carbonate.
-
Evacuate and backfill the flask with nitrogen three times to establish an inert atmosphere.
-
Add Palladium(II) Acetate and SPhos to the flask.
-
Add the degassed solvents (1,4-Dioxane and water).
-
Heat the reaction mixture to 90°C and stir vigorously for 12 hours. Monitor reaction progress by TLC or LC-MS.
-
Upon completion, cool the mixture to room temperature.
-
Dilute the mixture with Ethyl Acetate (50 mL) and water (50 mL).
-
Separate the organic layer. Wash with brine (2 x 25 mL), dry over anhydrous sodium sulfate, filter, and concentrate under reduced pressure.
-
Purify the crude residue by flash column chromatography (Silica gel, 20% Ethyl Acetate in Hexanes) to yield the pure Intermediate B.
-
Data Presentation: Purification and Characterization
All newly synthesized compounds must be rigorously characterized to confirm their identity, structure, and purity. Quantitative data should be summarized in a clear, tabular format.
Table 1: Analytical Characterization Data for Targesyn-1 and Key Intermediates
| Compound | Method | Yield (%) | Purity (HPLC, %) | Mass (m/z) [M+H]⁺ | ¹H NMR |
| Intermediate A | Step 1 | 85 | 98.2 | 212.14 | Conforms to expected structure. |
| Intermediate B | Step 2 | 78 | 99.1 | 354.28 | Conforms to expected structure. |
| Targesyn-1 | Step 3 | 91 | >99.5 | 482.35 | Conforms to final product structure. |
Phase 3: Biological Evaluation
For drug development, the newly synthesized compound must be tested for its intended biological activity. For a kinase inhibitor like Targesyn-1, a biochemical assay would be performed to measure its ability to inhibit the target kinase.
The workflow involves preparing the compound, performing the assay across a range of concentrations, and analyzing the data to determine key metrics like the half-maximal inhibitory concentration (IC₅₀).
Caption: Workflow for a typical in vitro kinase inhibition assay.
Data Presentation: Biological Activity
The quantitative results from biological assays are crucial for evaluating the compound's efficacy and selectivity.
Table 2: Kinase Inhibition Profile of Targesyn-1
| Kinase Target | IC₅₀ (nM) | Description |
| Target Kinase 1 | 15.2 | Primary target of interest |
| Off-Target Kinase A | 850.6 | Structurally related kinase |
| Off-Target Kinase B | >10,000 | Unrelated kinase (selectivity) |
| Off-Target Kinase C | 2,100 | Structurally related kinase |
This systematic approach, combining careful planning, precise execution, and rigorous analysis, provides a robust framework for the successful synthesis and evaluation of novel chemical compounds.
Navigating the Uncharted: A Technical Guide to Antibody Generation When Commercial Options Are Exhausted
For researchers, scientists, and drug development professionals, the absence of a commercially available antibody against a specific target of interest presents a significant roadblock. This in-depth guide provides a technical roadmap for navigating this challenge, outlining the primary strategies for custom antibody development, from traditional methods to cutting-edge recombinant technologies. We will delve into detailed experimental protocols, present comparative data to inform your strategic decisions, and visualize complex workflows to demystify the process of generating a novel antibody tailored to your specific research needs.
Section 1: Strategic Considerations: Choosing Your Path
When a commercial antibody is not available, several avenues can be explored. The optimal choice depends on factors such as the intended application, required specificity, timeline, and budget. The main strategies include generating custom polyclonal or monoclonal antibodies, leveraging recombinant antibody technologies, or exploring antibody alternatives.
An Overview of Antibody Generation Strategies
Custom antibody development is a multi-stage process that begins with careful antigen design and preparation, followed by immunization, screening, and finally, antibody production and purification.[1] This approach allows for the creation of antibodies with high specificity and affinity for novel targets.[2]
-
Polyclonal Antibodies: Produced by different B cells in an immunized animal, polyclonal antibodies are a heterogeneous mixture of immunoglobulins that recognize multiple epitopes on a single antigen. They are relatively quick and inexpensive to produce.
-
Monoclonal Antibodies: Originating from a single B cell clone, monoclonal antibodies are homogenous and recognize a single epitope.[3] They offer high specificity and batch-to-batch consistency, which is crucial for diagnostics, therapeutics, and quantitative assays.[4]
-
Recombinant Antibodies: Generated in vitro using synthetic genes, recombinant antibodies offer high reproducibility and the flexibility for engineering. Technologies like phage display allow for the rapid discovery of antibodies without the need for animal immunization.
Comparative Analysis of Antibody Generation Methods
Choosing the right method for antibody generation is a critical first step. The following table summarizes key quantitative metrics to aid in this decision-making process.
| Parameter | Polyclonal Antibodies | Monoclonal Antibodies (Hybridoma) | Recombinant Antibodies (Phage Display) |
| Development Time | 2-3 months | 4-6 months | 1-2 months |
| Specificity | Lower (recognizes multiple epitopes) | Higher (recognizes a single epitope) | High (can be selected for single epitope) |
| Consistency | Batch-to-batch variability | High batch-to-batch consistency | Highest batch-to-batch consistency |
| Cost | Lower | Higher | Variable (can be high initially) |
| Immunization | Required | Required | Not required for naïve libraries |
| Ideal Use Cases | Western Blot, Immunohistochemistry (IHC), Immunoprecipitation (IP) | ELISA, Flow Cytometry, Therapeutics, Diagnostics | All applications, Antibody engineering |
Section 2: Methodologies and Experimental Protocols
This section provides detailed protocols for the key experimental workflows in custom antibody generation.
Antigen Design and Preparation
The success of any custom antibody project hinges on the quality of the antigen.[1] The antigen, typically a protein or peptide, must be designed to elicit a robust and specific immune response.[2]
Detailed Protocol: Peptide Antigen Design and Conjugation
-
Epitope Prediction: Utilize bioinformatics tools to identify potential B-cell epitopes on the target protein. Key considerations include surface accessibility, antigenicity, and low homology to other proteins to avoid cross-reactivity.[2]
-
Peptide Synthesis: Synthesize a 10-20 amino acid peptide corresponding to the chosen epitope. A cysteine residue is often added to the N- or C-terminus to facilitate conjugation to a carrier protein.
-
Carrier Protein Conjugation: To enhance immunogenicity, the peptide is conjugated to a larger carrier protein, such as Keyhole Limpet Hemocyanin (KLH) or Bovine Serum Albumin (BSA).
-
Dissolve the peptide and carrier protein in conjugation buffer (e.g., PBS).
-
Add a crosslinker, such as maleimide-activated KLH, which will react with the sulfhydryl group of the cysteine residue on the peptide.
-
Incubate the reaction for 2 hours at room temperature.
-
Remove excess unconjugated peptide by dialysis or gel filtration.
-
-
Quality Control: Confirm successful conjugation using techniques like SDS-PAGE or MALDI-TOF mass spectrometry.
Monoclonal Antibody Production via Hybridoma Technology
Hybridoma technology is the classic method for producing monoclonal antibodies.[5] It involves fusing antibody-producing B cells from an immunized animal with immortal myeloma cells.[4]
Experimental Workflow: Hybridoma Development
Detailed Protocol: Key Steps in Hybridoma Development
-
Immunization: Immunize mice or rabbits with the prepared antigen mixed with an adjuvant over a period of several weeks.[4]
-
Cell Fusion: Fuse splenocytes from the immunized animal with myeloma cells using polyethylene glycol (PEG).
-
Selection: Select for fused hybridoma cells using HAT (hypoxanthine-aminopterin-thymidine) medium. Unfused myeloma cells will die, and unfused splenocytes have a limited lifespan.
-
Screening: Screen the supernatant from surviving hybridoma colonies for the presence of the desired antibody using an enzyme-linked immunosorbent assay (ELISA).
-
Subcloning: Isolate single antibody-producing cells by limiting dilution to ensure monoclonality.
-
Expansion and Production: Expand the selected monoclonal hybridoma clones and produce larger quantities of the antibody.[1]
-
Purification: Purify the antibody from the culture supernatant or ascites fluid using affinity chromatography (e.g., Protein A/G).[6]
Recombinant Antibody Production via Phage Display
Phage display is a powerful in vitro technology for selecting recombinant antibodies.[5] It involves displaying a library of antibody fragments on the surface of bacteriophages.
Experimental Workflow: Phage Display for Antibody Selection
Detailed Protocol: Biopanning for Phage Display
-
Library Selection: Start with a pre-existing naïve or immune antibody library displayed on phages.
-
Biopanning:
-
Immobilize the target antigen on a solid surface (e.g., a microtiter plate).
-
Incubate the phage library with the immobilized antigen to allow for binding.
-
Wash away non-specifically bound phages. The stringency of the washes can be increased in subsequent rounds to select for higher affinity binders.
-
Elute the specifically bound phages.
-
-
Amplification: Infect E. coli with the eluted phages to amplify the selected population.
-
Repeat Panning: Perform 2-3 rounds of biopanning to enrich for high-affinity binders.
-
Screening and Sequencing: After the final round of panning, screen individual phage clones for antigen binding, typically by ELISA. Sequence the DNA of the positive clones to identify the antibody variable regions.
-
Reformatting and Production: Clone the identified antibody genes into a suitable expression vector for production as a full-length antibody in a mammalian cell line like CHO or HEK293.[5][7]
Section 3: Antibody Validation: Ensuring Specificity and Functionality
Generation of a novel antibody is only the first step. Rigorous validation is essential to ensure that the antibody is specific for its intended target and functional in the desired application.
Key Validation Assays
A combination of assays should be used to characterize a new antibody.
| Validation Assay | Purpose | Key Considerations |
| ELISA | To confirm binding to the target antigen and determine antibody titer. | Use a purified antigen for coating. Include a negative control antigen. |
| Western Blot (WB) | To verify that the antibody recognizes the target protein at the correct molecular weight. | Use cell lysates or tissue homogenates from sources with and without the target protein. |
| Immunoprecipitation (IP) | To demonstrate that the antibody can bind to the native protein in a complex mixture. | Elute and analyze the precipitated protein by WB or mass spectrometry. |
| Immunohistochemistry (IHC) / Immunocytochemistry (ICC) | To confirm that the antibody recognizes the target protein in its cellular and tissue context. | Use tissues with known expression patterns of the target protein. |
| Flow Cytometry | To validate antibodies against cell surface or intracellular proteins. | Use positive and negative cell populations. |
Protocol: In-house ELISA for Antibody Validation
This protocol describes a standard indirect ELISA for testing the reactivity of a newly generated antibody.
-
Coating: Coat a 96-well microtiter plate with the purified antigen (1-10 µg/mL in coating buffer) and incubate overnight at 4°C.
-
Blocking: Wash the plate and block with a blocking buffer (e.g., 5% non-fat milk in PBS with 0.05% Tween-20) for 1-2 hours at room temperature.
-
Primary Antibody Incubation: Add serial dilutions of the antibody supernatant or purified antibody to the wells and incubate for 1-2 hours at room temperature.
-
Secondary Antibody Incubation: Wash the plate and add a horseradish peroxidase (HRP)-conjugated secondary antibody that recognizes the species and isotype of the primary antibody. Incubate for 1 hour at room temperature.
-
Detection: Wash the plate and add a TMB substrate. Stop the reaction with sulfuric acid and read the absorbance at 450 nm.[8]
Section 4: Exploring Alternatives to Traditional Antibodies
In some cases, non-antibody affinity reagents may be a suitable alternative. These molecules can be generated in vitro and often have advantages in terms of size, stability, and production.[9]
-
Aptamers: Single-stranded DNA or RNA molecules that can fold into specific three-dimensional structures to bind to a target.[10] They are generated through a process called SELEX (Systematic Evolution of Ligands by Exponential Enrichment).[11]
-
Affimers: Small, stable proteins engineered to bind to a target with high affinity and specificity.[10] They are based on a scaffold protein, such as the human protease inhibitor Stefin A.[12]
-
Nanobodies: Single-domain antibodies derived from camelids.[10] Their small size allows them to recognize epitopes that are inaccessible to conventional antibodies.[12]
These alternatives offer exciting possibilities for applications where traditional antibodies may have limitations.
Conclusion
The absence of a commercial antibody need not be a dead end for your research. By understanding the principles and protocols of custom antibody generation, researchers can successfully develop high-quality, specific reagents for their targets of interest. This guide provides a framework for making informed decisions and navigating the technical complexities of producing polyclonal, monoclonal, and recombinant antibodies, as well as exploring novel antibody alternatives. Rigorous planning, execution, and validation are the cornerstones of success in this endeavor, ultimately enabling groundbreaking discoveries in research and development.
References
- 1. precisionantibody.com [precisionantibody.com]
- 2. Custom Antibody Development: A Step-by-Step Guide [biointron.jp]
- 3. godubrovnik.com [godubrovnik.com]
- 4. Mastering Custom Antibody Production: An Essential Guide for R&D Directors [examples.tely.ai]
- 5. Recombinant antibodies - Wikipedia [en.wikipedia.org]
- 6. biomatik.com [biomatik.com]
- 7. sinobiological.com [sinobiological.com]
- 8. mdpi.com [mdpi.com]
- 9. Alternative reagents to antibodies in imaging applications - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Antibodies… What Are The Alternatives? - Pivotal Scientific [pivotalscientific.com]
- 11. Synthetic immune reagents as alternatives to antibodies [lubio.ch]
- 12. biocompare.com [biocompare.com]
Unconventional Protein Secretion: A Technical Guide to the Inflammasome-Gasdermin Pathway
Whitepaper | December 2025
Audience: Researchers, scientists, and drug development professionals.
Abstract: The classical secretory pathway, involving the endoplasmic reticulum and Golgi apparatus, has long been the textbook model for protein export. However, a growing body of evidence illuminates a diverse array of "Unconventional Protein Secretion" (UPS) pathways that bypass this traditional route. These pathways are critical for cellular homeostasis, immunity, and are implicated in numerous diseases. This technical guide provides an in-depth examination of a prominent UPS mechanism: the inflammasome-dependent secretion of leaderless cytokines, such as Interleukin-1β (IL-1β), via Gasdermin D (GSDMD) pore formation. We detail the core signaling cascade, present key quantitative data, provide comprehensive experimental protocols for studying this pathway, and offer visualizations of the critical molecular and experimental workflows.
Introduction to Unconventional Protein Secretion (UPS)
Most secreted proteins possess an N-terminal signal peptide that directs them into the endoplasmic reticulum (ER) for processing and subsequent export via the Golgi apparatus. In contrast, UPS pathways facilitate the export of proteins lacking a signal peptide (leaderless proteins) or transmembrane proteins that bypass the Golgi.[1][2] These alternative routes are often triggered by cellular stress and are integral to processes like inflammation.[2][3]
UPS mechanisms are broadly categorized:
-
Type I: Direct translocation across the plasma membrane, often through pores.
-
Type II: Secretion via ATP-binding cassette (ABC) transporters.
-
Type III: Vesicular pathways involving endosomes, lysosomes, and autophagosomes.[3]
-
Type IV: Golgi-bypass routes for proteins that enter the ER but do not transit through the Golgi stack.[1][4]
This guide focuses on a critical Type I pathway responsible for the massive release of pro-inflammatory cytokines, representing a significant paradigm shift in our understanding of cellular secretion and a fertile area for therapeutic intervention.
The IL-1β Secretion Pathway: A Paradigm of Pore-Forming UPS
The secretion of the potent pro-inflammatory cytokine IL-1β is one of the most extensively studied examples of UPS. Its release is a tightly regulated, two-step process, making it a key target in inflammatory diseases.[5][6]
Step 1: Priming (Signal 1) First, a priming signal, typically a Pathogen-Associated Molecular Pattern (PAMP) like lipopolysaccharide (LPS), engages with a Pattern Recognition Receptor (PRR) such as a Toll-like receptor (TLR) on the cell surface. This interaction triggers a signaling cascade, primarily through the NF-κB pathway, leading to the transcription and translation of pro-IL-1β, which accumulates in the cytoplasm in its inactive form.[5][7]
Step 2: Activation (Signal 2) A second stimulus, such as the bacterial toxin nigericin, ATP, or crystalline substances, activates a multi-protein complex in the cytoplasm known as the NLRP3 inflammasome .[7][8] This complex recruits and activates pro-caspase-1 into its proteolytically active form, caspase-1.
Active caspase-1 has two primary substrates in this pathway:
-
Pro-IL-1β: It cleaves the inactive pro-IL-1β into its mature, biologically active 17 kDa form.[5]
-
Gasdermin D (GSDMD): It cleaves GSDMD, separating its N-terminal pore-forming domain (GSDMD-NT) from its C-terminal autoinhibitory domain.[9][10]
The liberated GSDMD-NT fragments translocate to the plasma membrane, where they oligomerize and form large transmembrane pores, leading to a lytic form of cell death called pyroptosis.[9][10] These pores serve as conduits for the rapid release of mature IL-1β into the extracellular space.[11][12]
Signaling Pathway Diagram
Quantitative Data Presentation
The secretion of IL-1β via the GSDMD pathway can be precisely quantified. The following tables summarize representative data from key experimental assays.
Table 1: IL-1β Secretion in Bone Marrow-Derived Macrophages (BMDMs)
This table shows the concentration of secreted IL-1β measured by ELISA following stimulation. It demonstrates the necessity of both a priming signal (LPS) and an activation signal (Nigericin) and the inhibitory effect of a specific NLRP3 inhibitor, MCC950.
| Treatment Group | IL-1β Concentration (pg/mL) | Standard Deviation (±) |
| Control (Unstimulated) | 25.4 | 8.2 |
| LPS only (1 µg/mL) | 112.8 | 21.5 |
| Nigericin only (10 µM) | 45.1 | 11.9 |
| LPS + Nigericin | 2150.7 | 180.4 |
| LPS + Nigericin + MCC950 (10 µM) | 155.3 | 35.6 |
| Data are representative, compiled from studies such as[7][13][14]. |
Table 2: Gasdermin D Pore Dimensions
This table presents structural data on the pores formed by the N-terminal fragment of GSDMD, as determined by cryogenic electron microscopy (cryo-EM) and atomic force microscopy (AFM). The pore size is sufficient for the passage of mature IL-1β (diameter ~4.5 nm).[11]
| Measurement Technique | Number of Subunits | Inner Diameter (nm) | Outer Diameter (nm) | Source |
| Cryo-EM | ~33 | 21.5 | 31.0 | [2] |
| AFM (in cells) | 8 - 35 | 14 - 44 (avg. 24) | N/A | [11] |
| Molecular Dynamics Simulation | 33 | 21.6 | N/A | [12] |
Experimental Protocols
Investigating UPS requires specific methodologies to distinguish it from classical secretion and to dissect its molecular machinery.
Protocol: Brefeldin A Assay for Confirming Non-Classical Secretion
Objective: To determine if a protein's secretion is independent of the ER-Golgi pathway. Brefeldin A (BFA) is a fungal metabolite that blocks the formation of COPI-coated vesicles, causing the collapse of the Golgi into the ER and halting classical secretion.[9][15][16] Proteins secreted via UPS should be unaffected.
Methodology:
-
Cell Culture: Plate cells (e.g., THP-1 macrophages) at 80% confluency in 6-well plates.
-
Stimulation: Prime cells with LPS (1 µg/mL) for 3-4 hours to induce pro-IL-1β expression.
-
Inhibitor Treatment: Treat one set of wells with Brefeldin A (e.g., 5 µg/mL final concentration) for 30 minutes. Treat a control set with vehicle (DMSO).
-
Activation: Add the activation signal (e.g., Nigericin, 10 µM) to both BFA-treated and control wells. Incubate for 1-2 hours.
-
Sample Collection:
-
Carefully collect the culture supernatant from each well and centrifuge to remove cell debris.
-
Wash the remaining adherent cells with ice-cold PBS.
-
Lyse the cells directly in the well using RIPA buffer supplemented with protease inhibitors.
-
-
Analysis (Western Blot):
-
Resolve equal protein amounts of the supernatant and cell lysate fractions by SDS-PAGE.
-
Transfer to a PVDF membrane.
-
Probe with primary antibodies against IL-1β and a cytosolic loading control (e.g., β-actin).
-
Incubate with HRP-conjugated secondary antibodies and visualize using chemiluminescence.
-
Expected Result: In control cells, mature IL-1β will be detected predominantly in the supernatant. In BFA-treated cells, IL-1β secretion into the supernatant will be largely unaffected, confirming its exit via a Golgi-independent, unconventional pathway.
Protocol: In Vitro Gasdermin D Liposome Dye Release Assay
Objective: To directly measure the pore-forming activity of GSDMD-NT in a cell-free system. This assay uses liposomes loaded with a fluorescent dye. Pore formation by GSDMD-NT allows the dye to leak out, resulting in a measurable increase in fluorescence.[6][17]
Methodology:
-
Reagent Preparation:
-
Liposomes: Prepare liposomes containing a self-quenching concentration of a fluorescent dye (e.g., calcein or 6-carboxyfluorescein).
-
Proteins: Purify recombinant full-length GSDMD and active caspase-1.
-
-
Assay Setup:
-
Perform the assay in a 96-well black, clear-bottom plate.
-
In each well, combine assay buffer (e.g., 20 mM HEPES, 150 mM NaCl, pH 7.4), the dye-loaded liposome solution (final lipid concentration ~30-50 µM), and recombinant GSDMD (final concentration ~0.5 µM).[17]
-
Include control wells:
-
No caspase-1 (negative control).
-
Liposomes + Triton X-100 (100% lysis positive control).
-
Test wells with potential GSDMD inhibitors.
-
-
-
Initiate Reaction:
-
Initiate the reaction by adding active caspase-1 (final concentration ~0.2 µM) to the appropriate wells.[17] This will cleave GSDMD, releasing the pore-forming GSDMD-NT.
-
-
Fluorescence Measurement:
-
Immediately place the plate in a fluorescence plate reader pre-heated to 37°C.
-
Measure fluorescence kinetically (e.g., every 1-2 minutes for 180 minutes) at the appropriate excitation/emission wavelengths for the dye (e.g., 485/525 nm for calcein).[6]
-
-
Data Analysis:
-
Normalize the fluorescence data. For each time point, calculate the percentage of dye release using the formula: % Release = [(F_sample - F_neg_ctrl) / (F_pos_ctrl - F_neg_ctrl)] * 100
-
Plot the percentage of dye release over time to visualize pore formation kinetics.
-
Expected Result: Wells containing GSDMD and active caspase-1 will show a time-dependent increase in fluorescence, indicating dye leakage through newly formed pores. This activity should be absent in the negative control and can be attenuated by specific inhibitors.
Implications for Drug Development
The central role of the IL-1β/GSDMD pathway in inflammation makes it a prime target for therapeutic intervention in a range of conditions, including autoinflammatory disorders, gout, and sepsis.[10] Understanding the nuances of this unconventional secretion mechanism opens several avenues for drug discovery:
-
NLRP3 Inflammasome Inhibitors: Blocking the assembly or activation of the inflammasome prevents the activation of caspase-1, representing an upstream control point.
-
Caspase-1 Inhibitors: Directly inhibiting the enzyme that processes both pro-IL-1β and GSDMD.
-
GSDMD Pore Blockers: Developing molecules that directly bind to GSDMD-NT and prevent its oligomerization or insertion into the membrane, thereby blocking both cytokine release and pyroptotic cell death.[6]
The experimental protocols detailed in this guide are crucial for the screening and validation of such novel therapeutic agents.
References
- 1. researchgate.net [researchgate.net]
- 2. Gasdermin D pore structure reveals preferential release of mature interleukin-1 - PMC [pmc.ncbi.nlm.nih.gov]
- 3. taylorandfrancis.com [taylorandfrancis.com]
- 4. researchgate.net [researchgate.net]
- 5. Unconventional Secretion is a Major Contributor of Cancer Cell Line Secretomes - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Pyroptosis inhibiting nanobodies block Gasdermin D pore formation - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Koumine Suppresses IL-1β Secretion and Attenuates Inflammation Associated With Blocking ROS/NF-κB/NLRP3 Axis in Macrophages - PMC [pmc.ncbi.nlm.nih.gov]
- 8. biorxiv.org [biorxiv.org]
- 9. bitesizebio.com [bitesizebio.com]
- 10. Biochemical Methods for Assessing Gasdermin D Inactivation in Macrophages | Springer Nature Experiments [experiments.springernature.com]
- 11. portlandpress.com [portlandpress.com]
- 12. Sublytic gasdermin-D pores captured in atomistic molecular simulations - PMC [pmc.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
- 14. The three cytokines IL-1β, IL-18, and IL-1α share related but distinct secretory routes - PMC [pmc.ncbi.nlm.nih.gov]
- 15. benchchem.com [benchchem.com]
- 16. benchchem.com [benchchem.com]
- 17. Monitoring gasdermin pore formation in vitro - PMC [pmc.ncbi.nlm.nih.gov]
Methodological & Application
Revolutionizing Research: Advanced Protocols for CRISPR/Cas9 Transfection in Primary Cells
Introduction
The advent of CRISPR/Cas9 technology has opened up unprecedented possibilities for precise genome editing. However, the translation of this powerful tool to clinically relevant primary cells has been hampered by significant challenges in delivering the CRISPR/Cas9 machinery. Unlike immortalized cell lines, primary cells are notoriously difficult to transfect, often exhibiting low transfection efficiency and high cytotoxicity in response to conventional methods.[1][2] This application note provides detailed protocols and optimization strategies for the successful delivery of CRISPR/Cas9 components into challenging primary cells, including T cells and hematopoietic stem cells (HSCs). We will explore two of the most effective non-viral delivery methods: Electroporation/Nucleofection and Lipid Nanoparticle (LNP)-mediated transfection. Additionally, we will briefly discuss the use of adeno-associated virus (AAV) for delivery to primary neurons.
Challenges in Primary Cell Transfection
Efficiently delivering genetic material into primary cells is a major bottleneck for both research and therapeutic applications.[1][2] Key challenges include:
-
Low Transfection Efficiency: Primary cells are often resistant to common transfection methods that work well in cell lines.[1]
-
Poor Cell Viability: The delivery process itself can be harsh, leading to significant cell death.[1][2] Electroporation, for instance, can be particularly damaging if not optimized.[2][3]
-
Limited Proliferation: Many primary cells have a finite lifespan and limited proliferative capacity, making it difficult to select and expand edited cells.[1]
-
Innate Immune Responses: Introduction of foreign nucleic acids can trigger cellular immune responses, leading to cytotoxicity.[4]
To overcome these hurdles, careful optimization of the delivery method and cell handling procedures is paramount.
Recommended CRISPR/Cas9 Formats for Primary Cells
The CRISPR/Cas9 system can be delivered in three main formats: plasmid DNA, mRNA, or as a pre-complexed ribonucleoprotein (RNP). For primary cells, the RNP format, consisting of the Cas9 protein and a guide RNA (gRNA), is highly recommended.[4][5]
Advantages of the RNP format:
-
High Editing Efficiency: RNPs are immediately active upon entering the cell, leading to rapid and efficient gene editing.[5]
-
Reduced Off-Target Effects: The Cas9 protein is degraded relatively quickly, minimizing the time it has to cause unintended edits.[6]
-
Lower Toxicity: RNP delivery avoids the potential toxicity associated with plasmid DNA, which can trigger innate immune responses.[4]
Methods for CRISPR/Cas9 Delivery to Primary Cells
Electroporation and Nucleofection
Electroporation and its advanced iteration, nucleofection, are physical methods that use an electrical pulse to create transient pores in the cell membrane, allowing the entry of CRISPR/Cas9 components.[7] These methods are highly effective for a wide range of primary cells, including immune cells and stem cells.[2][5]
This protocol is adapted from successful methods for high-efficiency gene knockout in primary T cells.[8][9][10]
Materials:
-
Primary human T cells
-
T cell activation beads (e.g., anti-CD3/CD28)
-
Recombinant human IL-2
-
TrueCut™ Cas9 Protein v2 or similar
-
Synthesized or in vitro transcribed sgRNA
-
Neon™ Transfection System or similar electroporator
-
Electroporation buffer (e.g., Neon™ Buffer T)
-
DPBS (calcium and magnesium-free)
-
Complete T cell culture medium
Procedure:
-
T-Cell Isolation and Activation:
-
Isolate primary T cells from peripheral blood mononuclear cells (PBMCs).
-
Activate T cells at a density of 1 x 10^6 cells/mL with activation beads in culture medium containing IL-2.
-
Culture for 48-72 hours at 37°C, 5% CO2. Optimal activation time is typically 24-48 hours.[11]
-
-
RNP Complex Formation:
-
In a sterile microcentrifuge tube, combine 1 µg of Cas9 protein with 250 ng of sgRNA.
-
Incubate at room temperature for 15-20 minutes to allow for RNP complex formation.
-
-
Electroporation:
-
Count the activated T cells and pellet 2 x 10^5 cells per electroporation reaction.
-
Wash the cells once with DPBS.
-
Resuspend the cell pellet in the RNP complex solution in the appropriate electroporation buffer.
-
Aspirate the cell-RNP mixture into a 10 µL Neon™ tip (or equivalent for your system).
-
Electroporate the cells using an optimized program (e.g., for T cells, a common starting point is 1600 V, 10 ms, 3 pulses). Optimization of electroporation parameters is critical for each cell type and donor.[11][12]
-
-
Post-Electroporation Culture and Analysis:
-
Immediately transfer the electroporated cells into a pre-warmed 24-well plate containing 0.5 mL of complete culture medium without antibiotics.
-
Incubate the cells for 48-72 hours at 37°C, 5% CO2.
-
Assess editing efficiency using methods such as genomic cleavage detection assays (e.g., T7E1 assay) or next-generation sequencing.
-
Monitor cell viability using a cell counter or viability stain (e.g., Trypan Blue).
-
This protocol is based on established methods for gene editing in CD34+ HSPCs.[13][14]
Materials:
-
CD34+ Human Hematopoietic Stem Cells
-
Stem cell culture medium (e.g., StemSpan™ SFEM II) with appropriate cytokines (e.g., SCF, TPO, Flt3L)
-
Cas9 Nuclease
-
Chemically modified sgRNA
-
4D-Nucleofector™ System or similar
-
P3 Primary Cell Nucleofector™ Solution
-
DPBS
Procedure:
-
HSPC Culture and Pre-stimulation:
-
Thaw and culture CD34+ HSPCs in stem cell culture medium supplemented with cytokines for 48 hours to induce cell division.
-
-
RNP Complex Preparation:
-
For each reaction, mix Cas9 protein and chemically modified sgRNA in a sterile tube and incubate at room temperature for 20 minutes.
-
-
Nucleofection:
-
Harvest and pellet 2 x 10^5 HSPCs per reaction.
-
Resuspend the cell pellet in the Nucleofector™ solution containing the pre-formed RNP complex.
-
Transfer the mixture to a nucleofection cuvette and electroporate using an optimized program (e.g., DZ-100 for the 4D-Nucleofector™).[14]
-
-
Post-Nucleofection Culture and Analysis:
-
Immediately add pre-warmed culture medium to the cuvette and transfer the cells to a culture plate.
-
Incubate for 48-72 hours.
-
Analyze gene editing efficiency and cell viability as described for T cells.
-
Lipid Nanoparticle (LNP)-Mediated Transfection
LNPs are non-viral vectors that can encapsulate and deliver nucleic acids or RNPs into cells.[15][16] They are a promising alternative to electroporation, often exhibiting lower toxicity and high transfection efficiency.[15][17]
This is a general protocol that can be adapted for various primary cell types. The specific LNP formulation is crucial for success and may need to be optimized.[15]
Materials:
-
Primary cells of interest
-
Appropriate cell culture medium
-
Cas9 RNP complexes (prepared as described previously)
-
Commercially available or custom-formulated lipid nanoparticles
-
Opti-MEM™ or other serum-free medium
Procedure:
-
Cell Preparation:
-
Plate primary cells in a suitable culture vessel to achieve 70-90% confluency on the day of transfection. For suspension cells, adjust the cell density as recommended for the specific cell type.
-
-
LNP-RNP Complex Formation:
-
Dilute the Cas9 RNP complexes in a serum-free medium like Opti-MEM™.
-
In a separate tube, dilute the LNP reagent in the same serum-free medium.
-
Combine the diluted RNPs with the diluted LNP reagent.
-
Mix gently and incubate at room temperature for 10-20 minutes to allow for complex formation.
-
-
Transfection:
-
Add the LNP-RNP complexes dropwise to the cells in the culture vessel.
-
Gently rock the plate to ensure even distribution.
-
-
Post-Transfection Culture and Analysis:
-
Incubate the cells for 24-72 hours at 37°C, 5% CO2.
-
Analyze gene editing efficiency and cell viability.
-
Adeno-Associated Virus (AAV) Mediated Delivery to Primary Neurons
For post-mitotic cells like neurons, viral vectors such as AAV are often the most efficient delivery method. AAVs can be engineered to deliver the Cas9 nuclease and gRNA.[18]
-
Vector Design and Production:
-
Due to the packaging limit of AAV, a dual-vector system is often employed, with one AAV expressing Cas9 and another expressing the gRNA. Smaller Cas9 orthologs like SaCas9 can be used to fit both components into a single vector.[18]
-
-
Transduction of Primary Neurons:
-
Primary neurons are cultured and then transduced with the AAV vectors at a specific multiplicity of infection (MOI).
-
-
Analysis:
-
Gene editing efficiency is assessed at the genomic and protein levels after a suitable incubation period (typically several days to weeks).
-
Quantitative Data Summary
The following table summarizes reported efficiencies for CRISPR/Cas9 delivery in primary cells using different methods. It is important to note that efficiencies can vary significantly depending on the specific cell type, donor variability, and experimental conditions.
| Primary Cell Type | Delivery Method | CRISPR Format | Transfection/Transduction Efficiency | Gene Editing Efficiency | Cell Viability | Reference(s) |
| Human T Cells | Electroporation/Nucleofection | RNP | >90% | >90% (knockout) | ~80% | [8][11] |
| Human T Cells | Lipid Nanoparticles | mRNA/gRNA | High | High (single & double knockout) | High | [17] |
| Human HSCs (CD34+) | Electroporation/Nucleofection | RNP | Not specified | Up to 60-80% | High | [19] |
| Chicken Embryonic Mesenchymal Cells | Lipid Nanoparticles | Plasmid | ~90% | Not specified | >85% | [15] |
| Primary Mouse B cells, T cells, Macrophages | Retrovirus (from Cas9 transgenic mice) | gRNA | High | ~80% (knockout in B cells) | Not specified | [20] |
Experimental Workflows and Signaling Pathways
CRISPR/Cas9 RNP Electroporation Workflow
Caption: A generalized workflow for CRISPR/Cas9 RNP delivery into primary cells via electroporation.
Lipid Nanoparticle (LNP) Delivery Mechanism
Caption: The mechanism of LNP-mediated delivery of CRISPR/Cas9 components into a target cell.[15]
Conclusion
The successful application of CRISPR/Cas9 technology in primary cells holds immense potential for advancing our understanding of biology and developing novel cell-based therapies. While challenges remain, the optimization of non-viral delivery methods like electroporation and lipid nanoparticles has significantly improved the efficiency and viability of gene editing in these sensitive cells. The protocols and data presented here provide a comprehensive guide for researchers to establish robust and reproducible CRISPR/Cas9 workflows for a variety of primary cell types. As these technologies continue to evolve, we can expect even more efficient and safer methods for primary cell genome engineering to emerge, further accelerating the translation of this revolutionary technology from the bench to the clinic.
References
- 1. researchgate.net [researchgate.net]
- 2. stemcell.com [stemcell.com]
- 3. Blog - Improving Cell Viability During Transfection [btxonline.com]
- 4. mdpi.com [mdpi.com]
- 5. Increasing Gene Editing Efficiency via CRISPR/Cas9- or Cas12a-Mediated Knock-In in Primary Human T Cells [mdpi.com]
- 6. Challenges in delivery systems for CRISPR-based genome editing and opportunities of nanomedicine - PMC [pmc.ncbi.nlm.nih.gov]
- 7. synthego.com [synthego.com]
- 8. Optimized RNP transfection for highly efficient CRISPR/Cas9-mediated gene knockout in primary T cells - PMC [pmc.ncbi.nlm.nih.gov]
- 9. benchchem.com [benchchem.com]
- 10. researchgate.net [researchgate.net]
- 11. m.youtube.com [m.youtube.com]
- 12. Optimizing Electroporation Conditions in Primary and Other Difficult-to-Transfect Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 13. btxonline.com [btxonline.com]
- 14. Video: CRISPR/Cas9 Gene Editing of Hematopoietic Stem and Progenitor Cells for Gene Therapy Applications [jove.com]
- 15. Lipid-Nanoparticle-Based Delivery of CRISPR/Cas9 Genome-Editing Components - PMC [pmc.ncbi.nlm.nih.gov]
- 16. genscript.com [genscript.com]
- 17. ashpublications.org [ashpublications.org]
- 18. scienceopen.com [scienceopen.com]
- 19. Optimization of CRISPR/Cas9 Delivery to Human Hematopoietic Stem and Progenitor Cells for Therapeutic Genomic Rearrangements - PMC [pmc.ncbi.nlm.nih.gov]
- 20. pnas.org [pnas.org]
Application Notes and Protocols: Troubleshooting a Specific Antibody Not Working in Western Blot
Audience: Researchers, scientists, and drug development professionals.
Introduction
The Western blot is a powerful and widely used technique for the detection and quantification of specific proteins in a complex mixture. However, a common frustration in the laboratory is when a specific antibody fails to produce the expected signal. This can manifest as a complete lack of signal, a weak signal, or the presence of non-specific bands. These application notes provide a systematic guide to troubleshooting and resolving common issues encountered when a specific antibody is not performing as expected in a Western blot experiment.
Common Problems and Initial Checks
Before proceeding with extensive troubleshooting, it is crucial to perform some initial checks to rule out simple errors.
1. Antibody Validation: The primary reason an antibody may not work in a Western blot is that it has not been validated for this application. Antibodies that work in other applications like immunofluorescence (IF) or immunoprecipitation (IP) may not recognize the denatured, linear protein epitope present in a Western blot.[1] Always check the manufacturer's datasheet to confirm that the antibody is validated for Western blotting.[1]
2. Reagent and Buffer Integrity: Ensure that all buffers (lysis, running, transfer, wash, and antibody dilution) are freshly prepared and at the correct pH.[1][2] Check the expiration dates of all reagents, especially the chemiluminescent substrate, as expired substrates can lead to a lack of signal.[1] Importantly, ensure that buffers used with HRP-conjugated secondary antibodies do not contain sodium azide, as it strongly inhibits HRP activity.[1]
3. Positive and Negative Controls: The inclusion of appropriate controls is essential for interpreting your results.[3] A positive control, such as a cell lysate known to express the target protein or a purified recombinant protein, will confirm that the antibody and the overall protocol are working.[3][4] A negative control, from a cell line or tissue known not to express the protein, helps to assess non-specific binding.[3]
Systematic Troubleshooting Workflow
If the initial checks do not resolve the issue, a systematic approach to troubleshooting is necessary. The following workflow, illustrated in the diagram below, outlines the key areas to investigate.
Caption: A systematic workflow for troubleshooting the absence of a signal in a Western blot experiment.
Data Presentation: Recommended Starting Concentrations and Ranges
The following tables provide recommended starting concentrations and ranges for key components of the Western blot protocol. These should be optimized for each specific antibody and experimental system.
Table 1: Protein Loading and Antibody Concentrations
| Parameter | Recommended Starting Point | Optimization Range | Common Issues if Suboptimal |
| Total Protein Load | 20-30 µg per lane | 10-100 µg | Too Low: Weak or no signal.[1][5] Too High: High background, non-specific bands, smearing.[5] |
| Primary Antibody | 1:1000 dilution (or manufacturer's suggestion) | 1:250 to 1:5000 | Too Low: Weak or no signal. Too High: High background, non-specific bands.[6][7] |
| Secondary Antibody | 1:10,000 dilution | 1:2,500 to 1:40,000 | Too Low: Weak or no signal. Too High: High background, dark blots.[5][8] |
Table 2: Blocking and Washing Parameters
| Parameter | Recommended Protocol | Optimization Considerations | Common Issues if Suboptimal |
| Blocking Agent | 5% non-fat dry milk or 5% BSA in TBST | For phosphoproteins, use BSA as milk contains phosphoproteins.[1] | Inappropriate Agent: Masking of epitope, high background.[1][9] |
| Blocking Time | 1-2 hours at room temperature | Can be performed overnight at 4°C. | Too Short: High background. Too Long: May mask some epitopes.[4] |
| Washing Steps | 3 x 5-10 minutes with TBST | Increase number or duration of washes to reduce background. | Insufficient: High background.[5] Excessive: May reduce specific signal.[10] |
Experimental Protocols
Here are detailed protocols for key experiments to troubleshoot and optimize your antibody performance.
Protocol 1: Primary Antibody Titration by Western Blot
This protocol helps to determine the optimal concentration of the primary antibody that gives a strong specific signal with low background.
-
Prepare Identical Protein Samples: Load the same amount of a positive control lysate into multiple lanes of an SDS-PAGE gel (e.g., 8-10 lanes).
-
Electrophoresis and Transfer: Run the gel and transfer the proteins to a membrane (PVDF or nitrocellulose) as per your standard protocol.
-
Confirm Transfer: After transfer, stain the membrane with Ponceau S to visualize the protein bands and ensure even transfer across all lanes.[1] Mark the lanes and then destain with wash buffer.
-
Blocking: Block the entire membrane in 5% non-fat dry milk or BSA in TBST for 1-2 hours at room temperature.[8]
-
Sectioning the Membrane (Optional): To test multiple antibody concentrations on a single blot, you can cut the membrane into strips, ensuring each strip contains one lane of the protein sample.
-
Primary Antibody Incubation: Prepare a series of dilutions of your primary antibody in antibody dilution buffer (e.g., 1:250, 1:500, 1:1000, 1:2000, 1:4000).[8] Incubate each membrane strip with a different antibody dilution for 1 hour at room temperature or overnight at 4°C.[7][8] Include one strip with no primary antibody as a negative control to check for non-specific binding of the secondary antibody.
-
Washing: Wash all membrane strips 3 times for 5-10 minutes each with TBST.
-
Secondary Antibody Incubation: Incubate all strips with the same dilution of the appropriate HRP-conjugated secondary antibody for 1 hour at room temperature.
-
Final Washes: Repeat the washing step as in step 7.
-
Detection: Incubate the membrane with a chemiluminescent substrate according to the manufacturer's instructions and image the blot. Compare the signal-to-noise ratio for each dilution to determine the optimal concentration.
Protocol 2: Antibody Activity Assessment by Dot Blot
A dot blot is a simple and quick method to check if your primary and secondary antibodies are active and to optimize their concentrations without running a full Western blot.[11][12]
-
Prepare Protein Samples: Prepare serial dilutions of a positive control cell lysate or a purified protein in PBS or TBS.
-
Spotting onto Membrane: Cut a small piece of nitrocellulose membrane. Using a pipette, carefully spot 1-2 µL of each protein dilution onto the dry membrane, creating a series of dots.[8][12] Allow the spots to dry completely.
-
Blocking: Block the membrane in 5% non-fat dry milk or BSA in TBST for 30-60 minutes at room temperature.[11][12]
-
Primary Antibody Incubation: Incubate the membrane with your primary antibody at the desired concentration for 1 hour at room temperature.
-
Washing: Wash the membrane 3 times for 5 minutes each with TBST.
-
Secondary Antibody Incubation: Incubate with the secondary antibody for 30-60 minutes at room temperature.[11]
-
Final Washes: Repeat the washing step.
-
Detection: Add the chemiluminescent substrate and image. The presence of a signal on the dots confirms that both the primary and secondary antibodies are active and capable of binding to the target protein.
Signaling Pathway Example: MAPK/ERK Pathway
The MAPK/ERK pathway is a well-characterized signaling cascade frequently studied by Western blot, often by detecting the phosphorylation status of key proteins like ERK1/2. An antibody specific for phosphorylated ERK (p-ERK) is a common tool. If an anti-p-ERK antibody is not working, it could be due to issues with the antibody itself or the biological state of the samples (e.g., cells were not stimulated to activate the pathway).
Caption: A simplified diagram of the MAPK/ERK signaling pathway, a common target for Western blot analysis.
Conclusion
When a specific antibody fails to perform in a Western blot, a systematic and logical approach to troubleshooting is essential. By first verifying the antibody's suitability for the application and the integrity of reagents, and then methodically investigating potential issues in the protein sample, experimental procedure, and antibody concentrations, researchers can efficiently identify and resolve the root cause of the problem. The use of appropriate controls and optimization experiments, such as antibody titrations and dot blots, are invaluable tools in this process.
References
- 1. clyte.tech [clyte.tech]
- 2. Western Blot Troubleshooting | Thermo Fisher Scientific - HK [thermofisher.com]
- 3. neobiotechnologies.com [neobiotechnologies.com]
- 4. Western Blot Troubleshooting: Weak/No Signal & Other | Proteintech Group [ptglab.com]
- 5. Western Blotting Troubleshooting Guide | Cell Signaling Technology [cellsignal.com]
- 6. neobiotechnologies.com [neobiotechnologies.com]
- 7. researchgate.net [researchgate.net]
- 8. info.gbiosciences.com [info.gbiosciences.com]
- 9. bosterbio.com [bosterbio.com]
- 10. sinobiological.com [sinobiological.com]
- 11. documents.thermofisher.com [documents.thermofisher.com]
- 12. bosterbio.com [bosterbio.com]
Application Notes: Investigating and Troubleshooting Cell Line Non-Response to Drug Treatment
References
- 1. Measuring Cancer Drug Sensitivity and Resistance in Cultured Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. atcc.org [atcc.org]
- 4. Mechanisms of Cancer Drug Resistance | Canary Onco [canaryonco.com]
- 5. mdpi.com [mdpi.com]
- 6. ejcmpr.com [ejcmpr.com]
- 7. consensus.app [consensus.app]
- 8. researchgate.net [researchgate.net]
- 9. The Different Mechanisms of Cancer Drug Resistance: A Brief Review - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Efflux ABC transporters in drug disposition and their posttranscriptional gene regulation by microRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Mechanisms of tumor resistance to EGFR-targeted therapies - PMC [pmc.ncbi.nlm.nih.gov]
- 12. [PDF] EGFR in Cancer: Signaling Mechanisms, Drugs, and Acquired Resistance | Semantic Scholar [semanticscholar.org]
- 13. On Biology Mix-up mayhem: cell line contamination in biological research [blogs.biomedcentral.com]
- 14. Misidentified cell lines: failures of peer review, varying journal responses to misidentification inquiries, and strategies for safeguarding biomedical research - PMC [pmc.ncbi.nlm.nih.gov]
- 15. The repercussions of using misidentified cell lines | Culture Collections [culturecollections.org.uk]
- 16. benchchem.com [benchchem.com]
- 17. benchchem.com [benchchem.com]
- 18. biorxiv.org [biorxiv.org]
- 19. researchgate.net [researchgate.net]
- 20. cellgs.com [cellgs.com]
- 21. A Multi-center Study on the Reproducibility of Drug-Response Assays in Mammalian Cell Lines - PMC [pmc.ncbi.nlm.nih.gov]
- 22. Prospective pharmacological methodology for establishing and evaluating anti-cancer drug resistant cell lines - PMC [pmc.ncbi.nlm.nih.gov]
- 23. sorger.med.harvard.edu [sorger.med.harvard.edu]
- 24. Drug resistance mechanisms and progress in the treatment of EGFR-mutated lung adenocarcinoma - PMC [pmc.ncbi.nlm.nih.gov]
- 25. The ABC-type multidrug transport system | Scrub typhus and Orientia: [u.osu.edu]
- 26. researchgate.net [researchgate.net]
- 27. lifesciences.danaher.com [lifesciences.danaher.com]
- 28. creative-bioarray.com [creative-bioarray.com]
- 29. benchchem.com [benchchem.com]
Application Notes and Protocols for Troubleshooting Plasmid Expression in E. coli
For Researchers, Scientists, and Drug Development Professionals
Introduction
Recombinant protein production in Escherichia coli is a cornerstone of modern biotechnology, pivotal for basic research and the development of therapeutics. Despite its widespread use, achieving high levels of protein expression can be challenging, with failed or low expression being a common hurdle. This document provides a comprehensive guide to troubleshooting and optimizing plasmid-based protein expression in E. coli. We will delve into the critical factors that influence expression, from the molecular design of the expression vector to the physiological state of the host cell, and provide detailed protocols to diagnose and resolve common issues.
Section 1: Key Factors Influencing Recombinant Protein Expression
Successful protein expression is a multifactorial process. A systematic evaluation of each component can help identify the root cause of poor expression. The primary factors to consider are the expression vector, the E. coli host strain, and the cultivation & induction conditions.[1][2]
Expression Vector Design
The plasmid vector is the foundational tool for introducing and expressing your gene of interest. Key features of the vector significantly impact expression outcomes.[3]
-
Promoter Strength: The choice of promoter dictates the level of transcription. Strong inducible promoters like T7, tac, or araBAD are commonly used for high-level expression.[4][5] However, overly strong promoters can sometimes lead to the formation of insoluble inclusion bodies.[6]
-
Origin of Replication (ori): The ori determines the plasmid copy number. High-copy-number plasmids can increase the gene dosage, potentially leading to higher protein yields.[7] Conversely, low-copy plasmids are sometimes preferable for toxic proteins to reduce the metabolic burden on the host.[8]
-
Codon Usage: The codons in your gene of interest should be compatible with the tRNA pool of E. coli. The presence of rare codons can lead to translational stalling, premature termination, and reduced protein yield.[3][9] Codon optimization of the gene sequence can significantly enhance expression.[10]
-
Fusion Tags: N- or C-terminal fusion tags (e.g., His-tag, GST, MBP) can be employed to improve protein solubility, stability, and simplify purification.[9][11] Some tags, like MBP, are known to enhance the solubility of their fusion partners.[12]
E. coli Host Strain Selection
The genetic background of the E. coli host strain is critical for successful expression. Different strains are engineered for specific purposes.
-
Expression Strains (e.g., BL21(DE3)): These strains are deficient in proteases (Lon, OmpT) to minimize protein degradation.[7] BL21(DE3) and its derivatives carry the T7 RNA polymerase gene under the control of the lacUV5 promoter, making them suitable for vectors with a T7 promoter.[4]
-
Strains for Toxic Proteins (e.g., C41(DE3), C43(DE3), pLysS/E strains): For proteins toxic to the host, strains that offer tighter control over basal expression are recommended.[11][12] Strains containing pLysS or pLysE plasmids produce T7 lysozyme, which inhibits T7 RNA polymerase, thereby reducing basal expression.[12]
-
Strains for Codon Bias (e.g., Rosetta(DE3)): These strains contain a supplementary plasmid that provides tRNAs for codons that are rare in E. coli, which can improve the expression of heterologous proteins.[12]
Cultivation and Induction Conditions
The environment in which the E. coli cells grow and express the target protein plays a crucial role in the final yield and quality.[13]
-
Growth Medium: Rich media like Terrific Broth (TB) or 2xYT can support high cell densities, potentially leading to higher protein yields.[14] However, for some proteins, minimal media might be necessary to slow down growth and expression, which can improve solubility.[14]
-
Temperature: Induction at lower temperatures (e.g., 16-25°C) often slows down protein synthesis, which can promote proper folding and increase the yield of soluble protein.[6][8]
-
Inducer Concentration: The concentration of the inducer (e.g., IPTG for lac-based systems) should be optimized. High concentrations can sometimes be toxic or lead to rapid, insoluble protein accumulation.[8][15]
-
Timing of Induction (OD600): Induction is typically performed during the mid-logarithmic growth phase (OD600 of 0.6-0.8) when cells are metabolically active.[15]
Section 2: Troubleshooting Guide for No or Low Protein Expression
When faced with a lack of protein expression, a systematic troubleshooting approach is essential. The following sections outline a logical workflow to identify and address the problem.
Initial Verification Steps
Before proceeding with extensive optimization, it is crucial to verify the integrity of your expression construct and the transformation process.
Protocol 2.1.1: Plasmid Integrity Check
-
Plasmid Miniprep: Isolate the plasmid DNA from a fresh overnight culture of the transformed E. coli strain.
-
Restriction Digestion: Perform a diagnostic restriction digest of the isolated plasmid and run it on an agarose gel alongside an undigested control. This will confirm the presence of the insert and the overall plasmid structure.
-
DNA Sequencing: Sequence the insert and flanking regions to ensure the gene is in the correct reading frame, and that there are no mutations or premature stop codons.[16]
Protocol 2.1.2: Transformation Control
-
Positive Control Transformation: Transform your expression host with a control plasmid known to express a protein (e.g., GFP) under the same promoter system. This will verify the competency of the cells and the effectiveness of the transformation protocol.
-
Negative Control Plating: Plate untransformed competent cells onto a plate containing the selection antibiotic. No colonies should grow, confirming the antibiotic is active.
Systematic Troubleshooting Workflow
The following diagram outlines a systematic approach to troubleshooting the lack of plasmid expression.
Caption: A systematic workflow for troubleshooting the lack of protein expression in E. coli.
Section 3: Experimental Protocols
This section provides detailed protocols for key experiments in troubleshooting and optimizing protein expression.
Protocol 3.1: Small-Scale Expression Trial
This protocol is designed to quickly screen for expression under different conditions.
Materials:
-
LB Broth
-
Appropriate antibiotic
-
Inducer (e.g., IPTG)
-
Transformed E. coli strain
-
Shaking incubator
-
Spectrophotometer
-
SDS-PAGE reagents and equipment
Procedure:
-
Inoculate 5 mL of LB medium containing the appropriate antibiotic with a single colony of your transformed E. coli.
-
Incubate overnight at 37°C with shaking (200-250 rpm).
-
The next day, inoculate 10 mL of fresh LB with antibiotic in four separate flasks with 100 µL of the overnight culture.
-
Incubate at 37°C with shaking until the OD600 reaches 0.6-0.8.
-
Keep one flask as the un-induced control. Induce the other three flasks under the following conditions:
-
Flask 1: Induce with 0.1 mM IPTG, incubate at 37°C for 3-4 hours.
-
Flask 2: Induce with 1.0 mM IPTG, incubate at 37°C for 3-4 hours.
-
Flask 3: Induce with 0.5 mM IPTG, incubate at 18°C overnight.
-
-
After induction, measure the final OD600 of each culture.
-
Normalize the cell density of all samples by pelleting a volume of culture equivalent to 1 mL at an OD600 of 1.0.
-
Resuspend the cell pellets in 100 µL of 1X SDS-PAGE loading buffer.
-
Boil the samples for 5-10 minutes.
-
Analyze 10-15 µL of each sample by SDS-PAGE to check for a band corresponding to the expected molecular weight of your protein.
Protocol 3.2: Analysis of Protein Solubility
If expression is detected but the protein is not found in the soluble fraction, it is likely forming inclusion bodies.
Materials:
-
Cell pellet from an induced culture
-
Lysis Buffer (e.g., 50 mM Tris-HCl pH 8.0, 150 mM NaCl, 1 mM EDTA)
-
Lysozyme
-
DNase I
-
Sonciator or other cell disruption equipment
-
Centrifuge
Procedure:
-
Harvest cells from a 10 mL induced culture by centrifugation (e.g., 5000 x g for 10 minutes at 4°C).
-
Resuspend the cell pellet in 1 mL of ice-cold Lysis Buffer.
-
Add lysozyme to a final concentration of 1 mg/mL and incubate on ice for 30 minutes.
-
Add DNase I to a final concentration of 10 µg/mL.
-
Lyse the cells by sonication on ice.
-
Take a 50 µL sample of the total cell lysate.
-
Centrifuge the remaining lysate at high speed (e.g., 15,000 x g for 20 minutes at 4°C) to separate the soluble and insoluble fractions.
-
Carefully collect the supernatant (soluble fraction).
-
Resuspend the pellet (insoluble fraction) in 1 mL of Lysis Buffer.
-
Prepare samples of the total cell lysate, soluble fraction, and insoluble fraction for SDS-PAGE analysis by mixing with an equal volume of 2X SDS-PAGE loading buffer.
-
Analyze the samples by SDS-PAGE to determine the localization of your protein.
Section 4: Data Presentation - Optimization Parameters
The following tables summarize key parameters that can be optimized to improve protein expression.
Table 1: Vector and Host Strain Optimization
| Parameter | Standard Condition | Optimization Strategy | Rationale |
| Promoter | T7 | Use a weaker promoter (e.g., tac, araBAD) | Reduce expression rate to improve folding.[4][5] |
| Copy Number | High (e.g., pUC ori) | Switch to a low copy plasmid (e.g., p15A ori) | Decrease metabolic load and protein toxicity.[7][8] |
| Codon Usage | Wild-type | Synthesize a codon-optimized gene | Overcome tRNA limitations for efficient translation.[9][10] |
| Host Strain | BL21(DE3) | Use protease-deficient strains or strains for toxic proteins (C41, pLysS) | Minimize protein degradation and manage toxicity.[4][7][12] |
| Rare tRNAs | Standard strain | Use a strain supplemented with rare tRNAs (e.g., Rosetta) | Improve translation of genes with rare codons.[12] |
Table 2: Culture and Induction Condition Optimization
| Parameter | Standard Condition | Optimization Range | Rationale |
| Growth Medium | LB | 2xYT, TB, M9 minimal media | Richer media for higher cell density; minimal media to slow growth.[14] |
| Induction Temp. | 37°C | 16°C - 30°C | Lower temperatures can enhance protein solubility.[6][8] |
| Inducer Conc. | 1 mM IPTG | 0.01 - 1.0 mM IPTG | Lower concentrations can reduce toxicity and improve folding.[8][15] |
| Induction OD600 | 0.6 - 0.8 | 0.4 - 1.0 | Induce at different growth phases to find optimal expression window.[15] |
| Induction Time | 3-4 hours | 2 hours - overnight | Longer induction at lower temperatures may be required.[8] |
Section 5: Signaling Pathways and Logical Relationships
The following diagram illustrates the central dogma as it applies to recombinant protein expression in E. coli and highlights key points of potential failure.
References
- 1. 5 Key Factors Affecting Recombinant Protein Yield in E. coli [synapse.patsnap.com]
- 2. Recombinant Protein Expression in Escherichia coli (E.coli): What We Need to Know - Repository of Research and Investigative Information [eprints.mui.ac.ir]
- 3. goldbio.com [goldbio.com]
- 4. Critical Factors Affecting the Success of Cloning, Expression, and Mass Production of Enzymes by Recombinant E. coli - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Step-by-Step Protocol for Optimizing Recombinant Protein Expression [synapse.patsnap.com]
- 6. Troubleshooting Guide for Common Recombinant Protein Problems [synapse.patsnap.com]
- 7. Strategies to Optimize Protein Expression in E. coli - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Bacteria Expression Support—Troubleshooting | Thermo Fisher Scientific - HK [thermofisher.com]
- 9. bonopusbio.com [bonopusbio.com]
- 10. Protein Expression Protocol & Troubleshooting in E. coli [biologicscorp.com]
- 11. researchgate.net [researchgate.net]
- 12. neb.com [neb.com]
- 13. genextgenomics.com [genextgenomics.com]
- 14. blog.addgene.org [blog.addgene.org]
- 15. Troubleshooting Recombinant Protein Expression | VectorBuilder [en.vectorbuilder.com]
- 16. Bacteria Expression Support—Troubleshooting | Thermo Fisher Scientific - HK [thermofisher.com]
Application Notes and Protocols: Troubleshooting Unexpected PCR Results
For Researchers, Scientists, and Drug Development Professionals
Introduction
The polymerase chain reaction (PCR) is a cornerstone of molecular biology, enabling the amplification of specific DNA sequences for a vast array of applications, from gene expression analysis to diagnostics. Despite its routine use, PCR can sometimes yield unexpected or suboptimal results, leading to delays and confounding data interpretation. This document provides a comprehensive guide to troubleshooting common PCR problems, offering detailed protocols and optimization strategies to achieve reliable and reproducible results.
Common PCR Problems and Solutions
Unexpected PCR results typically fall into several categories: no amplification or low yield, nonspecific amplification (such as multiple bands or smears), or the presence of primer-dimers. Successful troubleshooting requires a systematic approach to identify the root cause and implement the appropriate corrective measures.
No Amplification or Low Yield
One of the most frequent issues encountered is the partial or complete failure of the amplification reaction. This can be due to a number of factors, including problems with the template DNA, PCR reagents, or reaction conditions.[1][2][3] A critical first step is to confirm the integrity and purity of the DNA template.[1] Contaminants such as phenol, EDTA, or residual salts from purification kits can inhibit DNA polymerase activity.[2]
Nonspecific Amplification and Smeared Bands
The appearance of multiple bands or a smear on an agarose gel indicates nonspecific amplification, where primers bind to unintended sites on the template DNA.[1] This is often a result of suboptimal annealing temperatures that are too low, allowing for mismatched primer binding.[1] The design of the primers themselves is also a critical factor; primers with complementarity to each other or to repetitive sequences in the template can lead to off-target amplification.[1][4]
Primer-Dimer Formation
Primer-dimers are small, nonspecific PCR products that are formed when primers anneal to each other.[4] They can compete with the target DNA for PCR reagents, leading to a decrease in the yield of the desired product.[5] Careful primer design and optimization of primer concentration and annealing temperature can minimize their formation.[1][4]
Troubleshooting Workflow
A logical workflow can streamline the troubleshooting process. The following diagram illustrates a typical decision-making process when faced with unexpected PCR results.
Caption: A decision tree for troubleshooting common PCR issues.
Experimental Protocols
Protocol 1: Assessment of DNA Template Quality and Quantity
Objective: To determine the concentration and purity of the DNA template.
Materials:
-
DNA sample
-
Nuclease-free water
-
TE buffer (pH 8.0)
-
UV-Vis spectrophotometer (e.g., NanoDrop)
-
Agarose gel (1%)
-
DNA ladder
-
Gel electrophoresis system
-
Gel documentation system
Method:
-
Spectrophotometric Analysis:
-
Blank the spectrophotometer with the same buffer your DNA is suspended in.
-
Measure the absorbance of your DNA sample at 260 nm and 280 nm.
-
Calculate the DNA concentration (A260 of 1.0 = 50 µg/ml of dsDNA).
-
Determine the A260/A280 ratio to assess purity. A ratio of ~1.8 is considered pure for DNA.
-
-
Agarose Gel Electrophoresis:
-
Load 50-100 ng of your DNA sample mixed with loading dye into a well of a 1% agarose gel.
-
Load a DNA ladder in an adjacent well.
-
Run the gel at 100 V for 30-45 minutes.
-
Visualize the DNA under UV light. A sharp, high-molecular-weight band indicates intact DNA, while smearing suggests degradation.[2]
-
Data Presentation:
| Sample ID | Concentration (ng/µL) | A260/A280 Ratio | Gel Electrophoresis Integrity |
| Sample A | 75.2 | 1.85 | Intact |
| Sample B | 15.8 | 1.60 | Degraded |
| Sample C | 120.5 | 1.90 | Intact |
Protocol 2: Optimizing Annealing Temperature using Gradient PCR
Objective: To determine the optimal annealing temperature for a specific primer-template pair to maximize product yield and specificity.
Materials:
-
DNA template (10-100 ng)
-
Forward and reverse primers (10 µM stock)
-
dNTP mix (10 mM)
-
DNA polymerase and corresponding buffer
-
MgCl₂ (if not in buffer)
-
Nuclease-free water
-
Thermal cycler with a gradient function
Method:
-
Calculate the theoretical melting temperature (Tm) of your primers. A good starting point for the annealing temperature is 3-5°C below the lowest primer Tm.
-
Prepare a master mix containing all PCR components except the template DNA.
-
Aliquot the master mix into PCR tubes.
-
Add the template DNA to each tube.
-
Set up the thermal cycler with a temperature gradient across the block for the annealing step. For example, set a gradient from 50°C to 65°C.
-
Run the PCR program.
-
Analyze the PCR products by agarose gel electrophoresis.
Data Presentation:
| Annealing Temp (°C) | Target Band Intensity | Nonspecific Bands | Primer-Dimers |
| 50 | ++ | +++ | ++ |
| 53 | +++ | ++ | + |
| 56 | ++++ | + | - |
| 59 | +++ | - | - |
| 62 | ++ | - | - |
| 65 | + | - | - |
| (++++ = very strong, +++ = strong, ++ = moderate, + = weak, - = none) |
Protocol 3: Titration of MgCl₂ Concentration
Objective: To determine the optimal MgCl₂ concentration for PCR.
Materials:
-
All components from Protocol 2
-
Stock solution of MgCl₂ (e.g., 25 mM or 50 mM)
Method:
-
Prepare a series of PCR reactions, each with a different final concentration of MgCl₂. A typical range to test is 1.5 mM to 4.0 mM in 0.5 mM increments.[6]
-
Use the optimal annealing temperature determined from Protocol 2.
-
Run the PCR and analyze the products on an agarose gel.
Data Presentation:
| MgCl₂ Conc. (mM) | Target Band Intensity | Nonspecific Bands |
| 1.5 | ++ | - |
| 2.0 | +++ | - |
| 2.5 | ++++ | + |
| 3.0 | +++ | ++ |
| 3.5 | ++ | +++ |
| 4.0 | + | +++ |
| (++++ = very strong, +++ = strong, ++ = moderate, + = weak, - = none) |
Advanced Troubleshooting Strategies
For particularly challenging PCRs, such as those with GC-rich templates or for long-range amplification, additional modifications may be necessary.
Hot-Start PCR
Hot-start PCR is a technique that inhibits DNA polymerase activity at room temperature, preventing the formation of nonspecific products and primer-dimers during reaction setup.[1] This can be achieved using specialized polymerases that are chemically modified or antibody-bound and require an initial high-temperature activation step.
PCR Additives
Certain additives can enhance PCR performance. For example, dimethyl sulfoxide (DMSO) or betaine can help to denature GC-rich templates, while bovine serum albumin (BSA) can overcome some PCR inhibitors.
The following diagram outlines the logical flow for deciding when to employ these advanced strategies.
Caption: Workflow for advanced PCR troubleshooting strategies.
Conclusion
A systematic and methodical approach is key to resolving unexpected PCR results. By carefully evaluating each component of the reaction and optimizing the reaction parameters, researchers can overcome common PCR challenges and obtain reliable and reproducible data. When standard troubleshooting is insufficient, advanced techniques such as hot-start PCR and the use of additives can provide a path to success.
References
- 1. mybiosource.com [mybiosource.com]
- 2. PCR Troubleshooting Guide | Thermo Fisher Scientific - TW [thermofisher.com]
- 3. PCR Basic Troubleshooting Guide [creative-biogene.com]
- 4. Optimizing PCR: Proven Tips and Troubleshooting Tricks | The Scientist [the-scientist.com]
- 5. mybiosource.com [mybiosource.com]
- 6. researchgate.net [researchgate.net]
Application Notes and Protocols: Troubleshooting Exosome Isolation Methods
For Researchers, Scientists, and Drug Development Professionals
Introduction
Exosomes, small extracellular vesicles ranging from 30-150 nm in diameter, are gaining significant attention in biomedical research and clinical applications due to their roles in intercellular communication and their potential as biomarkers and therapeutic delivery vehicles. However, the isolation of a pure and sufficient quantity of exosomes from complex biological fluids or cell culture media remains a significant challenge. Many researchers encounter issues with their chosen isolation method, leading to low yields, high levels of contamination, and inconsistent results.
These application notes provide a detailed guide to troubleshooting common problems encountered during exosome isolation. We present standardized protocols for the most frequently used isolation techniques, a comparative analysis of their expected outcomes, and a logical workflow to diagnose and resolve issues with your exosome preparations.
Common Challenges in Exosome Isolation
Several factors can contribute to the failure or suboptimal performance of exosome isolation protocols. Understanding these potential pitfalls is the first step toward successful troubleshooting.
-
Low Yield: The number of exosomes secreted by cells can vary significantly depending on the cell type, culture conditions, and the volume of the starting material.[1][2] Inefficient isolation techniques can also lead to the loss of a significant portion of the exosome population.
-
Contamination: Co-isolation of non-exosomal components is a major challenge.[3][4] Common contaminants include proteins (e.g., albumin in blood samples), lipoproteins, and other extracellular vesicles of similar size.[3] In urine samples, the Tamm-Horsfall protein can interfere with isolation.[3]
-
Exosome Damage: Harsh isolation methods, such as prolonged high-speed ultracentrifugation, can damage the integrity of exosome membranes, affecting their biological function and analytical characterization.[5]
-
Lack of Standardization: The absence of universally accepted protocols for exosome isolation makes it difficult to compare results across different studies and laboratories.[6]
Comparative Analysis of Exosome Isolation Methods
The choice of isolation method significantly impacts the yield, purity, and functionality of the resulting exosome preparation. Below is a summary of the most common techniques with their respective advantages and disadvantages.
| Method | Principle | Yield | Purity | Throughput | Advantages | Disadvantages |
| Differential Ultracentrifugation (dUC) | Separation based on size and density through sequential centrifugation steps at increasing speeds.[5][7] | High | Low to Medium | Low | Can process large volumes. | Time-consuming, requires specialized equipment, potential for exosome damage and protein contamination.[5][8][9] |
| Size-Exclusion Chromatography (SEC) | Separation of molecules based on their size as they pass through a column with porous beads.[10] | Medium | High | Medium | Gentle on exosomes, efficient removal of soluble proteins.[3][10] | Potential for sample dilution, may not separate exosomes from other vesicles of similar size.[3] |
| Polymer-based Precipitation (e.g., ExoQuick™) | Use of volume-excluding polymers to precipitate exosomes from solution.[11][12] | High | Low | High | Simple, fast, and does not require special equipment.[11][12] | Co-precipitation of non-exosomal proteins and other contaminants is a major issue.[13] |
| Immunoaffinity Capture | Use of antibodies targeting exosome surface proteins to specifically capture exosomes.[14] | Low | Very High | Medium | Highly specific, isolates subpopulations of exosomes. | Yield is dependent on the expression of the target antigen, elution can be harsh. |
Detailed Experimental Protocols
Here we provide step-by-step protocols for the most common exosome isolation methods.
Protocol 1: Differential Ultracentrifugation (dUC) from Cell Culture Media
This protocol is a widely used method for isolating exosomes from conditioned cell culture media.[7][15]
Materials:
-
Conditioned cell culture medium
-
Phosphate-buffered saline (PBS), sterile
-
Refrigerated centrifuge
-
Ultracentrifuge with a swinging bucket or fixed-angle rotor
-
Sterile centrifuge tubes (50 mL) and ultracentrifuge tubes
Procedure:
-
Culture cells in exosome-depleted fetal bovine serum (FBS) for 48-72 hours.
-
Collect the conditioned medium and centrifuge at 300 x g for 10 minutes at 4°C to pellet cells.[7]
-
Carefully transfer the supernatant to a new tube and centrifuge at 2,000 x g for 20 minutes at 4°C to remove dead cells and debris.[7]
-
Transfer the supernatant to a new tube and centrifuge at 10,000 x g for 30 minutes at 4°C to pellet larger vesicles.[7]
-
Filter the supernatant through a 0.22 µm filter to remove any remaining cellular debris.[15]
-
Transfer the filtered supernatant to ultracentrifuge tubes and centrifuge at 100,000 - 120,000 x g for 70-90 minutes at 4°C.[7][16]
-
Discard the supernatant and resuspend the exosome pellet in a large volume of sterile PBS.
-
Repeat the ultracentrifugation step (100,000 - 120,000 x g for 70-90 minutes at 4°C) to wash the exosomes and remove contaminating proteins.[7]
-
Discard the supernatant and resuspend the final exosome pellet in a small volume of PBS for downstream analysis or storage at -80°C.[7]
Protocol 2: Size-Exclusion Chromatography (SEC)
This protocol describes the purification of exosomes using commercially available SEC columns.[8][10]
Materials:
-
Pre-cleared biological fluid or cell culture supernatant (steps 1-5 from Protocol 3.1)
-
SEC columns for exosome isolation
-
PBS, sterile
-
Collection tubes
Procedure:
-
Equilibrate the SEC column by washing it with a generous volume of sterile PBS, as recommended by the manufacturer.[10]
-
Carefully load your pre-cleared sample onto the top of the column.[8]
-
Allow the sample to enter the column bed completely.
-
Begin eluting the column with sterile PBS and collect fractions of a defined volume (e.g., 500 µL).[8]
-
Exosomes, being larger, will elute in the earlier fractions (typically fractions 5-8), while smaller proteins and molecules will be retained in the column and elute in later fractions.[8]
-
Pool the exosome-containing fractions for further analysis.
Protocol 3: Polymer-Based Precipitation (using ExoQuick-TC™ as an example)
This protocol provides a general guideline for using a commercial precipitation reagent.[11][17] Always refer to the manufacturer's specific instructions.
Materials:
-
Cell culture supernatant
-
ExoQuick-TC™ Exosome Precipitation Solution
-
Refrigerated centrifuge
-
Sterile centrifuge tubes
Procedure:
-
Collect cell culture supernatant and centrifuge at 3,000 x g for 15 minutes to remove cells and debris.[11]
-
Transfer the cleared supernatant to a new tube.
-
Add the recommended volume of ExoQuick-TC™ solution to the supernatant (e.g., 2 mL of ExoQuick-TC™ for every 10 mL of supernatant).[11]
-
Mix well by inverting the tube and incubate at 4°C for at least 12 hours.[11]
-
Centrifuge the mixture at 1,500 x g for 30 minutes at 4°C.[17]
-
Aspirate and discard the supernatant, being careful not to disturb the exosome pellet.
-
Centrifuge the tube again at 1,500 x g for 5 minutes to remove any residual fluid.[17]
-
Resuspend the pellet in an appropriate buffer (e.g., PBS) for your downstream application.
Protocol 4: Immunoaffinity Capture
This protocol outlines the general steps for isolating exosomes using antibody-coated magnetic beads.
Materials:
-
Pre-cleared biological fluid or cell culture supernatant
-
Magnetic beads coated with an antibody against an exosome surface marker (e.g., CD9, CD63, or CD81)
-
Magnetic rack
-
Washing buffer (e.g., PBS with 0.1% BSA)
-
Elution buffer (specific to the kit or antibody-bead interaction)
Procedure:
-
Incubate the antibody-coated magnetic beads with your pre-cleared sample according to the manufacturer's instructions to allow for exosome binding.
-
Place the tube on a magnetic rack to capture the bead-exosome complexes.
-
Carefully remove and discard the supernatant.
-
Wash the bead-exosome complexes several times with the washing buffer to remove non-specifically bound contaminants.
-
Elute the captured exosomes from the beads using the appropriate elution buffer.
-
Alternatively, for some applications, downstream analysis can be performed with the exosomes still bound to the beads.
Troubleshooting Guide
When your exosome isolation method is not yielding the expected results, a systematic approach to troubleshooting is essential. The following guide will help you identify and address common issues.
Problem: Low or No Exosome Yield
A low yield of exosomes is one of the most frequent challenges.
Possible Causes & Solutions:
-
Low Exosome Secretion by Cells:
-
Cell Type and Health: Not all cell lines secrete high levels of exosomes. Ensure your cells are healthy and not overly confluent.[15]
-
Culture Conditions: Optimize cell culture conditions. Serum starvation or other cellular stressors can sometimes increase exosome production, but this should be empirically determined for your cell line.
-
-
Inefficient Isolation Protocol:
-
Starting Material Volume: Increase the volume of your starting material (cell culture media or biofluid).
-
Ultracentrifugation Issues:
-
Ensure the ultracentrifuge is reaching the correct speed and temperature.
-
The exosome pellet after ultracentrifugation can be very small and difficult to see.[18] Mark the expected location of the pellet on the tube before centrifugation.
-
Avoid over-resuspending the pellet in a large volume.
-
-
Precipitation Kit Issues:
-
-
Loss of Exosomes During the Procedure:
Problem: High Protein Contamination
Contamination with non-exosomal proteins can interfere with downstream applications.
Possible Causes & Solutions:
-
Incomplete Removal of Soluble Proteins:
-
Washing Steps (dUC): Ensure the exosome pellet is washed at least once with a large volume of PBS after the initial ultracentrifugation step to remove contaminating proteins.[20]
-
Precipitation Methods: These methods are known for co-precipitating proteins.[13] Consider adding a purification step after precipitation, such as SEC.
-
-
Contamination from the Starting Material:
-
Serum in Cell Culture Media: Use exosome-depleted FBS in your cell culture medium.
-
High Abundance Proteins in Biofluids: For samples like plasma, consider methods that are better at removing abundant proteins, such as SEC or immunoaffinity capture.
-
Validation of Exosome Preparations
It is crucial to validate the identity and purity of your isolated exosomes.
-
Western Blotting: Confirm the presence of exosome-specific markers (e.g., CD9, CD63, CD81, TSG101, Alix) and the absence of markers from other cellular compartments (e.g., Calnexin for the endoplasmic reticulum).[6][21][22][23]
-
Nanoparticle Tracking Analysis (NTA): Determine the size distribution and concentration of the isolated vesicles. Exosomes typically have a diameter between 30 and 150 nm.[24]
-
Transmission Electron Microscopy (TEM): Visualize the characteristic cup-shaped morphology of exosomes.[13]
-
Protein Quantification: A common metric for assessing purity is the ratio of particle number to protein concentration. A higher ratio generally indicates a purer exosome preparation.[25]
Visualizing Workflows and Troubleshooting Logic
The following diagrams, generated using the DOT language, illustrate the experimental workflows and a logical approach to troubleshooting.
References
- 1. sartorius.com [sartorius.com]
- 2. researchgate.net [researchgate.net]
- 3. Principles and Problems of Exosome Isolation from Biological Fluids - PMC [pmc.ncbi.nlm.nih.gov]
- 4. [Contamination of exosome preparations, isolated from biological fluids] - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. blog.mblintl.com [blog.mblintl.com]
- 6. Western Blotting-Based Exosome Characterization Service - Creative Biostructure Exosome [creative-biostructure.com]
- 7. documents.thermofisher.com [documents.thermofisher.com]
- 8. youtube.com [youtube.com]
- 9. Elucidating Methods for Isolation and Quantification of Exosomes: A Review - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Size exclusion chromatography for exosome isolation | Immunostep Biotech [immunostep.com]
- 11. biocat.com [biocat.com]
- 12. systembio.com [systembio.com]
- 13. researchgate.net [researchgate.net]
- 14. research.monash.edu [research.monash.edu]
- 15. biopsia-liquida.ciberonc.es [biopsia-liquida.ciberonc.es]
- 16. Exosome Ultracentrifugation Protocol - Creative Proteomics [creative-proteomics.com]
- 17. resources.amsbio.com [resources.amsbio.com]
- 18. researchgate.net [researchgate.net]
- 19. researchgate.net [researchgate.net]
- 20. bitesizebio.com [bitesizebio.com]
- 21. WB-Based Exosome Verification - Creative Proteomics [creative-proteomics.com]
- 22. Defining the purity of exosomes required for diagnostic profiling of small RNA suitable for biomarker discovery - PMC [pmc.ncbi.nlm.nih.gov]
- 23. stemcell.com [stemcell.com]
- 24. Quantification of Exosomes - PMC [pmc.ncbi.nlm.nih.gov]
- 25. beckman.com [beckman.com]
Application Notes and Protocols for Troubleshooting Non-Linear ELISA Standard Curves
FOR IMMEDIATE RELEASE
Understanding and Overcoming Non-Linearity in ELISA Standard Curves: A Guide for Researchers
[City, State] – [Date] – For researchers, scientists, and drug development professionals relying on Enzyme-Linked Immunosorbent Assay (ELISA) for quantitative analysis, a reliable standard curve is paramount. However, achieving a perfect linear relationship is a common challenge, as ELISA standard curves are inherently sigmoidal. This document provides detailed application notes and protocols to understand the causes of poor standard curve linearity, troubleshoot issues, and ensure accurate data interpretation through appropriate curve-fitting models.
A well-constructed standard curve serves as the foundation for accurate analyte quantification.[1] The relationship between the optical density (OD) signal and the known concentration of the analyte is plotted to generate this curve.[2] While a portion of this curve may appear linear, the overall shape is typically sigmoidal (S-shaped).[1][3] Attempting to fit this sigmoidal data to a linear regression model can lead to significant inaccuracies, especially at the lower and higher ends of the concentration range.[4] Therefore, it is crucial to employ non-linear regression models, such as the four-parameter logistic (4PL) or five-parameter logistic (5PL) fits, for accurate analysis.[5]
This guide will delve into the common causes of poor standard curve performance, provide a detailed protocol for generating a robust standard curve, and present a troubleshooting workflow to diagnose and resolve issues.
I. Common Causes of Poor Standard Curve Performance
A non-ideal standard curve can manifest as a poor fit (low R-squared value), inconsistent replicates, or a compressed dynamic range. The underlying causes can often be traced back to procedural errors or reagent issues. A summary of common problems and their solutions is presented in Table 1.
Table 1: Troubleshooting Guide for Non-Linear ELISA Standard Curves
| Problem | Potential Cause | Recommended Solution |
| Low R-squared (R²) Value (<0.99) | Improper Curve Fitting Model: Using a linear regression for sigmoidal data. | Utilize a non-linear regression model such as a four-parameter logistic (4PL) or five-parameter logistic (5PL) curve fit.[5] |
| Pipetting Errors: Inaccurate volumes of standards, reagents, or samples. | Ensure pipettes are properly calibrated. Use fresh tips for each dilution and sample. Dispense liquid against the side of the well to avoid splashing.[6] | |
| Improper Standard Dilutions: Errors in calculating or performing serial dilutions. | Double-check all dilution calculations. Prepare fresh standard dilutions for each plate. Avoid large, single-step dilutions.[3][7] | |
| High Background (High OD in Blank Wells) | Insufficient Washing: Residual conjugate remains in the wells. | Increase the number of wash cycles or the soaking time between washes. Ensure complete aspiration of wash buffer from all wells. |
| Contaminated Reagents: Substrate solution or wash buffer is contaminated. | Use fresh, properly stored reagents. Ensure the substrate solution is colorless before use. | |
| Excessive Antibody/Conjugate Concentration: Too much detection reagent leads to non-specific binding. | Optimize the concentration of detection antibody and enzyme conjugate according to the manufacturer's protocol. | |
| Low Optical Density (OD) Signal | Degraded Reagents: Standard, antibodies, or enzyme conjugate have lost activity due to improper storage. | Use fresh reagents and ensure they are stored at the recommended temperatures. Avoid repeated freeze-thaw cycles of the standard.[7] |
| Incorrect Incubation Times/Temperatures: Insufficient time or suboptimal temperature for binding reactions. | Adhere strictly to the incubation times and temperatures specified in the protocol. Allow all reagents to reach room temperature before use.[8] | |
| Presence of Inhibitors: Sodium azide in buffers can inhibit HRP activity. | Ensure that none of the buffers or solutions used contain sodium azide. | |
| Inconsistent Replicates (High %CV) | Pipetting Inaccuracy: Variation in volume dispensed between replicate wells. | Calibrate pipettes regularly. Ensure consistent pipetting technique. |
| Inadequate Mixing: Reagents or samples not mixed thoroughly before addition to the plate. | Gently vortex or pipette mix all reagents and samples before use. | |
| Edge Effects: Temperature or evaporation gradients across the plate. | Ensure the plate is sealed properly during incubations. Consider not using the outer wells of the plate if edge effects are persistent. |
II. Experimental Protocol for Generating a Reliable ELISA Standard Curve
This protocol outlines the key steps for preparing and running a standard curve to ensure accuracy and reproducibility.
Materials:
-
Lyophilized or concentrated analyte standard
-
Assay diluent (as specified in the ELISA kit protocol)
-
Calibrated micropipettes and sterile, low-retention pipette tips
-
Microcentrifuge tubes for serial dilutions
-
ELISA plate
-
Plate reader
Procedure:
-
Reconstitution of the Standard:
-
Briefly centrifuge the vial of lyophilized standard to ensure all the powder is at the bottom.
-
Reconstitute the standard with the volume of diluent specified in the kit's manual to create the stock solution.
-
Mix gently by inverting the vial several times or by gentle vortexing. Allow it to sit at room temperature for the recommended time to ensure complete dissolution.
-
-
Preparation of Serial Dilutions:
-
Label a series of microcentrifuge tubes for each standard dilution point (e.g., S1 to S7).
-
Pipette the appropriate volume of assay diluent into each tube.
-
Perform a serial dilution by transferring a defined volume of the stock solution into the first tube (S1), mixing thoroughly, and then transferring the same volume from S1 to S2, and so on. Use a fresh pipette tip for each transfer. A common dilution series is 2-fold.
-
-
Plate Loading:
-
Add the prepared standards to the appropriate wells of the ELISA plate in duplicate or triplicate.
-
Also, include a blank (zero standard) which contains only the assay diluent.[1]
-
-
Assay Execution:
-
Proceed with the ELISA protocol as instructed by the manufacturer, ensuring consistent incubation times, temperatures, and washing steps for all wells.
-
-
Data Acquisition:
-
Read the optical density (OD) of each well at the appropriate wavelength using a plate reader.
-
-
Data Analysis:
-
Subtract the average OD of the blank from all standard and sample ODs.
-
Calculate the average OD and coefficient of variation (%CV) for each set of standard replicates. The %CV should ideally be below 20%.[9][10]
-
Plot the average blank-corrected OD values (Y-axis) against the known concentrations of the standards (X-axis).
-
Fit the data using a 4-parameter logistic (4PL) or 5-parameter logistic (5PL) regression model to generate the standard curve.
-
Determine the concentration of unknown samples by interpolating their OD values from the standard curve.
-
III. Data Presentation: Comparing Good and Poor Standard Curves
The quality of the standard curve is a direct reflection of the assay's performance. Table 2 provides a quantitative comparison of data from a "good" versus a "poor" standard curve.
Table 2: Example Data for a "Good" vs. "Poor" ELISA Standard Curve
| Concentration (pg/mL) | "Good" Curve Avg. OD | "Poor" Curve Avg. OD | Comments on "Poor" Curve Data |
| 2000 | 2.510 | 1.850 | Lower than expected signal at high concentration. |
| 1000 | 2.150 | 1.750 | Signal saturation at higher concentrations. |
| 500 | 1.620 | 1.550 | Poor discrimination between points. |
| 250 | 1.050 | 1.250 | Inconsistent OD progression. |
| 125 | 0.610 | 0.850 | Non-monotonic response. |
| 62.5 | 0.350 | 0.550 | High signal at low concentrations. |
| 31.25 | 0.210 | 0.350 | High background noise. |
| 0 (Blank) | 0.050 | 0.250 | Very high blank reading. |
| R-squared (4PL Fit) | 0.998 | 0.850 | A low R² value indicates a poor fit. |
IV. Visualizing Workflows and Troubleshooting
To further aid researchers, the following diagrams illustrate the standard ELISA workflow and a logical approach to troubleshooting a non-linear standard curve.
Caption: A typical workflow for a sandwich ELISA, highlighting the key stages from preparation to data analysis.
Caption: A decision tree for troubleshooting a non-linear or poor ELISA standard curve.
By understanding the inherently non-linear nature of ELISA data and implementing meticulous laboratory practices, researchers can generate reliable standard curves, leading to accurate and reproducible quantification of target analytes. These guidelines serve as a comprehensive resource for achieving high-quality ELISA results.
References
- 1. betalifesci.com [betalifesci.com]
- 2. bosterbio.com [bosterbio.com]
- 3. bosterbio.com [bosterbio.com]
- 4. pblassaysci.com [pblassaysci.com]
- 5. Data analysis for ELISA | Abcam [abcam.com]
- 6. blog.abclonal.com [blog.abclonal.com]
- 7. arp1.com [arp1.com]
- 8. Troubleshooting ELISA | U-CyTech [ucytech.com]
- 9. mybiosource.com [mybiosource.com]
- 10. ELISA Analysis: How to Read and Analyze ELISA Data | R&D Systems [rndsystems.com]
Application Note: A Comprehensive Troubleshooting Guide for Flow Cytometry
For Researchers, Scientists, and Drug Development Professionals
Introduction
Flow cytometry is a powerful and indispensable technique in biological research and drug development, enabling multi-parametric analysis of single cells. However, the complexity of the instrumentation and the multi-step experimental protocols can lead to a variety of issues affecting data quality and reproducibility. This application note provides a detailed guide to systematically troubleshoot and resolve common problems encountered during flow cytometry experiments. By following these protocols and recommendations, researchers can ensure the acquisition of high-quality, reliable data.
Weak or No Fluorescence Signal
A common issue in flow cytometry is the lack of a discernible signal from the stained cell population. This can manifest as a complete absence of fluorescence or a signal that is too weak to distinguish from the unstained control.
Potential Causes and Solutions
| Potential Cause | Recommended Solution | Experimental Protocol |
| Improper Antibody Storage or Handling | Ensure antibodies are stored at the recommended temperature and protected from light. Avoid repeated freeze-thaw cycles by aliquoting antibodies upon receipt.[1][2] | Protocol 1: Antibody Aliquoting and Storage |
| Insufficient Antibody Concentration | Titrate the antibody to determine the optimal concentration for your specific cell type and experimental conditions.[2] | Protocol 2: Antibody Titration |
| Low Target Antigen Expression | Confirm antigen expression levels in the literature for your cell type.[2][3] If expression is low, consider using a brighter fluorochrome or an amplification strategy (e.g., biotin-streptavidin).[1] | Protocol 3: Signal Amplification using Biotin-Streptavidin |
| Incorrect Instrument Settings (Laser/Filter Mismatch) | Verify that the instrument's laser and filter configuration is appropriate for the fluorochrome being used.[1] | Refer to your flow cytometer's user manual for laser and filter specifications. |
| Suboptimal Staining Protocol | Optimize incubation times and temperatures. Ensure permeabilization is adequate for intracellular targets.[3] | Protocol 4: Intracellular Staining |
| Photobleaching of Fluorochromes | Minimize exposure of stained samples to light.[4] | Handle samples in a darkened room or use light-blocking tubes. |
| Incompatible Primary and Secondary Antibodies | Ensure the secondary antibody is raised against the host species of the primary antibody.[1][5] | Check the datasheets for both primary and secondary antibodies to confirm compatibility. |
High Background or Non-Specific Staining
High background fluorescence can mask true positive signals and lead to inaccurate data interpretation. This is often caused by non-specific binding of antibodies or cellular autofluorescence.
Potential Causes and Solutions
| Potential Cause | Recommended Solution | Experimental Protocol |
| Excess Antibody Concentration | Titrate the antibody to determine the optimal concentration.[4] Using too much antibody can lead to non-specific binding. | Protocol 2: Antibody Titration |
| Fc Receptor-Mediated Binding | Block Fc receptors on cells (e.g., macrophages, B cells) using an Fc blocking reagent or serum from the same species as the secondary antibody.[2][5] | Protocol 5: Fc Receptor Blocking |
| Dead Cells | Use a viability dye to exclude dead cells from the analysis, as they can non-specifically bind antibodies.[4] | Protocol 6: Viability Staining |
| High Autofluorescence | Use a buffer with reduced autofluorescence or select fluorochromes in the red or far-red spectrum, which typically have less interference from cellular autofluorescence.[4] | Analyze an unstained sample to determine the level of autofluorescence. |
| Inadequate Washing | Increase the number of wash steps or the volume of wash buffer to remove unbound antibodies.[4][6] | Modify your staining protocol to include additional washes. |
| Contamination of Reagents | Use sterile, filtered buffers and solutions to prevent microbial growth, which can cause background fluorescence. | Prepare fresh buffers and filter-sterilize them before use. |
Abnormal Event Rate (Too Low or Too High)
The event rate, or the number of cells passing through the laser per second, is a critical parameter for data quality. Deviations from the expected event rate can indicate problems with the sample or the instrument.
Potential Causes and Solutions
| Potential Cause | Recommended Solution | Experimental Protocol |
| Low Event Rate: Clogged Fluidics | Perform a cleaning cycle on the flow cytometer (e.g., run bleach followed by water) as per the manufacturer's instructions.[5][7] | Refer to your instrument's maintenance guide for the cleaning protocol. |
| Low Event Rate: Cell Clumping | Gently vortex or pipette the sample before acquisition. Consider filtering the sample through a cell strainer.[1] | Protocol 7: Preparation of a Single-Cell Suspension |
| Low Event Rate: Low Cell Concentration | Adjust the sample concentration to the optimal range for your instrument (typically 0.5-1 x 10^6 cells/mL).[2][5] | Count cells using a hemocytometer or automated cell counter before acquisition. |
| High Event Rate: High Cell Concentration | Dilute the sample to the recommended concentration.[4] | Perform serial dilutions and recount to achieve the desired concentration. |
| High Event Rate: Air Bubbles in the Sample Line | Ensure the sample tube is properly seated and that there is sufficient sample volume. Degas buffers if necessary. | Check for visible air bubbles in the tubing. |
| High Event Rate: Incorrect Threshold Settings | Adjust the threshold setting to exclude debris and electronic noise while including the cell population of interest.[8] | Set the threshold based on the forward scatter (FSC) of your unstained cell population. |
High Coefficient of Variation (CV)
The coefficient of variation (CV) is a measure of the spread of a population's fluorescence intensity. A high CV can indicate inconsistent staining or instrument instability, making it difficult to resolve distinct cell populations.
Potential Causes and Solutions
| Potential Cause | Recommended Solution | Experimental Protocol |
| Inconsistent Staining | Ensure thorough mixing of cells and antibodies during incubation. Use a consistent staining volume and cell number. | Follow a standardized and well-documented staining protocol. |
| High Flow Rate | Use a lower flow rate during acquisition to increase the time each cell spends in the laser beam, which can improve signal resolution.[7] | Adjust the flow rate settings on the cytometer software. |
| Instrument Misalignment | Run daily quality control (QC) beads to check for instrument performance and alignment.[3] If alignment is off, contact a qualified service engineer. | Follow the manufacturer's protocol for running QC beads. |
| Cell Clumping | As with low event rates, ensure a single-cell suspension to prevent doublets and clumps from being analyzed. | Protocol 7: Preparation of a Single-Cell Suspension |
| Non-uniform Cell Population | If staining a mixed population, ensure that the staining protocol is optimized for all cell types present. | Gate on specific populations to assess their individual CVs. |
Compensation Issues
In multi-color flow cytometry, spectral overlap from different fluorochromes can spill into detectors intended for other colors. Compensation is a mathematical correction for this spillover. Incorrect compensation can lead to false positive or false negative results.
Potential Causes and Solutions
| Potential Cause | Recommended Solution | Experimental Protocol |
| Incorrect Single-Stain Controls | Prepare a separate single-stain control for each fluorochrome used in the experiment. Ensure the positive signal in the control is bright enough for accurate compensation. | Protocol 8: Preparation of Compensation Controls |
| Mismatched Compensation Controls and Samples | Treat compensation controls with the same fixation and permeabilization reagents as the experimental samples, as these can alter the fluorescence properties of some fluorochromes.[9] | Ensure identical processing steps for controls and samples. |
| Compensation Beads vs. Cells | For some antibodies, compensation beads may not perfectly mimic the fluorescence of stained cells. In such cases, using cells for compensation is recommended.[9] | Compare compensation matrices generated with beads and cells to determine the best approach. |
| Incorrect Gating of Compensation Controls | Ensure that both the positive and negative populations are correctly gated in the compensation setup.[9] | Set gates based on unstained and single-stained populations. |
| Tandem Dye Degradation | Tandem dyes are sensitive to light and fixation. Improper handling can lead to uncoupling of the donor and acceptor fluorochromes, affecting their spectral properties. | Store tandem dye conjugates properly and prepare fresh staining solutions. |
Experimental Protocols
Protocol 1: Antibody Aliquoting and Storage
-
Upon receipt, briefly centrifuge the antibody vial to collect the contents at the bottom.
-
Determine the desired aliquot volume (e.g., 10 µL).
-
Dispense the antibody into low-protein-binding microcentrifuge tubes.
-
Label each aliquot clearly with the antibody name, concentration, and date.
-
Store aliquots at the manufacturer's recommended temperature (-20°C or -80°C). Avoid storing in a frost-free freezer.
-
For use, thaw one aliquot and keep it on ice. Avoid refreezing the remaining portion of the thawed aliquot.
Protocol 2: Antibody Titration
-
Prepare a series of dilutions of the antibody in staining buffer (e.g., 1:25, 1:50, 1:100, 1:200, 1:400).
-
Prepare a known number of cells for each dilution and for an unstained control.
-
Stain the cells with each antibody dilution according to your standard protocol.
-
Acquire the samples on the flow cytometer using consistent settings.
-
Analyze the data and calculate the stain index (SI) for each concentration. The optimal concentration is the one that provides the highest SI.
Protocol 3: Signal Amplification using Biotin-Streptavidin
-
Stain cells with the biotinylated primary antibody according to your standard protocol.
-
Wash the cells twice with staining buffer.
-
Resuspend the cells in a solution containing a fluorescently-labeled streptavidin conjugate.
-
Incubate for 20-30 minutes at 4°C, protected from light.
-
Wash the cells twice with staining buffer.
-
Resuspend in an appropriate buffer for flow cytometry analysis.
Protocol 4: Intracellular Staining
-
Perform surface staining as required, then wash the cells.
-
Resuspend the cells in a fixation buffer (e.g., 4% paraformaldehyde) and incubate for 15-20 minutes at room temperature.
-
Wash the cells twice with staining buffer.
-
Resuspend the cells in a permeabilization buffer (e.g., 0.1% Triton X-100 or saponin-based buffer).
-
Add the intracellular antibody and incubate for 30-60 minutes at room temperature or 4°C.
-
Wash the cells twice with permeabilization buffer.
-
Resuspend in staining buffer for analysis.
Protocol 5: Fc Receptor Blocking
-
Prepare a single-cell suspension.
-
Resuspend the cells in a staining buffer containing an Fc blocking reagent (e.g., purified anti-CD16/32 for mouse cells, or commercial Fc block).
-
Incubate for 10-15 minutes at 4°C.
-
Proceed with antibody staining without washing off the Fc block.
Protocol 6: Viability Staining
-
Prepare a single-cell suspension.
-
Wash the cells with a binding buffer appropriate for the viability dye (e.g., annexin V binding buffer).
-
Resuspend the cells in the binding buffer.
-
Add the viability dye (e.g., Propidium Iodide, 7-AAD, or a fixable viability dye) at the recommended concentration.
-
Incubate for 5-15 minutes at room temperature, protected from light.
-
Do not wash the cells (for non-fixable dyes). Proceed directly to flow cytometry analysis. For fixable viability dyes, wash the cells before proceeding with further staining steps.
Protocol 7: Preparation of a Single-Cell Suspension
-
For adherent cells, gently detach them using a non-enzymatic cell dissociation solution or gentle scraping. Avoid harsh trypsinization.
-
For tissue samples, use mechanical dissociation followed by enzymatic digestion.
-
Pass the cell suspension through a 40-70 µm cell strainer to remove clumps and debris.
-
Wash the cells by centrifuging at a low speed (300-400 x g) for 5 minutes.
-
Resuspend the cell pellet in an appropriate buffer.
Protocol 8: Preparation of Compensation Controls
-
For each fluorochrome in your panel, prepare a separate tube of cells or compensation beads.
-
Add a single antibody-fluorochrome conjugate to the corresponding tube.
-
Include an unstained tube of cells or beads as a negative control.
-
Process the compensation controls in the same manner as your experimental samples (including fixation and permeabilization steps).
-
Acquire the compensation controls on the flow cytometer, ensuring you collect a sufficient number of positive events (at least 5,000).
Troubleshooting Workflows
Caption: Troubleshooting workflow for weak or no fluorescence signal.
Caption: Troubleshooting workflow for high background or non-specific staining.
Caption: Troubleshooting workflow for compensation issues.
References
- 1. Flow Cytometry Troubleshooting | Tips & Tricks | StressMarq | StressMarq Biosciences Inc. [stressmarq.com]
- 2. bosterbio.com [bosterbio.com]
- 3. hycultbiotech.com [hycultbiotech.com]
- 4. Flow Cytometry Troubleshooting Guide - FluoroFinder [fluorofinder.com]
- 5. Flow Cytometry Troubleshooting Guide [sigmaaldrich.com]
- 6. curiox.com [curiox.com]
- 7. Flow Cytometry Troubleshooting Guide | Cell Signaling Technology [cellsignal.com]
- 8. Low event rate - SickKids-UHN Flow Cytometry Facility [lab.research.sickkids.ca]
- 9. How to Fix Flow Cytometry Compensation Errors (and Unmixing Errors) – Bad Data Part 4 | Cytometry and Antibody Technology [voices.uchicago.edu]
Navigating Statistical Analysis with Small Sample Sizes in Preclinical Research
Application Notes and Protocols for Researchers, Scientists, and Drug Development Professionals
Introduction: The Challenge of Small Samples
Furthermore, small datasets make it difficult to verify the assumptions of many common statistical tests, such as the normal distribution of data.[2] Outliers can have a disproportionately large effect on the results, and the sample may not accurately represent the broader population, limiting the generalizability of the findings. These factors increase the risk of spurious results and contribute to the challenge of reproducibility in neuroscience and other fields.[1][2] This document provides guidance on selecting appropriate statistical tests for small sample sizes and offers a detailed protocol for a representative preclinical experiment.
Selecting the Appropriate Statistical Test
The choice of statistical analysis for a small dataset is critical and depends on the experimental design, the type of data, and its distribution.
Parametric vs. Non-parametric Tests
-
Parametric tests , such as the t-test and ANOVA, assume that the data are sampled from a population with a specific distribution, typically a normal distribution. While they are more powerful than non-parametric tests when their assumptions are met, they can be misleading if these assumptions are violated, which is often the case with small samples.[3]
-
Non-parametric tests , also known as distribution-free tests, do not assume a particular data distribution.[3] They are generally more robust for small sample sizes and when the data is not normally distributed. However, they may have less statistical power than parametric tests if the assumptions for the parametric test are actually met.
A Decision-Making Workflow
The following diagram illustrates a workflow for selecting an appropriate statistical test when dealing with small sample sizes.
Caption: A decision-making workflow for selecting a statistical test with a small sample size.
Bayesian Statistics: An Alternative Approach
Bayesian statistics offer a powerful alternative for analyzing small datasets. Instead of relying solely on the data from the current experiment, Bayesian methods incorporate prior knowledge or beliefs about the parameter of interest. This "prior information" is combined with the data to produce a "posterior distribution," which reflects an updated understanding of the parameter. This approach can be particularly advantageous with small samples, as the prior information can help to stabilize the estimates.
Data Presentation for Small Sample Sizes
With small datasets, it is often more informative to present the individual data points rather than relying solely on summary statistics like means and standard errors. Bar graphs can be misleading as they can obscure the underlying distribution of the data. Scatterplots, box plots, or violin plots are often better choices as they provide a clearer picture of the data's distribution, spread, and potential outliers.
Experimental Protocols
The following is a representative protocol for a preclinical in vivo efficacy study in a mouse xenograft model of cancer, a common scenario where small sample sizes are employed.
Protocol: Efficacy of a Novel Kinase Inhibitor in a Human Non-Small Cell Lung Cancer Xenograft Model
1. Animal Model and Husbandry:
-
Species: Immunocompromised mice (e.g., NOD/SCID or similar).
-
Age: 6-8 weeks at the start of the experiment.
-
Housing: Animals are housed in sterile, individually ventilated cages with ad libitum access to food and water. The facility maintains a 12-hour light/dark cycle. All procedures are approved by the Institutional Animal Care and Use Committee (IACUC).
2. Tumor Cell Culture and Implantation:
-
Cell Line: A human non-small cell lung cancer cell line (e.g., A549) is cultured in appropriate media supplemented with fetal bovine serum and antibiotics.
-
Implantation: A suspension of 1 x 10^6 A549 cells in 100 µL of a 1:1 mixture of media and Matrigel is injected subcutaneously into the right flank of each mouse.
3. Tumor Growth Monitoring and Group Allocation:
-
Tumor growth is monitored three times a week using digital calipers. Tumor volume is calculated using the formula: (Length x Width^2) / 2.
-
When tumors reach an average volume of 100-150 mm³, animals are randomized into treatment and control groups (n=5 per group).
4. Drug Formulation and Administration:
-
Test Article: A novel kinase inhibitor is formulated in a vehicle of 5% DMSO, 40% PEG300, 5% Tween 80, and 50% saline.
-
Treatment Group (n=5): The kinase inhibitor is administered via oral gavage once daily at a dose of 20 mg/kg.
-
Vehicle Control Group (n=5): The vehicle solution is administered via oral gavage on the same schedule.
-
Dosing Volume: 10 mL/kg body weight.
5. Endpoint Measurement:
-
Primary Endpoint: Tumor growth inhibition. Tumors are measured three times weekly.
-
Secondary Endpoints:
-
Body weight is recorded three times weekly as a measure of toxicity.
-
At the end of the study (e.g., day 21, or when tumors in the control group reach a predetermined size), tumors are excised and weighed.
-
-
Euthanasia: Animals are euthanized at the end of the study or if they show signs of excessive toxicity (e.g., >20% body weight loss).
6. Statistical Analysis Plan:
-
The distribution of tumor volume data will be assessed.
-
If data are normally distributed, a two-tailed, unpaired Student's t-test will be used to compare the mean final tumor volumes between the treatment and control groups.
-
If data are not normally distributed, a Mann-Whitney U test will be used.
-
A p-value of < 0.05 will be considered statistically significant.
Quantitative Data Summary
The following tables present hypothetical data from the described experiment.
Table 1: Tumor Volume (mm³)
| Animal ID | Day 0 | Day 3 | Day 6 | Day 9 | Day 12 | Day 15 | Day 18 | Day 21 |
| Vehicle Control | ||||||||
| V1 | 125 | 180 | 255 | 360 | 510 | 720 | 1015 | 1430 |
| V2 | 130 | 195 | 290 | 430 | 630 | 910 | 1300 | 1850 |
| V3 | 120 | 170 | 240 | 340 | 480 | 680 | 960 | 1350 |
| V4 | 135 | 205 | 310 | 470 | 700 | 1020 | 1480 | 2100 |
| V5 | 128 | 185 | 270 | 390 | 560 | 800 | 1150 | 1650 |
| Mean | 127.6 | 187.0 | 273.0 | 402.0 | 576.0 | 826.0 | 1181.0 | 1676.0 |
| SD | 5.8 | 13.5 | 27.4 | 53.6 | 85.3 | 138.8 | 214.2 | 308.2 |
| Kinase Inhibitor | ||||||||
| T1 | 122 | 150 | 180 | 210 | 240 | 270 | 300 | 330 |
| T2 | 131 | 165 | 200 | 240 | 280 | 320 | 360 | 400 |
| T3 | 128 | 155 | 190 | 225 | 260 | 295 | 330 | 365 |
| T4 | 135 | 170 | 210 | 255 | 300 | 345 | 390 | 435 |
| T5 | 125 | 152 | 185 | 218 | 250 | 285 | 320 | 350 |
| Mean | 128.2 | 158.4 | 193.0 | 229.6 | 266.0 | 303.0 | 340.0 | 376.0 |
| SD | 5.1 | 8.2 | 12.2 | 18.6 | 25.5 | 29.5 | 34.6 | 40.4 |
Table 2: Final Tumor Weight and Body Weight Change
| Group | Final Tumor Weight (g) | Body Weight Change (%) |
| Vehicle Control | ||
| V1 | 1.45 | +5.2 |
| V2 | 1.88 | +4.8 |
| V3 | 1.38 | +6.1 |
| V4 | 2.12 | +3.9 |
| V5 | 1.67 | +5.5 |
| Mean | 1.70 | +5.1 |
| SD | 0.29 | 0.8 |
| Kinase Inhibitor | ||
| T1 | 0.34 | -2.1 |
| T2 | 0.41 | -1.5 |
| T3 | 0.37 | -2.5 |
| T4 | 0.44 | -1.8 |
| T5 | 0.36 | -2.3 |
| Mean | 0.38 | -2.0 |
| SD | 0.04 | 0.4 |
Signaling Pathway Visualization
The hypothetical kinase inhibitor in this protocol could be targeting a pathway crucial for cancer cell proliferation and survival, such as the PI3K/AKT/mTOR pathway.
Caption: A simplified diagram of the PI3K/AKT/mTOR signaling pathway, a common target in cancer therapy.
References
Application Notes and Protocols for Adapting a Scientific Protocol for a Different Species
Audience: Researchers, scientists, and drug development professionals.
Introduction
Adapting an experimental protocol from one species to another is a common necessity in biomedical research and drug development. However, a simple direct translation of parameters is rarely effective or ethical. Anatomical, physiological, and metabolic differences between species can drastically alter experimental outcomes, leading to invalid data and unnecessary animal use.[1][2] This document provides a comprehensive guide for systematically and successfully adapting protocols for a different species, ensuring scientific validity, reproducibility, and adherence to the highest standards of animal welfare.
Foundational Principles of Cross-Species Adaptation
Successful protocol adaptation hinges on understanding the fundamental biological differences between species. These differences influence how an animal will respond to a drug, substance, or experimental procedure.
-
Physiological & Anatomical Variation: Significant variations exist in organ systems, body size, and digestive processes (e.g., ruminant vs. non-ruminant).[1] These differences can affect drug absorption, distribution, and overall response.[1][2]
-
Metabolic Rate: An animal's metabolic rate, which is related to its body size and surface area, dictates how quickly it processes drugs and other compounds. As body size increases, the metabolic rate generally slows down.[3] This principle is the cornerstone of allometric scaling for dose calculation.
-
Pharmacokinetics (PK) & Pharmacodynamics (PD): PK describes what the body does to a drug (absorption, distribution, metabolism, excretion), while PD describes what the drug does to the body.[1] Both PK and PD can vary significantly between species due to differences in metabolic enzymes, such as cytochrome P450s, and receptor sensitivities.[1][2][4]
Core Protocol Adaptations
Drug Dosage Calculation: Allometric Scaling
Allometric scaling is an empirical method used to extrapolate drug doses between species based on the principle that many physiological processes scale with body size.[3][5] It is more accurate than simple weight-based (mg/kg) scaling because it accounts for differences in metabolic rate by normalizing the dose to body surface area (BSA).[6]
The Human Equivalent Dose (HED) or Animal Equivalent Dose (AED) can be calculated using a conversion factor known as Km, which is derived by dividing the average body weight (kg) by the BSA (m2) for a species.[5]
Formula for Dose Conversion:
Dose in Species 2 (mg/kg) = Dose in Species 1 (mg/kg) * (K_m for Species 1 / K_m for Species 2)
Table 1: Body Surface Area and Km Factors for Dose Conversion
| Species | Body Weight (kg) | Body Surface Area (m²) | Km Factor | Km Ratio (to Human) |
| Human | 60 | 1.62 | 37 | 1.0 |
| Mouse | 0.02 | 0.0066 | 3 | 12.3 |
| Rat | 0.15 | 0.025 | 6 | 6.2 |
| Hamster | 0.08 | 0.016 | 5 | 7.4 |
| Guinea Pig | 0.4 | 0.05 | 8 | 4.6 |
| Rabbit | 1.8 | 0.15 | 12 | 3.1 |
| Dog | 10 | 0.5 | 20 | 1.9 |
| Monkey | 3 | 0.25 | 12 | 3.1 |
Data sourced from FDA guidance and related publications.[5][6]
Experimental Protocol 1: Calculating an Equivalent Dose for a New Species
-
Identify the Known Dose: Record the effective or No Observed Adverse Effect Level (NOAEL) dose (in mg/kg) from the original species ("Species 1").
-
Determine Km Factors: Using Table 1, find the Km factor for Species 1 and the target species ("Species 2").
-
Calculate the Km Ratio: Divide the Km of Species 1 by the Km of Species 2.
-
Calculate the New Dose: Multiply the known dose (mg/kg) by the calculated Km ratio to get the estimated starting dose for Species 2.
-
Example: To convert a 50 mg/kg dose from a rat to a human equivalent dose (HED):
-
Rat Km = 6; Human Km = 37.
-
HED (mg/kg) = 50 mg/kg * (6 / 37) ≈ 8.1 mg/kg.[6]
-
-
-
Conduct Pilot Studies: The calculated dose is an estimate. It is critical to conduct pilot studies with a small number of animals, starting with the calculated dose and adjusting as necessary based on observed effects and tolerability.
Anesthesia and Analgesia
Anesthetic protocols must be carefully adapted, as sensitivity to anesthetic and analgesic agents varies widely among species.[7] A protocol that is safe for one species may be ineffective or lethal in another.
-
Agent Selection: The choice of inhalant (e.g., isoflurane, sevoflurane) or injectable anesthetics depends on the species, the nature and duration of the procedure, and available equipment.[8][9]
-
Monitoring: Regardless of the species, continuous monitoring of anesthetic depth is crucial. This includes assessing reflexes, respiratory rate, and body temperature.[8][10] Rodents are particularly susceptible to hypothermia during anesthesia and require external heat support.[10]
-
Analgesia: A multi-modal approach to pain management, combining different classes of analgesics, is recommended to ensure animal welfare.[9]
Table 2: General Anesthetic Dosage Guidelines for Common Laboratory Species
| Species | Anesthetic Agent | Induction Dose | Maintenance Dose | Notes |
| Mouse | Isoflurane | 3-5% | 1-2.5% | High metabolic rate requires careful monitoring. |
| Ketamine/Xylazine | 80-120 mg/kg / 5-10 mg/kg (IP) | N/A | Can cause significant respiratory depression. | |
| Rat | Isoflurane | 4-5% | 1.5-3% | Jugular sampling is often facilitated by anesthesia.[11] |
| Ketamine/Xylazine | 40-80 mg/kg / 5-10 mg/kg (IP) | N/A | Longer duration of action than in mice. | |
| Rabbit | Isoflurane | 5% | 2-3.5% | Prone to breath-holding; pre-medication is often required. |
| Ketamine/Xylazine | 35-50 mg/kg / 5-10 mg/kg (IM) | N/A | Use with caution due to variable response. | |
| Pig | Sevoflurane | 4-6% | 2-4% | Susceptible to malignant hyperthermia with some inhalants.[7] |
| Telazol/Ketamine/Xylazine | TKX Cocktail (IM) | N/A | Common combination for induction. |
Note: These are general guidelines. Dosages must be determined by a veterinarian and tailored to the individual animal's health status and the specific procedure.
Experimental Protocol 2: General Anesthesia Procedure Adaptation
-
Veterinary Consultation: Consult with a laboratory animal veterinarian to select the most appropriate anesthetic and analgesic agents and dosages for the target species and procedure.
-
Pre-Anesthetic Preparation: Fast the animal according to species-specific guidelines (e.g., longer for dogs, not required for rodents). Administer pre-emptive analgesics as prescribed.
-
Induction: Induce anesthesia in a properly ventilated area. For inhalant agents, use an induction chamber.[8] For injectable agents, use the correct route of administration (e.g., Intraperitoneal - IP, Intramuscular - IM).
-
Maintenance & Monitoring:
-
Move the animal to a nose cone for maintenance with inhalant anesthesia.
-
Apply ophthalmic ointment to prevent corneal drying for any procedure lasting longer than 5 minutes.[10]
-
Place the animal on a heating pad to maintain normothermia.[10]
-
Monitor vital signs and anesthetic depth every 15 minutes.[10] Adjust the anesthetic concentration as needed.
-
-
Recovery:
-
Discontinue the anesthetic.
-
Continue to monitor the animal in a warm, clean environment until it is fully ambulatory.
-
Administer post-operative analgesics as required by the protocol.
-
Blood Sampling
The appropriate technique, volume, and frequency for blood collection are highly species-dependent.[12] Exceeding recommended volumes can lead to hypovolemic shock and skewed experimental data.
-
Site Selection: The choice of blood collection site (e.g., saphenous vein, jugular vein, tail vein, cardiac puncture) depends on the species' anatomy, the volume of blood required, and whether the procedure is terminal or survival.[13][14]
-
Volume Limits: For survival studies, a maximum of 10% of the total circulating blood volume can be removed on a single occasion, with a recovery period of 3-4 weeks.[13] For repeated sampling, a maximum of 1.0% of the total blood volume can be removed every 24 hours.[13]
Table 3: Recommended Blood Collection Sites and Maximum Volumes
| Species | Total Blood Volume (approx. % of Body Weight) | Max. Single Bleed (10% of Total Volume) | Max. for Repeat Sampling (1% of Total Volume) | Common Survival Sampling Sites | Terminal Procedure Sites |
| Mouse (25g) | 7-8% | ~0.2 mL | ~0.02 mL | Saphenous, Facial Vein, Tail Vein | Cardiac Puncture, Vena Cava |
| Rat (300g) | 6-7% | ~2.0 mL | ~0.2 mL | Saphenous, Jugular, Tail Vein | Cardiac Puncture, Vena Cava |
| Rabbit (4kg) | 5.5-8% | ~25 mL | ~2.5 mL | Marginal Ear Vein/Artery, Saphenous | Cardiac Puncture |
| Dog (10kg) | 7-9% | ~80 mL | ~8.0 mL | Cephalic, Saphenous, Jugular | Cardiac Puncture |
| Pig (25kg) | 6-7% | ~160 mL | ~16.0 mL | Auricular (Ear) Vein, Jugular | Cardiac Puncture, Vena Cava |
Data compiled from multiple animal care and use guidelines.[11][12][13][15]
Experimental Protocol 3: Selecting a Blood Collection Technique
-
Determine Experimental Needs: Define the required blood volume, sampling frequency (single vs. serial), and sample type (e.g., arterial vs. venous).[12]
-
Consult Species Guidelines: Refer to Table 3 and institutional guidelines to identify appropriate sampling sites and volume limits for the target species.
-
Select Least Invasive Method: Choose the least invasive, refined method possible that meets the scientific objectives. For example, use a saphenous vein collection for a small volume instead of a more stressful jugular puncture.[12][13]
-
Anesthesia/Restraint: Determine if the procedure requires anesthesia or manual restraint. Many rodent procedures can be performed on conscious animals with proper handling, but anesthesia can reduce stress and improve safety for both the animal and the handler.[11][13]
-
Perform Procedure: Use a new, sterile needle for each animal.[15] Apply gentle pressure to the site after collection to ensure hemostasis.
-
Monitor Animal: Observe the animal post-procedure for any signs of distress, bleeding, or injury.
Visualizing the Adaptation Process
Diagrams can clarify complex workflows and decision-making processes involved in protocol adaptation.
Caption: Workflow for adapting an experimental protocol for a new species.
Caption: Decision tree for selecting a blood collection method.
Ethical and Regulatory Considerations
All research involving animals must be ethically justified and conducted in compliance with federal regulations and institutional policies.
-
The 3Rs: This is a guiding principle for ethical animal research.
-
Replacement: Using non-animal methods (e.g., in vitro assays, computer modeling) whenever possible.[16]
-
Reduction: Using the minimum number of animals necessary to obtain statistically valid results.[16]
-
Refinement: Modifying procedures to minimize animal pain, suffering, and distress.[16] Adapting a protocol correctly is a form of refinement.
-
-
Institutional Animal Care and Use Committee (IACUC): The IACUC is responsible for reviewing and approving all activities involving vertebrate animals.[17][18][19] Researchers must submit a detailed protocol that justifies the choice of species, the number of animals, and all experimental procedures.[20][21] Any deviation from an approved protocol requires a formal amendment.
Conclusion
Adapting a protocol for a new species is a rigorous scientific process that requires careful planning, consultation, and attention to detail. By thoroughly researching species-specific differences, applying principles like allometric scaling, and prioritizing animal welfare through refined procedures, researchers can generate valid, reproducible data while upholding their ethical responsibilities. The initial investment in protocol optimization and pilot studies is essential for the long-term success and integrity of the research.
References
- 1. Species differences in pharmacokinetics and pharmacodynamics - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. How can species differences affect DMPK outcomes? [synapse.patsnap.com]
- 3. allucent.com [allucent.com]
- 4. research.rug.nl [research.rug.nl]
- 5. Conversion between animals and human [targetmol.com]
- 6. A simple practice guide for dose conversion between animals and human - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Impact of different anesthetic protocols during anesthesia for the establishment of a porcine model of acute kidney injury - PMC [pmc.ncbi.nlm.nih.gov]
- 8. kentscientific.com [kentscientific.com]
- 9. Veterinary Recommendations for Anesthesia and Analgesia [research.wayne.edu]
- 10. Anesthesia (Guideline) | Vertebrate Animal Research - Office of the Vice President for Research | The University of Iowa [animal.research.uiowa.edu]
- 11. Guidelines for Blood Collection in Laboratory Animals | UK Research [research.uky.edu]
- 12. Blood sampling | NC3Rs [nc3rs.org.uk]
- 13. Blood sample collection in small laboratory animals - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Animal Blood Testing: Blood Collection Methods | Sample Types [en.seamaty.com]
- 15. acuc.berkeley.edu [acuc.berkeley.edu]
- 16. Ethical Considerations in Clinical Trials: Ethical Dilemmas in Patient Consent and Animal Testing [ijraset.com]
- 17. IACUC Policies and Guidelines - Office of Research [research.ucdavis.edu]
- 18. IACUC Protocol Requirements – Office of Animal Welfare [sites.uw.edu]
- 19. Protocol & Amendment Review | Research | WashU [research.washu.edu]
- 20. IACUC Protocol Application Guidance – UTA Faculty & Staff Resources [resources.uta.edu]
- 21. academic.oup.com [academic.oup.com]
Troubleshooting & Optimization
Technical Support Center: Troubleshooting In Vitro Protein Expression
Welcome to the technical support center for in vitro protein expression. This resource is designed for researchers, scientists, and drug development professionals to troubleshoot common issues encountered during in vitro transcription and translation experiments.
Frequently Asked Questions (FAQs)
Q1: I am not seeing any protein expression in my in vitro translation reaction. What are the common causes?
A1: The complete absence of protein expression can be attributed to several factors, broadly categorized into issues with the DNA template, the transcription process, or the translation process.
-
DNA Template Issues:
-
Sequence Errors: Ensure your DNA sequence is correct and the gene of interest is in-frame with any tags.[1][2] It is highly recommended to sequence-verify your plasmid construct before starting expression studies.[1]
-
Contaminants: DNA preparations can contain inhibitors such as ethanol, salts (e.g., sodium, ammonium acetate), or detergents (e.g., SDS) that interfere with transcription and translation machinery.[2][3] Re-purifying the DNA template is often a good first step.[2]
-
Incorrect Linearization: If using a linearized template, ensure complete and correct digestion with the appropriate restriction enzyme.[3][4]
-
Plasmid Integrity: For plasmid templates, ensure the preparation is of high quality and free from degradation.[2]
-
-
Transcription Problems:
-
RNase Contamination: RNases can degrade your newly synthesized mRNA, preventing translation. Always use nuclease-free water, tips, and tubes, and consider adding an RNase inhibitor to your reactions.[2][3][5]
-
Inactive RNA Polymerase: Ensure the RNA polymerase (e.g., T7, SP6) is active and has been stored correctly.[4]
-
Missing Components: Double-check that all necessary components for the transcription reaction, such as NTPs and the correct buffer, have been added.
-
-
Translation Problems:
-
Degraded mRNA: The synthesized mRNA might be unstable. Ensure proper handling and storage of the mRNA. The presence of a 5' cap and a 3' poly(A) tail can significantly enhance mRNA stability and translation efficiency in eukaryotic systems.[6]
-
Suboptimal Reaction Conditions: The temperature and incubation time of the translation reaction are critical.[7][8] Lowering the temperature can sometimes improve protein folding and yield.[9][10]
-
Depleted Reaction Components: Essential components like amino acids and energy sources (ATP, GTP) can be depleted during the reaction, especially in prolonged incubations.[7][11]
-
Q2: My protein expression is very low. How can I improve the yield?
A2: Low protein yield can be caused by many of the same factors as no expression, but can also be due to suboptimal conditions or inherent properties of the protein.
-
Optimize Vector Design:
-
Promoter Strength: Use a strong promoter appropriate for your in vitro system (e.g., T7 promoter).[12][13]
-
Codon Usage: The presence of codons that are rare for the expression system can slow down or terminate translation.[1][13][14] Consider codon optimization of your gene sequence.[10]
-
Fusion Tags: Adding a fusion tag (e.g., GST, MBP) can sometimes enhance the solubility and expression of the target protein.[15]
-
-
Optimize Reaction Conditions:
-
Temperature: Lowering the incubation temperature (e.g., from 37°C to 20-30°C) can improve protein solubility and yield.[7][8][9][14]
-
Inducer Concentration (for coupled systems): If using a system that requires an inducer like IPTG, optimizing its concentration can be crucial.[8][14]
-
Component Replenishment: For longer reactions, adding fresh amino acids and energy sources can boost protein synthesis.[7]
-
-
Protein-Specific Issues:
-
Toxicity: The expressed protein may be toxic to the components of the in vitro system.[14] Using a system with tighter regulation or a lower expression temperature can help.[14]
-
Improper Folding: The protein may be misfolding and aggregating.[9] Adding chaperones or reducing the reaction temperature can assist in proper folding.[10]
-
Q3: My protein is insoluble and forming aggregates. What can I do?
A3: Protein insolubility is a common issue, often leading to the formation of non-functional aggregates.
-
Lower the Temperature: Reducing the reaction temperature is a primary strategy to slow down protein synthesis, allowing more time for proper folding.[8][9][14]
-
Add Solubilizing Agents: Including mild detergents (e.g., Triton X-100) or other additives like glycerol in the reaction buffer can help maintain protein solubility.[9]
-
Fusion Tags: N-terminal fusion tags like GST or MBP are known to enhance the solubility of their fusion partners.[15]
-
Co-expression of Chaperones: Adding molecular chaperones to the reaction can assist in the correct folding of the target protein.[10]
Troubleshooting Guides
Table 1: Troubleshooting No or Low Protein Expression
| Observation | Possible Cause | Recommended Solution |
| No protein detected | DNA template sequence error (frameshift, premature stop codon).[1][14] | Sequence-verify the plasmid construct.[1] |
| DNA template contamination (ethanol, salts, SDS).[2][3] | Re-purify the DNA template using a suitable kit.[2] | |
| RNase contamination.[2][3][5] | Use nuclease-free reagents and consumables. Add an RNase inhibitor.[2] | |
| Inactive RNA polymerase or translation extract.[4] | Use a positive control template to verify the activity of the system components. | |
| Low protein yield | Suboptimal DNA template concentration.[2] | Titrate the amount of DNA template used in the reaction. |
| Rare codon usage in the gene of interest.[1][13][14] | Perform codon optimization of the gene sequence.[10] | |
| Depletion of amino acids or energy source.[7][11] | Add a fresh mixture of amino acids and energy sources during a long incubation.[7] | |
| Suboptimal reaction temperature.[7][8][9] | Optimize the incubation temperature (try a range from 20°C to 37°C).[10] | |
| Protein is insoluble | Protein misfolding and aggregation.[9] | Lower the reaction temperature.[8][9][14] Add molecular chaperones.[10] |
| Lack of post-translational modifications.[9] | Use a eukaryotic-based in vitro system (e.g., rabbit reticulocyte lysate, wheat germ extract) if modifications are required.[10] | |
| Incorrect disulfide bond formation. | Add reducing agents like DTT to the buffer for cytoplasmic proteins or use a system that promotes disulfide bond formation for secreted/extracellular proteins. |
Experimental Protocols
Protocol 1: DNA Template Quality Check
-
Quantification and Purity:
-
Measure the concentration of your DNA template using a spectrophotometer.
-
Assess the purity by checking the A260/A280 ratio (should be ~1.8) and the A260/A230 ratio (should be >2.0).[2]
-
-
Agarose Gel Electrophoresis:
-
Run an aliquot of your plasmid DNA on an agarose gel to verify its integrity and correct size.[2]
-
For linearized templates, confirm complete digestion by comparing it to the undigested plasmid.
-
Protocol 2: In Vitro Transcription/Translation Reaction Setup
This is a general protocol and should be adapted based on the specific kit manufacturer's instructions.
-
Thaw Components: Thaw all reaction components on ice.
-
Reaction Assembly: In a nuclease-free microcentrifuge tube, assemble the reaction on ice in the following order:
-
Nuclease-free water
-
Reaction buffer
-
Amino acid mixture
-
RNA polymerase
-
RNase inhibitor
-
DNA template (use optimized concentration)
-
Cell-free extract
-
-
Incubation: Mix the reaction gently and incubate at the recommended temperature (e.g., 30°C) for the specified time (e.g., 1-4 hours).
-
Analysis: Analyze the reaction products by SDS-PAGE and Coomassie staining or Western blotting.
Visual Troubleshooting Guides
Caption: Troubleshooting workflow for no protein expression.
Caption: Troubleshooting workflow for low protein yield.
References
- 1. goldbio.com [goldbio.com]
- 2. neb.com [neb.com]
- 3. promegaconnections.com [promegaconnections.com]
- 4. go.zageno.com [go.zageno.com]
- 5. bitesizebio.com [bitesizebio.com]
- 6. A highly optimized human in vitro translation system - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Troubleshooting coupled in vitro transcription–translation system derived from Escherichia coli cells: synthesis of high-yield fully active proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 8. youtube.com [youtube.com]
- 9. Cell-Free Expression Support—Troubleshooting | Thermo Fisher Scientific - TW [thermofisher.com]
- 10. bitesizebio.com [bitesizebio.com]
- 11. The Basics: In Vitro Translation | Thermo Fisher Scientific - FR [thermofisher.com]
- 12. Step-by-Step Protocol for Optimizing Recombinant Protein Expression [synapse.patsnap.com]
- 13. Strategies to Optimize Protein Expression in E. coli - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Bacteria Expression Support—Troubleshooting | Thermo Fisher Scientific - HK [thermofisher.com]
- 15. biologicscorp.com [biologicscorp.com]
Technical Support Center: PCR Amplification Troubleshooting
Welcome to the technical support center for PCR amplification. This guide is designed for researchers, scientists, and drug development professionals to troubleshoot and resolve common issues encountered during Polymerase Chain Reaction (PCR) experiments.
Frequently Asked Questions (FAQs)
Q1: Why am I not seeing any PCR product on my gel (No Amplification)?
There are several potential reasons for a complete PCR failure. It is recommended to systematically check each component and step of your protocol.
Possible Causes & Solutions:
-
Missing Reagent: It's a common mistake to omit a crucial component from the reaction mix.[1] Always use a checklist to ensure all reagents (polymerase, buffer, dNTPs, primers, template DNA, and MgCl₂) are added.[1][2] A positive control with a previously validated template and primer set can help confirm that the reagents are functional.[3]
-
Poor Template Quality or Quantity: The integrity and purity of your DNA template are critical.[4] Contaminants such as phenol, EDTA, and residual salts can inhibit the DNA polymerase.[4] Assess your DNA quality using gel electrophoresis or spectrophotometry (A260/280 ratio).[2] If the quality is poor, re-purify your template.[4] The amount of template is also crucial; too little may not be detectable, while too much can lead to inhibition or non-specific amplification.[5]
-
Suboptimal Primer Design: Poorly designed primers are a frequent cause of PCR failure.[6] They may not be specific to the target sequence, could have inappropriate melting temperatures (Tm), or form secondary structures like hairpins and primer-dimers.[6][7]
-
Incorrect Annealing Temperature: The annealing temperature is critical for primer binding. If it's too high, primers won't bind efficiently to the template. If it's too low, it can lead to non-specific binding.[6] The optimal annealing temperature is typically 5°C below the lowest primer's Tm.[8]
-
Issues with Thermal Cycling Parameters: Incorrect denaturation, annealing, or extension times and temperatures can all lead to amplification failure.[9] Ensure your thermal cycler is properly programmed and calibrated.[2]
-
Degraded Reagents: Repeated freeze-thaw cycles can degrade essential reagents like the DNA polymerase and dNTPs.[2] It is advisable to aliquot reagents into smaller volumes.[2]
Q2: Why do I have multiple bands or smeared bands on my gel?
The presence of non-specific bands or a smear indicates that your PCR conditions are not optimal, leading to the amplification of unintended products.
Possible Causes & Solutions:
-
Annealing Temperature is Too Low: A low annealing temperature allows primers to bind to non-target sites on the template DNA, resulting in non-specific products.[7] Gradually increase the annealing temperature in 2°C increments to enhance specificity.
-
Excessive Template or Primer Concentration: Too much template DNA or primers can increase the likelihood of non-specific binding and primer-dimer formation.[8] Optimize the concentrations of these components.
-
Suboptimal Magnesium Concentration: Magnesium concentration affects the stringency of primer annealing. While essential for polymerase activity, excessive Mg²⁺ can stabilize non-specific primer-template interactions.[6]
-
Contamination: Contamination with other DNA templates can lead to the amplification of unexpected products.[7] Always use proper aseptic techniques, dedicated PCR workstations, and negative controls (no template) to check for contamination.
-
Too Many Cycles: An excessive number of PCR cycles can lead to the accumulation of non-specific products and smears.[3] Try reducing the number of cycles.
Q3: Why is my PCR yield very low?
Low amplification yield can be caused by several factors that reduce the efficiency of the reaction.
Possible Causes & Solutions:
-
Suboptimal Reagent Concentrations: The concentration of components like MgCl₂, dNTPs, and DNA polymerase might not be optimal.[7] Titrating these components can help improve yield.
-
Presence of PCR Inhibitors: Inhibitors carried over from the DNA extraction process can reduce polymerase activity.[4] Diluting the template DNA can sometimes mitigate the effect of inhibitors.[3]
-
Incorrect Thermal Cycling Times: Insufficient denaturation or extension times can lead to incomplete strand separation and synthesis, respectively, resulting in lower yields.[9] Ensure the extension time is adequate for the length of your target amplicon (a general rule is 1 minute per kb).[10]
-
Degraded Template or Primers: The quality of your template DNA and primers is crucial. Degraded templates or primers will lead to inefficient amplification.[4]
Troubleshooting Guides
Guide 1: No PCR Product
This guide provides a systematic workflow to troubleshoot complete PCR amplification failure.
Caption: Troubleshooting workflow for the absence of a PCR product.
Guide 2: Non-Specific Amplification (Multiple Bands/Smears)
This guide outlines steps to take when your PCR results in non-specific products.
Caption: Troubleshooting workflow for non-specific PCR amplification.
Data Presentation
Table 1: Recommended Concentration Ranges for PCR Components
| Component | Typical Final Concentration | Optimization Range |
| Template DNA | 1 ng - 1 µg (genomic) 1 pg - 10 ng (plasmid) | Titrate within the recommended range.[8] |
| Primers | 0.1 - 0.5 µM each | 0.05 - 1 µM each.[2] |
| dNTPs | 200 µM each | 20 - 200 µM each.[11] |
| Taq DNA Polymerase | 1.25 units / 50 µL reaction | Varies by manufacturer; consult datasheet. |
| MgCl₂ | 1.5 - 2.0 mM | 0.5 - 5.0 mM.[11] |
Table 2: Typical Thermal Cycling Parameters
| Step | Temperature | Duration | Cycles |
| Initial Denaturation | 95°C | 2 minutes | 1 |
| Denaturation | 95°C | 15 - 30 seconds | 25 - 35 |
| Annealing | 50 - 60°C (5°C below lowest Tm) | 15 - 30 seconds | 25 - 35 |
| Extension | 72°C | 1 minute per kb of amplicon length | 25 - 35 |
| Final Extension | 72°C | 5 - 10 minutes | 1 |
| Hold | 4°C | Indefinite | 1 |
Experimental Protocols
Protocol 1: Temperature Gradient PCR for Annealing Temperature Optimization
This protocol is used to determine the optimal annealing temperature for a specific primer set.
Methodology:
-
Prepare a Master Mix: Prepare a PCR master mix containing all reagents except the template DNA, sufficient for the number of reactions in the gradient (e.g., 8 or 12 reactions).
-
Aliquot Master Mix: Aliquot the master mix into separate PCR tubes.
-
Add Template DNA: Add the template DNA to each tube.
-
Set up the Thermal Cycler: Program the thermal cycler with a temperature gradient for the annealing step. The gradient should span a range of temperatures, for example, from 50°C to 65°C. The cycler will set a different annealing temperature for each row or column of the block.
-
Run the PCR: Place the PCR tubes in the thermal cycler and start the program.
-
Analyze Results: Analyze the PCR products from each temperature on an agarose gel. The optimal annealing temperature will be the one that gives a strong, specific band with minimal or no non-specific products.
Protocol 2: Primer Titration
This protocol helps to determine the optimal concentration of forward and reverse primers.
Methodology:
-
Set up a Matrix: Plan a series of reactions with varying concentrations of the forward and reverse primers. For example, you can test concentrations of 0.1 µM, 0.2 µM, 0.5 µM, and 1.0 µM for each primer in different combinations.
-
Prepare Reactions: For each combination of primer concentrations, prepare a separate PCR reaction. It is efficient to create smaller master mixes for each primer concentration.
-
Run the PCR: Run all the reactions using the previously optimized annealing temperature and other cycling conditions.
-
Analyze Results: Run the products on an agarose gel. The optimal primer concentration is the lowest concentration that produces a strong, specific band without primer-dimer formation.[7]
References
- 1. No PCR Product! What Now? - Nordic Biosite [nordicbiosite.com]
- 2. PCR Basic Troubleshooting Guide [creative-biogene.com]
- 3. Troubleshooting your PCR [takarabio.com]
- 4. PCRに関するトラブルシューティングガイド | Thermo Fisher Scientific - JP [thermofisher.com]
- 5. What should the starting template DNA quality and quantity be for PCR? [qiagen.com]
- 6. Why Did My PCR Fail? 10 Common Problems and Fixes [synapse.patsnap.com]
- 7. mybiosource.com [mybiosource.com]
- 8. neb.com [neb.com]
- 9. Thermal Cycling Optimization | AAT Bioquest [aatbio.com]
- 10. Optimizing your PCR [takarabio.com]
- 11. Polymerase Chain Reaction: Basic Protocol Plus Troubleshooting and Optimization Strategies - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Troubleshooting Cell Culture Contamination
This technical support center provides researchers, scientists, and drug development professionals with comprehensive troubleshooting guides and frequently asked questions (FAQs) to address common cell culture contamination issues.
Frequently Asked Questions (FAQs)
Q1: What are the most common types of contaminants in cell culture?
The primary types of biological contaminants in cell culture are bacteria, yeast, molds, mycoplasma, and viruses.[1][2] Cross-contamination with other cell lines is also a significant issue.[1] These contaminants can arise from various sources, including laboratory personnel, unfiltered air, contaminated reagents and media, and non-sterile equipment.[3][4][5]
Q2: How can I visually identify different types of contamination?
Identifying contamination early is crucial to prevent widespread issues.[4] Here are some common visual cues:
-
Bacteria: A sudden drop in the medium's pH (turning yellow), cloudiness (turbidity), and sometimes a thin film on the surface are characteristic of bacterial contamination.[1][2]
-
Yeast: The culture medium may become turbid, and the pH can increase as the contamination becomes heavy.[1] Microscopically, yeast appears as individual ovoid or spherical particles, which may be budding.[1][6]
-
Mold: Mold contamination is often visible as filamentous structures or fuzzy clumps floating in the medium.[7] Under a microscope, thin, wisp-like filaments (mycelia) and denser clumps of spores can be seen.[1]
-
Mycoplasma: Mycoplasma contamination is particularly insidious as it often does not cause visible changes like turbidity or a shift in pH.[8] The only signs may be subtle changes in cell growth rates or morphology.[9]
Q3: Mycoplasma is a major concern. How can I reliably detect it?
Since mycoplasma is not typically visible, specific detection methods are necessary.[8] The most common and reliable methods include:
-
PCR (Polymerase Chain Reaction): This is a highly sensitive and rapid method that amplifies mycoplasma DNA for detection.[10]
-
DNA Staining (e.g., DAPI or Hoechst): This method uses fluorescent dyes that bind to DNA. When viewed under a fluorescence microscope, mycoplasma contamination will appear as small, bright dots outside of the cell nuclei.
-
ELISA (Enzyme-Linked Immunosorbent Assay): This method detects mycoplasma antigens.[5][11]
-
Microbiological Culture: This involves attempting to grow mycoplasma on specialized agar plates, which can result in characteristic "fried egg" colonies. However, this method is slow, taking up to 28 days to confirm a negative result.[12][13]
Q4: What are the immediate steps I should take if I detect contamination?
Upon detecting contamination, prompt action is necessary to prevent it from spreading.[4][14]
-
Isolate the Contaminated Culture: Immediately separate the contaminated flask(s) from other cultures.
-
Discard Contaminated Materials: The most prudent action is to discard the contaminated culture(s) and any media or reagents used with them.[4][15]
-
Thorough Decontamination: Decontaminate the biosafety cabinet, incubator, and any other equipment that may have come into contact with the contaminated culture using an appropriate disinfectant like 70% ethanol, followed by a more robust disinfectant if necessary.[14][15][16]
-
Investigate the Source: Try to identify the source of the contamination to prevent future occurrences.[4] This could involve checking your aseptic technique, testing reagents, and examining equipment.
Q5: Can I salvage a contaminated cell line?
While discarding the contaminated culture is the recommended course of action, if the cell line is irreplaceable, treatment can be attempted.[15] However, this is often a difficult and not always successful process. Specific antibiotics and antimycotics can be used for bacterial and fungal contamination, respectively.[3][6] For mycoplasma, there are commercially available elimination kits.[17] It's important to note that these treatments can be harsh on the cells and may alter their characteristics.[18]
Contaminant Identification Guide
The following table summarizes the key characteristics of common cell culture contaminants to aid in their identification.
| Contaminant | Appearance of Medium | pH Change | Microscopic Appearance |
| Bacteria | Turbid/Cloudy[1] | Decrease (Acidic/Yellow)[1] | Small, motile rod-shaped or spherical particles[1][6] |
| Yeast | Turbid in advanced stages[1] | Increases in advanced stages[1] | Small, ovoid or spherical budding particles[1][6] |
| Mold | Visible filamentous growth (mycelia)[1] | Tends to increase[1] | Multicellular, filamentous hyphae, may form clumps of spores[1] |
| Mycoplasma | Generally no change | Generally no change | Not visible with a standard light microscope |
Experimental Protocols
Mycoplasma Detection via PCR
Objective: To detect the presence of mycoplasma DNA in a cell culture sample.
Methodology:
-
Sample Preparation: Collect 1 mL of the cell culture supernatant from a culture that is 70-90% confluent. Centrifuge at 200 x g for 5 minutes to pellet the cells. Transfer the supernatant to a new microcentrifuge tube.
-
DNA Extraction: Extract DNA from the supernatant using a commercial PCR sample preparation kit, following the manufacturer's instructions.
-
PCR Amplification:
-
Prepare a PCR master mix containing a PCR buffer, dNTPs, forward and reverse primers specific for the 16S rRNA gene of mycoplasma, and Taq polymerase.[10]
-
Add the extracted DNA sample to the master mix. Include positive and negative controls.
-
Perform PCR using a thermal cycler with an appropriate amplification program.
-
-
Gel Electrophoresis:
-
Run the PCR products on a 1.5% agarose gel containing a DNA stain (e.g., ethidium bromide or SYBR Safe).
-
Visualize the DNA bands under UV light. The presence of a band of the expected size indicates mycoplasma contamination.
-
Basic Sterility Testing (Direct Inoculation)
Objective: To detect the presence of viable bacteria and fungi in a liquid sample (e.g., cell culture medium, serum).
Methodology:
-
Media Preparation: Use two types of sterile culture media: Fluid Thioglycollate Medium (FTM) for detecting anaerobic and some aerobic bacteria, and Soybean-Casein Digest Medium (SCDM) for fungi and aerobic bacteria.[19]
-
Inoculation:
-
Under aseptic conditions in a biosafety cabinet, directly inoculate a small volume of the test sample into tubes containing FTM and SCDM.[19]
-
The volume of the sample should not exceed 10% of the medium's volume.
-
-
Incubation:
-
Observation:
Troubleshooting Workflows and Diagrams
A high-level workflow for troubleshooting cell culture contamination.
A decision tree to help identify the type of microbial contaminant.
References
- 1. Cell Culture Contamination | Thermo Fisher Scientific - HK [thermofisher.com]
- 2. What are the major types of biological cell culture contamination? | AAT Bioquest [aatbio.com]
- 3. corning.com [corning.com]
- 4. cellculturecompany.com [cellculturecompany.com]
- 5. creative-bioarray.com [creative-bioarray.com]
- 6. asset-downloads.zeiss.com [asset-downloads.zeiss.com]
- 7. azolifesciences.com [azolifesciences.com]
- 8. Mycoplasma Contamination in Cell Culture | Detection & Removal [capricorn-scientific.com]
- 9. How to Deal with Mycoplasma Contamination in Cell Culture [creative-biogene.com]
- 10. Prevention and Detection of Mycoplasma Contamination in Cell Culture - PMC [pmc.ncbi.nlm.nih.gov]
- 11. goldbio.com [goldbio.com]
- 12. rapidmicrobiology.com [rapidmicrobiology.com]
- 13. journals.asm.org [journals.asm.org]
- 14. eppendorf.com [eppendorf.com]
- 15. yeasenbio.com [yeasenbio.com]
- 16. researchgate.net [researchgate.net]
- 17. assaygenie.com [assaygenie.com]
- 18. Mycoplasma contamination of cell cultures | Lonza [bioscience.lonza.com]
- 19. merckmillipore.com [merckmillipore.com]
- 20. rocker.com.tw [rocker.com.tw]
Technical Support Center: Optimizing Antibody Concentration for Immunofluorescence
This guide provides troubleshooting advice and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals optimize antibody concentrations for immunofluorescence (IF) experiments.
Frequently Asked Questions (FAQs)
Q1: Why is optimizing antibody concentration crucial for immunofluorescence?
Optimizing the antibody concentration is critical to achieving a high signal-to-noise ratio, which ensures that the observed fluorescence is specific to the target antigen.[1][2] Too high a concentration can lead to non-specific binding and high background, while too low a concentration will result in a weak or absent signal.[3] Proper titration helps determine the optimal dilution for the brightest signal with the lowest background.[1][4]
Q2: What is a typical starting concentration range for a primary antibody in IF?
For a purified antibody, a common starting concentration is between 1-10 µg/mL.[5][6] If you are using an antiserum, a starting dilution of 1:100 to 1:1000 is generally recommended.[5][6] For antibodies with a concentration of 1 mg/mL, a 1:1000 dilution (resulting in 1 µg/mL) is a good starting point.[4][7] However, it is essential to always consult the manufacturer's datasheet for their specific recommendations.[8]
Q3: How does incubation time and temperature affect antibody binding?
Incubation time and temperature are interdependent variables that influence signal intensity.[1] Longer incubation times, such as overnight at 4°C, often allow for the use of more dilute antibodies, which can enhance specificity and reduce background.[1][9] Shorter incubations at higher temperatures (e.g., 1-2 hours at room temperature or 37°C) may require a higher antibody concentration but can speed up the workflow.[1] It is crucial to titrate your antibody under the exact conditions you plan to use for your experiment.[10][11]
Q4: Should I titrate my secondary antibody as well?
Yes, optimizing the secondary antibody concentration is also important. A high concentration of secondary antibody can be a significant source of background noise.[12][13] A typical starting range for secondary antibodies is 1-10 µg/mL.[4][7] A secondary-only control (omitting the primary antibody) should always be included to check for non-specific binding of the secondary antibody.[12][14]
Troubleshooting Guide
Issue 1: High Background Staining
High background fluorescence can obscure specific signals and make data interpretation difficult.
| Possible Cause | Recommended Solution |
| Primary/Secondary antibody concentration is too high. | Perform a titration experiment to determine the optimal antibody dilution that maximizes the signal-to-noise ratio.[12][13][15] |
| Insufficient blocking. | Increase the blocking incubation time or try a different blocking agent. Using normal serum from the same species as the secondary antibody is often effective.[8][12][14] |
| Inadequate washing. | Increase the number and duration of wash steps between antibody incubations to remove unbound antibodies.[8][12][15] |
| Cross-reactivity of the secondary antibody. | Run a "secondary antibody only" control. If staining is observed, consider using a pre-adsorbed secondary antibody.[8][12] |
| Incubation temperature is too high. | Reduce the incubation temperature. Incubating at 4°C can often reduce non-specific binding.[9][12] |
Issue 2: Weak or No Signal
A faint or absent signal can be due to several factors related to antibody concentration and protocol steps.
| Possible Cause | Recommended Solution |
| Primary antibody concentration is too low. | Increase the concentration of the primary antibody or increase the incubation time.[13][14] A titration experiment is the best way to find the optimal concentration. |
| Incompatible primary and secondary antibodies. | Ensure the secondary antibody is raised against the host species of the primary antibody (e.g., use an anti-rabbit secondary for a primary antibody raised in a rabbit).[13][14] |
| Poor permeabilization (for intracellular targets). | If the target is intracellular, ensure a permeabilization step is included and optimized. Try increasing the detergent concentration or incubation time.[9][13] |
| Loss of antigenicity. | Harsh fixation or permeabilization can damage the epitope. Consider using a milder fixation method or reducing the duration of the fixation step.[9][13] |
| Fluorophore has faded. | Protect fluorescently-labeled antibodies and stained samples from light. Use an anti-fade mounting medium.[8][12] |
Experimental Protocols & Data
Antibody Titration Workflow
The process of determining the optimal antibody concentration involves testing a series of dilutions to find the best balance between specific signal and background noise.
Caption: Workflow for primary antibody concentration optimization.
Detailed Protocol: Primary Antibody Titration
This protocol outlines a method for determining the optimal concentration of a primary antibody for immunofluorescence.
-
Cell/Tissue Preparation : Prepare your samples on coverslips or slides as you would for your actual experiment. This includes fixation, permeabilization (if required), and blocking steps.
-
Prepare Antibody Dilutions : Create a series of 2-fold or 5-fold dilutions of your primary antibody in antibody dilution buffer. It is recommended to test a broad range.[4][10] For example, if the manufacturer suggests a 1:500 dilution, you might test 1:100, 1:250, 1:500, 1:750, and 1:1000.[4][7]
-
Primary Antibody Incubation : Incubate each coverslip with a different antibody dilution. Include a negative control that is incubated with only the antibody dilution buffer (no primary antibody).[7] The incubation time and temperature should be consistent with your planned experimental conditions (e.g., overnight at 4°C or 1 hour at room temperature).[11]
-
Washing : After incubation, wash all coverslips thoroughly (e.g., 3 times for 5 minutes each in PBS) to remove unbound primary antibody.[12]
-
Secondary Antibody Incubation : Incubate all coverslips, including the negative control, with the same, pre-determined optimal concentration of the appropriate fluorophore-conjugated secondary antibody. Protect from light from this point forward.[4]
-
Final Washes and Mounting : Perform a final series of washes to remove unbound secondary antibody. Mount the coverslips onto glass slides using an anti-fade mounting medium.
-
Imaging and Analysis : Acquire images of each sample using identical microscope settings (e.g., exposure time, gain). Compare the specific staining intensity against the background fluorescence to identify the dilution that provides the best signal-to-noise ratio.[1]
Data Presentation: Example Titration Results
The optimal concentration is the one that provides a strong specific signal without a significant increase in background staining.
| Primary Antibody Dilution | Signal Intensity (Target) | Background Intensity (Non-target area) | Signal-to-Noise Ratio (Signal/Background) | Comments |
| 1:100 | ++++ | +++ | Low | Bright signal but very high background. |
| 1:250 | +++ | ++ | Moderate | Good signal, but background is still noticeable. |
| 1:500 | +++ | + | High | Optimal: Strong, specific signal with low background. |
| 1:750 | ++ | + | Moderate | Signal is weaker but background remains low. |
| 1:1000 | + | + | Low | Signal is too weak to be clearly distinguished from background. |
| No Primary Ab | - | + | N/A | Secondary antibody control; shows minimal background. |
Note: The values (+, -, etc.) are illustrative and should be replaced with quantitative fluorescence intensity measurements from your imaging software.
References
- 1. blog.cellsignal.com [blog.cellsignal.com]
- 2. med.virginia.edu [med.virginia.edu]
- 3. abyntek.com [abyntek.com]
- 4. Immunolabeling Using Secondary Antibodies | Thermo Fisher Scientific - HK [thermofisher.com]
- 5. stjohnslabs.com [stjohnslabs.com]
- 6. Tips for Immunofluorescence Microscopy | Rockland [rockland.com]
- 7. sc.edu [sc.edu]
- 8. Immunofluorescence (IF) Troubleshooting Guide | Cell Signaling Technology [cellsignal.com]
- 9. IF Troubleshooting | Proteintech Group [ptglab.com]
- 10. lerner.ccf.org [lerner.ccf.org]
- 11. biotech.gsu.edu [biotech.gsu.edu]
- 12. hycultbiotech.com [hycultbiotech.com]
- 13. Immunofluorescence Troubleshooting Tips [elabscience.com]
- 14. stjohnslabs.com [stjohnslabs.com]
- 15. sinobiological.com [sinobiological.com]
Technical Support Center: Mass Spectrometry Troubleshooting
Welcome to the Mass Spectrometry Technical Support Center. This resource provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals resolve common issues encountered during mass spectrometry experiments, with a focus on solving high background noise.
Frequently Asked Questions (FAQs)
Q1: What are the primary sources of high background noise in my mass spectrometry data?
High background noise in mass spectrometry can originate from several sources, which can be broadly categorized as chemical, electronic, and environmental noise.[1]
-
Chemical Noise: This is the most common source and arises from ions that are not the analyte of interest.[1] Common sources include:
-
Solvents and Reagents: Impurities in solvents, even in high-purity, LC-MS grade ones, can contribute to background noise.[2] Always use fresh, high-purity solvents and reagents.[1][2]
-
LC System Contamination: Over time, contaminants can build up in the LC system, including tubing, injectors, and the column.[2][3]
-
Contamination from Consumables: Plasticizers like phthalates and polymers such as polyethylene glycol (PEG) and polypropylene glycol (PPG) can leach from plastic tubes, pipette tips, and other labware.[2]
-
Sample Matrix: Complex biological samples contain numerous endogenous compounds that can interfere with the signal of your analyte.[1]
-
Air Leaks: Leaks in the LC or MS system can introduce nitrogen, oxygen, and other atmospheric components, resulting in high background.[2]
-
-
Electronic Noise: This is inherent to the detector and electronic components of the mass spectrometer.[1]
-
Environmental Noise: This can include dust particles and volatile organic compounds from the laboratory environment.[1]
Q2: How can I distinguish between chemical and electronic noise?
A simple diagnostic test can help differentiate between chemical and electronic noise. Turn off the spray voltage and any liquid flow to the mass spectrometer. If the noise disappears, it is likely chemical in origin. If the noise persists, it is likely electronic, which may require servicing by a qualified engineer.[1]
Q3: My baseline is consistently high in all my runs, even with blank injections. What should I do?
A consistently high baseline, even in blank injections, strongly suggests contamination of your mobile phase or the LC-MS system itself.[1] A total ion chromatogram (TIC) background level should ideally be less than 200,000 counts on a clean system.[4]
Here’s a systematic approach to troubleshoot this issue:
-
Prepare Fresh Mobile Phase: Discard your current mobile phase and prepare a fresh batch using high-purity, LC-MS grade solvents and additives.[1][2] Sonicate the new mobile phase to remove dissolved gases.[1]
-
Run a Blank Injection: Perform several blank injections (injecting only your mobile phase) to see if the background noise has been reduced to an acceptable level.[1]
-
System Flush: If the high background persists, it is likely that the LC system is contaminated.[5] Perform a system flush with a series of high-purity solvents. A common procedure is to flush with isopropanol, followed by acetonitrile, and then water.[1]
Q4: I am observing repeating peaks in my spectra. What could be the cause?
Repeating peaks with regular mass differences are a classic sign of contamination from polymers.[2]
-
Polyethylene Glycol (PEG): Often appears as a series of peaks with a mass difference of 44 Da.[2]
-
Polypropylene Glycol (PPG): Can also be a source of repeating peaks.[2]
-
Siloxanes: These silicon-based polymers, often found in vacuum grease and some septa, lead to repeating peaks with a mass difference of 74 Da.[2]
To mitigate this, use glassware whenever possible. If plastics are necessary, choose polypropylene tubes and pipette tips that are certified as low-leachable.[2]
Troubleshooting Guides
Systematic Troubleshooting of High Background Noise
This guide provides a logical workflow to identify and eliminate the source of high background noise.
Caption: A step-by-step workflow for troubleshooting high background noise.
Data Presentation
Table 1: Common Contaminants and their m/z Values
This table summarizes common chemical contaminants observed in mass spectrometry and their corresponding mass-to-charge ratios (m/z).
| Contaminant Class | Common Examples | Typical m/z Values | Potential Sources |
| Plasticizers | Phthalates | 149, 279, 391 | Plastic labware (tubes, containers, pipette tips)[1] |
| Polymers | Polyethylene Glycol (PEG) | Series of peaks with 44 Da spacing | Detergents, plastics[2] |
| Polydimethylsiloxane (PDMS/Siloxanes) | Series of peaks with 74 Da spacing | Vacuum grease, septa, parafilm[2] | |
| Solvent Adducts | Sodium Formate Clusters | (HCOONa)n + Na+ | Mobile phase additives |
| Biological | Keratins | Various | Skin, hair, dust[1] |
Experimental Protocols
Protocol 1: LC System Flush ("Steam Clean")
This protocol is a robust cleaning procedure for the LC system to remove accumulated contaminants.[4]
Materials:
-
LC-MS Grade Isopropanol
-
LC-MS Grade Acetonitrile
-
LC-MS Grade Water
Procedure:
-
Disconnect the Column: Remove the analytical column from the system to prevent damage.
-
Solvent Line Preparation: Place all solvent lines into a bottle of fresh isopropanol.
-
System Purge: Purge the pumps to ensure they are filled with isopropanol.
-
High Flow Wash: Set the flow rate to a high level (e.g., 1-2 mL/min) and flush the entire system with isopropanol for at least 30 minutes.
-
Acetonitrile Wash: Replace the isopropanol with acetonitrile and repeat the high-flow wash for 30 minutes.
-
Water Wash: Replace the acetonitrile with water and repeat the high-flow wash for 30 minutes.
-
Overnight "Steam Clean": For a more thorough cleaning, set the LC flow to 0.5 ml/min with 75:25 methanol:water, nebulizer pressure to 60 psi, drying gas to 13 L/min, and drying gas temperature to 350°C overnight.[4]
-
Re-equilibration: Before your next analysis, re-install the column and equilibrate the system with your mobile phase until the baseline is stable.
Protocol 2: General Ion Source Cleaning
Caution: Always follow the specific instructions provided by your instrument manufacturer. This is a general guideline.[6]
Materials:
-
Manufacturer-recommended cleaning solvents (e.g., methanol, acetonitrile, water)
-
Lint-free swabs
-
Sonicator
-
Nylon gloves
Procedure:
-
Venting the System: Follow the manufacturer's procedure to safely vent the mass spectrometer.
-
Source Removal: Carefully remove the ion source components as per the manufacturer's instructions.
-
Disassembly: Disassemble the ion source components (e.g., capillary, skimmer, lenses) in a clean area. Keep track of all parts and their orientation.
-
Cleaning Metal Parts:
-
Sonication: Place the metal parts in a beaker with an appropriate solvent (e.g., methanol) and sonicate for 15-20 minutes.
-
Polishing: For stubborn residues, abrasive powders or cloths may be used, but be cautious not to scratch or damage the surfaces.[6]
-
-
Cleaning Ceramic Insulators: Clean with abrasive methods or bake at high temperatures as recommended by the manufacturer.[6]
-
Drying: Thoroughly dry all cleaned parts in an oven at a low temperature (e.g., 100-150°C) or under a stream of nitrogen.[6]
-
Reassembly: Wearing clean nylon gloves, carefully reassemble the ion source.[6]
-
System Pump Down: Re-install the ion source, and follow the manufacturer's procedure to pump down the system.
-
System Bake-out: Perform a system bake-out as recommended to remove any residual volatile contaminants.
-
Calibration: After the system has reached a stable vacuum, perform a system calibration.
Signaling Pathways and Logical Relationships
The following diagram illustrates the logical relationship between potential sources of contamination and the resulting high background noise in a typical LC-MS system.
Caption: The flow of contaminants from various sources to the mass analyzer.
References
Technical Support Center: Troubleshooting Failed Experimental Controls
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals address issues with failed experimental controls.
General Troubleshooting and FAQs
Q1: What is the first step I should take when an experimental control fails?
When an experimental control fails, the first step is to systematically analyze all elements of the experiment.[1] A thorough review of your protocol and a detailed examination of all reagents and equipment are crucial.[1] It's often beneficial to repeat the experiment with fresh supplies, if the budget allows, and have a colleague double-check your steps for accuracy.[1]
Q2: Can a failed control ever lead to a new discovery?
While most failed controls indicate an issue with the experimental setup, they can occasionally lead to unexpected discoveries.[2][3] If a control consistently produces an unexpected result despite rigorous troubleshooting, it might be worth investigating whether you have stumbled upon a novel biological phenomenon.[2][3]
Q3: How do I know if the issue is with my sample or the assay itself?
Distinguishing between a sample-specific problem and a systemic assay failure is a key troubleshooting step. If the positive control fails but your experimental samples yield results, the issue might be with the positive control reagent itself (e.g., degradation). Conversely, if both the positive control and your samples fail to produce a signal, it's more likely an issue with a common reagent or a step in the experimental procedure.
Assay-Specific Troubleshooting Guides
Polymerase Chain Reaction (PCR)
Q4: My negative control in a PCR experiment shows a band. What should I do?
A band in the negative control (No Template Control - NTC) of a PCR experiment is a strong indicator of contamination.[4] You should immediately stop and discard the results from that run, as they are not reliable.[5] The next step is to decontaminate your workspace, pipettes, and equipment using a 10% bleach solution or a commercial DNA decontamination solution.[5] To prevent future contamination, it is crucial to use dedicated pre-PCR and post-PCR areas, separate sets of pipettes, and aliquoted, single-use reagents.[5]
Troubleshooting Workflow for a Contaminated PCR Negative Control
References
- 1. m.youtube.com [m.youtube.com]
- 2. neb.com [neb.com]
- 3. The controls that got out of control: How failed control experiments paved the way to transformative discoveries - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. ELISA Troubleshooting Guide: Common Questions, Tips & Tricks | R&D Systems [rndsystems.com]
Technical Support Center: Troubleshooting Irreproducible Results
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals address the common challenge of irreproducible experimental results. The content is designed to offer practical solutions and detailed methodologies for key experimental techniques.
Frequently Asked Questions (FAQs)
Q1: What are the most common reasons my experimental results are not reproducible?
A: Lack of reproducibility in research can often be traced back to a few key areas.[1] These include invalidated biological materials, lack of access to original data and methodologies, insufficient knowledge for data analysis, and incorrect laboratory practices.[1] Studies have shown that a significant percentage of preclinical research is not reproducible, leading to substantial financial and time losses.[2]
Q2: How can I improve the reproducibility of my research from the start?
A: To enhance the reproducibility of your results, it is crucial to focus on transparency and rigorous documentation.[3] This includes creating detailed, written descriptions of all experimental protocols and ensuring that all data, including raw data and metadata, are accessible.[1][4][5] Implementing open science practices, such as sharing methods and data in public repositories, can also significantly improve reproducibility.[6]
Q3: What role does reagent variability play in irreproducibility?
A: Reagent variability is a significant contributor to inconsistent experimental outcomes.[7][8] Different lots of reagents can have variations in their characteristics, which can affect the consistency and reliability of results.[7] It is essential to validate reagents, especially antibodies and cell lines, to ensure they are performing as expected.[9] Using reagents from reputable brands and consistently recording lot numbers are good practices to minimize this variability.[10]
Q4: How do protocol deviations impact the reproducibility of a study?
A: Protocol deviations, which are any departures from the approved experimental plan, can significantly compromise data integrity and the reliability of study results.[11][12][13] Even minor deviations, if they occur frequently, can erode confidence in the findings.[11][12] Common causes for deviations include overly complex protocols and inadequate training of personnel.[12]
Q5: Can data analysis methods affect the reproducibility of my results?
A: Yes, data analysis is a critical step where errors can lead to irreproducible findings.[14][15] Common mistakes include using biased or too small sample sizes, confusing correlation with causation, and not standardizing data.[16] It is also important to avoid "p-hacking," which is the manipulation of data to achieve statistical significance.[2]
Troubleshooting Guides
Cell-Based Assays: Identifying Sources of Variation
Cell-based assays are susceptible to variability from numerous sources. Ensuring consistency in cell culture and handling is paramount for reproducible results.
Common Issues and Solutions:
| Issue | Potential Cause | Recommended Solution |
| Inconsistent Cell Growth | Variations in seeding density, media composition, or incubation conditions.[7] | Strictly adhere to the protocol for cell seeding. Use the same batch of media and serum for the duration of the experiment. Ensure incubators are properly calibrated for temperature and CO2 levels. |
| High Well-to-Well Variability | Uneven cell distribution, edge effects, or inconsistent reagent addition. | Gently swirl the cell suspension before and during plating. Avoid using the outer wells of the plate, or fill them with sterile media/PBS. Use calibrated multichannel pipettes for reagent addition. |
| Cell Line Misidentification or Contamination | Cross-contamination with other cell lines or microbial contamination. | Regularly authenticate cell lines using methods like Short Tandem Repeat (STR) profiling. Routinely test for mycoplasma contamination. |
| Changes in Cell Phenotype | High passage number leading to genetic drift.[1] | Use cells within a defined low passage number range. Establish a cell banking system to ensure a consistent supply of early-passage cells. |
Experimental Workflow for a Reproducible Cell-Based Assay:
A standardized workflow for cell-based assays to minimize variability.
Western Blotting: A Guide to Consistent Results
Western blotting is a technique prone to variability. Careful attention to detail at each step is crucial for reproducibility.
Common Issues and Solutions:
| Issue | Potential Cause | Recommended Solution |
| Inconsistent Band Intensities | Uneven sample loading, poor protein transfer, or variability in antibody incubation.[6] | Perform a protein concentration assay (e.g., BCA) to ensure equal loading.[6] Use a loading control (e.g., GAPDH, β-actin) to normalize results. Optimize transfer time and voltage. Use consistent antibody dilutions and incubation times. |
| High Background/Non-specific Bands | Antibody concentration too high, insufficient blocking, or cross-reactivity of the antibody. | Titrate the primary antibody to determine the optimal concentration. Increase blocking time or try a different blocking agent. Ensure the antibody is specific to the target protein. |
| No Signal or Weak Signal | Inactive antibody, insufficient protein loaded, or incorrect secondary antibody. | Use a fresh aliquot of the primary antibody. Increase the amount of protein loaded. Ensure the secondary antibody is specific to the primary antibody's host species and is conjugated to a functional enzyme/fluorophore. |
Key Steps in a Western Blotting Protocol:
-
Sample Preparation: Lyse cells or tissues in a suitable buffer containing protease and phosphatase inhibitors. Determine protein concentration using a reliable method.
-
Gel Electrophoresis: Separate proteins by size using SDS-PAGE.
-
Protein Transfer: Transfer separated proteins from the gel to a membrane (e.g., PVDF or nitrocellulose).
-
Blocking: Block the membrane to prevent non-specific antibody binding.
-
Antibody Incubation: Incubate the membrane with primary and then secondary antibodies.
-
Detection: Detect the protein of interest using a chemiluminescent or fluorescent substrate.
-
Data Analysis: Quantify band intensities and normalize to a loading control.
Logical Flow for Troubleshooting Western Blots:
A decision tree for troubleshooting common western blot issues.
PCR and qPCR: Minimizing Variation
Polymerase Chain Reaction (PCR) and quantitative PCR (qPCR) are sensitive techniques where small variations can lead to large differences in results.
Common Issues and Solutions:
| Issue | Potential Cause | Recommended Solution |
| No Amplification or Low Yield | Poor template quality, incorrect annealing temperature, or presence of PCR inhibitors.[5] | Assess DNA/RNA integrity and purity. Optimize the annealing temperature using a gradient PCR.[4] Purify the template to remove inhibitors. |
| Non-specific Amplification | Primer-dimer formation, low annealing stringency, or contaminated reagents.[4] | Design primers with minimal self-complementarity. Increase the annealing temperature.[4] Use fresh, nuclease-free water and reagents. |
| High Variability Between Replicates | Pipetting errors, inconsistent sample input, or thermal cycler non-uniformity. | Use a master mix to minimize pipetting variability.[3] Be precise when adding the template to each reaction. Ensure the thermal cycler is properly calibrated. |
Signaling Pathway Analysis: A Note on Reproducibility
The study of signaling pathways often relies on techniques like Western blotting and qPCR to measure changes in protein and gene expression. The reproducibility of these pathway analyses is therefore dependent on the reproducibility of the underlying techniques.
Factors Affecting Signaling Pathway Readouts:
-
Cell State: The activation state of a signaling pathway can be highly sensitive to cell density, passage number, and serum starvation conditions.
-
Timing: Signaling cascades can be transient. The time points chosen for analysis are crucial for capturing the relevant biological events.
Generic Signaling Pathway Diagram:
A simplified signaling pathway illustrating points of potential experimental variability.
References
- 1. Top 5 Factors Affecting Reproducibility in Research - Enago Academy [enago.com]
- 2. The Road to Reproducibility in Animal Research - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Microbe Insights [microbiosci.com]
- 4. neb.com [neb.com]
- 5. researchgate.net [researchgate.net]
- 6. integra-biosciences.com [integra-biosciences.com]
- 7. academia.stackexchange.com [academia.stackexchange.com]
- 8. kosheeka.com [kosheeka.com]
- 9. In Vitro Research Reproducibility: Keeping Up High Standards - PMC [pmc.ncbi.nlm.nih.gov]
- 10. quora.com [quora.com]
- 11. m.youtube.com [m.youtube.com]
- 12. licorbio.com [licorbio.com]
- 13. researchgate.net [researchgate.net]
- 14. blog.mblintl.com [blog.mblintl.com]
- 15. mybiosource.com [mybiosource.com]
- 16. PCR Troubleshooting Guide | Thermo Fisher Scientific - UK [thermofisher.com]
Technical Support Center: Troubleshooting Unexpected Artifacts in Microscopy Images
Welcome to our technical support center. This resource is designed to help researchers, scientists, and drug development professionals identify and resolve common and unexpected artifacts in their microscopy images. Browse our troubleshooting guides and frequently asked questions (FAQs) to find solutions to specific issues you may encounter during your experiments.
Frequently Asked questions (FAQs)
Q1: What are image artifacts in microscopy?
Q2: Why is it important to identify and minimize image artifacts?
Q3: What are the main categories of microscopy artifacts?
A3: Microscopy artifacts can be broadly categorized based on their source:
-
Sample Preparation Artifacts: These arise from the process of preparing the specimen for observation and can include air bubbles, crushed samples, contamination, and issues with fixation or staining.[1][6][7]
-
Optical System Artifacts: These are caused by the microscope's optical components and can include aberrations like chromatic and spherical aberration, as well as uneven illumination.[1][8]
-
Fluorescence-Specific Artifacts: These are unique to fluorescence microscopy and include photobleaching, phototoxicity, and bleed-through.[1][10][11]
Troubleshooting Guides
This section provides detailed troubleshooting for specific, common problems encountered during microscopy.
Issue 1: My image is blurry or out of focus.
An out-of-focus or blurry image is one of the most common problems in microscopy.[4][12] This can manifest as a general lack of sharpness or as specific regions of the image being less clear than others.
Troubleshooting Steps:
-
Check the Focus Adjustment: Ensure you have correctly focused on the specimen. For high-magnification objectives, fine focus adjustment is critical.
-
Verify Parfocality: If the image is sharp in the eyepieces but blurry in the captured image, the camera may not be parfocal with the eyepieces.[4][12] Adjust the camera focus or consult your microscope's manual for parfocality correction.
-
Inspect the Coverslip: An incorrect coverslip thickness can cause spherical aberration, especially with high numerical aperture objectives, leading to a blurry image.[4][12] Ensure you are using the correct type and thickness of coverslip for your objective.
-
Examine for Vibrations: External vibrations from equipment or the building can cause image blur, especially during long exposures.[12] Use an anti-vibration table and minimize movement in the room during image acquisition.
-
Clean the Optics: Contaminants like oil or dust on the objective lens, condenser, or coverslip can scatter light and reduce image sharpness.[12] Regularly clean all optical surfaces according to the manufacturer's instructions.
Troubleshooting Workflow: Blurry Image
Caption: Troubleshooting workflow for a blurry microscopy image.
Issue 2: The illumination in my image is uneven.
Uneven illumination, also known as vignetting, appears as a darkening of the image towards the corners or edges.[13][14][15] This can significantly impact quantitative analysis.
Troubleshooting Steps:
-
Check Microscope Alignment: Improper alignment of the light path is a common cause of uneven illumination.[14] Ensure the condenser is correctly centered and focused (Köhler illumination).
-
Objective Turret Position: Make sure the objective is fully clicked into position in the nosepiece.
-
Field Diaphragm Adjustment: The field diaphragm should be opened just enough to be outside the field of view. If it's too closed, it can cause darkening at the edges.[4]
-
Use Shading Correction: Many imaging software packages have a "shading correction" or "flat-field correction" feature.[13] This involves acquiring a reference image of an empty field of view and using it to normalize the illumination in your specimen images.
| Cause | Solution |
| Misaligned condenser | Perform Köhler illumination alignment. |
| Objective not fully engaged | Ensure the objective is clicked into place. |
| Field diaphragm too small | Open the field diaphragm until it is just outside the field of view. |
| Inherent to optics | Use software-based shading correction.[13] |
Issue 3: I see dark spots, dust, or debris in my image.
The presence of dark, well-defined spots or specks in an image is usually due to dust or debris on one of the optical surfaces.[16]
Troubleshooting Steps:
-
Identify the Location of the Debris:
-
Rotate the eyepiece: If the debris rotates, it's on the eyepiece.
-
Move the slide: If the debris moves with the slide, it's on the specimen or coverslip.
-
Rotate the camera: If the debris rotates with the camera, it's on the camera sensor or the C-mount adapter.
-
If the debris remains stationary during these actions, it is likely on the condenser or objective lens.
-
-
Clean the Contaminated Surface: Use appropriate lens cleaning paper and solution to gently clean the identified optical surface. For the camera sensor, follow the manufacturer's instructions for cleaning.
Logical Relationship: Locating Debris
References
- 1. Learn To Minimize Artifacts In Fluorescence Microscopy [expertcytometry.com]
- 2. edge-ai-vision.com [edge-ai-vision.com]
- 3. Major Imaging Challenges in Microscopy & How to Solve Them - e-con Systems [e-consystems.com]
- 4. Molecular Expressions Microscopy Primer: Photomicrography - Microscope Configuration and Other Common Errors [micro.magnet.fsu.edu]
- 5. Imaging Artefacts in Digital Microscopy [vanosta.be]
- 6. Visual artifact - Wikipedia [en.wikipedia.org]
- 7. Sample Preparation Best Practices [dtr-labs.com]
- 8. light microscopy and its components and also errors in light microscopy | PPTX [slideshare.net]
- 9. What Causes Blooming Artifacts in Microscopic Imaging and How to Prevent Them - e-con Systems [e-consystems.com]
- 10. benchchem.com [benchchem.com]
- 11. How to Minimize Photobleaching in Fluorescence Microscopy: A Comprehensive Guide | KEYENCE America [keyence.com]
- 12. Troubleshooting Microscope Configuration and Other Common Errors [evidentscientific.com]
- 13. Correction of uneven illumination (vignetting) in digital microscopy images - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Uneven Illumination in Fluorescence Imaging | Thermo Fisher Scientific - SG [thermofisher.com]
- 15. oncology.ox.ac.uk [oncology.ox.ac.uk]
- 16. Algae World: diatom microscopy - removing dust specks and other artifacts [websites.rbge.org.uk]
Technical Support Center: Troubleshooting Undetected Enzyme Activity
Welcome to the technical support center for enzyme assays. This guide is designed for researchers, scientists, and drug development professionals to troubleshoot experiments where no enzyme activity is detected.
Frequently Asked Questions (FAQs)
Q1: I am not detecting any signal in my enzyme assay. What are the primary reasons this could be happening?
A low or nonexistent signal is a common issue that can stem from several factors, from reagent integrity to suboptimal assay conditions.[1] The most common causes include an inactive enzyme, incorrect assay conditions (like pH or temperature), or issues with the substrate or other reagents.[1][2]
Q2: How can I be sure my enzyme is active?
The first step in troubleshooting is to confirm your enzyme's viability.[1] Enzymes can lose activity due to improper storage, repeated freeze-thaw cycles, or the presence of inhibitors.[1] To verify activity, run a positive control with a known, active enzyme and a reliable substrate.[1][3] If the positive control works, your enzyme preparation is likely the issue. If the positive control fails, the problem may lie with your assay conditions or other reagents.
Q3: My enzyme is active. What else could be wrong?
If you've confirmed your enzyme is active, the next step is to examine your assay conditions and reagents. Key areas to investigate include:
-
Suboptimal Reaction Conditions: The pH, temperature, or incubation time of your assay may not be optimal for your specific enzyme.[1][4]
-
Incorrect Substrate Concentration: The concentration of your substrate may be too low to generate a detectable signal.[1][5][6]
-
Substrate Insolubility or Degradation: The substrate may not be fully dissolved in the assay buffer or could be unstable under the assay conditions.[1]
-
Presence of Inhibitors: Your sample or reagents might contain inhibitors that are blocking enzyme activity.[7]
-
Issues with Detection Method: The instrumentation or detection reagents may not be sensitive enough or could be malfunctioning.[8]
Q4: How do I optimize my substrate concentration?
For routine assays, it is recommended to use a substrate concentration that is 5-10 times the Michaelis constant (Km).[1] If the Km is unknown, you can perform a substrate titration by varying the substrate concentration while keeping the enzyme concentration constant to determine the optimal concentration.[1][5] At low substrate concentrations, the reaction rate is limited by the amount of available substrate.[5]
Q5: What should I do if I suspect my substrate is not dissolving properly?
Many organic substrates are hydrophobic and may have limited solubility in aqueous buffers.[1] To improve solubility, you can:
-
Use a Co-solvent: Dissolve the substrate in a small amount of an organic solvent like DMSO before diluting it into the assay buffer. Ensure the final solvent concentration does not inhibit the enzyme (typically <1-5%).[1]
-
Sonication: Gently sonicate the substrate stock solution to aid dissolution.[1]
-
Include Detergents: Low concentrations (e.g., 0.01-0.1%) of non-ionic detergents like Triton X-100 or Tween-20 can help solubilize hydrophobic substrates.[1]
Q6: Could my buffer be the problem?
Yes, the buffer composition is critical for enzyme activity.[9][10] The buffer maintains the optimal pH for the enzyme and its components can sometimes interact with the assay.[11] For example, phosphate buffers can inhibit some kinases, and Tris buffers can chelate metal ions, which may be problematic for metalloenzymes.[11] It's crucial to select a buffer that is compatible with your enzyme and assay components.[10]
Troubleshooting Guide
If you are not detecting enzyme activity, follow this systematic troubleshooting workflow.
Logical Troubleshooting Workflow
Data Summary
The following table summarizes key quantitative parameters to consider when troubleshooting your enzyme assay.
| Parameter | Recommended Range/Action | Potential Issue if Not Optimal |
| Enzyme Concentration | Titrate to find a concentration that gives a linear response over time.[1] | Too low: No detectable signal. Too high: Substrate depletion, non-linear reaction rate.[1] |
| Substrate Concentration | 5-10 times the Km value.[1] | Too low: Reaction rate is limited, leading to a low signal.[5][6] Too high: Can cause substrate inhibition in some enzymes.[7] |
| pH | Optimal for the specific enzyme.[4][10] | Can lead to enzyme denaturation and loss of activity.[12][13] |
| Temperature | Optimal for the specific enzyme.[4] | Can cause enzyme denaturation if too high.[14][15] |
| Co-solvent (e.g., DMSO) | Typically <1-5% of the final assay volume.[1] | Higher concentrations can inhibit enzyme activity.[1] |
| Detergent (e.g., Triton X-100) | 0.01-0.1% | Can aid in solubilizing hydrophobic substrates.[1] |
Experimental Protocols
Standard Protocol for a Generic Enzyme Activity Assay
This protocol provides a general framework. Specific details will need to be optimized for your particular enzyme and substrate.
1. Reagent Preparation:
- Assay Buffer: Prepare a buffer at the optimal pH and ionic strength for your enzyme.[10][16] Ensure all components are fully dissolved.
- Enzyme Stock Solution: Prepare a concentrated stock of your enzyme in a suitable buffer. Store on ice.
- Substrate Stock Solution: Prepare a concentrated stock of your substrate. If solubility is an issue, dissolve in a minimal amount of an appropriate organic solvent (e.g., DMSO) first.[1]
- Positive Control: A sample of known active enzyme.[3][17]
- Negative Control: A reaction mixture lacking the enzyme or substrate.[16][18]
2. Assay Procedure:
- Equilibrate all reagents to the optimal reaction temperature.[4][19]
- In a suitable microplate, add the assay buffer, substrate, and any necessary cofactors.
- To initiate the reaction, add the enzyme solution to each well.
- Mix gently.
- Immediately begin monitoring the reaction using a plate reader at the appropriate wavelength for your detection method (e.g., absorbance, fluorescence).
- Collect data at regular time intervals to determine the initial reaction velocity.[20]
3. Data Analysis:
- Subtract the background signal (from the negative control) from all readings.
- Plot the signal versus time.
- Determine the initial velocity (the linear portion of the curve).
- Compare the activity of your experimental samples to your positive control.
Enzyme-Substrate Interaction and Inhibition Pathway
This diagram illustrates the basic principle of enzyme catalysis and how inhibitors can interfere with this process.
References
- 1. benchchem.com [benchchem.com]
- 2. quora.com [quora.com]
- 3. quora.com [quora.com]
- 4. Enzyme Assay Analysis: What Are My Method Choices? [thermofisher.com]
- 5. Untitled Document [ucl.ac.uk]
- 6. What is the effect of substrate concentration on enzyme activity? | AAT Bioquest [aatbio.com]
- 7. Enzyme inhibitor - Wikipedia [en.wikipedia.org]
- 8. Protein and Enzyme Activity Assays Support—Troubleshooting | Thermo Fisher Scientific - US [thermofisher.com]
- 9. A General Guide for the Optimization of Enzyme Assay Conditions Using the Design of Experiments Approach - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. How to Choose the Right Buffer for Enzyme Activity Tests [synapse.patsnap.com]
- 11. benchchem.com [benchchem.com]
- 12. monash.edu [monash.edu]
- 13. Denatured Enzyme: Definition, Causes & Effects - Lesson | Study.com [study.com]
- 14. youtube.com [youtube.com]
- 15. Changes in Enzyme Activity – MHCC Biology 112: Biology for Health Professions [openoregon.pressbooks.pub]
- 16. labtestsguide.com [labtestsguide.com]
- 17. home.sandiego.edu [home.sandiego.edu]
- 18. homework.study.com [homework.study.com]
- 19. docs.abcam.com [docs.abcam.com]
- 20. Basics of Enzymatic Assays for HTS - Assay Guidance Manual - NCBI Bookshelf [ncbi.nlm.nih.gov]
Validation & Comparative
Resolving Conflicting Assay Results: A Comparative Guide for Researchers
Understanding the Roots of Discrepancy
Conflicting results often arise from the fundamental differences in assay principles and methodologies. Each assay possesses its own set of strengths, weaknesses, and sensitivities to various interferences. Understanding these inherent differences is the first step toward diagnosing the source of the conflict.
Common causes for conflicting results include:
-
Different Analytes Measured: Assays may measure different forms of a target molecule (e.g., total protein vs. phosphorylated protein, or mRNA vs. protein).
-
Antibody Specificity and Cross-Reactivity: Immunoassays are dependent on the specificity of the antibodies used. Different antibodies may have varying affinities and cross-reactivity profiles, leading to different results.[1][2]
-
Sample Matrix Effects: Components within the biological sample (e.g., lipids, proteins, anticoagulants) can interfere with assay components, leading to either falsely elevated or decreased readouts.[1][2][3]
-
Assay Principle and Format: The fundamental technology of the assay (e.g., sandwich ELISA vs. competitive ELISA, endpoint vs. kinetic measurement) can influence the results.
-
Dynamic Range and Sensitivity: Assays may have different limits of detection and quantification, leading to discrepancies when analyzing samples with low or very high analyte concentrations.
-
Experimental Procedure Variations: Inconsistent sample handling, reagent preparation, and incubation times can introduce significant variability.
A Systematic Approach to Troubleshooting
When faced with conflicting results, a structured troubleshooting plan is essential. The following workflow provides a step-by-step approach to identifying and resolving the root cause of the discrepancy.
Case Study: Discrepancy Between Western Blot and ELISA
A common scenario in many labs is observing a strong signal for a target protein in an ELISA, but a weak or absent band in a Western Blot. This section provides a comparative guide to troubleshoot this specific issue.
Data Presentation
| Sample ID | ELISA Result (ng/mL) | Western Blot Result (Relative Intensity) |
| Control 1 | 0.5 | 0.1 |
| Control 2 | 0.6 | 0.15 |
| Test 1 | 50.2 | 0.2 |
| Test 2 | 48.9 | 0.25 |
| Positive Control | 100.0 | 1.0 |
Experimental Protocols
1. Sample Dilution Series:
-
Objective: To investigate the presence of interfering substances in the sample matrix that may affect one assay more than the other.
-
Method:
-
Prepare serial dilutions of the problematic sample (e.g., 1:2, 1:4, 1:8, 1:16) using an appropriate assay buffer.
-
Analyze the dilutions in both the ELISA and Western Blot assays.
-
Expected Outcome: In the ELISA, if an interfering substance is present, you may observe a non-linear relationship between the measured concentration and the dilution factor. The Western Blot results may show an increase in signal intensity at higher dilutions as the interference is diluted out.
-
2. Antibody Validation:
-
Objective: To confirm the specificity of the antibodies used in both assays for the target protein.
-
Method:
-
Western Blot:
-
Run a gel with a positive control lysate (known to express the target protein), a negative control lysate (does not express the target protein), and your sample.
-
Probe the membrane with the antibody used in the ELISA.
-
Expected Outcome: A single band at the correct molecular weight should be observed in the positive control and your sample, with no band in the negative control.
-
-
ELISA:
-
Perform a competition assay by pre-incubating the ELISA antibody with a purified, recombinant version of the target protein before adding it to the ELISA plate.
-
Expected Outcome: A significant reduction in the ELISA signal should be observed after pre-incubation, confirming the antibody's specificity.
-
-
3. Spike and Recovery:
-
Objective: To assess whether the sample matrix is inhibiting the detection of the target protein in the Western Blot.
-
Method:
-
"Spike" a known amount of purified, recombinant target protein into your sample and a control buffer.
-
Analyze both the spiked sample and the spiked buffer by Western Blot.
-
Expected Outcome: If the signal for the spiked protein is significantly lower in the sample compared to the buffer, it suggests the presence of an inhibitory substance in your sample matrix.
-
Signaling Pathway Considerations
Conflicting results can also arise when assays target different components of a signaling pathway. For instance, an assay measuring gene expression (qPCR) may show an increase in response to a stimulus, while an assay measuring protein expression (Western Blot) of the final protein product might not show a corresponding increase due to post-transcriptional regulation.
References
New Immunotherapy Combination Fails to Surpass Standard of Care in Upper Gastrointestinal Cancers
A recent Phase 3 clinical trial, STAR-221, investigating a new combination immunotherapy for advanced upper gastrointestinal (GI) cancers, was discontinued due to a lack of improved efficacy over the existing standard of care. The trial evaluated the addition of domvanalimab, an anti-TIGIT antibody, to the anti-PD-1 antibody zimberelimab and chemotherapy. The study was halted for futility at a planned interim analysis as the experimental regimen did not demonstrate an improvement in overall survival (OS) compared to the established first-line treatment of nivolumab plus chemotherapy.
This outcome is a significant setback for the development of TIGIT-targeting therapies, a novel class of immunotherapy drugs that have been under investigation for various cancers. The STAR-221 trial was a large, global, randomized, open-label study that enrolled 1,040 patients with locally advanced unresectable or metastatic HER2-negative gastric, gastroesophageal junction (GEJ), or esophageal adenocarcinoma.
Comparative Efficacy and Safety
The safety profile of the domvanalimab-based combination was reported to be similar to that of the nivolumab plus chemotherapy arm, with no new safety concerns identified.
| Outcome Measure | Drug X (Domvanalimab + Zimberelimab + Chemotherapy) | Drug Y (Nivolumab + Chemotherapy) |
| Primary Endpoint: Overall Survival (OS) | No improvement compared to Drug Y | Established as the standard of care with proven OS benefit over chemotherapy alone |
| Safety Profile | Similar to Drug Y, with no new safety signals identified | Well-characterized safety profile |
Experimental Protocol: STAR-221 Trial
The STAR-221 trial was a Phase 3, randomized, open-label, multicenter study designed to evaluate the efficacy and safety of the domvanalimab-based combination against the standard of care in the first-line treatment of advanced upper GI cancers.
Patient Population: The study enrolled adult patients with histologically confirmed, locally advanced unresectable or metastatic HER2-negative gastric, GEJ, or esophageal adenocarcinoma who had not received prior systemic therapy for their advanced disease. Key inclusion criteria included an ECOG performance status of 0 or 1.
Treatment Arms: Patients were randomized in a 1:1 ratio to one of two treatment arms:
-
Experimental Arm (Drug X): Domvanalimab (anti-TIGIT) and zimberelimab (anti-PD-1) in combination with either FOLFOX (oxaliplatin, leucovorin, and fluorouracil) or CAPOX (capecitabine and oxaliplatin) chemotherapy.
-
Control Arm (Drug Y): Nivolumab (anti-PD-1) in combination with either FOLFOX or CAPOX chemotherapy.
Endpoints: The primary endpoint of the study was overall survival. Secondary endpoints included progression-free survival (PFS), objective response rate (ORR), duration of response (DOR), and safety.
Signaling Pathways and Experimental Workflow
The following diagrams illustrate the targeted signaling pathways and the workflow of the STAR-221 clinical trial.
Caption: TIGIT and PD-1 signaling pathway inhibition in cancer immunotherapy.
Caption: Simplified workflow of the STAR-221 clinical trial.
Guide to Publishing Contradictory Research Findings
For Researchers, Scientists, and Drug Development Professionals
The process of scientific discovery is not always linear. Contradictory findings are a natural part of this process and, when reported transparently, contribute to a more robust and accurate scientific understanding.[1][2] This guide provides a framework for presenting research that diverges from previously published data, using the hypothetical case of "DrugX" and its effect on the MAPK/ERK signaling pathway.
Data Presentation: Acknowledging the Discrepancy
When your results differ from established literature, direct and clear presentation is paramount.[3][4][5] The goal is not to discredit previous work but to present your findings objectively and transparently, fostering a scientific dialogue. A comparative table is an effective tool for summarizing the quantitative differences between your findings and the published data.[3][5]
Table 1: Comparative Analysis of DrugX IC50 Values on ERK Phosphorylation
This table compares the half-maximal inhibitory concentration (IC50) of DrugX on ERK phosphorylation as determined in this study versus previously published data.
| Cell Line | My Findings (IC50 in µM) | Published Data (Smith et al., 2022) (IC50 in µM) | Fold Difference |
| HeLa | 45.2 | 1.5 | 30.1x |
| A549 | 60.7 | 2.1 | 28.9x |
| MCF-7 | 52.1 | 1.8 | 28.9x |
IC50 values represent the mean of three independent experiments (n=3).
Experimental Protocols: The Key to Understanding Differences
Providing meticulous detail in your methodology is crucial when results are unexpected.[6][7] Subtle variations in protocol can lead to significant differences in outcomes. By clearly outlining your methods, you allow the scientific community to accurately compare experimental setups and identify potential sources of discrepancy.
Detailed Methodologies for Key Experiments:
-
Cell Culture and Treatment:
-
HeLa, A549, and MCF-7 cells were sourced from ATCC (Manassas, VA, USA) and cultured in DMEM supplemented with 10% Fetal Bovine Serum (FBS) and 1% Penicillin-Streptomycin.
-
All cell lines were maintained in a humidified incubator at 37°C with 5% CO2.
-
Cells were seeded in 96-well plates at a density of 1x10⁴ cells/well and allowed to adhere for 24 hours.
-
DrugX was dissolved in DMSO to create a 10 mM stock solution and serially diluted in culture medium to final concentrations ranging from 0.1 µM to 100 µM. Cells were treated for 24 hours prior to analysis.
-
-
Western Blot Analysis for p-ERK:
-
Following treatment, cells were lysed in RIPA buffer containing protease and phosphatase inhibitors.
-
Protein concentration was determined using a BCA assay. 20 µg of protein per sample was loaded onto a 10% SDS-PAGE gel.
-
Proteins were transferred to a PVDF membrane. The membrane was blocked for 1 hour in 5% non-fat milk in TBST.
-
The membrane was incubated overnight at 4°C with primary antibodies against phospho-ERK1/2 (Cell Signaling Technology, Cat# 4370) and total ERK1/2 (Cell Signaling Technology, Cat# 4695).
-
Blots were washed and incubated with HRP-conjugated secondary antibodies for 1 hour at room temperature.
-
Bands were visualized using an ECL detection kit and imaged on a ChemiDoc Imaging System. Densitometry was performed using ImageJ software.
-
-
IC50 Determination:
-
The relative density of phospho-ERK was normalized to total ERK.
-
The normalized values were plotted against the logarithmic concentrations of DrugX.
-
A non-linear regression (dose-response, variable slope) was used to calculate the IC50 value using GraphPad Prism 9.
-
Visualizing Pathways and Processes
Visual aids are essential for clarifying complex information, such as signaling cascades and experimental designs.[3][4] Using standardized notations like the DOT language ensures clarity and reproducibility.
Signaling Pathway
The mitogen-activated protein kinase (MAPK) pathway is a critical signaling cascade that regulates cell growth, proliferation, and differentiation.[8][9] DrugX was reported to inhibit this pathway at the level of MEK, thereby preventing the phosphorylation of ERK.[8][10][11][12]
Figure 1. The MAPK/ERK signaling cascade and the reported inhibitory target of DrugX.
Experimental Workflow
A clear workflow diagram provides a high-level overview of the experimental process, from initial setup to final data analysis.[13][14]
Figure 2. Step-by-step workflow for determining the IC50 of DrugX.
Logical Relationship
When faced with conflicting data, a logical approach is necessary to frame the discussion. This involves acknowledging the published work, presenting your own data, and proposing testable hypotheses to explain the differences.
Figure 3. Logical framework for addressing conflicting research findings.
References
- 1. Dealing With Conflicting Evidence [individual.utoronto.ca]
- 2. quora.com [quora.com]
- 3. researchmate.net [researchmate.net]
- 4. Presenting Research Data Effectively Through Tables and Figures | Paperpal [paperpal.com]
- 5. How To Present Research Data? - PMC [pmc.ncbi.nlm.nih.gov]
- 6. What if scientific studies disagree? [nationalacademies.org]
- 7. We got opposite results using a similar research method. Is it ok to publish this in an article? | Editage Insights [editage.com]
- 8. spandidos-publications.com [spandidos-publications.com]
- 9. MAPK/ERK pathway - Wikipedia [en.wikipedia.org]
- 10. researchgate.net [researchgate.net]
- 11. cdn-links.lww.com [cdn-links.lww.com]
- 12. MAPK/Erk in Growth and Differentiation | Cell Signaling Technology [cellsignal.com]
- 13. researchgate.net [researchgate.net]
- 14. drugtargetreview.com [drugtargetreview.com]
A Researcher's Guide to Validating siRNA Off-Target Effects: A Comparative Analysis
For researchers, scientists, and drug development professionals, ensuring the specificity of RNA interference (RNAi) is paramount. While small interfering RNAs (siRNAs) are powerful tools for gene silencing, their potential for off-target effects—the unintended silencing of non-target genes—can lead to misleading results and therapeutic complications. This guide provides a comprehensive comparison of methods to validate and mitigate these off-target effects, complete with experimental data and detailed protocols.
Off-target effects primarily arise from the siRNA guide strand binding to unintended messenger RNAs (mRNAs) with partial sequence complementarity, often mimicking the action of microRNAs (miRNAs).[1][2] This can lead to the downregulation of numerous unintended genes, confounding experimental outcomes.[3] Therefore, rigorous validation of siRNA specificity is a critical step in any RNAi experiment.
Comparing the Arsenal: Methods for Off-Target Validation
A variety of techniques, ranging from computational prediction to genome-wide expression analysis, are available to assess the specificity of an siRNA. Each method offers distinct advantages and limitations in terms of sensitivity, throughput, and the type of information it provides.
Summary of Quantitative Performance
| Method | Primary Endpoint | Throughput | Sensitivity | Specificity | Cost | Key Limitation |
| In Silico Analysis (e.g., BLAST, Seed Region Analysis) | Predicted binding sites | High | Low to Moderate | Low to Moderate | Low | High false-positive rate; poor predictor of functional off-targets. |
| Genome-Wide mRNA Profiling (Microarray, RNA-Seq) | Changes in global mRNA levels | High | High | Moderate to High | High | Does not measure changes at the protein level; can be influenced by secondary effects. |
| Luciferase Reporter Assay | Functional validation of a specific siRNA:mRNA interaction | Low to Moderate | High | High | Moderate | Only tests one predicted off-target at a time; labor-intensive for many targets. |
| Rescue Experiment | Reversal of phenotype with an siRNA-resistant target | Low | High | High | Moderate | Requires a well-defined phenotype and a functional rescue construct. |
| Multiple siRNAs per Target | Phenotypic consistency across different siRNAs | Moderate | Moderate | High | Moderate | Relies on the assumption that different siRNAs will have distinct off-target profiles. |
| Dose-Response Analysis | Minimization of off-target effects at lower concentrations | Moderate | Moderate | Moderate | Low | Not all siRNAs maintain on-target efficacy at concentrations that reduce off-target effects. |
In-Depth Look at Key Validation Techniques
Genome-Wide Expression Profiling: A Global View
Microarray and RNA-sequencing (RNA-Seq) are powerful high-throughput methods that provide a global snapshot of gene expression changes following siRNA transfection.[2] These techniques can identify dozens of off-targeted genes, revealing the sequence-specific signature of an individual siRNA.[3]
Experimental Workflow: RNA-Seq for Off-Target Analysis
Caption: Workflow for identifying siRNA off-target effects using RNA-sequencing.
-
Cell Culture and Transfection:
-
Seed cells in 6-well plates to achieve 50-60% confluency at the time of transfection.
-
Transfect cells with the experimental siRNA and a non-targeting negative control siRNA at the desired concentration using a suitable transfection reagent.
-
Include a mock-transfected control (transfection reagent only).
-
Incubate for 24-72 hours, depending on the target and cell line.
-
-
RNA Isolation and Quality Control:
-
Harvest cells and isolate total RNA using a commercial kit (e.g., RNeasy Mini Kit, Qiagen).
-
Assess RNA integrity and quantity using a spectrophotometer (e.g., NanoDrop) and a bioanalyzer (e.g., Agilent 2100 Bioanalyzer). An RNA Integrity Number (RIN) > 8 is recommended.
-
-
Library Preparation and Sequencing:
-
Prepare sequencing libraries from 1 µg of total RNA using a commercial kit (e.g., TruSeq Stranded mRNA Library Prep Kit, Illumina).
-
Perform high-throughput sequencing on a platform such as the Illumina NovaSeq.
-
-
Data Analysis:
-
Perform quality control of raw sequencing reads.
-
Align reads to a reference genome.
-
Calculate gene expression levels and perform differential expression analysis between the experimental siRNA and negative control samples.
-
Perform seed region enrichment analysis to identify over-represented seed sequences in the 3' UTRs of downregulated genes.
-
Luciferase Reporter Assays: Functional Validation of Specific Interactions
Luciferase reporter assays provide a quantitative method to validate a direct interaction between an siRNA and a predicted off-target mRNA.[4] This is achieved by cloning the putative off-target sequence into the 3' untranslated region (UTR) of a luciferase reporter gene. A reduction in luciferase activity upon co-transfection with the siRNA confirms the interaction.
Logical Flow: Luciferase Assay for Off-Target Validation
Caption: Logical workflow for validating siRNA off-target interactions using a luciferase reporter assay.
-
Construct Preparation:
-
Synthesize oligonucleotides containing the predicted off-target sequence from the 3' UTR of the gene of interest.
-
Clone these oligonucleotides into the 3' UTR of a luciferase reporter vector (e.g., psiCHECK™-2, Promega).
-
-
Cell Culture and Transfection:
-
Seed HeLa cells in a 24-well plate at a density of 1 x 10^5 cells/well and incubate for 24 hours.[1]
-
Co-transfect the cells with the following mixture using a suitable transfection reagent (e.g., Lipofectamine 2000):
-
-
Luciferase Assay:
-
Data Analysis:
-
Normalize the Renilla luciferase activity (from the psiCHECK-2 vector) to the Firefly luciferase activity (from the pGL3-Control vector).[1]
-
Calculate the relative luciferase activity compared to cells transfected with a non-targeting control siRNA. A significant reduction indicates an off-target effect.[1]
-
Rescue Experiments: Confirming Phenotypic Specificity
Rescue experiments are the gold standard for confirming that a particular phenotype is a direct result of silencing the intended target and not due to off-target effects.[5] This involves re-introducing the target gene in a form that is resistant to the siRNA (e.g., by introducing silent mutations in the siRNA binding site) and observing if the original phenotype is reversed.[6]
Signaling Pathway: siRNA Action and Rescue
Caption: Diagram illustrating the principle of a rescue experiment to confirm siRNA specificity.
-
Construct Generation:
-
Obtain a plasmid expressing the full-length cDNA of the target gene.
-
Introduce silent point mutations in the siRNA-binding site using site-directed mutagenesis without altering the amino acid sequence.
-
-
Cell Culture and Transfection:
-
Seed the cells of interest in 6-well plates.
-
Transfect the cells with the experimental siRNA or a scrambled control siRNA.
-
After 24 hours, transfect the cells again with the siRNA-resistant rescue construct or a control plasmid. It can be beneficial to include a second dose of the siRNA during this transfection.[5]
-
-
Phenotypic Analysis:
-
After an appropriate incubation period (e.g., 24-48 hours), assess the phenotype of interest using relevant assays (e.g., cell viability, migration, protein expression via Western blot).
-
-
Data Analysis:
-
Compare the phenotype of cells treated with siRNA alone, siRNA plus control plasmid, and siRNA plus rescue construct. A reversal of the phenotype in the rescue condition confirms the on-target effect.
-
Best Practices for Minimizing and Controlling for Off-Target Effects
-
Use the Lowest Effective siRNA Concentration: Titrate your siRNA to determine the lowest concentration that achieves effective target knockdown, as off-target effects are often concentration-dependent.
-
Employ Multiple siRNAs: Use at least two, and preferably three to four, different siRNAs targeting the same gene. A consistent phenotype across different siRNAs provides strong evidence for an on-target effect.
-
Utilize Modified siRNAs: Chemical modifications to the siRNA duplex can reduce off-target effects by discouraging the sense strand from entering the RISC complex or by destabilizing seed region interactions.
-
Pool siRNAs: Using a pool of multiple siRNAs targeting the same mRNA can dilute the concentration of any single siRNA, thereby reducing the likelihood of off-target effects from any one sequence.[2]
-
Perform Rigorous Bioinformatic Analysis: Before ordering siRNAs, perform a BLAST search to ensure minimal homology to other genes. Pay close attention to potential seed sequence matches in the 3' UTRs of other transcripts.
References
- 1. The siRNA Off-Target Effect Is Determined by Base-Pairing Stabilities of Two Different Regions with Opposite Effects - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Methods for reducing siRNA off-target binding | Eclipsebio [eclipsebio.com]
- 3. horizondiscovery.com [horizondiscovery.com]
- 4. A rapid and sensitive assay for quantification of siRNA efficiency and specificity - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. Attenuated Protein Expression Vectors for Use in siRNA Rescue Experiments - PMC [pmc.ncbi.nlm.nih.gov]
A Researcher's Guide to Navigating the Sequencing Landscape: Illumina, PacBio, and Oxford Nanopore in Focus
For researchers, scientists, and drug development professionals, the choice of a sequencing platform is a critical decision that profoundly impacts experimental outcomes. This guide provides an objective comparison of the leading sequencing technologies: Illumina's sequencing by synthesis, Pacific Biosciences' single-molecule real-time (SMRT) sequencing, and Oxford Nanopore Technologies' nanopore sequencing. We present supporting experimental data, detailed methodologies for comparative experiments, and visualizations to clarify complex workflows and biological pathways.
The landscape of DNA sequencing is dominated by three major players, each with distinct strengths and weaknesses. Illumina platforms are renowned for their high throughput, accuracy, and cost-effectiveness, making them a popular choice for applications requiring high coverage, such as genome resequencing and transcriptomics.[1] PacBio's SMRT sequencing and Oxford Nanopore's technology, on the other hand, offer the significant advantage of producing long reads, which are invaluable for de novo genome assembly, resolving complex genomic regions, and detecting structural variants.[1][2]
The selection of a sequencing platform is contingent on the specific research question. While Illumina's short-read technology excels in applications demanding high accuracy at a lower cost, long-read platforms like PacBio and Oxford Nanopore are preferred for projects that require detailed structural information or the analysis of complex genomes.[1]
Performance Metrics: A Head-to-Head Comparison
The performance of sequencing platforms can be evaluated based on several key metrics. These include read length, sequencing accuracy, throughput (the amount of data generated per run), and the types of errors commonly observed. The following tables summarize the key quantitative data for each platform.
| Metric | Illumina | Pacific Biosciences (PacBio) | Oxford Nanopore Technologies (ONT) |
| Sequencing Technology | Sequencing by Synthesis (SBS) | Single-Molecule Real-Time (SMRT) | Nanopore Sequencing |
| Read Length | 75-300 bp (short reads)[1] | Up to 100,000 bp (long reads)[1] | >10,000 bp (ultra-long reads)[1] |
| Accuracy | High (99.9%, Q30)[3][4] | High (HiFi reads >99.9%)[1] | Improving (approaching Illumina's accuracy)[1] |
| Throughput | Very High (up to 13.5 Gb on MiSeq PE300)[5] | Moderate to High | High and scalable |
| Primary Error Type | Substitution errors[5] | Random errors (addressed by HiFi reads) | Insertions/Deletions (Indels) |
| Cost per Gigabase | Low[1] | Higher than Illumina[1] | Competitive and decreasing |
| Application | Illumina | Pacific Biosciences (PacBio) | Oxford Nanopore Technologies (ONT) |
| De novo Genome Assembly | Challenging for complex genomes | Excellent[1] | Excellent[1] |
| Structural Variant Detection | Limited by short reads | Excellent[1] | Excellent[1] |
| Transcriptome Analysis (RNA-Seq) | High-throughput and accurate | Full-length transcript sequencing[1] | Full-length transcript sequencing |
| Metagenomics | Good for taxonomic profiling | High-resolution species identification[2] | High-resolution species identification[2] |
| Epigenetics | Requires bisulfite conversion | Direct detection of methylation | Direct detection of methylation |
| Real-time Sequencing | No | No | Yes[1] |
Experimental Protocol: A Framework for Cross-Platform Comparison
To objectively compare sequencing data from different platforms, a standardized experimental protocol is crucial. This involves using the same reference material and applying consistent bioinformatics pipelines tailored to each technology. The Genome in a Bottle (GIAB) consortium provides well-characterized human genomes that serve as excellent reference materials for such comparisons.[6]
Key Experimental Steps:
-
Sample Preparation: A single, high-quality DNA sample from a well-characterized source (e.g., GIAB reference material) should be used to prepare sequencing libraries for each platform according to the manufacturer's protocols. For RNA sequencing comparisons, a reference RNA sample should be used.
-
Sequencing: Perform sequencing on each platform, aiming for a comparable depth of coverage to ensure a fair comparison.[2]
-
Data Pre-processing and Quality Control: Raw sequencing reads from each platform should be subjected to quality control using tools like FastQC. Platform-specific artifacts and low-quality reads should be filtered or trimmed.
-
Read Alignment: Align the quality-filtered reads to a common reference genome.
-
Variant Calling and Analysis: Use appropriate bioinformatics pipelines to call single nucleotide polymorphisms (SNPs), insertions/deletions (indels), and structural variants. The performance can be benchmarked against the known variants in the GIAB reference standard.
-
Assembly (for de novo sequencing): For de novo sequencing projects, assemble the reads from each platform and evaluate the contiguity and completeness of the assemblies.
Application in Drug Development: Studying Signaling Pathways
Sequencing data is instrumental in drug development for identifying novel drug targets, understanding disease mechanisms, and developing biomarkers. For instance, RNA sequencing (RNA-Seq) can be used to analyze the expression of genes within a signaling pathway in response to a drug treatment.
The MAPK/ERK pathway is a critical signaling cascade that regulates cell proliferation, differentiation, and survival, and its dysregulation is implicated in many cancers. Understanding how a drug candidate modulates this pathway is a key aspect of pre-clinical research.
By performing RNA-Seq on cells treated with a drug and comparing the gene expression profiles to untreated cells, researchers can determine the drug's effect on the MAPK/ERK pathway. Illumina's high-throughput capabilities are well-suited for such differential gene expression studies. Long-read sequencing from PacBio or ONT can provide additional insights into alternative splicing events within the pathway's genes that might be induced by the drug.
Challenges and Considerations
Despite the advancements in sequencing technologies, challenges in comparing data across platforms remain. These include biases introduced during library preparation, platform-specific error profiles, and differences in bioinformatics analysis pipelines.[5][7] It is crucial to be aware of these potential pitfalls and to account for them in the experimental design and data analysis. Combining data from different sequencing platforms should be done with caution, as it can introduce systematic biases.[8]
Conclusion
The choice of a sequencing platform is a critical decision that should be guided by the specific research goals, budget, and the nature of the biological question. Illumina remains a powerhouse for high-throughput, accurate, and cost-effective sequencing, particularly for applications that do not require long reads. PacBio and Oxford Nanopore have revolutionized genomics with their long-read capabilities, enabling the assembly of complex genomes and the comprehensive analysis of structural variation. As these technologies continue to evolve, researchers can look forward to even more powerful tools to unravel the complexities of the genome.
References
- 1. DNA Sequencing Technologies Compared: Illumina, Nanopore and PacBio [synapse.patsnap.com]
- 2. Comparative evaluation of sequencing platforms: Pacific Biosciences, Oxford Nanopore Technologies, and Illumina for 16S rRNA-based soil microbiome profiling - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. futurelearn.com [futurelearn.com]
- 4. knowledge.illumina.com [knowledge.illumina.com]
- 5. A comparison of sequencing platforms and bioinformatics pipelines for compositional analysis of the gut microbiome - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Determining Performance Metrics for Targeted Next Generation Sequencing Panels Using Reference Materials - PMC [pmc.ncbi.nlm.nih.gov]
- 7. The challenges of big data - PMC [pmc.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
The Perils of Uncorroborated Data: A Guide to Orthogonal Method Validation
This guide focuses on a common scenario in biopharmaceutical development: the quantification of Host Cell Proteins (HCPs), process-related impurities that can impact the safety and stability of a drug product.[1][3] We will compare the workhorse immunoassay, ELISA, with a powerful orthogonal method, Liquid Chromatography-Mass Spectrometry (LC-MS), to illustrate the potential pitfalls of relying on a single methodology.
Unmasking the Whole Truth: ELISA vs. LC-MS for HCP Analysis
The Enzyme-Linked Immunosorbent Assay (ELISA) has long been the industry standard for quantifying total HCP content due to its high sensitivity, throughput, and cost-effectiveness.[1][2] However, a significant limitation of ELISA is its reliance on polyclonal antibodies, which may not recognize every HCP species present in a sample. This can lead to an underestimation of the total HCP burden, with some estimates suggesting that ELISA may only detect around 70% of all potential HCPs.[1][4]
Liquid Chromatography-Mass Spectrometry (LC-MS) has emerged as a robust orthogonal method that overcomes this limitation.[3][5] By separating peptides from digested proteins and identifying them based on their mass-to-charge ratio, LC-MS can identify and quantify individual HCPs, providing a far more comprehensive profile of process-related impurities.[1][3][5] This level of detail is crucial for risk assessment, as certain HCPs may be more immunogenic or detrimental to product stability, even at low concentrations.[1]
Quantitative Data Comparison: A Tale of Two Methods
To illustrate the disparity that can arise between a primary assay and an orthogonal method, consider the following hypothetical data from the analysis of a monoclonal antibody (mAb) drug substance.
| Parameter | ELISA Result | LC-MS Result | Interpretation |
| Total HCP Content | 85 ng/mg | 120 ng/mg | ELISA underestimated the total HCP amount by over 29%. |
| Number of HCPs Detected | N/A (provides a total value) | 45 individual HCPs identified | LC-MS provides a detailed profile of specific protein impurities. |
| Detection of High-Risk HCP | Not Detected | Phospholipase B-like 2 (PLBL2) detected at 15 ng/mg | A known problematic HCP was missed by the ELISA but identified and quantified by LC-MS. |
| Process Consistency Monitoring | Lot A: 85 ng/mg, Lot B: 90 ng/mg | Lot A: 120 ng/mg (45 HCPs), Lot B: 125 ng/mg (52 HCPs) | While ELISA showed a minor difference, LC-MS revealed a change in the HCP profile, indicating a potential shift in the manufacturing process. |
Experimental Protocols
General Protocol for Host Cell Protein (HCP) ELISA
This protocol outlines the general steps for a sandwich ELISA for the quantification of total HCPs.
-
Plate Coating: A microplate is coated with a capture antibody, which is a polyclonal antibody raised against a wide range of HCPs.
-
Blocking: The remaining protein-binding sites on the plate are blocked to prevent non-specific binding.
-
Sample and Standard Incubation: The test samples and a series of known HCP standards are added to the wells. Any HCPs present in the samples will bind to the capture antibody.
-
Detection Antibody Incubation: A second, enzyme-conjugated polyclonal antibody (detection antibody) that recognizes different epitopes on the bound HCPs is added.
-
Substrate Addition: A chromogenic substrate is added, which is converted by the enzyme on the detection antibody into a colored product.
-
Measurement: The absorbance of the colored product is measured using a microplate reader. The intensity of the color is proportional to the amount of HCP in the sample.
-
Quantification: The HCP concentration in the samples is determined by comparing their absorbance to the standard curve generated from the known HCP standards.
General Protocol for Host Cell Protein (HCP) Analysis by LC-MS
This protocol provides a general workflow for the identification and quantification of individual HCPs using LC-MS.
-
Sample Preparation: The drug substance is denatured, reduced, alkylated, and then digested with an enzyme (e.g., trypsin) to break down the proteins into smaller peptides.
-
Liquid Chromatography (LC) Separation: The complex mixture of peptides is injected into a liquid chromatography system. The peptides are separated based on their physicochemical properties (e.g., hydrophobicity) as they pass through a chromatography column.
-
Mass Spectrometry (MS) Analysis: As the peptides elute from the LC column, they are ionized and introduced into the mass spectrometer.
-
MS1 Scan: The mass spectrometer scans and records the mass-to-charge ratio of the intact peptides.
-
MS/MS Scan (Fragmentation): The most abundant peptides from the MS1 scan are selected and fragmented. The mass spectrometer then scans and records the mass-to-charge ratio of the resulting fragment ions.
-
-
Data Analysis:
-
Database Searching: The fragmentation patterns (MS/MS spectra) are compared against a protein database of the host cell line to identify the amino acid sequence and thus the parent protein of each peptide.
-
Quantification: The abundance of each identified HCP can be estimated by label-free methods, such as comparing the summed peak areas of its most abundant peptides to those of a spiked-in protein standard.[5]
-
Visualizing the Pitfall of Unvalidated Results
The following diagrams illustrate the conceptual difference between a workflow that relies on a single assay versus one that incorporates an orthogonal method for validation.
References
Navigating the Nuances of Non-Significant Results in Alzheimer's Disease Clinical Trials
A Comparative Analysis of Anti-Amyloid Therapies
In the complex landscape of Alzheimer's disease research, the path to therapeutic breakthroughs is often paved with clinical trials that do not meet their primary statistical endpoints. While a "statistically significant" result is traditionally hailed as a success, a deeper dive into trials with non-significant outcomes reveals a wealth of information crucial for researchers, scientists, and drug development professionals. This guide provides an objective comparison of several anti-amyloid therapies, offering a lens through which to interpret the intricate relationship between statistical significance, clinical meaningfulness, and the future of Alzheimer's treatment.
The pursuit of a disease-modifying therapy for Alzheimer's has been heavily focused on the amyloid hypothesis, which posits that the accumulation of amyloid-beta plaques in the brain is a primary driver of the disease. This has led to the development of several monoclonal antibodies designed to clear these plaques. However, the clinical trial outcomes for these therapies have been a mixed bag, highlighting the complexities of translating a biological effect into a clear clinical benefit.
Comparative Efficacy of Anti-Amyloid Therapies
The following table summarizes the key quantitative outcomes from Phase 3 clinical trials of prominent anti-amyloid drugs. It is important to note that direct comparisons between these trials should be made with caution due to differences in study populations, trial designs, and duration.
| Drug Name (Trial Name) | Primary Endpoint | Change from Baseline in Primary Endpoint (Drug vs. Placebo) | p-value | Key Secondary Endpoints | Outcome |
| Aducanumab (EMERGE) | Change in Clinical Dementia Rating-Sum of Boxes (CDR-SB) at 78 weeks | -0.39 (22% slowing of decline) | 0.01 | ADAS-Cog13, ADCS-ADL-MCI | Met Primary Endpoint |
| Aducanumab (ENGAGE) | Change in CDR-SB at 78 weeks | +0.03 (2% worsening of decline) | 0.833 | ADAS-Cog13, ADCS-ADL-MCI | Did Not Meet Primary Endpoint[1][2] |
| Lecanemab (Clarity AD) | Change in CDR-SB at 18 months | -0.45 (27% slowing of decline)[3][4][5] | <0.001 | ADAS-Cog14, ADCS-MCI-ADL, Amyloid PET | Met Primary Endpoint[5] |
| Donanemab (TRAILBLAZER-ALZ 2) | Change in integrated Alzheimer's Disease Rating Scale (iADRS) | 35% slowing of decline | <0.001 | CDR-SB, ADAS-Cog13, Amyloid PET | Met Primary Endpoint[6][7][8][9] |
| Gantenerumab (GRADUATE I & II) | Change in CDR-SB at 116 weeks | I: -0.31; II: -0.19 (Not statistically significant)[10] | I: 0.10; II: 0.30[10] | Amyloid PET, CSF p-tau181 | Did Not Meet Primary Endpoint[10][11] |
| Semaglutide (EVOKE & EVOKE+) | Change in CDR-SB at 104 weeks | EVOKE: 0.06; EVOKE+: 0.15 (Not statistically significant)[12] | EVOKE: 0.7; EVOKE+: 0.4[12] | ADCS-ADL, MoCA, ADAS-Cog | Did Not Meet Primary Endpoint[12][13][14] |
Experimental Protocols: A Closer Look at Trial Design
Understanding the methodologies behind these clinical trials is paramount to interpreting their outcomes. Below are summaries of the key experimental protocols.
Aducanumab (EMERGE and ENGAGE Trials)
-
Objective: To evaluate the efficacy and safety of aducanumab in participants with early Alzheimer's disease.[1]
-
Study Design: Two Phase 3, multicenter, randomized, double-blind, placebo-controlled, parallel-group studies.[1]
-
Participants: Individuals aged 50-85 with a diagnosis of mild cognitive impairment due to Alzheimer's disease or mild Alzheimer's disease dementia, with confirmed amyloid pathology.[1][2]
-
Intervention: Intravenous infusions of aducanumab (high dose or low dose) or placebo every 4 weeks for 76 weeks.[1]
-
Primary Outcome Measure: Change from baseline in the Clinical Dementia Rating-Sum of Boxes (CDR-SB) score at week 78.[15]
Gantenerumab (GRADUATE I and II Trials)
-
Objective: To evaluate the efficacy and safety of gantenerumab in participants with early Alzheimer's disease.[11]
-
Study Design: Two Phase 3, randomized, double-blind, placebo-controlled studies.[11]
-
Participants: Individuals with mild cognitive impairment or mild dementia due to Alzheimer's disease.[11]
-
Intervention: Subcutaneous injections of gantenerumab or placebo every two weeks for 116 weeks.[11]
-
Primary Outcome Measure: Change from baseline in the CDR-SB score at week 116.[11]
Visualizing the Pathways and Processes
To better understand the concepts discussed, the following diagrams illustrate key signaling pathways and experimental workflows.
Discussion and Interpretation
The divergent outcomes of the anti-amyloid antibody trials underscore the critical distinction between statistical significance and clinical relevance. For instance, while Gantenerumab demonstrated a reduction in amyloid plaque burden, this did not translate into a statistically significant slowing of cognitive decline.[10][11] This raises pivotal questions about the amyloid hypothesis and whether amyloid clearance alone is a sufficient surrogate endpoint for clinical efficacy.
In the case of Aducanumab, the conflicting results of the EMERGE and ENGAGE trials presented a regulatory challenge.[1] The FDA's decision to grant accelerated approval based on the positive EMERGE trial and biomarker data, despite the negative ENGAGE trial, sparked considerable debate within the scientific community.[16][17] This highlights the complexities of interpreting trial data, especially when results are not consistently positive.
The failure of Semaglutide to meet its primary endpoints in the EVOKE and EVOKE+ trials, despite showing some positive changes in biomarkers, further illustrates that a biological effect does not always lead to a clinically meaningful outcome.[12][13][14]
References
- 1. Two Randomized Phase 3 Studies of Aducanumab in Early Alzheimer's Disease - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Aducanumab: evidence from clinical trial data and controversies - PMC [pmc.ncbi.nlm.nih.gov]
- 3. trial.medpath.com [trial.medpath.com]
- 4. Lecanemab - Wikipedia [en.wikipedia.org]
- 5. Eisai Presents Full Results of Lecanemab Phase 3 Confirmatory Clarity Ad Study for Early Alzheimer’s Disease At Clinical Trials On Alzheimer’s Disease (Ctad) Conference | Biogen [investors.biogen.com]
- 6. neuro-central.com [neuro-central.com]
- 7. Comment: Full results of donanemab Phase III trial presented [ukdri.ac.uk]
- 8. nia.nih.gov [nia.nih.gov]
- 9. Full Results from TRAILBLAZER-ALZ 2 Demonstrate Donanemab Effective at Slowing Cognitive and Functional Decline in Early Alzheimer Disease - - Practical Neurology [practicalneurology.com]
- 10. Gantenerumab Did Not Slow Cognitive Decline in People with Early Alzheimer Disease According to 2 Clinical Trial Results - - Practical Neurology [practicalneurology.com]
- 11. butler.org [butler.org]
- 12. medscape.com [medscape.com]
- 13. medcentral.com [medcentral.com]
- 14. The 5 Most Painful Clinical Trial Failures of 2025 - BioSpace [biospace.com]
- 15. Detailed Results of Phase 3 Trials of Aducanumab for Alzheimer’s Disease Presented - - Practical Neurology [practicalneurology.com]
- 16. Clinical trials of new drugs for Alzheimer disease: a 2020–2023 update - PMC [pmc.ncbi.nlm.nih.gov]
- 17. trial.medpath.com [trial.medpath.com]
Mind the Gap: A Guide to Navigating the Discrepancy Between In Vivo and In Vitro Results
For researchers, scientists, and drug development professionals, the journey from a promising in vitro result to a successful in vivo outcome is often fraught with challenges. A significant hurdle is the frequently observed discrepancy between how a potential therapeutic performs in a controlled laboratory setting versus within a complex living organism. This guide provides an objective comparison of in vivo and in vitro methodologies, supported by experimental data, to illuminate the reasons behind these differences and offer insights for bridging the gap.
The translation of preclinical research to clinical success hinges on a thorough understanding of why a compound that shows potent activity in a petri dish may exhibit diminished efficacy or unexpected toxicity in an animal model. This disparity stems from the inherent limitations of in vitro systems in recapitulating the multifaceted biological environment of a living organism.
Key Factors Contributing to In Vivo vs. In Vitro Discrepancies
Several critical factors contribute to the often-observed divergence between in vitro and in vivo experimental outcomes:
-
Biological Complexity: Living organisms are intricate systems with complex interactions between organs, tissues, and various physiological factors. In contrast, in vitro models are simplified, controlled environments that lack this systemic complexity.[1] Factors such as the immune system, the microbiome, and hormonal regulation are absent in most in vitro setups but play a crucial role in the overall response to a therapeutic agent in vivo.[2]
-
Drug Metabolism and Pharmacokinetics (ADME): The absorption, distribution, metabolism, and excretion (ADME) of a drug within a living organism significantly influence its concentration and availability at the target site.[2] The liver, a primary site of drug metabolism, can chemically alter a compound, potentially reducing its efficacy or producing toxic metabolites—a process not accounted for in simple cell-based assays.[3][4]
-
Tumor Microenvironment (TME): In oncology research, the TME presents a significant variable. In vivo, tumors are not just a collection of cancer cells but a complex ecosystem that includes stromal cells, immune cells, blood vessels, and the extracellular matrix.[5][6][7] This microenvironment can influence drug penetration, cell signaling, and the development of resistance, aspects that are difficult to replicate in vitro.
-
Physiological Conditions: Factors such as pH, oxygen levels (hypoxia), and nutrient gradients can differ significantly between the controlled environment of an in vitro culture and the physiological conditions within a living organism.[3] These differences can impact cellular behavior and drug response.
-
Route of Administration and Formulation: The way a drug is delivered and its formulation can dramatically affect its bioavailability and, consequently, its in vivo efficacy.[8] These considerations are not relevant in in vitro experiments where the compound is directly applied to the cells.
Data Presentation: A Comparative Look at Anticancer Drugs
The following tables provide a snapshot of the quantitative differences observed between in vitro and in vivo studies for several common anticancer agents. It is important to note that direct comparisons can be challenging due to variations in experimental conditions, cell lines, and animal models used across different studies.
| Drug | Cancer Type/Cell Line | In Vitro IC50/GI50 | In Vivo Model | In Vivo Efficacy |
| Paclitaxel | Lung Cancer (A549, NCI-H23, NCI-H460, DMS-273) | 4 - 24 nM[2] | Subcutaneous Xenografts (Nude Mice) | Significant tumor growth inhibition at 12 and 24 mg/kg/day[2] |
| Breast Cancer (SK-BR-3, MDA-MB-231, T-47D) | 2.5 - 7.5 nM[9][10] | N/A | N/A | |
| Doxorubicin | Ovarian Cancer (SK-OV-3, HEY A8, A2780) | 4.8 - 7.6 nM (Dox-DNA-AuNP)[11] | SK-OV-3 Xenograft Mice | ~2.5 times higher tumor growth inhibition rate than free Dox[11] |
| Colon Cancer (C26/DOX - resistant) | 40.0 µM[7] | C26/DOX-bearing mice | Similar antitumor effect to non-resistant cells with PEG liposomal DOX[7] | |
| Sorafenib | Glioblastoma (LN229, U87) | 1 - 2 µM[5] | Orthotopic Glioblastoma Model (Nude Mice) | Inhibition of tumor growth |
| Hepatocellular Carcinoma (HepG2, HuH-7) | ~6 µmol/L[8] | HuH-7 Xenograft Mice | 40% decrease in tumor growth at 40 mg/kg/day[8] | |
| Osteosarcoma (7 cell lines) | Varies by cell line (See Table 2 in source)[12] | N/A | N/A | |
| Gefitinib | Non-Small Cell Lung Cancer (HCC827/GR - resistant) | 15.47 ± 0.39 µM[13] | Xenografted Nude Mouse Model | Combination with genistein showed significant tumor growth inhibition[14] |
| Non-Small Cell Lung Cancer (A549) | IC50 for GEF-NPs: 37.8 µg/mL (24h), 8.1 µg/mL (48h)[4] | A549 Tumor-bearing Nude Mice | GEF-NPs showed significant antitumor activity compared to free GEF[4] |
Experimental Protocols: A Closer Look at Methodology
To appreciate the differences in experimental outcomes, it is crucial to understand the methodologies employed in both in vitro and in vivo studies.
In Vitro Cytotoxicity Assay: MTT Protocol
The MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) assay is a widely used colorimetric method to assess cell viability.
-
Cell Seeding: Plate cells in a 96-well plate at a predetermined density and allow them to adhere overnight.
-
Compound Treatment: Treat the cells with a range of concentrations of the test compound and incubate for a specified period (e.g., 24, 48, or 72 hours).
-
MTT Addition: Add MTT solution to each well and incubate for 2-4 hours. Metabolically active cells will reduce the yellow MTT to purple formazan crystals.
-
Solubilization: Add a solubilizing agent (e.g., DMSO or isopropanol) to dissolve the formazan crystals.
-
Absorbance Reading: Measure the absorbance of the solution at a specific wavelength (typically 570 nm) using a microplate reader. The intensity of the purple color is proportional to the number of viable cells.
In Vivo Efficacy Study: Xenograft Model Protocol
Xenograft models, where human tumor cells are implanted into immunodeficient mice, are a common in vivo platform for evaluating anticancer agents.
-
Cell Preparation: Culture and harvest a sufficient number of cancer cells. Resuspend the cells in a suitable medium, sometimes mixed with Matrigel to support tumor formation.
-
Animal Implantation: Subcutaneously inject the cancer cell suspension into the flank of immunodeficient mice (e.g., nude or SCID mice).
-
Tumor Growth Monitoring: Allow the tumors to grow to a palpable size. Measure the tumor volume regularly using calipers.
-
Drug Administration: Once tumors reach a specified size, randomize the animals into control and treatment groups. Administer the test compound according to the planned dose, schedule, and route of administration (e.g., oral, intravenous, intraperitoneal).
-
Efficacy Evaluation: Continue to monitor tumor volume and the general health of the animals throughout the study. At the end of the study, euthanize the animals and excise the tumors for further analysis (e.g., weight, histology, biomarker analysis).
Mandatory Visualizations
To further illustrate the concepts discussed, the following diagrams provide a visual representation of key biological pathways and experimental workflows.
Caption: A simplified workflow illustrating the progression from in vitro screening to in vivo validation.
Caption: Interactions between cancer cells and components of the tumor microenvironment.
Caption: A simplified overview of a drug's journey through the body, highlighting the role of the liver.
References
- 1. The NCI-60 screen and COMPARE algorithm as described by the original developers. - NCI [dctd.cancer.gov]
- 2. Anti-tumor efficacy of paclitaxel against human lung cancer xenografts - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. In vitro and in vivo antitumor effect of gefitinib nanoparticles on human lung cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Sorafenib exerts anti-glioma activity in vitro and in vivo - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Sorafenib | Cell Signaling Technology [cellsignal.com]
- 7. In vivo anti-tumor effect of PEG liposomal doxorubicin (DOX) in DOX-resistant tumor-bearing mice: Involvement of cytotoxic effect on vascular endothelial cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Sorafenib inhibits proliferation and invasion of human hepatocellular carcinoma cells via up-regulation of p53 and suppressing FoxM1 - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Cytotoxic studies of paclitaxel (Taxol) in human tumour cell lines - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. In Vivo and In Vitro Anticancer Activity of Doxorubicin-loaded DNA-AuNP Nanocarrier for the Ovarian Cancer Treatment - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Sorafenib blocks tumour growth, angiogenesis and metastatic potential in preclinical models of osteosarcoma through a mechanism potentially involving the inhibition of ERK1/2, MCL-1 and ezrin pathways - PMC [pmc.ncbi.nlm.nih.gov]
- 13. In Vitro and in Vivo Efficacy of NBDHEX on Gefitinib-resistant Human Non-small Cell Lung Cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Synergistic inhibitory effects by the combination of gefitinib and genistein on NSCLC with acquired drug-resistance in vitro and in vivo - PubMed [pubmed.ncbi.nlm.nih.gov]
A Head-to-Head Comparison of Data Visualization Software for Scientific Research
In the data-intensive fields of scientific research, drug development, and clinical trials, the ability to effectively visualize complex datasets is paramount. The right software can illuminate hidden patterns, facilitate groundbreaking discoveries, and accelerate the journey from lab to clinic. This guide provides a comparative analysis of four leading data visualization platforms: GraphPad Prism, OriginPro, Tableau, and Spotfire. We delve into their features, performance, and pricing, offering researchers, scientists, and drug development professionals the insights needed to select the optimal tool for their specific needs.
Quantitative Feature and Pricing Analysis
To aid in a direct comparison, the following tables summarize the key quantitative aspects of each software, including pricing structures and core functionalities relevant to a scientific audience.
Table 1: Pricing Comparison
| Feature | GraphPad Prism | OriginPro | Tableau | Spotfire |
| Individual Annual Subscription (Academic) | ~$260[1] | ~ | ~$840 (Creator License)[3][4] | ~$3,000 (Analytics User)[5] |
| Individual Annual Subscription (Corporate) | ~$520[1] | ~$435 (Annual)[2] | ~$840 (Creator License)[3][4] | ~$10,000 (Data Science User)[5] |
| Student Pricing | ~$142 (Annual)[1] | ~ | Not explicitly offered for individuals | Not explicitly offered for individuals |
| Free Trial | 30-day free trial available[6] | Trial version available[2] | 14-day free trial available[3] | 30-day free trial available[5] |
Table 2: Feature Comparison for Scientific Applications
| Feature | GraphPad Prism | OriginPro | Tableau | Spotfire |
| Core Strengths | Statistical analysis, curve fitting, and graphing for biological data.[6][7][8] | Advanced data analysis and graphing for physical sciences and engineering, including spectroscopy.[9] | Interactive dashboards and business intelligence for large and diverse datasets, including clinical trial data.[10][11] | Visual analytics for complex scientific data, including genomics and biomarker discovery.[12][13][14] |
| Statistical Analysis | Extensive library of statistical tests (t-tests, ANOVA, regression), designed for scientists.[7][15] | Comprehensive statistical analysis tools, including advanced options like principal component analysis for spectroscopy.[16] | Strong statistical functionalities, with the ability to integrate with R and Python for more advanced analyses. | Robust statistical analysis capabilities, including predictive analytics.[17] |
| Curve Fitting | User-friendly nonlinear regression, including dose-response curves (IC₅₀/EC₅₀).[8] | Advanced curve fitting and peak analysis tools.[18] | Can perform basic curve fitting, but often requires calculated fields or integration with other tools for advanced analysis. | Capable of advanced curve fitting and modeling, particularly for scientific data. |
| Data Handling | Best for structured, tabular data from lab experiments. | Efficiently handles large datasets, including those from spectroscopy and chromatography.[9] | Excellent for handling very large and diverse datasets from multiple sources.[19][20] | Optimized for large and complex scientific datasets, including genomic and chemical data.[12] |
| Ease of Use | Highly intuitive and user-friendly, even for those without extensive statistical knowledge.[7] | Steeper learning curve compared to Prism, but offers more advanced customization. | Known for its user-friendly drag-and-drop interface for creating interactive dashboards.[21] | Can have a significant learning curve for complex analytics.[5] |
| Publication Quality Graphics | A primary focus, with extensive options for creating high-quality graphs for scientific publications.[6][15] | Produces high-quality, customizable graphs suitable for publication.[18] | Can create visually appealing and interactive dashboards, but may require more effort to format for traditional publications. | Generates high-impact visualizations suitable for reports and presentations.[14] |
Experimental Protocols: Methodologies for Software Evaluation
To provide a practical framework for comparing these software packages, we outline two detailed experimental protocols that reflect common tasks in drug development and life sciences research.
Experimental Protocol 1: Dose-Response Curve Analysis and IC50 Determination
Objective: To assess the ease of use and accuracy of each software in analyzing a typical dose-response dataset from a drug screening experiment.
Methodology:
-
Data Import: A CSV file containing two columns, "Concentration (nM)" and "Inhibition (%)", will be imported into each software. The dataset will contain a concentration series of a test compound and the corresponding measured inhibition of a target enzyme.
-
Data Visualization: A scatter plot of Inhibition vs. Log(Concentration) will be generated.
-
Nonlinear Regression: A four-parameter logistic (4PL) model will be fitted to the data to generate a dose-response curve.
-
IC50 Calculation: The software's built-in functions will be used to calculate the half-maximal inhibitory concentration (IC50) from the fitted curve.
-
Graph Customization: The final graph will be customized for publication, including labeling axes, adding a title, and adjusting the appearance of the curve and data points.
-
Evaluation Criteria: The software will be evaluated based on the time taken to complete the task, the clarity of the steps involved, the accuracy of the IC50 calculation, and the quality of the final graph.
Experimental Protocol 2: Visualization of Gene Expression Data from a Microarray Experiment
Objective: To evaluate the capability of each software to visualize and identify patterns in a high-dimensional gene expression dataset.
Methodology:
-
Data Import: A tab-delimited text file containing gene expression data from a microarray experiment will be imported. The file will include columns for Gene ID, Fold Change, and p-value for multiple experimental conditions.
-
Data Filtering: The dataset will be filtered to include only genes with a p-value < 0.05 and an absolute Fold Change > 2.
-
Volcano Plot Generation: A volcano plot will be created with -Log10(p-value) on the y-axis and Log2(Fold Change) on the x-axis.
-
Interactive Exploration: The interactive features of the software will be used to identify and label significantly up- and down-regulated genes on the plot.
-
Heatmap Generation: A heatmap will be created to visualize the expression patterns of the significantly regulated genes across the different experimental conditions.
-
Evaluation Criteria: The software will be assessed on its ability to handle and filter large datasets, the ease of creating specialized plots like volcano plots and heatmaps, the effectiveness of its interactive exploration tools, and the clarity of the final visualizations.
Visualizing Workflows and Relationships
To further illustrate the concepts discussed, the following diagrams were created using the DOT language and rendered with Graphviz.
References
- 1. How to Buy - GraphPad [graphpad.com]
- 2. 360quadrants.com [360quadrants.com]
- 3. Tableau Pricing: How Much It Costs and the Hidden Costs for Data Analysts | Mode [mode.com]
- 4. julius.ai [julius.ai]
- 5. softwareconnect.com [softwareconnect.com]
- 6. construction.toolsinfo.com [construction.toolsinfo.com]
- 7. theenorm.com [theenorm.com]
- 8. collaborativedrug.com [collaborativedrug.com]
- 9. Origin for Spectroscopy [originlab.com]
- 10. tableau.com [tableau.com]
- 11. tableau.com [tableau.com]
- 12. Tibco Spotfire chosen to improve quality of genomics analyses | Scientific Computing World [scientific-computing.com]
- 13. spotfire.com [spotfire.com]
- 14. appliedclinicaltrialsonline.com [appliedclinicaltrialsonline.com]
- 15. Prism - GraphPad [graphpad.com]
- 16. Help Online - Apps - Principal Component Analysis for Spectroscopy(Pro) [originlab.com]
- 17. revvitysignals.com [revvitysignals.com]
- 18. selecthub.com [selecthub.com]
- 19. hopara.io [hopara.io]
- 20. computersciencejournals.com [computersciencejournals.com]
- 21. decisionfoundry.com [decisionfoundry.com]
Unsuccessful Validation of a Novel Biomarker: A Comparative Analysis of Urinary Apolipoprotein A1 and NMP22 for Bladder Cancer Detection
For Researchers, Scientists, and Drug Development Professionals
The quest for non-invasive, accurate biomarkers is a critical endeavor in oncology. Early and reliable detection of bladder cancer, for instance, can significantly improve patient outcomes. While numerous candidates are identified in the discovery phase, the path to clinical validation is fraught with challenges, and many promising biomarkers fail to demonstrate sufficient clinical utility to replace or augment existing standards. This guide provides a comparative analysis of urinary Apolipoprotein A1 (ApoA-1), a biomarker that has shown initial promise but has not been successfully validated for widespread clinical use, against the established, FDA-approved Nuclear Matrix Protein 22 (NMP22) test.
Performance Comparison: ApoA-1 vs. NMP22
The clinical utility of a biomarker is primarily determined by its sensitivity and specificity. While initial studies on urinary ApoA-1 suggested its potential as a diagnostic marker for bladder cancer, subsequent and broader evaluations have not consistently demonstrated superiority over established methods, leading to its lack of widespread adoption. In contrast, NMP22, while also possessing limitations, has a more established performance profile and has received regulatory approval.
| Biomarker | Sensitivity | Specificity | Overall Accuracy |
| Apolipoprotein A1 (ApoA-1) | 70.83% - 90.7%[1][2] | 85% - 92.85%[1][3][4] | Not widely reported |
| NMP22 (BladderChek) | 56% (pooled)[5] | 88% (pooled)[5] | 83.7%[6] |
Note: The performance of both biomarkers can vary depending on the study population, tumor grade, and stage. For instance, the sensitivity of the NMP22 test increases with higher tumor grade and stage[5]. Some studies have indicated that ApoA-1 may have better sensitivity for low-grade tumors compared to some other urinary biomarkers[2]. However, the lack of large-scale, multi-center validation studies for ApoA-1 in diverse populations remains a significant hurdle to its clinical implementation.
Experimental Workflows
A critical aspect of biomarker validation is the reproducibility and standardization of the assay. The methodologies for detecting ApoA-1 and NMP22 in urine are based on established immunoassay principles.
References
- 1. banglajol.info [banglajol.info]
- 2. Apolipoprotein A1 as a novel urinary biomarker for diagnosis of bladder cancer: A systematic review and meta-analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 3. bahrainmedicalbulletin.com [bahrainmedicalbulletin.com]
- 4. bahrainmedicalbulletin.com [bahrainmedicalbulletin.com]
- 5. Evaluation of the NMP22 BladderChek test for detecting bladder cancer: a systematic review and meta-analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 6. content.veeabb.com [content.veeabb.com]
Safety Operating Guide
Navigating the Labyrinth: A Comprehensive Guide to Proper Chemical Disposal in the Laboratory
For researchers, scientists, and drug development professionals, the meticulous management of chemical waste is not merely a regulatory hurdle, but a cornerstone of a safe and ethical research environment. This guide provides essential, step-by-step procedures for the proper disposal of laboratory chemicals, ensuring the safety of personnel, the protection of the environment, and compliance with stringent regulations. By fostering a culture of safety and responsibility, laboratories can build deep trust and establish themselves as leaders in chemical handling and stewardship.
The Critical Importance of Proper Disposal
Improper disposal of chemical waste can lead to severe consequences, including environmental contamination, costly fines, and potential legal action.[1] Adherence to established protocols is paramount for mitigating risks such as fires, toxic exposures, and dangerous chemical reactions.[1] A robust waste management plan is a critical component of any laboratory's Chemical Hygiene Plan and is mandated by regulatory bodies such as the Environmental Protection Agency (EPA) and the Occupational Safety and Health Administration (OSHA).[1][2][3]
Quantitative Overview of Laboratory Waste
While precise figures vary between institutions and research focus, laboratory waste generation is a significant logistical and financial consideration. A substantial portion of this waste is classified as hazardous, necessitating specialized handling and disposal.
| Waste Stream Category | Common Examples | Estimated Percentage of Total Laboratory Waste (by volume) | Key Disposal Considerations |
| Non-Hazardous Solid Waste | Paper towels, non-contaminated gloves, packaging materials | 40-60% | Can typically be disposed of in regular trash, but segregation from contaminated materials is crucial.[4] |
| Hazardous Solid Chemical Waste | Contaminated gloves, pipette tips, absorbent materials from spills, solid chemical reagents.[5] | 10-20% | Must be collected in designated, labeled, and compatible containers. Requires disposal through a licensed hazardous waste vendor.[5] |
| Hazardous Liquid Chemical Waste | Spent solvents (halogenated and non-halogenated), acidic and basic solutions, reaction mixtures, cleaning solutions.[5] | 20-30% | Segregation by chemical compatibility is critical to prevent dangerous reactions.[6] Must be collected in sealed, leak-proof containers.[7] |
| Sharps Waste (Chemically Contaminated) | Needles, scalpels, broken glass contaminated with hazardous chemicals.[8] | <5% | Must be collected in puncture-resistant containers specifically designated for chemically contaminated sharps.[8] |
| Universal Waste | Batteries, fluorescent lamps, mercury-containing equipment.[9] | <5% | Subject to less stringent regulations than hazardous waste but cannot be disposed of in regular trash. Requires specific recycling or disposal pathways.[9] |
Note: Percentages are estimates and can vary significantly based on the nature of the research conducted. Research facilities can produce up to 12 times more waste per square foot than office spaces, with laboratories generating as much as 5.5 million metric tons of plastic waste annually.[10]
Core Principles of Chemical Waste Management
A successful chemical waste management program is built on a foundation of clear, consistent procedures. The following principles should be integrated into all laboratory operations:
-
Identification and Categorization: The first and most critical step is the accurate identification and categorization of all chemical waste.[11] Waste is generally classified based on its characteristics: ignitability, corrosivity, reactivity, and toxicity.[1] The EPA further categorizes hazardous wastes into F, K, P, and U lists based on their source and chemical composition.[1][5]
-
Segregation: Never mix incompatible waste streams.[6][12] Mixing can lead to violent chemical reactions, the generation of toxic gases, or explosions. Halogenated and non-halogenated solvents, for example, should always be collected in separate containers as their disposal methods and costs differ significantly.[6] Acids and bases should also be stored separately.[13]
-
Containment: Use appropriate, clearly labeled containers for each type of waste.[11] Containers must be compatible with the chemicals they hold; for instance, hydrofluoric acid should never be stored in glass containers.[14] All containers must be kept closed except when adding waste and should be stored in secondary containment to prevent spills.[6][12]
-
Labeling: Every waste container must be clearly labeled with the words "Hazardous Waste," the full chemical name(s) of the contents (no abbreviations), the associated hazards (e.g., flammable, corrosive), and the date of accumulation.[6][12]
-
Storage: Designated satellite accumulation areas (SAAs) should be established at or near the point of waste generation.[15] These areas must be under the direct control of laboratory personnel.[16] There are strict limits on the volume of waste that can be accumulated and the timeframe for storage before it must be moved to a central accumulation area (CAA).[9]
Experimental Protocols for Common Disposal Procedures
Adherence to detailed, step-by-step protocols is essential for ensuring the safe handling and disposal of chemical waste.
Protocol 1: Neutralization of Acidic Waste
Objective: To safely neutralize acidic waste to a pH between 5.5 and 9.0 for compliant drain disposal (where permitted by local regulations and for solutions that do not contain other hazardous constituents).[17][18]
Materials:
-
Acidic waste solution
-
Appropriate neutralizing agent (e.g., sodium bicarbonate, sodium hydroxide, calcium hydroxide)[11][12][17]
-
Large, chemical-resistant container (e.g., polyethylene or polypropylene)
-
Stir bar and stir plate
-
pH meter or pH paper
-
Personal Protective Equipment (PPE): chemical splash goggles, face shield, acid-resistant gloves, lab coat
Procedure:
-
Don appropriate PPE.
-
Work in a well-ventilated fume hood.
-
Place a large container with a stir bar on a stir plate.
-
Slowly and cautiously add the acidic waste to a large volume of cold water in the container. A 1:10 ratio of acid to water is a safe starting point.[17] Always add acid to water, never the other way around, to avoid a violent exothermic reaction. [18]
-
Begin stirring the diluted acid solution.
-
Slowly add the neutralizing agent in small increments. Be prepared for gas evolution (effervescence) if using sodium bicarbonate.
-
Monitor the pH of the solution continuously with a pH meter or periodically with pH paper.
-
Continue adding the neutralizing agent until the pH is stable within the target range of 5.5-9.0.[17][18]
-
Once neutralized, the solution can be disposed of down the drain with copious amounts of running water, provided it does not contain any other regulated hazardous materials and is in accordance with local wastewater regulations.[8][17]
-
Record the neutralization procedure in the laboratory waste log.
Protocol 2: Disposal of Flammable Solvents
Objective: To safely collect and store flammable solvent waste for disposal by a licensed hazardous waste vendor.
Materials:
-
Flammable solvent waste
-
Approved, labeled hazardous waste container (typically a safety can or a chemically-resistant bottle with a screw cap)
-
Funnel
-
Secondary containment bin
-
PPE: chemical splash goggles, solvent-resistant gloves (e.g., nitrile for incidental contact, thicker gloves for handling larger volumes), flame-resistant lab coat
Procedure:
-
Don appropriate PPE.
-
Perform all transfers of flammable solvents in a well-ventilated fume hood, away from any potential ignition sources (e.g., hot plates, open flames, electrical equipment). [19]
-
Place the designated flammable solvent waste container in a secondary containment bin.
-
Using a funnel, carefully pour the solvent waste into the container.
-
Do not fill the container to more than 90% of its capacity to allow for vapor expansion.[14]
-
Securely close the container cap immediately after adding waste.
-
Ensure the hazardous waste label is complete and accurate, listing all solvent components and their approximate percentages.
-
Store the sealed container in a designated, well-ventilated satellite accumulation area, away from incompatible materials such as oxidizers.[19] Flammable waste is best stored in a fire-rated cabinet.[8]
-
When the container is full or has been in accumulation for the maximum allowed time, arrange for pickup by your institution's Environmental Health and Safety (EHS) department or a licensed hazardous waste disposal company.[20]
Visualizing Disposal Workflows and Logical Relationships
Clear visual aids are invaluable for reinforcing proper procedures and decision-making processes in the laboratory. The following diagrams, created using Graphviz, illustrate key workflows.
References
- 1. ehs.princeton.edu [ehs.princeton.edu]
- 2. Laboratory Safety Manual | Environment, Health and Safety [ehs.cornell.edu]
- 3. Laboratory Safety Manual | UW Environmental Health & Safety [ehs.washington.edu]
- 4. MedicalLab Management Magazine [medlabmag.com]
- 5. Common Hazardous Wastes Found in Laboratories [emsllcusa.com]
- 6. vumc.org [vumc.org]
- 7. acs.org [acs.org]
- 8. Hazardous Waste Disposal Guide: Research Safety - Northwestern University [researchsafety.northwestern.edu]
- 9. Managing Hazardous Chemical Waste in the Lab | Lab Manager [labmanager.com]
- 10. Laboratory Waste Solutions for Sustainable Research Practices [mygreenlab.org]
- 11. How to Dispose of Acid Safely: A Step-by-Step Guide [greenflow.com]
- 12. How to Treat Acid Waste: A Comprehensive Guide [greenflow.com]
- 13. Article - Laboratory Safety Manual - ... [policies.unc.edu]
- 14. How to Dispose of Chemical Waste in a Lab Correctly [gaiaca.com]
- 15. oehs.tulane.edu [oehs.tulane.edu]
- 16. ehs.utk.edu [ehs.utk.edu]
- 17. 7.1.2 Acid Neutralization | Environment, Health and Safety [ehs.cornell.edu]
- 18. esd.uga.edu [esd.uga.edu]
- 19. coral.washington.edu [coral.washington.edu]
- 20. chem.sites.mtu.edu [chem.sites.mtu.edu]
Personal protective equipment for handling Not found
Handling Unknown Materials in a Laboratory Setting: A Guide to Personal Protective Equipment and Safety Protocols
The fundamental principle when encountering an unidentified chemical substance is to treat it as hazardous until its properties are definitively known. This guide provides essential safety and logistical information for researchers, scientists, and drug development professionals on the appropriate personal protective equipment (PPE), and the operational and disposal plans required for handling such materials.
Levels of Protection: A Risk-Based Approach
The Occupational Safety and Health Administration (OSHA) outlines different levels of PPE to protect against chemical hazards. For an unknown substance, a conservative approach is mandated, starting with a high level of protection that can be adjusted only once more information is gathered.
-
Level A Protection: This is the highest level of respiratory, skin, and eye protection and should be considered in situations with a high potential for splashes, immersion, or exposure to unexpected vapors or gases.[1][2] This includes a fully encapsulating chemical-protective suit, a self-contained breathing apparatus (SCBA), and both inner and outer chemical-resistant gloves.[2]
-
Level B Protection: Required when the highest level of respiratory protection is needed but a lesser level of skin protection is sufficient.[1] This typically involves an SCBA, hooded chemical-resistant clothing, and inner and outer chemical-resistant gloves.[2][3]
-
Level C Protection: Used when the atmospheric contaminants are known and the criteria for using an air-purifying respirator are met.[3] This level includes a full-face or half-mask air-purifying respirator, hooded chemical-resistant clothing, and chemical-resistant gloves.[3]
-
Level D Protection: This is the minimum protection required and is used for nuisance-level contamination only.[2][4] It typically consists of coveralls and safety footwear.[4] Level D is not appropriate for handling unknown chemicals.[2]
For initial site entries or when dealing with a completely unidentified substance, Level B protection is the minimum recommended starting point until the hazards can be better characterized.[3]
Detailed Personal Protective Equipment (PPE) Specifications
The selection of specific PPE components is critical and should be based on a thorough risk assessment.
Eye and Face Protection:
-
Chemical Splash Goggles: These are essential to provide optimal protection against chemical splashes and should be worn at all times.[1]
-
Face Shields: Worn in conjunction with goggles, face shields offer an additional layer of protection for the entire face from splashes of corrosive or unknown liquids.[4][5]
Respiratory Protection: The appropriate respirator depends on the potential for airborne contaminants. For unknown substances, an atmosphere-supplying respirator is the safest choice.
-
Self-Contained Breathing Apparatus (SCBA): Provides the highest level of respiratory protection by supplying clean air from a portable source.[2]
-
Air-Purifying Respirators (APRs): Can only be used if the identity and concentration of the contaminant are known and there is sufficient oxygen.[6]
Skin and Body Protection:
-
Gloves: No single glove material protects against all chemicals.[7] For an unknown substance, layering gloves (double gloving) with two different materials is a common practice.[7] A combination of a robust outer glove and a dexterous inner glove is often used.
-
Laboratory Coats and Aprons: A chemical-resistant, flame-resistant lab coat is a baseline requirement. A chemical-resistant apron should be worn over the lab coat for added protection.[5]
-
Chemical Protective Clothing: This can range from splash suits to fully encapsulating suits, depending on the assessed risk level.[1][2]
Foot Protection:
-
Chemical-Resistant Boots: Steel-toe and shank boots are necessary to protect against physical and chemical hazards.[2]
Quantitative Data for PPE Selection
The following tables provide quantitative data to aid in the selection of appropriate PPE.
Table 1: Glove Material Chemical Resistance and Breakthrough Times
This table offers a general guide to the breakthrough times for common glove materials against various chemical classes. "Breakthrough time" is the time it takes for a chemical to permeate through the glove material.[7] For unknown chemicals, selecting a glove with broad resistance is recommended.
| Chemical Class | Natural Rubber | Neoprene | Butyl | Nitrile | PVC | Viton |
| Acids (Organic) | Fair | Good | Excellent | Not Rec. | Fair | Excellent |
| Alcohols | Good | Excellent | Excellent | Excellent | Good | Excellent |
| Aldehydes | Good | Good | Excellent | Fair | Good | Excellent |
| Aromatic Hydrocarbons | Not Rec. | Not Rec. | Not Rec. | Fair | Not Rec. | Excellent |
| Ketones | Good | Good | Excellent | Not Rec. | Fair | Excellent |
| Inorganic Acids | Good | Excellent | Excellent | Good | Good | Excellent |
Rating Key: Excellent: > 8 hours; Good: > 4 hours; Fair: > 1 hour; Not Recommended (Not Rec.): < 1 hour.[8] Data is generalized. Always consult the manufacturer's specific data for the gloves in use.[8][9]
Table 2: OSHA Assigned Protection Factors (APFs) for Respirators
The APF indicates the level of respiratory protection a respirator is expected to provide.[10][11][12] The Maximum Use Concentration (MUC) is calculated by multiplying the APF by the substance's exposure limit.[6][10]
| Respirator Type | Assigned Protection Factor (APF) |
| Half Mask Air-Purifying Respirator | 10[10][11] |
| Full Facepiece Air-Purifying Respirator | 50[10][11] |
| Loose-Fitting Facepiece Powered Air-Purifying Respirator (PAPR) | 25[11][13] |
| Hooded Powered Air-Purifying Respirator (PAPR) | 25 or 1,000 (manufacturer dependent)[11][13] |
| Full Facepiece Self-Contained Breathing Apparatus (SCBA) | 10,000 |
Operational and Disposal Plans
A systematic approach is crucial when handling and disposing of unknown materials.
Experimental Protocol: Initial Characterization of an Unknown Substance
-
Visual Assessment: From a safe distance and within a fume hood, observe the physical state (solid, liquid, gas), color, and any obvious properties (e.g., fuming, viscosity).
-
Container and Labeling Check: Examine the container for any residual labels, markings, or codes that might offer clues.
-
pH Test: If the substance is a liquid or can be dissolved in a neutral solvent, use pH paper to determine if it is a strong acid or base.[14]
-
Solubility Tests: Test the solubility of a small sample in water, ethanol, and hexane to understand its polarity.
-
Further Analysis (if deemed safe): Depending on the initial findings, more advanced analytical techniques like Fourier-Transform Infrared (FTIR) spectroscopy or Gas Chromatography-Mass Spectrometry (GC-MS) may be employed by trained personnel with appropriate containment.
Workflow for Handling Unknown Chemicals
The following diagram illustrates the logical workflow for safely managing an unknown chemical from initial discovery to final disposal.
Caption: Workflow for the safe handling of unknown chemical substances.
Decontamination and Disposal Plan
-
Decontamination: A formal decontamination plan should be in place before any handling begins.[15] All equipment and personnel in contact with the substance must be thoroughly decontaminated.[16] This may involve washing with appropriate solvents, followed by soap and water.[15] All materials used for decontamination, including rinsate, should be collected as hazardous waste.
-
Waste Containment: Place the unknown substance and any contaminated materials (e.g., gloves, absorbent pads) into a leak-proof, compatible container.[17]
-
Labeling: Clearly label the container as "Hazardous Waste - Unknown Material." Include any known information (e.g., "suspected solvent," "corrosive liquid pH < 2").
-
Disposal: It is crucial to note that you cannot dispose of a chemical without knowing its hazardous characteristics.[18] Contact your institution's Environmental Health and Safety (EHS) office or a certified hazardous waste disposal company.[19][20] They have the expertise to properly identify and manage the disposal of unknown waste.[21] Improper disposal, such as pouring it down the drain, is illegal and dangerous.[19][22]
References
- 1. realsafety.org [realsafety.org]
- 2. mscdirect.com [mscdirect.com]
- 3. Personal Protective Equipment (PPE) - CHEMM [chemm.hhs.gov]
- 4. hazmatschool.com [hazmatschool.com]
- 5. worksafe.nt.gov.au [worksafe.nt.gov.au]
- 6. 1910.134 - Respiratory protection. | Occupational Safety and Health Administration [osha.gov]
- 7. riskmanagement.sites.olt.ubc.ca [riskmanagement.sites.olt.ubc.ca]
- 8. allsafetyproducts.com [allsafetyproducts.com]
- 9. NIOSH Recommendations for Chemical Protective Clothing A-Z | NIOSH | CDC [archive.cdc.gov]
- 10. OSHA Assigned Protection Factors | Read Our Technical Brief | Moldex [moldex.com]
- 11. osha.gov [osha.gov]
- 12. natlenvtrainers.com [natlenvtrainers.com]
- 13. cdc.gov [cdc.gov]
- 14. How to Quickly Clean Up Unidentified Spills | Lab Manager [labmanager.com]
- 15. osha.gov [osha.gov]
- 16. acs.org [acs.org]
- 17. 5.4 Chemical Spill Procedures [ehs.cornell.edu]
- 18. youtube.com [youtube.com]
- 19. epa.gov [epa.gov]
- 20. wm.com [wm.com]
- 21. Homepage | Arcwood Environmental™ [arcwoodenviro.com]
- 22. calrecycle.ca.gov [calrecycle.ca.gov]
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
体外研究产品的免责声明和信息
请注意,BenchChem 上展示的所有文章和产品信息仅供信息参考。 BenchChem 上可购买的产品专为体外研究设计,这些研究在生物体外进行。体外研究,源自拉丁语 "in glass",涉及在受控实验室环境中使用细胞或组织进行的实验。重要的是要注意,这些产品没有被归类为药物或药品,他们没有得到 FDA 的批准,用于预防、治疗或治愈任何医疗状况、疾病或疾病。我们必须强调,将这些产品以任何形式引入人类或动物的身体都是法律严格禁止的。遵守这些指南对确保研究和实验的法律和道德标准的符合性至关重要。
