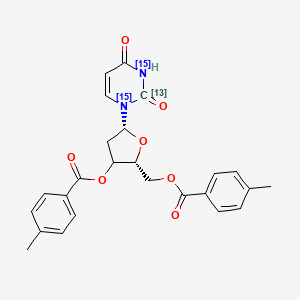
2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-13C,15N2
描述
BenchChem offers high-quality this compound suitable for many research applications. Different packaging options are available to accommodate customers' requirements. Please inquire for more information about this compound including the price, delivery time, and more detailed information at info@benchchem.com.
属性
分子式 |
C25H24N2O7 |
|---|---|
分子量 |
467.4 g/mol |
IUPAC 名称 |
[(2R,5R)-5-(2,4-dioxo(213C,1,3-15N2)pyrimidin-1-yl)-3-(4-methylbenzoyl)oxyoxolan-2-yl]methyl 4-methylbenzoate |
InChI |
InChI=1S/C25H24N2O7/c1-15-3-7-17(8-4-15)23(29)32-14-20-19(34-24(30)18-9-5-16(2)6-10-18)13-22(33-20)27-12-11-21(28)26-25(27)31/h3-12,19-20,22H,13-14H2,1-2H3,(H,26,28,31)/t19?,20-,22-/m1/s1/i25+1,26+1,27+1 |
InChI 键 |
PHIPERUMORAWER-RGVDKAPBSA-N |
手性 SMILES |
CC1=CC=C(C=C1)C(=O)OC[C@@H]2C(C[C@@H](O2)[15N]3C=CC(=O)[15NH][13C]3=O)OC(=O)C4=CC=C(C=C4)C |
规范 SMILES |
CC1=CC=C(C=C1)C(=O)OCC2C(CC(O2)N3C=CC(=O)NC3=O)OC(=O)C4=CC=C(C=C4)C |
产品来源 |
United States |
Foundational & Exploratory
An In-depth Technical Guide to the Chemical Properties of 2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-¹³C,¹⁵N₂
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive overview of the chemical properties, synthesis, purification, and applications of the isotopically labeled nucleoside analogue, 2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-¹³C,¹⁵N₂. While specific experimental data for this particular labeled compound is not extensively available in public literature, this document synthesizes information from vendor specifications, data from closely related analogues, and established chemical principles to serve as an authoritative resource.
Introduction: The Significance of Isotopically Labeled Nucleosides
Isotopically labeled compounds are indispensable tools in modern biomedical research and drug development. 2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-¹³C,¹⁵N₂ is a stable isotope-labeled derivative of 2'-deoxyuridine, a fundamental component of deoxyribonucleic acid (DNA). The incorporation of ¹³C and ¹⁵N isotopes into the uridine base provides a distinct mass signature, making it an invaluable internal standard for quantitative analysis by mass spectrometry (MS) and a probe for nuclear magnetic resonance (NMR) spectroscopy studies. The p-toluoyl protecting groups at the 3' and 5' positions of the deoxyribose sugar enhance its solubility in organic solvents and make it a key intermediate in the synthesis of modified oligonucleotides.
This guide will delve into the core chemical characteristics of this compound, offering insights into its structure, properties, and the rationale behind its application in sophisticated analytical and synthetic workflows.
Core Chemical and Physical Properties
The fundamental properties of 2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-¹³C,¹⁵N₂ are summarized below. These are based on information from various chemical suppliers.[1][2][3][4]
| Property | Value |
| Chemical Name | [(2R,5R)-5-(2,4-dioxo(2-¹³C,1,3-¹⁵N₂)pyrimidin-1-yl)-3-(4-methylbenzoyl)oxyoxolan-2-yl]methyl 4-methylbenzoate |
| Synonyms | 2'-Deoxyuridine 3',5'-Bis(4-methylbenzoate)-¹³C,¹⁵N₂; 2'-Deoxyuridine 3',5'-Di-p-toluate-¹³C,¹⁵N₂ |
| Molecular Formula | C₂₄¹³CH₂₄¹⁵N₂O₇ |
| Molecular Weight | 467.45 g/mol |
| Appearance | Off-White Powder |
| Storage Conditions | 2-8°C Refrigerator or Room Temperature[4] |
Solubility: While specific solubility data for the labeled compound is not published, the unlabeled analogue, 2-Deoxy-3,5-di-O-p-toluoyl-D-ribofuranosyl Chloride, is soluble in chloroform.[5] It is anticipated that 2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-¹³C,¹⁵N₂ will exhibit good solubility in a range of organic solvents such as dichloromethane (DCM), chloroform, and ethyl acetate, owing to the hydrophobic p-toluoyl groups.
Spectroscopic Characterization (Predicted)
Detailed experimental spectra for this specific isotopically labeled compound are not publicly available. However, based on its structure and data from related compounds, the following spectroscopic characteristics can be predicted.
Nuclear Magnetic Resonance (NMR) Spectroscopy
The ¹³C and ¹⁵N labels will introduce specific couplings that are observable in NMR spectra, providing unambiguous confirmation of the labeled positions.
-
¹H NMR: The proton spectrum will show characteristic signals for the deoxyribose sugar protons, the uracil base protons, and the p-toluoyl groups. Key signals would include the anomeric proton (H1') of the deoxyribose, the H6 proton of the uracil base, and the aromatic and methyl protons of the toluoyl groups. The coupling patterns of the protons on the uracil ring will be affected by the adjacent ¹⁵N atoms.
-
¹³C NMR: The ¹³C spectrum will be significantly influenced by the isotopic label at the C2 position of the uracil ring. This carbon will appear as a singlet with a chemical shift characteristic of a carbonyl group in a pyrimidine ring. The other carbon signals will correspond to the deoxyribose, the remaining uracil carbons, and the p-toluoyl groups.
-
¹⁵N NMR: Direct detection or indirect detection through heteronuclear correlation experiments (e.g., HMBC) would reveal two signals corresponding to the two nitrogen atoms in the uracil ring, confirming the isotopic labeling.
Mass Spectrometry (MS)
Mass spectrometry is a primary application for this compound, where it serves as an internal standard.
-
Electrospray Ionization (ESI-MS): In positive ion mode, the expected molecular ion peak would be [M+H]⁺ at m/z 468.5. Adducts with sodium [M+Na]⁺ at m/z 490.5 or potassium [M+K]⁺ at m/z 506.6 may also be observed. The isotopic labeling provides a clear mass shift from the unlabeled analogue.
-
Tandem Mass Spectrometry (MS/MS): Fragmentation of the molecular ion would be expected to yield characteristic product ions. Key fragmentation pathways would involve the cleavage of the glycosidic bond, leading to ions corresponding to the labeled uracil base and the di-toluoyl-deoxyribose moiety. The mass of the uracil fragment will reflect the ¹³C and ¹⁵N labels, making it a distinct marker for quantification.
Synthesis and Purification
A definitive, published protocol for the synthesis of 2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-¹³C,¹⁵N₂ is not available. However, a plausible synthetic route can be devised based on established methods for the synthesis of isotopically labeled pyrimidine nucleosides and the use of protected sugar intermediates.[6][7]
Representative Synthesis Protocol
The synthesis would likely involve the coupling of an isotopically labeled uracil base with a protected deoxyribose sugar, such as 2-deoxy-3,5-di-O-p-toluoyl-α-D-ribofuranosyl chloride.
Caption: Representative synthesis workflow for 2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-¹³C,¹⁵N₂.
Step-by-Step Methodology:
-
Silylation of Labeled Uracil: The isotopically labeled uracil (Uracil-¹³C,¹⁵N₂) is first silylated to increase its solubility and reactivity. This is typically achieved by refluxing with a silylating agent like hexamethyldisilazane (HMDS) and a catalyst such as trimethylsilyl chloride (TMSCl) or ammonium sulfate.
-
Glycosylation Reaction: The silylated uracil is then coupled with 2-deoxy-3,5-di-O-p-toluoyl-α-D-ribofuranosyl chloride in an appropriate aprotic solvent like acetonitrile. This reaction, a variation of the Hilbert-Johnson reaction, forms the N-glycosidic bond.
-
Work-up: Upon completion of the reaction, the mixture is quenched, and the crude product is extracted into an organic solvent. The organic layer is washed to remove unreacted starting materials and byproducts.
-
Purification: The crude product is purified to isolate the desired β-anomer from any unreacted starting materials and the α-anomer byproduct.
Purification Protocol: High-Performance Liquid Chromatography (HPLC)
Reverse-phase HPLC (RP-HPLC) is the method of choice for purifying protected nucleosides due to the hydrophobicity imparted by the p-toluoyl groups.
Caption: General workflow for the HPLC purification of the target compound.
Representative HPLC Conditions:
-
Column: C18 reverse-phase column (e.g., 5 µm particle size, 4.6 x 250 mm).
-
Mobile Phase A: Water.
-
Mobile Phase B: Acetonitrile.
-
Gradient: A linear gradient from approximately 50% B to 100% B over 20-30 minutes.
-
Flow Rate: 1.0 mL/min.
-
Detection: UV at 260 nm.
The exact gradient conditions would need to be optimized to achieve baseline separation of the product from impurities.
Applications in Research and Development
The primary utility of 2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-¹³C,¹⁵N₂ lies in its application as an internal standard and a synthetic precursor.
Internal Standard for Quantitative Mass Spectrometry
In quantitative bioanalysis, particularly in pharmacokinetic and metabolic studies, the use of a stable isotope-labeled internal standard is the gold standard. This compound can be added to biological samples (e.g., plasma, urine, tissue homogenates) at a known concentration before sample processing. As it is chemically identical to the analyte of interest (the unlabeled analogue), it co-elutes during chromatography and experiences similar matrix effects and ionization suppression in the mass spectrometer. By comparing the signal intensity of the analyte to that of the internal standard, precise and accurate quantification can be achieved.
Precursor in Oligonucleotide Synthesis
The p-toluoyl groups serve as protecting groups for the hydroxyl functions of the deoxyribose. This protected nucleoside can be further modified, for example, by phosphitylation at the 3'-hydroxyl group (after selective deprotection if necessary, though typically the protection scheme is designed for direct use) to create a phosphoramidite building block. This labeled phosphoramidite can then be incorporated into synthetic oligonucleotides at specific positions. These labeled oligonucleotides are crucial tools for:
-
NMR Structural Studies: The ¹³C and ¹⁵N labels facilitate advanced NMR experiments to determine the three-dimensional structure and dynamics of DNA and DNA-protein complexes.
-
Metabolic Flux Analysis: By introducing the labeled nucleoside into cellular systems, researchers can trace its metabolic fate, providing insights into nucleotide salvage pathways and DNA synthesis rates.[8]
Safety and Handling
-
Personal Protective Equipment (PPE): Wear standard laboratory attire, including a lab coat, safety glasses, and chemical-resistant gloves.
-
Handling: Avoid inhalation of dust and contact with skin and eyes. Handle in a well-ventilated area or in a fume hood.
-
Storage: Store in a tightly sealed container in a cool, dry place, as recommended by the supplier.
-
Disposal: Dispose of in accordance with local, state, and federal regulations for chemical waste.
Conclusion
2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-¹³C,¹⁵N₂ is a specialized chemical tool with significant potential in quantitative bioanalysis and nucleic acid research. Its stable isotopic labels provide the necessary properties for use as a high-fidelity internal standard, while its protected structure makes it a versatile intermediate for the synthesis of labeled oligonucleotides. This guide provides a foundational understanding of its chemical properties and applications, empowering researchers to effectively integrate this valuable compound into their experimental designs.
References
- 1. clearsynth.com [clearsynth.com]
- 2. medchemexpress.com [medchemexpress.com]
- 3. fishersci.fi [fishersci.fi]
- 4. pharmaffiliates.com [pharmaffiliates.com]
- 5. cdn.usbio.net [cdn.usbio.net]
- 6. researchgate.net [researchgate.net]
- 7. researchgate.net [researchgate.net]
- 8. An investigation by 1H NMR spectroscopy into the factors determining the beta:alpha ratio of the product in 2'-deoxynucleoside synthesis - PMC [pmc.ncbi.nlm.nih.gov]
The Cornerstone of Modern Life Sciences: A Technical Guide to the Synthesis and Application of ¹³C,¹⁵N Labeled Nucleosides
For the dedicated researcher in structural biology, drug development, and metabolic analysis, the ability to precisely track and quantify biological processes at the molecular level is paramount. Stable isotope labeling, particularly with Carbon-13 (¹³C) and Nitrogen-15 (¹⁵N), has emerged as an indispensable tool, offering unparalleled insights into the intricate world of nucleic acids. This guide provides a comprehensive technical overview of the synthesis of ¹³C,¹⁵N labeled nucleosides and their diverse applications, grounded in field-proven expertise and validated methodologies.
Part 1: The Strategic Synthesis of Labeled Nucleosides
The journey to harnessing the power of ¹³C,¹⁵N labeled nucleosides begins with their synthesis. The choice of synthetic strategy is a critical decision, dictated by the desired labeling pattern (uniform or site-specific), the scale of production, and the ultimate application. Two primary routes dominate the landscape: chemical synthesis and enzymatic (or chemo-enzymatic) synthesis.[1]
Chemical Synthesis: Precision and Versatility
Chemical synthesis offers the ultimate control over the placement of isotopic labels, allowing for the creation of virtually any desired isotopomer.[2] This precision is invaluable for detailed mechanistic studies and for assigning specific NMR signals. The cornerstone of chemical synthesis of oligonucleotides is the phosphoramidite method.[][4]
The Phosphoramidite Approach:
This robust, solid-phase synthesis method allows for the stepwise construction of DNA and RNA oligonucleotides.[][5] The process involves a cycle of four key steps:
-
Detritylation: Removal of the 5'-dimethoxytrityl (DMT) protecting group from the support-bound nucleoside.
-
Coupling: Addition of the next phosphoramidite monomer, activated by a catalyst like tetrazole.
-
Capping: Acetylation of any unreacted 5'-hydroxyl groups to prevent the formation of deletion mutants.[5]
-
Oxidation: Conversion of the unstable phosphite triester linkage to a stable phosphate triester.
Labeled nucleoside phosphoramidites are the key building blocks in this process.[][] These can be synthesized with ¹³C and/or ¹⁵N labels in either the nucleobase or the sugar moiety.
Experimental Protocol: A Generalized Phosphoramidite Coupling Cycle
Objective: To illustrate the fundamental steps of solid-phase oligonucleotide synthesis using phosphoramidite chemistry.
| Step | Reagent/Condition | Purpose |
| 1. Detritylation | 3% Trichloroacetic acid (TCA) in Dichloromethane (DCM) | Removes the 5'-DMT protecting group, exposing the 5'-hydroxyl for the next coupling reaction. |
| 2. Coupling | ¹³C,¹⁵N-labeled nucleoside phosphoramidite and Tetrazole in Acetonitrile | The labeled phosphoramidite is activated by tetrazole and couples to the free 5'-hydroxyl group of the growing oligonucleotide chain. |
| 3. Capping | Acetic Anhydride/N-Methylimidazole/Pyridine and THF | Acetylates any unreacted 5'-hydroxyl groups to prevent the formation of shorter, undesired sequences. |
| 4. Oxidation | Iodine/Water/Pyridine | Oxidizes the phosphite triester linkage to a more stable phosphate triester. |
The causality behind these steps is crucial for ensuring high-fidelity synthesis. The use of protecting groups is essential to prevent unwanted side reactions on the nucleobases and the 2'-hydroxyl group of ribose (in RNA synthesis).[4] The choice of protecting groups and deprotection strategies is a critical aspect of the overall synthetic design.
Enzymatic and Chemo-Enzymatic Synthesis: Nature's Efficiency
While chemical synthesis provides precision, enzymatic and chemo-enzymatic approaches offer significant advantages in terms of efficiency, particularly for the synthesis of uniformly labeled nucleic acids.[1][7][8] These methods leverage the high specificity and catalytic power of enzymes to produce labeled nucleoside triphosphates (NTPs) or directly incorporate them into DNA or RNA strands.[9]
Key Methodologies:
-
In Vitro Transcription: T7 RNA polymerase is widely used to synthesize uniformly labeled RNA from a DNA template using ¹³C,¹⁵N-labeled NTPs.[10]
-
Polymerase Chain Reaction (PCR): Labeled DNA can be produced by PCR using labeled deoxynucleoside triphosphates (dNTPs).[8][9]
-
Chemo-Enzymatic Synthesis: This hybrid approach combines the flexibility of chemical synthesis for creating labeled precursors with the efficiency of enzymatic reactions for subsequent steps.[11] For instance, a chemically synthesized labeled nucleobase can be enzymatically coupled to a ribose moiety and then phosphorylated to the corresponding NTP.[11][12]
This approach is particularly powerful for producing gram quantities of nucleotides with high yields.[11]
Workflow: Enzymatic Synthesis of Uniformly ¹³C,¹⁵N-Labeled RNA
References
- 1. isotope.com [isotope.com]
- 2. pubs.acs.org [pubs.acs.org]
- 4. twistbioscience.com [twistbioscience.com]
- 5. Synthesis of DNA/RNA and Their Analogs via Phosphoramidite and H-Phosphonate Chemistries - PMC [pmc.ncbi.nlm.nih.gov]
- 7. academic.oup.com [academic.oup.com]
- 8. Simple, efficient protocol for enzymatic synthesis of uniformly 13C, 15N-labeled DNA for heteronuclear NMR studies - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Synthesizing Stable Isotope-Labeled Nucleic Acids | Silantes [silantes.com]
- 10. isotope.com [isotope.com]
- 11. Chemo-enzymatic synthesis of selectively 13C/15N-labeled RNA for NMR structural and dynamics studies - PMC [pmc.ncbi.nlm.nih.gov]
- 12. benchchem.com [benchchem.com]
An In-Depth Technical Guide to the Physicochemical Properties of 3',5'-Di-O-toluoyl-2'-deoxyuridine
Introduction: The Strategic Role of Toluoyl Protection in Nucleoside Chemistry
In the field of medicinal chemistry and drug development, the precise synthesis of nucleoside analogues is a cornerstone for creating potent antiviral and antineoplastic agents. 2'-Deoxyuridine, a fundamental pyrimidine nucleoside, serves as a critical scaffold for many of these therapeutic molecules. However, its polyfunctional nature, specifically the presence of reactive hydroxyl groups at the 3' and 5' positions of the deoxyribose sugar, necessitates a strategic use of protecting groups to achieve regioselectivity in subsequent chemical modifications.
The toluoyl group, a derivative of benzoic acid, is an excellent choice for protecting these hydroxyl functions. Its aromatic character imparts crystallinity, often simplifying purification of intermediates by crystallization, while its ester linkage provides a balance of stability under various reaction conditions and susceptibility to clean, efficient cleavage when desired. This guide focuses on 3',5'-di-O-p-toluoyl-2'-deoxyuridine, a pivotal intermediate whose well-defined physical and chemical characteristics are essential for its reliable application in complex synthetic pathways. Understanding these properties is not merely an academic exercise; it is a prerequisite for robust process development, troubleshooting, and the successful synthesis of next-generation therapeutics. This document provides a comprehensive overview of its molecular structure, physicochemical parameters, spectroscopic profile, and practical methodologies for its synthesis and deprotection, tailored for researchers and drug development professionals.
Section 1: Molecular Structure and Core Physical Properties
The foundational characteristics of a synthetic intermediate dictate its handling, purification, and reaction kinetics. 3',5'-di-O-p-toluoyl-2'-deoxyuridine is a well-behaved compound under standard laboratory conditions, valued for its solid-state stability and predictable solubility profile.
Chemical Structure and Identifiers
The molecule consists of a 2'-deoxyuridine core where the hydroxyl groups at the 3' and 5' positions of the deoxyribose ring are protected as esters with p-toluic acid.
Caption: Chemical structure of 3',5'-di-O-p-toluoyl-2'-deoxyuridine.
Physicochemical Data Summary
The toluoyl groups render the molecule significantly more lipophilic than its parent nucleoside, which dictates its solubility primarily in organic solvents and its amenability to silica gel chromatography.
| Property | Value | Source(s) |
| IUPAC Name | 1-[(2R,4S,5R)-4-(4-methylbenzoyloxy)-5-[(4-methylbenzoyloxy)methyl]oxolan-2-yl]pyrimidine-2,4-dione | N/A |
| CAS Number | 4449-38-1 | |
| Molecular Formula | C₂₅H₂₄N₂O₇ | |
| Molecular Weight | 464.47 g/mol | N/A |
| Appearance | Off-White Powder | |
| Melting Point | Data not readily available in cited literature. | N/A |
| Solubility | Qualitatively soluble in ethyl acetate, dichloromethane, and chloroform. Expected to be soluble in DMSO and DMF. Insoluble in water. | [1] |
| Storage | 2-8°C, under inert atmosphere, desiccated. |
Section 2: Spectroscopic and Chromatographic Profile
Definitive structural confirmation of 3',5'-di-O-p-toluoyl-2'-deoxyuridine relies on a combination of spectroscopic techniques. The data presented here are consistent with those reported in peer-reviewed literature, providing a reliable benchmark for sample validation.[1]
Nuclear Magnetic Resonance (NMR) Spectroscopy
NMR is the most powerful tool for unambiguous structure elucidation. The p-toluoyl groups introduce characteristic aromatic signals and a downfield shift of the sugar protons at the 3' and 5' positions. Spectra are typically recorded in deuterated chloroform (CDCl₃).
| ¹H NMR (500 MHz, CDCl₃) | ¹³C NMR (126 MHz, CDCl₃) |
| Chemical Shift (δ, ppm) | Assignment |
| 8.29 | NH (Uracil) |
| 7.94, 7.90 | Aromatic (Toluoyl) |
| 7.53 | H6 (Uracil) |
| 7.30-7.24 | Aromatic (Toluoyl) |
| 6.40 | H1' (Anomeric) |
| 5.64-5.55 | H3', H5 (Uracil) |
| 4.73, 4.67 | H5'' |
| 4.54 | H4' |
| 2.74 | H2' |
| 2.44, 2.43 | CH₃ (Toluoyl) |
| 2.30 | H2'' |
| Data sourced from convenient syntheses of isotopically labeled pyrimidine 2´-deoxynucleosides and their 5-hydroxy oxidation products.[1] |
Mass Spectrometry (MS)
Electrospray Ionization Mass Spectrometry (ESI-MS) is used to confirm the molecular weight of the compound.
-
Calculated [M+H]⁺: 465.17
-
Observed [M+H]⁺: 465.44[1]
Chromatographic Behavior
During synthesis, reaction progress and purity are readily monitored by Thin Layer Chromatography (TLC) on silica gel plates. The compound is significantly less polar than unprotected deoxyuridine. For purification, silica gel column chromatography is effective, typically using a gradient of ethyl acetate in hexane.[1]
Section 3: Synthesis and Handling - A Practical Approach
The synthesis of 3',5'-di-O-p-toluoyl-2'-deoxyuridine is a robust and scalable process. The primary strategic consideration is the activation of the uracil base to facilitate glycosylation with a protected deoxyribose donor.
Experimental Rationale
The chosen synthetic route involves a Vorbrüggen glycosylation. The causality is as follows:
-
Silylation of Uracil: The uracil base is first treated with a silylating agent like N,O-bis(trimethylsilyl)acetamide (BSA). This crucial step enhances the nucleophilicity of the uracil nitrogen and increases its solubility in the organic solvent, preparing it for the subsequent coupling reaction.
-
Glycosylation: The silylated uracil is then coupled with a protected deoxyribose derivative, 3,5-di-O-(p-toluyl)-2-deoxy-D-ribofuranosyl chloride. This reaction is catalyzed by a Lewis acid, such as tin(IV) chloride (SnCl₄), which activates the anomeric carbon of the sugar, facilitating nucleophilic attack by the silylated uracil to form the desired β-anomer with high stereoselectivity.
-
Purification: The lipophilic nature of the toluoyl groups allows for straightforward purification via silica gel chromatography, separating the product from unreacted starting materials and reaction byproducts.
Step-by-Step Synthesis Protocol
This protocol is adapted from established literature procedures.[1]
Materials:
-
Uracil
-
N,O-bis(trimethylsilyl)acetamide (BSA)
-
3,5-di-O-(p-toluyl)-2-deoxy-D-ribofuranosyl chloride
-
Tin(IV) chloride (SnCl₄)
-
Anhydrous Acetonitrile (MeCN)
-
Ethyl Acetate (EtOAc)
-
Hexane
-
Saturated aqueous sodium bicarbonate (NaHCO₃)
-
Brine
-
Anhydrous sodium sulfate (Na₂SO₄)
-
Silica Gel
Procedure:
-
In a flame-dried flask under an inert atmosphere (e.g., Argon), suspend uracil (1.0 equivalent) in anhydrous acetonitrile.
-
Add N,O-bis(trimethylsilyl)acetamide (BSA) (2.5 equivalents) and stir the mixture at room temperature until the solution becomes clear.
-
In a separate flask, dissolve 3,5-di-O-(p-toluyl)-2-deoxy-D-ribofuranosyl chloride (1.2 equivalents) in anhydrous acetonitrile.
-
Add the solution of the chloro-sugar to the silylated uracil solution.
-
Cool the reaction mixture to 0 °C using an ice bath.
-
Slowly add a solution of SnCl₄ (1.2 equivalents) in anhydrous acetonitrile dropwise.
-
Allow the reaction to warm to room temperature and stir for 4-6 hours, monitoring progress by TLC.
-
Upon completion, quench the reaction by carefully adding saturated aqueous NaHCO₃.
-
Dilute the mixture with ethyl acetate and transfer to a separatory funnel.
-
Wash the organic layer sequentially with saturated aqueous NaHCO₃ and brine.
-
Dry the organic layer over anhydrous Na₂SO₄, filter, and concentrate under reduced pressure to obtain the crude product.
-
Purify the crude residue by silica gel column chromatography, eluting with a gradient of 50% to 100% ethyl acetate in hexane to afford 3',5'-di-O-p-toluoyl-2'-deoxyuridine as an off-white solid.
Section 4: Deprotection and Downstream Applications
The ultimate utility of 3',5'-di-O-p-toluoyl-2'-deoxyuridine lies in the facile removal of the toluoyl groups to unmask the 3' and 5' hydroxyls for further synthetic transformations.
Deprotection Workflow
Caption: Workflow for the deprotection of toluoyl groups.
Deprotection Protocol
The standard method for removing toluoyl esters is through base-catalyzed transesterification, typically using sodium methoxide (NaOMe) in methanol (MeOH). This method is highly efficient and proceeds under mild conditions.[2]
Materials:
-
3',5'-di-O-p-toluoyl-2'-deoxyuridine
-
Anhydrous Methanol (MeOH)
-
Sodium Methoxide (NaOMe) solution (e.g., 0.5 M in MeOH or freshly prepared)
-
Dowex® 50WX8 H⁺ resin or equivalent acidic resin
-
Dichloromethane (DCM)
Procedure:
-
Dissolve 3',5'-di-O-p-toluoyl-2'-deoxyuridine (1.0 equivalent) in anhydrous methanol.
-
Add a catalytic amount of sodium methoxide solution.
-
Stir the reaction at room temperature and monitor by TLC until the starting material is fully consumed.
-
Upon completion, neutralize the reaction by adding acidic resin (e.g., Dowex® H⁺) until the pH is neutral.
-
Filter off the resin and wash it with methanol.
-
Combine the filtrates and concentrate under reduced pressure.
-
The resulting residue, containing 2'-deoxyuridine, can be further purified if necessary (e.g., by recrystallization or chromatography) to remove the methyl p-toluate byproduct.
Conclusion
3',5'-di-O-p-toluoyl-2'-deoxyuridine is a cornerstone intermediate in the synthesis of modified nucleosides. Its well-defined characteristics—solid physical state, predictable spectroscopic signature, and robust synthetic and deprotection protocols—make it an invaluable tool for medicinal chemists. The strategic application of toluoyl protecting groups facilitates high-yield, stereoselective reactions and simplifies purification, underscoring the principle that effective protecting group strategy is fundamental to the successful construction of complex, biologically active molecules. This guide provides the foundational data and practical insights necessary for the confident and efficient use of this compound in demanding research and development environments.
References
The Architects of Precision: A Technical Guide to the Role of Protecting Groups in Oligonucleotide Synthesis
For Researchers, Scientists, and Drug Development Professionals
In the intricate world of synthetic biology and nucleic acid therapeutics, the automated chemical synthesis of oligonucleotides stands as a cornerstone technology. The ability to construct custom sequences of DNA and RNA with high fidelity is paramount. This feat of chemical precision is made possible by the strategic use of protecting groups – transient molecular shields that orchestrate the stepwise assembly of nucleotides. This guide, designed for the discerning researcher, delves into the core principles of protecting group chemistry in oligonucleotide synthesis, elucidating the causality behind experimental choices and providing a framework for understanding this self-validating system.
The Imperative of Protection: Ensuring Fidelity in a Stepwise Process
Solid-phase oligonucleotide synthesis, most commonly employing phosphoramidite chemistry, is a cyclical process. Each cycle, resulting in the addition of a single nucleotide to the growing chain, involves four key steps: deblocking, coupling, capping, and oxidation.[1] The success of this iterative process hinges on the precise control of reactivity at multiple functional groups within the nucleotide monomers. Without protection, the inherent reactivity of the 5'-hydroxyl group, the exocyclic amino groups of the nucleobases, and the phosphite/phosphate backbone would lead to a chaotic mixture of branched chains, incorrect linkages, and other unwanted side products.[2]
Protecting groups serve as temporary masks, ensuring that only the desired reaction occurs at the appropriate step.[3][4] An ideal protecting group strategy adheres to the principle of orthogonality , where each class of protecting group can be removed under specific conditions without affecting the others.[5][6] This allows for a highly controlled and sequential series of reactions, ultimately yielding the desired oligonucleotide sequence with high purity.
The 5'-Hydroxyl Guardian: The Dimethoxytrityl (DMT) Group
The 5'-hydroxyl group of the incoming nucleoside phosphoramidite is the point of chain elongation.[1] To prevent self-polymerization and to ensure a stepwise addition, this primary alcohol is protected, most commonly with the acid-labile 4,4'-dimethoxytrityl (DMT) group.[4][5][7][8]
The choice of the DMT group is a testament to elegant chemical design. Its bulky nature provides excellent steric hindrance, preventing unwanted reactions.[9] Crucially, it can be removed with high efficiency under mild acidic conditions, typically using trichloroacetic acid (TCA) or dichloroacetic acid (DCA) in a non-aqueous solvent like dichloromethane.[10][11] This deprotection step, often called detritylation, is the first step in each synthesis cycle.
A significant advantage of the DMT group is its use in real-time monitoring of synthesis efficiency. Upon cleavage, the DMT cation released into the solution has a strong orange color and a characteristic absorbance at 495 nm.[10][11] The intensity of this color is directly proportional to the number of successful coupling events in the preceding cycle, providing an immediate assessment of the synthesis performance.[12]
While highly effective, the acidic conditions required for DMT removal can pose a risk of depurination, especially for sensitive nucleosides.[13] This has led to the development of alternative 5'-hydroxyl protecting groups that can be removed under non-acidic conditions, although the DMT group remains the industry standard for most applications.[13][14]
Workflow: The Synthesis Cycle
Caption: The four-step phosphoramidite synthesis cycle.
Shielding the Nucleobases: Preventing Unwanted Reactivity
The exocyclic amino groups of adenine (A), guanine (G), and cytosine (C) are nucleophilic and must be protected to prevent them from reacting with the activated phosphoramidite during the coupling step.[8][10] Thymine (T) and uracil (U) lack exocyclic amino groups and therefore do not require protection.[5][15]
The choice of nucleobase protecting groups is critical and has evolved to accommodate the need for faster deprotection times and the synthesis of sensitive, modified oligonucleotides. These protecting groups are typically base-labile acyl groups that remain intact throughout the synthesis and are removed during the final deprotection step.[5][16]
Standard vs. Mild Protecting Groups
A key consideration in selecting nucleobase protecting groups is their lability under basic conditions. This has led to the development of different "flavors" of protection strategies, primarily categorized as standard and mild.
| Nucleobase | Standard Protecting Group | Mild Protecting Group | Ultra-Mild Protecting Group |
| Adenine (A) | Benzoyl (Bz) | Phenoxyacetyl (Pac) or Isobutyryl (iBu) | Dimethylformamidine (dmf) |
| Cytosine (C) | Benzoyl (Bz) | Acetyl (Ac) | Acetyl (Ac) |
| Guanine (G) | Isobutyryl (iBu) | Acetyl (Ac) or Isopropyl-phenoxyacetyl (iPr-Pac) | Dimethylformamidine (dmf) |
Rationale for Different Protecting Groups:
-
Standard Protection: The benzoyl (Bz) group for A and C, and the isobutyryl (iBu) group for G are robust and widely used.[5][8] However, their removal requires prolonged treatment with concentrated ammonium hydroxide at elevated temperatures (e.g., 55°C for 5 hours).[10] This can be detrimental to oligonucleotides containing sensitive modifications or labels.[16] The deprotection of the isobutyryl group from guanine is often the rate-limiting step.[10][11]
-
Mild Protection: For oligonucleotides with base-labile modifications, "mild" protecting groups are employed.[5] These include phenoxyacetyl (Pac) for adenine, and acetyl (Ac) for cytosine.[11] These groups can be removed under gentler conditions, such as using potassium carbonate in methanol at room temperature.[10][17]
-
Ultra-Mild Protection: For extremely sensitive oligonucleotides, "ultra-mild" protecting groups like phenoxyacetyl (Pac) for dA, acetyl (Ac) for dC, and isopropyl-phenoxyacetyl (iPr-Pac) for dG are used.[17] These can be deprotected with 0.05 M potassium carbonate in methanol at room temperature.[16][17]
-
Fast Deprotection: The use of a mixture of aqueous ammonium hydroxide and aqueous methylamine (AMA) allows for very rapid deprotection (5-10 minutes at 65°C).[17] This "UltraFAST" deprotection protocol requires the use of acetyl (Ac) protected dC to prevent a side reaction that can occur with benzoyl (Bz) protected dC.[10][17]
Orthogonal Protection Strategies
In some advanced applications, such as the synthesis of highly structured or repetitive DNA sequences, orthogonal protecting group strategies are employed to control hybridization and ligation.[18] For example, the dimethylacetamidine (Dma) group can be used to protect adenine bases, remaining intact while other "ultra-mild" protecting groups are removed. This allows for selective hybridization at specific sites before the final deprotection of the Dma groups.[18][19]
Protecting the Phosphate Backbone: The 2-Cyanoethyl Group
During the coupling step, a phosphite triester linkage is formed. This P(III) species is unstable to the acidic conditions of the subsequent detritylation step and must be oxidized to a more stable P(V) phosphate triester.[10][11] The non-bridging oxygen of the phosphate is protected throughout the synthesis, most commonly by a 2-cyanoethyl group.[5][8][10][11]
The 2-cyanoethyl group is ideal for this role due to its stability during the synthesis cycle and its facile removal under basic conditions via a β-elimination mechanism.[10][11] This deprotection occurs during the final cleavage and deprotection step, typically using concentrated ammonium hydroxide.[16][20]
However, the β-elimination of the cyanoethyl group generates acrylonitrile as a byproduct.[10] Acrylonitrile is a Michael acceptor and can react with the nucleobases, particularly thymine, to form unwanted adducts.[10] This side reaction is more prevalent during large-scale synthesis.[21] To mitigate this, deprotection strategies can be designed where the cyanoethyl groups are removed while the oligonucleotide is still attached to the solid support.[10]
The Final Act: Deprotection and Cleavage
After the final synthesis cycle, the fully assembled oligonucleotide is still attached to the solid support and fully protected.[5][16] The final deprotection is a multi-step process that can often be performed concurrently.[16][20]
-
Cleavage from the Solid Support: The oligonucleotide is cleaved from the solid support, typically using concentrated ammonium hydroxide at room temperature.[16]
-
Phosphate Deprotection: The 2-cyanoethyl groups are removed from the phosphate backbone.[20][22]
-
Nucleobase Deprotection: The protecting groups on the exocyclic amines of the nucleobases are removed.[20][22]
The specific conditions for deprotection (reagent, temperature, and time) are dictated by the lability of the protecting groups used and the presence of any sensitive modifications in the oligonucleotide sequence.[16]
Deprotection Workflow
Caption: A simplified workflow for the final deprotection and purification of a synthetic oligonucleotide.
Experimental Protocols
Protocol 1: Standard Deprotection of a DNA Oligonucleotide
This protocol is suitable for standard DNA oligonucleotides synthesized with Bz-dA, Bz-dC, and iBu-dG protecting groups.
-
Transfer the solid support containing the synthesized oligonucleotide to a 2 mL screw-cap vial.
-
Add 1 mL of concentrated ammonium hydroxide (28-30%).
-
Seal the vial tightly.
-
Incubate the vial at 55°C for 5-8 hours.
-
Allow the vial to cool to room temperature.
-
Centrifuge the vial to pellet the solid support.
-
Carefully transfer the supernatant containing the deprotected oligonucleotide to a new tube.
-
Dry the oligonucleotide solution using a vacuum concentrator.
-
Resuspend the oligonucleotide pellet in an appropriate buffer for purification.
Protocol 2: Ultra-Mild Deprotection of a Modified Oligonucleotide
This protocol is for sensitive oligonucleotides synthesized with Pac-dA, Ac-dC, and iPr-Pac-dG protecting groups.
-
Transfer the solid support to a 2 mL vial.
-
Add 1 mL of 0.05 M potassium carbonate in anhydrous methanol.
-
Seal the vial and let it stand at room temperature for 4 hours with occasional swirling.
-
Centrifuge the vial and transfer the supernatant to a new tube.
-
Wash the solid support with 0.5 mL of water and combine the supernatant with the previous one.
-
Neutralize the solution by adding a suitable buffer (e.g., TEAA buffer).
-
Proceed with purification.
Conclusion
The judicious selection and application of protecting groups are fundamental to the success of automated oligonucleotide synthesis. From the acid-labile DMT group that guards the 5'-hydroxyl and enables real-time monitoring, to the diverse array of base-labile groups that shield the nucleobases, and the β-eliminatable cyanoethyl group that protects the phosphate backbone, each protecting group plays a crucial and orchestrated role. Understanding the chemistry behind these molecular architects empowers researchers to troubleshoot syntheses, design novel modified oligonucleotides, and push the boundaries of what is possible in the fields of synthetic biology, diagnostics, and therapeutics. The continuous evolution of protecting group strategies promises even greater efficiency, purity, and versatility in the synthesis of these vital biomolecules.
References
- 1. benchchem.com [benchchem.com]
- 2. twistbioscience.com [twistbioscience.com]
- 3. inscinstech.quora.com [inscinstech.quora.com]
- 4. Protecting group - Wikipedia [en.wikipedia.org]
- 5. Oligonucleotide synthesis - Wikipedia [en.wikipedia.org]
- 6. fiveable.me [fiveable.me]
- 7. jocpr.com [jocpr.com]
- 8. journalirjpac.com [journalirjpac.com]
- 9. researchgate.net [researchgate.net]
- 10. atdbio.com [atdbio.com]
- 11. biotage.com [biotage.com]
- 12. benchchem.com [benchchem.com]
- 13. academic.oup.com [academic.oup.com]
- 14. A new protecting group for 5'-hydroxyl function of nucleotides in oligonucleotide synthesis without acid treatment utilizing unique properties of tritylthio group - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. Nucleoside phosphoramidite - Wikipedia [en.wikipedia.org]
- 16. blog.biosearchtech.com [blog.biosearchtech.com]
- 17. glenresearch.com [glenresearch.com]
- 18. An orthogonal oligonucleotide protecting group strategy that enables assembly of repetitive or highly structured DNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 19. [PDF] An orthogonal oligonucleotide protecting group strategy that enables assembly of repetitive or highly structured DNAs. | Semantic Scholar [semanticscholar.org]
- 20. glenresearch.com [glenresearch.com]
- 21. glenresearch.com [glenresearch.com]
- 22. selectscience.net [selectscience.net]
An In-depth Technical Guide to 13C and 15N Enrichment in Biomolecules
A Senior Application Scientist's Perspective on Core Methodologies and Field-Proven Insights for Researchers in Life Sciences and Drug Development
Abstract
The strategic incorporation of stable, non-radioactive isotopes, primarily Carbon-13 (¹³C) and Nitrogen-15 (¹⁵N), into biomolecules has become an indispensable and powerful tool in modern biological and chemical research.[] This guide provides a comprehensive overview of the principles, methodologies, and applications of ¹³C and ¹⁵N enrichment. We will delve into the causality behind experimental choices, from selecting a labeling strategy to the analytical techniques used for detection. This document is designed for researchers, scientists, and drug development professionals, offering field-proven insights to harness the full potential of stable isotope labeling for elucidating protein structure, quantifying proteomes, and mapping metabolic pathways.
The Foundation: Why Stable Isotope Labeling?
In the landscape of molecular and biochemical research, the ability to track and quantify specific molecules within complex biological systems is paramount. Stable isotope labeling involves replacing naturally abundant atoms (like ¹²C and ¹⁴N) with their heavier, non-radioactive counterparts (¹³C and ¹⁵N).[2] These labeled molecules are chemically identical to their native forms, ensuring they participate in biological processes without altering the system's physiology.[3] Their key advantage lies in the mass difference, which is readily detectable by advanced analytical techniques like mass spectrometry (MS) and nuclear magnetic resonance (NMR) spectroscopy.[]
Core Advantages of ¹³C and ¹⁵N:
-
Safety: Unlike radioactive isotopes, stable isotopes pose no radiation risk, making them suitable for a wide range of experiments, including in vivo studies in animals and humans.[][2]
-
Low Natural Abundance: The natural abundance of ¹³C is approximately 1.1%, and for ¹⁵N, it is a mere 0.37%.[] This low background ensures that the signal from the enriched biomolecule is clearly distinguishable, providing a high signal-to-noise ratio.[]
-
Versatility: These isotopes can be incorporated into a vast array of biomolecules, including amino acids, glucose, and nucleotides, allowing for the targeted study of proteins, metabolites, and nucleic acids.[][4]
Methodologies for Isotopic Enrichment: An Overview
The choice of labeling strategy is dictated by the biological question, the target biomolecule, and the available experimental system. Broadly, these methods can be categorized into in vivo and in vitro approaches.
In Vivo Enrichment: Labeling Within a Living System
In vivo labeling provides the most physiologically relevant data by incorporating isotopes directly within a living cell or organism.[5]
2.1.1. Metabolic Labeling in Cell Culture: The SILAC Revolution
Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) is a powerful and widely used metabolic labeling technique for quantitative proteomics.[3][6] The principle is elegant and robust: two populations of cells are grown in media that are identical except for specific essential amino acids.[3] One population receives the normal "light" amino acid (e.g., ¹²C₆-Arginine), while the other receives a "heavy" isotope-labeled version (e.g., ¹³C₆-Arginine).[7]
After several cell divisions, the heavy amino acid is fully incorporated into the entire proteome of the second population.[3][8] The two cell populations can then be subjected to different experimental conditions (e.g., drug treatment vs. control). Subsequently, the cell lysates are combined in a 1:1 ratio, and the proteins are analyzed by mass spectrometry.[9] Because the "light" and "heavy" proteins are chemically identical, they co-purify and co-elute during chromatography. In the mass spectrometer, every peptide containing the labeled amino acid appears as a pair of peaks separated by a distinct mass difference.[7] The ratio of the peak intensities directly reflects the relative abundance of that protein between the two conditions.[7][9]
Experimental Workflow: Quantitative Proteomics using SILAC
Caption: A typical workflow for a SILAC experiment.
2.1.2. Uniform Labeling in Bacterial and Yeast Systems
For structural biology studies using NMR, uniform labeling is often required.[10] This is typically achieved by growing bacteria (commonly E. coli) or yeast in a minimal medium where the sole nitrogen and carbon sources are isotopically labeled.[11][12] For double-labeled proteins, ¹⁵NH₄Cl is used as the nitrogen source and ¹³C-glucose as the carbon source.[11] This approach ensures that nearly all nitrogen and carbon atoms in the expressed protein are replaced with their heavy isotopes, which is essential for many multidimensional NMR experiments.[11][13]
2.1.3. Labeling in Whole Organisms
The principles of metabolic labeling can be extended to whole organisms like C. elegans, Drosophila, and mice.[6] For instance, MouseExpress™ feed, which contains ¹³C₆-Lysine, can be used to metabolically label the entire proteome of a mouse, enabling quantitative proteomics studies in a complex in vivo model.[14] While achieving high levels of enrichment can be more challenging in whole organisms compared to cell culture, these models provide invaluable insights into disease states and drug effects.[15]
In Vitro Enrichment: Cell-Free Protein Synthesis
Cell-free protein synthesis offers a powerful alternative to in vivo methods, particularly for producing proteins that are toxic to cells or for selective labeling strategies.[16][17] In this system, an extract containing all the necessary machinery for transcription and translation (e.g., from E. coli or wheat germ) is used to produce the protein of interest from a DNA template.[17][18]
Key Advantages of Cell-Free Systems:
-
Efficiency: Isotope-labeled amino acids are added directly to the reaction mixture, leading to highly efficient incorporation without the need for large quantities of labeled media.[16][18]
-
Control: It allows for precise control over the labeling scheme. Researchers can easily perform selective labeling by adding only specific labeled amino acids.
-
Speed: Protein synthesis occurs rapidly, and the resulting labeled protein can often be analyzed by NMR directly from the crude reaction mixture.[18]
Analytical Techniques: Decoding the Isotopic Signature
Once a biomolecule is labeled, specialized analytical instruments are required to detect and interpret the isotopic signature.
Nuclear Magnetic Resonance (NMR) Spectroscopy
NMR spectroscopy is a cornerstone technique for determining the three-dimensional structure and dynamics of biomolecules in solution.[16] Isotopic labeling is often a prerequisite for NMR studies of proteins larger than ~10 kDa.[19]
-
¹⁵N Labeling: Uniform ¹⁵N labeling is fundamental for acquiring a ¹H-¹⁵N HSQC (Heteronuclear Single Quantum Coherence) spectrum. This 2D experiment yields a "fingerprint" of the protein, with one peak for each amino acid residue (except proline). It is highly sensitive to changes in the chemical environment and is invaluable for studying protein folding, stability, and interactions.
-
¹³C and ¹⁵N Double Labeling: For de novo structure determination, proteins are typically uniformly labeled with both ¹³C and ¹⁵N.[11] This "double labeling" enables a suite of triple-resonance NMR experiments (e.g., HNCACB, HN(CO)CACB) that correlate the backbone atoms of adjacent amino acids, allowing for sequential resonance assignment, which is the first step in structure determination.[11][20]
-
Deuteration (²H Labeling): For very large proteins (>30 kDa), spectral quality can deteriorate due to rapid signal relaxation.[21] Uniformly labeling the protein with deuterium (²H) in addition to ¹³C and ¹⁵N ("triple labeling") dramatically improves relaxation properties by removing most ¹H-¹H dipolar interactions, resulting in sharper peaks and improved spectral quality.[13][21]
Experimental Workflow: Protein Structure Determination by NMR
Caption: General workflow for protein labeling and structure determination via NMR.
Mass Spectrometry (MS)
Mass spectrometry measures the mass-to-charge ratio of ions and is the technique of choice for quantitative proteomics and metabolic flux analysis.[22][23]
-
Quantitative Proteomics: As described in the SILAC method, MS is used to measure the intensity ratios of peptide pairs that are chemically identical but differ in mass due to isotopic labeling.[7] This allows for precise relative quantification of thousands of proteins simultaneously.
-
Metabolic Flux Analysis (MFA): In MFA, a ¹³C-labeled substrate (like ¹³C-glucose) is introduced to cells.[23] As the substrate is metabolized, the ¹³C atoms are incorporated into various downstream metabolites. By measuring the mass isotopomer distributions of these metabolites using MS, researchers can trace the flow of carbon through complex biochemical networks.[23][24] This provides a quantitative snapshot of cellular metabolism, revealing the activity of different pathways under specific conditions. Tandem MS (MS/MS) can provide even more detailed information for high-resolution flux quantification.[25]
Applications in Drug Discovery and Development
Stable isotope labeling is a critical tool throughout the drug development pipeline, from target identification to clinical trials.[4][26]
-
Target Engagement and Mechanism of Action: SILAC and other quantitative proteomics methods can identify which proteins change in abundance or post-translational modification state upon drug treatment, helping to confirm the drug's mechanism of action and identify potential off-target effects.[7]
-
Pharmacokinetics (ADME): Labeled compounds are used to study the absorption, distribution, metabolism, and excretion (ADME) of a drug candidate.[22][27] By tracking the labeled drug and its metabolites, scientists can gain a clear understanding of its fate in the body.[2][22]
-
Biomarker Discovery: Comparing the proteomes or metabolomes of healthy vs. diseased states using isotopic labeling can lead to the discovery of novel biomarkers for disease diagnosis or for monitoring treatment efficacy.[6]
-
Metabolic Research: Understanding how a disease alters cellular metabolism is crucial for developing targeted therapies.[2] ¹³C and ¹⁵N tracers can precisely map these metabolic alterations, identifying pathways that could be targeted by new drugs.[2][4]
Practical Considerations and Protocol Design
Choosing Between ¹³C and ¹⁵N Labeling
The choice between ¹³C and ¹⁵N, or using both, depends on the experimental goal.[]
| Isotope Labeling Strategy | Primary Application | Key Rationale |
| ¹⁵N Labeling | Protein Structure Analysis (¹H-¹⁵N HSQC), Simpler MS Quantification | Fundamental for backbone NMR experiments. Provides a simple mass shift pattern in MS, which can simplify data analysis.[] |
| ¹³C Labeling | Metabolic Flux Analysis | The carbon backbone is central to metabolism; ¹³C tracers like glucose are ideal for tracking pathway activity.[] |
| ¹³C and ¹⁵N Dual Labeling | Protein Structure Determination (Triple Resonance NMR), Quantitative Proteomics (SILAC) | Essential for sequential backbone assignment in NMR.[11] Provides a larger mass shift in SILAC, which is useful for complex samples.[] |
Protocol: Uniform ¹³C, ¹⁵N Labeling of a Protein in E. coli
This protocol outlines the key steps for producing a double-labeled protein for NMR studies.
Objective: To express and purify a recombinant protein with >95% incorporation of ¹³C and ¹⁵N.
Materials:
-
E. coli expression strain (e.g., BL21(DE3)) transformed with the expression plasmid.
-
M9 minimal medium components.
-
¹⁵NH₄Cl (sole nitrogen source).
-
¹³C₆-D-glucose (sole carbon source).
-
IPTG (for induction).
-
Appropriate antibiotic.
-
Standard protein purification equipment (e.g., FPLC system, affinity columns).
Methodology:
-
Starter Culture: Inoculate 50 mL of LB medium with a single colony of the transformed E. coli. Grow overnight at 37°C with shaking.
-
Adaptation to Minimal Medium: Pellet the overnight culture by centrifugation. Resuspend the cell pellet in 50 mL of M9 minimal medium (containing natural abundance ¹⁴NH₄Cl and ¹²C-glucose) and grow for 4-6 hours to adapt the cells.
-
Main Culture Growth: Use the adapted culture to inoculate 1 L of M9 minimal medium prepared with ¹⁵NH₄Cl (1 g/L) and ¹³C₆-D-glucose (2-4 g/L). Grow at 37°C with vigorous shaking.
-
Monitor Growth: Monitor the optical density at 600 nm (OD₆₀₀).
-
Induction: When the OD₆₀₀ reaches 0.6-0.8, induce protein expression by adding IPTG to a final concentration of 0.5-1.0 mM.
-
Expression: Reduce the temperature to 18-25°C and continue to grow the culture for an additional 12-18 hours. The lower temperature often improves protein solubility.
-
Harvesting: Harvest the cells by centrifugation. The cell pellet can be stored at -80°C.
-
Purification: Lyse the cells and purify the target protein using standard protocols (e.g., Ni-NTA affinity chromatography followed by size-exclusion chromatography).
-
Verification of Labeling: Confirm the incorporation of isotopes using mass spectrometry. The mass of the labeled protein should correspond to the calculated mass with full ¹³C and ¹⁵N incorporation.[28]
Conclusion
The enrichment of biomolecules with the stable isotopes ¹³C and ¹⁵N is a profoundly versatile and powerful methodology. It provides an unparalleled window into the molecular world, enabling the precise determination of protein structures, the accurate quantification of global protein expression changes, and the detailed mapping of intricate metabolic networks. For researchers in basic science and drug development, mastering these techniques is not merely an advantage but a necessity for pushing the boundaries of biological understanding and therapeutic innovation.
References
- 2. metsol.com [metsol.com]
- 3. ukisotope.com [ukisotope.com]
- 4. Applications of Stable Isotope-Labeled Molecules | Silantes [silantes.com]
- 5. fiveable.me [fiveable.me]
- 6. SILAC 代谢标记系统 | Thermo Fisher Scientific - CN [thermofisher.cn]
- 7. Stable isotope labeling by amino acids in cell culture - Wikipedia [en.wikipedia.org]
- 8. Stable isotope labeling by amino acids in cell culture, SILAC, as a simple and accurate approach to expression proteomics - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. sigmaaldrich.com [sigmaaldrich.com]
- 10. Specific isotopic labelling and reverse labelling for protein NMR spectroscopy: using metabolic precursors in sample preparation - PMC [pmc.ncbi.nlm.nih.gov]
- 11. protein-nmr.org.uk [protein-nmr.org.uk]
- 12. Protein labeling in Escherichia coli with (2)H, (13)C, and (15)N - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. pound.med.utoronto.ca [pound.med.utoronto.ca]
- 14. ckgas.com [ckgas.com]
- 15. f1000research.com [f1000research.com]
- 16. synthelis.com [synthelis.com]
- 17. academic.oup.com [academic.oup.com]
- 18. Cell-free synthesis of 15N-labeled proteins for NMR studies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 19. pound.med.utoronto.ca [pound.med.utoronto.ca]
- 20. Resonance assignment of 13C/15N labeled solid proteins by two- and three-dimensional magic-angle-spinning NMR - PubMed [pubmed.ncbi.nlm.nih.gov]
- 21. protein-nmr.org.uk [protein-nmr.org.uk]
- 22. Isotopic labeling of metabolites in drug discovery applications - PubMed [pubmed.ncbi.nlm.nih.gov]
- 23. Mass spectrometry for metabolic flux analysis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 24. One‐shot 13C15N‐metabolic flux analysis for simultaneous quantification of carbon and nitrogen flux - PMC [pmc.ncbi.nlm.nih.gov]
- 25. Frontiers | Tandem Mass Spectrometry for 13C Metabolic Flux Analysis: Methods and Algorithms Based on EMU Framework [frontiersin.org]
- 26. Future of Stable Isotope Labeling Services | Adesis [adesisinc.com]
- 27. researchgate.net [researchgate.net]
- 28. pubs.acs.org [pubs.acs.org]
The Alchemist's Guide to NMR: Unlocking Molecular Secrets with Labeled Compounds
A Senior Application Scientist's In-depth Technical Guide for Researchers, Scientists, and Drug Development Professionals
Foreword: Beyond the Spectrum—A Paradigm Shift in a Vial
In the realm of molecular inquiry, Nuclear Magnetic Resonance (NMR) spectroscopy stands as a titan, offering unparalleled insights into the structure, dynamics, and interactions of biomolecules at atomic resolution. However, the true power of this technique is only fully unleashed through the strategic use of isotopically labeled compounds. This guide is not merely a collection of protocols; it is an exposition on the core principles and field-proven strategies that transform a standard NMR experiment into a precision tool for discovery. As a senior application scientist, my aim is to move beyond the "how" and delve into the "why"—to explain the causality behind experimental choices and to provide a framework for designing robust, self-validating NMR studies. We will journey from the fundamental tenets of isotopic enrichment to the sophisticated strategies that are pushing the boundaries of structural biology and drug discovery.
The Imperative of the Isotope: Why We Label
At its heart, NMR spectroscopy listens to the faint whispers of atomic nuclei in a powerful magnetic field. However, nature has not been entirely cooperative. The most abundant isotopes of carbon (¹²C) and nitrogen (¹⁴N) are NMR-silent or problematic. The NMR-active isotopes, ¹³C and ¹⁵N, are present at very low natural abundance (1.1% and 0.37%, respectively).[1][2] This scarcity of detectable nuclei in unlabeled biomolecules leads to two major challenges:
-
Low Sensitivity: The NMR signal is directly proportional to the number of observed nuclei. With low natural abundance, acquiring a spectrum with an adequate signal-to-noise ratio for a complex biomolecule is often impractical, if not impossible.
-
Spectral Complexity and Overlap: In larger molecules, the sheer number of proton (¹H) signals leads to severe spectral overlap, making it incredibly difficult to resolve and assign individual resonances.[1][2]
Isotopic labeling elegantly overcomes these hurdles. By enriching a protein or other biomolecule with ¹³C and/or ¹⁵N, we dramatically increase the number of NMR-active nuclei, thereby boosting sensitivity.[3] Furthermore, this allows for the use of multidimensional heteronuclear NMR experiments, which spread the signals out into two, three, or even four dimensions, greatly enhancing resolution and enabling the assignment of resonances that would be hopelessly overlapped in a simple one-dimensional ¹H spectrum.[1][3]
The Labeling Palette: A Strategy for Every Question
The choice of labeling strategy is dictated by the specific scientific question being addressed, the size and properties of the molecule under investigation, and budgetary considerations. The most common approaches are outlined below.
Uniform Labeling: The Workhorse of Structural Biology
Uniform labeling is the most straightforward and cost-effective method for isotopic enrichment.[4] In this approach, the expression host (typically E. coli) is grown in a minimal medium where the sole nitrogen source is ¹⁵NH₄Cl and the sole carbon source is [U-¹³C]-glucose. This results in the incorporation of ¹⁵N and ¹³C at all possible positions in the protein.
-
¹⁵N-Labeling: This is often the first step in characterizing a protein by NMR. The resulting two-dimensional ¹H-¹⁵N Heteronuclear Single Quantum Coherence (HSQC) spectrum provides a unique "fingerprint" of the protein, with one peak for each backbone and sidechain amide group.[5] This spectrum is highly sensitive to the local chemical environment and can be used to assess protein folding, stability, and to map binding sites for ligands.
-
¹³C,¹⁵N-Double Labeling: This is the gold standard for de novo protein structure determination by NMR.[5] The uniform incorporation of both ¹³C and ¹⁵N enables a suite of triple-resonance experiments (e.g., HNCA, HN(CO)CA, HNCACB) that allow for the sequential assignment of backbone and sidechain resonances.[3]
Selective Labeling: Sharpening the Focus
For larger proteins (>25-30 kDa), uniform labeling can lead to overly complex spectra and significant signal broadening due to faster relaxation. Selective labeling strategies address these challenges by introducing isotopes only at specific sites.
-
Amino Acid-Specific Labeling: In this approach, one or more specific types of amino acids are isotopically labeled, while the rest of the protein remains at natural abundance. This is achieved by growing the expression host in a minimal medium containing a mixture of unlabeled amino acids and the desired labeled amino acid(s).[1][2] This dramatically simplifies the resulting NMR spectra, allowing for the unambiguous assignment and analysis of signals from specific regions of the protein.
-
Reverse Labeling: This is the inverse of selective labeling, where a protein is uniformly ¹³C/¹⁵N-labeled, except for one or more specific amino acid types, which are supplied in their unlabeled form.[1][2] This can be useful for "turning off" signals from specific residues that may be causing spectral overlap or to selectively observe interactions with a particular part of the protein.
Deuteration: Taming the Relaxation Beast
For very large proteins and protein complexes, even selective labeling may not be sufficient to overcome the rapid signal decay (relaxation) that leads to broad, undetectable NMR signals. Deuteration, the replacement of protons with deuterium (²H), is a powerful tool to combat this.[6] Deuterium has a much smaller gyromagnetic ratio than protons, which significantly reduces its contribution to relaxation. By expressing a protein in a deuterated medium (D₂O with deuterated glucose), the majority of the non-exchangeable protons are replaced with deuterium, leading to dramatically sharper lines and improved spectral quality.[6][7]
Methyl-Specific Labeling: Probing the Hydrophobic Core
A particularly powerful application of selective labeling and deuteration is methyl-specific labeling. The methyl groups of Isoleucine, Leucine, and Valine (ILV) are often located in the hydrophobic core of proteins and are excellent probes of protein structure and dynamics. By using specifically labeled precursors in a deuterated background, it is possible to produce proteins where only the methyl groups of these residues are protonated and ¹³C-labeled.[6][7] This, combined with TROSY (Transverse Relaxation-Optimized Spectroscopy) techniques, has enabled the study of protein complexes approaching 1 MDa in size.[6]
From Genes to Magnet: A Practical Workflow
The successful application of labeled compounds in NMR is underpinned by meticulous experimental execution. The following section provides a generalized workflow for the production and purification of isotopically labeled proteins for NMR analysis.
Experimental Workflow: A Visual Guide
Caption: A generalized workflow for the production of isotopically labeled proteins for NMR analysis.
Step-by-Step Protocol: Uniform ¹⁵N-Labeling in E. coli
This protocol provides a general framework for producing a ¹⁵N-labeled protein in E. coli. Optimization will be required for specific proteins.
Materials:
-
E. coli expression strain (e.g., BL21(DE3)) transformed with the expression plasmid for the protein of interest.
-
Rich medium (e.g., LB or 2xTY) with appropriate antibiotic.
-
M9 minimal medium components.
-
¹⁵NH₄Cl (Cambridge Isotope Laboratories, Inc. or equivalent).
-
Glucose (unlabeled).
-
Trace elements solution.
-
1 M MgSO₄.
-
1 M CaCl₂.
-
IPTG (for induction).
Procedure:
-
Starter Culture: Inoculate 5-10 mL of rich medium containing the appropriate antibiotic with a single colony of the transformed E. coli. Grow overnight at 37°C with shaking.
-
Pre-culture: The next morning, inoculate 100 mL of M9 minimal medium (with unlabeled NH₄Cl) with the overnight starter culture to an OD₆₀₀ of ~0.1. Grow at 37°C with shaking until the OD₆₀₀ reaches 0.6-0.8. This step helps the cells adapt to the minimal medium.
-
Main Culture: Pellet the pre-culture cells by centrifugation and resuspend them in 1 L of M9 minimal medium prepared with 1 g of ¹⁵NH₄Cl as the sole nitrogen source. Grow at 37°C with shaking until the OD₆₀₀ reaches 0.6-0.8.
-
Induction: Induce protein expression by adding IPTG to a final concentration of 0.5-1 mM. Reduce the temperature to 18-25°C and continue to grow for another 12-16 hours.
-
Harvesting: Harvest the cells by centrifugation. The cell pellet can be stored at -80°C or used immediately for purification.
Purification of Labeled Proteins for NMR
The purification of isotopically labeled proteins for NMR studies requires particular attention to achieving high purity and a final sample that is stable and soluble at high concentrations in a suitable NMR buffer.
-
Lysis and Chromatography: Standard purification protocols involving cell lysis followed by affinity and size-exclusion chromatography are generally applicable.[8]
-
Buffer Considerations: The final buffer for NMR should have a low ionic strength (ideally < 150 mM salt) to minimize heating effects in the spectrometer. The pH should be carefully chosen to ensure protein stability and to minimize the exchange of amide protons with the solvent.[9]
-
Concentration: NMR is a relatively insensitive technique, and protein concentrations in the range of 0.1 to 1.0 mM are typically required.[9][10]
-
Additives: The final NMR sample should contain 5-10% D₂O for the spectrometer's lock system. A reference compound such as DSS or TSP is also added for chemical shift referencing.[10]
Quantitative NMR (qNMR) with Labeled Compounds
While NMR is renowned for its structural capabilities, it is also an inherently quantitative technique. The area under an NMR peak is directly proportional to the number of nuclei contributing to that signal. Isotopic labeling can be leveraged for highly accurate and precise quantitative measurements.
Principles of qNMR
In qNMR, the concentration of an analyte is determined by comparing the integral of one of its signals to the integral of a signal from a certified reference standard of known concentration.[11][12] The use of isotopically labeled internal standards, which are chemically identical to the analyte but have a different mass, can further enhance the accuracy of qNMR measurements by correcting for variations in sample preparation and instrument response.
Applications in Drug Discovery and Metabolomics
qNMR with labeled compounds is a powerful tool in drug discovery for determining the concentration of lead compounds and for studying drug metabolism. In metabolomics, stable isotope tracers can be used to follow the fate of specific molecules through metabolic pathways, providing a quantitative understanding of metabolic fluxes.[13]
Advanced Applications and Future Horizons
The strategic use of labeled compounds continues to push the frontiers of what is possible with NMR spectroscopy.
-
In-Cell NMR: By expressing isotopically labeled proteins directly in living cells, it is possible to study their structure and interactions in their native environment. This emerging technique holds immense promise for understanding protein function in a cellular context.
-
Protein Dynamics: NMR is unique in its ability to probe molecular motions over a wide range of timescales. Isotope labeling, particularly with ¹⁵N and ²H, enables a suite of relaxation experiments that can provide detailed insights into protein dynamics, which are often crucial for function.[5]
-
Protein-Ligand Interactions: Isotopic labeling is indispensable for studying the interactions of proteins with small molecules, peptides, and other proteins. By monitoring changes in the NMR spectrum of a labeled protein upon the addition of an unlabeled ligand, it is possible to map the binding site, determine binding affinities, and elucidate the structural basis of molecular recognition.[14][15][16]
Troubleshooting Common Challenges
| Problem | Potential Cause | Recommended Solution |
| Low protein expression yield in minimal medium | Cells are not well-adapted to minimal medium; suboptimal growth conditions. | Include a pre-culture step in minimal medium; optimize temperature, aeration, and induction conditions. |
| Incomplete isotopic labeling | Contamination with unlabeled nutrients; metabolic scrambling. | Use high-purity isotopes; ensure all media components are free of unlabeled carbon/nitrogen sources. |
| Protein precipitation at high concentrations | Poor protein stability; inappropriate buffer conditions. | Screen for optimal buffer pH, ionic strength, and additives (e.g., glycerol, detergents); consider site-directed mutagenesis to improve solubility. |
| Poor spectral quality (broad lines) | Protein aggregation; high viscosity; suboptimal NMR parameters. | Optimize sample conditions; use deuteration for larger proteins; ensure proper shimming and tuning of the NMR probe. |
Conclusion: The Labeled Molecule as the Key
The principles and techniques outlined in this guide represent the cornerstone of modern biomolecular NMR. The strategic use of isotopically labeled compounds has transformed NMR from a niche technique for small molecules into an indispensable tool for elucidating the structure, dynamics, and interactions of complex biological systems. As we continue to refine our ability to manipulate the isotopic composition of molecules, we will undoubtedly unlock even deeper secrets of the molecular world, paving the way for new discoveries in medicine, biotechnology, and beyond. The labeled molecule is not just a sample; it is the key that unlocks the full potential of the NMR experiment.
References
- 1. Specific isotopic labelling and reverse labelling for protein NMR spectroscopy: using metabolic precursors in sample preparation - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Specific isotopic labelling and reverse labelling for protein NMR spectroscopy: using metabolic precursors in sample preparation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. pubs.acs.org [pubs.acs.org]
- 4. Isotope Labeling for Solution and Solid-State NMR Spectroscopy of Membrane Proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Unlocking Protein Mysteries: A Guide to NMR Spectroscopy in Protein Characterization - News - Alpha Lifetech-Antibody Engineering and Drug Discovery Expert. [alphalifetech.com]
- 6. Isotope labeling strategies for the study of high-molecular-weight proteins by solution NMR spectroscopy - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Isotope labeling strategies for the study of high-molecular-weight proteins by solution NMR spectroscopy | Springer Nature Experiments [experiments.springernature.com]
- 8. fbri.vtc.vt.edu [fbri.vtc.vt.edu]
- 9. nmr-bio.com [nmr-bio.com]
- 10. organomation.com [organomation.com]
- 11. nmr.chem.ox.ac.uk [nmr.chem.ox.ac.uk]
- 12. azom.com [azom.com]
- 13. Quantitative NMR-Based Biomedical Metabolomics: Current Status and Applications - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Selective isotope labeling for NMR structure determination of proteins in complex with unlabeled ligands - PMC [pmc.ncbi.nlm.nih.gov]
- 15. pubs.acs.org [pubs.acs.org]
- 16. NMR Studies of Protein-Ligand Interactions | Springer Nature Experiments [experiments.springernature.com]
Methodological & Application
Synthesis of High-Purity ¹³C,¹⁵N-Labeled Oligonucleotides Utilizing Protected Uridine Phosphoramidite Chemistry
Abstract
The site-specific incorporation of stable isotopes, such as Carbon-13 (¹³C) and Nitrogen-15 (¹⁵N), into oligonucleotides is a cornerstone of modern structural biology and drug development. These labeled biomolecules are indispensable for advanced analytical techniques, most notably Nuclear Magnetic Resonance (NMR) spectroscopy and mass spectrometry (MS), which provide unparalleled insights into nucleic acid structure, dynamics, and interactions with other molecules. This application note provides a comprehensive technical guide for the synthesis, purification, and analysis of ¹³C,¹⁵N-labeled oligonucleotides, with a specific focus on the incorporation of protected uridine phosphoramidites. The protocols detailed herein are designed for researchers, scientists, and drug development professionals seeking to produce high-purity, isotopically labeled oligonucleotides for demanding applications.
Introduction: The Rationale for Isotopic Labeling
The study of nucleic acid structure and function is fundamental to understanding biological processes and developing novel therapeutics. While techniques like X-ray crystallography provide static snapshots of molecular structures, NMR spectroscopy offers the unique ability to probe the dynamic nature of biomolecules in solution. The incorporation of stable isotopes, such as ¹³C and ¹⁵N, into oligonucleotides is essential for a variety of advanced NMR experiments that are crucial for resonance assignment and the determination of three-dimensional structures. Furthermore, isotopically labeled oligonucleotides serve as invaluable internal standards for quantitative mass spectrometry-based assays.
Chemical synthesis using phosphoramidite chemistry is the gold standard for producing oligonucleotides of a defined sequence. This method allows for the precise, site-specific incorporation of labeled monomers, a feat not easily achieved through enzymatic methods. This guide will focus on the practical aspects of synthesizing oligonucleotides containing ¹³C,¹⁵N-labeled uridine, a common pyrimidine base, using automated solid-phase synthesis.
The Chemistry of Labeled Oligonucleotide Synthesis
The synthesis of oligonucleotides on a solid support is a cyclical process involving four key chemical reactions: deblocking, coupling, capping, and oxidation. The success of this process hinges on the use of nucleoside phosphoramidites, which are nucleosides modified with protecting groups to prevent unwanted side reactions.
Protected ¹³C,¹⁵N-Uridine Phosphoramidite
The synthesis of a ¹³C,¹⁵N-labeled oligonucleotide begins with the corresponding labeled phosphoramidite monomer. For uridine, the key protecting groups are:
-
5'-Hydroxyl Group: Protected with a dimethoxytrityl (DMT) group, which is acid-labile and removed at the beginning of each synthesis cycle.
-
3'-Hydroxyl Group: Modified to a reactive phosphoramidite moiety, typically a diisopropylamino group, which is activated for coupling.
-
2'-Hydroxyl Group (for RNA synthesis): Protected with a silyl-based group, such as tert-butyldimethylsilyl (TBDMS), to prevent unwanted reactions.
The synthesis of the ¹⁵N(3)-uridine phosphoramidite has been described, providing a route to obtaining the necessary labeled building block. Commercially available ¹³C,¹⁵N-labeled uridine phosphoramidites are also an option for researchers.
The Solid-Phase Synthesis Cycle
The automated synthesis of the labeled oligonucleotide proceeds in a 3' to 5' direction on a solid support, typically controlled pore glass (CPG). The four-step cycle is repeated for each nucleotide addition:
-
Deblocking (Detritylation): The acid-labile DMT group is removed from the 5'-hydroxyl of the growing oligonucleotide chain, preparing it for the next coupling reaction.
-
Coupling: The ¹³C,¹⁵N-labeled uridine phosphoramidite is activated by a catalyst, such as a tetrazole derivative, and reacts with the free 5'-hydroxyl group of the growing chain, forming a phosphite triester linkage.
-
Capping: Any unreacted 5'-hydroxyl groups are acetylated to prevent the formation of deletion mutants (n-1 sequences).
-
Oxidation: The unstable phosphite triester linkage is oxidized to a more stable phosphate triester using an iodine solution.
This cycle is repeated until the desired full-length oligonucleotide is synthesized.
Experimental Protocols
Protocol 1: Automated Solid-Phase Synthesis of a ¹³C,¹⁵N-Labeled Oligonucleotide
This protocol outlines the steps for incorporating a ¹³C,¹⁵N-labeled uridine phosphoramidite into a growing oligonucleotide chain using a standard automated DNA/RNA synthesizer.
Materials:
-
¹³C,¹⁵N-labeled Uridine Phosphoramidite
-
Standard DNA or RNA phosphoramidites (A, C, G, T/U)
-
Anhydrous acetonitrile
-
Activator solution (e.g., 0.25 M DCI in acetonitrile)
-
Capping solutions (Cap A and Cap B)
-
Oxidizing solution
-
Deblocking solution (e.g., 3% trichloroacetic acid in dichloromethane)
-
Controlled Pore Glass (CPG) solid support with the initial nucleoside
Procedure:
-
Reagent Preparation:
-
Allow the ¹³C,¹⁵N-labeled uridine phosphoramidite vial to equilibrate to room temperature before opening.
-
Dissolve the phosphoramidite in anhydrous acetonitrile to the manufacturer's recommended concentration (typically 0.1 M).
-
Install the phosphoramidite solution on a designated port on the synthesizer.
-
-
Synthesis Program:
-
Program the desired oligonucleotide sequence into the synthesizer's software.
-
Ensure the synthesis protocol uses a coupling time appropriate for the labeled phosphoramidite (typically 3-5 minutes). While high coupling efficiencies of over 99% are standard, it is crucial to maintain this to avoid truncated products.
-
-
Initiate Synthesis:
-
Start the synthesis run. The instrument will automatically perform the repeated cycles of deblocking, coupling, capping, and oxidation.
-
-
Post-Synthesis:
-
Once the synthesis is complete, the solid support containing the full-length, protected oligonucleotide is ready for cleavage and deprotection.
-
Protocol 2: Cleavage and Deprotection
This protocol describes the removal of the synthesized oligonucleotide from the solid support and the removal of all protecting groups. Special care must be taken during this step, as some labeled compounds can be sensitive to harsh deprotection conditions.
Materials:
-
Concentrated ammonium hydroxide
-
Methylamine solution (for AMA deprotection, if applicable)
-
Triethylamine trihydrofluoride (for removal of TBDMS groups in RNA synthesis)
Procedure:
-
Cleavage from Solid Support:
-
Transfer the CPG support to a screw-cap vial.
-
Add concentrated ammonium hydroxide (or an AMA solution) to the vial.
-
Incubate at room temperature for 1-2 hours to cleave the oligonucleotide from the support.
-
-
Base and Phosphate Deprotection:
-
For standard protecting groups, heat the sealed vial at 55°C for 8-12 hours.
-
For oligonucleotides with sensitive modifications, a milder deprotection using potassium carbonate in methanol may be necessary.
-
-
Removal of 2'-TBDMS Protecting Groups (for RNA):
-
After deprotection of the bases and phosphates, evaporate the ammonia/AMA solution.
-
Resuspend the oligonucleotide in a solution of triethylamine trihydrofluoride in DMSO.
-
Incubate at 65°C for 2.5 hours.
-
-
Quenching and Precipitation:
-
Quench the deprotection reaction by adding a suitable quenching buffer.
-
Precipitate the deprotected oligonucleotide using a salt solution (e.g., sodium acetate) and ethanol.
-
Centrifuge to pellet the oligonucleotide, wash with ethanol, and dry the pellet.
-
Protocol 3: Purification by High-Performance Liquid Chromatography (HPLC)
Purification is a critical step to remove truncated sequences and other impurities, ensuring the final product is of high purity for downstream applications.
Materials:
-
HPLC system with a suitable reverse-phase or ion-exchange column
-
Mobile phases (e.g., acetonitrile and triethylammonium acetate buffer)
-
Nuclease-free water
Procedure:
-
Sample Preparation:
-
Resuspend the dried oligonucleotide pellet in nuclease-free water.
-
-
HPLC Purification:
-
Inject the sample onto the HPLC column.
-
Run a gradient of increasing organic mobile phase (acetonitrile) to elute the oligonucleotide.
-
Collect the fractions corresponding to the full-length product peak.
-
-
Desalting:
-
Pool the fractions containing the purified oligonucleotide.
-
Desalt the sample using a desalting cartridge or by ethanol precipitation.
-
-
Final Product:
-
Lyophilize the purified and desalted oligonucleotide to obtain a dry, stable powder.
-
Quality Control and Analysis
The identity and purity of the final ¹³C,¹⁵N-labeled oligonucleotide should be confirmed by mass spectrometry and NMR spectroscopy.
-
Mass Spectrometry: Electrospray ionization (ESI) or matrix-assisted laser desorption/ionization-time of flight (MALDI-TOF) mass spectrometry can be used to verify the molecular weight of the synthesized oligonucleotide. The observed mass should correspond to the calculated mass of the labeled sequence.
-
NMR Spectroscopy: One- and two-dimensional NMR experiments can confirm the incorporation and location of the ¹³C and ¹⁵N labels.
Quantitative Data Summary
| Parameter | Expected Value/Range | Reference |
| Coupling Efficiency (per step) | > 99% | |
| Overall Yield (20-mer, crude) | 30-50% | |
| Purity after HPLC | > 95% | |
| Mass Accuracy (ESI-MS) | ± 0.01% of theoretical mass |
Experimental Workflow and Logic
The following diagrams illustrate the key workflows and the rationale behind the experimental choices.
Caption: Automated synthesis workflow for ¹³C,¹⁵N-labeled oligonucleotides.
Caption: Decision logic for the deprotection of labeled oligonucleotides.
Conclusion
The chemical synthesis of ¹³C,¹⁵N-labeled oligonucleotides using protected uridine phosphoramidites is a robust and reliable method for producing high-purity materials for advanced research applications. By following the detailed protocols outlined in this application note, researchers can confidently generate labeled oligonucleotides for in-depth structural and functional studies using NMR spectroscopy and mass spectrometry. The careful selection of protecting groups, optimization of synthesis and deprotection conditions, and rigorous purification are paramount to achieving the high quality required for these demanding analytical techniques.
Application Note & Protocols: Site-Specific Isotopic Labeling of Oligonucleotides for Structural Biology Studies Using 2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-¹³C,¹⁵N₂
Abstract
The precise elucidation of nucleic acid structure, dynamics, and interactions is fundamental to understanding their biological roles and to the development of novel therapeutics. Nuclear Magnetic Resonance (NMR) spectroscopy is a uniquely powerful tool for these investigations, providing atomic-level insights in a solution state that mimics the physiological environment.[1][2] The full potential of NMR, however, is only realized through the incorporation of stable isotopes such as ¹³C and ¹⁵N into the DNA or RNA molecule.[2][3] This guide provides a comprehensive overview and detailed protocols for utilizing 2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-¹³C,¹⁵N₂ as a precursor for the site-specific introduction of an isotopically labeled uridine into a synthetic oligonucleotide via automated solid-phase synthesis. We will detail the necessary conversion of this protected nucleoside into a reactive phosphoramidite building block and its subsequent application in the well-established phosphoramidite synthesis cycle.
Introduction: The Rationale for Isotopic Labeling in DNA Synthesis
Solid-phase oligonucleotide synthesis, predominantly using phosphoramidite chemistry, is the universally accepted method for generating high-purity, custom DNA sequences.[4][5] This automated, cyclical process allows for the precise assembly of nucleotides on a solid support, a technique that has revolutionized molecular biology, diagnostics, and therapeutics.[6][7]
While standard synthesis yields unlabeled DNA, many advanced analytical techniques require the presence of NMR-active nuclei. The natural abundance of ¹³C (~1.1%) and ¹⁵N (~0.37%) is insufficient for most advanced heteronuclear NMR experiments. Therefore, enriching the DNA with these stable isotopes is essential.[8] By introducing ¹³C and ¹⁵N, researchers can:
-
Determine High-Resolution 3D Structures: Isotopic labels provide the necessary spectral resolution and constraints to solve the complete three-dimensional structures of DNA and its complexes in solution.[2][9]
-
Probe Molecular Dynamics: Labeled nuclei serve as probes to study the internal motions and conformational flexibility of DNA, which are often critical for its function.[10][11]
-
Map Binding Interfaces: By observing chemical shift perturbations upon the addition of a binding partner (e.g., a protein or small molecule drug), specific points of interaction can be mapped with residue-level precision.[1][3]
The precursor, 2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-¹³C,¹⁵N₂ , is a protected nucleoside containing stable isotopes in the uracil base. The p-toluoyl groups serve as protecting groups for the 3' and 5' hydroxyls of the deoxyribose sugar.[12][13] It is important to recognize that this compound is not a phosphoramidite and cannot be used directly on a DNA synthesizer. It must first be chemically converted into the corresponding 5'-DMT-3'-phosphoramidite, a process detailed in this guide.
The Core Workflow: From Protected Nucleoside to Purified Labeled Oligonucleotide
The overall process involves a logical progression from preparing the key building block to incorporating it into the desired DNA sequence and purifying the final product.
Detailed Protocols
Protocol 1: Preparation of 5'-O-DMT-2'-Deoxyuridine-¹³C,¹⁵N₂-3'-phosphoramidite
Causality: This multi-step chemical synthesis converts the stable, protected nucleoside precursor into a reactive phosphoramidite monomer compatible with automated DNA synthesizers. Each step is critical: toluoyl groups are removed to free the hydroxyls, the 5'-OH is re-protected with the acid-labile DMT group essential for the synthesis cycle, and the 3'-OH is phosphitylated to enable coupling.
Part A: Deprotection of p-toluoyl Groups
-
Dissolve 2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-¹³C,¹⁵N₂ in a solution of sodium methoxide (e.g., 0.5 M) in dry methanol.
-
Stir the reaction at room temperature and monitor by Thin Layer Chromatography (TLC) until the starting material is fully consumed.
-
Neutralize the reaction with an acidic resin (e.g., Dowex 50W-X8) or by careful addition of acetic acid.
-
Filter the solution and evaporate the solvent under reduced pressure to yield the crude 2'-Deoxyuridine-¹³C,¹⁵N₂.
Part B: Selective 5'-O-DMT Protection
-
Co-evaporate the dried nucleoside from Part A with anhydrous pyridine twice to ensure absolute dryness.
-
Dissolve the nucleoside in anhydrous pyridine. Add 4,4'-dimethoxytrityl chloride (DMT-Cl, ~1.1 equivalents) in portions.
-
Stir the reaction at room temperature, protected from moisture, until TLC analysis indicates completion.
-
Quench the reaction by adding methanol.
-
Evaporate the solvent and purify the resulting 5'-O-DMT-2'-Deoxyuridine-¹³C,¹⁵N₂ using silica gel column chromatography.
Part C: 3'-O-Phosphitylation
-
Thoroughly dry the purified 5'-O-DMT protected nucleoside from Part B under high vacuum.
-
Dissolve the nucleoside in anhydrous dichloromethane under an inert atmosphere (Argon or N₂).
-
Add N,N-diisopropylethylamine (DIPEA, ~2.0 equivalents).
-
Cool the mixture to 0°C and add 2-Cyanoethyl N,N-diisopropylchlorophosphoramidite (~1.5 equivalents) dropwise.
-
Allow the reaction to warm to room temperature and stir for 2-4 hours, monitoring by TLC.
-
Quench the reaction with ethyl acetate and wash with a saturated sodium bicarbonate solution, followed by brine.
-
Dry the organic layer over anhydrous sodium sulfate, filter, and evaporate the solvent.
-
Purify the final product, 5'-O-DMT-2'-Deoxyuridine-¹³C,¹⁵N₂-3'-O-(N,N-diisopropyl) phosphoramidite , by precipitation from cold hexanes or by flash chromatography on silica gel pre-treated with triethylamine. Confirm identity and purity via ³¹P NMR and Mass Spectrometry.
Protocol 2: Automated Solid-Phase Synthesis
Causality: This protocol leverages the gold-standard phosphoramidite cycle, a four-step process that is repeated for each nucleotide addition to build the DNA chain in the 3' to 5' direction.[7] The custom-synthesized labeled phosphoramidite is treated identically to the standard A, C, G, and T monomers by the automated synthesizer.
Materials & Setup:
-
Automated DNA Synthesizer
-
Controlled Pore Glass (CPG) solid support pre-loaded with the initial 3'-terminal nucleoside.
-
Standard DNA phosphoramidites (A, C, G, T) dissolved in anhydrous acetonitrile.
-
The labeled Uridine phosphoramidite from Protocol 1, dissolved in anhydrous acetonitrile to the manufacturer-specified concentration (e.g., 0.1 M).
-
Synthesis Reagents: Deblocking solution (e.g., 3% Trichloroacetic acid in Dichloromethane), Activator (e.g., 5-(Ethylthio)-1H-tetrazole), Capping solutions (A and B), and Oxidizer (Iodine solution).[14]
Procedure:
-
Preparation: Install the vial containing the dissolved labeled phosphoramidite onto a designated spare port on the synthesizer.
-
Programming: Enter the desired oligonucleotide sequence into the synthesizer's control software, specifying the use of the labeled uridine monomer at the desired position(s).
-
Initiation: Start the synthesis run. The instrument will automatically perform the following four-step cycle for each monomer addition:
-
Trityl Monitoring: The instrument's software can monitor the release of the orange dimethoxytrityl cation during each detritylation step. This provides a real-time estimate of the coupling efficiency for each step. A successful synthesis should exhibit consistent, high coupling efficiencies (>98%).
-
Completion: Upon completion of the sequence, the synthesizer can be programmed to either remove the final 5'-DMT group ("DMT-off") or leave it on ("DMT-on") to facilitate purification.
Protocol 3: Oligonucleotide Cleavage and Deprotection
Causality: After synthesis, the oligonucleotide is covalently attached to the solid support and carries protecting groups on the phosphate backbone (β-cyanoethyl) and the exocyclic amines of the nucleobases.[15] A strong base is required to cleave the oligo from the support and remove all these protecting groups, rendering the DNA biologically active.[7][16]
-
Cleavage: Transfer the CPG support from the synthesis column to a screw-cap vial. Add concentrated ammonium hydroxide (~1-2 mL). Let stand at room temperature for 1-2 hours to cleave the oligonucleotide from the CPG.
-
Deprotection: Transfer the ammonium hydroxide supernatant to a clean, sealable vial. Ensure the vial is tightly sealed and heat at 55-65°C for 8-16 hours. This step removes the cyanoethyl phosphate protecting groups and the standard protecting groups on the A, C, and G bases.[7]
-
Evaporation: Cool the vial to room temperature. Evaporate the solution to dryness using a centrifugal evaporator or a stream of dry nitrogen.
-
Resuspension: Resuspend the resulting DNA pellet in an appropriate buffer (e.g., sterile, nuclease-free water).
Note: For oligonucleotides containing sensitive modifications, milder deprotection strategies using reagents like AMA (Ammonium hydroxide/Methylamine) or potassium carbonate in methanol may be required.[16][17] Always verify the compatibility of your entire sequence with the chosen deprotection method.
Protocol 4: Purification and Quality Control
Causality: The crude, deprotected oligonucleotide solution contains full-length product as well as shorter, failed sequences (e.g., n-1). Purification is essential to isolate the desired product for downstream applications. Quality control validates the success of the synthesis and purification.
Purification Methods:
-
Reverse-Phase High-Performance Liquid Chromatography (RP-HPLC): This is the preferred method for "DMT-on" synthesized oligonucleotides. The lipophilic DMT group causes the full-length product to be retained strongly on the C18 column, allowing for excellent separation from the "DMT-off" failure sequences.[18] The DMT group is then removed post-purification with an acid wash.
-
Polyacrylamide Gel Electrophoresis (PAGE): This method separates oligonucleotides based on size and is highly effective for resolving long oligos or those requiring the highest purity.[18]
Quality Control:
-
Mass Spectrometry (MS): Electrospray Ionization (ESI) or MALDI-TOF MS should be used to confirm the molecular weight of the final product. The observed mass must match the theoretical mass calculated for the sequence, including the mass shift from the ¹³C and ¹⁵N isotopes.
-
Analytical HPLC or Capillary Electrophoresis (CE): These techniques are used to assess the purity of the final sample.
Quantitative Data Summary
The success of the synthesis can be quantified at several stages. The following table provides expected values for a typical synthesis incorporating a labeled monomer.
| Parameter | Method | Typical Value | Rationale & Importance |
| Coupling Efficiency | Trityl Cation Monitoring | > 98.0% per step | Ensures a high yield of full-length product. A 98% efficiency over a 20-mer synthesis results in (0.98)²⁰ ≈ 67% full-length product. |
| Final Crude Yield | UV Spectrophotometry (A₂₆₀) | 5 - 20 OD (40 nmol scale) | Provides a quantitative measure of the total amount of oligonucleotide synthesized before purification. |
| Final Purity | Analytical HPLC / CE | > 90% (post-purification) | Confirms the removal of failure sequences, ensuring the sample is suitable for sensitive applications like NMR. |
| Isotopic Incorporation | Mass Spectrometry | Confirmed Mass Shift | Validates that the labeled uridine was successfully incorporated at the correct position. |
References
- 1. Efficient enzymatic synthesis of 13C,15N-labeled DNA for NMR studies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. isotope-science.alfa-chemistry.com [isotope-science.alfa-chemistry.com]
- 3. Synthesizing Stable Isotope-Labeled Nucleic Acids | Silantes [silantes.com]
- 4. twistbioscience.com [twistbioscience.com]
- 5. Comprehensive Phosphoramidite chemistry capabilities for the synthesis of oligonucleotides - Aragen Life Sciences [aragen.com]
- 6. alfachemic.com [alfachemic.com]
- 7. benchchem.com [benchchem.com]
- 8. Selective 13C labeling of nucleotides for large RNA NMR spectroscopy using an E. coli strain disabled in the TCA cycle - PMC [pmc.ncbi.nlm.nih.gov]
- 9. isotope.com [isotope.com]
- 10. Synthesis and incorporation of 13C-labeled DNA building blocks to probe structural dynamics of DNA by NMR - PMC [pmc.ncbi.nlm.nih.gov]
- 11. academic.oup.com [academic.oup.com]
- 12. 2’-Deoxy-3’,5’-di-O-p-toluoyl Uridine-13C,15N2, TRC 5 mg | Buy Online | Toronto Research Chemicals | Fisher Scientific [fishersci.fi]
- 13. researchgate.net [researchgate.net]
- 14. Standard Protocol for Solid-Phase Oligonucleotide Synthesis using Unmodified Phosphoramidites | LGC, Biosearch Technologies [biosearchtech.com]
- 15. blog.biosearchtech.com [blog.biosearchtech.com]
- 16. glenresearch.com [glenresearch.com]
- 17. glenresearch.com [glenresearch.com]
- 18. lifesciences.danaher.com [lifesciences.danaher.com]
Illuminating DNA's Dynamic Landscape: Advanced NMR Spectroscopy Using ¹³C,¹⁵N Labeled Uridine
Introduction: Beyond the Static Helix
For decades, the double helix has been the iconic representation of DNA, a static blueprint of life. However, this picture is deceptively simple. In reality, DNA is a dynamic molecule, constantly undergoing conformational fluctuations, breathing, and bending. These motions are not random noise; they are fundamental to its biological functions, governing how proteins and drugs recognize and bind to their specific targets. To understand these intricate processes at an atomic level, researchers require tools that can capture both the structure and the dynamics of DNA in its native solution state.
Nuclear Magnetic Resonance (NMR) spectroscopy is uniquely powerful in this regard, providing unparalleled insights into the structure, dynamics, and interactions of biomolecules in solution.[1] However, the study of DNA by NMR is hampered by significant spectral overlap, a consequence of its composition from only four different nucleotides. The introduction of stable isotopes, specifically Carbon-13 (¹³C) and Nitrogen-15 (¹⁵N), revolutionizes the NMR analysis of DNA.[2][3] By enriching DNA with these NMR-active nuclei, we can exploit their distinct magnetic properties to disperse crowded spectra into multiple dimensions, dramatically enhancing resolution and enabling the application of powerful heteronuclear correlation experiments.
This comprehensive guide focuses on the application of ¹³C,¹⁵N labeled uridine (and its DNA analogue, thymidine) in the study of DNA by NMR spectroscopy. We will delve into the practical aspects of producing isotopically labeled DNA, detail the key NMR experiments that unlock its structural and dynamic secrets, and explore its application in the crucial field of drug development.
Part 1: Generating the Atomic Probes: Synthesis of ¹³C,¹⁵N Labeled DNA
The prerequisite for any heteronuclear NMR study is the efficient incorporation of ¹³C and ¹⁵N isotopes into the DNA molecule. While chemical synthesis using labeled phosphoramidites is an option, it can be prohibitively expensive for generating the milligram quantities of sample required for NMR.[4] A more cost-effective and widely adopted approach is enzymatic synthesis.
The Rationale for Enzymatic Synthesis
Enzymatic methods, particularly those employing thermostable DNA polymerases like Taq polymerase, offer a robust and efficient route to uniformly ¹³C,¹⁵N-labeled DNA oligonucleotides.[5][6] This approach relies on the in vitro amplification of a DNA template using ¹³C,¹⁵N-labeled deoxynucleoside triphosphates (dNTPs). The labeled dNTPs themselves are typically produced biosynthetically by growing bacteria, such as Methylophilus methylotrophus, in a minimal medium where the sole carbon and nitrogen sources are ¹³C-methanol and ¹⁵N-ammonium chloride, respectively.
Workflow for Enzymatic DNA Labeling
The overall process can be visualized as a multi-stage workflow, starting from basic isotopic precursors and culminating in a purified, NMR-ready DNA sample.
Protocol 1: Enzymatic Synthesis of Uniformly ¹³C,¹⁵N-Labeled DNA
This protocol is adapted from the efficient method developed by Masse, J. E., et al. (1998).[5]
Materials:
-
Unlabeled DNA template and primers
-
Uniformly ¹³C,¹⁵N-labeled dNTP mixture
-
Recombinantly expressed and purified Taq DNA polymerase
-
10x Polymerization Buffer (500 mM KCl, 100 mM Tris-HCl pH 9.0, 1% Triton X-100)
-
MgCl₂ solution (e.g., 100 mM stock)
-
Nuclease-free water
-
Denaturing polyacrylamide gel electrophoresis (PAGE) apparatus and reagents
-
Crush and soak buffer (e.g., 500 mM NH₄OAc, 10 mM Mg(OAc)₂, 1 mM EDTA, 0.1% SDS)
Methodology:
-
Reaction Setup:
-
In a sterile PCR tube, combine the DNA template, primers, 10x polymerization buffer, MgCl₂, nuclease-free water, and the ¹³C,¹⁵N-labeled dNTPs.
-
Causality: The ratio of dNTPs should be stoichiometric to the desired product sequence, with a slight excess (e.g., 20%) to ensure complete extension of the primers. The MgCl₂ concentration is critical for polymerase activity and should be optimized for each template, typically 1-4 times the total dNTP concentration.
-
-
Initiation of Polymerization:
-
Add Taq DNA polymerase to the reaction mixture (a typical concentration is ~24,000 units per micromole of template).
-
Place the reaction tube in a boiling water bath for 2 minutes.
-
Causality: The initial high-temperature step denatures the DNA template, allowing the primers to anneal as the reaction cools, and activates the thermostable Taq polymerase.
-
-
Polymerization Cycles:
-
Transfer the tube to a thermocycler programmed for the appropriate annealing and extension temperatures based on the primers and template. For many templates, simply incubating at 72°C for 2-4 hours is sufficient for quantitative polymerization.[5]
-
Causality: Taq polymerase extends the primers, incorporating the labeled dNTPs to synthesize the complementary DNA strand. The efficiency of this step is high, often resulting in ~80% incorporation of the labeled dNTPs into the final product.
-
-
Purification:
-
Terminate the reaction by adding EDTA.
-
Separate the labeled DNA product from the template, primers, and unincorporated dNTPs using denaturing PAGE.
-
Visualize the DNA bands by UV shadowing, excise the band corresponding to the full-length product.
-
Elute the DNA from the gel slice using a crush and soak method.
-
Desalt the purified DNA using a suitable method (e.g., dialysis or size-exclusion chromatography).
-
-
NMR Sample Preparation:
-
Lyophilize the purified DNA.
-
For duplex DNA, dissolve the labeled strand in NMR buffer (e.g., 10 mM Sodium Phosphate, 50 mM NaCl, pH 6.5) and titrate in the unlabeled complementary strand.
-
Transfer the final sample to a Shigemi or standard NMR tube. For experiments observing exchangeable protons, the sample should be dissolved in 90% H₂O / 10% D₂O.
-
Part 2: Deciphering the Spectra: Key NMR Experiments
With a ¹³C,¹⁵N-labeled DNA sample in hand, a suite of powerful multidimensional NMR experiments becomes accessible. These experiments correlate the chemical shifts of different nuclei through their scalar (through-bond) or dipolar (through-space) couplings, allowing for unambiguous resonance assignment and the extraction of detailed structural and dynamic information.
Resonance Assignment: The Starting Point
Before any structural or dynamic analysis can be performed, each NMR signal must be assigned to a specific atom in the DNA sequence. Isotopic labeling makes this process, which is often a bottleneck with unlabeled DNA, far more robust.
Key Assignment Experiments:
-
2D ¹H-¹⁵N HSQC (Heteronuclear Single Quantum Coherence): This is the cornerstone experiment, producing a 2D map with one peak for each ¹H-¹⁵N pair (e.g., imino protons in G and T/U bases, amino protons in A, G, C). It serves as a fingerprint of the DNA's secondary structure and is exquisitely sensitive to changes upon ligand binding.[7]
-
3D HCN Experiments: These experiments are crucial for linking the sugar backbone to the nitrogenous bases. Magnetization is transferred from the sugar H1' proton to its attached C1' carbon, and then to the N1 (pyrimidines) or N9 (purines) of the base. This provides a direct, through-bond correlation that is essential for sequential assignment.
-
3D HNCO-type Experiments: Adapted from protein NMR, these experiments correlate an imino proton (¹H) and its attached nitrogen (¹⁵N) with the carbonyl carbon (¹³C) of either the same or the preceding residue.[4][6][8] This provides invaluable information for tracing the connectivity along the DNA backbone. For example, an H(N)CO experiment can link the G(H1)-G(N1) pair to the G(C2) and G(C6) carbons.[4]
Probing DNA Dynamics with ¹³C,¹⁵N Labeling
DNA dynamics occur over a vast range of timescales, from fast picosecond-nanosecond bond vibrations to slower microsecond-millisecond conformational exchanges, such as the transient opening of base pairs ("breathing"). Relaxation dispersion NMR is a powerful technique for characterizing these slower, functionally important motions.[9][10]
Relaxation Dispersion (RD) NMR:
RD experiments, such as Carr-Purcell-Meiboom-Gill (CPMG) and R₁ρ experiments, measure how the relaxation rates of ¹³C and ¹⁵N nuclei change as a function of an applied radiofrequency field.[9][11] If a nucleus is exchanging between two or more conformations on the µs-ms timescale, this exchange process provides an additional pathway for relaxation, which can be quantified.
By applying RD experiments to ¹³C,¹⁵N labeled DNA, one can measure:
-
Kinetics: The rate of conformational exchange (k_ex).
-
Thermodynamics: The population of the minor, "excited" state.
-
Structure: The chemical shifts of the nuclei in the transiently formed excited state.
Specifically labeling pyrimidines like uridine/thymidine allows researchers to probe dynamics at U-A or T-A base pairs, which are often involved in the initial recognition or "breathing" events that allow proteins to access the DNA bases. Nuclei such as C2, C4, C6, N1, and N3 are excellent probes for these dynamic events.[9]
Protocol 2: Characterizing µs-ms Timescale Dynamics with ¹³C R₁ρ Relaxation Dispersion
This protocol provides a general workflow for an R₁ρ experiment targeting a ¹³C nucleus (e.g., C6 of a thymidine residue) in a labeled DNA sample.
Prerequisites:
-
A high-concentration (≥1 mM) ¹³C,¹⁵N-labeled DNA sample.
-
A high-field NMR spectrometer equipped with a cryoprobe.
-
Complete resonance assignments for the nuclei of interest.
Methodology:
-
Spectrometer Setup and Calibration:
-
Tune and match the probe for ¹H, ¹³C, and ¹⁵N frequencies.
-
Carefully calibrate the 90° pulse widths for both ¹H and ¹³C on the specific sample.
-
Calibrate the power levels for the ¹³C spin-lock field (ω_SL) to cover a range of effective fields (e.g., from 50 Hz to 3000 Hz).
-
-
Data Acquisition:
-
Implement a ¹³C R₁ρ pulse sequence.[9] This sequence typically involves selective excitation of the target ¹³C resonance, a variable-duration spin-lock period, and subsequent detection.
-
Acquire a series of 1D or 2D spectra, varying the duration of the spin-lock period (T_relax) for each desired spin-lock field strength (ω_SL).
-
Causality: The intensity of the target peak will decay as a function of T_relax. The rate of this decay is the R₁ρ value. If the nucleus is undergoing chemical exchange, the R₁ρ value will be dependent on the strength of the spin-lock field.
-
-
Data Processing and Analysis:
-
Process all spectra identically.
-
For each spectrum, measure the peak intensity or volume of the resonance of interest.
-
For each spin-lock field strength, fit the decay of peak intensity versus T_relax to a single exponential function to extract the R₁ρ value.
-
Plot the measured R₁ρ values as a function of the spin-lock field strength (ω_SL). This is the relaxation dispersion profile.
-
-
Interpretation:
-
Fit the dispersion profile to the appropriate model (e.g., the Bloch-McConnell equations) using specialized software.
-
The fitting will yield the kinetic (k_ex), thermodynamic (p_B), and structural (Δω, the chemical shift difference between states) parameters of the dynamic process.
-
Causality: A "flat" dispersion profile indicates no significant motion on the µs-ms timescale for that nucleus. A curved profile is the signature of conformational exchange, providing a window into the invisible, transiently populated states of the DNA.
-
Part 3: Applications in Drug Discovery and Development
Understanding how a potential drug molecule interacts with its DNA target is a cornerstone of rational drug design. ¹³C,¹⁵N labeling provides a high-resolution method to map binding interfaces, characterize binding-induced conformational changes, and even study the kinetics of the interaction.[7][12]
Chemical Shift Perturbation (CSP) Mapping
The simplest and most common NMR method for studying interactions is Chemical Shift Perturbation (CSP), also known as chemical shift mapping.
-
The Principle: The chemical shift of a nucleus is extremely sensitive to its local electronic environment. When a drug binds to DNA, the nuclei at the binding interface experience a change in their environment, causing their corresponding peaks in the NMR spectrum to shift.
-
The Experiment: A 2D ¹H-¹⁵N HSQC spectrum of the ¹³C,¹⁵N-labeled DNA is recorded. Then, small aliquots of the unlabeled drug are titrated into the sample, and an HSQC spectrum is recorded after each addition.
-
The Readout: By overlaying the spectra, one can track which peaks move upon addition of the drug. The residues whose peaks are significantly perturbed are identified as being at or near the binding site. Changes in the chemical shifts of the drug itself can also be monitored if a ¹³C-labeled drug is used with unlabeled DNA.[5][13]
Data Presentation: Quantifying Binding Effects
The observed chemical shift changes for both proton (Δδ_H) and nitrogen (Δδ_N) can be combined into a single weighted-average chemical shift perturbation value for each residue, allowing for easy visualization of the binding interface.
| Residue | Δδ ¹H (ppm) | Δδ ¹⁵N (ppm) | Combined CSP (ppm) |
| T5 | 0.02 | 0.10 | 0.04 |
| A6 | 0.15 | 0.80 | 0.21 |
| T7 | 0.45 | 2.50 | 0.65 |
| T8 | 0.51 | 2.80 | 0.73 |
| A9 | 0.18 | 0.95 | 0.26 |
| C10 | 0.01 | 0.05 | 0.02 |
| Table 1: Example of CSP data for a hypothetical drug binding to a DNA sequence. The largest perturbations are observed for thymidines T7 and T8, identifying them as the primary interaction site. |
Conclusion and Future Outlook
The incorporation of ¹³C and ¹⁵N stable isotopes, particularly within pyrimidine nucleosides like uridine and thymidine, has fundamentally advanced our ability to study DNA by solution NMR spectroscopy. These isotopic labels break the curse of spectral overlap, paving the way for sophisticated multidimensional experiments that can be used to solve complex structures and, crucially, to characterize the functionally important dynamic motions that were previously invisible. From elucidating the mechanisms of protein-DNA recognition to precisely mapping the binding sites of novel therapeutics, the applications are vast and continue to expand. As NMR hardware and methodologies continue to improve, ¹³C,¹⁵N-labeling will remain an indispensable tool for researchers, scientists, and drug development professionals dedicated to unraveling the complex and dynamic world of DNA.
References
- 1. Nuclear magnetic resonance spectroscopy of nucleic acids - Wikipedia [en.wikipedia.org]
- 2. Efficient enzymatic synthesis of 13C,15N-labeled DNA for NMR studies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. General method of preparation of uniformly 13C, 15N-labeled DNA fragments for NMR analysis of DNA structures - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. 1H, 13C and 15N chemical shift assignment of the stem-loops 5b + c from the 5′-UTR of SARS-CoV-2 - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Changes in drug 13C NMR chemical shifts as a tool for monitoring interactions with DNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. 3D HNCO Experiment [imserc.northwestern.edu]
- 7. NMR as a “Gold Standard” Method in Drug Design and Discovery - PMC [pmc.ncbi.nlm.nih.gov]
- 8. chem.libretexts.org [chem.libretexts.org]
- 9. Characterizing RNA Excited States using NMR Relaxation Dispersion - PMC [pmc.ncbi.nlm.nih.gov]
- 10. NMR studies of dynamics in RNA and DNA by 13C relaxation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. academic.oup.com [academic.oup.com]
- 12. Solution NMR Spectroscopy in Target-Based Drug Discovery - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Changes in 13C NMR chemical shifts of DNA as a tool for monitoring drug interactions - PubMed [pubmed.ncbi.nlm.nih.gov]
Application and Protocol for the Use of 2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-13C,15N2 as an Internal Standard in LC-MS Bioanalysis
Introduction: The Imperative for Precision in Bioanalysis
In the landscape of drug development and clinical research, the accurate quantification of therapeutic agents and their metabolites in biological matrices is paramount. Liquid chromatography coupled with tandem mass spectrometry (LC-MS/MS) has emerged as the gold standard for such bioanalytical endeavors, offering unparalleled sensitivity and selectivity.[1][2] However, the inherent variability of complex biological samples and the intricacies of the analytical process necessitate the use of an internal standard to ensure data integrity. A suitable internal standard is critical for correcting variations in sample preparation, injection volume, and matrix effects, which can significantly impact ionization efficiency.[3][4][5]
Stable isotope-labeled (SIL) internal standards are widely regarded as the superior choice for quantitative LC-MS/MS assays.[3][5] By incorporating heavy isotopes such as ¹³C, ¹⁵N, or ²H, SIL internal standards are chemically identical to the analyte of interest, yet distinguishable by their mass-to-charge ratio (m/z). This near-perfect analogy ensures that the internal standard co-elutes with the analyte and experiences similar extraction recovery and matrix effects, thereby providing the most accurate correction for analytical variability.[6]
This application note provides a comprehensive guide for researchers, scientists, and drug development professionals on the utilization of 2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-¹³C,¹⁵N₂ as a robust internal standard for the quantification of its unlabeled analogue or similar uridine-based nucleoside derivatives in various biological matrices. We will delve into the scientific rationale, provide detailed experimental protocols, and outline a self-validating system to ensure the generation of high-quality, reproducible, and defensible bioanalytical data.
Physicochemical Properties of the Internal Standard
Understanding the fundamental properties of the internal standard is crucial for method development. 2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-¹³C,¹⁵N₂ is a synthetically modified and isotopically labeled version of a uridine analog.[7][8] The p-toluoyl groups enhance its lipophilicity compared to native 2'-deoxyuridine, influencing its chromatographic behavior and extraction characteristics. The incorporation of one ¹³C and two ¹⁵N atoms provides a distinct mass shift, essential for its function as an internal standard.
| Property | Value | Source |
| IUPAC Name | 2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-¹³C,¹⁵N₂ | [8] |
| Molecular Formula | C₂₄¹³CH₂₄¹⁵N₂O₇ | [8] |
| Molecular Weight | ~467.45 g/mol | [8] |
| Isotopic Purity | Typically >99% | Vendor Specific |
| Chemical Purity | Typically >98% | Vendor Specific |
| Appearance | White to off-white powder | [9] |
| Solubility | Soluble in organic solvents (e.g., Methanol, Acetonitrile, DMSO) | General Knowledge |
Protocol for Quantitative Bioanalysis using LC-MS/MS
This section outlines a detailed protocol for the development and validation of a quantitative LC-MS/MS method for a target analyte (unlabeled 2'-Deoxy-3',5'-di-O-p-toluoyl Uridine or a structurally similar molecule) using 2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-¹³C,¹⁵N₂ as the internal standard.
Preparation of Stock and Working Solutions
The accuracy of your entire assay is founded on the precise preparation of your stock and working solutions.
-
Internal Standard (IS) Stock Solution (1 mg/mL): Accurately weigh approximately 1 mg of 2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-¹³C,¹⁵N₂ and dissolve it in a suitable organic solvent (e.g., methanol or acetonitrile) to a final volume of 1 mL in a Class A volumetric flask.
-
Analyte Stock Solution (1 mg/mL): Prepare a stock solution of the unlabeled analyte in the same manner as the internal standard.
-
Working Solutions: Prepare serial dilutions of the analyte stock solution in a 50:50 mixture of acetonitrile and water to create a series of calibration standards. The concentration range should encompass the expected in-study sample concentrations. Similarly, prepare a working solution of the internal standard at a concentration that provides an adequate response in the mass spectrometer (e.g., 100 ng/mL).
Sample Preparation: Protein Precipitation
Protein precipitation is a straightforward and effective method for extracting small molecules from plasma or serum.
-
Sample Aliquoting: To a 1.5 mL microcentrifuge tube, add 50 µL of the biological matrix (e.g., plasma, serum).
-
Internal Standard Spiking: Add 10 µL of the internal standard working solution to each sample, except for the blank matrix samples.
-
Precipitation: Add 200 µL of cold acetonitrile to each tube.
-
Vortexing: Vortex the samples vigorously for 1 minute to ensure thorough mixing and protein precipitation.
-
Centrifugation: Centrifuge the samples at a high speed (e.g., 14,000 rpm) for 10 minutes at 4°C to pellet the precipitated proteins.
-
Supernatant Transfer: Carefully transfer the supernatant to a clean 96-well plate or autosampler vials.
-
Injection: Inject a small volume (e.g., 5-10 µL) into the LC-MS/MS system.
Liquid Chromatography Conditions (A Starting Point)
The goal of the chromatographic separation is to resolve the analyte and internal standard from endogenous matrix components to minimize ion suppression.[10]
-
Column: A C18 reversed-phase column (e.g., 50 mm x 2.1 mm, 1.8 µm) is a good starting point for nucleoside analogs.[2][11]
-
Gradient: A linear gradient from 5% to 95% Mobile Phase B over 5-7 minutes is a typical starting point.[11]
-
Flow Rate: 0.4 mL/min.[2]
-
Column Temperature: 40°C.
Mass Spectrometry Conditions
The mass spectrometer should be operated in positive electrospray ionization (ESI) mode and Multiple Reaction Monitoring (MRM) mode for optimal sensitivity and selectivity.
-
Ionization Mode: Electrospray Ionization (ESI), Positive
-
MRM Transitions: The specific MRM transitions will need to be optimized by infusing a solution of the analyte and the internal standard into the mass spectrometer. The precursor ion will be the [M+H]⁺ adduct. The product ions are typically generated by the loss of the deoxyribose moiety or one of the p-toluoyl groups.
| Compound | Precursor Ion (m/z) | Product Ion (m/z) | Collision Energy (eV) |
| Analyte | To be determined | To be determined | To be optimized |
| IS (¹³C,¹⁵N₂) | Analyte m/z + 3 | To be determined | To be optimized |
Rationale for MRM Transition Selection: The precursor ion is selected in the first quadrupole (Q1), fragmented in the collision cell (Q2), and a specific fragment ion is selected in the third quadrupole (Q3). This highly selective process minimizes interferences and enhances the signal-to-noise ratio.[14]
Data Analysis and Quantification
-
Calibration Curve: A calibration curve is constructed by plotting the peak area ratio of the analyte to the internal standard against the nominal concentration of the analyte for the calibration standards. A linear regression with a 1/x² weighting is typically used.
-
Quantification: The concentration of the analyte in the unknown samples is then calculated from the calibration curve using the measured peak area ratio.
Experimental Workflow Diagram
Caption: A streamlined workflow for quantitative bioanalysis using LC-MS/MS.
Method Validation: Ensuring a Self-Validating System
A robust bioanalytical method must be validated to demonstrate its reliability and suitability for its intended purpose.[1] The validation process should adhere to regulatory guidelines such as those from the U.S. Food and Drug Administration (FDA).[10][15][16][17]
Key Validation Parameters:
-
Selectivity and Specificity: The ability of the method to differentiate and quantify the analyte from other components in the matrix. This is assessed by analyzing blank matrix samples from multiple sources.
-
Accuracy and Precision: The closeness of the measured values to the true values (accuracy) and the degree of scatter between a series of measurements (precision). These are evaluated at multiple concentration levels (L L O Q, L Q C, M Q C, H Q C).
-
Calibration Curve: The relationship between the instrument response and the known concentration of the analyte. The linearity and range of the curve are assessed.
-
Lower Limit of Quantification (LLOQ): The lowest concentration of the analyte that can be measured with acceptable accuracy and precision.
-
Stability: The stability of the analyte in the biological matrix under various storage and processing conditions (e.g., freeze-thaw, short-term benchtop, long-term storage).
-
Matrix Effect: The alteration of ionization efficiency due to co-eluting matrix components. This is evaluated by comparing the response of the analyte in post-extraction spiked matrix samples to that in a neat solution. The use of a stable isotope-labeled internal standard is crucial for mitigating and correcting for matrix effects.
Logical Framework for a Self-Validating Method
Caption: The interplay of key elements in a self-validating bioanalytical method.
Conclusion
The use of 2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-¹³C,¹⁵N₂ as an internal standard provides a robust and reliable approach for the quantitative analysis of its unlabeled counterpart or structurally related nucleoside analogs in biological matrices by LC-MS/MS. Its stable isotope-labeled nature ensures that it closely mimics the behavior of the analyte throughout the analytical process, leading to superior accuracy and precision. By following the detailed protocols and validation guidelines outlined in this application note, researchers can develop high-quality, defensible bioanalytical methods that are fit for purpose in the demanding environment of pharmaceutical research and development.
References
- 1. resolvemass.ca [resolvemass.ca]
- 2. LC-MS/MS Method Development and Validation for Determination of Favipiravir Pure and Tablet Dosage Forms - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Stable isotopically labeled internal standards in quantitative bioanalysis using liquid chromatography/mass spectrometry: necessity or not? - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. scispace.com [scispace.com]
- 5. crimsonpublishers.com [crimsonpublishers.com]
- 6. bioanalysis-zone.com [bioanalysis-zone.com]
- 7. pharmaffiliates.com [pharmaffiliates.com]
- 8. clearsynth.com [clearsynth.com]
- 9. 3,5-Di-O-(p-toluyl)-2-deoxy- D -ribofuranosyl chloride 90 4330-21-6 [sigmaaldrich.com]
- 10. fda.gov [fda.gov]
- 11. A sensitive LC-MS/MS method for quantification of a nucleoside analog in plasma: application to in vivo rat pharmacokinetic studies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Simultaneous Quantification of Nucleosides and Nucleotides from Biological Samples - PMC [pmc.ncbi.nlm.nih.gov]
- 13. protocols.io [protocols.io]
- 14. LC-MS/MS for Assessing the Incorporation and Repair of N2-Alkyl-2′-deoxyguanosine in Genomic DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 15. chromatographyonline.com [chromatographyonline.com]
- 16. labs.iqvia.com [labs.iqvia.com]
- 17. academy.gmp-compliance.org [academy.gmp-compliance.org]
Application Notes and Protocols: Efficient Deprotection of Toluoyl Groups in Oligonucleotides
For Researchers, Scientists, and Drug Development Professionals
Introduction: The Role of Aryl Acyl Protecting Groups in Oligonucleotide Synthesis
The chemical synthesis of oligonucleotides is a cornerstone of modern molecular biology and drug development. This process relies on a meticulously orchestrated series of chemical reactions, where the success of each step is contingent upon the precise use of protecting groups.[][2][3] These chemical moieties temporarily block reactive functional groups, preventing unintended side reactions during the stepwise assembly of the oligonucleotide chain.[4]
Among the most critical are the protecting groups for the exocyclic amino functions of the nucleobases adenine (A), guanine (G), and cytosine (C). Aryl acyl groups, such as the industry-standard benzoyl (Bz) group and the structurally similar p-toluoyl group, are frequently employed for this purpose. The p-toluoyl group, a derivative of benzoic acid, shares a nearly identical chemical reactivity profile with the benzoyl group. Both are stable throughout the phosphoramidite synthesis cycle but can be efficiently removed during the final deprotection step.[2][5]
This guide provides a comprehensive overview of the chemical principles and detailed protocols for the removal of p-toluoyl protecting groups from synthetic oligonucleotides. Given the chemical analogy, the methodologies presented are grounded in the well-established and extensively validated procedures for benzoyl group deprotection.
The Mechanism of Toluoyl Group Removal: Nucleophilic Acyl Substitution
The cleavage of a p-toluoyl group from a nucleobase is a classic example of nucleophilic acyl substitution. The deprotection process, often termed ammonolysis or aminolysis, involves the attack of a nucleophile (typically ammonia or methylamine) on the electrophilic carbonyl carbon of the toluoyl group.[6]
This attack forms a tetrahedral intermediate. Subsequently, the intermediate collapses, breaking the amide bond and liberating the exocyclic amine of the nucleobase. The toluoyl group is released as the corresponding amide (e.g., p-toluamide), which can be easily removed during downstream purification steps.
Caption: Mechanism of Toluoyl Group Removal.
Standard Deprotection Protocols
The choice of deprotection reagent and conditions is dictated by the overall chemical stability of the oligonucleotide, including any sensitive modifications or labels, and the desired processing time.[7]
Protocol 1: Standard Deprotection with Aqueous Ammonium Hydroxide
This is the most traditional method for removing standard acyl protecting groups. While reliable, it requires longer incubation times compared to more modern protocols.
Causality: Concentrated ammonium hydroxide provides a sufficient concentration of the ammonia nucleophile to drive the ammonolysis reaction to completion. Elevated temperatures are used to increase the reaction rate.
Methodology:
-
Transfer the solid support (e.g., CPG) containing the synthesized oligonucleotide to a 2 mL screw-cap vial.
-
Add 1-2 mL of concentrated aqueous ammonium hydroxide (28-30% NH₃).
-
Seal the vial tightly to prevent ammonia gas from escaping.
-
Incubate the vial in a heating block at 55 °C for 8-12 hours.
-
After incubation, allow the vial to cool completely to room temperature.
-
Carefully open the vial in a fume hood.
-
Transfer the supernatant containing the cleaved and deprotected oligonucleotide to a new tube.
-
Evaporate the ammonia to dryness using a vacuum concentrator.
Protocol 2: UltraFAST Deprotection with AMA
For high-throughput applications, a mixture of Ammonium Hydroxide and Methylamine (AMA) dramatically reduces deprotection times.
Causality: Methylamine is a stronger nucleophile than ammonia, leading to a significant acceleration of the deprotection reaction. The AMA mixture provides a highly reactive environment for rapid cleavage of acyl protecting groups.[7][8]
Critical Consideration - Transamination: When using methylamine-containing reagents with benzoyl- or toluoyl-protected deoxycytidine (dC), a side reaction can occur where the exocyclic N4-amine is converted to an N4-methylamine. To prevent this, it is mandatory to use phosphoramidites with an acetyl (Ac) protecting group for dC when employing the AMA protocol.
Methodology:
-
Prepare the AMA reagent by mixing concentrated aqueous ammonium hydroxide (28-30%) and 40% aqueous methylamine in a 1:1 (v/v) ratio. Caution: This should be done in a fume hood with appropriate personal protective equipment.
-
Add 1-2 mL of the freshly prepared AMA solution to the solid support in a 2 mL screw-cap vial.
-
Seal the vial tightly.
-
Incubate the vial in a heating block at 65 °C for 10-15 minutes.[8]
-
Allow the vial to cool completely to room temperature before opening.
-
Transfer the supernatant to a new tube and evaporate to dryness in a vacuum concentrator.
Mild Deprotection for Sensitive Oligonucleotides
Many oligonucleotides are synthesized with modifications, such as fluorescent dyes or complex ligands, that are unstable under standard deprotection conditions. In these cases, milder, non-nucleophilic base conditions are required.
Protocol 3: UltraMILD Deprotection with Potassium Carbonate in Methanol
This method is ideal for oligonucleotides containing base-sensitive functional groups. It avoids the use of strong amine nucleophiles.
Causality: This protocol relies on base-catalyzed methanolysis. The carbonate base generates a methoxide ion from the methanol solvent, which then acts as the nucleophile to cleave the toluoyl group. The conditions are significantly milder than aqueous ammonia or AMA. This method has been shown to be effective for the saponification of toluoyl groups.[9]
Methodology:
-
Prepare a 0.05 M solution of potassium carbonate (K₂CO₃) in anhydrous methanol.
-
Add 1-2 mL of the K₂CO₃/methanol solution to the solid support.
-
Incubate at room temperature for 4-6 hours.[8]
-
Monitor the reaction progress by analytical HPLC if necessary.
-
Once deprotection is complete, transfer the supernatant to a new tube.
-
Neutralize the solution by adding a small amount of acetic acid.
-
Evaporate the solvent in a vacuum concentrator.
Summary of Deprotection Protocols
| Protocol Name | Reagent(s) | Temperature | Time | Key Advantages | Key Considerations |
| Standard | Conc. NH₄OH | 55 °C | 8-12 hours | Well-established, compatible with most standard protecting groups. | Slow, not suitable for high-throughput. |
| UltraFAST | NH₄OH / Methylamine (AMA) (1:1) | 65 °C | 10-15 min | Extremely rapid, ideal for high-throughput synthesis. | Requires Ac-dC to prevent transamination. Not for base-sensitive oligos. |
| UltraMILD | 0.05 M K₂CO₃ in Methanol | Room Temp. | 4-6 hours | Protects sensitive modifications. | Slower than AMA; requires anhydrous conditions for best results. |
General Experimental Workflow and Verification
The deprotection process is integrated into the final steps of oligonucleotide processing after synthesis is complete.
Caption: Post-synthesis Oligonucleotide Workflow.
Verification of Complete Deprotection: It is crucial to verify that all protecting groups have been removed before using an oligonucleotide in a biological application. Incomplete deprotection can interfere with hybridization and other functions.
-
Reversed-Phase High-Performance Liquid Chromatography (RP-HPLC): The presence of residual toluoyl groups increases the hydrophobicity of the oligonucleotide, leading to a longer retention time on a C18 column compared to the fully deprotected product. A clean, single peak at the expected retention time is indicative of successful deprotection.
-
Mass Spectrometry (MS): Techniques like ESI-MS or MALDI-TOF MS provide an exact mass of the synthesized oligonucleotide. The observed mass should match the calculated theoretical mass of the fully deprotected sequence. Any deviation may indicate incomplete deprotection or other modifications.
References
- 2. Manual oligonucleotide synthesis using the phosphoramidite method - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Chemical Synthesis of Oligonucelotide Sequences: Phosphoramidite Chemistry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. twistbioscience.com [twistbioscience.com]
- 5. chem.libretexts.org [chem.libretexts.org]
- 6. Aminolysis as a surface functionalization method of aliphatic polyester nonwovens: impact on material properties and biological response - PMC [pmc.ncbi.nlm.nih.gov]
- 7. An evaluation of selective deprotection conditions for the synthesis of RNA on a light labile solid support - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. benchchem.com [benchchem.com]
- 9. pubs.acs.org [pubs.acs.org]
Incorporation of labeled nucleosides into DNA/RNA probes
Application Note & Protocols
A Comprehensive Guide to the Incorporation of Labeled Nucleosides for High-Performance DNA and RNA Probe Synthesis
Abstract
Chapter 1: The Foundation - Selecting the Appropriate Reporter Moiety
The utility of a nucleic acid probe is fundamentally dependent on its label, or reporter moiety, which allows for its detection after hybridization to a target sequence.[4] The choice of label is a critical decision dictated by the experimental application, required sensitivity, available detection instrumentation, and laboratory safety considerations. Labels can be broadly categorized into two main classes: radioactive and non-radioactive.[5]
1.1 Radioactive Labels
Historically, radioactive isotopes, particularly Phosphorus-32 (³²P), were the gold standard for probe labeling due to their exceptional sensitivity, allowing for the detection of minute quantities of target sequence.[6][7][8]
-
Mechanism: A radiolabeled deoxynucleoside triphosphate (dNTP), such as [α-³²P]dCTP, is enzymatically incorporated into the nucleic acid backbone.[9] Detection is achieved via autoradiography, where the radioactive emissions expose X-ray film, or through phosphorimaging screens or scintillation counting.
-
Causality: The high energy of the beta particles emitted by ³²P provides a very strong signal, making it ideal for detecting low-abundance targets in Southern or Northern blotting. However, this high energy also leads to lower resolution in techniques like in situ hybridization. For higher resolution applications, lower energy isotopes like ³⁵S are a more suitable choice.[9]
1.2 Non-Radioactive Labels
Due to safety concerns, cost of disposal, and the limited half-life of radioisotopes, non-radioactive labels have become the preferred choice in most modern laboratories.[5][8][10] They offer comparable or even superior sensitivity in many applications, combined with greater stability and versatility.[10]
-
Haptens (Indirect Labeling): Haptens are small molecules like biotin and digoxigenin (DIG) that are incorporated into the probe. They are not directly detected but are recognized by a secondary molecule with an extremely high affinity, which is in turn conjugated to a reporter enzyme (e.g., Alkaline Phosphatase (AP) or Horseradish Peroxidase (HRP)) or a fluorophore.[4][7]
-
Causality (Signal Amplification): The power of this indirect system lies in its capacity for signal amplification. The conjugated enzyme (AP or HRP) can process multiple substrate molecules, generating a strong colorimetric, chemiluminescent, or fluorescent signal from a single hybridization event.[4] This makes hapten-based systems extremely sensitive.
-
-
Fluorophores (Direct Labeling): Fluorophores are molecules that absorb light at one wavelength and emit it at a longer wavelength. These can be directly conjugated to a nucleoside and incorporated into a probe.[4][6]
-
Causality (Multiplexing): A key advantage of fluorescent labels is the availability of a wide spectrum of dyes with distinct excitation and emission profiles (e.g., Fluorescein, Cy®3, Cy®5).[6] This allows for the simultaneous use of multiple probes, each with a different color, to detect several targets in a single experiment, a technique known as multiplexing, which is fundamental to applications like Fluorescence in situ Hybridization (FISH).[6]
-
Data Presentation: Comparison of Common Probe Labels
| Label Type | Reporter Moiety | Detection Method | Sensitivity | Safety | Key Advantage | Key Disadvantage |
| Radioactive | ³²P, ³³P, ³⁵S | Autoradiography, Phosphorimaging | Very High | Low (Requires specialized handling and disposal) | Established sensitivity for low-abundance targets | Short half-life, safety hazards, poor resolution |
| Hapten | Biotin | Streptavidin-Enzyme/Fluorophore Conjugate | High to Very High | High | Signal amplification, versatility | Indirect detection requires additional steps |
| Hapten | Digoxigenin (DIG) | Anti-DIG Antibody-Enzyme/Fluorophore Conjugate | High to Very High | High | Low endogenous background in most tissues | Indirect detection requires additional steps |
| Fluorophore | Fluorescein, Cy® Dyes, etc. | Fluorescence Microscopy/Scanners | High | High | Direct detection, ideal for multiplexing | Potential for photobleaching, large fluorophores can cause steric hindrance[5] |
Chapter 2: Workhorse Techniques - Enzymatic Labeling of DNA Probes
The enzymatic synthesis of DNA probes relies on the catalytic activity of DNA polymerases, which incorporate labeled dNTPs into a growing DNA strand using an existing DNA template.[11][12] The choice of method depends on the nature of the template DNA, the desired probe length, and the required specific activity.
Method 1: Nick Translation
Nick translation is a classic method that generates uniformly labeled, double-stranded DNA probes. It is particularly well-suited for labeling larger DNA fragments (>1kb).[13]
Causality & Mechanism: The reaction is a concerted effort of two enzymes: DNase I and E. coli DNA Polymerase I.[13]
-
DNase I introduces random single-stranded breaks, or "nicks," into the DNA backbone, creating a free 3'-hydroxyl (OH) group.
-
DNA Polymerase I binds to these nicks. Its 5'→3' exonuclease activity removes existing nucleotides from the 5' side of the nick, while its 5'→3' polymerase activity simultaneously adds new nucleotides (including the labeled ones) to the 3' side.
-
This process effectively moves, or "translates," the nick along the DNA strand, replacing the original nucleotides with a new, labeled strand.[13]
Caption: Workflow for DNA probe labeling via Nick Translation.
Materials:
-
DNA Template (1 µg of plasmid or purified fragment)
-
10X Nick Translation Buffer (0.5 M Tris-HCl pH 7.5, 0.1 M MgCl₂, 1 mM DTT)
-
dNTP Mix (0.5 mM dATP, 0.5 mM dCTP, 0.5 mM dGTP)
-
Biotin-16-dUTP (0.35 mM)
-
DNase I/DNA Polymerase I Enzyme Mix
-
Stop Buffer (0.5 M EDTA)
-
Nuclease-free water
-
Spin column for purification (e.g., G-50)
Procedure:
-
In a microcentrifuge tube, combine the following on ice:
-
DNA Template: 1 µg
-
10X Nick Translation Buffer: 5 µL
-
dNTP Mix: 1 µL
-
Biotin-16-dUTP: 1 µL
-
Nuclease-free water: to a final volume of 45 µL
-
-
Add 5 µL of the DNase I/DNA Polymerase I enzyme mix. Mix gently by pipetting.
-
Incubate the reaction at 15°C for 60-90 minutes.[14] The low temperature helps to control the activity of DNase I, preventing excessive fragmentation of the template.
-
Stop the reaction by adding 5 µL of Stop Buffer.[15]
-
Purify the labeled probe from unincorporated biotin-dUTP using a G-50 spin column according to the manufacturer's protocol.
-
Self-Validation (QC): Assess probe size and yield. Run a small aliquot on an agarose gel. The labeled probe should appear as a smear of fragments, typically between 200-800 bp. Quantify the probe concentration using a spectrophotometer.
Method 2: Random Primed Labeling
This is arguably the most common and efficient method for generating DNA probes with very high specific activity.[16] It is based on the principles developed by Feinberg and Vogelstein and requires only nanogram amounts of template DNA.[17][18]
Causality & Mechanism:
-
Denaturation: The double-stranded DNA template is first denatured by heating, separating it into single strands. This step is crucial to allow access for the primers.[16]
-
Annealing: A mixture of random sequence oligonucleotides (typically hexamers or nonamers) is added. These primers anneal to complementary sequences at numerous random positions along the single-stranded template.[17][19]
-
Synthesis: The Klenow fragment of E. coli DNA Polymerase I is used for synthesis.[16] Klenow fragment retains the 5'→3' polymerase activity but lacks the 5'→3' exonuclease activity of the holoenzyme.[9] This is a key feature, as it ensures that the newly synthesized, labeled strand is not simultaneously degraded, leading to a net synthesis of DNA and very high incorporation of labeled nucleotides.[9]
Caption: Workflow for DNA probe labeling via the Random Primed method.
Materials:
-
DNA Template (25-50 ng of a purified fragment)
-
Random Primers (Hexamers or Nonamers)
-
5X Reaction Buffer
-
dNTP Mix (dATP, dGTP, dTTP at 5 mM each)
-
Klenow Fragment (exo-)
-
[α-³²P]dCTP (3000 Ci/mmol)
-
Stop Buffer (0.5 M EDTA)
-
Nuclease-free water
-
G-50 Spin Column
Procedure:
-
In a microcentrifuge tube, add 25-50 ng of DNA template. Adjust the volume to 10 µL with nuclease-free water.
-
Denature the DNA by heating in a boiling water bath for 5 minutes, then immediately chill on ice for 5 minutes.[20] This rapid chilling prevents re-annealing of the template strands.
-
On ice, add the following to the denatured template:
-
5X Reaction Buffer: 4 µL
-
dNTP Mix (A, G, T): 1 µL
-
Random Primers: 1 µL
-
[α-³²P]dCTP: 3-5 µL
-
Klenow Fragment: 1 µL
-
-
Mix gently and incubate at 37°C for 30-60 minutes. For higher yields, the reaction can be extended.[20]
-
Stop the reaction by adding 2 µL of Stop Buffer.
-
Purify the probe to remove unincorporated [α-³²P]dCTP using a G-50 spin column.
-
Self-Validation (QC): Determine the specific activity. This is done by measuring the total radioactivity incorporated (using a scintillation counter) and dividing it by the initial mass of the DNA template. Specific activities greater than 1 x 10⁹ dpm/µg are routinely achievable.[16][20]
Method 3: PCR-Based Labeling
Labeling via Polymerase Chain Reaction (PCR) is an extremely powerful method that combines probe synthesis with amplification of the target sequence. This is ideal when the starting template material is scarce.[21]
Causality & Mechanism: The process is identical to a standard PCR, with one key modification: one of the four dNTPs is partially or fully replaced by a labeled version (e.g., DIG-11-dUTP replacing some of the dTTP).[21][22] During the extension phase of each PCR cycle, a thermostable DNA polymerase (like Taq polymerase) incorporates the labeled nucleotide into the newly synthesized amplicon. The exponential nature of PCR results in a high yield of labeled probe.[21]
Caption: Workflow for generating labeled probes using PCR.
Materials:
-
DNA Template (1-10 ng plasmid or genomic DNA)
-
Forward and Reverse Primers (10 µM each)
-
10X PCR Buffer (with MgCl₂)
-
Taq DNA Polymerase
-
dATP, dCTP, dGTP (10 mM each)
-
dTTP (10 mM)
-
DIG-11-dUTP (1 mM)
-
Nuclease-free water
-
PCR Cleanup Kit
Procedure:
-
Prepare a PCR master mix. For a 50 µL reaction, a typical dNTP mix would be:
-
Rationale: A common ratio of dTTP to DIG-dUTP is 2:1 (e.g., 0.2 mM dTTP and 0.1 mM DIG-dUTP). This ensures efficient incorporation of the label without significantly inhibiting the polymerase. The exact ratio may require optimization.
-
-
Set up the 50 µL PCR reaction on ice:
-
10X PCR Buffer: 5 µL
-
dATP, dCTP, dGTP (10 mM each): 1 µL each
-
dTTP (10 mM): 0.65 µL
-
DIG-11-dUTP (1 mM): 3.5 µL
-
Forward Primer (10 µM): 1 µL
-
Reverse Primer (10 µM): 1 µL
-
DNA Template: 1-10 ng
-
Taq Polymerase: 0.5 µL
-
Nuclease-free water: to 50 µL
-
-
Perform PCR using standard cycling conditions:
-
Initial Denaturation: 95°C for 3 min
-
30-35 Cycles:
-
95°C for 30 sec
-
55-65°C for 30 sec (optimize for primers)
-
72°C for 1 min/kb
-
-
Final Extension: 72°C for 5 min
-
-
Self-Validation (QC): Analyze 5 µL of the PCR product on an agarose gel alongside an unlabeled control reaction. The labeled product may run slightly slower than the unlabeled one due to the bulky DIG groups. A single, sharp band of the expected size indicates a successful reaction.
-
Purify the remaining 45 µL using a PCR cleanup kit to remove primers and unincorporated dNTPs.
Chapter 3: Synthesizing RNA Probes (In Vitro Transcription)
Single-stranded RNA probes, or riboprobes, often provide higher sensitivity and lower background in hybridization experiments, particularly for in situ hybridization and Northern blots.[23] This is because RNA-RNA hybrids are more thermodynamically stable than DNA-RNA or DNA-DNA hybrids.[23]
Causality & Mechanism: The synthesis of riboprobes is achieved through in vitro transcription. A linearized plasmid DNA containing the sequence of interest cloned downstream of a bacteriophage promoter (e.g., T7, T3, or SP6) serves as the template.[23][24] The corresponding phage RNA polymerase (e.g., T7 RNA Polymerase) recognizes its specific promoter and transcribes the downstream DNA sequence into multiple RNA copies.[9] By including labeled ribonucleoside triphosphates (NTPs) in the reaction, a pool of labeled, single-stranded RNA probes is generated.[25]
Caption: Workflow for generating labeled RNA probes via in vitro transcription.
Materials:
-
Linearized Plasmid Template DNA (1 µg)
-
10X Transcription Buffer
-
DIG RNA Labeling Mix (contains ATP, CTP, GTP, UTP, and DIG-11-UTP at optimized concentrations)
-
RNase Inhibitor
-
T7 (or T3/SP6) RNA Polymerase
-
DNase I (RNase-free)
-
Nuclease-free water
-
RNA purification kit or LiCl precipitation reagents
Procedure:
-
Template Linearization (Pre-requisite): Digest 1-2 µg of your plasmid with a restriction enzyme that cuts at a single site downstream of the insert to be transcribed. Purify the linearized DNA. This step is critical to prevent the polymerase from generating long, heterogeneous transcripts by running around the circular plasmid.
-
In a nuclease-free tube at room temperature, combine the following:
-
Linearized Template DNA: 1 µg
-
10X Transcription Buffer: 2 µL
-
DIG RNA Labeling Mix: 2 µL
-
RNase Inhibitor: 1 µL
-
Nuclease-free water: to a final volume of 18 µL
-
-
Add 2 µL of the appropriate RNA Polymerase (e.g., T7). Mix gently.
-
Incubate at 37°C for 2 hours.[24]
-
To remove the DNA template, add 2 µL of RNase-free DNase I and incubate for a further 15 minutes at 37°C.
-
Purify the RNA probe using an RNA cleanup spin column or by lithium chloride (LiCl) precipitation.
-
Self-Validation (QC): Run an aliquot on a denaturing agarose gel to confirm the synthesis of a transcript of the correct size. Quantify the yield using a spectrophotometer (A₂₆₀). A typical reaction can yield 10-20 µg of labeled RNA from 1 µg of DNA template.[23]
References
- 1. DNA probes: applications of the principles of nucleic acid hybridization [pubmed.ncbi.nlm.nih.gov]
- 2. mlsu.ac.in [mlsu.ac.in]
- 3. ijppr.humanjournals.com [ijppr.humanjournals.com]
- 4. jenabioscience.com [jenabioscience.com]
- 5. bitesizebio.com [bitesizebio.com]
- 6. geneticeducation.co.in [geneticeducation.co.in]
- 7. histobiolab.com [histobiolab.com]
- 8. Radioactive and Non- radioactive probes | PPTX [slideshare.net]
- 9. revvity.com [revvity.com]
- 10. Generation of Labeled Probes by Polymerase Chain Reaction | Springer Nature Experiments [experiments.springernature.com]
- 11. What are the common methods for nucleic acid labeling? | AAT Bioquest [aatbio.com]
- 12. tandfonline.com [tandfonline.com]
- 13. search.cosmobio.co.jp [search.cosmobio.co.jp]
- 14. DNA Reaction - Radiolabeling by Nick Translation [rothlab.ucdavis.edu]
- 15. assets.fishersci.com [assets.fishersci.com]
- 16. chem.ucla.edu [chem.ucla.edu]
- 17. Random primed labeling of DNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. atzlabs.com [atzlabs.com]
- 19. Random Primed Labeling | Springer Nature Experiments [experiments.springernature.com]
- 20. agilent.com [agilent.com]
- 21. researchgate.net [researchgate.net]
- 22. biotium.com [biotium.com]
- 23. sigmaaldrich.com [sigmaaldrich.com]
- 24. In vitro Transcription for RNA in situ Probes [kingsley.stanford.edu]
- 25. Random RNA Labeling (in vitro Transcription-based) - Jena Bioscience [jenabioscience.com]
Application Notes and Protocols: A Senior Application Scientist's Guide to Methodologies for Studying DNA-Protein Interactions with Labeled Nucleosides
For researchers, scientists, and drug development professionals, understanding the intricate dance between proteins and DNA is fundamental to deciphering the mechanisms of gene regulation, replication, and repair. This guide provides an in-depth exploration of key methodologies that leverage labeled nucleosides to illuminate these critical interactions. Here, we move beyond simple procedural lists to explain the causality behind experimental choices, ensuring a robust and reproducible approach to your research.
Chapter 1: The Foundation - Labeling Strategies for Nucleoside Probes
The ability to detect and quantify DNA-protein interactions hinges on the effective labeling of the DNA probe. The choice of label is a critical decision that influences sensitivity, safety, and the downstream detection method.
The Historical Gold Standard: Radioactive Labeling
Historically, the use of radioactive isotopes, particularly Phosphorus-32 (³²P), has been the cornerstone of DNA-protein interaction studies.[1][2] The high energy of its beta decay allows for extremely sensitive detection through autoradiography.[1][2]
-
Mechanism: Enzymes like T4 polynucleotide kinase can transfer the gamma-phosphate from [γ-³²P]ATP to the 5' end of a DNA oligonucleotide. Alternatively, DNA polymerases can incorporate [α-³²P]deoxynucleoside triphosphates (dNTPs) during probe synthesis.[3]
-
Advantages: Unparalleled sensitivity, allowing for the detection of low-abundance interactions.[2]
-
Disadvantages: Significant safety concerns requiring specialized handling and disposal, a short half-life that necessitates frequent probe preparation, and the need for film development or phosphorimaging systems.[1]
Modern Alternatives: Non-Radioactive Labeling
Advances in detection technologies have led to the widespread adoption of safer and more convenient non-radioactive labels.[4][5] These can be broadly categorized into fluorescent and hapten-based labels.
1.2.1 Fluorescent Labels: Direct Detection and Multiplexing
Fluorescently labeled nucleosides offer a direct and increasingly sensitive method for detecting DNA-protein interactions.[4][6] Dyes such as infrared dyes (IRDyes) and cyanine dyes are commonly used.[4][7]
-
Mechanism: Oligonucleotides are synthesized with a fluorescent dye covalently attached to the 5' or 3' end.[7] Detection is achieved by scanning the gel with an imager that excites the fluorophore and detects the emitted light.[6]
-
Advantages: Eliminates the hazards of radioactivity, offers a stable signal, and allows for multiplexing by using different colored dyes.[4][7] The detection is also linear over a wide dynamic range, facilitating quantitative analysis.[7]
-
Disadvantages: Can be less sensitive than radioactive methods, although modern imaging systems have significantly closed this gap.[2] The fluorescent tag's size could potentially interfere with some protein-DNA interactions.
1.2.2 Hapten Labels: Indirect Detection and Signal Amplification
Haptens are small molecules like biotin and digoxigenin (DIG) that can be incorporated into a DNA probe.[5][8] They are detected indirectly through a secondary molecule with a high affinity for the hapten, which is conjugated to a reporter enzyme.[5]
-
Mechanism: Biotin or DIG is incorporated into the DNA probe, often at the 3' end using terminal deoxynucleotidyl transferase (TdT).[8] After the interaction with the protein and separation by electrophoresis, the DNA is transferred to a membrane. The membrane is then incubated with streptavidin (for biotin) or an anti-DIG antibody, which is conjugated to an enzyme like horseradish peroxidase (HRP) or alkaline phosphatase (AP).[5] A chemiluminescent substrate is added, and the light produced is detected.[1]
-
Advantages: High sensitivity due to enzymatic signal amplification.[5] Probes are stable, and the method avoids radioactivity.[9]
-
Disadvantages: This is an indirect method that requires more steps, such as blotting and enzymatic reactions, which can increase variability.[1]
Table 1: Comparison of Common Nucleoside Labeling Methods
| Feature | Radioactive (³²P) | Fluorescent (e.g., IRDye) | Hapten (e.g., Biotin) |
| Detection | Direct (Autoradiography/Phosphorimaging) | Direct (Fluorescence Imaging) | Indirect (Chemiluminescence) |
| Sensitivity | Very High | High | Very High (with amplification) |
| Safety | Hazardous | Non-hazardous | Non-hazardous |
| Probe Stability | Low (short half-life) | High | High |
| Workflow | Simple binding and gel run | Simple binding and gel run | Requires blotting and secondary detection steps |
| Quantification | Possible, but can be non-linear | Excellent, linear range | Possible, but can be complex |
Protocol 1: 3' End-Labeling of a DNA Probe with Biotin
This protocol describes the use of Terminal Deoxynucleotidyl Transferase (TdT) to add a biotin-labeled nucleotide to the 3' end of a DNA probe.
Materials:
-
DNA oligonucleotide probe
-
Biotin-11-dUTP
-
Terminal Deoxynucleotidyl Transferase (TdT) and reaction buffer
-
Nuclease-free water
-
EDTA (0.5 M)
Procedure:
-
Reaction Setup: In a sterile microfuge tube, combine the DNA probe, Biotin-11-dUTP, TdT reaction buffer, and TdT enzyme. The exact amounts will depend on the manufacturer's instructions.
-
Incubation: Incubate the reaction at 37°C for 30-60 minutes. This allows the TdT to add the biotinylated nucleotide to the 3' end of the probe.
-
Termination: Stop the reaction by adding EDTA. EDTA chelates the Mg²⁺ ions required by the TdT enzyme.
-
Purification (Optional but Recommended): Purify the labeled probe from unincorporated biotin-11-dUTP using a spin column or ethanol precipitation to reduce background in subsequent assays.
-
Quantification: Determine the concentration of the labeled probe using a spectrophotometer.
Chapter 2: Electrophoretic Mobility Shift Assay (EMSA) - Detecting Binding Events
The Electrophoretic Mobility Shift Assay (EMSA), or gel shift assay, is a rapid and sensitive method to detect DNA-protein interactions in vitro.[7][10]
Principle: The technique is based on the observation that a DNA-protein complex migrates more slowly through a non-denaturing polyacrylamide gel than the free, unbound DNA probe.[10][11] This difference in migration speed results in a "shift" of the band corresponding to the DNA probe.[10]
Why Native Gel Electrophoresis? It is crucial to perform EMSA under non-denaturing conditions to preserve the native structure of the protein and the integrity of the DNA-protein interaction. Denaturing agents like SDS would disrupt the interaction being studied.
Caption: A simplified workflow of the Electrophoretic Mobility Shift Assay (EMSA).
Protocol 2: Fluorescent EMSA (fEMSA) for a Transcription Factor
This protocol provides a framework for performing an EMSA using an infrared fluorescently labeled DNA probe.[4]
Materials:
-
IR-labeled DNA probe (e.g., IRDye 700-labeled oligo)
-
Purified transcription factor or nuclear extract
-
5x Binding Buffer (e.g., 100 mM Tris-HCl, 250 mM KCl, 5 mM DTT, 50% glycerol)
-
Poly(dI-dC) (a non-specific competitor DNA)
-
Unlabeled ("cold") specific competitor probe
-
Antibody against the transcription factor (for supershift)
-
Native polyacrylamide gel (e.g., 5% acrylamide in 0.5x TBE)
-
0.5x TBE buffer
-
Loading dye (low in SDS)
-
Infrared imaging system
Procedure:
-
Binding Reaction Setup: Prepare several reaction tubes on ice.
-
Negative Control: Labeled probe only.
-
Positive Control: Labeled probe + protein.
-
Specificity Control: Labeled probe + protein + excess unlabeled specific competitor probe.[7] The unlabeled probe will compete for binding, leading to a decrease in the shifted band if the interaction is specific.[7]
-
Supershift Control: Labeled probe + protein + specific antibody.[10] The antibody binding to the protein-DNA complex will cause a further retardation in mobility (a "supershift").[10]
-
-
Incubation: To each tube, add the binding buffer, poly(dI-dC) (to minimize non-specific binding), and the respective components. Add the protein last. Incubate at room temperature for 20-30 minutes.
-
Gel Electrophoresis: Add loading dye to each reaction and load the samples onto a pre-run native polyacrylamide gel. Run the gel at a constant voltage (e.g., 100-150V) in cold 0.5x TBE buffer.[6]
-
Imaging: After electrophoresis, image the gel directly using an infrared imaging system.[7] No transfer to a membrane is needed.[7]
Troubleshooting Common EMSA Issues:
-
No Shifted Band: The protein may be inactive, or the binding conditions may be suboptimal. Try varying salt concentrations, pH, or adding glycerol to the binding buffer.[12]
-
Smeared Bands: The complex may be dissociating during electrophoresis. Try running the gel at a lower temperature or for a shorter time.
-
Non-specific Bands: These are bands that are not reduced by the specific competitor. Increase the concentration of poly(dI-dC) or reduce the amount of protein extract used.[12]
Chapter 3: DNA Footprinting - Pinpointing the Binding Site
While EMSA confirms that a protein binds to a DNA sequence, DNA footprinting identifies the specific binding site.[13][14]
Principle: This technique relies on the principle that a protein bound to DNA will protect the DNA from cleavage by a nuclease (like DNase I) or a chemical agent.[3][15] When the resulting DNA fragments are separated on a denaturing gel, the protected region appears as a gap, or "footprint," in the ladder of fragments.[3][16]
Caption: The basic principle of DNase I footprinting.
Protocol 3: Fluorescent DNase I Footprinting
This protocol is an adaptation of the classic method using a fluorescently labeled primer for detection on a capillary electrophoresis instrument, which offers higher resolution and throughput than traditional slab gels.[13][16]
Materials:
-
DNA fragment of interest (100-400 bp), PCR amplified with one 5'-fluorescently labeled primer.[3][13]
-
Purified DNA-binding protein.
-
Binding buffer (similar to EMSA).
-
DNase I and stop solution (containing EDTA).
-
Formamide-based loading buffer.
-
Capillary electrophoresis DNA analyzer.
Procedure:
-
Binding Reaction: Incubate the fluorescently labeled DNA with varying concentrations of the protein in the binding buffer. Allow the binding to reach equilibrium (typically 20-30 minutes at room temperature).
-
DNase I Digestion: Add a diluted solution of DNase I to each reaction and incubate for a short, optimized time (e.g., 1-2 minutes). The goal is to achieve, on average, only one cut per DNA molecule.
-
Termination: Stop the digestion by adding a robust stop solution containing EDTA.
-
Purification: Purify the DNA fragments, typically by phenol-chloroform extraction followed by ethanol precipitation.
-
Capillary Electrophoresis: Resuspend the DNA in a formamide-based loading buffer to denature the strands. Analyze the fragments on a capillary DNA analyzer. A sequencing ladder (Sanger sequencing reaction) of the same DNA fragment should be run alongside to precisely map the protected bases.[16]
-
Data Analysis: The output will be an electropherogram. Compare the trace from the protein-bound sample to the control (no protein). The region where the protein was bound will show a significant reduction or absence of peaks, revealing the footprint.[16]
Chapter 4: Chromatin Immunoprecipitation (ChIP) - Interactions in a Cellular Context
ChIP is a powerful technique used to determine the in vivo location of DNA binding sites for a protein of interest.[17][18]
Principle: Cells are treated with a cross-linking agent (usually formaldehyde) to covalently link proteins to the DNA they are bound to.[11][19] The chromatin is then sheared, and an antibody specific to the target protein is used to immunoprecipitate the protein-DNA complexes.[11][20] The cross-links are then reversed, and the associated DNA is purified and analyzed.[19]
Role of Labeled Nucleosides: While the initial ChIP process does not directly use labeled nucleosides, the downstream analysis of the purified DNA often does. For example, in quantitative PCR (qPCR), fluorescently labeled probes (e.g., TaqMan probes) are used to quantify the amount of a specific DNA sequence that was co-precipitated with the target protein.[11] In ChIP-Seq, the entire library of precipitated DNA fragments is sequenced.[20]
Caption: An overview of the Cross-linking Chromatin Immunoprecipitation (X-ChIP) workflow.
Protocol 4: Chromatin Immunoprecipitation (X-ChIP) followed by qPCR
This protocol provides a general workflow for X-ChIP.
Materials:
-
Cultured cells or tissue
-
Formaldehyde (for cross-linking)
-
Glycine (to quench cross-linking)
-
Cell lysis and nuclear lysis buffers
-
Sonicator or micrococcal nuclease for chromatin shearing
-
Antibody specific to the target protein
-
Protein A/G magnetic beads
-
Wash buffers of increasing stringency
-
Elution buffer
-
Proteinase K and RNase A
-
Reagents for qPCR (polymerase, dNTPs, primers for target and control regions, fluorescent probe if using)
Procedure:
-
Cross-linking: Treat cells with formaldehyde to cross-link proteins to DNA. Quench the reaction with glycine.
-
Chromatin Preparation: Lyse the cells and nuclei. Shear the chromatin into fragments of 200-1000 bp using sonication.[18]
-
Immunoprecipitation: Incubate the sheared chromatin with a specific antibody overnight. Add protein A/G beads to capture the antibody-protein-DNA complexes.
-
Washing: Wash the beads with a series of buffers to remove non-specifically bound chromatin.
-
Elution and Cross-link Reversal: Elute the complexes from the beads and reverse the cross-links by heating at 65°C for several hours. Treat with RNase A and Proteinase K to remove RNA and protein.
-
DNA Purification: Purify the DNA using a spin column or precipitation.
-
qPCR Analysis: Use the purified DNA as a template for qPCR. Design primers to amplify a known target region and a negative control region (where the protein is not expected to bind). The relative enrichment of the target region compared to the control region indicates the extent of protein binding in vivo.[11]
Chapter 5: Photo-Crosslinking - Covalently Capturing Interactions
Photo-crosslinking is a powerful technique for "freezing" DNA-protein interactions, particularly those that are transient or weak.[21]
Principle: This method involves incorporating a photoreactive nucleoside analog into the DNA probe.[22] Upon exposure to UV light of a specific wavelength, the analog becomes highly reactive and forms a covalent bond with any protein in close proximity.[21][23]
Common Photoreactive Groups:
-
Aryl azides and Diazirines: These groups are activated by UV light to form highly reactive nitrenes and carbenes, respectively, which can insert into C-H and N-H bonds of nearby amino acid side chains.[22][23]
-
Halogenated Nucleosides (e.g., 5-Bromouracil): These analogs increase the sensitivity of DNA to UV-induced cross-linking.[21][22]
Caption: The principle of photo-crosslinking to form a covalent DNA-protein bond.
The major advantage of this technique is that it creates a stable, covalent link between the protein and the DNA. This allows for more stringent purification and analysis conditions that would otherwise disrupt a non-covalent interaction. The cross-linked complex can be analyzed by SDS-PAGE to determine the molecular weight of the binding protein.[21]
Conclusion
The choice of methodology for studying DNA-protein interactions depends heavily on the specific research question. EMSA provides a straightforward way to detect binding, DNA footprinting precisely maps the interaction site, ChIP allows for the investigation of interactions within a cellular context, and photo-crosslinking can capture transient interactions. The continuous development of non-radioactive labeling technologies, particularly in fluorescence and chemiluminescence, has made these powerful techniques safer, more stable, and more amenable to high-throughput and quantitative analysis, paving the way for deeper insights into the complex world of gene regulation.
References
- 1. An Optimized Protocol for Electrophoretic Mobility Shift Assay Using Infrared Fluorescent Dye-labeled Oligonucleotides - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Electrophoretic Mobility Shift Assay (EMSA) for Detecting Protein-Nucleic Acid Interactions - PMC [pmc.ncbi.nlm.nih.gov]
- 3. bitesizebio.com [bitesizebio.com]
- 4. Video: An Optimized Protocol for Electrophoretic Mobility Shift Assay Using Infrared Fluorescent Dye-labeled Oligonucleotides [jove.com]
- 5. jenabioscience.com [jenabioscience.com]
- 6. par.nsf.gov [par.nsf.gov]
- 7. licorbio.com [licorbio.com]
- 8. Methods for Labeling Nucleic Acids | Thermo Fisher Scientific - TW [thermofisher.com]
- 9. In Vitro Biochemical Assays using Biotin Labels to Study Protein-Nucleic Acid Interactions - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. bio.libretexts.org [bio.libretexts.org]
- 11. Methods for Detecting Protein-DNA Interactions | Thermo Fisher Scientific - TW [thermofisher.com]
- 12. Protein-Nucleic Acid Interactions Support—Troubleshooting | Thermo Fisher Scientific - SG [thermofisher.com]
- 13. DNA footprinting - Wikipedia [en.wikipedia.org]
- 14. mybiosource.com [mybiosource.com]
- 15. m.youtube.com [m.youtube.com]
- 16. Identification of the DNA Bases of a DNase I Footprint by the Use of Dye Primer Sequencing on an Automated Capillary DNA Analysis Instrument - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Overview of Chromatin Immunoprecipitation (ChIP) | Cell Signaling Technology [cellsignal.com]
- 18. Chromatin immunoprecipitation - Wikipedia [en.wikipedia.org]
- 19. Chromatin Immunoprecipitation Assay as a Tool for Analyzing Transcription Factor Activity - PMC [pmc.ncbi.nlm.nih.gov]
- 20. Chromatin Immunoprecipitation Sequencing (ChIP-Seq) [illumina.com]
- 21. med.upenn.edu [med.upenn.edu]
- 22. Photocross-linking of nucleic acids to associated proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 23. researchgate.net [researchgate.net]
Application Notes & Protocols: A Step-by-Step Guide for Using Labeled Uridine in Metabolic Studies
Introduction to Uridine Metabolic Labeling: Illuminating the Dynamics of the Transcriptome
The steady-state level of any given RNA molecule is a reflection of the delicate balance between its synthesis and degradation.[1][2] Traditional transcriptomic analyses, such as standard RNA sequencing, provide a static snapshot of RNA abundance at a single point in time.[1][3] However, these methods cannot decouple the rates of transcription and decay, which are crucial for understanding the dynamic regulation of gene expression in response to developmental cues, environmental stimuli, or therapeutic interventions.[1][3][4]
Metabolic labeling with uridine analogs offers a powerful solution to this challenge. By introducing a modified, "labeled" uridine into cell culture, researchers can tag and track newly synthesized RNA.[4][5][6] Uridine is a fundamental building block of RNA, and cells readily take it up from the culture medium via the nucleotide salvage pathway to be converted into uridine triphosphate (UTP) and incorporated into nascent RNA transcripts by RNA polymerases.[7][8][9] By using a labeled version of uridine, we can distinguish newly transcribed RNA from the pre-existing RNA pool, enabling the direct measurement of RNA synthesis, processing, and degradation rates.[1][5][10] This guide provides a comprehensive overview of the principles, protocols, and applications of labeled uridine in metabolic studies.
Choosing Your Labeled Uridine: The Right Tool for the Question
The choice of labeled uridine analog is dictated by the specific biological question and the available downstream detection methods. Each label has unique properties that make it suitable for different applications.
| Labeled Uridine Analog | Label Type | Common Applications | Detection Method | Advantages | Disadvantages |
| ³H-Uridine / ¹⁴C-Uridine | Radioactive | Measuring global RNA synthesis rates. | Liquid Scintillation Counting | High sensitivity for quantitative measurements. | Requires handling of radioactive materials; low spatial resolution. |
| ¹³C-Uridine / ¹⁵N-Uridine | Stable Isotope | Quantifying RNA turnover and modification dynamics.[11] | Mass Spectrometry (MS)[11] | Allows for precise quantification of RNA species and their modifications without radioactivity.[11][12][13] | Requires specialized and expensive MS equipment and expertise.[11] |
| 4-thiouridine (4sU) | Thiol-containing | Measuring RNA synthesis and decay rates (pulse-chase); identifying RNA-protein interactions (PAR-CLIP).[5][14][15][16] | Biotinylation followed by affinity purification or sequencing (SLAM-seq, TUC-seq).[2][3][5] | Versatile for both quantification and interaction studies; well-established protocols.[5][14][15] | Can have some cellular toxicity at high concentrations or long exposures.[10][17] |
| 5-ethynyluridine (5-EU) | Alkyne-containing | Visualizing newly synthesized RNA; isolating nascent RNA.[7][18][19] | Copper(I)-catalyzed "click" chemistry with fluorescent azides or biotin-azides.[7][18][19][20] | High specificity and efficiency of detection; excellent for imaging applications.[7][20] | The copper catalyst required for the click reaction can cause some RNA degradation.[20] |
| 5-bromouridine (BrU) | Halogenated | Measuring RNA synthesis and decay rates; used in older, established protocols.[21][22] | Immunoprecipitation with anti-BrU antibodies.[22] | Long history of use with established antibody reagents. | Antibody-based detection can be less efficient and more variable than biotin-streptavidin or click chemistry methods.[23] |
Expert Insight: For researchers aiming to quantify transcriptome-wide RNA half-lives, 4sU followed by sequencing (e.g., SLAM-seq) is currently a gold-standard approach due to its robustness and the development of computational tools like pulseR for data analysis.[3][24] For those interested in the spatial localization of transcription, 5-EU followed by fluorescence microscopy is unparalleled.[7][18]
Core Experimental Workflow: From Labeling to Analysis
The following sections provide a detailed, adaptable framework for a typical metabolic labeling experiment.
Phase 1: Experimental Design & Optimization
Careful planning is paramount for a successful metabolic labeling study. Key considerations include:
-
Cell Type: Different cell types have varying efficiencies of uridine uptake.[16][25] It is crucial to optimize labeling conditions for your specific cell line.
-
Label Concentration: The concentration of the labeled uridine should be high enough for robust detection but low enough to minimize cellular toxicity and perturbation of normal nucleotide pools. A typical starting point for 4sU or 5-EU is 100-200 µM, but this should be empirically determined.
-
Labeling Time (Pulse): The duration of the "pulse" (exposure to the label) depends on the research question.
Phase 2: The Labeling Experiment (Pulse-Chase Protocol Example)
This protocol details a pulse-chase experiment using 4sU to measure RNA decay rates.
Materials:
-
Cells cultured to 70-80% confluency.
-
Culture medium with and without serum.
-
4-thiouridine (4sU) stock solution (e.g., 100 mM in DMSO).
-
Unlabeled uridine stock solution (e.g., 1 M in water).
-
Phosphate-buffered saline (PBS).
-
TRIzol® reagent or similar lysis buffer.[27]
Protocol:
-
Cell Seeding: Seed cells in appropriate culture vessels to ensure they reach 70-80% confluency on the day of the experiment.[5]
-
Pulse:
-
Aspirate the existing medium.
-
Add fresh, pre-warmed medium containing the desired final concentration of 4sU (e.g., 100 µM).
-
Incubate the cells for the chosen pulse duration (e.g., 2-4 hours) under normal culture conditions.[5]
-
-
Chase:
-
Aspirate the 4sU-containing medium.
-
Wash the cells once with pre-warmed PBS to remove residual 4sU.[5]
-
Add fresh, pre-warmed medium containing a high concentration of unlabeled uridine (e.g., 10 mM) to effectively outcompete any remaining 4sU and halt its incorporation.[5] This marks the beginning of the chase (t=0).
-
-
Time-Course Collection:
Phase 3: Sample Processing - Total RNA Extraction
The integrity of the extracted RNA is critical for all downstream applications. Guanidinium thiocyanate-phenol-chloroform extraction (e.g., using TRIzol®) is a robust and widely used method.[27][28]
Protocol Synopsis (TRIzol®-based):
-
Homogenization: Lyse cells in TRIzol® reagent as per the manufacturer's instructions.[27]
-
Phase Separation: Add chloroform, mix vigorously, and centrifuge. The mixture will separate into a lower red organic phase, an interphase, and an upper colorless aqueous phase containing the RNA.[27]
-
RNA Precipitation: Carefully transfer the aqueous phase to a new tube and precipitate the RNA by adding isopropanol.[27]
-
RNA Wash: Pellet the RNA by centrifugation, remove the supernatant, and wash the pellet with 75% ethanol to remove residual salts and impurities.[27]
-
Resuspension: Air-dry the pellet briefly and resuspend it in RNase-free water.
-
Quality Control: Assess RNA concentration and purity using a spectrophotometer (e.g., NanoDrop) and integrity using a Bioanalyzer or denaturing agarose gel electrophoresis. An A260/A280 ratio of ~2.0 is indicative of pure RNA.
Downstream Analysis Techniques
Once the labeled RNA is isolated, a variety of techniques can be used for analysis.
Protocol: Visualizing Newly Synthesized RNA with 5-EU and Click Chemistry
This protocol allows for the fluorescent imaging of nascent RNA.[7][18]
Materials:
-
Cells grown on coverslips, labeled with 5-EU (e.g., 1 mM for 1 hour).[29]
-
Fixative (e.g., 3.7% formaldehyde in PBS).
-
Permeabilization buffer (e.g., 0.5% Triton® X-100 in PBS).
-
Click-iT® Reaction Cocktail (prepare fresh):
-
Click-iT® reaction buffer
-
Copper (II) sulfate (CuSO₄)
-
Fluorescent azide (e.g., Alexa Fluor® 488 azide)
-
Reaction buffer additive (reducing agent)
-
-
Nuclear stain (e.g., Hoechst 33342).
Protocol:
-
Labeling: Incubate cells with 5-EU-containing medium for the desired time.[29]
-
Fix and Permeabilize:
-
Wash cells with PBS.
-
Fix with formaldehyde for 15 minutes at room temperature.
-
Wash with PBS.
-
Permeabilize with Triton® X-100 for 20 minutes.
-
-
Click Reaction:
-
Staining and Imaging:
-
Wash cells with Click-iT® reaction rinse buffer.
-
Stain nuclei with Hoechst 33342.
-
Mount coverslips on microscope slides and image using fluorescence microscopy.
-
Protocol: Isolation of 4sU-Labeled RNA by Biotinylation and Affinity Purification
This method is used to separate newly transcribed RNA from total RNA for subsequent analysis like RT-qPCR or RNA-seq.[5][14][15]
Materials:
-
Total RNA containing 4sU-labeled transcripts.
-
EZ-Link Biotin-HPDP.
-
Streptavidin-coated magnetic beads.
-
Biotinylation buffer and wash buffers.
Protocol:
-
Biotinylation:
-
Dissolve Biotin-HPDP in DMF.
-
In a reaction tube, combine total RNA, biotinylation buffer, and the Biotin-HPDP solution.[30]
-
Incubate for 1.5 hours at room temperature with rotation.
-
-
Purification of Biotinylated RNA:
-
Remove excess biotin by chloroform/isoamyl alcohol extraction and isopropanol precipitation.
-
-
Affinity Purification:
-
Resuspend the biotinylated RNA and heat to denature.
-
Add pre-washed streptavidin-coated magnetic beads and incubate to allow binding.
-
Use a magnetic stand to capture the beads (bound to labeled RNA) and discard the supernatant (unlabeled RNA).
-
Wash the beads multiple times with wash buffer.
-
-
Elution:
-
Elute the purified 4sU-labeled RNA from the beads using a fresh solution of DTT.
-
The eluted RNA is now ready for downstream analysis.
-
Data Interpretation & Troubleshooting
| Problem | Potential Cause | Suggested Solution |
| Low RNA Yield | Incomplete cell lysis; sample overload; improper storage leading to degradation.[31][32] | Ensure complete homogenization; use the recommended amount of starting material; flash-freeze samples and use RNase inhibitors.[32] |
| RNA Degradation (smeared gel, low RIN) | RNase contamination; sample mishandling.[31] | Use RNase-free reagents and consumables; wear gloves; process samples quickly on ice.[31] |
| Low Label Incorporation | Inefficient uptake by cells; suboptimal label concentration or time; label degradation. | Optimize labeling conditions for your specific cell type; check the quality and storage of the uridine analog; perform a dot blot to assess incorporation efficiency.[30][33] |
| High Background in Imaging | Insufficient washing; non-specific binding of the fluorescent probe. | Increase the number and duration of wash steps; include a blocking step if necessary. |
| Discrepancies in Half-life Measurements | Toxicity from labeling reagents; differences between experimental systems (e.g., metabolic labeling vs. transcriptional inhibitors).[17] | Perform dose-response and time-course experiments to find optimal, non-toxic labeling conditions; be aware of the inherent differences and potential artifacts of each method.[17] |
Visualizations
Experimental Workflow Overview
dot
Caption: High-level overview of the metabolic labeling workflow.
Uridine Incorporation into Nascent RNA
dot
Caption: Cellular pathway of labeled uridine uptake and incorporation.
5-EU Click Chemistry Workflow
dot
Caption: Step-by-step workflow for visualizing 5-EU labeled RNA.
References
- 1. Global analysis of RNA metabolism using bio-orthogonal labeling coupled with next-generation RNA sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Metabolic labeling of RNA using multiple ribonucleoside analogs enables the simultaneous evaluation of RNA synthesis and degradation rates - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Determining mRNA Stability by Metabolic RNA Labeling and Chemical Nucleoside Conversion | Springer Nature Experiments [experiments.springernature.com]
- 4. benchchem.com [benchchem.com]
- 5. benchchem.com [benchchem.com]
- 6. Metabolic Labeling of RNAs Uncovers Hidden Features and Dynamics of the Arabidopsis Transcriptome - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Exploring RNA transcription and turnover in vivo by using click chemistry - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Uridine Metabolism and Its Role in Glucose, Lipid, and Amino Acid Homeostasis - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. Metabolic Labeling of Newly Synthesized RNA with 4sU to in Parallel Assess RNA Transcription and Decay | Springer Nature Experiments [experiments.springernature.com]
- 11. Stable Isotope Labeled Nucleotides | Leading Provider of Isotope Labeled Solutions [silantes.com]
- 12. pubs.acs.org [pubs.acs.org]
- 13. Production and Application of Stable Isotope-Labeled Internal Standards for RNA Modification Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Uncovering the Stability of Mature miRNAs by 4-Thio-Uridine Metabolic Labeling - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. researchgate.net [researchgate.net]
- 16. Synthesis of 4-thiouridines with prodrug functionalization for RNA metabolic labeling - PMC [pmc.ncbi.nlm.nih.gov]
- 17. biorxiv.org [biorxiv.org]
- 18. academic.oup.com [academic.oup.com]
- 19. 5-Ethynyl-uridine (5-EU), RNA synthesis monitoring - Jena Bioscience [jenabioscience.com]
- 20. assets.fishersci.com [assets.fishersci.com]
- 21. biorxiv.org [biorxiv.org]
- 22. youtube.com [youtube.com]
- 23. Development of Cell-Specific RNA Metabolic Labeling Applications in Cell and Animal Models - ProQuest [proquest.com]
- 24. pulseR: Versatile computational analysis of RNA turnover from metabolic labeling experiments - PubMed [pubmed.ncbi.nlm.nih.gov]
- 25. Uridine uptake in a unicellular eukaryote during the interdivision period and after growth arrest - PubMed [pubmed.ncbi.nlm.nih.gov]
- 26. Metabolic labeling of RNA uncovers principles of RNA production and degradation dynamics in mammalian cells - PMC [pmc.ncbi.nlm.nih.gov]
- 27. bitesizebio.com [bitesizebio.com]
- 28. A Guide to RNA Extraction, RNA Purification and Isolation - CD Genomics [rna.cd-genomics.com]
- 29. assets.fishersci.com [assets.fishersci.com]
- 30. Frontiers | A Protocol for Transcriptome-Wide Inference of RNA Metabolic Rates in Mouse Embryonic Stem Cells [frontiersin.org]
- 31. RNA Preparation Troubleshooting [sigmaaldrich.com]
- 32. neb.com [neb.com]
- 33. Metabolic Labeling of Newly Transcribed RNA for High Resolution Gene Expression Profiling of RNA Synthesis, Processing and Decay in Cell Culture - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols: Practical Applications of Dual-Labeled Nucleosides in Structural Biology
Introduction
In the intricate world of structural biology, understanding the precise three-dimensional architecture and dynamic nature of nucleic acids is paramount to deciphering their biological functions. Dual-labeled nucleosides have emerged as powerful tools, offering unprecedented insights into the structure, dynamics, and interactions of DNA and RNA. By incorporating two distinct labels within a single nucleoside or oligonucleotide, researchers can employ a range of sophisticated biophysical techniques to probe molecular conformations and real-time conformational changes with high precision. This guide provides an in-depth exploration of the practical applications of dual-labeled nucleosides, complete with detailed protocols and the scientific rationale behind experimental choices, to empower researchers in their quest to unravel the complexities of nucleic acid biology.
These custom-synthesized or enzymatically incorporated nucleosides can bear a combination of reporters, including stable isotopes for Nuclear Magnetic Resonance (NMR) spectroscopy, fluorescent dyes for Förster Resonance Energy Transfer (FRET), and paramagnetic tags for specialized NMR applications. The strategic placement of these labels provides a molecular ruler and a dynamic probe, enabling the study of nucleic acid folding, ligand binding, and the catalytic mechanisms of ribozymes. This document will serve as a comprehensive resource for researchers, scientists, and drug development professionals, offering both the foundational knowledge and the practical steps necessary to successfully implement these advanced techniques.
I. Elucidating Global Structure and Dynamics with Fluorescence Resonance Energy Transfer (FRET)
Förster Resonance Energy Transfer (FRET) is a quantum mechanical phenomenon that measures the distance between a donor and an acceptor fluorophore.[1] When a donor fluorophore is excited, it can non-radiatively transfer its energy to a nearby acceptor if their emission and absorption spectra overlap and they are in close proximity (typically 20-100 Å).[1] This energy transfer efficiency is exquisitely sensitive to the distance between the two dyes, making FRET an ideal tool for studying the global architecture and conformational changes of nucleic acids.[2][3]
Core Principles of FRET in Nucleic Acid Structural Analysis
The power of using dual-labeled nucleosides for FRET lies in the ability to site-specifically introduce a FRET pair into a DNA or RNA molecule.[4][5] This allows for the precise measurement of distances between defined points within the nucleic acid structure. Changes in FRET efficiency can signal conformational changes, such as the bending of a helix, the folding of a riboswitch upon ligand binding, or the dynamics of nucleosome breathing.[6][7] Single-molecule FRET (smFRET) further extends this capability by allowing the observation of individual molecules, revealing conformational heterogeneity and transient intermediates that are often obscured in ensemble measurements.[7][8]
Visualization of a FRET-based Experimental Workflow
References
- 1. mdpi.com [mdpi.com]
- 2. Christoph Gohlke [cgohlke.com]
- 3. Kinking of DNA and RNA helices by bulged nucleotides observed by fluorescence resonance energy transfer - PMC [pmc.ncbi.nlm.nih.gov]
- 4. academic.oup.com [academic.oup.com]
- 5. Site-Specific Dual-Color Labeling of Long RNAs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Synthesis and application of a 19F-labeled fluorescent nucleoside as a dual-mode probe for i-motif DNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Methods to investigate nucleosome structure and dynamics with single-molecule FRET - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Single-Molecule Fluorescence of Nucleic Acids | Basicmedical Key [basicmedicalkey.com]
Troubleshooting & Optimization
Technical Support Center: Troubleshooting Low Incorporation of Modified Nucleosides
A Guide for Researchers, Scientists, and Drug Development Professionals
Welcome to the Technical Support Center. This guide is designed to provide in-depth troubleshooting assistance for researchers encountering low incorporation rates of modified nucleosides in their enzymatic reactions. As Senior Application Scientists, we understand that the successful synthesis of modified nucleic acids is critical for a wide range of applications, from therapeutic mRNA development to advanced diagnostics.
This resource is structured in a question-and-answer format to directly address the specific challenges you may face. We will delve into the root causes of poor incorporation and provide logical, field-proven solutions to optimize your experiments.
Section 1: Foundational Questions & Initial Troubleshooting
Q1: I'm observing significantly lower yields or incomplete products after my enzymatic reaction with modified nucleoside triphosphates (NTPs). What are the most common initial factors to investigate?
Low incorporation of modified nucleosides can stem from several key areas. A systematic approach to troubleshooting is essential. We recommend starting with the most straightforward variables before moving to more complex optimizations.
Initial Checklist:
-
Substrate Quality: The purity and integrity of your modified NTPs are paramount.
-
Enzyme Selection: Not all polymerases are created equal; their tolerance for modified substrates varies significantly.
-
Reaction Conditions: Seemingly minor deviations in your reaction setup can have a substantial impact on incorporation efficiency.
Let's break down each of these areas in more detail.
Q2: How can I be sure that the quality of my modified NTPs is not the issue?
The quality of your modified nucleoside triphosphates is a critical determinant of successful incorporation. Even trace amounts of contaminants can inhibit polymerase activity.
Key Quality Control (QC) Parameters for Modified NTPs:
| Parameter | Importance | Recommended Analytical Method |
| Purity | Contaminants such as diphosphates can inhibit the polymerase. | High-Performance Liquid Chromatography (HPLC) is the gold standard for assessing triphosphate purity.[1] Aim for >99% purity.[1] |
| Identity | Verifies that you have the correct modified nucleoside. | Mass Spectrometry (MS) and Nuclear Magnetic Resonance (NMR) spectroscopy (¹H, ³¹P) confirm the chemical structure.[2] |
| Concentration | Accurate concentration is crucial for maintaining optimal stoichiometry in your reaction. | UV/Vis spectrophotometry is a standard method for determining concentration.[2] |
| Stability | Some modified nucleosides can be unstable, especially under certain pH conditions.[3][4] | Re-analysis by HPLC after a period of storage can assess stability. |
Troubleshooting Steps:
-
Verify Supplier QC Data: Reputable suppliers will provide a certificate of analysis with detailed QC results.[2]
-
In-House QC: If you suspect an issue, consider performing in-house analysis, particularly HPLC, to confirm purity.[5][6]
-
Proper Storage: Ensure your modified NTPs are stored under the recommended conditions to prevent degradation.
Q3: My modified NTPs appear to be high quality. Could the polymerase be the problem?
Absolutely. The choice of polymerase is a critical factor, as different polymerases exhibit varying levels of tolerance for modified substrates.[7]
Factors to Consider When Selecting a Polymerase:
-
Polymerase Family: Family B DNA polymerases, such as those from archaea, are often better suited for incorporating nucleobase-modified nucleotides than Family A polymerases.[7]
-
Engineered Polymerases: Several commercially available polymerases have been specifically engineered for enhanced incorporation of modified nucleotides. For example, "Therminator" DNA polymerase, a variant of 9°N DNA polymerase, can incorporate a wide variety of modified nucleotides.[8]
-
Processivity: A highly processive enzyme is more likely to perform multiple incorporations of modified nucleotides.
Troubleshooting Workflow for Polymerase Selection:
Caption: A workflow for selecting an appropriate polymerase.
Section 2: In-Depth FAQs and Advanced Troubleshooting
Q4: I've tried multiple polymerases with high-quality modified NTPs and still see low incorporation. What other reaction parameters should I optimize?
Once you've addressed the primary factors of substrate and enzyme, fine-tuning the reaction conditions is the next logical step.
Key Reaction Parameters for Optimization:
-
Magnesium Concentration: Magnesium ions are a critical cofactor for polymerases. However, the optimal concentration can vary, and excessive magnesium can decrease fidelity.[9]
-
NTP Ratios: For applications like modified mRNA synthesis, the ratio of the modified nucleoside to its unmodified counterpart, as well as the ratio of the cap analog to GTP, is crucial.[10]
-
Temperature and Incubation Time: Many mutant or engineered polymerases may not be as active as their wild-type counterparts and might require longer incubation times or different optimal temperatures.[9]
-
Enzyme Concentration: Increasing the polymerase concentration may enhance the efficiency of the reaction.[9]
Experimental Protocol for Optimizing Magnesium Concentration:
-
Set up a series of parallel reactions. Keep all other components (template, primers, NTPs, polymerase) at a constant concentration.
-
Create a magnesium gradient. Vary the concentration of MgCl₂ in each reaction (e.g., 2 mM, 4 mM, 6 mM, 8 mM, 10 mM).
-
Incubate the reactions under your standard conditions.
-
Analyze the products. Use an appropriate method (e.g., gel electrophoresis, HPLC, or mass spectrometry) to determine the yield and incorporation efficiency at each magnesium concentration.
Q5: I am working with multiple, bulky modifications. Are there special considerations for this?
Yes, incorporating multiple or bulky modifications presents additional challenges.
-
Steric Hindrance: Large modifications can create steric hindrance within the active site of the polymerase, impeding incorporation.[7] The position of the modification on the nucleobase is a key factor.[7]
-
Consecutive Incorporations: The sequential addition of multiple modified bases can be particularly difficult for the polymerase.[7] It has been observed that a modified nucleotide may be more efficiently processed when the 3'-primer terminus is also a modified nucleotide.[7]
Strategies for Incorporating Bulky or Multiple Modifications:
-
Polymerase Selection: As mentioned, some polymerases, like Therminator, are more adept at handling bulky substrates.[8]
-
Template Design: The sequence context surrounding the desired incorporation site can influence efficiency.[9]
-
Stepwise Incorporation: In some cases, a primer extension approach with sequential addition of the modified NTPs may be more effective than a one-pot PCR-style reaction.[11]
Q6: How can I accurately quantify the incorporation of my modified nucleosides?
Accurate quantification is essential to confirm the success of your optimization efforts.
Common Analytical Methods for Quantifying Incorporation:
| Method | Principle | Advantages | Considerations |
| HPLC | Separates nucleosides after enzymatic digestion of the nucleic acid product.[5][6] | Quantitative, can distinguish between different modifications. | Requires specialized equipment and method development. |
| Mass Spectrometry (MS) | Measures the mass-to-charge ratio of the digested nucleosides or intact nucleic acid.[12][13] | Highly sensitive and specific, provides definitive identification. | Can be complex to interpret, potential for ion suppression. |
| Gel Electrophoresis with Staining | Visualizes the full-length product. | Simple, readily available. | Semi-quantitative, does not confirm the identity of the incorporated nucleoside. |
| Radioactive Labeling | Incorporation of a radiolabeled modified NTP allows for quantification via scintillation counting. | Highly sensitive. | Requires handling of radioactive materials. |
Workflow for Quantifying Incorporation via LC-MS:
Caption: A streamlined workflow for LC-MS analysis.
Section 3: Concluding Remarks
Troubleshooting low incorporation of modified nucleosides is a multifaceted process that requires a systematic and logical approach. By carefully considering the quality of your reagents, the choice of polymerase, and the optimization of reaction conditions, you can significantly improve your experimental outcomes. Always remember to consult the literature for insights specific to your modified nucleoside and polymerase system.
References
- 1. High-Quality Modified Nucleotides for Research | Thermo Fisher Scientific - HK [thermofisher.com]
- 2. trilinkbiotech.com [trilinkbiotech.com]
- 3. Pitfalls in RNA Modification Quantification Using Nucleoside Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 4. pubs.acs.org [pubs.acs.org]
- 5. thepharmajournal.com [thepharmajournal.com]
- 6. protocols.io [protocols.io]
- 7. pubs.acs.org [pubs.acs.org]
- 8. Frontiers | Therminator DNA Polymerase: Modified Nucleotides and Unnatural Substrates [frontiersin.org]
- 9. In Vitro Selection Using Modified or Unnatural Nucleotides - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Optimizing Modified mRNA In Vitro Synthesis Protocol for Heart Gene Therapy - PMC [pmc.ncbi.nlm.nih.gov]
- 11. pubs.acs.org [pubs.acs.org]
- 12. shimadzu.com [shimadzu.com]
- 13. Detection of ribonucleoside modifications by liquid chromatography coupled with mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Synthesis of Toluoyl-Protected Nucleosides
Welcome to the technical support center for the synthesis of toluoyl-protected nucleosides. This guide is designed for researchers, scientists, and professionals in drug development who are navigating the complexities of nucleoside chemistry. Here, we move beyond simple protocols to provide in-depth, field-proven insights into improving reaction yields and troubleshooting common issues. Our approach is grounded in the principles of chemical causality, ensuring that every recommendation is backed by a clear understanding of the underlying mechanisms.
Section 1: Troubleshooting Guide - Enhancing Your Yield
Low yields in the synthesis of toluoyl-protected nucleosides are a frequent challenge. This section is structured to help you diagnose and resolve the most common issues encountered during this critical protection step.
Problem: Low or No Product Formation
Symptoms: TLC or LC-MS analysis shows predominantly unreacted starting nucleoside with little to no desired product.
Potential Causes & Solutions:
-
Cause 1: Inactive p-Toluoyl Chloride. The acylating agent, p-toluoyl chloride, is highly susceptible to hydrolysis.[1] Moisture in the reaction setup, solvents, or even on the surface of the glassware can rapidly convert it to the unreactive p-toluic acid.
-
Solution:
-
Reagent Quality: Use freshly opened or properly stored p-toluoyl chloride. Consider purchasing from a reputable supplier who provides a certificate of analysis.
-
Anhydrous Conditions: Dry all glassware in an oven at >100°C for several hours and cool under a stream of inert gas (e.g., argon or nitrogen). Use anhydrous solvents, preferably from a solvent purification system or freshly opened sealed bottles.
-
Inert Atmosphere: Conduct the reaction under a positive pressure of an inert gas to prevent atmospheric moisture from entering the reaction vessel.
-
-
-
Cause 2: Inadequate Activation of the Nucleoside Hydroxyl Groups. The hydroxyl groups of the nucleoside need to be sufficiently nucleophilic to attack the electrophilic carbonyl carbon of the p-toluoyl chloride. The choice and amount of base are critical here.
-
Solution:
-
Base Selection: Pyridine is a commonly used base and solvent for this reaction as it also acts as a nucleophilic catalyst. For more sterically hindered nucleosides or to accelerate the reaction, a stronger, non-nucleophilic base like triethylamine (TEA) in conjunction with a catalytic amount of 4-dimethylaminopyridine (DMAP) can be more effective.[2]
-
Stoichiometry: Ensure an adequate excess of the base is used to neutralize the HCl generated during the reaction and to activate the hydroxyl groups. A typical starting point is 2-3 equivalents of base per hydroxyl group to be protected.
-
-
-
Cause 3: Suboptimal Reaction Temperature. The reaction rate is highly dependent on temperature.
-
Solution:
-
Initial Cooling: Start the reaction at 0°C (ice bath) to control the initial exothermic reaction, especially when adding the p-toluoyl chloride.[1][3]
-
Gradual Warming: After the initial addition, allow the reaction to slowly warm to room temperature and stir for several hours. If the reaction is sluggish, gentle heating (e.g., to 40-50°C) can be beneficial, but this should be done cautiously as it can also promote side reactions.[1]
-
-
Problem: Formation of Multiple Products (Poor Selectivity)
Symptoms: TLC analysis shows multiple spots, indicating the formation of mono-, di-, and tri-toluoylated products, as well as potential N-acylation.
Potential Causes & Solutions:
-
Cause 1: Over-acylation. Using a large excess of p-toluoyl chloride or prolonged reaction times can lead to the protection of less reactive hydroxyl groups.
-
Solution:
-
Control Stoichiometry: For selective 5'-O-toluoylation, use a slight excess (e.g., 1.1-1.2 equivalents) of p-toluoyl chloride.[4] The primary 5'-hydroxyl is the most reactive due to less steric hindrance.[4][5][6][7]
-
Reaction Monitoring: Monitor the reaction progress closely by TLC. Once the starting material is consumed and the desired product is the major spot, quench the reaction to prevent further acylation.
-
-
-
Cause 2: N-Acylation. The exocyclic amino groups of adenosine and guanosine can also be acylated.
-
Solution:
-
Prior Protection: For syntheses requiring protection of only the hydroxyl groups, it is often necessary to first protect the exocyclic amino groups using a more labile protecting group, such as a benzoyl or isobutyryl group.[]
-
Reaction Conditions: In some cases, careful control of reaction conditions (e.g., lower temperature, specific base) can favor O-acylation over N-acylation.
-
-
Problem: Difficult Purification
Symptoms: The crude product is an inseparable mixture of the desired product and byproducts, leading to low isolated yield.
Potential Causes & Solutions:
-
Cause 1: Co-eluting Impurities. Byproducts such as p-toluic acid or excess reagents can have similar polarities to the product, making chromatographic separation challenging.
-
Solution:
-
Aqueous Workup: After the reaction is complete, quench with a saturated aqueous solution of sodium bicarbonate to neutralize excess acid and remove p-toluic acid.
-
Extraction: Perform a liquid-liquid extraction to separate the organic product from water-soluble impurities.
-
Optimized Chromatography: Experiment with different solvent systems for column chromatography. A gradient elution may be necessary to achieve good separation.
-
-
-
Cause 2: Product Instability. The toluoyl protecting groups can be labile under certain conditions.
-
Solution:
-
Avoid Strong Acids or Bases during Workup: Use mild conditions for workup and purification.
-
Prompt Purification: Purify the product as soon as possible after the reaction is complete to minimize degradation.
-
-
Section 2: Frequently Asked Questions (FAQs)
-
Q1: Why use a toluoyl protecting group over other acyl groups like benzoyl or acetyl?
-
A1: The toluoyl group offers a good balance of reactivity and stability. The methyl group on the aromatic ring provides a slight increase in lipophilicity compared to the benzoyl group, which can aid in solubility in organic solvents and purification by chromatography. It is generally more stable than the acetyl group, allowing for subsequent reaction steps without premature deprotection.
-
-
Q2: How can I monitor the progress of my reaction?
-
A2: Thin-layer chromatography (TLC) is the most common method.[9][10][11][12][13] Use a mobile phase that provides good separation between your starting nucleoside, the desired product, and any potential byproducts. A typical solvent system is a mixture of dichloromethane and methanol or ethyl acetate and hexanes. The spots can be visualized under UV light (254 nm).
-
-
Q3: What are the best conditions for removing the toluoyl protecting group?
-
A3: Toluoyl groups are typically removed under basic conditions. A common method is treatment with a solution of sodium methoxide in methanol or concentrated ammonium hydroxide in methanol. The reaction is usually carried out at room temperature and monitored by TLC until the deprotection is complete.
-
-
Q4: I am working with 2'-deoxyguanosine and see a significant amount of an unknown, highly polar byproduct. What could it be?
-
A4: 2'-deoxyguanosine is particularly susceptible to side reactions. One possibility is the formation of a byproduct where the N7 position of the guanine base has reacted.[14] Additionally, over-acylation at the exocyclic amine is a common issue. Careful control of stoichiometry and temperature is crucial when working with guanosine derivatives.
-
Section 3: Experimental Protocol & Data
Standard Protocol for 5'-O-Toluoyl Protection of Thymidine
This protocol provides a general procedure for the selective protection of the 5'-hydroxyl group of thymidine.
Materials:
-
Thymidine
-
Anhydrous Pyridine
-
p-Toluoyl chloride
-
Dichloromethane (DCM)
-
Saturated aqueous sodium bicarbonate solution
-
Brine
-
Anhydrous sodium sulfate
-
Silica gel for column chromatography
-
Solvents for chromatography (e.g., DCM/Methanol or Ethyl Acetate/Hexanes)
Procedure:
-
Dry thymidine (1 equivalent) under high vacuum for several hours.
-
Dissolve the dried thymidine in anhydrous pyridine in a flame-dried, two-neck round-bottom flask under an inert atmosphere.
-
Cool the solution to 0°C in an ice bath.
-
Slowly add p-toluoyl chloride (1.1 equivalents) dropwise to the stirred solution.
-
Allow the reaction mixture to stir at 0°C for 1 hour and then warm to room temperature.
-
Monitor the reaction by TLC until the starting material is consumed (typically 4-6 hours).
-
Once the reaction is complete, cool the mixture back to 0°C and quench by the slow addition of saturated aqueous sodium bicarbonate solution.
-
Extract the mixture with dichloromethane (3x).
-
Wash the combined organic layers with brine, dry over anhydrous sodium sulfate, filter, and concentrate under reduced pressure.
-
Purify the crude product by silica gel column chromatography using an appropriate solvent system.
Quantitative Data Summary
| Parameter | Recommended Range | Rationale |
| p-Toluoyl Chloride (equiv.) | 1.1 - 1.5 (for 5'-O-protection) | A slight excess drives the reaction to completion without significant di- or tri-protection. |
| Base (equiv. per OH) | 2 - 3 | Neutralizes generated HCl and activates the hydroxyl groups. |
| Temperature | 0°C to Room Temperature | Controls the initial exothermic reaction and prevents side reactions. |
| Reaction Time | 4 - 12 hours | Varies depending on the nucleoside and reaction scale; monitor by TLC. |
| Typical Yields | 70 - 90% | Dependent on the specific nucleoside and optimization of conditions. |
Section 4: Visualizing the Chemistry
Reaction Mechanism
The toluoyl protection of a nucleoside hydroxyl group proceeds via a nucleophilic acyl substitution mechanism.
Caption: Mechanism of Toluoyl Protection.
Troubleshooting Workflow
A logical approach to troubleshooting low yield issues.
Caption: Troubleshooting Decision Tree.
References
- 1. What are the reaction conditions for P - Toluoyl Chloride with phosphines? - Blog - Evergreensino [evergreensinochem.com]
- 2. researchgate.net [researchgate.net]
- 3. What are the reaction conditions for P - Toluoyl Chloride with enolates? - Blog - Evergreensino [evergreensinochem.com]
- 4. deepblue.lib.umich.edu [deepblue.lib.umich.edu]
- 5. Protection of 5'-hydroxy functions of nucleosides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. scispace.com [scispace.com]
- 7. [PDF] Protection of 5′‐Hydroxy Functions of Nucleosides | Semantic Scholar [semanticscholar.org]
- 9. researchgate.net [researchgate.net]
- 10. researchgate.net [researchgate.net]
- 11. researchgate.net [researchgate.net]
- 12. researchgate.net [researchgate.net]
- 13. electronicsandbooks.com [electronicsandbooks.com]
- 14. Formation of 2′-deoxyoxanosine from 2′-deoxyguanosine and nitrous acid: mechanism and intermediates - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Troubleshooting Labeled Internal Standards in Mass Spectrometry
Welcome to the Technical Support Center for Mass Spectrometry. This guide is designed for researchers, scientists, and drug development professionals who utilize stable isotope-labeled (SIL) internal standards for quantitative analysis. As a self-validating system, the proper use of an internal standard (IS) is paramount for achieving accurate and reproducible results, forming the cornerstone of robust bioanalytical methods.[1][2][3]
This document provides in-depth, field-proven insights into common challenges encountered when using SIL internal standards. We will move beyond simple procedural lists to explain the causality behind these issues and provide logical, step-by-step troubleshooting protocols to ensure the integrity of your data.
Section 1: Frequently Asked Questions (FAQs)
This section addresses common questions that arise during the implementation of SIL internal standards in quantitative LC-MS workflows.
Q1: Why is my stable isotope-labeled internal standard not perfectly co-eluting with my analyte?
A: This is a frequently observed phenomenon, particularly with deuterated standards, and is often referred to as an "isotope effect".[4][5] The substitution of hydrogen with deuterium, a heavier isotope, can lead to slight differences in the physicochemical properties of the molecule.[6] This can alter its interaction with the stationary phase in reversed-phase chromatography, typically causing the deuterated standard to elute slightly earlier than the non-labeled analyte.[7][8] While often minor, this shift can become problematic if the analyte and IS elute into regions with different levels of matrix-induced ion suppression, leading to inaccurate quantification.[4] Using standards labeled with ¹³C or ¹⁵N can minimize this issue as they have a much smaller impact on retention time.[6][9]
Q2: What is isotopic crosstalk and how do I know if it's affecting my assay?
A: Isotopic crosstalk occurs when the signal from the analyte interferes with the signal of the internal standard, or vice-versa.[10][11] A common cause is the contribution of naturally occurring heavy isotopes (e.g., ¹³C, ³⁴S) from the analyte to the mass channel of the IS.[10][11][12] This becomes more pronounced for high molecular weight compounds or those containing elements with significant natural isotopes like chlorine or bromine.[10][11] You can test for this by analyzing a high-concentration solution of the analyte without any internal standard and monitoring the mass channel of the IS. A significant signal indicates crosstalk. Regulatory guidelines suggest that any interference should be less than 20% of the response at the Lower Limit of Quantification (LLOQ) for the analyte and less than 5% for the internal standard.[13]
Q3: My internal standard response is highly variable across my sample batch. What are the likely causes?
A: High variability in the IS response is a critical issue that can compromise the entire analysis and is a focus of regulatory scrutiny.[14] The core purpose of a SIL-IS is to normalize variability; therefore, inconsistent response points to systemic problems.[1][2] Common causes include:
-
Inconsistent Sample Preparation: Errors in pipetting the IS, inconsistent extraction efficiencies, or sample-to-sample variations in pH can lead to variability.
-
Matrix Effects: Even with a SIL-IS, extreme or highly variable matrix effects between different samples can cause inconsistent ion suppression or enhancement.[15]
-
IS Instability: The labeled standard may be degrading during sample storage or processing. Deuterated standards can sometimes undergo back-exchange, where deuterium atoms are replaced by protons from the solvent.[9][16]
-
Injector or System Issues: Problems like inconsistent injection volumes, sample carryover, or fluctuating ion source conditions can also lead to a variable IS signal.[17]
Q4: How do I select the most appropriate SIL internal standard for my assay?
A: Selecting the right IS is crucial for method robustness.[1] Key criteria include:
-
Isotopic Purity: The IS should have a very low percentage of the unlabeled analyte to prevent artificial inflation of the analyte signal.[18]
-
Mass Difference: The mass difference between the analyte and the IS should be sufficient to prevent isotopic crosstalk. A minimum difference of 3 atomic mass units (amu) is recommended, with 4-5 Da being ideal for many applications.[2][6][15][19]
-
Label Position and Stability: The isotopic label should be placed on a part of the molecule that is chemically stable and will not be lost during sample preparation or in the mass spectrometer's ion source.[9][16] Avoid placing labels on exchangeable sites like hydroxyl (-OH) or amine (-NH) groups.[16]
-
Choice of Isotope: While deuterium (²H or D) is common and cost-effective, ¹³C or ¹⁵N-labeled standards are often preferred as they are less prone to chromatographic shifts and back-exchange.[2][9]
Section 2: In-Depth Troubleshooting Guides
This section provides structured, step-by-step protocols for diagnosing and resolving specific issues.
Issue 1: Poor Chromatographic Co-elution Leading to Inaccurate Quantification
Symptoms:
-
Noticeable and inconsistent shift in retention time (RT) between the analyte and the SIL-IS.
-
Poor precision and accuracy in quality control (QC) samples, especially when analyzing different matrix lots.
-
Analyte-to-IS response ratio is not constant across the calibration curve.
Root Cause Analysis: The primary cause is often the "deuterium effect," where extensive deuteration alters the molecule's hydrophobicity enough to affect its retention on a reversed-phase column.[6][7] If this RT shift causes the analyte and IS to elute in zones of differing ion suppression, the IS can no longer accurately compensate for the matrix effect, invalidating the quantitative assumption.[4]
Experimental Protocol: Diagnosing Differential Matrix Effects
-
Prepare Three Sample Sets:
-
Set A (Neat Solution): Analyte and IS in a clean solvent (e.g., methanol/water).
-
Set B (Post-Extraction Spike): Extract blank matrix from at least six different sources. Spike the analyte and IS into the extracted matrix after the cleanup steps.[20]
-
Set C (Pre-Extraction Spike): Spike the analyte and IS into the blank matrix from the same six sources before performing the full sample preparation procedure.
-
-
Analyze and Compare:
-
Inject all samples onto the LC-MS/MS system.
-
Calculate the Matrix Factor (MF): MF = (Peak Area in Set B) / (Peak Area in Set A). An MF < 1 indicates suppression; > 1 indicates enhancement.[15]
-
Assess Differential Effects: Compare the MF for the analyte to the MF for the IS in each of the six matrix lots. If the ratio of these MFs is not consistent and close to 1, then differential matrix effects are occurring.
-
Troubleshooting Workflow
Caption: Troubleshooting workflow for poor co-elution.
Issue 2: Isotopic Interference (Crosstalk) Compromising Low-Level Quantification
Symptoms:
-
Non-linear calibration curve, particularly at the high end.
-
The blank sample (containing only IS) shows a signal in the analyte's mass channel, or the zero sample (matrix + IS) shows a higher-than-expected analyte signal.
-
Inability to achieve the desired LLOQ due to high background.
Root Cause Analysis: Crosstalk arises from two main sources: (1) The presence of unlabeled analyte as an impurity in the IS material, and (2) The natural isotopic abundance of the analyte contributing signal to the IS mass channel (M+1, M+2, etc.).[10][11][21] This second effect becomes significant for larger molecules and can lead to a positive bias in results, as the IS signal is artificially inflated at high analyte concentrations.[11][12]
Experimental Protocol: Assessing Crosstalk Contribution
-
Prepare Solutions:
-
Analyte ULOQ Solution: Prepare the analyte at its Upper Limit of Quantification (ULOQ) concentration in a clean solvent. Do not add any IS.
-
IS Working Solution: Prepare the IS at its working concentration in a clean solvent. Do not add any analyte.
-
-
Acquire Data:
-
Inject the Analyte ULOQ Solution and acquire data, monitoring both the analyte and IS MRM transitions.
-
Inject the IS Working Solution and acquire data, monitoring both the analyte and IS MRM transitions.
-
-
Calculate Percentage Contribution:
-
Analyte to IS Crosstalk (%): (Area of IS transition in Analyte ULOQ Solution / Area of IS transition in IS Working Solution) * 100.
-
IS to Analyte Crosstalk (%): (Area of Analyte transition in IS Working Solution / Area of Analyte transition in a known LLOQ sample) * 100.
-
Data Interpretation and Actionable Limits
| Crosstalk Direction | Acceptance Criteria | Action if Exceeded |
| Analyte → IS | Contribution should be < 5% of the IS response.[13] | This can cause non-linearity. Consider using a non-linear calibration fit or selecting an IS with a greater mass difference.[11][21] |
| IS → Analyte (Impurity) | Contribution should be < 20% of the LLOQ response.[13] | This will bias all results and raise the LLOQ. Source a higher purity IS or adjust the LLOQ accordingly. |
Issue 3: Inconsistent Internal Standard Response due to Matrix Effects
Symptoms:
-
The absolute peak area of the IS varies significantly (>20-30%) across a batch of incurred samples.
-
The IS response in some samples is drastically lower or higher than in the calibration standards.
-
FDA guidance suggests investigating IS response variability that may impact data accuracy.[14]
Root Cause Analysis: Matrix effects are caused by co-eluting components from the biological matrix that interfere with the ionization of the analyte and IS in the mass spectrometer's source.[15][22] This leads to ion suppression (most common) or enhancement. While a SIL-IS is designed to track and correct for this, severe or inconsistent matrix effects can overwhelm its ability to compensate, leading to the observed variability.[6][22]
Diagram: Impact of Ion Suppression on Analyte and IS
Caption: How a co-eluting IS compensates for ion suppression.
Troubleshooting Steps:
-
Confirm the Issue: Plot the absolute IS peak area for all samples in the run (calibrators, QCs, and unknowns). Identify if the variability is random or shows a trend (e.g., signal drift over time).
-
Improve Sample Cleanup: This is the most effective strategy. If using Liquid-Liquid Extraction (LLE), try a different solvent or a back-extraction step. If using Solid-Phase Extraction (SPE), ensure the sorbent is appropriate for your analyte and experiment with stronger wash steps to remove more interfering components.
-
Modify Chromatography: Adjust the LC gradient to better separate the analyte/IS from the region of ion suppression. A simple test is to inject an extracted blank sample and monitor the baseline on the analyte/IS MRM transition to identify where matrix components are eluting.
-
Reduce Matrix Load: If possible, dilute the sample with the initial mobile phase. This reduces the total amount of matrix components injected onto the column, which can alleviate suppression. This may require a more sensitive instrument to maintain the desired LLOQ.
-
Check for IS Instability: As a final check, re-assay samples that showed aberrant IS response. If the re-analyzed results are consistent with the batch, it suggests the issue was analytical rather than related to sample stability. If the IS response remains low, investigate potential degradation or back-exchange issues, especially if using deuterated standards in aqueous matrices for extended periods.
References
- 1. Optimizing Laboratory-Developed LC-MS/MS Tests: Proper Use of Internal Standards - Insights from Two Troubleshooting Case Studies [labroots.com]
- 2. Internal Standards in LC−MS Bioanalysis: Which, When, and How - WuXi AppTec DMPK [dmpkservice.wuxiapptec.com]
- 3. nebiolab.com [nebiolab.com]
- 4. benchchem.com [benchchem.com]
- 5. Trends in the Hydrogen-Deuterium Exchange at the Carbon Centers. Preparation of Internal Standards for Quantitative Analysis by LC-MS - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. chromatographyonline.com [chromatographyonline.com]
- 7. Stable isotopically labeled internal standards in quantitative bioanalysis using liquid chromatography/mass spectrometry: necessity or not? - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. youtube.com [youtube.com]
- 9. hilarispublisher.com [hilarispublisher.com]
- 10. pubs.acs.org [pubs.acs.org]
- 11. Correction for isotopic interferences between analyte and internal standard in quantitative mass spectrometry by a nonlinear calibration function - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. downloads.regulations.gov [downloads.regulations.gov]
- 14. fda.gov [fda.gov]
- 15. tandfonline.com [tandfonline.com]
- 16. Designing Stable Isotope Labeled Internal Standards - Acanthus Research [acanthusresearch.com]
- 17. benchchem.com [benchchem.com]
- 18. s3-eu-west-1.amazonaws.com [s3-eu-west-1.amazonaws.com]
- 19. Liquid chromatography–tandem mass spectrometry for clinical diagnostics - PMC [pmc.ncbi.nlm.nih.gov]
- 20. benchchem.com [benchchem.com]
- 21. pubs.acs.org [pubs.acs.org]
- 22. chromatographyonline.com [chromatographyonline.com]
Technical Support Center: Strategies for Efficient Removal of p-Toluoyl Protecting Groups
Welcome to the Technical Support Center for p-Toluoyl Protecting Group Strategies. This guide is designed for researchers, scientists, and professionals in drug development. Here, you will find in-depth technical guidance, troubleshooting advice, and detailed protocols in a direct question-and-answer format to address challenges encountered during the deprotection of p-toluoyl groups.
Introduction to the p-Toluoyl (Tol) Protecting Group
What is the p-toluoyl group and why is it used?
The p-toluoyl (Tol) group is a member of the acyl-type protecting group family, structurally similar to the more common benzoyl (Bz) group but with a methyl substituent at the para position of the benzene ring. It is typically used to protect hydroxyl (-OH) and amino (-NH) functionalities by forming a p-toluoyl ester or amide, respectively.
The primary reasons for its use in multistep synthesis include:
-
Stability: Toluoyl esters and amides are robust and stable under a wide range of reaction conditions, particularly acidic conditions, making them suitable for syntheses where other protecting groups might be too labile.[1]
-
Crystallinity: The presence of the aromatic ring can often impart crystallinity to intermediates, which can aid in their purification by recrystallization.
-
Chromatographic handle: The aromatic ring provides a chromophore, making compounds containing this group easily detectable by UV light during chromatographic purification.
Frequently Asked Questions (FAQs)
Q1: What are the standard methods for deprotecting a p-toluoyl group from an alcohol?
The most common and reliable method for cleaving a p-toluoyl ester is through saponification (base-catalyzed hydrolysis).[2][3] This involves treating the protected compound with a strong base, such as sodium hydroxide (NaOH), lithium hydroxide (LiOH), or potassium carbonate (K2CO3), in a protic solvent system like methanol/water or THF/water. Acid-catalyzed hydrolysis is also possible but is often slower and the reaction is reversible, which can lead to incomplete deprotection.[2][4]
Q2: How does the stability of the p-toluoyl group compare to other acyl protecting groups like acetyl (Ac) and benzoyl (Bz)?
The reactivity of acyl protecting groups towards basic hydrolysis generally follows the order: acetyl > benzoyl ≈ p-toluoyl > pivaloyl.
-
Acetyl (Ac): More labile and easier to remove under milder basic conditions.
-
Benzoyl (Bz) and p-Toluoyl (Tol): These have similar stability. The electronic effect of the para-methyl group in the toluoyl group is small, so its lability is very close to that of the benzoyl group. They are significantly more stable than the acetyl group.
-
Pivaloyl (Piv): Due to the steric hindrance of the t-butyl group, the pivaloyl group is much more robust and requires harsher conditions for removal.[5]
This relative stability allows for some degree of selective deprotection. For example, an acetyl group can often be removed in the presence of a toluoyl group.
Q3: Can a p-toluoyl group be removed selectively in the presence of other sensitive functional groups?
Yes, this is a key consideration in synthetic strategy. The choice of deprotection conditions is crucial for maintaining the integrity of the rest of the molecule.
-
Base-labile groups: If your molecule contains other base-sensitive groups (e.g., other esters, β-lactams), standard saponification might not be suitable. In such cases, you may need to use milder basic conditions (e.g., K2CO3 in methanol) or consider alternative deprotection methods.
-
Acid-labile groups: The p-toluoyl group is generally stable to acidic conditions. This allows for the selective removal of acid-labile groups like silyl ethers (e.g., TBS, TIPS), acetals, or Boc-amines in the presence of a p-toluoyl group.[6]
The concept of using protecting groups that can be removed under different conditions is known as orthogonal protection , which is a cornerstone of modern organic synthesis.[1][7]
Q4: Are there any reductive methods to cleave a p-toluoyl group?
While less common than hydrolysis, reductive cleavage is a potential option, particularly for toluoyl esters. Strong reducing agents like lithium aluminum hydride (LiAlH4) will reduce the ester to the corresponding primary alcohol. However, this method is not a "deprotection" in the sense of regenerating the original alcohol, as the carboxylic acid portion is also reduced. For a true deprotection that regenerates the alcohol, specific reductive systems would be needed, and these are less frequently employed for toluoyl groups compared to other protecting groups like benzyl ethers.
Troubleshooting Guide
This section addresses common problems encountered during the deprotection of p-toluoyl groups.
| Problem | Possible Cause(s) | Suggested Solution(s) |
| Incomplete Deprotection / Slow Reaction | 1. Insufficient Reagent: The amount of base or acid is not enough to drive the reaction to completion. 2. Steric Hindrance: The p-toluoyl group is attached to a sterically hindered hydroxyl or amino group, slowing down the nucleophilic attack. 3. Low Temperature: The reaction temperature is too low, resulting in slow kinetics. 4. Poor Solubility: The substrate is not fully dissolved in the reaction solvent, preventing the reagent from accessing the reaction site. | 1. Increase the equivalents of the base or acid. For basic hydrolysis, using 2-5 equivalents of base is common. 2. Increase the reaction temperature and/or prolong the reaction time. Monitor the reaction progress by TLC or LC-MS. 3. Switch to a stronger nucleophile/base (e.g., from K2CO3 to NaOH). 4. Add a co-solvent (e.g., THF, dioxane) to improve solubility. |
| Formation of Side Products | 1. Epimerization: If there is a stereocenter adjacent to the carbonyl group of the protected alcohol, strong basic conditions can cause epimerization. 2. Cleavage of other groups: Other functional groups in the molecule (e.g., other esters) are not stable to the deprotection conditions. 3. Migration of the toluoyl group: In molecules with multiple hydroxyl groups (like carbohydrates), base-catalyzed acyl migration to an adjacent free hydroxyl group can occur. | 1. Use milder basic conditions (e.g., K2CO3 in methanol at room temperature) or an enzymatic hydrolysis method if applicable. 2. Carefully select deprotection conditions that are orthogonal to other protecting groups present. If not possible, a redesign of the synthetic route with a different protecting group strategy may be necessary. 3. Protect all hydroxyl groups that could participate in acyl migration, or use conditions that minimize the equilibrium, such as running the reaction at a lower temperature. |
| Low Yield of Deprotected Product | 1. Product Degradation: The deprotected product may be unstable under the reaction conditions (e.g., sensitive to strong base or acid). 2. Difficult Work-up: The product may be water-soluble, leading to loss during aqueous extraction. The by-product, p-toluic acid, must also be effectively removed. | 1. If the product is base-sensitive, use milder conditions or a shorter reaction time. If it is acid-sensitive, ensure the work-up procedure does not involve harsh acidic conditions for an extended period. 2. During work-up of a basic hydrolysis, acidify the aqueous layer to protonate the p-toluic acid, allowing it to be extracted into an organic solvent. For water-soluble products, consider extraction with a more polar solvent (e.g., ethyl acetate, n-butanol) or use solid-phase extraction (SPE). |
Experimental Protocols
Protocol 1: Standard Basic Hydrolysis (Saponification) of a p-Toluoyl Ester
This protocol describes a general procedure for the removal of a p-toluoyl group from a primary or secondary alcohol using sodium hydroxide.
Materials:
-
p-Toluoyl protected compound
-
Methanol (MeOH)
-
Tetrahydrofuran (THF) (optional, as a co-solvent)
-
1 M Sodium Hydroxide (NaOH) aqueous solution
-
1 M Hydrochloric Acid (HCl) aqueous solution
-
Ethyl acetate (EtOAc) or Dichloromethane (DCM) for extraction
-
Saturated sodium bicarbonate (NaHCO3) solution
-
Brine (saturated NaCl solution)
-
Anhydrous sodium sulfate (Na2SO4) or magnesium sulfate (MgSO4)
Procedure:
-
Dissolution: Dissolve the p-toluoyl protected compound in methanol (and THF if needed for solubility) in a round-bottom flask equipped with a magnetic stirrer. A typical concentration is 0.1-0.5 M.
-
Addition of Base: Add 2-3 equivalents of 1 M NaOH solution to the flask.
-
Reaction: Stir the mixture at room temperature or heat to 40-50 °C. Monitor the reaction progress by Thin Layer Chromatography (TLC) until the starting material is consumed. This can take anywhere from 1 to 12 hours, depending on the substrate.
-
Quenching and Neutralization: Cool the reaction mixture to room temperature. Carefully neutralize the excess base by adding 1 M HCl until the pH is approximately 7.
-
Solvent Removal: Remove the organic solvents (MeOH, THF) under reduced pressure using a rotary evaporator.
-
Extraction: Add water and an organic solvent (e.g., EtOAc or DCM) to the remaining aqueous residue. Transfer the mixture to a separatory funnel and extract the product into the organic layer. Repeat the extraction 2-3 times.
-
Washing: Combine the organic layers and wash sequentially with saturated NaHCO3 solution (to remove the p-toluic acid byproduct), water, and brine.
-
Drying and Concentration: Dry the organic layer over anhydrous Na2SO4 or MgSO4, filter, and concentrate under reduced pressure to obtain the crude deprotected alcohol.
-
Purification: Purify the crude product by flash column chromatography if necessary.
Diagram: Mechanism of Base-Catalyzed Hydrolysis of a p-Toluoyl Ester
Caption: Mechanism of saponification of a p-toluoyl ester.
Diagram: Decision Workflow for p-Toluoyl Deprotection
Caption: Decision tree for selecting a p-toluoyl deprotection strategy.
References
Technical Support Center: Resolving Peak Overlap in NMR with Site-Specific Labeling
Welcome to the technical support center for Nuclear Magnetic Resonance (NMR) spectroscopy. This guide is designed for researchers, scientists, and drug development professionals who are leveraging site-specific isotopic labeling to overcome the challenges of spectral overlap in their protein NMR studies. Here, we provide in-depth, field-proven insights in a question-and-answer format to address specific issues you may encounter during your experiments.
I. Foundational Concepts & FAQs
This section addresses the fundamental principles behind peak overlap and the strategic use of site-specific labeling to simplify complex NMR spectra.
Q1: What is the fundamental problem of peak overlap in protein NMR?
In protein NMR, each magnetically active nucleus (like ¹H, ¹³C, and ¹⁵N) within a protein gives rise to a signal, or "peak," in the spectrum. For small proteins, these peaks are often well-dispersed, allowing for individual assignment to specific atoms. However, as the size of the protein increases, so does the number of signals.[1][2][3] This leads to severe signal overlap, where multiple peaks crowd into the same region of the spectrum, making it difficult or impossible to resolve and assign individual resonances.[1][2][3] This spectral congestion is further exacerbated by the fact that larger molecules tumble more slowly in solution, which causes NMR signals to broaden, further contributing to overlap and a decrease in sensitivity.[1][2][3]
Q2: How does site-specific isotope labeling help resolve peak overlap?
Site-specific isotope labeling is a powerful strategy to simplify complex NMR spectra by reducing the number of NMR-active nuclei in the protein.[1][2][3] Instead of uniformly enriching the entire protein with ¹³C and/or ¹⁵N, only specific amino acid types, or even specific atoms within those amino acids, are isotopically labeled. This "turns on" signals at selected sites, while the rest of the protein remains "NMR-invisible" at those isotopes' frequencies.[1][2] This selective observation dramatically reduces spectral crowding, making it easier to assign resonances and extract structural and dynamic information, especially for large proteins or protein complexes.[4][5][6][7][8]
Q3: What are the primary types of site-specific labeling strategies?
Site-specific labeling encompasses several techniques, each with its own advantages for different research questions:
-
Amino Acid-Specific Labeling: In this approach, one or more specific types of amino acids (e.g., Leucine, Alanine, Tyrosine) are provided in their isotopically labeled form during protein expression, while all other amino acids are unlabeled.[8][9]
-
Reverse Labeling: This is a cost-effective alternative where the protein is expressed in a medium containing a labeled carbon source (e.g., ¹³C-glucose) and labeled nitrogen source (e.g., ¹⁵NH₄Cl), but supplemented with specific unlabeled amino acids. The host organism will incorporate the unlabeled amino acids, effectively "turning off" the signals from those residue types.[1][2][9][10]
-
Segmental Isotope Labeling: This advanced technique involves labeling only a specific segment or domain of a protein.[4][5][6][7] This is particularly useful for studying large, multi-domain proteins, as it allows researchers to focus on a particular region of interest without interference from the rest of the protein.[4][5][6][7] This is often achieved through methods like expressed protein ligation or protein trans-splicing.[4][5]
-
Site-Specific Labeling: This refers to the incorporation of a labeled amino acid at a single, specific position within the protein sequence.[8] This provides the highest level of spectral simplification and is ideal for probing the local environment of a key residue.[8]
Q4: When should I choose site-specific labeling over uniform labeling?
The decision to use site-specific labeling depends on your research goals and the nature of your protein. Here's a general guide:
| Scenario | Recommended Labeling Strategy | Rationale |
| Initial structural characterization of a small protein (<15 kDa) | Uniform ¹³C, ¹⁵N Labeling | Spectra are generally well-resolved, and uniform labeling provides the maximum amount of structural information. |
| Studying a large protein (>25 kDa) or protein complex | Site-Specific or Segmental Labeling | Reduces spectral overlap, allowing for focused analysis of specific regions or residue types.[4][5][6][7] |
| Investigating the active site of an enzyme | Amino Acid-Specific or Site-Specific Labeling | Allows for detailed characterization of the local environment and dynamics of key catalytic residues without interference from the rest of the protein. |
| Studying protein-ligand interactions | Amino Acid-Specific Labeling of residues at the binding interface | Simplifies the spectrum to focus on chemical shift perturbations of residues involved in binding. |
| Resonance assignment of a challenging protein | Amino Acid-Specific or Reverse Labeling | Helps to identify the amino acid type corresponding to a particular spin system, aiding in the assignment process.[11] |
II. Troubleshooting Guide: Experimental Design & Execution
This section provides practical advice for overcoming common hurdles during the experimental stages of site-specific labeling.
Q5: My labeled protein expression yield is low. What are the common causes and solutions?
Low expression yield is a frequent challenge in protein production. Here are some common culprits and troubleshooting strategies:
-
Toxicity of the expressed protein: High-level expression of some proteins can be toxic to the host cells.
-
Solution: Use a lower concentration of the inducing agent (e.g., IPTG), reduce the expression temperature (e.g., 18-25°C), and shorten the expression time.[12] Tightly regulated expression systems, such as those with vectors containing the pLysS plasmid, can also help minimize leaky expression before induction.[13]
-
-
Codon bias: The codons in your gene of interest may be rare for the E. coli expression host, leading to truncated or non-functional protein.
-
Protein insolubility and inclusion bodies: The overexpressed protein may misfold and aggregate into insoluble inclusion bodies.[12][14]
-
Media composition and reagent quality: The minimal media used for isotopic labeling can sometimes result in lower yields compared to rich media. The quality of reagents, including the inducing agent, can also impact expression.
-
Solution: Optimize the composition of your minimal media. If you suspect a reagent issue, try a fresh batch of the inducing agent or test your expression system with a control plasmid known to express well.[16]
-
Q6: I'm observing scrambling of my isotopic label to other amino acid types. How can I minimize this?
Isotope scrambling occurs when the host cell's metabolic pathways convert the labeled amino acid you've supplied into other amino acids, leading to unintended labeling.[8][9]
-
Understanding the Cause: In E. coli, enzymes like transaminases can transfer the isotopic label from the supplied amino acid to other metabolic precursors.[17]
-
Solutions to Minimize Scrambling:
-
Use Auxotrophic Strains: Employ E. coli strains that have mutations in specific amino acid biosynthesis pathways. These strains are unable to synthesize certain amino acids and will be forced to incorporate the labeled version you provide in the media.[8][9][18]
-
Add Unlabeled Amino Acids: Supplementing the growth media with a cocktail of unlabeled amino acids can help to suppress the metabolic pathways that lead to scrambling.
-
Use Metabolic Precursors: For certain amino acids, using a labeled metabolic precursor instead of the amino acid itself can lead to more specific labeling with less scrambling.[8] For example, using α-keto acids for methyl labeling is a cost-effective method that minimizes scrambling.
-
Cell-Free Protein Expression: Cell-free systems lack the metabolic pathways that cause scrambling, making them an excellent choice for achieving highly specific labeling, though this can be a more expensive option.[8][9][17][18][19]
-
Experimental Workflow: Amino Acid-Specific ¹⁵N Labeling
Caption: Workflow for amino acid-specific labeling.
Q7: How do I choose the right labeled amino acid for my specific research question?
The choice of which amino acid(s) to label is critical and should be guided by your scientific objectives:
-
Probing the Hydrophobic Core: Leucine, valine, isoleucine, and alanine are abundant in the hydrophobic core of proteins.[3] Labeling these residues can provide insights into protein folding and stability. Methyl-specific labeling of these residues is particularly powerful for studying the dynamics of large proteins.[8][20]
-
Investigating Active Sites: Histidine, aspartate, glutamate, lysine, and arginine are frequently found in enzyme active sites. Labeling these residues can report on the catalytic mechanism and interactions with substrates or inhibitors.
-
Mapping Protein-Protein Interfaces: By analyzing the sequence of your protein and any available structural data, you can predict which residues are likely to be at the interaction interface. Selectively labeling these residues will allow you to monitor changes upon complex formation.
-
General Structural Probes: Glycine is often found in flexible loop regions, while aromatic residues like phenylalanine, tyrosine, and tryptophan can provide information about packing and long-range interactions.
For protein structure analysis, ¹⁵N labeling is fundamental for acquiring the ¹H-¹⁵N HSQC spectrum, which provides a unique fingerprint of the protein. For more detailed structural information, dual labeling with ¹³C and ¹⁵N is necessary.[]
III. Troubleshooting Guide: Spectral Analysis & Interpretation
This section focuses on addressing challenges that arise after data acquisition.
Q8: I've collected my data, but the labeled peaks are still ambiguous. What are the next steps?
Even with site-specific labeling, some ambiguity can remain. Here's a logical progression for troubleshooting:
-
Confirm Labeling Specificity: Before extensive analysis, it's crucial to confirm that your labeling was successful and specific. This can be done by mass spectrometry to verify the incorporation of the labeled amino acid.
-
Vary Experimental Conditions: Small changes in pH, temperature, or buffer composition can sometimes induce chemical shift changes that resolve overlapping peaks.
-
Employ Higher-Dimensional NMR Experiments: If you are working with a 2D spectrum, acquiring 3D or 4D NMR data can provide an additional dimension of chemical shifts, which will almost certainly resolve the overlap.
-
Use a Different Labeling Scheme: If ambiguity persists, it may be necessary to prepare a new sample with a different set of labeled amino acids. For example, if you have labeled all leucines and some peaks are still overlapped, you could try labeling only valines in a separate experiment.
Q9: How can I confirm the success and specificity of my labeling?
Verifying your labeling is a critical quality control step:
-
Mass Spectrometry (MS): This is the most direct method. By comparing the mass of the labeled protein to its unlabeled counterpart, you can determine the extent of isotope incorporation. High-resolution MS can even confirm the number of incorporated labeled amino acids.
-
NMR Spectroscopy: The appearance of new peaks in the expected regions of your heteronuclear NMR spectrum (e.g., ¹H-¹⁵N HSQC) is a strong indication of successful labeling. The number of new peaks should correspond to the number of labeled residues in your protein.
-
SDS-PAGE and Western Blot: While not a direct measure of isotopic labeling, running an SDS-PAGE gel of your pre- and post-induction samples can confirm that your protein was expressed.[12] A Western blot can provide further confirmation of your protein's identity.[12]
Q10: Are there computational or software tools that can aid in analyzing spectra from site-specifically labeled proteins?
Yes, several computational tools can assist in the analysis of NMR data:
-
Peak Picking and Processing Software: Programs like NMRPipe and CCPNmr Analysis provide tools for processing raw NMR data and automatically or semi-automatically picking peaks.[22]
-
Resonance Assignment Software: Software packages such as CYANA, ARIA, and FALCON-NMR can help automate the process of assigning chemical shifts to specific atoms in the protein.[23]
-
Structure Calculation Programs: Once assignments are made, programs like CYANA and Xplor-NIH use the experimental restraints (such as NOEs) to calculate the 3D structure of the protein.
-
Chemical Shift Prediction: Tools like SHIFTX2 and SPARTA+ can predict the chemical shifts of a protein from its 3D structure.[24] This can be useful for validating assignments or for identifying regions of conformational change.
IV. Advanced Strategies & Future Perspectives
This final section touches upon more complex labeling techniques and emerging trends in the field.
Q11: What is segmental labeling and when should it be used?
Segmental isotope labeling involves the selective isotopic enrichment of a specific contiguous segment of the protein.[4][5][6][7] This is achieved by expressing and purifying different fragments of the protein separately (one labeled, the other unlabeled) and then ligating them together using techniques like protein trans-splicing or expressed protein ligation.[4][5][25]
When to Use Segmental Labeling:
-
Very Large Proteins or Complexes: For proteins that are too large for even amino acid-specific labeling to sufficiently simplify the spectrum.[4][5][6][7]
-
Studying Inter-domain Interactions: By labeling one domain and leaving the other unlabeled, you can specifically probe the interface between them.[6]
-
Investigating Conformational Changes in a Specific Domain: Segmental labeling allows you to focus on the structural and dynamic changes within a single domain upon ligand binding or post-translational modification.[6]
Decision Tree: Choosing a Labeling Strategy
Caption: Decision tree for selecting an appropriate labeling strategy.
Q12: What are the emerging trends in site-specific labeling for NMR?
The field of isotopic labeling is continually evolving, with several exciting trends on the horizon:
-
Cell-Free Expression Systems: The use of cell-free systems is becoming more widespread due to their ability to incorporate a wide range of labeled and unnatural amino acids with minimal isotope scrambling.[8][9][17][18][19]
-
Advanced Segmental Labeling Techniques: New and improved methods for protein ligation and splicing are making segmental labeling more accessible and efficient for a wider range of proteins, including membrane proteins.[25]
-
Labeling for Solid-State NMR: As solid-state NMR becomes more powerful for studying large and insoluble proteins, there is a growing interest in developing specific labeling schemes tailored for these experiments.[26]
-
Integration with Computational Methods: The combination of selective labeling with advanced computational methods is enabling the study of increasingly complex biological systems.[24][27] Molecular dynamics simulations, for example, can be used in conjunction with NMR data to generate detailed models of protein dynamics.[24]
References
- 1. portlandpress.com [portlandpress.com]
- 2. Specific isotopic labelling and reverse labelling for protein NMR spectroscopy: using metabolic precursors in sample preparation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Specific isotopic labelling and reverse labelling for protein NMR spectroscopy: using metabolic precursors in sample preparation - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Segmental isotopic labeling of proteins for nuclear magnetic resonance - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Segmental Isotopic Labeling of Proteins for Nuclear Magnetic Resonance - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. Improved segmental isotope labeling methods for the NMR study of multidomain or large proteins: application to the RRMs of Npl3p and hnRNP L. [sonar.ch]
- 8. Segmental and site-specific isotope labelling strategies for structural analysis of posttranslationally modified proteins - RSC Chemical Biology (RSC Publishing) DOI:10.1039/D1CB00045D [pubs.rsc.org]
- 9. protein-nmr.org.uk [protein-nmr.org.uk]
- 10. ckisotopes.com [ckisotopes.com]
- 11. researchgate.net [researchgate.net]
- 12. m.youtube.com [m.youtube.com]
- 13. goldbio.com [goldbio.com]
- 14. How to Troubleshoot Low Protein Yield After Elution [synapse.patsnap.com]
- 15. Segmental isotope labeling of proteins for NMR structural study using protein S tag for higher expression and solubility - PMC [pmc.ncbi.nlm.nih.gov]
- 16. researchgate.net [researchgate.net]
- 17. synthelis.com [synthelis.com]
- 18. Isotope Labeling for Solution and Solid-State NMR Spectroscopy of Membrane Proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 19. blog.synthelis.com [blog.synthelis.com]
- 20. pound.med.utoronto.ca [pound.med.utoronto.ca]
- 22. Structure-oriented methods for protein NMR data analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 23. academic.oup.com [academic.oup.com]
- 24. Applications of NMR and computational methodologies to study protein dynamics - PMC [pmc.ncbi.nlm.nih.gov]
- 25. pubs.acs.org [pubs.acs.org]
- 26. Isotopic Labeling for NMR Spectroscopy of Biological Solids [sigmaaldrich.com]
- 27. pubs.acs.org [pubs.acs.org]
Validation & Comparative
A Researcher's Guide to Isotopic Labeling in Nucleic Acid NMR: A Comparative Analysis of ¹³C and ¹⁵N Strategies
In the intricate world of nucleic acid structural biology, Nuclear Magnetic Resonance (NMR) spectroscopy stands as a powerful technique for elucidating the three-dimensional structures and dynamics of DNA and RNA in solution. However, the inherent complexity and spectral overlap in unlabeled nucleic acids, particularly as their size increases, present significant challenges. Isotopic labeling with NMR-active nuclei, primarily Carbon-13 (¹³C) and Nitrogen-15 (¹⁵N), has revolutionized the field, enabling the study of ever larger and more complex nucleic acid systems. This guide provides a comprehensive comparison of ¹³C and ¹⁵N labeling strategies, offering researchers, scientists, and drug development professionals the insights needed to make informed experimental choices.
The Rationale for Isotopic Labeling in Nucleic Acid NMR
The primary motivation for isotopic labeling is to overcome the limitations of proton (¹H) NMR spectroscopy. While rich in information, ¹H spectra of nucleic acids suffer from severe resonance overlap, making unambiguous assignment of signals a formidable task. Introducing ¹³C or ¹⁵N isotopes, both of which have a nuclear spin of ½, allows for the dispersal of signals into additional dimensions in multidimensional NMR experiments. This spectral simplification is the cornerstone of modern biomolecular NMR.[1][2]
The choice between ¹³C and ¹⁵N labeling, or a combination of both, is dictated by the specific scientific question, the size of the nucleic acid, and budgetary considerations. Each strategy offers unique advantages and comes with its own set of challenges.
¹⁵N Labeling: A Window into Base Pairing and Dynamics
Nitrogen atoms are integral to the nucleobases, participating directly in the hydrogen bonds that define the iconic double helix and other complex tertiary structures. This makes ¹⁵N a sensitive probe of base pairing, ligand binding, and conformational changes.[3]
Key Advantages of ¹⁵N Labeling:
-
Reduced Linewidths: The naturally abundant ¹⁴N isotope has a nuclear spin of 1 and a quadrupole moment, which leads to broad NMR signals. Replacing it with the spin-½ ¹⁵N nucleus results in significantly narrower and more easily detectable spectral lines.[4]
-
Direct Probe of Hydrogen Bonding: Imino and amino protons are directly bonded to nitrogen atoms in the nucleobases. ¹H-¹⁵N correlation experiments, such as the Heteronuclear Single Quantum Coherence (HSQC) experiment, provide a "fingerprint" of the base-paired regions of a nucleic acid.
-
Simplified Spectra: The chemical shift range of ¹⁵N is substantial, offering good resolution in the indirect dimension of 2D experiments.[4]
-
Cost-Effective Uniform Labeling: The production of uniformly ¹⁵N-labeled ribonucleoside triphosphates (NTPs) through bacterial expression in minimal media containing ¹⁵N-ammonium chloride as the sole nitrogen source is a well-established and relatively economical method.[5][6]
Limitations of ¹⁵N Labeling:
-
Limited Information on the Sugar-Phosphate Backbone: Nitrogen atoms are absent from the ribose or deoxyribose sugar rings and the phosphate backbone, meaning ¹⁵N labeling provides no direct information about these crucial structural elements.
-
Lower Sensitivity: The gyromagnetic ratio of ¹⁵N is low, which translates to inherently lower sensitivity compared to ¹H or ¹³C.[7]
¹³C Labeling: Unraveling the Complete Architecture
Carbon is the ubiquitous building block of nucleic acids, forming the framework of both the nucleobases and the sugar-phosphate backbone. ¹³C labeling, therefore, provides a comprehensive view of the entire molecule.
Key Advantages of ¹³C Labeling:
-
Large Chemical Shift Dispersion: ¹³C nuclei exhibit a very wide range of chemical shifts (approximately 200 ppm), which is significantly larger than that of ¹H (around 10 ppm).[8][9] This vast dispersion is highly effective at resolving spectral overlap, even in large and complex nucleic acids.[5]
-
Information on All Moieties: ¹³C labeling allows for the probing of both the nucleobases and the sugar-phosphate backbone, providing a complete picture of the nucleic acid's structure and dynamics.
-
Access to a Wealth of NMR Experiments: The presence of ¹³C enables a wide array of powerful multidimensional NMR experiments, including 3D and 4D techniques that correlate ¹H, ¹³C, and ¹⁵N nuclei, which are essential for the complete resonance assignment of larger RNAs and DNAs.[5][6]
Challenges and Solutions in ¹³C Labeling:
-
Spectral Complexity from ¹³C-¹³C Couplings: In uniformly ¹³C-labeled samples, the one-bond scalar couplings between adjacent ¹³C atoms lead to splitting of signals, which can complicate spectra and reduce sensitivity.[10]
-
Signal Attenuation in Larger Molecules: For larger RNA molecules, the long constant-time delays required in some ¹³C-edited experiments can lead to significant signal loss due to relaxation.[10]
-
Higher Cost: The precursors for ¹³C labeling, such as ¹³C-glucose, are generally more expensive than their ¹⁵N counterparts.[][12]
To mitigate these challenges, selective and site-specific ¹³C labeling strategies have been developed. These methods involve introducing ¹³C at specific positions within the nucleotide, thereby simplifying the spectra and avoiding the complexities of uniform labeling.[10][13]
Head-to-Head Comparison: ¹³C vs. ¹⁵N Labeling
| Feature | ¹³C Labeling | ¹⁵N Labeling |
| Information Content | Comprehensive (Bases & Sugar-Phosphate Backbone) | Primarily Nucleobases and Hydrogen Bonding |
| Spectral Resolution | Excellent due to large chemical shift dispersion[8][9] | Good, with narrow linewidths[4] |
| Sensitivity | Moderate | Lower due to low gyromagnetic ratio[7] |
| Cost | Generally higher | More cost-effective for uniform labeling[][12] |
| Primary Application | Complete structure determination, dynamics of all moieties | Probing base pairing, ligand interactions, and dynamics of bases |
| Key Experiments | ¹H-¹³C HSQC, HCCH-TOCSY, 3D/4D experiments | ¹H-¹⁵N HSQC, HNN-COSY |
| Main Challenge | Spectral complexity from ¹³C-¹³C couplings in uniform labeling[10] | Limited to information about nitrogen-containing moieties |
Experimental Workflows
The production of isotopically labeled nucleic acids for NMR studies typically involves in vitro transcription using T7 RNA polymerase with labeled NTPs.[1][14] For DNA, methods such as PCR-based amplification with labeled dNTPs or solid-phase synthesis with labeled phosphoramidites are employed.[15][16]
Workflow for Uniform ¹⁵N/¹³C Labeling of RNA
Caption: Workflow for producing uniformly labeled RNA for NMR studies.
Step-by-Step Protocol for Uniform ¹⁵N-Labeling of NTPs from E. coli
-
Culture Preparation: Inoculate a starter culture of an appropriate E. coli strain (e.g., BL21(DE3)) in a minimal medium containing natural abundance nitrogen and carbon sources.
-
Large-Scale Growth: Use the starter culture to inoculate a larger volume of minimal medium where the sole nitrogen source is ¹⁵NH₄Cl. Grow the cells until they reach the late logarithmic phase.
-
Cell Harvesting and Lysis: Harvest the bacterial cells by centrifugation. Resuspend the cell pellet in a suitable lysis buffer and lyse the cells (e.g., by sonication or French press).
-
RNA Extraction: Isolate the total RNA from the cell lysate using methods such as phenol-chloroform extraction followed by ethanol precipitation.
-
RNA Hydrolysis: Hydrolyze the purified RNA to ribonucleoside 5'-monophosphates (NMPs) using an enzyme like nuclease P1.
-
Enzymatic Conversion to NTPs: Convert the resulting NMPs to ribonucleoside 5'-triphosphates (NTPs) through a series of enzymatic reactions involving specific kinases.
-
Purification: Purify the labeled NTPs using techniques like anion-exchange chromatography (e.g., FPLC).
Case Study: Assigning a Small RNA Hairpin
Consider the challenge of assigning the NMR spectra of a 30-nucleotide RNA hairpin.
-
¹⁵N Labeling Approach: A ¹H-¹⁵N HSQC spectrum would reveal the number of base pairs by identifying the imino proton signals. This provides a rapid assessment of the secondary structure. However, assigning the non-exchangeable protons in the bases and the sugar protons would remain challenging.
-
¹³C Labeling Approach: A ¹H-¹³C HSQC spectrum would provide a wealth of resolved signals for both the base and sugar carbons, greatly facilitating the assignment process. Combining this with through-bond correlation experiments like HCCH-TOCSY would allow for the tracing of connectivities within each nucleotide.
-
Dual ¹³C/¹⁵N Labeling: The most powerful approach would be to use a dually labeled sample. This enables a suite of 3D NMR experiments (e.g., HNCA, HNCACB) that correlate the backbone amide proton and nitrogen with the alpha and beta carbons of the preceding and intra-residue. While these experiments are standard for proteins, analogous experiments have been developed for nucleic acids, providing unambiguous sequential assignments.[6]
Logical Framework for Choosing a Labeling Strategy
Caption: Decision tree for selecting an isotopic labeling strategy.
Conclusion and Future Outlook
The choice between ¹³C and ¹⁵N labeling for nucleic acid NMR is not a matter of one being definitively superior to the other. Instead, they are complementary tools in the researcher's arsenal. ¹⁵N labeling offers a focused and cost-effective method for probing the critical aspects of base pairing and recognition. In contrast, ¹³C labeling provides a global view of the nucleic acid's structure, albeit at a higher cost and with potential spectral complexity that often necessitates more sophisticated experimental designs and labeling schemes.
For smaller nucleic acids where the primary interest lies in secondary structure and ligand interactions, ¹⁵N labeling may be sufficient. For a complete high-resolution structure determination, particularly of larger and more complex RNAs and DNAs, ¹³C labeling, and often dual ¹³C/¹⁵N labeling, is indispensable. The continued development of novel selective labeling techniques and advanced NMR pulse sequences will undoubtedly push the boundaries of what is achievable, allowing for the study of ever more challenging and biologically significant nucleic acid systems.
References
- 1. Isotope labeling strategies for NMR studies of RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Use of 13C and 15N isotope labels for proton nuclear magnetic resonance and nuclear Overhauser effect. Structural and dynamic studies of larger proteins and nucleic acids - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. 15N labeling of oligodeoxynucleotides for NMR studies of DNA-ligand interactions - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Isotope Labels Combined with Solution NMR Spectroscopy Make Visible the Invisible Conformations of Small-to-Large RNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 5. academic.oup.com [academic.oup.com]
- 6. Preparation of 13C and 15N labelled RNAs for heteronuclear multi-dimensional NMR studies - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Nitrogen-15 nuclear magnetic resonance spectroscopy - Wikipedia [en.wikipedia.org]
- 8. Frontiers | An overview of methods using 13C for improved compound identification in metabolomics and natural products [frontiersin.org]
- 9. chem.libretexts.org [chem.libretexts.org]
- 10. Selective 13C labeling of nucleotides for large RNA NMR spectroscopy using an E. coli strain disabled in the TCA cycle - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Fermentation and Cost-Effective 13C/15N Labeling of the Nonribosomal Peptide Gramicidin S for Nuclear Magnetic Resonance Structure Analysis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. academic.oup.com [academic.oup.com]
- 14. researchgate.net [researchgate.net]
- 15. Synthesis and incorporation of 13C-labeled DNA building blocks to probe structural dynamics of DNA by NMR - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Efficient enzymatic synthesis of 13 C,15N-labeled DNA for NMR studies | Semantic Scholar [semanticscholar.org]
A Senior Scientist's Guide to Quantitative LC-MS Method Validation: The Indispensable Role of a Labeled Internal Standard
Introduction: The Quest for Unimpeachable Quantitative Data
In the landscape of drug discovery and development, the generation of precise and accurate quantitative data is not merely a goal; it is the bedrock upon which critical decisions are made. Liquid Chromatography coupled with Mass Spectrometry (LC-MS) stands as the preeminent analytical technique for this purpose, offering unparalleled sensitivity and selectivity for measuring drugs, metabolites, and biomarkers in complex biological matrices.[1][2][3] However, the journey from sample collection to final concentration value is fraught with potential variability. Every step—from sample preparation and extraction to chromatographic separation and ionization—introduces potential error.
To navigate this challenge and ensure the integrity of our results, we rely on a crucial methodological anchor: the internal standard (IS). This guide provides an in-depth comparison of internal standard strategies, making a data-driven case for the use of stable isotope-labeled internal standards (SIL-IS) and detailing the rigorous validation experiments that leverage their unique properties to build a self-validating, robust, and regulatory-compliant quantitative method.
The Gold Standard vs. The Alternative: Why a SIL-IS is the Superior Choice
The ideal internal standard should behave identically to the analyte of interest throughout the entire analytical process. Its sole purpose is to account for variability in sample processing and instrument response.[4][5] The choice of IS is therefore a critical experimental decision.
The Unmatched Fidelity of Stable Isotope Labeled Internal Standards (SIL-IS)
A SIL-IS is a version of the analyte molecule where one or more atoms have been replaced with their heavy stable isotopes (e.g., ²H/Deuterium, ¹³C, or ¹⁵N).[6][7] This subtle change in mass is detectable by the mass spectrometer but has a negligible effect on the compound's physicochemical properties.[7]
The Causality Behind the Choice: Because a SIL-IS is chemically and structurally almost identical to the analyte, it co-elutes chromatographically and experiences the same extraction recovery.[7] Most critically, it is affected by matrix-induced ionization suppression or enhancement in the MS source to virtually the same degree as the analyte.[6][7][8] This near-perfect tracking ensures that the ratio of the analyte peak area to the IS peak area remains constant, even if the absolute signal intensity fluctuates between injections. This ratio is the cornerstone of reliable quantitation.
The Compromise: Structural Analog Internal Standards
When a SIL-IS is unavailable or cost-prohibitive, scientists may turn to a structural analog—a different molecule that is chemically similar to the analyte.[4][5] While this approach is better than no internal standard, it is inherently a compromise.
The Inherent Limitations: A structural analog, by definition, is a different chemical entity. It will have different chromatographic retention times, different extraction efficiencies, and a different response to matrix effects.[5] While it may offer partial correction, it cannot provide the same level of confidence as a SIL-IS because it does not truly mirror the analyte's behavior.
Head-to-Head Comparison: A Data-Driven Verdict
Experimental data consistently demonstrates the superiority of SIL-IS in improving assay performance. In a published LC-MS/MS assay for the anticancer agent kahalalide F, a direct comparison was made between a structural analog IS and a SIL-IS.[4] The results clearly show that while the analog provided acceptable performance, the SIL-IS significantly reduced the variability of the measurements, thereby improving the precision and trustworthiness of the data.
Table 1: Performance Comparison of Internal Standards for Kahalalide F Assay [4]
| Performance Metric | Structural Analog IS | Stable Isotope Labeled (SIL) IS |
| Number of Samples (n) | 284 | 340 |
| Mean Bias (%) | 96.8 | 100.3 |
| Standard Deviation (%) | 8.6 | 7.6 |
| Statistical Significance (Variance) | - | p=0.02 (Significantly Lower) |
The data speaks for itself. The implementation of the SIL-IS resulted in a statistically significant improvement in assay precision, bringing the mean bias closer to the ideal 100% and tightening the data distribution.[4]
The Workflow: Integrating the SIL-IS for Robust Quantitation
The following diagram illustrates a typical bioanalytical workflow, highlighting the central role of the SIL-IS in ensuring data integrity from start to finish.
Caption: Workflow diagram illustrating the role of a SIL-IS.
Core Principles of Method Validation: A Self-Validating System
A full validation proves that the analytical method is fit for its intended purpose.[9][10][11] The use of a SIL-IS strengthens each validation parameter, creating a system where the integrity of the results is continuously verified. The following protocols are based on the principles outlined in the ICH M10, FDA, and EMA guidelines.[9][10][11][12]
Selectivity and Specificity
-
The "Why": This experiment proves that the method can distinguish and quantify the analyte from everything else in the sample, including endogenous matrix components, metabolites, and the SIL-IS itself.[3][13] Specificity is the ultimate goal, where the method is 100% selective for the analyte.[13][14]
-
Experimental Protocol:
-
Analyze at least six different lots of blank biological matrix (e.g., human plasma).
-
Check for any interfering peaks at the retention time of the analyte and the SIL-IS.
-
Analyze a blank matrix sample spiked only with the SIL-IS to confirm no analyte signal is present (and vice-versa).
-
Analyze a blank matrix sample spiked with the analyte at the Lower Limit of Quantitation (LLOQ) and the SIL-IS.
-
-
Acceptance Criteria: The response of any interfering peak in the blank matrix at the retention time of the analyte must be ≤ 20% of the analyte response at the LLOQ. The response of interference at the retention time of the SIL-IS must be ≤ 5% of the SIL-IS response.[12]
Linearity and Range
-
The "Why": This establishes the concentration range over which the method is accurate and precise. It defines the relationship between the peak area ratio (Analyte/IS) and the analyte concentration.[15][16]
-
Experimental Protocol:
-
Prepare a calibration curve consisting of a blank sample, a zero sample (matrix + IS), and at least six non-zero concentration standards spanning the expected range.
-
The concentration range is bracketed by the LLOQ and the Upper Limit of Quantitation (ULOQ).
-
Analyze the calibration curve and plot the peak area ratio (Analyte/IS) versus the nominal concentration of the analyte.
-
Apply a linear regression model, typically with a weighting factor (e.g., 1/x or 1/x²) to ensure accuracy at the low end of the curve.[17]
-
-
Acceptance Criteria: The back-calculated concentration for each standard should be within ±15% of the nominal value (±20% at the LLOQ).[12] The correlation coefficient (r²) should be ≥ 0.99.[16]
Accuracy and Precision
-
The "Why": This is the cornerstone of validation, demonstrating how close the measured values are to the true value (accuracy) and how reproducible the measurements are (precision).[15][18]
-
Experimental Protocol:
-
Prepare Quality Control (QC) samples in blank matrix at a minimum of four concentration levels: LLOQ, Low QC (≤ 3x LLOQ), Medium QC, and High QC (≥ 75% of ULOQ).
-
Analyze at least five replicates of each QC level against a calibration curve in at least three separate analytical runs.
-
Calculate the mean concentration, accuracy (% bias from nominal), and precision (% coefficient of variation, CV) for each level, both within each run (intra-run) and between all runs (inter-run).
-
-
Acceptance Criteria: The mean accuracy should be within ±15% of the nominal values (±20% at the LLOQ). The precision (%CV) should not exceed 15% (20% at the LLOQ).[12]
Matrix Effect
-
The "Why": This experiment directly assesses the impact of co-eluting matrix components on the ionization of the analyte.[8][19][20] A SIL-IS is critical here, as it is expected to experience the same matrix effect as the analyte, thus normalizing the result.[6]
-
Experimental Protocol:
-
Obtain at least six different lots of biological matrix.
-
Set A: Spike the analyte and SIL-IS into a neat solution (e.g., mobile phase) at low and high concentrations.
-
Set B: Extract blank matrix from each of the six lots, and then spike the analyte and SIL-IS into the post-extraction supernatant (post-extraction spike).
-
Calculate the Matrix Factor (MF) for the analyte and IS by dividing the peak area in Set B by the peak area in Set A.
-
Calculate the IS-normalized MF by dividing the analyte MF by the IS MF.
-
-
Acceptance Criteria: The CV of the IS-normalized MF across the different matrix lots should be ≤ 15%. This demonstrates that the SIL-IS adequately compensates for variability in the matrix effect between different sources.[12]
Stability
-
The "Why": Analyte stability is critical to ensure that the measured concentration reflects the true concentration at the time of sample collection.[21] Stability must be proven under all conditions the samples will experience.[22][23]
-
Experimental Protocol:
-
Using low and high QC samples, stability is assessed under various conditions:
-
Freeze-Thaw Stability: QC samples are subjected to at least three freeze-thaw cycles.
-
Bench-Top Stability: QC samples are kept at room temperature for a duration that mimics sample handling time.
-
Long-Term Stability: QC samples are stored at the intended storage temperature (e.g., -80°C) for a period equal to or longer than the time between sample collection and analysis.
-
Post-Preparative Stability: Processed extracts are stored in the autosampler to prove stability during the analytical run.
-
-
The stored QC samples are analyzed against a freshly prepared calibration curve.
-
-
Acceptance Criteria: The mean concentration of the stability QCs must be within ±15% of the nominal concentration.[12][22]
Logical Framework for Validation Parameters
The validation parameters are not independent; they form a logical hierarchy that builds confidence in the method's reliability.
Caption: Relationship between key validation parameters.
Expert Insights: Potential Pitfalls of SIL-IS
While SIL-IS are the gold standard, a senior scientist must be aware of their potential limitations. Trustworthiness comes from understanding and mitigating these risks.
-
Isotopic Crosstalk: If the mass difference between the analyte and SIL-IS is insufficient (ideally >4 Da), the isotopic peaks of the analyte may interfere with the SIL-IS signal, or vice-versa.[7] This must be checked during method development.
-
Deuterium Exchange: Deuterium atoms (²H) placed on or near exchangeable sites (like hydroxyl or amine groups) or on carbons adjacent to carbonyls can sometimes exchange with protons from the solvent, leading to a loss of the label.[24][25] Using ¹³C or ¹⁵N labels avoids this issue.[7][25]
-
Chromatographic Shift: High levels of deuteration can sometimes cause the SIL-IS to elute slightly earlier than the analyte due to the deuterium isotope effect.[5] If this shift is significant, the analyte and IS may experience different matrix effects, defeating the purpose of the SIL-IS.
-
Masking Analyte Instability: Because the SIL-IS degrades at the same rate as the analyte, it can sometimes mask stability problems. If both analyte and IS degrade by 50% during sample processing, the area ratio may remain correct, but the loss of sensitivity could be significant.[4][5] This is why absolute signal responses should always be monitored during routine analysis.
Conclusion
The validation of a quantitative LC-MS method is a systematic process designed to demonstrate its reliability and fitness for purpose. While regulatory guidelines provide the framework, true scientific integrity comes from understanding the causality behind each experimental choice. The use of a stable isotope-labeled internal standard is the single most effective decision a scientist can make to ensure the robustness and accuracy of their data. By perfectly tracking the analyte through every source of potential variability, the SIL-IS enables the creation of a truly self-validating system. This guide has provided the principles, protocols, and expert insights necessary to implement this gold-standard approach, ensuring that the data generated can be trusted to guide critical decisions in the advancement of medicine.
References
- 1. eijppr.com [eijppr.com]
- 2. alliedacademies.org [alliedacademies.org]
- 3. resolian.com [resolian.com]
- 4. scispace.com [scispace.com]
- 5. Stable isotopically labeled internal standards in quantitative bioanalysis using liquid chromatography/mass spectrometry: necessity or not? - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. crimsonpublishers.com [crimsonpublishers.com]
- 7. Internal Standards in LC−MS Bioanalysis: Which, When, and How - WuXi AppTec DMPK [dmpkservice.wuxiapptec.com]
- 8. bioanalysis-zone.com [bioanalysis-zone.com]
- 9. ema.europa.eu [ema.europa.eu]
- 10. Bioanalytical method validation - Scientific guideline | European Medicines Agency (EMA) [ema.europa.eu]
- 11. ICH M10 on bioanalytical method validation - Scientific guideline | European Medicines Agency (EMA) [ema.europa.eu]
- 12. fda.gov [fda.gov]
- 13. 2. Selectivity and identity confirmation – Validation of liquid chromatography mass spectrometry (LC-MS) methods [sisu.ut.ee]
- 14. chromatographytoday.com [chromatographytoday.com]
- 15. Bioanalytical method validation: An updated review - PMC [pmc.ncbi.nlm.nih.gov]
- 16. altabrisagroup.com [altabrisagroup.com]
- 17. Calibration and validation of linearity in chromatographic biopharmaceutical analysis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. mass-spec.stanford.edu [mass-spec.stanford.edu]
- 19. Assessment of matrix effect in quantitative LC-MS bioanalysis - PMC [pmc.ncbi.nlm.nih.gov]
- 20. nebiolab.com [nebiolab.com]
- 21. Stability: Recommendation for Best Practices and Harmonization from the Global Bioanalysis Consortium Harmonization Team - PMC [pmc.ncbi.nlm.nih.gov]
- 22. Stability Assessments in Bioanalytical Method Validation [celegence.com]
- 23. biopharmaservices.com [biopharmaservices.com]
- 24. Designing Stable Isotope Labeled Internal Standards - Acanthus Research [acanthusresearch.com]
- 25. hilarispublisher.com [hilarispublisher.com]
A Comparative Guide to 2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-¹³C,¹⁵N₂ and Other Labeled Internal Standards in Quantitative Bioanalysis
In the landscape of quantitative bioanalysis, particularly in drug development and clinical research, the pursuit of accuracy and precision is paramount. The use of liquid chromatography-mass spectrometry (LC-MS) has become the gold standard for its sensitivity and selectivity. However, the inherent variability in sample preparation and the notorious challenge of matrix effects can significantly compromise data integrity.[1][2] The judicious selection of an internal standard (IS) is therefore not merely a procedural step, but a cornerstone of a robust and reliable bioanalytical method.[3][4]
This guide provides an in-depth comparison of 2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-¹³C,¹⁵N₂ , a stable isotope-labeled internal standard (SIL-IS), with other commonly used labeled internal standards. We will delve into the mechanistic advantages of ¹³C and ¹⁵N labeling, present comparative data, and provide detailed experimental protocols for performance evaluation, empowering researchers to make informed decisions in their analytical endeavors.
The Critical Role of Internal Standards in LC-MS Bioanalysis
An internal standard is a compound of known concentration added to all samples, calibrators, and quality controls within an analytical run.[5] Its primary function is to normalize for variations that can occur at multiple stages of the analytical process, including:
-
Sample Preparation: Losses during extraction, evaporation, and reconstitution.[4]
-
Injection Volume: Inconsistencies in the autosampler.[5]
-
Matrix Effects: Ion suppression or enhancement caused by co-eluting components from the biological matrix.[1][2]
-
Instrumental Drift: Fluctuations in the mass spectrometer's response over time.[5]
By calculating the peak area ratio of the analyte to the internal standard, these variations can be effectively compensated for, leading to significantly improved accuracy and precision.[3]
The "Gold Standard": Stable Isotope-Labeled Internal Standards
The ideal internal standard co-elutes with the analyte and exhibits identical chemical and physical properties.[6] This ensures that it is affected by matrix effects and other sources of variability in the same way as the analyte. Stable isotope-labeled internal standards (SIL-ISs), where one or more atoms in the analyte molecule are replaced with their heavy stable isotopes (e.g., ¹³C, ¹⁵N, ²H), are the closest to this ideal.[7][8] The U.S. Food and Drug Administration (FDA) recommends the use of a stable isotope-labeled version of the analyte as the preferred choice for an internal standard in bioanalytical methods.[3][9]
2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-¹³C,¹⁵N₂: A Superior Choice
2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-¹³C,¹⁵N₂ is a SIL-IS designed for the accurate quantification of its corresponding unlabeled analyte or similar nucleoside analogs. The incorporation of both ¹³C and ¹⁵N isotopes offers distinct advantages over other labeling strategies, particularly deuteration.
Mechanistic Advantages of ¹³C and ¹⁵N Labeling
-
Chromatographic Co-elution: ¹³C and ¹⁵N are heavier isotopes of carbon and nitrogen, respectively. Their incorporation results in a negligible change in the physicochemical properties of the molecule.[10] This ensures that the labeled standard co-elutes perfectly with the unlabeled analyte, a critical factor for accurate matrix effect compensation.[7][11]
-
Isotopic Stability: The C-¹³C and N-¹⁵N bonds are chemically indistinguishable from their C-¹²C and N-¹⁴N counterparts, making the label exceptionally stable and eliminating the risk of isotopic exchange during sample processing and analysis.[10][11]
The Pitfalls of Deuterium Labeling: The "Isotope Effect"
Deuterated internal standards, while widely used due to their lower cost, can present a significant challenge known as the "isotope effect".[7][11] The difference in bond energy between C-H and C-D can lead to a slight change in the molecule's polarity and retention characteristics. This can result in a chromatographic shift, where the deuterated standard does not perfectly co-elute with the analyte.[11] If the analyte and the IS elute into regions with different degrees of ion suppression, the normalization will be inaccurate, leading to compromised data quality.[7]
Performance Comparison: ¹³C,¹⁵N-Labeled vs. Deuterated and Analog Internal Standards
Case Study 1: Quantification of Adenosine Monophosphate (AMP)
A comparison between ¹³C,¹⁵N-AMP and deuterated AMP as internal standards for AMP quantification highlights the key performance differences.[7]
| Parameter | ¹³C,¹⁵N-AMP | Deuterated AMP | Rationale |
| Chromatography | Co-elutes with native AMP | Potential for chromatographic shift | The isotope effect of deuterium can alter retention time.[7] |
| Matrix Effect | Superior compensation | Potentially incomplete compensation | Co-elution is crucial for accurate matrix effect correction.[7] |
| Isotopic Stability | Highly stable | Risk of D-H exchange | The label is less prone to exchange under analytical conditions.[11] |
| Accuracy & Precision | Higher | Potentially lower | Inaccurate normalization can lead to greater variability.[7] |
| Cost | Higher | Lower | Synthesis of ¹³C,¹⁵N-labeled compounds is more complex.[7] |
Case Study 2: Quantification of Tacrolimus
A study comparing a ¹³C,D₂-labeled tacrolimus (SIL-IS) with a structural analog internal standard (ascomycin) for tacrolimus quantification in whole blood demonstrated the superior performance of the SIL-IS.[12]
| Parameter | ¹³C,D₂-Tacrolimus (SIL-IS) | Ascomycin (Analog IS) |
| Accuracy (% Bias) | -1.2% to 2.5% | -8.5% to 9.1% |
| Precision (%CV) | 2.1% to 4.8% | 5.3% to 11.2% |
The data clearly shows that the SIL-IS provides significantly better accuracy and precision, which is attributed to its ability to more effectively track the analyte during sample preparation and analysis.[12]
Experimental Design for Internal Standard Performance Evaluation
To rigorously compare the performance of 2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-¹³C,¹⁵N₂ against other internal standards (e.g., a deuterated analog or a structural analog), a comprehensive validation study should be conducted in line with regulatory guidelines.[9][13]
Experimental Workflow
Caption: Workflow for evaluating and comparing internal standard performance.
Detailed Experimental Protocols
1. Preparation of Stock and Working Solutions:
-
Prepare individual stock solutions of the unlabeled analyte and each internal standard (2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-¹³C,¹⁵N₂, a deuterated version, and a structural analog) in a suitable organic solvent.
-
Prepare a series of working standard solutions for the analyte by serial dilution.
-
Prepare working solutions for each internal standard at a constant concentration.
2. Preparation of Calibration Standards and Quality Control (QC) Samples:
-
Spike the analyte working solutions into a blank biological matrix (e.g., human plasma) to prepare calibration standards at a minimum of six different concentration levels.
-
Prepare QC samples at a minimum of three concentration levels (low, medium, and high).
3. Sample Preparation (Example: Protein Precipitation):
-
To an aliquot of each sample (calibrator, QC, or unknown), add a fixed volume of the respective internal standard working solution.
-
Add a protein precipitation agent (e.g., ice-cold acetonitrile or methanol).
-
Vortex and centrifuge to pellet the precipitated proteins.
-
Transfer the supernatant to a clean tube for analysis.
4. LC-MS/MS Analysis:
-
Develop a chromatographic method that provides good peak shape and retention for the analyte.
-
Optimize the mass spectrometer parameters for the sensitive and specific detection of the analyte and each internal standard using multiple reaction monitoring (MRM).
-
Inject the prepared samples and acquire the data.
5. Data Analysis and Performance Assessment:
-
Accuracy and Precision: Analyze the QC samples in replicate over several days to determine the intra- and inter-day accuracy and precision for each internal standard. The acceptance criteria are typically within ±15% (±20% at the Lower Limit of Quantification, LLOQ) of the nominal concentration.[13]
-
Matrix Effect Assessment:
-
Objective: To determine if the biological matrix affects the ionization of the analyte and internal standard.
-
Procedure:
-
Prepare three sets of samples:
-
Set A: Analyte and IS in a neat solution.
-
Set B: Blank matrix extract spiked with analyte and IS.
-
Set C: Analyte and IS spiked into blank matrix before extraction.
-
-
Calculate the matrix factor (MF) for the analyte and IS: MF = (Peak area in Set B) / (Peak area in Set A).
-
Calculate the IS-normalized MF: (MF of analyte) / (MF of IS). The coefficient of variation (%CV) of the IS-normalized MF across at least six different matrix lots should be ≤15%.[9]
-
-
-
Recovery Assessment:
-
Objective: To evaluate the efficiency of the extraction procedure.
-
Procedure:
-
Calculate the recovery for the analyte and IS: Recovery (%) = (Peak area in Set C) / (Peak area in Set B) * 100.
-
The recovery should be consistent and reproducible across different concentration levels.
-
-
Logical Decision Framework for Internal Standard Selection
Caption: Decision logic for selecting an appropriate internal standard.
Conclusion and Recommendations
The choice of an internal standard is a critical decision in the development of a robust and reliable bioanalytical method. While various options exist, the scientific evidence strongly supports the use of stable isotope-labeled internal standards, with ¹³C and ¹⁵N labeling being the superior choice.
2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-¹³C,¹⁵N₂ represents the gold standard for the quantification of its unlabeled counterpart and related nucleoside analogs. Its key advantages include:
-
Optimal Accuracy and Precision: By perfectly co-eluting with the analyte, it provides the most accurate compensation for matrix effects and other analytical variabilities.
-
Enhanced Reliability: The chemical stability of the ¹³C and ¹⁵N labels ensures the integrity of the internal standard throughout the analytical process.
-
Regulatory Compliance: Its use aligns with the recommendations of regulatory agencies such as the FDA.[3][9]
For researchers and drug development professionals committed to the highest standards of data quality, the investment in a ¹³C,¹⁵N-labeled internal standard like 2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-¹³C,¹⁵N₂ is a scientifically sound decision that will enhance the robustness and reliability of their bioanalytical data.
References
- 1. FDA Adopts ICH Final Guidance On Bioanalytical Method Validation [outsourcedpharma.com]
- 2. eijppr.com [eijppr.com]
- 3. fda.gov [fda.gov]
- 4. Internal Standards in LC−MS Bioanalysis: Which, When, and How - WuXi AppTec DMPK [dmpkservice.wuxiapptec.com]
- 5. nebiolab.com [nebiolab.com]
- 6. benchchem.com [benchchem.com]
- 7. benchchem.com [benchchem.com]
- 8. scispace.com [scispace.com]
- 9. fda.gov [fda.gov]
- 10. ukisotope.com [ukisotope.com]
- 11. benchchem.com [benchchem.com]
- 12. benchchem.com [benchchem.com]
- 13. academy.gmp-compliance.org [academy.gmp-compliance.org]
A Senior Scientist's Guide to Protecting Groups in Uridine Synthesis: A Comparative Analysis
In the intricate world of nucleic acid chemistry, particularly in the synthesis of RNA fragments for therapeutic and research applications, the strategic use of protecting groups is paramount. For uridine, a fundamental component of RNA, the presence of multiple reactive hydroxyl groups and an imide nitrogen necessitates a robust and selective protection strategy. This guide provides an in-depth comparative analysis of the most common protecting groups employed in uridine synthesis, offering field-proven insights and experimental data to aid researchers in making informed decisions for their specific synthetic goals.
The Imperative of Selective Protection in Uridine Chemistry
The uridine molecule presents three key sites that require temporary masking during oligonucleotide synthesis: the 5'-primary hydroxyl, the 2'-secondary hydroxyl, and the N3-imide proton. The challenge lies in protecting and deprotecting these sites with high selectivity and efficiency, without compromising the integrity of the growing oligonucleotide chain. A successful strategy hinges on the principle of orthogonality , where each protecting group can be removed under specific conditions that do not affect the others.[1] This allows for a stepwise and controlled synthesis process.
Below is a diagram illustrating the key reactive sites on the uridine molecule that are the focus of protection strategies.
Caption: Key reactive sites on the uridine molecule requiring protection.
5'-Hydroxyl Protection: The Gatekeeper of Synthesis
The protection of the 5'-hydroxyl group is the inaugural step in nucleoside chemistry for solid-phase synthesis, as it dictates the 3' to 5' directionality of chain elongation.[2] The ideal protecting group for this position must be easily introduced, stable throughout the synthesis cycles, and quantitatively removed under mild conditions to allow for the subsequent coupling reaction.
The undisputed champion in this category is the 4,4'-dimethoxytrityl (DMT) group.[3] Its widespread adoption is due to its high affinity for the primary 5'-hydroxyl group, driven by steric accessibility.[4] Furthermore, its removal is conveniently achieved with a mild acid treatment, which releases a bright orange-colored DMT cation, providing a real-time spectrophotometric method to monitor the coupling efficiency of each cycle.[3][5]
Comparative Analysis of 5'-Hydroxyl Protecting Groups
| Protecting Group | Abbreviation | Reagents for Application | Deprotection Conditions | Key Advantages | Key Disadvantages |
| 4,4'-Dimethoxytrityl | DMT | DMT-Cl, Pyridine | Mild acid (e.g., 3% Trichloroacetic acid in Dichloromethane)[5][6] | High 5'-selectivity, Acid lability allows for easy removal, Orange cation allows for yield monitoring[3][5] | Can be sensitive to strongly acidic conditions required for some other deprotections. |
| 4-Monomethoxytrityl | MMT | MMT-Cl, Pyridine | Stronger acid than DMT | More acid-stable than DMT, useful in specific multi-step syntheses. | Slower deprotection kinetics, not typically used in standard automated synthesis. |
2'-Hydroxyl Protection: The Cornerstone of RNA Synthesis
The presence of the 2'-hydroxyl group distinguishes RNA from DNA and introduces a significant synthetic challenge. This group must be protected to prevent unwanted side reactions, such as chain cleavage and isomerization, during phosphoramidite coupling.[7] The choice of the 2'-hydroxyl protecting group is arguably the most critical decision in RNA synthesis, directly impacting coupling efficiency, synthesis time, and the purity of the final product.[8]
The two most prevalent protecting groups for the 2'-hydroxyl position are tert-butyldimethylsilyl (TBDMS) and [(triisopropylsilyl)oxy]methyl (TOM).[8][9] Both are silyl ethers, which are stable to the acidic and basic conditions of the synthesis cycle and are selectively removed by a fluoride source.[6][10]
Comparative Analysis of 2'-Hydroxyl Protecting Groups
| Protecting Group | Abbreviation | Typical Coupling Time | Average Coupling Efficiency | Deprotection Conditions | Key Advantages | Key Disadvantages |
| tert-Butyldimethylsilyl | TBDMS | Up to 6 minutes[8] | 98.5–99%[8] | Fluoride source (e.g., TBAF, TEA·3HF)[6][11] | Well-established, cost-effective. | Steric bulk can lower coupling efficiency, especially for longer RNA strands.[8] |
| [(Triisopropylsilyl)oxy]methyl | TOM | ~2.5 minutes[8][12] | >99%[8] | Fluoride source (e.g., TBAF)[12] | Higher coupling efficiency and shorter coupling times due to reduced steric hindrance, prevents 2'-3' silyl migration.[8][13][14] | Higher cost of phosphoramidite building blocks. |
The superior performance of the TOM group, particularly for the synthesis of long RNA oligonucleotides, is attributed to its oxymethyl spacer, which distances the bulky triisopropylsilyl group from the reaction center, thereby minimizing steric hindrance.[8][13]
N3-Imide Protection: Ensuring Nucleobase Integrity
While the imide proton of uridine is less reactive than the hydroxyl groups, its protection is often necessary to prevent side reactions during phosphitylation and coupling, especially when using more reactive reagents. Acyl groups are the most common choice for protecting the N3 position.[15]
Comparative Analysis of N3-Imide Protecting Groups
| Protecting Group | Abbreviation | Reagents for Application | Deprotection Conditions | Key Advantages | Key Disadvantages |
| Benzoyl | Bz | Benzoyl chloride, Pyridine | Concentrated ammonia or methylamine at elevated temperatures[16] | Robust, stable to a wide range of synthetic conditions. | Harsh deprotection conditions can be detrimental to sensitive modifications on the RNA strand. |
| Phenoxyacetyl | Pac | Phenoxyacetic anhydride | Milder basic conditions (e.g., ammonia at room temperature)[17][18] | Rapid and mild deprotection, compatible with sensitive oligonucleotides.[17][18] | Can be less stable than benzoyl under certain conditions. |
The choice between these groups often depends on the overall synthetic strategy and the presence of other sensitive functional groups in the target oligonucleotide. For complex RNA molecules with delicate modifications, the milder deprotection conditions afforded by the Pac group are highly advantageous.[17]
Orthogonal Deprotection Workflow
A well-designed synthesis relies on an orthogonal protection scheme where each group can be removed sequentially without affecting the others. The standard workflow for uridine synthesis and subsequent deprotection is illustrated below.
Caption: A standard orthogonal deprotection workflow for uridine.
Experimental Protocols
The following are representative, high-level protocols for the application and removal of the most common protecting groups for uridine.
Protocol 1: 5'-O-DMT Protection of Uridine
-
Dissolution: Dissolve uridine in anhydrous pyridine.
-
Reaction: Add 4,4'-dimethoxytrityl chloride (DMT-Cl) in a slight excess (e.g., 1.1 equivalents) portion-wise at 0°C.
-
Monitoring: Allow the reaction to warm to room temperature and stir until completion, monitoring by Thin Layer Chromatography (TLC).
-
Quenching: Quench the reaction by adding methanol.
-
Work-up and Purification: Evaporate the solvent and purify the resulting residue by silica gel column chromatography to yield 5'-O-DMT-uridine.
Protocol 2: 2'-O-TBDMS Protection of 5'-O-DMT-Uridine
-
Co-evaporation: Co-evaporate 5'-O-DMT-uridine with anhydrous pyridine to remove residual water.
-
Reaction Mixture: Dissolve the dried starting material in anhydrous pyridine and add silver nitrate (AgNO₃).
-
Silylation: Add tert-butyldimethylsilyl chloride (TBDMS-Cl) and stir the reaction at room temperature in the dark.
-
Monitoring: Monitor the reaction progress by TLC.
-
Work-up and Purification: Filter the reaction mixture, quench with a dichloromethane/saturated sodium bicarbonate solution, and purify by silica gel chromatography.
Protocol 3: Deprotection of a Fully Protected Uridine Monomer
-
Base and Phosphate Deprotection: The oligonucleotide, still on its solid support, is treated with a solution of concentrated ammonium hydroxide or a mixture of methylamine and ammonium hydroxide to cleave the acyl protecting groups from the nucleobase and the cyanoethyl groups from the phosphate backbone, as well as to release the oligonucleotide from the support.[6]
-
2'-Hydroxyl Deprotection: After removal of the base/phosphate protecting groups, the resulting solution is treated with a fluoride source, such as 1M tetrabutylammonium fluoride (TBAF) in tetrahydrofuran (THF) or triethylamine trihydrofluoride (TEA·3HF), to remove the 2'-TBDMS or 2'-TOM groups.[6] This reaction is typically heated to 65°C for a specific duration.[6]
-
5'-Hydroxyl Deprotection: The DMT group is typically removed during each cycle of solid-phase synthesis using a mild acid. If the final oligonucleotide is purified with the "DMT-on" strategy, the DMT group is removed post-purification with an aqueous acid solution (e.g., 80% acetic acid).[5]
Conclusion and Future Outlook
The selection of a protecting group strategy is a critical determinant of success in uridine synthesis. For the 5'-position, the DMT group remains the industry standard due to its reliability and the convenient monitoring it offers. At the N3-position, the choice between benzoyl and phenoxyacetyl depends on the desired balance between stability and the mildness of deprotection conditions.
The most significant advancements and points of comparison lie in the protection of the 2'-hydroxyl group. While TBDMS is a cost-effective and well-established option, the TOM group offers clear advantages in terms of coupling efficiency and speed, making it the preferred choice for the synthesis of long and complex RNA molecules.[8][14]
Future research will likely focus on the development of novel protecting groups that offer even greater efficiency, stability, and milder deprotection conditions, further streamlining the synthesis of RNA for the ever-expanding landscape of RNA-based therapeutics and diagnostics.
References
- 1. chemweb.bham.ac.uk [chemweb.bham.ac.uk]
- 2. Oligonucleotide synthesis - Wikipedia [en.wikipedia.org]
- 3. Dimethoxytrityl - Wikipedia [en.wikipedia.org]
- 4. researchgate.net [researchgate.net]
- 5. documents.thermofisher.com [documents.thermofisher.com]
- 6. benchchem.com [benchchem.com]
- 7. glenresearch.com [glenresearch.com]
- 8. benchchem.com [benchchem.com]
- 9. Synthesis of Nucleobase-Modified RNA Oligonucleotides by Post-Synthetic Approach - PMC [pmc.ncbi.nlm.nih.gov]
- 10. 2'-Hydroxyl-protecting groups that are either photochemically labile or sensitive to fluoride ions - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. Cleavage / Deprotection Reagents | Nucleic Acid Chemistry | [Synthesis & Materials] | Laboratory Chemicals-FUJIFILM Wako Pure Chemical Corporation [labchem-wako.fujifilm.com]
- 12. deepblue.lib.umich.edu [deepblue.lib.umich.edu]
- 13. atdbio.com [atdbio.com]
- 14. glenresearch.com [glenresearch.com]
- 15. Protecting group - Wikipedia [en.wikipedia.org]
- 16. chem.libretexts.org [chem.libretexts.org]
- 17. The final deprotection step in oligonucleotide synthesis is reduced to a mild and rapid ammonia treatment by using labile base-protecting groups - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. The final deprotection step in oligonucleotide synthesis is reduced to a mild and rapid ammonia treatment by using labile base-protecting groups - PMC [pmc.ncbi.nlm.nih.gov]
The Analytical Imperative: A Guide to Cross-Validation of Experimental Results
In the landscape of drug discovery and development, the reliability of experimental data is paramount. Decisions that impact project timelines, resource allocation, and ultimately, patient safety, are built upon the foundation of accurate and reproducible analytical results. However, reliance on a single analytical technique, no matter how robust, can introduce unforeseen biases and leave critical questions unanswered. This guide provides a comprehensive framework for the cross-validation of experimental findings using different analytical techniques, a practice essential for ensuring the scientific integrity of your work.
The Principle of Orthogonality: A Foundation of Trust
At the core of cross-validation is the principle of orthogonality. Orthogonal analytical methods are techniques that measure the same critical quality attribute (CQA) but utilize fundamentally different principles of detection or quantification.[1][2] This approach is a cornerstone of robust analytical data packages and is strongly encouraged by regulatory bodies such as the FDA and EMA.[1] By employing orthogonal methods, we create a self-validating system that significantly increases confidence in the generated data, helping to eliminate false positives and confirm the activity identified in primary assays.[1][2]
The power of this approach lies in its ability to mitigate the inherent limitations and potential biases of any single technique.[3] For instance, one method might be susceptible to interference from a specific matrix component, while an orthogonal method is not. If both techniques yield concordant results, it provides strong evidence for the accuracy of the findings. Conversely, discordant results can be equally valuable, highlighting potential issues with one or both methods and prompting further investigation.
A Visual Workflow for Cross-Validation
Caption: A generalized workflow for the cross-validation of experimental results.
Case Study: Characterizing a Therapeutic Monoclonal Antibody
To illustrate the practical application of cross-validation, let's consider a hypothetical case study involving the characterization of a newly developed therapeutic monoclonal antibody (mAb), "MabX," which targets the Epidermal Growth Factor Receptor (EGFR). A critical quality attribute for MabX is its binding affinity to the EGFR extracellular domain. In this scenario, we will use two orthogonal techniques to determine the equilibrium dissociation constant (KD): Enzyme-Linked Immunosorbent Assay (ELISA) and Surface Plasmon Resonance (SPR).
The EGFR Signaling Pathway: A Therapeutic Target
The EGFR signaling pathway plays a crucial role in regulating cell proliferation, differentiation, and survival.[4][5][6] Dysregulation of this pathway is a hallmark of many cancers, making it a prime target for therapeutic intervention.[5][6] MabX is designed to bind to EGFR and block the downstream signaling cascade.
Caption: Simplified EGFR signaling pathway and the inhibitory action of MabX.
Orthogonal Techniques for Measuring Binding Affinity
1. Enzyme-Linked Immunosorbent Assay (ELISA): This is a plate-based immunoassay that measures the binding of MabX to immobilized EGFR. The detection is indirect, relying on an enzyme-conjugated secondary antibody that generates a colorimetric signal proportional to the amount of bound MabX.[7]
2. Surface Plasmon Resonance (SPR): SPR is a label-free technique that measures binding events in real-time by detecting changes in the refractive index at the surface of a sensor chip.[8][9] In this case, EGFR is immobilized on the chip, and the binding of MabX is monitored as it flows over the surface. This allows for the determination of both association (ka) and dissociation (kd) rates, from which the KD can be calculated (KD = kd/ka).[2]
Experimental Data and Comparison
The following table summarizes the hypothetical data obtained from both ELISA and SPR experiments for two different lots of MabX.
| Analytical Technique | MabX Lot | Parameter | Result |
| ELISA | Lot A | KD (nM) | 1.2 |
| Lot B | KD (nM) | 1.5 | |
| SPR | Lot A | KD (nM) | 0.9 |
| ka (1/Ms) | 2.1 x 105 | ||
| kd (1/s) | 1.9 x 10-4 | ||
| Lot B | KD (nM) | 1.1 | |
| ka (1/Ms) | 1.8 x 105 | ||
| kd (1/s) | 2.0 x 10-4 |
The results show a good correlation between the two orthogonal methods. While there is a slight difference in the absolute KD values, which can be expected due to the different principles of the assays, both techniques consistently demonstrate that MabX binds to EGFR with high affinity (in the low nanomolar to sub-nanomolar range).[2][10][11] The SPR data further provides valuable kinetic information, showing that the high affinity is driven by a slow dissociation rate. This cross-validation provides a high degree of confidence in the binding characteristics of MabX.
Experimental Protocols
Sandwich ELISA for KD Determination
1. Coating:
-
Dilute recombinant human EGFR to 2 µg/mL in PBS.
-
Add 100 µL per well to a 96-well high-binding ELISA plate.[12]
-
Incubate overnight at 4°C.[12]
-
Wash the plate three times with wash buffer (PBS with 0.05% Tween-20).
2. Blocking:
-
Add 200 µL of blocking buffer (PBS with 1% BSA) to each well.[7]
-
Incubate for 1-2 hours at room temperature.[7]
-
Wash the plate three times with wash buffer.
3. Sample Incubation:
-
Prepare a serial dilution of MabX in blocking buffer.
-
Add 100 µL of each dilution to the appropriate wells.
-
Incubate for 2 hours at room temperature.[12]
-
Wash the plate three times with wash buffer.
4. Detection:
-
Add 100 µL of HRP-conjugated anti-human IgG secondary antibody, diluted in blocking buffer, to each well.
-
Incubate for 1 hour at room temperature.
-
Wash the plate five times with wash buffer.
-
Add 100 µL of TMB substrate and incubate in the dark until sufficient color develops.
-
Stop the reaction with 50 µL of 1M H2SO4.
-
Read the absorbance at 450 nm.
5. Data Analysis:
-
Plot the absorbance values against the concentration of MabX and fit the data to a one-site binding model to determine the KD.
Surface Plasmon Resonance (SPR) for Binding Kinetics
1. Chip Preparation and Ligand Immobilization:
-
Activate a CM5 sensor chip with a 1:1 mixture of 0.4 M EDC and 0.1 M NHS.[13]
-
Inject recombinant human EGFR (diluted in 10 mM sodium acetate, pH 4.5) over the activated surface to achieve the desired immobilization level.
-
Deactivate any remaining active esters with an injection of 1 M ethanolamine-HCl, pH 8.5.[13]
2. Analyte Binding:
-
Prepare a series of dilutions of MabX in running buffer (e.g., HBS-EP+).
-
Inject the MabX dilutions over the EGFR-immobilized surface at a constant flow rate.
-
Monitor the association phase in real-time.
3. Dissociation:
-
After the association phase, switch back to running buffer and monitor the dissociation of MabX from the EGFR surface.
4. Regeneration:
-
If necessary, inject a regeneration solution (e.g., 10 mM glycine-HCl, pH 1.5) to remove any remaining bound MabX.[9]
5. Data Analysis:
-
Fit the association and dissociation curves to a 1:1 binding model to determine the ka, kd, and KD.
Orthogonal Approaches for Measuring EGFR Pathway Activation
To further validate the inhibitory effect of MabX on EGFR signaling, two orthogonal assays can be employed to measure the phosphorylation of a key downstream effector, ERK.
1. Western Blotting: This technique separates proteins by size using gel electrophoresis, transfers them to a membrane, and detects specific proteins using antibodies. In this case, cell lysates from MabX-treated and untreated cells would be probed with antibodies specific for both total ERK and phosphorylated ERK (p-ERK). The ratio of p-ERK to total ERK provides a semi-quantitative measure of ERK activation.
2. In-Cell ELISA: This method allows for the quantification of intracellular proteins in a 96-well plate format. Cells are cultured and treated with MabX in the plate, then fixed and permeabilized. Primary antibodies against total ERK and p-ERK are added, followed by detection with enzyme-conjugated secondary antibodies and a colorimetric substrate. This provides a quantitative measure of ERK phosphorylation.
The cross-validation of results from these two distinct methods would provide strong evidence for the efficacy of MabX in inhibiting EGFR signaling.
Conclusion
The cross-validation of experimental results using orthogonal analytical techniques is not merely a confirmatory exercise; it is a fundamental component of rigorous scientific inquiry. By embracing this approach, researchers and drug development professionals can build a more complete and reliable understanding of their molecules of interest, leading to more informed decision-making and ultimately, the development of safer and more effective therapeutics. The investment in performing these comparative studies pays significant dividends in the form of increased data integrity and confidence in the path forward.
References
- 1. chromatographyonline.com [chromatographyonline.com]
- 2. rapidnovor.com [rapidnovor.com]
- 3. UWPR [proteomicsresource.washington.edu]
- 4. promega.com [promega.com]
- 5. creative-diagnostics.com [creative-diagnostics.com]
- 6. lifesciences.danaher.com [lifesciences.danaher.com]
- 7. ELISA: The Complete Guide | Antibodies.com [antibodies.com]
- 8. Binding kinetics of DNA-protein interaction using surface plasmon resonance [protocols.io]
- 9. nicoyalife.com [nicoyalife.com]
- 10. researchgate.net [researchgate.net]
- 11. Comparison of the results obtained by ELISA and surface plasmon resonance for the determination of antibody affinity - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. mabtech.com [mabtech.com]
- 13. bio-protocol.org [bio-protocol.org]
A Senior Application Scientist's Guide to Quantitative Proteomics: Isotopic Labeling vs. Label-Free Methods
For researchers, scientists, and drug development professionals navigating the complex landscape of quantitative proteomics, the choice between isotopic labeling and label-free methods is a critical decision that profoundly impacts experimental outcomes. This guide provides an in-depth, objective comparison of these two major quantitative strategies. Moving beyond a simple list of pros and cons, we will delve into the causality behind experimental choices, present supporting data, and offer field-proven insights to empower you to select the optimal approach for your research goals.
The Fundamental Choice in Quantitative Proteomics
Quantitative proteomics aims to determine the relative or absolute amount of proteins in a sample.[1] This is essential in drug discovery for identifying and validating drug targets, understanding disease mechanisms, and discovering biomarkers for diagnosis and treatment.[2][3] The core challenge lies in accurately measuring and comparing protein abundance across different samples, a task complicated by the inherent variability of mass spectrometry (MS) techniques.[4][5] To address this, two primary strategies have emerged: introducing stable isotope labels to facilitate direct comparison within a single MS analysis, or forgoing labels and relying on sophisticated data analysis to compare separate analyses.[6]
The decision between these approaches is not trivial and depends on the specific biological question, sample type, available resources, and desired level of quantitative precision. This guide will dissect the principles, workflows, and performance of each, providing a clear framework for making an informed choice.
Isotopic Labeling: Precision Through Controlled Comparison
Isotopic labeling methods introduce a "mass tag" to proteins or peptides, creating a known mass difference between samples.[1] This allows for the mixing of samples at an early stage, minimizing downstream experimental variability as the differentially labeled peptides are chemically identical and co-elute during chromatography.[7] Quantification is then based on the relative signal intensities of the heavy and light peptide pairs in the mass spectrometer.
Key Isotopic Labeling Techniques
There are two main categories of isotopic labeling: metabolic labeling and chemical labeling.
-
Metabolic Labeling (SILAC): Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) is an in vivo labeling method where cells are grown in media containing either normal ("light") or heavy isotope-labeled essential amino acids (e.g., ¹³C₆-Lysine, ¹³C₆¹⁵N₄-Arginine).[7] Over several cell divisions, the heavy amino acids are incorporated into the entire proteome.[8] This method is considered a gold standard for quantitative accuracy because samples can be mixed at the very beginning of the workflow, even before cell lysis, thereby accounting for nearly all procedural variance.[7]
-
Chemical Labeling (TMT and iTRAQ): Tandem Mass Tags (TMT) and isobaric Tags for Relative and Absolute Quantitation (iTRAQ) are in vitro methods that use chemical reagents to tag peptides at the N-terminus and lysine residues after protein extraction and digestion.[9] These tags are isobaric, meaning they have the same total mass and co-elute as a single precursor ion in the first stage of mass spectrometry (MS1).[10] Upon fragmentation (MS2 or MS3), reporter ions with different masses are generated, and the intensity of these reporter ions is used for quantification.[10] A key advantage of TMT and iTRAQ is their multiplexing capability, allowing for the simultaneous comparison of up to 18 samples in a single experiment.[9]
Isotopic Labeling Workflow
The following diagram illustrates a generalized workflow for isotopic labeling, highlighting the key stages for both metabolic (SILAC) and chemical (TMT/iTRAQ) labeling.
Figure 1: Generalized workflows for isotopic labeling quantitative proteomics.
Experimental Protocol: TMT Labeling
This protocol provides a detailed methodology for TMT-based quantitative proteomics.
-
Protein Extraction and Digestion:
-
Lyse cell pellets or tissues in a suitable buffer (e.g., 8M urea in 50 mM TEAB) containing protease and phosphatase inhibitors.
-
Determine protein concentration using a compatible assay (e.g., BCA).
-
Take equal amounts of protein (typically 25-100 µg) from each sample.
-
Reduce disulfide bonds with 10 mM DTT at 37°C for 1 hour.
-
Alkylate cysteine residues with 20 mM iodoacetamide in the dark at room temperature for 30 minutes.
-
Dilute the urea concentration to <2M with 50 mM TEAB.
-
Digest with trypsin (1:50 enzyme:protein ratio) overnight at 37°C.[11]
-
-
Peptide Desalting and Quantification:
-
Acidify the peptide solution with trifluoroacetic acid (TFA) to a final concentration of 0.1%.
-
Desalt the peptides using a C18 SPE column.[12]
-
Dry the purified peptides using a vacuum centrifuge.
-
Reconstitute a small aliquot of peptides and quantify using a colorimetric peptide assay.
-
-
TMT Labeling:
-
Reconstitute the dried peptides in 100 µL of 100 mM TEAB, pH 8.5.
-
Equilibrate the TMT reagent vials to room temperature.
-
Add anhydrous acetonitrile to each TMT reagent vial and vortex to dissolve.
-
Add the appropriate TMT reagent to each peptide sample and incubate for 1 hour at room temperature.[11]
-
Quench the reaction by adding 5% hydroxylamine and incubating for 15 minutes.[13]
-
-
Sample Pooling and Fractionation:
-
Combine equal amounts of each TMT-labeled sample into a new tube.
-
Desalt the pooled sample using a C18 SPE column and dry completely.
-
Fractionate the peptides using high pH reversed-phase HPLC to reduce sample complexity and improve proteome coverage.[12]
-
Dry the fractions and store at -80°C until LC-MS/MS analysis.
-
-
LC-MS/MS Analysis and Data Processing:
-
Reconstitute peptide fractions in a buffer suitable for LC-MS/MS (e.g., 0.1% formic acid).
-
Analyze samples on a high-resolution Orbitrap mass spectrometer.[10]
-
For TMT, it is highly recommended to use an MS3-based acquisition method to minimize co-isolation interference and ratio compression.[9]
-
Process the raw data using software such as Proteome Discoverer.[14] This involves peptide identification, reporter ion quantification, and statistical analysis.
-
Label-Free Methods: Simplicity and Scale
Label-free quantification (LFQ) determines relative protein abundance by comparing features from separate LC-MS/MS analyses.[1] This approach avoids the cost and potential experimental artifacts of labeling reagents. Its primary advantage lies in its simplicity and scalability, making it suitable for large-scale studies with many samples.[6]
Key Label-Free Techniques
Two main computational approaches are used for label-free quantification:
-
Spectral Counting: This method estimates protein abundance by counting the number of MS/MS spectra identified for a given protein.[1] More abundant proteins will generate more peptide ions, leading to a higher number of fragmentation spectra. While simple to implement, its dynamic range can be limited.[15]
-
Intensity-Based Quantification: This approach measures the area under the curve (AUC) of the peptide precursor ion's chromatographic peak in the MS1 scan.[1] This method generally offers a wider dynamic range and better quantitative accuracy than spectral counting.[15] Sophisticated algorithms are required to align retention times and normalize signal intensities across different runs to ensure accurate comparisons.[16]
Label-Free Workflow
The workflow for label-free proteomics is more linear than labeling methods, but places a heavy emphasis on the reproducibility of each step.
Figure 2: Generalized workflow for label-free quantitative proteomics.
Experimental Protocol: Label-Free (Intensity-Based)
This protocol outlines a standard procedure for intensity-based label-free quantification.
-
Sample Preparation (Perform identically for each sample):
-
Follow the same steps for protein extraction, quantification, reduction, alkylation, and digestion as described in the TMT protocol (Section 2.3, Step 1). Consistency is paramount.
-
After digestion, desalt each sample individually using C18 SPE columns.
-
Dry the peptides and reconstitute them in a standardized volume of LC-MS/MS loading buffer.
-
-
LC-MS/MS Analysis:
-
Analyze each sample via a separate LC-MS/MS run. It is crucial to use the same LC gradient, column, and MS parameters for all samples.[17]
-
To minimize batch effects, randomize the injection order of the samples.[5]
-
Include periodic runs of a quality control (QC) sample (e.g., a pooled mixture of all experimental samples) to monitor instrument performance and aid in data normalization.
-
-
Data Analysis:
-
Process the raw data using a specialized software package such as MaxQuant.[15]
-
Key steps in the software include:
-
Peak Detection and Feature Finding: Identifying peptide ions based on their m/z, retention time, and intensity.
-
Retention Time Alignment: Correcting for small shifts in elution time between runs.[16]
-
"Match Between Runs": A feature in MaxQuant that can identify peptides in a run even if they were not selected for MS/MS, based on their accurate mass and aligned retention time from another run. This significantly reduces missing values.[18]
-
Protein Identification: Searching the MS/MS spectra against a protein database.
-
Quantification: Calculating the Label-Free Quantification (LFQ) intensity for each protein, which is a normalized intensity value based on the summed peptide peak areas.[19]
-
Statistical Analysis: Performing t-tests or ANOVA to identify statistically significant changes in protein abundance between experimental groups.
-
-
Head-to-Head Comparison: Performance and Key Metrics
The choice between isotopic labeling and label-free methods often comes down to a trade-off between several key performance metrics. A systematic comparison study provides valuable data for this decision.[20]
| Feature | Isotopic Labeling (SILAC/TMT) | Label-Free Quantification (LFQ) | Rationale & Causality |
| Quantitative Precision | High (CVs often <15%) | Moderate to Low (CVs can be >30%) | Labeling methods mix samples early, minimizing process-induced variation. LFQ precision is highly dependent on the reproducibility of sample prep and LC-MS performance.[5][20] |
| Quantitative Accuracy | High (SILAC is gold standard) | Moderate | SILAC's in vivo labeling and early mixing makes it highly accurate. TMT accuracy can be compromised by ratio compression, though MS3 methods mitigate this.[9] LFQ accuracy depends on linear instrument response and robust normalization. |
| Proteome Coverage | Moderate to High | Highest | LFQ typically identifies more proteins because the sample complexity is not increased by isotopic labels, and there are no labeling efficiency issues.[21] |
| Throughput & Scalability | Moderate (TMT > SILAC) | High | LFQ is ideal for large cohorts as there's no limit on sample numbers. TMT multiplexing (up to 18-plex) offers good throughput, while SILAC is typically limited to 2-3 samples per run.[6][9] |
| Cost | High | Low | Isotopic labels, especially TMT reagents, are expensive. LFQ avoids these costs, making it more accessible.[21] |
| Sample Type | Limited (SILAC for culturable cells) | Universal | LFQ can be applied to virtually any sample type, including clinical tissues and biofluids. SILAC is restricted to metabolically active cells. TMT can be used on most samples.[7] |
| Data Analysis Complexity | Moderate | High | LFQ data analysis is computationally intensive, requiring sophisticated algorithms for alignment, normalization, and handling of missing values.[4] |
| Handling Missing Values | Low | High | In labeling, if a peptide is identified, it is quantified in all channels. In LFQ, a peptide may be detected in one run but not another (stochastic sampling), leading to missing values.[22] |
Common Pitfalls and Troubleshooting
Isotopic Labeling:
-
Incomplete Labeling (SILAC): Ensure cells undergo at least 5-6 doublings in SILAC media. Test for complete incorporation (>97%) with a small-scale pilot experiment before proceeding. Arginine-to-proline conversion can also be an issue in some cell lines.[14]
-
Ratio Compression (TMT): Co-isolation of a target peptide with other contaminating ions can lead to reporter ion signals from both, compressing the observed fold-changes. Using an MS3-based acquisition method on an Orbitrap Tribrid instrument is the most effective solution to this problem.[9][19]
-
Labeling Efficiency (TMT): Ensure the pH of the reaction buffer is optimal (around 8.5) and use an adequate reagent-to-peptide ratio.[10]
Label-Free:
-
Reproducibility: This is the primary challenge. Standardize every step of the sample preparation and LC-MS analysis. Use a randomized sample injection order and include QC samples to monitor and correct for batch effects.[5]
-
Missing Values: Use the "Match Between Runs" feature in software like MaxQuant. For remaining missing values, appropriate statistical imputation methods may be necessary, but should be used with caution.
-
Dynamic Range: The vast dynamic range of proteins in some samples (e.g., plasma) can lead to the undersampling of low-abundance proteins. Depletion of high-abundance proteins or extensive fractionation can help, but must be done reproducibly.[15]
Guiding the Decision: Which Method for Your Application?
The optimal choice of quantitative strategy is dictated by the research question.
Figure 3: Decision-making framework for selecting a quantitative proteomics strategy.
-
For large-scale biomarker discovery in clinical samples (e.g., plasma, tissue biopsies): Label-free quantification is often the method of choice due to its unlimited sample number capacity, lower cost, and ability to handle diverse sample types.[6] The lower precision can be compensated for by increasing the number of biological replicates.
-
For detailed mechanistic studies of signaling pathways or drug mechanism of action in cell culture models: SILAC provides the highest quantitative accuracy and precision, making it ideal for detecting subtle changes in protein expression or post-translational modifications.[20]
-
For studies with a moderate number of samples (e.g., 4-18) from various sources (cells, tissues, etc.) requiring high precision: TMT labeling offers a powerful solution, combining high precision with excellent multiplexing capabilities. It is particularly well-suited for preclinical drug development studies comparing multiple doses or time points.[9]
Conclusion
Both isotopic labeling and label-free strategies are powerful tools for quantitative proteomics, each with a distinct set of strengths and weaknesses. The "best" method is entirely context-dependent. Isotopic labeling, particularly SILAC, offers unparalleled precision and accuracy by minimizing experimental variability. Chemical labeling with TMT provides a high-throughput, precise option for a moderate number of diverse samples. Label-free quantification excels in its simplicity, cost-effectiveness, and scalability, making it the go-to for large-scale discovery projects.
As a senior application scientist, my final recommendation is to ground your decision in the specific demands of your biological question. Understand the trade-offs in precision, depth, cost, and throughput. By carefully considering the principles and practicalities outlined in this guide, you can design robust, well-controlled experiments that yield high-quality, reproducible data, ultimately accelerating your research and development efforts.
References
- 1. Mass Spectrometry for Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 2. japsonline.com [japsonline.com]
- 3. selectscience.net [selectscience.net]
- 4. How to Overcoming Reproducibility Issues in Label-Free Proteomics? | MtoZ Biolabs [mtoz-biolabs.com]
- 5. How to Improve Data Quality and Reproducibility in Label-Free Proteomics? | MtoZ Biolabs [mtoz-biolabs.com]
- 6. Experimental Programs for SILAC in Protein Interaction - Creative Proteomics Blog [creative-proteomics.com]
- 7. SILAC: Principles, Workflow & Applications in Proteomics - Creative Proteomics Blog [creative-proteomics.com]
- 8. researchgate.net [researchgate.net]
- 9. Advantages and Disadvantages of TMT-based Quantitative Proteomics | MtoZ Biolabs [mtoz-biolabs.com]
- 10. TMT Labeling for Optimized Sample Preparation in Quantitative Proteomics - Aragen Life Sciences [aragen.com]
- 11. BAF_Protocol_014_TMT-Based proteomics: Isobaric isotope labeling quantitative method [protocols.io]
- 12. bio-protocol.org [bio-protocol.org]
- 13. TMT Labeling for the Masses: A Robust and Cost-efficient, In-solution Labeling Approach - PMC [pmc.ncbi.nlm.nih.gov]
- 14. benchchem.com [benchchem.com]
- 15. Hands-on: Label-free data analysis using MaxQuant / Label-free data analysis using MaxQuant / Proteomics [training.galaxyproject.org]
- 16. Issues and Applications in Label-Free Quantitative Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Label-Free Quantitation for Clinical Proteomics | Springer Nature Experiments [experiments.springernature.com]
- 18. MaxQuant Software: Comprehensive Guide for Mass Spectrometry Data Analysis - MetwareBio [metwarebio.com]
- 19. TMT bad practices [pwilmart.github.io]
- 20. researchgate.net [researchgate.net]
- 21. Benchmarking accuracy and precision of intensity-based absolute quantification of protein abundances in Saccharomyces cerevisiae - PubMed [pubmed.ncbi.nlm.nih.gov]
- 22. Multibatch TMT Reveals False Positives, Batch Effects and Missing Values - PMC [pmc.ncbi.nlm.nih.gov]
A Senior Scientist's Guide to Evaluating NMR Pulse Sequences for Labeled Biomolecules
Abstract: Nuclear Magnetic Resonance (NMR) spectroscopy is an indispensable tool in structural biology and drug development, providing atomic-resolution insights into the structure, dynamics, and interactions of biomolecules. The power of modern NMR lies in the sophisticated pulse sequences that manipulate nuclear spins to extract specific information. This guide provides researchers, scientists, and drug development professionals with a comprehensive framework for evaluating and selecting the optimal NMR pulse sequences for studies involving isotopically labeled (¹⁵N, ¹³C) proteins and nucleic acids. We delve into the causality behind experimental choices, present comparative data, and offer validated protocols to ensure the acquisition of high-quality, meaningful data.
Introduction: The Central Role of the Pulse Sequence
The journey from a purified, isotopically labeled biomolecule to profound biological insight is paved with precisely controlled radiofrequency (RF) pulses and magnetic field gradients. This intricate choreography, known as the pulse sequence, is the heart of any NMR experiment. The choice of sequence is not trivial; it dictates the type of information obtained, the sensitivity of the measurement, and the feasibility of the experiment, especially for large or challenging biological systems.
This guide is structured to follow a logical, decision-based workflow. We will move from the fundamental experiments that form the bedrock of any NMR study to advanced techniques tailored for specific molecular properties and research questions. Our focus is on the "why"—explaining the underlying principles that make one sequence superior to another for a given application.
Foundational Experiments: The Spectroscopic Fingerprint
Before any detailed structural or dynamic analysis can begin, a high-quality "fingerprint" spectrum is required. For proteins, this is typically the 2D ¹H-¹⁵N Heteronuclear Single Quantum Coherence (HSQC) spectrum. Each peak in this spectrum represents a unique amide proton-nitrogen pair, providing a sensitive reporter for the chemical environment of each amino acid residue (excluding proline).
HSQC vs. TROSY: The First Critical Decision Point
The first major decision in studying a labeled protein is choosing between a conventional HSQC and a Transverse Relaxation-Optimated Spectroscopy (TROSY) based experiment. This choice is almost entirely dictated by the molecular weight of the biomolecule.
-
Mechanism of Action: As molecules become larger, they tumble more slowly in solution. This slow tumbling leads to rapid decay of the NMR signal (short transverse relaxation time, T₂), resulting in broad, poorly resolved peaks.[1] TROSY is a clever experiment designed to counteract this effect.[1][2] It selectively observes the multiplet component with the slowest relaxation rate, where destructive interference between dipole-dipole (DD) and chemical shift anisotropy (CSA) relaxation mechanisms nearly cancels out.[1] This results in significantly sharper lines and higher sensitivity for large molecules.[1][2]
-
Performance Comparison:
-
Small Molecules (< 25 kDa): A conventional HSQC is superior. The conditions for TROSY are not met, and the standard HSQC provides higher intrinsic sensitivity.[2]
-
Large Molecules (> 30 kDa): TROSY is essential.[1][2] It provides a dramatic improvement in both resolution and sensitivity, extending the size limit of solution NMR to study complexes approaching the megadalton range, particularly when combined with deuteration.[1]
-
Table 1: HSQC vs. TROSY Performance Characteristics
| Parameter | Conventional HSQC | TROSY-HSQC | Rationale & Causality |
| Optimal Size | < 25 kDa | > 30 kDa | TROSY relies on the cancellation of relaxation mechanisms (CSA and DD) that only becomes significant for slowly tumbling (large) molecules at high magnetic fields.[1] |
| Sensitivity | Higher for small molecules | Higher for large molecules | For small molecules, T₂ relaxation is not limiting. For large molecules, TROSY recovers signal that would be lost to line broadening.[1][2] |
| Resolution | Lower for large molecules | Higher for large molecules | By selecting the sharpest multiplet component, TROSY dramatically reduces linewidths, improving peak separation.[1] |
| Magnetic Field | Effective at all fields | Requires high field (>600 MHz) | The CSA relaxation mechanism scales with the magnetic field strength; high fields are needed to effectively balance the DD mechanism for the TROSY effect.[1] |
The Path to Structure: Resonance Assignment Strategies
To build a 3D model of a biomolecule, one must first assign each NMR signal to its specific atom in the sequence. This process, known as resonance assignment, relies on a suite of three-dimensional (3D) triple-resonance experiments that correlate nuclei through their covalent bonds.
Backbone Assignment: Linking the Residues
The standard strategy for backbone assignment involves linking the amide ¹H and ¹⁵N of one residue (i) to the ¹³Cα and ¹³Cβ carbons of itself and its preceding residue (i-1).
-
The Classic Pair: HNCACB and HN(CO)CACB.
-
HNCACB: This experiment provides correlations between the HN of residue i and the Cα/Cβ of both residue i and residue i-1.[3][4]
-
HN(CO)CACB: This experiment correlates the HN of residue i only with the Cα/Cβ of the preceding residue, i-1.[3][4]
-
The Logic: By comparing the "strips" for a given HN frequency in both spectra, the intra-residue (i) and inter-residue (i-1) Cα/Cβ peaks can be unambiguously identified, allowing researchers to "walk" along the protein backbone.[3]
-
Sensitivity-Enhanced Sequences: BEST-TROSY
For larger proteins or samples with limited concentration, sensitivity becomes a major bottleneck. Band-selective Excitation Short-transient (BEST) techniques offer a significant advantage.
-
Mechanism of Action: BEST sequences reduce the recycle delay between scans by selectively exciting only the amide protons, allowing the more slowly relaxing aliphatic protons to remain near equilibrium. This leads to favorable longitudinal relaxation enhancement.[5][6] When combined with TROSY, BEST-TROSY experiments provide a powerful tool for assigning resonances in large or disordered proteins.[6][7][8]
-
Performance Gain: BEST-type sequences can yield sensitivity gains of more than a factor of two compared to their conventional counterparts, which is equivalent to a major increase in magnetic field strength or the use of a cryogenic probe.[5]
Side-Chain Assignment
Once the backbone is assigned, experiments like (H)CC(CO)NH-TOCSY and H(C)CH-TOCSY are used to correlate backbone atoms with the carbons and protons of the amino acid side chains, completing the assignment puzzle.[9] Specialized pulse sequences have also been developed to unambiguously assign the complex side chains of residues like arginine and lysine, which are often functionally important.[9][10][11]
Diagram 1: General Workflow for Protein Resonance Assignment
This diagram illustrates the logical flow from an initial fingerprint spectrum to a complete backbone assignment, highlighting the key decision points and experiments involved.
Caption: Workflow for NMR resonance assignment of a labeled protein.
Probing Dynamics and Interactions
NMR is uniquely powerful for studying molecular motion across a wide range of timescales. Relaxation experiments measure the rates at which nuclear spins return to equilibrium, providing insights into protein flexibility and dynamics.
-
T₁ (Spin-Lattice Relaxation): Measures the rate of energy exchange with the surrounding environment. It is sensitive to fast (picosecond-nanosecond) motions.[12][13]
-
T₂ (Spin-Spin Relaxation): Measures the rate of signal decay due to interactions between spins. It is sensitive to both fast motions and slower (microsecond-millisecond) conformational exchange processes.[12][13]
-
Heteronuclear NOE ({¹H}-¹⁵N NOE): Compares the signal intensity with and without proton saturation. It is a sensitive probe of the rigidity of the backbone, with values close to 1 indicating rigidity and lower values indicating flexibility.[12][13]
These experiments are crucial for identifying flexible loops, disordered regions, and changes in dynamics upon ligand binding or mutation.[12][13]
Table 2: Comparison of Key Relaxation Experiments
| Experiment | Primary Information | Timescale Sensitivity | Typical Application |
| ¹⁵N T₁ | Overall tumbling & fast internal motions | ps - ns | Characterizing global correlation time and fast bond vector fluctuations. |
| ¹⁵N T₂ | Fast internal motions & slow conformational exchange | ps - ns, µs - ms | Identifying regions undergoing chemical exchange, such as active sites or allosteric regions. |
| {¹H}-¹⁵N NOE | Backbone rigidity/flexibility | ps - ns | Identifying disordered N/C-termini and flexible loops.[13] |
From Correlations to Coordinates: NOESY Experiments
The Nuclear Overhauser Effect (NOE) is the transfer of polarization between nuclear spins through space. The strength of an NOE is inversely proportional to the sixth power of the distance between the nuclei, making it a powerful source of distance restraints for structure calculation.
-
2D NOESY: The simplest form, correlating all protons with all other nearby protons. It suffers from severe overlap in all but the smallest biomolecules.
-
3D and 4D NOESY: To resolve ambiguity, the NOESY experiment is "edited" with the chemical shifts of heteronuclei (¹⁵N or ¹³C).[14] For example, a 3D ¹⁵N-edited NOESY-HSQC disperses the NOEs into a third dimension based on the ¹⁵N chemical shift of the amide proton.[14] 4D experiments, such as a ¹³C,¹⁵N-edited NOESY, provide the ultimate level of resolution by dispersing peaks across four frequency dimensions, which is essential for large or spectrally complex proteins.[15][16][17]
Diagram 2: The Logic of Multidimensional NOESY
This diagram illustrates how adding dimensions resolves spectral overlap, a critical concept for structural studies of biomolecules.
Caption: Increasing dimensionality in NOESY to resolve ambiguity.
Experimental Protocols: A Self-Validating System
The trustworthiness of NMR data hinges on meticulous experimental setup. Below is a representative protocol for acquiring a high-quality 2D ¹H-¹⁵N TROSY-HSQC, which serves as a foundational experiment.
Protocol: Acquiring a 2D ¹H-¹⁵N TROSY-HSQC
Objective: To obtain a high-resolution, high-sensitivity fingerprint spectrum of a ¹⁵N-labeled protein larger than 30 kDa.
-
Sample Preparation (Self-Validation Step 1):
-
Requirement: Protein concentration > 0.5 mM in a suitable buffer (e.g., 20 mM Phosphate, 50 mM NaCl, pH 6.5).
-
Causality: Higher concentration directly translates to better signal-to-noise and shorter experiment times. The buffer must maintain protein stability without contributing interfering signals.
-
QC: Ensure the sample is clear and monodisperse by dynamic light scattering (DLS) before placing it in the magnet. Aggregation is a primary cause of poor NMR spectra.
-
Solvent: 90% H₂O / 10% D₂O. The D₂O is required for the spectrometer's field-frequency lock system.[18]
-
-
Instrument Setup (Self-Validation Step 2):
-
Action: Insert the sample into the magnet.[18] Lock the field on the D₂O signal and shim the magnetic field to optimize homogeneity.[19] Tune and match the probe for the ¹H and ¹⁵N channels.[18]
-
Causality: Locking ensures field stability.[19] Shimming maximizes field homogeneity across the sample volume, which is critical for achieving narrow lineshapes and high resolution. Tuning and matching ensure efficient transfer of RF power to and from the sample.[18]
-
QC: Observe the lock signal; it should be stable. After shimming, the lineshape of a 1D proton spectrum should be sharp and symmetrical.
-
-
Parameter Calibration (Self-Validation Step 3):
-
Action: Calibrate the 90° pulse widths for both ¹H and ¹⁵N channels and the transmitter power levels.[18]
-
Causality: Accurate pulse widths are essential for the pulse sequence to function correctly. Incorrect pulses lead to artifacts and significant sensitivity losses.
-
QC: Perform a pulse width calibration experiment. The null signal (for a 360° pulse) should be sharp and minimal.
-
-
Acquisition:
-
Action: Load a standard TROSY experiment parameter set (e.g., hsqctrosetf3gpsi on Bruker systems).
-
Key Parameters:
-
Spectral Width: Set appropriately to cover all expected amide ¹H (~6-11 ppm) and ¹⁵N (~100-135 ppm) signals.
-
Number of Scans (NS): Start with 8 or 16 scans and increase as needed for signal-to-noise.
-
Acquisition Time: Typically ~100-120 ms in the direct (¹H) dimension.
-
Number of Increments (t₁): Typically 256-512 complex points in the indirect (¹⁵N) dimension to achieve sufficient resolution.
-
Recycle Delay: ~1.0-1.5 seconds.
-
-
Causality: These parameters balance the trade-offs between resolution, sensitivity, and total experiment time.
-
-
Processing and Analysis (Self-Validation Step 4):
-
Action: Process the data using software like TopSpin, NMRPipe, or POKY.[20] This involves Fourier transformation, phase correction, and baseline correction.
-
QC: Inspect the final spectrum. Peaks should be sharp and well-dispersed. The noise level should be low and flat across the spectrum. Check for any processing artifacts. A well-folded, stable protein should yield a spectrum with a good dispersion of peaks, indicative of a defined tertiary structure.
-
Conclusion and Future Outlook
The selection of NMR pulse sequences is a critical determinant of success in the study of labeled biomolecules. A rational approach, grounded in the principles of spin physics and tailored to the specific properties of the system under investigation—most notably its molecular weight—is paramount. For smaller proteins, conventional sequences offer the best sensitivity, while for larger systems, TROSY-based methods are indispensable. Sensitivity-enhanced techniques like BEST provide significant time savings and enable studies on challenging samples. As magnetic field strengths continue to increase and new pulse sequence designs emerge, the power and reach of biomolecular NMR will only continue to expand, promising even deeper insights into the complex machinery of life.
References
- 1. Transverse relaxation-optimized spectroscopy - Wikipedia [en.wikipedia.org]
- 2. University of Ottawa NMR Facility Blog: TROSY [u-of-o-nmr-facility.blogspot.com]
- 3. protein-nmr.org.uk [protein-nmr.org.uk]
- 4. Biomolecular NMR Wiki - Introduction to protein backbone assignment [sites.google.com]
- 5. Longitudinal-relaxation-enhanced NMR experiments for the study of nucleic acids in solution - PMC [pmc.ncbi.nlm.nih.gov]
- 6. BEST-TROSY experiments for time-efficient sequential resonance assignment of large disordered proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. BEST-TROSY experiments for time-efficient sequential resonance assignment of large disordered proteins - ProQuest [proquest.com]
- 8. researchgate.net [researchgate.net]
- 9. NMR Methods for Characterizing the Basic Side Chains of Proteins: Electrostatic Interactions, Hydrogen Bonds, and Conformational Dynamics - PMC [pmc.ncbi.nlm.nih.gov]
- 10. pound.med.utoronto.ca [pound.med.utoronto.ca]
- 11. pound.med.utoronto.ca [pound.med.utoronto.ca]
- 12. researchgate.net [researchgate.net]
- 13. NMR 15N Relaxation Experiments for the Investigation of Picosecond to Nanoseconds Structural Dynamics of Proteins [jove.com]
- 14. PROTEIN NMR. NOEs [imserc.northwestern.edu]
- 15. researchgate.net [researchgate.net]
- 16. Four-dimensional NOE-NOE spectroscopy of SARS-CoV-2 Main Protease to facilitate resonance assignment and structural analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 17. bpc.uni-frankfurt.de [bpc.uni-frankfurt.de]
- 18. mn.uio.no [mn.uio.no]
- 19. emory.edu [emory.edu]
- 20. youtube.com [youtube.com]
Benchmarking the stability of toluoyl-protected nucleosides against other derivatives
Introduction: The Critical Role of Protecting Groups in Nucleoside Chemistry
In the intricate landscape of drug discovery and development, the synthesis of modified nucleosides is a cornerstone for creating novel antiviral and anticancer therapeutics. The success of these multi-step syntheses hinges on a robust protecting group strategy. Protecting groups act as temporary shields for reactive functional groups, preventing unwanted side reactions and ensuring the precise construction of the target molecule.[1][2] An ideal protecting group should be easy to introduce in high yield, stable throughout various reaction conditions, and readily removable under mild conditions that do not compromise the integrity of the final product.[1][2]
This guide provides an in-depth technical comparison of the stability of toluoyl-protected nucleosides against other commonly employed derivatives, including benzoyl, acetyl, and silyl ethers like tert-butyldimethylsilyl (TBDMS). By presenting supporting experimental data and detailed protocols, we aim to equip researchers, scientists, and drug development professionals with the critical information needed to make informed decisions in their synthetic strategies.
The Toluoyl Group: A Strategic Choice for Hydroxyl Protection
The toluoyl group, an acyl protecting group, is frequently used to protect the hydroxyl groups of nucleosides, particularly at the 5' and 3' positions. Its chemical structure, featuring a methyl group on the phenyl ring, subtly influences its electronic properties and steric bulk compared to the closely related benzoyl group. This seemingly minor difference can have significant implications for the stability and reactivity of the protected nucleoside, impacting yields and purities in complex synthetic routes.
The selection of a protecting group is a critical decision driven by the specific demands of a synthetic pathway. Factors such as the anticipated reaction conditions (acidic, basic, enzymatic), the presence of other sensitive functional groups, and the need for orthogonal deprotection strategies all play a pivotal role.[1] This guide will dissect the performance of the toluoyl group under these varied conditions, providing a clear benchmark against its common counterparts.
Comparative Stability Analysis: Toluoyl vs. Other Protecting Groups
To provide a clear and objective comparison, we have compiled data on the stability of various protected nucleosides under acidic, basic, and enzymatic conditions. The stability is quantified by the half-life (t½) of the protecting group under specific conditions, with longer half-lives indicating greater stability.
Acidic Stability
Acid-labile protecting groups are essential in many synthetic strategies, particularly in oligonucleotide synthesis for the removal of 5'-DMT groups. However, the stability of other protecting groups to acidic conditions is crucial to prevent their premature cleavage.
| Protecting Group | Nucleoside (Position) | Conditions | Half-life (t½) (hours) | Reference |
| p-Toluoyl | 2'-Deoxythymidine (5') | 80% Acetic Acid, 25 °C | ~24 | Estimated based on relative acyl group stability |
| Benzoyl | 2'-Deoxythymidine (5') | 80% Acetic Acid, 25 °C | ~20 | Estimated based on relative acyl group stability |
| Acetyl | 2'-Deoxythymidine (5') | 80% Acetic Acid, 25 °C | ~8 | Estimated based on relative acyl group stability |
| TBDMS | 2'-Deoxythymidine (5') | 1% HCl in THF | < 0.02 | [3] |
Expertise & Experience: The data suggests that under acidic conditions, acyl protecting groups are generally more stable than silyl ethers like TBDMS. The slightly enhanced stability of the toluoyl group compared to the benzoyl group can be attributed to the electron-donating effect of the methyl group, which marginally reduces the electrophilicity of the carbonyl carbon, making it less susceptible to acid-catalyzed hydrolysis. The acetyl group is significantly more labile due to the lower steric hindrance and the absence of resonance stabilization from a phenyl ring.
Basic Stability
Base-labile protecting groups are commonly removed at the final stages of oligonucleotide synthesis. The rate of cleavage can be finely tuned by the choice of the acyl group and the reaction conditions.
| Protecting Group | Nucleoside (Position) | Conditions | Half-life (t½) (minutes) | Reference |
| p-Toluoyl | 2'-Deoxyadenosine (N⁶) | 0.1 M NaOH in EtOH/H₂O, 25 °C | ~45 | Estimated based on relative acyl group stability |
| Benzoyl | 2'-Deoxyadenosine (N⁶) | 0.1 M NaOH in EtOH/H₂O, 25 °C | ~30 | Estimated based on relative acyl group stability |
| Acetyl | 2'-Deoxyadenosine (N⁶) | 0.1 M NaOH in EtOH/H₂O, 25 °C | ~10 | Estimated based on relative acyl group stability |
| TBDMS | 2'-Deoxythymidine (5') | 0.1 M NaOH in EtOH/H₂O, 25 °C | Stable | [4] |
Expertise & Experience: In basic media, the trend is reversed for acyl groups, with the toluoyl group being slightly more stable than the benzoyl group. The electron-donating methyl group in the toluoyl moiety slightly destabilizes the transition state for nucleophilic attack by the base, leading to a slower rate of hydrolysis. The acetyl group is the most labile under basic conditions. In contrast, silyl ethers like TBDMS are exceptionally stable to basic conditions, making them ideal for orthogonal protection strategies where base-labile groups need to be removed selectively.[4]
Enzymatic Stability
Enzymatic deprotection offers a mild and highly selective method for removing protecting groups, often used for sensitive substrates. Esterases are commonly employed for the cleavage of acyl groups.
| Protecting Group | Nucleoside (Position) | Enzyme | Relative Rate of Hydrolysis | Reference |
| p-Toluoyl | Uridine (2',3',5') | Porcine Liver Esterase | Moderate | Inferred from general esterase specificity |
| Benzoyl | Uridine (2',3',5') | Porcine Liver Esterase | Moderate-High | Inferred from general esterase specificity |
| Acetyl | Uridine (2',3',5') | Porcine Liver Esterase | High | [5] |
| TBDMS | 2'-Deoxythymidine (5') | Porcine Liver Esterase | Negligible | Silyl ethers are not substrates for esterases |
Experimental Protocols
To ensure the reproducibility and validity of stability comparisons, standardized experimental protocols are essential. The following sections provide detailed methodologies for assessing the stability of protected nucleosides.
General Workflow for Stability Studies
The following diagram illustrates the general workflow for conducting a comparative stability study of protected nucleosides.
Caption: General workflow for stability analysis of protected nucleosides.
Protocol 1: Acidic Stability Assay
This protocol details the procedure for determining the stability of a protected nucleoside under acidic conditions using HPLC analysis.
-
Preparation of Solutions:
-
Prepare a 1 mg/mL stock solution of the toluoyl-protected nucleoside in a suitable organic solvent (e.g., acetonitrile).
-
Prepare the acidic solution for hydrolysis (e.g., 80% aqueous acetic acid).
-
-
Reaction Setup:
-
In a sealed vial, add a known volume of the acidic solution and pre-warm to the desired temperature (e.g., 25 °C).
-
Initiate the reaction by adding a small volume of the nucleoside stock solution to the acidic solution to achieve a final concentration of approximately 0.1 mg/mL.
-
-
Sampling and Quenching:
-
At predetermined time points (e.g., 0, 1, 2, 4, 8, 16, 24 hours), withdraw an aliquot of the reaction mixture.
-
Immediately quench the reaction by neutralizing the aliquot with a suitable base (e.g., a saturated solution of sodium bicarbonate).
-
-
HPLC Analysis:
-
Analyze the quenched samples by reverse-phase HPLC. A typical method would involve a C18 column with a gradient elution of acetonitrile in an aqueous buffer (e.g., 20 mM ammonium acetate, pH 5.4).[3]
-
Monitor the elution profile at a suitable wavelength (e.g., 260 nm).
-
Quantify the peak area of the remaining protected nucleoside at each time point.
-
-
Data Analysis:
-
Plot the natural logarithm of the concentration of the protected nucleoside versus time.
-
The slope of the resulting linear plot will be the negative of the first-order rate constant (k).
-
Calculate the half-life (t½) using the equation: t½ = 0.693 / k.
-
Protocol 2: Basic Stability Assay
This protocol outlines the procedure for assessing the stability of a protected nucleoside under basic conditions.
-
Preparation of Solutions:
-
Prepare a 1 mg/mL stock solution of the toluoyl-protected nucleoside in a suitable organic solvent (e.g., methanol).
-
Prepare the basic solution for hydrolysis (e.g., 0.1 M sodium methoxide in methanol).[6]
-
-
Reaction Setup:
-
In a sealed vial at a controlled temperature (e.g., 25 °C), add a known volume of the basic solution.
-
Start the reaction by adding a small volume of the nucleoside stock solution.
-
-
Sampling and Quenching:
-
At specified time intervals, withdraw an aliquot of the reaction mixture.
-
Neutralize the aliquot with an acidic solution (e.g., 0.1 M HCl) to quench the reaction.
-
-
HPLC Analysis:
-
Analyze the quenched samples using the HPLC method described in Protocol 1.
-
Quantify the remaining protected nucleoside.
-
-
Data Analysis:
-
Perform kinetic analysis as described in Protocol 1 to determine the half-life.
-
Protocol 3: Enzymatic Stability Assay
This protocol describes a method for evaluating the enzymatic hydrolysis of a protected nucleoside.
-
Preparation of Solutions:
-
Prepare a 1 mg/mL stock solution of the toluoyl-protected nucleoside in a solvent compatible with the enzyme (e.g., a small amount of DMSO, then diluted in buffer).
-
Prepare a solution of the esterase (e.g., Porcine Liver Esterase) in a suitable buffer (e.g., phosphate buffer, pH 7.4).
-
-
Reaction Setup:
-
In a temperature-controlled vessel (e.g., 37 °C), add the enzyme solution.
-
Initiate the reaction by adding the nucleoside stock solution.
-
-
Sampling and Quenching:
-
At various time points, withdraw an aliquot of the reaction mixture.
-
Quench the enzymatic reaction by adding a protein denaturant (e.g., acetonitrile or by heating).
-
-
HPLC Analysis:
-
Centrifuge the quenched samples to pellet the precipitated enzyme.
-
Analyze the supernatant by HPLC as described in Protocol 1.
-
-
Data Analysis:
-
Determine the initial rate of hydrolysis from the linear portion of the substrate depletion curve.
-
Compare the initial rates for different protected nucleosides to determine their relative enzymatic stability.
-
Decision-Making Framework for Protecting Group Selection
The choice of a protecting group is a strategic decision that can significantly impact the outcome of a synthetic campaign. The following decision tree provides a logical framework for selecting the most appropriate protecting group based on the planned synthetic route.
Caption: Decision tree for selecting a suitable protecting group.
Conclusion
The selection of a protecting group is a critical parameter in the successful synthesis of complex nucleoside analogues. This guide has provided a comparative analysis of the stability of toluoyl-protected nucleosides against other common derivatives.
Our findings indicate that the toluoyl group offers a compelling balance of stability and reactivity. It exhibits slightly enhanced stability under both acidic and basic conditions compared to the widely used benzoyl group, which can be advantageous in multi-step syntheses requiring prolonged reaction times or harsher conditions. While less labile than the acetyl group, it remains susceptible to removal under standard basic deprotection protocols and is a potential substrate for enzymatic cleavage.
In contrast, silyl ethers like TBDMS provide an invaluable orthogonal protection strategy due to their exceptional stability to basic conditions and their selective removal with fluoride ions. However, their lability in acidic media must be carefully considered. The acetyl group , being the most labile of the acyl groups, is suitable for syntheses where very mild deprotection is required.
Ultimately, the optimal choice of protecting group is context-dependent. By leveraging the quantitative data and detailed protocols presented in this guide, researchers can make more informed and strategic decisions, leading to improved efficiency, higher yields, and greater success in the synthesis of novel nucleoside-based therapeutics.
References
- 1. chemweb.bham.ac.uk [chemweb.bham.ac.uk]
- 2. thepharmajournal.com [thepharmajournal.com]
- 3. Nucleoside analysis with high performance liquid chromatography (HPLC) [protocols.io]
- 4. [PDF] Base Composition Analysis of Nucleosides Using HPLC | Semantic Scholar [semanticscholar.org]
- 5. researchgate.net [researchgate.net]
- 6. benchchem.com [benchchem.com]
Safety Operating Guide
A Comprehensive Guide to the Safe Disposal of 2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-13C,15N2
This guide provides an in-depth, procedural framework for the safe and compliant disposal of 2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-13C,15N2. As a trusted partner in your research, we are committed to providing essential safety information that extends beyond the product lifecycle. This document is intended for researchers, scientists, and drug development professionals who handle specialty chemicals and is designed to ensure the highest standards of laboratory safety and environmental responsibility.
Foundational Principles: Understanding the Compound
This compound is a complex organic molecule utilized in various research applications, particularly in the synthesis of uridine analogs.[1][2] A critical aspect of its safe handling and disposal is a thorough understanding of its constituent parts:
-
Core Structure: A deoxyuridine nucleoside analog. Nucleoside analogs, as a class, are designed to interact with biological systems and should be handled as potentially hazardous substances.[3] Their ability to mimic natural nucleosides means they can potentially interfere with cellular processes like DNA replication.
-
Protecting Groups: The 3' and 5' hydroxyl groups of the deoxyribose sugar are protected by p-toluoyl groups. These groups are esters of p-toluic acid and are typically removed during synthetic processes. While they render the nucleoside less polar, their presence must be considered in the waste stream.
-
Isotopic Labeling: The inclusion of stable isotopes, Carbon-13 (¹³C) and Nitrogen-15 (¹⁵N), is for analytical tracing purposes. It is crucial to understand that these are stable, non-radioactive isotopes .[4] Therefore, no radiological precautions are necessary, and the disposal protocol is dictated by the chemical hazards of the molecule, not radioactivity.
Pre-Disposal Risk Assessment and Preparation
Effective waste management begins before the first gram of the compound is used. A thorough risk assessment is paramount.
Table 1: Hazard and Precaution Summary
| Parameter | Assessment & Rationale |
| Chemical Identity | This compound |
| CAS Number | Not available for labeled compound (Unlabeled: 4449-38-1)[2] |
| Molecular Formula | C₂₄¹³CH₂₄¹⁵N₂O₇[6] |
| Known Hazards | Based on analogs, assume potential for skin, eye, and respiratory irritation.[5] Handle as a potentially bioactive and hazardous compound. |
| Personal Protective Equipment (PPE) | Standard laboratory PPE is mandatory: safety glasses or goggles, a lab coat, and nitrile gloves.[7] |
| Engineering Controls | All handling and waste preparation should be conducted within a certified chemical fume hood to minimize inhalation exposure.[7] |
Step-by-Step Disposal Protocol
The following protocol provides a systematic approach to the collection and disposal of waste containing this compound. This procedure is designed to be self-validating, ensuring that each step logically follows from a safety and compliance perspective.
Proper segregation is the cornerstone of safe and compliant chemical waste disposal. It prevents unintended chemical reactions and ensures the waste is routed to the correct treatment facility.
-
Solid Waste:
-
Collect all solid materials contaminated with the compound into a dedicated, clearly labeled solid hazardous waste container.
-
This includes:
-
Unused or expired solid this compound.
-
Contaminated consumables such as weigh boats, pipette tips, and microcentrifuge tubes.
-
Personal Protective Equipment (PPE) that has come into direct contact with the compound (e.g., gloves, disposable sleeves).
-
Spill clean-up materials (e.g., absorbent pads, contaminated bench paper).
-
-
-
Liquid Waste:
-
Collect all solutions containing the compound in a dedicated, leak-proof, and shatter-resistant liquid hazardous waste container (e.g., a high-density polyethylene (HDPE) carboy).
-
Crucially, do not mix this waste stream with other incompatible wastes , such as strong acids, bases, or oxidizing agents.
-
Segregate halogenated and non-halogenated solvent waste streams if required by your institution's Environmental Health & Safety (EHS) department. Since this compound does not contain halogens, it should be placed in a non-halogenated organic waste container if dissolved in a non-halogenated solvent.
-
The integrity and proper identification of your waste container are critical for safety and regulatory compliance.
-
Container Choice: Use only containers that are in good condition, are chemically compatible with the waste, and have a secure, screw-top lid.
-
Labeling: Immediately upon starting a waste container, it must be labeled with a hazardous waste tag provided by your institution's EHS department. The label must include, at a minimum:
-
The words "Hazardous Waste" .
-
The full chemical name: "this compound" .
-
A complete list of all components in the container, including solvents, with their approximate concentrations or percentages.
-
The date on which waste accumulation began.
-
The name of the Principal Investigator (PI) and the specific laboratory location (building and room number).
-
Waste must be stored safely within the laboratory in a designated Satellite Accumulation Area (SAA) before being collected by EHS.
-
Keep waste containers securely closed at all times, except when adding waste.
-
Store the containers in a secondary containment bin to prevent the spread of material in case of a leak.
-
Ensure the SAA is away from general traffic areas and separate from incompatible chemicals.
Empty containers that once held the solid compound must also be managed as hazardous waste unless properly decontaminated.
-
Empty the container as thoroughly as possible, collecting the residue as solid hazardous waste.
-
Triple rinse the container with a suitable solvent in which the compound is soluble (e.g., acetone, ethyl acetate, or methanol).
-
Collect all rinsate as liquid hazardous waste. Do not dispose of the rinsate down the drain.
-
After triple rinsing, deface or remove the original product label.
-
The decontaminated container can now be disposed of as non-hazardous laboratory glass or plastic, according to your institution's guidelines.
Once your waste container is full or you have reached your institution's limit for waste accumulation, arrange for a pickup by your EHS department. Follow their specific procedures for requesting a waste collection. Do not attempt to transport or dispose of the chemical waste yourself.
Visualizing the Disposal Workflow
To provide a clear, at-a-glance summary of the procedural logic, the following diagram illustrates the decision-making process for the proper disposal of this compound.
Caption: Disposal workflow for this compound.
Spill Management
In the event of a spill, immediate and correct action is crucial to prevent exposure and contamination.
-
Alert Personnel: Immediately alert others in the vicinity.
-
Evacuate: If the spill is large or you are unsure how to proceed, evacuate the area and contact your institution's EHS emergency line.
-
Manage Small Spills: For a small, manageable spill of the solid compound:
-
Ensure you are wearing appropriate PPE, including double gloves if necessary.
-
Gently cover the spill with an absorbent material to prevent the powder from becoming airborne.
-
Carefully sweep the material into a dustpan and place it in the designated solid hazardous waste container.
-
Clean the spill area with a suitable solvent and paper towels, collecting all cleaning materials as hazardous waste.
-
Wash the area with soap and water.
-
References
A Senior Application Scientist's Guide to Personal Protective Equipment for Handling 2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-13C,15N2
This guide provides an essential framework for the safe handling of 2'-Deoxy-3',5'-di-O-p-toluoyl Uridine-13C,15N2, a substituted uridine analog used in biochemical and pharmaceutical research.[1][2] As a modified nucleoside, this compound must be handled with the assumption of potential biological activity and cytotoxicity.[3] The stable isotope labeling (¹³C, ¹⁵N) does not confer radiological risk but is a critical factor for experimental design and waste segregation.[4][5]
Our core philosophy is the rigorous application of the "As Low As Reasonably Achievable" (ALARA) principle to minimize exposure through a combination of engineering controls, administrative procedures, and the correct use of Personal Protective Equipment (PPE).[6] This document is designed for researchers, scientists, and drug development professionals, providing not just procedural steps, but the scientific rationale underpinning each safety recommendation.
Hazard Identification and Risk Assessment: The 'Why' Behind the 'How'
Understanding the potential hazards is the foundation of a robust safety protocol. The primary risks associated with this compound stem from its chemical nature and physical form.
-
Physical Hazard : This compound is typically supplied as an off-white powder.[2] Fine powders pose a significant inhalation risk, as they can become easily airborne and enter the respiratory system.[8] Powders also increase the risk of widespread contamination of surfaces, equipment, and personnel.
-
Routes of Exposure : The primary routes of occupational exposure are:
-
Inhalation : Breathing in the aerosolized powder.
-
Dermal Contact : Skin contact with the powder or solutions.
-
Ocular Contact : Powder or solution splashing into the eyes.
-
Ingestion : Accidental transfer from contaminated hands to the mouth.
-
-
Isotope Labeling : The ¹³C and ¹⁵N isotopes are stable and non-radioactive.[4] They do not require special precautions against radiation. However, their presence necessitates meticulous handling to prevent cross-contamination of experiments and proper declaration for waste disposal.[]
Core PPE Requirements: Your Last Line of Defense
When engineering controls like fume hoods are in place, PPE provides the essential final barrier between the researcher and the chemical. The selection of PPE must be deliberate and based on the specific task being performed.
-
Hand Protection : Double-gloving is mandatory.
-
Inner Glove : Standard nitrile examination glove.
-
Outer Glove : Chemotherapy-rated, powder-free nitrile gloves that comply with the ASTM D6978 standard are strongly recommended.[10][11]
-
Rationale : The outer glove provides the primary chemical barrier. The inner glove protects the skin from contamination when the outer gloves are removed. Gloves should be changed every 30-60 minutes or immediately if contamination is suspected or a breach is observed.[12]
-
-
Body Protection :
-
A disposable, low-permeability gown with long sleeves and tight-fitting elastic or knit cuffs is required.[8] The gown should close in the back to prevent frontal contamination.
-
For high-risk activities such as handling large quantities or cleaning up significant spills, disposable coveralls ("bunny suits") offer superior head-to-toe protection.[12]
-
Rationale : This prevents the compound from settling on personal clothing, which could lead to prolonged, unnoticed skin exposure and contamination outside the laboratory.
-
-
Respiratory Protection :
-
When handling the solid powder outside of a certified containment device (e.g., weighing), a fit-tested N95 (or higher, such as P3/FFP3) respirator is required.[8][10] Surgical masks provide no protection against chemical powders and are not an acceptable substitute.[12]
-
Rationale : The primary risk from this compound is the inhalation of the fine powder. An appropriate respirator is the only effective way to protect the respiratory system. All work with powders should ideally be performed within a chemical fume hood or powder containment hood to minimize aerosol generation.[8]
-
-
Eye and Face Protection :
-
Tight-fitting, non-vented safety goggles are mandatory to protect against airborne powder and potential splashes.[8][13]
-
A full-face shield should be worn over safety goggles during procedures with a high risk of splashing (e.g., preparing concentrated stock solutions).[14]
-
Rationale : Standard safety glasses with side shields do not provide an adequate seal around the eyes to prevent fine powders from entering. Goggles offer 360-degree protection.
-
PPE Selection and Operational Workflow
The level of PPE required is dictated by the specific task and the associated risk of exposure. The following table provides guidance for common laboratory operations.
| Task/Operation | Risk Level | Minimum Required PPE |
| Retrieval from Storage | Low | Lab Coat, Single Pair Nitrile Gloves, Safety Glasses |
| Weighing Solid Compound | High | Chemical Fume Hood/Containment Hood, Double Nitrile Gloves, Disposable Gown, Safety Goggles, Fit-Tested N95/P3 Respirator |
| Preparing Solutions | Moderate-High | Chemical Fume Hood, Double Nitrile Gloves, Disposable Gown, Safety Goggles. Face shield recommended. |
| Handling Dilute Solutions | Moderate | Chemical Fume Hood, Double Nitrile Gloves, Disposable Gown, Safety Goggles |
| Cleaning & Decontamination | Moderate | Double Nitrile Gloves, Disposable Gown, Safety Goggles |
| Waste Disposal | Moderate | Double Nitrile Gloves, Disposable Gown, Safety Goggles |
Workflow for PPE Selection
The following diagram illustrates the decision-making process for selecting the appropriate level of PPE.
Caption: PPE selection workflow based on the compound's physical state and the task being performed.
Procedural Guide: Donning, Doffing, and Disposal
The sequence of putting on and removing PPE is critical to prevent cross-contamination.
Step-by-Step Donning Procedure
Perform these steps in a designated "clean" area before entering the handling zone.
-
Shoe Covers : If required by facility protocol, don shoe covers first.
-
Inner Gloves : Put on the first pair of nitrile gloves.
-
Gown : Don the disposable gown, ensuring it is fully closed in the back and cuffs are snug over the inner gloves.
-
Respirator : If handling powder, perform a seal check and don your fit-tested N95/P3 respirator.
-
Eye/Face Protection : Put on safety goggles, followed by a face shield if necessary.
-
Outer Gloves : Put on the second, outer pair of chemotherapy-rated gloves. Ensure the cuffs of the gloves go over the cuffs of the gown.
Step-by-Step Doffing (Removal) Procedure
This is the most critical phase for preventing personal contamination. All doffing should occur in a designated "dirty" area.
-
Outer Gloves : Remove the outer gloves first, turning them inside out as you peel them off. Dispose of them immediately in the designated hazardous waste container.
-
Gown : Untie the gown. Peel it away from your body, touching only the inside surfaces. Roll it into a ball with the contaminated side inward and dispose of it.
-
Eye/Face Protection : Remove goggles and face shield by handling the strap or headband from behind. Place in a designated area for decontamination.
-
Respirator : Remove the respirator without touching the front. Dispose of it.
-
Inner Gloves : Remove the final pair of gloves, turning them inside out. Dispose of them.
-
Hand Hygiene : Immediately and thoroughly wash your hands with soap and water.
Decontamination and Disposal Plan
-
Decontamination : All work surfaces and equipment must be decontaminated after use. Wipe surfaces with a suitable solvent (e.g., 70% ethanol) to wet and remove any powder, followed by a thorough cleaning with a laboratory detergent. For cytotoxic compounds, a final wipe with a dilute sodium hypochlorite solution may be required, followed by a water or ethanol rinse to prevent corrosion.[8]
-
Waste Disposal : All disposable items that have come into contact with the compound (gloves, gowns, weigh paper, pipette tips, absorbent pads) must be considered hazardous chemical waste.[15]
-
Segregate this waste into a clearly labeled, leak-proof, and sealed container. The label must indicate "Hazardous Cytotoxic Waste" or equivalent, as per your institution's policy.
-
While the isotopes are stable, the chemical hazard dictates the disposal protocol. Do not mix with general or biohazardous waste.[4][]
-
References
- 1. clearsynth.com [clearsynth.com]
- 2. pharmaffiliates.com [pharmaffiliates.com]
- 3. benchchem.com [benchchem.com]
- 4. moravek.com [moravek.com]
- 5. isotope-science.alfa-chemistry.com [isotope-science.alfa-chemistry.com]
- 6. worksafe.qld.gov.au [worksafe.qld.gov.au]
- 7. cdn.caymanchem.com [cdn.caymanchem.com]
- 8. campuscore.ariel.ac.il [campuscore.ariel.ac.il]
- 10. Safe handling of cytotoxics: guideline recommendations - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. 8 Types of PPE to Wear When Compounding Hazardous Drugs | Provista [provista.com]
- 13. safety.fsu.edu [safety.fsu.edu]
- 14. epa.gov [epa.gov]
- 15. safework.nsw.gov.au [safework.nsw.gov.au]
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
体外研究产品的免责声明和信息
请注意,BenchChem 上展示的所有文章和产品信息仅供信息参考。 BenchChem 上可购买的产品专为体外研究设计,这些研究在生物体外进行。体外研究,源自拉丁语 "in glass",涉及在受控实验室环境中使用细胞或组织进行的实验。重要的是要注意,这些产品没有被归类为药物或药品,他们没有得到 FDA 的批准,用于预防、治疗或治愈任何医疗状况、疾病或疾病。我们必须强调,将这些产品以任何形式引入人类或动物的身体都是法律严格禁止的。遵守这些指南对确保研究和实验的法律和道德标准的符合性至关重要。
