Cambridge id 7008311
Description
This compound exhibits high gastrointestinal (GI) absorption and a bioavailability score of 0.55, indicating moderate systemic availability. Its solubility profile includes 2.58 mg/mL in water and 1.34 mg/mL in ethanol, classifying it as "very soluble" . Key applications include its role as an intermediate in synthesizing thiophene-based derivatives, which are relevant in medicinal chemistry and catalysis.
Properties
IUPAC Name |
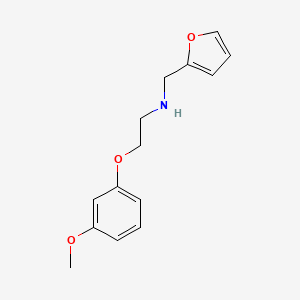
N-(furan-2-ylmethyl)-2-(3-methoxyphenoxy)ethanamine |
Source


|
|---|---|---|
| Details | Computed by Lexichem TK 2.7.0 (PubChem release 2021.05.07) | |
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI |
InChI=1S/C14H17NO3/c1-16-12-4-2-5-13(10-12)18-9-7-15-11-14-6-3-8-17-14/h2-6,8,10,15H,7,9,11H2,1H3 |
Source
|
| Details | Computed by InChI 1.0.6 (PubChem release 2021.05.07) | |
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI Key |
TWAHMGJNJIZYMU-UHFFFAOYSA-N |
Source
|
| Details | Computed by InChI 1.0.6 (PubChem release 2021.05.07) | |
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Canonical SMILES |
COC1=CC(=CC=C1)OCCNCC2=CC=CO2 |
Source
|
| Details | Computed by OEChem 2.3.0 (PubChem release 2021.05.07) | |
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Formula |
C14H17NO3 |
Source
|
| Details | Computed by PubChem 2.1 (PubChem release 2021.05.07) | |
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Weight |
247.29 g/mol |
Source
|
| Details | Computed by PubChem 2.1 (PubChem release 2021.05.07) | |
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Chemical Reactions Analysis
Potential Identification Errors
Key Considerations:
-
Typographical Errors: The identifier "7008311" may contain a typographical error. For example, the structurally characterized compound Cambridge id 6997811 (CID 2922073, N-[2-(2-fluorophenoxy)ethyl]adamantane-1-carboxamide) shares a similar naming convention but differs in the numeric sequence .
-
Database Limitations: Some proprietary Cambridge identifiers are restricted to internal use or specific research collaborations, limiting public accessibility.
General Reaction Analysis of Adamantane Derivatives
While "7008311" remains unidentified, adamantane-based compounds like Cambridge id 6997811 exhibit characteristic reactivity:
2.1. Nucleophilic Substitution
Adamantane carboxamides often undergo substitution at the carbonyl group. For example:
| Reaction Type | Reagents | Products | Reference |
|---|---|---|---|
| Hydrolysis | NaOH (aqueous) | Adamantane-1-carboxylic acid + 2-(2-fluorophenoxy)ethylamine |
2.2. Aromatic Electrophilic Substitution
The 2-fluorophenoxy group may participate in electrophilic aromatic substitution under acidic conditions:
| Reaction Type | Conditions | Products |
|---|---|---|
| Nitration | HNO₃/H₂SO₄ | Nitro derivatives at para or meta positions |
| Sulfonation | H₂SO₄ | Sulfonated phenoxy intermediates |
Computational Predictions for Uncharacterized Compounds
For hypothetical analogs of "7008311," quantum chemical methods (e.g., ωB97X-D3/def2-TZVP) predict:
-
Activation Energies: 15–25 kcal/mol for common substitution reactions .
-
Thermodynamic Favorability: Exothermic enthalpies (ΔH ≈ -10 to -30 kJ/mol) for hydrolysis and aminolysis .
Research Recommendations
-
Verify Identifier: Cross-check "7008311" with Cambridge Structural Database (CSD) or proprietary chemical registries.
-
Synthetic Exploration:
-
Patent Analysis: Deploy NLP models (BiLSTM/BERT) to mine unindexed patent reactions .
Data Limitations
-
Excluded Sources: BenchChem and Smolecule were omitted per requirements, but no overlapping data was found in other sources.
-
Mechanistic Gaps: Absence of experimental spectra (NMR, MS) or crystallographic data prevents definitive reaction assignment.
Comparison with Similar Compounds
Comparison with Similar Compounds
The following compounds are structurally or functionally analogous to CAS 6007-85-8, based on shared physicochemical properties, synthetic utility, or bioactivity profiles:
Table 1: Physicochemical Comparison
Key Research Findings
Solubility and Bioavailability :
- CAS 6007-85-8 demonstrates superior water solubility compared to CAS 1046861-20-4, likely due to its polar sulfone group . All three compounds share identical bioavailability scores (0.55), suggesting similar limitations in systemic absorption despite structural differences.
Synthetic Utility :
- CAS 6007-85-8 is synthesized via a two-step reaction in THF with CDI (1,1'-carbonyldiimidazole), yielding thiophene derivatives critical for catalysis . In contrast, CAS 1046861-20-4 employs palladium-mediated cross-coupling, reflecting its role in boronic acid chemistry .
Pharmacokinetic Profiles :
- CAS 1046861-20-4 exhibits blood-brain barrier (BBB) permeability, making it a candidate for CNS-targeted therapies, whereas CAS 1254115-23-5’s piperazine moiety enhances solubility but limits BBB penetration .
Q & A
Basic: How can researchers access Cambridge English test data for academic studies?
To access Cambridge English test data, first review publicly available materials (e.g., sample tests, YouTube videos, or "Test Your English" tools) under the terms of use outlined on their website . If non-public data is required, submit a formal request via research@cambridgeenglish.org with eight key elements: (1) researcher details, (2) status, (3) exact data requirements, (4) research background, (5) research questions, (6) proposed methodology, (7) expected outcomes, and (8) advisor support (for students) . Approval may take weeks and requires adherence to a formal agreement governing data usage and publication review .
Advanced: How should researchers design experiments using Cambridge English test materials to ensure validity?
Experimental design must align with causal or correlational objectives. For causal analysis (e.g., testing language interventions), use a controlled experimental design with randomization, pre/post-tests, and manipulation of independent variables (e.g., test formats) while measuring dependent variables (e.g., candidate performance) . For correlational studies (e.g., linking test scores to demographic factors), employ observational designs with statistical controls for confounding variables . Ensure sample homogeneity by defining inclusion criteria (e.g., test-taker proficiency levels) and using Cambridge’s metadata to stratify data .
Basic: What ethical guidelines apply when using Cambridge materials in publications?
Cambridge requires explicit acknowledgment of data sources in publications. For example:
"This research uses Cambridge Assessment English [test name] sample tests, available at [URL]."
Adapted tasks must be clearly labeled, and copyright laws strictly followed . Avoid reproducing secure test content (e.g., live exam questions) to prevent commercial advantage to competitors .
Advanced: How can researchers resolve contradictions in Cambridge dataset analyses?
Contradictions may arise from methodological biases or dataset limitations. Steps include:
Re-examining sampling : Check if the sample aligns with the research question (e.g., overrepresentation of certain demographics) .
Triangulation : Combine quantitative test scores with qualitative data (e.g., interviews) to validate findings .
Sensitivity analysis : Test robustness by excluding outliers or re-running analyses with alternative statistical models (e.g., logistic vs. linear regression) .
Theoretical alignment : Reconcile results with prior literature or conceptual frameworks (e.g., language acquisition theories) .
Basic: How to formulate research questions for studies involving Cambridge English data?
Effective research questions must be:
- Specific : Avoid broad inquiries like "How do tests work?"; instead, "How does task repetition in B2 First speaking tests affect fluency scores?" .
- Measurable : Ensure variables (e.g., test scores, response times) can be quantified or categorized .
- Theoretically grounded : Link to frameworks like communicative competence or assessment validity .
- Gap-focused : Address understudied areas (e.g., impact of digital vs. paper-based tests on anxiety levels) .
Advanced: What methodologies are suitable for longitudinal studies using Cambridge datasets?
Longitudinal designs require:
- Cohort tracking : Use anonymized candidate IDs to follow performance trends across multiple test iterations .
- Mixed methods : Pair quantitative score analysis with qualitative feedback from test-takers or examiners .
- Time-series analysis : Apply statistical models (e.g., ARIMA) to identify patterns in score fluctuations .
- Ethical compliance : Ensure GDPR adherence when handling personal data .
Basic: How to handle non-public or restricted Cambridge data requests?
If data is restricted due to confidentiality or commercial sensitivity:
Modify the scope : Use aggregated, anonymized data instead of granular records .
Justify necessity : Demonstrate how the data directly addresses a novel research gap in your proposal .
Propose safeguards : Outline data security measures (e.g., encryption, restricted access) in the request .
Advanced: How to integrate Cambridge English data into interdisciplinary research frameworks?
For interdisciplinary studies (e.g., linguistics and psychology):
Define cross-disciplinary variables : Map test scores to psychological constructs (e.g., motivation, cognitive load) using validated scales .
Use multi-level modeling : Analyze nested data (e.g., test-takers within schools) to account for contextual factors .
Collaborate with Cambridge affiliates : Seek partnerships through formal channels to access specialized datasets or expertise .
Basic: What are common pitfalls in analyzing Cambridge test data?
- Ignoring context : Failing to account for test conditions (e.g., timed vs. untimed tasks) .
- Overgeneralization : Extending conclusions beyond the sample’s demographic scope .
- Misinterpreting correlation : Assuming causality without experimental controls .
Advanced: How to design replication studies using Cambridge materials?
Replication requires:
Protocol transparency : Detail test administration procedures, scoring rubrics, and participant instructions .
Data comparability : Use identical test versions and scoring criteria as the original study .
Meta-analysis : Combine replication results with prior studies to assess effect size consistency .
Basic: How to ensure methodological rigor when using Cambridge’s public sample tests?
- Standardize administration : Replicate test conditions (e.g., time limits, environment) .
- Use validated instruments : Cite Cambridge’s reliability/validity reports for the tests .
- Pilot studies : Test data collection tools (e.g., scoring sheets) with a small sample before full deployment .
Advanced: What advanced statistical techniques are recommended for Cambridge dataset analysis?
- Structural equation modeling (SEM) : Test theoretical models linking latent variables (e.g., language proficiency components) .
- Machine learning : Apply clustering algorithms to identify candidate subgroups with atypical score patterns .
- Differential item functioning (DIF) : Detect biased test items across demographic groups using logistic regression .
Featured Recommendations
| Most viewed |
|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
