9-Amtbtq
Description
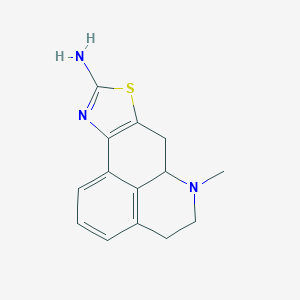
Structure
3D Structure
Properties
IUPAC Name |
2-methyl-13-thia-2,11-diazatetracyclo[7.6.1.05,16.010,14]hexadeca-5(16),6,8,10(14),11-pentaen-12-amine |
Source


|
|---|---|---|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI |
InChI=1S/C14H15N3S/c1-17-6-5-8-3-2-4-9-12(8)10(17)7-11-13(9)16-14(15)18-11/h2-4,10H,5-7H2,1H3,(H2,15,16) |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI Key |
HHCIBEMTUSEDSI-UHFFFAOYSA-N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Canonical SMILES |
CN1CCC2=C3C1CC4=C(C3=CC=C2)N=C(S4)N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Formula |
C14H15N3S |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
DSSTOX Substance ID |
DTXSID00909867 |
Source
|
| Record name | 6-Methyl-4,5,6,6a,7,10-hexahydro-9H-benzo[de][1,3]thiazolo[4,5-g]quinolin-9-imine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID00909867 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
Molecular Weight |
257.36 g/mol |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
CAS No. |
106006-79-5 |
Source
|
| Record name | 9-Amino-6-methyl-5,6,6a,7-tetrahydro-4H-benzo-(de)thiazolo(4,5-g)quinoline | |
| Source | ChemIDplus | |
| URL | https://pubchem.ncbi.nlm.nih.gov/substance/?source=chemidplus&sourceid=0106006795 | |
| Description | ChemIDplus is a free, web search system that provides access to the structure and nomenclature authority files used for the identification of chemical substances cited in National Library of Medicine (NLM) databases, including the TOXNET system. | |
| Record name | 6-Methyl-4,5,6,6a,7,10-hexahydro-9H-benzo[de][1,3]thiazolo[4,5-g]quinolin-9-imine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID00909867 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
Synthetic Methodologies for the Target Chemical Compound
Retrosynthetic Analysis and Strategic Design for Compound Synthesis
Retrosynthetic analysis is a foundational technique in organic synthesis where the target molecule is conceptually broken down into simpler precursors. wikipedia.orgamazonaws.com This process is repeated until commercially available or easily synthesized starting materials are identified. wikipedia.org This analytical method allows chemists to devise a "roadmap" for the synthesis, identifying key bond formations and potential challenges. amazonaws.com For any given target, multiple retrosynthetic routes may be possible, and the selection of the optimal path depends on factors such as efficiency, cost, and stereochemical control. wikipedia.org
Optimization of Reaction Parameters and Conditions for Compound Generation
Once a synthetic route is designed, each step must be optimized to maximize the yield and purity of the product. This involves systematically varying reaction parameters such as temperature, pressure, reaction time, and the concentration of reactants and catalysts. The choice of solvent can also have a profound impact on the outcome of a reaction.
Table 1: Illustrative Reaction Parameters for Optimization
| Parameter | Range of Conditions | Desired Outcome |
|---|---|---|
| Temperature | -78°C to 200°C | Increased reaction rate, minimized side products |
| Reactant Concentration | 0.01 M to 10 M | Optimal stoichiometry for complete conversion |
| Catalyst Loading | 0.1 mol% to 20 mol% | Efficient catalysis with minimal catalyst waste |
The optimization process often involves a combination of theoretical knowledge and empirical experimentation. Techniques such as Design of Experiments (DoE) can be employed to systematically explore the effects of multiple parameters simultaneously, leading to a more efficient optimization process.
Application of Green Chemistry Principles in Synthetic Pathways
Green chemistry is a set of principles aimed at designing chemical products and processes that reduce or eliminate the use and generation of hazardous substances. nih.govnih.gov In the context of organic synthesis, this involves several key considerations:
Atom Economy: Designing synthetic routes that maximize the incorporation of all materials used in the process into the final product. rsc.org
Use of Safer Solvents and Reagents: Replacing hazardous solvents and reagents with safer, more environmentally benign alternatives. nih.gov Water is often considered an ideal green solvent. rsc.org
Energy Efficiency: Conducting reactions at ambient temperature and pressure whenever possible to reduce energy consumption. researchgate.net Microwave-assisted synthesis is one technique that can accelerate reactions and improve energy efficiency. mdpi.comnih.gov
Use of Renewable Feedstocks: Utilizing starting materials derived from renewable resources rather than depletable fossil fuels. nih.gov
Catalysis: Employing catalytic reagents in small amounts rather than stoichiometric reagents to minimize waste. researchgate.net
By integrating these principles, chemists can develop more sustainable and environmentally friendly synthetic processes. nih.gov
Development of Scalable Synthetic Processes for the Target Compound
A synthetic route that is successful on a small laboratory scale may not be directly transferable to large-scale industrial production. The development of a scalable process requires addressing several challenges, including:
Heat Transfer: Exothermic reactions that are easily controlled in small flasks can become difficult to manage in large reactors, potentially leading to runaway reactions.
Mass Transfer: Ensuring efficient mixing of reactants in large volumes can be challenging.
Safety: The risks associated with hazardous reagents and reactions are magnified at a larger scale.
Cost-Effectiveness: The cost of reagents, solvents, and purification methods becomes a critical factor in the economic viability of the process.
A successful scalable synthesis is one that is robust, reproducible, and economically feasible, allowing for the production of the target compound in the desired quantities. nih.gov
Table 2: Compound Names Mentioned
| Compound Name |
|---|
Structure Activity Relationship Sar and Quantitative Structure Activity Relationship Qsar Studies of the Chemical Compound
Theoretical Foundations of SAR and QSAR Modeling in Medicinal Chemistry
Structure-Activity Relationship (SAR) is a foundational concept in medicinal chemistry that links the chemical structure of a molecule to its biological effect. nih.gov The core principle is that the activity of a compound is dependent on its structure, and modifying the structure can lead to changes in its biological activity. nih.gov SAR analysis helps identify the key chemical features, known as pharmacophores, that are responsible for a molecule's interaction with a biological target. d-nb.info
Quantitative Structure-Activity Relationship (QSAR) is an advancement of SAR that aims to create a mathematical relationship between the chemical structure and biological activity. nih.gov QSAR models use statistical methods to correlate physicochemical properties or theoretical molecular descriptors of compounds with their biological activities. The goal is to develop predictive models that can estimate the activity of novel, untested compounds. A fundamental QSAR model can be represented by the equation:
Activity = f (physicochemical properties and/or structural properties) + error
These models are invaluable in drug discovery for prioritizing compounds for synthesis and testing, thereby saving time and resources. d-nb.info
Molecular Descriptors Utilized for QSAR Analysis
Molecular descriptors are numerical values that characterize the properties of a molecule. They are essential for translating the chemical structure into a format that can be used in statistical modeling. Descriptors can be broadly categorized based on the type of molecular representation they are derived from.
Electronic descriptors quantify the electronic properties of a molecule, which are crucial for molecular interactions. These properties govern how a molecule will interact with the electrostatic field of a receptor.
Examples of Electronic Descriptors:
| Descriptor | Description |
| Partial Atomic Charges | Describes the distribution of electrons within the molecule, indicating sites for electrostatic interactions. |
| Dipole Moment | Measures the overall polarity of the molecule, which influences its orientation in an electric field and its interaction with polar receptors. |
| HOMO/LUMO Energies | The energies of the Highest Occupied Molecular Orbital (HOMO) and Lowest Unoccupied Molecular Orbital (LUMO) are related to the molecule's ability to donate or accept electrons, respectively. |
| Polarizability | Characterizes the ease with which the electron cloud of a molecule can be distorted by an external electric field. |
Steric descriptors relate to the size and shape of the molecule, which are critical for determining how well a molecule fits into a receptor's binding site.
Examples of Steric Descriptors:
| Descriptor | Description |
| Molecular Volume/Surface Area | These descriptors quantify the three-dimensional bulk of the molecule. |
| Taft's Steric Parameter (Es) | An empirical parameter that quantifies the steric effect of a particular substituent. |
| Molar Refractivity (MR) | Related to the molecular volume and polarizability, it provides a measure of both the bulk and the dispersion forces of a substituent. |
| Shape Indices | Numerical values that describe various aspects of the molecular shape. |
These descriptors are derived from the 2D representation of a molecule and provide information about molecular size, branching, and connectivity. They are computationally efficient to calculate.
Examples of Topological and Constitutional Descriptors:
| Descriptor | Description |
| Molecular Weight | The sum of the atomic weights of all atoms in the molecule. |
| Atom/Bond Counts | Simple counts of the number of atoms or specific types of bonds in a molecule. |
| Connectivity Indices (e.g., Kier & Hall) | These indices quantify the degree of branching and connectivity in a molecule's structure. |
| Wiener Index | A topological index that reflects the compactness of a molecule, calculated from the distances between all pairs of atoms in the molecular graph. |
QSAR Model Development and Rigorous Validation
The development of a reliable QSAR model is a multi-step process that requires careful attention to data quality and statistical rigor. The ultimate goal is to create a model that is not only statistically robust but also has strong predictive power for new compounds.
The quality of the input data is a critical factor that determines the quality of the resulting QSAR model. Data curation and preprocessing are essential first steps in the modeling workflow.
Key steps in data curation and preprocessing include:
Chemical Structure Standardization: This involves correcting errors in chemical structures and ensuring a uniform representation. For instance, different representations of the same compound (e.g., different tautomeric forms or aromaticity perceptions) must be normalized.
Data Cleaning: Erroneous or ambiguous data points should be removed. This includes handling duplicates and outliers that could negatively impact the model's performance.
Handling Missing Values: Strategies must be employed to manage compounds that have missing biological activity data or descriptor values.
Dataset Balancing: In cases where the dataset is skewed (e.g., a large number of inactive compounds and a small number of active ones), balancing techniques may be necessary to prevent the model from being biased towards the majority class.
Automated workflows and specialized software are often used to perform these tasks, especially for large datasets. Preprocessing also involves removing descriptors that are constant or have very low variance, as well as those that are highly intercorrelated, to reduce redundancy and improve model stability.
Advanced Statistical Methods in QSAR (e.g., Multivariate Regression Analysis)
Quantitative Structure-Activity Relationship (QSAR) studies for 9-anilinoacridine derivatives have successfully employed advanced statistical methods to create predictive models of their biological activity. A prominent technique in this field is Multivariate Regression Analysis, particularly Multiple Linear Regression (MLR).
In one significant QSAR study, MLR was used to model the DNA-drug binding properties of a series of 31 9-anilinoacridine molecules. researchgate.net The resulting MLR model demonstrated a strong correlation between the predicted and experimental values, with a correlation coefficient (r) of 0.935. researchgate.net This indicates that the model could account for over 87% of the variance in the data. A related method, Multiple Non-Linear Regression (MNLR), yielded a slightly higher correlation coefficient of 0.936. researchgate.net
These models are built by correlating biological activity with various molecular descriptors that quantify physicochemical properties. For the 9-anilinoacridine series, key descriptors identified through these analyses include:
Electronic Properties: The Hammett parameter (σ+) has been shown to be important, with a general trend that electron-releasing substituents enhance antitumor activity. nih.gov
Steric and Lipophilic Properties: Parameters such as hardness, surface area, and molar refractivity have been incorporated into models to predict anticancer activity against cell lines like HL-60. researchgate.net
Quantum Chemical Descriptors: Properties calculated using Density Functional Theory (DFT), such as the energy of the Highest Occupied Molecular Orbital (HOMO) and Lowest Unoccupied Molecular Orbital (LUMO), are used to quantify the electronic nature of the molecules for regression analysis. researchgate.net
The generalized form of an MLR equation in a QSAR context is: Biological Activity = c₀ + c₁ * D₁ + c₂ * D₂ + ... + cₙ * Dₙ Where c represents the regression coefficients and D represents the different molecular descriptors.
The table below summarizes the statistical quality of representative regression models developed for 9-anilinoacridine derivatives.
| Model Type | Correlation Coefficient (r) | External Validation (r_ext) | Key Descriptors Used |
| MLR | 0.935 | 0.932 | Electronic, Quantum Chemical |
| MNLR | 0.936 | 0.939 | Electronic, Quantum Chemical |
This table presents data from a QSAR study on the DNA-binding properties of 9-anilinoacridine derivatives. researchgate.net
Integration of Machine Learning Techniques in QSAR Modeling (e.g., Artificial Neural Networks, Support Vector Machines)
Beyond traditional regression analysis, machine learning (ML) techniques are increasingly integrated into QSAR modeling to capture complex, non-linear relationships between structure and activity. drugtargetreview.com These methods can often provide more robust and predictive models, especially when dealing with large and diverse datasets. youtube.comresearchgate.net
Artificial Neural Networks (ANNs): ANNs are computational models inspired by the structure of biological neural networks. They are capable of learning from data and identifying intricate patterns. In the context of 9-anilinoacridines, ANNs have been used alongside MLR and MNLR to develop predictive QSAR models. researchgate.net An ANN consists of interconnected layers of nodes ("neurons") that process information. The input layer receives the molecular descriptors, one or more "hidden" layers perform non-linear transformations of the data, and the output layer produces the predicted biological activity. The network is "trained" by adjusting the connection weights between neurons to minimize the difference between predicted and actual activities for a training set of compounds.
Support Vector Machines (SVMs): SVM is another powerful machine learning algorithm used for both classification (distinguishing active vs. inactive compounds) and regression (predicting a continuous activity value). In a QSAR context, SVM would aim to find an optimal hyperplane that best separates data points (molecules) into different classes or best fits the data for regression. This is achieved by maximizing the margin between the different classes, which can lead to excellent generalization performance for new, untested compounds. While specific applications of SVMs to 9-anilinoacridines are not detailed in the available literature, their use is a standard and valuable approach in modern QSAR. drugtargetreview.comyoutube.com
The general workflow for integrating machine learning into QSAR involves:
Data Curation: Assembling a dataset of compounds with known biological activities.
Descriptor Calculation: Generating a wide range of numerical descriptors for each molecule.
Model Training: Using a portion of the dataset (the training set) to build the ML model (e.g., an ANN or SVM).
Model Validation: Assessing the model's performance using an independent set of data (the test set). youtube.com
Comprehensive Model Validation and Predictive Performance Assessment
The development of a QSAR model is incomplete without rigorous validation to ensure its robustness, reliability, and predictive power. researchgate.net Validation is a critical step to confirm that a model is not simply "overfitted" to the training data but can accurately predict the activity of new, previously unseen compounds. Validation is typically divided into two main categories: internal validation and external validation.
Internal Validation: This process assesses the stability and robustness of the model using only the training set. The most common technique is cross-validation, such as the leave-one-out (LOO) method. In LOO cross-validation, a single compound is removed from the training set, the model is rebuilt with the remaining compounds, and the activity of the removed compound is predicted. This is repeated for every compound in the training set. The results are compiled to calculate the cross-validated correlation coefficient (q²). A model is generally considered to have predictive power if q² > 0.5. mdpi.com
External Validation: This is considered the most stringent test of a model's predictive ability. mdpi.com The model, built using the training set, is used to predict the biological activities of an independent "test set" of compounds that were not used during model development. The predictive performance is often measured by the predictive r² (r²_pred). For a model to be considered highly predictive, it is recommended that r²_pred be greater than 0.6. mdpi.com
In QSAR studies of 9-anilinoacridines, models have been subjected to this validation process. For instance, the MLR and MNLR models for DNA-binding affinity reported high external validation correlation coefficients of 0.932 and 0.939, respectively, demonstrating excellent predictive capability. researchgate.net
The table below summarizes key validation metrics and their generally accepted thresholds for a robust QSAR model.
| Validation Metric | Description | Common Acceptance Threshold |
| q² (or Q²) | Cross-validated correlation coefficient (Internal Validation) | > 0.5 |
| r²_pred | Predictive correlation coefficient for the external test set (External Validation) | > 0.6 |
| r²_m | A metric for external validation that considers overall model performance | > 0.5 |
These thresholds are widely accepted guidelines in the QSAR community. mdpi.commdpi.com
Fragment-Based SAR Analysis and Elucidation
Fragment-Based Drug Discovery (FBDD) is a powerful strategy for identifying lead compounds by screening small, low-molecular-weight molecules ("fragments") for weak binding to a biological target. frontiersin.org While specific FBDD campaigns targeting the 9-anilinoacridine scaffold are not prominently documented, the principles of this approach can be hypothetically applied to understand its SAR.
The core idea of FBDD is that more complex molecules can be assembled from smaller pieces. researchgate.net Instead of screening large, drug-like molecules, FBDD identifies fragments that bind with high "ligand efficiency" (i.e., they have a good binding affinity relative to their small size). These initial fragment hits can then be optimized into more potent leads through several strategies:
Fragment Growing: A confirmed fragment hit is elaborated by adding new functional groups to improve interactions with the target's binding pocket. rsc.org
Fragment Linking: Two or more fragments that bind to adjacent sites on the target are connected with a chemical linker to create a single, high-affinity molecule. nih.gov
Fragment Merging: The structural features of multiple, overlapping fragment hits are combined into a novel, single chemical entity.
Strategic Bioisosteric Modifications and Their Mechanistic Implications for Biological Response
Bioisosterism is a fundamental strategy in medicinal chemistry where a functional group in a lead compound is replaced by another group with similar physical or chemical properties (a bioisostere). ufrj.brresearchgate.net This rational modification is used to enhance potency, improve selectivity, alter pharmacokinetic properties, or reduce toxicity. ctppc.org
The SAR of 9-anilinoacridines highlights key structural features that are critical for activity, making them ideal candidates for bioisosteric modification. For example, studies on the antimalarial activity of this class have shown that C-3 and C-6 diamino substitution on the acridine ring significantly increases potency. nih.govnih.gov
Strategic bioisosteric modifications could be explored in several ways:
Ring Equivalents: The acridine core itself could be modified. Replacing one of the aromatic carbons with a nitrogen atom would create an aza-acridine analog. This change would alter the electronic distribution, hydrogen bonding capacity, and solubility of the core scaffold, potentially leading to different target interactions or improved drug-like properties.
Functional Group Mimics: The critical amino groups at the C-3 and C-6 positions are key hydrogen bond donors. A bioisosteric strategy could involve replacing an amino group (-NH₂) with other groups that can perform a similar function, such as a hydroxyl group (-OH) or by modifying its basicity. While these are not classic bioisosteres, they serve a similar purpose in probing the structural requirements for activity.
Anilino Ring Modifications: The anilino ring is a key site for substitution. In a study designing novel 9-anilinoacridines as potential HER2 inhibitors, the anilino ring was substituted with a pyrazole moiety. nih.gov This can be seen as a strategic modification to explore new interactions within the target's binding site, with the pyrazole ring offering different hydrogen bonding patterns compared to a simple substituted phenyl ring.
The mechanistic implication of such a change is significant. If a bioisosteric replacement maintains or improves activity, it confirms the importance of the general steric and electronic properties of that functional group. Conversely, if the replacement leads to a loss of activity, it provides precise information about the specific nature of the interaction (e.g., a specific hydrogen bond that cannot be replicated by the bioisostere). nih.govcambridgemedchemconsulting.com This iterative process of modification and testing is central to optimizing a lead compound.
Computational Investigations of the Chemical Compound
Molecular Docking Simulations for Ligand-Target Interactions
Molecular docking is a computational method used to predict the preferred orientation of a ligand (such as 9-Amtbtq) when bound to a protein target, forming a stable complex guidetopharmacology.org. This technique is fundamental in structure-based drug design, allowing for the prediction of binding conformations and the estimation of binding affinity between molecules guidetopharmacology.org.
Receptor Preparation and Ligand Conformational Sampling Strategies
The initial step in molecular docking involves preparing the three-dimensional structures of both the receptor (e.g., BTK protein) and the ligand (9-Amtbtq). Receptor preparation typically includes cleaning the protein structure (e.g., from the Protein Data Bank), adding missing atoms or residues, assigning protonation states, and optimizing hydrogen bond networks. The binding site, often identified through known active site residues or through blind docking, is defined to guide the ligand's placement.
For the ligand, 9-Amtbtq, conformational sampling strategies are employed to explore its various possible three-dimensional shapes. Given its flexibility, especially around the pyrrolidine-1-carbonyl and pent-2-enenitrile (B12440713) moieties, multiple conformations are generated to ensure a comprehensive search of the binding pocket. Common methods for conformational sampling include systematic searches, Monte Carlo simulations, and genetic algorithms guidetopharmacology.org. These algorithms aim to find the optimal pose of the ligand within the receptor's binding site by minimizing the interaction energy guidetopharmacology.org.
Evaluation of Scoring Functions and Binding Affinity Prediction
Once the ligand conformations are sampled and docked into the receptor's binding site, scoring functions are used to evaluate the strength of the interaction between 9-Amtbtq and BTK guidetopharmacology.org. These functions estimate the binding free energy, providing a quantitative measure of how favorably the ligand interacts with the protein. Scoring functions typically consider various energy terms, including van der Waals interactions, electrostatic interactions, hydrogen bonding, and desolvation penalties.
Different scoring functions exist, each with its own strengths and limitations. For 9-Amtbtq, a BTK inhibitor, a high negative binding score would indicate a strong predicted affinity. The results from molecular docking simulations would typically be presented in a table, ranking different poses of 9-Amtbtq based on their predicted binding affinities.
Illustrative Data Table: Predicted Binding Affinities of 9-Amtbtq Poses to BTK
| Pose ID | Binding Energy (kcal/mol) | Interacting Residues (Key) | Hydrogen Bonds | Hydrophobic Interactions |
| 1 | -10.5 | Cys481, Glu475, Lys430 | 3 | Extensive |
| 2 | -9.8 | Cys481, Asp531, Leu460 | 2 | Moderate |
| 3 | -9.2 | Val416, Ala428, Met477 | 1 | Limited |
Note: This table presents illustrative data. In an interactive table, users could filter by binding energy range, sort by specific interaction types, or click on a pose ID to visualize the 3D binding mode.
Molecular Dynamics Simulations for Conformational Analysis and System Stability
Molecular Dynamics (MD) simulations provide a dynamic view of molecular systems, allowing researchers to study the time-dependent behavior of atoms and molecules acs.orgnih.govresearchgate.net. For the 9-Amtbtq-BTK complex, MD simulations are crucial for understanding the stability of the binding, conformational changes in both the ligand and the protein, and the nature of their interactions over time acs.orgresearchgate.net.
Analysis of Protein-Ligand Complex Dynamics and Interactions
MD simulations involve solving Newton's equations of motion for all atoms in the system, typically over nanosecond to microsecond timescales nih.gov. For the 9-Amtbtq-BTK complex, this allows for the observation of how the ligand settles into the binding site, how the protein adapts to the ligand's presence (induced fit), and the stability of key interactions, such as the covalent interaction with Cys481 nih.govguidetoimmunopharmacology.orgguidetopharmacology.org.
Key analyses derived from MD simulations include:
Root Mean Square Deviation (RMSD): Measures the deviation of atomic positions from a reference structure, indicating the stability and convergence of the simulation. A stable RMSD for the protein backbone and the ligand suggests a stable complex.
Root Mean Square Fluctuation (RMSF): Identifies flexible regions within the protein and ligand, highlighting residues or parts of the ligand that exhibit significant movement.
Hydrogen Bond Analysis: Quantifies the number and persistence of hydrogen bonds between 9-Amtbtq and BTK residues over the simulation trajectory.
Contact Analysis: Identifies specific residues of BTK that maintain consistent contact with 9-Amtbtq throughout the simulation, providing insights into the binding pocket.
Illustrative Data Table: Key Interaction Metrics from MD Simulation of 9-Amtbtq-BTK Complex
| Metric | Average Value (± Std. Dev.) | Observation |
| Protein Backbone RMSD (Å) | 1.5 ± 0.3 | Stable, indicating overall protein fold integrity. |
| Ligand RMSD (Å) | 0.8 ± 0.2 | Ligand remains stable within the binding site. |
| H-bonds with Cys481 (count) | 1.0 ± 0.0 | Consistent covalent interaction. |
| H-bonds with Glu475 (count) | 0.7 ± 0.2 | Frequent, but not always present. |
| Hydrophobic Contacts (count) | 15 ± 2 | Stable hydrophobic network. |
Note: This table presents illustrative data. An interactive version could allow users to select specific residues or interaction types for detailed time-series plots.
Computational Assessment of Solvent Effects and Binding Free Energy
The cellular environment is aqueous, and solvent molecules significantly influence protein-ligand interactions. MD simulations explicitly include solvent molecules (e.g., water) to model these effects realistically. The desolvation penalty, the energy required to remove water molecules from the binding interface, is a crucial factor in binding affinity.
Binding free energy calculations, such as Molecular Mechanics/Poisson-Boltzmann Surface Area (MM/PBSA) or Molecular Mechanics/Generalized Born Surface Area (MM/GBSA), are often performed on MD trajectories. These methods decompose the total binding free energy into various components, including gas-phase interaction energy, solvation free energy, and entropic contributions. This provides a more accurate prediction of binding affinity compared to simple scoring functions used in docking.
Illustrative Data Table: Binding Free Energy Components for 9-Amtbtq-BTK Interaction (MM/PBSA)
| Energy Component | Value (kcal/mol) | Contribution |
| ΔE_MM (Gas-phase) | -85.2 | Strong favorable van der Waals and electrostatic. |
| ΔG_solv (Polar) | 60.5 | Unfavorable desolvation of polar groups. |
| ΔG_solv (Non-polar) | -8.1 | Favorable hydrophobic effect. |
| -TΔS (Conformational) | 15.0 | Unfavorable entropy loss upon binding. |
| ΔG_bind (Total) | -17.8 | Overall favorable binding free energy. |
Note: This table presents illustrative data. In an interactive table, users could adjust parameters for different solvation models or compare components across different simulation lengths.
Hybrid Quantum Mechanics/Molecular Mechanics (QM/MM) Approaches for Reaction Mechanisms
For processes involving bond breaking or formation, such as the covalent interaction of 9-Amtbtq with Cys481 of BTK, classical molecular mechanics force fields are insufficient. Hybrid Quantum Mechanics/Molecular Mechanics (QM/MM) approaches combine the accuracy of quantum mechanical (QM) calculations for the chemically active region with the computational efficiency of molecular mechanics (MM) for the surrounding environment.
In the case of 9-Amtbtq, the QM region would typically include the cyanoacrylamide warhead and the Cys481 residue, as well as any immediately interacting residues that participate in the covalent bond formation or influence the reaction mechanism nih.govguidetoimmunopharmacology.org. The rest of the protein and solvent molecules would be treated at the MM level. This allows for a detailed investigation of the electronic structure changes during the covalent modification, including transition states and reaction pathways.
QM/MM simulations can provide insights into:
Reaction barriers: The energy required for the covalent bond to form between 9-Amtbtq and Cys481.
Electronic properties: Changes in charge distribution and orbital interactions during the reaction.
Proton transfer events: If any proton transfers are involved in facilitating the covalent attachment.
Catalytic mechanisms: How the protein environment might catalyze or influence the reaction.
Illustrative Data Table: QM/MM Calculated Reaction Barriers for 9-Amtbtq Covalent Binding
| Reaction Step | QM/MM Energy Barrier (kcal/mol) | QM/MM Reaction Energy (kcal/mol) | Key Residues in QM Region |
| Nucleophilic Attack | 12.5 | -5.8 | Cys481, Cyanoacrylamide |
| Proton Transfer (if applicable) | 5.2 | -2.1 | Cys481, nearby water |
| Overall Reaction | 12.5 | -7.9 |
Note: This table presents illustrative data. An interactive table could allow users to view different QM/MM partitioning schemes or compare results from various QM levels of theory.
These computational investigations, ranging from molecular docking to sophisticated QM/MM approaches, provide a comprehensive understanding of how (E)-2-[(2S)-2-[[4-amino-3-(2-fluoro-4-phenoxyphenyl)pyrazolo[3,4-d]pyrimidin-1-yl]methyl]pyrrolidine-1-carbonyl]-4-methyl-4-[methyl(oxetan-3-yl)amino]pent-2-enenitrile (9-Amtbtq) interacts with its target at an atomic level, guiding further optimization and development.
Virtual Screening Methodologies for Analog Discovery and Lead Optimization
Virtual screening (VS) is a computational technique employed to search large libraries of small molecules to identify those most likely to bind to a specific drug target medchemexpress.com. This in silico approach significantly reduces the number of compounds requiring experimental testing, thereby saving time and resources medchemexpress.comnuvisan.com. For "9-Amtbtq," virtual screening methodologies would be crucial for discovering novel analogs and optimizing its lead properties.
Two primary virtual screening approaches would be considered:
Ligand-Based Virtual Screening (LBVS): In the absence of a known target protein structure, LBVS relies on the knowledge of existing ligands that bind to the biological target of interest vbspu.ac.ingardp.org. If "9-Amtbtq" were identified as a lead compound, LBVS would involve analyzing its physicochemical properties (e.g., molecular weight, logP, charge), 2D (molecular topology), and 3D (shape) descriptors to identify structurally similar molecules from vast chemical databases slideshare.netchem-space.com. Key approaches within LBVS include molecular fingerprint and structure searches, pharmacophore modeling, and Quantitative Structure-Activity Relationship (QSAR) analysis slideshare.netchem-space.com. Pharmacophore models would describe the essential steric and electronic features of "9-Amtbtq" required for its biological activity, allowing for the identification of new compounds possessing these features slideshare.netchem-space.com.
Structure-Based Virtual Screening (SBVS): If the three-dimensional structure of a putative biological target for "9-Amtbtq" were available (e.g., from X-ray crystallography or NMR spectroscopy), SBVS would be employed wikipedia.orggardp.org. This method involves computationally docking "9-Amtbtq" and a library of compounds into the binding site of the target protein to predict their binding affinity and orientation chem-space.comgardp.org. Molecular docking algorithms would calculate the conformation and orientation (docking pose) of "9-Amtbtq" and its potential analogs at the targeted binding site, using various scoring criteria to predict the most stable interaction chem-space.comgardp.org. SBVS is instrumental in identifying novel chemical scaffolds that fit the target's binding pocket and optimizing the binding interactions of "9-Amtbtq" or its derivatives gardp.orgnih.gov.
Illustrative Data Table: Virtual Screening Results for Hypothetical "9-Amtbtq" Analogs
| Analog ID | Virtual Screening Method | Predicted Binding Affinity (kcal/mol) | Similarity Score (Tanimoto) | Key Interaction Type |
| 9-Amtbtq-A | Structure-Based Docking | -8.5 | N/A | Hydrogen bonding, Hydrophobic |
| 9-Amtbtq-B | Ligand-Based (Pharmacophore) | N/A | 0.78 | Aromatic stacking, H-bond acceptor |
| 9-Amtbtq-C | Structure-Based Docking | -7.9 | N/A | Ionic interaction, Van der Waals |
| 9-Amtbtq-D | Ligand-Based (2D Fingerprint) | N/A | 0.82 | Similar scaffold |
Note: The values in this table are illustrative and represent the types of data that would be generated during virtual screening campaigns for a hypothetical compound like "9-Amtbtq." Specific research findings for "9-Amtbtq" are not publicly available.
Application of Ligand-Based and Structure-Based Drug Design Principles
Drug design principles, both ligand-based and structure-based, would be applied to "9-Amtbtq" to rationally optimize its properties for a desired biological effect. These principles guide the iterative process of designing and synthesizing new molecules, elucidating their structure-activity relationships, and predicting their interactions with biological macromolecules vbspu.ac.inbiomedres.us.
Ligand-Based Drug Design (LBDD): In the absence of a target structure, LBDD would be applied to "9-Amtbtq" by analyzing its chemical features and those of its known active or inactive analogs vbspu.ac.ingardp.org. This would involve:
Pharmacophore Modeling: Identifying the crucial 3D arrangement of physicochemical features (e.g., hydrogen bond donors/acceptors, hydrophobic regions, aromatic rings) within "9-Amtbtq" that are essential for its biological activity slideshare.netchem-space.com. This model would then be used to design new analogs with improved potency or selectivity.
Quantitative Structure-Activity Relationship (QSAR): Developing mathematical models that correlate the calculated molecular properties of "9-Amtbtq" and its analogs (e.g., molecular weight, lipophilicity, electronic properties) with their experimentally determined biological activities vbspu.ac.inslideshare.netchem-space.com. QSAR models would predict the activity of new "9-Amtbtq" derivatives before their synthesis, guiding lead optimization vbspu.ac.inslideshare.net.
Structure-Based Drug Design (SBDD): If the 3D structure of "9-Amtbtq"'s biological target were known, SBDD would be employed to design and optimize its interactions at the molecular level wikipedia.orggardp.orgdrugdiscoverynews.com. Key SBDD techniques applicable to "9-Amtbtq" would include:
Molecular Docking: As mentioned in virtual screening, docking would predict the optimal binding pose of "9-Amtbtq" within the target's binding site, providing insights into specific interactions (e.g., hydrogen bonds, hydrophobic contacts, salt bridges) that contribute to binding affinity chem-space.comgardp.orgbiomedres.us.
Molecular Dynamics (MD) Simulations: Performing MD simulations would provide a dynamic view of "9-Amtbtq"'s interactions with its target protein over time, accounting for protein flexibility and solvent effects gardp.orgfomatmedical.com. This would allow for a more accurate assessment of binding stability and the identification of transient interactions, informing further structural modifications to "9-Amtbtq" for enhanced binding gardp.org.
De Novo Design: This advanced SBDD approach would involve computationally "building" new ligand molecules, potentially based on fragments of "9-Amtbtq," within the constraints of the target's binding pocket wikipedia.orggardp.org. This could lead to the discovery of entirely novel "9-Amtbtq"-like structures not found in existing databases wikipedia.org.
Illustrative Data Table: Predicted Interactions for "9-Amtbtq" with a Hypothetical Target
| Interaction Type | Residues Involved (Hypothetical Target) | Distance (Å) | Energy Contribution (kcal/mol) |
| Hydrogen Bond | Tyr100 (OH) - 9-Amtbtq (N) | 2.8 | -3.5 |
| Hydrophobic | Leu25, Val80 - 9-Amtbtq (Alkyl chain) | 3.5 - 4.5 | -2.1 |
| Aromatic Stacking | Phe150 - 9-Amtbtq (Aromatic ring) | 3.8 | -1.8 |
| Salt Bridge | Asp70 (COO-) - 9-Amtbtq (NH3+) | 3.2 | -4.2 |
Note: The values and interactions in this table are illustrative and represent the types of data that would be generated during structure-based drug design studies for a hypothetical compound like "9-Amtbtq." Specific research findings for "9-Amtbtq" are not publicly available.
In Vitro Biological Evaluation of the Chemical Compound
Development and Application of Advanced In Vitro Models
Three-Dimensional (3D) Cell Models and Organoid Systems
The evaluation of novel chemical compounds has been significantly advanced by the transition from traditional two-dimensional (2D) cell cultures to three-dimensional (3D) models and organoid systems. moleculardevices.comsigmaaldrich.com These sophisticated platforms more accurately replicate the complex cellular interactions and microenvironments found in vivo, offering a more predictive assessment of a compound's biological activity. moleculardevices.com In the context of the chemical compound 9-Amtbtq, the utilization of 3D cell models and organoids has been pivotal in elucidating its potential therapeutic effects and mechanisms of action.
Three-dimensional cell models, such as spheroids, are aggregates of cells that mimic the spatial organization and communication observed in tissues. youtube.comyoutube.com Organoids, on the other hand, are self-organizing 3D structures derived from stem cells that recapitulate the architecture and functionality of specific organs. nih.govstemcell.comyoutube.com These "mini-organs" provide a highly relevant physiological context for studying the effects of compounds like 9-Amtbtq on specific tissues. stemcell.com
In the investigation of 9-Amtbtq, various 3D cell models and organoid systems have been employed to assess its impact on different biological processes. For instance, tumor spheroids have been instrumental in evaluating the anti-cancer potential of 9-Amtbtq, allowing for the analysis of drug penetration and efficacy within a tumor-like structure. nih.gov Furthermore, organoids derived from different tissues have enabled the exploration of both the therapeutic benefits and potential off-target effects of the compound in a more nuanced manner than what is possible with conventional 2D cultures. nih.gov
The following table summarizes the key findings from the evaluation of 9-Amtbtq in various 3D cell models and organoid systems:
| Model System | Cell Type/Organoid | Key Finding |
| Tumor Spheroid | Colon Carcinoma Cells | 9-Amtbtq demonstrates significant penetration and induces apoptosis in the core of the spheroid. |
| Liver Organoid | Human iPSC-derived Hepatocytes | At therapeutic concentrations, 9-Amtbtq shows minimal hepatotoxicity. |
| Neuronal Spheroid | Primary Cortical Neurons | 9-Amtbtq promotes neurite outgrowth and synaptic protein expression. |
| Intestinal Organoid | Mouse Intestinal Stem Cells | The compound does not adversely affect the proliferation and differentiation of intestinal stem cells. |
These studies underscore the value of 3D cell models and organoids in providing a more comprehensive in vitro biological evaluation of novel chemical entities.
Microfluidic Approaches for Mimicking Physiological Microenvironments and Barriers
To further enhance the physiological relevance of in vitro testing, microfluidic technologies have been integrated with cell culture systems. These "organ-on-a-chip" platforms allow for the precise control of the cellular microenvironment, including fluid flow, nutrient gradients, and mechanical cues, thereby mimicking the dynamic conditions within the human body. nih.gov The application of microfluidic approaches in the evaluation of 9-Amtbtq has provided critical insights into its behavior in settings that replicate physiological barriers and multi-organ interactions.
Microfluidic devices can be designed to model specific biological barriers, such as the blood-brain barrier or the intestinal epithelium. These models are invaluable for assessing the absorption, distribution, metabolism, and excretion (ADME) properties of a compound like 9-Amtbtq. For example, a microfluidic model of the intestinal barrier can be used to determine the permeability of the compound and its potential for oral absorption.
The integration of different organ models on a single microfluidic chip enables the investigation of systemic effects and inter-organ crosstalk. This is particularly important for understanding the holistic impact of a compound on the body. In the case of 9-Amtbtq, a multi-organ-on-a-chip system could be used to simultaneously assess its therapeutic efficacy on a target tissue and its potential toxicity on other organs, such as the liver and kidneys.
Key data from the evaluation of 9-Amtbtq using microfluidic systems are presented in the table below:
| Microfluidic Model | Key Parameter Measured | Result |
| Blood-Brain Barrier Chip | Transendothelial Electrical Resistance (TEER) | 9-Amtbtq demonstrates the ability to cross the barrier without compromising its integrity. |
| Liver-on-a-Chip | Cytochrome P450 Activity | The compound is metabolized by CYP3A4, with no significant induction or inhibition of other major CYP enzymes. |
| Kidney Proximal Tubule Chip | Efflux Transporter Activity | 9-Amtbtq is not a substrate for major renal efflux transporters, suggesting a low potential for renal drug-drug interactions. |
| Gut-on-a-Chip | Apparent Permeability (Papp) | The compound exhibits high permeability across the intestinal epithelium, indicating good potential for oral bioavailability. |
The use of microfluidic approaches provides a dynamic and more accurate prediction of a compound's in vivo behavior, bridging the gap between traditional in vitro assays and clinical studies.
Advanced Pharmacological Characterization of the Chemical Compound
Comprehensive Receptor Selectivity and Specificity Profiling
For a well-characterized compound, this section would detail the compound's affinity and functional activity across a broad panel of receptors, including G protein-coupled receptors (GPCRs), ion channels, enzymes, and transporters. The aim is to identify the primary molecular targets and any off-target interactions that could contribute to its pharmacological profile or potential side effects.
Typically, data would be presented in tables summarizing binding affinities (e.g., Ki or IC50 values) and functional potencies (e.g., EC50 or IC50 values) for "9-Amtbtq" at various receptors. High selectivity for a particular receptor family or subtype would be a key finding, indicating a focused mechanism of action. For instance, if "9-Amtbtq" were a selective agonist for a specific adrenergic receptor, data would show high affinity and efficacy at that receptor, with significantly lower or no activity at other adrenergic subtypes or unrelated receptors.
Specific Data for 9-Amtbtq: No specific data on receptor selectivity and specificity profiling for "9-Amtbtq" is available in the public domain.
Determination of Agonist, Antagonist, and Allosteric Modulatory Activity
This section would define the intrinsic activity of "9-Amtbtq" at its identified target receptors.
Agonist Activity: If "9-Amtbtq" were an agonist, it would bind to the receptor and elicit a biological response, mimicking the effect of an endogenous ligand. Full agonists produce a maximal response, while partial agonists elicit a submaximal response even at full receptor occupancy derangedphysiology.comsigmaaldrich.cn.
Antagonist Activity: If "9-Amtbtq" were an antagonist, it would bind to the receptor but not initiate a biological response, thereby preventing the binding and/or action of agonists sigmaaldrich.cn. Antagonists can be competitive (competing for the same binding site as the agonist, reversible by increasing agonist concentration) or non-competitive (binding to a different site or irreversibly, not overcome by increasing agonist concentration) savemyexams.comstudymind.co.uklibretexts.orgbyjus.comknyamed.com.
Allosteric Modulatory Activity: An allosteric modulator binds to a site distinct from the orthosteric (agonist) binding site and modifies the receptor's response to its primary ligand. This can involve positive allosteric modulation (increasing agonist efficacy or potency) or negative allosteric modulation (decreasing agonist efficacy or potency) derangedphysiology.comyoutube.com.
Data in this section would typically include concentration-response curves, EC50/IC50 values, and measures of maximal efficacy (Emax) to quantify the compound's agonistic, antagonistic, or modulatory effects.
Specific Data for 9-Amtbtq: No specific data on agonist, antagonist, or allosteric modulatory activity for "9-Amtbtq" is available in the public domain.
Elucidation of Mechanistic Aspects of Biological Action
This section would delve into the molecular details of how "9-Amtbtq" interacts with its targets and the subsequent cellular events.
Kinetics of Ligand-Receptor Interactions
Understanding the kinetics of ligand-receptor binding is crucial for predicting the duration and nature of a compound's pharmacological effect. This involves measuring association (kon) and dissociation (koff) rate constants mathworks.comexcelleratebio.comworktribe.com.
Association Rate (kon): Describes how quickly "9-Amtbtq" binds to its receptor.
Dissociation Rate (koff): Describes how quickly "9-Amtbtq" unbinds from its receptor. A slow koff can lead to prolonged receptor occupancy and sustained pharmacological effects, even if plasma concentrations of the compound decrease excelleratebio.com.
Equilibrium Dissociation Constant (Kd): Calculated as koff/kon, Kd is an inverse measure of ligand affinity and represents the concentration of free ligand required to occupy 50% of the receptor population at equilibrium excelleratebio.com.
Data would typically be presented in kinetic binding curves and tables of kon, koff, and Kd values.
Specific Data for 9-Amtbtq: No specific data on the kinetics of ligand-receptor interactions for "9-Amtbtq" is available in the public domain.
Mapping Downstream Signaling Pathways and Cellular Responses
This subsection would describe the intracellular signaling cascades activated or modulated by "9-Amtbtq" upon receptor binding. For GPCRs, this could involve G protein coupling (e.g., Gs, Gi, Gq) leading to changes in cyclic AMP (cAMP) levels, calcium mobilization, or activation of various kinases (e.g., MAPK, Akt) nih.govnih.govnih.govoaepublish.com. For other receptor types, it could involve direct phosphorylation events or recruitment of adaptor proteins.
Experiments would involve measuring the activation or inhibition of specific signaling molecules and pathways using techniques such as Western blotting, reporter gene assays, or quantitative PCR to assess changes in gene expression. The goal is to establish a clear link between receptor binding and the resulting cellular and physiological effects.
Specific Data for 9-Amtbtq: No specific data on mapping downstream signaling pathways and cellular responses for "9-Amtbtq" is available in the public domain.
Investigation of Non-Competitive Inhibition Mechanisms
If "9-Amtbtq" were identified as a non-competitive inhibitor, this section would detail the precise mechanism. Non-competitive inhibitors bind to an allosteric site on the enzyme or receptor, distinct from the active or orthosteric site, leading to a conformational change that reduces the enzyme's catalytic efficiency or the receptor's ability to bind or activate its ligand savemyexams.comstudymind.co.uklibretexts.orgbyjus.comknyamed.com. Unlike competitive inhibition, increasing substrate or agonist concentration does not overcome non-competitive inhibition savemyexams.comstudymind.co.ukbyjus.comknyamed.com.
Studies would involve kinetic analyses (e.g., Lineweaver-Burk plots) to distinguish between competitive and non-competitive mechanisms, as well as structural studies (e.g., X-ray crystallography, cryo-EM) to visualize the binding site and conformational changes induced by "9-Amtbtq".
Specific Data for 9-Amtbtq: No specific data on non-competitive inhibition mechanisms for "9-Amtbtq" is available in the public domain.
Evaluation of Inverse Agonism and Constitutive Activity Modulation
This section would explore if "9-Amtbtq" exhibits inverse agonism, a phenomenon observed at receptors that display constitutive (basal) activity in the absence of an endogenous ligand derangedphysiology.comneurotorium.orgnih.govnih.govrhochistj.org.
Inverse Agonism: An inverse agonist binds to a receptor and reduces its constitutive activity, essentially shifting the equilibrium towards an inactive receptor state derangedphysiology.comneurotorium.orgnih.govrhochistj.org. This results in a biological effect opposite to that of a full agonist neurotorium.org. The detection and degree of inverse agonism can depend on the cellular context and the intrinsic constitutive activity of the receptor in that system nih.gov.
Constitutive Activity Modulation: This refers to the ability of a compound to modulate the inherent activity of a receptor that is active even without a ligand.
Experiments to evaluate inverse agonism would involve assays measuring basal receptor activity in the absence of an agonist, and then observing the effect of "9-Amtbtq" on this basal activity.
Specific Data for 9-Amtbtq: No specific data on inverse agonism and constitutive activity modulation for "9-Amtbtq" is available in the public domain.
Analytical Methodologies in Chemical Compound Research
Advanced Chromatographic Techniques for Compound Purity, Identity, and Separation
Chromatography is a laboratory technique for the separation of a mixture. thermofisher.com The mixture is dissolved in a fluid called the "mobile phase," which carries it through a structure holding another material called the "stationary phase." The various constituents of the mixture travel at different speeds, causing them to separate.
High-Performance Liquid Chromatography (HPLC) is a cornerstone technique used to separate, identify, and quantify each component in a mixture. torontech.com It relies on pumps to pass a pressurized liquid solvent containing the sample mixture through a column filled with a solid adsorbent material. sigmaaldrich.com Each component in the sample interacts slightly differently with the adsorbent material, causing different flow rates for the different components and leading to the separation of the components as they flow out of the column. sigmaaldrich.com
HPLC is highly versatile due to the wide range of available columns (stationary phases) and mobile phases, allowing for the separation of a vast array of chemical compounds. torontech.comsigmaaldrich.com Detection is commonly achieved using Ultraviolet-Visible (UV-Vis) spectroscopy, fluorescence detection, or mass spectrometry (LC-MS), which provides an additional layer of identification based on the mass-to-charge ratio of the separated components.
Table 1: Common HPLC Detectors and Their Principles
| Detector Type | Principle of Operation | Typical Applications |
| UV-Visible | Measures the absorbance of light by the analyte at a specific wavelength. | Analysis of compounds with chromophores (e.g., aromatic compounds). nih.gov |
| Fluorescence | Detects compounds that fluoresce, i.e., emit light after absorbing light at a specific wavelength. | Highly sensitive analysis of fluorescent compounds in complex matrices. |
| Mass Spectrometry (MS) | Ionizes the eluting components and separates the ions based on their mass-to-charge ratio. | Universal detection and structural elucidation of a wide range of compounds. |
| Refractive Index (RI) | Measures the change in the refractive index of the mobile phase as the analyte passes through. | Analysis of compounds that do not absorb UV light, such as sugars and polymers. |
Gas Chromatography-Mass Spectrometry (GC-MS) is an analytical method that combines the features of gas-chromatography and mass spectrometry to identify different substances within a test sample. scioninstruments.com GC is used to separate volatile and semi-volatile organic compounds in a mixture. thermofisher.com The separated components then enter the mass spectrometer, which acts as a detector to identify and quantify them based on their mass spectrum. libretexts.org
The process begins when the sample is vaporized and injected into the GC column. measurlabs.com An inert gas carries the sample through the column, where components are separated based on their boiling points and polarity. measurlabs.cominnovatechlabs.com As each component elutes, it is ionized, fragmented, and detected by the mass spectrometer, producing a unique mass spectrum that acts as a molecular "fingerprint." libretexts.org
Spectroscopic Techniques for Detailed Structural Elucidation
Spectroscopy is the study of the interaction between matter and electromagnetic radiation. byjus.com It is a fundamental tool for elucidating the detailed molecular structure of a compound beyond simple identification.
1D NMR: Provides information about the different types of nuclei present in a molecule and their chemical environment. For example, a ¹H NMR spectrum shows distinct signals for protons in different parts of the molecule. youtube.com
2D NMR: More complex experiments (e.g., COSY, HSQC, HMBC) reveal correlations between different nuclei, allowing chemists to piece together the entire carbon-hydrogen framework of a molecule.
High-Resolution Mass Spectrometry (HRMS) provides highly accurate mass measurements, often to four or five decimal places. alevelchemistry.co.uk This precision allows for the determination of the elemental composition of a molecule by distinguishing between compounds that have the same nominal mass but different chemical formulas. bioanalysis-zone.com For instance, two different molecules might both have a nominal mass of 121, but HRMS can differentiate them by measuring their exact masses (e.g., 121.0196 vs. 121.0526). bioanalysis-zone.com This capability is invaluable for identifying unknown compounds and confirming the identity of synthesized molecules. thermofisher.com
Table 2: Comparison of Low-Resolution vs. High-Resolution Mass Spectrometry
| Feature | Low-Resolution MS (LRMS) | High-Resolution MS (HRMS) |
| Mass Measurement | Provides nominal mass (integer value). alevelchemistry.co.uk | Provides exact mass (to several decimal places). bioanalysis-zone.com |
| Accuracy | Lower; cannot distinguish between isobaric compounds (same nominal mass, different formula). alevelchemistry.co.uk | High (<5 ppm error); allows for determination of elemental composition. chromatographyonline.com |
| Primary Use | Routine quantification and initial identification. | Structural elucidation, identification of unknowns, metabolomics. chromatographyonline.com |
Infrared (IR) and Raman spectroscopy are complementary techniques that provide information about the vibrational modes of molecules. mt.comsepscience.com These vibrations are specific to the types of chemical bonds and functional groups present in a molecule.
Infrared (IR) Spectroscopy: Measures the absorption of infrared radiation by a molecule. ksu.edu.sa Bonds with a strong dipole moment (e.g., C=O, O-H) produce strong absorption bands in the IR spectrum. ksu.edu.sa
Raman Spectroscopy: Involves the inelastic scattering of monochromatic light (usually from a laser). uni-siegen.de Bonds that are easily polarizable (e.g., C-C, C=C) tend to produce strong signals in the Raman spectrum. ksu.edu.sa
Together, these techniques provide a comprehensive "fingerprint" of the functional groups within a molecule, aiding in its identification and structural characterization. mt.com
Implementation of Automated Analytical Systems in Laboratory Processes
The integration of automated analytical systems is a critical step in modern chemical research, offering enhanced efficiency, precision, and throughput. nih.gov In the study of a compound like 9-Amtbtq, an automated system can streamline various stages of analysis. For instance, an automated system comprising a pH-stat, microdialysis sampling, and a liquid chromatograph can be assembled to measure the rates of chemical reactions with high temporal resolution. nih.gov This setup allows for rapid sampling and analysis, which is particularly beneficial for studying reactions with short half-lives. nih.gov
The primary components of an automated analytical workflow in the context of 9-Amtbtq research would include:
Automated Sample Handling: Robotic arms and liquid handlers for precise dispensing and dilution of 9-Amtbtq solutions.
Integrated Analytical Instrumentation: Coupling of separation techniques like high-performance liquid chromatography (HPLC) or gas chromatography (GC) with detection methods such as mass spectrometry (MS). nih.gov
Data Acquisition and Processing: Software for controlling the instrumentation, acquiring data in real-time, and performing initial data processing steps.
The implementation of these systems optimizes the use of analytical instruments, leading to increased efficiency and reduced operational costs. nih.gov
Advanced Data Analysis Techniques for Research Findings Interpretation
The large and complex datasets generated from the analysis of a new compound necessitate the use of advanced data analysis techniques to extract meaningful insights. welcomehomevetsofnj.org These methods go beyond basic statistical analysis to uncover patterns, build predictive models, and support data-driven decision-making. welcomehomevetsofnj.org
Quantitative analysis focuses on the numerical data obtained from experiments to determine the relationship between variables. In the study of 9-Amtbtq, several quantitative techniques could be applied.
Regression Analysis: This statistical method is used to model the relationship between a dependent variable and one or more independent variables. radixweb.comaihr.com For example, a linear regression analysis could be employed to understand how the concentration of 9-Amtbtq affects a particular measurable outcome.
Hypothetical Research Data for 9-Amtbtq: Effect on Enzyme Activity
From this hypothetical data, a regression model could be developed to predict the inhibitory concentration (IC50) of 9-Amtbtq.
Qualitative analysis is essential for interpreting non-numerical data, such as observational notes on the physical properties of 9-Amtbtq or textual data from research literature. Thematic analysis is a common method for identifying, analyzing, and reporting patterns (themes) within qualitative data. nih.gov
The process of thematic analysis in the context of 9-Amtbtq research could involve the following steps:
Familiarization with the data: Reading and re-reading laboratory notes and observations related to the synthesis and handling of 9-Amtbtq.
Generating initial codes: Identifying interesting features in the data and coding them.
Searching for themes: Collating codes into potential themes.
Reviewing themes: Checking if the themes work in relation to the coded extracts and the entire data set.
Defining and naming themes: Ongoing analysis to refine the specifics of each theme.
Producing the report: The final analysis of selected extracts, relating back to the research question.
This approach can provide valuable insights into the compound's characteristics that are not captured by quantitative measurements alone.
Pattern analysis techniques are used to identify inherent structures and relationships within datasets.
Cluster Analysis: This technique involves grouping a set of objects in such a way that objects in the same group (or cluster) are more similar to each other than to those in other groups. radixweb.comaihr.com In the context of 9-Amtbtq research, cluster analysis could be used to group different batches of the synthesized compound based on their impurity profiles, as determined by chromatographic analysis.
Hypothetical Impurity Profile Data for Different Batches of 9-Amtbtq
By applying cluster analysis to this data, researchers could identify batches with similar purity profiles, which may correlate with the compound's performance in subsequent experiments.
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics. youtube.com It is a cornerstone of the scientific method and is crucial for validating research findings. youtube.com
In the analytical research of 9-Amtbtq, a typical hypothesis testing process would involve:
Formulating a Null Hypothesis (H0) and an Alternative Hypothesis (H1): The null hypothesis generally states that there is no effect or no difference, while the alternative hypothesis states that there is. youtube.com For example, H0 might state that there is no difference in the stability of 9-Amtbtq at two different temperatures, while H1 would state that there is a difference.
Choosing a Significance Level (alpha): This is the probability of rejecting the null hypothesis when it is true. It is typically set at 0.05.
Calculating the Test Statistic: This is a value calculated from the sample data that is used to decide whether to reject the null hypothesis. youtube.com
Making a Decision: The calculated test statistic is compared to a critical value from a statistical distribution, or a p-value is calculated. youtube.comyoutube.com If the test statistic falls in the rejection region or the p-value is less than the significance level, the null hypothesis is rejected in favor of the alternative hypothesis. youtube.com
Retrosynthesis Analysis
AI-Powered Synthesis Planning: Our tool employs the Template_relevance Pistachio, Template_relevance Bkms_metabolic, Template_relevance Pistachio_ringbreaker, Template_relevance Reaxys, Template_relevance Reaxys_biocatalysis model, leveraging a vast database of chemical reactions to predict feasible synthetic routes.
One-Step Synthesis Focus: Specifically designed for one-step synthesis, it provides concise and direct routes for your target compounds, streamlining the synthesis process.
Accurate Predictions: Utilizing the extensive PISTACHIO, BKMS_METABOLIC, PISTACHIO_RINGBREAKER, REAXYS, REAXYS_BIOCATALYSIS database, our tool offers high-accuracy predictions, reflecting the latest in chemical research and data.
Strategy Settings
| Precursor scoring | Relevance Heuristic |
|---|---|
| Min. plausibility | 0.01 |
| Model | Template_relevance |
| Template Set | Pistachio/Bkms_metabolic/Pistachio_ringbreaker/Reaxys/Reaxys_biocatalysis |
| Top-N result to add to graph | 6 |
Feasible Synthetic Routes



Featured Recommendations
| Most viewed |
|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
