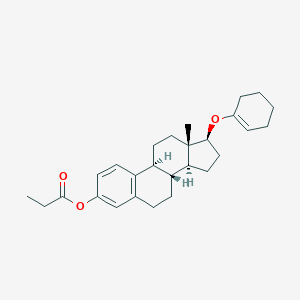
Orestrate
Description
Structure
3D Structure
Properties
IUPAC Name |
[(8R,9S,13S,14S,17S)-17-(cyclohexen-1-yloxy)-13-methyl-6,7,8,9,11,12,14,15,16,17-decahydrocyclopenta[a]phenanthren-3-yl] propanoate |
Source


|
|---|---|---|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI |
InChI=1S/C27H36O3/c1-3-26(28)30-20-10-12-21-18(17-20)9-11-23-22(21)15-16-27(2)24(23)13-14-25(27)29-19-7-5-4-6-8-19/h7,10,12,17,22-25H,3-6,8-9,11,13-16H2,1-2H3/t22-,23-,24+,25+,27+/m1/s1 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI Key |
VYAXJSIVAVEVHF-RYIFMDQWSA-N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Canonical SMILES |
CCC(=O)OC1=CC2=C(C=C1)C3CCC4(C(C3CC2)CCC4OC5=CCCCC5)C |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Isomeric SMILES |
CCC(=O)OC1=CC2=C(C=C1)[C@H]3CC[C@]4([C@H]([C@@H]3CC2)CC[C@@H]4OC5=CCCCC5)C |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Formula |
C27H36O3 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
DSSTOX Substance ID |
DTXSID80930230 |
Source
|
| Record name | Orestrate | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID80930230 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
Molecular Weight |
408.6 g/mol |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
CAS No. |
13885-31-9 |
Source
|
| Record name | Estra-1,3,5(10)-trien-3-ol, 17-(1-cyclohexen-1-yloxy)-, 3-propanoate, (17β)- | |
| Source | CAS Common Chemistry | |
| URL | https://commonchemistry.cas.org/detail?cas_rn=13885-31-9 | |
| Description | CAS Common Chemistry is an open community resource for accessing chemical information. Nearly 500,000 chemical substances from CAS REGISTRY cover areas of community interest, including common and frequently regulated chemicals, and those relevant to high school and undergraduate chemistry classes. This chemical information, curated by our expert scientists, is provided in alignment with our mission as a division of the American Chemical Society. | |
| Explanation | The data from CAS Common Chemistry is provided under a CC-BY-NC 4.0 license, unless otherwise stated. | |
| Record name | Orestrate [INN] | |
| Source | ChemIDplus | |
| URL | https://pubchem.ncbi.nlm.nih.gov/substance/?source=chemidplus&sourceid=0013885319 | |
| Description | ChemIDplus is a free, web search system that provides access to the structure and nomenclature authority files used for the identification of chemical substances cited in National Library of Medicine (NLM) databases, including the TOXNET system. | |
| Record name | Orestrate | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID80930230 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
| Record name | ORESTRATE | |
| Source | FDA Global Substance Registration System (GSRS) | |
| URL | https://gsrs.ncats.nih.gov/ginas/app/beta/substances/G9VC23W7W0 | |
| Description | The FDA Global Substance Registration System (GSRS) enables the efficient and accurate exchange of information on what substances are in regulated products. Instead of relying on names, which vary across regulatory domains, countries, and regions, the GSRS knowledge base makes it possible for substances to be defined by standardized, scientific descriptions. | |
| Explanation | Unless otherwise noted, the contents of the FDA website (www.fda.gov), both text and graphics, are not copyrighted. They are in the public domain and may be republished, reprinted and otherwise used freely by anyone without the need to obtain permission from FDA. Credit to the U.S. Food and Drug Administration as the source is appreciated but not required. | |
Foundational & Exploratory
The Orchestration of Gene Expression: A Technical Guide for Researchers
Audience: Researchers, scientists, and drug development professionals.
Introduction: The Symphony of the Genome
Gene expression is the intricate process by which the genetic information encoded in DNA is converted into functional products, such as proteins or functional RNA molecules. This process is not a simple linear pathway but a highly regulated and dynamic symphony of molecular interactions that orchestrate cellular function, differentiation, and response to the environment. Understanding the precise control of gene expression is fundamental to unraveling the complexities of biology and disease, and it is a cornerstone of modern drug discovery and development.
This technical guide provides an in-depth exploration of the core mechanisms governing the orchestration of gene expression. We will delve into the roles of signaling pathways in transmitting extracellular cues to the nucleus, the epigenetic modifications that shape the chromatin landscape, and the experimental techniques that allow us to interrogate these complex regulatory networks.
Core Mechanisms of Gene Expression Regulation
The regulation of gene expression occurs at multiple levels, from the accessibility of DNA to the final post-translational modification of proteins. Key control points include chromatin accessibility, transcription initiation, and post-transcriptional modifications.
Chromatin Accessibility and Epigenetic Modifications
In eukaryotic cells, DNA is packaged into a highly condensed structure called chromatin. For a gene to be transcribed, the chromatin must be in an "open" or accessible state, allowing transcription factors and RNA polymerase to bind to the DNA. The accessibility of chromatin is dynamically regulated by epigenetic modifications, which are chemical alterations to DNA or histone proteins that do not change the underlying DNA sequence.
Key epigenetic modifications include:
-
Histone Acetylation: Generally associated with active transcription, the addition of acetyl groups to histone tails neutralizes their positive charge, leading to a more relaxed chromatin structure.
-
Histone Methylation: The effect of histone methylation depends on the specific lysine or arginine residue that is methylated and the number of methyl groups added. For example, H3K4me3 is a mark of active promoters, while H3K27me3 is associated with transcriptional repression.[1][2][3]
-
DNA Methylation: The addition of a methyl group to cytosine bases, typically in the context of CpG dinucleotides, is often associated with gene silencing.[2]
Transcription Factors: The Master Conductors
Transcription factors (TFs) are proteins that bind to specific DNA sequences, known as promoter and enhancer regions, to control the rate of transcription. TFs can act as activators, recruiting co-activators and RNA polymerase to the transcription start site, or as repressors, blocking the binding of the transcriptional machinery. The activity of transcription factors is often regulated by upstream signaling pathways that are initiated by extracellular stimuli.
Signaling Pathways: Relaying the Message to the Nucleus
Cells constantly receive signals from their environment in the form of hormones, growth factors, and other signaling molecules. These signals are transmitted into the cell and ultimately to the nucleus through complex signaling pathways, which are cascades of protein-protein interactions and modifications. These pathways converge on transcription factors, altering their activity and leading to changes in gene expression.
The MAPK Signaling Pathway
The Mitogen-Activated Protein Kinase (MAPK) pathway is a key signaling cascade involved in regulating a wide range of cellular processes, including proliferation, differentiation, and apoptosis.[4][5] The pathway consists of a three-tiered kinase module: a MAP kinase kinase kinase (MAPKKK), a MAP kinase kinase (MAPKK), and a MAPK.[4][6] Activation of this cascade by extracellular signals, such as growth factors binding to receptor tyrosine kinases, leads to the phosphorylation and activation of a terminal MAPK (e.g., ERK). Activated MAPK then translocates to the nucleus and phosphorylates various transcription factors, such as c-Myc and CREB, thereby modulating the expression of target genes.[5]
Figure 1: The MAPK signaling pathway.
The PI3K/AKT Signaling Pathway
The Phosphoinositide 3-kinase (PI3K)/AKT pathway is another critical signaling cascade that regulates cell survival, growth, and proliferation.[7][8] Upon activation by growth factors, PI3K phosphorylates phosphatidylinositol (4,5)-bisphosphate (PIP2) to generate phosphatidylinositol (3,4,5)-trisphosphate (PIP3).[9][10][11] PIP3 acts as a second messenger, recruiting AKT to the cell membrane where it is activated through phosphorylation.[10][11] Activated AKT then phosphorylates a variety of downstream targets, including the transcription factor FOXO, leading to its cytoplasmic localization and the subsequent regulation of genes involved in apoptosis and cell cycle progression.[8]
References
- 1. ChIP-Seq Histone Modification Data | Genome Sciences Centre [bcgsc.ca]
- 2. news-medical.net [news-medical.net]
- 3. genome.ucsc.edu [genome.ucsc.edu]
- 4. creative-diagnostics.com [creative-diagnostics.com]
- 5. MAPK/ERK pathway - Wikipedia [en.wikipedia.org]
- 6. Function and Regulation in MAPK Signaling Pathways: Lessons Learned from the Yeast Saccharomyces cerevisiae - PMC [pmc.ncbi.nlm.nih.gov]
- 7. anygenes.com [anygenes.com]
- 8. KEGG PATHWAY: PI3K-Akt signaling pathway - Homo sapiens (human) [kegg.jp]
- 9. researchgate.net [researchgate.net]
- 10. researchgate.net [researchgate.net]
- 11. creative-diagnostics.com [creative-diagnostics.com]
Orchestrating Cellular Destiny: A Technical Guide to Signaling Pathways in Cell Fate Determination
For Researchers, Scientists, and Drug Development Professionals
Abstract
The determination of cell fate is a fundamental process in developmental biology and tissue homeostasis, governed by a complex interplay of intercellular signaling pathways. These pathways act as intricate communication networks, translating extracellular cues into specific programs of gene expression that dictate whether a cell will proliferate, differentiate, apoptose, or maintain a quiescent state. Dysregulation of these critical signaling networks is a hallmark of numerous diseases, including cancer and developmental disorders. This technical guide provides an in-depth exploration of three core signaling pathways—Notch, Wnt/β-catenin, and TGF-β—that are instrumental in orchestrating cell fate decisions. We will dissect their molecular mechanisms, present key quantitative data, and provide detailed experimental protocols for their study, offering a comprehensive resource for researchers and drug development professionals seeking to understand and manipulate these pivotal cellular processes.
Core Signaling Pathways in Cell Fate
The Notch Signaling Pathway: A Master of Binary Decisions
The Notch signaling pathway is a highly conserved, juxtacrine signaling system essential for cell-cell communication. It plays a critical role in determining binary cell fate decisions, a process known as lateral inhibition, where a cell adopting a specific fate inhibits its immediate neighbors from doing the same.[1] This mechanism is crucial for the precise patterning of tissues during embryonic development and for maintaining homeostasis in adult tissues.[1][2]
Mechanism of Action: The pathway is initiated when a transmembrane ligand (e.g., Delta-like [Dll] or Jagged [Jag]) on a "sending" cell binds to a Notch receptor (NOTCH1-4) on an adjacent "receiving" cell.[3] This interaction triggers a cascade of proteolytic cleavages of the Notch receptor. The first cleavage occurs in the Golgi apparatus, and the subsequent cleavages are ligand-dependent.[3] An ADAM metalloprotease performs the second cleavage (S2), followed by a third cleavage (S3) within the transmembrane domain by the γ-secretase complex.[3] This S3 cleavage releases the Notch Intracellular Domain (NICD) into the cytoplasm.[4] The NICD then translocates to the nucleus, where it forms a complex with the DNA-binding protein CSL (CBF1/Su(H)/Lag-1) and a coactivator of the Mastermind-like (MAML) family. This transcriptional activation complex drives the expression of Notch target genes, most notably the Hes and Hey families of transcriptional repressors, which in turn regulate downstream genes to execute a specific cell fate program.[1][4]
Quantitative Data Summary: Notch Pathway
| Parameter | Interacting Molecules | KD (Dissociation Constant) | Cell Type/System | Notes |
| Binding Affinity | Notch1 / Delta-like 4 (Dll4) | ~270 nM | In vitro (Biolayer interferometry) | Dll4 binds to Notch1 with over 10-fold higher affinity than Dll1.[5] |
| Binding Affinity | Notch1 / Delta-like 1 (Dll1) | ~3.4 µM | In vitro (Biolayer interferometry) | Weaker affinity compared to Dll4.[5] |
| Binding Affinity | Notch1 / Dll1 | ~10 µM | In solution (Analytical ultracentrifugation) | Demonstrates that apparent affinities can vary by technique.[6] |
| Signaling Potency | Dll1 vs. Dll4 on Notch1 | - | Cell-based reporter assays | Dll4 is a more potent activator of Notch1 signaling than Dll1.[7][8] |
| Fringe Modulation | Dll1-Notch1 | - | Cell-based reporter assays | Lfng glycosyltransferase can increase Dll1-Notch1 signaling up to 3-fold.[7][8] |
| Fringe Modulation | Jag1-Notch1 | - | Cell-based reporter assays | Lfng can decrease Jag1-Notch1 signaling by over 2.5-fold.[7][8] |
The Wnt/β-catenin Pathway: A Key Regulator of Development and Stem Cells
The Wnt signaling pathways are a group of signal transduction pathways activated by the binding of Wnt proteins to Frizzled (Fzd) family receptors.[9] The canonical Wnt/β-catenin pathway is crucial for regulating cell fate specification, proliferation, and body axis patterning during embryonic development and for maintaining adult tissue homeostasis.[9][10][11]
Mechanism of Action: In the absence of a Wnt ligand ("Off-state"), cytoplasmic β-catenin is targeted for degradation. It is phosphorylated by a "destruction complex" consisting of Axin, Adenomatous Polyposis Coli (APC), Casein Kinase 1 (CK1), and Glycogen Synthase Kinase 3β (GSK-3β).[10] Phosphorylated β-catenin is then ubiquitinated and degraded by the proteasome.[10]
Pathway activation ("On-state") occurs when a Wnt ligand binds to an Fzd receptor and its co-receptor, LRP5/6.[10] This binding event leads to the recruitment of the Dishevelled (Dvl) protein and the destruction complex to the plasma membrane. This sequesters GSK-3β, inhibiting its activity and leading to the stabilization and accumulation of β-catenin in the cytoplasm.[10] Accumulated β-catenin translocates to the nucleus, where it displaces co-repressors (like Groucho) from T-Cell Factor/Lymphoid Enhancer Factor (TCF/LEF) transcription factors, recruiting co-activators to initiate the transcription of Wnt target genes, such as c-Myc and Cyclin D1.[10]
References
- 1. Video: Genome Editing in Mammalian Cell Lines using CRISPR-Cas [jove.com]
- 2. genemedi.net [genemedi.net]
- 3. TGF-β family ligands exhibit distinct signalling dynamics that are driven by receptor localisation - PMC [pmc.ncbi.nlm.nih.gov]
- 4. bpsbioscience.com [bpsbioscience.com]
- 5. Intrinsic Selectivity of Notch 1 for Delta-like 4 Over Delta-like 1 - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. Diversity in Notch ligand-receptor signaling interactions [elifesciences.org]
- 8. Diversity in Notch ligand-receptor signaling interactions | eLife [elifesciences.org]
- 9. scienceopen.com [scienceopen.com]
- 10. researchgate.net [researchgate.net]
- 11. Development of a Bioassay for Detection of Wnt-Binding Affinities for Individual Frizzled Receptors - PMC [pmc.ncbi.nlm.nih.gov]
Revolutionizing Research: A Technical Guide to Laboratory Workflow Orchestration
For Researchers, Scientists, and Drug Development Professionals
In the fast-paced world of scientific research and drug development, efficiency, reproducibility, and data integrity are paramount. As laboratories handle increasingly complex workflows and generate vast amounts of data, the need for intelligent automation has never been more critical. Laboratory workflow orchestration emerges as a transformative solution, moving beyond simple automation to create a seamlessly integrated and highly efficient research ecosystem. This in-depth technical guide explores the core principles of laboratory workflow orchestration, its tangible benefits, practical implementation strategies, and its application in critical experimental procedures.
The Core of Laboratory Orchestration: From Automation to Intelligent Coordination
Laboratory workflow orchestration is the centralized and intelligent management of all components of a laboratory's processes, including instruments, software, data, and personnel.[1] It differs from simple automation, which typically focuses on automating a single task or a small series of tasks. Orchestration, in contrast, creates a dynamic and interconnected system where every step of a complex workflow is coordinated and optimized.[2]
At its heart, orchestration leverages a sophisticated software layer that acts as a central "conductor" for the entire laboratory. This platform communicates with a diverse range of instruments from various manufacturers, standardizes data formats, and manages the flow of samples and information.[3][4] This integration eliminates data silos and manual handoffs, which are often sources of errors and inefficiencies.[2]
The core components of a laboratory orchestration platform typically include:
-
A Centralized Scheduler: To manage and prioritize tasks across multiple instruments and workflows.
-
Instrument Integration Framework: To enable communication and control of a wide variety of laboratory devices.
-
Data Management System: To capture, store, and contextualize experimental data in a standardized format.[2]
-
Workflow Engine: To define, execute, and monitor complex experimental protocols.
-
User Interface: To provide a centralized point of control and visibility into all laboratory operations.
Quantifiable Impact: The Benefits of an Orchestrated Laboratory
The adoption of laboratory workflow orchestration delivers significant and measurable improvements across various aspects of laboratory operations. These benefits translate into accelerated research timelines, reduced costs, and more reliable scientific outcomes.
| Metric | Improvement with Orchestration | Source |
| Error Rate Reduction | Up to 95% reduction in pre-analytical errors.[5] | A study on an automated pre-analytical system in a clinical lab demonstrated a significant decrease in errors.[5] |
| Turnaround Time (TAT) | Mean TAT decreased by 6.1%; 99th percentile TAT decreased by 13.3%.[6] | An economic evaluation of total laboratory automation showed significant improvements in the timeliness of result reporting.[6] |
| Productivity and Throughput | Pharmaceutical companies could bring medicines to market more than 500 days faster.[7] | A McKinsey report highlighted the potential for automation to accelerate drug development.[7] |
| Staff Efficiency | Reduction in labor costs of $232,650 per year.[8] | A time-motion study in a laboratory showed significant labor cost savings after automation.[8] |
| Cost Savings | The total cost per test decreased from $0.79 to $0.15.[8] | A review of clinical chemistry laboratory automation reported a substantial reduction in the cost per test.[8] |
Visualizing a High-Throughput Screening Workflow
High-throughput screening (HTS) is a cornerstone of modern drug discovery, enabling the rapid testing of thousands of compounds. Orchestrating an HSF workflow is critical for ensuring efficiency and accuracy. The following diagram illustrates a typical automated HTS workflow for identifying kinase inhibitors.
Detailed Experimental Protocol: Automated Cell Viability (MTT) Assay
Cell viability assays are fundamental in drug discovery for assessing the cytotoxic effects of compounds. The MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) assay is a colorimetric assay that measures cellular metabolic activity. Automating this assay enhances reproducibility and throughput.
Objective: To determine the IC50 value of a test compound on a cancer cell line using an orchestrated workflow.
Materials:
-
Cancer cell line (e.g., HeLa)
-
Complete culture medium (e.g., DMEM with 10% FBS)
-
Test compound stock solution (in DMSO)
-
MTT solution (5 mg/mL in PBS)
-
Solubilization solution (e.g., 10% SDS in 0.01 M HCl)[9]
-
Sterile 96-well plates
-
Automated liquid handler
-
Automated plate incubator (37°C, 5% CO2)
-
Microplate reader
Methodology:
-
Cell Seeding (Day 1):
-
Harvest and count cells to ensure >90% viability.
-
Using an automated liquid handler, seed 1 x 10^4 cells in 100 µL of complete culture medium into each well of a 96-well plate.
-
Incubate the plate overnight in an automated incubator.
-
-
Compound Treatment (Day 2):
-
Prepare serial dilutions of the test compound in culture medium using the automated liquid handler.
-
Remove the old medium from the cell plate and add 100 µL of the diluted compound solutions to the respective wells. Include vehicle control (DMSO) and untreated control wells.
-
Return the plate to the automated incubator for 48 hours.
-
-
MTT Assay (Day 4):
-
After incubation, add 10 µL of MTT solution to each well using the automated liquid handler.
-
Incubate the plate for 4 hours in the automated incubator.[9]
-
Add 100 µL of solubilization solution to each well to dissolve the formazan crystals.
-
Place the plate on an orbital shaker for 15 minutes to ensure complete solubilization.
-
-
Data Acquisition:
-
Measure the absorbance at 570 nm using a microplate reader.[9]
-
The orchestration software automatically captures the absorbance data and associates it with the corresponding compound concentrations.
-
-
Data Analysis:
-
The software calculates the percentage of cell viability for each concentration relative to the untreated control.
-
A dose-response curve is generated, and the IC50 value is determined.
-
Signaling Pathway Visualization: The MAPK/ERK Pathway in Cancer
The Mitogen-Activated Protein Kinase (MAPK)/Extracellular signal-Regulated Kinase (ERK) pathway is a crucial signaling cascade that regulates cell proliferation, differentiation, and survival.[10] Its dysregulation is a hallmark of many cancers, making it a key target for drug development.[11] The following diagram illustrates the core components of the MAPK/ERK pathway.
The Future of Research: Towards the Self-Driving Laboratory
Laboratory workflow orchestration is a foundational step towards the vision of a "self-driving" or "closed-loop" laboratory. In this paradigm, artificial intelligence and machine learning algorithms analyze experimental data in real-time to design and execute the next round of experiments automatically. This iterative process of designing, building, testing, and learning has the potential to dramatically accelerate scientific discovery.
By embracing laboratory workflow orchestration, research organizations can unlock new levels of efficiency, improve the quality and reliability of their data, and empower their scientists to focus on innovation rather than manual tasks. As this technology continues to evolve, it will undoubtedly play a pivotal role in shaping the future of research and drug development.
References
- 1. Cost-Benefit Analysis of Laboratory Automation [wakoautomation.com]
- 2. Lab Orchestration: Streamlining Lab Workflows to Enhance Efficiency, Quality and User Experience [thermofisher.com]
- 3. ijcmph.com [ijcmph.com]
- 4. researchgate.net [researchgate.net]
- 5. How to reduce laboratory errors with automation [biosero.com]
- 6. Economic Evaluation of Total Laboratory Automation in the Clinical Laboratory of a Tertiary Care Hospital - PMC [pmc.ncbi.nlm.nih.gov]
- 7. arobs.com [arobs.com]
- 8. media.neliti.com [media.neliti.com]
- 9. CyQUANT MTT Cell Proliferation Assay Kit Protocol | Thermo Fisher Scientific - US [thermofisher.com]
- 10. MAPK/ERK pathway - Wikipedia [en.wikipedia.org]
- 11. mdpi.com [mdpi.com]
Orchestration of Protein-Protein Interaction Networks: A Technical Guide for Researchers
For Researchers, Scientists, and Drug Development Professionals
Introduction
Protein-protein interactions (PPIs) are the cornerstone of cellular function, forming intricate and dynamic networks that govern nearly every biological process. From signal transduction and gene expression to metabolic regulation and immune responses, the precise orchestration of these interactions is paramount to cellular homeostasis. Dysregulation of PPI networks is a hallmark of numerous diseases, including cancer, neurodegenerative disorders, and infectious diseases, making them a critical area of study for drug development and therapeutic intervention.
This technical guide provides an in-depth exploration of the core principles and methodologies for studying the orchestration of PPI networks. It is designed to serve as a comprehensive resource for researchers, scientists, and drug development professionals, offering detailed experimental protocols, quantitative data analysis, and visual representations of key signaling pathways.
I. Key Signaling Pathways in PPI Networks
Signal transduction pathways are exemplary models of orchestrated PPIs, where a cascade of specific binding events transmits information from the cell surface to the nucleus, culminating in a cellular response. Understanding the intricate connections within these pathways is crucial for identifying potential therapeutic targets.
Mitogen-Activated Protein Kinase (MAPK) Signaling Pathway
The MAPK signaling cascade is a highly conserved pathway that regulates a wide array of cellular processes, including proliferation, differentiation, and apoptosis.[1] The pathway is organized into a three-tiered kinase module: a MAP Kinase Kinase Kinase (MAPKKK), a MAP Kinase Kinase (MAPKK), and a MAP Kinase (MAPK).[1][2] Scaffold proteins play a crucial role in assembling these kinase complexes, ensuring signaling specificity and efficiency.[1]
Wnt/β-catenin Signaling Pathway
The Wnt signaling pathway is critical for embryonic development and adult tissue homeostasis.[3] In the canonical pathway, the binding of a Wnt ligand to its receptor complex leads to the stabilization and nuclear translocation of β-catenin, which then acts as a transcriptional co-activator.[4] The interactions between β-catenin and its binding partners are crucial for regulating the expression of target genes involved in cell proliferation and differentiation.[5]
NF-κB Signaling Pathway
The NF-κB (nuclear factor kappa-light-chain-enhancer of activated B cells) signaling pathway is a key regulator of the immune and inflammatory responses, cell survival, and proliferation.[6] In its inactive state, NF-κB is sequestered in the cytoplasm by inhibitor of κB (IκB) proteins.[6] Upon stimulation by various signals, the IκB kinase (IKK) complex is activated, which then phosphorylates IκB, leading to its ubiquitination and proteasomal degradation.[7][8] This allows NF-κB to translocate to the nucleus and activate the transcription of target genes.[6]
Epidermal Growth Factor Receptor (EGFR) Signaling Pathway
The EGFR signaling pathway is crucial for regulating cell growth, survival, and differentiation.[9] Binding of epidermal growth factor (EGF) to EGFR induces receptor dimerization and autophosphorylation, creating docking sites for various adaptor proteins and signaling molecules.[10] These interactions initiate downstream signaling cascades, including the MAPK and PI3K/AKT pathways.[9][10]
Transforming Growth Factor-beta (TGF-β) Signaling Pathway
The TGF-β signaling pathway is involved in a wide range of cellular processes, including cell growth, differentiation, and apoptosis.[11] TGF-β ligands bind to a complex of type I and type II serine/threonine kinase receptors.[12] The type II receptor phosphorylates and activates the type I receptor, which in turn phosphorylates receptor-regulated Smads (R-Smads).[12][13] Activated R-Smads then form a complex with a common-mediator Smad (Co-Smad), Smad4, and translocate to the nucleus to regulate target gene expression.[13][14]
II. Experimental Protocols for Studying PPIs
A variety of experimental techniques are available to identify and characterize protein-protein interactions. The choice of method depends on the specific research question, the nature of the interacting proteins, and the desired level of detail.
Co-Immunoprecipitation (Co-IP)
Co-IP is a widely used technique to study PPIs in their native cellular environment.[15] It involves using an antibody to specifically pull down a protein of interest (the "bait") from a cell lysate, along with any proteins that are bound to it (the "prey").
References
- 1. MAPK signaling pathway | Abcam [abcam.com]
- 2. academic.oup.com [academic.oup.com]
- 3. bioinformation.net [bioinformation.net]
- 4. researchgate.net [researchgate.net]
- 5. Decoding β-catenin associated protein-protein interactions: Emerging cancer therapeutic opportunities - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. NF-κB - Wikipedia [en.wikipedia.org]
- 7. NF-κB Signaling | Cell Signaling Technology [cellsignal.com]
- 8. The IκB kinase complex: master regulator of NF-κB signaling - PMC [pmc.ncbi.nlm.nih.gov]
- 9. nanobioletters.com [nanobioletters.com]
- 10. A comprehensive pathway map of epidermal growth factor receptor signaling | Molecular Systems Biology [link.springer.com]
- 11. TGF beta signaling pathway - Wikipedia [en.wikipedia.org]
- 12. TGF-β Signaling - PMC [pmc.ncbi.nlm.nih.gov]
- 13. TGF Beta Signaling Pathway | Thermo Fisher Scientific - JP [thermofisher.com]
- 14. TGF-β Signaling | Cell Signaling Technology [cellsignal.com]
- 15. bitesizebio.com [bitesizebio.com]
Orchestration of the Immune Response: A Technical Guide to Core Foundational Concepts
Authored for: Researchers, Scientists, and Drug Development Professionals
Introduction
The orchestration of an effective immune response is a highly complex and dynamic process, involving a symphony of cellular and molecular players that communicate and coordinate to eliminate pathogens and maintain homeostasis. This process is broadly divided into two interconnected arms: the rapid, non-specific innate immune system and the slower, highly specific adaptive immune system.[1][2][3] The innate system acts as the first line of defense, recognizing conserved molecular patterns on pathogens and initiating an inflammatory response.[1][3] Crucially, the innate response shapes the subsequent adaptive response, which provides long-lasting, specific memory.[1][4][5] This guide provides an in-depth technical overview of the foundational concepts governing this intricate orchestration, from initial antigen presentation to the generation of effector and memory cells.
The Innate-Adaptive Immune Interface: Antigen Presentation
The critical link between the innate and adaptive immune systems is the process of antigen presentation.[4] Professional antigen-presenting cells (APCs), primarily dendritic cells (DCs), but also macrophages and B cells, are central to this process.[6][7][8]
-
Antigen Capture and Processing: Following a pathogenic encounter, innate cells like DCs capture antigens.[9] The antigens are internalized and proteolytically processed into smaller peptide fragments.[8][10]
-
MHC Loading and Presentation: These peptides are then loaded onto Major Histocompatibility Complex (MHC) molecules.[7][8] Endogenous antigens (e.g., from viral-infected cells) are typically presented on MHC class I molecules, while exogenous antigens (from extracellular pathogens) are presented on MHC class II molecules.[11]
-
APC Maturation and Migration: Concurrently, the APC receives signals from the pathogen (e.g., via Toll-like receptors) that induce its maturation. This involves the upregulation of co-stimulatory molecules and migration from the site of infection to secondary lymphoid organs like lymph nodes.[12] It is within these lymphoid tissues that the APC will present the antigen to naive T cells.[12][13]
T Cell Activation and Differentiation
The activation of a naive T cell is a pivotal event, requiring a precise sequence of three signals delivered by the APC.[14]
-
Signal 1 (Activation): The T cell receptor (TCR) on a CD4+ helper T cell or a CD8+ cytotoxic T cell specifically recognizes and binds to the peptide-MHC complex on the surface of an APC.[7][14] This interaction provides antigen specificity.
-
Signal 2 (Survival/Co-stimulation): Full T cell activation requires a second, co-stimulatory signal.[6][7] This is typically delivered when the CD28 protein on the T cell surface binds to B7 molecules (CD80/CD86) on the APC.[14][15] This second signal ensures that T cells are only activated in the context of a genuine threat recognized by the innate system.[14]
-
Signal 3 (Differentiation): The local cytokine environment, largely produced by the APC and other innate cells, provides the third signal.[6][14] This signal dictates the differentiation pathway of the activated CD4+ T cell into various specialized effector subsets, each with distinct functions.[6][13][16]
CD4+ T Helper Cell Differentiation
Upon activation, naive CD4+ T cells (Th0) can differentiate into several subsets, guided by specific cytokines and master transcription factors.[13][15]
-
Th1 Cells: Driven by IL-12 and IFN-γ, they activate the transcription factors T-bet and STAT4.[13][16][17] Th1 cells are crucial for cell-mediated immunity against intracellular pathogens.[6]
-
Th2 Cells: Driven by IL-4, they activate GATA3 and STAT6.[13][16][17] Th2 cells orchestrate humoral immunity and defense against helminths.[13]
-
Th17 Cells: Differentiation is induced by TGF-β and IL-6 (or IL-21), activating RORγt and STAT3.[13][16] They are important in combating extracellular bacteria and fungi.
-
Regulatory T (Treg) Cells: Induced by TGF-β and IL-2, they activate the master transcription factor Foxp3 and STAT5.[13][17][18] Tregs are critical for maintaining immune tolerance and suppressing excessive immune responses.[6]
IL-2 and STAT5 Signaling
The Interleukin-2 (IL-2) signaling pathway is a prime example of a critical cytokine cascade. IL-2 signaling via its receptor activates the transcription factor STAT5.[19][20] This pathway is essential for the proliferation of activated T cells and plays a pivotal role in directing the balance between effector T cells and regulatory T cells, making it a key regulator of immune homeostasis.[18][19][21] Upon IL-2 binding, receptor-associated Janus kinases (JAKs) phosphorylate STAT5, leading to its dimerization, nuclear translocation, and regulation of target gene expression.[19]
B Cell Activation and the Humoral Response
Humoral immunity, mediated by antibodies produced by B cells, is essential for combating extracellular microbes and their toxins.[22][23][24] B cell activation can occur through two main pathways.
-
T-Dependent (TD) Activation: This is the most common pathway for protein antigens.[11][24] B cells act as APCs, internalizing an antigen via their B cell receptor (BCR), processing it, and presenting it on MHC class II to an already activated helper T cell (often a specialized T follicular helper, Tfh, cell).[11][25] The T cell then provides co-stimulation via CD40L-CD40 interaction and releases cytokines (like IL-4 and IL-21) that fully activate the B cell.[23][25] This leads to clonal expansion, isotype switching, affinity maturation within germinal centers, and the generation of long-lived plasma cells and memory B cells.[22][25]
-
T-Independent (TI) Activation: Certain antigens with highly repetitive structures, like bacterial polysaccharides, can directly activate B cells without T cell help.[11][25] This is achieved by extensively cross-linking multiple BCRs on the B cell surface, providing a strong enough signal for activation.[11][24] This response is faster but generally results in lower-affinity antibodies (primarily IgM) and does not produce robust immunological memory.[25]
Lymphocyte Trafficking and Homing
The immune system's effectiveness relies on the ability of lymphocytes to continuously circulate and home to specific locations.[26] This trafficking is a highly regulated, multi-step process controlled by adhesion molecules and chemical messengers called chemokines.[12][26][27]
-
Homing to Secondary Lymphoid Organs (SLOs): Naive T and B cells constantly recirculate between the blood and SLOs (like lymph nodes and Peyer's patches) in a process of immune surveillance.[12][28] This process is initiated by the binding of L-selectin on the lymphocyte to its ligand on specialized high endothelial venules (HEVs) in the SLO, causing the cell to slow down and roll.[28] Subsequent activation by chemokines (like CCL19 and CCL21) triggers integrin-mediated firm adhesion and transmigration into the lymph node.[28]
-
Homing to Inflamed Tissues: Upon activation, effector and memory lymphocytes downregulate SLO-homing receptors and upregulate receptors that direct them to sites of inflammation in peripheral tissues.[12][27] For example, T cells destined for the skin may express CCR4, which binds to chemokines present in inflamed skin.[27]
Quantitative Analysis of Immune Responses
Quantifying the components of the immune system is crucial for establishing baseline values and understanding deviations in disease states. Multiplexed imaging and flow cytometry have enabled detailed censuses of immune cell populations across various tissues.[29]
Table 1: Representative Distribution of Immune Cells in an Adult Human
| Tissue / Compartment | Predominant Immune Cell Types | Estimated Number of Cells | Percentage of Total Immune Cells |
| Bone Marrow | Myeloid precursors, B cell precursors, Plasma cells | ~1.0 x 1012 | ~50% |
| Lymphatic System | T cells, B cells, Dendritic cells | ~0.6 x 1012 | ~30% |
| (Lymph Nodes, Spleen) | |||
| Blood | Neutrophils, T cells, Monocytes, B cells, NK cells | ~5.0 x 1010 | ~2-3% |
| Gut | T cells, Plasma cells, Macrophages | ~1.5 x 1011 | ~7-8% |
| Skin | T cells, Langerhans cells, Macrophages | ~2.0 x 1010 | ~1% |
| Lungs | Alveolar Macrophages, T cells | ~1.0 x 1010 | ~0.5% |
Note: Data are compiled estimates and can vary significantly based on age, sex, health status, and the methodologies used for quantification.[29] Studies have shown that sex is a primary factor influencing blood immune cell composition, with females generally exhibiting more robust immune responses.[29]
Key Experimental Methodologies
A. Flow Cytometry: Immune Cell Phenotyping
Flow cytometry is a powerful technique for identifying and quantifying immune cell populations based on their expression of specific cell surface and intracellular markers.[30][31]
Detailed Protocol:
-
Single-Cell Suspension Preparation: Prepare a single-cell suspension from blood (e.g., via density gradient centrifugation) or non-lymphoid tissues (e.g., via enzymatic digestion and mechanical disruption).[30][32]
-
Fc Receptor Blocking: Incubate cells with an Fc block reagent to prevent non-specific antibody binding to Fc receptors on cells like macrophages and B cells.[32]
-
Surface Marker Staining: Incubate cells with a cocktail of fluorochrome-conjugated antibodies specific for cell surface markers (e.g., CD3 for T cells, CD19 for B cells, CD4, CD8).[31] Staining is typically performed for 20-30 minutes at 4°C in the dark.
-
Viability Staining: Add a viability dye to distinguish live cells from dead cells, which can non-specifically bind antibodies.[30]
-
(Optional) Intracellular/Intranuclear Staining: For intracellular cytokines or transcription factors (like Foxp3), cells are first fixed and then permeabilized to allow antibodies to access intracellular targets.
-
Data Acquisition: Analyze the stained cells on a flow cytometer. The instrument uses lasers to excite the fluorochromes, and detectors measure the emitted light, allowing for the simultaneous analysis of multiple parameters on thousands of cells per second.[31]
-
Data Analysis: Use specialized software to "gate" on specific cell populations based on their fluorescence patterns to determine their relative percentages and absolute numbers.[30]
B. ELISA: Cytokine Quantification
The Enzyme-Linked Immunosorbent Assay (ELISA) is a plate-based assay used to detect and quantify soluble substances such as cytokines, chemokines, and antibodies in biological fluids.[33][34] The sandwich ELISA is the most common format for cytokine measurement.[34][35]
Detailed Protocol:
-
Plate Coating: Coat the wells of a 96-well microplate with a "capture" antibody specific for the cytokine of interest.[33][35] Incubate overnight at 4°C.
-
Washing and Blocking: Wash the plate to remove unbound antibody.[35] Block the remaining protein-binding sites in the wells with an inert protein solution (e.g., bovine serum albumin) to prevent non-specific binding.[33]
-
Sample and Standard Incubation: Add standards (recombinant cytokine of known concentrations) and samples (e.g., cell culture supernatant, serum) to the wells.[33][36] Incubate for 1-2 hours to allow the cytokine to bind to the capture antibody.
-
Detection Antibody: Wash the plate and add a biotinylated "detection" antibody, which binds to a different epitope on the captured cytokine.[35] Incubate for 1 hour.
-
Enzyme Conjugate: Wash the plate and add an enzyme-conjugated streptavidin (e.g., streptavidin-horseradish peroxidase), which binds to the biotin on the detection antibody.[36]
-
Substrate Addition: Wash the plate and add a chromogenic substrate (e.g., TMB).[36] The enzyme converts the substrate into a colored product.
-
Analysis: Stop the reaction with an acid (e.g., H₂SO₄) and measure the absorbance (optical density) of each well using a microplate reader.[35] The concentration of the cytokine in the samples is determined by comparing their absorbance to the standard curve generated from the standards.[34]
C. ChIP-seq: Mapping Protein-DNA Interactions
Chromatin Immunoprecipitation followed by Sequencing (ChIP-seq) is a method used to identify the genome-wide binding sites of DNA-associated proteins, such as transcription factors (e.g., STAT5, T-bet) or modified histones.[37][38][39]
Detailed Protocol:
-
Cross-linking: Treat cells with a reagent (typically formaldehyde) to create reversible covalent cross-links between proteins and the DNA they are bound to.[39][40] This step is omitted in Native ChIP (NChIP).[38]
-
Cell Lysis and Chromatin Fragmentation: Lyse the cells and shear the chromatin into smaller fragments (typically 200-600 bp) using sonication or enzymatic digestion (e.g., micrococcal nuclease).[37][39][40]
-
Immunoprecipitation (IP): Incubate the sheared chromatin with an antibody specific to the protein of interest (e.g., anti-STAT5). The antibody-protein-DNA complexes are then captured, often using antibody-binding magnetic beads.[37][39]
-
Washing: Wash the captured complexes to remove non-specifically bound chromatin fragments.[38]
-
Elution and Reverse Cross-linking: Elute the complexes from the antibody/beads and reverse the formaldehyde cross-links by heating.[38] Digest the proteins using proteinase K.[40]
-
DNA Purification: Purify the enriched DNA fragments.[39][40]
-
Library Preparation and Sequencing: Prepare a DNA library from the purified fragments and sequence it using a next-generation sequencing (NGS) platform.[37]
-
Bioinformatic Analysis: Align the sequence reads to a reference genome to identify "peaks," which represent regions with significant enrichment and correspond to the protein's binding sites.[37]
References
- 1. creative-diagnostics.com [creative-diagnostics.com]
- 2. In brief: The innate and adaptive immune systems - InformedHealth.org - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 3. criver.com [criver.com]
- 4. Interactions Between the Innate and Adaptive Immune Responses - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Innate and Adaptive Immunity | Emory University | Atlanta GA [vaccines.emory.edu]
- 6. T helper cell - Wikipedia [en.wikipedia.org]
- 7. akadeum.com [akadeum.com]
- 8. T Cells and MHC Proteins - Molecular Biology of the Cell - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 9. Frontiers | A Novel Cellular Pathway of Antigen Presentation and CD4 T Cell Activation in vivo [frontiersin.org]
- 10. researchgate.net [researchgate.net]
- 11. B Lymphocytes and Humoral Immunity | Microbiology [courses.lumenlearning.com]
- 12. Lymphocyte trafficking and immunesurveillance [jstage.jst.go.jp]
- 13. Molecular Mechanisms of T Helper Cell Differentiation and Functional Specialization - PMC [pmc.ncbi.nlm.nih.gov]
- 14. T-cell activation | British Society for Immunology [immunology.org]
- 15. geneglobe.qiagen.com [geneglobe.qiagen.com]
- 16. beckman.com [beckman.com]
- 17. Helper T cell differentiation - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Interleukin-2 and STAT5 in regulatory T cell development and function - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Dynamic roles for IL-2-STAT5 signaling in effector and regulatory CD4+ T cell populations - PMC [pmc.ncbi.nlm.nih.gov]
- 20. researchgate.net [researchgate.net]
- 21. Dynamic Roles for IL-2-STAT5 Signaling in Effector and Regulatory CD4+ T Cell Populations - PubMed [pubmed.ncbi.nlm.nih.gov]
- 22. Humoral Immune Responses: Activation of B Lymphocytes and Production of Antibodies | Basicmedical Key [basicmedicalkey.com]
- 23. microrao.com [microrao.com]
- 24. bio.libretexts.org [bio.libretexts.org]
- 25. Cell Activation and Antibody Production in the Humoral Immune Response | Immunostep Biotech [immunostep.com]
- 26. Lymphocyte homing and homeostasis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 27. storage.imrpress.com [storage.imrpress.com]
- 28. Chemokine control of lymphocyte trafficking: a general overview - PMC [pmc.ncbi.nlm.nih.gov]
- 29. The total mass, number, and distribution of immune cells in the human body - PMC [pmc.ncbi.nlm.nih.gov]
- 30. A Protocol for the Comprehensive Flow Cytometric Analysis of Immune Cells in Normal and Inflamed Murine Non-Lymphoid Tissues | PLOS One [journals.plos.org]
- 31. bitesizebio.com [bitesizebio.com]
- 32. low input ChIP-sequencing of immune cells [protocols.io]
- 33. Detection and Quantification of Cytokines and Other Biomarkers - PMC [pmc.ncbi.nlm.nih.gov]
- 34. biomatik.com [biomatik.com]
- 35. Cytokine Elisa [bdbiosciences.com]
- 36. bowdish.ca [bowdish.ca]
- 37. mcw.edu [mcw.edu]
- 38. Chromatin immunoprecipitation - Wikipedia [en.wikipedia.org]
- 39. Overview of Chromatin Immunoprecipitation (ChIP) | Cell Signaling Technology [cellsignal.com]
- 40. Chromatin Immunoprecipitation Sequencing (ChIP-seq) Protocol - CD Genomics [cd-genomics.com]
The Orchestration of Metabolic Pathways: An In-depth Technical Guide
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the intricate orchestration of metabolic pathways, designed for researchers, scientists, and professionals in drug development. We delve into the core regulatory mechanisms, key signaling cascades, and the advanced experimental and computational methodologies used to elucidate metabolic networks. This guide emphasizes quantitative data presentation, detailed experimental protocols, and clear visual representations of complex biological processes to facilitate a deeper understanding and application in research and therapeutic development.
Core Principles of Metabolic Regulation
The intricate network of metabolic pathways within a cell is exquisitely regulated to maintain homeostasis, respond to environmental cues, and fulfill the bioenergetic and biosynthetic demands of the cell. The primary mechanisms of control can be categorized as follows:
-
Allosteric Regulation: This is a rapid control mechanism where a regulatory molecule binds to an enzyme at a site distinct from the active site, inducing a conformational change that either activates or inhibits the enzyme's activity.[1] A classic example is the feedback inhibition of phosphofructokinase, a key enzyme in glycolysis, by high levels of ATP, signaling an energy-replete state.[1][2]
-
Covalent Modification: The activity of metabolic enzymes can be modulated by the addition or removal of chemical groups, such as phosphate, acetyl, or methyl groups.[1][3] A prominent example is the regulation of glycogen phosphorylase, which is activated by phosphorylation to initiate the breakdown of glycogen into glucose.[1][3]
-
Genetic Control: The expression of genes encoding metabolic enzymes is a long-term regulatory strategy.[1] This involves the transcriptional upregulation or downregulation of enzymes in response to cellular needs. For instance, in the presence of lactose, bacterial cells induce the expression of genes for lactose-metabolizing enzymes.[1]
-
Substrate Availability: The rate of many metabolic pathways is directly influenced by the concentration of substrates. For example, the rate of fatty acid oxidation is largely dependent on the plasma concentration of fatty acids.[4]
Key Signaling Pathways in Metabolic Orchestration
Cellular metabolism is tightly integrated with signaling networks that translate extracellular cues into metabolic responses. Two of the most critical signaling pathways in this context are the PI3K/Akt/mTOR and AMPK pathways.
The PI3K/Akt/mTOR Pathway
The Phosphoinositide 3-kinase (PI3K)/Akt/mammalian Target of Rapamycin (mTOR) pathway is a central regulator of cell growth, proliferation, and metabolism.[3][4][5][6] Activated by growth factors and hormones like insulin, this pathway promotes anabolic processes such as protein and lipid synthesis, while inhibiting catabolic processes like autophagy.[3][4][5][6]
// Node Definitions GF [label="Growth Factor /\nInsulin", fillcolor="#FBBC05", fontcolor="#202124"]; Receptor [label="Receptor Tyrosine\nKinase (RTK)", fillcolor="#F1F3F4", fontcolor="#202124"]; PI3K [label="PI3K", fillcolor="#4285F4", fontcolor="#FFFFFF"]; PIP2 [label="PIP2", fillcolor="#FFFFFF", fontcolor="#202124", shape=ellipse]; PIP3 [label="PIP3", fillcolor="#FFFFFF", fontcolor="#202124", shape=ellipse]; PTEN [label="PTEN", fillcolor="#EA4335", fontcolor="#FFFFFF"]; PDK1 [label="PDK1", fillcolor="#34A853", fontcolor="#FFFFFF"]; Akt [label="Akt", fillcolor="#4285F4", fontcolor="#FFFFFF"]; mTORC2 [label="mTORC2", fillcolor="#34A853", fontcolor="#FFFFFF"]; TSC1_2 [label="TSC1/TSC2", fillcolor="#EA4335", fontcolor="#FFFFFF"]; Rheb [label="Rheb", fillcolor="#34A853", fontcolor="#FFFFFF"]; mTORC1 [label="mTORC1", fillcolor="#4285F4", fontcolor="#FFFFFF"]; S6K1 [label="S6K1", fillcolor="#FBBC05", fontcolor="#202124"]; fourEBP1 [label="4E-BP1", fillcolor="#FBBC05", fontcolor="#202124"]; Protein_Synthesis [label="Protein Synthesis", fillcolor="#F1F3F4", fontcolor="#202124"]; Lipid_Synthesis [label="Lipid Synthesis", fillcolor="#F1F3F4", fontcolor="#202124"]; Autophagy [label="Autophagy", fillcolor="#F1F3F4", fontcolor="#202124"];
// Edges GF -> Receptor [color="#5F6368"]; Receptor -> PI3K [color="#34A853"]; PI3K -> PIP2 [label=" P", arrowhead=none, style=dashed, color="#5F6368"]; PIP2 -> PIP3 [label=" P", color="#34A853"]; PIP3 -> PDK1 [color="#34A853"]; PIP3 -> Akt [color="#34A853"]; PTEN -> PIP3 [arrowhead=tee, color="#EA4335"]; PDK1 -> Akt [color="#34A853"]; mTORC2 -> Akt [color="#34A853"]; Akt -> TSC1_2 [arrowhead=tee, color="#EA4335"]; TSC1_2 -> Rheb [arrowhead=tee, color="#EA4335"]; Rheb -> mTORC1 [color="#34A853"]; mTORC1 -> S6K1 [color="#34A853"]; mTORC1 -> fourEBP1 [arrowhead=tee, color="#EA4335"]; mTORC1 -> Lipid_Synthesis [color="#34A853"]; mTORC1 -> Autophagy [arrowhead=tee, color="#EA4335"]; S6K1 -> Protein_Synthesis [color="#34A853"]; fourEBP1 -> Protein_Synthesis [arrowhead=tee, style=dashed, color="#EA4335"]; } END_DOT
Figure 1: The PI3K/Akt/mTOR signaling pathway.
The AMPK Pathway
The AMP-activated protein kinase (AMPK) pathway acts as a cellular energy sensor.[7][8] It is activated under conditions of low energy, such as nutrient deprivation or hypoxia, which lead to an increased AMP/ATP ratio.[7][8] Activated AMPK shifts the cellular metabolism from anabolic to catabolic processes, promoting ATP production through fatty acid oxidation and glycolysis, while inhibiting ATP-consuming processes like protein and lipid synthesis.[7][8]
// Node Definitions Low_Energy [label="Low Energy State\n(High AMP/ATP)", fillcolor="#FBBC05", fontcolor="#202124"]; LKB1 [label="LKB1", fillcolor="#34A853", fontcolor="#FFFFFF"]; CaMKK2 [label="CaMKKβ", fillcolor="#34A853", fontcolor="#FFFFFF"]; Calcium [label="Increased\nIntracellular Ca2+", fillcolor="#FBBC05", fontcolor="#202124"]; AMPK [label="AMPK", fillcolor="#4285F4", fontcolor="#FFFFFF"]; ACC [label="ACC", fillcolor="#EA4335", fontcolor="#FFFFFF"]; mTORC1 [label="mTORC1", fillcolor="#EA4335", fontcolor="#FFFFFF"]; ULK1 [label="ULK1", fillcolor="#34A853", fontcolor="#FFFFFF"]; Fatty_Acid_Oxidation [label="Fatty Acid\nOxidation", fillcolor="#F1F3F4", fontcolor="#202124"]; Fatty_Acid_Synthesis [label="Fatty Acid\nSynthesis", fillcolor="#F1F3F4", fontcolor="#202124"]; Protein_Synthesis [label="Protein Synthesis", fillcolor="#F1F3F4", fontcolor="#202124"]; Autophagy [label="Autophagy", fillcolor="#F1F3F4", fontcolor="#202124"];
// Edges Low_Energy -> LKB1 [color="#5F6368"]; Calcium -> CaMKK2 [color="#5F6368"]; LKB1 -> AMPK [label=" P", color="#34A853"]; CaMKK2 -> AMPK [label=" P", color="#34A853"]; AMPK -> ACC [arrowhead=tee, color="#EA4335"]; AMPK -> mTORC1 [arrowhead=tee, color="#EA4335"]; AMPK -> ULK1 [color="#34A853"]; ACC -> Fatty_Acid_Synthesis [arrowhead=tee, style=dashed, color="#EA4335"]; ACC -> Fatty_Acid_Oxidation [style=dashed, color="#34A853"]; mTORC1 -> Protein_Synthesis [arrowhead=tee, style=dashed, color="#EA4335"]; ULK1 -> Autophagy [color="#34A853"]; } END_DOT
Figure 2: The AMPK signaling pathway.
Quantitative Analysis of Metabolic Pathways
A quantitative understanding of metabolic pathways is essential for building predictive models and for identifying potential targets for therapeutic intervention. This involves the measurement of enzyme kinetics, metabolite concentrations, and metabolic fluxes.
Enzyme Kinetics
The kinetic properties of enzymes, such as the Michaelis constant (Km) and the maximum reaction velocity (Vmax), are fundamental parameters that govern the flux through a metabolic pathway.[9] Km represents the substrate concentration at which the reaction rate is half of Vmax and is an inverse measure of the enzyme's affinity for its substrate.[9]
| Enzyme (Glycolysis) | Substrate | Km (mM) | Vmax (µmol/min/mg protein) |
| Hexokinase | Glucose | 0.1 | 10 |
| Phosphofructokinase | Fructose-6-phosphate | 0.05 | 15 |
| Pyruvate Kinase | Phosphoenolpyruvate | 0.3 | 200 |
Table 1: Representative kinetic parameters for key glycolytic enzymes. Values are illustrative and can vary depending on the organism and experimental conditions.
Intracellular Metabolite Concentrations
The steady-state concentrations of intracellular metabolites provide a snapshot of the metabolic state of a cell. These concentrations are highly dynamic and can change in response to various stimuli. Mass spectrometry-based metabolomics is a powerful technique for the comprehensive measurement of these small molecules.
| Metabolite | Concentration in E. coli (mM) | Concentration in Mammalian Cells (mM) |
| Glucose-6-phosphate | 0.2 - 0.5 | 0.05 - 0.2 |
| Fructose-1,6-bisphosphate | 0.1 - 1.0 | 0.01 - 0.05 |
| ATP | 5.0 - 10.0 | 2.0 - 5.0 |
| NAD+ | 1.0 - 3.0 | 0.3 - 1.0 |
| NADH | 0.05 - 0.1 | 0.001 - 0.01 |
| Glutamate | 10 - 100 | 2 - 20 |
Table 2: Typical intracellular concentrations of key metabolites in E. coli and mammalian cells.[10] Concentrations can vary significantly based on cell type, growth conditions, and analytical methods.
Metabolic Flux Analysis
Metabolic flux analysis (MFA) is a powerful technique used to quantify the rates of metabolic reactions within a cell.[11][12][13] 13C-MFA, a common approach, involves feeding cells a 13C-labeled substrate and measuring the incorporation of the label into downstream metabolites using mass spectrometry or NMR.[12][13]
| Metabolic Flux | E. coli (mmol/gDW/h) | Mammalian Cell (mmol/gDW/h) |
| Glucose Uptake Rate | 10.0 | 1.0 |
| Glycolysis | 8.5 | 0.8 |
| Pentose Phosphate Pathway | 1.5 | 0.1 |
| TCA Cycle | 5.0 | 0.5 |
| Acetate Secretion | 3.0 | 0.05 |
Table 3: Representative metabolic flux values in central carbon metabolism. Values are illustrative and depend on the specific strain/cell line and culture conditions.[14]
Experimental Protocols
The following sections provide detailed methodologies for key experiments in the study of metabolic pathways.
Untargeted Metabolomics using LC-MS
This protocol outlines a general workflow for the analysis of polar metabolites in mammalian cells using liquid chromatography-mass spectrometry (LC-MS).
// Node Definitions Sample_Collection [label="1. Sample Collection\n(e.g., Adherent Cells)", fillcolor="#F1F3F4", fontcolor="#202124"]; Quenching [label="2. Quenching\n(e.g., Cold Methanol)", fillcolor="#FBBC05", fontcolor="#202124"]; Extraction [label="3. Metabolite Extraction\n(e.g., Methanol/Water)", fillcolor="#4285F4", fontcolor="#FFFFFF"]; LC_MS_Analysis [label="4. LC-MS Analysis", fillcolor="#34A853", fontcolor="#FFFFFF"]; Data_Processing [label="5. Data Processing\n(Peak Picking, Alignment)", fillcolor="#EA4335", fontcolor="#FFFFFF"]; Statistical_Analysis [label="6. Statistical Analysis\n(PCA, PLS-DA)", fillcolor="#FBBC05", fontcolor="#202124"]; Metabolite_ID [label="7. Metabolite Identification", fillcolor="#4285F4", fontcolor="#FFFFFF"]; Pathway_Analysis [label="8. Pathway Analysis", fillcolor="#34A853", fontcolor="#FFFFFF"];
// Edges Sample_Collection -> Quenching [color="#5F6368"]; Quenching -> Extraction [color="#5F6368"]; Extraction -> LC_MS_Analysis [color="#5F6368"]; LC_MS_Analysis -> Data_Processing [color="#5F6368"]; Data_Processing -> Statistical_Analysis [color="#5F6368"]; Statistical_Analysis -> Metabolite_ID [color="#5F6368"]; Metabolite_ID -> Pathway_Analysis [color="#5F6368"]; } END_DOT
Figure 3: General workflow for untargeted metabolomics.
4.1.1 Sample Preparation and Metabolite Extraction
-
Cell Culture: Culture adherent mammalian cells to ~80-90% confluency in a 6-well plate.
-
Quenching: Rapidly aspirate the culture medium. Immediately wash the cells with 1 mL of ice-cold 0.9% NaCl solution. Aspirate the saline and add 1 mL of ice-cold 80% methanol (-80°C) to each well to quench metabolic activity.
-
Scraping and Collection: Place the plate on dry ice and scrape the cells in the methanol solution using a cell scraper. Transfer the cell lysate to a pre-chilled microcentrifuge tube.
-
Extraction: Vortex the cell lysate vigorously for 1 minute. Centrifuge at 14,000 x g for 10 minutes at 4°C to pellet cell debris.
-
Supernatant Transfer: Carefully transfer the supernatant containing the metabolites to a new pre-chilled microcentrifuge tube.
-
Drying: Dry the metabolite extract completely using a vacuum concentrator (e.g., SpeedVac).
-
Storage: Store the dried metabolite pellet at -80°C until LC-MS analysis.
4.1.2 LC-MS Data Acquisition
-
Reconstitution: Reconstitute the dried metabolite pellet in a suitable volume (e.g., 100 µL) of the initial mobile phase (e.g., 95:5 water:acetonitrile with 0.1% formic acid).
-
Chromatography: Inject the sample onto a hydrophilic interaction liquid chromatography (HILIC) column for separation of polar metabolites.
-
Mass Spectrometry: Analyze the eluent using a high-resolution mass spectrometer (e.g., Q-TOF or Orbitrap) in both positive and negative ionization modes to cover a wide range of metabolites.
4.1.3 Data Analysis
-
Data Preprocessing: Use software such as XCMS or MZmine for peak picking, feature detection, retention time correction, and alignment across samples.[15]
-
Statistical Analysis: Perform multivariate statistical analysis, such as Principal Component Analysis (PCA) and Partial Least Squares-Discriminant Analysis (PLS-DA), to identify metabolites that are significantly different between experimental groups.[16]
-
Metabolite Identification: Identify significant metabolites by matching their accurate mass and fragmentation patterns (MS/MS spectra) to metabolite databases (e.g., METLIN, HMDB).
-
Pathway Analysis: Use tools like MetaboAnalyst or Ingenuity Pathway Analysis (IPA) to map the identified metabolites to metabolic pathways and identify perturbed pathways.[17]
Flux Balance Analysis (FBA)
Flux Balance Analysis (FBA) is a computational method used to predict metabolic flux distributions in a genome-scale metabolic model.[18][19] It relies on the assumption of a steady state, where the production and consumption of each internal metabolite are balanced.[18]
// Node Definitions Model_Reconstruction [label="1. Genome-Scale Metabolic\nModel Reconstruction", fillcolor="#F1F3F4", fontcolor="#202124"]; Stoichiometric_Matrix [label="2. Define Stoichiometric Matrix (S)", fillcolor="#FBBC05", fontcolor="#202124"]; Constraints [label="3. Set Constraints\n(Uptake/Secretion Rates)", fillcolor="#4285F4", fontcolor="#FFFFFF"]; Objective_Function [label="4. Define Objective Function\n(e.g., Maximize Biomass)", fillcolor="#34A853", fontcolor="#FFFFFF"]; Linear_Programming [label="5. Solve using Linear Programming", fillcolor="#EA4335", fontcolor="#FFFFFF"]; Flux_Distribution [label="6. Analyze Predicted\nFlux Distribution", fillcolor="#FBBC05", fontcolor="#202124"];
// Edges Model_Reconstruction -> Stoichiometric_Matrix [color="#5F6368"]; Stoichiometric_Matrix -> Constraints [color="#5F6368"]; Constraints -> Objective_Function [color="#5F6368"]; Objective_Function -> Linear_Programming [color="#5F6368"]; Linear_Programming -> Flux_Distribution [color="#5F6368"]; } END_DOT
Figure 4: Workflow for Flux Balance Analysis.
4.2.1 Step-by-Step Protocol
-
Obtain a Genome-Scale Metabolic Model: Start with a curated, genome-scale metabolic reconstruction of the organism of interest. These models are often available in public databases (e.g., BiGG Models).
-
Define the Stoichiometric Matrix (S): The model is represented by a stoichiometric matrix (S), where rows correspond to metabolites and columns to reactions. The entries in the matrix are the stoichiometric coefficients of the metabolites in each reaction.[18]
-
Set Constraints (Bounds): Define the lower and upper bounds for each reaction flux (v). This includes setting the uptake rates of nutrients (e.g., glucose, oxygen) and the secretion rates of byproducts based on experimental measurements. Irreversible reactions will have a lower bound of 0.[18]
-
Define an Objective Function (Z): Specify a biological objective to be optimized. A common objective is the maximization of the biomass production rate, which represents cell growth.[18] The objective function is a linear combination of fluxes.[18]
-
Solve the Linear Programming Problem: Use linear programming to find a flux distribution (v) that maximizes or minimizes the objective function (Z) subject to the steady-state assumption (S • v = 0) and the defined flux constraints.[18]
-
Analyze the Flux Distribution: The solution provides a predicted flux value for every reaction in the metabolic network, offering insights into the activity of different metabolic pathways under the simulated conditions.
Conclusion
The orchestration of metabolic pathways is a highly complex and dynamic process that is fundamental to cellular function. This guide has provided an in-depth overview of the key regulatory principles, signaling networks, and analytical techniques that are at the forefront of metabolic research. The ability to quantitatively measure and model metabolic networks is crucial for advancing our understanding of disease and for the development of novel therapeutic strategies. By integrating the experimental and computational approaches outlined here, researchers can continue to unravel the complexities of metabolic regulation and harness this knowledge for the benefit of human health.
References
- 1. researchgate.net [researchgate.net]
- 2. The GC-MS workflow | workflow4metabolomics [workflow4metabolomics.org]
- 3. geneglobe.qiagen.com [geneglobe.qiagen.com]
- 4. PI3K/AKT/mTOR Signaling Network in Human Health and Diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 5. PI3K/AKT/mTOR pathway - Wikipedia [en.wikipedia.org]
- 6. encyclopedia.pub [encyclopedia.pub]
- 7. AMPK Signaling | Cell Signaling Technology [cellsignal.com]
- 8. AMPK – sensing energy while talking to other signaling pathways - PMC [pmc.ncbi.nlm.nih.gov]
- 9. teachmephysiology.com [teachmephysiology.com]
- 10. » What are the concentrations of free metabolites in cells? [book.bionumbers.org]
- 11. shimadzu.com [shimadzu.com]
- 12. Guidelines for metabolic flux analysis in metabolic engineering: methods, tools, and applications - CD Biosynsis [biosynsis.com]
- 13. 13C metabolic flux analysis: Classification and characterization from the perspective of mathematical modeling and application in physiological research of neural cell - PMC [pmc.ncbi.nlm.nih.gov]
- 14. researchgate.net [researchgate.net]
- 15. The LC-MS workflow | workflow4metabolomics [workflow4metabolomics.org]
- 16. Processing and Analysis of GC/LC-MS-Based Metabolomics Data | Springer Nature Experiments [experiments.springernature.com]
- 17. LC-MS-based metabolomics - PMC [pmc.ncbi.nlm.nih.gov]
- 18. What is flux balance analysis? - PMC [pmc.ncbi.nlm.nih.gov]
- 19. researchgate.net [researchgate.net]
Orchestrating Development: A Technical Guide to the Core Principles of Developmental Biology
For Researchers, Scientists, and Drug Development Professionals
Introduction
Developmental biology is the study of the processes by which a single cell develops into a complex multicellular organism. This intricate orchestration involves a precise interplay of genetic and environmental cues that guide cells to proliferate, differentiate, and organize into tissues and organs.[1] Understanding these fundamental principles is not only crucial for advancing our knowledge of life but also holds immense potential for regenerative medicine and the development of novel therapeutics. This technical guide provides an in-depth exploration of the core pillars of developmental biology: cellular differentiation, pattern formation, and morphogenesis. It further details key signaling pathways that govern these processes and provides comprehensive protocols for essential experimental techniques in the field.
Core Principles of Developmental Orchestration
The development of a multicellular organism is underpinned by three fundamental processes:
-
Cellular Differentiation: This is the process by which a less specialized cell becomes a more specialized cell type.[2] Starting from a single totipotent zygote, a series of divisions and differentiations give rise to the vast array of specialized cells that constitute a complete organism. This process is driven by changes in gene expression, where specific sets of genes are turned on or off to dictate a cell's function and identity.[3]
-
Pattern Formation: This refers to the process by which cells in a developing embryo acquire distinct identities in a spatially organized manner, leading to the formation of a structured body plan.[4][5] A key mechanism in pattern formation is the establishment of morphogen gradients. Morphogens are signaling molecules that emanate from a source and form a concentration gradient across a field of cells. Cells respond to different concentrations of the morphogen by activating distinct sets of genes, thereby acquiring different fates based on their position.[6][7][8]
-
Morphogenesis: This is the biological process that causes an organism to develop its shape.[9][10] It involves the coordinated movement and rearrangement of cells and tissues to form the three-dimensional structures of organs and the overall body plan.[9][11][12] Morphogenesis is a highly dynamic process involving cell adhesion, migration, and changes in cell shape.[9][12]
Key Signaling Pathways in Development
A small number of highly conserved signaling pathways are repeatedly used throughout development to regulate cell fate decisions, proliferation, and movement. Understanding these pathways is critical for deciphering the logic of development and for identifying potential targets for therapeutic intervention.
Wnt Signaling Pathway
The Wnt signaling pathway is a crucial regulator of a wide range of developmental processes, including cell fate specification, proliferation, and migration.[13][14] The pathway can be broadly divided into two main branches: the canonical (β-catenin-dependent) and non-canonical (β-catenin-independent) pathways.[2][4][15]
-
Canonical Wnt Pathway: In the absence of a Wnt ligand, a "destruction complex" phosphorylates β-catenin, targeting it for degradation. Binding of a Wnt ligand to its Frizzled (Fzd) receptor and LRP5/6 co-receptor disrupts the destruction complex, leading to the accumulation of β-catenin in the cytoplasm and its subsequent translocation to the nucleus.[9][12][15] In the nucleus, β-catenin acts as a co-activator for TCF/LEF transcription factors to regulate the expression of Wnt target genes.[4][9][12]
-
Non-canonical Wnt Pathways: These pathways operate independently of β-catenin. The two major non-canonical pathways are the Planar Cell Polarity (PCP) pathway and the Wnt/Ca2+ pathway.[2][4] The PCP pathway regulates cell polarity and coordinated cell movements, while the Wnt/Ca2+ pathway modulates intracellular calcium levels to influence processes like cell adhesion and migration.[2][4][15]
Caption: Wnt Signaling Pathways.
TGF-β Signaling Pathway
The Transforming Growth Factor-beta (TGF-β) superfamily of ligands regulates a diverse array of cellular processes, including proliferation, differentiation, apoptosis, and cell migration.[16] The signaling cascade can be initiated through both SMAD-dependent and SMAD-independent pathways.
-
SMAD-Dependent Pathway: Binding of a TGF-β ligand to its type II receptor recruits and phosphorylates a type I receptor.[10][16] The activated type I receptor then phosphorylates receptor-regulated SMADs (R-SMADs), which subsequently bind to the common mediator SMAD4.[10][16] This SMAD complex translocates to the nucleus to regulate target gene expression.[10][17]
-
SMAD-Independent Pathways: TGF-β receptors can also activate other signaling pathways, such as the MAPK/ERK, PI3K/AKT, and Rho-like GTPase pathways, to regulate a variety of cellular responses.[10][16][18]
References
- 1. journals.plos.org [journals.plos.org]
- 2. Wnt signal transduction pathways - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Whole Mount In Situ Hybridization in Zebrafish [protocols.io]
- 4. researchgate.net [researchgate.net]
- 5. researchgate.net [researchgate.net]
- 6. Experiment < Expression Atlas < EMBL-EBI [ebi.ac.uk]
- 7. ChIP-seq Protocols and Methods | Springer Nature Experiments [experiments.springernature.com]
- 8. journals.biologists.com [journals.biologists.com]
- 9. zfin.org [zfin.org]
- 10. researchgate.net [researchgate.net]
- 11. Genome Editing in Mice Using CRISPR/Cas9 Technology - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Genome Editing in Mice Using CRISPR/Cas9 Technology | Semantic Scholar [semanticscholar.org]
- 13. Video: Genome Editing in Mammalian Cell Lines using CRISPR-Cas [jove.com]
- 14. Canonical and Non-Canonical Wnt Signaling in Immune Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 15. researchgate.net [researchgate.net]
- 16. creative-diagnostics.com [creative-diagnostics.com]
- 17. researchgate.net [researchgate.net]
- 18. bosterbio.com [bosterbio.com]
The Conductor of Discovery: A Technical Guide to Data Orchestration in Biomedical Research
For Researchers, Scientists, and Drug Development Professionals
In the era of big data, biomedical research is undergoing a profound transformation. The sheer volume, variety, and velocity of data generated from genomics, proteomics, high-throughput screening, and clinical trials present both unprecedented opportunities and significant challenges. To harness the full potential of this data deluge, researchers and drug development professionals are increasingly turning to data orchestration. This in-depth technical guide explores the core principles of data orchestration, its practical applications in biomedical research, and the tangible benefits it delivers in accelerating discovery and improving patient outcomes.
The Core of Data Orchestration: From Chaos to Cohesion
Data orchestration is the automated process of coordinating and managing complex data workflows across multiple systems and services. It goes beyond simple data integration by not just connecting data sources, but also automating the entire pipeline from data ingestion and processing to analysis and reporting. In the context of biomedical research, this means seamlessly moving vast datasets between different analytical tools, computational environments (such as high-performance computing clusters and cloud platforms), and storage systems in a reproducible and scalable manner.[1][2][3]
At its heart, data orchestration in biomedical research is about creating a unified and automated data ecosystem that breaks down data silos.[4] Traditionally, research labs and different departments within a pharmaceutical company often operate in isolation, with genomics, proteomics, and clinical data residing in disparate systems.[5] Data orchestration brings these together, enabling a more holistic and integrated approach to research.
The key components of a data orchestration framework typically include:
-
Workflow Management Systems (WMS): These are the engines of data orchestration, allowing researchers to define, execute, and monitor complex computational pipelines.[1][6] Popular WMS in the bioinformatics community include Nextflow, Snakemake, and platforms that support the Common Workflow Language (CWL).[7][8]
-
Containerization: Technologies like Docker and Singularity are used to package software and their dependencies into portable containers. This ensures that analysis pipelines can be run consistently across different computing environments, a cornerstone of reproducible research.
-
Scalable Infrastructure: Data orchestration platforms are often deployed on cloud computing platforms (e.g., Amazon Web Services, Google Cloud) or on-premise high-performance computing (HPC) clusters to handle the massive computational demands of biomedical data analysis.
The Quantitative Impact of Orchestration
The adoption of data orchestration yields significant, measurable benefits in biomedical research. By automating and optimizing data workflows, research organizations can achieve greater efficiency, reproducibility, and scalability.
A key advantage is the enhanced reproducibility of scientific findings.[2][6] By defining an entire analysis pipeline in a workflow language, every step, parameter, and software version is explicitly recorded, allowing other researchers to replicate the analysis precisely. This is crucial for validating research outcomes and building upon previous work.
Furthermore, data orchestration can lead to substantial improvements in computational efficiency. A comparative analysis of popular bioinformatics workflow management systems highlights these gains:
| Workflow Management System | Elapsed Time (minutes) | CPU Time (minutes) | Max. Memory (GB) |
| Pegasus-mpi-cluster | 130.5 | 10,783 | 11.5 |
| Snakemake | 132.2 | 10,812 | 12.1 |
| Nextflow | 135.8 | 10,925 | 12.3 |
| Cromwell-WDL | 145.1 | 11,041 | 13.0 |
| Toil-CWL | 155.6 | 11,234 | 13.5 |
Caption: Benchmark comparison of workflow management systems for a typical bioinformatics pipeline. Data adapted from a 2018 study evaluating WMS efficiency.[6]
In the realm of clinical trials, data orchestration platforms can significantly accelerate timelines and reduce costs. By automating data collection, quality control, and analysis, these platforms can reduce study timelines by up to 20% and cut trial costs by 15-25%.[9][10]
Orchestrated Workflows in Practice: Experimental Protocols
To illustrate the practical application of data orchestration, this section provides detailed methodologies for two common experimental workflows in biomedical research: RNA-Seq analysis for differential gene expression and ChIP-Seq analysis for identifying protein-DNA interactions.
RNA-Seq Analysis Workflow with Nextflow
This protocol outlines a reproducible workflow for analyzing RNA-Seq data to identify differentially expressed genes using Nextflow.
Objective: To identify genes that are differentially expressed between two experimental conditions.
Methodology:
-
Quality Control: Raw sequencing reads in FASTQ format are assessed for quality using FastQC.
-
Adapter Trimming: Adapters and low-quality bases are removed from the reads using Trim Galore!.
-
Alignment: The trimmed reads are aligned to a reference genome using the STAR aligner.[11]
-
Quantification: Gene and transcript expression levels are quantified using Salmon.[7][11]
-
Differential Expression Analysis: The gene counts are used to perform differential expression analysis between the experimental conditions using DESeq2.[11]
-
Reporting: A comprehensive report summarizing the results from all steps is generated using MultiQC.[7]
Caption: An orchestrated RNA-Seq analysis workflow.
ChIP-Seq Analysis Workflow with Snakemake
This protocol details a reproducible workflow for analyzing ChIP-Seq data to identify protein binding sites on a genome-wide scale using Snakemake.[8]
Objective: To identify the genomic regions where a specific protein binds.
Methodology:
-
Read Quality Control: The quality of the raw sequencing reads (FASTQ files) is evaluated.
-
Mapping to Reference Genome: Reads are aligned to a reference genome using an aligner like Bowtie2.[8]
-
Peak Calling: Genomic regions with a significant enrichment of reads (peaks) are identified using a peak caller such as MACS2. This step compares the ChIP sample to a control input sample.
-
Peak Annotation: The identified peaks are annotated to determine their proximity to known genes and genomic features.
-
Functional Enrichment Analysis: The genes associated with the peaks are analyzed for enrichment in specific biological pathways or functions.
Caption: A reproducible ChIP-Seq analysis workflow using Snakemake.
Visualizing Orchestrated Biological Insights: Signaling Pathways
Data orchestration is not only about managing computational workflows but also about integrating diverse datasets to gain deeper biological insights. A prime example is the analysis of complex signaling pathways, which are fundamental to understanding cellular processes and disease mechanisms.
The NF-κB Signaling Pathway
The Nuclear Factor kappa-light-chain-enhancer of activated B cells (NF-κB) signaling pathway is a crucial regulator of the immune response, inflammation, and cell survival.[12][13] Data from various 'omics' experiments, such as transcriptomics and proteomics, can be orchestrated to build a comprehensive picture of how this pathway is regulated and dysregulated in disease.
Caption: The canonical NF-κB signaling pathway.
The EGFR Signaling Pathway
The Epidermal Growth Factor Receptor (EGFR) signaling pathway plays a critical role in cell growth, proliferation, and differentiation.[14][15][16] Its aberrant activation is a hallmark of many cancers, making it a key target for drug development. Orchestrating data from genomic, transcriptomic, and proteomic studies allows researchers to model this pathway and identify potential therapeutic interventions.
Caption: A simplified view of the EGFR signaling pathway.
The Future of Orchestrated Biomedical Research
Data orchestration is poised to become an indispensable component of modern biomedical research and drug development. As datasets continue to grow in size and complexity, the need for automated, scalable, and reproducible workflows will only intensify. The integration of artificial intelligence and machine learning into orchestrated pipelines will further enhance our ability to extract meaningful insights from complex data, paving the way for personalized medicine and more effective therapies.[17] By embracing data orchestration, the biomedical community can accelerate the pace of discovery and translate big data into tangible improvements in human health.
References
- 1. Software pipelines for RNA-Seq, ChIP-Seq and germline variant calling analyses in common workflow language (CWL) - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Software pipelines for RNA-Seq, ChIP-Seq and germline variant calling analyses in common workflow language (CWL) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. youtube.com [youtube.com]
- 4. RNAflow: An Effective and Simple RNA-Seq Differential Gene Expression Pipeline Using Nextflow - PMC [pmc.ncbi.nlm.nih.gov]
- 5. academic.oup.com [academic.oup.com]
- 6. researchgate.net [researchgate.net]
- 7. training.nextflow.io [training.nextflow.io]
- 8. theoj.org [theoj.org]
- 9. lifebit.ai [lifebit.ai]
- 10. tfscro.com [tfscro.com]
- 11. Streamlined RNA-Seq Analysis Using Nextflow – Genomics Core at NYU CGSB [gencore.bio.nyu.edu]
- 12. creative-diagnostics.com [creative-diagnostics.com]
- 13. NF-κB Signaling in Macrophages: Dynamics, Crosstalk, and Signal Integration - PMC [pmc.ncbi.nlm.nih.gov]
- 14. EGF/EGFR Signaling Pathway Luminex Multiplex Assay - Creative Proteomics [cytokine.creative-proteomics.com]
- 15. A comprehensive pathway map of epidermal growth factor receptor signaling - PMC [pmc.ncbi.nlm.nih.gov]
- 16. creative-diagnostics.com [creative-diagnostics.com]
- 17. How data science and AI-based technologies impact genomics - PMC [pmc.ncbi.nlm.nih.gov]
Orchestrating Discovery: An Introductory Guide to Multi-Omics Studies
An In-depth Technical Guide for Researchers, Scientists, and Drug Development Professionals
The complexity of biological systems necessitates a multi-faceted approach to unravel the intricate molecular mechanisms underpinning health and disease. Multi-omics, the integrated analysis of diverse biological data layers—genomics, transcriptomics, proteomics, and metabolomics—offers a powerful paradigm to achieve a holistic understanding. This guide provides a technical overview of the core principles, experimental considerations, and data integration strategies essential for orchestrating successful multi-omics studies, with a focus on applications in drug discovery and development.
The Rationale for Multi-Omics: Beyond a Single Dimension
Biological information flows from the static blueprint of the genome to the dynamic functional landscape of the proteome and metabolome. Analyzing a single omics layer provides only a snapshot of this complex process. For instance, transcriptomic data reveals gene expression levels, but does not always correlate with protein abundance due to post-transcriptional, translational, and post-translational regulation.[1][2] A multi-omics approach allows researchers to trace the flow of biological information, identify regulatory hubs, and uncover novel biomarkers and therapeutic targets that would be missed by single-omics analyses.[3][4]
The integration of these diverse datasets is a cornerstone of systems biology and is increasingly pivotal in precision medicine, enabling patient stratification and the development of targeted therapies.[5][6]
Designing a Robust Multi-Omics Study
A well-designed multi-omics study is critical for generating high-quality, interpretable data. Key considerations include:
-
Clear Definition of the Biological Question: The specific research question will dictate the choice of omics platforms, sample types, and analytical strategies.
-
Sample Collection and Preparation: Standardized protocols for sample acquisition and processing are paramount to minimize batch effects and technical variability. It is crucial to use methods that are compatible with the extraction of multiple types of molecules (DNA, RNA, proteins, and metabolites) from the same sample where possible.
-
Selection of Omics Technologies: The choice of technology for each omic layer depends on the research question, sample availability, and desired depth of analysis.
-
Data Quality Control: Rigorous quality control at each stage, from sample preparation to data generation, is essential to ensure the reliability of the final dataset.
Core Experimental Protocols: A Practical Overview
This section provides a high-level summary of the methodologies for key omics experiments. It is essential to consult detailed, specific protocols for each experiment.
Genomics (DNA-Seq)
Genomic sequencing elucidates the DNA sequence of an organism, identifying variations such as single nucleotide polymorphisms (SNPs), insertions, deletions, and copy number variations.
Methodology:
-
DNA Extraction: High-quality genomic DNA is isolated from cells or tissues.
-
Library Preparation: The DNA is fragmented, and adapters are ligated to the ends of the fragments. This is followed by PCR amplification to create a sequencing library.
-
Sequencing: The library is sequenced using a high-throughput sequencing platform (e.g., Illumina).
-
Data Analysis: The raw sequencing reads are aligned to a reference genome, and genetic variants are identified and annotated.
Transcriptomics (RNA-Seq)
Transcriptomics captures the complete set of RNA transcripts in a cell, providing a snapshot of gene expression.
Methodology:
-
RNA Extraction: High-quality total RNA is isolated from cells or tissues.
-
Library Preparation: RNA is converted to cDNA, and sequencing adapters are ligated. This may involve selection for poly(A) RNA to enrich for mRNA.
-
Sequencing: The cDNA library is sequenced using a high-throughput sequencing platform.
-
Data Analysis: Raw reads are aligned to a reference genome or transcriptome, and gene expression levels are quantified. Differential expression analysis is then performed to identify genes that are up- or down-regulated between different conditions.[7]
Proteomics (Mass Spectrometry-based)
Proteomics is the large-scale study of proteins, their structures, functions, and interactions.
Methodology:
-
Protein Extraction and Digestion: Proteins are extracted from cells or tissues and digested into smaller peptides, typically using the enzyme trypsin.
-
Peptide Separation: The complex mixture of peptides is separated using liquid chromatography (LC).
-
Mass Spectrometry (MS): The separated peptides are ionized and their mass-to-charge ratio is measured by a mass spectrometer. Peptides are then fragmented, and the masses of the fragment ions are measured (MS/MS).
-
Data Analysis: The MS/MS spectra are searched against a protein sequence database to identify the peptides and, by inference, the proteins present in the sample. Quantitative analysis determines the relative abundance of proteins between samples.[8]
Metabolomics
Metabolomics is the comprehensive analysis of small molecules (metabolites) within a biological system.
Methodology:
-
Metabolite Extraction: Metabolites are extracted from samples using solvents like methanol, acetonitrile, or chloroform.
-
Analytical Platform: The extracted metabolites are analyzed using either mass spectrometry (MS) coupled with liquid chromatography (LC) or gas chromatography (GC), or nuclear magnetic resonance (NMR) spectroscopy.
-
Data Acquisition: The analytical instrument generates data that reflects the abundance of different metabolites.
-
Data Analysis: The raw data is processed to identify and quantify metabolites. This often involves comparison to spectral libraries and databases.
Quantitative Data Presentation
A key output of a multi-omics study is a set of quantitative measurements for each molecular layer. Summarizing this data in a structured format is crucial for comparison and integration. The following table provides a hypothetical example of integrated transcriptomic and proteomic data for a set of genes in a cancer cell line.
| Gene Symbol | Transcript Abundance (Normalized Counts) | Protein Abundance (Normalized Intensity) |
| EGFR | 15,234 | 2.5 x 10^6 |
| TP53 | 8,765 | 1.2 x 10^5 |
| KRAS | 12,345 | 1.8 x 10^6 |
| BRAF | 9,876 | 9.5 x 10^5 |
| MYC | 25,432 | 3.1 x 10^6 |
This table is a simplified representation. Real-world datasets are significantly larger and more complex.
Visualizing Multi-Omics Workflows and Pathways
Visual representations are invaluable for understanding the complex workflows and biological pathways in multi-omics studies. The following diagrams are generated using the Graphviz DOT language.
Experimental Workflow for a Multi-Omics Study
This diagram illustrates a typical workflow from patient sample acquisition to multi-omics data integration.
Logical Relationship of Multi-Omics Data Integration
This diagram illustrates the conceptual flow of integrating different omics data types to gain biological insights.
mTOR Signaling Pathway
The mTOR signaling pathway is a crucial regulator of cell growth, proliferation, and metabolism, and is frequently dysregulated in cancer. This diagram illustrates the core components and interactions of this pathway.
Challenges and Future Directions
Despite the immense potential of multi-omics approaches, several challenges remain. These include the high dimensionality of the data, the presence of missing values, and the need for sophisticated computational methods for data integration and interpretation.[3] The development of novel statistical and machine learning techniques is crucial for extracting meaningful biological insights from these complex datasets.
Future advancements in single-cell multi-omics technologies will provide unprecedented resolution to study cellular heterogeneity and intercellular communication. The continued development of computational tools and the generation of large-scale, well-annotated public datasets will further propel the application of multi-omics in biomedical research and drug development, ultimately leading to a new era of personalized medicine.
References
- 1. Quantitative Proteomics of the Cancer Cell Line Encyclopedia - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Pan-cancer proteomic map of 949 human cell lines - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Multi-omics Data Integration, Interpretation, and Its Application - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Multi-omics Data Integration — Part 1: Introduction | by Yalda Yaghooti | Medium [medium.com]
- 5. researchgate.net [researchgate.net]
- 6. A guide to multi-omics data collection and integration for translational medicine. - National Genomics Data Center (CNCB-NGDC) [ngdc.cncb.ac.cn]
- 7. researchgate.net [researchgate.net]
- 8. mdpi.com [mdpi.com]
Methodological & Application
Application Notes and Protocols for Studying the Orchestration of Signaling Cascades
Audience: Researchers, scientists, and drug development professionals.
Introduction: Cellular signaling cascades are intricate networks that govern a vast array of biological processes, from proliferation and differentiation to apoptosis.[1] These pathways are not linear but are highly orchestrated, involving complex protein-protein interactions (PPIs), post-translational modifications (PTMs), and feedback loops that ensure signal specificity and fidelity. Understanding this orchestration is critical for deciphering fundamental biology and for the development of targeted therapeutics.[2][3] This document provides detailed application notes and protocols for key experimental techniques used to investigate the multifaceted nature of signaling cascades.
Section 1: Identifying Protein-Protein Interactions (PPIs) in Signaling Cascades
Application Note: The assembly of signaling complexes through protein-protein interactions is a cornerstone of signal transduction. These interactions can be stable, forming multi-protein machines, or transient, mediating fleeting steps in a cascade.[4] A variety of methods exist to identify these interactions, each with its own strengths. Co-immunoprecipitation (Co-IP) is a gold-standard technique for capturing stable interacting partners.[5] Proximity labeling (PL) methods, such as BioID and APEX, are powerful for detecting weak or transient interactions by biotinylating nearby proteins in their native cellular environment.[6][7][8] Techniques like Fluorescence Resonance Energy Transfer (FRET) and Bioluminescence Resonance Energy Transfer (BRET) allow for the confirmation and visualization of these interactions in real-time within living cells.[5][9][10][11][12]
Table 1: Comparison of Key PPI Detection Methods
| Method | Principle | Advantages | Limitations |
| Co-Immunoprecipitation (Co-IP) | An antibody targets a "bait" protein, pulling it down from a cell lysate along with its bound "prey" proteins.[4][5] | Captures endogenous protein complexes; relatively straightforward. | Biased towards stable and abundant interactions; may miss transient interactions.[13] |
| Proximity Labeling (e.g., TurboID, APEX) | A promiscuous labeling enzyme (e.g., biotin ligase) fused to a protein of interest biotinylates proximal proteins, which are then purified and identified.[7][8] | Captures transient and weak interactions in vivo; provides spatial information.[6] | Can label non-interacting bystanders; requires genetic modification of the protein of interest. |
| FRET/BRET | Non-radiative energy transfer between a donor and acceptor molecule (fluorophores or a luciferase/fluorophore pair) fused to two proteins of interest when they are in close proximity (<10 nm).[9][10] | Real-time detection in living cells; provides spatial and dynamic information.[12] | Requires fusion proteins which may alter function; distance-dependent. |
Protocol 1.1: Co-Immunoprecipitation followed by Mass Spectrometry (Co-IP-MS)
This protocol describes the identification of binding partners for a target protein by immunoprecipitating the protein of interest and identifying co-precipitated proteins using mass spectrometry.[14][15]
Methodology:
-
Cell Lysis: Lyse cultured cells (typically >1x10^7 cells) with a non-denaturing lysis buffer (e.g., containing 1% Triton X-100 or NP-40, 150 mM NaCl, 50 mM Tris-HCl pH 7.5) supplemented with protease and phosphatase inhibitors.[14]
-
Centrifugation: Clarify the lysate by centrifuging at ~14,000 x g for 15 minutes at 4°C to pellet cellular debris.[14]
-
Pre-clearing (Optional): Incubate the supernatant with Protein A/G beads for 1 hour at 4°C to reduce non-specific binding.
-
Antibody Incubation: Add the specific antibody against the "bait" protein to the pre-cleared lysate and incubate for 2-4 hours or overnight at 4°C with gentle rotation.[14]
-
Immune Complex Capture: Add equilibrated Protein A/G magnetic or agarose beads and incubate for an additional 1-2 hours at 4°C to capture the antibody-protein complexes.[16]
-
Washing: Pellet the beads and wash them 3-5 times with ice-cold lysis buffer to remove non-specifically bound proteins.
-
Elution: Elute the bound proteins from the beads using an elution buffer (e.g., 8M urea or low pH glycine buffer).[16]
-
Sample Preparation for MS: Reduce, alkylate, and digest the eluted proteins into peptides using an enzyme like trypsin.[16][17]
-
LC-MS/MS Analysis: Analyze the resulting peptides by liquid chromatography-tandem mass spectrometry (LC-MS/MS).
-
Data Analysis: Identify proteins from the MS/MS spectra using a database search algorithm. Potential interaction partners are identified by comparing their abundance in the specific IP versus a negative control (e.g., an isotype-matched IgG).[18]
Protocol 1.2: Proximity Labeling using TurboID
This protocol outlines the general steps for identifying proximal proteins using the TurboID enzyme, an engineered biotin ligase that rapidly labels neighboring proteins in living cells.[6][19]
Methodology:
-
Construct Generation and Expression: Create a fusion construct of your protein of interest with TurboID. Transfect this construct into the desired cell line and select for stable expression.
-
Biotin Labeling: Culture the cells and supplement the medium with excess biotin (e.g., 50 µM) for a short period (e.g., 10 minutes) to initiate biotinylation of proximal proteins.[6]
-
Cell Lysis: Quench the labeling reaction by placing cells on ice and washing with ice-cold PBS. Lyse the cells using a strong lysis buffer containing detergents like SDS to ensure solubilization of all proteins.
-
Affinity Purification: Incubate the cell lysate with streptavidin-coated beads (e.g., magnetic beads) to capture all biotinylated proteins.
-
Washing: Perform extensive and stringent washes to remove non-biotinylated proteins that bind non-specifically to the beads.
-
Elution/Digestion: Elute the bound proteins or, more commonly, perform on-bead digestion with trypsin to release the peptides for MS analysis.
-
LC-MS/MS and Data Analysis: Analyze the peptides by LC-MS/MS. Identify and quantify the proteins. True proximal interactors are determined by comparing their abundance against negative controls (e.g., cells expressing only TurboID).
Section 2: Analyzing Protein Phosphorylation
Application Note: Reversible protein phosphorylation is a primary mechanism for regulating signaling cascades.[2] The ability to identify which proteins are phosphorylated at specific sites and to quantify changes in phosphorylation levels is essential for understanding pathway activation. Mass spectrometry-based phosphoproteomics provides a global, unbiased view of thousands of phosphorylation events simultaneously.[2][20] In contrast, Western blotting with phospho-specific antibodies offers a targeted, hypothesis-driven approach to validate and quantify phosphorylation changes at a specific site on a protein of interest.[2]
Protocol 2.1: Global Phosphoproteomics using LC-MS/MS
This protocol describes a typical bottom-up phosphoproteomics workflow, which involves digesting proteins into peptides, enriching for phosphopeptides, and analyzing them by LC-MS/MS.[20][21]
Table 2: Typical Sample Input Requirements for Phosphoproteomics
| Sample Type | Minimum Input for Comprehensive Profiling |
| Cultured Cells | ≥10⁷ cells[20] |
| Solid Tissues | ≥50 mg wet weight[20] |
| Plasma/Serum | ≥100 µL[20] |
| Total Protein | >1 mg[20] |
Methodology:
-
Sample Preparation: Lyse cells or tissues in a buffer containing strong denaturants (e.g., 8M urea) and potent phosphatase and protease inhibitors to preserve the phosphorylation state.[20]
-
Protein Digestion: Reduce and alkylate the proteins, then digest them into peptides using an enzyme like trypsin.
-
Phosphopeptide Enrichment: Due to the low stoichiometry of phosphorylation, it is crucial to enrich for phosphopeptides.[20] Common methods include Titanium Dioxide (TiO2) chromatography or Immobilized Metal Affinity Chromatography (IMAC).
-
LC-MS/MS Analysis: Analyze the enriched phosphopeptides using a high-resolution mass spectrometer. Data can be acquired in Data-Dependent (DDA) or Data-Independent (DIA) mode.[20]
-
Data Analysis: Use specialized software to search the MS/MS spectra against a protein database to identify the phosphopeptides and localize the exact site of phosphorylation.
-
Quantification: For quantitative studies, methods like label-free quantification (LFQ) or isobaric labeling (e.g., TMT) can be used to compare phosphopeptide abundance across different samples or conditions.[2]
Protocol 2.2: Western Blotting for Phospho-proteins
This protocol details the targeted detection of a specific phosphorylated protein using a phospho-specific antibody.[22][23][24][25]
Methodology:
-
Sample Preparation: Treat cells as required and lyse them directly in 1X SDS sample buffer. Sonicate briefly to shear DNA and reduce viscosity.[22] Heat the samples at 95-100°C for 5 minutes to denature proteins.[22]
-
SDS-PAGE: Load 20-30 µg of protein per lane onto an SDS-polyacrylamide gel and separate the proteins by electrophoresis.[22][25]
-
Protein Transfer: Transfer the separated proteins from the gel to a nitrocellulose or PVDF membrane.[24]
-
Blocking: Block the membrane for 1 hour at room temperature in a blocking buffer (e.g., 5% non-fat dry milk or 5% BSA in TBST) to prevent non-specific antibody binding.[25] For phospho-antibodies, BSA is often recommended.
-
Primary Antibody Incubation: Incubate the membrane with the primary antibody (specific to the phosphorylated epitope) diluted in blocking buffer, typically overnight at 4°C with gentle shaking.[22][23]
-
Washing: Wash the membrane three times for 5-10 minutes each with TBST to remove unbound primary antibody.[25]
-
Secondary Antibody Incubation: Incubate the membrane with a horseradish peroxidase (HRP)-conjugated secondary antibody (that recognizes the primary antibody species) for 1 hour at room temperature.[25]
-
Detection: Wash the membrane again as in step 6. Apply an enhanced chemiluminescence (ECL) substrate and detect the signal using X-ray film or a digital imager.[23] The band intensity corresponds to the amount of phosphorylated protein.
Section 3: Measuring Kinase Activity
Application Note: Directly measuring the enzymatic activity of kinases is crucial for understanding their regulation and for screening potential inhibitors in drug development.[26] Kinase assays typically measure the transfer of a phosphate group from ATP to a specific substrate.[26] These can be performed using purified recombinant enzymes (in vitro) or with kinases immunoprecipitated from cell lysates. A variety of detection methods are available, from traditional radiometric assays using ³²P-labeled ATP to safer and more high-throughput fluorescence- and luminescence-based methods.[26][27][28]
Protocol 3.1: In Vitro Kinase Assay (Fluorescence-based)
This protocol provides a general framework for a non-radioactive, fluorescence-based kinase assay.
Methodology:
-
Prepare Reagents:
-
Kinase: Purified, recombinant kinase enzyme.
-
Substrate: A specific peptide or protein substrate for the kinase.
-
Kinase Buffer: A buffer optimized for the kinase, typically containing Tris-HCl, MgCl₂, and DTT.
-
ATP: A stock solution of ATP.
-
Detection Reagent: A reagent that can distinguish between the phosphorylated and unphosphorylated substrate. For example, a phospho-specific antibody coupled to a fluorescent probe.
-
-
Kinase Reaction:
-
In a microplate well, combine the kinase, substrate, and kinase buffer.
-
Initiate the reaction by adding ATP to a final concentration typically near the Km of the kinase (e.g., 10-100 µM).[29]
-
Incubate the reaction at the optimal temperature (e.g., 30°C or 37°C) for a set period (e.g., 30-60 minutes).
-
-
Stop Reaction: Terminate the reaction by adding a stop solution, often containing a chelating agent like EDTA to sequester Mg²⁺, which is essential for kinase activity.[28]
-
Detection:
-
Add the detection reagent. This could involve, for example, adding a fluorescently labeled antibody that specifically binds the phosphorylated substrate.
-
Incubate to allow binding.
-
-
Measurement: Read the fluorescence signal (e.g., fluorescence polarization, TR-FRET, or intensity) on a plate reader.[27][28] The signal will be proportional to the amount of phosphorylated product, and thus to the kinase activity.
-
Controls: Include negative controls such as "no enzyme" (to measure background signal) and "no ATP" (to ensure the reaction is ATP-dependent).
Section 4: Case Study: The MAPK/ERK Signaling Pathway
Overview: The Mitogen-Activated Protein Kinase (MAPK) cascade is a central signaling pathway that converts extracellular stimuli into a wide range of cellular responses, including proliferation, differentiation, and survival.[1][30][31] A well-studied branch is the Ras-Raf-MEK-ERK pathway.[1] Upon growth factor stimulation, a cascade of sequential phosphorylation events occurs: Ras activates Raf (a MAP3K), which phosphorylates and activates MEK (a MAP2K), which in turn phosphorylates and activates ERK (a MAPK).[1][30] Activated ERK then phosphorylates numerous cytoplasmic and nuclear substrates.
Integrated Experimental Approach:
-
Confirm Pathway Activation: Treat cells with a growth factor. Use Western Blotting (Protocol 2.2) with phospho-specific antibodies against p-MEK and p-ERK to confirm the activation of the cascade over a time course.
-
Global Phosphorylation Changes: To discover novel downstream targets of ERK, perform Global Phosphoproteomics (Protocol 2.1) on cells with and without growth factor stimulation (and potentially with an ERK inhibitor).
-
Identify ERK Interactors: To understand how ERK is regulated and how it engages its substrates, perform a Co-IP-MS experiment (Protocol 1.1) using an antibody against ERK to pull down its binding partners.
-
Measure Kinase Activity: To test the effect of a potential drug candidate, perform an In Vitro Kinase Assay (Protocol 3.1) using purified ERK and a known substrate in the presence of varying concentrations of the compound.
Section 5: Computational Modeling of Signaling Networks
Application Note: Experimental data alone often provides a static snapshot of a dynamic system. Computational modeling integrates this data to simulate the behavior of signaling networks over time.[32][33] These models can help researchers understand complex properties like feedback loops, signal duration, and crosstalk, and can generate testable hypotheses to guide future experiments.[32] The process is iterative: experimental data is used to build and refine a model, and the model's predictions are then tested experimentally, leading to a deeper understanding of the signaling cascade's orchestration.[32][34]
References
- 1. spandidos-publications.com [spandidos-publications.com]
- 2. Phosphoproteomics: a valuable tool for uncovering molecular signaling in cancer cells - PMC [pmc.ncbi.nlm.nih.gov]
- 3. A Comprehensive Analysis of the PI3K/AKT Pathway: Unveiling Key Proteins and Therapeutic Targets for Cancer Treatment - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Overview of Protein–Protein Interaction Analysis | Thermo Fisher Scientific - US [thermofisher.com]
- 5. How to Analyze Protein-Protein Interaction: Top Lab Techniques - Creative Proteomics [creative-proteomics.com]
- 6. Proximity Labeling for Weak Protein Interactions Study - Creative Proteomics [creative-proteomics.com]
- 7. Proximity labeling - Wikipedia [en.wikipedia.org]
- 8. Proximity-dependent labeling methods for proteomic profiling in living cells: an update - PMC [pmc.ncbi.nlm.nih.gov]
- 9. nuvucameras.com [nuvucameras.com]
- 10. Bioluminescence resonance energy transfer-based imaging of protein-protein interactions in living cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. Imaging protein interactions with bioluminescence resonance energy transfer (BRET) in plant and mammalian cells and tissues - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Investigating Protein-protein Interactions in Live Cells Using Bioluminescence Resonance Energy Transfer - PMC [pmc.ncbi.nlm.nih.gov]
- 13. academic.oup.com [academic.oup.com]
- 14. IP-MS Protocol - Creative Proteomics [creative-proteomics.com]
- 15. Immunoprecipitation-Mass Spectrometry (IP-MS) Workshop: Tips and Best Practices | Proteintech Group [ptglab.com]
- 16. Immunoprecipitation (IP) and Mass Spectrometry [protocols.io]
- 17. researchgate.net [researchgate.net]
- 18. Immunoprecipitation-Mass Spectrometry (IP-MS) of Protein-Protein Interactions of Nuclear-Localized Plant Proteins | Springer Nature Experiments [experiments.springernature.com]
- 19. blog.addgene.org [blog.addgene.org]
- 20. Phosphoproteomics Workflow Explained: From Sample to Data - Creative Proteomics [creative-proteomics.com]
- 21. A Rapid One-Pot Workflow for Sensitive Microscale Phosphoproteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 22. Western Blot Procedure | Cell Signaling Technology [cellsignal.com]
- 23. CST | Cell Signaling Technology [cellsignal.com]
- 24. Western blot protocol | Abcam [abcam.com]
- 25. Western Blot Protocol | Proteintech Group [ptglab.com]
- 26. bellbrooklabs.com [bellbrooklabs.com]
- 27. What are the common methods available to detect kinase activities? | AAT Bioquest [aatbio.com]
- 28. Assay Development for Protein Kinase Enzymes - Assay Guidance Manual - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 29. In vitro kinase assay [protocols.io]
- 30. mdpi.com [mdpi.com]
- 31. The MAPK signaling cascade | Semantic Scholar [semanticscholar.org]
- 32. Computational Modeling of Mammalian Signaling Networks - PMC [pmc.ncbi.nlm.nih.gov]
- 33. Computational Modeling of Signaling Networks - Google Books [books.google.com]
- 34. journals.physiology.org [journals.physiology.org]
Application Notes and Protocols for Analyzing Gene Regulatory Network Orchestration
Audience: Researchers, scientists, and drug development professionals.
Introduction
Gene Regulatory Networks (GRNs) represent the complex web of interactions among genes and regulatory molecules, such as transcription factors (TFs), that govern the levels of gene expression within a cell.[1][2] These networks are fundamental to cellular processes, development, and responses to environmental stimuli.[1] Understanding the orchestration of these networks—how genes are collectively controlled—is a primary goal in systems biology and is critical for identifying novel therapeutic targets and understanding disease mechanisms.[2]
This document provides an overview of the key experimental and computational techniques used to dissect GRNs. It includes detailed protocols for core methodologies and summarizes complex data to guide researchers in designing and executing their own studies.
Part 1: Experimental Approaches for GRN Data Generation
The foundation of any GRN analysis is high-quality experimental data. Several high-throughput techniques are employed to capture different facets of gene regulation, from transcript abundance to the physical interactions between proteins and DNA.
Key Techniques:
-
Transcriptome Profiling (RNA-Sequencing): RNA-Seq, particularly single-cell RNA-Seq (scRNA-seq), is a cornerstone for GRN inference. It quantifies the expression levels of thousands of genes simultaneously.[3][4] By observing which genes, including transcription factors, are active in a cell at a given time, researchers can begin to infer regulatory relationships based on correlated expression patterns.[5]
-
Identifying Transcription Factor Binding Sites:
-
ATAC-Seq (Assay for Transposase-Accessible Chromatin with sequencing): This method identifies regions of open chromatin, which are often indicative of active regulatory elements like promoters and enhancers where TFs can bind.[1]
-
ChIP-Seq (Chromatin Immunoprecipitation with sequencing): ChIP-seq provides direct evidence of protein-DNA interactions. It maps the specific genomic locations where a given transcription factor is bound, thereby identifying its potential target genes.[1][5]
-
-
Probing Chromatin Architecture:
-
Chromosome Conformation Capture (e.g., Hi-C): These techniques are used to study the three-dimensional organization of the genome. They can identify long-range physical interactions between enhancers and promoters, helping to link regulatory elements to the genes they control.[6]
-
-
Functional Perturbation: To establish causal relationships within a network, it is essential to perturb the system.[7] This involves knocking down (using siRNA or shRNA), knocking out (using CRISPR-Cas9), or overexpressing a specific regulatory gene and then measuring the resulting changes in the expression of other genes in the network using techniques like qPCR or RNA-seq.[7][8]
Caption: General experimental workflow for generating multi-omics data for GRN analysis.
Part 2: Computational Approaches for GRN Inference
Raw experimental data must be processed and integrated using computational algorithms to reconstruct a GRN. These methods range from identifying simple correlations to building complex predictive models.
Key Approaches:
-
Co-expression Network Analysis: These methods, including tools like ARACNE and WGCNA, are based on the principle that genes controlled by the same regulatory program will exhibit similar expression patterns across different conditions.[5] They typically use metrics like mutual information to identify potential regulatory links.[6]
-
Regression-Based Inference: Methods like GENIE3 frame GRN inference as a machine learning problem. They attempt to predict the expression level of each target gene based on the expression levels of all known transcription factors, identifying the most informative TFs as regulators.[4]
-
Multi-Omics Integration: The most robust GRN inference methods integrate multiple data types.[3] For example, tools like SCENIC+ combine scRNA-seq (gene expression) with scATAC-seq (chromatin accessibility) to first identify potential TF binding sites near a gene and then confirm that the TF and the target gene are co-expressed. This integration constrains the network to more direct, causal relationships.[3][5]
-
Machine Learning and Deep Learning: Advanced techniques, including Graph Neural Networks (GNNs), are increasingly used to model the complex, non-linear relationships within GRNs.[1][9] These models can integrate diverse data sources and learn intricate patterns of gene regulation.[1][10]
Caption: Computational workflow for multi-omics GRN inference (e.g., SCENIC+).
Part 3: Data Presentation and Comparison
Choosing the right combination of experimental and computational techniques is crucial for successful GRN analysis. The tables below summarize the key features of common approaches.
Table 1: Comparison of Experimental Techniques for GRN Analysis
| Technique | Primary Data Output | Information Gained in GRN Context | Typical Resolution |
| Bulk RNA-Seq | Gene expression counts (averaged across a cell population) | Identifies co-expressed gene modules; infers regulatory links from correlations. | Low (population average) |
| scRNA-Seq | Gene expression counts per cell | Resolves cell-type-specific GRNs; identifies regulatory dynamics along developmental trajectories. | High (single-cell) |
| ATAC-Seq | Genomic coordinates of open chromatin regions (peaks) | Maps potential cis-regulatory elements (promoters, enhancers) active in a given cell state. | High (locus-specific) |
| ChIP-Seq | Genomic coordinates of TF binding sites (peaks) | Provides direct evidence of a specific TF binding to DNA, identifying its direct target genes. | High (locus-specific) |
| Perturb-Seq | scRNA-seq data following genetic perturbation (e.g., CRISPR) | Establishes causal links by showing how knocking out a TF affects target gene expression. | High (single-cell) |
Table 2: Comparison of Computational Approaches for GRN Inference
| Approach Category | Principle | Example Tools | Required Input Data |
| Co-expression | "Guilt-by-association"; genes with correlated expression patterns are likely functionally related. | ARACNE, WGCNA | Gene Expression Matrix |
| Regression-based | Models target gene expression as a function of TF expression levels to identify predictive regulators. | GENIE3, TIGRESS | Gene Expression Matrix, List of TFs |
| Boolean/Logical | Models gene states as ON/OFF and uses logical rules to describe regulatory interactions. | BoolNet | Time-series or perturbation expression data |
| Multi-omics Integration | Combines expression with epigenetic data (e.g., chromatin accessibility) to infer direct, mechanistic links. | SCENIC+, GRaNIE | scRNA-seq, scATAC-seq, TF motif database |
Part 4: Experimental and Computational Protocols
Protocol 1: Chromatin Immunoprecipitation sequencing (ChIP-seq)
This protocol provides a generalized workflow for performing ChIP-seq to identify the genomic binding sites of a specific transcription factor.
Objective: To isolate and sequence DNA fragments bound by a target transcription factor in vivo.
Materials:
-
Cells or tissue of interest
-
Formaldehyde (for cross-linking)
-
Glycine
-
Cell lysis buffers
-
Sonication or enzymatic digestion equipment
-
Antibody specific to the target transcription factor
-
Protein A/G magnetic beads
-
Wash buffers
-
Elution buffer
-
RNase A and Proteinase K
-
DNA purification kit (e.g., Qiagen PCR Purification Kit)
-
Reagents for NGS library preparation
Procedure:
-
Cross-linking: Treat cells with formaldehyde to create covalent cross-links between proteins and DNA that are in close proximity. This "freezes" the TF-DNA interactions. Quench the reaction with glycine.
-
Cell Lysis and Chromatin Fragmentation: Lyse the cells to release the nuclei. Isolate the chromatin and fragment it into smaller pieces (typically 200-600 bp) using sonication or enzymatic digestion.
-
Immunoprecipitation (IP): Add an antibody specific to the target transcription factor to the fragmented chromatin. The antibody will bind to the TF.
-
Immune Complex Capture: Add Protein A/G magnetic beads to pull down the antibody-TF-DNA complexes.
-
Washing: Wash the beads several times to remove non-specifically bound chromatin, reducing background noise.
-
Elution and Reverse Cross-linking: Elute the immunoprecipitated complexes from the beads. Reverse the formaldehyde cross-links by heating, and treat with RNase A and Proteinase K to remove RNA and proteins.
-
DNA Purification: Purify the remaining DNA fragments. These represent the genomic regions that were bound by the target TF.
-
Library Preparation and Sequencing: Prepare a sequencing library from the purified DNA fragments and sequence them using a next-generation sequencing platform.
-
Data Analysis: Align the sequencing reads to a reference genome. Use a peak-calling algorithm (e.g., MACS2) to identify genomic regions with a significant enrichment of reads, which correspond to the TF's binding sites.
Caption: Step-by-step workflow for a ChIP-seq experiment and data analysis.
Protocol 2: Computational GRN Inference with a SCENIC-like Workflow
This protocol outlines the key computational steps for inferring GRNs from single-cell RNA-seq data, based on the popular SCENIC workflow.
Objective: To reconstruct regulons (a TF and its direct target genes) from a gene expression matrix.
Software/Packages:
-
Python or R environment
-
SCENIC implementation (e.g., pySCENIC)
-
Gene expression matrix (cells x genes)
-
List of known transcription factors
-
Database of cis-regulatory motifs (e.g., cisTarget)
Procedure:
-
Identify Co-expression Modules:
-
Input: A normalized gene expression matrix.
-
Method: Use a regression-based tool (like GENIE3) to calculate potential regulatory relationships. For each gene, its expression is modeled as a function of all TFs.
-
Output: A list of potential TF-target gene pairs with corresponding importance scores. This creates co-expression modules for each TF.
-
-
Prune Modules via Motif Enrichment (cis-regulatory analysis):
-
Input: The co-expression modules from Step 1 and a database of TF binding motifs.
-
Method: For each co-expression module, search the promoter regions of all genes in the module for the binding motif of the corresponding TF. Only modules with significant motif enrichment are retained. This step selects for direct regulatory relationships.
-
Output: A pruned set of regulons where the target genes are both co-expressed with the TF and contain its binding motif.
-
-
Score Regulon Activity in Single Cells:
-
Input: The pruned regulons and the original expression matrix.
-
Method: Use an enrichment scoring algorithm (e.g., AUCell) to calculate the activity of each regulon in each individual cell. This transforms the gene-based matrix into a regulon-based matrix.
-
Output: A matrix showing the activity of each TF (regulon) in every cell, which can be used for downstream analysis like cell clustering and trajectory inference.
-
-
Network Visualization and Analysis:
-
Input: The final list of regulons.
-
Method: Use network visualization tools like Cytoscape to build and explore the GRN, identifying key regulators and network motifs.[11]
-
References
- 1. academic.oup.com [academic.oup.com]
- 2. The Reconstruction and Analysis of Gene Regulatory Networks - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. frontlinegenomics.com [frontlinegenomics.com]
- 4. researchgate.net [researchgate.net]
- 5. Computational approaches to understand transcription regulation in development - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Gene regulatory network reconstruction: harnessing the power of single-cell multi-omic data - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Experimental approaches for gene regulatory network construction: the chick as a model system - PMC [pmc.ncbi.nlm.nih.gov]
- 8. A protocol for unraveling gene regulatory networks | Springer Nature Experiments [experiments.springernature.com]
- 9. arxiv.org [arxiv.org]
- 10. [2504.12610] Machine Learning Methods for Gene Regulatory Network Inference [arxiv.org]
- 11. Charting gene regulatory networks: strategies, challenges and perspectives - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for Computational Modeling of Biological Orchestration
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive guide to applying computational models to understand the complex orchestration of biological processes, with a specific focus on the Mitogen-Activated Protein Kinase (MAPK) signaling pathway. This pathway is a critical regulator of cell proliferation, differentiation, and survival, and its dysregulation is implicated in numerous diseases, including cancer.[1][2][3] By integrating computational modeling with experimental data, researchers can gain deeper insights into the dynamic behavior of this pathway, identify potential drug targets, and predict cellular responses to therapeutic interventions.[1][3]
Introduction to Computational Modeling of the MAPK Pathway
The MAPK cascade is a multi-tiered signaling pathway initiated by extracellular stimuli, such as Epidermal Growth Factor (EGF), which bind to receptor tyrosine kinases on the cell surface.[1][2] This binding event triggers a phosphorylation cascade involving Ras, Raf, MEK, and ERK.[2] Activated (phosphorylated) ERK (p-ERK) then translocates to the nucleus to regulate the expression of target genes, such as c-Fos, which in turn orchestrate cellular responses.
Computational models, particularly those based on Ordinary Differential Equations (ODEs), are powerful tools for capturing the dynamic interactions between the components of the MAPK pathway.[1][4] These models represent the change in concentration of each molecular species over time as a set of coupled differential equations.[4] By simulating these models, researchers can investigate the emergent properties of the pathway, such as signal amplification, feedback loops, and ultrasensitivity.
Quantitative Data Summary
The following tables summarize quantitative data from experimental studies on the MAPK pathway, providing key parameters for model building and validation.
Table 1: Time-Course of ERK Phosphorylation in response to EGF Stimulation. This data, derived from Western blot analysis, shows the dynamic change in the concentration of phosphorylated ERK (p-ERK) over time following stimulation with Epidermal Growth Factor (EGF). The values are typically normalized to the total ERK concentration.
| Time (minutes) | Normalized p-ERK Concentration (Arbitrary Units) |
| 0 | 0.05 |
| 2 | 0.45 |
| 5 | 1.00 |
| 10 | 0.60 |
| 15 | 0.30 |
| 30 | 0.10 |
| 60 | 0.05 |
Table 2: Time-Course of c-Fos mRNA Expression in response to EGF Stimulation. This data, obtained through quantitative real-time PCR (qPCR), illustrates the transcriptional response downstream of MAPK activation. The values represent the fold change in c-Fos mRNA levels relative to the unstimulated state.
| Time (minutes) | c-Fos mRNA Fold Change |
| 0 | 1 |
| 15 | 25 |
| 30 | 80 |
| 60 | 40 |
| 90 | 15 |
| 120 | 5 |
Experimental Protocols
Protocol for Western Blotting of Phosphorylated ERK (p-ERK)
This protocol details the steps for quantifying the levels of phosphorylated ERK, a key indicator of MAPK pathway activation.
Materials:
-
Cell lysis buffer (e.g., RIPA buffer) with protease and phosphatase inhibitors
-
Protein assay kit (e.g., BCA assay)
-
SDS-PAGE gels and running buffer
-
PVDF membrane
-
Transfer buffer
-
Blocking buffer (e.g., 5% BSA or non-fat milk in TBST)
-
Primary antibody (anti-phospho-ERK)
-
Secondary antibody (HRP-conjugated)
-
Enhanced chemiluminescence (ECL) substrate
-
Stripping buffer
-
Primary antibody (anti-total-ERK)
Procedure:
-
Cell Lysis: Treat cells with EGF for the desired time points. Wash cells with ice-cold PBS and lyse them using lysis buffer containing protease and phosphatase inhibitors.
-
Protein Quantification: Determine the protein concentration of each lysate using a protein assay kit to ensure equal loading.
-
SDS-PAGE: Load equal amounts of protein from each sample onto an SDS-PAGE gel and separate the proteins by electrophoresis.
-
Protein Transfer: Transfer the separated proteins from the gel to a PVDF membrane.
-
Blocking: Block the membrane with blocking buffer for 1 hour at room temperature to prevent non-specific antibody binding.
-
Primary Antibody Incubation (p-ERK): Incubate the membrane with the anti-phospho-ERK primary antibody overnight at 4°C.
-
Secondary Antibody Incubation: Wash the membrane and incubate with the HRP-conjugated secondary antibody for 1 hour at room temperature.
-
Detection: Add ECL substrate to the membrane and visualize the protein bands using a chemiluminescence imaging system.
-
Stripping and Re-probing (Total ERK): To normalize for protein loading, strip the membrane using a stripping buffer and re-probe with an antibody against total ERK, following the same incubation and detection steps.
-
Quantification: Quantify the band intensities using densitometry software. The level of p-ERK is expressed as the ratio of the p-ERK signal to the total ERK signal.
Protocol for Quantitative Real-Time PCR (qPCR) of c-Fos
This protocol describes the measurement of c-Fos mRNA levels, a downstream target of the MAPK pathway.
Materials:
-
RNA extraction kit (e.g., TRIzol or column-based kits)
-
Reverse transcription kit
-
qPCR master mix (containing SYBR Green or TaqMan probes)
-
Primers for c-Fos and a housekeeping gene (e.g., GAPDH, Actin)
-
qPCR instrument
Procedure:
-
RNA Extraction: Treat cells with EGF for the desired time points. Isolate total RNA from the cells using an RNA extraction kit.
-
Reverse Transcription: Synthesize complementary DNA (cDNA) from the extracted RNA using a reverse transcription kit.
-
qPCR Reaction Setup: Prepare the qPCR reaction mix containing the qPCR master mix, forward and reverse primers for c-Fos or the housekeeping gene, and the cDNA template.
-
qPCR Amplification: Perform the qPCR reaction in a real-time PCR instrument. The instrument will monitor the fluorescence signal at each cycle of amplification.
-
Data Analysis: Determine the cycle threshold (Ct) value for c-Fos and the housekeeping gene in each sample. The relative expression of c-Fos is calculated using the ΔΔCt method, where the expression is normalized to the housekeeping gene and relative to the untreated control.
Diagrams of Signaling Pathways and Workflows
MAPK Signaling Pathway
Caption: The MAPK signaling cascade initiated by EGF.
Computational Modeling Workflow
Caption: Iterative workflow for computational modeling.
Protocol for Building an Ordinary Differential Equation (ODE) Model of the MAPK Pathway
This protocol provides a step-by-step guide to developing a simple ODE-based model of the core MAPK cascade.
1. Define the Model Scope and Components:
-
Identify the key molecular species to be included in the model. For a simplified MAPK model, this would include Ras, Raf, MEK, ERK, and their phosphorylated forms.
2. Formulate the Biochemical Reactions:
-
Represent the interactions between the molecular species as a series of biochemical reactions. For example:
-
Activation of Raf by Ras: Ras_active + Raf -> Ras_active + pRaf
-
Phosphorylation of MEK by pRaf: pRaf + MEK -> pRaf + pMEK
-
Phosphorylation of ERK by pMEK: pMEK + ERK -> pMEK + pERK
-
Dephosphorylation of pERK: pERK -> ERK
-
3. Write the Ordinary Differential Equations (ODEs):
-
Translate the biochemical reactions into a system of ODEs that describe the rate of change of concentration for each species. This is based on the law of mass action. For example, the rate of change of pERK concentration would be: d[pERK]/dt = k1 * [pMEK] * [ERK] - k2 * [pERK] where k1 is the rate constant for ERK phosphorylation and k2 is the rate constant for pERK dephosphorylation.
4. Parameter Estimation:
-
The rate constants (parameters) in the ODEs are often unknown and need to be estimated from experimental data.
-
Use the quantitative data from experiments (e.g., the time-course of p-ERK concentration from Table 1) to fit the model parameters. This is typically done using optimization algorithms that minimize the difference between the model simulation and the experimental data.
5. Model Simulation and Validation:
-
Once the parameters are estimated, simulate the model using numerical solvers (available in software like MATLAB, Python with SciPy, or COPASI).
-
Compare the simulation results with the experimental data that was used for parameter fitting to assess the goodness of fit.
-
Validate the model by comparing its predictions to a separate set of experimental data that was not used for fitting (e.g., predict the c-Fos mRNA expression and compare with the data in Table 2).
6. Model Analysis and Prediction:
-
If the model is validated, it can be used to perform in silico experiments. For example, you can simulate the effect of a drug that inhibits a specific kinase by reducing the corresponding rate constant in the model. This allows for the prediction of the drug's impact on the entire pathway and the generation of new, testable hypotheses.
References
Application Notes & Protocols for Mapping the Orchestration of Cellular Processes
These application notes provide researchers, scientists, and drug development professionals with detailed methodologies and protocols for mapping the complex orchestration of cellular processes. The following sections detail advanced techniques, from observing real-time signaling events to mapping spatial gene expression and integrating multi-omics data for a holistic understanding of cellular function.
Application Note 1: Real-Time Mapping of Signaling Dynamics with Live-Cell Imaging
Introduction: Live-cell imaging enables the visualization of cellular processes in real time, providing critical insights into the dynamic nature of signaling pathways.[1] Genetically encoded fluorescent reporters, particularly those based on Förster Resonance Energy Transfer (FRET), are powerful tools for monitoring molecular events such as protein-protein interactions, conformational changes, and second messenger dynamics within living cells.[2][3] FRET-based biosensors use a pair of fluorophores, a donor and an acceptor, where the transfer of energy from the donor to the acceptor occurs only when they are in close proximity, translating a molecular event into a measurable fluorescent signal.[3]
Signaling Pathway Visualization: GPCR Activation
The following diagram illustrates a simplified G-Protein Coupled Receptor (GPCR) signaling cascade, a common pathway studied using live-cell imaging techniques.
Caption: Simplified GPCR signaling pathway leading to a cellular response.
Experimental Protocol: FRET Imaging for Kinase Activity
This protocol describes the use of a FRET-based biosensor to measure the activity of a specific kinase (e.g., Protein Kinase A - PKA) in live cells. The biosensor consists of a donor fluorophore (e.g., CFP), an acceptor fluorophore (e.g., YFP), a phosphopeptide binding domain, and a kinase-specific substrate peptide. Upon phosphorylation by the active kinase, the biosensor undergoes a conformational change, altering the distance between CFP and YFP and thus changing the FRET efficiency.
Materials:
-
Mammalian cell line (e.g., HEK293T)
-
Expression plasmid for FRET biosensor (e.g., AKAR4)
-
Transfection reagent (e.g., Lipofectamine 3000)
-
Cell culture medium (e.g., DMEM) and supplements
-
Glass-bottom imaging dishes
-
Widefield or confocal fluorescence microscope equipped with filters for CFP and YFP, and a FRET filter cube.
-
Agonist to stimulate the signaling pathway (e.g., Forskolin to activate adenylyl cyclase and increase cAMP levels)
-
Image analysis software (e.g., ImageJ/Fiji with FRET plugins)
Procedure:
-
Cell Culture and Transfection:
-
One day prior to transfection, seed cells onto glass-bottom dishes at 60-80% confluency.
-
Transfect cells with the FRET biosensor plasmid according to the manufacturer's protocol for the transfection reagent.
-
Incubate for 24-48 hours to allow for biosensor expression.
-
-
Imaging Setup:
-
Replace the culture medium with imaging buffer (e.g., Hanks' Balanced Salt Solution) just before imaging.
-
Mount the dish on the microscope stage, enclosed in an environmental chamber maintained at 37°C and 5% CO2.
-
Locate a field of view with healthy, transfected cells expressing the biosensor.
-
-
Image Acquisition:
-
Acquire images in three channels:
-
Donor channel (CFP): Excitation ~430 nm, Emission ~475 nm.
-
Acceptor channel (YFP): Excitation ~500 nm, Emission ~535 nm.
-
FRET channel: Excitation ~430 nm (CFP), Emission ~535 nm (YFP).
-
-
Acquire baseline images for 5-10 minutes to ensure a stable signal.
-
Add the stimulating agonist (e.g., Forskolin) to the dish and continue acquiring images at regular intervals (e.g., every 30 seconds) for 30-60 minutes to capture the dynamic response.
-
-
Data Analysis:
-
Perform background subtraction on all images.
-
Select regions of interest (ROIs) within individual cells.
-
Calculate the FRET ratio (e.g., Acceptor intensity / Donor intensity or a normalized FRET index) for each ROI at each time point.
-
Plot the change in FRET ratio over time to visualize the kinase activity dynamics.
-
Quantitative Data: Comparison of Fluorescent Reporter Techniques
| Technique | Principle | Dynamic Range | Temporal Resolution | Key Advantage | Key Limitation |
| FRET | Energy transfer between two fluorophores upon interaction or conformational change.[3] | Moderate to High | Milliseconds to minutes | Quantitative, real-time measurement of molecular events.[2] | Requires careful fluorophore pair selection; sensitive to pH and temperature. |
| BiFC | Complementation of two non-fluorescent fragments of a fluorescent protein.[4] | High | Minutes to hours | Stable signal, good for detecting transient or weak interactions. | Irreversible association can lead to artifacts; slow maturation time.[4] |
| Dendra2 | Photoconvertible fluorescent protein for tracking cell populations.[5] | N/A | Seconds to hours | Allows for selective labeling and tracking of cells based on visual phenotype.[5] | Requires specific laser lines for photoconversion; potential phototoxicity. |
Application Note 2: In Situ Mapping of Protein Interactomes using Proximity Labeling Mass Spectrometry (PL-MS)
Introduction: Understanding protein-protein interactions (PPIs) within their native cellular environment is crucial for deciphering cellular function.[6] Proximity labeling (PL) coupled with mass spectrometry (MS) is a powerful technique for identifying both stable and transient protein interactions in situ.[4] This method utilizes an enzyme (e.g., TurboID, a promiscuous biotin ligase) fused to a protein of interest ("bait"). When provided with a substrate (e.g., biotin), the enzyme generates reactive biotin intermediates that covalently label nearby proteins ("prey") within a nanometer-scale radius. These biotinylated proteins can then be purified and identified by mass spectrometry.[4]
Experimental Workflow: Proximity Labeling (TurboID)
The diagram below outlines the major steps involved in a TurboID-based proximity labeling experiment.
Caption: Workflow for TurboID proximity labeling and mass spectrometry.
Experimental Protocol: TurboID-MS
Materials:
-
Cells expressing the bait protein fused to TurboID.
-
Control cells (e.g., expressing TurboID alone).
-
Biotin solution (50 mM stock in DMSO).
-
Quenching buffer (e.g., PBS with 10 mM sodium azide).
-
Lysis buffer (e.g., RIPA buffer with protease inhibitors).
-
Streptavidin-coated magnetic beads.
-
Wash buffers (e.g., RIPA, PBS).
-
Ammonium bicarbonate solution (for digestion).
-
DTT and iodoacetamide (for reduction and alkylation).
-
Sequencing-grade trypsin.
-
Elution buffer (e.g., 0.1% TFA in water).
-
LC-MS/MS instrument.
Procedure:
-
Biotin Labeling:
-
Culture TurboID-fusion and control cells to ~90% confluency.
-
Add biotin to the culture medium to a final concentration of 50 µM.
-
Incubate at 37°C for a short duration (e.g., 10-20 minutes for TurboID).
-
Aspirate the medium and wash cells with ice-cold quenching buffer to stop the reaction.
-
-
Cell Lysis:
-
Lyse the cells directly on the plate with ice-cold lysis buffer.
-
Scrape the cells and transfer the lysate to a microcentrifuge tube.
-
Sonicate or nuclease-treat the lysate to shear DNA and reduce viscosity.
-
Clarify the lysate by centrifugation at 14,000 x g for 15 minutes at 4°C.
-
-
Affinity Purification:
-
Incubate the clarified lysate with pre-washed streptavidin beads for 1-2 hours at 4°C with rotation.
-
Use a magnetic rack to separate the beads and discard the supernatant.
-
Perform a series of stringent washes to remove non-specifically bound proteins (e.g., wash with RIPA buffer, high-salt buffer, and PBS).
-
-
On-Bead Digestion:
-
Resuspend the beads in ammonium bicarbonate buffer.
-
Reduce the proteins with DTT and alkylate with iodoacetamide.
-
Add trypsin and incubate overnight at 37°C to digest the proteins into peptides.
-
-
Peptide Analysis:
-
Collect the supernatant containing the tryptic peptides.
-
Acidify the peptides with trifluoroacetic acid (TFA).
-
Analyze the peptide mixture by LC-MS/MS.
-
-
Data Analysis:
-
Search the raw MS data against a protein database to identify peptides and proteins.
-
Use a label-free quantification method to determine the abundance of each identified protein.
-
Compare the results from the bait-TurboID sample to the control sample to identify specific interaction partners. High-confidence interactors should be significantly enriched in the bait sample.
-
Quantitative Data: Comparison of Proximity Labeling Enzymes
| Enzyme | Labeling Time | Labeling Radius | Substrate | Key Advantage |
| BioID/BioID2 | 18-24 hours | ~10 nm | Biotin | Well-established, good for stable complexes. |
| APEX2 | ~1 minute | ~20 nm | Biotin-phenol, H₂O₂ | Very fast labeling, suitable for electron microscopy. |
| TurboID | ~10 minutes | ~10 nm | Biotin | Fast and efficient labeling in living cells.[4] |
Application Note 3: High-Resolution Mapping of Gene Expression with Spatial Transcriptomics
Introduction: Spatial transcriptomics (ST) technologies enable the quantification and visualization of gene expression within the native morphological context of a tissue.[7][8] This overcomes a major limitation of single-cell RNA sequencing (scRNA-seq), where spatial information is lost during tissue dissociation.[9] Sequencing-based ST methods, such as 10x Genomics' Visium platform, use slides with spatially barcoded capture probes to tag mRNA from an intact tissue section. Subsequent sequencing allows the transcriptome data to be mapped back to its original location in the tissue image.[10]
Experimental Workflow: Sequencing-Based Spatial Transcriptomics (Visium)
This diagram shows the key stages of a Visium spatial transcriptomics experiment, from tissue preparation to data analysis.
Caption: Workflow for sequencing-based spatial transcriptomics.
Experimental Protocol: 10x Visium Spatial Gene Expression
Materials:
-
Fresh-frozen tissue block.
-
Cryostat for tissue sectioning.
-
Visium Spatial Gene Expression slides (10x Genomics).
-
Staining reagents (e.g., H&E).
-
Microscope for imaging.
-
Reagents for permeabilization, reverse transcription, and library preparation (provided in Visium kits).
-
Next-generation sequencer (e.g., Illumina NovaSeq).
Procedure:
-
Tissue Preparation and Sectioning:
-
Embed fresh tissue in Optimal Cutting Temperature (OCT) compound and snap-freeze.
-
Using a cryostat, cut a 10 µm thick tissue section.
-
Mount the section onto the active capture area of a Visium slide.
-
-
Staining and Imaging:
-
Fix the tissue section (e.g., with methanol).
-
Perform histological staining (e.g., Hematoxylin and Eosin, H&E) to visualize tissue morphology.
-
Image the entire capture area using a brightfield microscope or slide scanner to create a high-resolution reference image.
-
-
Permeabilization and RNA Capture:
-
Permeabilize the tissue using a kit-provided enzyme to release mRNA molecules.
-
The released mRNA binds to the spatially barcoded oligonucleotides on the slide surface. Each spot on the slide has a unique barcode.
-
-
cDNA Synthesis and Library Preparation:
-
Perform on-slide reverse transcription to synthesize cDNA from the captured mRNA. The spatial barcode is incorporated into the cDNA.
-
Release the cDNA from the slide and perform second-strand synthesis and denaturation.
-
Amplify the cDNA via PCR.
-
Construct a sequencing-ready library by fragmentation, end-repair, A-tailing, and adapter ligation.
-
-
Sequencing and Data Analysis:
-
Sequence the prepared library on a compatible NGS platform.
-
Use specialized software (e.g., 10x Genomics' Space Ranger) to process the raw sequencing data.
-
The software uses the spatial barcodes to map the transcriptomic data back to the original x-y coordinates on the tissue image.
-
Visualize the data to explore gene expression patterns across different histological regions, identify spatial domains, and analyze cell-cell interactions.[8]
-
Quantitative Data: Comparison of Spatial Transcriptomics Technologies
| Technology | Principle | Resolution | Plexity (Genes/Run) | Key Advantage |
| Visium (10x) | Spatially barcoded oligo capture[10] | 55 µm spots (~1-10 cells) | Whole Transcriptome | Unbiased, whole-transcriptome coverage.[10] |
| Slide-seq | Barcoded beads ("pucks")[11] | 10 µm | Whole Transcriptome | Higher spatial resolution than Visium.[11] |
| MERFISH | Multiplexed single-molecule imaging (ISH)[12] | Subcellular (~100 nm) | ~100 - 1,000 | High multiplexing with subcellular resolution.[11] |
| Xenium (10x) | In situ sequencing (ISS)[10] | Subcellular | Hundreds to Thousands | High sensitivity and resolution in situ.[10] |
Application Note 4: Integrative Multi-Omics for a Systems-Level View
Introduction: Cellular processes are governed by a complex interplay of molecules at different biological levels. A comprehensive understanding requires integrating data from multiple "omics" layers, including genomics (DNA), transcriptomics (RNA), proteomics (protein), and metabolomics (metabolites).[13][14] This integrative multi-omics approach provides a holistic, systems-level view of cellular function, revealing regulatory networks and causal relationships that are not apparent from a single data type alone.[15]
Logical Workflow: Multi-Omics Data Integration
This diagram illustrates a conceptual workflow for integrating data from different omics platforms to gain biological insights.
Caption: Conceptual workflow for multi-omics data integration and analysis.
Protocol: Integrative Multi-Omics Analysis
This protocol provides a general framework for the computational analysis and integration of multi-omics datasets.
Platforms and Software:
-
Programming Languages: R or Python.
-
Key Packages/Libraries:
-
R: MultiAssayExperiment, mixOmics, KEGGREST, clusterProfiler.
-
Python: pandas, scikit-learn, statsmodels, networkx.
-
-
Pathway Databases: KEGG, Gene Ontology (GO), Reactome.
-
Visualization Tools: Cytoscape, ggplot2, Matplotlib.
Procedure:
-
Data Acquisition and Pre-processing (Per Omics Layer):
-
Acquire data from each omics experiment (e.g., raw sequencing reads, mass spectra).
-
Perform layer-specific pre-processing:
-
Transcriptomics: Read alignment, quantification (e.g., TPM/FPKM), normalization.
-
Proteomics/Metabolomics: Peak identification, quantification, normalization, imputation of missing values.
-
-
Perform quality control to identify and remove outliers.
-
-
Exploratory Data Analysis:
-
For each omics layer, perform dimensionality reduction (e.g., PCA, t-SNE) to visualize sample clustering and identify major sources of variation.
-
Identify differentially expressed/abundant features (genes, proteins, metabolites) between experimental conditions.
-
-
Data Integration:
-
Concatenation-based: Combine data matrices from different omics layers and apply unsupervised clustering or dimensionality reduction methods (e.g., iCluster, MOFA).
-
Correlation-based: Calculate pairwise correlations between features from different omics layers (e.g., gene-protein, protein-metabolite) to build association networks.
-
Network-based: Map the omics data onto known biological networks (e.g., PPI networks, metabolic pathways) to identify active modules and subnetworks.
-
-
Biological Interpretation:
-
Perform functional enrichment analysis (e.g., GO, KEGG) on clusters of correlated molecules or differentially abundant features to identify perturbed biological pathways.
-
Construct and visualize multi-layered networks to understand the flow of information from genetic regulation to metabolic output.
-
Validate key findings with targeted follow-up experiments.
-
Quantitative Data: Information Gained from Different Omics Layers
| Omics Layer | Technology Examples | Biological Information | Primary Insight |
| Genomics | NGS, ChIP-seq[16] | DNA sequence, genetic variants, epigenetic modifications.[16] | The "blueprint" and its regulation. |
| Transcriptomics | RNA-seq, Spatial Transcriptomics[7] | Gene expression levels, splice variants, non-coding RNAs. | Cellular intent and potential function. |
| Proteomics | Mass Spectrometry, Proximity Labeling[17] | Protein abundance, post-translational modifications, interactions.[17] | The functional machinery of the cell. |
| Metabolomics | MS, NMR | Small molecule concentrations and fluxes. | The biochemical activity and phenotype. |
References
- 1. Live Cell Imaging [labome.com]
- 2. Live-cell imaging of cell signaling using genetically encoded fluorescent reporters - PMC [pmc.ncbi.nlm.nih.gov]
- 3. theclarklab.org [theclarklab.org]
- 4. How to Analyze Protein-Protein Interaction: Top Lab Techniques - Creative Proteomics [creative-proteomics.com]
- 5. High‐throughput, microscope‐based sorting to dissect cellular heterogeneity | Molecular Systems Biology [link.springer.com]
- 6. Cross-linking mass spectrometry for mapping protein complex topologies in situ - PMC [pmc.ncbi.nlm.nih.gov]
- 7. labs.icahn.mssm.edu [labs.icahn.mssm.edu]
- 8. Research Techniques Made Simple: Spatial Transcriptomics - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Mapping Cellular Coordinates through Advances in Spatial Transcriptomics Technology - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. 10xgenomics.com [10xgenomics.com]
- 11. Mapping Cellular Coordinates through Advances in Spatial Transcriptomics Technology - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. Integrating Molecular Perspectives: Strategies for Comprehensive Multi-Omics Integrative Data Analysis and Machine Learning Applications in Transcriptomics, Proteomics, and Metabolomics - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Integrative multi-omics approaches to explore immune cell functions: Challenges and opportunities - PMC [pmc.ncbi.nlm.nih.gov]
- 15. JCI - Integrative omics approaches provide biological and clinical insights: examples from mitochondrial diseases [jci.org]
- 16. Methods for ChIP-seq analysis: A practical workflow and advanced applications - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. Recent progress in mass spectrometry-based strategies for elucidating protein–protein interactions - PMC [pmc.ncbi.nlm.nih.gov]
using CRISPR to investigate genetic orchestration
An in-depth guide to leveraging CRISPR technology for the systematic investigation of genetic orchestration, tailored for researchers, scientists, and drug development professionals.
Application Notes
Introduction to CRISPR-Based Genetic Orchestration
The advent of Clustered Regularly Interspaced Short Palindromic Repeats (CRISPR) and CRISPR-associated (Cas) protein systems has revolutionized functional genomics.[1] This technology provides a powerful toolkit for precisely editing, repressing, or activating genes, enabling a systematic exploration of "genetic orchestration"—the complex interplay of genes within regulatory networks and signaling pathways that governs cellular phenotypes.[2][3] Unlike traditional single-gene studies, CRISPR allows for genome-scale interrogation of gene function in a high-throughput manner.[4]
The core CRISPR-Cas9 system uses a guide RNA (gRNA) to direct the Cas9 nuclease to a specific genomic locus, where it creates a double-strand break (DSB). The cell's error-prone repair mechanism, non-homologous end joining (NHEJ), often results in insertions or deletions that lead to a gene knockout (CRISPRko).[5] Furthermore, modified versions of the Cas9 protein that are catalytically "dead" (dCas9) can be fused to effector domains to either repress (CRISPR interference or CRISPRi) or activate (CRISPR activation or CRISPRa) transcription of target genes without altering the DNA sequence.[6] These three modalities—knockout, interference, and activation—form the foundation for comprehensively mapping the genetic circuits that control cellular behavior.[2]
Core Applications in Research and Drug Development
-
Systematic Mapping of Genetic Interactions: A genetic interaction occurs when the combined effect of perturbing two genes results in an unexpected phenotype.[7] Combinatorial CRISPR screens, which use dual-guide RNA libraries to simultaneously perturb pairs of genes, are a powerful tool for systematically mapping these interactions.[8][9] This approach is particularly valuable for identifying synthetic lethal pairs—where the loss of either gene alone is tolerated, but the simultaneous loss of both is lethal.[7] Such interactions can reveal functional relationships between genes and uncover novel therapeutic targets, especially in oncology.[5][10]
-
Deconvolution of Cellular Signaling Pathways: CRISPR screens can effectively dissect complex signaling pathways by identifying genes that modulate a pathway's activity.[11] By coupling a genome-wide CRISPR library with a reporter system (e.g., a fluorescent protein expressed under a pathway-specific promoter), researchers can use fluorescence-activated cell sorting (FACS) to isolate cells with altered signaling.[12] Subsequent sequencing of the gRNAs in these sorted populations reveals the genes that act as positive or negative regulators of the pathway.[12][13]
-
Identification of Drug Targets and Resistance Mechanisms: Pooled CRISPR screens are widely used to identify genes that influence a cell's response to a specific drug.[14][15] In a typical drug resistance screen, a population of cells transduced with a CRISPR library is treated with a drug. Cells that survive and proliferate must harbor a gene knockout that confers resistance. By sequencing the gRNAs enriched in the surviving population, researchers can pinpoint these resistance genes, providing critical insights for developing more robust therapies and combination treatments.[4][15]
-
Elucidating Gene Regulatory Networks: CRISPRi and CRISPRa screens are ideal for mapping the architecture of gene regulatory networks.[16] By systematically repressing or activating every known transcription factor and measuring the downstream effects on a target gene's expression, it is possible to build a comprehensive map of regulatory connections.[17] This approach helps to understand how cell identity is maintained and how cellular programs are executed.[6]
Experimental Protocols
Protocol 1: Pooled CRISPRko Screen to Identify Drug Resistance Genes
This protocol outlines a standard workflow for a genome-scale, pooled CRISPR-Cas9 knockout screen to identify genes whose loss confers resistance to a cytotoxic agent.
1. Preparation and Quality Control of the sgRNA Library a. Amplify the pooled sgRNA plasmid library using electrocompetent cells to ensure sufficient quantity and maintain library representation.[18] b. Purify the plasmid DNA using a mega-scale plasmid purification kit.[18] c. Verify library representation via next-generation sequencing (NGS) to ensure all sgRNAs are present at comparable levels.[19]
2. Lentivirus Production a. In 10 cm plates, seed 5 million HEK293T cells, which are highly transfectable.[20] b. Transfect the cells with the sgRNA library plasmids along with packaging and envelope plasmids (e.g., psPAX2 and pMD2.G). c. Harvest the virus-containing supernatant at 48 and 72 hours post-transfection. d. Determine the viral titer to calculate the required volume for achieving the desired multiplicity of infection (MOI).
3. Cell Line Transduction and Selection a. Prepare the target cancer cell line stably expressing Cas9 nuclease. If using a one-component library system, this step is not necessary.[18] b. Transduce the cells with the lentiviral sgRNA library at a low MOI (0.3-0.5) to ensure that most cells receive a single sgRNA.[19] Maintain a library coverage of at least 200-1000 cells per sgRNA.[20] c. Select for successfully transduced cells using an appropriate antibiotic (e.g., puromycin). d. After selection, harvest a portion of the cells as the initial timepoint (T0) reference sample.[18]
4. Drug Selection Screen a. Split the remaining cell population into two groups: a control group (treated with vehicle, e.g., DMSO) and a treatment group (treated with the cytotoxic drug). b. Culture the cells for 15-20 cell doublings, maintaining library coverage at each passage.[19] The drug concentration should be sufficient to kill the majority of wild-type cells. c. Harvest cell pellets from both groups at the end of the screen (T-final).
5. Genomic DNA Extraction and Sequencing a. Extract genomic DNA from the T0 and T-final cell pellets. b. Amplify the sgRNA cassettes from the genomic DNA using a two-step PCR protocol to add sequencing adapters and sample-specific indices.[19] c. Purify the PCR products and submit them for high-throughput sequencing on an Illumina platform.[20]
6. Data Analysis a. Align sequencing reads to the sgRNA library reference to get sgRNA counts for each sample.[4] b. Normalize the counts and calculate the log2 fold change (LFC) of each sgRNA between the T-final treatment sample and the T0 sample. c. Use statistical packages like MAGeCK to identify sgRNAs and genes that are significantly enriched in the drug-treated population.[4] Enriched genes are candidate drug resistance genes.
Protocol 2: Combinatorial CRISPRi Screen for Mapping Genetic Interactions
This protocol describes a method for mapping genetic interactions by simultaneously repressing pairs of genes using a dual-sgRNA library and CRISPRi.
1. Dual-sgRNA Library Design and Construction a. Design a library where each vector expresses two distinct sgRNAs. The library should include all desired gene-gene pairs, as well as single-gene perturbations (gene-control sgRNA) for each gene in the set.[8][21] b. Synthesize the dual-sgRNA oligonucleotides on a microarray and clone them into a lentiviral vector.
2. Cell Line Preparation and Transduction a. Use a cell line that stably expresses the dCas9-KRAB repressor fusion protein.[21] b. Produce lentivirus for the dual-sgRNA library as described in Protocol 1. c. Transduce the dCas9-KRAB expressing cells with the library at a low MOI, ensuring high library coverage. d. Collect a T0 sample after antibiotic selection.
3. Growth Competition Assay a. Culture the transduced cell population for an extended period (e.g., 21-28 days), passaging as needed while maintaining high library coverage.[9] b. Harvest cell pellets at multiple time points (e.g., Day 14, Day 21, Day 28) to measure the depletion or enrichment of dual-sgRNA constructs over time.[8]
4. Sequencing and Data Analysis a. Extract genomic DNA, amplify sgRNA cassettes, and perform NGS as in Protocol 1. b. Count the abundance of each dual-sgRNA construct at each time point. c. Calculate the LFC for each construct relative to the T0 sample. This represents the growth phenotype. d. Calculate Genetic Interaction (GI) Score: i. The expected phenotype of a double perturbation (LFC_expected) is calculated from the observed phenotypes of the corresponding single perturbations (LFC_geneA and LFC_geneB). A common model is the multiplicative model: LFC_expected = LFC_geneA + LFC_geneB.[22] ii. The GI score is the difference between the observed double-perturbation phenotype (LFC_observed) and the expected phenotype: GI_score = LFC_observed - LFC_expected.[22] iii. A strong negative GI score indicates a synthetic lethal or synergistic interaction, while a strong positive score indicates a buffering or epistatic relationship.
Data Presentation
Quantitative data from CRISPR screens should be summarized to facilitate interpretation and hit identification.
Table 1: Representative Data from a Pooled CRISPRko Screen for Drug Resistance
This table shows hypothetical top hits from a screen identifying genes whose knockout confers resistance to the kinase inhibitor 'Drug-X'.
| Gene Symbol | Average sgRNA LFC (Drug vs. T0) | P-value | Rank | Putative Function |
| CUL3 | 5.85 | 1.2e-8 | 1 | E3 ubiquitin ligase |
| KEAP1 | 5.51 | 4.5e-8 | 2 | Substrate adapter for CUL3 |
| NF2 | 4.98 | 9.1e-7 | 3 | Tumor suppressor, Hippo pathway |
| PTEN | 4.23 | 2.0e-6 | 4 | Tumor suppressor, PI3K pathway |
| CIC | 3.89 | 8.4e-6 | 5 | Transcriptional repressor |
Table 2: Representative Data from a Combinatorial CRISPRi Screen
This table presents hypothetical genetic interaction scores between genes in a cancer signaling pathway. Negative scores suggest synthetic lethality.
| Gene Pair | LFC (Gene A) | LFC (Gene B) | LFC (Observed, Pair) | LFC (Expected) | GI Score | Interaction Type |
| PARP1 - BRCA1 | -0.21 | -0.15 | -3.55 | -0.36 | -3.19 | Negative (Synthetic Lethal) |
| KRAS - RAF1 | -2.10 | -1.95 | -2.25 | -4.05 | 1.80 | Positive (Buffering) |
| PIK3CA - PTEN | -1.80 | 0.05 | -1.70 | -1.75 | 0.05 | Neutral |
| MYC - MAX | -4.50 | -4.80 | -8.90 | -9.30 | 0.40 | Positive (Epistatic) |
| EZH2 - SUZ12 | -3.10 | -3.30 | -6.50 | -6.40 | -0.10 | Neutral |
Visualizations
Diagrams created using Graphviz to illustrate key workflows and concepts.
Caption: Workflow for a pooled CRISPR knockout screen to identify drug resistance genes.
Caption: Example MAPK signaling pathway illustrating potential CRISPR perturbation targets.
Caption: Logical relationship of a synthetic lethal genetic interaction.
References
- 1. CRISPR/Cas: A powerful tool for gene function study and crop improvement - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Bioinformatics approaches to analyzing CRISPR screen data: from dropout screens to single-cell CRISPR screens - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Using CRISPR to understand and manipulate gene regulation - PMC [pmc.ncbi.nlm.nih.gov]
- 4. How To Analyze CRISPR Screen Data For Complete Beginners - From FASTQ Files To Biological Insights - NGS Learning Hub [ngs101.com]
- 5. CRISPR-based genetic interaction maps inform therapeutic strategies in cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 6. journals.biologists.com [journals.biologists.com]
- 7. Combinatorial CRISPR-Cas9 screens for de novo mapping of genetic interactions - PMC [pmc.ncbi.nlm.nih.gov]
- 8. idekerlab.ucsd.edu [idekerlab.ucsd.edu]
- 9. escholarship.org [escholarship.org]
- 10. Cornerstones of CRISPR-Cas in drug development and therapy - PMC [pmc.ncbi.nlm.nih.gov]
- 11. mdpi.com [mdpi.com]
- 12. FACS-based genome-wide CRISPR screens define key regulators of DNA damage signaling pathways - PMC [pmc.ncbi.nlm.nih.gov]
- 13. signosisinc.com [signosisinc.com]
- 14. drugtargetreview.com [drugtargetreview.com]
- 15. depts.ttu.edu [depts.ttu.edu]
- 16. CRISPR Interference (CRISPRi) and CRISPR Activation (CRISPRa) to Explore the Oncogenic lncRNA Network - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. zenodo.org [zenodo.org]
- 18. media.addgene.org [media.addgene.org]
- 19. Video: Pooled CRISPR-Based Genetic Screens in Mammalian Cells [jove.com]
- 20. broadinstitute.org [broadinstitute.org]
- 21. Genetic interaction mapping in mammalian cells using CRISPR interference - PMC [pmc.ncbi.nlm.nih.gov]
- 22. biorxiv.org [biorxiv.org]
Application Notes and Protocols for High-Throughput Screening of Cellular Orchestration Modulators
For Researchers, Scientists, and Drug Development Professionals
Introduction
Cellular orchestration encompasses the complex and dynamic coordination of molecular and cellular events that govern cell fate, function, and organization within tissues. These processes, including signal transduction, gene expression, cytoskeletal dynamics, and cell-cell interactions, are often dysregulated in disease. High-throughput screening (HTS) and high-content screening (HCS) have emerged as powerful strategies in drug discovery and fundamental research to identify and characterize small molecules or genetic perturbations that can modulate these intricate cellular choreographies.[1][2][3] This document provides detailed application notes and protocols for designing and implementing HTS campaigns to discover novel modulators of cellular orchestration.
High-content screening, a key technology in this field, leverages automated microscopy and sophisticated image analysis to extract multiparametric data from cells, providing insights into various cellular processes simultaneously.[1][4] This approach allows for the monitoring of phenotypic changes, such as morphology, protein localization, and proliferation, offering a more predictive and translatable dataset compared to traditional HTS methods.[5]
Core Technologies and Assay Formats
A variety of assay formats can be employed to screen for modulators of cellular orchestration. The choice of assay depends on the specific biological question and the cellular process being investigated.
Commonly Used HTS/HCS Assay Formats:
-
Reporter Gene Assays: These assays are widely used to study the regulation of gene expression.[4][6] They involve the use of a reporter gene (e.g., luciferase, fluorescent proteins) linked to a promoter of interest. Changes in reporter protein expression reflect the activity of specific signaling pathways.[6]
-
Protein Translocation Assays: Many signaling events involve the movement of proteins between different cellular compartments.[6] HCS can quantify the translocation of fluorescently labeled proteins, such as transcription factors moving from the cytoplasm to the nucleus, providing a direct measure of pathway activation.[6]
-
Multiplexed Immunoassays: Bead-based multiplex assays enable the simultaneous measurement of multiple phosphoproteins and total proteins from a single sample, offering a comprehensive view of various signaling pathways.
-
Phenotypic Assays: These assays measure complex cellular phenotypes, including apoptosis, cell cycle progression, cell migration, and cytoskeletal rearrangement.[6] Automated image analysis is used to quantify these changes across large numbers of samples.[1]
-
Cell Painting: This is a powerful multiplexing technique where multiple fluorescent dyes are used to stain different cellular compartments.[5] The resulting morphological profiles can be used to identify the effects of compounds on various cellular processes and to classify their mechanisms of action.[5]
Featured Application: High-Content Screen for Modulators of the NF-κB Signaling Pathway
The NF-κB (nuclear factor kappa-light-chain-enhancer of activated B cells) signaling pathway is a crucial regulator of inflammation, immunity, and cell survival. Its dysregulation is implicated in numerous diseases, making it a prime target for therapeutic intervention. This application note details a high-content screening protocol to identify inhibitors of NF-κB activation by monitoring the translocation of the NF-κB p65 subunit from the cytoplasm to the nucleus.
Signaling Pathway Diagram
Caption: The NF-κB signaling pathway activated by TNF-α.
Experimental Protocols
High-Content Imaging Protocol for NF-κB Translocation
This protocol outlines the steps for a high-content screen to identify compounds that inhibit the translocation of NF-κB p65 from the cytoplasm to the nucleus upon stimulation with Tumor Necrosis Factor-alpha (TNF-α).
Materials:
-
HeLa cells (or other suitable cell line)
-
DMEM supplemented with 10% FBS and 1% Penicillin-Streptomycin
-
384-well black, clear-bottom imaging plates
-
Compound library
-
Recombinant human TNF-α
-
Primary antibody: Rabbit anti-NF-κB p65
-
Secondary antibody: Goat anti-rabbit IgG conjugated to a fluorescent dye (e.g., Alexa Fluor 488)
-
Hoechst 33342 nuclear stain
-
Paraformaldehyde (PFA)
-
Triton X-100
-
Bovine Serum Albumin (BSA)
-
Phosphate Buffered Saline (PBS)
-
Automated liquid handler
-
High-content imaging system
Protocol:
-
Cell Seeding:
-
Trypsinize and resuspend HeLa cells in complete medium.
-
Seed 2,500 cells per well in a 384-well imaging plate using an automated liquid handler.
-
Incubate at 37°C, 5% CO₂ for 24 hours.
-
-
Compound Treatment:
-
Using an acoustic dispenser or pin tool, transfer compounds from the library to the cell plate to achieve a final concentration of 10 µM.
-
Include appropriate controls: DMSO (negative control) and a known NF-κB inhibitor (positive control).
-
Incubate for 1 hour at 37°C.
-
-
Cell Stimulation:
-
Prepare a solution of TNF-α in serum-free medium at a final concentration of 20 ng/mL.
-
Add the TNF-α solution to all wells except for the unstimulated control wells.
-
Incubate for 30 minutes at 37°C.
-
-
Fixation and Permeabilization:
-
Aspirate the medium and wash the cells once with PBS.
-
Fix the cells by adding 4% PFA in PBS and incubating for 15 minutes at room temperature.
-
Wash the cells three times with PBS.
-
Permeabilize the cells with 0.1% Triton X-100 in PBS for 10 minutes.
-
Wash three times with PBS.
-
-
Immunostaining:
-
Block the cells with 3% BSA in PBS for 1 hour at room temperature.
-
Incubate with the primary anti-NF-κB p65 antibody (diluted in blocking buffer) overnight at 4°C.
-
Wash three times with PBS.
-
Incubate with the fluorescently labeled secondary antibody and Hoechst 33342 (for nuclear staining) for 1 hour at room temperature in the dark.
-
Wash three times with PBS.
-
-
Imaging and Analysis:
-
Acquire images using a high-content imaging system, capturing both the Hoechst (nuclear) and the Alexa Fluor 488 (NF-κB p65) channels.
-
Use image analysis software to segment the nuclei based on the Hoechst signal and define the cytoplasm as a ring around the nucleus.
-
Quantify the mean fluorescence intensity of NF-κB p65 in both the nuclear and cytoplasmic compartments for each cell.
-
Calculate the nuclear-to-cytoplasmic intensity ratio as the primary readout for NF-κB translocation.
-
HCS Workflow Diagram
Caption: A typical workflow for a high-content screening assay.
Data Presentation and Analysis
Quantitative data from HTS/HCS experiments should be summarized in a clear and structured manner to facilitate hit identification and comparison. The Z'-factor is a common statistical parameter used to assess the quality of an HTS assay.
Table 1: HTS Assay Performance Metrics
| Parameter | Value | Interpretation |
| Z'-Factor | 0.65 | An excellent assay with a large separation between positive and negative controls. |
| Signal-to-Background | 8.2 | A robust signal window for hit identification. |
| Hit Rate | 0.5% | A manageable number of initial hits for follow-up studies. |
Table 2: Summary of Primary Screen Hits
| Compound ID | Nuclear/Cytoplasmic Ratio | % Inhibition | Z-Score |
| DMSO (Control) | 3.5 ± 0.2 | 0% | N/A |
| Positive Control | 1.1 ± 0.1 | 95% | N/A |
| Hit_001 | 1.3 | 88% | -3.2 |
| Hit_002 | 1.5 | 80% | -2.9 |
| Hit_003 | 1.2 | 92% | -3.4 |
Logical Relationship for Hit Prioritization
Following the primary screen, a series of secondary and counter-screens are typically performed to confirm the activity of the initial hits and eliminate false positives.
Caption: A logical workflow for hit validation and prioritization.
Conclusion
High-throughput and high-content screening are indispensable tools for dissecting the complexities of cellular orchestration and for the discovery of novel therapeutic agents. The protocols and guidelines presented here provide a framework for conducting robust and reproducible screening campaigns. By combining carefully designed cellular assays, automated imaging, and rigorous data analysis, researchers can identify and characterize modulators of key cellular pathways, ultimately accelerating the pace of drug discovery and biomedical research.
References
- 1. Applications of High Content Screening in Life Science Research - PMC [pmc.ncbi.nlm.nih.gov]
- 2. eurekaselect.com [eurekaselect.com]
- 3. alitheagenomics.com [alitheagenomics.com]
- 4. Cell-Based Assay Design for High-Content Screening of Drug Candidates - PMC [pmc.ncbi.nlm.nih.gov]
- 5. criver.com [criver.com]
- 6. revvity.com [revvity.com]
Application Notes and Protocols for Implementing Automated Lab Orchestration Platforms
For Researchers, Scientists, and Drug Development Professionals
Introduction to Automated Lab Orchestration
Automated lab orchestration platforms represent a paradigm shift in modern research and drug development, moving beyond simple automation of individual tasks to the intelligent, dynamic management of entire laboratory workflows.[1][2] These platforms integrate instruments, software, robotics, and personnel into a cohesive ecosystem, enabling end-to-end automation, data management, and workflow optimization.[3] By synchronizing and coordinating complex processes, orchestration platforms enhance throughput, improve data quality and reproducibility, and accelerate discovery timelines.[1][4][5] This document provides a comprehensive protocol for implementing an automated lab orchestration platform, including key considerations, detailed experimental protocols for common applications, and expected quantitative impacts.
Core Components of an Automated Lab Orchestration Platform
A successful implementation begins with understanding the fundamental components of an orchestration platform.
-
Centralized Scheduler: The core of the platform, responsible for planning, scheduling, and executing workflows. It manages instrument availability, sample and reagent tracking, and task allocation to both robotic systems and human operators.
-
Instrument Integration Layer: A vendor-neutral interface that allows for the connection and control of a wide range of laboratory instruments, from liquid handlers and plate readers to sequencers and flow cytometers. This is often achieved through APIs and dedicated instrument drivers.
-
Data Management System: A robust system for capturing, storing, and contextualizing experimental data. This includes instrument readouts, metadata, and audit trails, often integrated with Laboratory Information Management Systems (LIMS) and Electronic Lab Notebooks (ELNs).
-
Workflow Editor: An intuitive graphical interface that allows users to design and modify experimental workflows without extensive programming knowledge. This empowers bench scientists to automate their own assays.
-
Robotics and Liquid Handling Integration: Seamless integration with robotic arms, plate movers, and automated liquid handlers to enable true walk-away automation of complex, multi-step processes.
Quantitative Impact of Lab Orchestration
The implementation of an automated lab orchestration platform can yield significant and measurable improvements across various laboratory metrics. The following tables summarize quantitative data from case studies and industry reports.
Table 1: Impact on Throughput and Turnaround Time (TAT)
| Metric | Improvement | Source |
| Sample Handling Capacity | 30-60% increase | Industry Report |
| Test Turnaround Time | Up to 50% reduction | Case Study |
| Tests Performed per FTE | 1.4x to 3.7x increase | Academic Study |
| High-Throughput Screening | Up to 50,000 wells/day | Application Note |
| NGS Library Preparation | 96 libraries in < 6 hours | [6] |
Table 2: Return on Investment (ROI) and Efficiency Gains
| Metric | Improvement | Source |
| Manual Data Entry | 30% reduction in labor hours | [7] |
| PCR Result Turnaround | 20% improvement | [7] |
| Drug Development Timelines | Potential to reduce by >500 days | [5] |
| Development Costs | Potential 25% reduction | [5] |
| Reagent and Consumable Waste | Significant reduction | [8] |
Protocol for Implementing an Automated Lab Orchestration Platform
This protocol outlines a phased approach to successfully implement an automated lab orchestration platform.
Figure 1: Phased implementation protocol for an automated lab orchestration platform.
Phase 1: Planning and Assessment
-
Define Goals and Key Performance Indicators (KPIs): Clearly articulate the objectives for implementing the orchestration platform.[9] Example KPIs include reducing turnaround time for a specific assay, increasing walk-away time for researchers, or improving data traceability.[9]
-
Workflow Assessment and Prioritization: Analyze existing laboratory workflows to identify bottlenecks and repetitive tasks that are prime candidates for automation. Prioritize workflows based on their potential for high impact and feasibility of automation.
-
Platform Selection: Evaluate different orchestration platforms based on your lab's specific needs, including instrument compatibility, scalability, data management capabilities, and vendor support.
Phase 2: Implementation and Integration
-
Software Installation and Configuration: Install the orchestration platform software and configure the user access levels and data management settings.
-
Instrument Integration: Connect and configure the laboratory instruments that will be part of the automated workflow. This may involve installing drivers and performing calibration routines.
-
Pilot Protocol Development: Select a prioritized workflow and use the platform's workflow editor to create an automated protocol. Start with a simpler workflow to gain experience with the platform.
Phase 3: Validation and Training
-
Protocol Validation: Rigorously validate the automated pilot protocol by comparing its performance against the manual workflow. Key validation criteria include accuracy, precision, and reproducibility of results.
-
User Training: Provide comprehensive training to all relevant personnel on how to use the orchestration platform, run automated workflows, and manage data.
-
Go-Live: Once the pilot protocol is validated and users are trained, formally launch the automated workflow for routine use.
Phase 4: Optimization and Scaling
-
Monitor KPIs: Continuously monitor the KPIs defined in the planning phase to track the performance of the automated workflow and the overall impact of the orchestration platform.[9]
-
Workflow Optimization: Use the data and insights gained from monitoring to identify areas for further optimization of the automated workflows.
-
Scale Operations: Gradually automate additional workflows and integrate more instruments into the orchestration platform to maximize its benefits across the laboratory.
Detailed Experimental Protocols
The following are detailed protocols for common laboratory workflows that can be implemented on an automated lab orchestration platform.
Automated High-Throughput Screening (HTS) for Compound Library Screening
This protocol describes a typical HTS workflow for identifying active compounds in a large chemical library.
Figure 2: High-Throughput Screening (HTS) workflow diagram.
Methodology:
-
Stage I: Assay Adaptation:
-
Stage II: Pilot Screen:
-
Screen a small, representative subset of the compound library (e.g., one 384-well plate) in duplicate.[10]
-
Use this pilot screen to establish a standard operating procedure (SOP) for the automated workflow, including liquid handling parameters and plate movement.[10]
-
Determine the assay timeframe and the number of plates that can be processed in a batch.[10]
-
-
Stage III: Full Library Screen:
-
Stage IV: Hit Validation and Dose-Response:
-
"Cherry-pick" the initial hits from the primary screen for re-testing.
-
Perform confirmatory screens on the selected hits.
-
Generate 8-point dose-response curves for the validated hits to determine their potency (EC50/IC50).[10]
-
Automated Next-Generation Sequencing (NGS) Library Preparation
This protocol outlines the automated preparation of up to 96 NGS libraries using a liquid handling workstation integrated into an orchestration platform.[6]
Figure 3: Automated NGS library preparation workflow.
Methodology:
-
Automated DNA Extraction:
-
Utilize an automated DNA extraction system (e.g., chemagic™ 360 instrument) to isolate high-quality DNA from up to 96 samples simultaneously.[6]
-
Input: 30 µL of sample.
-
The orchestration platform will initiate and monitor the extraction process.
-
-
Library Preparation on a Liquid Handler (e.g., Sciclone® G3 NGSx Workstation):
-
Tagmentation/Fragmentation: Transfer extracted DNA to a 96-well plate. The liquid handler will add tagmentation enzymes (e.g., Illumina DNA Prep) to fragment the DNA and add adapter sequences.
-
Adapter Ligation: The liquid handler will perform a series of steps to ligate sequencing adapters and unique dual indexes to the DNA fragments.
-
Library Purification: Perform bead-based purification steps to remove excess reagents and select for the desired library size. The liquid handler will manage the addition of beads, washing steps, and elution of the purified libraries.
-
-
Library Quantification, Normalization, and Pooling:
-
The liquid handler can be programmed to perform automated quantification of the prepared libraries (e.g., setting up a qPCR plate).
-
Based on the quantification results, the liquid handler will normalize the concentration of each library and pool them into a single tube for sequencing.
-
The entire process for 96 libraries can be completed in under 6 hours with minimal hands-on time.[6]
-
Automated Flow Cytometry for Immunophenotyping
This protocol describes a fully automated, walk-away workflow for immunophenotyping of peripheral blood mononuclear cells (PBMCs) using an integrated liquid handler and flow cytometer.[11]
Figure 4: Automated flow cytometry workflow for immunophenotyping.
Methodology:
-
Automated Sample Preparation (e.g., Beckman Coulter Biomek i7):
-
The Biomek i7 liquid handler dispenses 100 µL of PBMC samples into a 96-well plate containing a dried antibody cocktail (e.g., DURAClone T cell subset panel).[12]
-
The plate is automatically moved to an on-deck shaker for mixing and incubation.
-
For protocols requiring washing, the integrated centrifuge is used to pellet the cells, and the liquid handler performs the wash steps.[12]
-
A viability dye (e.g., DAPI) is added to each well.
-
-
Automated Data Acquisition (e.g., Beckman Coulter CytoFLEX LX):
-
The Biomek robotic arm transfers the 96-well plate to the integrated CytoFLEX LX flow cytometer.[11]
-
The orchestration platform initiates the automated acquisition of data from all wells.
-
-
Automated Data Analysis:
-
Upon completion of the acquisition, the data files are automatically uploaded to a data analysis platform (e.g., Cytobank) via an API.[11]
-
A pre-defined gating template is automatically applied to the new dataset to identify and quantify the immune cell subsets.
-
The results are then available for review by the researcher.
-
Conclusion
The implementation of an automated lab orchestration platform is a strategic investment that can transform laboratory operations.[1][4] By following a structured implementation protocol and leveraging the power of integrated automation for key applications such as HTS, NGS library preparation, and flow cytometry, research and drug development organizations can achieve significant improvements in efficiency, data quality, and the overall pace of innovation.[2][5] The detailed protocols and quantitative data presented in these application notes provide a roadmap for realizing the full potential of a truly orchestrated laboratory.
References
- 1. drugtargetreview.com [drugtargetreview.com]
- 2. frontlinegenomics.com [frontlinegenomics.com]
- 3. europeanpharmaceuticalreview.com [europeanpharmaceuticalreview.com]
- 4. azolifesciences.com [azolifesciences.com]
- 5. From bench to bedside: Transforming R&D labs through automation | McKinsey [mckinsey.com]
- 6. illumina.com [illumina.com]
- 7. prolisphere.com [prolisphere.com]
- 8. diagnostics.roche.com [diagnostics.roche.com]
- 9. KPIs for measuring lab automation success [biosero.com]
- 10. Screening workflow | High Throughput Screening Core [u.osu.edu]
- 11. beckman.com [beckman.com]
- 12. beckman.com [beckman.com]
Dissecting the Symphony of Development: A Guide to Single-Cell Sequencing in Tissue Orchestration
Application Notes and Protocols for Researchers, Scientists, and Drug Development Professionals
The intricate process of tissue development, from a single fertilized egg to a complex organism, is a tightly orchestrated symphony of cellular differentiation, migration, and interaction. For decades, researchers have sought to understand the molecular score that governs this symphony. The advent of single-cell sequencing (scRNA-seq) has provided an unprecedentedly high-resolution lens through which to view this process, allowing us to dissect the cellular and transcriptional heterogeneity that underpins tissue formation, maintenance, and disease.
These application notes provide a comprehensive overview of the principles, protocols, and applications of single-cell sequencing for studying tissue development. They are intended to serve as a practical guide for researchers, scientists, and drug development professionals embarking on single-cell studies to unravel the complexities of developmental biology.
I. Core Principles: Unveiling Cellular Heterogeneity
Traditional bulk RNA sequencing provides an averaged view of gene expression across a population of cells, masking the unique transcriptional profiles of individual cells. In contrast, scRNA-seq allows for the transcriptomic profiling of thousands to millions of individual cells, revealing the full spectrum of cellular diversity within a tissue. This is particularly crucial in developmental biology, where transient cell states and rare progenitor populations play pivotal roles.[1][2]
The general workflow of a single-cell sequencing experiment involves several key stages, each critical for generating high-quality data.[1][3]
II. Experimental Protocols: From Tissue to Transcriptome
The success of any scRNA-seq experiment hinges on the meticulous execution of a series of protocols, from sample preparation to data analysis. Here, we provide detailed methodologies for the key steps involved in a typical single-cell sequencing workflow for developmental tissues.
A. Protocol: Single-Cell Suspension from Embryonic Tissues
Obtaining a high-quality single-cell suspension with maximal viability is the foundational step for any scRNA-seq experiment.[4] The choice of dissociation method can significantly impact cell recovery and transcriptional profiles.[5] Therefore, optimization for the specific tissue type is crucial. Below are two common protocols for dissociating embryonic tissues.
1. Enzymatic Dissociation of Human Embryonic/Fetal Tissue [6]
This protocol is suitable for a variety of human embryonic and fetal tissues.
-
Reagents:
-
Earl's Balanced Salt Solution (EBSS), oxygenated with 95% O2:5% CO2
-
Papain
-
DNase I
-
Collagenase II (for heart tissue)
-
-
Procedure:
-
Prepare fire-polished Pasteur pipettes with varying tip diameters.
-
Oxygenate EBSS on ice for 5-10 minutes.
-
Dissolve Papain in EBSS at 37°C. For heart tissue, use Collagenase II (200 U/mL).
-
Pre-cool a centrifuge to 4-8°C.
-
Cut the tissue into small pieces and transfer to the enzyme solution.
-
Incubate at 37°C for 25-40 minutes (up to 1 hour or more for heart tissue), with gentle trituration every 10-15 minutes using the fire-polished Pasteur pipettes.
-
Monitor dissociation under a microscope until a single-cell suspension is achieved.
-
Proceed to cell washing and counting.
-
2. Cold Protease Dissociation for Delicate Embryonic Organs [7]
This method utilizes cold-active proteases to minimize stress-induced transcriptional changes in sensitive embryonic tissues.
-
Reagents:
-
Cold-active protease (e.g., from Bacillus licheniformis)
-
Hanks' Balanced Salt Solution (HBSS) with no calcium or magnesium
-
Bovine Serum Albumin (BSA)
-
-
Procedure:
-
Perform all steps on ice or in a cold room to maintain low temperatures.
-
Mince the tissue into small pieces in cold HBSS.
-
Incubate the tissue fragments in the cold protease solution with gentle agitation.
-
Monitor dissociation progress and gently triturate with a wide-bore pipette tip.
-
Once dissociated, filter the cell suspension through a cell strainer to remove any remaining clumps.
-
Wash the cells with cold HBSS containing BSA to inactivate the protease and stabilize the cells.
-
B. Protocol: Single-Cell RNA-Seq Library Preparation
Once a high-quality single-cell suspension is obtained, the next step is to prepare the sequencing libraries. Two of the most widely used platforms are 10x Genomics Chromium and SMART-Seq2.
1. 10x Genomics Chromium Workflow [3][8]
The 10x Genomics Chromium system utilizes a microfluidic platform to encapsulate single cells with barcoded gel beads in oil droplets (GEMs - Gel Bead-in-Emulsions).[9]
-
Principle: Within each GEM, the cell is lysed, and its mRNA is reverse transcribed into cDNA. During this process, a unique 10x barcode and a Unique Molecular Identifier (UMI) are incorporated into each cDNA molecule. The barcodes allow for the deconvolution of reads to their cell of origin, while the UMIs enable the correction of amplification bias.
-
Procedure (abbreviated):
-
Load the single-cell suspension, reverse transcription reagents, and barcoded gel beads onto a microfluidic chip.
-
The Chromium controller partitions the cells and reagents into GEMs.
-
Reverse transcription occurs within the GEMs.
-
The emulsion is broken, and the barcoded cDNA is pooled for amplification.
-
Sequencing libraries are constructed from the amplified cDNA.
-
2. SMART-Seq2 Workflow [10][11][12]
SMART-Seq2 (Switching Mechanism at 5' End of RNA Template) is a plate-based method that generates full-length cDNA from single cells.[11][13]
-
Principle: This method utilizes a template-switching reverse transcriptase to generate full-length cDNA. An oligo(dT) primer initiates reverse transcription, and when the reverse transcriptase reaches the 5' end of the mRNA, it adds a few non-templated cytosines. A template-switching oligonucleotide (TSO) then anneals to these cytosines and serves as a template for the reverse transcriptase to continue synthesis, effectively adding a universal primer binding site to the 3' end of the cDNA.
-
Procedure (abbreviated):
-
Single cells are sorted into individual wells of a 96- or 384-well plate containing lysis buffer.
-
Reverse transcription with template switching is performed in each well.
-
The resulting full-length cDNA is amplified by PCR.
-
Sequencing libraries are prepared from the amplified cDNA using a tagmentation-based method (e.g., Nextera XT).[10]
-
III. Data Presentation: Quantitative Insights
The quality and quantity of the starting material and the resulting sequencing data are critical for the success of a single-cell study. The following tables provide a summary of key quantitative metrics to consider.
Table 1: Comparison of Tissue Dissociation Methods for scRNA-seq
| Dissociation Method | Enzyme(s) | Temperature | Typical Viability | Advantages | Disadvantages | Reference(s) |
| Warm Enzymatic | Trypsin, Collagenase, Dispase, Papain | 37°C | 70-95% | Efficient for a wide range of tissues. | Can induce stress-related gene expression. May lead to loss of sensitive cell types. | [5][14] |
| Cold Protease | Cold-active proteases | 4-6°C | 85-98% | Minimizes transcriptional artifacts and cell stress. Preserves sensitive cell populations. | May be less efficient for dense, fibrotic tissues. | [7][15] |
| Mechanical | None | 4°C | Variable | Fast and simple. Avoids enzymatic artifacts. | Can cause significant cell damage and lower viability. May not be effective for all tissues. | [1] |
Table 2: Typical Quality Control Metrics for Single-Cell RNA-Seq Data
| Metric | 10x Genomics (v3) | SMART-Seq2 | Rationale for Filtering | Reference(s) |
| Number of Reads per Cell | 20,000 - 100,000 | 1-5 million | Ensures sufficient sequencing depth to capture the transcriptome. | [16] |
| Median Genes per Cell | 2,000 - 6,000 | 3,000 - 8,000 | Low numbers may indicate poor quality cells or empty droplets. | [17][18] |
| Percentage of Mitochondrial Reads | < 10-20% | < 10-20% | High percentage can indicate stressed or dying cells. | [17][18] |
| Number of UMIs per Cell | > 1,000 | N/A | Low UMI counts suggest low RNA content or technical issues. | [17] |
IV. Mandatory Visualizations: Signaling Pathways and Workflows
Visualizing the complex interplay of signaling pathways and the experimental process is crucial for understanding and communicating the findings of single-cell studies.
A. Signaling Pathways in Development
Single-cell transcriptomics has been instrumental in dissecting the roles of key signaling pathways in cell fate decisions and tissue patterning during development.[19]
1. Wnt Signaling Pathway
The Wnt signaling pathway is fundamental to numerous developmental processes, including cell proliferation, differentiation, and axis formation.[20][21][22] scRNA-seq can reveal which cells are sending and receiving Wnt signals by identifying the expression of Wnt ligands, Frizzled receptors, and downstream target genes in a cell-type-specific manner.[20]
Caption: Canonical Wnt signaling pathway.
2. TGF-β Signaling Pathway
The Transforming Growth Factor-beta (TGF-β) superfamily plays diverse roles in embryonic development, including the regulation of cell growth, differentiation, and apoptosis.[23][24] Single-cell analysis can delineate the specific effects of different TGF-β ligands on various cell lineages.[19][25]
Caption: TGF-β signaling pathway.
3. Notch Signaling Pathway
Notch signaling is a juxtacrine signaling pathway that is critical for cell-cell communication and plays a key role in binary cell fate decisions during development.[26][27][28][29] scRNA-seq can identify the expression of Notch receptors and their ligands (Delta and Jagged) in adjacent cells, providing insights into lateral inhibition and boundary formation.[26]
Caption: Notch signaling pathway.
B. Experimental and Computational Workflows
A clear understanding of the entire experimental and computational workflow is essential for planning and executing a successful single-cell sequencing project.
1. Single-Cell RNA Sequencing Experimental Workflow
Caption: Experimental workflow for scRNA-seq.
2. Single-Cell RNA-Seq Computational Analysis Workflow
Caption: Computational analysis workflow for scRNA-seq.
V. Conclusion: A New Era in Developmental Biology
Single-cell sequencing has ushered in a new era of discovery in developmental biology. By providing a high-resolution view of the cellular and transcriptional landscape of developing tissues, this technology is enabling researchers to ask and answer fundamental questions about how tissues are formed, how cell fates are determined, and how these processes go awry in disease. The protocols and principles outlined in these application notes provide a foundation for harnessing the power of single-cell genomics to further unravel the intricate symphony of tissue development. As the technology continues to evolve, so too will our understanding of the remarkable journey from a single cell to a fully formed organism.
References
- 1. Single-cell RNA sequencing for the study of development, physiology and disease - PMC [pmc.ncbi.nlm.nih.gov]
- 2. rna-seqblog.com [rna-seqblog.com]
- 3. 10x Genomics Single Cell: Principle,Workflow,Applications - CD Genomics [cd-genomics.com]
- 4. Approaches for single-cell RNA sequencing across tissues and cell types - PMC [pmc.ncbi.nlm.nih.gov]
- 5. communities.springernature.com [communities.springernature.com]
- 6. Preparing single-cell suspension from human embryo/fetus [protocols.io]
- 7. Preparation of cells from embryonic organs for single cell RNA sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 8. 10xgenomics.com [10xgenomics.com]
- 9. 10xgenomics.com [10xgenomics.com]
- 10. Smart-Seq2 [illumina.com]
- 11. Experimental design for single-cell RNA sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Smart-seq2 single-cell RNA-Seq modified method [protocols.io]
- 13. researchgate.net [researchgate.net]
- 14. Recent advancements in tissue dissociation techniques for cell manufacturing single-cell analysis and downstream processing - PMC [pmc.ncbi.nlm.nih.gov]
- 15. biorxiv.org [biorxiv.org]
- 16. FAQ | 10x Genomics - 10x Genomics - Single Cell Discoveries [scdiscoveries.com]
- 17. Single-cell RNA-seq: Quality Control Analysis | Introduction to Single-cell RNA-seq - ARCHIVED [hbctraining.github.io]
- 18. 10xgenomics.com [10xgenomics.com]
- 19. mdpi.com [mdpi.com]
- 20. Single-cell nuclear RNA-sequencing reveals dynamic changes in breast muscle cells during the embryonic development of Ding’an goose | PLOS One [journals.plos.org]
- 21. Wnt signaling pathways in biology and disease: mechanisms and therapeutic advances - PMC [pmc.ncbi.nlm.nih.gov]
- 22. mdpi.com [mdpi.com]
- 23. Tgf-beta superfamily signaling in embryonic development and homeostasis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 24. TGF-β Family Signaling in Embryonic and Somatic Stem-Cell Renewal and Differentiation - PMC [pmc.ncbi.nlm.nih.gov]
- 25. researchgate.net [researchgate.net]
- 26. Notch signaling determines cell-fate specification of the two main types of vomeronasal neurons of rodents - PMC [pmc.ncbi.nlm.nih.gov]
- 27. Notch Signaling | Cell Signaling Technology [cellsignal.com]
- 28. Notch signaling pathway - Wikipedia [en.wikipedia.org]
- 29. Frontiers | Notch signaling sculpts the stem cell niche [frontiersin.org]
Troubleshooting & Optimization
Technical Support Center: Modeling Complex Biological Orchestration
Welcome to the Technical Support Center for researchers, scientists, and drug development professionals engaged in modeling complex biological systems. This resource provides troubleshooting guides and frequently asked questions (FAQs) to address common challenges encountered during the modeling process.
Challenge 1: Integration of Multi-Omics Data
Integrating data from different omics layers (e.g., transcriptomics, proteomics, metabolomics) is a significant hurdle due to differences in data structure, noise profiles, and biological variability.[1][2][3] Effective integration is crucial for a holistic understanding of the biological system.[4][5][6]
Troubleshooting & FAQs
Q1: My transcriptomic (mRNA) and proteomic data show poor correlation for key genes. How can I resolve this discrepancy in my model?
A1: Poor correlation between mRNA and protein levels is common and can be attributed to several biological and technical factors, including differing half-lives of mRNA and proteins, post-transcriptional modifications, and measurement errors.[7]
Troubleshooting Steps:
-
Data Quality Control: Ensure both datasets have been properly pre-processed, including normalization and batch effect correction.[8][9]
-
Statistical Correlation Analysis: Perform a systematic correlation analysis to identify the extent of the discrepancy. It's not uncommon for the correlation to be low.
-
Incorporate Time Delays: Introduce a time-delay parameter in your model to account for the lag between transcription and translation.
-
Model Post-Transcriptional Regulation: Add model components that represent microRNA regulation or other post-transcriptional mechanisms.
-
Experimental Validation: Use a targeted method like qPCR or Western Blotting to validate the expression levels of a subset of discordant genes/proteins.
Q2: How can I effectively merge datasets from different platforms with varying scales and distributions (e.g., RNA-seq counts and Mass Spectrometry intensities)?
A2: Merging heterogeneous data requires careful normalization and transformation to bring them to a comparable scale.
Recommended Approaches:
-
Z-score Transformation: Convert all data to Z-scores to standardize the mean and standard deviation.
-
Rank-based Methods: Transform data to ranks to mitigate issues with differing distributions.
-
Network-based Integration: Construct separate networks for each data type (e.g., gene co-expression and protein-protein interaction networks) and then integrate them.[4][7] Tools like Cytoscape or Ingenuity Pathway Analysis can be used for this purpose.[10]
Quantitative Data Summary
The table below illustrates a common scenario of discordant fold-changes between transcriptomic and proteomic data for a set of genes in response to a stimulus.
| Gene | mRNA Fold Change (RNA-seq) | Protein Fold Change (MS) | Potential Reason for Discordance |
| Gene A | 4.5 | 1.2 | Long protein half-life, slow turnover |
| Gene B | 1.1 | 3.8 | Post-transcriptional regulation, increased translation efficiency |
| Gene C | -2.3 | -2.1 | Good correlation |
| Gene D | 3.0 | Not Detected | Protein below detection limit or rapidly degraded |
Experimental Protocol
Protocol: Western Blot for Protein Validation
This protocol provides a method to validate the relative abundance of a specific protein identified through high-throughput proteomics.
1. Sample Preparation:
- Lyse cells or tissues in RIPA buffer supplemented with protease and phosphatase inhibitors.
- Determine protein concentration using a BCA assay.
2. SDS-PAGE:
- Load 20-30 µg of protein per lane on a polyacrylamide gel.
- Run the gel at 100-120V until the dye front reaches the bottom.
3. Protein Transfer:
- Transfer proteins from the gel to a PVDF membrane at 100V for 90 minutes.
- Block the membrane with 5% non-fat milk or BSA in TBST for 1 hour at room temperature.
4. Antibody Incubation:
- Incubate the membrane with a primary antibody specific to the protein of interest overnight at 4°C.
- Wash the membrane three times with TBST.
- Incubate with a horseradish peroxidase (HRP)-conjugated secondary antibody for 1 hour at room temperature.
5. Detection:
- Wash the membrane three times with TBST.
- Apply an enhanced chemiluminescence (ECL) substrate and visualize the bands using a chemiluminescence imager.
- Quantify band intensity using software like ImageJ and normalize to a loading control (e.g., GAPDH, β-actin).
Visualizations
Caption: Workflow for integrating and validating multi-omics data.
Challenge 2: Parameter Estimation and Model Validation
A significant challenge in computational modeling is determining the values of model parameters (e.g., kinetic rate constants) and validating the model's predictions against experimental data.[11][12] This is often complicated by sparse and noisy experimental measurements.[13][14][15]
Troubleshooting & FAQs
Q1: My model has dozens of unknown parameters. How can I efficiently estimate their values?
A1: Estimating a large number of parameters is a common problem. A multi-step approach is often most effective.
Troubleshooting Steps:
-
Literature Review: Obtain initial estimates for parameters from published experimental studies, even if they are from different systems.
-
Sensitivity Analysis: Perform a sensitivity analysis to identify which parameters have the most significant impact on the model's output. This allows you to focus your estimation efforts on the most critical parameters.
-
Parameter Fitting Algorithms: Use optimization algorithms to fit the model to your experimental data. Gradient-based and gradient-free methods are available in various software packages.[11]
-
Bayesian Inference: Employ Bayesian methods to obtain a probability distribution for each parameter, which also provides a measure of uncertainty.[13][14]
Q2: My model simulations do not match my experimental results. What are the common reasons for this and how can I troubleshoot it?
A2: Discrepancies between model predictions and experimental data are a critical part of the model refinement process. The validation process involves checking that the model is implemented correctly and comparing its predictions against experimental data.[16]
Troubleshooting Steps:
-
Verify Model Implementation: Double-check the equations and logic in your model code for errors. This is a crucial first step known as verification.[16]
-
Check Experimental Data Quality: Ensure your experimental data is reliable and reproducible. Include appropriate controls in your experiments.[17]
-
Re-evaluate Model Assumptions: The underlying biological assumptions of your model may be incorrect. For example, a linear pathway might in reality have a feedback loop.
-
Iterative Refinement: Use the discrepancies to guide model refinement. If the model predicts a faster response than observed, consider adding an inhibitory step.
-
Cross-Validation: Validate your model using a dataset that was not used for parameter fitting to avoid overfitting.[18]
Quantitative Data Summary
Table: Sensitivity Analysis Results
This table shows the output of a hypothetical sensitivity analysis on a signaling pathway model. The sensitivity coefficient indicates how much the model output (e.g., concentration of phosphorylated protein) changes in response to a change in a given parameter.
| Parameter | Description | Normalized Sensitivity Coefficient | Rank |
| k_f1 | Forward rate of kinase binding | 0.92 | 1 |
| k_r1 | Reverse rate of kinase binding | 0.15 | 4 |
| k_cat | Catalytic rate of phosphorylation | 0.85 | 2 |
| k_p | Rate of dephosphorylation | -0.78 | 3 |
| D_prot | Degradation rate of protein | 0.05 | 5 |
Parameters with high sensitivity coefficients (e.g., k_f1, k_cat) are the most influential and should be prioritized for accurate estimation.
Experimental Protocol
Protocol: In Vitro Kinase Assay
This protocol is for determining the kinetic parameters of a specific kinase, which can then be used in a computational model.
1. Reagents and Setup:
- Purified recombinant kinase and substrate protein.
- ATP solution.
- Kinase reaction buffer.
- 96-well plate.
2. Assay Procedure:
- Create a serial dilution of the substrate protein in the 96-well plate.
- Add a fixed concentration of the kinase to each well.
- Initiate the reaction by adding ATP.
- Incubate at 30°C for a specified time course (e.g., 0, 5, 10, 20, 30 minutes).
- Stop the reaction by adding EDTA.
3. Detection:
- Use a method to detect the phosphorylated substrate (e.g., a phosphospecific antibody in an ELISA format or Phos-tag SDS-PAGE).
4. Data Analysis:
- Plot the initial reaction velocity against the substrate concentration.
- Fit the data to the Michaelis-Menten equation to determine the Vmax and Km, from which k_cat can be calculated.
Visualizations
References
- 1. academic.oup.com [academic.oup.com]
- 2. bigomics.ch [bigomics.ch]
- 3. mindwalkai.com [mindwalkai.com]
- 4. gmo-qpcr-analysis.info [gmo-qpcr-analysis.info]
- 5. Integrating Molecular Perspectives: Strategies for Comprehensive Multi-Omics Integrative Data Analysis and Machine Learning Applications in Transcriptomics, Proteomics, and Metabolomics [mdpi.com]
- 6. Integrating Molecular Perspectives: Strategies for Comprehensive Multi-Omics Integrative Data Analysis and Machine Learning Applications in Transcriptomics, Proteomics, and Metabolomics - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Integrated Analysis of Transcriptomic and Proteomic Data - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Ten quick tips for avoiding pitfalls in multi-omics data integration analyses - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. How to integrate transcriptomics and proteomics in biomarker discovery? [synapse.patsnap.com]
- 11. Parameter Estimation and Uncertainty Quantification for Systems Biology Models - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Parameter Estimation and Model Selection in Computational Biology | PLOS Computational Biology [journals.plos.org]
- 13. Bayesian parameter estimation for dynamical models in systems biology | PLOS Computational Biology [journals.plos.org]
- 14. Bayesian parameter estimation for dynamical models in systems biology - PMC [pmc.ncbi.nlm.nih.gov]
- 15. [2204.05415] Bayesian Parameter Estimation for Dynamical Models in Systems Biology [arxiv.org]
- 16. youtube.com [youtube.com]
- 17. Model Selection and Experimental Design in Screening | KCAS Bio [kcasbio.com]
- 18. fiveable.me [fiveable.me]
Technical Support Center: Optimizing Automated Laboratory Orchestration for Reproducibility
This technical support center is designed for researchers, scientists, and drug development professionals to address common challenges in automated laboratory orchestration and enhance experimental reproducibility.
Frequently Asked Questions (FAQs)
This section answers common questions about setting up and managing automated laboratory systems to ensure consistent and reliable results.
| Category | Question | Answer |
| General Automation | What are the primary sources of irreproducibility in automated lab workflows? | Inconsistent execution of protocols by different users, environmental fluctuations (temperature, humidity), variability in reagents and consumables, and inadequate data management can all contribute to a lack of reproducibility.[1] Automation aims to minimize these by standardizing processes. |
| How can we minimize human error in our automated workflows? | Implementing robust training programs for all users on the proper operation of automation systems is crucial.[2] Utilizing user-friendly interfaces and clear on-screen instructions can also reduce mistakes. Furthermore, automating as many manual steps as possible, such as sample labeling and data entry, will significantly decrease the chances of human error.[3] | |
| Liquid Handling | What are the key differences in performance between manual and automated pipetting? | Automated pipetting systems offer significantly higher accuracy and precision compared to manual methods by minimizing user-to-user variability.[4][5][6][7] This leads to greater experimental consistency, which is especially critical for sensitive assays like qPCR.[8] While manual pipetting is more cost-effective for low-throughput tasks, it is more susceptible to human error and repetitive strain injuries.[4][5] |
| How do I choose the right automated liquid handler for my lab? | Consider the volume range you will be working with, the types of liquids (viscosity, volatility), required throughput, and compatibility with your existing labware and software. For tasks requiring the highest precision with minimal reagent waste, consider systems with features like acoustic dispensing. | |
| Robotics & Hardware | What are the most common causes of robotic arm failures? | Common issues include mechanical problems like worn-out parts or misalignment, communication errors between the robot and the control software, and power supply issues.[2] Incorrect programming or calibration by the user can also lead to failures. |
| How often should we perform preventative maintenance on our automation equipment? | It is recommended to follow the manufacturer's guidelines for preventative maintenance schedules. Regular maintenance, including cleaning and calibration, is essential to prevent system failures, reduce downtime, and ensure the longevity of the equipment.[9] | |
| Software & Data | What is a Laboratory Information Management System (LIMS) and why is it important for reproducibility? | A LIMS is a software system designed to manage and track samples, experiments, results, and data.[10] It is crucial for reproducibility as it provides a centralized system for data management, ensures data integrity through audit trails, and helps standardize workflows.[10] |
| We are experiencing integration issues between new and existing automation systems. What can we do? | Lack of interoperability is a common challenge.[11] To address this, it's important to choose automation solutions with open APIs that support standard data formats. Collaborating with vendors who provide comprehensive integration support is also key to ensuring seamless communication between different systems.[9] | |
| Our scheduling software is creating bottlenecks in our workflow. How can we optimize it? | Review your scheduling software for inefficiencies such as double-booked equipment or unrealistic timelines. Simulating workflow runs can help identify potential deadlocks before they occur.[11] Ensure that the software provides real-time tracking of instrument availability and task progress to allow for dynamic adjustments. |
Troubleshooting Guides
This section provides step-by-step guidance for resolving specific issues you may encounter during your automated experiments.
Liquid Handler: Inaccurate or Inconsistent Dispensing
Symptom: You observe high variability in your assay results, or quality control checks indicate that the liquid handler is dispensing incorrect volumes.
Possible Causes and Solutions:
| Possible Cause | Troubleshooting Steps |
| Incorrect Pipette Tips | 1. Ensure you are using the correct type and size of pipette tips as specified by the liquid handler manufacturer. 2. Check that the tips are properly seated on the pipetting head. Loose tips can cause aspiration and dispensing errors. |
| Air Bubbles in Tubing or Tips | 1. Visually inspect the system tubing and pipette tips for any visible air bubbles. 2. If bubbles are present, perform a priming or flushing cycle as recommended by the manufacturer to purge the air from the system. 3. For viscous liquids, consider using a lower aspiration speed to prevent bubble formation.[12] |
| Clogged Tips or Tubing | 1. If you suspect a clog, run a cleaning cycle with an appropriate cleaning solution. 2. For persistent clogs, you may need to manually clean or replace the affected tips or tubing, following the manufacturer's instructions. |
| Incorrect Liquid Class Settings | 1. Verify that the selected liquid class settings (e.g., viscosity, surface tension) in the software are appropriate for the liquid you are dispensing. 2. If necessary, create a new liquid class and optimize the aspiration and dispensing parameters for your specific reagent. |
| Environmental Factors | 1. Ensure that the laboratory environment is stable. Fluctuations in temperature and humidity can affect the physical properties of liquids and lead to inaccurate dispensing.[12] |
Robotic Arm: Failure to Pick or Place Labware
Symptom: The robotic arm fails to grip a plate, drops labware during transport, or misaligns the labware when placing it on an instrument.
Possible Causes and Solutions:
| Possible Cause | Troubleshooting Steps |
| Incorrect Gripper Calibration | 1. Recalibrate the robotic arm's gripper according to the manufacturer's protocol. This ensures that the gripper is applying the correct amount of force and is properly aligned. |
| Labware Not in a Taught Position | 1. Verify that the location of the labware on the deck matches the position that was "taught" to the robot in the control software. 2. If the position is incorrect, re-teach the pick-and-place locations for that specific piece of labware. |
| Obstruction in the Robot's Path | 1. Check for any obstructions in the robotic arm's path of movement, such as cables, other labware, or debris. 2. Ensure that all labware is properly seated on the deck and that there are no unexpected items in the work area. |
| Worn or Damaged Gripper Pads | 1. Inspect the gripper pads for signs of wear, tear, or contamination. 2. If the pads are worn or damaged, replace them with new ones from the manufacturer. |
| Communication Error | 1. Power cycle the robotic arm and the control computer to re-establish communication. 2. Check the physical cable connections between the robot and the controller. |
Plate Reader: High Background or Low Signal
Symptom: Your plate reader is producing results with an unexpectedly high background signal or a lower-than-expected signal from your samples.
Possible Causes and Solutions:
| Possible Cause | Troubleshooting Steps |
| Incorrect Plate Type | 1. Ensure you are using the correct color and type of microplate for your assay. For example, use white plates for luminescence and black plates for fluorescence to minimize crosstalk and background.[13][14] |
| Autofluorescence from Media or Compounds | 1. If you suspect autofluorescence, run a blank plate with only the media and another with the media and your compounds to measure their background signal. 2. Consider using a media with low autofluorescence, such as FluoroBrite.[15] |
| Suboptimal Reader Settings (Gain, Exposure) | 1. Optimize the gain and exposure time settings on the plate reader. A gain setting that is too high can saturate the detector, while a setting that is too low can result in a weak signal.[13][14][15] 2. If available, use a positive control to determine the optimal settings. |
| Bubbles in Wells | 1. Visually inspect the wells for bubbles, which can interfere with the light path. 2. If bubbles are present, gently centrifuge the plate or use a sterile pipette tip to remove them.[13] |
| Dirty Optics | 1. Follow the manufacturer's instructions for cleaning the plate reader's optical components. Dust and other contaminants can scatter light and increase background noise.[16] |
Quantitative Data Summary
The following tables provide a summary of quantitative data highlighting the benefits of automated laboratory orchestration for reproducibility.
Table 1: Error Rate Reduction with Automation
| Metric | Manual Process | Automated Process | Improvement | Source |
| Sample Handling Errors | High Variability | Significantly Reduced | 73% decrease | [1] |
| Analytical Errors | Moderate Variability | Reduced | 45% decrease | [1] |
| Processing Mistakes (Blood Analyzers) | Prone to human error | Highly Accurate | 30% reduction in mistakes | [17] |
| Accuracy Rate (Blood Analyzers) | Dependent on operator | High | 98% accuracy | [17] |
Table 2: Throughput and Efficiency Gains with Automation
| Metric | Manual Process | Automated Process | Improvement | Source |
| High-Throughput Screening (compounds/day) | Hundreds | 10,000 - 100,000+ | Exponential Increase | [18] |
| Processing Time | High | Significantly Reduced | Up to 40% reduction | [17] |
| Throughput Increase | Baseline | Increased | 65% average increase | [1] |
Table 3: Return on Investment (ROI) Considerations for Lab Automation
| Key Performance Indicator (KPI) | Impact of Automation | Source |
| Cost Per Sample | Reduces material and reagent usage, lowering overall costs. | [19] |
| Labor Costs | Decreases the need for new hires and overtime to manage increasing sample volumes. | [20] |
| Turnaround Time (TAT) | Accelerates sample processing, leading to faster delivery of results. | [10] |
| Data Quality and Compliance | Enhances data integrity and traceability, simplifying regulatory compliance. | [20] |
Experimental Protocols
This section provides detailed methodologies for key experiments commonly performed in automated laboratory settings.
Protocol 1: Automated Adherent Cell Culture Passaging
Objective: To automatically subculture adherent cells to maintain them in a healthy, proliferative state.
Materials:
-
Adherent cell line (e.g., HeLa, HEK293)
-
Complete cell culture medium (e.g., DMEM + 10% FBS)
-
Phosphate-Buffered Saline (PBS), Ca2+/Mg2+ free
-
Trypsin-EDTA (0.25%)
-
T-75 flasks or multi-well plates
-
Automated liquid handler
-
Robotic arm
-
Automated incubator
-
Automated cell counter (optional)
Methodology:
-
Plate Retrieval: The robotic arm retrieves the cell culture plate from the automated incubator and places it on the deck of the liquid handler.[21]
-
Aspiration of Old Medium: The liquid handler aspirates the spent cell culture medium from the plate.
-
PBS Wash: The liquid handler dispenses a pre-defined volume of PBS into each well to wash the cells and then aspirates the PBS.
-
Trypsinization: A specified volume of Trypsin-EDTA is dispensed onto the cell monolayer. The plate is then either incubated at room temperature on the deck for a set time or returned to the incubator by the robotic arm for incubation at 37°C.
-
Neutralization: After incubation, the robotic arm returns the plate to the liquid handler deck. Complete medium is added to each well to neutralize the trypsin.
-
Cell Detachment and Resuspension: The liquid handler gently pipettes the cell suspension up and down to ensure a single-cell suspension.
-
Cell Counting (Optional): If an automated cell counter is integrated, a small aliquot of the cell suspension is transferred to the counter to determine cell density and viability.
-
Seeding New Plates: Based on a pre-set seeding density or the cell count, the liquid handler transfers the appropriate volume of the cell suspension into new plates containing fresh, pre-warmed medium.
-
Return to Incubator: The robotic arm transports the newly seeded plates to the automated incubator for continued growth.
Protocol 2: Automated Magnetic Bead-Based DNA Extraction
Objective: To isolate high-quality genomic DNA from samples using an automated magnetic bead-based purification system.
Materials:
-
Sample (e.g., whole blood, cell culture, tissue lysate)
-
Magnetic DNA extraction kit (containing magnetic beads, lysis buffer, wash buffers, and elution buffer)
-
Proteinase K
-
Ethanol (96-100%)
-
Automated liquid handler with a magnetic separation module
-
Deep-well plates
Methodology:
-
Sample and Reagent Preparation: The user loads the samples, pre-filled reagent cartridges or bulk reagent reservoirs (lysis buffer with Proteinase K, wash buffers, and elution buffer), and magnetic beads onto the deck of the automated liquid handler.
-
Lysis: The liquid handler dispenses the sample into a deep-well plate, followed by the addition of lysis buffer and Proteinase K. The plate is then agitated to ensure thorough mixing and incubated at a specified temperature to lyse the cells and digest proteins.[22]
-
Binding: Magnetic beads are added to the lysate, and the mixture is incubated with agitation to allow the DNA to bind to the surface of the beads.
-
Magnetic Capture and Washing: The plate is moved to a magnetic separation module, which pulls the DNA-bound magnetic beads to the side of the wells. The liquid handler then aspirates and discards the supernatant. The beads are washed by dispensing and aspirating a series of wash buffers to remove contaminants.[22] This wash step is typically repeated 2-3 times.
-
Drying: After the final wash, the beads are air-dried for a short period to allow any remaining ethanol to evaporate.
-
Elution: The plate is moved off the magnetic module, and an elution buffer is added to the beads. The plate is agitated to resuspend the beads and incubated to release the purified DNA into the solution.
-
Final Collection: The plate is returned to the magnetic separation module, and the liquid handler carefully aspirates the eluate containing the purified DNA and transfers it to a new collection plate or tubes.
Mandatory Visualizations
Signaling Pathway: EGFR Signaling
The following diagram illustrates a simplified view of the Epidermal Growth Factor Receptor (EGFR) signaling pathway, a critical pathway in cell proliferation and a common target in drug discovery.[23][24][25][26][27]
Experimental Workflow: High-Throughput Screening (HTS)
This diagram outlines a typical workflow for a high-throughput screening campaign designed to identify potential drug candidates.[28][29][30]
Logical Relationship: Troubleshooting Workflow
This diagram illustrates a logical workflow for troubleshooting common issues in an automated laboratory setting.[2]
References
- 1. ijirmps.org [ijirmps.org]
- 2. How to troubleshoot automation problems in the lab [biosero.com]
- 3. automata.tech [automata.tech]
- 4. Manual vs Electronic Pipetting Guide | Pros & Cons | FB Australia [fisherbiotec.com.au]
- 5. Manual vs. Electronic Pipetting: What You Need to Know [thermofisher.com]
- 6. Manual or Automated?: Choosing the Best Method of Pipetting | Lab Manager [labmanager.com]
- 7. Automated Liquid Handlers vs. Manual Pipetting: Pros and Cons [synapse.patsnap.com]
- 8. biocompare.com [biocompare.com]
- 9. Avoiding Common Pitfalls in Lab Automation Best Practices [wakoautomation.com]
- 10. sapiosciences.com [sapiosciences.com]
- 11. retisoft.com [retisoft.com]
- 12. Quantitative high-throughput screening data analysis: challenges and recent advances - PMC [pmc.ncbi.nlm.nih.gov]
- 13. selectscience.net [selectscience.net]
- 14. bitesizebio.com [bitesizebio.com]
- 15. ncbi.nlm.nih.gov [ncbi.nlm.nih.gov]
- 16. Common Mistakes to Avoid When Using Microplate Readers [hiwelldiatek.com]
- 17. researchgate.net [researchgate.net]
- 18. beckman.com [beckman.com]
- 19. KPIs for measuring lab automation success [biosero.com]
- 20. diagnostics.roche.com [diagnostics.roche.com]
- 21. theautomatedlab.com [theautomatedlab.com]
- 22. Automating Nucleic Acid Extraction [worldwide.promega.com]
- 23. researchgate.net [researchgate.net]
- 24. A comprehensive pathway map of epidermal growth factor receptor signaling - PMC [pmc.ncbi.nlm.nih.gov]
- 25. The EGF/EGFR axis and its downstream signaling pathways regulate the motility and proliferation of cultured oral keratinocytes - PMC [pmc.ncbi.nlm.nih.gov]
- 26. researchgate.net [researchgate.net]
- 27. researchgate.net [researchgate.net]
- 28. researchgate.net [researchgate.net]
- 29. bmglabtech.com [bmglabtech.com]
- 30. An Overview of High Throughput Screening | The Scientist [the-scientist.com]
Technical Support Center: Troubleshooting Data Integration in Multi-Platform Orchestration
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals encountering issues with data integration in a multi-platform orchestration environment.
Frequently Asked Questions (FAQs)
Q1: What are the most common initial steps to take when a data integration workflow fails?
A1: When a data integration workflow fails, begin with the following initial checks:
-
Review Error Logs: Examine the error logs from your orchestration tool and the platforms involved. These logs often provide specific error messages that can pinpoint the source of the problem.
-
Check Connectivity: Ensure that all platforms and services have network connectivity. Network issues are a frequent cause of integration failures.[1][2]
-
Verify Credentials: Double-check all API keys, tokens, and other credentials used for authentication. Expired or incorrect credentials are a common point of failure.[3]
-
Inspect Input Data: Ensure that the input data is in the expected format and meets the quality standards of the receiving platform.
Q2: How can I resolve API authentication errors (e.g., 401 Unauthorized, 403 Forbidden)?
A2: API authentication errors typically indicate a problem with the credentials or permissions for accessing a service.
-
401 Unauthorized: This error usually means the API key or token is missing, incorrect, or expired.[4]
-
Action: Regenerate the API key or token from the service provider and update it in your orchestration tool. Ensure there are no typos or extra spaces.
-
-
403 Forbidden: This error indicates that the credentials are valid, but the user or service account does not have the necessary permissions to access the requested resource.
-
Action: Review the user roles and permissions in the target platform. Ensure that the account has the appropriate read/write access for the specific data you are trying to integrate.
-
Q3: My data integration is failing due to file format incompatibility. What should I do?
A3: File format incompatibility is a common challenge, especially when integrating data from diverse 'omics platforms.
-
Identify the Required Format: Consult the documentation for the target platform to determine the exact file format, structure, and encoding it expects.
-
Use Conversion Tools: Employ bioinformatics tools or scripting languages like Python or R to convert your data to the required format. For example, you might need to convert a custom tabular format to a standardized format like VCF for genomic data or mzML for mass spectrometry data.
-
Standardize Data Preprocessing: Establish a standardized data preprocessing pipeline to ensure that all data is transformed into a consistent format before integration.[5]
Q4: How can I troubleshoot database connection issues in my workflow?
A4: Database connection problems can stem from several sources. A systematic approach to troubleshooting is recommended.
-
Verify Connection String: Check the database hostname, port, database name, username, and password in your connection string for any errors.
-
Test Network Connectivity: Use tools like ping or telnet to confirm that the server running the workflow can reach the database server over the network.
-
Check Firewall Rules: Ensure that firewalls on the client, server, or network are not blocking the database port.
-
Confirm Database Service is Running: Verify that the database service is active on the server.
Q5: What are best practices for maintaining data provenance in a multi-platform environment?
A5: Maintaining data provenance, or the history of your data, is crucial for reproducibility and troubleshooting.
-
Use a Workflow Management System: Employ a workflow manager that automatically logs each step of the integration process, including the tools, parameters, and versions used.
-
Implement a Metadata Strategy: Attach metadata to your data files that includes information about the source, creation date, and any transformations performed.[6]
-
Version Your Data: Use a version control system for your data, similar to how you would for code, to track changes over time.
-
Automate Provenance Capture: Whenever possible, use tools that automatically capture provenance information to reduce the risk of manual errors.[7]
Troubleshooting Guides
Guide 1: Resolving API Connection Timeouts
Issue: Your data integration workflow fails with an API connection timeout error.
Methodology:
-
Check API Server Status: Visit the status page of the API provider to ensure there are no ongoing outages or performance issues.
-
Test with a Simple Request: Use a tool like curl or Postman to make a simple API request from the same environment where your workflow is running. This helps to isolate whether the issue is with the workflow or the environment.
-
Review API Rate Limits: Check if your workflow is exceeding the number of allowed API requests per minute or day. If so, implement a delay or backoff mechanism in your script.[3]
-
Increase Timeout in Your Code: If the API server is slow to respond, you may need to increase the timeout setting in your HTTP client library.
-
Optimize Your Requests: If you are requesting a large amount of data, consider paginating your requests to retrieve smaller chunks of data at a time.
Guide 2: Handling Data Duplication During Integration
Issue: After integrating data from multiple sources, you notice a significant number of duplicate records.
Methodology:
-
Identify a Unique Identifier: Determine a reliable unique identifier for your records (e.g., a patient ID, sample ID, or a combination of fields).
-
Implement Deduplication Logic:
-
Pre-integration: Use a script to identify and remove duplicates from your source data before initiating the integration.
-
During Integration: If your integration tool supports it, configure it to check for existing records based on the unique identifier before inserting new data (an "upsert" operation).[8]
-
Post-integration: Run a cleanup script on the target database to merge or remove duplicate entries.
-
-
Establish a Data Governance Policy: Define clear rules for data entry and management to prevent the introduction of duplicates at the source.[9]
-
Use Automated Deduplication Tools: Consider using specialized tools that can automatically detect and resolve duplicate records.[10]
Quantitative Data on Data Integration Challenges
The following table summarizes error rates associated with different data processing methods in clinical research, highlighting the importance of robust data entry and integration practices.
| Data Processing Method | Pooled Error Rate (95% CI) | Range of Error Rates (per 10,000 fields) |
| Medical Record Abstraction | 6.57% (5.51% - 7.72%) | 70 - 2,784 |
| Optical Scanning | 0.74% (0.21% - 1.60%) | 2 - 358 |
| Single-Data Entry | 0.29% (0.24% - 0.35%) | 4 - 650 |
| Double-Data Entry | 0.14% (0.08% - 0.20%) | 4 - 33 |
Source: Systematic review and meta-analysis of data processing methods in clinical research.[11][12][13][14]
Experimental Protocols
Protocol 1: Integrating RNA-Seq and Mass Spectrometry Proteomics Data
This protocol outlines the key steps for integrating transcriptomic (RNA-Seq) and proteomic (Mass Spectrometry) data.
Methodology:
-
Data Acquisition:
-
Perform RNA-Seq on biological samples to obtain transcript expression data (e.g., in FASTQ format).
-
Perform mass spectrometry-based proteomics on the same or parallel biological samples to obtain protein identification and quantification data (e.g., in RAW or mzML format).[15]
-
-
Individual Data Processing:
-
RNA-Seq: Process the raw sequencing reads through a standard bioinformatics pipeline including quality control, alignment to a reference genome, and quantification of gene expression (e.g., as TPM or FPKM values).
-
Proteomics: Process the raw mass spectrometry data using a search engine (e.g., MaxQuant, Proteome Discoverer) to identify peptides and proteins and quantify their abundance.
-
-
Data Mapping and Integration:
-
Map the protein identifiers from the proteomics data to the corresponding gene identifiers from the RNA-Seq data. This can be done using a common database such as Ensembl or UniProt.
-
Combine the normalized expression values for corresponding genes and proteins into a single data matrix.
-
-
Correlation and Pathway Analysis:
-
Perform correlation analysis to identify genes and proteins with concordant or discordant expression patterns.
-
Use pathway analysis tools (e.g., GSEA, Reactome) to identify biological pathways that are enriched in the integrated dataset.
-
-
Data Validation:
-
Validate key findings using targeted experimental methods such as qPCR for gene expression or Western blotting for protein expression.[16]
-
Visualizations
Troubleshooting Workflow for API Failures
Caption: A flowchart for troubleshooting common API failures.
Multi-Omics Data Integration Workflow
Caption: A typical workflow for multi-omics data integration.
References
- 1. e-codi.org [e-codi.org]
- 2. What is API Failure? 6 Causes and How to Fix Them [apidog.com]
- 3. Fixing API Connection Issues in Analytics Platforms - Anlytic [anlytic.com]
- 4. Traceable - Blog: API Failure: 7 Causes and How to Fix Them [traceable.ai]
- 5. Multi-omics Data Integration, Interpretation, and Its Application - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Overcoming 3 common metadata management problems [datagalaxy.com]
- 7. devtoolsdaily.com [devtoolsdaily.com]
- 8. docs.dataddo.com [docs.dataddo.com]
- 9. blog.cogentconnective.com [blog.cogentconnective.com]
- 10. hopp.tech [hopp.tech]
- 11. researchgate.net [researchgate.net]
- 12. communities.springernature.com [communities.springernature.com]
- 13. Identifying abundant immunotherapy and other targets in solid tumors: integrating RNA-seq and Mass Spectrometry proteomics data sets - PMC [pmc.ncbi.nlm.nih.gov]
- 14. researchgate.net [researchgate.net]
- 15. How to integrate transcriptomics and proteomics in biomarker discovery? [synapse.patsnap.com]
- 16. Essential Checklist for Integrating Omics Data: What You Need to Know for Effective Analysis - Omics tutorials [omicstutorials.com]
Technical Support Center: Overcoming Bottlenecks in High-Throughput Screening Orchestration
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals overcome common bottlenecks in high-throughput screening (HTS) orchestration.
Section 1: Assay Development and Optimization
This section addresses frequent challenges encountered during the development and optimization of HTS assays.
FAQs
Q1: What are the most common sources of variability in HTS assays?
A1: Variability in HTS assays can be broadly categorized into systematic and random errors. Systematic errors often manifest as predictable patterns across a plate or a batch of plates, while random errors are unpredictable fluctuations.[1] Key sources include:
-
Reagent Stability and Pipetting Inaccuracy: Inconsistent reagent quality or imprecise liquid handling can introduce significant variability.
-
Environmental Factors: Fluctuations in temperature and humidity during incubation can lead to issues like the "edge effect," where wells on the perimeter of the microplate evaporate more rapidly.[2][3]
-
Cell-Based Assay Issues: Inconsistent cell seeding density, passage number, and media formulation can all contribute to variability.
-
Plate Position Effects: Systematic errors can be linked to specific rows, columns, or well locations on a microplate due to uneven heating or gas exchange.[1]
Q2: How can I identify the source of variability in my assay?
A2: A combination of visual data inspection, statistical analysis, and a thorough review of the experimental protocol is crucial for pinpointing the source of variability.[1] Heatmaps of plate data can reveal spatial patterns like edge effects, while tracking quality control metrics such as the Z'-factor and the coefficient of variation (%CV) for controls on each plate can help identify problematic plates or batches.[1]
Q3: What is the Z'-factor and why is it a critical quality control metric?
A3: The Z'-factor is a statistical parameter that quantifies the quality of an HTS assay by measuring the separation between the signals of the positive and negative controls while taking data variability into account.[1][4][5] An assay with a Z'-factor between 0.5 and 1.0 is considered excellent and suitable for HTS.[1][6][7] A value between 0 and 0.5 may be acceptable, but a Z'-factor below 0 indicates that the assay is not suitable for screening.[1][5][6]
Troubleshooting Guide: Low Z'-Factor
A low Z'-factor is a common and critical issue that must be resolved before proceeding with a full-scale screen.[4]
Table 1: Troubleshooting a Low Z'-Factor (<0.5)
| Symptom | Potential Cause | Recommended Solution |
| High %CV of Controls (>15%) | Dispensing Errors: Inaccurate or inconsistent liquid handling. | - Verify liquid handler calibration.[8] - Check for clogged dispenser tips. - Ensure proper mixing of reagents. |
| Reagent Instability: Degradation or precipitation of assay components. | - Prepare fresh reagents. - Assess reagent stability over the course of the experiment. - Optimize storage conditions. | |
| Plate Effects: Edge effects or temperature gradients across the plate. | - Use plates with moats and fill with sterile media or water.[2][4] - Exclude outer wells from analysis.[4] - Ensure uniform incubator humidity (>95%).[2][4] | |
| Low Signal-to-Background (S/B) Ratio | Suboptimal Reagent Concentration: Incorrect concentrations of enzymes, substrates, or cells. | - Perform a matrix titration of key reagents to find optimal concentrations. |
| Inappropriate Incubation Time: Insufficient or excessive incubation time leading to a weak signal or high background. | - Conduct a time-course experiment to determine the optimal incubation period. | |
| Incorrect Assay Conditions: Suboptimal pH, temperature, or buffer composition. | - Systematically vary assay conditions to identify the optimal parameters. |
Logical Workflow for Troubleshooting a Low Z'-Factor
A logical workflow for troubleshooting a low Z'-factor.
Experimental Protocol: Optimizing a Cell-Based HTS Assay
This protocol outlines a typical approach for optimizing key parameters for a cell-based assay, such as one using a luciferase reporter to measure the activation of a signaling pathway.[4]
-
Objective: To determine the optimal cell density, serum concentration, and incubation time to achieve the most robust assay signal window.
-
Materials:
-
Stable cell line expressing the reporter gene.
-
Assay-specific reagents (e.g., activating ligand, substrate).[4]
-
Cell culture medium with varying serum concentrations (e.g., 2.5%, 5%).[4]
-
384-well, solid white microplates suitable for luminescence assays.[4]
-
Automated liquid handlers and a plate reader.[4]
-
-
Methodology:
-
Cell Seeding: Plate cells at varying densities (e.g., 5,000 and 10,000 cells/well) in media with different serum concentrations. Incubate for 24 hours.[4]
-
Compound Addition: Add the activating ligand to stimulate the pathway. Include negative controls (DMSO vehicle) and positive controls.[4]
-
Incubation: Test different incubation times (e.g., 16, 24, 48 hours) post-compound addition.
-
Signal Detection: Add the luminescence substrate according to the manufacturer's protocol and read the plates on a compatible plate reader.[4]
-
Data Analysis: Calculate the Signal-to-Background ratio and Z'-factor for each condition.[4]
-
Table 2: Hypothetical Optimization Data Summary
| Condition | Cell Density (cells/well) | Serum Concentration (%) | Incubation Time (hr) | Signal-to-Background | Z'-Factor | Decision |
| 1 | 5,000 | 5 | 16 | 8.5 | 0.65 | Sub-optimal |
| 2 | 10,000 | 5 | 24 | 12.3 | 0.78 | Optimal |
| 3 | 5,000 | 2.5 | 16 | 7.9 | 0.61 | Sub-optimal |
| 4 | 10,000 | 2.5 | 24 | 11.8 | 0.75 | Near-optimal |
Based on hypothetical data, Condition 2 provides the best combination of a high Signal-to-Background ratio and a robust Z'-factor.[4]
Section 2: Liquid Handling and Automation
This section focuses on troubleshooting issues related to automated liquid handling systems, a common source of bottlenecks in HTS.
FAQs
Q1: My liquid handler's dispensing seems inaccurate. What should I check first?
A1: When encountering inaccurate dispensing, start by verifying the basics. Ensure the correct pipette tips are being used and are properly seated. Check for any visible leaks in the tubing or connections. It's also crucial to confirm that the liquid handler has been recently and correctly calibrated for the specific liquid class (e.g., aqueous, DMSO, viscous) you are using.
Q2: I'm observing a high number of outliers in my data. Could this be a liquid handling issue?
A2: Yes, inconsistent liquid handling is a frequent cause of outliers. This can stem from issues such as bubbles in the system lines, clogged tips, or improper dispensing heights. For air displacement pipettors, ensure there are no leaks in the lines. For positive displacement systems, check that the tubing is clean and clear of bubbles.
Q3: How can I minimize the risk of cross-contamination during automated liquid handling?
A3: To minimize cross-contamination, always use fresh pipette tips for each unique compound or reagent. If reusing tips for the same reagent, ensure thorough washing between dispenses. Implement a logical workflow that minimizes unnecessary movements over the plate. Using barrier tips can also prevent contaminants from entering the pipetting head.
Troubleshooting Guide: Inconsistent Liquid Dispensing
Table 3: Troubleshooting Inconsistent Reagent Dispensing
| Symptom | Potential Cause | Recommended Solution |
| Dripping tip or a drop hanging from the tip | Difference in vapor pressure between the sample and the water used for calibration. | - Sufficiently pre-wet the pipette tips. - Add an air gap after aspirating the liquid. |
| Droplets or trailing liquid during delivery | Viscosity and other physical properties of the liquid are different from the calibration liquid. | - Optimize the dispense speed and height. - Use specialized tips designed for viscous liquids. |
| Inconsistent volumes across a multi-dispense | Carryover or residual liquid in the tip. | - Waste the first dispense. - Optimize the dispense method (e.g., wet vs. dry dispense). |
| Air bubbles in the system | Leaks in tubing or connections; improper priming. | - Check all connections for tightness. - Thoroughly prime the system to remove all air. |
Experimental Protocol: Liquid Handler Performance Verification
-
Objective: To quickly verify the accuracy and precision of a multi-channel liquid handler.
-
Materials:
-
Calibrated verification tool (e.g., dye-based cassettes).[8]
-
The liquid handler to be tested.
-
The specific plate type used in the HTS assay.
-
-
Methodology:
-
Preparation: Set up the liquid handler with the appropriate tips and a plate.
-
Aspirate Dye: Program the liquid handler to aspirate a known volume of the verification dye.[8]
-
Dispense: Dispense the dye into the verification cassette wells.[8]
-
Measure: The dye will travel up capillary channels, and the volume can be read against the printed graduations.[8]
-
Analyze: Compare the dispensed volume to the expected volume to determine accuracy. Assess the consistency across all channels to determine precision.
-
Section 3: Data Management and Analysis
This section provides guidance on overcoming challenges related to the large volumes of data generated during HTS campaigns.
FAQs
Q1: Our HTS data transfer is very slow. What can we do to speed it up?
A1: Slow data transfer is a common bottleneck. To improve speed, consider upgrading your network infrastructure to support higher bandwidth, such as 10G Ethernet.[9] Optimizing data transmission protocols and using data compression techniques can also significantly reduce transfer times.[2][9] For very large datasets, ensure you are using high-speed storage solutions and network connections.
Q2: We are experiencing frequent data backup failures. What are the common causes?
A2: Data backup failures can often be attributed to human error, such as incorrect configuration, hardware problems with storage devices, and software glitches.[10][11] Network interruptions during the backup process can also lead to incomplete or corrupted backups.[11]
Q3: What are some common data artifacts in HTS and how can they be corrected?
A3: Common data artifacts include edge effects, row or column effects, and plate drift.[12] These systematic errors can be identified through data visualization (e.g., heatmaps) and statistical analysis.[12] Normalization methods, such as Z-score or B-score, can be applied to correct for these variations.[12][13] It's crucial to choose a normalization method that is appropriate for your data and does not introduce new biases.[14][15]
Troubleshooting Guide: HTS Data Issues
Table 4: Troubleshooting Common HTS Data Problems
| Issue | Potential Cause | Recommended Solution |
| Slow Data Transfer | Network Bottlenecks: Insufficient bandwidth or network congestion.[2][4] | - Upgrade to a higher bandwidth network.[9] - Schedule large data transfers during off-peak hours. - Optimize network settings and protocols.[2] |
| Inefficient Data Handling: Large, uncompressed file sizes. | - Implement data compression before transfer.[2][9] - Use efficient file formats for HTS data. | |
| Backup Failures | Hardware Issues: Failing storage media or servers.[11] | - Regularly test backup and restore procedures.[10][11] - Use redundant hardware for critical backup systems.[16] - Monitor the health of storage devices. |
| Software/Configuration Errors: Incorrect backup schedules, permissions, or software glitches.[11] | - Verify backup software configurations and permissions.[17] - Keep backup software updated. - Review backup logs for specific error codes.[17] | |
| Systematic Errors in Data (e.g., Edge Effects) | Environmental Factors: Uneven temperature or evaporation across the plate.[18] | - Implement physical solutions during the experiment (e.g., plate moats).[2][4] - Apply post-processing data correction methods (e.g., B-score, Loess normalization).[14][15] |
| LIMS Integration Errors | Data Format Incompatibility: Mismatched data formats between instruments and LIMS.[19][20] | - Standardize data formats across all systems.[21] - Use middleware to translate between different data formats.[19] |
| Network Connectivity Issues: Firewall restrictions or incorrect network settings. | - Ensure the LIMS and instruments are on the same network and can communicate. - Check firewall settings to allow traffic on the required ports.[22] |
Section 4: Signaling Pathways and Experimental Workflows
This section provides diagrams of common signaling pathways targeted in HTS and a typical experimental workflow.
Signaling Pathway Diagrams
Generic Kinase Signaling Pathway
A generic kinase signaling pathway often targeted in HTS.
G-Protein Coupled Receptor (GPCR) Signaling Pathway (Gq)
A Gq-coupled GPCR signaling pathway leading to calcium release.
Experimental Workflow: From Primary Screen to Hit Confirmation
A typical HTS workflow from primary screening to confirmed hits.
References
- 1. Perspectives on Validation of High-Throughput Assays Supporting 21st Century Toxicity Testing - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Speedy Data Transfer: Tips for High-Efficiency Transfers [hivo.co]
- 3. researchgate.net [researchgate.net]
- 4. Everything about High-Speed Data Transfer in 2025 [raysync.io]
- 5. academic.oup.com [academic.oup.com]
- 6. securedatarecovery.com [securedatarecovery.com]
- 7. medium.com [medium.com]
- 8. Software Normalization Deep Dive - Support and Troubleshooting - Now Support Portal [support.servicenow.com]
- 9. fiberopticom.com [fiberopticom.com]
- 10. zengrc.com [zengrc.com]
- 11. Why Data Backups Fail and How to Fix Them Effectively [febyte.com]
- 12. usitc.gov [usitc.gov]
- 13. researchgate.net [researchgate.net]
- 14. researchgate.net [researchgate.net]
- 15. Impact of normalization methods on high-throughput screening data with high hit rates and drug testing with dose–response data - PMC [pmc.ncbi.nlm.nih.gov]
- 16. techtarget.com [techtarget.com]
- 17. techcyph.com [techcyph.com]
- 18. Simulated High Throughput Sequencing Datasets: A Crucial Tool for Validating Bioinformatic Pathogen Detection Pipelines - PMC [pmc.ncbi.nlm.nih.gov]
- 19. splashlake.com [splashlake.com]
- 20. companysconnects.com [companysconnects.com]
- 21. limsey.com [limsey.com]
- 22. dbvis.com [dbvis.com]
Technical Support Center: Enhancing Research Workflow Efficiency
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in optimizing their orchestrated research workflows.
Frequently Asked Questions (FAQs)
Q1: My automated workflow is producing inconsistent results. What are the common causes and how can I troubleshoot this?
A1: Inconsistent results in automated workflows often stem from several factors. A primary cause can be variability in input data quality. Small errors or inconsistencies in initial data can propagate and amplify through the workflow, leading to significant deviations in the final output.[1] Another common issue is software and tool compatibility. Different versions of software or their dependencies can cause unexpected behavior and discrepancies in results.
Troubleshooting Steps:
-
Data Quality Control: Implement rigorous quality control checks at the beginning of your workflow. For sequencing data, tools like FastQC can be used to assess read quality. It's also crucial to have standardized data collection and processing protocols to minimize variability.[2]
-
Version Control: Utilize a version control system, such as Git, for all your scripts and analysis pipelines. This ensures that you can track changes and revert to a stable version if issues arise.
-
Environment Management: Use containerization tools like Docker or Singularity to create a reproducible computational environment. This encapsulates all the necessary software, libraries, and dependencies, ensuring that the workflow runs identically regardless of the underlying system.
-
Error Logging: Implement comprehensive logging within your workflow scripts to capture detailed error messages and warnings. This information is invaluable for debugging and identifying the specific step where inconsistencies are introduced.
Q2: How can I improve the computational efficiency of my bioinformatics pipeline to reduce processing time?
A2: Reducing the processing time of bioinformatics pipelines is crucial, especially when dealing with large datasets. Several strategies can be employed to enhance computational efficiency.
Optimization Strategies:
-
Parallelization: Many bioinformatics tools are designed to support multi-threading. By allocating more CPU cores to these tasks, you can significantly speed up processes like sequence alignment and variant calling.
-
Workflow Management Systems: Tools like Nextflow and Snakemake are designed to manage and optimize complex computational workflows. They can automatically parallelize tasks and efficiently manage resources on high-performance computing (HPC) clusters or cloud environments.
-
Algorithm Selection: Where possible, choose more recent and computationally efficient algorithms and software. For instance, aligners are continuously being updated for better speed and accuracy.
-
Data Subsetting: For initial testing and debugging of a pipeline, use a smaller subset of your data. This allows for quicker iterations and identification of bottlenecks before scaling up to the full dataset.
Q3: What are the best practices for managing large datasets in a multi-omics research project to ensure data integrity and accessibility?
A3: Effective data management in multi-omics studies is fundamental for ensuring the reliability and reproducibility of research findings. The heterogeneity and sheer volume of data from different 'omics' layers present significant challenges.[3]
Best Practices:
-
Centralized Data Repository: Establish a single, centralized repository for all project-related data. This can be a dedicated server, a cloud storage solution, or a Laboratory Information Management System (LIMS). Centralization prevents data silos and makes data more accessible to the research team.[4][5]
-
Standardized Naming Conventions and Metadata: Implement a consistent and descriptive file naming convention. Furthermore, comprehensive metadata, including experimental conditions, sample information, and processing steps, should be meticulously recorded and associated with the data.
-
Data Quality Assurance: Implement automated data quality checks at each stage of the workflow. This helps to identify and flag potential issues early on, preventing the propagation of errors.[2]
-
Data Backup and Archiving: Regularly back up all raw and processed data to prevent data loss. Establish a clear policy for long-term data archiving to ensure data is preserved and accessible for future analysis and verification.
Troubleshooting Guides
Issue: Workflow Failure Due to Software Dependency Conflicts
Symptoms:
-
The workflow script aborts unexpectedly with error messages related to missing libraries or incorrect software versions.
-
Different components of the workflow produce incompatible outputs.
Solution:
-
Create a Dedicated Environment: Use a virtual environment (e.g., Conda) or a container (e.g., Docker) to isolate the workflow's software dependencies from the system's default packages.
-
Specify Exact Versions: In your environment definition file (e.g., environment.yml for Conda or a Dockerfile), specify the exact versions of all required software and libraries. This ensures that the same environment can be recreated consistently.
-
Use a Workflow Manager with Environment Management: Workflow management systems like Snakemake and Nextflow have built-in support for Conda and Docker, allowing you to define the software environment for each step of the pipeline.
Issue: Poor Reproducibility of Analysis Results
Symptoms:
-
Running the same workflow on the same data produces slightly different results.
-
Another researcher is unable to obtain the same results using your scripts and data.
Solution:
-
Document Everything: Maintain a detailed record of every step of the analysis, including software versions, parameters used, and the exact order of commands. An electronic lab notebook (ELN) can be very helpful for this.
-
Share the Entire Workflow: When publishing or sharing your research, provide the complete workflow, including scripts, environment files, and a small test dataset.
-
Set Random Seeds: For any analysis steps that involve random processes (e.g., machine learning model training, simulations), set a fixed random seed to ensure that the results are deterministic.
Quantitative Data on Workflow Efficiency
Automating and orchestrating research workflows can lead to significant improvements in efficiency, accuracy, and cost savings.
| Metric | Manual Workflow | Automated/Orchestrated Workflow | Percentage Improvement | Source |
| Mean Turn-Around Time (TAT) | Varies | Decreased by 6.1% | 6.1% | [6] |
| TAT Outlier Rate (99th percentile) | Higher | Decreased by 13.3% | 13.3% | [6] |
| TAT Predictability (CV) | Lower | Decreased by 70.0% | 70.0% | [6] |
| Staff Safety (Weighted Tube Touch Moment) | Lower | Improved by 77.6% | 77.6% | [6] |
| Data Processing Time | High | Reduced by over 70% in some cases | >70% | [7] |
| Error Rates | Higher | Significantly Reduced | Varies | [8][9][10] |
| Labor Costs | Higher | Reduced | Varies | [8] |
| Impact of Laboratory Information Management Systems (LIMS) | Benefit | Source |
| Data Accuracy | Improved through reduced manual data entry and automated data capture. | [5][11] |
| Data Integrity | Enhanced with detailed audit trails and standardized data management. | [2][5] |
| Efficiency | Increased by automating routine tasks and streamlining workflows. | [4][5] |
| Collaboration | Facilitated through a centralized and accessible data repository. | [4] |
Experimental Protocols
Protocol: Mass Spectrometry-Based Protein Identification and Quantification
This protocol outlines the key steps for identifying and quantifying proteins from a biological sample using a bottom-up proteomics approach.
1. Sample Preparation: a. Protein Extraction: Lyse cells or tissues using a suitable buffer to release the proteins. Mechanical disruption or detergent-based lysis can be used depending on the sample type.[12] b. Reduction and Alkylation: Reduce disulfide bonds in the proteins using a reducing agent like dithiothreitol (DTT), followed by alkylation of the resulting free thiols with iodoacetamide (IAA) to prevent them from reforming.[13] c. Protein Digestion: Digest the proteins into smaller peptides using a protease, most commonly trypsin, which cleaves specifically at the C-terminus of lysine and arginine residues.[14][15] d. Peptide Cleanup: Remove salts and other contaminants from the peptide mixture using a desalting column or StageTips.[3]
2. Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS): a. Peptide Separation: Separate the complex peptide mixture using reverse-phase liquid chromatography. The peptides will elute from the column based on their hydrophobicity. b. Mass Spectrometry Analysis: i. MS1 Scan: As peptides elute from the LC column, they are ionized (e.g., by electrospray ionization) and their mass-to-charge ratio (m/z) is measured in the mass spectrometer. ii. MS2 Scan (Tandem MS): The most abundant peptide ions from the MS1 scan are selected, fragmented, and the m/z of the resulting fragment ions is measured.
3. Data Analysis: a. Database Searching: The fragmentation spectra (MS2) are searched against a protein sequence database (e.g., UniProt) to identify the corresponding peptide sequences.[15] b. Protein Inference: The identified peptides are grouped together to infer the proteins that were present in the original sample. c. Quantification: The abundance of each protein is determined. This can be done using label-free methods (based on the signal intensity of the peptides) or label-based methods (using isotopic labels).[14][15] d. Statistical Analysis: Perform statistical tests to identify proteins that are differentially abundant between different experimental conditions.
Protocol: Automated Cell-Based Assay for Drug Screening
This protocol describes a generalized workflow for an automated cell-based assay to screen a compound library for its effect on cell viability.
1. Cell Seeding: a. Culture cells to the desired confluency. b. Use an automated liquid handler to dispense a uniform number of cells into each well of a multi-well plate (e.g., 96- or 384-well). c. Incubate the plate under controlled conditions (e.g., 37°C, 5% CO2) to allow the cells to adhere.
2. Compound Treatment: a. Prepare a dilution series of the compounds to be tested. b. Use an automated liquid handler to add the compounds to the appropriate wells of the cell plate. Include positive and negative control wells. c. Incubate the plate for the desired treatment duration.
3. Viability Assay: a. After the incubation period, add a viability reagent (e.g., a reagent that measures ATP content or metabolic activity) to each well using an automated dispenser. b. Incubate the plate for the time specified by the assay manufacturer to allow the reaction to occur.
4. Data Acquisition: a. Place the plate in an automated plate reader to measure the signal (e.g., luminescence, fluorescence, or absorbance) from each well.
5. Data Analysis: a. The data from the plate reader is automatically transferred to an analysis software. b. The software calculates the cell viability for each compound concentration relative to the controls. c. Dose-response curves are generated, and parameters such as the IC50 (half-maximal inhibitory concentration) are calculated to determine the potency of the compounds.
Signaling Pathways and Experimental Workflows
ErbB Signaling Pathway
The ErbB signaling pathway is a crucial pathway involved in regulating cell proliferation, differentiation, and survival.[16][17] Dysregulation of this pathway is often implicated in cancer.[16] The following diagram illustrates a simplified version of the ErbB signaling pathway.
Caption: Simplified diagram of the ErbB signaling pathway.
Experimental Workflow: RNA-Seq Data Analysis
The following diagram outlines a typical workflow for analyzing RNA sequencing (RNA-Seq) data to identify differentially expressed genes.
Caption: A typical workflow for RNA-Seq data analysis.
References
- 1. Role of Artificial Intelligence in Reducing Error Rates in Radiology: A Scoping Review - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. 5 Reasons Why Data Quality Matters in the Lab | Achiever Medical LIMS [interactivesoftware.co.uk]
- 3. Step-by-Step Sample Preparation of Proteins for Mass Spectrometric Analysis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. amplelogic.com [amplelogic.com]
- 5. xcalibretraining.com [xcalibretraining.com]
- 6. Economic Evaluation of Total Laboratory Automation in the Clinical Laboratory of a Tertiary Care Hospital - PMC [pmc.ncbi.nlm.nih.gov]
- 7. cytena.com [cytena.com]
- 8. Cost-Benefit Analysis of Laboratory Automation [wakoautomation.com]
- 9. hudsonlabautomation.com [hudsonlabautomation.com]
- 10. AI Automation: Transforming Pharma R&D Workflows for Faster Results | Allex Blog [allex.ai]
- 11. Impact of LIMS Software on Data Management in Chemical Labs | Autoscribe Informatics [autoscribeinformatics.com]
- 12. spectroscopyonline.com [spectroscopyonline.com]
- 13. Implementing Lab Workflow Automation in the Pharma Industry - Janea Systems [janeasystems.com]
- 14. UWPR [proteomicsresource.washington.edu]
- 15. Protein Identification and Quantification: Techniques and Strategies | MtoZ Biolabs [mtoz-biolabs.com]
- 16. KEGG PATHWAY: ErbB signaling pathway - Homo sapiens (human) [kegg.jp]
- 17. KEGG PATHWAY: map04012 [genome.jp]
Technical Support Center: Navigating the Complexities of Orchestrated Biological Systems
Welcome to our technical support center, designed to assist researchers, scientists, and drug development professionals in troubleshooting common pitfalls encountered when analyzing orchestrated biological systems. This resource provides practical guidance in a question-and-answer format to help you navigate the intricacies of your experiments and data analysis.
Frequently Asked Questions (FAQs)
Q1: My differential gene expression analysis from RNA-seq data yields a vast number of significant genes that don't align with biological expectations. What could be the issue?
A1: This is a common issue often stemming from inadequate normalization or unaddressed batch effects. Different normalization methods can significantly impact the number of differentially expressed genes (DEGs) identified.[1][2] Moreover, technical variations across different experimental batches can introduce systematic noise that may be misinterpreted as biological signal.[3][4]
Troubleshooting Steps:
-
Assess for Batch Effects: Visualize your data using Principal Component Analysis (PCA). If samples cluster by batch rather than biological condition, a batch effect is likely present.
-
Apply Appropriate Normalization: For between-sample comparisons, methods like Trimmed Mean of M-values (TMM), Median Ratio Normalization (MRN), or DESeq2's size factor estimation are generally recommended over simpler methods like Reads Per Kilobase of transcript per Million mapped reads (RPKM) or Counts Per Million (CPM).[1][2][5]
-
Implement Batch Correction: Utilize tools like ComBat-seq, which is specifically designed for RNA-seq count data, to adjust for batch effects before differential expression analysis.[3][6]
Q2: I'm performing a Co-Immunoprecipitation (Co-IP) followed by mass spectrometry, but my results show high background and many non-specific protein interactions. How can I improve the specificity?
A2: High background in Co-IP-MS is often due to issues with antibody specificity, insufficient washing, or inappropriate lysis buffer conditions. Antibody cross-reactivity is a significant contributor to false positives.
Troubleshooting Steps:
-
Validate Your Antibody: Ensure your antibody is highly specific for the target protein. If possible, test multiple antibodies to find one with the lowest off-target binding.
-
Optimize Lysis and Wash Buffers: The stringency of your lysis and wash buffers is critical. Start with a gentle lysis buffer to preserve interactions and increase the stringency of your wash steps to remove non-specific binders.
-
Include Proper Controls: Always include an isotype control (an antibody of the same isotype but not specific to your target) and a mock IP (using beads only) to identify proteins that bind non-specifically to the antibody or the beads.
Q3: My flow cytometry data shows high variability between replicates and poor separation of cell populations. What are the likely causes?
A3: Variability in flow cytometry can arise from several sources, including instrument settings, sample preparation, and staining protocols.[7][8][9][10] Poor population separation is often due to incorrect compensation for spectral overlap between fluorochromes or high background staining.
Troubleshooting Steps:
-
Standardize Instrument Settings: Ensure consistent laser alignment, detector voltages, and fluidics speed for all samples and experiments.
-
Optimize Staining Protocol: Titrate your antibodies to determine the optimal concentration that provides the best signal-to-noise ratio. Include a viability dye to exclude dead cells, which can bind non-specifically to antibodies.
-
Properly Set Compensation: Use single-stained compensation controls for each fluorochrome in your panel to accurately calculate and apply compensation, minimizing spectral overlap artifacts.
Troubleshooting Guides
High-Throughput Screening (HTS) Data Analysis
Issue: High rate of false positives or false negatives in an HTS campaign.
Systematic errors are a common source of variability in HTS data and can arise from factors like reagent evaporation, malfunctioning liquid handlers, or plate position effects.[11][12] Studies have shown that a significant percentage of rows and columns on HTS plates can be affected by systematic bias.[13]
| Source of Error | Potential Impact | Troubleshooting Action |
| Plate-to-Plate Variation | Inconsistent results across different plates. | Normalize data on a per-plate basis using methods like Z-score or B-score normalization. |
| Edge Effects | Wells at the edge of the plate show different behavior due to temperature or evaporation gradients. | Avoid using edge wells for samples or apply a spatial correction algorithm. |
| Systematic Row/Column Effects | Consistent variations across specific rows or columns due to dispenser or reader issues. | Use statistical methods to identify and correct for these patterns. |
Protein Interaction Network Analysis
Issue: My protein-protein interaction network is a dense "hairball" that is difficult to interpret.
Large-scale protein interaction datasets often result in highly complex networks that are challenging to visualize and interpret.[14] The goal is to extract meaningful biological modules from this complexity.
| Problem | Consequence | Solution |
| High number of interactions | Overwhelming and uninterpretable network visualization. | Filter interactions based on confidence scores or experimental evidence. Use clustering algorithms to identify densely connected modules. |
| Lack of context | Difficult to derive biological meaning from the network structure alone. | Integrate other data types, such as gene expression or functional annotations (e.g., Gene Ontology), to enrich the network and provide context. |
| Static representation | Fails to capture the dynamic nature of protein interactions. | If data from different conditions or time points is available, build and compare condition-specific networks to identify dynamic changes in interactions. |
Detailed Experimental Protocols
Detailed Protocol for Chromatin Immunoprecipitation Sequencing (ChIP-seq)
This protocol is adapted for mammalian cells and aims to provide a robust workflow for identifying protein-DNA interactions.
1. Cell Cross-linking and Harvesting: a. Grow cells to 80-90% confluency. b. Add formaldehyde directly to the culture medium to a final concentration of 1% and incubate for 10 minutes at room temperature to cross-link proteins to DNA. c. Quench the cross-linking reaction by adding glycine to a final concentration of 125 mM. d. Wash cells twice with ice-cold PBS. e. Harvest cells by scraping and pellet by centrifugation. The cell pellet can be stored at -80°C.
2. Cell Lysis and Chromatin Sonication: a. Resuspend the cell pellet in a lysis buffer containing protease inhibitors. b. Incubate on ice to allow for cell lysis. c. Isolate the nuclei by centrifugation. d. Resuspend the nuclear pellet in a shearing buffer. e. Sonicate the chromatin to an average fragment size of 200-600 bp. The optimal sonication conditions should be determined empirically for each cell type and instrument.
3. Immunoprecipitation: a. Pre-clear the chromatin with Protein A/G beads to reduce non-specific binding. b. Incubate the pre-cleared chromatin with your ChIP-grade antibody overnight at 4°C with rotation. c. Add Protein A/G beads to capture the antibody-protein-DNA complexes. d. Wash the beads extensively with a series of wash buffers of increasing stringency to remove non-specifically bound chromatin.
4. Elution and Reverse Cross-linking: a. Elute the immunoprecipitated chromatin from the beads. b. Reverse the formaldehyde cross-links by incubating at 65°C overnight with the addition of NaCl. c. Treat with RNase A and Proteinase K to remove RNA and protein.
5. DNA Purification: a. Purify the DNA using phenol-chloroform extraction or a commercial DNA purification kit. b. The purified DNA is now ready for library preparation and sequencing.
Visualizations
Signaling Pathway: Correct vs. Incorrect Interpretation
A common pitfall is to assume a linear signaling pathway based on initial observations. However, biological systems are often characterized by complex, interconnected networks.
Caption: Simplified linear vs. complex network view of a signaling pathway.
Experimental Workflow: Identifying Points of Error in Co-IP
This diagram highlights critical steps in a Co-IP workflow where errors can be introduced.
Caption: Critical steps and potential pitfalls in a Co-IP experiment.
Logical Relationship: Correlation vs. Causation in Data Interpretation
A fundamental error in data analysis is inferring causation from correlation. This diagram illustrates this logical fallacy.
Caption: Illustrating the difference between correlation and causation.
References
- 1. rna-seqblog.com [rna-seqblog.com]
- 2. Comparison of normalization methods for differential gene expression analysis in RNA-Seq experiments: A matter of relative size of studied transcriptomes - PMC [pmc.ncbi.nlm.nih.gov]
- 3. biorxiv.org [biorxiv.org]
- 4. Highly effective batch effect correction method for RNA-seq count data - PMC [pmc.ncbi.nlm.nih.gov]
- 5. bigomics.ch [bigomics.ch]
- 6. academic.oup.com [academic.oup.com]
- 7. Flow Cytometry Troubleshooting Guide [sigmaaldrich.com]
- 8. Flow Cytometry Troubleshooting Guide - FluoroFinder [fluorofinder.com]
- 9. biocompare.com [biocompare.com]
- 10. Flow Cytometry Troubleshooting Guide: Novus Biologicals [novusbio.com]
- 11. Statistical analysis of systematic errors in high-throughput screening - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. info2.uqam.ca [info2.uqam.ca]
- 13. Detecting and overcoming systematic bias in high-throughput screening technologies: a comprehensive review of practical issues and methodological solutions - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. researchgate.net [researchgate.net]
Technical Support Center: Refining Experimental Design for Studying Cellular Orchestration
Welcome to the Technical Support Center, your resource for troubleshooting and refining experimental designs to study the complex interplay of cells. This guide provides researchers, scientists, and drug development professionals with detailed, practical solutions to common challenges in cellular orchestration research.
Frequently Asked Questions (FAQs) & Troubleshooting Guides
This section addresses specific issues you may encounter during your experiments in a question-and-answer format.
Co-Culture Systems
Question: My co-cultured cells are not behaving as expected. One cell type is outcompeting the other. How can I optimize my co-culture experiment?
Answer: This is a common challenge in co-culture systems. Here are several factors to consider for optimization:
-
Seeding Density and Ratio: The initial number of each cell type is critical. If one cell line proliferates much faster, it can quickly dominate the culture.
-
Troubleshooting: Start by seeding the slower-growing cell type first to allow it to establish before introducing the faster-growing cells. Experiment with different seeding ratios (e.g., 1:1, 1:3, 3:1) to find the optimal balance where both cell types can thrive and interact.
-
-
Media Composition: Different cell types may have distinct media requirements. A single medium may not be optimal for both.
-
Troubleshooting: You can try blending the recommended media for each cell type at a 1:1 ratio.[1] Alternatively, use the medium for the more sensitive cell line and supplement it with essential growth factors for the other.
-
-
Culture System: The method of co-culture can significantly impact outcomes.
-
Troubleshooting: If you are using a direct co-culture and observing competition, consider an indirect method using Transwell® inserts.[2] This separates the cell types with a porous membrane, allowing for communication via secreted factors without direct cell-cell contact, preventing one cell type from overgrowing the other.
-
Question: How can I assess the viability of a specific cell population within my co-culture after drug treatment?
Answer: Selectively assessing cell viability in a mixed culture requires a method to distinguish between the cell populations.
-
Fluorescent Labeling and Imaging: Pre-label one cell type with a fluorescent tracker (e.g., CFSE, CellTracker™ dyes) before co-culture.[1][3] After treatment, you can use fluorescence microscopy to count the number of viable labeled vs. unlabeled cells.[4]
-
Flow Cytometry: Use cell-type-specific surface markers to distinguish the populations via flow cytometry. You can then incorporate a viability dye (e.g., Propidium Iodide, 7-AAD) to quantify viability for each population independently.[3]
-
Luciferase-Based Assays: Engineer one cell line to express luciferase.[3][4] After treatment, the viability of the luciferase-expressing cells can be measured by adding the substrate and quantifying luminescence. This signal will be specific to that cell population.
| Parameter | Direct Cell Counting (Fluorescence Microscopy) | Flow Cytometry with Viability Dyes | Luciferase Assay |
| Principle | Manual or automated counting of pre-labeled cells. | High-throughput quantification of cell populations based on specific markers and dye exclusion. | Measurement of light output from luciferase-expressing cells. |
| Pros | Provides spatial information. Relatively low cost. | Highly quantitative. Can assess multiple parameters simultaneously (e.g., apoptosis). | High sensitivity and specificity to the engineered cell line. |
| Cons | Can be subjective and laborious.[4] Limited throughput. | Requires cell detachment, which can affect viability. Requires specific antibodies. | Requires genetic modification of one cell type. Signal can be lost if cells undergo apoptosis.[3] |
Single-Cell RNA Sequencing (scRNA-seq)
Question: My scRNA-seq data has a high percentage of low-quality cells and potential doublets. How can I improve my data quality?
Answer: Data quality in scRNA-seq is highly dependent on the initial sample preparation and subsequent computational filtering.
-
Sample Preparation: The health and integrity of your cells before sequencing are paramount.
-
Quality Control (QC) Metrics: During data analysis, it is crucial to filter out low-quality cells and doublets.
-
Troubleshooting: Apply standard QC filters. Common metrics include:
-
Gene Count: Cells with very few detected genes may be of low quality.
-
UMI Count: Low UMI counts can indicate poor capture efficiency.
-
Mitochondrial Gene Percentage: A high percentage of mitochondrial gene expression is often indicative of stressed or dying cells.
-
Utilize doublet detection tools to identify and remove computational doublets.
-
-
Question: How do I choose the right scRNA-seq protocol for my experiment?
Answer: The choice between full-length and tag-based protocols depends on your research question.
-
Full-length protocols (e.g., SMART-seq2): These aim to capture the entire transcript, providing information on isoforms and alternative splicing. This is beneficial for in-depth analysis of a smaller number of cells.[6]
-
Tag-based protocols (e.g., 10x Genomics Chromium): These methods sequence only the 3' or 5' end of the transcript, which is sufficient for gene expression quantification. They offer much higher throughput, allowing you to analyze thousands of cells.[6]
| Protocol Type | Throughput | Information Gained | Best For |
| Full-Length (e.g., SMART-seq2) | Lower | Gene expression, isoform detection, alternative splicing | Detailed transcriptomic analysis of a limited number of cells. |
| Tag-Based (e.g., 10x Genomics) | Higher | Gene expression quantification | Identifying cell types and states in heterogeneous populations. |
3D Cell Culture
Question: My cells are not forming consistent spheroids in my 3D culture. What can I do?
Answer: Spheroid formation is influenced by several factors, including cell type, seeding density, and culture plates.
-
Cell Seeding Density: The initial number of cells is crucial for spheroid formation.
-
Culture Plates: The surface of the culture plate is critical for preventing cell attachment and promoting aggregation.
-
Troubleshooting: Use ultra-low attachment (ULA) plates.[8] The geometry of the wells can also play a role; U-bottom plates are often preferred for spheroid formation.
-
-
Extracellular Matrix (ECM): Some cell lines require the presence of ECM components to form tight spheroids.
-
Troubleshooting: Consider adding a small amount of ECM, such as Matrigel® or collagen, to the culture medium.[8]
-
-
Centrifugation: A brief centrifugation step after seeding can facilitate initial cell aggregation.
-
Troubleshooting: After seeding the cells, centrifuge the plate at a low speed (e.g., 100-200 x g) for a few minutes.[8]
-
Live-Cell Imaging
Question: I am observing significant phototoxicity in my live-cell imaging experiments. How can I minimize it?
Answer: Phototoxicity is a major concern in live-cell imaging and can alter cellular behavior.
-
Reduce Excitation Light: The primary cause of phototoxicity is the exposure of cells to high-intensity light.
-
Troubleshooting: Use the lowest possible laser power or illumination intensity that still provides a detectable signal. Reduce the exposure time for each image.
-
-
Optimize Image Acquisition:
-
Troubleshooting: Decrease the frequency of image acquisition (increase the time interval between images). Only capture images for the duration necessary to observe the biological process of interest.
-
-
Use Sensitive Detectors: More sensitive detectors require less excitation light to produce a good image.
-
Environmental Control: Ensure cells are maintained in a stable environment (37°C, 5% CO2, and humidity) on the microscope stage to prevent stress, which can exacerbate phototoxicity.[9]
Experimental Protocols
Protocol 1: Co-culture of Cancer Cells and Fibroblasts using a Transwell® System
This protocol allows for the study of paracrine signaling between cancer cells and fibroblasts without direct cell-cell contact.
Materials:
-
Cancer cell line (e.g., SW480)
-
Fibroblast cell line (e.g., CCD-18Co)
-
Complete culture medium (e.g., RPMI-1640 with 10% FBS)
-
24-well plates
-
Transwell® inserts with a porous membrane (e.g., 0.4 µm pore size)
-
Trypsin-EDTA
-
Phosphate-Buffered Saline (PBS)
Procedure:
-
Seed 30,000 cancer cells in 500 µL of complete medium into the wells of a 24-well plate.[2]
-
In a separate tube, resuspend 30,000 fibroblasts in 100 µL of complete medium.[2]
-
Add the 100 µL of fibroblast suspension to the Transwell® insert.[2]
-
Allow the cells in both compartments to adhere for 6 hours in a 37°C, 5% CO2 incubator.
-
Carefully place the Transwell® insert containing the fibroblasts into the well with the cancer cells.[2]
-
For a control, place an insert with medium but no fibroblasts into a well with cancer cells.[2]
-
Co-culture the cells for the desired experimental duration, changing the medium in both the well and the insert every 2 days.[2]
-
At the end of the experiment, cells from each compartment can be harvested separately for downstream analysis (e.g., proliferation assay, RNA extraction).
Protocol 2: 3D Tumor Spheroid Formation in an Ultra-Low Attachment Plate
This protocol describes a basic method for generating tumor spheroids.
Materials:
-
Cancer cell line (e.g., HT-29)
-
Complete culture medium
-
96-well round-bottom ultra-low attachment (ULA) spheroid microplate
-
Trypsin-EDTA
-
PBS
Procedure:
-
Harvest and count the cancer cells.
-
Prepare a cell suspension at the desired concentration (e.g., 5,000 cells per 100 µL).
-
Dispense 100 µL of the cell suspension into each well of the 96-well ULA plate.[7]
-
For control wells, add 100 µL of medium without cells.[7]
-
Centrifuge the plate at a low speed (e.g., 200 x g) for 3 minutes to facilitate cell aggregation at the bottom of the well.[10]
-
Place the plate in a humidified incubator at 37°C and 5% CO2.
-
Monitor spheroid formation daily. Spheroids should form within 24-72 hours, depending on the cell line.[7]
-
Change the medium every 2-3 days by carefully aspirating half of the medium and adding fresh, pre-warmed medium.
Visualizations
TGF-β Signaling Pathway in Cancer-Associated Fibroblasts (CAFs)
Caption: TGF-β signaling cascade leading to the activation of Cancer-Associated Fibroblasts (CAFs).
Experimental Workflow: Single-Cell RNA Sequencing Data Analysis
Caption: A typical workflow for the analysis of single-cell RNA sequencing data.
Logical Relationship: Ligand-Receptor Interaction Network
Caption: A simplified network of ligand-receptor interactions between different cell types.
References
- 1. Co-culturing patient-derived cancer organoids with fibroblasts and endothelial cells - Behind the Bench [thermofisher.com]
- 2. spandidos-publications.com [spandidos-publications.com]
- 3. reddit.com [reddit.com]
- 4. researchgate.net [researchgate.net]
- 5. biocompare.com [biocompare.com]
- 6. Single-Cell RNA Sequencing Procedures and Data Analysis - Bioinformatics - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 7. corning.com [corning.com]
- 8. documents.thermofisher.com [documents.thermofisher.com]
- 9. biorxiv.org [biorxiv.org]
- 10. patrols-h2020.eu [patrols-h2020.eu]
Technical Support Center: Optimizing Bioinformatics Pipelines for Orchestration Analysis
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in optimizing their bioinformatics pipelines for orchestration analysis.
Troubleshooting Guides
This section addresses common issues encountered during bioinformatics pipeline execution.
Q1: My Nextflow pipeline is stalling, and the log shows an error Executor is not responding. What should I do?
A1: This error typically indicates that the communication between the Nextflow head process and the executor (e.g., SGE, LSF, Slurm, AWS Batch) has been disrupted. Here’s a step-by-step troubleshooting guide:
-
Check Executor Status: First, verify the status of the jobs directly on the execution environment. For example, with Slurm, you would use squeue -u $USER. Look for jobs that are in a failed (F), cancelled (CA), or timeout (TO) state.
-
Examine Job-Specific Logs: Navigate to the work directory of your Nextflow run. Each process instance will have its own subdirectory (e.g., work/ab/123456...). Inside this directory, you will find several hidden files that provide detailed execution information:
-
.command.sh: The actual script that was submitted to the executor.
-
.command.out: The standard output of the process.
-
.command.err: The standard error stream, which is often the most informative for debugging.
-
.exitcode: A file containing the exit code of the process. A non-zero exit code indicates an error.
-
-
Resource Allocation Issues: A common cause of this error is under-provisioning of resources. The job may have been killed by the scheduler for exceeding its allocated memory or runtime. Check the .command.err file for messages like "Killed" or "OutOfMemoryError". If you suspect a resource issue, you can increase the requested resources in your nextflow.config file or directly in your process definition. For example:
-
Filesystem and Network Connectivity: Ensure that the working directory is accessible from all compute nodes and that there are no network connectivity issues between the head node and the compute nodes.
Q2: My Snakemake pipeline fails with a MissingOutputException even though I can see the output file in the directory. What's going on?
A2: This is a frequent and often frustrating issue in Snakemake. Here are the most common causes and how to resolve them:
-
Race Conditions and Filesystem Latency: In a distributed or parallel computing environment, there can be a delay between when a file is written and when it becomes visible to the Snakemake master process. This is especially common on network file systems (NFS). To mitigate this, you can increase the latency Snakemake waits for output files to appear by using the --latency-wait or -w command-line argument (in seconds):
-
Inconsistent File Naming: Double-check that the output file names defined in your Snakefile exactly match the names of the files being created by the shell command or script within the rule. Pay close attention to typos, extensions, and path differences.
-
Shell Command Errors: If the command within the rule exits with a non-zero status, Snakemake will consider the job failed and may not recognize the output files, even if they were partially created. Check the job's log file (if specified in the rule) or run the command manually to ensure it completes successfully.
Q3: I'm getting a Workflow validation failed error when trying to run my Common Workflow Language (CWL) workflow. How do I debug this?
A3: CWL has a strict validation process. This error means your CWL document does not conform to the specification. Here's how to troubleshoot:
-
Use a CWL Validator: The most effective way to debug this is to use a dedicated CWL validator. cwltool itself has a validation function. Run the following command to get a more detailed error message:
This will often point you to the exact line and issue in your CWL file.
-
Check inputs and outputs Sections: Ensure that all inputs and outputs are correctly defined with the appropriate type. Mismatches between the outputSource of a workflow step and the type of the corresponding workflow output are a common source of errors.
-
Verify in and out Connections: In the steps section of your workflow, make sure that the in fields correctly reference either the workflow's top-level inputs or the outputs of other steps. The syntax for referencing outputs from other steps is step_name/output_name.
Frequently Asked Questions (FAQs)
This section provides answers to common questions about optimizing bioinformatics pipelines.
Q1: What are the most critical factors for optimizing the performance of a bioinformatics pipeline?
A1: The most critical factors for pipeline optimization are:
-
I/O (Input/Output) Operations: Bioinformatics pipelines are often I/O-bound, meaning the speed at which data can be read from and written to storage is the primary bottleneck. Using fast storage (e.g., SSDs, parallel file systems) and minimizing unnecessary file transfers can significantly improve performance.
-
Parallelization: Take advantage of multi-core processors by parallelizing tasks. Most modern bioinformatics tools have options to use multiple threads (e.g., the -t or --threads flag). Workflow management systems like Nextflow and Snakemake excel at parallelizing independent tasks.
-
Resource Allocation: Requesting appropriate amounts of CPU and memory is crucial. Over-requesting can lead to long queue times on a shared cluster, while under-requesting can cause jobs to fail.[1] Profile your tools to understand their resource requirements.
-
Algorithmic Efficiency: Sometimes, the biggest performance gain comes from choosing a more efficient tool for a particular task. It's worth benchmarking different tools to see which performs best for your specific data and analysis.[2]
Q2: How does containerization with Docker or Singularity impact pipeline performance?
A2: Containerization offers significant benefits for reproducibility and portability with a generally negligible impact on performance for most bioinformatics workloads.
-
Reproducibility: Containers package all the necessary software and dependencies, ensuring that the pipeline runs in the exact same environment every time, which is crucial for reproducible research.[3]
-
Portability: A containerized pipeline can be run on any system that has Docker or Singularity installed, from a laptop to a high-performance computing (HPC) cluster to the cloud.
-
Performance Overhead: Studies have shown that the performance overhead of using Docker or Singularity for CPU- and memory-intensive bioinformatics tasks is minimal, often less than 5%.[4][5] The I/O performance can be slightly more affected, but this can be mitigated by efficiently mounting volumes.
Q3: What are the best practices for managing software dependencies in bioinformatics pipelines?
A3: Managing dependencies is a major challenge in bioinformatics due to the large number of tools with specific version requirements. The recommended best practices are:
-
Use a Package Manager: Conda is the de facto standard for managing bioinformatics software. It allows you to create isolated environments with specific versions of tools and their dependencies.
-
Combine with Containerization: For maximum reproducibility, use Conda within a Docker or Singularity container. This ensures that the entire software stack, from the operating system up to the specific tool versions, is captured.[6]
-
Environment Files: Always define your Conda environments using an environment.yml file. This file lists all the required packages and their versions, making it easy for others to recreate the environment.
-
Version Pinning: Be explicit about the versions of the tools you are using in your environment files (e.g., bwa=0.7.17). This prevents unexpected changes in behavior due to tool updates.
Data Presentation
Table 1: Performance Comparison of Variant Calling Pipelines
This table compares the performance of GATK HaplotypeCaller and FreeBayes for variant calling on a whole-exome sequencing dataset.[1][7][8][9]
| Metric | GATK HaplotypeCaller | FreeBayes |
| SNP Sensitivity | 98.5% | 99.2% |
| SNP Precision | 99.1% | 98.8% |
| Indel Sensitivity | 95.2% | 92.1% |
| Indel Precision | 98.9% | 97.5% |
| Average Runtime (CPU hours) | 18.5 | 12.3 |
| Peak Memory Usage (GB) | 24.8 | 18.2 |
Table 2: Impact of Containerization on RNA-Seq Pipeline Runtime
This table shows the impact of running an RNA-Seq pipeline with and without Docker containerization. The pipeline includes read alignment with STAR and quantification with RSEM.[4][5]
| Configuration | Average Runtime (minutes) | Performance Overhead |
| Native Execution | 125.4 | - |
| Docker Container | 128.1 | +2.15% |
Experimental Protocols
Protocol 1: RNA-Seq Differential Expression Analysis
This protocol outlines the key steps for performing a differential gene expression analysis from raw RNA-Seq reads.
-
Quality Control of Raw Reads:
-
Use a tool like FastQC to assess the quality of the raw sequencing reads.
-
Examine metrics such as per-base sequence quality, GC content, and adapter content.
-
-
Read Trimming and Filtering:
-
If adapters are present or base quality is low, use a tool like Trimmomatic or Cutadapt to trim adapters and remove low-quality reads.
-
-
Alignment to Reference Genome:
-
Align the cleaned reads to a reference genome using a splice-aware aligner such as STAR or HISAT2.
-
-
Quantification of Gene Expression:
-
Use a tool like featureCounts or RSEM to count the number of reads mapping to each gene.
-
-
Differential Expression Analysis:
-
Import the count matrix into an R environment and use a package like DESeq2 or edgeR to perform differential expression analysis.[10] These packages will normalize the data, fit a statistical model, and identify genes that are significantly differentially expressed between conditions.
-
Mandatory Visualization
TGF-β Signaling Pathway
The Transforming Growth Factor Beta (TGF-β) signaling pathway plays a crucial role in many cellular processes, including cell growth, differentiation, and apoptosis.[11][12][13][14][15] Dysregulation of this pathway is implicated in various diseases, including cancer. The following diagram illustrates the canonical Smad-dependent signaling cascade.
References
- 1. Systematic comparison of variant calling pipelines using gold standard personal exome variants - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Benchmarking bioinformatics pipelines to improve accuracy and computing costs | CNAG, Centro Nacional de Análisis Genómico [cnag.eu]
- 3. scholars.northwestern.edu [scholars.northwestern.edu]
- 4. The impact of Docker containers on the performance of genomic pipelines - PMC [pmc.ncbi.nlm.nih.gov]
- 5. The impact of Docker containers on the performance of genomic pipelines - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. The impact of RNA-seq aligners on gene expression estimation - PMC [pmc.ncbi.nlm.nih.gov]
- 7. bcbio.wordpress.com [bcbio.wordpress.com]
- 8. biorxiv.org [biorxiv.org]
- 9. d-nb.info [d-nb.info]
- 10. researchgate.net [researchgate.net]
- 11. researchgate.net [researchgate.net]
- 12. researchgate.net [researchgate.net]
- 13. TGF-β Signaling - PMC [pmc.ncbi.nlm.nih.gov]
- 14. TGF-β Signaling | Cell Signaling Technology [cellsignal.com]
- 15. creative-diagnostics.com [creative-diagnostics.com]
Technical Support Center: Orchestrated Cell Culture Models
Welcome to the technical support center for orchestrated cell culture models. This resource provides researchers, scientists, and drug development professionals with troubleshooting guides and frequently asked questions to address variability in their experiments.
Frequently Asked Questions (FAQs)
Q1: What are the most common sources of variability in orchestrated cell culture models like organoids and spheroids?
A1: Variability in complex 3D cell culture models can stem from several factors. Key sources include inconsistencies in cell culture conditions, such as cell density and passage number.[1][2] Phenotypic drift can occur over multiple passages, leading to a cell population with different characteristics than the original.[1] Contamination, especially from hard-to-detect mycoplasma, can significantly alter experimental results.[1] Variations in ancillary materials like reagents, media, and the extracellular matrix (e.g., Matrigel) are also significant contributors.[3][4][5] Finally, subtle differences in handling procedures, like pipetting and cell dissociation, can introduce variability.[1][6]
Q2: How can I minimize variability between different batches of experiments?
A2: Minimizing batch-to-batch variability requires stringent standardization of protocols and procedures.[3] Implementing detailed Standard Operating Procedures (SOPs) for all experimental steps is crucial.[3][7] Using a large, quality-controlled, cryopreserved stock of cells for your experiments can significantly reduce variability by ensuring a consistent starting cell population.[1] It is also important to perform routine testing for contaminants like mycoplasma.[1]
Q3: My organoids are showing inconsistent growth and morphology. What could be the cause?
A3: Inconsistent organoid growth and morphology can be due to several factors. An inappropriate seeding density is a common issue; if cells are too sparse, they may not aggregate properly, and if they are too dense, it can lead to necrosis in the core of the organoid.[8] The composition and concentration of the extracellular matrix, such as Matrigel, are critical and lot-to-lot variability can be a source of inconsistency.[4][5] Additionally, the passaging technique can affect organoid formation; single-cell passaging may produce more uniform cultures than mechanical clump passaging.
Q4: I am observing a high degree of cell death in my 3D cultures. What are the likely causes and how can I assess viability?
A4: High cell death rates can be caused by suboptimal culture conditions, including nutrient depletion, waste accumulation, or incorrect atmospheric conditions.[9] The size of the spheroids or organoids can also be a factor, as larger constructs may have necrotic cores due to limitations in nutrient and oxygen diffusion.[8][10] To assess cell viability, several assays can be employed, such as colorimetric assays (MTT, XTT), fluorescence-based assays using dyes like Calcein-AM and Propidium Iodide, or flow cytometry to quantify live and dead cells.[11][12][13]
Q5: Why is my drug response variable across different experiments?
A5: Variable drug response in 3D cell models can be influenced by the inherent heterogeneity of the cell populations.[10] The complex 3D structure can create diffusion barriers, limiting drug penetration to the core of the spheroid or organoid.[10] Furthermore, cells in 3D cultures often exhibit increased drug resistance compared to 2D monolayers.[10][14] Inconsistent cell densities and metabolic states at the time of treatment can also lead to variable outcomes.[15]
Troubleshooting Guides
Guide 1: Inconsistent Organoid/Spheroid Size and Shape
This guide addresses common issues related to the physical characteristics of your 3D cell cultures.
Problem: Organoids or spheroids are not uniform in size and shape, leading to variability in experimental readouts.
Possible Causes and Solutions:
| Cause | Solution |
| Inconsistent Seeding Density | Optimize the initial cell seeding density. Create a titration of cell numbers to determine the optimal density for uniform aggregation.[8] |
| Non-uniform Cell Suspension | Ensure a single-cell suspension before seeding. Gently pipette the cell suspension up and down to break up any clumps. |
| Improper Plate/Surface | Use low-attachment plates to encourage cell aggregation and prevent adherence to the plate bottom.[8] |
| Variable ECM Concentration | If using an extracellular matrix (ECM) like Matrigel, ensure it is properly thawed on ice and mixed gently to achieve a homogenous consistency before embedding cells.[16] |
| Manual Passaging Technique | For more uniform cultures, consider switching from mechanical clump passaging to single-cell dissociation, ensuring the addition of a ROCK inhibitor like Y-27632 to maintain viability. |
Workflow for Troubleshooting Inconsistent Organoid Size:
Caption: A flowchart for troubleshooting inconsistent organoid size.
Guide 2: High Variability in Drug Response Assays
This guide provides steps to troubleshoot inconsistent results in drug screening and cytotoxicity assays.
Problem: High variability in IC50 values or other drug efficacy metrics across replicate experiments.
Possible Causes and Solutions:
| Cause | Solution |
| Heterogeneous Cell Population | Characterize the cellular heterogeneity of your model. Consider using single-cell analysis techniques to understand subpopulation dynamics.[17][18][19] |
| Inconsistent Culture Age/Passage | Use cells from a narrow passage number range for all experiments to minimize phenotypic drift.[1] |
| Variable Metabolic Activity | Standardize the time from cell seeding to drug treatment to ensure cells are in a consistent metabolic state.[1] |
| Limited Drug Penetration | For dense spheroids/organoids, consider longer incubation times or sectioning the 3D culture for analysis to assess drug effects in the core.[10] |
| Assay Readout Variability | Ensure the chosen viability or cytotoxicity assay is appropriate for 3D models and that the readout is not affected by the 3D structure or ECM. |
Logical Diagram of Factors Influencing Drug Response Variability:
Caption: Sources of variability in drug response assays.
Experimental Protocols
Protocol 1: Cell Viability Assessment using MTT Assay
This protocol outlines the steps for determining cell viability in 3D cell cultures using the MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) assay.
Principle: Viable cells with active metabolism convert the yellow MTT tetrazolium salt into a purple formazan product.[13] The amount of formazan is proportional to the number of viable cells and can be quantified spectrophotometrically.[13]
Materials:
-
MTT solution (5 mg/mL in PBS)
-
Cell culture medium
-
Solubilization solution (e.g., DMSO or a solution of 10% SDS in 0.01 M HCl)
-
96-well plates
-
Plate reader
Procedure:
-
Culture spheroids or organoids in a 96-well plate to the desired size and morphology.
-
Add your test compound at various concentrations and incubate for the desired treatment period.
-
Carefully remove the treatment medium from each well without disturbing the 3D structures.
-
Add 100 µL of fresh medium and 10 µL of MTT solution to each well.
-
Incubate the plate for 2-4 hours at 37°C.
-
After incubation, carefully remove the MTT-containing medium.
-
Add 100 µL of the solubilization solution to each well to dissolve the formazan crystals.
-
Incubate the plate at room temperature for at least 2 hours, or until the purple color is homogenous. Gentle shaking can aid dissolution.
-
Measure the absorbance at 570 nm using a plate reader. A reference wavelength of 630 nm can be used to subtract background absorbance.[13]
Protocol 2: Whole-Mount Immunofluorescence Staining of Organoids
This protocol provides a detailed methodology for the immunofluorescent staining of whole organoids.
Workflow for Immunofluorescence Staining:
Caption: A step-by-step workflow for organoid immunofluorescence.
Materials:
-
Phosphate-Buffered Saline (PBS)
-
Fixation Solution: 4% Paraformaldehyde (PFA) in PBS
-
Permeabilization Buffer: 0.5% Triton X-100 in PBS[20]
-
Blocking Buffer: 5% normal serum (from the same species as the secondary antibody) and 0.5% Triton X-100 in PBS[21]
-
Primary Antibodies
-
Fluorescently Labeled Secondary Antibodies
-
Nuclear Stain (e.g., DAPI)
-
Mounting Medium
Procedure:
-
Fixation: Gently remove the culture medium and wash the organoids twice with PBS. Fix the organoids in 4% PFA for 30-60 minutes at room temperature.[21]
-
Washing: Carefully aspirate the PFA and wash the organoids three times with PBS for 10-15 minutes each.[21]
-
Permeabilization: Incubate the fixed organoids in Permeabilization Buffer overnight at 4°C or for 2-4 hours at room temperature.[21]
-
Blocking: Remove the permeabilization buffer and add Blocking Buffer. Incubate for 1-2 hours at room temperature to block non-specific antibody binding.[20]
-
Primary Antibody Incubation: Dilute the primary antibody in the Blocking Buffer. Remove the blocking solution and incubate the organoids with the primary antibody solution overnight at 4°C with gentle rocking.[20][21]
-
Washing: Remove the primary antibody solution and wash the organoids three times with PBS for 15-20 minutes each.[21]
-
Secondary Antibody Incubation: Dilute the fluorescently labeled secondary antibody in Blocking Buffer. Incubate the organoids for 1-2 hours at room temperature, protected from light.[20]
-
Washing: Wash the organoids three times with PBS for 15-20 minutes each, keeping them protected from light.[21]
-
Nuclear Staining: Incubate with a nuclear stain like DAPI (e.g., 5 µg/mL in PBS) for 15-20 minutes at room temperature.[21]
-
Final Wash: Perform a final wash with PBS for 10-15 minutes.[21]
-
Mounting and Imaging: Carefully transfer the stained organoids to a slide, add mounting medium, and cover with a coverslip. Image using a confocal microscope.[20]
References
- 1. promegaconnections.com [promegaconnections.com]
- 2. The importance of cell culture parameter standardization: an assessment of the robustness of the 2102Ep reference cell line - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Enhancing Reproducibility in Cell-Based Labs with Digital Protocol Management | CellPort [cellportsoftware.com]
- 4. Strategies to overcome the limitations of current organoid technology - engineered organoids - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Three-Dimensional Cell Cultures in Drug Discovery and Development - PMC [pmc.ncbi.nlm.nih.gov]
- 6. integra-biosciences.com [integra-biosciences.com]
- 7. mdpi.com [mdpi.com]
- 8. 3D Cell Culture Tips To Optimize Your Workflow | Technology Networks [technologynetworks.com]
- 9. corning.com [corning.com]
- 10. Three-Dimensional Cell Culture Systems and Their Applications in Drug Discovery and Cell-Based Biosensors - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Experimental protocol to study cell viability and apoptosis | Proteintech Group [ptglab.com]
- 12. akadeum.com [akadeum.com]
- 13. Cell Viability Assays - Assay Guidance Manual - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 14. ASCO – American Society of Clinical Oncology [asco.org]
- 15. In Vitro Research Reproducibility: Keeping Up High Standards - PMC [pmc.ncbi.nlm.nih.gov]
- 16. A Practical Guide to Developing and Troubleshooting Patient-Derived “Mini-Gut” Colorectal Organoids for Clinical Research | MDPI [mdpi.com]
- 17. Quantifying Cell Heterogeneity and Subpopulations Using Single Cell Metabolomics - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Dissecting Cellular Heterogeneity Using Single-Cell RNA Sequencing - NCI [cancer.gov]
- 19. researchgate.net [researchgate.net]
- 20. tuvesonlab.labsites.cshl.edu [tuvesonlab.labsites.cshl.edu]
- 21. sigmaaldrich.com [sigmaaldrich.com]
Navigating the Complexities of L-I-M-S and Orchestration Software Integration: A Technical Support Guide
For Researchers, Scientists, and Drug Development Professionals
The seamless integration of Laboratory Information Management Systems (LIMS) with orchestration software is paramount for the modern laboratory, promising streamlined workflows, enhanced data integrity, and accelerated research and development cycles. However, achieving this synergy is not without its challenges. This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to empower users to navigate and resolve common integration issues encountered during their experiments.
Frequently Asked Questions (FAQs)
Q1: What are the most common initial hurdles when integrating a LIMS with orchestration software?
The initial phase of integration often presents challenges related to establishing a stable connection and ensuring both systems can "speak" the same language. Common hurdles include network configuration issues, such as blocked ports or firewall restrictions, and authentication errors due to incorrect API keys or credentials.[1][2][3] It is also common to encounter problems with data mapping, where the data fields in the LIMS do not correctly align with the fields in the orchestration software.[4]
Q2: How can I prevent data synchronization failures between the LIMS and orchestration software?
Proactive measures are key to preventing data synchronization failures. Establishing clear and robust data synchronization rules, including well-defined data formats and validation protocols, can help minimize errors. Implementing a phased data migration strategy, rather than a bulk transfer, allows for testing and validation at each stage, reducing the risk of widespread issues.[5] Regular monitoring of the integration points and setting up automated alerts for failed transfers are also crucial for early detection and resolution.
Q3: What role does middleware play in the integration process, and how do I troubleshoot it?
Middleware acts as a bridge between the LIMS and orchestration software, translating data formats and communication protocols to facilitate seamless interaction.[6] However, middleware itself can be a source of integration problems. Common issues include message queue failures, where data gets stuck in the middleware, and incorrect data transformation logic. Troubleshooting middleware often involves examining its logs for error messages, verifying the mapping and transformation rules, and ensuring it has adequate system resources to handle the data volume.
Q4: What are the best practices for ensuring data integrity during and after integration?
Maintaining data integrity is a critical aspect of LIMS and orchestration software integration. Key best practices include:
-
Data Validation: Implement stringent data validation rules in both the LIMS and the orchestration software to ensure data accuracy and consistency at the point of entry.[7]
-
Audit Trails: Ensure that both systems have comprehensive audit trails to track all data changes, including who made the change and when.[8][9]
-
Data Backups: Regularly back up LIMS and orchestration software data to prevent data loss in case of a critical failure.[5]
-
Post-Migration Validation: After any data migration, perform a thorough validation to ensure all data has been transferred accurately and completely.[10]
Troubleshooting Guides
This section provides detailed troubleshooting guides for specific issues that users may encounter.
Issue 1: "Connection Failed" Error Between LIMS and Orchestration Software
A "Connection Failed" error is one of the most common issues and can stem from various network-related problems.
Troubleshooting Protocol:
-
Verify Network Connectivity:
-
Ping Test: Open a command prompt or terminal and ping the server hosting the other application (LIMS or orchestration software). A successful ping indicates a basic network connection.
-
Telnet Test: Use a Telnet client to check if the specific port required for the integration is open. For example, if the LIMS communicates on port 3306, you would use the command telnet
3306 . A successful connection will typically result in a blank screen or a service banner. A "Connection refused" or "Connection timed out" error indicates a port or firewall issue.[2]
-
-
Check Firewall and Proxy Settings:
-
Review the firewall rules on both the client and server machines to ensure that communication on the required port is not being blocked.
-
If your institution uses a proxy server, ensure that the LIMS and orchestration software are configured to use the correct proxy settings.
-
-
Inspect API Credentials and Endpoint URLs:
-
Double-check that the API keys, tokens, usernames, and passwords used for authentication are correct and have not expired.[1]
-
Verify that the endpoint URL for the API is accurate and accessible.
-
Troubleshooting Workflow for Connection Issues
Caption: A logical workflow for troubleshooting connection failures.
Issue 2: Data Synchronization Failures and Discrepancies
Data synchronization issues can manifest as missing data, duplicate entries, or inconsistent information between the LIMS and orchestration software.
Troubleshooting Protocol:
-
Analyze Error Logs:
-
Examine the error logs of both the LIMS and the orchestration software for any messages related to data transfer failures. These logs often provide specific error codes and descriptions that can pinpoint the root cause.[11]
-
-
Verify Data Mapping:
-
Review the data mapping configuration to ensure that the fields in the source system are correctly mapped to the corresponding fields in the destination system. Pay close attention to data types, units, and formats.[4]
-
-
Perform a Manual Data Transfer:
-
Attempt to manually transfer a single, problematic data record. This can help determine if the issue is with the data itself or with the automated transfer process.
-
-
Validate Data Integrity:
-
Use data validation tools or scripts to compare the data in both systems and identify any discrepancies. This can help quantify the extent of the synchronization issue.
-
Common Data Synchronization Error Codes and Solutions
| Error Code | Description | Recommended Solution |
| 400 Bad Request | The server could not understand the request due to invalid syntax. | Check the API documentation to ensure the request is formatted correctly, including all required parameters and headers.[1][3] |
| 401 Unauthorized | The request lacks valid authentication credentials. | Verify that the API key or access token is correct and has not expired. Ensure the user has the necessary permissions.[1] |
| 404 Not Found | The requested resource could not be found on the server. | Double-check the endpoint URL to ensure it is correct.[1] |
| 500 Internal Server Error | A generic error message indicating a problem on the server. | Check the server logs for more detailed error information. The issue is likely on the server-side and may require assistance from the software vendor.[1] |
| 503 Service Unavailable | The server is temporarily unable to handle the request. | This is often a temporary issue due to server overload. Try the request again after a short period. If the problem persists, contact the software vendor.[3] |
Issue 3: Data Format and Validation Errors
These errors occur when the data being transferred does not conform to the expected format or fails validation rules in the receiving system.
Troubleshooting Protocol:
-
Identify the Problematic Data:
-
Isolate the specific data records that are causing the errors. The error messages in the system logs should provide clues as to which records are affected.
-
-
Review Data Formatting:
-
Carefully examine the format of the problematic data. Common issues include incorrect date/time formats, mismatched data types (e.g., sending text to a numeric field), and the use of special characters that are not supported by the receiving system.
-
-
Check Data Validation Rules:
-
Review the data validation rules configured in the receiving system. The data may be technically in the correct format but may be violating a business rule (e.g., a value outside of an acceptable range).[7]
-
-
Test with Sample Data:
-
Create a small set of sample data with known correct and incorrect formats. Use this to test the integration and confirm that the validation rules are working as expected.
-
Data Validation Troubleshooting Flow
Caption: A workflow for troubleshooting data format and validation errors.
References
- 1. blog.hubspot.com [blog.hubspot.com]
- 2. LIMS Connection Troubleshooting — BWP Informatics SOPs 1.0 documentation [bwp-informatics.readthedocs.io]
- 3. Understanding API Error Codes: 10 Status Errors When Building APIs For The First Time And How To Fix Them | Moesif Blog [moesif.com]
- 4. labhorizons.co.uk [labhorizons.co.uk]
- 5. Common Challenges With LIMS Implementation (and How To Solve Them) | Splashlake [splashlake.com]
- 6. clpmag.com [clpmag.com]
- 7. How To Perform LIMS Validation [genemod.net]
- 8. zifornd.com [zifornd.com]
- 9. What Every Lab Needs to Know About Data Integrity | QBench Cloud-Based LIMS [qbench.com]
- 10. assureallc.com [assureallc.com]
- 11. help.claritylims.illumina.com [help.claritylims.illumina.com]
Validation & Comparative
A Researcher's Guide to Validating Computational Models of Biological Orchestration
For researchers, scientists, and drug development professionals venturing into the complex world of biological systems, computational models offer a powerful lens to dissect intricate cellular processes. However, the predictive power of these in silico tools is only as robust as their validation. This guide provides an objective comparison of common computational modeling approaches, supported by experimental data, and details the methodologies crucial for their rigorous validation.
The orchestration of biological processes, from signaling cascades to gene regulatory networks, involves a dynamic interplay of numerous components. Computational models aim to capture this complexity, offering insights that can accelerate research and drug development. The choice of modeling formalism and the thoroughness of its validation are paramount to ensuring the reliability of these predictions.
Comparing the Tools of In Silico Biology: A Quantitative Look
Computational models of biological systems are diverse, each with its own strengths and weaknesses. The primary formalisms used include Ordinary Differential Equations (ODEs), Agent-Based Models (ABMs), and Rule-Based Models (RBMs). Their performance can be quantitatively compared using various metrics.
A common approach to benchmark these models is to use challenges such as the Dialogue on Reverse Engineering Assessments and Methods (DREAM) challenges, which provide standardized datasets and scoring metrics.[1][2][3] Performance is often assessed by the model's ability to predict the system's behavior under new conditions. Key metrics include:
-
Root Mean Squared Error (RMSE): Measures the average difference between the model's predictions and experimental data.
-
Coefficient of Determination (R²): Indicates the proportion of the variance in the experimental data that is predictable from the model.
-
Akaike Information Criterion (AIC) / Bayesian Information Criterion (BIC): Used for model selection, balancing model fit with complexity.
| Modeling Formalism | Key Strengths | Key Weaknesses | Typical RMSE | Typical R² | Notes |
| Ordinary Differential Equations (ODEs) | Computationally efficient for well-mixed systems; well-established mathematical framework. | Assumes spatial homogeneity; can become unwieldy for large, complex systems with many species. | 0.1 - 0.5 | 0.8 - 0.95 | Best suited for modeling population-level dynamics where spatial effects are negligible.[4][5][6] |
| Agent-Based Models (ABMs) | Can capture spatial heterogeneity and emergent behavior from individual agent interactions. | Computationally intensive; parameterization can be challenging due to the large number of individual-level rules. | 0.2 - 0.7 | 0.7 - 0.9 | Ideal for studying cellular interactions, tissue morphogenesis, and immune responses where spatial context is critical. |
| Rule-Based Models (RBMs) | Efficiently handles combinatorial complexity in signaling networks; avoids the "combinatorial explosion" of species seen in ODEs. | Can be less intuitive to formulate than ODEs; simulation can be computationally demanding depending on the number of rules. | 0.15 - 0.6 | 0.75 - 0.92 | Particularly useful for modeling complex signaling pathways with many protein modifications and interactions.[4][5][6][7][8] |
Experimental Protocols for Model Validation
The credibility of a computational model hinges on its validation against real-world experimental data. Below are detailed methodologies for key experiments commonly used to validate models of biological signaling pathways.
Western Blotting for Protein Phosphorylation Dynamics
Western blotting is a cornerstone technique for validating the predicted phosphorylation states of key signaling proteins in a pathway.
Objective: To quantify the relative changes in the phosphorylation of a target protein over time in response to a stimulus, and to compare these dynamics with the predictions of a computational model.
Detailed Methodology:
-
Cell Culture and Treatment:
-
Culture cells to 70-80% confluency in appropriate media.
-
Starve cells in serum-free media for 12-24 hours to reduce basal signaling activity.
-
Treat cells with the stimulus (e.g., a growth factor) at a specific concentration and for various time points as dictated by the model's predictions.
-
-
Protein Extraction:
-
Wash cells with ice-cold phosphate-buffered saline (PBS).
-
Lyse cells in radioimmunoprecipitation assay (RIPA) buffer supplemented with protease and phosphatase inhibitors to preserve protein integrity and phosphorylation states.
-
Centrifuge the lysate to pellet cell debris and collect the supernatant containing the protein extract.
-
-
Protein Quantification:
-
Determine the protein concentration of each sample using a Bradford or BCA protein assay to ensure equal loading of protein for each time point.
-
-
Gel Electrophoresis and Transfer:
-
Separate the protein lysates by sodium dodecyl sulfate-polyacrylamide gel electrophoresis (SDS-PAGE).
-
Transfer the separated proteins to a nitrocellulose or polyvinylidene difluoride (PVDF) membrane.
-
-
Immunoblotting:
-
Block the membrane with a blocking buffer (e.g., 5% non-fat milk or bovine serum albumin in Tris-buffered saline with Tween 20 - TBST) to prevent non-specific antibody binding.
-
Incubate the membrane with a primary antibody specific to the phosphorylated form of the target protein overnight at 4°C.
-
Wash the membrane with TBST to remove unbound primary antibody.
-
Incubate the membrane with a horseradish peroxidase (HRP)-conjugated secondary antibody that recognizes the primary antibody.
-
Wash the membrane again with TBST.
-
-
Detection and Quantification:
-
Detect the signal using an enhanced chemiluminescence (ECL) substrate and image the blot using a chemiluminescence detection system.
-
Quantify the band intensities using image analysis software.
-
Normalize the phosphorylated protein levels to a loading control (e.g., GAPDH or β-actin) to account for any variations in protein loading.
-
Compare the quantified time-course data with the corresponding predictions from the computational model.
-
Immunofluorescence for Protein Localization
Immunofluorescence is crucial for validating spatial aspects of a model, such as the translocation of a protein from the cytoplasm to the nucleus.
Objective: To visualize and quantify the subcellular localization of a target protein at different time points following stimulation and compare this with the spatial predictions of the model.
Detailed Methodology:
-
Cell Culture and Treatment:
-
Grow cells on glass coverslips to an appropriate confluency.
-
Treat the cells with the stimulus for the desired time points.
-
-
Fixation and Permeabilization:
-
Fix the cells with 4% paraformaldehyde in PBS to preserve cellular structures.
-
Permeabilize the cells with a detergent like 0.1% Triton X-100 in PBS to allow antibodies to access intracellular antigens.
-
-
Blocking and Antibody Incubation:
-
Block non-specific antibody binding sites with a blocking solution (e.g., 1% BSA in PBS).
-
Incubate the cells with a primary antibody specific to the target protein.
-
Wash the cells with PBS.
-
Incubate the cells with a fluorescently labeled secondary antibody.
-
Wash the cells again with PBS.
-
-
Counterstaining and Mounting:
-
Counterstain the cell nuclei with a DNA-binding dye like DAPI.
-
Mount the coverslips onto microscope slides using an anti-fade mounting medium.
-
-
Imaging and Analysis:
Quantitative PCR (qPCR) for Gene Expression
qPCR is used to validate model predictions related to the transcriptional regulation of downstream target genes.
Objective: To measure the relative changes in the mRNA levels of a target gene over time following pathway activation and compare these with the model's predictions of gene expression.
Detailed Methodology:
-
Cell Culture and Treatment:
-
Treat cells with the stimulus for the relevant time points.
-
-
RNA Extraction and cDNA Synthesis:
-
Extract total RNA from the cells using a suitable kit.
-
Reverse transcribe the RNA into complementary DNA (cDNA).
-
-
qPCR Reaction:
-
Set up the qPCR reaction with the cDNA template, gene-specific primers, and a fluorescent DNA-binding dye (e.g., SYBR Green) or a fluorescently labeled probe.
-
Run the qPCR reaction in a real-time PCR instrument.
-
-
Data Analysis:
-
Determine the cycle threshold (Ct) value for each sample, which is inversely proportional to the initial amount of target mRNA.
-
Normalize the Ct values of the target gene to a stably expressed housekeeping gene (e.g., GAPDH or ACTB) to control for variations in RNA input.
-
Calculate the fold change in gene expression using the ΔΔCt method.
-
Compare the measured gene expression dynamics with the model's predictions.[12][13][14][15][16]
-
Visualizing Biological Orchestration: Signaling Pathways and Workflows
Understanding the intricate connections within biological pathways is crucial for building and validating computational models. The following diagrams, generated using the DOT language, illustrate key signaling pathways and a typical experimental workflow for model validation.
References
- 1. GitHub - data2health/DREAM-Challenge: EHR DREAM Challenge [github.com]
- 2. Lessons from the DREAM2 Challenges - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Dream Challenges | Center for Data to Health [cd2h.org]
- 4. research.ed.ac.uk [research.ed.ac.uk]
- 5. Comparison of rule- and ordinary differential equation-based dynamic model of DARPP-32 signalling network - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Comparison of rule- and ordinary differential equation-based dynamic model of DARPP-32 signalling network - PMC [pmc.ncbi.nlm.nih.gov]
- 7. biorxiv.org [biorxiv.org]
- 8. biorxiv.org [biorxiv.org]
- 9. ibidi.com [ibidi.com]
- 10. clyte.tech [clyte.tech]
- 11. Immunofluorescence Staining of Paraffin Sections Step by Step - PMC [pmc.ncbi.nlm.nih.gov]
- 12. stackscientific.nd.edu [stackscientific.nd.edu]
- 13. Quantitative PCR validation for research scientists: Part 1 of 2 - VIROLOGY RESEARCH SERVICES [virologyresearchservices.com]
- 14. bu.edu [bu.edu]
- 15. youtube.com [youtube.com]
- 16. bio-rad.com [bio-rad.com]
A Researcher's Guide to Laboratory Workflow Orchestration: A Comparative Analysis
In the fast-paced environments of research, drug development, and clinical diagnostics, the seamless orchestration of laboratory workflows is paramount. The right software can dramatically enhance efficiency, reproducibility, and data integrity, while the wrong choice can lead to bottlenecks and errors. This guide provides a comprehensive comparison of leading software solutions for laboratory workflow orchestration, tailored for researchers, scientists, and drug development professionals. We delve into both comprehensive Laboratory Information Management Systems (LIMS) and specialized bioinformatics workflow managers, presenting their features, strengths, and weaknesses.
While direct, publicly available head-to-head benchmark studies with detailed experimental protocols are scarce, this guide synthesizes available information from user reviews, technical documentation, and academic publications to provide a robust comparative framework. We will focus on key performance indicators (KPIs) relevant to laboratory operations to facilitate a data-driven evaluation.
Key Performance Indicators for Laboratory Workflow Software
To objectively assess the performance of different software, we will consider the following key performance indicators:
-
Turnaround Time (TAT): The time elapsed from sample receipt to result reporting.
-
Throughput: The number of samples or processes that a system can handle in a given timeframe.
-
Scalability: The ability of the software to handle increasing workloads and data volumes.
-
Error Rate: The frequency of errors in data entry, sample tracking, and analysis.
-
User Adoption & Training Time: The ease with which new users can learn and effectively utilize the software.
-
Integration Capability: The ability to seamlessly connect with laboratory instruments and other software systems.
-
Compliance Support: Features that aid in adhering to regulatory standards such as GLP, GMP, and 21 CFR Part 11.
Comparison of Laboratory Information Management Systems (LIMS)
LIMS are comprehensive software solutions designed to manage all aspects of a laboratory's operations, from sample accessioning to reporting. Here, we compare two leading commercial platforms, Benchling and LabWare LIMS , and a prominent open-source alternative, eLabFTW .
Quantitative Data Summary
| Feature/KPI | Benchling | LabWare LIMS | eLabFTW |
| Target Audience | Life sciences R&D, biotech, pharma | Enterprise-level pharma, manufacturing, regulated labs | Academic labs, small to medium-sized research groups |
| Deployment | Cloud-based | On-premise, Cloud | Self-hosted (on-premise or cloud) |
| User Interface | Modern, intuitive, user-friendly[1] | Traditional, highly configurable but can be complex[1] | Simple, intuitive, designed by researchers[2] |
| Workflow Management | Intuitive design, praised for ease of use[1] | Comprehensive, supports complex process automation[1] | Flexible, customizable to specific lab needs |
| Sample Management | Adequate, lacks some advanced compliance tracking[1] | Excellent, detailed tracking and compliance features[1] | Good, with features for logging and tracking experiments[2] |
| Data Storage | User-friendly interface, may be less efficient for extensive data[1] | Robust capabilities for managing large datasets[1] | Dependent on server infrastructure |
| Inventory Management | Basic features[1] | Superior, with advanced tracking and reporting[1] | Integrated inventory management[3] |
| Compliance | Good, but may not meet all stringent requirements[1] | Strong, preferred for highly regulated environments[1] | Can be configured for compliance, requires user effort |
| Support Quality | Appreciated, but can have slower response times[1] | Strong, with responsive customer service and training[1] | Community-based support |
| Cost | Subscription-based, can be expensive | High upfront licensing and implementation costs | Free (open-source), requires IT resources for setup and maintenance |
Experimental Protocols for LIMS Evaluation
-
Define a Pilot Project: Select a representative workflow within your lab (e.g., a specific molecular biology protocol, a sample testing pipeline).
-
Establish Baseline Metrics: Manually track the key performance indicators (TAT, throughput, error rate) for this workflow over a defined period (e.g., one month) to establish a baseline.
-
Implement Trial Versions: Engage with vendors for trial versions or set up a pilot instance of the open-source software.
-
User Training and Adoption: Provide a small, dedicated team with training on each platform and monitor the time required to achieve proficiency.
-
Execute the Pilot Project: Run the selected workflow using each software for a comparable period.
-
Data Collection and Analysis: Collect quantitative data on the same KPIs as in the baseline. Additionally, gather qualitative feedback from the user team on ease of use, intuitiveness, and overall satisfaction.
-
Integration Testing: If possible, test the integration of each LIMS with a key laboratory instrument.
-
Reporting and Decision: Compile the quantitative and qualitative data into a comprehensive report to inform your decision.
LIMS Workflow Visualization
A typical laboratory workflow managed by a LIMS involves several interconnected stages, from sample reception to final reporting.
References
Case Study: Successful Orchestration of a Large-Scale Clinical Trial for the Prevention of Early Preterm Birth
A Comparative Guide for Researchers and Drug Development Professionals on the ADORE Trial
The "Assessment of Docosahexaenoic Acid on Reducing Early Preterm Birth" (ADORE) trial stands as a noteworthy example of a successfully orchestrated, large-scale clinical study that addressed a critical public health issue. This guide provides an in-depth comparison of the trial's interventions, a detailed breakdown of its experimental protocols, and a clear visualization of its operational workflow, offering valuable insights for researchers, scientists, and drug development professionals.
Comparative Analysis of Interventions
The ADORE trial was a multicenter, randomized, double-blind, superiority study designed to evaluate the efficacy of high-dose docosahexaenoic acid (DHA) supplementation in reducing the rate of early preterm birth (ePTB), defined as birth before 34 weeks of gestation.[1][2][3][4] The trial compared a high-dose DHA regimen against a standard-dose regimen, with all participants receiving a baseline prenatal supplement containing 200 mg of DHA.[1][4][5]
Table 1: Comparison of Intervention and Control Groups
| Feature | High-Dose DHA Group (Intervention) | Standard-Dose DHA Group (Control) |
| Daily DHA Dose | 1000 mg | 200 mg |
| Supplementation | Two daily capsules of algal oil (totaling 800 mg DHA) + one prenatal supplement capsule (200 mg DHA) | Two daily placebo capsules (soybean and corn oil) + one prenatal supplement capsule (200 mg DHA) |
| Number of Participants (Intention-to-Treat) | 576 | 524 |
| Number of Participants (Included in Primary Analysis) | 540 | 492 |
Efficacy and Safety Outcomes
The primary outcome of the ADORE trial was the rate of early preterm birth. The results demonstrated a clinically meaningful reduction in the high-dose DHA group, particularly in women with low baseline DHA levels.[1][2][3]
Table 2: Primary and Key Secondary Outcomes
| Outcome | High-Dose DHA Group (1000 mg) | Standard-Dose DHA Group (200 mg) | Posterior Probability (pp) |
| Early Preterm Birth Rate (<34 weeks) | 1.7% (9/540) | 2.4% (12/492) | 0.81 |
| Early Preterm Birth Rate (Low Baseline DHA) | 2.0% (5/249) | 4.1% (9/219) | 0.93 |
| Preterm Birth Rate (<37 weeks) | Reduced (specific % not stated) | - | 0.95 |
The high-dose DHA supplementation was also found to be safe and well-tolerated, with fewer serious adverse events reported in the high-dose group compared to the standard-dose group.[1][2]
Table 3: Participant Demographics and Baseline Characteristics (Intention-to-Treat Population)
| Characteristic | High-Dose DHA Group (n=576) | Standard-Dose DHA Group (n=524) |
| Maternal Age (years, mean ± SD) | 28.5 ± 5.9 | 28.4 ± 5.8 |
| Body Mass Index ( kg/m ², mean ± SD) | 29.3 ± 7.4 | 29.1 ± 7.2 |
| Race/Ethnicity | ||
| White | 68.6% | 69.1% |
| Black or African American | 21.5% | 20.2% |
| Hispanic | 11.6% | 12.0% |
| Asian | 2.3% | 2.5% |
| Previous Preterm Birth | 7.8% | 8.0% |
| Smoker (at enrollment) | 10.1% | 10.7% |
Note: Data extracted from the primary publication of the ADORE trial. The balanced distribution of baseline characteristics between the two groups supports the robustness of the randomization process.
Experimental Protocols
The successful orchestration of the ADORE trial was underpinned by a meticulously designed and executed protocol.
Study Design and Participants
The trial was a Phase III, multicenter, double-blind, randomized, adaptive-design, superiority trial conducted at three academic medical centers in the United States.[1][2] The adaptive design allowed for the randomization ratio to be adjusted during the trial to favor the better-performing arm, thereby optimizing the study's efficiency and ethical considerations.[5]
Eligible participants were pregnant women with a singleton pregnancy between 12 and 20 weeks of gestation.[1][4][5] A total of 1100 participants were enrolled and randomized.[1][2]
Intervention
Participants were randomly assigned to receive either 1000 mg/day of DHA (high-dose group) or 200 mg/day of DHA (standard-dose group).[1][4] The high-dose group received two capsules of algal oil (400 mg DHA each) and a prenatal supplement containing 200 mg DHA. The standard-dose group received two placebo capsules (a mix of soybean and corn oil) and the same prenatal supplement with 200 mg DHA.[5] This blinding ensured that neither the participants nor the investigators knew which treatment was being administered.
Data Collection and Analysis
The primary endpoint was the incidence of early preterm birth. Secondary outcomes included the incidence of all preterm births (<37 weeks) and various maternal and neonatal adverse events.[1] A Bayesian statistical approach was employed for the analysis, which allowed for the calculation of posterior probabilities (pp) to determine the likelihood of the superiority of one intervention over the other.[2]
Visualizing the Orchestration of the ADORE Trial
The following diagrams, created using the DOT language, illustrate the key workflows and logical relationships within the ADORE trial.
Caption: ADORE Trial Workflow from Screening to Analysis.
Caption: Proposed Mechanism of DHA in Reducing Preterm Birth.
References
- 1. Higher dose docosahexaenoic acid supplementation during pregnancy and early preterm birth: A randomised, double-blind, adaptive-design superiority trial - PMC [pmc.ncbi.nlm.nih.gov]
- 2. everydaycounts.com [everydaycounts.com]
- 3. everydaycounts.com [everydaycounts.com]
- 4. Assessment of DHA on reducing early preterm birth: the ADORE randomized controlled trial protocol - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Assessment of DHA on reducing early preterm birth: the ADORE randomized controlled trial protocol - PMC [pmc.ncbi.nlm.nih.gov]
A Comparative Analysis of Data Orchestration Approaches for Scientific Workflows
For Researchers, Scientists, and Drug Development Professionals
In the rapidly evolving landscape of scientific research and drug development, the ability to efficiently manage and process vast amounts of data is paramount. Data orchestration has emerged as a critical discipline for automating, scheduling, monitoring, and managing complex data workflows. This guide provides a comparative analysis of different approaches to data orchestration, with a focus on tools and methodologies relevant to the life sciences. We will explore the key features of popular orchestration tools, present a framework for their evaluation, and visualize common scientific data pipelines.
Key Concepts in Data Orchestration
Data orchestration is the automated coordination of a series of tasks that transform raw data into a desired output. This is distinct from simpler Extract, Transform, Load (ETL) processes, as it encompasses the entire workflow, including dependencies, error handling, and monitoring.[1] In the context of scientific research, this could involve a multi-step bioinformatics pipeline, a machine learning model training workflow for drug discovery, or the integration of data from various laboratory instruments.
Comparative Overview of Data Orchestration Tools
Table 1: Qualitative Comparison of Leading Data Orchestration Tools
| Feature | Apache Airflow | Prefect | Dagster |
| Primary Abstraction | Tasks and DAGs (Directed Acyclic Graphs) | Flows and Tasks | Software-Defined Assets and Ops |
| Workflow Definition | Python code defining static DAGs.[2][3] | Python functions decorated as tasks within a flow.[2][3] | Python functions as ops, composed into graphs that produce assets.[2][3] |
| Dynamic Workflows | Limited, as DAGs are static. | Native support for dynamic and conditional workflows.[2] | Supports dynamic pipelines and asset materializations.[3] |
| Developer Experience | Can have a steep learning curve and require significant configuration.[2] | Designed for simplicity and ease of use with a modern Pythonic API.[2] | Focuses on a strong developer experience with an emphasis on local development and testing.[3][4] |
| Data Awareness | Task-centric; less inherent understanding of the data being processed. | Data-aware; tasks can pass data to each other. | Asset-centric; strong focus on data lineage and quality. |
| Scalability | Proven scalability in large, complex production environments.[2] | Scales well with a flexible agent-based architecture. | Designed for scalability with a focus on modern data-intensive applications.[2] |
| Ecosystem & Community | Mature and extensive with a large, active community and many pre-built integrations.[2] | Rapidly growing community and ecosystem.[2] | Growing community with a strong focus on modern data engineering practices.[2] |
Quantitative Performance Metrics
While a direct quantitative comparison is challenging without standardized benchmarks, the performance of a data orchestration tool can be evaluated based on several key metrics.[5][6] These metrics are crucial for understanding the efficiency and reliability of a data pipeline.
Table 2: Key Performance Metrics for Data Orchestration
| Metric | Description | Importance in Scientific Workflows |
| Throughput | The amount of data processed per unit of time (e.g., samples/hour, GB/minute).[5] | High throughput is critical for processing large genomic or imaging datasets in a timely manner. |
| Latency | The time it takes for a single unit of data to move through the entire pipeline.[5] | Low latency is important for near-real-time analysis and iterative research cycles. |
| Resource Utilization | The amount of CPU, memory, and storage consumed by the workflow. | Efficient resource utilization is key to managing computational costs, especially in cloud environments. |
| Scalability | The ability of the system to handle an increasing workload by adding more resources.[7] | Essential for accommodating growing datasets and more complex analyses. |
| Error Rate | The frequency of failures or errors within the pipeline. | A low error rate is crucial for ensuring the reliability and reproducibility of scientific results. |
| Execution Time | The total time taken to complete a workflow from start to finish. | Reducing execution time accelerates the pace of research and discovery. |
Experimental Protocol for Benchmarking Data Orchestration Tools
To provide a framework for the quantitative evaluation of data orchestration tools, we propose the following experimental protocol. This protocol is designed to be adaptable to specific scientific workflows and computational environments.
Objective: To quantitatively compare the performance of different data orchestration tools (e.g., Apache Airflow, Prefect, Dagster, Nextflow) for a representative scientific workflow.
1. Workflow Selection:
-
Genomics Workflow: A variant calling pipeline using GATK, processing a set of whole-genome sequencing samples.[8] This workflow involves multiple steps with dependencies, representative of many bioinformatics analyses.
-
Drug Discovery Workflow: A virtual screening pipeline that docks a library of small molecules against a protein target and analyzes the results. This represents a computationally intensive and iterative process.
2. Environment Setup:
-
Computational Infrastructure: A standardized cloud environment (e.g., AWS, Google Cloud, Azure) with defined instance types, storage, and networking to ensure a fair comparison.
-
Containerization: All tools and dependencies for the workflow should be containerized using Docker or a similar technology to ensure reproducibility.
-
Orchestration Tool Deployment: Each orchestration tool should be deployed following its best practices documentation in the specified cloud environment.
3. Workload Generation:
-
Genomics: A synthetic dataset of FASTQ files of varying sizes and numbers of samples to test scalability.
-
Drug Discovery: A library of chemical compounds of varying sizes to be used for virtual screening.
4. Metrics Collection:
-
Throughput: Measure the number of samples processed or molecules screened per hour.
-
Latency: Measure the end-to-end time for a single sample or molecule to complete the pipeline.
-
Resource Utilization: Use cloud monitoring tools to collect data on CPU, memory, and disk I/O for each workflow run.
-
Execution Time: Log the start and end times of each workflow execution.
-
Cost: Track the cost of cloud resources consumed for each workflow run.
5. Experimental Procedure:
-
For each orchestration tool, execute the selected workflow with a range of workloads (e.g., increasing number of samples or molecules).
-
Repeat each experiment multiple times to ensure the statistical significance of the results.
-
Monitor and log all performance metrics for each run.
-
Introduce controlled failures (e.g., transient network issues, task failures) to evaluate the error handling and recovery mechanisms of each tool.
6. Data Analysis and Reporting:
-
Summarize the collected metrics in tables and charts for easy comparison.
-
Analyze the trade-offs between different tools in terms of performance, cost, and ease of use.
-
Document any challenges or limitations encountered during the benchmarking process.
Visualizing Scientific Workflows
Diagrams are essential for understanding the complex dependencies and logical flow of scientific data pipelines. The following workflows are represented using the DOT language for Graphviz.
Genomics: A Variant Calling Workflow
This diagram illustrates a common bioinformatics pipeline for identifying genetic variants from sequencing data, which can be orchestrated by tools like Nextflow.[9][10][11]
Drug Discovery: A Virtual Screening Pipeline
This diagram outlines a computational drug discovery workflow for identifying potential drug candidates through virtual screening.[12][13][14]
References
- 1. Data Orchestration 101: Process, Benefits, Challenges, And Tools [montecarlodata.com]
- 2. medium.com [medium.com]
- 3. risingwave.com [risingwave.com]
- 4. Orchestration Showdown: Dagster vs Prefect vs Airflow - ZenML Blog [zenml.io]
- 5. telm.ai [telm.ai]
- 6. ijraset.com [ijraset.com]
- 7. researchgate.net [researchgate.net]
- 8. training.nextflow.io [training.nextflow.io]
- 9. training.nextflow.io [training.nextflow.io]
- 10. Nextflow · Genomic Data Analysis II [barrydigby.github.io]
- 11. Intro to Nextflow – NGS Analysis [learn.gencore.bio.nyu.edu]
- 12. Understanding the Drug Discovery Pipeline [delta4.ai]
- 13. m.youtube.com [m.youtube.com]
- 14. researchgate.net [researchgate.net]
Validating the Role of p53 in the DNA Damage Response Pathway: A Comparative Guide
For Researchers, Scientists, and Drug Development Professionals
The tumor suppressor protein p53 is a cornerstone of genome integrity, orchestrating a complex signaling network in response to cellular stress, most notably DNA damage. Its activation can determine a cell's fate, leading to either cell cycle arrest to allow for DNA repair or apoptosis (programmed cell death) to eliminate severely damaged cells.[1][2][3] Understanding the precise role of p53 and distinguishing its functions from those of its homologues is critical for research and therapeutic development.
This guide provides a comparative analysis of p53 and its family member, p73, in the context of the DNA damage response. We present supporting experimental data, detailed protocols for key validation experiments, and visual diagrams to clarify the underlying molecular pathways and workflows.
Comparative Data Analysis: p53 vs. p73
While both p53 and its homologue p73 can activate downstream targets to control cell fate, their regulation and functional outcomes can differ significantly depending on the cellular context.[2] The primary role of p53 is as a stress-responsive tumor suppressor that is rapidly stabilized and activated following DNA damage.[3][4] In contrast, p73's role is more diverse, with certain isoforms (TAp73) mimicking p53's tumor-suppressive functions, while others (ΔNp73) can have opposing, oncogenic effects.[5] A key distinction is their response to genotoxic stress; p53 levels dramatically increase in response to DNA damage, whereas endogenous p73 levels often do not show the same stabilization.[2]
Below is a summary of quantitative data from studies comparing the functional output of p53 and p73 overexpression on cell cycle arrest and apoptosis.
| Parameter | Gene | Cell Line | Condition | Result | Reference |
| Cell Cycle Arrest | p73α | EJ (p53-mutant bladder cancer) | Tetracycline-inducible overexpression (3 days) | G1 Phase: 34.1% → 60.5%G2/M Phase: 20.2% → 33.6% | [2] |
| p73β | EJ (p53-mutant bladder cancer) | Tetracycline-inducible overexpression (3 days) | G1 Phase: 31.5% → 56.3%G2/M Phase: 16.0% → 26.5% | [2] | |
| Apoptosis | p53 | U2OS (osteosarcoma, wild-type p53) | Transient Overexpression | Significant increase in apoptotic cells (Trypan blue staining) | [6] |
| TAp73 | U2OS (osteosarcoma, wild-type p53) | Transient Overexpression | Significant increase in apoptotic cells (Trypan blue staining) | [6] | |
| ΔNp73 | U2OS (osteosarcoma, wild-type p53) | Transient Overexpression | No significant increase in apoptotic cells | [6] |
Note: The apoptosis data from U2OS cells indicates a qualitative increase; specific percentages vary between experiments.
Signaling Pathway and Experimental Workflow
To validate the role of a gene like p53, it is crucial to understand both the biological pathway it governs and the experimental process used to study it.
Caption: The p53 signaling pathway in response to DNA damage.
Caption: Workflow for validating p53's role in DNA damage response.
Experimental Protocols
Detailed methodologies are essential for reproducing and building upon scientific findings. The following are standard protocols for the key experiments cited in this guide.
Western Blot for p53 and Bax Protein Levels
This protocol is used to detect and quantify the levels of specific proteins in cell lysates, demonstrating p53 stabilization and activation of downstream targets like Bax.
-
Cell Lysis and Protein Extraction:
-
After treatment, wash cells with ice-cold Phosphate-Buffered Saline (PBS).
-
Lyse cells in RIPA buffer supplemented with protease and phosphatase inhibitors.
-
Centrifuge the lysates at 14,000 x g for 15 minutes at 4°C to pellet cell debris.
-
Collect the supernatant and determine protein concentration using a BCA or Bradford assay.
-
-
SDS-PAGE and Transfer:
-
Denature 20-50 µg of protein extract by boiling in Laemmli sample buffer.
-
Load samples onto a 12% SDS-polyacrylamide gel and separate proteins by electrophoresis.
-
Transfer the separated proteins from the gel to a polyvinylidene difluoride (PVDF) membrane.
-
-
Immunoblotting:
-
Block the membrane for 1 hour at room temperature in 5% non-fat dry milk or Bovine Serum Albumin (BSA) in Tris-buffered saline with 0.1% Tween-20 (TBST).
-
Incubate the membrane with primary antibodies (e.g., anti-p53, anti-Bax, and anti-β-actin as a loading control) overnight at 4°C.
-
Wash the membrane three times with TBST.
-
Incubate with an appropriate HRP-conjugated secondary antibody for 1 hour at room temperature.
-
Wash the membrane again three times with TBST.
-
-
Detection:
-
Incubate the membrane with an enhanced chemiluminescence (ECL) substrate.
-
Capture the signal using a digital imaging system and quantify band intensity using software like ImageJ.
-
Quantitative Real-Time PCR (qRT-PCR) for p21 Gene Expression
This protocol measures the relative abundance of mRNA transcripts, showing the transcriptional activation of p53 target genes like CDKN1A (p21).
-
RNA Extraction and cDNA Synthesis:
-
Extract total RNA from harvested cells using an RNA isolation kit (e.g., RNeasy Kit) according to the manufacturer's protocol.
-
Assess RNA purity and concentration using a spectrophotometer (e.g., NanoDrop).
-
Synthesize complementary DNA (cDNA) from 1 µg of total RNA using a reverse transcription kit.
-
-
qPCR Reaction:
-
Prepare the qPCR reaction mix containing cDNA template, forward and reverse primers for the target gene (e.g., p21) and a reference gene (e.g., GAPDH), and a SYBR Green master mix.
-
Run the reaction on a real-time PCR system with a standard thermal cycling program (e.g., 95°C for 10 min, followed by 40 cycles of 95°C for 15s and 60°C for 1 min).
-
-
Data Analysis:
-
Determine the cycle threshold (Ct) for each gene.
-
Calculate the relative gene expression using the 2-ΔΔCt method, normalizing the expression of the target gene to the reference gene.
-
TUNEL Assay for Apoptosis Detection
The Terminal deoxynucleotidyl transferase dUTP Nick End Labeling (TUNEL) assay is used to detect DNA fragmentation, a hallmark of late-stage apoptosis.
-
Cell Fixation and Permeabilization:
-
Grow and treat cells on glass coverslips or in 96-well plates.
-
Wash cells with PBS and fix with 4% paraformaldehyde in PBS for 15 minutes at room temperature.
-
Wash again with PBS and permeabilize the cells with 0.25% Triton X-100 in PBS for 20 minutes.
-
-
TUNEL Reaction:
-
Prepare the TUNEL reaction cocktail containing Terminal deoxynucleotidyl Transferase (TdT) and a fluorescently labeled dUTP (e.g., EdU-Alexa Fluor™ 488) according to the kit manufacturer's instructions.
-
Incubate the cells with the reaction cocktail for 60 minutes at 37°C in a humidified chamber, protected from light.
-
-
Staining and Imaging:
-
Wash the cells twice with PBS.
-
(Optional) Counterstain the nuclei with a DNA stain like DAPI or Hoechst.
-
Mount the coverslips onto microscope slides or image the plate directly using a fluorescence microscope.
-
-
Quantification:
-
Count the number of TUNEL-positive (fluorescent) nuclei and the total number of nuclei (DAPI/Hoechst stained).
-
Calculate the percentage of apoptotic cells.
-
References
- 1. Structure and apoptotic function of p73 - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Comparative Analysis of P73 and P53 Regulation and Effector Functions - PMC [pmc.ncbi.nlm.nih.gov]
- 3. p63 and p73 are required for p53-dependent apoptosis in response to DNA damage - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. p53 and p73 Regulate Apoptosis but Not Cell-Cycle Progression in Mouse Embryonic Stem Cells upon DNA Damage and Differentiation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Specific isoforms of p73 control the induction of cell death induced by the viral proteins, E1A or apoptin - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
A Comparative Guide to Automated Orchestration Platforms for Life Sciences
For Researchers, Scientists, and Drug Development Professionals
The life sciences are experiencing a data deluge, making efficient and reproducible research more critical than ever. Automated orchestration platforms have emerged as essential tools for managing complex workflows, from high-throughput screening to next-generation sequencing data analysis. This guide provides an objective comparison of leading platforms, supported by available experimental and performance data, to help you select the best solution for your research needs.
At a Glance: Platform Categories
Automated orchestration platforms in the life sciences can be broadly categorized into two main types:
-
Bioinformatics Workflow Managers: These platforms are designed to create, execute, and manage complex data analysis pipelines, particularly in genomics and other 'omics' fields. They excel at ensuring reproducibility and scalability of computational workflows.
-
Laboratory Information Management Systems (LIMS) & Electronic Lab Notebooks (ELN): These solutions focus on the management of laboratory operations, including sample tracking, experiment documentation, and instrument integration. Many modern platforms now offer integrated suites that combine the features of both LIMS and ELN.
Bioinformatics Workflow Managers: A Head-to-Head Comparison
For researchers heavily involved in computational biology and data analysis, the choice of a workflow management system is critical. Nextflow and Snakemake are two of the most popular open-source options available.
A study evaluating workflow management systems for a typical bioinformatics workflow (combining sequential, parallelized, and merged steps) provides some key performance insights.[1] While specific hardware and dataset details can influence outcomes, the relative performance offers a valuable comparison.
| Feature | Nextflow | Snakemake | Cromwell (with WDL) |
| Primary Language | Groovy (DSL) | Python (DSL) | WDL (Workflow Description Language) |
| Execution Model | Dataflow | File-based | Declarative |
| Community & Support | Very active nf-core community with curated pipelines.[2][3] | Active developer community with good documentation for beginners.[4] | Supported by the Broad Institute; less centralized community. |
| Ease of Learning | Can have a steeper learning curve due to Groovy-based DSL.[4] | Generally considered easier for those familiar with Python.[4] | WDL is a declarative language, which can be intuitive for defining workflows. |
| Reproducibility | Excellent, with strong support for containers (Docker, Singularity) and Conda.[4] | Excellent, with integrated support for Conda environments and containers.[4] | Strong focus on reproducibility through containerization. |
| Scalability | Highly scalable, well-suited for cloud and HPC environments.[4] | Good for parallelism, but can face stability issues with very large and complex workflows.[4] | Designed for scalability on various platforms, including cloud and HPC. |
Experimental Protocol: Bioinformatics Workflow Benchmark
The performance data cited above was generated using a bioinformatics workflow designed to be representative of common analysis tasks. The workflow consisted of a series of steps including data pre-processing, alignment to a reference genome, and variant calling. The key performance metrics measured were:
-
Execution Time: The total time taken to complete the workflow from start to finish.
-
CPU Usage: The amount of processing power consumed by the workflow.
-
Memory Usage: The amount of RAM utilized during workflow execution.
The experiment was conducted on a standardized computing environment to ensure a fair comparison between the different workflow management systems.
Quantitative Performance Data
| Workflow Manager | Relative Execution Time | Relative CPU Usage | Relative Memory Usage |
| Nextflow | 1.0x (Baseline) | 1.0x (Baseline) | High (Java Virtual Machine)[1] |
| Snakemake | ~0.9x (Faster) | ~1.0x (Similar) | Moderate |
| Cromwell (WDL) | ~1.5x (Slower) | High | High (Java Virtual Machine)[1] |
Note: This data is based on a specific bioinformatics use case and may vary depending on the complexity of the workflow and the computing environment.[1] The higher memory usage of Nextflow and Cromwell is attributed to their use of the Java Virtual Machine (JVM).[1]
LIMS & ELN Platforms: A Feature-Based Comparison
For laboratory-focused orchestration, platforms like Benchling and Dotmatics offer comprehensive solutions for managing samples, experiments, and data. While direct, publicly available head-to-head performance benchmarks are limited, we can compare them based on their features and available performance-related data.
| Feature | Benchling | Dotmatics | Genedata Biologics |
| Core Functionality | Integrated ELN, LIMS, and molecular biology tools.[5] | End-to-end solutions for biology, chemistry, and data management.[5] | Specialized platform for biotherapeutic discovery workflows. |
| Integration | Open integration capabilities.[5] | Offers a suite of integrated products and connects with various instruments. | Integrates all R&D processes from library design to analytics. |
| Customization | Codeless configuration and customizable dashboards.[5] | Customizable ELN templates and flexible R&D workflows.[6] | Tailored to biopharmaceutical R&D processes. |
| Deployment | Cloud-based. | Cloud-based and on-premise options. | Available as a comprehensive platform. |
| Performance Metrics | API Rate Limits: Tenant-wide limit of 60 requests per 30 seconds. Throughput limits on data creation/updates in the tens of thousands of objects per hour. | Deployment Time: A case study reported establishing a parsing environment in under 10 hours and onboarding 5 instruments and 20 users in one week.[7] | Specific performance metrics not publicly available. |
Experimental Protocol: LIMS/ELN Performance Evaluation
A comprehensive benchmark for LIMS/ELN platforms would involve evaluating the following key metrics under controlled conditions:
-
Sample Throughput: The number of samples that can be registered, processed, and tracked within a given timeframe.[8]
-
Data Import/Export Speed: The time taken to import and export large datasets of various formats.
-
Query Response Time: The time taken to retrieve specific information from the database under different load conditions.
-
User Concurrency: The platform's performance when multiple users are accessing and modifying data simultaneously.
Visualizing Common Life Science Workflows
To better understand how these orchestration platforms are applied, here are diagrams of three common workflows in the life sciences, created using the DOT language.
Caption: A typical Next-Generation Sequencing (NGS) data analysis workflow.
Caption: A generalized High-Throughput Screening (HTS) workflow.
Caption: The Design-Build-Test-Learn (DBTL) cycle in synthetic biology.
Conclusion
Choosing the right automated orchestration platform is a critical decision that can significantly impact research efficiency and reproducibility.
For computationally intensive bioinformatics research , Nextflow and Snakemake offer powerful, open-source solutions. Nextflow, with its strong community support through nf-core and excellent scalability, is a robust choice for complex, large-scale analyses. Snakemake's Python-based syntax may be more approachable for many researchers and it demonstrates strong performance for a variety of workflows.
For laboratory operations and data management , integrated LIMS/ELN platforms like Benchling and Dotmatics provide comprehensive solutions. The choice between them may depend on specific needs such as the balance between biological and chemical research, desired level of customization, and existing instrument infrastructure.
Ultimately, the best platform will depend on your specific experimental and computational needs, existing infrastructure, and the technical expertise of your team. It is recommended to conduct a thorough evaluation, including demos and pilot projects, before making a final decision.
References
- 1. researchgate.net [researchgate.net]
- 2. nf-co.re [nf-co.re]
- 3. nf-co.re [nf-co.re]
- 4. excelra.com [excelra.com]
- 5. researchgate.net [researchgate.net]
- 6. Case Study | Sygnature Discovery Optimizes CRO Workflows with Dotmatics ELN Platform [dotmatics.com]
- 7. Case Study | Dotmatics Luma Flow Cytometry Workflow [dotmatics.com]
- 8. cloudlims.com [cloudlims.com]
Validating Orchestrated Experiments: A Comparative Guide to In Vivo Models
For researchers, scientists, and drug development professionals, the validation of findings from high-throughput screening and other orchestrated experiments is a critical step in the therapeutic development pipeline. In vivo models provide a complex, physiologically relevant system to assess the efficacy and safety of novel compounds. This guide offers a comparative overview of two widely used in vivo models: the Cell Line-Derived Xenograft (CDX) and the Patient-Derived Xenograft (PDX) model, with a focus on validating therapies targeting the Epidermal Growth Factor Receptor (EGFR) signaling pathway in Non-Small Cell Lung Cancer (NSCLC).
Comparative Efficacy of Novel EGFR Inhibitors: In Vivo Data
The following tables summarize quantitative data from representative in vivo studies evaluating the efficacy of novel EGFR inhibitors in NSCLC xenograft models. These tables provide a clear comparison of tumor growth inhibition across different models and treatment regimens.
| Treatment Group | Dosing Regimen | Mean Tumor Volume (mm³) ± SEM (Day 21) | Tumor Growth Inhibition (%) | p-value vs. Vehicle |
| Vehicle Control | 10 mL/kg, p.o., QD | 1500 ± 150 | - | - |
| Novel Inhibitor (Low Dose) | 25 mg/kg, p.o., QD | 825 ± 95 | 45 | <0.05 |
| Novel Inhibitor (High Dose) | 50 mg/kg, p.o., QD | 375 ± 60 | 75 | <0.001 |
| Standard-of-Care | 20 mg/kg, p.o., QD | 450 ± 70 | 70 | <0.001 |
Table 1: In Vivo Efficacy of a Novel EGFR Inhibitor in a CDX Model.[1]
| Treatment Group | Dosing Regimen | Mean Tumor Volume (mm³) ± SEM (Day 28) | Tumor Growth Inhibition (%) | p-value vs. Vehicle |
| Vehicle Control | 10 mL/kg, p.o., QD | 1200 ± 130 | - | - |
| Gefitinib | 50 mg/kg, p.o., QD | 300 ± 50 | 75 | <0.001 |
| Novel Compound 3 | 25 mg/kg, p.o., QD | 180 ± 40 | 85 | <0.001 |
Table 2: Comparative Efficacy in an EGFR-mutant NSCLC PDX Model.[2][3]
Experimental Protocols: CDX vs. PDX Models
Detailed methodologies are crucial for the reproducibility of in vivo studies. The following is a comparative overview of the key steps in establishing and utilizing CDX and PDX models.
| Step | Cell Line-Derived Xenograft (CDX) Protocol | Patient-Derived Xenograft (PDX) Protocol |
| 1. Source Material | Established and well-characterized human cancer cell lines (e.g., NCI-H1650 for NSCLC with EGFR exon 19 deletion).[1] | Fresh tumor tissue obtained directly from consenting patients under sterile conditions.[4] |
| 2. Animal Model | Immunodeficient mice (e.g., NOD-SCID, NSG) housed in a sterile environment.[5] | Immunodeficient mice (e.g., NOD/SCID, NSG) are essential to prevent graft rejection.[4] |
| 3. Preparation | Cells are cultured in appropriate media, harvested at 80-90% confluency, and resuspended in a sterile medium or a mixture with Matrigel. Cell viability should exceed 90%.[5] | Tumor tissue is washed, non-tumor tissue is removed, and the tumor is minced into small fragments (2-3 mm³).[4][6] |
| 4. Implantation | A specific number of cells (e.g., 5 x 10^6) are injected subcutaneously into the flank of the anesthetized mouse.[5] | Tumor fragments are surgically implanted subcutaneously into the flank or orthotopically into the relevant organ of the anesthetized mouse.[4][6] |
| 5. Tumor Growth & Monitoring | Tumors become palpable and are measured 2-3 times per week with calipers. Treatment typically begins when tumors reach a volume of 100-200 mm³.[1] | Tumor growth is monitored 2-3 times per week. Passaging to new mice occurs when the tumor reaches 1000-1500 mm³.[4] |
| 6. Treatment & Analysis | Mice are randomized into treatment and control groups. The therapeutic agent and vehicle are administered according to the study design. Tumor volume and body weight are monitored throughout the study.[1] | Once tumors are established, mice are randomized for efficacy studies. Treatment administration and monitoring follow a similar protocol to CDX models.[4] |
Visualizing Key Processes
To better understand the biological and experimental frameworks, the following diagrams illustrate a relevant signaling pathway and a typical in vivo experimental workflow.
EGFR Signaling Pathway in NSCLC.[7][8][9][10][11]
Generalized Experimental Workflow for In Vivo Validation.
References
- 1. benchchem.com [benchchem.com]
- 2. Induction of Acquired Resistance towards EGFR Inhibitor Gefitinib in a Patient-Derived Xenograft Model of Non-Small Cell Lung Cancer and Subsequent Molecular Characterization - PMC [pmc.ncbi.nlm.nih.gov]
- 3. In vitro and in vivo characterization of irreversible mutant-selective EGFR inhibitors that are wild-type sparing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. benchchem.com [benchchem.com]
- 5. benchchem.com [benchchem.com]
- 6. Establishment of Patient-Derived Xenografts in Mice [bio-protocol.org]
- 7. researchgate.net [researchgate.net]
- 8. researchgate.net [researchgate.net]
- 9. researchgate.net [researchgate.net]
- 10. Epidermal Growth Factor Receptor (EGFR) Pathway, Yes-Associated Protein (YAP) and the Regulation of Programmed Death-Ligand 1 (PD-L1) in Non-Small Cell Lung Cancer (NSCLC) - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
A Guide to Cross-Validation of Orchestrated High-Content Screening Data
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive comparison of computational and experimental methods for the cross-validation of data generated from orchestrated high-content screening (HCS) campaigns. We present detailed experimental protocols, comparative performance data, and visual workflows to aid in the selection of appropriate validation strategies, ensuring the robustness and reliability of your screening results.
Introduction to High-Content Screening and the Need for Rigorous Validation
High-content screening (HCS) is a powerful technology in drug discovery and biological research that combines automated microscopy with sophisticated image analysis to extract quantitative, multi-parametric data from cells.[1] An orchestrated HCS workflow involves a series of automated steps, from cell culture and treatment to imaging and data analysis, to assess the effects of thousands of compounds on cellular phenotypes.[2]
The vast and complex datasets generated by HCS necessitate rigorous validation to distinguish true "hits" (compounds with a desired biological effect) from false positives.[3] Cross-validation, in this context, encompasses both computational methods to assess the statistical robustness of a predictive model and experimental approaches to confirm the biological activity of identified hits through independent assays.[4]
The Orchestrated High-Content Screening Workflow
A typical orchestrated HCS workflow is a multi-step process designed for high-throughput and reproducibility. Automation is key to minimizing variability and handling the large scale of these experiments.[2] The process generally follows these stages:
-
Assay Development and Plate Setup: Cells are seeded in multi-well plates (e.g., 96, 384, or 1536 wells). Controls (positive, negative, and vehicle) are strategically placed across the plates to monitor for and correct systematic errors.
-
Compound Treatment: A robotic liquid handling system dispenses compounds from a library into the appropriate wells at precise concentrations.
-
Cell Incubation: Plates are incubated for a defined period to allow the compounds to exert their biological effects.
-
Cell Staining: Fluorescent dyes or antibodies are used to label specific subcellular components or proteins of interest.
-
Automated Imaging: A high-content imaging system automatically acquires images from each well. These systems often have features like hardware autofocus and environmental control to ensure image quality.[5]
-
Image Analysis: Specialized software performs image segmentation to identify individual cells and subcellular regions, followed by feature extraction to quantify various morphological and intensity-based parameters.[1]
-
Data Analysis and Hit Identification: The quantitative data is normalized, and statistical methods are applied to identify "hits" that induce a significant phenotypic change compared to controls.
Below is a diagram illustrating a generalized orchestrated HCS workflow.
Computational Cross-Validation: Assessing Model Robustness
Before committing to expensive and time-consuming experimental validation, computational cross-validation techniques are employed to assess the predictive power and robustness of the models used for hit selection. These methods involve partitioning the dataset into training and testing subsets to evaluate how well the model generalizes to new, unseen data.[6]
Common Computational Cross-Validation Methods
-
k-Fold Cross-Validation: The dataset is randomly divided into k equal-sized subsets (or "folds"). The model is trained on k-1 folds and tested on the remaining fold. This process is repeated k times, with each fold used as the test set once. The performance is then averaged across all k trials. A common choice for k is 10.[7]
-
Leave-One-Out Cross-Validation (LOOCV): This is a more intensive form of k-fold cross-validation where k is equal to the number of data points. In each iteration, the model is trained on all data points except one, which is then used for testing.[7]
Performance Metrics for Computational Cross-Validation
Several metrics can be used to evaluate the performance of a classification model in identifying "hits" from "non-hits":
-
Accuracy: The proportion of correctly classified instances.
-
Precision: The proportion of predicted positives that are true positives.
-
Recall (Sensitivity): The proportion of true positives that are correctly identified.
-
F1-Score: The harmonic mean of precision and recall, providing a balanced measure.
-
Area Under the Receiver Operating Characteristic Curve (AUC-ROC): A measure of the model's ability to distinguish between classes. An AUC of 1.0 represents a perfect model, while 0.5 indicates a random guess.
Comparison of Computational Cross-Validation Methods
The choice between k-fold and LOOCV often involves a trade-off between computational cost and the bias-variance of the performance estimate. LOOCV is computationally expensive but provides a less biased estimate of the model's performance. In contrast, k-fold cross-validation is more computationally efficient.[7]
Below is a table with illustrative data comparing the performance of these two methods on a hypothetical HCS dataset aimed at identifying inhibitors of the TGF-β signaling pathway.
| Performance Metric | 10-Fold Cross-Validation | Leave-One-Out Cross-Validation (LOOCV) |
| Accuracy | 0.92 | 0.91 |
| Precision | 0.85 | 0.83 |
| Recall (Sensitivity) | 0.88 | 0.90 |
| F1-Score | 0.86 | 0.86 |
| AUC-ROC | 0.95 | 0.94 |
| Computational Time (hours) | 2.5 | 24 |
This illustrative data suggests that for this hypothetical large dataset, 10-fold cross-validation provides comparable performance to LOOCV with significantly lower computational cost.
The logical relationship between the initial HCS data and its computational validation is depicted in the following diagram.
Experimental Validation: Orthogonal Assays for Hit Confirmation
Computationally validated hits must be confirmed through experimental assays that are independent of the primary screening assay. These "orthogonal" assays use different technologies and methodologies to confirm the biological activity of the hit compounds, thereby reducing the likelihood of false positives arising from assay-specific artifacts.[3]
Key Orthogonal Validation Assays
Several biophysical and cell-based assays are commonly used for hit confirmation:
-
Cellular Thermal Shift Assay (CETSA): This assay assesses target engagement in a cellular context. It is based on the principle that the binding of a compound to its target protein increases the protein's thermal stability.[8]
-
Surface Plasmon Resonance (SPR): SPR is a label-free technique that measures the binding kinetics and affinity of a compound to a purified target protein immobilized on a sensor chip.
-
Isothermal Titration Calorimetry (ITC): ITC directly measures the heat released or absorbed during the binding of a compound to a target protein in solution, providing a complete thermodynamic profile of the interaction.
Methodologies for Orthogonal Assays
-
Cell Treatment: Treat intact cells with the hit compound or a vehicle control.
-
Heating: Heat the cell suspensions at a range of temperatures.
-
Cell Lysis and Centrifugation: Lyse the cells and separate the soluble protein fraction from aggregated proteins by centrifugation.
-
Protein Quantification: Quantify the amount of soluble target protein at each temperature using methods like Western blotting or ELISA.
-
Data Analysis: Plot the amount of soluble protein as a function of temperature to generate a melting curve. A shift in the melting curve in the presence of the compound indicates target engagement.[8]
-
Target Immobilization: Covalently attach the purified target protein to the surface of a sensor chip.
-
Compound Injection: Inject a series of concentrations of the hit compound over the sensor surface.
-
Data Acquisition: Monitor the change in the refractive index at the sensor surface in real-time to generate a sensorgram, which shows the association and dissociation of the compound.
-
Data Analysis: Fit the sensorgram data to a binding model to determine the association rate constant (ka), dissociation rate constant (kd), and the equilibrium dissociation constant (KD).
-
Sample Preparation: Prepare solutions of the purified target protein and the hit compound in the same buffer.
-
Titration: Place the target protein in the sample cell and the compound in the injection syringe. A series of small injections of the compound into the sample cell are performed.
-
Heat Measurement: The instrument measures the small heat changes that occur with each injection.
-
Data Analysis: Integrate the heat signals and plot them against the molar ratio of the compound to the target. Fit the data to a binding model to determine the binding affinity (KD), stoichiometry (n), and enthalpy of binding (ΔH).
Comparison of Orthogonal Validation Assays
The choice of orthogonal assay depends on factors such as the nature of the target protein, the availability of purified protein, and the desired information (e.g., target engagement in cells vs. in vitro binding kinetics).
Below is a table with illustrative data comparing the outcomes of these orthogonal assays for a set of 20 computationally predicted hits from our hypothetical TGF-β signaling HCS.
| Validation Method | Number of Confirmed Hits (out of 20) | Confirmation Rate | Key Information Obtained |
| CETSA | 16 | 80% | Target engagement in a cellular environment |
| SPR | 14 | 70% | Binding affinity (KD) and kinetics (ka, kd) |
| ITC | 12 | 60% | Binding affinity (KD) and thermodynamics (ΔH, ΔS) |
This illustrative data highlights that different orthogonal assays may yield slightly different confirmation rates, emphasizing the value of using multiple validation methods to increase confidence in a hit compound.
Case Study: Cross-Validation of a High-Content Screen for EGFR Signaling Pathway Inhibitors
To further illustrate the cross-validation process, we present a hypothetical case study of an HCS campaign designed to identify inhibitors of the Epidermal Growth Factor Receptor (EGFR) signaling pathway. The EGFR pathway is a critical regulator of cell proliferation and is often dysregulated in cancer.
HCS Assay Design
-
Cell Line: A549 human lung carcinoma cells, which express high levels of EGFR.
-
Phenotypic Readout: Inhibition of EGF-induced nuclear translocation of the transcription factor ERK (Extracellular signal-regulated kinase), a key downstream effector of EGFR signaling.
-
Staining: DAPI for nuclear staining and a fluorescently labeled antibody against phosphorylated ERK (pERK).
Cross-Validation Strategy
-
Computational Validation: A machine learning model (e.g., a support vector machine) is trained on the HCS data to classify compounds as hits or non-hits based on the degree of pERK nuclear translocation. A 10-fold cross-validation is performed to assess the model's predictive performance.
-
Orthogonal Experimental Validation: The top 50 computationally predicted hits are subjected to a series of orthogonal assays:
-
CETSA: To confirm target engagement with EGFR in intact A549 cells.
-
SPR: To determine the binding affinity and kinetics of the compounds to purified EGFR protein.
-
The following diagram illustrates the signaling pathway and the points of intervention and measurement in this case study.
Conclusion
Rigorous cross-validation is indispensable for the success of orchestrated high-content screening campaigns. By combining robust computational validation with orthogonal experimental assays, researchers can confidently identify true biological hits and minimize the pursuit of false positives. This guide provides a framework for designing and implementing a comprehensive cross-validation strategy, ultimately enhancing the efficiency and productivity of the drug discovery process.
References
- 1. Accelerating Drug Discovery with High Content Screening | Core Life Analytics [corelifeanalytics.com]
- 2. chemrxiv.org [chemrxiv.org]
- 3. Quantitative assessment of hit detection and confirmation in single and duplicate high-throughput screenings - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. Practical Considerations and Applied Examples of Cross-Validation for Model Development and Evaluation in Health Care: Tutorial - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Comparative Analysis of Cross-Validation Techniques: LOOCV, K-folds Cross-Validation, and Repeated K-folds Cross-Validation in Machine Learning Models , American Journal of Theoretical and Applied Statistics, Science Publishing Group [sciencepublishinggroup.com]
- 7. academic.oup.com [academic.oup.com]
- 8. Empirical investigation of multi-source cross-validation in clinical machine learning [arxiv.org]
Orchestration of Cellular States: A Comparative Guide to Healthy vs. Diseased Conditions
For Researchers, Scientists, and Drug Development Professionals
The intricate orchestration of cellular processes is fundamental to maintaining tissue homeostasis and overall organismal health. This guide provides a comparative analysis of key signaling pathways in healthy versus diseased states, focusing on the molecular dysregulation that drives cancer and neurodegenerative disorders. We delve into the experimental methodologies used to elucidate these differences, offering detailed protocols and data presentation to support further research and therapeutic development.
Dysregulation of Cellular Signaling in Cancer
Cancer is characterized by the hijacking of normal cellular signaling pathways to promote uncontrolled proliferation, survival, and metastasis. Two of the most critical pathways implicated in various cancers are the PI3K/Akt and MAPK/ERK cascades.[1][2]
The PI3K/Akt Signaling Pathway
In a healthy state, the PI3K/Akt pathway is tightly regulated to control cell growth, survival, and metabolism. Upon stimulation by growth factors, Phosphoinositide 3-kinase (PI3K) is activated, leading to the phosphorylation and activation of Akt. Activated Akt then modulates a plethora of downstream targets to maintain cellular homeostasis.
In a diseased state, such as in many cancers, mutations in components of this pathway, like PIK3CA (the catalytic subunit of PI3K) or loss of the tumor suppressor PTEN, lead to its constitutive activation.[3][4] This sustained signaling promotes hallmark cancer phenotypes, including relentless cell proliferation and resistance to apoptosis (programmed cell death).
Quantitative Comparison of PI3K/Akt Pathway Activation
| Protein | Healthy State (Relative Phosphorylation) | Cancer State (Relative Phosphorylation) | Fold Change | Reference |
| p-Akt (Ser473) | Low/Transient | High/Sustained | 5-20 fold increase | [3] |
| p-mTOR (Ser2448) | Low/Transient | High/Sustained | 3-10 fold increase | [5] |
| p-S6 Ribosomal Protein (Ser235/236) | Low/Transient | High/Sustained | 4-15 fold increase | [5] |
Note: Fold changes are illustrative and can vary significantly depending on the cancer type and specific mutation.
PI3K/Akt Signaling Pathways
References
- 1. Quantitative cell signalling analysis reveals down-regulation of MAPK pathway activation in colorectal cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Measurement of constitutive MAPK and PI3K/AKT signaling activity in human cancer cell lines - PMC [pmc.ncbi.nlm.nih.gov]
- 3. benchchem.com [benchchem.com]
- 4. researchgate.net [researchgate.net]
- 5. benchchem.com [benchchem.com]
Safety Operating Guide
A Researcher's Guide to Proper Chemical and Pharmaceutical Waste Disposal
In the fast-paced environments of research, drug development, and scientific discovery, the responsible management of laboratory waste is paramount to ensuring the safety of personnel, protecting the environment, and maintaining regulatory compliance. This guide provides essential, step-by-step procedures for the proper disposal of chemical and pharmaceutical waste, designed for researchers, scientists, and drug development professionals. By adhering to these protocols, laboratories can build a culture of safety and trust that extends beyond the products they create.
Immediate Safety and Logistical Information
Proper waste disposal begins with a clear understanding of the immediate safety and logistical requirements. All laboratory personnel must be trained on these procedures before handling any chemical waste.
Key Principles of Laboratory Waste Management:
-
Identification and Classification: Accurately determine the type of waste being generated (e.g., chemical, biological, hazardous, non-hazardous) to ensure it is handled according to the correct protocols.
-
Segregation: Never mix incompatible waste streams.[1][2] Separate containers should be used for different waste categories to prevent dangerous reactions and facilitate proper disposal.[3]
-
Labeling: Clearly label all waste containers with the contents, date of accumulation, and any associated hazards. This is crucial for correct identification and handling during the disposal process.
-
Safe Storage: Store waste in a secure, designated area away from potential hazards and in compliance with all relevant regulations. This may involve using specific storage units for certain types of hazardous materials.
-
Professional Disposal: Partner with a licensed waste disposal service for the collection, treatment, and disposal of laboratory waste.
Quantitative Data on Laboratory Waste
While specific waste generation rates can vary significantly between laboratories, the following tables provide an overview of common laboratory waste streams and the associated disposal costs.
Table 1: Common Categories of Laboratory Waste
| Waste Category | Description | Examples |
| Chemical Waste | By-products, residues, or surplus chemicals from laboratory processes. | Solvents, reagents, acids, bases, heavy metals, and other chemical compounds.[3] |
| Infectious Waste | Also known as biohazardous waste, this includes materials contaminated with biological agents. | Cultures, stocks of infectious agents, and waste from the production of biologicals.[3] |
| Pathological Waste | Human or animal tissues, organs, and body parts. | Excised human tissues and organs, and animal carcasses from research.[3] |
| Sharps Waste | Items that can puncture or cut skin and are contaminated with biohazardous material. | Needles, syringes, scalpels, and broken glass.[3] |
| Pharmaceutical Waste | Unused, expired, or contaminated drugs and related materials. | Expired medications, contaminated personal protective equipment (PPE), and production residues.[4] |
Table 2: Average Chemical Waste Disposal Costs
The following data illustrates the average costs associated with the disposal of different classes of chemical waste, highlighting the financial benefit of bulking compatible wastes where permissible.
| Waste Classification | Average Cost per Kilogram (BULK) | Average Cost per Kilogram (LABPACK) |
| Class 9 | $2 | $9 |
| Combustible Liquid | $2 | $6 |
| Corrosive & Flammable liquid | x | $8 |
| Corrosive & Oxidizer | x | $7 |
| Corrosive & Poison | x | $26 |
| Dangerous When Wet, Flammable liquid and Corrosive | x | $41 |
| Dangerous When Wet, Spontaneously Combustible | x | $23 |
| Dangerous When Wet | x | $29 |
| Flammable Liquid | $3 | $10 |
| Flammable Liquid & Corrosive | $3 | $9 |
| Flammable Liquid & Poison | x | $16 |
| Flammable Solid | x | $23 |
| Oxidizer | x | $16 |
| Poison | x | $9 |
| (Data sourced from Missouri S&T Environmental Health and Safety; 'x' indicates that these chemicals are not typically bulked)[5] |
Experimental Protocols for Waste Handling
In some instances, it is permissible and recommended to treat certain chemical wastes within the laboratory before disposal. The following protocols provide detailed methodologies for common in-lab waste treatment procedures.
Protocol 1: Acid-Base Neutralization
This protocol is intended for the neutralization of small quantities of corrosive acids and bases that do not contain other hazardous components such as heavy metals.
Materials:
-
Appropriate personal protective equipment (PPE): lab coat, gloves, and safety goggles. A face shield is also recommended.[2]
-
Large beaker or container
-
Stirring rod
-
pH paper or pH meter
-
Cooling bath (e.g., ice water)
-
Dilute acidic or basic solution for neutralization
Procedure:
-
Preparation: Perform the neutralization in a fume hood.[2] For concentrated acids or bases (quantities of 25 ml or less), dilute them to a concentration of less than 10% by slowly adding the acid or base to a large volume of cold water.[2][3] Place the container in a cooling bath to manage heat generation.[2]
-
Neutralization of Acids: While stirring, slowly add a dilute basic solution (e.g., sodium bicarbonate or sodium hydroxide) to the acidic waste.[2][4]
-
Neutralization of Bases: While stirring, slowly add a dilute acidic solution (e.g., hydrochloric acid) to the basic waste.[2][4]
-
Monitoring pH: Continuously monitor the pH of the solution using pH paper or a pH meter.
-
Completion: Continue adding the neutralizing agent until the pH is between 5.5 and 9.0.[2]
-
Disposal: The neutralized solution can be disposed of down the sanitary sewer with a copious amount of water (at least 20 parts water).[2]
Protocol 2: Identification of Unknown Chemical Waste
When an unlabeled container of chemical waste is discovered, a series of simple tests can be performed to broadly categorize the hazard before sending it for professional analysis and disposal.
Materials:
-
Appropriate PPE (lab coat, gloves, safety goggles)
-
pH litmus paper
-
Potassium iodide (KI) starch paper
-
Flame source (e.g., Bunsen burner)
-
Cotton swab
Procedure:
-
Consult Personnel: Inquire with all laboratory personnel to determine if anyone can identify the unknown substance.[6]
-
Visual Inspection: Observe the physical characteristics of the substance (color, state) without opening the container if possible.
-
Corrosivity Test: Carefully obtain a small sample and test its pH using litmus paper. A pH between 0-2.5 (acidic) or 12-14 (basic) indicates a corrosive hazardous waste.
-
Oxidizer Test: Apply a small amount of a liquid sample to potassium iodide (KI) starch paper. The formation of a dark blue or violet color indicates the presence of an oxidizer.
-
Flammability Test (for liquids): In a safe, controlled environment such as a fume hood, dip a cotton swab into the liquid and pass it through a flame. Observe if it ignites.[7]
-
Labeling: Based on the results, label the container with the identified characteristics (e.g., "Unknown Corrosive Liquid," "Unknown Flammable Liquid"). This information is crucial for the waste disposal company.
Visualizing Disposal Procedures
The following diagrams illustrate key workflows and decision-making processes in laboratory waste management.
Caption: Chemical Waste Disposal Workflow.
Caption: Waste Segregation Decision Tree.
References
- 1. merckmillipore.com [merckmillipore.com]
- 2. Chapter 7 - Management Procedures For Specific Waste Types [ehs.cornell.edu]
- 3. In-Lab Disposal Methods: Waste Management Guide: Waste Management: Public & Environmental Health: Environmental Health & Safety: Protect IU: Indiana University [protect.iu.edu]
- 4. uwb.edu [uwb.edu]
- 5. haz_waste_mgmt_wmcost – Environmental Health and Safety | Missouri S&T [ehs.mst.edu]
- 6. Unknown Chemicals - Environmental Health and Safety - Purdue University [purdue.edu]
- 7. uttyler.edu [uttyler.edu]
Essential Safety and Logistical Information for Handling Orestrate
Disclaimer: There is limited specific safety and handling data available for Orestrate. This guide is based on the safety protocols for Estradiol, a closely related estrogenic compound, and should be used as a primary reference for establishing laboratory procedures. It is imperative to conduct a thorough risk assessment before handling Orestrate and to always consult with your institution's Environmental Health and Safety (EHS) department.
This document provides essential guidance for researchers, scientists, and drug development professionals on the safe handling, storage, and disposal of Orestrate. Adherence to these procedures is critical to ensure personal safety and minimize environmental impact.
Personal Protective Equipment (PPE)
The following personal protective equipment is mandatory when handling Orestrate to prevent skin contact, inhalation, and eye exposure.
| PPE Category | Specific Requirements |
| Hand Protection | Double-layered nitrile gloves are recommended. Change gloves immediately if contaminated. |
| Eye Protection | Chemical safety goggles or a face shield are required. |
| Body Protection | A buttoned-up lab coat must be worn. Consider a disposable gown for larger quantities. |
| Respiratory Protection | For powdered forms or when generating aerosols, a NIOSH-approved respirator is necessary. |
Operational Plan: Safe Handling Procedures
All work with Orestrate, particularly when handling the solid form or preparing solutions, must be conducted in a designated area, such as a chemical fume hood, to control exposure.
Step-by-Step Handling Protocol:
-
Preparation:
-
Ensure the chemical fume hood is functioning correctly.
-
Cover the work surface with absorbent, disposable bench paper.
-
Assemble all necessary equipment and reagents before introducing Orestrate to the work area.
-
Don the required personal protective equipment as outlined in the table above.
-
-
Weighing and Aliquoting:
-
Perform all weighing and aliquoting of solid Orestrate within the fume hood.
-
Use anti-static weigh boats to prevent dispersal of the powder.
-
Handle with care to avoid generating dust.
-
-
Solution Preparation:
-
When dissolving Orestrate, add the solvent to the powder slowly to avoid splashing.
-
Keep containers tightly sealed when not in use.
-
-
Post-Handling:
-
Decontaminate all surfaces and equipment after use.
-
Remove PPE in the correct order to avoid cross-contamination.
-
Wash hands thoroughly with soap and water after removing gloves.
-
Disposal Plan
Proper disposal of Orestrate and contaminated materials is crucial to prevent environmental contamination and ensure regulatory compliance.
Waste Segregation and Disposal:
-
Solid Waste: All disposable items that have come into contact with Orestrate, including gloves, bench paper, and weigh boats, must be collected in a designated, sealed hazardous waste container.
-
Liquid Waste: Unused solutions and solvent rinses should be collected in a clearly labeled, sealed hazardous waste container. Do not dispose of liquid waste down the drain.
-
Sharps: Any contaminated sharps, such as needles or razor blades, must be disposed of in a puncture-resistant sharps container.
All waste must be disposed of through your institution's hazardous waste management program.
Emergency Procedures
In the event of an exposure or spill, follow these immediate steps:
| Exposure Type | First Aid Measures |
| Skin Contact | Immediately wash the affected area with copious amounts of soap and water for at least 15 minutes. Remove contaminated clothing. |
| Eye Contact | Immediately flush eyes with a gentle stream of water for at least 15 minutes, holding the eyelids open. |
| Inhalation | Move to fresh air immediately. |
| Ingestion | Do not induce vomiting. Rinse mouth with water. |
In all cases of exposure, seek immediate medical attention and report the incident to your supervisor and EHS department.
Spill Response:
-
Small Spills: For small spills of solid material, gently cover with a damp paper towel to avoid raising dust, and then clean the area with a suitable decontaminating solution. For small liquid spills, absorb with an inert material and place in the hazardous waste container.
-
Large Spills: Evacuate the area and alert your institution's emergency response team.
Safe Handling Workflow Diagram
The following diagram illustrates the key steps for the safe handling of Orestrate in a laboratory setting.
Caption: Workflow for the safe handling of Orestrate.
Retrosynthesis Analysis
AI-Powered Synthesis Planning: Our tool employs the Template_relevance Pistachio, Template_relevance Bkms_metabolic, Template_relevance Pistachio_ringbreaker, Template_relevance Reaxys, Template_relevance Reaxys_biocatalysis model, leveraging a vast database of chemical reactions to predict feasible synthetic routes.
One-Step Synthesis Focus: Specifically designed for one-step synthesis, it provides concise and direct routes for your target compounds, streamlining the synthesis process.
Accurate Predictions: Utilizing the extensive PISTACHIO, BKMS_METABOLIC, PISTACHIO_RINGBREAKER, REAXYS, REAXYS_BIOCATALYSIS database, our tool offers high-accuracy predictions, reflecting the latest in chemical research and data.
Strategy Settings
| Precursor scoring | Relevance Heuristic |
|---|---|
| Min. plausibility | 0.01 |
| Model | Template_relevance |
| Template Set | Pistachio/Bkms_metabolic/Pistachio_ringbreaker/Reaxys/Reaxys_biocatalysis |
| Top-N result to add to graph | 6 |
Feasible Synthetic Routes




Featured Recommendations
| Most viewed |
|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
