nor-1
Description
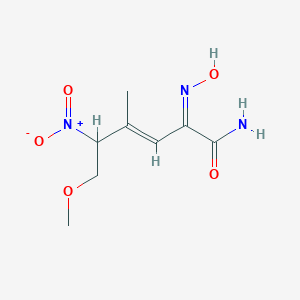
The exact mass of the compound (E,2Z)-2-hydroxyimino-6-methoxy-4-methyl-5-nitrohex-3-enamide is unknown and the complexity rating of the compound is unknown. Its Medical Subject Headings (MeSH) category is Chemicals and Drugs Category - Organic Chemicals - Carboxylic Acids - Acids, Carbocyclic - Benzoates - Supplementary Records. The United Nations designated GHS hazard class pictogram is Irritant, and the GHS signal word is WarningThe storage condition is unknown. Please store according to label instructions upon receipt of goods.
BenchChem offers high-quality nor-1 suitable for many research applications. Different packaging options are available to accommodate customers' requirements. Please inquire for more information about nor-1 including the price, delivery time, and more detailed information at info@benchchem.com.
Properties
CAS No. |
163032-70-0 |
|---|---|
Molecular Formula |
C8H13N3O5 |
Molecular Weight |
231.21 g/mol |
IUPAC Name |
(E)-2-hydroxyimino-6-methoxy-4-methyl-5-nitrohex-3-enamide |
InChI |
InChI=1S/C8H13N3O5/c1-5(3-6(10-13)8(9)12)7(4-16-2)11(14)15/h3,7,13H,4H2,1-2H3,(H2,9,12)/b5-3+,10-6? |
InChI Key |
HCUOEKSZWPGJIM-MPSCHTTFSA-N |
SMILES |
CC(=CC(=NO)C(=O)N)C(COC)[N+](=O)[O-] |
Isomeric SMILES |
C/C(=C\C(=NO)C(=O)N)/C(COC)[N+](=O)[O-] |
Canonical SMILES |
CC(=CC(=NO)C(=O)N)C(COC)[N+](=O)[O-] |
Pictograms |
Irritant |
Synonyms |
1,3-dihydroxy-4,4,5,5-tetramethyl-2-(4-carboxyphenyl)tetrahydroimidazole 1,3-DTCTI 2-(4-carboxyphenyl)-4,4,5,5-tetramethylimidazoline-1-oxyl-3-oxide carboxy-PTIO cPTIO NOR 1 |
Origin of Product |
United States |
The Function of NOR-1 in Apoptosis: A Technical Guide
For: Researchers, Scientists, and Drug Development Professionals
Executive Summary
Neuron-derived orphan receptor 1 (NOR-1), also known as NR4A3, is a member of the NR4A nuclear receptor family. Initially identified for its role in neuronal development, NOR-1 has emerged as a critical, albeit complex, regulator of apoptosis.[1][2] Its function is highly context-dependent, acting as a pro-apoptotic tumor suppressor in various cancers, while exhibiting anti-apoptotic, protective effects in other cell types like cardiomyocytes under specific stress conditions.[3][4] In cancer cells, NOR-1 typically induces apoptosis by modulating the intrinsic mitochondrial pathway, altering the expression of Bcl-2 family proteins and activating the caspase cascade, often in conjunction with the MAPK signaling pathway.[3][5] Conversely, in doxorubicin-stressed cardiomyocytes, NOR-1 can promote survival by enhancing ERK signaling and upregulating the anti-apoptotic protein Bcl-xL.[4] This guide provides an in-depth technical overview of the molecular mechanisms, signaling pathways, and experimental methodologies used to elucidate the multifaceted role of NOR-1 in apoptosis.
Core Mechanisms of NOR-1 in Apoptosis
NOR-1's role in apoptosis is not monolithic; it is dictated by the cellular environment and the nature of the apoptotic stimulus. The two primary, contrasting roles are detailed below.
Pro-Apoptotic Function in Cancer Cells
In several types of cancer, including prostate, nasopharyngeal, and cervical cancer, NOR-1 functions as a tumor suppressor by promoting apoptosis.[3][6] Overexpression of NOR-1 in these cells triggers a cascade of events leading to programmed cell death. The mechanism primarily involves the intrinsic (mitochondrial) pathway of apoptosis.
Signaling Pathway Overview: Overexpression of NOR-1 leads to the activation of the MAPK signaling pathway.[3] This, in turn, modulates the balance of Bcl-2 family proteins at the mitochondria. NOR-1 upregulates the expression of pro-apoptotic members Bax and Bak while downregulating the anti-apoptotic proteins Bcl-2 and Bcl-xL.[3][5] This shift disrupts the mitochondrial outer membrane integrity, leading to the release of cytochrome c into the cytosol. Cytochrome c then binds to Apaf-1, forming the apoptosome, which recruits and activates initiator caspase-9.[7] Activated caspase-9 proceeds to cleave and activate executioner caspase-3, which orchestrates the final stages of apoptosis by cleaving key cellular substrates.[3][8]
Anti-Apoptotic Function in Stressed Cardiomyocytes
In contrast to its role in cancer, NOR-1 can exert a protective, anti-apoptotic effect in specific contexts, such as in human cardiomyocytes subjected to Doxorubicin (DOX)-induced stress.[4][9] DOX is an anti-cancer drug known for its cardiotoxicity, which is partly mediated by the induction of apoptosis.[9]
Signaling Pathway Overview: In this scenario, overexpression of NOR-1 enhances the phosphorylation and activation of extracellular signal-regulated kinase (ERK).[4] Activated ERK is a key component of pro-survival signaling pathways. This leads to a significant increase in the expression of the anti-apoptotic protein Bcl-xL.[4] Elevated levels of Bcl-xL stabilize the mitochondrial membrane, preventing the release of cytochrome c and subsequent activation of the caspase cascade. The net result is a significant decrease in caspase-3 activity, reduced cell death, and improved cardiomyocyte viability.[4]
Quantitative Data on NOR-1's Apoptotic Function
The effects of NOR-1 on apoptosis have been quantified in various studies. The following table summarizes key findings from experiments involving NOR-1 overexpression or knockdown.
| Cell Line | Condition / Treatment | NOR-1 Status | Observed Effect | Quantitative Result | Reference |
| PC3 (Prostate Cancer) | Standard Culture (72h) | Overexpression | Increased Apoptosis | Total apoptotic rate increased by 46% | [3][5] |
| AC16 (Cardiomyocyte) | Doxorubicin (DOX) Stress | Overexpression | Decreased Apoptosis | Significant decrease in caspase-3 activity (p < 0.01) | [4] |
| AC16 (Cardiomyocyte) | Doxorubicin (DOX) Stress | Overexpression | Increased Viability | Significant increase in cell viability (p < 0.05) | [4] |
| AC16 (Cardiomyocyte) | Doxorubicin (DOX) Stress | Overexpression | Increased ERK Activation | Significant increase in ERK phosphorylation (p < 0.01) | [4] |
| AC16 (Cardiomyocyte) | Doxorubicin (DOX) Stress | Overexpression | Increased Bcl-xL | Significant increase in Bcl-xL expression (p < 0.01) | [4] |
| HeLa (Cervical Cancer) | H₂O₂ Stress | Knockdown | Decreased Apoptosis | Attenuated H₂O₂-induced apoptosis | [10] |
Experimental Protocols for Studying NOR-1 in Apoptosis
Investigating the role of NOR-1 requires a combination of molecular biology, cell biology, and biochemical techniques. Below are detailed protocols for key experiments.
Gene Overexpression and Knockdown
-
Objective: To modulate NOR-1 expression levels to study its functional effects.
-
Overexpression Protocol:
-
Vector Construction: The full-length cDNA of NOR-1 is cloned into an expression vector (e.g., pcDNA3.1-myc-his).
-
Transfection: Cancer cell lines (e.g., PC3, HeLa) are seeded to reach 70-80% confluency. Transfection is performed using a lipid-based reagent like Lipofectamine 2000, with the NOR-1 expression vector or an empty vector control.[6]
-
Stable Cell Line Generation: 48 hours post-transfection, cells are cultured in a selection medium containing an appropriate antibiotic (e.g., G418 at 500 µg/ml).[6]
-
Verification: Overexpression is confirmed at both mRNA (RT-qPCR) and protein (Western Blot) levels.
-
-
Knockdown Protocol:
-
Reagent Design: Small interfering RNAs (siRNAs) or short hairpin RNAs (shRNAs) targeting the NOR-1 mRNA sequence are designed. For shRNA, sequences are cloned into a suitable vector like pSUPER.neo+GFP.[10]
-
Transfection/Transduction: Cells are transfected with siRNA duplexes or transduced with shRNA-containing vectors.
-
Verification: Knockdown efficiency is assessed by measuring the reduction in NOR-1 mRNA and protein levels compared to a scramble/non-targeting control.[10]
-
Apoptosis Quantification by Flow Cytometry
-
Objective: To quantify the percentage of apoptotic and necrotic cells.
-
Protocol (Annexin V/PI Staining):
-
Cell Harvest: Both adherent and floating cells are collected, washed with cold PBS.
-
Resuspension: Cells are resuspended in 1X Annexin V Binding Buffer at a concentration of 1 x 10⁶ cells/ml.
-
Staining: Fluorescein isothiocyanate (FITC)-conjugated Annexin V and Propidium Iodide (PI) are added to the cell suspension.
-
Incubation: The mixture is incubated for 15 minutes at room temperature in the dark.
-
Analysis: Stained cells are analyzed immediately by flow cytometry.[3]
-
Annexin V- / PI-: Live cells.
-
Annexin V+ / PI-: Early apoptotic cells.
-
Annexin V+ / PI+: Late apoptotic/necrotic cells.
-
-
Western Blot Analysis of Apoptotic Proteins
-
Objective: To measure changes in the expression levels of key proteins in the apoptotic pathway.
-
Protocol:
-
Protein Extraction: Cells are lysed in RIPA buffer containing protease and phosphatase inhibitors. Protein concentration is determined using a BCA assay.
-
SDS-PAGE: Equal amounts of protein (20-40 µg) are separated on a polyacrylamide gel.
-
Transfer: Proteins are transferred from the gel to a PVDF membrane.
-
Blocking: The membrane is blocked for 1 hour in 5% non-fat milk or BSA in TBST.
-
Primary Antibody Incubation: The membrane is incubated overnight at 4°C with primary antibodies against target proteins (e.g., NOR-1, Bcl-2, Bax, cleaved caspase-3, cleaved PARP, p-ERK) and a loading control (e.g., β-actin, GAPDH).[11]
-
Secondary Antibody Incubation: After washing, the membrane is incubated with an HRP-conjugated secondary antibody for 1 hour at room temperature.
-
Detection: The signal is detected using an enhanced chemiluminescence (ECL) substrate and imaged. Band intensity is quantified using densitometry software.
-
Subcellular Localization and Apoptotic Function
The location of NOR-1 within the cell is crucial to its function. Studies have shown that NOR-1 is a cytoplasmic protein that can also partially localize to the mitochondria and the endoplasmic reticulum (ER).[6] This distribution is significant because both organelles are central hubs for apoptosis regulation.
-
Mitochondrial Localization: Its presence at the mitochondria places it in direct proximity to the Bcl-2 family proteins it regulates, allowing it to efficiently influence mitochondrial outer membrane permeabilization.[6]
-
ER Localization: Localization at the ER suggests a potential role in ER stress-induced apoptosis.[11] ER stress, caused by the accumulation of unfolded proteins, can trigger apoptosis through pathways involving caspase activation, and NOR-1 may be a component of this response.[12][13]
Conclusion and Future Directions
NOR-1 is a potent, context-dependent modulator of apoptosis. In cancer cells, it typically acts as a tumor suppressor by activating the intrinsic apoptotic pathway. In contrast, it can protect cardiomyocytes from toxin-induced apoptosis, highlighting its therapeutic potential in both oncology and cardiology.
Future research should focus on:
-
Upstream Regulation: Identifying the specific signals and transcription factors that regulate NOR-1 expression in different cellular contexts.
-
Direct Targets: Uncovering the direct downstream gene targets of NOR-1's transcriptional activity that mediate its apoptotic effects.
-
Post-Translational Modifications: Investigating how phosphorylation, SUMOylation, or other modifications affect NOR-1's stability, localization, and apoptotic function.[14]
-
Therapeutic Targeting: Developing small molecules or biologics that can either mimic the pro-apoptotic activity of NOR-1 in cancer cells or enhance its protective effects in conditions like chemotherapy-induced cardiotoxicity.
References
- 1. Comprehensive insights into the function and molecular and pharmacological regulation of neuron-derived orphan receptor 1, an orphan receptor - PMC [pmc.ncbi.nlm.nih.gov]
- 2. frontiersin.org [frontiersin.org]
- 3. spandidos-publications.com [spandidos-publications.com]
- 4. Overexpression of Neuron-Derived Orphan Receptor 1 (NOR-1) Rescues Cardiomyocytes from Cell Death and Improves Viability after Doxorubicin Induced Stress - PMC [pmc.ncbi.nlm.nih.gov]
- 5. spandidos-publications.com [spandidos-publications.com]
- 6. spandidos-publications.com [spandidos-publications.com]
- 7. Apoptosis: A Comprehensive Overview of Signaling Pathways, Morphological Changes, and Physiological Significance and Therapeutic Implications - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Human Caspases: Activation, Specificity, and Regulation - PMC [pmc.ncbi.nlm.nih.gov]
- 9. mdpi.com [mdpi.com]
- 10. [Effect of NOR1 gene knockdown on the biological behavior of HeLa cells]. | Semantic Scholar [semanticscholar.org]
- 11. researchgate.net [researchgate.net]
- 12. Mediators of endoplasmic reticulum stress-induced apoptosis - PMC [pmc.ncbi.nlm.nih.gov]
- 13. ER stress-induced cell death mechanisms - PMC [pmc.ncbi.nlm.nih.gov]
- 14. researchgate.net [researchgate.net]
An In-depth Technical Guide to NR4A3 Gene Regulation and Transcriptional Control
Audience: Researchers, Scientists, and Drug Development Professionals
Executive Summary
The Nuclear Receptor Subfamily 4 Group A Member 3 (NR4A3), also known as Neuron-Derived Orphan Receptor 1 (NOR-1), is a member of the orphan nuclear receptor superfamily.[1][2] Unlike typical nuclear receptors, NR4A3 and its family members (NR4A1/Nur77 and NR4A2/Nurr1) are considered constitutively active, with their transcriptional activity being largely dependent on their expression levels and post-translational modifications rather than direct ligand binding.[3] NR4A3 is an immediate-early gene, rapidly and transiently induced by a wide array of stimuli, including growth factors, cytokines, hormones, and cellular stress.[3][4] It plays a pivotal role in a multitude of cellular processes such as proliferation, apoptosis, inflammation, metabolism, and differentiation.[1][5] Its dysregulation is implicated in various pathologies, including cancer, cardiovascular diseases, and inflammatory disorders, making it a subject of intense research and a potential therapeutic target.[3][6] This guide provides a comprehensive overview of the molecular mechanisms governing NR4A3 gene expression and its function as a transcription factor.
Regulation of NR4A3 Gene Expression
The expression of the NR4A3 gene is tightly controlled by a variety of signaling pathways that respond to extracellular and intracellular cues. This rapid inducibility is a hallmark of its function as a critical sensor and responder to changes in the cellular microenvironment.[4]
Upstream Signaling Pathways
Several key signaling cascades converge on the NR4A3 promoter to activate its transcription.
-
Protein Kinase A (PKA) Pathway: In neutrophils and other cell types, factors that elevate intracellular cyclic adenosine (B11128) monophosphate (cAMP) levels, such as adenosine and prostaglandin (B15479496) E2 (PGE2), lead to the activation of PKA.[7] This activation results in a profound upregulation of NR4A3 expression.[7] The induction of NR4A3 by these agonists is shown to be PKA-dependent.[7]
-
Growth Factor Signaling: Growth factors are potent inducers of NR4A3 expression.[3] For instance, Vascular Endothelial Growth Factor (VEGF) and Platelet-Derived Growth Factor (PDGF) have been shown to strongly and transiently upregulate NR4A3 in endothelial cells and vascular smooth muscle cells, respectively.[3][5]
-
Stress and Inflammatory Signals: Cellular stressors like hypoxia and inflammatory cytokines such as Tumor Necrosis Factor-alpha (TNF-α) and Lipopolysaccharide (LPS) can induce NR4A3 expression in various cell types, including macrophages.[3]
-
p53 Tumor Suppressor Pathway: In the context of cancer, the tumor suppressor p53 can directly activate NR4A3 gene expression, suggesting that NR4A3 may function as a downstream effector of p53-mediated apoptosis and tumor suppression in certain cancers like breast and lung cancer.[4][8]
Epigenetic Control
Recent evidence suggests that epigenetic modifications play a role in regulating NR4A3 expression. In response to muscle contraction, the Nr4a3 promoter undergoes rapid hydroxymethylation, which is preceded by demethylation.[9] This dynamic epigenetic remodeling highlights a sophisticated layer of control that fine-tunes NR4A3 expression in response to physiological stimuli like exercise.[9]
Transcriptional Control by the NR4A3 Protein
Once translated, the NR4A3 protein moves to the nucleus where it functions as a transcription factor to regulate a specific set of target genes.[1][10]
DNA Binding Mechanisms
NR4A3 can bind to specific DNA sequences in the promoter regions of its target genes through several mechanisms:[3][5]
-
Monomeric Binding: It can bind as a monomer to the NGFI-B response element (NBRE), which has a consensus sequence of 5'-AAAAGGTCA-3'.[3][5]
-
Homodimeric Binding: It can form a homodimer and bind to the Nur response element (NurRE).[3][5]
-
Heterodimerization: Unlike its family members NR4A1 and NR4A2, NR4A3 does not typically heterodimerize with the Retinoid X Receptor (RXR).[3]
-
Tethering/Crosstalk: NR4A3 can indirectly modulate gene expression by interacting with other transcription factors, such as NF-κB and Myb, thereby influencing their activity.[3][11]
Downstream Target Genes and Cellular Functions
NR4A3 orchestrates a wide range of biological outcomes by controlling the expression of specific target genes. Its function can be highly context- and cell-type-dependent, sometimes exhibiting paradoxical roles as both a tumor suppressor and a pro-oncogenic factor.[6]
-
Cell Proliferation and Survival: In vascular smooth muscle cells, NR4A3 promotes proliferation by upregulating key cell cycle genes like CCND1, CCND2, and SKP2.[5] Conversely, in hematopoietic stem cells, it can suppress hyper-proliferation by activating the transcription of Cebpa.[2] In some contexts, it promotes cell survival by mediating CREB-induced neuronal survival signals.[5]
-
Inflammation: NR4A3 plays a complex role in inflammation. Upon TNF stimulation in monocytes, it can induce the expression of adhesion molecules VCAM1 and ICAM1.[5] However, other studies support an anti-inflammatory role, potentially through the antagonism of the NF-κB pathway.[3]
-
Metabolism: In skeletal muscle, NR4A3 is induced by exercise and repressed by inactivity.[12] It is a key regulator of glucose metabolism, with its downregulation leading to reduced glucose oxidation and increased lactate (B86563) production.[12][13] It also influences the translocation of the SLC2A4 (GLUT4) glucose transporter to the cell surface.[5]
-
Cancer: The role of NR4A3 in cancer is multifaceted. In acute myeloid leukemia (AML) and some lymphomas, it acts as a tumor suppressor.[6][14] In contrast, in acinic cell carcinomas and extraskeletal myxoid chondrosarcoma, it exhibits pro-oncogenic activity, sometimes through cooperation with other oncoproteins like MYB.[6][11]
Data Presentation
Table 1: NR4A3 Expression in Human Tissues
This table summarizes the relative expression of NR4A3 at the RNA level across various human tissues, based on data from the Human Protein Atlas.[15]
| Tissue Group | Specific Tissue | Consensus Normalized Expression (NX) |
| Brain | Cerebral Cortex | 27.6 |
| Cerebellum | 15.6 | |
| Muscle Tissues | Skeletal Muscle | 24.5 |
| Heart Muscle | 14.8 | |
| Endocrine Tissues | Adrenal Gland | 22.8 |
| Thyroid Gland | 14.0 | |
| Adipose Tissue | Adipose Tissue | 19.9 |
| Immune System | Bone Marrow | 16.7 |
| Lymph Node | 5.2 | |
| Glandular Tissues | Salivary Gland | 10.1 |
| Reproductive | Ovary | 10.3 |
| Testis | 6.8 |
Data sourced from The Human Protein Atlas. NX values represent normalized expression from a combination of HPA and GTEx datasets.[15]
Table 2: Inducers of NR4A3 Expression
| Stimulus/Inducer | Cell/Tissue Type | Key Signaling Pathway |
| Prostaglandin E2 (PGE2) | Neutrophils | PKA |
| Adenosine | Neutrophils | PKA |
| Forskolin / db-cAMP | INS-1E cells, Rat Islets | PKA |
| VEGF | Endothelial Cells | Receptor Tyrosine Kinase |
| PDGF | Vascular Smooth Muscle Cells | Receptor Tyrosine Kinase |
| Thrombin | Endothelial Cells | G-protein Coupled Receptor |
| LDL | Vascular Smooth Muscle Cells | CREB |
| TNF-α / LPS | THP-1 Macrophages | Inflammatory Pathways |
| Exercise / Muscle Contraction | Skeletal Muscle | Physiological Stress |
| p53 Activation | Breast and Lung Cancer Cells | p53 Pathway |
This table is a synthesis of information from multiple sources.[3][4][7][9][16]
Table 3: Selected Downstream Target Genes of NR4A3
| Target Gene | Regulation by NR4A3 | Biological Process | Cell Type |
| CCND1 (Cyclin D1) | Upregulation | Cell Cycle Progression, Proliferation | Vascular Smooth Muscle Cells |
| SKP2 | Upregulation | Cell Cycle Progression | Vascular Smooth Muscle Cells |
| CDKN2AIP | Upregulation | Cell Cycle Arrest (G0/G1) | Hepatocellular Carcinoma Cells |
| VCAM1, ICAM1 | Upregulation | Monocyte Adhesion, Inflammation | Monocytes |
| RUNX1 | Repression | Myeloid Progenitor Proliferation | Myeloid Progenitor Cells |
| Cebpa | Upregulation | Hematopoietic Stem Cell Differentiation | Hematopoietic Stem Cells |
| FOXO1 | Indirect Repression | DC Migration (via CCR7) | CD103+ Dendritic Cells |
| ENO3, SERPINE2 | Upregulation | Metabolism, Other | NCI-H292 Cells |
This table is a synthesis of information from multiple sources.[2][5][11][17][18]
Key Experimental Protocols
This section provides detailed methodologies for common experiments used to study NR4A3 regulation and function.
RT-qPCR for NR4A3 Expression Analysis
This protocol is used to quantify the relative abundance of NR4A3 mRNA in cells or tissues.
-
RNA Isolation: Extract total RNA from cells or homogenized tissue using a TRIzol-based method or a column-based kit (e.g., RNeasy Kit, Qiagen) according to the manufacturer's instructions. Assess RNA quality and quantity using a spectrophotometer (e.g., NanoDrop).
-
cDNA Synthesis: Synthesize first-strand complementary DNA (cDNA) from 1 µg of total RNA using a reverse transcription kit (e.g., iScript cDNA Synthesis Kit, Bio-Rad) with a mix of oligo(dT) and random hexamer primers.[19]
-
Primer Design: Design primers specific to the human NR4A3 transcript. Primers should span an exon-exon junction to avoid amplification of genomic DNA. Use tools like Primer-BLAST (NCBI) to ensure specificity. Also, design primers for a stable housekeeping gene (e.g., GAPDH, ACTB) for normalization.
-
Quantitative PCR (qPCR): Prepare the qPCR reaction mix containing cDNA template, forward and reverse primers, and a SYBR Green-based qPCR master mix. Perform the reaction on a real-time PCR system. A typical thermal cycling profile is: 95°C for 5 min, followed by 40 cycles of 95°C for 15 s and 60°C for 60 s.[18]
-
Data Analysis: Determine the cycle threshold (Ct) for NR4A3 and the housekeeping gene. Calculate the relative expression of NR4A3 using the ΔΔCt method, normalizing the expression in the test sample to a control sample.
Chromatin Immunoprecipitation (ChIP) Assay
This protocol is used to identify the genomic regions where NR4A3 protein binds.
-
Cross-linking: Treat cells (e.g., 1x10⁷ MHCC-97L cells) with 1% formaldehyde (B43269) for 10 minutes at room temperature to cross-link proteins to DNA. Quench the reaction with 0.125 M glycine.[20]
-
Cell Lysis and Chromatin Shearing: Lyse the cells and isolate the nuclei. Shear the chromatin into fragments of 200-1000 bp using sonication or enzymatic digestion (e.g., micrococcal nuclease).
-
Immunoprecipitation (IP): Pre-clear the chromatin lysate with Protein A/G beads. Incubate the cleared chromatin overnight at 4°C with an anti-NR4A3 antibody or a control IgG.
-
Immune Complex Capture: Add Protein A/G beads to the antibody-chromatin mixture to capture the immune complexes.
-
Washing: Wash the beads sequentially with low-salt, high-salt, LiCl, and TE buffers to remove non-specific binding.
-
Elution and Reverse Cross-linking: Elute the chromatin from the beads. Reverse the protein-DNA cross-links by heating at 65°C overnight with NaCl. Treat with RNase A and Proteinase K to remove RNA and protein.
-
DNA Purification: Purify the immunoprecipitated DNA using a PCR purification kit.
-
Analysis: Analyze the purified DNA by qPCR using primers specific for a suspected target promoter (e.g., the CDKN2AIP promoter) or by high-throughput sequencing (ChIP-seq) to identify binding sites genome-wide.[20]
References
- 1. Nuclear receptor 4A3 - Wikipedia [en.wikipedia.org]
- 2. taylorandfrancis.com [taylorandfrancis.com]
- 3. NR4A3: A Key Nuclear Receptor in Vascular Biology, Cardiovascular Remodeling, and Beyond | MDPI [mdpi.com]
- 4. Targeting NR4A Nuclear Receptors to Control Stromal Cell Inflammation, Metabolism, Angiogenesis, and Tumorigenesis - PMC [pmc.ncbi.nlm.nih.gov]
- 5. uniprot.org [uniprot.org]
- 6. The Paradoxical Roles of Orphan Nuclear Receptor 4A (NR4A) in Cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 7. NR4A orphan nuclear receptor family members, NR4A2 and NR4A3, regulate neutrophil number and survival - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Frontiers | Targeting NR4A Nuclear Receptors to Control Stromal Cell Inflammation, Metabolism, Angiogenesis, and Tumorigenesis [frontiersin.org]
- 9. Muscle Contraction Induces Acute Hydroxymethylation of the Exercise-Responsive Gene Nr4a3 - PMC [pmc.ncbi.nlm.nih.gov]
- 10. genecards.org [genecards.org]
- 11. mdpi.com [mdpi.com]
- 12. biorxiv.org [biorxiv.org]
- 13. Inactivity-induced NR4A3 downregulation in human skeletal muscle affects glucose metabolism and translation: Insights from in vitro analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 14. aacrjournals.org [aacrjournals.org]
- 15. Tissue expression of NR4A3 - Summary - The Human Protein Atlas [proteinatlas.org]
- 16. researchgate.net [researchgate.net]
- 17. The transcription factor NR4A3 controls CD103+ dendritic cell migration - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. NR4A3 inhibits the tumor progression of hepatocellular carcinoma by inducing cell cycle G0/G1 phase arrest and upregulation of CDKN2AIP expression - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Analysing the gene expression profiles of the orphan nuclear receptors NR4A1, NR4A2 and NR4A3 in premalignant lesions of the cervix and cervicitis - PMC [pmc.ncbi.nlm.nih.gov]
- 20. NR4A3 inhibits the tumor progression of hepatocellular carcinoma by inducing cell cycle G0/G1 phase arrest and upregulation of CDKN2AIP expression [ijbs.com]
Neuron-derived Orphan Receptor 1 (NOR-1/NR4A3): A Technical Guide to its Discovery and Initial Characterization
For Researchers, Scientists, and Drug Development Professionals
Introduction
Neuron-derived orphan receptor 1 (NOR-1), also known as Nuclear Receptor Subfamily 4 Group A Member 3 (NR4A3), is a member of the NR4A family of orphan nuclear receptors, which also includes Nur77 (NR4A1) and Nurr1 (NR4A2).[1][2] These transcription factors are termed "orphan" receptors because their endogenous ligands have not yet been identified.[1][2] NOR-1 was first identified in 1994 in a study focused on apoptotic rat forebrain neurons.[2][3] As an immediate-early gene, its expression is rapidly and transiently induced by a wide array of stimuli, including growth factors, neurotransmitters, and cellular stress, implicating it in a variety of physiological and pathological processes.[4] This technical guide provides an in-depth overview of the discovery and initial characterization of NOR-1, with a focus on the foundational experimental data and methodologies.
Data Presentation
Table 1: Molecular Characteristics of Rat Neuron-derived Orphan Receptor 1 (NOR-1)
| Property | Value | Reference |
| Protein Size | 628 amino acids | [2][3] |
| Molecular Weight | 68 kDa | [2][3] |
| DNA Binding Motif | Monomer: NBRE (5'-AAAGGTCA-3') | [5] |
| Homodimer: NurRE | [5] |
Table 2: Initial Observations on NOR-1 mRNA Expression in Rodent Tissues
| Tissue/Region | Expression Level | Reference |
| Fetal Mouse Brain (E17) | High | [2][3] |
| Adult Rat Brain | ||
| - Hippocampus | Low | [2][3] |
| - Striatum | Low | [2][3] |
| - Nucleus Accumbens | Low | [2][3] |
| - Prefrontal Cortex | Low | [2][3] |
| - Substantia Nigra | Deficient in dopaminergic neurons | [2] |
| - Ventral Tegmental Area | Deficient in dopaminergic neurons | [2] |
| Skeletal Muscle | Expressed (multiple transcripts) | [6] |
| Heart (fetal) | Expressed | [6] |
| Pituitary | Expressed | [6] |
| Adrenal Gland | Expressed | [6] |
| Thymus | Expressed | [6] |
| Kidney | Expressed | [6] |
Experimental Protocols
Cloning of the Rat NOR-1 cDNA
The initial identification of NOR-1 was achieved through the cloning of its cDNA from a library derived from cultured rat neuronal cells.
Methodology:
-
cDNA Library Screening: A cDNA library was constructed from cultured rat forebrain cells. This library was screened using a probe derived from a conserved region of the steroid/thyroid hormone receptor superfamily.
-
Clone Isolation and Sequencing: Positive clones were isolated, and the full-length cDNA of NOR-1 was sequenced. The resulting sequence revealed a novel member of the Nur77/NGFI-B subfamily.[7]
-
Sequence Analysis: The deduced amino acid sequence of rat NOR-1 was determined to be 628 amino acids in length, with a calculated molecular weight of 68 kDa.[2][3]
Northern Blot Analysis for mRNA Distribution
To determine the tissue distribution of NOR-1 mRNA, Northern blot analysis was performed on various rat tissues.
Methodology:
-
RNA Isolation: Total RNA was extracted from different rat tissues using standard protocols (e.g., guanidinium (B1211019) thiocyanate-phenol-chloroform extraction).
-
Electrophoresis and Blotting: A total of 10-20 µg of total RNA per lane was separated on a 1% agarose (B213101) gel containing formaldehyde (B43269) to denature the RNA. The separated RNA was then transferred to a nylon membrane.
-
Probe Labeling: A cDNA fragment of rat NOR-1 was labeled with [α-³²P]dCTP using a random priming kit to generate a high-specific-activity probe.
-
Hybridization: The membrane was prehybridized and then hybridized overnight at 42°C in a solution containing the radiolabeled NOR-1 probe.
-
Washing and Autoradiography: The membrane was washed under stringent conditions to remove non-specific binding of the probe. The blot was then exposed to X-ray film to visualize the NOR-1 mRNA transcripts.[8][9][10]
In Situ Hybridization for Cellular Localization of mRNA
To pinpoint the specific cell types expressing NOR-1 mRNA within the brain, in situ hybridization was employed.
Methodology:
-
Tissue Preparation: Adult rat brains were fixed, cryoprotected, and sectioned on a cryostat.
-
Probe Synthesis: A cRNA probe complementary to NOR-1 mRNA was synthesized and labeled with ³⁵S-UTP.
-
Hybridization: The brain sections were hybridized with the labeled cRNA probe.
-
Washing and Autoradiography: After stringent washes, the sections were coated with photographic emulsion and exposed for several weeks. The resulting silver grains indicated the cellular localization of NOR-1 mRNA. This technique revealed high expression in the fetal forebrain and lower levels in specific regions of the adult brain like the hippocampus and striatum.[2][3][11]
Antisense Oligonucleotide-Mediated Inhibition of NOR-1 Expression
To investigate the function of NOR-1 in neuronal cells, an antisense oligonucleotide strategy was used to specifically inhibit its expression.
Methodology:
-
Oligonucleotide Design: A phosphorothioate (B77711) antisense oligonucleotide was designed to be complementary to the translation initiation region of NOR-1 mRNA. A sense oligonucleotide was used as a control.[1]
-
Cell Culture and Treatment: Primary cultured forebrain cells were treated with the antisense or sense oligonucleotides.[1]
-
Phenotypic Analysis: The morphological changes in the cultured neurons were observed over time. Treatment with the NOR-1 antisense oligonucleotide resulted in increased cell migration and neurite extension, suggesting a role for NOR-1 in regulating neural differentiation.[1]
Mandatory Visualization
Caption: Signaling pathways leading to the expression and function of NOR-1.
Caption: Experimental workflow for the initial characterization of NOR-1.
Caption: DNA binding mechanisms of the NOR-1 transcription factor.
References
- 1. Antisense oligonucleotide to NOR-1, a novel orphan nuclear receptor, induces migration and neurite extension of cultured forebrain cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Comprehensive insights into the function and molecular and pharmacological regulation of neuron-derived orphan receptor 1, an orphan receptor - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Frontiers | Comprehensive insights into the function and molecular and pharmacological regulation of neuron-derived orphan receptor 1, an orphan receptor [frontiersin.org]
- 4. Expression of NOR-1 and its closely related members of the steroid/thyroid hormone receptor superfamily in human neuroblastoma cell lines - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. uniprot.org [uniprot.org]
- 6. youtube.com [youtube.com]
- 7. The NGFI-B Family: Orphan Nuclear Receptors of the Steroid/Thyroid Receptor Superfamily [jstage.jst.go.jp]
- 8. ruo.mbl.co.jp [ruo.mbl.co.jp]
- 9. Northern Blot [protocols.io]
- 10. Northern blot - PMC [pmc.ncbi.nlm.nih.gov]
- 11. In situ hybridization technique to localize rRNA and mRNA in mammalian neurons - PubMed [pubmed.ncbi.nlm.nih.gov]
The Role of NOR-1 (NR4A3) in the Development of Metabolic Diseases: A Technical Guide
Audience: Researchers, scientists, and drug development professionals.
Executive Summary
Neuron-derived orphan receptor 1 (NOR-1), also known as NR4A3, is a member of the NR4A subfamily of orphan nuclear receptors.[1] As a ligand-independent transcription factor, its activity is primarily regulated by its expression levels, which are induced by a wide array of physiological and pathophysiological stimuli.[1][2] Emerging evidence has firmly positioned NOR-1 as a critical regulator of glucose, lipid, and energy homeostasis.[3] Its dysregulation is implicated in several metabolic diseases, including obesity, type 2 diabetes (T2DM), and atherosclerosis. This document provides a comprehensive technical overview of the current understanding of NOR-1's role in metabolic diseases, summarizing key signaling pathways, quantitative data from pivotal studies, and the experimental methodologies used to elucidate its function.
NOR-1 in Core Metabolic Tissues
NOR-1 exerts tissue-specific effects on metabolism, primarily in skeletal muscle, pancreatic β-cells, and the vasculature.
Skeletal Muscle: A Hub for Oxidative Metabolism
In skeletal muscle, NOR-1 is a key mediator of oxidative metabolism.[4] Its expression is robustly induced by stimuli such as β2-adrenergic agonists and exercise.[4][5][6] Overexpression of NOR-1 in the skeletal muscle of transgenic mice leads to a phenotype characterized by decreased adiposity, resistance to diet-induced obesity, increased oxidative muscle fibers (type IIA/X), and a higher number of mitochondria.[5][7] Conversely, silencing NOR-1 in muscle cells results in decreased fatty acid oxidation and increased lactate (B86563) production, indicating a shift towards anaerobic metabolism.[4][8]
Studies in humans show that the insulin-stimulated induction of NOR-1 protein is significantly blunted in obese and T2DM individuals compared to lean, healthy controls.[9][10] This impaired response is inversely correlated with BMI and age, and positively correlated with insulin (B600854) sensitivity, highlighting its clinical relevance in the progression of insulin resistance.[9]
Pancreatic β-Cells: A Dual Role in Function and Survival
In pancreatic β-cells, NOR-1 plays a complex, dual role. It is a target of the CREB transcription factor and is induced by incretins and glucose, where it then binds to regulatory sequences in insulin genes to promote insulin gene expression and secretion.[11] However, NOR-1 expression is also significantly increased by pro-inflammatory cytokines.[12] Overexpression of NOR-1 in this context induces apoptosis, while its knockdown can prevent cytokine-induced β-cell death.[12] Notably, NOR-1 expression is up-regulated in the islets of individuals with T2DM, suggesting it may contribute to the β-cell dysfunction seen in the disease.[12] Genetic deletion of NOR-1 in mice leads to increased β-cell mass and improved glucose tolerance.[12]
Vasculature: A Pro-Atherogenic Factor
Within the vascular system, NOR-1 is implicated in the pathogenesis of atherosclerosis. It is overexpressed in human coronary atherosclerotic lesions.[13] In endothelial cells, inflammatory stimuli trigger NOR-1 expression via NF-κB signaling.[14] NOR-1 then directly transactivates the promoters of key adhesion molecules, VCAM-1 and ICAM-1, promoting the adhesion of monocytes to the endothelium—a critical early step in atherosclerosis.[14] In vascular smooth muscle cells (VSMCs), NOR-1 is induced by growth factors and promotes their proliferation and migration, which contributes to the progression of atherosclerotic plaques and neointimal formation after vascular injury.[13][15]
Key Signaling Pathways Involving NOR-1
The function of NOR-1 is governed by upstream signals that control its expression and its own downstream actions as a transcription factor.
Upstream Regulation of NOR-1 Expression in Skeletal Muscle
In skeletal muscle, β-adrenergic signaling is a primary driver of NOR-1 expression. This pathway is crucial for adapting muscle metabolism to physiological demands like exercise.
Downstream Metabolic Regulation by NOR-1 in Skeletal Muscle
Once expressed, NOR-1 orchestrates a transcriptional program that shifts muscle metabolism towards a more oxidative state, enhancing the utilization of both fatty acids and glucose.
NOR-1 Signaling in Endothelial Cells and Atherosclerosis
In the vasculature, NOR-1 acts as a key intermediary between inflammatory signals and the expression of adhesion molecules that facilitate the development of atherosclerotic lesions.
Quantitative Data Summary
The following tables summarize key quantitative findings from studies on NOR-1, demonstrating its altered expression in human metabolic disease and the metabolic benefits of its overexpression in preclinical models.
Table 1: Human Skeletal Muscle NOR-1 Protein Expression in Response to Insulin Data from hyperinsulinemic-euglycemic clamp studies.
| Subject Group | Fold Increase in NOR-1 Protein (Mean ± SEM) | Key Finding | Citation |
| Lean Healthy Controls (LHC) | 3.6 ± 1.1 | Robust induction by insulin. | [9][10] |
| Obese (OB) | Unaffected | Blunted response to insulin. | [9][10] |
| Type 2 Diabetes (T2DM) | Unaffected | Blunted response to insulin. | [9][10] |
Table 2: Correlations of Insulin-Stimulated NOR-1 Protein Response in Humans
| Parameter | Correlation with NOR-1 Response (r²) | Implication | Citation |
| Glucose Disposal Rate | 0.12 | Positive association with insulin sensitivity. | [9][10] |
| Age | 0.25 | Negative correlation. | [9][10] |
| Body Mass Index (BMI) | 0.42 | Strong negative correlation. | [9][10] |
Table 3: Metabolic Effects of Muscle-Specific NOR-1 Overexpression in Transgenic Mice Comparison between transgenic (Tg-Nor-1) and wild-type (WT) mice.
| Parameter | Diet | Result in Tg-Nor-1 Mice vs. WT | Implication | Citation |
| Total Fat Mass | Normal Chow | Significantly reduced | Decreased adiposity. | [6][7] |
| Body Weight Gain | High-Fat Diet | Resistant to gain | Protection from diet-induced obesity. | [6][7] |
| Fasting Blood Glucose | High-Fat Diet | Maintained at normoglycemic levels | Improved glucose homeostasis. | [6][7] |
| Skeletal Muscle Glycogen | Normal Chow | Significantly higher | Enhanced energy storage capacity. | [5][6] |
Key Experimental Methodologies
The investigation of NOR-1's role in metabolism has employed a range of standard and advanced molecular and physiological techniques.
Workflow for Human Studies
Studies involving human subjects typically follow a workflow to assess insulin sensitivity and corresponding molecular changes in tissues like skeletal muscle.
Gene and Protein Expression Analysis
-
Quantitative PCR (qPCR): Used to measure NOR-1 mRNA levels in tissues and cells in response to various stimuli (e.g., exercise, insulin, inflammatory cytokines).[6][9]
-
Western Blotting: The primary method for quantifying NOR-1 protein expression. It has been used to demonstrate the blunted insulin response in obese/T2DM subjects and the effects of exercise training.[9]
-
Northern Blot Analysis: Employed in early studies to detect upregulation of NOR-1 mRNA by growth factors in vascular smooth muscle cells.[13]
In Vitro Functional Assays
-
siRNA-mediated Knockdown: Used in cell lines (e.g., C2C12 myotubes, endothelial cells) to silence NOR-1 expression and subsequently measure changes in metabolic function, such as fatty acid oxidation, lactate production, and adhesion molecule expression.[4][14][16]
-
Overexpression Studies: Transfection of cells with NOR-1 expression vectors to study its gain-of-function effects, such as the induction of VCAM-1 promoter activity.[14]
-
Chromatin Immunoprecipitation (ChIP) Assays: Utilized to confirm the direct binding of the NOR-1 transcription factor to the promoter regions of its target genes, such as VCAM-1, Lipin-1α, and PDK4.[4][14]
Preclinical Animal Models
-
Transgenic Mice: Mice with muscle-specific overexpression of an activated form of NOR-1 have been instrumental in demonstrating its causal role in promoting an oxidative, endurance phenotype and protecting against diet-induced obesity.[5][7]
-
Knockout Mice: NOR-1 deficient (NOR1-/-) mice crossed with atherosclerosis-prone (apoE-/-) mice were used to establish that loss of NOR-1 reduces atherosclerosis formation and macrophage recruitment to the arterial wall.[14] β-cell specific knockout models revealed its role in regulating β-cell mass.[12]
-
Acute Intervention Studies: Administration of β2-AR agonists to mice has been used to study the in vivo induction of NOR-1 and its downstream target genes in skeletal muscle.[4]
Conclusion and Therapeutic Outlook
NOR-1 (NR4A3) is a multifaceted transcription factor that plays a significant and often contradictory role in metabolic health. In skeletal muscle, it is a positive regulator of oxidative metabolism, and its activity is beneficially enhanced by exercise.[5][9] Conversely, its expression is blunted in states of insulin resistance.[9] In the vasculature and in pancreatic islets under inflammatory stress, its induction can be pathogenic, promoting atherosclerosis and β-cell death, respectively.[12][14]
This tissue-specific complexity makes NOR-1 a challenging but promising therapeutic target. Strategies aimed at selectively increasing NOR-1 activity in skeletal muscle could offer benefits for treating obesity and type 2 diabetes. Conversely, inhibiting NOR-1 action in endothelial cells or pancreatic islets could be a viable strategy for mitigating atherosclerosis and preserving β-cell mass. The development of tissue-specific modulators for NOR-1 and other NR4A family members will be a critical next step in translating our understanding of this receptor into novel therapies for metabolic diseases.[1][3]
References
- 1. Minireview: Nuclear hormone receptor 4A signaling: implications for metabolic disease - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Frontiers | Role of the Orphan Nuclear Receptor NR4A Family in T-Cell Biology [frontiersin.org]
- 3. Minireview: Nuclear Hormone Receptor 4A Signaling: Implications for Metabolic Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 4. The orphan nuclear receptor, NOR-1, a target of beta-adrenergic signaling, regulates gene expression that controls oxidative metabolism in skeletal muscle [pubmed.ncbi.nlm.nih.gov]
- 5. Transgenic muscle-specific Nor-1 expression regulates multiple pathways that effect adiposity, metabolism, and endurance - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. Transgenic Muscle-Specific Nor-1 Expression Regulates Multiple Pathways That Effect Adiposity, Metabolism, and Endurance - PMC [pmc.ncbi.nlm.nih.gov]
- 8. academic.oup.com [academic.oup.com]
- 9. Skeletal muscle Nur77 and NOR1 insulin responsiveness is blunted in obesity and type 2 diabetes but improved after exercise training - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Skeletal muscle Nur77 and NOR1 insulin responsiveness is blunted in obesity and type 2 diabetes but improved after exercise training - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. Nor-1, a novel incretin-responsive regulator of insulin genes and insulin secretion - PMC [pmc.ncbi.nlm.nih.gov]
- 12. The orphan nuclear receptor Nor1/Nr4a3 is a negative regulator of β-cell mass - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. Neuron-derived orphan receptor-1 (NOR-1) modulates vascular smooth muscle cell proliferation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. Deficiency of the NR4A Orphan Nuclear Receptor NOR1 Decreases Monocyte Adhesion and Atherosclerosis - PMC [pmc.ncbi.nlm.nih.gov]
- 15. researchgate.net [researchgate.net]
- 16. Loss of NOR-1 represses muscle metabolism through mTORC1-mediated signaling and mitochondrial gene expression in C2C12 myotubes - PubMed [pubmed.ncbi.nlm.nih.gov]
An In-depth Technical Guide to the NOR-1 Protein: Structure, Function, and Experimental Analysis
For Researchers, Scientists, and Drug Development Professionals
Introduction
Neuron-derived orphan receptor 1 (NOR-1), also known as Nuclear Receptor Subfamily 4 Group A Member 3 (NR4A3), is a ligand-independent orphan nuclear receptor that plays a pivotal role in a diverse array of physiological and pathological processes. As a member of the NR4A subfamily, which also includes Nur77 (NR4A1) and Nurr1 (NR4A2), NOR-1 functions as an immediate-early gene, rapidly responding to a variety of extracellular signals to modulate gene expression. Its involvement in cellular proliferation, apoptosis, metabolism, and inflammation has positioned it as a significant target of interest in drug development for conditions ranging from cancer to cardiovascular disease. This technical guide provides a comprehensive overview of the current understanding of NOR-1's structure, functional domains, and the experimental methodologies employed in its study.
NOR-1 Protein Structure and Functional Domains
The human NOR-1 protein is a modular transcription factor characterized by a canonical nuclear receptor architecture. While a crystal structure for NOR-1 is not currently available in the Protein Data Bank (PDB), its high sequence homology with other NR4A members, particularly Nurr1 (NR4A2), allows for structural inferences. The crystal structure of the Nurr1 Ligand-Binding Domain (PDB ID: 1OVL, 5Y41) and its DNA-binding domain (PDB ID: 7WNH) provide valuable models for understanding NOR-1's three-dimensional organization[1][2][3][4][5]. The protein is composed of three primary functional domains: an N-terminal Activation Function-1 (AF-1) domain, a central DNA-Binding Domain (DBD), and a C-terminal Ligand-Binding Domain (LBD).
Domain Organization of NOR-1
Domain architecture of the NOR-1 protein.
N-Terminal Activation Function-1 (AF-1) Domain: This region is highly variable among the NR4A subfamily members and is responsible for ligand-independent transactivation[6][7]. Studies have delimited the functional AF-1 domain of NOR-1 to amino acid residues 1-112[8][9][10]. This domain is crucial for the recruitment of coactivators and mediates the transcriptional activity of NOR-1 in response to various signaling pathways[8][9][10].
DNA-Binding Domain (DBD): The DBD is highly conserved across the NR4A family (over 90% homology) and contains two zinc finger motifs that facilitate binding to specific DNA sequences known as response elements[7][11]. NOR-1 binds as a monomer to the NGFI-B Response Element (NBRE) with the consensus sequence AAAGGTCA[7][11][12]. While NOR-1 does not typically form heterodimers with the Retinoid X Receptor (RXR), other NR4A members can[11][12][13].
Ligand-Binding Domain (LBD): Located at the C-terminus, the LBD of NR4A receptors, including NOR-1, is unique. Unlike classical nuclear receptors, the LBD of NOR-1 does not possess a conventional ligand-binding pocket, rendering it constitutively active[10][11]. The amino acid residues for the human NOR-1 LBD have been defined as 398-626[14]. Homology modeling based on the Nurr1 LBD structure suggests that bulky hydrophobic side chains occupy the space where a ligand would typically bind[1][5]. This domain also contains the Activation Function-2 (AF-2) helix, which in other nuclear receptors is crucial for ligand-dependent coactivator recruitment. In NOR-1, the AF-2's role is less defined due to the ligand-independent nature of the receptor.
Quantitative Data on NOR-1 Protein and its Domains
| Property | Value | Reference(s) |
| Protein Name | Neuron-derived orphan receptor 1 (NOR-1), NR4A3 | [15] |
| Gene Name | NR4A3 | [15][16] |
| Organism | Homo sapiens (Human) | [15][16] |
| Predicted Molecular Weight | ~69.3 kDa | [1] |
| Amino Acid Length | 626 (isoform a) | [17] |
| AF-1 Domain | Residues 1-112 | [8][9][10] |
| LBD | Residues 398-626 | [14] |
| Functional Domain Activity | Observation | Reference(s) |
| AF-1 Transactivation | Deletion of the AF-1 domain abolishes NOR-1's transcriptional activity. The isolated AF-1 domain (aa 1-112) fused to a GAL4-DBD shows significant transactivation. | [8][9][10] |
| DNA Binding | Binds as a monomer to the NBRE (AAAGGTCA) response element. Unlike Nur77 and Nurr1, NOR-1 does not efficiently form heterodimers with RXR to bind DR-5 elements. | [11][12] |
Key Signaling Pathways Involving NOR-1
NOR-1 expression and activity are regulated by a multitude of signaling pathways, reflecting its role as an immediate-early response gene.
Regulation of NOR-1 Expression
Upstream signaling pathways regulating NOR-1 expression.
A variety of extracellular stimuli, including growth factors, neurotransmitters, and cellular stress, can rapidly induce NOR-1 expression. This induction is often mediated through G-protein coupled receptors (GPCRs) and receptor tyrosine kinases (RTKs), which in turn activate downstream signaling cascades involving Protein Kinase A (PKA), Protein Kinase C (PKC), and calcium/calmodulin-dependent pathways[18]. These pathways converge on transcription factors such as CREB (cAMP response element-binding protein), which binds to response elements in the NOR-1 promoter to drive its transcription[18].
Downstream Effects of NOR-1
Key downstream signaling pathways modulated by NOR-1.
Once expressed, NOR-1 translocates to the nucleus to regulate the transcription of a wide range of target genes involved in metabolism, apoptosis, and cell proliferation. NOR-1 has been shown to influence the mTORC1 signaling pathway, a central regulator of cell growth and metabolism. By inhibiting mTORC1, NOR-1 can promote autophagy. Furthermore, NOR-1 can directly modulate the expression of Bcl-2 family proteins, thereby influencing the mitochondrial apoptotic pathway. Its role in cell cycle regulation contributes to its effects on cell proliferation.
Experimental Protocols
A variety of experimental techniques are employed to study the structure, function, and regulation of the NOR-1 protein. Below are detailed methodologies for some of the key experiments.
Quantitative Real-Time PCR (qRT-PCR) for NOR-1 mRNA Expression
Objective: To quantify the relative expression levels of NOR-1 mRNA in different samples.
Methodology:
-
RNA Isolation: Isolate total RNA from cells or tissues using a suitable method, such as TRIzol reagent or a column-based kit. Assess RNA quality and quantity using a spectrophotometer (e.g., NanoDrop) and by agarose (B213101) gel electrophoresis.
-
cDNA Synthesis: Reverse transcribe 1-2 µg of total RNA into complementary DNA (cDNA) using a reverse transcriptase enzyme and a mix of oligo(dT) and random primers.
-
qPCR Reaction Setup: Prepare a qPCR master mix containing SYBR Green or a TaqMan probe, forward and reverse primers specific for NOR-1, and cDNA template. Include a no-template control (NTC) and a no-reverse-transcriptase control (-RT) to check for contamination. Use a housekeeping gene (e.g., GAPDH, ACTB) for normalization.
-
Thermal Cycling: Perform the qPCR reaction in a real-time PCR thermal cycler using a standard three-step cycling protocol (denaturation, annealing, extension).
-
Data Analysis: Determine the cycle threshold (Ct) values for NOR-1 and the housekeeping gene. Calculate the relative expression of NOR-1 using the ΔΔCt method, expressed as fold change relative to a control sample.
Western Blotting for NOR-1 Protein Detection and Quantification
Objective: To detect and quantify the levels of NOR-1 protein in cell or tissue lysates.
Methodology:
-
Protein Extraction: Lyse cells or tissues in a suitable lysis buffer (e.g., RIPA buffer) supplemented with protease and phosphatase inhibitors.
-
Protein Quantification: Determine the total protein concentration of the lysates using a protein assay such as the Bradford or BCA assay.
-
SDS-PAGE: Denature equal amounts of protein (20-50 µg) by boiling in Laemmli sample buffer and separate the proteins by size using sodium dodecyl sulfate-polyacrylamide gel electrophoresis (SDS-PAGE).
-
Protein Transfer: Transfer the separated proteins from the gel to a nitrocellulose or polyvinylidene difluoride (PVDF) membrane.
-
Blocking: Block the membrane with a blocking solution (e.g., 5% non-fat milk or BSA in TBST) to prevent non-specific antibody binding.
-
Antibody Incubation: Incubate the membrane with a primary antibody specific to NOR-1 overnight at 4°C. Following washes with TBST, incubate with a horseradish peroxidase (HRP)-conjugated secondary antibody.
-
Detection: Detect the protein bands using an enhanced chemiluminescence (ECL) substrate and visualize the signal using an imaging system.
-
Quantification: Quantify the band intensities using densitometry software. Normalize the NOR-1 signal to a loading control (e.g., β-actin, GAPDH) to determine relative protein levels[19].
Chromatin Immunoprecipitation (ChIP) for NOR-1 DNA Binding
Objective: To identify the genomic regions to which NOR-1 binds.
Methodology:
-
Cross-linking: Treat cells with formaldehyde (B43269) to cross-link proteins to DNA.
-
Cell Lysis and Chromatin Shearing: Lyse the cells and shear the chromatin into fragments of 200-1000 bp by sonication or enzymatic digestion.
-
Immunoprecipitation: Incubate the sheared chromatin with an antibody specific for NOR-1. Use a non-specific IgG as a negative control.
-
Immune Complex Capture: Capture the antibody-chromatin complexes using protein A/G-agarose or magnetic beads.
-
Washes: Wash the beads extensively to remove non-specifically bound chromatin.
-
Elution and Reverse Cross-linking: Elute the chromatin from the beads and reverse the cross-links by heating at 65°C.
-
DNA Purification: Purify the DNA using a column-based kit or phenol-chloroform extraction.
-
Analysis: Analyze the purified DNA by qPCR to quantify the enrichment of specific target gene promoters or by next-generation sequencing (ChIP-seq) for genome-wide analysis[20][21].
Luciferase Reporter Assay for NOR-1 Transactivation Activity
Objective: To measure the transcriptional activity of NOR-1 on a specific gene promoter.
Methodology:
-
Plasmid Construction: Clone the promoter region of a putative NOR-1 target gene upstream of a luciferase reporter gene in an expression vector.
-
Cell Transfection: Co-transfect cells with the luciferase reporter plasmid, a NOR-1 expression plasmid (or siRNA to knockdown endogenous NOR-1), and a control plasmid expressing Renilla luciferase (for normalization of transfection efficiency).
-
Cell Lysis: After 24-48 hours, lyse the cells using a passive lysis buffer.
-
Luciferase Assay: Measure the firefly luciferase activity in the cell lysate using a luminometer. Subsequently, measure the Renilla luciferase activity in the same sample.
-
Data Analysis: Normalize the firefly luciferase activity to the Renilla luciferase activity for each sample. Express the results as fold change in luciferase activity relative to a control condition[8][16][21][22].
Co-Immunoprecipitation (Co-IP) for Identifying NOR-1 Interacting Proteins
Objective: To identify proteins that interact with NOR-1 in a cellular context.
Methodology:
-
Cell Lysis: Lyse cells under non-denaturing conditions to preserve protein-protein interactions.
-
Immunoprecipitation: Incubate the cell lysate with an antibody specific to NOR-1 or a tag on an overexpressed NOR-1 protein.
-
Immune Complex Capture: Capture the antibody-protein complexes using protein A/G beads.
-
Washes: Wash the beads with a gentle wash buffer to remove non-specific binding proteins.
-
Elution: Elute the protein complexes from the beads.
-
Analysis: Separate the eluted proteins by SDS-PAGE and identify the interacting partners by Western blotting with specific antibodies or by mass spectrometry for a broader, unbiased identification.
Conclusion
NOR-1 (NR4A3) is a multifaceted orphan nuclear receptor with significant implications in health and disease. Its unique structural features, particularly its ligand-independent mode of action, distinguish it from classical nuclear receptors and present both challenges and opportunities for therapeutic intervention. The experimental protocols detailed in this guide provide a robust framework for researchers to further elucidate the complex biology of NOR-1. A deeper understanding of its structure, function, and regulatory networks will be instrumental in the development of novel therapeutic strategies targeting the diverse pathways it governs.
References
- 1. rcsb.org [rcsb.org]
- 2. rcsb.org [rcsb.org]
- 3. rcsb.org [rcsb.org]
- 4. researchgate.net [researchgate.net]
- 5. researchgate.net [researchgate.net]
- 6. Orphan Nuclear Receptor 4A1 (NR4A1) and Novel Ligands - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Function of Nr4a Orphan Nuclear Receptors in Proliferation, Apoptosis and Fuel Utilization Across Tissues - PMC [pmc.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. The AF-1 domain of the orphan nuclear receptor NOR-1 mediates trans-activation, coactivator recruitment, and activation by the purine anti-metabolite 6-mercaptopurine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. espace.library.uq.edu.au [espace.library.uq.edu.au]
- 11. NR4A Orphan Nuclear Receptors: Transcriptional Regulators of Gene Expression in Metabolism and Vascular Biology - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Structural basis of binding of homodimers of the nuclear receptor NR4A2 to selective Nur-responsive DNA elements - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Structural Perspective of NR4A Nuclear Receptor Family and Their Potential Endogenous Ligands [jstage.jst.go.jp]
- 14. caymanchem.com [caymanchem.com]
- 15. Nuclear receptor 4A3 - Wikipedia [en.wikipedia.org]
- 16. A Dual Luciferase System for Analysis of Post-Transcriptional Regulation of Gene Expression in Leishmania - PMC [pmc.ncbi.nlm.nih.gov]
- 17. NR4A3 nuclear receptor subfamily 4 group A member 3 [Homo sapiens (human)] - Gene - NCBI [ncbi.nlm.nih.gov]
- 18. bitesizebio.com [bitesizebio.com]
- 19. genecards.org [genecards.org]
- 20. Robust Normalization of Luciferase Reporter Data - PMC [pmc.ncbi.nlm.nih.gov]
- 21. promega.com [promega.com]
- 22. youtube.com [youtube.com]
The Role of Neuron-Derived Orphan Receptor 1 (NOR-1) in the Inflammatory Response: A Technical Guide
Audience: Researchers, scientists, and drug development professionals.
Executive Summary
Neuron-derived orphan receptor 1 (NOR-1), also known as NR4A3, is a member of the nuclear receptor subfamily 4 group A. Initially identified for its role in neuronal apoptosis and vascular remodeling, a growing body of evidence has implicated NOR-1 as a critical modulator of the inflammatory response. This technical guide provides an in-depth analysis of the molecular mechanisms through which NOR-1 exerts its influence on inflammatory signaling pathways. We will explore its intricate interplay with key inflammatory mediators, such as nuclear factor-kappa B (NF-κB) and mitogen-activated protein kinases (MAPKs), and its cell-type-specific functions in macrophages, vascular smooth muscle cells, and endothelial cells. This document summarizes key quantitative data, details relevant experimental protocols, and provides visual representations of the underlying signaling networks to serve as a comprehensive resource for researchers in the field.
Introduction
Inflammation is a fundamental biological process that is essential for host defense against pathogens and tissue injury. However, dysregulated inflammatory responses are at the core of a wide range of chronic diseases, including atherosclerosis, rheumatoid arthritis, and inflammatory bowel disease. The NR4A family of orphan nuclear receptors, which includes NOR-1 (NR4A3), Nur77 (NR4A1), and Nurr1 (NR4A2), has emerged as a key regulator of inflammation and immunity. These transcription factors are classified as immediate early genes, rapidly induced by a variety of stimuli, including growth factors, stress signals, and inflammatory mediators. NOR-1 lacks a known endogenous ligand, and its activity is primarily regulated at the transcriptional level. This guide will focus on the multifaceted role of NOR-1 in modulating the inflammatory cascade, highlighting its potential as a therapeutic target for inflammatory diseases.
Data Presentation: Quantitative Effects of NOR-1 on Inflammatory Mediators
The following tables summarize the quantitative data from various studies on the impact of NOR-1 expression on key inflammatory markers.
| Cell Type | Treatment/Condition | NOR-1 Modulation | Target Gene/Protein | Fold Change/Percentage Change | Reference |
| Human Vascular Smooth Muscle Cells (VSMCs) | Lipopolysaccharide (LPS) | Lentiviral Overexpression | IL-1β mRNA | Reduced upregulation | [1] |
| Human VSMCs | LPS | Lentiviral Overexpression | IL-6 mRNA | Reduced upregulation | [1] |
| Human VSMCs | LPS | Lentiviral Overexpression | IL-8 mRNA | Reduced upregulation | [1] |
| Human VSMCs | LPS | Lentiviral Overexpression | MCP-1 mRNA | Reduced upregulation | [1] |
| Human VSMCs | LPS | Lentiviral Overexpression | CCL20 mRNA | Reduced upregulation | [1] |
| Human VSMCs | TNF-α | Lentiviral Overexpression | IL-1β, IL-6, IL-8, MCP-1, CCL20 mRNA | Similar reduction to LPS stimulation | [1] |
| Human VSMCs | Oxidized LDL | Lentiviral Overexpression | IL-1β, IL-6, IL-8, MCP-1, CCL20 mRNA | Similar reduction to LPS stimulation | [1] |
| Human VSMCs | Inflammatory stimuli | siRNA-mediated knockdown | Pro-inflammatory mediators | Significantly increased expression | [1] |
| Aortas from TgNOR-1 mice | LPS | Transgenic Overexpression in VSMCs | Cytokine/chemokine upregulation | Lower compared to wild-type | [1] |
| Cell Type | Polarization Stimulus | NOR-1 Modulation | Marker | Effect | Reference |
| Macrophages | IL-4 | Endogenous | M2 polarization | Induces M2 polarization | [2] |
| Macrophages | Inflammatory stimuli | Endogenous | M1 polarization | Limits activation | [2] |
Signaling Pathways and Molecular Mechanisms
NOR-1's involvement in the inflammatory response is primarily mediated through its interaction with the NF-κB and MAPK signaling pathways.
Regulation of NF-κB Signaling
The NF-κB pathway is a cornerstone of inflammatory signaling, responsible for the transcription of numerous pro-inflammatory genes, including cytokines, chemokines, and adhesion molecules. NOR-1 has been shown to negatively regulate this pathway through multiple mechanisms.
A key mechanism involves the inhibition of the p65 subunit of NF-κB. NOR-1 can prevent the phosphorylation and subsequent translocation of p65 to the nucleus. This is achieved by decreasing the phosphorylation and degradation of IκBα, the inhibitory protein that sequesters NF-κB in the cytoplasm. By stabilizing IκBα, NOR-1 effectively traps NF-κB in an inactive state, thereby suppressing the expression of its target genes.
Modulation of MAPK Signaling
The Mitogen-Activated Protein Kinase (MAPK) pathways, including ERK1/2, p38, and JNK, are also critical in transducing inflammatory signals. NOR-1 has been shown to attenuate the phosphorylation of these key kinases. The activation of MAPK pathways is often upstream of NF-κB activation, suggesting that NOR-1's inhibitory effects on MAPKs contribute to its overall anti-inflammatory profile by dampening the entire signaling cascade.
Experimental Protocols
This section provides an overview of key experimental methodologies used to investigate the role of NOR-1 in the inflammatory response.
Lentiviral Overexpression of NOR-1
Objective: To achieve stable overexpression of NOR-1 in target cells (e.g., VSMCs, macrophages) to study its gain-of-function effects on inflammatory responses.
Methodology:
-
Vector Construction: The full-length human or mouse NOR-1 cDNA is cloned into a lentiviral expression vector (e.g., pLVX-Puro). An empty vector is used as a control.
-
Lentivirus Production: HEK293T cells are co-transfected with the NOR-1 expression vector and packaging plasmids (e.g., psPAX2 and pMD2.G) using a suitable transfection reagent.
-
Virus Harvest and Titration: The supernatant containing the lentiviral particles is collected 48-72 hours post-transfection, filtered, and concentrated. The viral titer is determined using methods such as qPCR or flow cytometry.
-
Transduction of Target Cells: Target cells are incubated with the lentiviral particles at a specific multiplicity of infection (MOI) in the presence of polybrene to enhance transduction efficiency.
-
Selection of Transduced Cells: After 24-48 hours, the medium is replaced with fresh medium containing a selection agent (e.g., puromycin) to select for successfully transduced cells.
-
Verification of Overexpression: The overexpression of NOR-1 is confirmed at both the mRNA (RT-qPCR) and protein (Western blot) levels.
siRNA-mediated Knockdown of NOR-1
Objective: To transiently silence the expression of NOR-1 in target cells to investigate its loss-of-function effects on inflammatory pathways.
Methodology:
-
siRNA Design and Synthesis: Validated siRNAs targeting NOR-1 and a non-targeting control siRNA are commercially synthesized.
-
Transfection: Target cells are transfected with the siRNAs using a lipid-based transfection reagent (e.g., Lipofectamine RNAiMAX) or electroporation. The optimal siRNA concentration and transfection time are determined empirically.
-
Incubation: Cells are incubated for 24-72 hours to allow for the degradation of the target mRNA.
-
Verification of Knockdown: The efficiency of NOR-1 knockdown is assessed at the mRNA (RT-qPCR) and protein (Western blot) levels.
-
Functional Analysis: The effect of NOR-1 silencing on inflammatory gene expression and signaling pathways is analyzed.
Chromatin Immunoprecipitation (ChIP) Assay
Objective: To determine if NOR-1 directly binds to the promoter regions of specific inflammatory genes.
Methodology:
-
Cross-linking: Cells are treated with formaldehyde (B43269) to cross-link proteins to DNA.
-
Chromatin Shearing: The chromatin is sheared into smaller fragments (200-1000 bp) by sonication or enzymatic digestion.
-
Immunoprecipitation: The sheared chromatin is incubated with an antibody specific to NOR-1 or a control IgG. The antibody-protein-DNA complexes are then pulled down using protein A/G beads.
-
Washing and Elution: The beads are washed to remove non-specific binding, and the protein-DNA complexes are eluted.
-
Reverse Cross-linking: The cross-links are reversed by heating, and the DNA is purified.
-
DNA Analysis: The purified DNA is analyzed by qPCR to quantify the enrichment of specific promoter regions, or by next-generation sequencing (ChIP-seq) for genome-wide analysis of NOR-1 binding sites.
Western Blot Analysis of Phosphorylated Proteins
Objective: To quantify the levels of phosphorylated MAPKs (e.g., p-p38, p-JNK) in response to inflammatory stimuli and NOR-1 modulation.
Methodology:
-
Cell Lysis: Cells are lysed in a buffer containing protease and phosphatase inhibitors to preserve the phosphorylation status of proteins.
-
Protein Quantification: The protein concentration of the lysates is determined using a standard assay (e.g., BCA assay).
-
SDS-PAGE and Transfer: Equal amounts of protein are separated by SDS-polyacrylamide gel electrophoresis and transferred to a PVDF or nitrocellulose membrane.
-
Blocking: The membrane is blocked with a solution containing bovine serum albumin (BSA) or non-fat dry milk to prevent non-specific antibody binding.
-
Antibody Incubation: The membrane is incubated with primary antibodies specific for the phosphorylated forms of the target proteins (e.g., anti-p-p38) and total protein as a loading control. Subsequently, the membrane is incubated with a horseradish peroxidase (HRP)-conjugated secondary antibody.
-
Detection and Quantification: The protein bands are visualized using an enhanced chemiluminescence (ECL) substrate and imaged. The band intensities are quantified using densitometry software.
Conclusion and Future Directions
NOR-1 is a critical negative regulator of the inflammatory response, primarily through its inhibition of the NF-κB and MAPK signaling pathways. Its ability to suppress the expression of pro-inflammatory cytokines and chemokines in various cell types underscores its potential as a therapeutic target for a wide range of inflammatory diseases. Future research should focus on the identification of small molecule modulators of NOR-1 activity. Given that NOR-1 is an orphan nuclear receptor, the development of agonists or antagonists presents a significant challenge but also a promising avenue for novel anti-inflammatory therapies. Furthermore, a deeper understanding of the cell-type-specific functions of NOR-1 and its downstream target genes will be crucial for the development of targeted and effective treatments. The methodologies and data presented in this guide provide a solid foundation for continued investigation into the intricate role of NOR-1 in inflammation.
References
role of NOR-1 in T-cell apoptosis and immune regulation
An In-Depth Technical Guide on the Role of NOR-1 in T-Cell Apoptosis and Immune Regulation
Audience: Researchers, scientists, and drug development professionals.
Executive Summary
Neuron-derived orphan receptor 1 (NOR-1), also known as NR4A3, is a member of the NR4A nuclear receptor subfamily, which also includes Nur77 (NR4A1) and Nurr1 (NR4A2).[1][2] These transcription factors are classified as orphan receptors as no endogenous ligands have been identified to date.[1][2] They are characterized as immediate early genes, rapidly induced by a variety of stimuli, including T-cell receptor (TCR) engagement.[3][4] In the context of the immune system, NOR-1 plays a critical and functionally redundant role with Nur77 in mediating T-cell apoptosis, a process vital for eliminating self-reactive thymocytes during negative selection.[5][6] This guide provides a comprehensive overview of the molecular mechanisms, signaling pathways, and experimental methodologies related to NOR-1's function in T-cell fate and immune regulation.
NOR-1 and the NR4A Family in T-Cells
The NR4A family members are ligand-independent transcription factors composed of a central DNA-binding domain, an N-terminal transactivation domain, and a C-terminal ligand-binding domain that lacks a classical binding pocket.[3] Their activity is primarily regulated by their expression levels.[3]
In T-lymphocytes, both NOR-1 and Nur77 are induced to very high levels upon TCR stimulation, with similar kinetics.[5][6] In contrast, Nurr1 expression is undetectable in stimulated thymocytes, suggesting that NOR-1 and Nur77 are the dominant players in this context.[6] This shared expression pattern and functional redundancy are crucial, as demonstrated by the lack of an apoptotic phenotype in Nur77-deficient mice, which points to NOR-1 compensating for its absence.[6] Both NOR-1 and Nur77 can bind to and transactivate through the same DNA response element, the NGFI-B response element (NBRE), to exert their transcriptional control.[5][6]
The Pivotal Role of NOR-1 in T-Cell Apoptosis
The primary function of NOR-1 in the thymus is the induction of apoptosis, a key mechanism of negative selection to ensure self-tolerance.
2.1. TCR-Mediated Apoptosis in Thymocytes TCR engagement on immature thymocytes that bind strongly to self-antigens initiates a signaling cascade that leads to clonal deletion via apoptosis.[6] NOR-1 is a critical downstream effector in this process.
-
Induction: Upon strong TCR signaling, NOR-1 expression is rapidly and robustly upregulated in CD4+CD8+ double-positive thymocytes.[6]
-
Apoptosis Execution: Studies using transgenic mice that constitutively express NOR-1 in thymocytes show massive cell death, leading to a significant reduction in thymic cellularity.[5][6] This demonstrates that NOR-1 expression is sufficient to trigger apoptosis.
-
Fas-Independent Pathway: The apoptosis induced by NOR-1 (and Nur77) appears to be independent of the Fas/FasL pathway.[5][6] In NOR-1 transgenic mice with massive thymocyte apoptosis, FasL expression is not elevated.[6] This distinguishes it from other forms of activation-induced cell death.
2.2. Immune Regulation in Peripheral T-Cells Beyond the thymus, NR4A family members are also induced in mature peripheral T-cells following antigen recognition and contribute to the overall immune response.[3]
-
CD8+ T-Cell Responses: All NR4A family members, including NOR-1 (NR4A3), are implicated in the differentiation of resident memory CD8+ T cells.[3]
-
Controlling T-Cell Activation: The absence of Nur77 (and presumably NOR-1, due to redundancy) lowers the threshold for T-cell activation, leading to enhanced proliferation and spontaneous activation.[4] This suggests that NOR-1 helps to constrain excessive T-cell responses and maintain homeostasis.
Signaling Pathways and Molecular Mechanisms
The induction of NOR-1 and its pro-apoptotic function are controlled by specific signaling cascades downstream of the TCR.
3.1. Upstream Signaling The MEK5-ERK5 pathway has been identified as a key regulator of Nur77 expression downstream of the TCR signal and is proposed to similarly regulate NOR-1.[3] This pathway can also enhance NR4A transcriptional activity through phosphorylation.[3]
Caption: TCR signaling pathway leading to NOR-1-mediated apoptosis.
Quantitative Data Summary
The following table summarizes the key qualitative and quantitative findings from studies on NOR-1 and its family members in T-cell apoptosis.
| Model System | Key Protein(s) Studied | Observation | Quantitative Effect | Reference |
| Transgenic Mice | Constitutive NOR-1 Expression | Massive apoptosis of thymocytes | Significant reduction in total thymocyte numbers; Up-regulation of CD25 | [5][6] |
| Transgenic Mice | Constitutive Nur77 Expression | Massive apoptosis of thymocytes | Phenotype similar to NOR-1 transgenic mice | [6] |
| Knockout Mice | Nur77-deficient (Nr4a1-/-) | No significant phenotype in thymocyte development | Normal thymocyte apoptosis and development | [6] |
| T-Cell Hybridomas | NOR-1, Nur77, Nurr1 | Rapid induction of NOR-1/Nur77 by PMA/ionomycin | Nurr1 induction is low and transient; NOR-1/Nur77 kinetics are similar | [6] |
| In Vitro CD8+ T-cells | NR4A Family | Enriched transcription in resident memory T-cells | - | [3] |
Experimental Protocols
Detailed methodologies are crucial for reproducing and building upon existing research. Below are protocols for key experiments used to study NOR-1 function.
5.1. Protocol: Flow Cytometry Analysis of Apoptosis in Transgenic Thymocytes
This protocol details the method for quantifying apoptosis in thymocytes isolated from mice constitutively expressing NOR-1.
I. Materials and Reagents:
-
Phosphate-Buffered Saline (PBS)
-
Fetal Bovine Serum (FBS)
-
Fluorescently-conjugated antibodies (e.g., anti-CD4, anti-CD8)
-
Annexin V binding buffer
-
Fluorescently-conjugated Annexin V probe
-
Viability dye (e.g., Propidium Iodide (PI) or 7-AAD)
-
Flow cytometer
II. Procedure:
-
Thymocyte Isolation:
-
Euthanize NOR-1 transgenic and wild-type control mice according to institutional guidelines.
-
Aseptically dissect the thymus and place it in a petri dish with cold PBS.
-
Gently disrupt the thymus using the plunger of a syringe or frosted glass slides to create a single-cell suspension.
-
Pass the cell suspension through a 70 µm cell strainer into a 50 mL conical tube.
-
Centrifuge at 400 x g for 5 minutes at 4°C. Discard the supernatant.
-
Resuspend the cell pellet in an appropriate volume of PBS or flow cytometry buffer.
-
-
Cell Counting and Staining:
-
Count the cells using a hemocytometer or automated cell counter.
-
Aliquot approximately 1 x 10^6 cells per tube for staining.
-
Add fluorescently-conjugated antibodies against cell surface markers (e.g., anti-CD4, anti-CD8) to identify T-cell subpopulations. Incubate for 20-30 minutes on ice, protected from light.
-
Wash the cells twice with cold PBS by centrifuging at 400 x g for 5 minutes.
-
-
Apoptosis Detection:
-
Resuspend the cell pellet in 100 µL of Annexin V binding buffer.
-
Add the fluorescently-conjugated Annexin V probe.
-
Add the viability dye (e.g., PI).
-
Incubate for 15 minutes at room temperature, protected from light.[7]
-
Add 400 µL of Annexin V binding buffer to each tube. Do not wash the cells.
-
-
Flow Cytometry Acquisition and Analysis:
-
Analyze the samples on a flow cytometer immediately.
-
Gate on the lymphocyte population based on forward and side scatter.
-
Further gate on T-cell subpopulations (e.g., CD4+CD8+).
-
Analyze the gated populations for Annexin V and PI staining to distinguish between live (Annexin V-/PI-), early apoptotic (Annexin V+/PI-), and late apoptotic/necrotic (Annexin V+/PI+) cells.
-
Caption: Experimental workflow for analyzing T-cell apoptosis.
Conclusion and Future Directions
NOR-1 is an indispensable transcription factor in T-cell biology, acting as a critical executioner of apoptosis during thymic negative selection. Its functional redundancy with Nur77 ensures the robust elimination of self-reactive T-cells, thereby maintaining central tolerance. The signaling pathways leading to its induction and its downstream transcriptional targets represent key nodes in the regulation of T-cell fate.
For drug development professionals, understanding the NOR-1 pathway offers potential therapeutic opportunities. Modulating the activity or expression of NOR-1 could be a strategy for either enhancing the deletion of pathogenic T-cells in autoimmune diseases or, conversely, inhibiting apoptosis to improve T-cell persistence in cancer immunotherapies. Future research should focus on identifying the full spectrum of NOR-1's downstream target genes in T-cells and exploring small molecule modulators that can selectively target its activity.
References
- 1. frontiersin.org [frontiersin.org]
- 2. Comprehensive insights into the function and molecular and pharmacological regulation of neuron-derived orphan receptor 1, an orphan receptor - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Frontiers | Role of the Orphan Nuclear Receptor NR4A Family in T-Cell Biology [frontiersin.org]
- 4. pnas.org [pnas.org]
- 5. Functional redundancy of the Nur77 and Nor-1 orphan steroid receptors in T-cell apoptosis - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Functional redundancy of the Nur77 and Nor‐1 orphan steroid receptors in T‐cell apoptosis | The EMBO Journal [link.springer.com]
- 7. Experimental protocol to study cell viability and apoptosis | Proteintech Group [ptglab.com]
An In-Depth Technical Guide to NOR-1 Signaling in Vascular Smooth Muscle Cell Proliferation
For Researchers, Scientists, and Drug Development Professionals
Abstract
The proliferation of vascular smooth muscle cells (VSMCs) is a pivotal event in the pathogenesis of atherosclerosis and restenosis. Neuron-derived orphan receptor-1 (NOR-1), a member of the NR4A nuclear receptor subfamily, has emerged as a critical immediate-early gene that modulates VSMC proliferation. This technical guide provides a comprehensive overview of the NOR-1 signaling pathway in VSMCs, detailing its upstream regulators, mechanism of transcriptional activation, downstream target genes, and its role in vascular disease. This document summarizes key quantitative data, provides detailed experimental protocols for studying NOR-1, and presents visual diagrams of the signaling cascades to facilitate a deeper understanding and guide future research and therapeutic development.
Introduction
Vascular smooth muscle cell (VSMC) proliferation is a hallmark of vascular remodeling in response to injury and is a key contributor to the development of occlusive vascular diseases such as atherosclerosis and in-stent restenosis.[1][2] A complex network of signaling pathways governs the transition of VSMCs from a quiescent, contractile state to a proliferative, synthetic phenotype. Among the key regulators of this phenotypic switch is the Neuron-derived orphan receptor-1 (NOR-1), also known as NR4A3.[3][4]
NOR-1 is a ligand-independent transcription factor that is rapidly and transiently induced in VSMCs by a variety of mitogenic stimuli.[3][5] Its expression is tightly regulated and its induction is a critical step in the cascade of events leading to VSMC proliferation.[3] Understanding the intricacies of NOR-1 signaling is therefore paramount for the development of novel therapeutic strategies aimed at mitigating pathological vascular remodeling. This guide will provide an in-depth exploration of the molecular mechanisms underpinning NOR-1's role in VSMC proliferation.
Upstream Regulation of NOR-1 Expression in VSMCs
The expression of NOR-1 in VSMCs is induced by a range of mitogenic stimuli, including growth factors and vasoactive agents. These stimuli activate distinct cell surface receptors and intracellular signaling cascades that converge on the NOR-1 promoter to drive its transcription.
Key Inducers of NOR-1 Expression
Several potent mitogens for VSMCs have been shown to be strong inducers of NOR-1 expression. These include:
-
Platelet-Derived Growth Factor (PDGF): A major stimulus for VSMC proliferation, PDGF robustly induces NOR-1 expression.[5]
-
Thrombin: This serine protease, involved in the coagulation cascade, also acts as a powerful mitogen for VSMCs and upregulates NOR-1.[3]
-
Epidermal Growth Factor (EGF): Another well-characterized growth factor that promotes VSMC proliferation and induces NOR-1.[3]
-
Serum: As a complex mixture of growth factors and other signaling molecules, serum is a potent inducer of NOR-1 expression.[3]
Signaling Pathways Leading to NOR-1 Transcription
The induction of NOR-1 by these mitogens is mediated by the activation of G protein-coupled receptors (GPCRs) and tyrosine kinase receptors (TKRs).[3] These receptor systems, in turn, trigger a cascade of intracellular signaling events that include:
-
Calcium (Ca²⁺) Mobilization: An increase in intracellular calcium concentration is a key early event in NOR-1 induction.[3]
-
Protein Kinase C (PKC) Activation: The activation of PKC isoforms is another critical step in the signaling pathway leading to NOR-1 expression.[3]
-
Mitogen-Activated Protein Kinase (MAPK) / Extracellular Signal-Regulated Kinase (ERK) Pathway: The MAPK/ERK signaling cascade is a central pathway that integrates signals from various growth factor receptors to regulate gene expression, including that of NOR-1.[5]
These upstream signaling pathways ultimately converge on the activation of the transcription factor cAMP response element-binding protein (CREB) . Activated, phosphorylated CREB binds to specific cAMP response elements (CREs) within the NOR-1 promoter, leading to the recruitment of the transcriptional machinery and the initiation of NOR-1 gene transcription.[3][5]
Downstream Effects of NOR-1 on VSMC Proliferation
Once expressed, NOR-1 translocates to the nucleus and acts as a transcription factor to regulate the expression of genes involved in cell cycle progression and proliferation.
Regulation of Cell Cycle Machinery
NOR-1 plays a direct role in promoting the G1 to S phase transition of the cell cycle by upregulating the expression of key G1 cyclins:
-
Cyclin D1: A critical regulator of the G1 phase, Cyclin D1 expression is induced by NOR-1.[5]
-
Cyclin D2: Similar to Cyclin D1, Cyclin D2 is also a downstream target of NOR-1.[5]
The increased expression of these cyclins leads to the activation of cyclin-dependent kinases (CDKs), which in turn phosphorylate the retinoblastoma protein (pRb). Phosphorylated pRb releases the E2F transcription factor, allowing for the transcription of genes necessary for DNA replication and entry into the S phase.
Modulation of Redox Signaling
Recent evidence has implicated NOR-1 in the regulation of cellular redox homeostasis in VSMCs. NOR-1 has been shown to increase the production of reactive oxygen species (ROS) by upregulating the expression of NADPH oxidase 1 (NOX1) , a major source of ROS in VSMCs. This increase in ROS can further contribute to VSMC proliferation and migration.
Quantitative Data Summary
The following tables summarize the key quantitative findings from studies on NOR-1 signaling in VSMC proliferation.
Table 1: Induction of NOR-1 Expression in VSMCs
| Stimulus | Cell Type | Fold Induction of NOR-1 mRNA | Time Point | Reference |
| Serum (10%) | Porcine Coronary SMCs | Strong induction | 1-6 hours | [3] |
| PDGF-BB | Porcine Coronary SMCs | Strong induction | 1-6 hours | [3] |
| Thrombin | Porcine Coronary SMCs | Strong induction | 1-6 hours | [3] |
| EGF | Porcine Coronary SMCs | Strong induction | 1-6 hours | [3] |
Table 2: Effect of NOR-1 on VSMC Proliferation
| Experimental Approach | Cell Type | Effect on Proliferation | Quantitative Change | Reference |
| Antisense Oligonucleotides against NOR-1 | Human Coronary SMCs | Inhibition | Significant reduction in DNA synthesis | [3] |
| NOR-1 deficient mice | Mouse Aortic SMCs | Decreased proliferation | Attenuated cell proliferation | [5] |
Table 3: Downstream Targets of NOR-1 in VSMCs
| Target Gene | Effect of NOR-1 | Method of Analysis | Quantitative Change | Reference |
| Cyclin D1 | Upregulation | Western Blot | Increased protein expression | [5] |
| Cyclin D2 | Upregulation | Western Blot | Increased protein expression | [5] |
| NOX1 | Upregulation | Not specified | Not specified | - |
Detailed Experimental Protocols
This section provides detailed methodologies for key experiments used to investigate NOR-1 signaling in VSMC proliferation.
Cell Culture
-
Cell Lines: Primary human or porcine coronary/aortic smooth muscle cells are commonly used.
-
Culture Medium: Dulbecco's Modified Eagle's Medium (DMEM) supplemented with 10% fetal bovine serum (FBS), 100 U/mL penicillin, and 100 µg/mL streptomycin.
-
Culture Conditions: Cells are maintained in a humidified incubator at 37°C with 5% CO₂.
-
Quiescence: To synchronize cells in the G0/G1 phase, confluent cultures are serum-starved for 48 hours in DMEM containing 0.5% FBS.
Induction of NOR-1 Expression
-
Stimulation: Quiescent VSMCs are stimulated with mitogens such as PDGF-BB (20 ng/mL), thrombin (1 U/mL), or 10% FBS for various time points (e.g., 0, 1, 2, 4, 6, and 24 hours).
Analysis of Gene Expression
-
RNA Isolation: Total RNA is extracted from VSMCs using TRIzol reagent according to the manufacturer's instructions.
-
Northern Blot Analysis: 10-20 µg of total RNA is separated on a 1% agarose-formaldehyde gel, transferred to a nylon membrane, and hybridized with a ³²P-labeled NOR-1 cDNA probe.
-
Quantitative Real-Time PCR (qRT-PCR): First-strand cDNA is synthesized from 1 µg of total RNA using a reverse transcriptase kit. qRT-PCR is performed using SYBR Green master mix and primers specific for NOR-1 and a housekeeping gene (e.g., GAPDH) for normalization.
Western Blot Analysis
-
Protein Extraction: Cells are lysed in RIPA buffer containing protease and phosphatase inhibitors. Protein concentration is determined using a BCA protein assay kit.
-
Electrophoresis and Transfer: 20-50 µg of protein is separated by SDS-PAGE and transferred to a PVDF membrane.
-
Immunoblotting: Membranes are blocked with 5% non-fat milk in TBST and incubated overnight at 4°C with primary antibodies against NOR-1, Cyclin D1, Cyclin D2, or GAPDH. After washing, membranes are incubated with HRP-conjugated secondary antibodies and visualized using an enhanced chemiluminescence (ECL) detection system.
Cell Proliferation Assays
-
BrdU Incorporation Assay: VSMCs are seeded in 96-well plates, serum-starved, and then stimulated with mitogens in the presence or absence of NOR-1 inhibitors. BrdU is added to the culture medium for the final 2-4 hours of stimulation. BrdU incorporation is measured using a colorimetric ELISA kit according to the manufacturer's protocol.
-
Cell Counting: VSMCs are seeded at a low density, treated as required, and then harvested by trypsinization at different time points. The number of viable cells is determined using a hemocytometer or an automated cell counter.
Antisense Oligonucleotide-Mediated Knockdown of NOR-1
-
Oligonucleotides: Phosphorothioate-modified antisense and sense oligonucleotides targeting the translation start site of human NOR-1 are synthesized.
-
Transfection: VSMCs are transfected with antisense or sense oligonucleotides (1-10 µM) using a lipofection reagent for 4-6 hours in serum-free medium. The medium is then replaced with complete medium, and cells are incubated for 24-48 hours before further experiments.
Luciferase Reporter Assay for Promoter Activity
-
Constructs: A luciferase reporter construct containing the NOR-1 promoter region is generated.
-
Transfection: VSMCs are co-transfected with the NOR-1 promoter-luciferase construct and a Renilla luciferase control vector.
-
Assay: 24 hours post-transfection, cells are stimulated with mitogens. Luciferase activity is measured using a dual-luciferase reporter assay system, and the firefly luciferase activity is normalized to the Renilla luciferase activity.
Chromatin Immunoprecipitation (ChIP) Assay
-
Cross-linking and Sonication: VSMCs are treated with formaldehyde (B43269) to cross-link proteins to DNA. The chromatin is then sheared to fragments of 200-1000 bp by sonication.
-
Immunoprecipitation: The sheared chromatin is immunoprecipitated overnight with an antibody against phospho-CREB or a control IgG.
-
DNA Purification and Analysis: The immunoprecipitated DNA is purified and analyzed by qPCR using primers flanking the CRE sites in the NOR-1 promoter.
NOR-1 in Vascular Disease
The aberrant proliferation of VSMCs is a cornerstone of the pathology of both atherosclerosis and restenosis following angioplasty. Given its pro-proliferative role in VSMCs, NOR-1 is implicated in the progression of these vascular diseases.
-
Atherosclerosis: NOR-1 expression is upregulated in human atherosclerotic plaques, particularly in the neointima where VSMC proliferation is prominent.[5]
-
Restenosis: In animal models, balloon angioplasty, a procedure that induces vascular injury and subsequent restenosis, leads to a transient and robust induction of NOR-1 in the arterial wall.[3] Inhibition of NOR-1 using antisense oligonucleotides has been shown to reduce neointimal formation in these models.[3]
Conclusion and Future Directions
NOR-1 has been firmly established as a key transcriptional regulator of VSMC proliferation. The signaling cascade from mitogen stimulation to NOR-1 induction and its subsequent effects on cell cycle progression and redox signaling are well-characterized. The pro-proliferative function of NOR-1 in VSMCs positions it as a promising therapeutic target for vascular proliferative diseases.
Future research should focus on:
-
Identifying specific and potent small molecule inhibitors of NOR-1 transcriptional activity.
-
Elucidating the full spectrum of NOR-1 target genes in VSMCs using genome-wide approaches.
-
Investigating the potential for cell-specific targeting of NOR-1 to avoid off-target effects.
-
Further exploring the interplay between NOR-1 and other signaling pathways, such as the NF-κB pathway, in the context of the complex inflammatory environment of atherosclerotic plaques. [6]
A deeper understanding of NOR-1 signaling will undoubtedly pave the way for the development of novel and more effective therapies to combat atherosclerosis and restenosis.
References
- 1. researchgate.net [researchgate.net]
- 2. biorxiv.org [biorxiv.org]
- 3. Neuron-derived orphan receptor-1 (NOR-1) modulates vascular smooth muscle cell proliferation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. ahajournals.org [ahajournals.org]
- 5. The NR4A Orphan Nuclear Receptor NOR1 Is Induced by Platelet-derived Growth Factor and Mediates Vascular Smooth Muscle Cell Proliferation - PMC [pmc.ncbi.nlm.nih.gov]
- 6. NOR-1 modulates the inflammatory response of vascular smooth muscle cells by preventing NFκB activation - PubMed [pubmed.ncbi.nlm.nih.gov]
NOR-1 ChIP-seq protocol for identifying binding sites
Identifying Genome-Wide Binding Sites of the Orphan Nuclear Receptor NOR-1
Audience: Researchers, scientists, and drug development professionals.
Introduction
Neuron-derived orphan receptor 1 (NOR-1), also known as Nuclear Receptor Subfamily 4 Group A Member 3 (NR4A3), is a ligand-independent transcription factor that plays a crucial role in a variety of physiological processes, including neuronal function, metabolism, inflammation, and vascular remodeling.[1][2][3] As an immediate-early gene, NOR-1 expression is rapidly induced by a range of stimuli, such as growth factors and β-adrenergic signaling, allowing it to quickly modulate gene expression programs in response to cellular cues.[1][4] Chromatin Immunoprecipitation followed by sequencing (ChIP-seq) is a powerful technique to identify the genome-wide binding sites of transcription factors like NOR-1, providing critical insights into its regulatory networks and downstream target genes.
These application notes provide a detailed protocol for performing NOR-1 ChIP-seq to identify its direct binding sites on a genomic scale.
Signaling Pathways Involving NOR-1 Activation
NOR-1 expression and its subsequent binding to DNA are regulated by several signaling pathways. A key pathway involves β-adrenergic receptor stimulation, which can be triggered by agonists like isoproterenol. This leads to the activation of Protein Kinase A (PKA) and Mitogen-Activated Protein Kinase (MAPK) cascades, culminating in the phosphorylation of cAMP response element-binding protein (CREB). Activated CREB then binds to the NOR-1 promoter, inducing its transcription.[1][4] Another important pathway is initiated by increased intracellular calcium levels, which activate calcineurin, a calcium/calmodulin-dependent serine/threonine phosphatase.
NOR-1 ChIP-seq Experimental Workflow
The ChIP-seq protocol for NOR-1 involves several key stages, from cell culture and treatment to data analysis. The general workflow includes cross-linking of protein-DNA complexes, chromatin fragmentation, immunoprecipitation with a NOR-1 specific antibody, DNA purification, library preparation, and high-throughput sequencing.
Detailed Experimental Protocol
This protocol is a general guideline and may require optimization for specific cell types and experimental conditions.
1. Cell Culture and Treatment:
-
Cell Line: C2C12 myotubes are a relevant model for studying NOR-1 in skeletal muscle.[1]
-
Culture Conditions: Culture C2C12 myoblasts in DMEM supplemented with 10% FBS. To differentiate into myotubes, switch to DMEM with 2% horse serum for 4-6 days.
-
Stimulation: To induce NOR-1 expression, treat differentiated myotubes with a β2-adrenergic receptor agonist (e.g., 100 nM isoproterenol) for a time course (e.g., 30-60 minutes) prior to harvesting.[4]
2. Cross-linking:
-
Add formaldehyde (B43269) directly to the culture medium to a final concentration of 1%.
-
Incubate for 10 minutes at room temperature with gentle shaking.
-
Quench the cross-linking reaction by adding glycine (B1666218) to a final concentration of 0.125 M and incubate for 5 minutes at room temperature.
-
Wash the cells twice with ice-cold PBS.
3. Cell Lysis and Chromatin Shearing:
-
Scrape the cells in PBS and pellet by centrifugation.
-
Resuspend the cell pellet in a suitable lysis buffer containing protease inhibitors.
-
Isolate the nuclei by dounce homogenization or centrifugation.
-
Resuspend the nuclear pellet in a shearing buffer.
-
Shear the chromatin to an average size of 200-600 bp using sonication or enzymatic digestion (e.g., micrococcal nuclease). The optimization of shearing is a critical step.
4. Immunoprecipitation (IP):
-
Pre-clear the chromatin lysate with Protein A/G beads to reduce non-specific binding.
-
Take an aliquot of the pre-cleared chromatin as the "input" control.
-
Incubate the remaining chromatin overnight at 4°C with a ChIP-validated NOR-1 antibody (e.g., Santa Cruz Biotechnology, sc-393903 or sc-393902, which are listed as suitable for ChIP applications).[5][6] A negative control IP with a non-specific IgG antibody should also be performed.
-
Add Protein A/G beads to capture the antibody-protein-DNA complexes and incubate for 2-4 hours.
-
Wash the beads sequentially with low salt, high salt, LiCl, and TE buffers to remove non-specifically bound proteins.
5. Reverse Cross-links and DNA Purification:
-
Elute the chromatin from the beads using an elution buffer (e.g., 1% SDS, 0.1 M NaHCO3).
-
Reverse the cross-links by adding NaCl and incubating at 65°C for at least 6 hours or overnight.
-
Treat with RNase A and Proteinase K to remove RNA and protein.
-
Purify the DNA using phenol-chloroform extraction or a commercial DNA purification kit.
6. Library Preparation and Sequencing:
-
Prepare the ChIP and input DNA for sequencing using a library preparation kit (e.g., Illumina ChIP-seq Sample Preparation Kit). This typically involves end-repair, A-tailing, adapter ligation, and PCR amplification.
-
Perform size selection of the library to enrich for fragments of the desired size.
-
Quantify the library and perform high-throughput sequencing on a platform such as the Illumina HiSeq.
7. Data Analysis:
-
Align the sequencing reads to the appropriate reference genome.
-
Use a peak-calling algorithm (e.g., MACS2) to identify regions of the genome that are significantly enriched in the NOR-1 IP sample compared to the input control.
-
Perform motif analysis on the identified peaks to determine if they are enriched for the known NOR-1 binding motif (NBRE: 5'-AAAAGGTCA-3').
-
Annotate the peaks to identify the nearest genes and perform gene ontology analysis to understand the biological processes regulated by NOR-1.
Quantitative Data Summary
While a comprehensive public NOR-1 ChIP-seq dataset is not yet readily available, studies have identified specific gene promoters to which NOR-1 is recruited. This table summarizes validated NOR-1 target gene promoters and the expected outcome of a successful ChIP-qPCR or ChIP-seq experiment.
| Cell Type | Treatment | Validated Target Gene Promoter | Expected Outcome | Reference |
| Skeletal Muscle Cells (e.g., C2C12) | β2-adrenergic agonist | Lipin-1α | Enrichment of NOR-1 binding | [1] |
| Skeletal Muscle Cells (e.g., C2C12) | β2-adrenergic agonist | PDK4 | Enrichment of NOR-1 binding | [1] |
Conclusion
This application note provides a comprehensive protocol for performing NOR-1 ChIP-seq to identify its genome-wide binding sites. By understanding the direct downstream targets of NOR-1, researchers can gain valuable insights into its role in various physiological and pathological processes, potentially identifying new therapeutic targets for a range of diseases. The success of this protocol is highly dependent on the use of a validated antibody and careful optimization of the experimental conditions for the specific cell type of interest.
References
- 1. The orphan nuclear receptor, NOR-1, a target of beta-adrenergic signaling, regulates gene expression that controls oxidative metabolism in skeletal muscle - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. researchoutput.csu.edu.au [researchoutput.csu.edu.au]
- 3. academic.oup.com [academic.oup.com]
- 4. academic.oup.com [academic.oup.com]
- 5. scbt.com [scbt.com]
- 6. datasheets.scbt.com [datasheets.scbt.com]
Detecting NOR-1 Protein Expression by Western Blot: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
Introduction
Neuron-derived orphan receptor 1 (NOR-1), also known as NR4A3, is a member of the NR4A nuclear receptor subfamily. Unlike typical nuclear receptors, NOR-1 is considered an orphan receptor as it does not have a known endogenous ligand.[1] Its expression is induced by a variety of physiological stimuli, including exercise, growth factors, and stress, functioning as an immediate-early gene.[1] NOR-1 plays a crucial role in a wide range of biological processes, including the regulation of cellular growth, differentiation, apoptosis, and metabolism.[1] It is expressed in numerous tissues, including skeletal muscle, brain, heart, and T lymphocytes, and its dysregulation has been implicated in several pathologies such as cancer, metabolic disorders, and cardiovascular diseases.[1]
Given its significant role in cellular signaling and disease, the accurate detection and quantification of NOR-1 protein expression are essential for research and drug development. Western blotting is a powerful and widely used technique for this purpose, allowing for the sensitive and specific measurement of NOR-1 protein levels in various biological samples. This document provides detailed application notes and protocols for the successful detection of NOR-1 by Western blot.
Data Presentation: NOR-1 Protein Expression
The expression of NOR-1 varies significantly across different tissues and under various physiological conditions. The following table summarizes qualitative and quantitative data on NOR-1 protein expression from Western blot analyses.
| Tissue/Cell Type | Condition | Relative Expression Level/Fold Change | Reference |
| Human Nasopharynx | Normal | High | [2] |
| Human Trachea | Normal | High | [2] |
| Human Brain | Normal | Weak | [2] |
| Human Lung | Normal | Weak | [2] |
| Human Spinal Cord | Normal | Weak | [2] |
| Human Heart | Normal | Not Detected | [2] |
| Human Liver | Normal | Not Detected | [2] |
| Human Spleen | Normal | Not Detected | [2] |
| Human Stomach | Normal | Not Detected | [2] |
| Human Kidney | Normal | Not Detected | [2] |
| Human Skeletal Muscle | Basal (Lean Healthy Controls) | Baseline | [3] |
| Human Skeletal Muscle | Insulin (B600854) Stimulation (Lean Healthy Controls) | ~3.6-fold increase | [3] |
| Human Skeletal Muscle | Basal (Obese) | No significant change with insulin | [3] |
| Human Skeletal Muscle | Basal (Type 2 Diabetes) | No significant change with insulin | [3] |
Signaling Pathway and Experimental Workflow
NOR-1 Signaling Pathway
NOR-1 is a key transcriptional regulator involved in multiple signaling cascades. Its expression is notably induced by exercise through a calcium/calcineurin-dependent pathway. Downstream, NOR-1 influences metabolic processes and autophagy, partly through the mTOR signaling pathway.
Western Blot Experimental Workflow
The following diagram outlines the key steps for detecting NOR-1 protein expression, from sample preparation to data analysis.
References
Application Notes and Protocols for Measuring NOR-1 Transcriptional Activity using a Luciferase Reporter Assay
For Researchers, Scientists, and Drug Development Professionals
Introduction
The Neuron-Derived Orphan Receptor 1 (NOR-1), also known as NR4A3, is a member of the nuclear receptor subfamily 4 group A (NR4A).[1] As an orphan receptor, NOR-1's transcriptional activity is regulated by cellular signaling pathways rather than direct ligand binding.[1] NOR-1 plays crucial roles in a variety of physiological and pathological processes, including cell proliferation, apoptosis, inflammation, and metabolism.[2] Its dysregulation has been implicated in diseases such as cancer and atherosclerosis. Therefore, understanding the mechanisms that control NOR-1 transcriptional activity is of significant interest for basic research and therapeutic development.
The luciferase reporter assay is a sensitive and quantitative method widely used to study gene expression and regulation.[3][4] This application note provides a detailed protocol for utilizing a dual-luciferase reporter assay to measure the transcriptional activity of NOR-1 in response to key signaling pathways. The assay relies on a firefly luciferase reporter construct containing the NOR-1-specific DNA binding sequence, the Nerve Growth Factor I-B Response Element (NBRE), with the consensus sequence AAAGGTCA.[3][5][6] This document outlines the experimental workflow, data analysis, and expected outcomes when investigating the influence of the Protein Kinase A (PKA), Protein Kinase C (PKC), and Mitogen-Activated Protein Kinase (MAPK) signaling pathways on NOR-1 activity.
Principle of the Assay
The dual-luciferase reporter assay system allows for the sequential measurement of two different luciferases, firefly and Renilla, from a single sample.[7][8] The experimental reporter, firefly luciferase, is placed under the control of a promoter containing multiple copies of the NOR-1 response element (NBRE). When NOR-1 is activated, it binds to the NBRE and drives the transcription of the firefly luciferase gene. The amount of light produced upon addition of the firefly luciferase substrate is directly proportional to the transcriptional activity of NOR-1.
The second reporter, Renilla luciferase, is driven by a constitutive promoter and serves as an internal control. Co-transfection of this control plasmid allows for normalization of the firefly luciferase activity, correcting for variations in cell number and transfection efficiency across different samples. The ratio of firefly to Renilla luciferase activity provides a reliable measure of NOR-1 transcriptional activation.
Materials and Reagents
| Reagent | Supplier (Example) | Catalog Number (Example) |
| HEK293T Cells | ATCC | CRL-3216 |
| Dulbecco's Modified Eagle's Medium (DMEM) | Gibco | 11965092 |
| Fetal Bovine Serum (FBS) | Gibco | 26140079 |
| Penicillin-Streptomycin (B12071052) | Gibco | 15140122 |
| Lipofectamine® 3000 Transfection Reagent | Invitrogen | L3000015 |
| pGL4.27[luc2P/minP/Hygro] Vector | Promega | E8451 |
| pRL-TK Vector | Promega | E2241 |
| Human NOR-1 Expression Vector (e.g., pcDNA3.1-NOR-1) | GenScript | (Custom Synthesis) |
| Dual-Luciferase® Reporter Assay System | Promega | E1910 |
| Forskolin (PKA activator) | Sigma-Aldrich | F6886 |
| Phorbol 12-myristate 13-acetate (PMA) (PKC activator) | Sigma-Aldrich | P8139 |
| Epidermal Growth Factor (EGF) (MAPK activator) | R&D Systems | 236-EG |
| 96-well white, clear-bottom tissue culture plates | Corning | 3610 |
| Luminometer | (e.g., GloMax® Discover) |
Experimental Protocols
Construction of the NOR-1 Reporter Plasmid
-
Synthesize complementary oligonucleotides containing 3-5 tandem repeats of the NOR-1 response element (NBRE) with the consensus sequence 5'-AAAGGTCA-3' . Include appropriate restriction enzyme sites (e.g., NheI and XhoI) at the ends for cloning.
-
Anneal the complementary oligonucleotides to form a double-stranded DNA insert.
-
Digest the pGL4.27[luc2P/minP/Hygro] vector and the double-stranded NBRE insert with the corresponding restriction enzymes.
-
Ligate the NBRE insert into the pGL4.27 vector upstream of the minimal promoter (minP).
-
Transform the ligated product into competent E. coli, select for ampicillin-resistant colonies, and verify the correct insertion by Sanger sequencing. The resulting plasmid is designated as pGL4.27-NBRE-luc.
Cell Culture and Transfection
-
Maintain HEK293T cells in DMEM supplemented with 10% FBS and 1% penicillin-streptomycin at 37°C in a 5% CO₂ incubator.
-
One day prior to transfection, seed 2 x 10⁴ HEK293T cells per well in a 96-well white, clear-bottom plate.
-
On the day of transfection, prepare the following DNA mixture per well in Opti-MEM® I Reduced Serum Medium:
-
100 ng of pGL4.27-NBRE-luc reporter plasmid
-
50 ng of NOR-1 expression vector (e.g., pcDNA3.1-NOR-1)
-
10 ng of pRL-TK control plasmid
-
-
In a separate tube, dilute Lipofectamine® 3000 reagent in Opti-MEM® according to the manufacturer's instructions.
-
Combine the DNA mixture and the diluted transfection reagent, incubate for 15 minutes at room temperature to allow for complex formation.
-
Add the transfection complex dropwise to each well.
-
Incubate the cells for 24 hours at 37°C and 5% CO₂.
Treatment with Signaling Pathway Activators
-
After 24 hours of transfection, gently remove the medium and replace it with fresh DMEM containing 1% FBS.
-
Prepare stock solutions of the activators in DMSO (Forskolin, PMA) or sterile PBS (EGF).
-
Treat the cells with the following final concentrations for 6-8 hours:
-
PKA Activation: 10 µM Forskolin
-
PKC Activation: 100 nM PMA
-
MAPK Activation: 100 ng/mL EGF
-
Control: Vehicle (DMSO or PBS)
-
-
Include a set of wells with each treatment for each experimental condition. It is recommended to perform each treatment in triplicate.
Luciferase Assay
-
After the treatment period, remove the medium from the wells and wash once with 100 µL of PBS.
-
Lyse the cells by adding 20 µL of 1X Passive Lysis Buffer (from the Dual-Luciferase® Reporter Assay System) to each well.
-
Incubate the plate on an orbital shaker for 15 minutes at room temperature to ensure complete lysis.
-
Prepare the Luciferase Assay Reagent II (LAR II) according to the kit protocol.
-
In a luminometer, program the instrument to inject 100 µL of LAR II and measure the firefly luciferase activity.
-
Next, program the instrument to inject 100 µL of Stop & Glo® Reagent and measure the Renilla luciferase activity.
Data Presentation and Analysis
Data Analysis
-
For each well, calculate the ratio of firefly luciferase activity to Renilla luciferase activity (Relative Luciferase Units, RLU). This normalizes for transfection efficiency.
-
RLU = (Firefly Luciferase Reading) / (Renilla Luciferase Reading)
-
-
Calculate the average RLU for each treatment group (and control).
-
Determine the "Fold Induction" by dividing the average RLU of each treatment group by the average RLU of the vehicle control group.
-
Fold Induction = (Average RLU of Treated Group) / (Average RLU of Control Group)
-
Representative Quantitative Data
The following table summarizes representative data from a luciferase reporter assay measuring NOR-1 transcriptional activity in response to signaling pathway activators.
| Treatment Group | Activator | Concentration | Average Firefly Luciferase (RLU) | Average Renilla Luciferase (RLU) | Normalized Ratio (Firefly/Renilla) | Fold Induction (vs. Control) |
| Control | Vehicle (DMSO) | - | 15,000 | 5,000 | 3.0 | 1.0 |
| PKA Activation | Forskolin | 10 µM | 60,000 | 5,100 | 11.8 | 3.9 |
| PKC Activation | PMA | 100 nM | 97,500 | 4,900 | 19.9 | 6.6 |
| MAPK Activation | EGF | 100 ng/mL | 75,000 | 5,050 | 14.9 | 5.0 |
Visualization of Pathways and Workflow
Signaling Pathways Regulating NOR-1 Transcriptional Activity
Signaling pathways activating NOR-1 transcriptional activity.
Experimental Workflow for NOR-1 Luciferase Reporter Assay
Workflow for NOR-1 luciferase reporter assay.
Troubleshooting
| Issue | Possible Cause | Recommendation |
| Low Luciferase Signal | Low transfection efficiency. | Optimize transfection reagent to DNA ratio and cell density. Use a positive control vector (e.g., CMV promoter driving luciferase) to check transfection efficiency. |
| Insufficient cell lysis. | Ensure complete cell lysis by extending incubation time in lysis buffer or by gentle agitation. | |
| Inactive luciferase enzyme or substrate. | Ensure proper storage of assay reagents. Prepare fresh reagents for each experiment. | |
| High Background Signal | Leaky promoter in the reporter vector. | Use a reporter vector with a minimal promoter (e.g., pGL4.27). |
| Endogenous transcription factor activity. | Test the reporter construct without the co-transfected NOR-1 expression vector to determine basal activity. | |
| High Variability Between Replicates | Inconsistent cell seeding. | Ensure a homogenous cell suspension and careful pipetting when seeding cells. |
| Pipetting errors during transfection or assay. | Use calibrated pipettes and be consistent with pipetting technique. | |
| Cell toxicity from treatment. | Perform a cell viability assay (e.g., MTT or LDH) in parallel to ensure that the observed effects are not due to cytotoxicity. |
Conclusion
The dual-luciferase reporter assay is a robust and sensitive method for quantifying the transcriptional activity of NOR-1. By following the detailed protocols outlined in this application note, researchers can effectively investigate the impact of various signaling pathways on NOR-1 function. This assay is a valuable tool for dissecting the molecular mechanisms that regulate this important nuclear receptor and for screening potential therapeutic modulators of its activity.
References
- 1. Illuminating Cell Signaling Pathways: The Power of Luciferase-Based Reporter Assays | Scientist.com [app.scientist.com]
- 2. NFAT - Wikipedia [en.wikipedia.org]
- 3. spandidos-publications.com [spandidos-publications.com]
- 4. Activation and Function of the MAPKs and Their Substrates, the MAPK-Activated Protein Kinases - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Nanoluciferase Reporter Gene System Directed by Tandemly Repeated Pseudo-Palindromic NFAT-Response Elements Facilitates Analysis of Biological Endpoint Effects of Cellular Ca2+ Mobilization [mdpi.com]
- 6. academic.oup.com [academic.oup.com]
- 7. MAPK/ERK pathway - Wikipedia [en.wikipedia.org]
- 8. researchgate.net [researchgate.net]
Application Notes and Protocols for NOR-1 Immunofluorescence
For researchers, scientists, and drug development professionals, accurate and reliable detection of the Neuron-derived orphan receptor 1 (NOR-1), also known as NR4A3, is critical for investigating its role in various physiological and pathological processes, including neuronal function, metabolism, and cancer. This document provides a comprehensive guide to the best commercially available antibodies for NOR-1 immunofluorescence, complete with detailed protocols and supporting information.
Recommended Commercial Antibodies for NOR-1 Immunofluorescence
Two antibodies have been identified as highly effective for the immunofluorescent detection of NOR-1 in cultured cells and tissue sections. The selection is based on manufacturer validation, citation in peer-reviewed publications, and available protocol details.
Santa Cruz Biotechnology, Inc. NOR-1 Antibody (H-7), sc-393902
This mouse monoclonal antibody is a widely cited option for the detection of human, mouse, and rat NOR-1.[1][2] Its versatility across various applications, including immunofluorescence (IF), makes it a reliable choice.[1][2]
Proteintech NR4A3 Antibody, 55405-1-AP
This rabbit polyclonal antibody is validated for the detection of human and mouse NOR-1/NR4A3.[3] The manufacturer provides a representative immunofluorescence image, demonstrating its specificity and performance.[3]
Quantitative Data Summary
The following table summarizes the key features and recommended starting concentrations for the selected NOR-1 antibodies. It is important to note that optimal dilutions should be determined experimentally by the end-user.
| Feature | Santa Cruz Biotechnology sc-393902 | Proteintech 55405-1-AP |
| Product Name | NOR-1 Antibody (H-7) | NR4A3 Polyclonal Antibody |
| Host Species | Mouse | Rabbit |
| Clonality | Monoclonal | Polyclonal |
| Reactivity | Human, Mouse, Rat | Human, Mouse |
| Validated Applications | WB, IP, IF, ELISA | WB, IF/ICC, ELISA |
| Recommended IF Starting Dilution | 1:50[4] | 1:200 - 1:800[3] |
| Example IF Dilution | Not specified in publications found | 1:400 in 4% PFA-fixed ROS1728 cells[3][5] |
NOR-1 Signaling Pathway
NOR-1 is an orphan nuclear receptor that acts as a transcription factor, playing a crucial role in the cellular response to a variety of stimuli. Its expression is induced by growth factors, stress, and physiological signals, which in turn modulates genes involved in cell proliferation, apoptosis, metabolism, and inflammation. The diagram below illustrates a simplified overview of the NOR-1 signaling pathway.
Caption: Simplified NOR-1 signaling pathway.
Experimental Protocols
This section provides detailed protocols for immunofluorescence staining of NOR-1 in cultured cells. The protocols are based on the manufacturer's recommendations and general immunofluorescence best practices.[6][7][8][9]
Protocol 1: Immunofluorescence Staining with Santa Cruz Biotechnology sc-393902
Materials:
-
NOR-1 Antibody (H-7), sc-393902
-
Cells grown on coverslips or in chamber slides
-
Phosphate-Buffered Saline (PBS)
-
Fixation Solution: 4% Paraformaldehyde (PFA) in PBS or ice-cold Methanol (B129727)
-
Permeabilization Buffer: 0.1-0.5% Triton X-100 in PBS
-
Blocking Buffer: 1-5% Bovine Serum Albumin (BSA) or 10% Normal Goat Serum in PBS
-
Fluorophore-conjugated anti-mouse secondary antibody
-
DAPI or Hoechst for nuclear counterstaining
-
Antifade mounting medium
Procedure:
-
Cell Seeding: Seed cells onto coverslips or chamber slides and culture until they reach the desired confluency.
-
Washing: Gently wash the cells twice with PBS.
-
Fixation:
-
For PFA fixation: Incubate cells with 4% PFA in PBS for 15 minutes at room temperature.
-
For Methanol fixation: Incubate cells with ice-cold methanol for 10 minutes at -20°C.
-
-
Washing: Wash the cells three times with PBS for 5 minutes each.
-
Permeabilization (for PFA-fixed cells): Incubate cells with Permeabilization Buffer for 10 minutes at room temperature.
-
Blocking: Incubate cells with Blocking Buffer for 1 hour at room temperature to block non-specific antibody binding.
-
Primary Antibody Incubation: Dilute the NOR-1 antibody (sc-393902) to a starting concentration of 1:50 in Blocking Buffer. Incubate overnight at 4°C in a humidified chamber.
-
Washing: Wash the cells three times with PBS for 5 minutes each.
-
Secondary Antibody Incubation: Dilute the fluorophore-conjugated anti-mouse secondary antibody in Blocking Buffer according to the manufacturer's instructions. Incubate for 1 hour at room temperature, protected from light.
-
Washing: Wash the cells three times with PBS for 5 minutes each, protected from light.
-
Counterstaining: Incubate cells with DAPI or Hoechst solution for 5 minutes at room temperature.
-
Washing: Wash the cells once with PBS.
-
Mounting: Mount the coverslips onto microscope slides using an antifade mounting medium.
-
Imaging: Visualize the staining using a fluorescence microscope with the appropriate filters.
Protocol 2: Immunofluorescence Staining with Proteintech 55405-1-AP
Materials:
-
NR4A3 Polyclonal Antibody, 55405-1-AP
-
Cells grown on coverslips or in chamber slides
-
Phosphate-Buffered Saline (PBS)
-
Fixation Solution: 4% Paraformaldehyde (PFA) in PBS
-
Permeabilization Buffer: 0.1-0.5% Triton X-100 in PBS
-
Blocking Buffer: 1-5% Bovine Serum Albumin (BSA) or 10% Normal Goat Serum in PBS
-
Fluorophore-conjugated anti-rabbit secondary antibody
-
DAPI or Hoechst for nuclear counterstaining
-
Antifade mounting medium
Procedure:
-
Cell Seeding: Seed cells onto coverslips or chamber slides and culture to the desired confluency.
-
Washing: Gently wash the cells twice with PBS.
-
Fixation: Incubate cells with 4% PFA in PBS for 15 minutes at room temperature.
-
Washing: Wash the cells three times with PBS for 5 minutes each.
-
Permeabilization: Incubate cells with Permeabilization Buffer for 10-15 minutes at room temperature.
-
Blocking: Incubate cells with Blocking Buffer for 1 hour at room temperature.
-
Primary Antibody Incubation: Dilute the NR4A3 antibody (55405-1-AP) to a concentration between 1:200 and 1:800 (a starting dilution of 1:400 is recommended) in Blocking Buffer.[3][5] Incubate overnight at 4°C in a humidified chamber.
-
Washing: Wash the cells three times with PBS for 5 minutes each.
-
Secondary Antibody Incubation: Dilute the fluorophore-conjugated anti-rabbit secondary antibody in Blocking Buffer according to the manufacturer's instructions. Incubate for 1 hour at room temperature, protected from light.
-
Washing: Wash the cells three times with PBS for 5 minutes each, protected from light.
-
Counterstaining: Incubate cells with DAPI or Hoechst solution for 5 minutes at room temperature.
-
Washing: Wash the cells once with PBS.
-
Mounting: Mount the coverslips onto microscope slides using an antifade mounting medium.
-
Imaging: Visualize the staining using a fluorescence microscope with the appropriate filters.
Experimental Workflow
The following diagram outlines the general workflow for an immunofluorescence experiment.
References
- 1. (sc-393902) NOR-1 Antibody (H-7) - Santa Cruz Biotechnology - CiteAb [citeab.com]
- 2. scbt.com [scbt.com]
- 3. ptgcn.com [ptgcn.com]
- 4. protilatky.biopticka.cz [protilatky.biopticka.cz]
- 5. NR4A3 antibody (55405-1-AP) | Proteintech [ptglab.com]
- 6. scbt.com [scbt.com]
- 7. ptglab.com [ptglab.com]
- 8. arigobio.com [arigobio.com]
- 9. IF Staining Protocols | Proteintech Group [ptglab.co.jp]
Cloning of a NOR-1 Expression Vector for Mammalian Cells: An Application Note and Protocol
For Researchers, Scientists, and Drug Development Professionals
Abstract
This document provides a comprehensive guide for the cloning of the human Neuron-Derived Orphan Receptor 1 (NOR-1), also known as Nuclear Receptor Subfamily 4 Group A Member 3 (NR4A3), into a mammalian expression vector. NOR-1 is a key transcriptional regulator involved in cellular proliferation, apoptosis, and metabolism.[1][2][3] The ability to express NOR-1 in mammalian cells is crucial for studying its function and for the development of therapeutic agents targeting its signaling pathways. This guide details two effective cloning strategies: traditional restriction enzyme cloning and ligation-independent cloning (LIC). Furthermore, it provides protocols for the verification of the final construct and its subsequent transfection into mammalian cells for protein expression.
Introduction
Neuron-Derived Orphan Receptor 1 (NOR-1) is a member of the NR4A nuclear receptor family, which also includes Nur77 and Nurr1.[4] These receptors are classified as orphan receptors as their endogenous ligands have not yet been identified.[1][2] NOR-1 functions as a transcriptional activator that binds to specific DNA response elements.[3] It is rapidly induced by a variety of stimuli, including growth factors and neurotransmitters, and plays a significant role in diverse physiological and pathological processes such as neuronal function, inflammation, and vascular remodeling.[1][2] The study of NOR-1 is of great interest in several research areas, including neuroscience, oncology, and cardiovascular disease.
To facilitate the investigation of NOR-1's cellular functions, its overexpression in mammalian cell lines is a common and powerful tool. This requires the construction of a robust expression vector containing the full-length coding sequence of the NOR-1 gene. The pcDNA3.1(+) vector is a widely used and highly effective plasmid for achieving high-level constitutive expression of a gene of interest in a variety of mammalian cell lines.[5] It contains a strong human cytomegalovirus (CMV) promoter, a bovine growth hormone (BGH) polyadenylation signal for enhanced mRNA stability, and a neomycin resistance gene for the selection of stable cell lines.[5]
This application note provides detailed protocols for the cloning of the human NOR-1 gene into the pcDNA3.1(+) mammalian expression vector using two distinct methodologies. It also includes procedures for the verification of the resulting plasmid and its transfection into Human Embryonic Kidney 293T (HEK293T) cells, a commonly used cell line for high-efficiency transfection and protein expression.[6]
Materials and Methods
Vector and Gene of Interest
-
Mammalian Expression Vector: pcDNA3.1(+) (5.4 kb). This vector provides high-level, constitutive expression in a wide range of mammalian cells.[5]
-
Gene of Interest: Human NOR-1 (NR4A3), transcript variant 1. The coding sequence (CDS) is 1878 bp.
Experimental Workflow
The overall workflow for cloning NOR-1 into a mammalian expression vector is depicted below.
References
- 1. Frontiers | Comprehensive insights into the function and molecular and pharmacological regulation of neuron-derived orphan receptor 1, an orphan receptor [frontiersin.org]
- 2. Comprehensive insights into the function and molecular and pharmacological regulation of neuron-derived orphan receptor 1, an orphan receptor - PMC [pmc.ncbi.nlm.nih.gov]
- 3. uniprot.org [uniprot.org]
- 4. The orphan nuclear receptor Nor1/Nr4a3 is a negative regulator of β-cell mass - PMC [pmc.ncbi.nlm.nih.gov]
- 5. documents.thermofisher.com [documents.thermofisher.com]
- 6. Optimized Transfection Strategy for Expression and Electrophysiological Recording of Recombinant Voltage-Gated Ion Channels in HEK-293T Cells - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for CRISPR-Cas9 Mediated Knockout of NR4A3
For Researchers, Scientists, and Drug Development Professionals
Introduction
The Nuclear Receptor Subfamily 4 Group A Member 3 (NR4A3), also known as NOR-1, is a member of the orphan nuclear receptor superfamily. It functions as a transcription factor that plays a pivotal role in a diverse range of physiological and pathological processes. These include cell proliferation, differentiation, apoptosis, inflammation, and metabolism. The functional context of NR4A3 is highly tissue-specific; it can act as a tumor suppressor in some cancers while promoting oncogenesis in others. Given its significant involvement in human health and disease, NR4A3 has emerged as a promising target for therapeutic intervention.
The CRISPR-Cas9 system offers a powerful and precise tool for genome editing, enabling the targeted knockout of genes like NR4A3 to elucidate their function and validate their potential as drug targets. This document provides a comprehensive guide for designing and validating guide RNAs (gRNAs) to achieve efficient CRISPR-Cas9 mediated knockout of the NR4A3 gene.
NR4A3 Signaling Pathway
NR4A3 is an immediate early gene, rapidly induced by a variety of stimuli. It exerts its effects by binding to specific DNA response elements in the promoter regions of its target genes, thereby modulating their transcription. A key signaling pathway influenced by NR4A3 involves the nuclear factor-kappa B (NF-κB) pathway, a central regulator of inflammation and immunity. The interaction is complex, with NR4A3 capable of both enhancing and suppressing NF-κB activity depending on the cellular context. For instance, in some cell types, NR4A3 can directly bind to the p65 subunit of NF-κB, influencing its transcriptional activity and promoting the polarization of macrophages towards an M1 phenotype.
Application Notes and Protocols for NOR-1 Protein-Protein Interaction Pulldown Assay
For Researchers, Scientists, and Drug Development Professionals
Introduction
Neuron-derived orphan receptor 1 (NOR-1), also known as NR4A3, is a member of the NR4A nuclear receptor subfamily. As an orphan receptor, no endogenous ligand has been identified to date. NOR-1 is an immediate-early gene that is rapidly induced by a variety of stimuli and plays crucial roles in cellular proliferation, apoptosis, inflammation, and metabolism. Understanding the protein-protein interactions of NOR-1 is critical for elucidating its molecular mechanisms and for the development of novel therapeutic strategies targeting pathways regulated by this transcription factor.
This document provides a detailed protocol for a glutathione (B108866) S-transferase (GST) pulldown assay to identify and confirm protein interactions with NOR-1. The GST pulldown assay is a widely used in vitro technique to study protein-protein interactions. It utilizes a recombinant "bait" protein (in this case, GST-tagged NOR-1) to capture "prey" proteins from a cell lysate.
Principle of the GST Pulldown Assay
The core principle of the GST pulldown assay involves three main steps:
-
Immobilization of the Bait Protein: A recombinant fusion protein of GST and the bait protein (GST-NOR-1) is expressed and purified. This fusion protein is then immobilized on glutathione-conjugated beads.
-
Binding of the Prey Protein: The immobilized GST-NOR-1 is incubated with a cell lysate containing potential interacting proteins (prey). If a prey protein interacts with NOR-1, it will bind to the complex on the beads.
-
Detection of the Interacting Proteins: After washing away non-specific binders, the interacting proteins are eluted from the beads and detected by methods such as Western blotting.
Potential NOR-1 Interacting Proteins
Several proteins have been identified or suggested as interacting partners for NOR-1, primarily involved in apoptosis and autophagy:
-
Beclin-1: A key protein in the initiation of autophagy.
-
ATG3: An E2-like enzyme involved in the elongation of the autophagosome.
-
Bax and Bcl-xL: Pro- and anti-apoptotic proteins of the Bcl-2 family, respectively.
-
ATP synthase subunit ATP5O: A component of the mitochondrial ATP synthase complex.
-
Nurr1-interacting protein (NuIP): While shown to interact with the related protein Nurr1, its potential interaction with NOR-1 is worth investigating.
Experimental Protocols
Recombinant GST-NOR-1 Fusion Protein Expression and Purification
This protocol describes the expression of GST-NOR-1 in E. coli and its purification.
Materials:
-
pGEX vector containing the NOR-1 cDNA sequence
-
E. coli BL21 strain
-
LB broth with ampicillin (B1664943)
-
Isopropyl β-D-1-thiogalactopyranoside (IPTG)
-
Phosphate-buffered saline (PBS)
-
Lysozyme
-
Triton X-100
-
DNase I
-
Glutathione-agarose beads
Procedure:
-
Transform the pGEX-NOR-1 plasmid into competent E. coli BL21 cells.
-
Inoculate a single colony into 5 mL of LB broth with ampicillin and grow overnight at 37°C with shaking.
-
Inoculate 500 mL of LB broth with the overnight culture and grow at 37°C until the OD600 reaches 0.6-0.8.
-
Induce protein expression by adding IPTG to a final concentration of 0.1-1 mM and continue to grow for 3-4 hours at 37°C or overnight at a lower temperature (e.g., 18-25°C) for better protein folding.
-
Harvest the cells by centrifugation at 5,000 x g for 15 minutes at 4°C.
-
Resuspend the cell pellet in ice-cold PBS.
-
Lyse the cells by sonication on ice.
-
Add Triton X-100 to a final concentration of 1% and incubate for 30 minutes on ice to solubilize the fusion protein.
-
Clarify the lysate by centrifugation at 12,000 x g for 20 minutes at 4°C.
-
Add the clarified supernatant to pre-equilibrated glutathione-agarose beads and incubate for 1-2 hours at 4°C with gentle rocking.
-
Wash the beads three to five times with ice-cold PBS.
-
Elute the GST-NOR-1 protein with elution buffer (e.g., 50 mM Tris-HCl, pH 8.0, containing 10-20 mM reduced glutathione).
-
Analyze the purified protein by SDS-PAGE and Coomassie blue staining to confirm its size and purity.
Preparation of Cell Lysate
This protocol describes the preparation of a whole-cell lysate from mammalian cells to be used as the source of "prey" proteins.
Materials:
-
Mammalian cell line of interest (e.g., HEK293T, HeLa)
-
Ice-cold PBS
-
Lysis buffer (e.g., RIPA buffer or a non-denaturing lysis buffer: 50 mM Tris-HCl pH 7.4, 150 mM NaCl, 1 mM EDTA, 1% NP-40) supplemented with protease and phosphatase inhibitors.
Procedure:
-
Culture cells to 80-90% confluency.
-
Wash the cells twice with ice-cold PBS.
-
Add ice-cold lysis buffer to the cells and scrape them from the plate.
-
Incubate the cell suspension on ice for 30 minutes with occasional vortexing.
-
Clarify the lysate by centrifugation at 14,000 x g for 15 minutes at 4°C.
-
Transfer the supernatant (cell lysate) to a new pre-chilled tube.
-
Determine the protein concentration of the lysate using a standard protein assay (e.g., Bradford or BCA assay).
GST Pulldown Assay
This protocol describes the interaction assay between the GST-NOR-1 "bait" and the "prey" proteins in the cell lysate.
Materials:
-
Purified GST-NOR-1 bound to glutathione-agarose beads
-
GST protein bound to glutathione-agarose beads (as a negative control)
-
Prepared cell lysate
-
Wash buffer (e.g., lysis buffer with a lower concentration of detergent)
-
Elution buffer (e.g., SDS-PAGE sample buffer or glutathione elution buffer)
Procedure:
-
Incubate approximately 20-50 µg of GST-NOR-1 bound to beads with 500 µg to 1 mg of cell lysate in a final volume of 500 µL to 1 mL.
-
As a negative control, incubate GST-bound beads with the same amount of cell lysate.
-
Incubate the mixtures for 2-4 hours or overnight at 4°C with gentle rotation.
-
Pellet the beads by centrifugation at 500-1000 x g for 1-2 minutes at 4°C.
-
Carefully remove the supernatant.
-
Wash the beads three to five times with 1 mL of ice-cold wash buffer. After each wash, pellet the beads by centrifugation and discard the supernatant.
-
After the final wash, remove all residual supernatant.
-
Elute the bound proteins by adding 2X SDS-PAGE sample buffer and boiling for 5-10 minutes. Alternatively, elute with glutathione elution buffer.
Analysis of Pulldown Proteins by Western Blot
This protocol describes the detection of interacting proteins by Western blot.
Materials:
-
Eluted protein samples from the pulldown assay
-
SDS-PAGE gels
-
Western blotting apparatus
-
PVDF or nitrocellulose membrane
-
Blocking buffer (e.g., 5% non-fat milk or BSA in TBST)
-
Primary antibody against the potential interacting protein (e.g., anti-Beclin-1, anti-ATG3)
-
HRP-conjugated secondary antibody
-
Chemiluminescent substrate
Procedure:
-
Separate the eluted proteins by SDS-PAGE.
-
Transfer the proteins to a PVDF or nitrocellulose membrane.
-
Block the membrane with blocking buffer for 1 hour at room temperature.
-
Incubate the membrane with the primary antibody overnight at 4°C.
-
Wash the membrane three times with TBST.
-
Incubate the membrane with the HRP-conjugated secondary antibody for 1 hour at room temperature.
-
Wash the membrane three times with TBST.
-
Detect the protein bands using a chemiluminescent substrate and an imaging system.
Data Presentation
The results of a pulldown assay followed by Western blotting can be quantified by densitometry. The intensity of the band corresponding to the co-precipitated protein is measured and can be normalized to the amount of bait protein pulled down. Below is an example table summarizing hypothetical quantitative data from a GST pulldown experiment investigating the interaction of NOR-1 with Beclin-1 and ATG3.
| Bait Protein | Prey Protein | Input (Relative Densitometry Units) | Pulldown (Relative Densitometry Units) | Fold Enrichment (Pulldown/Input) |
| GST | Beclin-1 | 100 | 5 | 0.05 |
| GST-NOR-1 | Beclin-1 | 100 | 85 | 0.85 |
| GST | ATG3 | 100 | 3 | 0.03 |
| GST-NOR-1 | ATG3 | 100 | 78 | 0.78 |
Note: The data in this table is for illustrative purposes only and represents a hypothetical outcome of a successful pulldown experiment.
Visualizations
Experimental Workflow Diagram
Caption: Experimental workflow for a GST pulldown assay to identify NOR-1 interacting proteins.
NOR-1 Signaling Pathway Diagram
Caption: Simplified signaling pathway of NOR-1 protein-protein interactions in autophagy and apoptosis.
Application Note: Synthesis, Purification, and Characterization of a Novel NOR-1 Agonist, "Noragon-1"
Audience: Researchers, scientists, and drug development professionals.
Abstract: The Neuron-derived orphan receptor 1 (NOR-1), also known as NR4A3, is a member of the nuclear receptor subfamily 4 group A. As a ligand-activated transcription factor, NOR-1 is implicated in various physiological processes, including muscle reprogramming, metabolism, and inflammation, making it an attractive therapeutic target. This document provides a detailed methodology for the synthesis, purification, and biological evaluation of a novel, potent, and selective NOR-1 agonist, designated "Noragon-1." The protocols herein describe a reproducible synthetic route, a robust purification workflow achieving >99.5% purity, and key biological assays to confirm on-target activity and potency.
Synthesis of Noragon-1
The synthesis of Noragon-1 is achieved via a two-step process involving a Williamson ether synthesis followed by saponification. The general workflow is outlined below.
Caption: Synthetic workflow for the novel NOR-1 agonist, Noragon-1.
Experimental Protocol: Synthesis
Step 1: Williamson Ether Synthesis to yield Methyl 2-(4-((4-(trifluoromethyl)phenyl)oxy)phenyl)acetate (Noragon-1-Me)
-
To a dry 250 mL round-bottom flask, add 4-hydroxyphenylacetic acid methyl ester (1.0 eq), potassium carbonate (K₂CO₃, 2.5 eq), and dimethylformamide (DMF, 5 mL/mmol).
-
Stir the suspension at room temperature for 15 minutes.
-
Add 4-fluorobenzotrifluoride (1.2 eq) to the mixture.
-
Heat the reaction mixture to 80°C and stir for 12-16 hours. Monitor reaction progress by Thin Layer Chromatography (TLC).
-
After completion, cool the reaction to room temperature and pour it into 100 mL of cold water.
-
Extract the aqueous layer with ethyl acetate (B1210297) (3 x 50 mL).
-
Combine the organic layers, wash with brine (2 x 30 mL), dry over anhydrous sodium sulfate (B86663) (Na₂SO₄), filter, and concentrate under reduced pressure to yield the crude intermediate, Noragon-1-Me.
Step 2: Saponification to yield 2-(4-((4-(trifluoromethyl)phenyl)oxy)phenyl)acetic acid (Noragon-1)
-
Dissolve the crude Noragon-1-Me intermediate (1.0 eq) in a mixture of tetrahydrofuran (B95107) (THF) and water (3:1, 4 mL/mmol).
-
Add lithium hydroxide (B78521) (LiOH, 3.0 eq) to the solution.
-
Stir the mixture vigorously at room temperature for 4-6 hours. Monitor the hydrolysis by TLC or LC-MS.
-
Once the reaction is complete, concentrate the mixture under reduced pressure to remove the THF.
-
Dilute the remaining aqueous solution with 50 mL of water and wash with diethyl ether (2 x 25 mL) to remove any unreacted starting material.
-
Cool the aqueous layer in an ice bath and acidify to pH 2-3 by the dropwise addition of 1M hydrochloric acid (HCl). A white precipitate should form.
-
Extract the product with ethyl acetate (3 x 40 mL).
-
Combine the organic layers, wash with brine (1 x 30 mL), dry over anhydrous Na₂SO₄, filter, and concentrate in vacuo to yield crude Noragon-1 as a white to off-white solid.
Data Presentation: Synthesis Results
| Step | Reaction | Product | Theoretical Yield (g) | Actual Yield (g) | % Yield |
| 1 | Williamson Ether Synthesis | Noragon-1-Me | 5.15 | 4.38 | 85% |
| 2 | Saponification | Noragon-1 | 4.38 | 3.99 | 91% |
Purification of Noragon-1
The crude product is purified using a two-step process: initial purification via flash column chromatography followed by final polishing with preparative high-performance liquid chromatography (HPLC) to achieve high purity suitable for biological assays.
Caption: Purification and quality control workflow for Noragon-1.
Experimental Protocol: Purification
Step 1: Flash Column Chromatography (Silica Gel)
-
Prepare a silica (B1680970) gel column using a hexane:ethyl acetate solvent system (gradient elution from 9:1 to 7:3 is typical).
-
Dissolve the crude Noragon-1 (from section 1.1) in a minimal amount of dichloromethane (B109758) (DCM).
-
Adsorb the dissolved product onto a small amount of silica gel and dry it to a free-flowing powder.
-
Load the dry powder onto the top of the prepared column.
-
Elute the column with the hexane:ethyl acetate gradient, collecting fractions.
-
Monitor the fractions by TLC (visualized with UV light).
-
Combine the fractions containing the pure product (typically Rf ≈ 0.3 in 8:2 Hex:EtOAc).
-
Analyze the pooled fractions by LC-MS to confirm purity is >95%.
-
Evaporate the solvent under reduced pressure to yield a semi-pure solid.
Step 2: Preparative Reverse-Phase HPLC (RP-HPLC)
-
Dissolve the semi-pure product from the flash chromatography step in a minimal amount of methanol (B129727) or DMSO.
-
Purify the material using a preparative C18 column.
-
Mobile Phase A: 0.1% Trifluoroacetic acid (TFA) in Water.
-
Mobile Phase B: 0.1% Trifluoroacetic acid (TFA) in Acetonitrile.
-
Gradient: A typical gradient would be 30-90% Mobile Phase B over 30 minutes.
-
Detection: Monitor the elution at 254 nm.
-
Collect fractions corresponding to the main product peak.
-
Confirm the purity of each fraction using analytical HPLC (>99.5%).
-
Pool the pure fractions and freeze-dry (lyophilize) to remove the solvent, yielding Noragon-1 as a fluffy, white powder.
Data Presentation: Purification and Characterization
Table 2.1: Purification Summary
| Step | Method | Starting Purity (Approx.) | Final Purity | Recovery |
| 1 | Flash Chromatography | ~85% | >95% | 90% |
| 2 | Preparative HPLC | >95% | >99.5% | 88% |
Table 2.2: Final Compound Characterization
| Analysis | Method | Result |
| Purity | Analytical HPLC (254 nm) | 99.7% |
| Identity | LC-MS (ESI+) | [M+H]⁺: Calculated: 299.07, Found: 299.1 |
| Structure | ¹H NMR (400 MHz, DMSO-d₆) | Signals consistent with the proposed chemical structure. |
Biological Evaluation of Noragon-1
The biological activity of Noragon-1 is assessed by its ability to activate the NOR-1 receptor in a cell-based reporter assay and by its affinity for the receptor in a competitive binding assay.
Caption: Simplified NOR-1 signaling pathway and points of activation.
Protocol: NOR-1 Gal4-LBD Reporter Gene Assay
This assay measures the ability of a compound to activate the NOR-1 ligand-binding domain (LBD) in a cellular context.
Materials:
-
HEK293T cells
-
DMEM with 10% FBS, 1% Penicillin-Streptomycin
-
Expression Plasmid 1: pFA-NOR1-LBD (encodes Gal4 DNA-binding domain fused to NOR-1 LBD)
-
Reporter Plasmid: pFR-Luc (encodes firefly luciferase downstream of a Gal4 upstream activation sequence)
-
Control Plasmid: pRL-SV40 (encodes Renilla luciferase for normalization)
-
Transfection Reagent (e.g., Lipofectamine 3000)
-
96-well white, clear-bottom cell culture plates
-
Dual-Glo Luciferase Assay System
-
Luminometer
Method:
-
Cell Seeding: Seed HEK293T cells in a 96-well plate at a density of 2 x 10⁴ cells per well. Incubate overnight at 37°C, 5% CO₂.
-
Transfection:
-
Prepare a DNA master mix containing pFA-NOR1-LBD, pFR-Luc, and pRL-SV40 plasmids in a 10:10:1 ratio.
-
Transfect the cells according to the manufacturer's protocol for your chosen transfection reagent.
-
Incubate for 4-6 hours.
-
-
Compound Treatment:
-
Prepare serial dilutions of Noragon-1 (e.g., from 10 µM to 0.1 nM) in serum-free DMEM. Include a DMSO vehicle control.
-
After the transfection incubation, replace the medium with the compound dilutions.
-
Incubate for 18-24 hours at 37°C, 5% CO₂.
-
-
Luciferase Assay:
-
Equilibrate the plate and Dual-Glo reagents to room temperature.
-
Add the Dual-Glo Luciferase Reagent to each well, mix, and incubate for 10 minutes.
-
Measure the firefly luminescence (experimental reporter).
-
Add the Dual-Glo Stop & Glo Reagent, mix, and incubate for 10 minutes.
-
Measure the Renilla luminescence (control reporter).
-
-
Data Analysis:
-
Normalize the firefly luminescence readings to the Renilla luminescence readings for each well.
-
Plot the normalized luminescence versus the log of the compound concentration.
-
Fit the data to a four-parameter logistic equation to determine the EC₅₀ value.
-
Protocol: Competitive Radioligand Binding Assay
This assay determines the affinity (Ki) of Noragon-1 for the NOR-1 LBD by measuring its ability to displace a known radioligand.
Materials:
-
Purified His-tagged NOR-1 LBD protein
-
Radioligand (e.g., a tritiated known ligand for a related NR4A receptor, as a specific NOR-1 radioligand is not commercially available; this is a common approach for orphan receptors)
-
Noragon-1 (unlabeled competitor)
-
Assay Buffer: 50 mM HEPES, 150 mM NaCl, 1 mM DTT, 10% glycerol, 0.1% BSA, pH 7.4
-
Scintillation Proximity Assay (SPA) beads (e.g., Nickel chelate YSi beads)
-
384-well microplates
-
Microplate scintillation counter
Method:
-
Reagent Preparation:
-
Dilute the His-tagged NOR-1 LBD and SPA beads in assay buffer. Incubate for 1 hour at 4°C to allow the protein to bind to the beads.
-
Prepare serial dilutions of Noragon-1 in assay buffer.
-
Prepare the radioligand at a fixed concentration (typically at or below its Kd) in assay buffer.
-
-
Assay Plate Setup:
-
Add assay buffer to all wells.
-
Add the Noragon-1 dilutions to the appropriate wells.
-
Add a known non-specific binding control (a high concentration of a known unlabeled ligand).
-
Add the radioligand to all wells.
-
Initiate the binding reaction by adding the NOR-1 LBD/SPA bead slurry to all wells.
-
-
Incubation: Seal the plate and incubate for 2-4 hours at room temperature with gentle shaking to allow the binding to reach equilibrium.
-
Detection: Centrifuge the plate briefly to settle the beads. Read the plate on a microplate scintillation counter.
-
Data Analysis:
-
Plot the scintillation counts (CPM) against the log of the competitor (Noragon-1) concentration.
-
Fit the data to a sigmoidal dose-response curve to determine the IC₅₀ value.
-
Calculate the inhibitor constant (Ki) using the Cheng-Prusoff equation: Ki = IC₅₀ / (1 + [L]/Kd), where [L] is the concentration of the radioligand and Kd is its dissociation constant.
-
Data Presentation: Biological Activity
Table 3.1: In Vitro Activity of Noragon-1
| Assay | Parameter | Noragon-1 |
| NOR-1 Reporter Gene Assay | EC₅₀ (nM) | 150 ± 25 |
| Competitive Binding Assay | IC₅₀ (nM) | 210 ± 30 |
| Competitive Binding Assay | Ki (nM) | 95 ± 18 |
Disclaimer: This document is for informational purposes only. The synthesis and handling of the described chemicals should be performed by trained professionals in a suitably equipped laboratory, following all appropriate safety precautions. The biological assays described are standard methods and may require optimization for specific laboratory conditions.
Application Notes and Protocols: High-Throughput Screening for NR4A3 Inhibitors
For Researchers, Scientists, and Drug Development Professionals
Introduction
The Nuclear Receptor Subfamily 4 Group A Member 3 (NR4A3), also known as NOR-1, is a member of the steroid-thyroid hormone-retinoid receptor superfamily.[1] NR4A3 is an orphan nuclear receptor with significant roles in a variety of physiological and pathological processes, including cell proliferation, apoptosis, inflammation, and metabolism.[2][3] Its involvement in cancer is particularly complex, where it can function as either a tumor suppressor or an oncogene depending on the cellular context.[4][5] For instance, in hematological malignancies like acute myeloid leukemia, NR4A3 often acts as a tumor suppressor.[4] In contrast, in certain solid tumors such as acinic cell carcinoma, it can exhibit pro-oncogenic activities.[5][6] This dual role makes NR4A3 a compelling therapeutic target. The development of small molecule inhibitors of NR4A3 could provide novel therapeutic strategies for cancers where NR4A3 activity is oncogenic.
These application notes provide a comprehensive protocol for developing and implementing a robust high-throughput screening (HTS) assay to identify novel inhibitors of the NR4A3 nuclear receptor. The described assay is a time-resolved fluorescence resonance energy transfer (TR-FRET) based biochemical assay, a technology well-suited for HTS due to its sensitivity, low background, and homogeneous format.[7] A secondary cell-based reporter assay is also detailed for hit confirmation and validation.
Assay Principle
The primary screening assay is a competitive binding TR-FRET assay. This assay measures the disruption of the interaction between the NR4A3 Ligand Binding Domain (LBD) and a coactivator peptide. The NR4A3 LBD is tagged with a long-lifetime terbium (Tb) lanthanide donor, and the coactivator peptide is labeled with a fluorescent acceptor, such as fluorescein (B123965) or green fluorescent protein (GFP). When the tagged LBD and coactivator peptide interact, they are in close proximity, allowing for fluorescence resonance energy transfer upon excitation of the terbium donor. This results in a high TR-FRET signal. Small molecule inhibitors that bind to the NR4A3 LBD will disrupt the interaction with the coactivator peptide, leading to a decrease in the TR-FRET signal. This reduction in signal is the primary readout for identifying potential NR4A3 inhibitors.
Signaling Pathway and Experimental Workflow
To contextualize the assay, it is important to understand the signaling cascade involving NR4A3 and the overall workflow for inhibitor screening and validation.
References
- 1. Nuclear receptor 4A3 - Wikipedia [en.wikipedia.org]
- 2. caymanchem.com [caymanchem.com]
- 3. uniprot.org [uniprot.org]
- 4. aacrjournals.org [aacrjournals.org]
- 5. The Paradoxical Roles of Orphan Nuclear Receptor 4A (NR4A) in Cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Oncogenic Orphan Nuclear Receptor NR4A3 Interacts and Cooperates with MYB in Acinic Cell Carcinoma - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Microplate Assays for High-Throughput Drug Screening in Cancer Research [moleculardevices.com]
Application Notes and Protocols: Generation of a Stable Cell Line with Doxycycline-Inducible NOR-1 Expression
For Researchers, Scientists, and Drug Development Professionals
Introduction
Neuron-derived orphan receptor 1 (NOR-1), also known as NR4A3, is a member of the nuclear receptor superfamily of transcription factors. As an orphan receptor, it lacks a known endogenous ligand.[1] NOR-1 is an immediate early gene that is rapidly induced by a variety of stimuli including growth factors, stress, and neurotransmitters.[1] It plays crucial roles in a multitude of physiological and pathological processes such as neuronal development, T-cell apoptosis, inflammation, metabolism, and muscle remodeling.[1][2] Given its involvement in diverse cellular pathways, the ability to precisely control its expression is a valuable tool for functional studies and for identifying potential therapeutic targets.
These application notes provide a comprehensive protocol for generating a stable mammalian cell line with inducible expression of human NOR-1 using the Lenti-X™ Tet-On® 3G Inducible Expression System. This system allows for tight, dose-dependent, and reversible control over NOR-1 expression through the administration of doxycycline (B596269) (Dox).
Experimental Workflow Overview
The overall workflow for generating and validating the inducible NOR-1 stable cell line involves several key stages: cloning the NOR-1 cDNA into a lentiviral vector, producing lentivirus, transducing a host cell line, selecting for stably transduced cells, and validating the inducible expression of NOR-1.
Materials and Reagents
| Item | Supplier | Catalog Number |
| Lenti-X™ Tet-On® 3G Inducible Expression System | Takara Bio | 631343 |
| Human NOR-1 cDNA Clone | OriGene | e.g., RC202379 |
| High-Fidelity DNA Polymerase | New England Biolabs | M0491 |
| Restriction Enzymes (as per vector's MCS) | New England Biolabs | Various |
| T4 DNA Ligase | New England Biolabs | M0202 |
| Lenti-X™ 293T Cell Line | Takara Bio | 632180 |
| Transfection Reagent | Mirus Bio | MIR 2300 |
| Doxycycline Hyclate | Sigma-Aldrich | D9891 |
| Puromycin | InvivoGen | ant-pr-1 |
| Anti-NOR-1 Antibody (for Western Blot) | Santa Cruz Biotechnology | sc-393902 |
| HRP-conjugated Secondary Antibody | Cell Signaling Technology | e.g., 7074 |
| qPCR Primers for Human NOR-1 | OriGene | e.g., HP206775 |
| SYBR Green qPCR Master Mix | Bio-Rad | 1725121 |
| Cell Culture Media (DMEM, etc.) | Gibco | Various |
| Fetal Bovine Serum (FBS) | Gibco | Various |
Experimental Protocols
Protocol 1: Cloning of Human NOR-1 into pLVX-TRE3G Vector
-
Primer Design: Design PCR primers to amplify the full-length coding sequence of human NOR-1. Add restriction enzyme sites to the 5' ends of the primers that are compatible with the multiple cloning site (MCS) of the pLVX-TRE3G vector. Include a 6-nucleotide clamp sequence upstream of the restriction site to ensure efficient digestion.
-
Forward Primer Example (for EcoRI): 5'- GCGGAATTCATG ...[NOR-1 sequence]... -3'
-
Reverse Primer Example (for BamHI): 5'- CGCGGATCCTCA ...[reverse complement of NOR-1 sequence]... -3'
-
-
PCR Amplification: Perform PCR using a high-fidelity DNA polymerase with a human NOR-1 cDNA clone as the template.
-
Purification and Digestion: Purify the PCR product using a PCR purification kit. Digest both the purified PCR product and the pLVX-TRE3G vector with the selected restriction enzymes.
-
Ligation: Ligate the digested NOR-1 insert into the digested pLVX-TRE3G vector using T4 DNA ligase.
-
Transformation and Verification: Transform the ligation product into competent E. coli. Select colonies and isolate plasmid DNA. Verify the correct insertion of the NOR-1 gene by restriction digest and Sanger sequencing.
Protocol 2: Generation of Inducible Lentivirus
-
Cell Seeding: The day before transfection, seed Lenti-X 293T cells at a density that will result in 70-80% confluency on the day of transfection.
-
Transfection: Co-transfect the 293T cells with the pLVX-TRE3G-NOR1 vector and the Lenti-X Packaging Single Shots (VSV-G) using a suitable transfection reagent.
-
Virus Harvest: Harvest the lentiviral supernatant 48-72 hours post-transfection. The supernatant can be filtered through a 0.45 µm filter to remove cellular debris.
-
Virus Tittering (Optional but Recommended): Determine the lentiviral titer to ensure appropriate multiplicity of infection (MOI) for transduction.
Protocol 3: Creation of the Stable Cell Line
-
Determination of Antibiotic Selection Concentration (Kill Curve):
-
Seed the parental host cell line in a multi-well plate at a low density.
-
The next day, add a range of concentrations of the selection antibiotic (e.g., Puromycin at 0, 0.5, 1, 2, 4, 6, 8, 10 µg/mL).
-
Replenish the medium with the corresponding antibiotic concentration every 3-4 days.
-
Observe the cells daily and determine the lowest concentration of the antibiotic that kills all the cells within 7-10 days. This concentration will be used for selecting stable transductants.
-
-
Transduction: Seed the host cell line and transduce with the NOR-1 lentivirus at a low MOI (e.g., 0.1-0.5) to favor single integration events.
-
Selection: 48 hours post-transduction, replace the medium with fresh medium containing the predetermined optimal concentration of the selection antibiotic.
-
Expansion: Continue to culture the cells in the selection medium, replacing it every 3-4 days, until antibiotic-resistant colonies are visible. Pool the resistant colonies to create a polyclonal stable cell line.
-
Clonal Isolation (Optional): To obtain a monoclonal cell line, perform limiting dilution cloning to isolate and expand single cell-derived colonies.
Validation of Inducible NOR-1 Expression
Protocol 4: Induction of NOR-1 Expression
-
Seed the stable NOR-1 inducible cell line in appropriate culture vessels.
-
Allow the cells to adhere and grow for 24 hours.
-
To induce NOR-1 expression, replace the culture medium with fresh medium containing doxycycline. A dose-response experiment should be performed to determine the optimal concentration, typically ranging from 10 to 1000 ng/mL.[3]
-
Incubate the cells for the desired duration (e.g., 24-48 hours) before harvesting for analysis. Include a non-induced control (no doxycycline) for comparison.
Protocol 5: Verification by quantitative PCR (qPCR)
-
RNA Extraction and cDNA Synthesis: Extract total RNA from both induced and non-induced cells and synthesize cDNA.
-
qPCR: Perform qPCR using primers specific for human NOR-1 and a housekeeping gene (e.g., GAPDH, ACTB) for normalization.
-
Data Analysis: Calculate the fold change in NOR-1 mRNA expression in induced versus non-induced cells using the ΔΔCt method.
Table 1: Expected qPCR Results for NOR-1 Induction
| Condition | Average Ct (NOR-1) | Average Ct (Housekeeping) | ΔCt | Fold Change (vs. Non-Induced) |
| Non-Induced | >35 or Undetected | 20.5 | N/A | 1 |
| Induced (100 ng/mL Dox) | 22.3 | 20.4 | 1.9 | >5000 |
Protocol 6: Verification by Western Blot
-
Protein Extraction: Lyse induced and non-induced cells and determine the protein concentration.
-
SDS-PAGE and Transfer: Separate equal amounts of protein from each sample by SDS-PAGE and transfer to a PVDF or nitrocellulose membrane.
-
Immunoblotting:
-
Block the membrane to prevent non-specific antibody binding.
-
Incubate with a primary antibody specific for NOR-1.
-
Incubate with an appropriate HRP-conjugated secondary antibody.
-
-
Detection: Detect the protein bands using a chemiluminescent substrate. Use a loading control (e.g., β-actin, GAPDH) to ensure equal protein loading.
Expected Western Blot Results: A specific band for NOR-1 (approximately 64-68 kDa) should be detected in the lysate from doxycycline-induced cells, with little to no signal in the non-induced control lane.[4][5] The intensity of the band should correlate with the dose and duration of doxycycline treatment.
Table 2: Densitometry Analysis of Western Blot
| Condition | NOR-1 Band Intensity (Arbitrary Units) | Loading Control Intensity (Arbitrary Units) | Normalized NOR-1 Expression |
| Non-Induced | < 100 | 50,000 | < 0.002 |
| Induced (100 ng/mL Dox) | 45,000 | 51,000 | 0.88 |
NOR-1 Signaling Pathways
NOR-1 is implicated in several key signaling pathways. The generated inducible cell line can be a powerful tool to dissect its role in these networks.
MAPK Signaling Pathway
NOR-1 expression can be regulated by the MAPK/ERK pathway, and in turn, NOR-1 may modulate downstream components of this pathway, influencing cell proliferation and survival.[6]
References
- 1. Cloning, expression, and mutation analysis of NOR1, a novel human gene down-regulated in HNE1 nasopharyngeal carcinoma cell line - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Inserting a specific sequence in any vector [takarabio.com]
- 3. Function and Regulation in MAPK Signaling Pathways: Lessons Learned from the Yeast Saccharomyces cerevisiae - PMC [pmc.ncbi.nlm.nih.gov]
- 4. cytivalifesciences.com [cytivalifesciences.com]
- 5. bosterbio.com [bosterbio.com]
- 6. bellbrooklabs.com [bellbrooklabs.com]
Application Notes and Protocols for NOR-1 DNA Binding Analysis using Electrophoretic Mobility Shift Assay (EMSA)
For Researchers, Scientists, and Drug Development Professionals
Application Notes
Introduction
The Electrophoretic Mobility Shift Assay (EMSA), also known as a gel shift or gel retardation assay, is a widely used technique to study protein-DNA interactions in vitro.[1][2] This method is based on the principle that a protein-DNA complex migrates more slowly through a non-denaturing polyacrylamide gel than the free, unbound DNA probe.[3] This shift in mobility provides evidence of a binding interaction. EMSA is a rapid and highly sensitive method for identifying DNA-binding proteins and the specific DNA sequences they recognize.[4][5]
Neuron-derived orphan receptor 1 (NOR-1), also known as NR4A3, is a member of the NR4A subfamily of orphan nuclear receptors.[6][7] These proteins act as transcription factors that are rapidly induced by a variety of stimuli, including growth factors and stress signals, making them immediate-early genes.[8][9] NOR-1 plays crucial roles in cellular proliferation, apoptosis, inflammation, and metabolism.[3][10] As a transcription factor, NOR-1 exerts its effects by binding to specific DNA sequences in the promoter regions of its target genes.
Members of the NR4A family, including NOR-1, share a highly conserved DNA-binding domain and recognize a consensus DNA sequence known as the NGFI-B Response Element (NBRE), with the core sequence 5'-AAAGGTCA-3' .[1][3][6] This application note provides a detailed protocol for using EMSA to detect and characterize the binding of NOR-1 to its cognate NBRE DNA sequence. This assay is critical for understanding the molecular mechanisms of NOR-1 function and for screening compounds that may modulate its DNA binding activity.
Key Applications:
-
Qualitative detection of NOR-1 in nuclear extracts or purified protein preparations.
-
Identification of the specific DNA sequence (NBRE) that NOR-1 binds to.
-
Screening of small molecules or potential drugs that inhibit or enhance NOR-1 DNA binding.
-
Confirmation of NOR-1 identity in a DNA-protein complex through "supershift" assays using a specific antibody.
Experimental Protocols
This protocol outlines the necessary steps to perform an EMSA for NOR-1 DNA binding, from probe design to data analysis. Non-radioactive, biotin-based detection is described, which offers a safer and more convenient alternative to traditional radioactive methods.
I. Reagent and Equipment Preparation
A. Buffers and Reagents:
| Reagent | Stock Concentration | Storage | Notes |
| 10X Binding Buffer | See Recipe | -20°C | Aliquot to avoid freeze-thaw cycles. |
| 10X TBE Buffer | 0.89 M Tris, 0.89 M Boric Acid, 20 mM EDTA, pH 8.3 | Room Temp | Dilute to 0.5X for gel and running buffer. |
| Poly(dI-dC) | 1 mg/mL | -20°C | Non-specific competitor DNA. |
| Nuclear Extract | Variable | -80°C | Prepare from cells stimulated to express NOR-1. |
| Biotin-labeled DNA Probe | 20 fmol/µL | -20°C | See Section II for sequence. Protect from light. |
| Unlabeled (Cold) Probe | 2 pmol/µL | -20°C | For competition assays. |
| Anti-NOR-1 Antibody | Variable | -20°C | For supershift assays. |
| 50% Glycerol | 50% (v/v) in water | Room Temp | For gel loading. |
| 30% Acrylamide/Bis | 29:1 ratio | 4°C | Caution: Neurotoxin. Handle with care. |
| Ammonium Persulfate (APS) | 10% (w/v) | 4°C | Prepare fresh. |
| TEMED | N/A | Room Temp | Caution: Catalyst. Handle in a fume hood. |
Recipe: 10X Binding Buffer
-
100 mM Tris-HCl, pH 7.5
-
500 mM KCl
-
10 mM DTT
-
50% Glycerol
-
Store in aliquots at -20°C.
B. Equipment:
-
Vertical electrophoresis unit (e.g., Mini-PROTEAN® system)
-
Power supply
-
Gel casting equipment
-
Nylon membrane
-
UV cross-linking instrument (e.g., Stratalinker®)
-
Chemiluminescent detection system (e.g., imaging system with CCD camera)
-
Standard laboratory equipment (pipettes, tubes, centrifuges, etc.)
II. Oligonucleotide Probe Design and Preparation
The specificity of the EMSA is determined by the DNA probe sequence. For NOR-1, a double-stranded oligonucleotide containing the NBRE consensus sequence is used.
-
Design Oligonucleotides: Synthesize complementary single-stranded oligonucleotides. One oligo (typically the sense strand) should be end-labeled with biotin (B1667282).
-
Sense Strand (Biotinylated): 5'-GAT CTC GAG AAAGGTCA TTA GAT C-3'-Biotin
-
Antisense Strand: 3'-CTA GAG CTC TTTCCAGT AAT CTA G-5'
-
-
Anneal Oligonucleotides:
-
Combine the biotin-labeled sense and unlabeled antisense oligos in a 1:1 molar ratio in annealing buffer (e.g., 10 mM Tris, pH 8.0; 50 mM NaCl; 1 mM EDTA).
-
Heat the mixture to 95°C for 5 minutes.
-
Allow the mixture to cool slowly to room temperature (e.g., by turning off the heat block and leaving the tube in it).
-
The resulting double-stranded, biotin-labeled probe can be stored at -20°C. Dilute to a working concentration of ~20 fmol/µL.
-
III. Binding Reaction Setup
Perform all binding reactions on ice in 0.5 mL microcentrifuge tubes. The order of addition is critical.[2] A typical reaction volume is 20 µL.
-
Master Mix Preparation: Prepare a master mix of common reagents (Buffer, Poly(dI-dC), Glycerol) to ensure consistency.
-
Reaction Assembly: Add components in the following order:
| Component | Volume | Final Concentration | Purpose |
| Nuclease-Free Water | to 20 µL | N/A | Reaction volume adjustment. |
| 10X Binding Buffer | 2 µL | 1X | Provides optimal binding conditions. |
| 50% Glycerol | 1 µL | 2.5% | Increases sample density for loading. |
| Poly(dI-dC) (1 µg/µL) | 1 µL | 50 ng/µL | Blocks non-specific DNA binding proteins. |
| Nuclear Extract | 2-8 µg | 0.1-0.4 µg/µL | Source of NOR-1 protein. |
| Specific Competitor/Antibody (for control lanes): | |||
| Unlabeled "Cold" Probe | 1 µL | 100X excess | Add for specificity control. |
| Anti-NOR-1 Antibody | 1 µL | Varies | Add for supershift control. |
-
Incubation 1: Gently mix and incubate at room temperature for 10-15 minutes. This allows the non-specific competitor to bind non-specific proteins.
-
Add Labeled Probe: Add 1 µL of the biotin-labeled NBRE probe (20 fmol/µL) to each reaction.
-
Incubation 2: Gently mix and incubate at room temperature for 20-30 minutes, protected from light.[5]
IV. Non-Denaturing Polyacrylamide Gel Electrophoresis
-
Gel Preparation: Prepare a 5-6% native polyacrylamide gel in 0.5X TBE buffer. The absence of SDS is crucial for maintaining protein-DNA interactions.
-
Pre-electrophoresis: Assemble the electrophoresis unit with 0.5X TBE running buffer. Pre-run the gel at 100-120 V for 15-30 minutes at 4°C to equilibrate the gel.
-
Sample Loading: Add 2-3 µL of loading dye (if not included in the binding buffer) to each reaction. Carefully load the samples into the wells. Also, load a "free probe" lane containing only the labeled probe and binding buffer.
-
Electrophoresis: Run the gel at 100-120 V at 4°C. Monitor the migration of the loading dye (e.g., bromophenol blue). Electrophoresis is typically complete when the dye front is near the bottom of the gel (approx. 1.5-2 hours).
V. Transfer, Cross-linking, and Detection
-
Transfer to Membrane: Transfer the DNA from the gel to a positively charged nylon membrane using a semi-dry or wet electroblotting apparatus, following the manufacturer's instructions.
-
Cross-linking: Immediately after transfer, place the membrane DNA-side-up in a UV cross-linker and irradiate at the optimal energy (e.g., 120 mJ/cm²).
-
Chemiluminescent Detection:
-
Block the membrane using a suitable blocking buffer.
-
Incubate with a Streptavidin-Horseradish Peroxidase (HRP) conjugate, which will bind to the biotin on the probe.
-
Wash the membrane thoroughly.
-
Apply a chemiluminescent HRP substrate and immediately image the membrane using a CCD camera-based imager.
-
Data Presentation and Interpretation
Quantitative data from EMSA, such as the inhibition of NOR-1 binding by a test compound, should be summarized in a clear, tabular format.
Table 1: Example Data - Inhibition of NOR-1 DNA Binding by Compound X
| Lane | Nuclear Extract | Labeled Probe | Cold Probe (100x) | Compound X (µM) | Shifted Band Intensity (Arbitrary Units) | % Inhibition |
| 1 | - | + | - | 0 | 0 | N/A |
| 2 | + | + | - | 0 | 15,430 | 0% |
| 3 | + | + | + | 0 | 815 | 94.7% |
| 4 | + | + | - | 1 | 11,250 | 27.1% |
| 5 | + | + | - | 10 | 6,330 | 59.0% |
| 6 | + | + | - | 50 | 2,110 | 86.3% |
Interpretation of Results:
-
Lane 1 (Free Probe): Shows the migration of the unbound biotin-labeled probe.
-
Lane 2 (Positive Control): A slower-migrating ("shifted") band appears, representing the NOR-1/DNA complex.
-
Lane 3 (Specificity Control): The addition of excess unlabeled (cold) probe outcompetes the labeled probe, causing the shifted band to disappear or significantly diminish. This confirms the binding is specific to the NBRE sequence.
-
Supershift Lane (Not shown): Addition of an anti-NOR-1 antibody would result in a further retarded band (a "supershift"), confirming the presence of NOR-1 in the complex.
-
Lanes 4-6 (Test Compound): Show a dose-dependent decrease in the intensity of the shifted band, indicating that Compound X inhibits NOR-1 DNA binding.
Visualizations
Signaling Pathway for NOR-1 Induction
Caption: Simplified pathway of mitogen-induced NOR-1 expression and DNA binding.
EMSA Experimental Workflow
Caption: Step-by-step workflow for the NOR-1 electrophoretic mobility shift assay.
Logical Diagram of EMSA Components and Results
References
- 1. NGFI-B (Nurr77/Nr4a1) orphan nuclear receptor in rat pinealocytes: circadian expression involves an adrenergic-cyclic AMP mechanism - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Gel Shift Assays (EMSA) | Thermo Fisher Scientific - HK [thermofisher.com]
- 3. uniprot.org [uniprot.org]
- 4. genecards.org [genecards.org]
- 5. Electrophoretic Mobility Shift Assay (EMSA) for Detecting Protein-Nucleic Acid Interactions - PMC [pmc.ncbi.nlm.nih.gov]
- 6. mdpi.com [mdpi.com]
- 7. genecards.org [genecards.org]
- 8. Functional Changes Associated With the Subcellular Localization of the Nuclear Receptor NR4A1 - PMC [pmc.ncbi.nlm.nih.gov]
- 9. static1.squarespace.com [static1.squarespace.com]
- 10. Electrophoretic Mobility Shift Assay (EMSA) for the Study of RNA-Protein Interactions: The IRE/IRP Example - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for Isolating Primary Macrophages from NOR-1 Knockout Mice
Audience: Researchers, scientists, and drug development professionals.
Introduction
Neuron-derived orphan receptor 1 (NOR-1), also known as NR4A3, is a member of the nuclear receptor subfamily 4 group A. It has been implicated in the regulation of inflammation and macrophage polarization. Studies in human macrophages have shown that NOR-1 can promote an anti-inflammatory M2-like phenotype. However, it is noteworthy that while interleukin-4 (IL-4) stimulation enhances NOR-1 expression in human macrophages, this effect has not been observed in murine macrophages.[1] This highlights a potential species-specific difference in the regulation of NOR-1.
Investigating the role of NOR-1 in macrophage biology often requires the use of knockout mouse models. The isolation of primary macrophages from these mice is a critical first step for in vitro studies. This document provides a detailed protocol for the isolation, culture, and characterization of bone marrow-derived macrophages (BMDMs) from NOR-1 knockout mice and their wild-type littermates.
Pre-experimental Considerations: Genotyping
Prior to macrophage isolation, it is essential to confirm the genotype of the mice. This is typically performed on a small tissue sample, such as a tail snip or ear punch, obtained at the time of weaning.
Representative Genotyping PCR Protocol
1. Genomic DNA Extraction:
-
Digest tissue samples in a lysis buffer containing Proteinase K overnight at 55°C.
-
Purify genomic DNA using a standard phenol:chloroform extraction or a commercial DNA extraction kit.
2. PCR Amplification:
-
Prepare a PCR master mix containing DNA polymerase, dNTPs, and forward and reverse primers specific for the wild-type and knockout alleles.
-
A three-primer approach is often used: a common forward primer and two reverse primers, one specific for the wild-type allele and one for the knockout allele (e.g., targeting the inserted selection cassette).
3. Gel Electrophoresis:
-
Resolve the PCR products on an agarose (B213101) gel.
-
The resulting banding pattern will distinguish between wild-type (+/+), heterozygous (+/-), and homozygous knockout (-/-) mice.
Table 1: Representative Genotyping Results
| Genotype | Expected Band Size(s) |
| Wild-Type (+/+) | ~200 bp |
| Heterozygous (+/-) | ~200 bp and ~400 bp |
| Knockout (-/-) | ~400 bp |
Note: Actual band sizes will depend on the specific gene targeting strategy and primer design.
Experimental Workflow for BMDM Isolation and Culture
The following diagram outlines the key steps for isolating and culturing bone marrow-derived macrophages.
Caption: Workflow for isolating bone marrow-derived macrophages.
Detailed Protocol for Isolation of Primary Macrophages
This protocol is adapted from standard procedures for isolating murine bone marrow-derived macrophages.[2][3][4]
Materials and Reagents
-
NOR-1 knockout and wild-type control mice (6-12 weeks of age)
-
Sterile Phosphate-Buffered Saline (PBS)
-
BMDM Complete Medium:
-
DMEM or RPMI-1640
-
10% Fetal Bovine Serum (FBS), heat-inactivated
-
1% Penicillin-Streptomycin
-
20-50 ng/mL Macrophage Colony-Stimulating Factor (M-CSF) or 10-20% L929-conditioned medium[2]
-
-
Sterile dissection tools (scissors, forceps)
-
Syringes (10 mL) and needles (25-27 gauge)
-
50 mL conical tubes
-
Cell strainer (70 µm)
-
Non-tissue culture treated petri dishes (10 cm)
-
Cell scraper
Procedure
Day 0: Isolation and Plating of Bone Marrow Cells
-
Euthanize the mouse according to approved institutional protocols.
-
Spray the mouse carcass thoroughly with 70% ethanol to sterilize the fur.
-
In a sterile environment (e.g., a laminar flow hood), make a midline incision and peel back the skin to expose the hind limbs.
-
Carefully dissect the femurs and tibias, removing as much of the surrounding muscle and connective tissue as possible.[2][3] Place the cleaned bones in a petri dish containing sterile PBS on ice.
-
Cut off the ends of each bone with sterile scissors.
-
Using a 10 mL syringe with a 25-gauge needle filled with BMDM complete medium, flush the marrow from the bones into a 50 mL conical tube.[1] Repeat until the bones appear white.
-
Create a single-cell suspension by gently pipetting the marrow clumps up and down.
-
Pass the cell suspension through a 70 µm cell strainer to remove any remaining clumps or debris.
-
Centrifuge the cells at 300 x g for 7-10 minutes.[4]
-
Discard the supernatant and resuspend the cell pellet in 5 mL of BMDM complete medium. If significant red blood cell contamination is present, perform an RBC lysis step.
-
Count the cells using a hemocytometer.
-
Plate approximately 5-10 x 10^6 cells per 10 cm non-tissue culture treated petri dish in 10 mL of BMDM complete medium.
-
Incubate at 37°C in a 5% CO2 incubator.
Day 3: Media Change
-
Add 5 mL of fresh, pre-warmed BMDM complete medium to each dish. Do not remove the old medium, as it contains proliferating progenitor cells.
Day 7-10: Macrophage Harvest
-
Observe the cells under a microscope. Mature macrophages will be adherent and have a characteristic fried-egg morphology.
-
To harvest, aspirate the culture medium.
-
Gently wash the adherent cells with sterile PBS.
-
Add 5 mL of cold PBS or cell-dissociation buffer and incubate at 4°C for 10-15 minutes.
-
Dislodge the adherent macrophages by forcefully pipetting the cold PBS over the plate surface or by using a cell scraper.
-
Collect the cell suspension and centrifuge at 300 x g for 7-10 minutes.
-
Resuspend the macrophage pellet in the desired medium for downstream applications.
Characterization of Macrophages from NOR-1 KO Mice
After isolation, it is important to characterize the macrophages to confirm their purity and assess any phenotypic differences due to the absence of NOR-1.
Flow Cytometry
A common method for macrophage identification is flow cytometry using cell surface markers.
Table 2: Representative Flow Cytometry Antibody Panel
| Marker | Fluorochrome | Cell Type Identified |
| F4/80 | PE | Mature Macrophages |
| CD11b | APC | Myeloid Cells (incl. Macrophages) |
| CD68 | FITC | Macrophages (intracellular) |
| Mrc1 (CD206) | PerCP-Cy5.5 | M2-like Macrophages |
| CD86 | BV421 | M1-like Macrophages |
Researchers can expect a high percentage of F4/80 and CD11b double-positive cells, typically >90% for a successful BMDM culture.
Functional Assays
Based on the known functions of NOR-1, researchers might expect to see differences in the inflammatory response and polarization potential of macrophages from NOR-1 knockout mice compared to wild-type controls.
Table 3: Expected Functional Differences in NOR-1 KO vs. WT Macrophages
| Assay | Expected Outcome in NOR-1 KO Macrophages (Hypothetical) | Rationale |
| Cytokine Secretion (LPS stimulation) | Increased pro-inflammatory cytokines (e.g., TNF-α, IL-6) | NOR-1 may have anti-inflammatory functions; its absence could lead to a heightened pro-inflammatory response. |
| M2 Polarization (IL-4 stimulation) | Decreased expression of M2 markers (e.g., Arg1, Ym1, Fizz1) | In human macrophages, NOR-1 is involved in M2 polarization. A similar, though perhaps less pronounced, effect might be seen in mice.[5] |
| Phagocytosis Assay | No significant change expected | The direct role of NOR-1 in phagocytosis is not well-established. |
| Gene Expression (qPCR) | Lower baseline and IL-4-induced expression of M2-associated genes | Consistent with a role for NOR-1 in promoting the M2 phenotype. |
NOR-1 Signaling in Macrophage Polarization
The following diagram illustrates a potential signaling pathway for NOR-1 in the context of M2 macrophage polarization, based on studies in human cells. As mentioned, the induction of NOR-1 by IL-4 is not observed in mice, which is a key difference to consider.
Caption: Hypothetical NOR-1 signaling in M2 macrophage polarization.
Conclusion
This document provides a comprehensive guide for the isolation and initial characterization of primary bone marrow-derived macrophages from NOR-1 knockout mice. While the fundamental isolation protocol is consistent with that for wild-type mice, careful genotyping and consideration of the potential functional differences are crucial for designing and interpreting subsequent experiments. The provided tables and diagrams serve as a reference for the expected outcomes and underlying biological pathways. Researchers should always include wild-type littermate controls in all experiments to ensure the observed phenotypes are directly attributable to the absence of NOR-1.
References
- 1. The neuron-derived orphan receptor 1 (NOR1) is induced upon human alternative macrophage polarization and stimulates the expression of markers of the M2 phenotype - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. boneandcancer.org [boneandcancer.org]
- 4. How to Perform Quick Mouse Genotyping–6 PCR Tips | Thermo Fisher Scientific - HK [thermofisher.com]
- 5. researchgate.net [researchgate.net]
Technical Support Center: Troubleshooting Low NOR-1 Expression in Western Blot Analysis
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals resolve issues related to the detection of low NOR-1 expression in Western blot analysis.
Frequently Asked Questions (FAQs)
Q1: Why am I not seeing a band for NOR-1 in my Western blot?
A1: Several factors can contribute to the absence of a NOR-1 signal. These can range from issues with your sample preparation, low abundance of the NOR-1 protein in your sample, problems with the gel electrophoresis and transfer, suboptimal antibody concentrations, to issues with the detection reagents. This guide will walk you through troubleshooting each of these steps.
Q2: What is the expected molecular weight of NOR-1?
A2: NOR-1, also known as NR4A3, has a predicted molecular mass of approximately 68 kDa.[1] However, post-translational modifications can sometimes alter the apparent molecular weight on a Western blot.
Q3: Is NOR-1 a low-abundance protein?
A3: The expression level of NOR-1 can vary significantly depending on the tissue or cell type and the experimental conditions.[2][3] In some cases, it may be expressed at low endogenous levels, making its detection challenging.[4][5]
Q4: Which type of membrane is best for detecting NOR-1?
A4: For low-abundance proteins like NOR-1, a PVDF (polyvinylidene difluoride) membrane is generally recommended over nitrocellulose due to its higher binding capacity.[4][6]
Troubleshooting Guide
Section 1: Sample Preparation and Protein Extraction
Problem: My NOR-1 signal is very weak or absent, and I suspect an issue with my sample preparation.
| Possible Cause | Recommended Solution |
| Insufficient Protein Loaded | Increase the total protein loaded per lane to 30-100 µg.[7] For low-abundance proteins, a higher protein load is often necessary. |
| Incomplete Cell Lysis | Use a strong lysis buffer, such as RIPA buffer, which contains detergents like SDS, to ensure complete lysis, especially for nuclear proteins like NOR-1.[4] Sonication can also help to disrupt cells and shear DNA. |
| Protein Degradation | Always work on ice and add a broad-spectrum protease inhibitor cocktail to your lysis buffer to prevent protein degradation.[8] |
| Low NOR-1 Expression in Sample | If possible, use a positive control, such as a cell line known to express NOR-1 or a recombinant NOR-1 protein, to validate your protocol. Consider techniques to enrich your sample for NOR-1, such as nuclear fractionation, as NOR-1 is a nuclear receptor.[4] |
| Inaccurate Protein Quantification | Use a reliable protein quantification assay, such as the BCA assay, to ensure you are loading equal amounts of protein in each lane.[8] |
Section 2: Gel Electrophoresis and Protein Transfer
Problem: I'm still not getting a good signal, and I think the issue might be with my gel or the transfer step.
| Possible Cause | Recommended Solution |
| Poor Protein Separation | Choose a gel percentage that provides optimal resolution for the molecular weight of NOR-1 (~68 kDa). A 7.5% or 10% SDS-PAGE gel is typically suitable.[1] |
| Inefficient Protein Transfer | Ensure good contact between the gel and the membrane, and remove any air bubbles.[9] For a protein of ~68 kDa, a standard wet transfer for 1-2 hours at 100V or a semi-dry transfer according to the manufacturer's instructions should be efficient. You can verify transfer efficiency by staining the membrane with Ponceau S after transfer.[10] |
| Protein Transferring Through the Membrane | If you suspect that NOR-1 is passing through the membrane, especially if using a larger pore size, consider using a membrane with a smaller pore size (e.g., 0.2 µm).[9] |
Section 3: Antibody Incubation
Problem: I've optimized my sample prep and transfer, but the NOR-1 band is still weak.
| Possible Cause | Recommended Solution |
| Suboptimal Primary Antibody Concentration | The optimal antibody concentration is crucial. Start with the dilution recommended on the antibody datasheet and then perform a titration to find the best concentration for your specific experimental conditions.[7][10] For low-abundance proteins, you may need to use a higher concentration of the primary antibody. |
| Insufficient Incubation Time | For low-abundance proteins, incubating the primary antibody overnight at 4°C with gentle agitation can enhance the signal.[7] |
| Improper Blocking | Blocking is essential to prevent non-specific antibody binding. Use a common blocking agent like 5% non-fat dry milk or 5% BSA in TBST for 1-1.5 hours at room temperature.[7] However, excessive blocking can sometimes mask the epitope, so you may need to optimize the blocking time and concentration. |
| Inactive Antibody | Ensure your antibody has been stored correctly and has not expired. Repeated freeze-thaw cycles should be avoided. You can test the activity of your secondary antibody by dotting a small amount onto the membrane and adding the detection reagent.[9] |
Section 4: Signal Detection
Problem: I can see a faint band, but the signal-to-noise ratio is very low.
| Possible Cause | Recommended Solution |
| Inadequate Detection Reagent | For low-abundance proteins, a high-sensitivity enhanced chemiluminescence (ECL) substrate is highly recommended.[4] These substrates can detect proteins at the femtogram level. |
| Insufficient Exposure Time | Increase the exposure time to capture a stronger signal. However, be mindful that longer exposures can also increase background noise. |
| Inactive HRP-conjugated Secondary Antibody | Avoid using sodium azide (B81097) in any buffers when using HRP-conjugated antibodies, as it inhibits HRP activity.[9] Ensure your secondary antibody is fresh and has been stored properly. |
| Excessive Washing | While washing is necessary to reduce background, excessive washing can also wash away the bound antibodies, leading to a weaker signal.[9] Adhere to the recommended washing times and volumes. |
Experimental Protocols
Protocol 1: Cell Lysis using RIPA Buffer
-
Place the cell culture dish on ice and wash the cells twice with ice-cold PBS.
-
Aspirate the PBS and add ice-cold RIPA buffer containing a protease inhibitor cocktail (e.g., 1 mL per 10^7 cells).
-
Scrape the adherent cells off the dish using a cold plastic cell scraper and transfer the cell suspension to a pre-cooled microcentrifuge tube.
-
Agitate the suspension for 30 minutes at 4°C.
-
Centrifuge the lysate at approximately 14,000 x g for 15 minutes at 4°C.
-
Carefully transfer the supernatant (the protein extract) to a new pre-cooled tube, avoiding the pellet.
-
Determine the protein concentration using a BCA assay.
Protocol 2: Western Blotting for NOR-1
-
Sample Preparation: Mix your protein lysate with 2x Laemmli sample buffer in a 1:1 ratio. Boil the samples at 95-100°C for 5 minutes to denature the proteins.
-
Gel Electrophoresis: Load 30-50 µg of protein per lane onto an SDS-PAGE gel. Run the gel according to the manufacturer's instructions until the dye front reaches the bottom.
-
Protein Transfer: Transfer the proteins from the gel to a PVDF membrane using a wet or semi-dry transfer system.
-
Blocking: Block the membrane with 5% non-fat dry milk or 5% BSA in TBST for 1 hour at room temperature.
-
Primary Antibody Incubation: Incubate the membrane with the primary NOR-1 antibody at the optimized dilution in blocking buffer overnight at 4°C with gentle shaking.
-
Washing: Wash the membrane three times for 5-10 minutes each with TBST.
-
Secondary Antibody Incubation: Incubate the membrane with an HRP-conjugated secondary antibody, diluted in blocking buffer, for 1 hour at room temperature.
-
Washing: Wash the membrane three times for 10 minutes each with TBST.
-
Signal Detection: Incubate the membrane with a high-sensitivity ECL substrate according to the manufacturer's instructions.
-
Imaging: Capture the chemiluminescent signal using a digital imager or X-ray film.
Visualizations
Caption: A flowchart illustrating the key stages of the Western blot workflow for NOR-1 detection.
Caption: A simplified diagram of a potential signaling pathway involving NOR-1.
References
- 1. Anti-NOR1/TEC antibody (ab155535) | Abcam [abcam.com]
- 2. researchgate.net [researchgate.net]
- 3. The Nuclear Receptor, Nor-1, Induces the Physiological Responses Associated With Exercise - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Detecting low abundance proteins via Western Blot | Proteintech Group [ptglab.com]
- 5. Western Blotting Troubleshooting Guide | Cell Signaling Technology [cellsignal.com]
- 6. bio-rad-antibodies.com [bio-rad-antibodies.com]
- 7. researchgate.net [researchgate.net]
- 8. m.youtube.com [m.youtube.com]
- 9. sinobiological.com [sinobiological.com]
- 10. Western Blot Troubleshooting Guide - TotalLab [totallab.com]
how to reduce non-specific bands in NR4A3 Western blot
This technical support center provides troubleshooting guidance and answers to frequently asked questions to help researchers, scientists, and drug development professionals achieve high-quality results when performing Western blots for the NR4A3 protein.
Troubleshooting Guide: Reducing Non-Specific Bands in NR4A3 Western Blot
Non-specific bands can obscure the correct identification and quantification of NR4A3. The following guide, presented in a question-and-answer format, addresses common causes of non-specific banding and provides targeted solutions.
Q1: I am observing multiple bands in addition to the expected NR4A3 band. What is the likely cause and how can I fix it?
Possible Causes & Solutions:
-
Primary Antibody Concentration is Too High: An excess of primary antibody can lead to off-target binding.
-
Solution: Optimize the primary antibody concentration by performing a dot blot or testing a range of dilutions. For instance, if the datasheet recommends a 1:1000 dilution, try a range from 1:500 to 1:5000.[1]
-
-
Secondary Antibody Cross-Reactivity: The secondary antibody may be binding to other proteins in the lysate.
-
Solution: Run a control lane with only the secondary antibody to check for non-specific binding. If bands appear, consider using a pre-adsorbed secondary antibody.
-
-
Protein Degradation: NR4A3 may be degrading during sample preparation, leading to lower molecular weight bands.
-
Solution: Always prepare fresh lysates and keep them on ice. Ensure that a sufficient concentration of protease inhibitors is added to the lysis buffer.
-
-
Post-Translational Modifications or Isoforms: NR4A3 is known to have isoforms, which may appear as distinct bands.
-
Solution: Consult literature and protein databases like UniProt to determine the expected molecular weights of NR4A3 isoforms and post-translationally modified forms. The calculated molecular weight of NR4A3 is approximately 68-70 kDa.[1]
-
Q2: My Western blot has a high background, making it difficult to see the specific NR4A3 band. What can I do to reduce the background?
Possible Causes & Solutions:
-
Insufficient Blocking: Incomplete blocking of the membrane allows for non-specific antibody binding.
-
Solution: Increase the blocking time (e.g., 1-2 hours at room temperature or overnight at 4°C) or try a different blocking agent. Common blocking buffers are 5% non-fat dry milk or 3-5% Bovine Serum Albumin (BSA) in TBST.
-
-
Inadequate Washing: Insufficient washing can leave behind unbound primary and secondary antibodies.
-
Solution: Increase the number and duration of wash steps. For example, perform three to five washes of 5-10 minutes each with TBST.
-
-
Membrane Drying: Allowing the membrane to dry out at any stage can cause high background.
-
Solution: Ensure the membrane remains fully submerged in buffer during all incubation and washing steps.
-
Frequently Asked Questions (FAQs)
Q: What is the expected molecular weight of NR4A3?
A: The calculated molecular weight of human NR4A3 is approximately 68-70 kDa.[1] However, the apparent molecular weight on an SDS-PAGE gel can vary due to post-translational modifications.
Q: Which blocking buffer is best for NR4A3 Western blotting?
A: Both 5% non-fat dry milk and 3-5% BSA in TBST are commonly used and effective blocking buffers. If you are detecting a phosphorylated form of NR4A3, BSA is generally recommended as milk contains phosphoproteins that can increase background.
Q: What are the recommended antibody dilutions for NR4A3?
A: The optimal dilution should be determined experimentally. However, a good starting point for many commercially available NR4A3 antibodies is a 1:500 to 1:2000 dilution for the primary antibody and 1:2000 to 1:10,000 for the secondary antibody.[2][3]
Q: Can I strip and re-probe my membrane for NR4A3 and another protein?
A: Yes, membranes can be stripped and re-probed. However, be aware that the stripping process can remove some of the transferred protein, potentially leading to a weaker signal for the subsequent antibody. It is advisable to probe for the less abundant protein first.
Data Presentation
Table 1: Recommended Starting Dilutions for NR4A3 Primary Antibodies
| Antibody Type | Host Species | Recommended Starting Dilution | Reference |
| Polyclonal | Rabbit | 1:500 - 1:1000 | [1] |
| Monoclonal | Mouse | 1:2000 | [3] |
Table 2: Common Blocking Buffers and Incubation Times
| Blocking Buffer | Concentration | Incubation Time | Temperature |
| Non-fat Dry Milk | 5% in TBST | 1-2 hours or overnight | Room Temp or 4°C |
| Bovine Serum Albumin (BSA) | 3-5% in TBST | 1-2 hours or overnight | Room Temp or 4°C |
Experimental Protocols
Detailed Western Blot Protocol for NR4A3
-
Cell Lysis:
-
Wash cells with ice-cold PBS.
-
Lyse cells in RIPA buffer supplemented with a protease inhibitor cocktail.
-
Incubate on ice for 30 minutes, vortexing occasionally.
-
Centrifuge at 14,000 x g for 15 minutes at 4°C.
-
Collect the supernatant containing the protein lysate.
-
-
Protein Quantification:
-
Determine the protein concentration of the lysate using a BCA or Bradford protein assay.
-
-
SDS-PAGE:
-
Mix 20-30 µg of protein lysate with Laemmli sample buffer and heat at 95-100°C for 5 minutes.
-
Load samples onto a 10% polyacrylamide gel.
-
Run the gel at 100-120V until the dye front reaches the bottom.
-
-
Protein Transfer:
-
Transfer proteins from the gel to a PVDF or nitrocellulose membrane at 100V for 1-2 hours or using a semi-dry transfer apparatus according to the manufacturer's instructions.
-
-
Blocking:
-
Block the membrane in 5% non-fat dry milk or 3% BSA in TBST for 1 hour at room temperature with gentle agitation.
-
-
Primary Antibody Incubation:
-
Incubate the membrane with the primary NR4A3 antibody at the optimized dilution in blocking buffer overnight at 4°C with gentle agitation.
-
-
Washing:
-
Wash the membrane three times for 10 minutes each with TBST.
-
-
Secondary Antibody Incubation:
-
Incubate the membrane with the HRP-conjugated secondary antibody at the appropriate dilution in blocking buffer for 1 hour at room temperature with gentle agitation.
-
-
Washing:
-
Wash the membrane three times for 10 minutes each with TBST.
-
-
Detection:
-
Incubate the membrane with an ECL substrate according to the manufacturer's instructions.
-
Capture the chemiluminescent signal using a digital imager or X-ray film.
-
Visualizations
Caption: A flowchart of the major steps in a Western blot experiment.
Caption: A decision tree for troubleshooting non-specific bands in NR4A3 Western blots.
References
reducing high background in NOR-1 immunofluorescence staining
This technical support center provides troubleshooting guidance and answers to frequently asked questions to help researchers, scientists, and drug development professionals overcome challenges with high background staining in NOR-1 immunofluorescence experiments.
Troubleshooting Guide: Reducing High Background
High background fluorescence can obscure the specific signal from your target protein, making it difficult to interpret your results. This guide addresses common causes of high background in NOR-1 immunofluorescence and provides actionable solutions.
Question: My entire sample is fluorescent, masking any specific NOR-1 signal. What is causing this high background?
Answer: High background can stem from several factors throughout the immunofluorescence protocol. The most common culprits include issues with antibody concentrations, inadequate blocking, improper fixation and permeabilization, insufficient washing, and endogenous autofluorescence. A systematic approach to troubleshooting is recommended to identify and resolve the specific cause.
Question: How can I determine if my primary or secondary antibody concentration is too high?
Answer: Using an excessive concentration of either the primary or secondary antibody is a frequent cause of high background.[1][2]
-
Primary Antibody: If the primary antibody concentration is too high, it can bind non-specifically to cellular components. To optimize this, perform a titration experiment to determine the lowest concentration of the antibody that still provides a strong, specific signal without high background. A typical starting point for purified antibodies is 1-10 µg/mL, or a 1:100 to 1:1000 dilution for antiserum.[1][2]
-
Secondary Antibody: Non-specific binding of the secondary antibody can also contribute significantly to background. To test for this, include a control where the primary antibody is omitted. If you still observe significant fluorescence, the secondary antibody is likely binding non-specifically. Consider using a lower concentration, or switching to a pre-adsorbed secondary antibody that has been purified to remove antibodies that cross-react with off-target species.
Question: I'm seeing a lot of non-specific staining. How can I improve my blocking step?
Answer: The blocking step is crucial for preventing non-specific antibody binding.
-
Choice of Blocking Agent: A common and effective blocking buffer is 1% Bovine Serum Albumin (BSA) in Phosphate-Buffered Saline (PBS).[3] Alternatively, using 5-10% normal serum from the same species as the secondary antibody's host is highly recommended.[4] For example, if your secondary antibody was raised in a goat, you should use normal goat serum for blocking. Using serum from the same species as the primary antibody can lead to high background as the secondary antibody will bind to the blocking serum.[5]
-
Blocking Incubation Time: Ensure you are incubating your samples in the blocking solution for a sufficient amount of time, typically at least 1 hour at room temperature.[5]
Question: Could my fixation and permeabilization protocol be causing high background?
Answer: Yes, improper fixation and permeabilization can lead to artifacts and increased background.
-
Fixation: Over-fixation with aldehydes like paraformaldehyde (PFA) can cross-link proteins excessively, which can sometimes increase non-specific binding. Conversely, under-fixation can lead to poor preservation of cellular morphology and antigen loss. A typical fixation protocol involves 4% PFA for 10-15 minutes at room temperature.
-
Permeabilization: Since NOR-1 is a nuclear protein, permeabilization is necessary to allow the antibody to access its target. Triton X-100 is a commonly used detergent for this purpose. However, excessive permeabilization can damage cellular membranes and lead to higher background. A concentration of 0.1-0.25% Triton X-100 in PBS for 10-15 minutes is generally sufficient.
Question: How important are the washing steps?
Answer: Insufficient washing between antibody incubation steps is a frequent and easily correctable cause of high background. Thorough washing removes unbound and loosely bound antibodies. It is recommended to perform at least three washes with PBS containing a low concentration of detergent (e.g., 0.05% Tween-20) for 5-10 minutes each after both the primary and secondary antibody incubations.
Question: My "no primary antibody" control looks clean, but I still have high background in my stained samples. What else could be the cause?
Answer: In this case, you might be dealing with autofluorescence, which is the natural fluorescence of the biological sample.
-
Identifying Autofluorescence: To check for autofluorescence, examine an unstained sample under the microscope using the same filter sets you use for your stained samples.
-
Reducing Autofluorescence:
-
Choice of Fluorophore: Autofluorescence is often more prominent in the shorter wavelength regions (blue and green). If possible, choose secondary antibodies conjugated to fluorophores that emit in the far-red or near-infrared spectrum.
-
Quenching Reagents: Commercial quenching reagents are available that can help reduce autofluorescence.
-
Perfusion: If working with tissues, perfusing the animal with PBS before fixation can help to remove red blood cells, which are a major source of autofluorescence.
-
Frequently Asked Questions (FAQs)
Q1: What is the typical subcellular localization of NOR-1? A1: NOR-1 is a nuclear receptor and is primarily localized in the nucleus of the cell. Your immunofluorescence staining should reflect this.
Q2: What is a good starting dilution for my primary NOR-1 antibody? A2: A good starting point for a purified monoclonal or polyclonal antibody is typically in the range of 1:100 to 1:500. However, it is always best to perform a titration experiment to determine the optimal dilution for your specific antibody lot and experimental conditions.
Q3: Can I use the same blocking buffer for both my primary and secondary antibodies? A3: Yes, it is common practice to dilute both the primary and secondary antibodies in the same blocking buffer used for the initial blocking step. This helps to maintain the blocking effect throughout the staining procedure.
Q4: How long should I incubate my primary antibody? A4: Incubation times can vary, but a common practice is to incubate overnight at 4°C. This allows for specific binding to the target antigen while minimizing non-specific interactions that can be more prevalent at higher temperatures. Shorter incubations of 1-2 hours at room temperature can also be effective but may require a higher antibody concentration.
Q5: My signal is very weak. What can I do? A5: Weak signal can be due to several factors, including low antibody concentration, insufficient incubation time, or a low abundance of the target protein. Try increasing the primary antibody concentration or extending the incubation time. You can also consider using a signal amplification system, such as a biotin-streptavidin-based detection method.
Data Presentation
| Primary Antibody Dilution | Blocking Buffer | Mean Fluorescence Intensity (MFI) - Nucleus (Signal) | Mean Fluorescence Intensity (MFI) - Cytoplasm (Background) | Signal-to-Noise Ratio (Signal/Background) |
| 1:100 | 1% BSA in PBS | 1500 | 500 | 3.0 |
| 1:250 | 1% BSA in PBS | 1200 | 200 | 6.0 |
| 1:500 | 1% BSA in PBS | 950 | 100 | 9.5 |
| 1:1000 | 1% BSA in PBS | 500 | 80 | 6.3 |
| 1:500 | 5% Normal Goat Serum in PBS | 1100 | 120 | 9.2 |
| 1:500 | 10% Normal Goat Serum in PBS | 1050 | 110 | 9.5 |
This table presents hypothetical data for a nuclear transcription factor to illustrate the process of optimizing antibody dilution and comparing blocking buffers. The optimal condition (bolded) is the one that yields the highest signal-to-noise ratio, not necessarily the highest absolute signal.
Experimental Protocols
Detailed Protocol for NOR-1 Immunofluorescence Staining
This protocol provides a general framework for immunofluorescent staining of NOR-1 in cultured cells. Optimization of specific steps, such as antibody concentrations and incubation times, is recommended for each new antibody and cell line.
Materials:
-
Phosphate-Buffered Saline (PBS)
-
Fixation Solution: 4% Paraformaldehyde (PFA) in PBS
-
Permeabilization Buffer: 0.2% Triton X-100 in PBS
-
Blocking Buffer: 5% Normal Goat Serum and 1% BSA in PBS with 0.1% Triton X-100
-
Primary Antibody: Anti-NOR-1 antibody (diluted in blocking buffer)
-
Secondary Antibody: Fluorophore-conjugated goat anti-species IgG (e.g., Goat anti-Rabbit Alexa Fluor 488), diluted in blocking buffer
-
Nuclear Counterstain: DAPI (4′,6-diamidino-2-phenylindole)
-
Antifade Mounting Medium
-
Glass coverslips and microscope slides
Procedure:
-
Cell Culture: Grow cells on sterile glass coverslips in a petri dish or multi-well plate to the desired confluency.
-
Washing: Gently wash the cells three times with PBS for 5 minutes each.
-
Fixation: Fix the cells with 4% PFA in PBS for 15 minutes at room temperature.
-
Washing: Wash the cells three times with PBS for 5 minutes each.
-
Permeabilization: Permeabilize the cells with 0.2% Triton X-100 in PBS for 10 minutes at room temperature.
-
Washing: Wash the cells three times with PBS for 5 minutes each.
-
Blocking: Block non-specific binding by incubating the cells in blocking buffer for 1 hour at room temperature.
-
Primary Antibody Incubation: Incubate the cells with the diluted primary anti-NOR-1 antibody overnight at 4°C in a humidified chamber.
-
Washing: Wash the cells three times with PBS containing 0.1% Triton X-100 for 10 minutes each.
-
Secondary Antibody Incubation: Incubate the cells with the diluted fluorophore-conjugated secondary antibody for 1 hour at room temperature, protected from light.
-
Washing: Wash the cells three times with PBS containing 0.1% Triton X-100 for 10 minutes each, protected from light.
-
Counterstaining: Incubate the cells with DAPI solution for 5 minutes at room temperature to stain the nuclei.
-
Washing: Wash the cells two times with PBS for 5 minutes each.
-
Mounting: Mount the coverslips onto microscope slides using an antifade mounting medium.
-
Imaging: Visualize the staining using a fluorescence or confocal microscope with the appropriate filter sets.
Visualizations
Immunofluorescence Workflow
Caption: A standard workflow for indirect immunofluorescence staining.
NOR-1 Signaling in Vascular Smooth Muscle Cell Proliferation
Caption: Simplified signaling pathway of NOR-1 in VSMC proliferation.
References
- 1. stjohnslabs.com [stjohnslabs.com]
- 2. 9 Tips to optimize your IF experiments | Proteintech Group [ptglab.com]
- 3. blog.cellsignal.com [blog.cellsignal.com]
- 4. ICC/IF Blocking | Blocking Buffers for Immunofluorescence | Bio-Techne [bio-techne.com]
- 5. Blocking Buffers in Immunofluorescence Workflows [visikol.com]
Technical Support Center: Troubleshooting High Variability in NOR-1 Luciferase Reporter Assays
This technical support center is designed to assist researchers, scientists, and drug development professionals in troubleshooting and resolving issues related to high variability in Neuron-derived Orphan Receptor 1 (NOR-1 or NR4A3) luciferase reporter assays. The following information is presented in a question-and-answer format to directly address common challenges.
Frequently Asked Questions (FAQs) & Troubleshooting Guides
Q1: We are observing high variability between replicate wells in our NOR-1 luciferase assay. What are the common causes and how can we minimize this?
High variability between replicates is a frequent issue in luciferase assays and can often be traced back to inconsistencies in experimental technique.[1][2][3]
Key Areas to Investigate:
-
Pipetting Inaccuracy: Even small variations in the volumes of reagents or cell suspensions can lead to significant differences in luminescence readings. Luciferase assays are highly sensitive to these minor discrepancies.[2]
-
Inconsistent Cell Seeding: An uneven distribution of cells across the wells of a microplate is a major contributor to variability. If some wells receive more cells than others, the resulting luciferase expression will naturally differ.
-
Reagent Inhomogeneity: Failure to properly mix master mixes or reagent stocks can result in inconsistent concentrations being dispensed into each well.
-
Edge Effects: Wells on the perimeter of a microplate are more susceptible to evaporation and temperature fluctuations, which can impact cell health and reporter gene expression.[4]
Troubleshooting Solutions:
| Potential Cause | Recommended Solution |
| Pipetting Errors | - Use calibrated pipettes and ensure they are functioning correctly.- Employ reverse pipetting techniques for viscous solutions.- Prepare a master mix for all common reagents to be added to multiple wells.[1][2]- For high-throughput applications, consider using a luminometer with an automated injector for reagent dispensing.[1][5] |
| Inconsistent Cell Seeding | - Thoroughly resuspend cells before and during plating to maintain a homogenous suspension.- Allow the plate to sit at room temperature on a level surface for 15-20 minutes before placing it in the incubator to ensure even cell distribution. |
| Reagent Issues | - Ensure all reagents are fully thawed and mixed before use.- Use fresh, high-quality plasmid DNA for transfections.[2]- Prepare fresh substrate solutions for each experiment and protect them from light. |
| Edge Effects | - To minimize evaporation, fill the outer wells of the plate with sterile media or phosphate-buffered saline (PBS).- Use plate sealers during long incubation periods.[4] |
Q2: Our results are inconsistent from one experiment to the next (inter-assay variability). What factors could be contributing to this?
Inter-assay variability can be frustrating and is often due to subtle changes in experimental conditions or reagents between different assay runs.
Key Areas to Investigate:
-
Cell Passage Number and Health: Cells can undergo phenotypic changes at high passage numbers, affecting their transfection efficiency and overall physiology. Using cells from a consistent and low passage number range is crucial.[3]
-
Reagent Batch Variation: Different lots of reagents, such as fetal bovine serum (FBS) or transfection reagents, can have slightly different compositions, leading to variability in results.
-
Inconsistent Incubation Times: Variations in the timing of steps like transfection, treatment, and lysis can impact the levels of luciferase expression.
-
Cell Confluency at Transfection: The density of cells at the time of transfection significantly influences the efficiency of DNA uptake.[2]
Troubleshooting Solutions:
| Potential Cause | Recommended Solution |
| Cellular Factors | - Maintain a consistent cell passage number for all experiments.- Regularly check cell viability and morphology.- Seed cells to achieve a consistent confluency (typically 70-90%) at the time of transfection.[2] |
| Reagent Consistency | - If possible, purchase reagents in larger batches to use across multiple experiments.- Always prepare fresh dilutions of reagents for each experiment. |
| Protocol Adherence | - Strictly adhere to a standardized protocol with consistent incubation times.- Document all experimental parameters for each assay run to identify any deviations. |
Q3: We are using a dual-luciferase system to normalize our NOR-1 reporter data, but the variability is still high. What could be wrong?
While dual-luciferase assays are designed to reduce variability by normalizing the experimental reporter (e.g., Firefly luciferase) to a control reporter (e.g., Renilla luciferase), several factors can still lead to inconsistent results.[2]
Key Areas to Investigate:
-
Suboptimal Reporter Ratios: An inappropriate ratio of the experimental NOR-1 reporter plasmid to the control reporter plasmid can lead to competition for cellular machinery or signal interference.
-
Promoter Strength of Control Vector: The promoter driving the control reporter should provide consistent, moderate expression that is not affected by the experimental treatments. A very strong promoter may deplete resources needed for the experimental reporter.[2]
-
Signal Quenching or Bleed-through: Inadequate quenching of the first luciferase reaction can lead to bleed-through and affect the measurement of the second luciferase.
Troubleshooting Solutions:
| Potential Cause | Recommended Solution |
| Plasmid Ratio | - Optimize the ratio of the NOR-1 reporter plasmid to the control plasmid. Start with a 10:1 or 20:1 ratio (experimental:control) and test other ratios to find the optimal balance. |
| Control Promoter | - Use a control vector with a promoter that provides moderate and constitutive expression in your cell line (e.g., a TK promoter is often weaker than a CMV or SV40 promoter).[2] |
| Assay Chemistry | - Ensure complete quenching of the first signal by using the recommended volume of the stop reagent and mixing thoroughly.- Verify that the correct emission filters are being used for each luciferase if your luminometer has this option. |
Experimental Protocols
Detailed Methodology for a Dual-Luciferase Reporter Assay
This protocol provides a general framework for a dual-luciferase assay to measure NOR-1 activity. Optimization of cell number, DNA amount, and transfection reagent volume is recommended for each specific cell line and plasmid combination.
Materials:
-
Cells of interest
-
Cell culture medium
-
NOR-1 reporter plasmid (Firefly luciferase)
-
Control plasmid (Renilla luciferase)
-
Transfection reagent
-
Phosphate-Buffered Saline (PBS)
-
Passive Lysis Buffer
-
Luciferase Assay Reagent II (LAR II)
-
Stop & Glo® Reagent
-
Opaque, white-walled 96-well plates
-
Luminometer with injectors (recommended)
Procedure:
-
Cell Seeding:
-
The day before transfection, seed cells in a white, opaque 96-well plate at a density that will result in 70-90% confluency at the time of transfection. The optimal cell number will vary by cell type.
-
-
Transfection:
-
Prepare a master mix of DNA and transfection reagent in serum-free medium according to the manufacturer's protocol. Optimize the ratio of transfection reagent to DNA for your specific cell line.
-
Add the transfection complex to the cells and incubate for the recommended time (typically 24-48 hours).
-
-
Cell Lysis:
-
After incubation, remove the culture medium from the wells.
-
Wash the cells once with PBS.
-
Add an appropriate volume of Passive Lysis Buffer to each well (e.g., 20 µL for a 96-well plate).
-
Incubate at room temperature for 15-20 minutes with gentle shaking to ensure complete lysis.
-
-
Luminescence Measurement:
-
Program the luminometer to inject LAR II and measure the Firefly luminescence, followed by the injection of Stop & Glo® Reagent and measurement of Renilla luminescence.
-
Add 20 µL of cell lysate to a new opaque plate if not lysing directly in the assay plate.
-
Place the plate in the luminometer.
-
The instrument will inject LAR II (e.g., 100 µL) and measure the Firefly signal.
-
Subsequently, the instrument will inject Stop & Glo® Reagent (e.g., 100 µL) to quench the Firefly reaction and initiate the Renilla reaction, followed by the measurement of the Renilla signal.
-
-
Data Analysis:
-
Calculate the ratio of Firefly luminescence to Renilla luminescence for each well to normalize for transfection efficiency and cell number.
-
Express the results as fold change relative to a control condition.
-
Quantitative Data Tables
Table 1: Recommended Cell Seeding Densities for Luciferase Assays
The optimal cell seeding density is crucial for achieving reproducible results and should be determined empirically for each cell line. The following are general starting recommendations for different plate formats.
| Plate Format | Surface Area (cm²) | Recommended Seeding Density (cells/well) |
| 96-well | 0.32 | 5,000 - 20,000 |
| 48-well | 0.95 | 20,000 - 50,000 |
| 24-well | 1.9 | 40,000 - 100,000 |
| 12-well | 3.8 | 80,000 - 200,000 |
| 6-well | 9.5 | 200,000 - 500,000 |
Note: These are starting recommendations and should be optimized for your specific cell line and experimental conditions.
Table 2: Example of Transfection Optimization
Optimizing the ratio of transfection reagent to DNA is critical for maximizing transfection efficiency while minimizing cytotoxicity. Below is an example of a titration experiment.
| Well | DNA (µg) | Transfection Reagent (µL) | Reagent:DNA Ratio | Relative Luciferase Units (RLU) | Coefficient of Variation (%CV) |
| 1 | 0.5 | 1.0 | 2:1 | 150,000 | 18% |
| 2 | 0.5 | 1.5 | 3:1 | 350,000 | 12% |
| 3 | 0.5 | 2.0 | 4:1 | 420,000 | 10% |
| 4 | 0.5 | 2.5 | 5:1 | 380,000 | 15% |
In this example, a 4:1 ratio of transfection reagent to DNA yielded the highest signal with a low coefficient of variation.
Visualizations
References
Technical Support Center: Optimizing NR4A3 siRNA Knockdown Efficiency
Welcome to the technical support center for improving the efficiency of Nuclear Receptor Subfamily 4 Group A Member 3 (NR4A3) siRNA knockdown. This resource is designed for researchers, scientists, and drug development professionals to provide troubleshooting guidance and answers to frequently asked questions.
Frequently Asked Questions (FAQs)
Q1: What is the optimal siRNA concentration for NR4A3 knockdown?
A1: The optimal siRNA concentration for NR4A3 knockdown can vary depending on the cell type and transfection reagent used. It is recommended to perform a dose-response experiment to determine the lowest effective concentration that provides maximal knockdown with minimal cytotoxicity.[1] A typical starting range for siRNA concentration is 10-50 nM.
Q2: How long after transfection should I assess NR4A3 knockdown?
A2: The optimal time point for assessing knockdown depends on the stability of the NR4A3 mRNA and protein. Generally, mRNA levels can be assessed 24-48 hours post-transfection.[2][3] Protein knockdown may take longer to become apparent, typically between 48-72 hours, due to the half-life of the existing protein pool. A time-course experiment is recommended to determine the peak of knockdown for your specific experimental system.
Q3: My NR4A3 knockdown is inefficient. What are the common causes?
A3: Inefficient knockdown of NR4A3 can be attributed to several factors:
-
Suboptimal siRNA delivery: This is the most common reason for poor knockdown. Transfection efficiency is highly cell-type dependent.[1]
-
Poor siRNA design: The sequence of the siRNA is critical for its efficacy.
-
Low NR4A3 expression in your cell model: If the target gene expression is very low, it can be challenging to detect a significant reduction.[4]
-
Incorrect timing of analysis: Assessing knockdown too early or too late can miss the optimal window.
-
Degradation of siRNA: Improper storage or handling of siRNA can lead to degradation.
Q4: How can I validate the specificity of my NR4A3 siRNA?
A4: To ensure the observed effects are specific to NR4A3 knockdown and not due to off-target effects, it is crucial to include proper controls:
-
Negative Control siRNA: A non-targeting siRNA with a scrambled sequence that has no known homology to any gene in the target organism.[1]
-
Multiple NR4A3 siRNAs: Using at least two different siRNAs targeting different regions of the NR4A3 mRNA can help confirm that the phenotype is not due to an off-target effect of a single siRNA.
-
Rescue Experiment: After knockdown, re-introducing an NR4A3 expression vector that is resistant to the siRNA (e.g., due to silent mutations in the siRNA target site) should rescue the observed phenotype.
Q5: Should I measure knockdown at the mRNA or protein level?
A5: It is recommended to measure knockdown at both the mRNA and protein levels.[5]
Troubleshooting Guides
Problem 1: Low Transfection Efficiency
| Possible Cause | Recommended Solution |
| Cell health and density | Ensure cells are healthy, actively dividing, and plated at the optimal density (typically 60-80% confluency at the time of transfection).[10] |
| Transfection reagent | The choice of transfection reagent is critical and cell-type specific. Optimize the reagent-to-siRNA ratio. Consider trying different reagents if efficiency remains low.[1] |
| Serum and antibiotics | Some transfection reagents are inhibited by serum and antibiotics. Check the manufacturer's protocol and consider performing transfection in serum-free and antibiotic-free media.[1] |
| siRNA-lipid complex formation | Ensure proper mixing and incubation times for the siRNA and transfection reagent to allow for efficient complex formation as per the manufacturer's protocol.[2][11] |
Problem 2: High Cell Toxicity/Death After Transfection
| Possible Cause | Recommended Solution |
| High siRNA concentration | Use the lowest effective concentration of siRNA determined from your dose-response experiment.[12] |
| Excess transfection reagent | Too much transfection reagent can be toxic to cells. Optimize the amount of reagent used. |
| Prolonged exposure to complexes | For sensitive cell lines, consider reducing the incubation time with the siRNA-lipid complexes. The medium can be replaced with fresh growth medium after 4-6 hours.[3] |
Problem 3: Inconsistent Knockdown Results
| Possible Cause | Recommended Solution |
| Variable cell conditions | Maintain consistent cell passage number, plating density, and growth conditions for all experiments. |
| Pipetting inaccuracies | Ensure accurate and consistent pipetting of siRNA and transfection reagents. |
| siRNA quality | Store siRNA according to the manufacturer's instructions to prevent degradation. Aliquot stocks to avoid multiple freeze-thaw cycles. |
Quantitative Data Summary
The following table provides representative data on the optimization of NR4A3 siRNA knockdown. Note that these are example values and optimal conditions should be determined empirically for each specific cell line and experimental setup.
| Parameter | Condition 1 | Condition 2 | Condition 3 | Condition 4 |
| siRNA Concentration | 10 nM | 25 nM | 50 nM | 100 nM |
| Transfection Reagent Volume (per well) | 0.5 µL | 1.0 µL | 1.5 µL | 2.0 µL |
| % NR4A3 mRNA Knockdown (qPCR) | 65% | 85% | 90% | 92% |
| % NR4A3 Protein Knockdown (Western Blot) | 50% | 75% | 85% | 88% |
| Cell Viability | 95% | 90% | 80% | 65% |
Data is hypothetical and for illustrative purposes.
Experimental Protocols
Protocol 1: NR4A3 siRNA Transfection using Lipofectamine™ RNAiMAX
This protocol is adapted for a 24-well plate format.[2][3] Adjust volumes accordingly for other plate formats.
Materials:
-
NR4A3 siRNA (and negative control siRNA)
-
Lipofectamine™ RNAiMAX Transfection Reagent
-
Opti-MEM™ I Reduced Serum Medium
-
Cells to be transfected
-
Complete growth medium
Procedure:
-
Cell Plating: The day before transfection, seed cells in a 24-well plate in 500 µL of complete growth medium without antibiotics, so that they will be 60-80% confluent at the time of transfection.
-
siRNA-Lipid Complex Preparation (per well): a. In a sterile tube, dilute the desired amount of NR4A3 siRNA (e.g., 6 pmol for a final concentration of 10 nM) in 50 µL of Opti-MEM™ Medium. Mix gently. b. In a separate sterile tube, dilute 1 µL of Lipofectamine™ RNAiMAX in 50 µL of Opti-MEM™ Medium. Mix gently and incubate for 5 minutes at room temperature. c. Combine the diluted siRNA and the diluted Lipofectamine™ RNAiMAX. Mix gently and incubate for 10-20 minutes at room temperature to allow for complex formation.
-
Transfection: a. Add the 100 µL of siRNA-lipid complex dropwise to each well containing cells. b. Gently rock the plate back and forth to distribute the complexes evenly.
-
Incubation: Incubate the cells at 37°C in a CO2 incubator for 24-72 hours before analysis. The medium may be changed after 4-6 hours if toxicity is a concern.
Protocol 2: Validation of NR4A3 Knockdown by qRT-PCR
Materials:
-
RNA extraction kit
-
cDNA synthesis kit
-
qPCR master mix
-
Primers for NR4A3 and a housekeeping gene (e.g., GAPDH, ACTB)
Procedure:
-
RNA Extraction: At the desired time point post-transfection (e.g., 24-48 hours), harvest the cells and extract total RNA using a commercial kit according to the manufacturer's instructions.
-
cDNA Synthesis: Synthesize cDNA from an equal amount of RNA from each sample using a reverse transcription kit.
-
qPCR: a. Set up the qPCR reaction with the appropriate master mix, cDNA template, and primers for NR4A3 and the housekeeping gene. b. Run the qPCR reaction on a real-time PCR instrument.
-
Data Analysis: Calculate the relative expression of NR4A3 mRNA using the ΔΔCt method, normalizing to the housekeeping gene and comparing to the negative control siRNA-treated sample.
Protocol 3: Validation of NR4A3 Knockdown by Western Blot
Materials:
-
Lysis buffer (e.g., RIPA buffer with protease inhibitors)
-
Protein quantification assay (e.g., BCA assay)
-
SDS-PAGE gels and running buffer
-
Transfer buffer and membrane (e.g., PVDF or nitrocellulose)
-
Blocking buffer (e.g., 5% non-fat milk or BSA in TBST)
-
Primary antibody against NR4A3
-
Primary antibody against a loading control (e.g., GAPDH, β-actin)
-
HRP-conjugated secondary antibody
-
Chemiluminescent substrate
Procedure:
-
Protein Extraction: At the desired time point post-transfection (e.g., 48-72 hours), wash the cells with ice-cold PBS and lyse them in lysis buffer.
-
Protein Quantification: Determine the protein concentration of each lysate using a protein quantification assay.
-
SDS-PAGE and Transfer: a. Load equal amounts of protein from each sample onto an SDS-PAGE gel and separate the proteins by electrophoresis. b. Transfer the separated proteins to a membrane.
-
Immunoblotting: a. Block the membrane in blocking buffer for 1 hour at room temperature. b. Incubate the membrane with the primary anti-NR4A3 antibody overnight at 4°C. c. Wash the membrane and incubate with the HRP-conjugated secondary antibody for 1 hour at room temperature.
-
Detection: a. Wash the membrane and add the chemiluminescent substrate. b. Visualize the protein bands using an imaging system.
-
Analysis: Quantify the band intensities and normalize the NR4A3 signal to the loading control to determine the extent of protein knockdown.
Signaling Pathways and Experimental Workflows
Caption: Experimental workflow for NR4A3 siRNA knockdown and validation.
Caption: Simplified NR4A3 and NF-κB signaling interaction.[13][14][15][16]
Caption: Putative modulation of the mTORC1 pathway by NR4A3.
References
- 1. Optimizing siRNA Transfection | Thermo Fisher Scientific - US [thermofisher.com]
- 2. ulab360.com [ulab360.com]
- 3. RNAiMAX Forward Transfections Lipofectamine | Thermo Fisher Scientific - US [thermofisher.com]
- 4. Target Gene Abundance Contributes to the Efficiency of siRNA-Mediated Gene Silencing - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Reddit - The heart of the internet [reddit.com]
- 6. qiagen.com [qiagen.com]
- 7. Validation of short interfering RNA knockdowns by quantitative real-time PCR - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Quantitation siRNA-induced Knockdown by qRT-PCR and WB - Altogen Labs [altogenlabs.com]
- 9. siRNA knockdown validation 101: Incorporating negative controls in antibody research - PMC [pmc.ncbi.nlm.nih.gov]
- 10. documents.thermofisher.com [documents.thermofisher.com]
- 11. biocat.com [biocat.com]
- 12. Guidelines for transfection of siRNA [qiagen.com]
- 13. Molecular Interactions between NR4A Orphan Nuclear Receptors and NF-κB Are Required for Appropriate Inflammatory Responses and Immune Cell Homeostasis - PMC [pmc.ncbi.nlm.nih.gov]
- 14. NR4A3 affects fibrotic activation of orbital fibroblasts and thyroid-associated ophthalmopathy through regulating NF-κB signaling - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. NR4A3 potentials M1-like macrophage polarization to facilitate anti-tumor immune responses in breast cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 16. NR4A3: A Key Nuclear Receptor in Vascular Biology, Cardiovascular Remodeling, and Beyond - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Assessing Off-Target Effects of NR4A3 CRISPR/Cas9 Editing
This technical support center provides researchers, scientists, and drug development professionals with a comprehensive guide to assessing the off-target effects of CRISPR/Cas9 editing of the NR4A3 gene. It includes frequently asked questions, troubleshooting guides for common experimental issues, detailed protocols for key off-target detection methods, and illustrative diagrams to clarify complex workflows and pathways.
Frequently Asked Questions (FAQs)
Q1: What are off-target effects in the context of CRISPR/Cas9 editing of NR4A3?
A1: Off-target effects are unintended genetic modifications, such as insertions, deletions, or point mutations, that occur at genomic locations other than the intended NR4A3 target site.[1] These effects arise because the Cas9 nuclease, guided by the single-guide RNA (sgRNA), can tolerate a certain number of mismatches between the sgRNA sequence and the genomic DNA, leading to cleavage at sites with high sequence similarity to the on-target site.[2][3]
Q2: Why is it critical to assess off-target effects when editing NR4A3?
A2: NR4A3 is a nuclear receptor involved in various cellular processes, including inflammation, metabolism, and cell proliferation.[4][5][6] Unintended mutations at off-target sites could disrupt the function of other essential genes, potentially leading to unforeseen and deleterious cellular phenotypes, confounding experimental results, or causing safety concerns in therapeutic applications.[7]
Q3: How can I design sgRNAs for NR4A3 to minimize off-target effects from the start?
A3: Minimizing off-target effects begins with careful sgRNA design. Utilize computational tools like CRISPOR or CHOPCHOP, which use algorithms to predict and score potential off-target sites.[8][9] These tools can help you select sgRNAs with high on-target activity and the lowest possible number of predicted off-target sites. Key considerations include ensuring the uniqueness of the 20-nucleotide target sequence and the presence of a suitable Protospacer Adjacent Motif (PAM).[10]
Q4: What are the main strategies for identifying NR4A3 off-target effects?
A4: There are two main approaches for identifying off-target effects:
-
Computational Prediction: In silico tools predict potential off-target sites based on sequence homology to the sgRNA.[11] These predictions are a necessary first step but require experimental validation.
-
Experimental Detection: Unbiased, genome-wide methods identify actual cleavage events in a cellular or in vitro context. Key methods include GUIDE-seq, CIRCLE-seq, and SITE-seq.[3][8] Following identification, candidate off-target sites should be validated, often using targeted deep sequencing methods like rhAmpSeq.[12][13]
Q5: What is the difference between cell-based and in vitro methods for off-target detection?
A5: Cell-based methods like GUIDE-seq are performed in living cells, providing a more physiologically relevant assessment of off-target activity as they account for cellular factors like chromatin accessibility.[14] In vitro methods like CIRCLE-seq use purified genomic DNA, which can be more sensitive in detecting all potential cleavage sites but may identify sites that are not accessible in a cellular context, potentially leading to a higher rate of false positives.[15][16][17]
Troubleshooting Guides
GUIDE-seq Troubleshooting
| Problem | Possible Cause | Suggested Solution |
| Low Library Yield or Low dsODN Integration | Inefficient delivery of Cas9, gRNA, and dsODN. | Optimize transfection or electroporation protocol for your cell type. Titrate the amount of dsODN to maximize integration while maintaining cell viability.[18][19] |
| Low on-target cleavage efficiency. | Confirm high on-target editing efficiency using a method like T7E1 assay or targeted deep sequencing before proceeding with GUIDE-seq. | |
| Poor quality of genomic DNA. | Ensure genomic DNA is of high molecular weight and free of contaminants. Measure DNA concentration using fluorometry.[20] | |
| High Number of False Positives | RGN-independent genomic breakpoint "hotspots". | Include a negative control with dsODN only (no Cas9/gRNA) to identify background noise and inherent fragile sites in the genome.[14] |
| Contamination during library preparation. | Maintain a sterile work environment and use filtered pipette tips. | |
| Failure to Detect Known Off-Targets | Insufficient sequencing depth. | Increase the sequencing depth to improve the detection of rare off-target events.[14] |
| Very low cleavage efficiency at the off-target site. | The efficiency of dsODN integration is correlated with cleavage frequency. Sites with very low cleavage rates may be below the detection limit of the assay.[14] |
CIRCLE-seq Troubleshooting
| Problem | Possible Cause | Suggested Solution |
| High Background of Random DNA Reads | Incomplete removal of linear DNA fragments. | Ensure complete digestion of linear DNA with exonuclease treatment. Optimize the duration and concentration of the enzyme.[21] |
| Suboptimal circularization of genomic DNA. | Use high-quality DNA ligase and optimize the reaction conditions (e.g., DNA concentration, temperature, incubation time).[21] | |
| Low Yield of Sequencing Library | Inefficient Cas9 cleavage of circularized DNA. | Verify the activity of the Cas9 RNP complex. Ensure the gRNA is of high quality. |
| Issues with adapter ligation or PCR amplification. | Use high-quality reagents for library preparation. Optimize PCR cycle numbers to avoid over-amplification. | |
| Discrepancy between in vitro and in vivo results | In vitro conditions do not fully replicate the cellular environment. | Validate CIRCLE-seq identified off-target sites in cells using targeted deep sequencing to confirm their relevance.[15][17] |
| Epigenetic modifications affecting Cas9 binding in cells are absent in vitro. | Acknowledge that CIRCLE-seq provides a comprehensive map of potential sites, which must be filtered through cellular validation. |
Experimental Protocols
Protocol 1: GUIDE-seq for Genome-wide Off-Target Identification
This protocol provides a condensed workflow. Researchers should consult detailed original publications for specifics.
-
Cell Preparation and Transfection:
-
Co-transfect the cells of interest with:
-
An expression plasmid for the Cas9 variant and the NR4A3-targeting gRNA, or a pre-complexed Cas9 RNP.
-
A blunt-ended, phosphorylated double-stranded oligodeoxynucleotide (dsODN) tag.[14]
-
-
-
Genomic DNA Extraction:
-
After 48-72 hours, harvest the cells and extract high-molecular-weight genomic DNA using a standard kit.
-
-
Library Preparation:
-
Fragment the genomic DNA by sonication to an average size of ~300-500 bp.
-
Perform end-repair, A-tailing, and ligation of a universal NGS adapter (Y-adapter).
-
Carry out two rounds of nested PCR. The first PCR uses primers specific to the integrated dsODN tag and the universal adapter. The second PCR adds the full sequencing adapters and indexes.
-
-
Sequencing and Analysis:
-
Sequence the final library on an Illumina platform.
-
Align reads to the reference genome. Sites with a high number of reads starting at the same genomic coordinate indicate a Cas9 cleavage site. These can then be mapped as on-target (NR4A3) or off-target events.
-
Protocol 2: CIRCLE-seq for In Vitro Off-Target Identification
This protocol provides a condensed workflow based on published methods.[15][16][17][21]
-
Genomic DNA Preparation:
-
Extract high-quality genomic DNA from the desired cell type.
-
Shear the DNA to an average size of ~300 bp using sonication.
-
-
DNA Circularization:
-
Perform end-repair and A-tailing on the fragmented DNA.
-
Ligate the DNA fragments to form circular DNA molecules.
-
Treat with exonuclease to remove any remaining linear DNA.
-
-
In Vitro Cleavage:
-
Incubate the circularized DNA with the pre-assembled Cas9 RNP targeting NR4A3. This will linearize the circles at on- and off-target sites.
-
-
Library Preparation and Sequencing:
-
Ligate sequencing adapters to the ends of the linearized DNA fragments.
-
Perform PCR to amplify the library.
-
Sequence the library using an Illumina platform. Paired-end reads will map to the locations of the cleavage events.
-
Protocol 3: Targeted Deep Sequencing (rhAmpSeq) for Off-Target Validation
This protocol outlines the general steps for validating putative off-target sites identified by methods like GUIDE-seq or computational prediction.[12][13][22]
-
Site Selection:
-
Compile a list of potential off-target sites for your NR4A3 gRNA from unbiased experimental methods or in silico prediction tools.
-
-
Primer Design:
-
Design rhAmpSeq PCR primer panels that flank each predicted off-target site, as well as the on-target site.
-
-
Library Preparation:
-
Perform two rounds of PCR using the rhAmpSeq library kit:
-
PCR 1: A multiplex PCR reaction to amplify all target regions.
-
PCR 2: A second PCR to add unique indexes and Illumina sequencing adapters to each sample.
-
-
-
Sequencing and Data Analysis:
-
Pool the indexed libraries and perform deep sequencing.
-
Analyze the sequencing data to quantify the frequency of insertions and deletions (indels) at each on- and off-target site. Compare the indel frequencies in edited samples to those in untreated controls.
-
Quantitative Data Summary
The following table provides an example of how to present quantitative data from an off-target analysis of an NR4A3-targeting sgRNA. The data shown here is illustrative.
| Site | Genomic Location | Sequence | Mismatches | GUIDE-seq Reads | Indel Frequency (%) |
| On-Target | chr9:99,845,123-99,845,142 | GAGCCT CCAG TGAC TCAA GG | 0 | 15,432 | 85.6 |
| Off-Target 1 | chr2:45,678,901-45,678,920 | GAGCCA CCAG TGAC TCAA GG | 1 | 2,109 | 12.3 |
| Off-Target 2 | chr11:12,345,678-12,345,697 | GAGCCT CCAA TGAC TCAA GG | 1 | 876 | 5.1 |
| Off-Target 3 | chrX:98,765,432-98,765,451 | GAGCCT CCAG TGAT TCAG GG | 2 | 112 | 0.8 |
| Off-Target 4 | chr4:54,321,987-54,322,006 | GAGCCT CCAG TGAC TCAA AA | 2 | 34 | < 0.1 |
Visualizations
NR4A3 Signaling Pathway
Caption: Simplified signaling pathway showing the induction and function of NR4A3.
Overall Off-Target Analysis Workflow
Caption: A comprehensive workflow for identifying and validating CRISPR off-target effects.
Experimental Workflow: GUIDE-seq vs. CIRCLE-seq
Caption: Comparison of the experimental workflows for GUIDE-seq and CIRCLE-seq.
References
- 1. jitc.bmj.com [jitc.bmj.com]
- 2. Off-target effects in CRISPR/Cas9 gene editing - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Off-target interactions in the CRISPR-Cas9 Machinery: mechanisms and outcomes - PMC [pmc.ncbi.nlm.nih.gov]
- 4. mdpi.com [mdpi.com]
- 5. biorxiv.org [biorxiv.org]
- 6. Frontiers | Targeting NR4A Nuclear Receptors to Control Stromal Cell Inflammation, Metabolism, Angiogenesis, and Tumorigenesis [frontiersin.org]
- 7. dovepress.com [dovepress.com]
- 8. mdpi.com [mdpi.com]
- 9. researchgate.net [researchgate.net]
- 10. addgene.org [addgene.org]
- 11. Frontiers | Beyond the promise: evaluating and mitigating off-target effects in CRISPR gene editing for safer therapeutics [frontiersin.org]
- 12. nanomedicines.ca [nanomedicines.ca]
- 13. rhAmpSeq™ CRISPR Analysis System - LubioScience [lubio.ch]
- 14. benchchem.com [benchchem.com]
- 15. CIRCLE-Seq for Interrogation of Off-Target Gene Editing [jove.com]
- 16. Defining CRISPR–Cas9 genome-wide nuclease activities with CIRCLE-seq | Springer Nature Experiments [experiments.springernature.com]
- 17. CIRCLE-seq for interrogation of off-target gene editing - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Defining genome-wide CRISPR-Cas genome editing nuclease activity with GUIDE-seq - PMC [pmc.ncbi.nlm.nih.gov]
- 19. vedtopkar.com [vedtopkar.com]
- 20. GUIDE-seq simplified library preparation protocol (CRISPR/Cas9 off-target cleavage detection) [protocols.io]
- 21. Comprehensive Review of Circle Sequencing - CD Genomics [cd-genomics.com]
- 22. sfvideo.blob.core.windows.net [sfvideo.blob.core.windows.net]
NOR-1 (NR4A3) Antibody in IHC: A Technical Support Resource
This technical support center provides troubleshooting guidance and answers to frequently asked questions regarding the performance of the NOR-1 (NR4A3) antibody in immunohistochemistry (IHC). It is designed for researchers, scientists, and drug development professionals to help identify and resolve common issues encountered during their experiments.
Frequently Asked Questions (FAQs)
Q1: What is the expected subcellular localization of NOR-1 protein in IHC?
A1: NOR-1 (NR4A3) is a transcription factor and a member of the nuclear receptor superfamily. Therefore, the expected localization is primarily nuclear .[1][2] Staining observed exclusively in the cytoplasm should be interpreted with caution and may indicate a technical issue.
Q2: In which tissues is NOR-1 expression typically observed?
A2: NOR-1 expression is found in various tissues, including the brain, muscle, and pancreas.[3] It is notably upregulated in specific pathological conditions, such as Acinic Cell Carcinoma of the salivary gland, where it serves as a highly sensitive and specific diagnostic marker.[1][2] Non-neoplastic salivary gland tissue generally shows no reactivity.
Q3: My NOR-1 staining is completely negative, even in my positive control tissue. What could be the cause?
A3: A complete lack of staining can stem from several factors. First, confirm that your chosen positive control tissue is appropriate and known to express NOR-1. Issues could also arise from improper sample preparation, such as prolonged fixation, which can mask the antigen. Ensure that the primary antibody has not expired and has been stored correctly. An error in the protocol, such as omitting the primary antibody or using an incompatible secondary antibody, is also a common cause. Finally, the antigen retrieval step is critical; using an inappropriate buffer or method can prevent antibody binding.
Q4: I am observing very weak NOR-1 staining. How can I enhance the signal?
A4: To amplify a weak signal, consider the following adjustments:
-
Primary Antibody Concentration: Increase the concentration of the primary antibody or extend the incubation period (e.g., overnight at 4°C).
-
Antigen Retrieval: Ensure the heat-induced epitope retrieval (HIER) is performed optimally. For NOR-1, a Tris-EDTA buffer with a pH of 9.0 is often recommended.[1]
-
Detection System: Employ a more sensitive detection system, such as a polymer-based detection kit or a tyramide signal amplification (TSA) system.
-
Tissue Preparation: Use freshly cut tissue sections, as antigenicity can diminish over time in stored slides.
Q5: The background staining in my IHC experiment is too high. What are the common causes and solutions?
A5: High background can obscure specific staining and is a frequent issue in IHC. Key causes and their solutions are outlined below:
-
Endogenous Peroxidase Activity: If using an HRP-based detection system, endogenous peroxisomes in tissues like the kidney or liver can produce a high background. Quench this activity by treating slides with a 3% hydrogen peroxide (H2O2) solution before primary antibody incubation.
-
Non-specific Antibody Binding: This can be caused by using too high a concentration of the primary or secondary antibody. Titrate your antibodies to find the optimal dilution that provides a strong signal with low background. Additionally, ensure adequate blocking with a suitable serum (from the same species as the secondary antibody).
-
Incomplete Deparaffinization: Residual paraffin (B1166041) can cause patchy, uneven background staining. Ensure complete removal of paraffin by using fresh xylene and sufficient incubation times.
Troubleshooting Common IHC Issues with NOR-1 Antibody
| Problem | Potential Cause | Recommended Solution |
| No Staining | Incorrect primary antibody used or antibody omitted. | Verify the correct antibody was used and applied. Rerun the experiment with careful attention to this step. |
| Incompatible secondary antibody. | Ensure the secondary antibody is raised against the host species of the primary antibody (e.g., anti-mouse secondary for a mouse monoclonal primary). | |
| Suboptimal antigen retrieval. | Optimize the antigen retrieval method. For NOR-1 in FFPE tissues, heat-induced retrieval with Tris-EDTA buffer (pH 9.0) for 20 minutes is effective.[1] | |
| Antibody storage/activity issue. | Use a new vial of antibody. Confirm proper storage conditions (typically 4°C for short-term, -20°C for long-term). | |
| Weak Staining | Primary antibody concentration is too low. | Increase the primary antibody concentration or extend the incubation time (e.g., overnight at 4°C). |
| Insufficient incubation time. | Ensure adequate incubation time for both primary and secondary antibodies as per the optimized protocol. | |
| Low abundance of the target protein. | Use a signal amplification system (e.g., polymer-based detection, TSA). | |
| Tissue sections are old. | Use freshly cut sections for your experiments. | |
| High Background | Primary or secondary antibody concentration is too high. | Titrate the antibodies to determine the optimal dilution. |
| Inadequate blocking. | Increase the blocking time or use a different blocking agent (e.g., 5% normal goat serum). | |
| Endogenous peroxidase/phosphatase activity. | Quench endogenous peroxidase with 3% H2O2. If using an AP system, use levamisole (B84282) to block endogenous alkaline phosphatase. | |
| Sections dried out during staining. | Keep slides in a humidified chamber throughout the staining procedure. | |
| Non-specific Staining | Cross-reactivity of the primary or secondary antibody. | Run a negative control with the secondary antibody only. If staining persists, consider a pre-adsorbed secondary antibody. |
| Formation of antibody aggregates. | Centrifuge the antibody solution before use to pellet any aggregates. | |
| Edge effect or drying artifact. | Ensure the entire tissue section is covered with reagent at all times. |
Experimental Protocols & Methodologies
Recommended IHC Protocol for NOR-1 on Paraffin-Embedded Tissues
This protocol is a general guideline. Optimization may be required for specific tissues and antibody lots.
1. Deparaffinization and Rehydration: a. Xylene: 2 changes for 10 minutes each. b. 100% Ethanol: 2 changes for 5 minutes each. c. 95% Ethanol: 2 changes for 5 minutes each. d. 70% Ethanol: 2 changes for 5 minutes each. e. Distilled Water: 2 changes for 5 minutes each.
2. Antigen Retrieval: a. Immerse slides in Tris-EDTA buffer (10mM Tris Base, 1mM EDTA, pH 9.0). b. Heat in a pressure cooker or water bath at 95-100°C for 20-30 minutes. c. Allow slides to cool to room temperature in the buffer (approx. 20 minutes).
3. Peroxidase Block (for HRP detection): a. Incubate slides in 3% Hydrogen Peroxide in methanol (B129727) or PBS for 10-15 minutes. b. Rinse with PBS.
4. Blocking: a. Incubate slides with a blocking solution (e.g., 5% normal goat serum in PBS) for 30-60 minutes at room temperature.
5. Primary Antibody Incubation: a. Dilute the NOR-1 primary antibody (e.g., clone H-7 or OTI2B11) in antibody diluent. Common starting dilutions are 1:50 to 1:100.[1][2] b. Incubate overnight at 4°C in a humidified chamber.
6. Detection: a. Rinse slides with PBS. b. Incubate with a biotinylated secondary antibody or an HRP-polymer-conjugated secondary antibody according to the manufacturer's instructions (typically 30-60 minutes at room temperature). c. Rinse with PBS. d. If using a biotin-based system, incubate with Streptavidin-HRP. e. Rinse with PBS.
7. Chromogen Development: a. Incubate with a chromogen solution such as DAB (3,3'-Diaminobenzidine) until the desired stain intensity develops. b. Rinse with distilled water.
8. Counterstaining, Dehydration, and Mounting: a. Counterstain with Hematoxylin. b. Dehydrate through graded alcohols and clear in xylene. c. Mount with a permanent mounting medium.
Recommended Antibody Dilutions and Retrieval Methods
| Antibody Clone | Supplier | Recommended Dilution | Antigen Retrieval |
| H-7 (sc-393902) | Santa Cruz Biotechnology | 1:50 - 1:100 | Heat-mediated, Tris-EDTA pH 9.0[1][2] |
| OTI2B11 | Origene Technologies | 1:100 | Heat-mediated, Tris-EDTA pH 9.0[1] |
Visual Guides
IHC Troubleshooting Workflow
Caption: A flowchart for troubleshooting common IHC staining issues.
Simplified NOR-1 (NR4A3) Signaling Pathway
Caption: Simplified pathway of NOR-1 (NR4A3) induction and function.
References
- 1. NR4A3 Immunostain Is a Highly Sensitive and Specific Marker for Acinic Cell Carcinoma in Cytologic and Surgical Specimens - PMC [pmc.ncbi.nlm.nih.gov]
- 2. NR4A3 (NOR-1) Immunostaining Shows Better Performance than DOG1 Immunostaining in Acinic Cell Carcinoma of Salivary Gland: a Preliminary Study - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Anti-NOR1/TEC antibody - C-terminal (ab188752) | Abcam [abcam.com]
Technical Support Center: Optimizing Binding Conditions for NOR-1 EMSA
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals optimize the binding conditions for Electrophoretic Mobility Shift Assays (EMSAs) involving the Neuron-derived orphan receptor 1 (NOR-1), also known as NR4A3.
Troubleshooting Guide
This guide addresses common issues encountered during NOR-1 EMSA experiments in a question-and-answer format.
Question 1: Why am I observing a weak or no signal for the NOR-1/DNA complex?
Possible Causes and Solutions:
A weak or absent signal can stem from several factors related to your protein, probe, or binding conditions. Here are some troubleshooting steps:
-
Integrity and Activity of NOR-1 Protein:
-
Degradation: Ensure that your nuclear extract or purified NOR-1 protein has not been subjected to excessive freeze-thaw cycles. It is recommended to aliquot your protein stocks and store them at -80°C. The addition of protease inhibitors to your extraction and binding buffers is crucial.
-
Low Concentration: The concentration of active NOR-1 in your extract might be too low. You can try to enrich your nuclear extract or use a higher amount of protein in the binding reaction.
-
-
DNA Probe Issues:
-
Labeling Inefficiency: Verify the efficiency of your probe labeling (e.g., with 32P or a fluorescent dye). Run a small amount of the labeled probe on a denaturing gel to check for successful incorporation of the label.
-
Probe Integrity: Ensure your oligonucleotide probe is not degraded. It's best to use freshly prepared or properly stored probes.
-
Suboptimal Probe Design: NOR-1, as a member of the NGFI-B family of orphan nuclear receptors, binds to the NGFI-B Response Element (NBRE). The consensus sequence for monomeric binding is AAAGGTCA .[1] Ensure your probe contains this core sequence.
-
-
Suboptimal Binding Conditions:
-
Incubation Time and Temperature: The binding reaction may not have reached equilibrium. Try increasing the incubation time (e.g., from 20 minutes to 30-60 minutes) or optimizing the temperature. While many binding reactions are performed on ice or at room temperature, testing a range of temperatures (4°C, 25°C) can be beneficial.[2]
-
Binding Buffer Composition: The components of your binding buffer are critical for the stability of the NOR-1/DNA complex. Refer to the optimized binding buffer table below for recommended concentration ranges.
-
Question 2: How can I reduce non-specific binding in my NOR-1 EMSA?
Possible Causes and Solutions:
Non-specific binding can obscure your specific NOR-1/DNA interaction. Here are several strategies to minimize it:
-
Increase Non-Specific Competitor DNA:
-
Poly(dI-dC) is a commonly used non-specific competitor that sequesters general DNA-binding proteins. If you are already using it, try increasing its concentration in the binding reaction. A typical starting concentration is 1 µg per reaction, but this can be optimized.[3]
-
-
Optimize Binding Buffer Components:
-
Salt Concentration: Increasing the salt concentration (e.g., KCl) in the binding buffer can help to disrupt weak, non-specific electrostatic interactions.[4]
-
Detergents: The inclusion of a non-ionic detergent, such as NP-40 or Tween-20, can reduce non-specific hydrophobic interactions.[5]
-
Bovine Serum Albumin (BSA): BSA can act as a blocking agent, preventing the binding of NOR-1 to non-specific sites on the probe and the walls of the reaction tube.
-
-
Reduce the Amount of Nuclear Extract:
-
Using too much nuclear extract can lead to an excess of other DNA-binding proteins that may bind non-specifically to your probe. Try titrating down the amount of extract used in the binding reaction.[3]
-
Question 3: My shifted band appears smeared. What could be the cause?
Possible Causes and Solutions:
Smeared bands often indicate dissociation of the protein-DNA complex during electrophoresis or issues with the gel itself.
-
Complex Instability:
-
The NOR-1/DNA complex may be dissociating as it moves through the gel. Running the gel at a lower voltage and for a longer duration in a cold room (4°C) can help to stabilize the complex.
-
The composition of the gel and running buffer can also affect complex stability. Ensure that the pH and ionic strength are appropriate.
-
-
Gel Polymerization Issues:
-
Uneven or incomplete polymerization of the polyacrylamide gel can lead to inconsistent migration and smeared bands. Ensure that the ammonium (B1175870) persulfate (APS) and TEMED are fresh and that the gel is allowed to polymerize completely.
-
-
High Salt Concentration in the Sample:
-
Excessive salt in your binding reaction can lead to "streaking" or smearing of the bands. If you have optimized your binding buffer with a high salt concentration, you may need to load a smaller volume onto the gel.
-
Question 4: How do I confirm the specificity of the NOR-1/DNA interaction?
Solution:
To demonstrate that the observed shift is due to the specific binding of NOR-1 to your probe, you should perform a competition experiment.
-
Specific (Cold) Competitor: In a parallel binding reaction, add a 50- to 100-fold molar excess of an unlabeled ("cold") version of your specific probe sequence. If the binding is specific, the unlabeled probe will compete with the labeled probe for binding to NOR-1, leading to a significant reduction or complete disappearance of the shifted band.
-
Non-Specific (Mutant) Competitor: As a further control, use an unlabeled probe with a mutated version of the NBRE binding site. This mutant competitor should not be able to effectively compete for NOR-1 binding, and therefore, the intensity of the shifted band should not be significantly reduced.
Frequently Asked Questions (FAQs)
Q1: What is the consensus DNA binding sequence for NOR-1?
A1: NOR-1 is a member of the NR4A family of nuclear receptors. As a monomer, it binds to the Nur77/NGFI-B response element (NBRE), which has a consensus sequence of AAAGGTCA .[1] NOR-1 can also bind as a homodimer to a Nur-responsive element (NuRE), which consists of two inverted NBRE-like half-sites separated by a variable spacer.
Q2: What are the key components of an optimized binding buffer for NOR-1 EMSA?
A2: While the optimal conditions should be determined empirically, a good starting point for a NOR-1 EMSA binding buffer is outlined in the table below.
| Component | Concentration Range | Purpose |
| Tris-HCl (pH 7.5-8.0) | 10-20 mM | Buffering agent to maintain a stable pH. |
| KCl or NaCl | 50-100 mM | Provides the appropriate ionic strength for binding. |
| MgCl2 | 1-5 mM | Divalent cation that can be required for DNA binding by some proteins. |
| EDTA | 0.1-1 mM | Chelates divalent cations that could activate nucleases. |
| DTT | 0.5-1 mM | Reducing agent to prevent oxidation of cysteine residues in the protein. |
| Glycerol | 5-10% | Stabilizes the protein and the protein-DNA complex. |
| Poly(dI-dC) | 0.5-2 µ g/reaction | Non-specific competitor DNA to reduce non-specific binding. |
| BSA | 0.1 mg/mL | Blocking agent to prevent non-specific interactions. |
Q3: What percentage of polyacrylamide gel should I use for NOR-1 EMSA?
A3: The choice of gel percentage depends on the size of your DNA probe and the expected size of the NOR-1/DNA complex. For relatively small probes (20-50 bp), a 5-6% non-denaturing polyacrylamide gel is a good starting point. This should provide adequate resolution to separate the shifted complex from the free probe.
Q4: Can I use a non-radioactive method to detect the shifted bands?
A4: Yes, several non-radioactive methods are available for EMSA. These include using probes labeled with biotin (B1667282) or fluorescent dyes (e.g., Cy3, Cy5, IRDyes). Biotin-labeled probes are typically detected using a streptavidin-horseradish peroxidase (HRP) conjugate and a chemiluminescent substrate. Fluorescently labeled probes can be visualized using an appropriate imaging system. These methods offer the advantages of increased safety and reduced waste disposal issues compared to radioactive methods.
Experimental Protocols & Visualizations
Detailed Methodology for a Standard NOR-1 EMSA
-
Probe Labeling: The oligonucleotide probe containing the NBRE consensus sequence (AAAGGTCA) is typically end-labeled with [γ-32P]ATP using T4 polynucleotide kinase. Alternatively, non-radioactive labeling methods can be used.
-
Binding Reaction:
-
In a microcentrifuge tube, combine the following components in the specified order:
-
Nuclease-free water
-
5x Binding Buffer (to achieve a 1x final concentration)
-
Poly(dI-dC) (non-specific competitor)
-
Nuclear extract or purified NOR-1 protein
-
-
Incubate the mixture on ice for 10-15 minutes to block non-specific binding.
-
Add the labeled probe to the reaction mixture.
-
Incubate at room temperature for 20-30 minutes to allow for the formation of the NOR-1/DNA complex.
-
-
Gel Electrophoresis:
-
Load the binding reactions onto a pre-run 5-6% non-denaturing polyacrylamide gel.
-
Run the gel in 0.5x TBE buffer at a constant voltage (e.g., 100-150V) at 4°C.
-
-
Detection:
-
After electrophoresis, dry the gel and expose it to X-ray film or a phosphorimager screen to visualize the radioactive signal. For non-radioactive methods, follow the manufacturer's instructions for detection.
-
Visualizations
References
- 1. Neuron-derived orphan receptor 1 | 4A. Nerve growth factor IB-like receptors | IUPHAR/BPS Guide to PHARMACOLOGY [guidetopharmacology.org]
- 2. Electrophoretic Mobility Shift Assay (EMSA) for the Study of RNA-Protein Interactions: The IRE/IRP Example - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Protein-Nucleic Acid Interactions Support—Troubleshooting | Thermo Fisher Scientific - US [thermofisher.com]
- 4. Electrophoretic Mobility Shift Assay (EMSA) for Detecting Protein-Nucleic Acid Interactions - PMC [pmc.ncbi.nlm.nih.gov]
- 5. licorbio.com [licorbio.com]
Technical Support Center: Expression and Purification of Full-Length NOR-1 Protein
This technical support center provides researchers, scientists, and drug development professionals with troubleshooting guides and frequently asked questions (FAQs) to address common challenges encountered during the expression and purification of the full-length human NOR-1 (Neuron-derived orphan receptor 1, also known as NR4A3) protein.
Frequently Asked Questions (FAQs)
Q1: What are the main challenges in expressing full-length NOR-1 protein?
A1: The primary challenges in expressing full-length NOR-1, particularly in E. coli, are low solubility and the formation of inclusion bodies.[1] This indicates that the protein often misfolds when expressed at high levels in a prokaryotic system. Eukaryotic proteins, like NOR-1, often require specific post-translational modifications and chaperone proteins for proper folding, which are absent in bacteria.[2]
Q2: Which expression system is recommended for full-length NOR-1?
A2: Both prokaryotic and eukaryotic systems have been used.
-
E. coli (e.g., BL21(DE3), Rosettablue(DE3) strains): This system can produce high yields of NOR-1 protein, but it predominantly results in the formation of insoluble inclusion bodies.[1][3] This necessitates purification under denaturing conditions followed by a refolding step.
-
Mammalian Cells (e.g., HEK293T, AC16): These systems are more likely to produce soluble, properly folded, and post-translationally modified NOR-1. However, the yields are typically lower, and the process is more time-consuming and expensive compared to E. coli.[4]
Q3: My NOR-1 protein is found in inclusion bodies in E. coli. What should I do?
A3: The formation of inclusion bodies is a common issue. You have two main options:
-
Optimize Expression for Solubility: Attempt to increase the proportion of soluble protein by modifying expression conditions. This includes lowering the induction temperature (e.g., 16-25°C), reducing the inducer concentration (e.g., 0.1-0.5 mM IPTG), and using a richer medium.[5][6] Co-expression with chaperones or using solubility-enhancing fusion tags (e.g., GST, MBP, SUMO) can also be beneficial.
-
Purify from Inclusion Bodies: If optimizing for solubility is unsuccessful, you can purify the protein from inclusion bodies. This involves isolating the inclusion bodies, solubilizing them with strong denaturants (e.g., 8 M urea (B33335) or 6 M guanidine (B92328) hydrochloride), and then refolding the protein into its native conformation.[1][7]
Q4: What is the expected yield of purified full-length NOR-1 protein?
A4: The yield of purified NOR-1 can vary significantly depending on the expression system and purification strategy. While specific yields for NOR-1 are not extensively reported, yields for recombinant proteins expressed in E. coli can range from a few milligrams to tens of milligrams per liter of culture.[4][8][9] Purification from inclusion bodies often results in lower final yields of correctly folded protein (typically in the range of 5-20% recovery from the refolding step).[10] Mammalian expression systems generally produce lower yields, often in the range of micrograms to a few milligrams per liter of culture.[4]
Q5: How can I improve the stability of my purified NOR-1 protein?
A5: Protein aggregation is a common problem after purification. To improve stability, consider the following:
-
Buffer Optimization: Screen different pH values and salt concentrations to find the optimal buffer for your protein.[11]
-
Additives: Include additives such as glycerol (B35011) (5-20%), non-detergent sulfobetaines, or low concentrations of non-denaturing detergents (e.g., Tween-20) in your storage buffer.[11]
-
Reducing Agents: If your protein has cysteine residues, include a reducing agent like DTT or TCEP to prevent disulfide-linked aggregation.[12]
-
Storage: Flash-freeze your protein in small aliquots and store at -80°C. Avoid repeated freeze-thaw cycles.[11]
Troubleshooting Guides
Problem 1: Low or No Expression of NOR-1 Protein
| Possible Cause | Recommended Solution |
| Codon Bias | The human NOR-1 gene may contain codons that are rare in E. coli, leading to translational stalling. Solution: Synthesize a codon-optimized version of the NOR-1 gene for expression in E. coli.[13] |
| Protein Toxicity | High levels of NOR-1 expression may be toxic to the host cells. Solution: Use a tightly regulated promoter (e.g., pBAD) or a lower induction temperature and inducer concentration to reduce the expression level.[14] |
| Plasmid Instability | The expression plasmid may be lost during cell division. Solution: Ensure consistent antibiotic selection throughout the culture. Verify plasmid integrity by restriction digest or sequencing. |
| Inefficient Induction | The inducer concentration or induction time may be suboptimal. Solution: Perform a time-course and dose-response experiment to determine the optimal induction parameters. For E. coli with a pET vector, try a range of IPTG concentrations (0.1 mM to 1 mM) and induction times (2 hours to overnight at lower temperatures).[5] |
Problem 2: NOR-1 Protein is in Inclusion Bodies (Insoluble)
| Possible Cause | Recommended Solution |
| High Expression Rate | Rapid protein synthesis overwhelms the cellular folding machinery. Solution: Lower the induction temperature to 16-25°C and reduce the inducer concentration.[6] |
| Lack of Chaperones | E. coli lacks the specific chaperones required for NOR-1 folding. Solution: Co-express molecular chaperones (e.g., GroEL/GroES, DnaK/DnaJ) to assist in proper folding. |
| Hydrophobic Patches | Exposed hydrophobic regions on the protein surface can lead to aggregation. The ligand-binding domain of NOR-1, while lacking a canonical ligand-binding pocket, has hydrophobic regions that could contribute to this. Solution: Use a solubility-enhancing fusion tag (e.g., MBP, GST, SUMO) at the N- or C-terminus. |
| Incorrect Disulfide Bonds | The reducing environment of the E. coli cytoplasm can prevent the formation of necessary disulfide bonds. Solution: Express the protein in an E. coli strain engineered to facilitate disulfide bond formation in the cytoplasm (e.g., SHuffle strains). |
Problem 3: Low Yield After Purification
| Possible Cause | Recommended Solution |
| Inefficient Cell Lysis | Incomplete cell disruption results in loss of protein. Solution: Ensure efficient lysis by using a combination of enzymatic (lysozyme) and mechanical (sonication, French press) methods. Monitor lysis efficiency under a microscope. |
| Poor Binding to Affinity Resin | The affinity tag (e.g., His-tag) may be inaccessible or the binding conditions may be suboptimal. Solution: Ensure the tag is not buried within the protein structure. For His-tagged proteins, perform binding at a pH of 7.5-8.0 and include a low concentration of imidazole (B134444) (10-20 mM) in the lysis and wash buffers to reduce non-specific binding.[15] |
| Protein Loss During Washing | Stringent wash conditions can elute the target protein. Solution: Analyze the wash fractions by SDS-PAGE to check for your protein. If present, reduce the stringency of the wash buffer (e.g., lower the imidazole concentration for His-tag purification).[16] |
| Inefficient Elution | Elution conditions are not optimal for releasing the protein from the resin. Solution: For His-tagged proteins, try a stepwise or gradient elution with increasing concentrations of imidazole (up to 500 mM). Ensure the elution buffer pH is appropriate.[17] |
| Low Recovery from Refolding | Protein aggregation during the refolding process is a major cause of low yield. Solution: Optimize the refolding protocol by screening different refolding buffers, additives (e.g., L-arginine, glycerol), and refolding methods (e.g., dialysis, rapid dilution, on-column refolding).[7] |
Quantitative Data Summary
| Parameter | E. coli Expression | Mammalian Expression | References |
| Typical Protein Yield (Crude Lysate) | 1-100 mg/L | µg/L to low mg/L | [4][8][18] |
| Purification from Soluble Fraction (Efficiency) | >80% (single affinity step) | >80% (single affinity step) | [15] |
| Recovery from Inclusion Body Refolding | 5-20% | N/A | [10] |
| Final Yield of Purified, Folded Protein | 0.1 - 20 mg/L | µg/L to low mg/L | [4][18] |
Note: These are general estimates for recombinant proteins and can vary widely for NOR-1 depending on the specific construct and experimental conditions.
Detailed Experimental Protocols
Protocol 1: Expression of His-tagged NOR-1 in E. coli
-
Transformation: Transform a pET vector containing the full-length human NOR-1 cDNA with an N- or C-terminal His-tag into an E. coli expression strain (e.g., BL21(DE3) or Rosettablue(DE3)). Plate on LB agar (B569324) with the appropriate antibiotic and incubate overnight at 37°C.
-
Starter Culture: Inoculate a single colony into 10 mL of LB medium containing the selective antibiotic. Grow overnight at 37°C with shaking.
-
Main Culture: Inoculate 1 L of LB medium with the starter culture. Grow at 37°C with shaking until the OD600 reaches 0.6-0.8.
-
Induction: Cool the culture to the desired induction temperature (e.g., 18°C for improved solubility or 37°C for higher yield in inclusion bodies). Add IPTG to a final concentration of 0.1-1.0 mM.[3]
-
Expression: Continue to incubate with shaking for 4-6 hours at 37°C or overnight at 18°C.
-
Harvesting: Harvest the cells by centrifugation at 5,000 x g for 15 minutes at 4°C. The cell pellet can be stored at -80°C.
Protocol 2: Purification of NOR-1 from Inclusion Bodies and On-Column Refolding
This protocol is adapted for a His-tagged protein.
-
Cell Lysis: Resuspend the cell pellet in lysis buffer (50 mM Tris-HCl pH 8.0, 300 mM NaCl, 10 mM imidazole, 1 mg/mL lysozyme, DNase I). Incubate on ice for 30 minutes, then sonicate until the lysate is no longer viscous.
-
Inclusion Body Isolation: Centrifuge the lysate at 15,000 x g for 30 minutes at 4°C. Discard the supernatant (soluble fraction).
-
Washing Inclusion Bodies: Wash the pellet sequentially with:
-
Lysis buffer with 1% Triton X-100.
-
Lysis buffer with 2 M urea.
-
Lysis buffer without any additives. Resuspend the pellet thoroughly for each wash and centrifuge at 15,000 x g for 20 minutes.
-
-
Solubilization: Solubilize the washed inclusion body pellet in binding buffer (8 M urea or 6 M Guanidine-HCl, 50 mM Tris-HCl pH 8.0, 300 mM NaCl, 10 mM imidazole, 5 mM DTT). Stir for 1-2 hours at room temperature.
-
Clarification: Centrifuge the solubilized protein at 20,000 x g for 30 minutes to remove any remaining insoluble material. Filter the supernatant through a 0.45 µm filter.
-
On-Column Refolding (IMAC):
-
Equilibrate a Ni-NTA column with binding buffer.
-
Load the clarified, solubilized protein onto the column.
-
Wash the column with binding buffer.
-
Gradually exchange the denaturant with a refolding buffer (50 mM Tris-HCl pH 8.0, 300 mM NaCl, 20 mM imidazole, 1 mM DTT, optional: 0.5 M L-arginine, 5% glycerol) by applying a linear gradient from 100% binding buffer to 100% refolding buffer over several column volumes.
-
Wash the column with several volumes of refolding buffer.
-
-
Elution: Elute the refolded protein with elution buffer (50 mM Tris-HCl pH 8.0, 300 mM NaCl, 250-500 mM imidazole).
-
Buffer Exchange: Immediately exchange the buffer of the eluted protein into a suitable storage buffer (e.g., PBS with 10% glycerol and 1 mM DTT) using dialysis or a desalting column.
Visualizations
References
- 1. Solubilization and Refolding of Inclusion Body Proteins | Springer Nature Experiments [experiments.springernature.com]
- 2. Regulation of the viability of Nf1 deficient cells by PKC isoforms - PMC [pmc.ncbi.nlm.nih.gov]
- 3. documents.thermofisher.com [documents.thermofisher.com]
- 4. researchgate.net [researchgate.net]
- 5. Protein Expression Protocol & Troubleshooting in E. coli [biologicscorp.com]
- 6. Troubleshooting Guide for Common Recombinant Protein Problems [synapse.patsnap.com]
- 7. biotechrep.ir [biotechrep.ir]
- 8. Frontiers | Recombinant protein expression in Escherichia coli: advances and challenges [frontiersin.org]
- 9. Practical protocols for production of very high yields of recombinant proteins using Escherichia coli - PMC [pmc.ncbi.nlm.nih.gov]
- 10. A guide to ERK dynamics, part 1: mechanisms and models - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Controlling and quantifying protein concentration in Escherichia coli - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Strategies to Optimize Protein Expression in E. coli - PMC [pmc.ncbi.nlm.nih.gov]
- 13. goldbio.com [goldbio.com]
- 14. neb.com [neb.com]
- 15. med.upenn.edu [med.upenn.edu]
- 16. Structural Basis of Protein Kinase C Isoform Function - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Crosstalk via the NF-κB Signaling System - PMC [pmc.ncbi.nlm.nih.gov]
- 18. hyvonen.bioc.cam.ac.uk [hyvonen.bioc.cam.ac.uk]
Technical Support Center: Strategies to Minimize NOR-1 Agonist/Inhibitor Toxicity in Cell Culture
This guide provides researchers, scientists, and drug development professionals with troubleshooting strategies and frequently asked questions to minimize and understand the toxicity of Neuron-derived orphan receptor 1 (NOR-1/NR4A3) agonists and inhibitors in cell culture experiments.
Frequently Asked Questions (FAQs)
Q1: What is the primary mechanism of on-target toxicity for NOR-1 agonists?
A1: NOR-1 is an orphan nuclear receptor that can play a role in apoptosis (programmed cell death).[1] Activation of NOR-1 by an agonist can lead to the upregulation of pro-apoptotic genes and the downregulation of anti-apoptotic genes, ultimately triggering the caspase cascade and resulting in cell death.[2] Therefore, a certain level of cytotoxicity in cancer cell lines might be an expected on-target effect.
Q2: My NOR-1 inhibitor is showing toxicity. Is this expected?
A2: While NOR-1 agonists are more commonly associated with pro-apoptotic effects, some inhibitors, like Celastrol (B190767), can also induce cytotoxicity. This can occur through various mechanisms, including off-target effects or by interfering with cellular pathways essential for survival.[3][4] It is crucial to determine if the observed toxicity is related to NOR-1 inhibition or other interactions.
Q3: Could the solvent for my compound be the source of toxicity?
A3: Yes, solvents such as DMSO can be toxic to cells, especially at higher concentrations. It is recommended to keep the final DMSO concentration in the culture medium below 0.5%. Always include a vehicle control (cells treated with the same concentration of solvent used to dissolve the compound) in your experiments to differentiate between solvent-induced and compound-induced toxicity.
Q4: How can I distinguish between on-target and off-target toxicity?
A4: Differentiating between on-target and off-target effects is critical. Here are a few strategies:
-
Use a NOR-1 Knockout/Knockdown Cell Line: The most definitive way is to test your compound in a cell line where NOR-1 has been genetically removed (knockout) or its expression is significantly reduced (knockdown). If the toxicity persists in these cells, it is likely an off-target effect.
-
Employ Structurally Different Modulators: Use another NOR-1 agonist or inhibitor with a different chemical scaffold. If both compounds produce a similar toxic phenotype, it is more likely to be an on-target effect.
-
Rescue Experiments: For an agonist, see if an antagonist can reverse the toxic effects.
Q5: What are some known off-target effects of NR4A family modulators?
A5: The NR4A family of receptors (including NOR-1) can be targeted by a range of small molecules, and off-target effects are a known challenge. For instance, some compounds may interact with other nuclear receptors or kinases.[5] The natural product Celastrol, for example, has multiple targets in the cell beyond NOR-1.[3][4] Thorough characterization is necessary to understand the full activity of a compound.
Troubleshooting Guide
Problem 1: Significant cell death is observed at the intended effective concentration of my NOR-1 agonist.
-
Possible Cause 1: On-target apoptosis.
-
Solution: Confirm that the cell death is apoptotic by performing a caspase activity assay (e.g., Caspase-Glo 3/7). If apoptosis is confirmed, this may be an inherent activity of the agonist. Consider using a lower concentration or a shorter incubation time to find a therapeutic window where you can observe other biological effects before widespread cell death occurs.
-
-
Possible Cause 2: Off-target cytotoxicity.
-
Solution: Test the agonist in a NOR-1 null cell line. If toxicity is still present, the effect is off-target. Consider screening the compound against a panel of common off-targets, such as kinases or other nuclear receptors.
-
-
Possible Cause 3: Solvent toxicity.
-
Solution: Ensure the final solvent concentration is non-toxic (typically <0.5% for DMSO). Always compare with a vehicle-only control.
-
Problem 2: My NOR-1 inhibitor is causing unexpected cell death in a non-cancerous cell line.
-
Possible Cause 1: Off-target effects.
-
Solution: This is a strong indicator of off-target toxicity, as NOR-1 inhibition is not typically expected to be cytotoxic to normal cells. Use chemical proteomics or thermal proteome profiling to identify potential off-target proteins.
-
-
Possible Cause 2: Compound instability.
-
Solution: Ensure the compound is stable in your cell culture medium over the course of the experiment. Degradation products could be toxic. This can be checked by analytical methods like HPLC-MS.
-
Problem 3: My results are inconsistent between experiments.
-
Possible Cause 1: Variability in cell health and density.
-
Solution: Standardize your cell culture practices. Ensure cells are in the logarithmic growth phase and seeded at a consistent density. Perform regular checks for mycoplasma contamination.
-
-
Possible Cause 2: Issues with compound preparation.
-
Solution: Prepare fresh stock solutions of your compound regularly and store them appropriately. Ensure accurate dilution to the final concentration for each experiment.
-
-
Possible Cause 3: Serum components.
-
Solution: Fetal bovine serum (FBS) contains endogenous ligands that can activate various nuclear receptors. For sensitive assays, consider using charcoal-stripped FBS to reduce background activation.[6]
-
Data Presentation
Table 1: Example Concentrations and Effects of NOR-1/NR4A Modulators
| Compound | Class | Example Concentration for Effect | Observed Toxicity | Reference(s) |
| Celastrol | Inhibitor | 1 µM | Significant cytotoxicity at concentrations >1.0 µM in some cell lines.[7][8] | [3][4][7][8] |
| Amodiaquine | Agonist (NR4A2) | Activates NR4A-dependent transactivation in vitro. | Can have NR4A-independent effects on transcription.[9] | [9][10] |
| Chloroquine | Agonist (NR4A2) | Activates NR4A-dependent transactivation in vitro. | Can have NR4A-independent effects on transcription.[9] | [9][10] |
| Vidofludimus | Agonist (Nurr1) | EC50 = 0.4 µM for Nurr1 activation. | Weaker activation of NOR-1 (EC50 = 2.9 µM).[11] | [11] |
Experimental Protocols
Protocol 1: Cell Viability Assessment using MTT Assay
-
Cell Seeding: Seed cells in a 96-well plate at a predetermined optimal density and allow them to adhere overnight.
-
Compound Treatment: Treat cells with a range of concentrations of the NOR-1 agonist/inhibitor. Include a vehicle-only control and a positive control for cytotoxicity. Incubate for the desired time (e.g., 24, 48, or 72 hours).
-
MTT Addition: Add 10 µL of 5 mg/mL MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) solution to each well and incubate for 2-4 hours at 37°C.
-
Formazan (B1609692) Solubilization: Carefully remove the medium and add 100 µL of DMSO to each well to dissolve the formazan crystals.
-
Absorbance Measurement: Measure the absorbance at 570 nm using a microplate reader.
-
Data Analysis: Calculate cell viability as a percentage relative to the vehicle-treated control cells.
Protocol 2: Cytotoxicity Assessment using LDH Release Assay
-
Cell Seeding and Treatment: Follow steps 1 and 2 from the MTT assay protocol.
-
Supernatant Collection: After the incubation period, carefully collect a portion of the cell culture supernatant from each well.
-
LDH Reaction: Transfer the supernatant to a new 96-well plate and add the LDH reaction mixture according to the manufacturer's instructions (e.g., CytoTox 96® Non-Radioactive Cytotoxicity Assay, Promega).
-
Incubation: Incubate the plate at room temperature for the recommended time, protected from light.
-
Absorbance Measurement: Measure the absorbance at 490 nm.
-
Data Analysis: Calculate the percentage of cytotoxicity relative to a maximum LDH release control.
Protocol 3: Apoptosis Assessment using Caspase-Glo® 3/7 Assay
-
Cell Seeding and Treatment: Follow steps 1 and 2 from the MTT assay protocol, preferably in a white-walled 96-well plate.
-
Reagent Preparation: Prepare the Caspase-Glo® 3/7 reagent according to the manufacturer's instructions.
-
Reagent Addition: Add 100 µL of the Caspase-Glo® 3/7 reagent to each well.
-
Incubation: Mix the contents of the wells on a plate shaker at a low speed for 30 seconds and then incubate at room temperature for 1-2 hours.
-
Luminescence Measurement: Measure the luminescence using a plate-reading luminometer.
-
Data Analysis: An increase in luminescence indicates an increase in caspase-3/7 activity and apoptosis.
Mandatory Visualizations
References
- 1. mdpi.com [mdpi.com]
- 2. Overexpression of Neuron-Derived Orphan Receptor 1 (NOR-1) Rescues Cardiomyocytes from Cell Death and Improves Viability after Doxorubicin Induced Stress - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Celastrol: A Potential Natural Lead Molecule for New Drug Design, Development and Therapy for Memory Impairment - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Celastrol: A Review of Useful Strategies Overcoming its Limitation in Anticancer Application - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. benchchem.com [benchchem.com]
- 7. Celastrol reduces cisplatin-induced nephrotoxicity by downregulating SNORD3A level in kidney organoids derived from human iPSCs - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Dose-dependent immunotoxic mechanisms of celastrol via modulation of the PI3K-Akt signaling pathway - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Assessment of NR4A Ligands that Directly Bind and Modulate the Orphan Nuclear Receptor Nurr1 - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Natural products and synthetic analogs as selective orphan nuclear receptor 4A (NR4A) modulators - PMC [pmc.ncbi.nlm.nih.gov]
- 11. pubs.acs.org [pubs.acs.org]
dealing with poor transfection efficiency in NOR-1 overexpression studies
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals overcome challenges associated with poor transfection efficiency in NOR-1 (Neuron-derived orphan receptor 1, also known as NR4A3) overexpression studies.
Frequently Asked Questions (FAQs)
Q1: What is NOR-1 and why is its overexpression challenging?
A1: NOR-1 (Nuclear Receptor Subfamily 4 Group A Member 3) is a member of the nuclear receptor family of intracellular transcription factors.[1] As a transcription factor, it plays a crucial role in regulating gene expression related to cell proliferation, apoptosis, and inflammation. While not inherently toxic, high levels of exogenous NOR-1 expression can sometimes lead to cellular stress or unexpected phenotypic changes, which may indirectly affect transfection efficiency and cell viability. The size of the NOR-1 protein is approximately 68 kDa.[2]
Q2: What are the most critical factors for achieving high transfection efficiency for a NOR-1 expression plasmid?
A2: The most critical factors include:
-
Plasmid DNA Quality: High-purity, endotoxin-free, and supercoiled plasmid DNA is essential for successful transfection.[3]
-
Cell Health and Viability: Cells should be healthy, actively dividing, and have a viability of over 90%.
-
Cell Confluency: The optimal confluency for transfection is typically between 70-90%.[4]
-
Transfection Reagent and Protocol: The choice of transfection reagent and a well-optimized protocol are crucial.
Q3: Which transfection methods are recommended for NOR-1 overexpression?
A3: Both chemical-based methods, like lipid-based transfection (e.g., Lipofectamine™ 3000), and physical methods, like electroporation, can be effective. For difficult-to-transfect cells, viral-mediated gene delivery is also a powerful option. The choice depends on the cell type, experimental goals, and available resources.
Troubleshooting Guide: Poor NOR-1 Transfection Efficiency
This guide provides a systematic approach to troubleshooting common issues encountered during NOR-1 overexpression experiments.
Issue 1: Low Percentage of Transfected Cells (Low Transfection Efficiency)
Possible Causes and Solutions:
| Possible Cause | Recommended Solution |
| Suboptimal Plasmid DNA Quality | 1. Verify Plasmid Purity: Use a spectrophotometer to ensure the A260/A280 ratio is between 1.8 and 2.0. 2. Check Plasmid Integrity: Run the plasmid on an agarose (B213101) gel to confirm it is predominantly supercoiled. 3. Use Endotoxin-Free Kits: Prepare plasmid DNA using kits specifically designed to remove endotoxins, which are toxic to many cell types. |
| Poor Cell Health | 1. Check Cell Viability: Ensure cell viability is >90% using a method like trypan blue exclusion. 2. Use Low Passage Number Cells: Use cells with a low passage number, as prolonged culturing can alter cell characteristics. 3. Test for Mycoplasma Contamination: Regularly screen your cell cultures for mycoplasma contamination. |
| Inappropriate Cell Confluency | 1. Optimize Seeding Density: Plate cells so they are 70-90% confluent at the time of transfection.[4] Actively dividing cells are more receptive to transfection. |
| Incorrect DNA:Reagent Ratio | 1. Perform a Titration Experiment: Optimize the ratio of plasmid DNA to transfection reagent. Start with the manufacturer's recommended ratio and test a range of higher and lower ratios. |
| Presence of Serum or Antibiotics | 1. Use Serum-Free Medium for Complex Formation: Prepare the DNA-reagent complexes in a serum-free medium like Opti-MEM™. 2. Transfect in Antibiotic-Free Medium: Although some modern reagents are compatible with antibiotics, it is a good practice to perform transfection in their absence. |
| Incorrect Incubation Times | 1. Optimize Complex Formation Time: Follow the manufacturer's protocol for the incubation time of the DNA-reagent complex (typically 10-20 minutes). 2. Optimize Post-Transfection Incubation: Determine the optimal time for gene expression (usually 24-72 hours) before analysis. |
Issue 2: High Cell Death (Cytotoxicity) After Transfection
Possible Causes and Solutions:
| Possible Cause | Recommended Solution |
| Toxicity of Transfection Reagent | 1. Reduce Reagent Concentration: Use the lowest amount of transfection reagent that still provides acceptable efficiency. 2. Change Media Post-Transfection: For sensitive cell lines, replace the transfection medium with fresh, complete growth medium 4-6 hours after adding the complexes. |
| Toxicity of Overexpressed NOR-1 | 1. Use an Inducible Promoter: Employ an inducible expression system to control the timing and level of NOR-1 expression. 2. Perform a Time-Course Experiment: Analyze cells at earlier time points post-transfection before significant cytotoxicity occurs. |
| High DNA Concentration | 1. Reduce DNA Amount: Use a lower concentration of plasmid DNA in the transfection complex. |
| Suboptimal Cell Density | 1. Increase Seeding Density: A higher cell density can sometimes mitigate the toxic effects of the transfection process. |
Quantitative Data Summary
Table 1: Comparison of Transfection Efficiencies with Lipofectamine™ 3000
| Cell Line | Transfection Efficiency (GFP Reporter) | Cell Viability |
| HEK293 | >80% | High |
| A549 | ~60%[5] | High |
| C2C12 Myoblasts | 60-70% (with Matrigel)[6] | High |
| HeLa | >70% | High |
| HepG2 | >60% | High |
Data is compiled from various sources and represents typical efficiencies. Actual results may vary depending on experimental conditions.
Experimental Protocols
Protocol 1: Plasmid DNA Transfection using Lipofectamine™ 3000
This protocol is for transfecting plasmid DNA into adherent cells in a 24-well plate format.
Materials:
-
NOR-1 expression plasmid (high purity, endotoxin-free)
-
Lipofectamine™ 3000 Reagent
-
P3000™ Reagent
-
Opti-MEM™ I Reduced Serum Medium
-
Adherent cells in a 24-well plate (70-90% confluent)
-
Complete growth medium
Procedure:
-
Cell Plating: The day before transfection, seed cells in a 24-well plate at a density that will result in 70-90% confluency on the day of transfection.
-
Complex Formation (per well):
-
Tube A: Dilute 0.5 µg of NOR-1 plasmid DNA in 25 µL of Opti-MEM™. Add 1 µL of P3000™ Reagent and mix gently.
-
Tube B: Dilute 0.75 µL of Lipofectamine™ 3000 Reagent in 25 µL of Opti-MEM™.
-
-
Combine and Incubate: Add the contents of Tube A to Tube B. Mix gently by pipetting up and down and incubate for 15 minutes at room temperature.
-
Transfection: Add the 50 µL of the DNA-lipid complex mixture dropwise to the well containing cells and medium. Gently rock the plate to ensure even distribution.
-
Incubation: Incubate the cells at 37°C in a CO2 incubator for 24-72 hours.
-
Analysis: After the incubation period, analyze the cells for NOR-1 expression.
Visualizations
NOR-1 Signaling Pathway
Caption: Simplified NOR-1 signaling pathway.
General Transfection Workflow
Caption: A general workflow for plasmid DNA transfection.
Troubleshooting Flowchart for Poor Transfection Efficiency
Caption: A troubleshooting flowchart for low transfection efficiency.
References
- 1. Nuclear receptor 4A3 - Wikipedia [en.wikipedia.org]
- 2. uniprot.org [uniprot.org]
- 3. benchchem.com [benchchem.com]
- 4. documents.thermofisher.com [documents.thermofisher.com]
- 5. Transfecting Plasmid DNA Into A549 Cells Using Lipofectamine 3000 Reagent | Thermo Fisher Scientific - SG [thermofisher.com]
- 6. Efficient transfection of mouse-derived C2C12 myoblasts using a matrigel basement membrane matrix - PubMed [pubmed.ncbi.nlm.nih.gov]
Technical Support Center: NOR-1 Plasmid Construct Design for Optimal Expression
Welcome to the technical support center for the Neuron-derived orphan receptor 1 (NOR-1), also known as NR4A3, plasmid construct design. This resource is tailored for researchers, scientists, and drug development professionals to provide guidance on optimizing NOR-1 expression for experimental purposes. Here, you will find troubleshooting guides and frequently asked questions (FAQs) to address common challenges encountered during the design and implementation of NOR-1 expression vectors.
Frequently Asked Questions (FAQs) & Troubleshooting
This section addresses common issues related to NOR-1 plasmid construct design and expression, offering potential causes and solutions in a question-and-answer format.
Q1: I am observing very low or no expression of my NOR-1 protein. What are the potential causes and how can I troubleshoot this?
A1: Low or undetectable protein expression is a common issue that can stem from several factors, from plasmid design to experimental procedures.
Potential Causes & Solutions:
-
Suboptimal Promoter Choice: The promoter driving your gene of interest is a critical determinant of expression levels.
-
Recommendation: For high-level constitutive expression in a wide range of mammalian cells, the Cytomegalovirus (CMV) or human elongation factor-1 alpha (EF-1α) promoters are strong choices. While CMV is widely used, it can be prone to silencing in some cell types during long-term culture.[1][2][3] The EF-1α promoter often provides more stable and sustained expression.[2][3]
-
-
Inefficient Translation Initiation: The sequence context surrounding the start codon (AUG) significantly impacts the efficiency of translation initiation.
-
Recommendation: Ensure your construct includes a strong Kozak consensus sequence (GCCGCCACC) immediately upstream of the ATG start codon. This sequence facilitates ribosome binding and initiation of translation.
-
-
mRNA Instability: The 5' and 3' untranslated regions (UTRs) of your mRNA transcript can contain elements that affect its stability.
-
Recommendation: Review the 5' and 3' UTR sequences in your construct. Avoid AU-rich elements (AREs) in the 3' UTR, as they can signal for mRNA degradation. Conversely, incorporating stable UTRs, such as from the human β-globin gene, can enhance mRNA half-life and protein yield.
-
-
Inefficient Transcription Termination and Polyadenylation: A weak polyadenylation (polyA) signal can lead to inefficient transcription termination and reduced mRNA stability.
-
Recommendation: Utilize a strong and efficient polyadenylation signal. The bovine growth hormone (BGH) polyA and Simian virus 40 (SV40) late polyA signals are commonly used and have been shown to be effective. Some studies suggest the BGH polyA signal may result in higher expression levels than the SV40 early polyA signal.[4][5]
-
-
Codon Usage: The codon usage of your NOR-1 coding sequence may not be optimal for the expression host.
-
Recommendation: While human NOR-1 expressed in human cell lines should not have major codon usage issues, if expressing in a non-human mammalian system, consider codon optimization. This involves synthesizing a version of the NOR-1 gene with codons that are more frequently used in the host organism, which can enhance translation efficiency.[6][7][8][9]
-
-
Problems with Transfection: Low transfection efficiency will naturally lead to low protein expression.
-
Recommendation: Optimize your transfection protocol. This includes using high-quality plasmid DNA, optimizing the DNA-to-transfection reagent ratio, and ensuring your cells are healthy and at the appropriate confluency. Refer to the detailed transfection protocols provided below.
-
-
Protein Instability and Degradation: NOR-1, like many nuclear receptors, is subject to post-translational modifications and degradation pathways.
-
Recommendation: The N-terminal region of the related nuclear receptor Nurr1 has been shown to be crucial for its degradation via the ubiquitin-proteasome pathway.[10][11] While specific data for NOR-1 is less clear, consider that the protein itself may be rapidly turned over. You can investigate this by treating your cells with a proteasome inhibitor (e.g., MG132) to see if NOR-1 protein levels increase.
-
Q2: My NOR-1 expression is inconsistent between experiments. What could be causing this variability?
A2: High variability can be frustrating and can obscure real experimental effects.
Potential Causes & Solutions:
-
Cell Health and Passage Number: Inconsistent cell health or using cells at a high passage number can lead to variable transfection efficiency and protein expression.
-
Recommendation: Use cells that are healthy, actively dividing, and within a low passage number range. Maintain consistent cell culture conditions.
-
-
Inconsistent Transfection Efficiency: Minor variations in the transfection procedure can lead to significant differences in expression.
-
Recommendation: Standardize your transfection protocol meticulously. This includes the amount of DNA and reagent used, incubation times, and cell density at the time of transfection. Using an internal control, such as a co-transfected plasmid expressing a reporter gene like GFP or Renilla luciferase, can help normalize for transfection efficiency.[12][13]
-
-
Plasmid DNA Quality: The quality and purity of your plasmid DNA can impact transfection efficiency and subsequent expression.
-
Recommendation: Use high-purity plasmid DNA, preferably prepared using a commercial kit that yields endotoxin-free DNA. Verify the integrity of your plasmid by restriction digest and sequencing.
-
Q3: How do I choose the best components for my NOR-1 expression plasmid?
A3: The optimal plasmid construct will depend on your specific experimental needs (e.g., transient vs. stable expression, cell type). The following table summarizes key components and their recommended choices for robust NOR-1 expression.
Data Presentation: Comparison of Plasmid Components for Optimal Expression
| Plasmid Component | Option 1 | Option 2 | Recommendation for NOR-1 | Rationale |
| Promoter | CMV | EF-1α | EF-1α for stable expression, CMV for high transient expression | The CMV promoter provides very high levels of expression in transient transfections.[2][3] However, the EF-1α promoter is less prone to silencing and can provide more consistent, long-term expression in stable cell lines.[1][2][3] |
| 5' UTR | Minimal/Vector-derived | Optimized Synthetic UTR | Include a strong Kozak sequence (GCCGCCACC) immediately upstream of the start codon. | The Kozak sequence is crucial for efficient translation initiation. While complex 5' UTRs can be engineered, ensuring a strong Kozak sequence is a fundamental step for high expression.[14][15] |
| 3' UTR | SV40 polyA | BGH polyA | BGH polyA | Both are strong polyadenylation signals, but some studies have shown that the BGH polyA signal can lead to higher and more stable mRNA levels compared to the SV40 polyA signal.[4][5] |
| Selectable Marker | Neomycin (G418) | Puromycin | Puromycin | Puromycin is a potent selection agent that can result in the rapid selection of stable cell lines, often faster than G418. |
Mandatory Visualizations
Experimental Workflow for NOR-1 Plasmid Construction and Expression Analysis
Caption: Workflow for cloning NOR-1 and analyzing its expression.
Simplified NOR-1 Signaling Pathway
Caption: Simplified overview of NOR-1 signaling pathways.
Experimental Protocols
Protocol 1: Cloning Human NOR-1 into a Mammalian Expression Vector (e.g., pcDNA3.1)
This protocol outlines the steps for cloning the human NOR-1 coding sequence into a standard mammalian expression vector.
1. Primer Design and PCR Amplification:
-
Design forward and reverse primers to amplify the full-length coding sequence of human NOR-1 (NR4A3).
-
Incorporate restriction sites into the 5' ends of your primers that are compatible with the multiple cloning site (MCS) of your chosen vector (e.g., pcDNA3.1). Ensure these sites are not present within the NOR-1 sequence.
-
The forward primer should include a Kozak sequence (GCCGCCACC) immediately preceding the start codon (ATG).
-
Perform PCR using a high-fidelity DNA polymerase and human cDNA as a template.
-
Run the PCR product on an agarose (B213101) gel to confirm the correct size and purify the DNA fragment.
2. Restriction Digest and Ligation:
-
Digest both the purified PCR product and the pcDNA3.1 vector with the selected restriction enzymes.
-
Purify the digested vector and insert.
-
Perform a ligation reaction to insert the NOR-1 coding sequence into the pcDNA3.1 vector.
3. Transformation and Screening:
-
Transform the ligation mixture into competent E. coli cells.
-
Plate the transformed cells on LB agar (B569324) plates containing the appropriate antibiotic for selection (e.g., ampicillin (B1664943) for pcDNA3.1).
-
Pick individual colonies and grow them in liquid culture.
-
Isolate plasmid DNA from the liquid cultures (miniprep).
-
Confirm the presence and orientation of the NOR-1 insert by restriction digest and Sanger sequencing.[14][16][17]
Protocol 2: Transient Transfection of HEK293 Cells with NOR-1 Plasmid
This protocol describes a general method for transiently transfecting HEK293 cells.
Materials:
-
Healthy, sub-confluent HEK293 cells
-
High-quality, purified NOR-1 plasmid DNA
-
Transfection reagent (e.g., Lipofectamine™-based reagents or PEI)
-
Serum-free medium (e.g., Opti-MEM™)
-
Complete growth medium (e.g., DMEM with 10% FBS)
Procedure:
-
Cell Seeding: The day before transfection, seed HEK293 cells in your desired culture vessel (e.g., 6-well plate) so that they are 70-90% confluent on the day of transfection.
-
Complex Formation:
-
In a sterile tube, dilute the NOR-1 plasmid DNA in serum-free medium.
-
In a separate sterile tube, dilute the transfection reagent in serum-free medium.
-
Combine the diluted DNA and diluted transfection reagent, mix gently, and incubate at room temperature for 15-30 minutes to allow for complex formation.
-
-
Transfection:
-
Carefully add the DNA-transfection reagent complexes to the cells in a drop-wise manner.
-
Gently rock the plate to ensure even distribution.
-
-
Incubation: Return the cells to the incubator and culture for 24-48 hours before analysis.[4][5][18][19][20]
Protocol 3: Western Blot Analysis of NOR-1 Expression
This protocol provides a general workflow for detecting NOR-1 protein expression by Western blot.
1. Cell Lysis:
-
After 24-48 hours of transfection, wash the cells with ice-cold PBS.
-
Lyse the cells in a suitable lysis buffer (e.g., RIPA buffer) containing protease inhibitors.
-
Incubate on ice and then centrifuge to pellet cell debris. Collect the supernatant containing the protein lysate.
2. Protein Quantification:
-
Determine the protein concentration of each lysate using a standard protein assay (e.g., BCA or Bradford assay).
3. SDS-PAGE and Transfer:
-
Denature equal amounts of protein from each sample by boiling in Laemmli buffer.
-
Separate the proteins by size using SDS-polyacrylamide gel electrophoresis (SDS-PAGE).
-
Transfer the separated proteins to a nitrocellulose or PVDF membrane.
4. Immunoblotting:
-
Block the membrane with a blocking solution (e.g., 5% non-fat milk or BSA in TBST) to prevent non-specific antibody binding.
-
Incubate the membrane with a primary antibody specific for NOR-1 overnight at 4°C.
-
Wash the membrane several times with TBST.
-
Incubate the membrane with a horseradish peroxidase (HRP)-conjugated secondary antibody for 1 hour at room temperature.
-
Wash the membrane again with TBST.
5. Detection:
-
Apply an enhanced chemiluminescence (ECL) substrate to the membrane and visualize the protein bands using an imaging system.[6][21][22][23]
Protocol 4: Quantitative RT-PCR (qRT-PCR) for NOR-1 mRNA Expression
This protocol details the steps for quantifying NOR-1 mRNA levels.
1. RNA Extraction:
-
Harvest the transfected cells and extract total RNA using a commercial RNA isolation kit.
-
Treat the RNA with DNase I to remove any contaminating plasmid DNA.
2. cDNA Synthesis:
-
Synthesize complementary DNA (cDNA) from the total RNA using a reverse transcriptase enzyme and oligo(dT) or random primers.
3. qPCR:
-
Set up the qPCR reaction using a SYBR Green or TaqMan-based master mix, your synthesized cDNA, and primers specific for NOR-1.
-
Also, include primers for a housekeeping gene (e.g., GAPDH, ACTB) for normalization.
-
Run the qPCR reaction in a real-time PCR machine.
4. Data Analysis:
-
Calculate the relative expression of NOR-1 mRNA using the ΔΔCt method, normalizing to the expression of the housekeeping gene.[1][12][24]
Protocol 5: Dual-Luciferase Reporter Assay for NOR-1 Transcriptional Activity
This assay can be used to measure the ability of NOR-1 to activate transcription from a target promoter.
1. Plasmid Preparation:
-
You will need three plasmids:
-
Your NOR-1 expression plasmid.
-
A reporter plasmid containing a luciferase gene (e.g., Firefly luciferase) downstream of a promoter with NOR-1 response elements.
-
A control plasmid expressing a different luciferase (e.g., Renilla luciferase) from a constitutive promoter for normalization of transfection efficiency.
-
2. Transfection:
-
Co-transfect your cells of interest with all three plasmids using the protocol described above.
3. Cell Lysis and Luciferase Assay:
-
After 24-48 hours, lyse the cells using the passive lysis buffer provided with a dual-luciferase assay kit.
-
Measure the Firefly and Renilla luciferase activities sequentially in a luminometer according to the manufacturer's instructions.
4. Data Analysis:
-
Normalize the Firefly luciferase activity to the Renilla luciferase activity for each sample to account for differences in transfection efficiency and cell number. Compare the normalized luciferase activity in the presence and absence of NOR-1 expression to determine its transcriptional activity.[7][12][13][25][26][27]
References
- 1. lup.lub.lu.se [lup.lub.lu.se]
- 2. Comparison of the EF-1 alpha and the CMV promoter for engineering stable tumor cell lines using recombinant adeno-associated virus - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Difference between EF-1 alpha and the CMV promoter NovoPro [novoprolabs.com]
- 4. researchgate.net [researchgate.net]
- 5. Novel upstream and downstream sequence elements contribute to polyadenylation efficiency - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. Codon optimization of genes for efficient protein expression in mammalian cells by selection of only preferred human codons - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. A critical analysis of codon optimization in human therapeutics - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Considerations in the Use of Codon Optimization for Recombinant Protein Expression | Springer Nature Experiments [experiments.springernature.com]
- 10. The N-Terminal Region of Nurr1 (a.a 1–31) Is Essential for Its Efficient Degradation by the Ubiquitin Proteasome Pathway - PMC [pmc.ncbi.nlm.nih.gov]
- 11. The N-terminal region of Nurr1 (a.a 1-31) is essential for its efficient degradation by the ubiquitin proteasome pathway - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Improved Dual-Luciferase Reporter Assays for Nuclear Receptors - PMC [pmc.ncbi.nlm.nih.gov]
- 13. eubopen.org [eubopen.org]
- 14. compbio.mit.edu [compbio.mit.edu]
- 15. Differences in 5'untranslated regions highlight the importance of translational regulation of dosage sensitive genes - PMC [pmc.ncbi.nlm.nih.gov]
- 16. pnas.org [pnas.org]
- 17. Quantitative Comparison of Constitutive Promoters in Human ES cells | PLOS One [journals.plos.org]
- 18. DSpace [helda.helsinki.fi]
- 19. Loss of NOR-1 represses muscle metabolism through mTORC1-mediated signaling and mitochondrial gene expression in C2C12 myotubes - PubMed [pubmed.ncbi.nlm.nih.gov]
- 20. Reporter Gene Assays Support—Troubleshooting | Thermo Fisher Scientific - HK [thermofisher.com]
- 21. biorxiv.org [biorxiv.org]
- 22. goldbio.com [goldbio.com]
- 23. Mechanisms of NURR1 Regulation: Consequences for Its Biological Activity and Involvement in Pathology - PMC [pmc.ncbi.nlm.nih.gov]
- 24. Target (In)Validation: A Critical, Sometimes Unheralded, Role of Modern Medicinal Chemistry - PMC [pmc.ncbi.nlm.nih.gov]
- 25. Untranslated regions of brain-derived neurotrophic factor mRNA control its translatability and subcellular localization - PMC [pmc.ncbi.nlm.nih.gov]
- 26. benchchem.com [benchchem.com]
- 27. assaygenie.com [assaygenie.com]
selecting the best lysis buffer for NOR-1 immunoprecipitation
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers in selecting the optimal lysis buffer and successfully performing immunoprecipitation (IP) of the Neuron-derived Orphan Receptor 1 (NOR-1), also known as Nuclear Receptor Subfamily 4 Group A Member 3 (NR4A3).
Frequently Asked Questions (FAQs)
Q1: What is the primary subcellular localization of NOR-1, and why is it important for lysis buffer selection?
A1: NOR-1 is primarily a nuclear receptor that functions as a transcription factor.[1][2] However, studies have indicated that NOR-1 can also be present in the cytoplasm and can translocate to the mitochondria under specific cellular conditions.[3][4] The subcellular localization of your NOR-1 protein of interest is a critical factor in choosing the right lysis buffer. A buffer that efficiently lyses only the plasma membrane may not release nuclear proteins, leading to a failed immunoprecipitation. Conversely, a very harsh buffer might denature the protein or disrupt interactions if you are performing a co-immunoprecipitation (Co-IP) experiment.
Q2: Which lysis buffers are commonly used for immunoprecipitation, and what are their main differences?
A2: The three most common lysis buffers for immunoprecipitation are RIPA, NP-40 (or Triton X-100), and digitonin-based buffers. Their primary differences lie in the strength and type of detergents they contain.
-
RIPA (Radioimmunoprecipitation Assay) Buffer: This is a harsh lysis buffer containing both ionic detergents (SDS and sodium deoxycholate) and a non-ionic detergent (NP-40).[5][6][7] It is very effective at solubilizing nuclear and mitochondrial proteins.[7][8][9] However, its denaturing properties can disrupt protein-protein interactions, making it less suitable for Co-IP studies.[7][10]
-
NP-40 (Nonidet P-40) or Triton X-100 Buffers: These are milder, non-ionic detergent-based buffers.[7] They are effective at solubilizing cytoplasmic and membrane-bound proteins while generally preserving the native protein structure and protein-protein interactions, making them a good choice for Co-IP.[7] However, they are typically not strong enough to efficiently lyse the nuclear membrane on their own.[7]
-
Digitonin Buffer: This is a very mild non-ionic detergent that selectively permeabilizes the plasma membrane, leaving the nuclear and mitochondrial membranes intact. It is often used for isolating cytoplasmic proteins.
Q3: What is the recommended starting point for selecting a lysis buffer for NOR-1 IP?
A3: Given that NOR-1 is predominantly a nuclear protein, a RIPA buffer is a good starting point for standard immunoprecipitation to ensure the release of the nuclear protein fraction.[8][9][11] If you are performing a Co-IP and need to preserve protein interactions, you may need to start with a milder buffer like an NP-40-based buffer and optimize the lysis conditions. It is often necessary to empirically test different buffers to find the optimal one for your specific cell type and experimental goals.[12]
Q4: How can I ensure the stability of NOR-1 during the lysis and immunoprecipitation process?
A4: To prevent protein degradation and maintain the integrity of NOR-1, it is crucial to work on ice or at 4°C throughout the entire procedure.[13] Additionally, always supplement your lysis buffer with a fresh cocktail of protease and phosphatase inhibitors just before use.[6][9]
Troubleshooting Guide
| Problem | Possible Cause | Recommended Solution |
| Weak or No NOR-1 Signal | Inefficient cell lysis: The lysis buffer may not be strong enough to release nuclear NOR-1. | Switch to a harsher lysis buffer, such as RIPA buffer, which is more effective at disrupting the nuclear membrane.[8][9] Consider including mechanical disruption steps like sonication to aid in nuclear lysis.[10] |
| Low protein expression: The cells may not be expressing enough NOR-1 for detection. | Confirm NOR-1 expression in your starting material (input) by Western blot. If expression is low, you may need to increase the amount of cell lysate used for the IP.[14] | |
| Antibody issues: The antibody may not be suitable for immunoprecipitation or may not be used at the optimal concentration. | Use an antibody that has been validated for IP. Perform a titration experiment to determine the optimal antibody concentration.[15] Polyclonal antibodies often perform better in IP than monoclonal antibodies.[16] | |
| High Background/Non-specific Binding | Non-specific protein binding to beads: Proteins in the lysate are binding non-specifically to the Protein A/G beads. | Pre-clear the lysate by incubating it with beads alone before adding the primary antibody. This will help remove proteins that non-specifically bind to the beads.[10] |
| Ineffective washing: Insufficient washing of the immunoprecipitated complex. | Increase the number and duration of washes. You can also try increasing the stringency of the wash buffer by slightly increasing the detergent or salt concentration.[16] | |
| Too much antibody: Using an excessive amount of primary antibody can lead to non-specific binding. | Reduce the amount of antibody used in the IP reaction.[14] | |
| Co-immunoprecipitation (Co-IP) Not Successful | Disruption of protein-protein interactions: The lysis buffer is too harsh and is breaking apart the protein complex. | Use a milder lysis buffer, such as one containing NP-40 or Triton X-100, which are known to preserve protein-protein interactions.[7] Avoid RIPA buffer for Co-IP experiments as it can denature proteins.[10] |
| Weak or transient interaction: The interaction between NOR-1 and its binding partner may be weak or transient. | Consider cross-linking the proteins in vivo before cell lysis to stabilize the interaction. |
Experimental Protocols
Protocol 1: Standard RIPA Lysis for NOR-1 Immunoprecipitation
-
Cell Lysis:
-
Wash cells with ice-cold PBS.
-
Add ice-cold RIPA buffer (50 mM Tris-HCl pH 8.0, 150 mM NaCl, 1% NP-40, 0.5% sodium deoxycholate, 0.1% SDS) supplemented with fresh protease and phosphatase inhibitors.[11]
-
Incubate on ice for 30 minutes with occasional vortexing.
-
For enhanced nuclear lysis, sonicate the lysate briefly on ice.[10]
-
Centrifuge at high speed (e.g., 14,000 x g) for 15 minutes at 4°C to pellet cell debris.
-
Transfer the supernatant (lysate) to a new pre-chilled tube.
-
-
Immunoprecipitation:
-
Determine the protein concentration of the lysate.
-
Pre-clear the lysate by incubating with Protein A/G beads for 30-60 minutes at 4°C.[10]
-
Centrifuge to pellet the beads and transfer the supernatant to a new tube.
-
Add the anti-NOR-1 antibody to the pre-cleared lysate and incubate for 2 hours to overnight at 4°C with gentle rotation.
-
Add fresh Protein A/G beads and incubate for another 1-3 hours at 4°C.[17]
-
Collect the beads by centrifugation and wash them 3-5 times with cold lysis buffer.[8]
-
-
Elution and Analysis:
-
Elute the immunoprecipitated proteins from the beads by adding 1X Laemmli sample buffer and boiling for 5-10 minutes.
-
Analyze the eluted proteins by SDS-PAGE and Western blotting.
-
Protocol 2: Milder NP-40 Lysis for NOR-1 Co-Immunoprecipitation
-
Cell Lysis:
-
Follow the same initial steps as the RIPA protocol, but use an ice-cold NP-40 lysis buffer (e.g., 50 mM Tris-HCl pH 8.0, 150 mM NaCl, 1% NP-40) supplemented with fresh protease and phosphatase inhibitors.[8]
-
-
Immunoprecipitation and Elution:
-
Proceed with the immunoprecipitation and elution steps as described in the RIPA protocol. Be aware that washing steps may need to be less stringent to preserve weak interactions.
-
Visualizations
References
- 1. Comprehensive insights into the function and molecular and pharmacological regulation of neuron-derived orphan receptor 1, an orphan receptor - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Nuclear receptor 4A3 - Wikipedia [en.wikipedia.org]
- 3. researchgate.net [researchgate.net]
- 4. researchgate.net [researchgate.net]
- 5. fortislife.com [fortislife.com]
- 6. Cell Lysis Buffers | Thermo Fisher Scientific - US [thermofisher.com]
- 7. Which Detergent Lysis Buffer Should You Use? - Advansta Inc. [advansta.com]
- 8. usbio.net [usbio.net]
- 9. Choosing The Right Lysis Buffer | Proteintech Group [ptglab.com]
- 10. Immunoprecipitation Troubleshooting Guide | Cell Signaling Technology [cellsignal.com]
- 11. Immunoprecipitation (IP) and co-immunoprecipitation protocol | Abcam [abcam.com]
- 12. researchgate.net [researchgate.net]
- 13. assaygenie.com [assaygenie.com]
- 14. docs.abcam.com [docs.abcam.com]
- 15. antibody-creativebiolabs.com [antibody-creativebiolabs.com]
- 16. hycultbiotech.com [hycultbiotech.com]
- 17. Immunoprecipitation Protocol For Native Proteins | Cell Signaling Technology [cellsignal.com]
A Researcher's Guide to Validating a New NOR-1 (NR4A3) Antibody
This guide provides a comprehensive framework for validating the specificity of a new antibody against the Neuron-derived orphan receptor 1 (NOR-1), also known as Nuclear Receptor Subfamily 4 Group A Member 3 (NR4A3). We present a series of essential validation experiments, comparing the performance of a hypothetical "New NOR-1 Antibody" with an established "Competitor Antibody."
NOR-1 is an orphan nuclear receptor that plays crucial roles in apoptosis, inflammation, and metabolism.[1][2] It is a member of the NR4A family, which also includes Nur77 (NR4A1) and Nurr1 (NR4A2). Due to the high sequence homology within this family, rigorous specificity testing is paramount to ensure an antibody reliably detects NOR-1 without cross-reacting with its counterparts.[3]
Core Validation Strategies
To ensure confidence and reproducibility, antibody validation should be multifaceted. The International Working Group for Antibody Validation (IWGAV) has proposed a framework built on several conceptual "pillars". This guide focuses on the most critical strategies for demonstrating specificity:
-
Genetic Strategies : Using knockout (KO) cell lines or tissues to provide a true negative control is considered the gold standard for specificity validation.[4] A specific antibody should show no signal in a KO sample.
-
Western Blot (WB) Analysis : This technique verifies that the antibody detects a protein of the correct molecular weight (~60 kDa for NOR-1) in positive control lysates and that this band is absent in negative controls.[5]
-
Orthogonal Strategies : Comparing the antibody-based results with data from a non-antibody-based method, such as mRNA expression levels in different tissues.
-
Immunohistochemistry (IHC) and Immunocytochemistry (ICC) : These methods are crucial for confirming that the antibody recognizes the target protein in its correct subcellular location (e.g., the nucleus for a transcription factor) and tissue distribution.[6][7]
The following sections provide detailed protocols and comparative data for the most essential of these validation techniques.
Experimental Protocols
Protocol 1: Western Blot Validation Using Knockout Cell Lines
This protocol is the definitive test for specificity. It compares the antibody's performance in a wild-type (WT) cell line known to express NOR-1 against a CRISPR-Cas9 generated NOR-1 knockout (KO) derivative of the same line.[8]
-
Lysate Preparation :
-
Culture WT and NOR-1 KO HCT116 cells to 80-90% confluency.
-
Wash cells with ice-cold PBS and lyse in RIPA buffer containing protease and phosphatase inhibitors.
-
Determine protein concentration using a BCA assay.
-
-
SDS-PAGE and Transfer :
-
Load 20-30 µg of protein per lane onto a 4-12% Bis-Tris polyacrylamide gel. Include a protein ladder.
-
Run the gel until adequate separation is achieved.
-
Transfer proteins to a PVDF membrane. Let the membrane dry completely after transfer to improve protein retention.[9]
-
-
Immunoblotting :
-
Block the membrane for 1 hour at room temperature in Intercept (TBS) Blocking Buffer.[9]
-
Incubate the membrane overnight at 4°C with the "New NOR-1 Ab" (e.g., at 1:1000 dilution) or the "Competitor Ab" (at its recommended dilution) in Intercept T20 Antibody Diluent.
-
Wash the membrane 4 times for 5 minutes each with TBS containing 0.1% Tween-20 (TBS-T).[9]
-
Incubate with an appropriate secondary antibody (e.g., IRDye-conjugated) for 1 hour at room temperature, protected from light.
-
Wash the membrane as in the previous step.
-
Image the blot using a digital imaging system (e.g., Odyssey).
-
Probe for a loading control (e.g., GAPDH or Beta-actin) to ensure equal protein loading.
-
References
- 1. Frontiers | Comprehensive insights into the function and molecular and pharmacological regulation of neuron-derived orphan receptor 1, an orphan receptor [frontiersin.org]
- 2. Comprehensive insights into the function and molecular and pharmacological regulation of neuron-derived orphan receptor 1, an orphan receptor - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Nuclear receptor 4A3 - Wikipedia [en.wikipedia.org]
- 4. 5 ways to validate and extend your research with Knockout Cell Lines [horizondiscovery.com]
- 5. Antibody validation - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Anti-NOR-1 Antibodies | Invitrogen [thermofisher.com]
- 7. NR4A3/NOR1 Antibody - BSA Free (NBP1-92198): Novus Biologicals [novusbio.com]
- 8. cyagen.com [cyagen.com]
- 9. licorbio.com [licorbio.com]
Confirming NR4A3 Gene Knockout: A Comparative Guide to Validation Techniques
For researchers, scientists, and drug development professionals, rigorous validation of a gene knockout is a critical step to ensure the reliability and reproducibility of experimental results. This guide provides a comparative overview of common techniques to confirm the successful knockout of the Nuclear Receptor Subfamily 4 Group A Member 3 (NR4A3) gene in a new cell line. We present supporting data, detailed experimental protocols, and visualizations to aid in the selection of the most appropriate validation strategy.
Comparison of NR4A3 Knockout Confirmation Methods
The choice of method to confirm a gene knockout depends on various factors, including the desired level of validation (DNA, RNA, or protein), available resources, and the specific experimental question. Below is a summary of commonly used techniques with their respective advantages and disadvantages.
| Method | Target Molecule | Information Provided | Throughput | Cost | Key Advantages | Key Disadvantages |
| Genomic PCR | DNA | Presence or absence of the targeted genomic region.[1] | High | Low | Simple, fast, and inexpensive initial screening method. | Does not confirm functional knockout (i.e., absence of protein); potential for false negatives if primers are not designed correctly. |
| Sanger Sequencing | DNA | Precise nucleotide sequence of the targeted region.[1][2][3][4] | Low | Moderate | Gold standard for confirming indels (insertions/deletions) at the DNA level; provides definitive proof of the genetic modification.[1][2][3][4] | Can be challenging to interpret with mixed cell populations; not ideal for high-throughput screening.[2] |
| Quantitative PCR (qPCR) | mRNA | Relative expression level of the NR4A3 transcript.[1] | High | Moderate | Quantitative assessment of gene expression knockdown. | Reduced mRNA levels do not always correlate with a complete absence of protein. |
| Western Blot | Protein | Presence and size of the NR4A3 protein.[1][2][5] | Moderate | Moderate | Directly confirms the absence of the target protein, which is the ultimate goal of a knockout.[1][2][5] | Requires a specific and validated antibody; can be semi-quantitative. |
| Next-Generation Sequencing (NGS) | DNA | Comprehensive analysis of on-target and off-target mutations.[6] | High | High | Provides a genome-wide view of CRISPR-Cas9 editing events, including unintended off-target effects.[6][7][8] | Data analysis can be complex and computationally intensive; higher cost compared to other methods.[9] |
| RNA-Sequencing (RNA-Seq) | RNA | Transcriptome-wide changes resulting from the knockout.[10][11] | High | High | Confirms knockout and provides insights into the functional consequences and potential off-target effects on gene expression.[10][11] | Complex data analysis; does not directly confirm the absence of protein. |
Experimental Protocols
Here are detailed methodologies for the key experiments used to validate NR4A3 gene knockout.
Genomic PCR for Initial Screening
This protocol is designed to quickly screen for the deletion of the NR4A3 gene at the genomic level.
-
DNA Extraction: Isolate genomic DNA from both the wild-type (WT) and putative NR4A3 knockout (KO) cell lines using a standard DNA extraction kit.
-
Primer Design: Design primers flanking the targeted region of the NR4A3 gene. Additionally, design a set of control primers for a different, unaffected genomic region to ensure DNA quality.
-
PCR Amplification:
-
Set up PCR reactions with the extracted DNA, primers, and a suitable DNA polymerase.
-
A typical PCR program includes an initial denaturation step, followed by 30-35 cycles of denaturation, annealing, and extension, and a final extension step.
-
-
Gel Electrophoresis: Run the PCR products on an agarose (B213101) gel.[2] A successful knockout should result in a smaller band or no band for the NR4A3 target region in the KO cells compared to the WT cells, while the control band should be present in both.[2]
Sanger Sequencing for Indel Confirmation
This method provides precise sequence information to confirm the presence of insertions or deletions (indels) introduced by gene editing.
-
PCR Amplification: Amplify the targeted region of the NR4A3 gene from the genomic DNA of both WT and KO cells using high-fidelity DNA polymerase.
-
PCR Product Purification: Purify the PCR products to remove primers and dNTPs.
-
Sequencing Reaction: Send the purified PCR products for Sanger sequencing using both forward and reverse primers.[2]
-
Sequence Analysis: Align the sequencing results from the KO cells to the WT sequence. The presence of overlapping peaks in the chromatogram after the target site can indicate a mixed population of cells with different indels.[2] Specialized software can be used to deconvolute these mixed traces.[3][12]
Quantitative PCR (qPCR) for mRNA Expression Analysis
qPCR is used to quantify the level of NR4A3 mRNA, providing evidence of transcriptional disruption.
-
RNA Extraction and cDNA Synthesis: Extract total RNA from WT and KO cells and reverse transcribe it into cDNA.
-
Primer Design: Use validated qPCR primers for the human NR4A3 gene. A suitable primer pair is Forward: 5'-ACTGCCCAGTAGACAAGAGACG-3' and Reverse: 5'-GTTTGGAAGGCAGACGACCTCT-3'.[13] Also, include primers for a stable housekeeping gene (e.g., GAPDH, ACTB) for normalization.
-
qPCR Reaction: Set up the qPCR reaction using a SYBR Green or TaqMan-based assay.
-
Data Analysis: Calculate the relative expression of NR4A3 mRNA in KO cells compared to WT cells using the ΔΔCt method. A significant reduction in NR4A3 mRNA levels in the KO cells indicates successful gene disruption at the transcriptional level.
Western Blot for Protein Knockout Confirmation
This is a crucial step to confirm the absence of the NR4A3 protein.
-
Protein Extraction: Lyse WT and KO cells in a suitable lysis buffer to extract total protein.
-
Protein Quantification: Determine the protein concentration of each lysate using a standard protein assay (e.g., BCA assay).
-
SDS-PAGE and Transfer: Separate the protein lysates by SDS-PAGE and transfer them to a PVDF or nitrocellulose membrane.
-
Immunoblotting:
-
Block the membrane to prevent non-specific antibody binding.
-
Incubate the membrane with a primary antibody specific for NR4A3. Polyclonal and monoclonal antibodies against NR4A3 are commercially available.[14][15][16] A typical starting dilution is 1:600.[15]
-
Wash the membrane and incubate with a horseradish peroxidase (HRP)-conjugated secondary antibody.
-
Detect the protein bands using an enhanced chemiluminescence (ECL) substrate.
-
-
Analysis: The absence of a band corresponding to the molecular weight of NR4A3 (approximately 68 kDa) in the KO lane confirms a successful knockout at the protein level.[15] A loading control protein (e.g., β-actin, GAPDH) should be detected in all lanes to ensure equal protein loading.
Visualizing Experimental Workflows and Signaling Pathways
Workflow for Confirming NR4A3 Gene Knockout
The following diagram illustrates a typical workflow for validating a gene knockout, starting from the edited cells to the final confirmation at the protein level.
NR4A3 Signaling Pathway
NR4A3 is a nuclear receptor that acts as a transcriptional activator and is involved in various cellular processes, including proliferation, apoptosis, and metabolism.[17][18][19] The diagram below depicts a simplified signaling pathway involving NR4A3.
Off-Target Analysis
A significant concern with CRISPR-based gene editing is the potential for off-target effects, where the Cas9 nuclease cuts at unintended sites in the genome.[9][20] It is crucial to assess for such events, as they can confound experimental results.[9]
-
Prediction of Off-Target Sites: Several online tools can predict potential off-target sites based on sequence homology to the guide RNA.[7][8]
-
Experimental Validation:
-
Targeted Sequencing: PCR amplification and Sanger sequencing of the top predicted off-target sites.
-
Unbiased Methods: Techniques like GUIDE-seq, CIRCLE-seq, and whole-genome sequencing (WGS) can identify off-target mutations across the entire genome.[8]
-
References
- 1. How to Validate Gene Knockout Efficiency: Methods & Best Practices [synapse.patsnap.com]
- 2. bitesizebio.com [bitesizebio.com]
- 3. CRISPR Gene Editing Confirmation with Sanger Sequencing | Thermo Fisher Scientific - HK [thermofisher.com]
- 4. Validating CRISPR/Cas9-mediated Gene Editing [sigmaaldrich.com]
- 5. How to Validate a CRISPR Knockout [biognosys.com]
- 6. CRISPR Genome Editing & NGS | Off-target analysis and knockout confirmation [illumina.com]
- 7. Summary of CRISPR-Cas9 off-target Detection Methods - CD Genomics [cd-genomics.com]
- 8. Genome-Wide Off-Target Analysis in CRISPR-Cas9 Modified Mice and Their Offspring - PMC [pmc.ncbi.nlm.nih.gov]
- 9. synthego.com [synthego.com]
- 10. Techniques for Validating CRISPR Changes Using RNA-Sequencing Data - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. Techniques for Validating CRISPR Changes Using RNA-Sequencing Data - PMC [pmc.ncbi.nlm.nih.gov]
- 12. CRISPR Gene Editing Confirmation with Sanger Sequencing | Thermo Fisher Scientific - US [thermofisher.com]
- 13. origene.com [origene.com]
- 14. Anti-NR4A3 Antibody (A42985) | Antibodies.com [antibodies.com]
- 15. NR4A3 antibody (55405-1-AP) | Proteintech [ptglab.com]
- 16. NR4A3 Monoclonal Antibody (OTI4D1) (CF804895) [thermofisher.com]
- 17. uniprot.org [uniprot.org]
- 18. Nuclear receptor 4A3 - Wikipedia [en.wikipedia.org]
- 19. genecards.org [genecards.org]
- 20. blog.addgene.org [blog.addgene.org]
Assessing Off-Target Effects of a Novel NOR-1 Inhibitor: A Comparative Guide
For Researchers, Scientists, and Drug Development Professionals
The development of selective inhibitors for nuclear receptors is a critical endeavor in modern drug discovery, offering therapeutic potential for a range of diseases. Neuron-derived orphan receptor 1 (NOR-1), also known as NR4A3, has emerged as a promising target in cancer, inflammation, and metabolic disorders. However, ensuring the specificity of any novel inhibitor is paramount to minimize off-target effects and potential toxicity. This guide provides a comparative framework for evaluating the off-target profile of a novel NOR-1 inhibitor, "N1I-X," against other known nuclear receptor modulators.
Comparative Off-Target Profile
The following table summarizes the hypothetical off-target binding profile of our novel NOR-1 inhibitor, N1I-X, in comparison to other known nuclear receptor modulators, including the non-selective NR4A ligand Celastrol and a hypothetical selective Estrogen Receptor alpha (ERα) modulator. The data presented here is for illustrative purposes to guide the experimental approach for a novel inhibitor.
| Target | N1I-X (Novel NOR-1 Inhibitor) | Celastrol | Selective ERα Modulator |
| Primary Target | |||
| NOR-1 (NR4A3) | IC₅₀ = 50 nM | IC₅₀ = 200 nM | IC₅₀ > 10,000 nM |
| NR4A Family Selectivity | |||
| NUR77 (NR4A1) | IC₅₀ = 500 nM | IC₅₀ = 150 nM | IC₅₀ > 10,000 nM |
| NURR1 (NR4A2) | IC₅₀ = 800 nM | IC₅₀ = 300 nM | IC₅₀ > 10,000 nM |
| Other Nuclear Receptors | |||
| Estrogen Receptor α (ERα) | IC₅₀ > 10,000 nM | IC₅₀ = 5,000 nM | IC₅₀ = 10 nM |
| Androgen Receptor (AR) | IC₅₀ > 10,000 nM | IC₅₀ = 8,000 nM | IC₅₀ > 10,000 nM |
| Progesterone Receptor (PR) | IC₅₀ > 10,000 nM | IC₅₀ > 10,000 nM | IC₅₀ > 10,000 nM |
| Glucocorticoid Receptor (GR) | IC₅₀ > 10,000 nM | IC₅₀ = 7,500 nM | IC₅₀ > 10,000 nM |
| Key Off-Target Kinases | |||
| Kinase Panel (468 kinases) | No significant inhibition at 1 µM | Multiple off-target hits | No significant inhibition at 1 µM |
Experimental Protocols
To generate the comparative data presented above, a series of robust experimental assays are required. The following are detailed methodologies for key experiments to assess the on-target and off-target effects of a novel NOR-1 inhibitor.
Cellular Thermal Shift Assay (CETSA®) for Target Engagement
Objective: To confirm direct binding of the novel inhibitor to NOR-1 in a cellular context.
Principle: Ligand binding stabilizes the target protein, leading to an increase in its melting temperature (Tm).
Protocol:
-
Cell Culture and Treatment:
-
Culture a human cell line endogenously expressing NOR-1 (e.g., HEK293T, Panc-1) to 80-90% confluency.
-
Treat cells with the novel NOR-1 inhibitor (N1I-X) at various concentrations (e.g., 0.1, 1, 10 µM) or vehicle control (DMSO) for 1 hour at 37°C.
-
-
Heat Shock:
-
Harvest cells and resuspend in PBS supplemented with protease inhibitors.
-
Aliquot cell suspensions into PCR tubes.
-
Heat the samples to a range of temperatures (e.g., 40-70°C) for 3 minutes using a thermal cycler, followed by cooling at room temperature for 3 minutes.
-
-
Lysis and Protein Quantification:
-
Lyse the cells by three freeze-thaw cycles using liquid nitrogen and a 25°C water bath.
-
Separate the soluble fraction (containing stabilized protein) from the precipitated, denatured protein by centrifugation at 20,000 x g for 20 minutes at 4°C.
-
Collect the supernatant and determine the protein concentration using a BCA assay.
-
-
Western Blot Analysis:
-
Normalize the protein concentrations of all samples.
-
Separate proteins by SDS-PAGE and transfer to a PVDF membrane.
-
Probe the membrane with a primary antibody specific for NOR-1, followed by a secondary HRP-conjugated antibody.
-
Detect the signal using an enhanced chemiluminescence (ECL) substrate and image the blot.
-
Quantify band intensities to determine the amount of soluble NOR-1 at each temperature.
-
-
Data Analysis:
-
Plot the percentage of soluble NOR-1 against the temperature for each treatment condition to generate melting curves.
-
Determine the Tm for each curve. A shift in the Tm in the presence of the inhibitor indicates target engagement.
-
Kinase Panel Screening
Objective: To assess the selectivity of the novel inhibitor against a broad range of protein kinases.
Protocol:
This assay is typically performed by a specialized contract research organization (CRO). The general workflow is as follows:
-
Compound Submission: Provide the novel inhibitor at a specified concentration (e.g., 10 mM in DMSO).
-
Assay Format: The CRO will typically use a radiometric assay (e.g., ³³P-ATP filter binding) or a fluorescence-based assay to measure kinase activity.
-
Kinase Panel: The inhibitor is screened at a fixed concentration (e.g., 1 µM) against a large panel of recombinant human kinases (e.g., >400 kinases).
-
Data Analysis: The percentage of inhibition for each kinase is determined relative to a vehicle control. A significant inhibition (typically >50%) is considered a "hit."
-
Follow-up Studies: For any identified off-target kinases, dose-response curves are generated to determine the IC₅₀ values.
Proteomic Profiling for Off-Target Identification
Objective: To identify unintended protein targets of the novel inhibitor in an unbiased manner.
Method: Isothermal Dose-Response Cellular Thermal Shift Assay coupled with Mass Spectrometry (ITDR-CETSA-MS)
-
Cell Treatment and Lysis:
-
Treat cells with a range of concentrations of the novel inhibitor or vehicle control.
-
Heat the cell lysate to a specific temperature that causes partial denaturation of NOR-1.
-
Separate soluble and aggregated proteins by centrifugation.
-
-
Sample Preparation for Mass Spectrometry:
-
The soluble fractions are subjected to in-solution trypsin digestion.
-
The resulting peptides are labeled with tandem mass tags (TMT) for multiplexed quantitative analysis.
-
-
LC-MS/MS Analysis:
-
The labeled peptides are analyzed by liquid chromatography-tandem mass spectrometry (LC-MS/MS).
-
-
Data Analysis:
-
The relative abundance of each identified protein in the inhibitor-treated samples is compared to the vehicle control.
-
Proteins that show a dose-dependent increase in thermal stability are considered potential off-targets.
-
Visualizing Key Pathways and Workflows
To facilitate a clearer understanding of the biological context and experimental design, the following diagrams illustrate the NOR-1 signaling pathway and the workflow for off-target effect testing.
Caption: Simplified NOR-1 signaling pathway.
Caption: Experimental workflow for off-target testing.
Navigating the Maze of Specificity: A Guide to Commercial NOR-1 Antibodies and their Cross-Reactivity with Nur77 and Nurr1
For researchers in immunology, neuroscience, and cancer biology, the nuclear receptor subfamily 4 group A (NR4A) members—NOR-1 (NR4A3), Nur77 (NR4A1), and Nurr1 (NR4A2)—are critical targets of investigation. However, the high degree of homology among these transcription factors presents a significant challenge for antibody-based detection methods. This guide provides a comparative overview of the cross-reactivity of commercial NOR-1 antibodies, offering supporting data and experimental protocols to aid researchers in selecting the most specific reagents for their studies.
The NR4A family of orphan nuclear receptors plays a crucial role in a variety of cellular processes, including apoptosis, inflammation, and neuronal function. Due to their sequence similarity, particularly within the DNA-binding domain, developing antibodies that can distinguish between NOR-1, Nur77, and Nurr1 is a formidable task. This inherent cross-reactivity can lead to ambiguous or misleading results, underscoring the importance of careful antibody selection and validation.
Understanding the Challenge: NR4A Family Homology
The significant sequence homology among NOR-1, Nur77, and Nurr1 is the primary driver of antibody cross-reactivity. This is especially true for antibodies raised against conserved regions of the proteins. To circumvent this, researchers and manufacturers have focused on developing antibodies that target more divergent regions, such as the N-terminal (A/B) domain or the C-terminal ligand-binding domain (LBD).[1][2] Production of specific polyclonal antibodies has been achieved by immunizing with these more distinct regions, followed by affinity purification and pre-adsorption steps to remove antibodies that cross-react with other family members.[2][3]
Comparison of Commercial NOR-1 Antibodies
While comprehensive, quantitative cross-reactivity data from manufacturers is often limited, this section summarizes available information for several commercial NOR-1 antibodies. Researchers are strongly encouraged to perform their own validation experiments to confirm specificity in their specific application.
| Antibody (Supplier) | Host | Type | Immunogen | Reported Applications | Cross-Reactivity Information (Nur77/Nurr1) |
| NOR-1 Antibody (H-7), Santa Cruz Biotechnology (sc-393902) | Mouse | Monoclonal | Epitope mapping between amino acids 222-259 of human NOR-1 | WB, IP, IF, ELISA | Datasheet does not provide specific cross-reactivity data with Nur77 and Nurr1.[4] |
| NOR-1 Polyclonal Antibody, Thermo Fisher Scientific (PA5-114330) | Rabbit | Polyclonal | Synthetic peptide corresponding to a region within the C-terminus of human NOR-1 | WB, IHC, IF | Specific cross-reactivity data with Nur77 and Nurr1 is not provided on the product datasheet. |
| NR4A3/NOR1 Antibody, Novus Biologicals (NBP1-89569) | Rabbit | Polyclonal | Recombinant protein corresponding to amino acids 256-578 of human NOR-1 | WB, IHC | The manufacturer does not provide specific data on cross-reactivity with Nur77 and Nurr1. |
| Anti-NOR1 Antibody, Assay Biotechnology (C17569) | Rabbit | Polyclonal | Not specified | WB, ELISA | The datasheet indicates the antibody detects endogenous levels of NOR-1 but lacks specific data on Nur77/Nurr1 cross-reactivity.[5] |
Note: The absence of explicit cross-reactivity data on a product datasheet does not guarantee specificity. It is imperative for researchers to validate antibody performance using appropriate controls.
Experimental Protocols for Assessing Cross-Reactivity
To ensure the specificity of a NOR-1 antibody, several key experiments should be performed.
Western Blotting
This is a fundamental technique to assess antibody specificity.
Protocol:
-
Protein Lysate Preparation: Prepare whole-cell lysates from cells known to express NOR-1, Nur77, and Nurr1 individually. Overexpression systems (e.g., HEK293T cells transfected with expression plasmids for each NR4A member) are ideal for this purpose. Include a negative control lysate from untransfected cells.
-
SDS-PAGE and Transfer: Separate the protein lysates by sodium dodecyl sulfate-polyacrylamide gel electrophoresis (SDS-PAGE) and transfer the proteins to a polyvinylidene difluoride (PVDF) or nitrocellulose membrane.
-
Blocking: Block the membrane with a suitable blocking buffer (e.g., 5% non-fat dry milk or bovine serum albumin in Tris-buffered saline with 0.1% Tween-20) for 1 hour at room temperature.
-
Primary Antibody Incubation: Incubate the membrane with the primary NOR-1 antibody at the manufacturer's recommended dilution overnight at 4°C.
-
Washing: Wash the membrane extensively with wash buffer (e.g., Tris-buffered saline with 0.1% Tween-20).
-
Secondary Antibody Incubation: Incubate the membrane with an appropriate horseradish peroxidase (HRP)-conjugated secondary antibody for 1 hour at room temperature.
-
Detection: Detect the signal using an enhanced chemiluminescence (ECL) substrate and image the blot.
Expected Outcome: A specific NOR-1 antibody should produce a strong band at the expected molecular weight for NOR-1 and no or minimal signal in the lanes containing Nur77 and Nurr1 lysates.
Enzyme-Linked Immunosorbent Assay (ELISA)
ELISA can provide a more quantitative assessment of antibody binding.
Protocol:
-
Coating: Coat the wells of a 96-well plate with purified recombinant NOR-1, Nur77, and Nurr1 proteins overnight at 4°C. Include a well with a control protein (e.g., BSA).
-
Blocking: Wash the wells and block with a suitable blocking buffer for 1-2 hours at room temperature.
-
Primary Antibody Incubation: Add serial dilutions of the primary NOR-1 antibody to the wells and incubate for 2 hours at room temperature.
-
Washing: Wash the wells extensively.
-
Secondary Antibody Incubation: Add an HRP-conjugated secondary antibody and incubate for 1 hour at room temperature.
-
Detection: Add a substrate solution (e.g., TMB) and stop the reaction. Measure the absorbance at the appropriate wavelength.
Expected Outcome: A specific NOR-1 antibody will show a strong signal in the wells coated with NOR-1 protein and significantly lower or no signal in the wells with Nur77 and Nurr1.
Visualizing the Molecular Context and Experimental Design
To further aid in understanding the biological system and the experimental approach to antibody validation, the following diagrams are provided.
Caption: Overview of the NR4A signaling pathway.
Caption: Experimental workflow for assessing antibody cross-reactivity.
Conclusion
The selection of a highly specific NOR-1 antibody is critical for obtaining reliable and reproducible data in studies involving the NR4A family. Due to the high homology between NOR-1, Nur77, and Nurr1, researchers must be vigilant in validating the specificity of their chosen antibodies. While manufacturers' datasheets provide a starting point, independent verification through Western blotting and ELISA using appropriate controls is essential. By following the protocols and considering the challenges outlined in this guide, researchers can confidently select and validate NOR-1 antibodies, leading to more accurate and impactful scientific discoveries.
References
- 1. Functional redundancy of the Nur77 and Nor‐1 orphan steroid receptors in T‐cell apoptosis | The EMBO Journal [link.springer.com]
- 2. Production of Nurr-1 Specific Polyclonal Antibodies Free of Cross-reactivity Against Its Close Homologs, Nor1 and Nur77 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Production of Nurr-1 Specific Polyclonal Antibodies Free of Cross-reactivity Against Its Close Homologs, Nor1 and Nur77 - PMC [pmc.ncbi.nlm.nih.gov]
- 4. scbt.com [scbt.com]
- 5. assaybiotechnology.com [assaybiotechnology.com]
A Comparative Guide to the Function of NOR-1 and Nur77 in T-Cell Development
For Researchers, Scientists, and Drug Development Professionals
This guide provides an objective comparison of the nuclear receptors NOR-1 (NR4A3) and Nur77 (NR4A1), focusing on their roles in the intricate process of T-cell development. We present supporting experimental data, detailed methodologies for key experiments, and visual aids to elucidate signaling pathways and workflows.
Introduction: The NR4A Family in Thymic Selection
T-cell development in the thymus is a tightly regulated process that ensures a functional and self-tolerant T-cell repertoire. A critical checkpoint is negative selection, where thymocytes expressing T-cell receptors (TCRs) that bind too strongly to self-antigens are eliminated to prevent autoimmunity.[1] The orphan nuclear receptors Nur77 and Neuron-derived orphan receptor 1 (NOR-1) are members of the NR4A subfamily and are key players in this process.[2][3] Both are classified as immediate-early genes, rapidly induced in thymocytes following strong TCR signaling, which is a hallmark of negative selection.[3][4] While structurally similar, their specific and potentially redundant functions are of significant interest in immunology and therapeutic development.
Comparative Function in T-Cell Apoptosis and Development
Shared Role in Negative Selection:
The primary and most well-documented function of both NOR-1 and Nur77 in the thymus is to mediate apoptosis following the strong TCR signaling that triggers negative selection.[2][5] Overexpression of a dominant-negative Nur77 protein, which effectively blocks the activity of all family members, has been shown to inhibit the apoptosis associated with negative selection.[2][6] This points to a crucial and shared role for the family in this T-cell tolerance checkpoint.
They execute this pro-apoptotic function through two distinct pathways:
-
Transcriptional Activation: As transcription factors, Nur77 and NOR-1 can translocate to the nucleus and regulate the expression of pro-apoptotic genes.[2][7] They bind to the same DNA element, indicating a shared set of downstream targets.[8]
-
Mitochondrial (Non-Transcriptional) Pathway: In a pivotal, transcription-independent mechanism, both NOR-1 and Nur77 can translocate from the nucleus to the mitochondria.[2][9] There, they interact directly with the anti-apoptotic protein Bcl-2, inducing a conformational change that exposes its pro-apoptotic BH3 domain and effectively converts it into a killer protein, triggering the mitochondrial apoptosis pathway.[2][9][10]
Functional Redundancy:
A key aspect of the relationship between NOR-1 and Nur77 is their functional redundancy.[3][8] This is most evident from knockout mouse studies. Mice deficient in Nur77 alone (Nur77-/-) exhibit no major defects in thymic negative selection, which is attributed to compensation by NOR-1.[1][2] In contrast, transgenic mice that constitutively express either NOR-1 or Nur77 in their thymocytes undergo massive apoptosis, leading to a dramatic reduction in thymocyte numbers.[3][8] This demonstrates that either protein is sufficient to induce the apoptotic program. The similar kinetics of their induction in response to TCR signals further supports their redundant roles.[3]
Differential Roles in T-Cell Activation and Metabolism:
While their roles in apoptosis are largely redundant, studies focusing on peripheral T-cells suggest more distinct functions, particularly for Nur77. Nur77 has been identified as a key regulator of T-cell activation and metabolism, acting as a molecular brake to restrict autoimmunity.[11] Nur77-deficient T-cells show enhanced proliferation and activation, leading to an accumulation of memory-phenotype T-cells.[11][12] It achieves this by limiting metabolic pathways like mitochondrial respiration and glycolysis upon T-cell activation.[11]
Quantitative Data Analysis
The following tables summarize quantitative data from studies using genetically modified mouse models to investigate the functions of NOR-1 and Nur77.
Table 1: Comparison of Phenotypes in NOR-1 and Nur77 Genetically Modified Mice
| Mouse Model | Genetic Modification | Key Phenotype in Thymus | Thymocyte Count | Reference(s) |
| Wild-Type | None | Normal T-cell development | Normal | [8] |
| Nur77-FL | Transgenic; constitutive expression of Nur77 in thymocytes | Massive apoptosis of CD4+CD8+ thymocytes | ~10-fold reduction | [3] |
| Nor-1-FL | Transgenic; constitutive expression of NOR-1 in thymocytes | Massive apoptosis of CD4+CD8+ thymocytes | ~15-fold reduction | [8] |
| Nurr1-FL | Transgenic; constitutive expression of Nurr1 in thymocytes | No significant changes in T-cell development | Normal | [8] |
| Nur77 KO | Nur77-/- (knockout) | No major defect in negative selection | Normal | [1][2] |
| Dom-Neg Nur77 | Transgenic; dominant-negative Nur77 expression | Inefficient clonal deletion of self-reactive T-cells | 5-fold increase in specific self-reactive thymocytes | [6] |
Table 2: Impact of Nur77 Deficiency on Peripheral CD4+ T-Cell Phenotype (30-week-old mice)
| Marker | Cell Phenotype | Wild-Type (% Positive Cells) | Nur77 KO (% Positive Cells) | p-value | Reference(s) |
| CD25 | Early Activation | ~10% | ~18% | < 0.05 | [11][12] |
| CD69 | Early Activation | ~5% | ~12% | < 0.05 | [11][12] |
| CD44hiCD62Llow | Memory Phenotype | ~15% | ~30% | < 0.05 | [11][12] |
Signaling Pathways and Experimental Workflows
Visualizations created using Graphviz DOT language provide a clear overview of the molecular interactions and experimental processes.
References
- 1. Verify Access [regis.lunaimaging.com]
- 2. During negative selection, Nur77 family proteins translocate to mitochondria where they associate with Bcl-2 and expose its proapoptotic BH3 domain - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Functional redundancy of the Nur77 and Nor-1 orphan steroid receptors in T-cell apoptosis - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Endogenous Nur77 is a specific indicator of antigen receptor signaling in human T and B cells - PMC [pmc.ncbi.nlm.nih.gov]
- 5. geneglobe.qiagen.com [geneglobe.qiagen.com]
- 6. Regulation of Negative Selection in the Thymus by Cytokines - Signaling Mechanisms Regulating T Cell Diversity and Function - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. Functional redundancy of the Nur77 and Nor‐1 orphan steroid receptors in T‐cell apoptosis | The EMBO Journal [link.springer.com]
- 9. During negative selection, Nur77 family proteins translocate to mitochondria where they associate with Bcl-2 and expose its proapoptotic BH3 domain - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Protein kinase C regulates mitochondrial targeting of Nur77 and its family member Nor-1 in thymocytes undergoing apoptosis - PMC [pmc.ncbi.nlm.nih.gov]
- 11. pnas.org [pnas.org]
- 12. researchgate.net [researchgate.net]
Validating a Novel NOR-1 Agonist: A Comparative Cell-Based Assay Guide
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive framework for the validation of a newly synthesized Neuron-Derived Orphan Receptor 1 (NOR-1, also known as NR4A3) agonist. It outlines a direct comparison with a known agonist, Cytosporone B, using established cell-based assays. The included protocols and data presentation formats are designed to facilitate objective evaluation and support further development.
Experimental Overview
The validation process employs a two-tiered approach to confirm the efficacy and specificity of the novel compound ("SYN-1"). First, a luciferase reporter assay will quantify the direct activation of the NOR-1 receptor. Second, a quantitative Polymerase Chain Reaction (qPCR) will measure the expression of a known downstream target gene, c-Myc, to verify functional cellular activity.
The Dichotomous Role of NOR-1 in Cancer: A Comparative Analysis of Expression and Signaling Across Subtypes
For Immediate Release
A comprehensive analysis of Neuron-derived orphan receptor 1 (NOR-1), also known as NR4A3, reveals a complex and often contradictory role in the landscape of human cancers. This guide synthesizes current research to provide a comparative overview of NOR-1 expression levels, its associated signaling pathways, and the experimental methodologies used for its characterization across various cancer subtypes. This information is critical for researchers, scientists, and drug development professionals seeking to understand and potentially target this multifaceted nuclear receptor.
NOR-1, a member of the NR4A family of orphan nuclear receptors, functions as a transcription factor that can either promote or suppress tumorigenesis depending on the cellular context. Its expression is significantly altered in a wide range of cancers, with data from large-scale analyses like The Cancer Genome Atlas (TCGA) and numerous individual studies highlighting its differential expression.
Comparative Analysis of NOR-1 (NR4A3) mRNA and Protein Expression
Quantitative data from RNA sequencing (RNA-seq) and protein analysis through immunohistochemistry (IHC) across a panel of cancer types are summarized below. These tables provide a snapshot of the varied expression landscape of NOR-1, underscoring its context-dependent role.
Table 1: Comparative mRNA Expression of NOR-1 (NR4A3) in Various Cancer Subtypes (TCGA RNA-seq Data)
| Cancer Subtype | Expression Level (Median FPKM) in Tumor Tissue | Expression Trend Compared to Normal Tissue | Reference |
| Stomach Adenocarcinoma | ~2.5 | Upregulated | [1] |
| Adrenocortical Carcinoma | ~5 | Upregulated | [2] |
| Hepatocellular Carcinoma (HCC) | ~1.5 | Downregulated | [1][3] |
| Lung Adenocarcinoma | ~1 | Downregulated | [1] |
| Breast Cancer | ~0.8 | Downregulated | [1] |
| Colon Adenocarcinoma | ~0.5 | Downregulated | [1] |
| Rectum Adenocarcinoma | ~0.5 | Downregulated | [1] |
| Bladder Urothelial Carcinoma | ~0.4 | Downregulated | [1] |
| Kidney Renal Clear Cell Carcinoma | ~0.3 | Downregulated | [1] |
| Prostate Adenocarcinoma | ~0.2 | Downregulated | [1] |
| Thyroid Carcinoma | ~0.2 | Downregulated | [1] |
| Uterine Corpus Endometrial Carcinoma | ~0.1 | Downregulated | [1] |
| Ovarian Serous Cystadenocarcinoma | ~0.1 | Downregulated | [1] |
| Pancreatic Adenocarcinoma | ~0.1 | Downregulated | [1] |
| Glioblastoma Multiforme | ~0.1 | Downregulated | [1] |
| Head and Neck Squamous Cell Carcinoma | ~0.1 | Downregulated | [1] |
| Skin Cutaneous Melanoma | ~0.1 | Downregulated | [1] |
FPKM: Fragments Per Kilobase of transcript per Million mapped reads. Data is approximate based on graphical representations in the cited source.
Table 2: Comparative Protein Expression of NOR-1 (NR4A3) in Various Cancer Subtypes (Immunohistochemistry Data)
| Cancer Subtype | Protein Expression Level | Cellular Localization | Reference |
| Acinic Cell Carcinoma | High | Nuclear | [4][5] |
| Hepatocellular Carcinoma (HCC) | Low to Moderate | Cytoplasmic/Nuclear | [1][6] |
| Lymphoma | Weakly stained or Negative | - | [1] |
| Squamous Cell Carcinoma | Weakly stained or Negative | - | [1] |
| Nasopharyngeal Carcinoma (NPC) | Low | Cytoplasmic | [7] |
| Glioma | Low | - | [4] |
| Prostate Cancer | Low | - | [1] |
Experimental Protocols
The determination of NOR-1 expression levels relies on a variety of well-established molecular and cellular biology techniques. Below are synopses of the common experimental protocols cited in the literature.
RNA-Seq Analysis of TCGA Data
Objective: To quantify and compare the mRNA expression levels of NOR-1 (NR4A3) across a wide range of cancer types and corresponding normal tissues.
Methodology:
-
Data Acquisition: RNA-seq data, typically in the form of Fragments Per Kilobase of transcript per Million mapped reads (FPKM) or Transcripts Per Million (TPM), is obtained from The Cancer Genome Atlas (TCGA) database.[2][3]
-
Data Processing: The raw count data is normalized to account for differences in sequencing depth and gene length.
-
Differential Expression Analysis: Statistical methods are employed to identify significant differences in NOR-1 expression between tumor and normal tissues across various cancer cohorts.
-
Survival Analysis: Kaplan-Meier survival analysis is often performed to correlate NOR-1 expression levels with patient prognosis.[3]
Quantitative Real-Time PCR (qRT-PCR)
Objective: To validate RNA-seq data and accurately quantify NOR-1 mRNA levels in specific cancer cell lines or patient-derived tissues.
Methodology:
-
RNA Extraction: Total RNA is isolated from cultured cancer cells or frozen tissue samples using commercially available kits.
-
cDNA Synthesis: Reverse transcription is performed to synthesize complementary DNA (cDNA) from the extracted RNA.
-
Primer Design: Specific primers for the NOR-1 gene and a stable housekeeping gene (e.g., GAPDH, ACTB) are designed and validated.
-
Real-Time PCR: The PCR reaction is carried out in a real-time PCR system using a fluorescent dye (e.g., SYBR Green) to monitor the amplification of the target and reference genes in real-time.
-
Data Analysis: The relative expression of NOR-1 is calculated using the 2-ΔΔCt method, normalized to the expression of the housekeeping gene.[3]
Immunohistochemistry (IHC)
Objective: To visualize and semi-quantitatively assess the protein expression and subcellular localization of NOR-1 in formalin-fixed, paraffin-embedded (FFPE) tumor tissues.
Methodology:
-
Tissue Preparation: FFPE tissue sections are deparaffinized and rehydrated.
-
Antigen Retrieval: Heat-induced epitope retrieval is performed to unmask the antigenic sites.
-
Antibody Incubation: The tissue sections are incubated with a primary antibody specific for NOR-1 (e.g., NOR-1 (H-7) sc-393902, Santa Cruz Biotechnology).[4][5]
-
Detection: A secondary antibody conjugated to an enzyme (e.g., HRP) is applied, followed by a chromogenic substrate (e.g., DAB) to produce a colored precipitate at the site of the antigen.
-
Counterstaining: The sections are counterstained with hematoxylin (B73222) to visualize the cell nuclei.
-
Scoring: The staining intensity and the percentage of positive cells are evaluated by a pathologist to determine the expression level.[1][6]
Signaling Pathways and Logical Relationships
The functional role of NOR-1 in cancer is dictated by its involvement in various signaling pathways that regulate cell proliferation, apoptosis, and differentiation. The following diagrams, generated using the DOT language, illustrate some of the key signaling cascades influenced by NOR-1 in different cancer contexts.
Caption: NOR-1 as a Tumor Suppressor.
In some cancers, such as breast and lung cancer, NOR-1 acts as a tumor suppressor.[8][9] It is a direct transcriptional target of the tumor suppressor p53.[8] Upregulated NOR-1 can then promote apoptosis by increasing the expression of pro-apoptotic proteins like Bax and PUMA, and by directly binding to and inhibiting the anti-apoptotic protein Bcl-2.[8] Furthermore, in hepatocellular carcinoma, NOR-1 can induce cell cycle arrest at the G0/G1 phase by upregulating the transcription of CDKN2AIP.[10]
Caption: NOR-1 as an Oncogene in HCC.
Conversely, in certain contexts of hepatocellular carcinoma, NOR-1 has been shown to act as an oncogene.[2] Overexpression of NOR-1 can activate the Notch signaling pathway, leading to increased levels of Notch1 and its active intracellular domain (NICD).[2] This, in turn, upregulates the transcription of downstream targets Hes1 and Hey1, which promote cell proliferation and migration.[2]
References
- 1. spandidos-publications.com [spandidos-publications.com]
- 2. NOR1 promotes hepatocellular carcinoma cell proliferation and migration through modulating the Notch signaling pathway - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Oxidored-nitro domain-containing protein 1 expression is associated with the progression of hepatocellular carcinoma - PMC [pmc.ncbi.nlm.nih.gov]
- 4. The tumor suppressor NOR1 suppresses cell growth, invasiveness, and tumorigenicity in glioma - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. encyclopedia.pub [encyclopedia.pub]
- 6. Signaling Pathways in Leukemic Stem Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 7. spandidos-publications.com [spandidos-publications.com]
- 8. Orphan receptor NR4A3 is a novel target of p53 that contributes to apoptosis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Frontiers | Targeting NR4A Nuclear Receptors to Control Stromal Cell Inflammation, Metabolism, Angiogenesis, and Tumorigenesis [frontiersin.org]
- 10. NR4A3 inhibits the tumor progression of hepatocellular carcinoma by inducing cell cycle G0/G1 phase arrest and upregulation of CDKN2AIP expression [ijbs.com]
Differential Gene Regulation by NOR-1 and Nurr1 in Macrophages: A Comparative Guide
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive comparison of the differential roles of Neuron-derived orphan receptor 1 (NOR-1, also known as NR4A3) and Nuclear receptor related 1 (Nurr1, also known as NR4A2) in macrophage gene regulation. As members of the NR4A orphan nuclear receptor family, both transcription factors are crucial in modulating macrophage functions, particularly in the context of inflammation and polarization. Understanding their distinct regulatory networks is pivotal for developing targeted therapeutics for inflammatory diseases and cancer.
At a Glance: NOR-1 vs. Nurr1 in Macrophage Polarization
| Feature | NOR-1 (NR4A3) | Nurr1 (NR4A2) |
| Predominant Macrophage Phenotype | M2 (Alternatively Activated) | M1 (Classically Activated) |
| Primary Stimulus | Interleukin-4 (IL-4) | Lipopolysaccharide (LPS) and other pro-inflammatory signals |
| Key Function | Promotes M2 polarization and anti-inflammatory responses | Acts as a brake on pro-inflammatory responses in M1 macrophages |
| Signaling Pathway Interaction | IL-4 signaling pathway | NF-κB signaling pathway |
Quantitative Analysis of Target Gene Regulation
The differential effects of NOR-1 and Nurr1 are evident in the distinct sets of genes they regulate within different macrophage subtypes.
NOR-1-Mediated Gene Upregulation in M2 Macrophages
Overexpression of NOR-1 in human macrophages, particularly in the context of alternative activation (M2 polarization) by IL-4, leads to the upregulation of key M2 markers. While extensive quantitative high-throughput data is still emerging, studies have shown that silencing NOR-1 in human alternative macrophages decreases the expression of several M2 markers, indicating its positive regulatory role.[1]
| Target Gene | Gene Symbol | Function |
| Mannose Receptor | MRC1 | Pattern recognition receptor, phagocytosis |
| Interleukin-1 Receptor Antagonist | IL1RN | Anti-inflammatory cytokine |
| CD200 Receptor | CD200R1 | Immune suppression |
| Coagulation factor XIII A1 | F13A1 | Tissue repair, cross-linking of fibrin |
| Interleukin 10 | IL10 | Anti-inflammatory cytokine |
| Peroxisome Proliferator-Activated Receptor γ | PPARG | M2 polarization, lipid metabolism |
Data derived from studies involving silencing of NOR-1, which leads to decreased expression of these M2 markers.
Nurr1-Mediated Gene Downregulation in M1 Macrophages
Nurr1 is preferentially expressed in pro-inflammatory (M1) macrophages and functions to limit the inflammatory response.[2][3] Activation of Nurr1 has been shown to decrease the production of a range of pro-inflammatory cytokines and chemokines.[3][4] Furthermore, knockdown of Nurr1 results in increased expression of these inflammatory mediators.[2]
| Target Gene | Gene Symbol | Function |
| Tumor Necrosis Factor | TNF | Pro-inflammatory cytokine |
| Interleukin-1β | IL1B | Pro-inflammatory cytokine |
| Interleukin-6 | IL6 | Pro-inflammatory cytokine |
| Interleukin-8 | CXCL8 | Chemokine (neutrophil chemoattractant) |
| C-C Motif Chemokine Ligand 2 | CCL2 | Chemokine (monocyte chemoattractant) |
| Interferon β1 | IFNB1 | Antiviral and immunomodulatory cytokine |
| Ras Guanyl Releasing Protein 1 | RASGRP1 | Signal transduction |
Data derived from studies involving Nurr1 activation or deficiency, demonstrating its inhibitory role on the expression of these pro-inflammatory genes.
Signaling Pathways and Regulatory Mechanisms
The differential gene regulation by NOR-1 and Nurr1 stems from their integration into distinct signaling pathways that define macrophage polarization states.
NOR-1 in the IL-4-Mediated M2 Polarization Pathway
NOR-1 is a key downstream effector of the IL-4 signaling cascade, which drives M2 macrophage polarization. IL-4 stimulation initiates a signaling cascade that leads to the expression and activation of NOR-1, which in turn promotes the expression of M2-specific genes.
Caption: IL-4 signaling pathway leading to NOR-1-mediated M2 gene expression.
Nurr1 in the LPS-Induced M1 Inflammatory Pathway
In M1 macrophages, Nurr1 expression is induced by pro-inflammatory stimuli such as LPS.[5] Nurr1 then acts as a negative feedback regulator by interfering with the NF-κB signaling pathway, a central driver of inflammation. Mechanistically, Nurr1 can interact with the p65 subunit of NF-κB, leading to the recruitment of the CoREST corepressor complex and subsequent transrepression of NF-κB target genes.[2]
Caption: Nurr1-mediated negative feedback loop in the LPS/NF-κB pathway.
Experimental Protocols
Detailed methodologies are crucial for the replication and validation of the findings discussed. Below are summaries of key experimental protocols.
Macrophage Differentiation and Polarization
-
Cell Source: Human peripheral blood mononuclear cells (PBMCs) are isolated from healthy donor blood by Ficoll-Paque density gradient centrifugation. Monocytes are then purified by magnetic-activated cell sorting (MACS) using CD14 microbeads. Alternatively, the human monocytic cell line THP-1 can be used.
-
Differentiation: Monocytes are differentiated into macrophages by culturing for 5-7 days in RPMI-1640 medium supplemented with 10% fetal bovine serum (FBS), 1% penicillin-streptomycin, and either 50 ng/mL of macrophage colony-stimulating factor (M-CSF) for M2 polarization or 50 ng/mL of granulocyte-macrophage colony-stimulating factor (GM-CSF) for M1 polarization.
-
Polarization:
-
M1 Polarization: Differentiated macrophages are stimulated with 100 ng/mL of lipopolysaccharide (LPS) and 20 ng/mL of interferon-gamma (IFN-γ) for 24-48 hours.
-
M2 Polarization: Differentiated macrophages are stimulated with 20 ng/mL of interleukin-4 (IL-4) for 24-48 hours.
-
Lentiviral Overexpression of NOR-1 and Nurr1
-
Vector Production: Human NOR-1 or Nurr1 cDNA is cloned into a lentiviral expression vector (e.g., pLVX-Puro). Lentiviral particles are produced by co-transfecting HEK293T cells with the expression vector and packaging plasmids (e.g., psPAX2 and pMD2.G) using a transfection reagent like Lipofectamine 3000.
-
Transduction: Differentiated macrophages are transduced with the collected lentiviral particles at a specific multiplicity of infection (MOI) in the presence of polybrene (8 µg/mL).
-
Selection: Transduced cells are selected with puromycin (B1679871) (1-2 µg/mL) for 48-72 hours to obtain a stable population of cells overexpressing the target protein.
Chromatin Immunoprecipitation (ChIP) Sequencing
-
Cross-linking: Macrophages are cross-linked with 1% formaldehyde (B43269) for 10 minutes at room temperature to fix protein-DNA interactions. The reaction is quenched with glycine.
-
Chromatin Shearing: Cells are lysed, and the chromatin is sheared to an average size of 200-500 bp using a sonicator.
-
Immunoprecipitation: The sheared chromatin is incubated overnight at 4°C with an antibody specific to the transcription factor of interest (e.g., anti-Nurr1 or anti-NOR-1) or a control IgG. The antibody-chromatin complexes are captured using protein A/G magnetic beads.
-
DNA Purification: The cross-links are reversed, and the DNA is purified using a spin column-based kit.
-
Library Preparation and Sequencing: The purified DNA is used to prepare a sequencing library, which is then sequenced on a next-generation sequencing platform.
RNA Sequencing (RNA-seq) and Data Analysis
-
RNA Extraction: Total RNA is extracted from polarized macrophages using a TRIzol-based method or a commercial kit.
-
Library Preparation: mRNA is enriched using oligo(dT) magnetic beads, fragmented, and reverse-transcribed into cDNA. Sequencing adapters are ligated to the cDNA fragments.
-
Sequencing: The prepared libraries are sequenced on a high-throughput sequencing platform.
-
Data Analysis: The raw sequencing reads are quality-controlled, aligned to the human reference genome, and the number of reads mapping to each gene is counted. Differential gene expression analysis is performed using packages like DESeq2 or edgeR to identify genes that are significantly up- or downregulated between different conditions.
Experimental Workflow Visualization
Caption: Overview of the experimental workflow for studying NOR-1 and Nurr1.
Conclusion
NOR-1 and Nurr1, despite being members of the same nuclear receptor subfamily, exhibit distinct and context-dependent roles in macrophage gene regulation. NOR-1 is a key driver of the M2 phenotype in response to IL-4, promoting an anti-inflammatory and tissue-reparative gene program. In contrast, Nurr1 is induced in M1 macrophages by pro-inflammatory signals and functions as a crucial negative feedback regulator to dampen excessive inflammation. This differential gene regulation underscores the complexity of macrophage biology and highlights NOR-1 and Nurr1 as promising, yet distinct, therapeutic targets for a variety of diseases underpinned by macrophage dysfunction. Further research, particularly utilizing high-throughput sequencing techniques, will continue to unravel the intricacies of their regulatory networks and inform the development of next-generation immunomodulatory therapies.
References
- 1. creative-diagnostics.com [creative-diagnostics.com]
- 2. QIAGEN Bioinformatics Manuals [resources.qiagenbioinformatics.com]
- 3. The nuclear receptor Nurr1 is preferentially expressed in human pro-inflammatory macrophages and limits their inflammatory profile - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. ahajournals.org [ahajournals.org]
Binding Affinity of NOR-1 and Nurr1 to the NBRE: A Comparative Guide
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comparative analysis of the binding affinity of two closely related orphan nuclear receptors, NOR-1 (NR4A3) and Nurr1 (NR4A2), to the Nerve Growth Factor-Induced gene B Response Element (NBRE). Both NOR-1 and Nurr1 are members of the NR4A subfamily of transcription factors and play crucial roles in a variety of physiological processes, including neuronal function, inflammation, and metabolism. They exert their effects by binding to specific DNA sequences in the promoter regions of target genes, with the NBRE (5'-AAAGGTCA-3') being a key response element for their monomeric activity.
Executive Summary
This guide presents a qualitative comparison based on existing literature, detailed experimental protocols for assessing binding affinity, and an overview of their respective signaling pathways.
Qualitative Comparison of NBRE Binding
| Feature | NOR-1 (NR4A3) | Nurr1 (NR4A2) |
| Binding to NBRE | Binds as a monomer to the NBRE to activate transcription.[1][2][3] | Binds as a monomer to the NBRE to activate transcription.[4][5][6][7] |
| Quantitative Affinity (Kd) | Specific Kd value for NBRE binding is not well-documented in publicly available literature. | Specific Kd value for monomeric NBRE binding is not consistently reported in publicly available literature. |
| Functional Outcomes | Regulates genes involved in vascular remodeling, inflammation, and cell survival through NBRE binding.[1] | Crucial for the development and maintenance of dopaminergic neurons by regulating target genes via the NBRE.[5] |
Experimental Protocols
To quantitatively determine and compare the binding affinities of NOR-1 and Nurr1 to the NBRE, researchers can employ techniques such as the Electrophoretic Mobility Shift Assay (EMSA) or Surface Plasmon Resonance (SPR). Below are detailed, generalized protocols for these methods.
Electrophoretic Mobility Shift Assay (EMSA)
EMSA is a common technique used to study protein-DNA interactions. The principle is based on the fact that a protein-DNA complex will migrate more slowly than the free DNA fragment in a non-denaturing polyacrylamide gel.
1. Preparation of NBRE Probe:
- Synthesize complementary single-stranded oligonucleotides corresponding to the NBRE sequence (e.g., 5'-GATCCGAAAAAGGTCA TCGAG-3' and 3'-GCTTTTTCCAGT AGCTCCTAG-5'), including flanking sequences for stability and labeling.
- Anneal the oligonucleotides to form a double-stranded DNA probe.
- Label the probe at the 5' or 3' end with a radioactive isotope (e.g., 32P) using T4 polynucleotide kinase or with a non-radioactive label (e.g., biotin, fluorescent dye).
- Purify the labeled probe to remove unincorporated nucleotides.
2. Protein Preparation:
- Express and purify recombinant NOR-1 and Nurr1 proteins (full-length or DNA-binding domain).
- Determine the protein concentration accurately using a method such as the Bradford or BCA assay.
3. Binding Reaction:
- In a final volume of 20 µL, combine the following in order:
- Binding Buffer (e.g., 10 mM Tris-HCl pH 7.5, 50 mM KCl, 1 mM DTT, 5% glycerol).
- Non-specific competitor DNA (e.g., 1 µg poly(dI-dC)) to prevent non-specific binding.
- Varying concentrations of the purified NOR-1 or Nurr1 protein.
- A constant, low concentration of the labeled NBRE probe (e.g., 20-50 fmol).
- Incubate the reaction mixture at room temperature for 20-30 minutes.
4. Electrophoresis:
- Load the samples onto a pre-run 4-6% non-denaturing polyacrylamide gel.
- Run the gel in a low ionic strength buffer (e.g., 0.5X TBE) at 4°C to minimize complex dissociation.
5. Detection and Analysis:
- For radioactive probes, dry the gel and expose it to a phosphor screen or X-ray film.
- For non-radioactive probes, transfer the DNA to a nylon membrane and detect using appropriate methods (e.g., streptavidin-HRP for biotin).
- Quantify the intensity of the bands corresponding to the free probe and the protein-DNA complex.
- The dissociation constant (Kd) can be calculated by plotting the fraction of bound probe against the protein concentration and fitting the data to a binding isotherm (e.g., the Hill equation).
Signaling Pathways
Both NOR-1 and Nurr1 are immediate-early genes, meaning their expression is rapidly and transiently induced by a wide range of extracellular signals. Once expressed, they act as transcription factors to regulate downstream gene networks.
NOR-1 Signaling:
NOR-1 is involved in various cellular processes, including proliferation, apoptosis, and inflammation. Its expression is induced by stimuli such as growth factors, cytokines, and cellular stress. In vascular smooth muscle cells, NOR-1 promotes proliferation by transactivating the Skp2 promoter through an NBRE.[1] In endothelial cells, it has a pro-survival role by inducing the expression of the anti-apoptotic protein cIAP2, also via an NBRE.[1] Furthermore, NOR-1 plays a role in the development and function of regulatory T cells, highlighting its importance in immune homeostasis.[1]
Nurr1 Signaling:
Nurr1 is essential for the development, maintenance, and survival of midbrain dopaminergic neurons.[5] Its dysregulation is linked to neurodegenerative diseases like Parkinson's disease. Nurr1's transcriptional activity is critical for the expression of genes involved in dopamine (B1211576) synthesis and transport, such as tyrosine hydroxylase (TH).[4][5] The expression and activity of Nurr1 are regulated by multiple signaling pathways, including those involving ERK2 and ERK5.[8] Nurr1 can also be recruited to NBRE-containing promoters by these kinases to enhance its transcriptional activity.[8]
Visualizations
References
- 1. NR4A3: A Key Nuclear Receptor in Vascular Biology, Cardiovascular Remodeling, and Beyond - PMC [pmc.ncbi.nlm.nih.gov]
- 2. NR4A3 nuclear receptor subfamily 4 group A member 3 [Homo sapiens (human)] - Gene - NCBI [ncbi.nlm.nih.gov]
- 3. uniprot.org [uniprot.org]
- 4. Assessment of NR4A Ligands that Directly Bind and Modulate the Orphan Nuclear Receptor Nurr1 - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. Frontiers | Nr4a2 Transcription Factor in Hippocampal Synaptic Plasticity, Memory and Cognitive Dysfunction: A Perspective Review [frontiersin.org]
- 7. Differential Regulation of Transcription by the NURR1/NUR77 Subfamily of Nuclear Transcription Factors - PMC [pmc.ncbi.nlm.nih.gov]
- 8. ovid.com [ovid.com]
Functional Redundancy Between NOR-1 and Other NR4A Family Members: A Comparative Guide
For Researchers, Scientists, and Drug Development Professionals
The NR4A family of orphan nuclear receptors, comprising NOR-1 (NR4A3), Nur77 (NR4A1), and Nurr1 (NR4A2), are crucial regulators of various physiological processes, including apoptosis, inflammation, and metabolism.[1][2] These transcription factors are classified as immediate early genes, rapidly induced by a multitude of signals.[1] A significant body of evidence points towards a considerable degree of functional redundancy among these family members, particularly between NOR-1 and Nur77. This guide provides a comprehensive comparison of their functions, supported by experimental data, detailed protocols, and signaling pathway diagrams to elucidate their overlapping and distinct roles.
Overlapping Roles in T-Cell Apoptosis
A primary area of functional redundancy between NOR-1 and Nur77 is in the regulation of T-cell receptor (TCR)-mediated apoptosis.[3][4][5] Initial studies of Nur77-deficient mice revealed no discernible phenotype, suggesting a compensatory mechanism from other functionally similar proteins.[4][5] Subsequent research identified NOR-1 as the key redundant player in this process.
Both NOR-1 and Nur77 are rapidly induced in thymocytes following TCR stimulation, whereas Nurr1 expression is undetectable in this context.[3][4] This co-induction points to their shared involvement in the apoptotic response. Further evidence for their redundant functions comes from studies using transgenic mice. Constitutive expression of either NOR-1 or Nur77 in thymocytes leads to massive apoptosis, highlighting their potent and similar pro-apoptotic capabilities.[3][4] This apoptotic pathway appears to be independent of the Fas/FasL signaling axis.[3][4]
The molecular basis for this redundancy lies in their shared ability to bind to the same DNA response element, the NGFI-B response element (NBRE), and transactivate downstream target genes.[3] Experiments have shown that both NOR-1 and Nur77 can activate a reporter gene under the control of NBRE.[3] Furthermore, a dominant-negative form of Nur77 can inhibit the transactivation activity of both its own and that of NOR-1, indicating a shared mechanism of action.[3]
Quantitative Data Comparison
The following tables summarize the quantitative data from key experiments comparing the activities of NOR-1 and other NR4A family members.
Table 1: Transactivation of NBRE-Luciferase Reporter Gene
This table presents the fold induction of luciferase activity in Jurkat T-cells transfected with expression plasmids for each NR4A family member and a reporter construct containing three copies of the NBRE. Data is sourced from Cheng et al., 1997, The EMBO Journal.[3]
| NR4A Family Member | Fold Induction of Luciferase Activity (Mean ± SD) |
| Nur77 (NR4A1) | >400 |
| Nurr1 (NR4A2) | ~100 |
| NOR-1 (NR4A3) | ~100 |
Data are the average of three independent experiments. Fold induction is calculated relative to a vector control.[3]
Table 2: Phenotypic Comparison of Transgenic Mice
This table provides a qualitative comparison of the phenotypes observed in transgenic mice overexpressing different NR4A family members in thymocytes, based on findings from Cheng et al., 1997, The EMBO Journal.[3]
| Transgene | Thymocyte Phenotype | CD25 Upregulation |
| Nur77 (NR4A1) | Massive Apoptosis | Yes |
| Nurr1 (NR4A2) | No significant change | Not reported |
| NOR-1 (NR4A3) | Massive Apoptosis | Yes |
Experimental Protocols
NBRE-Driven Reporter Gene Assay
This protocol is adapted from the methodology described in Cheng et al., 1997, The EMBO Journal, used to quantify the transactivation potential of NR4A family members.[3]
Objective: To measure the ability of NOR-1, Nur77, and Nurr1 to activate transcription from the NBRE.
Materials:
-
Jurkat T-cells
-
Expression plasmids: pCI-Nur77, pCI-Nurr1, pCI-Nor-1
-
Reporter plasmid: 3xNBRE-luciferase (containing three copies of the NBRE upstream of a luciferase gene)
-
Control plasmid: pCI (empty vector)
-
Transfection reagent (e.g., DEAE-dextran)
-
Luciferase assay system
-
Luminometer
Method:
-
Culture Jurkat T-cells to the appropriate density for transfection.
-
Co-transfect the cells with an NR4A expression plasmid (or empty vector control) and the 3xNBRE-luciferase reporter plasmid using DEAE-dextran. Ensure equimolar concentrations of the expression plasmids are used across different experimental groups.
-
Incubate the transfected cells for 36-48 hours.
-
Lyse the cells and prepare cell extracts.
-
Measure the luciferase activity in the cell extracts using a luminometer according to the manufacturer's instructions for the luciferase assay system.
-
Calculate the fold induction of luciferase activity by normalizing the readings from cells transfected with NR4A expression plasmids to the readings from cells transfected with the empty vector control.
Generation and Analysis of Transgenic Mice
This protocol outlines the general workflow for creating and analyzing transgenic mice that constitutively express NR4A family members in thymocytes, based on the approach in Cheng et al., 1997, The EMBO Journal.[3]
Objective: To assess the in vivo function of NOR-1, Nur77, and Nurr1 in T-cell development and apoptosis.
Materials:
-
Transgenic constructs: Full-length cDNAs for mouse Nur77, Nurr1, and NOR-1 cloned into an expression vector suitable for generating transgenic mice (e.g., under the control of a ubiquitous promoter).
-
Fertilized mouse eggs
-
Pseudopregnant female mice
-
Microinjection apparatus
-
Flow cytometer
-
Antibodies for cell surface markers (e.g., CD4, CD8, CD25)
-
Apoptosis detection kit (e.g., Annexin V staining)
Method:
-
Generation of Transgenic Mice:
-
Microinject the purified transgenic DNA construct into the pronuclei of fertilized mouse eggs.
-
Implant the microinjected eggs into the oviducts of pseudopregnant female mice.
-
Screen the resulting offspring for the presence of the transgene by PCR analysis of tail DNA.
-
-
Analysis of Thymocyte Populations:
-
Isolate thymocytes from transgenic and wild-type control mice.
-
Perform flow cytometry to analyze the different thymocyte subpopulations based on the expression of CD4 and CD8.
-
Quantify the total number of thymocytes.
-
-
Apoptosis Assay:
-
Stain thymocytes with Annexin V and a viability dye (e.g., propidium (B1200493) iodide).
-
Analyze the percentage of apoptotic cells (Annexin V positive) by flow cytometry.
-
-
Analysis of Activation Markers:
-
Stain thymocytes with antibodies against activation markers such as CD25.
-
Analyze the expression of these markers on different thymocyte subpopulations by flow cytometry.
-
Signaling Pathways and Workflows
References
- 1. revvity.com [revvity.com]
- 2. pnas.org [pnas.org]
- 3. Functional redundancy of the Nur77 and Nor‐1 orphan steroid receptors in T‐cell apoptosis | The EMBO Journal [link.springer.com]
- 4. Functional redundancy of the Nur77 and Nor-1 orphan steroid receptors in T-cell apoptosis - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Functional redundancy of the Nur77 and Nor-1 orphan steroid receptors in T-cell apoptosis - PubMed [pubmed.ncbi.nlm.nih.gov]
Validating NOR-1 as a Therapeutic Target: A Preclinical Comparison Guide
For Researchers, Scientists, and Drug Development Professionals
This guide provides an objective comparison of Neuron-derived orphan receptor 1 (NOR-1) as a therapeutic target in various preclinical models. We present supporting experimental data, detailed methodologies for key experiments, and a comparative analysis with alternative therapeutic strategies.
Executive Summary
Neuron-derived orphan receptor 1 (NOR-1), a member of the NR4A nuclear receptor subfamily, has emerged as a promising therapeutic target in a range of diseases, including cardiovascular disorders, cancer, and metabolic conditions. Preclinical studies have demonstrated that modulation of NOR-1 activity can significantly impact disease progression. This guide summarizes the key preclinical findings, compares NOR-1 targeting with alternative approaches, and provides detailed experimental protocols to aid in the design and interpretation of future studies.
Data Presentation: Quantitative Comparison of NOR-1 Modulation in Preclinical Models
The following tables summarize the quantitative data from key preclinical studies investigating the therapeutic potential of NOR-1.
Table 1: NOR-1 in Doxorubicin-Induced Cardiotoxicity
| Experimental Model | Intervention | Key Assays | Results | Reference |
| AC16 human cardiomyocytes | Overexpression of NOR-1 + 5 µM Doxorubicin (12h) | LDH Activity Assay (Cell Death) | Decreased cell death (p<0.05) compared to control. | [1][2] |
| MTT Assay (Cell Viability) | Increased cell viability (p<0.05) compared to control. | [1][2] | ||
| Caspase-3 Activity Assay (Apoptosis) | Significant reduction in caspase-3 activity (p<0.01) compared to control. | [1][2] | ||
| Western Blot | Increased expression of Bcl-xL (p<0.01) and phosphorylation of ERK (p<0.01). | [1][2] |
Table 2: NOR-1 in Abdominal Aortic Aneurysm (AAA)
| Experimental Model | Intervention | Key Parameters Measured | Results | Reference |
| Transgenic mice overexpressing NOR-1 in vascular wall | Angiotensin II infusion | Incidence and severity of AAA | Similar incidence and severity of AAA in two different transgenic models. | [3] |
| Vascular inflammation, MMP activity, elastin (B1584352) integrity | Exacerbated Ang II-induced inflammation, MMP activity, and elastin disruption. | [3] | ||
| Effect of MMP inhibitor (doxycycline) | Prevention of AAA formation and associated pathological changes. | [3] |
Table 3: NOR-1 in Cancer
| Experimental Model | Intervention | Key Parameters Measured | Results | Reference |
| Human nasopharyngeal carcinoma (6-10B) and cervical cancer (HeLa) cells | Stable NOR-1 overexpression | Cell proliferation, cell cycle, apoptosis | Suppression of cell proliferation, S-phase cell cycle arrest, and enhanced apoptosis. | |
| Prostate cancer PC3 cells | NOR-1 overexpression | Apoptosis-related protein expression | Decreased Bcl-2 and Bcl-xl; increased Bax and Bak; activation of caspase-3. | |
| PC3 tumor-bearing nude mice | NOR-1 overexpression | Tumor growth | Significant inhibition of tumor growth. |
Comparison with Alternative Therapeutic Targets
Abdominal Aortic Aneurysm (AAA)
| Therapeutic Target | Mechanism of Action | Preclinical Model | Key Findings |
| NOR-1 | Transcription factor involved in vascular inflammation and remodeling. | Transgenic mice overexpressing NOR-1 | Exacerbates Ang II-induced AAA formation.[3] |
| mPGES-1 | Enzyme involved in prostaglandin (B15479496) E2 synthesis, a key inflammatory mediator. | ApoE-/- angiotensin II mouse model | A selective inhibitor (UK4b) completely blocked further growth of AAA. |
| Stem Cells | Modulate local immunoinflammatory reactions and promote tissue regeneration. | Swine model of AAA | Stem cell-treated AAAs demonstrated no growth (-1.6 ± 8.8% vs. 34.8 ± 13.7% in controls, p<0.001). |
Cancer
| Therapeutic Target | Therapeutic Approach | Preclinical Model | Key Findings |
| NOR-1 | Overexpression | Prostate cancer xenograft | Significantly inhibited tumor growth. |
| IGF-1R | Antisense oligonucleotide (CT102) | Orthotopic mouse xenograft (HepG2) | Suppressed tumor growth in a dose-dependent manner (up to 83.9% inhibition).[4] |
| Neuropilin-1 (NRP1) | Antisense oligonucleotide (SECN-15) | Syngeneic murine tumor models | Monotherapy induced significant tumor growth delay and complete tumor regression in 20% of animals. Combination with anti-PD-1 led to complete tumor eradication in ~70% of animals.[5] |
Experimental Protocols
Detailed methodologies for the key experiments cited in this guide are provided below.
Cell Viability (MTT) Assay
-
Cell Seeding: Plate cells in a 96-well plate at a density of 1 x 10^4 cells/well and incubate for 24 hours.
-
Treatment: Treat cells with the desired concentrations of the test compound (e.g., doxorubicin) for the specified duration.
-
MTT Addition: Add 20 µL of MTT solution (5 mg/mL in PBS) to each well and incubate for 4 hours at 37°C.
-
Solubilization: Remove the medium and add 150 µL of DMSO to each well to dissolve the formazan (B1609692) crystals.
-
Absorbance Measurement: Measure the absorbance at 570 nm using a microplate reader. Cell viability is expressed as a percentage of the control.
Caspase-3 Activity Assay
-
Cell Lysis: Lyse cells with a specific lysis buffer on ice for 10 minutes.
-
Protein Quantification: Determine the protein concentration of the cell lysates using a BCA protein assay.
-
Assay Reaction: In a 96-well plate, mix cell lysate with a reaction buffer containing the caspase-3 substrate (e.g., DEVD-pNA).
-
Incubation: Incubate the plate at 37°C for 1-2 hours.
-
Absorbance Measurement: Measure the absorbance at 405 nm. The fold-increase in caspase-3 activity is determined by comparing the results from treated and untreated cells.
Western Blotting
-
Protein Extraction and Quantification: Extract total protein from cells or tissues using RIPA buffer and determine the concentration using a BCA assay.
-
SDS-PAGE: Separate 20-40 µg of protein per lane on a 10-12% SDS-polyacrylamide gel.
-
Protein Transfer: Transfer the separated proteins to a PVDF membrane.
-
Blocking: Block the membrane with 5% non-fat milk in TBST for 1 hour at room temperature.
-
Primary Antibody Incubation: Incubate the membrane with primary antibodies (e.g., anti-NOR-1, anti-Bcl-2, anti-Bax, anti-caspase-3, anti-β-actin) overnight at 4°C.
-
Secondary Antibody Incubation: Wash the membrane with TBST and incubate with HRP-conjugated secondary antibody for 1 hour at room temperature.
-
Detection: Visualize the protein bands using an enhanced chemiluminescence (ECL) detection system.
Quantitative Real-Time PCR (RT-qPCR)
-
RNA Extraction: Isolate total RNA from cells or tissues using TRIzol reagent according to the manufacturer's instructions.
-
cDNA Synthesis: Reverse transcribe 1 µg of total RNA into cDNA using a high-capacity cDNA reverse transcription kit.
-
qPCR Reaction: Perform qPCR using a SYBR Green master mix and gene-specific primers on a real-time PCR system. A typical thermal cycling profile is: 95°C for 10 min, followed by 40 cycles of 95°C for 15s and 60°C for 1 min.
-
Data Analysis: Analyze the data using the 2^-ΔΔCt method, with a housekeeping gene (e.g., GAPDH) for normalization.
Mandatory Visualizations
Signaling Pathways and Experimental Workflows
Caption: NOR-1 signaling in cellular stress and disease.
Caption: General workflow for therapeutic target validation.
Caption: Comparison of therapeutic targets in AAA.
References
- 1. Overexpression of Neuron-Derived Orphan Receptor 1 (NOR-1) Rescues Cardiomyocytes from Cell Death and Improves Viability after Doxorubicin Induced Stress - PMC [pmc.ncbi.nlm.nih.gov]
- 2. nva.sikt.no [nva.sikt.no]
- 3. ahajournals.org [ahajournals.org]
- 4. Preclinical and phase I studies of an antisense oligonucleotide drug targeting IGF-1R in liver cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Secarna Pharmaceuticals presents data at SITC demonstrating the potential of antisense oligonucleotides in targeting NRP1 [secarna.com]
A Researcher's Guide to Selecting and Validating NR4A3 siRNA Sequences
For researchers and drug development professionals targeting the nuclear receptor subfamily 4 group A member 3 (NR4A3), effective and specific gene silencing using small interfering RNA (siRNA) is a critical first step. This guide provides a framework for the side-by-side comparison of different NR4A3 siRNA sequences, supported by experimental protocols and an understanding of the underlying signaling pathways. While publicly available data directly comparing multiple NR4A3 siRNA sequences is limited, this guide offers a template for conducting such comparisons in your own research.
Side-by-Side Comparison of NR4A3 siRNA Sequences
A direct comparison of knockdown efficiency and off-target effects is essential for selecting the optimal siRNA sequence for your experiments. Below is a table summarizing published siRNA sequences targeting human NR4A3 and a template for your own comparative studies.
Table 1: Comparison of Human NR4A3 siRNA Sequences
| siRNA Identifier | Sequence (5'-3') | Predicted Efficacy (%) | Observed Knockdown Efficiency (mRNA, %)a | Observed Knockdown Efficiency (Protein, %)a | Cell Viability (%)b | Off-Target Effectsc | Source |
| si-h-NR4A3_001 | CGAGCAACUACGAACUCAATT | Data not available | User-determined | User-determined | User-determined | User-determined | [1] |
| si-h-NR4A3_002 | CAAGAGAACAGUGCAGAAATT | Data not available | User-determined | User-determined | User-determined | User-determined | [1] |
| Your Candidate 1 | Enter sequence | Use prediction tool | Measure by RT-qPCR | Measure by Western Blot | Measure by MTT/alamarBlue | Measure by RNA-seq/microarray | In-house/Vendor |
| Your Candidate 2 | Enter sequence | Use prediction tool | Measure by RT-qPCR | Measure by Western Blot | Measure by MTT/alamarBlue | Measure by RNA-seq/microarray | In-house/Vendor |
| Control siRNA | Non-targeting sequence | N/A | No significant change | No significant change | ~100% | Minimal changes | Vendor |
aKnockdown efficiency should be determined relative to a non-targeting control siRNA. bCell viability should be assessed to identify potential toxicity of the siRNA sequence or transfection reagent. cOff-target effects can be initially predicted using bioinformatics tools and experimentally validated through whole-transcriptome analysis.
Experimental Protocols
To ensure reproducible and comparable results, standardized experimental protocols are crucial. The following are detailed methodologies for key experiments in siRNA validation.
siRNA Transfection Protocol (General)
This protocol is a general guideline and should be optimized for your specific cell line and siRNA.
-
Cell Seeding: Twenty-four hours before transfection, seed cells in antibiotic-free growth medium to achieve 60-80% confluency at the time of transfection.
-
siRNA-Lipid Complex Formation:
-
In tube A, dilute the desired concentration of siRNA (e.g., 10-50 nM) in serum-free medium.
-
In tube B, dilute the appropriate amount of transfection reagent (e.g., Lipofectamine™ RNAiMAX) in serum-free medium.
-
Add the contents of tube A to tube B, mix gently, and incubate at room temperature for 15-20 minutes.
-
-
Transfection:
-
Aspirate the cell culture medium and wash the cells once with serum-free medium.
-
Add the siRNA-lipid complexes to the cells.
-
Incubate the cells for 4-6 hours at 37°C in a CO2 incubator.
-
Add antibiotic-free complete growth medium to the cells and continue incubation.
-
-
Post-Transfection Analysis: Analyze gene and protein expression 24-72 hours post-transfection.
Quantification of NR4A3 mRNA Knockdown by RT-qPCR
-
RNA Extraction: At 24-48 hours post-transfection, lyse the cells and extract total RNA using a commercially available kit.
-
cDNA Synthesis: Reverse transcribe the RNA to cDNA using a reverse transcriptase kit.
-
qPCR: Perform quantitative PCR using primers specific for NR4A3 and a housekeeping gene (e.g., GAPDH, ACTB).
-
Data Analysis: Calculate the relative expression of NR4A3 using the ΔΔCt method, normalizing to the housekeeping gene and comparing to cells treated with a non-targeting control siRNA.
Quantification of NR4A3 Protein Knockdown by Western Blot
-
Protein Lysate Preparation: At 48-72 hours post-transfection, lyse the cells in RIPA buffer containing protease inhibitors.
-
Protein Quantification: Determine the protein concentration of each lysate using a BCA or Bradford assay.
-
SDS-PAGE and Transfer: Separate equal amounts of protein on an SDS-polyacrylamide gel and transfer to a PVDF or nitrocellulose membrane.
-
Immunoblotting:
-
Block the membrane with 5% non-fat milk or BSA in TBST.
-
Incubate with a primary antibody specific for NR4A3 overnight at 4°C.
-
Wash the membrane and incubate with an HRP-conjugated secondary antibody.
-
-
Detection: Visualize the protein bands using an enhanced chemiluminescence (ECL) substrate and quantify the band intensity, normalizing to a loading control (e.g., GAPDH, β-actin).
Visualizing Experimental and Biological Pathways
Understanding the experimental workflow and the biological context of NR4A3 is crucial for interpreting knockdown results.
Caption: Experimental workflow for the selection of optimal NR4A3 siRNA sequences.
NR4A3 is a key regulator in various cellular processes, including inflammation, apoptosis, and cell proliferation.[2][3] Its transcriptional activity is induced by a range of stimuli and can have context-dependent pro- or anti-inflammatory effects.[4]
Caption: Simplified signaling pathway involving NR4A3.
By following this guide, researchers can systematically evaluate and select the most effective NR4A3 siRNA for their studies, leading to more reliable and impactful results in understanding the role of NR4A3 in health and disease.
References
- 1. mdpi.com [mdpi.com]
- 2. Frontiers | Targeting NR4A Nuclear Receptors to Control Stromal Cell Inflammation, Metabolism, Angiogenesis, and Tumorigenesis [frontiersin.org]
- 3. taylorandfrancis.com [taylorandfrancis.com]
- 4. The pro‐inflammatory effect of NR4A3 in osteoarthritis - PMC [pmc.ncbi.nlm.nih.gov]
A Cross-Species Comparative Guide to the NOR-1 Gene and Protein
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive cross-species comparison of the Neuron-derived orphan receptor 1 (NOR-1) gene and its corresponding protein, also known as Nuclear receptor subfamily 4 group A member 3 (NR4A3). NOR-1 is a member of the nuclear receptor superfamily and functions as a transcription factor, playing a crucial role in a variety of cellular processes, including proliferation, apoptosis, and metabolism. This guide offers a detailed analysis of NOR-1 sequences, functional domains, and its involvement in key signaling pathways across human, mouse, and zebrafish, providing valuable insights for research and drug development.
Ortholog Information
To facilitate a comprehensive comparison, the following orthologs of the NOR-1 gene and protein were selected, representing key model organisms in biomedical research.
| Species | Common Name | Gene Symbol | NCBI Gene ID | UniProtKB Accession |
| Homo sapiens | Human | NR4A3 | (--INVALID-LINK--) | --INVALID-LINK-- |
| Mus musculus | Mouse | Nr4a3 | (--INVALID-LINK--) | --INVALID-LINK-- |
| Danio rerio | Zebrafish | nr4a3 | (--INVALID-LINK--) | --INVALID-LINK-- |
Sequence Homology: A High Degree of Conservation
Multiple sequence alignment of the NOR-1 protein sequences from human, mouse, and zebrafish reveals a high degree of conservation, particularly within the functional domains. The overall percentage identity between the species is summarized in the table below. The high similarity, especially between human and mouse, suggests a conserved function of NOR-1 across mammals. While the zebrafish ortholog shows a slightly lower identity, the core functional domains remain highly conserved, highlighting its utility as a model organism for studying fundamental aspects of NOR-1 biology.
| Comparison | Percentage Identity |
| Human vs. Mouse | 95.5% |
| Human vs. Zebrafish | 73.8% |
| Mouse vs. Zebrafish | 74.5% |
Domain Architecture: Conserved Functional Units
The NOR-1 protein is characterized by a modular structure consisting of three primary functional domains: a ligand-binding domain (LBD), a DNA-binding domain (DBD), and a zinc finger domain. These domains are crucial for its function as a transcription factor. The table below outlines the specific coordinates of these domains in human, mouse, and zebrafish NOR-1 proteins, demonstrating their remarkable conservation across these species.
| Domain | Human (Q92570) | Mouse (P43356) | Zebrafish (A0A8M3AQK6) |
| Ligand-binding domain, nuclear hormone receptor type | 393 - 622 | 392 - 621 | 447 - 684 |
| DNA-binding domain, NR with C4-type zinc finger | 288 - 363 | 287 - 362 | 345 - 420 |
| Zinc finger, C4-type, nuclear hormone receptor-type | 291 - 355 | 290 - 354 | 348 - 412 |
Signaling Pathways and Experimental Workflows
The following diagrams, generated using Graphviz, illustrate a key signaling pathway involving NOR-1 and the experimental workflow for the cross-species comparison detailed in this guide.
Featured Recommendations


Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
