SBP-1
描述
BenchChem offers high-quality this compound suitable for many research applications. Different packaging options are available to accommodate customers' requirements. Please inquire for more information about this compound including the price, delivery time, and more detailed information at info@benchchem.com.
属性
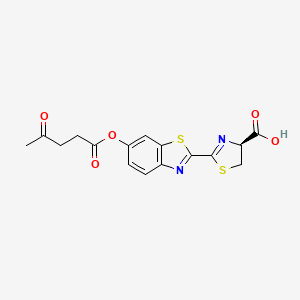
分子式 |
C16H14N2O5S2 |
|---|---|
分子量 |
378.4 g/mol |
IUPAC 名称 |
(4S)-2-[6-(4-oxopentanoyloxy)-1,3-benzothiazol-2-yl]-4,5-dihydro-1,3-thiazole-4-carboxylic acid |
InChI |
InChI=1S/C16H14N2O5S2/c1-8(19)2-5-13(20)23-9-3-4-10-12(6-9)25-15(17-10)14-18-11(7-24-14)16(21)22/h3-4,6,11H,2,5,7H2,1H3,(H,21,22)/t11-/m1/s1 |
InChI 键 |
LTRSNTAZJUGRHL-LLVKDONJSA-N |
手性 SMILES |
CC(=O)CCC(=O)OC1=CC2=C(C=C1)N=C(S2)C3=N[C@H](CS3)C(=O)O |
规范 SMILES |
CC(=O)CCC(=O)OC1=CC2=C(C=C1)N=C(S2)C3=NC(CS3)C(=O)O |
产品来源 |
United States |
Foundational & Exploratory
The Role of SBP-1 in Caenorhabditis elegans Lipid Metabolism: A Technical Guide
Authored for: Researchers, Scientists, and Drug Development Professionals
Abstract
The Sterol Regulatory Element-Binding Protein (SREBP) family of transcription factors are master regulators of lipid homeostasis in metazoans. In the nematode Caenorhabditis elegans, the single SREBP ortholog, SBP-1 (Y47D3B.7), plays a functionally conserved and critical role in controlling the synthesis, storage, and composition of fats. Dysregulation of this compound activity is linked to profound changes in fat accumulation, growth, and stress responses, making it a valuable model for studying metabolic diseases. This technical guide provides an in-depth examination of this compound's function, its regulatory networks, the phenotypic consequences of its modulation, and the experimental methodologies used to elucidate its role in lipid metabolism.
Core Function of this compound in Lipid Homeostasis
This compound is a key transcription factor that maintains normal fat levels in C. elegans.[1] It is the homolog of the mammalian SREBP-1c, which is a primary regulator of fatty acid synthesis and storage.[2][3] this compound is strongly expressed in the intestine, the primary site of fat metabolism in the nematode, where it orchestrates the expression of a suite of genes involved in the production of fatty acids.[2][3][4]
Upon activation, this compound promotes the synthesis of monounsaturated and polyunsaturated fatty acids. Its activity is essential for converting saturated fatty acids (SFAs) into unsaturated fatty acids (UFAs), a crucial step for maintaining membrane fluidity and synthesizing complex lipids.[5] The central role of this compound is highlighted by the severe phenotypes observed upon its depletion, which include a marked reduction in fat storage, altered fatty acid composition, delayed growth, and decreased fecundity.[2][6]
Regulatory and Signaling Pathways Involving this compound
The activity of this compound is tightly controlled by a complex network of upstream signals and co-regulatory factors, ensuring that lipid metabolism is appropriately coupled to nutrient availability and environmental conditions.
Upstream Activation and Regulation
Several key factors and conditions have been identified as activators of this compound:
-
Nutrient Availability (Glucose): High-glucose diets lead to a significant increase in this compound protein levels and subsequent fat accumulation.[2][5] This suggests this compound is a critical mediator of diet-induced obesity in this model organism.
-
Hypoxia: Extended oxygen deprivation activates this compound, leading to increased fat accumulation.[4][7] This links this compound to cellular stress responses and highlights its role in metabolic adaptation to low-oxygen environments.
-
MDT-15 (Mediator Complex Subunit): MDT-15 is a transcriptional co-activator that is essential for this compound activity.[2] It acts upstream of this compound, particularly in the intestine, to regulate responses to environmental stressors like simulated microgravity.[8] The this compound/MDT-15 complex is crucial for activating lipogenic gene expression.[5]
-
MXL-3: The transcription factor MXL-3, a Myc-family member, positively regulates the expression of this compound in response to high-glucose conditions.[9][10] The MXL-3/SBP-1 axis is a key pathway for glucose-dependent fat accumulation.[9]
-
Phosphatidylcholine (PC) Feedback Loop: this compound activity is regulated by a feedback mechanism involving PC, a key membrane phospholipid. This compound controls the expression of genes in the one-carbon cycle, which produces the methyl donor S-adenosylmethionine (SAMe) required for PC synthesis.[11] Low levels of PC feedback to activate this compound processing, thereby increasing this compound-dependent gene expression and lipogenesis.[11]
References
- 1. uniprot.org [uniprot.org]
- 2. Fat accumulation in Caenorhabditis elegans is mediated by SREBP homolog this compound - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Fat accumulation in Caenorhabditis elegans is mediated by SREBP homolog this compound - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. SREBP and MDT-15 protect C. elegans from glucose-induced accelerated aging by preventing accumulation of saturated fat - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Fat synthesis and adiposity regulation in Caenorhabditis elegans - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Essential role of this compound activation in oxygen deprivation induced lipid accumulation and increase in body width/length ratio in Caenorhabditis elegans - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Lipid metabolic sensors of MDT-15 and this compound regulated the response to simulated microgravity in the intestine of Caenorhabditis elegans - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. The MXL-3/SBP-1 Axis Is Responsible for Glucose-Dependent Fat Accumulation in C. elegans - PMC [pmc.ncbi.nlm.nih.gov]
- 10. mdpi.com [mdpi.com]
- 11. A conserved SREBP-1/phosphatidylcholine feedback circuit regulates lipogenesis in metazoans - PMC [pmc.ncbi.nlm.nih.gov]
The SBP-1/SREBP-1 Signaling Pathway: A Core Regulator in Metabolic Disease
An In-depth Technical Guide for Researchers, Scientists, and Drug Development Professionals
Abstract
Sterol Regulatory Element-Binding Protein 1 (SREBP-1), also known as SBP-1, is a master transcriptional regulator pivotal to lipid homeostasis. It orchestrates the expression of a wide array of genes involved in fatty acid and triglyceride synthesis. Dysregulation of the SREBP-1 signaling pathway is a key contributor to the pathogenesis of prevalent metabolic diseases, including non-alcoholic fatty liver disease (NAFLD), obesity, and type 2 diabetes. This technical guide provides a comprehensive overview of the core SREBP-1 signaling cascade, its upstream regulatory networks, and its downstream effector genes. We present detailed experimental protocols for investigating this pathway and summarize key quantitative data from seminal studies. Furthermore, this guide offers visual representations of the signaling pathways and experimental workflows to facilitate a deeper understanding for researchers and professionals in drug development seeking to target this critical metabolic node.
The Core SREBP-1 Signaling Pathway
SREBP-1 is synthesized as an inactive precursor protein anchored to the endoplasmic reticulum (ER) membrane. Its activation is a tightly regulated multi-step process involving intracellular transport and proteolytic cleavage. The two major isoforms of SREBP-1, SREBP-1a and SREBP-1c, are produced from a single gene (SREBF1) through the use of alternative promoters. SREBP-1c is the predominant isoform in the liver and plays a crucial role in insulin-mediated lipogenesis.[1][2][3]
The activation cascade is initiated by the transport of the SREBP-1 precursor from the ER to the Golgi apparatus. This transport is chaperoned by the SREBP Cleavage-Activating Protein (SCAP). In the Golgi, the precursor undergoes sequential proteolytic cleavage by two proteases: Site-1 Protease (S1P) and Site-2 Protease (S2P).[1][4][5] This two-step cleavage releases the mature, transcriptionally active N-terminal fragment of SREBP-1 (nSREBP-1). The nSREBP-1 then translocates to the nucleus, where it binds to Sterol Regulatory Elements (SREs) in the promoter regions of its target genes, thereby activating their transcription.[1][4]
References
- 1. SREBPs in Lipid Metabolism, Insulin Signaling, and Beyond - PMC [pmc.ncbi.nlm.nih.gov]
- 2. preprints.org [preprints.org]
- 3. SREBPs: activators of the complete program of cholesterol and fatty acid synthesis in the liver - PMC [pmc.ncbi.nlm.nih.gov]
- 4. benchchem.com [benchchem.com]
- 5. mdpi.com [mdpi.com]
A Technical Guide to the Discovery and Characterization of Human Selenium-Binding Protein 1 (SBP1)
Audience: Researchers, scientists, and drug development professionals.
Abstract: Selenium-Binding Protein 1 (SBP1) is a highly conserved protein implicated in a variety of fundamental physiological processes, including redox modulation, protein degradation, and the metabolism of sulfur-containing molecules.[1][2] Initially discovered through its ability to covalently bind selenium, SBP1's functions are now known to extend to enzymatic activities, such as its role as a methanethiol oxidase.[1][3][4][5] Its expression is frequently dysregulated in numerous human diseases, most notably being reduced in many cancer types, where low levels often correlate with poor clinical outcomes.[1][2][6] This guide provides a comprehensive overview of the discovery, molecular characterization, and functional roles of human SBP1. It includes detailed summaries of its key characteristics, its involvement in signaling pathways, and validated experimental protocols for its study, serving as a critical resource for researchers investigating its biological significance and therapeutic potential.
Discovery and Core Characteristics
SBP1 was first identified in 1989 in mouse liver cytosols through experiments using 75Se labelling to isolate selenium-associated proteins.[1][7][8] These studies revealed a 56 kDa protein that covalently bound selenium.[1][7][8] The full-length human SBP1 cDNA was subsequently cloned and described in 1997.[1][6][8] Human SBP1 is a highly conserved protein, sharing 86% homology with its murine counterpart, which suggests a conservation of its fundamental cellular functions across species.[1]
Gene and Protein Profile
The human SBP1 gene, SELENBP1, is located on chromosome 1.[6] It encodes a protein with multiple isoforms identified, including native and phosphorylated forms.[9] The core characteristics are summarized below.
| Feature | Description | Reference |
| Gene Symbol | SELENBP1 | [10] |
| Full Name | Selenium Binding Protein 1 | [10] |
| Aliases | hSP56, SBP56, Methanethiol Oxidase (MTO) | [1][10] |
| Chromosomal Location | 1q21-22 | [6] |
| Protein Length | 472 amino acids | [1][6][7] |
| cDNA Length | 1668 base pairs | [1][8] |
| Apparent Molecular Weight | ~56 kDa | [1] |
| Isoforms | Native and phosphorylated forms identified in 2-D gels. | [9] |
| Tissue Expression | Abundantly expressed in liver, lung, prostate, colon, and pancreas; moderately in spleen, heart, and ovary; barely detectable in thymus, testis, and peripheral blood leukocytes. | [1][8] |
Molecular Function and Biological Roles
SBP1 is a multifunctional protein involved in diverse cellular processes. Its functions range from enzymatic catalysis to the modulation of protein stability and cellular redox balance.
Enzymatic Activity: Methanethiol Oxidase
A key enzymatic function of SBP1 was recently identified as a methanethiol oxidase (MTO).[3][4][5][10] In this role, it catalyzes the oxidation of methanethiol (MT), a sulfur-containing compound, into formaldehyde, hydrogen sulfide (H₂S), and hydrogen peroxide (H₂O₂).[3][4] This activity is crucial for detoxifying MT and producing signaling molecules like H₂S and H₂O₂.[3][4]
Redox Modulation
SBP1 plays a role in modulating the cellular redox state.[1] The protein sequence contains two Cys-X-X-Cys motifs, which are characteristic features of proteins involved in redox regulation.[1] Furthermore, SBP1 has a reciprocal regulatory relationship with Glutathione Peroxidase 1 (GPX1), a key enzyme in detoxifying hydrogen and lipid peroxides.[1] Overexpression of SBP1 can inhibit GPX1 activity, while expressing GPX1 can lead to a decrease in SBP1 mRNA and protein levels, highlighting a complex interplay in maintaining cellular redox homeostasis.[1]
Protein Degradation and Transport
SBP1 is implicated in pathways related to protein degradation.[1] It physically interacts with the von Hippel-Lindau protein-interacting deubiquitinating enzyme 1 (VDU1), a component of the proteasomal degradation pathway.[1][6] This interaction is selenium-dependent, as the dissociation of selenium from SBP1 completely blocks its binding to VDU1.[1] This suggests SBP1 may function in ubiquitination/deubiquitination-mediated protein degradation.[1] SBP1 may also be involved in intra-Golgi protein transport.[5][6]
Key Signaling Interactions and Pathways
SBP1 functions by interacting with a network of other proteins to influence cellular signaling. The following diagrams illustrate key characterized interactions and their functional consequences.
SBP1 Identification and Characterization Workflow
A typical experimental workflow for identifying and characterizing SBP1 from tissue samples involves proteomic techniques. The process begins with protein separation, followed by mass spectrometry for identification and subsequent validation with antibody-based methods.
Caption: Experimental workflow for the identification and validation of SBP1.
SBP1-VDU1 Interaction in Protein Degradation
SBP1's interaction with VDU1 links it to the cellular machinery for protein turnover. This binding is notably dependent on the presence of selenium, highlighting the element's importance for SBP1's function in this pathway.
Caption: Selenium-dependent interaction of SBP1 with VDU1.
Reciprocal Regulation of SBP1 and GPX1
SBP1 and GPX1 exhibit a negative feedback relationship, suggesting a coordinated role in managing cellular oxidative stress. The expression level of one protein inversely affects the activity or expression of the other.
Caption: Reciprocal inhibitory relationship between SBP1 and GPX1.
SBP1-TXN Pathway in Thyroid Cancer
In the context of thyroid cancer, SBP1 has been shown to promote tumorigenesis by positively regulating Thioredoxin (TXN), which in turn suppresses the Sodium/Iodide Symporter (NIS), a key protein for thyroid function and differentiation.[11]
Caption: SBP1 promotes thyroid tumorigenesis via the TXN/NIS pathway.[11]
SBP1 in Human Cancer
A significant body of research highlights the role of SBP1 in cancer.[1] A recurring observation is the downregulation of SBP1 expression in various tumor types compared to corresponding normal tissues.[1][6] This reduction is often associated with increased proliferation and poor clinical prognosis, suggesting a tumor-suppressive role.[1][6]
Quantitative Data in Lung Adenocarcinoma
Studies using quantitative 2-D PAGE analysis have provided specific data on SBP1 protein levels in cancer. In lung adenocarcinomas, the levels of an acidic isoform of SBP1 were significantly decreased compared to normal lung tissue.[9]
| Protein/Ratio Analyzed | Lung Adenocarcinoma (n=76) | Normal Lung (n=9) | P-value | Conclusion |
| Acidic SBP1 (spot 457) | Mean level decreased | Higher mean level | p = 0.02 | Significantly decreased in tumors.[9] |
| Ratio (spot 457/460) | Mean ratio decreased | Higher mean ratio | p = 0.01 | Significantly decreased in tumors.[9] |
| Native SBP1 (spot 460) | Not significantly different | Not significantly different | NS | No significant change.[9] |
| Total SBP1 (457+460) | Not significantly different | Not significantly different | NS | No significant change.[9] |
Furthermore, a significant negative correlation was found between SBP1 protein staining and the proliferation marker Ki-67 in lung adenocarcinomas (r = -0.97, p = 0.002), indicating that SBP1 expression is lower in highly proliferating tumors.[9]
Methodologies for SBP1 Characterization
The study of SBP1 relies on a combination of proteomic, immunochemical, and molecular biology techniques. Below are detailed protocols for key experiments.
Protocol: Immunoprecipitation (IP) for SBP1 Interaction Studies
This protocol is designed to isolate SBP1 and its binding partners from a cell lysate.
1. Cell Lysate Preparation: a. Harvest approximately 1x10⁷ cells by centrifugation (e.g., 400 x g for 10 minutes).[12] b. Wash the cell pellet twice with ice-cold Phosphate-Buffered Saline (PBS). c. Resuspend the pellet in 1 mL of ice-cold IP Lysis Buffer (e.g., 50mM Tris-HCl pH 8.0, 150mM NaCl, 1% NP-40) supplemented with a protease inhibitor cocktail.[12] d. Incubate on ice for 30 minutes with periodic vortexing.[13] e. Clarify the lysate by centrifugation at >12,000 x g for 15 minutes at 4°C. Transfer the supernatant to a new pre-chilled tube.
2. Pre-clearing the Lysate: a. Add 20-25 µL of Protein A/G agarose bead slurry to ~500 µL of the clarified lysate.[14] b. Incubate on a rotator for 1 hour at 4°C to reduce non-specific binding.[14] c. Pellet the beads by centrifugation (e.g., 200 x g for 5 minutes) and carefully transfer the supernatant (pre-cleared lysate) to a new tube.[15]
3. Immunoprecipitation: a. Add 2-10 µg of anti-SBP1 primary antibody to the pre-cleared lysate. For a negative control, add an equivalent amount of isotype-matched IgG.[15] b. Incubate on a rotator for 3 hours to overnight at 4°C. c. Add 50 µL of fresh Protein A/G bead slurry to each reaction.[12] d. Incubate on a rotator for an additional 1-3 hours at 4°C to capture the antibody-antigen complexes.[15]
4. Washing and Elution: a. Pellet the beads by centrifugation (200 x g for 5 minutes) and discard the supernatant.[15] b. Wash the beads three to five times with 500 µL of cold IP Lysis Buffer. After each wash, pellet the beads and completely remove the supernatant.[12][15] c. After the final wash, add 40-50 µL of 1X Laemmli sample buffer to the bead pellet.[15] d. Boil the samples at 95-100°C for 5-10 minutes to dissociate the complexes from the beads.[12] e. Centrifuge to pellet the beads, and collect the supernatant containing the immunoprecipitated proteins for analysis by Western blotting or mass spectrometry.
Protocol: Mass Spectrometry (MS) for SBP1 Identification
This protocol outlines the steps for identifying SBP1 from a protein band excised from a polyacrylamide gel.
1. In-Gel Digestion: a. Excise the protein spot of interest (e.g., ~56 kDa) from a Coomassie-stained SDS-PAGE gel. b. Destain the gel piece with a solution of 50% acetonitrile (ACN) and 50 mM ammonium bicarbonate until clear. c. Dehydrate the gel piece with 100% ACN. d. Reduce the proteins with 10 mM DTT in 100 mM ammonium bicarbonate for 1 hour at 56°C. e. Alkylate the proteins with 55 mM iodoacetamide in 100 mM ammonium bicarbonate for 45 minutes in the dark. f. Wash the gel piece with ammonium bicarbonate and dehydrate again with ACN. g. Rehydrate the gel piece in a minimal volume of sequencing-grade trypsin solution (e.g., 10-20 ng/µL) and incubate overnight at 37°C.
2. Peptide Extraction and Preparation: a. Extract the peptides from the gel piece using a series of ACN and 5% formic acid washes. b. Pool the extracts and dry them completely in a vacuum centrifuge. c. Reconstitute the dried peptides in a small volume of MS-grade solvent (e.g., 0.1% formic acid in water) for analysis.
3. LC-MS/MS Analysis: a. Inject the peptide sample into a liquid chromatography system coupled to a tandem mass spectrometer (e.g., ESI-MS/MS). b. Peptides are separated on a reversed-phase column using a gradient of increasing ACN concentration. c. The mass spectrometer acquires MS1 scans to measure the mass-to-charge ratio (m/z) of eluting peptides, followed by MS2 scans where selected peptides are fragmented to determine their amino acid sequence.
4. Data Analysis: a. Process the raw MS/MS data using a database search algorithm (e.g., Mascot, Sequest). b. Search the fragmentation spectra against a human protein database (e.g., UniProt/Swiss-Prot).[5] c. Identify SBP1 based on matched peptides, sequence coverage, and statistical scores.[9]
Protocol: Cellular Localization by Immunofluorescence
This protocol describes how to visualize the subcellular location of SBP1 within cultured cells.
1. Cell Preparation: a. Grow cells to 60-80% confluency on sterile glass coverslips in a petri dish. b. Wash the cells gently with PBS.
2. Fixation and Permeabilization: a. Fix the cells by incubating with 4% paraformaldehyde in PBS for 15 minutes at room temperature. b. Wash the cells three times with PBS. c. Permeabilize the cell membranes by incubating with 0.1-0.25% Triton X-100 in PBS for 10 minutes. This allows antibodies to access intracellular antigens.
3. Blocking and Antibody Incubation: a. Wash the cells three times with PBS. b. Block non-specific antibody binding by incubating with a blocking buffer (e.g., 1-5% BSA in PBS) for 1 hour at room temperature. c. Dilute the primary anti-SBP1 antibody in the blocking buffer to its optimal concentration. d. Aspirate the blocking buffer and incubate the cells with the primary antibody solution overnight at 4°C in a humidified chamber.
4. Secondary Antibody Incubation and Mounting: a. Wash the cells three times with PBS. b. Dilute a fluorescently-conjugated secondary antibody (e.g., Alexa Fluor 488 anti-rabbit IgG) in blocking buffer. Protect from light. c. Incubate the cells with the secondary antibody solution for 1 hour at room temperature in the dark. d. (Optional) Counterstain nuclei by incubating with a DNA dye like DAPI for 5 minutes. e. Wash the cells three times with PBS. f. Mount the coverslip onto a microscope slide using a drop of anti-fade mounting medium.
5. Imaging: a. Visualize the cells using a fluorescence or confocal microscope with the appropriate filters for the chosen fluorophore and DAPI. The resulting image will show the location of SBP1 within the cell.
References
- 1. Selenium-Binding Protein 1 in Human Health and Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Selenium-Binding Protein 1 in Human Health and Disease - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. mdpi.com [mdpi.com]
- 4. Selenium-Binding Protein 1 (SBP1): A New Putative Player of Stress Sensing in Plants - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. uniprot.org [uniprot.org]
- 6. Selenium-binding protein 1 as a tumor suppressor and a prognostic indicator of clinical outcome - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Selenium-Binding Protein 1 (SBP1): A New Putative Player of Stress Sensing in Plants - PMC [pmc.ncbi.nlm.nih.gov]
- 8. mdpi.com [mdpi.com]
- 9. researchgate.net [researchgate.net]
- 10. genecards.org [genecards.org]
- 11. SBP1 promotes tumorigenesis of thyroid cancer through TXN/NIS pathway - PMC [pmc.ncbi.nlm.nih.gov]
- 12. usbio.net [usbio.net]
- 13. protocols.io [protocols.io]
- 14. neb.com [neb.com]
- 15. www2.nau.edu [www2.nau.edu]
The Role of Selenium-Binding Protein 1 in Cancer Progression: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Abstract
Selenium-Binding Protein 1 (SELENBP1) is a ubiquitously expressed protein that has garnered significant attention for its putative role as a tumor suppressor. Accumulating evidence indicates a frequent downregulation of SELENBP1 expression across a spectrum of human malignancies, which often correlates with poor prognosis and advanced disease stages. This technical guide provides a comprehensive overview of the current understanding of SELENBP1's role in cancer progression, detailing its involvement in key cellular processes and signaling pathways. We present a compilation of quantitative data on SELENBP1 expression, detailed experimental protocols for its study, and visual representations of its molecular interactions and regulatory networks. This document aims to serve as a valuable resource for researchers and professionals in the fields of oncology and drug development, facilitating further investigation into SELENBP1 as a potential biomarker and therapeutic target.
Introduction
Selenium, an essential trace element, is known for its cancer-preventive properties, which are mediated in part by a class of proteins known as selenoproteins and selenium-binding proteins. Among these, Selenium-Binding Protein 1 (SELENBP1) has emerged as a key player in carcinogenesis.[1] Encoded by the SELENBP1 gene, this protein is involved in a variety of cellular functions, including the regulation of cell growth, migration, and apoptosis.[2][3] Numerous studies have documented the diminished expression of SELENBP1 in various cancers, including but not limited to lung, breast, colorectal, gastric, ovarian, and prostate cancers.[4][5][6][7] This downregulation is often associated with tumor progression, metastasis, and resistance to therapy, highlighting its clinical significance.[8][9] This guide will delve into the molecular mechanisms underlying the tumor-suppressive functions of SELENBP1, the signaling pathways it modulates, and the experimental approaches used to elucidate its role in cancer.
Quantitative Data on SELENBP1 Expression in Cancer
The downregulation of SELENBP1 is a recurrent observation in many cancer types. Analysis of large-scale cancer genomics datasets, such as The Cancer Genome Atlas (TCGA) and Gene Expression Omnibus (GEO), has consistently shown lower SELENBP1 mRNA and protein levels in tumor tissues compared to their normal counterparts.[3][10][11] Furthermore, reduced SELENBP1 expression has been demonstrated to be an independent prognostic factor for poor survival in several cancers.[5][8]
Table 1: SELENBP1 Expression in Various Cancers and its Correlation with Clinicopathological Features
| Cancer Type | Expression Status in Tumor vs. Normal Tissue | Correlation with Poor Prognosis/Advanced Stage | Reference(s) |
| Lung Cancer (NSCLC) | Significantly decreased in NSCLC tissues. | Associated with higher lymph node metastasis and lower overall survival. | [2][7] |
| Breast Cancer | Reduced compared to normal breast tissue. | Low expression in ER+ patients is significantly associated with poor survival and advancing clinical stages. | [4][9] |
| Colorectal Cancer (CRC) | Significantly decreased in CRC tissues. | High expression is an independent predictor of favorable prognosis. Decreased in metastatic vs. primary CRCs. | [3][10] |
| Gastric Cancer | Significantly decreased. | Correlated with differentiation, TNM stage, and lymph node metastasis. Associated with a poor survival rate. | [6][7] |
| Oral Squamous Cell Carcinoma (OSCC) | Downregulated. | Positively correlated with a poor prognosis. | [7] |
| Bladder Cancer | Frequently downregulated. | Significantly correlates with tumor progression and unfavorable prognosis. | [12] |
| Renal Cell Carcinoma (RCC) | Significantly lower in tumor tissues. | Independent predictor of cancer-specific death. | [5] |
| Nasopharyngeal Carcinoma (NPC) | Low expression. | Associated with poor overall survival, tumor recurrence-free survival, and tumor metastasis-free survival. | [8] |
Key Signaling Pathways Involving SELENBP1
SELENBP1 exerts its tumor-suppressive effects by modulating several critical signaling pathways that govern cell proliferation, survival, and stress responses.
PI3K/AKT/mTOR Pathway
In non-small cell lung cancer (NSCLC), overexpression of SELENBP1 has been shown to inhibit malignant characteristics by inactivating the PI3K/AKT/mTOR signaling pathway.[2] This pathway is a central regulator of cell growth, proliferation, and survival, and its aberrant activation is a hallmark of many cancers.
KEAP1-NRF2 Signaling Pathway
SELENBP1 has been identified as a regulator of the KEAP1-NRF2 pathway, which is a critical cellular defense mechanism against oxidative and electrophilic stress.[13] Under normal conditions, KEAP1 targets the transcription factor NRF2 for ubiquitination and proteasomal degradation. In response to stress, NRF2 is stabilized, translocates to the nucleus, and activates the transcription of antioxidant and cytoprotective genes. In some cancer contexts, SELENBP1 can promote NRF2 degradation, thereby sensitizing cancer cells to chemotherapy.
p53-Independent Induction of p21
In bladder cancer, SELENBP1 has been shown to transcriptionally activate the cyclin-dependent kinase inhibitor p21 in a p53-independent manner.[14][15] This induction of p21 is crucial for SELENBP1-mediated cell cycle arrest at the G0/G1 phase.
Experimental Protocols
This section provides an overview of the key experimental methodologies used to investigate the function of SELENBP1 in cancer research.
Analysis of SELENBP1 Expression
4.1.1. Quantitative Real-Time PCR (qRT-PCR)
-
Objective: To quantify SELENBP1 mRNA expression levels in tissues and cells.
-
Procedure:
-
Total RNA is extracted from samples using a suitable kit (e.g., RNeasy Purification Kit).[16]
-
RNA quality and quantity are assessed using a spectrophotometer.
-
cDNA is synthesized from the total RNA using a reverse transcription kit with random hexamer or oligo(dT) primers.[16][17]
-
qRT-PCR is performed using a real-time PCR system with SELENBP1-specific primers and a fluorescent dye (e.g., SYBR Green) or a probe.
-
A housekeeping gene (e.g., GAPDH, ACTB) is used as an internal control for normalization.
-
Relative quantification is typically calculated using the 2-ΔΔCT method.[18]
-
4.1.2. Western Blotting
-
Objective: To detect and quantify SELENBP1 protein levels.
-
Procedure:
-
Cells or tissues are lysed in a suitable buffer (e.g., RIPA buffer) containing protease inhibitors.[19][20]
-
Protein concentration is determined using a protein assay (e.g., BCA or Bradford assay).[20]
-
Equal amounts of protein are separated by SDS-PAGE and transferred to a PVDF or nitrocellulose membrane.[21][22]
-
The membrane is blocked with a blocking agent (e.g., 5% non-fat milk or 3% BSA in TBST) to prevent non-specific antibody binding.[21]
-
The membrane is incubated with a primary antibody specific for SELENBP1.[14][23][24]
-
After washing, the membrane is incubated with a horseradish peroxidase (HRP)-conjugated secondary antibody.[21]
-
The protein bands are visualized using an enhanced chemiluminescence (ECL) detection system.[19]
-
A loading control protein (e.g., GAPDH, β-actin) is used to ensure equal protein loading.[12]
-
4.1.3. Immunohistochemistry (IHC)
-
Objective: To examine the expression and localization of SELENBP1 protein in tissue sections.
-
Procedure:
-
Paraffin-embedded tissue sections are deparaffinized and rehydrated.[25]
-
Antigen retrieval is performed to unmask the antigenic epitopes, often using heat-induced methods with a citrate or EDTA buffer.[25][26]
-
Endogenous peroxidase activity is blocked with hydrogen peroxide.[25]
-
Sections are incubated with a blocking solution (e.g., normal serum) to reduce non-specific binding.[27]
-
Sections are incubated with a primary antibody against SELENBP1.[26][28]
-
A secondary antibody, often biotinylated or polymer-based, is applied, followed by an enzyme conjugate (e.g., streptavidin-HRP).[29]
-
The signal is developed using a chromogen (e.g., DAB), resulting in a colored precipitate at the site of the antigen.[27]
-
Sections are counterstained (e.g., with hematoxylin) and mounted.[25]
-
Staining intensity and distribution are evaluated microscopically.
-
Functional Assays
4.2.1. Cell Proliferation, Migration, and Invasion Assays
-
Objective: To assess the effect of SELENBP1 on cancer cell proliferation, migration, and invasion.
-
Methods:
-
Proliferation: CCK-8 or MTS assays, EdU incorporation assays, and colony formation assays.[3]
-
Migration: Wound healing (scratch) assays and Transwell migration assays (without Matrigel).[3][30][31][32]
-
Invasion: Transwell invasion assays where the insert is coated with a basement membrane matrix (e.g., Matrigel).[3][32][33]
-
4.2.2. Apoptosis Assays
-
Objective: To determine if SELENBP1 induces apoptosis.
-
Methods:
Gene Manipulation Techniques
4.3.1. SELENBP1 Overexpression
-
Objective: To study the effects of restoring SELENBP1 expression in cancer cells.
-
Procedure:
-
The full-length coding sequence of SELENBP1 is cloned into an expression vector (e.g., pcDNA3.1).
-
The expression plasmid is transfected into cancer cells with low endogenous SELENBP1 expression using a suitable transfection reagent (e.g., Lipofectamine).
-
Overexpression is confirmed by qRT-PCR and Western blotting.
-
Stable cell lines can be generated by selecting transfected cells with an appropriate antibiotic.
-
4.3.2. SELENBP1 Knockdown
-
Objective: To investigate the consequences of reduced SELENBP1 expression.
-
Methods:
-
Procedure (shRNA):
-
Design and clone shRNA sequences targeting SELENBP1 into a suitable vector.
-
Produce lentiviral or retroviral particles by co-transfecting the shRNA plasmid with packaging plasmids into a packaging cell line (e.g., HEK293T).
-
Infect the target cancer cells with the viral particles.
-
Select for transduced cells using an appropriate selection marker (e.g., puromycin).
-
Knockdown efficiency is validated by qRT-PCR and Western blotting.
-
Experimental and Logical Workflows
Visualizing the workflow of experiments designed to study SELENBP1 function can aid in understanding the research process.
References
- 1. researchgate.net [researchgate.net]
- 2. Selenium-binding protein 1 inhibits malignant progression and induces apoptosis via distinct mechanisms in non-small cell lung cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. SELENBP1 inhibits progression of colorectal cancer by suppressing epithelial–mesenchymal transition - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. Decreased selenium-binding protein 1 mRNA expression is associated with poor prognosis in renal cell carcinoma - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Frontiers | The role of SELENBP1 and its epigenetic regulation in carcinogenic progression [frontiersin.org]
- 7. The role of SELENBP1 and its epigenetic regulation in carcinogenic progression - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Selenium-binding protein 1 in head and neck cancer is low-expression and associates with the prognosis of nasopharyngeal carcinoma - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. Tumor microenvironment-related gene selenium-binding protein 1 (SELENBP1) is associated with immunotherapy efficacy and survival in colorectal cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. researchgate.net [researchgate.net]
- 13. mdpi.com [mdpi.com]
- 14. Selenium-binding protein 1 transcriptionally activates p21 expression via p53-independent mechanism and its frequent reduction associates with poor prognosis in bladder cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Selenium-binding protein 1 transcriptionally activates p21 expression via p53-independent mechanism and its frequent reduction associates with poor prognosis in bladder cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. Short Hairpin RNA (shRNA): Design, Delivery, and Assessment of Gene Knockdown - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Protective Role of Selenium-Binding Protein 1 (SELENBP1) in Patients with Ulcerative Colitis - PMC [pmc.ncbi.nlm.nih.gov]
- 18. aacrjournals.org [aacrjournals.org]
- 19. Selenium-binding protein 1 (SELENBP1) is a marker of mature adipocytes - PMC [pmc.ncbi.nlm.nih.gov]
- 20. assaygenie.com [assaygenie.com]
- 21. bio-rad.com [bio-rad.com]
- 22. biomol.com [biomol.com]
- 23. researchgate.net [researchgate.net]
- 24. researchgate.net [researchgate.net]
- 25. genscript.com [genscript.com]
- 26. origene.com [origene.com]
- 27. docs.abcam.com [docs.abcam.com]
- 28. SELENBP1 antibody Immunohistochemistry HPA005741 [sigmaaldrich.com]
- 29. Immunohistochemistry Procedure [sigmaaldrich.com]
- 30. researchgate.net [researchgate.net]
- 31. researchgate.net [researchgate.net]
- 32. Frontiers | In vitro Cell Migration, Invasion, and Adhesion Assays: From Cell Imaging to Data Analysis [frontiersin.org]
- 33. Cell Migration and Invasion Assay Guidance using Millicell® Cell Culture Inserts [sigmaaldrich.com]
- 34. Selenium‐binding protein 1 inhibits malignant progression and induces apoptosis via distinct mechanisms in non‐small cell lung cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 35. scbt.com [scbt.com]
- 36. Preparation and Use of shRNA for Knocking Down Specific Genes | Springer Nature Experiments [experiments.springernature.com]
- 37. Preparation and Use of shRNA for Knocking Down Specific Genes - PubMed [pubmed.ncbi.nlm.nih.gov]
- 38. go.technologynetworks.com [go.technologynetworks.com]
SBP-1: A Potential Biomarker for Oxidative Stress - An In-depth Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Executive Summary
Oxidative stress, an imbalance between the production of reactive oxygen species (ROS) and the cellular antioxidant defense system, is a key contributor to the pathophysiology of numerous diseases, including cancer, neurodegenerative disorders, and cardiovascular diseases. The identification of reliable biomarkers to monitor oxidative stress is crucial for diagnostics, prognostics, and the development of novel therapeutic interventions. Selenium-Binding Protein 1 (SBP-1), a highly conserved protein, has emerged as a promising candidate biomarker for oxidative stress. This technical guide provides a comprehensive overview of the core evidence supporting the role of this compound in oxidative stress, detailing its molecular mechanisms, quantitative expression data, and standardized experimental protocols for its measurement.
Introduction to this compound and Oxidative Stress
Selenium-Binding Protein 1 (this compound), also known as methanethiol oxidase (MTO), is a ubiquitously expressed protein with a multifaceted role in cellular physiology.[1][2] While initially identified for its ability to bind selenium, recent research has unveiled its enzymatic function in metabolizing sulfur-containing compounds.[3] Oxidative stress arises from an excess of ROS, which can damage cellular components like lipids, proteins, and DNA.[4] Cells have evolved intricate defense mechanisms to counteract oxidative stress, with the Keap1-Nrf2 signaling pathway being a central regulator of antioxidant gene expression.[5][6] this compound is implicated in cellular stress responses, and its expression and activity are modulated under conditions of oxidative stress, positioning it as a potential indicator of this pathological state.[7][8]
Molecular Mechanisms of this compound in Oxidative Stress
Methanethiol Oxidase Activity
The primary enzymatic function of this compound is the copper-dependent oxidation of methanethiol, a byproduct of metabolism.[1][7] This reaction produces hydrogen peroxide (H₂O₂), hydrogen sulfide (H₂S), and formaldehyde.[2][9] Both H₂O₂ and H₂S are recognized as important signaling molecules that can modulate cellular responses to oxidative stress.[8][9] At low concentrations, they can activate protective pathways, while at high concentrations, they contribute to cellular damage.
Figure 1: Methanethiol Oxidase Activity of this compound.
Interaction with the Keap1-Nrf2 Pathway
The Keap1-Nrf2 pathway is a master regulator of the antioxidant response.[5] Under basal conditions, Keap1 targets the transcription factor Nrf2 for degradation.[4] Upon exposure to oxidative stress, Keap1 is modified, leading to the stabilization and nuclear translocation of Nrf2.[4] Nrf2 then activates the transcription of a battery of antioxidant and cytoprotective genes. While a direct interaction between this compound and the Keap1-Nrf2 pathway is still under investigation, the production of H₂O₂ by this compound suggests a potential for crosstalk. H₂O₂ is a known activator of the Nrf2 pathway, indicating that this compound activity could indirectly lead to the upregulation of antioxidant defenses.
Figure 2: Potential Crosstalk between this compound and the Keap1-Nrf2 Pathway.
Quantitative Data on this compound in Oxidative Stress
The utility of a biomarker lies in its quantifiable change in response to a specific condition. Several studies have demonstrated alterations in this compound expression or related proteins under oxidative stress.
| Model System | Stress Inducer | Analyte | Fold Change | Reference |
| SH-SY5Y neuroblastoma cells | Hydrogen Peroxide (H₂O₂) | Polypyrimidine tract-binding protein 1 (PTBP1) | 2.12 (Upregulation) | [5] |
| Chlamydomonas reinhardtii | Hydrogen Peroxide (H₂O₂) | CrGAPN1 (this compound interacting protein) | Upregulated (Statistically significant) | [10] |
| Channa punctatus (liver) | Mancozeb | XBP1s mRNA | 2.4 - 5.1 (Upregulation) | [4] |
| Channa punctatus (liver) | Mancozeb | NOX4 mRNA | 3.3 (Upregulation) | [4] |
Table 1: Quantitative Changes in this compound and Related Molecules Under Oxidative Stress. Note: While direct quantitative data for mammalian this compound is emerging, the data presented for related and interacting proteins provide a strong rationale for its potential as a quantitative biomarker.
Experimental Protocols for this compound Measurement
Accurate and reproducible measurement is paramount for validating a biomarker. The following section details key experimental protocols for quantifying this compound.
Measurement of this compound Methanethiol Oxidase (MTO) Activity
This coupled enzymatic assay measures the production of H₂O₂ resulting from this compound's MTO activity.[1]
Materials:
-
Recombinant methionine gamma-lyase (MGL)
-
L-methionine
-
Fluorometric Hydrogen Peroxide Assay Kit
-
384-well plates
-
Microplate reader with fluorescence capabilities (e.g., CLARIOstar)
Procedure:
-
Prepare MTO reaction mixes in a 384-well plate containing the sample with potential MTO activity (e.g., recombinant this compound, cell lysates).
-
In adjacent wells, prepare MGL reaction mixes to generate methanethiol from L-methionine.
-
Incubate the plate to allow the MGL-produced methanethiol to diffuse and react with this compound in the MTO reaction wells.
-
Measure the H₂O₂ produced in the MTO reaction wells using a fluorometric hydrogen peroxide assay kit according to the manufacturer's instructions.
-
Read the fluorescence at an excitation of 540 nm and an emission of 590 nm.
-
The MTO activity is proportional to the measured fluorescence.
Figure 3: Workflow for this compound MTO Activity Assay.
Western Blotting for this compound Protein Levels
Western blotting allows for the semi-quantitative detection of this compound protein in cell or tissue lysates.[11][12][13]
Materials:
-
Lysis buffer (e.g., RIPA buffer) with protease inhibitors
-
SDS-PAGE gels
-
Nitrocellulose or PVDF membranes
-
Transfer buffer
-
Blocking buffer (e.g., 5% non-fat milk or BSA in TBST)
-
Primary antibody specific for this compound
-
HRP-conjugated secondary antibody
-
Chemiluminescent substrate
-
Imaging system
Procedure:
-
Sample Preparation: Lyse cells or tissues in lysis buffer on ice. Centrifuge to pellet debris and collect the supernatant. Determine protein concentration using a BCA assay.
-
Gel Electrophoresis: Denature protein samples in Laemmli buffer and separate them by SDS-PAGE.
-
Protein Transfer: Transfer the separated proteins to a nitrocellulose or PVDF membrane.
-
Blocking: Block the membrane with blocking buffer for 1 hour at room temperature to prevent non-specific antibody binding.
-
Primary Antibody Incubation: Incubate the membrane with the primary anti-SBP-1 antibody overnight at 4°C with gentle agitation.
-
Washing: Wash the membrane three times with TBST for 5-10 minutes each.
-
Secondary Antibody Incubation: Incubate the membrane with the HRP-conjugated secondary antibody for 1 hour at room temperature.
-
Washing: Repeat the washing steps.
-
Detection: Add the chemiluminescent substrate and visualize the protein bands using an imaging system.
-
Analysis: Quantify band intensities using densitometry software and normalize to a loading control (e.g., GAPDH, β-actin).
Enzyme-Linked Immunosorbent Assay (ELISA) for this compound Concentration
ELISA provides a quantitative measurement of this compound concentration in various biological samples.[6][14] A sandwich ELISA is a common format.
Materials:
-
ELISA plate pre-coated with a capture antibody specific for this compound
-
Detection antibody specific for this compound (biotinylated)
-
Streptavidin-HRP conjugate
-
TMB substrate
-
Stop solution (e.g., H₂SO₄)
-
Wash buffer
-
Sample diluent
-
This compound standard
-
Microplate reader
Procedure:
-
Sample and Standard Preparation: Prepare a standard curve using the this compound standard. Dilute samples as required.
-
Incubation with Sample/Standard: Add standards and samples to the wells and incubate for 2 hours at room temperature.
-
Washing: Wash the plate several times with wash buffer.
-
Detection Antibody Incubation: Add the biotinylated detection antibody to each well and incubate for 1 hour at room temperature.
-
Washing: Repeat the washing steps.
-
Streptavidin-HRP Incubation: Add the streptavidin-HRP conjugate to each well and incubate for 30 minutes at room temperature.
-
Washing: Repeat the washing steps.
-
Substrate Development: Add the TMB substrate and incubate in the dark for 15-30 minutes.
-
Stopping the Reaction: Add the stop solution to each well.
-
Absorbance Reading: Read the absorbance at 450 nm using a microplate reader.
-
Analysis: Calculate the this compound concentration in the samples by interpolating from the standard curve.
Conclusion and Future Directions
The evidence presented in this technical guide strongly supports the potential of this compound as a valuable biomarker for oxidative stress. Its well-defined enzymatic activity, its link to the production of key signaling molecules involved in redox homeostasis, and its quantifiable changes in response to oxidative insults make it a compelling target for further investigation.
Future research should focus on:
-
Validation in Clinical Samples: Large-scale studies are needed to validate the correlation between this compound levels and the severity of diseases associated with oxidative stress in human patients.
-
Development of Standardized Assays: The development of commercially available, validated ELISA kits for this compound will facilitate its widespread use in clinical and research settings.
-
Elucidation of Upstream Regulation: A deeper understanding of the transcriptional and post-translational regulation of this compound in response to oxidative stress, including its definitive relationship with the Keap1-Nrf2 pathway, will provide further insights into its role as a biomarker.
References
- 1. Transcription factor Nrf2 regulates SHP and lipogenic gene expression in hepatic lipid metabolism - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Quantitative Proteomics Reveals that the OGT Interactome Is Remodeled in Response to Oxidative Stress - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. Hydrogen Peroxide-induced Cell Death in Mammalian Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Quantitative proteomics study of the neuroprotective effects of B12 on hydrogen peroxide-induced apoptosis in SH-SY5Y cells - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Regulation of Nrf2 Signaling - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. biorxiv.org [biorxiv.org]
- 8. mdpi.com [mdpi.com]
- 9. mdpi.com [mdpi.com]
- 10. Emerging functional cross-talk between the Keap1-Nrf2 system and mitochondria - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. Molecular cross-talk between the NRF2/KEAP1 signaling pathway, autophagy, and apoptosis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Efficient peroxide-mediated oxidative refolding of a protein at physiological pH and implications for oxidative folding in the endoplasmic reticulum - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
- 14. Transcriptional Profile of Genes Involved in Oxidative Stress and Antioxidant Defense in a Dietary Murine Model of Steatohepatitis - PMC [pmc.ncbi.nlm.nih.gov]
The Mechanism of SBP-1 Interaction with the SARS-CoV-2 Spike Protein: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Introduction
The severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2), the causative agent of the COVID-19 pandemic, initiates infection by binding to the human angiotensin-converting enzyme 2 (ACE2) receptor via its spike (S) glycoprotein. The receptor-binding domain (RBD) of the spike protein is a prime target for therapeutic intervention. One such strategy involves the development of peptide-based inhibitors that mimic the ACE2 receptor, thereby competitively blocking the virus from entering host cells. This technical guide provides an in-depth analysis of the interaction between a promising peptide inhibitor, Spike-Binding Peptide 1 (SBP-1), and the SARS-CoV-2 spike protein.
This compound is a 23-amino acid peptide derived from the α1 helix of the human ACE2 peptidase domain, specifically mimicking the binding interface with the spike protein's RBD.[1] Its design is predicated on the principle of steric hindrance, aiming to physically obstruct the spike-ACE2 interaction. This document will delve into the quantitative binding data, detailed experimental protocols used to characterize this interaction, and the underlying molecular mechanisms.
Quantitative Analysis of this compound and SARS-CoV-2 Spike Protein Interaction
The binding affinity of this compound to the SARS-CoV-2 spike protein has been a subject of investigation, with some conflicting reports in the literature. These discrepancies may arise from the use of different recombinant spike protein preparations (e.g., produced in insect vs. mammalian cells), the specific experimental techniques employed, and the monomeric versus oligomeric state of this compound in solution.
| Interacting Molecules | Method | Reported Affinity (Kd) | Reported Potency (IC50/EC50) | Reference |
| This compound and Spike RBD | Bio-layer Interferometry | 47 nM | - | [2] |
| This compound and Spike RBD | Microscale Thermophoresis | Weak to no binding | - | [2] |
| This compound and Full-Length Spike Trimer | switchSENSE | - | - | [3][4] |
| This compound fused to IgG1 Fc (SBP1-Ig) | Pseudovirus Neutralization Assay | - | 12-14 pM (D614G variant) | [5] |
| CSNP1 (this compound derivative) | Pseudovirus Neutralization Assay | - | 18 µM (Delta variant) | [1] |
| CSNP4 (this compound derivative) | Pseudovirus Neutralization Assay | - | 0.2 µM (Delta variant) | [1] |
| pep1c (short this compound derivative) | In vitro RBD-ACE2 Inhibition Assay | - | 3.3 ± 0.8 mM | [6] |
Core Interaction Mechanism
The fundamental mechanism of this compound is to act as a competitive inhibitor of the ACE2 receptor. By mimicking the ACE2 α1 helix, this compound binds to the RBD of the spike protein, physically blocking the binding site for ACE2.
Molecular dynamics simulations have been employed to understand the structural basis of this interaction at the atomic level. These simulations suggest that this compound, when bound to the spike RBD, maintains a stable conformation. However, biophysical studies have revealed that in solution, this compound is largely disordered and has a propensity to form oligomers, which may explain the observed lower binding affinities in some experimental setups.[7]
Experimental Protocols
Enzyme-Linked Immunosorbent Assay (ELISA) for Binding Assessment
ELISA is a widely used method to detect and quantify the binding between this compound and the spike protein.
Materials:
-
High-binding 96-well microtiter plates
-
Recombinant SARS-CoV-2 Spike Protein (RBD or full-length)
-
Synthetic this compound peptide
-
Coating Buffer (e.g., 50 mM sodium carbonate, pH 9.6)
-
Wash Buffer (e.g., PBS with 0.05% Tween-20)
-
Blocking Buffer (e.g., 5% BSA in PBS)
-
Primary antibody against the spike protein or a tag (e.g., anti-His)
-
Enzyme-conjugated secondary antibody
-
Substrate solution (e.g., TMB)
-
Stop solution (e.g., 2 M H₂SO₄)
-
Plate reader
Procedure:
-
Coating: Dilute the spike protein to 1-10 µg/mL in coating buffer and add 100 µL to each well. Incubate overnight at 4°C or for 2 hours at room temperature.[8]
-
Washing: Discard the coating solution and wash the wells three times with 200 µL of wash buffer.[9]
-
Blocking: Add 200 µL of blocking buffer to each well and incubate for 1-2 hours at 37°C to prevent non-specific binding.[9][10]
-
Peptide Incubation: Discard the blocking buffer and wash the wells three times. Add serial dilutions of this compound in binding buffer to the wells and incubate for 1-2 hours at 37°C.
-
Primary Antibody Incubation: Wash the wells three times. Add the primary antibody diluted in blocking buffer and incubate for 1 hour at 37°C.[8]
-
Secondary Antibody Incubation: Wash the wells three times. Add the enzyme-conjugated secondary antibody diluted in blocking buffer and incubate for 1 hour at room temperature.[8]
-
Detection: Wash the wells five times with wash buffer. Add 100 µL of substrate solution and incubate in the dark for 15-30 minutes.[8]
-
Readout: Stop the reaction by adding 100 µL of stop solution. Read the absorbance at the appropriate wavelength (e.g., 450 nm for TMB).
Surface Plasmon Resonance (SPR) for Kinetic Analysis
SPR is a label-free technique used to measure the kinetics (association and dissociation rates) and affinity of biomolecular interactions in real-time.
Materials:
-
SPR instrument (e.g., Biacore)
-
Sensor chip (e.g., CM5)
-
Immobilization reagents (e.g., EDC, NHS, ethanolamine)
-
Running buffer (e.g., HBS-EP+)
-
Recombinant spike protein (ligand)
-
This compound peptide (analyte)
-
Regeneration solution (e.g., glycine-HCl, pH 2.5)
Procedure:
-
Ligand Immobilization: Covalently immobilize the spike protein onto the sensor chip surface using amine coupling chemistry.[11]
-
Analyte Injection: Inject a series of concentrations of this compound over the sensor surface at a constant flow rate.[11]
-
Association Phase: Monitor the increase in the SPR signal (response units, RU) as this compound binds to the immobilized spike protein.
-
Dissociation Phase: Flow running buffer over the surface and monitor the decrease in the SPR signal as this compound dissociates.
-
Regeneration: Inject the regeneration solution to remove any remaining bound this compound, preparing the surface for the next injection.
-
Data Analysis: Fit the association and dissociation curves to a suitable binding model (e.g., 1:1 Langmuir) to determine the association rate constant (ka), dissociation rate constant (kd), and the equilibrium dissociation constant (Kd).[12]
Pseudovirus Neutralization Assay
This assay assesses the ability of this compound to inhibit the entry of a non-replicating virus (pseudovirus) carrying the SARS-CoV-2 spike protein into host cells engineered to express the ACE2 receptor.
Materials:
-
Lentiviral or VSV-based pseudovirus expressing the SARS-CoV-2 spike protein and a reporter gene (e.g., luciferase or GFP)
-
Host cell line expressing human ACE2 (e.g., HEK293T-ACE2 or Vero E6)
-
Cell culture medium and supplements
-
This compound peptide
-
96-well cell culture plates
-
Luciferase assay reagent (if applicable)
-
Plate reader or fluorescence microscope
Procedure:
-
Cell Seeding: Seed the ACE2-expressing host cells in a 96-well plate and incubate overnight.
-
Peptide-Virus Incubation: Serially dilute this compound and incubate with a fixed amount of pseudovirus for 1 hour at 37°C.[13][14]
-
Infection: Add the this compound/pseudovirus mixture to the cells and incubate for 48-72 hours.[13]
-
Readout: Measure the reporter gene expression (e.g., luciferase activity or GFP-positive cells).
-
Data Analysis: Calculate the percentage of neutralization for each this compound concentration relative to the virus-only control. Determine the half-maximal inhibitory concentration (IC50) by fitting the data to a dose-response curve.[14]
Signaling Pathways and Downstream Effects
Currently, the primary mechanism of action attributed to this compound is the direct competitive inhibition of the spike-ACE2 interaction. There is limited evidence to suggest that the binding of this compound to the spike protein directly modulates downstream intracellular signaling pathways. SARS-CoV-2 infection itself is known to dysregulate numerous host cell signaling cascades, including those involved in inflammation and the interferon response.[15][16] However, whether this compound can indirectly influence these pathways by preventing viral entry remains an area for further investigation. The focus of this compound research has been on its role as a viral entry blocker.
Conclusion and Future Directions
This compound represents a rationally designed peptide inhibitor of the SARS-CoV-2 spike protein. While initial reports of its binding affinity have varied, its ability to neutralize pseudovirus, particularly when engineered for improved stability and presentation (e.g., as an Fc fusion protein), demonstrates its potential as a therapeutic candidate. The detailed experimental protocols provided in this guide offer a framework for the continued investigation and characterization of this compound and other peptide-based inhibitors.
Future research should focus on several key areas:
-
Structural Elucidation: Obtaining a high-resolution crystal or cryo-EM structure of the this compound/spike protein complex would provide invaluable insights for optimizing peptide design.
-
Improving Biophysical Properties: Strategies to enhance the helical stability and reduce the oligomerization of this compound in solution are crucial for improving its binding affinity and therapeutic efficacy.
-
In Vivo Efficacy: Further studies in animal models are needed to evaluate the in vivo potency, pharmacokinetics, and safety of this compound-based therapeutics.
-
Broad-Spectrum Activity: Investigating the efficacy of this compound against a wider range of SARS-CoV-2 variants is essential to assess its potential as a pan-coronavirus inhibitor.
By addressing these research questions, the scientific community can continue to advance the development of this compound and other peptide-based antivirals as a critical component of our arsenal against COVID-19 and future coronavirus threats.
References
- 1. SARS-CoV-2 pan-variant inhibitory peptides deter S1-ACE2 interaction and neutralize delta and omicron pseudoviruses - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Peptide Inhibitors of the Interaction of the SARS-CoV-2 Receptor-Binding Domain with the ACE2 Cell Receptor - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. Characterization of binding interactions of SARS-CoV-2 spike protein and DNA-peptide nanostructures - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Comparison of SARS-CoV-2 entry inhibitors based on ACE2 receptor or engineered Spike-binding peptides - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Native Structure-Based Peptides as Potential Protein–Protein Interaction Inhibitors of SARS-CoV-2 Spike Protein and Human ACE2 Receptor [mdpi.com]
- 7. Biophysical properties of the isolated spike protein binding helix of human ACE2 - PMC [pmc.ncbi.nlm.nih.gov]
- 8. affbiotech.com [affbiotech.com]
- 9. ulab360.com [ulab360.com]
- 10. ELISA-Peptide Assay Protocol | Cell Signaling Technology [cellsignal.com]
- 11. files01.core.ac.uk [files01.core.ac.uk]
- 12. reactionbiology.com [reactionbiology.com]
- 13. Evaluation of a Pseudovirus Neutralization Assay for SARS-CoV-2 and Correlation with Live Virus-Based Micro Neutralization Assay - PMC [pmc.ncbi.nlm.nih.gov]
- 14. tandfonline.com [tandfonline.com]
- 15. SARS-CoV-2 infection induces ZBP1-dependent PANoptosis in bystander cells - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Inhibition of the SREBP pathway prevents SARS-CoV-2 replication and inflammasome activation - PMC [pmc.ncbi.nlm.nih.gov]
Evolutionary Conservation of the SBP-1/SREBP Pathway: An In-depth Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Introduction
The Sterol Regulatory Element-Binding Protein (SREBP) pathway is a critical evolutionarily conserved signaling cascade that governs lipid homeostasis across a wide range of species, from yeast to humans. In mammals, this pathway is essential for the synthesis and uptake of cholesterol, fatty acids, and triglycerides.[1][2][3] The core components and regulatory logic of this pathway are remarkably well-preserved, making it a valuable system for studying metabolic regulation and a promising target for therapeutic intervention in diseases such as metabolic syndrome, fatty liver disease, and cancer. This technical guide provides a comprehensive overview of the evolutionary conservation of the SBP-1/SREBP pathway, detailing its core components, regulatory mechanisms, and the experimental methodologies used for its investigation.
Core Components and Their Evolutionary Conservation
The central components of the SREBP pathway include the SREBP transcription factors themselves, the SREBP Cleavage-Activating Protein (SCAP), and two proteases, Site-1 Protease (S1P) and Site-2 Protease (S2P).[1][3] The functional conservation of these proteins is evident from studies in various model organisms, including the nematode Caenorhabditis elegans and the fruit fly Drosophila melanogaster.
This compound/SREBP: The Master Transcriptional Regulator
Sterol Regulatory Element-Binding Proteins (SREBPs) are transcription factors of the basic helix-loop-helix leucine zipper (bHLH-Zip) family.[1] A defining feature of SREBPs is a tyrosine residue within the basic region, which allows them to bind to Sterol Regulatory Elements (SREs) in the promoters of target genes.[1]
In mammals, there are three main SREBP isoforms encoded by two genes: SREBP-1a and SREBP-1c (from the SREBF1 gene) and SREBP-2 (from the SREBF2 gene).[2] SREBP-1c primarily regulates fatty acid synthesis, while SREBP-2 is the main regulator of cholesterol metabolism.[3][4] C. elegans possesses a single SREBP homolog, this compound, which is functionally analogous to mammalian SREBP-1c and is crucial for fat storage and fatty acid metabolism.[5][6] Drosophila also has a single SREBP homolog (dSREBP or HLH106) that primarily regulates fatty acid synthesis.[7][8][9]
| Protein | Human Ortholog | C. elegans Ortholog | Drosophila Ortholog | Key Conserved Features |
| SREBP | SREBP-1c (SREBF1) | This compound | dSREBP (HLH106) | bHLH-Zip domain, two transmembrane helices, tyrosine in the basic region for SRE binding. |
| SCAP | SCAP | SCAP homolog | dSCAP | Sterol-Sensing Domain (SSD), WD40 repeats for SREBP binding. |
| S1P | MBTPS1 | S1P homolog | dS1P | Serine protease catalytic domain. |
| S2P | MBTPS2 | S2P homolog | dS2P | Zinc metalloprotease catalytic domain. |
SCAP: The Sterol Sensor and Escort Protein
SREBP Cleavage-Activating Protein (SCAP) is a polytopic membrane protein that acts as both a sterol sensor and an escort for SREBP.[1][3] A key feature of SCAP is the Sterol-Sensing Domain (SSD), a conserved motif also found in other proteins involved in cholesterol homeostasis.[1] In the presence of high sterol levels, SCAP binds to cholesterol and undergoes a conformational change that promotes its interaction with the Insulin-induced gene (INSIG) proteins, retaining the SREBP-SCAP complex in the endoplasmic reticulum (ER).[1] When sterol levels are low, SCAP escorts SREBP from the ER to the Golgi apparatus for processing.[3] Homologs of SCAP have been identified in Drosophila (dSCAP) and C. elegans, where they perform a similar escort function, although the regulation by sterols can differ.[8]
S1P and S2P: The Proteolytic Machinery
Site-1 Protease (S1P) and Site-2 Protease (S2P) are the enzymes responsible for the sequential cleavage of SREBP in the Golgi apparatus.[3] S1P is a serine protease that initiates the cleavage, while S2P is a zinc metalloprotease that performs the second cleavage within the transmembrane domain, releasing the mature, transcriptionally active N-terminal domain of SREBP.[3] This proteolytic cascade is highly conserved, with functional homologs of S1P and S2P found in Drosophila and other metazoans.[8]
Regulatory Mechanisms: A Conserved Logic with Species-Specific Adaptations
The central regulatory mechanism of the SREBP pathway involves the controlled proteolytic release of the SREBP transcription factor from the ER membrane in response to cellular lipid status. This process is tightly regulated by sterols and other metabolic signals.
The SREBP Activation Pathway
Caption: The SREBP activation pathway is regulated by cellular sterol levels.
While the core machinery is conserved, the specific signals that regulate SREBP processing have adapted to the unique metabolic needs of different organisms. In mammals, cholesterol is a primary regulator.[1] In contrast, Drosophila, a cholesterol auxotroph, regulates its SREBP in response to palmitic acid, a saturated fatty acid.[8] This suggests that the ancestral role of the SREBP pathway was likely to maintain membrane integrity rather than cholesterol homeostasis.[8]
SREBP Target Genes: Conserved and Divergent Roles
The transcriptional targets of SREBP reflect the metabolic priorities of the organism. In mammals, SREBP-1c activates genes involved in fatty acid synthesis such as Fatty Acid Synthase (FASN) and Acetyl-CoA Carboxylase (ACC), while SREBP-2 upregulates genes in the cholesterol biosynthetic pathway, including HMG-CoA Reductase (HMGCR).
In C. elegans, this compound regulates the expression of genes involved in fatty acid desaturation and elongation, such as fat-5, fat-6, and fat-7.[5] Similarly, in Drosophila, dSREBP controls the expression of fatty acid synthesis genes.[8]
| Organism | Key SREBP/SBP-1 Target Genes | Primary Metabolic Pathway Regulated |
| Human | FASN, ACC, SCD (SREBP-1c) HMGCR, LDLR (SREBP-2) | Fatty Acid & Cholesterol Synthesis |
| C. elegans | fat-5, fat-6, fat-7, elo-2 | Fatty Acid Desaturation & Elongation |
| Drosophila | FAS, ACC | Fatty Acid Synthesis |
Experimental Protocols for Studying the this compound/SREBP Pathway
A variety of experimental techniques are employed to investigate the different aspects of the this compound/SREBP pathway.
Analysis of this compound/SREBP Activation: Nuclear Translocation
Objective: To determine the amount of active, nuclear this compound/SREBP.
Methodology: Protein Extraction and Western Blotting [11][12][13]
-
Cell/Tissue Lysis:
-
For cultured cells, wash with ice-cold PBS and lyse in a hypotonic buffer to swell the cells.
-
For tissues, homogenize in a suitable lysis buffer.
-
-
Nuclear and Cytoplasmic Fractionation:
-
Disrupt the cell membrane using a detergent (e.g., NP-40) and centrifuge to pellet the nuclei. The supernatant contains the cytoplasmic fraction.
-
Wash the nuclear pellet and then lyse it using a high-salt nuclear extraction buffer to release nuclear proteins.
-
-
Protein Quantification: Determine the protein concentration of both fractions using a BCA or Bradford assay.
-
SDS-PAGE and Western Blotting:
-
Separate 20-30 µg of protein from each fraction on an SDS-polyacrylamide gel.
-
Transfer the separated proteins to a PVDF or nitrocellulose membrane.
-
Block the membrane with 5% non-fat milk or BSA in TBST.
-
Incubate with a primary antibody specific for the N-terminal of this compound/SREBP.
-
Wash and incubate with an HRP-conjugated secondary antibody.
-
Detect the protein bands using a chemiluminescent substrate.
-
Caption: Workflow for analyzing this compound/SREBP nuclear translocation by Western blot.
Analysis of this compound/SREBP Transcriptional Activity
Objective: To measure the ability of this compound/SREBP to activate the transcription of its target genes.
Methodology: Luciferase Reporter Assay [14][15][16][17][18]
-
Construct Preparation: Clone a promoter region of a known SREBP target gene containing SREs upstream of a luciferase reporter gene (e.g., Firefly luciferase). A control plasmid expressing a different luciferase (e.g., Renilla) under a constitutive promoter is used for normalization.
-
Cell Transfection: Co-transfect the reporter construct and the control plasmid into cultured cells.
-
Cell Treatment: Treat the transfected cells with compounds or conditions expected to modulate SREBP activity (e.g., sterols, LXR agonists).
-
Cell Lysis: After treatment, lyse the cells using a passive lysis buffer.
-
Luciferase Activity Measurement:
-
Add the Firefly luciferase substrate to the cell lysate and measure the luminescence.
-
Add a quencher and the Renilla luciferase substrate and measure the luminescence again.
-
-
Data Analysis: Normalize the Firefly luciferase activity to the Renilla luciferase activity to control for transfection efficiency.
Caption: Workflow for measuring SREBP transcriptional activity using a luciferase reporter assay.
Identification of this compound/SREBP Target Genes
Objective: To identify the genomic binding sites of this compound/SREBP on a genome-wide scale.
Methodology: Chromatin Immunoprecipitation followed by Sequencing (ChIP-seq) [19][20][21][22][23][24]
-
Cross-linking: Treat cells or tissues with formaldehyde to cross-link proteins to DNA.
-
Chromatin Preparation: Lyse the cells/tissues and sonicate or enzymatically digest the chromatin to generate fragments of 200-600 bp.
-
Immunoprecipitation: Incubate the sheared chromatin with an antibody specific for this compound/SREBP. Use protein A/G beads to pull down the antibody-protein-DNA complexes.
-
Washing and Elution: Wash the beads to remove non-specific binding and then elute the complexes.
-
Reverse Cross-linking: Reverse the formaldehyde cross-links by heating.
-
DNA Purification: Purify the DNA fragments.
-
Library Preparation and Sequencing: Prepare a sequencing library from the purified DNA and perform high-throughput sequencing.
-
Data Analysis: Align the sequencing reads to the reference genome and use peak-calling algorithms to identify regions of enrichment, which represent this compound/SREBP binding sites.
Caption: Workflow for identifying this compound/SREBP target genes using ChIP-seq.
Functional Analysis of this compound in C. elegans
Objective: To study the in vivo function of this compound by reducing its expression.
-
RNAi Clone Preparation: Transform E. coli (HT115 strain) with a plasmid expressing double-stranded RNA (dsRNA) corresponding to the this compound gene.
-
Bacterial Culture: Grow the transformed bacteria and induce dsRNA expression with IPTG.
-
Seeding NGM Plates: Seed Nematode Growth Medium (NGM) plates with the induced bacteria.
-
Worm Synchronization: Synchronize a population of C. elegans to the L1 larval stage.
-
Feeding: Place the synchronized L1 larvae onto the RNAi plates.
-
Phenotypic Analysis: Observe the worms at different developmental stages for phenotypes such as changes in fat storage (using Oil Red O or Nile Red staining), body size, and expression of target genes (using qRT-PCR or GFP reporters).
Caption: Workflow for functional analysis of this compound in C. elegans using RNAi.
Conclusion
The this compound/SREBP pathway represents a remarkable example of evolutionary conservation in metabolic regulation. Its core components and the fundamental logic of its operation are maintained from invertebrates to humans, highlighting its ancient and essential role in maintaining lipid homeostasis. The species-specific adaptations in its regulation provide valuable insights into how this pathway has evolved to meet the diverse metabolic demands of different organisms. The experimental methodologies outlined in this guide provide a robust toolkit for researchers to further dissect the intricacies of this pathway, paving the way for the development of novel therapeutic strategies for a range of metabolic diseases.
References
- 1. Evolutionary conservation and adaptation in the mechanism that regulates SREBP action: what a long, strange tRIP it's been - PMC [pmc.ncbi.nlm.nih.gov]
- 2. SREBPs in Lipid Metabolism, Insulin Signaling, and Beyond - PMC [pmc.ncbi.nlm.nih.gov]
- 3. A pathway approach to investigate the function and regulation of SREBPs - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Sterol Regulatory Element-binding Protein-1 (SREBP-1) Is Required to Regulate Glycogen Synthesis and Gluconeogenic Gene Expression in Mouse Liver - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Fat accumulation in Caenorhabditis elegans is mediated by SREBP homolog this compound - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Fat accumulation in Caenorhabditis elegans is mediated by SREBP homolog this compound - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Alternative Processing of Sterol Regulatory Element Binding Protein During Larval Development in Drosophila melanogaster - PMC [pmc.ncbi.nlm.nih.gov]
- 8. The SREBP pathway in Drosophila: regulation by palmitate, not sterols - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. SREBP Sterol regulatory element binding protein [Drosophila melanogaster (fruit fly)] - Gene - NCBI [ncbi.nlm.nih.gov]
- 10. Scap Structures Highlight Key Role for Rotation of Intertwined Luminal Loops in Cholesterol Sensing - PMC [pmc.ncbi.nlm.nih.gov]
- 11. benchchem.com [benchchem.com]
- 12. WB检测样本前处理:细胞裂解和蛋白提取 [sigmaaldrich.com]
- 13. Integrated Transcriptomic and Proteomic Analysis Associated with Knockdown and Overexpression Studies Revealed ECHDC1 as a Regulator of Intramuscular Fat Deposition in Cattle [mdpi.com]
- 14. Identification of Novel Genes and Pathways Regulating SREBP Transcriptional Activity - PMC [pmc.ncbi.nlm.nih.gov]
- 15. activemotif.jp [activemotif.jp]
- 16. Luciferase-based reporter to monitor the transcriptional activity of the SIRT3 promoter - PMC [pmc.ncbi.nlm.nih.gov]
- 17. assaygenie.com [assaygenie.com]
- 18. bpsbioscience.com [bpsbioscience.com]
- 19. researchgate.net [researchgate.net]
- 20. Genome-wide analysis of SREBP-1 binding in mouse liver chromatin reveals a preference for promoter proximal binding to a new motif - PMC [pmc.ncbi.nlm.nih.gov]
- 21. ChIP-seq Protocols and Methods | Springer Nature Experiments [experiments.springernature.com]
- 22. pnas.org [pnas.org]
- 23. Practical Guidelines for the Comprehensive Analysis of ChIP-seq Data - PMC [pmc.ncbi.nlm.nih.gov]
- 24. encodeproject.org [encodeproject.org]
- 25. researchgate.net [researchgate.net]
- 26. Using RNA-mediated Interference Feeding Strategy to Screen for Genes Involved in Body Size Regulation in the Nematode C. elegans - PMC [pmc.ncbi.nlm.nih.gov]
Subcellular Localization of Selenium-Binding Protein 1 (SBP-1): An In-depth Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Introduction
Selenium-Binding Protein 1 (SBP-1) is a highly conserved protein implicated in a variety of critical cellular processes, including cell differentiation, redox modulation, and protein degradation. Emerging evidence has highlighted the significance of its subcellular localization, which appears to be dynamically regulated and can have profound implications for cellular function and disease pathogenesis, particularly in cancer. This technical guide provides a comprehensive overview of the subcellular distribution of this compound in different cell types, detailed experimental protocols for its analysis, and an exploration of the signaling pathways that may govern its nucleocytoplasmic transport.
Data Presentation: Subcellular Localization of this compound
The distribution of this compound between the nucleus and cytoplasm is not static and varies depending on the cell type and pathological state. In many cancers, a shift in localization from the nucleus to the cytoplasm is associated with a more aggressive phenotype.
| Cell Type/Condition | Predominant Localization | Nuclear-to-Cytoplasmic Ratio | Associated Findings |
| Normal Prostate Epithelium | Nuclear and Cytoplasmic | Higher | - |
| Prostate Cancer (Low Grade) | Nuclear and Cytoplasmic | Intermediate | A lower nuclear-to-cytoplasmic distribution of this compound is associated with a higher tumor grade (Gleason score)[1]. |
| Prostate Cancer (High Grade) | Predominantly Cytoplasmic | Lower | Reduced nuclear this compound levels are associated with a higher likelihood of cancer recurrence[1]. |
| Normal Thyroid Tissue | Strong Nuclear Staining | Higher | - |
| Thyroid Cancer | Strong Plasma/Cytoplasmic Staining | Lower | The translocation of this compound from the nucleus to the cytoplasm is suggested to be related to the degree of malignancy[1]. |
| Invasive Breast Carcinoma | Cytoplasmic and Nuclear | Variable | Strong cytoplasmic expression correlates with nuclear positivity, increased tumor size, and nodal positivity. A shift from exclusively nuclear to simultaneous nuclear and cytoplasmic localization is observed in approximately 90% of breast carcinomas[2]. |
| Colorectal Cancer | Nuclear | - | In normal colonic tissue, this compound is maximally expressed in terminally differentiated epithelial cells on the luminal surface. |
| 3T3-L1 Adipocytes | Predominantly Cytoplasmic | - | This compound is induced during terminal differentiation and maturation of preadipocytes. |
| T98G Glioblastoma Cells | Tips of rapidly extending protrusions | - | Associated with cell protrusive motility and actin filament polymerization. |
| Saccharomyces cerevisiae | Cytoplasm, Nucleolus, P-bodies, Stress Granules | - | Appears evenly distributed throughout the cytoplasm in mid-log phase cells. |
| Caenorhabditis elegans | Endoplasmic Reticulum (precursor), Nucleus (processed) | - | Nuclear localization is enhanced in a sams-1-dependent manner and reduced by lowering zinc levels. |
| Plants (general) | Cytoplasm and Nucleus | - | In wheat, the homolog is solely localized in the cytoplasm. |
Experimental Protocols
Immunofluorescence Staining for this compound Subcellular Localization
This protocol outlines the steps for visualizing the subcellular localization of this compound in cultured cells using immunofluorescence microscopy.
Materials:
-
Phosphate-Buffered Saline (PBS)
-
4% Paraformaldehyde (PFA) in PBS
-
Permeabilization Buffer (e.g., 0.1-0.5% Triton X-100 in PBS)
-
Blocking Buffer (e.g., 1-5% BSA or 10% Normal Goat Serum in PBST)
-
Primary Antibody: Anti-SBP-1 antibody (dilution to be optimized, typically 1:200-1:1000)
-
Fluorophore-conjugated Secondary Antibody (e.g., Alexa Fluor 488 anti-rabbit IgG)
-
Nuclear Counterstain (e.g., DAPI)
-
Antifade Mounting Medium
-
Glass coverslips and microscope slides
Procedure:
-
Cell Culture: Grow cells on sterile glass coverslips in a petri dish or multi-well plate to the desired confluency.
-
Fixation:
-
Aspirate the culture medium and wash the cells twice with PBS.
-
Fix the cells with 4% PFA for 15 minutes at room temperature.
-
Wash the cells three times with PBS for 5 minutes each.
-
-
Permeabilization:
-
Incubate the cells with Permeabilization Buffer for 10-15 minutes at room temperature.
-
Wash the cells three times with PBS for 5 minutes each.
-
-
Blocking:
-
Incubate the cells with Blocking Buffer for 1 hour at room temperature to minimize non-specific antibody binding.
-
-
Primary Antibody Incubation:
-
Dilute the anti-SBP-1 primary antibody in Blocking Buffer.
-
Incubate the cells with the diluted primary antibody overnight at 4°C in a humidified chamber.
-
-
Secondary Antibody Incubation:
-
Wash the cells three times with PBST (PBS with 0.1% Tween-20) for 5 minutes each.
-
Dilute the fluorophore-conjugated secondary antibody in Blocking Buffer.
-
Incubate the cells with the diluted secondary antibody for 1-2 hours at room temperature, protected from light.
-
-
Counterstaining and Mounting:
-
Wash the cells three times with PBST for 5 minutes each.
-
Incubate the cells with DAPI solution for 5 minutes to stain the nuclei.
-
Wash the cells twice with PBS.
-
Mount the coverslips onto microscope slides using an antifade mounting medium.
-
-
Imaging:
-
Visualize the stained cells using a fluorescence or confocal microscope. Capture images using the appropriate filter sets for the chosen fluorophores.
-
Subcellular Fractionation and Western Blotting for this compound
This protocol describes the separation of nuclear and cytoplasmic fractions from cultured cells to determine the relative abundance of this compound in each compartment by Western blotting.
Materials:
-
PBS, ice-cold
-
Cytoplasmic Lysis Buffer (e.g., 10 mM HEPES pH 7.9, 10 mM KCl, 0.1 mM EDTA, 0.1 mM EGTA, 1 mM DTT, protease inhibitors)
-
Nuclear Lysis Buffer (e.g., 20 mM HEPES pH 7.9, 0.4 M NaCl, 1 mM EDTA, 1 mM EGTA, 1 mM DTT, protease inhibitors)
-
Dounce homogenizer
-
Microcentrifuge
-
SDS-PAGE gels, transfer apparatus, and blotting membranes
-
Primary Antibody: Anti-SBP-1 antibody
-
Secondary Antibody: HRP-conjugated secondary antibody
-
Antibodies for loading controls (e.g., anti-GAPDH for cytoplasm, anti-Lamin B1 or anti-Histone H3 for nucleus)
-
Chemiluminescent substrate
Procedure:
-
Cell Harvesting:
-
Wash cultured cells with ice-cold PBS and scrape them into a pre-chilled microcentrifuge tube.
-
Pellet the cells by centrifugation at 500 x g for 5 minutes at 4°C.
-
-
Cytoplasmic Fractionation:
-
Resuspend the cell pellet in ice-cold Cytoplasmic Lysis Buffer.
-
Incubate on ice for 10-15 minutes.
-
Lyse the cells using a Dounce homogenizer with a loose-fitting pestle.
-
Centrifuge the lysate at 1,000 x g for 10 minutes at 4°C.
-
Carefully collect the supernatant, which contains the cytoplasmic fraction.
-
-
Nuclear Fractionation:
-
Wash the remaining pellet with Cytoplasmic Lysis Buffer.
-
Resuspend the nuclear pellet in ice-cold Nuclear Lysis Buffer.
-
Incubate on ice for 30 minutes with intermittent vortexing to lyse the nuclei.
-
Centrifuge at 14,000 x g for 15 minutes at 4°C.
-
Collect the supernatant, which contains the nuclear fraction.
-
-
Protein Quantification:
-
Determine the protein concentration of both the cytoplasmic and nuclear fractions using a standard protein assay (e.g., BCA assay).
-
-
Western Blotting:
-
Denature equal amounts of protein from each fraction by boiling in SDS-PAGE sample buffer.
-
Separate the proteins by SDS-PAGE and transfer them to a blotting membrane.
-
Block the membrane with a suitable blocking agent (e.g., 5% non-fat milk in TBST).
-
Incubate the membrane with the primary anti-SBP-1 antibody, followed by the HRP-conjugated secondary antibody.
-
Detect the protein bands using a chemiluminescent substrate.
-
Probe separate blots with antibodies against cytoplasmic and nuclear markers to assess the purity of the fractions.
-
Signaling Pathways and Visualization
The precise mechanisms governing the subcellular localization of this compound are still under investigation. However, several lines of evidence suggest the involvement of key signaling pathways and post-translational modifications.
Potential Regulatory Signaling Pathways
Description: Extracellular signals like growth factors and stress can activate intracellular signaling cascades such as the PI3K/AKT and MAPK/ERK pathways. These pathways may lead to post-translational modifications of this compound, such as phosphorylation, which could in turn modulate its interaction with nuclear import/export machinery, thereby altering its subcellular distribution. Sumoylation has also been implicated in regulating protein localization and degradation.
Experimental Workflow for Determining this compound Localization
Description: This diagram illustrates the two primary experimental approaches for determining the subcellular localization of this compound. Immunofluorescence provides qualitative and quantitative spatial information within intact cells, while subcellular fractionation followed by Western blotting offers a biochemical method to quantify the relative amounts of this compound in different cellular compartments.
Conclusion
The subcellular localization of this compound is a key aspect of its biological function and its role in disease. The shift from a predominantly nuclear to a more cytoplasmic localization in several cancers underscores its potential as a biomarker and a therapeutic target. The experimental protocols and workflows provided in this guide offer a robust framework for researchers to investigate the intricate mechanisms that control this compound's cellular address and its impact on cellular physiology and pathology. Further research into the signaling pathways that dictate this compound's nucleocytoplasmic trafficking will be crucial for a complete understanding of its role in health and disease and for the development of novel therapeutic strategies.
References
Identifying Novel SBP-1 Interacting Proteins: A Technical Guide for Researchers
An In-depth Technical Guide for Researchers, Scientists, and Drug Development Professionals
Introduction
Selenium-Binding Protein 1 (SBP-1), a highly conserved protein, has garnered significant attention in the scientific community for its diverse and critical roles in fundamental cellular processes. These include protein degradation, redox modulation, and the metabolism of sulfur-containing molecules.[1] Notably, this compound expression is frequently diminished in various cancers compared to normal tissues, and reduced levels often correlate with a poor clinical prognosis.[1] Elucidating the intricate network of this compound protein-protein interactions is paramount for a comprehensive understanding of its physiological functions and its implications in disease, particularly in cancer. This guide provides a technical overview of known this compound interacting proteins, detailed methodologies for identifying novel interactors, and insights into the signaling pathways governed by these interactions.
Current Knowledge of this compound Interacting Proteins
Several key proteins have been identified as interacting with this compound, shedding light on its functional mechanisms. These interactions, identified through various experimental approaches, are crucial for understanding this compound's role in cellular homeostasis and disease. A summary of these interactions is presented below.
| Interacting Protein | Organism/Cell Type | Method of Identification | Quantitative Data/Notes |
| VDU1 (von Hippel-Lindau protein-interacting deubiquitinating enzyme 1) | Human | Not specified in abstracts | The interaction is selenium-dependent and is completely blocked by β-mercaptoethanol treatment.[1] this compound's interaction with VDU1 suggests a role in ubiquitination/deubiquitination-mediated protein degradation.[1] |
| GPX1 (Glutathione Peroxidase 1) | Human colorectal and breast cancer cells; mouse colonic epithelial cells | Co-immunoprecipitation, Fluorescence Resonance Energy Transfer (FRET) | A physical association has been demonstrated.[2] There is a reciprocal regulatory relationship: this compound overexpression reduces GPX1 enzyme activity, while GPX1 overexpression represses this compound at both the mRNA and protein levels.[2][3] |
| TXN (Thioredoxin) | Human thyroid cancer tissues | Co-immunoprecipitation (Co-IP) | This compound directly interacts with and positively regulates TXN, which in turn negatively regulates the sodium/iodide symporter (NIS). This interaction promotes tumorigenesis in thyroid cancer.[4] |
Experimental Protocols for Identifying Novel this compound Interactors
The identification of novel protein-protein interactions is a cornerstone of modern molecular biology. Several robust techniques can be employed to uncover the this compound interactome. Detailed below are protocols for commonly used and powerful methods.
Tandem Affinity Purification coupled with Mass Spectrometry (TAP-MS)
TAP-MS is a high-yield, high-specificity method for purifying protein complexes under near-physiological conditions.
Principle: The protein of interest (bait), in this case this compound, is fused with a tandem affinity tag (e.g., Protein A and Calmodulin Binding Peptide separated by a TEV protease cleavage site). The tagged protein is expressed in cells, and the resulting protein complex is purified through two successive affinity chromatography steps. The final eluate, containing the bait protein and its interacting partners, is then analyzed by mass spectrometry to identify the components of the complex.
Detailed Protocol:
-
Vector Construction and Cell Line Generation:
-
Clone the full-length human this compound cDNA into a mammalian expression vector containing a suitable tandem affinity tag (e.g., SFB-tag: S-protein, 2xFLAG, and Streptavidin-Binding Peptide).
-
Establish a stable cell line (e.g., HEK293T) expressing the tagged this compound. A control cell line expressing the tag alone should also be generated.
-
-
Cell Lysis and Initial Affinity Purification:
-
Harvest cultured cells and lyse them in a non-denaturing lysis buffer containing protease and phosphatase inhibitors.
-
Clarify the lysate by centrifugation.
-
Incubate the soluble lysate with the first affinity resin (e.g., IgG Sepharose for the Protein A tag) to capture the tagged this compound and its associated proteins.
-
Wash the resin extensively with wash buffer to remove non-specific binders.
-
-
Elution and Second Affinity Purification:
-
Elute the protein complex from the first resin by enzymatic cleavage of the tag (e.g., with TEV protease).
-
Incubate the eluate with the second affinity resin (e.g., Calmodulin Sepharose in the presence of Ca²⁺).
-
Wash the second resin thoroughly.
-
-
Final Elution and Sample Preparation for Mass Spectrometry:
-
Elute the purified protein complex from the second resin using a specific elution buffer (e.g., EGTA to chelate Ca²⁺).
-
Precipitate the proteins (e.g., with trichloroacetic acid) and resuspend in a buffer suitable for mass spectrometry.
-
Perform in-solution or in-gel trypsin digestion of the protein mixture.
-
-
Mass Spectrometry and Data Analysis:
-
Analyze the resulting peptides by liquid chromatography-tandem mass spectrometry (LC-MS/MS).
-
Identify the proteins using a protein database search algorithm (e.g., Mascot, Sequest) against a human protein database.
-
Filter the identified proteins against a database of common contaminants and compare the results from the this compound pulldown to the control pulldown to identify specific interactors.
-
Co-Immunoprecipitation (Co-IP) followed by Mass Spectrometry
Co-IP is a widely used technique to identify protein-protein interactions from cell or tissue lysates.
Principle: An antibody specific to a known protein (the "bait," this compound) is used to pull down the bait protein from a lysate. Any proteins that are bound to the bait protein (the "prey") will also be pulled down. The entire complex is then analyzed by mass spectrometry to identify the interacting proteins.
Detailed Protocol:
-
Cell Lysis:
-
Harvest cells and lyse them in a suitable Co-IP lysis buffer (e.g., RIPA buffer with reduced detergent concentration) containing protease inhibitors.
-
Incubate on ice to ensure complete lysis.
-
Centrifuge the lysate to pellet cellular debris and collect the supernatant.
-
-
Immunoprecipitation:
-
Pre-clear the lysate by incubating with protein A/G beads to reduce non-specific binding.
-
Incubate the pre-cleared lysate with an antibody specific for this compound (or a control IgG) overnight at 4°C with gentle rotation.
-
Add protein A/G beads to the lysate-antibody mixture and incubate for a few hours to capture the antibody-protein complexes.
-
Pellet the beads by centrifugation and wash them several times with Co-IP wash buffer to remove non-specifically bound proteins.
-
-
Elution and Mass Spectrometry Preparation:
-
Elute the protein complexes from the beads using an acidic elution buffer or by boiling in SDS-PAGE sample buffer.
-
Separate the eluted proteins by SDS-PAGE.
-
Excise the entire protein lane or specific bands and perform in-gel trypsin digestion.
-
Extract the peptides for LC-MS/MS analysis.
-
-
Data Analysis:
-
Identify the proteins by searching the MS/MS data against a protein database.
-
Compare the proteins identified in the this compound Co-IP with those from the control IgG Co-IP to determine specific interactors.
-
Signaling Pathways and Experimental Workflows
Visualizing the known signaling pathways involving this compound and the experimental workflows for discovering new interactors can provide a clearer understanding of its function and the methods to study it.
References
- 1. scilit.com [scilit.com]
- 2. researchgate.net [researchgate.net]
- 3. academic.oup.com [academic.oup.com]
- 4. Protocol for establishing a protein-protein interaction network using tandem affinity purification followed by mass spectrometry in mammalian cells [escholarship.org]
- 5. researchgate.net [researchgate.net]
- 6. Selenium-Binding Protein 1 in Human Health and Disease - PMC [pmc.ncbi.nlm.nih.gov]
The Role of SBP-1 in Caenorhabditis elegans Developmental Processes: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Abstract
Sterol Regulatory Element-Binding Protein-1 (SBP-1), the Caenorhabditis elegans homolog of the mammalian SREBP-1, is a critical transcription factor governing lipid homeostasis and influencing a spectrum of developmental processes. This technical guide provides an in-depth analysis of this compound's function, regulation, and impact on C. elegans development, with a focus on its role in lipid metabolism, body size determination, and reproductive capacity. We present a compilation of quantitative data from key studies, detailed experimental protocols for investigating this compound function, and visual representations of the associated signaling pathways and experimental workflows. This document is intended to serve as a comprehensive resource for researchers leveraging C. elegans as a model to study metabolic regulation and its intersection with developmental biology, as well as for professionals in drug development targeting metabolic pathways.
Introduction to this compound/SREBP-1 in C. elegans
This compound is the sole ortholog of the mammalian Sterol Regulatory Element-Binding Protein (SREBP) family in C. elegans.[1] Like its mammalian counterparts, this compound is a key regulator of genes involved in lipid biosynthesis and metabolism.[2][3] It plays a pivotal role in maintaining normal fat levels and responding to nutrient availability.[2] The study of this compound in C. elegans offers a powerful, genetically tractable model to dissect the conserved functions of SREBP-1 in metazoans and its impact on development.[3]
Core Functions of this compound in Developmental Processes
This compound's primary role in development is intrinsically linked to its regulation of lipid metabolism. This has profound effects on several key developmental outcomes, including fat storage, body size, and reproductive fitness.
Regulation of Fat Storage and Lipid Metabolism
This compound is a master regulator of lipogenesis.[4] It controls the expression of a suite of genes involved in fatty acid synthesis, elongation, and desaturation, including fat-5, fat-6, and fat-7, which encode fatty acid desaturases.[2] Inactivation of this compound through RNA interference (RNAi) or mutation leads to a dramatic reduction in fat storage, resulting in a characteristic "clear" or pale and skinny phenotype due to the absence of lipid-laden granules in the intestine.[2]
Influence on Body Size and Growth
Proper this compound function is essential for normal post-embryonic growth. Knockdown of this compound results in a significant reduction in body size and delayed growth.[2][5] This phenotype can be partially rescued by supplementing the growth media with oleic or linoleic acid, highlighting the importance of this compound-mediated fatty acid synthesis for achieving normal body size.[5]
Role in Reproduction and Egg-Laying
This compound is crucial for reproductive success. Worms with reduced this compound function lay considerably fewer eggs.[2][5] Furthermore, a fascinating and detrimental phenotype observed in this compound(RNAi) animals is internal hatching, where eggs hatch inside the mother's body 5-6 days after being laid.[2] Similar to the body size defect, the reduced egg-laying phenotype can be partially ameliorated by the addition of polyunsaturated fatty acids.[5] this compound, in conjunction with MDT-15 and NHR-49, is also important for the post-dauer reproductive program, likely by upregulating fat metabolism genes necessary for recovery and reproduction after a period of starvation-induced developmental arrest.[6]
Quantitative Data on this compound Phenotypes
To provide a clear overview of the impact of this compound on C. elegans development, the following tables summarize quantitative data from relevant studies.
| Phenotype | Genotype/Condition | Result | Reference |
| Fat Storage | This compound(RNAi) | Significantly reduced fat storage, "clear" phenotype | [2][5] |
| This compound(ep79) mutant | Low fat stores | [7] | |
| Body Size | This compound(RNAi) | Reduced body size and delayed growth | [2][5] |
| This compound(RNAi) + Oleic/Linoleic Acid | Restoration of body size to near wild-type | [5] | |
| Brood Size | This compound(RNAi) | Considerably decreased number of eggs laid | [2][5] |
| This compound(ep79) mutant | Reduced brood size | [7] | |
| This compound(RNAi) + Oleic/Linoleic Acid | Increase in the number of eggs laid to ~60% of control | [5] |
| Gene Target | Condition | Change in Expression | Reference |
| elo-2, fat-2, fat-5, fat-6, fat-7 | This compound(RNAi) | Decreased mRNA levels | [5] |
| acs-2 (starvation-inducible gene) | This compound(RNAi) | Increased mRNA levels | [5] |
| fat-2, fat-5, fat-6, fat-7 | Glucose-rich diet + this compound(RNAi) | Significantly decreased mRNA levels | [8] |
| fat-5, fat-7 | This compound overexpression | Increased mRNA levels | [8] |
Signaling Pathways and Regulation of this compound
The activity of this compound is tightly regulated by nutrient availability and environmental cues, and it functions within a complex network of interacting proteins.
Upstream Regulation by Nutrients and Environment
-
Glucose: A high-glucose diet leads to an increase in this compound protein levels, promoting fatty acid synthesis.[4][8] This response appears to be post-transcriptional, as this compound mRNA levels do not increase with glucose treatment.[8]
-
Oxygen: this compound is activated in response to oxygen deprivation (anoxia/hypoxia), playing an essential role in hypoxia-induced lipid accumulation.[9]
-
Phosphatidylcholine (PC): A feedback circuit exists where low levels of PC, a key membrane phospholipid, lead to the activation of this compound. This suggests that this compound activity is modulated by the cell's membrane composition.[3]
Key Interaction Partners
-
MDT-15: This subunit of the Mediator transcriptional co-activator complex is a crucial partner for this compound.[10] MDT-15 and this compound act together to regulate the expression of lipogenic genes.[8] Genetic inhibition of either mdt-15 or this compound leads to similar phenotypes, and they appear to function in the same pathway.[8]
-
MXL-3: This transcription factor, a homolog of the mammalian MAX-like protein, acts in concert with this compound to mediate glucose-dependent fat accumulation.[4] High glucose activates MXL-3, which in turn increases lipid levels via this compound.[4]
-
NHR-49: This nuclear hormone receptor also plays a role in regulating fatty acid metabolism and cooperates with this compound and MDT-15.[5]
Downstream Targets
The primary downstream targets of this compound are genes involved in fatty acid metabolism. These include:
-
Fatty Acid Desaturases: fat-5, fat-6, and fat-7 (Δ9 desaturases)[2]
-
Fatty Acid Elongases: elo-2[5]
-
Other Lipogenic Enzymes: Acetyl-CoA carboxylase (pod-2), fatty acid synthase (fasn-1)[4]
Signaling Pathway Diagrams
Experimental Protocols
This section provides detailed methodologies for key experiments used to study this compound function in C. elegans.
RNA Interference (RNAi) by Feeding
This protocol is used to knockdown the expression of this compound to study its loss-of-function phenotype.
Materials:
-
NGM (Nematode Growth Medium) plates containing ampicillin (50 µg/mL) and IPTG (1 mM)
-
E. coli strain HT115(DE3) transformed with an L4440 vector containing a genomic fragment of this compound
-
Control E. coli HT115(DE3) with an empty L4440 vector
-
LB medium with ampicillin (50 µg/mL)
-
Synchronized L1-stage C. elegans
Procedure:
-
Inoculate a single colony of the this compound(RNAi) and control bacterial strains into separate tubes of LB with ampicillin.
-
Incubate overnight at 37°C with shaking.
-
Seed NGM/amp/IPTG plates with 100 µL of the overnight bacterial culture.
-
Allow the bacterial lawn to grow overnight at room temperature.
-
Place synchronized L1 worms onto the RNAi plates.
-
Incubate the worms at 20°C.
-
Score for phenotypes (e.g., body size, fat storage, brood size) at the appropriate developmental stages (e.g., L4, young adult).
Quantification of Fat Storage using Oil Red O Staining
This method allows for the visualization and quantification of neutral lipid stores.
Materials:
-
M9 buffer
-
2x MRWB buffer with 2% paraformaldehyde (PFA)
-
60% isopropanol
-
Oil Red O (ORO) stock solution (0.5 g in 100 mL isopropanol)
-
Microscope slides and coverslips
Procedure:
-
Wash synchronized worms off NGM plates with M9 buffer.
-
Fix the worms in 2x MRWB with 2% PFA for 1 hour at room temperature.
-
Wash the worms with M9 to remove PFA.
-
Dehydrate the worms in 60% isopropanol for 15 minutes.
-
Prepare a fresh 60% ORO working solution from the stock and filter it.
-
Incubate the dehydrated worms in the ORO working solution for at least 4 hours at room temperature with gentle rocking.
-
Wash the worms with M9 buffer to remove excess stain.
-
Mount the stained worms on a microscope slide for imaging.
-
Quantify the staining intensity using image analysis software (e.g., ImageJ).
Quantitative Real-Time PCR (qRT-PCR)
This protocol is used to measure the mRNA expression levels of this compound target genes.
Materials:
-
TRIzol reagent for RNA extraction
-
cDNA synthesis kit
-
SYBR Green qPCR master mix
-
Primers for target genes (fat-5, fat-6, fat-7, etc.) and a reference gene (e.g., act-1)
-
qPCR instrument
Procedure:
-
Collect synchronized worms and homogenize in TRIzol.
-
Extract total RNA according to the manufacturer's protocol.
-
Synthesize cDNA from the extracted RNA using a reverse transcriptase kit.
-
Set up qPCR reactions with SYBR Green master mix, cDNA, and gene-specific primers.
-
Run the qPCR program on a real-time PCR machine.
-
Analyze the data using the ΔΔCt method to determine the relative expression of target genes, normalized to the reference gene.
Experimental Workflow Diagram
This compound in Other Developmental Contexts
While the primary role of this compound is in lipid metabolism, its influence extends to other developmental processes, though these are less well-characterized.
Dauer Larva Development
The direct role of this compound in the decision to enter the stress-resistant dauer larval stage is not yet fully elucidated. However, as mentioned, this compound is important for the reproductive recovery of post-dauer animals, suggesting a role in metabolic adaptation following prolonged starvation.[6]
Germline Development
The reduced brood size in this compound deficient animals points to a role in germline development or function. This is likely due to the critical requirement of lipids for oocyte development and embryogenesis. However, a more direct role for this compound in regulating germline stem cell proliferation or gametogenesis remains an area for further investigation.
Cuticle Formation
The C. elegans cuticle contains lipids, which are essential for its function as a protective barrier. While a direct regulatory link between this compound and cuticle-specific collagen or lipid synthesis genes has not been firmly established, it is plausible that this compound's broad control over lipid metabolism could indirectly affect the composition and integrity of the cuticle.
Conclusion and Future Directions
This compound is a central regulator of lipid metabolism in C. elegans, with profound and pleiotropic effects on development, including fat storage, body size, and fecundity. The conservation of the this compound/SREBP-1 pathway makes C. elegans an invaluable model for understanding the fundamental principles of metabolic control and its impact on developmental biology.
Future research should focus on several key areas:
-
Elucidating the this compound Activation Mechanism: While proteolytic cleavage is the canonical activation mechanism for mammalian SREBPs, the specific proteases and regulatory details of this process in C. elegans require further investigation.
-
Defining Roles Beyond Lipid Metabolism: A more in-depth exploration of this compound's role in dauer formation, germline development, and cuticle maintenance will provide a more complete picture of its developmental functions.
-
Translational Relevance: Given the link between SREBP-1, obesity, and metabolic diseases in humans, further dissection of the this compound regulatory network in C. elegans could uncover novel targets for therapeutic intervention.
This guide provides a solid foundation for researchers and drug development professionals to understand and investigate the multifaceted role of this compound in C. elegans development. The provided data, protocols, and pathway diagrams offer a starting point for designing experiments and interpreting results in this exciting field of research.
References
- 1. A lipid transfer protein ensures nematode cuticular impermeability - PMC [pmc.ncbi.nlm.nih.gov]
- 2. uniprot.org [uniprot.org]
- 3. A conserved SREBP-1/phosphatidylcholine feedback circuit regulates lipogenesis in metazoans - PMC [pmc.ncbi.nlm.nih.gov]
- 4. The MXL-3/SBP-1 Axis Is Responsible for Glucose-Dependent Fat Accumulation in C. elegans - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Fat accumulation in Caenorhabditis elegans is mediated by SREBP homolog this compound - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Somatic aging pathways regulate reproductive plasticity in Caenorhabditis elegans | eLife [elifesciences.org]
- 7. Gene: this compound, Species: Caenorhabditis elegans - Caenorhabditis Genetics Center (CGC) - College of Biological Sciences [cgc.umn.edu]
- 8. SREBP and MDT-15 protect C. elegans from glucose-induced accelerated aging by preventing accumulation of saturated fat - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Essential role of this compound activation in oxygen deprivation induced lipid accumulation and increase in body width/length ratio in Caenorhabditis elegans - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Lipid metabolic sensors of MDT-15 and this compound regulated the response to simulated microgravity in the intestine of Caenorhabditis elegans - PubMed [pubmed.ncbi.nlm.nih.gov]
The Enzymatic Soul of a Sentinel: An In-depth Technical Guide to the Core Activities of Human Selenium Binding Protein 1 (SBP1)
For Researchers, Scientists, and Drug Development Professionals
Abstract
Human Selenium Binding Protein 1 (SBP1), a protein historically enigmatic in its function, has recently been identified as a crucial enzyme in sulfur metabolism. This guide provides a comprehensive technical overview of the enzymatic activity of human SBP1, focusing on its role as a methanethiol oxidase (MTO). We delve into its kinetic properties, substrate specificity, and the intricate signaling pathways modulated by its enzymatic products. Detailed experimental protocols for assessing SBP1's MTO activity are provided, alongside visual representations of key pathways and workflows to facilitate a deeper understanding and further research into this pivotal protein.
Introduction: Unmasking the Enzymatic Identity of SBP1
For decades, the precise molecular function of human SBP1 remained elusive, despite its observed correlation with various cancers. Recent groundbreaking research has illuminated its primary enzymatic role as a methanethiol oxidase (MTO)[1][2][3]. This discovery has redefined our understanding of SBP1, positioning it as a key player in the metabolism of volatile sulfur compounds. SBP1 catalyzes the oxidation of methanethiol, a toxic byproduct of gut microbial metabolism, into the signaling molecules hydrogen peroxide (H₂O₂), hydrogen sulfide (H₂S), and formaldehyde[1][2][3][4]. This enzymatic activity is not only a detoxification mechanism but also a critical node in cellular signaling, influencing pathways that govern cellular energy homeostasis and stress responses.
Enzymatic Activity of Human SBP1: A Quantitative Overview
The core enzymatic function of human SBP1 is the copper-dependent oxidation of methanethiol[4][5]. While selenium binding is a characteristic feature of the protein, it is not essential for its MTO activity[4]. The enzymatic reaction proceeds as follows:
Methanethiol + O₂ + H₂O → Hydrogen Sulfide (H₂S) + Formaldehyde + Hydrogen Peroxide (H₂O₂)[2]
Kinetic Parameters
To date, the most well-characterized kinetic parameter for the methanethiol oxidase activity of human SBP1 is its remarkable affinity for its primary substrate, methanethiol.
| Parameter | Value | Substrate | Source |
| Apparent Km | 4.8 nM | Methanethiol | [3][6] |
Further research is required to determine the Vmax and kcat for the human SBP1-catalyzed reaction.
Substrate Specificity
While methanethiol is the primary substrate, human SBP1 has been shown to exhibit activity towards other volatile sulfur compounds. This broader specificity suggests a role for SBP1 in the metabolism of various dietary and microbiome-derived thiols.
| Substrate | Activity Observed | Source |
| Methanethiol | Yes | [1][2][3][4] |
| Ethanethiol | Yes | [4] |
| 1-Pentanethiol | Yes | [4] |
| 2-Propene-1-thiol | Yes | [4] |
SBP1-Mediated Signaling Pathways
The enzymatic products of SBP1, namely H₂S, H₂O₂, and formaldehyde, are potent signaling molecules that can modulate a variety of cellular pathways. A significant signaling axis that has been identified is the SBP1-AMPK pathway, particularly in the context of cancer metabolism.
The SBP1-AMPK Signaling Axis
In prostate cancer cells, the expression of SBP1 and its subsequent production of H₂O₂ and H₂S have been shown to activate AMP-activated protein kinase (AMPK)[7]. AMPK is a master regulator of cellular energy homeostasis. Its activation by SBP1's enzymatic products leads to the suppression of mitochondrial respiration and an attenuation of anchorage-independent growth, a hallmark of cancer[7]. This positions SBP1 as a potential tumor suppressor that links sulfur metabolism to the control of cell growth and energy utilization.
Experimental Protocols: Assay of Methanethiol Oxidase Activity
The assessment of SBP1's MTO activity can be achieved through a coupled enzymatic assay. This method relies on the in-situ generation of the volatile substrate methanethiol by a bacterial L-methionine γ-lyase (MGL), followed by the detection of the SBP1-produced H₂S, H₂O₂, and formaldehyde[4][8][9].
Experimental Workflow
The workflow for the coupled MTO assay involves the parallel execution of the methanethiol-generating reaction and the SBP1-catalyzed oxidation reaction, followed by the specific detection of each product.
References
- 1. Mutations in SELENBP1, encoding a novel human methanethiol oxidase, cause extra-oral halitosis - PMC [pmc.ncbi.nlm.nih.gov]
- 2. uniprot.org [uniprot.org]
- 3. dacemirror.sci-hub.box [dacemirror.sci-hub.box]
- 4. Selenium-binding protein 1 (SELENBP1) is a copper-dependent thiol oxidase - PMC [pmc.ncbi.nlm.nih.gov]
- 5. H 2 O 2 Release Assay - PMC [pmc.ncbi.nlm.nih.gov]
- 6. files01.core.ac.uk [files01.core.ac.uk]
- 7. researchgate.net [researchgate.net]
- 8. A coupled enzyme assay for detection of selenium-binding protein 1 (SELENBP1) methanethiol oxidase (MTO) activity in mature enterocytes - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
Initial Studies on Selenium-Binding Protein 1 (SBP-1) in Neurodegenerative Disorders: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides an in-depth overview of the foundational research concerning Selenium-Binding Protein 1 (SBP-1), also known as SELENBP1, and its emerging role in the pathophysiology of neurodegenerative and neurological disorders. This document synthesizes key quantitative data from initial studies, details relevant experimental methodologies, and visualizes the proposed molecular pathways and workflows.
Introduction to this compound (SELENBP1)
Selenium-Binding Protein 1 (this compound) is a highly conserved 56 kDa protein that, as its name suggests, covalently binds the essential trace element selenium.[1][2] While it is not a selenocysteine-containing selenoprotein, its functions are linked to selenium's biological roles.[1] this compound is implicated in a variety of critical physiological processes, including cell differentiation, intra-Golgi transport, and protein degradation through its physical interaction with von Hippel–Lindau protein–interacting deubiquitinating enzyme 1 (VDU1).[1]
Recent groundbreaking studies have identified a novel enzymatic function for this compound as a methanethiol oxidase (MTO).[1][3][4] In this role, this compound catalyzes the conversion of methanethiol into formaldehyde and the key signaling molecules hydrogen sulfide (H₂S) and hydrogen peroxide (H₂O₂).[3][4] Given that oxidative stress and dysregulated protein degradation are hallmark features of many neurodegenerative diseases, this compound has emerged as a protein of significant interest. Initial studies have linked this compound to a range of neurologic disorders, including Parkinson's disease, schizophrenia, and depression, primarily through its role in modulating redox balance and inflammation.[5][6]
Quantitative Data from Initial Studies
The following tables summarize key quantitative findings from foundational studies investigating the role of this compound in models of neurological disorders. The data is primarily derived from studies using mouse models of depression, which serve as an initial proxy for stress-related neurodegeneration.
Table 2.1: this compound Expression Levels in Neurological Disorder Models
| Condition/Model | Tissue/Sample | Analyte | Change vs. Control | Significance | Reference |
|---|---|---|---|---|---|
| Human Patients w/ Depression | Blood | This compound Protein | Decreased | - | [5] |
| CUMS¹ Mouse Model of Depression | Hippocampus | This compound Protein | Decreased | - | [5] |
| Human Patients w/ Schizophrenia | Frontal Cortex | This compound mRNA | Elevated | - | [2] |
¹ Chronic Unpredictable Mild Stress
Table 2.2: Biomarkers of Oxidative Stress in this compound Knockout (KO) Mice Subjected to CUMS¹
| Biomarker | Sample | Mouse Group | Mean Activity / Level (Units) | % Change (KO vs. WT) | Significance (KO vs. WT) | Reference |
|---|---|---|---|---|---|---|
| GPX² | Serum | WT + CUMS | ~125 U/mL | - | - | [7] |
| KO + CUMS | ~90 U/mL | ~ -28% | p < 0.01 | [7] | ||
| CAT³ | Serum | WT + CUMS | ~12 U/mL | - | - | [7] |
| KO + CUMS | ~8 U/mL | ~ -33% | p < 0.05 | [7] | ||
| MDA⁴ | Serum | WT + CUMS | ~10 nmol/mL | - | - | [7] |
| KO + CUMS | ~14 nmol/mL | ~ +40% | p < 0.05 | [7] | ||
| GPX² | Hippocampus | WT + CUMS | ~1.0 U/mgprot | - | - | [7] |
| KO + CUMS | ~0.6 U/mgprot | ~ -40% | p < 0.01 | [7] | ||
| CAT³ | Hippocampus | WT + CUMS | ~1.5 U/mgprot | - | - | [7] |
| KO + CUMS | ~1.0 U/mgprot | ~ -33% | p < 0.05 | [7] | ||
| MDA⁴ | Hippocampus | WT + CUMS | ~1.0 nmol/mgprot | - | - | [7] |
| KO + CUMS | ~1.5 nmol/mgprot | ~ +50% | p < 0.01 | [7] |
¹ Chronic Unpredictable Mild Stress; ² Glutathione Peroxidase; ³ Catalase; ⁴ Malondialdehyde. Absolute values are estimated from source graphs.
Signaling Pathways and Logical Frameworks
Visualizations of this compound's proposed molecular interactions and its role in the broader context of neurodegeneration are presented below.
Experimental Protocols & Workflows
This section provides detailed methodologies for key experiments relevant to the study of this compound in brain tissue.
Protocol: Quantification of this compound Protein by Western Blot
This protocol details the steps for measuring this compound protein levels in rodent brain tissue.
-
Tissue Homogenization:
-
Harvest brain tissue (e.g., hippocampus) from euthanized animals and immediately flash-freeze in liquid nitrogen.[8] Store at -80°C.
-
On ice, weigh a frozen tissue sample (~50-100 mg) and place it in a pre-chilled tube.
-
Add 10 volumes (e.g., 500 µL for 50 mg tissue) of ice-cold RIPA lysis buffer (detergent-based) supplemented with protease and phosphatase inhibitor cocktails.[9]
-
Homogenize the tissue using an ultrasonic homogenizer (sonicator) with short pulses on ice until the solution is clear.[9]
-
Centrifuge the homogenate at 20,000 x g for 30 minutes at 4°C.[9]
-
Carefully collect the supernatant containing the soluble protein fraction into a new pre-chilled tube.
-
-
Protein Quantification:
-
Determine the total protein concentration of the supernatant using a BCA (Bicinchoninic Acid) protein assay kit according to the manufacturer's instructions.
-
-
SDS-PAGE and Electrotransfer:
-
Denature 20-40 µg of protein from each sample by boiling for 5 minutes in Laemmli sample buffer.
-
Load samples onto a 10% or 12% SDS-polyacrylamide gel. Include a protein ladder.
-
Perform electrophoresis until the dye front reaches the bottom of the gel.
-
Transfer the separated proteins from the gel to a PVDF (polyvinylidene difluoride) membrane using a wet or semi-dry transfer system.
-
-
Immunoblotting:
-
Block the membrane for 1 hour at room temperature in 5% non-fat dry milk or bovine serum albumin (BSA) in Tris-buffered saline with 0.1% Tween-20 (TBST).
-
Incubate the membrane with a primary antibody specific for this compound (SELENBP1) overnight at 4°C with gentle agitation. (Dilution to be optimized based on antibody datasheet).
-
Wash the membrane three times for 10 minutes each with TBST.
-
Incubate the membrane with a horseradish peroxidase (HRP)-conjugated secondary antibody (e.g., anti-rabbit IgG) for 1 hour at room temperature.
-
Wash the membrane three times for 10 minutes each with TBST.
-
-
Detection and Analysis:
-
Apply an enhanced chemiluminescence (ECL) substrate to the membrane.
-
Capture the signal using a digital imaging system.
-
Perform densitometry analysis using software (e.g., ImageJ). Normalize this compound band intensity to a loading control protein (e.g., GAPDH or β-actin) run on the same blot.
-
Protocol: Quantification of this compound mRNA by qRT-PCR
This protocol details the steps for measuring this compound mRNA transcript levels in rodent brain tissue.
-
RNA Extraction:
-
Homogenize ~50 mg of flash-frozen brain tissue in 1 mL of TRIzol reagent or a similar RNA lysis buffer.
-
Isolate total RNA according to the manufacturer's protocol, typically involving chloroform extraction and isopropanol precipitation.
-
Resuspend the RNA pellet in nuclease-free water.
-
Assess RNA quality and quantity using a spectrophotometer (e.g., NanoDrop).
-
-
DNase Treatment and cDNA Synthesis:
-
Treat 1-2 µg of total RNA with DNase I to remove any contaminating genomic DNA.
-
Synthesize first-strand complementary DNA (cDNA) from the DNase-treated RNA using a reverse transcriptase enzyme and oligo(dT) or random hexamer primers.
-
-
Quantitative Real-Time PCR (qPCR):
-
Prepare a reaction mix containing cDNA template, forward and reverse primers specific for the this compound gene, and a SYBR Green or TaqMan-based qPCR master mix.
-
Run the qPCR reaction on a real-time PCR instrument using a standard thermal cycling protocol (e.g., initial denaturation, followed by 40 cycles of denaturation, annealing, and extension).
-
Include no-template controls (NTCs) to check for contamination and no-reverse-transcriptase (-RT) controls to confirm the absence of genomic DNA amplification.
-
-
Data Analysis:
-
Determine the cycle threshold (Ct) value for this compound and a stable housekeeping gene (e.g., GAPDH, ACTB) for each sample.
-
Calculate the relative expression of this compound mRNA using the ΔΔCt method, normalizing the this compound Ct value to the housekeeping gene Ct value.
-
Conclusion and Future Directions
Initial studies strongly suggest that this compound is a key player in the neuronal response to stress, particularly oxidative stress.[5][7] Its downregulation in certain neurological models, coupled with the heightened susceptibility to oxidative damage in this compound knockout mice, points to a neuroprotective function.[5][7] The discovery of its methanethiol oxidase activity provides a direct mechanistic link between this compound and the production of redox-active signaling molecules.[4]
Future research should focus on:
-
Disease-Specific Expression: Quantifying this compound protein and mRNA levels across different stages of specific neurodegenerative diseases like Alzheimer's and Parkinson's disease in both patient tissues and animal models.
-
Mechanism of Action: Elucidating the precise downstream effects of this compound's MTO activity in neurons and determining how its interaction with the protein degradation machinery is regulated in a disease context.
-
Therapeutic Potential: Investigating whether modulating this compound expression or its enzymatic activity can mitigate neurodegenerative pathology and rescue functional deficits in preclinical models.
Understanding the core functions of this compound in the central nervous system will be crucial for evaluating its potential as a novel biomarker or therapeutic target for a range of devastating neurodegenerative disorders.
References
- 1. Selenium-Binding Protein 1 in Human Health and Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. researchgate.net [researchgate.net]
- 4. Selenium-Binding Protein 1 (SBP1): A New Putative Player of Stress Sensing in Plants - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Knocking out Selenium Binding Protein 1 Induces Depressive-Like Behavior in Mice - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Frontiers | Experimental procedures for flow cytometry of wild-type mouse brain: a systematic review [frontiersin.org]
- 7. researchgate.net [researchgate.net]
- 8. Protocol for mouse brain tissue processing and downstream analysis of circRNA-protein interactions in vivo - PMC [pmc.ncbi.nlm.nih.gov]
- 9. mdpi.com [mdpi.com]
Methodological & Application
Measuring SBP-1 Activity In Vivo: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
Introduction
The designation "SBP-1" can refer to two distinct and functionally important proteins: Sterol Regulatory Element-Binding Protein 1 (SREBP-1) and Selenium-Binding Protein 1 (Selenbp1) . Both proteins are subjects of intense research and are relevant to drug development in various therapeutic areas. This document provides detailed application notes and protocols for measuring the in vivo activity of both SREBP-1 and Selenbp1.
-
SREBP-1 is a master transcriptional regulator of lipid homeostasis. Its activity is crucial in the synthesis of fatty acids, triglycerides, and cholesterol. Dysregulation of SREBP-1 is implicated in metabolic diseases such as non-alcoholic fatty liver disease (NAFLD), type 2 diabetes, and certain cancers. Measuring its activity is key to understanding and targeting these conditions.[1][2][3][4]
-
Selenbp1 has been identified as a methanethiol oxidase (MTO), an enzyme that catalyzes the oxidation of methanethiol.[5][6][7] This activity is important for detoxifying volatile sulfur compounds.[8] Alterations in Selenbp1 activity are linked to conditions like extraoral halitosis, and it is being explored as a biomarker for various diseases, including cancer and cardiovascular events.[9][10][11][12]
Given their distinct functions, the "activity" of each this compound is measured using different methodologies. This guide will detail the primary in vivo and ex vivo (using samples obtained from an in vivo context) approaches for each protein.
Part 1: Measuring Sterol Regulatory Element-Binding Protein 1 (SREBP-1) Activity
The activity of SREBP-1, a transcription factor, is determined by its proteolytic processing, nuclear translocation, and subsequent activation of target gene expression.[2][3][13] Direct measurement of its transcriptional activity in vivo can be complex, but several robust methods provide reliable readouts of its activation state.
SREBP-1 Signaling and Activation Pathway
SREBP-1 is synthesized as an inactive precursor bound to the endoplasmic reticulum (ER) membrane. Upon stimulation (e.g., by insulin or low sterol levels), the SREBP-1/SCAP complex is transported to the Golgi apparatus, where it undergoes sequential proteolytic cleavage by Site-1 Protease (S1P) and Site-2 Protease (S2P). This releases the mature, transcriptionally active N-terminal domain (nSREBP-1), which translocates to the nucleus to activate target gene expression.[2][3]
Experimental Protocols for Measuring SREBP-1 Activity
This is the most common method to assess SREBP-1 activation by comparing the ratio of the mature nuclear form (nSREBP-1, ~68 kDa) to the precursor form (pSREBP-1, ~125 kDa).[14][15]
Methodology:
-
Tissue Collection and Homogenization:
-
Euthanize the animal (e.g., mouse) and rapidly excise the tissue of interest (e.g., liver, adipose tissue).
-
Snap-freeze the tissue in liquid nitrogen and store at -80°C.
-
For analysis, weigh the frozen tissue and homogenize in ice-cold lysis buffer containing protease and phosphatase inhibitors. For separate nuclear and cytoplasmic fractions, use a nuclear extraction kit.[16]
-
-
Protein Quantification:
-
Centrifuge the homogenate to pellet debris.
-
Determine the protein concentration of the supernatant using a standard method (e.g., BCA assay).
-
-
SDS-PAGE and Western Blotting:
-
Load equal amounts of protein onto an SDS-polyacrylamide gel.
-
Separate proteins by electrophoresis and transfer to a PVDF or nitrocellulose membrane.
-
Block the membrane (e.g., with 5% non-fat milk or BSA in TBST).
-
Incubate with a primary antibody specific for SREBP-1. Ensure the antibody can detect both precursor and mature forms.
-
Wash and incubate with an appropriate HRP-conjugated secondary antibody.
-
Detect the signal using an enhanced chemiluminescence (ECL) substrate and image the blot.
-
-
Data Analysis:
-
Quantify band intensities for both pSREBP-1 and nSREBP-1 using densitometry software.
-
Calculate the ratio of nSREBP-1 to pSREBP-1 or normalize nSREBP-1 to a loading control (e.g., Histone H3 for nuclear fraction, Tubulin for total lysate). An increase in this ratio indicates enhanced SREBP-1 activity.
-
Since nSREBP-1 is a transcription factor, its activity can be inferred by measuring the mRNA levels of its downstream target genes involved in lipogenesis.
Methodology:
-
Tissue Collection and RNA Extraction:
-
Collect tissue as described in Protocol 1.
-
Extract total RNA using a suitable method (e.g., TRIzol reagent or a column-based kit).
-
Assess RNA quality and quantity (e.g., using a NanoDrop spectrophotometer or Bioanalyzer).
-
-
Reverse Transcription:
-
Synthesize cDNA from the extracted RNA using a reverse transcriptase enzyme and oligo(dT) or random primers.
-
-
Quantitative PCR:
-
Perform qPCR using SYBR Green or TaqMan probes with primers specific for SREBP-1 target genes (e.g., Fasn, Scd1, Acaca).
-
Include a housekeeping gene (e.g., Gapdh, Actb) for normalization.
-
Run the reaction on a real-time PCR cycler.
-
-
Data Analysis:
-
Calculate the relative expression of target genes using the ΔΔCt method.
-
An increase in the expression of lipogenic genes indicates higher SREBP-1 activity.
-
ChIP followed by sequencing (ChIP-seq) or qPCR (ChIP-qPCR) can identify the specific genomic regions occupied by SREBP-1 in a given tissue, providing direct evidence of its DNA-binding activity.[17][18][19]
Methodology:
-
Cross-linking and Tissue Preparation:
-
Perfuse the tissue (e.g., liver) in situ with a cross-linking agent (e.g., formaldehyde) or mince fresh tissue and cross-link ex vivo.
-
Quench the cross-linking reaction (e.g., with glycine).
-
Homogenize the tissue and isolate nuclei.
-
-
Chromatin Shearing:
-
Lyse the nuclei and shear the chromatin into small fragments (200-1000 bp) using sonication or enzymatic digestion (e.g., MNase).
-
-
Immunoprecipitation:
-
Incubate the sheared chromatin with an antibody specific for SREBP-1 overnight at 4°C. Use a non-specific IgG as a negative control.
-
Add protein A/G beads to pull down the antibody-protein-DNA complexes.
-
Wash the beads to remove non-specific binding.
-
-
Elution and Reverse Cross-linking:
-
Elute the complexes from the beads and reverse the formaldehyde cross-links by heating.
-
Treat with RNase A and Proteinase K to remove RNA and protein.
-
-
DNA Purification and Analysis:
-
Purify the DNA using a column-based kit or phenol-chloroform extraction.
-
Analyze the precipitated DNA by qPCR using primers for the promoter regions of known target genes or by high-throughput sequencing (ChIP-seq) for genome-wide analysis.[19]
-
Data Presentation: SREBP-1 Activity
| Method | Model/Tissue | Condition | Result (Fold Change vs. Control) | Reference |
| Immunoblotting (nSREBP-1/pSREBP-1) | Mouse Liver | Fasted vs. Refed (High Carb Diet) | ~3-5 fold increase in nSREBP-1 | [18][20] |
| Immunoblotting (nSREBP-1) | db/db Mouse Liver | Control vs. SREBP-1 Silencing | ~70% decrease in nSREBP-1 | [14] |
| qRT-PCR (Fasn mRNA) | Mouse Liver | Control vs. alb-SREBP-1c overexpression | ~15-fold increase | [21] |
| qRT-PCR (Scd1 mRNA) | Mouse Liver | Control vs. alb-SREBP-1c overexpression | ~12-fold increase | [21] |
| ChIP-seq | Human Hepatocytes | - | 1,141 occupied gene promoters identified | [17] |
Part 2: Measuring Selenium-Binding Protein 1 (Selenbp1) Activity
The primary "activity" of Selenbp1 is its enzymatic function as a methanethiol oxidase (MTO), which converts methanethiol into hydrogen sulfide (H₂S), hydrogen peroxide (H₂O₂), and formaldehyde.[22][23] Its activity can be measured directly through its enzymatic products or indirectly by quantifying its protein levels in circulation.
Selenbp1 Metabolic Pathway
Selenbp1 plays a key role in the metabolism of volatile sulfur compounds. Methanethiol, primarily produced by the gut microbiota, is oxidized by Selenbp1 in tissues like the colon and liver. This process is crucial for detoxification and cellular signaling, as H₂S and H₂O₂ are important signaling molecules.[6][7][24]
Experimental Protocols for Measuring Selenbp1 Activity
This assay measures the production of H₂S and H₂O₂ from the Selenbp1-catalyzed oxidation of methanethiol. To overcome the difficulty of handling gaseous methanethiol, the substrate is generated in situ.[22][23][25]
Methodology:
-
Tissue Homogenate Preparation:
-
Collect tissue (e.g., colon, liver) and prepare a soluble protein fraction as described in Protocol 1, Step 1.
-
Determine protein concentration of the supernatant (cell lysate).
-
-
Reaction Setup:
-
The assay is performed in a sealed vial or 96-well plate.
-
The reaction mixture contains:
-
Tissue lysate (source of Selenbp1).
-
L-methionine.
-
Recombinant L-methionine γ-lyase (MGL) to generate methanethiol from methionine.
-
A detection reagent for either H₂S (e.g., a fluorescent probe) or H₂O₂ (e.g., Amplex Red with horseradish peroxidase).
-
-
-
Measurement:
-
Incubate the reaction mixture at 37°C.
-
Monitor the increase in fluorescence or absorbance over time using a plate reader. The rate of product formation is proportional to the MTO activity in the lysate.
-
-
Data Analysis:
-
Generate a standard curve using known concentrations of H₂S or H₂O₂.
-
Calculate the specific activity as nmol of product formed per minute per mg of protein in the lysate.
-
Selenbp1 can be detected in serum and may serve as a biomarker for tissue damage or stress.[11][12] Its concentration can be quantified using a luminometric immunoassay (LIA) or an enzyme-linked immunosorbent assay (ELISA).
Methodology:
-
Sample Collection:
-
Collect whole blood from the subject into a serum separator tube.
-
Allow the blood to clot, then centrifuge to separate the serum.
-
Store serum samples at -80°C until analysis.
-
-
Immunoassay Procedure (General Steps):
-
Coat a 96-well plate with a capture antibody specific for Selenbp1.
-
Block non-specific binding sites.
-
Add serum samples and standards to the wells and incubate.
-
Wash the plate, then add a detection antibody (which may be biotinylated or enzyme-conjugated).
-
If using a biotinylated detection antibody, follow with an enzyme-conjugated streptavidin step.
-
Wash the plate and add a substrate (e.g., a chemiluminescent substrate for LIA or a colorimetric substrate like TMB for ELISA).
-
Measure the signal (luminescence or absorbance) using a plate reader.
-
-
Data Analysis:
-
Generate a standard curve from the signal of the known standards.
-
Interpolate the concentration of Selenbp1 in the serum samples from the standard curve.
-
Results are typically expressed in nmol/L or µg/L.
-
Data Presentation: Selenbp1 Activity
| Method | Sample Type | Condition | Result | Reference |
| MTO Coupled Assay | Differentiated Caco-2 cell lysate | - | H₂S production: ~4.5 nmol/mg/h | [22] |
| MTO Coupled Assay | Undifferentiated Caco-2 cell lysate | - | H₂S production: ~1.0 nmol/mg/h | [22] |
| Luminometric Immunoassay (LIA) | Human Serum | Healthy Controls | Close to limit of detection | [11][12] |
| Luminometric Immunoassay (LIA) | Human Serum | Acute Coronary Syndrome Patients | Elevated, >0.8 nmol/L associated with high risk | [11][12] |
Experimental Workflow Diagrams
Workflow for SREBP-1 Activity Assessment
Workflow for Selenbp1 Activity Assessment
References
- 1. Progress in the Study of Sterol Regulatory Element Binding Protein 1 Signal Pathway [gavinpublishers.com]
- 2. Frontiers | Targeting SREBP-1-Mediated Lipogenesis as Potential Strategies for Cancer [frontiersin.org]
- 3. A pathway approach to investigate the function and regulation of SREBPs - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Frontiers | Role of the Sterol Regulatory Element Binding Protein Pathway in Tumorigenesis [frontiersin.org]
- 5. uniprot.org [uniprot.org]
- 6. researchgate.net [researchgate.net]
- 7. mdpi.com [mdpi.com]
- 8. Selenium-binding protein 1 (SELENBP1) is a copper-dependent thiol oxidase - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Quantitative Proteomic Analysis Reveals That Anti-Cancer Effects of Selenium-Binding Protein 1 In Vivo Are Associated with Metabolic Pathways - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. researchgate.net [researchgate.net]
- 12. Circulating levels of selenium-binding protein 1 (SELENBP1) are associated with risk for major adverse cardiac events and death - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
- 14. Sterol Regulatory Element-binding Protein-1 (SREBP-1) Is Required to Regulate Glycogen Synthesis and Gluconeogenic Gene Expression in Mouse Liver - PMC [pmc.ncbi.nlm.nih.gov]
- 15. researchgate.net [researchgate.net]
- 16. caymanchem.com [caymanchem.com]
- 17. Genome-Wide Occupancy of SREBP1 and Its Partners NFY and SP1 Reveals Novel Functional Roles and Combinatorial Regulation of Distinct Classes of Genes - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Selective Binding of Sterol Regulatory Element-binding Protein Isoforms and Co-regulatory Proteins to Promoters for Lipid Metabolic Genes in Liver - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Genome-wide analysis of SREBP-1 binding in mouse liver chromatin reveals a preference for promoter proximal binding to a new motif - PMC [pmc.ncbi.nlm.nih.gov]
- 20. Assessment of SREBP Activation Using a Microsomal Vesicle Budding Assay - PMC [pmc.ncbi.nlm.nih.gov]
- 21. Liver-Specific Expression of Transcriptionally Active SREBP-1c Is Associated with Fatty Liver and Increased Visceral Fat Mass - PMC [pmc.ncbi.nlm.nih.gov]
- 22. A coupled enzyme assay for detection of selenium-binding protein 1 (SELENBP1) methanethiol oxidase (MTO) activity in mature enterocytes - PMC [pmc.ncbi.nlm.nih.gov]
- 23. A coupled enzyme assay for detection of selenium-binding protein 1 (SELENBP1) methanethiol oxidase (MTO) activity in mature enterocytes - PubMed [pubmed.ncbi.nlm.nih.gov]
- 24. Selenium-Binding Protein 1 (SBP1): A New Putative Player of Stress Sensing in Plants [mdpi.com]
- 25. researchgate.net [researchgate.net]
Application Notes and Protocols for the Purification of Recombinant Human Selenium-Binding Protein 1 (SBP1)
For Researchers, Scientists, and Drug Development Professionals
These application notes provide detailed methodologies for the expression and purification of recombinant human Selenium-Binding Protein 1 (SBP1), a protein of significant interest in cancer research and other physiological and pathological processes. The following protocols outline strategies for obtaining high-purity SBP1 from common laboratory expression systems.
Introduction to Recombinant Human SBP1 Purification
Human Selenium-Binding Protein 1 (SELENBP1) is a cytosolic protein whose expression is often dysregulated in various cancers. Access to highly purified, active recombinant SBP1 is crucial for structural studies, functional assays, and the development of potential therapeutic agents. The purification of recombinant proteins typically involves a multi-step chromatographic process to isolate the target protein from host cell contaminants. A common and effective strategy employs a combination of affinity, ion-exchange, and size-exclusion chromatography.
The choice of expression system and affinity tag is a critical first step. Escherichia coli is a cost-effective and widely used host for recombinant protein production. Affinity tags, such as the polyhistidine (His)-tag or Glutathione S-transferase (GST)-tag, are genetically fused to the SBP1 sequence to facilitate initial capture from the cell lysate. Subsequent polishing steps, including ion-exchange and size-exclusion chromatography, are then used to remove remaining impurities and protein aggregates, yielding a highly pure and homogenous final product.
Biochemical Properties of Human SBP1
A thorough understanding of the biochemical properties of human SBP1 is essential for designing an effective purification strategy.
| Property | Value | Source |
| Full-Length Molecular Weight (Theoretical) | 52.8 kDa | UniProt: Q13228 |
| Isoelectric Point (pI) (Theoretical) | 6.09 | Calculated from sequence |
| Subcellular Localization | Cytoplasm, Nucleus | UniProt: Q13228 |
Recommended Purification Strategies
Two primary workflows are presented below, based on the use of either a His-tag or a GST-tag for the initial affinity capture of recombinant human SBP1 expressed in E. coli.
Strategy 1: Purification of His-tagged Human SBP1
This protocol describes the purification of N-terminally or C-terminally hexahistidine-tagged (6xHis) human SBP1.
Experimental Workflow Diagram
Caption: Workflow for His-tagged SBP1 purification.
Detailed Protocols
1. Expression in E. coli
-
Transform a suitable E. coli expression strain (e.g., BL21(DE3)) with a plasmid encoding His-tagged human SBP1.
-
Grow the transformed cells in Luria-Bertani (LB) medium containing the appropriate antibiotic at 37°C with shaking until the optical density at 600 nm (OD600) reaches 0.6-0.8.
-
Induce protein expression by adding isopropyl β-D-1-thiogalactopyranoside (IPTG) to a final concentration of 0.5-1.0 mM.
-
Incubate the culture for a further 4-6 hours at 30°C or overnight at 18°C to enhance protein solubility.
-
Harvest the cells by centrifugation at 5,000 x g for 15 minutes at 4°C.
2. Cell Lysis and Clarification
-
Resuspend the cell pellet in Lysis Buffer (50 mM Tris-HCl, pH 8.0, 300 mM NaCl, 10 mM imidazole, 1 mM DTT, 1x protease inhibitor cocktail).
-
Lyse the cells by sonication on ice or by using a high-pressure homogenizer.
-
Clarify the lysate by centrifugation at 20,000 x g for 30 minutes at 4°C to pellet cell debris.
3. Affinity Chromatography (IMAC)
-
Equilibrate a Ni-NTA (Nickel-Nitrilotriacetic Acid) affinity column with Lysis Buffer.
-
Load the clarified lysate onto the column.
-
Wash the column with 10-20 column volumes of Wash Buffer (50 mM Tris-HCl, pH 8.0, 300 mM NaCl, 20 mM imidazole, 1 mM DTT) to remove non-specifically bound proteins.
-
Elute the His-tagged SBP1 with Elution Buffer (50 mM Tris-HCl, pH 8.0, 300 mM NaCl, 250 mM imidazole, 1 mM DTT).
-
Collect fractions and analyze by SDS-PAGE to identify those containing the purified protein.
4. Ion-Exchange Chromatography (Anion Exchange)
-
Rationale: The theoretical pI of human SBP1 is approximately 6.09. At a pH above its pI, the protein will have a net negative charge and will bind to an anion-exchange resin. A working pH of 7.5 is recommended.
-
Pool the fractions containing His-SBP1 from the affinity step and dialyze against Anion-Exchange Buffer A (20 mM Tris-HCl, pH 7.5, 25 mM NaCl, 1 mM DTT).
-
Equilibrate a strong anion-exchange column (e.g., a quaternary ammonium-based resin) with Anion-Exchange Buffer A.
-
Load the dialyzed sample onto the column.
-
Wash the column with Anion-Exchange Buffer A until the baseline absorbance at 280 nm is stable.
-
Elute the protein using a linear gradient of 0-100% Anion-Exchange Buffer B (20 mM Tris-HCl, pH 7.5, 1 M NaCl, 1 mM DTT) over 20 column volumes.
-
Collect fractions and analyze by SDS-PAGE.
5. Size-Exclusion Chromatography (Gel Filtration)
-
Pool the fractions containing SBP1 from the ion-exchange step and concentrate using an appropriate centrifugal filter device.
-
Equilibrate a size-exclusion chromatography column (with a fractionation range suitable for ~53 kDa) with SEC Buffer (20 mM Tris-HCl, pH 7.5, 150 mM NaCl, 1 mM DTT).
-
Load the concentrated protein sample onto the column.
-
Elute the protein with SEC Buffer at a constant flow rate.
-
Collect fractions and analyze by SDS-PAGE for purity. Pool the fractions containing pure, monomeric SBP1.
Strategy 2: Purification of GST-tagged Human SBP1
This protocol outlines the purification of human SBP1 fused to Glutathione S-transferase (GST).
Experimental Workflow Diagram
Caption: Workflow for GST-tagged SBP1 purification.
Detailed Protocols
1. Expression and Lysis
-
Follow the same procedure as for His-tagged SBP1, using a plasmid encoding GST-tagged human SBP1.
-
For lysis, use a buffer compatible with GST affinity chromatography, such as PBS (140 mM NaCl, 2.7 mM KCl, 10 mM Na2HPO4, 1.8 mM KH2PO4, pH 7.3) supplemented with 1 mM DTT and a protease inhibitor cocktail.
2. Affinity Chromatography (Glutathione Agarose)
-
Equilibrate a glutathione agarose column with GST Lysis Buffer.
-
Load the clarified lysate onto the column.
-
Wash the column with 10-20 column volumes of GST Lysis Buffer to remove unbound proteins.
-
Elute the GST-SBP1 fusion protein with Elution Buffer (50 mM Tris-HCl, pH 8.0, 10 mM reduced glutathione).
-
Alternatively, for tag cleavage, proceed with on-column cleavage.
3. GST Tag Cleavage (Optional but Recommended)
-
On-Column Cleavage:
-
After the wash step, equilibrate the column with Cleavage Buffer (e.g., 50 mM Tris-HCl, pH 7.5, 150 mM NaCl, 1 mM EDTA, 1 mM DTT).
-
Add a site-specific protease (e.g., PreScission Protease or TEV protease, depending on the cleavage site in the fusion construct) to the column and incubate at 4°C for 4-16 hours.
-
Elute the tagless SBP1 with Cleavage Buffer. The GST tag and the protease (if GST-tagged) will remain bound to the resin.
-
-
In-Solution Cleavage:
-
Elute the GST-SBP1 fusion protein as described above.
-
Add the specific protease to the eluted protein and incubate according to the manufacturer's instructions.
-
The cleaved SBP1 can then be separated from the GST tag and the protease by passing the mixture back over the glutathione agarose column (SBP1 will be in the flow-through) or by subsequent chromatography steps.
-
4. Ion-Exchange and Size-Exclusion Chromatography
-
Follow the same protocols as described for the His-tagged SBP1 purification (Steps 4 and 5), starting with the cleaved, tagless SBP1.
Quantitative Data Summary
The following table provides expected outcomes for the purification of recombinant human SBP1 from a 1-liter E. coli culture. These are estimates and will vary depending on the expression level and solubility of the specific construct.
| Purification Step | Total Protein (mg) | SBP1 (mg) | Purity (%) |
| Clarified Lysate | 1000 - 2000 | 20 - 50 | 2 - 5 |
| Affinity Chromatography (His-tag or GST-tag) | 10 - 25 | 8 - 20 | > 80 |
| Ion-Exchange Chromatography | 5 - 15 | 4 - 12 | > 90 |
| Size-Exclusion Chromatography | 3 - 10 | 2 - 8 | > 95 |
Conclusion
The protocols outlined provide a robust framework for the purification of recombinant human SBP1. The choice between a His-tag and a GST-tag will depend on the specific experimental needs and the expression characteristics of the SBP1 construct. For applications requiring tagless native protein, the GST-fusion system with enzymatic cleavage is advantageous. Optimization of buffer conditions, especially pH and salt concentrations, may be necessary to achieve the highest yield and purity. The successful purification of SBP1 will enable further investigation into its biological functions and its role in disease.
Application Notes and Protocols for SBP-1 Inhibitors in Cell Culture Experiments
For Researchers, Scientists, and Drug Development Professionals
Introduction
The designation "SBP-1" can refer to two distinct transcription factors of significant interest in biomedical research: Specificity Protein 1 (Sp1) and Sterol Regulatory Element-Binding Protein 1 (SREBP-1) . Both are critical regulators of cellular processes and have been implicated in various diseases, including cancer and metabolic disorders. This document provides detailed application notes and protocols for the use of inhibitors targeting both Sp1 and SREBP-1 in cell culture experiments.
Section 1: Specificity Protein 1 (Sp1) Inhibitors
Sp1 is a ubiquitously expressed transcription factor that binds to GC-rich promoter regions of numerous genes involved in cell proliferation, survival, and angiogenesis.[1] Its overexpression is a common feature in a variety of cancers, making it a promising target for therapeutic intervention.[1]
Mechanism of Action of Sp1 Inhibitors
Sp1 inhibitors primarily function by disrupting the ability of the Sp1 transcription factor to bind to its consensus GC-rich DNA binding sites within the promoter regions of its target genes. This interference can occur through several mechanisms, including direct binding to the Sp1 protein or, more commonly, by binding to the minor groove of GC-rich DNA sequences, which physically obstructs Sp1 binding.[2] A prominent class of Sp1 inhibitors, including Mithramycin and its analogs like EC-8042, function via this latter mechanism.[3] The downstream effects of Sp1 inhibition include cell cycle arrest, induction of apoptosis, and inhibition of angiogenesis.[3][4]
Quantitative Data of Sp1 Inhibitors
The efficacy of Sp1 inhibitors varies across different cancer cell lines and inhibitor types. The following tables summarize the half-maximal inhibitory concentration (IC50) values for representative Sp1 inhibitors.
Table 1: IC50 Values of Mithramycin in Various Cancer Cell Lines
| Cell Line | Cancer Type | IC50 (nM) | Reference |
| CHLA-10 | Ewing Sarcoma | 9.11 | [3] |
| TC205 | Ewing Sarcoma | 4.32 | [3] |
| PC3-TR | Prostate Cancer | ~200 | [5] |
| Panc-1 | Pancreatic Cancer | ~200 | [5] |
| Various | Gynecologic Cancers | 20 - 60 | [6] |
Table 2: IC50 Values of EC-8042 in Sarcoma Cell Lines
| Cell Line | Cancer Type | IC50 (µM) | Reference |
| MSC-4H-GFP | Sarcoma | 0.233 | [7] |
| MSC-4H-FC | Sarcoma | 0.311 | [7] |
| T-4H-GFP#1 | Sarcoma | 0.107 | [7] |
| T-4H-FC#1 | Sarcoma | 0.134 | [7] |
| MSC-5H-GFP | Sarcoma | 0.201 | [7] |
| MSC-5H-FC | Sarcoma | 0.254 | [7] |
| T-5H-GFP#1 | Sarcoma | 0.158 | [7] |
| T-5H-FC#1 | Sarcoma | 0.187 | [7] |
Experimental Protocols
This protocol is used to determine the cytotoxic effects of an Sp1 inhibitor on a cell line of interest.
Materials:
-
Sp1 inhibitor stock solution (e.g., in DMSO)
-
Complete cell culture medium
-
96-well microtiter plates
-
MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) solution (5 mg/mL in PBS)
-
DMSO
-
Microplate reader
Procedure:
-
Cell Seeding: Seed cells in a 96-well plate at a density of 5,000-10,000 cells/well in 100 µL of complete medium. Allow cells to adhere overnight in a humidified incubator at 37°C with 5% CO2.[8][9]
-
Compound Treatment: Prepare serial dilutions of the Sp1 inhibitor in complete medium. Remove the overnight medium from the cells and add 100 µL of the diluted inhibitor solutions to the respective wells. Include a vehicle control (e.g., DMSO).[8][9]
-
Incubation: Incubate the plate for the desired treatment duration (e.g., 24, 48, or 72 hours).[8]
-
MTT Addition: After incubation, add 10 µL of MTT solution to each well and incubate for 4 hours at 37°C.[8][9]
-
Solubilization: Aspirate the medium and add 150 µL of DMSO to each well to dissolve the formazan crystals.[8]
-
Absorbance Measurement: Measure the absorbance at 570 nm using a microplate reader.[8]
-
Data Analysis: Calculate cell viability as a percentage of the vehicle-treated control.
This protocol is used to confirm the mechanism of action of the Sp1 inhibitor by assessing the protein levels of Sp1 and its downstream targets (e.g., c-Myc, Bcl-2).
Materials:
-
Sp1 inhibitor
-
Cell lysis buffer (e.g., RIPA buffer with protease and phosphatase inhibitors)
-
BCA protein assay kit
-
SDS-PAGE gels
-
PVDF membrane
-
Blocking buffer (e.g., 5% non-fat milk or BSA in TBST)
-
Primary antibodies (targeting Sp1, c-Myc, Bcl-2, and a loading control like β-actin or GAPDH)
-
HRP-conjugated secondary antibody
-
Chemiluminescence detection reagent
Procedure:
-
Cell Treatment and Lysis: Treat cells with the Sp1 inhibitor at various concentrations for a specified time (e.g., 24 hours). Wash cells with ice-cold PBS and lyse them with lysis buffer.[10]
-
Protein Quantification: Determine the protein concentration of each lysate using a BCA assay.[10]
-
Sample Preparation: Denature equal amounts of protein (e.g., 20-30 µg) by boiling in Laemmli sample buffer.[10]
-
SDS-PAGE and Transfer: Separate the proteins by SDS-PAGE and transfer them to a PVDF membrane.[10]
-
Blocking: Block the membrane with blocking buffer for 1 hour at room temperature.[10]
-
Antibody Incubation: Incubate the membrane with primary antibodies overnight at 4°C.[10]
-
Secondary Antibody Incubation: Wash the membrane with TBST and incubate with the appropriate HRP-conjugated secondary antibody for 1 hour at room temperature.[10]
-
Detection: Wash the membrane again with TBST and visualize the protein bands using a chemiluminescence detection system.[10]
Signaling Pathway and Experimental Workflow
Caption: Sp1 signaling pathway and points of inhibition.
Caption: Experimental workflow for evaluating Sp1 inhibitors.
Section 2: Sterol Regulatory Element-Binding Protein 1 (SREBP-1) Inhibitors
SREBP-1 is a key transcription factor that regulates the expression of genes involved in lipid biosynthesis.[11] Dysregulation of SREBP-1 has been linked to various metabolic diseases and certain cancers.
Mechanism of Action of SREBP-1 Inhibitors
SREBP-1 is synthesized as an inactive precursor bound to the endoplasmic reticulum (ER) membrane. For activation, it must translocate to the Golgi apparatus where it is cleaved by two proteases to release the mature transcription factor. SREBP-1 inhibitors, such as fatostatin and betulin, block this activation process. Fatostatin binds to the SREBP cleavage-activating protein (SCAP), preventing the ER-to-Golgi translocation of SREBPs.[12] Betulin has also been shown to inhibit SREBP-1 activation, leading to decreased lipogenesis.[13]
Quantitative Data of SREBP-1 Inhibitors
The following tables summarize the IC50 values for representative SREBP-1 inhibitors in various cancer cell lines.
Table 3: IC50 Values of Fatostatin in Various Cancer Cell Lines
| Cell Line | Cancer Type | IC50 (µM) | Reference |
| Ishikawa | Endometrial Cancer | 17.96 | [13] |
| HEC-1A | Endometrial Cancer | 4.53 | [13] |
| LNCaP | Prostate Cancer | 10.4 | [14] |
| C4-2B | Prostate Cancer | 9.1 | [14] |
| HeLa | Cervical Cancer | 2.11 | [15] |
Table 4: IC50 Values of Betulinic Acid in Various Cancer Cell Lines
| Cell Line | Cancer Type | IC50 (µM) | Reference(s) |
| MCF-7 | Breast Cancer | 8.32 - 11.5 | [16][17] |
| A549 | Lung Cancer | 15.51 | [18] |
| PC-3 | Prostate Cancer | 32.46 | [18] |
| MV4-11 | Leukemia | 18.16 | [18] |
| MDA-MB-231 | Breast Cancer | 17.21 | [19] |
Experimental Protocols
This protocol is adapted for testing the cytotoxicity of SREBP-1 inhibitors.
Materials:
-
SREBP-1 inhibitor stock solution (e.g., fatostatin in DMSO)
-
Complete cell culture medium
-
96-well plates
-
MTT solution (5 mg/mL in PBS)
-
DMSO
-
Microplate reader
Procedure:
-
Cell Seeding: Seed cells in a 96-well plate at a density of 6,000-8,000 cells/well and allow them to adhere overnight.[8]
-
Compound Treatment: Prepare serial dilutions of the SREBP-1 inhibitor in complete culture medium. Ensure the final DMSO concentration is less than 0.1% (v/v). Include a vehicle control (DMSO only). Remove the old medium and add 100 µL of the medium containing different concentrations of the inhibitor or vehicle control.[8]
-
Incubation: Incubate the plate for 24, 48, or 72 hours at 37°C in a humidified incubator with 5% CO2.[8]
-
MTT Addition: At the end of the incubation period, add 20 µL of MTT solution to each well and incubate for 4 hours.[8]
-
Solubilization: Remove the medium and add 150 µL of DMSO to each well to dissolve the formazan crystals.[8]
-
Absorbance Measurement: Measure the absorbance at 490 nm using a microplate reader.[8]
-
Data Analysis: Calculate cell viability as a percentage of the vehicle-treated control.
This protocol is designed to assess the effect of an inhibitor on the proteolytic processing of SREBP-1.
Materials:
-
SREBP-1 inhibitor
-
Cell lysis buffer (e.g., RIPA buffer)
-
BCA protein assay kit
-
SDS-PAGE gels
-
PVDF membrane
-
Blocking buffer (5% non-fat milk or BSA in TBST)
-
Primary antibody targeting SREBP-1 (recognizing both precursor and mature forms)
-
HRP-conjugated secondary antibody
-
Chemiluminescence detection reagent
Procedure:
-
Cell Treatment and Lysis: Seed cells in 6-well plates and grow to 70-80% confluency. Treat cells with various concentrations of the SREBP-1 inhibitor or vehicle control for 24 hours. Wash cells with ice-cold PBS and lyse them in RIPA buffer.[8]
-
Protein Quantification: Determine the protein concentration of the lysates using a BCA assay.[8]
-
Sample Preparation: Denature equal amounts of protein by boiling in Laemmli sample buffer.[8]
-
SDS-PAGE and Transfer: Separate the proteins by SDS-PAGE and transfer them to a PVDF membrane.[8]
-
Blocking: Block the membrane with 5% non-fat milk or BSA in TBST for 1 hour at room temperature.[8]
-
Antibody Incubation: Incubate the membrane with the primary SREBP-1 antibody overnight at 4°C.[8]
-
Secondary Antibody Incubation: Wash the membrane with TBST and incubate with HRP-conjugated secondary antibody for 1 hour at room temperature.[8]
-
Detection: Wash the membrane again and detect the protein bands using a chemiluminescence detection system. Look for a decrease in the mature, cleaved form of SREBP-1 and a potential accumulation of the precursor form.[8]
Signaling Pathway and Experimental Workflow
Caption: SREBP-1 activation pathway and point of inhibition.
Caption: Workflow for evaluating SREBP-1 inhibitors.
References
- 1. benchchem.com [benchchem.com]
- 2. Anticancer Potential of Betulonic Acid Derivatives - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Evaluation of Mithramycin in Combination with Chemotherapeutic Agents Against Ewing Sarcoma Cell Lines - PMC [pmc.ncbi.nlm.nih.gov]
- 4. benchchem.com [benchchem.com]
- 5. researchgate.net [researchgate.net]
- 6. Low‐dose mithramycin exerts its anticancer effect via the p53 signaling pathway and synergizes with nutlin‐3 in gynecologic cancers - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Inhibition of SP1 by the mithramycin analog EC-8042 efficiently targets tumor initiating cells in sarcoma - PMC [pmc.ncbi.nlm.nih.gov]
- 8. benchchem.com [benchchem.com]
- 9. benchchem.com [benchchem.com]
- 10. benchchem.com [benchchem.com]
- 11. researchgate.net [researchgate.net]
- 12. medchemexpress.com [medchemexpress.com]
- 13. spandidos-publications.com [spandidos-publications.com]
- 14. aacrjournals.org [aacrjournals.org]
- 15. Fatostatin Inhibits Cancer Cell Proliferation by Affecting Mitotic Microtubule Spindle Assembly and Cell Division - PMC [pmc.ncbi.nlm.nih.gov]
- 16. benchchem.com [benchchem.com]
- 17. Tuning of the Anti-Breast Cancer Activity of Betulinic Acid via Its Conversion to Ionic Liquids [mdpi.com]
- 18. mdpi.com [mdpi.com]
- 19. researchgate.net [researchgate.net]
Application Note: Quantification of Selenium Binding Protein 1 (SBP1) using a Sandwich ELISA
For Researchers, Scientists, and Drug Development Professionals
Introduction
Selenium Binding Protein 1 (SBP1) is a highly conserved 56 kDa protein that plays a crucial role in various cellular processes, including redox modulation, protein degradation, and intra-Golgi transport.[1] Emerging evidence strongly suggests that SBP1 functions as a tumor suppressor.[2] Its expression is frequently downregulated in a variety of cancers, including prostate, colon, lung, and ovarian cancers, and this reduced expression often correlates with poor clinical outcomes.[1][3][4] SBP1 has been implicated in several cancer-related signaling pathways, including those involving p53, MAPK, and Wnt.[3][5] This makes the quantification of SBP1 a valuable tool for cancer research and a potential biomarker for disease progression and therapeutic response.
This application note provides a detailed protocol for the quantification of human SBP1 in cell culture lysates and serum samples using a sandwich Enzyme-Linked Immunosorbent Assay (ELISA). The sandwich ELISA format offers high specificity and sensitivity by utilizing two antibodies that recognize different epitopes on the SBP1 protein.[6][7][8][9]
Assay Principle
The SBP1 sandwich ELISA is a quantitative immunoassay. A capture antibody specific for SBP1 is pre-coated onto the wells of a microplate. When the sample or standard is added, SBP1 present in the solution binds to the immobilized antibody. After washing away unbound substances, a biotinylated detection antibody that recognizes a different epitope on SBP1 is added, forming a "sandwich" complex. Subsequently, a streptavidin-horseradish peroxidase (HRP) conjugate is added, which binds to the biotinylated detection antibody. A chromogenic substrate (TMB) is then introduced, and the HRP enzyme catalyzes a color change. The intensity of the color is directly proportional to the amount of SBP1 captured in the well. The reaction is stopped, and the absorbance is measured at 450 nm. A standard curve is generated using a recombinant SBP1 protein of known concentration, which allows for the determination of SBP1 concentration in unknown samples.
Required Materials
| Reagent/Material | Recommended Supplier | Catalog Number |
| SBP1 Matched Antibody Pair (Capture & Detection) | Multiple vendors available | User-defined |
| Recombinant Human SBP1 Protein Standard | Multiple vendors available | User-defined |
| 96-well high-binding ELISA microplate | Multiple vendors available | User-defined |
| Coating Buffer (0.1 M Carbonate-Bicarbonate, pH 9.6) | Prepare in-house | N/A |
| Wash Buffer (PBS with 0.05% Tween-20) | Prepare in-house | N/A |
| Blocking Buffer (PBS with 1% BSA) | Prepare in-house | N/A |
| Assay Diluent (PBS with 0.1% BSA, 0.05% Tween-20) | Prepare in-house | N/A |
| Streptavidin-HRP Conjugate | Multiple vendors available | User-defined |
| TMB Substrate Solution | Multiple vendors available | User-defined |
| Stop Solution (2 M H₂SO₄) | Multiple vendors available | User-defined |
| Cell Lysis Buffer (e.g., RIPA buffer) with Protease Inhibitors | Multiple vendors available | User-defined |
| Microplate reader with 450 nm filter | N/A | N/A |
| Pipettes and tips | N/A | N/A |
| Squirt bottle, manifold dispenser, or automated plate washer | N/A | N/A |
Experimental Protocols
Protocol 1: Preparation of Reagents
-
Coating Buffer (0.1 M Carbonate-Bicarbonate, pH 9.6): Dissolve 1.59 g of Na₂CO₃ and 2.93 g of NaHCO₃ in deionized water to a final volume of 1 L. Adjust pH to 9.6.
-
Wash Buffer (1X PBS with 0.05% Tween-20): Prepare 1X PBS from a 10X stock. Add 0.5 mL of Tween-20 per liter of 1X PBS and mix well.
-
Blocking Buffer (1% BSA in 1X PBS): Dissolve 1 g of Bovine Serum Albumin (BSA) in 100 mL of 1X PBS.
-
Assay Diluent (0.1% BSA, 0.05% Tween-20 in 1X PBS): Dissolve 0.1 g of BSA in 100 mL of Wash Buffer.
-
SBP1 Standard Preparation: Reconstitute the lyophilized recombinant human SBP1 protein standard according to the manufacturer's instructions to obtain a stock solution (e.g., 100 ng/mL). Prepare serial dilutions in Assay Diluent to generate standards ranging from (for example) 10 ng/mL to 0.156 ng/mL. Also, prepare a blank (0 ng/mL) using only Assay Diluent.
-
Capture and Detection Antibody Preparation: Dilute the capture and biotinylated detection antibodies to their optimal working concentrations in the appropriate buffers (Coating Buffer for capture antibody, Assay Diluent for detection antibody) as determined by titration experiments.
Protocol 2: Sample Preparation
A. Cell Culture Lysates
-
Culture cells to 70-80% confluency.
-
Aspirate the culture medium and wash the cells twice with ice-cold 1X PBS.
-
Add an appropriate volume of ice-cold cell lysis buffer (e.g., RIPA buffer) containing a protease inhibitor cocktail to the cells.[10][11]
-
Scrape the cells and transfer the lysate to a pre-chilled microcentrifuge tube.
-
Incubate on ice for 30 minutes, vortexing briefly every 10 minutes.
-
Centrifuge at 14,000 x g for 15 minutes at 4°C to pellet cellular debris.[12]
-
Transfer the supernatant (cell lysate) to a new tube.
-
Determine the total protein concentration of the lysate using a BCA protein assay.
-
Dilute the lysates in Assay Diluent to a concentration within the range of the standard curve. A starting dilution of 1:10 is recommended, but this may need to be optimized.
-
Store aliquots at -80°C to avoid repeated freeze-thaw cycles.
B. Serum and Plasma
-
Serum: Collect whole blood in a serum separator tube. Allow the blood to clot for 30-60 minutes at room temperature. Centrifuge at 1000 x g for 15 minutes at 4°C.[12][13] Carefully collect the serum (supernatant).
-
Plasma: Collect whole blood into a tube containing an anticoagulant (e.g., EDTA or heparin). Centrifuge at 1000 x g for 15 minutes at 4°C within 30 minutes of collection.[13][14] Collect the plasma (supernatant).
-
Dilute serum or plasma samples in Assay Diluent. A starting dilution of 1:2 is recommended, but this should be optimized for your specific samples.
-
Store aliquots at -80°C.
Protocol 3: SBP1 ELISA Procedure
-
Coating: Add 100 µL of the diluted capture antibody to each well of the 96-well microplate. Incubate overnight at 4°C.
-
Washing: Aspirate the coating solution and wash the plate three times with 300 µL of Wash Buffer per well.
-
Blocking: Add 200 µL of Blocking Buffer to each well. Incubate for 2 hours at room temperature.
-
Washing: Repeat the wash step as in step 2.
-
Sample and Standard Incubation: Add 100 µL of the prepared SBP1 standards and diluted samples to the appropriate wells. Incubate for 2 hours at room temperature.
-
Washing: Repeat the wash step as in step 2.
-
Detection Antibody Incubation: Add 100 µL of the diluted biotinylated detection antibody to each well. Incubate for 1 hour at room temperature.
-
Washing: Repeat the wash step as in step 2.
-
Streptavidin-HRP Incubation: Add 100 µL of Streptavidin-HRP conjugate to each well. Incubate for 30 minutes at room temperature in the dark.
-
Washing: Repeat the wash step, but increase to five washes.
-
Substrate Development: Add 100 µL of TMB Substrate Solution to each well. Incubate for 15-30 minutes at room temperature in the dark, monitoring for color development.
-
Stop Reaction: Add 50 µL of Stop Solution to each well. The color will change from blue to yellow.
-
Absorbance Reading: Read the absorbance of each well at 450 nm using a microplate reader within 30 minutes of adding the Stop Solution.
Data Presentation and Analysis
-
Data Collection: Record the absorbance values at 450 nm for all standards and samples.
-
Standard Curve Generation: Subtract the mean absorbance of the blank (0 ng/mL standard) from the mean absorbance of all other standards and samples. Plot the mean corrected absorbance (Y-axis) against the corresponding SBP1 concentration (X-axis) for the standards. A four-parameter logistic (4-PL) curve fit is recommended.
-
SBP1 Quantification: Use the generated standard curve to determine the concentration of SBP1 in your samples. Multiply the calculated concentration by the dilution factor to obtain the final SBP1 concentration in the original sample.
Table 1: Example SBP1 Standard Curve Data
| SBP1 Conc. (ng/mL) | Absorbance at 450 nm (Mean) | Corrected Absorbance |
| 10 | 2.150 | 2.050 |
| 5 | 1.625 | 1.525 |
| 2.5 | 1.050 | 0.950 |
| 1.25 | 0.600 | 0.500 |
| 0.625 | 0.350 | 0.250 |
| 0.313 | 0.225 | 0.125 |
| 0.156 | 0.160 | 0.060 |
| 0 (Blank) | 0.100 | 0.000 |
Table 2: Example SBP1 Quantification in Samples
| Sample ID | Dilution Factor | Corrected Absorbance | Calculated Conc. (ng/mL) | Final Conc. (ng/mL) |
| Cell Lysate 1 | 10 | 0.850 | 2.2 | 22 |
| Cell Lysate 2 | 10 | 0.450 | 0.9 | 9 |
| Serum 1 | 2 | 1.200 | 3.0 | 6 |
| Serum 2 | 2 | 0.750 | 1.8 | 3.6 |
Mandatory Visualizations
Caption: Workflow of the SBP1 Sandwich ELISA.
Caption: Simplified diagram of SBP1's tumor suppressor role.
References
- 1. Selenium-Binding Protein 1 in Human Health and Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Selenium-binding protein 1 as a tumor suppressor and a prognostic indicator of clinical outcome - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Evidence that selenium binding protein 1 is a tumor suppressor in prostate cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. mdpi.com [mdpi.com]
- 5. aacrjournals.org [aacrjournals.org]
- 6. Matched Antibody Pairs | Proteintech [ptglab.com]
- 7. creative-diagnostics.com [creative-diagnostics.com]
- 8. antbioinc.com [antbioinc.com]
- 9. Assay Setup: Sandwich ELISA for Allergy [jacksonimmuno.com]
- 10. raybiotech.com [raybiotech.com]
- 11. bosterbio.com [bosterbio.com]
- 12. ELISA Sample Preparation & Collection Guide: R&D Systems [rndsystems.com]
- 13. Preparation of Serum and Plasma from Blood - FineTest ELISA Kit [fn-test.com]
- 14. raybiotech.com [raybiotech.com]
Application of SBP1 Peptide in Viral Entry Assays: Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
Introduction
The Spike-Binding Peptide 1 (SBP1) is a 23-amino acid synthetic peptide derived from the N-terminal α1-helix of the human angiotensin-converting enzyme 2 (ACE2) protein.[1][2] It has emerged as a valuable tool in virology research, particularly in the study of SARS-CoV-2 entry mechanisms and the development of potential therapeutic inhibitors. SBP1 functions by mimicking the natural binding site of the host cell receptor, competitively inhibiting the interaction between the viral spike protein and ACE2, a critical step for viral entry into host cells.[1][3][4] This document provides detailed application notes and protocols for the use of SBP1 in viral entry assays.
Mechanism of Action
SBP1 is designed to target the Receptor Binding Domain (RBD) of the SARS-CoV-2 spike protein.[1][3] By binding to the RBD, SBP1 physically obstructs the virus from engaging with the ACE2 receptor on the host cell surface, thereby preventing viral attachment and subsequent membrane fusion, the initial and essential steps for infection.[3][4]
Applications
The primary application of SBP1 is in viral entry assays to:
-
Screen for antiviral compounds: SBP1 can be used as a positive control for inhibitors of SARS-CoV-2 entry.
-
Study viral entry mechanisms: By competitively blocking the ACE2 binding site, SBP1 helps in dissecting the molecular interactions required for viral entry.
-
Evaluate the efficacy of neutralizing antibodies: SBP1 can be used to compete with antibodies that target the RBD, helping to characterize their binding epitopes.
-
Develop novel therapeutics: Modifications of the SBP1 peptide are being explored to enhance its binding affinity and stability, with the goal of creating potent antiviral drugs.[1]
Quantitative Data Summary
The following table summarizes the reported binding affinities and inhibitory concentrations of SBP1 against SARS-CoV-2. It is important to note that absolute values can vary depending on the experimental setup, such as the specific cell lines, viral strains (or pseudotypes), and assay readouts used.[5]
| Parameter | Virus/Component | Method | Value | Reference |
| Binding Affinity (KD) | SARS-CoV-2 RBD | Bio-layer Interferometry | 47 nM | [1][3] |
| SARS-CoV-2 S-RBD | Bio-layer Interferometry | 1.3 µM | [4] | |
| Inhibitory Concentration (IC50) | VSV pseudovirus (Wuhan Spike) | Neutralization Assay | Not effective (monomeric) | [5] |
| VSV pseudovirus (Delta Spike) | Neutralization Assay | Active (as SBP1-1-Ig) | [5] | |
| Live SARS-CoV-2 | Viral Infection Assay | Weakly active | [6] |
Note: The efficacy of monomeric SBP1 in cell-based assays has been reported as weak or ineffective in some studies, while constructs with tandem repeats or fused to an Fc domain (SBP1-Ig) have shown improved neutralization potency.[5]
Experimental Protocols
Protocol 1: Pseudovirus Neutralization Assay
This protocol describes a common method to assess the inhibitory activity of SBP1 using a pseudovirus system. Pseudoviruses are replication-defective viral particles that express a specific viral envelope protein (e.g., SARS-CoV-2 Spike) and contain a reporter gene (e.g., luciferase or GFP).[5][7][8]
Materials:
-
SBP1 peptide (lyophilized)
-
HEK293T cells stably expressing human ACE2 (293T-ACE2)[7][9]
-
SARS-CoV-2 Spike-pseudotyped lentiviral or VSV particles carrying a luciferase reporter gene
-
Dulbecco's Modified Eagle's Medium (DMEM) supplemented with 10% Fetal Bovine Serum (FBS) and 1% Penicillin-Streptomycin (D10 medium)
-
Poly-L-lysine coated 96-well plates[7]
-
Luciferase assay reagent
-
Luminometer
Procedure:
-
Cell Seeding:
-
Seed 293T-ACE2 cells in a poly-L-lysine-coated 96-well plate at a density of 1.25 x 104 cells per well in 50 µL of D10 medium.[7]
-
Incubate at 37°C, 5% CO2 for 18-24 hours.
-
-
Peptide Preparation:
-
Reconstitute lyophilized SBP1 peptide in sterile water or PBS to create a stock solution.
-
Prepare serial dilutions of the SBP1 peptide in D10 medium in a separate 96-well plate.
-
-
Neutralization Reaction:
-
Infection:
-
Incubation:
-
Incubate the plates at 37°C, 5% CO2 for 48-72 hours.
-
-
Luciferase Assay:
-
Remove the medium from the wells.
-
Lyse the cells and measure the luciferase activity according to the manufacturer's instructions using a luminometer.
-
-
Data Analysis:
-
Calculate the percentage of inhibition for each SBP1 concentration relative to the virus-only control.
-
Plot the percentage of inhibition against the log of the SBP1 concentration and determine the IC50 value using a non-linear regression curve fit.
-
Protocol 2: Live Virus Plaque Reduction Neutralization Test (PRNT)
This protocol is for use with live, replication-competent SARS-CoV-2 and must be performed in a Biosafety Level 3 (BSL-3) laboratory.
Materials:
-
SBP1 peptide
-
Vero E6 cells
-
Replication-competent SARS-CoV-2
-
DMEM with 2% FBS
-
Agarose or methylcellulose overlay
-
Crystal violet staining solution
Procedure:
-
Cell Seeding:
-
Seed Vero E6 cells in a 24-well plate to form a confluent monolayer.
-
-
Peptide-Virus Incubation:
-
Prepare serial dilutions of the SBP1 peptide.
-
Mix the peptide dilutions with a standardized amount of SARS-CoV-2 (e.g., 100 plaque-forming units, PFU).
-
Incubate the mixture at 37°C for 1 hour.
-
-
Infection:
-
Wash the Vero E6 cell monolayers with PBS.
-
Inoculate the cells with the peptide-virus mixtures.
-
Allow the virus to adsorb for 1 hour at 37°C.
-
-
Overlay:
-
Remove the inoculum and overlay the cells with DMEM containing 2% FBS and either 1% low-melting-point agarose or methylcellulose to restrict virus spread to adjacent cells.
-
-
Incubation:
-
Incubate the plates at 37°C, 5% CO2 for 2-3 days until visible plaques are formed.
-
-
Plaque Visualization:
-
Fix the cells with 4% paraformaldehyde.
-
Remove the overlay and stain the cells with 0.1% crystal violet solution.
-
Wash the plates with water and allow them to dry.
-
-
Data Analysis:
-
Count the number of plaques in each well.
-
Calculate the percentage of plaque reduction for each SBP1 concentration compared to the virus-only control.
-
Determine the IC50 value as the concentration of SBP1 that reduces the number of plaques by 50%.
-
Limitations and Considerations
-
Virus Specificity: The SBP1 peptide is designed based on the ACE2 binding site for SARS-CoV-2 and its efficacy against other viruses is not well-documented. While the prompt was for general "viral entry assays," the current literature primarily supports its use for SARS-CoV-2.
-
In Vitro vs. In Vivo: The in vitro efficacy of SBP1 may not directly translate to in vivo therapeutic effects due to factors such as peptide stability, pharmacokinetics, and bioavailability.[3]
-
Viral Variants: Mutations in the spike protein RBD of emerging SARS-CoV-2 variants may affect the binding affinity and inhibitory potency of SBP1.[5] For instance, monomeric SBP1-Ig was not effective against the Omicron BA.1 variant in one study.[5]
-
Peptide Stability: As a peptide, SBP1 may be susceptible to degradation by proteases. Modified versions or delivery systems may be required for in vivo applications.[1]
Conclusion
The SBP1 peptide is a valuable research tool for investigating the mechanisms of SARS-CoV-2 entry and for the initial screening of entry inhibitors. The provided protocols for pseudovirus and live virus assays offer standardized methods for evaluating the antiviral activity of SBP1 and its derivatives. Researchers should consider the limitations of this peptide, particularly concerning its in vivo stability and its efficacy against emerging viral variants, when designing experiments and interpreting results.
References
- 1. SARS-CoV-2 Entry Inhibitors: Small Molecules and Peptides Targeting Virus or Host Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Peptide Inhibitors of the Interaction of the SARS-CoV-2 Receptor-Binding Domain with the ACE2 Cell Receptor - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Synthetic Peptides That Antagonize the Angiotensin-Converting Enzyme-2 (ACE-2) Interaction with SARS-CoV-2 Receptor Binding Spike Protein - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Comparison of SARS-CoV-2 entry inhibitors based on ACE2 receptor or engineered Spike-binding peptides - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. Protocol and Reagents for Pseudotyping Lentiviral Particles with SARS-CoV-2 Spike Protein for Neutralization Assays - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Frontiers | Generation of SARS-CoV-2 Spike Pseudotyped Virus for Viral Entry and Neutralization Assays: A 1-Week Protocol [frontiersin.org]
- 9. researchgate.net [researchgate.net]
Application Notes and Protocols for Identifying SBP-1 Target Genes using ChIP-seq
For Researchers, Scientists, and Drug Development Professionals
This document provides a detailed protocol for Chromatin Immunoprecipitation followed by sequencing (ChIP-seq) to identify the genomic targets of the transcription factor SBP-1. The primary focus of this protocol is on this compound in Caenorhabditis elegans, a key regulator of lipid metabolism.[1] The methodologies outlined here are also broadly applicable to other transcription factors and model organisms, with appropriate modifications.
Introduction to this compound and ChIP-seq
This compound (Sterol Regulatory Element-Binding Protein 1) is a crucial transcription factor involved in maintaining normal fat levels and regulating the expression of genes associated with lipid metabolism in response to nutrient availability.[1] Understanding the direct genomic targets of this compound is essential for elucidating the molecular pathways it governs, which can provide insights into metabolic diseases and potential therapeutic interventions.
ChIP-seq is a powerful and widely used method to identify the genome-wide binding sites of a protein of interest, such as a transcription factor.[2][3][4] The technique begins with the cross-linking of proteins to DNA, followed by chromatin fragmentation, immunoprecipitation of the protein-DNA complexes using a specific antibody, and finally, sequencing of the associated DNA.[5] The resulting sequence reads are then mapped to a reference genome to identify enriched binding regions, or "peaks".[2][6]
Experimental Design and Controls
A well-designed ChIP-seq experiment is critical for obtaining high-quality, interpretable results. Key considerations include:
-
Antibody Specificity: The use of a highly specific antibody that recognizes the target protein is paramount. Antibody validation through techniques like Western blotting is essential.
-
Biological Replicates: Performing at least two biological replicates is crucial to assess the reproducibility of the findings.[7]
-
Control Samples: The inclusion of appropriate control samples is necessary to distinguish true binding events from background noise. Common controls include:
-
Input DNA Control: A sample of sonicated chromatin that has not been subjected to immunoprecipitation. This control helps to account for biases in chromatin shearing and sequencing.[7]
-
IgG Control: A mock immunoprecipitation using a non-specific IgG antibody. This control helps to identify non-specific binding of antibodies to chromatin.[7]
-
Detailed ChIP-seq Protocol for C. elegans this compound
This protocol is specifically optimized for use with Caenorhabditis elegans, a model organism where biochemical approaches can be challenging due to the animal's tough outer cuticle.[8]
Part 1: Growth and Harvesting of Synchronized C. elegans [8][9]
-
Culturing Worms: Grow synchronized populations of C. elegans on Nematode Growth Medium (NGM) plates seeded with E. coli OP50.
-
Harvesting: Collect worms by washing the plates with M9 buffer.
-
Cross-linking: Resuspend the worm pellet in M9 buffer and add formaldehyde to a final concentration of 1% to cross-link proteins to DNA. Incubate for 15-30 minutes at room temperature with gentle rotation.
-
Quenching: Quench the cross-linking reaction by adding glycine to a final concentration of 125 mM.
-
Washing: Wash the cross-linked worms multiple times with ice-cold PBS containing a protease inhibitor cocktail.
Part 2: Chromatin Preparation and Sonication [5][8]
-
Lysis: Efficiently break the tough cuticle of C. elegans by freeze-grinding the worm pellet into a fine powder using a pre-chilled mortar and pestle or a biopulverizer.[8][10]
-
Nuclear Isolation: Resuspend the powdered worms in a lysis buffer to isolate the nuclei.
-
Chromatin Shearing: Sonicate the nuclear lysate to shear the chromatin into fragments of 200-500 base pairs. Optimization of sonication conditions is critical and should be assessed by running a small aliquot of the sheared chromatin on an agarose gel.
Part 3: Immunoprecipitation [5][11]
-
Pre-clearing: Pre-clear the chromatin lysate with Protein A/G magnetic beads to reduce non-specific background binding.
-
Antibody Incubation: Add a specific anti-SBP-1 antibody to the pre-cleared chromatin and incubate overnight at 4°C with rotation.
-
Immunocomplex Capture: Add pre-blocked Protein A/G magnetic beads to the chromatin-antibody mixture and incubate for 2-4 hours at 4°C to capture the immunocomplexes.
-
Washing: Wash the beads extensively with a series of low salt, high salt, and LiCl wash buffers to remove non-specifically bound proteins and DNA.
Part 4: Elution, Reverse Cross-linking, and DNA Purification [5]
-
Elution: Elute the protein-DNA complexes from the beads using an elution buffer.
-
Reverse Cross-linking: Reverse the formaldehyde cross-links by incubating the eluate at 65°C overnight with the addition of NaCl.
-
Protein and RNA Digestion: Treat the samples with RNase A and Proteinase K to remove RNA and protein.
-
DNA Purification: Purify the DNA using phenol:chloroform extraction or a commercial DNA purification kit.
Part 5: Library Preparation and Sequencing [8]
-
Library Construction: Prepare a sequencing library from the purified ChIP DNA and input control DNA. This typically involves end-repair, A-tailing, and ligation of sequencing adapters.
-
Sequencing: Perform high-throughput sequencing of the prepared libraries.
Data Presentation and Analysis
The analysis of ChIP-seq data involves several computational steps to identify and characterize this compound binding sites.[2][3]
Table 1: Summary of a Typical ChIP-seq Data Analysis Workflow
| Step | Description | Commonly Used Tools |
| Quality Control | Assess the quality of raw sequencing reads. | FastQC |
| Read Mapping | Align sequencing reads to the reference genome. | Bowtie2, BWA[6] |
| Peak Calling | Identify regions of the genome with significant enrichment of ChIP signal over the control. | MACS2, HOMER[6][12] |
| Peak Annotation | Associate called peaks with nearby genes and genomic features. | ChIPseeker, HOMER[6][12] |
| Motif Analysis | Identify enriched DNA sequence motifs within the called peaks to determine the this compound binding motif. | MEME-ChIP, HOMER[12] |
| Differential Binding Analysis | Compare binding patterns between different conditions. | DiffBind[12] |
| Functional Analysis | Perform Gene Ontology (GO) and pathway analysis on the target genes to understand their biological functions. | DAVID, Metascape |
Table 2: Example of Quantitative Data from a ChIP-seq Experiment
| Sample | Total Reads | Mapped Reads | Mapping Rate (%) | Number of Peaks |
| This compound ChIP Replicate 1 | 35,000,000 | 32,550,000 | 93.0 | 8,500 |
| This compound ChIP Replicate 2 | 38,000,000 | 35,340,000 | 93.0 | 8,900 |
| Input Control | 30,000,000 | 27,900,000 | 93.0 | 250 |
| IgG Control | 32,000,000 | 29,440,000 | 92.0 | 300 |
Visualizing the ChIP-seq Workflow and Data Analysis Pipeline
Caption: High-level overview of the ChIP-seq experimental and data analysis workflow.
Caption: Detailed workflow for the computational analysis of ChIP-seq data.
Conclusion
This comprehensive protocol provides a robust framework for the identification of this compound target genes in C. elegans using ChIP-seq. The successful implementation of this methodology will enable researchers to gain deeper insights into the gene regulatory networks controlled by this compound, ultimately contributing to our understanding of metabolic regulation and related diseases. Careful attention to experimental design, including the use of appropriate controls and biological replicates, is essential for generating high-quality and reliable results.
References
- 1. uniprot.org [uniprot.org]
- 2. Pipeline and Tools for ChIP-Seq Analysis - CD Genomics [cd-genomics.com]
- 3. basepairtech.com [basepairtech.com]
- 4. ChIP-seq Protocols and Methods | Springer Nature Experiments [experiments.springernature.com]
- 5. Cross-linking ChIP-seq protocol | Abcam [abcam.com]
- 6. A ChIP-Seq Data Analysis Pipeline Based on Bioconductor Packages - PMC [pmc.ncbi.nlm.nih.gov]
- 7. biohpc.cornell.edu [biohpc.cornell.edu]
- 8. Chromatin Immunoprecipitation and Sequencing (ChIP-seq) Optimized for Application in Caenorhabditis elegans - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. biorxiv.org [biorxiv.org]
- 11. Chromatin immunoprecipitation (ChIP) coupled to detection by quantitative real-time PCR to study transcription factor binding to DNA in Caenorhabditis elegans - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Bioinformatics Data Analysis Pipeline- ChIP-Seq | Clinical and Translational Science Institute [ctsi.osu.edu]
Visualizing SBP-1 Localization in Tissues: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
Introduction
Selenium-Binding Protein 1 (SBP1) is a highly conserved protein implicated in a variety of crucial cellular processes, including lipid metabolism, redox regulation, and protein degradation.[1] Notably, alterations in SBP1 expression and subcellular localization have been linked to the progression of numerous diseases, including various cancers.[1][2] Downregulation of SBP1 is frequently observed in tumor tissues and is often associated with a poor clinical prognosis.[1][3] Consequently, the precise visualization and quantification of SBP1 localization within tissues are critical for both basic research and the development of novel therapeutic strategies.
These application notes provide detailed protocols for the immunohistochemical and immunofluorescent detection of SBP1 in both paraffin-embedded and frozen tissue sections. Additionally, quantitative data on SBP1 expression in various human cancers are presented, alongside diagrams of the SBP1-related signaling pathway and experimental workflows.
Quantitative Data on SBP-1 Expression
The following tables summarize the observed changes in SBP1 expression in various human cancers compared to normal tissues.
Table 1: SBP1 Protein Expression in Human Cancers
| Cancer Type | Tissue Type | Change in SBP1 Expression in Cancer vs. Normal Tissue | Subcellular Localization Changes in Cancer | Reference |
| Lung Adenocarcinoma | Paraffin-embedded | Significantly decreased | Decreased nuclear and cytoplasmic staining | [4] |
| Prostate Cancer | Paraffin-embedded | Decreased | Lower nuclear-to-cytoplasmic ratio associated with higher tumor grade | [3] |
| Breast Cancer | Paraffin-embedded | Reduced | Weak positive to negative staining in cancer tissues | [5] |
| Colorectal Cancer | Paraffin-embedded | Decreased | Variable, but generally reduced expression | [2] |
| Liver Cancer | Paraffin-embedded | Decreased | Not specified | [1][2] |
| Kidney Cancer | Not specified | Reduced | Not specified | [1] |
| Ovarian Cancer | Not specified | Reduced | Not specified | [1] |
| Stomach Cancer | Not specified | Reduced | Not specified | [1] |
| Thyroid Cancer | Not specified | Reduced | Not specified | [1] |
Table 2: Association of SBP1 Expression with Clinical Outcome
| Cancer Type | Low SBP1 Expression Correlates With | Reference |
| Lung Adenocarcinoma | Poor survival | [4] |
| Prostate Cancer | Higher likelihood of biochemical recurrence | [3] |
| Breast Cancer | Poor survival | [5] |
| Colorectal Cancer | Poor prognosis | [3] |
| Ovarian Cancer | Poor prognosis | [3] |
| Hepatocellular Carcinoma | Poor prognosis | [3] |
Experimental Protocols
Detailed methodologies for visualizing this compound in tissue samples are provided below.
Protocol 1: Immunohistochemistry (IHC) for this compound in Formalin-Fixed, Paraffin-Embedded (FFPE) Tissues
This protocol outlines the steps for the chromogenic detection of this compound in FFPE tissue sections.
Materials:
-
FFPE tissue sections on charged slides
-
Xylene
-
Ethanol (100%, 95%, 80%, 70%)
-
Deionized water (dH2O)
-
Antigen Retrieval Buffer (e.g., 10 mM Sodium Citrate, pH 6.0)
-
Hydrogen Peroxide (3%)
-
Blocking Buffer (e.g., 10% Normal Goat Serum in PBS)
-
Primary antibody against this compound (human-specific)
-
Biotinylated secondary antibody (e.g., goat anti-rabbit IgG)
-
Streptavidin-HRP conjugate
-
DAB (3,3'-Diaminobenzidine) substrate kit
-
Hematoxylin counterstain
-
Mounting medium
Procedure:
-
Deparaffinization and Rehydration:
-
Immerse slides in xylene (2 x 5 minutes).
-
Immerse in 100% ethanol (2 x 3 minutes).
-
Immerse in 95% ethanol (1 x 2 minutes).
-
Immerse in 80% ethanol (1 x 2 minutes).
-
Immerse in 70% ethanol (1 x 2 minutes).
-
Rinse in dH2O.
-
-
Antigen Retrieval:
-
Immerse slides in Antigen Retrieval Buffer.
-
Heat in a pressure cooker or water bath according to manufacturer's instructions (e.g., 120°C for 2.5 minutes).
-
Allow slides to cool to room temperature.
-
Wash slides in dH2O.
-
-
Peroxidase Blocking:
-
Incubate sections with 3% hydrogen peroxide for 10-15 minutes to block endogenous peroxidase activity.
-
Wash with PBS (3 x 5 minutes).
-
-
Blocking:
-
Incubate sections with Blocking Buffer for 1 hour at room temperature to block non-specific antibody binding.
-
-
Primary Antibody Incubation:
-
Dilute the primary anti-SBP-1 antibody in blocking buffer at the recommended concentration.
-
Incubate sections with the primary antibody overnight at 4°C in a humidified chamber.
-
-
Secondary Antibody Incubation:
-
Wash slides with PBS (3 x 5 minutes).
-
Incubate sections with the biotinylated secondary antibody for 30-60 minutes at room temperature.
-
-
Signal Amplification:
-
Wash slides with PBS (3 x 5 minutes).
-
Incubate sections with Streptavidin-HRP conjugate for 30 minutes at room temperature.
-
-
Chromogenic Detection:
-
Wash slides with PBS (3 x 5 minutes).
-
Incubate sections with DAB substrate until the desired brown color develops.
-
Rinse with dH2O to stop the reaction.
-
-
Counterstaining and Mounting:
-
Counterstain with hematoxylin.
-
Dehydrate through graded ethanol and xylene.
-
Mount coverslip with mounting medium.
-
Protocol 2: Immunofluorescence (IF) for this compound in Frozen Tissues
This protocol describes the fluorescent detection of this compound in fresh-frozen tissue sections.
Materials:
-
Fresh-frozen tissue sections on charged slides
-
Acetone or 4% Paraformaldehyde (PFA) for fixation
-
PBS (Phosphate-Buffered Saline)
-
Permeabilization Buffer (e.g., 0.1% Triton X-100 in PBS)
-
Blocking Buffer (e.g., 5% Normal Goat Serum in PBS)
-
Primary antibody against this compound (human-specific)
-
Fluorophore-conjugated secondary antibody (e.g., Alexa Fluor 488 goat anti-rabbit IgG)
-
DAPI (4',6-diamidino-2-phenylindole) for nuclear counterstaining
-
Mounting medium with antifade reagent
Procedure:
-
Fixation:
-
Air dry frozen sections for 30 minutes at room temperature.
-
Fix in ice-cold acetone for 10 minutes or 4% PFA for 15 minutes.
-
Wash with PBS (3 x 5 minutes).
-
-
Permeabilization (if using PFA fixation):
-
Incubate sections with Permeabilization Buffer for 10 minutes.
-
Wash with PBS (3 x 5 minutes).
-
-
Blocking:
-
Incubate sections with Blocking Buffer for 1 hour at room temperature.
-
-
Primary Antibody Incubation:
-
Dilute the primary anti-SBP-1 antibody in blocking buffer.
-
Incubate sections with the primary antibody for 1-2 hours at room temperature or overnight at 4°C.
-
-
Secondary Antibody Incubation:
-
Wash slides with PBS (3 x 5 minutes).
-
Incubate sections with the fluorophore-conjugated secondary antibody for 1 hour at room temperature, protected from light.
-
-
Counterstaining and Mounting:
-
Wash slides with PBS (3 x 5 minutes).
-
Incubate with DAPI solution for 5 minutes to stain nuclei.
-
Wash with PBS (2 x 5 minutes).
-
Mount coverslip with antifade mounting medium.
-
Signaling Pathways and Experimental Workflows
This compound (SREBP-1c) Signaling Pathway in Lipid Metabolism
This compound is the human homolog of Sterol Regulatory Element-Binding Protein 1c (SREBP-1c), a key transcription factor that regulates lipogenesis.[6][7] The following diagram illustrates the major components of the SREBP-1c signaling pathway.
Caption: SREBP-1c signaling pathway in lipid metabolism.
Experimental Workflow for this compound Immunohistochemistry
The following diagram outlines the key steps in the IHC workflow for visualizing this compound in FFPE tissues.
Caption: Immunohistochemistry workflow for this compound detection.
This compound Protein Interaction Network
This compound is known to interact with several other proteins, influencing various cellular functions.
Caption: this compound protein interaction network.[1][8]
References
- 1. Selenium-Binding Protein 1 in Human Health and Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Quantitative Proteomic Analysis Reveals That Anti-Cancer Effects of Selenium-Binding Protein 1 In Vivo Are Associated with Metabolic Pathways - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Evidence That Selenium Binding Protein 1 Is a Tumor Suppressor in Prostate Cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 4. aacrjournals.org [aacrjournals.org]
- 5. researchgate.net [researchgate.net]
- 6. SREBPs in Lipid Metabolism, Insulin Signaling, and Beyond - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Sterol regulatory element-binding protein 1 - Wikipedia [en.wikipedia.org]
- 8. The RNA-binding protein SERBP1 interacts selectively with the signaling protein RACK1 - PubMed [pubmed.ncbi.nlm.nih.gov]
Practical Guide to SBP-1/SREBP-1 Western Blotting: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
Introduction
Sterol Regulatory Element-Binding Protein-1 (SREBP-1), and its C. elegans homolog SBP-1, are crucial transcription factors that regulate the expression of genes involved in lipid biosynthesis and metabolism. Dysregulation of the SREBP-1 pathway is implicated in various metabolic diseases, including fatty liver disease, insulin resistance, and certain cancers, making it a key target for therapeutic intervention. Western blotting is a fundamental technique to study SREBP-1, allowing for the detection and quantification of both its precursor and active nuclear forms. This guide provides a comprehensive overview and detailed protocols for performing Western blot analysis of SREBP-1.
SREBP-1 is synthesized as an inactive precursor of approximately 125 kDa, which is bound to the endoplasmic reticulum (ER) membrane.[1] Upon activation, typically in response to low cellular sterol levels or insulin signaling, the precursor protein is transported to the Golgi apparatus.[2] There, it undergoes sequential proteolytic cleavage by Site-1 Protease (S1P) and Site-2 Protease (S2P), releasing the mature, transcriptionally active N-terminal fragment of about 60-70 kDa.[2][3] This mature form then translocates to the nucleus to regulate gene expression.[4] Therefore, a key aspect of SREBP-1 Western blotting is the ability to distinguish between the precursor and mature forms, often requiring nuclear and cytoplasmic fractionation.
SREBP-1 Signaling Pathway
The activation of SREBP-1 is a tightly regulated process involving several key proteins and signaling pathways. The diagram below illustrates the canonical activation cascade. Under conditions of high cellular sterols, the SREBP-1-SCAP complex is retained in the ER through binding to INSIG. When sterol levels are low, INSIG dissociates, allowing the SREBP-1-SCAP complex to move to the Golgi. Insulin signaling, via the PI3K-Akt-mTORC1 pathway, can also promote SREBP-1 activation.[2][5] In the Golgi, S1P and S2P sequentially cleave the SREBP-1 precursor, releasing the mature fragment that translocates to the nucleus and activates the transcription of lipogenic genes such as FASN, ACC, and SCD.[2][6]
Experimental Protocols
A. Nuclear and Cytoplasmic Protein Extraction
This protocol is essential for separating the precursor (cytoplasmic/ER-bound) and mature (nuclear) forms of SREBP-1.[4][7]
Reagents:
-
Phosphate-Buffered Saline (PBS)
-
Hypotonic Lysis Buffer (e.g., 10 mM HEPES pH 7.9, 1.5 mM MgCl₂, 10 mM KCl, 0.5 mM DTT, with protease and phosphatase inhibitors)
-
10% NP-40 (or similar detergent)
-
Nuclear Extraction Buffer (e.g., 20 mM HEPES pH 7.9, 25% glycerol, 420 mM NaCl, 1.5 mM MgCl₂, 0.2 mM EDTA, with protease and phosphatase inhibitors)
Procedure:
-
Harvest cells (e.g., by scraping for adherent cells or centrifugation for suspension cells) and wash twice with ice-cold PBS.
-
Centrifuge at 500 x g for 5 minutes at 4°C and discard the supernatant.
-
Resuspend the cell pellet in 200 µL of hypotonic lysis buffer and incubate on ice for 15 minutes to allow cells to swell.[4]
-
Add 10 µL of 10% NP-40 and vortex for 10 seconds to lyse the cell membrane.[4]
-
Centrifuge at 12,000 x g for 1 minute at 4°C. The supernatant contains the cytoplasmic fraction.[4]
-
Carefully collect the supernatant (cytoplasmic extract) into a new pre-chilled tube.
-
Resuspend the remaining nuclear pellet in 50 µL of nuclear extraction buffer.[4]
-
Incubate on ice for 30 minutes with intermittent vortexing to lyse the nuclei.[4]
-
Centrifuge at 14,000 x g for 10 minutes at 4°C. The supernatant is the nuclear extract.[4]
-
Determine the protein concentration of both cytoplasmic and nuclear extracts using a BCA protein assay.
B. Western Blotting Protocol
Materials:
-
SDS-PAGE gels (e.g., 4-12% Tris-Glycine)
-
PVDF or nitrocellulose membrane
-
Transfer buffer
-
Blocking buffer (e.g., 5% non-fat dry milk or 5% BSA in TBST)
-
Primary antibody: Anti-SREBP-1 antibody (recognizing both precursor and mature forms)
-
Secondary antibody: HRP-conjugated anti-rabbit or anti-mouse IgG
-
Chemiluminescent substrate (ECL)
-
Loading control antibodies (e.g., anti-Lamin B1 for nuclear fraction, anti-GAPDH or anti-β-actin for cytoplasmic fraction)
Procedure:
-
Prepare protein samples by mixing 20-30 µg of protein from each extract with Laemmli sample buffer and boiling for 5 minutes.
-
Load the samples onto an SDS-PAGE gel and perform electrophoresis to separate the proteins by size.
-
Transfer the separated proteins from the gel to a PVDF or nitrocellulose membrane.[4]
-
Block the membrane with blocking buffer for 1 hour at room temperature with gentle agitation.[4]
-
Incubate the membrane with the primary anti-SREBP-1 antibody (e.g., 1:1000 dilution in 5% BSA in TBST) overnight at 4°C with gentle agitation.[4]
-
Wash the membrane three times with TBST for 10 minutes each.[4]
-
Incubate the membrane with the HRP-conjugated secondary antibody (e.g., 1:5000 dilution in 5% non-fat dry milk in TBST) for 1 hour at room temperature.[4]
-
Wash the membrane three times with TBST for 10 minutes each.[4]
-
Apply the chemiluminescent substrate and visualize the bands using an imaging system.
-
If necessary, strip the membrane and re-probe with a loading control antibody to ensure equal protein loading.
Experimental Workflow
The following diagram outlines the key steps in performing a Western blot for this compound/SREBP-1 analysis, from sample preparation to data analysis.
Data Presentation and Analysis
Quantitative analysis of SREBP-1 Western blots typically involves densitometry to measure the intensity of the bands corresponding to the precursor (pSREBP-1, ~125 kDa) and mature (mSREBP-1, ~60-70 kDa) forms.[1][8] These values are then normalized to a loading control. It is crucial to use a nuclear-specific loading control (e.g., Lamin B1) for the nuclear fraction and a cytoplasmic loading control (e.g., GAPDH, β-actin) for the cytoplasmic fraction.[4] The results are often presented as a fold change relative to a control or vehicle-treated sample.
Table 1: Representative Quantitative Data for SREBP-1 Expression
This table summarizes hypothetical quantitative data from a Western blot experiment investigating the effect of a compound (e.g., an LXR agonist) on SREBP-1 processing in HepG2 cells.[4]
| Treatment Group | pSREBP-1 (Cytoplasmic) (Fold Change vs. Vehicle) | mSREBP-1 (Nuclear) (Fold Change vs. Vehicle) |
| Vehicle (DMSO) | 1.0 | 1.0 |
| Compound (10 nM) | 1.2 ± 0.1 | 2.5 ± 0.3 |
| Compound (50 nM) | 1.3 ± 0.2 | 4.8 ± 0.5 |
| Compound (100 nM) | 1.1 ± 0.1 | 7.2 ± 0.8 |
| Compound (500 nM) | 0.9 ± 0.1 | 9.5 ± 1.1 |
Data are presented as mean ± standard deviation. Fold change is calculated after normalization to the respective loading controls.
Table 2: Recommended Antibody and Reagent Information
| Reagent | Supplier | Catalog Number (Example) | Recommended Dilution |
| Primary Antibody (Rabbit anti-SREBP-1) | Abcam | ab313881 | 1:1000 |
| Primary Antibody (Mouse anti-SREBP-1) | Santa Cruz Biotechnology | sc-13551 | 1:500 - 1:1000 |
| Nuclear Loading Control (Lamin B1) | Cell Signaling Technology | #13435 | 1:1000 |
| Cytoplasmic Loading Control (GAPDH) | Abcam | ab8245 | 1:20000 |
| HRP-conjugated anti-rabbit IgG | Various | - | 1:2000 - 1:10000 |
| HRP-conjugated anti-mouse IgG | Various | - | 1:2000 - 1:10000 |
Troubleshooting
Common issues in Western blotting, such as weak or no signal, high background, and non-specific bands, can often be resolved through systematic optimization.[9][10][11]
Table 3: SREBP-1 Western Blot Troubleshooting Guide
| Issue | Possible Cause | Suggested Solution |
| Weak or No Signal | Insufficient protein loading | Increase the amount of protein loaded (20-40 µg). |
| Inactive primary/secondary antibody | Use fresh antibody dilutions; check antibody storage conditions. | |
| Inefficient protein transfer | Confirm transfer with Ponceau S staining; optimize transfer time/voltage. | |
| Low abundance of SREBP-1 | Consider using a more sensitive ECL substrate. | |
| High Background | Insufficient blocking | Increase blocking time to 1.5-2 hours or try a different blocking agent (e.g., BSA instead of milk). |
| Antibody concentration too high | Decrease the concentration of primary and/or secondary antibodies. | |
| Inadequate washing | Increase the number and duration of wash steps with TBST.[9] | |
| Non-specific Bands | Primary antibody cross-reactivity | Use a more specific monoclonal antibody; confirm specificity with knockout/knockdown cell lines. |
| Protein degradation | Use fresh samples and ensure protease inhibitors are always present. | |
| Antibody concentration too high | Titrate the primary antibody to a lower concentration. |
By following these detailed protocols and considering the key aspects of SREBP-1 biology, researchers can obtain reliable and reproducible Western blot data to advance our understanding of lipid metabolism and develop novel therapeutics.
References
- 1. researchgate.net [researchgate.net]
- 2. Frontiers | Targeting SREBP-1-Mediated Lipogenesis as Potential Strategies for Cancer [frontiersin.org]
- 3. SREBP1 Monoclonal Antibody (2A4) (MA5-16124) [thermofisher.com]
- 4. benchchem.com [benchchem.com]
- 5. Progress in the Study of Sterol Regulatory Element Binding Protein 1 Signal Pathway [gavinpublishers.com]
- 6. dovepress.com [dovepress.com]
- 7. Nuclear extraction and fractionation protocol | Abcam [abcam.com]
- 8. researchgate.net [researchgate.net]
- 9. benchchem.com [benchchem.com]
- 10. Western Blot Troubleshooting | Thermo Fisher Scientific - HK [thermofisher.com]
- 11. Western blot troubleshooting guide! [jacksonimmuno.com]
Application Note: Mass Spectrometry-Based Identification and Quantification of Post-Translational Modifications on Selenium-Binding Protein 1 (SBP-1)
Audience: Researchers, scientists, and drug development professionals.
Introduction
Selenium-Binding Protein 1 (SBP-1) is a protein implicated in various cellular processes, including translational repression, mRNA metabolism, and potentially as a tumor suppressor.[1][2] The function of proteins like this compound is often dynamically regulated by post-translational modifications (PTMs), which can alter their activity, localization, stability, and interaction partners.[3][4][5] Mass spectrometry (MS) has become an indispensable tool for the comprehensive identification and quantification of PTMs due to its high sensitivity, specificity, and throughput.[6][7][8]
This document provides a detailed overview and protocols for the systematic identification of PTMs on this compound using a liquid chromatography-tandem mass spectrometry (LC-MS/MS) workflow. The protocols cover sample preparation, PTM enrichment, mass spectrometry analysis, and data interpretation, providing a robust framework for investigating the regulatory landscape of this compound.
General Experimental Workflow
The overall strategy for identifying this compound PTMs involves several key stages: purification of this compound, enzymatic digestion into peptides, enrichment of peptides bearing specific PTMs, and subsequent analysis by LC-MS/MS.[9][10][11] This "bottom-up" proteomics approach allows for the precise localization of modifications on the protein sequence.
Figure 1. General workflow for the identification of this compound post-translational modifications.
Potential Regulatory Pathways of this compound
This compound's function in mRNA translation and stability suggests it is a node in cellular signaling pathways that respond to environmental cues and stress.[1][12] PTMs like phosphorylation, methylation, and ubiquitination are key mechanisms for rapidly modulating such processes. For instance, stress-activated kinases could phosphorylate this compound to alter its RNA-binding affinity or its interaction with the translational machinery. While specific upstream regulators of this compound are still under investigation, a conceptual pathway can be proposed.
Figure 2. Conceptual signaling pathways regulating this compound function via PTMs.
Experimental Protocols
The following protocols provide a detailed methodology for the identification of this compound PTMs.
Protocol 1: this compound Immunoprecipitation and Protein Digestion
-
Cell Lysis :
-
Harvest cultured cells and wash twice with ice-cold phosphate-buffered saline (PBS).
-
Lyse cells in a suitable lysis buffer (e.g., RIPA buffer) supplemented with protease and phosphatase inhibitors.
-
Incubate on ice for 30 minutes with periodic vortexing.
-
Clarify the lysate by centrifugation at 14,000 x g for 15 minutes at 4°C. Collect the supernatant.
-
-
Immunoprecipitation (IP) :
-
Pre-clear the lysate by incubating with Protein A/G agarose beads for 1 hour at 4°C.
-
Incubate the pre-cleared lysate with an anti-SBP-1 antibody overnight at 4°C with gentle rotation.
-
Add fresh Protein A/G agarose beads and incubate for 2-4 hours at 4°C.
-
Wash the beads three times with lysis buffer and twice with PBS to remove non-specific binders.
-
-
In-Gel Digestion :
-
Elute the protein from the beads by boiling in SDS-PAGE loading buffer and separate on a 1D SDS-PAGE gel.
-
Stain the gel with Coomassie Brilliant Blue and excise the band corresponding to the molecular weight of this compound.
-
Destain the gel slice with a solution of 50% acetonitrile (ACN) in 50 mM ammonium bicarbonate.
-
Reduce disulfide bonds with 10 mM dithiothreitol (DTT) at 56°C for 1 hour.
-
Alkylate cysteine residues with 55 mM iodoacetamide (IAA) at room temperature in the dark for 45 minutes.[13]
-
Wash and dehydrate the gel slice with ACN.
-
Rehydrate the gel slice in a solution containing sequencing-grade trypsin (e.g., 10-20 ng/µL in 50 mM ammonium bicarbonate) and incubate overnight at 37°C.
-
Extract the peptides from the gel slice using a series of ACN and formic acid washes. Pool the extracts and dry in a vacuum centrifuge.
-
Protocol 2: Enrichment of Modified Peptides
Due to the often low stoichiometry of PTMs, an enrichment step is crucial for their detection.[3][4][14][15]
-
A. Phosphopeptide Enrichment (IMAC or TiO2) :
-
Reconstitute the dried peptide mixture in a loading buffer appropriate for the chosen enrichment resin (e.g., 80% ACN, 5% trifluoroacetic acid for TiO2).
-
Incubate the peptides with Immobilized Metal Affinity Chromatography (IMAC) beads or Titanium Dioxide (TiO2) micro-columns.[16][17][18]
-
Wash the resin extensively to remove non-phosphorylated peptides.
-
Elute the phosphopeptides using a high pH buffer (e.g., 10% ammonia solution or 5% ammonium hydroxide).
-
Acidify the eluted phosphopeptides with formic acid and desalt using a C18 StageTip before LC-MS/MS analysis.
-
-
B. Ubiquitinated Peptide Enrichment (Anti-K-ε-GG) :
-
Tryptic digestion of ubiquitinated proteins leaves a characteristic di-glycine (GG) remnant on the modified lysine residue.[13][19][20]
-
Reconstitute the total peptide digest in an immunoprecipitation buffer.
-
Incubate the peptides with beads cross-linked to an antibody that specifically recognizes the K-ε-GG remnant.[19][20]
-
Wash the beads to remove non-specific peptides.
-
Elute the K-ε-GG-containing peptides, typically using a low pH solution like 0.15% trifluoroacetic acid.
-
Desalt the eluted peptides using a C18 StageTip prior to LC-MS/MS analysis.
-
Protocol 3: LC-MS/MS Analysis
-
Chromatographic Separation : Reconstitute the final peptide samples in a solution of 0.1% formic acid. Load the peptides onto a nano-flow liquid chromatography system equipped with a reversed-phase column. Separate the peptides using a gradient of increasing acetonitrile concentration.[21][22]
-
Mass Spectrometry :
-
The eluting peptides are ionized by electrospray ionization (ESI) and analyzed in a high-resolution mass spectrometer (e.g., Orbitrap or Q-TOF).[7][11]
-
The mass spectrometer should be operated in a data-dependent acquisition (DDA) or data-independent acquisition (DIA) mode.[7][23]
-
In DDA mode, the instrument performs a full scan (MS1) to measure the mass-to-charge ratio (m/z) of intact peptide ions, followed by fragmentation (MS/MS or MS2) of the most intense precursor ions.[9][24]
-
Different fragmentation methods like Collision-Induced Dissociation (CID) or Higher-energy Collisional Dissociation (HCD) can be used.[25][26]
-
Protocol 4: Data Analysis
-
Database Searching :
-
The raw MS/MS spectra are processed and searched against a protein database (e.g., UniProt) containing the sequence of this compound. Use a search algorithm like SEQUEST, Mascot, or MaxQuant.[9]
-
Specify the protease used (e.g., Trypsin) and allow for potential missed cleavages.
-
Set precursor and fragment ion mass tolerances according to the instrument's performance.
-
-
PTM Identification :
-
Include the expected mass shifts of the PTMs of interest as variable modifications in the search parameters. For example:
-
Use software tools like PTMProphet or MaxQuant's PTM scoring algorithm to confidently localize the modification to a specific amino acid residue.[9]
-
-
Quantitative Analysis : For quantitative studies (e.g., comparing PTM levels between different conditions), use label-free quantification (LFQ) or isobaric labeling tags (e.g., TMT).[9][29] The software will calculate the relative abundance of a modified peptide across different samples.
Data Presentation
Quantitative data from PTM analysis should be presented in a clear, tabular format to facilitate comparison. The following table is a hypothetical example of how quantitative results for this compound PTMs could be summarized.
| PTM Type | Amino Acid Site | Peptide Sequence | Mass Shift (Da) | Fold Change (Treatment vs. Control) | p-value |
| Phosphorylation | Serine 85 | R.Sp GISLVYSK.T | +79.9663 | 2.5 | 0.012 |
| Phosphorylation | Threonine 152 | K.ATp LVEAIVK.E | +79.9663 | -1.8 | 0.045 |
| Acetylation | Lysine 210 | A.IQDLKac AAVR.L | +42.0106 | 1.3 | 0.210 |
| Ubiquitination | Lysine 334 | V.EGLTQKgg DEIR.N | +114.0429 | 3.1 | 0.008 |
| Di-methylation | Arginine 401 | G.Rme2 GFVDFVTK.P | +28.0313 | 1.1 | 0.850 |
Table 1: Hypothetical quantitative data for identified post-translational modifications on this compound. The table includes the type of modification, the specific amino acid site, the identified peptide sequence (with the modified residue in bold), the observed mass shift, and example quantitative data comparing a treated sample to a control.
References
- 1. Sbp1p Affects Translational Repression and Decapping in Saccharomyces cerevisiae - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. researchgate.net [researchgate.net]
- 4. Advances in enrichment methods for mass spectrometry-based proteomics analysis of post-translational modifications - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Regulation of poly(ADP-Ribose) polymerase 1 functions by post-translational modifications - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Status of Large-scale Analysis of Post-translational Modifications by Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Mass Spectrometry for Proteomics | Technology Networks [technologynetworks.com]
- 8. Mapping protein post-translational modifications with mass spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. Proteomics Mass Spectrometry Workflows | Thermo Fisher Scientific - SG [thermofisher.com]
- 11. portlandpress.com [portlandpress.com]
- 12. Sbp1 modulates the translation of Pab1 mRNA in a poly(A)- and RGG-dependent manner - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Characterizing Ubiquitination Sites by Peptide-based Immunoaffinity Enrichment - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Peptide Enrichment for Mass Spectrometry-Based Analysis - Creative Proteomics [creative-proteomics.com]
- 15. Sample Preparation for Mass Spectrometry | Thermo Fisher Scientific - US [thermofisher.com]
- 16. Peptide Enrichment and Fractionation for Mass Spectrometry | Thermo Fisher Scientific - HK [thermofisher.com]
- 17. Characterization of Phosphorylated Proteins Using Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Determining in vivo Phosphorylation Sites using Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Post-Translational Modifications [utmb.edu]
- 20. Large-Scale Identification of Ubiquitination Sites by Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 21. How to Detect Post-Translational Modifications (PTMs) Sites? - Creative Proteomics [creative-proteomics.com]
- 22. books.rsc.org [books.rsc.org]
- 23. Quantification and Identification of Post-Translational Modifications Using Modern Proteomics Approaches - PMC [pmc.ncbi.nlm.nih.gov]
- 24. Mapping and analysis of phosphorylation sites: a quick guide for cell biologists - PMC [pmc.ncbi.nlm.nih.gov]
- 25. Mass Spectrometry-Based Detection and Assignment of Protein Posttranslational Modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 26. pubs.acs.org [pubs.acs.org]
- 27. Mass Spectrometry for Post-Translational Modifications - Neuroproteomics - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 28. Proteomic Identification of Protein Ubiquitination Events - PMC [pmc.ncbi.nlm.nih.gov]
- 29. researchgate.net [researchgate.net]
Application Notes and Protocols: SBP-1 Reporter Assays for Screening Studies
For Researchers, Scientists, and Drug Development Professionals
Introduction
Sterol Regulatory Element-Binding Protein 1 (SREBP-1) is a master transcriptional regulator of lipogenesis, controlling the expression of genes involved in fatty acid and cholesterol synthesis.[1][2] Dysregulation of the SREBP-1 pathway is implicated in various diseases, including cancer, metabolic disorders, and viral infections, making it an attractive target for therapeutic intervention.[1][2][3][4] SBP-1 reporter assays are powerful tools for high-throughput screening (HTS) of small molecules and genetic modulators that can influence SREBP-1 activity. These assays typically employ a reporter gene, such as luciferase, under the control of SREBP-1-responsive elements, providing a quantitative measure of pathway activation.[5]
This document provides detailed application notes and protocols for the use of this compound reporter assays in screening studies, intended to guide researchers in the design, execution, and analysis of such experiments.
Signaling Pathway
The SREBP-1 signaling pathway is a multi-step process initiated by cellular sterol levels and regulated by upstream signaling cascades such as the PI3K/Akt/mTOR pathway.[1][3] Under low sterol conditions, the SREBP-1 precursor protein, anchored in the endoplasmic reticulum (ER), is transported to the Golgi apparatus. In the Golgi, it undergoes sequential proteolytic cleavage by Site-1 Protease (S1P) and Site-2 Protease (S2P), releasing the mature, transcriptionally active N-terminal domain. This mature form of SREBP-1 then translocates to the nucleus, where it binds to Sterol Regulatory Elements (SREs) in the promoters of its target genes, activating their transcription.[3][6]
Figure 1: SREBP-1 Signaling Pathway.
Experimental Workflow for this compound Reporter Assay Screening
A typical workflow for a high-throughput screening campaign using an this compound reporter assay involves several key steps, from initial assay development and validation to primary and secondary screening, and finally hit confirmation.
References
- 1. Targeting SREBP-1-driven lipid metabolism to treat cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Targeting SREBP-1-Mediated Lipogenesis as Potential Strategies for Cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Activation of sterol regulatory element‐binding protein 1 (SREBP1)‐mediated lipogenesis by the Epstein–Barr virus‐encoded latent membrane protein 1 (LMP1) promotes cell proliferation and progression of nasopharyngeal carcinoma - PMC [pmc.ncbi.nlm.nih.gov]
- 4. The roles and mechanisms of SREBP1 in cancer development and drug response - PMC [pmc.ncbi.nlm.nih.gov]
- 5. opentrons.com [opentrons.com]
- 6. Frontiers | Role of the Sterol Regulatory Element Binding Protein Pathway in Tumorigenesis [frontiersin.org]
Application Notes and Protocols for Assessing SBP-1 Dependent Lipogenesis
Audience: Researchers, scientists, and drug development professionals.
Introduction: Sterol Regulatory Element-Binding Protein-1 (SBP-1), and its mammalian ortholog SREBP-1, is a critical transcription factor that governs the process of de novo lipogenesis—the synthesis of fatty acids from other sources.[1][2] this compound/SREBP-1 directly activates the transcription of a suite of genes involved in fatty acid and triglyceride synthesis, such as Fatty Acid Synthase (FASN), Acetyl-CoA Carboxylase (ACC), and Stearoyl-CoA Desaturase (SCD).[1] Its activity is tightly regulated by various signaling pathways, primarily the insulin and mTORC1 pathways, and its dysregulation is implicated in metabolic diseases like non-alcoholic fatty liver disease (NAFLD) and in various cancers.[1][3][4]
These application notes provide a comprehensive methodological framework to investigate this compound dependent lipogenesis, from analyzing upstream signaling and transcriptional activation to quantifying downstream lipid accumulation.
Section 1: this compound/SREBP-1 Activation and Signaling Pathway
The activation of this compound is a multi-step process. In its inactive state, the this compound precursor protein is retained in the endoplasmic reticulum (ER) by binding to the SREBP cleavage-activating protein (SCAP). Upon stimulation by upstream signals like insulin, the SCAP-SBP-1 complex is released from its anchor protein, INSIG, and translocates to the Golgi apparatus.[1] In the Golgi, two proteases sequentially cleave the this compound precursor, releasing the mature, transcriptionally active N-terminal domain. This mature form then enters the nucleus, binds to Sterol Regulatory Elements (SREs) in the promoters of target genes, and initiates their transcription, leading to lipogenesis. The PI3K/Akt/mTORC1 pathway is a key upstream regulator of this process.[1][5]
Caption: this compound/SREBP-1 signaling pathway from cell surface to nuclear activation.
Section 2: Experimental Workflow for Assessing this compound Activity
A multi-faceted approach is required to fully assess this compound dependent lipogenesis. The following workflow outlines the key experimental stages, from initial treatment or perturbation to the final analysis of lipid accumulation.
Caption: A comprehensive workflow for investigating this compound dependent lipogenesis.
Section 3: Detailed Protocols and Data Presentation
Protocol 1: Analysis of Lipogenic Gene Expression by qRT-PCR
Application Note: This protocol quantifies the mRNA levels of this compound and its key target genes (e.g., FASN, SCD1, ACC) to determine if an experimental condition alters the transcriptional output of the this compound pathway. An increase in the expression of these genes suggests activation of this compound.[3][6]
Methodology:
-
Cell/Tissue Treatment: Culture cells or treat animals with the compound or condition of interest. Include appropriate vehicle and positive controls.
-
RNA Extraction: Isolate total RNA from cells or tissues using a TRIzol-based method or a commercial RNA purification kit. Assess RNA quality and quantity using a spectrophotometer (e.g., NanoDrop).
-
cDNA Synthesis: Reverse transcribe 1-2 µg of total RNA into complementary DNA (cDNA) using a reverse transcriptase kit with oligo(dT) and random hexamer primers.
-
Quantitative PCR (qPCR):
-
Prepare a qPCR reaction mix containing cDNA template, forward and reverse primers for target genes and a housekeeping gene (e.g., GAPDH, ACTB), and a SYBR Green master mix.
-
Run the reaction on a real-time PCR instrument.
-
Use the 2-ΔΔCt method to calculate the relative fold change in gene expression, normalized to the housekeeping gene and the control group.
-
Data Presentation:
| Gene | Treatment Group | Normalized Fold Change (Mean ± SEM) | p-value |
| This compound/SREBF1 | Control (Vehicle) | 1.0 ± 0.12 | - |
| Compound X (10 µM) | 2.5 ± 0.21 | <0.01 | |
| FASN | Control (Vehicle) | 1.0 ± 0.15 | - |
| Compound X (10 µM) | 4.2 ± 0.35 | <0.001 | |
| SCD1 | Control (Vehicle) | 1.0 ± 0.09 | - |
| Compound X (10 µM) | 3.8 ± 0.28 | <0.001 |
Protocol 2: Analysis of this compound Protein Processing by Western Blot
Application Note: This assay distinguishes between the inactive precursor form (pthis compound, ~125 kDa) and the active nuclear form (nthis compound, ~68 kDa) of this compound. An increase in the nthis compound/pthis compound ratio indicates enhanced proteolytic processing and activation.
Methodology:
-
Protein Extraction:
-
For total protein, lyse cells in RIPA buffer with protease and phosphatase inhibitors.
-
For nuclear/cytoplasmic fractionation, use a commercial kit to separate fractions. This is crucial for observing the accumulation of mature this compound in the nucleus.[5]
-
-
Protein Quantification: Determine protein concentration using a BCA or Bradford assay.
-
SDS-PAGE and Transfer:
-
Load 20-40 µg of protein per lane onto an SDS-polyacrylamide gel.
-
Separate proteins by electrophoresis.
-
Transfer proteins to a PVDF or nitrocellulose membrane.
-
-
Immunoblotting:
-
Block the membrane with 5% non-fat milk or BSA in TBST for 1 hour.
-
Incubate with a primary antibody specific for this compound/SREBP-1 overnight at 4°C. The antibody should recognize both precursor and mature forms.
-
Wash and incubate with an HRP-conjugated secondary antibody for 1 hour at room temperature.
-
Detect the signal using an enhanced chemiluminescence (ECL) substrate and an imaging system.
-
-
Analysis: Quantify band intensity using software like ImageJ. Normalize this compound bands to a loading control (e.g., β-actin for total lysate, Lamin B1 for nuclear fraction).[3]
Data Presentation:
| Protein | Fraction | Treatment Group | Relative Band Intensity (Normalized) | p-value |
| pthis compound (~125 kDa) | Total | Control | 1.0 ± 0.08 | - |
| Compound X | 0.7 ± 0.06 | <0.05 | ||
| nthis compound (~68 kDa) | Nuclear | Control | 1.0 ± 0.11 | - |
| Compound X | 3.1 ± 0.25 | <0.001 |
Protocol 3: Chromatin Immunoprecipitation (ChIP) Assay
Application Note: ChIP is used to determine if this compound directly binds to the promoter regions of its putative target genes in vivo.[7][8] This provides direct evidence of this compound's role as a transcriptional activator for those genes.
Caption: Step-by-step workflow for the Chromatin Immunoprecipitation (ChIP) assay.
Methodology:
-
Cross-linking: Treat cells with 1% formaldehyde for 10 minutes at room temperature to cross-link proteins to DNA. Quench with glycine.[9]
-
Chromatin Preparation: Lyse cells and shear chromatin to an average size of 200-1000 bp by sonication.[10]
-
Immunoprecipitation: Incubate sheared chromatin overnight at 4°C with an this compound specific antibody or a negative control IgG antibody.
-
Complex Capture: Add Protein A/G magnetic beads to pull down the antibody-protein-DNA complexes.
-
Washing and Elution: Wash beads to remove non-specific binding, then elute the complexes.
-
Reverse Cross-linking: Reverse the cross-links by heating at 65°C. Treat with RNase A and Proteinase K to remove RNA and protein.
-
DNA Purification: Purify the immunoprecipitated DNA using a spin column kit.
-
qPCR Analysis: Use qPCR to quantify the amount of specific promoter DNA (e.g., FASN promoter) in the this compound IP sample relative to the total input and IgG control.
Data Presentation:
| Target Promoter | Treatment Group | % Input (Mean ± SEM) | Fold Enrichment vs. IgG | p-value |
| FASN | Control | 0.5 ± 0.07 | 12.5 ± 1.5 | <0.01 |
| Compound X | 1.5 ± 0.18 | 35.2 ± 3.8 | <0.001 | |
| Negative Locus | Control | 0.02 ± 0.01 | 1.1 ± 0.3 | ns |
| Compound X | 0.03 ± 0.01 | 1.3 ± 0.4 | ns |
Protocol 4: Luciferase Reporter Assay
Application Note: This assay measures the transcriptional activity of this compound.[11] A reporter construct containing the promoter of a known this compound target gene (e.g., FASN) upstream of a luciferase gene is introduced into cells. An increase in luciferase activity reflects enhanced binding and activation of the promoter by this compound.
Methodology:
-
Plasmid Transfection: Co-transfect cells with:
-
A firefly luciferase reporter plasmid containing the SRE from a lipogenic gene promoter.
-
A Renilla luciferase plasmid as an internal control for transfection efficiency.
-
-
Cell Treatment: After 24 hours, treat the transfected cells with the experimental compound or condition.
-
Cell Lysis: Lyse the cells using the passive lysis buffer provided in the assay kit.
-
Luminescence Measurement: Use a dual-luciferase reporter assay system.[12]
-
Add the firefly luciferase substrate to the cell lysate and measure the luminescence.
-
Add the Stop & Glo reagent to quench the firefly reaction and activate the Renilla luciferase, then measure the second luminescence signal.
-
-
Analysis: Calculate the ratio of firefly to Renilla luminescence to normalize for transfection efficiency. Express results as fold induction over the control group.
Data Presentation:
| Treatment Group | Normalized Luciferase Activity (Firefly/Renilla Ratio) | Fold Induction vs. Control | p-value |
| Control (Vehicle) | 150.5 ± 12.8 | 1.0 | - |
| Compound X (10 µM) | 620.2 ± 45.1 | 4.1 | <0.001 |
| This compound siRNA | 25.1 ± 5.6 | 0.17 | <0.001 |
Protocol 5: Quantification of Lipid Accumulation
Application Note: This protocol visualizes and quantifies the end-point of the lipogenic pathway: the accumulation of neutral lipids (triglycerides) in lipid droplets. Stains like Oil Red O or fluorescent dyes (Bodipy) are used.
Methodology:
-
Cell Culture and Treatment: Grow cells on glass coverslips and apply experimental treatments.
-
Fixation: Wash cells with PBS and fix with 10% formalin for 30 minutes.
-
Staining (Oil Red O):
-
Wash cells with water and then with 60% isopropanol.
-
Stain with freshly filtered Oil Red O working solution for 20-30 minutes.
-
Wash again with 60% isopropanol and then with water.
-
(Optional) Counterstain nuclei with hematoxylin.
-
-
Imaging: Mount coverslips on slides and visualize using a bright-field microscope. Lipid droplets will appear as red-orange spheres.
-
Quantification:
-
Image Analysis: Capture multiple images per condition and use software (e.g., ImageJ) to calculate the percentage of the total cell area stained positive for Oil Red O.
-
Dye Elution: To get quantitative data from a whole plate, after staining, elute the dye from the cells using 100% isopropanol and measure the absorbance at ~510 nm.
-
Data Presentation:
| Treatment Group | Absorbance at 510 nm (Mean ± SEM) | % Lipid Accumulation (vs. Control) | p-value |
| Control (Vehicle) | 0.12 ± 0.01 | 100 | - |
| Compound X (10 µM) | 0.45 ± 0.04 | 375 | <0.001 |
| This compound siRNA | 0.15 ± 0.02 | 125 | ns |
Protocol 6: Measurement of De Novo Lipogenesis (DNL) Rate
Application Note: While lipid staining shows accumulation, it doesn't distinguish between lipid uptake and new synthesis. Isotope tracing directly measures the rate of DNL.[13][14] This protocol uses 14C-labeled acetate, a precursor for fatty acid synthesis.
Methodology:
-
Cell Culture and Treatment: Culture and treat cells as required.
-
Isotope Labeling: For the final 2-4 hours of treatment, replace the medium with fresh medium containing a known concentration of 14C-labeled acetic acid.[3]
-
Cell Lysis and Lipid Extraction:
-
Wash cells thoroughly with cold PBS to remove unincorporated tracer.
-
Lyse cells and extract total lipids using a chloroform:methanol (2:1) solution.[15]
-
-
Scintillation Counting: Transfer the lipid-containing chloroform phase to a scintillation vial, evaporate the solvent, add scintillation fluid, and measure the incorporated radioactivity (counts per minute, CPM) using a scintillation counter.
-
Normalization: Normalize the CPM value to the total protein content of the cell lysate from a parallel well to account for differences in cell number.
Data Presentation:
| Treatment Group | 14C-Acetate Incorporation (CPM/mg protein) | DNL Rate (% of Control) | p-value |
| Control (Vehicle) | 1,520 ± 130 | 100 | - |
| Compound X (10 µM) | 5,890 ± 450 | 388 | <0.001 |
| FASN Inhibitor | 450 ± 65 | 30 | <0.001 |
References
- 1. Targeting SREBP-1-Mediated Lipogenesis as Potential Strategies for Cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Oleate activates SREBP-1 signaling activity in SCD1-deficient hepatocytes - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Akt stimulates hepatic SREBP1c and lipogenesis through parallel mTORC1-dependent and independent pathways - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Oncogenic signaling upstream of mTORC1 drives lipogenesis and proliferation through SREBP - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. A conserved SREBP-1/phosphatidylcholine feedback circuit regulates lipogenesis in metazoans - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. Chromatin immunoprecipitation - Wikipedia [en.wikipedia.org]
- 9. static1.squarespace.com [static1.squarespace.com]
- 10. Overview of Chromatin Immunoprecipitation (ChIP) | Cell Signaling Technology [cellsignal.com]
- 11. Development of luciferase reporter-based cell assays - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. assaygenie.com [assaygenie.com]
- 13. Serine catabolism generates liver NADPH and supports hepatic lipogenesis - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Stable isotope methods for the in vivo measurement of lipogenesis and triglyceride metabolism - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. Determination of Fatty Acid Oxidation and Lipogenesis in Mouse Primary Hepatocytes - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for the Synthesis and Purification of Spike-binding Peptide 1 (SBP1)
For Researchers, Scientists, and Drug Development Professionals
Abstract
This document provides detailed application notes and protocols for the chemical synthesis and purification of Spike-binding Peptide 1 (SBP1). SBP1 is a 23-amino acid peptide derived from the α1 helix of the human angiotensin-converting enzyme 2 (ACE2) protein. It has been identified as a potent binder to the Receptor Binding Domain (RBD) of the SARS-CoV-2 Spike protein, effectively inhibiting its interaction with the ACE2 receptor and thus blocking viral entry into host cells. The protocols herein describe the synthesis of SBP1 via Fmoc-based solid-phase peptide synthesis (SPPS), followed by its purification using reversed-phase high-performance liquid chromatography (RP-HPLC).
Introduction to Spike-binding Peptide 1 (SBP1)
Spike-binding Peptide 1 (SBP1) is a linear peptide with the following amino acid sequence:
Sequence: Isoleucine-Glutamic acid-Glutamic acid-Glutamine-Alanine-Lysine-Threonine-Phenylalanine-Leucine-Aspartic acid-Lysine-Phenylalanine-Asparagine-Histidine-Glutamic acid-Alanine-Glutamic acid-Aspartic acid-Leucine-Phenylalanine-Y-Glutamine-Serine
(IEEQAKTFLDKFNHEAEDLFYQS)
SBP1 was designed to mimic the binding interface of the ACE2 receptor with the SARS-CoV-2 Spike protein. By competitively binding to the Spike protein's RBD, SBP1 can prevent the virus from engaging with the host cell receptor, a critical step in the viral infection process.
Quantitative Data Summary
The following table summarizes key quantitative parameters for synthesized and purified SBP1.
| Parameter | Value | Method of Determination | Reference |
| Molecular Weight (Avg.) | 2755.02 Da | Mass Spectrometry | Calculated |
| Purity | >95% | RP-HPLC | [1] |
| Binding Affinity (Kd) to SARS-CoV-2 RBD | 47 nM | Bio-layer Interferometry | [1] |
Experimental Protocols
Solid-Phase Peptide Synthesis (SPPS) of SBP1
This protocol outlines the manual synthesis of SBP1 using the Fmoc/tBu strategy. The synthesis is performed on a Rink Amide resin to yield a C-terminally amidated peptide.
3.1.1. Materials and Reagents
-
Rink Amide MBHA resin (0.5 mmol/g substitution)
-
Fmoc-protected amino acids (5 eq. per coupling)
-
Coupling reagent: HCTU (4.95 eq.)
-
Base: N,N-Diisopropylethylamine (DIPEA) (10 eq.)
-
Fmoc deprotection solution: 20% (v/v) piperidine in N,N-Dimethylformamide (DMF)
-
Solvents: DMF, Dichloromethane (DCM)
-
Washing solvent: DMF, DCM, Isopropanol (IPA)
-
Cleavage cocktail: 95% Trifluoroacetic acid (TFA), 2.5% Triisopropylsilane (TIS), 2.5% water
-
Cold diethyl ether
3.1.2. SPPS Workflow Diagram
Caption: Workflow for the solid-phase synthesis of SBP1.
3.1.3. Step-by-Step Synthesis Protocol
-
Resin Swelling: Swell the Rink Amide resin in DMF for 30 minutes in a reaction vessel.
-
First Amino Acid Coupling (Serine):
-
Perform Fmoc deprotection by treating the resin with 20% piperidine in DMF for 5 minutes, then repeat for 15 minutes.
-
Wash the resin with DMF (3x), DCM (3x), and DMF (3x).
-
In a separate vessel, dissolve Fmoc-Ser(tBu)-OH (5 eq.), HCTU (4.95 eq.), and DIPEA (10 eq.) in DMF.
-
Add the activated amino acid solution to the resin and shake for 2 hours.
-
Wash the resin as described above.
-
-
Chain Elongation: Repeat the deprotection and coupling steps for the remaining 22 amino acids in the SBP1 sequence, from the C-terminus to the N-terminus. For amino acids prone to difficult coupling, a double coupling protocol may be employed.
-
Final Deprotection: After the final coupling, perform a final Fmoc deprotection as described in step 2.
-
Washing and Drying: Wash the peptide-resin with DMF (3x), IPA (3x), and DCM (3x). Dry the resin under vacuum.
-
Cleavage and Side-Chain Deprotection:
-
Treat the dried peptide-resin with the cleavage cocktail (95% TFA, 2.5% TIS, 2.5% water) for 2-3 hours at room temperature.
-
Filter the resin and collect the filtrate containing the cleaved peptide.
-
-
Peptide Precipitation: Precipitate the crude peptide by adding the TFA filtrate to cold diethyl ether.
-
Collection and Drying: Centrifuge the precipitated peptide, decant the ether, and wash the peptide pellet with cold diethyl ether twice. Dry the crude peptide pellet under vacuum.
Purification of SBP1 by RP-HPLC
The crude SBP1 peptide is purified using preparative RP-HPLC on a C18 column.
3.2.1. Materials and Reagents
-
Crude SBP1 peptide
-
RP-HPLC system with a preparative C18 column
-
Mobile Phase A: 0.1% TFA in water
-
Mobile Phase B: 0.1% TFA in acetonitrile
-
Lyophilizer
3.2.2. HPLC Purification Workflow Diagram
Caption: Workflow for the purification of SBP1 by RP-HPLC.
3.2.3. Step-by-Step Purification Protocol
-
Sample Preparation: Dissolve the crude SBP1 peptide in Mobile Phase A.
-
HPLC Setup: Equilibrate the preparative C18 column with Mobile Phase A.
-
Injection and Elution: Inject the dissolved crude peptide onto the column. Elute the peptide using a linear gradient of Mobile Phase B (e.g., 5-65% over 60 minutes) at a suitable flow rate.
-
Fraction Collection: Monitor the elution profile at 220 nm and collect fractions corresponding to the major peptide peak.
-
Purity Analysis: Analyze the purity of the collected fractions using analytical RP-HPLC and confirm the identity by mass spectrometry.
-
Pooling and Lyophilization: Pool the fractions with a purity of >95%. Lyophilize the pooled fractions to obtain the pure SBP1 peptide as a white powder.
Characterization of Purified SBP1
The purified SBP1 should be characterized to confirm its identity and purity.
-
Analytical RP-HPLC: A sharp, single peak should be observed, confirming the high purity of the peptide. An example chromatogram for a similar ACE2-derived peptide is shown in Figure 1A.[2]
-
Mass Spectrometry: The observed molecular weight should match the calculated average molecular weight of SBP1 (2755.02 Da). An example ESI-MS spectrum for a similar peptide is shown in Figure 1B, demonstrating the expected charge state distribution.[2]
Conclusion
The protocols described in this document provide a comprehensive guide for the successful synthesis and purification of Spike-binding Peptide 1 (SBP1). The use of Fmoc-based SPPS and RP-HPLC purification allows for the production of highly pure SBP1 suitable for research and drug development applications aimed at inhibiting SARS-CoV-2 entry. Careful execution of these protocols and thorough characterization of the final product are essential for obtaining reliable and reproducible results in downstream applications.
References
Troubleshooting & Optimization
Technical Support Center: Recombinant SBP1 Protein Expression
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in overcoming challenges associated with the low yield of recombinant Selenium Binding Protein 1 (SBP1).
Frequently Asked Questions (FAQs)
Q1: What are the common initial hurdles when expressing recombinant SBP1?
A1: The primary challenges in recombinant SBP1 production often revolve around achieving high expression levels and maintaining the protein in a soluble and correctly folded state. Initial troubleshooting should focus on the expression system, vector design, and culture conditions.
Q2: Which expression systems are suitable for producing recombinant SBP1?
A2: Recombinant SBP1 has been successfully produced in both prokaryotic and eukaryotic systems. Escherichia coli (E. coli) strains like BL21(DE3) and Rosetta 2 are commonly used for their rapid growth and cost-effectiveness.[1] For proteins requiring specific post-translational modifications, mammalian cell lines such as HEK293T can be employed.[2]
Q3: My SBP1 protein is forming inclusion bodies. What can I do?
A3: Inclusion body formation is a frequent issue when overexpressing proteins in E. coli.[3] To improve the solubility of SBP1, consider the following strategies:
-
Lower the induction temperature: Reducing the temperature to 16-25°C can slow down protein synthesis, allowing more time for proper folding.[4]
-
Optimize inducer concentration: Using a lower concentration of the inducing agent (e.g., IPTG) can reduce the rate of protein expression and minimize aggregation.[5][6]
-
Utilize a solubility-enhancing fusion tag: Tags like Maltose-Binding Protein (MBP) can improve the solubility of the target protein.[7]
-
Co-express with chaperones: Chaperone proteins can assist in the correct folding of recombinant proteins.[8]
Q4: What is the expected yield for recombinant SBP1 from an E. coli expression system?
A4: The yield of recombinant protein can vary significantly based on the expression system and protocol used. With optimized high-cell-density expression methods in E. coli, it is possible to obtain yields in the range of 17–34 mg of unlabeled protein from a 50 mL culture.[9][10] However, for His-tagged proteins, yields can range from 3 to 10 milligrams of protein from a 1-liter culture.[11]
Troubleshooting Guides
Issue 1: Low or No Expression of SBP1 Protein
If you are observing low or no expression of your recombinant SBP1, work through the following troubleshooting steps.
Caption: Troubleshooting workflow for low or no SBP1 expression.
Detailed Steps:
-
Verify the Integrity of Your Expression Construct:
-
DNA Sequencing: Ensure the SBP1 gene is correctly cloned into the expression vector, is in the correct reading frame, and contains no mutations.
-
Promoter and Ribosome Binding Site (RBS): Confirm the presence and integrity of a suitable promoter (e.g., T7) and a strong RBS upstream of your gene.
-
-
Assess Transformation and Culture Initiation:
-
Transformation Efficiency: Use a control plasmid to verify the competency of your E. coli cells.
-
Fresh Culture: Always inoculate from a fresh bacterial colony, as this generally leads to higher protein yields.
-
-
Evaluate the E. coli Host Strain:
-
Codon Bias: SBP1 is a eukaryotic protein, and its codon usage may not be optimal for E. coli. Consider using a strain like Rosetta(DE3), which contains a plasmid with genes for rare tRNAs.[12]
-
Protease Deficiency: Use a protease-deficient strain such as BL21(DE3) to prevent degradation of your recombinant protein.[13]
-
-
Optimize Induction Conditions:
-
Inducer Concentration: Titrate the concentration of the inducer (e.g., IPTG). A common starting range is 0.1 mM to 1.0 mM.[5][6] Sometimes, lower concentrations can improve protein solubility and yield.[14]
-
Cell Density at Induction: Induce expression during the mid-log phase of growth, typically at an OD600 of 0.4-0.6.[2][5]
-
Induction Temperature and Duration: Test a range of temperatures (e.g., 18°C, 25°C, 37°C) and induction times (e.g., 4 hours to overnight).[4] Lower temperatures often favor proper protein folding.[4]
-
Issue 2: SBP1 is Expressed but Insoluble (Inclusion Bodies)
If your SBP1 protein is being expressed but is found in the insoluble fraction, follow this guide.
References
- 1. Optimizing recombinant protein expression via automated induction profiling in microtiter plates at different temperatures - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Troubleshooting Guide for Common Recombinant Protein Problems [synapse.patsnap.com]
- 4. genextgenomics.com [genextgenomics.com]
- 5. How to Induce Protein Expression in E. coli Using IPTG [synapse.patsnap.com]
- 6. nbinno.com [nbinno.com]
- 7. Expression and Purification of Recombinant Proteins in Escherichia coli with a His6 or Dual His6-MBP Tag - PMC [pmc.ncbi.nlm.nih.gov]
- 8. 5 Key Factors Affecting Recombinant Protein Yield in E. coli [synapse.patsnap.com]
- 9. Practical protocols for production of very high yields of recombinant proteins using Escherichia coli - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Practical protocols for production of very high yields of recombinant proteins using Escherichia coli - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. What Are the Top E. coli Strains for High-Yield Protein Expression? [synapse.patsnap.com]
- 13. E. coli expression strains – Protein Expression and Purification Core Facility [embl.org]
- 14. goldbio.com [goldbio.com]
Technical Support Center: Optimizing SBP-1 RNAi Efficiency in C. elegans
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) for researchers utilizing RNA interference (RNAi) to study the function of the sterol regulatory element-binding protein homolog, SBP-1, in Caenorhabditis elegans.
Frequently Asked Questions (FAQs)
| Question | Answer |
| What is the primary function of this compound in C. elegans? | This compound is a key transcription factor that plays a crucial role in lipid metabolism.[1] It regulates the expression of genes involved in fatty acid synthesis and desaturation, thereby maintaining normal fat levels in the worm.[1] |
| What are the expected phenotypes of successful this compound RNAi knockdown? | Successful knockdown of this compound typically results in a "Clear" phenotype, characterized by a transparent body due to reduced fat storage.[1] Other common phenotypes include reduced body size, delayed growth, and a significant decrease in the number of eggs laid.[1] |
| Which tissues express this compound? | This compound mRNA is strongly expressed in the intestine of C. elegans.[1] |
| What are the common methods for inducing RNAi in C. elegans? | The most common methods for delivering double-stranded RNA (dsRNA) to C. elegans are feeding with dsRNA-expressing E. coli, microinjection of dsRNA directly into the worm's body, and soaking the worms in a dsRNA solution.[2][3] |
| How does the efficiency of RNAi by feeding compare to microinjection? | While microinjection is often considered the most reliable and potent method for inducing RNAi, optimized feeding protocols can achieve comparable effectiveness for many genes, particularly those with maternal-effect embryonic lethal phenotypes.[4][5][6] For some genes, both methods can result in 100% penetrance of the expected phenotype.[4][5] |
Troubleshooting Guide
Issue 1: No or Weak this compound RNAi Phenotype
| Potential Cause | Recommended Solution |
| Inefficient dsRNA delivery | - Feeding: Ensure the E. coli strain (e.g., HT115(DE3)) is expressing the dsRNA by including IPTG in the NGM plates.[2][7] Verify the integrity of the dsRNA construct. - Injection: Confirm the concentration and quality of the injected dsRNA. Ensure the injection technique is targeting the gonad or intestine effectively.[2] |
| Ineffective RNAi machinery in the worm strain | Use an RNAi-sensitive mutant strain, such as rrf-3(pk1426) or strains with mutations in the eri-1 gene, which have been shown to enhance the RNAi response, particularly in neurons. |
| Suboptimal experimental conditions | - Temperature: Perform RNAi experiments at a consistent temperature, typically between 15°C and 22°C. - Timing: Score phenotypes at the appropriate developmental stage. For this compound, phenotypes like reduced body size and fat storage are often observable in late larval stages and adults.[1] |
| Off-target effects of the vector | The commonly used L4440 vector can sometimes cause unexpected phenotypes.[7] Use an empty L4440 vector as a negative control to distinguish vector-specific effects from the this compound knockdown phenotype. |
| Target gene properties | Some genes are inherently more resistant to RNAi. Consider synthesizing dsRNA targeting a different region of the this compound gene. |
Issue 2: Inconsistent or Variable this compound RNAi Phenotypes
| Potential Cause | Recommended Solution |
| Variability in dsRNA ingestion (Feeding) | Ensure a uniform lawn of bacteria on the RNAi plates. Synchronize the worm population to minimize developmental stage-dependent variations in feeding behavior. |
| Inconsistent injection volume or location (Injection) | Practice the microinjection technique to ensure consistent delivery of dsRNA. Aim for the same region of the worm (e.g., gonad syncytium) in each injection. |
| Environmental fluctuations | Maintain consistent temperature and humidity during the experiment, as these factors can influence worm development and physiology. |
| Plate-to-plate variation | Prepare a single large batch of RNAi plates to minimize variations in IPTG and antibiotic concentrations. |
Data Presentation
Table 1: Phenotypic Outcomes of this compound RNAi Knockdown
| Phenotype | Description | Method of Observation | Expected Outcome |
| Fat Storage | Visualization of lipid droplets. | Staining with Oil Red O or Nile Red, or observation of body transparency. | Significant reduction in fat storage, leading to a "Clear" or transparent appearance.[1] |
| Body Size | Measurement of worm length and width. | Microscopy with image analysis software. | Noticeable decrease in overall body size compared to control worms.[1] |
| Growth Rate | Time to reach specific developmental milestones. | Observation of developmental stages over time. | Delayed post-embryonic development.[1] |
| Fecundity | Number of progeny produced. | Counting the number of eggs laid over a specific period. | A considerable reduction in the number of eggs laid.[1] |
Table 2: General Comparison of RNAi Efficiency by Feeding vs. Injection for Maternal-Effect Embryonic Lethal Genes
| Gene | RNAi by Feeding (% Embryonic Lethality) | RNAi by Injection (% Embryonic Lethality) |
| gpb-1 | 100% | 100% |
| par-1 | 100% | 100% |
| par-2 | 100% | 100% |
| par-3 | 97% | 100% |
| cyk-1 | 55% | 100% |
| skn-1 | 100% | 100% |
| dnc-1 | 100% | 100% |
| bir-1 | 100% | 100% |
| pal-1 | 100% | 100% |
| dif-1 | 100% | 100% |
| plk-1 | 100% | 100% |
| dhc-1 | 100% | 100% |
| mex-3 | 100% | 100% |
| Data adapted from a study comparing RNAi methods for maternal-effect embryonic lethal genes, demonstrating that feeding can be as effective as injection for many targets.[4] |
Experimental Protocols
Protocol 1: this compound RNAi by Feeding
-
Prepare RNAi Plates:
-
Prepare Nematode Growth Medium (NGM) agar.
-
After autoclaving and cooling to ~55°C, add ampicillin (100 µg/mL) and IPTG (1 mM).
-
Pour the plates and let them solidify.
-
-
Bacterial Culture:
-
Inoculate a single colony of E. coli HT115(DE3) containing the this compound RNAi construct (in L4440 vector) into LB medium with ampicillin (100 µg/mL) and tetracycline (12.5 µg/mL).
-
Grow overnight at 37°C with shaking.
-
-
Seed Plates:
-
Spot 50-100 µL of the overnight bacterial culture onto the center of the NGM/amp/IPTG plates.
-
Allow the bacterial lawn to grow at room temperature for 1-2 days.
-
-
Worm Synchronization:
-
Prepare a synchronized population of L1 larvae by bleaching gravid adult worms.
-
-
RNAi Treatment:
-
Transfer the synchronized L1 larvae onto the this compound RNAi plates.
-
As a control, transfer L1 larvae to plates seeded with E. coli HT115(DE3) containing the empty L4440 vector.
-
-
Incubation and Phenotypic Analysis:
-
Incubate the worms at 20°C.
-
Score for phenotypes (reduced body size, decreased fat storage) at the L4 and young adult stages (approximately 48-72 hours post-plating).
-
Protocol 2: this compound RNAi by Microinjection
-
Prepare dsRNA:
-
Synthesize this compound dsRNA in vitro using a commercial kit with T7 RNA polymerase and a PCR product of the this compound gene flanked by T7 promoters as a template.
-
Purify and quantify the dsRNA. Dilute to a working concentration (e.g., 1-2 µg/µL) in injection buffer.
-
-
Prepare Injection Pads:
-
Melt a 3% agarose solution and place a small drop on a coverslip to create a thin, flat pad.
-
-
Prepare Worms:
-
Select young adult hermaphrodites for injection.
-
Transfer the worms to a drop of M9 buffer on the agarose pad. Use a worm pick to gently align them.
-
-
Microinjection:
-
Load the dsRNA solution into a microinjection needle.
-
Mount the needle on a micromanipulator.
-
Under a dissecting microscope, insert the needle into the gonad or intestine of the worm and inject a small volume of the dsRNA solution.
-
-
Recovery:
-
Carefully transfer the injected worms to a seeded NGM plate.
-
Allow the worms to recover and lay eggs.
-
-
Phenotypic Analysis:
-
Score the F1 progeny for the expected this compound knockdown phenotypes (e.g., reduced body size, "Clear" appearance) at the appropriate developmental stages.
-
Visualizations
Caption: this compound signaling pathway in C. elegans.
Caption: Experimental workflows for this compound RNAi.
References
- 1. Fat accumulation in Caenorhabditis elegans is mediated by SREBP homolog this compound - PMC [pmc.ncbi.nlm.nih.gov]
- 2. RNA Interference in Caenorhabditis Elegans - PMC [pmc.ncbi.nlm.nih.gov]
- 3. PROTOCOL 4 RNAi mediated inactivation of autophagy genes - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Effectiveness of specific RNA-mediated interference through ingested double-stranded RNA in Caenorhabditis elegans - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. researchgate.net [researchgate.net]
- 7. RNA interference may result in unexpected phenotypes in Caenorhabditis elegans - PMC [pmc.ncbi.nlm.nih.gov]
SBP-1 Antibody Specificity: Technical Support Center
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) regarding common issues encountered with SBP-1 antibody specificity. These resources are intended for researchers, scientists, and drug development professionals to help ensure accurate and reproducible experimental results.
FAQs: Quick Solutions to Common Problems
Q1: What is the difference between Selenium Binding Protein 1 (this compound) and SBP-tag?
It is crucial to distinguish between two common "this compound" references in biological research:
-
Selenium Binding Protein 1 (SELENBP1 or this compound): A ~56 kDa protein involved in selenium metabolism and detoxification. It has various cellular roles and is expressed in tissues like the liver, kidney, and colon.
-
Streptavidin-Binding Peptide (SBP-tag): A 38-amino acid peptide tag used for protein purification and detection, which binds to streptavidin.[1]
Antibodies designed for this compound (the protein) will not recognize the SBP-tag, and vice-versa. Ensure you have purchased the correct antibody for your target of interest.
Q2: My this compound antibody is showing multiple bands on my Western Blot. What could be the cause?
Multiple bands can arise from several factors:
-
Protein Isoforms: The human this compound protein has identified isoforms which may differ in molecular weight.[2][3] Consult protein databases like UniProt for information on the expected sizes of this compound isoforms.
-
Post-Translational Modifications (PTMs): PTMs such as glycosylation can cause a protein to migrate slower on an SDS-PAGE gel, appearing as a higher molecular weight band.
-
Protein Degradation: If samples are not handled properly with protease inhibitors, the target protein can be degraded, leading to lower molecular weight bands.[4] Always use fresh samples and appropriate inhibitors.[4]
-
Non-Specific Binding: The antibody may be cross-reacting with other proteins.[5] See the detailed troubleshooting section below for mitigation strategies.
-
Antibody Concentration: Using too high a concentration of the primary antibody can lead to non-specific bands.[6][7]
Q3: I am getting weak or no signal in my experiment. What should I do?
A weak or absent signal can be due to several reasons:[6][8]
-
Low Target Protein Expression: The cell line or tissue you are using may not express this compound at a detectable level. It is recommended to use a positive control, such as a cell lysate known to express this compound, to validate your experimental setup.
-
Improper Antibody Dilution: The primary antibody concentration may be too low. Perform a titration experiment to determine the optimal antibody concentration.[5]
-
Inactive Antibody: Ensure the antibody has been stored correctly according to the manufacturer's datasheet and has not expired.[6][9] Avoid repeated freeze-thaw cycles.[10]
-
Suboptimal Protocol: Review your protocol for steps like blocking, washing, and incubation times. Insufficient washing can lead to high background, while excessive washing can remove the signal.[5]
Q4: How can I control for lot-to-lot variability with my this compound antibody?
Lot-to-lot variability is a known issue, especially with polyclonal antibodies, and can lead to inconsistent results.[9][10]
-
Purchase Sufficient Quantity: For long-term studies, it is advisable to purchase a single, larger lot of the antibody.
-
Validate New Lots: When switching to a new lot, it is critical to re-validate the antibody's performance. This can be done by running the old and new lots in parallel on the same samples to ensure comparable results.[10]
-
Titration: The optimal dilution may vary between lots, so a new titration is recommended for each new lot.[10]
Troubleshooting Guides
Issue 1: High Background in Western Blotting and IHC
High background can obscure the specific signal from your target protein.[8][11]
| Potential Cause | Recommended Solution |
| Blocking is insufficient. | Increase the blocking time and/or the concentration of the blocking agent (e.g., 5-10% non-fat milk or BSA). Consider testing different blocking buffers. Block for at least 1 hour at room temperature or overnight at 4°C.[8] |
| Primary antibody concentration is too high. | Decrease the concentration of the primary antibody. Perform a titration to find the optimal concentration that gives a strong signal with low background.[6] |
| Secondary antibody is binding non-specifically. | Run a control experiment with only the secondary antibody to check for non-specific binding. Consider using a cross-adsorbed secondary antibody to minimize cross-reactivity with endogenous immunoglobulins.[12] |
| Washing steps are inadequate. | Increase the number and duration of wash steps. Adding a detergent like Tween 20 (0.05-0.1%) to the wash buffer can help reduce non-specific binding.[8] |
| Membrane was allowed to dry out. | Ensure the membrane remains hydrated throughout the entire process.[6] |
Issue 2: Non-Specific Bands or Cross-Reactivity
Non-specific bands occur when the antibody recognizes proteins other than the intended target.[5]
| Potential Cause | Recommended Solution |
| Antibody lacks specificity. | Perform a BLAST search of the immunogen sequence against the proteome of your sample's species to identify potential off-targets with high homology.[12] If significant homology exists with other proteins, consider using a different antibody raised against a more unique epitope. |
| Polyclonal antibody heterogeneity. | Polyclonal antibodies recognize multiple epitopes and may have a higher likelihood of cross-reactivity.[12] If specificity is a major concern, switching to a monoclonal antibody that recognizes a single epitope may be beneficial.[9] |
| Sample contains closely related proteins. | Use a knockout or knockdown cell line/tissue that does not express the target protein as a negative control. An antibody that is specific should not produce a band in the knockout/knockdown sample. |
| High antibody concentration. | As with high background, an overly concentrated primary antibody can bind to low-affinity, non-target proteins. Optimize the antibody dilution.[5] |
Experimental Protocols & Workflows
Western Blotting Protocol for this compound Detection
This protocol provides a general framework. Always refer to the antibody manufacturer's specific recommendations.
-
Sample Preparation:
-
Lyse cells or tissues in RIPA buffer supplemented with a protease inhibitor cocktail.
-
Determine protein concentration using a BCA or Bradford assay.
-
-
SDS-PAGE:
-
Load 20-30 µg of total protein per lane onto a polyacrylamide gel.
-
Run the gel until adequate separation of proteins is achieved.
-
-
Protein Transfer:
-
Transfer proteins from the gel to a PVDF or nitrocellulose membrane.
-
Confirm successful transfer by staining the membrane with Ponceau S.
-
-
Blocking:
-
Block the membrane for 1 hour at room temperature with 5% non-fat dry milk or BSA in Tris-buffered saline with 0.1% Tween 20 (TBST).
-
-
Primary Antibody Incubation:
-
Dilute the this compound primary antibody in the blocking buffer at the manufacturer's recommended concentration (or your optimized dilution).
-
Incubate the membrane overnight at 4°C with gentle agitation.
-
-
Washing:
-
Wash the membrane three times for 10 minutes each with TBST.
-
-
Secondary Antibody Incubation:
-
Incubate the membrane with an appropriate HRP-conjugated secondary antibody (diluted in blocking buffer) for 1 hour at room temperature.
-
-
Washing:
-
Wash the membrane three times for 10 minutes each with TBST.
-
-
Detection:
-
Incubate the membrane with an ECL substrate.
-
Capture the chemiluminescent signal using an imaging system.
-
Workflow for Troubleshooting this compound Antibody Specificity
Caption: A logical workflow for diagnosing and resolving common this compound antibody issues.
Hypothetical this compound Signaling Pathway
While the complete signaling pathway of this compound is still under investigation, it is known to be a negative regulator of hedgehog signaling.[2] The following diagram illustrates a simplified hypothetical pathway.
Caption: Simplified diagram of this compound's potential role in hedgehog signaling.
References
- 1. merckmillipore.com [merckmillipore.com]
- 2. biocompare.com [biocompare.com]
- 3. biocompare.com [biocompare.com]
- 4. Western Blotting Troubleshooting Guide | Cell Signaling Technology [cellsignal.com]
- 5. Western Blot Troubleshooting: 10 Common Problems and Solutions [synapse.patsnap.com]
- 6. Western Blot Troubleshooting | Thermo Fisher Scientific - HK [thermofisher.com]
- 7. IHC Troubleshooting Guide | Thermo Fisher Scientific - HK [thermofisher.com]
- 8. bosterbio.com [bosterbio.com]
- 9. bitesizebio.com [bitesizebio.com]
- 10. Approach to Antibody Lot-to-Lot Variability | GeneTex [genetex.com]
- 11. bosterbio.com [bosterbio.com]
- 12. How do I know if the antibody will cross-react? | Proteintech Group [ptglab.com]
how to resolve non-specific bands in SBP-1 western blots
Welcome to the technical support center for SBP-1 Western blots. This resource is designed for researchers, scientists, and drug development professionals to help troubleshoot and resolve common issues encountered during the immunodetection of Selenium-Binding Protein 1 (this compound).
Troubleshooting Guides
This section provides a detailed, question-and-answer guide to address the issue of non-specific bands in your this compound Western blots.
Problem: I am observing multiple non-specific bands in my this compound Western blot. What are the potential causes and solutions?
Non-specific bands can arise from various factors throughout the Western blot workflow. Below is a systematic guide to help you identify and resolve the issue.
Question: Could the concentration of my primary or secondary antibody be causing the non-specific bands?
Answer: Yes, excessively high antibody concentrations are a common cause of non-specific binding.[1][2][3][4]
-
Primary Antibody: If the primary antibody concentration is too high, it can bind to proteins other than this compound that have similar epitopes or binding sites.[2][3] It is crucial to optimize the dilution of your this compound primary antibody.[1] If the manufacturer provides a recommended dilution range, this should be used as a starting point for your optimization.[4][5] You can perform a dot blot or run test blots with a range of dilutions (e.g., 1:500, 1:1000, 1:2000, 1:5000) to determine the optimal concentration that provides a strong signal for this compound with minimal background.[6][7]
-
Secondary Antibody: Similarly, a high concentration of the secondary antibody can lead to non-specific binding and increased background.[1] You can test for non-specific binding of the secondary antibody by incubating a blot with only the secondary antibody (no primary antibody).[1] If bands appear, it indicates that the secondary antibody is binding non-specifically. Consider increasing the dilution of your secondary antibody.[8][9]
Question: How can I be sure that my blocking step is effective in preventing non-specific binding?
Answer: Incomplete or inadequate blocking is a frequent reason for non-specific bands and high background.[3][10] The blocking buffer works by occupying non-specific binding sites on the membrane, preventing the antibodies from binding to them.[1][11]
-
Choice of Blocking Agent: The most common blocking agents are non-fat dry milk and bovine serum albumin (BSA).[1][12] Typically, a 3-5% solution in TBST or PBST is used.[10][12] The choice between milk and BSA can be critical. Milk contains casein, a phosphoprotein, which can interfere with the detection of phosphorylated proteins.[1][11] Therefore, if you are detecting a phosphorylated form of this compound, BSA would be the preferred blocking agent.[12] For general this compound detection, either can be effective, and it may be worth testing both to see which yields a cleaner blot.[12][13]
-
Blocking Duration and Temperature: For effective blocking, incubate the membrane for at least 1 hour at room temperature or overnight at 4°C with gentle agitation.[1][11] Ensure that the blocking solution is freshly prepared, as bacterial growth in old buffer can contribute to background.[1][14]
Question: Are my washing steps sufficient to remove non-specifically bound antibodies?
Answer: Insufficient washing is a common culprit for high background and non-specific bands.[15][16] The purpose of washing is to remove unbound primary and secondary antibodies.[14][15]
-
Washing Buffer and Detergent: A common washing buffer is TBS or PBS containing a detergent, typically Tween-20 (TBST or PBST).[1][15] The concentration of Tween-20 is usually between 0.05% and 0.1%.[15] If you are experiencing high background, you can try increasing the Tween-20 concentration to 0.1% or slightly higher, but be aware that very high concentrations can strip the antibody from the target protein.[2][15]
-
Washing Duration and Volume: Increase the number and duration of your washes.[2][16] A typical protocol involves three to five washes of 5-10 minutes each.[16] Ensure you are using a sufficient volume of wash buffer to completely submerge the membrane and that there is constant, gentle agitation.[15]
Question: Could the issue originate from my protein samples?
Answer: Yes, issues with sample preparation can lead to the appearance of non-specific bands.
-
Protein Degradation: If your this compound protein is degrading, you may see smaller, non-specific bands.[2][10] To prevent this, always work on ice and add protease inhibitors to your lysis buffer.[9][10]
-
Protein Overload: Loading too much protein per lane can cause "ghost" bands and increase the likelihood of non-specific antibody binding.[2][10] For cell lysates, a typical loading amount is 20-30 µg of total protein per well.[2][10] If your this compound is highly abundant, you may need to load less protein.[17]
Question: Does the type of membrane I use matter?
Answer: The choice of membrane can influence the level of background and non-specific binding.
-
PVDF vs. Nitrocellulose: Polyvinylidene difluoride (PVDF) membranes have a higher protein binding capacity than nitrocellulose, which can lead to higher sensitivity but also potentially higher background.[1][11] If this compound is abundant in your samples, switching to a nitrocellulose membrane might help reduce non-specific signal.[1][16]
-
Membrane Handling: It is critical to never let the membrane dry out during the Western blotting process, as this can cause irreversible and non-specific antibody binding.[1][16] Also, ensure that PVDF membranes are properly activated with methanol before use.[1]
Experimental Protocols
Optimized Western Blot Protocol for this compound Detection
This protocol provides a general framework. Optimal conditions may vary depending on the specific antibodies and reagents used.
-
Sample Preparation:
-
Lyse cells or tissues in RIPA buffer supplemented with a protease inhibitor cocktail.
-
Determine the protein concentration of the lysate using a BCA or Bradford assay.
-
Mix the desired amount of protein (e.g., 20-30 µg) with Laemmli sample buffer and heat at 95-100°C for 5-10 minutes.
-
-
SDS-PAGE and Transfer:
-
Separate the protein samples on an appropriate percentage SDS-polyacrylamide gel.
-
Transfer the separated proteins to a low-fluorescence PVDF or nitrocellulose membrane.
-
-
Blocking:
-
Block the membrane in 5% non-fat dry milk or 5% BSA in TBST (Tris-Buffered Saline with 0.1% Tween-20) for 1 hour at room temperature with gentle agitation.
-
-
Primary Antibody Incubation:
-
Dilute the this compound primary antibody in the blocking buffer at its optimized concentration.
-
Incubate the membrane with the primary antibody solution overnight at 4°C with gentle agitation.
-
-
Washing:
-
Wash the membrane three times for 10 minutes each with TBST.
-
-
Secondary Antibody Incubation:
-
Dilute the appropriate HRP-conjugated secondary antibody in the blocking buffer at its optimized concentration.
-
Incubate the membrane with the secondary antibody solution for 1 hour at room temperature with gentle agitation.
-
-
Final Washes:
-
Wash the membrane three times for 10 minutes each with TBST.
-
-
Detection:
-
Incubate the membrane with an enhanced chemiluminescence (ECL) substrate according to the manufacturer's instructions.
-
Image the blot using a chemiluminescence detection system.
-
Data Presentation
| Parameter | Recommendation | Starting Point for Optimization |
| Protein Load | 20-30 µg of total cell lysate | 25 µg |
| Blocking Buffer | 5% non-fat dry milk or 5% BSA in TBST | 5% non-fat dry milk |
| Blocking Time | 1 hour at RT or overnight at 4°C | 1 hour at RT |
| Primary Antibody Dilution | Varies; refer to datasheet | 1:1000 |
| Secondary Antibody Dilution | Varies; refer to datasheet | 1:5000 |
| Wash Buffer | TBST (0.1% Tween-20) | TBST (0.1% Tween-20) |
| Wash Steps | 3 x 10 minutes | 3 x 10 minutes |
Mandatory Visualization
Caption: The general workflow of a Western blot experiment.
Caption: A logical flowchart for troubleshooting non-specific bands.
FAQs
Q1: My this compound antibody is polyclonal. Does this make it more likely to show non-specific bands?
A1: Yes, polyclonal antibodies are derived from multiple B-cell clones and recognize multiple epitopes on the target protein. This can sometimes lead to a higher likelihood of cross-reactivity with other proteins, resulting in non-specific bands compared to monoclonal antibodies.[2] If you continue to have issues, consider trying a monoclonal antibody specific for this compound if one is available.
Q2: I see non-specific bands at a much higher or lower molecular weight than this compound. What could be the cause?
A2: Higher molecular weight bands could be due to protein aggregates or complexes that are not fully denatured during sample preparation. Ensure your sample buffer contains a sufficient concentration of reducing agent (like DTT or β-mercaptoethanol) and that you are adequately heating your samples. Lower molecular weight bands could be a result of protein degradation.[2] Always use protease inhibitors and keep your samples on ice.[10]
Q3: Can the age of my reagents affect the outcome of my Western blot?
A3: Absolutely. Buffers, especially those containing biological components like milk, can be prone to microbial growth over time, which can increase background noise.[1][14] It is always best to use freshly prepared buffers.[18] Additionally, antibodies can lose their efficacy over time, so ensure they have been stored correctly and are within their expiration date.
Q4: I performed a control with only the secondary antibody and saw no bands, but I still get non-specific bands with the primary antibody. What should I do next?
A4: This indicates that the non-specific binding is likely due to the primary antibody. The next steps would be to further optimize the primary antibody concentration by increasing its dilution.[1][3] You can also try incubating the primary antibody at 4°C overnight instead of at room temperature to reduce the chances of non-specific interactions.[1][3] Additionally, ensure your blocking and washing steps are stringent.
References
- 1. biossusa.com [biossusa.com]
- 2. arp1.com [arp1.com]
- 3. azurebiosystems.com [azurebiosystems.com]
- 4. How to Select the Right Antibody Dilution for Western Blot [synapse.patsnap.com]
- 5. bio-rad.com [bio-rad.com]
- 6. researchgate.net [researchgate.net]
- 7. 7 Tips For Optimizing Your Western Blotting Experiments | Proteintech Group | 武汉三鹰生物技术有限公司 [ptgcn.com]
- 8. researchgate.net [researchgate.net]
- 9. blog.addgene.org [blog.addgene.org]
- 10. researchgate.net [researchgate.net]
- 11. 5 Tips for Reducing Non-specific Signal on Western Blots - Nordic Biosite [nordicbiosite.com]
- 12. Western blot blocking: Best practices | Abcam [abcam.com]
- 13. Troubleshooting Western Blot: Common Problems and Fixes [synapse.patsnap.com]
- 14. agrisera.com [agrisera.com]
- 15. Western blotting guide: Part 7, Membrane Washing [jacksonimmuno.com]
- 16. clyte.tech [clyte.tech]
- 17. biocompare.com [biocompare.com]
- 18. azurebiosystems.com [azurebiosystems.com]
Technical Support Center: Optimizing SBP-1 Nuclear Extraction
This technical support center provides researchers, scientists, and drug development professionals with comprehensive troubleshooting guides and frequently asked questions (FAQs) to optimize cell lysis conditions for the nuclear extraction of Selenium Binding Protein 1 (SBP-1).
Troubleshooting Guide
This guide addresses common issues encountered during this compound nuclear extraction, offering potential causes and solutions to enhance experimental outcomes.
| Issue | Potential Cause(s) | Recommended Solution(s) |
| Low Yield of Nuclear this compound | Incomplete cell lysis: The initial hypotonic buffer may not have sufficiently swollen the cells, or the mechanical disruption was inadequate. | - Increase the incubation time in the hypotonic lysis buffer. - For adherent cells, ensure they are fully scraped and resuspended. - Optimize the number of passes through a narrow-gauge needle or strokes with a Dounce homogenizer.[1] - Monitor cell lysis under a microscope. Lysis can be confirmed by adding trypan blue; the nuclei of lysed cells will stain blue while intact cells exclude the dye. |
| Inefficient nuclear lysis: The high-salt nuclear extraction buffer may not be effectively solubilizing nuclear proteins. | - Ensure the nuclear pellet is fully resuspended in the nuclear extraction buffer before incubation. - Increase the incubation time on ice with periodic vortexing to aid in lysis.[2] - Consider brief sonication of the nuclear lysate on ice to shear genomic DNA and improve protein extraction.[3] | |
| Protein degradation: Proteases released during cell lysis can degrade this compound. | - Always work on ice and use pre-chilled buffers and equipment.[1] - Add a fresh protease inhibitor cocktail to all lysis buffers immediately before use.[4][5] | |
| Suboptimal buffer composition: The choice and concentration of detergents and salts may not be ideal for this compound. | - The choice of lysis buffer is critical for efficient protein extraction.[6][7] For nuclear proteins, RIPA buffer is often recommended due to its stringent properties.[1] - Test different detergents (e.g., NP-40, Triton X-100) and their concentrations. Some proteins may require stronger detergents for efficient extraction. | |
| Cytoplasmic Contamination in Nuclear Fraction | Incomplete removal of cytoplasm: Residual cytoplasmic proteins may remain with the nuclear pellet. | - After the initial centrifugation to pellet the nuclei, carefully aspirate the supernatant containing the cytoplasmic fraction without disturbing the pellet. - Consider an additional wash step for the nuclear pellet with the hypotonic buffer. |
| Cross-contamination during lysis: Overly harsh initial lysis can rupture the nuclear membrane, releasing nuclear proteins into the cytoplasmic fraction. | - Use a Dounce homogenizer with a loose-fitting pestle for the initial cell lysis to minimize nuclear damage. - Avoid excessive vortexing or sonication during the initial lysis step. | |
| High Viscosity of Nuclear Lysate | Release of genomic DNA: Lysis of the nucleus releases large amounts of DNA, which increases the viscosity of the solution. | - Briefly sonicate the nuclear lysate on ice to shear the DNA.[3] - Alternatively, add a DNase I to the nuclear extraction buffer. However, be aware that this adds an exogenous protein to your sample. |
| This compound Detected in Both Cytoplasmic and Nuclear Fractions | Physiological distribution: this compound is known to be present in both the cytoplasm and the nucleus.[8] | - This may reflect the true subcellular localization of this compound in your cell type and experimental conditions. - Post-translational modifications can influence the localization of proteins.[4][9][10] Consider if your experimental conditions may be altering these modifications. |
Frequently Asked Questions (FAQs)
Q1: What is the first step I should take to optimize my this compound nuclear extraction?
A1: The first step is to ensure efficient and gentle lysis of the plasma membrane to isolate intact nuclei. Start by optimizing the incubation time in a hypotonic buffer and the mechanical disruption method (e.g., Dounce homogenizer or needle shearing). Visual confirmation of cell lysis and nuclear integrity using a microscope and trypan blue staining is highly recommended.
Q2: Which lysis buffer is best for this compound nuclear extraction?
A2: While there is no single "best" buffer, a good starting point is a RIPA (Radioimmunoprecipitation assay) buffer, which is effective for extracting nuclear proteins.[1] However, the optimal buffer may be cell-type and protein-specific.[6][7][11] One study on this compound used a total cell lysis buffer containing 1% Triton X-100, which you could adapt for nuclear extraction by using a two-step protocol.[12] For a commercial option, NE-PER™ Nuclear and Cytoplasmic Extraction Reagents have been successfully used for this compound fractionation.[3]
Q3: How can I be sure that my extracted protein is from the nucleus?
A3: To verify the purity of your nuclear extract, you should perform a Western blot and probe for marker proteins of different subcellular compartments. For example, use an antibody against Histone H3 as a nuclear marker and an antibody against GAPDH or Tubulin as a cytoplasmic marker. The nuclear fraction should be enriched in the nuclear marker and depleted of the cytoplasmic markers.
Q4: Can post-translational modifications of this compound affect its nuclear extraction?
A4: Yes, post-translational modifications (PTMs) can affect a protein's subcellular localization and its interaction with other proteins, which could potentially influence its extractability.[9][10] For instance, sumoylation has been shown to alter the localization of the Sp1 transcription factor.[4] While specific PTMs affecting this compound extraction are not well-documented, it is a factor to consider, especially if you observe changes in its subcellular distribution under different experimental conditions.
Q5: My nuclear extract is very viscous. How can I solve this?
A5: High viscosity is usually due to the release of genomic DNA from the lysed nuclei. To reduce viscosity, you can sonicate the nuclear lysate briefly on ice. This will shear the DNA into smaller fragments. Alternatively, you can treat the lysate with DNase I.
Experimental Protocols
Protocol 1: Detergent-Based Nuclear Extraction for this compound
This protocol is a starting point for optimizing this compound nuclear extraction and is based on common methodologies for nuclear protein isolation.
Materials:
-
Phosphate-Buffered Saline (PBS), ice-cold
-
Hypotonic Lysis Buffer (see table below)
-
Nuclear Extraction Buffer (see table below)
-
Protease Inhibitor Cocktail (add fresh to buffers before use)
-
Dounce homogenizer or 25-gauge needle and syringe
-
Microcentrifuge
Buffer Compositions:
| Buffer | Component | Final Concentration | Purpose |
| Hypotonic Lysis Buffer | HEPES, pH 7.9 | 10 mM | Buffering agent |
| KCl | 10 mM | Salt | |
| EDTA | 0.1 mM | Chelating agent | |
| DTT | 1 mM | Reducing agent | |
| Protease Inhibitors | 1X | Inhibit protein degradation | |
| Nuclear Extraction Buffer | HEPES, pH 7.9 | 20 mM | Buffering agent |
| NaCl | 400 mM | High salt for nuclear lysis | |
| EDTA | 1 mM | Chelating agent | |
| DTT | 1 mM | Reducing agent | |
| Glycerol | 10% (v/v) | Protein stabilizer | |
| Protease Inhibitors | 1X | Inhibit protein degradation |
Procedure:
-
Cell Harvest: For adherent cells, wash with ice-cold PBS, then scrape cells in fresh ice-cold PBS. For suspension cells, wash by pelleting and resuspending in ice-cold PBS.
-
Cell Lysis: Centrifuge cells at 500 x g for 5 minutes at 4°C. Discard the supernatant and resuspend the cell pellet in 5 volumes of ice-cold Hypotonic Lysis Buffer.
-
Incubate on ice for 15 minutes to allow cells to swell.
-
Homogenize the cells using a pre-chilled Dounce homogenizer with a loose-fitting pestle (10-15 strokes) or by passing the suspension through a 25-gauge needle 10-15 times.[2]
-
Isolate Nuclei: Centrifuge the homogenate at 1,000 x g for 10 minutes at 4°C. The supernatant is the cytoplasmic fraction.
-
Carefully remove the supernatant. The pellet contains the nuclei.
-
Nuclear Lysis: Resuspend the nuclear pellet in 2/3 of the packed cell volume of ice-cold Nuclear Extraction Buffer.
-
Incubate on ice for 30 minutes with gentle vortexing every 10 minutes to lyse the nuclei.
-
Collect Nuclear Extract: Centrifuge at 16,000 x g for 20 minutes at 4°C.
-
The supernatant contains the nuclear proteins. Aliquot and store at -80°C.
Visualizing the Workflow
Experimental Workflow for this compound Nuclear Extraction
Caption: Workflow for this compound nuclear protein extraction.
Troubleshooting Logic for Low this compound Yield
References
- 1. Choosing The Right Lysis Buffer | Proteintech Group [ptglab.com]
- 2. uniprot.org [uniprot.org]
- 3. Selenium-binding protein 1 (SELENBP1) is a marker of mature adipocytes - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Sumoylation of specificity protein 1 augments its degradation by changing the localization and increasing the specificity protein 1 proteolytic process - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. Lysis Buffer Choices Are Key Considerations to Ensure Effective Sample Solubilization for Protein Electrophoresis | Springer Nature Experiments [experiments.springernature.com]
- 7. Lysis Buffer Choices Are Key Considerations to Ensure Effective Sample Solubilization for Protein Electrophoresis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Evidence That Selenium Binding Protein 1 Is a Tumor Suppressor in Prostate Cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Posttranslational Modifications Regulate the Postsynaptic Localization of PSD-95 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Post-translational modifications of the beta-1 subunit of AMP-activated protein kinase affect enzyme activity and cellular localization [pubmed.ncbi.nlm.nih.gov]
- 11. bostonbib.com [bostonbib.com]
- 12. Decreased selenium binding protein-1 (SELENBP1) in esophageal adenocarcinoma results from post-transcriptional and epigenetic regulation and affects chemosensitivity - PMC [pmc.ncbi.nlm.nih.gov]
troubleshooting SBP-1 plasmid transfection efficiency
Welcome to the technical support center for SBP-1 plasmid transfection. This resource provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals optimize their this compound plasmid transfection experiments for maximal efficiency and reproducibility.
Troubleshooting Guide
This guide addresses common issues encountered during this compound plasmid transfection in a question-and-answer format.
Q1: Why am I observing low transfection efficiency with my this compound plasmid?
A1: Low transfection efficiency is a common issue that can be attributed to several factors. Systematically evaluating each component of your experimental workflow can help identify the root cause. Key areas to investigate include cell health and culture conditions, the quality and quantity of the this compound plasmid DNA, the choice and optimization of the transfection reagent, and the transfection protocol itself.
Troubleshooting Workflow for Low Transfection Efficiency
Caption: Troubleshooting workflow for low this compound transfection efficiency.
Q2: How does cell health impact this compound plasmid transfection?
A2: The health and condition of your cells are critical for successful transfection.[1] Unhealthy or suboptimal cells will not take up foreign DNA efficiently.
-
Cell Viability: Ensure cells are at least 90% viable before transfection.[2] You can assess viability using a trypan blue exclusion assay.
-
Cell Confluency: The optimal cell confluency for transfection is typically between 70-90%.[2][3][4] Overly confluent cells may have reduced uptake of the plasmid due to contact inhibition, while sparse cultures may not be healthy enough to tolerate the transfection process.[1][5]
-
Passage Number: Use cells with a low passage number.[4] High passage numbers can lead to altered cell characteristics and reduced transfection efficiency. It is recommended to passage cells 3-4 times after thawing before using them in experiments.[2]
-
Contamination: Regularly check for microbial contamination, especially mycoplasma, which can significantly impact cellular processes and transfection outcomes.[5]
Q3: What are the key considerations for this compound plasmid DNA quality?
A3: The quality of your this compound plasmid DNA is paramount for achieving high transfection efficiency.[6]
-
Purity: Use high-purity plasmid DNA. The A260/A280 ratio should be ≥1.8.[4] Contaminants such as proteins, RNA, and chemicals can negatively affect transfection.[7]
-
Endotoxins: Plasmid preparations should be free of endotoxins, which are components of bacterial cell walls that can significantly reduce transfection efficiency and induce cytotoxicity, especially in sensitive cell types like primary cells.[6] Using commercial kits designed for endotoxin removal is recommended.[6]
-
Plasmid Topology: Supercoiled plasmid DNA is generally the most efficient for transient transfection.[1][6][8] Linearized DNA is less efficient for uptake but is preferred for stable transfection as it facilitates integration into the host genome.[6]
-
Plasmid Size: While most liposome-based reagents work well for plasmids up to ~15 kb, efficiency may decrease with larger plasmids.[9]
Q4: How can I optimize the transfection reagent and protocol for the this compound plasmid?
A4: Optimization of the transfection reagent and protocol is crucial and often cell-type dependent.[2]
-
Reagent-to-DNA Ratio: The ratio of transfection reagent to this compound plasmid DNA is a critical parameter that needs to be optimized.[2][9] A titration experiment varying this ratio (e.g., 1:1, 2:1, 3:1 of reagent volume to DNA mass) is recommended to determine the optimal condition for your specific cell line.[9]
-
Complex Formation: Allow sufficient time for the transfection reagent and this compound plasmid DNA to form complexes. This typically involves a 15-30 minute incubation at room temperature.[4] Use a serum-free medium for complex formation, as serum can interfere with some reagents.[7][10]
-
Incubation Time: The optimal time for cells to be exposed to the transfection complexes can vary. For some reagents and cell lines, a shorter incubation period (e.g., 4-6 hours) followed by a media change can reduce cytotoxicity.[9]
-
Presence of Serum and Antibiotics: While some modern transfection reagents are compatible with serum and antibiotics, their presence can sometimes inhibit transfection.[11] If you are experiencing low efficiency, consider performing the transfection in serum-free and antibiotic-free media.[12]
Frequently Asked Questions (FAQs)
Q: My cells are dying after transfection with the this compound plasmid. What could be the cause?
A: Cell death post-transfection can be caused by several factors:
-
Toxicity of the Transfection Reagent: High concentrations of the transfection reagent can be toxic to cells.[5] Try reducing the amount of reagent or the incubation time.[9]
-
Toxicity of the this compound Gene Product: If the this compound protein is toxic to the cells when overexpressed, this can lead to cell death.[6] Consider using a weaker or inducible promoter to control the expression level of this compound.[6]
-
Poor Cell Health: Transfecting unhealthy cells can lead to increased cell death.[9] Ensure your cells are healthy and in the logarithmic growth phase.
-
Suboptimal DNA Amount: Using too much plasmid DNA can also contribute to cytotoxicity.[13]
Q: How soon after transfection can I expect to see this compound protein expression?
A: For transient transfections, protein expression is typically detectable within 24-72 hours.[9] The exact timing will depend on the cell type, the promoter driving this compound expression, and the method used for detection (e.g., Western blot, immunofluorescence).
Q: Can I co-transfect the this compound plasmid with another plasmid?
A: Yes, co-transfection is a common technique. When co-transfecting, ensure that the total amount of DNA is within the optimal range for your transfection protocol.[9] The molar ratio of the plasmids may need to be adjusted to achieve the desired expression levels of both proteins.[9] A common strategy is to use a reporter plasmid (e.g., expressing GFP) at a lower concentration (e.g., 1:5 to 1:10 ratio) to monitor transfection efficiency without significantly impacting the expression of the primary plasmid.[9]
Data Presentation
Table 1: Troubleshooting Guide for Low this compound Transfection Efficiency
| Potential Cause | Recommended Solution |
| Cell Health & Culture | |
| Low Cell Viability (<90%) | Use a fresh stock of cells; ensure proper handling and culture conditions.[2] |
| Suboptimal Confluency | Plate cells to be 70-90% confluent at the time of transfection.[2][3][4] |
| High Passage Number | Use cells with a low passage number; thaw a new vial of cells.[4][10] |
| Mycoplasma Contamination | Test for and eliminate mycoplasma contamination.[5] |
| This compound Plasmid DNA | |
| Low Purity (A260/A280 < 1.8) | Re-purify the plasmid DNA using a high-quality kit.[4] |
| Endotoxin Contamination | Use an endotoxin-free plasmid purification kit.[6] |
| Incorrect Plasmid Topology | Use supercoiled plasmid for transient transfection.[6][8] |
| Transfection Protocol | |
| Suboptimal Reagent:DNA Ratio | Perform a titration to find the optimal ratio for your cell line.[2][9] |
| Incorrect Complex Formation | Use serum-free media for complex formation and incubate for 15-30 mins.[4][10] |
| Presence of Inhibitors | Transfect in serum-free and antibiotic-free media if necessary.[11][12] |
Experimental Protocols
Protocol 1: Optimizing Reagent-to-DNA Ratio for this compound Plasmid Transfection
This protocol describes a method to determine the optimal ratio of a cationic lipid-based transfection reagent to this compound plasmid DNA in a 24-well plate format.
-
Cell Plating: The day before transfection, seed your cells in a 24-well plate at a density that will result in 70-90% confluency at the time of transfection.[3]
-
Prepare DNA and Reagent Dilutions:
-
In separate tubes, prepare four dilutions of the transfection reagent in 50 µL of serum-free medium (e.g., Opti-MEM®). For example, add 0.5 µL, 1.0 µL, 1.5 µL, and 2.0 µL of the reagent to tubes labeled 1 through 4, respectively.
-
In another tube, dilute 0.5 µg of your this compound plasmid DNA in 50 µL of serum-free medium. If you are also using a reporter plasmid (e.g., GFP), include it in this mix.
-
-
Form Transfection Complexes:
-
Add the 50 µL of diluted this compound plasmid DNA to each of the four tubes containing the diluted transfection reagent. This will result in reagent-to-DNA ratios of 1:1, 2:1, 3:1, and 4:1 (µL:µg).
-
Mix gently by flicking the tubes and incubate at room temperature for 20 minutes to allow complexes to form.[10]
-
-
Transfect Cells:
-
Add the 100 µL of the transfection complex drop-wise to the cells in each well.
-
Gently rock the plate to ensure even distribution.
-
-
Incubation and Analysis:
-
Incubate the cells at 37°C in a CO2 incubator for 24-72 hours.
-
Assess transfection efficiency by your desired method (e.g., fluorescence microscopy for a GFP reporter, Western blot for this compound protein, or qPCR for this compound mRNA).
-
General Signaling Pathway for Lipid-Mediated Transfection
Caption: Mechanism of lipid-mediated this compound plasmid delivery into a cell.
References
- 1. Factors Influencing Transfection Efficiency | Thermo Fisher Scientific - US [thermofisher.com]
- 2. Optimization of Plasmid DNA Transfection Protocol | Thermo Fisher Scientific - US [thermofisher.com]
- 3. m.youtube.com [m.youtube.com]
- 4. bioscience.co.uk [bioscience.co.uk]
- 5. Troubleshooting Low Transfection Rates in Primary Cells [synapse.patsnap.com]
- 6. Guidelines for transfection of DNA [qiagen.com]
- 7. Transfection Guide | Overview of Transfection Methods | Promega [promega.sg]
- 8. biotage.com [biotage.com]
- 9. yeasenbio.com [yeasenbio.com]
- 10. thermofisher.com [thermofisher.com]
- 11. benchchem.com [benchchem.com]
- 12. researchgate.net [researchgate.net]
- 13. Tuning plasmid DNA amounts for cost-effective transfections of mammalian cells: when less is more - PMC [pmc.ncbi.nlm.nih.gov]
SBP-1 Immunofluorescence Staining: Technical Support Center
This technical support center provides troubleshooting guidance and answers to frequently asked questions for researchers performing SBP-1 immunofluorescence staining. The information is tailored for scientists and professionals in research and drug development.
Troubleshooting Guide
Immunofluorescence (IF) protocols for this compound can present several challenges. This guide addresses the most common issues in a question-and-answer format.
Problem: Weak or No Signal
Question: I am not seeing any fluorescent signal, or the signal is very weak. What could be the cause?
Answer: Weak or no signal is a frequent issue in immunofluorescence. Several factors, from the primary antibody to the imaging equipment, could be the cause. Consider the following potential issues and solutions:
-
Primary Antibody Issues:
-
Inactivity: The primary antibody may be inactive. It's crucial to use a new batch or validate the current one.
-
Improper Storage: Antibodies can lose activity if not stored according to the manufacturer's instructions. It is best to aliquot antibodies into smaller volumes to avoid repeated freeze-thaw cycles.[1]
-
Low Concentration: The antibody concentration might be too low. An increase in the concentration or a longer incubation period, such as overnight at 4°C, may be necessary.[1]
-
Unsuitability for IF: Not all antibodies are suitable for detecting the native form of a protein in IF. It's recommended to confirm that the antibody has been validated for this application.[2]
-
-
Protocol and Reagent Issues:
-
Inadequate Fixation: The fixation step may have altered the epitope that the antibody recognizes. Trying different fixation methods or reducing the fixation time could resolve this.[1]
-
Incorrect Secondary Antibody: Ensure the secondary antibody is compatible with the primary antibody (e.g., if the primary is a mouse antibody, use an anti-mouse secondary).[2]
-
Fluorochrome Issues: The fluorochrome may have bleached due to light exposure. Always store fluorescently-labeled antibodies and stained samples in the dark.[1]
-
-
Sample and Imaging Issues:
-
Low Protein Expression: The target protein may not be abundantly present in your sample. In such cases, using a signal amplification step can help maximize the signal.[1]
-
Incorrect Microscope Settings: Verify that the microscope's light source and filters are appropriate for the fluorophore you are using.[2]
-
Problem: High Background
Question: My images have high background fluorescence, making it difficult to see the specific signal. What can I do?
Answer: High background can obscure your specific signal and is often caused by non-specific binding of antibodies or issues with the sample itself. Here are some common causes and their solutions:
-
Antibody Concentration: The concentration of the primary or secondary antibody may be too high. Reducing the concentration can help decrease non-specific binding.[1]
-
Insufficient Blocking: The blocking step is critical to prevent non-specific antibody binding. Increasing the incubation time for blocking or trying a different blocking agent may be beneficial.[1]
-
Inadequate Washing: Insufficient washing between antibody incubation steps can lead to high background. Ensure you are washing the samples thoroughly as per the protocol.[1]
-
Autofluorescence: Some tissues and cells have endogenous molecules that cause autofluorescence. You can check for this by examining an unstained sample under the microscope.[2]
Problem: Non-Specific Staining
Question: I am seeing staining in locations where I don't expect to see my protein. How can I troubleshoot this?
Answer: Non-specific staining can be misleading. It's important to differentiate it from a true signal. Here are some troubleshooting tips:
-
Primary Antibody Cross-Reactivity: The primary antibody may be binding to other proteins in the sample. Running a control with an isotype-matched antibody can help determine if the staining is specific.
-
Secondary Antibody Issues: The secondary antibody may be binding non-specifically. A control experiment without the primary antibody should be performed to check for this.[1]
-
High Antibody Concentration: As with high background, a high concentration of the primary or secondary antibody can lead to non-specific binding.[1]
Frequently Asked Questions (FAQs)
Q1: What is the difference between Selenium Binding Protein 1 (SBP1) and Sterol Regulatory Element Binding Protein 1 (SREBP-1)?
A1: It is crucial to distinguish between these two proteins as the antibody selection will be different. Selenium Binding Protein 1 (SBP1) is involved in selenium metabolism. Sterol Regulatory Element Binding Protein 1 (SREBP-1), sometimes referred to as this compound in organisms like C. elegans, is a transcription factor that regulates lipid metabolism. Ensure you are using an antibody specific to the protein you are studying.
Q2: Which anti-SBP1 antibody is validated for immunofluorescence?
A2: The rabbit polyclonal antibody to Selenium Binding Protein 1/SBP (ab90135) from Abcam has been cited in publications and is suitable for immunocytochemistry/immunofluorescence (ICC/IF).
Q3: What is a good starting concentration for my primary antibody?
A3: The optimal antibody concentration should be determined by titration. A usual starting range is between 3 to 30 µg/ml.[3] For the Abcam anti-SBP1 antibody (ab90135), a concentration of 5µg/ml has been used successfully.
Q4: How long should I incubate my primary antibody?
A4: Incubation times can vary. A common practice is to incubate for 60 minutes at room temperature or overnight at 4°C.[4]
Q5: What fixation method should I use?
A5: The choice of fixative can impact your results. Common fixatives include 4% paraformaldehyde (PFA), methanol, and acetone.[5][6] For the anti-SBP1 antibody (ab90135), 4% PFA fixation has been shown to work.
Experimental Protocols
This compound Immunofluorescence Staining Protocol (Adherent Cells)
This protocol is a general guideline and may require optimization for your specific cell type and experimental conditions.
Materials:
-
Cells grown on coverslips
-
Phosphate Buffered Saline (PBS)
-
Fixation Solution (e.g., 4% Paraformaldehyde in PBS)
-
Permeabilization Buffer (e.g., 0.1% Triton X-100 in PBS)
-
Blocking Buffer (e.g., 1% BSA in PBS)
-
Primary Antibody (e.g., Anti-SBP1 antibody)
-
Fluorophore-conjugated Secondary Antibody
-
Nuclear Counterstain (e.g., DAPI)
-
Antifade Mounting Medium
Procedure:
-
Cell Seeding: Seed cells on sterile coverslips in a culture plate and grow to the desired confluency.
-
Washing: Gently wash the cells three times with PBS.
-
Fixation: Fix the cells with 4% PFA for 10-15 minutes at room temperature.[5]
-
Washing: Wash the cells three times with PBS.
-
Permeabilization: If this compound is an intracellular protein, permeabilize the cells with 0.1% Triton X-100 in PBS for 10-15 minutes.[5]
-
Washing: Wash the cells three times with PBS.
-
Blocking: Block non-specific binding by incubating the cells in 1% BSA in PBS for 30-60 minutes at room temperature.[7]
-
Primary Antibody Incubation: Dilute the primary anti-SBP1 antibody in the blocking buffer to the desired concentration. Incubate the coverslips with the primary antibody solution for 1-2 hours at room temperature or overnight at 4°C.[7]
-
Washing: Wash the cells three times with PBS.
-
Secondary Antibody Incubation: Dilute the fluorophore-conjugated secondary antibody in the blocking buffer. Incubate the coverslips with the secondary antibody solution for 1 hour at room temperature, protected from light.[7]
-
Washing: Wash the cells three times with PBS, protected from light.
-
Counterstaining: Incubate the cells with a nuclear counterstain like DAPI for 5 minutes.[5]
-
Washing: Wash the cells a final three times with PBS.
-
Mounting: Mount the coverslips onto microscope slides using an antifade mounting medium.
-
Imaging: Visualize the staining using a fluorescence microscope with the appropriate filters.
| Parameter | Recommended Range/Value | Notes |
| Primary Antibody Concentration | 1-10 µg/ml | Titration is recommended for optimal results. |
| Primary Antibody Incubation | 1-2 hours at RT or overnight at 4°C | Longer incubation at 4°C may increase signal. |
| Secondary Antibody Concentration | 1:200 - 1:1000 dilution | Follow manufacturer's recommendation. |
| Secondary Antibody Incubation | 1 hour at RT | Protect from light to prevent photobleaching. |
| Fixation Time (4% PFA) | 10-20 minutes | Over-fixation can mask epitopes. |
| Permeabilization Time (Triton X-100) | 10-15 minutes | Necessary for intracellular targets. |
| Blocking Time | 30-60 minutes | Crucial for reducing background. |
Visualizations
Caption: General workflow for this compound immunofluorescence staining.
Caption: Troubleshooting flowchart for common immunofluorescence issues.
References
- 1. hycultbiotech.com [hycultbiotech.com]
- 2. Immunofluorescence Troubleshooting | Tips & Tricks | StressMarq Biosciences Inc. [stressmarq.com]
- 3. med.upenn.edu [med.upenn.edu]
- 4. scbt.com [scbt.com]
- 5. Immunofluorescence Guide [elabscience.com]
- 6. neurodegenerationlab.org [neurodegenerationlab.org]
- 7. How to Prepare your Specimen for Immunofluorescence Microscopy | Learn & Share | Leica Microsystems [leica-microsystems.com]
Technical Support Center: Expression and Purification of SBP-1
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) for researchers encountering challenges in expressing and purifying full-length Selenium-Binding Protein 1 (SBP1) and SBP-tagged proteins.
Section 1: Full-Length Selenium-Binding Protein 1 (SBP1)
The expression and purification of full-length, functional SBP1, a selenoprotein, presents unique challenges due to the presence of multiple selenocysteine (Sec) residues. Sec is encoded by the UGA codon, which typically signals translation termination.
Frequently Asked Questions (FAQs)
Q1: Why is the expression of full-length SBP1 in E. coli resulting in low yield or truncated products?
A1: The primary challenge is the translation of the UGA codon as selenocysteine instead of a stop signal. Standard E. coli strains lack the necessary machinery for efficient selenocysteine incorporation. This can lead to premature termination of translation and the production of truncated, non-functional protein fragments.
-
Troubleshooting:
-
Specialized Expression Systems: Utilize expression systems specifically designed for selenoprotein production. These systems often involve co-expression of the selenocysteine insertion machinery, including SelA, SelB, and SelC, and supplementation of the growth media with selenium.
-
Codon Optimization: While the UGA codon is essential for Sec incorporation, optimizing the surrounding codons for the chosen expression host can sometimes improve translation efficiency.
-
Alternative Hosts: Consider eukaryotic expression systems, such as insect or mammalian cells, which possess the native machinery for selenoprotein synthesis. However, yields may still be variable.
-
Q2: My full-length SBP1 is expressed, but it's insoluble and forms inclusion bodies. What can I do?
A2: Insolubility is a common issue for many recombinant proteins, including SBP1. This can be caused by the high expression rate in E. coli, leading to misfolding and aggregation. The presence of multiple cysteine and selenocysteine residues can also contribute to improper disulfide bond formation.
-
Troubleshooting:
-
Lower Expression Temperature: Reduce the induction temperature to 15-25°C to slow down protein synthesis, allowing more time for proper folding.[1]
-
Solubilization and Refolding: Inclusion bodies can be solubilized using strong denaturants like 6 M guanidinium chloride or 8 M urea. The protein can then be refolded by gradually removing the denaturant through dialysis or rapid dilution into a refolding buffer. This process often requires optimization of buffer conditions (pH, additives).
-
Co-expression of Chaperones: Co-expressing molecular chaperones, such as DnaK/J or GroEL/ES, can assist in the proper folding of SBP1 and prevent aggregation.[2]
-
Fusion Partners: Expressing SBP1 with a highly soluble fusion partner, like Maltose-Binding Protein (MBP), can enhance its solubility.[3]
-
Q3: I'm observing multiple bands on my SDS-PAGE after purification. What could be the cause?
A3: The presence of multiple bands can be attributed to several factors, including protein degradation, post-translational modifications, or the presence of different SBP1 isoforms. SBP1 is known to exist in multiple isoforms and can undergo post-translational modifications, which can affect its migration on a gel.[4][5]
-
Troubleshooting:
-
Protease Inhibitors: Add a cocktail of protease inhibitors to your lysis buffer to minimize degradation by host cell proteases.
-
Expression in Protease-Deficient Strains: Use E. coli strains deficient in certain proteases (e.g., BL21(DE3)pLysS) to reduce proteolytic cleavage.
-
Characterization of Isoforms: If multiple bands persist, it may be necessary to use techniques like mass spectrometry to determine if they represent different isoforms or post-translationally modified versions of SBP1.
-
Experimental Protocol: Solubilization and Refolding of SBP1 from Inclusion Bodies
-
Inclusion Body Isolation:
-
Harvest the cell pellet expressing SBP1 by centrifugation.
-
Resuspend the pellet in lysis buffer (e.g., 50 mM Tris-HCl pH 8.0, 150 mM NaCl, 1 mM EDTA) and lyse the cells by sonication or high-pressure homogenization.
-
Centrifuge the lysate at high speed (e.g., 15,000 x g) for 30 minutes to pellet the inclusion bodies.
-
Wash the inclusion body pellet with a buffer containing a mild detergent (e.g., 1% Triton X-100) to remove contaminating proteins. Repeat the wash step.
-
-
Solubilization:
-
Resuspend the washed inclusion body pellet in a solubilization buffer containing a strong denaturant (e.g., 50 mM Tris-HCl pH 8.0, 150 mM NaCl, 6 M Guanidinium-HCl, 10 mM DTT).
-
Incubate at room temperature with gentle agitation for 1-2 hours to ensure complete solubilization.
-
Clarify the solubilized protein by centrifugation to remove any remaining insoluble material.
-
-
Refolding:
-
Rapid Dilution: Rapidly dilute the solubilized protein into a large volume of refolding buffer (e.g., 50 mM Tris-HCl pH 8.0, 150 mM NaCl, 0.5 M L-Arginine, 1 mM GSH/0.1 mM GSSG) to a final protein concentration of 10-50 µg/mL.
-
Dialysis: Alternatively, place the solubilized protein in a dialysis bag and dialyze against a series of buffers with decreasing concentrations of the denaturant.
-
Incubate the refolding solution at 4°C for 12-48 hours with gentle stirring.
-
-
Purification of Refolded Protein:
-
Concentrate the refolded protein using ultrafiltration.
-
Purify the refolded SBP1 using affinity chromatography (if a tag was used) followed by size-exclusion chromatography to separate correctly folded monomeric protein from aggregates.
-
Section 2: SBP-tagged Protein Purification
The Streptavidin-Binding Peptide (SBP) tag is a 38-amino acid peptide that binds to streptavidin with high affinity, allowing for efficient one-step purification of recombinant proteins.[6][7]
Troubleshooting Guide
| Problem | Possible Cause | Solution |
| Low or No Protein Expression | Incorrect plasmid sequence (frameshift, premature stop codon). | Sequence the expression vector to verify the in-frame fusion of the SBP-tag to the target protein.[8] |
| Suboptimal induction conditions. | Optimize IPTG concentration, induction temperature, and induction time.[9] | |
| Protein is Expressed but Does Not Bind to Streptavidin Resin | SBP-tag is inaccessible or buried within the folded protein. | Purify under denaturing conditions (with 6M Guanidinium-HCl or 8M urea) to expose the tag.[8] Consider moving the tag to the other terminus of the protein. |
| Incorrect buffer composition. | Ensure the binding buffer has a physiological pH (around 7.4) and lacks components that interfere with streptavidin-biotin interaction. | |
| Low Yield of Purified Protein | Insufficient amount of streptavidin resin. | Increase the amount of resin used. The capacity of streptavidin resin is typically around 0.5 mg of SBP-tagged protein per ml of matrix.[6] |
| Protein loss during wash steps. | The binding between the SBP-tag and streptavidin is strong, but excessive or harsh washing can lead to some dissociation. Reduce the number or stringency of wash steps. | |
| Inefficient elution. | Elution is typically performed with a buffer containing biotin. Ensure the biotin concentration is sufficient (e.g., 2-5 mM) to competitively displace the SBP-tagged protein.[10] | |
| Non-specific Protein Contamination | Insufficient washing. | Increase the number of wash steps or the volume of wash buffer. |
| Non-specific binding to the resin matrix. | Add a non-ionic detergent (e.g., 0.1% Tween-20) or increase the salt concentration (e.g., up to 500 mM NaCl) in the wash buffer to reduce non-specific interactions. | |
| Difficulty Eluting the Protein | Very high affinity interaction or protein precipitation on the column. | Increase the concentration of biotin in the elution buffer. If precipitation is suspected, try eluting with a buffer containing additives that increase protein solubility (e.g., glycerol, L-arginine). |
Quantitative Data Summary
| Parameter | Value | Reference |
| SBP-tag length | 38 amino acids | [6] |
| SBP-tag dissociation constant (Kd) for streptavidin | 2.5 nM | [6][11] |
| Streptavidin resin binding capacity | ~0.5 mg/mL | [6] |
| Recommended Biotin concentration for elution | 2-5 mM | [10] |
Experimental Protocol: One-Step Purification of an SBP-tagged Protein
-
Cell Lysis:
-
Resuspend the cell pellet expressing the SBP-tagged protein in a suitable lysis buffer (e.g., 50 mM Tris-HCl pH 7.5, 150 mM NaCl, 1 mM EDTA, 1x protease inhibitor cocktail).
-
Lyse the cells by sonication on ice.
-
Clarify the lysate by centrifugation at 15,000 x g for 30 minutes at 4°C.
-
-
Binding to Streptavidin Resin:
-
Equilibrate the streptavidin resin with lysis buffer.
-
Add the clarified lysate to the equilibrated resin and incubate for 1-2 hours at 4°C with gentle rotation.
-
-
Washing:
-
Pellet the resin by centrifugation and discard the supernatant (flow-through).
-
Wash the resin 3-5 times with wash buffer (lysis buffer with or without 0.1% Tween-20).
-
-
Elution:
-
Add elution buffer (wash buffer containing 2-5 mM biotin) to the resin and incubate for 30-60 minutes at 4°C with gentle rotation.
-
Pellet the resin and collect the supernatant containing the purified SBP-tagged protein.
-
Repeat the elution step to maximize recovery.
-
Visualizations
Caption: Workflow for the expression and purification of full-length SBP1.
Caption: One-step affinity purification workflow for SBP-tagged proteins.
References
- 1. Additivities for Soluble Recombinant Protein Expression in Cytoplasm of Escherichia coli | MDPI [mdpi.com]
- 2. Improvement of solubility and yield of recombinant protein expression in E. coli using a two-step system - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Expression and Purification of Recombinant Proteins in Escherichia coli with a His6 or Dual His6-MBP Tag - PMC [pmc.ncbi.nlm.nih.gov]
- 4. mdpi.com [mdpi.com]
- 5. researchgate.net [researchgate.net]
- 6. One-step purification of recombinant proteins using a nanomolar-affinity streptavidin-binding peptide, the SBP-Tag - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. SBP-tag - Wikipedia [en.wikipedia.org]
- 8. goldbio.com [goldbio.com]
- 9. neb.com [neb.com]
- 10. researchgate.net [researchgate.net]
- 11. Streptavidin-Binding Peptide (SBP)-tagged SMC2 allows single-step affinity fluorescence, blotting or purification of the condensin complex - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Spike-Binding Peptide 1 (SBP1)
Welcome to the technical support center for Spike-binding peptide 1 (SBP1). This guide provides troubleshooting advice and answers to frequently asked questions regarding the solubility of SBP1, a peptide derived from the N-terminal helix of the human ACE2 receptor.[1][2] Researchers may encounter challenges in dissolving and handling this peptide due to its biophysical properties.[3]
Frequently Asked Questions (FAQs)
Q1: What is Spike-binding peptide 1 (SBP1) and why is its solubility a concern?
A1: Spike-binding peptide 1 (SBP1) is a 23-amino-acid helical segment from the human ACE2 protein that interacts with the receptor-binding domain (RBD) of the SARS-CoV-2 spike protein.[1] Its potential as a therapeutic or diagnostic tool is under investigation. However, when isolated from its parent protein, SBP1 can exhibit poor solubility and a tendency to aggregate or oligomerize, which can affect its binding affinity and experimental results.[3]
Q2: What are the primary factors affecting SBP1 solubility?
A2: The primary factors influencing peptide solubility are its amino acid composition, length, net charge, and the pH of the solution.[4] Peptides with a high percentage of hydrophobic amino acids, like SBP1, tend to have lower solubility in aqueous solutions.[4][5] The peptide's tendency to be least soluble at its isoelectric point (pI) is also a critical factor.[6]
Q3: Is it recommended to dissolve the entire peptide sample at once?
A3: No, it is highly recommended to first test the solubility with a small portion of the lyophilized peptide before attempting to dissolve the entire sample.[4][5] This approach prevents the loss of valuable material if the chosen solvent is inappropriate.
Q4: Can sonication or heating be used to improve the solubility of SBP1?
A4: Yes, brief sonication can help break up particles and improve dissolution.[4][5] Gentle warming of the solution (e.g., to less than 40°C) may also increase solubility.[7] However, these methods should be used with caution as excessive heating or sonication can cause peptide degradation.[7]
Troubleshooting Guide for SBP1 Solubility Issues
If you are encountering difficulties in dissolving SBP1, follow this step-by-step troubleshooting guide. The process is designed to start with the mildest conditions before proceeding to more aggressive methods.
Step 1: Initial Assessment of Peptide Properties
-
Calculate the Net Charge: Determine the net charge of your specific SBP1 sequence at a neutral pH (pH 7).
-
Determine Hydrophobicity: Calculate the percentage of hydrophobic amino acids (e.g., W, F, V, I, L, M, Y, A).[5] SBP1 is known to be hydrophobic.
Step 2: Systematic Solubility Testing
Always begin solubility tests with a small amount of peptide. A properly solubilized peptide will result in a clear, particle-free solution.[5]
-
Start with Sterile Water or Buffer: Attempt to dissolve the peptide in sterile deionized water or a common biological buffer (e.g., PBS, Tris) at the desired final concentration.
-
Adjust pH:
-
If the peptide is basic (net charge > 0): Try dissolving it in an acidic solution, such as 10% acetic acid, and then dilute it with your buffer.[4][5][7]
-
If the peptide is acidic (net charge < 0): Try dissolving it in a basic solution, such as 10% ammonium bicarbonate or aqueous ammonia, before diluting.[4][5]
-
If the peptide is neutral or hydrophobic: Proceed to the next step involving organic solvents.[4][5]
-
-
Use an Organic Co-Solvent: For hydrophobic peptides like SBP1, dissolving in a minimal amount of an organic solvent first is often effective.
-
Add a small volume of 100% DMSO or DMF to the lyophilized peptide to create a concentrated stock solution.[5]
-
Once fully dissolved, slowly add the aqueous buffer to the peptide stock solution drop-by-drop while vortexing to reach the desired final concentration.[4]
-
Caution: For cellular assays, the final concentration of DMSO should generally not exceed 1% (v/v).[4] If the peptide contains Cysteine (Cys) or Methionine (Met), avoid DMSO as it can cause oxidation; DMF is a safer alternative.[8][9]
-
Step 3: Advanced Strategies for Persistent Solubility Issues
If the above steps fail, consider chemical or formulation modifications. These often require re-synthesis of the peptide.
-
Chemical Modification:
-
Amino Acid Substitution: Replace hydrophobic residues with more hydrophilic or neutral ones (e.g., Glycine, Alanine) to enhance solubility.[7][8] Incorporating charged residues can also significantly improve aqueous solubility.[10][11]
-
PEGylation: Attaching polyethylene glycol (PEG) chains creates a "hydrophilic shield" that increases water solubility.
-
-
Use of Chaotropic Agents: For highly aggregated peptides, strong denaturing agents like 6 M Guanidine Hydrochloride or 8 M Urea can be used, but these will disrupt protein structure and are often incompatible with biological assays.[12]
Data Summary
Table 1: Recommended Solvents for Peptides
| Solvent | Peptide Type | Typical Usage | Considerations & Limitations |
| Water / Aqueous Buffer | Charged/Hydrophilic Peptides | Initial solvent of choice for most peptides. | Often ineffective for hydrophobic peptides like SBP1. |
| Acetic Acid (10%) | Basic Peptides (Net Charge > 0) | Lowers the pH to increase the solubility of basic peptides.[4] | The acidic environment may affect peptide stability or downstream assays. |
| Ammonium Bicarbonate (10%) | Acidic Peptides (Net Charge < 0) | Raises the pH to increase the solubility of acidic peptides.[4] | The basic environment may not be suitable for all peptides or experiments. |
| Dimethyl Sulfoxide (DMSO) | Hydrophobic / Neutral Peptides | A biocompatible organic solvent used to create concentrated stock solutions.[5] | Can oxidize Cys and Met residues.[8][9] Final concentration should be low (<1%) for cell-based assays.[4] |
| Dimethylformamide (DMF) | Hydrophobic / Neutral Peptides | An alternative to DMSO, especially for peptides sensitive to oxidation.[9] | More cytotoxic than DMSO; generally used for protein-based, not cell-based, assays.[9] |
Table 2: Peptide Modification Strategies to Enhance Solubility
| Strategy | Description | Advantages | Disadvantages |
| Amino Acid Substitution | Replacing hydrophobic amino acids with hydrophilic ones (e.g., Lys, Arg, Glu).[6] | Can significantly improve intrinsic solubility in aqueous buffers. | May alter the peptide's structure, binding affinity, or biological activity. |
| PEGylation | Covalent attachment of polyethylene glycol (PEG) chains. | Greatly increases hydrophilicity and can prolong the peptide's half-life. | Increases the overall size of the molecule, which might interfere with binding. |
| Terminal Capping | Acetylation of the N-terminus or amidation of the C-terminus. | Neutralizes terminal charges, which can sometimes prevent aggregation. | May not be sufficient for highly hydrophobic peptides. |
| Addition of Solubility Tags | Fusing a hydrophilic polypeptide tag (e.g., poly-arginine) to the peptide.[13] | Increases net charge and reduces aggregation by promoting repulsive forces. | The tag may need to be cleaved, adding an extra step to the workflow. |
Experimental Protocols
Protocol 1: General Procedure for Peptide Solubilization
-
Preparation: Before opening, allow the lyophilized peptide vial to warm to room temperature. Centrifuge the vial briefly (e.g., 10,000 x g for 1 minute) to ensure all powder is at the bottom of the tube.[5]
-
Solvent Selection: Choose an initial solvent based on the peptide's properties (see Table 1 and the troubleshooting workflow below).
-
Reconstitution: Add the selected solvent to the vial to achieve the desired stock concentration.
-
Dissolution: Vortex the vial for 10-30 seconds. If dissolution is incomplete, sonicate the solution in a water bath for 10-15 seconds. Repeat sonication up to three times if necessary, cooling the sample on ice between cycles.[5]
-
Dilution (if using co-solvents): If the peptide was dissolved in an organic solvent, slowly add your aqueous buffer of choice to the concentrated stock while mixing to prevent precipitation.[4]
-
Inspection & Storage: Visually inspect the solution to ensure it is clear and free of particulates. For storage, aliquot the peptide solution into smaller volumes to avoid repeated freeze-thaw cycles and store at -20°C or -80°C.
Visual Guides
Caption: A workflow diagram for troubleshooting SBP1 solubility issues.
Caption: Decision tree for selecting an appropriate initial solvent.
References
- 1. Characterization of binding interactions of SARS-CoV-2 spike protein and DNA-peptide nanostructures - PMC [pmc.ncbi.nlm.nih.gov]
- 2. covid-19.conacyt.mx [covid-19.conacyt.mx]
- 3. pubs.acs.org [pubs.acs.org]
- 4. jpt.com [jpt.com]
- 5. Peptide Solubility Guidelines - How to solubilize a peptide [sb-peptide.com]
- 6. lifetein.com [lifetein.com]
- 7. Peptide Dissolving Guidelines - Creative Peptides [creative-peptides.com]
- 8. News - How to increase the solubility of peptides? [gtpeptide.com]
- 9. chemistry.stackexchange.com [chemistry.stackexchange.com]
- 10. Enhancing the solubility of SARS-CoV-2 inhibitors to increase future prospects for clinical development - PMC [pmc.ncbi.nlm.nih.gov]
- 11. journals.asm.org [journals.asm.org]
- 12. benchchem.com [benchchem.com]
- 13. genscript.com [genscript.com]
Technical Support Center: Optimizing SBP-1 Activity Assays
Welcome to the technical support center for S-nitrosoglutathione reductase (SBP-1), also known as GSNOR, activity assays. This resource is designed for researchers, scientists, and drug development professionals to troubleshoot and optimize their experimental conditions.
Frequently Asked Questions (FAQs)
Q1: What is the principle of the this compound/GSNOR activity assay?
A1: The most common this compound activity assay is a spectrophotometric method that measures the enzyme's ability to catalyze the decomposition of S-nitrosoglutathione (GSNO) in an NADH-dependent manner. The activity is quantified by monitoring the decrease in NADH absorbance at a wavelength of 340 nm.[1][2]
Q2: What are the key components of the reaction buffer for an this compound activity assay?
A2: A typical reaction buffer includes a buffering agent to maintain pH (commonly Tris-HCl), the cofactor NADH, the substrate GSNO, and often a chelating agent like EDTA to prevent interference from metal ions.
Q3: What is the role of EDTA in the assay buffer?
A3: EDTA is a chelating agent that binds divalent metal ions.[3] Its primary functions in an this compound assay are to inhibit metal-dependent proteases that could degrade the this compound enzyme and to prevent metal-catalyzed degradation of the substrate, GSNO.[4]
Q4: Why is it important to use freshly prepared GSNO for the assay?
A4: GSNO is susceptible to decomposition, a process influenced by factors such as temperature, light, and pH.[5] Using freshly prepared GSNO solutions helps to ensure that the substrate concentration is accurate and consistent, which is crucial for reliable kinetic measurements.
Q5: Can I use NADPH instead of NADH as a cofactor for this compound?
A5: this compound is highly specific for NADH and shows negligible activity with NADPH.[6] Therefore, NADH is the required cofactor for this assay.
Troubleshooting Guide
| Problem | Potential Cause | Recommended Solution |
| No or very low enzyme activity | Inactive enzyme | Ensure proper storage and handling of the enzyme. Avoid repeated freeze-thaw cycles. |
| Incorrect buffer pH | Verify the pH of your buffer. The optimal pH for this compound activity is typically around 8.0. | |
| Degraded NADH or GSNO | Prepare fresh solutions of NADH and GSNO before each experiment. Store stock solutions appropriately (on ice and protected from light). | |
| Presence of an inhibitor | Check if any of your reagents contain known this compound inhibitors. | |
| High background signal (high initial absorbance) | Contaminated reagents | Use high-purity water and reagents. Prepare fresh buffers. |
| Sample matrix interference | If using complex samples like cell lysates, endogenous molecules may absorb at 340 nm. Run a sample blank (without enzyme or substrate) to measure and subtract the background absorbance.[7] | |
| Light scattering | Particulate matter in the sample can cause light scattering. Centrifuge your samples before the assay to pellet any precipitates.[7] | |
| Inconsistent or irreproducible results | Pipetting errors | Use calibrated pipettes and ensure accurate and consistent pipetting, especially for small volumes. |
| Temperature fluctuations | Ensure all reagents and the reaction plate are equilibrated to the assay temperature before starting the reaction.[8] | |
| Variable metal ion contamination | The inclusion of EDTA in the buffer can help to chelate contaminating metal ions, leading to more consistent results.[4] | |
| Non-linear reaction curve | Substrate depletion | If the reaction proceeds too quickly, the substrate may be rapidly consumed. Reduce the amount of enzyme used in the assay. |
| Enzyme instability | The enzyme may be unstable under the assay conditions. Optimize the buffer composition, including pH and ionic strength. |
Data Presentation
Table 1: Effect of pH on this compound Activity
The pH of the reaction buffer is a critical parameter for this compound activity. The optimal pH is generally in the slightly alkaline range. Deviations from the optimal pH can lead to a significant decrease in enzyme activity.
| pH | Relative Activity (%) | Notes |
| 6.5 | Low | Suboptimal pH, enzyme activity is significantly reduced. |
| 7.0 | Moderate | Activity increases as pH approaches the optimum. |
| 7.5 | High | Nearing optimal activity. |
| 8.0 | 100 (Optimal) | Generally considered the optimal pH for this compound activity. |
| 8.5 | High | Activity begins to decline. |
| 9.0 | Moderate | Significant decrease in activity; GSNO stability may also be compromised at higher pH.[9][10] |
Table 2: Effect of Ionic Strength on this compound Activity
The ionic strength of the buffer, primarily determined by the salt concentration, can influence enzyme activity by affecting protein stability and substrate binding.
| Salt Concentration (e.g., NaCl) | Relative Activity (%) | Notes |
| 0 mM | Suboptimal | Very low ionic strength may not be optimal for enzyme stability. |
| 50 mM | High | Often a good starting point for optimizing ionic strength. |
| 100 mM | 100 (Optimal) | Typically within the optimal range for many enzymes. |
| 200 mM | Moderate | High salt concentrations can start to inhibit enzyme activity. |
| 500 mM | Low | Significant inhibition of enzyme activity is likely. |
Experimental Protocols
Detailed Methodology for this compound Activity Assay
This protocol describes a spectrophotometric assay to measure this compound activity by monitoring the consumption of NADH at 340 nm.
1. Reagent Preparation:
-
Assay Buffer: 50 mM Tris-HCl, pH 8.0, containing 0.5 mM EDTA. Prepare fresh and adjust the pH at the desired reaction temperature.
-
NADH Stock Solution: 10 mM NADH in assay buffer. Prepare fresh for each experiment and keep on ice, protected from light.
-
GSNO Stock Solution: 10 mM GSNO in assay buffer. Prepare fresh and keep on ice, protected from light.
-
Enzyme Solution: Dilute the this compound enzyme preparation to the desired concentration in assay buffer immediately before use.
2. Assay Procedure:
-
Set up a 96-well UV-transparent microplate or quartz cuvettes.
-
Add the following reagents to each well/cuvette in the specified order:
-
Assay Buffer
-
NADH solution to a final concentration of 200 µM.
-
Enzyme solution.
-
-
Include a "no-enzyme" control for each sample to measure the non-enzymatic degradation of NADH.
-
Incubate the plate/cuvettes at the desired temperature (e.g., 25°C or 37°C) for 5 minutes to allow for temperature equilibration.
-
Initiate the reaction by adding GSNO solution to a final concentration of 400 µM.
-
Immediately start monitoring the decrease in absorbance at 340 nm every 30 seconds for 10-15 minutes using a microplate reader or spectrophotometer.
3. Data Analysis:
-
Calculate the rate of NADH consumption (ΔAbs/min) from the linear portion of the absorbance vs. time plot.
-
Subtract the rate of the "no-enzyme" control from the rate of the enzyme-containing samples.
-
Calculate the this compound activity using the Beer-Lambert law:
-
Activity (µmol/min/mL) = (ΔAbs/min) / (ε * l)
-
ε (molar extinction coefficient of NADH) = 6220 M⁻¹cm⁻¹
-
l (path length of the well/cuvette in cm)
-
-
Visualizations
References
- 1. Structural and functional insights into nitrosoglutathione reductase from Chlamydomonas reinhardtii - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Measurement of S-Nitrosoglutathione Reductase Activity in Plants - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Ethylenediaminetetraacetic acid - Wikipedia [en.wikipedia.org]
- 4. benchchem.com [benchchem.com]
- 5. S-Nitrosoglutathione exhibits greater stability than S-nitroso-N-acetylpenicillamine under common laboratory conditions: A comparative stability study - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. mdpi.com [mdpi.com]
- 7. benchchem.com [benchchem.com]
- 8. benchchem.com [benchchem.com]
- 9. osti.gov [osti.gov]
- 10. S-Nitrosoglutathione formation at gastric pH is augmented by ascorbic acid and by the antioxidant vitamin complex, Resiston - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Troubleshooting Variability in SBP-1 Dependent Reporter Gene Expression
This technical support center provides researchers, scientists, and drug development professionals with comprehensive troubleshooting guides and frequently asked questions (FAQs) to address common issues encountered during SBP-1 dependent reporter gene expression experiments.
Frequently Asked Questions (FAQs)
Q1: What is this compound and how does it regulate gene expression?
A1: this compound (Sterol Regulatory Element-Binding Protein-1) is a transcription factor that plays a crucial role in regulating the expression of genes involved in lipid biosynthesis and homeostasis. Under conditions of low cellular sterol levels, this compound is activated and translocates to the nucleus where it binds to specific DNA sequences known as Sterol Regulatory Elements (SREs) in the promoter regions of its target genes, thereby initiating their transcription.
Q2: What is a reporter gene assay and how is it used to study this compound activity?
A2: A reporter gene assay is a common molecular biology technique used to study the regulation of gene expression. In the context of this compound, a reporter construct is created by linking a known this compound responsive element (SRE) to a reporter gene, such as luciferase. When this construct is introduced into cells, the level of reporter gene expression (e.g., light produced by luciferase) serves as a proxy for the transcriptional activity of this compound.
Q3: What is a dual-luciferase reporter assay and why is it recommended?
A3: A dual-luciferase reporter assay utilizes two different luciferase enzymes, typically Firefly and Renilla luciferase, expressed from two separate plasmids. The experimental reporter (Firefly luciferase) is driven by the this compound responsive promoter, while the control reporter (Renilla luciferase) is driven by a constitutive promoter. By measuring the activity of both luciferases, the experimental signal can be normalized to the control signal, which helps to correct for variability in transfection efficiency and cell number, leading to more reliable and reproducible results.[1][2]
Q4: What are some common causes of high variability in this compound reporter gene assays?
A4: High variability in reporter gene assays can stem from several factors, including:
-
Inconsistent cell seeding and confluency.
-
Variations in transfection efficiency.[3]
-
Pipetting errors.[1]
-
Reagent quality and consistency.[1]
-
Cell health and passage number.[3]
-
"Edge effects" in multi-well plates.
Troubleshooting Guide
This guide addresses specific issues that may arise during your this compound dependent reporter gene expression experiments.
| Issue | Potential Cause | Recommended Solution |
| High Variability Between Replicates | Inconsistent Cell Seeding: Uneven cell numbers across wells. | Ensure a homogenous cell suspension before and during plating. Allow the plate to sit at room temperature for a few minutes before incubation to promote even cell distribution. |
| Pipetting Inaccuracy: Small errors in dispensing cells, reagents, or compounds. | Calibrate pipettes regularly. Use a multi-channel pipette for adding common reagents to all wells. Prepare master mixes for transfection and assay reagents to minimize well-to-well differences.[1] | |
| Variable Transfection Efficiency: Differences in the amount of plasmid DNA delivered to cells. | Optimize the DNA-to-transfection reagent ratio. Ensure high-quality, endotoxin-free plasmid DNA. Use a control plasmid (e.g., expressing GFP) to visually assess transfection efficiency.[3][4] | |
| Edge Effects: Evaporation and temperature gradients in the outer wells of the plate. | Avoid using the outer wells for experimental samples. Fill the perimeter wells with sterile PBS or media to create a humidity barrier. | |
| Low or No Signal | Low Transfection Efficiency: Insufficient delivery of reporter plasmids into the cells. | Optimize the transfection protocol for your specific cell line. Consider using a different transfection reagent or method (e.g., electroporation).[3][4] |
| Poor Cell Health: Cells are stressed, senescent, or contaminated. | Use cells at a low passage number and ensure they are in the logarithmic growth phase. Regularly test for mycoplasma contamination.[3] | |
| Inactive this compound: The experimental conditions do not sufficiently activate this compound. | Ensure that the treatment to induce this compound activation (e.g., sterol depletion) is effective. Include a positive control known to activate this compound. | |
| Reporter Construct Issues: The SRE in the reporter construct is not functional or the promoter is too weak. | Verify the sequence of your reporter construct. Consider using a construct with a stronger minimal promoter or multiple copies of the SRE.[1] | |
| Assay Reagent Problems: Luciferase substrate has degraded or is inhibited. | Prepare fresh assay reagents for each experiment. Avoid repeated freeze-thaw cycles of the luciferase substrate.[1] | |
| High Background Signal | Contamination: Reagents or cell cultures are contaminated with bacteria or other luminescent sources. | Use sterile techniques for all procedures. Prepare fresh, sterile reagents.[1] |
| Autoluminescence of Compounds: The tested compound itself emits light. | Include a control well with the compound but without cells to measure its intrinsic luminescence and subtract this from the experimental values. | |
| Non-specific Transcription: The reporter construct has cryptic transcription factor binding sites. | Use a well-characterized reporter plasmid with a minimal promoter to reduce non-specific activation. | |
| Plate Type: Using clear-bottom or black plates for luminescence assays. | Use opaque, white-walled plates for luminescence measurements to maximize signal and minimize well-to-well crosstalk.[2] |
Quantitative Data Summary
The following table provides hypothetical data illustrating the impact of common variables on this compound reporter gene expression. The data is presented as normalized luciferase activity (Firefly/Renilla).
| Variable | Condition 1 | Normalized Luciferase Activity (Mean ± SD) | Condition 2 | Normalized Luciferase Activity (Mean ± SD) | Interpretation |
| Transfection Reagent:DNA Ratio | 1:1 | 150 ± 35 | 3:1 | 450 ± 50 | Optimizing the reagent-to-DNA ratio can significantly improve transfection efficiency and reporter expression. |
| Cell Seeding Density (cells/well) | 1 x 10^4 | 200 ± 40 | 5 x 10^4 | 500 ± 60 | Higher cell density can lead to a stronger signal, but over-confluency should be avoided as it can negatively impact cell health and transfection. |
| This compound Activator (e.g., Statin) | Vehicle Control | 100 ± 20 | 10 µM Statin | 800 ± 90 | A potent activator of the this compound pathway should lead to a significant increase in reporter gene expression. |
| This compound Inhibitor (e.g., Fatostatin) | Vehicle Control | 800 ± 90 | 10 µM Fatostatin | 150 ± 30 | An effective inhibitor should significantly reduce this compound dependent reporter gene expression. |
Experimental Protocols
Key Experiment: Dual-Luciferase® Reporter Assay
This protocol provides a general workflow for a dual-luciferase reporter assay to measure this compound activity.
1. Cell Culture and Seeding:
- Culture cells (e.g., HEK293T, HepG2) in the appropriate medium supplemented with fetal bovine serum and antibiotics.
- The day before transfection, seed cells into a 96-well, white, clear-bottom plate at a density that will result in 70-90% confluency at the time of transfection.
2. Transfection:
- Prepare a master mix of DNA for each experimental condition. This should include the this compound responsive Firefly luciferase reporter plasmid and the constitutive Renilla luciferase control plasmid at an optimized ratio (e.g., 50:1).
- In a separate tube, dilute the transfection reagent in serum-free medium according to the manufacturer's instructions.
- Combine the DNA master mix and the diluted transfection reagent. Incubate at room temperature for 15-20 minutes to allow for complex formation.
- Add the transfection complexes to the cells in each well.
- Incubate the cells for 24-48 hours.
3. Cell Lysis and Luciferase Assay:
- After the incubation period, remove the growth medium from the cells.
- Wash the cells once with phosphate-buffered saline (PBS).
- Add passive lysis buffer to each well and incubate on a shaker for 15 minutes at room temperature to ensure complete cell lysis.
- Add the Firefly luciferase assay reagent to each well.
- Immediately measure the luminescence using a plate-reading luminometer. This is the Firefly luciferase reading.
- Add the Stop & Glo® reagent to quench the Firefly reaction and activate the Renilla luciferase.
- Immediately measure the luminescence again. This is the Renilla luciferase reading.
4. Data Analysis:
- For each well, calculate the ratio of the Firefly luciferase reading to the Renilla luciferase reading to normalize the data.
- Average the normalized values for your replicate wells.
- Further analysis can include calculating fold change relative to a control condition.
Visualizations
References
Technical Support Center: Crystallization of Selenium-Binding Protein 1 (SBP-1)
A Researcher's Guide to Navigating the Challenges of SBP-1 Structural Studies
Disclaimer: As of the latest literature review, the three-dimensional crystal structure of Selenium-Binding Protein 1 (this compound) has not been experimentally determined. The absence of a solved structure indicates that this compound is a challenging target for crystallization. This guide is intended to provide researchers, scientists, and drug development professionals with a comprehensive framework for approaching this difficult crystallization problem. The following troubleshooting guides, FAQs, and protocols are based on general principles of protein crystallography and the known biochemical and biophysical properties of this compound and its homologs.
Frequently Asked Questions (FAQs)
Q1: What are the primary known functions and characteristics of this compound that might influence its crystallization?
A1: this compound is a multifaceted protein with several features that are critical to consider for crystallization strategies:
-
Enzymatic Activity: this compound has been identified as a methanethiol oxidase, which may imply conformational flexibility related to substrate binding and catalysis.[1]
-
Selenium Binding: this compound binds selenium, and the presence of this element may be crucial for the protein's stability and a homogeneous conformational state. For Arabidopsis thaliana this compound, two cysteine residues are involved in selenium binding.[2]
-
Conserved Motifs: It contains several conserved motifs, including CC/CXXC, KDEL, CSSC, HXD, and HXXHC, which may be involved in redox activity, metal binding, and protein-protein interactions.[1]
-
Post-Translational Modifications (PTMs): this compound is known to undergo arginine methylation, which can affect its interactions and potentially its surface properties, thereby influencing crystal packing. The C. elegans homolog is also ubiquitinated.
Q2: My this compound protein is aggregating/precipitating. What are the likely causes and how can I address this?
A2: Protein aggregation is a common hurdle in crystallization. For this compound, consider the following:
-
Purity: Ensure your protein is highly pure (>95%). Contaminating proteins can interfere with crystallization and lead to precipitation.
-
Buffer Conditions: The pH of your buffer should be sufficiently far from the isoelectric point (pI) of this compound to ensure a net charge that promotes solubility. Experiment with a range of pH values (e.g., 1-2 units above and below the theoretical pI).
-
Additives: Including additives such as mild detergents (e.g., 0.01-0.1% n-octyl-β-D-glucopyranoside), reducing agents (e.g., DTT or TCEP, especially given the cysteine motifs), or small molecules that are known to interact with this compound could improve stability.
-
Protein Concentration: You may be working at a concentration that is too high. Try reducing the protein concentration and performing solubility screening.
Q3: I am observing phase separation instead of crystals. What does this mean and what should I do?
A3: Phase separation, where the protein solution separates into a dense, protein-rich phase and a dilute phase, can sometimes be a precursor to crystallization. However, it can also be a dead end. To encourage the transition to a crystalline state:
-
Fine-tune Precipitant Concentration: The concentration of your precipitant (e.g., PEG, ammonium sulfate) may be too high. Try setting up optimization screens with finer increments of the precipitant concentration around the condition that produced phase separation.
-
Vary the Temperature: Temperature can significantly influence protein solubility and the kinetics of crystallization. Try setting up trays at different temperatures (e.g., 4°C, 12°C, 20°C).
-
Seeding: If you have any microcrystalline material from the phase-separated drops, you can try micro- or macro-seeding into fresh drops with slightly lower precipitant concentrations.
Q4: Should I include selenium in my purification and crystallization buffers?
A4: Given that this compound is a selenium-binding protein, the presence of selenium could be critical for its structural integrity. It is highly recommended to experiment with the addition of a selenium source, such as sodium selenite, to your buffers during purification and in the crystallization trials. This may help to obtain a homogeneous population of the protein in its native conformation.
Troubleshooting Guide
| Problem | Potential Cause | Suggested Solution |
| No Crystals, Clear Drops | Protein concentration is too low; Precipitant concentration is too low; Protein is too soluble. | Increase protein concentration; Increase precipitant concentration; Try different precipitants or a wider range of pH. |
| Amorphous Precipitate | Protein concentration is too high; Precipitant concentration is too high; Protein is unstable or aggregated. | Decrease protein concentration; Decrease precipitant concentration; Screen for stabilizing additives (salts, glycerol, ligands); Check protein purity and monodispersity by DLS. |
| Microcrystals or Spherulites | Nucleation is too rapid; Crystal growth is inhibited. | Decrease protein and/or precipitant concentration; Add viscosity-increasing agents (e.g., glycerol); Try micro-seeding; Optimize with additive screens. |
| Poorly Diffracting Crystals | High solvent content; Crystal lattice disorder; Twinning. | Try crystal annealing; Dehydrate crystals by increasing precipitant concentration; Screen for different crystallization conditions to obtain a different crystal form. |
| Inconsistent Results | Variability in protein batches; Inconsistent experimental setup. | Ensure a consistent and reproducible purification protocol; Use freshly purified protein; Carefully control temperature and drop volumes. |
Experimental Protocols
Protocol 1: this compound Expression and Purification (Hypothetical)
This protocol is a generalized approach for the expression and purification of a recombinant this compound construct.
-
Expression:
-
Clone the this compound gene into an appropriate expression vector (e.g., pET vector with an N-terminal His-tag).
-
Transform the plasmid into a suitable E. coli expression strain (e.g., BL21(DE3)).
-
Grow the cells in a suitable medium (e.g., LB or TB) at 37°C to an OD600 of 0.6-0.8.
-
Induce protein expression with an appropriate concentration of IPTG (e.g., 0.1-1 mM) and continue to grow the cells at a lower temperature (e.g., 18-25°C) overnight.
-
-
Lysis and Clarification:
-
Harvest the cells by centrifugation.
-
Resuspend the cell pellet in a lysis buffer (e.g., 50 mM Tris-HCl pH 8.0, 300 mM NaCl, 10 mM imidazole, 1 mM TCEP, and protease inhibitors).
-
Lyse the cells by sonication or high-pressure homogenization.
-
Clarify the lysate by centrifugation at high speed (e.g., 20,000 x g for 30 minutes).
-
-
Affinity Chromatography:
-
Load the clarified lysate onto a Ni-NTA affinity column.
-
Wash the column with the lysis buffer containing a higher concentration of imidazole (e.g., 20-40 mM).
-
Elute the His-tagged this compound with a high concentration of imidazole (e.g., 250-500 mM).
-
-
Size Exclusion Chromatography (SEC):
-
Concentrate the eluted protein.
-
Load the concentrated protein onto a size exclusion chromatography column (e.g., Superdex 200) pre-equilibrated with a final storage buffer (e.g., 20 mM HEPES pH 7.5, 150 mM NaCl, 1 mM TCEP).
-
Collect the fractions corresponding to the monomeric this compound peak.
-
Assess the purity by SDS-PAGE.
-
Protocol 2: Setting Up Crystallization Trials (Vapor Diffusion)
-
Prepare the Reservoir Solution: Pipette 500 µL of the desired crystallization screen condition into the reservoir of a 96-well crystallization plate.
-
Set the Drop (Sitting Drop):
-
Pipette 1 µL of the purified this compound protein solution (at a concentration of 5-10 mg/mL) onto the sitting drop post.
-
Pipette 1 µL of the reservoir solution into the protein drop.
-
Carefully mix by pipetting up and down without introducing air bubbles.
-
-
Set the Drop (Hanging Drop):
-
Pipette 2 µL of the protein solution onto a siliconized glass coverslip.
-
Pipette 2 µL of the reservoir solution onto the protein drop.
-
Invert the coverslip and place it over the reservoir, sealing it with grease.
-
-
Incubation and Observation:
-
Incubate the plates at a constant temperature.
-
Regularly observe the drops under a microscope for the formation of crystals, precipitate, or other outcomes.
-
Visualizations
Caption: A generalized experimental workflow for this compound crystallization and structure determination.
Caption: A decision tree for troubleshooting common outcomes in this compound crystallization trials.
References
Technical Support Center: Process Improvement for Large-Scale SBP1 Peptide Synthesis
This technical support center provides comprehensive guidance for researchers, scientists, and drug development professionals engaged in the large-scale synthesis of the SBP1 peptide (Sequence: H-Ile-Glu-Glu-Gln-Ala-Lys-Thr-Phe-Leu-Asp-Lys-Phe-Asn-His-Glu-Ala-Glu-Asp-Leu-Phe-Tyr-Gln-Ser-NH2). The following sections offer troubleshooting advice, frequently asked questions, detailed protocols, and process visualizations to address common challenges and enhance synthesis efficiency and purity.
Section 1: Troubleshooting Guide
This guide addresses specific issues that may arise during the large-scale synthesis of the SBP1 peptide.
| Problem | Potential Cause | Recommended Solution |
| Low Yield After Cleavage | Incomplete Coupling: Steric hindrance from bulky residues (e.g., Ile, Phe, Tyr) or aggregation of the growing peptide chain can lead to incomplete coupling reactions. | - Perform a test cleavage: Analyze a small resin sample by mass spectrometry to confirm the presence of the target peptide and identify any major deletion sequences.[1] - Optimize coupling: Increase coupling time, use a more potent activating agent like HATU, or perform double couplings for difficult residues.[2] - Monitor reactions: Use the Kaiser test to confirm the completion of each coupling step.[1] |
| Peptide Aggregation: The SBP1 sequence contains hydrophobic residues that can lead to inter-chain aggregation on the resin, blocking reagent access.[3] | - Modify synthesis conditions: Switch to a more polar solvent like N-Methyl-2-pyrrolidone (NMP) or use a "magic mixture" of solvents to disrupt secondary structures. - Incorporate pseudoprolines: If aggregation is severe, consider redesigning the synthesis with pseudoproline dipeptides to break up secondary structures. - Elevated temperature: Synthesizing at a higher temperature (e.g., 60°C) can improve solvation and reduce aggregation.[4] | |
| Poor Purity of Crude Peptide | Aspartimide Formation: The presence of Aspartic acid (Asp) residues in the SBP1 sequence creates a risk of aspartimide formation, especially during piperidine-mediated Fmoc deprotection. This side reaction can lead to hard-to-separate impurities.[5][6][7] | - Use specialized protecting groups: Employ an Asp protecting group that minimizes aspartimide formation. - Modify deprotection: Add a weak acid, such as 0.1 M HOBt, to the piperidine deprotection solution to suppress this side reaction.[4] |
| Dehydration of Asn/Gln: The side chains of Asparagine (Asn) and Glutamine (Gln) can dehydrate to form nitriles during activation. | - Use side-chain protection: For large-scale synthesis, it is advisable to use Fmoc-Asn(Trt)-OH and Fmoc-Gln(Trt)-OH to prevent this side reaction and improve solubility. | |
| Racemization of Histidine: The Histidine (His) residue in the SBP1 sequence can be prone to racemization during coupling. | - Choose the appropriate protecting group: Use a His protecting group that minimizes racemization, such as Fmoc-His(Trt)-OH. | |
| Difficulties During Purification | Aggregation in HPLC: The crude SBP1 peptide may aggregate in the purification buffer, leading to broad peaks and poor separation. | - Adjust mobile phase: Add a chaotropic agent like guanidinium chloride or an organic modifier like isopropanol to the mobile phase to disrupt aggregation.[4] - Elevated temperature: Perform the HPLC purification at a higher temperature (40-60°C) to improve solubility.[4] |
| Co-elution of Impurities: Deletion sequences or products of side reactions may have similar retention times to the target SBP1 peptide. | - Optimize gradient: Use a shallower gradient during HPLC to improve the resolution between the target peptide and closely eluting impurities. |
Section 2: Frequently Asked Questions (FAQs)
Q1: What is the recommended synthesis strategy for large-scale production of SBP1?
A1: For a 23-amino acid peptide like SBP1, Solid-Phase Peptide Synthesis (SPPS) using the Fmoc/tBu strategy is the most common and effective approach. This method allows for straightforward purification by washing away excess reagents after each step.
Q2: Which resin is most suitable for the synthesis of SBP1, which has a C-terminal amide?
A2: A Rink Amide resin is the ideal choice for synthesizing SBP1, as cleavage with trifluoroacetic acid (TFA) will directly yield the peptide with a C-terminal amide.
Q3: How can I monitor the progress and success of my SBP1 synthesis?
A3: Regular monitoring is crucial. Use a qualitative method like the Kaiser test after each coupling step to check for free primary amines.[1] Additionally, performing small-scale test cleavages at intermediate steps and analyzing the products by mass spectrometry can help identify any issues early on.[1]
Q4: What are the best coupling reagents for SBP1 synthesis?
A4: For large-scale synthesis, a balance between efficiency and cost is important. Standard reagents like HBTU/HCTU are highly efficient.[1] For difficult couplings, a more potent reagent like HATU may be necessary.
Q5: What is the role of scavengers in the cleavage cocktail for SBP1?
A5: Scavengers are essential to prevent the re-attachment of protecting groups to sensitive residues like Tyrosine and Phenylalanine in the SBP1 sequence. A common cleavage cocktail is Reagent K, which contains TFA, water, phenol, thioanisole, and ethanedithiol.
Section 3: Experimental Protocols
Protocol 1: Automated Fmoc Solid-Phase Peptide Synthesis of SBP1
This protocol outlines the general steps for automated synthesis of the SBP1 peptide on a Rink Amide resin.
-
Resin Swelling: Swell the Rink Amide resin in dimethylformamide (DMF) for at least 1 hour before the first coupling.
-
Fmoc Deprotection: Treat the resin with 20% piperidine in DMF for 5-10 minutes to remove the Fmoc protecting group from the resin or the growing peptide chain.
-
Washing: Thoroughly wash the resin with DMF to remove residual piperidine and by-products.
-
Coupling:
-
Pre-activate the Fmoc-protected amino acid (4 equivalents) with a coupling agent like HBTU (4 equivalents) and a base like N,N-diisopropylethylamine (DIPEA) (8 equivalents) in DMF.
-
Add the activated amino acid solution to the resin and allow it to react for 1-2 hours.
-
For potentially difficult couplings (e.g., Phe, Tyr, Ile), consider a longer coupling time or a double coupling.
-
-
Washing: Wash the resin with DMF to remove excess reagents and by-products.
-
Monitoring (Optional but Recommended): Perform a Kaiser test on a small sample of resin beads to ensure the coupling reaction is complete.
-
Repeat: Repeat steps 2-6 for each amino acid in the SBP1 sequence.
Protocol 2: Cleavage and Deprotection of SBP1 from Resin
This protocol describes the final step of releasing the synthesized peptide from the solid support.
-
Resin Preparation: After the final Fmoc deprotection, thoroughly wash the peptide-resin with DMF, followed by dichloromethane (DCM), and dry it under a vacuum.
-
Cleavage Cocktail Preparation: Prepare a cleavage cocktail such as Reagent K (e.g., TFA/water/phenol/thioanisole/EDT 82.5:5:5:5:2.5 v/v). Caution: Handle TFA in a fume hood with appropriate personal protective equipment.
-
Cleavage Reaction: Add the cleavage cocktail to the dried peptide-resin (approximately 10 mL per gram of resin).
-
Incubation: Gently agitate the mixture at room temperature for 2-3 hours.
-
Peptide Precipitation: Filter the resin and collect the filtrate. Add the filtrate dropwise to a large volume of cold diethyl ether to precipitate the crude SBP1 peptide.
-
Isolation: Centrifuge the mixture to pellet the precipitated peptide. Decant the ether and wash the peptide pellet with cold ether two more times.
-
Drying: Dry the crude peptide pellet under a vacuum.
Protocol 3: Purification of SBP1 by Reverse-Phase HPLC
This protocol provides a general method for purifying the crude SBP1 peptide.
-
Sample Preparation: Dissolve the crude SBP1 peptide in a minimal amount of a suitable solvent, such as a mixture of acetonitrile and water with a small amount of TFA.
-
HPLC System: Use a preparative reverse-phase HPLC system with a C18 column.
-
Mobile Phases:
-
Mobile Phase A: 0.1% TFA in water.
-
Mobile Phase B: 0.1% TFA in acetonitrile.
-
-
Gradient Elution: Purify the peptide using a linear gradient of Mobile Phase B (e.g., 5% to 65% over 60 minutes). The optimal gradient may need to be determined empirically.
-
Fraction Collection: Collect fractions based on the UV absorbance at 220 nm.
-
Analysis: Analyze the collected fractions by analytical HPLC and mass spectrometry to identify those containing the pure SBP1 peptide.
-
Lyophilization: Pool the pure fractions and lyophilize to obtain the final purified SBP1 peptide as a white powder.
Section 4: Visualizations
Diagram 1: General Workflow for Large-Scale SBP1 Synthesis
Caption: A high-level overview of the solid-phase synthesis process for the SBP1 peptide.
Diagram 2: Troubleshooting Decision Tree for Low Yield
Caption: A logical workflow for diagnosing the cause of low peptide yield in SPPS.
Diagram 3: Aspartimide Formation Side Reaction
Caption: A simplified pathway of the aspartimide side reaction during Fmoc-SPPS.
References
- 1. biochem-caflisch.uzh.ch [biochem-caflisch.uzh.ch]
- 2. peptide.com [peptide.com]
- 3. knowledge.lancashire.ac.uk [knowledge.lancashire.ac.uk]
- 4. Advances in Fmoc solid‐phase peptide synthesis - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. d-nb.info [d-nb.info]
- 7. peptide.com [peptide.com]
Validation & Comparative
Validating SBP-1 as a Therapeutic Target for Metabolic Syndrome: A Comparative Guide
For Researchers, Scientists, and Drug Development Professionals
Metabolic syndrome is a constellation of conditions that increase the risk of heart disease, stroke, and type 2 diabetes. These conditions include high blood pressure, high blood sugar, excess body fat around the waist, and abnormal cholesterol or triglyceride levels. A key player in the pathology of metabolic syndrome is the Sterol Regulatory Element-Binding Protein-1 (SREBP-1), and its Caenorhabditis elegans homolog, SBP-1. This guide provides a comparative analysis of this compound as a therapeutic target against other established treatments for metabolic syndrome, supported by experimental data.
This compound/SREBP-1: A Central Regulator of Lipid Homeostasis
This compound, the worm homolog of the mammalian SREBP-1, is a crucial transcription factor that governs the synthesis of fatty acids and triglycerides.[1] Aberrant activation of this compound/SREBP-1 is linked to excessive fat storage, insulin resistance, and fatty liver disease, which are hallmarks of metabolic syndrome.[2] Studies in C. elegans have demonstrated that knocking down this compound leads to a reduction in fat content.[3] In mammalian models, inhibiting SREBP-1 has been shown to ameliorate diet-induced obesity, improve insulin sensitivity, and reduce atherosclerotic plaques.[4]
Therapeutic Alternatives for Metabolic Syndrome
Current therapeutic strategies for metabolic syndrome often involve a multi-drug approach to manage its individual components.[5] Prominent among these are GLP-1 receptor agonists and biguanides like metformin, which have shown considerable efficacy in improving metabolic parameters.
-
GLP-1 Receptor Agonists (e.g., Semaglutide, Liraglutide): These agents mimic the action of the native glucagon-like peptide-1, leading to enhanced insulin secretion, suppressed glucagon release, delayed gastric emptying, and increased satiety.[6] Clinical and preclinical studies have demonstrated their potent effects on weight loss and glycemic control.[3][7]
-
Biguanides (e.g., Metformin): Metformin is a first-line therapy for type 2 diabetes that primarily acts by reducing hepatic glucose production and improving insulin sensitivity.[8] It has also been shown to have beneficial effects on lipid metabolism, partly through the inhibition of SREBP-1.[8][9]
Comparative Performance: this compound Inhibition vs. Alternatives
Direct head-to-head experimental data comparing this compound/SREBP-1 specific inhibitors with GLP-1 receptor agonists or metformin in a comprehensive metabolic syndrome model is limited in the currently available literature. However, we can infer a comparative performance based on their mechanisms of action and data from individual studies.
Data Presentation
The following tables summarize the quantitative effects of targeting this compound/SREBP-1 and the use of GLP-1 receptor agonists and metformin on key metabolic parameters.
Table 1: Effects of this compound/SREBP-1 Inhibition on Metabolic Parameters
| Intervention | Model Organism/System | Key Findings | Reference |
| This compound knockdown (RNAi) | C. elegans | Reduced fat storage | [3] |
| Betulin (SREBP inhibitor) | Diet-induced obese mice | Decreased body weight, reduced serum and tissue lipids, improved insulin sensitivity, reduced atherosclerotic plaque size | [4] |
| Fatostatin (SREBP inhibitor) | Obese mice | Weight loss, reversal of diabetes, lowered cholesterol | [10] |
| SCAP deletion (blocks SREBP activation) | Insulin-resistant ob/ob mice | Abolished hepatic steatosis, reduced lipid synthesis | [11] |
Table 2: Effects of GLP-1 Receptor Agonists on Metabolic Parameters
| Intervention | Model Organism/System | Key Findings | Reference |
| Semaglutide | High-fat diet-induced obese mice | Significant reduction in body weight, body fat, fasting blood glucose, and insulin levels; improved insulin resistance | [3] |
| Semaglutide | FATZO/Pco mice (diabetic model) | Dose-dependent body weight loss, reduced blood glucose, improved glucose disposal | [2] |
| Semaglutide | Diet-induced obese mice | Reduced body weight, decreased cumulative daily food intake, reduced liver lipid content | [7] |
| Liraglutide | Obese subjects with prediabetes or early T2D | Weight loss, reduced visceral and subcutaneous adipose tissue | [12] |
Table 3: Effects of Metformin on Metabolic Parameters
| Intervention | Model Organism/System | Key Findings | Reference |
| Metformin | High-fat diet-fed mice | Reduced body weight gain, visceral fat accumulation, improved insulin sensitivity, attenuated hepatic steatosis | [13] |
| Metformin | FaO cells (hepatocellular carcinoma) | Reduced cellular lipid content | [8] |
| Metformin | Obese, leptin-deficient mice | Reversed hepatomegaly and steatosis | [14] |
| Metformin | HepG2 cells | Decreased intracellular total cholesterol, reduced SREBP-2 expression | [15] |
Experimental Protocols
Detailed methodologies for key experiments cited in this guide are provided below.
This compound Knockdown in C. elegans via RNAi Feeding
Objective: To silence the this compound gene in C. elegans to study its effect on fat storage.
Protocol:
-
Prepare RNAi Plates:
-
Prepare NGM agar plates containing carbenicillin (to select for bacteria with the RNAi plasmid) and IPTG (to induce dsRNA expression).
-
Seed the plates with a 24-hour culture of E. coli HT115 strain carrying the L4440 plasmid with the this compound gene insert. Allow the bacterial lawn to grow overnight at room temperature.[6]
-
-
Synchronize Worms:
-
Wash gravid adult worms from a standard NGM plate with M9 buffer.
-
Treat with a bleach solution (sodium hypochlorite and NaOH) to dissolve the adults and release the eggs.
-
Wash the eggs several times with M9 buffer and allow them to hatch overnight in M9 buffer without food to obtain a synchronized population of L1 larvae.
-
-
RNAi Treatment:
-
Transfer the synchronized L1 larvae to the prepared this compound RNAi plates. Use plates with bacteria carrying the empty L4440 vector as a control.
-
Incubate the plates at 20°C and allow the worms to develop to the desired stage (e.g., young adult).[16]
-
-
Phenotypic Analysis:
-
Observe the worms under a dissecting microscope for any visible phenotypes, such as changes in body size or fat storage (assessed by Oil Red O staining).
-
Lipid Quantification using Oil Red O Staining in C. elegans
Objective: To visualize and quantify the neutral lipid content in C. elegans.
Protocol:
-
Sample Preparation:
-
Collect synchronized worms at the desired developmental stage in M9 buffer.
-
Wash the worms several times with M9 buffer to remove bacteria.
-
-
Fixation:
-
Staining:
-
Prepare a working solution of Oil Red O stain.
-
Incubate the fixed worms in the Oil Red O working solution for several hours at room temperature with gentle rocking.[13]
-
-
Washing and Mounting:
-
Wash the stained worms with M9 buffer or a similar wash buffer to remove excess stain.
-
Mount the worms on a microscope slide with a coverslip.[3]
-
-
Imaging and Quantification:
-
Capture images of the stained worms using a light microscope.
-
Quantify the intensity of the red stain using image analysis software such as ImageJ. The intensity of the stain is proportional to the amount of neutral lipid.
-
qRT-PCR for Measuring Lipogenic Gene Expression
Objective: To quantify the mRNA levels of genes involved in lipid synthesis.
Protocol:
-
RNA Extraction:
-
Collect synchronized worm populations or mammalian tissue/cell samples.
-
Homogenize the samples and extract total RNA using a TRIzol-based method or a commercial RNA extraction kit.[17]
-
-
cDNA Synthesis:
-
Treat the extracted RNA with DNase I to remove any contaminating genomic DNA.
-
Synthesize first-strand cDNA from the purified RNA using a reverse transcriptase enzyme and oligo(dT) or random primers.[18]
-
-
Quantitative PCR:
-
Prepare a reaction mixture containing the synthesized cDNA, gene-specific forward and reverse primers for the target lipogenic genes (e.g., fasn, acc, scd-1), and a SYBR Green or TaqMan-based qPCR master mix.
-
Perform the qPCR reaction in a real-time PCR machine.
-
Analyze the amplification data to determine the relative expression levels of the target genes, normalized to a stable housekeeping gene.
-
Mandatory Visualization
This compound/SREBP-1 Signaling Pathway
References
- 1. Liraglutide - overview of the preclinical and clinical data and its role in the treatment of type 2 diabetes - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Glucose dysregulation and response to common anti-diabetic agents in the FATZO/Pco mouse - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Frontiers | Effects of semaglutide on metabolism and gut microbiota in high-fat diet-induced obese mice [frontiersin.org]
- 4. Semaglutide Improves Liver Steatosis and De Novo Lipogenesis Markers in Obese and Type-2-Diabetic Mice with Metabolic-Dysfunction-Associated Steatotic Liver Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 5. SREBP Regulation of Lipid Metabolism in Liver Disease, and Therapeutic Strategies - PMC [pmc.ncbi.nlm.nih.gov]
- 6. benchchem.com [benchchem.com]
- 7. sygnaturediscovery.com [sygnaturediscovery.com]
- 8. Metformin inhibits hepatocellular glucose, lipid and cholesterol biosynthetic pathways by transcriptionally suppressing steroid receptor coactivator 2 (SRC-2) - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Effects of Metformin on Hepatic Steatosis in Adults with Nonalcoholic Fatty Liver Disease and Diabetes: Insights from the Cellular to Patient Levels - PMC [pmc.ncbi.nlm.nih.gov]
- 10. fiercebiotech.com [fiercebiotech.com]
- 11. The Scap/SREBP Pathway Is Essential for Developing Diabetic Fatty Liver and Carbohydrate-Induced Hypertriglyceridemia in Animals - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Effects of Liraglutide on Weight Loss, Fat Distribution, and beta-Cell Function in Obese Subjects With Prediabetes or Early Type 2 Diabetes [sfera.unife.it]
- 13. Metformin and berberine synergistically improve NAFLD via the AMPK–SREBP1–FASN signaling pathway - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Scholars@Duke publication: Metformin reverses fatty liver disease in obese, leptin-deficient mice. [scholars.duke.edu]
- 15. SREBP-2, a new target of metformin? - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Comparative efficacy and safety of GLP-1 receptor agonists for weight reduction: A model-based meta-analysis of placebo-controlled trials - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Comparative Effects of Weight Loss and Incretin-Based Therapies on Vascular Endothelial Function, Fibrinolysis, and Inflammation in Individuals with Obesity and Pre-Diabetes: A Randomized, Controlled Trial - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Semaglutide Versus Other Glucagon-Like Peptide-1 Agonists for Weight Loss in Type 2 Diabetes Patients: A Systematic Review and Meta-Analysis - PubMed [pubmed.ncbi.nlm.nih.gov]
A Comparative Analysis of SBP-1 and SREBP-2 Functions: A Guide for Researchers
For researchers, scientists, and drug development professionals, understanding the nuanced roles of key metabolic regulators is paramount. This guide provides a detailed comparative analysis of two critical transcription factors in lipid metabolism: Sterol Regulatory Element-Binding Protein-1 (SBP-1) from Caenorhabditis elegans and its mammalian counterpart, Sterol Regulatory Element-Binding Protein-2 (SREBP-2).
This document outlines their distinct and overlapping functions, target genes, and regulatory mechanisms, supported by experimental data. Detailed protocols for key experimental assays are also provided to facilitate further research in this area.
Core Functional Comparison: Fatty Acid vs. Cholesterol Synthesis
This compound, the single SREBP ortholog in the nematode C. elegans, primarily governs fatty acid metabolism, a role similar to mammalian SREBP-1c.[1][2][3] In contrast, mammalian SREBP-2 is the master regulator of cholesterol biosynthesis and uptake.[4][5][6] While there is some degree of overlap in their functions, their primary domains of influence are distinct, making them crucial for maintaining lipid homeostasis in their respective organisms.
Quantitative Data Summary
The following tables summarize the key functional differences and target genes of this compound and SREBP-2 based on available experimental data.
Table 1: General Functional Comparison of this compound and SREBP-2
| Feature | This compound (C. elegans) | SREBP-2 (Mammals) |
| Primary Function | Regulation of fatty acid synthesis and storage.[1][2] | Regulation of cholesterol synthesis and uptake.[4][5] |
| Homology | Ortholog of mammalian SREBP-1.[1][7] | - |
| Tissue Expression | Primarily in the intestine.[1][2] | Ubiquitously expressed.[8] |
| Key Regulators | Nutrient availability (glucose), MDT-15.[1][9] | Cellular sterol levels, SCAP, INSIGs.[4][5] |
| Phenotype of Loss-of-Function | Reduced body size, decreased fat storage, reduced egg-laying.[1][2] | Embryonic lethality, defects in limb development, reduced cholesterol levels.[10][11] |
Table 2: Key Target Genes of this compound and SREBP-2
| Metabolic Pathway | This compound Target Genes (C. elegans) | SREBP-2 Target Genes (Mammals) |
| Fatty Acid Synthesis | fat-5, fat-6, fat-7 (stearoyl-CoA desaturases), elo-2 (fatty acid elongase), pod-2 (acetyl-CoA carboxylase), fasn-1 (fatty acid synthase).[1][12][13] | FASN (fatty acid synthase), ACACA (acetyl-CoA carboxylase), SCD (stearoyl-CoA desaturase) - primarily regulated by SREBP-1, but some overlap.[4][5] |
| Cholesterol Synthesis | Not a primary function; C. elegans are cholesterol auxotrophs. | HMGCS1 (HMG-CoA synthase), HMGCR (HMG-CoA reductase), MVK (mevalonate kinase), SQLE (squalene epoxidase), LSS (lanosterol synthase), CYP51A1.[4][5][14] |
| Cholesterol Uptake | - | LDLR (low-density lipoprotein receptor).[4][5] |
| One-Carbon Metabolism | sams-1 (S-adenosylmethionine synthetase).[7] | - |
Table 3: Quantitative Effects of this compound and SREBP-2 Modulation on Lipid Metabolism
| Organism/System | Genetic Modification | Observed Effect on Lipid Profile | Fold Change (approx.) |
| C. elegans | This compound knockdown | Decrease in total body fat.[1][2] | Not explicitly quantified in fold change. |
| C. elegans | This compound mutant | 4-fold reduction in cholesterol level.[15] | 4 |
| Mouse | SREBP-2 knockout (liver) | Reduced hepatic cholesterol and triglyceride levels.[10] | Not explicitly quantified in fold change. |
| Mouse | Intestinal overexpression of active SREBP-2 | Increased hepatic triglycerides, total cholesterol, and cholesterol esters.[16] | Not explicitly quantified in fold change. |
Table 4: Comparative Transcriptional Activity of SREBP Isoforms on Different Promoters (Luciferase Reporter Assays)
| Promoter | SREBP-1a Activation | SREBP-1c Activation | SREBP-2 Activation |
| Cholesterogenic genes (classic SREs) | Strong | Weak/None | Strong |
| Lipogenic genes (SRE-like sequences) | Strong | Modest | Modest |
| E-box containing reporters | Modest | Modest | Inactive |
| Data synthesized from Amemiya-Kudo et al. (2002) which indicates the differential activation potential of mammalian SREBP isoforms.[17][18] this compound from C. elegans is considered functionally homologous to mammalian SREBP-1c. |
Signaling Pathways and Regulatory Mechanisms
The activation of both this compound and SREBP-2 is tightly regulated, primarily through a conserved proteolytic cleavage mechanism.
SREBP-2 Activation Pathway
In mammals, SREBP-2 is synthesized as an inactive precursor anchored to the endoplasmic reticulum (ER) membrane, where it is bound to SREBP-cleavage activating protein (SCAP). When cellular sterol levels are low, the SREBP-2/SCAP complex is transported to the Golgi apparatus. There, it is sequentially cleaved by two proteases, Site-1 Protease (S1P) and Site-2 Protease (S2P). This releases the N-terminal transcriptionally active domain, which then translocates to the nucleus to activate target gene expression.[4][5] High sterol levels cause a conformational change in SCAP, leading to its binding to Insulin-induced gene (INSIG) proteins, which retains the SREBP-2/SCAP complex in the ER, thus inhibiting its activation.[19]
References
- 1. Fat accumulation in Caenorhabditis elegans is mediated by SREBP homolog this compound - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Fat accumulation in Caenorhabditis elegans is mediated by SREBP homolog this compound - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. SREBPs: activators of the complete program of cholesterol and fatty acid synthesis in the liver - PMC [pmc.ncbi.nlm.nih.gov]
- 5. journals.biologists.com [journals.biologists.com]
- 6. Regulation of SREBP-Mediated Gene Expression - PMC [pmc.ncbi.nlm.nih.gov]
- 7. A conserved SREBP-1/phosphatidylcholine feedback circuit regulates lipogenesis in metazoans - PMC [pmc.ncbi.nlm.nih.gov]
- 8. SREBPs: Metabolic Integrators in Physiology and Metabolism - PMC [pmc.ncbi.nlm.nih.gov]
- 9. SREBP and MDT-15 protect C. elegans from glucose-induced accelerated aging by preventing accumulation of saturated fat - PMC [pmc.ncbi.nlm.nih.gov]
- 10. SREBP-2-deficient and hypomorphic mice reveal roles for SREBP-2 in embryonic development and SREBP-1c expression - PMC [pmc.ncbi.nlm.nih.gov]
- 11. SREBP-2-deficient and hypomorphic mice reveal roles for SREBP-2 in embryonic development and SREBP-1c expression - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. uniprot.org [uniprot.org]
- 14. researchgate.net [researchgate.net]
- 15. Label-free quantitative analysis of lipid metabolism in living Caenorhabditis elegans - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Overactivation of Intestinal SREBP2 in Mice Increases Serum Cholesterol - PMC [pmc.ncbi.nlm.nih.gov]
- 17. researchgate.net [researchgate.net]
- 18. Transcriptional activities of nuclear SREBP-1a, -1c, and -2 to different target promoters of lipogenic and cholesterogenic genes - PubMed [pubmed.ncbi.nlm.nih.gov]
- 19. academic.oup.com [academic.oup.com]
Confirming the Interaction Between SBP-1 and a Novel Binding Partner: A Comparative Guide
For Researchers, Scientists, and Drug Development Professionals
Selenium-Binding Protein 1 (SBP-1) is a highly conserved protein implicated in a multitude of critical cellular functions, including protein degradation, redox modulation, and the metabolism of sulfur-containing molecules.[1][2] Altered expression of this compound has been linked to various cancers, often correlating with poor clinical outcomes.[1][2] this compound is known to interact with several proteins, including the von Hippel-Lindau protein-interacting deubiquitinating enzyme 1 (VDU1) and glutathione peroxidase 1 (GPX1), highlighting its role in complex cellular signaling networks.[1][3][4] The identification of novel this compound binding partners is crucial for elucidating its full range of biological functions and for the development of novel therapeutic strategies.
This guide provides a comparative overview of key experimental methods to confirm a hypothesized interaction between this compound and a novel binding partner. It includes detailed experimental protocols and data presentation guidelines to aid researchers in designing and executing their validation studies.
Comparison of Key In Vitro and In Vivo Interaction Validation Methods
Choosing the appropriate method to confirm a protein-protein interaction is critical and depends on the nature of the interaction, the available reagents, and the desired level of evidence. Below is a comparison of three widely used techniques.
| Method | Principle | Advantages | Disadvantages | Throughput |
| Co-Immunoprecipitation (Co-IP) | An antibody targets a known protein ("bait"), pulling it out of a cell lysate along with any interacting proteins ("prey") for detection by Western blotting or mass spectrometry.[5][6][7] | Detects interactions in a near-physiological cellular environment.[6] Can identify endogenous protein complexes. | Can be prone to false positives from non-specific antibody binding. May not detect transient or weak interactions.[6] | Low to Medium |
| Yeast Two-Hybrid (Y2H) | The interaction between a "bait" and "prey" protein, each fused to a separate domain of a transcription factor, reconstitutes the transcription factor's function and activates a reporter gene in yeast.[6][8][9] | A powerful in vivo method for screening entire cDNA libraries for novel interactions.[6][8] Sensitive to transient interactions. | High rate of false positives.[6] Interactions are detected in the yeast nucleus, which may not be the native environment for the proteins. | High |
| Pull-down Assay | A purified "bait" protein, tagged with an affinity ligand (e.g., GST, His-tag), is immobilized on beads and used to capture interacting "prey" proteins from a cell lysate or a solution of purified proteins.[6][10][11][12] | A versatile in vitro method that allows for precise control over experimental conditions.[6] Useful for confirming direct physical interactions. | The use of tagged, recombinant proteins may not reflect the native protein conformation and interactions. Requires purified bait protein. | Low to Medium |
Experimental Protocols
Co-Immunoprecipitation (Co-IP) Protocol
This protocol outlines the general steps for performing a Co-IP experiment to validate the interaction between this compound and a novel binding partner.
Materials:
-
Cells expressing both this compound and the putative binding partner.
-
Lysis buffer (e.g., RIPA buffer) supplemented with protease and phosphatase inhibitors.
-
Primary antibody specific to this compound (or the novel partner).
-
Isotype-matched control IgG antibody.
-
Protein A/G magnetic beads or agarose resin.
-
Wash buffer (e.g., PBS with 0.1% Tween-20).
-
Elution buffer (e.g., low pH glycine buffer or SDS-PAGE loading buffer).
-
SDS-PAGE gels and Western blotting reagents.
-
Antibody against the novel binding partner for detection.
Procedure:
-
Cell Lysis: Harvest cells and lyse them on ice using a non-denaturing lysis buffer to preserve protein-protein interactions.[13]
-
Pre-clearing (Optional but Recommended): Incubate the cell lysate with protein A/G beads alone to reduce non-specific binding of proteins to the beads.[13]
-
Immunoprecipitation: Add the primary antibody against this compound (or an isotype control IgG for a negative control) to the pre-cleared lysate and incubate with gentle rotation at 4°C to allow antibody-antigen complexes to form.[7]
-
Capture of Immune Complexes: Add protein A/G beads to the lysate-antibody mixture and incubate to capture the antibody-protein complexes.
-
Washing: Pellet the beads by centrifugation or using a magnetic rack and wash them several times with wash buffer to remove non-specifically bound proteins.[14]
-
Elution: Elute the bound proteins from the beads using an appropriate elution buffer.[7]
-
Analysis: Analyze the eluted proteins by SDS-PAGE and Western blotting using an antibody against the novel binding partner to confirm its presence in the immunoprecipitated complex.[7]
Yeast Two-Hybrid (Y2H) Assay Protocol
This protocol provides a general workflow for a Y2H screen to identify or confirm an interaction.
Materials:
-
Saccharomyces cerevisiae strain appropriate for Y2H screening.
-
"Bait" plasmid vector (e.g., pGBKT7) containing the coding sequence for this compound fused to a DNA-binding domain (DBD).
-
"Prey" plasmid vector (e.g., pGADT7) containing the coding sequence for the novel partner (or a cDNA library) fused to an activation domain (AD).[9]
-
Yeast transformation reagents (e.g., PEG/LiAc).
-
Appropriate selective media (e.g., SD/-Trp/-Leu for selecting co-transformants, and SD/-Trp/-Leu/-His/-Ade for selecting for interactions).[15]
-
X-Gal or other reagents for reporter gene assays.
Procedure:
-
Bait and Prey Plasmid Construction: Clone the cDNA of this compound into the bait vector and the cDNA of the novel partner into the prey vector.
-
Yeast Transformation: Co-transform the bait and prey plasmids into the yeast host strain.[15]
-
Selection for Co-transformants: Plate the transformed yeast on medium lacking tryptophan and leucine to select for cells that have taken up both plasmids.
-
Selection for Interaction: Replica-plate the colonies onto a higher stringency selective medium lacking histidine and adenine. Growth on this medium indicates a positive interaction.[15]
-
Reporter Gene Assay (e.g., LacZ): Perform a β-galactosidase assay (e.g., colony-lift filter assay with X-Gal) to further confirm the interaction. Blue colonies indicate a positive interaction.[9]
-
Controls: Include positive and negative controls to ensure the validity of the results. A negative control would be co-transformation with a non-interacting protein.
Pull-down Assay Protocol
This protocol describes a GST pull-down assay, a common variation of this technique.
Materials:
-
Purified GST-tagged this compound ("bait" protein).
-
Purified GST alone (as a negative control).
-
Cell lysate containing the novel binding partner ("prey" protein).
-
Glutathione-agarose or magnetic beads.
-
Binding/Wash buffer (e.g., PBS with protease inhibitors and a mild detergent).
-
Elution buffer (e.g., buffer containing reduced glutathione).
-
SDS-PAGE gels and Western blotting reagents.
-
Antibody against the novel binding partner.
Procedure:
-
Immobilization of Bait Protein: Incubate the purified GST-SBP-1 and GST control with glutathione beads to immobilize the proteins.
-
Washing: Wash the beads to remove any unbound bait protein.
-
Binding of Prey Protein: Incubate the immobilized bait protein with the cell lysate containing the prey protein to allow for interaction.[12]
-
Washing: Wash the beads extensively with binding/wash buffer to remove non-specifically bound proteins.[11]
-
Elution: Elute the bound protein complexes from the beads using elution buffer containing glutathione.
-
Analysis: Analyze the eluted fractions by SDS-PAGE and Western blotting using an antibody specific to the novel binding partner to detect its presence. A band should be present in the GST-SBP-1 lane but not in the GST-only control lane.
Visualizing the Experimental Workflow and Signaling Context
To effectively communicate the experimental strategy and the potential biological relevance of the this compound interaction, diagrams are indispensable.
References
- 1. Selenium-Binding Protein 1 in Human Health and Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. mdpi.com [mdpi.com]
- 4. Functional and physical interaction between the selenium-binding protein 1 (SBP1) and the glutathione peroxidase 1 selenoprotein - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Common Methods for Assessing Protein-Protein Interactions | MtoZ Biolabs [mtoz-biolabs.com]
- 6. Methods for Detection of Protein-Protein Interactions [biologicscorp.com]
- 7. Co-IP Protocol-How To Conduct A Co-IP - Creative Proteomics [creative-proteomics.com]
- 8. A High-Throughput Yeast Two-Hybrid Protocol to Determine Virus-Host Protein Interactions - PMC [pmc.ncbi.nlm.nih.gov]
- 9. ableweb.org [ableweb.org]
- 10. home.sandiego.edu [home.sandiego.edu]
- 11. Understanding Pull-Down Protocol: Key FAQs for Users - Alpha Lifetech [alpha-lifetech.com]
- 12. Principle and Protocol of Pull-down Technology - Creative BioMart [creativebiomart.net]
- 13. bitesizebio.com [bitesizebio.com]
- 14. creative-diagnostics.com [creative-diagnostics.com]
- 15. Y2HGold Yeast Two-Hybrid Screening and Validation Experiment Protocol [bio-protocol.org]
A Comparative Guide to the Efficacy of SBP-1/SREBP-1 Inhibitors
For Researchers, Scientists, and Drug Development Professionals
This guide provides a detailed comparison of the efficacy of prominent small-molecule inhibitors targeting the Sterol Regulatory Element-Binding Protein-1 (SBP-1), also known as Sterol Regulatory Element-Binding Factor 1 (SREBF1 or SREBP-1). This compound is a critical transcription factor in the regulation of lipid homeostasis, and its inhibition is a key area of research for various metabolic diseases and cancers. This document outlines the mechanisms of action, comparative efficacy with supporting experimental data, and detailed experimental protocols for the evaluation of this compound inhibitors.
Mechanism of Action and Signaling Pathway
This compound is synthesized as an inactive precursor anchored to the endoplasmic reticulum (ER) membrane. Its activation is a multi-step process involving regulated transport to the Golgi apparatus and sequential proteolytic cleavages.[1] When cellular sterol levels are low, the SREBP cleavage-activating protein (SCAP) escorts the this compound precursor from the ER to the Golgi.[1] In the Golgi, Site-1 Protease (S1P) and Site-2 Protease (S2P) cleave the precursor, releasing the mature N-terminal domain.[1] This active fragment then translocates to the nucleus, where it binds to Sterol Response Elements (SREs) on target gene promoters, upregulating the expression of genes involved in fatty acid and cholesterol synthesis.[1][2]
Several small-molecule inhibitors have been identified that disrupt this pathway at different stages. This guide focuses on three well-characterized inhibitors: Fatostatin, Betulin, and PF-429242.
References
A Comparative Guide to Validating SBP-1 Downstream Targets Identified by RNA-Seq
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive comparison of experimental methods for validating downstream targets of the Caenorhabditis elegans transcription factor SBP-1 (Sterol Regulatory Element-Binding Protein-1), a key regulator of lipid metabolism. Following the identification of potential targets by RNA sequencing (RNA-seq), rigorous validation is crucial to confirm these findings and elucidate the regulatory network of this compound. This document outlines and compares three common validation techniques: quantitative reverse transcription PCR (qRT-PCR), Western blotting, and Chromatin Immunoprecipitation sequencing (ChIP-seq), complete with experimental data and detailed protocols.
Data Presentation: Comparing Validation Methods
The following tables summarize the validation of two well-established this compound downstream targets, fat-6 and fat-7, which encode for stearoyl-CoA desaturases. The data is based on a hypothetical RNA-seq experiment where this compound expression is knocked down, with subsequent validation by qRT-PCR, Western blot, and ChIP-seq.
| Gene | RNA-seq (Fold Change in this compound(RNAi) vs. Control) | qRT-PCR (Fold Change in this compound(RNAi) vs. Control) |
| fat-6 | -3.5 | -3.8 ± 0.4 |
| fat-7 | -4.2 | -4.5 ± 0.6 |
| tbg-1 (control) | -1.1 | -1.0 ± 0.2 |
Table 1: Comparison of RNA-seq and qRT-PCR data for this compound target genes. Data is presented as fold change in gene expression in this compound knockdown worms relative to control worms. The qRT-PCR data represents the mean ± standard deviation from three biological replicates.
| Protein | Western Blot (Relative Protein Level in this compound(RNAi) vs. Control) |
| FAT-6 | 0.3 ± 0.08 |
| FAT-7 | 0.25 ± 0.06 |
| Tubulin (loading control) | 1.0 ± 0.05 |
Table 2: Western blot analysis of FAT-6 and FAT-7 protein levels. Data is presented as the relative protein abundance in this compound knockdown worms compared to control worms, normalized to the loading control (Tubulin). The data represents the mean ± standard deviation from three biological replicates.
| Gene Promoter | ChIP-seq (Fold Enrichment of this compound Binding) |
| p fat-6 | 15.2 ± 2.1 |
| p fat-7 | 18.5 ± 2.8 |
| p tbg-1 (negative control) | 1.2 ± 0.3 |
Table 3: ChIP-seq analysis of this compound binding to target gene promoters. Data is presented as fold enrichment of this compound binding to the promoter regions of target genes compared to a negative control region. The data represents the mean ± standard deviation from two biological replicates.
Experimental Protocols
Detailed methodologies for the key experiments cited in this guide are provided below.
Quantitative Reverse Transcription PCR (qRT-PCR)
This technique is used to validate changes in mRNA expression levels identified by RNA-seq.
-
RNA Isolation: Synchronized L4 stage C. elegans populations (control and this compound(RNAi)) are harvested. Total RNA is extracted using a TRIzol-based method, followed by DNase treatment to remove any contaminating genomic DNA.
-
cDNA Synthesis: 1 µg of total RNA is reverse transcribed into complementary DNA (cDNA) using a high-capacity cDNA reverse transcription kit with a mix of oligo(dT) and random hexamer primers.
-
Real-Time PCR: qRT-PCR is performed using a SYBR Green-based master mix on a real-time PCR system. Gene-specific primers for fat-6, fat-7, and a reference gene (e.g., tbg-1) are used. The cycling conditions are typically: 95°C for 10 min, followed by 40 cycles of 95°C for 15 s and 60°C for 60 s.
-
Data Analysis: The relative expression of target genes is calculated using the ΔΔCt method, normalizing the expression of the target gene to the reference gene.
Western Blotting
Western blotting is employed to determine if the changes in mRNA levels translate to changes in protein levels.[1][2]
-
Protein Extraction: Worm pellets from control and this compound(RNAi) animals are lysed in RIPA buffer supplemented with protease inhibitors. The total protein concentration is determined using a BCA protein assay.
-
SDS-PAGE and Transfer: Equal amounts of protein (20-30 µg) are separated by SDS-polyacrylamide gel electrophoresis (SDS-PAGE) and then transferred to a polyvinylidene difluoride (PVDF) membrane.[2]
-
Immunoblotting: The membrane is blocked with 5% non-fat milk or bovine serum albumin (BSA) in Tris-buffered saline with Tween 20 (TBST) for 1 hour at room temperature.[2] The membrane is then incubated overnight at 4°C with primary antibodies specific to the target proteins (e.g., anti-FAT-6, anti-FAT-7) and a loading control (e.g., anti-tubulin). After washing with TBST, the membrane is incubated with a horseradish peroxidase (HRP)-conjugated secondary antibody for 1 hour at room temperature.
-
Detection and Analysis: The protein bands are visualized using an enhanced chemiluminescence (ECL) detection system.[3] The band intensities are quantified using densitometry software, and the relative protein levels are normalized to the loading control.
Chromatin Immunoprecipitation (ChIP-seq)
ChIP-seq is used to confirm the direct binding of a transcription factor to the regulatory regions of its putative target genes.[4][5][6][7][8]
-
Cross-linking and Chromatin Preparation: Mixed-stage populations of C. elegans expressing a tagged version of this compound (e.g., this compound::GFP) are treated with formaldehyde to cross-link proteins to DNA. The worms are then lysed, and the nuclei are isolated. The chromatin is sheared into fragments of 200-500 bp using sonication.[5]
-
Immunoprecipitation: The sheared chromatin is incubated overnight at 4°C with an antibody against the tag (e.g., anti-GFP) or a control IgG antibody. The antibody-chromatin complexes are then captured using protein A/G magnetic beads.[4][5]
-
Washing and Elution: The beads are washed with a series of buffers to remove non-specifically bound chromatin. The immunoprecipitated chromatin is then eluted from the beads.
-
Reverse Cross-linking and DNA Purification: The protein-DNA cross-links are reversed by heating at 65°C. The DNA is then purified using a PCR purification kit.
-
Library Preparation and Sequencing: The purified DNA is used to prepare a sequencing library, which is then sequenced on a next-generation sequencing platform.
-
Data Analysis: The sequencing reads are aligned to the C. elegans genome, and peak calling algorithms are used to identify regions of the genome that are enriched for this compound binding. The fold enrichment is calculated by comparing the signal in the this compound ChIP sample to the IgG control sample.
Visualizations
The following diagrams illustrate the signaling pathway of this compound, the experimental workflow for target validation, and the logical relationship between the different validation methods.
References
- 1. uniprot.org [uniprot.org]
- 2. amywalkerlab.com [amywalkerlab.com]
- 3. Genome-Wide Identification and Characterization of the SBP Gene Family in Passion Fruit (Passiflora edulis Sims) - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Fat accumulation in Caenorhabditis elegans is mediated by SREBP homolog this compound - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Fat accumulation in Caenorhabditis elegans is mediated by SREBP homolog this compound - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Chromatin Immunoprecipitation and Sequencing (ChIP-seq) Optimized for Application in Caenorhabditis elegans - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Frontiers | Comprehensive Analysis of the SBP Family in Blueberry and Their Regulatory Mechanism Controlling Chlorophyll Accumulation [frontiersin.org]
- 8. Fatty Acid Desaturation and the Regulation of Adiposity in Caenorhabditis elegans - PMC [pmc.ncbi.nlm.nih.gov]
comparative study of SBP1 expression in different cancer types
A Comparative Analysis of Selenium-Binding Protein 1 (SBP1) Expression and Prognostic Significance Across Diverse Cancer Types
Introduction
Selenium-Binding Protein 1 (SBP1) is a ubiquitously expressed protein whose role in cancer is increasingly being recognized, yet its function appears to be highly context-dependent, varying significantly across different malignancies. Emerging evidence suggests that SBP1 can act as both a tumor suppressor and a promoter of tumorigenesis, highlighting the need for a comparative understanding of its expression and prognostic value. This guide provides a comprehensive overview of SBP1 expression in various cancers, its correlation with clinical outcomes, and the experimental methodologies used for its characterization, aimed at researchers, scientists, and drug development professionals.
Data Presentation: SBP1 Expression and Prognostic Significance
The expression of SBP1 and its impact on patient prognosis display a notable dichotomy across different cancer types. Generally, SBP1 expression is downregulated in a majority of studied cancers, and this decrease is often correlated with a poor prognosis. However, in a notable exception, thyroid cancer, SBP1 is found to be upregulated and associated with tumor progression. The following tables summarize the available quantitative and qualitative data on SBP1 expression and its prognostic implications.
Table 1: Comparative Expression of SBP1 in Cancer vs. Normal Tissues
| Cancer Type | SBP1 Expression Status in Tumor Tissue | Supporting Evidence |
| Breast Cancer | Downregulated | Decreased SBP1 expression has been observed in breast cancer tissues compared to normal breast tissue.[1] |
| Colorectal Cancer | Downregulated | Studies have consistently shown lower levels of SBP1 in colorectal tumors in comparison to non-tumor tissues.[2] |
| Liver Cancer | Downregulated | A reduction in SBP1 expression is a frequent finding in hepatocellular carcinoma.[2] |
| Lung Cancer | Downregulated | Lower levels of SBP1 have been reported in lung cancer tissues.[2] |
| Prostate Cancer | Downregulated | Decreased SBP1 expression has been documented in prostate cancer.[2] |
| Thyroid Cancer | Upregulated | In contrast to other cancers, SBP1 is frequently upregulated in thyroid cancer tissues and cells.[3] |
| Ovarian Cancer | Downregulated | Reduced expression of SBP1 has been noted in invasive ovarian cancer.[3] |
Table 2: Prognostic Significance of SBP1 Expression in Various Cancers
| Cancer Type | Correlation of SBP1 Expression with Prognosis | Details of Prognostic Impact |
| Breast Cancer | Low SBP1 expression correlates with poor prognosis. | BP1, an isoform of DLX4, is overexpressed in a large percentage of invasive ductal breast carcinomas and is linked to an aggressive phenotype and poor prognosis.[1] |
| Colorectal Cancer | Low SBP1 expression is associated with poor clinical outcomes. | Reduced SBP1 is linked to poorer survival in colorectal cancer patients.[2] |
| Liver Cancer | Low SBP1 expression is associated with a worse prognosis. | Decreased SBP1 levels are correlated with poor clinical outcomes in liver cancer.[2] |
| Lung Cancer | Low SBP1 expression is associated with poor prognosis. | Lower SBP1 levels are a negative prognostic indicator in lung cancer.[2] |
| Prostate Cancer | Low SBP1 levels are associated with an increased risk of recurrence. | Lower nuclear SBP1 levels in tumor tissues are associated with a higher likelihood of recurrence after radical prostatectomy. |
| Thyroid Cancer | High SBP1 expression is associated with tumorigenesis. | Upregulated SBP1 promotes cell proliferation and dedifferentiation in thyroid cancer.[3] |
| Ovarian Cancer | High SBP1 levels are associated with poor survival. | Despite reduced expression in invasive ovarian cancer, higher SBP1 levels are paradoxically linked to worse survival outcomes.[3] |
Experimental Protocols
Accurate and reproducible measurement of SBP1 expression is critical for its validation as a biomarker. The following are detailed methodologies for the key experimental techniques used in the cited studies.
Immunohistochemistry (IHC) for SBP1 in Formalin-Fixed Paraffin-Embedded (FFPE) Tissues
Immunohistochemistry is a vital technique for assessing protein expression and localization within the tissue context.
-
Deparaffinization and Rehydration:
-
Immerse slides in xylene (3 changes, 5 minutes each).
-
Hydrate through graded alcohols: 100% ethanol (2 changes, 10 minutes each), 95% ethanol (2 changes, 10 minutes each), and finally rinse in distilled water.[4]
-
-
Antigen Retrieval:
-
Perform heat-induced epitope retrieval (HIER) by immersing slides in a citrate buffer (pH 6.0) and heating in a steamer or water bath at 95-100°C for 20-30 minutes.[5]
-
Allow slides to cool to room temperature.
-
-
Blocking:
-
Block endogenous peroxidase activity by incubating sections in 3% hydrogen peroxide for 10-15 minutes.
-
Block non-specific antibody binding with a blocking serum (e.g., 5% normal goat serum) for 1 hour at room temperature.[4]
-
-
Primary Antibody Incubation:
-
Incubate sections with a primary antibody against SBP1 at a predetermined optimal dilution overnight at 4°C in a humidified chamber.
-
-
Detection:
-
Counterstaining and Mounting:
-
Counterstain with hematoxylin to visualize cell nuclei.
-
Dehydrate the sections through graded alcohols and xylene.
-
Mount with a permanent mounting medium and coverslip.
-
Western Blotting for SBP1 in Cancer Cell Lines
Western blotting is used to quantify the total amount of SBP1 protein in cell lysates.
-
Protein Extraction:
-
Wash cells with ice-cold PBS.
-
Lyse cells in a suitable lysis buffer (e.g., RIPA buffer) containing protease inhibitors.[6]
-
Centrifuge the lysate to pellet cellular debris and collect the supernatant.
-
-
Protein Quantification:
-
Determine the protein concentration of the lysate using a protein assay (e.g., BCA assay).
-
-
Gel Electrophoresis:
-
Denature protein samples by boiling in Laemmli sample buffer.
-
Load equal amounts of protein per lane onto an SDS-polyacrylamide gel.
-
Run the gel to separate proteins by molecular weight.[6]
-
-
Protein Transfer:
-
Transfer the separated proteins from the gel to a nitrocellulose or PVDF membrane.[6]
-
-
Blocking and Antibody Incubation:
-
Block the membrane with a blocking buffer (e.g., 5% non-fat milk or BSA in TBST) for 1 hour at room temperature.
-
Incubate the membrane with a primary antibody against SBP1 overnight at 4°C.[7]
-
-
Detection:
-
Wash the membrane with TBST.
-
Incubate with an HRP-conjugated secondary antibody for 1 hour at room temperature.[6]
-
Detect the signal using an enhanced chemiluminescence (ECL) substrate and imaging system.
-
Quantitative Real-Time PCR (qRT-PCR) for SBP1 mRNA
qRT-PCR is employed to measure the relative abundance of SBP1 mRNA transcripts.
-
RNA Extraction:
-
Isolate total RNA from cells or tissues using a suitable RNA extraction kit or Trizol reagent.
-
-
cDNA Synthesis:
-
Synthesize first-strand cDNA from the total RNA using a reverse transcriptase enzyme and random primers or oligo(dT) primers.[8]
-
-
qPCR Reaction:
-
Data Analysis:
-
Run the qPCR reaction in a real-time PCR thermal cycler.
-
Determine the cycle threshold (Ct) values for SBP1 and a reference gene (e.g., GAPDH, ACTB).
-
Calculate the relative expression of SBP1 mRNA using the ΔΔCt method.
-
Signaling Pathways and Experimental Workflows
The multifaceted role of SBP1 in cancer is underscored by its involvement in several key signaling pathways. The following diagrams, generated using the DOT language, illustrate these relationships and a typical experimental workflow for studying SBP1.
References
- 1. Characterization of SHCBP1 to prognosis and immunological landscape in pan-cancer: novel insights to biomarker and therapeutic targets - PMC [pmc.ncbi.nlm.nih.gov]
- 2. schnablelab.plantgenomics.iastate.edu [schnablelab.plantgenomics.iastate.edu]
- 3. Characterization of SHCBP1 to prognosis and immunological landscape in pan-cancer: novel insights to biomarker and therapeutic targets - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. youtube.com [youtube.com]
- 5. Immunohistochemistry of tissue sections from formalin-fixed paraffin embedded (FFPE) samples [protocols.io]
- 6. origene.com [origene.com]
- 7. Western Blot Procedure | Cell Signaling Technology [cellsignal.com]
- 8. Brief guide to RT-qPCR - PMC [pmc.ncbi.nlm.nih.gov]
SBP1 Peptide: A Comparative Analysis of Antiviral Efficacy Against SARS-CoV-2 Variants
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comparative analysis of the antiviral activity of the SBP1 peptide and its derivatives against various strains of SARS-CoV-2. While initial studies on the standalone SBP1 peptide showed limited in vitro antiviral efficacy, subsequent modifications, particularly through fusion with antibody fragments and creation of tandem repeats, have demonstrated potent neutralizing capabilities. This report summarizes the quantitative data from key studies, details the experimental methodologies employed, and illustrates the underlying mechanism of action.
Comparative Antiviral Activity of SBP1 and its Derivatives
The antiviral potency of SBP1 and its engineered constructs has been evaluated against multiple SARS-CoV-2 variants. The data reveals that while the monomeric SBP1 peptide has weak to no activity, its fusion constructs, particularly the tandem SBP1-1-Ig, exhibit significant neutralization, often in the picomolar range. The following table summarizes the half-maximal inhibitory concentrations (IC50) of different SBP1 constructs against various SARS-CoV-2 pseudoviruses.
| Construct | Virus Variant (Spike Protein) | IC50 (pM) | Cell Line | Assay Type | Reference |
| SBP1-Ig (LCB1-Ig) | D614G | ~14 | 293T-ACE2 | Pseudovirus Neutralization | [1] |
| SBP1-Ig (LCB1-Ig) | Alpha | >1000 | 293T-ACE2 | Pseudovirus Neutralization | [1] |
| SBP1-Ig (LCB1-Ig) | Beta | >1000 | 293T-ACE2 | Pseudovirus Neutralization | [1] |
| SBP1-Ig (LCB1-Ig) | Gamma | >1000 | 293T-ACE2 | Pseudovirus Neutralization | [1] |
| SBP1-Ig (LCB1-Ig) | Delta | ~20 | 293T-ACE2 | Pseudovirus Neutralization | [1] |
| SBP1-Ig (LCB1-Ig) | Epsilon | ~15 | 293T-ACE2 | Pseudovirus Neutralization | [1] |
| SBP1-Ig (LCB1-Ig) | Omicron (BA.1) | >1000 | 293T-ACE2 | Pseudovirus Neutralization | [1] |
| SBP1-1-Ig (Tandem) | Omicron (BA.5) | 3.5 | 293T-ACE2 | Pseudovirus Neutralization | [2] |
| SBP1 (control peptide) | Wuhan | No antiviral activity reported | Vero cells | Not specified | [3] |
Mechanism of Action: Blocking Viral Entry
The SBP1 peptide is derived from the α1 helix of the human angiotensin-converting enzyme 2 (ACE2) receptor, the primary entry point for SARS-CoV-2 into host cells.[4] The antiviral mechanism of SBP1 and its derivatives is based on competitive inhibition. By mimicking the ACE2 binding site, the peptide binds directly to the receptor-binding domain (RBD) of the viral spike protein. This binding occludes the RBD, preventing its interaction with the host cell's ACE2 receptor and thereby blocking viral entry.[5][6]
References
- 1. Comparison of SARS-CoV-2 entry inhibitors based on ACE2 receptor or engineered Spike-binding peptides - PMC [pmc.ncbi.nlm.nih.gov]
- 2. journals.asm.org [journals.asm.org]
- 3. Peptide Inhibitors of the Interaction of the SARS-CoV-2 Receptor-Binding Domain with the ACE2 Cell Receptor - PMC [pmc.ncbi.nlm.nih.gov]
- 4. SARS-CoV-2 pan-variant inhibitory peptides deter S1-ACE2 interaction and neutralize delta and omicron pseudoviruses - PMC [pmc.ncbi.nlm.nih.gov]
- 5. A Novel Therapeutic Peptide Blocks SARS-CoV-2 Spike Protein Binding with Host Cell ACE2 Receptor - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Identification of a Potential Peptide Inhibitor of SARS-CoV-2 Targeting its Entry into the Host Cells - PMC [pmc.ncbi.nlm.nih.gov]
Navigating the SBP-1 Antibody Landscape: A Comparative Guide for Researchers
For researchers, scientists, and drug development professionals, selecting the right antibody is paramount for accurate and reproducible results. This guide provides a comprehensive cross-validation of SBP-1 antibody performance across various applications, offering a comparative analysis with available alternatives and detailed experimental protocols to support your research needs.
The term "this compound" can be ambiguous, referring to at least two distinct proteins: Sterol Regulatory Element-Binding Protein 1 (SREBP-1) and Selenium-Binding Protein 1 (SELENBP1). This guide will focus on antibodies targeting SREBP-1, a critical transcription factor in lipid metabolism, due to the greater availability of pathway information. Researchers should always verify the specific target of any antibody designated as "anti-SBP-1."
Performance Comparison of Anti-SREBP-1 (this compound) Antibodies
The performance of an antibody can vary significantly depending on the application. Below is a summary of commercially available anti-SREBP-1 antibodies and their validated applications. This data is compiled from various supplier datasheets and should be used as a starting point for your own validation experiments.
| Supplier | Catalog Number | Host Species | Validated Applications | Reported Reactivity | Notes |
| Supplier A | AB-12345 | Rabbit | Western Blot (WB), Immunohistochemistry (IHC), ELISA | Human, Mouse, Rat | Recommended for detecting the precursor form in WB. |
| Supplier B | CD-67890 | Mouse | Western Blot (WB), Immunoprecipitation (IP) | Human, Mouse | Monoclonal antibody, may offer higher specificity. |
| Supplier C | EF-54321 | Goat | Western Blot (WB), ELISA | Human | Polyclonal, may recognize multiple epitopes. |
Note: This table is a representative example. Researchers are strongly encouraged to consult the specific datasheets for the most up-to-date information and to perform in-house validation.
Experimental Protocols
Detailed and consistent protocols are crucial for reliable antibody performance. The following are standardized protocols for key applications involving this compound antibodies.
Western Blotting (WB) Protocol
This protocol outlines the essential steps for detecting SREBP-1 protein in total cell lysates or nuclear extracts.
-
Sample Preparation: Lyse cells in RIPA buffer supplemented with protease and phosphatase inhibitors. Determine protein concentration using a BCA assay.
-
SDS-PAGE: Load 20-40 µg of protein per lane on a 4-12% SDS-polyacrylamide gel.[1]
-
Protein Transfer: Transfer proteins to a nitrocellulose or PVDF membrane.[1]
-
Blocking: Block the membrane with 5% non-fat dry milk or BSA in TBST for 1 hour at room temperature.[1][2]
-
Primary Antibody Incubation: Incubate the membrane with the anti-SREBP-1 antibody (diluted in blocking buffer as per the manufacturer's recommendation) overnight at 4°C with gentle agitation.[2]
-
Washing: Wash the membrane three times for 10 minutes each with TBST.[1]
-
Secondary Antibody Incubation: Incubate the membrane with an HRP-conjugated secondary antibody (diluted in blocking buffer) for 1 hour at room temperature.[1]
-
Washing: Repeat the washing step.
-
Detection: Visualize the protein bands using an enhanced chemiluminescence (ECL) substrate.[3][4]
Immunohistochemistry (IHC) Protocol for Paraffin-Embedded Tissues
This protocol is designed for the localization of SREBP-1 in formalin-fixed, paraffin-embedded tissue sections.
-
Deparaffinization and Rehydration: Immerse slides in xylene, followed by a graded series of ethanol washes (100%, 95%, 70%) and finally in distilled water.[5][6]
-
Antigen Retrieval: Perform heat-induced epitope retrieval using a sodium citrate buffer (pH 6.0).[5]
-
Blocking: Block endogenous peroxidase activity with 3% hydrogen peroxide and block non-specific binding with a suitable blocking serum.
-
Primary Antibody Incubation: Incubate the sections with the anti-SREBP-1 antibody overnight at 4°C in a humidified chamber.[5]
-
Washing: Wash slides with PBS.
-
Secondary Antibody Incubation: Apply a biotinylated secondary antibody, followed by a streptavidin-HRP complex.
-
Washing: Repeat the washing step.
-
Detection: Visualize the staining using a DAB substrate kit, which produces a brown precipitate.
-
Counterstaining: Counterstain with hematoxylin to visualize cell nuclei.[6]
-
Dehydration and Mounting: Dehydrate the slides through a graded ethanol series and xylene, and then mount with a coverslip.[6]
Enzyme-Linked Immunosorbent Assay (ELISA) Protocol (Sandwich ELISA)
This protocol describes a sandwich ELISA for the quantitative detection of SREBP-1.
-
Coating: Coat a 96-well plate with a capture antibody specific for SREBP-1 and incubate overnight at 4°C.[7][8]
-
Washing: Wash the plate with wash buffer (e.g., PBST).
-
Blocking: Block the plate with a blocking buffer (e.g., 1% BSA in PBS) for 1-2 hours at room temperature.[8]
-
Sample and Standard Incubation: Add standards and samples to the wells and incubate for 2 hours at room temperature.[7]
-
Washing: Repeat the washing step.
-
Detection Antibody Incubation: Add a biotinylated detection antibody specific for a different epitope of SREBP-1 and incubate for 1-2 hours at room temperature.
-
Washing: Repeat the washing step.
-
Enzyme Conjugate Incubation: Add streptavidin-HRP conjugate and incubate for 30 minutes at room temperature.[8]
-
Washing: Repeat the washing step.
-
Substrate Addition: Add TMB substrate and incubate in the dark until a color develops.[7]
-
Stop Reaction: Stop the reaction with a stop solution (e.g., sulfuric acid).[7]
-
Measurement: Read the absorbance at 450 nm using a microplate reader.[9]
Signaling Pathways and Experimental Workflows
Visualizing the biological context and experimental procedures is crucial for understanding the role of this compound and the application of its antibodies.
SREBP-1 Signaling Pathway
SREBP-1 is a key regulator of lipogenesis. Its activity is primarily controlled by cellular sterol levels. When sterol levels are low, SREBP-1 is transported from the endoplasmic reticulum to the Golgi, where it is cleaved and activated. The activated N-terminal domain then translocates to the nucleus to regulate the expression of genes involved in fatty acid and cholesterol synthesis.[10]
Caption: SREBP-1 signaling pathway activation under low sterol conditions.
Western Blot Experimental Workflow
The following diagram illustrates the key stages of the Western Blotting procedure.
Caption: Key steps in the Western Blotting experimental workflow.
Alternatives to Traditional Antibodies
While monoclonal and polyclonal antibodies are the mainstay of protein detection, several alternative affinity reagents are emerging. These can offer advantages in terms of specificity, reproducibility, and stability.
-
Recombinant Antibodies: Produced in vitro, offering high batch-to-batch consistency and the potential for engineering.
-
Aptamers: Single-stranded DNA or RNA molecules that can bind to targets with high affinity and specificity. They are chemically synthesized, offering high purity and stability.[11]
-
Affimers: Small, engineered proteins that can be selected to bind to a wide range of targets. They are stable and can be produced in bacteria.[11]
The selection of an appropriate affinity reagent depends on the specific experimental needs and the nature of the target protein. Researchers should consider these alternatives, especially when traditional antibodies fail to provide the desired performance.
This guide provides a framework for the cross-validation and application of this compound antibodies. By carefully considering the available options, adhering to detailed protocols, and performing thorough in-house validation, researchers can ensure the generation of reliable and reproducible data in their studies of this compound and its crucial role in cellular metabolism.
References
- 1. resources.novusbio.com [resources.novusbio.com]
- 2. Western Blot Procedure | Cell Signaling Technology [cellsignal.com]
- 3. merckmillipore.com [merckmillipore.com]
- 4. Western Blot Protocol - Immunoblotting or Western Blot [sigmaaldrich.com]
- 5. bosterbio.com [bosterbio.com]
- 6. genscript.com [genscript.com]
- 7. sysy.com [sysy.com]
- 8. acebiolab.com [acebiolab.com]
- 9. Mouse SBP1(Selenium-binding protein 1) ELISA Kit - FineTest ELISA Kit | FineTest Antibody | FineTest® [fn-test.com]
- 10. Fat accumulation in Caenorhabditis elegans is mediated by SREBP homolog this compound - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Antibodies… What Are The Alternatives? - Pivotal Scientific [pivotalscientific.com]
SBP-1 Gene Modulation: A Comparative Analysis of Knockout and Knockdown Phenotypes in C. elegans
For Researchers, Scientists, and Drug Development Professionals: An Objective Comparison of SBP-1 Gene Inactivation Models
The Sterol Regulatory Element-Binding Protein 1 (this compound), a homolog of the mammalian SREBP-1, is a critical transcription factor in Caenorhabditis elegans that governs lipid homeostasis. Its role in regulating fatty acid synthesis and storage makes it a key target for metabolic research. Understanding the phenotypic consequences of its disruption is paramount for elucidating its function and for the development of therapeutic strategies targeting lipid metabolism. This guide provides a comprehensive comparison of this compound knockout and knockdown models in C. elegans, supported by experimental data and detailed protocols.
Distinguishing Knockout and Knockdown Models
Gene knockout and knockdown are two distinct loss-of-function approaches. A knockout (KO) model involves the complete and permanent inactivation of a gene at the genomic level, typically through techniques like CRISPR/Cas9. This results in a total absence of the corresponding protein. In contrast, a knockdown (KD) model entails the reduction of gene expression, usually at the mRNA level, through methods such as RNA interference (RNAi). This leads to a diminished, but not entirely absent, level of the protein. The choice between these models often depends on the gene's essentiality and the specific research question.
This compound Knockout: An Early Developmental Block
A complete knockout of the this compound gene in C. elegans results in a severe and lethal phenotype. Homozygous this compound deletion mutants exhibit early larval arrest , indicating that this compound is essential for normal development.[1][2] This lethality precludes the study of this compound function in adult worms using a full knockout model.
This compound Knockdown: A Window into Metabolic Function
Phenotypic Comparison: this compound Knockout vs. Knockdown
| Phenotypic Category | This compound Knockout (Deletion Mutant) | This compound Knockdown (RNAi) |
| Viability | Lethal (early larval arrest)[1][2] | Viable, but with developmental and reproductive defects[3][4] |
| Morphology | Not applicable in adults | Reduced body size, pale and skinny appearance due to the absence of lipid-laden fat granules in the intestine.[1] |
| Fat Storage | Not applicable in adults | Significantly reduced fat storage.[3][4] |
| Reproduction | Not applicable in adults | Reduced egg-laying activity.[3][4] |
| Gene Expression | Not applicable in adults | - Downregulation of lipogenic genes: fat-2, fat-5, fat-6, fat-7, elo-2, pod-2, fasn-1.[3][4][5][6] - Upregulation of the starvation-inducible gene acs-2.[3] |
Experimental Data from this compound Knockdown Studies
The following tables summarize quantitative and qualitative findings from key studies on this compound knockdown in C. elegans.
Table 1: Effects of this compound(RNAi) on Phenotype
| Parameter | Observation in this compound(RNAi) Worms | Reference |
| Body Size | Significant reduction compared to wild-type. | [3][4] |
| Fat Storage | Marked decrease in intestinal fat stores, visualized by Oil Red O staining. | [5] |
| Egg Production | Reduced number of eggs laid. | [1] |
| Response to Fatty Acids | Supplementation with oleic or linoleic acid restores body size and egg-laying but not fat accumulation.[4] | [4] |
| Response to Hypoxia | Knockdown prevents hypoxia-induced fat accumulation and increase in body width/length ratio. |
Table 2: Gene Expression Changes in this compound(RNAi) Worms
| Gene | Function | Change in Expression | Reference |
| fat-5 , fat-6 , fat-7 | Stearoyl-CoA desaturases (SCDs) | Decreased | [5] |
| fat-2 | Δ12 fatty acid desaturase | Decreased | [3] |
| elo-2 | Fatty acid elongase | Decreased | [3] |
| pod-2 | Acetyl-CoA carboxylase | Decreased | [6] |
| fasn-1 | Fatty acid synthase | Decreased | [6] |
| acs-2 | Acyl-CoA synthetase (starvation-inducible) | Increased | [3] |
Signaling Pathways and Experimental Workflows
To visualize the regulatory network of this compound and the experimental procedures used to study its function, the following diagrams are provided in DOT language.
This compound Signaling Pathway in Lipid Metabolism
Caption: this compound regulatory pathway in C. elegans lipid metabolism.
Experimental Workflow: this compound Knockdown via RNAi Feeding
Logical Comparison: Knockout vs. Knockdown
Caption: Core differences between this compound knockout and knockdown models.
Experimental Protocols
RNAi-Mediated Knockdown of this compound in C. elegans (Feeding Method)
This protocol is a generalized procedure based on common practices.
Materials:
-
C. elegans N2 (wild-type) strain
-
NGM (Nematode Growth Medium) plates containing ampicillin and IPTG
-
E. coli strain HT115(DE3) transformed with a plasmid expressing this compound dsRNA (or an empty vector control, e.g., L4440)
-
M9 buffer
-
Synchronized L1 larvae
Procedure:
-
Bacterial Culture Preparation: Inoculate a single colony of the appropriate RNAi bacteria into LB medium with ampicillin. Grow overnight at 37°C with shaking.
-
Plate Seeding: Seed NGM/IPTG/ampicillin plates with 50-100 µL of the overnight bacterial culture. Allow the plates to dry at room temperature for 1-2 days to form a bacterial lawn.
-
Worm Synchronization: Obtain a synchronized population of L1 larvae using a standard bleaching protocol.
-
RNAi Treatment: Transfer the synchronized L1 larvae onto the seeded RNAi plates.
-
Incubation: Incubate the plates at a controlled temperature (e.g., 20°C).
-
Phenotypic Analysis: After the desired developmental stage is reached (e.g., young adult), perform phenotypic analyses such as microscopy for body size and fat storage (using Oil Red O or Sudan Black staining), brood size assays, and collection of worms for qRT-PCR to assess gene expression levels.
Generation of this compound Knockout C. elegans using CRISPR/Cas9
This is a generalized protocol for generating a deletion mutant.
Materials:
-
C. elegans N2 (wild-type) strain
-
Purified Cas9 protein
-
Custom-synthesized single guide RNAs (sgRNAs) targeting the this compound locus
-
Repair template (single-stranded or double-stranded DNA) if using homology-directed repair
-
Microinjection setup
-
NGM plates
Procedure:
-
sgRNA Design and Synthesis: Design two sgRNAs that flank a critical region of the this compound gene to induce a deletion. Synthesize these sgRNAs.
-
Injection Mix Preparation: Prepare a microinjection mix containing Cas9 protein, the two sgRNAs, and any co-injection markers (e.g., a plasmid expressing a fluorescent protein).
-
Microinjection: Inject the mix into the gonads of young adult wild-type hermaphrodites.
-
Screening for Mutants:
-
Single the injected worms (P0 generation) onto individual plates and allow them to lay eggs.
-
Screen the F1 progeny for the desired phenotype or for the presence of the co-injection marker.
-
Isolate F1s and allow them to self-fertilize to produce the F2 generation.
-
-
Genotyping:
-
From the F2 generation, screen for homozygous mutants by PCR using primers that flank the targeted deletion site. A smaller PCR product will indicate a successful deletion.
-
Confirm the deletion by Sanger sequencing of the PCR product.
-
-
Strain Maintenance: Establish a stable line from the confirmed homozygous knockout animals. Note that for this compound, this will result in a strain that arrests at the early larval stage.
Conclusion
The study of this compound in C. elegans provides a clear example of how the choice between knockout and knockdown models is dictated by the essentiality of the gene. While the lethality of the this compound knockout confirms its indispensable role in development, the knockdown model has been invaluable for dissecting its specific functions in lipid metabolism in post-larval stages. The data consistently show that reduced this compound function leads to decreased fat storage and altered expression of key lipogenic enzymes. These findings underscore the conserved role of SREBP family members in metabolic regulation and highlight the utility of C. elegans as a model system for studying complex metabolic pathways. For drug development professionals, the downstream targets of this compound, such as the fatty acid desaturases, represent potential points of therapeutic intervention for metabolic disorders.
References
- 1. uniprot.org [uniprot.org]
- 2. Gene: this compound, Species: Caenorhabditis elegans - Caenorhabditis Genetics Center (CGC) - College of Biological Sciences [cgc.umn.edu]
- 3. Fat accumulation in Caenorhabditis elegans is mediated by SREBP homolog this compound - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Fat accumulation in Caenorhabditis elegans is mediated by SREBP homolog this compound - PMC [pmc.ncbi.nlm.nih.gov]
- 5. SREBP and MDT-15 protect C. elegans from glucose-induced accelerated aging by preventing accumulation of saturated fat - PMC [pmc.ncbi.nlm.nih.gov]
- 6. The MXL-3/SBP-1 Axis Is Responsible for Glucose-Dependent Fat Accumulation in C. elegans - PMC [pmc.ncbi.nlm.nih.gov]
comparative analysis of SBP-1 orthologs across different species
A Comparative Analysis of SBP-1 Orthologs for Researchers, Scientists, and Drug Development Professionals
This guide provides a detailed comparative analysis of Selenium-Binding Protein 1 (this compound) orthologs across various species, including human (Homo sapiens), the nematode worm (Caenorhabditis elegans), and plants like Arabidopsis thaliana. This compound and its orthologs are a conserved family of proteins implicated in a wide range of cellular processes, from stress responses and detoxification to the regulation of lipid metabolism. This document summarizes key quantitative data, details relevant experimental methodologies, and visualizes associated signaling pathways to facilitate further research and drug development efforts.
Quantitative Data Summary
The following tables provide a summary of the known quantitative data for this compound orthologs. While extensive comparative data is still an area of active research, this section consolidates available information on sequence homology and enzymatic activity.
Table 1: Sequence Identity of this compound Orthologs (%)
| Species | Homo sapiens (SELENBP1) | Caenorhabditis elegans (SEMO-1) | Arabidopsis thaliana (AtSBP1) | Mus musculus (SBP1) |
| Homo sapiens (SELENBP1) | 100 | - | 57-60 | 86[1] |
| Caenorhabditis elegans (SEMO-1) | - | 100 | - | - |
| Arabidopsis thaliana (AtSBP1) | 57-60[1] | - | 100 | - |
| Mus musculus (SBP1) | 86[1] | - | - | 100 |
Note: A dash (-) indicates that specific comparative data was not available in the searched literature.
Table 2: Kinetic Parameters of Methanethiol Oxidase (MTO) Activity
| Ortholog | Species | Substrate | Km | Vmax | Notes |
| SELENBP1 | Homo sapiens | Methanethiol | 4.8 nM[2] | - | Activity is copper-dependent.[3] |
| SEMO-1 | C. elegans | Methanethiol | - | - | Activity is copper-dependent.[3] |
Note: A dash (-) indicates that specific quantitative data was not available in the searched literature.
Key Signaling Pathways and Functions
This compound orthologs participate in diverse signaling pathways across different species. This section outlines two prominent examples: the regulation of lipid metabolism in C. elegans and the heat shock response in humans.
C. elegans: this compound in Lipid Metabolism
In C. elegans, this compound is a key transcription factor that regulates fat metabolism. It is involved in a signaling cascade that responds to nutrient availability and environmental stressors.
-
MDT-15-SBP-1-FAT-6 Pathway: The Mediator complex subunit MDT-15 acts as an upstream regulator of this compound. This pathway is crucial for the expression of fatty acid desaturases like fat-6, which are involved in maintaining lipid homeostasis, particularly in response to conditions like simulated microgravity.[4]
-
MXL-3/SBP-1 Axis: In response to high glucose, the transcription factor MXL-3 promotes the nuclear localization of this compound, leading to increased expression of genes involved in fatty acid synthesis and accumulation of fat.[5]
-
Regulation by SIR-2.1: The sirtuin SIR-2.1, an ortholog of mammalian SIRT1, has been shown to negatively regulate this compound activity during fasting, thereby inhibiting lipid synthesis and storage.[6]
Figure 1: this compound signaling in C. elegans lipid metabolism.
Human: HSBP1 in the Heat Shock Response
In humans, the this compound ortholog, Heat Shock Factor Binding Protein 1 (HSBP1), is a negative regulator of the heat shock response. This response is a crucial cellular defense mechanism against proteotoxic stress.
-
Interaction with HSF1: Under stress conditions such as heat shock, Heat Shock Factor 1 (HSF1) forms a trimer, translocates to the nucleus, and activates the transcription of heat shock proteins (HSPs). HSBP1 interacts with the active trimeric form of HSF1, leading to the attenuation of this response.[5][7] This interaction negatively affects the DNA-binding activity of HSF1.[5][7]
Figure 2: HSBP1 in the human heat shock response.
Experimental Protocols
This section provides detailed methodologies for key experiments relevant to the study of this compound orthologs.
RNAi-Mediated Knockdown of this compound in C. elegans by Feeding
This protocol describes a standard method for inducing RNA interference (RNAi) in C. elegans by feeding them bacteria engineered to express double-stranded RNA (dsRNA) corresponding to the this compound gene.
Materials:
-
NGM (Nematode Growth Medium) agar plates containing ampicillin (50 µg/mL) and IPTG (1 mM).
-
E. coli strain HT115(DE3) transformed with the L4440 vector containing a genomic fragment of this compound.
-
E. coli strain HT115(DE3) with the empty L4440 vector (control).
-
Synchronized L1-stage wild-type (N2) worms.
-
M9 buffer.
Procedure:
-
Bacterial Culture: Inoculate a single colony of the this compound(RNAi) and control bacteria into separate 3 mL LB cultures with ampicillin (50 µg/mL). Grow overnight at 37°C with shaking.
-
Seeding Plates: Pipette 150 µL of the overnight bacterial culture onto the center of the NGM/ampicillin/IPTG plates. Allow the plates to dry overnight at room temperature to form a bacterial lawn. The IPTG in the media will induce the expression of the this compound dsRNA.
-
Worm Synchronization: Prepare a synchronized population of L1 larvae using standard bleaching methods.
-
RNAi Treatment: Transfer approximately 50-100 synchronized L1 worms in M9 buffer to the center of the prepared RNAi plates.
-
Incubation: Incubate the plates at 20°C.
-
Phenotypic Analysis: After 3 days, observe the F1 progeny for phenotypes associated with this compound knockdown, such as reduced body size, decreased fat storage (which can be visualized by Oil Red O or Sudan Black staining), and reduced brood size.[8]
Figure 3: Workflow for This compound RNAi by feeding in C. elegans.
Coupled Enzyme Assay for Methanethiol Oxidase (MTO) Activity
This protocol details a coupled enzyme assay to measure the MTO activity of this compound orthologs, such as human SELENBP1.[1][9] The assay relies on the in situ generation of the substrate, methanethiol, by L-methionine-gamma-lyase (MGL), and the subsequent detection of the reaction products, hydrogen sulfide (H₂S) and hydrogen peroxide (H₂O₂).
Materials:
-
Purified recombinant this compound ortholog.
-
Purified recombinant MGL.
-
L-methionine.
-
Pyridoxal 5'-phosphate (PLP).
-
HEPES-buffered saline (HBS).
-
Lead (II) acetate paper strips.
-
Fluorescent probe for H₂O₂ detection (e.g., Amplex Red).
-
Horseradish peroxidase (HRP).
-
384-well microplate.
Procedure:
-
Reaction Setup: The assay is performed in a 384-well plate. In one well (the "generator well"), prepare the MGL reaction mix containing MGL, L-methionine, and PLP in HBS. This will continuously generate volatile methanethiol.
-
MTO Reaction: In an adjacent well (the "detector well"), add the purified this compound ortholog in HBS. The methanethiol gas produced in the generator well will diffuse and dissolve into the detector well, serving as the substrate for the MTO reaction.
-
H₂S Detection: Place a strip of lead (II) acetate paper over the top of the wells. H₂S produced from the MTO reaction will react with the lead acetate to form a dark precipitate (PbS), providing a qualitative or semi-quantitative measure of H₂S production.
-
H₂O₂ Detection: To the detector well, add the fluorescent probe for H₂O₂ and HRP. The H₂O₂ produced by the MTO reaction will be reduced by HRP, leading to the oxidation of the probe and a measurable increase in fluorescence.
-
Measurement: Monitor the change in fluorescence over time using a microplate reader. The rate of fluorescence increase is proportional to the MTO activity.
References
- 1. Selenium-Binding Protein 1 in Human Health and Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Heat shock factor protein 1 - Wikipedia [en.wikipedia.org]
- 3. Selenium-binding protein 1 (SELENBP1) is a copper-dependent thiol oxidase - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Lipid metabolic sensors of MDT-15 and this compound regulated the response to simulated microgravity in the intestine of Caenorhabditis elegans - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. MDT-15/MED15 permits longevity at low temperature via enhancing lipidostasis and proteostasis - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. The Repertoire of Solute-Binding Proteins of Model Bacteria Reveals Large Differences in Number, Type, and Ligand Range - PMC [pmc.ncbi.nlm.nih.gov]
- 9. genecards.org [genecards.org]
A Comparative Guide to the Binding Affinity of SBP1 Peptide Variants
For Researchers, Scientists, and Drug Development Professionals
This guide provides an objective comparison of the binding affinities of various Spike-Binding Peptide 1 (SBP1) variants to the Receptor-Binding Domain (RBD) of the SARS-CoV-2 Spike protein. The information is compiled from multiple studies and is intended to aid researchers in selecting and developing potent peptide-based inhibitors of the SARS-CoV-2 virus.
Introduction
The entry of SARS-CoV-2 into host cells is primarily mediated by the interaction between the viral Spike (S) protein's Receptor-Binding Domain (RBD) and the human Angiotensin-Converting Enzyme 2 (ACE2) receptor.[1][2] Peptides derived from the ACE2 receptor, such as SBP1, have been investigated as potential therapeutic agents that can competitively inhibit this interaction.[1][3] SBP1 is a 23-amino acid peptide derived from the α1 helix of the ACE2 peptidase domain.[4][5] However, the binding affinity of the original SBP1 peptide has shown variability in different studies, leading to the development of several variants with improved binding characteristics and stability.[6]
This guide compares the binding affinities of SBP1 and its notable variants, presents the experimental methodologies used for their characterization, and illustrates the underlying mechanism of action.
Data Presentation: Binding Affinity of SBP1 Peptide Variants
The following table summarizes the reported dissociation constants (Kd) for SBP1 and its variants. It is important to note that the binding affinity of SBP1 has been reported with significant variability, with Kd values ranging from 47 nM to over 1.3 µM.[1][3][6] This discrepancy is often attributed to the different expression systems used for the SARS-CoV-2 S-RBD (e.g., insect vs. human cells) and the propensity of the SBP1 peptide to form oligomers.[3][6]
| Peptide Variant | Description | Reported Kd | Experimental Method | Reference |
| SBP1 | Original 23-mer peptide from ACE2 α1 helix. | 47 nM | Bio-layer Interferometry | [3][4] |
| 1.3 µM | Bio-layer Interferometry | [1] | ||
| >1 µM | Not specified | [6] | ||
| SBP1mod | SBP1 with mutations to reduce oligomerization. | Binding measured, but specific Kd not provided. | Fluorescence Correlation Spectroscopy | [6] |
| SPB25 Variants | 25-mer peptides based on ACE2 α1 helix, computationally designed for enhanced binding. | Predicted to have better binding affinity than SBP1 and ACE2. | Computational (MM-GBSA) | [4][7][8][9][10] |
| LCB1 | Computationally designed 56-amino acid miniprotein. | 0.2 nM | Not specified | [11] |
| Sub-nanomolar affinity | Not specified | [12] | ||
| LCB3 | Computationally designed 64-amino acid miniprotein. | Picomolar range | Not specified | [5] |
| Chimeric Peptides (X1, X2) | Designed peptides mimicking the ACE2 receptor. | 1-10 µM | Microscale Thermophoresis | [3] |
Experimental Protocols
The determination of binding affinity for SBP1 and its variants has been accomplished using several biophysical techniques. Below are detailed methodologies for the key experiments cited.
Bio-layer Interferometry (BLI)
Bio-layer Interferometry is an optical analytical technique that analyzes the interference pattern of white light reflected from two surfaces: a layer of immobilized protein on the biosensor tip and an internal reference layer. The binding of an analyte to the immobilized ligand on the biosensor tip causes a shift in the interference pattern, which is measured in real-time to determine association and dissociation rates.[13][14]
Protocol:
-
Immobilization: A biotinylated version of the SBP1 peptide or its variant (ligand) is immobilized onto a streptavidin-coated biosensor tip.[13][15]
-
Baseline: The biosensor tip with the immobilized peptide is dipped into a buffer-containing well to establish a stable baseline reading.[14]
-
Association: The biosensor tip is then moved to a well containing the SARS-CoV-2 S-RBD protein (analyte) at a known concentration. The change in interference is monitored over time as the RBD binds to the peptide.[13][14]
-
Dissociation: After the association phase, the biosensor tip is moved back to a buffer-only well, and the dissociation of the RBD from the peptide is monitored.[13][14]
-
Data Analysis: The association and dissociation curves are fitted to a binding model to calculate the association rate constant (kon), the dissociation rate constant (koff), and the equilibrium dissociation constant (Kd = koff/kon).[16]
Microscale Thermophoresis (MST)
Microscale Thermophoresis measures the motion of molecules in a microscopic temperature gradient. A change in the hydration shell, charge, or size of a molecule upon binding to a ligand alters its movement in the temperature gradient, which is detected by a change in fluorescence.[17][18]
Protocol:
-
Labeling: The SARS-CoV-2 S-RBD protein is fluorescently labeled.
-
Sample Preparation: A series of dilutions of the unlabeled SBP1 peptide or its variant (ligand) is prepared. A constant concentration of the fluorescently labeled RBD is added to each dilution.[19]
-
Measurement: The samples are loaded into glass capillaries, and an infrared laser is used to create a precise temperature gradient. The movement of the fluorescently labeled RBD is monitored.[18][19]
-
Data Analysis: The change in the thermophoretic movement is plotted against the ligand concentration, and the resulting binding curve is fitted to determine the dissociation constant (Kd).[19]
Fluorescence Correlation Spectroscopy (FCS)
Fluorescence Correlation Spectroscopy is a technique that analyzes fluorescence fluctuations to measure the diffusion of fluorescently labeled molecules through a tiny, focused laser beam. The binding of a small fluorescently labeled peptide to a larger protein results in a slower diffusion time, which can be used to determine the binding affinity.[20][21]
Protocol:
-
Labeling: The SBP1 peptide or its variant is labeled with a fluorescent dye.[6][20]
-
Sample Preparation: The fluorescently labeled peptide is mixed with varying concentrations of the SARS-CoV-2 S-RBD protein.[20]
-
Measurement: The samples are placed on a microscope, and the fluorescence fluctuations within the focused laser volume are recorded over time.[20][21]
-
Data Analysis: The autocorrelation of the fluorescence intensity fluctuations is calculated to determine the diffusion times of the free and bound peptide. The fraction of bound peptide is then plotted against the RBD concentration to determine the dissociation constant (Kd).[20][22]
Mandatory Visualization
Signaling Pathway: Inhibition of SARS-CoV-2 Entry
The primary mechanism of action for SBP1 and its variants is the competitive inhibition of the interaction between the SARS-CoV-2 Spike protein's Receptor-Binding Domain (RBD) and the human ACE2 receptor. By binding to the RBD, the SBP1 peptide blocks the virus from engaging with the host cell receptor, thereby preventing viral entry and subsequent infection.
Caption: SBP1 peptide competitively inhibits SARS-CoV-2 entry.
Experimental Workflow: Bio-layer Interferometry (BLI)
The following diagram illustrates a typical workflow for determining the binding affinity of an SBP1 peptide variant to the SARS-CoV-2 S-RBD using Bio-layer Interferometry.
Caption: Workflow for measuring binding affinity using BLI.
References
- 1. Synthetic Peptides That Antagonize the Angiotensin-Converting Enzyme-2 (ACE-2) Interaction with SARS-CoV-2 Receptor Binding Spike Protein - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Frontiers | Receptor-binding domain-anchored peptides block binding of severe acute respiratory syndrome coronavirus 2 spike proteins with cell surface angiotensin-converting enzyme 2 [frontiersin.org]
- 3. Peptide Inhibitors of the Interaction of the SARS-CoV-2 Receptor-Binding Domain with the ACE2 Cell Receptor - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Computational design of SARS-CoV-2 peptide binders with better predicted binding affinities than human ACE2 receptor - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. Biophysical properties of the isolated spike protein binding helix of human ACE2 - PMC [pmc.ncbi.nlm.nih.gov]
- 7. pubs.acs.org [pubs.acs.org]
- 8. researchgate.net [researchgate.net]
- 9. Computational Design of 25-mer Peptide Binders of SARS-CoV-2 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Designing peptides predicted to bind to the omicron variant better than ACE2 via computational protein design and molecular dynamics - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. Fusion of SARS-CoV-2 neutralizing LCB1 peptide with Bacillus amyloliquefaciens RNase improves antiviral efficacy - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Identifying Protein Interactions with Histone Peptides Using Bio-layer Interferometry - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Bio-layer Interferometry for Measuring Kinetics of Protein-protein Interactions and Allosteric Ligand Effects [jove.com]
- 15. researchgate.net [researchgate.net]
- 16. Determining the Binding Kinetics of Peptide Macrocycles Using Bio-Layer Interferometry (BLI) | Springer Nature Experiments [experiments.springernature.com]
- 17. MicroScale Thermophoresis as a Tool to Study Protein-peptide Interactions in the Context of Large Eukaryotic Protein Complexes - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. repozitorij.unizg.hr [repozitorij.unizg.hr]
- 19. Video: Use of Microscale Thermophoresis to Measure Protein-Lipid Interactions [jove.com]
- 20. Fluorescence Correlation Spectroscopy Studies of Peptide and Protein Binding to Phospholipid Vesicles - PMC [pmc.ncbi.nlm.nih.gov]
- 21. Frontiers | A Comprehensive Review of Fluorescence Correlation Spectroscopy [frontiersin.org]
- 22. fluorescencecorrelation.com [fluorescencecorrelation.com]
Unveiling a Novel SBP-1 Mediated Metabolic Network: A Comparative Guide
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive comparison of a novel SBP-1 mediated metabolic pathway, the phosphatidylcholine feedback circuit, against the classical sterol-regulated pathway. We present supporting experimental data, detailed protocols for validation, and visual diagrams to facilitate a deeper understanding of these critical lipid homeostasis mechanisms.
Introduction to this compound and Lipid Metabolism
Sterol Regulatory Element-Binding Proteins (SREBPs) are master transcription factors governing the synthesis of lipids and cholesterol. In the nematode C. elegans, the SREBP homolog, this compound, plays a pivotal role in fat storage and metabolism, making it a valuable model for studying lipid homeostasis.[1][2] this compound, much like its mammalian counterpart SREBP-1, activates a suite of genes involved in de novo lipogenesis in response to various stimuli, including high glucose levels and oxygen deprivation.[3][4][5]
Recent research has uncovered a novel this compound mediated pathway that links the one-carbon cycle (1CC) to phosphatidylcholine (PC) biosynthesis, revealing a sophisticated feedback mechanism for maintaining membrane integrity.[1] This guide will compare this novel pathway with the well-established sterol-dependent activation of SREBPs.
Comparative Analysis of this compound/SREBP-Mediated Pathways
The regulation of lipid homeostasis is intricate, with multiple pathways converging to ensure cellular integrity and energy balance. Below is a comparison of the key features of the novel this compound/phosphatidylcholine feedback circuit and the classical SREBP-2/sterol-regulated pathway.
| Feature | Novel this compound/PC Feedback Circuit | Classical SREBP-2/Sterol-Regulated Pathway |
| Primary Inducer | Low phosphatidylcholine (PC) levels | Low cellular sterol levels |
| Key Transcription Factor | This compound (C. elegans) / SREBP-1 (mammals) | SREBP-2 |
| Core Metabolic Pathway Regulated | One-carbon cycle (1CC) for SAMe production | Cholesterol biosynthesis |
| Primary Function | Maintain phospholipid homeostasis | Maintain cholesterol homeostasis |
| Key Regulated Genes | sams-1 (SAMe synthase), other 1CC genes | Genes of the mevalonate pathway (e.g., HMG-CoA reductase) |
| Activation Mechanism | Independent of SCAP/sterol sensing | Dependent on SCAP as a sterol sensor |
Experimental Validation Protocols
The validation of metabolic pathways requires a multi-pronged approach, combining genetic, molecular, and biochemical techniques. Here are detailed methodologies for key experiments.
Protocol 1: RNA Interference (RNAi) for this compound Knockdown
Objective: To assess the necessity of this compound in regulating the target metabolic pathway.
Methodology:
-
Construct Preparation: Prepare RNAi feeding constructs targeting the this compound gene in an appropriate vector (e.g., L4440).
-
Bacterial Culture: Transform the RNAi construct into a suitable E. coli strain (e.g., HT115) and grow overnight in LB medium with appropriate antibiotics.
-
NGM Plate Preparation: Seed Nematode Growth Medium (NGM) plates with the cultured bacteria and induce dsRNA expression with IPTG.
-
Worm Synchronization: Synchronize a population of C. elegans by bleaching and hatching the eggs in M9 buffer.
-
RNAi Treatment: Place the synchronized L1 larvae onto the prepared RNAi plates and allow them to grow at 20°C.
-
Phenotypic Analysis: After the desired duration (e.g., 48-72 hours), score the worms for relevant phenotypes, such as fat storage (using Oil Red O staining), growth, and fecundity.
-
Gene Expression Analysis: Harvest the worms and perform qRT-PCR to confirm the knockdown of this compound and to measure the expression of downstream target genes.
Protocol 2: Quantitative Real-Time PCR (qRT-PCR) for Gene Expression Analysis
Objective: To quantify the expression levels of this compound target genes.
Methodology:
-
RNA Extraction: Extract total RNA from control and experimental groups of C. elegans using a suitable method (e.g., Trizol).
-
cDNA Synthesis: Synthesize complementary DNA (cDNA) from the extracted RNA using a reverse transcriptase kit.
-
Primer Design: Design and validate primers specific to the target genes (e.g., fat-6, fat-7, sams-1) and a reference gene (e.g., act-1).
-
qPCR Reaction: Set up the qPCR reaction using a SYBR Green master mix, the synthesized cDNA, and the specific primers.
-
Data Analysis: Analyze the amplification data using the ΔΔCt method to determine the relative fold change in gene expression between the control and experimental groups.
Protocol 3: Lipid Analysis by Oil Red O Staining
Objective: To visualize and quantify neutral lipid stores in C. elegans.
Methodology:
-
Worm Collection and Washing: Collect worms from NGM plates and wash them with M9 buffer to remove bacteria.
-
Fixation: Fix the worms in a solution of paraformaldehyde.
-
Staining: Stain the fixed worms with a filtered Oil Red O solution.
-
Mounting and Imaging: Mount the stained worms on an agarose pad on a glass slide and image using a light microscope equipped with a camera.
-
Quantification: Quantify the intensity of the Oil Red O staining using image analysis software (e.g., ImageJ) to determine the relative fat content.
Visualizing the Pathways and Experimental Workflow
To further elucidate the this compound mediated pathway and the experimental approaches to its validation, the following diagrams are provided.
Caption: Comparison of the this compound/PC feedback circuit and the classical SREBP-2 pathway.
Caption: A typical experimental workflow for validating a novel metabolic pathway.
Conclusion
The discovery of the this compound/phosphatidylcholine feedback circuit adds a new layer of complexity to our understanding of lipid metabolism. This pathway, which operates independently of the classical sterol-sensing mechanism, highlights the intricate regulatory networks that have evolved to maintain cellular homeostasis. By employing the experimental strategies outlined in this guide, researchers can further dissect this and other novel metabolic pathways, paving the way for the development of new therapeutic interventions for metabolic diseases.
References
- 1. A conserved SREBP-1/phosphatidylcholine feedback circuit regulates lipogenesis in metazoans - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Fat accumulation in Caenorhabditis elegans is mediated by SREBP homolog this compound - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. Essential role of this compound activation in oxygen deprivation induced lipid accumulation and increase in body width/length ratio in Caenorhabditis elegans - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. The MXL-3/SBP-1 Axis Is Responsible for Glucose-Dependent Fat Accumulation in C. elegans - PMC [pmc.ncbi.nlm.nih.gov]
comparative transcriptomics of wild-type vs. SBP-1 mutant organisms
For Researchers, Scientists, and Drug Development Professionals
This guide provides an objective comparison of the transcriptomic landscapes of wild-type Caenorhabditis elegans and organisms with mutated or suppressed Sterol Regulatory Element-Binding Protein (SBP-1). This compound, a homolog of the mammalian SREBP, is a critical transcription factor that governs lipid homeostasis. Understanding the genetic downstream effects of its disruption is vital for research into metabolic disorders and potential therapeutic interventions. This document summarizes key transcriptomic changes, details the experimental protocols used to obtain this data, and visualizes the relevant biological pathways and workflows.
Quantitative Data Summary
Loss of this compound function, typically achieved through RNA interference (RNAi), leads to significant alterations in the expression of genes predominantly involved in lipid metabolism. The following table summarizes the key differentially expressed genes in this compound(RNAi) nematodes compared to wild-type controls.
| Gene | Description | Regulation in this compound Mutant |
| fat-5 | Stearoyl-CoA desaturase | Downregulated |
| fat-6 | Stearoyl-CoA desaturase | Downregulated |
| fat-7 | Stearoyl-CoA desaturase | Downregulated |
| elo-2 | Fatty acid elongase | Downregulated |
| pod-2 | Acetyl-CoA carboxylase | Downregulated |
| fasn-1 | Fatty acid synthase | Downregulated |
| Genes in the one-carbon cycle | Involved in S-adenosylmethionine (SAM) production | Downregulated |
| acs-2 | Acyl-CoA synthetase (starvation-inducible) | Upregulated |
Experimental Protocols
The transcriptomic data presented is primarily derived from RNA sequencing (RNA-seq) experiments. Below is a detailed methodology for a typical comparative transcriptomic study of wild-type vs. This compound(RNAi)C. elegans.
I. C. elegans Culture and RNAi Treatment
-
Worm Strain and Culture: Wild-type C. elegans (Bristol N2 strain) are cultured at 20°C on Nematode Growth Medium (NGM) agar plates seeded with E. coli OP50 as a food source.[1]
-
RNAi Clone: An E. coli HT115 strain carrying an L4440 vector with a fragment of the this compound gene is used for RNAi by feeding. A control group is fed E. coli HT115 with an empty L4440 vector.
-
Synchronization: A synchronized population of L1 larvae is obtained by treating gravid adult worms with a bleach solution to isolate eggs, which are then allowed to hatch in M9 buffer.
-
RNAi Treatment: Synchronized L1 larvae are placed on NGM plates seeded with the this compound RNAi or control bacteria and are grown to the young adult stage.
II. RNA Extraction and Sequencing
-
Harvesting: Young adult worms are harvested from the NGM plates by washing with M9 buffer.
-
RNA Isolation: Total RNA is extracted from the worm pellets using a TRIzol-based method, followed by purification to remove contaminating DNA. RNA quality and integrity are assessed using a bioanalyzer.
-
Library Preparation: An RNA-seq library is prepared from the total RNA. This typically involves poly(A) selection for mRNA, fragmentation of the mRNA, reverse transcription to cDNA, and ligation of sequencing adapters.
-
Sequencing: The prepared library is sequenced on a high-throughput sequencing platform (e.g., Illumina).
III. Bioinformatic Analysis
-
Quality Control: Raw sequencing reads are assessed for quality, and adapters are trimmed.
-
Alignment: The processed reads are aligned to the C. elegans reference genome.
-
Differential Gene Expression Analysis: The number of reads mapping to each gene is counted, and statistical analysis is performed to identify genes that are differentially expressed between the this compound(RNAi) and control samples. A significance threshold is typically set for the p-value and fold change.
-
Functional Annotation and Pathway Analysis: Gene Ontology (GO) and pathway enrichment analyses are performed on the list of differentially expressed genes to identify overrepresented biological processes and pathways.
Visualizations
This compound Signaling Pathway in Lipid Metabolism
The following diagram illustrates the central role of this compound in regulating the expression of genes involved in fatty acid biosynthesis and desaturation.
Caption: this compound mediated regulation of lipid biosynthesis.
Experimental Workflow for Comparative Transcriptomics
This diagram outlines the key steps involved in the comparative transcriptomic analysis of wild-type versus this compound mutant C. elegans.
Caption: Workflow for comparative transcriptomic analysis.
Logical Relationship of this compound and Downstream Effects
The following diagram illustrates the logical flow from this compound function to the resulting phenotype.
References
Safety Operating Guide
Essential Safety and Handling Guide for SBP-1 Peptide
This document provides crucial safety and logistical information for the handling of SBP-1, a 23-amino acid peptide derived from the human ACE2 receptor.[1][2][3][4] It is intended for researchers, scientists, and drug development professionals. The guidance provided herein is based on standard laboratory practices for non-hazardous biological materials and assumes the substance is the this compound peptide used in research, not to be confused with industrial chemicals of a similar name. Always refer to the supplier-specific Safety Data Sheet (SDS) for definitive safety information.
Product Identification and Properties
This compound is a synthetic peptide used in laboratory research, particularly in studies involving the SARS-CoV-2 spike protein.[1][2][3][4] While specific hazard data for this compound is not widely available, it is handled as a non-hazardous biological material under Biosafety Level 1 (BSL-1) conditions.[5][6]
Quantitative Data Summary
| Property | Value | Source |
| Molecular Weight | 2802.05 g/mol | [1][3] |
| Molecular Formula | C₁₂₇H₁₈₅N₃₁O₄₁ | [1][3] |
| Amino Acid Sequence | IEEQAKTFLDKFNHEAEDLFYQS | [1][3] |
| Purity | ≥95% | [1][3] |
| Solubility | Soluble to 1 mg/ml in PBS or water | [1][2][3] |
| Storage | Store at -20°C, desiccated and in the dark | [1][2][3] |
Personal Protective Equipment (PPE)
A risk assessment should be conducted to determine the appropriate PPE for the specific procedures being performed.[7] However, the following table outlines the minimum recommended PPE for handling this compound under standard laboratory conditions.
| PPE Item | Specification | Purpose |
| Gloves | Nitrile or latex, disposable | Protect hands from contact with the peptide solution.[7][8] |
| Lab Coat | Standard, buttoned | Protect skin and personal clothing from splashes.[5][6] |
| Eye Protection | Safety glasses with side shields or goggles | Protect eyes from splashes.[7][9] |
| Face Protection | Face shield (in addition to goggles) | Recommended if there is a significant risk of splashes or aerosols.[9] |
PPE Usage Workflow
Figure 1: Standard workflow for donning and doffing Personal Protective Equipment (PPE).
Handling and Operational Plan
Receiving and Storage:
-
Upon receipt, inspect the package for any damage or leaks.
-
Store the lyophilized peptide at -20°C in a desiccated environment, protected from light.[1][2][3]
Reconstitution:
-
Allow the vial to equilibrate to room temperature before opening to prevent condensation.
-
Reconstitute the peptide using sterile Phosphate Buffered Saline (PBS) or sterile water to a stock concentration of 1 mg/ml.[1][2][3]
-
Gently vortex or pipette to dissolve the powder. Avoid vigorous shaking.
-
If the entire stock solution is not used immediately, aliquot into smaller working volumes to avoid repeated freeze-thaw cycles. Store aliquots at -20°C for up to one month.[2]
Experimental Use:
-
All work should be conducted in a designated and clean laboratory area.[5]
-
Use aseptic techniques to prevent microbial contamination.
-
Perform all procedures in a manner that minimizes the creation of splashes and aerosols.[6][8]
-
Do not eat, drink, smoke, or apply cosmetics in the laboratory.[6][8]
-
Wash hands thoroughly after handling the material and before leaving the laboratory.[6][8]
Experimental Workflow for this compound Handling
Figure 2: Procedural workflow for the safe handling and use of this compound peptide in a laboratory setting.
Spill and Exposure Procedures
Spill Response:
-
Alert others in the immediate area of the spill.
-
For a small spill of this compound solution, absorb the liquid with paper towels.
-
Decontaminate the spill area with a 10% bleach solution or another appropriate laboratory disinfectant, allowing for a contact time of at least 10 minutes.[10][11]
-
Wipe the area clean with fresh paper towels.
-
Dispose of all contaminated materials in the biohazardous waste.[10][11]
Personnel Exposure:
-
Eye Contact: Immediately flush eyes with copious amounts of water for at least 15 minutes, occasionally lifting the upper and lower eyelids. Seek medical attention.
-
Skin Contact: Remove contaminated clothing and wash the affected area with soap and water for at least 15 minutes.
-
Inhalation: Move the individual to fresh air. If breathing is difficult, seek medical attention.
-
Ingestion: Do NOT induce vomiting. If the person is conscious, rinse their mouth with water and have them drink one to two glasses of water. Seek immediate medical attention.
Disposal Plan
All materials that have come into contact with this compound, including pipette tips, tubes, and gloves, should be considered biohazardous waste.
Disposal Protocol:
-
Collect all contaminated solid waste in a designated biohazard bag.
-
Liquid waste can be decontaminated by adding bleach to a final concentration of 10% and allowing it to sit for at least 30 minutes before disposing down the drain with copious amounts of water, in accordance with institutional guidelines.
-
Sharps, such as needles or contaminated glassware, must be disposed of in a designated sharps container.[8][11]
-
All biohazardous waste must be autoclaved before final disposal according to institutional and local regulations.
Disposal Decision Tree
Figure 3: Decision tree for the proper segregation and disposal of waste generated during work with this compound.
References
- 1. rndsystems.com [rndsystems.com]
- 2. SBP1 | ACE2 derived peptide | Hello Bio [hellobio.com]
- 3. lifescienceproduction.co.uk [lifescienceproduction.co.uk]
- 4. SBP1 peptide [novoprolabs.com]
- 5. Basics of Biosafety Level 1 | Office of Clinical and Research Safety [vumc.org]
- 6. Standard Laboratory Practices for BSL-1 Laboratories – Laboratory Safety Manual [lsm.alfaisal.edu]
- 7. Personal Protective Equipment (PPE) – Biorisk Management [aspr.hhs.gov]
- 8. sc.edu [sc.edu]
- 9. epa.gov [epa.gov]
- 10. ehs.oregonstate.edu [ehs.oregonstate.edu]
- 11. ehs.utexas.edu [ehs.utexas.edu]
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
体外研究产品的免责声明和信息
请注意,BenchChem 上展示的所有文章和产品信息仅供信息参考。 BenchChem 上可购买的产品专为体外研究设计,这些研究在生物体外进行。体外研究,源自拉丁语 "in glass",涉及在受控实验室环境中使用细胞或组织进行的实验。重要的是要注意,这些产品没有被归类为药物或药品,他们没有得到 FDA 的批准,用于预防、治疗或治愈任何医疗状况、疾病或疾病。我们必须强调,将这些产品以任何形式引入人类或动物的身体都是法律严格禁止的。遵守这些指南对确保研究和实验的法律和道德标准的符合性至关重要。
