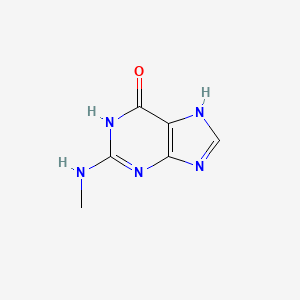
6-Hydroxy-2-methylaminopurine
描述
属性
IUPAC Name |
2-(methylamino)-1,7-dihydropurin-6-one |
Source


|
|---|---|---|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI |
InChI=1S/C6H7N5O/c1-7-6-10-4-3(5(12)11-6)8-2-9-4/h2H,1H3,(H3,7,8,9,10,11,12) |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI Key |
SGSSKEDGVONRGC-UHFFFAOYSA-N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Canonical SMILES |
CNC1=NC2=C(C(=O)N1)NC=N2 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Formula |
C6H7N5O |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
DSSTOX Substance ID |
DTXSID60143124 |
Source
|
| Record name | 6H-Purin-6-one, 1,7-dihydro-2-(methylamino)- (9CI) | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID60143124 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
Molecular Weight |
165.15 g/mol |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Physical Description |
Solid; [Sigma-Aldrich MSDS], Solid |
Source
|
| Record name | 6-Hydroxy-2-methylaminopurine | |
| Source | Haz-Map, Information on Hazardous Chemicals and Occupational Diseases | |
| URL | https://haz-map.com/Agents/11294 | |
| Description | Haz-Map® is an occupational health database designed for health and safety professionals and for consumers seeking information about the adverse effects of workplace exposures to chemical and biological agents. | |
| Explanation | Copyright (c) 2022 Haz-Map(R). All rights reserved. Unless otherwise indicated, all materials from Haz-Map are copyrighted by Haz-Map(R). No part of these materials, either text or image may be used for any purpose other than for personal use. Therefore, reproduction, modification, storage in a retrieval system or retransmission, in any form or by any means, electronic, mechanical or otherwise, for reasons other than personal use, is strictly prohibited without prior written permission. | |
| Record name | N2-Methylguanine | |
| Source | Human Metabolome Database (HMDB) | |
| URL | http://www.hmdb.ca/metabolites/HMDB0006040 | |
| Description | The Human Metabolome Database (HMDB) is a freely available electronic database containing detailed information about small molecule metabolites found in the human body. | |
| Explanation | HMDB is offered to the public as a freely available resource. Use and re-distribution of the data, in whole or in part, for commercial purposes requires explicit permission of the authors and explicit acknowledgment of the source material (HMDB) and the original publication (see the HMDB citing page). We ask that users who download significant portions of the database cite the HMDB paper in any resulting publications. | |
CAS No. |
10030-78-1 |
Source
|
| Record name | N2-Methylguanine | |
| Source | CAS Common Chemistry | |
| URL | https://commonchemistry.cas.org/detail?cas_rn=10030-78-1 | |
| Description | CAS Common Chemistry is an open community resource for accessing chemical information. Nearly 500,000 chemical substances from CAS REGISTRY cover areas of community interest, including common and frequently regulated chemicals, and those relevant to high school and undergraduate chemistry classes. This chemical information, curated by our expert scientists, is provided in alignment with our mission as a division of the American Chemical Society. | |
| Explanation | The data from CAS Common Chemistry is provided under a CC-BY-NC 4.0 license, unless otherwise stated. | |
| Record name | 6-Hydroxy-2-methylaminopurine | |
| Source | ChemIDplus | |
| URL | https://pubchem.ncbi.nlm.nih.gov/substance/?source=chemidplus&sourceid=0010030781 | |
| Description | ChemIDplus is a free, web search system that provides access to the structure and nomenclature authority files used for the identification of chemical substances cited in National Library of Medicine (NLM) databases, including the TOXNET system. | |
| Record name | N2-Methylguanine | |
| Source | DTP/NCI | |
| URL | https://dtp.cancer.gov/dtpstandard/servlet/dwindex?searchtype=NSC&outputformat=html&searchlist=90400 | |
| Description | The NCI Development Therapeutics Program (DTP) provides services and resources to the academic and private-sector research communities worldwide to facilitate the discovery and development of new cancer therapeutic agents. | |
| Explanation | Unless otherwise indicated, all text within NCI products is free of copyright and may be reused without our permission. Credit the National Cancer Institute as the source. | |
| Record name | 6H-Purin-6-one, 1,7-dihydro-2-(methylamino)- (9CI) | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID60143124 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
| Record name | N2-Methylguanine | |
| Source | Human Metabolome Database (HMDB) | |
| URL | http://www.hmdb.ca/metabolites/HMDB0006040 | |
| Description | The Human Metabolome Database (HMDB) is a freely available electronic database containing detailed information about small molecule metabolites found in the human body. | |
| Explanation | HMDB is offered to the public as a freely available resource. Use and re-distribution of the data, in whole or in part, for commercial purposes requires explicit permission of the authors and explicit acknowledgment of the source material (HMDB) and the original publication (see the HMDB citing page). We ask that users who download significant portions of the database cite the HMDB paper in any resulting publications. | |
Foundational & Exploratory
The Biological Significance of N6-methyladenosine (m6A): An In-depth Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Abstract
N6-methyladenosine (m6A) is the most abundant and conserved internal modification in eukaryotic messenger RNA (mRNA) and has emerged as a critical regulator of gene expression.[1][2][3][4] This epitranscriptomic mark is dynamically installed, removed, and recognized by a dedicated set of proteins, collectively known as "writers," "erasers," and "readers." These proteins modulate the fate of m6A-modified transcripts, influencing their splicing, nuclear export, stability, and translation. The dysregulation of m6A methylation has been implicated in a wide array of physiological and pathological processes, including embryonic development, neurogenesis, immune responses, and the progression of various diseases such as cancer and neurodegenerative disorders.[1][2][5] This technical guide provides a comprehensive overview of the biological significance of m6A, with a focus on quantitative data, detailed experimental methodologies for its detection, and the intricate signaling pathways it governs.
The m6A Machinery: Writers, Erasers, and Readers
The biological effects of m6A are orchestrated by a complex interplay of proteins that regulate its deposition, removal, and recognition.
-
Writers: The m6A modification is co-transcriptionally deposited by a methyltransferase complex. The core components of this complex are Methyltransferase-like 3 (METTL3) and METTL14, which form a stable heterodimer.[1] Other associated proteins, such as WTAP (Wilms' tumor 1-associating protein), VIRMA (Vir-like m6A methyltransferase associated), and RBM15/15B (RNA binding motif protein 15/15B), are crucial for the localization and activity of the writer complex.
-
Erasers: The m6A mark is reversible and can be removed by demethylases. The two known m6A erasers are the fat mass and obesity-associated protein (FTO) and AlkB homolog 5 (ALKBH5).[5][6] These enzymes belong to the Fe(II)- and α-ketoglutarate-dependent dioxygenase family.
-
Readers: The functional consequences of m6A modification are mediated by a diverse set of reader proteins that specifically recognize and bind to m6A-containing RNAs. The most well-characterized family of m6A readers are the YTH domain-containing proteins, including YTHDF1, YTHDF2, YTHDF3, YTHDC1, and YTHDC2.[7] These readers can influence mRNA stability, translation, and splicing. Other proteins, such as the insulin-like growth factor 2 mRNA-binding proteins (IGF2BP1/2/3) and heterogeneous nuclear ribonucleoproteins (HNRNPs), have also been identified as m6A readers.[7]
Quantitative Data on N6-methyladenosine
The abundance and distribution of m6A vary across different tissues, developmental stages, and disease states. The following tables summarize key quantitative data related to m6A.
Table 1: N6-methyladenosine (m6A) Levels in Human Tissues and Cancers
| Tissue/Condition | m6A Abundance/Change | Reference |
| Brain | Higher prevalence compared to most other tissues.[1] | [1] |
| Subcutaneous Adipose Tissue (Lean vs. Obesity) | Differentially methylated targets identified, including TSC22D1, FMNL2, and IL1R1.[8] | [8] |
| Visceral Adipose Tissue (Lean vs. Obesity) | Higher number of genes containing m6A in non-adipocyte cells in visceral adipose tissue with obesity.[8] | [8] |
| Colorectal Cancer (Serum) | Average m6A concentration: 5.57 ± 1.67 nM (n=51).[9] | [9] |
| Gastric Cancer (Serum) | Average m6A concentration: 6.93 ± 1.38 nM (n=27).[9] | [9] |
| Healthy Controls (Serum) | Average m6A concentration: Not explicitly stated, but significantly lower than cancer patients.[9] | [9] |
| Bladder Cancer | 10,601 m6A peaks in tumor tissues vs. 9,198 in adjacent normal tissues.[10] | [10] |
| Ameloblastoma | 3,673 differentially methylated m6A sites in coding genes compared to normal oral tissues. | [11] |
| Hepatocellular Carcinoma | Decreased m6A levels in tumor tissues compared to adjacent tissues.[12] | [12] |
| Endometrial Cancer | Reduced m6A methylation levels in cancer cells compared to adjacent normal tissues. | [6] |
Table 2: Impact of m6A Modification on mRNA Stability and Translation
| Gene/Condition | Effect on mRNA Half-life/Stability | Effect on Translation Efficiency | Reference |
| METTL3 Knockdown | Increased half-life of m6A-containing mRNAs.[13] | Decreased translation efficiency of YTHDF1 targets.[5] | [5][13] |
| YTHDF2 Knockdown | Increased mRNA half-life of 626 genes out of ~3,600 bound genes in HeLa cells.[7] | Small effect on translation efficiency.[5] | [5][7] |
| YTHDF1 Knockdown | No significant change in mRNA abundance. | Reduced translation efficiency of target mRNAs.[5] | [5] |
| MIS12 mRNA | Loss of m6A modification accelerates turnover and decreases expression.[14] | Not specified. | [14] |
| SETD1A, SETD1B, KMT2B mRNAs | METTL3 depletion prolongs mRNA half-life.[15] | Not specified. | [15] |
| LHPP and NKX3-1 mRNAs | YTHDF2 mediates mRNA degradation.[16] | Not specified. | [16] |
| m6A in 3' UTR | Generally promotes mRNA decay. | Can be decreased. | |
| m6A in 5' UTR | Can promote cap-independent translation.[6] | Increased. | [6] |
Experimental Protocols for m6A Detection
Several techniques have been developed to map and quantify m6A modifications across the transcriptome. Below are detailed methodologies for key experiments.
Methylated RNA Immunoprecipitation Sequencing (MeRIP-Seq)
MeRIP-seq is a widely used antibody-based method for transcriptome-wide profiling of m6A.[2]
Methodology:
-
RNA Extraction and Fragmentation: Isolate total RNA from cells or tissues and fragment it into ~100 nucleotide-long segments.[13]
-
Immunoprecipitation: Incubate the fragmented RNA with an anti-m6A antibody to specifically capture m6A-containing RNA fragments.[2]
-
Bead Capture: Add protein A/G magnetic beads to pull down the antibody-RNA complexes.
-
Washing and Elution: Wash the beads to remove non-specifically bound RNA and then elute the m6A-enriched RNA fragments.
-
Library Preparation: Construct a cDNA library from the eluted RNA fragments. An input control library should be prepared in parallel from a small fraction of the fragmented RNA before immunoprecipitation.
-
High-Throughput Sequencing: Sequence both the immunoprecipitated and input libraries using next-generation sequencing platforms.
-
Data Analysis: Align the sequencing reads to a reference genome/transcriptome and identify m6A peaks by comparing the enrichment in the immunoprecipitated sample to the input control.
Site-Specific Cleavage and Radioactive-Labeling followed by Ligation-Assisted Extraction and Thin-Layer Chromatography (SCARLET)
SCARLET is a high-resolution method that can identify and quantify m6A at single-nucleotide resolution.[1][5][7]
Methodology:
-
Site-Specific Cleavage: Utilize a sequence-specific RNase H or DNAzyme to cleave the target RNA molecule immediately adjacent to the potential m6A site.
-
Radioactive Labeling: Label the 3' end of the cleaved fragment with a radioactive isotope, typically [5'-32P]pCp, using T4 RNA ligase.
-
Ligation-Assisted Extraction: Ligate a specific biotinylated DNA adapter to the 3'-end of the radiolabeled RNA fragment.
-
Enrichment: Use streptavidin-coated magnetic beads to capture the biotinylated RNA-DNA hybrids.
-
Nuclease Digestion: Digest the captured RNA down to single nucleotides using P1 nuclease.
-
Thin-Layer Chromatography (TLC): Separate the resulting radiolabeled nucleotides on a TLC plate.
-
Quantification: Detect and quantify the radioactive spots corresponding to adenosine and N6-methyladenosine to determine the modification stoichiometry.
m6A Individual-Nucleotide-Resolution Cross-linking and Immunoprecipitation (m6A-CLIP-seq/miCLIP)
m6A-CLIP-seq combines UV cross-linking and immunoprecipitation to map m6A sites at single-nucleotide resolution.[3]
Methodology:
-
UV Cross-linking: Irradiate cells or tissues with UV light to induce covalent cross-links between RNA and interacting proteins, including the anti-m6A antibody which is added after RNA fragmentation.
-
RNA Fragmentation and Immunoprecipitation: Fragment the RNA and perform immunoprecipitation with an anti-m6A antibody.
-
Adapter Ligation: Ligate RNA adapters to the 3' and 5' ends of the immunoprecipitated RNA fragments.
-
Reverse Transcription: Perform reverse transcription, during which the cross-linked amino acid adduct often causes mutations or truncations in the resulting cDNA.
-
Library Preparation and Sequencing: Prepare a cDNA library and perform high-throughput sequencing.
-
Data Analysis: Identify m6A sites by analyzing the characteristic mutations (e.g., C-to-T transitions) and truncations in the sequencing reads at the cross-linking sites.
Photo-Crosslinking-Assisted m6A Sequencing (PA-m6A-seq)
PA-m6A-seq is another high-resolution method that utilizes photoactivatable ribonucleosides to map m6A sites.[3][14]
Methodology:
-
Metabolic Labeling: Culture cells with a photoactivatable ribonucleoside analog, such as 4-thiouridine (4SU).[14]
-
RNA Isolation and Immunoprecipitation: Isolate total RNA and perform immunoprecipitation with an anti-m6A antibody.
-
UV Cross-linking: Expose the immunoprecipitated RNA to UV light (365 nm) to induce cross-linking between the 4SU and the antibody at the m6A site.[14]
-
RNase Digestion and Library Preparation: Digest the cross-linked RNA into smaller fragments and prepare a sequencing library.
-
Sequencing and Data Analysis: During reverse transcription, the cross-linked 4SU is often read as a cytosine (C) instead of a thymine (T). Therefore, m6A sites can be identified by detecting T-to-C transitions in the sequencing data.
Signaling Pathways and Logical Relationships
m6A modification is intricately linked with various signaling pathways, thereby influencing a multitude of cellular processes. The following diagrams, generated using the DOT language for Graphviz, illustrate these complex interactions.
Conclusion
N6-methyladenosine has emerged from being a relatively obscure RNA modification to a pivotal player in the regulation of gene expression and cellular function. Its dynamic nature, governed by the interplay of writers, erasers, and readers, provides a sophisticated layer of epitranscriptomic control that is essential for normal development and physiology. The growing body of evidence linking aberrant m6A modification to a multitude of human diseases, including cancer and neurological disorders, underscores its significance as a potential therapeutic target. The continued development of high-resolution mapping techniques and functional genomics approaches will undoubtedly unravel further complexities of the m6A code and pave the way for novel diagnostic and therapeutic strategies in the years to come.
References
- 1. epigenie.com [epigenie.com]
- 2. researchgate.net [researchgate.net]
- 3. embopress.org [embopress.org]
- 4. m6A-Mediated Translation Regulation - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Understanding YTHDF2-mediated mRNA degradation by m6A-BERT-Deg - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Settling the m6A debate: methylation of mature mRNA is not dynamic but accelerates turnover - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. researchgate.net [researchgate.net]
- 9. YTHDF2 mediates the mRNA degradation of the tumor suppressors to induce AKT phosphorylation in N6-methyladenosine-dependent way in prostate cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. m6A links mRNA transcription to translation | The Agami Group [research.nki.nl]
- 12. m6A RNA methylation correlates with immune microenvironment and immunotherapy response of melanoma - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Studying m6A in the brain: a perspective on current methods, challenges, and future directions - PMC [pmc.ncbi.nlm.nih.gov]
- 14. academic.oup.com [academic.oup.com]
- 15. academic.oup.com [academic.oup.com]
- 16. Frontiers | Comprehensive analysis of m6A RNA methylation modification patterns and the immune microenvironment in osteoarthritis [frontiersin.org]
An In-depth Technical Guide to 6-Hydroxy-2-methylaminopurine: Chemical Properties and Synthesis
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the chemical properties, spectral data, and synthetic methodologies for 6-Hydroxy-2-methylaminopurine. Also known as N2-Methylguanine, this modified purine nucleobase is a subject of interest in various fields of biochemical and medical research due to its role as a human metabolite and its presence in modified RNA structures.[1][2] This document serves as a detailed resource, offering structured data, experimental protocols, and visual diagrams of synthetic pathways to facilitate further research and application.
Chemical and Physical Properties
This compound is a solid, light yellow to khaki-colored compound.[1][2][3] Its chemical structure consists of a purine core with a hydroxyl group at the C6 position and a methylamino group at the C2 position. It is the keto tautomer of N2-methylguanine. The compound is poorly soluble in common organic solvents like DMSO.[2][3] Below is a summary of its key chemical and physical properties.
| Property | Value | Reference(s) |
| IUPAC Name | 2-(methylamino)-1,7-dihydropurin-6-one | [1] |
| Synonyms | N2-Methylguanine, 2-Methylamino-6-oxopurine | [1][4][5] |
| CAS Number | 10030-78-1 | [1][4][6] |
| Molecular Formula | C₆H₇N₅O | [1][4][7] |
| Molecular Weight | 165.15 g/mol | [1][4][7] |
| Appearance | Light yellow to khaki solid | [2][3] |
| Melting Point | >300 °C (decomposes) | [2][3] |
| Boiling Point | 280 °C at 760 mmHg (Predicted) | [4] |
| Density | 1.79 g/cm³ (Predicted) | [2][4] |
| pKa | 9.86 ± 0.20 (Predicted) | [2][3] |
| Solubility | Insoluble or slightly soluble in DMSO | [2][3] |
Spectral Data Summary
Spectroscopic analysis is crucial for the identification and characterization of this compound.
| Analysis Technique | Data Summary | Reference(s) |
| Mass Spectrometry | GC-MS and LC-MS data are available, confirming the molecular weight. The LC-MS precursor ion [M+H]⁺ is observed at m/z 166.0723. | [1] |
| ¹H NMR | ¹H NMR spectral data is available for structural elucidation. | [8] |
| IR, ¹³C NMR, etc. | Other spectral data including IR, ¹³C NMR, and Raman spectroscopy are available and can be used for comprehensive structural confirmation. | [8] |
Synthesis of this compound
The synthesis of N2-substituted guanine derivatives can be approached through several strategic routes. A common and effective method involves the modification of a pre-existing, suitably functionalized purine core. One of the most viable strategies starts from guanosine, which is converted into a more reactive intermediate for nucleophilic substitution.[1] The key transformation is the displacement of a leaving group (such as a fluoro group) at the C2 position by methylamine.
Below is a representative synthetic pathway, starting from the readily available guanosine. This multi-step process involves protection of reactive groups, activation of the C2 position, nucleophilic substitution, and subsequent deprotection.
Caption: Synthetic pathway for this compound from guanosine.
Experimental Protocols
This section provides a detailed, representative methodology for the synthesis of this compound based on the principles of nucleophilic aromatic substitution on a purine intermediate.[1]
Protocol 1: Synthesis via 2-Fluoro Intermediate
This protocol is adapted from established methods for the synthesis of N2-substituted guanosine analogues.[1]
Step 1: Preparation of Protected 2-Fluoro-O6-arylinosine
-
Guanosine Protection: Commercially available guanosine is first peracetylated to protect the hydroxyl groups of the ribose moiety. The O6 position is then protected, for example, as a 2-(4-nitrophenyl)ethyl ether.
-
Diazotization and Fluorination: The protected guanosine derivative is dissolved in a solution of HF/pyridine. An aqueous solution of sodium nitrite is added dropwise at a controlled low temperature (e.g., -15 °C) to convert the N2-amino group into a diazonium salt, which is subsequently replaced by fluoride.
-
Work-up and Purification: The reaction is quenched, and the product is extracted with an organic solvent. The crude product is purified by column chromatography to yield the fully protected 2-fluoro inosine derivative.
Step 2: Nucleophilic Substitution with Methylamine
-
Reaction Setup: The purified 2-fluoro intermediate is dissolved in an anhydrous polar aprotic solvent, such as dimethylsulfoxide (DMSO).
-
Addition of Amine: A solution of methylamine (in a solvent like THF or as a gas) is added in excess to the reaction mixture.
-
Reaction Conditions: The mixture is heated (e.g., to 60 °C) and stirred for several hours to days, depending on the reactivity. The reaction progress is monitored by Thin Layer Chromatography (TLC) or High-Performance Liquid Chromatography (HPLC).
-
Isolation: Upon completion, the solvent is removed under vacuum, and the residue is processed to isolate the crude N2-methylated product.
Step 3: Deprotection and Cleavage
-
Base-catalyzed Deprotection: The protecting groups (acetyl and O6-aryl) are removed under basic conditions (e.g., with ammonia in methanol or sodium methoxide).
-
Acid-catalyzed Hydrolysis: The resulting N2-methylguanosine is subjected to acid hydrolysis (e.g., with 1M HCl) at an elevated temperature to cleave the glycosidic bond, releasing the free purine base.
-
Purification: The final product, this compound, is isolated from the reaction mixture by neutralization and purified by recrystallization or chromatography.
The following diagram illustrates the general workflow for each synthetic step.
Caption: General experimental workflow for organic synthesis.
Conclusion
This compound is an important modified nucleobase with established biological relevance. This guide provides essential data on its chemical and physical properties, along with a robust, representative synthetic strategy. The detailed protocols and visual workflows are intended to equip researchers with the necessary information to synthesize, characterize, and utilize this compound in their respective fields of study, from drug discovery to molecular biology.
References
- 1. Synthesis of N2-modified 7-methylguanosine 5’-monophosphates as nematode translation inhibitors - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Methylation of guanine – DNA Mismatch [dnamismatch.com]
- 3. Frontiers | N2-methylguanosine and N2, N2-dimethylguanosine in cytosolic and mitochondrial tRNAs [frontiersin.org]
- 4. chemrxiv.org [chemrxiv.org]
- 5. Synthesis and properties of oligonucleotides modified with an N-methylguanidine-bridged nucleic acid (GuNA[Me]) bearing adenine, guanine, or 5-methylcytosine nucleobases - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. Translesional synthesis on a DNA template containing N2-methyl-2′-deoxyguanosine catalyzed by the Klenow fragment of Escherichia coli DNA polymerase I - PMC [pmc.ncbi.nlm.nih.gov]
- 8. pubs.acs.org [pubs.acs.org]
N2-methylguanine (m2G): A Comprehensive Technical Guide to a Key Post-Transcriptional RNA Modification
For Researchers, Scientists, and Drug Development Professionals
Introduction
Post-transcriptional modifications of RNA molecules represent a critical layer of gene expression regulation, influencing RNA stability, structure, and function.[1] Among the more than 170 known RNA modifications, N2-methylguanine (m2G) is a prevalent and highly conserved modification found across all domains of life.[2][3] This technical guide provides an in-depth overview of m2G, focusing on its biochemical nature, the enzymatic machinery responsible for its deposition, its diverse biological roles, and the experimental methodologies used for its study. Particular emphasis is placed on quantitative data, detailed experimental protocols, and the visualization of key cellular pathways and workflows.
Biochemistry and Location of N2-methylguanine
N2-methylguanine is formed by the addition of a methyl group to the exocyclic amine at the N2 position of a guanine residue within an RNA molecule.[3] This modification is found in various types of RNA, including transfer RNA (tRNA), ribosomal RNA (rRNA), and small nuclear RNA (snRNA).[4] In tRNA, m2G is frequently located at positions 6, 7, 9, 10, and 26, often at the junctions between stem and loop structures, where it plays a crucial role in maintaining tRNA structure and stability.[1][2][3] For instance, methylation at guanosine 26 occurs in approximately 80% of eukaryotic tRNAs that contain a guanosine at this position.[2]
The m2G Methyltransferase Machinery
The deposition of m2G is catalyzed by a family of S-adenosyl-L-methionine (SAM)-dependent methyltransferases. In humans, several key enzymes have been identified, often working in complex with the activating subunit TRMT112.[3][5][6]
-
TRMT11-TRMT112 Complex: This complex is responsible for the methylation of guanosine at position 10 (m2G10) in tRNAs.[6][7]
-
THUMPD3-TRMT112 Complex: This complex catalyzes the formation of m2G at position 6 (m2G6) in a broad range of cytoplasmic tRNAs.[3][5] It recognizes the characteristic 3'-CCA end of mature tRNAs.[3][5]
-
THUMPD2-TRMT112 Complex: This complex is responsible for the N2-methylation of guanosine at position 72 (m2G72) of the U6 snRNA, a core component of the spliceosome.[8][9]
-
TRMT1: This enzyme catalyzes the formation of both m2G and N2,N2-dimethylguanosine (m2,2G) at position 26 of both cytoplasmic and mitochondrial tRNAs in a substrate-dependent manner.[10]
Functional Roles of N2-methylguanine
The m2G modification has been implicated in a variety of fundamental cellular processes:
-
tRNA Structure and Stability: m2G modifications, particularly at the junctions of tRNA stems and loops, are critical for maintaining the correct three-dimensional structure of tRNA molecules, which is essential for their proper function in translation.[1][2]
-
Protein Synthesis: By ensuring the structural integrity of tRNAs, m2G modifications contribute to the efficiency and fidelity of protein synthesis.[3][5] Depletion of m2G methyltransferases, such as THUMPD3, has been shown to impair global protein synthesis and inhibit cell proliferation.[3][5]
-
Pre-mRNA Splicing: The m2G72 modification in U6 snRNA, catalyzed by THUMPD2, is crucial for the catalytic activity of the spliceosome.[8][9] Loss of this modification impairs pre-mRNA splicing, leading to widespread changes in alternative splicing events.[8][9]
-
Cell Proliferation and Disease: Dysregulation of m2G modification has been linked to various human diseases, including cancer.[11] For example, the m2G methyltransferase THUMPD3 is implicated in regulating the alternative splicing of transcripts related to the extracellular matrix in lung cancer cells, thereby promoting proliferation and migration.[11]
Quantitative Data on m2G Modification
The stoichiometry of RNA modifications can vary depending on cellular conditions and cell type. While comprehensive quantitative data for m2G across all RNA species is still an active area of research, studies on related modifications provide some context. For instance, the stoichiometry of N7-methylguanosine (m7G) in human tRNAs has been measured to be in the range of 60-85%.[12]
Table 1: Kinetic Parameters of m2G Methyltransferases
| Enzyme Complex | Substrate | Km (µM) | kcat (min-1) | Reference |
| EcTrmD (E. coli) | G37-tRNA | 5 | - | [13] |
| MjTrm5 (M. jannaschii) | G37-tRNA | 0.5 | - | [13] |
Experimental Protocols
Detection and Quantification of m2G by HPLC-Mass Spectrometry
This protocol outlines the general steps for the analysis of m2G in RNA using High-Performance Liquid Chromatography coupled with Mass Spectrometry (HPLC-MS).
Materials:
-
Purified RNA sample
-
Nuclease P1
-
Bacterial alkaline phosphatase
-
LC-MS grade water and acetonitrile
-
Ammonium acetate
-
HPLC system with a C18 reversed-phase column
-
Triple quadrupole mass spectrometer
Procedure:
-
RNA Digestion:
-
To 1-5 µg of purified RNA, add 1 unit of nuclease P1 in a final volume of 20 µL of a buffer containing 10 mM ammonium acetate (pH 5.3).
-
Incubate at 42°C for 2 hours.
-
Add 1 µL of 1 M ammonium bicarbonate and 0.1 units of bacterial alkaline phosphatase.
-
Incubate at 37°C for 2 hours.
-
-
HPLC Separation:
-
Inject the digested sample onto a C18 reversed-phase HPLC column.
-
Use a gradient of mobile phase A (e.g., 5 mM ammonium acetate in water) and mobile phase B (e.g., acetonitrile). A typical gradient could be 0-40% B over 30 minutes.
-
Monitor the elution of nucleosides by UV absorbance at 254 nm.
-
-
Mass Spectrometry Analysis:
-
Couple the HPLC eluent to the electrospray ionization (ESI) source of the mass spectrometer.
-
Operate the mass spectrometer in positive ion, multiple reaction monitoring (MRM) mode.
-
Monitor the specific precursor-to-product ion transitions for guanosine (G) and N2-methylguanosine (m2G). The mass transition for m2G is typically m/z 298.1 → 166.1.[8]
-
-
Quantification:
-
Generate a standard curve using known concentrations of pure G and m2G nucleoside standards.
-
Calculate the amount of m2G relative to the amount of unmodified guanosine in the sample by comparing the peak areas from the sample chromatogram to the standard curve.
-
Identification of m2G Sites using a Reverse Genetics Approach Coupled with RNA-Mass Spectrometry
This workflow describes a strategy to identify the enzyme responsible for a specific m2G modification.
Procedure:
-
Candidate Enzyme Selection:
-
Perform a phylogenetic analysis of known and predicted RNA m2G methyltransferases to identify potential candidates in the organism of interest.[14]
-
-
Gene Knockout/Knockdown:
-
Generate a cell line or organism with a knockout or knockdown of the candidate methyltransferase gene using techniques like CRISPR-Cas9 or RNA interference (RNAi).
-
-
RNA Purification:
-
Isolate the specific RNA species of interest (e.g., U6 snRNA) from both wild-type and knockout/knockdown cells/organisms.
-
-
RNA-Mass Spectrometry Analysis:
-
Digest the purified RNA to oligonucleotides or single nucleosides as described in the HPLC-MS protocol.
-
Analyze the digests by LC-MS/MS to determine the presence or absence of the m2G modification at the specific site.
-
-
Validation:
Visualizations
Signaling Pathway: The m2G Methyltransferase Machinery
Caption: The enzymatic pathway of N2-methylguanine deposition.
Experimental Workflow: Identification and Quantification of m2G
Caption: Workflow for m2G analysis.
Conclusion and Future Perspectives
N2-methylguanine is a vital post-transcriptional RNA modification with profound implications for fundamental cellular processes and human health. The continued development of sensitive and quantitative methods for the detection and mapping of m2G will be crucial for a deeper understanding of its regulatory roles. Future research will likely focus on elucidating the dynamic regulation of m2G deposition in response to cellular signals and environmental stresses, as well as exploring the therapeutic potential of targeting m2G methyltransferases in diseases such as cancer. This technical guide provides a solid foundation for researchers and drug development professionals to delve into the intricate world of m2G and its impact on the epitranscriptome.
References
- 1. scispace.com [scispace.com]
- 2. The Chemical Diversity of RNA Modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 3. THUMPD3–TRMT112 is a m2G methyltransferase working on a broad range of tRNA substrates - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. THUMPD3-TRMT112 is a m2G methyltransferase working on a broad range of tRNA substrates - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. N 2-methylguanosine modifications on human tRNAs and snRNA U6 are important for cell proliferation, protein translation and pre-mRNA splicing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. uniprot.org [uniprot.org]
- 8. THUMPD2 catalyzes the N2-methylation of U6 snRNA of the spliceosome catalytic center and regulates pre-mRNA splicing and retinal degeneration - PMC [pmc.ncbi.nlm.nih.gov]
- 9. THUMPD2 catalyzes the N2-methylation of U6 snRNA of the spliceosome catalytic center and regulates pre-mRNA splicing and retinal degeneration - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Human TRMT1 catalyzes m2G or m22G formation on tRNAs in a substrate-dependent manner - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. THUMPD3 regulates alternative splicing of ECM transcripts in human lung cancer cells and promotes proliferation and migration - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. Kinetic Analysis of tRNA Methylfransferases - PMC [pmc.ncbi.nlm.nih.gov]
- 14. academic.oup.com [academic.oup.com]
Introduction: The Importance of Post-Transcriptional Modifications in tRNA
An In-Depth Technical Guide on the Role of N2-Methylguanine in Stabilizing tRNA Three-Dimensional Structure
For Researchers, Scientists, and Drug Development Professionals
Transfer RNA (tRNA) molecules are central to protein synthesis, acting as the crucial adaptors that translate the genetic code from messenger RNA (mRNA) into the amino acid sequence of proteins. While all primary tRNA transcripts are composed of the four canonical ribonucleosides (A, C, G, U), they undergo extensive post-transcriptional modification to become fully functional.[1] These modifications, particularly those within the tRNA core, are essential for the proper folding, stability, and maintenance of the conserved L-shaped three-dimensional structure.[2][3] This precise architecture is critical for interactions with aminoacyl-tRNA synthetases, ribosomes, and other components of the translational machinery.[2]
Among the more than 100 known modifications, methylation is the most prevalent.[3] N2-methylguanosine (m2G) and its dimethylated form, N2,N2-dimethylguanosine (m2,2G), are universally conserved modifications found in tRNAs across all domains of life, from bacteria to eukaryotes and archaea.[1][3] They are typically located at key junctions in the tRNA structure, such as position 10 in the D-loop and position 26 in the hinge region between the D-arm and the anticodon stem, where they play a pivotal role in ensuring structural integrity and preventing misfolding.[1][3] This guide provides a detailed examination of the structural contributions of m2G and m2,2G, the enzymes responsible for their deposition, and the experimental methodologies used to study their function.
The Structural Role and Enzymology of N2-Methylguanine
The stabilizing effect of N2-methylguanine modifications stems from their direct involvement in tertiary interactions and their ability to act as structural determinants that prevent the formation of non-functional or alternative tRNA conformations.[2][4]
-
N2-methylguanosine (m2G) at Position 10: Located at the corner of the L-shaped structure, m2G10 is typically involved in a tertiary base triple interaction with the C25-G45 pair.[3] The single methyl group on the exocyclic N2 amine does not disrupt Watson-Crick pairing but adds hydrophobicity, which is thought to stabilize the D-loop structure.[4] This modification is catalyzed by the Trm11-Trm112 enzyme complex in eukaryotes and archaea.[5]
-
N2,N2-dimethylguanosine (m2,2G) at Position 26: This modification is found in the vast majority of eukaryotic tRNAs in the bend between the D-stem and the anticodon stem.[4] The addition of two methyl groups to the N2 amine prevents it from acting as a hydrogen bond donor, thereby blocking canonical Watson-Crick base pairing with cytosine.[2][4] This feature is critical for preventing an aberrant base pair between G26 and C11, which would lead to a misfolded, inactive structure.[2] Instead, m2,2G26 often forms a non-canonical pair with A44, an interaction that is crucial for maintaining the global L-shaped architecture.[4] By precluding incorrect secondary structures, m2,2G26 effectively acts as an RNA chaperone, ensuring the tRNA adopts its correct, functional fold.[2][4] In humans, this modification is catalyzed by the tRNA methyltransferase TRMT1.[6][7]
The critical role of these modifications is underscored by the fact that mutations in the human TRMT1 gene are associated with intellectual disability, arising from perturbations in global protein synthesis and cellular homeostasis due to the lack of m2,2G modifications.[6]
Quantitative Data on the Stabilizing Effects of N2-Methylguanine
While the primary role of m2,2G26 is often characterized as preventing misfolding rather than simply increasing thermostability, post-transcriptional modifications as a whole contribute significantly to the stability of the tRNA structure. Direct measurements of the change in melting temperature (ΔTm) upon addition or removal of m2G are not widely reported, but its contribution can be inferred from several lines of evidence summarized below.
| Evidence Type | Observation | Implication for Stability |
| Thermostability in Hyperthermophiles | In the hyperthermophile Pyrococcus furiosus, the measured melting temperature of tRNA is approximately 20°C higher than what is predicted based on its GC content alone.[2] These organisms feature a high prevalence of modifications, including m2,2G. | N2-methylguanine and other modifications are crucial for the extraordinary thermal stability required for tRNA function at extreme temperatures. |
| Prevention of Misfolding | The m2,2G modification at position 10 or 26 prevents the formation of aberrant, non-functional base pairs (e.g., G26-C11), thereby directing the tRNA into its correct L-shaped fold.[2][4] This shifts the conformational equilibrium away from misfolded states. | m2,2G acts as a key structural determinant, ensuring the formation of the single, stable, and functional tRNA conformation. This "chaperone-like" activity is a primary mechanism of stabilization. |
| Molecular Dynamics Simulations | Computer simulations of tRNA structures show that versions containing the full set of modified nucleotides (WT) consistently exhibit lower root-mean-square deviations (RMSDs) from the crystal structure compared to canonical, unmodified (CAN) versions.[8] This indicates that modifications reduce structural fluctuations. | The presence of modifications, including m2G and m2,2G, directly contributes to maintaining the correct, stable tRNA conformation by reducing conformational flexibility.[8] |
| Enzyme Chaperone Activity | The Trm1 enzyme, which creates m2,2G26, has been shown to possess RNA chaperone activity (enhancing RNA strand annealing and dissociation) that is independent of its catalytic methyltransferase function.[9] | The process of achieving a stable tRNA structure is aided by both the chemical modification itself and the enzyme that installs it, highlighting the multifaceted approach cells use to ensure tRNA integrity.[9] |
Logical and Experimental Visualizations
The following diagrams illustrate the structural role of m2,2G26 and a typical workflow for its analysis.
Caption: Logical diagram of m2,2G26's role in ensuring correct tRNA folding.
Caption: Experimental workflow for analyzing m2G's impact on tRNA stability.
Experimental Protocols
This section provides detailed methodologies for key experiments used to investigate the role of N2-methylguanine in tRNA stability.
Protocol: In Vitro Analysis of tRNA Stability (Unmodified vs. m2,2G-Modified)
This protocol outlines the complete workflow for producing unmodified tRNA, enzymatically modifying it in vitro to introduce m2,2G, and comparing the thermal stability of the two species.
Part A: In Vitro Transcription of Unmodified tRNA This procedure uses T7 RNA polymerase to synthesize tRNA from a DNA template.[10]
-
Template Preparation:
-
Synthesize two complementary DNA oligonucleotides. The forward oligo should contain the T7 promoter sequence (5'-TAATACGACTCACTATA-3') followed by the desired tRNA gene sequence (starting with a G). The reverse oligo is the reverse complement.
-
Anneal the oligos by mixing them in equimolar amounts (e.g., 25 µM each) in an annealing buffer (e.g., 10 mM Tris-HCl, 50 mM NaCl), heating to 95°C for 5 minutes, and allowing them to cool slowly to room temperature.[10]
-
-
Transcription Reaction:
-
Assemble the transcription reaction at room temperature in a final volume of 100 µL. A typical reaction contains:
-
40 mM Tris-HCl, pH 8.0
-
22 mM MgCl2
-
1 mM Spermidine
-
5 mM DTT
-
4 mM each of ATP, GTP, CTP, UTP
-
1-2 µg of annealed DNA template
-
T7 RNA Polymerase (e.g., 30 nM)[10]
-
-
Incubate the reaction at 37°C for 3-4 hours.
-
-
Purification of tRNA Transcript:
-
Stop the reaction by adding EDTA to a final concentration of 50 mM.
-
Extract the RNA using a phenol/chloroform procedure, followed by ethanol precipitation.
-
Resuspend the pellet and purify the full-length tRNA transcript from shorter products using denaturing polyacrylamide gel electrophoresis (PAGE) (e.g., 10-12% acrylamide, 8 M urea).
-
Excise the band corresponding to the tRNA, elute it from the gel (e.g., by crush-and-soak method in a high-salt buffer), and recover by ethanol precipitation.[11]
-
Resuspend the purified, unmodified tRNA in RNase-free water.
-
Part B: In Vitro tRNA Methylation This procedure uses recombinant TRMT1 enzyme to install the m2,2G modification.[5]
-
Refolding the tRNA Substrate:
-
Take an aliquot of the purified, unmodified tRNA (e.g., to a final concentration of 5 µM in the reaction).
-
Heat the tRNA at 85-95°C for 2 minutes, then allow it to cool slowly to room temperature for at least 15 minutes to ensure proper folding.[11]
-
-
Methylation Reaction:
-
Prepare a 5X methylation buffer (e.g., 100 mM Tris-HCl pH 7.5-8.0, 10 mM MgCl2, 100 mM NH4OAc or NH4Cl, 0.1 mM EDTA, 5 mM DTT).[5][11]
-
Assemble the reaction on ice. For a 25 µL reaction:
-
5 µL of 5X Methylation Buffer
-
Folded tRNA (to 5 µM final)
-
S-adenosylmethionine (SAM) (to 100-200 µM final)
-
Recombinant TRMT1 enzyme (e.g., 5 µM final)[5]
-
RNase-free water to 25 µL
-
-
Incubate at 32°C or 37°C for 1-3 hours.
-
Stop the reaction and purify the methylated tRNA using a suitable RNA cleanup kit or phenol/chloroform extraction and ethanol precipitation.
-
Part C: Thermal Denaturation by UV Spectrophotometry This procedure measures the melting temperature (Tm), the temperature at which 50% of the tRNA is unfolded.[12]
-
Instrumentation:
-
Use a UV-Vis spectrophotometer equipped with a Peltier-based temperature controller.
-
-
Sample Preparation:
-
Prepare two samples: one with the unmodified tRNA and one with the in vitro methylated tRNA.
-
Dilute each tRNA to a final concentration of ~0.2-0.5 A260 units in a buffer appropriate for maintaining tRNA structure (e.g., 10 mM sodium phosphate pH 7.0, 100 mM NaCl, 5 mM MgCl2).
-
-
Measurement:
-
Place the samples in quartz cuvettes in the spectrophotometer.
-
Set the instrument to monitor absorbance at 260 nm.
-
Program a temperature ramp from a starting temperature (e.g., 25°C) to a final temperature (e.g., 95°C) at a slow, constant rate (e.g., 0.5°C or 1°C per minute).[13]
-
Record the absorbance at each temperature increment.
-
-
Data Analysis:
-
Plot the absorbance at 260 nm (y-axis) against the temperature (x-axis) to generate a melting curve.
-
The curve will be sigmoidal, with the absorbance increasing as the tRNA unfolds (hyperchromic effect).
-
The Tm is the temperature at the midpoint of this transition, which can be determined by finding the peak of the first derivative of the melting curve.[12]
-
Compare the Tm of the modified tRNA to the unmodified tRNA. An increase in Tm indicates stabilization by the m2,2G modification.
-
Protocol: Quantification of tRNA Modifications by LC-MS/MS
This protocol provides a workflow for the sensitive detection and quantification of m2G and other modifications from a total tRNA sample.[14][15]
-
tRNA Isolation and Purification:
-
Isolate total RNA from cells or tissues using a standard RNA extraction method (e.g., TRIzol or a column-based kit).
-
Purify the tRNA fraction from the total RNA. This can be done by size-selection chromatography, preparative PAGE, or affinity purification using biotinylated oligonucleotides complementary to a specific tRNA.[14][16]
-
-
Enzymatic Digestion to Nucleosides:
-
Hydrolyze the purified tRNA down to its constituent ribonucleosides.
-
Incubate ~1-5 µg of tRNA with a mixture of nucleases, such as Nuclease P1 (to remove 5'-phosphates) followed by bacterial alkaline phosphatase (to remove 3'-phosphates).
-
A typical reaction involves incubating tRNA with Nuclease P1 in a buffer (e.g., 20 mM HEPES, pH 7.0) at 37°C for 2 hours, followed by the addition of alkaline phosphatase and further incubation.[15]
-
-
Liquid Chromatography (LC) Separation:
-
Separate the resulting mixture of nucleosides using reversed-phase high-performance liquid chromatography (HPLC).
-
Use a C18 column and a gradient of two mobile phases, typically an aqueous solution with a weak acid (e.g., ammonium acetate) and an organic solvent (e.g., acetonitrile). The gradient allows for the separation of the canonical and modified nucleosides based on their polarity.[14]
-
-
Mass Spectrometry (MS/MS) Detection and Quantification:
-
Couple the HPLC eluent directly to a tandem mass spectrometer (e.g., a triple quadrupole instrument).
-
Operate the mass spectrometer in positive ion mode using electrospray ionization (ESI).
-
Use a Multiple Reaction Monitoring (MRM) method for quantification. For each nucleoside, a specific "transition" is monitored: the fragmentation of a specific precursor ion (the protonated nucleoside, [M+H]+) into a specific product ion (typically the protonated base, [B+H]+).
-
The identity of each modified nucleoside is confirmed by both its retention time from the HPLC and its specific precursor/product ion transition.
-
Quantify the amount of each nucleoside by integrating the area under the peak in the MRM chromatogram. The relative abundance of a modification like m2G can be expressed as a ratio to a canonical nucleoside like guanosine (G).[15]
-
References
- 1. researchgate.net [researchgate.net]
- 2. tRNA Modifications: Impact on Structure and Thermal Adaptation - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Frontiers | N2-methylguanosine and N2, N2-dimethylguanosine in cytosolic and mitochondrial tRNAs [frontiersin.org]
- 4. researchgate.net [researchgate.net]
- 5. biorxiv.org [biorxiv.org]
- 6. TRMT1-Catalyzed tRNA Modifications Are Required for Redox Homeostasis To Ensure Proper Cellular Proliferation and Oxidative Stress Survival - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Isolation and characterization of the TRM1 locus, a gene essential for the N2,N2-dimethylguanosine modification of both mitochondrial and cytoplasmic tRNA in Saccharomyces cerevisiae - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Structural effects of modified ribonucleotides and magnesium in transfer RNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Crosstalk between the tRNA methyltransferase Trm1 and RNA chaperone La influences eukaryotic tRNA maturation - PMC [pmc.ncbi.nlm.nih.gov]
- 10. A one-step method for in vitro production of tRNA transcripts - PMC [pmc.ncbi.nlm.nih.gov]
- 11. In vitro tRNA Methylation Assay with the Entamoeba histolytica DNA and tRNA Methyltransferase Dnmt2 (Ehmeth) Enzyme - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. Optical Melting Measurements of Nucleic Acid Thermodynamics - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Quantitative analysis of tRNA modifications by HPLC-coupled mass spectrometry [dspace.mit.edu]
- 15. Quantitative analysis of tRNA modifications by HPLC-coupled mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Characterization of UVA-Induced Alterations to Transfer RNA Sequences - PMC [pmc.ncbi.nlm.nih.gov]
The Enzymatic Architecture of N2-Methylguanine Formation: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Abstract
N2-methylguanine (m2G) is a post-transcriptional modification found in various RNA species, most notably transfer RNA (tRNA) and ribosomal RNA (rRNA), across all domains of life. This modification, installed by a dedicated class of S-adenosyl-L-methionine (SAM)-dependent methyltransferases, plays a crucial role in maintaining the structural integrity and function of RNA molecules. Dysregulation of m2G formation has been implicated in human diseases, including neurological disorders, highlighting the enzymes responsible for its catalysis as potential therapeutic targets. This technical guide provides a comprehensive overview of the enzymatic pathways leading to m2G formation, with a focus on the key enzymes, their substrate recognition, and catalytic mechanisms. Detailed experimental protocols for the characterization of these enzymes and the detection of m2G are provided, alongside a summary of available quantitative data to facilitate comparative analysis.
Introduction to N2-Methylguanine and its Biological Significance
N2-methylguanine is a methylated nucleoside derived from guanine. The addition of a methyl group to the exocyclic amine at the N2 position of the guanine base is a conserved modification that influences RNA structure and function. In tRNA, m2G is frequently found at position 10 in the D-loop and position 26 at the junction of the D-arm and the anticodon stem.[1][2] This modification is critical for stabilizing the tertiary structure of tRNA, which is essential for its proper folding and function in protein synthesis.[3] In rRNA, m2G residues are located in functionally important regions, such as the peptidyl transferase center and the subunit interface, where they are thought to contribute to ribosome assembly and translational fidelity.[3][4]
The formation of N2,N2-dimethylguanine (m2,2G), a related modification, often proceeds via an m2G intermediate and is catalyzed by the same or similar enzymes.[5] The biological importance of these modifications is underscored by the fact that mutations in the human TRMT1 gene, which is responsible for m2,2G formation in tRNA, lead to intellectual disability.[1][6]
Key Enzymes in N2-Methylguanine Formation
The formation of m2G is catalyzed by a family of enzymes known as tRNA and rRNA (guanine-N2-)-methyltransferases. These enzymes utilize S-adenosyl-L-methionine (SAM) as the methyl donor. Upon transfer of the methyl group, SAM is converted to S-adenosyl-L-homocysteine (SAH).
Eukaryotic and Archaeal Enzymes
In eukaryotes and archaea, several key enzymes have been identified to be responsible for m2G formation in tRNA:
-
TRMT1 (tRNA methyltransferase 1): In humans, TRMT1 is the primary enzyme responsible for the formation of m2,2G at position 26 of both cytosolic and mitochondrial tRNAs.[2][7] This process occurs in a stepwise manner, with the formation of an m2G intermediate.[5] Patient cells with mutations in TRMT1 show a significant deficit in m2,2G levels, highlighting its crucial role.[1]
-
TRMT11 (tRNA methyltransferase 11): Human TRMT11, in complex with its activating subunit TRMT112, is responsible for the formation of m2G at position 10 of specific tRNAs.[8]
-
THUMPD3: This enzyme, also in a complex with TRMT112, has been identified as the methyltransferase responsible for m2G formation at position 6 of a broad range of human tRNAs.[5][8]
-
Trm1: The homolog of TRMT1 in yeast (Saccharomyces cerevisiae) and archaea is known as Trm1.[5] It also catalyzes the formation of m2,2G26 in tRNA.
Bacterial Enzymes
In bacteria, a different set of enzymes, primarily from the Rsm and Rlm families, are responsible for m2G formation in rRNA:
-
RsmD (YhhF): Responsible for the methylation of G966 in 16S rRNA.[3][4]
-
RlmG (YgjO): Catalyzes the formation of m2G at position 1835 of the 23S rRNA.[3][4]
-
RlmL (YcbY): Responsible for m2G formation at position 2445 of the 23S rRNA.[3][4]
The following table summarizes the key enzymes involved in m2G formation.
| Enzyme Family | Organism | Substrate RNA | Position | Function |
| TRMT1/Trm1 | Humans, Yeast, Archaea | tRNA | G26 | Forms m2,2G (via m2G intermediate); tRNA stability and function.[1][2][5][7] |
| TRMT11 | Humans | tRNA | G10 | Forms m2G; tRNA processing.[8] |
| THUMPD3 | Humans | tRNA | G6 | Forms m2G on a broad range of tRNAs.[5][8] |
| RsmC | Bacteria | 16S rRNA | G1207 | rRNA methylation.[3][4] |
| RsmD | Bacteria | 16S rRNA | G966 | rRNA methylation.[3][4] |
| RlmG | Bacteria | 23S rRNA | G1835 | rRNA methylation.[3][4] |
| RlmL | Bacteria | 23S rRNA | G2445 | rRNA methylation.[3][4] |
Catalytic Mechanism and Substrate Recognition
The enzymatic formation of m2G follows a general mechanism for SAM-dependent methyltransferases. The enzyme binds both the RNA substrate and the SAM cofactor in its active site. The methyl group from SAM is then transferred to the N2 atom of the target guanine residue.
Substrate recognition is highly specific and depends on the enzyme. For tRNA methyltransferases like Trm1, recognition elements often include features of the D-arm and the variable loop of the tRNA molecule.[9] In contrast, the bacterial Trm1 from Aquifex aeolicus recognizes the T-arm structure.[9] For rRNA methyltransferases, some, like RlmG and RlmL, act on naked rRNA or early assembly intermediates, while others, such as RsmC and RsmD, recognize the assembled ribosomal subunit.[3][4]
Quantitative Data on Enzymatic Activity
| Enzyme | Substrate | Km | kcat | Catalytic Efficiency (kcat/Km) | Organism | Reference |
| Trm1 | tRNA Tyr (wild-type) | 2.0 ± 0.2 µM | 0.11 ± 0.01 min-1 | 0.055 µM-1min-1 | Aquifex aeolicus | [10] |
| Trm1 | tRNA Tyr (G27A mutant) | 2.1 ± 0.3 µM | 0.10 ± 0.01 min-1 | 0.048 µM-1min-1 | Aquifex aeolicus | [10] |
Note: The data for Aquifex aeolicus Trm1 pertains to the formation of N2,N2-dimethylguanine, for which N2-methylguanine is an intermediate.
Experimental Protocols
In Vitro tRNA Methyltransferase Assay
This protocol describes a method to measure the activity of a recombinant N2-guanine methyltransferase on a tRNA substrate using a radiolabeled methyl donor.
5.1.1. Materials
-
Purified recombinant N2-guanine methyltransferase (e.g., TRMT1, TRMT11)
-
In vitro transcribed or purified tRNA substrate
-
S-adenosyl-L-[methyl-3H]-methionine ([3H]-SAM)
-
Unlabeled S-adenosyl-L-methionine (SAM)
-
5X Methylation Buffer (e.g., 100 mM Tris-HCl pH 8.0, 50 mM KCl, 10 mM MgCl2, 1 mM DTT)
-
DEPC-treated water
-
Filter paper discs (e.g., Whatman 3MM)
-
5% Trichloroacetic acid (TCA)
-
Ethanol
-
Scintillation cocktail
-
Scintillation counter
5.1.2. Procedure
-
tRNA Substrate Preparation:
-
If using in vitro transcribed tRNA, purify the transcript using methods such as denaturing polyacrylamide gel electrophoresis.
-
Resuspend the purified tRNA in DEPC-treated water.
-
To ensure proper folding, heat the tRNA solution to 85°C for 2 minutes, then add MgCl2 to a final concentration of 10 mM and allow it to cool slowly to room temperature.[11]
-
-
Reaction Setup:
-
Prepare a reaction mixture on ice in a microcentrifuge tube. For a 50 µL reaction, combine:
-
10 µL of 5X Methylation Buffer
-
X µL of folded tRNA substrate (to a final concentration in the low µM range, e.g., 1-10 µM)
-
X µL of [3H]-SAM (final concentration will depend on the specific activity and desired sensitivity)
-
X µL of unlabeled SAM (to achieve the desired final SAM concentration, typically in the µM range)
-
DEPC-treated water to bring the volume to 45 µL.
-
-
Pre-incubate the mixture at the optimal temperature for the enzyme (e.g., 37°C for human enzymes) for 5 minutes.
-
-
Initiation of Reaction:
-
Add 5 µL of the purified N2-guanine methyltransferase to the reaction mixture to initiate the reaction.
-
Incubate at the optimal temperature for a defined period (e.g., 30-60 minutes). The incubation time should be within the linear range of the reaction.
-
-
Quenching and Sample Spotting:
-
Stop the reaction by placing the tube on ice.
-
Spot a 25 µL aliquot of the reaction mixture onto a labeled filter paper disc.
-
-
Washing:
-
Wash the filter discs three times for 10 minutes each in a beaker containing cold 5% TCA.
-
Perform one wash with 70% ethanol for 5 minutes.
-
Air dry the filter discs completely.
-
-
Scintillation Counting:
-
Place each dried filter disc in a scintillation vial.
-
Add an appropriate volume of scintillation cocktail.
-
Measure the incorporated radioactivity using a scintillation counter.
-
Detection of N2-Methylguanine by HPLC-MS
This protocol outlines the general steps for the sensitive detection and quantification of m2G in RNA samples using High-Performance Liquid Chromatography coupled with Mass Spectrometry (HPLC-MS).
5.2.1. Materials
-
Purified total RNA or specific RNA fraction
-
Nuclease P1
-
Bacterial alkaline phosphatase
-
Ammonium acetate buffer
-
Acetonitrile (HPLC grade)
-
Formic acid (MS grade)
-
m2G standard
-
C18 reverse-phase HPLC column
-
HPLC system coupled to a triple quadrupole mass spectrometer
5.2.2. Procedure
-
RNA Digestion to Nucleosides:
-
To 1-5 µg of purified RNA, add nuclease P1 and incubate in a suitable buffer (e.g., 10 mM ammonium acetate, pH 5.3) at 37°C for 2 hours.
-
Add bacterial alkaline phosphatase and continue the incubation at 37°C for another 2 hours to dephosphorylate the nucleosides.
-
-
Sample Preparation for HPLC-MS:
-
Centrifuge the digested sample to pellet any undigested material.
-
Transfer the supernatant to an HPLC vial.
-
-
HPLC Separation:
-
Inject the sample onto a C18 reverse-phase column.
-
Separate the nucleosides using a gradient of a mobile phase consisting of an aqueous component (e.g., water with 0.1% formic acid) and an organic component (e.g., acetonitrile with 0.1% formic acid).
-
-
Mass Spectrometry Detection:
-
The eluent from the HPLC is directed to the mass spectrometer.
-
Operate the mass spectrometer in positive ion mode using electrospray ionization (ESI).
-
Monitor for the specific mass transition of m2G (e.g., m/z 298.1 → 166.1).
-
Use a stable isotope-labeled internal standard for accurate quantification if available.
-
-
Data Analysis:
-
Identify the m2G peak in the chromatogram based on its retention time and mass transition, by comparison with the m2G standard.
-
Quantify the amount of m2G by integrating the peak area and comparing it to a standard curve generated with known amounts of the m2G standard.
-
Conclusion and Future Perspectives
The enzymatic formation of N2-methylguanine is a fundamental process in RNA biology, with significant implications for cellular function and human health. The enzymes responsible for this modification represent a diverse family with distinct substrate specificities and regulatory mechanisms. While significant progress has been made in identifying and characterizing these methyltransferases, a comprehensive understanding of their kinetic properties and the full spectrum of their biological roles remains an active area of research. The development of specific inhibitors for these enzymes could provide valuable tools for dissecting their functions and may hold therapeutic potential for diseases linked to aberrant m2G formation. The experimental protocols and data presented in this guide offer a foundation for researchers to further explore the fascinating world of N2-methylguanine and its enzymatic architects.
References
- 1. An intellectual disability-associated missense variant in TRMT1 impairs tRNA modification and reconstitution of enzymatic activity - PMC [pmc.ncbi.nlm.nih.gov]
- 2. TRMT1-Catalyzed tRNA Modifications Are Required for Redox Homeostasis To Ensure Proper Cellular Proliferation and Oxidative Stress Survival - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Ribosomal RNA guanine-(N2)-methyltransferases and their targets - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. academic.oup.com [academic.oup.com]
- 5. THUMPD3–TRMT112 is a m2G methyltransferase working on a broad range of tRNA substrates - PMC [pmc.ncbi.nlm.nih.gov]
- 6. An intellectual disability-associated missense variant in TRMT1 impairs tRNA modification and reconstitution of enzymatic activity - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Human TRMT1 and TRMT1L paralogs ensure the proper modification state, stability, and function of tRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 8. THUMPD3-TRMT112 is a m2G methyltransferase working on a broad range of tRNA substrates - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Single-Turnover Kinetics of Methyl Transfer to tRNA by Methyltransferases - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. Kinetic Analysis of tRNA Methyltransferases - PubMed [pubmed.ncbi.nlm.nih.gov]
The Enigmatic Presence of 6-Hydroxy-2-methylaminopurine: A Scientific Inquiry into its Natural Occurrence
A Technical Guide for Researchers, Scientists, and Drug Development Professionals
Abstract
6-Hydroxy-2-methylaminopurine, a substituted purine, remains a molecule of significant interest yet elusive presence in the natural world. Despite the vast exploration of natural products, direct evidence of its isolation from biological sources is conspicuously absent from mainstream scientific literature. This technical guide addresses this knowledge gap by exploring the potential for its natural occurrence, particularly within marine ecosystems, which are known hotspots for novel purine derivatives. By examining structurally related compounds and established methodologies for the discovery of marine natural products, this document provides a foundational framework for researchers aiming to uncover the existence and potential biological significance of this compound.
Introduction: The Scarcity of Evidence
A thorough review of existing literature reveals a significant lack of documented natural sources for this compound. While the compound is commercially available as a synthetic chemical, its natural biosynthesis and ecological distribution are currently uncharacterized. This absence of data presents both a challenge and an opportunity for natural product chemists and pharmacologists. The structural similarity of this compound to biologically active purines, such as isoguanine, suggests that its discovery in a natural context could unveil novel biochemical pathways and therapeutic leads.
A Marine Hypothesis: A Promising Frontier for Discovery
Marine invertebrates, particularly sponges, are prolific producers of modified and often bioactive purine alkaloids.[1] These organisms host symbiotic microbial communities that are believed to be the true biosynthetic sources of many of these unique compounds. The chemical diversity of purines isolated from marine sources, including methylated and hydroxylated analogs, provides a strong rationale for hypothesizing the existence of this compound in these environments.[1] The investigation into marine sponges and their associated microorganisms therefore represents a logical and promising starting point for the search for this elusive molecule.
Quantitative Data: A Present Void
Due to the lack of confirmed natural sources, there is currently no quantitative data available on the concentration or distribution of this compound in any organism. The following table is presented as a template for future research, to be populated upon the successful identification and quantification of this compound.
| Organism/Source | Tissue/Extract Type | Concentration (µg/g or µM) | Method of Quantification | Reference |
| Data Not Available | Data Not Available | Data Not Available | Data Not Available | Data Not Available |
Hypothetical Experimental Protocol for Discovery and Characterization
The following is a detailed, albeit hypothetical, experimental workflow for the systematic search for and characterization of this compound from marine sponge samples. This protocol is based on established and widely practiced methodologies in the field of marine natural product discovery.
Sample Collection and Preparation
-
Collection: Collect marine sponge specimens from biodiverse marine environments. Record species identification, location, depth, and collection date.
-
Preservation: Immediately freeze the collected samples in liquid nitrogen or store in ethanol to prevent enzymatic degradation of secondary metabolites.
-
Homogenization and Extraction:
-
Lyophilize the frozen sponge tissue to remove water.
-
Grind the dried tissue into a fine powder.
-
Perform a sequential extraction with solvents of increasing polarity (e.g., hexane, dichloromethane, ethyl acetate, methanol) to fractionate compounds based on their chemical properties.
-
Chromatographic Separation and Isolation
-
Initial Fractionation: Subject the crude extracts to vacuum liquid chromatography (VLC) or solid-phase extraction (SPE) for initial separation into less complex fractions.
-
High-Performance Liquid Chromatography (HPLC):
-
Employ reversed-phase HPLC with a C18 column for the separation of polar to moderately polar compounds, such as purine derivatives.[2][3]
-
Use a gradient elution system with a mobile phase consisting of water (with 0.1% formic acid or trifluoroacetic acid) and acetonitrile or methanol.[3]
-
Monitor the elution profile using a photodiode array (PDA) detector to identify peaks with UV absorbance characteristic of purine rings (around 250-280 nm).
-
-
Purification: Collect fractions corresponding to peaks of interest and perform further rounds of semi-preparative or analytical HPLC until pure compounds are isolated.
Structure Elucidation
-
Mass Spectrometry (MS):
-
Obtain high-resolution mass spectra (HRMS) using techniques like electrospray ionization (ESI) or atmospheric pressure chemical ionization (APCI) to determine the exact molecular formula of the isolated compound.
-
Perform tandem mass spectrometry (MS/MS) to obtain fragmentation patterns that can provide structural clues.
-
-
Nuclear Magnetic Resonance (NMR) Spectroscopy:
-
Acquire a suite of NMR spectra, including 1H, 13C, COSY, HSQC, and HMBC, in a suitable deuterated solvent (e.g., DMSO-d6, Methanol-d4).
-
These spectra will allow for the unambiguous determination of the chemical structure, including the positions of the hydroxyl, methyl, and amino groups on the purine core.
-
Visualizing the Path Forward: Hypothetical Workflows and Pathways
The following diagrams, rendered in Graphviz DOT language, illustrate the proposed experimental workflow and a hypothetical signaling pathway where this compound might play a role, based on the known functions of other purine analogs.
Caption: Proposed experimental workflow for the discovery of this compound.
Caption: Hypothetical signaling pathway involving this compound.
Conclusion and Future Directions
The natural occurrence of this compound remains an open question in the field of natural products chemistry. The information and hypothetical frameworks presented in this guide are intended to stimulate and direct future research efforts. The discovery of this compound in a natural source would be a significant finding, potentially leading to the identification of new enzymes, metabolic pathways, and bioactive molecules with applications in drug development. Researchers are encouraged to explore the rich chemical diversity of marine organisms, employing modern analytical techniques to uncover the secrets that molecules like this compound may hold.
References
Physical and chemical properties of N2-methylguanine.
An In-depth Technical Guide to N2-Methylguanine
Introduction
N2-methylguanine (m2G) is a modified purine nucleobase, structurally analogous to guanine but with a methyl group substitution on its exocyclic amine (N2 position). This modification can occur in both DNA and RNA and is of significant interest to researchers in toxicology, cancer biology, and drug development.[1][2] The formation of N2-methylguanine in DNA, often resulting from exposure to environmental mutagens or certain chemotherapeutic alkylating agents, can lead to significant biological consequences, including the disruption of DNA replication and transcription.[3][4][5] In RNA, m2G is a naturally occurring modification found in various RNA species, such as transfer RNA (tRNA) and ribosomal RNA (rRNA), where it plays a role in modulating RNA structure and function.[6][7][8] This guide provides a comprehensive overview of the core physical and chemical properties of N2-methylguanine, details key experimental protocols for its study, and outlines its biological significance.
Chemical and Physical Properties
The fundamental properties of N2-methylguanine are crucial for understanding its behavior in biological systems and for developing analytical techniques. Quantitative data are summarized in the tables below.
Table 1: General and Physical Properties of N2-Methylguanine
| Property | Value | Source |
| Molecular Formula | C6H7N5O | [2][9][10] |
| Molecular Weight | 165.15 g/mol | [2][9] |
| CAS Number | 10030-78-1 | [2][9][10] |
| Appearance | Solid | [2] |
| Melting Point | >200 °C (with decomposition) | [11] |
| Solubility | Insoluble or slightly soluble in Water, Ethanol, and DMSO. | [12][13] |
| Canonical SMILES | CNC1=NC2=C(C(=O)N1)NC=N2 | [2][13] |
| InChI Key | SGSSKEDGVONRGC-UHFFFAOYSA-N | [2] |
Table 2: Chemical and Physicochemical Properties of N2-Methylguanine
| Property | Value | Source |
| pKa (Strongest Acidic) | 8.92 | [1] |
| pKa (Strongest Basic) | 2.22 | [1] |
| pKa (N1 position) | 9.7 | [14][15] |
| pKa (N7 position) | 2.2 - 2.3 | [14][15] |
| Hydrogen Bond Acceptor Count | 5 | [1] |
| Hydrogen Bond Donor Count | 3 | [1] |
| Polar Surface Area | 82.17 Ų | [1] |
Table 3: Spectroscopic Data for N2-Methylguanine
| Spectroscopic Method | Key Data Points | Source |
| ¹H NMR (in D₂O, 400 MHz) | δ 7.820 (s, 1H, H-8), δ 3.260 (s, 3H, N-CH₃) | [16] |
| LC-MS/MS (Precursor Ion) | [M+H]⁺ m/z 166.0723 | [2] |
Biological Significance and Mechanisms
Formation and Role as a DNA Adduct
N2-methylguanine in DNA is primarily formed by the covalent binding of methylating agents to the N2 position of guanine.[1] This can be a result of exposure to environmental carcinogens or endogenous metabolic byproducts like formaldehyde.[4][17] The presence of the methyl group in the minor groove of the DNA helix can interfere with the function of DNA polymerases.[3][18] While some polymerases are significantly blocked by this lesion, others, like DNA polymerase η, can bypass it, albeit sometimes with reduced fidelity, potentially leading to G→A transition mutations.[3][4][18]
DNA Repair Mechanisms
Cells have evolved mechanisms to repair DNA adducts like N2-methylguanine. While not a substrate for all repair pathways, evidence suggests that certain enzymes may be involved in its removal. For instance, some studies point to the potential involvement of human AlkB homolog 3 (ALKBH3) in the reversal of N2-alkyl-dG lesions from the nucleotide pool through oxidative dealkylation.[17] The nucleotide excision repair (NER) pathway has also been shown to have a moderate effect on the removal of N2-methylguanine from genomic DNA.[17][19]
Experimental Protocols
Protocol 1: Synthesis of N2-Methyl-2'-deoxyguanosine (N2-MedG)
The chemical synthesis of N2-methylated nucleosides is essential for creating standards for analytical studies and for incorporation into oligonucleotides to study their biological effects. A common strategy involves the nucleophilic displacement of a leaving group at the C2 position of a protected deoxyinosine derivative.
Methodology Summary: This protocol is adapted from procedures involving the reaction of a protected 2-fluoro-deoxyinosine derivative with methylamine.[20][21]
-
Starting Material: Begin with a suitably protected 2'-deoxyguanosine, which is converted to 2-fluoro-6-O-(trimethylsilylethyl)-2′-deoxyinosine.
-
Reaction: Dissolve 2-fluoro-6-O-(trimethylsilylethyl)-2′-deoxyinosine (1 equivalent) in anhydrous dimethyl sulfoxide (DMSO).
-
Addition of Amine: Add methylamine (e.g., 33% in ethanol, ~5 equivalents) and a non-nucleophilic base such as N,N-diisopropylethylamine (DIEA, ~2 equivalents).
-
Incubation: Stir the reaction mixture at an elevated temperature (e.g., 55°C) for several days, monitoring progress by TLC or LC-MS.
-
Deprotection: After the reaction is complete, evaporate the solvent. Reconstitute the residue in a mild acidic solution (e.g., 5% acetic acid) to remove the trimethylsilylethyl protecting group from the O6 position.
-
Purification: Neutralize the solution and purify the crude product (N2-MedG) using reverse-phase High-Performance Liquid Chromatography (HPLC).
-
Verification: Confirm the identity and purity of the final product by Electrospray Ionization Mass Spectrometry (ESI-MS) and NMR spectroscopy.[20]
Protocol 2: Quantification of N2-Methylguanine in DNA by LC-MS/MS
Isotope-dilution liquid chromatography-tandem mass spectrometry (LC-MS/MS) is a highly sensitive and specific method for detecting and quantifying DNA adducts from biological samples.
Methodology Summary:
-
DNA Extraction: Isolate genomic DNA from cells or tissues using a standard DNA extraction kit or phenol-chloroform extraction protocol.
-
Internal Standard: Add a known amount of a stable isotope-labeled internal standard (e.g., [¹⁵N₅]-N7-methylguanine, though a specific N2-methylguanine standard is ideal) to the DNA sample.
-
DNA Hydrolysis: Digest the DNA to its constituent nucleobases or nucleosides. This is typically achieved through enzymatic hydrolysis using a cocktail of enzymes such as nuclease P1, snake venom phosphodiesterase, and alkaline phosphatase.
-
Sample Cleanup: Remove proteins and other macromolecules, often by ultrafiltration or solid-phase extraction (SPE), to prepare the sample for LC-MS/MS analysis.[22]
-
LC Separation: Inject the hydrolysate onto a reverse-phase HPLC column (e.g., C18). Use a gradient elution (e.g., with water and methanol, both containing a small amount of acid like formic acid) to separate N2-methylguanine from other nucleobases.
-
MS/MS Detection: Analyze the column eluent using a tandem mass spectrometer operating in positive ion mode with selected reaction monitoring (SRM).
-
Monitor Transition for N2-methylguanine: m/z 166 → [fragment ion]
-
Monitor Transition for Internal Standard: e.g., m/z 171 → [fragment ion]
-
-
Quantification: Calculate the amount of N2-methylguanine in the original sample by comparing the peak area ratio of the analyte to the internal standard against a standard calibration curve.[17][22]
N2-methylguanine is a chemically and biologically significant modified nucleobase. Its physical properties, particularly its poor solubility, present challenges for in vitro studies, while its chemical characteristics dictate its interactions within the DNA minor groove and its recognition by cellular machinery. As a DNA lesion, it serves as a biomarker for exposure to certain alkylating agents and is a critical subject in the study of DNA damage and repair, mutagenesis, and carcinogenesis. The detailed protocols provided herein offer standardized approaches for the synthesis and quantification of N2-methylguanine, facilitating further research into its roles in health and disease for scientists and drug development professionals.
References
- 1. Human Metabolome Database: Showing metabocard for N2-Methylguanine (HMDB0006040) [hmdb.ca]
- 2. 6-Hydroxy-2-methylaminopurine | C6H7N5O | CID 135426867 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 3. pubs.acs.org [pubs.acs.org]
- 4. Translesional synthesis on a DNA template containing N2-methyl-2′-deoxyguanosine catalyzed by the Klenow fragment of Escherichia coli DNA polymerase I - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Transcription blocking properties and transcription-coupled repair of N2-alkylguanine adducts as a model for aldehyde-induced DNA damage - PMC [pmc.ncbi.nlm.nih.gov]
- 6. academic.oup.com [academic.oup.com]
- 7. Synthesis of N2-modified 7-methylguanosine 5’-monophosphates as nematode translation inhibitors - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Frontiers | N2-methylguanosine and N2, N2-dimethylguanosine in cytosolic and mitochondrial tRNAs [frontiersin.org]
- 9. N2-Methylguanine Datasheet DC Chemicals [dcchemicals.com]
- 10. N-Methylguanine | CAS#:10030-78-1 | Chemsrc [chemsrc.com]
- 11. N2-Methylguanin – Wikipedia [de.wikipedia.org]
- 12. medchemexpress.com [medchemexpress.com]
- 13. glpbio.com [glpbio.com]
- 14. schlegelgroup.wayne.edu [schlegelgroup.wayne.edu]
- 15. pubs.acs.org [pubs.acs.org]
- 16. PhytoBank: 1H NMR Spectrum (PHY0085693) [phytobank.ca]
- 17. LC-MS/MS for Assessing the Incorporation and Repair of N2-Alkyl-2′-deoxyguanosine in Genomic DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 18. The N2-ethylguanine and the O6-ethyl- and O6-methylguanine lesions in DNA: contrasting responses from the "bypass" DNA polymerase eta and the replicative DNA polymerase alpha - PubMed [pubmed.ncbi.nlm.nih.gov]
- 19. LC-MS/MS for Assessing the Incorporation and Repair of N2-Alkyl-2'-deoxyguanosine in Genomic DNA. | Semantic Scholar [semanticscholar.org]
- 20. s3-eu-west-1.amazonaws.com [s3-eu-west-1.amazonaws.com]
- 21. pubs.acs.org [pubs.acs.org]
- 22. Simultaneous determination of N7-alkylguanines in DNA by isotope-dilution LC-tandem MS coupled with automated solid-phase extraction and its application to a small fish model - PMC [pmc.ncbi.nlm.nih.gov]
The Pivotal Role of N2-Methylguanine in Eukaryotic and Archaeal Cellular Processes: A Technical Guide
An In-depth Exploration of N2-Methylguanine's Function, Regulation, and Therapeutic Potential for Researchers, Scientists, and Drug Development Professionals
Executive Summary
N2-methylguanine (m2G) and its dimethylated counterpart, N2,N2-dimethylguanine (m22G), are crucial post-transcriptional RNA modifications that play fundamental roles in the cellular machinery of both eukaryotes and archaea. These modifications, primarily found in transfer RNA (tRNA) and ribosomal RNA (rRNA), are essential for maintaining the structural integrity and functional fidelity of these molecules, thereby impacting protein synthesis, cellular proliferation, and stress responses. Dysregulation of m2G and m22G deposition has been implicated in a range of human diseases, including cancer and neurological disorders, making the enzymes that catalyze these modifications attractive targets for novel therapeutic interventions. This technical guide provides a comprehensive overview of the biological significance of N2-methylguanine, detailing the enzymatic pathways governing its metabolism, its diverse functional roles, and the state-of-the-art methodologies for its detection and quantification. Furthermore, this document explores the emerging landscape of drug discovery efforts targeting N2-methylguanine methyltransferases, offering insights for the development of next-generation therapeutics.
Introduction to N2-Methylguanine Modifications
N2-methylguanosine (m2G) and N2,N2-dimethylguanosine (m22G) are conserved RNA modifications found across the domains of life, including eukaryotes, archaea, and bacteria.[1] These modifications involve the addition of one or two methyl groups to the exocyclic amine at the second position of guanine. In the context of RNA, these modifications are predominantly found in non-coding RNAs such as tRNA and rRNA, where they play critical roles in fine-tuning RNA structure and function.[2][3]
In eukaryotes, m2G and m22G are found at several positions in tRNA, most notably at positions G10 and G26.[2] The presence of these modifications is crucial for tRNA stability, folding, and accurate translation.[3] Dysregulation of these modifications has been linked to various human pathologies, including cancer and neurodevelopmental disorders.[4]
In archaea, N2-methylguanine modifications are also prevalent in tRNA and are particularly important for organisms living in extreme environments. For instance, the dimethylation of guanosine at position 10 in the tRNA of hyperthermophilic archaea is thought to be a key adaptation for maintaining tRNA structural integrity at high temperatures.[5]
Enzymatic Regulation of N2-Methylguanine Levels
The cellular levels of m2G and m22G are tightly controlled by the coordinated action of methyltransferases ("writers") and demethylases ("erasers").
Methyltransferases: The "Writers"
The methylation of N2-guanine is catalyzed by a family of S-adenosyl-L-methionine (SAM)-dependent methyltransferases.[6] In this reaction, SAM serves as the methyl donor, and S-adenosyl-L-homocysteine (SAH) is produced as a byproduct.
In Eukaryotes:
-
TRMT1 (tRNA Methyltransferase 1): This is the primary enzyme responsible for the formation of m22G at position 26 in both cytosolic and mitochondrial tRNAs.[7][8]
-
TRMT11 (tRNA Methyltransferase 11): In complex with its activating partner TRMT112, TRMT11 catalyzes the formation of m2G at position 10 of tRNAs.[4][9]
-
THUMPD3: Also in a complex with TRMT112, this enzyme is responsible for m2G formation at position 6 of specific tRNAs.[4]
In Archaea:
-
Trm-G10 (also known as aTrm11): This enzyme is the archaeal homolog of the eukaryotic TRMT11 and is responsible for the formation of both m2G and m22G at position 10 in tRNA.[6][10] The aTrm11 enzyme consists of an N-terminal THUMP domain and a C-terminal catalytic domain.[11]
Demethylases: The "Erasers"
While the addition of methyl groups to RNA was once thought to be irreversible, the discovery of RNA demethylases has revealed a dynamic regulatory landscape. The AlkB family of dioxygenases are iron(II) and α-ketoglutarate-dependent enzymes that can remove methyl groups from nucleic acids. While no specific demethylase for m2G in eukaryotes has been definitively characterized, engineered mutants of the E. coli AlkB protein have been shown to demethylate m22G to m2G, providing a valuable tool for research.
Biological Functions of N2-Methylguanine
The presence of m2G and m22G at key positions within tRNA molecules has profound effects on their structure and function.
Impact on tRNA Structure and Stability
N2-methylation of guanine alters its base-pairing properties. While m2G can still form a Watson-Crick base pair with cytosine, the presence of two methyl groups in m22G sterically hinders this interaction.[2] However, m22G can still form non-canonical base pairs with uracil and adenine. This altered base-pairing potential is critical for establishing and maintaining the correct tertiary structure of tRNA.
In hyperthermophilic archaea, the presence of m22G at position 10 is crucial for tRNA stability at elevated temperatures, preventing the molecule from unfolding and degrading.[5]
Role in Translation and Cellular Proliferation
By ensuring the correct folding and stability of tRNA, m2G and m22G are indispensable for efficient and accurate protein synthesis. Hypomodification of tRNAs can lead to reduced translational fidelity and efficiency, which in turn can impact cell growth and proliferation.[4] Studies have shown that the absence of m2G modifications in human tRNAs impairs protein synthesis.[9]
Connection to Cellular Signaling Pathways
Recent evidence suggests a link between the modification status of tRNA and major cellular signaling pathways, such as the Target of Rapamycin (TOR) pathway. The TOR pathway is a central regulator of cell growth and metabolism in response to nutrient availability.[12] Uncharged tRNAs, which can accumulate under conditions of amino acid starvation, are known to activate the GCN2 kinase, which in turn can inhibit TORC1 signaling.[7][13] While the direct role of m2G hypomodification in this process is still under investigation, it is plausible that alterations in tRNA structure due to the lack of methylation could affect aminoacylation levels and thereby influence GCN2 activation and TORC1 signaling.[14]
N2-Methylguanine in Archaea: Adaptations to Extreme Environments
In the archaeal domain, N2-methylguanine modifications, particularly m22G at position 10 of tRNA, are a hallmark of thermoadaptation. The Trm-G10/aTrm11 family of enzymes is responsible for these modifications. Phylogenetic analyses suggest that these enzymes are ancient and have co-evolved with the tRNA substrates, leading to a diversity of modification patterns across different archaeal lineages.[15] The presence of these modifications is not only crucial for tRNA stability but also for the overall fitness of hyperthermophilic archaea in their extreme habitats.
While the role of N2-methylguanine in archaeal RNA is well-established, its presence and function in archaeal DNA are less clear. Archaea possess robust DNA repair mechanisms to cope with the DNA-damaging conditions of their environments.[16][17] It is conceivable that archaea have specialized DNA glycosylases or other repair enzymes to handle N2-methylguanine adducts in their DNA, but this remains an active area of research.
Quantitative Analysis of N2-Methylguanine
Accurate quantification of m2G and m22G is essential for understanding their biological roles. Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is the gold standard for the sensitive and specific detection and quantification of RNA modifications.
Table 1: Abundance of N2-Methylguanine in tRNA from Various Organisms
| Organism | RNA Type | Modification | Position | Abundance/Stoichiometry | Reference |
| Methanocaldococcus jannaschii | tRNA | m2G/m22G | 10 | Present in multiple tRNAs | [18] |
| Haloferax volcanii | tRNA | m22G | 26 | Modulates translation of specific genes | [14] |
| Pyrococcus furiosus | tRNA | m7G | 1, 10 | Frequent occurrence | [1] |
| Sulfolobus acidocaldarius | tRNA | ac4C | various | Frequent occurrence | [1] |
| Escherichia coli | tRNA | m2G | various | Second most frequent nucleoside analog | [5] |
| Saccharomyces cerevisiae | tRNA | m2G | 10 | Catalyzed by Trm11-Trm112 | [3] |
| Homo sapiens (HEK293T cells) | tRNA | m2G/m22G | 26 | TRMT1-dependent | [11] |
Note: The table provides a qualitative and semi-quantitative summary based on available literature. Absolute quantification remains a challenge and is an active area of research.
Experimental Protocols
Quantification of N2-Methylguanine by LC-MS/MS
This protocol outlines the general steps for the analysis of m2G and m22G in RNA samples.
Materials:
-
Purified RNA sample (e.g., total RNA, tRNA fraction)
-
Nuclease P1
-
Bacterial Alkaline Phosphatase (BAP) or Calf Intestinal Phosphatase (CIP)
-
HEPES buffer (pH 7.0) or Ammonium Acetate buffer (pH 5.3)
-
Ultrapure water
-
LC-MS/MS system with a C18 reverse-phase column
-
Standards for canonical and modified nucleosides (G, m2G, m22G)
Procedure:
-
RNA Digestion: a. In a microcentrifuge tube, combine up to 2.5 µg of RNA with nuclease P1 (0.5-1 U) and alkaline phosphatase (0.5-1 U) in a suitable buffer (e.g., 20 mM HEPES, pH 7.0).[19] b. Incubate the reaction at 37°C for 2-3 hours. For RNAs that may be resistant to digestion, the incubation time can be extended.[19] c. After digestion, the sample should be processed immediately for LC-MS/MS analysis or stored at -20°C.
-
LC-MS/MS Analysis: a. Inject the digested sample onto a C18 reverse-phase column. b. Separate the nucleosides using a gradient of a suitable mobile phase (e.g., a mixture of ammonium acetate buffer and acetonitrile). c. Detect the eluted nucleosides using a tandem mass spectrometer operating in positive ion mode. d. Monitor the specific mass-to-charge (m/z) transitions for guanosine, m2G, and m22G.
-
Data Analysis: a. Integrate the peak areas for each nucleoside. b. Quantify the amount of m2G and m22G by comparing their peak areas to a standard curve generated from known concentrations of the modified nucleoside standards. c. The abundance can be expressed as a ratio to the amount of unmodified guanosine.
Detection of N2-Methylguanine by PhOxi-Seq
PhOxi-Seq is a sequencing-based method that enables the detection of m2G and m22G at single-nucleotide resolution. The method relies on the chemical oxidation of N2-methylated guanosines, which induces mutations during reverse transcription that can be identified by sequencing.
Principle: Visible light-mediated photoredox catalysis selectively oxidizes m2G and m22G, leading to the formation of mutagenic lesions. During reverse transcription, these lesions cause misincorporation of nucleotides, creating a specific mutational signature at the site of modification.
General Workflow:
-
RNA Fragmentation: The RNA sample is fragmented to a suitable size for sequencing.
-
Photo-oxidation Reaction: The fragmented RNA is subjected to a photo-oxidation reaction using a photocatalyst (e.g., riboflavin) and an oxidant in the presence of visible light.
-
RNA Cleanup: The oxidized RNA is purified to remove reaction components.
-
Reverse Transcription: The oxidized RNA is reverse transcribed into cDNA.
-
Library Preparation and Sequencing: The cDNA is used to prepare a sequencing library, which is then sequenced using a high-throughput sequencing platform.
-
Data Analysis: The sequencing data is analyzed to identify positions with a high frequency of specific mutations (e.g., G-to-T transversions), which correspond to the locations of m2G or m22G.
Primer Extension Assay for m22G Detection
The presence of the bulky m22G modification can cause reverse transcriptase to stall or dissociate from the RNA template. This property can be exploited in a primer extension assay to map the location of m22G.
Procedure:
-
Primer Design and Labeling: Design a DNA oligonucleotide primer that is complementary to a region downstream of the suspected m22G site. The 5' end of the primer is typically labeled with a radioactive isotope (e.g., 32P) or a fluorescent dye.
-
Primer Annealing: The labeled primer is annealed to the target RNA.
-
Primer Extension Reaction: The primer is extended using a reverse transcriptase in the presence of dNTPs.
-
Gel Electrophoresis: The reaction products are resolved on a denaturing polyacrylamide gel.
-
Detection: The gel is imaged to visualize the radiolabeled or fluorescently labeled DNA fragments. A band that terminates one nucleotide before the expected position of the guanosine indicates the presence of m22G.[15]
N2-Methylguanine in Drug Development
The critical role of tRNA methyltransferases in cell proliferation and their frequent dysregulation in diseases like cancer make them compelling targets for therapeutic intervention.[19][20] The development of small-molecule inhibitors that specifically target these enzymes is an active area of research.
tRNA Methyltransferases as Therapeutic Targets
Inhibition of tRNA methyltransferases can lead to the accumulation of hypomodified tRNAs, which can disrupt protein synthesis and selectively inhibit the growth of rapidly dividing cancer cells.[20] For example, inhibitors of METTL1, a tRNA methyltransferase responsible for m7G modification, have shown anti-tumor activity in preclinical models.[21][22][23] This provides a strong rationale for targeting other tRNA methyltransferases, including those responsible for N2-methylguanine formation.
High-Throughput Screening for Inhibitors
High-throughput screening (HTS) is a key strategy for identifying novel inhibitors of tRNA methyltransferases.[24] Several assay formats can be adapted for HTS, including:
-
Fluorescence-based assays: These assays can monitor the production of SAH, the byproduct of the methylation reaction.[25]
-
Luminescence-based assays: Similar to fluorescence-based assays, these can detect SAH with high sensitivity.
-
Activity-based fluorescence polarization assays: These assays can be used to identify compounds that bind to the active site of the enzyme.[25]
Conclusion and Future Perspectives
N2-methylguanine is a small modification with a large impact on the biology of eukaryotes and archaea. Its fundamental role in tRNA structure and function places it at the heart of protein synthesis and cellular homeostasis. The ongoing elucidation of the enzymatic machinery that governs N2-methylguanine metabolism and its connections to major signaling pathways is opening up new avenues for understanding and treating human diseases. The development of sophisticated analytical techniques for the detection and quantification of m2G and m22G will be crucial for advancing our knowledge in this field. Furthermore, the validation of tRNA methyltransferases as druggable targets provides exciting opportunities for the development of novel therapeutics for cancer and other disorders. Future research will likely focus on a deeper understanding of the regulatory networks that control N2-methylguanine levels, the identification of the full spectrum of its biological functions, and the translation of this knowledge into clinical applications.
References
- 1. Comparative patterns of modified nucleotides in individual tRNA species from a mesophilic and two thermophilic archaea - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Identification and characterization of archaeal and fungal tRNA methyltransferases - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Frontiers | N2-methylguanosine and N2, N2-dimethylguanosine in cytosolic and mitochondrial tRNAs [frontiersin.org]
- 4. N 2-methylguanosine modifications on human tRNAs and snRNA U6 are important for cell proliferation, protein translation and pre-mRNA splicing - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. Structural and functional analyses of the archaeal tRNA m2G/m22G10 methyltransferase aTrm11 provide mechanistic insights into site specificity of a tRNA methyltransferase that contains common RNA-binding modules - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Tripartite suppression of fission yeast TORC1 signaling by the GATOR1-Sea3 complex, the TSC complex, and Gcn2 kinase | eLife [elifesciences.org]
- 8. semanticscholar.org [semanticscholar.org]
- 9. biorxiv.org [biorxiv.org]
- 10. Structural and functional analyses of the archaeal tRNA m2G/m22G10 methyltransferase aTrm11 provide mechanistic insights into site specificity of a tRNA methyltransferase that contains common RNA-binding modules - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. Novel Links between TORC1 and Traditional Non-Coding RNA, tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 13. General Control Nonderepressible 2 (GCN2) Kinase Inhibits Target of Rapamycin Complex 1 in Response to Amino Acid Starvation in Saccharomyces cerevisiae - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Evolutionary Dynamics, Functional Adaptations in Stress Response, and Direct Detection of tRNA modifications in Archaea [escholarship.org]
- 15. The Landscape of tRNA Modifications in Archaea - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. The question of DNA repair in hyperthermophilic archaea - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. Stability and repair of DNA in hyperthermophilic Archaea - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. journals.asm.org [journals.asm.org]
- 19. Targeting tRNA methyltransferases: from molecular mechanisms to drug discovery - PubMed [pubmed.ncbi.nlm.nih.gov]
- 20. Dysregulation of tRNA methylation in cancer: Mechanisms and targeting therapeutic strategies - PMC [pmc.ncbi.nlm.nih.gov]
- 21. aacrjournals.org [aacrjournals.org]
- 22. STORM Therapeutics to Present Findings on its First-in-Class METTL1 tRNA Methyltransferase Inhibitors at ESMO Targeted Anticancer Therapies Congress [prnewswire.com]
- 23. STORM Therapeutics’ First-in-Class tRNA methyltransferase inhibitor of METTL1 to be Presented at the 65th Annual ASH Conference | Harnessing the power of RNA epigenetics | Cambridge, UK | STORM Therapeutics [stormtherapeutics.com]
- 24. High Throughput Screening — Target Discovery Institute [tdi.ox.ac.uk]
- 25. Novel inhibitors for PRMT1 discovered by high-throughput screening using activity-based fluorescence polarization - PubMed [pubmed.ncbi.nlm.nih.gov]
N²-methylguanine versus N²,N²-dimethylguanosine in Cytosolic and Mitochondrial tRNAs: An In-depth Technical Guide
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the tRNA modifications N²-methylguanine (m²G) and N²,N²-dimethylguanosine (m²,²G), with a specific focus on their differential presence and functional implications in cytosolic and mitochondrial tRNAs. This document details the biosynthesis of these modifications, the enzymes involved, their impact on tRNA structure and function, and the analytical methods used for their study.
Introduction to N²-Guanine Methylation in tRNA
Post-transcriptional modifications of transfer RNA (tRNA) are crucial for their proper folding, stability, and function in protein synthesis.[1] Among the more than 170 known RNA modifications, methylation is one of the most common. N²-methylguanine (m²G) and N²,N²-dimethylguanosine (m²,²G) are highly conserved modifications found predominantly in tRNAs across all domains of life.[2] These modifications are typically located at key positions within the tRNA structure, such as the D-arm and the anticodon stem-loop, where they play critical roles in maintaining the tRNA's L-shaped tertiary structure and ensuring translational fidelity.[2]
The presence and extent of m²G and m²,²G modifications can vary significantly between cytosolic and mitochondrial tRNAs, reflecting the distinct translational environments and evolutionary pressures of these cellular compartments. Understanding these differences is critical for elucidating the specific roles of these modifications in both normal cellular physiology and disease.
Biosynthesis of m²G and m²,²G in Cytosolic and Mitochondrial tRNAs
The formation of m²G and m²,²G is catalyzed by a family of S-adenosyl-L-methionine (SAM)-dependent methyltransferases.[2]
Cytosolic tRNA Modification
In the cytosol of eukaryotes, the formation of m²G and m²,²G at position 26 (G26) is primarily catalyzed by the TRMT1 (tRNA methyltransferase 1) enzyme.[3] TRMT1 is a dual-function enzyme that can catalyze both the mono- and dimethylation of G26.[4] The majority of cytosolic tRNAs that contain a guanosine at position 26 are modified to m²,²G.[4]
The formation of m²G at other positions, such as G10, is carried out by a different enzymatic complex, TRMT11-TRMT112.[5]
Mitochondrial tRNA Modification
Mitochondrial tRNAs (mt-tRNAs) are also substrates for N²-guanine methylation. The nuclear-encoded TRMT1 is imported into the mitochondria to modify mt-tRNAs.[4] However, the modification landscape of mt-tRNAs is distinct from that of their cytosolic counterparts. Many mt-tRNAs that have a guanosine at position 26 are only monomethylated to m²G, or remain unmodified, in contrast to the predominant dimethylation seen in cytosolic tRNAs.[4] For instance, human mt-tRNA-Ile is one of the few mitochondrial tRNAs known to contain m²,²G26, while others like mt-tRNA-Ala contain m²G at position 10.[4] This differential modification pattern suggests a distinct regulatory mechanism or substrate recognition by TRMT1 within the mitochondrial environment.
Data Presentation: Distribution of m²G and m²,²G
The following tables summarize the known distribution of m²G and m²,²G in cytosolic and mitochondrial tRNAs. It is important to note that comprehensive quantitative data on the stoichiometry of these modifications across all tRNA species and organisms is still an active area of research.
| Modification | Location | Organism/Compartment | Key Enzyme(s) | Predominant Form | Reference(s) |
| m²,²G | G26 | Eukaryotic Cytosol | TRMT1 | Dimethylated | [3] |
| m²G / m²,²G | G26 | Eukaryotic Mitochondria | TRMT1 | Mostly Monomethylated or Unmodified | [4] |
| m²G | G10 | Eukaryotic Cytosol | TRMT11-TRMT112 | Monomethylated | [5] |
| m²G | G10 | Eukaryotic Mitochondria | TRMT11-TRMT112 | Monomethylated | [4] |
| tRNA Species | Compartment | Position | Modification | Organism | Reference(s) |
| tRNA-Ile | Mitochondria | 26 | m²,²G | Human | [4] |
| tRNA-Ala | Mitochondria | 10 | m²G | Human | [4] |
| Most G26-containing tRNAs | Cytosol | 26 | m²,²G | Human | [4] |
| tRNA-Tyr, tRNA-Val | Cytosol | 26 | m²G or m²,²G | Human | [4] |
Functional Roles of m²G and m²,²G Modifications
tRNA Structure and Stability
The methylation of G26 is critical for maintaining the correct tertiary structure of tRNA. The m²,²G26 modification helps to prevent alternative, non-functional tRNA conformations by sterically hindering improper base pairing.[6] This is particularly important for cytosolic tRNAs, which need to adopt a canonical L-shape to function in translation. The absence of this modification in many mitochondrial tRNAs may be related to their often atypical structures.[6]
Translation and Cellular Homeostasis
Proper modification of tRNAs is essential for efficient and accurate protein synthesis. Deficiencies in m²,²G formation due to mutations in TRMT1 have been linked to reduced global protein translation, perturbations in cellular redox homeostasis, and increased sensitivity to oxidative stress.[4] This highlights the critical role of these modifications in maintaining cellular health.
Link to Human Disease
Mutations in the TRMT1 gene that lead to a loss of m²,²G modification in tRNAs are associated with autosomal recessive intellectual disability.[7][8] This underscores the importance of proper tRNA modification for neurodevelopment and cognitive function. The molecular basis for this is thought to be the disruption of normal protein synthesis in neuronal cells.
Mandatory Visualizations
Biosynthetic Pathway of m²G and m²,²G
Caption: Biosynthesis of m²G and m²,²G in cytosolic and mitochondrial tRNAs.
Experimental Workflow for tRNA Modification Analysis
Caption: General workflow for the analysis of tRNA modifications.
Logical Relationship of TRMT1 Dysfunction and Disease
Caption: Logical pathway from TRMT1 mutation to neurodevelopmental disorders.
Experimental Protocols
tRNA Isolation from Mammalian Cells
This protocol describes the isolation of total tRNA from cultured mammalian cells.
Materials:
-
Phosphate-buffered saline (PBS)
-
TRIzol reagent or similar phenol-based lysis solution
-
Chloroform
-
Isopropanol
-
75% Ethanol (prepared with DEPC-treated water)
-
DEPC-treated water
-
Glycogen (RNase-free)
Procedure:
-
Cell Harvesting: Harvest cultured cells by centrifugation and wash the cell pellet with ice-cold PBS.
-
Lysis: Add 1 mL of TRIzol reagent per 5-10 million cells and lyse the cells by repetitive pipetting.
-
Phase Separation: Incubate the homogenate for 5 minutes at room temperature. Add 0.2 mL of chloroform per 1 mL of TRIzol reagent, cap the tube securely, and shake vigorously for 15 seconds. Incubate at room temperature for 3 minutes.
-
Centrifuge the sample at 12,000 x g for 15 minutes at 4°C. The mixture will separate into a lower red phenol-chloroform phase, an interphase, and a colorless upper aqueous phase. RNA remains exclusively in the aqueous phase.
-
RNA Precipitation: Transfer the aqueous phase to a fresh tube. Precipitate the RNA by adding 0.5 mL of isopropanol per 1 mL of TRIzol reagent used for the initial homogenization. Add glycogen to a final concentration of 200 µg/mL to aid in precipitation. Mix and incubate at room temperature for 10 minutes.
-
Centrifuge at 12,000 x g for 10 minutes at 4°C. The RNA will form a gel-like pellet on the side and bottom of the tube.
-
RNA Wash: Remove the supernatant and wash the RNA pellet once with 1 mL of 75% ethanol.
-
Resuspension: Briefly dry the RNA pellet and dissolve it in an appropriate volume of DEPC-treated water.
Quantitative Analysis of tRNA Modifications by LC-MS/MS
This protocol outlines the general steps for the quantitative analysis of m²G and m²,²G in tRNA samples using liquid chromatography-tandem mass spectrometry (LC-MS/MS).
Materials:
-
Purified tRNA
-
Nuclease P1
-
Bacterial alkaline phosphatase
-
LC-MS grade water and acetonitrile
-
Formic acid
-
LC-MS/MS system
Procedure:
-
tRNA Digestion:
-
To 1-5 µg of purified tRNA, add nuclease P1 and incubate at 37°C for 2 hours.
-
Add bacterial alkaline phosphatase and continue to incubate at 37°C for another 2 hours to dephosphorylate the nucleosides.
-
-
LC-MS/MS Analysis:
-
Inject the digested nucleoside mixture into an LC-MS/MS system equipped with a C18 reversed-phase column.
-
Separate the nucleosides using a gradient of mobile phases (e.g., water with 0.1% formic acid and acetonitrile with 0.1% formic acid).
-
Detect and quantify the modified nucleosides using a triple quadrupole mass spectrometer operating in multiple reaction monitoring (MRM) mode. Specific parent-to-daughter ion transitions for m²G and m²,²G should be used for accurate quantification.
-
-
Data Analysis:
-
Quantify the amount of m²G and m²,²G relative to the canonical nucleosides (A, C, G, U) to determine the stoichiometry of the modifications.
-
In Vitro tRNA Methyltransferase Assay
This protocol can be used to assess the activity of recombinant tRNA methyltransferases, such as TRMT1.
Materials:
-
Recombinant tRNA methyltransferase
-
In vitro transcribed tRNA substrate
-
S-adenosyl-L-[methyl-³H]methionine ([³H]SAM)
-
Reaction buffer (e.g., 50 mM Tris-HCl pH 8.0, 5 mM MgCl₂, 5 mM DTT)
-
Scintillation cocktail
Procedure:
-
Reaction Setup: In a microcentrifuge tube, combine the reaction buffer, in vitro transcribed tRNA substrate, and recombinant methyltransferase.
-
Initiation: Start the reaction by adding [³H]SAM.
-
Incubation: Incubate the reaction at the optimal temperature for the enzyme (e.g., 37°C) for a specified time.
-
Termination: Stop the reaction by spotting the mixture onto a filter paper disc and precipitating the tRNA with trichloroacetic acid (TCA).
-
Washing: Wash the filter discs extensively with TCA and then with ethanol to remove unincorporated [³H]SAM.
-
Quantification: Dry the filter discs and measure the incorporated radioactivity using a scintillation counter. The amount of radioactivity is proportional to the enzyme activity.
Conclusion
The differential methylation of guanine at the N² position in cytosolic and mitochondrial tRNAs highlights the intricate regulation of translation in different cellular compartments. While m²,²G at position 26 is a hallmark of cytosolic tRNAs, ensuring their structural integrity and translational fidelity, mitochondrial tRNAs exhibit a more varied modification landscape with a prevalence of m²G or unmodified guanosine at the same position. This distinction is governed by the dual localization and substrate preferences of the TRMT1 methyltransferase. The link between deficiencies in these modifications and human diseases, particularly neurodevelopmental disorders, underscores the critical importance of tRNA modification in cellular health and opens new avenues for therapeutic intervention. The experimental protocols provided in this guide offer a robust framework for researchers to further investigate the roles of m²G and m²,²G in biology and disease.
References
- 1. 2.1. Isolation of tRNA from Biological Samples [bio-protocol.org]
- 2. Frontiers | N2-methylguanosine and N2, N2-dimethylguanosine in cytosolic and mitochondrial tRNAs [frontiersin.org]
- 3. Identification of the enzymes responsible for m2,2G and acp3U formation on cytosolic tRNA from insects and plants - PMC [pmc.ncbi.nlm.nih.gov]
- 4. TRMT1-Catalyzed tRNA Modifications Are Required for Redox Homeostasis To Ensure Proper Cellular Proliferation and Oxidative Stress Survival - PMC [pmc.ncbi.nlm.nih.gov]
- 5. N2-methylguanosine and N2, N2-dimethylguanosine in cytosolic and mitochondrial tRNAs [agris.fao.org]
- 6. A correlation between N2-dimethylguanosine presence and alternate tRNA conformers - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. medrxiv.org [medrxiv.org]
- 8. medrxiv.org [medrxiv.org]
Methodological & Application
Detecting N6-methyladenosine (m6A) in RNA: Application Notes and Protocols for Researchers
For researchers, scientists, and drug development professionals, the accurate detection and quantification of N6-methyladenosine (m6A), the most abundant internal modification in eukaryotic mRNA, is crucial for unraveling its role in gene expression, cellular physiology, and disease. This document provides detailed application notes and experimental protocols for various methods of m6A detection in RNA samples.
N6-methyladenosine is a dynamic and reversible RNA modification that plays a critical role in many biological processes, including RNA splicing, nuclear export, stability, and translation. The dysregulation of m6A has been implicated in various diseases, making its detection and quantification a key area of research. A variety of techniques have been developed to identify and quantify m6A, each with its own advantages and limitations. These methods can be broadly categorized into antibody-based approaches, sequencing-independent methods, enzyme-based methods, chemical-based methods, and direct RNA sequencing.
Comparative Analysis of m6A Detection Methods
The choice of method for m6A detection depends on the specific research question, available resources, and desired resolution. The following table summarizes the key quantitative parameters of the most common techniques.
| Method | Principle | Resolution | Minimum RNA Input | Sensitivity | Specificity | Throughput |
| MeRIP-seq/m6A-seq | Antibody-based enrichment of m6A-containing RNA fragments followed by high-throughput sequencing.[1][2] | ~100-200 nucleotides[3] | ~1-15 µg total RNA[4] | Moderate to High | Dependent on antibody specificity | High |
| SCARLET | Site-specific cleavage, radioactive labeling, and thin-layer chromatography to quantify m6A at a specific site.[5] | Single nucleotide | ~1 µg polyA+ RNA | High | High | Low |
| DART-seq | Fusion protein (YTH-APOBEC1) induces C-to-U editing adjacent to m6A sites, detected by sequencing.[6][7] | Single nucleotide[6] | As low as 10 ng total RNA[7][8] | High | High | High |
| m6A-SEAL | FTO-mediated oxidation of m6A followed by chemical labeling and enrichment.[9] | High | Low | High | High | High |
| Nanopore Direct RNA Sequencing | Direct sequencing of native RNA molecules, detecting m6A through characteristic changes in the electrical current signal.[10][11] | Single nucleotide[10] | ~150 ng mRNA[12] | High (Accuracy ~90-95%)[11][13] | High | High |
| LC-MS/MS | Liquid chromatography-mass spectrometry to quantify the absolute amount of m6A nucleosides.[9][14] | Not site-specific (global quantification) | ~1 µg RNA | High | High | Low to Medium |
| m6A-ELISA | Enzyme-linked immunosorbent assay for the relative quantification of global m6A levels.[15][16] | Not site-specific (global quantification) | As low as 25 ng mRNA[15][17] | Good (detection limit ~5 pg of m6A)[18] | Dependent on antibody specificity | High |
The m6A Regulatory Pathway
The levels of m6A in RNA are dynamically regulated by a set of proteins collectively known as "writers," "erasers," and "readers".[19][20][21] "Writers" are methyltransferases that install the m6A mark, with the METTL3-METTL14 complex being the primary enzyme.[19][20] "Erasers" are demethylases, such as FTO and ALKBH5, that remove the m6A modification.[20] Finally, "readers" are proteins that recognize and bind to m6A-containing RNAs to mediate downstream effects on RNA metabolism.[19][20]
Experimental Protocols
This section provides detailed protocols for key m6A detection methods.
Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq)
MeRIP-seq is a widely used antibody-based method for transcriptome-wide mapping of m6A.[1][2]
Protocol:
-
mRNA Isolation: Isolate total RNA from cells or tissues using a standard RNA extraction method. Purify mRNA from the total RNA using oligo(dT) magnetic beads.
-
RNA Fragmentation: Fragment the purified mRNA to an average size of 100-200 nucleotides using chemical or enzymatic methods.
-
Immunoprecipitation:
-
Take an aliquot of the fragmented RNA as the "input" control.
-
Incubate the remaining fragmented RNA with an anti-m6A antibody to form RNA-antibody complexes.
-
Add protein A/G magnetic beads to capture the RNA-antibody complexes.
-
-
Washing: Wash the beads several times to remove non-specifically bound RNA fragments.
-
Elution: Elute the m6A-containing RNA fragments from the antibody-bead complexes.
-
Library Preparation: Prepare sequencing libraries from both the immunoprecipitated (IP) and the input RNA samples.
-
Sequencing: Perform high-throughput sequencing of the prepared libraries.
-
Data Analysis: Align the sequencing reads to a reference genome/transcriptome. Use peak-calling algorithms to identify regions enriched for m6A in the IP sample relative to the input.
Site-specific Cleavage and Radioactive-Labeling followed by Ligation-assisted Extraction and Thin-layer Chromatography (SCARLET)
SCARLET is a highly sensitive and specific method for quantifying the m6A fraction at a single, specific nucleotide site.[5]
Protocol:
-
Hybridization: Hybridize the target RNA with a site-specific chimeric oligonucleotide containing both 2'-O-methyl and deoxyribonucleotides.
-
RNase H Cleavage: Treat the RNA-oligonucleotide hybrid with RNase H, which specifically cleaves the RNA strand of the hybrid, leaving a 5'-hydroxyl group on the target adenosine.
-
Radioactive Labeling: Label the 5' end of the cleaved RNA fragment with 32P using T4 polynucleotide kinase and [γ-32P]ATP.
-
Splint Ligation: Ligate the 32P-labeled RNA fragment to a single-stranded DNA adapter using a splint oligonucleotide and T4 DNA ligase.
-
Nuclease P1 Digestion: Digest the ligated product with nuclease P1 to release the 32P-labeled 5'-mononucleotides.
-
Thin-Layer Chromatography (TLC): Separate the resulting 32P-labeled adenosine (pA) and N6-methyladenosine (pm6A) mononucleotides by two-dimensional thin-layer chromatography.
-
Quantification: Quantify the radioactivity of the pA and pm6A spots to determine the m6A fraction at the specific site.
Deamination Adjacent to RNA Modification Targets Sequencing (DART-seq)
DART-seq is an antibody-free method that utilizes an engineered protein to induce a detectable mutation adjacent to m6A sites.[6][7]
Protocol:
-
Incubation with Fusion Protein: Incubate the total RNA sample with a purified fusion protein consisting of the m6A-binding YTH domain and the cytidine deaminase APOBEC1.
-
Deamination: The YTH domain binds to m6A sites, and the tethered APOBEC1 enzyme catalyzes the deamination of nearby cytosine (C) residues to uracil (U).
-
RNA Purification: Purify the RNA to remove the fusion protein and other reaction components.
-
Library Preparation: Prepare a standard RNA sequencing library from the treated RNA.
-
Sequencing: Perform high-throughput sequencing.
-
Data Analysis: Align the sequencing reads to a reference genome/transcriptome and identify C-to-T mismatches (representing the C-to-U edits) that are significantly enriched in the treated sample compared to a control.
Nanopore Direct RNA Sequencing
This technology enables the direct sequencing of native RNA molecules, allowing for the detection of m6A and other modifications without the need for reverse transcription or amplification.[10][11]
Protocol:
-
Library Preparation: Ligate a sequencing adapter, which includes a motor protein, to the 3' end of poly(A)+ RNA molecules.
-
Loading: Load the prepared RNA library onto a Nanopore flow cell.
-
Sequencing: An ionic current is passed through nanopores in a membrane. As an RNA molecule is ratcheted through a nanopore by the motor protein, the bases cause characteristic disruptions in the current.
-
Basecalling and Signal Analysis: The changes in the electrical current are recorded and used to determine the sequence of the RNA molecule.
-
Modification Detection: The presence of m6A alters the ionic current signal in a predictable way compared to an unmodified adenosine. Computational models are used to analyze the raw signal data and identify the locations of m6A modifications.[11]
References
- 1. MeRIP-seq: Comprehensive Guide to m6A RNA Modification Analysis - CD Genomics [rna.cd-genomics.com]
- 2. How MeRIP-seq Works: Principles, Workflow, and Applications Explained - CD Genomics [rna.cd-genomics.com]
- 3. m6A-SAC-seq for quantitative whole transcriptome m6A profiling - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Improved Methods for Deamination-Based m6A Detection - PMC [pmc.ncbi.nlm.nih.gov]
- 5. raybiotech.com [raybiotech.com]
- 6. Resources — The Meyer Lab [themeyerlab.com]
- 7. DART-seq: an antibody-free method for global m6A detection - PMC [pmc.ncbi.nlm.nih.gov]
- 8. pacb.com [pacb.com]
- 9. Frontiers | Current progress in strategies to profile transcriptomic m6A modifications [frontiersin.org]
- 10. manuals.plus [manuals.plus]
- 11. nanoporetech.com [nanoporetech.com]
- 12. academic.oup.com [academic.oup.com]
- 13. nanoporetech.com [nanoporetech.com]
- 14. Quantitative analysis of m6A RNA modification by LC-MS - PMC [pmc.ncbi.nlm.nih.gov]
- 15. m6A-ELISA, a simple method for quantifying N6-methyladenosine from mRNA populations - PMC [pmc.ncbi.nlm.nih.gov]
- 16. An Improved m6A-ELISA for Quantifying N6-methyladenosine in Poly(A)-purified mRNAs [en.bio-protocol.org]
- 17. researchgate.net [researchgate.net]
- 18. MethylFlash m6A DNA Methylation ELISA Kit (Colorimetric) | EpigenTek [epigentek.com]
- 19. Exploring m6A RNA Methylation: Writers, Erasers, Readers | EpigenTek [epigentek.com]
- 20. m6A writers, erasers, readers and their functions | Abcam [abcam.com]
- 21. mdpi.com [mdpi.com]
Mass spectrometry protocols for the quantification of N2-methylguanine.
An exacting guide to the quantification of N2-methylguanine (N2-MeG), a critical DNA adduct, is presented here for researchers, scientists, and professionals in drug development. This document provides detailed application notes and protocols for the use of liquid chromatography-tandem mass spectrometry (LC-MS/MS) in the precise measurement of N2-MeG.
Application Notes
N2-methylguanine is a DNA lesion that can result from exposure to certain alkylating agents and is also formed endogenously. Its presence and quantity in DNA are significant biomarkers for assessing DNA damage and repair, making its accurate quantification crucial in toxicology, cancer research, and drug development. LC-MS/MS, particularly when coupled with stable isotope dilution, stands as the gold standard for this type of analysis due to its high sensitivity and specificity.[1][2]
The protocols outlined below are designed to guide the user through the entire workflow, from sample preparation to data acquisition and analysis. Adherence to these detailed steps will ensure reliable and reproducible quantification of N2-methylguanine in biological samples.
Experimental Protocols
A robust and validated protocol is essential for the accurate quantification of N2-methylguanine. The following sections detail the necessary steps from DNA extraction to LC-MS/MS analysis.
DNA Extraction and Purification
High-quality DNA is the prerequisite for accurate adduct analysis. Various commercial kits and established methods can be employed for DNA isolation from cells or tissues.[3][4] It is critical to ensure that the final DNA sample is free from contaminants such as proteins and RNA.
Protocol:
-
Homogenize tissue samples or lyse cultured cells using appropriate buffers and mechanical disruption (e.g., bead beating or sonication).
-
Perform sequential enzymatic digestion with RNase A and Proteinase K to remove RNA and protein contaminants.
-
Extract DNA using phenol-chloroform or a column-based purification kit.[4]
-
Precipitate the DNA with ice-cold ethanol and wash the pellet with 70% ethanol.
-
Resuspend the purified DNA pellet in nuclease-free water.
-
Determine the DNA concentration and purity using a spectrophotometer (A260/A280 ratio should be ~1.8).
DNA Hydrolysis
To release the modified nucleobases from the DNA backbone, enzymatic or acid hydrolysis is performed. Enzymatic hydrolysis is generally preferred as it is milder and less likely to induce artificial modifications.
Protocol for Enzymatic Hydrolysis: [1]
-
To a solution containing 10-50 µg of DNA, add a known amount of a stable isotope-labeled internal standard for N2-methylguanine (e.g., [¹⁵N₅]-N2-methyl-2'-deoxyguanosine). The use of an internal standard is crucial for accurate quantification by correcting for sample loss during preparation and for variations in ionization efficiency.[2][5]
-
Add nuclease P1 and incubate at 37°C for 2 hours.
-
Add alkaline phosphatase and continue the incubation at 37°C for another 2 hours.[1]
-
Terminate the reaction by adding a solvent suitable for protein precipitation, such as cold acetonitrile.
-
Centrifuge the sample to pellet the precipitated enzymes and proteins.
-
Transfer the supernatant containing the nucleosides to a new tube and dry it under vacuum.
-
Reconstitute the sample in a mobile phase-compatible solvent for LC-MS/MS analysis.[1]
Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS) Analysis
The separation and detection of N2-methylguanine are achieved using a high-performance liquid chromatography (HPLC) or ultra-high-performance liquid chromatography (UHPLC) system coupled to a triple quadrupole mass spectrometer.
Typical LC-MS/MS Parameters:
-
LC Column: A C18 reversed-phase column is commonly used for the separation of nucleosides.
-
Mobile Phase: A gradient of water with a small amount of formic acid (for protonation) and an organic solvent like methanol or acetonitrile is typically employed.
-
Mass Spectrometer: A triple quadrupole mass spectrometer operating in positive electrospray ionization (ESI+) mode is used.
-
Detection Mode: Multiple Reaction Monitoring (MRM) is used for its high selectivity and sensitivity. This involves monitoring specific precursor-to-product ion transitions for both the analyte (N2-methylguanine) and the internal standard.[6][7]
MRM Transitions for N2-methylguanine (as the nucleoside, N2-methyl-2'-deoxyguanosine):
| Analyte | Precursor Ion (m/z) | Product Ion (m/z) |
| N2-methyl-2'-deoxyguanosine | 282.1 | 166.1 |
| [¹⁵N₅]-N2-methyl-2'-deoxyguanosine | 287.1 | 171.1 |
Note: The exact m/z values may vary slightly depending on the instrument and calibration.
Quantitative Data Summary
The following table summarizes representative quantitative data for N2-methylguanine found in various studies. This data illustrates the levels of this adduct detected in different biological systems under specific conditions.
| Sample Type | Exposure Condition | N2-methylguanine Level | Reference |
| HEK293T cells | 10 µM N2-MedG for 16 h | ~90 modifications per 10⁶ nucleosides | [1] |
| Mouse Tissues | 4-week exposure to 1.5 mg/kg methanol | 1.9–4.2 per 10⁶ nucleosides | [1] |
| Human Breast Tumor | - | 3-12 adducts/10⁷ dG (for a related adduct, CEdG) | [8] |
| Liver of control mosquito fish | - | 7.89±1.38 μmol/mol of guanine (for N7-MeG) | [6] |
| Liver of mosquito fish | 1 mg/l NDMA | Significantly induced (for N7-MeG) | [6] |
Visualizations
The following diagrams illustrate the key processes involved in the quantification of N2-methylguanine.
References
- 1. LC-MS/MS for Assessing the Incorporation and Repair of N2-Alkyl-2′-deoxyguanosine in Genomic DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 2. One-pot stable isotope dilution- and LC-MS/MS-based quantitation of guanine, O6-methylguanine, and N7-methylguanine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Determination of O6-Methylguanine in dried blood spot of breast cancer patients after cyclophosphamide administration - PMC [pmc.ncbi.nlm.nih.gov]
- 4. frontlinegenomics.com [frontlinegenomics.com]
- 5. Isotope-dilution mass spectrometry for exact quantification of noncanonical DNA nucleosides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Simultaneous determination of N7-alkylguanines in DNA by isotope-dilution LC-tandem MS coupled with automated solid-phase extraction and its application to a small fish model - PMC [pmc.ncbi.nlm.nih.gov]
- 7. tandfonline.com [tandfonline.com]
- 8. Advanced glycation end products of DNA: quantification of N2-(1-Carboxyethyl)-2'-deoxyguanosine in biological samples by liquid chromatography electrospray ionization tandem mass spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
Applications of 6-Hydroxy-2-methylaminopurine in Cancer Research: Information Not Currently Available in Publicly Accessible Resources
Despite a comprehensive search of publicly available scientific literature and databases, there is currently no specific information regarding the applications of 6-Hydroxy-2-methylaminopurine in cancer research.
Extensive searches for the cytotoxic effects, mechanism of action, and involvement in signaling pathways of this compound against cancer cells did not yield any direct results. Consequently, the creation of detailed application notes, experimental protocols, and data tables as requested is not possible at this time.
The scientific community has actively investigated a wide array of purine analogs for their potential as anticancer agents. These related compounds often exert their effects by interfering with DNA and RNA synthesis, inhibiting key enzymes involved in cellular proliferation, or modulating signaling pathways crucial for cancer cell survival and growth.
While general methodologies for evaluating novel purine derivatives in cancer research are well-established, their specific application to this compound remains undocumented in the accessible literature.
It is conceivable that research on this specific compound exists but has not been published or is part of proprietary drug discovery programs. Researchers, scientists, and drug development professionals interested in the potential of this compound are encouraged to initiate novel research to explore its properties and potential therapeutic applications. Such studies would need to begin with fundamental in vitro screening against various cancer cell lines to determine any cytotoxic or antiproliferative activity. If promising activity is observed, further investigations into its mechanism of action and preclinical in vivo studies would be warranted.
Application Notes and Protocols for High-Throughput Sequencing of N2-methylguanine (m2G) Sites in RNA
For Researchers, Scientists, and Drug Development Professionals
Introduction
N2-methylguanine (m2G) is a post-transcriptional RNA modification found in various RNA species, including transfer RNA (tRNA), ribosomal RNA (rRNA), and messenger RNA (mRNA).[1] This modification, catalyzed by specific methyltransferases, plays a crucial role in regulating RNA stability, structure, and function.[1] For instance, m2G modifications in tRNA are important for maintaining the structural integrity of the D-arm and anticodon stem-loop, thereby ensuring proper protein translation.[1] Dysregulation of m2G levels has been implicated in various diseases, making the mapping of m2G sites a critical area of research for understanding disease mechanisms and for the development of novel therapeutics.
This document provides detailed application notes and protocols for the high-throughput sequencing of m2G sites in RNA, with a focus on the recently developed PhOxi-Seq method.
High-Throughput m2G Mapping Methods: A Comparative Overview
Several methods have been developed for the transcriptome-wide mapping of RNA modifications. While techniques like MeRIP-seq (Methylated RNA Immunoprecipitation Sequencing) are widely used for modifications like N6-methyladenosine (m6A), their application to m2G has been limited by the availability of highly specific and efficient antibodies.[2][3][4][5] A promising and specific method for m2G detection is PhOxi-Seq, which offers single-nucleotide resolution.[1][3]
| Method | Principle | Resolution | Advantages | Limitations |
| PhOxi-Seq | Photo-oxidative chemical conversion of m2G induces mutations during reverse transcription, which are then identified by sequencing.[1][3] | Single-nucleotide | High specificity and resolution. Does not rely on antibodies. | Requires specific chemical reagents and a photoredox catalysis setup. |
| m2G-MeRIP-seq (Hypothetical) | Immunoprecipitation of m2G-containing RNA fragments using an m2G-specific antibody, followed by high-throughput sequencing. | ~100-200 nucleotides | Utilizes a well-established workflow (MeRIP-seq). | Heavily dependent on the availability and specificity of a high-quality anti-m2G antibody. Potential for off-target binding. |
PhOxi-Seq: A Detailed Protocol for Single-Nucleotide Resolution m2G Mapping
PhOxi-Seq (Photo-oxidative Sequencing) is a chemical-based method that enables the precise mapping of N2-methylguanine (m2G) and N2,N2-dimethylguanosine (m22G) in RNA at single-nucleotide resolution. The method relies on the chemoselective oxidation of m2G and m22G using visible light-mediated organic photoredox catalysis. This chemical conversion induces a distinct mutational signature during reverse transcription, allowing for the identification of modified sites through high-throughput sequencing.[1][3]
Experimental Workflow of PhOxi-Seq
Caption: Experimental workflow of the PhOxi-Seq method.
Detailed Experimental Protocol for PhOxi-Seq
1. RNA Preparation
1.1. Total RNA Extraction:
- Extract total RNA from cells or tissues using a standard method such as TRIzol reagent or a commercial kit.
- Assess RNA quality and quantity using a spectrophotometer (e.g., NanoDrop) and a bioanalyzer (e.g., Agilent Bioanalyzer). Ensure high-quality RNA with an RNA Integrity Number (RIN) > 7.
1.2. RNA Fragmentation:
- Fragment the total RNA to an average size of 100-200 nucleotides. This can be achieved using enzymatic methods (e.g., RNase III) or chemical fragmentation (e.g., metal-ion catalyzed hydrolysis).
- Purify the fragmented RNA using a suitable clean-up kit.
2. Photo-oxidative Reaction
2.1. Reaction Setup:
- In a reaction tube, combine the fragmented RNA with the photocatalyst (e.g., riboflavin) and an oxidant (e.g., Selectfluor™) in a suitable reaction buffer.
- Note: The optimal concentrations of the photocatalyst and oxidant should be empirically determined.
2.2. Photoredox Catalysis:
- Expose the reaction mixture to visible light (e.g., a blue LED light source) for a specific duration. This initiates the photoredox cycle, leading to the selective oxidation of m2G and m22G residues.
- Note: The irradiation time is a critical parameter and should be optimized to achieve efficient oxidation without causing significant RNA degradation.
2.3. Reaction Quenching and RNA Purification:
- Quench the reaction by adding a suitable quenching agent.
- Purify the oxidized RNA to remove the photocatalyst, oxidant, and other reaction components.
3. Library Preparation and Sequencing
3.1. Reverse Transcription:
- Perform reverse transcription on the purified, oxidized RNA. The oxidized m2G and m22G bases will cause misincorporation of nucleotides by the reverse transcriptase, introducing specific mutations (e.g., G-to-T or G-to-C transitions) into the resulting cDNA.[1]
3.2. Library Preparation:
- Prepare a sequencing library from the cDNA using a standard library preparation kit for high-throughput sequencing (e.g., Illumina TruSeq).
3.3. High-Throughput Sequencing:
- Sequence the prepared library on a high-throughput sequencing platform (e.g., Illumina NovaSeq).
4. Data Analysis
4.1. Read Alignment:
- Align the sequencing reads to the reference genome or transcriptome using a standard alignment tool (e.g., Bowtie, STAR).
4.2. Mutation Calling:
- Identify single nucleotide polymorphisms (SNPs) or mutations in the aligned reads compared to the reference sequence.
- Focus on identifying the specific mutation signatures (e.g., G>T, G>C) that are characteristic of oxidized m2G sites.
4.3. Peak Calling and Annotation:
- Use a peak calling algorithm to identify genomic regions with a significant enrichment of the m2G-specific mutation signature.
- Annotate the identified m2G sites to specific genes and RNA features.
Signaling Pathway Involving m2G Methyltransferases
The methylation of guanosine at the N2 position is carried out by a family of N2-guanosine methyltransferases (MTases). In humans, several enzymes have been identified to be responsible for m2G formation in different RNA molecules. For example, the THUMPD3-TRMT112 complex is responsible for m2G6 formation in a wide range of tRNAs.[6] The activity of these enzymes is crucial for proper tRNA function and, consequently, for accurate and efficient protein synthesis.
Caption: Role of the THUMPD3-TRMT112 complex in tRNA methylation.
Conclusion
The ability to map m2G sites at high resolution is essential for understanding the regulatory roles of this RNA modification in health and disease. PhOxi-Seq provides a powerful tool for the specific and quantitative analysis of m2G at the single-nucleotide level. The detailed protocol and workflows presented here offer a comprehensive guide for researchers, scientists, and drug development professionals to implement this technology in their studies. Further research into the development of highly specific antibodies may also enable the broader application of antibody-based methods for m2G mapping. A deeper understanding of the enzymes that regulate m2G deposition and the signaling pathways they influence will open new avenues for therapeutic intervention.
References
- 1. PhOxi-Seq: Single-Nucleotide Resolution Sequencing of N2-Methylation at Guanosine in RNA by Photoredox Catalysis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. High-resolution Digital Mapping of N-Methylpurines in Human Cells Reveals Modulation of Their Induction and Repair by Nearest-neighbor Nucleotides - PMC [pmc.ncbi.nlm.nih.gov]
- 3. PhOxi-Seq: Single-Nucleotide Resolution Sequencing of N2-Methylation at Guanosine in RNA by Photoredox Catalysis. (2022) | Kimberley Chung Kim Chung | 5 Citations [scispace.com]
- 4. High-resolution mapping of DNA hypermethylation and hypomethylation in lung cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 5. High-resolution Digital Mapping of N-Methylpurines in Human Cells Reveals Modulation of Their Induction and Repair by Nearest-neighbor Nucleotides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. chemrxiv.org [chemrxiv.org]
Synthesis of N2-methylguanosine-containing RNA: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
Introduction
N2-methylguanosine (m2G) is a post-transcriptional modification found in various RNA species, including transfer RNA (tRNA) and ribosomal RNA (rRNA). This modification plays a crucial role in maintaining the structural integrity and function of RNA molecules. The targeted incorporation of m2G into synthetic RNA substrates is of significant interest for a range of applications, including the study of RNA-protein interactions, the development of RNA-based therapeutics, and the elucidation of RNA-mediated biological pathways.
This document provides detailed application notes and protocols for the two primary methodologies used to synthesize N2-methylguanosine-containing RNA substrates: Chemical Synthesis via the phosphoramidite method and Enzymatic Synthesis using methyltransferases.
Data Presentation: Comparison of Synthesis Methods
The choice of synthesis method depends on several factors, including the desired length of the RNA, the position of the modification, required yield and purity, and available resources. The following table summarizes the key quantitative aspects of each method.
| Parameter | Chemical Synthesis (Phosphoramidite Method) | Enzymatic Synthesis (Methyltransferase) |
| Overall Yield | Moderate to High (typically 10-40% for a 20-mer RNA, highly dependent on coupling efficiency) | Variable (dependent on enzyme activity, substrate concentration, and reaction optimization) |
| Purity of final product | High (>95% achievable with HPLC purification) | High (enzyme specificity generally ensures modification at the target site) |
| Scalability | Readily scalable from nanomoles to micromoles | More challenging to scale up due to enzyme production and cost |
| Sequence Length | Practical for short to medium length RNAs (up to ~100 nucleotides) | Can modify long, pre-synthesized RNAs |
| Positional Control | Precise, site-specific incorporation at any desired position | Dependent on the specific recognition site of the methyltransferase |
| Cost | High, primarily due to the cost of modified phosphoramidites and synthesis reagents | Potentially lower for large-scale production if the enzyme is readily available or can be produced in-house |
| Time | Relatively fast for short sequences (automated synthesis takes a few hours per oligonucleotide) | Can be time-consuming, including enzyme expression, purification, and the methylation reaction itself |
Experimental Protocols
Chemical Synthesis of N2-methylguanosine RNA via Solid-Phase Synthesis
This method involves the synthesis of an N2-methylguanosine phosphoramidite building block and its incorporation into an RNA oligonucleotide using an automated solid-phase synthesizer.
Protocol 1: Solid-Phase Synthesis of an m2G-containing RNA Oligonucleotide
Materials:
-
DNA/RNA synthesizer
-
Controlled Pore Glass (CPG) solid support functionalized with the initial nucleoside
-
Standard RNA phosphoramidites (A, C, G, U)
-
N2-methylguanosine phosphoramidite (e.g., 5'-O-DMT-2'-O-TBDMS-N2-isobutyryl-N2-methylguanosine-3'-CE phosphoramidite)
-
Activator solution (e.g., 0.25 M DCI in acetonitrile)
-
Capping solution (e.g., Cap A: acetic anhydride/pyridine/THF; Cap B: 16% N-methylimidazole/THF)
-
Oxidizing solution (e.g., 0.02 M iodine in THF/water/pyridine)
-
Deblocking solution (e.g., 3% trichloroacetic acid in dichloromethane)
-
Anhydrous acetonitrile
-
Cleavage and deprotection solution (e.g., a mixture of aqueous ammonia and methylamine (AMA))
-
Triethylamine trihydrofluoride (TEA·3HF) for 2'-O-silyl deprotection
-
HPLC purification system
Procedure:
-
Synthesizer Setup: Program the RNA synthesizer with the desired sequence, incorporating the N2-methylguanosine phosphoramidite at the appropriate step.
-
Automated Synthesis Cycle: The synthesis proceeds through a series of automated steps for each nucleotide addition:
-
Deblocking: Removal of the 5'-dimethoxytrityl (DMT) protecting group.
-
Coupling: Activation of the phosphoramidite and its coupling to the 5'-hydroxyl of the growing RNA chain.
-
Capping: Acetylation of unreacted 5'-hydroxyl groups to prevent the formation of deletion mutants.
-
Oxidation: Conversion of the phosphite triester linkage to a more stable phosphate triester.
-
-
Cleavage and Deprotection:
-
Following synthesis, the solid support is treated with AMA solution at 65°C for 15-20 minutes to cleave the RNA from the support and remove the protecting groups from the nucleobases and the phosphate backbone.
-
The supernatant is collected and dried.
-
-
2'-O-Silyl Group Deprotection: The dried residue is resuspended in TEA·3HF and incubated to remove the 2'-O-TBDMS protecting groups.
-
Purification: The crude RNA is purified by reverse-phase or ion-exchange high-performance liquid chromatography (HPLC).
-
Analysis: The purity and identity of the final product are confirmed by mass spectrometry (e.g., ESI-MS) and analytical HPLC.
Enzymatic Synthesis of N2-methylguanosine RNA
This method utilizes a specific N2-guanosine methyltransferase, such as the human TRMT11 (also known as Trm11), to introduce a methyl group at a specific guanosine residue within a pre-synthesized RNA substrate.[1][2]
Protocol 2: In Vitro Enzymatic Methylation of an RNA Substrate
Materials:
-
Purified, active N2-guanosine methyltransferase (e.g., recombinant human TRMT11)
-
Pre-synthesized RNA substrate containing the target guanosine
-
S-adenosyl-L-methionine (SAM), the methyl donor
-
Reaction buffer (e.g., 50 mM Tris-HCl pH 8.0, 50 mM KCl, 5 mM MgCl2, 1 mM DTT)
-
RNase inhibitor
-
HPLC-MS system for analysis
Procedure:
-
Reaction Setup: In a microcentrifuge tube, combine the following components:
-
RNA substrate (e.g., 10 µM final concentration)
-
N2-guanosine methyltransferase (e.g., 1 µM final concentration)
-
SAM (e.g., 100 µM final concentration)
-
Reaction buffer
-
RNase inhibitor
-
Nuclease-free water to the final volume.
-
-
Incubation: Incubate the reaction mixture at 37°C for 1-2 hours. The optimal time may need to be determined empirically.
-
Enzyme Inactivation: Stop the reaction by heat inactivation (e.g., 65°C for 10 minutes) or by phenol-chloroform extraction.
-
RNA Purification: Purify the RNA from the reaction mixture using a suitable RNA cleanup kit or ethanol precipitation.
-
Analysis of Methylation:
-
Enzymatic Digestion: The purified RNA is digested to single nucleosides using a mixture of nucleases (e.g., nuclease P1 and alkaline phosphatase).
-
HPLC-MS Analysis: The resulting nucleoside mixture is analyzed by liquid chromatography-mass spectrometry (LC-MS).[3][4] The presence of N2-methylguanosine is confirmed by its characteristic retention time and mass-to-charge ratio compared to a known standard. The extent of methylation can be quantified by comparing the peak areas of m2G and unmodified guanosine.[5]
-
Mandatory Visualizations
References
- 1. genecards.org [genecards.org]
- 2. uniprot.org [uniprot.org]
- 3. Frontiers | N2-methylguanosine and N2, N2-dimethylguanosine in cytosolic and mitochondrial tRNAs [frontiersin.org]
- 4. Quantitative analysis of tRNA modifications by HPLC-coupled mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 5. academic.oup.com [academic.oup.com]
Application Note: Quantitative Analysis of N2-methylguanine in Biological Samples by LC-MS/MS
Introduction
N2-methylguanine (N2-MeG) is a modified nucleobase with significant implications in cellular processes and disease. It can be formed in DNA as a result of exposure to alkylating agents, leading to DNA damage that, if unrepaired, can contribute to mutagenesis and carcinogenesis.[1][2] In RNA, N2-methylguanosine (m2G) and its dimethylated form (m2,2G) are post-transcriptional modifications, particularly in transfer RNA (tRNA), that play a role in the regulation of gene expression by influencing RNA folding, stability, and interactions with other molecules.[3][4] Given its dual role in DNA damage and RNA regulation, the accurate quantification of N2-MeG in biological matrices is crucial for toxicology, cancer research, and molecular biology.
This application note details a robust and sensitive method for the quantification of N2-methylguanine in DNA and RNA samples using Liquid Chromatography with tandem Mass Spectrometry (LC-MS/MS). The method employs enzymatic hydrolysis of nucleic acids to release the constituent nucleosides, followed by chromatographic separation and detection by a triple quadrupole mass spectrometer operating in Multiple Reaction Monitoring (MRM) mode. This approach offers high selectivity and sensitivity for reliable quantification of N2-MeG.
Experimental
Materials and Reagents
-
N2-methylguanine (N2-MeG) standard
-
[¹⁵N₅]-N2-methylguanine internal standard (IS)
-
Deoxyribonuclease I (DNase I)
-
Nuclease P1
-
Alkaline Phosphatase
-
Proteinase K
-
Formic acid, LC-MS grade
-
Acetonitrile, LC-MS grade
-
Methanol, LC-MS grade
-
Ultrapure water
-
Solid-Phase Extraction (SPE) cartridges (e.g., Polymeric Reversed Phase)
Sample Preparation: DNA Hydrolysis
-
DNA Isolation : Isolate genomic DNA from cells or tissues using a standard DNA isolation kit or protocol.
-
Enzymatic Digestion :
-
To 20 µg of DNA, add DNase I and incubate at 37°C for 2 hours.
-
Add Nuclease P1 and continue incubation at 37°C for 18 hours.
-
Finally, add Alkaline Phosphatase and incubate for an additional 2 hours at 37°C.[1]
-
-
Protein Removal : Precipitate proteins by adding two volumes of cold ethanol and centrifuging at 10,000 x g for 10 minutes.
-
Supernatant Collection : Carefully transfer the supernatant containing the digested nucleosides to a new tube.
-
Internal Standard Spiking : Add the [¹⁵N₅]-N2-methylguanine internal standard to the supernatant.
-
Solid-Phase Extraction (SPE) :
-
Condition the SPE cartridge with methanol followed by water.
-
Load the sample onto the cartridge.
-
Wash the cartridge with water to remove salts and other polar impurities.
-
Elute the nucleosides with a methanol/water mixture.
-
-
Drying and Reconstitution : Evaporate the eluate to dryness under a stream of nitrogen and reconstitute the residue in a suitable volume of the initial mobile phase for LC-MS/MS analysis.
LC-MS/MS Analysis
-
Liquid Chromatography :
-
Mass Spectrometry :
-
Instrument : Triple quadrupole mass spectrometer.
-
Ionization Mode : Positive Electrospray Ionization (ESI+).
-
Monitoring Mode : Multiple Reaction Monitoring (MRM).
-
Ion Source Parameters :
-
Capillary Voltage : 3.5 kV
-
Source Temperature : 120 °C
-
Desolvation Temperature : 350 °C
-
-
MRM Transitions :
-
The MRM transition for N2-MedG typically involves the neutral loss of the deoxyribose moiety (116 Da) from the protonated molecule [M+H]+.[1]
-
-
Results and Discussion
The developed LC-MS/MS method demonstrated excellent performance for the quantification of N2-methylguanine. The chromatographic conditions provided good separation of N2-MeG from other nucleosides. The use of a stable isotope-labeled internal standard ensured high accuracy and precision by compensating for matrix effects and variations in sample preparation and instrument response.
Quantitative Performance
The method was validated for linearity, limit of detection (LOD), limit of quantification (LOQ), precision, and accuracy. A summary of the quantitative performance is presented in Table 1.
| Parameter | Result |
| Linearity (r²) | > 0.99 |
| Limit of Detection (LOD) | 0.5 fmol |
| Limit of Quantification (LOQ) | 1.5 fmol |
| Intra-day Precision (%RSD) | < 10% |
| Inter-day Precision (%RSD) | < 15% |
| Accuracy (% Recovery) | 95 - 105% |
Table 1: Summary of quantitative performance of the LC-MS/MS method for N2-methylguanine analysis.
Conclusion
This application note describes a sensitive and reliable LC-MS/MS method for the quantitative analysis of N2-methylguanine in biological samples. The method involves enzymatic digestion of DNA/RNA, optional solid-phase extraction for sample cleanup, and analysis by reversed-phase LC-MS/MS. The presented method is suitable for researchers, scientists, and drug development professionals investigating DNA damage, RNA modification, and related cellular pathways.
Detailed Protocols
Protocol 1: Enzymatic Hydrolysis of DNA to Nucleosides
-
Sample Preparation : Resuspend 10-50 µg of isolated DNA in 100 µL of 10 mM Tris-HCl buffer (pH 7.4).
-
Denaturation : Heat the DNA sample at 100°C for 5 minutes to denature the DNA, then immediately place it on ice for 2 minutes.
-
Initial Digestion : Add 10 µL of 1 M sodium acetate (pH 5.2) and 10 units of Nuclease P1. Incubate at 37°C for 2 hours.
-
Final Digestion : Add 10 µL of 1 M Tris-HCl (pH 8.0) and 10 units of alkaline phosphatase. Incubate at 37°C for an additional 2 hours.
-
Enzyme Removal : Add 200 µL of chloroform to the reaction mixture. Vortex vigorously for 1 minute and then centrifuge at 14,000 x g for 5 minutes.[1]
-
Sample Collection : Carefully collect the upper aqueous layer containing the nucleosides.
-
Internal Standard : Spike the sample with a known amount of [¹⁵N₅]-N2-methylguanine internal standard.
-
Storage : The digested sample is now ready for LC-MS/MS analysis or can be stored at -20°C.
Protocol 2: LC-MS/MS Method Parameters
Liquid Chromatography
| Parameter | Setting |
| Column | Waters ACQUITY UPLC BEH C18, 1.7 µm, 2.1 x 100 mm |
| Mobile Phase A | 0.1% Formic Acid in Water |
| Mobile Phase B | 0.1% Formic Acid in Acetonitrile |
| Flow Rate | 0.4 mL/min |
| Injection Volume | 5 µL |
| Column Temperature | 40 °C |
| Gradient | 0-1 min: 2% B; 1-8 min: 2-50% B; 8-8.1 min: 50-95% B; 8.1-9 min: 95% B; 9-9.1 min: 95-2% B; 9.1-12 min: 2% B |
Mass Spectrometry
| Parameter | Setting |
| Ionization Mode | ESI Positive |
| Capillary Voltage | 3.0 kV |
| Cone Voltage | 30 V |
| Source Temperature | 150 °C |
| Desolvation Temperature | 400 °C |
| Cone Gas Flow | 50 L/hr |
| Desolvation Gas Flow | 800 L/hr |
| Collision Gas | Argon |
MRM Transitions
| Analyte | Precursor Ion (m/z) | Product Ion (m/z) | Collision Energy (eV) |
| N2-methylguanine | 282.1 | 166.1 | 15 |
| [¹⁵N₅]-N2-methylguanine (IS) | 287.1 | 171.1 | 15 |
Visualizations
References
- 1. LC-MS/MS for Assessing the Incorporation and Repair of N2-Alkyl-2′-deoxyguanosine in Genomic DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 2. LC-MS/MS for Assessing the Incorporation and Repair of N2-Alkyl-2'-deoxyguanosine in Genomic DNA. | Semantic Scholar [semanticscholar.org]
- 3. Frontiers | N2-methylguanosine and N2, N2-dimethylguanosine in cytosolic and mitochondrial tRNAs [frontiersin.org]
- 4. researchgate.net [researchgate.net]
- 5. pubs.acs.org [pubs.acs.org]
Application Notes and Protocols for Isotope-Dilution LC-Tandem MS Quantification of N7-Alkylguanines
For Researchers, Scientists, and Drug Development Professionals
Introduction
The alkylation of DNA at the N7-position of guanine is a common form of DNA damage induced by a wide range of endogenous and exogenous alkylating agents. These N7-alkylguanine adducts, such as N7-methylguanine (N7-MeG) and N7-ethylguanine (N7-EtG), can serve as valuable biomarkers for assessing exposure to carcinogens and for monitoring the efficacy of certain chemotherapeutic drugs. Isotope-dilution liquid chromatography-tandem mass spectrometry (LC-tandem MS) has emerged as a highly sensitive and specific method for the accurate quantification of these adducts in biological samples.[1][2][3] This document provides detailed application notes and experimental protocols for the quantification of N7-alkylguanines using this advanced analytical technique.
The N7 position of guanine is the most reactive nucleophilic site in DNA.[3] However, N7-guanine adducts are chemically unstable and can be lost from DNA through spontaneous depurination, which involves the cleavage of the N-glycosidic bond.[3][4] This inherent instability is a critical consideration in sample handling and analysis.[3]
Principle of the Method
Isotope-dilution LC-tandem MS combines the high separation efficiency of liquid chromatography with the specificity and sensitivity of tandem mass spectrometry. The core of this method lies in the use of stable isotope-labeled internal standards (e.g., ¹⁵N₅-N7-MeG and ¹⁵N₅-N7-EtG) that are chemically identical to the analytes of interest but have a different mass.[1][2] These internal standards are spiked into the samples at the beginning of the sample preparation process, allowing for accurate quantification by correcting for any analyte loss during extraction, purification, and ionization.[1]
The general workflow involves the isolation of DNA from biological samples, followed by hydrolysis to release the adducted bases. The resulting hydrolysate is then analyzed by LC-tandem MS, often coupled with an on-line solid-phase extraction (SPE) system for sample cleanup and enrichment, which enhances sensitivity and throughput.[1][2][5]
Experimental Protocols
DNA Isolation from Tissues
This protocol is adapted from a method used for isolating DNA from liver tissue.[1]
Materials:
-
Buffer A: 320 mM sucrose, 5 mM MgCl₂, 10 mM Tris/HCl (pH 7.5), 0.1 mM desferrioxamine, 1% (v/v) Triton X-100
-
Ice-cold ethanol
-
Homogenizer
-
Centrifuge
Procedure:
-
Homogenize approximately 40 mg of tissue in 3 ml of Buffer A.
-
Centrifuge the homogenate at 1500 x g for 10 minutes.
-
Discard the supernatant. Wash the resulting pellet with 1.5 ml of Buffer A and centrifuge again at 1500 x g for 10 minutes.
-
Proceed to DNA hydrolysis.
DNA Hydrolysis to Release N7-Alkylguanines
N7-alkylguanine adducts have labile N-glycosidic bonds and can be released from the DNA backbone by neutral thermal hydrolysis.[1][4]
Procedure:
-
Resuspend the DNA pellet in an appropriate buffer.
-
Incubate the DNA solution at a neutral pH and elevated temperature (e.g., heating) to induce depurination of the N7-alkylguanine adducts.
-
After hydrolysis, precipitate the depurinated DNA by adding 2 volumes of ice-cold ethanol and centrifuging at 5000 x g for 15 minutes.[1]
-
Collect the supernatant, which contains the released N7-alkylguanines.
-
Dry the supernatant under vacuum.
-
Redissolve the dried residue in a solvent compatible with the LC-MS analysis, such as 96% (v/v) acetonitrile with 0.1% formic acid.[1]
Sample Preparation for Urine Analysis
This protocol is for the analysis of N7-ethylguanine in urine.[5]
Materials:
-
Deionized water (DIW)
-
¹⁵N₅-N7-EtG internal standard solution
-
Sep-Pak C18 cartridges
-
Methanol
-
Acetonitrile (ACN) with 0.1% formic acid (FA)
Procedure:
-
Thaw urine samples at room temperature and centrifuge at 10,000 x g for 5 minutes.
-
To 0.5 ml of urine, add 2.5 ml of DIW and 100 µl of the ¹⁵N₅-N7-EtG internal standard solution.
-
Load the mixture onto a Sep-Pak C18 cartridge preconditioned with 5 ml of methanol and 5 ml of DIW.
-
Wash the cartridge with 5 ml of 5% methanol.
-
Elute the analyte with 3 ml of 40% methanol.
-
Dry the eluate under vacuum.
-
Redissolve the residue in 300 µl of 96% ACN containing 0.1% FA for LC-MS/MS analysis.
LC-Tandem MS Analysis
The following are example conditions for the analysis of N7-MeG and N7-EtG.[1][6] An on-line SPE system can be used for automated sample cleanup and enrichment.[1][5]
Liquid Chromatography (LC) Conditions:
-
Column: Acquity UPLC BEH C₁₈ column (2.1 mm × 100 mm; 1.7 μm) or similar.[7]
-
Mobile Phase: Isocratic elution with 0.1% formic acid in water and acetonitrile.[7]
-
Flow Rate: 0.1 ml/min.[7]
-
Column Temperature: 50 °C.[7]
Tandem Mass Spectrometry (MS/MS) Conditions:
Data Presentation
The quantitative data obtained from various studies are summarized in the tables below for easy comparison.
Table 1: Levels of N7-Methylguanine (N7-MeG) in Biological Samples
| Sample Type | Organism | Exposure Group | N7-MeG Level | Reference |
| Liver DNA | Mosquito Fish | Control | 7.89 ± 1.38 µmol/mol of guanine | [1][2] |
| Human Tissue | Human | Background | ~2.5 adducts/10⁶ dGp | [1] |
| Urine | Human | Smokers | 4215 ± 1739 ng/mg creatinine | [8] |
| Urine | Human | Non-smokers | 3035 ± 720 ng/mg creatinine | [8] |
Table 2: Levels of N7-Ethylguanine (N7-EtG) in Biological Samples
| Sample Type | Organism | Exposure Group | N7-EtG Level | Reference |
| Liver DNA | Mosquito Fish | Control | 0.05–0.19 µmol/mol of guanine | [1][2] |
| Human Tissue | Human | Background | ~0.2 adducts/10⁶ dGp | [1] |
| Urine | Human | Smokers | 85.5 ± 105 pg/mg creatinine | [5][9] |
| Urine | Human | Non-smokers | 28.1 ± 19.4 pg/mg creatinine | [5][9] |
Table 3: Limits of Detection (LOD) for N7-Alkylguanines
| Analyte | Method | LOD | Reference |
| N7-MeG | On-line SPE LC-MS/MS | 0.42 fmol on-column | [1][2] |
| N7-EtG | On-line SPE LC-MS/MS | 0.17 fmol on-column | [1][2] |
| N7-EtG (urine) | On-line enrichment LC/MS/MS | 0.59 pg/ml (0.33 pmol) on-column | [5][9] |
| N7-MeG (urine) | On-line SPE LC/MS/MS | 8.0 pg/mL (4.8 pmol) on-column | [8] |
Visualizations
Caption: Experimental workflow for N7-alkylguanine quantification.
Caption: Formation and fate of N7-alkylguanine adducts.
References
- 1. Simultaneous determination of N7-alkylguanines in DNA by isotope-dilution LC-tandem MS coupled with automated solid-phase extraction and its application to a small fish model - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Simultaneous determination of N7-alkylguanines in DNA by isotope-dilution LC-tandem MS coupled with automated solid-phase extraction and its application to a small fish model - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. The Formation and Biological Significance of N7-Guanine Adducts - PMC [pmc.ncbi.nlm.nih.gov]
- 4. escholarship.org [escholarship.org]
- 5. academic.oup.com [academic.oup.com]
- 6. Method Development and Validation for Measuring O6-Methylguanine in Dried Blood Spot Using Ultra High-Performance Liquid Chromatography Tandem Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Analysis of N7-(2-carbamoyl-2-hydroxyethyl)guanine in dried blood spot after food exposure by Ultra High Performance Liquid Chromatography–Tandem Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Rapid and sensitive quantification of urinary N7-methylguanine by isotope-dilution liquid chromatography/electrospray ionization tandem mass spectrometry with on-line solid-phase extraction - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Quantitative determination of urinary N7-ethylguanine in smokers and non-smokers using an isotope dilution liquid chromatography/tandem mass spectrometry with on-line analyte enrichment - PubMed [pubmed.ncbi.nlm.nih.gov]
Troubleshooting & Optimization
Technical Support Center: Troubleshooting Peak Tailing in HPLC Analysis of Purine Compounds
This guide provides researchers, scientists, and drug development professionals with a comprehensive resource for troubleshooting peak tailing issues encountered during the High-Performance Liquid Chromatography (HPLC) analysis of purine compounds. The information is presented in a question-and-answer format to directly address common problems.
Frequently Asked Questions (FAQs) and Troubleshooting
Q1: What is peak tailing and how is it measured?
Peak tailing is a common chromatographic issue where a peak is asymmetrical, having a trailing edge that is longer or more drawn out than the leading edge.[1][2][3] In an ideal chromatogram, peaks are perfectly symmetrical, known as Gaussian peaks.[1][2] Peak tailing is problematic because it can compromise the accuracy of peak integration, reduce resolution between adjacent peaks, and indicate inefficiencies in the separation method.[2]
The degree of tailing is often quantified using the USP Tailing Factor (Tf) or the Asymmetry Factor (As) . A value of 1.0 indicates a perfectly symmetrical peak, while values greater than 1.2 are generally considered to be tailing.[4]
Q2: Why are purine compounds particularly susceptible to peak tailing in reversed-phase HPLC?
Purine compounds like guanine, adenine, and inosine often exhibit poor peak shape in reversed-phase HPLC for several key reasons:[5]
-
Secondary Silanol Interactions: The most common cause is the interaction between the basic functional groups on the purine molecule and acidic residual silanol groups (Si-OH) on the surface of silica-based stationary phases (like C18).[1][3][4][5] These polar interactions are a secondary retention mechanism to the primary hydrophobic interaction, leading to peak distortion.[3][4]
-
High Polarity: Many purines are highly polar and may have insufficient retention on traditional C18 columns, causing them to elute early with poor shape.[5]
-
Analyte Ionization: The pH of the mobile phase can influence the ionization state of purine compounds. If the pH is close to the analyte's pKa, a mix of ionized and non-ionized forms can exist simultaneously, leading to split or tailing peaks.[1][6]
Q3: How can I systematically troubleshoot peak tailing for my purine analysis?
A systematic approach is crucial for identifying and resolving the root cause of peak tailing. The workflow below provides a logical sequence of steps to follow.
References
- 1. chromtech.com [chromtech.com]
- 2. uhplcs.com [uhplcs.com]
- 3. Understanding Peak Tailing in HPLC | Phenomenex [phenomenex.com]
- 4. elementlabsolutions.com [elementlabsolutions.com]
- 5. HPLC Troubleshooting for Purine Peak Issues: Strategies to Improve Retention and Performance | Separation Science [sepscience.com]
- 6. The Importance Of Mobile Phase PH in Chromatographic Separations - Industry news - News [alwsci.com]
Technical Support Center: Optimizing Mass Spectrometry Ion Sources for Oligonucleotide Analysis
Welcome to the technical support center for optimizing mass spectrometry ion sources for oligonucleotide analysis. This resource is designed for researchers, scientists, and drug development professionals to provide troubleshooting guidance and frequently asked questions (FAQs) to address common challenges encountered during experiments.
Frequently Asked Questions (FAQs)
Q1: Why am I observing low signal intensity for my oligonucleotide sample?
A1: Low signal intensity in oligonucleotide analysis can stem from several factors, including suboptimal ionization efficiency, ion suppression from matrix components, and inadequate sample preparation. Oligonucleotides are inherently challenging to analyze due to their polyanionic nature.[1][2]
Potential causes and solutions include:
-
Suboptimal Mobile Phase Composition: The choice and concentration of ion-pairing reagents and organic modifiers are critical.[3] Using volatile buffers like triethylamine (TEA) and hexafluoroisopropanol (HFIP) is common for enhancing ESI efficiency.[4] The ratio of these components needs to be optimized to ensure good retention and minimize ion suppression.[3]
-
Inefficient Desolvation: Incomplete desolvation of the oligonucleotide ions can lead to reduced signal. Optimizing the drying gas flow and temperature in the ion source is crucial.
-
Ion Suppression: Co-eluting species from the sample matrix can interfere with the ionization of the target oligonucleotide.[5] Enhanced sample cleanup using solid-phase extraction (SPE) can mitigate this issue.[6][7]
-
Inappropriate Instrument Parameters: The spray voltage, capillary temperature, and other source parameters may not be optimal for your specific oligonucleotide. Systematic optimization of these parameters is necessary.[8]
Q2: I am seeing multiple adduct peaks in my mass spectrum. How can I reduce them?
A2: Adduct formation, particularly with sodium (Na+) and potassium (K+), is a common issue in oligonucleotide analysis that can complicate data interpretation and reduce the intensity of the desired molecular ion peak.[9][10] These adducts arise from trace metal contaminants in reagents, solvents, and LC system components.[9][11]
Strategies to minimize adduct formation include:
-
Use High-Purity Reagents and Solvents: Employing LC-MS grade solvents and high-purity reagents is the first step in reducing metal ion contamination.
-
Mobile Phase Additives: The addition of ion-pairing reagents like triethylamine (TEA) can help to outcompete metal ions for binding to the oligonucleotide backbone. Some studies have shown that larger, more hydrophobic amines like octylamine (OA) can be particularly effective at reducing sodium adduction.[12]
-
Sample Preparation: Thorough desalting of the oligonucleotide sample before analysis is critical. Techniques like solid-phase extraction (SPE) or dialysis can be effective.[13]
-
LC System Conditioning: Flushing the LC system with a low pH solution can help to remove adsorbed metal ions from the fluidic path.[11]
-
Source Parameter Optimization: Increasing the in-source collision energy can sometimes help to dissociate adducts in the gas phase, but care must be taken to avoid fragmentation of the oligonucleotide itself.[8][14]
Q3: My oligonucleotide appears to be fragmenting in the ion source. What can I do to prevent this?
A3: In-source fragmentation or in-source decay can lead to the observation of smaller fragments in the mass spectrum, which can be misinterpreted as impurities.[15][16] This is often caused by excessive energy being applied to the ions in the source region.
To minimize in-source fragmentation:
-
Optimize Source Conditions: Reduce the in-source collision energy (cone voltage or fragmentor voltage).[8][14] Also, optimize the capillary temperature, as excessively high temperatures can induce thermal degradation.[17][18][19][20][21]
-
Gentle Ionization: Ensure that the electrospray process is stable and gentle. This can be influenced by the spray voltage and the composition of the mobile phase.
-
Tandem MS for Confirmation: If fragmentation is unavoidable, tandem mass spectrometry (MS/MS) can be used to control the fragmentation process and obtain structural information for sequence confirmation.[22][23][24]
Troubleshooting Guides
Guide 1: Troubleshooting Low Signal Intensity
This guide provides a systematic approach to diagnosing and resolving low signal intensity issues during oligonucleotide analysis.
Caption: Workflow for troubleshooting low signal intensity in oligonucleotide mass spectrometry.
Guide 2: Systematic Approach to Reducing Adduct Formation
This guide outlines a step-by-step process to identify the source of adducts and minimize their presence in the mass spectrum.
Caption: A systematic workflow for reducing adduct formation in oligonucleotide analysis.
Quantitative Data Summary
Table 1: Recommended Ion Source Parameters for Oligonucleotide Analysis
| Parameter | Typical Range | Notes |
| Spray Voltage (Negative Ion Mode) | -2.5 to -4.5 kV | Start with a lower voltage and gradually increase to achieve a stable spray. |
| Capillary/Inlet Temperature | 250 - 350 °C | Higher temperatures can improve desolvation but may lead to in-source fragmentation.[17][18][19][20][21] |
| Drying Gas Flow | 5 - 12 L/min | Optimize for efficient solvent evaporation without causing excessive cooling of the ESI needle. |
| Nebulizing Gas Pressure | 30 - 60 psi | Adjust to achieve a fine, stable spray. |
| In-source Collision Energy | 10 - 50 V | Use lower energies to minimize fragmentation. Higher energies may help in adduct removal.[8][14] |
Table 2: Common Ion-Pairing Reagents and their Typical Concentrations
| Ion-Pairing Reagent | Co-reagent | Typical Concentration Range | Key Characteristics |
| Triethylamine (TEA) | Hexafluoroisopropanol (HFIP) | TEA: 5-20 mM; HFIP: 100-400 mM | The most common combination, provides good chromatographic resolution and MS sensitivity.[4] |
| N,N-Diisopropylethylamine (DIPEA) | Hexafluoroisopropanol (HFIP) | DIPEA: 5-15 mM; HFIP: 100-400 mM | A bulkier amine that can sometimes offer different selectivity. |
| Hexylamine (HA) | Hexafluoroisopropanol (HFIP) | HA: 10-20 mM; HFIP: 50-200 mM | Can provide excellent chromatographic performance and high MS signal intensity.[4][25] |
| N,N-dimethylbutylamine | Hexafluoroisopropanol (HFIP) | 15 mM | Found to be effective for medium-sized oligonucleotides.[4] |
| Dibutylamine | Hexafluoroisopropanol (HFIP) | 15 mM | Showed good performance for larger oligonucleotides.[4] |
Experimental Protocols
Protocol 1: General Procedure for Ion Source Optimization
This protocol provides a general workflow for optimizing the key ion source parameters for a new oligonucleotide or when troubleshooting poor performance.
-
Initial Setup:
-
Prepare a standard solution of your oligonucleotide at a known concentration (e.g., 10 pmol/µL) in a suitable mobile phase.
-
Infuse the sample directly into the mass spectrometer using a syringe pump to establish a stable signal.
-
-
Spray Voltage Optimization:
-
Start with a low spray voltage (e.g., -2.5 kV for negative ion mode).
-
Gradually increase the voltage in small increments (e.g., 0.2 kV) while monitoring the signal intensity and stability.
-
Select the voltage that provides the highest and most stable signal without evidence of electrical discharge (arcing).
-
-
Capillary and Gas Temperature Optimization:
-
Set the spray voltage to its optimal value.
-
Begin with a moderate capillary temperature (e.g., 275 °C).
-
Increase the temperature in 25 °C increments, allowing the system to stabilize at each step.
-
Monitor the signal intensity and the presence of any fragment ions.
-
Choose the temperature that maximizes the signal of the intact oligonucleotide while minimizing fragmentation.
-
Optimize the drying gas temperature in a similar manner.
-
-
Gas Flow Optimization:
-
With the optimal voltages and temperatures set, begin with a mid-range drying gas flow.
-
Incrementally increase and decrease the flow rate, observing the effect on signal intensity and stability.
-
Repeat this process for the nebulizing gas.
-
-
In-source Collision Energy (Cone/Fragmentor Voltage) Tuning:
-
After optimizing other parameters, start with the lowest possible in-source collision energy.
-
Gradually increase the voltage and monitor for the appearance of fragment ions and the reduction of adducts.
-
Select a voltage that provides a good balance between adduct removal and the preservation of the intact molecular ion.
-
Protocol 2: Solid-Phase Extraction (SPE) for Oligonucleotide Desalting
This protocol describes a general method for removing salts and other impurities from oligonucleotide samples prior to MS analysis.
-
Cartridge Selection: Choose an appropriate SPE cartridge based on the properties of your oligonucleotide (e.g., a polymer-based reversed-phase or ion-exchange cartridge).
-
Conditioning: Condition the SPE cartridge by passing 1-2 mL of methanol through it, followed by 1-2 mL of LC-MS grade water.
-
Equilibration: Equilibrate the cartridge with 1-2 mL of a low-salt buffer (e.g., 50 mM ammonium acetate).
-
Sample Loading: Dilute your oligonucleotide sample in the equilibration buffer and load it onto the cartridge.
-
Washing: Wash the cartridge with 1-2 mL of the equilibration buffer to remove any unbound impurities. A subsequent wash with a low percentage of organic solvent (e.g., 5% acetonitrile in water) can help remove more hydrophobic impurities.
-
Elution: Elute the desalted oligonucleotide from the cartridge using a suitable elution buffer, typically containing a higher concentration of organic solvent (e.g., 50% acetonitrile in water with a small amount of a volatile base like ammonium hydroxide).
-
Drying and Reconstitution: Dry the eluted sample using a vacuum centrifuge and reconstitute it in the initial mobile phase for LC-MS analysis. To prevent irreversible adsorption, avoid complete dryness and instead evaporate to near dryness before reconstitution.[26]
References
- 1. anacura.com [anacura.com]
- 2. researchgate.net [researchgate.net]
- 3. spectroscopyonline.com [spectroscopyonline.com]
- 4. analyticalscience.wiley.com [analyticalscience.wiley.com]
- 5. resolvemass.ca [resolvemass.ca]
- 6. chromatographyonline.com [chromatographyonline.com]
- 7. Sample Prep Tech Tip: Oligonucleotides | Phenomenex [phenomenex.com]
- 8. Optimisation of Heated Electrospray Ionisation Parameters to Minimise In-Source Generated Impurities in the Analysis of Oligonucleotide Therapeutics - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Reduction of metal adducts in oligonucleotide mass spectra in ion‐pair reversed‐phase chromatography/mass spectrometry analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 10. casss.org [casss.org]
- 11. reduction-of-metal-adducts-in-oligonucleotide-mass-spectra-in-ion-pair-reversed-phase-chromatography-mass-spectrometry-analysis - Ask this paper | Bohrium [bohrium.com]
- 12. pubs.acs.org [pubs.acs.org]
- 13. A comparative study on methods of optimal sample preparation for the analysis of oligonucleotides by matrix-assisted laser desorption/ionization mass spectrometry - Analyst (RSC Publishing) [pubs.rsc.org]
- 14. eprints.whiterose.ac.uk [eprints.whiterose.ac.uk]
- 15. enovatia.com [enovatia.com]
- 16. idtdna.com [idtdna.com]
- 17. Optimization of Capillary Vibrating Sharp-Edge Spray Ionization for Native Mass Spectrometry of Triplex DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 18. pubs.acs.org [pubs.acs.org]
- 19. Item - Optimization of Capillary Vibrating Sharp-Edge Spray Ionization for Native Mass Spectrometry of Triplex DNA - American Chemical Society - Figshare [acs.figshare.com]
- 20. pubs.acs.org [pubs.acs.org]
- 21. researchgate.net [researchgate.net]
- 22. Tandem mass spectrometric sequence characterization of synthetic thymidine‐rich oligonucleotides - PMC [pmc.ncbi.nlm.nih.gov]
- 23. m.youtube.com [m.youtube.com]
- 24. waters.com [waters.com]
- 25. Comparing ion-pairing reagents and sample dissolution solvents for ion-pairing reversed-phase liquid chromatography/electrospray ionization mass spectrometry analysis of oligonucleotides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 26. chromatographytoday.com [chromatographytoday.com]
Technical Support Center: Enhancing Polar Analyte Retention in Reversed-Phase HPLC
Welcome to the Technical Support Center for scientists, researchers, and drug development professionals. This resource provides comprehensive troubleshooting guides and frequently asked questions (FAQs) to address challenges encountered when retaining polar analytes in reversed-phase high-performance liquid chromatography (RP-HPLC).
Frequently Asked Questions (FAQs) & Troubleshooting Guides
This section is designed in a question-and-answer format to directly address specific issues you may encounter during your experiments.
Core Issue: Poor or No Retention of Polar Analytes
Q1: My polar analyte is eluting at or near the void volume on my C18 column. What are the primary strategies to increase its retention?
A1: When polar analytes show little to no retention on a standard C18 column, several strategies can be employed. These can be broadly categorized into modifications of the mobile phase, exploring alternative column chemistries, or employing different chromatographic techniques.
-
Mobile Phase Modification: Adjusting the mobile phase is often the simplest and first approach. This includes decreasing the organic solvent content, operating at 100% aqueous mobile phase, and adjusting the pH to suppress the ionization of the analyte.[1]
-
Alternative Column Chemistries: If mobile phase modifications are insufficient, consider using a reversed-phase column with a more polar character, such as those with embedded polar groups (EPG) or phenyl-hexyl phases.[1]
-
Alternative Chromatographic Techniques: For highly polar compounds, switching to a different chromatographic mode may be necessary. The most common alternatives are Hydrophilic Interaction Liquid Chromatography (HILIC) and Ion-Pair Chromatography.[1][2] In some cases, derivatization of the analyte to make it less polar can also be a viable option.[1]
Mobile Phase Optimization
Q2: How does adjusting the mobile phase pH improve the retention of ionizable polar analytes?
A2: The retention of ionizable compounds in reversed-phase HPLC is highly dependent on their ionization state. By adjusting the mobile phase pH, you can suppress the ionization of acidic or basic analytes.[3]
-
For Acidic Compounds: Lowering the pH of the mobile phase to at least two pH units below the analyte's pKa will suppress its ionization, making it more neutral and, therefore, more retained on a nonpolar stationary phase.
-
For Basic Compounds: Increasing the mobile phase pH to at least two pH units above the analyte's pKb will suppress its ionization, leading to increased retention.[4]
It is crucial to operate within the pH stability range of your column to avoid damaging the stationary phase.
Q3: I'm trying to use a 100% aqueous mobile phase, but my retention is still not reproducible. What could be the issue?
A3: The issue you are likely encountering is "phase dewetting" or "hydrophobic collapse." This occurs when a highly aqueous mobile phase is used with a traditional, highly hydrophobic stationary phase (like C18). The high surface tension of water can cause it to be expelled from the pores of the stationary phase, leading to a dramatic loss of retention.[5]
To address this, you should use columns specifically designed for use in highly aqueous mobile phases. These are often labeled as "AQ" or have polar-embedded or polar-endcapped functionalities. These modifications prevent phase collapse and ensure reproducible retention in 100% aqueous conditions.
Ion-Pair Chromatography (IPC)
Q4: What is ion-pair chromatography, and when should I consider using it?
A4: Ion-pair chromatography is a technique used to increase the retention of ionic and highly polar compounds in reversed-phase HPLC. It involves adding an ion-pairing reagent to the mobile phase.[6] This reagent has a hydrophobic part that interacts with the stationary phase and a charged part that is available to interact with oppositely charged analytes. This effectively creates an in-situ ion-exchanger on the surface of the stationary phase, increasing the retention of charged analytes.[3][7]
Consider using IPC when you have ionic or highly polar analytes that are not sufficiently retained by conventional reversed-phase chromatography, even after optimizing the mobile phase.[6]
Q5: What are the common problems encountered in ion-pair chromatography?
A5: While effective, IPC has several potential drawbacks:
-
Long Equilibration Times: It can take a significant amount of time for the ion-pairing reagent to equilibrate with the stationary phase, leading to long start-up times.[8]
-
Column Contamination: Ion-pairing reagents can be difficult to completely remove from the column, often requiring the dedication of a column specifically for ion-pair methods.
-
MS Incompatibility: Many common ion-pairing reagents are not volatile and can cause ion suppression or contaminate the mass spectrometer.[1]
-
Peak Shape Issues: While IPC can improve peak shape in some cases, it can also lead to peak distortion if not properly optimized.[8]
-
Blank Solvent Peaks: Ghost peaks can appear in blank injections due to differences between the mobile phase and the sample solvent.[8]
Hydrophilic Interaction Liquid Chromatography (HILIC)
Q6: When is HILIC a better choice than reversed-phase HPLC for polar analytes?
A6: HILIC is particularly well-suited for the separation of very polar compounds that are poorly retained in reversed-phase chromatography, even with 100% aqueous mobile phases.[7] HILIC utilizes a polar stationary phase (e.g., silica, amide) and a mobile phase with a high concentration of organic solvent (typically acetonitrile) and a small amount of aqueous solvent.[2][9] In HILIC, water acts as the strong eluting solvent, which is the opposite of reversed-phase chromatography.[1][2] This technique is often complementary to reversed-phase HPLC, providing an orthogonal separation mechanism.[1]
Q7: I'm having trouble with reproducibility in my HILIC method. What are the key factors to consider?
A7: Reproducibility issues in HILIC are common and often stem from the following:
-
Column Equilibration: HILIC columns require a thorough equilibration to establish a stable water layer on the stationary phase. Insufficient equilibration can lead to drifting retention times. It is recommended to flush the column with at least 50 column volumes for isocratic methods and perform at least 10 blank gradient runs for gradient methods before the actual analysis.[2]
-
Injection Solvent: The injection solvent should be as close as possible in composition to the initial mobile phase (i.e., high organic content). Injecting a sample dissolved in a strong solvent (high water content) can lead to poor peak shape and retention.[2][9]
-
Mobile Phase pH and Buffer Concentration: The pH and ionic strength of the mobile phase can significantly affect retention and selectivity. A good starting point for buffer concentration is 10 mM.[2]
-
System Contamination: Polar analytes are more prone to interacting with metal surfaces in the HPLC system, which can cause peak tailing and signal loss. Using bio-inert hardware can mitigate these issues.[9]
Derivatization
Q8: When should I consider derivatizing my polar analytes?
A8: Derivatization is a chemical modification of the analyte to improve its chromatographic properties or detectability. For polar analytes, derivatization is typically used to:
-
Increase Hydrophobicity: By adding a nonpolar functional group, the analyte becomes less polar and is better retained on a reversed-phase column.
-
Enhance Detection: If your analyte lacks a chromophore or fluorophore, derivatization can introduce a tag that allows for sensitive UV or fluorescence detection.[10]
Derivatization can be performed either before (pre-column) or after (post-column) the chromatographic separation.[11][12] However, it adds an extra step to the sample preparation process, which can introduce variability.[1]
Data Presentation: Quantitative Comparisons
The following tables summarize quantitative data to aid in method selection and optimization.
Table 1: Comparison of Retention Factors (k') for Polar Analytes on C18 vs. HILIC Columns
| Analyte | C18 Retention Factor (k')* | HILIC Retention Factor (k')** | Fold Increase in Retention |
| Uracil | 0.2 | 3.5 | 17.5 |
| Cytosine | 0.1 | 5.2 | 52.0 |
| Adenine | 0.3 | 6.8 | 22.7 |
| Guanine | 0.1 | 8.1 | 81.0 |
*Representative data under typical reversed-phase conditions (e.g., 95:5 Water:Acetonitrile). Actual values will vary with specific conditions. **Representative data under typical HILIC conditions (e.g., 95:5 Acetonitrile:Water). Actual values will vary with specific conditions.
Table 2: Effect of Ion-Pairing Reagent on the Retention Time of a Basic Analyte (e.g., a Peptide)
| Ion-Pairing Reagent | Concentration | Retention Time (min)* |
| None | - | 1.5 |
| Trifluoroacetic Acid (TFA) | 0.1% | 8.2 |
| Heptafluorobutyric Acid (HFBA) | 0.1% | 12.5 |
*Illustrative data; actual retention times are highly dependent on the analyte, column, and specific chromatographic conditions. Increasing the hydrophobicity of the ion-pairing reagent generally leads to increased retention of oppositely charged analytes.[13]
Experimental Protocols
This section provides detailed methodologies for key experimental techniques.
Protocol 1: General Method Development for Ion-Pair Reversed-Phase HPLC
-
Column Selection: Start with a standard C18 or C8 column.[4]
-
Initial Mobile Phase without Ion-Pairing Reagent: Develop a preliminary reversed-phase method without the ion-pairing reagent to get a baseline separation of any non-ionic or less polar compounds in your sample.
-
Select an Ion-Pairing Reagent:
-
For acidic analytes (anions), choose a cationic ion-pairing reagent (e.g., tetrabutylammonium phosphate).
-
For basic analytes (cations), choose an anionic ion-pairing reagent (e.g., sodium dodecyl sulfate, hexane sulfonate).[3]
-
-
Determine Initial Ion-Pairing Reagent Concentration: Start with a low concentration of the ion-pairing reagent in the mobile phase, typically around 5 mM.[4]
-
Mobile Phase Preparation: Prepare the mobile phase containing the chosen ion-pairing reagent and adjust the pH to ensure the analyte of interest is ionized.
-
Column Equilibration: Equilibrate the column with the ion-pairing mobile phase for an extended period (e.g., 30-60 minutes or longer) until a stable baseline is achieved.
-
Injection and Optimization: Inject the sample and observe the retention. To optimize the separation:
-
Adjust the concentration of the ion-pairing reagent.
-
Modify the organic solvent content.
-
Fine-tune the mobile phase pH.
-
-
Column Wash: After analysis, flush the column thoroughly with a mobile phase containing a high percentage of organic solvent to remove the ion-pairing reagent. It is often recommended to dedicate a column for ion-pairing applications.[4]
Protocol 2: Pre-Column Derivatization of Amino Acids with OPA and FMOC
This protocol is for the automated pre-column derivatization of primary and secondary amino acids using o-phthalaldehyde (OPA) and 9-fluorenylmethyl chloroformate (FMOC), respectively.
Reagents:
-
Boric Acid Buffer: 0.4 M, pH 10.2.
-
OPA Reagent: Dissolve 10 mg of OPA in 1 mL of methanol. Add 9 mL of the Boric Acid Buffer and 100 µL of 3-mercaptopropionic acid.[10]
-
FMOC Reagent: Dissolve 2.5 mg of FMOC in 1 mL of acetonitrile.[10]
Procedure (for automated autosampler):
-
Transfer 1 µL of the amino acid standard or sample into an autosampler vial.[10]
-
Add 2.5 µL of Boric Acid Buffer.[10]
-
Add 0.5 µL of OPA reagent and mix. Allow the reaction to proceed for 1 minute.[10] This step derivatizes the primary amino acids.
-
Add 0.5 µL of FMOC reagent and mix.[10] This step derivatizes the secondary amino acids.
-
Inject 1 µL of the final mixture onto the HPLC column.[10]
Note: The derivatized amino acids can then be separated on a reversed-phase column using a suitable gradient elution.
Mandatory Visualizations
Diagram 1: Decision Tree for Improving Polar Analyte Retention
Caption: A decision tree to guide the selection of an appropriate strategy for improving the retention of polar analytes.
Diagram 2: Workflow for Ion-Pair Chromatography Method Development
References
- 1. agilent.com [agilent.com]
- 2. restek.com [restek.com]
- 3. pharmagrowthhub.com [pharmagrowthhub.com]
- 4. jk-sci.com [jk-sci.com]
- 5. halocolumns.com [halocolumns.com]
- 6. Analysis of Polar Compounds with Ion Pair Reagents [sigmaaldrich.com]
- 7. The Case of the Unintentional Ion-Pairing Reagent | Separation Science [sepscience.com]
- 8. welch-us.com [welch-us.com]
- 9. agilent.com [agilent.com]
- 10. benchchem.com [benchchem.com]
- 11. actascientific.com [actascientific.com]
- 12. Amino Acid Pre-column Derivatization HPLC Analysis Methods - Creative Proteomics [creative-proteomics.com]
- 13. Effects of ion-pairing reagents on the prediction of peptide retention in reversed-phase high-performance liquid chromatography - PubMed [pubmed.ncbi.nlm.nih.gov]
Overcoming challenges in the quantification of modified nucleosides.
Welcome to the technical support center for the quantification of modified nucleosides. This resource is designed to assist researchers, scientists, and drug development professionals in overcoming common challenges encountered during their experiments. Here you will find troubleshooting guides, frequently asked questions (FAQs), detailed experimental protocols, and quantitative data summaries to support your work.
Troubleshooting Guides & FAQs
This section addresses specific issues that may arise during the quantification of modified nucleosides, providing potential causes and solutions in a question-and-answer format.
Sample Preparation
-
Q1: I am observing low recovery of my modified nucleosides after sample preparation. What could be the cause?
A1: Low recovery can stem from several factors during sample preparation. A primary concern is the potential for incomplete enzymatic digestion of the RNA, which would leave some modified nucleosides inaccessible for analysis. Another significant issue can be the loss of hydrophobic nucleosides due to adsorption onto filter materials during the enzyme removal step.[1][2] Specifically, poly(ether sulfone) (PES) filters have been shown to retain certain hydrophobic modified nucleosides.[1][2]
Troubleshooting Steps:
-
Ensure complete enzymatic digestion by optimizing enzyme concentrations and incubation times.
-
Consider alternative filter materials, such as composite regenerated cellulose (CRC) filters, which have demonstrated better recovery for hydrophobic nucleosides.[1]
-
Alternatively, you can omit the filtration step if you are analyzing for specific hydrophobic modifications like m6,6A or i6A, though this may increase instrument contamination.[1]
-
-
Q2: My results show inconsistent quantification between replicates. What could be causing this variability?
A2: Inconsistent quantification often points to issues with sample homogeneity or the introduction of contaminants. Variability can also be introduced by matrix effects, where other components in the sample interfere with the ionization of the target analytes.[3][4][5]
Troubleshooting Steps:
-
Use high-purity solvents and reagents to minimize contamination.
-
To mitigate matrix effects, the use of stable isotope-labeled internal standards (SILIS) is highly recommended.[2][8][9] These standards co-elute with the analyte and experience similar ionization suppression or enhancement, allowing for accurate correction.[2]
LC-MS/MS Analysis
-
Q3: I am observing peak tailing and broadening in my chromatograms. What are the likely causes?
A3: Poor peak shape, such as tailing and broadening, can be caused by several factors related to the liquid chromatography (LC) system.[10] These include column degradation, improper mobile phase composition or pH, and column contamination.[10]
Troubleshooting Steps:
-
Evaluate the performance of your analytical column; it may need to be replaced.
-
Ensure the mobile phase is correctly prepared and that the pH is appropriate for the analytes.
-
Implement a column washing protocol to remove potential contaminants.
-
-
Q4: I am detecting a signal for a modified nucleoside that is not expected to be in my sample. How can I investigate this?
A4: The unexpected detection of a modified nucleoside can be a result of chemical instability and rearrangement of other modifications.[1][2] A well-documented example is the Dimroth rearrangement of 1-methyladenosine (m1A) to 6-methyladenosine (m6A) under mild alkaline conditions.[1] This can lead to the false-positive detection and over-quantification of m6A.[1]
Troubleshooting Steps:
-
Carefully control the pH of your samples and standards throughout the preparation and analysis process. Maintaining a slightly acidic pH (e.g., pH 5.3) can help to stabilize labile modifications.[1]
-
If you need to quantify both m1A and m6A, it is recommended to prepare separate calibration standards for m1A to accurately assess any potential conversion.[1]
-
-
Q5: My signal intensity is low or inconsistent. What aspects of the mass spectrometer should I check?
A5: Low or inconsistent signal intensity can be attributed to several mass spectrometry-related issues. These include problems with the ion source, incorrect mass calibration, or the presence of salt adducts that can hamper quantification.[1][2][10]
Troubleshooting Steps:
Experimental Protocols
Below are detailed methodologies for key experiments in the quantification of modified nucleosides.
Protocol 1: RNA Extraction and Enzymatic Digestion
This protocol outlines the steps for isolating total RNA from biological samples and digesting it into individual nucleosides for LC-MS/MS analysis.
-
RNA Isolation: Isolate total RNA from cells or tissues using a standard method such as phenol-chloroform extraction or a commercial kit.[1]
-
RNA Purification: Purify the RNA of interest. This can be achieved by size-exclusion chromatography to separate tRNA or rRNA.[8][11]
-
Enzymatic Digestion:
-
Prepare a digestion mixture containing the purified RNA, a suitable buffer (e.g., 10 mM ammonium acetate, pH 5.3), and a cocktail of nucleases.[12]
-
A common enzyme combination includes nuclease P1, snake venom phosphodiesterase, and alkaline phosphatase to ensure complete digestion of RNA into nucleosides.[11]
-
Incubate the reaction at 37°C for a sufficient time to ensure complete hydrolysis.
-
-
Enzyme Removal (Optional but Recommended):
-
Internal Standard Spiking: Add a known amount of a stable isotope-labeled internal standard (SILIS) mixture to each sample.[1] This is crucial for accurate quantification.[2][8][9]
-
Sample Dilution: Dilute the final sample to a concentration that is within the linear range of your calibration curve.
Protocol 2: LC-MS/MS Analysis
This protocol provides a general framework for the liquid chromatography-tandem mass spectrometry analysis of modified nucleosides.
-
Chromatographic Separation:
-
Use a reversed-phase column suitable for nucleoside analysis.
-
The mobile phase typically consists of a weak acid in water (e.g., 0.1% formic acid or 10 mM ammonium acetate) as mobile phase A and an organic solvent like acetonitrile or methanol as mobile phase B.[6]
-
Develop a gradient elution method to achieve optimal separation of the various modified and unmodified nucleosides.
-
-
Mass Spectrometry Detection:
-
Use a triple quadrupole mass spectrometer operating in positive electrospray ionization (ESI) mode.
-
Operate the mass spectrometer in Multiple Reaction Monitoring (MRM) mode for the highest sensitivity and selectivity.[8]
-
For each nucleoside and its corresponding SILIS, optimize the precursor ion (the protonated molecule [M+H]+) and a specific product ion transition.
-
-
Quantification:
-
Generate a calibration curve for each modified nucleoside using a series of known concentrations of standards, each spiked with the same amount of SILIS.[1]
-
Calculate the ratio of the peak area of the analyte to the peak area of the corresponding SILIS for both the standards and the unknown samples.
-
Determine the concentration of the modified nucleosides in the samples by interpolating their area ratios on the calibration curve.
-
Quantitative Data Summary
The following tables summarize key quantitative data related to the challenges in modified nucleoside analysis.
Table 1: Impact of Filter Type on the Recovery of Hydrophobic Modified Nucleosides
| Modified Nucleoside | Relative Quantity after PES Filter (%) | Relative Quantity after CRC Filter (%) |
| N6,N6-dimethyladenosine (m6,6A) | Significantly Reduced | No Significant Reduction |
| N6-isopentenyladenosine (i6A) | Significantly Reduced | No Significant Reduction |
Data adapted from studies highlighting the adsorption of hydrophobic nucleosides to PES filters. The use of CRC filters shows improved recovery.[1][2]
Table 2: Common Adducts Observed in Mass Spectrometry
| Analyte | Adduct Ion | Potential Source | Impact on Quantification |
| Nucleosides | [M+Na]+ | Sodium contamination from glassware or reagents | Can reduce the intensity of the desired [M+H]+ ion, leading to underestimation. |
| Nucleosides | [M+K]+ | Potassium contamination from glassware or reagents | Similar to sodium adducts, can decrease the signal of the protonated molecule. |
Visualizations
The following diagrams illustrate key workflows and logical relationships in the quantification of modified nucleosides.
Caption: General workflow for modified nucleoside quantification.
Caption: Troubleshooting logic for common quantification issues.
Caption: Conceptual pathway of RNA modification and its function.
References
- 1. Pitfalls in RNA Modification Quantification Using Nucleoside Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 2. pubs.acs.org [pubs.acs.org]
- 3. Tracking Matrix Effects in the Analysis of DNA Adducts of Polycyclic Aromatic Hydrocarbons - PMC [pmc.ncbi.nlm.nih.gov]
- 4. What is matrix effect and how is it quantified? [sciex.com]
- 5. bataviabiosciences.com [bataviabiosciences.com]
- 6. jove.com [jove.com]
- 7. Video: Plant Sample Preparation for Nucleoside/Nucleotide Content Measurement with An HPLC-MS/MS [jove.com]
- 8. Production and Application of Stable Isotope-Labeled Internal Standards for RNA Modification Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 9. pubs.acs.org [pubs.acs.org]
- 10. zefsci.com [zefsci.com]
- 11. researchgate.net [researchgate.net]
- 12. Protocol for preparation and measurement of intracellular and extracellular modified RNA using liquid chromatography-mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Minimizing Mobile Phase Adducts in LC-MS
Welcome to our technical support center. This resource is designed to assist researchers, scientists, and drug development professionals in troubleshooting and minimizing mobile phase adducts in Liquid Chromatography-Mass Spectrometry (LC-MS).
Troubleshooting Guide
This section addresses specific issues you may be encountering during your LC-MS experiments in a question-and-answer format.
Q1: I am observing unexpected peaks in my mass spectra, specifically at M+23 and M+39. What are these, and how can I get rid of them?
A1: These peaks are very likely sodium ([M+Na]⁺) and potassium ([M+K]⁺) adducts of your analyte.[1][2] These are common contaminants in LC-MS analysis.
Troubleshooting Steps:
-
Solvent and Reagent Purity: The primary source of sodium and potassium ions is often impurities in solvents and reagents.[3][4]
-
Glassware and Containers: Glassware can leach sodium and potassium ions into your mobile phase.[1][6]
-
Action: Whenever possible, use polypropylene or other suitable plastic containers for mobile phase preparation and storage.[1][6] If glassware must be used, opt for borosilicate glass and ensure it is meticulously cleaned.[5][7] Avoid using detergents for cleaning as they can be a source of salts.[6]
-
-
Sample Matrix: Biological samples often have high concentrations of endogenous salts.[1]
-
Action: Implement a sample preparation step to remove salts. Solid-phase extraction (SPE) is a common and effective method for desalting.
-
-
Mobile Phase pH: Lowering the pH of the mobile phase can promote the formation of the protonated molecule [M+H]⁺ and reduce the prevalence of metal adducts.[1]
Q2: My analyte signal is split between multiple adducts ([M+H]⁺, [M+NH₄]⁺, [M+Na]⁺), leading to poor sensitivity. How can I consolidate the signal into a single adduct?
A2: When your analyte's signal is distributed among several adducts, the intensity of your target ion is diminished. The goal is to drive the ionization towards a single, desired adduct.
Troubleshooting Steps:
-
Promote a Specific Adduct: You can intentionally add a volatile salt to the mobile phase to encourage the formation of a specific adduct.
-
Optimize Additive Concentration: The concentration of the additive is crucial. Too little may be ineffective, while too much can cause ion suppression.
-
Action: Start with a low concentration (e.g., 2-10 mM) of the ammonium salt and optimize based on your analyte's response.[9]
-
Q3: I am analyzing oligonucleotides and see a large number of sodium adducts and multiple charge states, which complicates my data. What is the best strategy to overcome this?
A3: Oligonucleotide analysis is particularly prone to adduct formation and multiple charging due to the polyanionic nature of the phosphodiester backbone.[10][11]
Troubleshooting Steps:
-
Specialized Mobile Phase: A specific mobile phase composition has been shown to be highly effective for reducing adducts and charge states in oligonucleotide analysis.[10][11]
-
System Passivation: Metal ions from the LC system itself can contribute to adduct formation.[10][12]
Frequently Asked Questions (FAQs)
Q1: What are the most common mobile phase adducts I should be aware of?
A1: In positive ion mode, the most common adducts are:
-
[M+H]⁺: Protonated molecule, often the desired ion.[13]
-
[M+NH₄]⁺: Ammonium adduct, often intentionally formed.[2][13]
In negative ion mode, you may observe:
-
[M-H]⁻: Deprotonated molecule.[13]
-
[M+formate]⁻: Formate adduct, from formic acid in the mobile phase.[2][13]
-
[M+acetate]⁻: Acetate adduct, from acetic acid or ammonium acetate in the mobile phase.[2][13]
Q2: How does the choice of solvent affect adduct formation?
A2: The purity of the solvent is a critical factor.[4][14]
-
LC-MS grade solvents undergo additional purification steps to remove trace metals and other impurities that can form adducts.[4][14] Using lower grade solvents, such as HPLC grade, can introduce contaminants that lead to unwanted adducts and increased background noise.[3][5]
Q3: Can my sample preparation method contribute to adduct formation?
A3: Yes. If your sample preparation involves the use of non-volatile buffers (e.g., phosphates, sulfates) or salts, these can lead to significant adduct formation and ion suppression. It is crucial to use volatile buffers and salts in LC-MS methods.[15] If your sample has a high salt matrix, incorporating a desalting step like solid-phase extraction (SPE) is highly recommended.
Q4: What is system passivation and when should I perform it?
A4: System passivation is a process to remove metal ion contamination from the surfaces of your HPLC system.[10][12] Trace metal ions can interact with analytes, causing peak shape issues and adduct formation.[12] You should consider passivation if you consistently observe metal adducts despite using high-purity solvents and reagents, especially when analyzing compounds that can chelate metals, such as those with phosphate or carboxylic acid groups.[12]
Data and Protocols
Table 1: Effect of Mobile Phase Additives on Adduct Formation
The following table summarizes the impact of different mobile phase additives on the formation of protonated molecules versus metal adducts for a hypothetical analyte.
| Mobile Phase Additive | [M+H]⁺ Relative Abundance | [M+Na]⁺ + [M+K]⁺ Relative Abundance | Notes |
| None | 40% | 60% | Significant metal adduct formation is observed. |
| 0.1% Formic Acid | 95% | 5% | Lowers pH, promoting protonation and significantly reducing metal adducts.[1][8] |
| 2 mM Ammonium Acetate | 15% | 5% (Ammonium adduct at 80%) | Promotes the formation of the ammonium adduct, suppressing both protonated and metal adducts.[8] |
| 0.1% Formic Acid + 2 mM Ammonium Acetate | 85% | <5% (Ammonium adduct at 10%) | A combination that can enhance protonation while still suppressing metal adducts.[8] |
Experimental Protocol: HPLC System Passivation with EDTA
This protocol describes a general procedure for removing metal ion contamination from an HPLC system using EDTA. Always consult your instrument manufacturer's documentation before proceeding.
Objective: To purge the HPLC system of metal ions that can cause unwanted adduct formation.
Materials:
-
Ethylenediaminetetraacetic acid (EDTA)
-
LC-MS grade water and organic solvent (e.g., methanol or acetonitrile)
-
A new, clean HPLC column is not required for this procedure; in fact, the column should be removed.
Procedure:
-
Disconnect the Column: Before starting, disconnect the analytical column from the system to prevent damage.
-
Prepare EDTA Solutions:
-
Prepare a 5-10 µM (micromolar) solution of EDTA in your aqueous mobile phase (Solvent A).
-
Prepare a 5-10 µM (micromolar) solution of EDTA in your organic mobile phase (Solvent B).
-
Caution: Ensure the concentration is in the micromolar range. Higher concentrations can lead to precipitation and system damage.[12]
-
-
System Flush:
-
Place the solvent lines for both pumps into the freshly prepared EDTA-containing mobile phases.
-
Purge the entire HPLC system, including the pump heads, autosampler, and tubing, with both Solvent A and Solvent B containing EDTA for an extended period (e.g., 30-60 minutes for each solvent line) at a moderate flow rate (e.g., 0.5-1 mL/min).
-
-
Rinse the System:
-
Replace the EDTA-containing mobile phases with fresh, EDTA-free mobile phases.
-
Thoroughly flush the entire system with the new mobile phases to remove any residual EDTA.
-
-
Re-equilibration: Once the system is thoroughly rinsed, you can reconnect your analytical column and re-equilibrate the system with your analytical mobile phase.
Visualizations
References
- 1. learning.sepscience.com [learning.sepscience.com]
- 2. Ion Formation and Organic Fragmentation in LCMS: Unlocking the Secrets of Mass Spectra - MetwareBio [metwarebio.com]
- 3. fishersci.com [fishersci.com]
- 4. chromatographyonline.com [chromatographyonline.com]
- 5. chromatographyonline.com [chromatographyonline.com]
- 6. chromatographyonline.com [chromatographyonline.com]
- 7. support.waters.com [support.waters.com]
- 8. pdfs.semanticscholar.org [pdfs.semanticscholar.org]
- 9. academic.oup.com [academic.oup.com]
- 10. Novel Mobile Phase to Control Charge States and Metal Adducts in the LC/MS for mRNA Characterization Assays - PMC [pmc.ncbi.nlm.nih.gov]
- 11. pubs.acs.org [pubs.acs.org]
- 12. Purge metals from HPLC system using EDTA - How To [mtc-usa.com]
- 13. Principles and Applications of Liquid Chromatography-Mass Spectrometry in Clinical Biochemistry - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Exploring the Impact of Organic Solvent Quality and Unusual Adduct Formation during LC-MS-Based Lipidomic Profiling - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Impact of Mobile Phase Additives on LC-MS Sensitivity, Demonstrated using Spice Cannabinoids [sigmaaldrich.com]
Common issues and solutions in HPLC system performance.
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals resolve common issues with High-Performance Liquid Chromatography (HPLC) system performance.
Frequently Asked Questions (FAQs)
Q1: What are the most common issues encountered in HPLC analysis?
A1: Typical issues that users most commonly encounter are pressure fluctuations, baseline noise, peak shape problems (such as tailing, fronting, and splitting), retention time drift, and the appearance of ghost peaks.[1] These problems can often be resolved by the user without the need for a service technician.
Q2: How often should I perform preventative maintenance on my HPLC system?
A2: Regular preventative maintenance is crucial for optimal HPLC performance. Daily checks should include inspecting for leaks and ensuring solvent levels are adequate. Pump seals and check valves should be replaced every 6–12 months, depending on usage.[2] Regular cleaning and monitoring can prevent most pressure and baseline issues.
Q3: What grade of solvents should I use for my mobile phase?
A3: It is essential to use high-purity, HPLC-grade solvents. Using lower-grade solvents can introduce impurities that lead to baseline noise, ghost peaks, and column contamination.[3] For gradient elution, gradient-grade solvents are a must to ensure a clean and reproducible baseline.
Troubleshooting Guides
Pressure Fluctuations and Issues
Q: My HPLC system is showing abnormal pressure. What should I do?
A: First, determine if the pressure is higher or lower than your typical operating range for the specific method.
-
High backpressure often indicates a blockage in the system.
-
Low backpressure usually points to a leak or a problem with the pump.[4]
Troubleshooting High Backpressure:
A systematic approach, starting from the detector and working backward, is the best way to locate the source of high pressure.
-
Isolate the Column: Disconnect the column from the system and replace it with a union. If the pressure returns to normal, the blockage is in the column. If the high pressure persists, the issue is within the HPLC system components.
-
System Components Check: If the system is the source of the high pressure, systematically check components by disconnecting them one by one, starting from the detector and moving upstream (detector, tubing, injector, pump).
Troubleshooting Low Backpressure:
-
Check for Leaks: Carefully inspect all fittings and connections for any signs of leaks. Even a small leak can cause a significant drop in pressure.[5]
-
Pump Issues: Ensure the pump is primed and free of air bubbles. A faulty check valve or worn pump seals can also lead to low pressure.[6]
Quantitative Data on System Pressure
| Parameter | Typical Range | Potential Indication of an Issue |
| Standard HPLC Pressure | 500–4000 psi (35–275 bar) | Significant deviation from method-specific normal operating pressure. |
| UHPLC Pressure | 4000–15,000 psi (275–1034 bar) | Significant deviation from method-specific normal operating pressure. |
| Pressure Fluctuation (Rhythmic) | < 1% of total system pressure | > 2% fluctuation may indicate pump issues (e.g., check valves, seals, air bubbles). |
| Pressure Drop Across Column | Varies by column dimensions, particle size, mobile phase, and flow rate. | A sudden increase suggests a column frit blockage; a gradual increase indicates contamination. |
Note: These are general ranges. Always refer to your specific method parameters and column manufacturer's guidelines for expected pressure ranges.
Retention Time Drift and Variability
Q: My retention times are shifting from one run to the next. What is causing this?
A: Retention time variability can be either random or systematic (drifting). Identifying the pattern will help diagnose the cause.
-
Random Fluctuation: Often related to issues with the pump, injector, or inconsistent mobile phase preparation.
-
Systematic Drift: Typically caused by changes in mobile phase composition over time, column temperature fluctuations, or a column that is not fully equilibrated.[7][8]
Troubleshooting Retention Time Issues:
-
Mobile Phase Composition: In reversed-phase chromatography, a 1% error in the organic solvent concentration can change retention times by 5-15%.[7] Ensure accurate and consistent mobile phase preparation, preferably by gravimetric measurement.
-
Column Temperature: A 1°C change in column temperature can alter retention times by approximately 2%.[9] Using a column oven is crucial for maintaining stable retention.
-
Flow Rate: Check for leaks or pump malfunctions that could lead to an inconsistent flow rate.[10]
-
Column Equilibration: Ensure the column is fully equilibrated with the mobile phase before starting a sequence. This is especially important for methods using ion-pairing reagents or in normal-phase chromatography.[8]
Quantitative Data on Retention Time and Peak Shape
| Parameter | Acceptable Range | Potential Indication of an Issue |
| Retention Time Variation | Typically ±0.02–0.05 min | Larger variations suggest issues with the mobile phase, temperature, or flow rate. |
| Relative Retention Time (RRT) | ± 2.5% for LC | Exceeding this may indicate a problem with system stability. |
| Peak Asymmetry/Tailing Factor | 0.9 - 1.2 is ideal; 0.8 - 1.8 is generally acceptable. | Values > 1.2 indicate significant tailing; values < 0.9 indicate fronting. |
| Baseline Noise | S/N Ratio > 3:1 for Limit of Detection (LOD) | A low S/N ratio can obscure small peaks and affect integration. |
| Baseline Drift | < 2-3 mAU over 5 minutes | Significant drift can indicate column contamination or temperature instability. |
Peak Shape Problems (Tailing, Fronting, Splitting)
Q: My peaks are tailing/fronting/splitting. How can I fix this?
A: Poor peak shape can compromise resolution and quantification. The first step is to determine if the issue affects all peaks or only specific ones.
-
All Peaks Affected: This usually points to a physical problem, such as a blocked column frit, a void in the column, or extra-column volume.[11]
-
Specific Peaks Affected: This is more likely a chemical issue, such as secondary interactions between the analyte and the stationary phase.[11]
Troubleshooting Peak Tailing:
-
Secondary Silanol Interactions: For basic compounds, interactions with acidic silanol groups on the silica packing are a common cause. Lowering the mobile phase pH or adding a competing base (e.g., triethylamine) can help.
-
Column Overload: Injecting too much sample can lead to tailing. Try diluting the sample.[12]
-
Column Contamination: Strongly retained compounds from previous injections can build up at the column head. Flushing the column with a strong solvent is recommended.[12]
Troubleshooting Peak Fronting:
-
Sample Solvent Incompatibility: If the sample is dissolved in a solvent that is stronger than the mobile phase, peak fronting can occur. Whenever possible, dissolve the sample in the mobile phase.[13]
-
Column Overload: Similar to tailing, injecting too much sample can also cause fronting.
Troubleshooting Split Peaks:
-
Partially Blocked Frit or Column Void: This can cause the sample to travel through different paths in the column, resulting in a split peak. Back-flushing the column (if permissible) or replacing the frit may resolve the issue.[14]
-
Injector Issues: A partially blocked injector port can also lead to peak splitting.
Ghost Peaks
Q: I am seeing unexpected peaks in my chromatogram, even in blank runs. What are these "ghost peaks"?
A: Ghost peaks are signals in a chromatogram that are not from the injected sample. They can originate from various sources.
Troubleshooting Ghost Peaks:
-
Mobile Phase Contamination: Impurities in the solvents or additives can accumulate on the column and elute as ghost peaks, especially during gradient runs. Use fresh, high-purity solvents.
-
System Contamination: Carryover from previous injections is a common cause. Ensure the injector and system are thoroughly washed between runs.
-
Sample Contamination: The sample itself or the vials and caps can be a source of contamination.
Experimental Protocols
Protocol 1: HPLC Column Washing and Regeneration
This protocol is for cleaning a contaminated reversed-phase (e.g., C18) column that is showing high backpressure or poor peak shape.
Materials:
-
HPLC-grade water
-
HPLC-grade methanol
-
HPLC-grade acetonitrile
-
HPLC-grade isopropanol
-
Standalone HPLC pump (recommended)[7]
-
Waste container
Procedure:
-
Disconnect from Detector: Disconnect the column from the detector to avoid contaminating the flow cell.[7]
-
Backflush (if applicable): For columns with particle sizes >1.8 µm, reversing the flow direction (backflushing) is more effective for removing contaminants from the inlet frit. Do not backflush columns with sub-2 µm particles. [7]
-
Buffer Removal: Flush the column with 10-20 column volumes of HPLC-grade water (or mobile phase without the buffer salts) at a flow rate of 0.5-1.0 mL/min.
-
Organic Wash: Flush with 10-20 column volumes of 100% methanol or acetonitrile.
-
Stronger Organic Wash (if needed): If backpressure is still high, flush with 10-20 column volumes of 75% acetonitrile / 25% isopropanol. For very non-polar contaminants, 100% isopropanol can be used.
-
Re-equilibration: Before returning to your analytical method, flush the column with the initial mobile phase until the baseline is stable.
Protocol 2: HPLC System Leak Test (Pressure Drop Method)
This protocol helps to identify leaks within the HPLC system.
Materials:
-
Blanking nut or plug for the pump outlet
-
HPLC-grade water or isopropanol
Procedure:
-
Prepare the System: Remove the column and any in-line filters from the system. Connect the injector directly to the detector with a short piece of tubing.
-
Prime the Pump: Purge the pump with HPLC-grade water or isopropanol to ensure it is free of air bubbles.
-
Pressurize the System:
-
Set the pump flow rate to a low value (e.g., 0.1 mL/min).
-
Cap the pump outlet with a blanking nut.
-
The pressure will begin to rise. Set the pump's upper pressure limit to a value that is safe for your system (e.g., 300 bar or 4500 psi).
-
-
Monitor Pressure Drop:
-
Once the pressure limit is reached, the pump will shut down.
-
Monitor the system pressure for 5-10 minutes.
-
A stable pressure indicates a leak-free system. A significant pressure drop (e.g., > 10 bar/min) suggests a leak.
-
-
Isolate the Leak: If a leak is detected, systematically check each fitting and connection by wiping with a lint-free wipe to identify the source. Start from the pump and move towards the detector.[5]
Visual Troubleshooting Workflows
References
- 1. HPLC Troubleshooting Guide [scioninstruments.com]
- 2. uhplcs.com [uhplcs.com]
- 3. mastelf.com [mastelf.com]
- 4. mastelf.com [mastelf.com]
- 5. HPLC Instrumentation for Analysis: Identifying and Repairing HPLC Leaks [theoverbrookgroup.com]
- 6. HPLC Pump Troubleshooting: Resolve Pressure & Performance Issues in HPLC Systems [labx.com]
- 7. ccc.chem.pitt.edu [ccc.chem.pitt.edu]
- 8. Troubleshooting HPLC Column Retention Time Drift - Hawach [hawachhplccolumn.com]
- 9. Factors Impacting Chromatography Retention Time | Separation Science [sepscience.com]
- 10. elementlabsolutions.com [elementlabsolutions.com]
- 11. benchchem.com [benchchem.com]
- 12. [3]Troubleshooting HPLC- Tailing Peaks [restek.com]
- 13. Effects of Sample Solvents on Peak Shape : SHIMADZU (Shimadzu Corporation) [shimadzu.com]
- 14. agilent.com [agilent.com]
Technical Support Center: Optimizing Collision Energy for Fragmentation in MS/MS Analysis
Welcome to the technical support center for optimizing collision energy in tandem mass spectrometry (MS/MS). This resource is designed for researchers, scientists, and drug development professionals to provide troubleshooting guidance and answer frequently asked questions related to achieving optimal fragmentation in your experiments.
Frequently Asked Questions (FAQs)
Q1: What is collision energy and why is it a critical parameter in MS/MS?
Collision energy (CE) is the kinetic energy imparted to a precursor ion in the collision cell of a mass spectrometer to induce fragmentation.[1][2] This fragmentation is essential for structural elucidation and confident identification of molecules.[3] Optimizing the collision energy is crucial because insufficient energy will result in poor or no fragmentation, while excessive energy can lead to extensive fragmentation, losing structurally informative ions.[4] The optimal CE is the energy that produces the most informative MS/MS spectrum, characterized by a rich series of fragment ions with good signal intensity.[5]
Q2: What is the difference between Collision-Induced Dissociation (CID) and Higher-Energy Collisional Dissociation (HCD)?
CID and HCD are two common fragmentation techniques, and the primary difference lies in the location and energy of the collision process.[6] CID is typically performed in an ion trap and involves multiple low-energy collisions with a neutral gas, which slowly increases the internal energy of the precursor ion until it fragments.[2][7] HCD, on the other hand, occurs in a separate collision cell and involves higher collision energies.[6] This often results in a different fragmentation pattern and is particularly useful for isobaric tag-based quantification as it efficiently generates reporter ions.[6][8][9]
Q3: What are stepped and ramped collision energy, and when should I use them?
Stepped and ramped collision energy are techniques used to improve fragmentation across a range of different precursor ions in a single analysis.
-
Stepped Collision Energy: In this approach, a precursor ion is fragmented at two or more discrete collision energy values, and the resulting fragment ions are combined into a single spectrum.[6][10][11] This is beneficial for complex samples where a single CE may not be optimal for all analytes, such as in proteomics studies with post-translational modifications or in intact protein analysis.[6][11]
-
Ramped Collision Energy: This involves systematically increasing the collision energy for a specific precursor ion across multiple MS/MS scans.[5] This is a common method for determining the optimal collision energy for a new compound.[5][12] By observing the fragmentation pattern at different energies, you can identify the "sweet spot" that provides the best balance of precursor ion depletion and fragment ion generation.[10]
Q4: How do I determine the optimal collision energy for a novel compound?
A common and effective method is to perform a collision energy ramping experiment.[5][12] This involves infusing a standard of the compound into the mass spectrometer and acquiring MS/MS spectra at a range of collision energy values.[12] The optimal collision energy is the one that produces the highest intensity and greatest number of structurally informative fragment ions.[5] For peptides, linear equations based on the precursor's mass-to-charge ratio (m/z) and charge state can also be used to predict a starting point for optimization.[1][13]
Troubleshooting Guides
Problem 1: I am not observing any fragmentation of my precursor ion.
-
Possible Cause: The collision energy is too low.[4][5]
-
Troubleshooting Steps:
-
Gradually increase the collision energy in small increments (e.g., 2-5 units of normalized collision energy) and monitor the MS/MS spectrum for the appearance of fragment ions.[5]
-
Ensure that the collision gas is turned on and the pressure is within the manufacturer's recommended range.[14]
-
Verify that the instrument is properly calibrated.[3]
-
-
-
Possible Cause: The precursor ion is very stable.
-
Troubleshooting Steps:
-
Significantly increase the collision energy beyond the typical range.
-
Consider using a different, more energetic fragmentation technique if available, such as HCD instead of CID.[6]
-
For certain classes of molecules, derivatization can be employed to introduce more labile bonds, promoting fragmentation.[15]
-
-
Problem 2: My precursor ion is completely gone, and I only see very small, uninformative fragment ions.
-
Possible Cause: The collision energy is too high.[4]
Problem 3: I am seeing inconsistent fragmentation from run to run.
-
Possible Cause: The ion source is unstable.[4]
-
Troubleshooting Steps:
-
Check the stability of the electrospray. An inconsistent spray can lead to fluctuations in ion intensity and, consequently, fragmentation.[4]
-
Ensure that the sample concentration is consistent between runs.
-
-
-
Possible Cause: The instrument parameters are not optimized.
-
Troubleshooting Steps:
-
Review all instrument settings, not just the collision energy. Parameters such as automatic gain control (AGC) and maximum injection time can influence the number of ions in the trap, which can affect fragmentation efficiency.[6]
-
Perform regular instrument maintenance and calibration to ensure consistent performance.[3]
-
-
Quantitative Data Summary
The optimal collision energy is highly dependent on the analyte, its charge state, and the instrument being used.[3][5] The following table provides general starting points for normalized collision energy (NCE) for peptides using HCD.
| Precursor Charge State | Recommended NCE Starting Range (%) | Notes |
| 2+ | 25 - 35 | A good starting point for most doubly charged tryptic peptides.[5] |
| 3+ | 20 - 30 | Triply charged peptides often require slightly lower collision energy.[5] |
| >3+ | 15 - 25 | Higher charge states generally require lower collision energy. |
Note: These are general guidelines. Empirical optimization is always recommended for achieving the best results.[1]
Experimental Protocols
Protocol: Collision Energy Ramping for a Novel Compound
This protocol describes a systematic approach to determine the optimal collision energy for a new analyte using a liquid chromatography-tandem mass spectrometry (LC-MS/MS) system.
-
Sample Preparation: Prepare a pure standard of the compound of interest at a concentration that provides a stable and robust signal.
-
LC Method: Develop a simple isocratic or shallow gradient LC method that ensures the compound elutes as a sharp, symmetrical peak.
-
MS/MS Method Setup:
-
Create a targeted MS/MS method selecting the precursor ion (m/z) of your compound.
-
Set up a series of experiments where the only variable that changes is the collision energy.
-
Choose a range of collision energies to test. For example, for a small molecule, you might test from 5 to 50 eV in steps of 5 eV. For a peptide, you might test a normalized collision energy range from 10% to 45% in steps of 5%.[5]
-
-
Data Acquisition: Inject the sample for each collision energy setting.
-
Data Analysis:
-
Manually inspect the MS/MS spectrum obtained at each collision energy.[5]
-
Identify the collision energy that produces the highest number and intensity of structurally informative fragment ions.[5]
-
Plot the intensity of key fragment ions as a function of collision energy to visualize the optimal range.
-
Visualizations
Caption: A troubleshooting workflow for addressing poor or no fragmentation.
References
- 1. scispace.com [scispace.com]
- 2. Dissociation Technique Technology Overview | Thermo Fisher Scientific - US [thermofisher.com]
- 3. researchgate.net [researchgate.net]
- 4. benchchem.com [benchchem.com]
- 5. benchchem.com [benchchem.com]
- 6. Optimization of Higher-Energy Collisional Dissociation Fragmentation Energy for Intact Protein-level Tandem Mass Tag Labeling - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. pubs.acs.org [pubs.acs.org]
- 9. Optimization of Higher-Energy Collisional Dissociation Fragmentation Energy for Intact Protein-Level Tandem Mass Tag Labeling - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Energy dependence of HCD on peptide fragmentation: Stepped collisional energy finds the sweet spot - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Energy dependence of HCD on peptide fragmentation: stepped collisional energy finds the sweet spot - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. 4 Steps to Successful Compound Optimization on LC-MS/MS | Technology Networks [technologynetworks.com]
- 13. Effect of Collision Energy Optimization on the Measurement of Peptides by Selected Reaction Monitoring (SRM) Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 14. No fragmentation in ESI - Chromatography Forum [chromforum.org]
- 15. benchchem.com [benchchem.com]
Technical Support Center: Sample Preparation for LC-MS/MS in Clinical Research
This guide provides researchers, scientists, and drug development professionals with detailed troubleshooting advice, frequently asked questions (FAQs), and standardized protocols for common sample preparation techniques used in liquid chromatography-tandem mass spectrometry (LC-MS/MS) analysis.
General Workflow and Technique Selection
The initial preparation of a biological sample is a critical step that significantly influences the accuracy, sensitivity, and reproducibility of LC-MS/MS results.[1][2] The primary goals are to remove interfering matrix components, such as proteins and phospholipids, and to concentrate the analyte of interest.[3][4]
References
Technical Support Center: UPLC-MS/MS Analysis of Methylguanine
Welcome to the technical support center for UPLC-MS/MS analysis of methylguanine. This resource provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals address challenges related to carryover in their experiments.
Troubleshooting Guide: Reducing Methylguanine Carryover
Carryover, the appearance of an analyte signal in a blank injection following a high-concentration sample, is a common issue in sensitive UPLC-MS/MS analyses, particularly for polar and "sticky" compounds like methylguanine.[1][2] This guide provides a systematic approach to identify and mitigate carryover.
Q1: How can I determine the source of methylguanine carryover in my UPLC-MS/MS system?
A systematic approach is crucial to pinpoint the source of carryover.[3] The primary suspects are the autosampler, the column, and associated tubing and valves.[2] A logical troubleshooting workflow can help isolate the contributing components.
Experimental Protocol: Systematic Source Identification
-
Establish a Baseline: Inject a high-concentration methylguanine standard followed by a series of blank injections (e.g., mobile phase or sample diluent) to confirm and quantify the carryover.
-
Bypass the Column: Replace the analytical column with a union. Repeat the injection sequence. If carryover is significantly reduced or eliminated, the column is a major contributor.[4]
-
Isolate the Autosampler: If carryover persists after bypassing the column, the autosampler (injection needle, sample loop, rotor seal) is the likely source.[3]
-
Evaluate the MS Source: If the above steps do not resolve the issue, direct infusion of a clean solvent into the mass spectrometer can help determine if the source itself is contaminated.
Below is a diagram illustrating the logical flow for troubleshooting carryover sources.
Q2: What are the most effective wash solutions for reducing methylguanine carryover from the autosampler?
The choice of wash solvent is critical for minimizing carryover from the autosampler needle and injection port.[5] For polar basic compounds like methylguanine, an effective wash solution should be capable of solubilizing the analyte.[5] A mixture of aqueous and organic solvents, sometimes with additives, is often more effective than pure organic solvent.[5]
Data Presentation: Comparison of Needle Wash Solvents for a Polar Basic Compound (Granisetron HCl)
The following table summarizes the effectiveness of different needle wash solvents in reducing the carryover of granisetron HCl, a polar basic compound, which can serve as a proxy for methylguanine. The data is adapted from a study by Waters Corporation.[5]
| Wash Solvent Composition | Average Carryover (%) |
| 90:10 Water:Acetonitrile | 0.0015 |
| 50:50 Water:Acetonitrile | 0.0008 |
| 100% Acetonitrile | 0.0025 |
| 90:10 Water:Methanol | 0.0012 |
| 50:50 Water:Methanol | 0.0010 |
| 100% Methanol | 0.0020 |
Data adapted from a study on Granisetron HCl, a polar basic compound, and may serve as a starting point for optimizing methylguanine analysis.[5]
Experimental Protocol: Optimizing Autosampler Wash
-
Initial Wash Solution: Start with a wash solution that mimics your mobile phase composition, for example, a mixture of water and the strong organic solvent used in your gradient.[5]
-
Test Different Compositions: Evaluate the effectiveness of various aqueous/organic ratios (e.g., 90:10, 50:50, 10:90 water:acetonitrile or methanol).
-
Consider Additives: For basic compounds, adding a small amount of acid (e.g., 0.1% formic acid) to the wash solution can improve cleaning efficiency. For particularly stubborn carryover, specialty surfactants like FOS-choline-12 have shown to be highly effective.[6]
-
Optimize Wash Volume and Duration: Increase the volume and/or duration of the needle wash cycle in your instrument method.[7]
-
Implement Pre- and Post-Injection Washes: Utilizing both pre- and post-injection washes can further reduce carryover.[7]
Q3: How can I address carryover originating from the analytical column?
Column-related carryover can be significant, especially with "sticky" compounds.[4][8]
Experimental Protocol: Mitigating Column Carryover
-
Column Selection: Choose a column with a stationary phase that is less likely to exhibit strong secondary interactions with methylguanine.
-
Guard Column: If using a guard column, consider removing it as it can be a source of carryover.[4]
-
Column Wash Gradient: Instead of a continuous high-organic wash, a "saw-tooth" or cycling gradient that alternates between high and low organic mobile phase percentages can be more effective at removing retained compounds.[8]
-
Dedicated Column Wash: After a batch of high-concentration samples, perform a dedicated column wash with a strong solvent mixture.
The following diagram illustrates a signaling pathway for addressing column-specific carryover.
Frequently Asked Questions (FAQs)
Q: What is an acceptable level of carryover for methylguanine analysis? A: An acceptable level of carryover is typically defined as a peak in a blank injection that is less than 20% of the response of the lower limit of quantitation (LLOQ) for the analyte.[3]
Q: Can my mobile phase be a source of contamination that looks like carryover? A: Yes. To differentiate between carryover and mobile phase contamination, inject a series of blanks. If the peak area remains constant across multiple blank injections, the mobile phase is likely contaminated.[3]
Q: Are there any instrument components that are prone to causing carryover? A: Yes, worn or dirty autosampler rotor seals and stators are common sources of carryover. Regular maintenance and cleaning or replacement of these parts are recommended.[3] Poorly seated tubing connections can also create dead volumes where the sample can be trapped.
Q: Can the sample preparation method contribute to carryover? A: While not a direct cause of instrument carryover, a complex sample matrix can exacerbate the issue by introducing components that may compete for active sites in the system or foul the column. Optimizing sample cleanup to remove interferences can be beneficial.
Q: How often should I perform system maintenance to prevent carryover? A: The frequency of maintenance depends on the number of samples analyzed and the cleanliness of the samples. For high-throughput labs, regular checks of the autosampler wash system, replacement of rotor seals, and inspection of tubing and fittings are recommended.
References
- 1. youtube.com [youtube.com]
- 2. researchgate.net [researchgate.net]
- 3. documents.thermofisher.com [documents.thermofisher.com]
- 4. Troubleshooting Carry-Over in the LC-MS Analysis of Biomolecules: The Case of Neuropeptide Y - PMC [pmc.ncbi.nlm.nih.gov]
- 5. lcms.cz [lcms.cz]
- 6. Rapid removal of IgG1 carryover on protease column using protease-safe wash solutions delivered with LC pump for HDX-MS systems - PMC [pmc.ncbi.nlm.nih.gov]
- 7. lcms.cz [lcms.cz]
- 8. Universal LC-MS method for minimized carryover in a discovery bioanalytical setting - PubMed [pubmed.ncbi.nlm.nih.gov]
Technical Support Center: UPLC-MS/MS Analysis of Methylguanine
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in optimizing the flow rate for UPLC-MS/MS analysis of methylguanine and resolving common experimental issues.
Frequently Asked Questions (FAQs)
Q1: What is the optimal flow rate for UPLC-MS/MS analysis of O⁶-methylguanine?
An optimal flow rate for the analysis of O⁶-methylguanine using a C18 Acquity® Bridged Ethylene Hybrid (BEH) column (1.7 µm, 100 mm x 2.1 mm) has been determined to be 0.1 mL/minute.[1][2] While higher flow rates can shorten the retention time, a flow rate of 0.1 mL/min has been shown to produce the greatest peak area, indicating better sensitivity, despite a longer retention time of approximately 3.47 minutes.[1] It is important to note that faster flow rates can lead to increased column pressure, which may cause damage to the column over time.[1]
Q2: How does flow rate generally affect sensitivity in UPLC-MS/MS?
In liquid chromatography-mass spectrometry (LC-MS), sensitivity is closely related to the efficiency of ionization and the transfer of ions from the atmospheric pressure source to the low-pressure zone of the mass spectrometer.[3] For standard flow LC-ESI-MS systems, the best performance is often observed in the range of 10–300 µL/min.[3] Reducing the flow rate can lead to significant gains in sensitivity. This is because at lower flow rates, the electrospray plume becomes smaller and more focused, allowing the mass spectrometer inlet to capture a larger percentage of the generated ions.[4] Gains in sensitivity of 10 to 20 times can be achieved by moving from a traditional 2.1-mm column diameter to a microflow format with reduced solvent flow.[4]
Q3: What are the typical starting conditions for developing a UPLC-MS/MS method for methylguanine?
A good starting point for method development for O⁶-methylguanine analysis is based on validated methods from existing literature. Key parameters include:
-
Column: C18 Acquity® BEH column (1.7 µm, 100 mm x 2.1 mm)[1][2]
-
Mobile Phase: A gradient elution using 0.05% formic acid in water and acetonitrile. A common composition is a 95:5 (v/v) mixture of 0.05% formic acid and acetonitrile.[1][2]
-
Internal Standard: Allopurinol can be used as an internal standard.[1][2]
-
Detection: Multiple Reaction Monitoring (MRM) mode with transitions of m/z 165.95 > 149 for O⁶-methylguanine and m/z 136.9 > 110 for allopurinol.[1][2]
Troubleshooting Guides
Problem: Low Signal Intensity or Poor Sensitivity
| Possible Cause | Suggested Solution |
| Suboptimal Flow Rate | For a 2.1 mm i.d. column, an optimal flow rate is typically between 200-300 µL/min.[3] However, for enhanced sensitivity with O⁶-methylguanine, a lower flow rate of 0.1 mL/min has been shown to be effective.[1] Consider performing a flow rate optimization experiment (e.g., testing 0.1, 0.2, and 0.3 mL/min) to determine the best signal-to-noise ratio for your specific setup. |
| Ion Source Contamination | The MS interface is prone to contamination from biological samples, which can suppress the analyte signal.[5] Regularly clean the ion source components as per the manufacturer's instructions. |
| Improper Ion Source Positioning | The position of the capillary tip relative to the sampling orifice is crucial for optimal ion sampling and is dependent on the flow rate.[3] At higher flow rates, the tip should be further away to allow for sufficient desolvation.[3] Optimize the source position while infusing a standard solution at the analytical flow rate. |
| Matrix Effects | Co-eluting compounds from the sample matrix can compete with the analyte for ionization, leading to signal suppression.[6] Improve sample preparation with techniques like solid-phase extraction (SPE) or liquid-liquid extraction (LLE) to remove interfering substances.[6] Also, ensure adequate chromatographic separation from matrix components. |
Problem: Peak Tailing or Broadening
| Possible Cause | Suggested Solution |
| Column Degradation | High backpressure or injection of unfiltered samples can damage the column.[1] If the column has been used for a large number of injections (e.g., over 500), its performance may degrade.[6] Replace the column with a new one. |
| Secondary Interactions | The analyte may be interacting with active sites on the column packing material. Ensure the mobile phase pH is appropriate for the analyte's pKa. The use of a volatile acid like formic acid in the mobile phase helps to control the ionization state of the analyte and improve peak shape.[3] |
| Extra-column Volume | Excessive tubing length or large-volume fittings between the column and the detector can cause band broadening.[7] Minimize the length and internal diameter of all connections post-column. |
Experimental Protocols
Detailed Methodology for UPLC-MS/MS Analysis of O⁶-Methylguanine
This protocol is adapted from a validated method for the analysis of O⁶-methylguanine in dried blood spots.[1][2]
1. Sample Preparation
-
Prepare stock solutions of O⁶-methylguanine and the internal standard (e.g., allopurinol) at 1.0 mg/mL in methanol.[1]
-
Create a series of working standard solutions by diluting the stock solutions with water containing 0.5% (v/v) formic acid.[1]
-
For calibration curves, spike whole blood with the working solutions to achieve a concentration range of 0.5–20 ng/mL.[1]
-
Prepare quality control (QC) samples at low, medium, and high concentrations (e.g., 1.5, 10, and 15 ng/mL).[1]
2. UPLC-MS/MS System and Conditions
| Parameter | Setting |
| UPLC System | Waters ACQUITY UPLC or equivalent |
| Mass Spectrometer | Thermo Scientific Q-Exactive or equivalent[8] |
| Column | C18 Acquity® BEH (1.7 µm, 100 mm x 2.1 mm)[1][2] |
| Mobile Phase A | 0.05% Formic Acid in Water |
| Mobile Phase B | Acetonitrile |
| Mobile Phase Composition | 95:5 (v/v) Mobile Phase A:Mobile Phase B[1][2] |
| Flow Rate | 0.1 mL/minute[1][2] |
| Elution Mode | Gradient elution over 6 minutes[1][2] |
| Injection Volume | 5-10 µL |
| Column Temperature | 40 °C |
| Ionization Mode | Positive Electrospray Ionization (ESI+) |
| MS/MS Detection | Multiple Reaction Monitoring (MRM) |
| MRM Transitions | O⁶-methylguanine: m/z 165.95 > 149, Allopurinol: m/z 136.9 > 110[1][2] |
Visualizations
Caption: UPLC-MS/MS workflow for methylguanine analysis.
Caption: Troubleshooting low signal intensity in UPLC-MS/MS.
References
- 1. Method Development and Validation for Measuring O6-Methylguanine in Dried Blood Spot Using Ultra High-Performance Liquid Chromatography Tandem Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Method Development and Validation for Measuring O6-Methylguanine in Dried Blood Spot Using Ultra High-Performance Liquid Chromatography Tandem Mass Spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. chromatographyonline.com [chromatographyonline.com]
- 4. lcms.cz [lcms.cz]
- 5. myadlm.org [myadlm.org]
- 6. alfresco-static-files.s3.amazonaws.com [alfresco-static-files.s3.amazonaws.com]
- 7. chromatographyonline.com [chromatographyonline.com]
- 8. metabolon.com [metabolon.com]
Validation & Comparative
Comparative Guide to Therapeutic Drug Monitoring Markers for Alkylating Agents: A Focus on O6-Methylguanine and Alternatives
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive comparison of O6-methylguanine (O6-meG) as a therapeutic drug monitoring (TDM) marker for alkylating agents like procarbazine and temozolomide, alongside alternative monitoring strategies including O6-methylguanine-DNA methyltransferase (MGMT) promoter methylation status and circulating tumor DNA (ctDNA). While the initial topic of interest was N2-methylguanine, a thorough review of current scientific literature reveals a lack of validation for N2-methylguanine as a clinical TDM marker for these agents. Therefore, this guide focuses on evidence-based, clinically relevant biomarkers.
The primary mechanism of action for many alkylating agents involves the methylation of DNA, with the formation of O6-meG being a critical cytotoxic lesion[1][2]. The persistence of this adduct can lead to cell cycle arrest and apoptosis[1]. Consequently, monitoring O6-meG levels provides a direct measure of the drug's biological effect.
Comparative Analysis of TDM Markers
The selection of a TDM marker depends on its clinical utility, analytical validity, and the specific clinical question being addressed. Here, we compare O6-methylguanine, MGMT promoter methylation, and ctDNA across several key parameters.
| Parameter | O6-Methylguanine (O6-meG) | MGMT Promoter Methylation | Circulating Tumor DNA (ctDNA) |
| Biomarker Type | Direct measure of DNA damage (pharmacodynamic) | Predictive biomarker of drug resistance | Real-time measure of tumor burden and genetic alterations |
| Clinical Utility | - Direct assessment of target engagement by the drug.- Potential to individualize dosing to optimize efficacy and minimize toxicity. | - Predicts response to alkylating agents in gliomas.[3][4]- Guides treatment decisions (e.g., use of temozolomide). | - Early detection of treatment resistance.[5][6][7]- Longitudinal monitoring of tumor dynamics.[5] |
| Sample Matrix | Leukocyte DNA from blood, Dried Blood Spots (DBS)[8][9] | Tumor tissue (formalin-fixed paraffin-embedded - FFPE)[10] | Plasma[5][6][11][7] |
| Analytical Method | UPLC-MS/MS, Competitive Repair Assay[8][9] | Methylation-Specific PCR (MSP), Pyrosequencing[10][12][13] | Next-Generation Sequencing (NGS), Digital PCR (dPCR)[5][14] |
| Reported Levels/Findings | - Levels up to 0.28 fmol/µg DNA in patients treated with procarbazine.[9]- Linearly correlated with cumulative procarbazine dose.[9]- Average of 0.25 ± 0.09 µmol/molG on day 10 of MOPP therapy. | - Methylated status associated with longer overall and progression-free survival in glioblastoma patients treated with temozolomide.[3][4][15] | - Glioma-derived ctDNA mutations detected in 93.8% of plasma samples in one study.[5][7]- Can detect resistance mutations (e.g., in MSH2, MSH6) before they are apparent in tumor tissue.[5][7] |
| Limitations | - Levels can be influenced by DNA repair capacity (MGMT activity).- Requires sensitive analytical methods for detection. | - Requires invasive tumor biopsy.- Methylation status can be heterogeneous within a tumor and may change over time.[16] | - Low levels of ctDNA in some cancers (e.g., gliomas) can be challenging to detect.[5][6][11][7]- Requires highly sensitive and specific assays. |
Experimental Protocols
Detailed methodologies are crucial for the accurate and reproducible measurement of these biomarkers.
Quantification of O6-Methylguanine in Dried Blood Spots (DBS) by UPLC-MS/MS
This method provides a sensitive and minimally invasive approach for measuring O6-meG levels.
a. Sample Collection and Preparation:
-
Collect whole blood via a finger prick onto a PerkinElmer 226 filter paper[17].
-
Allow the DBS to dry at room temperature for at least 2 hours[17].
-
Punch out a disc from the DBS and place it in a microcentrifuge tube[17].
-
Add an internal standard (e.g., allopurinol)[8].
-
Extract DNA from the DBS disc using a commercial kit (e.g., QIAamp DNA Mini Kit)[8][17].
-
Perform acid hydrolysis to release the methylated purines from the DNA backbone[17].
b. UPLC-MS/MS Analysis:
-
Chromatographic Separation:
-
Mass Spectrometry Detection:
c. Data Analysis:
-
Construct a calibration curve using standards of known O6-methylguanine concentrations (e.g., 0.5–20 ng/mL)[18].
-
Quantify the amount of O6-methylguanine in the samples by comparing their peak area ratios (analyte/internal standard) to the calibration curve.
Analysis of MGMT Promoter Methylation by Methylation-Specific PCR (MSP)
MSP is a widely used method to determine the methylation status of the MGMT promoter in tumor DNA.
a. DNA Extraction and Bisulfite Conversion:
-
Extract genomic DNA from FFPE tumor tissue using a suitable kit (e.g., QIAamp DNA FFPE Tissue kit)[10].
-
Assess DNA concentration and purity using a spectrophotometer[10].
-
Treat the genomic DNA with sodium bisulfite (e.g., using the EpiTect Bisulfite Kit). This step converts unmethylated cytosines to uracil, while methylated cytosines remain unchanged[10][12].
b. Methylation-Specific PCR:
-
Perform two separate PCR reactions for each sample using primer sets that are specific for either the methylated or the unmethylated MGMT promoter sequence.
-
Include positive controls (fully methylated and unmethylated DNA) and a negative control (no DNA) in each run[10].
c. Gel Electrophoresis and Interpretation:
-
Separate the PCR products on a 3% agarose gel[10].
-
Visualize the bands under UV light. The presence of a band in the reaction with methylated-specific primers indicates a methylated MGMT promoter. The presence of a band in the reaction with unmethylated-specific primers indicates an unmethylated promoter[10].
Quantification of Circulating Tumor DNA (ctDNA) from Plasma
This protocol outlines a general workflow for ctDNA analysis, which is often tailored to the specific platform and cancer type.
a. Plasma Collection and cfDNA Extraction:
-
Collect whole blood in specialized cell-free DNA blood collection tubes (e.g., Streck tubes) to prevent contamination from genomic DNA[19].
-
Isolate plasma by double centrifugation within a few hours of blood collection[20].
-
Extract cell-free DNA (cfDNA) from the plasma using a magnetic bead-based or column-based kit (e.g., QIAamp Circulating Nucleic Acid Kit)[14][19].
b. cfDNA Quantification and Quality Control:
-
Quantify the extracted cfDNA using a sensitive method like qPCR or dPCR, as concentrations are often low[20]. Fluorometric methods can also be used for a qualitative assessment[20].
-
Assess the size distribution of the cfDNA using an automated electrophoresis system (e.g., Bioanalyzer) to confirm the presence of the characteristic ~167 bp peak[21].
c. ctDNA Analysis by Next-Generation Sequencing (NGS):
-
Prepare a sequencing library from the extracted cfDNA.
-
Perform targeted sequencing of a panel of cancer-related genes or whole-exome/genome sequencing.
-
Analyze the sequencing data to identify tumor-specific mutations and calculate their variant allele frequencies.
Visualizations
Metabolic Activation of Procarbazine and DNA Adduct Formation
Caption: Metabolic pathway of procarbazine leading to DNA methylation.
Mechanism of Action of Temozolomide
Caption: Mechanism of action of temozolomide resulting in DNA adduct formation.
Experimental Workflow for O6-methylguanine Quantification
Caption: Experimental workflow for the quantification of O6-methylguanine.
References
- 1. Mechanisms of temozolomide resistance in glioblastoma - a comprehensive review - PMC [pmc.ncbi.nlm.nih.gov]
- 2. go.drugbank.com [go.drugbank.com]
- 3. O6-Methylguanine-methyltransferase (MGMT) promoter methylation status in glioma stem-like cells is correlated to temozolomide sensitivity under differentiation-promoting conditions - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Frontiers | O6-Methylguanine-DNA Methyltransferase (MGMT): Challenges and New Opportunities in Glioma Chemotherapy [frontiersin.org]
- 5. Plasma ctDNA enables early detection of temozolomide resistance mutations in glioma - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Plasma ctDNA enables early detection of temozolomide resistance mutations in glioma : Find an Expert : The University of Melbourne [findanexpert.unimelb.edu.au]
- 7. Plasma ctDNA enables early detection of temozolomide resistance mutations in glioma - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Method Development and Validation for Measuring O6-Methylguanine in Dried Blood Spot Using Ultra High-Performance Liquid Chromatography Tandem Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Accumulation of O6-methylguanine in human blood leukocyte DNA during exposure to procarbazine and its relationships with dose and repair - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. MGMT promoter methylation analysis [bio-protocol.org]
- 11. researchgate.net [researchgate.net]
- 12. MGMT promoter methylation status testing to guide therapy for glioblastoma: refining the approach based on emerging evidence and current challenges - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Detection of MGMT promoter methylation in glioblastoma using pyrosequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 14. tandfonline.com [tandfonline.com]
- 15. Changes of O6-Methylguanine DNA Methyltransferase (MGMT) Promoter Methylation in Glioblastoma Relapse-A Meta-Analysis Type Literature Review - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. Variation of O(6)-methylguanine-DNA methyltransferase (MGMT) promoter methylation in serial samples in glioblastoma - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. Determination of O6-Methylguanine in dried blood spot of breast cancer patients after cyclophosphamide administration - PMC [pmc.ncbi.nlm.nih.gov]
- 18. dovepress.com [dovepress.com]
- 19. tandfonline.com [tandfonline.com]
- 20. revvity.com [revvity.com]
- 21. Clinical Practice Guidelines for Pre-Analytical Procedures of Plasma Epidermal Growth Factor Receptor Variant Testing - PMC [pmc.ncbi.nlm.nih.gov]
A Comparative Guide: HPLC and LC-MS/MS for the Analysis of Modified Nucleosides
For researchers, scientists, and drug development professionals engaged in the study of epigenetics and RNA therapeutics, the accurate and sensitive detection of modified nucleosides is paramount. These modifications play a crucial role in a myriad of biological processes, and their dysregulation is implicated in various diseases. High-Performance Liquid Chromatography (HPLC) with UV detection and Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS) are two powerful analytical techniques employed for this purpose. This guide provides a comprehensive comparison of these methods, supported by experimental data and detailed protocols, to aid in the selection of the most appropriate technique for specific research needs.
At a Glance: HPLC vs. LC-MS/MS
| Feature | HPLC with UV Detection | LC-MS/MS |
| Principle | Separation based on polarity, with detection via UV absorbance. | Separation based on polarity, coupled with mass-based detection and fragmentation for structural elucidation. |
| Sensitivity | Generally lower, suitable for more abundant modifications. | High sensitivity, capable of detecting and quantifying low-abundance modifications.[1] |
| Selectivity | Relies on chromatographic separation and UV absorbance spectra, which can be limited for co-eluting compounds or isomers. | Highly selective, based on mass-to-charge ratio and fragmentation patterns, allowing for the differentiation of isomers and isobars. |
| Identification | Based on retention time comparison with standards and UV spectra. | Based on retention time, precursor ion mass, and specific fragment ions, providing a higher degree of confidence in identification. |
| Quantification | Reliable for well-separated and abundant nucleosides. | Offers a wider dynamic range and lower limits of detection, making it the gold standard for quantitative analysis.[1] |
| Cost & Complexity | Lower initial instrument cost and less complex operation and maintenance. | Higher initial investment and requires more specialized expertise for operation and data analysis. |
Data Presentation: A Quantitative Comparison
The following tables summarize the performance characteristics of HPLC-UV and LC-MS/MS for the analysis of modified nucleosides. It is important to note that a direct comparison of absolute values should be approached with caution, as the limits of detection (LOD) and quantification (LOQ) are highly dependent on the specific instrumentation, experimental conditions, and the analyte itself.
Table 1: Performance of HPLC with UV Detection for Nucleoside Analysis
| Analyte | Retention Time (min) | LOD (nM) | LOQ (nM) | Linearity Range |
| Adenosine (Ado) | 10.361[2] | 0.89[3] | 2.97[3] | N/A |
| Guanosine (Guo) | 9.657[2] | N/A | N/A | N/A |
| Uridine (Urd) | 9.620[2] | N/A | N/A | N/A |
| Cytidine (Cyd) | N/A | N/A | N/A | N/A |
| N6-methyladenosine (m6A) | 11.624[2] | N/A | N/A | 0.0566 - 0.5662 µg[2] |
Note: Data is compiled from multiple sources and experimental conditions may vary. "N/A" indicates that the data was not available in the cited sources.
Table 2: Performance of LC-MS/MS for Modified Nucleoside Analysis
| Analyte | LOD (fmol) | LOQ (fmol) | Dynamic Range (orders of magnitude) |
| Pseudouridine (Ψ) | 10[1] | 20[1] | 4[1] |
| 5-Methyluridine (m5U) | 10[1] | 20[1] | 4[1] |
| Inosine (I) | 2[1] | 5[1] | 4[1] |
| N6-methyladenosine (m6A) | < LOQ[4] | < LOQ[4] | N/A |
| 7-methylguanosine (m7G) | 0.01[1] | 0.05[1] | 4[1] |
Note: Data is compiled from multiple sources and experimental conditions may vary. The dynamic range for many nucleosides in LC-MS/MS analysis typically spans several orders of magnitude.[1]
Experimental Workflows
The general workflows for the analysis of modified nucleosides using HPLC and LC-MS/MS are depicted below. The initial sample preparation steps are largely similar, involving the hydrolysis of RNA into individual nucleosides. The key differences lie in the detection and data analysis stages.
References
- 1. Absolute and relative quantification of RNA modifications via biosynthetic isotopomers - PMC [pmc.ncbi.nlm.nih.gov]
- 2. thepharmajournal.com [thepharmajournal.com]
- 3. Simultaneous quantification of 12 different nucleotides and nucleosides released from renal epithelium and in human urine samples using ion-pair reversed-phase HPLC - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Global analysis by LC-MS/MS of N6-methyladenosine and inosine in mRNA reveal complex incidence - PMC [pmc.ncbi.nlm.nih.gov]
Navigating the Epitranscriptome: A Comparative Guide to RNA Modification Detection
For researchers, scientists, and drug development professionals, understanding the landscape of RNA modifications is paramount. This guide provides an objective comparison of key methods for detecting these modifications, supported by experimental data and detailed protocols to aid in the selection of the most appropriate techniques for your research needs.
The field of epitranscriptomics has illuminated the critical role of chemical modifications on RNA molecules in regulating gene expression and cellular function. With over 170 distinct RNA modifications identified, the ability to accurately detect and quantify these marks is essential for unraveling their biological significance and their implications in health and disease. This guide offers a cross-validation of prevalent methods, focusing on their principles, performance, and practical application.
High-Throughput Sequencing-Based Methods: A Comparative Overview
The advent of next-generation sequencing has revolutionized the study of RNA modifications, enabling transcriptome-wide mapping. These methods can be broadly categorized into three main approaches: antibody-based enrichment, chemical- or enzyme-based modification followed by sequencing, and direct RNA sequencing. The choice of method depends on the specific modification of interest, the desired resolution, and the available sample material.
Here, we compare some of the most widely used techniques for detecting N6-methyladenosine (m6A), the most abundant internal modification in eukaryotic mRNA.
| Method | Principle | Resolution | Quantitative | Advantages | Limitations |
| MeRIP-seq/m6A-seq | Immunoprecipitation of m6A-containing RNA fragments using an anti-m6A antibody, followed by high-throughput sequencing. | ~100-200 nucleotides | Semi-quantitative (enrichment-based) | Widely used, robust for identifying m6A-enriched regions. | Low resolution, potential for antibody cross-reactivity and PCR bias.[1][2] |
| miCLIP | UV crosslinking of the m6A antibody to RNA, followed by immunoprecipitation and sequencing. The reverse transcriptase often truncates or introduces mutations at the crosslink site, enabling single-nucleotide resolution. | Single nucleotide | Semi-quantitative | High resolution, provides information on the binding sites of the antibody. | Technically challenging, potential for UV-induced biases. |
| Nanopore Direct RNA Sequencing | Direct sequencing of native RNA molecules as they pass through a nanopore. Modifications cause disruptions in the electrical current, which can be detected by specialized algorithms. | Single nucleotide | Quantitative (modification frequency at a specific site) | Direct detection without reverse transcription or amplification, provides long reads, and can detect multiple modifications simultaneously.[3][4] | Data analysis is complex and relies on evolving computational models; lower throughput compared to some short-read methods.[1] |
| SCARLET | Site-specific cleavage of RNA at the target nucleotide, followed by radioactive labeling, ligation-assisted extraction, and thin-layer chromatography to identify and quantify the modification. | Single nucleotide | Quantitative (modification fraction) | Highly accurate for validating and quantifying modifications at specific sites.[5][6] | Low-throughput, not suitable for transcriptome-wide discovery. |
| AlkAniline-Seq | Chemical treatment induces cleavage at specific modified residues (e.g., m7G, m3C), and the resulting RNA fragments are selectively ligated to sequencing adapters. | Single nucleotide | Semi-quantitative | Highly sensitive and specific for certain modifications.[7][8] | Limited to modifications that can be chemically cleaved. |
Performance Metrics from Comparative Studies
Direct comparative studies provide valuable insights into the performance of different methods. A recent benchmark of computational models for detecting m6A from Nanopore direct RNA sequencing data highlighted the strengths and weaknesses of different analytical approaches.
| Tool (for Nanopore data) | Recall (Sensitivity) | False Discovery Rate (FDR) | Key Findings from a Benchmarking Study |
| Dorado | ~0.92 | ~40% | Higher recall for m6A sites with ≥10% modification ratio and ≥10X coverage.[1] |
| m6Anet | ~0.51 | ~80% | Performance is influenced by sequence context.[1] |
A study comparing MeRIP-seq and Nanopore dRNA-seq for identifying m6A in glioblastoma non-coding RNAs found that MeRIP-seq identified a larger number of modified lncRNAs, while dRNA-seq provided precise location and quantification.[9] This suggests that MeRIP-seq is well-suited for initial screening, whereas dRNA-seq is ideal for in-depth analysis.[9]
Experimental Workflows and Logical Diagrams
Understanding the experimental workflow is crucial for implementing these techniques and interpreting the results. Below are graphical representations of the key steps involved in antibody-based enrichment and direct RNA sequencing for RNA modification analysis.
Detailed Experimental Protocols
Accurate and reproducible results depend on meticulous execution of experimental protocols. Below are summaries of the methodologies for key RNA modification detection techniques.
Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq)
This protocol outlines the key steps for performing MeRIP-seq to identify m6A modifications across the transcriptome.[2][10][11]
-
RNA Preparation:
-
Extract total RNA from cells or tissues of interest.
-
Isolate mRNA using oligo(dT) magnetic beads.
-
Assess the quality and quantity of the purified mRNA.
-
-
RNA Fragmentation and Immunoprecipitation:
-
Fragment the mRNA to an average size of ~100 nucleotides using fragmentation buffer.
-
Incubate the fragmented RNA with an anti-m6A antibody coupled to magnetic beads. A portion of the fragmented RNA should be saved as an "input" control.
-
Perform stringent washing steps to remove non-specifically bound RNA fragments.
-
Elute the m6A-containing RNA fragments from the antibody-bead complex.
-
-
Library Preparation and Sequencing:
-
Construct sequencing libraries from both the immunoprecipitated (IP) and input RNA samples. This typically involves reverse transcription, second-strand synthesis, adapter ligation, and PCR amplification.
-
Perform high-throughput sequencing on a platform such as Illumina.
-
-
Data Analysis:
-
Align the sequencing reads to a reference genome or transcriptome.
-
Use peak-calling algorithms to identify regions that are significantly enriched in the IP sample compared to the input control. These enriched regions, or "peaks," correspond to sites of m6A modification.
-
Nanopore Direct RNA Sequencing
This protocol describes the general workflow for preparing a direct RNA sequencing library for the Oxford Nanopore Technologies platform.[4][12][13]
-
RNA Sample Preparation:
-
Start with total RNA or poly(A) selected RNA. The quality of the input RNA is critical for optimal sequencing results.
-
-
Library Preparation (using Oxford Nanopore Direct RNA Sequencing Kit):
-
Reverse Transcription: A reverse transcriptase is used to synthesize a complementary DNA (cDNA) strand. This creates an RNA:cDNA hybrid which improves sequencing stability.
-
Adapter Ligation: A sequencing adapter, which includes a motor protein, is ligated to the 3' end of the RNA strand.
-
-
Sequencing:
-
Flow Cell Priming: The Nanopore flow cell is primed with a buffer to ensure the pores are ready for sequencing.
-
Library Loading: The prepared RNA library is loaded onto the flow cell. The motor protein guides the RNA molecule through the nanopore.
-
Sequencing Run: As the RNA molecule passes through the nanopore, changes in the ionic current are measured. This raw signal data is collected in real-time.
-
-
Data Analysis:
-
Basecalling: The raw electrical signal is translated into a nucleotide sequence using basecalling software.
-
Alignment: The basecalled reads are aligned to a reference genome or transcriptome.
-
Modification Detection: Specialized computational tools (e.g., Dorado, m6Anet) are used to analyze the raw signal data to detect deviations from the expected signal for unmodified bases. These deviations are indicative of RNA modifications. The frequency of these deviations at a specific site provides a quantitative measure of the modification.
-
SCARLET (Site-specific Cleavage And Radioactive-labeling followed by Ligation-assisted Extraction and Thin-layer chromatography)
This method provides precise quantification of a modification at a single-nucleotide resolution.[5][6][14]
-
Site-Specific Cleavage:
-
A DNA oligo complementary to the target RNA sequence is annealed to the RNA.
-
RNase H is used to cleave the RNA at the RNA-DNA hybrid, immediately 5' to the nucleotide of interest.
-
-
Radioactive Labeling:
-
The 5' hydroxyl group of the target nucleotide is radioactively labeled with 32P using T4 polynucleotide kinase.
-
-
Ligation-assisted Extraction:
-
A splint DNA oligo and a second DNA oligo are used to ligate the radiolabeled nucleotide to the second DNA oligo.
-
The ligation product is then treated with RNases to digest the remaining RNA.
-
-
Thin-Layer Chromatography (TLC):
-
The ligated, radiolabeled nucleotide is released and separated by 2D-TLC.
-
The identity of the nucleotide (modified or unmodified) is determined by its position on the TLC plate, and the modification fraction is quantified by the radioactivity of the corresponding spots.
-
Conclusion
The detection of RNA modifications is a rapidly evolving field with a diverse array of available methods. Antibody-based techniques like MeRIP-seq are valuable for initial, transcriptome-wide screens, while methods providing single-nucleotide resolution, such as miCLIP and Nanopore direct RNA sequencing, offer deeper insights into the precise locations of modifications. For quantitative validation of specific sites, techniques like SCARLET remain highly accurate. The choice of method should be guided by the specific research question, the required resolution and sensitivity, and the available resources. As technologies continue to advance, particularly in the realm of direct RNA sequencing and its associated analytical tools, our ability to comprehensively and accurately map the epitranscriptome will undoubtedly expand, shedding further light on the intricate roles of RNA modifications in biology and disease.
References
- 1. A comparative evaluation of computational models for RNA modification detection using nanopore sequencing with RNA004 chemistry - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Frontiers | Current progress in strategies to profile transcriptomic m6A modifications [frontiersin.org]
- 3. researchgate.net [researchgate.net]
- 4. nanoporetech.com [nanoporetech.com]
- 5. liulab.life.tsinghua.edu.cn [liulab.life.tsinghua.edu.cn]
- 6. Probing N⁶-methyladenosine (m⁶A) RNA Modification in Total RNA with SCARLET [pubmed.ncbi.nlm.nih.gov]
- 7. Mapping of 7-methylguanosine (m7G), 3-methylcytidine (m3C), dihydrouridine (D) and 5-hydroxycytidine (ho5C) RNA modifications by AlkAniline-Seq - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. AlkAniline-Seq: A Highly Sensitive and Specific Method for Simultaneous Mapping of 7-Methyl-guanosine (m7G) and 3-Methyl-cytosine (m3C) in RNAs by High-Throughput Sequencing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Identification and comparison of m6A modifications in glioblastoma non-coding RNAs with MeRIP-seq and Nanopore dRNA-seq - PMC [pmc.ncbi.nlm.nih.gov]
- 10. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 11. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Nanopore Direct RNA Sequencing Protocol - CD Genomics [cd-genomics.com]
- 13. nanoporetech.com [nanoporetech.com]
- 14. Probing N 6-methyladenosine (m6A) RNA Modification in Total RNA with SCARLET | Springer Nature Experiments [experiments.springernature.com]
N2-methylguanine vs. N7-methylguanine: A Comparative Analysis of Their Biological Consequences
A comprehensive guide for researchers, scientists, and drug development professionals on the distinct biological effects of N2-methylguanine and N7-methylguanine, two critical DNA adducts formed by alkylating agents. This guide provides a detailed comparison of their impact on DNA integrity, transcription, translation, and cytotoxicity, supported by experimental data and methodologies.
Introduction
Alkylation of DNA at the guanine base is a frequent consequence of exposure to both endogenous and exogenous alkylating agents, leading to the formation of various methylated guanine adducts. Among these, N2-methylguanine (N2-MeG) and N7-methylguanine (N7-MeG) are two of the most common lesions. Despite their structural similarity, the position of the methyl group profoundly influences their biological effects, from mutagenic potential to the cellular repair mechanisms they trigger. Understanding these differences is crucial for assessing the genotoxicity of chemical compounds and for the development of targeted cancer therapies. This guide provides a comparative analysis of the biological impacts of N2-MeG and N7-MeG, presenting key experimental findings in a structured format.
Comparative Biological Effects: A Tabular Summary
The following tables summarize the key quantitative data comparing the biological effects of N2-methylguanine and N7-methylguanine.
| Parameter | N2-methylguanine (N2-MeG) | N7-methylguanine (N7-MeG) | References |
| Formation | Formed by various carcinogens and metabolic by-products. The N2 position is less nucleophilic than N7. | The most frequent product of DNA methylation by many alkylating agents, accounting for 70-80% of guanine alkylation.[1] | [1] |
| Chemical Stability | Chemically stable. | Chemically unstable, leading to spontaneous depurination and the formation of an abasic site. Can also undergo imidazole ring-opening to form the more mutagenic N5-methyl-formamidopyrimidine (Me-Fapy-G).[2][3] | [2][3] |
| DNA Structure | Can cause significant distortion of the DNA double helix, especially with bulkier alkyl groups. | Does not significantly alter the DNA duplex structure.[1] | [1] |
| Parameter | N2-methylguanine (N2-MeG) | N7-methylguanine (N7-MeG) | References |
| DNA Replication Fidelity | Can be bypassed by DNA polymerases, but with reduced efficiency and fidelity. Can lead to G→A transition mutations. | Does not significantly block DNA replication.[2] Considered non-mutagenic or weakly mutagenic, with a reported mutation frequency of less than 0.5%.[2][4] | [2][4] |
| Miscoding Potential | Can mispair with thymine (T), leading to G to A transitions. | dTTP misincorporation opposite N7-MeG is slightly favored by human DNA polymerase η. | |
| Transcriptional Fidelity | Does not significantly block transcription by RNA polymerase II.[5] However, bulkier N2-adducts can be strong blocks to transcription. | Generally considered to be bypassed by RNA polymerase with minimal blockage. | [5] |
| Cytotoxicity | Can contribute to cytotoxicity, particularly if repair is deficient. | Considered to be of low cytotoxicity. However, its secondary lesions (abasic sites and Me-Fapy-G) are cytotoxic.[1][6] | [1][6] |
| Primary DNA Repair Pathway | Transcription-Coupled Nucleotide Excision Repair (TC-NER) for bulky adducts. The repair of N2-MeG itself is less clearly defined and may involve other mechanisms.[5] | Base Excision Repair (BER), initiated by N-methylpurine DNA glycosylase (MPG).[2] | [2][5] |
Experimental Protocols
This section details the methodologies for key experiments used to characterize and compare the biological effects of N2-methylguanine and N7-methylguanine.
Quantification of DNA Adducts by Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS)
This method is a highly sensitive and specific technique for the detection and quantification of DNA adducts.
-
DNA Isolation and Hydrolysis:
-
Genomic DNA is isolated from cells or tissues exposed to an alkylating agent.
-
The purified DNA is enzymatically hydrolyzed to individual deoxyribonucleosides using a cocktail of DNase I, snake venom phosphodiesterase, and alkaline phosphatase.
-
-
Stable Isotope-Labeled Internal Standards:
-
Synthesized stable isotope-labeled analogs of N2-MeG and N7-MeG (e.g., [¹³C,¹⁵N]-labeled) are added to the hydrolyzed DNA samples. These internal standards are crucial for accurate quantification, as they co-elute with the target analytes and correct for variations in sample processing and instrument response.
-
-
LC-MS/MS Analysis:
-
The mixture of deoxyribonucleosides is injected into a high-performance liquid chromatography (HPLC) system coupled to a tandem mass spectrometer (MS/MS).
-
The different deoxyribonucleosides are separated by the HPLC column based on their physicochemical properties.
-
The mass spectrometer is operated in multiple reaction monitoring (MRM) mode. This involves selecting the specific precursor ion (the protonated molecular ion of the adduct) and then fragmenting it to produce a characteristic product ion. The specific precursor-to-product ion transition for each adduct and its internal standard is monitored.
-
-
Data Analysis:
-
The amount of N2-MeG and N7-MeG in the sample is quantified by comparing the peak area of the analyte to that of its corresponding internal standard.
-
The results are typically expressed as the number of adducts per 10⁶ or 10⁷ normal nucleotides.
-
In Vitro DNA Polymerase Fidelity Assay (Single-Nucleotide Insertion Kinetics)
This assay determines the efficiency and fidelity with which a DNA polymerase bypasses a specific DNA lesion.
-
Oligonucleotide Template-Primer Design:
-
A short single-stranded DNA oligonucleotide containing a site-specific N2-MeG or N7-MeG adduct is synthesized.
-
A shorter, complementary primer is annealed to the template, with the 3'-end of the primer positioned just before the lesion. The 5'-end of the primer is typically labeled with a fluorescent dye or ³²P for detection.
-
-
Single-Nucleotide Incorporation Reaction:
-
The template-primer duplex is incubated with a specific DNA polymerase and a single type of deoxynucleoside triphosphate (dNTP) (dATP, dCTP, dGTP, or dTTP).
-
The reaction is allowed to proceed for a short time to ensure that only a single nucleotide is incorporated.
-
-
Product Analysis:
-
The reaction is stopped, and the DNA products are separated by size using denaturing polyacrylamide gel electrophoresis (PAGE).
-
The amount of extended primer (product) and unextended primer (substrate) is quantified using a phosphorimager or fluorescence scanner.
-
-
Kinetic Analysis:
-
The initial velocity of nucleotide incorporation is measured at various dNTP concentrations.
-
The data are fitted to the Michaelis-Menten equation to determine the kinetic parameters Vmax (maximum velocity) and Km (Michaelis constant).
-
The efficiency of incorporation (Vmax/Km) for each correct and incorrect nucleotide opposite the lesion is calculated. The fidelity of the polymerase is determined by comparing the incorporation efficiency of the correct nucleotide to that of the incorrect nucleotides.
-
Cytotoxicity Assay (MTT Assay)
The MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) assay is a colorimetric assay for assessing cell metabolic activity, which is an indicator of cell viability.
-
Cell Culture and Treatment:
-
Cells are seeded in a 96-well plate and allowed to attach overnight.
-
The cells are then treated with various concentrations of an alkylating agent known to induce N2-MeG and/or N7-MeG. Control cells are left untreated.
-
-
MTT Incubation:
-
After the desired treatment period, the culture medium is replaced with fresh medium containing MTT.
-
The plate is incubated for a few hours, during which viable cells with active mitochondrial dehydrogenases reduce the yellow MTT to purple formazan crystals.
-
-
Solubilization and Absorbance Measurement:
-
A solubilizing agent (e.g., DMSO or a specialized detergent solution) is added to each well to dissolve the formazan crystals.
-
The absorbance of the resulting purple solution is measured using a microplate reader at a wavelength of approximately 570 nm.
-
-
Data Analysis:
-
The absorbance values are proportional to the number of viable cells.
-
The percentage of cell viability is calculated for each treatment concentration relative to the untreated control.
-
The IC50 value (the concentration of the agent that causes 50% inhibition of cell viability) can be determined from the dose-response curve.
-
Signaling Pathways and Experimental Workflows
The following diagrams, generated using Graphviz (DOT language), illustrate key signaling pathways and experimental workflows related to the biological effects of N2-methylguanine and N7-methylguanine.
Caption: DNA damage response pathway for N7-methylguanine.
Caption: DNA damage response pathway for N2-methylguanine.
Caption: Workflow for DNA adduct quantification by LC-MS/MS.
Conclusion
The biological consequences of N2-methylguanine and N7-methylguanine are markedly different, underscoring the importance of the precise location of DNA adducts. N7-MeG, while being the more abundant lesion from many alkylating agents, is chemically labile and generally considered less directly mutagenic, although its degradation products pose a significant threat. Its repair is efficiently handled by the base excision repair pathway. In contrast, N2-MeG, particularly when part of a bulkier adduct, can present a more formidable challenge to the cell, potentially blocking DNA replication and transcription and requiring the more complex transcription-coupled nucleotide excision repair pathway. The distinct mutagenic signatures and repair mechanisms of these two adducts have profound implications for chemical carcinogenesis and the design of chemotherapeutic agents. This guide provides a foundational understanding for researchers aiming to further elucidate the intricate interplay between DNA damage, repair, and cellular fate.
References
- 1. Studying the DNA damage response pathway in hematopoietic canine cancer cell lines, a necessary step for finding targets to generate new therapies to treat cancer in dogs - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Genotoxic effects of the major alkylation damage N7-methylguanine and methyl formamidopyrimidine - PMC [pmc.ncbi.nlm.nih.gov]
- 3. mdpi.com [mdpi.com]
- 4. Genotoxic effects of the major alkylation damage N7-methylguanine and methyl formamidopyrimidine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Transcription blocking properties and transcription-coupled repair of N2-alkylguanine adducts as a model for aldehyde-induced DNA damage - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Quantification of Intracellular DNA–Protein Cross-Links with N7-Methyl-2′-Deoxyguanosine and Their Contribution to Cytotoxicity - PMC [pmc.ncbi.nlm.nih.gov]
Structural and functional comparison of N2-methylguanosine and N2,N2-dimethylguanosine.
A Comprehensive Guide to N2-Methylguanosine (m2G) and N2,N2-Dimethylguanosine (m2,2G): Structure, Function, and Experimental Considerations
For Researchers, Scientists, and Drug Development Professionals
N2-methylguanosine (m2G) and N2,N2-dimethylguanosine (m2,2G) are post-transcriptional modifications of RNA that play crucial roles in fine-tuning RNA structure and function. While both involve methylation of the exocyclic amine of guanosine, the addition of a second methyl group imparts distinct structural and functional properties to m2,2G. This guide provides a detailed comparison of these two important RNA modifications, supported by experimental data and methodologies.
Structural Comparison: A Tale of One vs. Two Methyl Groups
The primary structural difference between m2G and m2,2G lies in the number of methyl groups attached to the nitrogen atom at position 2 of the guanine base.[1][2] This seemingly minor difference has profound implications for their base-pairing capabilities and overall impact on RNA structure.
Key Structural Differences:
| Feature | N2-Methylguanosine (m2G) | N2,N2-Dimethylguanosine (m2,2G) |
| Methylation | Single methyl group at the N2 position. | Two methyl groups at the N2 position. |
| Watson-Crick Base Pairing with Cytosine (C) | Can form a stable, canonical Watson-Crick base pair. The methyl group adopts an s-trans conformation.[1] | Sterically hindered from forming a canonical Watson-Crick base pair.[1][3] |
| Non-Canonical Base Pairing | Can form non-canonical base pairs with adenine (A) and uracil (U).[1] | Can form non-canonical base pairs with adenine (A) and uracil (U).[1] |
| G-A Base Pair Geometry | Forms a sheared G-A base pair.[1] | Induces a more stable imino-hydrogen bonded G-A base pair, preventing the sheared conformation.[1][3] |
Functional Comparison: From Subtle Regulation to Structural Scaffolding
Both m2G and m2,2G are integral to the function of various RNA species, most notably transfer RNA (tRNA) and ribosomal RNA (rRNA).[1][2][4] Their functional roles are intimately linked to the structural constraints they impose.
Functional Roles and Characteristics:
| Function/Characteristic | N2-Methylguanosine (m2G) | N2,N2-Dimethylguanosine (m2,2G) |
| Location in tRNA | Found at various positions, including 6, 7, 9, 10, 18, 26, and 27.[5] | Predominantly found at position 26 in the "D-arm" of eukaryotic tRNAs, often paired with A44.[2][3] |
| Impact on RNA Stability | Contributes to the overall structure and stability of RNA.[4] However, its incorporation can be isoenergetic with unmodified guanosine in certain contexts.[3][6] | Plays a critical role in ensuring the correct L-shaped tertiary structure of tRNA, acting as a "molecular chaperone" to prevent misfolding.[3][7] It tends to favor hairpin structures over duplexes.[1][2] |
| Role in Translation | The absence of m2G in tRNAs has been shown to impair protein synthesis.[8] It is thought to be important for the recognition of tRNA by aminoacyl-tRNA synthetases.[4] | Essential for efficient and accurate translation by maintaining the proper tRNA conformation.[7] |
| Enzymatic Synthesis ("Writers") | Installed by various S-adenosyl-L-methionine (SAM)-dependent methyltransferases (MTases). For example, TRMT11 and THUMPD3 are responsible for m2G at positions 10 and 6 of tRNAs, respectively.[1][8] | Primarily catalyzed by the Trm1 family of enzymes (TRMT1 in humans), which are also SAM-dependent MTases.[7] |
Experimental Protocols and Considerations
The study of m2G and m2,2G requires specialized techniques for their detection, quantification, and functional analysis.
Protocol 1: Detection and Differentiation by Reverse Transcription Signature
The presence of m2G and m2,2G can be detected during reverse transcription-based sequencing methods due to the misincorporation of nucleotides by reverse transcriptase at the modification site.
Methodology:
-
RNA Isolation: Isolate total RNA or the specific RNA species of interest from cells or tissues.
-
Primer Extension: Perform a primer extension reaction using a fluorescently or radioactively labeled primer that anneals downstream of the suspected modification site.
-
Reverse Transcription: Use a reverse transcriptase to synthesize cDNA. The presence of m2G and particularly m2,2G will cause the enzyme to pause or misincorporate nucleotides.
-
Analysis: Analyze the cDNA products on a sequencing gel or by capillary electrophoresis. The location of the pause or misincorporation identifies the modified nucleotide.
-
Differentiation: m2,2G typically induces a higher rate of misincorporation compared to m2G. The specific pattern of misincorporated bases can also help distinguish between the two modifications.[9]
Protocol 2: Enzymatic Demethylation for Sequencing
The steric hindrance caused by m2,2G can impede high-throughput sequencing.[10][11] Enzymatic demethylation can overcome this challenge.
Methodology:
-
RNA Fragmentation and Ligation: Prepare RNA sequencing libraries as per standard protocols.
-
Enzymatic Treatment: Treat the RNA with a specific AlkB mutant enzyme (e.g., D135S/L118V) that selectively removes one methyl group from m2,2G, converting it to m2G.[10][11]
-
Reverse Transcription and Sequencing: Proceed with the reverse transcription and sequencing steps. The conversion to m2G reduces the hindrance to the reverse transcriptase, improving sequencing read-through.
-
Data Analysis: Compare sequencing data from treated and untreated samples to identify the locations of m2,2G.
Signaling Pathways and Workflows
The formation of m2G and m2,2G is a key step in the maturation of tRNA and is essential for its function in protein synthesis.
Caption: Enzymatic pathway for the formation of m2G and m2,2G on tRNA.
Caption: Experimental workflow for the analysis of m2G and m2,2G in RNA.
References
- 1. Frontiers | N2-methylguanosine and N2, N2-dimethylguanosine in cytosolic and mitochondrial tRNAs [frontiersin.org]
- 2. researchgate.net [researchgate.net]
- 3. Effects of N2,N2-dimethylguanosine on RNA structure and stability: Crystal structure of an RNA duplex with tandem m2 2G:A pairs - PMC [pmc.ncbi.nlm.nih.gov]
- 4. medchemexpress.com [medchemexpress.com]
- 5. Structural and functional analyses of the archaeal tRNA m2G/m22G10 methyltransferase aTrm11 provide mechanistic insights into site specificity of a tRNA methyltransferase that contains common RNA-binding modules - PMC [pmc.ncbi.nlm.nih.gov]
- 6. academic.oup.com [academic.oup.com]
- 7. selleckchem.com [selleckchem.com]
- 8. academic.oup.com [academic.oup.com]
- 9. Human TRMT1 and TRMT1L paralogs ensure the proper modification state, stability, and function of tRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 10. medchemexpress.com [medchemexpress.com]
- 11. medchemexpress.com [medchemexpress.com]
N7-Methylguanine's Subtle Influence on Duplex DNA: A Structural Comparison to Unmodified DNA
For researchers, scientists, and professionals in drug development, understanding the structural nuances of DNA modifications is paramount. N7-methylguanine (m7G), a common form of DNA damage, presents a compelling case study. While not grossly distorting the iconic double helix, its presence introduces subtle yet significant alterations compared to unmodified DNA. This guide provides a comprehensive comparison, supported by experimental data, to elucidate the structural and functional consequences of this prevalent DNA lesion.
At a Glance: Unmodified vs. N7-Methylguanine-Containing DNA
| Structural Parameter | Unmodified B-DNA | N7-Methylguanine (m7G) Modified DNA | Key Observations |
| Overall Duplex Structure | Canonical right-handed double helix.[1] | Largely maintains B-form conformation without significant distortion.[2][3] | m7G is not a major structure-disrupting lesion.[2] |
| Base Pairing | Watson-Crick pairing: Guanine (G) forms three hydrogen bonds with Cytosine (C).[4] | m7G paired with Cytosine (m7G:C) shows nearly identical base pairing to G:C.[3] When paired with Thymine (m7G:T), it can adopt a Watson-Crick-like geometry with three hydrogen bonds, suggesting a shift to the enol tautomer of m7G.[5][6][7] | N7-methylation can alter hydrogen bonding patterns in mismatched pairs.[5][6][7] |
| Duplex Stability (Melting Temperature, Tm) | Sequence-dependent. | A slight decrease in Tm has been observed in some contexts.[8] However, an m7G:T mispair can have a stabilizing effect.[9] | The effect on thermal stability appears to be context-dependent. |
| Chemical Stability | Generally stable under physiological conditions. | The N7-methylated guanine is chemically labile and prone to spontaneous depurination, creating an abasic site.[10][11] | The instability of the m7G adduct itself is a key characteristic. |
| Recognition by DNA Repair Proteins | Not recognized by repair machinery in its native state. | The lack of significant structural distortion suggests that repair proteins like AlkA and Aag may recognize m7G through mechanisms other than shape complementarity, possibly involving DNA dynamics or steric clashes.[2][3] | The subtle nature of the modification poses a unique challenge for cellular repair mechanisms. |
Visualizing the Structural Comparison
The following diagram illustrates the key structural features of unmodified DNA versus DNA containing an N7-methylguanine modification.
Caption: Comparison of Unmodified and m7G DNA Structures.
Experimental Methodologies
The characterization of N7-methylguanine's effects on DNA structure relies on a combination of high-resolution biophysical and computational techniques.
Nuclear Magnetic Resonance (NMR) Spectroscopy
-
Objective: To determine the three-dimensional structure of DNA in solution and to probe its dynamic properties.
-
Methodology:
-
Sample Preparation: A short DNA oligonucleotide containing a site-specific N7-methylguanine is synthesized. Due to the instability of m7G, this often requires specialized chemical and enzymatic synthesis strategies.[2] The DNA is then dissolved in a suitable buffer.
-
Data Acquisition: A series of 1D and 2D NMR experiments (e.g., COSY, TOCSY, NOESY) are performed. NOESY (Nuclear Overhauser Effect Spectroscopy) is particularly crucial as it provides distance constraints between protons that are close in space.
-
Resonance Assignment: The signals in the NMR spectra are assigned to specific protons in the DNA molecule.
-
Structural Calculation: The distance and dihedral angle restraints derived from the NMR data are used as input for computational algorithms to generate a family of 3D structures consistent with the experimental data.
-
Analysis: The resulting structures are analyzed to determine helical parameters, base pairing geometry, and any local conformational changes.
-
X-ray Crystallography
-
Objective: To obtain a high-resolution, static picture of the DNA molecule in a crystalline state.
-
Methodology:
-
Synthesis and Purification: An oligonucleotide with a site-specific m7G is synthesized and purified to a high degree. To overcome the instability of m7G for crystallography, a 2'-fluorine-mediated transition-state destabilization strategy has been employed to stabilize the adduct.[5][6]
-
Crystallization: The purified DNA is subjected to a wide range of conditions (e.g., varying pH, salt concentration, temperature) to induce the formation of well-ordered crystals.
-
X-ray Diffraction: The crystals are exposed to a high-intensity X-ray beam. The electrons in the atoms of the DNA molecule diffract the X-rays, producing a pattern of spots.
-
Data Processing and Structure Solution: The intensities and positions of the diffraction spots are used to calculate an electron density map. A model of the DNA structure is then built into this map and refined.
-
Structural Analysis: The final atomic coordinates provide precise information about bond lengths, angles, and the overall conformation of the DNA duplex.
-
Molecular Dynamics (MD) Simulations
-
Objective: To simulate the dynamic behavior of DNA over time to understand its flexibility and conformational landscape.[12][13]
-
Methodology:
-
System Setup: An initial 3D model of the m7G-containing DNA duplex is generated. This model is placed in a simulation box filled with water molecules and ions to mimic physiological conditions.[14]
-
Force Field Application: A classical force field (a set of parameters describing the potential energy of the system) is applied to all atoms.
-
Simulation: Newton's equations of motion are solved iteratively for all atoms in the system, generating a trajectory of atomic positions and velocities over time. This process is computationally intensive.
-
Trajectory Analysis: The resulting trajectory is analyzed to extract information about structural parameters (e.g., helical twist, roll, slide), hydrogen bonding patterns, and the overall flexibility of the DNA molecule.[12]
-
The following workflow diagram illustrates the general process for studying DNA structure using these techniques.
Caption: General workflow for DNA structural analysis.
Conclusion
The presence of N7-methylguanine in duplex DNA does not induce large-scale structural perturbations typically associated with bulky adducts. Instead, it introduces subtle changes in hydrogen bonding potential and chemical stability. NMR, X-ray crystallography, and MD simulations have been instrumental in revealing that the overall B-form helix is maintained. This has profound implications for its biological processing, suggesting that its recognition by repair enzymes is not based on significant structural distortion but likely on more nuanced features such as altered DNA dynamics or direct steric hindrance. For drug development, particularly in the context of alkylating agents, understanding these subtle yet critical effects is essential for predicting the biological consequences of DNA damage and for designing more effective therapeutic strategies.
References
- 1. davuniversity.org [davuniversity.org]
- 2. The effects of N7-methylguanine on duplex DNA structure - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Synthesis and structure of duplex DNA containing the genotoxic nucleobase lesion N7-methylguanine. | Semantic Scholar [semanticscholar.org]
- 4. d-nb.info [d-nb.info]
- 5. researchgate.net [researchgate.net]
- 6. N7 Methylation Alters Hydrogen Bonding Patterns of Guanine in Duplex DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 7. N7 methylation alters hydrogen-bonding patterns of guanine in duplex DNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Structural and kinetic studies of the effect of guanine-N7 alkylation and metal cofactors on DNA replication - PMC [pmc.ncbi.nlm.nih.gov]
- 9. repositories.lib.utexas.edu [repositories.lib.utexas.edu]
- 10. The Formation and Biological Significance of N7-Guanine Adducts - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. Understanding the structural and dynamic consequences of DNA epigenetic modifications: Computational insights into cytosine methylation and hydroxymethylation - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Molecular dynamics simulations of DNA-DNA and DNA-protein interactions - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. The role of methylation in the intrinsic dynamics of B- and Z-DNA [pubmed.ncbi.nlm.nih.gov]
N2 vs. N7 Modified mRNA Cap Analogues: A Comparative Guide to Inhibitory Efficacy
For researchers, scientists, and drug development professionals, understanding the nuances of mRNA cap analogue modifications is critical for designing potent inhibitors of cap-dependent translation, a key mechanism in protein synthesis and a target for therapeutic intervention. This guide provides an objective comparison of the inhibitory efficacy of N2- and N7-modified mRNA cap analogues, supported by experimental data and detailed methodologies.
The 5' cap structure of mRNA, typically a 7-methylguanosine (m7G), is essential for the initiation of translation. It is recognized by the eukaryotic initiation factor 4E (eIF4E), a crucial step for ribosome recruitment. Modifications to this cap structure can significantly alter its binding affinity to eIF4E, thereby modulating translation efficiency. Synthetic cap analogues that competitively bind to eIF4E can act as potent inhibitors of this process. This guide focuses on comparing modifications at two key positions on the guanine base: the N2 and N7 positions.
Quantitative Comparison of Inhibitory Efficacy
The inhibitory potential of different cap analogues is typically quantified by their half-maximal inhibitory concentration (IC50), which represents the concentration of an analogue required to reduce the activity of a biological process (in this case, cap-dependent translation) by 50%. A lower IC50 value indicates a more potent inhibitor.
The following table summarizes the IC50 values for various N2- and N7-modified mRNA cap analogues, as determined by in vitro translation inhibition assays in a rabbit reticulocyte lysate (RRL) system.
| Cap Analogue | Modification Position | Substituent | IC50 (µM) | Reference |
| m7GpppG | N7 | Methyl | ~10-20 | [1] |
| bn7GMP | N7 | Benzyl | - | [2] |
| bn2m7,2ʹOGpppG | N2 & N7 | Benzyl & Methyl | - | [1] |
| (4-Cl-bn)2m7GppppG | N2 & N7 | 4-Chlorobenzyl & Methyl | 0.60 ± 0.29 | [3] |
| bn2m7GppppG | N2 & N7 | Benzyl & Methyl | 0.43 ± 0.16 | [3] |
| N2-p-methoxybenzyl-7-methylguanosine-5′-monophosphate | N2 & N7 | p-methoxybenzyl & Methyl | ~0.9 | [1] |
| Doubly modified monophosphate (N2 and N7) | N2 & N7 | Aromatic substituent & Benzyl | 2.70 ± 0.30 | [2] |
| N2-only modified monophosphate | N2 | Aromatic substituent | 1.80 ± 0.21 | [2] |
Key Observations:
-
N2 modifications can be highly effective: Analogues with aromatic substituents at the N2 position have demonstrated strong inhibitory properties, in some cases being more effective than the standard m7GpppG.[1] For instance, N2-p-methoxybenzyl-7-methylguanosine-5′-monophosphate showed a significantly lower IC50 value.[1]
-
N7 modifications beyond methyl can enhance inhibition: Replacing the N7-methyl group with a larger aromatic group, such as a benzyl group, can lead to increased inhibitory activity.[4]
-
Synergistic effects of dual modifications: Combining modifications at both the N2 and N7 positions can result in highly potent inhibitors.[2][5] However, the interplay is complex, and the resulting efficacy can be dependent on the specific substituents used.[2] For example, one study showed that a doubly modified monophosphate had a higher IC50 (lower potency) than its N2-only modified counterpart, suggesting that not all dual modifications are beneficial.[2]
-
Phosphate chain length matters: The presence of a tetraphosphate bridge in some N2-modified analogues has been shown to enhance their inhibitory effect.[3]
Experimental Protocols
The determination of the inhibitory efficacy of mRNA cap analogues is predominantly carried out using in vitro translation assays. A common and well-established method is the use of a rabbit reticulocyte lysate (RRL) system.
In Vitro Translation Inhibition Assay in Rabbit Reticulocyte Lysate
This assay measures the ability of a cap analogue to inhibit the translation of a reporter mRNA in a cell-free system that contains all the necessary components for protein synthesis.
Materials:
-
Rabbit Reticulocyte Lysate (commercially available)
-
Reporter mRNA (e.g., Firefly Luciferase mRNA) with a standard m7G cap
-
N2- and N7-modified cap analogues of interest
-
Amino acid mixture (including a radiolabeled amino acid like [35S]-methionine or a non-radioactive mixture for luminescence-based assays)
-
Nuclease-free water
Procedure:
-
Reaction Setup: In a microcentrifuge tube, combine the rabbit reticulocyte lysate, the amino acid mixture, and the reporter mRNA at a predetermined optimal concentration.
-
Addition of Inhibitors: Add varying concentrations of the N2- or N7-modified cap analogues to the reaction mixtures. A control reaction with no added analogue is essential.
-
Incubation: Incubate the reactions at 30°C for a specified period, typically 60-90 minutes, to allow for translation to occur.[6]
-
Analysis of Protein Synthesis: The amount of newly synthesized protein is quantified. This can be done by:
-
Radiolabeling: If a radiolabeled amino acid was used, the proteins are separated by SDS-PAGE, and the incorporated radioactivity is measured using autoradiography or phosphorimaging.
-
Luminescence: If a luciferase reporter mRNA was used, the luciferase activity is measured by adding a substrate and quantifying the light output with a luminometer.
-
-
Data Analysis: The percentage of translation inhibition for each concentration of the cap analogue is calculated relative to the control reaction. The IC50 value is then determined by plotting the percentage of inhibition against the logarithm of the analogue concentration and fitting the data to a dose-response curve.[7]
Visualizing the Experimental Workflow
The following diagram illustrates the general workflow for assessing the inhibitory efficacy of mRNA cap analogues.
Caption: Workflow for determining the inhibitory efficacy of mRNA cap analogues.
Conclusion
Both N2 and N7 positions of the guanine cap are viable targets for modification to create potent inhibitors of cap-dependent translation. The introduction of aromatic substituents at the N2 position has proven to be a particularly effective strategy. Furthermore, the synergistic modification of both N2 and N7 positions holds promise for the development of next-generation inhibitors, although careful selection of substituents is crucial to achieve enhanced potency. The in vitro translation assay in a rabbit reticulocyte lysate system remains the gold standard for evaluating and comparing the inhibitory efficacy of these novel cap analogues. This guide provides a foundational understanding for researchers aiming to design and screen effective modulators of mRNA translation.
References
- 1. N2 modified cap analogues as translation inhibitors and substrates for preparation of therapeutic mRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 2. mdpi.com [mdpi.com]
- 3. Frontiers | The potential of N2-modified cap analogues for precise genetic manipulation through mRNA engineering [frontiersin.org]
- 4. Inhibition of eukaryotic translation by nucleoside 5'-monophosphate analogues of mRNA 5'-cap: changes in N7 substituent affect analogue activity - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Novel cap analogs for in vitro synthesis of mRNAs with high translational efficiency - PMC [pmc.ncbi.nlm.nih.gov]
- 6. benchchem.com [benchchem.com]
- 7. The potential of N2-modified cap analogues for precise genetic manipulation through mRNA engineering - PMC [pmc.ncbi.nlm.nih.gov]
A Head-to-Head Battle in the Clinical Lab: LC-MS/MS vs. HPLC-UV for Sample Analysis
For researchers, scientists, and drug development professionals navigating the complexities of clinical sample analysis, the choice of analytical technique is paramount. This guide provides an objective comparison of two stalwart methods: Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS) and High-Performance Liquid Chromatography with Ultraviolet detection (HPLC-UV). Supported by experimental data, this document delves into the performance, methodologies, and core principles of each, offering a comprehensive resource for informed decision-making.
At the heart of clinical diagnostics and pharmaceutical development lies the need for accurate and reliable measurement of analytes in complex biological matrices. Both LC-MS/MS and HPLC-UV have carved out significant roles in this domain, yet they offer distinct advantages and limitations. While HPLC-UV has long been a workhorse due to its simplicity and cost-effectiveness, LC-MS/MS has emerged as a powerhouse, offering unparalleled sensitivity and specificity.
Quantitative Performance: A Data-Driven Comparison
The selection of an analytical method often hinges on its quantitative performance. The following tables summarize key performance indicators for LC-MS/MS and HPLC-UV in the analysis of various clinical samples, providing a clear, data-centric overview.
| Analyte Class | Technique | Sensitivity (Lower Limit of Quantification, LLOQ) | Specificity | Linearity (r²) | Throughput | Reference |
| Therapeutic Drugs | ||||||
| Meropenem & Piperacillin | LC-MS/MS | Meropenem: 0.08 mg/L; Piperacillin: 0.2 mg/L | High (mass-based) | >0.99 | High (multiplexing possible) | [1][2][3] |
| HPLC-UV | Meropenem: 0.2 mg/L; Piperacillin: 2.0 mg/L | Moderate (potential interferences) | >0.99 | Moderate | [1][2][3] | |
| Immunosuppressants (e.g., Tacrolimus) | LC-MS/MS | 0.1 - 0.5 ng/mL | Very High | >0.99 | High (multiplexing) | [4][5] |
| HPLC-UV | 1 - 5 ng/mL | Lower (cross-reactivity) | >0.98 | Lower | [6] | |
| Steroid Hormones | ||||||
| Cortisol | LC-MS/MS | 0.1 - 0.5 ng/mL | Very High | >0.99 | High | [7] |
| HPLC-UV | 1 - 10 ng/mL | Moderate (isobaric interferences) | >0.99 | Moderate | [7] | |
| Vitamins | ||||||
| Vitamin D Metabolites (25-OH-D3) | LC-MS/MS | 0.5 - 2 ng/mL | High (separates epimers) | >0.99 | High | |
| HPLC-UV | 5 - 10 ng/mL | Lower (co-elution of isomers) | >0.99 | Moderate | ||
| Catecholamines | ||||||
| Epinephrine, Norepinephrine | LC-MS/MS | 10 - 50 pg/mL | Very High | >0.99 | High | [8][9] |
| HPLC-ECD* | 50 - 100 pg/mL | Moderate (potential interferences) | >0.99 | Moderate | [10][11] |
*Note: For catecholamines, HPLC is more commonly coupled with Electrochemical Detection (ECD) rather than UV for enhanced sensitivity.
Experimental Protocols: A Look Under the Hood
To provide a practical understanding of the application of these techniques, detailed methodologies for key experiments are outlined below.
Analysis of Meropenem in Human Serum by LC-MS/MS
This protocol describes a typical workflow for the therapeutic drug monitoring of the antibiotic meropenem.
1. Sample Preparation:
-
To 100 µL of serum, add 20 µL of an internal standard solution (e.g., Meropenem-d6).
-
Precipitate proteins by adding 300 µL of acetonitrile.
-
Vortex for 1 minute and centrifuge at 10,000 x g for 10 minutes.
-
Transfer the supernatant to a clean tube and evaporate to dryness under a stream of nitrogen.
-
Reconstitute the residue in 100 µL of the mobile phase.
2. LC-MS/MS Conditions:
-
LC System: A high-performance liquid chromatography system.
-
Column: A C18 reversed-phase column (e.g., 50 x 2.1 mm, 1.8 µm).
-
Mobile Phase: A gradient of 0.1% formic acid in water (A) and 0.1% formic acid in acetonitrile (B).
-
Flow Rate: 0.4 mL/min.
-
Injection Volume: 5 µL.
-
Mass Spectrometer: A triple quadrupole mass spectrometer with an electrospray ionization (ESI) source.
-
Ionization Mode: Positive.
-
MRM Transitions: Monitor specific precursor-to-product ion transitions for meropenem and its internal standard.
Analysis of an Analyte in Human Plasma by HPLC-UV
This protocol provides a general workflow for the quantification of a drug in plasma using HPLC-UV.
1. Sample Preparation:
-
To 500 µL of plasma, add 50 µL of an appropriate internal standard.
-
Perform liquid-liquid extraction by adding 2 mL of a suitable organic solvent (e.g., ethyl acetate).
-
Vortex for 2 minutes and centrifuge at 3000 x g for 10 minutes.
-
Transfer the organic layer to a new tube and evaporate to dryness.
-
Reconstitute the residue in 200 µL of the mobile phase.
2. HPLC-UV Conditions:
-
HPLC System: A standard high-performance liquid chromatography system.
-
Column: A C18 reversed-phase column (e.g., 150 x 4.6 mm, 5 µm).
-
Mobile Phase: An isocratic or gradient mixture of a buffer (e.g., phosphate buffer) and an organic solvent (e.g., acetonitrile).
-
Flow Rate: 1.0 mL/min.
-
Injection Volume: 20 µL.
-
UV Detector: Set to a wavelength where the analyte exhibits maximum absorbance.
Visualizing the Workflow and Key Differences
To further clarify the processes and the comparative aspects of LC-MS/MS and HPLC-UV, the following diagrams are provided.
Conclusion: Selecting the Right Tool for the Job
The choice between LC-MS/MS and HPLC-UV is not a matter of one being definitively superior to the other, but rather a decision based on the specific requirements of the analysis.
LC-MS/MS is the undisputed champion when:
-
High sensitivity and specificity are critical. This is particularly true for low-concentration analytes, complex matrices, and when distinguishing between structurally similar compounds.[7]
-
Multiplexing is desired. The ability to analyze multiple analytes in a single run significantly increases throughput.[4]
-
Structural confirmation is necessary. Mass spectrometry provides molecular weight and fragmentation data, offering a higher degree of confidence in analyte identification.
HPLC-UV remains a valuable and practical choice when:
-
Cost is a major consideration. The instrumentation and operational costs are significantly lower than for LC-MS/MS.[12]
-
The analytes are present at relatively high concentrations and have a strong UV chromophore.
-
The sample matrix is relatively clean, minimizing the risk of interferences.
-
A robust and straightforward method is preferred. Method development and routine operation are generally less complex than with LC-MS/MS.[3]
For many routine applications, a well-validated HPLC-UV method can provide reliable and accurate results.[3] However, for challenging assays, trace-level quantification, and in research settings where unambiguous identification is paramount, the analytical power of LC-MS/MS is indispensable. Ultimately, a thorough understanding of the analytical needs, coupled with the information presented in this guide, will enable researchers and scientists to make the most appropriate and effective choice for their clinical sample analysis.
References
- 1. Comparative LC-MS/MS and HPLC-UV Analyses of Meropenem and Piperacillin in Critically Ill Patients - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Comparative LC-MS/MS and HPLC-UV Analyses of Meropenem and Piperacillin in Critically Ill Patients. | Semantic Scholar [semanticscholar.org]
- 3. researchgate.net [researchgate.net]
- 4. ICI Journals Master List [journals.indexcopernicus.com]
- 5. LC-MS/MS for immunosuppressant therapeutic drug monitoring. | Semantic Scholar [semanticscholar.org]
- 6. Review of Chromatographic Methods Coupled with Modern Detection Techniques Applied in the Therapeutic Drugs Monitoring (TDM) - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. data.biotage.co.jp [data.biotage.co.jp]
- 9. agilent.com [agilent.com]
- 10. A Convenient Method for Extraction and Analysis with High-Pressure Liquid Chromatography of Catecholamine Neurotransmitters and Their Metabolites - PMC [pmc.ncbi.nlm.nih.gov]
- 11. mdpi.com [mdpi.com]
- 12. researchgate.net [researchgate.net]
A Researcher's Guide to Natural Product Screening: A Comparative Analysis of LC-HR-MS² and MS³
In the intricate world of natural product discovery, researchers are constantly seeking more sensitive and specific methods to identify novel bioactive compounds from complex biological matrices. High-resolution mass spectrometry (HR-MS) coupled with liquid chromatography (LC) has become an indispensable tool in this endeavor. This guide provides a detailed comparison of two powerful tandem mass spectrometry techniques: high-resolution tandem mass spectrometry (MS²) and multi-stage mass spectrometry (MS³), offering insights into their respective strengths and optimal applications in natural product screening.
Core Principles: Understanding MS² and MS³
Liquid chromatography-high-resolution mass spectrometry (LC-HR-MS) is a cornerstone for compound screening.[1][2][3] In a typical tandem MS (MS²) experiment, a precursor ion of interest is selected, fragmented, and the resulting product ions are analyzed to elucidate the structure of the parent molecule. MS³ takes this a step further: a specific product ion from the MS² scan is isolated and fragmented again, providing an additional layer of structural information.[4] This multi-stage fragmentation can be particularly advantageous for distinguishing between structurally similar compounds.
Quantitative Performance: A Side-by-Side Comparison
While both techniques are adept at identifying compounds, MS³ can offer enhanced performance in specific scenarios, particularly when dealing with complex samples or isomeric compounds. A study comparing the two methods for the screening of 85 toxic natural products in serum and urine found that for a small subset of these compounds, MS³ provided better identification at lower concentrations.[1][2][3][4][5]
| Performance Metric | LC-HR-MS² | LC-HR-MS³ | Key Insights |
| Compound Identification | High | High | For the majority of analytes (92-96%), both methods provide identical identification results.[1][2][3][4][5] |
| Low Concentration Identification | Good | Superior for a subset of analytes | MS³ can extend the identification of a small number of compounds to lower concentrations where MS² may fail.[4][5] |
| Isomer Differentiation | Challenging for some isomers | Superior | The additional fragmentation step in MS³ can generate unique fragment ions for structural isomers that may appear identical in MS² spectra.[6] |
| Limit of Detection (LOD) | Variable | Generally Better | In one study, the MS³ assay demonstrated a better LOD for 43 out of 80 analytes compared to the MS² assay, which was superior for 21 analytes.[6] |
| Signal-to-Noise (S/N) Ratio | Good | Often Higher | By reducing matrix interference through an additional fragmentation step, MS³ can achieve a higher signal-to-noise ratio.[7] |
| Analysis Speed | Faster | Slower | MS² is a faster method as it involves one less fragmentation step.[8] |
| Data Complexity | High | Higher | The additional fragmentation stage in MS³ generates more complex datasets that may require more sophisticated data analysis approaches. |
Experimental Protocols
The following provides a generalized methodology for the screening of natural products using LC-HR-MS² and MS³.
Sample Preparation
-
Extraction: Natural product samples (e.g., plant material, microbial cultures) are typically extracted using an appropriate solvent (e.g., methanol, ethyl acetate) to isolate the compounds of interest.
-
Spiking (for quantitative analysis): For method validation and quantitative studies, samples such as drug-free serum and urine can be spiked with a known concentration of natural product standards.[1][2][3] To avoid ion suppression, standards, especially structural isomers, may be divided into groups for analysis.[1][2][3]
-
Cleanup: Solid-phase extraction (SPE) or liquid-liquid extraction may be employed to remove interfering substances from the sample matrix.
LC-HR-MS Analysis
-
Chromatography: Separation of the extracted compounds is performed using a high-performance liquid chromatography (HPLC) or ultra-high-performance liquid chromatography (UHPLC) system, typically with a C18 column. A gradient elution with solvents such as water with formic acid (A) and acetonitrile with formic acid (B) is commonly used.
-
Mass Spectrometry: The eluent from the LC system is introduced into a high-resolution mass spectrometer (e.g., an Orbitrap or Q-TOF).
-
Data Acquisition (MS²): The mass spectrometer is operated in a data-dependent acquisition (DDA) mode. A full scan MS¹ survey is performed to detect precursor ions. The most intense ions are then selected for fragmentation (MS²) via collision-induced dissociation (CID) or higher-energy collisional dissociation (HCD).
-
Data Acquisition (MS³): For an MS³ experiment, a specific product ion from the MS² scan is further isolated and fragmented.[4] This is often triggered in a data-dependent manner upon the detection of a specific fragment or neutral loss in the MS² spectrum.[9]
Data Analysis
-
Spectral Matching: The acquired MS² and MS³ spectra are matched against a spectral library for compound identification.[1][2][3][4]
-
Dereplication: The identified compounds are compared against databases of known natural products to distinguish novel compounds from previously discovered ones.
Visualizing the Workflow and Logic
To better understand the practical application and fundamental differences between these techniques, the following diagrams illustrate a typical experimental workflow and the logical distinction between MS² and MS³ fragmentation.
References
- 1. Comparison of liquid chromatography-high-resolution tandem mass spectrometry (MS2) and multi-stage mass spectrometry (MS3) for screening toxic natural products - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Comparison of liquid chromatography-high-resolution tandem mass spectrometry (MS2) and multi-stage mass spectrometry (MS3) for screening toxic natural products. [escholarship.org]
- 3. researchgate.net [researchgate.net]
- 4. Comparison of liquid chromatography-high-resolution tandem mass spectrometry (MS2) and multi-stage mass spectrometry (MS3) for screening toxic natural products - PMC [pmc.ncbi.nlm.nih.gov]
- 5. escholarship.org [escholarship.org]
- 6. myadlm.org [myadlm.org]
- 7. Comparison of LC-MS3 and LC-MRM Method for Quantifying Voriconazole and Its Application in Therapeutic Drug Monitoring of Human Plasma - PMC [pmc.ncbi.nlm.nih.gov]
- 8. documents.thermofisher.com [documents.thermofisher.com]
- 9. Comparison of MS2-only, MSA, and MS2/MS3 Methodologies for Phosphopeptide Identification - PMC [pmc.ncbi.nlm.nih.gov]
Safety Operating Guide
Navigating the Safe Disposal of 6-Hydroxy-2-methylaminopurine: A Comprehensive Guide
For researchers, scientists, and professionals in drug development, the proper handling and disposal of chemical compounds is a cornerstone of laboratory safety and environmental responsibility. This guide provides a detailed, procedural framework for the safe disposal of 6-Hydroxy-2-methylaminopurine, a purine analog also known as N2-Methylguanine. Adherence to these protocols is essential to mitigate risks and ensure compliance with safety regulations.
The primary directive for the disposal of any chemical is to consult its specific Safety Data Sheet (SDS).[1] This document provides comprehensive information regarding the substance's properties, hazards, and explicit disposal instructions. In the absence of a specific SDS for this compound, the following procedures, based on general guidelines for purine analogs and laboratory chemical waste, should be strictly followed.
I. Hazard Identification and Personal Protective Equipment (PPE)
Before initiating any disposal procedures, it is crucial to understand the potential hazards associated with this compound. While specific toxicity data may be limited, it is prudent to treat this compound with caution. It may cause irritation upon contact.[2]
Recommended Personal Protective Equipment (PPE):
| PPE Item | Specification | Purpose |
| Gloves | Chemical-resistant (e.g., nitrile) | To prevent skin contact. |
| Eye Protection | Safety goggles or face shield | To protect eyes from splashes or dust. |
| Lab Coat | Standard laboratory coat | To protect skin and clothing from contamination. |
| Respiratory Protection | NIOSH-approved respirator | Recommended if handling powders or creating aerosols. |
II. Step-by-Step Disposal Protocol
The disposal of this compound must be conducted in a designated area, preferably within a chemical fume hood to minimize inhalation exposure.
Step 1: Consultation and Preparation
-
Obtain and Review the SDS: If available, the Safety Data Sheet is the most critical resource for disposal information.
-
Consult Institutional Guidelines: Familiarize yourself with your institution's specific chemical waste disposal procedures and local regulations.[3]
-
Assemble Materials: Gather all necessary PPE and waste disposal containers.
Step 2: Waste Segregation and Collection
-
Solid Waste:
-
Liquid Waste (Solutions):
-
Contaminated Materials:
-
Any materials that have come into contact with this compound, such as gloves, weighing paper, or pipette tips, should be considered contaminated.
-
Place all contaminated disposable materials into the designated solid chemical waste container.
-
Step 3: Labeling and Storage
-
Proper Labeling: Clearly label the waste container with "Hazardous Waste," the full chemical name ("this compound"), and any known hazard symbols.
-
Secure Storage: Store the sealed waste container in a designated, well-ventilated, and secure area away from incompatible materials, such as strong oxidizing agents.[3] Keep the container tightly closed.[3][4]
Step 4: Final Disposal
-
Arrange for Pickup: Contact your institution's Environmental Health and Safety (EHS) office or a licensed chemical waste disposal contractor to arrange for the pickup and final disposal of the hazardous waste.
-
Documentation: Complete any required waste disposal forms or manifests as per your institution's protocol.
III. Emergency Procedures
In the event of a spill or exposure, immediate action is necessary.
| Emergency Scenario | Immediate Action |
| Spill | Contain the spill and collect the material as appropriate. Sweep up solids and transfer to a chemical waste container. Ensure adequate ventilation.[3] |
| Skin Contact | Wash the affected area immediately with plenty of soap and water.[4] |
| Eye Contact | Rinse cautiously with water for several minutes. Remove contact lenses if present and easy to do. Continue rinsing.[4] |
| Inhalation | Move to fresh air. If breathing is difficult, seek medical attention.[4] |
| Ingestion | Rinse mouth with water. Do not induce vomiting. Seek immediate medical attention. |
IV. Disposal Workflow Diagram
The following diagram illustrates the logical steps for the proper disposal of this compound.
Caption: Disposal workflow for this compound.
References
Personal protective equipment for handling 6-Hydroxy-2-methylaminopurine
For Researchers, Scientists, and Drug Development Professionals
This guide provides critical safety and logistical information for the handling and disposal of 6-Hydroxy-2-methylaminopurine (CAS RN: 10030-78-1), a purine analog that requires careful management in a laboratory setting. Due to its classification and potential bioactivity, adherence to these procedures is essential to ensure personnel safety and regulatory compliance.
Immediate Safety and Personal Protective Equipment (PPE)
Given that purine analogs can interfere with biological processes, a cautious approach is mandatory.[1] Treat this compound as a potentially hazardous substance. The following personal protective equipment is required to minimize exposure.
Table 1: Personal Protective Equipment (PPE) Requirements
| PPE Component | Specification | Rationale |
| Hand Protection | Double-layered nitrile gloves.[1] | Provides a robust barrier against chemical permeation.[1] |
| Body Protection | Standard lab coat. A chemically resistant apron or coveralls are recommended for procedures with a higher risk of contamination.[1] | Protects skin and clothing from incidental contact and splashes.[1] |
| Eye and Face Protection | Chemical splash goggles are mandatory. A face shield should be worn over goggles when there is a significant risk of splashes.[1] | Protects against accidental splashes and airborne particles. |
| Respiratory Protection | A NIOSH-approved respirator is necessary if there is a risk of aerosol generation and engineering controls are not sufficient.[1] | Prevents inhalation of potentially harmful aerosols or dust. |
Operational Plan: Step-by-Step Handling Procedures
All handling of solid or powdered this compound should be conducted within a certified chemical fume hood to minimize inhalation risks.[1]
1. Preparation and Weighing:
-
Before handling, ensure that the fume hood is functioning correctly.
-
When weighing the solid compound, do so within the fume hood.
-
Use a tared container to minimize the transfer of powder.[1]
2. Solution Preparation:
-
Slowly add the solid this compound to the solvent to prevent splashing.[1]
-
Keep all containers with the compound sealed when not in use.[1]
3. Post-Handling Decontamination:
-
Wipe down the work area within the fume hood with an appropriate solvent (e.g., 70% ethanol) to remove any residual contamination.[1]
-
Properly remove PPE in the correct order to avoid cross-contamination: first gloves, then face shield or goggles, and finally the lab coat.[1]
-
Thoroughly wash hands with soap and water after removing all PPE.[1]
Workflow for Handling this compound
Caption: Experimental workflow for handling this compound.
Disposal Plan
Contaminated materials and waste generated from handling this compound must be disposed of as hazardous chemical waste.
Table 2: Disposal Guidelines
| Waste Type | Disposal Procedure |
| Solid Waste | Collect in a designated, sealed, and clearly labeled hazardous waste container. |
| Liquid Waste | Collect in a designated, sealed, and clearly labeled hazardous waste container. |
| Contaminated PPE | Dispose of as hazardous waste in a designated container. Do not discard in regular trash. |
Follow all local, state, and federal regulations for hazardous waste disposal. If you are unsure about the proper disposal procedures, consult with your institution's Environmental Health and Safety (EHS) department.
Logical Relationship for Safe Disposal
References
Featured Recommendations
| Most viewed |
|
|
|---|---|---|
| Most popular with customers |
|
体外研究产品的免责声明和信息
请注意,BenchChem 上展示的所有文章和产品信息仅供信息参考。 BenchChem 上可购买的产品专为体外研究设计,这些研究在生物体外进行。体外研究,源自拉丁语 "in glass",涉及在受控实验室环境中使用细胞或组织进行的实验。重要的是要注意,这些产品没有被归类为药物或药品,他们没有得到 FDA 的批准,用于预防、治疗或治愈任何医疗状况、疾病或疾病。我们必须强调,将这些产品以任何形式引入人类或动物的身体都是法律严格禁止的。遵守这些指南对确保研究和实验的法律和道德标准的符合性至关重要。
