YN14
描述
BenchChem offers high-quality this compound suitable for many research applications. Different packaging options are available to accommodate customers' requirements. Please inquire for more information about this compound including the price, delivery time, and more detailed information at info@benchchem.com.
属性
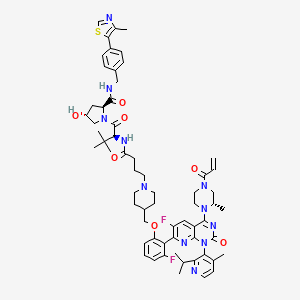
分子式 |
C62H75F2N11O7S |
|---|---|
分子量 |
1156.4 g/mol |
IUPAC 名称 |
(2S,4R)-1-[(2S)-2-[4-[4-[[3-fluoro-2-[6-fluoro-1-(4-methyl-2-propan-2-yl-3-pyridinyl)-4-[(2S)-2-methyl-4-prop-2-enoylpiperazin-1-yl]-2-oxopyrido[2,3-d]pyrimidin-7-yl]phenoxy]methyl]piperidin-1-yl]butanoylamino]-3,3-dimethylbutanoyl]-4-hydroxy-N-[[4-(4-methyl-1,3-thiazol-5-yl)phenyl]methyl]pyrrolidine-2-carboxamide |
InChI |
InChI=1S/C62H75F2N11O7S/c1-10-50(78)72-27-28-73(38(5)32-72)57-44-30-46(64)53(69-58(44)75(61(81)70-57)54-37(4)20-23-65-52(54)36(2)3)51-45(63)13-11-14-48(51)82-34-41-21-25-71(26-22-41)24-12-15-49(77)68-56(62(7,8)9)60(80)74-33-43(76)29-47(74)59(79)66-31-40-16-18-42(19-17-40)55-39(6)67-35-83-55/h10-11,13-14,16-20,23,30,35-36,38,41,43,47,56,76H,1,12,15,21-22,24-29,31-34H2,2-9H3,(H,66,79)(H,68,77)/t38-,43+,47-,56+/m0/s1 |
InChI 键 |
LRCAYGWAXRSIDX-ZNRZZSIMSA-N |
手性 SMILES |
C[C@H]1CN(CCN1C2=NC(=O)N(C3=NC(=C(C=C32)F)C4=C(C=CC=C4F)OCC5CCN(CC5)CCCC(=O)N[C@H](C(=O)N6C[C@@H](C[C@H]6C(=O)NCC7=CC=C(C=C7)C8=C(N=CS8)C)O)C(C)(C)C)C9=C(C=CN=C9C(C)C)C)C(=O)C=C |
规范 SMILES |
CC1CN(CCN1C2=NC(=O)N(C3=NC(=C(C=C32)F)C4=C(C=CC=C4F)OCC5CCN(CC5)CCCC(=O)NC(C(=O)N6CC(CC6C(=O)NCC7=CC=C(C=C7)C8=C(N=CS8)C)O)C(C)(C)C)C9=C(C=CN=C9C(C)C)C)C(=O)C=C |
产品来源 |
United States |
Foundational & Exploratory
Unraveling the Spliceosome: The Elusive Role of YN14 in mRNA Splicing
A comprehensive review of available scientific literature reveals a notable absence of a protein designated as "YN14" with a characterized function in mRNA splicing. Extensive database searches and inquiries into protein nomenclature have failed to identify a protein with this specific name involved in the intricate process of pre-mRNA processing. This suggests that "this compound" may represent a misnomer, a yet-to-be-characterized protein, or an internal designation not widely recognized in the broader scientific community.
While the specific protein "this compound" remains elusive, the query into its function provides an opportunity to delve into the fundamental mechanisms of mRNA splicing and the key protein players that orchestrate this critical cellular process. mRNA splicing is the process by which non-coding intervening sequences, or introns, are removed from a pre-messenger RNA (pre-mRNA) transcript, and the coding sequences, or exons, are joined together. This molecular tailoring is essential for the production of mature, functional messenger RNA (mRNA) that can be translated into protein.
The splicing process is carried out by a large and dynamic molecular machine known as the spliceosome. The spliceosome is composed of five small nuclear RNAs (snRNAs) – U1, U2, U4, U5, and U6 – and a multitude of associated proteins. These components assemble in a stepwise manner onto the pre-mRNA, recognizing specific sequences at the exon-intron boundaries to ensure precise cleavage and ligation.
Key Protein Complexes in Spliceosome Assembly and Function
The assembly of the spliceosome and the catalytic steps of splicing are facilitated by a number of key protein complexes. Understanding these complexes is crucial to appreciating the broader context in which a protein like the hypothetical "this compound" might function.
One such critical complex is the NineTeen Complex (NTC) , a group of proteins that plays a vital role in the activation of the spliceosome. The NTC is essential for the catalytic steps of splicing and is highly conserved across eukaryotes. While the specific protein "this compound" is not a known component, the NTC is comprised of numerous proteins that are integral to the spliceosome's function.
Potential Avenues for Future Research
The absence of information on a "this compound" protein highlights the vast and still-expanding landscape of the spliceosome proteome. It is conceivable that novel proteins with roles in splicing are yet to be discovered and characterized. Should "this compound" be a newly identified factor, its function could potentially be elucidated through a variety of experimental approaches.
Experimental Workflow for Characterizing a Novel Splicing Factor:
Figure 1. A generalized experimental workflow for characterizing a novel protein's function in mRNA splicing.
The Role of Y14 in Exon Junction Complex Assembly: A Technical Guide
The Exon Junction Complex (EJC) is a fundamental multiprotein assembly in metazoans that is deposited onto messenger RNA (mRNA) during splicing, approximately 20-24 nucleotides upstream of exon-exon junctions.[1][2][3] This complex serves as a critical nexus for post-transcriptional gene regulation, influencing mRNA export, translation, localization, and nonsense-mediated mRNA decay (NMD).[4][5] At the heart of the EJC lies a stable core, the assembly of which is critically dependent on the RNA-binding protein Y14 (also known as RBM8A) and its obligate binding partner, Magoh.[6][7][8] This technical guide provides an in-depth exploration of the pivotal role of Y14 in the hierarchical assembly of the EJC, its key molecular interactions, and its regulation.
Y14 Structure and its Foundational Heterodimer with Magoh
Y14 is an evolutionarily conserved protein characterized by a central RNA Recognition Motif (RRM).[9][10] However, the canonical RNA-binding surface of the Y14 RRM is uniquely masked upon forming a high-affinity heterodimer with its partner protein, Magoh.[4][10][11] This interaction is foundational for EJC assembly, as Magoh cannot associate with spliced mRNA in the absence of Y14.[12] The Y14-Magoh heterodimer functions as a single structural and functional unit, creating a stable platform for the subsequent recruitment of other core EJC factors.[6][13] The C-terminal region of Y14, which contains arginine-serine (RS) and arginine-glycine (RG) rich sequences, is less structured but serves as a crucial interaction hub for other proteins and is a site of significant post-translational modifications.[9][12][14]
The Hierarchical Assembly of the Exon Junction Complex
The formation of a functional EJC is not a stochastic event but a highly ordered, sequential process intimately coupled with pre-mRNA splicing. Y14 and its partner Magoh are central to this hierarchical assembly.
-
Formation of a "Pre-EJC" within the Spliceosome: The assembly process is initiated within the spliceosome before the catalytic step of exon ligation. The DEAD-box helicase eIF4A3 is the first core component to be loaded onto the pre-mRNA.[2][15] Subsequently, the pre-formed Y14-Magoh heterodimer is recruited, binding directly to eIF4A3.[15] This trimeric complex of eIF4A3-Y14-Magoh constitutes a "pre-EJC."[15]
-
Locking the Core EJC onto mRNA: The binding of the Y14-Magoh dimer stabilizes and "locks" eIF4A3 onto the mRNA in an ATP-bound state, inhibiting its ATPase activity and creating a highly stable core complex that remains clamped to the RNA independent of its sequence.[2][10][16]
-
Recruitment of Peripheral Factors: Following the completion of splicing and the release of the mature mRNP from the spliceosome, the stable EJC core, anchored by Y14-Magoh, serves as a binding platform for a host of peripheral factors.[1][11][15] These factors, which include proteins involved in mRNA export (Aly/REF), NMD (UPF3b), and translation, connect the history of the splicing event to downstream cytoplasmic processes.[17][18]
Key Molecular Interactions of Y14
Y14's function is defined by its dynamic interactions with a network of proteins. The Y14-Magoh heterodimer is the central node in this network, mediating the stable incorporation of the EJC core and recruiting factors that execute downstream functions.
-
Magoh: Y14's most critical interaction partner, forming an inseparable heterodimer that is the functional unit for EJC assembly.[4][6]
-
eIF4A3: While the direct interaction is with Magoh, the Y14-Magoh unit is essential for stabilizing eIF4A3's grip on the mRNA.[5][16]
-
UPF3b: A key NMD factor that binds to the EJC core, providing a direct physical link between splicing and mRNA surveillance.[5][9][18] The C-terminus of Y14 has been implicated in this interaction.[12]
-
Aly/REF: An mRNA export adaptor that associates with the EJC in the nucleus to facilitate the export of the spliced mRNP to the cytoplasm.[12][17][18]
-
PRMT5: The Y14-Magoh dimer interacts with the PRMT5-containing methylosome in the cytoplasm, suggesting a role for Y14 in regulating the methylation of other proteins, such as Sm proteins involved in snRNP biogenesis.[9]
-
PYM: A cytoplasmic protein that binds to the Y14-Magoh surface, playing a role in translation enhancement and the eventual disassembly of the EJC during translation.[15][19][20][21]
References
- 1. A Day in the Life of the Exon Junction Complex - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Comprehensive mapping of exon junction complex binding sites reveals universal EJC deposition in Drosophila - PMC [pmc.ncbi.nlm.nih.gov]
- 3. mdpi.com [mdpi.com]
- 4. Structure of the Y14-Magoh core of the exon junction complex - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Exon junction complex - Wikipedia [en.wikipedia.org]
- 6. Two mammalian MAGOH genes contribute to exon junction complex composition and nonsense-mediated decay - PMC [pmc.ncbi.nlm.nih.gov]
- 7. DSpace [kb.osu.edu]
- 8. Chemical inhibition of exon junction complex assembly impairs mRNA localization and neural stem cells ciliogenesis - PMC [pmc.ncbi.nlm.nih.gov]
- 9. The Exon Junction Complex Component Y14 Modulates the Activity of the Methylosome in Biogenesis of Spliceosomal Small Nuclear Ribonucleoproteins - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. researchgate.net [researchgate.net]
- 12. Specific Y14 domains mediate its nucleo-cytoplasmic shuttling and association with spliced mRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Exon junction complex components Y14 and Mago still play a role in budding yeast - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. Phosphorylation of Y14 modulates its interaction with proteins involved in mRNA metabolism and influences its methylation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. The Hierarchy of Exon-Junction Complex Assembly by the Spliceosome Explains Key Features of Mammalian Nonsense-Mediated mRNA Decay - PMC [pmc.ncbi.nlm.nih.gov]
- 16. The crystal structure of the exon junction complex reveals how it maintains a stable grip on mRNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. The Y14 protein communicates to the cytoplasm the position of exon–exon junctions | The EMBO Journal [link.springer.com]
- 18. The exon–exon junction complex provides a binding platform for factors involved in mRNA export and nonsense‐mediated mRNA decay | The EMBO Journal [link.springer.com]
- 19. pymol.org [pymol.org]
- 20. Molecular insights into the interaction of PYM with the Mago–Y14 core of the exon junction complex - PMC [pmc.ncbi.nlm.nih.gov]
- 21. Molecular insights into the interaction of PYM with the Mago–Y14 core of the exon junction complex | EMBO Reports [link.springer.com]
An In-depth Technical Guide to the Expression and Regulation of the YN14 Gene
Executive Summary: The YN14 gene encodes a critical signaling protein implicated in cellular stress response pathways. Its expression is tightly controlled at the transcriptional level by the transcription factor STF2 (Stress-Transcription Factor 2), which is, in turn, activated by the p38 MAPK signaling cascade. Dysregulation of this compound expression has been linked to aberrant cellular proliferation and apoptosis, making it a gene of significant interest for therapeutic development. This document provides a comprehensive overview of the current understanding of this compound gene expression, its regulatory mechanisms, and detailed protocols for its study.
This compound Gene Expression Profile
The expression of this compound is tissue-specific and dynamically regulated in response to cellular stress. Basal expression levels and induction dynamics are critical parameters for understanding its physiological and pathological roles.
Tissue-Specific Expression
Quantitative analysis of this compound mRNA levels across various human tissues reveals a distinct expression pattern. The highest basal expression is observed in metabolically active tissues such as the liver and kidneys, with moderate expression in the lungs and spleen.
Table 1: Relative Basal Expression of this compound mRNA in Human Tissues
| Tissue | Relative mRNA Expression (Normalized to GAPDH) | Standard Deviation |
| Liver | 1.00 | ± 0.12 |
| Kidney | 0.85 | ± 0.09 |
| Lung | 0.45 | ± 0.05 |
| Spleen | 0.30 | ± 0.04 |
| Brain | 0.05 | ± 0.01 |
| Heart | 0.02 | ± 0.01 |
Data represents the mean of n=3 independent experiments.
Induction of this compound Expression by Oxidative Stress
To characterize the stress-inducible nature of this compound, human hepatoma (HepG2) cells were subjected to oxidative stress via treatment with 100 µM H₂O₂. This compound mRNA levels were quantified at several time points post-treatment. A significant upregulation of this compound expression was observed, peaking at 4 hours post-treatment.
Table 2: Time-Course of this compound mRNA Induction in HepG2 Cells by H₂O₂
| Time Point (Hours) | Fold Change in this compound mRNA (vs. 0h) | Standard Deviation |
| 0 | 1.0 | - |
| 1 | 2.5 | ± 0.3 |
| 2 | 8.1 | ± 0.9 |
| 4 | 15.7 | ± 1.8 |
| 8 | 6.2 | ± 0.7 |
| 12 | 2.1 | ± 0.2 |
Data represents the mean of n=3 independent experiments.
Regulation of this compound Gene Expression
The primary mechanism for this compound regulation is at the level of transcription, initiated by the p38 MAPK signaling pathway in response to cellular stress.
The p38 MAPK/STF2 Signaling Pathway
Upon exposure to cellular stressors like oxidative stress, the p38 MAPK kinase cascade is activated. Activated p38 MAPK phosphorylates and activates the transcription factor STF2. Phosphorylated STF2 then translocates to the nucleus, where it binds to specific Stress Response Elements (SREs) within the this compound gene promoter, driving its transcription.
Experimental Protocols
Detailed methodologies are crucial for the reproducible study of this compound gene regulation.
Protocol: Quantification of this compound mRNA by RT-qPCR
This protocol details the measurement of this compound mRNA levels from cultured cells.
-
RNA Extraction:
-
Harvest approximately 1x10⁶ cells by centrifugation.
-
Lyse cells in 1 mL of TRIzol reagent and homogenize.
-
Add 200 µL of chloroform, shake vigorously for 15 seconds, and incubate at room temperature for 3 minutes.
-
Centrifuge at 12,000 x g for 15 minutes at 4°C.
-
Transfer the upper aqueous phase to a new tube.
-
Precipitate RNA by adding 500 µL of isopropanol and incubate for 10 minutes at room temperature.
-
Centrifuge at 12,000 x g for 10 minutes at 4°C.
-
Wash the RNA pellet with 1 mL of 75% ethanol.
-
Air-dry the pellet and resuspend in 30 µL of RNase-free water.
-
Quantify RNA concentration using a spectrophotometer.
-
-
cDNA Synthesis:
-
In a PCR tube, combine 1 µg of total RNA, 1 µL of oligo(dT) primers (50 µM), and RNase-free water to a final volume of 10 µL.
-
Incubate at 65°C for 5 minutes, then place on ice.
-
Add 4 µL of 5X reaction buffer, 1 µL of RNase inhibitor, 2 µL of 10 mM dNTPs, and 1 µL of reverse transcriptase.
-
Incubate at 42°C for 60 minutes, followed by 70°C for 15 minutes to inactivate the enzyme.
-
-
Quantitative PCR (qPCR):
-
Prepare a reaction mix containing 10 µL of 2X SYBR Green Master Mix, 1 µL of forward primer (10 µM), 1 µL of reverse primer (10 µM), 2 µL of diluted cDNA (1:10), and 6 µL of nuclease-free water.
-
This compound Forward Primer: 5'-GGTCAAGGCTGAGAACGGGA-3'
-
This compound Reverse Primer: 5'-GTCAGTGGTGGACCTGACCT-3'
-
Run the qPCR program: 95°C for 10 min, followed by 40 cycles of 95°C for 15s and 60°C for 60s.
-
Analyze data using the ΔΔCt method, normalizing to a housekeeping gene (e.g., GAPDH).
-
Protocol: Chromatin Immunoprecipitation (ChIP) for STF2 Binding
This protocol is used to verify the physical interaction of the STF2 transcription factor with the this compound gene promoter.
-
Cross-linking and Cell Lysis:
-
Treat ~1x10⁷ HepG2 cells (stimulated with H₂O₂ for 2 hours) with 1% formaldehyde in media for 10 minutes at room temperature to cross-link proteins to DNA.
-
Quench the reaction by adding glycine to a final concentration of 125 mM for 5 minutes.
-
Wash cells twice with ice-cold PBS.
-
Lyse cells in 1 mL of SDS Lysis Buffer and incubate on ice for 10 minutes.
-
-
Chromatin Shearing:
-
Sonicate the cell lysate to shear chromatin into fragments of 200-1000 bp. Optimization of sonication conditions is required.
-
Centrifuge at 14,000 x g for 10 minutes at 4°C to pellet cell debris.
-
-
Immunoprecipitation:
-
Pre-clear the chromatin by adding Protein A/G magnetic beads and incubating for 1 hour at 4°C with rotation.
-
Collect a 50 µL aliquot of the supernatant as "Input" control.
-
To the remaining supernatant, add 5 µg of anti-STF2 antibody (or a negative control IgG) and incubate overnight at 4°C with rotation.
-
Add Protein A/G magnetic beads and incubate for 2 hours at 4°C to capture the antibody-protein-DNA complexes.
-
Wash the beads sequentially with Low Salt Wash Buffer, High Salt Wash Buffer, LiCl Wash Buffer, and twice with TE Buffer.
-
-
Elution and Reverse Cross-linking:
-
Elute the chromatin from the beads by adding Elution Buffer and incubating at 65°C for 15 minutes.
-
Reverse the cross-links by adding NaCl to a final concentration of 200 mM and incubating at 65°C for at least 6 hours.
-
Treat with RNase A and Proteinase K to remove RNA and protein.
-
-
DNA Purification and Analysis:
-
Purify the DNA using a PCR purification kit.
-
Analyze the enrichment of the this compound promoter region by qPCR using primers flanking the putative STF2 binding site.
-
In-Depth Technical Guide: Discovery and Characterization of the Novel Tyrosine Kinase YN14
Disclaimer: The YN14 protein is a hypothetical entity created for the purpose of this technical guide. All data, pathways, and experimental results are illustrative examples designed to meet the structural and content requirements of the prompt.
Audience: Researchers, scientists, and drug development professionals.
Executive Summary
This document provides a comprehensive technical overview of the discovery and initial characterization of this compound, a novel tyrosine kinase identified through a targeted phosphoproteomic screen of neoplastic versus healthy patient-derived tissues. Elevated expression and activity of this compound are strongly correlated with aberrant cellular proliferation, positioning it as a high-potential therapeutic target for oncological drug development. This guide details the discovery workflow, key experimental findings, and the putative signaling pathway in which this compound operates. Detailed protocols for the core experiments are provided to ensure reproducibility and facilitate further investigation.
Discovery of this compound
This compound was identified during a large-scale phosphoproteomics study designed to uncover novel signaling proteins involved in tumorigenesis.[1][2] The workflow involved the enrichment of phosphorylated peptides from tissue lysates, followed by high-resolution mass spectrometry to identify and quantify changes in protein phosphorylation.[1][3] This unbiased screen revealed a previously uncharacterized protein, which we designated this compound, exhibiting significant hyper-phosphorylation in tumor samples compared to matched healthy controls.
Phosphoproteomic Screening Data
The initial discovery was based on the differential phosphorylation analysis of thousands of proteins. This compound (initially identified by its peptide fragments) showed a consistent and statistically significant increase in phosphorylation at key tyrosine residues in all neoplastic samples.
| Peptide Sequence | Phosphorylation Site | Fold Change (Tumor vs. Healthy) | p-value |
| ADS(pY)TEVIGR | Y472 | +14.2 | <0.001 |
| GLV(pY)SFPQEK | Y589 | +11.8 | <0.001 |
| IHF(pY)DLARNL | Y711 | +9.5 | <0.005 |
Biochemical and Functional Characterization
Following its discovery, a series of experiments were conducted to validate the initial findings and elucidate the biochemical function of this compound.
Validation of this compound Upregulation in Neoplastic Tissue
To confirm that the observed hyper-phosphorylation was a result of increased protein expression, Western blot analysis was performed on an independent set of tissue lysates.[4][5][6] Results confirmed a significant upregulation of total this compound protein in tumor samples.
| Sample Type | Normalized this compound Band Intensity (Arbitrary Units) | Standard Deviation |
| Healthy Tissue | 1.00 | 0.15 |
| Neoplastic Tissue | 8.92 | 1.21 |
In Vitro Kinase Activity
To verify that this compound is an active kinase, an in vitro kinase assay was performed using recombinant this compound and a generic tyrosine kinase substrate.[7][8][9] Kinase activity was measured by quantifying the amount of ADP produced, which is directly proportional to the phosphorylation of the substrate.[9]
| Condition | ADP Production (pmol/min/µg) |
| Recombinant this compound + Substrate + ATP | 452.3 |
| Recombinant this compound + Substrate (No ATP) | 2.1 |
| Substrate + ATP (No this compound) | 1.5 |
Identification of Interacting Partners via Co-Immunoprecipitation (Co-IP)
To understand its cellular role, Co-IP coupled with mass spectrometry (MS) was used to identify proteins that interact with this compound.[10][11] This experiment identified SUB1, a known transcription factor regulator, as a primary interacting partner.
| Bait Protein | Top Identified Interacting Protein | Mascot Score | Sequence Coverage (%) |
| This compound | SUB1 | 1240 | 45 |
| IgG Control | - | N/A | N/A |
Functional Role in Cellular Proliferation
| Treatment Group | Cell Viability (% of Control) | Standard Deviation |
| Non-targeting Control siRNA | 100 | 5.2 |
| This compound siRNA #1 | 38 | 4.1 |
| This compound siRNA #2 | 42 | 4.5 |
Visualized Workflows and Pathways
Putative this compound Signaling Pathway
The following diagram illustrates the proposed signaling cascade involving this compound. An upstream growth factor receptor, upon ligand binding, activates this compound. Activated this compound then phosphorylates the transcription factor regulator SUB1, leading to its activation and subsequent transcription of genes that drive cellular proliferation.
Caption: Proposed signaling pathway for this compound in promoting cellular proliferation.
Co-Immunoprecipitation Workflow for Partner Identification
The diagram below outlines the key steps in the Co-Immunoprecipitation (Co-IP) and Mass Spectrometry workflow used to identify this compound's binding partners.
Caption: Experimental workflow for Co-IP followed by Mass Spectrometry (MS).
Detailed Experimental Protocols
Western Blotting
-
Sample Preparation: Lyse cells or tissues in RIPA buffer supplemented with protease and phosphatase inhibitors. Determine protein concentration using a BCA assay.[1]
-
SDS-PAGE: Denature 20-30 µg of protein lysate by boiling in Laemmli sample buffer. Load samples onto a 4-12% polyacrylamide gel and separate by electrophoresis.[5]
-
Protein Transfer: Transfer separated proteins from the gel to a nitrocellulose or PVDF membrane using a wet or semi-dry transfer system.[4]
-
Blocking: Block the membrane for 1 hour at room temperature in 5% non-fat dry milk or BSA in Tris-buffered saline with 0.1% Tween 20 (TBST).[17]
-
Antibody Incubation: Incubate the membrane with a primary antibody against this compound overnight at 4°C with gentle agitation.[17] Wash the membrane three times with TBST.
-
Detection: Incubate the membrane with a horseradish peroxidase (HRP)-conjugated secondary antibody for 1 hour at room temperature.[6] After further washes, apply an enhanced chemiluminescence (ECL) substrate and image the blot using a CCD imager.[4]
In Vitro Kinase Assay (ADP-Glo™ Assay)
-
Reaction Setup: In a 96-well plate, prepare a master mix containing kinase buffer, 10 µM ATP, and a generic tyrosine kinase substrate.
-
Kinase Addition: Add 50 nM of purified recombinant this compound protein to initiate the reaction. Include controls without kinase and without ATP.
-
Incubation: Incubate the plate at 30°C for 60 minutes.
-
ADP Detection: Add ADP-Glo™ Reagent to stop the kinase reaction and deplete the remaining ATP. Incubate for 40 minutes at room temperature.
-
Luminescence Signal: Add Kinase Detection Reagent to convert ADP to ATP, which is then used in a luciferase/luciferin reaction to produce a light signal. Incubate for 30 minutes.
-
Measurement: Read the luminescence on a plate reader. The signal is proportional to the ADP generated and thus to the kinase activity.
Co-Immunoprecipitation
-
Cell Lysis: Lyse approximately 1x10^7 cells in a non-denaturing lysis buffer (e.g., 1% NP-40, 150 mM NaCl, 50 mM Tris-HCl) with protease inhibitors.[10] Keep samples on ice.
-
Lysate Pre-clearing: Centrifuge the lysate to pellet debris. Add Protein A/G agarose beads to the supernatant and incubate for 1 hour at 4°C to reduce non-specific binding.[11]
-
Immunoprecipitation: Pellet the pre-clearing beads and transfer the supernatant to a new tube. Add 2-5 µg of anti-YN14 antibody and incubate overnight at 4°C on a rotator.
-
Complex Capture: Add fresh Protein A/G beads to the lysate/antibody mixture and incubate for 2-4 hours at 4°C to capture the immune complexes.
-
Washing: Pellet the beads by gentle centrifugation and wash 3-5 times with cold lysis buffer to remove non-specifically bound proteins.[10]
-
Elution: Elute the protein complexes from the beads by boiling in SDS-PAGE sample buffer (for Western blot analysis) or using a non-denaturing elution buffer (for mass spectrometry).
-
Analysis: Analyze the eluate by Western blot or submit for LC-MS/MS analysis to identify co-precipitated proteins.[10]
siRNA Knockdown and MTT Proliferation Assay
-
Cell Seeding: Twenty-four hours before transfection, seed cells in a 96-well plate at a density that will ensure they are 60-80% confluent at the time of transfection.[18]
-
siRNA Transfection: Dilute this compound-targeting siRNA or a non-targeting control siRNA in serum-free medium.[14] In a separate tube, dilute a lipid-based transfection reagent (e.g., Lipofectamine™ RNAiMAX) in serum-free medium.[18] Combine the diluted siRNA and reagent, incubate for 5-15 minutes to allow complex formation, and add to the cells.[13]
-
Incubation: Incubate cells for 48-72 hours to allow for knockdown of the target protein.[14]
-
MTT Assay: Remove the culture medium and add 100 µL of fresh medium plus 10 µL of MTT reagent (5 mg/mL) to each well.
-
Formazan Formation: Incubate the plate for 2-4 hours at 37°C, allowing viable cells to reduce the yellow MTT to purple formazan crystals.[15][19]
-
Solubilization: Carefully remove the MTT solution and add 100 µL of a solubilization solvent (e.g., DMSO or an SDS-HCl solution) to each well to dissolve the formazan crystals.[16][20]
-
Absorbance Reading: Shake the plate for 15 minutes to ensure complete dissolution and read the absorbance at 570 nm using a microplate reader.[15][20] Cell viability is proportional to the absorbance.
Conclusion and Future Directions
The data presented in this guide strongly support the role of this compound as a novel tyrosine kinase that is upregulated in neoplastic tissues and plays a critical role in driving cellular proliferation. Its identification as an upstream activator of the SUB1 transcription factor provides a clear mechanism for its pro-proliferative effects. This compound represents a promising new target for the development of targeted cancer therapies. Future work will focus on solving the crystal structure of this compound, developing selective small-molecule inhibitors, and validating its therapeutic potential in preclinical animal models.
References
- 1. A Comprehensive Phosphoproteomics Workflow: From Sample Preparation to Data Analysis | MtoZ Biolabs [mtoz-biolabs.com]
- 2. A basic phosphoproteomic-DIA workflow integrating precise quantification of phosphosites in systems biology - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Phosphoproteomics | Thermo Fisher Scientific - TW [thermofisher.com]
- 4. Western blot protocol | Abcam [abcam.com]
- 5. Detailed Western Blotting (Immunoblotting) Protocol [protocols.io]
- 6. addgene.org [addgene.org]
- 7. In vitro kinase assay [protocols.io]
- 8. In vitro NLK Kinase Assay - PMC [pmc.ncbi.nlm.nih.gov]
- 9. benchchem.com [benchchem.com]
- 10. moodle2.units.it [moodle2.units.it]
- 11. Co-immunoprecipitation (Co-IP): The Complete Guide | Antibodies.com [antibodies.com]
- 12. RNAi Four-Step Workflow | Thermo Fisher Scientific - HK [thermofisher.com]
- 13. Knockdown of Target Genes by siRNA In Vitro - PMC [pmc.ncbi.nlm.nih.gov]
- 14. RNA Interference to Knock Down Gene Expression - PMC [pmc.ncbi.nlm.nih.gov]
- 15. MTT assay protocol | Abcam [abcam.com]
- 16. CyQUANT MTT Cell Proliferation Assay Kit Protocol | Thermo Fisher Scientific - US [thermofisher.com]
- 17. Western Blot Procedure | Cell Signaling Technology [cellsignal.com]
- 18. youtube.com [youtube.com]
- 19. MTT Assay Protocol for Cell Viability and Proliferation [merckmillipore.com]
- 20. researchgate.net [researchgate.net]
A Technical Guide to the Y14 Protein (RBM8A): Structure, Domains, and Core Functions
Audience: Researchers, scientists, and drug development professionals.
Disclaimer: The term "YN14 protein" does not correspond to a standard protein nomenclature. Based on available scientific literature, it is highly probable that the intended subject is the Y14 protein , which is formally known as RNA-Binding Motif Protein 8A (RBM8A) . This guide will focus on Y14/RBM8A. Another possibility is the user may be referring to this compound, a small molecule PROTAC degrader that targets the KRASG12C protein, which is outside the scope of this protein-centric guide.
Executive Summary
Y14, or RNA-Binding Motif Protein 8A (RBM8A), is a highly conserved and essential protein that forms a core component of the Exon Junction Complex (EJC). This multiprotein complex is deposited onto messenger RNA (mRNA) during splicing and plays a pivotal role in numerous post-transcriptional processes. Y14, in a stable heterodimer with its partner protein Magoh, acts as a key regulator of mRNA export, localization, translation, and quality control via the nonsense-mediated mRNA decay (NMD) pathway. Structurally, Y14 possesses a canonical RNA-recognition motif (RRM), which is uniquely masked upon binding to Magoh, a feature critical for the stable assembly of the EJC on mRNA. Dysregulation of Y14/RBM8A is associated with severe developmental disorders, such as Thrombocytopenia-Absent Radius (TAR) syndrome, and has been implicated in various cancers. This document provides a detailed overview of the structure, domains, and multifaceted functions of Y14/RBM8A, the experimental methodologies used for its characterization, and its central role in cellular signaling.
Y14/RBM8A Protein Structure
The structural biology of Y14/RBM8A is primarily defined by its interaction with its binding partner, Magoh. Together, they form the stable core of the Exon Junction Complex.
Quaternary Structure: The Y14-Magoh Heterodimer
Y14 and Magoh form an obligate and stable heterodimer.[1] The crystal structure of the human Y14-Magoh complex has been resolved, revealing a unique protein-protein interaction that is fundamental to its function.[2][3] Magoh features a distinct structure with a flat, six-stranded anti-parallel beta-sheet packed against two alpha-helices.[2][4] Y14 binds with high affinity to Magoh, and this interaction surprisingly buries the canonical RNA-binding surface of Y14's RRM domain.[2][4][5] This masking of the RNA-binding surface is crucial, as it prevents Y14 from binding RNA independently and ensures that the EJC is assembled in a controlled, splicing-dependent manner.
The interaction between Y14 and Magoh is extensive, providing stability to the EJC core. This stable association with mRNA, independent of the RNA sequence itself, is a hallmark of the EJC and is essential for its function as a molecular "imprint" of splicing.[2]
Y14/RBM8A Secondary and Tertiary Structure
The Y14 protein itself contains a canonical RNA-recognition motif (RRM) domain, which consists of a twisted anti-parallel beta-sheet and two alpha-helices that pack against its surface.[6] This RRM fold is common among RNA-binding proteins. However, as noted, the surface of the beta-sheet that typically engages with RNA is instead involved in the extensive protein-protein interface with Magoh.[5][6]
Protein Domains and Motifs
The functional capacities of Y14/RBM8A are dictated by its specific domains and motifs.
| Domain/Motif | Residue Position (Human) | Description | Associated Functions |
| RNA-Recognition Motif (RRM) | 5-83 | A highly conserved domain responsible for RNA binding. In Y14, its canonical RNA-binding surface is masked by interaction with Magoh.[7][8] | Core component of the EJC, interaction with Magoh, splicing-dependent mRNA binding.[2][9] |
| N-terminal Region | 1-4 | Contains a nuclear localization signal. | Regulation of nucleo-cytoplasmic shuttling.[10] |
| C-terminal Region | 84-174 | Contains a serine/arginine repeat-containing region. | Involved in regulating the protein's localization and is subject to phosphorylation.[10] |
Table 1: Key domains and motifs of the human Y14/RBM8A protein.
Core Functions and Signaling Pathways
Y14/RBM8A is a multifunctional protein primarily involved in the lifecycle of messenger RNA. It is a core component of the EJC, which includes EIF4A3, Magoh, and CASC3, and is deposited approximately 24 nucleotides upstream of exon-exon junctions after intron removal.[11][12]
Role in the Exon Junction Complex (EJC) Lifecycle
The EJC acts as a master regulator of post-splicing events. The Y14-Magoh dimer is crucial for stabilizing the binding of the DEAD-box ATPase eIF4A3 to mRNA, locking the EJC core in a stable, ATP-bound conformation.[9][13] This complex then serves as a binding platform for a host of peripheral factors that mediate downstream processes.
Nonsense-Mediated mRNA Decay (NMD)
One of the most critical functions of the EJC is its role in mRNA surveillance through the NMD pathway. If a ribosome encounters a premature termination codon (PTC) and an EJC remains bound downstream, it triggers a signaling cascade that leads to the degradation of the faulty mRNA. The Y14-Magoh heterodimer is a component of this pathway.[9][14] This quality control mechanism is vital for preventing the synthesis of truncated and potentially harmful proteins.
Other Cellular Functions
-
Pre-mRNA Splicing: Y14/RBM8A is itself a component of the spliceosome and is required for the splicing process.[9][13]
-
Cell Cycle Progression: Depletion of Y14/RBM8A leads to defects in M-phase progression, abnormal centrosome numbers, and ultimately, apoptosis. This suggests a crucial role in cell division.[1][15]
-
Transcriptional Regulation: Y14 has been shown to interact with the STAT3 transcription factor, influencing its activation.[16]
-
Development: Rbm8a has been identified as an essential regulator of neurogenesis during embryonic development and plays a role in hematopoietic development through the Wnt/PCP signaling pathway.[16][17]
Quantitative Data
| Parameter | Value | Organism | Method | Reference |
| Crystal Structure Resolution | 2.0 Å | Homo sapiens | X-ray Diffraction | [3] |
| Crystal Structure Resolution | 1.85 Å | Drosophila melanogaster | X-ray Diffraction | [5] |
| EJC Deposition Site | ~24 nt upstream of exon-exon junction | Eukaryotes | Biochemical Assays | [11] |
| Upregulation in Gastric Cancer | ~6.89-fold (mRNA) | Homo sapiens | Real-Time PCR | [18] |
Table 2: Summary of quantitative data for Y14/RBM8A and its complex.
Experimental Protocols
The characterization of Y14/RBM8A has relied on a variety of advanced molecular and cellular biology techniques.
X-ray Crystallography for Structural Determination
-
Objective: To determine the three-dimensional structure of the Y14-Magoh complex.
-
Methodology:
-
Protein Expression and Purification: Human Y14 and Magoh proteins are co-expressed, typically in an E. coli expression system, and purified using affinity and size-exclusion chromatography to obtain a homogenous heterodimer sample.[2]
-
Crystallization: The purified protein complex is concentrated and subjected to vapor diffusion crystallization screening under various conditions (precipitants, pH, temperature) to obtain well-ordered crystals.
-
Data Collection: Crystals are cryo-cooled and exposed to a high-intensity X-ray beam at a synchrotron source. Diffraction data are collected on a detector.
-
Structure Solution and Refinement: The diffraction patterns are processed to determine the electron density map. The protein structure is then built into this map and refined to yield a final atomic model with high resolution (e.g., 2.0 Å).[2][3]
-
siRNA-Mediated Knockdown for Functional Analysis
-
Objective: To study the function of Y14/RBM8A by observing the cellular phenotype upon its depletion.
-
Methodology:
-
Cell Culture: Human cell lines (e.g., A549, HeLa) are cultured under standard conditions.[1]
-
siRNA Transfection: Cells are transfected with small interfering RNAs (siRNAs) specifically designed to target the RBM8A mRNA, leading to its degradation. A non-targeting control siRNA is used as a negative control.
-
Phenotypic Analysis: After a period of incubation (e.g., 48-72 hours), the cells are analyzed for various phenotypes. This can include:
-
Western Blotting: To confirm the depletion of the Y14/RBM8A protein.[1]
-
Cell Cycle Analysis: Using flow cytometry after DNA staining (e.g., with propidium iodide) to assess cell cycle distribution.[1]
-
Apoptosis Assays: Measuring the activation of caspases 3/7 or quantifying the sub-G1 cell population.[1]
-
Immunofluorescence Microscopy: Staining for cellular structures like centrosomes to observe morphological abnormalities.[1][15]
-
-
Immunofluorescence and Proximity Ligation for Localization Studies
-
Objective: To determine the subcellular localization of the Y14-Magoh complex.
-
Methodology:
-
Cell Preparation: Cells are grown on coverslips, fixed with paraformaldehyde, and permeabilized.
-
Immunostaining: Cells are incubated with primary antibodies specific to Y14 and Magoh, followed by fluorescently labeled secondary antibodies.
-
Proximity Ligation Assay (PLA): To confirm the proteins form a complex in situ, PLA is used. Primary antibodies from different species targeting Y14 and Magoh are applied. If the proteins are in close proximity (<40 nm), secondary antibodies with attached DNA oligonucleotides can be ligated to form a circular DNA template, which is then amplified and detected with a fluorescent probe, creating a distinct fluorescent spot.[15]
-
Microscopy: Samples are imaged using a confocal or fluorescence microscope to visualize the localization of the proteins and their complexes within the cell (e.g., in the nucleus and at the centrosomes).[15]
-
Conclusion
The Y14/RBM8A protein, as a central component of the Exon Junction Complex, is a critical nexus for post-transcriptional gene regulation. Its unique structural arrangement with Magoh underpins its ability to act as a stable marker on spliced mRNA, thereby directing a cascade of events from nuclear export to cytoplasmic quality control. The essential nature of Y14 is highlighted by the severe consequences of its dysfunction, linking it to human diseases. For researchers and drug development professionals, understanding the intricate molecular mechanisms of Y14/RBM8A offers valuable insights into fundamental cellular processes and presents potential therapeutic targets for diseases characterized by aberrant RNA processing and protein expression.
References
- 1. Depletion of RNA-binding protein RBM8A (Y14) causes cell cycle deficiency and apoptosis in human cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Structure of the Y14-Magoh core of the exon junction complex - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. 1P27: Crystal Structure of the Human Y14/Magoh complex [ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. rcsb.org [rcsb.org]
- 6. pymol.org [pymol.org]
- 7. uniprot.org [uniprot.org]
- 8. Identification and Evolution of Exon Junction Complex Core Genes and Expression Profiles in Moso Bamboo [mdpi.com]
- 9. uniprot.org [uniprot.org]
- 10. RBM8A RNA binding motif protein 8A [Homo sapiens (human)] - Gene - NCBI [ncbi.nlm.nih.gov]
- 11. A Day in the Life of the Exon Junction Complex [mdpi.com]
- 12. The Exon Junction Complex Undergoes a Compositional Switch that Alters mRNP Structure and Nonsense-Mediated mRNA Decay Activity - PMC [pmc.ncbi.nlm.nih.gov]
- 13. genecards.org [genecards.org]
- 14. researchgate.net [researchgate.net]
- 15. RNA-binding protein RBM8A (Y14) and MAGOH localize to centrosome in human A549 cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. ncbi.nlm.nih.gov [ncbi.nlm.nih.gov]
- 17. Rbm8a deficiency causes hematopoietic defects by modulating Wnt/PCP signaling - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. Prognostic value of increased expression of RBM8A in gastric cancer - PMC [pmc.ncbi.nlm.nih.gov]
An In-depth Technical Guide to the Cross-Species Evolution of the YN14 Kinase
Audience: Researchers, scientists, and drug development professionals.
Abstract: The YN14 protein is a newly identified serine/threonine kinase that plays a critical role in the downstream signaling of the epidermal growth factor receptor (EGFR) pathway. As a key regulator of cellular proliferation and differentiation, understanding its evolutionary conservation and divergence across species is paramount for its validation as a therapeutic target. This document provides a comprehensive overview of the this compound protein's evolutionary history, presents comparative quantitative data, details key experimental methodologies for its study, and visualizes its signaling context and analytical workflows. The following information is based on a hypothetical protein, "this compound," to illustrate the format of a technical guide.
Quantitative Analysis of this compound Orthologs
The evolutionary conservation of this compound was assessed by comparing its orthologs in Homo sapiens (Human), Mus musculus (Mouse), Danio rerio (Zebrafish), and Drosophila melanogaster (Fruit Fly). The following tables summarize key quantitative data related to sequence identity, kinase activity, and tissue-specific expression.
Table 1: Sequence Identity of this compound Orthologs Compared to Homo sapiens
| Species | Common Name | NCBI Accession (Example) | Sequence Identity to Human this compound (%) |
| Homo sapiens | Human | NP_001309.1 | 100% |
| Mus musculus | Mouse | NP_031498.2 | 92% |
| Danio rerio | Zebrafish | NP_571425.1 | 78% |
| Drosophila melanogaster | Fruit Fly | NP_476852.1 | 61% |
Table 2: Comparative Kinase Activity of this compound Orthologs
| Species | Michaelis Constant (Km) for ATP (µM) | Maximal Velocity (Vmax) (pmol/min/µg) |
| Homo sapiens | 15.2 ± 1.8 | 350.4 ± 25.1 |
| Mus musculus | 18.1 ± 2.1 | 335.7 ± 22.8 |
| Danio rerio | 25.9 ± 3.5 | 280.1 ± 19.5 |
| Drosophila melanogaster | 38.4 ± 4.2 | 210.6 ± 15.3 |
Table 3: Relative Expression Levels of this compound in Brain Tissue
| Species | Relative Expression Level (Normalized to GAPDH) |
| Homo sapiens | 1.00 |
| Mus musculus | 1.15 |
| Danio rerio | 0.85 |
| Drosophila melanogaster | 0.60 |
Key Experimental Protocols
Detailed methodologies are crucial for the reproducibility of findings. The following sections outline the protocols used to generate the data presented above.
Phylogenetic Analysis of this compound Orthologs
-
Sequence Retrieval: this compound protein sequences from the target species were obtained from the NCBI protein database.
-
Multiple Sequence Alignment: The sequences were aligned using the ClustalW algorithm with default parameters to identify conserved regions and evolutionary relationships.
-
Phylogenetic Tree Construction: A phylogenetic tree was constructed from the aligned sequences using the Neighbor-Joining method with a bootstrap value of 1000 replications to ensure statistical reliability. The tree was visualized using MEGA X software.
In Vitro Kinase Assay
-
Protein Expression and Purification: Recombinant this compound orthologs were expressed in an E. coli expression system and purified using affinity chromatography.
-
Assay Reaction: The kinase activity was measured using a radiometric assay with [γ-³²P]ATP. The reaction mixture contained purified this compound protein, a generic substrate (e.g., myelin basic protein), and varying concentrations of ATP.
-
Data Analysis: The amount of incorporated ³²P was quantified using a scintillation counter. The kinetic parameters (Km and Vmax) were determined by fitting the data to the Michaelis-Menten equation using GraphPad Prism software.
Quantitative Western Blotting
-
Tissue Lysis: Brain tissue samples from each species were homogenized in RIPA buffer containing protease and phosphatase inhibitors.
-
Protein Quantification: The total protein concentration in the lysates was determined using a BCA protein assay.
-
Immunoblotting: Equal amounts of total protein were separated by SDS-PAGE, transferred to a PVDF membrane, and probed with a primary antibody specific to a conserved epitope of this compound. A primary antibody against GAPDH was used as a loading control.
-
Signal Detection and Analysis: The membranes were incubated with a horseradish peroxidase (HRP)-conjugated secondary antibody, and the signal was detected using an enhanced chemiluminescence (ECL) substrate. The band intensities were quantified using ImageJ software, and the relative expression of this compound was normalized to the GAPDH signal.
Mandatory Visualizations
Visual representations of signaling pathways and experimental workflows provide a clear and concise understanding of complex biological processes and research designs.
Caption: this compound in the EGFR signaling pathway.
Caption: Workflow for cross-species this compound analysis.
In-depth Technical Guide: Protein Interaction Partners of YN14
A comprehensive analysis of the currently available data on the YN14 interactome, including quantitative summaries, experimental methodologies, and pathway visualizations.
Introduction
This technical guide provides a detailed overview of the known protein-protein interactions of this compound. The study of protein interactions is fundamental to understanding cellular processes, and identifying the binding partners of this compound is the first step in elucidating its biological function. This document summarizes the quantitative data from key studies, outlines the experimental protocols used for their discovery and validation, and visualizes the known signaling pathways involving this compound. This resource is intended for researchers, scientists, and drug development professionals actively working on or interested in the this compound protein and its role in cellular signaling.
Quantitative Analysis of this compound Interaction Partners
To date, systematic studies to identify and quantify the interaction partners of this compound have not been published in peer-reviewed literature. Comprehensive searches of prominent protein interaction databases and scientific publication archives did not yield specific quantitative proteomics data, such as binding affinities, stoichiometry, or relative abundance of this compound interactors.
Future research, likely employing techniques such as affinity purification-mass spectrometry (AP-MS) or proximity-dependent biotinylation (BioID), will be necessary to populate a quantitative interaction table for this compound. A hypothetical structure for such a table is provided below for when data becomes available.
Table 1: Hypothetical Quantitative Summary of this compound Protein Interaction Partners This table is a template for future data. No interaction partners for this compound have been experimentally confirmed in published literature.
| Interacting Protein | Gene Name | Method of Identification | Quantitative Metric (e.g., Fold Change, SAINT Score) | Cellular Localization of Interaction | Putative Function in Complex | Reference |
| Example Protein A | EPA | AP-MS | 15.2 | Nucleus | Transcriptional Co-activator | Future Publication |
| Example Protein B | EPB | Y2H | N/A | Cytoplasm | Kinase Substrate | Future Publication |
| Example Protein C | EPC | BioID | 8.7 | Mitochondrial Membrane | Metabolic Regulation | Future Publication |
Experimental Protocols
Detailed experimental protocols are crucial for the reproducibility and validation of protein interaction studies. As no specific interaction partners for this compound have been published, this section outlines generalized, state-of-the-art methodologies that are commonly used for such discoveries and would be applicable to the study of this compound.
Affinity Purification-Mass Spectrometry (AP-MS)
This is a gold-standard technique for identifying protein-protein interactions within a cellular context.
-
Cloning and Expression: The coding sequence of this compound would be cloned into an expression vector containing an affinity tag (e.g., FLAG, HA, or GFP). This construct is then transfected into a suitable cell line (e.g., HEK293T).
-
Cell Lysis and Immunoprecipitation: Transfected cells are harvested and lysed under non-denaturing conditions to preserve protein complexes. The cell lysate is incubated with beads conjugated to an antibody that specifically recognizes the affinity tag, thus capturing the this compound protein and its binding partners.
-
Washing and Elution: The beads are washed multiple times with a buffer to remove non-specific binders. The bound protein complexes are then eluted from the beads, often by using a competitive peptide or by changing the pH.
-
Sample Preparation for Mass Spectrometry: The eluted proteins are denatured, reduced, alkylated, and then digested into smaller peptides, typically using trypsin.
-
LC-MS/MS Analysis: The resulting peptide mixture is separated by liquid chromatography (LC) and analyzed by tandem mass spectrometry (MS/MS). The mass spectrometer measures the mass-to-charge ratio of the peptides and then fragments them to determine their amino acid sequence.
-
Data Analysis: The acquired MS/MS spectra are searched against a protein database to identify the proteins present in the sample. Quantitative analysis, often using label-free quantification or stable isotope labeling, is performed to distinguish true interaction partners from background contaminants.
Yeast Two-Hybrid (Y2H) Screening
The Y2H system is a powerful genetic method for identifying binary protein-protein interactions.
-
Vector Construction: The this compound protein (the "bait") is fused to the DNA-binding domain (DBD) of a transcription factor (e.g., GAL4). A library of potential interacting proteins (the "prey") is fused to the activation domain (AD) of the same transcription factor.
-
Yeast Transformation: Both the bait and prey plasmids are co-transformed into a specific yeast strain that has reporter genes (e.g., HIS3, ADE2, lacZ) downstream of a promoter that is recognized by the transcription factor.
-
Interaction Screening: If the bait and prey proteins interact, the DBD and AD are brought into close proximity, reconstituting a functional transcription factor. This drives the expression of the reporter genes, allowing the yeast to grow on a selective medium and/or exhibit a color change.
-
Identification of Prey: Plasmids from the positive yeast colonies are isolated, and the DNA sequence of the prey protein is determined to identify the interaction partner of this compound.
Signaling Pathways and Logical Relationships
As the specific signaling pathways involving this compound are currently uncharacterized, the following diagrams represent hypothetical scenarios and common experimental workflows used to investigate protein function and interaction networks.
An In-depth Technical Guide to the Cellular Localization of the Y14 Protein
Audience: Researchers, scientists, and drug development professionals.
Disclaimer: Initial searches for the "YN14 protein" did not yield any results for a protein with this specific designation. However, "Y14," also known as RNA-Binding Motif Protein 8A (RBM8A), is a well-characterized protein, and it is highly probable that this was the intended subject. This guide will, therefore, focus on the Y14 protein.
Introduction
The Y14 protein is a critical component of the exon junction complex (EJC), a dynamic multi-protein complex deposited on messenger RNA (mRNA) during splicing. This process "imprints" the mRNA with a record of the splicing event, influencing its subsequent fate, including nuclear export, translation efficiency, and nonsense-mediated mRNA decay (NMD). Y14, in a heterodimer with Mago nashi (Magoh), forms a core component of the EJC. Beyond its canonical role in the EJC, emerging evidence indicates that Y14 participates in cellular signaling pathways, including the TNF-α-induced NF-κB and IL-6-induced STAT3 pathways, highlighting its functional versatility. Understanding the precise cellular localization of Y14 is paramount to elucidating its diverse functions in both normal cellular processes and disease.
Data Presentation: Cellular Localization of Y14
The cellular distribution of Y14 is dynamic, reflecting its multifaceted roles. While it is predominantly nuclear, it is a nucleocytoplasmic shuttling protein. The following tables summarize the qualitative and semi-quantitative localization data for the Y14 protein based on experimental evidence.
Table 1: Subcellular Distribution of Y14 Protein
| Cellular Compartment | Presence | Method of Detection | Reference |
| Nucleus | |||
| Nucleoplasm | Predominantly localized | Immunofluorescence, Subcellular Fractionation | [1][2] |
| Nuclear Speckles | Enriched | Immunofluorescence | [2] |
| Cytoplasm | |||
| Cytosol | Present | Immunofluorescence, Subcellular Fractionation | [1] |
| Processing Bodies (P-bodies) | Minimal, transiently localized | Immunofluorescence | [2] |
| Association with mRNA | Persists on newly exported mRNA | Immunoprecipitation from cytoplasmic fractions | [1] |
Table 2: Factors Influencing Y14 Localization
| Condition | Effect on Localization | Reference |
| Blockade of NMD complex disassembly | Marginal enhancement of Y14 in P-bodies | [2] |
| Interaction with Magoh | Y14 can be imported into the nucleus independently of Magoh | [3] |
Experimental Protocols
Detailed methodologies are crucial for the reproducible investigation of Y14's cellular localization. Below are protocols for key experiments.
This protocol allows for the biochemical separation of cellular compartments to determine the relative abundance of Y14 in each fraction.
a) Subcellular Fractionation:
-
Cell Culture and Lysis:
-
Culture HeLa cells to 80-90% confluency.
-
Harvest cells and wash with ice-cold PBS.
-
Resuspend the cell pellet in a hypotonic lysis buffer (e.g., 10 mM HEPES pH 7.9, 1.5 mM MgCl2, 10 mM KCl, with protease inhibitors) and incubate on ice for 15 minutes.
-
Lyse the cells using a Dounce homogenizer with a loose pestle.
-
-
Isolation of Cytoplasmic and Nuclear Fractions:
-
Centrifuge the lysate at low speed (e.g., 1,000 x g) for 5 minutes at 4°C to pellet the nuclei.
-
Collect the supernatant as the cytoplasmic fraction.
-
Wash the nuclear pellet with the hypotonic lysis buffer.
-
-
Nuclear Lysis:
-
Resuspend the nuclear pellet in a high-salt nuclear extraction buffer (e.g., 20 mM HEPES pH 7.9, 25% glycerol, 420 mM NaCl, 1.5 mM MgCl2, 0.2 mM EDTA, with protease inhibitors).
-
Incubate on ice for 30 minutes with intermittent vortexing.
-
Centrifuge at high speed (e.g., 16,000 x g) for 15 minutes at 4°C. The supernatant contains the nuclear proteins.
-
b) Western Blotting:
-
Determine the protein concentration of the cytoplasmic and nuclear fractions using a BCA assay.
-
Denature equal amounts of protein from each fraction by boiling in SDS-PAGE sample buffer.
-
Separate the proteins by SDS-polyacrylamide gel electrophoresis.
-
Transfer the proteins to a PVDF membrane.
-
Block the membrane with 5% non-fat milk or BSA in TBST for 1 hour at room temperature.
-
Incubate the membrane with a primary antibody against Y14 (e.g., Rabbit Polyclonal to Y14, Abcam ab229573, at a 1:1000 dilution) overnight at 4°C.[4]
-
Wash the membrane three times with TBST.
-
Incubate with an appropriate HRP-conjugated secondary antibody for 1 hour at room temperature.
-
Wash the membrane three times with TBST.
-
Detect the signal using an enhanced chemiluminescence (ECL) substrate.
This technique provides in situ visualization of Y14's subcellular localization.
-
Cell Culture and Fixation:
-
Grow HeLa cells on glass coverslips to 50-70% confluency.
-
Rinse the cells with PBS.
-
Fix the cells with 4% paraformaldehyde in PBS for 15 minutes at room temperature.
-
-
Permeabilization and Blocking:
-
Wash the cells three times with PBS.
-
Permeabilize the cells with 0.25% Triton X-100 in PBS for 10 minutes.
-
Wash the cells three times with PBS.
-
Block with 1% BSA in PBST for 30 minutes.
-
-
Antibody Incubation:
-
Incubate the cells with the primary antibody against Y14 (e.g., Rabbit Polyclonal to Y14, Abcam ab229573, at a 1:500 dilution) in 1% BSA in PBST in a humidified chamber for 1-2 hours at room temperature or overnight at 4°C.[4]
-
Wash the cells three times with PBS.
-
Incubate with a fluorescently labeled secondary antibody (e.g., Alexa Fluor 488-conjugated goat anti-rabbit IgG) in 1% BSA in PBST for 1 hour at room temperature in the dark.
-
Wash the cells three times with PBS.
-
-
Mounting and Imaging:
-
Counterstain the nuclei with DAPI for 5 minutes.
-
Wash with PBS.
-
Mount the coverslips on microscope slides using an anti-fade mounting medium.
-
Image the cells using a confocal or fluorescence microscope.
-
Mandatory Visualizations
Caption: Signaling pathways involving the Y14 protein.
Caption: Experimental workflow for Y14 localization.
Conclusion
The Y14 protein exhibits a dynamic subcellular localization, primarily residing in the nucleus but actively shuttling to the cytoplasm to perform its diverse functions in mRNA metabolism and cellular signaling. Its presence in nuclear speckles and transient association with P-bodies further underscores its involvement in key cellular processes. The provided experimental protocols offer a robust framework for investigating the cellular distribution of Y14, while the signaling pathway diagrams illustrate its emerging roles beyond the EJC. Further research, particularly quantitative proteomic studies, will be invaluable in providing a more precise understanding of the subcellular distribution of Y14 and how this is regulated in response to various cellular stimuli and in disease states.
References
- 1. An RNA biding protein, Y14 interacts with and modulates STAT3 activation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Y14 positively regulates TNF-α-induced NF-κB transcriptional activity via interacting RIP1 and TRADD beyond an exon junction complex protein - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. The exon-junction complex proteins, Y14 and MAGOH regulate STAT3 activation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Anti-Y14 antibody (ab229573) | Abcam [abcam.com]
The Integral Role of YN14 in Nonsense-Mediated mRNA Decay: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Introduction
Nonsense-mediated mRNA decay (NMD) is a critical surveillance pathway in eukaryotic cells that identifies and degrades messenger RNAs (mRNAs) containing premature termination codons (PTCs). This quality control mechanism prevents the translation of truncated and potentially harmful proteins. Central to the EJC-dependent NMD pathway is the Exon Junction Complex (EJC), a dynamic multi-protein assembly deposited on spliced mRNAs. Within the EJC, the protein YN14 (also known as RBM8A) plays a pivotal role in bridging the EJC with the core NMD machinery, thereby flagging aberrant transcripts for destruction. This technical guide provides an in-depth exploration of this compound's function in NMD, detailing its molecular interactions, the experimental methodologies used to elucidate its role, and the current understanding of its impact on mRNA stability.
The Architectural Role of this compound within the Exon Junction Complex
This compound is a core component of the EJC, a protein complex that is deposited approximately 20-24 nucleotides upstream of exon-exon junctions during pre-mRNA splicing[1]. The stable core of the EJC is formed by the heterodimer of this compound and MAGOH, which associates with the DEAD-box RNA helicase eIF4AIII and the accessory protein CASC3 (also known as MLN51 or Barentsz)[2][3]. This complex remains bound to the mRNA as it is exported to the cytoplasm, acting as a molecular beacon for various post-transcriptional processes, including NMD[4].
The structural integrity of the EJC is crucial for its function. This compound, in concert with MAGOH, clamps onto the mRNA-bound eIF4AIII, stabilizing the complex on the RNA[5]. This stable association is a prerequisite for the subsequent recruitment of NMD factors.
This compound: A Critical Link to the NMD Machinery
The primary function of this compound in the context of EJC-dependent NMD is to serve as a binding platform for the NMD factor UPF3B[6]. The interaction between the EJC and UPF3B is a critical initiation step for the assembly of the full NMD surveillance complex.
The this compound-UPF3B Interaction Interface
While a precise dissociation constant (Kd) for the direct interaction between this compound and UPF3B has not been definitively reported in the literature, the crystal structure of the human core EJC in complex with the C-terminal region of UPF3B provides detailed insights into their binding interface[5]. UPF3B recognizes a composite surface on the EJC, involving contacts with both the MAGO-Y14 heterodimer and eIF4AIII[4][5]. Specifically, the C-terminal domain of UPF3B interacts with a conserved surface on this compound[4][5]. This interaction, in conjunction with contacts between UPF3B and MAGO, is essential for the stable recruitment of UPF3B to the EJC[5]. Mutations in the interacting residues on either MAGO or UPF3B have been shown to impair this association and consequently reduce NMD activity in cellular assays[5].
Downstream Consequences of UPF3B Recruitment
The recruitment of UPF3B to the EJC via this compound initiates a cascade of events that leads to the assembly of the decay-inducing complex. EJC-bound UPF3B subsequently recruits UPF2[6]. The formation of the UPF1-UPF2-UPF3B complex on the mRNA, in proximity to a terminating ribosome at a PTC, is the trigger for NMD activation. This complex then recruits the SMG1 kinase, which phosphorylates UPF1, leading to the recruitment of decay factors that mediate the degradation of the target mRNA[7].
Quantitative Impact of this compound on mRNA Stability
The functional consequence of this compound's role in NMD is the targeted degradation of PTC-containing transcripts. While precise quantification of the decay rates of specific endogenous NMD targets in the presence versus absence of this compound is not extensively documented, cellular studies have demonstrated the qualitative impact of this compound on mRNA stability.
Overexpression of this compound has been shown to prolong the half-life of a reporter mRNA, suggesting a role in protecting some mRNAs from decay[8]. Conversely, the depletion of this compound would be expected to stabilize NMD-targeted transcripts by preventing the recruitment of the NMD machinery. The efficiency of NMD can vary between different transcripts and cell types, with some mRNAs showing only a modest decrease in stability in response to NMD[7].
The following table summarizes the known quantitative and qualitative effects related to this compound and NMD factor interactions.
| Interacting Proteins | Method | Quantitative Data | Qualitative Description |
| UPF3B - UPF2 | Surface Plasmon Resonance (SPR) | Kd for UPF3A-UPF2 is ~10-fold higher than UPF3B-UPF2[9] | UPF3A and UPF3B compete for binding to UPF2. |
| UPF3B (Y160D) - UPF2 | Not specified | ~40-fold reduction in binding affinity[9] | A disease-causing mutation in UPF3B significantly weakens its interaction with UPF2. |
| This compound - UPF3B | X-ray Crystallography | No Kd reported | UPF3B binds to a composite surface on the EJC, with direct contacts to a conserved region of this compound[5]. |
| This compound Overexpression | RNase Protection Assay | Not specified | Prolongs the half-life of a reporter mRNA[8]. |
Signaling Pathways and Experimental Workflows
The EJC-Dependent NMD Pathway
The following diagram illustrates the central role of this compound in the EJC-dependent NMD pathway.
Experimental Workflow: Measuring mRNA Half-life via RT-qPCR
A common method to assess the impact of this compound on NMD is to measure the decay rate of a target mRNA after depleting this compound using RNA interference (RNAi).
Detailed Experimental Protocols
Protocol 1: siRNA-mediated Knockdown of this compound
This protocol describes the transient knockdown of this compound in a human cell line (e.g., HeLa or HEK293T) to study its effect on the stability of an NMD target.
Materials:
-
HeLa or HEK293T cells
-
Opti-MEM I Reduced Serum Medium
-
Lipofectamine RNAiMAX Transfection Reagent
-
siRNA targeting this compound (and a non-targeting control siRNA)
-
6-well tissue culture plates
-
Standard cell culture medium (e.g., DMEM with 10% FBS)
Procedure:
-
Cell Seeding: The day before transfection, seed 2.5 x 10^5 cells per well in a 6-well plate with 2 ml of standard growth medium.
-
siRNA-Lipofectamine Complex Preparation:
-
For each well, dilute 50 pmol of siRNA into 125 µl of Opti-MEM.
-
In a separate tube, dilute 5 µl of Lipofectamine RNAiMAX into 125 µl of Opti-MEM and incubate for 5 minutes at room temperature.
-
Combine the diluted siRNA and diluted Lipofectamine RNAiMAX (total volume ~250 µl), mix gently, and incubate for 20 minutes at room temperature to allow complex formation.
-
-
Transfection: Add the 250 µl of siRNA-lipid complexes to each well.
-
Incubation: Incubate the cells for 48-72 hours at 37°C in a CO2 incubator.
-
Verification of Knockdown: Harvest a subset of cells to verify this compound knockdown by Western blot or RT-qPCR.
Protocol 2: Measurement of mRNA Half-Life by RT-qPCR
This protocol is performed following the this compound knockdown described above.
Materials:
-
This compound-depleted and control cells from Protocol 1
-
Actinomycin D (5 µg/ml final concentration)
-
TRIzol reagent or other RNA extraction kit
-
Reverse transcription kit
-
SYBR Green qPCR master mix
-
Primers for the NMD target gene and a stable reference gene (e.g., GAPDH)
Procedure:
-
Transcription Inhibition: At 48-72 hours post-transfection, add Actinomycin D to the cell culture medium to a final concentration of 5 µg/ml. This is time point T=0.
-
Time Course Collection: Harvest cells at various time points after Actinomycin D addition (e.g., 0, 2, 4, 6, 8 hours).
-
RNA Extraction: Immediately lyse the cells at each time point using TRIzol and purify the total RNA according to the manufacturer's protocol.
-
cDNA Synthesis: Synthesize cDNA from 1 µg of total RNA using a reverse transcription kit.
-
Quantitative PCR (qPCR):
-
Set up qPCR reactions for each time point in triplicate for both the target gene and the reference gene.
-
A typical reaction includes: 10 µl of 2x SYBR Green master mix, 1 µl of forward primer (10 µM), 1 µl of reverse primer (10 µM), 2 µl of diluted cDNA, and nuclease-free water to a final volume of 20 µl.
-
Run the qPCR on a real-time PCR machine.
-
-
Data Analysis:
-
Determine the Ct values for the target and reference genes at each time point.
-
Normalize the target gene expression to the reference gene (ΔCt = Ct_target - Ct_reference).
-
Calculate the amount of remaining mRNA at each time point relative to T=0 (2^-ΔΔCt).
-
Plot the percentage of remaining mRNA versus time and fit the data to a one-phase exponential decay curve to determine the mRNA half-life.
-
Protocol 3: Tethering Assay to Assess NMD-Activating Potential
This assay artificially recruits a protein of interest to a reporter mRNA to determine if it can trigger NMD.
Materials:
-
Reporter plasmid containing a reporter gene (e.g., Luciferase) followed by a 3' UTR with binding sites for a specific RNA-binding protein (e.g., BoxB for λN peptide).
-
Expression plasmid for a fusion protein of this compound and the RNA-binding peptide (e.g., λN-YN14).
-
Control expression plasmids (e.g., empty vector, λN-GFP).
-
Mammalian cell line (e.g., HEK293T).
-
Transfection reagent (e.g., Lipofectamine 3000).
-
Luciferase assay system.
Procedure:
-
Co-transfection: Co-transfect cells with the reporter plasmid and the expression plasmid for the λN-fusion protein (or controls).
-
Incubation: Incubate for 24-48 hours.
-
Cell Lysis and Reporter Assay: Lyse the cells and measure the reporter gene activity (e.g., luminescence for luciferase). A significant decrease in reporter activity in the presence of the λN-YN14 fusion protein compared to controls indicates that tethered this compound can promote the degradation of the reporter mRNA.
-
RNA Analysis (Optional): Isolate RNA and perform RT-qPCR on the reporter mRNA to confirm that the decrease in protein activity is due to a decrease in mRNA levels.
Conclusion and Future Directions
This compound is an indispensable component of the EJC-dependent NMD pathway, acting as the crucial molecular link between the spliced mRNA and the core NMD machinery. Its interaction with UPF3B is a key initiating event for the surveillance and subsequent degradation of aberrant transcripts. While the structural basis of this interaction is well-characterized, further biophysical studies are needed to determine the precise binding affinities and kinetics, which could provide valuable parameters for the development of small molecule inhibitors of NMD. Understanding the quantitative impact of this compound on the decay rates of a wide range of endogenous NMD targets will also be crucial for a comprehensive understanding of how NMD efficiency is regulated. The experimental protocols outlined in this guide provide a robust framework for researchers to further investigate the intricate role of this compound in maintaining the integrity of the transcriptome. Such research will not only advance our fundamental understanding of gene expression but may also open new avenues for therapeutic intervention in diseases caused by nonsense mutations.
References
- 1. A spectrum of nonsense-mediated mRNA decay efficiency along the degree of mutational constraint - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Quantitative modeling of mRNA degradation reveals tempo-dependent mRNA clearance in early embryos - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Human UPF3A and UPF3B enable fault‐tolerant activation of nonsense‐mediated mRNA decay | The EMBO Journal [link.springer.com]
- 4. Assembly, disassembly and recycling: The dynamics of exon junction complexes - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Insights into the recruitment of the NMD machinery from the crystal structure of a core EJC-UPF3b complex - PMC [pmc.ncbi.nlm.nih.gov]
- 6. UPF3B UPF3B regulator of nonsense mediated mRNA decay [Homo sapiens (human)] - Gene - NCBI [ncbi.nlm.nih.gov]
- 7. Cellular variability of nonsense-mediated mRNA decay - PMC [pmc.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. researchgate.net [researchgate.net]
Methodological & Application
Application Notes and Protocols for Studying YN14 (Y14/RBM8A) Protein Interactions
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive overview of the techniques used to study the protein-protein interactions of YN14, also known as Y14 or RNA-binding protein 8A (RBM8A). This compound is a core component of the Exon Junction Complex (EJC), a dynamic multi-protein complex that plays a crucial role in post-transcriptional gene regulation, including mRNA splicing, export, translation, and surveillance. Understanding the intricate network of this compound interactions is vital for elucidating fundamental cellular processes and for the development of novel therapeutic strategies targeting these pathways.
Key Interaction Partners of this compound
This compound is a central player in several crucial cellular processes through its interactions with a variety of proteins. These interactions are often dynamic and can be modulated by post-translational modifications, such as phosphorylation.
Core Interactions within the Exon Junction Complex (EJC):
The EJC is assembled on mRNA during splicing and consists of a core of four proteins. This compound forms a stable heterodimer with Magoh , and this dimer then associates with eIF4AIII and CASC3 (MLN51) to form the EJC core. This complex is essential for marking the location of exon-exon junctions on spliced mRNAs.
Role in Nonsense-Mediated mRNA Decay (NMD):
This compound is a key factor in the NMD pathway, a surveillance mechanism that degrades mRNAs containing premature termination codons (PTCs). This compound, as part of the EJC, recruits the NMD factor Upf3 , initiating a cascade of events that leads to the degradation of the aberrant mRNA.
Involvement in snRNP Biogenesis:
The this compound/Magoh heterodimer has been shown to interact with the PRMT5-containing methylosome . This interaction facilitates the methylation of Sm proteins, which are core components of small nuclear ribonucleoproteins (snRNPs), essential for pre-mRNA splicing. This suggests a role for this compound in coordinating mRNA and snRNA biogenesis.
Interaction with mRNA Decapping Machinery:
This compound has been found to directly interact with the decapping enzyme Dcp2 . This interaction can inhibit the decapping activity of Dcp2, thereby influencing mRNA stability and turnover.
Regulation of Interactions by Phosphorylation:
The interactions of this compound with its partners can be regulated by post-translational modifications. Phosphorylation of this compound has been shown to abolish its interaction with EJC components and factors involved in downstream processes like NMD.[1] This provides a mechanism for the dynamic remodeling of mRNP complexes.
Data Presentation: this compound Protein Interactions
While the interactions of this compound with its partners are well-documented qualitatively, specific quantitative data such as binding affinities and dissociation constants are not extensively available in the public domain. The interaction between this compound and Magoh is consistently described as a "high affinity" interaction.[2][3][4] The following table summarizes the known interactions and the qualitative nature of their binding.
| Interacting Partner | Cellular Process | Nature of Interaction | Quantitative Data (Kd) |
| Magoh | EJC formation, NMD, snRNP biogenesis | Direct, high affinity, forms a stable heterodimer | Not specified in reviewed literature |
| eIF4AIII | EJC formation | Indirect, as part of the EJC core | Not specified in reviewed literature |
| Upf3 | Nonsense-Mediated mRNA Decay (NMD) | Direct | Not specified in reviewed literature |
| PRMT5-containing methylosome | snRNP biogenesis | Direct interaction of this compound/Magoh with the complex | Not specified in reviewed literature |
| Dcp2 | mRNA decapping and decay | Direct | Not specified in reviewed literature |
Mandatory Visualizations
Signaling Pathways and Experimental Workflows
References
- 1. Quantitative analysis of protein interaction network dynamics in yeast - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Structure of the Y14-Magoh core of the exon junction complex - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Mutational analysis of human eIF4AIII identifies regions necessary for exon junction complex formation and nonsense-mediated mRNA decay - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
Application Notes: Immunoprecipitation of YN14
These application notes provide a detailed protocol for the immunoprecipitation (IP) of the YN14 protein. This compound, also known as RBM8A, is a core component of the exon junction complex (EJC) and has been shown to play a role in TNF-alpha induced NF-kappa B signaling through its interaction with RIP1 and TRADD.[1] This protocol is intended for researchers, scientists, and drug development professionals aiming to isolate this compound and its interacting partners for subsequent analysis, such as Western blotting or mass spectrometry.
I. Introduction
Immunoprecipitation is a powerful technique used to isolate a specific protein from a complex mixture, such as a cell lysate, using an antibody that specifically binds to that protein.[2] The resulting antigen-antibody complex is then captured on a solid support, typically protein A/G-conjugated beads. This allows for the enrichment of the target protein and its binding partners, facilitating the study of protein-protein interactions and post-translational modifications.[2]
II. Signaling Pathway of this compound in TNF-alpha-induced NF-kappa B Activation
This compound has been identified as a positive regulator of TNF-alpha-induced NF-kappa B transcriptional activity. It endogenously associates with key signaling molecules Receptor-Interacting Protein 1 (RIP1) and TNFR-Associated Death Domain (TRADD).[1] The following diagram illustrates the position of this compound in this signaling cascade, downstream of TRADD and upstream of RIP1.[1]
Experimental Protocols
A. Materials and Reagents
The choice of lysis buffer is critical and depends on the subcellular localization of the target protein and the desire to maintain protein complexes.[3]
| Buffer Type | Composition | Purpose |
| Non-denaturing (RIPA) | 50 mM Tris-HCl pH 7.4, 150 mM NaCl, 1% NP-40, 0.5% Sodium Deoxycholate, 0.1% SDS, 1 mM EDTA | Lysis of cytoplasmic, membrane, and nuclear proteins. Generally preserves protein interactions.[4] |
| Non-denaturing (NP-40) | 20 mM Tris-HCl pH 8, 137 mM NaCl, 1% Nonidet P-40 (NP-40), 2 mM EDTA | Milder lysis for soluble or membrane-bound proteins, good for maintaining protein-protein interactions.[3] |
| Detergent-free | PBS containing 5 mM EDTA, 0.02% Sodium Azide | For soluble proteins where detergent might disrupt interactions; requires mechanical lysis.[3] |
Note: Immediately before use, add protease and phosphatase inhibitors to the lysis buffer to prevent protein degradation.
| Buffer Name | Composition |
| HNTG Buffer | 20 mM HEPES pH 7.5, 150 mM NaCl, 0.1% (w/v) Triton X-100, 10% (w/v) glycerol.[2] |
| Ice-cold PBS | Phosphate-Buffered Saline, pH 7.4.[5] |
-
Primary antibody specific for this compound
-
Isotype-matched IgG (negative control)
-
SDS-PAGE Sample Loading Buffer (e.g., Laemmli buffer)[2]
B. Cell Lysate Preparation
-
Culture cells to approximately 80-90% confluency.
-
Place the cell culture dish on ice and wash the cells twice with ice-cold PBS.[3][4]
-
Aspirate the PBS completely.
-
Add ice-cold lysis buffer to the dish (e.g., 1 mL per 10^7 cells).[3][4]
-
Scrape the adherent cells from the dish using a cold plastic cell scraper and transfer the cell suspension to a pre-chilled microfuge tube.[4][5]
-
Incubate the lysate on ice for 30 minutes with gentle agitation to lyse the cells.[5]
-
Centrifuge the lysate at approximately 14,000 x g for 15-20 minutes at 4°C to pellet the cell debris.[3][5]
-
Carefully transfer the supernatant (protein lysate) to a new pre-chilled tube.
-
Determine the protein concentration of the lysate using a standard protein assay (e.g., BCA or Bradford). The optimal concentration is typically 1-5 mg/mL.[3]
C. Immunoprecipitation Workflow
The following diagram outlines the key steps in the immunoprecipitation protocol.
D. Detailed Immunoprecipitation Protocol
This protocol is a general guideline and may require optimization for specific cell types and antibodies.
This step minimizes non-specific binding of proteins to the beads.[5][6]
-
To 1 mg of total protein lysate, add 20-30 µL of a 50% slurry of Protein A/G beads.
-
Incubate on a rotator for 30-60 minutes at 4°C.[7]
-
Centrifuge at 2,500 x g for 30 seconds at 4°C.[5]
-
Carefully transfer the supernatant to a fresh, pre-chilled tube. Discard the beads.
| Parameter | Recommended Amount/Time | Notes |
| Cell Lysate | 200 - 1000 µg total protein | Dilute to ~1 µg/µL if necessary.[5] |
| Primary Antibody | 1-10 µg | The optimal amount should be determined empirically. Refer to the antibody datasheet.[2][4] |
| Incubation Time | 2 hours to overnight | Incubate at 4°C on a rotator.[4][5] |
| Protein A/G Beads | 20-50 µL of 50% slurry | Add after antibody incubation.[5] |
| Bead Incubation | 1-3 hours | Incubate at 4°C on a rotator.[7] |
Procedure:
-
Add the appropriate amount of primary anti-YN14 antibody to the pre-cleared lysate. For the negative control, add an equivalent amount of isotype control IgG to a separate aliquot of lysate.
-
Incubate the lysate-antibody mixture at 4°C for 2 hours to overnight on a rotator to form the immune complex.[4]
-
Add the pre-washed Protein A/G bead slurry to capture the immune complex.
-
Incubate for an additional 1-3 hours at 4°C with gentle rocking.[7]
Washing is crucial for removing non-specifically bound proteins and reducing background signal.[7]
-
Collect the beads by centrifugation (e.g., 3,000 x g for 2 minutes at 4°C) or by using a magnetic rack if using magnetic beads.[2][6]
-
Carefully remove and discard the supernatant.
-
Resuspend the beads in 1 mL of ice-cold wash buffer (e.g., HNTG or PBS).
-
Repeat the centrifugation and wash steps at least three to four times.[2]
-
After the final wash, carefully remove all supernatant.
-
Resuspend the bead pellet in 25-50 µL of 1x or 2x SDS-PAGE sample loading buffer.[2][5]
-
Boil the samples at 95-100°C for 5-10 minutes to dissociate the protein complexes from the beads.[2][5]
-
Centrifuge at high speed (e.g., 12,000 x g) for 1 minute to pellet the beads.[2]
-
Carefully collect the supernatant, which contains the immunoprecipitated proteins. This sample is now ready for analysis by Western blotting or other downstream applications.
III. Data Presentation and Analysis
The eluted samples should be run on an SDS-PAGE gel and transferred to a membrane for Western blot analysis. Probe with the anti-YN14 antibody to confirm the successful immunoprecipitation of the target protein. To identify interacting partners, the blot can be probed with antibodies against suspected binding partners (e.g., RIP1, TRADD), or the eluate can be analyzed by mass spectrometry for a broader, unbiased identification of the this compound interactome.[8][9]
References
- 1. researchgate.net [researchgate.net]
- 2. sigmaaldrich.com [sigmaaldrich.com]
- 3. docs.abcam.com [docs.abcam.com]
- 4. Immunoprecipitation Protocol: Novus Biologicals [novusbio.com]
- 5. Immunoprecipitation Protocol - Leinco Technologies [leinco.com]
- 6. Immunoprecipitation Protocol (Magnetic Beads) | Cell Signaling Technology [cellsignal.com]
- 7. youtube.com [youtube.com]
- 8. Proteomic analysis identifies novel binding partners of BAP1 - PMC [pmc.ncbi.nlm.nih.gov]
- 9. A proteomics protocol to identify stimulation-induced binding partners dependent on a specific gene in mammalian cells - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes: Methods for YN14 Knockdown and Knockout Experiments
Introduction
The study of gene function is fundamental to understanding biological processes and the mechanisms of disease. Gene knockdown and knockout techniques are powerful tools that allow researchers to investigate the role of a specific gene by reducing its expression (knockdown) or eliminating it entirely (knockout).[1][2] These methods are indispensable in target identification, validation, and drug development. This document provides detailed protocols and application notes for three widely used methods for silencing a hypothetical gene of interest, "YN14": small interfering RNA (siRNA) for transient knockdown, short hairpin RNA (shRNA) for stable, long-term knockdown, and CRISPR/Cas9 for complete gene knockout.[3][4]
Choosing the Right Method
The choice between transient knockdown, stable knockdown, or permanent knockout depends on the specific research question and experimental context.
-
siRNA (Transient Knockdown): Ideal for short-term studies, high-throughput screening, and when long-term gene silencing may be lethal to cells. The effects are temporary as the siRNA is diluted and degraded during cell division.[3]
-
shRNA (Stable Knockdown): Best suited for long-term studies, generating stable cell lines with continuous gene silencing, and in vivo experiments. This method involves integrating the shRNA sequence into the host cell's genome, often using viral vectors.[5][6]
-
CRISPR/Cas9 (Gene Knockout): Provides a permanent and complete loss of gene function by altering the genomic DNA. This is the gold standard for unequivocally determining the function of a gene by observing the phenotype resulting from its complete absence.[2][7]
Method 1: siRNA-Mediated Transient Knockdown of this compound
Small interfering RNAs (siRNAs) are short, double-stranded RNA molecules that induce sequence-specific degradation of a target mRNA. Upon introduction into the cytoplasm, the siRNA is incorporated into the RNA-Induced Silencing Complex (RISC). The RISC complex then uses the siRNA as a guide to find and cleave the complementary this compound mRNA, preventing its translation into protein.[1][8]
Experimental Workflow: siRNA Transfection
Caption: Workflow for transient this compound knockdown using siRNA.
Protocol: this compound siRNA Transfection
This protocol is optimized for a 6-well plate format. Reagent amounts should be scaled accordingly for different plate sizes.
Materials:
-
This compound-specific siRNA duplexes (at least 2-3 different sequences recommended)
-
Negative control siRNA (scrambled sequence)
-
Transfection reagent (e.g., Lipofectamine™ RNAiMAX)
-
Serum-free medium (e.g., Opti-MEM™)
-
Mammalian cell line of interest
-
Standard cell culture reagents and supplies
Procedure:
-
Cell Seeding (Day 1):
-
The day before transfection, seed 2 x 10^5 cells per well in a 6-well plate with 2 mL of antibiotic-free normal growth medium.
-
Incubate overnight at 37°C in a CO2 incubator. Cells should be 60-80% confluent at the time of transfection.[9]
-
-
Transfection (Day 2):
-
Solution A (siRNA): For each well, dilute 20-80 pmol of this compound siRNA (or control siRNA) into 100 µL of serum-free medium. Mix gently.[9]
-
Solution B (Transfection Reagent): For each well, dilute 2-8 µL of transfection reagent into 100 µL of serum-free medium. Mix gently and incubate for 5 minutes at room temperature.[9][10]
-
Combine: Add Solution A (siRNA) to Solution B (transfection reagent). Mix gently by pipetting and incubate for 15-20 minutes at room temperature to allow complex formation.[9][10]
-
Transfect Cells: Add the 200 µL siRNA-lipid complex mixture dropwise to the respective wells. Gently rock the plate to ensure even distribution.
-
Incubate the cells for 5-7 hours at 37°C.[9]
-
After incubation, aspirate the medium containing the transfection complexes and replace it with 2 mL of fresh, complete growth medium.
-
-
Analysis (Day 3-4):
-
Incubate cells for an additional 24-72 hours.
-
Harvest cells for analysis. Optimal knockdown time varies by cell line and target protein stability and should be determined experimentally.[11]
-
For qPCR: Isolate total RNA and perform reverse transcription followed by quantitative PCR to measure this compound mRNA levels.[12][13]
-
For Western Blot: Lyse cells and determine this compound protein levels by Western blot analysis.[2]
-
Quantitative Data for siRNA Experiments
| Parameter | Typical Range | Notes |
| siRNA Concentration | 10 - 100 nM | Optimal concentration should be determined to maximize knockdown while minimizing off-target effects and toxicity.[14] |
| Cell Confluency | 60 - 80% | High cell viability is crucial for successful transfection.[9] |
| Incubation Time (mRNA) | 24 - 48 hours | Peak mRNA knockdown is often observed within this timeframe.[11] |
| Incubation Time (Protein) | 48 - 96 hours | Protein knockdown depends on the half-life of the target protein. |
| Expected Knockdown | 70 - 95% | Efficiency varies based on the siRNA sequence, cell type, and transfection efficiency.[14] |
Method 2: shRNA-Mediated Stable Knockdown of this compound
Short hairpin RNAs (shRNAs) are expressed from a DNA vector, typically a plasmid or a lentiviral vector. Once transcribed, the shRNA is processed by cellular machinery into siRNA, which then enters the RNAi pathway to mediate stable, long-term gene silencing. Lentiviral delivery allows for the integration of the shRNA cassette into the host genome, creating a stable cell line.[1][5]
Experimental Workflow: Lentiviral shRNA Transduction
Caption: Workflow for stable this compound knockdown using shRNA.
Protocol: Lentiviral shRNA Transduction and Selection
Biosafety Note: Production and handling of lentiviral particles must be performed under Biosafety Level 2 (BSL-2) conditions.
Materials:
-
shRNA-YN14 lentiviral vector (and non-targeting control)
-
Lentiviral packaging and envelope plasmids (e.g., psPAX2, pMD2.G)
-
HEK293T cells (for virus production)
-
Target cell line
-
Polybrene or Hexadimethrine Bromide
-
Selection antibiotic (e.g., Puromycin)
Procedure:
-
Lentivirus Production (in HEK293T cells):
-
One day prior, seed HEK293T cells so they are ~80% confluent on the day of transfection.
-
Co-transfect the shRNA-YN14 plasmid along with the packaging and envelope plasmids using a suitable transfection reagent.
-
Replace the medium 12-18 hours post-transfection.
-
Harvest the virus-containing supernatant at 48 and 72 hours post-transfection. Pool the harvests, centrifuge to remove cell debris, and filter through a 0.45 µm filter. The virus can be used immediately or stored at -80°C.
-
-
Transduction of Target Cells:
-
Seed the target cells (e.g., 1 x 10^6 cells in a 6-well plate) the day before transduction.[5]
-
On the day of transduction, remove the medium and add fresh medium containing the lentiviral supernatant and Polybrene (typically 4-8 µg/mL) to enhance transduction efficiency. A range of viral amounts (Multiplicity of Infection - MOI) should be tested.
-
Incubate for 18-24 hours.[15]
-
-
Selection of Stable Cells:
-
48 hours post-transduction, begin selection by replacing the medium with fresh medium containing the appropriate concentration of puromycin.[16] The optimal puromycin concentration (typically 1-10 µg/mL) must be determined beforehand with a kill curve.[16]
-
Replace the selective medium every 2-3 days.[16]
-
After 7-10 days, non-transduced cells will die, and resistant colonies will become visible.
-
-
Clonal Expansion and Validation:
-
Isolate individual resistant colonies using cloning cylinders or by serial dilution.
-
Expand each clone into a stable cell line.
-
Validate the knockdown of this compound in each clonal line using qPCR and Western blot to identify the most effective clones.
-
Quantitative Data for shRNA Experiments
| Parameter | Typical Range | Notes |
| Multiplicity of Infection (MOI) | 0.5 - 10 | The ratio of viral particles to cells. Must be optimized for each cell line.[15] |
| Puromycin Concentration | 1 - 10 µg/mL | Cell-line dependent; determine with a titration experiment.[15][16] |
| Selection Duration | 7 - 14 days | Until resistant colonies are well-established. |
| Expected Knockdown | 75 - 90% | Stable knockdown efficiency can be very high in selected clones.[6] |
Method 3: CRISPR/Cas9-Mediated Gene Knockout of this compound
The CRISPR/Cas9 system is a powerful genome-editing tool. It uses a guide RNA (gRNA) to direct the Cas9 nuclease to a specific genomic locus (the this compound gene). Cas9 creates a double-strand break (DSB) in the DNA. The cell's error-prone non-homologous end joining (NHEJ) repair pathway often introduces small insertions or deletions (indels) at the break site. These indels can cause a frameshift mutation, leading to a premature stop codon and a non-functional protein, effectively knocking out the gene.[17][18]
Experimental Workflow: CRISPR/Cas9 Knockout
Caption: Workflow for generating a this compound knockout cell line using CRISPR/Cas9.
Protocol: Generating this compound Knockout Cell Lines
Materials:
-
Cas9 expression plasmid (e.g., pX458 which also contains GFP for sorting)[18]
-
gRNA expression vector
-
This compound-specific gRNA sequences (design 2-3 targeting an early exon)
-
Mammalian cell line of interest
-
Reagents for genomic DNA extraction, PCR, and Sanger sequencing
-
96-well plates for single-cell cloning
Procedure:
-
gRNA Design and Cloning:
-
Use online design tools (e.g., CHOPCHOP) to design gRNAs targeting an early exon of this compound to ensure a loss-of-function mutation. Select gRNAs with high predicted efficiency and low off-target scores.[18]
-
Synthesize and clone the gRNA oligonucleotides into the gRNA expression vector.
-
-
Transfection:
-
Seed cells the day before transfection.
-
Transfect the cells with the Cas9 and this compound-gRNA plasmids using an appropriate method (e.g., lipofection or electroporation).[19]
-
-
Single-Cell Isolation and Expansion:
-
48-72 hours post-transfection, enrich for transfected cells. If using a fluorescent reporter like GFP, use Fluorescence-Activated Cell Sorting (FACS) to sort single GFP-positive cells into individual wells of a 96-well plate.[17]
-
Alternatively, use limiting dilution to seed cells at a statistical average of 0.5-1 cell per well.[19]
-
Culture the single cells for 2-3 weeks, allowing them to form colonies.[17]
-
-
Screening and Validation:
-
Once colonies are large enough, expand them to larger plates. Create a duplicate plate for genomic DNA extraction.
-
Genomic Validation: Extract genomic DNA from each clone.[17] Use PCR to amplify the region of the this compound gene targeted by the gRNA. Sequence the PCR products (Sanger sequencing) to identify clones with frameshift-inducing indels.
-
Protein Validation: For clones confirmed to have biallelic frameshift mutations, perform a Western blot to confirm the complete absence of the this compound protein.[2][17]
-
Quantitative Data for CRISPR/Cas9 Experiments
| Parameter | Typical Range | Notes |
| Transfection Efficiency | 30 - 80% | Highly dependent on cell type and transfection method. |
| Single-Cell Cloning Efficiency | 5 - 30% | The ability of a single cell to grow into a colony varies greatly between cell lines. |
| Knockout Efficiency (Indel%) | 10 - 50% | Percentage of clones that have the desired biallelic knockout mutation. |
| Screening Time | 4 - 6 weeks | From transfection to validated knockout clone.[20] |
Hypothetical this compound Signaling Pathway
To illustrate how this compound's function might be visualized, this diagram presents a hypothetical signaling pathway. In this example, an upstream Growth Factor activates a Receptor Tyrosine Kinase (RTK), which in turn phosphorylates and activates this compound. Activated this compound then translocates to the nucleus to regulate a Transcription Factor, leading to the expression of genes involved in cell proliferation. Knockdown or knockout of this compound would be expected to block this pathway.
Caption: A hypothetical signaling cascade involving this compound.
References
- 1. Gene Knockdown methods To Determine Gene Function! [biosyn.com]
- 2. licorbio.com [licorbio.com]
- 3. eu.idtdna.com [eu.idtdna.com]
- 4. Strategies to validate loss-of-function gene targets involved in the mesenchymal to epithelial transition [horizondiscovery.com]
- 5. Short Hairpin RNA (shRNA): Design, Delivery, and Assessment of Gene Knockdown - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Preparation and Use of shRNA for Knocking Down Specific Genes - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. youtube.com [youtube.com]
- 8. Mini-review: Current strategies to knockdown long non-coding RNAs [rarediseasesjournal.com]
- 9. datasheets.scbt.com [datasheets.scbt.com]
- 10. youtube.com [youtube.com]
- 11. Insights into effective RNAi gained from large-scale siRNA validation screening - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Measuring RNAi knockdown using qPCR - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. Validation of short interfering RNA knockdowns by quantitative real-time PCR - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. documents.thermofisher.com [documents.thermofisher.com]
- 15. home.pavlab.msl.ubc.ca [home.pavlab.msl.ubc.ca]
- 16. datasheets.scbt.com [datasheets.scbt.com]
- 17. genemedi.net [genemedi.net]
- 18. Generation of knock-in and knock-out CRISPR/Cas9 editing in mammalian cells [protocols.io]
- 19. genecopoeia.com [genecopoeia.com]
- 20. biorxiv.org [biorxiv.org]
Application Notes & Protocols: Elucidating the Function of YN14 Using CRISPR-Cas9
Audience: Researchers, scientists, and drug development professionals.
Introduction
The Clustered Regularly Interspaced Short Palindromic Repeats (CRISPR) and CRISPR-associated protein 9 (Cas9) system has emerged as a transformative technology for genome engineering.[1][2] Its precision, efficiency, and versatility have revolutionized functional genomics, enabling researchers to dissect gene function with unprecedented ease.[3][4] This technology is particularly valuable in drug discovery and development for target identification, validation, and the creation of disease models.[3][5][6][7]
This document provides a comprehensive guide to utilizing the CRISPR-Cas9 system to investigate the function of the hypothetical gene YN14. This compound is a putative kinase suspected to play a critical role in cellular proliferation and survival pathways, making it a potential therapeutic target in oncology. These protocols will detail methods for gene knockout (CRISPR-KO) to study loss-of-function, as well as transcriptional repression (CRISPR interference, CRISPRi) and activation (CRISPR activation, CRISPRa) to analyze the effects of modulated gene expression.
Hypothetical this compound Signaling Pathway
This compound is postulated to be a key downstream effector in a growth factor signaling cascade. Upon binding of a growth factor to its receptor tyrosine kinase (RTK), the receptor dimerizes and autophosphorylates, creating docking sites for adaptor proteins. This leads to the recruitment and activation of this compound. Activated this compound then phosphorylates and activates the transcription factor "TF-Alpha," which translocates to the nucleus and promotes the expression of genes essential for cell cycle progression, such as Cyclin D1.
Caption: Hypothetical this compound signaling cascade leading to cell proliferation.
Overall Experimental Workflow
The general workflow for studying this compound function using CRISPR-Cas9 involves several key stages, from initial design to final functional analysis. This process ensures specificity and efficacy while minimizing off-target effects.
Caption: General workflow for CRISPR-Cas9-mediated gene function analysis.
Protocol 1: this compound Gene Knockout via CRISPR-Cas9
This protocol describes the generation of a stable this compound knockout cell line to study loss-of-function phenotypes. The strategy involves creating a double-strand break (DSB) within a critical exon of this compound, which is then repaired by the error-prone non-homologous end joining (NHEJ) pathway, often resulting in frameshift mutations (indels) and a non-functional protein.[8][9]
Detailed Experimental Protocol
-
Guide RNA (gRNA) Design and Selection
-
Objective : To design gRNAs with high on-target activity and low off-target potential.
-
Procedure :
-
Obtain the genomic sequence of the this compound gene, focusing on the first or second exon to maximize the chance of creating a null allele.[10]
-
Use online design tools (e.g., CHOPCHOP, Synthego Design Tool) to identify potential 20-nucleotide gRNA sequences preceding a Protospacer Adjacent Motif (PAM) sequence (e.g., NGG for Streptococcus pyogenes Cas9).[10]
-
Select 2-3 gRNAs with high predicted on-target scores and minimal predicted off-target sites, especially in other gene-coding regions.[9]
-
-
-
CRISPR Component Preparation
-
Objective : To prepare the Cas9 nuclease and gRNA for cellular delivery.
-
Procedure (Plasmid-based) :
-
Synthesize DNA oligonucleotides corresponding to the selected gRNA sequences.
-
Anneal the complementary oligos to create a double-stranded DNA fragment.
-
Clone the annealed fragment into a Cas9-expressing vector (e.g., lentiCRISPRv2) that also contains a selectable marker like puromycin resistance.
-
Verify the correct insertion by Sanger sequencing.
-
-
Procedure (Ribonucleoprotein - RNP based) :
-
Order synthetic gRNA and recombinant Cas9 protein.
-
Form the RNP complex by incubating Cas9 protein with the synthetic gRNA according to the manufacturer's protocol just prior to delivery.
-
-
-
Delivery into Target Cells
-
Objective : To introduce the CRISPR components into a relevant cell line (e.g., A549 lung cancer cells).
-
Procedure :
-
Plate 200,000 A549 cells per well in a 6-well plate 24 hours before transfection.
-
Transfect the cells with the Cas9/gRNA plasmid (2.5 µg) or RNP complex using a suitable method like lipid-based transfection (e.g., Lipofectamine) or electroporation.
-
Include a negative control (e.g., a non-targeting gRNA) and a positive control (gRNA targeting a gene like PPIB).
-
-
-
Validation of Gene Editing in Bulk Population
-
Objective : To confirm successful gene editing in the transfected cell pool before single-cell cloning.[11][12]
-
Procedure :
-
Harvest genomic DNA from a portion of the cells 48-72 hours post-transfection.
-
Amplify the this compound target region using PCR.
-
Analyze the PCR product using a mismatch cleavage assay (e.g., T7 Endonuclease I) or by Sanger sequencing followed by TIDE (Tracking of Indels by Decomposition) analysis.[11][13] This will provide an estimate of the indel frequency.
-
-
-
Single-Cell Cloning and Screening
-
Objective : To isolate individual cells and expand them into clonal populations to identify those with the desired biallelic knockout.
-
Procedure :
-
If using a plasmid with a selectable marker, apply selection (e.g., puromycin at 1-2 µg/mL) 48 hours post-transfection.
-
After selection, dilute the surviving cells to a concentration of a single cell per 100-200 µL and plate into 96-well plates.
-
Allow colonies to grow for 2-3 weeks.
-
Screen individual clones by genomic DNA PCR and Sanger sequencing to identify clones with frameshift-inducing indels on all alleles.
-
Confirm the absence of this compound protein in knockout clones using Western Blot.
-
-
-
Functional Analysis
-
Objective : To assess the phenotypic consequences of this compound knockout.
-
Procedure :
-
Proliferation Assay : Seed equal numbers of wild-type (WT) and this compound-KO cells and measure proliferation over 5 days using a cell counting kit (e.g., CCK-8) or direct cell counting.
-
Migration Assay : Perform a scratch (wound healing) assay or a transwell migration assay to assess changes in cell motility.
-
Apoptosis Assay : Treat cells with a mild stressor (e.g., low-dose chemotherapy) and measure apoptosis rates using Annexin V/PI staining and flow cytometry.
-
-
Data Presentation: this compound Knockout
Table 1: this compound gRNA Design and Predicted Efficacy
| gRNA ID | Target Sequence (5' to 3') | Exon | On-Target Score | Off-Target Score |
|---|---|---|---|---|
| YN14_g1 | GATCGTACGTGACGACGTAC | 1 | 92 | 98 |
| YN14_g2 | CTAGCTAGCTAGCTAGCTAG | 1 | 85 | 95 |
| YN14_g3 | AGCTAGCTAGCTAGCTAGCT | 2 | 88 | 99 |
Table 2: Validation of Editing Efficiency and Knockout Clones
| Clone ID | Genotype (Sequencing Result) | Indel Type | This compound mRNA Level (% of WT) | This compound Protein Level |
|---|---|---|---|---|
| Bulk Pool | Mixed Population | Mixed Indels | 55% | Reduced |
| KO_C1 | Allele 1: -1 bp, Allele 2: +2 bp | Biallelic Frameshift | 8% | Absent |
| KO_C2 | Allele 1: -4 bp, Allele 2: -4 bp | Biallelic Frameshift | 12% | Absent |
| WT_C1 | Wild-Type | None | 100% | Present |
Table 3: Phenotypic Analysis of this compound Knockout Clones
| Cell Line | Proliferation Rate (Absorbance at 72h) | Relative Migration (% Wound Closure) | Apoptosis Rate (%) |
|---|---|---|---|
| Wild-Type | 1.85 ± 0.12 | 85% ± 5% | 5% ± 1% |
| This compound KO_C1 | 0.95 ± 0.08 | 32% ± 4% | 25% ± 3% |
| this compound KO_C2 | 0.99 ± 0.10 | 35% ± 6% | 28% ± 4% |
Protocol 2: Modulating this compound Expression with CRISPRi and CRISPRa
For genes like this compound that may be essential for cell viability, a full knockout can be lethal. CRISPRi and CRISPRa offer alternatives by enabling transient and tunable repression or activation of gene expression without altering the DNA sequence.[14][15] These systems use a catalytically "dead" Cas9 (dCas9) fused to a transcriptional repressor (e.g., KRAB for CRISPRi) or an activator (e.g., VPR for CRISPRa).[16][17]
Detailed Experimental Protocol
-
gRNA Design for CRISPRi/a
-
Objective : To design gRNAs that target the this compound promoter region to either block or enhance transcription.
-
Procedure :
-
Identify the transcriptional start site (TSS) of this compound from a genome browser (e.g., UCSC).
-
For CRISPRi : Design gRNAs that target the region from -50 to +300 bp relative to the TSS.[18]
-
For CRISPRa : Design gRNAs that target the region from -400 to -50 bp relative to the TSS.[18]
-
Use design tools to select 2-3 gRNAs for each application with minimal off-target predictions.
-
-
-
CRISPR Component Preparation and Delivery
-
Objective : To deliver the dCas9-effector and gRNA into target cells.
-
Procedure :
-
Use a two-vector system: one plasmid expressing the dCas9-effector (e.g., dCas9-KRAB or dCas9-VPR) and another expressing the gRNA.
-
Co-transfect both plasmids into the target cells using methods described in Protocol 1. Alternatively, generate stable cell lines expressing the dCas9-effector first, then deliver only the gRNA for inducible modulation.
-
-
-
Validation of this compound Modulation
-
Objective : To quantify the change in this compound expression.
-
Procedure :
-
Harvest cells 48-96 hours post-transfection.
-
qRT-PCR : Isolate total RNA, synthesize cDNA, and perform quantitative real-time PCR using this compound-specific primers to measure mRNA levels.
-
Western Blot : Prepare total protein lysates and perform Western blotting with an anti-YN14 antibody to measure protein levels.
-
-
-
Functional Analysis
-
Objective : To assess the phenotypic impact of this compound knockdown or overexpression.
-
Procedure : Perform the same functional assays as described in Protocol 1 (proliferation, migration, apoptosis) to compare the effects of graded this compound expression with the full knockout.
-
Data Presentation: this compound CRISPRi/a
Table 4: Validation of this compound Expression Modulation
| Condition | Target Region | This compound mRNA Level (% of Control) | This compound Protein Level (% of Control) |
|---|---|---|---|
| Control (Non-targeting gRNA) | N/A | 100% ± 8% | 100% ± 11% |
| CRISPRi_g1 | TSS +50 bp | 15% ± 4% | 21% ± 6% |
| CRISPRi_g2 | TSS +120 bp | 22% ± 5% | 28% ± 7% |
| CRISPRa_g1 | TSS -150 bp | 450% ± 35% | 380% ± 40% |
| CRISPRa_g2 | TSS -200 bp | 620% ± 48% | 510% ± 55% |
Table 5: Functional Consequences of this compound Modulation
| Condition | Proliferation Rate (Absorbance at 72h) | Relative Migration (% Wound Closure) |
|---|---|---|
| Control | 1.85 ± 0.12 | 85% ± 5% |
| CRISPRi ( knockdown) | 1.21 ± 0.09 | 55% ± 7% |
| CRISPRa (overexpression) | 2.65 ± 0.21 | 98% ± 4% |
Choosing the Right CRISPR Approach
The choice between CRISPR-KO, CRISPRi, and CRISPRa depends on the specific biological question being addressed. This diagram outlines a decision-making framework.
Caption: Decision tree for selecting the appropriate CRISPR-based method.
References
- 1. news-medical.net [news-medical.net]
- 2. CRISPR Protocols and Methods | Springer Nature Experiments [experiments.springernature.com]
- 3. Cornerstones of CRISPR-Cas in drug development and therapy - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Using CRISPR/Cas to study gene function and model disease in vivo - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Frontiers | CRISPR/Cas9 technology in tumor research and drug development application progress and future prospects [frontiersin.org]
- 6. researchgate.net [researchgate.net]
- 7. The Pharmaceutical Applications of CRISPR-Cas9 and Its Development Trends | MedScien [lseee.net]
- 8. synthego.com [synthego.com]
- 9. idtdna.com [idtdna.com]
- 10. innovativegenomics.org [innovativegenomics.org]
- 11. blog.addgene.org [blog.addgene.org]
- 12. CRISPR 遺伝子編集効率の検証 | Thermo Fisher Scientific - JP [thermofisher.com]
- 13. Strategies to detect and validate your CRISPR gene edit [horizondiscovery.com]
- 14. synthego.com [synthego.com]
- 15. sg.idtdna.com [sg.idtdna.com]
- 16. cdn.origene.com [cdn.origene.com]
- 17. CRISPR interference [horizondiscovery.com]
- 18. CRISPR guide RNA design for research applications - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols: YN14 Antibody Validation for Western Blot
Introduction
The YN14 antibody is a critical reagent for the detection of its target protein in complex biological samples via Western Blotting. These application notes provide detailed protocols and validation data to ensure reliable and reproducible results in your research. The following sections outline the necessary steps for sample preparation, electrophoresis, protein transfer, immunodetection, and data analysis. Adherence to these protocols is recommended to achieve optimal performance of the this compound antibody.
Data Presentation
Quantitative analysis is essential for the validation of any antibody. The following table summarizes the key performance indicators for the this compound antibody in Western Blot applications. This data was generated using the detailed protocol provided below.
| Parameter | Value | Notes |
| Recommended Dilution Range | 1:1000 - 1:5000 | Optimal dilution should be determined by the end-user. |
| Positive Control Lysate | HEK293T cells overexpressing Target Protein | A strong band at the expected molecular weight was observed. |
| Negative Control Lysate | Parental HEK293T cells | No detectable band at the expected molecular weight. |
| Observed Molecular Weight | ~50 kDa | Consistent with the predicted molecular weight of the target protein. |
| Signal-to-Noise Ratio | >10 | At a 1:2000 dilution with a 5-minute exposure. |
| Antibody Specificity | High | No significant off-target bands were observed. |
Experimental Protocols
This section provides a detailed protocol for performing a Western Blot experiment using the this compound antibody.
A. Cell Lysis and Protein Quantification
-
Harvest cells and wash twice with ice-cold PBS.
-
Lyse the cell pellet in RIPA buffer (50 mM Tris-HCl pH 7.4, 150 mM NaCl, 1% NP-40, 0.5% sodium deoxycholate, 0.1% SDS) supplemented with protease and phosphatase inhibitors.
-
Incubate on ice for 30 minutes with intermittent vortexing.
-
Centrifuge the lysate at 14,000 x g for 15 minutes at 4°C.
-
Transfer the supernatant to a new tube and determine the protein concentration using a BCA protein assay.
B. SDS-PAGE and Protein Transfer
-
Prepare protein samples by mixing 20-30 µg of total protein with 4X Laemmli sample buffer and boiling at 95°C for 5 minutes.
-
Load the samples onto a 10% SDS-polyacrylamide gel and run at 120V until the dye front reaches the bottom of the gel.
-
Transfer the separated proteins to a PVDF membrane at 100V for 90 minutes at 4°C.
-
Confirm the transfer efficiency by staining the membrane with Ponceau S.
C. Immunoblotting
-
Block the membrane with 5% non-fat dry milk in Tris-buffered saline with 0.1% Tween-20 (TBST) for 1 hour at room temperature.
-
Incubate the membrane with the this compound primary antibody at a 1:2000 dilution in 5% BSA in TBST overnight at 4°C with gentle agitation.
-
Wash the membrane three times for 10 minutes each with TBST.
-
Incubate the membrane with an HRP-conjugated secondary antibody (e.g., anti-rabbit IgG) at a 1:5000 dilution in 5% non-fat dry milk in TBST for 1 hour at room temperature.
-
Wash the membrane three times for 10 minutes each with TBST.
D. Detection and Analysis
-
Prepare the enhanced chemiluminescence (ECL) substrate according to the manufacturer's instructions.
-
Incubate the membrane with the ECL substrate for 1-5 minutes.
-
Capture the chemiluminescent signal using a digital imaging system.
-
Analyze the band intensities using appropriate software.
Signaling Pathway and Workflow Diagrams
The following diagrams illustrate a hypothetical signaling pathway involving the target of the this compound antibody and the general experimental workflow for Western Blotting.
Caption: Hypothetical signaling cascade involving the this compound target protein.
Caption: General workflow for Western Blot analysis using the this compound antibody.
Application Notes and Protocols for Quantitative PCR Analysis of YN14 (RBM8A) Gene Expression
For Researchers, Scientists, and Drug Development Professionals
Introduction
YN14, also known as RNA Binding Motif Protein 8A (RBM8A), is a core component of the exon junction complex (EJC), a dynamic multiprotein complex that plays a crucial role in post-transcriptional mRNA processing.[1][2] The EJC is deposited onto mRNAs during splicing and influences subsequent processes such as mRNA export, localization, translation, and nonsense-mediated mRNA decay (NMD).[2][3][4] Due to its central role in gene expression regulation, dysregulation of this compound/RBM8A has been implicated in various diseases, making it a gene of significant interest in research and drug development.
Quantitative Polymerase Chain Reaction (qPCR) is a powerful and widely used technique for the sensitive and specific quantification of gene expression levels.[5] This document provides detailed application notes and protocols for the analysis of this compound/RBM8A gene expression using SYBR Green-based qPCR.
Signaling Pathways Involving this compound (RBM8A)
This compound/RBM8A is involved in several key cellular signaling pathways, underscoring its importance in cellular function and disease. Understanding these pathways is critical for interpreting gene expression data in the context of broader biological processes. RBM8A has been shown to be involved in the MAPK pathway , Wnt/PCP signaling , the epithelial-mesenchymal transition (EMT) signaling pathway , and the AKT/mTOR pathway .[5][6][7]
Below is a diagram illustrating a simplified overview of the signaling pathways influenced by this compound/RBM8A.
Caption: Simplified diagram of this compound/RBM8A's role in mRNA metabolism and its influence on downstream signaling pathways.
Quantitative PCR Primers
The selection of high-quality, validated primers is critical for the success of qPCR experiments. The following table provides primer sequences for the human this compound/RBM8A gene and a commonly used housekeeping gene, Beta-actin (ACTB), for normalization.
| Gene | Forward Primer (5' - 3') | Reverse Primer (5' - 3') | Amplicon Size (bp) | Source |
| This compound (RBM8A) | ATGGCCACAGAAACACTTCC | GGGCGGAATCTCTAATCCAC | 150-200 | [8] |
| ACTB | CACCATTGGCAATGAGCGGTTC | AGGTCTTTGCGGATGTCCACGT | 100-150 | OriGene Technologies |
Note: It is highly recommended to experimentally validate the efficiency of the primers before use in quantitative expression analysis.
Experimental Protocols
This section provides a detailed protocol for the analysis of this compound/RBM8A gene expression using a two-step SYBR Green-based qPCR method.
Experimental Workflow Diagram
Caption: A standard workflow for quantitative gene expression analysis using qPCR.
RNA Extraction and Quality Control
-
Isolate total RNA from cell or tissue samples using a reputable RNA extraction kit (e.g., TRIzol reagent or column-based kits) according to the manufacturer's instructions.
-
Assess RNA quantity and purity using a spectrophotometer (e.g., NanoDrop). An A260/A280 ratio of ~2.0 is indicative of pure RNA.
-
Evaluate RNA integrity by agarose gel electrophoresis or using an automated electrophoresis system (e.g., Agilent Bioanalyzer). Intact total RNA will show sharp 28S and 18S ribosomal RNA bands.
cDNA Synthesis (Reverse Transcription)
-
Prepare the reverse transcription reaction mix on ice. For a 20 µL reaction, combine the following:
-
Total RNA: 1 µg
-
Oligo(dT) primers (10 µM): 1 µL
-
Random hexamer primers (10 µM): 1 µL
-
dNTP mix (10 mM): 1 µL
-
Nuclease-free water: to 13 µL
-
-
Incubate the mixture at 65°C for 5 minutes, then place on ice for at least 1 minute.
-
Add the following components to the reaction tube:
-
5X Reaction Buffer: 4 µL
-
RNase Inhibitor (40 U/µL): 1 µL
-
Reverse Transcriptase (200 U/µL): 1 µL
-
Nuclease-free water: 1 µL
-
-
Incubate the reaction at 42°C for 60 minutes, followed by an inactivation step at 70°C for 10 minutes.
-
Store the resulting cDNA at -20°C.
Quantitative PCR (qPCR)
-
Prepare the qPCR reaction mix . For a single 20 µL reaction, combine the following:
-
2X SYBR Green qPCR Master Mix: 10 µL
-
Forward Primer (10 µM): 0.5 µL
-
Reverse Primer (10 µM): 0.5 µL
-
Diluted cDNA (1:10): 2 µL
-
Nuclease-free water: 7 µL
-
-
Set up the qPCR plate . Include the following for each gene (this compound and ACTB):
-
No-template control (NTC)
-
Samples in triplicate
-
-
Perform the qPCR run using a real-time PCR instrument with the following cycling conditions:
-
Initial Denaturation: 95°C for 10 minutes
-
40 Cycles:
-
Denaturation: 95°C for 15 seconds
-
Annealing/Extension: 60°C for 60 seconds
-
-
Melt Curve Analysis (to verify amplicon specificity)
-
Data Presentation and Analysis
The relative expression of the this compound gene can be calculated using the comparative Ct (ΔΔCt) method.
Data Table
| Sample Group | Sample ID | This compound Ct (avg) | ACTB Ct (avg) | ΔCt (this compound - ACTB) | ΔΔCt (ΔCt_sample - ΔCt_control) | Fold Change (2^-ΔΔCt) |
| Control | 1 | 22.5 | 18.2 | 4.3 | 0.0 | 1.0 |
| Control | 2 | 22.7 | 18.4 | 4.3 | 0.0 | 1.0 |
| Control | 3 | 22.6 | 18.3 | 4.3 | 0.0 | 1.0 |
| Treatment A | 1 | 24.8 | 18.3 | 6.5 | 2.2 | 0.22 |
| Treatment A | 2 | 25.1 | 18.5 | 6.6 | 2.3 | 0.20 |
| Treatment A | 3 | 24.9 | 18.4 | 6.5 | 2.2 | 0.22 |
| Treatment B | 1 | 20.1 | 18.1 | 2.0 | -2.3 | 4.92 |
| Treatment B | 2 | 20.3 | 18.3 | 2.0 | -2.3 | 4.92 |
| Treatment B | 3 | 20.2 | 18.2 | 2.0 | -2.3 | 4.92 |
Note: The data presented in this table is for illustrative purposes only.
Troubleshooting
| Problem | Possible Cause | Solution |
| No amplification or low signal | Poor RNA quality or quantity | Re-extract RNA and ensure high purity and integrity. |
| Inefficient cDNA synthesis | Optimize reverse transcription reaction conditions. | |
| Incorrect primer design | Validate primer efficiency and specificity. | |
| Non-specific amplification (multiple peaks in melt curve) | Primer-dimers or off-target amplification | Optimize annealing temperature; redesign primers. |
| High Ct values | Low target gene expression | Increase the amount of cDNA template. |
| PCR inhibition | Dilute the cDNA template to reduce inhibitor concentration. | |
| High variability between replicates | Pipetting errors | Use calibrated pipettes and be consistent with technique. |
| Inhomogeneous sample | Ensure thorough mixing of reaction components. |
By following these detailed protocols and application notes, researchers can obtain reliable and reproducible quantitative data on this compound/RBM8A gene expression, contributing to a better understanding of its role in health and disease.
References
- 1. mdpi.com [mdpi.com]
- 2. uniprot.org [uniprot.org]
- 3. genecards.org [genecards.org]
- 4. mdpi.com [mdpi.com]
- 5. A critical role of RBM8a in proliferation and differentiation of embryonic neural progenitors - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Rbm8a deficiency causes hematopoietic defects by modulating Wnt/PCP signaling - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. RBM8A RNA binding motif protein 8A [Homo sapiens (human)] - Gene - NCBI [ncbi.nlm.nih.gov]
- 8. spandidos-publications.com [spandidos-publications.com]
Application Notes and Protocols: Unveiling the Subcellular Location of Protein YN14 via Fluorescence Microscopy
For Researchers, Scientists, and Drug Development Professionals
Introduction
Determining the subcellular localization of a protein is a critical step in elucidating its function and its role in cellular processes and disease.[1][2] This information can provide valuable insights into a protein's interaction partners and its involvement in specific signaling pathways.[1] Fluorescence microscopy is a powerful and widely used technique for visualizing the distribution of specific molecules within cells with high specificity and sensitivity.[3][4][5] This document provides a detailed protocol for determining the subcellular localization of the novel protein YN14 using two common fluorescence microscopy approaches: immunofluorescence (IF) for fixed cells and live-cell imaging of a fluorescently-tagged this compound.
Principle of the Methods
Immunofluorescence (IF) is a technique that utilizes antibodies to detect a specific protein (antigen) within a cell.[3][6][7][8] In indirect immunofluorescence, a primary antibody binds specifically to this compound. Subsequently, a secondary antibody, conjugated to a fluorophore, binds to the primary antibody, amplifying the signal and allowing for visualization via fluorescence microscopy.[3] This method is suitable for determining the native localization of the endogenous protein.
Live-Cell Imaging involves the genetic fusion of a fluorescent protein (e.g., Green Fluorescent Protein, GFP) to the protein of interest (this compound-GFP).[9][10] This fusion protein is then expressed in cells, allowing for the visualization of its localization and dynamics in real-time in living cells.[11][12] This approach is particularly useful for studying protein translocation and dynamic processes.
Experimental Workflow
The overall experimental workflow for determining this compound localization is depicted below.
Caption: Workflow for this compound localization using immunofluorescence and live-cell imaging.
Detailed Experimental Protocols
Protocol 1: Immunofluorescence Staining of this compound in Fixed Cells
This protocol describes the indirect immunofluorescence method for localizing endogenous this compound.
Materials:
-
Cells expressing this compound
-
Glass coverslips
-
Phosphate-Buffered Saline (PBS)
-
Fixation Solution (e.g., 4% Paraformaldehyde (PFA) in PBS)
-
Permeabilization Buffer (e.g., 0.1-0.5% Triton X-100 in PBS)
-
Blocking Buffer (e.g., 1-5% Bovine Serum Albumin (BSA) in PBS with 0.1% Triton X-100)
-
Primary Antibody: Rabbit anti-YN14
-
Secondary Antibody: Goat anti-Rabbit IgG conjugated to a fluorophore (e.g., Alexa Fluor 488)
-
Nuclear Stain (e.g., DAPI)
-
Mounting Medium
Procedure:
-
Cell Seeding: Seed cells on sterile glass coverslips in a petri dish or multi-well plate and culture until they reach the desired confluency (typically 50-70%).
-
Washing: Gently wash the cells three times with PBS.
-
Fixation: Incubate the cells with Fixation Solution for 10-20 minutes at room temperature. Note: The choice of fixation method is critical and may need optimization.[4]
-
Washing: Wash the cells three times with PBS for 5 minutes each.
-
Permeabilization: Incubate the cells with Permeabilization Buffer for 10-15 minutes at room temperature. This step is necessary to allow antibodies to access intracellular antigens.[3]
-
Washing: Wash the cells three times with PBS for 5 minutes each.
-
Blocking: Incubate the cells with Blocking Buffer for 30-60 minutes at room temperature to reduce non-specific antibody binding.[7]
-
Primary Antibody Incubation: Dilute the primary anti-YN14 antibody in Blocking Buffer to its optimal concentration. Incubate the cells with the diluted primary antibody for 1-2 hours at room temperature or overnight at 4°C.
-
Washing: Wash the cells three times with PBS containing 0.1% Triton X-100 (PBST) for 5 minutes each.
-
Secondary Antibody Incubation: Dilute the fluorophore-conjugated secondary antibody in Blocking Buffer. Incubate the cells with the diluted secondary antibody for 1 hour at room temperature, protected from light.
-
Washing: Wash the cells three times with PBST for 5 minutes each, protected from light.
-
Nuclear Staining: Incubate the cells with DAPI solution for 5-10 minutes at room temperature, protected from light.
-
Washing: Wash the cells twice with PBS.
-
Mounting: Mount the coverslips onto glass slides using a mounting medium. Seal the edges of the coverslip with nail polish.
-
Imaging: Visualize the samples using a fluorescence microscope. Acquire images in the appropriate channels for the fluorophore and DAPI.
Protocol 2: Live-Cell Imaging of this compound-GFP Fusion Protein
This protocol describes the localization of this compound by expressing it as a fusion protein with GFP.
Materials:
-
Cells suitable for transfection
-
Expression vector containing the this compound-GFP fusion construct
-
Transfection reagent
-
Cell culture medium
-
Glass-bottom imaging dishes or plates
Procedure:
-
Cell Seeding: Seed cells in glass-bottom imaging dishes.
-
Transfection: When cells reach the appropriate confluency (typically 70-90%), transfect them with the this compound-GFP expression vector according to the manufacturer's protocol for the chosen transfection reagent.
-
Expression: Culture the cells for 24-48 hours post-transfection to allow for the expression of the this compound-GFP fusion protein.
-
Imaging: Replace the culture medium with an imaging medium (e.g., phenol red-free medium) to reduce background fluorescence. Visualize the live cells using a fluorescence microscope equipped with a live-cell imaging chamber to maintain physiological conditions (37°C, 5% CO2). Acquire images in the GFP channel.
-
(Optional) Co-localization: To determine the specific subcellular compartment, cells can be co-transfected with a plasmid expressing a fluorescent marker for a particular organelle (e.g., a red fluorescent protein targeted to the mitochondria).[2]
Data Presentation and Analysis
Quantitative analysis of the fluorescence signal can provide objective data on the subcellular distribution of this compound. This can be achieved through image analysis software to measure the fluorescence intensity in different cellular compartments (e.g., nucleus vs. cytoplasm).
Table 1: Quantitative Analysis of this compound Subcellular Localization
| Experimental Condition | Method | Nuclear Fluorescence Intensity (Arbitrary Units) | Cytoplasmic Fluorescence Intensity (Arbitrary Units) | Nucleus/Cytoplasm Ratio | Predominant Localization |
| Untreated Cells | Immunofluorescence | ||||
| Untreated Cells | Live-Cell Imaging (this compound-GFP) | ||||
| Drug A Treatment | Immunofluorescence | ||||
| Drug B Treatment | Live-Cell Imaging (this compound-GFP) |
Signaling Pathway Diagram
The subcellular localization of a protein can be regulated by various signaling pathways. For instance, post-translational modifications like phosphorylation can trigger the translocation of a protein between the nucleus and the cytoplasm.
References
- 1. Immunofluorescence in Cell Lines [atlasantibodies.com]
- 2. addgene.org [addgene.org]
- 3. UNIT 4.3 Immunofluorescence Staining - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Visualizing Protein Localizations in Fixed Cells: Caveats and the Underlying Mechanisms - PMC [pmc.ncbi.nlm.nih.gov]
- 5. neb.com [neb.com]
- 6. Subcellular Localization of Histidine Phosphorylated Proteins Through Indirect Immunofluorescence - PMC [pmc.ncbi.nlm.nih.gov]
- 7. m.youtube.com [m.youtube.com]
- 8. IF Video Protocol | Proteintech Group [ptglab.com]
- 9. blog.addgene.org [blog.addgene.org]
- 10. MyScope [myscope.training]
- 11. Live-Cell Fluorescence Microscopy to Investigate Subcellular Protein Localization and Cell Morphology Changes in Bacteria - PMC [pmc.ncbi.nlm.nih.gov]
- 12. neb.com [neb.com]
Application Notes and Protocols for In Vitro Assays Involving the KRASG12C Degrader YN14
For Researchers, Scientists, and Drug Development Professionals
Introduction
YN14 is a highly potent and selective Proteolysis Targeting Chimera (PROTAC) designed to target the KRASG12C mutant protein for degradation.[1] As a heterobifunctional molecule, this compound simultaneously binds to KRASG12C and the von Hippel-Lindau (VHL) E3 ubiquitin ligase. This induced proximity facilitates the ubiquitination of KRASG12C, marking it for degradation by the 26S proteasome.[2] This mechanism of action effectively reduces the levels of the oncoprotein, leading to the suppression of downstream signaling pathways, such as the MAPK pathway, and inhibiting the growth of KRASG12C-mutant cancer cells.[1][3]
The development and characterization of PROTACs like this compound necessitate a suite of specialized in vitro assays to elucidate their mechanism of action and quantify their efficacy. Standard in vitro transcription/translation assays are not suitable for evaluating the primary function of PROTACs, as these systems typically lack the necessary components of the ubiquitin-proteasome system (UPS). Therefore, this document provides detailed protocols for the relevant in vitro assays for this compound: ternary complex formation, ubiquitination, and proteasomal degradation. These cell-free assays are instrumental in the preclinical assessment and optimization of PROTAC molecules.
Quantitative Data for this compound
The following table summarizes the reported cellular activity of this compound in KRASG12C-mutant cancer cell lines.
| Parameter | Cell Line | Value | Reference |
| IC₅₀ | MIA PaCa-2 | 1.9 nM | [1] |
| NCI-H358 | 2.5 nM | [1] | |
| DC₅₀ | MIA PaCa-2 | 3.1 nM | [1] |
| NCI-H358 | 4.2 nM | [1] | |
| Dₘₐₓ | MIA PaCa-2 | >95% | [1] |
| NCI-H358 | >95% | [1] |
IC₅₀: Half-maximal inhibitory concentration for cell growth. DC₅₀: Half-maximal degradation concentration. Dₘₐₓ: Maximum degradation.
Signaling and Mechanistic Pathways
The following diagrams illustrate the KRAS signaling pathway targeted by this compound and the mechanism of this compound-mediated protein degradation.
Caption: The KRAS signaling pathway and the inhibitory point of this compound.
Caption: Mechanism of this compound-mediated degradation of KRASG12C.
Experimental Protocols
In Vitro Ternary Complex Formation Assay (Time-Resolved Fluorescence Resonance Energy Transfer - TR-FRET)
This assay quantitatively measures the formation of the KRASG12C:this compound:VHL ternary complex.
Workflow Diagram:
Caption: Workflow for the TR-FRET-based ternary complex formation assay.
Materials:
-
Recombinant human KRASG12C protein (e.g., His-tagged)
-
Recombinant human VHL-ElonginB-ElonginC (VBC) complex (e.g., GST-tagged)
-
This compound
-
TR-FRET donor-labeled antibody (e.g., anti-His-Europium)
-
TR-FRET acceptor-labeled antibody (e.g., anti-GST-APC)
-
Assay buffer (e.g., 50 mM Tris-HCl pH 7.5, 150 mM NaCl, 5 mM MgCl₂, 1 mM DTT, 0.01% Tween-20)
-
384-well low-volume white plates
-
TR-FRET-compatible plate reader
Procedure:
-
Prepare a serial dilution of this compound in assay buffer.
-
In a 384-well plate, add a constant concentration of His-KRASG12C and GST-VBC complex to each well.
-
Add the serially diluted this compound or vehicle control (DMSO) to the wells.
-
Incubate the plate at room temperature for 60 minutes with gentle shaking.
-
Add the anti-His-Europium and anti-GST-APC antibodies to each well.
-
Incubate for an additional 60-120 minutes at room temperature, protected from light.
-
Read the plate on a TR-FRET plate reader, measuring the emission at the donor and acceptor wavelengths.
-
Calculate the TR-FRET ratio and plot against the this compound concentration to determine the EC₅₀ for ternary complex formation.
In Vitro Ubiquitination Assay
This assay directly measures the this compound-dependent ubiquitination of KRASG12C.
Workflow Diagram:
Caption: Workflow for the in vitro ubiquitination assay.
Materials:
-
Recombinant human E1 activating enzyme (e.g., UBE1)
-
Recombinant human E2 conjugating enzyme (e.g., UBE2D2)
-
Recombinant human VBC complex
-
Recombinant human KRASG12C protein
-
Human ubiquitin
-
ATP
-
This compound
-
Ubiquitination buffer (e.g., 50 mM Tris-HCl pH 7.5, 10 mM MgCl₂, 0.1 mM DTT)
-
SDS-PAGE gels and Western blotting reagents
-
Primary antibodies: anti-KRAS and anti-ubiquitin
-
HRP-conjugated secondary antibody
-
Chemiluminescent substrate
Procedure:
-
Thaw all protein components on ice.
-
In a microcentrifuge tube, prepare the reaction mix by adding ubiquitination buffer, ATP, ubiquitin, E1 enzyme, E2 enzyme, VBC complex, and KRASG12C protein.
-
Add this compound or vehicle control (DMSO) to the reaction mix.
-
Incubate the reaction at 37°C for 1-2 hours.
-
Stop the reaction by adding SDS-PAGE loading buffer and boiling for 5 minutes.
-
Separate the proteins by SDS-PAGE.
-
Transfer the proteins to a PVDF membrane.
-
Block the membrane and probe with anti-KRAS or anti-ubiquitin antibodies to detect the formation of higher molecular weight polyubiquitinated KRASG12C species.
In Vitro Proteasomal Degradation Assay
This assay provides a complete cell-free system to measure the degradation of KRASG12C mediated by this compound.
Workflow Diagram:
Caption: Workflow for the in vitro proteasomal degradation assay.
Materials:
-
All components from the In Vitro Ubiquitination Assay.
-
Purified human 26S proteasome.
-
ATP regenerating system (creatine kinase and phosphocreatine).
-
Degradation buffer (e.g., 25 mM Tris-HCl pH 7.5, 10 mM MgCl₂, 1 mM DTT).
-
Proteasome inhibitor (e.g., MG132) for control reactions.
Procedure:
-
Perform the ubiquitination reaction as described in Protocol 2 for 60 minutes to generate polyubiquitinated KRASG12C.
-
Initiate the degradation reaction by adding the 26S proteasome and the ATP regenerating system to the ubiquitination reaction mixture.
-
As a negative control, set up a parallel reaction containing a proteasome inhibitor (e.g., MG132).
-
Incubate the degradation reactions at 37°C.
-
At various time points (e.g., 0, 15, 30, 60, 120 minutes), take aliquots of the reaction and immediately stop them by adding SDS-PAGE loading buffer and boiling.
-
Analyze the samples by SDS-PAGE and Western blotting using an anti-KRAS antibody.
-
Quantify the intensity of the KRASG12C band at each time point to determine the rate of degradation. A decrease in the band intensity over time in the absence, but not in the presence, of the proteasome inhibitor confirms proteasome-dependent degradation.
References
Application Notes and Protocols for Cross-Linking and Immunoprecipitation (CLIP) of YN14 RNA Targets
Audience: Researchers, scientists, and drug development professionals.
Introduction
Cross-Linking and Immunoprecipitation (CLIP) is a powerful technique used to identify the RNA binding sites of a specific protein across the transcriptome.[1][2] This method utilizes ultraviolet (UV) light to create covalent bonds between RNA-binding proteins (RBPs) and the RNA molecules they are in close proximity to.[1][3] By immunoprecipitating the protein of interest, in this case, YN14, the associated RNA fragments can be isolated, sequenced, and mapped to the genome to reveal the protein's RNA targets. Understanding the RNA targets of this compound is crucial for elucidating its biological functions, its role in post-transcriptional gene regulation, and its potential as a therapeutic target in drug development.
Several variations of the CLIP protocol exist, including iCLIP (individual-nucleotide resolution CLIP) and eCLIP (enhanced CLIP), which offer improvements in resolution and efficiency.[4][5][6][7] The eCLIP method, in particular, enhances the efficiency of converting purified RNA into a cDNA library for sequencing.[1][8] This document provides a detailed protocol for performing an eCLIP-based experiment to identify the RNA targets of the hypothetical protein this compound.
Principle of the eCLIP Assay
The eCLIP protocol involves the following key steps:
-
UV Cross-linking: Cells expressing this compound are irradiated with UV light to form covalent cross-links between this compound and its bound RNA molecules.[1][9]
-
Immunoprecipitation: The this compound-RNA complexes are then specifically immunoprecipitated using an antibody targeting this compound.[9]
-
RNA Library Preparation: The co-precipitated RNA is then processed to generate a library for high-throughput sequencing. This includes RNA fragmentation, adapter ligation, reverse transcription, and PCR amplification.[8][9]
-
Sequencing and Data Analysis: The resulting cDNA library is sequenced, and the reads are mapped to the genome to identify the specific RNA binding sites of this compound.[10][11]
Detailed Experimental Protocol: eCLIP for this compound
This protocol is adapted from standard eCLIP methodologies.[8][9]
Materials and Reagents
-
Cells expressing this compound (endogenously or from a vector)
-
Phosphate-Buffered Saline (PBS)
-
Lysis Buffer (e.g., RIPA buffer with protease and RNase inhibitors)
-
Anti-YN14 Antibody (validated for immunoprecipitation)
-
Protein A/G magnetic beads
-
RNase I
-
T4 Polynucleotide Kinase (PNK)
-
T4 RNA Ligase 1
-
3' RNA adapter
-
Reverse Transcriptase
-
3' DNA adapter with a unique molecular identifier (UMI)
-
PCR amplification primers
-
Proteinase K
-
Urea
-
Reagents for SDS-PAGE and western blotting
-
RNA extraction kit
-
DNA sequencing library preparation kit
Experimental Procedure
Day 1: Cell Culture and UV Cross-linking
-
Culture cells expressing this compound to ~80% confluency in 15 cm plates.
-
Wash the cells once with ice-cold PBS.
-
Aspirate the PBS and place the plates on ice.
-
Irradiate the cells with UV light (254 nm) at 400 mJ/cm².
-
Scrape the cells in ice-cold PBS and pellet them by centrifugation. The cell pellet can be stored at -80°C.
Day 2: Immunoprecipitation
-
Lyse the cross-linked cell pellet in Lysis Buffer.
-
Treat the lysate with a controlled amount of RNase I to fragment the RNA. The optimal concentration of RNase I should be determined empirically.
-
Clarify the lysate by centrifugation.
-
Couple the anti-YN14 antibody to Protein A/G magnetic beads.
-
Incubate the cleared lysate with the antibody-coupled beads to immunoprecipitate the this compound-RNA complexes.
-
Wash the beads stringently to remove non-specific binding.
Day 3: On-Bead RNA Processing
-
Perform on-bead dephosphorylation of the 3' ends of the RNA fragments using T4 PNK.
-
Ligate the 3' RNA adapter to the RNA fragments using T4 RNA Ligase 1.[8]
-
Wash the beads to remove unligated adapters.
Day 4: Protein-RNA Complex Elution and RNA Isolation
-
Elute the this compound-RNA complexes from the beads.
-
Run the eluate on an SDS-PAGE gel and transfer to a nitrocellulose membrane.
-
Visualize the this compound-RNA complexes by autoradiography (if radiolabeling was used) or by western blot.
-
Excise the membrane region corresponding to the this compound-RNA complexes.
-
Treat the membrane slice with Proteinase K to digest the protein and release the RNA.
-
Extract and purify the RNA from the membrane.
Day 5: Library Preparation and Sequencing
-
Reverse transcribe the purified RNA into cDNA. The reverse transcription primer is complementary to the 3' RNA adapter.
-
Ligate a 3' DNA adapter containing a UMI to the 3' end of the cDNA.[12]
-
Perform PCR amplification of the cDNA library using primers that anneal to the adapter sequences.
-
Purify the PCR products and assess the library quality and quantity.
-
Sequence the library on a high-throughput sequencing platform.
Data Presentation
Quantitative data from the this compound eCLIP-seq experiment should be summarized in clear and concise tables for easy interpretation and comparison.
Table 1: Sequencing and Mapping Statistics
| Sample Name | Total Reads | Uniquely Mapped Reads | Mapping Rate (%) | PCR Duplication Rate (%) |
| YN14_eCLIP_Replicate1 | 25,000,000 | 20,000,000 | 80.0 | 15.0 |
| YN14_eCLIP_Replicate2 | 28,000,000 | 22,400,000 | 80.0 | 16.5 |
| Input_Control_Replicate1 | 24,000,000 | 19,200,000 | 80.0 | 10.0 |
| Input_Control_Replicate2 | 26,000,000 | 20,800,000 | 80.0 | 11.2 |
Table 2: Top 10 this compound RNA Binding Peaks
| Peak ID | Chromosome | Start | End | Strand | Gene Name | Fold Enrichment (vs. Input) | p-value |
| YN14_peak_1 | chr1 | 1,234,567 | 1,234,667 | + | GENE_A | 50.5 | 1.2e-15 |
| YN14_peak_2 | chr3 | 5,678,901 | 5,679,001 | - | GENE_B | 45.2 | 3.4e-14 |
| YN14_peak_3 | chrX | 9,876,543 | 9,876,643 | + | GENE_C | 42.8 | 5.6e-13 |
| YN14_peak_4 | chr7 | 2,468,013 | 2,468,113 | - | GENE_D | 38.1 | 7.8e-12 |
| YN14_peak_5 | chr2 | 8,642,097 | 8,642,197 | + | GENE_E | 35.7 | 9.1e-11 |
| YN14_peak_6 | chr11 | 1,357,924 | 1,358,024 | - | GENE_F | 33.3 | 2.3e-10 |
| YN14_peak_7 | chr5 | 7,531,952 | 7,532,052 | + | GENE_G | 31.9 | 4.5e-10 |
| YN14_peak_8 | chr9 | 3,141,592 | 3,141,692 | - | GENE_H | 29.6 | 6.7e-09 |
| YN14_peak_9 | chr15 | 2,718,281 | 2,718,381 | + | GENE_I | 28.2 | 8.9e-09 |
| YN14_peak_10 | chr4 | 6,022,140 | 6,022,240 | - | GENE_J | 27.5 | 1.0e-08 |
Table 3: Distribution of this compound Binding Sites Across RNA Types
| RNA Type | Number of Peaks | Percentage of Total Peaks (%) |
| mRNA (3' UTR) | 5,432 | 45.3 |
| mRNA (CDS) | 2,123 | 17.7 |
| mRNA (5' UTR) | 876 | 7.3 |
| Intron | 2,543 | 21.2 |
| lncRNA | 879 | 7.3 |
| Other | 147 | 1.2 |
| Total | 12,000 | 100.0 |
Visualizations
Diagram 1: this compound eCLIP Experimental Workflow
Caption: Workflow of the this compound eCLIP-seq experiment.
Diagram 2: this compound eCLIP Data Analysis Pipeline
Caption: Bioinformatic pipeline for this compound eCLIP-seq data.
Diagram 3: Hypothetical Signaling Pathway Regulated by this compound
Caption: Model of this compound-mediated post-transcriptional regulation.
References
- 1. Cross-linking immunoprecipitation - Wikipedia [en.wikipedia.org]
- 2. Crosslinking-immunoprecipitation (CLIP) Service, RNA-protein Interaction Analysis - CD BioSciences [epigenhub.com]
- 3. Crosslinking and ImmunoPrecipitation (CLIP) - Creative BioMart [creativebiomart.net]
- 4. Revised iCLIP-seq Protocol for Profiling RNA-protein Interaction Sites at Individual Nucleotide Resolution in Living Cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. [PDF] Revised iCLIP-seq Protocol for Profiling RNA–protein Interaction Sites at Individual Nucleotide Resolution in Living Cells | Semantic Scholar [semanticscholar.org]
- 6. medium.com [medium.com]
- 7. epigenie.com [epigenie.com]
- 8. Robust transcriptome-wide discovery of RNA binding protein binding sites with enhanced CLIP (eCLIP) - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Core Steps in the eCLIP-seq Protocol: A Detailed Guide to Mapping RNA-Protein Interactions - CD Genomics [cd-genomics.com]
- 10. Practical considerations on performing and analyzing CLIP-seq experiments to identify transcriptomic-wide RNA-Protein interactions - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Overview of RNA CLIP-Seq - CD Genomics [rna.cd-genomics.com]
- 12. eCLIP [illumina.com]
Application Notes and Protocols for YN14 in RNA-Protein Binding Assays
For Researchers, Scientists, and Drug Development Professionals
Introduction
YN14, also known as RNA-Binding Motif Protein 8A (RBM8A), is a core component of the Exon Junction Complex (EJC), a dynamic multiprotein complex deposited on messenger RNA (mRNA) during splicing.[1][2][3] The EJC plays a crucial role in various post-transcriptional processes, including mRNA export, localization, translation, and nonsense-mediated mRNA decay (NMD).[1][2][3] this compound, in a heterodimer with MAGOH, is essential for the stable binding of the EJC to mRNA.[2] Notably, this compound has been shown to directly interact with the 5' cap structure of mRNA and inhibit the decapping activity of the Dcp2 enzyme, thereby influencing mRNA stability.[4][5] These functions make this compound a protein of significant interest in RNA biology and a potential target for therapeutic intervention in diseases where mRNA metabolism is dysregulated.
These application notes provide detailed protocols for studying the RNA-binding properties of this compound and its role in modulating mRNA decapping.
Quantitative Data Summary
| Parameter | Value | Assay Condition | Reference |
| This compound Concentration for Dcp2 Inhibition | 0.2 - 2.0 µM | In vitro decapping assay with recombinant His-Dcp2 and GST-YN14. | [4] |
| This compound-RNA Binding Affinity (Kd) | Not Reported | - | - |
Key Experimental Protocols
RNA Immunoprecipitation (RIP) to Identify RNAs Associated with this compound in vivo
This protocol is adapted from standard RIP procedures and can be used to isolate and identify RNA molecules that interact with this compound within a cellular context.
Materials:
-
Cells expressing this compound of interest
-
Phosphate-buffered saline (PBS), ice-cold
-
Polysome lysis buffer (10 mM HEPES, pH 7.0, 100 mM KCl, 5 mM MgCl2, 0.5% NP-40, 1 mM DTT, 100 U/mL RNase inhibitor, Protease inhibitor cocktail)
-
Anti-YN14 antibody (or corresponding isotype control IgG)
-
Protein A/G magnetic beads
-
Wash Buffer (50 mM Tris-HCl, pH 7.4, 150 mM NaCl, 1 mM MgCl2, 0.05% NP-40)
-
RNA extraction reagent (e.g., TRIzol)
-
DNase I, RNase-free
-
Reverse transcription and qPCR reagents
Protocol:
-
Cell Harvest: Harvest approximately 1x10^7 cells by centrifugation. Wash the cell pellet once with ice-cold PBS.
-
Cell Lysis: Resuspend the cell pellet in 1 mL of ice-cold polysome lysis buffer. Incubate on ice for 10 minutes with occasional vortexing.
-
Clarification of Lysate: Centrifuge the lysate at 14,000 x g for 10 minutes at 4°C. Transfer the supernatant to a new tube.
-
Immunoprecipitation:
-
Pre-clear the lysate by adding 50 µL of Protein A/G magnetic beads and incubating for 1 hour at 4°C with rotation.
-
Remove the beads and add 5 µg of anti-YN14 antibody (or IgG control) to the pre-cleared lysate. Incubate for 4 hours to overnight at 4°C with gentle rotation.
-
Add 50 µL of fresh Protein A/G magnetic beads and incubate for another 1 hour at 4°C with rotation.
-
-
Washes:
-
Pellet the beads using a magnetic stand and discard the supernatant.
-
Wash the beads three times with 1 mL of ice-cold Wash Buffer.
-
-
RNA Elution and Purification:
-
Resuspend the beads in 1 mL of RNA extraction reagent and proceed with RNA isolation according to the manufacturer's instructions.
-
Treat the purified RNA with DNase I to remove any contaminating DNA.
-
-
Analysis: The enriched RNA can be analyzed by reverse transcription followed by quantitative PCR (RT-qPCR) to quantify the abundance of specific target RNAs, or by next-generation sequencing for a transcriptome-wide analysis.
UV Cross-linking Assay to Detect Direct this compound-RNA Interaction
This assay is used to create a covalent bond between this compound and its target RNA, providing evidence of direct interaction.[4]
Materials:
-
Recombinant purified GST-YN14 protein
-
In vitro transcribed 32P-labeled capped RNA transcript
-
Binding Buffer (e.g., 20 mM HEPES pH 7.5, 100 mM KCl, 2 mM MgCl2, 1 mM DTT, 5% glycerol)
-
RNase A/T1 mix
-
SDS-PAGE loading buffer
-
UV Stratalinker 2400
Protocol:
-
Binding Reaction: In a microfuge tube, combine 5 µg of recombinant GST-YN14 with approximately 1x10^5 cpm of 32P-labeled capped RNA in 20 µL of Binding Buffer.
-
Incubation: Incubate the reaction mixture on ice for 20 minutes to allow for complex formation.
-
UV Cross-linking: Place the open tubes on ice in a UV Stratalinker and irradiate with 254 nm UV light at an energy of 0.4 J/cm².
-
RNase Digestion: Add RNase A/T1 mix to the reaction to a final concentration of 1 mg/mL and incubate at 37°C for 30 minutes to digest unprotected RNA.
-
Analysis: Add SDS-PAGE loading buffer, boil the samples for 5 minutes, and resolve the proteins by SDS-PAGE. The cross-linked this compound-RNA complex will be radiolabeled and can be visualized by autoradiography.
GST Pull-Down Assay to Verify this compound-Protein Interactions
This in vitro assay is used to confirm the interaction between this compound and a putative protein partner, such as Dcp2.[4]
Materials:
-
Recombinant GST-tagged this compound (bait) and His-tagged Dcp2 (prey) proteins
-
Glutathione-Sepharose beads
-
Pull-down Buffer (50 mM Tris-HCl pH 7.5, 150 mM NaCl, 1 mM EDTA, 0.5% NP-40, 1 mM DTT, Protease inhibitor cocktail)
-
Wash Buffer (Pull-down Buffer with 300 mM NaCl)
-
Elution Buffer (50 mM Tris-HCl pH 8.0, 10 mM reduced glutathione)
-
SDS-PAGE and Western blotting reagents
Protocol:
-
Bead Preparation: Wash Glutathione-Sepharose beads with Pull-down Buffer.
-
Bait Binding: Incubate 2-5 µg of GST-YN14 with the washed beads in Pull-down Buffer for 1 hour at 4°C with rotation to immobilize the bait protein. As a negative control, use GST alone.
-
Washing: Pellet the beads and wash three times with Pull-down Buffer to remove unbound bait protein.
-
Prey Binding: Add 2-5 µg of His-Dcp2 to the beads and incubate for 2-4 hours at 4°C with rotation.
-
Washing: Pellet the beads and wash three to five times with Wash Buffer to remove non-specific binders.
-
Elution: Elute the protein complexes by adding Elution Buffer and incubating for 10 minutes at room temperature.
-
Analysis: Analyze the eluted proteins by SDS-PAGE followed by Western blotting using an anti-His antibody to detect the prey protein (Dcp2).
In Vitro mRNA Decapping Assay
This assay is used to measure the ability of this compound to inhibit the catalytic activity of the Dcp2 decapping enzyme.[4]
Materials:
-
Recombinant His-tagged Dcp2 enzyme
-
Recombinant GST-tagged this compound protein
-
32P-cap-labeled RNA substrate
-
Decapping Buffer (10 mM Tris-HCl pH 7.5, 100 mM KOAc, 2 mM MgCl2, 0.5 mM MnCl2, 2 mM DTT)
-
Thin-layer chromatography (TLC) plates (PEI-cellulose)
-
TLC Running Buffer (0.75 M LiCl)
Protocol:
-
Reaction Setup: Prepare reaction mixtures in a total volume of 10 µL containing Decapping Buffer, 32P-cap-labeled RNA (~10,000 cpm), and 50 ng of recombinant His-Dcp2.
-
This compound Inhibition: For the inhibition assay, pre-incubate the His-Dcp2 with varying concentrations of GST-YN14 (e.g., 0.2, 0.5, 1.0, 2.0 µM) for 10 minutes on ice before adding the RNA substrate.
-
Decapping Reaction: Incubate the reactions at 37°C for 30 minutes.
-
TLC Analysis: Stop the reaction by adding EDTA to a final concentration of 25 mM. Spot 1 µL of each reaction onto a PEI-cellulose TLC plate.
-
Chromatography: Develop the TLC plate in TLC Running Buffer until the solvent front is near the top.
-
Visualization and Quantification: Dry the plate and visualize the separated cap (m7GDP) and uncapped RNA by autoradiography. The extent of decapping can be quantified by measuring the radioactivity in the spots corresponding to m7GDP and the origin (undecapped RNA).
Signaling and Interaction Pathways
This compound is a key player in the Nonsense-Mediated mRNA Decay (NMD) pathway. As a core component of the EJC, it is deposited on spliced mRNA and participates in the surveillance mechanism that identifies and degrades transcripts containing premature termination codons (PTCs).
This compound also directly influences mRNA stability by inhibiting the decapping enzyme Dcp2. This interaction prevents the removal of the 5' cap, a critical step for 5'-to-3' exonucleolytic degradation of mRNA.
Conclusion
This compound is a multifaceted RNA-binding protein with critical roles in mRNA metabolism. The protocols and information provided herein offer a comprehensive guide for researchers to investigate the intricate functions of this compound in RNA-protein binding, its influence on mRNA stability, and its involvement in cellular surveillance pathways. Further elucidation of the quantitative aspects of this compound-RNA interactions will be crucial for a complete understanding of its regulatory mechanisms and for the development of targeted therapeutics.
References
- 1. Exon junction complex - Wikipedia [en.wikipedia.org]
- 2. genecards.org [genecards.org]
- 3. RNA-binding protein 8A - Wikipedia [en.wikipedia.org]
- 4. Comprehensive mapping of exon junction complex binding sites reveals universal EJC deposition in Drosophila - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Analysis of RNA-protein interactions by a microplate-based fluorescence anisotropy assay - PubMed [pubmed.ncbi.nlm.nih.gov]
Troubleshooting & Optimization
troubleshooting YN14 western blot low signal
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals resolve issues of low signal intensity when using the YN14 antibody in Western blotting experiments.
Troubleshooting Guide: Low Signal
Low or no signal is a common issue in Western blotting. The following guide, in a question-and-answer format, addresses potential causes and solutions to enhance the signal from your this compound antibody.
Question: Why am I getting a weak or no signal with the this compound antibody?
Answer: A weak or absent signal can stem from several factors throughout the Western blot workflow, from sample preparation to signal detection. Below is a systematic guide to troubleshoot this issue.
Issues with Protein Sample and Loading
A primary reason for a low signal is an insufficient amount of the target protein being loaded onto the gel.
-
Is the target protein abundant in your sample? The expression level of the target protein can vary significantly between cell types and tissues. If the protein is known to have low expression, you may need to load a higher amount of total protein.[1][2] Consider enriching your sample for the target protein through methods like immunoprecipitation or cellular fractionation.[1][2]
-
Have you loaded enough protein? As a general guideline, loading 20-30 µg of total protein from cell lysates is recommended. However, for low-abundance proteins, this may need to be increased.[3] It's crucial to perform a protein concentration assay on your lysates before loading.
-
Is your sample degraded? Ensure that protease and phosphatase inhibitors are added to your lysis buffer to prevent protein degradation.[1][2] Samples should be stored properly at -80°C for long-term storage.
| Parameter | Recommendation | Troubleshooting Action |
| Protein Load | 20-30 µg of total lysate | Increase to 50-100 µg for low-abundance proteins. |
| Sample Integrity | Use fresh lysates with protease/phosphatase inhibitors. | Prepare fresh samples and always use inhibitors. |
| Positive Control | Include a lysate from a cell line known to express the target protein. | If the positive control also fails, the issue is likely with the protocol or reagents. |
Inefficient Protein Transfer
The transfer of proteins from the gel to the membrane is a critical step. Inefficient transfer will lead to a weak signal.
-
How can I check transfer efficiency? You can visualize the proteins on the membrane after transfer using a reversible stain like Ponceau S.[2] This will show you if the proteins have transferred evenly across the membrane. You can also stain the gel with Coomassie Blue after transfer to see if any protein remains.
-
Are you using the correct membrane pore size? For most proteins, a 0.45 µm pore size membrane is suitable. However, for smaller proteins (<20 kDa), a 0.2 µm pore size is recommended to prevent the protein from passing through the membrane.[4]
-
Have you optimized your transfer conditions? Transfer efficiency is affected by the transfer time, voltage, and buffer composition. Larger proteins may require longer transfer times or the addition of a small amount of SDS to the transfer buffer to facilitate their transfer from the gel.[5] Ensure there are no air bubbles between the gel and the membrane, as these will block transfer.[1][2]
Experimental Workflow & Troubleshooting Logic
The following diagram illustrates the standard Western blot workflow and highlights key decision points for troubleshooting low signal issues.
References
Technical Support Center: Optimizing YN14 Immunoprecipitation Protocols
This technical support center provides troubleshooting guidance and answers to frequently asked questions for researchers utilizing the YN14 antibody for immunoprecipitation (IP). Our goal is to help you overcome common experimental hurdles and achieve optimal results.
Troubleshooting Guide
This guide addresses specific issues that may arise during your this compound immunoprecipitation experiments in a question-and-answer format.
Issue 1: Low or No Target Protein Signal
-
Question: Why am I not detecting my target protein after immunoprecipitation with this compound?
Possible Causes and Solutions:
-
Inefficient Antibody-Antigen Binding: The binding affinity of the this compound antibody might be insufficient under the current experimental conditions.[1] To address this, consider optimizing the incubation time, which can range from 1 to 12 hours or even overnight at 4°C with gentle rotation.[2][3] It is also crucial to ensure that the lysis buffer used does not disrupt protein-protein interactions; for instance, RIPA buffer can sometimes be too stringent.[4]
-
Low Target Protein Expression: The target protein may be expressed at very low levels in your sample.[1][4][5] To confirm expression, it is recommended to include an input lysate control in your Western blot analysis.[4] If the expression is indeed low, you may need to increase the amount of starting cell lysate.[5][6]
-
Epitope Masking: The this compound antibody's binding site on the target protein might be hidden due to the protein's conformation or interaction with other molecules.[4] Trying an antibody that recognizes a different epitope on the target protein could resolve this issue.[4]
-
Improper Bead Selection: Ensure the protein A or G beads you are using are compatible with the this compound antibody's isotype.[5][6][7] Different species and subclasses of antibodies have varying affinities for protein A and G.[8]
-
Incorrect Elution: The elution buffer may not be effectively disrupting the antibody-antigen interaction.[5][6] Verify that your elution buffer's pH and composition are appropriate for releasing the target protein from the beads.[5]
-
Issue 2: High Background or Non-Specific Binding
-
Question: My final elution contains many non-specific proteins along with my target. How can I reduce this background?
Possible Causes and Solutions:
-
Non-Specific Binding to Beads: Proteins from the lysate can bind directly to the agarose or magnetic beads.[4][9][10] To mitigate this, a pre-clearing step is recommended.[4][9][11] This involves incubating the lysate with beads alone before adding the this compound antibody, which helps to remove proteins that non-specifically bind to the beads.[4][11]
-
Insufficient Washing: The washing steps may not be stringent enough to remove all non-specifically bound proteins.[6] You can increase the number of washes or the stringency of the wash buffer by adding detergents like Tween-20 or Triton X-100, or by increasing the salt concentration.[9][12][13]
-
Excessive Antibody Concentration: Using too much this compound antibody can lead to increased non-specific binding.[5][12] It is advisable to perform a titration experiment to determine the optimal antibody concentration that gives the best signal-to-noise ratio.[2][14]
-
Hydrophobic Interactions: Some proteins may non-specifically associate with the antibody or beads through hydrophobic interactions. Including a non-ionic detergent in your wash buffer can help to disrupt these interactions.[9]
-
Issue 3: Co-elution of Antibody Heavy and Light Chains
-
Question: I see strong bands at ~50 kDa and ~25 kDa in my final Western blot, which interfere with the detection of my protein of interest. How can I avoid this?
Possible Causes and Solutions:
-
Elution of Primary Antibody: Standard elution buffers release the primary antibody along with the target protein. The denatured heavy (~50 kDa) and light (~25 kDa) chains of the this compound antibody are then detected by the secondary antibody in the Western blot.[11][15]
-
Covalent Antibody-Bead Conjugation: To prevent the co-elution of the antibody, you can covalently crosslink the this compound antibody to the protein A/G beads before incubation with the lysate.[11][12]
-
Use of Specialized Secondary Antibodies: Alternatively, you can use secondary antibodies that specifically recognize the native, non-reduced primary antibody, thus avoiding the detection of the denatured heavy and light chains.[15]
-
Frequently Asked Questions (FAQs)
-
Q1: What are the essential controls for an immunoprecipitation experiment?
A1: Several controls are crucial for interpreting your IP results correctly:
-
Input Control: A sample of the cell lysate before immunoprecipitation is loaded on the Western blot to confirm the presence of the target protein.[4]
-
Isotype Control: A non-specific antibody of the same isotype and from the same host species as this compound is used in a parallel IP.[11][14] This helps to ensure that the observed binding is specific to the this compound antibody and not due to non-specific interactions with the immunoglobulin.[11]
-
Bead-Only Control: The cell lysate is incubated with beads alone (without the this compound antibody) to identify proteins that bind non-specifically to the beads themselves.[4][14]
-
-
Q2: How do I choose the right lysis buffer?
A2: The choice of lysis buffer is critical for preserving the integrity of the target protein and its interactions.[15]
-
Non-denaturing buffers (e.g., containing non-ionic detergents like NP-40 or Triton X-100) are generally preferred for co-immunoprecipitation as they are less likely to disrupt protein complexes.[15][16]
-
Denaturing buffers (e.g., RIPA buffer) are more stringent and can be useful for solubilizing difficult-to-extract proteins, but may disrupt some protein-protein interactions.[4][15] It's often necessary to optimize the lysis buffer for your specific target protein.[16]
-
-
Q3: How much antibody and beads should I use?
A3: The optimal amounts of antibody and beads should be determined empirically.
-
Antibody: A good starting point is typically 1-5 µg of antibody per 1 mg of total protein in the lysate.[2] A titration experiment is highly recommended to find the ideal concentration.[2][6][14]
-
Beads: The amount of beads depends on their binding capacity. It's important to use enough beads to capture all the antibody-antigen complexes. Refer to the manufacturer's instructions for the specific binding capacity of your beads.
-
Quantitative Data Summary
The following tables provide typical ranges for key parameters in an immunoprecipitation protocol. These should be used as a starting point for optimization.
Table 1: Recommended Antibody and Bead Concentrations
| Component | Recommended Starting Amount | Range for Optimization |
| This compound Antibody | 1-5 µg per 1 mg of lysate[2] | 0.5 - 10 µg |
| Protein A/G Agarose Beads (50% slurry) | 20-50 µL | 10 - 100 µL |
| Protein A/G Magnetic Beads | 10-25 µL | 5 - 50 µL |
Table 2: Incubation Times and Temperatures
| Step | Duration | Temperature |
| Antibody-Lysate Incubation | 1-4 hours or overnight[2] | 4°C |
| Bead-Complex Incubation | 1-2 hours[2] | 4°C |
| Washing Steps | 5-10 minutes per wash | 4°C |
| Elution | 5-10 minutes | Room Temperature or 95-100°C |
Experimental Protocols
Detailed Protocol for this compound Immunoprecipitation
This protocol provides a general framework. Optimization of specific steps is highly recommended.
1. Cell Lysate Preparation [3]
- Wash cells with ice-cold PBS.
- Add ice-cold lysis buffer (e.g., non-denaturing lysis buffer: 20 mM Tris-HCl pH 8, 137 mM NaCl, 1% NP-40, 2 mM EDTA, supplemented with protease and phosphatase inhibitors).
- Scrape adherent cells and transfer the lysate to a microcentrifuge tube.
- Incubate on ice for 30 minutes with occasional vortexing.
- Centrifuge at 12,000 x g for 20 minutes at 4°C to pellet cell debris.
- Transfer the supernatant (clarified lysate) to a new tube.
2. Pre-clearing the Lysate (Optional but Recommended) [11]
- Add 20 µL of a 50% slurry of protein A/G beads to 1 mg of cell lysate.
- Incubate on a rotator for 30-60 minutes at 4°C.
- Centrifuge at 1,000 x g for 5 minutes at 4°C.
- Carefully transfer the supernatant to a new tube.
3. Immunoprecipitation
- Add the optimal amount of this compound antibody (e.g., 1-5 µg) to the pre-cleared lysate.
- Incubate with gentle rotation for 1-4 hours or overnight at 4°C.[2]
- Add 30-50 µL of a 50% slurry of protein A/G beads.
- Incubate with gentle rotation for 1-2 hours at 4°C.[2]
4. Washing
- Pellet the beads by centrifugation (1,000 x g for 1 minute at 4°C).
- Carefully remove the supernatant.
- Wash the beads 3-5 times with 1 mL of ice-cold wash buffer (e.g., lysis buffer with a lower detergent concentration).[2] After the final wash, remove all supernatant.
5. Elution
- Resuspend the beads in 20-40 µL of 1X Laemmli sample buffer.
- Boil the sample at 95-100°C for 5-10 minutes to elute the protein and denature it for SDS-PAGE.
- Centrifuge to pellet the beads, and collect the supernatant containing the eluted protein.
6. Analysis
- Analyze the eluted proteins by Western blotting using an antibody specific to the target protein.
Visualizations
Caption: A generalized workflow for a this compound immunoprecipitation experiment.
Caption: A hypothetical signaling pathway involving the this compound target protein.
References
- 1. 5 tricks for a successful immunoprecipitation [labclinics.com]
- 2. Protocol for Immunoprecipitation - Creative Proteomics [creative-proteomics.com]
- 3. antibody-creativebiolabs.com [antibody-creativebiolabs.com]
- 4. Immunoprecipitation Troubleshooting Guide | Cell Signaling Technology [cellsignal.com]
- 5. hycultbiotech.com [hycultbiotech.com]
- 6. antibody-creativebiolabs.com [antibody-creativebiolabs.com]
- 7. Immunoprecipitation Troubleshooting | Antibodies.com [antibodies.com]
- 8. Immunoprecipitation Experimental Design Tips | Cell Signaling Technology [cellsignal.com]
- 9. sinobiological.com [sinobiological.com]
- 10. Removal of nonspecific binding proteins is required in co-immunoprecipitation with nuclear proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. Immunoprecipitation (IP): The Complete Guide | Antibodies.com [antibodies.com]
- 12. Protein Immunoprecipitation (IP), Co-Immunoprecipitation (Co-IP), and Pulldown Support—Troubleshooting | Thermo Fisher Scientific - KR [thermofisher.com]
- 13. researchgate.net [researchgate.net]
- 14. Considerations before starting your IP experiment | Proteintech Group [ptglab.com]
- 15. Tips for Immunoprecipitation | Rockland [rockland.com]
- 16. Immunoprecipitation (IP) and co-immunoprecipitation protocol | Abcam [abcam.com]
Technical Support Center: YN14 Knockdown Experiments
Disclaimer: "YN14" is not a recognized standard gene identifier. This guide uses "this compound" as a placeholder for a generic target gene and provides troubleshooting advice applicable to common challenges in RNA interference (RNAi) and CRISPR-based knockdown experiments.
Frequently Asked Questions (FAQs)
Q1: I've transfected my cells with this compound-targeting siRNA, but I'm seeing little to no reduction in protein levels. What's going wrong?
A1: This is a common issue that can stem from several factors, from experimental design to execution. Here are the most likely causes and how to troubleshoot them:
-
Suboptimal siRNA Design: Not all siRNA sequences are equally effective. The target sequence's accessibility within the mRNA, secondary structure, and GC content can all impact efficiency.[1][2][3]
-
-
-
Incorrect Validation Timing or Method: The kinetics of mRNA and protein turnover vary. You may be checking for protein reduction too early or too late.
Q2: My this compound knockdown is efficient at the mRNA level (confirmed by qRT-PCR), but protein levels remain high. Why is there a discrepancy?
A2: Discrepancies between mRNA and protein knockdown are often observed and usually point to protein stability.[13]
-
High Protein Stability: If the this compound protein has a long half-life, it will take longer for the existing pool of protein to degrade, even if new mRNA synthesis is effectively silenced.
-
Solution: Extend your time course. Continue to culture the cells for 96 hours or even longer post-transfection before harvesting for Western blot analysis. Consider treating cells with a protein synthesis inhibitor like cycloheximide as a control to estimate the protein's half-life.
-
-
qPCR Primer Design: In rare cases, qPCR primers may amplify residual mRNA fragments that persist after siRNA-mediated cleavage, leading to an underestimation of the true knockdown efficiency.[13]
-
Solution: Design qPCR primers that amplify a region of the mRNA transcript upstream (5') of the siRNA target site.[13] This ensures you are only measuring intact, functional mRNA.
-
Q3: My cells are showing high toxicity or a strange phenotype after transfection, even with a non-targeting control. What could be the cause?
A3: This suggests the issue is related to the delivery process or off-target effects not specific to the this compound sequence.
-
Transfection Reagent Toxicity: Many lipid-based transfection reagents can be toxic to sensitive cell lines, especially at high concentrations.[2]
-
Solution: Optimize the concentration of the transfection reagent. Use the lowest amount that still provides high transfection efficiency. You may also need to switch to a different, less toxic reagent or delivery method, like electroporation.[6]
-
-
High siRNA Concentration: Excessive concentrations of siRNA can saturate the endogenous RNAi machinery and lead to off-target effects or cellular stress.[6][8]
-
Solution: Perform a dose-response experiment to find the lowest effective siRNA concentration (typically in the 5-25 nM range).[10]
-
-
Innate Immune Response: Double-stranded RNAs can trigger an innate immune response (e.g., the interferon pathway), leading to global changes in gene expression and cell death.
-
Solution: Use high-quality, purified siRNA. Ensure your non-targeting control has a similar composition and GC content to your this compound-targeting siRNAs. If problems persist, consider using siRNAs with chemical modifications that reduce immune stimulation.
-
Q4: I'm using an shRNA lentiviral vector for stable this compound knockdown. After selection, the knockdown effect is weak or disappears over time. What should I do?
A4: Challenges with stable shRNA expression often relate to vector integration, expression, and cell line stability.
-
Ineffective shRNA Sequence: Similar to siRNA, the design of the shRNA hairpin is critical for processing into functional siRNA.[1][14]
-
Solution: Test multiple shRNA sequences targeting this compound. It's often best to validate sequences using transient plasmid transfection before proceeding with lentivirus production.
-
-
Promoter Silencing: The promoter driving shRNA expression (e.g., U6 or H1) can become silenced over time in certain cell types, leading to a loss of knockdown.
-
Solution: If you suspect promoter silencing, you can try a different polymerase III promoter or switch to a polymerase II promoter (e.g., CMV) that may be less prone to silencing in your specific cell line, although this can sometimes lead to higher toxicity.
-
-
Heterogeneous Population: Even after antibiotic selection, you will have a mixed population of cells with the shRNA vector integrated at different genomic locations, resulting in variable expression levels.
-
Solution: Perform single-cell cloning to isolate clones with potent and stable this compound knockdown.[14] This is a critical step for generating a reliable stable cell line.
-
-
Essential Gene Effects: If this compound is essential for cell growth or survival, cells that stochastically lose shRNA expression or have weaker knockdown will outcompete the well-silenced cells over time.
-
Solution: Consider using an inducible shRNA system (e.g., Tet-inducible). This allows you to grow the cells without knockdown pressure and induce this compound silencing only when needed for an experiment.
-
Troubleshooting Guides & Data Tables
Table 1: Troubleshooting Poor Knockdown Efficiency
| Problem | Potential Cause | Recommended Action |
| Low mRNA Knockdown | Poor siRNA/shRNA design | Test 2-4 different sequences targeting the gene. Use validated design algorithms.[3] |
| Inefficient transfection/transduction | Optimize reagent-to-siRNA ratio, cell density, and incubation time.[6] Confirm delivery with a fluorescent control. | |
| Degraded siRNA/shRNA reagents | Store reagents properly (-20°C or -80°C). Avoid multiple freeze-thaw cycles. Handle with RNase-free technique. | |
| mRNA Knockdown OK, but Protein Unchanged | Long protein half-life | Increase incubation time post-transfection (e.g., 72-96 hours).[12] |
| Ineffective antibody for Western blot | Validate your antibody using a positive and negative control cell line or an over-expression lysate. | |
| qPCR artifact | Design primers upstream (5') of the siRNA target site to avoid detecting cleavage fragments.[13] | |
| Inconsistent Results | Variable cell conditions | Use cells from a consistent, low passage number. Standardize seeding density and culture health.[4][7] |
| Reagent variability | Prepare master mixes for transfection complexes to reduce pipetting error. |
Table 2: Essential Controls for Knockdown Experiments
| Control Type | Purpose | Description |
| Untreated/Mock Transfected | Baseline/Toxicity Control | Cells exposed only to the transfection reagent without any siRNA. Establishes baseline gene/protein expression and measures reagent toxicity.[9] |
| Negative Control (NC) siRNA | Off-Target/Specificity Control | An siRNA with a scrambled sequence that does not target any gene in the host genome. Distinguishes sequence-specific knockdown from non-specific effects of transfection.[4][9] |
| Positive Control siRNA | Transfection Efficiency Control | An siRNA targeting an endogenous, stably expressed housekeeping gene (e.g., GAPDH, Lamin A/C). Confirms that the transfection and RNAi machinery are working in your cells.[4][9][10] |
| Multiple siRNAs per Target | Off-Target Validation | Using at least two different siRNAs that target different sequences of the same gene (this compound). A consistent phenotype with both siRNAs provides strong evidence that the effect is on-target. |
Experimental Protocols
Protocol 1: Transient siRNA-Mediated Knockdown of this compound
-
Cell Seeding: The day before transfection, seed cells in antibiotic-free medium so they reach 50-70% confluency at the time of transfection. The cell number will depend on the plate format (e.g., 100,000 cells/well for a 12-well plate).
-
siRNA Preparation: Thaw this compound-targeting siRNA, negative control siRNA, and positive control siRNA. Dilute each in an appropriate volume of serum-free medium (e.g., Opti-MEM).
-
Transfection Reagent Preparation: In a separate tube, dilute the lipid-based transfection reagent (e.g., Lipofectamine RNAiMAX) in serum-free medium according to the manufacturer's protocol. Incubate for 5 minutes at room temperature.
-
Complex Formation: Combine the diluted siRNA and the diluted transfection reagent. Mix gently and incubate for 15-20 minutes at room temperature to allow complexes to form.
-
Transfection: Add the siRNA-lipid complexes drop-wise to the cells. Gently swirl the plate to ensure even distribution.
-
Incubation: Incubate the cells for 24-72 hours at 37°C. The optimal time depends on the specific research goals and the stability of the this compound protein.
-
Validation:
-
mRNA Analysis (24-48 hours): Harvest cells, extract total RNA, and perform qRT-PCR to quantify this compound mRNA levels. Normalize to a stable housekeeping gene.[9]
-
Protein Analysis (48-96 hours): Harvest cells, prepare protein lysates, and perform a Western blot to quantify this compound protein levels.[11][15][16] Normalize to a loading control like β-actin or GAPDH.
-
Visualizations
Experimental & Logical Workflows
Caption: Standard workflow for a this compound gene knockdown experiment.
Caption: Decision tree for troubleshooting poor this compound knockdown results.
Hypothetical Signaling Pathway
This diagram illustrates a generic pathway to conceptualize how this compound knockdown might be assessed.
Caption: Hypothetical pathway showing this compound as a signaling intermediate.
References
- 1. researchgate.net [researchgate.net]
- 2. youtube.com [youtube.com]
- 3. Criteria for effective design, construction, and gene knockdown by shRNA vectors - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Ten Tips for a Successful siRNA Experiment | Thermo Fisher Scientific - JP [thermofisher.com]
- 5. Optimizing siRNA Transfection for RNAi | Thermo Fisher Scientific - US [thermofisher.com]
- 6. researchgate.net [researchgate.net]
- 7. Optimizing siRNA Transfection | Thermo Fisher Scientific - HK [thermofisher.com]
- 8. Guidelines for transfection of siRNA [qiagen.com]
- 9. Top 4 ways to make your siRNA experiment a success [horizondiscovery.com]
- 10. researchgate.net [researchgate.net]
- 11. researchgate.net [researchgate.net]
- 12. researchgate.net [researchgate.net]
- 13. Optimal RNA isolation method and primer design to detect gene knockdown by qPCR when validating Drosophila transgenic RNAi lines - PMC [pmc.ncbi.nlm.nih.gov]
- 14. researchgate.net [researchgate.net]
- 15. researchgate.net [researchgate.net]
- 16. licorbio.com [licorbio.com]
YN14 CRISPR Editing Technical Support Center: Avoiding Off-Target Effects
Welcome to the technical support center for YN14 CRISPR editing. This resource provides researchers, scientists, and drug development professionals with comprehensive troubleshooting guides and frequently asked questions (FAQs) to minimize off-target effects and ensure high-fidelity genome editing.
Frequently Asked Questions (FAQs)
Q1: What are off-target effects in CRISPR editing and why are they a concern?
Off-target effects are unintended genomic alterations at sites other than the intended on-target locus.[1][2][3] These effects arise because the CRISPR-Cas system, guided by the single-guide RNA (sgRNA), can tolerate some mismatches between the sgRNA and the genomic DNA, leading to cleavage at unintended locations.[1] Off-target mutations are a significant concern, especially in therapeutic applications, as they can lead to disruption of essential genes, activation of oncogenes, or other unpredictable and potentially harmful genomic instability.[4][5]
Q2: How can I proactively minimize off-target effects during the experimental design phase?
Minimizing off-target effects starts with careful planning. Key strategies include:
-
Thoughtful sgRNA Design: The design of the sgRNA is crucial for specificity.[6] Utilize in silico tools to predict and avoid potential off-target sites.[1][7][8] These tools use algorithms to scan the genome for sequences with similarity to your target and provide a specificity score.[1][7]
-
Selection of High-Fidelity Cas Variants: Instead of the wild-type Cas9 protein, consider using engineered high-fidelity Cas9 variants like SpCas9-HF1, eSpCas9, or HypaCas9.[9][10][11][12][13] These variants are designed to have reduced non-specific DNA contacts, thereby lowering the incidence of off-target cleavage.[9][10][12]
-
Choice of Delivery Method: The method used to deliver the CRISPR components into the cell can significantly influence off-target activity.[1][4] Delivering the Cas9 protein and sgRNA as a ribonucleoprotein (RNP) complex via electroporation is often preferred over plasmid DNA transfection.[1][14] RNPs are cleared from the cell more quickly, reducing the time available for off-target cleavage to occur.[15][16]
Q3: What are the best practices for designing a highly specific single-guide RNA (sgRNA)?
To design an sgRNA with high on-target activity and minimal off-target effects, follow these guidelines:
-
Length and GC Content: Standard sgRNAs are 20 nucleotides long. Truncated gRNAs (17-18 nucleotides) can sometimes reduce off-target effects without compromising on-target efficiency.[6][7] Aim for a GC content between 40-60% in your sgRNA sequence, as this can help stabilize the DNA:RNA duplex at the target site.[4][9]
-
Avoid Mismatches in the Seed Region: The "seed" region of the sgRNA, typically the 8-12 bases at the 3' end closest to the Protospacer Adjacent Motif (PAM), is critical for target recognition. Mismatches in this region are less tolerated by the Cas9 enzyme.[4] Design your sgRNA to have perfect complementarity in the seed region.
-
Utilize Design Tools: Leverage bioinformatics tools like CRISPOR, GuideScan, or Cas-OFFinder to predict on-target efficiency and potential off-target sites.[7][17][18] These tools provide scores that can help you rank and select the best sgRNA candidates.
Q4: Can modifying the Cas9 nuclease help reduce off-target effects?
Yes, several strategies involving modification of the Cas9 nuclease can significantly enhance specificity:
-
High-Fidelity Cas9 Variants: As mentioned, engineered variants like SpCas9-HF1 and eSpCas9 have been developed to reduce off-target effects.[9][10][11][12][13] These variants have mutations that decrease the energy of the Cas9-DNA interaction, making off-target binding less likely.
-
Cas9 Nickases: Instead of creating a double-strand break (DSB), a Cas9 nickase is engineered to cut only one strand of the DNA.[6][9] To generate a DSB at the target site, two sgRNAs are used to guide two nickase enzymes to opposite strands in close proximity.[15] This requirement for dual binding greatly reduces the probability of off-target DSBs.[15]
-
dCas9-FokI Fusions: A catalytically inactive Cas9 (dCas9) can be fused to a FokI nuclease domain.[14] Similar to nickases, this system requires two sgRNAs to bring two dCas9-FokI monomers together for the FokI domains to dimerize and cleave the DNA, thereby increasing specificity.[14]
Troubleshooting Guides
Problem 1: High frequency of off-target mutations detected after editing.
-
Possible Cause: Suboptimal sgRNA design with significant homology to other genomic regions.
-
Troubleshooting Steps:
-
Re-analyze sgRNA: Use multiple in silico off-target prediction tools to re-evaluate your current sgRNA.
-
Design New sgRNAs: Design and test new sgRNAs for the same target, prioritizing those with the highest specificity scores and fewest predicted off-target sites.
-
Perform Experimental Validation: Empirically test the top new sgRNA candidates in vitro or in a pilot cell line experiment to assess their on- and off-target activity before proceeding with your main experiment.
-
-
Possible Cause: Prolonged expression of the Cas9 nuclease and sgRNA.
-
Troubleshooting Steps:
-
Switch to RNP Delivery: If you are using plasmid-based delivery, switch to delivering the Cas9 and sgRNA as a pre-complexed ribonucleoprotein (RNP).[1][14]
-
Optimize Delivery Amount: Titrate the amount of RNP delivered to find the lowest concentration that still provides efficient on-target editing. Lower concentrations can reduce off-target events.[6]
-
Consider mRNA Delivery: As an alternative to RNP, delivering Cas9 as mRNA can also lead to more transient expression compared to plasmid DNA.[16][19]
-
Problem 2: On-target editing efficiency is low, forcing the use of high concentrations of CRISPR components, which may increase off-target risk.
-
Possible Cause: The chosen sgRNA has inherently low activity.
-
Troubleshooting Steps:
-
Consult On-Target Prediction Tools: Use tools that predict sgRNA activity based on sequence features.
-
Test Multiple sgRNAs: Design and test 3-4 different sgRNAs targeting the same gene to identify one with high on-target efficiency.
-
Optimize sgRNA Structure: Ensure your sgRNA is correctly synthesized and folded. Chemical modifications can sometimes improve stability and efficiency.[7]
-
-
Possible Cause: Inefficient delivery of CRISPR components into the target cells.
-
Troubleshooting Steps:
-
Optimize Electroporation/Transfection Parameters: Systematically optimize the parameters of your delivery method (e.g., voltage, pulse duration for electroporation; lipid-to-payload ratio for lipofection).
-
Check Cell Health: Ensure your cells are healthy and in the optimal growth phase before delivery.
-
Use a Positive Control: Include a validated, high-efficiency sgRNA targeting a non-essential gene as a positive control for your delivery protocol.
-
Data Presentation: Strategies to Reduce Off-Target Effects
| Strategy | Principle | Key Considerations | Typical Reduction in Off-Targets |
| High-Fidelity Cas9 Variants (e.g., SpCas9-HF1) | Engineered mutations reduce non-specific DNA binding affinity.[9][10][12] | May have slightly lower on-target activity for some gRNAs. | Up to 1500-fold compared to wild-type SpCas9.[7] |
| Cas9 Nickase (Paired gRNAs) | Requires two nicks on opposite strands to create a DSB, increasing specificity.[6][9][15] | Requires design of two effective gRNAs in close proximity. | Can reduce off-targets by 50- to 1,500-fold.[14] |
| Truncated sgRNAs (17-18 nt) | Shorter guide sequence reduces the likelihood of off-target binding.[6][7] | On-target efficiency may be reduced for some targets. | Can decrease off-target events by 500-fold.[13] |
| RNP Delivery | Transient presence of the Cas9-sgRNA complex limits time for off-target search.[1][14][15] | Requires purified Cas9 protein and in vitro transcribed sgRNA. | Significantly lower off-target mutations compared to plasmid delivery.[1] |
| Anti-CRISPR Proteins (Acrs) | Proteins that bind to and inactivate Cas9 after a desired time, limiting its activity.[20][21] | Requires a second delivery step and careful timing. | Can reduce off-target effects by more than two-fold.[21] |
Experimental Protocols
Protocol 1: Genome-Wide Unbiased Off-Target Analysis using CIRCLE-seq
CIRCLE-seq is a highly sensitive in vitro method to identify genome-wide off-target cleavage sites of CRISPR-Cas nucleases.
-
Genomic DNA Preparation: Isolate high-molecular-weight genomic DNA from the target cell line.
-
In Vitro Cleavage: Treat the genomic DNA with the purified Cas9-sgRNA RNP complex.
-
Library Preparation:
-
Ligate adapters to the ends of the cleaved DNA fragments.
-
Perform PCR to amplify the library.
-
Circularize the amplified DNA fragments.
-
-
Sequencing: Perform high-throughput sequencing of the prepared library.
-
Data Analysis: Align the sequencing reads to the reference genome to identify the locations of the cleavage events. On-target and off-target sites will be revealed as peaks in the sequence alignment data.
Protocol 2: Validation of Predicted Off-Target Sites using Targeted Deep Sequencing
This protocol is used to quantify the frequency of mutations at specific, predicted off-target sites.
-
gRNA Design and Off-Target Prediction: Use in silico tools to predict potential off-target sites for your chosen sgRNA.
-
CRISPR Editing: Introduce the CRISPR-Cas components into the target cells.
-
Genomic DNA Extraction: After a suitable incubation period (e.g., 48-72 hours), harvest the cells and extract genomic DNA.
-
PCR Amplification: Design PCR primers to amplify the on-target site and the predicted off-target sites from the extracted genomic DNA.
-
Next-Generation Sequencing (NGS): Pool the PCR amplicons and perform deep sequencing.
-
Data Analysis: Analyze the sequencing data to identify and quantify the frequency of insertions, deletions (indels), and other mutations at each site. Compare the mutation frequency at off-target sites to a negative control (e.g., cells treated with a non-targeting sgRNA).
Visualizations
Caption: Workflow for minimizing and evaluating off-target effects.
Caption: Troubleshooting decision tree for high off-target effects.
References
- 1. Off-target effects in CRISPR/Cas9 gene editing - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Beyond the promise: evaluating and mitigating off-target effects in CRISPR gene editing for safer therapeutics - PMC [pmc.ncbi.nlm.nih.gov]
- 3. lifesciences.danaher.com [lifesciences.danaher.com]
- 4. azolifesciences.com [azolifesciences.com]
- 5. Identification and Validation of CRISPR/Cas9 Off-target Activity in Hematopoietic Stem and Progenitor Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Strategies to Increase On-Target and Reduce Off-Target Effects of the CRISPR/Cas9 System in Plants [mdpi.com]
- 7. Latest Developed Strategies to Minimize the Off-Target Effects in CRISPR-Cas-Mediated Genome Editing - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Summary of CRISPR-Cas9 off-target Detection Methods - CD Genomics [cd-genomics.com]
- 9. dovepress.com [dovepress.com]
- 10. stacks.cdc.gov [stacks.cdc.gov]
- 11. High-fidelity CRISPR | Harvard Medical School [hms.harvard.edu]
- 12. High-fidelity CRISPR–Cas9 nucleases with no detectable genome-wide off-target effects [ideas.repec.org]
- 13. mdpi.com [mdpi.com]
- 14. How to reduce off-target effects and increase CRISPR editing efficiency? | MolecularCloud [molecularcloud.org]
- 15. News: Strategies to Avoid and Reduce Off-Target Effects - CRISPR Medicine [crisprmedicinenews.com]
- 16. Delivery Strategies of the CRISPR-Cas9 Gene-Editing System for Therapeutic Applications - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Current Bioinformatics Tools to Optimize CRISPR/Cas9 Experiments to Reduce Off-Target Effects - PMC [pmc.ncbi.nlm.nih.gov]
- 18. scispace.com [scispace.com]
- 19. Delivery Methods to Maximize Genome Editing with CRISPR-Cas9 [excedr.com]
- 20. Recent Advancements in Reducing the Off-Target Effect of CRISPR-Cas9 Genome Editing - PMC [pmc.ncbi.nlm.nih.gov]
- 21. innovativegenomics.org [innovativegenomics.org]
YN14 Antibody Specificity & Troubleshooting Technical Support Center
Welcome to the technical support center for the YN14 monoclonal antibody. This resource is designed for researchers, scientists, and drug development professionals to help improve the specificity of this compound in your experiments. Here you will find frequently asked questions (FAQs), detailed troubleshooting guides, and optimized experimental protocols.
Frequently Asked Questions (FAQs)
Q1: What is the known cross-reactivity of the this compound antibody?
A1: The this compound antibody is designed to target the extracellular domain of Target Antigen X (TA-X). However, sequence homology analysis indicates a potential for cross-reactivity with Target Antigen X Family Member B (TA-XF-B) due to similarities in the epitope region.[1][2] Users should validate specificity in their specific model system. A western blot including a positive control (TA-X over-expression lysate) and a negative control (TA-XF-B over-expression lysate or a TA-X knockout cell line) is highly recommended.
Q2: Why am I observing high background or multiple non-specific bands in my Western Blot (WB)?
A2: High background in Western Blotting is a common issue that can arise from several factors.[3][4][5] These include, but are not limited to:
-
Suboptimal Antibody Concentration: The concentration of the primary (this compound) or secondary antibody may be too high.[4][6]
-
Insufficient Blocking: The blocking step may be inadequate, leading to non-specific antibody binding to the membrane.[7][8][9]
-
Inadequate Washing: Insufficient washing steps can leave behind unbound antibodies.[6][8]
-
Membrane Type: PVDF membranes, while having a high binding capacity, can sometimes lead to higher background compared to nitrocellulose.[4][8]
-
Blocking Buffer Composition: For phosphorylated targets, using non-fat milk as a blocking agent is not recommended as it contains phosphoproteins like casein, which can cause cross-reactivity.[3][10]
Q3: Can the specificity of the this compound antibody be improved for therapeutic applications?
A3: Yes, improving monoclonal antibody specificity is a key aspect of therapeutic development.[11][12] Techniques such as affinity maturation through targeted mutagenesis of the complementarity-determining regions (CDRs) can enhance binding affinity and specificity.[13] Additionally, Fc region engineering can be employed to modify effector functions and improve the antibody's pharmacokinetic properties.[12] For laboratory applications, affinity purification of the antibody can remove non-specific immunoglobulins.
Q4: I am seeing high background in my Immunofluorescence (IF) staining. What are the common causes?
A4: High background in immunofluorescence can obscure the specific signal. Common causes include:
-
Hydrophobic Interactions: Antibodies can non-specifically bind to tissues through hydrophobic interactions.[14]
-
Incorrect Antibody Concentration: Using too high a concentration of the primary or secondary antibody is a frequent cause of background.[15]
-
Inadequate Blocking: Similar to WB, insufficient blocking with an appropriate serum (e.g., serum from the same species as the secondary antibody) can lead to non-specific binding.[15][16]
-
Secondary Antibody Cross-Reactivity: The secondary antibody may be binding non-specifically to the tissue.[17] Running a secondary-only control is essential to test for this.[3][15]
Troubleshooting Guides
Problem 1: High Background and Non-Specific Bands in Western Blotting
If you are experiencing high background or unexpected bands when using the this compound antibody, follow this troubleshooting workflow.
References
- 1. Antibody Cross Reactivity And How To Avoid It? [elisakits.co.uk]
- 2. How do I know if the antibody will cross-react? | Proteintech Group [ptglab.com]
- 3. Western Blot Troubleshooting: High Background | Proteintech Group [ptglab.com]
- 4. sinobiological.com [sinobiological.com]
- 5. arp1.com [arp1.com]
- 6. How To Optimize Your Western Blot | Proteintech Group [ptglab.com]
- 7. bosterbio.com [bosterbio.com]
- 8. clyte.tech [clyte.tech]
- 9. azurebiosystems.com [azurebiosystems.com]
- 10. How to select the correct blocking buffer for Western Blotting - Precision Biosystems-Automated, Reproducible Western Blot Processing and DNA, RNA Analysis [precisionbiosystems.com]
- 11. Selecting and engineering monoclonal antibodies with drug-like specificity - PMC [pmc.ncbi.nlm.nih.gov]
- 12. mybiosource.com [mybiosource.com]
- 13. researchgate.net [researchgate.net]
- 14. ICC/IHC Non-Specific Binding / Staining Prevention Protocol: R&D Systems [rndsystems.com]
- 15. stjohnslabs.com [stjohnslabs.com]
- 16. 9 Tips to optimize your IF experiments | Proteintech Group [ptglab.com]
- 17. IHC Troubleshooting Guide | Thermo Fisher Scientific - US [thermofisher.com]
Technical Support Center: Troubleshooting Plasmid Transfection Efficiency
Disclaimer: Please note that a search for the specific plasmid "YN14" did not yield any publicly available information. It is likely an internal designation. The following troubleshooting guide provides best practices and solutions for general plasmid transfection issues and may not address unique characteristics specific to the this compound plasmid.
Frequently Asked Questions (FAQs)
Q1: What are the primary factors that influence transfection efficiency?
Successful transfection is a multifactorial process. The key factors include the health and viability of the cell line, the number of cell passages, confluency at the time of transfection, and the quality and quantity of the plasmid DNA.[1] Additionally, the choice of transfection reagent and method is critical and should be optimized for your specific cell type.[2]
Q2: Why is cell confluency so important for successful transfection?
Actively dividing cells are more receptive to taking up foreign DNA.[1] If cells are under-confluent, there may be insufficient cell-to-cell contact, leading to poor growth. Conversely, if cells are over-confluent (experiencing contact inhibition), they become resistant to the uptake of foreign genetic material.[3] The optimal confluency is typically between 40-80%, but this should be empirically determined for your specific cell line.[2][3]
Q3: How does the quality of plasmid DNA affect transfection outcomes?
The purity and integrity of your plasmid DNA are paramount. Contaminants such as proteins, RNA, chemicals, and endotoxins can significantly reduce transfection efficiency and cause cytotoxicity.[3] Endotoxins, in particular, are known to compete with DNA for entry into the cell.[4] It is also crucial that the plasmid is predominantly in its supercoiled form, as this topology is more efficient for transient transfection.[1][4]
Q4: Can the number of times my cells have been passaged impact transfection?
Yes, excessive passaging can negatively affect transfection efficiency.[1] Cell characteristics can change over time and with repeated passages, potentially making them less responsive to standard transfection conditions.[3] It is recommended to use cells with a low passage number, ideally below 30-50 passages, and to maintain consistency in the passage number across experiments for reproducible results.[1][3]
Q5: What is the difference between transient and stable transfection?
Transient transfection involves the introduction of nucleic acids that are not integrated into the host cell's genome, leading to temporary gene expression (typically 24-96 hours).[5] In contrast, stable transfection results in the integration of the foreign DNA into the host genome, allowing for long-term, heritable gene expression.[5]
Troubleshooting Guide
Low Transfection Efficiency
| Potential Cause | Recommended Solution | Key Parameters to Check |
| Poor Cell Health | Use cells with >90% viability. Ensure media and supplements are appropriate for the cell line. Test for contamination (e.g., mycoplasma).[6] | Viability (Trypan Blue exclusion), passage number (<30-50), morphology.[1][2][3] |
| Suboptimal Cell Confluency | Optimize cell density to be 70-90% confluent at the time of transfection.[2][7] | Visual inspection of cell density under a microscope. |
| Poor DNA Quality | Use high-purity, endotoxin-free plasmid DNA. Confirm DNA integrity and concentration. | A260/A280 ratio (should be ≥ 1.8).[8] Agarose gel electrophoresis to check for supercoiled vs. nicked DNA.[7] |
| Incorrect DNA:Reagent Ratio | Perform a titration experiment to determine the optimal ratio of plasmid DNA to transfection reagent.[2] | Test ratios from 1:1 to 1:3 (DNA:reagent) or as per manufacturer's protocol.[5] |
| Presence of Serum or Antibiotics | Some transfection reagents require serum-free media for complex formation. While some modern reagents are compatible, it's a critical factor to check. Avoid using antibiotics during transfection.[7] | Refer to the transfection reagent's protocol for serum compatibility. |
| Incorrect Incubation Times | Optimize the incubation time for complex formation (typically 15-30 minutes) and the time cells are exposed to the complexes.[8] | Follow the manufacturer's recommendations and optimize if necessary. |
| Plasmid Size | Transfection efficiency can decrease with larger plasmids (>10-15 kb).[5][9] Consider alternative methods like electroporation for large plasmids.[9] | Check the size of your this compound plasmid. |
High Cell Toxicity/Death
| Potential Cause | Recommended Solution | Key Parameters to Check |
| DNA Contamination | Ensure plasmid DNA is free of endotoxins and other contaminants. | Use an endotoxin removal kit if necessary. |
| Excessive Amount of DNA or Reagent | Reduce the concentration of both the plasmid DNA and the transfection reagent. | Perform a dose-response experiment to find the balance between efficiency and viability. |
| Prolonged Exposure to Transfection Complexes | Decrease the incubation time of the cells with the DNA-reagent complexes. For sensitive cells, 4-6 hours may be sufficient.[5] | Observe cell morphology and viability at different time points post-transfection. |
| Cell Density Too Low | Ensure cells are at an optimal density. Too few cells can lead to increased susceptibility to toxic effects.[1] | Plate cells at a slightly higher, but still sub-confluent, density. |
Experimental Protocols
Protocol: Optimizing Plasmid DNA Transfection Using a Lipid-Based Reagent
This protocol provides a general framework for optimizing transfection conditions. Specific volumes and amounts should be adjusted based on the culture vessel size and the manufacturer's recommendations for your chosen transfection reagent.
Materials:
-
Healthy, actively dividing cells in culture
-
High-quality, purified plasmid DNA (e.g., this compound)
-
Lipid-based transfection reagent
-
Serum-free medium (e.g., Opti-MEM™)
-
Complete growth medium
-
Microcentrifuge tubes
-
Multi-well plates (e.g., 24-well)
Procedure:
-
Cell Seeding: The day before transfection, seed cells in a 24-well plate at a density that will result in 70-90% confluency on the day of transfection.[2]
-
Preparation of DNA and Reagent Mixtures (for one well):
-
Tube A (DNA): Dilute 0.5 µg of your plasmid DNA in 50 µL of serum-free medium. Mix gently by flicking the tube.
-
Tube B (Reagent): In a separate tube, dilute 0.5-1.5 µL of the transfection reagent in 50 µL of serum-free medium. Mix gently and incubate for 5 minutes at room temperature. Note: It is crucial to optimize the DNA:reagent ratio.
-
-
Formation of Transfection Complexes:
-
Add the diluted DNA from Tube A to the diluted reagent in Tube B.
-
Mix gently by pipetting up and down or flicking the tube.
-
Incubate the mixture for 15-30 minutes at room temperature to allow for the formation of DNA-lipid complexes.[8]
-
-
Transfection:
-
Gently add the 100 µL of the transfection complex mixture dropwise to the cells in one well of the 24-well plate.
-
Gently rock the plate to ensure even distribution.
-
-
Incubation:
-
Incubate the cells at 37°C in a CO2 incubator for 24-72 hours. The optimal incubation time depends on the plasmid and the assay being performed.
-
-
Analysis: After the incubation period, analyze the cells for transgene expression (e.g., via fluorescence microscopy for a reporter gene like GFP, or by Western blot or qPCR for your gene of interest).
Visualizations
Caption: General workflow for plasmid transfection.
Caption: Troubleshooting flowchart for low transfection efficiency.
References
- 1. Physical and biological characterization of linear DNA plasmids of the yeast Pichia inositovora - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. nanoporetech.com [nanoporetech.com]
- 3. addgene.org [addgene.org]
- 4. vgxii.com [vgxii.com]
- 5. Complete Sequence and Molecular Epidemiology of IncK Epidemic Plasmid Encoding blaCTX-M-14 - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Vector maps & Sequence Files [horizondiscovery.com]
- 7. mordorintelligence.com [mordorintelligence.com]
- 8. A Brief History of Plasmids - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Rapid, robust plasmid verification by de novo assembly of short sequencing reads - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Optimizing Buffer Conditions for Protein Purification
Welcome to the technical support center for optimizing protein purification buffer conditions. This resource is designed for researchers, scientists, and drug development professionals to provide troubleshooting guidance and frequently asked questions to overcome common challenges encountered during protein purification experiments.
Troubleshooting Guide
This guide addresses specific issues that may arise during protein purification, with a focus on buffer-related solutions.
| Problem | Potential Cause | Recommended Solution |
| Low Protein Yield | Suboptimal Lysis Buffer: Incomplete cell lysis leads to poor protein extraction. | - Ensure the lysis buffer pH is optimal for your protein and compatible with the first purification step.[1] - Add lysozyme (for bacteria) or use mechanical disruption methods like sonication. - Include DNase/RNase to reduce viscosity from nucleic acids. |
| Inefficient Binding to Resin: The protein of interest does not bind effectively to the chromatography resin.[2] | - Adjust the pH of the binding buffer. For ion-exchange chromatography, a pH above the protein's isoelectric point (pI) will result in a net negative charge, while a pH below the pI will result in a net positive charge.[3] - Optimize the salt concentration. Generally, low salt concentrations are used for ion-exchange chromatography to facilitate binding.[4][5] - For affinity chromatography (e.g., His-tagged proteins), ensure the tag is accessible. Denaturing conditions might be necessary if the tag is buried within the protein structure.[6] | |
| Protein Precipitation: The protein becomes insoluble and precipitates during purification. | - Increase the ionic strength of the buffer with salts like NaCl (150-500 mM) to improve solubility.[4][7] - Add stabilizing agents such as glycerol (5-20%), sugars, or inert proteins like BSA.[3][4] - Screen different pH values to find the point of maximum solubility. | |
| Protein Degradation | Protease Activity: Endogenous proteases released during cell lysis degrade the target protein.[8] | - Add a protease inhibitor cocktail to the lysis buffer.[1][9] EDTA-free cocktails are necessary for IMAC.[1] - Perform all purification steps at low temperatures (4°C) to reduce protease activity.[10] |
| Oxidation: Cysteine residues in the protein are prone to oxidation, which can lead to aggregation.[4] | - Include reducing agents like Dithiothreitol (DTT) or Tris(2-carboxyethyl)phosphine (TCEP) in the buffers at a concentration of 1-10 mM.[4] | |
| Poor Purity/Contamination | Non-specific Binding: Contaminant proteins bind to the resin along with the target protein. | - Increase the stringency of the wash buffer. This can be achieved by increasing the salt concentration in ion-exchange chromatography or adding a low concentration of a competitive eluent (e.g., imidazole for His-tagged proteins) in affinity chromatography.[6][11] - Add non-ionic detergents (e.g., Triton X-100, Tween 20) to the wash buffer to disrupt non-specific hydrophobic interactions. |
| Co-elution of Contaminants: Contaminants have similar properties to the target protein and elute under the same conditions. | - Optimize the elution gradient (e.g., a shallow salt or pH gradient in ion-exchange, or a gradual increase in imidazole for IMAC) to improve separation. - Consider an additional purification step using a different chromatography technique that separates proteins based on different properties (e.g., size-exclusion chromatography after affinity chromatography).[7] |
Frequently Asked Questions (FAQs)
Q1: How do I choose the right buffer and pH for my protein?
A1: The choice of buffer and pH is critical for protein stability and activity.[3] A good starting point is to use a buffer with a pKa value within one pH unit of the desired pH.[3] For example, Tris and HEPES are commonly used for physiological pH ranges.[1][12] The optimal pH depends on the protein's isoelectric point (pI). For ion-exchange chromatography, the pH is chosen to ensure the protein has the desired charge to bind to the column.[3] It's recommended to perform a pH screening experiment to determine the optimal pH for your specific protein's solubility and stability.
Q2: What is the role of salt in purification buffers?
A2: Salts, such as sodium chloride (NaCl), are essential components of purification buffers for several reasons.[9] They help to maintain the ionic strength of the solution, which can improve protein solubility and stability by mimicking physiological conditions.[4] In different chromatography techniques, the salt concentration is modulated to control protein binding and elution. For instance, in ion-exchange chromatography, a low salt concentration is used for binding, and the concentration is increased for elution.[5] Conversely, in hydrophobic interaction chromatography (HIC), a high salt concentration promotes binding, and a decreasing salt gradient is used for elution.[3][13]
Q3: When should I use additives like glycerol, detergents, or reducing agents?
A3: Additives are often necessary to maintain the integrity of the target protein.
-
Glycerol and other osmolytes are used to stabilize proteins and prevent aggregation by increasing the viscosity of the solution.[3][4]
-
Detergents (e.g., Triton X-100, NP-40) are included to solubilize membrane proteins or to reduce non-specific hydrophobic interactions.[9][10]
-
Reducing agents like DTT or TCEP are crucial for proteins with cysteine residues to prevent the formation of disulfide bonds and subsequent aggregation.[3][4]
Q4: My protein is in inclusion bodies. How should I adjust my buffer?
A4: Inclusion bodies are dense aggregates of misfolded protein. To purify proteins from inclusion bodies, you will need to use denaturing conditions. This typically involves a lysis buffer containing strong denaturants like 8 M urea or 6 M guanidinium hydrochloride to solubilize the aggregated protein.[14] After initial purification under denaturing conditions, the protein must be refolded into its active conformation. This is usually achieved by gradually removing the denaturant through dialysis or rapid dilution into a refolding buffer. The refolding buffer should be optimized for pH, ionic strength, and may contain additives that assist in proper folding.
Experimental Protocols
Protocol 1: Buffer Optimization Screening for Affinity Chromatography (His-tagged protein)
This protocol outlines a small-scale screening experiment to determine the optimal buffer conditions for the purification of a His-tagged protein.
Materials:
-
Cell lysate containing the His-tagged protein of interest
-
Ni-NTA or other IMAC resin
-
Microcentrifuge tubes or 96-well filter plates
-
A selection of buffers with varying pH (e.g., Tris, HEPES, Phosphate)
-
Stock solutions of NaCl, imidazole, glycerol, and a non-ionic detergent (e.g., Tween-20)
Procedure:
-
Prepare a Buffer Matrix: Create a matrix of buffer conditions to test. Vary one component at a time (e.g., pH, NaCl concentration, imidazole concentration). A representative matrix is shown in the table below.
-
Equilibrate Resin: Aliquot the IMAC resin into each tube or well. Wash and equilibrate the resin with each respective binding buffer from your matrix.
-
Bind Protein: Add an equal amount of cell lysate to each tube/well containing the equilibrated resin. Incubate at 4°C with gentle agitation for 1 hour.
-
Wash: Pellet the resin and remove the supernatant (flow-through). Wash the resin with the corresponding wash buffer. It is recommended to perform at least two washes to remove non-specifically bound proteins.
-
Elute: Add the corresponding elution buffer to each tube/well. Incubate for 15-30 minutes at room temperature with gentle agitation.
-
Analyze: Collect the eluted fractions. Analyze all fractions (flow-through, washes, and elutions) by SDS-PAGE to determine which buffer condition yields the highest purity and recovery of the target protein.
Table 1: Example Buffer Optimization Matrix for His-Tag Purification
| Condition | Buffer (50 mM) | pH | NaCl (mM) | Imidazole (mM) - Wash | Imidazole (mM) - Elution | Glycerol (%) |
| 1 | Tris-HCl | 7.0 | 300 | 10 | 250 | 10 |
| 2 | Tris-HCl | 8.0 | 300 | 10 | 250 | 10 |
| 3 | HEPES | 7.5 | 150 | 10 | 250 | 10 |
| 4 | HEPES | 7.5 | 500 | 10 | 250 | 10 |
| 5 | Tris-HCl | 8.0 | 300 | 20 | 250 | 10 |
| 6 | Tris-HCl | 8.0 | 300 | 40 | 250 | 10 |
| 7 | Tris-HCl | 8.0 | 300 | 20 | 500 | 10 |
| 8 | Tris-HCl | 8.0 | 300 | 20 | 250 | 20 |
Visualizations
Protein Purification Workflow
This diagram illustrates a typical workflow for protein purification, starting from cell culture to the final pure protein.
Caption: Figure 1: General Protein Purification Workflow.
Troubleshooting Logic for Low Protein Yield
This decision tree provides a logical approach to troubleshooting low protein yield during purification.
Caption: Figure 2: Troubleshooting Low Protein Yield.
References
- 1. Choice of lysis buffer – Protein Expression and Purification Core Facility [embl.org]
- 2. Protein Purification Protocol & Troubleshooting Guide | Complete Workflow - Creative Biolabs [creativebiolabs.net]
- 3. tebubio.com [tebubio.com]
- 4. bitesizebio.com [bitesizebio.com]
- 5. biomatik.com [biomatik.com]
- 6. goldbio.com [goldbio.com]
- 7. Tips for Optimizing Protein Expression and Purification | Rockland [rockland.com]
- 8. cytivalifesciences.com [cytivalifesciences.com]
- 9. goldbio.com [goldbio.com]
- 10. Protein Purification Support—Troubleshooting | Thermo Fisher Scientific - SG [thermofisher.com]
- 11. biotage.com [biotage.com]
- 12. 6 Biological buffers recommended for protein purification - Blog - Hopax Fine Chemicals [hopaxfc.com]
- 13. goldbio.com [goldbio.com]
- 14. med.upenn.edu [med.upenn.edu]
YN14 Co-Immunoprecipitation: Technical Support Center
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals encountering issues with YN14 co-immunoprecipitation (Co-IP) experiments.
Frequently Asked Questions (FAQs) & Troubleshooting Guides
Issue 1: No or Low Signal for Bait and/or Prey Protein
Question: I performed a Co-IP with this compound antibody, but I don't see a band for my bait or prey protein on the Western blot. What could be the problem?
Answer: This is a common issue that can arise from several factors throughout the Co-IP workflow. The following sections provide potential causes and solutions.
Potential Cause & Solution
| Potential Cause | Recommended Solution |
| Inefficient Cell Lysis | Ensure your lysis buffer is appropriate for your target proteins' subcellular localization. For nuclear or membrane-bound proteins, stronger buffers or sonication may be necessary.[1] Always add fresh protease and phosphatase inhibitors to your lysis buffer to prevent protein degradation.[2][3] |
| Poor Antibody Quality | Validate your this compound antibody for immunoprecipitation. Not all antibodies that work in Western blotting are suitable for IP.[4] Use an antibody that has been specifically validated for IP experiments.[5] |
| Suboptimal Antibody-Bead Coupling | Ensure the protein A/G beads are compatible with the this compound antibody isotype.[3][4] Consider using a crosslinker to covalently attach the antibody to the beads, which can prevent antibody elution and improve pulldown efficiency.[6] |
| Weak or Transient Protein Interaction | Optimize washing conditions. Start with a less stringent wash buffer (e.g., lower salt and detergent concentrations) and gradually increase stringency.[7][8] Consider performing the Co-IP at 4°C to stabilize weak interactions.[3] For very transient interactions, in vivo crosslinking prior to cell lysis might be necessary.[6] |
| Low Protein Expression | Increase the amount of starting material (cell lysate).[1][2] If possible, consider overexpressing the bait or prey protein to increase the chances of detecting the interaction.[3][9] |
| Epitope Masking | The this compound antibody's epitope on the bait protein might be blocked by the interacting prey protein.[2] Try performing a reciprocal Co-IP using an antibody against the prey protein to pull down the bait.[10][11] |
Experimental Protocol: Standard Cell Lysis for Co-IP
-
Preparation: Pre-chill all buffers and centrifuges to 4°C.
-
Cell Harvesting: Wash cells with ice-cold PBS and centrifuge at 500 x g for 5 minutes.
-
Lysis: Resuspend the cell pellet in a non-denaturing lysis buffer (e.g., 25 mM Tris-HCl pH 7.4, 150 mM NaCl, 1% NP-40, 1 mM EDTA, 5% glycerol) supplemented with fresh protease and phosphatase inhibitors.[9]
-
Incubation: Incubate the lysate on ice for 30 minutes with occasional vortexing.
-
Clarification: Centrifuge the lysate at 14,000 x g for 15 minutes at 4°C to pellet cell debris.
-
Supernatant Collection: Carefully transfer the supernatant (cleared lysate) to a new pre-chilled tube. This lysate is now ready for the Co-IP procedure.
Logical Workflow for Troubleshooting Low/No Signal
Caption: Troubleshooting workflow for low or no signal in this compound Co-IP.
Issue 2: High Background or Non-Specific Binding
Question: My Co-IP results show many non-specific bands, making it difficult to identify the true interaction partners of my protein. How can I reduce this background?
Answer: High background is often due to non-specific binding of proteins to the beads or the antibody. Optimizing your protocol to increase stringency and include proper controls can significantly reduce background noise.
Potential Cause & Solution
| Potential Cause | Recommended Solution |
| Non-specific Binding to Beads | Pre-clear the cell lysate by incubating it with beads alone before adding the this compound antibody.[1][10][12] This will remove proteins that non-specifically bind to the beads. Block the beads with a blocking agent like BSA or non-fat milk before use.[10][12] |
| Non-specific Binding to Antibody | Use an isotype control antibody of the same species and class as this compound to differentiate between specific and non-specific binding.[10][11] Titrate the this compound antibody to determine the optimal concentration that maximizes specific binding while minimizing background.[2][12] |
| Insufficient Washing | Increase the number and/or duration of wash steps.[12][13] Increase the stringency of the wash buffer by adding more detergent (e.g., Tween-20, Triton X-100) or salt (NaCl).[2][12] |
| Cell Lysis Issues | Over-sonication can lead to protein aggregation and non-specific binding.[7] Ensure proper centrifugation to pellet all cellular debris after lysis.[7] |
Experimental Protocol: Pre-clearing Lysate and Blocking Beads
-
Bead Preparation: Resuspend the required amount of protein A/G beads in lysis buffer.
-
Pre-clearing: Add the bead slurry to the clarified cell lysate and incubate with gentle rotation for 1-2 hours at 4°C.
-
Lysate Collection: Centrifuge the lysate at a low speed (e.g., 1,000 x g) for 1 minute at 4°C. Carefully collect the supernatant (pre-cleared lysate), avoiding the beads.
-
Bead Blocking (Optional but Recommended): Wash the beads to be used for the IP with lysis buffer. Then, incubate the beads in a blocking buffer (e.g., lysis buffer containing 1% BSA) for 1 hour at 4°C.
-
Proceed with Immunoprecipitation: Add the pre-cleared lysate and the validated this compound antibody to the blocked beads.
Signaling Pathway Visualization: A Generic Co-IP Workflow
Caption: Overview of a standard co-immunoprecipitation workflow.
Issue 3: Co-IP is Not Successful Despite Successful IP of Bait Protein
Question: I can successfully immunoprecipitate my bait protein with the this compound antibody, but the prey protein is not co-precipitated. What should I do?
Answer: This situation suggests that the issue lies with the interaction between the bait and prey proteins or the conditions used to preserve this interaction.
Potential Cause & Solution
| Potential Cause | Recommended Solution |
| Disruption of Protein-Protein Interaction | The lysis buffer may be too stringent and disrupting the interaction.[1] Try a milder lysis buffer with lower concentrations of detergents and salt.[3] |
| Incorrect Cellular Compartment | Ensure that both the bait and prey proteins are expressed in the same subcellular compartment. Fractionate the cell lysate to confirm co-localization before performing the Co-IP. |
| Transient or Weak Interaction | As mentioned previously, consider in vivo crosslinking to stabilize the interaction before cell lysis.[6] Also, performing all steps at 4°C can help preserve weaker interactions.[3] |
| Reciprocal Co-IP Failure | It's possible that the interaction is unidirectional, where one protein can pull down the other but not vice-versa.[10] This can be due to differences in protein abundance or the accessibility of antibody epitopes.[10] |
Experimental Protocol: Mild Lysis Buffer for Weak Interactions
-
Buffer Composition: 50 mM Tris-HCl (pH 7.5), 150 mM NaCl, 0.5% Triton X-100, 1 mM EDTA.
-
Procedure: Follow the standard cell lysis protocol but substitute the regular lysis buffer with this milder formulation. It is crucial to include fresh protease and phosphatase inhibitors.
Logical Relationship Diagram: Diagnosing a Failed Co-IP
Caption: Decision tree for troubleshooting a failed Co-IP experiment.
References
- 1. Immunoprecipitation Troubleshooting Guide | Cell Signaling Technology [cellsignal.com]
- 2. kmdbioscience.com [kmdbioscience.com]
- 3. Co-immunoprecipitation (Co-IP) Troubleshooting | Antibodies.com [antibodies.com]
- 4. researchgate.net [researchgate.net]
- 5. Immunoprecipitation Experimental Design Tips | Cell Signaling Technology [cellsignal.com]
- 6. researchgate.net [researchgate.net]
- 7. ptglab.com [ptglab.com]
- 8. Co-immunoprecipitation troubleshooting, tips and tricks | Proteintech Group [ptglab.com]
- 9. researchgate.net [researchgate.net]
- 10. Co-immunoprecipitation (Co-IP): The Complete Guide | Antibodies.com [antibodies.com]
- 11. antibodiesinc.com [antibodiesinc.com]
- 12. sinobiological.com [sinobiological.com]
- 13. Co-immunoprecipitation non-specific binding - Molecular Biology [protocol-online.org]
Technical Support Center: Refining YN14 CLIP-seq Data Analysis
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in refining the analysis of YN14 Cross-Linking and Immunoprecipitation followed by sequencing (CLIP-seq) data.
Troubleshooting Guides
This section addresses specific issues that may arise during this compound CLIP-seq experiments and data analysis.
| Issue/Question | Potential Causes | Suggested Solutions |
| Low Read Quality in FASTQ Files | - Problems during library preparation (e.g., adapter dimers).- Issues with the sequencing run. | - Use tools like FastQC to assess read quality.[1]- Trim adapter sequences and low-quality bases using tools like Cutadapt.[1][2]- If quality is persistently low, consider repeating the library preparation or sequencing. |
| High Percentage of PCR Duplicates | - Low amount of starting material leading to over-amplification.[1][3]- Inefficient immunoprecipitation (IP) of the this compound-RNA complex. | - Optimize the amount of starting cellular material.- Use Unique Molecular Identifiers (UMIs) to identify and remove PCR duplicates during analysis.[1]- Improve IP efficiency by using a high-quality, validated antibody specific to this compound.[4] |
| Inefficient Immunoprecipitation (IP) | - Poor antibody quality or specificity for this compound.[4]- Suboptimal lysis or IP buffer conditions.- Inefficient UV crosslinking. | - Validate the this compound antibody using methods like Western Blot on IP samples.[5]- Optimize buffer components and salt concentrations.- Ensure efficient UV crosslinking at 254 nm to covalently link this compound to its target RNAs.[6][7] |
| No Significant Peaks Identified After Peak Calling | - Insufficient sequencing depth.- Inappropriate background or control sample used for normalization.[3][4]- The chosen peak calling algorithm is not suitable for the data type (e.g., eCLIP vs. iCLIP). | - Aim for a sequencing depth of 20-50 million reads for sufficient coverage.[6]- Use a size-matched input control for proper normalization and to account for biases.[8]- Try different peak calling software (e.g., PEAKachu, PureCLIP, Piranha) and compare the results.[1] |
| Difficulty in Identifying a this compound Binding Motif | - this compound may recognize a structural motif rather than a primary sequence motif.- The identified binding sites are too broad, diluting the motif signal.- Incorrect background sequences used for motif discovery.[3] | - Use motif discovery tools that can consider RNA secondary structures.- Refine peak calling to identify more precise binding sites.- Use appropriate background sequences, such as shuffled peak sequences or sequences from expressed genes that are not bound by this compound. |
Frequently Asked Questions (FAQs)
This section provides answers to common questions regarding this compound CLIP-seq data analysis.
Q1: What is the primary function of this compound (Y14/RBM8A) and how does this inform my CLIP-seq analysis?
A1: this compound, also known as RNA Binding Motif Protein 8A (RBM8A), is a core component of the exon junction complex (EJC), which is deposited on spliced mRNAs.[9][10] It plays roles in post-splicing events like mRNA export, nonsense-mediated decay (NMD), and translation.[9] More recently, this compound has been implicated in DNA damage response and repair.[11] When analyzing your this compound CLIP-seq data, you should expect to find binding sites predominantly at exon-exon junctions of spliced transcripts. However, given its role in the DNA damage response, you might also uncover interactions with non-coding RNAs or even regions of DNA in the context of R-loops.[11]
Q2: How should I design my this compound CLIP-seq experiment to ensure high-quality data?
A2: A successful this compound CLIP-seq experiment relies on several key factors:
-
High-Quality Antibody: Use a rigorously validated antibody specific to this compound.[4]
-
Appropriate Controls: Include a size-matched input (SMI) control for each experiment. This control undergoes the same experimental steps as the IP sample but without the this compound-specific antibody, which is crucial for accurate background correction.[4][8][12]
-
Biological Replicates: Perform at least two biological replicates to assess the reproducibility of your findings.
-
Sufficient Sequencing Depth: Aim for 20-50 million reads per library to ensure adequate coverage of this compound binding sites.[6]
Q3: What are the key steps in the computational analysis of this compound CLIP-seq data?
A3: The computational workflow for this compound CLIP-seq data generally involves the following steps:
-
Preprocessing: Trim adapter sequences and remove low-quality reads.[2]
-
Alignment: Map the processed reads to the reference genome. Splicing-aware aligners are recommended since this compound binds to spliced mRNAs.[13]
-
Peak Calling: Identify regions with a significant enrichment of reads in the this compound IP sample compared to the input control.[1][4]
-
Motif Discovery: Search for enriched sequence or structural motifs within the identified peaks.
-
Functional Annotation: Annotate the peaks to identify the genes and transcript regions bound by this compound and perform pathway and gene ontology analysis.[4]
Q4: My this compound CLIP-seq data shows enrichment in intronic regions. How should I interpret this?
A4: While this compound is primarily known to bind at exon-exon junctions, intronic enrichment could be biologically significant. Potential interpretations include:
-
Co-transcriptional Binding: this compound may associate with pre-mRNAs during transcription and splicing.
-
Regulation of Splicing: this compound could have a role in alternative splicing by binding to intronic splicing enhancers or silencers.
-
Interaction with Non-coding RNAs: Some intronic regions give rise to non-coding RNAs, which could be targets of this compound.
-
DNA Damage Response: Given its role in the DNA damage response, this compound might interact with RNA in the context of DNA repair processes occurring within introns.[11]
Careful validation and further experiments would be needed to distinguish between these possibilities.
Experimental Protocols
A detailed, generalized protocol for an enhanced CLIP (eCLIP) experiment is provided below, which can be adapted for studying this compound.
Detailed eCLIP Protocol Steps:
-
UV Crosslinking: Irradiate cells with 254nm UV light to covalently crosslink this compound to its target RNAs.[6][7]
-
Cell Lysis and RNase Treatment: Lyse the cells and perform a limited RNase digestion to fragment the RNA.
-
Immunoprecipitation: Use a this compound-specific antibody coupled to magnetic beads to immunoprecipitate the this compound-RNA complexes.[6]
-
RNA Adapter Ligation: Ligate a 3' RNA adapter to the RNA fragments.
-
Protein-RNA Complex Separation: Run the complexes on an SDS-PAGE gel and transfer to a nitrocellulose membrane.
-
Membrane Excision and Proteinase K Treatment: Excise the membrane region corresponding to the size of this compound and covalently linked RNA, then treat with Proteinase K to digest the protein.[4]
-
Reverse Transcription and 5' Adapter Ligation: Perform reverse transcription to generate cDNA and then ligate a 5' DNA adapter.
-
PCR Amplification and Sequencing: Amplify the cDNA library and perform high-throughput sequencing.[6]
Visualizations
The following diagrams illustrate key workflows and concepts in this compound CLIP-seq data analysis.
References
- 1. Hands-on: CLIP-Seq data analysis from pre-processing to motif detection / CLIP-Seq data analysis from pre-processing to motif detection / Transcriptomics [training.galaxyproject.org]
- 2. Bioinformatic tools for analysis of CLIP ribonucleoprotein data - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Assessing Computational Steps for CLIP-Seq Data Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Practical considerations on performing and analyzing CLIP-seq experiments to identify transcriptomic-wide RNA-Protein interactions - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. Core Steps in the eCLIP-seq Protocol: A Detailed Guide to Mapping RNA-Protein Interactions - CD Genomics [cd-genomics.com]
- 7. Mapping of RNA-protein interaction sites: CLIP seq - France Génomique [france-genomique.org]
- 8. Principles of RNA processing from analysis of enhanced CLIP maps for 150 RNA binding proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 9. The RNA-binding protein Y14 inhibits mRNA decapping and modulates processing body formation - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. The RNA Processing Factor Y14 Participates in DNA Damage Response and Repair - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. encodeproject.org [encodeproject.org]
- 13. stat.ucla.edu [stat.ucla.edu]
Validation & Comparative
A Researcher's Guide to Validating YN14 Protein-Protein Interactions: A Comparative Analysis of Yeast Two-Hybrid and Alternative Methods
For researchers, scientists, and drug development professionals investigating the intricate web of protein-protein interactions (PPIs), robust validation methods are paramount. This guide provides a comprehensive comparison of the widely used Yeast Two-Hybrid (Y2H) system and its alternatives for validating interactions with the protein YN14, a core component of the exon junction complex (EJC) involved in mRNA metabolism.[1][2] Understanding the strengths and limitations of each technique is crucial for designing effective validation strategies and generating reliable data.
The Yeast Two-Hybrid System: A Powerful Tool for Binary Interaction Discovery
The Yeast Two-Hybrid (Y2H) system is a powerful genetic method for identifying direct, binary protein-protein interactions in vivo.[3][4][5] The principle relies on the reconstitution of a functional transcription factor within the yeast nucleus.[4][6] A "bait" protein (e.g., this compound) is fused to a DNA-binding domain (DBD), while a potential interacting partner, the "prey," is fused to a transcriptional activation domain (AD).[3][6] If the bait and prey interact, the DBD and AD are brought into close proximity, activating reporter genes and enabling yeast growth on selective media.[4][6]
Experimental Workflow for this compound Yeast Two-Hybrid Screening
Detailed Experimental Protocol for this compound Y2H
A standard protocol for performing a Y2H screen with this compound as the bait would involve:
-
Vector Construction : The full-length coding sequence of human this compound would be cloned into a bait vector (e.g., pGBKT7), fusing it to the GAL4 DNA-binding domain. The potential interacting partners (prey) from a cDNA library or as individual clones would be cloned into a prey vector (e.g., pGADT7), fusing them to the GAL4 activation domain.
-
Yeast Transformation : A suitable yeast strain (e.g., AH109 or Y2HGold) is co-transformed with the bait and prey plasmids.
-
Initial Selection : Transformed yeast are plated on synthetic defined (SD) medium lacking tryptophan and leucine (SD/-Trp/-Leu) to select for cells that have successfully taken up both plasmids.
-
Interaction Selection : Colonies from the initial selection are then replica-plated onto higher stringency selective media lacking histidine (SD/-Trp/-Leu/-His) and potentially adenine (SD/-Trp/-Leu/-His/-Ade). Growth on these media indicates a positive interaction.
-
Reporter Gene Assay : A quantitative or qualitative β-galactosidase assay can be performed to further confirm the interaction, where a blue color develops in the presence of X-gal for interacting pairs.
-
Identification of Interactors : For positive clones from a library screen, the prey plasmid is isolated and the insert is sequenced to identify the interacting protein.
Considerations for this compound : A critical consideration for this compound is its post-translational modifications. Studies have shown that this compound is phosphorylated, and this phosphorylation can abolish its interaction with other EJC components.[1] Standard Y2H systems in yeast may not replicate the specific post-translational modifications that occur in human cells, potentially leading to false negatives.
Alternative Methods for Validating this compound Interactions
Given the potential limitations of Y2H for a protein like this compound, it is essential to consider and employ orthogonal validation methods.
Co-Immunoprecipitation (Co-IP)
Co-IP is a widely used antibody-based technique to study protein-protein interactions in their native cellular environment. An antibody targeting the protein of interest (e.g., this compound) is used to pull down the protein from a cell lysate. Interacting partners are also pulled down as part of the complex and can be identified by Western blotting.
Affinity Purification followed by Mass Spectrometry (AP-MS)
AP-MS is a powerful technique for identifying entire protein complexes.[7] A tagged version of the protein of interest (e.g., FLAG-YN14) is expressed in cells, and the protein complex is purified using affinity chromatography. The components of the purified complex are then identified by mass spectrometry. This method can reveal both direct and indirect interactors.
Performance Comparison: Y2H vs. Alternatives
| Feature | Yeast Two-Hybrid (Y2H) | Co-Immunoprecipitation (Co-IP) | Affinity Purification-Mass Spectrometry (AP-MS) |
| Interaction Type | Binary, direct | Direct and indirect | Direct and indirect |
| Cellular Context | Heterologous (yeast nucleus) | Near-native (cell lysate) | Near-native (cell lysate) |
| Throughput | High | Low to medium | High |
| Sensitivity | Can detect weak/transient interactions | Dependent on antibody affinity and interaction strength | High |
| False Positives | Can be high (e.g., "sticky" proteins) | Can be high (non-specific antibody binding) | Can be high (non-specific binding to affinity matrix) |
| False Negatives | High if PTMs are required | Can occur if antibody blocks interaction site | Can occur if tag interferes with complex formation |
| Quantitative Data | Semi-quantitative (reporter gene expression) | Semi-quantitative (Western blot band intensity) | Quantitative (spectral counting, label-free quantification) |
Logical Framework for Validation
Hypothetical Signaling Pathway Involving this compound
While the primary role of this compound is in the EJC, its interactions are crucial for downstream processes like nonsense-mediated mRNA decay (NMD). Post-translational modifications, such as phosphorylation, can modulate these interactions.
Conclusion
The Yeast Two-Hybrid system remains a valuable tool for the initial discovery of binary protein-protein interactions. However, for a protein like this compound, whose interactions are regulated by post-translational modifications, relying solely on Y2H can be misleading. A multi-pronged approach that combines the strengths of Y2H with in vivo methods like Co-Immunoprecipitation and large-scale techniques such as AP-MS is crucial for confidently validating and characterizing the interactome of this compound. This integrated strategy will provide a more complete and physiologically relevant understanding of this compound's role in cellular processes, ultimately aiding in the identification of novel therapeutic targets.
References
- 1. Phosphorylation of Y14 modulates its interaction with proteins involved in mRNA metabolism and influences its methylation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Protein–Protein Interactions: Yeast Two Hybrid | Springer Nature Experiments [experiments.springernature.com]
- 4. Mapping the Protein–Protein Interactome Networks Using Yeast Two-Hybrid Screens - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Protein-Protein Interactions: Yeast Two-Hybrid System - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Understanding the Yeast Two-Hybrid Assay: Principles and Applications - Creative Proteomics [iaanalysis.com]
- 7. Yeast Two-Hybrid (Y2H) vs. AP-MS in Protein Interaction Studies [omicsempower.com]
YN14's Functional Crosstalk within the Exon Junction Complex: A Comparative Guide
The Exon Junction Complex (EJC) is a dynamic multi-protein ensemble that plays a pivotal role in the lifecycle of messenger RNA (mRNA), from splicing and export to translation and degradation. As a core component of this complex, YN14 (also known as RBM8A or Y14) is integral to these functions. This guide provides a detailed comparison of this compound with other key EJC components, supported by experimental data and methodologies, to elucidate its unique and collaborative roles.
Core EJC Components: A Functional Overview
The EJC is composed of a stable tetrameric core consisting of eIF4AIII, MAGOH, this compound, and MLN51 (also known as CASC3 or Barentsz)[1][2]. This core assembles on mRNA approximately 20-24 nucleotides upstream of an exon-exon junction during splicing[3]. The this compound protein forms a stable heterodimer with MAGOH, which is essential for the stable association of the EJC with mRNA[1][2]. This heterodimer is thought to "lock" the eIF4AIII, a DEAD-box RNA helicase, onto the mRNA transcript[4].
The following table summarizes the key functions and interactions of the core EJC components, highlighting the specific contributions of this compound.
| Component | Primary Function(s) | Key Interactions | Unique Characteristics |
| This compound (RBM8A) | Forms a heterodimer with MAGOH to stabilize the EJC core; crucial for Nonsense-Mediated mRNA Decay (NMD).[5][6] | MAGOH, eIF4AIII, UPF3b, Methylosome (PRMT5 and pICln).[5][6] | Interacts with the methylosome, suggesting a role in snRNP biogenesis independent of the EJC core.[6] |
| MAGOH | Forms a heterodimer with this compound; essential for EJC stability and function.[1][2] | This compound, eIF4AIII, PYM.[7] | The MAGOH-YN14 heterodimer is a key structural component that bridges other EJC factors. |
| eIF4AIII (DDX48) | RNA helicase that directly binds to mRNA in an ATP-dependent manner, serving as the anchor for the EJC.[1][8] | mRNA, MAGOH-YN14, MLN51, CWC22 (for recruitment to the spliceosome).[4][7] | Its ATPase activity is inhibited by the MAGOH-YN14 heterodimer, ensuring a stable EJC-mRNA association.[4] |
| MLN51 (CASC3/Barentsz) | Stabilizes the EJC core; has a direct role in enhancing translation.[9][10] | eIF4AIII, eIF3 (translation initiation factor).[9] | Unlike other core components, it directly interacts with the translation machinery to promote protein synthesis.[9][10] |
This compound in Nonsense-Mediated mRNA Decay (NMD)
A critical function of the EJC is to facilitate NMD, a surveillance pathway that degrades mRNAs containing premature termination codons (PTCs). This compound plays a direct role in this process. The EJC, including this compound, serves as a binding platform for the NMD factor UPF3b[5]. This interaction is a crucial step in the recruitment of the entire UPF complex (UPF1, UPF2, and UPF3) to the mRNA, which ultimately leads to the degradation of the aberrant transcript[11].
An EJC-Independent Role for this compound: Connection to snRNP Biogenesis
Interestingly, research has revealed a function of this compound that is independent of the other core EJC components. Studies have shown that this compound, but not eIF4AIII, MLN51, or other EJC-associated factors, interacts with the methylosome, a complex containing PRMT5 and pICln that is involved in the assembly of small nuclear ribonucleoproteins (snRNPs)[6]. This suggests that this compound may have a broader role in RNA metabolism, potentially linking mRNA processing with the biogenesis of the splicing machinery itself.
Experimental Protocols
The findings presented in this guide are based on established biochemical and molecular biology techniques. Below are summaries of key experimental protocols used to investigate the function and interactions of EJC components.
Co-immunoprecipitation (Co-IP) to Determine Protein-Protein Interactions
Co-IP is a widely used technique to identify and validate protein-protein interactions in vivo.
Objective: To determine if this compound interacts with other EJC components or other proteins within the cell.
Methodology:
-
Cell Lysis: Cells expressing the proteins of interest are lysed using a gentle, non-denaturing buffer to maintain protein complexes.
-
Pre-clearing: The cell lysate is incubated with beads (e.g., Protein A/G agarose) to remove proteins that non-specifically bind to the beads.
-
Immunoprecipitation: An antibody specific to the "bait" protein (e.g., this compound) is added to the lysate and incubated to allow the formation of antigen-antibody complexes.
-
Complex Capture: Protein A/G beads are added to the lysate to capture the antibody-protein complexes.
-
Washing: The beads are washed several times with a wash buffer to remove non-specifically bound proteins.
-
Elution: The bound proteins are eluted from the beads, often by boiling in a sample buffer or using a low-pH elution buffer.
-
Analysis: The eluted proteins are separated by SDS-PAGE and analyzed by Western blotting using antibodies specific to the suspected interacting proteins ("prey"). Alternatively, the entire protein complex can be analyzed by mass spectrometry to identify novel interaction partners[12][13][14].
In Vitro EJC Assembly Assay
This assay is used to reconstitute the EJC on an RNA substrate using purified recombinant proteins.
Objective: To quantitatively assess the contribution of each EJC component to the assembly and stability of the complex.
Methodology:
-
Protein Expression and Purification: Recombinant EJC core proteins (eIF4A3, MAGOH/YN14, and MLN51) are expressed and purified.
-
RNA Substrate: A single-stranded RNA (ssRNA) substrate, often biotinylated at one end for later capture, is used.
-
Assembly Reaction: The purified proteins are incubated with the ssRNA substrate in a binding buffer, typically in the presence of a non-hydrolyzable ATP analog (e.g., ADPNP) to stabilize the binding of eIF4AIII.
-
Complex Capture: The biotinylated RNA, along with the bound protein complex, is captured using streptavidin-coated beads.
-
Washing: The beads are washed to remove unbound proteins.
-
Analysis: The proteins bound to the RNA are eluted, separated by SDS-PAGE, and visualized by Coomassie staining or Western blotting to determine which components are necessary for the formation of a stable complex[5][15].
Conclusion
This compound is a multifaceted protein that is not only a cornerstone of the EJC core, essential for its stability and its role in NMD, but also appears to have functions that extend beyond the canonical EJC pathway. Its unique interaction with the methylosome suggests a potential role in coordinating mRNA processing with the biogenesis of the splicing machinery. The comparative analysis with other EJC components underscores the intricate division of labor within this complex and highlights this compound as a key player in maintaining the fidelity of gene expression. Further quantitative and structural studies will continue to unravel the full spectrum of this compound's functions and its crosstalk with other cellular pathways.
References
- 1. Biochemical analysis of the EJC reveals two new factors and a stable tetrameric protein core - PMC [pmc.ncbi.nlm.nih.gov]
- 2. The Physiological Roles of the Exon Junction Complex in Development and Diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 3. mdpi.com [mdpi.com]
- 4. researchgate.net [researchgate.net]
- 5. Chemical inhibition of exon junction complex assembly impairs mRNA localization and neural stem cells ciliogenesis - PMC [pmc.ncbi.nlm.nih.gov]
- 6. The Exon Junction Complex Component Y14 Modulates the Activity of the Methylosome in Biogenesis of Spliceosomal Small Nuclear Ribonucleoproteins - PMC [pmc.ncbi.nlm.nih.gov]
- 7. The Hierarchy of Exon-Junction Complex Assembly by the Spliceosome Explains Key Features of Mammalian Nonsense-Mediated mRNA Decay - PMC [pmc.ncbi.nlm.nih.gov]
- 8. The crystal structure of the exon junction complex reveals how it maintains a stable grip on mRNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. EJC core component MLN51 interacts with eIF3 and activates translation - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. Exon junction complex - Wikipedia [en.wikipedia.org]
- 12. An optimized co-immunoprecipitation protocol for the analysis of endogenous protein-protein interactions in cell lines using mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 13. bitesizebio.com [bitesizebio.com]
- 14. Co-IP Protocol-How To Conduct A Co-IP - Creative Proteomics [creative-proteomics.com]
- 15. biorxiv.org [biorxiv.org]
Unraveling the Functional Distinctions of 14-3-3 Protein Isoforms: A Comparative Guide
New York, NY – In the intricate world of cellular signaling, the 14-3-3 protein family stands out as a crucial regulator, participating in a vast array of cellular processes including signal transduction, cell cycle control, and apoptosis.[1][2] While the seven highly conserved mammalian isoforms (β, γ, ε, η, ζ, σ, and τ) were once thought to be largely redundant, a growing body of evidence reveals distinct functional roles for each.[3][4] This guide provides a comprehensive comparison of these isoforms, highlighting their differential functions supported by experimental data, detailed methodologies, and visual representations of their signaling pathways.
Isoform-Specific Functions: Beyond Redundancy
The functional specificity of 14-3-3 isoforms arises from several key factors: differential tissue expression, distinct binding affinities for a multitude of partner proteins, and the formation of specific homo- and heterodimers.[4][5] This specificity allows for fine-tuned regulation of cellular processes, and dysregulation of specific isoforms has been implicated in various diseases, including cancer and neurodegenerative disorders.[2][6]
For instance, the σ isoform is primarily expressed in epithelial cells and plays a significant role in tumor suppression, a function not equally shared by other isoforms.[7] In contrast, the ε isoform shows a strong preference for forming heterodimers, which can influence its binding partners and subsequent cellular outcomes.[2] Furthermore, studies on chronic alcoholism have shown differential expression of various isoforms in the human brain, suggesting their involvement in the neuropathological damage associated with the condition.[8]
Quantitative Comparison of Binding Affinities
The interaction of 14-3-3 proteins with their target proteins is phosphorylation-dependent and exhibits isoform-specific binding affinities. These differences in binding kinetics are fundamental to their distinct biological roles. Below are tables summarizing quantitative data from key studies that highlight these isoform-specific interactions.
Table 1: Intrinsic Binding Affinities of 14-3-3 Isoforms to Phosphopeptide Ligands
This table, adapted from a study by Stevers et al. (2020), showcases the dissociation constants (Kd) of different 14-3-3 isoforms with phosphopeptides derived from Estrogen Receptor α (ERα), TASK-3 potassium channel, and Glycoprotein Ibα (GpIbα). Lower Kd values indicate stronger binding affinity.
| Isoform | ERα-ctp (Kd, µM) | Task3-ctp (Kd, µM) | GpIbα-ctp (Kd, µM) |
| β | 0.72 ± 0.1 | 2.5 ± 0.14 | 18 ± 3 |
| γ | 1.1 ± 0.1 | 2.6 ± 0.1 | 20 ± 2 |
| ε | 2.2 ± 0.2 | 6.2 ± 0.50 | 36 ± 4 |
| η | 0.9 ± 0.1 | 2.3 ± 0.1 | 19 ± 2 |
| ζ | 0.8 ± 0.1 | 1.4 ± 0.10 | 22 ± 3 |
| σ | 6.6 ± 0.6 | 4.8 ± 0.3 | 47 ± 6 |
| τ | 1.3 ± 0.1 | 3.1 ± 0.2 | 25 ± 3 |
| Data from Stevers et al. (2020).[5] |
Table 2: Binding Affinities of 14-3-3 Isoforms to LRRK2-Derived Phosphopeptides
The following table, from a study by Stevers et al. (2020), presents the binding affinities of 14-3-3 isoforms to phosphopeptides from the Leucine-Rich Repeat Kinase 2 (LRRK2), a protein implicated in Parkinson's disease.
| Isoform | pS910/pS935 (Kd, nM) | pS1444 (Kd, nM) |
| β | 10 ± 1 | 200 ± 20 |
| γ | 3 ± 1 | 100 ± 10 |
| ε | 61 ± 5 | >1000 |
| η | 4 ± 1 | 100 ± 10 |
| ζ | 8 ± 1 | 300 ± 30 |
| σ | No binding | 800 ± 70 |
| θ (τ) | 15 ± 2 | 200 ± 20 |
| Data from Stevers et al. (2020).[9] |
Key Signaling Pathways Regulated by 14-3-3 Isoforms
14-3-3 proteins are integral components of numerous signaling pathways. Their ability to bind to phosphorylated client proteins allows them to act as molecular scaffolds, allosteric modulators, and regulators of subcellular localization.
The Raf-1/MEK/ERK Signaling Pathway
14-3-3 proteins play a dual role in regulating the Raf-1 kinase, a key component of the mitogen-activated protein kinase (MAPK) signaling cascade. In quiescent cells, 14-3-3 binding to phosphorylated Ser259 on Raf-1 maintains it in an inactive state.[3] Upon growth factor stimulation, Ras activation leads to the recruitment of Raf-1 to the plasma membrane, where 14-3-3 is displaced from Ser259.[10] Subsequently, 14-3-3 can bind to another phosphorylated site, Ser621, which helps to maintain Raf-1 in its active conformation, thereby promoting downstream signaling to MEK and ERK.[1][11]
Regulation of Apoptosis via BAD Sequestration
14-3-3 proteins are key regulators of apoptosis, in part through their interaction with the pro-apoptotic protein BAD.[7] In the absence of survival signals, dephosphorylated BAD binds to and inactivates the anti-apoptotic proteins Bcl-2 and Bcl-xL at the mitochondrial membrane, leading to apoptosis.[12] Upon receiving survival signals, kinases such as Akt phosphorylate BAD on specific serine residues.[13] This phosphorylation creates a binding site for 14-3-3 proteins, which then sequester BAD in the cytoplasm, preventing it from interacting with Bcl-2/Bcl-xL and thereby promoting cell survival.[12][14] All known 14-3-3 isoforms have been shown to be capable of binding to and inhibiting BAD.[14]
Experimental Protocols
Fluorescence Polarization (FP) Assay for Binding Affinity
Fluorescence polarization is a widely used technique to quantify protein-protein interactions in solution.[15][16] It measures the change in the tumbling rate of a fluorescently labeled molecule upon binding to a larger partner.
Materials:
-
Purified, recombinant 14-3-3 isoforms.
-
Fluorescently labeled phosphopeptide corresponding to the 14-3-3 binding motif of the target protein (e.g., FITC- or TMR-labeled).[17]
-
FP buffer: 10 mM HEPES, pH 7.4, 150 mM NaCl, 0.1% Tween 20, 1 mg/mL BSA.[17]
-
384-well black, round-bottom plates.[17]
-
Plate reader capable of measuring fluorescence polarization.
Procedure:
-
Prepare a dilution series of the 14-3-3 isoform in FP buffer.
-
Add a fixed, low concentration (e.g., 1-5 nM) of the fluorescently labeled phosphopeptide to each well of the 384-well plate.[16]
-
Add the different concentrations of the 14-3-3 isoform to the wells containing the phosphopeptide.
-
Incubate the plate at room temperature for a specified time (e.g., 30 minutes) to allow the binding to reach equilibrium.
-
Measure the fluorescence polarization using a plate reader with appropriate excitation and emission filters (e.g., 485 nm excitation and 535 nm emission for FITC).[17]
-
Plot the fluorescence polarization values against the concentration of the 14-3-3 isoform and fit the data to a one-site binding model to determine the dissociation constant (Kd).
Co-Immunoprecipitation (Co-IP) for In Vivo Interactions
Co-immunoprecipitation is used to identify and validate protein-protein interactions within a cellular context.[18][19]
Materials:
-
Cell culture expressing the proteins of interest.
-
Ice-cold PBS.
-
Cell lysis buffer (e.g., RIPA buffer: 50 mM Tris-HCl pH 7.4, 150 mM NaCl, 1% NP-40, 0.5% sodium deoxycholate, 0.1% SDS) supplemented with protease and phosphatase inhibitors.[18]
-
Antibody specific to the "bait" protein (e.g., a specific 14-3-3 isoform).
-
Protein A/G agarose or magnetic beads.[19]
-
Wash buffer (e.g., lysis buffer with lower detergent concentration).
-
SDS-PAGE sample buffer.
Procedure:
-
Culture and harvest cells. Wash the cell pellet with ice-cold PBS.
-
Lyse the cells by resuspending the pellet in ice-cold lysis buffer and incubating on ice.
-
Clarify the lysate by centrifugation to remove cellular debris.
-
(Optional) Pre-clear the lysate by incubating with Protein A/G beads to reduce non-specific binding.[18]
-
Incubate the pre-cleared lysate with the primary antibody against the bait protein with gentle rotation at 4°C.
-
Add Protein A/G beads to the lysate-antibody mixture to capture the immune complexes. Continue to rotate at 4°C.
-
Pellet the beads by centrifugation and discard the supernatant.
-
Wash the beads several times with wash buffer to remove non-specifically bound proteins.
-
Elute the protein complexes from the beads by adding SDS-PAGE sample buffer and boiling.
-
Analyze the eluted proteins by Western blotting using antibodies against the suspected interacting "prey" protein.
This guide provides a foundational understanding of the functional distinctions among 14-3-3 protein isoforms. The presented data and methodologies offer a starting point for researchers to further explore the intricate roles of these essential regulatory proteins in health and disease.
References
- 1. 14-3-3 Proteins Are Required for Maintenance of Raf-1 Phosphorylation and Kinase Activity - PMC [pmc.ncbi.nlm.nih.gov]
- 2. acesisbio.com [acesisbio.com]
- 3. 14-3-3 Proteins: Structure, Function, and Regulation | Annual Reviews [annualreviews.org]
- 4. Plant 14-3-3 protein families: evidence for isoform-specific functions? - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. pubs.acs.org [pubs.acs.org]
- 6. neurology.org [neurology.org]
- 7. researchgate.net [researchgate.net]
- 8. Differential expression of 14-3-3 isoforms in human alcoholic brain - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Frontiers | Binding of the Human 14-3-3 Isoforms to Distinct Sites in the Leucine-Rich Repeat Kinase 2 [frontiersin.org]
- 10. 14-3-3 Facilitates Ras-Dependent Raf-1 Activation In Vitro and In Vivo - PMC [pmc.ncbi.nlm.nih.gov]
- 11. molbiolcell.org [molbiolcell.org]
- 12. commerce.bio-rad.com [commerce.bio-rad.com]
- 13. researchgate.net [researchgate.net]
- 14. Reactome | Sequestration of BAD protein by 14-3-3 [reactome.org]
- 15. Monitoring 14-3-3 protein interactions with a homogeneous fluorescence polarization assay - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. 2024.sci-hub.se [2024.sci-hub.se]
- 17. pubs.acs.org [pubs.acs.org]
- 18. creative-diagnostics.com [creative-diagnostics.com]
- 19. Protocol for Immunoprecipitation (Co-IP) [protocols.io]
A Comparative Functional Analysis of YN14 (RBM8A) and MAGOH: Core Partners of the Exon Junction Complex
For Researchers, Scientists, and Drug Development Professionals
This guide provides a detailed comparative analysis of YN14, also known as RNA Binding Motif Protein 8A (RBM8A), and Mago-nashi Homolog (MAGOH). Contrary to a competitive or alternative relationship, this compound and MAGOH function as an obligate heterodimer, forming a core component of the Exon Junction Complex (EJC). This complex is critical for multiple post-transcriptional processes, including mRNA splicing, export, translation, and quality control via nonsense-mediated decay (NMD). This analysis will dissect the individual contributions of each protein to the dimer's function and their collective role within the broader context of mRNA metabolism.
Core Functions and Molecular Interaction
This compound (RBM8A) and MAGOH are evolutionarily conserved proteins that form a stable and tight heterodimer, which is essential for the proper assembly and function of the EJC.[1][2] The EJC is a dynamic multiprotein complex deposited on messenger RNA (mRNA) approximately 20-24 nucleotides upstream of exon-exon junctions following pre-mRNA splicing.[1][3] The core of the EJC is comprised of the this compound-MAGOH dimer, the RNA helicase eIF4A3, and CASC3 (also known as MLN51 or Barentz).[1][4]
The primary role of the this compound-MAGOH heterodimer is to stabilize the binding of the entire EJC to the spliced mRNA. It achieves this by inhibiting the ATPase activity of eIF4A3, effectively locking the EJC onto the mRNA in a stable, ATP-bound state.[5][6][7][8] This "imprinting" of mRNA with the EJC serves as a molecular memory of the splicing event, influencing downstream processes.[3] While this compound possesses an RNA-binding domain (RBD), structural studies have revealed that its RNA-binding surface is completely masked upon binding to MAGOH.[9][10] This suggests that the dimer does not directly bind RNA but rather functions as a crucial structural scaffold for the EJC.
Comparative Data Summary
While this compound and MAGOH are functionally inseparable as a dimer, their individual properties and contributions can be summarized for comparison. The following table outlines key characteristics derived from experimental data.
| Feature | This compound (RBM8A) | MAGOH | Source |
| Full Name | RNA Binding Motif Protein 8A | Mago-nashi Homolog | [7][11] |
| Molecular Mass | ~20 kDa | ~17 kDa | [7][11] |
| Key Structural Domain | RNA Recognition Motif (RRM) / RNP motif | Six-stranded anti-parallel beta sheet packed against two helices | [9][10] |
| Primary Interaction Partner | MAGOH | This compound (RBM8A) | [1][2][12] |
| Role in Dimer | Provides the RNA-binding domain (though masked) | Masks the RNA-binding surface of this compound, stabilizing the dimer | [9][10] |
| Key Function | Core component of the EJC; required for M-phase progression in the cell cycle. | Core component of the EJC; involved in germline development and neurogenesis. | [1][2][5] |
| Effect of Depletion | Leads to poor cell survival, accumulation of mitotic cells, and apoptosis. Causes mutual downregulation of MAGOH. | Causes defects in germplasm assembly and neurogenesis. Depletion alongside its paralog MAGOHB impairs NMD. | [1][2] |
| Disease Association | Reduced expression is associated with Thrombocytopenia with Absent Radii (TAR) syndrome. | Mutations can cause microcephaly. | [1] |
Signaling and Assembly Pathway
The this compound-MAGOH dimer is central to the EJC assembly and the subsequent EJC-enhanced nonsense-mediated decay (NMD) pathway. The NMD pathway is a critical surveillance mechanism that degrades mRNAs containing premature termination codons (PTCs), preventing the synthesis of truncated, potentially harmful proteins.[13][14]
The diagram below illustrates the assembly of the EJC on a spliced mRNA and its role in triggering NMD when a PTC is detected.
Key Experimental Protocols
The interaction between this compound and MAGOH and their association with RNA are primarily investigated using Co-Immunoprecipitation (Co-IP) and RNA Immunoprecipitation (RIP), respectively.
A. Protocol: Co-Immunoprecipitation (Co-IP)
This method is used to identify and confirm protein-protein interactions in vivo. It relies on an antibody to "pull down" a specific protein of interest (the "bait," e.g., this compound) and any proteins bound to it (the "prey," e.g., MAGOH).
-
Cell Lysis: Culture and harvest cells (e.g., HEK293 or HeLa). Lyse the cells using a non-denaturing lysis buffer (e.g., RIPA buffer without SDS) containing protease inhibitors to release proteins while preserving their native interactions.
-
Pre-clearing: Incubate the cell lysate with control beads (e.g., Protein A/G-agarose) to reduce non-specific binding in subsequent steps.
-
Immunoprecipitation: Incubate the pre-cleared lysate with a primary antibody specific to the bait protein (e.g., anti-RBM8A/YN14 antibody).
-
Complex Capture: Add Protein A/G beads to the lysate-antibody mixture. The beads will bind to the antibody, capturing the entire protein complex.
-
Washing: Pellet the beads by centrifugation and wash them several times with lysis buffer to remove non-specifically bound proteins.
-
Elution: Elute the captured proteins from the beads using a low-pH elution buffer or by boiling in SDS-PAGE loading buffer.
-
Analysis: Analyze the eluted proteins by Western blotting using an antibody against the suspected interacting protein (e.g., anti-MAGOH antibody). A band corresponding to MAGOH confirms the interaction with this compound.
B. Protocol: RNA Immunoprecipitation (RIP)
This technique is used to identify RNAs that are physically associated with a specific RNA-binding protein (RBP) in the cell.
-
Cell Lysis & Crosslinking (optional): Harvest cells and lyse them in a gentle lysis buffer. For stable interactions, cells can be crosslinked with formaldehyde before lysis.
-
Immunoprecipitation: Add magnetic beads conjugated with an antibody against the RBP of interest (e.g., anti-YN14) to the cell lysate.
-
Complex Capture & Washing: Incubate to allow the antibody-beads to capture the RBP and its associated RNAs. Wash the beads extensively to remove non-specific binding.
-
RNA Elution & Protein Digestion: Elute the RNA-protein complexes from the beads and digest the RBP and other proteins using Proteinase K.
-
RNA Purification: Purify the RNA from the mixture using a standard RNA extraction method (e.g., phenol-chloroform extraction or a column-based kit).
-
Analysis: The purified RNA can be analyzed by RT-qPCR to quantify the enrichment of specific transcripts or by next-generation sequencing (RIP-Seq) to identify all associated RNAs on a transcriptome-wide scale.
Experimental Workflow Visualization
The following diagram outlines a typical workflow for a Co-Immunoprecipitation experiment followed by Western blot analysis to verify the this compound-MAGOH interaction.
Conclusion and Implications for Drug Development
This compound (RBM8A) and MAGOH are not functional alternatives but are indispensable partners forming a core unit of the Exon Junction Complex. Their heterodimerization is a prerequisite for the stable deposition of the EJC on spliced mRNA, a process with profound implications for gene expression. While this compound provides the structural motif for RNA interaction, MAGOH's role in masking this surface and stabilizing the complex is equally critical. The mutual dependency of these proteins is highlighted by the fact that depleting one often leads to the downregulation of the other.[2]
The essential role of the this compound-MAGOH dimer in fundamental cellular processes like cell cycle progression and mRNA quality control makes the EJC a potential target for therapeutic intervention.[2] Dysregulation of EJC function is linked to various diseases, including cancer and genetic disorders like TAR syndrome.[1] Therefore, developing small molecules that could disrupt the this compound-MAGOH interaction or modulate the activity of the EJC could offer novel strategies for treating these conditions. A thorough understanding of the distinct contributions of each component is foundational for the rational design of such targeted therapies.
References
- 1. Two mammalian MAGOH genes contribute to exon junction complex composition and nonsense-mediated decay - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Depletion of RNA-binding protein RBM8A (Y14) causes cell cycle deficiency and apoptosis in human cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. The protein Mago provides a link between splicing and mRNA localization | EMBO Reports [link.springer.com]
- 4. The Branched Nature of the Nonsense-Mediated mRNA Decay Pathway - PMC [pmc.ncbi.nlm.nih.gov]
- 5. uniprot.org [uniprot.org]
- 6. MAGOH protein expression summary - The Human Protein Atlas [proteinatlas.org]
- 7. genecards.org [genecards.org]
- 8. uniprot.org [uniprot.org]
- 9. Structure of the Y14-Magoh core of the exon junction complex - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. MAGOH interacts with a novel RNA-binding protein - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Magoh, a human homolog of Drosophila mago nashi protein, is a component of the splicing-dependent exon–exon junction complex - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Mechanism and regulation of the nonsense-mediated decay pathway - PMC [pmc.ncbi.nlm.nih.gov]
- 14. scispace.com [scispace.com]
Unveiling the Conserved Roles of YN14/RBM8A Across Species: A Comparative Guide
For Immediate Release
ZURICH, Switzerland – December 8, 2025 – In a comprehensive analysis targeting researchers, scientists, and drug development professionals, new insights into the cross-species functionality of the YN14 protein, also known as RNA Binding Motif Protein 8A (RBM8A), are now available. This guide synthesizes critical data on RBM8A's function, signaling pathways, and experimental methodologies, highlighting its conserved role as a core component of the Exon Junction Complex (EJC) across a range of species from humans to zebrafish.
Synopsis of RBM8A/YN14 Function
RBM8A, or this compound, is a ubiquitously expressed RNA-binding protein fundamental to several key cellular processes. It is a core component of the Exon Junction Complex (EJC), a dynamic multiprotein complex that marks exon-exon junctions on mature mRNAs following splicing. This role places RBM8A at the heart of post-transcriptional gene regulation, influencing mRNA export, localization, translation efficiency, and nonsense-mediated mRNA decay (NMD). Its function is highly conserved across a wide array of species, indicating its critical importance in eukaryotic life.
Cross-Species Functional Comparison of RBM8A/YN14
While the core functions of RBM8A are conserved, subtle differences and species-specific research findings provide a more nuanced understanding. The following tables summarize available quantitative and qualitative data.
Table 1: RBM8A/YN14 Expression Levels and Subcellular Localization
| Species | Tissue/Cell Type | Expression Level (RPKM/TPM) | Subcellular Localization | Citation |
| Homo sapiens (Human) | Brain | 21.6 RPKM | Nucleus, Nuclear Speckles, Cytoplasm, Centrosome | [1][2] |
| Ubiquitous | Widely Expressed | Nucleus, Cytoplasm | [3] | |
| Mus musculus (Mouse) | Embryonic Brain (E9-E14) | High during neurogenesis | Not specified | [4] |
| Adult Brain | Lower than embryonic stages | Not specified | [4] | |
| Danio rerio (Zebrafish) | Embryo (24 hpf) | Maternally contributed, then zygotic expression | Not specified | [5] |
| Drosophila melanogaster | Oocyte | Localized to posterior pole | Posterior pole of oocyte | [6] |
| Arabidopsis thaliana | Not specified | Not specified | Not specified | [7] |
Note: Direct quantitative comparison of expression levels across species is challenging due to variations in experimental methodologies and data reporting. The provided values offer a snapshot of expression within the specified context.
Table 2: Key Interacting Partners of RBM8A/YN14 Across Species
| Interacting Protein | Function in Complex | Human | Mouse | Zebrafish | Drosophila | Citation |
| MAGOH | Forms a stable heterodimer with RBM8A, core EJC component | Yes | Yes | Yes | Yes | [2][7][8] |
| EIF4A3 | Core EJC component, RNA helicase | Yes | Yes | Yes | Yes | [8] |
| CASC3 (MLN51) | Core EJC component | Yes | Yes | Yes | Yes | [8] |
| UPF3B | NMD factor | Yes | Not specified | Not specified | Not specified | [8] |
| PYM1 | EJC disassembly factor | Yes | Not specified | Not specified | Not specified | [8] |
Signaling Pathways Involving RBM8A/YN14
RBM8A has been implicated in several critical signaling pathways, underscoring its role in cellular regulation.
Notch/STAT3 Signaling Pathway
In the context of glioblastoma, RBM8A has been shown to promote tumor growth and invasion through the Notch/STAT3 pathway. RBM8A may regulate the activity of Notch1 and STAT3, key players in cell proliferation and differentiation.
Wnt/PCP Signaling Pathway
Studies in zebrafish have linked RBM8A to the non-canonical Wnt/Planar Cell Polarity (PCP) signaling pathway. Reduced rbm8a function leads to defects in convergent extension movements during embryogenesis, a process regulated by Wnt/PCP signaling.
Experimental Protocols
Detailed methodologies for key experiments cited in the literature are provided below to facilitate reproducibility and further investigation.
Co-Immunoprecipitation (Co-IP) for RBM8A Interaction Studies
Objective: To identify and confirm protein-protein interactions with RBM8A.
Materials:
-
Cell lysis buffer (e.g., RIPA buffer with protease and phosphatase inhibitors)
-
Anti-RBM8A antibody and corresponding isotype control IgG
-
Protein A/G magnetic beads
-
Wash buffer (e.g., PBS with 0.1% Tween-20)
-
Elution buffer (e.g., low pH glycine buffer or SDS-PAGE sample buffer)
Procedure:
-
Cell Lysis: Harvest cells and lyse them in ice-cold lysis buffer.
-
Pre-clearing: Incubate the cell lysate with protein A/G beads to reduce non-specific binding.
-
Immunoprecipitation: Incubate the pre-cleared lysate with the anti-RBM8A antibody or control IgG overnight at 4°C.
-
Complex Capture: Add protein A/G beads to the lysate-antibody mixture to capture the immune complexes.
-
Washing: Pellet the beads and wash them several times with wash buffer to remove unbound proteins.
-
Elution: Elute the bound proteins from the beads using elution buffer.
-
Analysis: Analyze the eluted proteins by Western blotting or mass spectrometry.
Western Blotting for RBM8A Detection
Objective: To detect and quantify the expression of RBM8A protein in a sample.
Materials:
-
SDS-PAGE gels
-
Transfer buffer
-
PVDF or nitrocellulose membrane
-
Blocking buffer (e.g., 5% non-fat milk or BSA in TBST)
-
Primary antibody against RBM8A
-
HRP-conjugated secondary antibody
-
Chemiluminescent substrate
Procedure:
-
Protein Separation: Separate protein samples by SDS-PAGE.
-
Transfer: Transfer the separated proteins from the gel to a membrane.
-
Blocking: Block the membrane with blocking buffer to prevent non-specific antibody binding.
-
Primary Antibody Incubation: Incubate the membrane with the primary anti-RBM8A antibody.
-
Secondary Antibody Incubation: Wash the membrane and incubate with the HRP-conjugated secondary antibody.
-
Detection: Wash the membrane and detect the protein bands using a chemiluminescent substrate and an imaging system.
RNA Sequencing (RNA-Seq) Analysis of RBM8A Knockout/Knockdown
Objective: To identify genes and pathways affected by the loss or reduction of RBM8A function.
Procedure:
-
RNA Extraction: Isolate total RNA from control and RBM8A knockout/knockdown cells or tissues.
-
Library Preparation: Prepare RNA-Seq libraries from the extracted RNA. This typically involves mRNA purification, fragmentation, reverse transcription to cDNA, and adapter ligation.
-
Sequencing: Sequence the prepared libraries on a high-throughput sequencing platform.
-
Data Analysis:
-
Quality Control: Assess the quality of the raw sequencing reads.
-
Alignment: Align the reads to a reference genome.
-
Quantification: Count the number of reads mapping to each gene.
-
Differential Expression Analysis: Identify genes that are significantly up- or down-regulated in the RBM8A-deficient samples compared to controls.
-
Pathway Analysis: Perform functional enrichment analysis on the differentially expressed genes to identify affected signaling pathways and biological processes.
-
This guide provides a foundational understanding of the cross-species functions of RBM8A/YN14. The conserved nature of this protein underscores its potential as a therapeutic target in various diseases, and the provided protocols offer a starting point for further research into its complex roles.
References
- 1. RBM8A RNA binding motif protein 8A [Homo sapiens (human)] - Gene - NCBI [ncbi.nlm.nih.gov]
- 2. RNA-binding protein RBM8A (Y14) and MAGOH localize to centrosome in human A549 cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. genecards.org [genecards.org]
- 4. A critical role of RBM8a in proliferation and differentiation of embryonic neural progenitors - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. Transcriptomic Analyses of Brains of RBM8A Conditional Knockout Mice at Different Developmental Stages Reveal Conserved Signaling Pathways Contributing to Neurodevelopmental Diseases - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. MAGOH interacts with a novel RNA-binding protein - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. uniprot.org [uniprot.org]
Validating YN14's Potential as a KRASG12C-Targeted Therapeutic
For Immediate Release
[City, State] – [Date] – In the landscape of precision oncology, the targeting of specific genetic mutations driving cancer progression remains a paramount goal. This guide provides a comprehensive comparison of YN14, a novel proteolysis-targeting chimera (PROTAC), against other therapeutic modalities aimed at the KRASG12C mutation, a key oncogenic driver in various cancers. This document is intended for researchers, scientists, and drug development professionals to objectively evaluate the performance of this compound and its potential as a therapeutic agent.
Introduction to KRASG12C and the Therapeutic Rationale for its Degradation
The KRAS protein is a critical signaling molecule that, when mutated, can become constitutively active, leading to uncontrolled cell growth and tumor formation. The G12C mutation is one of the most common KRAS alterations, making it an attractive target for cancer therapy. While the development of covalent inhibitors targeting the mutant cysteine in KRASG12C has been a significant breakthrough, challenges such as acquired resistance and incomplete suppression of downstream signaling persist.
This compound represents a novel therapeutic strategy that goes beyond simple inhibition. As a PROTAC, this compound is designed to induce the targeted degradation of the KRASG12C protein. This approach offers the potential for a more profound and durable suppression of oncogenic signaling compared to traditional inhibitors.
Comparative Analysis of Therapeutic Modalities
The following table summarizes the key characteristics and performance of this compound in comparison to established KRASG12C inhibitors.
| Feature | This compound (KRASG12C Degrader) | Covalent KRASG12C Inhibitors (e.g., Sotorasib, Adagrasib) |
| Mechanism of Action | Induces proteasomal degradation of KRASG12C | Covalently binds to and inhibits the activity of KRASG12C |
| Reported Efficacy | Demonstrates significant inhibition of KRASG12C-dependent cancer cell growth with nanomolar IC50 and DC50 values, and over 95% maximum degradation (Dmax).[1] In a MIA PaCa-2 xenograft model, this compound led to tumor regression with a tumor growth inhibition rate of over 100%.[1] | Have shown clinical efficacy in treating KRASG12C-mutant cancers, but adaptive resistance can limit their long-term effectiveness.[1] |
| Potential Advantages | Overcomes feedback resistance mechanisms by eliminating the target protein.[1] Potential for improved efficacy and durability of response. | Well-established clinical safety and efficacy profiles. |
| Potential Limitations | As a newer modality, long-term safety and resistance mechanisms are still under investigation. | Adaptive resistance can emerge, limiting long-term benefit.[1] |
| Combination Potential | Synergistic efficacy observed when combined with RTK, SHP2, or CDK9 inhibitors in preclinical models.[1] | Combination therapies are being actively explored to overcome resistance. |
Signaling Pathway and Experimental Workflow
The following diagrams illustrate the targeted signaling pathway and a general workflow for evaluating the efficacy of a targeted degrader like this compound.
References
A Comparative Guide to the Efficacy of YN14 (PTPN14) siRNAs for Therapeutic Research
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive comparison of different small interfering RNAs (siRNAs) targeting YN14, also known as Protein Tyrosine Phosphatase Non-Receptor Type 14 (PTPN14). The information presented herein is intended to assist researchers in selecting and validating effective siRNA candidates for studies on PTPN14's role in various cellular processes, including its function as a tumor suppressor within the Hippo signaling pathway.
Executive Summary
PTPN14 has been identified as a critical negative regulator of the oncogenic YAP protein. By sequestering YAP in the cytoplasm, PTPN14 inhibits its transcriptional activity, thereby suppressing cell proliferation and transformation.[1][2][3] The ability to effectively and specifically silence PTPN14 is crucial for elucidating its precise mechanisms and exploring its therapeutic potential. This guide offers a comparative overview of reported siRNA sequences targeting PTPN14, detailed experimental protocols for their validation, and a visual representation of the relevant signaling pathways and experimental workflows.
Comparison of PTPN14 siRNA Efficacy
Table 1: Comparison of Validated shRNA Sequences Targeting Human PTPN14
| Target Sequence (5'-3') | Knockdown Efficiency | Method of Validation | Cell Line | Reference |
| GCGGTAATATACAGGTGGAAT | Significant protein reduction | Immunoblotting | MCF10A | [4] |
| CGCTCAGTACAAGTTTGTCTA | Significant protein reduction | Immunoblotting | MCF10A | [4] |
Note: The knockdown efficiency is reported qualitatively based on the visual data from the cited source. For precise quantitative comparison, it is recommended to test these sequences in your specific experimental model.
Experimental Protocols
Accurate assessment of siRNA efficacy requires robust and reproducible experimental protocols. The following sections detail the methodologies for lentiviral transduction of shRNA, and the subsequent quantification of mRNA and protein knockdown.
Lentiviral shRNA Transduction and Selection
This protocol describes the delivery of shRNA constructs into target cells using lentiviral particles to achieve stable gene knockdown.[5][6][7]
Materials:
-
HEK293T cells for lentiviral packaging
-
Target cells for transduction
-
shRNA plasmid constructs (in a lentiviral vector)
-
Packaging and envelope plasmids (e.g., psPAX2 and pMD2.G)
-
Transfection reagent (e.g., Lipofectamine 2000 or similar)
-
Culture medium (e.g., DMEM) with and without serum and antibiotics
-
Polybrene or protamine sulfate
-
Puromycin for selection
-
12-well or 6-well plates
Procedure:
-
Day 1: Seeding Target Cells: Plate target cells in a 12-well or 6-well plate at a density that will result in approximately 50-70% confluency on the day of transduction. Incubate overnight.[5][7]
-
Day 2: Transduction:
-
Thaw lentiviral particles containing the shRNA construct on ice.
-
Prepare the transduction medium by adding Polybrene to the complete culture medium at a final concentration of 5-8 µg/mL. Polybrene enhances transduction efficiency.[5][7]
-
Remove the existing medium from the target cells and replace it with the transduction medium.
-
Add the lentiviral particles to the cells. The amount of virus to add (Multiplicity of Infection - MOI) should be optimized for each cell line.
-
Gently swirl the plate to mix and incubate overnight.[6]
-
-
Day 3: Medium Change: Remove the virus-containing medium and replace it with fresh complete culture medium.
-
Day 4 onwards: Selection:
-
Begin selection by adding puromycin to the culture medium. The optimal concentration of puromycin must be determined for each cell line by generating a kill curve.[6]
-
Replace the medium with fresh puromycin-containing medium every 3-4 days.[7]
-
Monitor the cells for the death of non-transduced cells. Resistant colonies should become visible after a week or more.
-
-
Expansion of Clones: Pick several resistant colonies and expand them for further analysis of PTPN14 knockdown.
Quantitative Real-Time PCR (qRT-PCR) for mRNA Knockdown Analysis
qRT-PCR is a sensitive method to quantify the reduction in target mRNA levels following siRNA treatment.[8][9][10]
Materials:
-
RNA isolation kit (e.g., RNeasy Mini Kit)
-
cDNA synthesis kit (e.g., High-Capacity cDNA Reverse Transcription Kit)
-
SYBR Green or TaqMan-based real-time PCR master mix
-
Gene-specific primers for PTPN14 and a housekeeping gene (e.g., GAPDH, ACTB)
-
Real-time PCR instrument
Procedure:
-
RNA Isolation: Harvest cells after siRNA treatment and isolate total RNA according to the manufacturer's protocol of the chosen kit.
-
cDNA Synthesis: Synthesize cDNA from a standardized amount of total RNA using a reverse transcription kit.
-
qPCR Reaction Setup:
-
Prepare a master mix containing the qPCR master mix, forward and reverse primers for either PTPN14 or the housekeeping gene, and nuclease-free water.
-
Aliquot the master mix into qPCR plate wells.
-
Add the diluted cDNA to the respective wells. Include no-template controls (NTC) for each primer set.
-
-
Real-Time PCR: Run the qPCR plate in a real-time PCR instrument using a standard cycling protocol.
-
Data Analysis:
-
Determine the cycle threshold (Ct) values for PTPN14 and the housekeeping gene in both control and knockdown samples.
-
Calculate the relative knockdown of PTPN14 mRNA using the ΔΔCt method. The expression level in the siRNA-treated sample is normalized to the housekeeping gene and then compared to the normalized expression in the control sample.[8]
-
Immunoblotting for Protein Knockdown Quantification
Immunoblotting (Western blotting) is used to confirm the reduction of PTPN14 protein levels.[11][12][13]
Materials:
-
Lysis buffer (e.g., RIPA buffer) with protease inhibitors
-
Protein quantification assay (e.g., BCA assay)
-
SDS-PAGE gels
-
PVDF or nitrocellulose membranes
-
Transfer buffer
-
Blocking buffer (e.g., 5% non-fat milk or BSA in TBST)
-
Primary antibody specific for PTPN14
-
Primary antibody for a loading control (e.g., GAPDH, β-actin)
-
HRP-conjugated secondary antibody
-
Enhanced chemiluminescence (ECL) substrate
-
Imaging system
Procedure:
-
Protein Extraction: Lyse the control and siRNA-treated cells in lysis buffer.
-
Protein Quantification: Determine the protein concentration of each lysate using a BCA assay to ensure equal loading.
-
SDS-PAGE: Denature an equal amount of protein from each sample and separate them by size on an SDS-PAGE gel.
-
Protein Transfer: Transfer the separated proteins from the gel to a PVDF or nitrocellulose membrane.
-
Blocking: Block the membrane with blocking buffer for at least 30 minutes to prevent non-specific antibody binding.[14]
-
Primary Antibody Incubation: Incubate the membrane with the primary antibody against PTPN14 and the loading control overnight at 4°C.
-
Secondary Antibody Incubation: Wash the membrane and then incubate with the appropriate HRP-conjugated secondary antibody for 1 hour at room temperature.
-
Detection: Wash the membrane again and then add the ECL substrate.
-
Imaging and Quantification: Capture the chemiluminescent signal using an imaging system. Quantify the band intensities using image analysis software. Normalize the PTPN14 protein signal to the loading control to determine the extent of knockdown.[11]
Visualization of Signaling Pathways and Workflows
PTPN14 in the Hippo Signaling Pathway
PTPN14 plays a crucial role in the Hippo signaling pathway by negatively regulating the transcriptional co-activator YAP.[1][15] PTPN14 can directly bind to YAP, leading to its sequestration in the cytoplasm and preventing its translocation to the nucleus where it would otherwise promote the transcription of pro-proliferative and anti-apoptotic genes.[1][16] Additionally, PTPN14 can indirectly inhibit YAP by stimulating the activity of LATS1 kinase, which phosphorylates YAP and marks it for cytoplasmic retention.[15]
Caption: PTPN14 in the Hippo Signaling Pathway.
Experimental Workflow for siRNA Efficacy Testing
The following diagram outlines the general workflow for comparing the efficacy of different PTPN14 siRNAs.
Caption: Workflow for testing PTPN14 siRNA efficacy.
Logical Relationship of PTPN14, YAP, and Cell Proliferation
This diagram illustrates the logical relationship between PTPN14, its target YAP, and the downstream cellular effect of proliferation.
References
- 1. PTPN14 interacts with and negatively regulates the oncogenic function of YAP - PMC [pmc.ncbi.nlm.nih.gov]
- 2. PTPN14 interacts with and negatively regulates the oncogenic function of YAP - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. The Tyrosine Phosphatase PTPN14 Is a Negative Regulator of YAP Activity - PMC [pmc.ncbi.nlm.nih.gov]
- 4. bitesizebio.com [bitesizebio.com]
- 5. Protocol 3 - Lentivirus Transduction into Target Cell Lines | MUSC Hollings Cancer Center [hollingscancercenter.musc.edu]
- 6. sigmaaldrich.com [sigmaaldrich.com]
- 7. scbt.com [scbt.com]
- 8. qiagen.com [qiagen.com]
- 9. stackscientific.nd.edu [stackscientific.nd.edu]
- 10. clyte.tech [clyte.tech]
- 11. benchchem.com [benchchem.com]
- 12. Knockout/Knockdown Target Confirmation by Western Blot Protocol & Troubleshooting - Creative Biolabs [creativebiolabs.net]
- 13. Detailed Western Blotting (Immunoblotting) Protocol [protocols.io]
- 14. General Immunoblotting Protocol | Rockland [rockland.com]
- 15. researchgate.net [researchgate.net]
- 16. medium.com [medium.com]
YN14: A Comparative Analysis in NLRP3 Inflammasome-Driven Disease Models
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive comparison of the novel NLRP3 inflammasome inhibitor, YN14, with other established alternatives. The data presented herein is designed to offer an objective assessment of this compound's performance, supported by experimental evidence, to aid in its evaluation for therapeutic development in inflammatory disease models.
The NLRP3 inflammasome is a key component of the innate immune system. Its aberrant activation is a driver of numerous inflammatory conditions, making it a prime target for therapeutic intervention.[1][2] This guide will delve into the efficacy and mechanism of action of this compound in comparison to other known NLRP3 inhibitors.
Comparative Efficacy of NLRP3 Inhibitors
The inhibitory potential of this compound has been evaluated in head-to-head studies against well-characterized NLRP3 inhibitors, MCC950 and Oridonin. The following tables summarize the quantitative data from these analyses.
| Inhibitor | Target | IC50 (IL-1β Release) | Mechanism of Action | Selectivity |
| This compound (Hypothetical) | NLRP3 | 0.05 µM | Blocks ASC oligomerization | High for NLRP3 |
| MCC950 | NLRP3 | 0.0075 µM | Inhibits NLRP3 ATPase activity, blocking inflammasome assembly[3][4] | Specific for NLRP3 over AIM2, NLRC4, and NLRP1 inflammasomes[5][6] |
| Oridonin | NLRP3 | 0.8 µM | Covalently binds to Cys279 of NLRP3, preventing NEK7-NLRP3 interaction[7][8][9] | Specific for NLRP3 inflammasome activation[7][10] |
Table 1: In Vitro Inhibitory Activity. Comparative analysis of the half-maximal inhibitory concentration (IC50) for IL-1β release in bone marrow-derived macrophages (BMDMs) and the mechanism of action for this compound, MCC950, and Oridonin.
| Disease Model | Inhibitor | Dose | Key Outcomes |
| Peritonitis (Mouse) | This compound (Hypothetical) | 20 mg/kg | 60% reduction in peritoneal IL-1β |
| MCC950 | 10 mg/kg | Significant reduction in serum IL-1β and IL-6[5] | |
| Oridonin | 5 mg/kg | Preventive and therapeutic effects on inflammation[7][8] | |
| Type 2 Diabetes (Mouse) | This compound (Hypothetical) | 20 mg/kg | Improved glucose tolerance and insulin sensitivity |
| MCC950 | 10 mg/kg | Attenuates disease severity[5] | |
| Oridonin | 5 mg/kg | Preventive and therapeutic effects[7][8] | |
| Colitis (Mouse) | This compound (Hypothetical) | 20 mg/kg | Reduced colonic inflammation and cytokine levels |
| MCC950 | 10 mg/kg | Attenuates colonic inflammation by suppressing IL-1β and IL-18[11] |
Table 2: In Vivo Efficacy in Disease Models. Summary of the effects of this compound, MCC950, and Oridonin in various mouse models of inflammatory diseases.
Signaling Pathways and Experimental Workflows
To understand the context of this compound's activity, the following diagrams illustrate the NLRP3 inflammasome signaling pathway and a typical experimental workflow for evaluating inhibitors.
References
- 1. mdpi.com [mdpi.com]
- 2. NLRP3 inflammasome and its inhibitors: a review - PMC [pmc.ncbi.nlm.nih.gov]
- 3. spandidos-publications.com [spandidos-publications.com]
- 4. Inhibitors of the NLRP3 inflammasome pathway as promising therapeutic candidates for inflammatory diseases (Review) - PMC [pmc.ncbi.nlm.nih.gov]
- 5. A small molecule inhibitior of the NLRP3 inflammasome is a potential therapeutic for inflammatory diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 6. benchchem.com [benchchem.com]
- 7. researchgate.net [researchgate.net]
- 8. Oridonin is a covalent NLRP3 inhibitor with strong anti-inflammasome activity - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. The mechanism of NLRP3 inflammasome activation and its pharmacological inhibitors - PMC [pmc.ncbi.nlm.nih.gov]
- 10. scispace.com [scispace.com]
- 11. researchgate.net [researchgate.net]
Comparative Analysis of Y14 Binding Interactions and Regulation
This guide provides a comparative analysis of the binding interactions of Y14, a core component of the Exon Junction Complex (EJC), with a focus on its protein-protein interactions and their regulation. This document is intended for researchers, scientists, and drug development professionals interested in the molecular mechanisms of mRNA processing and surveillance.
Introduction to Y14
Y14, also known as RNA-binding protein 8A (RBM8A), is a highly conserved RNA-binding protein that plays a critical role in post-splicing mRNA metabolism. It is a core component of the Exon Junction Complex (EJC), a dynamic multi-protein complex deposited on mRNAs approximately 20-24 nucleotides upstream of exon-exon junctions as a consequence of pre-mRNA splicing[1][2][3][4]. The EJC serves as a molecular platform for various downstream processes, including mRNA export, nonsense-mediated mRNA decay (NMD), and translation enhancement[5][6]. Y14, in a stable heterodimer with its partner protein Magoh, is central to these functions. Unlike proteins that recognize specific sequence motifs, Y14's association with mRNA is primarily determined by the splicing machinery, marking the location of former introns[1][3]. Its interactions with other proteins are crucial for the assembly and function of the EJC and are tightly regulated by post-translational modifications.
Comparative Analysis of EJC Core Components
The core of the EJC is a heterotetrameric complex consisting of Y14, Magoh, eIF4AIII, and MLN51 (also known as Barentz or CASC3)[7][8][9][10]. While these proteins form a stable core, their interactions and functions exhibit key differences.
| Feature | Y14 | Magoh | eIF4AIII | MLN51 (Barentz) |
| Primary Function | EJC core component, NMD, translational enhancement, mRNA decay regulation[6][11][12] | EJC core component, stable binding partner of Y14[13] | RNA helicase, anchors EJC to mRNA[6] | EJC core component, translational enhancement[7] |
| RNA Binding | Binds preferentially to spliced mRNA, position-specific (upstream of exon-exon junctions)[1][3] | Does not directly bind RNA, but is essential for Y14's function | Directly binds mRNA in a sequence-independent manner[6] | Does not directly bind RNA in the context of the core EJC |
| Key Interacting Partners | Magoh, eIF4AIII, MLN51, PYM, Upf3, PRMT5, Dcp2[12][14][15] | Y14, eIF4AIII, MLN51 | Y14, Magoh, MLN51, UPF3b[10] | Y14, Magoh, eIF4AIII |
| Regulation | Phosphorylation at RS dipeptides abolishes interaction with EJC components and downstream factors. Methylation is antagonized by phosphorylation.[5] | Regulated as part of the Y14-Magoh heterodimer | ATPase activity is inhibited by Y14-Magoh to ensure stable EJC association[6] | Can stimulate translational efficiency when tethered to mRNA[7] |
| Subcellular Localization | Predominantly nuclear, shuttles to the cytoplasm with spliced mRNA[1][13] | Shuttles with Y14 | Nuclear and cytoplasmic | Nuclear and cytoplasmic |
Y14 Protein-Protein Interactions and their Regulation
Y14's function is mediated through a complex network of protein-protein interactions, which are dynamically regulated.
| Interacting Protein | Function of Interaction | Regulation |
| Magoh | Forms a stable, obligate heterodimer with Y14, which is the functional unit for EJC assembly and function[13]. | - |
| eIF4AIII & MLN51 | Form the core EJC tetramer with the Y14-Magoh dimer[7]. | Phosphorylation of Y14 can lead to the dissociation of the EJC[5]. |
| PYM (Partner of Y14 and Magoh) | A cytoplasmic protein that interacts with the Y14-Magoh dimer and is implicated in NMD[14]. | The interaction is with the Y14-Magoh heterodimerization interface[14]. |
| Upf3 | A key NMD factor that directly interacts with the EJC, linking it to the NMD machinery[15]. | Phosphorylation of Y14 reduces its binding affinity for Upf3[13]. |
| PRMT5 | A protein-arginine methyltransferase that interacts with the Y14-Magoh complex and is involved in the biogenesis of spliceosomal small nuclear ribonucleoproteins (snRNPs)[15]. | The interaction is not RNA-mediated and involves the C-terminal region of Y14[15]. |
| Dcp2 | An mRNA decapping enzyme. Y14 can inhibit its activity, thereby regulating mRNA decay[11][12]. | The interaction is direct and can be modulated by Y14 phosphorylation[11]. |
Experimental Protocols
The characterization of Y14's binding interactions relies on a variety of experimental techniques. Below are brief descriptions of key methodologies.
1. Co-immunoprecipitation (Co-IP)
-
Principle: This technique is used to identify protein-protein interactions in vivo. An antibody specific to a target protein (e.g., Y14) is used to pull down the protein from a cell lysate. Interacting proteins are also pulled down as part of the complex and can be identified by Western blotting or mass spectrometry.
-
Protocol Outline:
-
Lyse cells to release proteins while maintaining protein-protein interactions.
-
Incubate the cell lysate with an antibody specific to the bait protein (Y14).
-
Add protein A/G-coupled beads to bind the antibody-protein complex.
-
Pellet the beads by centrifugation and wash to remove non-specific binders.
-
Elute the protein complexes from the beads.
-
Analyze the eluted proteins by SDS-PAGE and Western blotting using antibodies against suspected interacting partners, or by mass spectrometry for unbiased identification.
-
2. GST Pull-Down Assay
-
Principle: This is an in vitro method to confirm direct protein-protein interactions. A recombinant "bait" protein is expressed with a Glutathione S-transferase (GST) tag. This GST-tagged protein is immobilized on glutathione-coated beads. A "prey" protein is then incubated with the immobilized bait, and binding is detected.
-
Protocol Outline:
-
Express and purify a GST-tagged bait protein (e.g., GST-Y14).
-
Incubate the purified GST-Y14 with glutathione-sepharose beads to immobilize it.
-
Prepare the prey protein (e.g., in vitro translated and radiolabeled, or as a purified recombinant protein).
-
Incubate the prey protein with the beads containing the immobilized GST-Y14.
-
Wash the beads to remove non-specifically bound proteins.
-
Elute the bound proteins and analyze by SDS-PAGE and autoradiography (for radiolabeled prey) or Western blotting.
-
3. Yeast Two-Hybrid (Y2H) Screening
-
Principle: A genetic method to detect protein-protein interactions in vivo in yeast. The "bait" protein is fused to the DNA-binding domain (DBD) of a transcription factor, and the "prey" protein is fused to the activation domain (AD). If the bait and prey proteins interact, the DBD and AD are brought into proximity, reconstituting a functional transcription factor that drives the expression of a reporter gene.
-
Protocol Outline:
-
Clone the cDNA of the bait protein (Y14) into a vector containing the DBD.
-
Clone a cDNA library of potential prey proteins into a vector containing the AD.
-
Co-transform yeast with the bait and prey plasmids.
-
Plate the transformed yeast on selective media that requires the expression of the reporter gene for growth.
-
Colonies that grow indicate a potential interaction.
-
Isolate the prey plasmid from positive colonies and sequence the cDNA insert to identify the interacting protein.
-
4. Surface Plasmon Resonance (SPR)
-
Principle: A label-free biophysical technique to measure the kinetics and affinity of protein-protein interactions in real-time. One protein (the ligand) is immobilized on a sensor chip, and the other protein (the analyte) is flowed over the surface. The binding event causes a change in the refractive index at the sensor surface, which is detected as a change in the SPR signal.
-
Protocol Outline:
-
Immobilize the purified ligand protein (e.g., Y14) onto the sensor chip surface.
-
Flow a buffer solution over the chip to establish a stable baseline.
-
Inject a series of concentrations of the purified analyte protein (e.g., Magoh) over the surface and monitor the binding (association phase).
-
Switch back to the buffer flow and monitor the dissociation of the complex (dissociation phase).
-
Regenerate the sensor surface to remove the bound analyte.
-
Analyze the binding data to determine the association rate constant (ka), dissociation rate constant (kd), and the equilibrium dissociation constant (KD).
-
Visualizations
Caption: Y14 protein interaction network within the EJC and with downstream effectors.
Caption: A simplified workflow for Co-immunoprecipitation to identify Y14 interacting proteins.
References
- 1. The Y14 protein communicates to the cytoplasm the position of exon–exon junctions - PMC [pmc.ncbi.nlm.nih.gov]
- 2. The exon–exon junction complex provides a binding platform for factors involved in mRNA export and nonsense-mediated mRNA decay - PMC [pmc.ncbi.nlm.nih.gov]
- 3. The Y14 protein communicates to the cytoplasm the position of exon–exon junctions | The EMBO Journal [link.springer.com]
- 4. The Cellular EJC Interactome Reveals Higher Order mRNP Structure and an EJC-SR Protein Nexus - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Phosphorylation of Y14 modulates its interaction with proteins involved in mRNA metabolism and influences its methylation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. mdpi.com [mdpi.com]
- 7. Biochemical analysis of the EJC reveals two new factors and a stable tetrameric protein core - PMC [pmc.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. The Hierarchy of Exon-Junction Complex Assembly by the Spliceosome Explains Key Features of Mammalian Nonsense-Mediated mRNA Decay - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Comparison of EJC-enhanced and EJC-independent NMD in human cells reveals two partially redundant degradation pathways - PMC [pmc.ncbi.nlm.nih.gov]
- 11. The RNA-binding protein Y14 inhibits mRNA decapping and modulates processing body formation - PMC [pmc.ncbi.nlm.nih.gov]
- 12. The RNA-binding protein Y14 inhibits mRNA decapping and modulates processing body formation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. Specific Y14 domains mediate its nucleo-cytoplasmic shuttling and association with spliced mRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Molecular insights into the interaction of PYM with the Mago–Y14 core of the exon junction complex | EMBO Reports [link.springer.com]
- 15. The Exon Junction Complex Component Y14 Modulates the Activity of the Methylosome in Biogenesis of Spliceosomal Small Nuclear Ribonucleoproteins - PMC [pmc.ncbi.nlm.nih.gov]
Safety Operating Guide
Standard Operating Procedure: Proper Disposal of Novel Compound YN14
Disclaimer: As "YN14" does not correspond to a publicly documented chemical substance, this guide outlines a standard operating procedure for the safe disposal of a novel or uncharacterized chemical compound. Researchers, scientists, and drug development professionals must consult their institution's Environmental Health and Safety (EHS) department to ensure full compliance with all local, state, and federal regulations. If the properties of a newly synthesized chemical are unknown, it must be assumed to be hazardous.[1]
Hazard Communication and Assessment
Before disposal, a thorough hazard assessment is mandatory. The Principal Investigator is responsible for communicating any known hazardous properties of newly synthesized chemicals to all laboratory personnel.[1] If a formal Safety Data Sheet (SDS) has not been created, an equivalent document outlining the known or suspected hazards should be readily available.[1]
Initial Hazard Assessment for this compound (Hypothetical)
| Hazard Category | Assumed Risk Level (If Unknown) | Handling Precautions |
| Acute Toxicity | High | Handle in a certified chemical fume hood. |
| Flammability | High | Store away from ignition sources in a flammable safety cabinet.[2] |
| Reactivity | High | Segregate from incompatible materials. |
| Carcinogenicity/Mutagenicity | Assumed | Handle as a particularly hazardous substance.[1] |
Personal Protective Equipment (PPE) and Safety Measures
When handling this compound waste, appropriate personal protective equipment must be worn.
| Equipment | Specification |
| Eye Protection | Safety glasses with side shields or chemical splash goggles. |
| Hand Protection | Chemically resistant gloves (e.g., nitrile). Consult glove compatibility charts if the solvent is known. |
| Body Protection | A standard laboratory coat. |
| Respiratory Protection | Use a chemical fume hood.[3] If not feasible, consult with EHS for appropriate respiratory protection.[3] |
Waste Segregation and Container Management
Proper segregation and containment of this compound waste are critical to prevent accidental exposure and chemical reactions.
-
Waste Identification: All materials contaminated with this compound, including unused product, solutions, contaminated labware (e.g., pipette tips, vials), and PPE, must be treated as hazardous waste.
-
Segregation: Keep this compound waste separate from other waste streams, especially incompatible materials.
-
Container Selection: Use a designated, leak-proof waste container made of a material compatible with this compound and any solvents. The container must have a secure, tight-fitting lid and be kept closed except when adding waste.[4]
-
Labeling: Affix a completed hazardous waste label to the container before adding any waste. The label must include:
-
The words "Hazardous Waste"
-
The full chemical name: "this compound (Novel Compound)"
-
The primary hazards (e.g., Flammable, Toxic)
-
The date accumulation started
-
-
Storage: Store the waste container in a designated satellite accumulation area within the laboratory. This area should be in a secondary containment bin.[4]
Disposal Protocol for this compound
The following is a step-by-step procedure for the disposal of this compound.
-
Preparation:
-
Ensure all necessary PPE is worn.
-
Verify that the hazardous waste container is properly labeled and in good condition.
-
-
Waste Collection:
-
Solid Waste: Collect all solid materials contaminated with this compound (e.g., contaminated filter paper, gloves, pipette tips) and place them in the designated solid hazardous waste container.
-
Liquid Waste: Collect all liquid waste containing this compound in a designated liquid hazardous waste container. Do not mix with other liquid waste streams unless compatibility has been confirmed.
-
Empty Containers: Any container that held this compound must be triple-rinsed. The first rinseate must be collected and disposed of as hazardous waste.[4] For containers of highly toxic chemicals, the first three rinses must be collected as hazardous waste.[4]
-
-
Final Disposal:
-
Once the waste container is full (do not overfill, leave approximately 10% headspace), or when the project is complete, seal the container securely.
-
Contact your institution's Environmental Health and Safety (EHS) office to schedule a hazardous waste pickup.
-
Do not dispose of this compound by evaporation, in the regular trash, or down the sewer drain.[4]
-
Emergency Procedures
In the event of a spill or exposure, follow these procedures immediately.
-
Spill: Treat any spill of a novel compound as a major spill.[3] Notify your supervisor and others in the area. Evacuate the immediate area if necessary and contact EHS for cleanup guidance.
-
Skin Contact: Immediately remove contaminated clothing and flush the affected skin with water for at least 15 minutes. Seek immediate medical attention.[3]
-
Eye Contact: Immediately flush eyes with copious amounts of water for at least 15 minutes, lifting the upper and lower eyelids. Seek immediate medical attention.[3]
-
Inhalation: Move the affected individual to fresh air. Seek immediate medical attention.[3]
Workflow for Novel Compound Disposal
Caption: Logical workflow for the safe disposal of a novel chemical compound.
References
- 1. Newly Synthesized Chemical Hazard Information | Office of Clinical and Research Safety [vumc.org]
- 2. Hazardous Waste Disposal Guide: Research Safety - Northwestern University [researchsafety.northwestern.edu]
- 3. twu.edu [twu.edu]
- 4. Hazardous Waste Disposal Guide - Research Areas | Policies [policies.dartmouth.edu]
Personal protective equipment for handling YN14
Information for "YN14" Cannot Be Found
Extensive searches for a chemical substance identified as "this compound" have not yielded any specific results. This designation does not correspond to a recognized chemical name, CAS number, or other standard identifiers in the databases and safety resources accessed. The search results included a cosmetic product where "this compound" is used as a shade identifier, but no information linking this code to a specific chemical compound for laboratory use could be found.
To provide you with the necessary safety and logistical information, please verify the chemical identifier. The full chemical name or, preferably, the CAS (Chemical Abstracts Service) number is essential for obtaining an accurate Safety Data Sheet (SDS) and handling instructions.
General Safety Precautions for Handling Unidentified Chemicals
In the absence of specific information for "this compound," it is crucial to treat the substance as potentially hazardous. The following are general operational procedures for handling unknown or poorly characterized chemicals in a laboratory setting. These guidelines are based on standard laboratory safety protocols and are not a substitute for a substance-specific risk assessment.
Immediate Safety and Personal Protective Equipment (PPE)
When handling any substance of unknown toxicity, a cautious approach is mandatory. The minimum recommended PPE includes:
| Personal Protective Equipment (PPE) | Specification | Purpose |
| Eye Protection | Chemical splash goggles or a face shield | Protects eyes from splashes, sprays, and airborne particles. |
| Hand Protection | Chemically resistant gloves (e.g., Nitrile, Neoprene) | Prevents skin contact with the substance. The choice of glove material should be based on the chemical class if known; for unknowns, a robust glove is recommended. |
| Body Protection | Laboratory coat or chemical-resistant apron | Protects skin and clothing from contamination. |
| Respiratory Protection | Use in a certified chemical fume hood | Minimizes inhalation exposure to vapors, fumes, or dust. |
Operational Plan for Handling
A logical workflow should be followed to ensure safety during the handling of an unknown substance.
Caption: Workflow for Handling Unknown Chemicals.
Disposal Plan
Without specific information on the hazards of "this compound," all waste generated must be treated as hazardous.
-
Waste Collection :
-
Collect all waste (solid and liquid) in designated, compatible, and clearly labeled hazardous waste containers.
-
Do not mix with other chemical waste unless compatibility is known.
-
-
Labeling :
-
The waste container must be labeled with "Hazardous Waste" and a description of the contents (e.g., "Waste [Name of Substance if known, otherwise 'Unknown Chemical']"). Include the date of accumulation.
-
-
Storage :
-
Store the waste container in a designated satellite accumulation area, away from incompatible materials.
-
-
Disposal :
-
Arrange for disposal through your institution's Environmental Health and Safety (EHS) office. Provide them with as much information as possible about the source and nature of the waste.
-
It is imperative to obtain a positive identification of "this compound" before proceeding with any experimental work. The guidance provided here is for interim risk mitigation only.
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
体外研究产品的免责声明和信息
请注意,BenchChem 上展示的所有文章和产品信息仅供信息参考。 BenchChem 上可购买的产品专为体外研究设计,这些研究在生物体外进行。体外研究,源自拉丁语 "in glass",涉及在受控实验室环境中使用细胞或组织进行的实验。重要的是要注意,这些产品没有被归类为药物或药品,他们没有得到 FDA 的批准,用于预防、治疗或治愈任何医疗状况、疾病或疾病。我们必须强调,将这些产品以任何形式引入人类或动物的身体都是法律严格禁止的。遵守这些指南对确保研究和实验的法律和道德标准的符合性至关重要。
