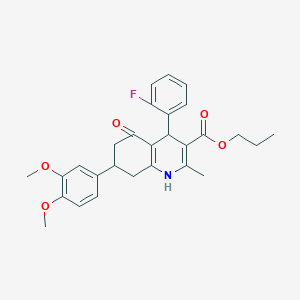
SJ000025081
Description
Structure
3D Structure
Properties
Molecular Formula |
C28H30FNO5 |
|---|---|
Molecular Weight |
479.5g/mol |
IUPAC Name |
propyl 7-(3,4-dimethoxyphenyl)-4-(2-fluorophenyl)-2-methyl-5-oxo-4,6,7,8-tetrahydro-1H-quinoline-3-carboxylate |
InChI |
InChI=1S/C28H30FNO5/c1-5-12-35-28(32)25-16(2)30-21-13-18(17-10-11-23(33-3)24(15-17)34-4)14-22(31)27(21)26(25)19-8-6-7-9-20(19)29/h6-11,15,18,26,30H,5,12-14H2,1-4H3 |
InChI Key |
JYAOIVVCGRSAFZ-UHFFFAOYSA-N |
SMILES |
CCCOC(=O)C1=C(NC2=C(C1C3=CC=CC=C3F)C(=O)CC(C2)C4=CC(=C(C=C4)OC)OC)C |
Canonical SMILES |
CCCOC(=O)C1=C(NC2=C(C1C3=CC=CC=C3F)C(=O)CC(C2)C4=CC(=C(C=C4)OC)OC)C |
Pictograms |
Acute Toxic; Environmental Hazard |
Origin of Product |
United States |
Foundational & Exploratory
An In-Depth Technical Guide to the Primary Structures of GLP-1 and Exendin-4
Audience: Researchers, Scientists, and Drug Development Professionals
This technical guide provides a detailed comparison of the primary structures of Glucagon-Like Peptide-1 (GLP-1) and Exendin-4. It includes a quantitative summary, an overview of experimental protocols for sequence determination, and visualizations of key molecular relationships and signaling pathways.
Introduction: GLP-1 and Exendin-4 as Incretin Mimetics
Glucagon-like peptide-1 (GLP-1) is a crucial incretin hormone secreted by intestinal L-cells in response to nutrient intake.[1] It plays a vital role in glucose homeostasis by potentiating glucose-dependent insulin secretion, suppressing glucagon release, delaying gastric emptying, and promoting satiety.[1] The therapeutic potential of GLP-1 is limited by its short in vivo half-life (approximately 2 minutes) due to rapid degradation by the enzyme dipeptidyl peptidase-4 (DPP-4).[2]
Exendin-4, a peptide hormone discovered in the saliva of the Gila monster (Heloderma suspectum), emerged as a potent and long-acting agonist for the GLP-1 receptor (GLP-1R).[3][4] Despite sharing only moderate sequence homology with human GLP-1, Exendin-4 mimics most of its glucoregulatory actions.[3] Its resistance to DPP-4 degradation results in a significantly longer duration of action, making it a valuable therapeutic agent for type 2 diabetes.[5] Understanding the differences in their primary structures is fundamental to appreciating their distinct pharmacokinetic and pharmacodynamic profiles.
Comparative Analysis of Primary Structures
The primary structure, or amino acid sequence, dictates the peptide's folding, receptor binding affinity, and susceptibility to enzymatic degradation. While both peptides activate the same receptor, their sequences have key differences that confer distinct properties.
Amino Acid Sequence Alignment
The biologically active forms of human GLP-1 are GLP-1(7-36)amide and GLP-1(7-37).[2] Exendin-4 is a 39-amino acid peptide.[6] The sequence alignment below highlights the similarities and differences. The homology between GLP-1 and Exendin-4 is approximately 53%.[4][5]
| Peptide | Position 1-10 | Position 11-20 | Position 21-30 | Position 31-39 |
| GLP-1(7-36)NH₂ | H A E G T F T S D V | S S Y L E G Q A A | K E F I A W L V K G | R G |
| Exendin-4 | H G E G T F T S D L | S K Q M E E E A V R | L F I E W L K N G G | P S S G A P P P S |
| Homology |
-
N-Terminus: A critical difference lies at position 8 (GLP-1's position 2), where GLP-1 has an Alanine (A) while Exendin-4 has a Glycine (G). The His-Ala N-terminal sequence of GLP-1 is a primary recognition site for DPP-4 cleavage. The His-Gly sequence in Exendin-4 is not recognized by DPP-4, rendering it resistant to this degradation pathway.[5]
-
C-Terminus: Exendin-4 possesses a nine-amino acid C-terminal extension (Pro-Ser-Ser-Gly-Ala-Pro-Pro-Pro-Ser) that is absent in GLP-1.[4] This tail, particularly the final proline-rich segment, contributes to a compact tertiary fold known as a "Trp-cage," which can enhance receptor binding.[4][7]
Quantitative Data Summary
The table below summarizes the key quantitative differences between the two peptides.
| Property | Human GLP-1 (7-36)amide | Exendin-4 |
| Amino Acid Length | 30 | 39[6] |
| Molecular Formula | C₁₄₉H₂₂₅N₄₃O₄₇ | C₁₈₄H₂₈₂N₅₀O₆₀S[6] |
| Molecular Weight | ~3298 g/mol | ~4187 g/mol [6] |
| Sequence Homology | 100% (Reference) | ~53%[4][5] |
| DPP-4 Susceptibility | High | Resistant[5] |
Experimental Protocols for Primary Structure Determination
The determination of a peptide's amino acid sequence is a fundamental step in its characterization. The two primary methods employed for this purpose are Edman degradation and mass spectrometry.[8]
Edman Degradation
Edman degradation is a classic chemical method for sequencing amino acids from the N-terminus of a peptide.[9]
Methodology:
-
Coupling: The peptide is treated with phenyl isothiocyanate (PITC) under alkaline conditions. PITC reacts with the free N-terminal amino group to form a phenylthiocarbamoyl (PTC) derivative.[10]
-
Cleavage: The PTC-peptide is treated with a strong acid (e.g., trifluoroacetic acid), which cleaves the first peptide bond, releasing the N-terminal amino acid as a thiazolinone derivative. The rest of the peptide chain remains intact.
-
Conversion & Identification: The thiazolinone derivative is extracted and converted to a more stable phenylthiohydantoin (PTH) amino acid. This PTH-amino acid is then identified using chromatography, typically High-Performance Liquid Chromatography (HPLC).
-
Cycling: The remaining peptide (now one amino acid shorter) is subjected to the next cycle of coupling, cleavage, and identification. This process is repeated sequentially to determine the sequence.[9]
Mass Spectrometry (MS)
Mass spectrometry has become the dominant technology for protein and peptide sequencing due to its high sensitivity, speed, and ability to handle complex mixtures.[10] Tandem mass spectrometry (MS/MS) is the cornerstone of this approach.
Methodology:
-
Proteolytic Digestion: The protein or peptide is cleaved into smaller fragments using specific proteases (e.g., trypsin, chymotrypsin). This step is often omitted for shorter peptides like GLP-1 and Exendin-4.
-
Ionization: The peptide fragments are ionized, typically using Electrospray Ionization (ESI) or Matrix-Assisted Laser Desorption/Ionization (MALDI).
-
First Mass Analysis (MS1): The ionized peptides are separated in a mass analyzer based on their mass-to-charge (m/z) ratio, producing a spectrum of precursor ions.
-
Fragmentation (Collision-Induced Dissociation): A specific precursor ion is selected and fragmented by colliding it with an inert gas (e.g., argon or nitrogen). This breaks the peptide bonds at predictable locations, generating a series of product ions.
-
Second Mass Analysis (MS2): The resulting product ions are separated in a second mass analyzer, producing an MS/MS spectrum.
-
Sequence Deduction: The amino acid sequence is determined by analyzing the mass differences between the peaks in the MS/MS spectrum. This can be done de novo (without a reference) or by matching the fragmentation pattern to theoretical spectra from a protein sequence database.[10]
Visualizations: Pathways and Workflows
GLP-1 Receptor Signaling Pathway
Both GLP-1 and Exendin-4 exert their effects by binding to the GLP-1 receptor, a Class B G-protein coupled receptor (GPCR).[11] This initiates a cascade of intracellular events.
Caption: GLP-1 Receptor (GLP-1R) signaling cascade upon agonist binding.
Experimental Workflow: MS-Based Peptide Sequencing
The following diagram illustrates a generalized workflow for determining a peptide's primary structure using tandem mass spectrometry.
Caption: A generalized workflow for peptide sequencing via tandem mass spectrometry.
Logical Relationship: GLP-1 vs. Exendin-4
This diagram illustrates the structural relationship and key distinguishing features of GLP-1 and Exendin-4.
Caption: Structural and functional comparison of GLP-1 and Exendin-4.
References
- 1. The structure and function of the glucagon-like peptide-1 receptor and its ligands - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Glucagon-like peptide-1 - Wikipedia [en.wikipedia.org]
- 3. researchgate.net [researchgate.net]
- 4. The importance of the nine-amino acid C-terminal sequence of exendin-4 for binding to the GLP-1 receptor and for biological activity - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. Exendin-4 | C184H282N50O60S | CID 56927919 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 7. pubs.acs.org [pubs.acs.org]
- 8. Protein sequencing - Wikipedia [en.wikipedia.org]
- 9. kmdbioscience.com [kmdbioscience.com]
- 10. creative-biolabs.com [creative-biolabs.com]
- 11. Glucagon-like peptide-1 receptor - Wikipedia [en.wikipedia.org]
Key structural differences between GLP-1 and Exendin-4 peptides.
An In-depth Technical Guide on the Core Structural Differences Between GLP-1 and Exendin-4 Peptides
Introduction
Glucagon-like peptide-1 (GLP-1) and Exendin-4 are potent incretin mimetics that have revolutionized the treatment of type 2 diabetes. Both peptides exert their therapeutic effects by activating the GLP-1 receptor (GLP-1R), a class B G-protein coupled receptor, which leads to glucose-dependent insulin secretion, suppressed glucagon release, delayed gastric emptying, and reduced appetite.[1][2] Despite sharing a common receptor and mechanism of action, their structural nuances result in significant differences in their pharmacokinetic and pharmacodynamic profiles. Exendin-4, originally isolated from the saliva of the Gila monster (Heloderma suspectum), exhibits approximately 53% sequence homology to human GLP-1 but possesses a markedly longer half-life, making it a more robust therapeutic agent.[3][4][5] This guide provides a detailed examination of the key structural differences between these two peptides, the experimental methodologies used to characterize them, and the signaling pathways they trigger.
Primary Structure: Amino Acid Sequence
The foundational differences between GLP-1 and Exendin-4 lie in their amino acid sequences. Human GLP-1 is a 30-amino acid peptide, while Exendin-4 is comprised of 39 amino acids.[3] The sequence alignment reveals critical substitutions, particularly at the N-terminus, and a nine-residue C-terminal extension in Exendin-4 that is absent in GLP-1.[5]
Table 1: Amino Acid Sequence Alignment of Human GLP-1 and Exendin-4
| Position | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31-39 |
| GLP-1 | H | A | E | G | T | F | T | S | D | V | S | S | Y | L | E | G | Q | A | A | K | E | F | I | A | W | L | V | K | G | R | - |
| Exendin-4 | H | G | E | G | T | F | T | S | D | L | S | K | Q | M | E | E | E | A | V | R | L | F | I | E | W | L | K | N | G | G | PSSGAPPPS |
Key differences are highlighted.
One of the most functionally significant differences is at position 2. GLP-1 has an Alanine (A), which is a recognition site for the enzyme dipeptidyl peptidase-IV (DPP-4).[6][7] DPP-4 rapidly cleaves and inactivates GLP-1, contributing to its very short in vivo half-life of 1-2 minutes.[8][9] In contrast, Exendin-4 has a Glycine (G) at this position, which confers resistance to DPP-4 degradation, a primary reason for its extended duration of action.[4][10]
Secondary and Tertiary Structure
While both peptides bind to the same receptor, their conformational characteristics in solution and upon receptor binding differ significantly.
-
Helical Propensity: In aqueous solution, GLP-1 is largely unstructured.[8] It adopts a stable α-helical conformation primarily upon binding to the GLP-1R or in the presence of membrane-like environments.[8] Exendin-4, however, exhibits a greater intrinsic propensity to form an α-helix, even in solution.[1][11] This pre-formed helical structure is thought to contribute to its high-affinity binding to the receptor's N-terminal extracellular domain (nGLP-1R). NMR studies show that both peptides display significant helicity from approximately residue 7 to 28 when associated with micelles.[3][12]
-
Impact of Specific Residues: The presence of a flexible, helix-destabilizing Glycine at position 16 in GLP-1 makes it less helical compared to Exendin-4, which has a helix-favoring Glutamate at the same position.[3][12]
-
The "Trp-cage": The nine-amino acid C-terminal extension of Exendin-4 (residues 31-39) forms a compact tertiary structure known as a "Trp-cage".[3][13] This motif shields the side chain of Tryptophan at position 25 from the solvent.[3] While initial hypotheses suggested this structure was crucial for the superior binding affinity of Exendin-4, crystal structures later revealed that the Trp-cage is not directly involved in binding to the nGLP-1R.[14] Its primary role is likely to enhance the peptide's overall stability.[12]
Table 2: Comparative Structural and Binding Properties
| Property | GLP-1 | Exendin-4 | Reference |
| Length (Amino Acids) | 30 | 39 | [3] |
| Structure in Solution | Largely unstructured | Partially helical, stable tertiary structure | [8][12] |
| Key Structural Feature | Flexible Glycine at position 16 | C-terminal "Trp-cage", helix-favoring Glutamate at position 16 | [3] |
| DPP-4 Susceptibility | High (cleaved at position 2) | Resistant | [4][8] |
| Affinity for isolated nGLP-1R | Low (Kd >500 nM) | High (Kd = 6 nM) | [8] |
| Affinity for full-length GLP-1R | High (similar to Exendin-4) | High (full agonist) | [1][11] |
Signaling Pathways
Activation of the GLP-1R by either GLP-1 or Exendin-4 initiates a cascade of intracellular signaling events. The primary pathway involves the coupling of the receptor to the stimulatory G-protein, Gαs.
-
Receptor Activation: Binding of the agonist (GLP-1 or Exendin-4) to the GLP-1R induces a conformational change.
-
G-Protein Coupling: The activated receptor promotes the exchange of GDP for GTP on the α-subunit of the associated Gs protein.
-
Adenylyl Cyclase Activation: The activated Gαs-GTP complex stimulates adenylyl cyclase (AC), an enzyme that converts ATP into cyclic AMP (cAMP).[4]
-
Downstream Effectors: The rise in intracellular cAMP activates Protein Kinase A (PKA) and potentially other effectors like Exchange Protein Activated by cAMP (Epac).[2][15] These effectors then phosphorylate various downstream targets, leading to the physiological responses associated with GLP-1R activation, such as enhanced insulin vesicle exocytosis in pancreatic β-cells. Studies have also shown that this pathway leads to the phosphorylation of the cAMP-responsive element-binding protein (CREB).[2]
Experimental Protocols
The structural and functional differences between GLP-1 and Exendin-4 have been elucidated through a variety of biophysical and pharmacological experiments.
Structural Analysis Methodologies
Nuclear Magnetic Resonance (NMR) Spectroscopy NMR is used to determine the three-dimensional structure of peptides in solution or in membrane-mimicking environments.
-
Sample Preparation: Peptides like GLP-1 and Exendin-4 are synthesized using solid-phase peptide synthesis and purified by HPLC.[3] For structural studies, samples are prepared at concentrations suitable for NMR (e.g., 1.5 mM) in various media, such as aqueous buffers, aqueous trifluoroethanol (TFE) to promote helicity, or with dodecylphosphocholine (DPC) micelles to simulate a membrane environment.[3][12]
-
Data Acquisition: A series of NMR experiments, including Total Correlation Spectroscopy (TOCSY) and Nuclear Overhauser Effect Spectroscopy (NOESY), are performed to assign proton resonances and measure through-space distances between protons (NOEs), respectively.[3]
-
Structure Calculation: The collected NOE distance constraints are used in molecular dynamics and simulated annealing protocols to generate an ensemble of structures consistent with the experimental data. Chemical shift deviations from random coil values are also used to identify regions of secondary structure like α-helices.[3][12]
X-ray Crystallography This technique provides high-resolution structures of peptides when bound to their receptors.
-
Protein Expression and Purification: The N-terminal extracellular domain of the GLP-1 receptor (nGLP-1R) is expressed, typically in E. coli or insect cells, and purified.
-
Complex Formation and Crystallization: The purified nGLP-1R is incubated with the peptide (e.g., Exendin-4(9-39), an antagonist used for structural studies) to form a stable complex.[14] This complex is then subjected to various crystallization screening conditions (e.g., vapor diffusion) to obtain well-ordered crystals.
-
Data Collection and Structure Determination: The crystals are exposed to an X-ray beam, and the resulting diffraction pattern is collected. The phases are determined (e.g., via multiwavelength anomalous dispersion), and an electron density map is calculated, into which the atomic model of the receptor-peptide complex is built and refined.[14]
Functional Assay Methodologies
Competitive Radioligand Binding Assay This assay is used to determine the binding affinity (IC50) of unlabeled peptides by measuring their ability to compete with a radiolabeled ligand for binding to the receptor.
-
Protocol:
-
Cell membranes are prepared from a cell line stably expressing the GLP-1R.
-
A constant concentration of a radiolabeled tracer (e.g., 125I-Exendin(9-39)) is incubated with the membranes.[16]
-
Increasing concentrations of the unlabeled competitor peptides (GLP-1, Exendin-4, or their analogues) are added to the incubation mixture.
-
After reaching equilibrium, the bound and free radioligand are separated by filtration.
-
The radioactivity of the filter-bound complex is measured using a gamma counter.
-
The IC50 value, the concentration of competitor that inhibits 50% of the specific binding of the radioligand, is calculated by non-linear regression.[16]
-
cAMP Accumulation Assay This functional assay measures the potency (EC50) of an agonist in stimulating the GLP-1R signaling pathway.
-
Protocol:
-
Cells expressing the GLP-1R are seeded in multi-well plates.
-
The cells are treated with increasing concentrations of the agonist (GLP-1 or Exendin-4) for a defined period (e.g., 3 hours) in the presence of a phosphodiesterase inhibitor to prevent cAMP degradation.[17]
-
Following stimulation, the cells are lysed.
-
The concentration of intracellular cAMP in the cell lysates is quantified using a competitive immunoassay, such as an ELISA kit.[8][17]
-
The EC50 value, the concentration of agonist that produces 50% of the maximal response, is determined by plotting the cAMP concentration against the log of the agonist concentration.
-
Conclusion
The structural disparities between GLP-1 and Exendin-4, though seemingly subtle at the level of sequence homology, have profound functional consequences. The substitution at position 2 renders Exendin-4 resistant to DPP-4 degradation, while its higher intrinsic helicity and stabilizing C-terminal Trp-cage contribute to its favorable pharmacokinetic profile. These differences, elucidated through detailed structural and functional studies, explain why Exendin-4 and its synthetic analogues have become highly successful long-acting therapeutics for managing type 2 diabetes, representing a triumph of translating molecular structure into clinical benefit.
References
- 1. Differential structural properties of GLP-1 and exendin-4 determine their relative affinity for the GLP-1 receptor N-terminal extracellular domain - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. diabetesjournals.org [diabetesjournals.org]
- 3. pubs.acs.org [pubs.acs.org]
- 4. GLP-1: Molecular mechanisms and outcomes of a complex signaling system - PMC [pmc.ncbi.nlm.nih.gov]
- 5. The importance of the nine-amino acid C-terminal sequence of exendin-4 for binding to the GLP-1 receptor and for biological activity - PMC [pmc.ncbi.nlm.nih.gov]
- 6. More than just an enzyme: Dipeptidyl peptidase-4 (DPP-4) and its association with diabetic kidney remodelling - PMC [pmc.ncbi.nlm.nih.gov]
- 7. DPP-4 Inhibition and the Path to Clinical Proof - PMC [pmc.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. researchprofiles.ku.dk [researchprofiles.ku.dk]
- 10. Exendin-4 as a Versatile Therapeutic Agent for the Amelioration of Diabetic Changes - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Crystal Structure of Glucagon-like Peptide-1 in Complex with the Extracellular Domain of the Glucagon-like Peptide-1 Receptor - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. A model for receptor–peptide binding at the glucagon-like peptide-1 (GLP-1) receptor through the analysis of truncated ligands and receptors - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Crystal structure of the ligand-bound glucagon-like peptide-1 receptor extracellular domain - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. Signaling Mechanism for Modulation by GLP-1 and Exendin-4 of GABA Receptors on Rat Retinal Ganglion Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 16. The major determinant of exendin-4/glucagon-like peptide 1 differential affinity at the rat glucagon-like peptide 1 receptor N-terminal domain is a hydrogen bond from SER-32 of exendin-4 - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Exendin-4, a Glucagon-Like Protein-1 (GLP-1) Receptor Agonist, Reverses Hepatic Steatosis in ob/ob Mice - PMC [pmc.ncbi.nlm.nih.gov]
A Technical Deep Dive into the Structural Biology of GLP-1 and Exendin-4
An In-depth Guide for Researchers and Drug Development Professionals
This technical guide provides a comprehensive overview of the structural characteristics of Glucagon-Like Peptide-1 (GLP-1) and its potent agonist, Exendin-4. The document delves into their three-dimensional structures, the experimental methodologies used for their determination, and the intricate signaling pathways they trigger upon binding to the GLP-1 receptor (GLP-1R). This information is critical for the rational design and development of novel therapeutics for type 2 diabetes and other metabolic disorders.
The identifier "SJ000025081" did not correspond to publicly available research on GLP-1 or Exendin-4 and is not referenced in this document.
Structural and Physical Properties of GLP-1 and Exendin-4
Glucagon-like peptide-1 (GLP-1) is a 30- or 31-amino acid peptide hormone, while Exendin-4, originally isolated from the saliva of the Gila monster, is a 39-amino acid peptide.[1] Despite sharing only about 50% sequence homology, Exendin-4 is a full and potent agonist of the GLP-1 receptor.[2][3] The structural and physical data for these peptides, as determined from various structural studies, are summarized below.
| Property | GLP-1 (PDB: 6X18)[3][4] | GLP-1 (PDB: 3IOL)[2] | Exendin-4 (PDB: 1JRJ)[5][6] | Exendin-4 (PDB: 5NIQ)[7] | Exendin-4 (PDB: 2MJ9)[8] | Exendin-4 (PDB: 7LLL)[9] |
| Total Structure Weight | 163.41 kDa | 18.6 kDa | 4.19 kDa | 4.61 kDa | 4.31 kDa | 164.3 kDa |
| Atom Count | 10,381 | 1,130 | 295 | 324 | 303 | 8,940 |
| Modeled Residue Count | 1,289 | 126 | 39 | 40 | 39 | 1,153 |
| Deposited Residue Count | 1,441 | 157 | 39 | 40 | 39 | 1,450 |
| Experimental Method | Electron Microscopy | X-Ray Diffraction | NMR | NMR | NMR | Electron Microscopy |
| Resolution | 2.10 Å | 2.10 Å | Not Applicable | Not Applicable | Not Applicable | 3.70 Å |
Experimental Protocols for Structural Determination
The three-dimensional structures of GLP-1 and Exendin-4 have been elucidated primarily through Nuclear Magnetic Resonance (NMR) spectroscopy and X-ray crystallography. Below are detailed overviews of the typical methodologies employed in these studies.
NMR Spectroscopy for Peptide Structure in Solution
NMR spectroscopy is a powerful technique for determining the structure of peptides in a solution state, which can mimic their physiological environment.
2.1.1. Sample Preparation
-
Peptide Synthesis and Purification: GLP-1 and Exendin-4 peptides are typically synthesized using solid-phase peptide synthesis (SPPS) and purified by reverse-phase high-performance liquid chromatography (RP-HPLC).
-
Isotopic Labeling: For detailed structural analysis, peptides are often isotopically labeled with ¹⁵N and ¹³C by using labeled amino acids during synthesis.
-
NMR Sample Formulation: The purified peptide is dissolved in a suitable buffer, often containing a percentage of an organic solvent like trifluoroethanol (TFE) to induce and stabilize helical structures.[10][11][12] The pH is adjusted, and a D₂O lock is added for the spectrometer.
2.1.2. NMR Data Acquisition
A series of multidimensional NMR experiments are performed to obtain structural restraints:
-
TOCSY (Total Correlation Spectroscopy): To identify amino acid spin systems.
-
NOESY (Nuclear Overhauser Effect Spectroscopy): To identify protons that are close in space (< 5 Å), providing distance restraints.
-
HSQC (Heteronuclear Single Quantum Coherence): To correlate backbone amide protons and nitrogens.
-
HNHA/HNCACB/CBCA(CO)NH: A suite of triple-resonance experiments used for backbone resonance assignment.
2.1.3. Structure Calculation and Validation
-
Resonance Assignment: The collected spectra are processed, and the chemical shifts of the backbone and side-chain atoms are assigned.
-
Restraint Generation: NOESY cross-peaks are converted into upper-limit distance restraints. Dihedral angle restraints are often derived from chemical shifts using programs like TALOS.
-
Structure Calculation: A family of structures is calculated using software like CYANA or XPLOR-NIH, which employs molecular dynamics and simulated annealing to find conformations that satisfy the experimental restraints.
-
Validation: The final ensemble of structures is validated using tools like PROCHECK to assess stereochemical quality and Ramachandran plot statistics.
X-ray Crystallography for High-Resolution Structures
X-ray crystallography provides high-resolution static snapshots of molecules in a crystalline lattice.
2.2.1. Protein Expression, Purification, and Crystallization
-
Construct Design: For GLP-1 and Exendin-4, crystallization is often performed in complex with the extracellular domain (ECD) of the GLP-1 receptor to stabilize a specific conformation.[2]
-
Expression and Purification: The protein complex is typically expressed in insect or mammalian cells and purified using a combination of affinity, ion-exchange, and size-exclusion chromatography.
-
Crystallization: The purified protein is concentrated and subjected to crystallization screening using techniques like hanging-drop or sitting-drop vapor diffusion.[13] A wide range of precipitants, buffers, and additives are screened to find conditions that yield diffraction-quality crystals.
2.2.2. X-ray Diffraction Data Collection and Processing
-
Cryo-protection: Crystals are typically cryo-cooled in liquid nitrogen to minimize radiation damage during data collection. A cryoprotectant is added to the crystallization solution before freezing.
-
Data Collection: Diffraction data are collected at a synchrotron X-ray source. The crystal is rotated in the X-ray beam, and the resulting diffraction patterns are recorded on a detector.
-
Data Processing: The diffraction images are processed to integrate the intensities of the reflections and to determine the unit cell parameters and space group. Software like HKL2000 or XDS is commonly used for this purpose.
2.2.3. Structure Solution and Refinement
-
Phasing: The phase problem is solved using methods like molecular replacement (if a homologous structure is available) or experimental phasing techniques (e.g., MAD or SAD).
-
Model Building: An initial atomic model is built into the electron density map using software like Coot.
-
Refinement: The model is refined against the diffraction data using programs like PHENIX or REFMAC5. This process iteratively improves the fit of the model to the data and optimizes the geometry.
-
Validation: The final model is validated for its geometric and stereochemical quality using tools like MolProbity.
Signaling Pathways of GLP-1 and Exendin-4
Upon binding to the GLP-1R, both GLP-1 and Exendin-4 initiate a cascade of intracellular signaling events. The GLP-1R is a class B G-protein coupled receptor (GPCR) that primarily couples to the stimulatory G-protein, Gαs.[14]
Canonical Gαs-cAMP-PKA Pathway
The primary signaling pathway activated by GLP-1R agonists is the Gαs-cAMP pathway.
References
- 1. pubs.acs.org [pubs.acs.org]
- 2. rcsb.org [rcsb.org]
- 3. 6X18: GLP-1 peptide hormone bound to Glucagon-Like peptide-1 (GLP-1) Receptor [ncbi.nlm.nih.gov]
- 4. rcsb.org [rcsb.org]
- 5. rcsb.org [rcsb.org]
- 6. researchgate.net [researchgate.net]
- 7. rcsb.org [rcsb.org]
- 8. rcsb.org [rcsb.org]
- 9. rcsb.org [rcsb.org]
- 10. NMR studies of the aggregation of glucagon-like peptide-1: formation of a symmetric helical dimer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. files.core.ac.uk [files.core.ac.uk]
- 12. researchgate.net [researchgate.net]
- 13. phys.libretexts.org [phys.libretexts.org]
- 14. GLP-1: Molecular mechanisms and outcomes of a complex signaling system - PMC [pmc.ncbi.nlm.nih.gov]
An In-depth Technical Guide to the Initial Investigations into GLP-1 Receptor Binding Mechanisms
Audience: Researchers, scientists, and drug development professionals.
This technical guide delves into the foundational research that first elucidated the binding mechanisms of the Glucagon-Like Peptide-1 Receptor (GLP-1R), a critical target in the treatment of type 2 diabetes and obesity. We will explore the core experimental protocols, summarize key quantitative data, and visualize the associated signaling pathways and experimental workflows that have formed the bedrock of our understanding of GLP-1R pharmacology.
Core Concepts in GLP-1 Receptor Binding
The initial investigations into the GLP-1 receptor, a Class B G-protein coupled receptor (GPCR), established a fundamental model of its interaction with its endogenous ligand, GLP-1, and other agonists like exendin-4. A key concept that emerged from early research is the two-step binding mechanism . This model posits that the C-terminal region of the peptide agonist first engages with the large N-terminal extracellular domain (ECD) of the receptor. This initial, lower-affinity interaction is thought to "capture" the ligand, thereby facilitating the subsequent, higher-affinity binding of the N-terminal region of the peptide into the transmembrane (TM) domain of the receptor, which in turn triggers receptor activation and downstream signaling.
Key Signaling Pathways
Activation of the GLP-1R primarily initiates signaling through the Gαs protein, leading to the production of cyclic AMP (cAMP) and the subsequent activation of Protein Kinase A (PKA) and Exchange Protein Directly Activated by cAMP (EPAC). These pathways are central to the insulinotropic effects of GLP-1. However, early studies also hinted at the complexity of GLP-1R signaling, with evidence for the involvement of other pathways, including the activation of extracellular signal-regulated kinases (ERK1/2) and phosphatidylinositol 3-kinase (PI3K).
Foundational Experimental Protocols
The initial characterization of GLP-1R binding relied on a few key experimental techniques. Below are detailed methodologies adapted from seminal papers in the field.
Radioligand Binding Assays
Radioligand binding assays were fundamental in determining the affinity of GLP-1 and its analogs for the newly cloned receptor. These assays measure the interaction between a radiolabeled ligand (e.g., ¹²⁵I-GLP-1) and the receptor.
Objective: To determine the binding affinity (Kd) and receptor density (Bmax) or to measure the inhibitory concentration (IC50) of unlabeled competitor ligands.
Experimental Protocol (adapted from Thorens et al., 1993 and Montrose-Rafizadeh et al., 1997):
-
Cell Culture and Membrane Preparation:
-
COS-7 cells or Baby Hamster Kidney (BHK) cells were transiently or stably transfected with the cDNA encoding the rat or human GLP-1 receptor using standard methods (e.g., DEAE-dextran or lipofection).
-
Cells were cultured for 48-72 hours post-transfection.
-
For membrane preparations, cells were harvested, washed in ice-cold phosphate-buffered saline (PBS), and homogenized in a buffer (e.g., 20 mM Tris-HCl, 5 mM MgCl₂, pH 7.4) using a Dounce or Polytron homogenizer.
-
The homogenate was centrifuged at low speed (e.g., 500 x g) to remove nuclei, and the supernatant was then centrifuged at high speed (e.g., 40,000 x g) to pellet the cell membranes.
-
The membrane pellet was resuspended in assay buffer and protein concentration was determined (e.g., by Bradford assay).
-
-
Binding Assay:
-
Saturation Binding:
-
A fixed amount of membrane protein (e.g., 10-50 µg) was incubated with increasing concentrations of ¹²⁵I-GLP-1 (e.g., 10 pM to 2 nM).
-
Incubations were performed in a binding buffer (e.g., 50 mM Tris-HCl, 5 mM MgCl₂, 0.1% BSA, pH 7.4) in a total volume of 200-500 µL.
-
To determine non-specific binding, a parallel set of tubes was incubated with a high concentration of unlabeled GLP-1 (e.g., 1 µM).
-
The reaction was incubated to equilibrium (e.g., 60-120 minutes at room temperature).
-
-
Competition Binding:
-
A fixed amount of membrane protein and a fixed concentration of ¹²⁵I-GLP-1 (typically near the Kd value, e.g., 50-100 pM) were incubated with increasing concentrations of an unlabeled competitor ligand (e.g., GLP-1, exendin-4, or peptide fragments).
-
Incubation conditions were the same as for saturation binding.
-
-
-
Separation of Bound and Free Ligand:
-
The incubation was terminated by rapid filtration through glass fiber filters (e.g., Whatman GF/C) that had been presoaked (e.g., in 0.5% polyethyleneimine) to reduce non-specific binding.
-
Filters were washed rapidly with ice-cold wash buffer (e.g., 50 mM Tris-HCl, pH 7.4) to remove unbound radioligand.
-
-
Quantification:
-
The radioactivity retained on the filters was measured using a gamma counter.
-
Specific binding was calculated by subtracting non-specific binding from total binding.
-
Data were analyzed using non-linear regression (e.g., Scatchard analysis for older studies, or more commonly, one-site binding models) to determine Kd, Bmax, or IC50 values.
-
Site-Directed Mutagenesis
Site-directed mutagenesis was employed to identify specific amino acid residues in the GLP-1R that are crucial for ligand binding and receptor activation. By changing a single amino acid and observing the effect on function, researchers could map the binding pocket.
Objective: To assess the importance of individual amino acid residues for ligand binding affinity and signal transduction.
Experimental Protocol (adapted from Wheeler et al., 1995 and Adelhorst et al., 1994):
-
Mutagenesis:
-
The cDNA for GLP-1R, typically in a plasmid vector (e.g., pcDNA), was used as a template.
-
Mutagenesis was performed using techniques such as oligonucleotide-directed in vitro mutagenesis. In early studies, this often involved PCR-based methods with primers containing the desired mutation.
-
The entire coding region of the mutated receptor was sequenced to confirm the desired mutation and ensure no other mutations were introduced.
-
-
Expression and Functional Assays:
-
The wild-type and mutant receptor cDNAs were transiently expressed in a suitable cell line (e.g., COS-7).
-
Parallel cultures of cells were transfected with wild-type receptor, mutant receptor, or an empty vector control.
-
48-72 hours post-transfection, the cells were used for functional assays.
-
-
Binding and Signaling Analysis:
-
Binding: Radioligand binding assays (as described in 3.1) were performed on membranes from cells expressing the wild-type or mutant receptors to determine if the mutation affected ligand affinity (IC50 or Kd).
-
Signaling: A cAMP accumulation assay was performed to assess the ability of the mutant receptor to signal.
-
Transfected cells were incubated with a phosphodiesterase inhibitor (e.g., IBMX) to prevent cAMP degradation.
-
Cells were then stimulated with various concentrations of GLP-1 or another agonist.
-
The reaction was stopped, and intracellular cAMP levels were measured using a radioimmunoassay (RIA) or an enzyme immunoassay (EIA).
-
Dose-response curves were generated to determine the EC50 for cAMP production.
-
-
Quantitative Data from Initial Investigations
The following tables summarize key quantitative data from foundational studies on GLP-1R binding and activation. These values were instrumental in defining the pharmacological profile of the receptor.
Table 1: Ligand Binding Affinities at the GLP-1 Receptor
| Ligand | Receptor Species | Cell System | Assay Type | Binding Affinity (Kd or IC50) | Reference |
| ¹²⁵I-GLP-1 | Human | Stably transfected fibroblasts | Saturation | Kd = 0.5 nM | Thorens et al., 1993[1] |
| GLP-1 | Rat | Cloned receptor | Competition | IC50 ≈ 1-5 nM | Adelhorst et al., 1994[2] |
| Exendin-4 | Human | Stably transfected fibroblasts | Competition | Similar to GLP-1 | Thorens et al., 1993[1] |
| Exendin-(9-39) | Human | Stably transfected fibroblasts | Competition | Similar to GLP-1 | Thorens et al., 1993[1] |
Table 2: Agonist Potency for cAMP Production
| Agonist | Receptor Species | Cell System | EC50 | Reference |
| GLP-1 | Human | Stably transfected fibroblasts | 93 pM | Thorens et al., 1993[1] |
| GLP-1 | Rat | RIN 2A18 plasma membranes | ~0.1-1 nM | Adelhorst et al., 1994[2] |
| Exendin-4 | Human | Stably transfected fibroblasts | Similar to GLP-1 | Thorens et al., 1993[1] |
Table 3: Effects of Alanine Scanning Mutagenesis of GLP-1 on Receptor Binding
This table highlights key findings from the systematic replacement of each amino acid in GLP-1 with alanine to identify residues critical for receptor interaction.
| GLP-1 Analog (Substitution) | Relative Binding Affinity (% of GLP-1) | Conclusion on Residue's Importance | Reference |
| His⁷ -> Ala | < 1% | Critical for interaction | Adelhorst et al., 1994[2] |
| Gly¹⁰ -> Ala | < 1% | Critical for interaction | Adelhorst et al., 1994[2] |
| Thr¹² -> Ala | ~1% | Important for interaction | Adelhorst et al., 1994[2] |
| Phe¹³ -> Ala | ~1% | Important for interaction | Adelhorst et al., 1994[2] |
| Asp¹⁵ -> Ala | < 1% | Critical for interaction | Adelhorst et al., 1994[2] |
| Phe²⁸ -> Ala | ~5% | Important for conformation | Adelhorst et al., 1994[2] |
| Trp²⁹ -> Ala | ~5% | Important for conformation | Adelhorst et al., 1994[2] |
Conclusion
The initial investigations into the GLP-1 receptor laid a robust foundation for decades of subsequent research. The cloning of the receptor, coupled with meticulous radioligand binding studies and site-directed mutagenesis, provided the first molecular map of how GLP-1 and related peptides interact with their target. These early studies not only defined the primary signaling pathways but also highlighted the key amino acid residues in both the ligand and the receptor that govern this critical biological interaction. This foundational knowledge has been indispensable for the rational design of the highly effective GLP-1R agonists that are now cornerstones in the management of metabolic diseases.
References
Unraveling the Dance: A Technical Guide to the Conformational Flexibility of GLP-1 in Solution
For Researchers, Scientists, and Drug Development Professionals
Glucagon-like peptide-1 (GLP-1) is a critical incretin hormone with significant therapeutic applications in the management of type 2 diabetes and obesity. Its efficacy is intrinsically linked to its ability to recognize and activate its receptor, a process governed by its dynamic conformational landscape in solution. This technical guide delves into the intricate conformational flexibility of GLP-1, providing a comprehensive overview of its structural dynamics, the experimental techniques used to probe them, and the downstream signaling events that follow receptor engagement.
The Conformational Ensemble of GLP-1: A Peptide in Motion
In aqueous solution, GLP-1 exists as a highly flexible and largely unstructured peptide. However, its conformation is exquisitely sensitive to its environment, adopting more ordered structures in the presence of membrane-mimicking solvents or upon binding to the GLP-1 receptor (GLP-1R). Understanding this conformational equilibrium is paramount for the rational design of potent and stable GLP-1 analogues.
Nuclear Magnetic Resonance (NMR) spectroscopy and Circular Dichroism (CD) are powerful techniques that have provided significant insights into the solution structure of GLP-1. In a purely aqueous environment, GLP-1 predominantly adopts a random coil conformation. However, in the presence of trifluoroethanol (TFE), a solvent known to promote helicity, GLP-1 undergoes a significant conformational transition to a more helical structure.[1][2] This induced helicity is believed to mimic the conformation adopted by the peptide as it approaches the cell membrane to engage with its receptor.
Molecular dynamics (MD) simulations have further illuminated the dynamic nature of GLP-1, revealing the transient formation of helical segments even in aqueous solution and providing a detailed picture of the conformational landscape accessible to the peptide.[3][4]
Table 1: Conformational States of GLP-1 in Different Solvent Environments
| Solvent Condition | Predominant Conformation | Key Structural Features | References |
| Aqueous Buffer (e.g., pure water, phosphate buffer) | Random Coil | Highly flexible, lacking persistent secondary structure. | [1][2] |
| Aqueous Trifluoroethanol (TFE) | α-helix | Increased helical content, particularly in the C-terminal region.[1][2] The N-terminus remains more flexible.[5] | [1][2][5] |
| Dodecylphosphocholine (DPC) Micelles (Membrane Mimic) | α-helix | Two helical regions (residues 13-20 and 24-35) separated by a flexible linker.[5] | [5] |
Experimental Protocols for Probing GLP-1 Conformation
The study of GLP-1's conformational flexibility relies on a suite of biophysical and computational techniques. Below are detailed methodologies for the key experiments cited in the literature.
Circular Dichroism (CD) Spectroscopy
CD spectroscopy is a rapid and sensitive method for assessing the secondary structure of peptides in solution.
Methodology:
-
Sample Preparation: Lyophilized GLP-1 is dissolved in the desired buffer (e.g., 25 mM phosphate buffer at pH 7.5 or various concentrations of TFE in water) to a final concentration typically ranging from 10 to 100 µM.[6][7]
-
Spectra Acquisition: Far-UV CD spectra are recorded at room temperature (e.g., 25 °C) using a CD spectrometer.[6] Data is typically collected from 190 to 260 nm in a quartz cuvette with a path length of 1 mm.[7]
-
Data Processing: The raw data is corrected by subtracting the spectrum of the buffer alone. The resulting signal in millidegrees is then converted to mean residue ellipticity ([θ]) in deg·cm²·dmol⁻¹.
-
Secondary Structure Estimation: The percentage of α-helix, β-sheet, and random coil is estimated by deconvolution of the CD spectra using various algorithms available in software packages like CDSSTR or CONTIN.
Nuclear Magnetic Resonance (NMR) Spectroscopy
NMR spectroscopy provides high-resolution structural information, allowing for the determination of the three-dimensional structure of GLP-1 in solution.
Methodology:
-
Sample Preparation: Recombinant or synthetic GLP-1 is dissolved in an appropriate buffer (e.g., H₂O/D₂O mixture or aqueous TFE) to a concentration of approximately 1.4 mM at a specific pH (e.g., 2.5).[1]
-
NMR Experiments: A series of one- and two-dimensional NMR experiments are performed, including TOCSY (Total Correlation Spectroscopy) for assigning spin systems to specific amino acid residues and NOESY (Nuclear Overhauser Effect Spectroscopy) for obtaining distance restraints between protons that are close in space.
-
Resonance Assignment: The collected spectra are analyzed to assign all proton resonances to their respective amino acids in the GLP-1 sequence.
-
Structure Calculation: The distance restraints derived from NOESY spectra, along with dihedral angle restraints obtained from coupling constants, are used as input for structure calculation programs (e.g., CYANA, XPLOR-NIH) to generate an ensemble of 3D structures consistent with the experimental data.
Molecular Dynamics (MD) Simulations
MD simulations provide a computational lens to visualize the dynamic behavior of GLP-1 at an atomic level.
Methodology:
-
System Setup: An initial 3D structure of GLP-1 (e.g., from NMR or a predicted helical conformation) is placed in a simulation box filled with a chosen solvent model (e.g., explicit water molecules). Ions are added to neutralize the system and mimic physiological salt concentrations.[3]
-
Force Field Selection: An appropriate force field (e.g., AMBER, CHARMM, GROMOS) is chosen to describe the interactions between all atoms in the system.
-
Minimization and Equilibration: The system is first energy-minimized to remove any steric clashes. This is followed by a period of equilibration where the temperature and pressure of the system are gradually brought to the desired values (e.g., 300 K and 1 bar).
-
Production Run: A long simulation (typically nanoseconds to microseconds) is run, during which the positions and velocities of all atoms are calculated by integrating Newton's equations of motion.
-
Trajectory Analysis: The resulting trajectory is analyzed to study various properties, including secondary structure evolution, root-mean-square deviation (RMSD) from the initial structure, and interatomic distances, providing insights into the conformational flexibility of the peptide.[3]
Visualizing the GLP-1 Signaling Pathway and Experimental Workflow
To provide a clearer understanding of the biological context and experimental approach, the following diagrams illustrate the GLP-1 signaling cascade and a typical workflow for studying its conformation.
Caption: The GLP-1 signaling cascade, initiated by ligand binding and culminating in insulin release.
Caption: A generalized experimental workflow for characterizing the conformational properties of GLP-1.
Conclusion: From Flexibility to Function
The conformational flexibility of GLP-1 is not a random phenomenon but a finely tuned characteristic that is essential for its biological function. The ability of GLP-1 to transition from a disordered state in circulation to a more ordered, helical conformation upon approaching the cell membrane is a key step in its mechanism of action. A thorough understanding of this conformational landscape, aided by the experimental and computational techniques outlined in this guide, is crucial for the development of next-generation GLP-1 receptor agonists with enhanced stability, potency, and therapeutic profiles. The continued exploration of GLP-1's structural dynamics will undoubtedly pave the way for novel therapeutic strategies targeting metabolic diseases.
References
- 1. files.core.ac.uk [files.core.ac.uk]
- 2. Crystal Structure of Glucagon-like Peptide-1 in Complex with the Extracellular Domain of the Glucagon-like Peptide-1 Receptor - PMC [pmc.ncbi.nlm.nih.gov]
- 3. worldscientific.com [worldscientific.com]
- 4. Computational insight into conformational states of glucagon-like peptide-1 receptor (GLP-1R) and its binding mode with GLP-1 - RSC Advances (RSC Publishing) [pubs.rsc.org]
- 5. The structure and function of the glucagon-like peptide-1 receptor and its ligands - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. pubs.acs.org [pubs.acs.org]
The Therapeutic Potential of GLP-1 Analogs: A Technical Guide
An In-depth Exploration for Researchers, Scientists, and Drug Development Professionals
Glucagon-like peptide-1 (GLP-1) receptor agonists, or GLP-1 analogs, have emerged as a transformative class of therapeutics, initially for type 2 diabetes and now revolutionizing the management of obesity. Their pleiotropic effects extend to cardiovascular protection and potential neuroprotective benefits, making them a focal point of intensive research and drug development. This guide provides a comprehensive overview of the core science behind GLP-1 analogs, from their molecular mechanism of action to clinical efficacy, with a focus on the technical details relevant to the scientific community.
Mechanism of Action: Mimicking the Incretin Effect
GLP-1 is an incretin hormone secreted by L-cells of the distal ileum and colon in response to nutrient intake. Its primary physiological role is to potentiate glucose-dependent insulin secretion from pancreatic β-cells. GLP-1 analogs are synthetic peptides that mimic the action of endogenous GLP-1 but are engineered for a longer half-life, overcoming the rapid degradation of native GLP-1 by the enzyme dipeptidyl peptidase-4 (DPP-4).
The multifaceted mechanism of action of GLP-1 analogs includes:
-
Pancreatic Effects:
-
Stimulation of Insulin Secretion: In a glucose-dependent manner, GLP-1 analogs bind to GLP-1 receptors on pancreatic β-cells, leading to increased insulin synthesis and release. This glucose dependency confers a low risk of hypoglycemia.
-
Suppression of Glucagon Secretion: They act on pancreatic α-cells to suppress the release of glucagon, a hormone that raises blood glucose levels, particularly in the postprandial state.
-
β-cell Preservation: Preclinical studies suggest that GLP-1 analogs may promote β-cell proliferation and inhibit apoptosis, potentially preserving β-cell mass and function.
-
-
Extra-Pancreatic Effects:
-
Delayed Gastric Emptying: GLP-1 analogs slow the rate at which food leaves the stomach, contributing to a feeling of fullness and reducing postprandial glucose excursions.
-
Central Nervous System Effects: They act on receptors in the hypothalamus to enhance satiety and reduce appetite, leading to decreased food intake and subsequent weight loss.
-
The GLP-1 Receptor Signaling Pathway
The binding of a GLP-1 analog to the GLP-1 receptor (GLP-1R), a class B G protein-coupled receptor (GPCR), initiates a cascade of intracellular signaling events.
Upon agonist binding, the GLP-1R couples with the Gs alpha subunit of the G protein complex, leading to the activation of adenylyl cyclase. This enzyme catalyzes the conversion of ATP to cyclic AMP (cAMP). The subsequent increase in intracellular cAMP activates two main downstream effectors: Protein Kinase A (PKA) and Exchange protein directly activated by cAMP (EPAC).
Activation of PKA and EPAC leads to a variety of cellular responses, including the potentiation of glucose-stimulated insulin secretion through mechanisms that involve the closure of ATP-sensitive potassium channels, membrane depolarization, and an influx of calcium ions. Furthermore, PKA can translocate to the nucleus and phosphorylate the cAMP response element-binding protein (CREB), which in turn modulates the transcription of genes involved in insulin synthesis and β-cell survival.
Therapeutic Applications and Clinical Efficacy
The therapeutic utility of GLP-1 analogs has expanded significantly since their initial approval for type 2 diabetes.
Type 2 Diabetes Mellitus
GLP-1 analogs are a cornerstone in the management of type 2 diabetes, recommended as an early-line therapy, particularly in patients with established atherosclerotic cardiovascular disease or obesity. They effectively lower HbA1c levels, with long-acting formulations demonstrating slightly better glycemic control than short-acting ones.
Table 1: Efficacy of Selected GLP-1 Analogs in Type 2 Diabetes (Head-to-Head and Placebo-Controlled Trials)
| GLP-1 Analog | Trial(s) | Comparator | Mean HbA1c Reduction (from baseline) | Mean Weight Change (from baseline) | Citation(s) |
| Semaglutide (s.c.) | SUSTAIN program | Placebo/Active Comparators | ~1.5% | ~ -4.5 kg | |
| SUSTAIN-2 | Sitagliptin | -1.5% vs -0.9% | - | ||
| Liraglutide | LEAD-6 | Exenatide BID | -1.12% vs -0.79% | -2.45 kg vs -2.87 kg | |
| Dulaglutide | REWIND | Placebo | -0.61% | - | |
| Exenatide (once-weekly) | DURATION-1 | Exenatide BID | -1.9% vs -1.5% | -3.7 kg vs -3.6 kg | |
| DURATION-2 | Sitagliptin/Pioglitazone | -1.5% vs -0.9%/-1.2% | -2.3 kg vs -0.8 kg/+2.8 kg | ||
| Tirzepatide (GIP/GLP-1) | SURPASS-2 | Semaglutide 1mg | -2.01% to -2.3% vs -1.86% | -7.6 kg to -11.2 kg vs -5.7 kg |
Obesity
The profound effect of GLP-1 analogs on appetite and food intake has led to their approval for chronic weight management in individuals with obesity or who are overweight with at least one weight-related comorbidity.
Table 2: Efficacy of Selected GLP-1 Analogs in Obesity (in individuals with or without Type 2 Diabetes)
| GLP-1 Analog | Trial(s) | Patient Population | Mean Placebo-Subtracted Weight Loss | Percentage of Patients Achieving ≥5% Weight Loss | Citation(s) |
| Semaglutide (2.4mg) | STEP 1 | Without T2D | -12.4% | 86.4% vs 31.5% (placebo) | |
| STEP 2 | With T2D | -6.2% | - | ||
| Liraglutide (3.0mg) | SCALE Obesity and Prediabetes | Without T2D | -5.4% | 63.2% vs 27.1% (placebo) | |
| SCALE Diabetes | With T2D | -4.0% | 54.3% vs 21.4% (placebo) | ||
| Tirzepatide (GIP/GLP-1) | SURMOUNT-1 | Without T2D | -15.0% to -20.9% (dose-dependent) | 85% to 91% (dose-dependent) |
Cardiovascular Disease
Large cardiovascular outcome trials (CVOTs) have demonstrated that several GLP-1 analogs significantly reduce the risk of major adverse cardiovascular events (MACE), a composite of cardiovascular death, non-fatal myocardial infarction, and non-fatal stroke. These benefits are thought to be mediated through a combination of improved glycemic control, weight loss, and potentially direct effects on the cardiovascular system, such as reducing inflammation and improving endothelial function.
Table 3: Cardiovascular Outcomes with Selected GLP-1 Analogs
| GLP-1 Analog | Trial | Primary Outcome (MACE) | Hazard Ratio (95% CI) vs. Placebo | Citation(s) |
| Semaglutide (s.c.) | SUSTAIN-6 | 3-point MACE | 0.74 (0.58 to 0.95) | |
| Liraglutide | LEADER | 3-point MACE | 0.87 (0.78 to 0.97) | |
| Dulaglutide | REWIND | 3-point MACE | 0.88 (0.79 to 0.99) |
Emerging Therapeutic Areas
The neuroprotective properties of GLP-1 analogs are an active area of investigation. Preclinical studies and some early clinical data suggest potential benefits in neurodegenerative diseases such as Alzheimer's and Parkinson's disease, possibly through anti-inflammatory and anti-apoptotic mechanisms in the brain. Additionally, their anti-inflammatory effects are being explored in a range of conditions, including non-alcoholic fatty liver disease (NAFLD) and chronic kidney disease.
Experimental Protocols and Methodologies
A robust understanding of the preclinical and clinical evaluation of GLP-1 analogs requires familiarity with key experimental protocols.
In Vitro Receptor Binding and Functional Assays
These assays are crucial for determining the affinity and potency of novel GLP-1 analogs.
Experimental Workflow: GLP-1 Receptor Binding Assay
A common method is a competitive radioligand binding assay. In this setup, cell membranes expressing the GLP-1 receptor are incubated with a fixed concentration of a radiolabeled GLP-1 analog and varying concentrations of the unlabeled test compound. The ability of the test compound to displace the radioligand is measured, and from this, the inhibitory constant (Ki) or the half-maximal inhibitory concentration (IC50) can be determined, providing a measure of the compound's binding affinity.
Functional assays, such as measuring cAMP production in response to agonist stimulation, are used to determine the potency (EC50) and efficacy of the compound.
In Vivo Models: Oral Glucose Tolerance Test (OGTT)
The OGTT is a fundamental in vivo experiment to assess the glucose-lowering efficacy of GLP-1 analogs in animal models, typically mice or rats.
Experimental Workflow: Oral Glucose Tolerance Test (OGTT)
Following an overnight fast, a baseline blood glucose measurement is taken. The animals are then administered the GLP-1 analog or a vehicle control. After a set period, a bolus of glucose is given orally. Blood glucose levels are then monitored at several time points. The area under the curve (AUC) for glucose is calculated to quantify the improvement in glucose tolerance conferred by the GLP-1 analog.
Clinical Trial Design
The clinical development of GLP-1 analogs typically involves a series of phase I, II, and III trials to establish safety, efficacy, and optimal dosing. For regulatory approval in type 2 diabetes and obesity, key endpoints include changes in HbA1c and body weight, respectively.
Cardiovascular outcome trials (CVOTs) are large-scale, long-term, randomized, placebo-controlled trials designed to assess the cardiovascular safety and, ideally, the benefit of new diabetes medications. The primary endpoint in these trials is typically the time to the first occurrence of a 3-point MACE.
Future Directions and Conclusion
The therapeutic landscape of GLP-1 analogs continues to evolve rapidly. The development of dual GIP/GLP-1 receptor agonists, such as tirzepatide, has demonstrated even greater efficacy in glycemic control and weight loss. Research is also focused on the development of oral formulations to improve patient convenience and adherence.
The expanding understanding of the pleiotropic effects of GLP-1 signaling opens up new avenues for therapeutic intervention in a wide range of diseases. The anti-inflammatory and neuroprotective properties of these agents hold particular promise.
The Intricate Dance: A Technical Guide to GLP-1 and its Receptor Interactions
For Researchers, Scientists, and Drug Development Professionals
This in-depth technical guide delves into the fundamental interactions between Glucagon-Like Peptide-1 (GLP-1) and its receptor (GLP-1R), a critical axis in metabolic regulation and a prime target for therapeutic intervention in type 2 diabetes and obesity. This document provides a comprehensive overview of the binding kinetics, activation mechanisms, and downstream signaling cascades, supported by quantitative data, detailed experimental methodologies, and visual representations of the key pathways.
Quantitative Analysis of GLP-1 and GLP-1R Interaction
The affinity and potency of various ligands for the GLP-1R are crucial determinants of their biological activity. The following tables summarize key quantitative data from various in vitro studies, providing a comparative landscape of endogenous ligands and synthetic analogs.
Table 1: Binding Affinity (IC50/Kd) of Selected Ligands for the GLP-1 Receptor
| Ligand | Assay Type | Cell Line/System | IC50 / Kd | Citation |
| GLP-1 (7-36) | Radioligand Binding | - | 1.18 nM (IC50) | [1] |
| Exendin-4 | Radioligand Binding | - | 1.3 nM (IC50) | [1] |
| Semaglutide | Radioligand Binding | - | 1.13 µM (IC50) | [1] |
| Tirzepatide | Radioligand Binding | - | 645 nM (IC50) | [1] |
| Retatrutide | Radioligand Binding | - | 720 nM (IC50) | [1] |
| Danuglipron | Radioligand Binding | - | 2540 nM (IC50) | [1] |
| Semaglutide | Computational Modeling | GLP-1R Extracellular Domain | 3.4 x 10⁻⁶ M (Kd) | [2][3] |
| Semaglutide Analogue | Computational Modeling | GLP-1R Extracellular Domain | 3.0 x 10⁻⁸ M (Kd) | [2][3] |
Table 2: Potency (EC50) of GLP-1R Agonists in cAMP Accumulation Assays
| Agonist | Cell Line | EC50 | Citation |
| GLP-1 (7-36)NH2 | CHO (human GLP-1R) | Single-digit pM range | [4] |
| Ecnoglutide | - | 2.322 ng/mL | [5] |
| M2 Analogue | - | 1.996 ng/mL | [5] |
| Semaglutide | - | 2.437 ng/mL | [5] |
| GLP-1 (7-36) amide | HEK-GLP-1R | 85 pM | [6] |
| Compound 2 | HEK-GLP-1R | pEC50 = 6.23 ± 0.07 | [6] |
| GLP-1 | GLP1R Nomad Cell Line | 4.54 x 10⁻⁹ M | [7] |
| Exendin-4 | GLP1R Nomad Cell Line | 4.54 x 10⁻⁹ M | [7] |
| GLP-1 | HEK293 (stable GLP-1R) | 0.54 nM | [8] |
Table 3: β-Arrestin Recruitment Potency of GLP-1R Ligands
| Ligand | Assay Type | Key Findings | Citation |
| GLP-1 Analogues (α/β-peptides) | BRET | Some analogues show bias towards β-arrestin recruitment over cAMP production. | [9][10][11][12] |
| P5 and Exendin-F1 | BRET | Exendin-F1 has higher affinity but lower efficacy for β-arrestin-2 recruitment compared to P5. | [13] |
Core Signaling Pathways of the GLP-1 Receptor
Upon agonist binding, the GLP-1R, a class B G protein-coupled receptor (GPCR), undergoes a conformational change that initiates a cascade of intracellular signaling events. The primary and most well-characterized pathway involves the coupling to the stimulatory G protein, Gαs. However, evidence also points to the involvement of other G proteins and β-arrestin-mediated signaling, leading to a complex and nuanced cellular response.
The Canonical Gαs/cAMP Pathway
The activation of Gαs by the GLP-1R leads to the stimulation of adenylyl cyclase, which in turn catalyzes the conversion of ATP to cyclic AMP (cAMP).[6] This increase in intracellular cAMP activates two main downstream effectors: Protein Kinase A (PKA) and Exchange protein directly activated by cAMP (Epac).[14] These pathways are central to the insulinotropic effects of GLP-1 in pancreatic β-cells.
Gαq/PLC Pathway
In addition to Gαs, the GLP-1R can also couple to Gαq proteins. This interaction activates Phospholipase C (PLC), which cleaves phosphatidylinositol 4,5-bisphosphate (PIP2) into inositol trisphosphate (IP3) and diacylglycerol (DAG). IP3 triggers the release of calcium from intracellular stores, while DAG activates Protein Kinase C (PKC), contributing to the overall cellular response to GLP-1.
β-Arrestin Mediated Signaling and Receptor Internalization
Following agonist-induced phosphorylation by G protein-coupled receptor kinases (GRKs), β-arrestins (β-arrestin-1 and β-arrestin-2) are recruited to the GLP-1R.[9][10][11][12] This recruitment not only desensitizes G protein-mediated signaling but also initiates a distinct wave of signaling through pathways such as the ERK1/2 cascade. Furthermore, β-arrestin recruitment is a key step in the clathrin-mediated endocytosis of the receptor, a process crucial for receptor resensitization and downregulation.[15]
Detailed Experimental Protocols
Reproducible and rigorous experimental design is paramount in the study of receptor pharmacology. This section provides detailed methodologies for key assays used to characterize the interaction between GLP-1 and its receptor.
Radioligand Competition Binding Assay
This assay is used to determine the binding affinity (Ki or IC50) of unlabeled compounds by measuring their ability to compete with a radiolabeled ligand for binding to the GLP-1R.
Materials:
-
HEK293 cells stably expressing human GLP-1R
-
Membrane preparation buffer (e.g., 50 mM Tris-HCl, 5 mM MgCl2, 1 mM EDTA, pH 7.4)[16]
-
Radioligand (e.g., ¹²⁵I-GLP-1 or ¹²⁵I-Exendin(9-39))[8]
-
Unlabeled competitor ligands (GLP-1, Exendin-4, etc.)
-
Assay buffer (e.g., 50 mM Tris-HCl, 5 mM MgCl2, 0.1% BSA, pH 7.4)
-
Wash buffer (ice-cold PBS)
-
96-well plates
-
Glass fiber filters (e.g., Whatman GF/C) pre-soaked in 0.3-0.5% polyethyleneimine (PEI)[16]
-
Scintillation fluid
-
Scintillation counter
Procedure:
-
Membrane Preparation:
-
Culture HEK293-GLP-1R cells to confluency.
-
Harvest cells and homogenize in ice-cold membrane preparation buffer containing protease inhibitors.
-
Centrifuge the homogenate at low speed (e.g., 500 x g for 10 min) to remove nuclei and cellular debris.
-
Centrifuge the supernatant at high speed (e.g., 40,000 x g for 30 min) to pellet the membranes.
-
Wash the membrane pellet with fresh buffer and resuspend in assay buffer. Determine protein concentration using a suitable method (e.g., BCA assay).
-
-
Binding Assay:
-
In a 96-well plate, add in the following order:
-
Assay buffer
-
A fixed concentration of radioligand (typically at or below its Kd value, e.g., 75 pM of ¹²⁵I-Exendin(9-39))[8]
-
A range of concentrations of the unlabeled competitor ligand.
-
Membrane preparation (typically 5-20 µg of protein per well).
-
-
For total binding wells, add buffer instead of the competitor. For non-specific binding wells, add a high concentration of an unlabeled ligand (e.g., 1 µM GLP-1).
-
Incubate the plate at room temperature for a sufficient time to reach equilibrium (e.g., 60-120 minutes) with gentle agitation.[16]
-
-
Filtration and Counting:
-
Rapidly filter the contents of each well through the pre-soaked glass fiber filters using a cell harvester.
-
Wash the filters multiple times with ice-cold wash buffer to remove unbound radioligand.
-
Dry the filters and place them in scintillation vials with scintillation fluid.
-
Measure the radioactivity in a scintillation counter.
-
-
Data Analysis:
-
Calculate specific binding by subtracting non-specific binding from total binding.
-
Plot the percentage of specific binding against the logarithm of the competitor concentration.
-
Fit the data to a sigmoidal dose-response curve to determine the IC50 value.
-
Calculate the Ki value using the Cheng-Prusoff equation: Ki = IC50 / (1 + [L]/Kd), where [L] is the concentration of the radioligand and Kd is its dissociation constant.
-
cAMP Accumulation Assay
This functional assay measures the ability of a ligand to stimulate the production of intracellular cAMP, a key second messenger in GLP-1R signaling.
Materials:
-
HEK293 or CHO cells stably expressing human GLP-1R[4]
-
Cell culture medium (e.g., DMEM) supplemented with fetal bovine serum (FBS)
-
Stimulation buffer (e.g., HBSS or serum-free medium containing a phosphodiesterase inhibitor like IBMX, typically 0.5 mM)
-
Test agonists (GLP-1, analogues, etc.)
-
Lysis buffer
-
cAMP detection kit (e.g., HTRF, ELISA, or BRET-based biosensor)[8]
-
96- or 384-well plates
-
Plate reader compatible with the chosen detection method
Procedure:
-
Cell Seeding:
-
Seed the GLP-1R expressing cells into 96- or 384-well plates at an appropriate density (e.g., 20,000-40,000 cells/well) and culture overnight.[17]
-
-
Assay:
-
Wash the cells with stimulation buffer.
-
Pre-incubate the cells with stimulation buffer containing a phosphodiesterase inhibitor (e.g., 0.5 mM IBMX) for a short period (e.g., 15-30 minutes) at 37°C to prevent cAMP degradation.
-
Add varying concentrations of the test agonist to the wells.
-
Incubate for a defined period (e.g., 15-30 minutes) at 37°C.[6]
-
-
Cell Lysis and Detection:
-
Lyse the cells according to the cAMP detection kit manufacturer's instructions.
-
Perform the cAMP measurement using the chosen detection method (e.g., read fluorescence for HTRF or luminescence for BRET).
-
-
Data Analysis:
-
Generate a standard curve if using an ELISA-based kit.
-
Plot the measured signal (e.g., fluorescence ratio or luminescence) against the logarithm of the agonist concentration.
-
Fit the data to a sigmoidal dose-response curve to determine the EC50 value and the maximum response (Emax).
-
β-Arrestin Recruitment BRET Assay
This assay measures the recruitment of β-arrestin to the GLP-1R upon agonist stimulation, providing insights into receptor desensitization, internalization, and β-arrestin-mediated signaling. Bioluminescence Resonance Energy Transfer (BRET) is a commonly used technology for this purpose.
Materials:
-
HEK293 cells
-
Expression plasmids for GLP-1R fused to a BRET donor (e.g., Renilla Luciferase, Rluc) and β-arrestin fused to a BRET acceptor (e.g., Green Fluorescent Protein, GFP).[10]
-
Transfection reagent
-
Cell culture medium
-
Assay buffer (e.g., HBSS)
-
Coelenterazine h (luciferase substrate)
-
Test agonists
-
White 96-well plates
-
BRET-compatible plate reader
Procedure:
-
Transfection:
-
Co-transfect HEK293 cells with the GLP-1R-Rluc and β-arrestin-GFP plasmids using a suitable transfection reagent.
-
Seed the transfected cells into white 96-well plates and culture for 24-48 hours.
-
-
Assay:
-
Wash the cells with assay buffer.
-
Add varying concentrations of the test agonist to the wells.
-
Add the luciferase substrate, coelenterazine h, to each well.
-
Incubate for a short period (e.g., 5-15 minutes) at room temperature.
-
-
BRET Measurement:
-
Measure the luminescence signal at two different wavelengths simultaneously using a BRET-compatible plate reader (one for the donor emission and one for the acceptor emission).
-
-
Data Analysis:
-
Calculate the BRET ratio by dividing the acceptor emission intensity by the donor emission intensity.
-
Subtract the basal BRET ratio (from vehicle-treated cells) to obtain the net BRET ratio.
-
Plot the net BRET ratio against the logarithm of the agonist concentration.
-
Fit the data to a sigmoidal dose-response curve to determine the EC50 and Emax for β-arrestin recruitment.
-
Conclusion
The interaction between GLP-1 and its receptor is a multifaceted process involving precise molecular recognition, conformational changes, and the orchestration of multiple intracellular signaling pathways. A thorough understanding of these fundamental mechanisms is essential for the rational design and development of novel GLP-1R agonists with improved therapeutic profiles. The quantitative data and detailed experimental protocols provided in this guide serve as a valuable resource for researchers dedicated to advancing our knowledge in this critical area of metabolic science. The continued exploration of biased agonism and the structural basis of ligand-receptor interactions will undoubtedly pave the way for the next generation of therapies targeting the GLP-1 system.
References
- 1. apac.eurofinsdiscovery.com [apac.eurofinsdiscovery.com]
- 2. An Exhaustive Exploration of the Semaglutide-GLP-1R Sequence Space towards the Design of Semaglutide Analogues with Elevated Binding Affinity to GLP-1R[v1] | Preprints.org [preprints.org]
- 3. Optimizing GLP-1R Agonist: A Computational Semaglutide Analogue with 112-fold Enhanced Binding Affinity to GLP-1R[v1] | Preprints.org [preprints.org]
- 4. researchgate.net [researchgate.net]
- 5. researchgate.net [researchgate.net]
- 6. Comparative Effects of the Endogenous Agonist Glucagon-Like Peptide-1 (GLP-1)-(7-36) Amide and the Small-Molecule Ago-Allosteric Agent “Compound 2” at the GLP-1 Receptor - PMC [pmc.ncbi.nlm.nih.gov]
- 7. innoprot.com [innoprot.com]
- 8. The peptide agonist-binding site of the glucagon-like peptide-1 (GLP-1) receptor based on site-directed mutagenesis and knowledge-based modelling - PMC [pmc.ncbi.nlm.nih.gov]
- 9. pubs.acs.org [pubs.acs.org]
- 10. β-Arrestin-biased agonists of the GLP-1 receptor from β-amino acid residue incorporation into GLP-1 analogues - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. [PDF] β-Arrestin-Biased Agonists of the GLP-1 Receptor from β-Amino Acid Residue Incorporation into GLP-1 Analogues. | Semantic Scholar [semanticscholar.org]
- 13. Evaluation of efficacy- versus affinity-driven agonism with biased GLP-1R ligands P5 and exendin-F1 - PMC [pmc.ncbi.nlm.nih.gov]
- 14. cdn.caymanchem.com [cdn.caymanchem.com]
- 15. Functional Consequences of Glucagon-like Peptide-1 Receptor Cross-talk and Trafficking - PMC [pmc.ncbi.nlm.nih.gov]
- 16. giffordbioscience.com [giffordbioscience.com]
- 17. innoprot.com [innoprot.com]
Methodological & Application
Application Notes and Protocols for Molecular Dynamics Simulation of GLP-1
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive guide to performing molecular dynamics (MD) simulations of Glucagon-like peptide-1 (GLP-1), a critical hormone in glucose metabolism and a key target for the treatment of type 2 diabetes and obesity.[1][2][3][4] This document outlines the necessary protocols, from system preparation to simulation and analysis, and includes detailed parameters and visualizations to aid researchers in their investigations of GLP-1 dynamics, its interactions with its receptor (GLP-1R), and the development of novel therapeutics.
Introduction to GLP-1 and Molecular Dynamics Simulations
Glucagon-like peptide-1 (GLP-1) is an incretin hormone that plays a crucial role in regulating blood sugar levels by stimulating insulin secretion and inhibiting glucagon release.[5][6][7] Understanding the conformational dynamics and binding mechanisms of GLP-1 and its analogues to the GLP-1 receptor (GLP-1R) is paramount for the design of more effective and stable therapeutic agents.[4] Molecular dynamics (MD) simulations have emerged as a powerful computational tool to investigate the behavior of biological macromolecules at an atomic level, providing insights that are often inaccessible through experimental methods alone.[8][9] These simulations can elucidate the structural flexibility of GLP-1, the key residues involved in receptor binding, and the allosteric mechanisms of receptor activation.[1][10]
GLP-1 Receptor Signaling Pathway
Upon binding of GLP-1 to its receptor, a cascade of intracellular signaling events is initiated, primarily through the Gαs protein pathway, leading to an increase in cyclic AMP (cAMP) levels.[6] This in turn activates Protein Kinase A (PKA) and Exchange protein directly activated by cAMP (EPAC), culminating in enhanced insulin secretion, improved beta-cell health, and other metabolic benefits.[5][6]
References
- 1. connectsci.au [connectsci.au]
- 2. Novel insights into the dynamics behavior of glucagon-like peptide-1 receptor with its small molecule agonists - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Computational insight into conformational states of glucagon-like peptide-1 receptor (GLP-1R) and its binding mode with GLP-1 - RSC Advances (RSC Publishing) [pubs.rsc.org]
- 4. Rational Design by Structural Biology of Industrializable, Long-Acting Antihyperglycemic GLP-1 Receptor Agonists - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Activation of the GLP-1 Receptor Signalling Pathway: A Relevant Strategy to Repair a Deficient Beta-Cell Mass - PMC [pmc.ncbi.nlm.nih.gov]
- 6. GLP-1: Molecular mechanisms and outcomes of a complex signaling system - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. Assessing the Performance of Peptide Force Fields for Modeling the Solution Structural Ensembles of Cyclic Peptides - PMC [pmc.ncbi.nlm.nih.gov]
- 9. pubs.acs.org [pubs.acs.org]
- 10. Dynamics of GLP-1R peptide agonist engagement are correlated with kinetics of G protein activation - PMC [pmc.ncbi.nlm.nih.gov]
Application Note and Protocol: Comparative Structural Analysis of Peptide Hormones
For Researchers, Scientists, and Drug Development Professionals
Introduction
Peptide hormones are a diverse class of signaling molecules that play crucial roles in a myriad of physiological processes.[1] Their biological activity is intrinsically linked to their three-dimensional structure. Comparative structural analysis of different peptide hormones or their synthetic analogs is therefore fundamental for understanding their structure-function relationships, designing novel therapeutics with improved efficacy and stability, and elucidating their mechanisms of action.[2]
This document provides a comprehensive set of protocols for the comparative structural analysis of peptide hormones, covering primary, secondary, and tertiary structure determination. It also includes a protocol for assessing receptor binding, a critical functional readout. The methodologies described herein are essential for researchers in endocrinology, pharmacology, and drug development.
Experimental Workflow for Comparative Structural Analysis
The following diagram outlines a general workflow for the comprehensive structural and functional comparison of peptide hormones.
Caption: A general workflow for the comparative structural analysis of peptide hormones.
Experimental Protocols
Primary Structure and Post-Translational Modification Analysis by Mass Spectrometry
Mass spectrometry (MS) is a powerful technique for the accurate determination of the molecular weight and amino acid sequence of peptide hormones.[3][4] It is also instrumental in identifying and characterizing post-translational modifications (PTMs).
Protocol: Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS)
-
Sample Preparation:
-
Dissolve purified peptide hormones in a solvent compatible with reverse-phase liquid chromatography, such as 0.1% formic acid in water.
-
The concentration should be in the range of 1-10 pmol/µL.
-
-
LC Separation:
-
Inject the sample onto a C18 reverse-phase column.
-
Elute the peptides using a gradient of increasing acetonitrile concentration (e.g., 5-60%) containing 0.1% formic acid.
-
The flow rate should be optimized for the specific column and mass spectrometer.
-
-
Mass Spectrometry Analysis:
-
The eluent from the LC is introduced into the mass spectrometer via an electrospray ionization (ESI) source.
-
Acquire full scan MS spectra to determine the mass-to-charge ratio (m/z) of the intact peptide hormones.
-
Select the precursor ions of interest for fragmentation using collision-induced dissociation (CID) or higher-energy collisional dissociation (HCD).
-
Acquire tandem mass (MS/MS) spectra of the fragment ions.
-
-
Data Analysis:
-
Process the raw data using appropriate software to de-noise and de-isotope the spectra.
-
Use database search algorithms (e.g., Mascot, SEQUEST) to identify the peptide sequence by matching the experimental MS/MS spectra to theoretical fragmentation patterns from a protein sequence database.
-
Manually inspect the MS/MS spectra to confirm the sequence and identify any PTMs, which will manifest as mass shifts on specific amino acid residues.
-
Secondary Structure Analysis by Circular Dichroism (CD) Spectroscopy
Circular dichroism (CD) spectroscopy is a widely used method for the rapid evaluation of the secondary structure of peptides in solution.[5][6][7] It measures the differential absorption of left and right circularly polarized light by chiral molecules like peptides.[8]
Protocol: Far-UV CD Spectroscopy
-
Sample Preparation:
-
Prepare peptide hormone solutions in a buffer that does not have high absorbance in the far-UV region (190-250 nm).[9] Suitable buffers include phosphate or borate buffers.[9]
-
The peptide concentration should be in the range of 0.1-1 mg/mL.
-
Ensure the sample is free of aggregates by centrifugation or filtration.
-
-
Instrument Setup:
-
Data Acquisition:
-
Record a baseline spectrum with the buffer alone.
-
Record the CD spectrum of the peptide sample.
-
Acquire multiple scans (e.g., 3-5) and average them to improve the signal-to-noise ratio.
-
-
Data Analysis:
-
Subtract the baseline spectrum from the sample spectrum.
-
Convert the raw data (ellipticity) to mean residue ellipticity [θ].
-
Use deconvolution algorithms (e.g., K2D2, CONTIN) to estimate the percentage of α-helix, β-sheet, and random coil structures.[7] The characteristic spectral patterns for these structures include:
-
Tertiary Structure Determination by Nuclear Magnetic Resonance (NMR) Spectroscopy
NMR spectroscopy is a powerful technique for determining the three-dimensional structure of peptides in solution at atomic resolution.[10][11] It provides information about the spatial proximity of atoms and the dihedral angles of the peptide backbone.
Protocol: 2D NMR Spectroscopy
-
Sample Preparation:
-
Dissolve the peptide hormone in a suitable buffer (e.g., phosphate buffer) to a concentration of 0.5-2 mM.
-
The buffer should contain 5-10% D₂O for the lock signal.
-
Adjust the pH to a value where the peptide is stable and soluble.
-
-
NMR Data Acquisition:
-
Acquire a series of 2D NMR spectra, including:
-
TOCSY (Total Correlation Spectroscopy): To identify amino acid spin systems.
-
NOESY (Nuclear Overhauser Effect Spectroscopy): To identify protons that are close in space (< 5 Å).
-
COSY (Correlation Spectroscopy): To identify scalar-coupled protons.
-
-
-
Data Processing and Analysis:
-
Process the NMR data using software such as TopSpin or NMRPipe.
-
Perform resonance assignments to assign each peak in the spectra to a specific proton in the peptide sequence.
-
Extract distance restraints from the NOESY spectra and dihedral angle restraints from the COSY spectra.
-
-
Structure Calculation and Refinement:
-
Use the experimental restraints in structure calculation programs (e.g., CYANA, Xplor-NIH) to generate an ensemble of 3D structures.
-
Refine the structures using molecular dynamics simulations in a water box to obtain a final, high-resolution structure.
-
Tertiary Structure Determination by X-ray Crystallography
X-ray crystallography is a technique that can provide a high-resolution three-dimensional structure of a molecule in its crystalline state.[12][13]
Protocol: Peptide Crystallization and Structure Determination
-
Crystallization:
-
Synthesize and purify the peptide hormone to >95% purity.[12]
-
Screen for crystallization conditions using commercially available kits that vary precipitants, buffers, and salts.
-
Set up crystallization trials using vapor diffusion (hanging drop or sitting drop) methods.
-
Incubate the trials at a constant temperature and monitor for crystal growth.
-
-
Data Collection:
-
Mount a suitable crystal in a cryo-loop and flash-cool it in liquid nitrogen.
-
Collect X-ray diffraction data at a synchrotron source.[13]
-
-
Structure Determination and Refinement:
-
Process the diffraction data to obtain a set of structure factor amplitudes.
-
Determine the initial phases using methods like molecular replacement (if a homologous structure is available) or experimental phasing.
-
Build an initial atomic model into the electron density map.
-
Refine the model against the experimental data to improve its fit and geometry.
-
Functional Analysis: Receptor Binding Assay
A key aspect of comparative analysis is to determine how structural differences affect the biological function of peptide hormones. Receptor binding assays are crucial for quantifying the affinity of a peptide hormone for its receptor.[14]
Protocol: Competitive Radioligand Binding Assay
-
Reagent Preparation:
-
Prepare a membrane fraction from cells expressing the receptor of interest.
-
Obtain a radiolabeled version of a known ligand (the "tracer").
-
Prepare a series of dilutions of the unlabeled peptide hormones to be tested (the "competitors").
-
-
Assay Procedure:
-
In a multi-well plate, combine the receptor preparation, a fixed concentration of the radiolabeled tracer, and varying concentrations of the unlabeled competitor peptides.
-
Incubate the mixture to allow binding to reach equilibrium.
-
Separate the receptor-bound tracer from the free tracer using a filter plate.
-
Measure the amount of radioactivity on the filter using a scintillation counter.
-
-
Data Analysis:
-
Plot the percentage of bound tracer as a function of the competitor concentration.
-
Fit the data to a sigmoidal dose-response curve to determine the IC₅₀ value (the concentration of competitor that inhibits 50% of the specific binding of the tracer).
-
Calculate the inhibition constant (Ki) to determine the affinity of the competitor for the receptor.
-
Data Presentation
Summarize all quantitative data in clearly structured tables for easy comparison.
Table 1: Physicochemical Properties
| Peptide Hormone | Molecular Weight (Da) | Isoelectric Point (pI) |
| Hormone A | ||
| Hormone B | ||
| Hormone C |
Table 2: Secondary Structure Content from CD Spectroscopy
| Peptide Hormone | α-Helix (%) | β-Sheet (%) | Random Coil (%) |
| Hormone A | |||
| Hormone B | |||
| Hormone C |
Table 3: Receptor Binding Affinity
| Peptide Hormone | Receptor | IC₅₀ (nM) | Ki (nM) |
| Hormone A | Receptor X | ||
| Hormone B | Receptor X | ||
| Hormone C | Receptor X |
Peptide Hormone Signaling Pathway
Most peptide hormones bind to G-protein coupled receptors (GPCRs) on the cell surface, initiating intracellular signaling cascades.[15][16] The following diagram illustrates a generic GPCR signaling pathway.
Caption: A simplified diagram of a G-protein coupled receptor (GPCR) signaling pathway.
References
- 1. Peptide Hormones Characterization - Creative Proteomics [creative-proteomics.com]
- 2. experts.arizona.edu [experts.arizona.edu]
- 3. Principle of Peptide Structure Determination | MtoZ Biolabs [mtoz-biolabs.com]
- 4. How to Identify the Structure of Peptides | MtoZ Biolabs [mtoz-biolabs.com]
- 5. Circular dichroism of peptides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. CD-Based Peptide Secondary Structure Analysis - Creative Proteomics [creative-proteomics.com]
- 7. Using circular dichroism spectra to estimate protein secondary structure - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Use of Circular Dichroism to Determine Secondary Structure of Neuropeptides | Springer Nature Experiments [experiments.springernature.com]
- 9. How to Use CD Spectroscopy for Protein Secondary Structure Analysis: A Complete Guide | MtoZ Biolabs [mtoz-biolabs.com]
- 10. UQ eSpace [espace.library.uq.edu.au]
- 11. Three-Dimensional Structure Determination of Peptides Using Solution Nuclear Magnetic Resonance Spectroscopy - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. A Newcomer’s Guide to Peptide Crystallography - PMC [pmc.ncbi.nlm.nih.gov]
- 13. phys.libretexts.org [phys.libretexts.org]
- 14. uwyo.edu [uwyo.edu]
- 15. geneglobe.qiagen.com [geneglobe.qiagen.com]
- 16. Transmembrane signal transduction by peptide hormones via family B G protein-coupled receptors - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for Studying Exendin-4 Receptor Binding Using Molecular Dynamics Simulations
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive guide to utilizing molecular dynamics (MD) simulations for investigating the binding of Exendin-4 to its receptor, the Glucagon-like peptide-1 receptor (GLP-1R). This document outlines the theoretical background, detailed experimental protocols, data analysis techniques, and visualization of the underlying biological processes.
Introduction
Exendin-4, a potent and long-acting agonist of the GLP-1R, is a crucial therapeutic agent for the management of type 2 diabetes. Understanding the atomic-level details of its interaction with the GLP-1R is paramount for the rational design of novel agonists with improved pharmacological profiles. Molecular dynamics simulations offer a powerful computational microscope to elucidate the dynamic nature of this binding process, providing insights into conformational changes, key residue interactions, and binding energetics that are often inaccessible through experimental methods alone.
This document will guide researchers through the process of setting up, running, and analyzing MD simulations of the Exendin-4/GLP-1R complex, and how to interpret the results in the context of the downstream signaling pathways.
Quantitative Data from MD Simulations
MD simulations can provide a wealth of quantitative data that characterizes the stability and energetics of the Exendin-4/GLP-1R complex. Below are representative tables summarizing the types of data that can be extracted from these simulations.
Table 1: Root Mean Square Deviation (RMSD) and Root Mean Square Fluctuation (RMSF) Analysis
| Metric | Component | Average Value (Å) | Interpretation |
| RMSD | GLP-1R Cα atoms | 1.5 - 3.5 | Indicates the stability of the receptor backbone during the simulation. Values in this range suggest the protein has reached equilibrium.[1] |
| Exendin-4 Heavy Atoms | 1.0 - 2.5 | Reflects the stability of the ligand's conformation within the binding pocket. | |
| RMSF | GLP-1R Ligand Binding Site Residues | < 2.0 | Lower values in the binding pocket indicate stable interactions with the ligand.[1] |
| GLP-1R Loop Regions | > 3.0 | Higher fluctuations are expected in flexible loop regions that are not directly involved in binding. |
Table 2: Key Residue Interactions and Binding Energy Contributions
| Exendin-4 Residue | GLP-1R Residue | Interaction Type | Estimated Interaction Energy (kcal/mol) |
| His1 | E364 (TM6) | Hydrogen Bond (transient) | -2.5 to -5.0 |
| Ser32 | Asp68 (rat GLP-1R) | Hydrogen Bond | -4.0 to -7.0 |
| Trp-cage (C-terminus) | N-terminal Domain | Hydrophobic Interactions | Variable, contributes to higher affinity over GLP-1[2] |
| N-terminal region | Transmembrane Domain | Multiple contacts | Contributes significantly to receptor activation[3] |
Table 3: Binding Free Energy Calculations
| Method | System | Calculated ΔGbind (kcal/mol) | Reference |
| MM/GBSA | Compound 9 - GLP-1R | -102.78 | [1] |
| Computational (CG and PDLD) | Truncated Exendin-4 - GLP-1R | ~ -10 | [4] |
Note: The values presented in these tables are representative and can vary depending on the specific simulation parameters, force fields, and analysis methods used.
Experimental Protocols
This section provides a detailed, step-by-step protocol for performing an MD simulation of the Exendin-4/GLP-1R complex using GROMACS with the CHARMM36m force field.
System Preparation
-
Obtain Initial Structures:
-
Download the crystal structure of the GLP-1R in complex with an agonist (e.g., from the Protein Data Bank). If a structure with Exendin-4 is unavailable, homology modeling or docking can be used to generate an initial complex.
-
Prepare the protein by removing any non-essential molecules (e.g., crystallization aids), modeling missing loops or residues, and adding hydrogen atoms.
-
Obtain the 3D structure of Exendin-4.
-
-
Force Field and Topology Generation:
-
Use the GROMACS pdb2gmx tool to generate the topology for the GLP-1R, selecting the CHARMM36m force field and a suitable water model (e.g., TIP3P).
-
Generate the topology and parameters for Exendin-4. For non-standard residues or ligands, a parameterization server like CGenFF may be required.[5]
-
-
Membrane Embedding (for GPCRs):
-
Since GLP-1R is a transmembrane protein, it must be embedded in a lipid bilayer. Use a tool like CHARMM-GUI's membrane builder to place the receptor in a realistic membrane environment (e.g., POPC).
-
-
Solvation and Ionization:
-
Place the protein-membrane system in a periodic box of appropriate dimensions.
-
Solvate the system with water molecules using gmx solvate.
-
Add ions (e.g., Na+ and Cl-) to neutralize the system and mimic physiological salt concentration using gmx genion.
-
Simulation Execution
-
Energy Minimization:
-
Perform a steep descent energy minimization of the system to remove any steric clashes or unfavorable geometries. This is a crucial step to relax the system before dynamics.
-
-
Equilibration (NVT and NPT):
-
NVT (Canonical) Ensemble Equilibration: Equilibrate the system at a constant number of particles (N), volume (V), and temperature (T) for a short period (e.g., 1 ns). This allows the temperature to stabilize.
-
NPT (Isothermal-Isobaric) Ensemble Equilibration: Following NVT, equilibrate the system at a constant number of particles (N), pressure (P), and temperature (T) for a longer duration (e.g., 10 ns). This step allows the pressure and density of the system to stabilize. Position restraints on the protein and ligand heavy atoms are typically applied and gradually released during equilibration.
-
-
Production MD Run:
-
Once the system is well-equilibrated, remove the position restraints and run the production MD simulation for the desired length of time (typically hundreds of nanoseconds to microseconds). Save the trajectory and energy data at regular intervals.
-
Data Analysis
-
Trajectory Analysis:
-
RMSD: Calculate the Root Mean Square Deviation of the protein backbone and ligand heavy atoms to assess the overall stability of the simulation.
-
RMSF: Calculate the Root Mean Square Fluctuation of individual residues to identify flexible and rigid regions of the protein.
-
Hydrogen Bond Analysis: Analyze the formation and lifetime of hydrogen bonds between Exendin-4 and GLP-1R to identify key interactions.
-
Interaction Energy Calculation: Use tools like g_mmpbsa to calculate the binding free energy and decompose it into contributions from individual residues.
-
-
Visualization:
-
Use molecular visualization software such as VMD or PyMOL to visually inspect the trajectory, analyze conformational changes, and create high-quality images and videos of the binding process.
-
Visualizations
MD Simulation Workflow
Exendin-4/GLP-1R Signaling Pathway: PKA Activation
Exendin-4/GLP-1R Signaling Pathway: PI3K/Akt Activation
References
- 1. mdpi.com [mdpi.com]
- 2. Differential structural properties of GLP-1 and exendin-4 determine their relative affinity for the GLP-1 receptor N-terminal extracellular domain - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. A model for receptor–peptide binding at the glucagon-like peptide-1 (GLP-1) receptor through the analysis of truncated ligands and receptors - PMC [pmc.ncbi.nlm.nih.gov]
- 4. A free-energy landscape for the glucagon-like peptide 1 receptor GLP1R - PMC [pmc.ncbi.nlm.nih.gov]
- 5. GROMACS: MD Simulation of a Protein-Ligand Complex [angeloraymondrossi.github.io]
Setting Up a GLP-1 Receptor Simulation in GROMACS: A Step-by-Step Guide
Audience: Researchers, scientists, and drug development professionals.
This guide provides a detailed protocol for setting up and running a molecular dynamics (MD) simulation of the Glucagon-Like Peptide-1 (GLP-1) receptor, a crucial target in the treatment of type 2 diabetes and obesity, using the GROMACS software package. The GLP-1 receptor is a Class B G protein-coupled receptor (GPCR) that is embedded in the cell membrane.[1] This protocol will therefore focus on the specifics of a membrane protein simulation.
Introduction to GLP-1 Signaling
The GLP-1 receptor (GLP-1R) is activated by the binding of the GLP-1 peptide hormone. This event triggers a cascade of intracellular signaling pathways, primarily through the Gαs protein, which stimulates adenylyl cyclase to produce cyclic AMP (cAMP).[2][3] The subsequent activation of Protein Kinase A (PKA) and Exchange protein directly activated by cAMP (EPAC) leads to various cellular responses, most notably the potentiation of glucose-stimulated insulin secretion from pancreatic β-cells.[2][3][4] Understanding the dynamics of this receptor is key to designing novel therapeutics.
Below is a diagram illustrating the primary GLP-1 signaling pathway.
References
- 1. Glucagon-like peptide-1 receptor - Wikipedia [en.wikipedia.org]
- 2. GLP-1: Molecular mechanisms and outcomes of a complex signaling system - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Neuronal and intracellular signaling pathways mediating GLP-1 energy balance and glycemic effects - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Frontiers | Pleiotropic Effects of GLP-1 and Analogs on Cell Signaling, Metabolism, and Function [frontiersin.org]
Practical applications of "SJ000025081" structural findings.
Following a comprehensive search of publicly available scientific databases and literature, the identifier "SJ000025081" does not correspond to a recognized protein, small molecule, gene, or other biological entity with established structural findings.
The search results did not yield any specific information related to a molecule or entity with the identifier "this compound". Consequently, it is not possible to provide the requested Application Notes, Protocols, and visualizations based on its structural findings. The identifier may be an internal designation within a private database, a new or uncatalogued entity, or a typographical error.
To proceed with your request, please provide additional information to clarify the identity of "this compound". This could include:
-
Alternative identifiers: Are there other names, codes, or accession numbers associated with this entity (e.g., a PDB ID, a chemical name, a gene name)?
-
The source of the identifier: Where did you encounter this identifier (e.g., a specific publication, a database, a presentation)?
-
The nature of the molecule: Is it a protein, a nucleic acid, a small molecule, or another type of substance?
-
Any known biological context: What is its suspected function, the organism it is from, or the pathway it is involved in?
Once more specific information is available, a detailed analysis of its structural findings and the development of practical applications and protocols can be initiated.
Application Notes and Protocols for In Silico Analysis of Protein-Ligand Interactions
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a detailed overview and step-by-step protocols for key in silico techniques used to analyze protein-ligand interactions. The included methodologies are essential for structure-based drug design, enabling the prediction of binding modes, estimation of binding affinities, and elucidation of the dynamics of protein-ligand complexes.
Section 1: Molecular Docking
Molecular docking is a computational method that predicts the preferred orientation of one molecule to a second when bound to each other to form a stable complex. It is widely used to predict the binding mode of small molecule ligands to their protein targets.
Application Note:
Molecular docking is a fundamental tool in drug discovery for virtual screening of large compound libraries to identify potential drug candidates. It provides a static picture of the protein-ligand interaction, highlighting key residues involved in binding. The scoring functions used in docking programs provide an estimate of the binding affinity, which can be used to rank potential ligands. However, it is important to note that docking scores are not absolute binding energies and should be interpreted with caution.
Protocol: Molecular Docking using AutoDock Vina
This protocol outlines the basic steps for performing molecular docking using AutoDock Vina, a widely used open-source docking program.
1. Preparation of the Receptor (Protein):
-
Obtain the 3D structure of the protein from the Protein Data Bank (PDB) or a homology model.
-
Remove all water molecules and any co-crystallized ligands or ions not relevant to the study.
-
Add polar hydrogens to the protein structure.
-
Assign partial charges (e.g., Gasteiger charges).
-
Convert the prepared protein file to the PDBQT format using tools like AutoDockTools.
2. Preparation of the Ligand:
-
Obtain the 3D structure of the ligand from a database (e.g., PubChem, ZINC) or draw it using a molecule editor.
-
Generate a 3D conformation of the ligand and assign partial charges.
-
Define the rotatable bonds in the ligand.
-
Convert the prepared ligand file to the PDBQT format.
3. Grid Box Definition:
-
Define a 3D grid box that encompasses the binding site of the protein. The size and center of the grid box should be large enough to allow the ligand to move and rotate freely within the binding pocket.
4. Running AutoDock Vina:
-
Create a configuration file (conf.txt) specifying the paths to the receptor and ligand PDBQT files, the grid box parameters, and the output file name.
-
Execute AutoDock Vina from the command line using the configuration file.
5. Analysis of Results:
-
AutoDock Vina will generate an output file containing the predicted binding poses of the ligand, ranked by their binding affinity scores (in kcal/mol).
-
Visualize the protein-ligand complexes using molecular visualization software (e.g., PyMOL, Chimera) to analyze the interactions, such as hydrogen bonds and hydrophobic contacts.
Section 2: Molecular Dynamics (MD) Simulations
MD simulations provide a dynamic view of protein-ligand interactions, allowing for the study of conformational changes and the stability of the complex over time.
Application Note:
MD simulations are crucial for refining the static poses obtained from molecular docking and for gaining a deeper understanding of the binding process. They can reveal the role of solvent molecules, the flexibility of the protein and ligand, and the key interactions that stabilize the complex. MD simulations are computationally more intensive than molecular docking but provide a more realistic representation of the biological system.
Protocol: Protein-Ligand Complex MD Simulation using GROMACS
This protocol provides a general workflow for setting up and running an MD simulation of a protein-ligand complex using GROMACS.[1][2][3]
1. System Preparation:
-
Start with a docked protein-ligand complex structure.
-
Choose a suitable force field (e.g., CHARMM36, AMBER).[1]
-
Generate the topology files for the protein and the ligand. The ligand topology may need to be generated using a separate server or tool like CGenFF.[1][2]
-
Combine the protein and ligand coordinates and topologies into a single complex system.
2. Solvation and Ionization:
-
Create a simulation box (e.g., cubic, dodecahedron) around the complex.
-
Solvate the system with a chosen water model (e.g., TIP3P).[1]
-
Add ions to neutralize the system and to mimic physiological salt concentration.
3. Energy Minimization:
-
Perform energy minimization to remove any steric clashes or unfavorable geometries in the initial system.
4. Equilibration:
-
Perform a two-step equilibration process:
-
NVT (isothermal-isochoric) ensemble: Equilibrate the temperature of the system while keeping the volume constant.[1]
-
NPT (isothermal-isobaric) ensemble: Equilibrate the pressure of the system while keeping the temperature constant.
-
5. Production MD Run:
-
Run the production MD simulation for the desired length of time (e.g., nanoseconds to microseconds).
6. Trajectory Analysis:
-
Analyze the MD trajectory to study the stability of the complex (e.g., Root Mean Square Deviation - RMSD), the flexibility of the protein and ligand (e.g., Root Mean Square Fluctuation - RMSF), and the specific interactions over time.
Section 3: Binding Free Energy Calculations
Binding free energy calculations are used to estimate the binding affinity of a ligand to a protein, providing a more quantitative measure than docking scores.
Application Note:
Several methods are available for calculating binding free energies, each with a different balance of accuracy and computational cost. End-point methods like MM/PBSA and MM/GBSA are computationally efficient and useful for ranking a series of ligands. Alchemical free energy methods like Free Energy Perturbation (FEP) are more rigorous and accurate but are computationally very demanding.
Protocol: MM/PBSA and MM/GBSA Calculations using AMBER
1. Generate MD Trajectory:
-
Run an MD simulation of the protein-ligand complex as described in the previous section.
2. Extract Snapshots:
-
Extract a set of snapshots (frames) from the production part of the MD trajectory.
3. Create Topology Files:
-
Create separate topology files for the complex, the receptor, and the ligand.
4. Prepare Input File:
-
Create an input file for MMPBSA.py specifying the calculation parameters, such as the method (MM/PBSA or MM/GBSA), the snapshots to be used, and the dielectric constants.
5. Run MMPBSA.py:
-
Execute the MMPBSA.py script with the prepared input and topology files.
6. Analyze Results:
-
The output will provide the calculated binding free energy and its components (van der Waals, electrostatic, polar solvation, and nonpolar solvation energies).
Protocol: Alchemical Free Energy Perturbation (FEP) using NAMD
This protocol provides a simplified overview of an FEP calculation to determine the relative binding free energy of two ligands using NAMD.[6][7][8][9]
1. System Setup (Dual Topology):
-
Create a hybrid topology and coordinate file where the atoms of the initial ligand are "alchemically" transformed into the atoms of the final ligand. This is often done using a "dual-topology" approach where both ligands are present but interact with the environment based on a coupling parameter (lambda).[7][9]
2. Solvation and Equilibration:
-
Solvate and equilibrate the system containing the protein and the hybrid ligand.
3. Stratification (Lambda Windows):
-
Divide the alchemical transformation into a series of discrete steps or "windows" by varying the lambda parameter from 0 (initial ligand) to 1 (final ligand).
4. MD Simulation for Each Window:
-
Run a separate MD simulation for each lambda window to sample the system's conformations at that intermediate state.
5. Free Energy Calculation:
-
Calculate the free energy change for each lambda window using statistical mechanics formulas (e.g., Bennett's Acceptance Ratio).
-
Sum the free energy changes from all windows to obtain the total free energy difference for the alchemical transformation.
6. Thermodynamic Cycle:
-
Perform the FEP calculation for the ligands in solution (unbound state) and in the protein binding site (bound state).
-
The relative binding free energy is then calculated using a thermodynamic cycle.
Quantitative Data Summary
The following tables provide a summary of typical quantitative data obtained from in silico protein-ligand interaction studies.
Table 1: Comparison of Docking Scores and Experimental Binding Affinities
| Compound | Docking Score (kcal/mol) | Experimental IC50 (µM) |
| Ligand A | -9.5 | 0.1 |
| Ligand B | -8.2 | 1.5 |
| Ligand C | -7.1 | 10.2 |
| Ligand D | -6.5 | 50.8 |
Note: While a general trend of lower docking scores correlating with higher experimental affinity is often observed, it is not always a direct linear relationship.[10]
Table 2: Comparison of Calculated and Experimental Binding Free Energies (ΔG in kcal/mol)
| Method | System | Calculated ΔG | Experimental ΔG |
| MM/PBSA | Protein X + Ligand 1 | -8.5 ± 0.7 | -9.2 |
| MM/GBSA | Protein X + Ligand 1 | -7.9 ± 0.6 | -9.2 |
| FEP | Protein Y + Ligand 2 -> 3 | -1.2 ± 0.2 (ΔΔG) | -1.5 (ΔΔG) |
Note: The accuracy of binding free energy calculations can vary depending on the system and the method used. MM/PBSA and MM/GBSA can provide good relative rankings, while FEP aims for higher accuracy in predicting absolute or relative binding affinities.[11][12]
Visualizations
In Silico Protein-Ligand Interaction Analysis Workflow
Caption: A general workflow for in silico protein-ligand interaction analysis.
Thermodynamic Cycle for Relative Binding Free Energy Calculation
Caption: Thermodynamic cycle for calculating relative binding free energy (ΔΔG).
References
- 1. bioinformaticsreview.com [bioinformaticsreview.com]
- 2. GROMACS: MD Simulation of a Protein-Ligand Complex [angeloraymondrossi.github.io]
- 3. m.youtube.com [m.youtube.com]
- 4. m.youtube.com [m.youtube.com]
- 5. amber.tkanai-lab.org [amber.tkanai-lab.org]
- 6. In silico alchemy: A tutorial for alchemical FEP and TI free-energy calculations with NAMD | Semantic Scholar [semanticscholar.org]
- 7. researchgate.net [researchgate.net]
- 8. ks.uiuc.edu [ks.uiuc.edu]
- 9. ks.uiuc.edu [ks.uiuc.edu]
- 10. tandfonline.com [tandfonline.com]
- 11. Assessing the performance of the MM/PBSA and MM/GBSA methods: I. The accuracy of binding free energy calculations based on molecular dynamics simulations - PMC [pmc.ncbi.nlm.nih.gov]
- 12. A head-to-head comparison of MM/PBSA and MM/GBSA in predicting binding affinities for the CB1 cannabinoid ligands - PubMed [pubmed.ncbi.nlm.nih.gov]
Application Notes & Protocols: In Vitro Assays for Measuring GLP-1 Receptor Activation
Audience: Researchers, scientists, and drug development professionals.
Introduction: The Glucagon-Like Peptide-1 Receptor (GLP-1R) is a class B G protein-coupled receptor (GPCR) that has emerged as a critical therapeutic target for type 2 diabetes and obesity.[1][2] Its activation by endogenous GLP-1 or synthetic agonists stimulates insulin secretion, suppresses glucagon release, slows gastric emptying, and promotes satiety.[1][3] Accurate and robust in vitro methods for quantifying GLP-1R activation are essential for discovering and characterizing new therapeutic agents. These application notes provide detailed protocols for key assays used to measure GLP-1R activation, focusing on second messenger quantification, reporter gene expression, and direct receptor binding.
GLP-1 Receptor Signaling Pathway
Upon agonist binding, the GLP-1R primarily couples to the Gαs protein, which activates adenylyl cyclase (AC).[1][4] This enzyme catalyzes the conversion of ATP to cyclic adenosine monophosphate (cAMP), a key second messenger.[1][4][5] Elevated intracellular cAMP levels lead to the activation of two main downstream effectors: Protein Kinase A (PKA) and Exchange Protein directly activated by cAMP (EPAC).[4][6][7] PKA and EPAC mediate a wide range of cellular responses, including the potentiation of glucose-stimulated insulin secretion and the regulation of gene expression through the phosphorylation of the cAMP Response Element-Binding Protein (CREB).[3][8][9] While the Gαs-cAMP pathway is the canonical signaling route, GLP-1R can also engage other pathways, such as those involving ERK1/2 activation and intracellular calcium mobilization, which are important in the context of biased agonism.[4]
Key In Vitro Assays & Protocols
The primary methods for assessing GLP-1R activation in vitro can be categorized into three main types: cAMP accumulation assays, reporter gene assays, and receptor binding assays.
cAMP Accumulation Assays
These assays directly quantify the production of cAMP following receptor stimulation and are considered a gold standard for assessing GLP-1R functional activity. Time-Resolved Fluorescence Resonance Energy Transfer (TR-FRET) is a widely used technology for this purpose due to its high sensitivity and robustness.[1][10]
Protocol: Homogeneous TR-FRET cAMP Assay
This protocol is adapted for a 384-well plate format using a commercial HTRF cAMP kit.
Materials:
-
Cells: CHO or HEK293 cells stably expressing the human GLP-1R.
-
Reagents:
-
Cell culture medium (e.g., DMEM/F-12)
-
Assay Buffer (e.g., HBSS with 20 mM HEPES)
-
Phosphodiesterase inhibitor (e.g., IBMX)
-
GLP-1R agonists (test compounds and reference agonist like GLP-1 (7-36))
-
Commercial TR-FRET cAMP detection kit (e.g., HTRF cAMP Gs HiRange from Revvity) containing cAMP-d2 and anti-cAMP-cryptate antibody.
-
-
Equipment:
-
384-well white, low-volume assay plates
-
Multichannel pipette or automated liquid handler
-
Cell incubator (37°C, 5% CO2)
-
HTRF-compatible plate reader
-
Procedure:
-
Cell Plating:
-
Trypsinize and resuspend GLP-1R expressing cells in culture medium.
-
Seed 2,000-5,000 cells per well in a 384-well plate.
-
Incubate overnight at 37°C with 5% CO2.
-
-
Compound Preparation:
-
Prepare serial dilutions of test and reference agonists in assay buffer containing IBMX (final concentration typically 0.5-1 mM).
-
-
Cell Stimulation:
-
Carefully remove the culture medium from the cell plate.
-
Add the agonist dilutions to the wells.
-
Incubate the plate at room temperature or 37°C for 30 minutes.
-
-
Lysis and Detection:
-
Prepare the TR-FRET detection reagents according to the manufacturer's instructions by diluting the cAMP-d2 and anti-cAMP-cryptate antibody in the provided lysis buffer.
-
Add the combined lysis and detection reagents to each well.
-
Incubate the plate for 60 minutes at room temperature, protected from light.
-
-
Data Acquisition:
-
Read the plate on an HTRF-compatible reader, measuring fluorescence emission at 665 nm (acceptor) and 620 nm (donor).
-
-
Data Analysis:
-
Calculate the HTRF ratio: (Emission 665nm / Emission 620nm) * 10,000.
-
Plot the HTRF ratio against the logarithm of agonist concentration.
-
Fit the data to a four-parameter logistic equation to determine the EC50 value.
-
Reporter Gene Assays
Reporter gene assays provide a downstream, transcriptional readout of GLP-1R activation. They typically use a reporter gene, such as luciferase, under the control of a promoter containing multiple cAMP Response Elements (CRE).[7][9] Agonist-induced cAMP production activates PKA, which in turn phosphorylates CREB, leading to the transcription of the luciferase gene.[9]
Protocol: CRE-Luciferase Reporter Assay
This protocol is based on a commercially available reporter cell line (e.g., from BPS Bioscience or INDIGO Biosciences) in a 96-well format.[7][11]
Materials:
-
Cells: HEK293 cells stably co-expressing human GLP-1R and a CRE-luciferase reporter construct.
-
Reagents:
-
Thaw/Growth Medium (as recommended by the cell provider)
-
Assay Medium (e.g., Opti-MEM)
-
GLP-1R agonists
-
Luciferase detection reagent (e.g., ONE-Step™ Luciferase System)
-
-
Equipment:
-
96-well white, clear-bottom assay plates
-
Cell incubator (37°C, 5% CO2)
-
Luminometer
-
Procedure:
-
Cell Plating:
-
Compound Treatment:
-
Prepare serial dilutions of agonists in Assay Medium.
-
Carefully aspirate the Thaw/Growth Medium from the cells.
-
Add the agonist dilutions to the wells.
-
-
Incubation for Reporter Expression:
-
Signal Detection:
-
Prepare the luciferase detection reagent according to the manufacturer's protocol.
-
Add the detection reagent to each well.
-
Incubate at room temperature for approximately 15 minutes to ensure complete cell lysis and signal stabilization.[11]
-
-
Data Acquisition:
-
Measure luminescence using a plate-reading luminometer.
-
-
Data Analysis:
-
Plot the Relative Light Units (RLU) against the logarithm of agonist concentration.
-
Fit the data to a four-parameter logistic equation to determine the EC50 value.
-
Receptor Binding Assays
Binding assays measure the direct interaction between a ligand and the GLP-1R, providing information on binding affinity (Kd) and the concentration at which a test compound inhibits the binding of a known ligand by 50% (IC50).
Protocol: TR-FRET Saturation Binding Assay (Tag-lite)
This protocol describes how to determine the binding affinity (Kd) of a fluorescently labeled ligand to cells expressing a SNAP-tagged GLP-1R.[13]
Materials:
-
Cells: Cells expressing SNAP-tag labeled GLP-1R.
-
Reagents:
-
SNAP-Lumi4-Tb (terbium cryptate donor)
-
Fluorescently labeled GLP-1R ligand (e.g., Exendin-4-Red, the acceptor)
-
Unlabeled ligand (for non-specific binding determination)
-
Assay Buffer
-
-
Equipment:
-
384-well white, low-volume assay plates
-
HTRF-compatible plate reader
-
Procedure:
-
Receptor Labeling:
-
Incubate SNAP-GLP-1R expressing cells with the SNAP-Lumi4-Tb substrate to covalently label the receptor with the terbium donor.
-
Wash the cells to remove excess, unbound substrate.
-
Resuspend the labeled cells in assay buffer.
-
-
Assay Plate Setup:
-
Dispense the labeled cells into a 384-well plate.
-
For Total Binding: Prepare serial dilutions of the fluorescently labeled ligand (e.g., Exendin-4-Red) and add them to the cells.
-
For Non-Specific Binding: In a separate set of wells, add the same serial dilutions of the fluorescent ligand, but also add a high concentration (e.g., 100-fold molar excess) of unlabeled ligand to all wells.[13]
-
-
Incubation:
-
Incubate the plate for 1-2 hours at room temperature, protected from light, to allow the binding to reach equilibrium.[13]
-
-
Data Acquisition:
-
Read the plate on an HTRF-compatible reader.
-
-
Data Analysis:
-
Calculate the HTRF ratio for both total and non-specific binding wells.
-
Calculate Specific Binding by subtracting the non-specific binding signal from the total binding signal at each concentration of the fluorescent ligand.[13]
-
Plot Specific Binding against the concentration of the fluorescent ligand.
-
Fit the data to a one-site binding (hyperbola) equation to determine the Kd (dissociation constant) and Bmax (maximum number of binding sites).
-
Data Presentation and Quality Control
Quantitative Data Summary
Summarizing potency and affinity data in a structured format is crucial for comparing compounds.
Table 1: Functional Potency (EC50) of GLP-1 Agonists in cAMP Assays
| Compound | Cell Line | Assay Type | EC50 (pM) | Reference(s) |
|---|---|---|---|---|
| GLP-1 (7-37), native | CHO-hGLP-1R | cAMP Accumulation | 16.2 | [14] |
| Semaglutide | CHO-hGLP-1R | cAMP Accumulation | ~30-70* | [2][15] |
| Liraglutide | CHO-hGLP-1R | cAMP Accumulation | 1.2 | [16] |
| Exendin-4 | HEK293 | cAMP Nomad Biosensor | 4540 | [17] |
| Ecnoglutide (M4) | Not Specified | cAMP Induction | ~625* | [18] |
| Danuglipron | HEK293-hGLP-1R | CRE-Luciferase | ~1110 | [19] |
| Tirzepatide | HEK293-hGLP-1R | CRE-Luciferase | 1110 | [19] |
Converted from ng/mL to pM assuming approximate molecular weights.
Table 2: Binding Affinity (IC50) of GLP-1 Agonists
| Compound | Cell Line | Assay Type | IC50 (nM) | Reference(s) |
|---|---|---|---|---|
| Semaglutide | BHK | Radioligand Binding | 0.38 | [14] |
| Liraglutide | BHK | Radioligand Binding | ~0.11 | [14] |
| GLP-1 (WT) | COS-7 | Radioligand Binding | 5.2 |[20] |
Assay Quality Control: The Z'-Factor
For high-throughput screening (HTS), it is critical to evaluate the quality and reliability of an assay. The Z'-factor (Z-prime) is a statistical parameter used for this purpose, reflecting both the dynamic range and data variation of the assay.[21][22][23]
Formula: Z' = 1 - (3 * (SD_positive + SD_negative)) / |Mean_positive - Mean_negative|
Where:
-
Mean_positive: Mean signal of the positive control (e.g., max concentration of a reference agonist).
-
SD_positive: Standard deviation of the positive control.
-
Mean_negative: Mean signal of the negative control (e.g., vehicle only).
-
SD_negative: Standard deviation of the negative control.
Table 3: Interpretation of Z'-Factor Values
| Z'-Factor Value | Assay Classification | Interpretation |
|---|---|---|
| 1.0 | Ideal | An excellent assay with large dynamic range and small standard deviations (theoretically unachievable).[22][24] |
| 0.5 to < 1.0 | Excellent | A robust assay suitable for HTS.[22][24][25] |
| 0 to < 0.5 | Marginal | The assay is acceptable but may have high variability.[22][24] |
| < 0 | Unsuitable | The signals from positive and negative controls overlap, making the assay unusable for screening.[23][24] |
It is best practice to optimize an assay to achieve a Z'-factor of >0.5 before initiating any screening campaign to ensure the data generated is reliable and meaningful.[25]
References
- 1. axxam.com [axxam.com]
- 2. Establishing a Relationship between In Vitro Potency in Cell-Based Assays and Clinical Efficacious Concentrations for Approved GLP-1 Receptor Agonists - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Activation of the GLP-1 Receptor Signalling Pathway: A Relevant Strategy to Repair a Deficient Beta-Cell Mass - PMC [pmc.ncbi.nlm.nih.gov]
- 4. GLP-1: Molecular mechanisms and outcomes of a complex signaling system - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Glucose and GLP-1 Stimulate cAMP Production via Distinct Adenylyl Cyclases in INS-1E Insulinoma Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 6. cAMP-independent effects of GLP-1 on β cells - PMC [pmc.ncbi.nlm.nih.gov]
- 7. indigobiosciences.com [indigobiosciences.com]
- 8. JCI - Antiinflammatory actions of glucagon-like peptide-1–based therapies beyond metabolic benefits [jci.org]
- 9. caymanchem.com [caymanchem.com]
- 10. researchgate.net [researchgate.net]
- 11. bpsbioscience.com [bpsbioscience.com]
- 12. indigobiosciences.com [indigobiosciences.com]
- 13. Determine Kd for the glucagon GLP-1 receptor with Tag-lite HTRF technology [moleculardevices.com]
- 14. clinicasande.com.uy [clinicasande.com.uy]
- 15. researchgate.net [researchgate.net]
- 16. Quantification of the effect of GLP‐1R agonists on body weight using in vitro efficacy information: An extension of the Hall body composition model - PMC [pmc.ncbi.nlm.nih.gov]
- 17. innoprot.com [innoprot.com]
- 18. researchgate.net [researchgate.net]
- 19. Human GLP-1R (Luc) HEK293 Reporter Cell | ACROBiosystems [acrobiosystems.com]
- 20. jme.bioscientifica.com [jme.bioscientifica.com]
- 21. What is Z' (read Z-factor)? - RxPlora [rxplora.com]
- 22. Z-factors – BIT 479/579 High-throughput Discovery [htds.wordpress.ncsu.edu]
- 23. Z-factor - Wikipedia [en.wikipedia.org]
- 24. Calculating a Z-factor to assess the quality of a screening assay. - FAQ 1153 - GraphPad [graphpad.com]
- 25. bmglabtech.com [bmglabtech.com]
Application Notes and Protocols for Studying Peptide Hormone Stability
For Researchers, Scientists, and Drug Development Professionals
Introduction
Peptide hormones are a critical class of therapeutic agents and biomarkers. However, their inherent instability in biological matrices and under various environmental conditions presents a significant challenge for their development and clinical application. Understanding the degradation pathways and kinetics of peptide hormones is paramount for optimizing their formulation, storage, and delivery, thereby ensuring their therapeutic efficacy and safety.
These application notes provide a comprehensive overview of the experimental setups and detailed protocols for assessing the stability of peptide hormones. The methodologies cover stability in biological fluids, susceptibility to enzymatic degradation, and forced degradation studies under various stress conditions. The accompanying analytical procedures, primarily High-Performance Liquid Chromatography (HPLC) and Mass Spectrometry (MS), are detailed to allow for accurate quantification of the parent peptide and identification of its degradation products.
Key Analytical Techniques for Stability Assessment
The cornerstone of any peptide stability study is the ability to accurately separate and quantify the intact peptide from its degradation products. Reversed-Phase High-Performance Liquid Chromatography (RP-HPLC) is the most common technique for this purpose, offering high resolution for separating peptides with minor modifications.[1] Mass Spectrometry (MS), often coupled with HPLC (LC-MS), is indispensable for identifying degradation products by providing precise mass information, which allows for the elucidation of degradation pathways.[2] Techniques like Matrix-Assisted Laser Desorption/Ionization Time-of-Flight (MALDI-TOF) MS are also valuable for rapid analysis of peptide degradation in complex mixtures like plasma.[3]
Experimental Protocols
A series of in vitro experiments are essential to comprehensively evaluate the stability of a peptide hormone. These include assessing its stability in a biologically relevant matrix like plasma, its susceptibility to specific enzymes, and its degradation profile under forced stress conditions.
Protocol for In Vitro Peptide Hormone Stability in Human Plasma
This protocol is designed to assess the stability of a peptide hormone in human plasma, which contains a complex mixture of proteases.
Materials:
-
Test peptide hormone
-
Human plasma (with anticoagulant, e.g., EDTA, Heparin)
-
Protease inhibitor cocktail (optional, e.g., BD™ P800 tube which contains a DPP-IV inhibitor)[3]
-
Phosphate-buffered saline (PBS), pH 7.4
-
Incubator or water bath at 37°C
-
Precipitating agent (e.g., acetonitrile with 1% trifluoroacetic acid (TFA))
-
Centrifuge
-
HPLC system with a C18 column
-
Mass spectrometer (optional, for identification of degradation products)
Procedure:
-
Peptide Solution Preparation: Prepare a stock solution of the test peptide in an appropriate solvent (e.g., water or PBS) at a known concentration (e.g., 1 mg/mL).
-
Plasma Preparation: Thaw frozen human plasma at room temperature or 37°C. If not using plasma collection tubes with inhibitors, a protease inhibitor cocktail can be added to a control set of plasma samples.
-
Incubation:
-
Spike the test peptide into the plasma to a final concentration of approximately 0.4 µM.
-
Incubate the samples at 37°C.
-
At designated time points (e.g., 0, 15, 30, 60, 120, 240 minutes), withdraw an aliquot of the plasma-peptide mixture.
-
-
Reaction Quenching and Protein Precipitation:
-
Immediately add the withdrawn aliquot to a tube containing a precipitating agent (e.g., 2 volumes of cold acetonitrile with 1% TFA) to stop enzymatic degradation and precipitate plasma proteins.
-
Vortex the mixture thoroughly.
-
-
Centrifugation: Centrifuge the samples at high speed (e.g., 14,000 rpm) for 10 minutes to pellet the precipitated proteins.
-
Sample Analysis:
-
Carefully collect the supernatant containing the peptide and its degradation products.
-
Analyze the supernatant by RP-HPLC to quantify the remaining parent peptide.
-
If desired, the samples can also be analyzed by LC-MS to identify the mass of the degradation products.
-
-
Data Analysis: Plot the percentage of the remaining parent peptide against time. Calculate the half-life (t½) of the peptide in plasma.
Protocol for Enzymatic Degradation Assay using Trypsin
This protocol assesses the susceptibility of a peptide hormone to a specific protease, such as trypsin, which is a common digestive enzyme.
Materials:
-
Test peptide hormone
-
Trypsin (sequencing grade)
-
Ammonium bicarbonate (AmBic) buffer (e.g., 50 mM, pH 8.0)
-
Incubator or water bath at 37°C
-
Quenching solution (e.g., 10% TFA)
-
HPLC system with a C18 column
-
Mass spectrometer
Procedure:
-
Peptide and Enzyme Preparation:
-
Dissolve the test peptide in AmBic buffer to a final concentration of 1 mg/mL.
-
Reconstitute trypsin in a suitable buffer (as per the manufacturer's instructions) to a stock concentration (e.g., 1 mg/mL).
-
-
Digestion Reaction:
-
Add trypsin to the peptide solution at a specific enzyme-to-substrate ratio (e.g., 1:20 to 1:100 w/w).
-
Incubate the reaction mixture at 37°C.
-
At various time points (e.g., 0, 30, 60, 120, 240 minutes), withdraw aliquots of the reaction mixture.
-
-
Reaction Termination: Stop the enzymatic reaction by adding a quenching solution (e.g., 10% TFA) to lower the pH.
-
Analysis:
-
Analyze the samples directly by RP-HPLC to monitor the disappearance of the parent peptide peak and the appearance of new peaks corresponding to degradation fragments.
-
Utilize LC-MS to identify the mass of the generated peptide fragments and determine the cleavage sites.
-
-
Data Analysis: Plot the percentage of the remaining parent peptide over time to determine the rate of degradation.
Protocol for Forced Degradation Studies
Forced degradation studies, or stress testing, are performed to understand the intrinsic stability of a peptide hormone and to identify potential degradation products under various stress conditions. This information is crucial for developing stability-indicating analytical methods.[4] An ideal forced degradation study aims for 5-20% degradation of the active pharmaceutical ingredient (API).[5]
3.3.1. Acidic and Basic Hydrolysis
-
Acidic Conditions: Dissolve the peptide in 0.1 M to 1.0 M hydrochloric acid (HCl). Incubate at room temperature or elevate the temperature (e.g., 50-60°C) if no degradation is observed.[5][6]
-
Basic Conditions: Dissolve the peptide in 0.1 M to 1.0 M sodium hydroxide (NaOH). Incubate under the same conditions as the acidic stress test.[5][6]
-
Procedure:
-
Prepare a solution of the peptide in the acidic or basic medium.
-
Incubate for a defined period (e.g., up to 7 days), taking samples at various time points.[5]
-
Neutralize the samples before analysis.
-
Analyze by RP-HPLC and LC-MS.
-
3.3.2. Oxidative Degradation
-
Conditions: Treat the peptide solution with 0.1% to 3.0% hydrogen peroxide (H₂O₂).[5][6]
-
Procedure:
-
Prepare a solution of the peptide and add H₂O₂.
-
Incubate at room temperature for up to 7 days, with periodic sampling.[5]
-
Analyze the samples by RP-HPLC and LC-MS.
-
3.3.3. Thermal Degradation
-
Conditions: Expose a solid or solution of the peptide to elevated temperatures (e.g., 50°C, 60°C, or 70°C).[7][8] For solutions, the peptide can be incubated in a temperature-controlled oven or water bath.
-
Procedure:
-
Place the peptide sample (solid or solution) in a temperature-controlled environment.
-
Collect samples at different time intervals.
-
For solid samples, dissolve in an appropriate solvent before analysis.
-
Analyze by RP-HPLC and LC-MS.
-
3.3.4. Photostability
-
Conditions: Expose the peptide (solid or in solution) to a light source that provides both UV and visible light, as per ICH Q1B guidelines. The total exposure should be not less than 1.2 million lux hours for visible light and 200 watt-hours/square meter for UVA light.[9][10]
-
Procedure:
-
Place the peptide sample in a photostability chamber.
-
Simultaneously, expose a control sample protected from light (e.g., wrapped in aluminum foil).
-
After the exposure period, analyze both the exposed and control samples by RP-HPLC and LC-MS.
-
Data Presentation
Quantitative data from stability studies should be summarized in clear and concise tables to facilitate comparison and interpretation.
Table 1: Half-life (t½) of Peptide Hormones in Human Plasma at Room Temperature.
| Peptide Hormone | Matrix | t½ (hours) without Protease Inhibitors | t½ (hours) with Protease Inhibitors (BD™ P800) | Citation |
| GLP-1 | EDTA Plasma | 6.0 | > 96 | |
| GIP | EDTA Plasma | Data not specified | > 96 | |
| Glucagon | EDTA Plasma | 5 - 24 | > 45 | |
| Oxyntomodulin (OXM) | EDTA Plasma | Data not specified | > 72 |
Table 2: Common Degradation Products of GLP-1 and its Analogs under Forced Degradation.
| Peptide/Analog | Stress Condition | Major Degradation Products Identified by MS | Citation |
| GLP-1 (7-36)amide | Human Plasma (in vitro) | GLP-1 (9-36)amide (N-terminal cleavage) | [11] |
| GLP-1 Agonists | Oxidative (H₂O₂) | Mono-, di-, and tri-oxidation products (+16, +32, +48 Da mass shifts) | [6] |
| Exenatide | pH 5.5 - 6.5 | Oxidation products | [12] |
| Exenatide | pH 7.5 - 8.5 | Deamidation products | [12] |
Visualizations: Signaling Pathways and Experimental Workflows
Visual diagrams are crucial for understanding complex biological pathways and experimental procedures. The following diagrams are generated using Graphviz (DOT language).
Signaling Pathways
Experimental Workflows
References
- 1. Optimal Conditions for Carrying Out Trypsin Digestions on Complex Proteomes: From Bulk Samples to Single Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Accelerated Forced Degradation of Therapeutic Peptides in Levitated Microdroplets - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. biopharminternational.com [biopharminternational.com]
- 5. Forced Degradation Study in Pharmaceutical Stability | Pharmaguideline [pharmaguideline.com]
- 6. Development of forced degradation and stability indicating studies of drugs—A review - PMC [pmc.ncbi.nlm.nih.gov]
- 7. news-medical.net [news-medical.net]
- 8. Monitoring the stabilities of a mixture of peptides by mass-spectrometry-based techniques - PMC [pmc.ncbi.nlm.nih.gov]
- 9. youtube.com [youtube.com]
- 10. ICH Testing of Pharmaceuticals – Part 1 - Exposure Conditions [atlas-mts.com]
- 11. help.waters.com [help.waters.com]
- 12. Proteins & Peptides Forced Degradation Studies - Therapeutic Proteins & Peptides - CD Formulation [formulationbio.com]
Application Notes and Protocols: Visualizing Peptide Structures from Molecular Dynamics Simulations
Audience: Researchers, scientists, and drug development professionals.
Introduction
Data Presentation: Summarizing Quantitative Analyses
A crucial first step in analyzing an MD trajectory is to quantify the structural behavior of the peptide over time. The following tables provide a structured format for presenting key quantitative metrics, facilitating comparison between different simulations or conditions.
Table 1: System Stability Metrics
This table summarizes global stability parameters of the peptide throughout the simulation.
| Simulation ID | Equilibration Time (ns)[1] | Production Time (µs)[1] | RMSD (Å) (Mean ± SD)[2] | Radius of Gyration (Rg) (Å) (Mean ± SD)[3] |
| PeptideA_WT | 200 | 4 | 2.5 ± 0.3 | 15.2 ± 0.5 |
| PeptideA_Mutant | 200 | 4 | 3.1 ± 0.5 | 16.1 ± 0.7 |
| ... | ... | ... | ... | ... |
Table 2: Local Flexibility Analysis
This table details the flexibility of individual residues, highlighting regions of high mobility.
| Simulation ID | Residue | RMSF (Å)[1] |
| PeptideA_WT | LYS1 | 1.2 |
| ALA2 | 0.8 | |
| ... | ... | |
| PeptideA_Mutant | LYS1 | 1.8 |
| ALA2 | 0.9 | |
| ... | ... |
Table 3: Secondary Structure Analysis
This table quantifies the percentage of different secondary structure elements adopted by the peptide during the simulation.
| Simulation ID | % α-helix[1] | % β-sheet[1] | % Turn/Bend[1] | % Coil |
| PeptideA_WT | 45 | 15 | 20 | 20 |
| PeptideA_Mutant | 30 | 25 | 15 | 30 |
| ... | ... | ... | ... | ... |
Table 4: Intermolecular Interaction Analysis
This table summarizes key interactions, such as hydrogen bonds, which are critical for understanding peptide stability and binding.
| Simulation ID | Interaction Pair | Hydrogen Bond Occupancy (%)[1] | Average Distance (Å) |
| PeptideA_WT | LYS1(N)-ASP5(O) | 85 | 2.8 |
| ... | ... | ... | |
| PeptideA_Mutant | LYS1(N)-ASP5(O) | 60 | 3.1 |
| ... | ... | ... |
Experimental Protocols
Detailed methodologies are essential for reproducibility and for understanding the nuances of the visualization process.
Protocol 1: Trajectory Preparation and Analysis using GROMACS
This protocol outlines the initial processing and analysis of an MD trajectory file.
-
System Preparation :
-
Prepare the initial peptide structure, ensuring there are no missing atoms or non-standard residues.[4] Tools like MODELLER can be used for this purpose.[4]
-
Generate the topology for the peptide using a tool like pdb2gmx in GROMACS, selecting an appropriate force field (e.g., AMBER99, CHARMM36).[3][5][6]
-
Create a simulation box and solvate the peptide with an appropriate water model (e.g., SPC).[5][6]
-
Add ions to neutralize the system and mimic physiological salt concentrations using genion.[3][4]
-
-
Energy Minimization and Equilibration :
-
Production MD Simulation :
-
Trajectory Analysis :
-
RMSD Calculation : Use gmx rms to calculate the Root Mean Square Deviation of the peptide backbone relative to the starting structure to assess overall structural stability.[2]
-
RMSF Calculation : Use gmx rmsf to compute the Root Mean Square Fluctuation for each residue to identify flexible regions.[2]
-
Secondary Structure Analysis : Employ do_dssp or gmx dssp to analyze the evolution of secondary structure elements over time.[1]
-
Hydrogen Bond Analysis : Use gmx hbond to identify and quantify the occurrence of hydrogen bonds.[1]
-
Protocol 2: 3D Visualization and Rendering using VMD and PyMOL
This protocol details the steps for creating high-quality visualizations of peptide structures.
-
Loading Trajectory Data :
-
Visual Representation :
-
In the graphical representations menu, select the desired atoms (e.g., protein or backbone).[9]
-
Choose a suitable drawing style. Common representations include:
-
NewCartoon : Ideal for visualizing secondary structures.[9]
-
Licorice or CPK : Useful for showing sidechain interactions and packing.
-
Surface : Shows the solvent-accessible surface area and can be colored by properties like electrostatic potential.
-
-
-
Coloring Scheme :
-
Apply a coloring method to highlight features of interest.[9] Common schemes include:
-
Secondary Structure : Colors the peptide based on α-helices, β-sheets, and coils.
-
ResType : Assigns a unique color to each amino acid type.
-
Beta (B-factor) : Can be used to color by RMSF values to visualize flexibility.
-
-
-
Creating Publication-Quality Images :
-
Adjust lighting and material properties to enhance clarity.[9]
-
Use the built-in rendering engines (e.g., Tachyon in VMD, ray command in PyMOL) to generate high-resolution images.
-
Protocol 3: Advanced Trajectory Analysis and Visualization
This protocol covers more advanced techniques for a deeper understanding of peptide dynamics.
-
Principal Component Analysis (PCA) :
-
Use GROMACS tools like gmx covar and gmx anaeig to perform PCA on the trajectory.
-
This analysis identifies the dominant modes of motion (eigenvectors) of the peptide.
-
Visualize the projection of the trajectory onto the first few principal components to understand the conformational landscape sampled during the simulation.
-
-
Cluster Analysis :
-
Contact Map Analysis :
-
Generate a 2D contact map that shows which residues are in close proximity to each other over time. This can be visualized as a heatmap.[10]
-
This is useful for identifying stable and transient interactions within the peptide.
-
Mandatory Visualizations
Diagrams created using Graphviz to illustrate workflows and logical relationships.
Caption: Overall workflow for MD simulation and visualization of peptides.
Caption: Decision tree for choosing appropriate visualization techniques.
References
- 1. 4.3. Trajectory Analysis [bio-protocol.org]
- 2. How to Analyze Results from Molecular Dynamics Simulations - Creative Proteomics [iaanalysis.com]
- 3. Molecular Dynamics Simulation of the p53 N-terminal peptide – Bonvin Lab [bonvinlab.org]
- 4. Molecular Dynamics Simulation of the p53 N-terminal peptide – Bonvin Lab [bonvinlab.org]
- 5. 3.2. Molecular Dynamics and Trajectory Analysis [bio-protocol.org]
- 6. pubs.acs.org [pubs.acs.org]
- 7. VMD - Visual Molecular Dynamics [ks.uiuc.edu]
- 8. PyMOL | pymol.org [pymol.org]
- 9. ks.uiuc.edu [ks.uiuc.edu]
- 10. kops.uni-konstanz.de [kops.uni-konstanz.de]
Troubleshooting & Optimization
Technical Support Center: GLP-1 and Exendin-4 Structural Modeling
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals working on improving the accuracy of Glucagon-Like Peptide-1 (GLP-1) and Exendin-4 structural models.
Frequently Asked Questions (FAQs)
Q1: What are the main challenges in determining the high-resolution structures of GLP-1R bound to its agonists?
A1: The main challenges stem from the intrinsic properties of G protein-coupled receptors (GPCRs) like the GLP-1 receptor (GLP-1R). These include:
-
Conformational Flexibility: GPCRs are highly dynamic and exist in multiple conformational states (inactive, intermediate, and active). Capturing a specific state, especially the fully active state bound to both an agonist and a G protein, is difficult.[1][2][3]
-
Instability: When extracted from the cell membrane, GPCRs become unstable and are prone to aggregation and unfolding.[1][4] This necessitates the use of stabilizing mutations, fusion partners (e.g., T4 lysozyme, BRIL), or nanobodies.[2][4]
-
Low Expression Levels: Recombinant expression of functional GPCRs in systems like insect or mammalian cells can be low, making it challenging to obtain sufficient quantities of high-quality protein for structural studies.[1][4]
Q2: Why do GLP-1 and Exendin-4 show different structural characteristics in solution versus when bound to the receptor or a membrane mimetic?
A2: In aqueous solution, peptides like GLP-1 and Exendin-4 are often flexible and may not adopt a stable, single conformation.[5][6] However, upon binding to the GLP-1R or interacting with a membrane-mimicking environment (like micelles or bicelles), they adopt a more defined helical structure.[5][6] This "folding-upon-binding" is a common feature of many peptide hormones. For instance, NMR studies have shown that Exendin-4 exhibits a more regular and less fluxional helix compared to GLP-1 in various media.[5][6]
Q3: What is the "Trp-cage" motif in Exendin-4 and is it relevant for receptor binding?
A3: The "Trp-cage" is a compact tertiary fold observed in the C-terminal region of Exendin-4 in certain solution conditions, which shields a tryptophan residue from the solvent.[6] However, when Exendin-4 is bound to dodecylphosphocholine (DPC) micelles, this tertiary structure is not observed, suggesting that the tryptophan ring may insert into the micelle.[5][6] Crystal structures of Exendin-4(9-39) bound to the isolated N-terminal domain of GLP-1R also do not show the Trp-cage motif. This indicates that while the Trp-cage is a stable fold in some solution environments, it may not be the conformation responsible for receptor engagement.
Troubleshooting Guides
Cryo-Electron Microscopy (Cryo-EM) of GLP-1R Complexes
Problem: Low particle density and preferential orientation on cryo-EM grids.
-
Question: My GLP-1R complex particles are not distributing well in the vitreous ice, and they all seem to adopt the same orientation. How can I improve this?
-
Answer: This is a common issue with membrane proteins. Here are some troubleshooting steps:
-
Optimize Detergent/Lipid Composition: The choice and concentration of detergent or the use of nanodiscs are critical. Screen different detergents (e.g., DDM, LMNG, GDN) and cholesterol analogs. The detergent micelle or nanodisc size and shape can influence particle distribution and orientation.[1][4]
-
Vitrification Conditions: Adjusting blotting parameters (blot time, blot force, humidity) on the vitrification device (e.g., Vitrobot) can help create a thinner ice layer, which can sometimes alleviate preferred orientation.[7]
-
Grid Type: Try different types of grids. Gold grids can sometimes reduce beam-induced motion and improve particle behavior compared to standard carbon grids.
-
Additive Screening: The addition of a small percentage of certain additives to the buffer just before freezing can sometimes disrupt interactions that lead to preferential orientation.
-
Problem: Low resolution of the final 3D reconstruction.
-
Question: I have a good number of particles, but my final cryo-EM map has a low resolution, especially in the transmembrane domain. What could be the cause?
-
Answer: Low resolution can arise from several factors:
-
Conformational Heterogeneity: The GLP-1R complex may exist in multiple conformational states.[1] Extensive 3D classification in your data processing workflow (e.g., in RELION or cryoSPARC) is crucial to separate these different states.
-
Instability of the Complex: The agonist and G protein may not be stably bound. Ensure you are using a non-hydrolyzable GTP analog (e.g., GTPγS) and apyrase to stabilize the G protein in its active state. The use of stabilizing nanobodies like Nb35 is also highly recommended.[8]
-
Data Quality: Factors like thick ice, beam-induced motion, and suboptimal CTF estimation can limit resolution. Optimizing grid preparation and data collection parameters is key.[9]
-
Data Processing: Ensure you are using appropriate processing strategies, including robust 2D and 3D classification, particle polishing, and CTF refinement.
-
NMR Spectroscopy of GLP-1 and Exendin-4
Problem: Signal overlap and broad peaks in NMR spectra.
-
Question: My 2D NMR spectra of Exendin-4 in solution show significant resonance overlap and line broadening, making assignments difficult. How can I improve spectral quality?
-
Answer: These are common challenges for peptides of this size.
-
Optimize Solution Conditions:
-
pH: The pH of the sample can significantly affect the chemical shifts and exchange rates of amide protons. Experiment with a range of pH values (typically between 4 and 6) to find the optimal condition for minimal exchange broadening.[10]
-
Temperature: Temperature affects both tumbling rates and conformational exchange. Acquiring spectra at different temperatures can help resolve some overlaps.
-
Concentration: High peptide concentrations can lead to aggregation and broader lines. Work at the lowest concentration that provides an adequate signal-to-noise ratio (typically >1mM).[10][11]
-
-
Use of Co-solvents or Micelles: Adding co-solvents like trifluoroethanol (TFE) or incorporating the peptide into micelles (e.g., DPC or SDS) can induce a more stable helical structure, which often leads to better-dispersed spectra.[5][6]
-
Isotopic Labeling: If feasible, uniform or selective 15N and 13C labeling of your peptide will allow you to use higher-dimensionality (3D, 4D) and heteronuclear-edited experiments, which greatly reduce spectral overlap and are essential for larger peptides.[10]
-
Molecular Dynamics (MD) Simulations of GLP-1R Complexes
Problem: Instability of the simulation system, leading to crashes or unrealistic structures.
-
Question: My MD simulation of the GLP-1R-Exendin-4 complex in a lipid bilayer is unstable. The protein is unfolding, or the simulation is crashing. What should I check?
-
Answer: System instability in MD simulations of membrane proteins can have several causes:
-
Poor Initial Model: Starting with a low-quality or unresolved experimental structure can lead to instability. Ensure any missing loops or sidechains are modeled in a reasonable manner before starting the simulation.[12]
-
Improper System Setup:
-
Membrane Composition: Use a lipid bilayer composition that mimics a mammalian cell membrane (e.g., POPC with cholesterol).[12] Ensure the protein is correctly embedded in the membrane using tools like OPM or CHARMM-GUI.[12]
-
Solvation and Ionization: The system must be fully solvated with an appropriate water model (e.g., TIP3P) and neutralized with ions at a physiological concentration (e.g., 0.15 M NaCl).[12]
-
-
Inadequate Equilibration: A thorough equilibration protocol is crucial. This typically involves several steps of minimization and restrained MD simulations, gradually releasing the restraints on the protein, ligand, lipids, and solvent to allow the system to relax gently.
-
Force Field Choice: Use a well-validated force field for proteins and lipids (e.g., CHARMM36m, AMBER).[12]
-
Problem: The peptide ligand dissociates from the receptor during the simulation.
-
Question: In my MD simulation, the GLP-1 peptide starts to dissociate from the GLP-1R binding pocket. Is this expected, and how can I prevent it if I want to study the bound state?
-
Answer: Spontaneous dissociation of a high-affinity ligand is generally not expected on the timescale of conventional MD simulations (nanoseconds to a few microseconds). If you observe this, it could indicate:
-
Inaccurate Starting Pose: The initial docking pose of the peptide might be incorrect or in a low-energy local minimum. It is crucial to start from a high-quality experimental structure if available.
-
Force Field Inaccuracies: The force field parameters for the peptide or specific non-standard residues might not accurately represent the interactions.
-
Insufficient Sampling: The observed dissociation might be a rare event that occurred due to the stochastic nature of MD.
-
To study the bound state: If you are confident in the initial binding pose and want to analyze the dynamics of the complex, you can apply positional restraints to the ligand or key interacting residues during the initial phase of the simulation to ensure it remains in the binding pocket. However, these restraints should be used with caution as they can introduce bias. For studying binding/unbinding events, more advanced techniques like steered MD or umbrella sampling are required.[13]
-
Data and Protocols
Table 1: Summary of Experimental Conditions for GLP-1/Exendin-4 Structural Studies
| Parameter | Cryo-EM of GLP-1R | NMR of Exendin-4 in Micelles |
| Expression System | Insect cells (Sf9, Tni) or HEK cells[1][4] | E. coli (for isotopically labeled peptide) or solid-phase synthesis[5] |
| Solubilization/Membrane Mimetic | Detergents (e.g., LMNG, DDM) with cholesterol analogs[1][4] | Dodecylphosphocholine (DPC) or Sodium dodecyl sulfate (SDS) micelles[5][6] |
| Stabilization Strategy | Stabilizing mutations, fusion with T4 Lysozyme or BRIL, addition of Nb35 nanobody[4][8] | N/A |
| Typical Concentration | 5-15 mg/mL for grid preparation[7] | 1-3 mM peptide[10][11] |
| Key Buffer Components | HEPES or Tris buffer, NaCl, agonist, apyrase, non-hydrolyzable GTP analog[1] | Phosphate or Acetate buffer, D2O for lock[10] |
| Typical Resolution/Data | 2.5 - 4 Å[9] | NOEs, J-couplings, chemical shift assignments[5][11] |
Experimental Protocol: Cryo-EM Sample Preparation for GLP-1R-G protein Complex
-
Expression and Purification: Co-express GLP-1R and the G protein heterotrimer (Gαs, Gβ, Gγ) in insect cells.
-
Membrane Preparation: Harvest cells and prepare cell membranes containing the expressed proteins.
-
Complex Formation: Incubate the membranes with the agonist (e.g., GLP-1 or Exendin-4), apyrase (to hydrolyze any remaining GDP), and a non-hydrolyzable GTP analog (e.g., GTPγS) to promote the formation of the active GLP-1R-Gs complex. Add a stabilizing nanobody (e.g., Nb35).[1][8]
-
Solubilization: Solubilize the complex from the membrane using a mild detergent (e.g., LMNG or DDM) supplemented with a cholesterol analog.
-
Purification: Purify the intact complex using affinity chromatography (e.g., against a tag on the receptor or nanobody) followed by size-exclusion chromatography to ensure homogeneity.
-
Grid Preparation: Apply the purified complex (typically at 5-15 mg/mL) to a cryo-EM grid, blot away excess liquid, and plunge-freeze in liquid ethane to create a thin layer of vitreous ice.[7]
Visualizations
Signaling Pathway
Caption: GLP-1R Signaling Pathway.
Experimental Workflow
Caption: Structural Modeling Workflow.
Troubleshooting Logic
Caption: Cryo-EM Troubleshooting Logic.
References
- 1. Cryo-EM structure of the activated GLP-1 receptor in complex with G protein - PMC [pmc.ncbi.nlm.nih.gov]
- 2. PDB-101: Learn: Structural Biology Highlights: G Protein-Coupled Receptors [pdb101.rcsb.org]
- 3. Blog | Structural Biology Informs the Development of GPCRs [nanoimagingservices.com]
- 4. GPCR Structural Biology: From Stubborn To Stress-Free [peakproteins.com]
- 5. pubs.acs.org [pubs.acs.org]
- 6. researchgate.net [researchgate.net]
- 7. EMDB-24445: cryo-EM of human Glucagon-like peptide 1 receptor GLP-1R in apo form - Yorodumi [pdbj.org]
- 8. biorxiv.org [biorxiv.org]
- 9. researchgate.net [researchgate.net]
- 10. chem.uzh.ch [chem.uzh.ch]
- 11. pharmacy.nmims.edu [pharmacy.nmims.edu]
- 12. Exploring Conformational Transitions in Biased and Balanced Ligand Binding of GLP-1R[v1] | Preprints.org [preprints.org]
- 13. Using molecular dynamics simulations to interrogate T cell receptor non-equilibrium kinetics - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Simulating Membrane Protein Interactions
Welcome to the technical support center for researchers, scientists, and drug development professionals engaged in the simulation of membrane protein interactions. This resource provides troubleshooting guides and frequently asked questions (FAQs) to address common challenges encountered during your in silico experiments.
Frequently Asked Questions (FAQs)
Q1: My membrane protein simulation is unstable and crashing. What are the common causes?
A1: System instability is a frequent issue. Common causes include:
-
Steric Clashes: Initial structures may have overlapping atoms between the protein and the lipid bilayer, leading to extremely high forces.[1]
-
Improper Equilibration: Insufficient or improper equilibration of the lipid bilayer around the protein can lead to instability. It's crucial to allow the lipids to pack correctly around the protein.[2]
-
Force Field Incompatibility: Mixing and matching force fields for proteins and lipids without proper validation can cause issues.[2]
-
Incorrect System Setup: Errors in solvation, ion placement, or periodic boundary conditions can lead to simulation failure.
Q2: How do I choose the right force field for my membrane protein simulation?
A2: The choice of force field is critical for accurate simulation results. Here are some guidelines:
-
CHARMM force fields are well-regarded for their accuracy in simulating lipids and membrane systems, particularly for lipid bilayers and their interactions with proteins.[3]
-
AMBER force fields are widely used for proteins and nucleic acids. While they don't have native lipid parameters, they can be effectively combined with lipid force fields like Berger or Slipids.[4][5] The AMBER99SB/Berger combination has been shown to be a reliable choice.[4][5]
-
GROMOS force fields are known for their computational efficiency, making them suitable for large-scale and long-timescale simulations of proteins and lipid membranes.[3]
-
OPLS-AA is another all-atom force field that can be used, often in combination with Berger lipid parameters.[4]
-
Consistency is key: You should not mix and match different force fields for different components of your system unless they have been specifically parameterized to be compatible.[2]
Q3: My protein is drifting out of the membrane during the simulation. What should I do?
A3: This often indicates a problem with the initial setup and equilibration.
-
Initial Placement: Ensure the protein is correctly oriented and embedded within the membrane at the start. Tools like OPM (Orientations of Proteins in Membranes) database can provide the correct orientation.[6]
-
Equilibration with Restraints: During equilibration, apply position restraints to the protein's heavy atoms while allowing the lipids and water to relax around it. This helps to form a stable protein-lipid interface.[2][7] These restraints should be gradually released over several steps.[7]
-
Lipid Packing: Insufficient packing of lipids around the protein can create gaps, leading to instability. Methods that "shrink" a grid of lipids around the protein can help ensure a snug fit.[8]
Q4: How can I be sure my simulated membrane is realistic?
A4: Validating the properties of your simulated lipid bilayer against experimental data is crucial. Key parameters to check include:
-
Area per lipid: This should be consistent with experimental values for the specific lipid type and temperature.[9]
-
Bilayer thickness: The distance between the headgroups of the two leaflets should match experimental measurements.[9]
-
Lipid order parameters: These describe the conformational freedom of the lipid acyl chains and can be compared with NMR data.[10]
Troubleshooting Guides
Problem 1: Steric Clashes and High Initial Energy
Symptom: The energy minimization step fails or reports extremely high initial energies and forces.[1]
Cause: Overlapping atoms between the protein, lipids, or solvent molecules. This is common when inserting a protein into a pre-equilibrated membrane.
Solution:
-
Visualize the System: Load your initial structure into a molecular visualization program (e.g., VMD, PyMOL) to identify the regions with clashes.[1]
-
Lipid Removal: Before inserting the protein, remove any lipid molecules that overlap with the protein's volume.[9] Some tools can automate this by creating a hole in the membrane based on the protein's shape.[11]
-
Gradual Insertion/Shrinking Methods: Utilize methods that gently embed the protein into the membrane. This can involve "shrinking" a grid of lipids around the protein or using steered molecular dynamics to slowly insert the protein.[8][11]
-
Energy Minimization: Perform a robust energy minimization, often using the steepest descent algorithm initially, to relax the system and remove the most severe clashes.[7]
Problem 2: Incorrect Handling of Long-Range Electrostatics
Symptom: Unrealistic structural distortions or drift in the protein structure over time, especially in surface loops.[11]
Cause: Inadequate treatment of long-range electrostatic interactions. Using a simple cutoff can introduce artifacts.
Solution:
-
Use Particle-Mesh Ewald (PME): For most simulations, PME is the recommended method for calculating long-range electrostatics in periodic systems. It has been shown to result in less structural drift compared to cutoff methods.[11]
-
Proper Parameterization: Ensure that your simulation parameters for electrostatics are appropriate for your chosen force field and system size.
Problem 3: Artifacts from Engineered Protein Structures
Symptom: The simulated protein behaves unexpectedly or does not maintain its expected structure, especially if the starting structure was heavily engineered for crystallization.[12][13]
Cause: Modifications made to the protein for experimental structure determination (e.g., mutations, fusion partners, detergents) can introduce non-native interactions and conformations.[12][13]
Solution:
-
Revert Modifications Systematically: Instead of removing all modifications at once, revert them in a stepwise manner, followed by equilibration at each step. This allows the protein structure to gradually relax to a more native-like state.[12]
-
Thorough Equilibration: After reverting modifications, perform extensive equilibration to ensure the protein has adapted to its new, more native environment.
-
Compare with Experimental Data: Where possible, validate your simulated structure and dynamics against any available experimental data for the wild-type protein.
Quantitative Data Summary
The following table summarizes key quantitative parameters that should be monitored during membrane protein simulations to assess stability and realism.
| Parameter | Typical Values/Behavior | Significance |
| Protein RMSD | Should plateau after an initial equilibration period. | Indicates overall structural stability of the protein. |
| Protein RMSF | Higher values for loop regions, lower for secondary structure elements. | Shows the flexibility of different parts of the protein. |
| Area per Lipid | e.g., ~0.63 nm² for DPPC at 320 K.[9] | A key indicator of the physical state of the lipid bilayer. |
| Bilayer Thickness | e.g., ~38.7 Å head-to-head distance for DPPC.[9] | Reflects the overall structure and packing of the membrane. |
| Potential Energy | Should reach a stable, negative value. | Indicates the thermodynamic stability of the system. |
| Temperature | Should fluctuate around the target temperature. | Confirms proper temperature coupling and equilibration. |
| Pressure | Should fluctuate around the target pressure (typically 1 bar). | Confirms proper pressure coupling and equilibration. |
Experimental Protocols & Workflows
General Workflow for Membrane Protein Simulation Setup
This workflow outlines the key steps for preparing a membrane protein system for molecular dynamics simulation.
Detailed Protocol: System Setup using CHARMM-GUI
CHARMM-GUI is a web-based tool that simplifies the setup of complex biological simulations, including membrane proteins.[6]
-
Input Generation:
-
Go to the CHARMM-GUI website and select "Membrane Builder".
-
Provide the PDB ID of your protein. It is often recommended to use the OPM database as the source to obtain a pre-oriented structure.[6]
-
-
Protein Orientation:
-
The tool will automatically orient the protein along the Z-axis, which is defined as the membrane normal.[6]
-
-
Membrane Composition:
-
Select the desired lipid types for the upper and lower leaflets to create a symmetric or asymmetric bilayer.
-
-
System Size and Solvation:
-
Define the dimensions of the membrane patch and the thickness of the water layers above and below the membrane.[6]
-
-
Ionization:
-
Specify the ion types and concentration to neutralize the system and mimic physiological conditions.
-
-
Assembly and Output:
-
CHARMM-GUI will then assemble the entire system, including the protein, lipids, water, and ions.
-
It generates all the necessary input files for various simulation packages like GROMACS, NAMD, and AMBER.
-
Troubleshooting Logic for Unstable Simulations
This diagram illustrates a logical approach to diagnosing and resolving simulation instabilities.
References
- 1. researchgate.net [researchgate.net]
- 2. Running membrane simulations in GROMACS - GROMACS 2023.2 documentation [manual.gromacs.org]
- 3. Force Fields in Molecular Dynamics Simulations: Choosing the Right One - Creative Proteomics [iaanalysis.com]
- 4. Membrane Protein Simulations Using AMBER Force Field and Berger Lipid Parameters - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. pubs.acs.org [pubs.acs.org]
- 6. Preparing membrane proteins for simulation using CHARMM-GUI - PMC [pmc.ncbi.nlm.nih.gov]
- 7. A Beginner’s Guide to Perform Molecular Dynamics Simulation of a Membrane Protein using GROMACS — GROMACS tutorials https://tutorials.gromacs.org documentation [tutorials.gromacs.org]
- 8. researchgate.net [researchgate.net]
- 9. biological membranes [mptg-cbp.github.io]
- 10. pubs.aip.org [pubs.aip.org]
- 11. researchgate.net [researchgate.net]
- 12. How To Minimize Artifacts in Atomistic Simulations of Membrane Proteins, Whose Crystal Structure Is Heavily Engineered: β2-Adrenergic Receptor in the Spotlight | Biological Physics and Soft Matter | University of Helsinki [helsinki.fi]
- 13. researchgate.net [researchgate.net]
Refining force field parameters for incretin peptide simulations.
Welcome to the Technical Support Center for Incretin Peptide Simulations. This resource provides troubleshooting guides, FAQs, and experimental protocols to assist researchers, scientists, and drug development professionals in refining force field parameters for accurate molecular dynamics (MD) simulations.
Frequently Asked Questions (FAQs)
Q1: What is force field refinement and why is it critical for incretin peptides?
A1: A force field is a set of mathematical functions and parameters used to describe the potential energy of a system of particles, like atoms in a peptide. Force field refinement is the process of adjusting these parameters to ensure the simulation accurately reproduces experimental data. This is crucial for incretins (e.g., GLP-1, GIP) and their analogs because their biological function is tightly linked to their conformational flexibility and structural dynamics. Standard force fields might not perfectly capture the subtle energy balances governing their secondary structure or interactions with receptors, necessitating refinement.
Q2: Which force fields are commonly used for peptide simulations and what are their general characteristics?
A2: Several force field families are widely used, each with different parameterization philosophies. The choice can significantly impact simulation outcomes, particularly for flexible peptides like incretins. A systematic comparison is often necessary to select the best starting point for refinement.[1][2][3]
Table 1: Comparison of Common Force Fields for Peptide Simulations
| Force Field Family | Common Variants | Strengths | Potential Weaknesses/Considerations |
| AMBER | ff99SB, ff03, ff14SB, ff19SB | Well-validated for proteins, good balance of secondary structure propensity.[1][2] ff19SB improves amino-acid-specific Ramachandran maps.[4] | Some older versions may overstabilize helical structures.[1][2] Performance can vary with the chosen water model.[2] |
| CHARMM | CHARMM22, CHARMM27, CHARMM36(m) | Robust for a wide range of biomolecules, including lipids and carbohydrates. CHARMM36m is often used for intrinsically disordered proteins (IDPs).[5] | CHARMM27 can sometimes overstabilize helices.[6] CHARMM22* was developed to improve helix-coil balance.[7] |
| GROMOS | 53A6, 54A7, 54A8 | Good for studying protein folding and long-timescale dynamics. Parameterized against condensed-phase properties. | Can have high barriers for cis-trans isomerization, which may require careful initial state setup.[8] |
| OPLS | OPLS-AA/L | Known for accurate liquid property reproduction. Re-parameterized backbone torsions for better peptide folding representation.[7] | May require specific water models (e.g., TIP4P) for optimal performance.[7] |
Q3: How do I parameterize non-standard amino acids (ncAAs) in my incretin analog?
A3: Parameterizing ncAAs is a multi-step process since their parameters are not present in standard force fields.[9][10] The general workflow involves:
-
Initial Parameter Assignment: Assign parameters by analogy to similar, existing residues.
-
Charge Derivation: Calculate partial atomic charges using quantum mechanics (QM). The Restrained Electrostatic Potential (RESP) fitting approach is common.[10][11][12] This is often done on a small model compound, like a methylated dipeptide, to be consistent with the parent force field's methodology.[10]
-
Dihedral Fitting: Scan the potential energy surface of rotatable bonds in the ncAA using QM calculations. The resulting energy profiles are used to fit the torsional parameters in the force field.
-
Validation: Perform short MD simulations of the isolated ncAA or a small peptide containing it to ensure conformational stability and reasonable behavior.
Q4: What is an iterative refinement procedure?
A4: Iterative refinement is a cyclical process to systematically improve force field parameters. It involves running simulations, comparing the output to experimental or QM data, adjusting the parameters to reduce the discrepancy, and then repeating the cycle until the simulation results converge with the reference data.[13][14] This method helps prevent overfitting and ensures the parameters are robust.[14]
Troubleshooting Guides
Q: My simulation is unstable, and the peptide is unfolding unrealistically. What force field issues could be the cause?
A: Simulation instability can arise from several parameter-related issues. A systematic check is required.
-
Improper Dihedral Potentials: Incorrect dihedral parameters can lead to an unrealistic preference for extended or collapsed structures, causing instability.[8][15] This is a common issue when refining parameters for intrinsically disordered proteins (IDPs) or flexible peptides.[15]
-
Incorrect Charges: Especially with non-standard residues, inaccurate partial charges can lead to electrostatic repulsion or attraction artifacts, destabilizing the peptide structure.[16] Ensure charges were derived using a method consistent with the base force field (e.g., RESP for AMBER).[11]
-
Van der Waals (vdW) Clashes: If new residues are parameterized, ensure their vdW parameters (size and energy well) are reasonable. Incorrect vdW terms can cause atomic clashes or prevent proper packing.
-
Initial Conformation: While not strictly a force field issue, an initial structure with high internal energy (e.g., cis-peptide bonds that should be trans) can cause crashes. Some force fields have high energy barriers for isomerization, trapping the incorrect conformation.[8]
Q: My simulated peptide's helicity does not match our Circular Dichroism (CD) data. How do I adjust the force field?
A: Discrepancies with CD data often point to an imbalance in the force field's preference for certain secondary structures. This is typically governed by the backbone dihedral angle potentials (φ/ψ).[15]
-
Select a Balanced Force Field: Start with a force field known to have a good helix-coil balance, such as AMBER ff99SB-ILDN or CHARMM22.[6]
-
Refine Backbone Dihedral Parameters: The most direct way to alter secondary structure propensity is to adjust the energy terms associated with φ/ψ angles. This can be done by re-fitting the dihedral parameters to high-level QM calculations of dipeptide models.[17]
-
Use Energy Correction Maps (CMAPs): Modern force fields (like CHARMM36 and later AMBER versions) use CMAPs, which are grid-based energy correction terms applied to the φ/ψ map.[15][17] Adjusting the CMAP can fine-tune the energy landscape to favor or disfavor helical regions (like αL) and better match experimental data.[15]
Table 2: Example Impact of Force Field on Helical Content of a Model Peptide (Note: Data is illustrative, based on general findings in literature)
| Force Field | Helical Content (Simulated)[6] | Experimental (CD/NMR)[6] | Assessment |
| AMBER ff03 | ~65% | ~45% | Overstabilizes helix |
| CHARMM27 | ~70% | ~45% | Overstabilizes helix |
| AMBER ff99SB-ILDN | ~30% | ~45% | Understabilizes helix |
| AMBER ff99SB-ILDN | ~48% | ~45% | Good agreement |
| CHARMM22 | ~50% | ~45% | Good agreement |
Q: My simulation results show poor agreement with NMR data (³J-couplings and NOEs). Which parameters need refinement?
A: NMR data provides precise, localized structural information, making it excellent for targeted parameter refinement.
-
For ³J-Coupling Constants: These values are related to backbone dihedral angles (primarily φ) through the Karplus equation. If your calculated J-couplings don't match experimental values, it's a strong indication that your φ dihedral potential needs refinement.[1][2][18]
-
For NOE (Nuclear Overhauser Effect) Restraints: NOEs provide through-space distance information between protons. Discrepancies here can point to several issues:
-
Non-bonded (vdW and Electrostatic) Parameters: If side chains are incorrectly packed, it may be due to inaccurate vdW or charge parameters.
-
Dihedral Potentials: Incorrect backbone or side-chain dihedral potentials can lead to a conformational ensemble where key proton pairs are, on average, too far apart or too close.
-
Experimental Validation Protocols
Protocol 1: Secondary Structure Analysis via Circular Dichroism (CD) Spectroscopy
This protocol provides a general method for determining the secondary structure content of an incretin peptide to validate simulation results.[19][20]
-
Objective: To quantify the percentage of α-helix, β-sheet, and random coil structures of the peptide in solution.
-
Methodology:
-
Sample Preparation: Dissolve the purified peptide in a suitable buffer (e.g., phosphate buffer) that is transparent in the far-UV region (190-250 nm).[19][21] The typical peptide concentration is 0.1-1 mg/mL.[19]
-
Instrument Setup: Use a CD spectrometer with a quartz cuvette (path length typically 1 mm).[19][20] Purge the instrument with nitrogen gas.
-
Data Acquisition: Record the CD spectrum from ~250 nm down to ~190 nm at a controlled temperature (e.g., 20°C).[20][22] Acquire a baseline spectrum of the buffer alone.
-
Data Processing: Subtract the buffer baseline from the sample spectrum. Convert the resulting signal (in millidegrees) to Mean Residue Ellipticity [θ].[19][21]
-
Analysis: Use deconvolution algorithms (e.g., CONTIN, SELCON3) to estimate the percentage of each secondary structure element from the shape of the CD spectrum.[21][23] α-helices show characteristic negative bands near 208 nm and 222 nm, while β-sheets have a negative band around 218 nm.[21]
-
Protocol 2: Binding Affinity Measurement via Isothermal Titration Calorimetry (ITC)
This protocol measures the thermodynamics of peptide-receptor binding, providing key validation data (K_d, ΔH, ΔS) for the force field's non-bonded parameters.[24][25][26]
-
Objective: To determine the binding affinity (K_d), stoichiometry (n), enthalpy (ΔH), and entropy (ΔS) of the incretin peptide binding to its receptor.
-
Methodology:
-
Sample Preparation: Prepare purified peptide (ligand) and receptor (macromolecule) in identical, degassed dialysis buffer.[27] A typical starting concentration is 40 µM of receptor in the sample cell and 400 µM of peptide in the syringe.[27] This 10:1 ratio is a good starting point.[26][27]
-
Instrument Setup: Set up the ITC instrument to the desired experimental temperature (e.g., 25°C). Set the reference power and stirring speed (e.g., 750 rpm).[27]
-
Titration: Perform a series of small, precise injections (e.g., 2 µL) of the peptide solution from the syringe into the sample cell containing the receptor.[27] Allow the system to reach equilibrium between injections (e.g., 180 seconds).[27]
-
Data Analysis: The instrument measures the minute heat changes upon each injection. Integrate the heat peaks to generate a binding isotherm (heat change vs. molar ratio).
-
Model Fitting: Fit the binding isotherm to a suitable binding model (e.g., one-site model) to extract the thermodynamic parameters K_d, n, and ΔH. Entropy (ΔS) can then be calculated.
-
Protocol 3: Conformational Validation using NMR Spectroscopy (³J-Couplings)
This protocol details how to use ³J(HN,Hα) scalar couplings to validate the backbone φ dihedral angle distribution from simulations.[1][2]
-
Objective: To measure ³J(HN,Hα) coupling constants, which are sensitive to the backbone φ dihedral angle.
-
Methodology:
-
Sample Preparation: Dissolve a high-concentration sample (~1-5 mM) of the isotopically labeled (if necessary) peptide in a suitable NMR buffer (e.g., H₂O/D₂O mixture).
-
Data Acquisition: Acquire a high-resolution 1D ¹H or 2D correlation spectrum (e.g., DQF-COSY, HOHAHA) on a high-field NMR spectrometer. The high resolution is necessary to resolve the fine splitting of the amide proton signals.
-
Data Analysis: Measure the separation (in Hz) between the peaks of the doublet corresponding to the amide proton (HN) for each residue. This splitting is the ³J(HN,Hα) coupling constant.
-
Comparison with Simulation:
-
Calculate the time-averaged ³J(HN,Hα) values from the MD trajectory using the Karplus equation: J(φ) = A·cos²(θ) + B·cos(θ) + C, where θ = |φ - 60°| for L-amino acids.
-
Compare the calculated average J-couplings with the experimental values. A low Root Mean Square Deviation (RMSD) between the two datasets indicates good agreement.
-
-
Table 3: Sample Comparison of Experimental vs. Simulated ³J(HN,Hα) Couplings (Hz) (Note: Data is for illustrative purposes)
| Residue | Experimental ³J-Coupling | Simulated (Initial FF) | Simulated (Refined FF) |
| Ala-2 | 7.8 | 5.1 | 7.5 |
| Val-3 | 8.2 | 5.5 | 8.0 |
| Gln-4 | 4.5 | 7.9 | 4.8 |
| RMSD | - | 2.65 | 0.25 |
References
- 1. pubs.acs.org [pubs.acs.org]
- 2. Experimental verification of force fields for molecular dynamics simulations using Gly-Pro-Gly-Gly - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Systematic comparison of empirical forcefields for molecular dynamic simulation of insulin - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. pubs.acs.org [pubs.acs.org]
- 5. Force Field Effects in Simulations of Flexible Peptides with Varying Polyproline II Propensity - PMC [pmc.ncbi.nlm.nih.gov]
- 6. journals.plos.org [journals.plos.org]
- 7. Influence of force field choice on the conformational landscape of rat and human islet amyloid polypeptide - PMC [pmc.ncbi.nlm.nih.gov]
- 8. pubs.acs.org [pubs.acs.org]
- 9. ks.uiuc.edu [ks.uiuc.edu]
- 10. scholarsarchive.byu.edu [scholarsarchive.byu.edu]
- 11. Molecular Dynamics (MD)-Derived Features for Canonical and Noncanonical Amino Acids - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. researchgate.net [researchgate.net]
- 14. researchgate.net [researchgate.net]
- 15. Recent Force Field Strategies for Intrinsically Disordered Proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 16. gromacs.bioexcel.eu [gromacs.bioexcel.eu]
- 17. Force Field for Peptides and Proteins based on the Classical Drude Oscillator - PMC [pmc.ncbi.nlm.nih.gov]
- 18. A critical assessment of force field accuracy against NMR data for cyclic peptides containing β-amino acids - Physical Chemistry Chemical Physics (RSC Publishing) [pubs.rsc.org]
- 19. A comprehensive guide for secondary structure and tertiary structure determination in peptides and proteins by circular dichroism spectrometer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 20. CD-Based Peptide Secondary Structure Analysis - Creative Proteomics [creative-proteomics.com]
- 21. How to Use CD Spectroscopy for Protein Secondary Structure Analysis: A Complete Guide | MtoZ Biolabs [mtoz-biolabs.com]
- 22. Tools and methods for circular dichroism spectroscopy of proteins: a tutorial review - Chemical Society Reviews (RSC Publishing) DOI:10.1039/D0CS00558D [pubs.rsc.org]
- 23. pnas.org [pnas.org]
- 24. Isothermal Titration Calorimetry to Study Plant Peptide Ligand-Receptor Interactions - PubMed [pubmed.ncbi.nlm.nih.gov]
- 25. Isothermal Titration Calorimetry to Study Plant Peptide Ligand-Receptor Interactions | Springer Nature Experiments [experiments.springernature.com]
- 26. edepot.wur.nl [edepot.wur.nl]
- 27. Isothermal Titration Calorimetry (ITC) [protocols.io]
Technical Support Center: GLP-1 Receptor Molecular Dynamics Simulations
Welcome to the technical support center for researchers conducting molecular dynamics (MD) simulations of the Glucagon-Like Peptide-1 Receptor (GLP-1R). This resource provides troubleshooting guidance and frequently asked questions (FAQs) to address common convergence issues encountered during these complex simulations.
Frequently Asked Questions (FAQs)
Q1: My GLP-1R simulation is not converging. What are the first things I should check?
A1: Non-convergence in GLP-1R MD simulations can stem from several factors. Start by assessing the following:
-
System Equilibration: Inadequate equilibration is a primary cause of instability. Ensure you have performed a thorough, multi-stage equilibration protocol, including solvent and lipid relaxation around the protein.[1][2][3] A rushed equilibration can lead to artifacts, such as lipid invasion into the protein core.[3]
-
Force Field Choice: The force field must be appropriate for both the protein and the lipid bilayer. Mismatches can lead to unrealistic interactions and structural instability.
-
Initial Structure Quality: The starting structure of the GLP-1R, whether from experimental data or homology modeling, may contain high-energy contacts or clashes that need to be resolved through energy minimization.[2]
Q2: I'm observing large-scale conformational fluctuations in the transmembrane helices. Is this normal?
A2: While some degree of flexibility is expected, especially in loop regions, excessive and persistent fluctuations in the transmembrane (TM) helices can indicate a problem. The activation of GLP-1R involves significant conformational changes, particularly the outward movement of TM6.[4][5] However, if the overall fold is not maintained, consider the following:
-
Lipid Bilayer Composition: The lipid environment can significantly influence GPCR stability and dynamics.[6][7][8] Ensure your membrane composition is a reasonable mimic of a mammalian plasma membrane.
-
Simulation Time: GPCR activation is a slow process, often occurring on the microsecond to millisecond timescale.[9][10] Conventional MD simulations may not be long enough to observe convergence to a stable state. Consider extending your simulation time or employing enhanced sampling techniques.[9][10][11]
Q3: My peptide ligand (e.g., GLP-1, Exendin-4) keeps dissociating or adopting an unstable conformation. How can I address this?
A3: Ligand stability is crucial for studying receptor activation. Issues with ligand binding can be due to:
-
Initial Docking Pose: An incorrect initial placement of the ligand can lead to rapid dissociation. It's important to start from a well-validated binding pose, potentially derived from experimental structures or robust docking protocols.[12]
-
Force Field Parameters for the Ligand: Ensure that the force field parameters for your specific peptide agonist are accurate.
-
Receptor Conformation: The binding of peptide agonists to GLP-1R is a complex process involving interactions with both the extracellular domain (ECD) and the transmembrane domain (TMD).[13][14] The conformation of the ECD is critical for initial ligand capture.[15][16]
Q4: What are enhanced sampling methods, and when should I consider using them for my GLP-1R simulations?
A4: Enhanced sampling methods are computational techniques designed to accelerate the exploration of conformational space and overcome high energy barriers, which is particularly useful for studying rare events like GPCR activation.[9][10][11][17] You should consider using them when:
-
You are studying large-scale conformational changes, such as receptor activation or deactivation.[18][19]
-
Conventional MD simulations are not converging within accessible timescales.[9]
-
You want to calculate the free energy landscape of a particular process.[9]
Commonly used methods include Accelerated Molecular Dynamics (aMD), Gaussian Accelerated Molecular Dynamics (GaMD), and Metadynamics.[9][17]
Troubleshooting Guides
Issue 1: System Instability and "Exploding" Simulations
Symptoms:
-
Rapid increase in temperature or pressure.
-
The simulation crashes with errors related to invalid coordinates or velocities.
-
Visual inspection shows the protein deforming unnaturally or lipids becoming disordered.
Troubleshooting Workflow:
Caption: Troubleshooting workflow for system instability.
Issue 2: Lack of Convergence in Root Mean Square Deviation (RMSD)
Symptoms:
-
The RMSD of the protein backbone continues to drift upwards without reaching a stable plateau.
-
Large, persistent fluctuations are observed in the RMSD plot.
Troubleshooting Workflow:
Caption: Troubleshooting workflow for RMSD convergence issues.
Experimental Protocols
Protocol 1: System Setup and Equilibration for GLP-1R in a Lipid Bilayer
This protocol provides a general framework for setting up and equilibrating a GLP-1R system for MD simulations using GROMACS.
-
System Preparation:
-
Obtain the initial coordinates of GLP-1R (and any bound ligand) from the PDB or a homology model.
-
Use a tool like CHARMM-GUI to embed the protein into a realistic lipid bilayer (e.g., POPC).
-
Solvate the system with an appropriate water model (e.g., TIP3P) and add ions to neutralize the system and achieve a physiological concentration (e.g., 0.15 M NaCl).
-
-
Energy Minimization:
-
Perform a steepest descent energy minimization to remove steric clashes and bad contacts.[2]
-
-
Multi-Stage Equilibration:
-
NVT Equilibration (Constant Volume and Temperature):
-
NPT Equilibration (Constant Pressure and Temperature):
-
-
Production Run:
-
Once the system is well-equilibrated (as assessed by RMSD, temperature, pressure, and density), remove all restraints and perform the production simulation for the desired length of time.
-
GLP-1R Signaling Pathway
The GLP-1R primarily signals through the Gs protein pathway, leading to the production of cyclic AMP (cAMP).
Caption: Simplified GLP-1R Gs signaling pathway.
Data Presentation
Table 1: Representative Simulation Parameters for GLP-1R Systems
| Parameter | Value | Reference/Note |
| Force Field (Protein) | CHARMM36m | A commonly used and well-validated force field for proteins. |
| Force Field (Lipid) | CHARMM36 | Compatible with the protein force field. |
| Water Model | TIP3P | A standard water model for biomolecular simulations. |
| Membrane Composition | POPC | A common choice for simple membrane simulations. More complex mixtures can be used for greater biological realism.[6] |
| Ensemble | NPT | Simulates constant pressure and temperature, mimicking physiological conditions. |
| Temperature | 310 K | Approximate human body temperature. |
| Pressure | 1 bar | Standard atmospheric pressure. |
| Integration Timestep | 2 fs | A standard timestep for all-atom simulations with constraints on hydrogen bonds. |
| Production Run Length | >500 ns | Longer simulations (microseconds) are often necessary to observe significant conformational changes.[13][18][21][22] |
Table 2: Convergence Criteria and Expected Timescales
| Phenomenon | Typical Simulation Time Required | Key Analysis Metrics |
| System Equilibration | 10 - 100 ns | RMSD, Temperature, Pressure, Density, Area per lipid |
| Ligand Binding Stability | 100 - 500 ns | Ligand RMSD, Ligand-receptor interaction energies, Hydrogen bond analysis |
| Local Conformational Sampling | 500 ns - 1 µs | RMSF, Dihedral angle analysis, Principal Component Analysis (PCA) |
| Large-scale Conformational Change (e.g., activation) | >1 µs to ms | RMSD of TM helices, Distance between key residues, Enhanced sampling methods often required.[9][10] |
References
- 1. compchems.com [compchems.com]
- 2. A Beginner’s Guide to Perform Molecular Dynamics Simulation of a Membrane Protein using GROMACS — GROMACS tutorials https://tutorials.gromacs.org documentation [tutorials.gromacs.org]
- 3. Importance of molecular dynamics equilibrium protocol on protein-lipid interaction near channel pore - PMC [pmc.ncbi.nlm.nih.gov]
- 4. eprints.whiterose.ac.uk [eprints.whiterose.ac.uk]
- 5. A mechanism for agonist activation of the glucagon-like peptide-1 (GLP-1) receptor through modelling & molecular dynamics - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Molecular mapping and functional validation of GLP-1R cholesterol binding sites in pancreatic beta cells [elifesciences.org]
- 7. Molecular mapping and functional validation of GLP-1R cholesterol binding sites in pancreatic beta cells | eLife [elifesciences.org]
- 8. biorxiv.org [biorxiv.org]
- 9. Development of enhanced conformational sampling methods to probe the activation landscape of GPCRs - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Showcasing Modern Molecular Dynamics Simulations of Membrane Proteins Through G Protein-Coupled Receptors - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. Computational insight into conformational states of glucagon-like peptide-1 receptor (GLP-1R) and its binding mode with GLP-1 - RSC Advances (RSC Publishing) [pubs.rsc.org]
- 13. Dynamics of GLP-1R peptide agonist engagement are correlated with kinetics of G protein activation - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Glucagon-Like Peptide-1 Receptor Ligand Interactions: Structural Cross Talk between Ligands and the Extracellular Domain | PLOS One [journals.plos.org]
- 15. Investigation of ECD conformational transition mechanism of GLP-1R by molecular dynamics simulations and Markov state model - Physical Chemistry Chemical Physics (RSC Publishing) [pubs.rsc.org]
- 16. researchgate.net [researchgate.net]
- 17. Hidden GPCR structural transitions addressed by multiple walker supervised molecular dynamics (mwSuMD) [elifesciences.org]
- 18. connectsci.au [connectsci.au]
- 19. researchgate.net [researchgate.net]
- 20. pubs.acs.org [pubs.acs.org]
- 21. mdpi.com [mdpi.com]
- 22. Dynamic spatiotemporal determinants modulate GPCR:G protein coupling selectivity and promiscuity - PMC [pmc.ncbi.nlm.nih.gov]
Optimizing simulation time for accurate peptide folding analysis.
This technical support center provides troubleshooting guidance and answers to frequently asked questions (FAQs) for researchers, scientists, and drug development professionals engaged in peptide folding analysis using molecular dynamics (MD) simulations. Our goal is to help you optimize simulation time while maintaining the accuracy required for meaningful results.
Troubleshooting Guides
Issue 1: Simulations are running too slowly or not converging.
Symptoms:
-
The simulation is taking an impractically long time to reach the desired timescale (microseconds or beyond).[1][2][3]
-
The root-mean-square deviation (RMSD) of the peptide conformation does not plateau, indicating that the simulation has not reached equilibrium.
-
The simulation gets trapped in local energy minima, preventing the exploration of the complete conformational space.[4]
Possible Causes and Solutions:
| Cause | Solution | Data & Considerations |
| Insufficient Sampling | Employ enhanced sampling techniques like Accelerated Molecular Dynamics (aMD) or Replica Exchange Molecular Dynamics (REMD). aMD modifies the potential energy surface to facilitate escape from energy minima, while REMD runs multiple simulations at different temperatures to enhance conformational sampling.[5][6][7] | aMD can provide a sampling power comparable to a classical MD simulation that is orders of magnitude longer (e.g., 500 ns of aMD can be equivalent to 1 ms of conventional MD).[5] REMD is effective for overcoming energy barriers but requires significant computational resources due to the need for multiple replicas.[6][8] |
| Explicit Solvent Model | Consider using an implicit solvent model (e.g., Generalized Born) instead of an explicit one (e.g., TIP3P). Implicit solvent models reduce the number of atoms in the system, significantly speeding up calculations.[9][10] | The speedup can be substantial (from ~7-fold to over 100-fold depending on the system and the conformational change being studied).[9][10] However, be aware that implicit solvent models can sometimes lead to inaccuracies in the free energy landscape and may not correctly predict the native structure for all peptides.[11][12] |
| Large System Size | Minimize the size of the simulation box and the number of solvent molecules. Ensure the box is large enough to prevent the peptide from interacting with its periodic image but no larger. | A smaller system size directly translates to fewer calculations per time step, leading to faster simulations. |
| Inefficient Hardware Utilization | Utilize Graphics Processing Units (GPUs) for MD simulations. Modern MD simulation packages are highly optimized for GPUs, which can offer orders of magnitude better performance than CPUs for these types of calculations.[1] | The performance gain depends on the specific hardware and software configuration. |
Issue 2: The simulated peptide does not fold into its known native structure.
Symptoms:
-
The final conformation from the simulation has a high RMSD from the experimentally determined native structure.
-
The simulation consistently predicts a secondary structure different from experimental observations (e.g., predicting a helix for a known beta-hairpin peptide).[5][13]
Possible Causes and Solutions:
| Cause | Solution | Data & Considerations |
| Inappropriate Force Field | The choice of force field is critical for accurate folding.[5][14] Some force fields have known biases towards certain secondary structures. Benchmark different force fields (e.g., AMBER ff19SB, CHARMM36m, GROMOS96) for your specific peptide or class of peptides. | For β-hairpin peptides, ff19SB has shown good performance with both TIP3P and OPC solvation models. For helical peptides, ff14SB and ff19SB generally perform well. Be aware that no single force field performs optimally across all types of peptides.[14] |
| Inaccurate Solvent Model | While implicit solvents are faster, they may not always accurately represent the solvent environment, which can influence folding.[11] If accuracy is paramount and an implicit solvent model is failing, switching to an explicit solvent model may be necessary. | Explicit solvent simulations are computationally more expensive but generally provide a more accurate representation of the solvent's effect on peptide conformation. |
| Insufficient Simulation Time | Peptide folding can be a slow process, occurring on the microsecond to millisecond timescale.[3][15] Even with enhanced sampling, your simulation may not be long enough to observe the complete folding event. | Accelerated MD simulations have been shown to fold helical proteins in the range of 40-180 ns.[16] However, the required time is highly dependent on the specific peptide. |
| Starting Conformation | Starting the simulation from a fully extended conformation can increase the time required to find the native state. Consider starting from a partially folded or misfolded conformation to explore different folding pathways.[13] | Simulations starting from different initial conformations can provide a more comprehensive picture of the folding landscape. |
Frequently Asked Questions (FAQs)
Q1: How long should I run my peptide folding simulation?
A1: The required simulation time depends on the size and complexity of your peptide, the force field and solvent model used, and the simulation method. For small peptides, timescales of hundreds of nanoseconds to several microseconds are often necessary to observe folding events with conventional MD.[1] Enhanced sampling techniques like aMD can significantly reduce this time, potentially achieving folding in tens to hundreds of nanoseconds.[5][16] It is crucial to monitor convergence metrics like RMSD to determine if the simulation has reached a stable state.
Q2: What is the trade-off between using an explicit versus an implicit solvent model?
A2: The primary trade-off is between computational speed and accuracy.
-
Implicit Solvent: Significantly faster due to the reduced number of atoms.[9][10] This allows for longer simulation timescales and more extensive conformational sampling. However, it is an approximation of the solvent environment and may not accurately capture all the subtle interactions that drive folding, potentially leading to incorrect final structures.[11]
-
Explicit Solvent: Computationally expensive due to the need to simulate thousands of individual solvent molecules. However, it provides a more physically realistic representation of the solvent and is generally considered more accurate for detailed folding studies.[12]
Q3: How do I choose the right force field for my peptide?
A3: The choice of force field can significantly impact the accuracy of your simulation.[5][14] There is no single "best" force field for all peptides. Some force fields are known to have biases towards certain secondary structures. For example, some older AMBER force fields have a helical bias.[13] It is recommended to consult literature for studies that have benchmarked force fields on peptides similar to yours. If such data is unavailable, you may need to test several modern force fields (e.g., AMBER ff19SB, CHARMM36m) to see which one best reproduces experimental data for your system.
Q4: What are enhanced sampling methods and when should I use them?
A4: Enhanced sampling methods are techniques designed to accelerate the exploration of a system's conformational space, allowing for the observation of rare events like peptide folding in a computationally feasible amount of time. You should consider using them when conventional MD simulations are too slow to observe the desired folding event.
Two popular methods are:
-
Accelerated Molecular Dynamics (aMD): This method adds a boost potential to the system's potential energy surface, which helps to overcome energy barriers more quickly.[5]
-
Replica Exchange Molecular Dynamics (REMD): This technique involves running multiple simulations of the same system in parallel at different temperatures. Periodically, the coordinates of the simulations at different temperatures are exchanged, allowing the system to overcome energy barriers at higher temperatures and then sample the low-energy conformations at lower temperatures.[6][8]
Q5: How can I be sure that my simulation has converged and the results are reliable?
A5: Ensuring convergence is crucial for the reliability of your results. Here are a few key checks:
-
RMSD Analysis: Plot the RMSD of the peptide's backbone atoms relative to the starting structure and the native structure over time. The simulation has likely converged if the RMSD reaches a stable plateau.
-
Cluster Analysis: Group similar conformations from your trajectory into clusters. If the relative populations of the major clusters remain stable over the latter part of the simulation, it suggests convergence.
-
Multiple Runs: Perform multiple independent simulations starting from different initial velocities or conformations. If they all converge to the same final structure or ensemble of structures, it increases confidence in the results.[5][13]
-
Free Energy Landscape: For enhanced sampling simulations, calculating the free energy landscape can help determine if you have adequately sampled the major conformational states. The landscape should show well-defined basins for the stable states.
Experimental Protocols
Protocol 1: Accelerated Molecular Dynamics (aMD) for a Helical Peptide
This protocol provides a general workflow for setting up and running an aMD simulation to study the folding of a small helical peptide using the AMBER software package.
-
System Preparation:
-
Start with a PDB file of the peptide in a linear, unfolded conformation.
-
Use the LEaP module in AMBER to add missing hydrogen atoms, cap the termini (e.g., with ACE and NME groups), and solvate the peptide in a TIP3P water box, ensuring a minimum distance of 10 Å from the peptide to the box edge.
-
Add counterions to neutralize the system.
-
Use a modern force field known to perform well for helical peptides, such as ff14SB or ff19SB.[5][13]
-
-
Minimization and Equilibration:
-
Perform a series of minimizations to remove bad contacts, first with restraints on the peptide, then with restraints only on the backbone, and finally with no restraints.
-
Gradually heat the system from 0 K to 300 K over 50-100 ps in the NVT ensemble (constant volume and temperature) with weak restraints on the peptide backbone.
-
Run a subsequent equilibration step in the NPT ensemble (constant pressure and temperature) for 1-2 ns to ensure the system has reached the correct density.
-
-
Conventional MD (cMD) Run:
-
Run a short cMD simulation (e.g., 10-50 ns) in the NPT ensemble. This is necessary to calculate the average potential and dihedral energies that will be used to set the aMD boost parameters.
-
-
aMD Parameter Calculation:
-
Calculate the average total potential energy (Ep_avg) and dihedral energy (Ed_avg) from the cMD trajectory.
-
Set the aMD boost parameters (Ep, αp, Ed, αd) based on these averages. A common approach is:
-
Ep = Ep_avg + 0.2 * Natoms
-
αp = 0.2 * Natoms
-
Ed = Ed_avg + 2.5 * Nresidues
-
αd = 2.5 * Nresidues
-
-
-
aMD Production Run:
-
Run the aMD simulation using the calculated boost parameters. Start with a simulation length of at least 200-500 ns.
-
Monitor the simulation in real-time by tracking the RMSD to the native structure.
-
-
Analysis:
-
Perform RMSD, radius of gyration, secondary structure analysis (e.g., using DSSP), and cluster analysis on the trajectory to characterize the folding process and the final folded state.
-
Protocol 2: Temperature Replica Exchange Molecular Dynamics (T-REMD)
This protocol outlines the general steps for a T-REMD simulation.
-
System Preparation:
-
Prepare the initial system (solvated peptide) as you would for a standard MD simulation.
-
-
Determining the Number and Temperature Range of Replicas:
-
The number of replicas and their temperature range are critical for the efficiency of the simulation. The temperatures should be chosen to ensure a reasonable exchange probability between adjacent replicas (typically 20-30%).
-
The temperature range should span from the temperature of interest (e.g., 300 K) to a high enough temperature where the peptide is fully unfolded and can easily cross energy barriers.
-
Use a temperature generator tool or script to determine an appropriate set of temperatures for your system size.
-
-
Simulation Setup:
-
Create input files for each replica, with each file specifying a different temperature.
-
The simulation parameters for each replica (except for the temperature) should be identical.
-
-
Running the T-REMD Simulation:
-
Use an MD engine that supports REMD (e.g., GROMACS, AMBER, NAMD).
-
The simulation will run multiple trajectories in parallel. At specified intervals (e.g., every 1-2 ps), the simulation will attempt to exchange the coordinates between pairs of adjacent replicas based on the Metropolis criterion.
-
-
Analysis:
-
After the simulation is complete, you will have a trajectory for each temperature. For analyzing the folding at the temperature of interest (e.g., 300 K), you need to extract all the frames that were simulated at that temperature, regardless of which replica they originated from.
-
Analyze this sorted trajectory using standard tools for RMSD, clustering, and secondary structure analysis.
-
Visualizations
References
- 1. Challenges in protein folding simulations: Timescale, representation, and analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 2. dasher.wustl.edu [dasher.wustl.edu]
- 3. To Milliseconds and Beyond: Challenges in the Simulation of Protein Folding - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. pubs.acs.org [pubs.acs.org]
- 6. Enhanced sampling of peptide and protein conformations using replica exchange simulations with a peptide backbone biasing-potential - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Enhanced Sampling Techniques in Molecular Dynamics Simulations of Biological Systems - PMC [pmc.ncbi.nlm.nih.gov]
- 8. bunsen.de [bunsen.de]
- 9. Speed of conformational change: comparing explicit and implicit solvent molecular dynamics simulations - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. pnas.org [pnas.org]
- 12. A test of implicit solvent models on the folding simulation of the GB1 peptide | The Journal of Chemical Physics | AIP Publishing [pubs.aip.org]
- 13. air.unimi.it [air.unimi.it]
- 14. How Well Do Molecular Dynamics Force Fields Model Peptides? A Systematic Benchmark Across Diverse Folding Behaviors - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Applications of Molecular Dynamics Simulation in Structure Prediction of Peptides and Proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Frontiers | Accelerated Molecular Dynamics Simulation for Helical Proteins Folding in Explicit Water [frontiersin.org]
Troubleshooting guide for setting up GLP-1R complex simulations.
Technical Support Center: GLP-1R Complex Simulations
This guide provides troubleshooting assistance and frequently asked questions for researchers setting up and running molecular dynamics (MD) simulations of the Glucagon-like peptide-1 receptor (GLP-1R) complex.
Frequently Asked Questions (FAQs) & Troubleshooting
System Preparation & Setup
Q1: My simulation is unstable or crashing during the initial steps. What are the common causes?
A1: Initial instability often stems from problems in the system setup. Key areas to check include:
-
Imperfect Input Coordinates: Using homology-modeled structures without proper refinement can lead to aberrant behavior like protein unfolding or ligand dissociation[1]. Ensure your starting protein structure (PDB) is of high quality, with missing loops and residues modeled and refined.
-
Protonation States: Incorrect protonation of titratable residues (e.g., Histidine, Aspartate, Glutamate) at the simulated pH can introduce clashes or unrealistic electrostatic interactions. Use tools like PROPKA or H++ to predict the correct protonation states[2].
-
Membrane Packing: For membrane-bound simulations, improper insertion of the receptor into the lipid bilayer can cause clashes between protein and lipid atoms. Ensure the system is correctly oriented and use a multi-stage equilibration process, starting with constraints on the protein and gradually releasing them[2].
-
Force Field Compatibility: Ensure that the force field parameters for the protein (e.g., CHARMM36, AMBER), ligand, and lipids are compatible. Using force fields for applications they were not designed for is a major source of error[1].
Q2: How do I handle missing loops or domains in the crystal structure of GLP-1R?
A2: Missing loops in cryo-EM or X-ray crystal structures are common and must be addressed before simulation. These can be reconstructed using software like Modeller or through molecular superposition with other complete structures[2]. After modeling, the new loops must be properly minimized and equilibrated to relax them into a stable conformation.
Q3: What is the correct way to parameterize a novel or non-standard ligand for GLP-1R simulations?
A3: Parameterizing a novel ligand requires generating accurate force field parameters, especially for atomic charges and dihedral angles. This typically involves:
-
Performing quantum mechanics (QM) calculations (e.g., using DFT) to obtain the molecule's electrostatic potential.
-
Using a charge-fitting procedure (e.g., RESP) to derive partial atomic charges.
-
Using tools like the CHARMM General Force Field (CGenFF) or Amber's antechamber to generate the remaining parameters. It's crucial to validate the generated parameters against QM calculations or experimental data.
Simulation Execution & Analysis
Q4: My protein's Root Mean Square Deviation (RMSD) does not stabilize during the simulation. What does this indicate?
A4: A continuously increasing RMSD suggests that the protein has not reached equilibrium and may be unfolding or undergoing a significant conformational change.
-
Check Equilibration: The system may not have been equilibrated for long enough. A typical multi-stage equilibration for a membrane protein complex can last for tens of nanoseconds[2].
-
Analyze Trajectories: Visualize the trajectory to identify which parts of the protein are most mobile. High fluctuations in the extracellular domain (ECD) or intracellular loops (ICLs) are expected due to their intrinsic flexibility[2]. However, instability in the transmembrane (TM) helical core could indicate a more serious problem.
-
Ligand Binding: The ligand may be dissociating from its binding pocket, causing the receptor to transition to an unstable state. Analyze ligand-receptor interactions throughout the simulation.
Q5: The extracellular domain (ECD) of my GLP-1R model shows very high flexibility. Is this normal?
A5: Yes, high flexibility in the ECD is a known characteristic of Class B GPCRs like GLP-1R.[2][3] The ECD is dynamic and can adopt different conformations ('open' and 'closed' states) depending on whether a ligand is bound.[3][4] This flexibility is crucial for its role in capturing the peptide agonist before the N-terminus engages with the transmembrane domain.[5] In simulations, this is often reflected by higher Root Mean Square Fluctuation (RMSF) values for ECD residues compared to the more rigid TM domain.[6][7]
Q6: How do I know if my simulation has converged and is long enough for meaningful analysis?
A6: Assessing convergence is critical. Common methods include:
-
RMSD Plateau: The RMSD of the protein backbone (especially the stable TM domain) should reach a stable plateau.
-
Principal Component Analysis (PCA): Analyzing the conformational sampling along the first few principal components can show if the simulation is exploring a limited conformational space or has converged to stable states.
-
Block Averaging: Divide the trajectory into several blocks and calculate key properties (e.g., average interaction energies, distances) for each block. If the values are consistent across blocks, it suggests convergence. For complex events like receptor activation, much longer timescales (microseconds) and potentially enhanced sampling methods may be needed.[8]
Experimental Protocols & Methodologies
General Protocol for GLP-1R MD Simulation Setup
This protocol outlines a typical workflow for setting up an all-atom MD simulation of a GLP-1R complex embedded in a lipid bilayer.
-
Protein Preparation:
-
Start with a high-resolution experimental structure (e.g., from PDB).
-
Model any missing loops or residues using tools like Modeller[2].
-
Add hydrogen atoms and determine the protonation state of titratable residues at a physiological pH (e.g., 7.0) using software like PDB2PQR and PROPKA[2].
-
If simulating a complex with a G-protein, ensure all subunits (Gα, Gβ, Gγ) are correctly assembled.
-
-
System Assembly (Membrane Embedding):
-
Orient the protein complex correctly with respect to the membrane using a database like OPM (Orientations of Proteins in Membranes)[2].
-
Embed the oriented protein into a pre-equilibrated lipid bilayer (e.g., POPC).
-
Solvate the system with an appropriate water model (e.g., TIP3P) and add ions (e.g., Na+, Cl-) to neutralize the system and achieve a physiological concentration (e.g., 150 mM).
-
-
Equilibration:
-
Perform a multi-stage equilibration to gradually relax the system. This is crucial to avoid instabilities.
-
Stage 1: Minimize the energy of the system to remove initial steric clashes, particularly between lipid atoms[2].
-
Stage 2: Run a short MD simulation (e.g., 2 ns) with strong positional restraints on the protein and lipid phosphorus atoms to allow lipids to pack around the protein[2].
-
Stage 3: Continue the simulation (e.g., 20 ns) with restraints only on the protein atoms to allow the lipids to fully equilibrate[2].
-
Stage 4: Gradually release the restraints on the protein, for example, by only constraining the backbone alpha carbons for an extended period (e.g., 60 ns) before the final production run[2].
-
-
Production Simulation:
-
Run the production MD simulation without any restraints in the appropriate ensemble (e.g., NVT or NPT) at the desired temperature (e.g., 300 K)[2].
-
Use an appropriate time step (e.g., 2-4 fs) with constraints on bonds involving hydrogen atoms (e.g., M-SHAKE or P-LINCS)[2][9].
-
Handle long-range electrostatic interactions using methods like Particle Mesh Ewald (PME)[2].
-
Quantitative Data Summary
Table 1: Example Simulation Parameters for GLP-1R Complexes
| Parameter | GLP-1R:Gs Complex[2] | GLP-1R Activation Study[8] |
| Force Field | CHARMM36 | CHARMM |
| Water Model | Not Specified | Not Specified |
| Membrane | POPC Bilayer | POPC Bilayer |
| Equilibration Time | >80 ns (multi-stage) | Not Specified |
| Production Time | 4 x 500 ns replicas (2 µs total) | 2 µs (aMD), 400 ns (cMD) |
| Time Step | 4 fs (with M-SHAKE) | 2 fs |
| Temperature | 300 K | Not Specified |
| Pressure | Not Specified | Not Specified |
| Long-Range Electrostatics | Particle Mesh Ewald (PME) | Not Specified |
Table 2: Key Receptor Conformational Metrics
| Metric | Inactive State (Reference) | Active State (G-protein Bound) | Source |
| TM3-TM6 Distance (Cα of 3.50 & 6.34) | ~12.1 Å | ~25.3 Å | [10][11] |
| TM7 RMSD (Relative to Inactive) | 0 Å | Varies by ligand | [10] |
| Intracellular Binding Site Volume | Smaller | Larger (to accommodate G-protein) | [10] |
Visualizations: Workflows and Pathways
GLP-1R Simulation Workflow
Caption: General workflow for setting up a GLP-1R molecular dynamics simulation.
GLP-1R Signaling Pathways
Caption: Simplified view of biased vs. balanced agonism at the GLP-1 receptor.
References
- 1. quora.com [quora.com]
- 2. Dynamics of GLP-1R peptide agonist engagement are correlated with kinetics of G protein activation - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Investigation of ECD conformational transition mechanism of GLP-1R by molecular dynamics simulations and Markov state model - Physical Chemistry Chemical Physics (RSC Publishing) [pubs.rsc.org]
- 4. Computational insight into conformational states of glucagon-like peptide-1 receptor (GLP-1R) and its binding mode with GLP-1 - RSC Advances (RSC Publishing) [pubs.rsc.org]
- 5. The peptide agonist-binding site of the glucagon-like peptide-1 (GLP-1) receptor based on site-directed mutagenesis and knowledge-based modelling - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Exploring Conformational Transitions in Biased and Balanced Ligand Binding of GLP-1R [mdpi.com]
- 7. preprints.org [preprints.org]
- 8. connectsci.au [connectsci.au]
- 9. Molecular insights into ago-allosteric modulation of the human glucagon-like peptide-1 receptor - PMC [pmc.ncbi.nlm.nih.gov]
- 10. preprints.org [preprints.org]
- 11. eprints.whiterose.ac.uk [eprints.whiterose.ac.uk]
Technical Support Center: Enhancing Sampling Methods for Flexible Peptide Loops
Welcome to the technical support center for researchers, scientists, and drug development professionals working on the conformational analysis of flexible peptide loops. This resource provides troubleshooting guides and frequently asked questions (FAQs) to address common challenges encountered during experimental and computational studies.
Frequently Asked Questions (FAQs)
Q1: My computational model of a flexible loop is not converging to a single structure. Is this an error?
A1: Not necessarily. Flexible loops, by their nature, can exist as an ensemble of conformations rather than a single, static structure.[1] The goal of many sampling methods is to capture this conformational diversity. If your simulations are exploring a range of low-energy states, this may be a true representation of the loop's flexibility.
Troubleshooting Steps:
-
Analyze the Energy Landscape: Use clustering algorithms to group the sampled conformations and analyze the free-energy landscape.[2] This can help determine if there are multiple meta-stable states.
-
Assess Experimental Data: Compare the conformational ensemble with experimental data. For instance, high B-factors in X-ray crystallography suggest flexibility.[3][4] NMR chemical shift perturbations can also indicate regions of conformational exchange.[5][6]
-
Check Simulation Length: Insufficient simulation time can lead to inadequate sampling. However, simply extending the simulation does not always guarantee better sampling or understanding of transitions between states.[7]
Q2: There is a significant discrepancy between my computationally predicted loop structure and my experimental results (e.g., NMR, X-ray). What are the common causes and how can I resolve this?
A2: Discrepancies between computational and experimental results are common and can arise from various sources.[8][9]
Common Causes & Troubleshooting:
| Potential Cause | Troubleshooting/Resolution |
| Inaccurate Force Field | The force field used in the simulation may not accurately represent the energetics of the peptide loop. Try different force fields or consider using quantum mechanics/molecular mechanics (QM/MM) for critical regions.[10] |
| Insufficient Sampling | The simulation may not have explored the entire conformational space. Employ enhanced sampling techniques like replica-exchange molecular dynamics (REMD) or metadynamics. |
| Experimental Data Ambiguity | Experimental data can sometimes be ambiguous. For example, NMR chemical shifts represent a population-weighted average over all conformations.[2][5] Ensure your interpretation of the experimental data is consistent with the dynamic nature of the loop. |
| Crystal Packing Artifacts | In X-ray crystallography, the observed loop conformation can be influenced by crystal packing forces, which are absent in most simulations. Analyze the crystal contacts of the loop to assess this possibility. |
| Solvent Effects | The solvent model used in the simulation can impact the conformational preferences of the loop. Ensure an appropriate solvent model is used, especially for highly solvent-exposed loops.[7] |
Q3: How can I experimentally validate the conformational ensemble of a flexible peptide loop generated by my simulations?
A3: Several experimental techniques can be used to validate and refine computational models of flexible loops. Integrating experimental data is crucial for improving the accuracy of predictions.[1][11]
| Experimental Technique | Application in Loop Sampling Validation |
| Nuclear Magnetic Resonance (NMR) Spectroscopy | - Chemical Shift Perturbations (CSPs): Identify residues involved in conformational changes upon ligand binding or other perturbations.[5][6] - Residual Dipolar Couplings (RDCs) & Nuclear Overhauser Effects (NOEs): Provide distance and orientation restraints to guide and validate the conformational ensemble. |
| X-ray Crystallography | - B-factors (Temperature Factors): High B-factors in a loop region indicate flexibility and conformational disorder.[3][4] This can be qualitatively compared with the diversity of conformations in your simulated ensemble. |
| Förster Resonance Energy Transfer (FRET) | - Single-molecule FRET (smFRET): Measures intramolecular distances and their fluctuations over time, providing direct insights into the dynamics and conformational transitions of the loop.[12] |
| Circular Dichroism (CD) Spectroscopy | Provides information about the secondary structure content (e.g., α-helix, β-sheet, random coil) of the peptide, which can be compared to the average secondary structure of the simulated ensemble.[13] |
Troubleshooting Guides
Problem: Poor sampling of long flexible loops (>12 residues).
Symptoms:
-
The simulation gets trapped in a local energy minimum.
-
The root-mean-square deviation (RMSD) of the loop backbone does not plateau.
-
Generated conformations are sterically hindered or have high energies.
Possible Solutions:
-
Utilize Enhanced Sampling Methods: Standard molecular dynamics may be insufficient. Implement methods like:
-
Replica Exchange Molecular Dynamics (REMD): Simulates multiple replicas of the system at different temperatures to overcome energy barriers.
-
Metadynamics: Adds a history-dependent bias potential to discourage the system from revisiting previously explored conformations.
-
Knowledge-Based Approaches: Use fragments from known protein structures to guide the initial sampling of the loop.[1]
-
-
Employ Coarse-Grained Models: Reduce the degrees of freedom by using a simplified representation of the peptide, allowing for longer simulation timescales and broader exploration of the conformational space.
-
Integrate Experimental Restraints: If available, incorporate distance or orientational restraints from NMR or FRET to guide the sampling towards experimentally relevant conformations.[11]
Problem: Difficulty in modeling peptide-protein interactions involving a flexible loop.
Symptoms:
-
Docking algorithms fail to predict the correct binding pose.
-
The binding affinity is poorly predicted.
-
The simulation does not capture the induced fit or conformational selection mechanism.
Possible Solutions:
-
Ensemble Docking: Dock the ligand into an ensemble of receptor conformations that includes the flexibility of the loop, rather than a single static structure.
-
Induced Fit Docking: Allow both the ligand and the receptor, particularly the flexible loop, to change conformation during the docking process.
-
Integrative Modeling with Experimental Data: Use experimental data, such as NMR chemical shift perturbations, to identify the binding interface and guide the docking.[5][6] The MELD-NMR approach is a powerful tool for this.[11]
Experimental Protocols
Protocol 1: Validation of a Simulated Loop Ensemble using NMR Chemical Shift Perturbation (CSP)
Objective: To experimentally validate a computationally generated ensemble of a peptide loop's conformations upon binding to a protein partner.
Methodology:
-
Sample Preparation:
-
Express and purify the 15N-labeled protein containing the flexible loop.
-
Synthesize or purify the unlabeled peptide ligand.
-
Prepare a series of NMR samples with a constant concentration of the 15N-labeled protein and increasing concentrations of the peptide ligand.
-
-
NMR Data Acquisition:
-
Acquire a series of 2D 1H-15N HSQC spectra for each sample.
-
Assign the backbone amide resonances of the protein in the free and bound states.
-
-
Data Analysis:
-
Calculate the chemical shift perturbations for each residue using the following equation: Δδ = √[ (ΔδH)^2 + (α * ΔδN)^2 ] where ΔδH and ΔδN are the changes in the proton and nitrogen chemical shifts, and α is a scaling factor (typically ~0.2).
-
Map the residues with significant CSPs onto the protein structure.
-
-
Comparison with Simulation:
-
From the computational ensemble of the protein-peptide complex, identify the residues in the loop and surrounding regions that show significant interaction with the peptide.
-
Compare the computationally identified interaction sites with the residues showing large CSPs. A good correlation provides validation for the simulated binding mode and loop conformation.
-
Protocol 2: Assessing Loop Dynamics with smFRET
Objective: To measure the conformational dynamics of a flexible peptide loop.
Methodology:
-
Fluorophore Labeling:
-
Introduce two different fluorophores (a donor and an acceptor) at specific sites flanking the flexible loop. This is typically done by introducing cysteine residues at the desired positions and using maleimide chemistry for labeling.
-
-
smFRET Data Acquisition:
-
Immobilize the labeled protein on a microscope slide.
-
Use a total internal reflection fluorescence (TIRF) microscope to excite the donor fluorophore and detect the emission from both the donor and acceptor fluorophores for individual molecules.
-
-
Data Analysis:
-
Calculate the FRET efficiency (E) for each molecule over time: E = I_A / (I_A + I_D) where I_A and I_D are the fluorescence intensities of the acceptor and donor, respectively.
-
Generate FRET efficiency histograms to identify different conformational states of the loop.
-
Analyze the time trajectories of the FRET signal to observe transitions between these states and determine their kinetics.
-
-
Comparison with Simulation:
-
Calculate the donor-acceptor distances from the simulated conformational ensemble.
-
Convert these distances into a theoretical FRET efficiency distribution.
-
Compare the theoretical distribution with the experimentally measured FRET histogram.
-
Visualizations
Caption: Workflow for integrating computational and experimental methods.
Caption: Troubleshooting guide for model vs. experimental discrepancies.
References
- 1. Current approaches to flexible loop modeling - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Multiple loop conformations of peptides predicted by molecular dynamics simulations are compatible with nuclear magnetic resonance - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Validation and Quality Assessment of X-ray Protein Structures [proteinstructures.com]
- 4. m.youtube.com [m.youtube.com]
- 5. Integrative Modeling of Protein-Polypeptide Complexes by Bayesian Model Selection using AlphaFold and NMR Chemical Shift Perturbation Data - PMC [pmc.ncbi.nlm.nih.gov]
- 6. biorxiv.org [biorxiv.org]
- 7. Simple Selection Procedure to Distinguish between Static and Flexible Loops [mdpi.com]
- 8. Addressing Discrepancies between Experimental and Computational Procedures | MDPI [mdpi.com]
- 9. researchgate.net [researchgate.net]
- 10. Making sure you're not a bot! [academiccommons.columbia.edu]
- 11. researchgate.net [researchgate.net]
- 12. Single-molecule FRET methods to study the dynamics of proteins at work - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Computational study, synthesis and evaluation of active peptides derived from Parasporin-2 and spike protein from Alphacoronavirus against colorectal cancer cells - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Mitigating Artifacts in Long-Timescale Molecular Dynamics
Welcome to the technical support center for troubleshooting and mitigating artifacts in long-timescale molecular dynamics (MD) simulations. This resource is designed for researchers, scientists, and drug development professionals to identify and resolve common issues encountered during their experiments.
Frequently Asked Questions (FAQs)
Q1: What are the most common artifacts in long-timescale MD simulations?
A1: Long-timescale MD simulations can be susceptible to several artifacts that can compromise the accuracy and reliability of the results. Some of the most frequently observed artifacts include:
-
Flying Ice Cube Effect: This artifact is characterized by a significant drop in the potential energy of the system, leading to a "frozen" or glassy state. It often results from the kinetic energy draining from thermal motions into coordinated, collective motions of the entire system.[1][2][3] This can be caused by issues with thermostatting algorithms, particularly those that suppress kinetic energy fluctuations.[3][4]
-
Energy Drift: An unphysical, systematic increase or decrease in the total energy of the system over time in a microcanonical (NVE) ensemble simulation. This indicates a lack of energy conservation and can arise from a variety of factors including a large integration time step, inadequate constraint algorithms, or inappropriate force field parameters.[5][6]
-
Pressure and Temperature Instabilities: Unrealistic spikes, dips, or oscillations in pressure and temperature can occur, often due to inappropriate choices of thermostats or barostats, or poor coupling parameters.[7][8]
-
Neighbor List and Cutoff Artifacts: Infrequent updating of the neighbor list or using overly short cutoff distances for non-bonded interactions can lead to missed interactions.[9][10] This can cause systematic imbalances in the pressure tensor, leading to unphysical deformations of the simulation box, such as the crumpling of membranes.[9][10]
-
Structural Collapse of Biomolecules: In some cases, particularly with certain force fields and water models, biomolecules like intrinsically disordered proteins may exhibit an artificial collapse into overly compact structures.[11]
Q2: How can I detect if my simulation is suffering from artifacts?
A2: Detecting artifacts requires careful analysis of the simulation trajectory and various system properties. Key indicators to monitor include:
-
System Energy: In an NVE ensemble, the total energy should remain constant. Any significant drift is a clear sign of a problem. In NVT or NPT ensembles, while the total energy will fluctuate, its average should remain stable. A steady, long-term drift in potential or kinetic energy can also indicate an issue.[6]
-
Temperature and Pressure: Monitor the instantaneous temperature and pressure. Large, non-physical oscillations or a consistent deviation from the target values can signal problems with the thermostat or barostat.[7][8]
-
Root Mean Square Deviation (RMSD): While RMSD is used to track conformational changes, an unusually rapid and continuous increase in RMSD without reaching a plateau might indicate system instability or unfolding, which could be an artifact.
-
Visual Inspection: Regularly visualize your trajectory. Look for unusual collective motions, such as the entire system moving or rotating together (indicative of the flying ice cube effect), or unrealistic deformations of molecules or the simulation box.[1][2]
-
Physical Observables: Compare calculated properties like density, diffusion coefficients, or radial distribution functions with experimental values or previously validated simulations. Significant deviations can point to underlying artifacts.
-
Radius of Gyration (Rg): For proteins, a sudden and persistent drop in Rg can indicate an artificial collapse of the structure.[11]
Q3: What is the "flying ice cube" effect and how can I prevent it?
A3: The "flying ice cube" effect is an artifact where the kinetic energy from the thermal motion of individual atoms is transferred to the collective motion (translation and rotation) of the entire system.[1][2] This leads to a decrease in the internal temperature of the system, causing it to "freeze" into a glassy or icy state, while the whole system moves or rotates rapidly.[3][4]
Causes:
-
Thermostats: It is often associated with thermostats that aggressively rescale velocities to maintain a constant temperature, such as the Berendsen thermostat, which can suppress natural kinetic energy fluctuations.[3]
-
Center-of-Mass Motion: The accumulation of center-of-mass (COM) motion coupled with velocity rescaling is a primary cause.[1][2]
Mitigation Strategies:
-
Periodically Remove COM Motion: The most direct way to prevent this is to periodically remove the center-of-mass motion during the simulation. Most MD simulation packages have options to do this automatically.[1][2]
-
Choose an Appropriate Thermostat: Use thermostats that generate a correct canonical ensemble, such as the Nosé-Hoover or velocity rescaling thermostats, which are less prone to this artifact than the Berendsen thermostat.[3]
-
Increase Simulation Accuracy: Improving the overall accuracy of the simulation can also help. This includes using a smaller integration time step, tighter tolerances for constraint algorithms like SHAKE, and more frequent updates of the non-bonded pair list.[1][2]
Troubleshooting Guides
Issue 1: Unstable Energy, Temperature, or Pressure
| Symptom | Possible Cause | Troubleshooting Steps |
| Total energy consistently increases or decreases in an NVE simulation. | Integration time step is too large.[5] | Decrease the time step. A common starting point for all-atom simulations is 1-2 fs. |
| Inadequate constraint algorithm settings. | For algorithms like SHAKE or LINCS, try tightening the tolerance. | |
| Improper force field parameters for the system.[3][4] | Ensure the chosen force field is appropriate for your molecule and has been well-validated. | |
| Large oscillations or spikes in temperature. | Thermostat coupling constant (τ_t) is too small. | Increase the coupling constant to dampen the response of the thermostat. |
| Inappropriate thermostat for the system.[3] | Consider switching to a different thermostat (e.g., from Berendsen to Nosé-Hoover). | |
| Large oscillations or spikes in pressure. | Barostat coupling constant (τ_p) is too small.[12] | Increase the coupling constant to slow down the response of the barostat. |
| System is not well-equilibrated before applying pressure coupling.[8][12] | Ensure the system is properly equilibrated in the NVT ensemble before switching to NPT. | |
| Anisotropic pressure coupling on an isotropic system. | Use isotropic pressure coupling for systems that should be isotropic. |
Issue 2: Unphysical Structural Changes or System Deformation
| Symptom | Possible Cause | Troubleshooting Steps |
| Membrane bilayer crumples or deforms asymmetrically. | Infrequent neighbor list updates.[9][10] | Decrease the number of steps between neighbor list updates (e.g., nstlist in GROMACS). |
| Cutoff for non-bonded interactions is too short.[9][10] | Increase the cutoff radius for van der Waals and electrostatic interactions. | |
| Imbalance in the pressure tensor due to missed interactions.[9][10] | Review and adjust neighbor searching and cutoff parameters. | |
| Protein or ligand rapidly unfolds or dissociates at the beginning of the simulation. | Poor initial structure with steric clashes. | Perform a thorough energy minimization of the starting structure. |
| System is not well-equilibrated. | Run a sufficiently long equilibration phase, possibly with positional restraints on the solute that are gradually released. | |
| Intrinsically disordered protein artificially collapses. | Choice of force field and water model.[11] | Experiment with different force fields and water models that are known to perform well for disordered systems (e.g., TIP4P-D water model).[11] |
Experimental Protocols
Protocol 1: Systematic Parameter Adjustment for Stable Simulations
This protocol outlines a systematic approach to optimizing key simulation parameters to prevent common instabilities.
Methodology:
-
Initial Setup:
-
Prepare your system (solvation, ionization) using standard procedures.
-
Choose a well-validated force field for your biomolecule.[13]
-
-
Energy Minimization:
-
Perform a robust energy minimization to remove any steric clashes or unfavorable contacts in the initial structure. Use a method like steepest descent followed by conjugate gradients.
-
-
NVT Equilibration:
-
Run a short simulation in the NVT ensemble (constant number of particles, volume, and temperature).
-
Apply positional restraints to the heavy atoms of the solute to allow the solvent to equilibrate around it.
-
Monitor the temperature to ensure it reaches and stabilizes around the target value.
-
-
NPT Equilibration:
-
Continue the simulation in the NPT ensemble (constant number of particles, pressure, and temperature).
-
Gradually release the positional restraints on the solute over several short simulation stages.
-
Monitor the pressure and density of the system until they reach a stable plateau.
-
-
Production Run:
-
Once the system is well-equilibrated, initiate the long-timescale production run without any restraints.
-
Continuously monitor key parameters (energy, temperature, pressure, RMSD) for any signs of artifacts.
-
Protocol 2: Enhanced Sampling with Replica Exchange Molecular Dynamics (REMD)
REMD is a powerful technique to overcome energy barriers and improve sampling, which can also help in avoiding getting trapped in artifactual states.
Methodology:
-
System Preparation: Prepare your initial system as you would for a standard MD simulation.
-
Replica Setup:
-
Create multiple replicas of your system.
-
Assign a different temperature to each replica, typically spanning a range from the target temperature to a higher temperature.
-
-
Simulation Execution:
-
Run independent MD simulations for all replicas simultaneously.
-
Periodically (e.g., every few hundred or thousand steps), attempt to exchange the coordinates of adjacent replicas based on a Metropolis criterion.[14]
-
-
Trajectory Analysis:
-
After the simulation, discard the trajectories from the higher temperature replicas.
-
Analyze the trajectory from the replica at the target temperature, which will have sampled a broader conformational space.
-
Visualizations
References
- 1. experts.illinois.edu [experts.illinois.edu]
- 2. researchgate.net [researchgate.net]
- 3. quora.com [quora.com]
- 4. quora.com [quora.com]
- 5. Advancing Simulation in Time – Practical considerations for Molecular Dynamics [computecanada.github.io]
- 6. epfl.ch [epfl.ch]
- 7. 12 GROMACS Errors: From Setup to Execution - Where Things Go Wrong [parssilico.com]
- 8. Common errors when using GROMACS - GROMACS 2024.3 documentation [manual.gromacs.org]
- 9. pubs.acs.org [pubs.acs.org]
- 10. researchgate.net [researchgate.net]
- 11. Choice of Force Field for Proteins Containing Structured and Intrinsically Disordered Regions - PMC [pmc.ncbi.nlm.nih.gov]
- 12. blog.bioinfoquant.com [blog.bioinfoquant.com]
- 13. Force Fields in Molecular Dynamics Simulations: Choosing the Right One - Creative Proteomics [iaanalysis.com]
- 14. Molecular dynamics-based approaches for enhanced sampling of long-time, large-scale conformational changes in biomolecules - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Process Improvements for High-Throughput Peptide Analog Screening
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in optimizing their high-throughput peptide analog screening experiments.
Frequently Asked Questions (FAQs) & Troubleshooting Guides
This section addresses specific issues that may arise during high-throughput peptide analog screening, presented in a question-and-answer format.
Peptide Synthesis & Quality Control
Q1: What are the common causes of low yield and purity in solid-phase peptide synthesis (SPPS)?
A1: Low yields and purity in SPPS can stem from several factors, including incomplete coupling or deprotection, resin overloading, or poor resin swelling. To troubleshoot these issues, consider double coupling, especially after proline residues or for consecutive identical amino acids.[1][2] It's also crucial to confirm complete deprotection before proceeding with the next coupling step, for instance, by using a Kaiser test.[1] Optimizing resin swelling by pre-swelling the resin in a suitable solvent like dichloromethane (DCM) for at least 30 minutes can also improve results.[1]
Q2: How can I minimize the presence of deletion or truncation sequences in my synthesized peptides?
A2: Incomplete Fmoc group removal is a common reason for deletion sequences. To address this, you can prolong the deblocking times or add 2% 1,8-diazabicyclo[5.4.0]undec-7-ene (DBU) to the deblocking solution.[3] Performing acidic washes between deblocking steps can also be beneficial.[3] If coupling is incomplete due to steric hindrance, using a stronger activation method or Fmoc-amino acid fluorides may be necessary.[3] Additionally, incorporating capping steps with a reagent like acetic anhydride after each coupling cycle can reduce the number of deletion sequences.[3]
Q3: What level of peptide purity is recommended for different high-throughput screening applications?
A3: The required peptide purity depends on the specific application. For initial, non-sensitive screening, crude peptides may be acceptable, but for most assays, some level of purification is necessary to avoid false positives or negatives.[4][5][6] Impurities such as truncated sequences, salts, and other organic residues can interfere with biological assays.[5]
| Purity Level | Recommended Applications | Rationale |
| >70% (Crude to Immuno-grade) | Initial non-sensitive screening, generating polyclonal antibodies, ELISA testing.[7] | Sufficient for preliminary studies where high precision is not critical. |
| >85% (Biochemistry Grade) | In-vitro bioassays, enzyme-substrate studies, epitope mapping.[7] | Reduces the risk of interference from impurities in functional assays. |
| >95% (High Purity Grade) | Quantitative receptor-ligand interaction studies, in-vivo studies, NMR.[7] | Essential for accurate and reproducible quantitative data. |
| >98% (Industrial Grade) | Crystallography, GMP peptides for drug development.[7] | Required for structural studies and therapeutic applications where purity is critical. |
Peptide Handling & Solubility
Q4: My peptide is not dissolving. What solvents should I try?
A4: Peptide solubility is highly dependent on its amino acid sequence.[8][9][10] First, determine if your peptide is acidic, basic, or neutral.
-
Acidic peptides (net negative charge): Try dissolving in a basic buffer like 0.1% ammonium hydroxide or ammonium bicarbonate, then dilute with water.[9]
-
Basic peptides (net positive charge): Attempt to dissolve in an acidic solution such as 10% acetic acid or 0.1% trifluoroacetic acid (TFA), followed by dilution.[11]
-
Neutral or hydrophobic peptides : These are often soluble in organic solvents like DMSO, DMF, or acetonitrile.[8] Dissolve the peptide in a small amount of the organic solvent first, and then slowly add it to your aqueous buffer.[11]
Sonication can also aid in dissolving peptides.[9] If a peptide fails to dissolve, it can be lyophilized and another solvent can be attempted.
| Peptide Type | Primary Solvent | Secondary Solvent/Diluent | Notes |
| Acidic (Net Charge < 0) | 0.1% Ammonium Hydroxide (NH4OH) | Water or PBS | Avoid NH4OH for Cys-containing peptides.[11] |
| Basic (Net Charge > 0) | 10-30% Acetic Acid or 0.1% TFA | Water or PBS | TFA may interfere with some cell-based assays.[11] |
| Neutral/Hydrophobic | DMSO, DMF, Acetonitrile | Aqueous Buffer | Add organic solvent solution dropwise to the buffer.[11] |
Q5: How should I store my peptides to ensure their stability?
A5: For long-term storage, peptides should be kept in lyophilized form at -20°C or -80°C in a sealed container with a desiccant.[12] This minimizes degradation. Once in solution, it is best to aliquot the peptide to avoid multiple freeze-thaw cycles.[12] Peptides containing cysteine, methionine, or tryptophan are susceptible to oxidation and should be dissolved in oxygen-free water or buffers.[9]
Assay-Specific Troubleshooting
Q6: I'm observing high background in my ELISA-based screening. What are the common causes and solutions?
A6: High background in an ELISA can obscure real hits and lead to false positives. Common causes include insufficient washing, inadequate blocking, or cross-reactivity of antibodies.
| Potential Cause | Solution |
| Insufficient Washing | Increase the number of wash steps and ensure complete removal of the wash buffer by inverting and tapping the plate on absorbent paper.[13] |
| Inadequate Blocking | Increase the blocking time or try a different blocking agent. Modern, commercially available blockers can be more effective than BSA.[14] |
| Non-specific Antibody Binding | Add a non-ionic detergent like Tween-20 (0.05%) to the wash buffers. Ensure the correct antibody concentrations are used. |
| Reagent Contamination | Use fresh, sterile buffers and reagents. |
| Light Exposure of Substrate | Store and incubate substrate solutions in the dark.[15] |
Q7: My fluorescence polarization (FP) assay has a low signal window. How can I improve it?
A7: A small signal window in an FP assay can make it difficult to distinguish between hits and non-hits. To improve the signal window, first, titrate the fluorescently labeled peptide to find the lowest concentration that gives a stable and robust signal, typically at least 10-fold higher than the buffer-only control.[16] Next, perform a saturation binding experiment by titrating the protein against a fixed concentration of the labeled peptide to determine the Kd and the protein concentration that gives a maximal signal.[16] Using a protein concentration at or slightly above the Kd often provides a good assay window for competitive binding experiments.
Q8: How can I identify and mitigate false positives caused by assay artifacts?
A8: False positives in high-throughput screening can arise from compounds that interfere with the assay technology rather than interacting with the target.[17][18] Common mechanisms include aggregation, chemical reactivity, and interference with detection methods (e.g., luciferase inhibition, fluorescence).[17] To identify these, one can perform counter-screens, such as running the assay in the absence of the target protein to identify aggregators or compounds that directly affect the detection system. Computational tools and filters can also be used to flag problematic compounds early in the process.[17]
Experimental Protocols
Protocol 1: Solid-Phase Peptide Synthesis (Fmoc/tBu Strategy) - Standard Protocol
This protocol is based on the widely used Fmoc/tBu strategy.[3][19]
-
Resin Swelling: Swell the resin (e.g., Rink Amide resin) in DMF for at least 30 minutes in a reaction vessel.
-
Fmoc Deprotection: Treat the resin with 20% piperidine in DMF for 5-10 minutes. Drain and repeat for another 15-20 minutes. Wash the resin thoroughly with DMF.
-
Amino Acid Coupling:
-
Dissolve the Fmoc-protected amino acid (3-5 equivalents) and a coupling reagent like HBTU (3-5 equivalents) in DMF.
-
Add a base such as N,N-diisopropylethylamine (DIEA) (6-10 equivalents).
-
Add the activated amino acid solution to the resin and agitate for 1-2 hours.
-
Monitor the coupling reaction using a qualitative test like the Kaiser test.[1]
-
-
Washing: After complete coupling, wash the resin with DMF to remove excess reagents.
-
Repeat: Repeat steps 2-4 for each amino acid in the sequence.
-
Final Deprotection: After the final coupling, perform a final Fmoc deprotection as described in step 2.
-
Cleavage and Deprotection: Treat the resin with a cleavage cocktail (e.g., 95% TFA, 2.5% water, 2.5% triisopropylsilane) for 2-3 hours to cleave the peptide from the resin and remove side-chain protecting groups.
-
Precipitation and Purification: Precipitate the peptide in cold diethyl ether, centrifuge, and wash the pellet. The crude peptide can then be purified by reverse-phase HPLC.
Protocol 2: Fluorescence Polarization (FP) Peptide-Protein Binding Assay
This protocol describes a competitive FP assay to measure the binding of unlabeled peptides to a protein.[19][20][21]
-
Reagent Preparation:
-
Prepare a stock solution of the fluorescently labeled peptide (probe) in an appropriate buffer (e.g., 50 mM Tris, 100 mM NaCl, pH 8.0).[21]
-
Prepare a stock solution of the target protein in the same buffer.
-
Prepare serial dilutions of the unlabeled competitor peptides in the assay buffer.
-
-
Assay Setup (384-well plate):
-
Add a fixed concentration of the target protein and the fluorescent probe to each well. The optimal concentrations should be determined empirically but are often around the Kd of the probe-protein interaction.
-
Add the serial dilutions of the competitor peptides to the wells.
-
Include control wells:
-
Probe only (no protein, for minimum polarization).
-
Probe + Protein (no competitor, for maximum polarization).
-
-
-
Incubation: Incubate the plate at room temperature for 30-60 minutes to reach equilibrium.[16][19]
-
Measurement: Read the fluorescence polarization on a plate reader equipped with appropriate filters for the fluorophore used.
-
Data Analysis: Plot the FP values against the log of the competitor peptide concentration and fit the data to a sigmoidal dose-response curve to determine the IC50 value.
Protocol 3: Cell-Based GPCR Signaling Assay (Calcium Mobilization)
This protocol outlines a method to screen for peptide agonists of a Gq-coupled GPCR by measuring intracellular calcium mobilization.[5][22][23]
-
Cell Culture and Transfection:
-
Culture a suitable host cell line (e.g., HEK293) in appropriate media.
-
Transiently transfect the cells with a plasmid encoding the GPCR of interest. For Gi or Gs coupled receptors, co-transfection with a promiscuous G-protein like Gα16 may be necessary to redirect signaling through the calcium pathway.[5][23]
-
-
Cell Plating: Plate the transfected cells into a 96- or 384-well black-walled, clear-bottom plate and allow them to adhere overnight.
-
Dye Loading:
-
Prepare a loading buffer containing a calcium-sensitive fluorescent dye (e.g., Fluo-4 AM) according to the manufacturer's instructions.
-
Remove the culture medium from the cells and add the dye loading buffer.
-
Incubate the plate at 37°C for 1 hour in the dark.
-
-
Peptide Addition:
-
Prepare serial dilutions of the peptide analogs in an appropriate assay buffer.
-
Use a fluorescence plate reader with an injection system to add the peptide solutions to the wells while simultaneously monitoring the fluorescence signal.
-
-
Data Acquisition: Measure the fluorescence intensity before and after the addition of the peptides. The change in fluorescence indicates a change in intracellular calcium concentration.
-
Data Analysis: Plot the peak fluorescence response against the log of the peptide concentration and fit the data to a dose-response curve to determine the EC50 of the peptide agonists.
Visualizations
References
- 1. kilobio.com [kilobio.com]
- 2. biotage.com [biotage.com]
- 3. luxembourg-bio.com [luxembourg-bio.com]
- 4. biotage.com [biotage.com]
- 5. Tools for GPCR drug discovery - PMC [pmc.ncbi.nlm.nih.gov]
- 6. qinglishangmao.com [qinglishangmao.com]
- 7. genscript.com [genscript.com]
- 8. Peptide Solubility Testing - Creative Peptides-Peptide Drug Discovery [pepdd.com]
- 9. bachem.com [bachem.com]
- 10. jpt.com [jpt.com]
- 11. Measurement and modelling solubility of amino acids and peptides in aqueous 2-propanol solutions - Physical Chemistry Chemical Physics (RSC Publishing) DOI:10.1039/D1CP00005E [pubs.rsc.org]
- 12. Interpretation of the dissolution of insoluble peptide sequences based on the acid-base properties of the solvent - PMC [pmc.ncbi.nlm.nih.gov]
- 13. ELISA Troubleshooting Guide | Thermo Fisher Scientific - US [thermofisher.com]
- 14. biocompare.com [biocompare.com]
- 15. biomatik.com [biomatik.com]
- 16. sussexdrugdiscovery.wordpress.com [sussexdrugdiscovery.wordpress.com]
- 17. Frequent hitters: nuisance artifacts in high-throughput screening - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. Lies and Liabilities: Computational Assessment of High-Throughput Screening Hits to Identify Artifact Compounds - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Fluorescence Polarization (FP) Binding Assays. [bio-protocol.org]
- 20. Measurement of peptide binding to MHC class II molecules by fluorescence polarization - PMC [pmc.ncbi.nlm.nih.gov]
- 21. Fluorescence Polarization Binding Assay [bio-protocol.org]
- 22. Evaluating functional ligand-GPCR interactions in cell-based assays - PMC [pmc.ncbi.nlm.nih.gov]
- 23. m.youtube.com [m.youtube.com]
Validation & Comparative
Validating Computational Models of GLP-1R: A Comparative Guide for Researchers
For researchers, scientists, and drug development professionals, this guide provides a comprehensive comparison of computational models of the Glucagon-Like Peptide-1 Receptor (GLP-1R) with key experimental data. It offers detailed methodologies for crucial validation assays and presents quantitative data in structured tables to facilitate objective comparison.
The GLP-1R, a class B G protein-coupled receptor (GPCR), is a prime therapeutic target for type 2 diabetes and obesity.[1] Computational modeling plays an increasingly vital role in understanding its complex signaling mechanisms and in the design of novel agonists.[2] Validating these in silico models against robust experimental data is critical to ensure their predictive accuracy and relevance in drug discovery.
This guide outlines the primary signaling pathways of GLP-1R, details the experimental protocols for their investigation, and compares the performance of various computational models against experimental benchmarks.
GLP-1R Signaling Pathways
Upon agonist binding, the GLP-1R initiates a cascade of intracellular signaling events, primarily through the activation of G proteins and β-arrestins. The canonical pathway involves the coupling of the receptor to the stimulatory G protein (Gs), which activates adenylyl cyclase, leading to the production of cyclic AMP (cAMP).[3] This second messenger, in turn, activates Protein Kinase A (PKA) and Exchange Protein directly Activated by cAMP (EPAC).[3]
Beyond the canonical Gs/cAMP pathway, GLP-1R can also signal through other G protein subtypes, such as Gq, and recruit β-arrestins. β-arrestin recruitment can lead to receptor desensitization and internalization, as well as initiate G protein-independent signaling, including the activation of the Extracellular signal-Regulated Kinase 1/2 (ERK1/2) pathway.[4] The ability of different agonists to preferentially activate one pathway over another, a phenomenon known as biased agonism, is a key area of research in GLP-1R drug development.[1]
Figure 1: Simplified GLP-1R signaling pathways.
Experimental Validation Protocols
Accurate validation of computational models requires standardized and reproducible experimental data. Below are detailed protocols for key assays used to quantify GLP-1R activation.
cAMP Signaling Assay
This assay measures the intracellular accumulation of cAMP following receptor activation.
Materials:
-
HEK293 cells stably expressing the human GLP-1R.
-
Assay medium (e.g., Opti-MEM).[5]
-
GLP-1R agonists (e.g., GLP-1, Exendin-4).
-
cAMP assay kit (e.g., Nomad cAMP Assay, DiscoverX cAMP Hunter).[5][6]
-
96-well microplate.
-
Humidified incubator (37°C, 5% CO2).
-
Plate reader capable of luminescence or fluorescence detection.
Protocol:
-
Seed GLP-1R expressing cells into a 96-well plate at a density of approximately 20,000-30,000 cells per well and incubate overnight.[5]
-
The following day, replace the culture medium with assay medium.[5]
-
Prepare serial dilutions of the GLP-1R agonists in assay medium.
-
Add the agonist solutions to the wells in triplicate. Include a vehicle control.[5]
-
Incubate the plate for the desired time (e.g., 30 minutes to 24 hours) in a humidified incubator.[5][7]
-
Lyse the cells and measure intracellular cAMP levels according to the manufacturer's instructions for the chosen cAMP assay kit.
-
Analyze the data by plotting the response (e.g., luminescence) against the logarithm of the agonist concentration and fit to a sigmoidal dose-response curve to determine EC50 and Emax values.[1]
β-Arrestin Recruitment Assay
This assay quantifies the recruitment of β-arrestin to the activated GLP-1R.
Materials:
-
CHO-K1 or HEK293 cells co-expressing GLP-1R and a β-arrestin fusion protein (e.g., PathHunter β-Arrestin Assay).[2][8]
-
Cell culture medium.
-
GLP-1R agonists.
-
Assay buffer.
-
96- or 384-well white, clear-bottom microplate.
-
Humidified incubator (37°C, 5% CO2).
-
Luminometer.
Protocol:
-
Plate the cells in a white, clear-bottom microplate and incubate overnight.[2]
-
Prepare serial dilutions of the GLP-1R agonists in assay buffer.
-
Add the agonist solutions to the cells.
-
Incubate for 60-90 minutes at 37°C or room temperature, as recommended by the assay manufacturer.[8]
-
Add the detection reagents as per the kit's instructions.
-
Incubate for 60 minutes at room temperature.[8]
-
Measure the chemiluminescent signal using a plate reader.
-
Analyze the data to determine EC50 and Emax values for β-arrestin recruitment.
ERK1/2 Phosphorylation Assay
This assay measures the phosphorylation of ERK1/2, a downstream event in GLP-1R signaling.
Materials:
-
MIN6 or INS-1 cells endogenously expressing GLP-1R.
-
Krebs-Ringer bicarbonate (KRB) buffer.
-
GLP-1R agonists.
-
Lysis buffer.
-
SDS-PAGE gels and Western blot apparatus.
-
Primary antibodies: anti-phospho-ERK1/2 and anti-total-ERK1/2.
-
HRP-conjugated secondary antibody.
-
Chemiluminescent substrate.
-
Imaging system.
Protocol:
-
Culture cells to 70-80% confluency.
-
Serum-starve the cells for 2-4 hours in KRB buffer.
-
Stimulate the cells with different concentrations of GLP-1R agonists for various time points (e.g., 5, 10, 20, 30 minutes).
-
Lyse the cells in cold lysis buffer.
-
Determine the protein concentration of the lysates.
-
Separate equal amounts of protein by SDS-PAGE and transfer to a PVDF membrane.
-
Block the membrane and incubate with the primary antibody against phospho-ERK1/2 overnight at 4°C.
-
Wash the membrane and incubate with the HRP-conjugated secondary antibody for 1-2 hours at room temperature.[6]
-
Wash the membrane and add the chemiluminescent substrate.
-
Capture the image using an imaging system.
-
Strip the membrane and re-probe with an antibody against total ERK1/2 for normalization.
-
Quantify the band intensities to determine the fold-change in ERK1/2 phosphorylation relative to the vehicle control.
Figure 2: General workflows for key experimental assays.
Comparison of Computational Models and Experimental Data
The validation of computational models hinges on their ability to accurately predict experimental outcomes. The following tables summarize quantitative data from both in silico predictions and in vitro experiments for various GLP-1R agonists.
Table 1: Comparison of Predicted and Experimental Binding Affinities (Kd)
| Agonist | Computational Model | Predicted Kd (M) | Experimental Kd (M) | Reference |
| Semaglutide | Homology Modeling & Docking | 3.28 x 10⁻⁶ | 3.4 x 10⁻⁶ | [9] |
| Semaglutide Analogue | Homology Modeling & Docking | 3.0 x 10⁻⁸ | - | [9] |
Table 2: Comparison of Predicted and Experimental Agonist Potency (EC50) for cAMP Signaling
| Agonist | Computational Model | Predicted pEC50 | Experimental EC50 (nM) | Reference |
| Ultra-short GLP-1 Analogs | QSAR | R² = 0.66 (correlation) | Varies (nM to µM range) | [5] |
| Exendin-F1 | ODE Model | - | ~0.1 | [6] |
| Exendin-D3 | ODE Model | - | ~1 | [6] |
Table 3: Comparison of Experimental Agonist Potency (EC50) for β-Arrestin Recruitment
| Agonist | Experimental EC50 (nM) | Reference |
| GLP-1 | ~1.3 (β-arrestin 1) | |
| Tirzepatide | ~3.1 (β-arrestin 1) | |
| GLP-1 Val8 | Impaired recruitment | [7] |
Alternative Approaches and Considerations
While homology modeling, molecular dynamics, and QSAR are powerful tools, other computational approaches can also contribute to understanding GLP-1R function. Machine learning algorithms, for instance, are being used to predict the activity of novel GLP-1R agonists.
It is crucial to consider the limitations of both computational and experimental methods. The accuracy of computational models is highly dependent on the quality of the template structures and the force fields used. Experimental results can be influenced by the cell line, assay conditions, and specific reagents employed. Therefore, a direct comparison should always be interpreted with these factors in mind.
Figure 3: The iterative process of computational model validation.
Conclusion
The validation of computational models of GLP-1R with high-quality experimental data is an indispensable step in modern drug discovery. This guide provides a framework for this process by detailing essential experimental protocols and presenting a comparative analysis of available data. By fostering a closer integration of computational and experimental approaches, researchers can accelerate the development of novel and more effective therapies targeting the GLP-1R.
References
- 1. Investigating Potential GLP-1 Receptor Agonists in Cyclopeptides from Pseudostellaria heterophylla, Linum usitatissimum, and Drymaria diandra, and Peptides Derived from Heterophyllin B for the Treatment of Type 2 Diabetes: An In Silico Study - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Drug Design of GLP-1 Receptor Agonists: Importance of In Silico Methods - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. mdpi.com [mdpi.com]
- 4. Computational modelling of dynamic cAMP responses to GPCR agonists for exploration of GLP-1R ligand effects in pancreatic β-cells and neurons - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. In-silico and in-vitro hybrid approach to identify glucagon-like peptide-1 receptor agonists from anti-diabetic natural products - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. pubs.acs.org [pubs.acs.org]
- 7. preprints.org [preprints.org]
- 8. researchgate.net [researchgate.net]
- 9. Structural Modeling and in Silico Screening of Potential Small-Molecule Allosteric Agonists of a Glucagon-like Peptide 1 Receptor - PMC [pmc.ncbi.nlm.nih.gov]
Cross-Validation of SJ000025081 Findings with Other Novel Antimalarial Agents
A Comparative Guide for Researchers and Drug Development Professionals
The urgent need for novel antimalarial therapies to combat emerging drug resistance has driven the discovery of new chemical scaffolds with unique mechanisms of action. This guide provides a cross-validation of the findings for SJ000025081, a potent dihydropyridine antimalarial, with other promising preclinical and clinical candidates, including the spiroindolone KAE609 (NITD609) and the phosphatidylinositol 4-kinase (PI4K) inhibitor MMV390048. The objective is to offer a comparative overview of their in vivo efficacy and the experimental protocols employed in their evaluation.
Comparative In Vivo Efficacy of Novel Antimalarial Compounds
The following table summarizes the in vivo efficacy data for this compound and selected comparator compounds from preclinical studies in murine models of malaria.
| Compound | Chemical Class | Mouse Model | Parasite Strain | Dosing Regimen | Efficacy | Reference |
| This compound | Dihydropyridine | Not Specified | P. yoelii | 100 mg/kg, twice daily for 3 days (intraperitoneal) | 90% suppression of parasitemia | [1] |
| KAE609 (NITD609) | Spiroindolone | Not Specified | P. berghei | Single oral dose of 100 mg/kg | Complete cure | [2][3] |
| MMV390048 | Aminopyridine | Humanized SCID mice | P. falciparum (3D7) | Once daily oral administration for 4 days | ED₉₀ at day 7 of 0.57 mg/kg | [4] |
Experimental Protocols
Detailed methodologies are crucial for the interpretation and replication of experimental findings. Below are the protocols for the key in vivo efficacy experiments cited in this guide.
In Vivo Efficacy Model for this compound (P. yoelii)
The in vivo antimalarial activity of this compound was evaluated in a murine model infected with Plasmodium yoelii.
-
Animal Model: The specific mouse strain used was not detailed in the primary publication.
-
Parasite and Infection: Mice were infected with P. yoelii. The route and inoculum size for infection were not explicitly stated.
-
Drug Administration: this compound was administered via intraperitoneal injection at a dose of 100 mg/kg twice daily for three consecutive days.
-
Parasitemia Measurement: Parasitemia was monitored to determine the percentage of infected red blood cells. The method for counting and the time points for measurement post-treatment were not specified in the available literature. A 90% suppression of parasitemia was observed with this treatment regimen.[1]
In Vivo Efficacy Model for KAE609 (NITD609) (P. berghei)
The in vivo efficacy of the spiroindolone KAE609 was assessed in a Plasmodium berghei infection model in mice.
-
Animal Model: The specific mouse strain was not detailed in the primary publication.
-
Parasite and Infection: Mice were infected with a lethal strain of P. berghei.
-
Drug Administration: A single oral dose of KAE609 at 100 mg/kg was administered.
-
Efficacy Assessment: The treatment resulted in a complete cure of the infection in all treated mice.[2][3] A 50% cure rate was achieved with a single oral dose of 30 mg/kg.[3]
In Vivo Efficacy Model for MMV390048 (P. falciparum in humanized mice)
The in vivo efficacy of MMV390048 was evaluated in a humanized severe combined immunodeficient (SCID) mouse model infected with Plasmodium falciparum.
-
Animal Model: Humanized SCID mice engrafted with human erythrocytes.
-
Parasite and Infection: Mice were infected with the drug-sensitive 3D7 strain of P. falciparum.
-
Drug Administration: MMV390048 was administered orally once daily for four consecutive days.
-
Parasitemia Measurement: Blood parasitemia was measured by flow cytometry.
-
Efficacy Calculation: The effective dose required to reduce parasitemia by 90% (ED₉₀) at day 7 post-treatment was determined to be 0.57 mg/kg.[4]
Visualizing Experimental Workflows and Signaling Pathways
To further elucidate the processes described, the following diagrams have been generated using the DOT language.
References
- 1. Chemical genetics of Plasmodium falciparum - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Spiroindolones, a potent compound class for the treatment of malaria - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. www2.chem.wisc.edu [www2.chem.wisc.edu]
- 4. Antimalarial efficacy of MMV390048, an inhibitor of Plasmodium phosphatidylinositol 4-kinase - PMC [pmc.ncbi.nlm.nih.gov]
A Comparative Analysis of GLP-1 Receptor Agonists: Efficacy in Glycemic Control and Weight Management
A comprehensive review of leading glucagon-like peptide-1 (GLP-1) receptor agonists, including dual-action agents, reveals significant advancements in the management of type 2 diabetes and obesity. Head-to-head clinical trials provide robust data demonstrating varying degrees of efficacy in glycemic control, weight reduction, and cardiovascular benefits among these therapies. This guide synthesizes findings from major clinical trial programs to offer a comparative perspective for researchers and drug development professionals.
Glucagon-like peptide-1 (GLP-1) receptor agonists have revolutionized the treatment landscape for type 2 diabetes, offering potent glucose-lowering effects with a low risk of hypoglycemia, coupled with the significant benefit of weight loss. The class has expanded to include both single GLP-1 receptor agonists and dual-action agonists that also target the glucose-dependent insulinotropic polypeptide (GIP) receptor. This guide provides an objective comparison of the efficacy and safety profiles of prominent GLP-1 receptor agonists, drawing on data from key clinical trials such as SUSTAIN (semaglutide), AWARD (dulaglutide), LEADER (liraglutide), and SURPASS (tirzepatide).
Glycemic Control: A Head-to-Head Comparison
The primary measure of efficacy for anti-diabetic agents is the reduction in glycated hemoglobin (HbA1c). Clinical trial data consistently demonstrates the superiority of GLP-1 receptor agonists over placebo and other diabetes medications.
A pivotal head-to-head comparison in the SUSTAIN 7 trial showed that once-weekly subcutaneous semaglutide at both 0.5 mg and 1.0 mg doses resulted in statistically significant greater reductions in HbA1c compared to dulaglutide at 0.75 mg and 1.5 mg doses, respectively, after 40 weeks of treatment.[1] Specifically, semaglutide 0.5 mg reduced HbA1c by 1.5% from a baseline of 8.2%, while dulaglutide 0.75 mg showed a reduction of 1.1%. At the higher doses, semaglutide 1.0 mg led to a 1.8% reduction compared to 1.4% with dulaglutide 1.5 mg.[1]
The introduction of the dual GIP and GLP-1 receptor agonist, tirzepatide, has set a new benchmark. In the SURPASS-2 trial, all three doses of tirzepatide (5 mg, 10 mg, and 15 mg) demonstrated superior HbA1c reductions from baseline compared to semaglutide 1 mg after 40 weeks.[2] The mean change from a baseline HbA1c of 8.28% was -2.01%, -2.24%, and -2.30% for tirzepatide 5 mg, 10 mg, and 15 mg, respectively, compared to -1.86% for semaglutide 1 mg.[3][4]
The AWARD-6 trial established the non-inferiority of once-weekly dulaglutide (1.5 mg) to once-daily liraglutide (1.8 mg) in reducing HbA1c at 26 weeks, with mean reductions of -1.42% and -1.36%, respectively.[4]
Table 1: Comparative Efficacy in HbA1c Reduction in Head-to-Head Trials
| Trial (Duration) | Comparator 1 | Comparator 2 | Mean Baseline HbA1c | Mean HbA1c Reduction (Comparator 1) | Mean HbA1c Reduction (Comparator 2) |
| SUSTAIN 7 (40 weeks) | Semaglutide 0.5 mg | Dulaglutide 0.75 mg | 8.2% | -1.5% | -1.1% |
| Semaglutide 1.0 mg | Dulaglutide 1.5 mg | 8.2% | -1.8% | -1.4% | |
| SURPASS-2 (40 weeks) | Tirzepatide 5 mg | Semaglutide 1 mg | 8.28% | -2.01% | -1.86% |
| Tirzepatide 10 mg | Semaglutide 1 mg | 8.28% | -2.24% | -1.86% | |
| Tirzepatide 15 mg | Semaglutide 1 mg | 8.28% | -2.30% | -1.86% | |
| AWARD-6 (26 weeks) | Dulaglutide 1.5 mg | Liraglutide 1.8 mg | ~8.1% | -1.42% | -1.36% |
| PIONEER 4 (26 weeks) | Oral Semaglutide 14 mg | Liraglutide 1.8 mg | ~8.0% | -1.2% | -1.1% |
Weight Reduction: A Key Secondary Endpoint
A significant advantage of GLP-1 receptor agonist therapy is the associated weight loss, a crucial factor in the management of type 2 diabetes and obesity.
In the SUSTAIN 7 trial, semaglutide demonstrated superior weight loss compared to dulaglutide at both dose levels.[5][6] Patients treated with semaglutide 0.5 mg experienced a mean weight reduction of 4.6 kg, while those on dulaglutide 0.75 mg lost an average of 2.3 kg.[5][6] At the higher doses, the weight loss was 6.5 kg with semaglutide 1.0 mg versus 3.0 kg with dulaglutide 1.5 mg.[5][6]
The SURPASS-2 trial also highlighted the potent weight-reducing effects of tirzepatide, which were significantly greater than those of semaglutide.[3][4] The mean reductions in body weight were 7.6 kg, 9.3 kg, and 11.2 kg for tirzepatide 5 mg, 10 mg, and 15 mg, respectively, compared to 5.7 kg for semaglutide 1 mg.[2]
Furthermore, the PIONEER 4 trial, which compared oral semaglutide to subcutaneous liraglutide, found that oral semaglutide led to a superior mean weight loss of -4.4 kg compared to -3.1 kg with liraglutide at 26 weeks.[7]
Table 2: Comparative Efficacy in Weight Reduction in Head-to-Head Trials
| Trial (Duration) | Comparator 1 | Comparator 2 | Mean Baseline Weight | Mean Weight Reduction (Comparator 1) | Mean Weight Reduction (Comparator 2) |
| SUSTAIN 7 (40 weeks) | Semaglutide 0.5 mg | Dulaglutide 0.75 mg | ~96 kg | -4.6 kg | -2.3 kg |
| Semaglutide 1.0 mg | Dulaglutide 1.5 mg | ~96 kg | -6.5 kg | -3.0 kg | |
| SURPASS-2 (40 weeks) | Tirzepatide 5 mg | Semaglutide 1 mg | 93.7 kg | -7.6 kg | -5.7 kg |
| Tirzepatide 10 mg | Semaglutide 1 mg | 93.7 kg | -9.3 kg | -5.7 kg | |
| Tirzepatide 15 mg | Semaglutide 1 mg | 93.7 kg | -11.2 kg | -5.7 kg | |
| AWARD-6 (26 weeks) | Dulaglutide 1.5 mg | Liraglutide 1.8 mg | ~92 kg | -2.9 kg | -3.6 kg |
| PIONEER 4 (26 weeks) | Oral Semaglutide 14 mg | Liraglutide 1.8 mg | ~91 kg | -4.4 kg | -3.1 kg |
Cardiovascular Outcomes: Beyond Glycemic Control
Several large-scale cardiovascular outcomes trials (CVOTs) have demonstrated that certain GLP-1 receptor agonists reduce the risk of major adverse cardiovascular events (MACE), a composite of cardiovascular death, non-fatal myocardial infarction, and non-fatal stroke.
The LEADER trial was a landmark study that showed liraglutide significantly reduced the risk of the primary composite outcome of MACE by 13% compared to placebo in patients with type 2 diabetes at high cardiovascular risk.[8] The trial also demonstrated a 22% reduction in cardiovascular death.[8]
Similarly, the SUSTAIN-6 trial found that semaglutide significantly reduced the risk of the primary MACE outcome by 26% compared to placebo.
Table 3: Cardiovascular Outcomes in Key Clinical Trials
| Trial | Drug | Comparator | Primary Outcome (MACE) | Hazard Ratio (95% CI) |
| LEADER | Liraglutide | Placebo | CV death, non-fatal MI, non-fatal stroke | 0.87 (0.78-0.97) |
| SUSTAIN-6 | Semaglutide | Placebo | CV death, non-fatal MI, non-fatal stroke | 0.74 (0.58-0.95) |
Experimental Protocols: A Methodological Overview
The head-to-head clinical trials cited in this guide were multicenter, randomized, and controlled studies. Below is a summary of the methodologies for key trials.
SUSTAIN 7: Semaglutide vs. Dulaglutide
This was an open-label, parallel-group, phase 3b trial involving 1,201 patients with type 2 diabetes inadequately controlled on metformin.[5][6] Patients were randomized 1:1:1:1 to receive once-weekly subcutaneous injections of semaglutide 0.5 mg, dulaglutide 0.75 mg, semaglutide 1.0 mg, or dulaglutide 1.5 mg for 40 weeks.[5][6] The primary endpoint was the change in HbA1c from baseline to week 40.[5]
SURPASS-2: Tirzepatide vs. Semaglutide
This was a 40-week, open-label, phase 3 trial that randomized 1,879 patients with type 2 diabetes inadequately controlled with metformin to receive once-weekly subcutaneous injections of tirzepatide (5 mg, 10 mg, or 15 mg) or semaglutide (1 mg) in a 1:1:1:1 ratio.[2][3] The primary endpoint was the mean change in HbA1c from baseline to 40 weeks.[3] Tirzepatide was initiated at 2.5 mg once weekly and the dose was increased by 2.5 mg every 4 weeks to the assigned dose.[9] Semaglutide was initiated at 0.25 mg once weekly, with the dose doubled every 4 weeks until the 1 mg dose was reached.[9]
AWARD-6: Dulaglutide vs. Liraglutide
This was a 26-week, randomized, open-label, phase 3, non-inferiority trial that included 599 patients with type 2 diabetes treated with metformin.[4] Patients were randomized to receive either once-weekly subcutaneous dulaglutide 1.5 mg or once-daily subcutaneous liraglutide 1.8 mg.[4] The primary outcome was to establish the non-inferiority of dulaglutide to liraglutide in HbA1c reduction at 26 weeks, with a non-inferiority margin of 0.4%.[4][8]
LEADER: Liraglutide Cardiovascular Outcomes Trial
This was a randomized, double-blind, placebo-controlled trial that enrolled 9,340 patients with type 2 diabetes and high cardiovascular risk.[8] Patients were randomized 1:1 to receive either once-daily subcutaneous liraglutide (up to 1.8 mg) or placebo, in addition to standard care.[8] The median follow-up was 3.8 years.[8] The primary outcome was a composite of death from cardiovascular causes, nonfatal myocardial infarction, or nonfatal stroke.[10]
PIONEER 4: Oral Semaglutide vs. Liraglutide
This was a randomized, double-blind, double-dummy, phase 3a trial that enrolled 711 patients with type 2 diabetes inadequately controlled with metformin, with or without an SGLT-2 inhibitor.[7] Participants were randomized 2:2:1 to receive once-daily oral semaglutide (escalated to 14 mg), once-daily subcutaneous liraglutide (escalated to 1.8 mg), or placebo for 52 weeks.[7] The primary endpoint was the change in HbA1c from baseline at week 26.[7]
Signaling Pathways of GLP-1 and Dual GIP/GLP-1 Receptor Agonists
GLP-1 receptor agonists exert their effects by binding to the GLP-1 receptor, a G-protein coupled receptor, primarily expressed in pancreatic β-cells, the brain, and other tissues. This binding activates adenylyl cyclase, leading to an increase in intracellular cyclic AMP (cAMP). Elevated cAMP levels activate Protein Kinase A (PKA) and Exchange protein activated by cAMP 2 (EPAC2), which in turn potentiate glucose-dependent insulin secretion.
Dual GIP/GLP-1 receptor agonists, such as tirzepatide, also activate the GIP receptor. The co-activation of both GLP-1 and GIP receptors is believed to have synergistic effects on insulin secretion and glycemic control.[9]
Safety and Tolerability
The most common adverse events associated with GLP-1 receptor agonists are gastrointestinal in nature, including nausea, vomiting, and diarrhea.[4][11] These side effects are typically mild to moderate in severity and tend to decrease over time.[11] In the SURPASS-2 trial, the incidence of nausea was 17-22% in the tirzepatide groups and 18% in the semaglutide group, while diarrhea was reported in 13-16% and 12% of patients, respectively.[4] In the AWARD-6 trial, nausea was reported by 20% of patients in the dulaglutide group and 18% in the liraglutide group.[4]
Conclusion
The landscape of GLP-1 receptor agonist therapy is rapidly evolving, with newer agents demonstrating superior efficacy in both glycemic control and weight management. Head-to-head clinical trials are invaluable for informing clinical decision-making and guiding future drug development. The dual GIP/GLP-1 receptor agonist tirzepatide has shown superior efficacy compared to the potent GLP-1 receptor agonist semaglutide. Semaglutide, in turn, has demonstrated superiority over dulaglutide. These findings underscore the importance of continued research to optimize treatment strategies for type 2 diabetes and obesity, with a focus on maximizing efficacy while maintaining a favorable safety profile.
References
- 1. researchgate.net [researchgate.net]
- 2. medwirenews.com [medwirenews.com]
- 3. rxfiles.ca [rxfiles.ca]
- 4. Tirzepatide versus Semaglutide Once Weekly in Patients with Type 2 Diabetes - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Tirzepatide as Compared with Semaglutide for the Treatment of Obesity - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. ClinicalTrials.gov [clinicaltrials.gov]
- 7. A Study of Tirzepatide (LY3298176) in Participants With Type 2 Diabetes Not Controlled With Diet and Exercise Alone - American College of Cardiology [acc.org]
- 8. Liraglutide Effect and Action in Diabetes: Evaluation of Cardiovascular Outcome Results - American College of Cardiology [acc.org]
- 9. researchgate.net [researchgate.net]
- 10. scienmag.com [scienmag.com]
- 11. Gastrointestinal adverse events and weight reduction in people with type 2 diabetes treated with tirzepatide in the SURPASS clinical trials - PubMed [pubmed.ncbi.nlm.nih.gov]
Validating the Handshake: A Guide to Experimental Verification of Peptide-Receptor Interactions
For researchers, scientists, and drug development professionals, the prediction of a peptide binding to its receptor is a critical first step. However, this computational handshake must be validated through rigorous experimental methods to confirm its biological relevance and therapeutic potential. This guide provides a comparative overview of key experimental techniques, complete with data interpretation, detailed protocols, and visual workflows to aid in the selection of the most appropriate validation strategy.
The journey from a predicted peptide-receptor interaction to a validated lead candidate hinges on a multi-faceted experimental approach. A variety of in vitro and cell-based assays are available, each offering unique insights into the binding event, from the physical kinetics of the interaction to the functional cellular response.[1] The choice of method depends on the specific questions being asked, the available resources, and the stage of the drug discovery process.
Comparing the Arsenal: A Guide to Validation Techniques
The validation of peptide-receptor interactions can be broadly categorized into biophysical, biochemical, and cell-based assays. Biophysical methods directly measure the physical parameters of binding, while biochemical and cell-based assays assess the functional consequences of this interaction.
Biophysical Assays: These techniques provide quantitative data on binding affinity, kinetics, and thermodynamics without the need for labels, offering a direct measure of the interaction.[2][3]
-
Surface Plasmon Resonance (SPR): A label-free optical biosensing technique that measures molecular interactions in real-time.[4] One binding partner (the receptor) is immobilized on a sensor chip, and the other (the peptide) is flowed over the surface.[5] The binding event causes a change in the refractive index at the surface, which is detected and plotted as a sensorgram.[6] This allows for the determination of association (k_a_) and dissociation (k_d_) rate constants, and the equilibrium dissociation constant (K_D_).[5]
-
Isothermal Titration Calorimetry (ITC): A technique that directly measures the heat released or absorbed during a binding event.[2][7] A solution of the peptide is titrated into a solution containing the receptor, and the resulting heat change is measured.[8] ITC is the gold standard for determining the thermodynamic parameters of an interaction, including the binding affinity (K_D_), stoichiometry (n), enthalpy (ΔH), and entropy (ΔS).[7][8][9]
Biochemical and Cell-Based Functional Assays: These assays measure the biological response triggered by the peptide-receptor interaction, providing crucial information about the peptide's efficacy as an agonist or antagonist.
-
Resonance Energy Transfer (RET) Assays (FRET and BRET): Förster Resonance Energy Transfer (FRET) and Bioluminescence Resonance Energy Transfer (BRET) are powerful techniques for monitoring protein-protein interactions and conformational changes in living cells.[10][11][12] These assays rely on the transfer of energy from a donor molecule to an acceptor molecule when they are in close proximity (typically within 10 nm).[11][12] They can be used to study receptor dimerization, ligand binding, and the recruitment of downstream signaling molecules like G-proteins and β-arrestins.[11][13]
-
Second Messenger Assays: Many peptide receptors, particularly G-protein coupled receptors (GPCRs), initiate intracellular signaling cascades that involve the production of second messengers like cyclic AMP (cAMP) and calcium (Ca2+).[12][14] Assays that measure changes in the levels of these second messengers are a common way to functionally characterize peptide-receptor interactions and determine the potency (EC50) of a peptide.[14][15]
-
Radioligand Binding Assays: These are classic, highly sensitive assays used to determine the affinity and specificity of a peptide for its receptor.[1][16] They involve the use of a radiolabeled version of the peptide (or a known ligand) to compete for binding to the receptor.[1] By measuring the displacement of the radioligand by the unlabeled test peptide, one can determine the inhibitory concentration (IC50) and the binding affinity (Ki).[16]
Quantitative Data at a Glance
The following table summarizes the key quantitative parameters obtained from each of the discussed techniques.
| Technique | Key Parameters Measured | Typical Range of Values | Primary Application |
| Surface Plasmon Resonance (SPR) | K_D_ (Equilibrium Dissociation Constant), k_a_ (Association Rate), k_d_ (Dissociation Rate) | K_D_: 10⁻³ to 10⁻¹² M | Binding kinetics and affinity |
| Isothermal Titration Calorimetry (ITC) | K_D_, ΔH (Enthalpy), ΔS (Entropy), n (Stoichiometry) | K_D_: 10⁻³ to 10⁻⁹ M | Binding thermodynamics and affinity |
| FRET/BRET Assays | BRET/FRET Ratio, EC₅₀/IC₅₀ | Varies depending on the system | Real-time protein-protein interactions |
| Second Messenger Assays (e.g., cAMP) | EC₅₀ (Half-maximal effective concentration), E_max_ (Maximum effect) | 10⁻⁶ to 10⁻¹² M | Functional potency and efficacy |
| Radioligand Binding Assays | K_D_, K_i_ (Inhibition Constant), B_max_ (Receptor Density), IC₅₀ (Half-maximal inhibitory concentration) | K_D_/K_i_: 10⁻⁶ to 10⁻¹² M | Binding affinity and receptor density |
Visualizing the Process
To better understand the experimental workflows and the underlying biological processes, the following diagrams have been generated using Graphviz.
Caption: A typical workflow for the experimental validation of a predicted peptide-receptor interaction.
Caption: Simplified signaling pathway for a Gs-coupled G-protein coupled receptor (GPCR).
Caption: A step-by-step workflow for a Surface Plasmon Resonance (SPR) experiment.
Detailed Experimental Protocols
Here are condensed protocols for three key validation techniques.
Surface Plasmon Resonance (SPR) for Kinetic Analysis
Objective: To determine the association rate (k_a_), dissociation rate (k_d_), and equilibrium dissociation constant (K_D_) of a peptide binding to its receptor.
Methodology:
-
Receptor Immobilization: Covalently immobilize the purified receptor onto a sensor chip surface using amine coupling chemistry.[17] The density of immobilization should be optimized to avoid mass transport limitations.[17]
-
Peptide Preparation: Prepare a series of dilutions of the peptide in a suitable running buffer. A buffer-only sample will serve as the blank.
-
Binding Measurement:
-
Inject the peptide solutions over the immobilized receptor surface at a constant flow rate.[17]
-
Monitor the change in SPR signal in real-time to observe the association phase.
-
Switch back to the running buffer to monitor the dissociation phase.
-
-
Surface Regeneration: Inject a regeneration solution (e.g., low pH buffer) to remove the bound peptide and prepare the surface for the next injection.
-
Data Analysis:
-
Subtract the blank sensorgram from the peptide sensorgrams.
-
Fit the resulting curves to a suitable binding model (e.g., 1:1 Langmuir binding) to calculate k_a_, k_d_, and K_D_.[5]
-
BRET Assay for Receptor-Effector Interaction
Objective: To monitor the interaction between a peptide-activated GPCR and a downstream effector protein (e.g., β-arrestin) in living cells.
Methodology:
-
Plasmid Construction: Create expression vectors where the receptor is fused to a BRET donor (e.g., Renilla luciferase, Rluc) and the effector protein is fused to a BRET acceptor (e.g., Yellow Fluorescent Protein, YFP).[13]
-
Cell Transfection: Co-transfect cells (e.g., HEK293) with the donor- and acceptor-fused constructs.
-
Cell Plating: Plate the transfected cells into a white, clear-bottom 96-well plate.
-
Peptide Stimulation: Add the BRET substrate (e.g., coelenterazine) to the cells, followed by the addition of the test peptide at various concentrations.
-
Signal Detection: Measure the light emission at the donor and acceptor wavelengths using a plate reader equipped for BRET measurements.
-
Data Analysis:
-
Calculate the BRET ratio (acceptor emission / donor emission).
-
Plot the BRET ratio as a function of peptide concentration and fit the data to a dose-response curve to determine the EC50.
-
cAMP Assay for Functional Receptor Activation
Objective: To quantify the activation of a Gs- or Gi-coupled receptor by a peptide through the measurement of intracellular cyclic AMP (cAMP) levels.
Methodology:
-
Cell Culture: Culture cells expressing the receptor of interest in a 96-well plate.
-
Peptide Treatment: Treat the cells with various concentrations of the test peptide. Include a known agonist as a positive control and untreated cells as a negative control. For Gi-coupled receptors, cells are typically co-stimulated with forskolin to induce cAMP production.[14]
-
Cell Lysis: Lyse the cells to release the intracellular contents, including cAMP.
-
cAMP Detection: Measure the cAMP concentration in the cell lysates using a competitive immunoassay, such as a LANCE Ultra cAMP assay or an HTRF cAMP assay.[14][15] These assays typically involve a labeled cAMP tracer that competes with the sample cAMP for binding to a specific antibody.
-
Data Analysis:
-
Generate a standard curve using known concentrations of cAMP.
-
Determine the cAMP concentration in the samples based on the standard curve.
-
Plot the cAMP concentration against the peptide concentration and fit the data to a sigmoidal dose-response curve to calculate the EC50 and E_max_.
-
References
- 1. In vitro receptor binding assays: general methods and considerations - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. bitesizebio.com [bitesizebio.com]
- 3. researchgate.net [researchgate.net]
- 4. An Introduction to Surface Plasmon Resonance [jacksonimmuno.com]
- 5. ProteOn Surface Plasmon Resonance Detection System | Bio-Rad [bio-rad.com]
- 6. m.youtube.com [m.youtube.com]
- 7. stevensonlab.com [stevensonlab.com]
- 8. edepot.wur.nl [edepot.wur.nl]
- 9. High-Quality Data of Protein/Peptide Interaction by Isothermal Titration Calorimetry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Monitoring G protein activation in cells with BRET - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Multiple GPCR Functional Assays Based on Resonance Energy Transfer Sensors - PMC [pmc.ncbi.nlm.nih.gov]
- 12. ecosystem.drgpcr.com [ecosystem.drgpcr.com]
- 13. Frontiers | BRET biosensors to study GPCR biology, pharmacology, and signal transduction [frontiersin.org]
- 14. A High-Throughput Method for Screening Peptide Activators of G-Protein-Coupled Receptors - PMC [pmc.ncbi.nlm.nih.gov]
- 15. revvity.com [revvity.com]
- 16. Binding Assays & Cell Based Assays | Chelatec [chelatec.com]
- 17. files.core.ac.uk [files.core.ac.uk]
Unveiling Functional Divergence from Structural Nuances: A Comparative Analysis of Carvedilol and Metoprolol
For researchers, scientists, and professionals in drug development, understanding how subtle variations in molecular structure can translate into significant differences in functional outcomes is paramount. This guide provides a detailed comparison of two widely used β-blockers, carvedilol and metoprolol, highlighting how their distinct structural attributes lead to different pharmacological effects. The information presented is supported by experimental data to illustrate the functional consequences of their structural disparities.
Carvedilol and metoprolol are both classified as β-adrenergic receptor antagonists, or beta-blockers, and are commonly prescribed for cardiovascular conditions such as hypertension and heart failure. However, their mechanisms of action and clinical profiles differ significantly due to their distinct molecular structures. Metoprolol is a β1-selective adrenergic antagonist, meaning it primarily targets β1 receptors, which are predominantly found in the heart. In contrast, carvedilol is a non-selective β-blocker, antagonizing both β1 and β2 adrenergic receptors, and it also possesses α1-blocking activity, which contributes to its vasodilatory effects.[1][2][3]
These structural differences dictate their interactions with their target receptors and the subsequent downstream signaling pathways they modulate. The β-adrenergic receptors are G-protein coupled receptors (GPCRs) that, upon stimulation by catecholamines like epinephrine and norepinephrine, primarily activate the Gs protein, leading to the production of cyclic AMP (cAMP) and subsequent downstream signaling cascades that increase heart rate and contractility.[4] More recent research has also highlighted the role of β-arrestin-mediated signaling, which can be independent of G-protein activation.[5][6][7]
The differing receptor selectivity of carvedilol and metoprolol results in distinct physiological effects. Metoprolol's β1-selectivity leads to a more targeted reduction in heart rate and contractility with less impact on the β2 receptors in the lungs and peripheral blood vessels. This makes it a generally safer option for patients with respiratory conditions like asthma.[1] Carvedilol's non-selective β-blockade and α1-antagonism result in a broader range of effects, including a more pronounced reduction in blood pressure due to vasodilation.[1][2]
Interestingly, studies suggest that carvedilol acts as a "biased ligand." While it antagonizes the G-protein-mediated signaling pathway, it can simultaneously act as a partial agonist for β-arrestin-mediated signaling.[5][6][8] This biased agonism may contribute to some of carvedilol's unique clinical benefits, particularly in heart failure.[5][7]
Comparative Experimental Data
To quantitatively assess the functional consequences of the structural differences between carvedilol and metoprolol, their binding affinities for β1 and β2 adrenergic receptors and their functional potencies in modulating downstream signaling pathways are compared. The following tables summarize key experimental data from various studies.
| Drug | Receptor | Binding Affinity (Ki in nM) | Reference |
| Carvedilol | β1-adrenergic | 0.32 | [3] |
| Carvedilol | β2-adrenergic | 0.13 - 0.40 | [3] |
| Metoprolol | β1-adrenergic | Data not available in a direct comparative study | |
| Metoprolol | β2-adrenergic | Data not available in a direct comparative study |
| Drug | Assay | Receptor | Functional Potency (EC50/IC50 in nM) | Reference |
| Carvedilol | cAMP Accumulation (Inverse Agonism) | β2-adrenergic | Inverse agonist | [5] |
| Metoprolol | cAMP Accumulation (Inverse Agonism) | β2-adrenergic | Inverse agonist | [5] |
| Carvedilol | β-arrestin Recruitment | β2AR-V2R chimera | Agonist | [5] |
| Metoprolol | β-arrestin Recruitment | β2AR-V2R chimera | No recruitment | [5] |
| Carvedilol | ERK 1/2 Activation | β2-adrenergic | Agonist | [5] |
| Metoprolol | ERK 1/2 Activation | β2-adrenergic | No activation | [5] |
Note: Directly comparative Ki and EC50/IC50 values from a single study under identical experimental conditions were not available in the searched literature. The provided data is compiled from various sources and should be interpreted with this in mind.
Experimental Protocols
The following are generalized protocols for key experiments used to characterize the functional consequences of β-blockers.
Radioligand Binding Assay
This assay is used to determine the binding affinity (Ki) of a drug for its receptor.
Objective: To measure the affinity of carvedilol and metoprolol for β1 and β2 adrenergic receptors.
Methodology:
-
Membrane Preparation: Cell membranes expressing the β-adrenergic receptor of interest are prepared from cultured cells or tissue homogenates.
-
Incubation: A fixed concentration of a radiolabeled ligand (e.g., [125I]-Iodocyanopindolol) is incubated with the cell membranes in the presence of varying concentrations of the unlabeled competitor drug (carvedilol or metoprolol).
-
Separation: The bound radioligand is separated from the unbound radioligand by rapid filtration through glass fiber filters.
-
Detection: The radioactivity retained on the filters is quantified using a scintillation counter.
-
Data Analysis: The concentration of the competitor drug that inhibits 50% of the specific binding of the radioligand (IC50) is determined. The Ki value is then calculated using the Cheng-Prusoff equation: Ki = IC50 / (1 + [L]/Kd), where [L] is the concentration of the radioligand and Kd is its dissociation constant.
cAMP Functional Assay
This assay measures the ability of a drug to modulate the production of cyclic AMP, a key second messenger in β-adrenergic receptor signaling.
Objective: To determine the functional potency (EC50 or IC50) of carvedilol and metoprolol in activating or inhibiting the Gs/cAMP pathway.
Methodology:
-
Cell Culture: Cells expressing the β-adrenergic receptor of interest are cultured in appropriate media.
-
Stimulation: Cells are pre-incubated with a phosphodiesterase inhibitor to prevent cAMP degradation. For antagonist/inverse agonist testing, cells are then treated with varying concentrations of the test drug (carvedilol or metoprolol) before stimulation with a known agonist (e.g., isoproterenol). For agonist testing, cells are treated directly with the test drug.
-
Lysis and Detection: After incubation, the cells are lysed, and the intracellular cAMP concentration is measured using a competitive immunoassay, such as a Homogeneous Time-Resolved Fluorescence (HTRF) assay or an enzyme-linked immunosorbent assay (ELISA).
-
Data Analysis: Dose-response curves are generated by plotting the cAMP concentration against the drug concentration. The EC50 (for agonists) or IC50 (for antagonists/inverse agonists) is then calculated.
β-Arrestin Recruitment Assay
This assay measures the recruitment of β-arrestin to the activated GPCR, a key event in G-protein-independent signaling and receptor desensitization.
Objective: To assess the ability of carvedilol and metoprolol to induce β-arrestin recruitment to β-adrenergic receptors.
Methodology:
-
Cell Line: A cell line is used that co-expresses the β-adrenergic receptor fused to one component of a reporter system (e.g., a fragment of β-galactosidase, ProLink) and β-arrestin fused to the complementary component (e.g., Enzyme Acceptor).
-
Ligand Stimulation: The cells are treated with varying concentrations of the test drug (carvedilol or metoprolol).
-
Detection: If the drug induces β-arrestin recruitment, the two reporter fragments come into close proximity, leading to the reconstitution of a functional enzyme. A substrate is then added, and the resulting chemiluminescent signal is measured.
-
Data Analysis: Dose-response curves are generated by plotting the luminescent signal against the drug concentration to determine the EC50 for β-arrestin recruitment.
Visualizing the Divergent Signaling Pathways
The structural differences between metoprolol and carvedilol lead to distinct downstream signaling cascades.
Caption: Metoprolol's selective blockade of β1-AR inhibits the Gs-cAMP pathway.
Caption: Carvedilol's complex signaling via β-AR, α1-AR, and β-arrestin pathways.
References
- 1. Carvedilol vs. Metoprolol for Heart Disease - GoodRx [goodrx.com]
- 2. juniperpublishers.com [juniperpublishers.com]
- 3. Carvedilol - Wikipedia [en.wikipedia.org]
- 4. Gαi is required for carvedilol-ind ... | Article | H1 Connect [archive.connect.h1.co]
- 5. A unique mechanism of β-blocker action: Carvedilol stimulates β-arrestin signaling - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Gαi is required for carvedilol-induced β1 adrenergic receptor β-arrestin biased signaling - PMC [pmc.ncbi.nlm.nih.gov]
- 7. pnas.org [pnas.org]
- 8. biorxiv.org [biorxiv.org]
A Side-by-Side Comparison of GLP-1 and GIP Receptor Activation: A Guide for Researchers
For Immediate Publication
This guide provides an objective, data-supported comparison of Glucagon-Like Peptide-1 (GLP-1) and Glucose-Dependent Insulinotropic Polypeptide (GIP) receptor activation. It is intended for researchers, scientists, and drug development professionals engaged in metabolic disease research. The content covers signaling pathways, physiological outcomes, and detailed experimental methodologies, presenting quantitative data in structured tables and visualizing complex processes with diagrams.
Introduction to Incretin Hormones: GLP-1 and GIP
GLP-1 and GIP are the two primary incretin hormones, released from the gut in response to nutrient ingestion.[1] They play a crucial role in glucose homeostasis, primarily by stimulating insulin secretion from pancreatic β-cells in a glucose-dependent manner.[1][2] Both hormones exert their effects by binding to specific G-protein coupled receptors (GPCRs): the GLP-1 receptor (GLP-1R) and the GIP receptor (GIPR).[1][3] While their primary insulinotropic effect is similar, the downstream signaling cascades and broader physiological effects of their receptor activation exhibit significant differences. Understanding these distinctions is critical for the development of targeted therapies for type 2 diabetes and obesity.
Receptor Characteristics and Signaling Pathways
GLP-1R and GIPR are both members of the Class B family of GPCRs.[3][4] Upon binding their respective ligands, they primarily couple to the Gαs protein, which activates adenylyl cyclase, leading to an increase in intracellular cyclic adenosine monophosphate (cAMP).[1][3][5] This rise in cAMP is a key event that mediates many of the hormones' biological actions, including the potentiation of insulin secretion.[5]
However, the signaling pathways are not identical. For instance, in murine pancreatic β-cells, GLP-1R can activate both Gαs and Gαq proteins, whereas GIPR selectively activates Gαs.[6] The shared and distinct signaling pathways are visualized below.
Quantitative Comparison of Receptor Activation
The activation dynamics and physiological concentrations of GLP-1 and GIP differ, which influences their overall biological impact. Postprandial GIP levels are approximately 3 to 4 times higher in molar concentration than GLP-1 levels.[4]
| Parameter | GLP-1 Receptor (GLP-1R) | GIP Receptor (GIPR) |
| Receptor Class | Class B GPCR[3][4] | Class B GPCR[3][4] |
| Primary G-Protein Coupling | Gαs (also Gαq in some systems)[6][7] | Gαs[6] |
| EC₅₀ (cAMP Production) | 8.0 pM (for GLP-1 7-36)[8] | Dose-dependent cAMP increase observed[9] |
| Fasting Plasma Concentration | 5 - 15 pM[4][6] | 10 - 20 pM[4][6] |
| Postprandial Plasma Conc. | 3-5 fold increase[4] | Peak values ~80 - 150 pM[4] |
Side-by-Side Comparison of Physiological Effects
While both hormones are incretins, their activation leads to distinct and sometimes opposing physiological effects beyond insulin secretion. GLP-1 has a strong inhibitory effect on gastric emptying, a property not shared by GIP.[1][10] Furthermore, their actions on pancreatic α-cells are contrary; GLP-1 suppresses glucagon secretion during hyperglycemia, whereas GIP can stimulate it during hypoglycemia.[6][11]
| Physiological Effect | GLP-1 Receptor Activation | GIP Receptor Activation |
| Pancreatic β-Cells (Insulin) | Potently stimulates glucose-dependent insulin secretion.[1][6] | Stimulates glucose-dependent insulin secretion (effect may be blunted in T2DM).[1][11] |
| Pancreatic α-Cells (Glucagon) | Suppresses glucagon secretion during hyperglycemia.[2][4][6] | Stimulates glucagon secretion during euglycemia and hypoglycemia; no effect during hyperglycemia.[4][6][11] |
| Gastric Emptying | Strongly delays gastric emptying.[2][10][12] | Little to no effect.[1][10] |
| Appetite and Food Intake | Reduces appetite and food intake, promoting satiety.[1][13] | Involved in central appetite control.[1][6] |
| Adipose Tissue | Indirectly promotes lipolysis.[14] | Facilitates fat deposition and storage.[1][15] |
| Bone Metabolism | Inhibits bone resorption.[1][2] | Promotes bone formation.[1][2] |
| β-Cell Mass | Promotes β-cell proliferation and inhibits apoptosis.[1][16] | Promotes β-cell proliferation and inhibits apoptosis.[1] |
Experimental Protocols and Methodologies
To quantitatively assess and compare the activation of GLP-1R and GIPR, several key in vitro and in vivo experiments are employed. Below is a typical workflow and detailed protocols for foundational assays.
Experimental Protocol 1: Intracellular cAMP Assay
This protocol describes a general method for measuring cAMP accumulation in response to receptor activation using a competitive immunoassay format (e.g., HTRF or AlphaScreen).[17][18][19]
-
Cell Preparation:
-
Culture cells stably or transiently expressing the human GLP-1R or GIPR in a suitable medium.
-
Seed cells into a 384-well white opaque plate at an optimized density and allow them to adhere overnight.[18]
-
-
Compound Stimulation:
-
Prepare serial dilutions of the test agonists (e.g., GLP-1, GIP, or synthetic analogs) in a stimulation buffer.
-
Remove the culture medium from the cells and add the diluted compounds.
-
Incubate the plate for a specified time (e.g., 30 minutes) at room temperature to allow for cAMP production.[17]
-
-
Lysis and Detection:
-
Add a lysis buffer containing the detection reagents. These typically include a europium cryptate-labeled anti-cAMP antibody and a d2-labeled cAMP analog (for HTRF) or antibody-coated acceptor beads and biotin-cAMP/streptavidin-donor beads (for AlphaScreen).[17][18]
-
Incubate for 1 hour at room temperature to allow the competitive binding reaction to reach equilibrium.[17]
-
-
Data Acquisition:
-
Read the plate on a compatible reader (e.g., an HTRF-certified reader). The signal is inversely proportional to the amount of cAMP produced by the cells.
-
-
Data Analysis:
-
Generate a standard curve using known concentrations of cAMP.
-
Convert the sample readings to cAMP concentrations and plot the concentration-response curve.
-
Calculate the EC₅₀ value using a four-parameter nonlinear regression model.
-
Experimental Protocol 2: ERK Phosphorylation Western Blot Assay
This protocol details the detection of phosphorylated ERK1/2 (p-ERK), a downstream marker of GPCR activation, via Western blotting.[20][21][22]
-
Cell Culture and Stimulation:
-
Grow cells to 70-90% confluence in culture flasks. For the assay, seed cells in 6-well or 12-well plates and grow to confluence.
-
Serum-starve the cells for 4-6 hours to reduce basal ERK phosphorylation.
-
Treat cells with various concentrations of the agonist for a short duration (typically 5-10 minutes).
-
-
Protein Extraction:
-
Aspirate the medium and wash the cells once with ice-cold PBS.
-
Lyse the cells directly in the well with ice-cold RIPA buffer containing protease and phosphatase inhibitors.
-
Scrape the cells, transfer the lysate to a microfuge tube, and centrifuge at high speed (e.g., 14,000 rpm) for 15 minutes at 4°C to pellet cell debris.
-
Collect the supernatant and determine the protein concentration using a BCA or Bradford assay.
-
-
SDS-PAGE and Protein Transfer:
-
Immunoblotting:
-
Block the membrane for 1 hour at room temperature in a blocking buffer (e.g., 5% BSA or non-fat milk in TBST).[21]
-
Incubate the membrane overnight at 4°C with a primary antibody specific for phospho-ERK1/2 (p44/42).[21]
-
Wash the membrane three times with TBST.
-
Incubate with an HRP-conjugated secondary antibody for 1-2 hours at room temperature.[21]
-
Wash the membrane again three times with TBST.
-
-
Detection and Analysis:
-
Apply an enhanced chemiluminescence (ECL) substrate to the membrane and visualize the protein bands using a chemiluminescence imaging system.[22]
-
Strip the membrane and re-probe with an antibody for total ERK1/2 as a loading control.[21]
-
Quantify the band intensities using densitometry software. Normalize the p-ERK signal to the total ERK signal for each sample.
-
Experimental Protocol 3: In Vivo Intraperitoneal Glucose Tolerance Test (IPGTT) in Mice
This protocol is used to assess how an agonist affects glucose disposal in a living organism.[23][24]
-
Animal Preparation:
-
Baseline Measurement and Compound Administration:
-
Weigh each mouse.
-
Obtain a baseline blood sample (Time 0) from the tail vein to measure blood glucose using a glucometer.
-
Administer the test agonist (GLP-1, GIP analog, or vehicle control) via an appropriate route (e.g., intraperitoneal or subcutaneous injection).
-
-
Glucose Challenge:
-
After a set period following compound administration (e.g., 15-30 minutes), administer a glucose solution (e.g., 2 g/kg body weight) via intraperitoneal (i.p.) injection.[24]
-
-
Blood Glucose Monitoring:
-
Data Analysis:
-
Plot the blood glucose concentration versus time for each treatment group.
-
Calculate the Area Under the Curve (AUC) for the glucose excursion. A lower AUC in the agonist-treated group compared to the vehicle group indicates improved glucose tolerance.
-
References
- 1. GIP and GLP‐1, the two incretin hormones: Similarities and differences - PMC [pmc.ncbi.nlm.nih.gov]
- 2. droracle.ai [droracle.ai]
- 3. GLP-1 and GIP receptor signaling in beta cells - A review of receptor interactions and co-stimulation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Mechanisms of action and therapeutic applications of GLP-1 and dual GIP/GLP-1 receptor agonists - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. Frontiers | Mechanisms of action and therapeutic applications of GLP-1 and dual GIP/GLP-1 receptor agonists [frontiersin.org]
- 7. innoprot.com [innoprot.com]
- 8. Optical tools for visualizing and controlling human GLP-1 receptor activation with high spatiotemporal resolution - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. Differential incretin effects of GIP and GLP-1 on gastric emptying, appetite, and insulin-glucose homeostasis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. The Effects of Dual GLP-1/GIP Receptor Agonism on Glucagon Secretion—A Review - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. healthcentral.com [healthcentral.com]
- 14. Mechanisms of action and therapeutic applications of GLP-1 and dual GIP/GLP-1 receptor agonists - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. pritikin.com [pritikin.com]
- 16. youtube.com [youtube.com]
- 17. m.youtube.com [m.youtube.com]
- 18. resources.revvity.com [resources.revvity.com]
- 19. Measurement of cAMP for Gαs- and Gαi Protein-Coupled Receptors (GPCRs) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 20. Measuring agonist-induced ERK MAP kinase phosphorylation for G-protein-coupled receptors - PMC [pmc.ncbi.nlm.nih.gov]
- 21. 3.4. Western Blotting and Detection [bio-protocol.org]
- 22. pubcompare.ai [pubcompare.ai]
- 23. dovepress.com [dovepress.com]
- 24. joe.bioscientifica.com [joe.bioscientifica.com]
- 25. Oral Glucose Tolerance Test in Mouse [protocols.io]
Safety Operating Guide
Information Not Available for SJ000025081
A thorough search for the proper disposal procedures for the substance identified as SJ000025081 has been conducted. Unfortunately, no specific Safety Data Sheet (SDS) or other documentation detailing its chemical composition, hazards, and required disposal methods could be located in publicly available resources.
For the safety of researchers, scientists, and drug development professionals, and to ensure full compliance with environmental regulations, it is imperative that the specific chemical properties and associated hazards of any substance are fully understood before any handling or disposal takes place. Without the official SDS, providing a disposal procedure would be unsafe and could lead to improper handling and potential environmental contamination.
Recommended Action:
To obtain the necessary safety and disposal information for this compound, it is essential to:
-
Contact the Manufacturer or Supplier: The entity that provided the substance is legally obligated to furnish a Safety Data Sheet (SDS). The SDS will contain a dedicated section on disposal considerations, providing guidance that is specific to the material.
-
Provide Product Details: When contacting the manufacturer or supplier, provide them with the product identifier "this compound" and any other relevant information from the product's label or packaging, such as the product name, lot number, and any other identifying codes.
-
Consult Your Institution's Environmental Health and Safety (EHS) Office: Your organization's EHS department is a critical resource for chemical safety and waste disposal. They can provide guidance on proper storage of the material while awaiting the SDS and will be able to advise on the correct disposal procedures once the chemical's identity and hazards are known.
General Guidance for Unidentified Chemical Waste:
In the absence of specific information, this compound should be treated as hazardous waste. The following general procedures for managing unknown chemical waste should be followed until a definitive disposal plan can be established based on the SDS:
-
Labeling: Clearly label the container with "Caution: Unknown Material. Awaiting Identification and Disposal Instructions." Include any known information and the date.
-
Storage: Store the container in a designated hazardous waste accumulation area. This area should be secure, well-ventilated, and away from incompatible materials.
-
Personal Protective Equipment (PPE): When handling the container, assume the substance is hazardous. Wear appropriate PPE, including safety goggles, chemical-resistant gloves, and a lab coat.
A generalized workflow for handling unidentified chemical waste is provided below.
Caption: Workflow for handling and obtaining disposal information for an unidentified chemical substance.
It is the responsibility of the user to obtain the Safety Data Sheet and follow the specific guidance provided by the manufacturer and their institution's Environmental Health and Safety department. Proceeding with disposal without this information is not recommended.
Essential Safety and Logistical Information for Handling SJ000025081
For Researchers, Scientists, and Drug Development Professionals
This document provides immediate, essential guidance for the safe handling and disposal of SJ000025081, a dihydropyridine derivative identified as a potent antimalarial agent. Developed to be a preferred source for laboratory safety, this guide offers procedural steps to ensure the well-being of laboratory personnel and the integrity of research.
Compound Identification and Activity
This compound is a dihydropyridine compound that has been investigated for its potent antimalarial activity. It was identified through phenotypic screening and has shown efficacy in murine models of malaria. As a potent biological agent, it requires careful handling to minimize exposure and ensure a safe laboratory environment.
Personal Protective Equipment (PPE)
Given that a specific Safety Data Sheet (SDS) for this compound is not publicly available, a conservative approach to personal protective equipment is warranted, treating it as a potent compound with unknown long-term health effects. The following table summarizes the recommended PPE for handling this compound.
| Operation | Eye Protection | Hand Protection | Body Protection | Respiratory Protection |
| Receiving and Unpacking | Safety glasses with side shields | Nitrile gloves | Laboratory coat | Not generally required |
| Weighing and Aliquoting (Solid) | Chemical splash goggles | Double nitrile gloves | Disposable gown over lab coat | N95 or higher respirator (if not in a ventilated enclosure) |
| Solution Preparation | Chemical splash goggles | Nitrile gloves | Laboratory coat | Not required if performed in a fume hood |
| In-vitro/In-vivo Experiments | Safety glasses with side shields | Nitrile gloves | Laboratory coat | Dependent on experimental procedure and risk assessment |
| Waste Disposal | Chemical splash goggles | Nitrile gloves | Laboratory coat | Not generally required |
Operational Plan for Safe Handling
A systematic approach is crucial when working with potent research compounds. The following step-by-step guidance will help ensure safe handling of this compound.
-
Preparation and Pre-Handling:
-
Review all available literature on this compound and related dihydropyridine compounds to understand potential hazards.
-
Ensure all necessary PPE is available and in good condition.
-
Prepare the designated work area, preferably a certified chemical fume hood or a ventilated balance enclosure for handling solids.
-
Have a spill kit readily accessible.
-
-
Handling the Compound:
-
When handling the solid form, use powder-free gloves to minimize static.
-
Weigh the compound in a ventilated enclosure to prevent inhalation of airborne particles.
-
When preparing solutions, add the solid to the solvent slowly to avoid splashing.
-
Clearly label all containers with the compound name, concentration, date, and appropriate hazard warnings.
-
-
During Experimentation:
-
Follow all established laboratory protocols for the specific experiment.
-
Avoid skin contact and inhalation.
-
If working with animals, ensure all procedures are approved by the Institutional Animal Care and Use Committee (IACUC) and that appropriate containment is used.
-
-
Post-Handling and Decontamination:
-
Decontaminate all surfaces and equipment that may have come into contact with the compound. A 70% ethanol solution is generally effective for initial decontamination, followed by a thorough cleaning with soap and water.
-
Remove and dispose of PPE in the appropriate waste stream.
-
Wash hands thoroughly with soap and water after handling is complete.
-
Disposal Plan
Proper disposal of this compound and associated waste is critical to prevent environmental contamination and ensure compliance with regulations.
-
Solid Waste:
-
Collect all solid waste, including contaminated PPE (gloves, gowns), weigh paper, and empty vials, in a dedicated, labeled hazardous waste container.
-
-
Liquid Waste:
-
Collect all liquid waste containing this compound in a sealed, labeled hazardous waste container. Do not mix with other chemical waste streams unless compatibility is confirmed.
-
-
Sharps Waste:
-
Dispose of any contaminated needles or other sharps in a designated sharps container.
-
-
Final Disposal:
-
All hazardous waste must be disposed of through the institution's environmental health and safety (EHS) office in accordance with local, state, and federal regulations.
-
Workflow for Safe Handling of Potent Research Compounds
The following diagram illustrates a logical workflow for the safe handling of a potent research compound like this compound, from initial receipt to final disposal.
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
