S-Gem
描述
BenchChem offers high-quality this compound suitable for many research applications. Different packaging options are available to accommodate customers' requirements. Please inquire for more information about this compound including the price, delivery time, and more detailed information at info@benchchem.com.
属性
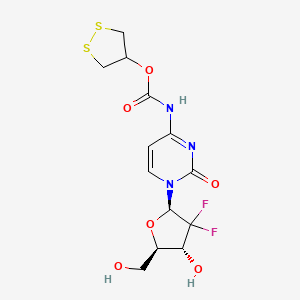
分子式 |
C13H15F2N3O6S2 |
|---|---|
分子量 |
411.4 g/mol |
IUPAC 名称 |
dithiolan-4-yl N-[1-[(2R,4R,5R)-3,3-difluoro-4-hydroxy-5-(hydroxymethyl)oxolan-2-yl]-2-oxopyrimidin-4-yl]carbamate |
InChI |
InChI=1S/C13H15F2N3O6S2/c14-13(15)9(20)7(3-19)24-10(13)18-2-1-8(16-11(18)21)17-12(22)23-6-4-25-26-5-6/h1-2,6-7,9-10,19-20H,3-5H2,(H,16,17,21,22)/t7-,9-,10-/m1/s1 |
InChI 键 |
WVNDMEFISJHXOM-SZEHBUNVSA-N |
手性 SMILES |
C1C(CSS1)OC(=O)NC2=NC(=O)N(C=C2)[C@H]3C([C@@H]([C@H](O3)CO)O)(F)F |
规范 SMILES |
C1C(CSS1)OC(=O)NC2=NC(=O)N(C=C2)C3C(C(C(O3)CO)O)(F)F |
产品来源 |
United States |
Foundational & Exploratory
The Core Principles of Simultaneous Single-Cell DNA and RNA Analysis: An In-depth Technical Guide
For Researchers, Scientists, and Drug Development Professionals
The ability to simultaneously analyze the genome and transcriptome of a single cell is revolutionizing our understanding of cellular heterogeneity, particularly in complex biological systems like tumors. This multi-omics approach provides a powerful tool to directly link genotype to phenotype at the most fundamental level, offering unprecedented insights into disease progression, drug resistance, and cellular evolution. This guide delves into the core principles of prominent techniques for concurrent single-cell DNA and RNA analysis, providing detailed experimental protocols and comparative data to inform your research.
Introduction to Single-Cell Multi-Omics
Traditional bulk sequencing methods provide an averaged view of molecular information across a population of cells, masking the critical variations between individual cells. Single-cell sequencing has overcome this limitation, but analyzing different types of molecules from separate single cells still requires computational integration and inference. Simultaneous co-assays of genomic DNA and RNA from the same single cell eliminate this ambiguity, enabling the direct correlation of genetic variants, such as single nucleotide variations (SNVs) and copy number variations (CNVs), with changes in gene expression.[1][2][3] This capability is particularly crucial in cancer research for dissecting tumor heterogeneity, identifying rare drug-resistant clones, and understanding the molecular underpinnings of therapeutic resistance.[2][4][5][6]
Key Methodologies for Simultaneous DNA and RNA Analysis
Several innovative methods have been developed to facilitate the co-analysis of DNA and RNA from a single cell. These techniques can be broadly categorized into two main approaches: those that physically separate the nucleic acids before library preparation, and those that employ a one-pot approach for simultaneous library construction.
Physical Separation-Based Methods
These methods involve the lysis of a single cell and the subsequent separation of its genomic DNA and RNA content for parallel processing.
-
G&T-seq (Genome and Transcriptome Sequencing): This technique involves the lysis of a single cell, followed by the capture of polyadenylated mRNA using biotinylated oligo-dT primers on magnetic beads. The beads are then separated, and the gDNA in the supernatant and the mRNA on the beads are amplified and sequenced independently.[7][8][9][10]
-
SIDR-seq (Simultaneous Isolation of DNA and RNA): This method utilizes hypotonic lysis to maintain the integrity of the nuclear lamina, followed by the capture of the entire cell lysate using antibody-conjugated magnetic microbeads. The supernatant containing total RNA is then separated from the nucleus-bound gDNA for individual library preparation.[11][12][13][14][15]
Simultaneous Library Preparation Methods
These approaches avoid the physical separation of DNA and RNA, instead relying on specific enzymatic reactions to process both molecules in the same reaction vessel.
-
Simul-seq: This technique leverages the distinct enzymatic specificities of Tn5 transposase for DNA and RNA ligase for RNA to generate whole-genome and transcriptome libraries without the need for physical separation of the nucleic acids.[16][17][18][19][20]
-
DEFND-seq (DNA and Expression Following Nucleosome Depletion): This highly scalable method involves treating nuclei with lithium diiodosalicylate to deplete nucleosomes and expose genomic DNA. The nuclei are then processed using a commercial droplet microfluidics platform to generate barcoded mRNA and gDNA libraries from thousands of individual nuclei.[21][22][23][24][25][26][27]
Quantitative Data Summary
The performance of these techniques varies in terms of sensitivity, throughput, and other key metrics. The following table summarizes available quantitative data for comparison.
| Technique | Throughput | DNA Recovery/Coverage | RNA Recovery/Gene Detection | Key Advantages | Limitations |
| G&T-seq | Manual: 8 cells/3 days; Automated: 96 cells/3 days[7] | Reproducible copy number profiles; 87% of annotated SNVs detected[8] | Thousands of transcripts detected per cell[7] | Physical separation minimizes cross-contamination; compatible with various amplification methods.[7][9] | Lower throughput; potential for loss of material during separation. |
| SIDR-seq | Not explicitly stated, but amenable to 96-well plate format | High recovery of genomic DNA with minimal RNA contamination[11][12] | ~80% recovery of RNA molecules; 2,400-11,000 genes detected per cell[11][12] | High recovery rates for both DNA and total RNA (not just polyA+).[11][13] | Requires specific antibodies for cell capture; potential for variability in lysis efficiency. |
| Simul-seq | Amenable to small quantities of cells or tissues[16][19] | High-quality whole-genome sequencing data[16] | Produces high-quality transcriptome data, including non-polyadenylated RNAs.[17] | Streamlined, one-pot library preparation reduces time and potential for sample loss.[18][20] | Primarily demonstrated on bulk samples or small cell pools, not extensively on single cells. |
| DEFND-seq | Highly scalable, up to 40,000 nuclei per sample[26] | High-complexity gDNA libraries with uniform coverage[22][23] | Median of 4,421 transcripts per nucleus in a glioblastoma sample[22][27] | High throughput using a widely available commercial platform; applicable to fresh and archived specimens.[22][23][25] | Requires nucleosome depletion step; performance can be influenced by chromatin accessibility. |
Experimental Protocols
G&T-seq: Detailed Methodology
-
Single-Cell Isolation: Isolate single cells into individual wells of a 96-well plate containing lysis buffer using fluorescence-activated cell sorting (FACS) or micromanipulation.
-
Cell Lysis: Lyse the cells to release the genomic DNA and mRNA.
-
mRNA Capture: Introduce biotinylated oligo(dT) primers that bind to the poly(A) tails of the mRNA molecules. Add streptavidin-coated magnetic beads, which will bind to the biotinylated primers, thus capturing the mRNA.
-
Physical Separation: Use a magnet to pellet the magnetic beads with the attached mRNA. Carefully collect the supernatant, which contains the genomic DNA.
-
gDNA Amplification: Perform whole-genome amplification (WGA) on the collected supernatant using methods like Multiple Displacement Amplification (MDA).
-
mRNA Amplification: On the magnetic beads, perform reverse transcription and whole-transcriptome amplification (WTA) using a method like SMART-seq2.
-
Library Preparation and Sequencing: Prepare sequencing libraries from the amplified gDNA and cDNA for parallel sequencing on a next-generation sequencing platform.[7][8][9]
DEFND-seq: Detailed Methodology
-
Nuclei Isolation: Isolate nuclei from single-cell suspensions.
-
Nucleosome Depletion: Treat the isolated nuclei with a solution containing lithium diiodosalicylate to strip histones and other proteins from the DNA, making the genome more accessible.
-
Tagmentation: Incubate the nucleosome-depleted nuclei with a transposase enzyme (e.g., Tn5) that simultaneously fragments the gDNA and adds adapter sequences.
-
Droplet-Based Encapsulation: Load the tagmented nuclei onto a microfluidic chip (e.g., from 10x Genomics) where they are encapsulated into individual droplets with barcoded beads and reverse transcription reagents.
-
Simultaneous Barcoding: Inside each droplet, the mRNA is reverse transcribed into cDNA with a barcoded primer, and the tagmented gDNA is also barcoded.
-
Library Preparation and Sequencing: Break the emulsion and perform separate library preparation for the barcoded cDNA and gDNA. The resulting libraries are then sequenced.[22][23][27]
Visualizing the Principles and Workflows
Signaling Pathway: Linking Genotype to Phenotype in Cancer
The following diagram illustrates the central principle of how simultaneous DNA and RNA analysis can be used to understand the functional consequences of genetic alterations in cancer.
Caption: Linking genetic alterations to functional outcomes in a single cell.
Experimental Workflow: Physical Separation vs. Simultaneous Library Preparation
This diagram contrasts the workflows of physical separation methods (like G&T-seq) and simultaneous library preparation methods (like DEFND-seq).
Caption: Contrasting workflows for single-cell DNA and RNA co-assays.
Applications in Research and Drug Development
The ability to directly link genomic alterations to transcriptomic changes in individual cells has profound implications for:
-
Cancer Biology: Unraveling the complexity of tumor heterogeneity, identifying driver mutations in specific subclones, and understanding the mechanisms of tumor evolution and metastasis.[1][2][4][5]
-
Drug Development: Identifying rare cell populations that are resistant to therapy, discovering novel drug targets, and developing personalized treatment strategies.[25]
-
Developmental Biology: Tracing cell lineages and understanding how genetic variations influence cell fate decisions during development.
-
Immunology: Characterizing the genomic and transcriptomic diversity of immune cells and their roles in health and disease.
Conclusion
Simultaneous single-cell DNA and RNA analysis provides an unparalleled view of the interplay between the genome and the transcriptome. The choice of method will depend on the specific research question, required throughput, and available resources. As these technologies continue to evolve and become more accessible, they will undoubtedly play an increasingly critical role in advancing our understanding of fundamental biology and in the development of next-generation therapeutics.
References
- 1. Applications of single-cell sequencing in cancer research: progress and perspectives - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Single-cell multi-omics in cancer immunotherapy: from tumor heterogeneity to personalized precision treatment - PMC [pmc.ncbi.nlm.nih.gov]
- 3. academic.oup.com [academic.oup.com]
- 4. mdpi.com [mdpi.com]
- 5. Frontiers | Application of Single-Cell Multi-Omics in Dissecting Cancer Cell Plasticity and Tumor Heterogeneity [frontiersin.org]
- 6. Advances in Single-Cell Techniques for Linking Phenotypes to Genotypes - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Separation and parallel sequencing of the genomes and transcriptomes of single cells using G&T-seq - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. G&T-Seq - Wikipedia [en.wikipedia.org]
- 9. G&T-Seq [illumina.com]
- 10. G&T-seq: parallel sequencing of single-cell genomes and transcriptomes | Springer Nature Experiments [experiments.springernature.com]
- 11. SIDR: simultaneous isolation and parallel sequencing of genomic DNA and total RNA from single cells - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. rna-seqblog.com [rna-seqblog.com]
- 14. cuk.elsevierpure.com [cuk.elsevierpure.com]
- 15. SIDR: simultaneous isolation and parallel sequencing of genomic DNA and total RNA from single cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. Simul-seq: combined DNA and RNA sequencing for whole-genome and transcriptome profiling - PMC [pmc.ncbi.nlm.nih.gov]
- 17. researchgate.net [researchgate.net]
- 18. rna-seqblog.com [rna-seqblog.com]
- 19. Simul-seq: combined DNA and RNA sequencing for whole-genome and transcriptome profiling | Springer Nature Experiments [experiments.springernature.com]
- 20. Simul-seq: combined DNA and RNA sequencing for whole-genome and transcriptome profiling - PubMed [pubmed.ncbi.nlm.nih.gov]
- 21. parkinsonsroadmap.org [parkinsonsroadmap.org]
- 22. Scalable co-sequencing of RNA and DNA from individual nuclei - PMC [pmc.ncbi.nlm.nih.gov]
- 23. Scalable co-sequencing of RNA and DNA from individual nuclei - PMC [pmc.ncbi.nlm.nih.gov]
- 24. biorxiv.org [biorxiv.org]
- 25. New Technique for Single-Cell Sequencing Enhances Drug Screening Research | Herbert Irving Comprehensive Cancer Center (HICCC) - New York [cancer.columbia.edu]
- 26. 10xgenomics.com [10xgenomics.com]
- 27. biorxiv.org [biorxiv.org]
Revolutionizing Cancer Research: A Technical Guide to Single-Cell Genetically Engineered Model (sc-GEM) Applications in Unraveling Tumor Heterogeneity
For Immediate Release
A comprehensive technical guide detailing the application of single-cell technologies to Genetically Engineered Models (GEMs) in cancer heterogeneity research is now available for researchers, scientists, and drug development professionals. This whitepaper provides an in-depth exploration of the core methodologies, data interpretation, and signaling pathways integral to this cutting-edge approach, positioning sc-GEMs as a pivotal tool in the future of oncology.
The guide addresses the critical need for more sophisticated models that accurately recapitulate the clonal nature and complexity of human cancers. By integrating single-cell analysis with GEMs, researchers can dissect the intricate cellular and molecular landscapes of tumors, offering unprecedented insights into cancer initiation, progression, and therapeutic resistance.
Core Concepts and Applications of sc-GEMs
Genetically Engineered Models, particularly mouse models, have long been mainstays in cancer research. However, traditional models often fail to capture the sporadic and clonal evolution that characterizes human tumors. The advent of technologies like CRISPR/Cas9 and Cre-Lox systems has enabled the creation of mosaic mouse models, where genetic alterations are introduced into single cells, more faithfully mimicking the natural course of tumorigenesis.
The application of single-cell sequencing to these advanced GEMs allows for a granular analysis of the resulting tumor heterogeneity. This technical guide delves into the primary applications of this synergistic approach, which include:
-
Dissecting Clonal Evolution: Tracking the lineage and evolution of individual cancer cells to understand the emergence of aggressive and drug-resistant clones.
-
Characterizing the Tumor Microenvironment (TME): Elucidating the complex interplay between tumor cells and the surrounding stromal and immune cells at a single-cell resolution.
-
Modeling Therapeutic Resistance: Investigating the mechanisms by which subpopulations of cancer cells survive and repopulate tumors following treatment.
-
Developing Novel Therapeutic Strategies: Utilizing GEMM-derived organoids for high-throughput drug screening to identify vulnerabilities in heterogeneous tumor populations.
Experimental Protocols: A Step-by-Step Guide
This whitepaper provides detailed methodologies for the key experiments central to sc-GEM research, offering a roadmap for investigators looking to implement these techniques.
Generation of Mosaic Genetically Engineered Mouse Models
The foundation of sc-GEM research lies in the creation of sophisticated mouse models that mirror the genetic mosaicism of human cancers. This is primarily achieved through two powerful techniques:
-
CRISPR/Cas9-Mediated Somatic Gene Editing: This revolutionary technology allows for the direct and precise editing of genes in somatic cells of adult mice. Lentiviral or adeno-associated viral (AAV) vectors are commonly used to deliver the CRISPR/Cas9 machinery to target tissues, inducing specific mutations in a subset of cells.[1][2][3]
-
Cre-LoxP Recombination System: This conditional system allows for tissue-specific and temporally controlled gene expression or deletion. By crossing mice carrying a Cre recombinase driven by a tissue-specific promoter with mice harboring a target gene flanked by loxP sites, researchers can induce genetic alterations in specific cell lineages.[4][5]
A detailed protocol for generating mosaic mouse models using CRISPR/Cas9 is outlined below:
| Step | Procedure | Key Considerations |
| 1. Design and Cloning of sgRNA | Design single guide RNAs (sgRNAs) targeting the gene of interest. Clone the sgRNA expression cassette into a lentiviral or AAV vector that also expresses Cas9. | Ensure high on-target efficiency and minimal off-target effects of the sgRNA. |
| 2. Viral Vector Production | Transfect packaging cells (e.g., HEK293T) with the CRISPR vector and packaging plasmids to produce high-titer viral particles. | Optimize transfection and harvesting conditions to maximize viral titer. |
| 3. In vivo Delivery | Deliver the viral vectors to the target tissue in adult mice via methods such as retro-orbital injection, direct tissue injection, or inhalation, depending on the target organ.[2] | The choice of delivery method is critical for achieving efficient and tissue-specific gene editing. |
| 4. Tumor Initiation and Monitoring | Monitor the mice for tumor development using imaging techniques or palpation. | The latency of tumor formation will vary depending on the genetic alterations and the mouse strain. |
Single-Cell RNA Sequencing (scRNA-seq) of GEMM-Derived Tumors
Once tumors develop in the GEMMs, the next critical step is to dissociate the tumor into a single-cell suspension for transcriptomic analysis.
A generalized protocol for tumor dissociation is as follows:
| Step | Procedure | Key Considerations |
| 1. Tumor Excision | Carefully excise the tumor from the euthanized mouse under sterile conditions.[6][7] | Minimize contamination from surrounding tissues. |
| 2. Mechanical Dissociation | Mince the tumor into small pieces using sterile scalpels or scissors.[7][8] | Thorough mincing facilitates subsequent enzymatic digestion. |
| 3. Enzymatic Digestion | Incubate the minced tissue in a digestion buffer containing enzymes such as collagenase and dispase to break down the extracellular matrix.[6][7][8] | The composition of the digestion buffer and incubation time should be optimized for the specific tumor type. |
| 4. Cell Filtration and Lysis | Pass the digested tissue through a cell strainer to obtain a single-cell suspension. Lyse red blood cells using an appropriate buffer.[8][9] | Ensure complete dissociation while maintaining cell viability. |
| 5. Cell Counting and Viability Assessment | Count the cells and assess their viability using a hemocytometer and trypan blue staining. | High cell viability is crucial for successful scRNA-seq. |
| 6. scRNA-seq Library Preparation | Proceed with a commercial single-cell library preparation platform (e.g., 10x Genomics Chromium) according to the manufacturer's protocol.[10][11] |
Lineage Tracing
Lineage tracing techniques are employed to track the progeny of individual cells, providing invaluable information about clonal dynamics and metastatic dissemination.
| Step | Procedure | Key Considerations |
| 1. Genetic Labeling | Introduce a heritable genetic marker (e.g., a fluorescent protein) into a subset of cells using Cre-LoxP systems or other inducible methods.[4][5] | The choice of promoter to drive the marker expression determines the specificity of labeling. |
| 2. Induction of Labeling | Administer an inducing agent (e.g., tamoxifen (B1202) for CreER systems) at a specific time point to activate the expression of the genetic marker.[4] | The timing of induction is critical for labeling the desired cell population. |
| 3. Clonal Analysis | Analyze the distribution and characteristics of the labeled cell populations and their descendants in the primary tumor and metastatic sites over time using imaging or flow cytometry.[5] |
GEMM-Derived Organoid Culture and Drug Screening
GEMM-derived tumors can be used to establish three-dimensional organoid cultures that recapitulate the heterogeneity of the original tumor, providing a powerful platform for preclinical drug testing.
| Step | Procedure | Key Considerations |
| 1. Organoid Establishment | Dissociate the GEMM tumor into single cells or small cell clusters and embed them in a basement membrane matrix (e.g., Matrigel) with appropriate growth factors.[12] | The composition of the culture medium is critical for successful organoid formation and maintenance. |
| 2. High-Throughput Drug Screening | Plate the organoids in multi-well plates and treat them with a library of therapeutic compounds at various concentrations.[13][14] | |
| 3. Viability and Response Assessment | Assess organoid viability and drug response using assays such as CellTiter-Glo or high-content imaging.[13][14] | Determine dose-response curves and IC50 values for each compound. |
Quantitative Data from sc-GEM Studies
The integration of single-cell analysis with GEMMs generates a wealth of quantitative data that can be used to characterize tumor heterogeneity. The following tables provide examples of the types of data that can be obtained from such studies.
Table 1: Cellular Composition of GEMM-Derived Tumors by scRNA-seq
| Cell Type | MMTV-PyMT (Breast Cancer) | KPC (Pancreatic Cancer) |
| Epithelial Cells | 65% | 45% |
| Cancer-Associated Fibroblasts | 15% | 30% |
| T-cells | 8% | 10% |
| Macrophages | 7% | 12% |
| Endothelial Cells | 5% | 3% |
Table 2: Differential Gene Expression in Tumor Subclones
| Gene | Subclone A (Fold Change) | Subclone B (Fold Change) | p-value |
| Metastasis-Associated Gene 1 | 4.2 | 1.1 | <0.01 |
| Drug Resistance Gene 1 | 1.3 | 5.8 | <0.001 |
| Proliferation Marker 1 | 3.5 | 3.7 | 0.45 |
Table 3: Drug Response of GEMM-Derived Organoids
| Drug | IC50 (μM) - Primary Tumor Organoids | IC50 (μM) - Metastatic Site Organoids |
| Standard Chemotherapy | 10.5 | 25.2 |
| Targeted Therapy A | 2.1 | 18.7 |
| Novel Compound B | 0.8 | 1.2 |
Key Signaling Pathways in Cancer Heterogeneity
The study of cancer heterogeneity in sc-GEM models often focuses on key signaling pathways that are dysregulated during tumorigenesis. Understanding these pathways at a single-cell level can reveal novel therapeutic targets.
Wnt Signaling Pathway in Colorectal Cancer
The Wnt signaling pathway is a critical regulator of intestinal stem cells and is frequently mutated in colorectal cancer.[15][16][17][18][19] In GEMM models of colorectal cancer, aberrant Wnt signaling drives tumor initiation and progression.
JAK/STAT Signaling Pathway in Breast Cancer
The JAK/STAT pathway is a key signaling cascade involved in cell proliferation, differentiation, and immune responses.[20][21][22] In breast cancer, constitutive activation of the JAK/STAT pathway is associated with tumor growth and metastasis.
Hedgehog Signaling Pathway in Medulloblastoma
The Hedgehog signaling pathway plays a crucial role in embryonic development and its aberrant activation is a hallmark of medulloblastoma, the most common malignant brain tumor in children.[1][23][24][25][26][27][28]
References
- 1. CRISPR-Cas9 Knockin Mice for Genome Editing and Cancer Modeling - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Precision cancer mouse models through genome editing with CRISPR-Cas9 - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Efficient cancer modeling through CRISPR-Cas9/HDR-based somatic precision gene editing in mice - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Generation of a squamous cell carcinoma mouse model for lineage tracing of BMI1+ cancer stem cells - PMC [pmc.ncbi.nlm.nih.gov]
- 5. The Theory and Practice of Lineage Tracing - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Preparation of mouse pancreatic tumor for single-cell RNA sequencing and analysis of the data - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Tumor dissociation into single-cell suspension [bio-protocol.org]
- 8. stemcell.com [stemcell.com]
- 9. Dissociation of Human and Mouse Tumor Tissue Samples for Single-cell RNA Sequencing [jove.com]
- 10. 10xgenomics.com [10xgenomics.com]
- 11. 15. Lineage tracing — Single-cell best practices [sc-best-practices.org]
- 12. JAK–STAT Signaling in Inflammatory Breast Cancer Enables Chemotherapy-Resistant Cell States - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Frontiers | JAK/STAT Signaling: Molecular Targets, Therapeutic Opportunities, and Limitations of Targeted Inhibitions in Solid Malignancies [frontiersin.org]
- 14. CRISPR Protocols and Methods | Springer Nature Experiments [experiments.springernature.com]
- 15. Wnt signaling in colorectal cancer: pathogenic role and therapeutic target - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. Wnt Signaling and Colorectal Cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Advances of Wnt Signalling Pathway in Colorectal Cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Analysis of Single-Cell RNA-Seq Identifies Cell-Cell Communication Associated with Tumor Characteristics - PMC [pmc.ncbi.nlm.nih.gov]
- 19. sciencedaily.com [sciencedaily.com]
- 20. researchgate.net [researchgate.net]
- 21. mdpi.com [mdpi.com]
- 22. eurekaselect.com [eurekaselect.com]
- 23. Modeling pediatric medulloblastoma - PMC [pmc.ncbi.nlm.nih.gov]
- 24. Mouse models of medulloblastoma - PMC [pmc.ncbi.nlm.nih.gov]
- 25. Hedgehog Signaling Promotes Medulloblastoma Survival via BclII - PMC [pmc.ncbi.nlm.nih.gov]
- 26. Epigenetic regulation in medulloblastoma pathogenesis revealed by genetically engineered mouse models - PMC [pmc.ncbi.nlm.nih.gov]
- 27. Signaling pathway and molecular subgroups of medulloblastoma - PMC [pmc.ncbi.nlm.nih.gov]
- 28. Targeting of JAK-STAT Signaling in Breast Cancer: Therapeutic Strategies to Overcome Drug Resistance - PubMed [pubmed.ncbi.nlm.nih.gov]
For Researchers, Scientists, and Drug Development Professionals
An In-depth Technical Guide to Understanding Epigenetic and Genetic Links at the Single-Cell Level
Introduction
The intricate interplay between the genome and the epigenome dictates cellular identity, function, and fate. While traditional bulk sequencing methods have provided population-level averages, they obscure the profound heterogeneity present within complex biological systems. The advent of single-cell multi-omics technologies has opened a new frontier, allowing for the simultaneous profiling of genetic and epigenetic landscapes within individual cells. This guide provides a detailed exploration of the core methodologies that link genomics and epigenomics at the single-cell level, offering insights into their experimental protocols, data integration strategies, and applications in deciphering complex biological processes and disease mechanisms.
Recent advancements enable the concurrent analysis of multiple molecular layers—such as the genome, epigenome, and transcriptome—from the same cell.[1] These integrated approaches are crucial for understanding how genetic variation influences epigenetic states and, consequently, gene expression and cellular phenotype. By dissecting these relationships at the ultimate resolution of a single cell, researchers can uncover cell-type-specific regulatory mechanisms, trace developmental trajectories, and identify rare cell populations that drive disease progression. This technical document serves as a comprehensive resource for professionals seeking to leverage these powerful techniques in their research and development endeavors.
Core Methodologies for Single-Cell Multi-Omic Profiling
Several innovative techniques have been developed to simultaneously measure different molecular modalities from a single cell. These methods provide a direct way to characterize the coordination between layers of genomic regulation.[1] Below are detailed descriptions of key experimental approaches.
scM&T-seq: Single-Cell Methylome and Transcriptome Sequencing
The scM&T-seq protocol enables the parallel analysis of the DNA methylome and the transcriptome from the same cell.[2][3] This method is built upon the Genome and Transcriptome Sequencing (G&T-seq) protocol, but it incorporates bisulfite sequencing (scBS-seq) to determine DNA methylation patterns instead of standard whole-genome amplification.[3]
Experimental Workflow
The core principle of scM&T-seq involves the physical separation of RNA and genomic DNA from a single lysed cell.[3] Oligo-dT-coated magnetic beads are used to capture polyadenylated mRNA, which is then processed separately to generate a cDNA library using a method like Smart-seq2.[3][4] The remaining genomic DNA undergoes bisulfite conversion, which converts unmethyllated cytosines to uracils, while methylated cytosines remain unchanged. Subsequent amplification and sequencing allow for the identification of methylation sites at single-base resolution.[3][5]
Detailed Experimental Protocol (scM&T-seq)
-
Single-Cell Isolation : Isolate single cells into individual wells of a 96-well plate using fluorescence-activated cell sorting (FACS) or manual pipetting.
-
Cell Lysis : Lyse cells in a buffer containing proteinase K to release genomic DNA (gDNA) and mRNA.
-
mRNA-gDNA Separation : Introduce oligo-dT-coated magnetic beads to capture poly(A)+ mRNA. Physically separate the beads (with bound mRNA) from the supernatant containing the gDNA.[3]
-
Transcriptome Library Preparation (Smart-seq2) :
-
On the beads, perform reverse transcription using an oligo-dT primer and a template-switching oligo to generate full-length cDNA.
-
Amplify the cDNA using PCR.
-
Construct sequencing libraries from the amplified cDNA, typically using a transposase-based method (e.g., Nextera XT).[3]
-
-
Methylome Library Preparation (scBS-seq) :
-
Treat the gDNA in the supernatant with sodium bisulfite to convert unmethylated cytosines to uracils.[3]
-
Perform random-primed amplification to generate the second strand and amplify the bisulfite-converted DNA.
-
Construct sequencing libraries from the amplified gDNA.
-
-
Sequencing : Sequence both the transcriptome and methylome libraries on a compatible next-generation sequencing platform.
scNMT-seq: Single-Cell Nucleosome, Methylation, and Transcriptome Sequencing
scNMT-seq expands upon scM&T-seq by adding a layer of information on chromatin accessibility.[6][7] It simultaneously profiles chromatin accessibility, DNA methylation, and the transcriptome from a single cell, providing a powerful tool to link all three molecular layers.[7][8]
Experimental Workflow
The key innovation in scNMT-seq is the initial treatment of the intact single cell with a GpC methyltransferase (M.CviPI).[9][10] This enzyme methylates cytosines in GpC contexts that are not protected by nucleosomes or other DNA-binding proteins, effectively labeling accessible chromatin regions.[6] After this labeling step, the cell is lysed, and the RNA and gDNA are separated as in scM&T-seq. The gDNA then undergoes bisulfite sequencing. Post-sequencing, the data is bioinformatically deconvoluted: endogenous DNA methylation is read from CpG contexts, while chromatin accessibility is inferred from the methylation status of GpC contexts.[6]
Detailed Experimental Protocol (scNMT-seq)
-
Single-Cell Collection and Methylase Reaction : Collect single cells in a GpC methylase reaction buffer containing M.CviPI and the SAM cofactor. Incubate to allow methylation of accessible GpC sites.[8][9]
-
Cell Lysis : Stop the reaction and lyse the cells by adding a lysis buffer (e.g., RLT plus).[8][9]
-
mRNA-gDNA Separation : Use oligo-dT magnetic beads to capture and physically separate mRNA from the gDNA, as described for scM&T-seq.[9]
-
Transcriptome Library Preparation : Prepare the cDNA library from the captured mRNA using the Smart-seq2 protocol.[6]
-
Genomic DNA Purification and Bisulfite Conversion : Purify the gDNA from the lysate and perform bisulfite conversion.[9]
-
Combined Epigenome Library Preparation : Synthesize the first and second strands of the bisulfite-converted DNA, followed by library amplification via PCR.[9]
-
Sequencing : Sequence the transcriptome and the combined epigenome libraries.
-
Data Processing : After sequencing, align reads to a bisulfite-converted reference genome. Analyze methylation levels at CpG sites to determine endogenous DNA methylation and at GpC sites to infer chromatin accessibility.[6]
sci-Hi-C: Single-Cell Combinatorial Indexed Hi-C
To understand the three-dimensional (3D) organization of the genome, single-cell Hi-C methods are employed. sci-Hi-C is a high-throughput method that uses combinatorial indexing to map chromatin interactomes in a large number of single cells without requiring physical isolation of each cell.[11][12] This technique is crucial for linking distal regulatory elements to their target genes and for understanding how genome architecture varies from cell to cell.
Experimental Workflow
The sci-Hi-C protocol involves cross-linking cells to fix chromatin interactions.[11] Nuclei are then permeabilized and the chromatin is fragmented with a restriction enzyme. The key to the method is combinatorial indexing: nuclei are distributed into a 96-well plate where the first set of barcodes is introduced via ligation of barcoded adaptors. The nuclei are then pooled, subjected to proximity ligation (to ligate DNA fragments that were spatially close), and then redistributed into a second 96-well plate for ligation of a second set of barcodes.[11][12] This two-step barcoding ensures that the vast majority of cells receive a unique barcode combination, allowing for the deconvolution of sequencing data into single-cell contact maps.[12]
Detailed Experimental Protocol (sci-Hi-C)
-
Cell Fixation and Chromatin Fragmentation : Cross-link a population of 5-10 million cells with formaldehyde. Lyse the cells to generate intact, permeabilized nuclei. Fragment the chromatin in situ using a restriction enzyme like DpnII.[11][12]
-
First Round of Barcoding : Distribute the nuclei into a 96-well plate. In each well, ligate a unique, barcoded, biotinylated double-stranded bridge adaptor to the digested chromatin ends.[11]
-
Pooling and Proximity Ligation : Pool all nuclei from the 96-well plate into a single tube. Perform proximity ligation under dilute conditions to favor ligation between DNA ends that were cross-linked together.
-
Second Round of Barcoding : Dilute and redistribute the pooled nuclei into a second 96-well plate, ensuring a low number of nuclei per well (e.g., ~25). Lyse the nuclei completely and introduce the second set of barcodes through ligation of barcoded Y-adaptors.[12]
-
Library Preparation : Pool all material again. Purify the biotinylated ligation junctions using streptavidin beads. Further process the DNA to generate Illumina-compatible sequencing libraries.[11]
-
Sequencing and Analysis : Perform deep paired-end sequencing. During analysis, reads are assigned to individual cells based on their unique combination of Barcode 1 and Barcode 2. This allows the generation of genome-wide contact maps for each single cell.[12]
Comparison of Methodologies
The choice of method depends on the specific biological question, available resources, and the trade-offs between throughput, data sparsity, and the number of molecular layers profiled.
| Feature | scM&T-seq | scNMT-seq | sci-Hi-C | Alleloscope (with scATAC-seq) |
| Primary Ouputs | DNA Methylome, Transcriptome | DNA Methylome, Chromatin Accessibility, Transcriptome | 3D Genome Architecture | Allele-Specific Copy Number, Chromatin Accessibility |
| Key Principle | Physical separation of gDNA/mRNA, Bisulfite-Seq | GpC methyltransferase labeling, Bisulfite-Seq | Combinatorial indexing, Proximity ligation | Allele-specific read counting |
| Cell Throughput | Low to Medium (plate-based) | Low to Medium (plate-based) | High (96x96 indexing) | High (compatible with 10x Genomics) |
| Data Sparsity | High for methylome | High for methylome & accessibility | Very High | Moderate to High |
| Strengths | Direct link between methylation and expression.[2] | 3-layer integration from one cell.[7] | High-throughput 3D genome mapping.[12] | Links CNAs and chromatin state.[13][14] |
| Limitations | No chromatin accessibility data. | Complex protocol and data analysis. | Extremely sparse data per cell. | Indirectly links to expression; requires separate assay. |
Data Integration and Allele-Specific Analysis
The generation of multi-modal single-cell data necessitates sophisticated computational methods to integrate the different layers of information and extract biological insights.[15][16] A primary goal is to link genetic variants (the genome) to their functional consequences on the epigenome and transcriptome.
Computational Integration Workflow
Integrating multi-omics data typically involves several steps. First, data from each modality is pre-processed and subjected to quality control.[16] Next, dimensionality reduction and cell clustering are often performed on one modality (e.g., transcriptome) to define cell populations. These cell labels can then be transferred to the other data modalities from the same cells. Finally, integrative models, such as matrix factorization or neural network-based methods, are used to identify co-variation patterns across the different molecular layers, revealing the relationships between chromatin state, methylation, and gene expression within specific cell types.[15]
Allele-Specific Analysis
A key advantage of linking genomic and epigenomic data at the single-cell level is the ability to perform allele-specific analysis. This allows researchers to dissect the effects of genetic variants on epigenetic regulation in a parent-of-origin-specific manner.
-
Allele-Specific Methylation (ASM) : By combining genotype information with single-cell bisulfite sequencing data, it is possible to identify ASM, where one parental allele is methylated while the other is not.[17] This is critical for studying genomic imprinting and identifying cis-regulatory variants that influence methylation patterns (meQTLs - methylation quantitative trait loci).[17][18]
-
Allele-Specific Chromatin Accessibility (ASCA) : Similarly, by phasing scATAC-seq reads based on heterozygous single nucleotide polymorphisms (SNPs), one can identify variants that lead to differential chromatin accessibility between the two alleles.[19] This can pinpoint functional non-coding variants that alter transcription factor binding sites.
-
Allele-Specific Expression (ASE) and eQTLs : Single-cell RNA-seq data can be used to quantify expression from each allele separately. This allows for the identification of expression quantitative trait loci (eQTLs)—genetic variants that are associated with changes in gene expression levels—at a cell-type-specific resolution.[20][21] Identifying cell-type-specific eQTLs is crucial, as many disease-associated variants exert their effects in only one particular cell type.[21][22]
-
Alleloscope : This computational method is designed to estimate allele-specific copy number from scDNA-seq or scATAC-seq data.[13][23] It enables the integrative analysis of how somatic copy number aberrations (CNAs) and chromatin remodeling interplay to drive clonal evolution in diseases like cancer.[14][23]
Applications in Research and Drug Development
The ability to forge direct links between genetic variation, epigenetic regulation, and transcriptional output in single cells has profound implications:
-
Disease Mechanism : Identifying the specific cell types where disease-associated genetic variants (from GWAS) exert their regulatory effects through eQTLs or meQTLs.[21]
-
Oncology : Dissecting intra-tumor heterogeneity by simultaneously profiling somatic mutations, copy number alterations, DNA methylation, and gene expression to understand clonal evolution, therapy resistance, and the tumor microenvironment.[13][23]
-
Developmental Biology : Tracing cell lineages and understanding how epigenetic landscapes are dynamically coupled with transcriptional programs during differentiation.[1]
-
Drug Discovery : Identifying cell-type-specific regulatory elements and pathways that can be targeted for therapeutic intervention and understanding the epigenetic basis of drug response and resistance at the single-cell level.
By providing a multi-faceted view of individual cells, these integrated approaches are moving the field beyond correlative observations toward a mechanistic understanding of how the genome is regulated in health and disease.
References
- 1. Single-Cell Multiomics Techniques: From Conception to Applications - PMC [pmc.ncbi.nlm.nih.gov]
- 2. sciencedaily.com [sciencedaily.com]
- 3. scM&T-Seq [illumina.com]
- 4. researchgate.net [researchgate.net]
- 5. Technologies and applications of single-cell DNA methylation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. Item - ScNMT-seq enables joint profiling of chromatin accessibility DNA methylation and transcription in single cells - Open Research Newcastle - Figshare [openresearch.newcastle.edu.au]
- 8. scNMT-seq v2 [protocols.io]
- 9. scNMT-seq [protocols.io]
- 10. scNMT-seq [protocols.io]
- 11. Sci-Hi-C: a single-cell Hi-C method for mapping 3D genome organization in large number of single cells - PMC [pmc.ncbi.nlm.nih.gov]
- 12. krishna.gs.washington.edu [krishna.gs.washington.edu]
- 13. Integrative single-cell analysis of allele-specific copy number alterations and chromatin accessibility in cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. researchgate.net [researchgate.net]
- 15. academic.oup.com [academic.oup.com]
- 16. Computational Methods for Single-cell DNA Methylome Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Investigating the potential of single-cell DNA methylation data to detect allele-specific methylation and imprinting - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. eQTL studies: from bulk tissues to single cells - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Interpretation of allele-specific chromatin accessibility using cell state–aware deep learning - PMC [pmc.ncbi.nlm.nih.gov]
- 20. Single-Cell eQTL Analysis - Singleron [singleron.bio]
- 21. Frontiers | Expression quantitative trait locus studies in the era of single-cell omics [frontiersin.org]
- 22. push-zb.helmholtz-munich.de [push-zb.helmholtz-munich.de]
- 23. biorxiv.org [biorxiv.org]
Exploring Cellular Subpopulations with sc-GEM: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
This in-depth technical guide provides a comprehensive overview of the single-cell Genotype, Expression, and Methylation (sc-GEM) technique. This powerful multimodal approach allows for the simultaneous profiling of genetic, transcriptomic, and epigenetic information from individual cells, offering unprecedented resolution into cellular heterogeneity within complex biological systems. Such detailed analysis is critical for advancing research in areas such as oncology, developmental biology, and regenerative medicine, and for the development of novel therapeutic strategies.
Core Principles of sc-GEM
Sample heterogeneity often conceals crucial molecular signatures present in rare cell subpopulations.[1][2] sc-GEM addresses this challenge by integrating three distinct assays at the single-cell level:
-
Genotyping: Identifies single nucleotide variants (SNVs) and other genetic markers to distinguish between different cell types or clonal populations.
-
Gene Expression Analysis: Quantifies mRNA transcripts to elucidate the transcriptional state of individual cells.
-
DNA Methylation Analysis: Interrogates the methylation status of CpG sites, providing insights into the epigenetic regulation of gene expression.
This integrated workflow is implemented on an automated, high-throughput microfluidic platform, enabling the analysis of a large number of single cells in a reproducible and scalable manner.[1]
Data Presentation: Performance Metrics of sc-GEM
The performance of the sc-GEM technique has been rigorously evaluated, demonstrating its high sensitivity and accuracy. The following tables summarize key quantitative performance metrics.
| Metric | Value | Description |
| Cell Capture Efficiency | > 90% | Percentage of single cells successfully captured in the microfluidic device. |
| Genotyping Concordance | > 99% | Agreement of single-cell genotyping results with bulk sequencing data. |
| Gene Expression Detection | ~9,000 genes/cell | Average number of genes detected per single cell. |
| Methylation Assay Dropout Rate | < 10% | Percentage of targeted CpG sites that failed to yield a measurement.[3] |
| Parameter | Sensitivity | Specificity |
| Mutation Detection | > 95% | > 99% |
| Methylation Status | > 98% | > 99% |
Experimental Protocols
The sc-GEM protocol is performed on the Fluidigm C1™ Single-Cell Auto Prep System. The following provides a detailed methodology for the key experimental stages.
Single-Cell Capture and Lysis
-
A suspension of single cells is loaded onto a C1 Integrated Fluidic Circuit (IFC).
-
The C1 system automatically captures individual cells in nanoliter-volume chambers.
-
Each capture site is imaged to confirm the presence of a single cell.
-
Cells are lysed in the individual chambers to release their genomic DNA and mRNA.
Reverse Transcription and Preamplification
-
Reverse transcription is performed in each chamber to convert mRNA into cDNA.
-
The cDNA and genomic DNA are then preamplified using a multiplex PCR approach. This targeted amplification enriches for specific genes of interest for both expression and genotyping analysis.
Genotyping and Gene Expression Analysis
-
The preamplified cDNA is harvested from the IFC.
-
Gene expression levels are quantified using high-throughput quantitative PCR (qPCR) or by sequencing the amplified cDNA.
-
Genotyping is performed by sequencing the preamplified genomic DNA to identify SNVs and other genetic markers.
DNA Methylation Analysis (Single Cell Restriction Analysis of Methylation - SCRAM)
-
Following cell lysis, the genomic DNA in each chamber is treated with a methylation-sensitive restriction enzyme.
-
This enzyme will only cut unmethylated DNA at its specific recognition site.
-
The digested DNA is then subjected to qPCR to quantify the amount of uncut (methylated) DNA at specific CpG sites.
Data Analysis
-
The raw data from the genotyping, gene expression, and methylation assays are collected and processed.
-
Quality control is performed to filter out low-quality data points.
-
The multimodal data is then integrated to link genetic, transcriptomic, and epigenetic information for each single cell.
-
Downstream analysis, such as clustering and trajectory inference, is performed to identify and characterize distinct cellular subpopulations.
Mandatory Visualizations
Experimental Workflow
Caption: The sc-GEM experimental workflow from single-cell isolation to data analysis.
Cellular Reprogramming Signaling Pathway
The process of cellular reprogramming, such as the generation of induced pluripotent stem cells (iPSCs), involves complex changes in signaling pathways. sc-GEM can be used to dissect the heterogeneity of these changes at the single-cell level. The TGF-β signaling pathway is known to play a crucial role in this process.
Caption: Simplified TGF-β signaling pathway involved in cellular reprogramming.
Wnt Signaling Pathway in Cancer Stem Cells
The Wnt signaling pathway is frequently dysregulated in cancer and plays a critical role in the maintenance of cancer stem cells (CSCs). sc-GEM can be employed to identify and characterize CSC subpopulations based on their unique Wnt signaling activity.
References
- 1. Single-cell multimodal profiling reveals cellular epigenetic heterogeneity | Springer Nature Experiments [experiments.springernature.com]
- 2. Single-cell multimodal profiling reveals cellular epigenetic heterogeneity - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Frontiers | The emerging field of opportunities for single-cell DNA methylation studies in hematology and beyond [frontiersin.org]
The Core of Cellular Analysis: A Technical Guide to Microfluidics in sc-GEM Protocols
For Researchers, Scientists, and Drug Development Professionals
In the landscape of modern biological research and therapeutic development, the ability to dissect cellular heterogeneity at the single-cell level is paramount. Single-cell genomic, transcriptomic, epigenomic, and proteomic (sc-GEM) analyses have emerged as powerful tools, and at the heart of these revolutionary protocols lies the elegant science of microfluidics. This technical guide provides an in-depth exploration of the basic principles of microfluidics that underpin sc-GEM, offering a comprehensive resource for researchers, scientists, and drug development professionals seeking to leverage these transformative technologies.
Fundamental Principles of Microfluidics in Single-Cell Analysis
Microfluidics is the science and technology of manipulating minute volumes of fluids, typically in the nanoliter to picoliter range, within channels of micrometer dimensions.[1] This miniaturization offers profound advantages for single-cell analysis, including drastically reduced reagent consumption, faster reaction times due to shorter diffusion distances, and a high degree of parallelism, enabling the analysis of thousands to millions of individual cells in a single experiment.[1][2]
At the microscale, fluid behavior is dominated by viscous forces rather than inertial forces, leading to a phenomenon known as laminar flow.[1] In this regime, fluids flow in parallel streams without turbulent mixing, allowing for the precise control and manipulation of cells and reagents.[1] This predictable fluid behavior is the cornerstone of sc-GEM microfluidic devices.
Two primary microfluidic strategies have become central to sc-GEM protocols: droplet-based microfluidics and microwell-based platforms.
Droplet-Based Microfluidics: Encapsulating Single Cells in Picoliter Reactors
Droplet-based microfluidics involves the generation of monodisperse aqueous droplets within an immiscible oil phase. These droplets serve as independent, picoliter-sized reaction vessels, each capable of encapsulating a single cell along with the necessary reagents for downstream genomic analysis. The most common geometries for droplet generation are T-junctions and flow-focusing devices.[3]
A key innovation in droplet-based sc-GEM is the use of gel beads in emulsion (GEMs).[2] In this approach, a microfluidic chip brings together a stream of cells, a stream of barcoded gel beads, and an oil-surfactant mixture.[4] The precise control of flow rates results in the formation of droplets, with the goal of encapsulating one cell and one gel bead per droplet.[4] To minimize the occurrence of multiple cells in a single droplet (a "doublet"), cells are loaded at a limiting dilution.[5] Once encapsulated, the cells are lysed, and their molecular contents (e.g., mRNA) are captured by the barcoded primers on the co-encapsulated gel bead.[6] This barcoding step is crucial as it assigns a unique identifier to all molecules from a single cell, allowing for the pooling of material from thousands of cells for sequencing while retaining the single-cell origin of the data.[6]
Microwell-Based Platforms: High-Throughput Analysis in Miniaturized Arrays
Microwell-based platforms utilize chips containing thousands of microscopic wells.[3] A suspension of single cells is flowed over the chip, and cells settle into the individual microwells by gravity.[7] Subsequently, beads carrying barcoded primers are added and also settle into the wells.[7] Lysis buffer is then introduced, releasing the cellular contents, which are captured by the barcoded beads within each well.[7] This method also allows for the massive parallelization of single-cell reactions.
Quantitative Performance of sc-GEM Microfluidic Platforms
The choice of a microfluidic platform for sc-GEM studies is often guided by key performance metrics that impact data quality and experimental cost. Below is a summary of reported quantitative data for prominent droplet-based platforms.
| Parameter | 10x Genomics Chromium | inDrop | Drop-seq |
| Cell Throughput per Run | Up to 80,000 (standard); up to 160,000 (GEM-X)[4][8] | >15,000 per hour[9] | ~10,000 per day[6] |
| Cell Capture Efficiency | 50-65% (standard); up to 80% (GEM-X)[8][10] | >75%[9] | Not explicitly stated, relies on Poisson loading |
| Doublet Rate | ~0.9% per 1,000 cells (standard); ~0.4% per 1,000 cells (GEM-X)[8][10] | Dependent on cell concentration | Dependent on cell concentration |
| Transcripts Detected per Cell | ~17,000 (on average)[11] | ~2,700 (on average)[11] | ~8,000 (on average)[11] |
| Genes Detected per Cell | ~3,000 (on average)[11] | ~1,250 (on average)[11] | ~2,500 (on average)[11] |
| Cost per Cell (approx.) | $0.87[11] | $0.44 - $0.47[11] | $0.44 - $0.47[11] |
Experimental Protocols
Detailed Methodology for Droplet-Based Single-Cell RNA-Seq (A Representative Protocol)
This protocol outlines the key steps for encapsulating single cells with barcoded beads in a droplet-based microfluidic system, followed by reverse transcription and library preparation.
Materials:
-
Single-cell suspension in a suitable buffer (e.g., PBS with 0.04% BSA)
-
Microfluidic device for droplet generation (e.g., 10x Genomics Chromium chip)
-
Barcoded gel beads in bead buffer
-
Partitioning oil
-
Lysis and reverse transcription master mix
-
Reagents for cDNA amplification and sequencing library construction
Procedure:
-
Prepare Single-Cell Suspension: Start with a high-quality single-cell suspension with minimal clumps and debris. Cell viability should be greater than 90%. Adjust the cell concentration to the target loading concentration for the specific microfluidic system.
-
Assemble Microfluidic Chip: Load the single-cell suspension, barcoded gel beads, and partitioning oil into the appropriate inlets of the microfluidic chip.
-
GEM Generation: Place the loaded chip into the instrument (e.g., Chromium Controller). The instrument applies precise pressure to the inlets, driving the fluids through the microchannels to generate GEMs.
-
Cell Lysis and Barcoding: Within the droplets, the cells are lysed, and the released mRNA molecules are captured by the poly(dT) primers on the gel beads. Each primer contains a unique cell barcode and a unique molecular identifier (UMI).
-
Reverse Transcription: The droplets are collected and incubated under conditions that allow for reverse transcription of the captured mRNA into cDNA. The cell barcode and UMI are incorporated into the cDNA.
-
Droplet Breaking and cDNA Cleanup: After reverse transcription, the emulsion is broken, and the barcoded cDNA is purified.
-
cDNA Amplification: The purified cDNA is amplified by PCR to generate sufficient material for sequencing.
-
Library Construction: The amplified cDNA is fragmented, and sequencing adapters are ligated to the ends to create a sequencing-ready library.
-
Sequencing: The final library is sequenced on a high-throughput sequencing platform.
Detailed Methodology for Microwell-Based Single-Cell RNA-Seq
This protocol provides a general workflow for capturing single cells in microwells and subsequent RNA capture and library preparation.
Materials:
-
Microwell array chip
-
Single-cell suspension
-
Barcoded magnetic beads
-
Lysis buffer
-
Wash buffer
-
Reverse transcription reagents
-
cDNA amplification and library preparation reagents
Procedure:
-
Chip Preparation: Prime the microwell chip with a wash buffer.
-
Cell Loading: Load the single-cell suspension onto the chip. The cells will settle into the microwells by gravity.
-
Bead Loading: Add the barcoded magnetic beads to the chip. The beads will also settle into the microwells, ideally one bead per well containing a cell.
-
Cell Lysis and RNA Capture: Add lysis buffer to the chip to lyse the cells. The released mRNA will hybridize to the primers on the beads within each well.
-
Bead Collection: Invert the chip and use a magnet to collect the beads with the captured mRNA.
-
Reverse Transcription and Library Preparation: The subsequent steps of reverse transcription, cDNA amplification, and library construction are performed in bulk with the collected beads, similar to the droplet-based method.
Visualization of Workflows and Signaling Pathways
Experimental Workflow for Droplet-Based sc-GEM
References
- 1. TGF-β Signaling | Cell Signaling Technology [cellsignal.com]
- 2. Microfluidics Facilitates the Development of Single-Cell RNA Sequencing [mdpi.com]
- 3. Microfluidics Facilitates the Development of Single-Cell RNA Sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 4. commerce.bio-rad.com [commerce.bio-rad.com]
- 5. Benchmarking computational doublet-detection methods for single-cell RNA sequencing data - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Droplet-Sequencing (Drop-Seq) - Elveflow [elveflow.com]
- 7. integra-biosciences.com [integra-biosciences.com]
- 8. 10xgenomics.com [10xgenomics.com]
- 9. rna-seqblog.com [rna-seqblog.com]
- 10. Advances in Microfluidic Single-Cell RNA Sequencing and Spatial Transcriptomics - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Comparative analysis of droplet-based ultra-high-throughput single-cell RNA-seq systems - preLights [prelights.biologists.com]
Methodological & Application
Revolutionizing Lung Adenocarcinoma Research: The sc-GEM Protocol for Integrated Single-Cell Genomic and Transcriptomic Analysis
Application Note & Protocol
Audience: Researchers, scientists, and drug development professionals in oncology and genomics.
Introduction:
The heterogeneity of primary human lung adenocarcinoma presents a significant challenge in developing effective therapies. To address this, we introduce the single-cell Genome and Expression Method (sc-GEM), a comprehensive protocol for the simultaneous genomic and transcriptomic profiling of individual cancer cells. This powerful technique, based on the principles of Genome and Transcriptome Sequencing (G&T-seq), allows for the direct correlation of genetic variants with gene expression signatures from the same cell. Such a multi-omics approach at single-cell resolution is critical for elucidating the complex interplay between genotype and phenotype that drives tumor evolution, metastasis, and drug resistance. This document provides detailed application notes and a step-by-step protocol for the implementation of sc-GEM on primary human lung adenocarcinoma cells.
Data Presentation
A summary of expected quantitative data from the sc-GEM protocol is presented in the tables below. These values are compiled from various studies and represent typical outcomes.
Table 1: Primary Cell Isolation and Culture Success Rates
| Parameter | Value | Reference |
| Initial Cell Viability | > 80% | Internal data |
| Primary Culture Success Rate | 70-85% | [1] |
| Time to First Passage | 10-14 days | [1] |
| Spheroid Formation Efficiency | ~70% | [1] |
Table 2: Single-Cell Sequencing Library Quality Control
| Parameter | Genomic DNA Library | Transcriptomic (cDNA) Library |
| Reads per cell | 1-5 million | 1-3 million |
| Mapping Rate | > 90% | > 85% |
| Genes detected per cell | N/A | 3,000 - 6,000 |
| Duplication Rate | < 20% | < 10% |
Experimental Protocols
This section details the methodologies for the key experiments in the sc-GEM protocol.
Part 1: Isolation and Culture of Primary Human Lung Adenocarcinoma Cells
-
Tissue Acquisition and Transport:
-
Obtain fresh primary lung adenocarcinoma tissue immediately after surgical resection.
-
Transport the tissue to the laboratory in a sterile container with ice-cold RPMI-1640 medium supplemented with 1% Penicillin-Streptomycin.
-
-
Tissue Dissociation:
-
Wash the tissue twice with sterile phosphate-buffered saline (PBS).
-
Mechanically mince the tissue into small fragments (~1-2 mm³) using sterile scalpels.
-
Transfer the fragments to a gentleMACS C Tube containing a digestion solution of RPMI-1640, 2 mg/mL collagenase IV, and 0.25% Trypsin-EDTA.
-
Incubate at 37°C for 30-60 minutes with gentle agitation.
-
-
Cell Filtration and Red Blood Cell Lysis:
-
Neutralize the enzymatic digestion with an equal volume of DMEM/F12 medium containing 10% fetal bovine serum (FBS).
-
Filter the cell suspension sequentially through 100 µm and 40 µm cell strainers.
-
Centrifuge the filtered suspension at 300 x g for 5 minutes.
-
Resuspend the cell pellet in 1 mL of ACK lysis buffer and incubate for 5 minutes at room temperature to lyse red blood cells.
-
Add 10 mL of PBS and centrifuge again.
-
-
Primary Cell Culture:
-
Resuspend the cell pellet in complete growth medium (e.g., DMEM/F12 supplemented with 10% FBS, 1% Penicillin-Streptomycin, 20 ng/mL EGF, and 10 ng/mL bFGF).
-
Plate the cells in a T25 flask and incubate at 37°C in a humidified atmosphere with 5% CO₂.
-
Change the medium every 2-3 days and monitor for cell attachment and growth.
-
Part 2: sc-GEM Protocol (G&T-seq)
-
Single-Cell Isolation:
-
Once the primary culture reaches 70-80% confluency, detach the cells using TrypLE Express.
-
Prepare a single-cell suspension in PBS with 0.04% BSA.
-
Isolate individual cells into separate wells of a 96-well plate using fluorescence-activated cell sorting (FACS) or limiting dilution.
-
-
Cell Lysis and Separation of gDNA and mRNA:
-
To each well containing a single cell, add lysis buffer containing oligo-dT primers with biotin (B1667282) tags.
-
The oligo-dT primers will bind to the poly(A) tails of the mRNA.
-
Introduce streptavidin-coated magnetic beads to capture the biotinylated mRNA-primer hybrids.
-
Use a magnet to separate the beads (with bound mRNA) from the supernatant containing the genomic DNA (gDNA).
-
-
Genomic DNA Processing:
-
Carefully transfer the gDNA-containing supernatant to a new 96-well plate.
-
Perform whole-genome amplification (WGA) using a suitable method such as Multiple Displacement Amplification (MDA).
-
Prepare a sequencing library from the amplified gDNA using a commercial kit (e.g., Nextera XT).
-
-
mRNA Processing:
-
On the magnetic beads, perform reverse transcription to synthesize the first strand of cDNA.
-
Amplify the full-length cDNA using a modified Smart-seq2 protocol.
-
Prepare a sequencing library from the amplified cDNA.
-
-
Sequencing and Data Analysis:
-
Sequence both the gDNA and cDNA libraries on a high-throughput sequencing platform.
-
For the gDNA data, perform alignment to a reference genome, variant calling (SNVs, indels), and copy number variation (CNV) analysis.
-
For the cDNA data, perform alignment, gene expression quantification, and differential expression analysis.
-
Integrate the genomic and transcriptomic data for each single cell to correlate genetic alterations with gene expression profiles.
-
Visualizations
Experimental Workflow
Caption: Workflow for the sc-GEM protocol.
Signaling Pathways in Lung Adenocarcinoma
EGFR and KRAS Signaling Pathway
Caption: Simplified EGFR and KRAS signaling pathways.
PI3K/AKT/mTOR Signaling Pathway
Caption: The PI3K/AKT/mTOR signaling cascade.
Wnt Signaling Pathway
Caption: Overview of the canonical Wnt signaling pathway.
References
Application Notes and Protocols for sc-GEM Library Preparation
For Researchers, Scientists, and Drug Development Professionals
Introduction:
This document provides a comprehensive, step-by-step guide for preparing single-cell gene expression (sc-GEM) libraries using the 10x Genomics Chromium platform. The term "sc-GEM" refers to the core Gel Bead-in-Emulsion (GEM) technology that enables the partitioning of individual cells and the barcoding of their transcripts, forming the basis for single-cell RNA sequencing (scRNA-seq). This protocol is a synthesis of the methodologies for the Chromium Next GEM Single Cell 3' and 5' gene expression assays, which are widely used for high-throughput single-cell transcriptomic analysis.
These protocols are intended for researchers, scientists, and drug development professionals familiar with standard molecular biology techniques. Adherence to the detailed steps and best practices outlined below is critical for generating high-quality single-cell libraries for downstream sequencing and analysis.
I. Experimental Workflow Overview
The sc-GEM library preparation workflow is a multi-stage process that begins with a high-quality single-cell suspension and culminates in a sequencing-ready library. The key stages involve cell partitioning and barcoding within GEMs, followed by reverse transcription, cDNA amplification, and library construction.
Figure 1. High-level overview of the sc-GEM library preparation workflow.
II. Detailed Experimental Protocols
This section provides detailed methodologies for the key steps in the sc-GEM library preparation process. The protocols are based on the 10x Genomics Chromium Next GEM Single Cell 3' v3.1 and 5' v3 assays.
Protocol 1: Single-Cell Suspension Preparation
A high-quality single-cell suspension is paramount for a successful sc-GEM experiment. Proper handling and preparation are crucial to minimize cell stress, aggregation, and lysis.
1.1. Cell Source and Dissociation:
-
Start with a viable cell culture or freshly dissociated tissue.
-
Use appropriate enzymatic or mechanical dissociation methods optimized for your specific sample type to obtain a single-cell suspension.
-
Minimize the duration of enzymatic digestion to maintain cell viability.
1.2. Washing and Resuspension:
-
Wash the cells to remove debris and enzymes from the dissociation process.
-
Resuspend the cell pellet in a suitable buffer, such as 1X PBS with 0.04% BSA. The buffer should be free of EDTA (>0.1 mM) and magnesium (>3 mM) as these can interfere with downstream enzymatic reactions.[1]
1.3. Cell Counting and Viability Assessment:
-
Accurately determine the cell concentration and viability using a hemocytometer or an automated cell counter.
-
Aim for a cell viability of >90%. Lower viability can lead to the release of ambient RNA, which increases background noise.
1.4. Final Concentration Adjustment:
-
Adjust the cell suspension concentration to the target range for the specific 10x Genomics assay being used. This is typically in the range of 700-1,200 cells/µL.[1]
Protocol 2: GEM Generation and Barcoding
This step involves the use of a microfluidic chip to partition single cells into nanoliter-scale Gel Beads-in-emulsion (GEMs).
2.1. Reagent and Chip Preparation:
-
Thaw all necessary reagents from the 10x Genomics kit on ice.
-
Equilibrate the Gel Beads to room temperature for at least 30 minutes before use.
-
Prepare the Master Mix containing reverse transcription reagents as specified in the user guide.[2]
2.2. Loading the Chromium Chip:
-
Assemble the Chromium Next GEM Chip G in the chip holder.[3]
-
Carefully load the appropriate volumes of the single-cell suspension, Master Mix, Gel Beads, and Partitioning Oil into the designated wells of the chip.[3]
2.3. Running the Chromium Controller:
-
Place the assembled chip in the Chromium Controller.
-
The instrument will then partition the cells with Gel Beads and oil to form GEMs.
Protocol 3: Reverse Transcription and cDNA Amplification
3.1. Reverse Transcription in GEMs:
-
Following GEM generation, the chip is removed from the controller, and the GEMs are transferred to a PCR tube or plate.
-
Incubate the GEMs in a thermal cycler to allow for cell lysis and reverse transcription of mRNA into barcoded cDNA.
3.2. Post-GEM Cleanup:
-
After incubation, the GEMs are broken, and the pooled cDNA is purified using magnetic beads (e.g., Dynabeads MyOne SILANE). This step removes leftover reagents and primers.
3.3. cDNA Amplification:
-
The purified, full-length barcoded cDNA is amplified via PCR to generate sufficient material for library construction.
Protocol 4: Library Construction
4.1. Fragmentation, End Repair, and A-tailing:
-
The amplified cDNA is enzymatically fragmented to an appropriate size for sequencing.
-
The fragmented cDNA then undergoes end repair and A-tailing to prepare it for adapter ligation.
4.2. Adapter Ligation:
-
Sequencing adapters are ligated to the ends of the cDNA fragments.
4.3. Sample Index PCR:
-
A final PCR step is performed to add sample indices and amplify the final library.
Protocol 5: Library Quantification and Quality Control
5.1. Library Quantification:
-
Quantify the final library concentration using a Qubit fluorometer or a similar fluorescence-based method.
5.2. Library Quality Assessment:
-
Assess the size distribution of the final library using an Agilent Bioanalyzer or TapeStation. A successful library will show a distinct peak at the expected size range.
III. Quantitative Data Summary
The following tables provide a summary of key quantitative parameters for the sc-GEM library preparation workflow.
Table 1: Single-Cell Suspension Parameters
| Parameter | Recommended Range | Notes |
| Cell Viability | > 90% | Lower viability increases background from ambient RNA. |
| Cell Concentration | 700 - 1,200 cells/µL | Optimal concentration for maximizing cell capture while minimizing multiplets.[1] |
| Input Cell Suspension Volume | Varies | Refer to the specific 10x Genomics User Guide for the Cell Suspension Volume Calculator Table. |
Table 2: Key Reagent Volumes for Chromium Chip Loading (per sample)
| Reagent | Volume |
| Single-Cell Suspension & Master Mix | ~70 µL |
| Gel Beads | ~50 µL |
| Partitioning Oil | ~45 µL |
Table 3: Thermal Cycler Conditions for Reverse Transcription
| Step | Temperature (°C) | Time |
| Incubation | 53 | 45 minutes |
| Enzyme Denaturation | 85 | 5 minutes |
| Hold | 4 | Hold |
Table 4: Final Library Quality Control Metrics
| Metric | Expected Result |
| Library Concentration | > 2 nM |
| Average Library Size | 400 - 600 bp (assay dependent) |
IV. Signaling Pathway and Workflow Diagrams
The following diagrams illustrate the core concepts of the sc-GEM technology and the detailed library construction workflow.
Figure 2. Conceptual diagram of GEM formation and transcript barcoding.
Figure 3. Detailed workflow for sc-GEM library construction from amplified cDNA.
References
Application Notes and Protocols: Applying sc-GEM to Study Epigenetic Variations in Human Embryonic Stem Cells (hESCs)
Audience: Researchers, scientists, and drug development professionals.
Introduction: The Challenge of Heterogeneity in hESCs
Human embryonic stem cells (hESCs) hold immense promise for regenerative medicine and disease modeling due to their capacity for indefinite self-renewal and pluripotency. However, hESC populations are not uniform; they exhibit significant cell-to-cell heterogeneity in gene expression and epigenetic states.[1][2] This variability, which can arise from asynchronous cell cycles, culture-induced adaptations, or stochastic fluctuations, complicates efforts to understand the fundamental mechanisms of pluripotency and to direct consistent differentiation into desired cell lineages.[1][3]
Epigenetic modifications, particularly DNA methylation, are critical for regulating gene expression and maintaining the pluripotent state.[4][5] Pluripotency-associated genes like OCT4 and NANOG are typically unmethylated in hESCs, becoming methylated upon differentiation.[4] Studying these epigenetic landscapes at the single-cell level is crucial to deconvolute population heterogeneity and understand the intricate link between the epigenome and transcriptome.
Single-cell Genotype, Expression, and Methylation (sc-GEM) analysis is a targeted, multimodal technique designed to address this challenge. It allows for the simultaneous interrogation of gene expression, DNA methylation at specific loci, and genotype from an individual cell.[6] This powerful approach, often implemented on automated microfluidic platforms, enables researchers to directly link epigenetic status to transcriptional output within the same cell, providing unprecedented resolution into the molecular underpinnings of hESC identity and fate decisions.[7][8]
Application Notes
The sc-GEM technique offers several key applications for studying epigenetic variations in hESCs:
-
Dissecting Epigenetic Heterogeneity: sc-GEM can quantify the methylation status of key pluripotency and differentiation-associated gene promoters (e.g., OCT4, NANOG, lineage-specific markers) in individual cells. This allows for the identification and characterization of distinct epigenetic subpopulations within a seemingly homogeneous hESC culture.
-
Linking Methylation to Gene Expression: By measuring both DNA methylation and mRNA levels from the same cell, sc-GEM provides a direct method to correlate the epigenetic state of a gene's regulatory region with its transcriptional activity. This is critical for confirming regulatory relationships that are often inferred from population-level data.[9]
-
Monitoring Differentiation Dynamics: The technique can be used to track epigenetic and transcriptional changes in single cells as they exit pluripotency and commit to a specific lineage. This provides insights into the sequence of molecular events that govern cell fate decisions and can help identify epigenetic barriers or facilitators of differentiation.
-
Quality Control of hESC Cultures: Culture-induced epigenetic changes can affect the differentiation potential of hESCs.[3] sc-GEM can serve as a quality control tool to assess the epigenetic stability of hESC lines over time, ensuring the reliability and reproducibility of experiments.
-
Understanding Reprogramming Mechanisms: The reverse process, cellular reprogramming, can be monitored with sc-GEM to understand the epigenetic and transcriptional dynamics as somatic cells reacquire pluripotency.[8]
Limitations and Considerations:
While powerful, sc-GEM is a targeted approach . It analyzes a pre-selected set of loci for methylation and a defined panel of genes for expression via RT-qPCR.[7] This contrasts with genome-wide methods like single-cell Methylome and Transcriptome sequencing (scM&T-seq), which provide a more comprehensive, unbiased view of the epigenome and transcriptome.[9][10] The choice between a targeted or genome-wide approach depends on the specific research question—sc-GEM is ideal for hypothesis-driven research focusing on known regulatory elements, while scM&T-seq is suited for discovery-based studies.
Data Presentation: Unveiling Single-Cell Correlations
Quantitative data from sc-GEM can be summarized to highlight the relationships between DNA methylation and gene expression at the single-cell level.
Table 1: Correlation of Promoter Methylation and Gene Expression for Pluripotency Factors in a Single hESC Colony. This table illustrates hypothetical data from a sc-GEM experiment on 96 individual hESCs, showing the relationship between the methylation status of the OCT4 and NANOG promoters and their respective mRNA expression levels.
| Cell ID | OCT4 Promoter Methylation Status | OCT4 Expression (Relative Quantity) | NANOG Promoter Methylation Status | NANOG Expression (Relative Quantity) | Inferred State |
| Cell_001 | Unmethylated | 1.05 | Unmethylated | 0.98 | Pluripotent |
| Cell_002 | Unmethylated | 0.95 | Unmethylated | 1.10 | Pluripotent |
| ... | ... | ... | ... | ... | ... |
| Cell_048 | Unmethylated | 0.21 | Methylated | < 0.01 | Primed for Differentiation |
| Cell_049 | Methylated | < 0.01 | Methylated | < 0.01 | Differentiating |
| ... | ... | ... | ... | ... | ... |
| Cell_096 | Unmethylated | 1.12 | Unmethylated | 1.05 | Pluripotent |
Table 2: Dynamic Changes in Methylation During Directed Endoderm Differentiation. This table shows representative data tracking the percentage of cells with methylated promoters for a pluripotency marker (NANOG) and an endoderm marker (SOX17) over a 5-day differentiation protocol.
| Time Point | Gene | % of Cells with Methylated Promoter |
| Day 0 (hESCs) | NANOG | 5% |
| SOX17 | 95% | |
| Day 3 | NANOG | 45% |
| SOX17 | 60% | |
| Day 5 (Endoderm) | NANOG | 98% |
| SOX17 | 10% |
Experimental Protocols and Workflows
sc-GEM Experimental Workflow
The sc-GEM protocol integrates several steps, often automated on a microfluidic platform like the Fluidigm C1 system, to process single cells.[7][11] The core method combines the Single Cell Restriction Analysis of Methylation (SCRAM) assay with single-cell RT-qPCR and genotyping.[6]
Detailed sc-GEM Protocol (Microfluidic Platform)
This protocol is adapted for an automated microfluidic system (e.g., Fluidigm C1).
I. Cell Preparation and Loading
-
hESC Culture: Culture hESCs under desired conditions (e.g., feeder-free on Matrigel).
-
Dissociation: Dissociate hESC colonies into a single-cell suspension using a gentle enzyme (e.g., Accutase). Ensure high viability (>90%).
-
Cell Concentration: Resuspend cells in an appropriate buffer at the optimal concentration for the microfluidic chip (e.g., 300-500 cells/µL).
-
IFC Priming and Loading: Prime the integrated fluidic circuit (IFC) as per the manufacturer's instructions.[12] Load the cell suspension into the IFC. The system will automatically capture single cells into individual reaction chambers.
-
Imaging: Image the IFC to confirm the capture of single, viable cells in each chamber. This is a critical quality control step.[13]
II. On-Chip Lysis and Nucleic Acid Processing
-
Cell Lysis: The automated script initiates cell lysis, releasing genomic DNA (gDNA) and mRNA.[11]
-
Reverse Transcription (RT): An RT mix containing specific primers for target genes is added. Polyadenylated mRNA is reverse-transcribed into cDNA.
-
Expression Pre-amplification: The cDNA is subjected to a multiplexed, specific-target amplification (STA) PCR to enrich for the genes of interest.
-
SCRAM Assay (on gDNA):
-
The gDNA is treated with a methylation-sensitive restriction enzyme (e.g., HpaII) and a methylation-insensitive isoschizomer (e.g., MspI) in parallel reactions or chambers. HpaII cuts unmethylated CCGG sites but is blocked by CpG methylation, while MspI cuts regardless of methylation status.
-
A control reaction with no enzyme is also performed.
-
-
Methylation/Genotype Pre-amplification: The digested gDNA is amplified using primers flanking the target CpG sites and any desired genotyping loci.
III. Harvesting and Downstream Analysis
-
Harvesting: The amplified cDNA and gDNA products from each single-cell chamber are harvested into a 96-well plate.[14]
-
Gene Expression Analysis:
-
The pre-amplified cDNA is analyzed using quantitative PCR (qPCR) on a high-throughput platform (e.g., Fluidigm BioMark HD).
-
Relative gene expression is calculated using the ΔΔCt method.
-
-
Methylation and Genotype Analysis:
-
The pre-amplified gDNA products are prepared for next-generation sequencing (NGS). Barcodes are added to identify the cell of origin and the specific locus.
-
Methylation Quantification: After sequencing, the methylation status is determined by comparing the read counts from the HpaII-digested sample to the MspI (or no-enzyme) control. A lack of product in the HpaII sample indicates an unmethylated site.
-
Genotyping: Sequence variants (SNPs) can be called from the NGS data.
-
Signaling Pathways Maintaining hESC Pluripotency
The maintenance of hESC pluripotency is governed by a complex and finely balanced network of signaling pathways.[15] Key pathways include TGF-β/Activin/Nodal, FGF, and Wnt signaling.[16] These pathways converge on a core network of transcription factors—OCT4, SOX2, and NANOG—to maintain the self-renewing, undifferentiated state.
References
- 1. Single cell heterogeneity in human pluripotent stem cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Integrative single-cell omics analyses reveal epigenetic heterogeneity in mouse embryonic stem cells - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Single cell heterogeneity in human pluripotent stem cells - PMC [pmc.ncbi.nlm.nih.gov]
- 4. DNA methylation in embryonic stem cells - PMC [pmc.ncbi.nlm.nih.gov]
- 5. DNA methylation and hydroxymethylation in stem cells - PMC [pmc.ncbi.nlm.nih.gov]
- 6. standardbio.com [standardbio.com]
- 7. Technologies and applications of single-cell DNA methylation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Single-cell multimodal profiling reveals cellular epigenetic heterogeneity | Springer Nature Experiments [experiments.springernature.com]
- 9. Parallel single-cell sequencing links transcriptional and epigenetic heterogeneity - PMC [pmc.ncbi.nlm.nih.gov]
- 10. scM&T-Seq [illumina.com]
- 11. The use of the Fluidigm C1 for RNA expression analyses of single cells - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. Using Fluidigm C1 to Generate Single-Cell Full-Length cDNA Libraries for mRNA Sequencing | Springer Nature Experiments [experiments.springernature.com]
- 14. takara.co.kr [takara.co.kr]
- 15. Signaling networks in human pluripotent stem cells - PMC [pmc.ncbi.nlm.nih.gov]
- 16. researchgate.net [researchgate.net]
Single-Cell Genotyping using Next-Generation Sequencing in sc-GEM: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
Introduction
Single-cell analysis has emerged as a powerful tool for dissecting cellular heterogeneity within complex biological systems. The sc-GEM (single-cell Genotype, Expression, and Methylation) method provides a unique multimodal approach to simultaneously profile the genome, transcriptome, and methylome from a single cell. This capability is particularly valuable in fields such as oncology, developmental biology, and immunology, where understanding the interplay between genetic mutations, gene expression, and epigenetic regulation at the single-cell level is crucial. By integrating targeted genotyping with gene expression and DNA methylation analysis, sc-GEM enables researchers to link specific genetic variants to phenotypic changes within individual cells, offering unprecedented insights into disease mechanisms and therapeutic responses.
This document provides detailed application notes and protocols for performing single-cell genotyping using next-generation sequencing (NGS) as part of the sc-GEM workflow.
Principle of the Method
The sc-GEM methodology leverages a high-throughput microfluidic platform to isolate and process individual cells. The workflow integrates three distinct analyses:
-
Genotyping: Targeted amplification of specific genomic loci followed by next-generation sequencing to identify single nucleotide variants (SNVs) and other genetic alterations.
-
Gene Expression Analysis: Reverse transcription quantitative PCR (RT-qPCR) for the targeted quantification of mRNA transcripts.
-
DNA Methylation Analysis: Single-Cell Restriction Analysis of Methylation (SCRAM), which utilizes methylation-sensitive restriction enzymes to assess the methylation status of specific CpG sites.
This integrated workflow allows for the direct correlation of a cell's genotype with its transcriptional and epigenetic state.
Applications
The sc-GEM technique is applicable to a wide range of research areas, including:
-
Oncology: Characterizing intra-tumor heterogeneity, identifying rare drug-resistant clones, and linking specific mutations to changes in gene expression and methylation patterns in cancer cells.
-
Developmental Biology: Tracing cell lineages and understanding the role of genetic mosaicism in development.
-
Immunology: Studying the genetic and epigenetic basis of immune cell differentiation and function.
-
Drug Discovery and Development: Evaluating the on-target and off-target effects of novel therapeutics at the single-cell level and identifying biomarkers for patient stratification.
Performance Characteristics
The sc-GEM method has been demonstrated to be a robust and reliable technique for single-cell multi-omics analysis. Key performance metrics are summarized in the table below.
| Performance Metric | Typical Value | Reference |
| Genotyping | ||
| Genotyping Concordance with Sanger Sequencing | >95% | [1](1) |
| DNA Methylation | ||
| DNA Methylation Detection Efficiency | High | [1](1) |
| Incidence of Dropouts in Methylation Assay | Low | [1](1) |
| Gene Expression | ||
| Correlation with Bulk Gene Expression | High | [1](1) |
| Sensitivity | High | [2(https://vertexaisearch.cloud.google.com/grounding-api-redirect/AUZIYQF7fjDpy0dXzLzXSJ97rUYsojvSxRZr7W9w7-AiakASI1TlFzPsHX3Nw7o1lROzM8U_D7ObDwqv5vB16R2drU2uofdqWnDf5aQOO8ubNN04FgWzCtNbV04bPOb-b47LgO52fyPisyD64oX3GWmVIqctabZ5hQW3KottrtG6Ro2-eHyqGshxXNbuJ6jRcoOY5bXlz0cDB4NJpMMYlzVzMANt8oEicpeRJnI=) |
Experimental Workflow
The sc-GEM workflow can be broken down into four main stages: Single-Cell Capture and Lysis, Reverse Transcription and Pre-amplification, Methylation Analysis (SCRAM), and Genotyping Library Preparation and Sequencing.
Detailed Protocols
Single-Cell Capture and Lysis
This protocol is designed for use with a microfluidic system, such as the Fluidigm C1.
Materials:
-
Single-cell suspension in a suitable buffer (e.g., PBS with 0.1% BSA)
-
C1 Single-Cell Auto Prep IFC (Integrated Fluidic Circuit)
-
C1 Lysis Reagent
-
Nuclease-free water
Procedure:
-
Prepare a single-cell suspension at a concentration of 300-500 cells/µL. Ensure the suspension is free of clumps and debris.
-
Prime the C1 IFC with priming reagent according to the manufacturer's instructions.
-
Load the cell suspension, lysis reagent, and other necessary reagents into the designated wells of the IFC.
-
Place the IFC into the C1 instrument and run the cell loading and lysis script. This script will automatically capture single cells in individual chambers and perform lysis.
-
After the run, visually inspect the IFC under a microscope to confirm the capture of single cells.
Reverse Transcription and Pre-amplification
Materials:
-
Reverse transcription master mix (containing reverse transcriptase, dNTPs, and random primers)
-
Gene-specific primers for targeted gene expression analysis
-
Genotyping-specific primers for targeted genomic loci
-
PCR master mix for pre-amplification
Procedure:
-
Prepare a master mix containing reverse transcription reagents and gene-specific primers for both expression and genotyping.
-
Load the master mix into the appropriate wells of the C1 IFC.
-
Run the reverse transcription and pre-amplification script on the C1 instrument. This script will perform reverse transcription of mRNA to cDNA and then a limited number of PCR cycles to pre-amplify both the cDNA and the genomic DNA targets within each chamber.
-
After the run, harvest the pre-amplified product from each chamber of the IFC.
Single-Cell Restriction Analysis of Methylation (SCRAM)
Materials:
-
Methylation-sensitive restriction enzyme (e.g., HhaI or HpaII) and its corresponding buffer.
-
Control restriction enzyme (methylation-insensitive isoschizomer, if available)
-
PCR master mix
-
Primers flanking the CpG site of interest
Procedure:
-
Divide the pre-amplified product from each single cell into two reactions: one for digestion with the methylation-sensitive enzyme and a control reaction (no enzyme or digestion with a methylation-insensitive enzyme).
-
Perform the restriction digest according to the enzyme manufacturer's protocol.
-
Following digestion, perform qPCR using primers that flank the restriction site.
-
Analyze the qPCR data. If the CpG site is methylated, the methylation-sensitive enzyme will not cut, and the PCR product will be amplified. If the site is unmethylated, the enzyme will cut, and no PCR product will be generated.
NGS Library Preparation for Genotyping
Materials:
-
NGS library preparation kit (e.g., Illumina Nextera XT)
-
PCR master mix
-
Barcoded primers for multiplexing
Procedure:
-
Use the remaining portion of the pre-amplified product for NGS library preparation.
-
Perform a second round of PCR to add sequencing adapters and barcodes to the pre-amplified genomic DNA targets. This allows for the pooling of multiple single-cell libraries for sequencing.
-
Purify the barcoded PCR products using magnetic beads or a column-based method.
-
Quantify the final library and assess its quality using a Bioanalyzer or similar instrument.
-
Pool the libraries from all single cells and sequence on an Illumina sequencer (e.g., MiSeq or HiSeq).
Data Analysis Workflow
The data generated from the sc-GEM experiment requires a multi-step bioinformatics pipeline for analysis.
1. Genotyping Data Analysis:
-
Quality Control: Raw sequencing reads are assessed for quality using tools like FastQC.
-
Alignment: Reads are aligned to a reference genome using aligners such as BWA or Bowtie2.
-
Variant Calling: Aligned reads are processed to identify SNVs and other variants using tools like GATK or Samtools.
-
Annotation: Called variants are annotated to determine their functional impact.
2. Gene Expression Data Analysis:
-
Raw qPCR data is analyzed using the ΔΔCt method to determine the relative expression of target genes in each single cell.
3. Methylation Data Analysis:
-
The qPCR data from the SCRAM assay is analyzed to determine the methylation status (methylated or unmethylated) of the targeted CpG sites.
4. Integrated Analysis:
-
The genotyping, gene expression, and methylation data for each single cell are integrated to identify correlations and build a comprehensive picture of cellular heterogeneity.
Troubleshooting
| Problem | Possible Cause | Suggested Solution |
| Low cell capture efficiency | Cell suspension has low viability or contains aggregates. | Optimize cell isolation protocol to ensure high viability and a single-cell suspension. Filter the cell suspension before loading. |
| PCR amplification failure | Poor cell lysis; inhibitors in the reaction. | Ensure complete cell lysis. Purify the initial cell suspension to remove potential inhibitors. |
| High dropout rate in genotyping | Low amount of starting genomic DNA; inefficient pre-amplification. | Optimize the pre-amplification protocol to increase the yield of target amplicons. |
| Inconsistent qPCR results | Pipetting errors; poor primer design. | Use a master mix to minimize pipetting variability. Validate primer efficiency and specificity. |
| Low-quality sequencing data | Poor library quality; issues with the sequencing run. | Quantify and qualify the library before sequencing. Consult the sequencing facility for troubleshooting the run. |
Conclusion
The sc-GEM method provides a powerful platform for multimodal single-cell analysis, enabling researchers to unravel the complex interplay between a cell's genotype, transcriptome, and methylome. The detailed protocols and application notes provided here serve as a comprehensive guide for implementing this technique in your own research, with the potential to yield significant new insights into the fundamental mechanisms of health and disease. with the potential to yield significant new insights into the fundamental mechanisms of health and disease.
References
Application Notes and Protocols for Quantitative Gene Expression Analysis with Single-Cell RT-qPCR
Audience: Researchers, scientists, and drug development professionals.
Introduction
Single-cell gene expression analysis has revolutionized our understanding of cellular heterogeneity within complex biological systems. Unlike bulk-level analysis, which provides an average expression profile of a cell population, single-cell analysis allows for the dissection of individual cellular responses, revealing rare cell populations and subtle variations in gene expression that are critical in disease progression and drug response. Reverse transcription quantitative real-time PCR (RT-qPCR) is a highly sensitive and specific method for quantifying gene expression in individual cells. Its high precision and wide dynamic range make it an invaluable tool for validating findings from high-throughput sequencing technologies and for targeted analysis of specific gene sets in drug discovery and development.[1]
These application notes provide a comprehensive overview and detailed protocols for performing quantitative gene expression analysis using single-cell RT-qPCR, with a specific focus on studying the Mitogen-Activated Protein Kinase (MAPK) signaling pathway in the context of cancer research and drug development.
Key Applications in Drug Development
-
Identifying and characterizing rare cell populations: Isolate and analyze rare drug-resistant cells within a tumor to understand mechanisms of resistance.
-
Assessing cellular heterogeneity in drug response: Determine how individual cells within a population respond differently to a drug candidate.[2][3]
-
Validating biomarkers: Confirm the expression of potential biomarkers in individual target cells.
-
Mechanism of action studies: Elucidate the effects of a drug on specific signaling pathways, such as the MAPK pathway, at the single-cell level.
Experimental Workflow Overview
The workflow for single-cell RT-qPCR involves several critical steps, each requiring careful execution to ensure high-quality, reproducible data.
Caption: A general workflow for single-cell RT-qPCR experiments.
Detailed Experimental Protocols
Protocol 1: Single-Cell Isolation
Accurate and gentle isolation of single cells is paramount to preserving their transcriptional state. Several methods can be employed, with the choice depending on the sample type and available instrumentation.
Materials:
-
Phosphate-Buffered Saline (PBS), Ca2+/Mg2+ free
-
Bovine Serum Albumin (BSA)
-
Cell strainers (e.g., 40 µm)
-
Fluorescence-Activated Cell Sorter (FACS), Micromanipulator, or Laser Capture Microdissection (LCM) system
-
96-well or 384-well PCR plates
Method (using FACS):
-
Prepare a single-cell suspension:
-
For adherent cells, wash with PBS, and detach using a gentle enzyme (e.g., TrypLE).
-
For tissue samples, mechanically and enzymatically dissociate the tissue to release single cells.
-
Filter the cell suspension through a cell strainer to remove clumps.
-
-
Stain cells (optional): If specific cell populations are targeted, stain with fluorescently labeled antibodies against cell surface markers.
-
Set up the FACS sorter: Calibrate the instrument for single-cell sorting into individual wells of a PCR plate.
-
Sort single cells: Sort individual cells directly into wells of a PCR plate containing cell lysis buffer. Include no-cell controls (wells with only lysis buffer) to monitor for contamination.
Protocol 2: Cell Lysis and Genomic DNA Removal
This step is crucial for releasing RNA from the cell and eliminating contaminating genomic DNA (gDNA), which can interfere with accurate gene expression quantification.
Materials:
-
Single-cell lysis buffer (commercial kits are recommended, e.g., SingleShot Cell Lysis Kit)
-
DNase I, RNase-free
-
Reaction stop solution
Method:
-
Prepare Lysis Solution: On ice, prepare a master mix of lysis buffer and DNase I according to the manufacturer's instructions.
-
Cell Lysis:
-
For sorted cells, ensure each well of the PCR plate contains the appropriate volume of lysis solution.
-
Incubate the plate at room temperature for 10 minutes to lyse the cells and allow for DNase I activity.
-
-
DNase Inactivation: Add a stop solution to each well to inactivate the DNase I. This is often accomplished by a chelating agent and a short incubation at a specific temperature (e.g., 75°C for 5 minutes). The cell lysates can typically be stored at -80°C.
Protocol 3: Reverse Transcription (RT)
In this step, the messenger RNA (mRNA) from the single cell is converted into more stable complementary DNA (cDNA).
Materials:
-
Reverse transcriptase (e.g., SuperScript VILO)
-
RT buffer
-
Random primers and/or oligo(dT) primers
-
dNTPs
-
RNase inhibitor
Method:
-
Prepare RT Master Mix: On ice, prepare a master mix containing RT buffer, primers, dNTPs, RNase inhibitor, and reverse transcriptase.
-
Perform Reverse Transcription:
-
Add the RT master mix to each well containing the cell lysate.
-
Incubate the plate in a thermal cycler using the recommended temperature profile for the reverse transcriptase (e.g., 25°C for 10 min, 42°C for 60 min, and 85°C for 5 min to inactivate the enzyme).
-
The resulting cDNA can be stored at -20°C.
-
Protocol 4: Preamplification (Optional but Recommended)
Due to the low starting amount of RNA in a single cell, a preamplification step is often necessary to enrich for the target cDNA sequences before qPCR analysis.[1] This allows for the analysis of a larger number of genes from a single cell.
Materials:
-
Preamplification master mix (e.g., TaqMan PreAmp Master Mix)
-
Pooled primers for all target genes of interest (at a low concentration)
Method:
-
Prepare Preamplification Mix: On ice, prepare a master mix containing the preamplification master mix and the pooled primers.
-
Perform Preamplification:
-
Add the preamplification mix to each well containing the cDNA.
-
Perform a limited number of PCR cycles (e.g., 10-14 cycles) in a thermal cycler. This targeted amplification increases the amount of the specific cDNA targets without introducing significant bias.
-
-
Dilute Preamplified cDNA: Dilute the preamplified product (e.g., 1:5 or 1:10) with nuclease-free water to reduce the concentration of inhibitors before qPCR.
Protocol 5: Quantitative PCR (qPCR)
This final step quantifies the amount of each target gene in the single-cell cDNA sample.
Materials:
-
qPCR master mix (e.g., SsoAdvanced Universal SYBR Green Supermix or TaqMan Universal PCR Master Mix)
-
Gene-specific primers (or TaqMan assays)
Method:
-
Prepare qPCR Reactions: For each gene of interest, prepare a qPCR master mix containing the qPCR master mix and the specific forward and reverse primers (or TaqMan assay).
-
Set up qPCR Plate: Dispense the qPCR master mix for each gene into different wells of a new PCR plate. Add the diluted, preamplified cDNA to each well.
-
Perform qPCR: Run the qPCR plate on a real-time PCR instrument using a standard cycling protocol (e.g., 95°C for 3 min, followed by 40 cycles of 95°C for 10 sec and 60°C for 30 sec).
-
Data Collection: Collect the fluorescence data at each cycle. The cycle at which the fluorescence crosses a set threshold is the quantification cycle (Cq).
Data Presentation and Analysis
Quantitative data from single-cell RT-qPCR experiments should be presented clearly to facilitate interpretation and comparison. The raw output from the qPCR instrument is the Cq value, which is inversely proportional to the amount of starting template.
Data Normalization and Quality Control
-
Quality Control:
-
No-Template Controls (NTCs): Should not show any amplification, indicating no contamination.
-
No-RT Controls: Should not amplify to rule out gDNA contamination.
-
Melting Curve Analysis (for SYBR Green): Should show a single peak, indicating the amplification of a specific product.
-
-
Data Filtering: Cells with very low numbers of detected genes or very high Cq values for housekeeping genes may be excluded from further analysis.
-
Normalization: Normalizing to one or more stably expressed housekeeping genes (e.g., GAPDH, ACTB) is a common practice in bulk qPCR. However, in single-cell analysis, the expression of these genes can be highly variable. An alternative is to use the average expression of a panel of reference genes or to perform a global mean normalization. The delta-delta Cq (ΔΔCq) method is often used for relative quantification.[4]
Example: Quantitative Analysis of MAPK Pathway Genes in Single Cancer Cells
This example demonstrates the analysis of key genes in the MAPK signaling pathway in single melanoma cells treated with a BRAF inhibitor.
Table 1: Raw Cq Values for MAPK Pathway Genes in Single Melanoma Cells
| Cell ID | BRAF | MEK1 (MAP2K1) | ERK2 (MAPK1) | c-Fos | GAPDH |
| Cell 1 | 24.5 | 26.8 | 25.1 | 28.9 | 21.2 |
| Cell 2 | 25.1 | 27.2 | 25.5 | 29.5 | 21.5 |
| Cell 3 | 23.9 | 26.1 | 24.8 | 28.1 | 20.9 |
| Cell 4 | 28.2 | 29.5 | 28.7 | 31.8 | 22.1 |
| Cell 5 | 24.8 | 27.0 | 25.3 | 29.1 | 21.4 |
| NTC | N/A | N/A | N/A | N/A | N/A |
N/A: No Amplification
Table 2: Relative Quantification (Fold Change) of MAPK Pathway Genes in Single Melanoma Cells Treated with a BRAF Inhibitor (vs. Untreated Control)
To calculate the fold change, the ΔΔCq method was used, with GAPDH as the reference gene and the average expression in untreated single cells as the control.
| Gene | Average Fold Change | Standard Deviation |
| BRAF | 0.95 | 0.12 |
| MEK1 (MAP2K1) | 1.85 | 0.45 |
| ERK2 (MAPK1) | 1.52 | 0.38 |
| c-Fos | 0.45 | 0.15 |
Note: This is example data for illustrative purposes.
Application Focus: MAPK Signaling Pathway in Cancer Drug Development
The Mitogen-Activated Protein Kinase (MAPK) pathway is a critical signaling cascade that regulates cell proliferation, differentiation, and survival. Dysregulation of this pathway, often through mutations in genes like BRAF and RAS, is a hallmark of many cancers, including melanoma.[3]
Caption: A simplified diagram of the MAPK signaling pathway.
Targeted therapies, such as BRAF and MEK inhibitors, have shown significant efficacy in treating BRAF-mutant melanomas. However, the development of drug resistance is a major clinical challenge. Single-cell RT-qPCR can be employed to:
-
Investigate Heterogeneity in Drug Response: By analyzing the expression of key MAPK pathway genes (e.g., BRAF, MEK1, ERK2, and downstream targets like c-Fos) in individual tumor cells before and after treatment, researchers can identify subpopulations of cells that exhibit an altered signaling response.
-
Identify Mechanisms of Resistance: Upregulation of bypass signaling pathways or feedback mechanisms can be detected in drug-resistant single cells. For example, an increase in MEK1 expression in some cells following BRAF inhibitor treatment might suggest a mechanism of adaptive resistance.
-
Develop Combination Therapies: By understanding the specific signaling changes in resistant cells, more effective combination therapies can be designed to target these escape pathways.
Conclusion
Single-cell RT-qPCR is a powerful and precise technique for quantitative gene expression analysis that provides invaluable insights into cellular heterogeneity. The detailed protocols and application examples provided here offer a solid foundation for researchers, scientists, and drug development professionals to implement this technology in their workflows. By enabling the study of individual cellular responses to therapeutic agents, single-cell RT-qPCR plays a crucial role in advancing our understanding of disease mechanisms and in the development of more effective and personalized medicines.
References
- 1. Tutorial: Guidelines for Single-Cell RT-qPCR - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Single-cell RNA-seq analysis identifies markers of resistance to targeted BRAF inhibitors in melanoma cell populations - PMC [pmc.ncbi.nlm.nih.gov]
- 3. academic.oup.com [academic.oup.com]
- 4. A new mathematical model for relative quantification in real-time RT–PCR - PMC [pmc.ncbi.nlm.nih.gov]
Unlocking Single-Cell Epigenetics: Application and Protocols for DNA Methylation Analysis at Single CpG Sites using sc-GEM
Authored for Researchers, Scientists, and Drug Development Professionals, this document provides a detailed overview and practical guidance for the application of Single-cell Genotype, Expression, and Methylation (sc-GEM) analysis. This powerful multimodal technique enables the simultaneous interrogation of genetic, transcriptomic, and epigenetic states within individual cells, offering unprecedented resolution to dissect cellular heterogeneity in complex biological systems.
At its core, the sc-GEM method provides a targeted approach to quantify DNA methylation at specific CpG sites, revealing cell-to-cell variability that is often obscured in bulk sample analyses.[1][2] This is particularly valuable in fields such as oncology, developmental biology, and pharmacology, where understanding the epigenetic landscape of rare cell populations can provide critical insights into disease mechanisms and drug response.
The methylation analysis component of sc-GEM, known as Single Cell Restriction Analysis of Methylation (SCRAM), leverages methylation-sensitive restriction enzymes to determine the methylation status of specific CpG sites.[1][3] This enzyme-based approach, followed by quantitative PCR (qPCR), offers a cost-effective and targeted alternative to whole-genome bisulfite sequencing.[4] The entire workflow is frequently implemented on automated microfluidic platforms, such as the Fluidigm C1 system, to ensure high throughput and minimize contamination.[1][5]
Core Applications in Research and Drug Development
The ability to link genotype, gene expression, and DNA methylation in a single cell provides a powerful tool for:
-
Dissecting Tumor Heterogeneity: Identify rare, drug-resistant cell populations within a tumor by linking specific genetic mutations to distinct epigenetic and transcriptional profiles.[2][5]
-
Understanding Cellular Reprogramming and Differentiation: Track epigenetic changes at key developmental loci as cells differentiate or are reprogrammed, correlating methylation status with the expression of pluripotency or lineage-specific genes.[6]
-
Pharmacodynamic Biomarker Discovery: Assess the epigenetic impact of DNA methyltransferase inhibitors (DNMTis) or other epigenetic modifiers at the single-cell level to understand the mechanism of action and identify biomarkers of response.
-
Safety and Efficacy Screening: Evaluate off-target epigenetic effects of drug candidates in heterogeneous cell populations, such as in primary tissue samples.
Performance Characteristics
The sc-GEM method has been shown to be highly sensitive with a low incidence of dropouts in the DNA methylation assay.[1] The methylation state of a single CpG site determined by sc-GEM has been demonstrated to be representative of the methylation status of the surrounding region.[1]
| Performance Metric | Typical Value | Source |
| Assay Principle | Methylation-Sensitive Restriction Enzyme (MSRE) digestion followed by qPCR | [1][4] |
| Target Loci Analyzed | Up to 24 loci per 48 cells in a single run | [4] |
| Concordance with Bisulfite Sequencing | High concordance for methylation calls | Cheow et al., 2016[1] |
| Dropout Rate (Methylation) | Low | [1] |
| Input Material | Single cells from cell lines or primary tissues | [1] |
Experimental and Data Analysis Workflow
The sc-GEM workflow integrates cell capture, multi-omic processing, and data analysis. The process begins with the isolation of single cells, followed by parallel enzymatic reactions to probe the genome, transcriptome, and epigenome.
Detailed Experimental Protocol: SCRAM Methylation Analysis
This protocol is adapted from the sc-GEM methodology and focuses on the DNA methylation analysis (SCRAM) portion. It assumes single cells have been isolated and lysed within a microfluidic system.
1. Reagents and Materials:
-
Methylation-Sensitive Restriction Enzyme (MSRE): e.g., HpaII (recognizes CCGG) and its methylation-insensitive isoschizomer MspI (for controls).
-
Restriction Enzyme Buffer
-
DNA Polymerase for pre-amplification and qPCR
-
Sequence-Specific Primers for target CpG loci
-
qPCR Master Mix with a fluorescent dye (e.g., SYBR Green or EvaGreen)
-
Nuclease-free water
2. Methylation-Sensitive Restriction Enzyme (MSRE) Digestion:
-
Following cell lysis and reverse transcription (for the gene expression component), the genomic DNA (gDNA) of the single cell is ready for digestion.
-
Prepare a master mix containing the appropriate 10X restriction enzyme buffer and the MSRE (e.g., HpaII). A parallel control reaction using a methylation-insensitive enzyme (e.g., MspI) or a mock digestion (no enzyme) should be run for each locus to establish a baseline.
-
Add the MSRE master mix to each single-cell reaction chamber containing gDNA.
-
Incubate the reaction according to the enzyme manufacturer's specifications (e.g., 37°C for 1-2 hours).
-
Heat-inactivate the enzyme (e.g., 65°C for 20 minutes).
3. Locus-Specific Preamplification:
-
Prepare a multiplex PCR master mix containing a suitable DNA polymerase, buffer, dNTPs, and a pool of forward and reverse primers for all target loci.
-
Add the preamplification master mix to the digested gDNA.
-
Perform a limited number of PCR cycles (e.g., 14-18 cycles) to enrich for the target sequences without introducing significant amplification bias.
-
Initial Denaturation: 95°C for 3 minutes
-
Cycling (14-18x):
-
95°C for 30 seconds
-
60°C for 30 seconds
-
72°C for 30 seconds
-
-
Final Extension: 72°C for 5 minutes
-
4. Quantitative PCR (qPCR) Analysis:
-
Dilute the preamplified product (e.g., 1:5 or 1:10) in nuclease-free water.
-
Prepare individual qPCR reactions for each target locus. Each reaction should contain the diluted preamplified product, a suitable qPCR master mix, and a single primer pair for one target locus.
-
Run the qPCR plate on a real-time PCR instrument. Standard cycling conditions are typically:
-
Initial Denaturation: 95°C for 5 minutes
-
Cycling (40x):
-
95°C for 15 seconds
-
60°C for 45 seconds (acquire fluorescence)
-
-
-
Perform a melt curve analysis at the end of the run to ensure product specificity.
Data Analysis Protocol
The methylation status of a target CpG site is determined by comparing the qPCR amplification from the MSRE-digested sample to a control.
1. Cq Value Extraction:
-
Obtain the raw quantification cycle (Cq) values for each reaction from the real-time PCR instrument software.
2. ΔCq Calculation and Interpretation:
-
The principle relies on the fact that if a CpG site within the enzyme's recognition sequence is unmethylated , the enzyme will cut the DNA, preventing subsequent PCR amplification (resulting in a high Cq value or no amplification).
-
If the site is methylated , the enzyme is blocked, the DNA remains intact, and it will be amplified (resulting in a lower Cq value).
3. Methylation Calling:
-
For each locus in each cell, calculate the ΔCq between the HpaII-digested sample and the mock-digested (or MspI-digested) control: ΔCq = Cq(HpaII) - Cq(Control)
-
A low ΔCq value (e.g., < 3) indicates that HpaII digestion was blocked, meaning the site is likely methylated .
-
A high ΔCq value (e.g., > 5-7, depending on empirical thresholds) indicates successful digestion, meaning the site is likely unmethylated .
-
The final output is a binary matrix of methylation calls (methylated/unmethylated) for each targeted CpG site in every successfully analyzed single cell.
4. Integrated Analysis:
-
This binary methylation matrix can then be integrated with the corresponding single-cell gene expression data (from RT-qPCR) and genotyping information to build a comprehensive multi-omic picture of each cell, enabling powerful downstream analyses like correlating promoter methylation with gene silencing or identifying epigenetic subtypes within a cancer cell population.
References
- 1. Single-cell multimodal profiling reveals cellular epigenetic heterogeneity | Springer Nature Experiments [experiments.springernature.com]
- 2. na01.alma.exlibrisgroup.com [na01.alma.exlibrisgroup.com]
- 3. Single Cell Restriction Enzyme-Based Analysis of Methylation at Genomic Imprinted Regions in Preimplantation Mouse Embryos - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Technologies and applications of single-cell DNA methylation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Single-cell multimodal profiling reveals cellular epigenetic heterogeneity - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
Application Notes and Protocols for Integrating sc-GEM Data with Other Single-Cell Assays
For Researchers, Scientists, and Drug Development Professionals
Introduction
Single-cell multi-omics is revolutionizing our understanding of complex biological systems by providing a high-resolution view of cellular heterogeneity. While individual single-cell assays like transcriptomics (scRNA-seq), epigenomics (scATAC-seq), and proteomics (CITE-seq) offer deep insights into one dimension of cellular function, integrating these modalities provides a more comprehensive picture of the genotype-phenotype relationship. This document provides a guide to integrating data from various single-cell assays, with a focus on leveraging the multi-modal nature of technologies like sc-GEM (single-cell Genotype, Expression, and Methylation).
sc-GEM is a powerful targeted technique that simultaneously measures genotype, gene expression, and DNA methylation from the same single cell.[1] This "true" multi-modal data from the same cell is invaluable for directly linking genetic variants to epigenetic and transcriptional changes. However, the principles of data integration discussed here are broadly applicable, including to more common high-throughput approaches where different omics are measured from different cells from the same sample population.
The integration of these diverse datasets allows researchers to:
-
Achieve a more accurate and robust identification of cell types and states.
-
Understand the regulatory logic connecting chromatin accessibility and DNA methylation to gene expression.
-
Link genetic variants to specific molecular and cellular phenotypes.
-
Uncover complex signaling dynamics that are invisible to single-modality analyses.
Experimental Strategies for Multi-Omics Data Generation
There are two primary experimental strategies for generating single-cell multi-omics data:
-
Separate Assays on the Same Sample: A common approach involves splitting a single-cell or single-nucleus suspension into multiple aliquots, with each being used for a different single-cell assay (e.g., scRNA-seq, scATAC-seq). This strategy is flexible and allows for the use of optimized protocols for each modality. Computational integration is then used to align the datasets and identify corresponding cell populations.
-
Simultaneous Multi-Modal Assays: An increasing number of technologies allow for the measurement of multiple modalities from the same single cell. This provides a direct, one-to-one linkage between different molecular layers. Examples include:
-
10x Genomics Multiome: Simultaneously profiles gene expression (3' scRNA-seq) and chromatin accessibility (scATAC-seq) from the same nucleus.
-
sc-GEM: As mentioned, provides targeted analysis of genotype, gene expression (via RT-qPCR), and DNA methylation.[1]
-
CITE-seq (Cellular Indexing of Transcriptomes and Epitopes by Sequencing): Measures cell surface protein levels (via oligo-tagged antibodies) along with the transcriptome.
-
scNMT-seq (single-cell nucleosome, methylation and transcription sequencing): Measures chromatin accessibility, DNA methylation, and gene expression from the same cell.
-
The choice of experimental strategy depends on the biological question, sample availability, and the specific modalities of interest.
Experimental Protocol: Simultaneous Profiling of Gene Expression and Chromatin Accessibility using a 10x Genomics Multiome-like Workflow
This protocol provides a generalized workflow for the simultaneous analysis of the transcriptome and chromatin accessibility from the same single nucleus, based on the principles of the 10x Genomics Multiome ATAC + Gene Expression assay.
1. Nuclei Isolation and Tagmentation:
-
Objective: To isolate high-quality nuclei from a cell suspension or tissue and then use a transposase to preferentially cut and insert sequencing adapters into accessible chromatin regions.
-
Methodology:
-
Start with a single-cell suspension. If using tissue, first dissociate into single cells using appropriate enzymatic and mechanical methods.
-
Lyse the cells using a non-ionic detergent (e.g., NP-40) in a lysis buffer to release the nuclei, while keeping the nuclear membrane intact.
-
Perform a density gradient centrifugation or use fluorescence-activated cell sorting (FACS) to purify the nuclei from cellular debris.
-
Incubate the isolated nuclei with a Tn5 transposase enzyme pre-loaded with sequencing adapters. The transposase will enter the nuclei and "tagment" the DNA, preferentially fragmenting open chromatin regions and simultaneously ligating adapters to the ends of these fragments.
-
2. Single-Nuclei Barcoding in Droplets:
-
Objective: To encapsulate individual nuclei into nanoliter-scale droplets with uniquely barcoded gel beads.
-
Methodology:
-
Load the tagmented nuclei suspension, along with reverse transcription reagents, onto a microfluidic chip (e.g., 10x Genomics Chromium Controller).
-
Simultaneously, load gel beads that are co-functionalized with two types of oligonucleotides: one with an oligo-dT sequence to capture polyadenylated mRNA, and another with a spacer sequence to capture the adapter-ligated DNA fragments from the ATAC-seq library. Each gel bead contains a unique 10x Barcode.
-
The microfluidic device partitions the nuclei and gel beads into Gel Beads-in-emulsion (GEMs). The concentration is controlled such that the vast majority of GEMs contain a single nucleus and a single gel bead.
-
3. In-Droplet Reverse Transcription and Barcoding:
-
Objective: To generate barcoded cDNA from mRNA and capture barcoded ATAC DNA fragments within each GEM.
-
Methodology:
-
Once encapsulated, the gel beads are dissolved, releasing the barcoded oligos into the droplet.
-
The oligo-dT primers initiate reverse transcription of mRNA, creating first-strand cDNA that incorporates the 10x Barcode and a Unique Molecular Identifier (UMI).
-
The adapter-ligated ATAC DNA fragments are also barcoded through a ligation or amplification step.
-
4. Library Preparation and Sequencing:
-
Objective: To generate separate, sequencing-ready libraries for gene expression and ATAC-seq.
-
Methodology:
-
Break the emulsion and pool the barcoded molecules from all droplets.
-
Perform a pre-amplification step.
-
Separate the pre-amplified product into two fractions for gene expression and ATAC library construction.
-
For the Gene Expression Library: Perform standard scRNA-seq library preparation steps, including amplification, fragmentation, and addition of Illumina sequencing adapters.
-
For the ATAC Library: Perform PCR to amplify the barcoded ATAC fragments and add Illumina sequencing adapters.
-
Sequence both libraries on a compatible Illumina sequencer.
-
Computational Protocol: Integrating scRNA-seq and scATAC-seq Data using Seurat
This protocol outlines a typical computational workflow for integrating scRNA-seq and scATAC-seq datasets, whether they are from the same cells (like in a Multiome experiment) or from parallel experiments on the same biological sample. This workflow is based on the popular Seurat R package and its extension for chromatin data, Signac.
1. Pre-processing of Individual Modalities:
-
Objective: To perform quality control and normalization for each dataset independently.
-
scRNA-seq Data:
-
Create a Seurat object from the gene expression count matrix.
-
Filter out low-quality cells based on the number of genes detected, UMI counts, and the percentage of mitochondrial reads.
-
Normalize the data (e.g., using NormalizeData with a log-transformation).
-
Identify highly variable genes using FindVariableFeatures.
-
Scale the data and perform Principal Component Analysis (PCA) using ScaleData and RunPCA.
-
-
scATAC-seq Data:
-
Create a Seurat object with a ChromatinAssay from the peak count matrix and the fragments file.
-
Calculate QC metrics such as nucleosome signal, transcription start site (TSS) enrichment score, and the fraction of reads in peaks (FRiP). Filter out low-quality cells based on these metrics.
-
Normalize the data and perform dimensionality reduction using Term Frequency-Inverse Document Frequency (TF-IDF) followed by Singular Value Decomposition (SVD), which is often referred to as Latent Semantic Indexing (LSI) in this context.
-
2. Gene Activity Matrix Generation (for scATAC-seq):
-
Objective: To create a gene-based matrix from the scATAC-seq data that can be compared to the scRNA-seq data.
-
Methodology:
-
Quantify the accessibility of each gene's promoter region (and optionally the gene body) by summing the ATAC-seq reads in these regions. The GeneActivity() function in Signac can be used for this purpose. This creates a "gene activity" matrix, which serves as a proxy for gene expression.
-
3. Integration and Label Transfer:
-
Objective: To align the two datasets and transfer cell type annotations from the scRNA-seq data (which is typically easier to annotate) to the scATAC-seq data.
-
Methodology:
-
Use the FindTransferAnchors() function in Seurat to identify "anchors" between the scRNA-seq dataset (the reference) and the scATAC-seq gene activity matrix (the query). These anchors represent pairs of cells (one from each dataset) that are in a similar biological state.
-
Use the TransferData() function to transfer the cell type labels from the annotated scRNA-seq reference to the scATAC-seq cells. This function uses the identified anchors to predict the cell type for each cell in the query dataset.
-
4. Joint Visualization and Analysis:
-
Objective: To create a shared low-dimensional embedding for both modalities to visualize the integrated data and perform downstream analysis.
-
Methodology:
-
Use the identified anchors to co-embed the scRNA-seq and scATAC-seq datasets into a single UMAP or t-SNE plot using functions like RunUMAP on the merged object. This allows for the visualization of how well the datasets align and the identification of shared and unique cell populations.
-
Perform joint clustering on the integrated data to identify cell populations that are consistent across both modalities.
-
Identify differentially accessible chromatin regions and differentially expressed genes between cell types in the integrated dataset.
-
Link enhancers to target genes by correlating the accessibility of distal chromatin regions with the expression of nearby genes across cell types.
-
Data Presentation: Quantitative Summaries
A key outcome of multi-omic integration is the ability to generate quantitative summaries that compare and contrast the information from each modality.
Table 1: Comparison of Cell Type Proportions
This table shows a hypothetical comparison of cell type proportions as identified by unimodal analysis of scRNA-seq and scATAC-seq data, versus the proportions determined after computational integration. The integrated analysis often provides a more refined and accurate cell type classification.
| Cell Type | scRNA-seq Alone (%) | scATAC-seq Alone (%) | Integrated Analysis (%) |
| CD4+ Naive T Cells | 35.2 | 33.8 | 34.5 |
| CD8+ Effector T Cells | 18.5 | 20.1 | 19.2 |
| B Cells | 15.8 | 14.9 | 15.5 |
| CD14+ Monocytes | 12.1 | 13.5 | 12.7 |
| NK Cells | 8.9 | 9.2 | 9.0 |
| Dendritic Cells | 4.3 | 3.9 | 4.1 |
| Plasmacytoid DCs | 1.1 | 0.8 | 1.0 |
| Other | 4.1 | 3.8 | 4.0 |
Table 2: Linking Differentially Accessible Regions (DARs) to Differentially Expressed Genes (DEGs)
This table illustrates how integrated analysis can link enhancers (represented by DARs) to their putative target genes (DEGs) in a specific cell type, for example, in activated CD4+ T cells compared to naive CD4+ T cells.
| Gene Symbol | Log2FC (Expression) | Linked Enhancer (DAR) | Log2FC (Accessibility) | Distance to TSS |
| IL2RA | 2.5 | chr10:6,145,230-6,145,890 | 3.1 | -2 kb |
| TBX21 | 3.1 | chr17:45,987,110-45,987,750 | 2.8 | +15 kb |
| IFNG | 4.2 | chr12:68,990,400-68,991,100 | 3.5 | -5 kb |
| STAT4 | 1.8 | chr2:191,845,300-191,845,950 | 2.2 | +50 kb |
| GZMB | 3.8 | chr14:24,598,320-24,598,900 | 2.9 | -25 kb |
Visualizations
Experimental and Computational Workflows
Signaling Pathway Example: NF-κB Regulation
The NF-κB (nuclear factor kappa-light-chain-enhancer of activated B cells) signaling pathway is a crucial regulator of the immune response, inflammation, and cell survival. Its activity is controlled at multiple levels, making it an ideal candidate for multi-omic investigation.
How Multi-Omics Illuminates NF-κB Signaling:
-
CITE-seq can quantify the levels of cytokine receptors (like TNFR) on the cell surface, providing a measure of a cell's potential to respond to stimuli.
-
scATAC-seq can map the chromatin accessibility of NF-κB target gene promoters and enhancers. An increase in accessibility at these sites indicates that the regulatory regions are being prepared for transcription.
-
scRNA-seq measures the transcriptional output of the pathway by quantifying the mRNA levels of NF-κB target genes.
By integrating these modalities, researchers can trace the flow of information from receptor expression to chromatin remodeling and finally to gene transcription, all at the single-cell level. This allows for the identification of cell populations that are actively signaling, those that are primed to respond, and the specific regulatory elements that control the expression of key inflammatory and survival genes.
Conclusion
The integration of sc-GEM data with other single-cell assays provides an unparalleled opportunity to dissect the complex interplay between the genome, epigenome, and transcriptome in defining cellular identity and function. The experimental and computational protocols outlined here offer a robust framework for researchers to embark on multi-omic single-cell studies. By carefully designing experiments and applying appropriate computational integration strategies, scientists can uncover novel biological insights that are critical for basic research and the development of new therapeutic strategies.
References
Troubleshooting & Optimization
Technical Support Center: Troubleshooting Low Cell Capture Efficiency in sc-GEM Experiments
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals address low cell capture efficiency in single-cell Gene Expression Omnibus (sc-GEM) experiments.
Frequently Asked Questions (FAQs)
Q1: What is a typical cell capture efficiency for sc-GEM experiments?
A1: Cell capture efficiency, the percentage of single cells from the input sample that are successfully encapsulated into GEMs, can vary depending on the specific single-cell platform and the cell type being analyzed. Generally, a capture rate of 50-80% is considered good. However, it is crucial to consult the manufacturer's documentation for the expected range for your specific system.
Q2: How does low cell viability impact capture efficiency?
A2: Low cell viability is a primary contributor to poor capture efficiency. Dead or dying cells are fragile and can lyse during sample processing and loading onto the microfluidic chip. This lysis releases cellular debris and ambient RNA, which can clog the microfluidic channels and interfere with GEM formation, ultimately reducing the number of viable cells captured.[1][2][3][4] Many single-cell sequencing platforms recommend a minimum viability threshold of 80% or higher to ensure high-quality data.[4]
Q3: Can cell size and type affect capture efficiency?
A3: Yes, cell size and type can influence capture efficiency. Most microfluidic systems are optimized for a specific range of cell sizes. Very large or small cells may be captured less efficiently. Additionally, some cell types are inherently more fragile or prone to aggregation, which can negatively impact their capture. It is important to understand the characteristics of your specific sample.[5]
Q4: What is the role of cell concentration in capture efficiency?
A4: The concentration of the cell suspension is a critical parameter. An optimal concentration ensures a high probability of capturing single cells in individual GEMs while minimizing the occurrence of doublets (more than one cell per GEM).[6][7] A concentration that is too low will result in a low number of captured cells and a high percentage of empty GEMs. Conversely, a concentration that is too high increases the likelihood of doublets and can lead to clogging of the microfluidic device.[8]
Troubleshooting Guides
Low cell capture efficiency can arise from issues at various stages of the sc-GEM workflow. This guide is structured to help you identify and resolve potential problems from sample preparation to GEM generation.
Guide 1: Pre-Loading: Sample Preparation Issues
| Problem | Potential Cause | Recommended Solution |
| Low Cell Viability (<80%) | Harsh dissociation methods (enzymatic or mechanical stress). | Optimize dissociation protocols by reducing incubation times, using lower enzyme concentrations, or employing gentler mechanical disruption. Consider using a dead cell removal kit. |
| Prolonged or improper sample storage. | Process fresh samples whenever possible. If storage is necessary, use appropriate cryopreservation techniques and minimize storage time.[2] Store cell suspensions on ice and aim to proceed with downstream steps within 30 minutes of preparation.[8] | |
| Contamination in cell culture. | Regularly check cell cultures for contamination. Use sterile techniques and appropriate antibiotics. | |
| Cell Aggregates and Clumps | Incomplete dissociation. | Ensure complete dissociation of tissues or cell pellets. Use cell strainers (e.g., 40 µm) immediately before loading to remove any remaining aggregates.[6] |
| Presence of extracellular DNA from lysed cells. | Treat the cell suspension with DNase I to minimize cell clumping.[6] | |
| Inappropriate resuspension buffer. | Resuspend cells in a calcium and magnesium-free buffer, such as PBS with a low concentration of BSA (e.g., 0.04%).[8] | |
| Presence of Debris and Contaminants | Incomplete removal of red blood cells or other contaminants. | For blood samples, perform a thorough red blood cell lysis. For tissue samples, optimize the dissociation and washing steps to remove debris. |
| Carryover of enzymes or other reagents from dissociation. | Wash the cell pellet thoroughly after dissociation to remove any residual enzymes or reagents that could interfere with downstream reactions.[8] | |
| Inaccurate Cell Counting | Human error in manual counting. | Use an automated cell counter for more accurate and reproducible cell counts. |
| Uneven cell suspension. | Gently pipette mix the cell suspension before taking an aliquot for counting to ensure a homogenous sample.[8] |
Guide 2: On-Chip: GEM Generation Issues
| Problem | Potential Cause | Recommended Solution |
| Clogged Microfluidic Chip | Presence of cell aggregates or debris in the cell suspension. | Filter the cell suspension through a cell strainer immediately before loading.[6][8] |
| Cell concentration is too high. | Optimize the cell concentration according to the manufacturer's recommendations. | |
| Low Number of Cells Loaded | Inaccurate initial cell count. | Re-count the cells using a reliable method. |
| Cell settling in the pipette tip or tube. | Gently mix the cell suspension immediately before loading to ensure a uniform concentration.[8] | |
| Suboptimal Microfluidic Chip Performance | Manufacturing defects in the chip. | Inspect the chip for any visible defects before use. Contact the manufacturer if issues are suspected. |
| Improper handling or storage of the chip. | Store and handle the microfluidic chips according to the manufacturer's instructions to prevent damage. |
Experimental Protocols
Protocol 1: Cell Viability Assessment using Trypan Blue
-
Prepare a 1:1 dilution of your cell suspension with 0.4% Trypan Blue stain. For example, mix 10 µL of your cell suspension with 10 µL of Trypan Blue.
-
Incubate the mixture for 1-2 minutes at room temperature.
-
Load 10 µL of the mixture into a hemocytometer.
-
Under a microscope, count the number of viable (unstained) and non-viable (blue) cells in the four large corner squares of the hemocytometer grid.
-
Calculate the cell viability:
-
Total Cells = Viable Cells + Non-Viable Cells
-
% Viability = (Number of Viable Cells / Total Cells) x 100
-
Protocol 2: Preparation of a Single-Cell Suspension from Cultured Cells
-
Aspirate the culture medium from the cell culture flask or plate.
-
Wash the cells once with sterile, calcium and magnesium-free PBS.
-
Add an appropriate volume of a dissociation reagent (e.g., Trypsin-EDTA) to cover the cell monolayer and incubate at 37°C until the cells detach.
-
Neutralize the dissociation reagent with an equal volume of complete culture medium.
-
Gently pipette the cell suspension up and down to create a single-cell suspension.
-
Transfer the cell suspension to a conical tube and centrifuge at a low speed (e.g., 300 x g) for 5 minutes to pellet the cells.
-
Aspirate the supernatant and resuspend the cell pellet in a suitable buffer for single-cell analysis (e.g., PBS with 0.04% BSA).
-
Filter the cell suspension through a 40 µm cell strainer into a new tube.
-
Proceed with cell counting and viability assessment.
Visualizations
Caption: sc-GEM experimental workflow with key potential failure points highlighted.
Caption: A decision tree for troubleshooting low cell capture efficiency.
References
- 1. 10xgenomics.com [10xgenomics.com]
- 2. Overcoming Common Challenges in Sample Viability for Single-Cell Research | Labcompare.com [labcompare.com]
- 3. selectscience.net [selectscience.net]
- 4. resources.revvity.com [resources.revvity.com]
- 5. frontlinegenomics.com [frontlinegenomics.com]
- 6. How to Optimize Benchtop Cell Sorting for Single-Cell RNA Sequencing Workflows - Nodexus [nodexus.com]
- 7. What are some challenges and solutions in single cell RNA-Seq data analysis? | AAT Bioquest [aatbio.com]
- 8. biocompare.com [biocompare.com]
Technical Support Center: sc-GEM DNA Methylation Assays
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals minimize dropouts and optimize their single-cell Genotype, Expression, and Methylation (sc-GEM) DNA methylation assays.
Frequently Asked Questions (FAQs)
Q1: What is the sc-GEM assay?
A1: Single-cell Genotype, Expression, and Methylation (sc-GEM) is a powerful multimodal technique that allows for the simultaneous analysis of genotype, gene expression, and DNA methylation from a single cell. It integrates the Single Cell Restriction Analysis of Methylation (SCRAM) assay with single-cell RT-qPCR and next-generation sequencing-based genotyping.[1] This approach is particularly useful for dissecting cellular heterogeneity and understanding the interplay between genetic, epigenetic, and transcriptomic variations.[2]
Q2: What are "dropouts" in the context of sc-GEM DNA methylation data?
A2: In sc-GEM DNA methylation analysis, a "dropout" refers to the failure to obtain a methylation measurement at a specific CpG site in a given single cell. This results in missing data, often represented as "Not Available" (NA) values in the final data matrix.[3][4][5][6][7] High dropout rates can significantly impact downstream analyses, such as cell clustering and the identification of differentially methylated regions.
Q3: What are the key experimental stages where dropouts can occur in sc-GEM?
A3: Dropouts in sc-GEM can be introduced at several stages of the experimental workflow. Critical steps include single-cell isolation, cell lysis, restriction enzyme digestion, and multiplex PCR amplification.[1] Inefficient execution of any of these steps can lead to the loss of genomic DNA or the failure to amplify the target loci.
Q4: How does sc-GEM's methylation analysis differ from bisulfite-based methods?
A4: The sc-GEM assay utilizes the SCRAM method for methylation analysis, which is a restriction enzyme-based approach.[1][8] This method employs methylation-sensitive restriction enzymes to digest unmethylated CpG sites, followed by PCR amplification of the target loci. In contrast, bisulfite-based methods involve the chemical conversion of unmethylated cytosines to uracil, which can lead to DNA degradation and loss, a common source of dropouts in those assays.[2][9] sc-GEM avoids the harsh chemical treatments associated with bisulfite sequencing.
Troubleshooting Guides
Issue 1: High Dropout Rates in Methylation Data (>20%)
High dropout rates in the DNA methylation data can compromise the entire sc-GEM experiment. The following sections provide potential causes and solutions categorized by experimental stage.
-
Question: Could the quality of my single cells be causing high dropout rates?
-
Answer: Yes, poor single-cell quality is a primary source of data dropouts.
-
Potential Cause: Cell clumping or doublets can lead to ambiguous results, while damaged or dying cells will have fragmented DNA, resulting in failed amplification.
-
Troubleshooting Steps:
-
Optimize Cell Dissociation: Use gentle enzymatic and mechanical dissociation methods to obtain a single-cell suspension with high viability.
-
Cell Straining: Pass the cell suspension through a cell strainer to remove clumps before single-cell isolation.
-
Viability Staining: Use a viability dye (e.g., Trypan Blue) to assess cell health and ensure that the majority of cells are viable before proceeding.
-
Microscopy Inspection: Visually inspect the single cells after isolation to ensure that only single, intact cells are used for downstream processing.
-
-
-
Question: How can I ensure efficient cell lysis without degrading the genomic DNA?
-
Answer: Incomplete cell lysis will result in inaccessible DNA, while overly harsh lysis can cause DNA degradation. Optimizing the lysis step is critical.
-
Potential Cause: The lysis buffer composition or incubation time may not be optimal for your cell type.
-
Troubleshooting Steps:
-
Select an Appropriate Lysis Buffer: The choice of lysis buffer is crucial. For sc-GEM, a mild lysis protocol that keeps the nucleus intact is often preferred to prevent DNA and RNA from mixing.[9]
-
Optimize Incubation Time and Temperature: Adjust the lysis incubation time and temperature. Many protocols benefit from keeping samples on ice to slow down enzymatic degradation.
-
Inhibitor Cocktails: Include RNase and protease inhibitors in your lysis buffer to protect the integrity of the nucleic acids.
-
Test Different Lysis Buffers: If you are not using a commercial kit, you may need to test a few different lysis buffer formulations to find the one that works best for your cells.
-
-
-
Question: My methylation data seems random, with high dropouts. Could the restriction digest be the problem?
-
Answer: Yes, inefficient or non-specific digestion by the methylation-sensitive restriction enzymes will directly lead to failed methylation calls.
-
Potential Cause: Inactive enzymes, incorrect buffer composition, or suboptimal incubation conditions can all lead to digestion failure.
-
Troubleshooting Steps:
-
Enzyme Quality: Ensure your restriction enzymes are active and have been stored correctly. Avoid repeated freeze-thaw cycles.
-
Buffer Compatibility: Use the buffer recommended by the enzyme manufacturer.
-
Incubation Time and Temperature: Optimize the digestion time and temperature as recommended for the specific enzymes you are using.
-
DNA Purity: Ensure the lysate is free of contaminants that could inhibit enzyme activity.
-
-
-
Question: I am observing a high frequency of "NA" values for many of my targeted loci. What could be wrong with my PCR?
-
Answer: Amplification failure is a common cause of dropouts in targeted single-cell assays.
-
Potential Cause: Poor primer design, suboptimal PCR cycling conditions, or the presence of PCR inhibitors can all contribute to amplification failure.
-
Troubleshooting Steps:
-
Primer Design and Validation: Ensure your multiplex PCR primers are designed to have similar annealing temperatures and are free of hairpins or self-dimers. Validate new primer sets on bulk genomic DNA before using them in a single-cell experiment.
-
Optimize Annealing Temperature: Perform a temperature gradient PCR to determine the optimal annealing temperature for your primer panel.
-
Increase PCR Cycles: For single-cell applications, a higher number of PCR cycles may be necessary, but be mindful of introducing amplification bias.
-
Use a High-Fidelity Polymerase: A high-fidelity, hot-start DNA polymerase is recommended for multiplex PCR to minimize non-specific amplification and primer-dimers.
-
-
Issue 2: Inconsistent Results Across Replicates
-
Question: I am seeing a lot of variability in dropout rates and methylation patterns between my technical replicates. What could be the cause?
-
Answer: Inconsistency across replicates often points to issues with experimental technique and workflow standardization.
-
Potential Cause: Pipetting errors, temperature fluctuations across the plate, and inconsistencies in reagent preparation can all contribute to variability.
-
Troubleshooting Steps:
-
Standardize Pipetting: Use calibrated pipettes and be consistent with your pipetting technique, especially when working with small volumes.
-
Use a Master Mix: Prepare a master mix of all reaction components to minimize pipetting errors and ensure consistency across all single-cell reactions.
-
Ensure Uniform Heating and Cooling: Use a PCR machine with a well-calibrated thermal block to ensure uniform temperature across all wells.
-
Single-Tube Reactions: Whenever possible, perform sequential enzymatic reactions in a single tube to minimize sample loss during transfers.[3]
-
-
Data Presentation
Table 1: Example Dropout Rate Analysis
This table can be used to track dropout rates for different experimental conditions or batches. Populate it with your own data to identify potential issues.
| Experiment ID | Cell Type | Lysis Buffer | # of Cells | # of Targeted Loci | Average Dropout Rate (%) | Notes |
| EXP-001 | H1 hESC | Buffer A | 96 | 24 | 15% | Baseline experiment |
| EXP-002 | H1 hESC | Buffer B | 96 | 24 | 8% | Optimized lysis buffer |
| EXP-003 | Fibroblast | Buffer A | 96 | 24 | 25% | Potential cell type-specific issue |
Experimental Protocols
Detailed Protocol: Optimized Cell Lysis for sc-GEM
This protocol provides a starting point for optimizing cell lysis to minimize DNA degradation and improve data quality.
-
Preparation:
-
Prepare a lysis buffer containing: 10 mM Tris-HCl (pH 7.4), 100 mM NaCl, 3 mM MgCl2, 0.5% NP-40.
-
On the day of the experiment, add fresh protease inhibitor cocktail and RNase inhibitor to the lysis buffer.
-
Pre-chill all buffers and equipment on ice.
-
-
Cell Lysis:
-
After single-cell isolation, transfer each cell to a PCR tube containing 5 µL of the chilled lysis buffer.
-
Incubate the tubes on ice for 10 minutes to lyse the cell membrane while keeping the nucleus intact.
-
After incubation, centrifuge the tubes at a low speed (e.g., 500 x g) for 5 minutes at 4°C to pellet the nuclei.
-
Carefully remove the supernatant containing the cytoplasmic RNA for gene expression analysis.
-
-
DNA Extraction:
-
The remaining pellet contains the genomic DNA within the nucleus. This can now be processed for the SCRAM assay.
-
Mandatory Visualizations
Diagrams
References
- 1. Technologies and applications of single-cell DNA methylation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Single-cell bisulfite-free 5mC and 5hmC sequencing with high sensitivity and scalability - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. researchgate.net [researchgate.net]
- 5. biorxiv.org [biorxiv.org]
- 6. researchgate.net [researchgate.net]
- 7. biorxiv.org [biorxiv.org]
- 8. Single Cell Restriction Enzyme-Based Analysis of Methylation at Genomic Imprinted Regions in Preimplantation Mouse Embryos - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. mdpi.com [mdpi.com]
dealing with amplification bias in single-cell genotyping
Welcome to the Technical Support Center for Single-Cell Genotyping. This resource provides researchers, scientists, and drug development professionals with comprehensive guidance on mitigating amplification bias during single-cell genotyping experiments.
Frequently Asked Questions (FAQs)
Here are some of the most common questions about amplification bias in single-cell genotyping.
Q1: What is amplification bias in single-cell genotyping?
A: Amplification bias in single-cell genotyping refers to the non-uniform representation of the genome after whole-genome amplification (WGA).[1][2] Because the starting material from a single cell is minuscule (only a few picograms of DNA), it must be amplified to generate enough material for sequencing.[1][3] This amplification process is not always even, leading to some regions of the genome being over-represented while others are under-represented or lost entirely.[1] This can result in several technical errors, including allele dropout (ADO), locus dropout (LDO), and amplification errors, which complicate the interpretation of sequencing data.[4]
Q2: What are the main causes of amplification bias?
A: Amplification bias can arise from several factors:
-
Stochastic Effects: During the initial amplification cycles, random events can lead to the preferential amplification of certain DNA fragments over others.
-
DNA Quality: The quality of the initial DNA template is crucial. Degraded or damaged DNA can prevent the polymerase from amplifying certain regions, leading to incomplete genome coverage.[5][6] Any DNA damage that inhibits amplification can result in the loss of those DNA sites.[6]
-
Primer Annealing: The efficiency of primer binding can vary across the genome. For methods using random primers, like Multiple Displacement Amplification (MDA), this can lead to random amplification bias.[7][8]
-
GC Content: Regions with very high or very low GC content can be difficult to amplify, leading to their under-representation in the final library.[1]
-
PCR-Induced Errors: Methods that rely on PCR can introduce bias during exponential amplification, where small differences in amplification efficiency are magnified over many cycles.[9]
Q3: What is Allele Dropout (ADO) and why is it a problem?
A: Allele Dropout (ADO) is a common issue in single-cell genotyping where one of the two alleles present at a heterozygous locus fails to be amplified.[4][10] This leads to the incorrect genotyping of a heterozygous cell as homozygous.[10] ADO is a significant problem because it can lead to misdiagnosis in genetic testing, false assumptions in research, and an underestimation of genetic diversity.[11] The main cause is often the failure of a primer to anneal to one of the alleles due to sequence variations or suboptimal PCR conditions.[10]
Q4: How do different Whole Genome Amplification (WGA) methods compare in terms of bias?
A: There are several WGA methods, each with its own profile of amplification bias. The main categories are Multiple Displacement Amplification (MDA) and PCR-based methods.
-
Multiple Displacement Amplification (MDA): This isothermal method uses the high-fidelity phi29 polymerase and random primers.[1] It generally produces long DNA fragments and provides good genome coverage but is known for a high allele dropout rate and can be sensitive to DNA quality.[8][12]
-
PCR-Based Methods (e.g., PicoPLEX, MALBAC): These methods involve cycles of polymerase chain reaction.
-
Multiple Annealing and Looping-Based Amplification Cycles (MALBAC): This method combines features of MDA and PCR to reduce non-linear amplification bias, resulting in better uniformity and specificity compared to MDA.[13]
-
PicoPLEX: This method also uses a combination of displacement pre-amplification and PCR. While it can be reliable, some studies have shown it to have a higher ADO rate and lower target coverage compared to MALBAC.[14][15]
-
-
TruePrime™: This method is a variation of MDA that uses a primase to synthesize primers directly on the DNA template, which can lead to more uniform amplification and less bias compared to methods using random synthetic primers.[8]
No single method is perfect, and the choice often depends on the specific application and research question.[3]
Troubleshooting Guides
This section provides solutions to common problems encountered during single-cell genotyping experiments.
Problem 1: Low or No DNA Yield After Whole Genome Amplification
| Possible Cause | Recommended Solution |
| Failed Cell Lysis | Ensure the lysis buffer is fresh and the incubation times and temperatures are correct for your cell type. Incomplete lysis will result in a poor DNA template. |
| Poor DNA Quality | The initial DNA from the single cell may have been degraded. If possible, assess the quality of a parallel bulk sample. For future experiments, minimize the time between cell isolation and lysis/amplification.[5] Fragmented DNA should be processed immediately.[5] |
| Presence of Inhibitors | Carryover of salts or other inhibitors from cell sorting or culture media can disrupt the amplification reaction.[5] Ensure proper washing of the cell before lysis or consider a purification step if inhibitors are suspected. |
| Incorrect Reaction Setup | Double-check the concentrations and volumes of all reagents. Ensure that the master mix is properly prepared and stored. Use a positive control (e.g., a small amount of genomic DNA) to verify the reaction components are working.[5] |
| Suboptimal Incubation Temperature | For isothermal methods like MDA, ensure the incubator or water bath maintains a stable and accurate temperature throughout the reaction. |
Problem 2: High Allele Dropout (ADO) Rate
| Possible Cause | Recommended Solution |
| Suboptimal PCR Conditions | Re-optimize your PCR protocol. Adjusting the annealing temperature can significantly impact primer binding and reduce ADO.[10] Increasing the denaturation temperature in the initial PCR cycles may also help make the target allele more accessible.[16] |
| Primer Design Issues | If targeting specific loci, ensure primers are not located in a region with known polymorphisms that could affect binding to one allele.[10] Consider designing alternative primer sets for the same locus. |
| Low-Quality DNA Template | Degraded DNA is more prone to ADO. Handle cells gently during isolation and proceed to amplification as quickly as possible to maintain DNA integrity. |
| Choice of WGA Kit | Some WGA methods are inherently more prone to ADO. MDA-based methods, for instance, tend to have higher ADO rates than some PCR-based methods like Ampli1.[3][14] Consider switching to a different WGA kit if ADO is a persistent issue. |
| G-Quadruplex Structures and DNA Methylation | Certain genomic regions with G-quadruplex motifs and differential methylation can be prone to systematic ADO.[11] If you suspect this, specific chemical treatments or alternative amplification strategies may be required. |
Problem 3: Uneven Genome Coverage
| Possible Cause | Recommended Solution |
| Inherent Bias of WGA Method | All WGA methods have some level of bias. MDA can have random bias, while PCR-based methods may have sequence-dependent bias.[1][13] Consider using a method known for better uniformity, such as MALBAC.[13] |
| GC-Rich or GC-Poor Regions | These regions are notoriously difficult to amplify. Some specialized polymerases and buffer formulations are designed to improve amplification of GC-rich regions. |
| DNA Fragmentation | Excessive fragmentation of the starting DNA will lead to poor amplification and uneven coverage.[5] Ensure that the fragmentation step in your protocol (if applicable) is optimized. A 4-minute fragmentation at 99°C is often optimal.[5] |
| Insufficient Sequencing Depth | What appears as uneven coverage may simply be a result of not sequencing deep enough to cover the entire genome adequately. Increase sequencing depth for better coverage. |
| Computational Correction | If experimental approaches are insufficient, bioinformatic tools can be used to computationally correct for GC bias and other systematic amplification biases.[17] |
Quantitative Data Summary
The performance of different Whole Genome Amplification (WGA) methods can vary significantly. The table below summarizes key performance metrics from comparative studies.
| WGA Method | Primary Amplification | Genome Coverage | Allele Dropout (ADO) Rate | Uniformity | Key Advantages | Key Disadvantages |
| REPLI-g (MDA) | Isothermal (MDA) | High[3] | High[14] | Random Bias[3] | High DNA yield, long amplicons.[3] | High ADO rate, amplification bias.[14] |
| MALBAC | Quasi-linear + PCR | Moderate to High[14][18] | Low to Moderate[14] | High[13] | Good uniformity, reduced bias.[13] | Can have higher PCR duplicate rates.[18] |
| PicoPlex | Pre-amplification + PCR | Low to Moderate[14][18] | High[14] | Moderate | Reliable with tight inter-quartile range.[15] | Lower target coverage, higher ADO rate.[14][18] |
| Ampli1 | PCR-based | Moderate[14] | Low[3][14] | High[3] | Low ADO, reliable copy-number profiles.[3] | Lower DNA yield compared to MDA methods. |
| TruePrime | Isothermal (MDA-like) | High | Moderate | High | Reduced primer artifacts, good sensitivity.[8] | Can still exhibit MDA-like biases. |
Experimental Protocols
Protocol: General Workflow for Single-Cell Genotyping
This protocol outlines the key steps from single-cell isolation to data analysis.
-
Single-Cell Isolation:
-
Isolate a single cell using methods such as fluorescence-activated cell sorting (FACS), laser capture microdissection, or manual micromanipulation.
-
Transfer the single cell into a PCR tube containing a small volume of PBS.
-
-
Cell Lysis:
-
Add a lysis buffer to the single cell. This buffer typically contains detergents and proteases to break open the cell and release the DNA.
-
Incubate according to the WGA kit manufacturer's instructions (e.g., a specific temperature and time).
-
-
Whole Genome Amplification (WGA):
-
Perform WGA using your chosen method (e.g., MDA, MALBAC, PicoPLEX). This step will amplify the picogram-level genomic DNA to the microgram level.
-
For MDA (e.g., REPLI-g):
-
Add reaction buffer and phi29 polymerase to the lysed cell.
-
Incubate at a constant temperature (e.g., 30°C) for several hours.
-
-
For MALBAC:
-
Perform initial cycles of quasi-linear pre-amplification.
-
Follow with exponential amplification using PCR.
-
-
-
Library Preparation and Sequencing:
-
Purify the amplified DNA.
-
Prepare a sequencing library using a standard library preparation kit (e.g., for Illumina sequencing). This involves DNA fragmentation, end-repair, A-tailing, and adapter ligation.
-
Perform sequencing on a next-generation sequencing platform.
-
-
Data Analysis:
-
Perform quality control on the raw sequencing reads.
-
Align reads to a reference genome.
-
Call variants (SNPs, indels, CNVs).
-
Assess for amplification bias by analyzing genome coverage uniformity and allele frequencies at heterozygous sites.
-
Visualizations
Diagrams of Workflows and Concepts
Caption: Workflow for single-cell genotyping, highlighting the WGA step where bias is introduced.
Caption: Comparison of MDA-based and PCR-based Whole Genome Amplification (WGA) methods.
Caption: A troubleshooting decision tree for addressing high Allele Dropout (ADO) rates.
References
- 1. mdpi.com [mdpi.com]
- 2. Bias in Whole Genome Amplification: Causes and Considerations - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. researchgate.net [researchgate.net]
- 5. GenomePlex® Single Cell Whole Genome Amplification Kit (WGA4) - Protocol [sigmaaldrich.com]
- 6. researchgate.net [researchgate.net]
- 7. rootbiome.tamu.edu [rootbiome.tamu.edu]
- 8. m.youtube.com [m.youtube.com]
- 9. academic.oup.com [academic.oup.com]
- 10. geneticeducation.co.in [geneticeducation.co.in]
- 11. Allelic Dropout During Polymerase Chain Reaction due to G-Quadruplex Structures and DNA Methylation Is Widespread at Imprinted Human Loci - PMC [pmc.ncbi.nlm.nih.gov]
- 12. SCELLECTOR: ranking amplification bias in single cells using shallow sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Comparison of Multiple Displacement Amplification (MDA) and Multiple Annealing and Looping-Based Amplification Cycles (MALBAC) in Single-Cell Sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Comparison of whole genome amplification techniques for human single cell exome sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 15. researchgate.net [researchgate.net]
- 16. Reduced allele dropout in single-cell analysis for preimplantation genetic diagnosis of cystic fibrosis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. [PDF] Calibrating genomic and allelic coverage bias in single-cell sequencing | Semantic Scholar [semanticscholar.org]
- 18. Comparison of whole genome amplification techniques for human single cell exome sequencing | PLOS One [journals.plos.org]
Technical Support Center: Enhancing Sensitivity and Accuracy of sc-GEM Data
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals improve the sensitivity and accuracy of their single-cell Gene Expression Mapping (sc-GEM) data.
Frequently Asked Questions (FAQs)
Q1: What is the typical workflow for analyzing sc-GEM data, and where are the common points of failure?
A1: The analysis of sc-GEM data follows a multi-step bioinformatics pipeline. Key stages include:
-
Raw Data Processing: Converting raw sequencing data into a cell-by-gene count matrix.
-
Quality Control (QC): Filtering out low-quality cells and genes to ensure data reliability.
-
Normalization: Adjusting for technical variability between cells, such as differences in sequencing depth.
-
Feature Selection: Identifying the most variable genes to be used in downstream analysis.
-
Dimensionality Reduction: Reducing the complexity of the data for visualization and clustering (e.g., using PCA, t-SNE, or UMAP).
-
Batch Effect Correction: Mitigating technical variation arising from processing samples in different batches.
-
Doublet Detection and Removal: Identifying and removing artificial signals originating from two or more cells being captured in the same droplet.
-
Ambient RNA Removal: Correcting for contamination from cell-free RNA present in the cell suspension.
-
Clustering and Cell Type Annotation: Grouping cells into clusters based on their expression profiles and assigning biological cell types to these clusters.
-
Downstream Analysis: Performing differential gene expression analysis, pathway analysis, and other biological interpretations.
Common points of failure that can compromise data sensitivity and accuracy include inadequate quality control, the presence of strong batch effects, contamination from doublets and ambient RNA, and suboptimal clustering. Each of these issues is addressed in the troubleshooting guides below.
Q2: What are the key quality control metrics I should check for my sc-GEM data?
A2: Thorough quality control is crucial for reliable sc-GEM analysis. Key metrics to assess at the cell level include:
-
Number of unique molecular identifiers (UMIs) or reads per cell: Very low counts may indicate poor cell viability or inefficient capture, while extremely high counts could suggest the presence of doublets.
-
Number of detected genes per cell: Similar to UMI counts, this metric helps identify cells with sufficient transcriptional complexity.
-
Percentage of mitochondrial gene expression: A high percentage of reads mapping to mitochondrial genes is often indicative of stressed or dying cells, as mitochondrial transcripts can be preferentially retained in apoptotic cells.
-
Percentage of ribosomal gene expression: High levels of ribosomal protein gene expression can sometimes indicate cellular stress or be a characteristic of highly proliferative cells.
These metrics should be evaluated for each cell, and appropriate filtering thresholds should be applied to remove low-quality cells from downstream analysis.
Q3: How does sequencing depth affect the quality of my sc-GEM data?
A3: Sequencing depth, the number of reads sequenced per cell, directly impacts the sensitivity of gene detection.[1]
-
Higher sequencing depth allows for the detection of more genes per cell, including those with lower expression levels. This increased sensitivity is particularly important for identifying rare cell types or subtle transcriptional changes.
-
Lower sequencing depth may be sufficient for identifying major cell populations but can lead to a higher rate of "dropout" events, where a gene is detected in one cell but not in another simply due to chance during sequencing.
The optimal sequencing depth depends on the biological question and the complexity of the sample. For cell type clustering, a moderate depth may be adequate, while studies focused on detailed gene expression dynamics within populations may require deeper sequencing.
Troubleshooting Guides
Issue 1: Strong Batch Effects Obscuring Biological Variation
Symptom: Cells in UMAP or t-SNE plots cluster primarily by experimental batch (e.g., sequencing run, sample preparation date) rather than by expected biological cell types. This indicates that technical variation is overwhelming the biological signal in the data.
Solution: Apply a batch correction algorithm to integrate data from different batches. Several well-established methods are available, each with its own strengths.
Recommended Tools: Harmony, Seurat v3/v4, and LIGER are highly recommended methods for batch integration.[2][3] Harmony is often a good first choice due to its computational efficiency.[2][3]
Experimental Protocol: Batch Correction using Harmony with Seurat
This protocol assumes you have a merged Seurat object containing uncorrected data from multiple batches, with a metadata column named "batch" identifying the origin of each cell.
Quantitative Data: Comparison of Batch Correction Methods
Benchmarking studies have evaluated various batch correction methods based on their ability to mix batches while preserving biological distinctions. The following table summarizes key findings from a comprehensive benchmark study.[2][3][4]
| Method | Performance in Mixing Batches | Preservation of Cell Type Purity | Computational Runtime |
| Harmony | Excellent | Excellent | Fast |
| Seurat v3 | Excellent | Excellent | Moderate |
| LIGER | Good | Good | Slow |
| fastMNN | Good | Good | Moderate |
| ComBat | Poor | Good | Fast |
Issue 2: Presence of Doublets Confounding Cell Clustering
Symptom: Identification of cell clusters with hybrid gene expression profiles, seemingly co-expressing marker genes from two distinct cell types. These are often not true biological intermediates but rather technical artifacts called doublets, where two cells are encapsulated in the same droplet.
Solution: Computationally identify and remove doublets from your dataset. Several tools are available that simulate artificial doublets and identify real cells with similar expression profiles.
Recommended Tool: DoubletFinder is a widely used R package for this purpose.[5][6][7]
Experimental Protocol: Doublet Detection using DoubletFinder
This protocol should be run on a per-sample basis before merging data from multiple samples.
Quantitative Data: Expected Doublet Rates in 10x Genomics Chromium
The rate of doublet formation is proportional to the number of cells loaded onto the microfluidic chip.[8][9]
| Number of Cells Loaded | Number of Cells Recovered | Multiplet Rate (%) |
| 870 | 500 | 0.4 |
| 1700 | 1000 | 0.8 |
| 3500 | 2000 | 1.6 |
| 5300 | 3000 | 2.3 |
| 7000 | 4000 | 3.1 |
| 8700 | 5000 | 3.9 |
| 10500 | 6000 | 4.6 |
| 12200 | 7000 | 5.4 |
| 14000 | 8000 | 6.1 |
| 15700 | 9000 | 6.9 |
| 17400 | 10000 | 7.6 |
Issue 3: Ambient RNA Contamination Masking True Expression Profiles
Symptom: Low-level expression of highly expressed marker genes from one cell type is observed across all other cell types. This is often due to the presence of cell-free "ambient" RNA in the cell suspension that gets captured along with the cells in droplets.
Solution: Estimate the profile of the ambient RNA and computationally subtract it from the expression profile of each cell.
Recommended Tool: SoupX is an R package designed to correct for ambient RNA contamination.[10][11][12][13]
Experimental Protocol: Ambient RNA Removal using SoupX
This protocol requires both the raw and filtered count matrices from Cell Ranger.
Issue 4: Low Cell Viability Leading to Poor Data Quality
Symptom: A high percentage of cells are filtered out during quality control due to low UMI counts, low gene counts, or high mitochondrial gene expression. This can result from cell stress or death during sample preparation.
Solution: Optimize the sample preparation protocol to maximize cell viability.
Troubleshooting Steps:
-
Minimize processing time: Reduce the time between tissue dissociation and cell capture to prevent cell degradation.
-
Gentle dissociation: Use optimized enzymatic and mechanical dissociation protocols to minimize cell damage.[14]
-
Maintain optimal temperature: Keep cells on ice or at the recommended temperature throughout the process.
-
Use appropriate buffers: Resuspend cells in a buffer that is free of EDTA, calcium, and magnesium, as these can inhibit downstream enzymatic reactions.[14]
-
Dead cell removal: If high levels of cell death are unavoidable, consider using a dead cell removal kit prior to loading the cells on the microfluidic chip.[9]
Experimental Protocol: Assessing Cell Viability
A simple and effective method for assessing cell viability is using Trypan Blue staining with a hemocytometer or an automated cell counter.
-
Mix a small aliquot of your cell suspension with an equal volume of 0.4% Trypan Blue solution.
-
Incubate for 1-2 minutes.
-
Load the mixture onto a hemocytometer.
-
Under a microscope, count the number of live (unstained) and dead (blue) cells.
-
Calculate the percentage of viable cells: (Number of live cells / Total number of cells) * 100.
A cell viability of >90% is recommended for optimal results, though samples with >70% viability can often be used with caution.[4]
Visualizing Workflows and Logical Relationships
sc-GEM Data Analysis Workflow
Caption: A generalized workflow for sc-GEM data analysis.
Troubleshooting Decision Tree for Batch Effects
Caption: A decision tree for addressing batch effects in sc-GEM data.
Impact of Data Quality on Pathway Analysis
Caption: How poor data quality can lead to inaccurate pathway analysis.
References
- 1. Challenges in Single-Cell RNA Seq Data Analysis & Solutions [elucidata.io]
- 2. researchgate.net [researchgate.net]
- 3. A benchmark of batch-effect correction methods for single-cell RNA sequencing data - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. rna-seqblog.com [rna-seqblog.com]
- 5. biostatsquid.com [biostatsquid.com]
- 6. youtube.com [youtube.com]
- 7. DoubletFinder: Doublet Detection in Single-Cell RNA Sequencing Data Using Artificial Nearest Neighbors - PMC [pmc.ncbi.nlm.nih.gov]
- 8. rna seq - determining doublets in single-cell RNA-seq - Bioinformatics Stack Exchange [bioinformatics.stackexchange.com]
- 9. HTG 10X Genomics 3’ Gene Expression | University of Utah Health | University of Utah Health [uofuhealth.utah.edu]
- 10. academic.oup.com [academic.oup.com]
- 11. biorxiv.org [biorxiv.org]
- 12. SoupX removes ambient RNA contamination from droplet-based single-cell RNA sequencing data - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. m.youtube.com [m.youtube.com]
- 14. 5 tips for successful single-cell RNA-seq [takarabio.com]
Contamination Control in Automated Single-Cell Workflows: A Technical Support Center
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals identify, mitigate, and prevent contamination in their automated single-cell workflows.
Frequently Asked Questions (FAQs)
Q1: What are the most common types of contamination in automated single-cell workflows?
A1: The two most prevalent types of contamination in single-cell RNA sequencing (scRNA-seq) are ambient RNA and barcode swapping.
-
Ambient RNA: This refers to free-floating RNA molecules in the cell suspension, often released from lysed or damaged cells during sample preparation. These molecules can be captured in droplets along with intact cells, leading to a "background" of RNA that does not originate from the cell being analyzed.[1][2] This can obscure the true gene expression profile of the cell and lead to incorrect biological interpretations.[1]
-
Barcode Swapping (Index Hopping): This is a phenomenon that occurs during the sequencing process on certain Illumina platforms with patterned flow cells (e.g., HiSeq 4000, NovaSeq).[3][4][5] It results in the misassignment of sequencing reads to the wrong sample barcode, leading to a mixing of data between multiplexed samples.[3][5]
Q2: How can I detect ambient RNA contamination in my data?
A2: Several indicators can suggest the presence of ambient RNA contamination:
-
Expression of cell-type-specific markers in other cell types: For example, the presence of T-cell receptor transcripts in B-cells.
-
High mitochondrial gene expression: A high percentage of mitochondrial reads can indicate cell stress or lysis, which is a source of ambient RNA.[6]
-
Lack of a steep "cliff" in the barcode rank plot: This plot of UMI counts per barcode should show a sharp drop-off between cell-containing droplets and empty droplets. A more gradual slope can indicate a high level of ambient RNA.[6]
-
Computational tools: Software packages like SoupX, CellBender, and DecontX are specifically designed to estimate and profile ambient RNA.[7][8][9]
Q3: What is the difference between SoupX, CellBender, and DecontX for ambient RNA removal?
A3: These are all popular computational tools for correcting ambient RNA contamination, but they employ different algorithms:
-
SoupX: Estimates the "soup" of ambient RNA from empty droplets and subtracts it from the expression profile of each cell. It can be run in an automated way or with manual guidance based on known non-expressed genes in certain cell types.[10]
-
CellBender: Uses a deep generative model to distinguish cell-containing droplets from empty ones and learns the profile of the background noise to remove it.[7]
-
DecontX: Assumes that each cell's expression profile is a mixture of its native transcripts and contaminating transcripts and uses a Bayesian approach to estimate and remove the contamination.[8]
Q4: How can I prevent barcode swapping?
A4: The most effective way to prevent barcode swapping is to use unique dual indexing (UDI) for your sequencing libraries. This means that each library has a unique combination of i5 and i7 indices. Using UDIs allows for the computational identification and removal of swapped reads. Sequencing on non-patterned flow cell instruments like the MiSeq can also reduce the rate of index hopping.[4]
Q5: What are some general best practices to minimize contamination during sample preparation?
A5: Maintaining a sterile and controlled environment is crucial. Key practices include:
-
Aseptic Technique: Work in a biological safety cabinet, use sterile reagents and consumables, and practice proper aseptic technique to prevent microbial contamination.
-
Gentle Cell Handling: Minimize mechanical stress on cells during dissociation and washing to reduce cell lysis and the release of ambient RNA.[9] Use wide-bore pipette tips and gentle centrifugation.[11]
-
Optimize Dissociation: Use optimized enzymatic and mechanical dissociation protocols for your specific tissue type to ensure high cell viability.[6][12]
-
Work Quickly and on Ice: Process samples quickly and keep them on ice to minimize RNA degradation and cell death.[13]
-
Debris and Dead Cell Removal: Use techniques like Fluorescence-Activated Cell Sorting (FACS) or density gradient centrifugation to remove dead cells and debris.[14][15]
Troubleshooting Guides
Issue 1: High Ambient RNA Contamination Detected
Symptoms:
-
Marker genes for one cell type are expressed at low levels across all other cell types.
-
Clustering analysis is confounded, with cell types not separating cleanly.
-
High background noise in empty droplets.
Possible Causes and Solutions:
| Cause | Solution |
| Poor sample quality: High percentage of dead or dying cells. | Optimize tissue dissociation and cell handling protocols to maximize cell viability (>90% is recommended).[11] Use a viability dye and FACS to sort for live cells.[15] |
| Excessive cell lysis during preparation: Harsh mechanical or enzymatic treatment. | Use gentle dissociation methods and minimize pipetting and centrifugation steps.[11][13] Consider using a lower centrifuge speed.[15] |
| Contaminated reagents or media: Introduction of exogenous RNA. | Use fresh, sterile, and nuclease-free reagents. Aliquot reagents to avoid repeated freeze-thaw cycles and potential contamination. |
| Carryover from previous experiments: Inadequate cleaning of automated liquid handlers. | Implement rigorous cleaning and decontamination protocols for all equipment between runs. |
Diagram: Troubleshooting High Ambient RNA
Caption: A flowchart for troubleshooting high ambient RNA contamination.
Issue 2: Barcode Swapping Suspected
Symptoms:
-
Unexpected clustering of samples that should be distinct.
-
Presence of reads from one sample in another (cross-talk).
-
Identification of "ghost" cell populations that are mixtures of other cell types.
Possible Causes and Solutions:
| Cause | Solution |
| Sequencing on a patterned flow cell instrument (e.g., HiSeq 4000, NovaSeq): These platforms are known to have higher rates of index hopping.[4][5] | If possible, sequence on a non-patterned flow cell instrument (e.g., MiSeq).[4] |
| Use of non-unique dual indexes (combinatorial indexing): This makes it impossible to computationally identify and remove swapped reads. | Use Unique Dual Indexes (UDIs). This is the most effective way to mitigate barcode swapping. |
| High concentration of free adapters/primers: Can increase the likelihood of index hopping. | Ensure thorough library cleanup to remove excess adapters and primers. |
Diagram: Barcode Swapping Mitigation Workflow
Caption: A workflow for mitigating barcode swapping in single-cell experiments.
Quantitative Data Summary
Table 1: Comparison of Ambient RNA Removal Tools
| Tool | Principle | Key Features | Performance Considerations |
| SoupX | Estimates and subtracts the ambient RNA profile from empty droplets. | Can be run automatically or with manual guidance. Computationally efficient. | Performance can depend on the quality of clustering and the choice of non-expressed genes for manual correction. May not be as effective as CellBender in some cases.[16] |
| CellBender | Uses a deep learning model to differentiate signal from noise. | Can simultaneously perform cell calling and ambient RNA removal. Generally provides precise estimates of background noise.[16] | Computationally intensive and may require a GPU for efficient processing.[8] |
| DecontX | Employs a Bayesian method to model native and contaminating transcripts. | Can be effective in identifying and removing contamination. | Performance can be variable across different datasets.[8] |
Note: The performance of these tools can be dataset-dependent. It is recommended to evaluate their performance on a subset of your data.
Table 2: Reported Barcode Swapping Rates on Illumina Sequencers
| Sequencing Platform | Flow Cell Type | Reported Swapping Rate | Reference |
| HiSeq 4000 | Patterned | ~2.5% | [17] |
| NovaSeq 6000 | Patterned | 0.1% - 2% | [4] |
| NextSeq 2000 | Patterned | up to 0.5% | [4] |
| MiSeq | Non-patterned | < 0.05% | [4] |
Experimental Protocols
Protocol 1: Best Practices for Preparing a Single-Cell Suspension from Tissues
This protocol provides general guidelines for minimizing contamination during the preparation of single-cell suspensions from solid tissues.
Materials:
-
Sterile, nuclease-free PBS and buffers
-
Appropriate enzymes for tissue digestion (e.g., collagenase, dispase, trypsin)
-
Sterile cell strainers (e.g., 40 µm, 70 µm)
-
Sterile, wide-bore pipette tips
-
Refrigerated centrifuge with a swinging bucket rotor
Procedure:
-
Work in a sterile environment: Perform all steps in a Class II biological safety cabinet.
-
Tissue Dissection and Mincing:
-
Place the fresh tissue in a sterile petri dish on ice containing cold, sterile PBS.
-
Wash the tissue thoroughly with cold PBS to remove any blood and other contaminants.[14]
-
Mince the tissue into small pieces (1-2 mm) using sterile scalpels or scissors.
-
-
Enzymatic Digestion:
-
Transfer the minced tissue to a tube containing an optimized enzymatic digestion buffer for your specific tissue type.
-
Incubate at the recommended temperature and time with gentle agitation. Avoid over-digestion as this can lead to increased cell death.
-
-
Mechanical Dissociation:
-
Gently triturate the digested tissue using a wide-bore pipette to create a single-cell suspension. Avoid vigorous pipetting to minimize cell shearing.
-
-
Filtering and Washing:
-
Pass the cell suspension through a series of cell strainers (e.g., starting with 100 µm followed by 40 µm) to remove clumps and debris.[12][18]
-
Wash the cells by centrifuging at a low speed (e.g., 300-400 x g) for 5-10 minutes at 4°C.[15]
-
Carefully aspirate the supernatant and gently resuspend the cell pellet in a cold, sterile buffer. Repeat the wash step at least once.
-
-
Cell Viability and Counting:
-
Assess cell viability using a method like trypan blue exclusion or a fluorescence-based assay. Aim for >90% viability.
-
Count the cells to determine the final concentration.
-
-
Proceed to Single-Cell Workflow: Immediately proceed to the automated single-cell capture workflow to minimize further cell stress and death.
Diagram: Single-Cell Suspension Workflow
Caption: A generalized workflow for preparing a single-cell suspension from tissue.
Protocol 2: Computational Removal of Ambient RNA using SoupX
This protocol outlines the basic steps for using the SoupX R package to correct for ambient RNA contamination.
Prerequisites:
-
R and SoupX package installed.
-
Cell Ranger output files, including both the raw_feature_bc_matrix.h5 and filtered_feature_bc_matrix.h5 files.
Procedure:
-
Load Libraries and Data:
-
Create a SoupChannel Object:
-
Estimate the Contamination Fraction:
-
Automated Estimation: SoupX can automatically estimate the contamination fraction.
-
Manual Estimation (Recommended for higher accuracy): Provide a set of genes known to be non-expressed in certain cell clusters.
-
-
Correct the Expression Matrix:
-
Create a Corrected Seurat Object:
This corrected Seurat object can then be used for downstream analysis. For more detailed instructions, refer to the official SoupX vignette.
References
- 1. Chapter 5 Problems with ambient RNA | Multi-Sample Single-Cell Analyses with Bioconductor [bioconductor.org]
- 2. rna-seqblog.com [rna-seqblog.com]
- 3. researchgate.net [researchgate.net]
- 4. Index hopping in Illumina NGS: what it is, why it matters, and how unique dual indexing solves the problem. | Revvity [revvity.co.jp]
- 5. Detection and removal of barcode swapping in single-cell RNA-seq data - PMC [pmc.ncbi.nlm.nih.gov]
- 6. DSpace [repositori.upf.edu]
- 7. Understanding and mitigating the impact of ambient mRNA contamination in single-cell RNA-sequencing analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 8. biorxiv.org [biorxiv.org]
- 9. Help Center [kb.10xgenomics.com]
- 10. SoupX removes ambient RNA contamination from droplet-based single-cell RNA sequencing data - PMC [pmc.ncbi.nlm.nih.gov]
- 11. cdn.10xgenomics.com [cdn.10xgenomics.com]
- 12. Best Practices for Preparing a Single Cell Suspension from Solid Tissues for Flow Cytometry - PMC [pmc.ncbi.nlm.nih.gov]
- 13. 5 tips for successful single-cell RNA-seq [takarabio.com]
- 14. medium.com [medium.com]
- 15. cancer.wisc.edu [cancer.wisc.edu]
- 16. The effect of background noise and its removal on the analysis of single-cell expression data - Anthropology and Human Genetics - LMU Munich [humangenetik.bio.lmu.de]
- 17. Detection and removal of barcode swapping in single-cell RNA-seq data - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. youtube.com [youtube.com]
Technical Support Center: Data Normalization Strategies for Integrated sc-GEM Analysis
This guide provides researchers, scientists, and drug development professionals with answers to frequently asked questions and troubleshooting advice for data normalization in integrated single-cell Genomics, Epigenomics, and Transcriptomics (sc-GEM) analysis.
Frequently Asked Questions (FAQs)
Q1: What is data normalization in the context of sc-GEM analysis, and why is it a critical step?
A1: Data normalization is a crucial process of adjusting raw single-cell data to account for and remove systematic technical variations between cells and experiments.[1][2] Its primary goal is to make gene or feature counts comparable across different cells and samples, ensuring that observed variations are due to true biological differences rather than technical artifacts.[3][4] This step is critical because technical noise can arise from differences in tissue fixation, antibody concentrations, and imaging conditions.[5] Without proper normalization, downstream analyses like differential expression, cell clustering, and data integration can be significantly skewed, leading to inaccurate biological interpretations.[3][4][6]
Q2: What are the primary sources of technical variability that normalization aims to correct?
A2: Technical variability in single-cell experiments stems from multiple sources. Key among them are:
-
Sequencing Depth: The number of sequenced molecules (read counts) can vary significantly from cell to cell. Normalization adjusts for these differences in "library size."[4][7]
-
Batch Effects: Samples processed at different times or with different reagent lots can exhibit systematic variations. Batch correction methods are often integrated with or performed after initial normalization to address this.[8]
-
Gene-Specific Effects: Factors like gene length and GC content can introduce biases during the library preparation and sequencing steps.
-
Data Sparsity: Single-cell data often contains a high proportion of zero counts ("dropouts"), which can complicate normalization and downstream analysis.
Q3: What are the main categories of normalization methods available for sc-GEM data?
A3: Normalization methods can be broadly categorized based on their underlying mathematical models.[3]
-
Global Scaling Methods: These methods assume that the total RNA content is similar across cells and apply a single scaling factor to each cell to adjust for library size. Examples include Counts Per Million (CPM), Trimmed Mean of M-values (TMM), and Relative Log Expression (RLE).[4][7][9][10]
-
Generalized Linear Models (GLMs) and Regression-Based Methods: These more advanced methods model the technical noise in the data. For example, sctransform uses a regularized negative binomial regression to model the relationship between gene expression and sequencing depth, effectively removing this technical confounder while preserving biological heterogeneity.[7]
-
Bayesian-Based Methods: Methods like BASiCS (Bayesian Analysis of Single-Cell Sequencing Data) use a Bayesian hierarchical model to distinguish technical noise from biological variability, often using spike-ins to estimate technical parameters.[4]
Q4: How can I assess the performance of a chosen normalization method?
A4: There is no single best-performing normalization method for all datasets.[3] Therefore, it's recommended to evaluate performance using data-driven metrics.[3] Useful metrics include the silhouette width to assess clustering quality, the K-nearest neighbor batch-effect test (kBET) to check for residual batch effects, and the preservation of highly variable genes (HVGs) that are known to be biologically relevant.[3] Comparing the results of a few different methods on a subset of your data can help you make an informed decision.
Troubleshooting Guide
Problem: My datasets show poor integration and are clustering by batch, even after normalization.
Solution: This is a classic sign of residual batch effects.
-
Verify Normalization Method: Simple scaling methods like CPM may not be sufficient to handle strong batch effects.[8] Consider using a more advanced, integrated workflow like sctransform or applying a dedicated batch correction method (e.g., Harmony, MNN Correct, Scanorama) after an initial normalization step.[4]
-
Check for Confounding Variables: Ensure that your experimental design is not perfectly confounded (e.g., all of cell type A is in batch 1, and all of cell type B is in batch 2). If so, batch correction becomes statistically impossible.
-
Visualize Post-Normalization: Use visualization techniques like UMAP or t-SNE colored by batch ID to visually inspect whether cells are mixing appropriately or if they remain separated by batch.
Problem: I'm losing important biological variation after applying a strong normalization or batch correction method.
Solution: This can happen if the normalization method is too aggressive and "over-corrects" the data.
-
Reduce Correction Strength: Some batch correction algorithms have parameters that control the extent of correction. Try tuning these to be less aggressive.
-
Preserve Cell-Type Markers: Before and after normalization, check the expression of known marker genes for your expected cell populations. If their distinct expression patterns are lost, the normalization may be too strong.
-
Use a Gentler Method: Consider methods known for preserving biological variance. For instance, regression-based approaches can be effective at removing technical noise while retaining cellular heterogeneity.[7]
Quantitative Comparison of Normalization Strategies
The choice of normalization method significantly impacts downstream results. The following tables summarize common strategies and metrics for their evaluation.
Table 1: Overview of Common Normalization Strategies
| Strategy Category | Method Examples | Principle | Pros | Cons |
| Global Scaling | LogNormalize (Seurat), CPM, TMM[9][10], RLE[9][10] | Calculates a single size factor per cell to scale counts. | Simple, fast, and easy to interpret. | Fails when compositional biases are strong or when there are large differences in RNA content between cell types.[4] |
| Regression-Based | SCTransform (Seurat) | Uses a regularized negative binomial model to account for sequencing depth.[7] | Effectively removes technical noise while preserving biological variation; often outperforms scaling methods.[7] | More computationally intensive; may be sensitive to parameter choices. |
| Pooling & Deconvolution | Scran | Pools cells with similar library sizes to improve the accuracy of size factor estimation.[7] | More robust to compositional bias and high numbers of zero counts than simple scaling. | Requires a coarse clustering step as input, which can add complexity.[7] |
| Bayesian Models | BASiCS | Implements a Bayesian hierarchical model to decompose variation into biological and technical components.[4] | Provides robust estimates of cell-specific normalizing constants. | Can be computationally slow; original implementation relied on spike-in controls.[4] |
Table 2: Performance Metrics for Evaluating Normalization
| Metric | Purpose | How to Interpret |
| Silhouette Width | Measures how similar a cell is to its own cluster compared to other clusters. | Higher values indicate better-defined clusters. A metric to assess the performance of normalization methods.[3] |
| kBET | Quantifies the extent of batch effects by comparing the local batch label distribution to the global one. | Lower values indicate better batch mixing and less residual batch effect. |
| Highly Variable Genes (HVGs) | Assesses the preservation of genes with high biological variability. | A good normalization should retain known biological HVGs while reducing the variance of technical noise-driven genes.[3] |
| Cell Graph Overlap | Compares the nearest-neighbor graph of the normalized data to a ground-truth reference. | Higher overlap suggests better preservation of the underlying biological structure. |
Experimental Protocols (Computational Workflows)
Below are high-level computational workflows for two popular normalization methods within the Seurat R package.
Protocol 1: Standard Log-Normalization Workflow
This is a widely used global scaling method.
-
Create Seurat Object: Load your raw count matrix into a Seurat object.
-
Quality Control: Filter out low-quality cells based on metrics like the number of unique genes, total molecules, and percentage of mitochondrial DNA.
-
Normalize Data: Apply the NormalizeData function with the normalization.method = "LogNormalize" argument. This converts counts to log(CPM+1).
-
Identify Variable Features: Use the FindVariableFeatures function to identify a subset of genes with high cell-to-cell variation.
-
Scale Data: Apply the ScaleData function. This step linearly transforms the data so that the mean expression across cells is 0 and the variance is 1. This is important for downstream dimensional reduction.
Protocol 2: SCTransform Workflow
This workflow uses a regression-based model to normalize data and is often recommended for its ability to handle technical noise effectively.
-
Create Seurat Object & QC: Follow steps 1 and 2 from the Log-Normalization workflow.
-
Run SCTransform: Apply the SCTransform function directly to the filtered Seurat object. This single function replaces the NormalizeData, FindVariableFeatures, and ScaleData steps. It stores the normalized values in a new assay.
-
Downstream Analysis: Proceed with dimensional reduction (PCA, UMAP) and clustering using the SCTransformed data. When integrating datasets, this workflow can be applied to each dataset individually before identifying integration anchors.
Visual Guides
Caption: A general workflow for integrated sc-GEM data analysis.
Caption: Decision flowchart for selecting a normalization strategy.
References
- 1. Correlation Patterns in Experimental Data Are Affected by Normalization Procedures: Consequences for Data Analysis and Network Inference - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Normalization and experimental design for ChIP-chip data - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Data normalization for addressing the challenges in the analysis of single-cell transcriptomic datasets - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Data normalization for addressing the challenges in the analysis of single-cell transcriptomic datasets - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. A statistical selection strategy for normalization procedures in LC-MS proteomics experiments through dataset-dependent ranking of normalization scaling factors - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. 7. Normalization — Single-cell best practices [sc-best-practices.org]
- 8. Frontiers | Evaluation of normalization methods for predicting quantitative phenotypes in metagenomic data analysis [frontiersin.org]
- 9. Comparison of the effectiveness of different normalization methods for metagenomic cross-study phenotype prediction under heterogeneity - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Comparison of normalization methods for the analysis of metagenomic gene abundance data - PMC [pmc.ncbi.nlm.nih.gov]
refining cell lysis protocols for simultaneous DNA and RNA extraction
Welcome to the technical support center for refining cell lysis protocols for simultaneous DNA and RNA extraction. This resource is designed for researchers, scientists, and drug development professionals to troubleshoot common issues and find answers to frequently asked questions.
Troubleshooting Guide
This guide addresses specific issues that may be encountered during simultaneous DNA and RNA extraction experiments.
| Problem | Potential Cause | Recommended Solution | Expected Outcome (Post-Solution) |
| Low Yield of Both DNA and RNA | Incomplete cell lysis. | Optimize the lysis protocol by choosing a method appropriate for the cell/tissue type. This may involve mechanical disruption (e.g., bead beating, homogenization) in addition to chemical lysis.[1][2] Ensure the lysis buffer is suitable for your sample and that incubation times and temperatures are optimized.[1] For tough-to-lyse samples, consider enzymatic digestion (e.g., Proteinase K, lysozyme).[3] | Increased yield of both DNA and RNA. Spectrophotometer readings (A260) should show higher concentrations. |
| Insufficient starting material. | Increase the amount of starting material. If sample is limited, consider methods optimized for low-input samples.[4][5] | Yields will be proportional to the starting material. For low-input methods, expect yields in the nanogram or picogram range. | |
| Low RNA Yield or RNA Degradation | Presence of RNases. | Work quickly and keep samples on ice.[1] Use RNase-free reagents and consumables.[6] Immediately homogenize tissue in a guanidine-based lysis buffer to inactivate RNases.[4][7] | Intact RNA bands (e.g., 28S and 18S rRNA for eukaryotes) on a gel. High RNA Integrity Number (RIN) value (>7) from a bioanalyzer. |
| Improper storage of samples. | Snap-freeze fresh samples in liquid nitrogen and store at -80°C.[3][8] Use a stabilizing agent like RNAlater for tissue samples. | Preserved RNA integrity, leading to higher quality and yield upon extraction. | |
| Low DNA Yield | Inefficient DNA binding to the column. | Ensure the binding buffer has the correct pH and composition. Optimize incubation time and mixing to maximize binding.[1] | Increased DNA yield, as measured by spectrophotometry or fluorometry. |
| Incomplete elution. | Use the recommended elution buffer and volume. Optimize elution incubation time and temperature as per the protocol.[1] Consider a second elution step.[8] | Higher recovery of DNA from the purification column. | |
| DNA Contamination in RNA Sample | Incomplete removal of genomic DNA. | Perform an on-column DNase I treatment or a DNase treatment in solution after RNA elution.[3][7][8] Ensure proper phase separation if using a phenol-based method.[7] | Absence of high molecular weight DNA band on an agarose (B213101) gel run with the RNA sample. No amplification in a no-RT control in RT-qPCR. |
| Overloading the purification column. | Reduce the amount of starting material to be within the recommended range for the extraction kit.[4] | Purer RNA with less DNA carryover. | |
| RNA Contamination in DNA Sample | Incomplete removal of RNA. | Add RNase A to the cell lysate and incubate as recommended in the protocol.[2][9][10] | Absence of RNA smear on an agarose gel run with the DNA sample. A260/A280 ratio closer to 1.8. |
| Poor Nucleic Acid Purity (Low A260/A280 or A260/A230 Ratios) | Carryover of inhibitors (e.g., salts, phenol, ethanol). | Ensure thorough washing steps are performed.[1] Make sure no residual wash buffer is carried over before elution.[8] For low A260/A230, an additional wash step may be necessary.[4] | A260/A280 ratio of ~1.8 for DNA and ~2.0 for RNA. A260/A230 ratio between 2.0 and 2.2 for both. |
| Reagent contamination. | Use fresh, high-quality reagents.[6] Test reagents for contamination using negative controls.[6][11] Some studies have shown that filtering extraction kit reagents can remove contaminating DNA.[12][13] | Clean baseline in negative controls for downstream applications like PCR. | |
| Cross-Contamination Between Samples | Procedural errors. | Practice meticulous sterile technique. Use fresh pipette tips for each sample and reagent.[1] Process samples in a unidirectional workflow from pre-amplification to post-amplification areas.[1][11] | No amplification in negative extraction controls.[11] |
Frequently Asked Questions (FAQs)
Q1: How can I efficiently lyse my cells for simultaneous DNA and RNA extraction?
A1: Effective cell lysis is critical for maximizing the yield of both DNA and RNA.[1] The choice of lysis method depends on the sample type. For cultured cells, a detergent-based lysis buffer is often sufficient.[9] For tissues, mechanical disruption (e.g., homogenization with a bead beater or rotor-stator homogenizer) is usually necessary to break down the extracellular matrix and cell walls.[3][7] Combining mechanical and chemical lysis is often the most effective approach.[3] For difficult-to-lyse samples like bacteria with tough cell walls, enzymatic pre-treatment (e.g., with lysozyme) may be required.[3]
Q2: What is the best way to prevent RNA degradation during the lysis step?
A2: RNA is highly susceptible to degradation by RNases, which are ubiquitous.[3] To prevent degradation, it is crucial to inactivate RNases immediately upon cell lysis. This is typically achieved by using a lysis buffer containing strong chaotropic agents like guanidinium (B1211019) thiocyanate.[14] Additionally, working quickly, keeping samples cold, and using certified RNase-free labware and reagents are essential preventative measures.[1][4]
Q3: My RNA sample is contaminated with genomic DNA. How can I remove it?
A3: Genomic DNA contamination is a common issue in RNA extractions.[7] Most commercially available kits for simultaneous extraction include an on-column DNase digestion step.[8] Alternatively, you can perform a DNase treatment in solution after the RNA has been eluted. It is important to ensure the DNase is subsequently removed or inactivated, as it can interfere with downstream enzymatic reactions.[7]
Q4: Can I use the same lysis buffer for different types of cells and tissues?
A4: While some lysis buffers are versatile, it is generally recommended to optimize the lysis buffer for the specific cell or tissue type.[1] Different samples have varying compositions of proteins, lipids, and extracellular matrix, which may require different detergent concentrations or types of chaotropic salts for efficient lysis. For example, tough tissues may require a more stringent lysis buffer and more vigorous mechanical disruption than cultured cells.[2][3]
Q5: What are the key differences in lysis protocols when using manual vs. automated extraction systems?
A5: Manual extraction protocols offer more flexibility for optimization at each step but are also more prone to human error and cross-contamination.[15] Automated nucleic acid extraction systems provide a more standardized and high-throughput approach, often utilizing pre-filled cartridges and robotic handling to minimize variability and contamination risk.[6][16] The lysis step in automated systems is typically integrated into a closed workflow, following the principles of lysis, binding, washing, and elution.[6]
Experimental Protocols
Protocol 1: Manual Simultaneous DNA and RNA Extraction using Spin Columns
This protocol is a generalized method and may require optimization based on the specific kit and sample type.
-
Sample Preparation and Lysis:
-
For cultured cells (up to 5 x 10^6), pellet the cells and resuspend in 100 µl of cold PBS.[9]
-
For tissue (10-20 mg), homogenize in 350 µl of a guanidinium thiocyanate-based lysis buffer.
-
Add Proteinase K and mix immediately by vortexing.[9]
-
Incubate at 56°C for 10-15 minutes to facilitate protein digestion.[9]
-
-
Genomic DNA Binding:
-
Add ethanol (B145695) to the lysate to promote DNA binding.
-
Transfer the mixture to a DNA-binding spin column and centrifuge. The DNA will bind to the silica (B1680970) membrane.
-
Save the flow-through for RNA extraction.
-
-
DNA Washing and Elution:
-
Wash the DNA-binding column with the provided wash buffers to remove impurities.
-
Dry the column by centrifugation.
-
Elute the purified DNA with an appropriate elution buffer.
-
-
RNA Precipitation and Binding:
-
Add ethanol to the flow-through from the DNA binding step to precipitate the RNA.
-
Transfer the sample to an RNA-binding spin column and centrifuge.
-
-
On-Column DNase Treatment (Optional but Recommended):
-
Wash the RNA-binding column.
-
Apply a DNase I solution directly to the column membrane and incubate at room temperature to digest any contaminating DNA.
-
Wash the column again to remove the DNase I.
-
-
RNA Washing and Elution:
-
Wash the RNA-binding column with wash buffers.
-
Dry the column by centrifugation.
-
Elute the purified RNA with RNase-free water or elution buffer.
-
Visualizations
Caption: Workflow for simultaneous DNA and RNA extraction.
Caption: Troubleshooting logic for nucleic acid extraction.
References
- 1. 10 Common Mistakes in Nucleic Acid Extraction and How to Avoid Them - FOUR E's Scientific [4esci.com]
- 2. aiconceptlimited.com.ng [aiconceptlimited.com.ng]
- 3. zymoresearch.com [zymoresearch.com]
- 4. mpbio.com [mpbio.com]
- 5. willowfort.co.uk [willowfort.co.uk]
- 6. Blog/How to Reduce Chances of Lab Contamination During DNA and RNA Extraction | Tianlong [medtl.net]
- 7. bitesizebio.com [bitesizebio.com]
- 8. neb.com [neb.com]
- 9. neb.com [neb.com]
- 10. neb.com [neb.com]
- 11. Contamination | MB [molecular.mlsascp.com]
- 12. Removal of contaminating DNA from commercial nucleic acid extraction kit reagents - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. gene-quantification.de [gene-quantification.de]
- 14. Co-extraction of RNA and DNA from plant tissue [protocols.io]
- 15. Nucleic Acid Extraction Common Problems — Sterilab Services Pathology Solutions [sterilab.co.uk]
- 16. Reagent and laboratory contamination can critically impact sequence-based microbiome analyses - PMC [pmc.ncbi.nlm.nih.gov]
Validation & Comparative
A Comparative Guide to sc-GEM and scRNA-seq for Gene Expression Profiling
For researchers, scientists, and drug development professionals navigating the landscape of single-cell analysis, choosing the optimal technology is paramount. This guide provides a detailed comparison of two powerful methodologies: single-cell Genotype, Expression, and Methylation (sc-GEM) and single-cell RNA sequencing (scRNA-seq), with a focus on their application in gene expression profiling.
While both techniques provide insights into the transcriptome of individual cells, they are fundamentally different in their scope. scRNA-seq is a dedicated method for quantifying gene expression, offering high-throughput and in-depth transcriptomic data. In contrast, sc-GEM is a multi-modal technology that simultaneously assays genotype, DNA methylation, and gene expression from the same single cell, providing a more holistic view of cellular regulation, albeit with a more targeted approach to expression analysis.[1]
This guide will objectively compare the performance of sc-GEM with a widely used scRNA-seq platform, the 10x Genomics Chromium system, and provide supporting experimental data where available.
Quantitative Data Summary
| Feature | sc-GEM | scRNA-seq (10x Genomics Chromium with GEM-X) |
| Primary Output | Genotype, DNA Methylation, and Targeted Gene Expression | Whole Transcriptome Gene Expression |
| Gene Expression Method | RT-qPCR (targeted) | Next-Generation Sequencing (whole transcriptome) |
| Gene Detection Sensitivity | High for targeted genes.[1] | High; significant increase in detected genes with GEM-X technology.[2] |
| Transcript Quantification | Accurate relative quantification.[1] | High, with Unique Molecular Identifiers (UMIs) for accurate molecule counting. |
| Cell Throughput | Lower (e.g., 96 cells per run on C1 Open App IFC).[1] | High (up to 20,000 cells per channel).[2] |
| Cell Capture Efficiency | Dependent on the microfluidic platform used. | Up to 80%.[2] |
| Cost per Cell | Higher, due to multi-modal nature and lower throughput. | Lower, especially at high throughputs.[2] |
Experimental Protocols
sc-GEM Experimental Workflow
The sc-GEM protocol is a multi-step process that combines different molecular biology techniques on a microfluidic platform.[1]
-
Single-Cell Isolation : A single-cell suspension is loaded onto a microfluidic chip, such as the Fluidigm C1 Open App IFC, where individual cells are captured in separate reaction chambers.[1]
-
Cell Lysis and Pre-amplification : Inside each chamber, the cell is lysed to release its genomic DNA and RNA. The RNA is reverse transcribed into cDNA for gene expression analysis, and the genomic DNA is prepared for genotyping and methylation analysis.
-
Multi-Omic Analysis :
-
Gene Expression : The cDNA is used for targeted quantitative PCR (RT-qPCR) to measure the expression levels of a predefined set of genes.[1]
-
DNA Methylation : The genomic DNA is subjected to the Single Cell Restriction Analysis of Methylation (SCRAM) assay, which uses methylation-sensitive restriction enzymes to determine the methylation status of specific CpG sites.[1]
-
Genotyping : A separate aliquot of the genomic DNA is amplified and prepared for next-generation sequencing to determine the genotype of the cell.[1]
-
scRNA-seq Experimental Workflow (10x Genomics Chromium)
The 10x Genomics Chromium platform utilizes a droplet-based microfluidic system for high-throughput single-cell transcriptomics.[3]
-
GEM Generation : A single-cell suspension is loaded onto a microfluidic chip along with reverse transcription reagents and barcoded gel beads. The chip partitions the cells and gel beads into nanoliter-scale droplets called Gel Bead-in-Emulsions (GEMs).
-
Barcoding and Reverse Transcription : Inside each GEM, the cell is lysed, and its RNA is captured by the primers on the gel bead. Each primer contains a unique molecular identifier (UMI) and a cell-specific barcode. Reverse transcription then generates barcoded cDNA.
-
Library Preparation : The GEMs are broken, and the barcoded cDNA from all cells is pooled. The cDNA is amplified, and a sequencing library is constructed.
-
Sequencing and Analysis : The library is sequenced on a next-generation sequencing platform. The data is then processed using software like Cell Ranger, which demultiplexes the reads based on the cell barcodes and quantifies gene expression using the UMIs.[4]
Cross-Validation of Gene Expression Profiles
Direct experimental cross-validation between sc-GEM and scRNA-seq for gene expression is not a standard practice due to their different intended applications. However, a conceptual framework for such a comparison can be outlined.
A robust cross-validation experiment would involve splitting a single-cell suspension into two aliquots. One aliquot would be processed using the sc-GEM protocol, and the other using a standard scRNA-seq protocol. The resulting gene expression data would then be compared.
Key Comparison Metrics would include:
-
Correlation of Gene Expression: For the subset of genes targeted by sc-GEM, their expression levels would be correlated with the corresponding measurements from scRNA-seq across individual cells or cell populations.
-
Concordance of Cell Clustering: Unsupervised clustering of cells based on the targeted gene panel from sc-GEM would be compared to the clustering results from the whole transcriptome data from scRNA-seq.
-
Differential Gene Expression Analysis: If the experimental design includes different conditions, the differentially expressed genes identified by both methods would be compared for consistency.
Conclusion
The choice between sc-GEM and scRNA-seq for gene expression profiling depends on the specific research question.
-
scRNA-seq is the preferred method for comprehensive, discovery-driven transcriptomic analysis . Its high-throughput nature and whole-transcriptome coverage are ideal for identifying novel cell types, characterizing cellular heterogeneity, and building detailed cell atlases. The continuous improvements in technologies like GEM-X further enhance its sensitivity and efficiency.[2]
-
sc-GEM is a powerful tool for integrative, multi-modal single-cell analysis . It is particularly valuable for studies aiming to directly link genotype and epigenotype with phenotype (as reflected by targeted gene expression) within the same cell. While its gene expression analysis is targeted, the ability to obtain a multi-layered view of cellular regulation is its unique strength.[1]
For researchers primarily focused on in-depth gene expression analysis, scRNA-seq offers a more powerful and cost-effective solution. However, for those investigating the interplay between the genome, epigenome, and transcriptome, sc-GEM provides an unparalleled multi-modal approach. Future developments in single-cell multi-omics will likely continue to bridge the gap between these two powerful technologies, offering even more comprehensive insights into the complexities of cellular life.
References
A Researcher's Guide to Microfluidic Platforms for Single-Cell Gene Expression Profiling
An in-depth comparison of leading microfluidic systems for single-cell genomics, providing researchers with the data and protocols needed to make informed decisions for their experimental needs.
For researchers at the forefront of cellular biology, single-cell genomic and transcriptomic (sc-GEM) analysis has become an indispensable tool. The ability to dissect cellular heterogeneity, uncover rare cell types, and delineate complex biological pathways at the level of the individual cell has revolutionized fields from oncology to immunology and drug development. At the heart of this revolution are microfluidic platforms that enable the isolation and processing of thousands of cells in a single run. This guide provides a comprehensive evaluation of the performance of four leading microfluidic platforms: 10x Genomics Chromium, Bio-Rad ddSEQ, Dolomite Bio Nadia, and Parse Biosciences Evercode.
Performance Metrics: A Head-to-Head Comparison
The choice of a microfluidic platform can significantly impact the quality and scale of single-cell sequencing data. Key performance indicators include cell capture efficiency, the rate of multiplets (more than one cell per partition), and the sensitivity in detecting genes and transcripts. The following tables summarize quantitative data from various studies to facilitate a direct comparison of these platforms.
| Performance Metric | 10x Genomics Chromium (v3/v3.1) | Bio-Rad ddSEQ | Dolomite Bio Nadia (using Drop-seq) | Parse Biosciences Evercode (WT v2/v3) |
| Cell Capture Efficiency | Up to 80%[1] | >50%[2] | ~10% of cells encapsulated with a bead[3] | ~57% cell retention after barcoding[4] |
| Cell Throughput per Run | 100 - 80,000+ cells[5][6] | 500 - 7,000 cells[7] | Up to 48,000 cells (8 samples)[8] | Up to 1,000,000 cells |
| Multiplet (Doublet) Rate | ~0.9% per 1,000 cells[9] | Low multiplet rates[7] | As low as 6.7% with over 6,000 cells captured[10] | ~2.3% in a species mixing experiment[11] |
| Median Genes per Cell | ~2,500 - 4,800 (PBMCs)[12] | ≥4,500 (mixed species cell lines)[2] | High gene capture reported[10] | ~2,300 - 2,400 (PBMCs)[4][13] |
| Technology Principle | Droplet-based microfluidics[5][6] | Droplet-based microfluidics[5][14] | Droplet-based microfluidics (implements Drop-seq)[15][16] | Split-pool combinatorial barcoding (instrument-free)[17][18] |
Experimental Workflows and Protocols
Understanding the experimental workflow is crucial for planning and executing successful sc-GEM experiments. Below are detailed outlines of the typical protocols for each platform.
Experimental Workflow Overview
The general workflow for most single-cell RNA sequencing experiments involves several key stages, from sample preparation to data analysis. While the core principles are similar, the specific implementation varies between platforms.
References
- 1. Comparative Analysis of Commercial Single-Cell RNA Sequencing Technologies | bioRxiv [biorxiv.org]
- 2. labunlimited.co.uk [labunlimited.co.uk]
- 3. 10xgenomics.com [10xgenomics.com]
- 4. Understanding 10x Chromium: How It Works and Key Features [scdiscoveries.com]
- 5. youtube.com [youtube.com]
- 6. GitHub - SydneyBioX/sc_bench_benchmark [github.com]
- 7. nsk.dia-m.ru [nsk.dia-m.ru]
- 8. cellenion.com [cellenion.com]
- 9. Comparative Analysis of Single-Cell RNA Sequencing Methods with and without Sample Multiplexing - PMC [pmc.ncbi.nlm.nih.gov]
- 10. insights.opentrons.com [insights.opentrons.com]
- 11. 10X genomics - single cell RNA-seq – 4DN Data Portal [data.4dnucleome.org]
- 12. biocompare.com [biocompare.com]
- 13. support.parsebiosciences.com [support.parsebiosciences.com]
- 14. parsebiosciences.com [parsebiosciences.com]
- 15. library.opentrons.com [library.opentrons.com]
- 16. uth.edu [uth.edu]
- 17. bio-rad.com [bio-rad.com]
- 18. news.lifesciencenewswire.com [news.lifesciencenewswire.com]
Safety Operating Guide
Essential Safety and Disposal Protocols for S-Gem
This document provides comprehensive safety, handling, and disposal procedures for the laboratory chemical S-Gem. Adherence to these guidelines is crucial for ensuring personnel safety and environmental compliance. The following information is intended for researchers, scientists, and drug development professionals.
This compound Safety and Hazard Information
Proper handling and storage of this compound are paramount to preventing accidents and ensuring a safe laboratory environment. The following table summarizes the key safety data for this compound.
| Parameter | Value/Information | Precautions and Notes |
| Physical State | Crystalline solid | Minimize dust generation and accumulation.[1] |
| Color | White to opaque | |
| Odor | Odorless | |
| pH | Not available | |
| Melting Point | 1473.8 °F (801 °C) | |
| Boiling Point | 2669 °F (1465 °C) | |
| Incompatible Materials | Strong acids, Oxidizing agents | May evolve chlorine gas when in contact with strong acids.[1] Store away from incompatible materials.[2] |
| Storage | Store in a cool, dry, well-ventilated place. | Store in original tightly closed container.[1] Avoid humid or wet conditions.[1] |
| Personal Protective Equipment (PPE) | Safety glasses/goggles, rubber gloves, NIOSH-approved dust mask.[3][4] | Wear protective equipment to prevent skin and eye contamination.[2] |
This compound Disposal Protocol
The following step-by-step protocol outlines the required procedures for the safe disposal of this compound waste.
1. Waste Identification and Classification:
- All waste containing this compound must be treated as hazardous waste.
- Do not mix this compound waste with other chemical waste streams unless explicitly permitted by your institution's Environmental Health and Safety (EHS) office.
2. Personal Protective Equipment (PPE):
- Before handling this compound waste, ensure you are wearing appropriate PPE, including:
- Safety goggles or a face shield.
- Chemical-resistant gloves (e.g., nitrile or rubber).[3][4]
- A lab coat.
- A NIOSH-approved respirator if there is a risk of dust inhalation.[3]
3. Waste Containerization:
- Use a designated, leak-proof, and sealable hazardous waste container.[5]
- The container must be compatible with this compound.
- Ensure the container is clearly labeled with the words "Hazardous Waste" and the full chemical name "this compound".[6] Do not use abbreviations.[6]
- Keep the waste container closed except when adding waste.[6]
4. Waste Segregation and Storage:
- Store the this compound waste container in a designated, well-ventilated secondary containment area.[6]
- Segregate the this compound waste from incompatible materials, such as strong acids.[6]
5. Scheduling Waste Pickup:
- Once the waste container is ready for disposal, contact your institution's EHS office to schedule a waste pickup.
- Provide the EHS office with all necessary information about the waste, including its composition and volume.
6. Emergency Procedures:
- Spills: In the event of a spill, clear the area of all unprotected personnel.[2] Wear appropriate PPE and contain the spill using an absorbent material like sand or earth.[2][7] Collect the spilled material and place it in a labeled hazardous waste container.[2]
- Eye Contact: Immediately rinse eyes with plenty of water for at least 15 minutes, removing contact lenses if present and easy to do.[8] Seek medical attention if irritation persists.[8]
- Skin Contact: Wash the affected area with soap and water.[1] Get medical attention if irritation develops and persists.[1] Remove and wash contaminated clothing before reuse.[2]
- Inhalation: If dust is inhaled, move the affected person to fresh air.[1] Seek medical attention if symptoms develop.[1]
- Ingestion: If swallowed, give one or two glasses of water if the person is conscious.[1] Do not induce vomiting.[7] Seek immediate medical attention.[7]
This compound Disposal Workflow
The following diagram illustrates the key steps in the proper disposal of this compound.
Caption: this compound Disposal Workflow Diagram.
References
- 1. images.thdstatic.com [images.thdstatic.com]
- 2. chemts.com.au [chemts.com.au]
- 3. scribd.com [scribd.com]
- 4. msdsdigital.com [msdsdigital.com]
- 5. Hazardous Waste Disposal Procedures | The University of Chicago Environmental Health and Safety [safety.uchicago.edu]
- 6. campussafety.lehigh.edu [campussafety.lehigh.edu]
- 7. butterycompany.com [butterycompany.com]
- 8. brenntaglubricantsne.com [brenntaglubricantsne.com]
Standard Operating Procedure: Handling Potent Compound S-Gem
This document provides essential safety and logistical procedures for the handling and disposal of S-Gem, a potent cytotoxic compound utilized in preclinical research. Adherence to these protocols is mandatory for all personnel to ensure occupational safety and prevent environmental contamination.
Hazard Identification and Engineering Controls
This compound is a highly potent, powdered cytotoxic agent. The primary routes of occupational exposure include inhalation of aerosolized particles, dermal contact, and accidental ingestion.[1] Engineering controls are the primary method for exposure mitigation.[2]
-
Primary Containment: All handling of powdered this compound must occur within a certified chemical fume hood or a containment ventilated enclosure (CVE) with a face velocity between 0.4 and 0.6 m/s.
-
Secondary Containment: Operations should be performed over a disposable work surface liner to contain spills.
Personal Protective Equipment (PPE)
Appropriate PPE is the primary control on which workers rely and serves as the final barrier between the operator and the hazardous material.[3] The following PPE is required for all procedures involving this compound.
-
Respiratory Protection: A powered air-purifying respirator (PAPR) is mandatory when handling this compound powder.
-
Eye Protection: Chemical splash goggles must be worn.[3]
-
Hand Protection: Double-gloving is required.[3] Use nitrile gloves as the inner layer and chemotherapy-rated gloves as the outer layer.
-
Body Protection: A disposable, solid-front, back-tying gown with elastic cuffs is required.[3]
-
Foot Protection: Disposable shoe covers must be worn over laboratory shoes.[3]
Table 1: Glove Material Chemical Resistance for this compound
| Glove Material | Splash Resistance (minutes) | Breakthrough Time (minutes) | Recommendation |
| Nitrile | 15 | > 480 | Inner Glove |
| Neoprene | 30 | > 480 | Outer Glove (Chemo-rated) |
| Latex | < 5 | 120 | Not Recommended |
| Vinyl | < 1 | 15 | Not Recommended |
Procedural Protocols
Donning PPE Protocol
This protocol outlines the mandatory sequence for putting on PPE to ensure maximum protection before entering the designated handling area.
Methodology:
-
Preparation: Visually inspect all PPE for defects, tears, or expiration dates before beginning.[4]
-
Shoe Covers: Don the first pair of shoe covers before entering the designated hazardous work area.
-
Inner Gloves: Don the first pair of nitrile gloves.
-
Gown: Don the protective gown, ensuring complete coverage. Secure all ties.
-
Respirator: Don the PAPR hood and ensure it is functioning correctly.
-
Outer Gloves: Don the second pair of chemotherapy-rated gloves, ensuring they overlap the cuffs of the gown.
Doffing PPE Protocol
This protocol minimizes the risk of self-contamination when removing PPE after handling this compound. All removed PPE is considered cytotoxic waste.
Methodology:
-
Outer Gloves: Remove the outer pair of gloves, turning them inside out.
-
Gown: Untie the gown and pull it away from the body, touching only the inside. Roll it into a ball and dispose of it.
-
Shoe Covers: Remove shoe covers.
-
Inner Gloves: Remove the inner pair of gloves.
-
Hand Hygiene: Immediately wash hands thoroughly with soap and water.[5]
-
Respirator: Remove the PAPR hood outside of the immediate work area.
Disposal Plan
All materials contaminated with this compound are classified as cytotoxic waste and must be disposed of accordingly.
-
Waste Segregation: All used PPE, disposable liners, and contaminated labware must be placed in a designated, sealed, and labeled cytotoxic waste container.
-
Container Management: Waste containers must be puncture-resistant, have a tight-fitting lid, and be clearly labeled with the cytotoxic symbol.
-
Final Disposal: Full containers must be collected by a certified hazardous waste disposal contractor.
Spill Management
In the event of a spill, immediately alert personnel in the area and follow the established spill response protocol.
Table 2: Spill Response Actions
| Spill Size | Containment Action | Required PPE | Decontamination |
| < 5g (Powder) | Cover with absorbent pads dampened with water. | Full this compound Handling PPE | Wipe area with 1% Sodium Hypochlorite solution, followed by 70% ethanol. |
| > 5g (Powder) | Evacuate the area. Contact EH&S immediately. | Do Not Enter | Area secured for professional decontamination. |
| Liquid Solution | Cover with absorbent pads. | Full this compound Handling PPE | Wipe area with 1% Sodium Hypochlorite solution, followed by 70% ethanol. |
For any spill, a cytotoxic spill kit must be used.[1] All materials used for cleanup must be disposed of as cytotoxic waste.[6]
References
- 1. apps.worcsacute.nhs.uk [apps.worcsacute.nhs.uk]
- 2. pharmtech.com [pharmtech.com]
- 3. Safe handling of cytotoxics: guideline recommendations - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Basic Rules for the Safe Handling of Hazardous Materials [globalhazmat.com]
- 5. blog.idrenvironmental.com [blog.idrenvironmental.com]
- 6. ipservices.care [ipservices.care]
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
体外研究产品的免责声明和信息
请注意,BenchChem 上展示的所有文章和产品信息仅供信息参考。 BenchChem 上可购买的产品专为体外研究设计,这些研究在生物体外进行。体外研究,源自拉丁语 "in glass",涉及在受控实验室环境中使用细胞或组织进行的实验。重要的是要注意,这些产品没有被归类为药物或药品,他们没有得到 FDA 的批准,用于预防、治疗或治愈任何医疗状况、疾病或疾病。我们必须强调,将这些产品以任何形式引入人类或动物的身体都是法律严格禁止的。遵守这些指南对确保研究和实验的法律和道德标准的符合性至关重要。
