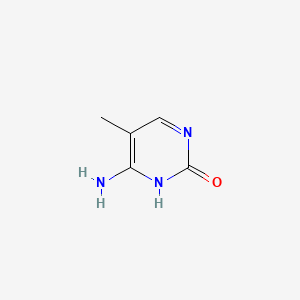
5-Methylcytosine
Description
Structure
3D Structure
Properties
IUPAC Name |
6-amino-5-methyl-1H-pyrimidin-2-one |
Source


|
|---|---|---|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI |
InChI=1S/C5H7N3O/c1-3-2-7-5(9)8-4(3)6/h2H,1H3,(H3,6,7,8,9) |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI Key |
LRSASMSXMSNRBT-UHFFFAOYSA-N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Canonical SMILES |
CC1=C(NC(=O)N=C1)N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Formula |
C5H7N3O |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Related CAS |
58366-64-6 (mono-hydrochloride) |
Source
|
| Record name | 5-Methylcytosine | |
| Source | ChemIDplus | |
| URL | https://pubchem.ncbi.nlm.nih.gov/substance/?source=chemidplus&sourceid=0000554018 | |
| Description | ChemIDplus is a free, web search system that provides access to the structure and nomenclature authority files used for the identification of chemical substances cited in National Library of Medicine (NLM) databases, including the TOXNET system. | |
DSSTOX Substance ID |
DTXSID50203948 |
Source
|
| Record name | 5-Methylcytosine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID50203948 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
Molecular Weight |
125.13 g/mol |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Physical Description |
Solid |
Source
|
| Record name | 5-Methylcytosine | |
| Source | Human Metabolome Database (HMDB) | |
| URL | http://www.hmdb.ca/metabolites/HMDB0002894 | |
| Description | The Human Metabolome Database (HMDB) is a freely available electronic database containing detailed information about small molecule metabolites found in the human body. | |
| Explanation | HMDB is offered to the public as a freely available resource. Use and re-distribution of the data, in whole or in part, for commercial purposes requires explicit permission of the authors and explicit acknowledgment of the source material (HMDB) and the original publication (see the HMDB citing page). We ask that users who download significant portions of the database cite the HMDB paper in any resulting publications. | |
Solubility |
34.5 mg/mL |
Source
|
| Record name | 5-Methylcytosine | |
| Source | Human Metabolome Database (HMDB) | |
| URL | http://www.hmdb.ca/metabolites/HMDB0002894 | |
| Description | The Human Metabolome Database (HMDB) is a freely available electronic database containing detailed information about small molecule metabolites found in the human body. | |
| Explanation | HMDB is offered to the public as a freely available resource. Use and re-distribution of the data, in whole or in part, for commercial purposes requires explicit permission of the authors and explicit acknowledgment of the source material (HMDB) and the original publication (see the HMDB citing page). We ask that users who download significant portions of the database cite the HMDB paper in any resulting publications. | |
CAS No. |
554-01-8 |
Source
|
| Record name | 5-Methylcytosine | |
| Source | CAS Common Chemistry | |
| URL | https://commonchemistry.cas.org/detail?cas_rn=554-01-8 | |
| Description | CAS Common Chemistry is an open community resource for accessing chemical information. Nearly 500,000 chemical substances from CAS REGISTRY cover areas of community interest, including common and frequently regulated chemicals, and those relevant to high school and undergraduate chemistry classes. This chemical information, curated by our expert scientists, is provided in alignment with our mission as a division of the American Chemical Society. | |
| Explanation | The data from CAS Common Chemistry is provided under a CC-BY-NC 4.0 license, unless otherwise stated. | |
| Record name | 5-Methylcytosine | |
| Source | ChemIDplus | |
| URL | https://pubchem.ncbi.nlm.nih.gov/substance/?source=chemidplus&sourceid=0000554018 | |
| Description | ChemIDplus is a free, web search system that provides access to the structure and nomenclature authority files used for the identification of chemical substances cited in National Library of Medicine (NLM) databases, including the TOXNET system. | |
| Record name | 5-Methylcytosine | |
| Source | DTP/NCI | |
| URL | https://dtp.cancer.gov/dtpstandard/servlet/dwindex?searchtype=NSC&outputformat=html&searchlist=137776 | |
| Description | The NCI Development Therapeutics Program (DTP) provides services and resources to the academic and private-sector research communities worldwide to facilitate the discovery and development of new cancer therapeutic agents. | |
| Explanation | Unless otherwise indicated, all text within NCI products is free of copyright and may be reused without our permission. Credit the National Cancer Institute as the source. | |
| Record name | 5-Methylcytosine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID50203948 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
| Record name | 5-methylcytosine | |
| Source | European Chemicals Agency (ECHA) | |
| URL | https://echa.europa.eu/substance-information/-/substanceinfo/100.008.236 | |
| Description | The European Chemicals Agency (ECHA) is an agency of the European Union which is the driving force among regulatory authorities in implementing the EU's groundbreaking chemicals legislation for the benefit of human health and the environment as well as for innovation and competitiveness. | |
| Explanation | Use of the information, documents and data from the ECHA website is subject to the terms and conditions of this Legal Notice, and subject to other binding limitations provided for under applicable law, the information, documents and data made available on the ECHA website may be reproduced, distributed and/or used, totally or in part, for non-commercial purposes provided that ECHA is acknowledged as the source: "Source: European Chemicals Agency, http://echa.europa.eu/". Such acknowledgement must be included in each copy of the material. ECHA permits and encourages organisations and individuals to create links to the ECHA website under the following cumulative conditions: Links can only be made to webpages that provide a link to the Legal Notice page. | |
| Record name | 5-METHYLCYTOSINE | |
| Source | FDA Global Substance Registration System (GSRS) | |
| URL | https://gsrs.ncats.nih.gov/ginas/app/beta/substances/6R795CQT4H | |
| Description | The FDA Global Substance Registration System (GSRS) enables the efficient and accurate exchange of information on what substances are in regulated products. Instead of relying on names, which vary across regulatory domains, countries, and regions, the GSRS knowledge base makes it possible for substances to be defined by standardized, scientific descriptions. | |
| Explanation | Unless otherwise noted, the contents of the FDA website (www.fda.gov), both text and graphics, are not copyrighted. They are in the public domain and may be republished, reprinted and otherwise used freely by anyone without the need to obtain permission from FDA. Credit to the U.S. Food and Drug Administration as the source is appreciated but not required. | |
| Record name | 5-Methylcytosine | |
| Source | Human Metabolome Database (HMDB) | |
| URL | http://www.hmdb.ca/metabolites/HMDB0002894 | |
| Description | The Human Metabolome Database (HMDB) is a freely available electronic database containing detailed information about small molecule metabolites found in the human body. | |
| Explanation | HMDB is offered to the public as a freely available resource. Use and re-distribution of the data, in whole or in part, for commercial purposes requires explicit permission of the authors and explicit acknowledgment of the source material (HMDB) and the original publication (see the HMDB citing page). We ask that users who download significant portions of the database cite the HMDB paper in any resulting publications. | |
Melting Point |
270 °C |
Source
|
| Record name | 5-Methylcytosine | |
| Source | Human Metabolome Database (HMDB) | |
| URL | http://www.hmdb.ca/metabolites/HMDB0002894 | |
| Description | The Human Metabolome Database (HMDB) is a freely available electronic database containing detailed information about small molecule metabolites found in the human body. | |
| Explanation | HMDB is offered to the public as a freely available resource. Use and re-distribution of the data, in whole or in part, for commercial purposes requires explicit permission of the authors and explicit acknowledgment of the source material (HMDB) and the original publication (see the HMDB citing page). We ask that users who download significant portions of the database cite the HMDB paper in any resulting publications. | |
Foundational & Exploratory
role of 5-Methylcytosine in gene silencing
An In-depth Technical Guide on the Role of 5-Methylcytosine (B146107) in Gene Silencing
For Researchers, Scientists, and Drug Development Professionals
This compound (5mC) is a critical epigenetic modification that plays a fundamental role in the regulation of gene expression, cellular differentiation, and genome stability.[1] This technical guide provides a comprehensive overview of the molecular mechanisms by which 5mC mediates gene silencing. It details the enzymatic machinery responsible for its deposition and maintenance, the reader proteins that recognize and interpret this mark, and the subsequent downstream events that lead to transcriptional repression. This document also includes detailed experimental protocols for key techniques used to study 5mC and presents quantitative data to illustrate the functional consequences of this epigenetic mark.
The Molecular Basis of this compound (5mC)
This compound is a modification of the DNA base cytosine, where a methyl group is covalently attached to the 5th carbon of the pyrimidine (B1678525) ring.[2][3][4] In mammals, this modification predominantly occurs in the context of CpG dinucleotides (a cytosine followed by a guanine).[2][4] While CpG dinucleotides are generally underrepresented in the genome, they are often clustered in regions known as CpG islands (CGIs), which are frequently located in the promoter regions of genes.[2][5] The methylation status of these CGIs is a key determinant of gene activity.[2][6]
Mechanisms of 5mC-Mediated Gene Silencing
Gene silencing orchestrated by 5mC is a multi-layered process involving the establishment of the methylation mark, its recognition by specific proteins, and the subsequent recruitment of repressive machinery that alters chromatin structure.
Establishment and Maintenance of DNA Methylation
The methylation patterns are established and maintained by a family of enzymes called DNA methyltransferases (DNMTs).[2][6][7][8]
-
De Novo Methylation: DNMT3A and DNMT3B are responsible for establishing new methylation patterns during development.[2][7][9] They add methyl groups to previously unmethylated CpG sites.
-
Maintenance Methylation: During DNA replication, the newly synthesized strand is unmethylated. DNMT1 recognizes these hemi-methylated CpG sites and methylates the new strand, ensuring the faithful propagation of methylation patterns through cell division.[2][7][9]
Recognition of 5mC and Recruitment of Repressor Complexes
The repressive signals encoded by 5mC are interpreted by methyl-CpG-binding proteins (MBPs).[6][9]
-
Methyl-CpG-Binding Domain (MBD) Proteins: This family includes well-studied proteins like MeCP2, MBD1, and MBD2.[2][10][11] These proteins use their methyl-CpG-binding domain to specifically recognize and bind to methylated CpG dinucleotides.[11][12]
-
Recruitment of Corepressors: Upon binding to 5mC, MBD proteins act as platforms to recruit larger corepressor complexes.[10][12] These complexes often contain histone deacetylases (HDACs) and histone methyltransferases (HMTs). HDACs remove acetyl groups from histones, leading to a more compact chromatin structure, while HMTs can add repressive marks (like H3K9me3), further reinforcing the silenced state.
Direct Inhibition of Transcription Factor Binding
In addition to recruiting repressor complexes, 5mC can directly interfere with gene expression. The presence of a methyl group in the major groove of the DNA can physically obstruct the binding of specific transcription factors to their cognate recognition sequences, thereby preventing the initiation of transcription.[6][9][10]
// Edges for Establishment & Maintenance Unmethylated_DNA -> DNMT3A_B [label=" Establishes\n new patterns"]; DNMT3A_B -> Methylated_DNA; Methylated_DNA -> Hemi_Methylated_DNA [label=" DNA\n Replication"]; Hemi_Methylated_DNA -> DNMT1 [label=" Recognizes & acts on"]; DNMT1 -> Methylated_DNA [label=" Maintains\n pattern"];
// Edges for Recognition & Repression Methylated_DNA -> MBD [label=" Binds to 5mC"]; MBD -> Corepressors [label=" Recruits"]; Chromatin -> Condensed_Chromatin [style=dashed]; Corepressors -> Condensed_Chromatin [label=" Catalyzes\n condensation"];
// Edges for Direct Interference Methylated_DNA -> TF_Blocked [label=" Physically hinders"]; TF -> TF_Blocked [style=dashed, arrowhead=none];
{rank=same; DNMT3A_B; DNMT1;} {rank=same; MBD; TF;} {rank=same; Corepressors; TF_Blocked;} } end_dot Caption: Overview of 5mC-mediated gene silencing pathways.
Quantitative Data on 5mC and Gene Expression
The relationship between DNA methylation and gene expression is often inversely correlated, especially when methylation occurs in promoter CpG islands.
| Feature | Location | 5mC Level | Associated Gene Expression | Reference |
| CpG Islands (CGIs) | Promoters, Transcription Start Sites (TSSs) | High | Stable, long-term silencing | [2][6] |
| Gene Bodies | Intragenic regions | High | Positively associated with expression | [6] |
| Enhancer Elements | Distal regulatory regions | Dynamic | Repressed when methylated, active when demethylated | [7][13] |
| Repetitive Elements | Transposons, viral elements | High | Silenced to maintain genome stability | [2] |
| Low Methylation Regions (LMRs) | Genome-wide | ~30% | Associated with enhancer activity | [7] |
| CGI Shores | Regions flanking CpG Islands (up to 2kb) | Variable | Methylation changes often correlate with cancer-related gene expression changes | [14] |
Experimental Protocols for 5mC Analysis
Several key techniques are employed to study 5mC and its role in gene silencing. Below are detailed protocols for three widely used methods.
Protocol: Whole-Genome Bisulfite Sequencing (WGBS)
WGBS is the gold-standard method for single-base resolution mapping of 5mC across the entire genome.[15][16] The principle relies on the chemical treatment of DNA with sodium bisulfite, which converts unmethylated cytosines to uracil (B121893), while 5mC residues remain unchanged.[4][15] Subsequent PCR amplification and sequencing reads uracils as thymines, allowing for the precise identification of methylated sites by comparing to a reference genome.[15]
Methodology:
-
Genomic DNA Extraction:
-
DNA Fragmentation & Library Preparation:
-
Fragment the DNA to a desired size range (e.g., 200-300 bp) using sonication or enzymatic methods.
-
Perform end-repair, A-tailing, and ligation of methylated sequencing adapters.
-
-
Bisulfite Conversion:
-
Denature the DNA library (e.g., using NaOH or heat).[17][18]
-
Incubate the denatured DNA with a freshly prepared sodium bisulfite solution at an elevated temperature (e.g., 50-70°C) in the dark for a specified time (1-16 hours).[18]
-
Purify the DNA to remove bisulfite using a desalting column.[18]
-
Perform desulfonation by incubating with NaOH to convert sulfonyl uracil adducts to uracil.[18]
-
Purify the converted DNA.
-
-
PCR Amplification:
-
Amplify the bisulfite-converted library using a high-fidelity polymerase that can read uracil-containing templates.
-
Use a minimal number of PCR cycles to avoid amplification bias.
-
-
Sequencing and Data Analysis:
-
Sequence the library on a high-throughput platform (e.g., Illumina).[17]
-
Align the sequencing reads to both a C-to-T converted and a G-to-A converted reference genome.
-
Calculate the methylation level for each CpG site as the ratio of reads supporting methylation (C) to the total number of reads covering that site (C + T).
-
Protocol: Methyl-CpG Binding Domain Sequencing (MBD-seq)
MBD-seq is an affinity-based method used to enrich for methylated DNA regions. It utilizes the high affinity of MBD proteins for 5mC to capture methylated DNA fragments from a genomic sample.[16][19]
Methodology:
-
Genomic DNA Preparation:
-
Extract genomic DNA. The amount can be much lower than for WGBS, with protocols optimized for as little as 5 ng.[20]
-
Fragment the DNA by sonication to an average size of 150-300 bp.
-
-
Enrichment of Methylated DNA:
-
Prepare magnetic beads coupled with recombinant MBD proteins (e.g., MBD2).[20]
-
Incubate the fragmented DNA with the MBD-beads in a binding buffer to allow the capture of methylated fragments.[20]
-
Wash the beads multiple times with buffers of increasing salt concentration to remove non-specifically bound and low-methylated DNA fragments.
-
-
Elution and Library Preparation:
-
Elute the captured, highly methylated DNA fragments from the beads using a high-salt buffer or a specific elution buffer. A single elution with a low-salt buffer can also be effective for capturing regions with lower CpG density.[20]
-
Purify the eluted DNA.
-
Construct a sequencing library from the enriched DNA fragments (end-repair, A-tailing, adapter ligation, and PCR amplification).
-
-
Sequencing and Data Analysis:
-
Sequence the library.
-
Align reads to a reference genome.
-
Identify peaks of read enrichment, which correspond to methylated regions of the genome. The height and width of the peaks correlate with the density of methylation.
-
Protocol: Chromatin Immunoprecipitation Sequencing (ChIP-seq) for MBDs
ChIP-seq is used to identify the in vivo binding sites of DNA-associated proteins. When applied to MBD proteins like MeCP2, it reveals the precise genomic locations where these proteins are engaged with methylated DNA within the native chromatin context.
Methodology:
-
Cross-linking and Cell Lysis:
-
Treat cultured cells with formaldehyde (B43269) to cross-link proteins to DNA.[21]
-
Quench the reaction with glycine.[21]
-
Harvest and lyse the cells to release nuclei. Isolate the nuclei.
-
-
Chromatin Fragmentation:
-
Lyse the nuclei and shear the chromatin into fragments of 200-600 bp using sonication or enzymatic digestion (e.g., MNase).[21]
-
-
Immunoprecipitation (IP):
-
Incubate the sheared chromatin overnight at 4°C with an antibody specific to the MBD protein of interest (e.g., anti-MeCP2).
-
Add Protein A/G magnetic beads to capture the antibody-protein-DNA complexes.[21]
-
Wash the beads extensively to remove non-specifically bound chromatin.
-
-
Elution and Reverse Cross-linking:
-
DNA Purification and Library Preparation:
-
Purify the immunoprecipitated DNA.
-
Prepare a sequencing library from the purified ChIP DNA. An input control library should also be prepared from a portion of the sheared chromatin that did not undergo IP.
-
-
Sequencing and Data Analysis:
-
Sequence both the ChIP and input libraries.
-
Align reads to a reference genome.
-
Perform peak calling analysis, comparing the ChIP sample to the input control to identify genomic regions with significant enrichment of MBD protein binding.
-
Conclusion and Future Directions
This compound is a cornerstone of epigenetic regulation, providing a stable and heritable mechanism for gene silencing. The interplay between DNMTs, MBD proteins, and chromatin-modifying enzymes establishes a robust system for controlling gene expression that is essential for normal development and is frequently dysregulated in diseases like cancer.[7][8] The advancement of high-throughput sequencing techniques continues to refine our understanding of 5mC's role, revealing context-dependent functions and complex interactions with other epigenetic marks. For professionals in drug development, targeting the enzymes that write, read, and erase DNA methylation offers promising therapeutic avenues for diseases driven by epigenetic aberrations.
References
- 1. mdpi.com [mdpi.com]
- 2. epigenie.com [epigenie.com]
- 3. taylorandfrancis.com [taylorandfrancis.com]
- 4. This compound - Wikipedia [en.wikipedia.org]
- 5. Quantitative DNA Methylation Analysis: The Promise of High-Throughput Epigenomic Diagnostic Testing in Human Neoplastic Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 6. This compound turnover: Mechanisms and therapeutic implications in cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 7. New themes in the biological functions of this compound and 5-hydroxymethylcytosine - PMC [pmc.ncbi.nlm.nih.gov]
- 8. encyclopedia.pub [encyclopedia.pub]
- 9. Frontiers | this compound turnover: Mechanisms and therapeutic implications in cancer [frontiersin.org]
- 10. This compound, a possible epigenetic link between ageing and ocular disease - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Direct Homo- and Hetero-Interactions of MeCP2 and MBD2 - PMC [pmc.ncbi.nlm.nih.gov]
- 12. MBD5 and MBD6 couple DNA methylation to gene silencing via the J-domain protein SILENZIO - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Cytosine modifications modulate the chromatin architecture of transcriptional enhancers - PMC [pmc.ncbi.nlm.nih.gov]
- 14. profiles.wustl.edu [profiles.wustl.edu]
- 15. Bisulfite Sequencing (BS-Seq)/WGBS [illumina.com]
- 16. epigenie.com [epigenie.com]
- 17. Principles and Workflow of Whole Genome Bisulfite Sequencing - CD Genomics [cd-genomics.com]
- 18. Bisulfite Sequencing of DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Methyl-CpG-Binding Domain Sequencing: MBD-seq | Springer Nature Experiments [experiments.springernature.com]
- 20. A MBD-seq protocol for large-scale methylome-wide studies with (very) low amounts of DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 21. Chromatin Immunoprecipitation Sequencing (ChIP-seq) Protocol - CD Genomics [cd-genomics.com]
- 22. encodeproject.org [encodeproject.org]
The Biological Functions of 5-Methylcytosine in Mammals: An In-depth Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Executive Summary
5-Methylcytosine (B146107) (5mC) is a critical epigenetic modification in mammals, playing a pivotal role in the regulation of gene expression and the maintenance of genome stability. This technical guide provides a comprehensive overview of the core biological functions of 5mC, its dynamic regulation, and its implications in development and disease. We delve into the molecular mechanisms orchestrated by DNA methyltransferases (DNMTs) and Ten-Eleven Translocation (TET) enzymes, the methodologies used to study this epigenetic mark, and the quantitative landscape of 5mC across various physiological and pathological states. This document is intended to serve as a valuable resource for researchers, scientists, and drug development professionals engaged in the field of epigenetics and its therapeutic applications.
Core Biological Functions of this compound
This compound is a modified form of the DNA base cytosine, where a methyl group is covalently attached to the 5th carbon of the pyrimidine (B1678525) ring.[1] This modification primarily occurs in the context of CpG dinucleotides and is a cornerstone of epigenetic regulation in mammals.[2]
Transcriptional Regulation
The most well-characterized function of 5mC is its role in transcriptional silencing.[3] Methylation of CpG islands, which are CpG-rich regions often located in gene promoters, is strongly associated with stable, long-term gene repression.[3] This silencing can be achieved through two primary mechanisms:
-
Inhibition of Transcription Factor Binding: The presence of a methyl group in the major groove of the DNA can physically hinder the binding of transcription factors to their recognition sequences.[3]
-
Recruitment of Methyl-CpG Binding Proteins: 5mC is recognized by a family of proteins known as Methyl-CpG Binding Domain (MBD) proteins.[4] These proteins, in turn, recruit larger corepressor complexes that include histone deacetylases (HDACs) and other chromatin-modifying enzymes, leading to a more condensed and transcriptionally repressive chromatin state.
Conversely, 5mC within gene bodies is often positively correlated with gene expression, although the precise mechanisms are still under investigation.[5]
Embryonic Development
DNA methylation patterns are dynamically reprogrammed during early embryonic development, a process crucial for establishing cellular identity and pluripotency.[6][7] Following fertilization, the paternal genome undergoes rapid active demethylation, while the maternal genome is passively demethylated through successive cell divisions.[8] De novo methylation, primarily carried out by DNMT3A and DNMT3B, then establishes new, lineage-specific methylation patterns during gastrulation.[5][9] These dynamic changes in 5mC are essential for proper embryogenesis.[6]
Genomic Imprinting and X-Chromosome Inactivation
Genomic imprinting is an epigenetic phenomenon that results in the monoallelic expression of a subset of genes in a parent-of-origin-specific manner. Differentially methylated regions (DMRs) at imprinting control regions (ICRs) are established in the germline and are essential for regulating the expression of imprinted genes.[5]
X-chromosome inactivation (XCI) is the process by which one of the two X chromosomes in female mammals is transcriptionally silenced to ensure dosage compensation with males. The initiation and maintenance of XCI are heavily dependent on DNA methylation.[10]
Genome Stability
5mC plays a crucial role in maintaining genome stability by suppressing the activity of transposable elements and repetitive sequences, which constitute a significant portion of the mammalian genome.[1] Methylation of these elements prevents their transcription and mobilization, thereby reducing the risk of insertional mutagenesis and genomic rearrangements.
The Dynamic Lifecycle of this compound
The levels and patterns of 5mC are dynamically regulated by the opposing actions of DNA methyltransferases (DNMTs) and the Ten-Eleven Translocation (TET) family of dioxygenases.
Establishment and Maintenance of 5mC
-
De novo methylation , the establishment of new methylation patterns, is primarily catalyzed by DNMT3A and DNMT3B .[9]
-
Maintenance methylation , the process of copying existing methylation patterns onto the newly synthesized DNA strand during replication, is carried out by DNMT1 , which has a high affinity for hemimethylated CpG sites.[9]
Demethylation of 5mC
DNA demethylation can occur through two main pathways:
-
Passive Demethylation: This occurs during DNA replication when DNMT1 is not available or is inhibited, leading to a dilution of the methylation mark with each cell division.[3]
-
Active Demethylation: This process is initiated by the TET family of enzymes (TET1, TET2, TET3) , which are α-ketoglutarate-dependent dioxygenases.[11] TET enzymes iteratively oxidize 5mC to 5-hydroxymethylcytosine (B124674) (5hmC), 5-formylcytosine (B1664653) (5fC), and 5-carboxylcytosine (5caC).[2][11] 5fC and 5caC can then be excised by thymine-DNA glycosylase (TDG) and replaced with an unmethylated cytosine through the base excision repair (BER) pathway.[11] 5hmC is now recognized not just as an intermediate in demethylation but as a stable epigenetic mark with its own distinct biological functions.[12][13]
Quantitative Landscape of this compound
The levels of 5mC vary significantly across different tissues, developmental stages, and in disease states. The following tables summarize quantitative data from various studies.
Table 1: Global this compound Levels in Normal Mammalian Tissues
| Tissue | Species | 5mC (% of total Cytosines) | Reference |
| Liver | Human | 3.43 - 4.26 | [14] |
| Lung | Human | 3.43 - 4.26 | [14] |
| Kidney | Human | 3.43 - 4.26 | [14] |
| Spleen | Human | 3.43 - 4.26 | [14] |
| Thyroid | Human | 3.43 - 4.26 | [14] |
| Cerebellum | Human | 3.43 - 4.26 | [14] |
Table 2: Global 5-Hydroxymethylcytosine and this compound Levels in Cancer
| Cancer Type | Tissue | 5hmC (% of total Nucleosides) | 5mC (% of total Nucleosides) | Comparison to Normal | Reference |
| Colorectal Cancer | Tumor | 0.05% | - | Lower 5hmC and 5mC | [15] |
| Colorectal Cancer | Normal | 0.07% | - | [15] | |
| Prostate Cancer | Tumor | - | - | Profoundly reduced 5hmC | [16] |
| Breast Cancer | Tumor | - | - | Profoundly reduced 5hmC | [16] |
| Colon Carcinoma | Tumor | - | - | Profoundly reduced 5hmC | [16] |
| Renal Cell Carcinoma | Tumor | - | - | Dramatically reduced 5hmC | [1] |
| Urothelial Carcinoma | Tumor | - | - | Dramatically reduced 5hmC | [1] |
Table 3: this compound and 5-Hydroxymethylcytosine Levels in Neuronal vs. Glial Cells
| Cell Type | Gene (Region) | 5mC Level | 5hmC Level | Comparison | Reference |
| Neurons | Ntrk2 (DMSs) | Hypermethylated | - | Neurons vs. Astrocytes | [17] |
| Astrocytes | Ntrk2 (DMSs) | Hypomethylated | - | Neurons vs. Astrocytes | [17] |
| Astrocytes | Ntrk2 (DhMRs) | - | Hypermethylated | Astrocytes vs. Neurons | [17] |
Experimental Protocols for this compound Analysis
Several key techniques are employed to study 5mC at both a global and locus-specific level.
Whole Genome Bisulfite Sequencing (WGBS)
WGBS is considered the gold standard for single-base resolution mapping of 5mC across the entire genome.[18][19]
Methodology:
-
DNA Fragmentation: Genomic DNA is fragmented to a desired size range (e.g., 200-500 bp) using sonication.[20]
-
End Repair and A-tailing: The fragmented DNA is end-repaired to create blunt ends, and a single adenine (B156593) nucleotide is added to the 3' ends.[20]
-
Adapter Ligation: Methylated sequencing adapters are ligated to the DNA fragments. These adapters are methylated to protect their cytosines from bisulfite conversion.[21]
-
Bisulfite Conversion: The adapter-ligated DNA is treated with sodium bisulfite, which converts unmethylated cytosines to uracils, while 5-methylcytosines remain unchanged.[19]
-
PCR Amplification: The bisulfite-converted DNA is amplified by PCR to generate a sequencing library.[22]
-
Sequencing: The library is sequenced using a next-generation sequencing platform.
-
Data Analysis: Sequencing reads are aligned to a reference genome, and the methylation status of each cytosine is determined by comparing the sequenced base (C or T) to the reference base (C).
Reduced Representation Bisulfite Sequencing (RRBS)
RRBS is a cost-effective method that enriches for CpG-rich regions of the genome.[21][23]
Methodology:
-
Enzymatic Digestion: Genomic DNA is digested with a methylation-insensitive restriction enzyme, typically MspI, which cuts at CCGG sites, enriching for CpG-containing fragments.[21][23]
-
End Repair and A-tailing: The digested fragments are end-repaired and A-tailed.[23]
-
Adapter Ligation: Methylated sequencing adapters are ligated to the fragments.[23]
-
Size Selection: Fragments of a specific size range (e.g., 40-220 bp) are selected to further enrich for CpG islands.[23]
-
Bisulfite Conversion: The size-selected fragments are treated with sodium bisulfite.[23]
-
PCR Amplification: The converted DNA is amplified.[23]
-
Sequencing and Data Analysis: The library is sequenced, and data is analyzed similarly to WGBS.
Methylated DNA Immunoprecipitation Sequencing (MeDIP-seq)
MeDIP-seq is an enrichment-based method that uses an antibody to specifically pull down methylated DNA fragments.[24][25]
Methodology:
-
DNA Fragmentation: Genomic DNA is sonicated into random fragments.[13]
-
Denaturation: The DNA is heat-denatured to create single-stranded DNA.[13]
-
Immunoprecipitation: The single-stranded DNA is incubated with an antibody that specifically recognizes 5-methylcytidine.[24]
-
Capture of Antibody-DNA Complexes: The antibody-DNA complexes are captured using magnetic beads.[12]
-
Washing and Elution: The beads are washed to remove non-specifically bound DNA, and the methylated DNA is then eluted.[13]
-
Library Preparation and Sequencing: The enriched methylated DNA is used to prepare a sequencing library for next-generation sequencing.
-
Data Analysis: Sequencing reads are mapped to the genome to identify regions with high methylation levels.
Signaling Pathways and Logical Relationships
The following diagrams, generated using the DOT language, illustrate key pathways and workflows related to this compound.
DNA Methylation and Demethylation Cycle
Caption: The dynamic cycle of DNA methylation and active demethylation in mammals.
Experimental Workflow for Whole Genome Bisulfite Sequencing (WGBS)
Caption: A streamlined workflow for Whole Genome Bisulfite Sequencing (WGBS).
Role of 5mC in Cancer-Related Signaling Pathways
Caption: The impact of aberrant this compound patterns on key cancer pathways.
Conclusion and Future Directions
This compound is a fundamental epigenetic mark that governs a multitude of biological processes in mammals. Its dynamic regulation is essential for normal development and cellular function, while its dysregulation is a hallmark of various diseases, most notably cancer. The advent of high-throughput sequencing technologies has revolutionized our ability to study 5mC at a genome-wide scale, providing unprecedented insights into its role in health and disease.
For drug development professionals, the enzymes that write, erase, and read 5mC represent promising therapeutic targets. Inhibitors of DNMTs are already in clinical use for certain hematological malignancies, and the development of more specific and potent modulators of the DNA methylation machinery holds great promise for precision medicine. Furthermore, the distinct 5mC and 5hmC profiles in disease states, particularly the loss of 5hmC in many cancers, are being actively explored as valuable biomarkers for early diagnosis, prognosis, and monitoring of therapeutic response.
Future research will likely focus on elucidating the intricate interplay between 5mC and other epigenetic modifications, understanding the context-dependent functions of 5mC in different genomic regions and cell types, and harnessing this knowledge to develop novel epigenetic therapies for a wide range of human diseases.
References
- 1. Global 5-Hydroxymethylcytosine Levels Are Profoundly Reduced in Multiple Genitourinary Malignancies - PMC [pmc.ncbi.nlm.nih.gov]
- 2. home.cc.umanitoba.ca [home.cc.umanitoba.ca]
- 3. Quantitative assessment of Tet-induced oxidation products of this compound in cellular and tissue DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 4. 5-Hydroxymethylcytosine: a key epigenetic mark in cancer and chemotherapy response - PMC [pmc.ncbi.nlm.nih.gov]
- 5. This compound turnover: Mechanisms and therapeutic implications in cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 6. A Lexicon of DNA Modifications: Their Roles in Embryo Development and the Germline - PMC [pmc.ncbi.nlm.nih.gov]
- 7. The link between 5-hydroxymethylcytosine and DNA demethylation in early embryos - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Tet family of this compound dioxygenases in mammalian development - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. Differences in DNA methylation between human neuronal and glial cells are concentrated in enhancers and non-CpG sites - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Regulation of Canonical Oncogenic Signaling Pathways in Cancer via DNA Methylation | MDPI [mdpi.com]
- 12. chayon.co.kr [chayon.co.kr]
- 13. MeDIP Sequencing Protocol - CD Genomics [cd-genomics.com]
- 14. researchgate.net [researchgate.net]
- 15. Global changes of 5-hydroxymethylcytosine and this compound from normal to tumor tissues are associated with carcinogenesis and prognosis in colorectal cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 16. oncotarget.com [oncotarget.com]
- 17. Neuron and astrocyte specific 5mC and 5hmC signatures of BDNF’s receptor, TrkB - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Whole-Genome Bisulfite Sequencing Protocol for the Analysis of Genome-Wide DNA Methylation and Hydroxymethylation Patterns at Single-Nucleotide Resolution - PubMed [pubmed.ncbi.nlm.nih.gov]
- 19. Principles and Workflow of Whole Genome Bisulfite Sequencing - CD Genomics [cd-genomics.com]
- 20. support.illumina.com [support.illumina.com]
- 21. Reduced representation bisulfite sequencing - Wikipedia [en.wikipedia.org]
- 22. Whole-Genome Bisulfite Sequencing (WGBS) Protocol - CD Genomics [cd-genomics.com]
- 23. What are the steps involved in reduced representation bisulfite sequencing (RRBS)? | AAT Bioquest [aatbio.com]
- 24. Methylated DNA immunoprecipitation (MeDIP) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 25. Protocol for Methylated DNA Immunoprecipitation (MeDIP) Analysis | Springer Nature Experiments [experiments.springernature.com]
5-Methylcytosine: An In-depth Technical Guide to a Core Epigenetic Marker
For Researchers, Scientists, and Drug Development Professionals
Executive Summary
5-Methylcytosine (B146107) (5mC) is a pivotal epigenetic modification, playing a crucial role in the regulation of gene expression and the maintenance of genome stability. This technical guide provides a comprehensive overview of 5mC as a core epigenetic marker. It delves into the molecular mechanisms governing its establishment, removal, and function. Detailed experimental protocols for the analysis of 5mC are provided, alongside a summary of quantitative data on its distribution in human tissues and its deregulation in disease, particularly cancer. Furthermore, this guide explores the clinical significance of 5mC as a biomarker and a therapeutic target, offering insights for researchers and professionals in drug development.
The Core Science of this compound
This compound is a modified form of the DNA base cytosine, where a methyl group is covalently attached to the 5th carbon of the pyrimidine (B1678525) ring.[1] This modification predominantly occurs in the context of CpG dinucleotides (a cytosine followed by a guanine).[1] While not altering the primary DNA sequence, 5mC has profound effects on gene expression.[2]
Gene Regulation: In promoter regions, particularly within CpG islands (regions with a high density of CpG sites), the presence of 5mC is strongly associated with transcriptional silencing.[1] This can occur by directly inhibiting the binding of transcription factors or by recruiting methyl-CpG-binding domain (MBD) proteins, which in turn recruit chromatin remodeling complexes to create a repressive chromatin state.[1]
Genomic Stability: DNA methylation is also crucial for maintaining genomic stability through the silencing of transposable elements and repetitive sequences, preventing their potentially mutagenic activity.
The Dynamic Machinery of DNA Methylation and Demethylation
The levels and patterns of 5mC are dynamically regulated by two families of enzymes: DNA methyltransferases (DNMTs) and Ten-Eleven Translocation (TET) enzymes.
DNA Methyltransferases (DNMTs): These enzymes catalyze the transfer of a methyl group from S-adenosylmethionine (SAM) to cytosine.[3]
-
DNMT1 is the maintenance methyltransferase that copies existing methylation patterns onto the newly synthesized strand during DNA replication.[4]
-
DNMT3A and DNMT3B are the de novo methyltransferases that establish new methylation patterns during development and cellular differentiation.[4]
Ten-Eleven Translocation (TET) Enzymes: These enzymes initiate the process of DNA demethylation by iteratively oxidizing 5mC.[5] This process is dependent on the cofactor α-ketoglutarate (α-KG).[5][6][7]
-
TET enzymes convert 5mC to 5-hydroxymethylcytosine (B124674) (5hmC).[8]
-
Further oxidation by TET enzymes can lead to the formation of 5-formylcytosine (B1664653) (5fC) and 5-carboxylcytosine (5caC).[2][8][9]
-
These oxidized forms can be recognized and excised by the base excision repair (BER) machinery, ultimately replacing the modified cytosine with an unmodified one.[8]
Quantitative Landscape of this compound
The abundance of 5mC and its oxidized derivative, 5hmC, varies significantly across different human tissues and is often altered in disease states.
Table 1: Global Levels of this compound (5mC) and 5-Hydroxymethylcytosine (5hmC) in Normal Human Tissues
| Tissue | % 5mC of total Cytosine (approx.) | % 5hmC of total Cytosine | Reference |
| Brain | ~4.0% | 0.67% | [10] |
| Liver | N/A | 0.46% | [10] |
| Kidney | N/A | 0.38% | [10] |
| Colon | N/A | 0.45% | [10] |
| Rectum | N/A | 0.57% | [10] |
| Lung | N/A | 0.14% - 0.18% | [10] |
| Heart | N/A | 0.05% | [10] |
| Breast | N/A | 0.05% | [10] |
| Placenta | N/A | 0.06% | [10] |
| Thymus | 1.00 (mole % 5mC) | N/A | [11] |
| Sperm | 0.84 (mole % 5mC) | N/A | [11] |
Note: Data for % 5mC and % 5hmC are from different studies and methodologies, hence direct comparison should be made with caution.
Table 2: Aberrant this compound and 5-Hydroxymethylcytosine Levels in Cancer
| Cancer Type | Change in Global 5mC | Change in Global 5hmC | CpG Island Methylation Changes | Reference |
| Colorectal Cancer | Lower in tumor vs. normal | Significantly reduced in tumor (0.02-0.06% vs 0.46-0.57%) | Hypermethylation of specific gene promoters | [10][12] |
| Lung Cancer | Depleted in most tumors | Depleted up to 5-fold in squamous cell carcinoma | Hypermethylation of specific gene promoters | [13] |
| Breast Cancer | N/A | Low levels in normal tissue | 15-24% of CpG islands hypermethylated in cell lines | [14] |
| Prostate Cancer | N/A | Profoundly reduced | Hypermethylation of specific gene promoters | [15] |
| Gastric Cancer | N/A | N/A | High frequency of methylated genes (average of 6.5 genes out of 13 studied) | [16] |
| Liver Cancer | N/A | N/A | High frequency of methylated genes (average of 4.4 genes out of 13 studied) | [16] |
| Brain Tumors | N/A | Drastically reduced (up to >30-fold) | N/A | [13] |
Experimental Protocols for this compound Analysis
A variety of techniques are available to analyze DNA methylation, ranging from global quantification to single-base resolution mapping.
Whole-Genome Bisulfite Sequencing (WGBS)
WGBS is considered the gold standard for single-base resolution, genome-wide methylation profiling.
Methodology:
-
DNA Fragmentation: High-molecular-weight genomic DNA is fragmented to a desired size range (e.g., 200-500 bp) using sonication or enzymatic digestion.
-
End Repair and A-tailing: The fragmented DNA is end-repaired to create blunt ends, and a single adenine (B156593) nucleotide is added to the 3' ends.
-
Adapter Ligation: Methylated sequencing adapters are ligated to the DNA fragments. These adapters contain 5mC instead of cytosine to protect them from bisulfite conversion.
-
Bisulfite Conversion: The adapter-ligated DNA is treated with sodium bisulfite, which converts unmethylated cytosines to uracil, while 5mC residues remain unchanged.
-
PCR Amplification: The bisulfite-converted DNA is amplified by PCR to generate a sequencing library. During PCR, uracils are replaced by thymines.
-
Sequencing: The library is sequenced using next-generation sequencing platforms.
-
Data Analysis: Sequencing reads are aligned to a reference genome, and the methylation status of each cytosine is determined by comparing the sequenced reads to the reference. A cytosine that remains a cytosine was methylated, while one that is read as a thymine (B56734) was unmethylated.
Methylated DNA Immunoprecipitation (MeDIP)
MeDIP is an enrichment-based method that uses an antibody to isolate methylated DNA fragments.
Methodology:
-
DNA Fragmentation: Genomic DNA is fragmented by sonication.
-
Denaturation: The fragmented DNA is denatured to produce single-stranded DNA.
-
Immunoprecipitation: The single-stranded DNA is incubated with an antibody specific for 5mC.
-
Capture of Antibody-DNA Complexes: Protein A/G beads are used to capture the antibody-DNA complexes.
-
Washing: Unbound DNA is washed away.
-
Elution and Proteinase K Treatment: The enriched methylated DNA is eluted from the beads, and the antibody is digested with proteinase K.
-
DNA Purification: The methylated DNA is purified.
-
Downstream Analysis: The enriched DNA can be analyzed by qPCR, microarrays (MeDIP-chip), or next-generation sequencing (MeDIP-seq).[2][5]
Pyrosequencing
Pyrosequencing is a real-time sequencing method that can be used to quantify the methylation level of specific CpG sites.
Methodology:
-
Bisulfite Conversion: Genomic DNA is treated with sodium bisulfite.
-
PCR Amplification: The target region is amplified by PCR using one biotinylated primer.
-
Template Preparation: The biotinylated PCR products are captured on streptavidin-coated beads, and the non-biotinylated strand is removed to generate single-stranded templates.
-
Sequencing Primer Annealing: A sequencing primer is annealed to the single-stranded template.
-
Pyrosequencing Reaction: The pyrosequencing reaction is performed in a series of steps where individual deoxynucleotides are added sequentially. The incorporation of a nucleotide generates a light signal that is proportional to the number of incorporated nucleotides.
-
Data Analysis: The methylation percentage at each CpG site is calculated from the ratio of cytosine to thymine signals.[17][18][19]
Clinical Significance and Drug Development
Aberrant DNA methylation is a hallmark of many diseases, most notably cancer, making 5mC a valuable biomarker and a promising target for therapeutic intervention.
This compound as a Biomarker
-
Cancer Diagnosis and Prognosis: Specific hypermethylation patterns in the promoter regions of tumor suppressor genes can serve as biomarkers for the early detection and prognosis of various cancers.[20][21][22][23] For example, analysis of 5mC in circulating cell-free DNA (cfDNA) is a promising non-invasive approach for cancer screening.[22]
-
Disease Monitoring: Changes in 5mC patterns can be used to monitor disease progression and response to therapy.
Drug Development Targeting DNA Methylation
The reversibility of epigenetic modifications makes them attractive targets for drug development.
DNMT Inhibitors:
-
Mechanism of Action: Nucleoside analogs such as Azacitidine (Vidaza) and Decitabine (Dacogen) are incorporated into DNA and trap DNMTs, leading to their degradation and subsequent passive demethylation during DNA replication.[4][17][24]
-
Clinical Applications: These drugs are approved by the FDA for the treatment of myelodysplastic syndromes (MDS) and acute myeloid leukemia (AML).[4][24][25]
TET Enzyme Modulators:
-
Research is ongoing to develop small molecules that can modulate the activity of TET enzymes. This could involve compounds that enhance TET activity to promote demethylation or inhibitors for specific contexts.
Table 3: Selected Epigenetic Drugs Targeting DNA Methylation
| Drug Name (Brand Name) | Target | Mechanism of Action | Approved Indications | Status | Reference |
| Azacitidine (Vidaza) | DNMTs | Nucleoside analog, DNMT trapping | Myelodysplastic Syndromes (MDS), Acute Myeloid Leukemia (AML) | Approved | [4][24][25] |
| Decitabine (Dacogen) | DNMTs | Nucleoside analog, DNMT trapping | Myelodysplastic Syndromes (MDS), Acute Myeloid Leukemia (AML) | Approved | [4][17][24] |
| Guadecitabine (SGI-110) | DNMTs | Dinucleotide prodrug of decitabine | Various cancers | Clinical Trials | [26] |
Conclusion and Future Directions
This compound stands as a central pillar in the field of epigenetics, with its role in gene regulation and disease pathogenesis firmly established. The continuous refinement of detection technologies is enabling a more detailed and comprehensive understanding of the methylome. For researchers and drug development professionals, the dynamic nature of 5mC offers a wealth of opportunities. Future research will likely focus on elucidating the complex interplay between DNA methylation and other epigenetic modifications, developing more specific and potent epigenetic drugs with fewer side effects, and harnessing the power of liquid biopsies for real-time monitoring of methylation changes in response to treatment. The journey from understanding the fundamental biology of 5mC to its successful application in the clinic is well underway, promising a future of more personalized and effective therapies for a range of diseases.
References
- 1. mdpi.com [mdpi.com]
- 2. researchgate.net [researchgate.net]
- 3. researchgate.net [researchgate.net]
- 4. Targeting DNA Methylation for Epigenetic Therapy - PMC [pmc.ncbi.nlm.nih.gov]
- 5. TET enzymes - Wikipedia [en.wikipedia.org]
- 6. rep.bioscientifica.com [rep.bioscientifica.com]
- 7. researchgate.net [researchgate.net]
- 8. researchgate.net [researchgate.net]
- 9. 5-Carboxylcytosine - Wikipedia [en.wikipedia.org]
- 10. Distribution of 5-Hydroxymethylcytosine in Different Human Tissues - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. Global changes of 5-hydroxymethylcytosine and this compound from normal to tumor tissues are associated with carcinogenesis and prognosis in colorectal cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 13. 5-hydroxymethylcytosine is strongly depleted in human cancers but its levels do not correlate with IDH1 mutations - PMC [pmc.ncbi.nlm.nih.gov]
- 14. academic.oup.com [academic.oup.com]
- 15. Global 5-hydroxymethylcytosine content is significantly reduced in tissue stem/progenitor cell compartments and in human cancers - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Methylation Profiles of CpG Island Loci in Major Types of Human Cancers - PMC [pmc.ncbi.nlm.nih.gov]
- 17. aacrjournals.org [aacrjournals.org]
- 18. researchgate.net [researchgate.net]
- 19. S-Adenosylmethionine and methylation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 20. jcp.bmj.com [jcp.bmj.com]
- 21. Short history of this compound: from discovery to clinical applications - PubMed [pubmed.ncbi.nlm.nih.gov]
- 22. Towards precision medicine: advances in 5-hydroxymethylcytosine cancer biomarker discovery in liquid biopsy - PMC [pmc.ncbi.nlm.nih.gov]
- 23. biorxiv.org [biorxiv.org]
- 24. Advances in epigenetic therapeutics with focus on solid tumors - PMC [pmc.ncbi.nlm.nih.gov]
- 25. Epigenetic drugs in cancer therapy - PMC [pmc.ncbi.nlm.nih.gov]
- 26. Current Approaches to Epigenetic Therapy - PMC [pmc.ncbi.nlm.nih.gov]
The Dawn of a Fifth Base: An In-depth Technical Guide to the Discovery and History of 5-Methylcytosine
For Researchers, Scientists, and Drug Development Professionals
Introduction
The landscape of genetics was once thought to be elegantly simple, defined by the four canonical bases of DNA: adenine, guanine (B1146940), cytosine, and thymine. However, lurking in the shadows of this fundamental code was a fifth base, a subtle modification that would revolutionize our understanding of gene regulation and cellular function. This technical guide delves into the discovery and history of 5-methylcytosine (B146107) (5mC), a pivotal epigenetic marker. We will journey through the seminal experiments that unveiled its existence, explore the development of techniques to study it, and chart the discovery of the enzymatic machinery that governs its placement and function. This guide is intended for researchers, scientists, and drug development professionals seeking a comprehensive understanding of the origins of this critical component of the epigenome.
The Initial Discovery: Unveiling a Modified Pyrimidine (B1678525)
The story of this compound begins not in the realm of complex eukaryotic genetics, but within the study of bacteria. In the late 19th and early 20th centuries, chemists were diligently working to unravel the chemical constituents of nucleic acids.
The first hint of a modified base came in 1898 when W.G. Ruppel isolated a novel nucleic acid, which he named "tuberculinic acid," from Tubercle bacillus. It was later, in the 1920s, that 5mC was confirmed as a hydrolysis product of nucleic acids from Bacillus tuberculosis, identifying it as the fourth distinct pyrimidine base.
However, it was the meticulous work of Rollin Hotchkiss in 1948 that firmly established the presence of 5mC in higher eukaryotes. While studying the components of nucleic acids from calf thymus, he observed an additional, unexpected spot on his paper chromatograms, which he termed 'epicytosine'.[1] This discovery marked a turning point, suggesting that the genetic code was more nuanced than previously imagined.
A few years later, in 1951, Gerard Wyatt expanded on Hotchkiss's findings, demonstrating the presence of 5mC in a variety of species, including beef spleen, ram sperm, herring sperm, and wheat germ.[2][3] His work solidified the notion that 5mC was a widespread, conserved feature of DNA.
Experimental Protocols: Paper Chromatography for Base Separation
The primary tool for these early discoveries was paper chromatography, a technique that separates chemical substances based on their differential partitioning between a stationary phase (the paper) and a mobile phase (a solvent).
Hotchkiss's 1948 Protocol for the Separation of Pyrimidines:
-
DNA Hydrolysis: DNA was hydrolyzed to its constituent bases by heating in a strong acid (e.g., perchloric acid or formic acid).[4]
-
Chromatography Paper: Whatman No. 1 filter paper was used as the stationary phase.
-
Solvent System (Mobile Phase): A mixture of n-butanol, water, and morpholine (B109124) was commonly used. The exact ratios were optimized to achieve the best separation of the bases. A typical system involved a mixture of butanol, water, and picric acid.
-
Development: The chromatogram was developed by allowing the solvent to ascend the paper strip in a sealed tank saturated with the solvent vapor. This process could take several hours.
-
Visualization: The separated bases were visualized as dark spots under ultraviolet (UV) light.
-
Elution and Quantification: The spots corresponding to each base were cut out from the paper, and the base was eluted using a known volume of acid (e.g., 0.1 N HCl). The concentration of each base was then determined spectrophotometrically by measuring its UV absorbance at its characteristic maximum wavelength.
Wyatt's 1951 Modifications for the Estimation of this compound:
Wyatt refined the paper chromatography technique to improve the separation and quantification of 5mC.
-
Hydrolysis: He utilized formic acid for hydrolysis, which he found to give good yields of the bases.[4]
-
Solvent System: To overcome the low solubility of guanine and achieve better separation of all bases, including 5mC, Wyatt tested numerous solvent systems. He ultimately selected a combination of isopropanol (B130326) and hydrochloric acid (HCl), which produced compact spots and clear separation of guanine, adenine, cytosine, thymine, and this compound.[4]
The workflow for these pioneering experiments can be visualized as follows:
Early Quantitative Analysis of this compound
Wyatt's 1951 paper not only confirmed the existence of 5mC in various species but also provided the first quantitative data on its abundance. These early studies revealed that the amount of 5mC varied significantly between different organisms.
| Organism | Tissue/Source | Mole % this compound (of total bases) | Reference |
| Calf | Thymus | 1.4 | Wyatt, 1951 |
| Beef | Spleen | 1.3 | Wyatt, 1951 |
| Ram | Sperm | 1.3 | Wyatt, 1951 |
| Herring | Sperm | 0.9 | Wyatt, 1951 |
| Locust | Whole | 0.3 | Wyatt, 1951 |
| Wheat | Germ | 6.0 | Wyatt, 1951 |
These findings were crucial as they demonstrated that DNA methylation was not a random occurrence but a species-specific characteristic, hinting at a potential functional role.
The Advent of Methylation-Sensitive Restriction Enzymes
A major leap forward in the study of 5mC came in 1978 with the application of methylation-sensitive restriction enzymes. Cees Waalwijk and Richard Flavell published a seminal paper describing the use of the isoschizomers HpaII and MspI to probe the methylation status of specific DNA sequences.[3]
Isoschizomers are restriction enzymes that recognize the same DNA sequence but may have different sensitivities to methylation within that sequence. HpaII and MspI both recognize the sequence 5'-CCGG-3'. However, their cutting activity is affected differently by the methylation of the internal cytosine:
-
HpaII: Is sensitive to methylation of the internal cytosine. It will not cut if the internal C is methylated (C-5mC-G-G).
-
MspI: Is insensitive to methylation of the internal cytosine. It will cut regardless of the methylation status of the internal C.
This differential sensitivity provided a powerful tool to interrogate the methylation status of specific CCGG sites within the genome.
Experimental Protocol: HpaII/MspI Digestion and Southern Blotting
The general workflow for using HpaII and MspI to analyze DNA methylation is as follows:
-
DNA Extraction: High-quality genomic DNA is extracted from the tissue or cells of interest.
-
Restriction Enzyme Digestion: The DNA is divided into three aliquots:
-
One aliquot is digested with HpaII.
-
A second aliquot is digested with MspI.
-
A third aliquot remains undigested as a control.
-
Digestion Conditions: Digestions are typically carried out overnight at 37°C in a buffer supplied by the enzyme manufacturer. The specific buffer composition ensures optimal enzyme activity.
-
-
Agarose (B213101) Gel Electrophoresis: The digested DNA fragments are separated by size on an agarose gel.
-
Southern Blotting: The DNA fragments are transferred from the gel to a nitrocellulose or nylon membrane.
-
Hybridization: The membrane is incubated with a radiolabeled DNA probe specific to the gene or region of interest.
-
Autoradiography: The membrane is exposed to X-ray film. The resulting bands reveal the size of the DNA fragments that hybridized with the probe.
By comparing the banding patterns of the HpaII- and MspI-digested DNA, researchers could infer the methylation status of the CCGG sites within the region of interest.
The Discovery of DNA Methyltransferases (DNMTs)
The existence of 5mC begged the question: what is the enzymatic machinery responsible for its creation and maintenance? The search for these enzymes, the DNA methyltransferases (DNMTs), was a critical next step in understanding the biological significance of DNA methylation.
The Discovery of DNMT1: The Maintenance Methyltransferase
In 1988, Timothy Bestor and his colleagues reported the cloning and sequencing of a cDNA encoding a mammalian DNA methyltransferase, which would later be named DNMT1 .[5][6] Their work revealed that the C-terminal domain of this enzyme showed significant homology to bacterial cytosine methyltransferases, suggesting a common evolutionary origin. The N-terminal domain, however, was much larger and its function was initially unknown, though it was speculated to have a regulatory role.[6]
Subsequent studies demonstrated that DNMT1 has a preference for hemimethylated DNA (DNA where only one strand is methylated), which is the state of DNA immediately after replication. This led to the model of DNMT1 as the "maintenance" methyltransferase, responsible for faithfully copying the methylation pattern from the parental strand to the newly synthesized daughter strand during cell division.
The Discovery of DNMT3A and DNMT3B: The De Novo Methyltransferases
For years, DNMT1 was thought to be the sole DNA methyltransferase in mammals. However, the observation that embryonic stem cells lacking DNMT1 could still establish new methylation patterns suggested the existence of other methyltransferases.
In 1998, the laboratories of En Li and Masaki Okano independently reported the cloning of two novel DNA methyltransferase genes, Dnmt3a and Dnmt3b .[7][8][9] These enzymes were shown to be responsible for de novo methylation, the process of establishing new methylation patterns during development and in response to cellular signals. Unlike DNMT1, DNMT3A and DNMT3B do not show a strong preference for hemimethylated DNA and can methylate completely unmethylated DNA.
The discovery of these three key DNMTs provided the molecular basis for understanding how DNA methylation patterns are established, maintained, and dynamically regulated.
Conclusion
The journey from the initial observation of an anomalous spot on a paper chromatogram to the elucidation of the complex enzymatic machinery that governs DNA methylation is a testament to the power of meticulous scientific inquiry. The discovery of this compound and the subsequent unraveling of its history have fundamentally altered our understanding of heredity and gene regulation. This "fifth base" is no longer an obscure chemical modification but a central player in development, disease, and the intricate dance between our genes and the environment. For researchers and drug development professionals, a deep appreciation of this history is essential for navigating the complexities of the epigenome and harnessing its therapeutic potential. The foundational experiments and discoveries outlined in this guide provide the bedrock upon which the ever-expanding field of epigenetics is built.
References
- 1. (Open Access) The quantitative separation of purines, pyrimidines, and nucleosides by paper chromatography (1948) | Rollin D. Hotchkiss | 727 Citations [scispace.com]
- 2. jcp.bmj.com [jcp.bmj.com]
- 3. jcp.bmj.com [jcp.bmj.com]
- 4. garfield.library.upenn.edu [garfield.library.upenn.edu]
- 5. Cloning of a mammalian DNA methyltransferase - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Cloning and sequencing of a cDNA encoding DNA methyltransferase of mouse cells. The carboxyl-terminal domain of the mammalian enzymes is related to bacterial restriction methyltransferases - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Cloning and characterization of a family of novel mammalian DNA (cytosine-5) methyltransferases - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. DNA methyltransferases Dnmt3a and Dnmt3b are essential for de novo methylation and mammalian development - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Genetic analyses of DNA methyltransferase genes in mouse model system - PubMed [pubmed.ncbi.nlm.nih.gov]
The Core Mechanism of DNMT-mediated 5-Methylcytosine Formation
An In-depth Technical Guide on the Core Mechanism of 5-Methylcytosine (B146107) Formation by DNA Methyltransferases (DNMTs)
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive overview of the molecular mechanisms underlying the formation of this compound (5mC) by DNA methyltransferases (DNMTs), central enzymes in epigenetic regulation. It covers the catalytic cycle, enzyme kinetics, and detailed experimental protocols for studying DNMT activity, designed for professionals in biomedical research and drug development.
DNA methylation is a fundamental epigenetic modification involving the covalent addition of a methyl group to the C5 position of a cytosine pyrimidine (B1678525) ring, forming this compound (5mC).[1] This reaction is catalyzed by a family of enzymes known as DNA methyltransferases (DNMTs), which utilize S-adenosyl-L-methionine (SAM) as the methyl group donor.[1] In mammals, this process is primarily carried out by three key enzymes: DNMT1, DNMT3A, and DNMT3B.
-
DNMT1: The Maintenance Methyltransferase DNMT1 is predominantly responsible for maintaining existing DNA methylation patterns following DNA replication. It recognizes hemimethylated CpG sites on the newly synthesized DNA strand and methylates the corresponding cytosine, ensuring the faithful propagation of the epigenetic code through cell division.[2]
-
DNMT3A and DNMT3B: The De Novo Methyltransferases DNMT3A and DNMT3B are primarily responsible for establishing new DNA methylation patterns during embryonic development and in response to cellular signaling.[2] They can methylate both unmethylated and hemimethylated DNA, playing a crucial role in cellular differentiation and gene regulation. While they have distinct and overlapping functions, DNMT3A is essential for postnatal development, whereas DNMT3B is critical during embryogenesis.
The Catalytic Cycle of this compound Formation
The formation of 5mC by DNMTs is a multi-step enzymatic process:
-
Base Flipping: The target cytosine base is flipped out of the DNA double helix and into the catalytic pocket of the DNMT enzyme. This conformational change makes the C5 position of the cytosine accessible for the methylation reaction.
-
Nucleophilic Attack: A conserved cysteine residue within the DNMT's active site performs a nucleophilic attack on the C6 position of the cytosine ring. This forms a transient covalent intermediate between the enzyme and the DNA.
-
Methyl Group Transfer: The methyl group from the cofactor S-adenosyl-L-methionine (SAM) is transferred to the C5 position of the activated cytosine.
-
Resolution: The covalent bond between the enzyme and the DNA is resolved, and the newly methylated cytosine is flipped back into the DNA helix. S-adenosyl-L-homocysteine (SAH) is released as a byproduct.
Quantitative Data on DNMT Activity
The enzymatic activity of DNMTs can be characterized by their kinetic parameters, such as the Michaelis constant (Km) and the catalytic rate (kcat). These parameters provide insights into the substrate affinity and turnover rate of the enzymes. The inhibitory potential of various compounds is quantified by the half-maximal inhibitory concentration (IC50).
Kinetic Parameters of DNMTs
The kinetic parameters of DNMTs can vary depending on the specific enzyme, the substrate (unmethylated vs. hemimethylated DNA), and the experimental conditions.
| Enzyme | Substrate | Km (DNA) (µM) | kcat (h⁻¹) | Reference |
| DNMT1 | Hemimethylated DNA | ~0.4 | ~13.5 - 14.5 | [3][4] |
| DNMT3A | Unmethylated poly(dG-dC) | ~0.2 | ~1.8 | Madel et al., 2002 (PMID: 12135593) |
| DNMT3B | Unmethylated poly(dG-dC) | ~0.3 | ~1.3 | Madel et al., 2002 (PMID: 12135593) |
Note: The kcat values for DNMT1 were determined using poly(dI-dC)-poly(dI-dC) as the methyl acceptor.
IC50 Values of Common DNMT Inhibitors
Several small molecules have been identified as inhibitors of DNMTs, some of which are used in cancer therapy.
| Inhibitor | Target(s) | IC50 | Reference |
| 5-Azacytidine | DNMTs | ~0.019 µg/ml | [5] |
| Decitabine (5-aza-2'-deoxycytidine) | DNMTs | Varies | - |
| RG108 | DNMT1 | 115 nM | [6] |
| SGI-1027 | DNMT1, DNMT3A, DNMT3B | ~0.25 µM | Datta et al., 2009 (PMID: 19696025) |
| Zebularine | DNMTs | Varies | - |
Experimental Protocols for Studying DNMT Activity
Several methods are available to measure DNMT activity and to screen for inhibitors. Below are detailed protocols for three common assays.
Radioactive Filter Binding Assay
This assay measures the incorporation of a radiolabeled methyl group from [³H]-SAM into a DNA substrate.
Materials:
-
Purified DNMT enzyme
-
DNA substrate (e.g., poly(dI-dC) or a specific oligonucleotide)
-
[³H]-S-adenosyl-L-methionine
-
Assay Buffer (e.g., 20 mM HEPES pH 7.2, 1 mM EDTA, 50 mM KCl)
-
Nitrocellulose and DE81 ion-exchange filter papers
-
Wash Buffer (e.g., 5% trichloroacetic acid (TCA))
-
Scintillation cocktail and counter
Procedure:
-
Reaction Setup: In a microcentrifuge tube, prepare the reaction mixture containing the assay buffer, DNA substrate (e.g., 0.5 µg poly(dI-dC)), and purified DNMT enzyme (e.g., 100-500 ng).
-
Initiation: Start the reaction by adding [³H]-SAM (e.g., to a final concentration of 1 µM).
-
Incubation: Incubate the reaction at 37°C for a specified time (e.g., 1 hour).
-
Termination: Stop the reaction by adding an equal volume of ice-cold 10% TCA.
-
Precipitation: Incubate on ice for 30 minutes to precipitate the DNA.
-
Filtration: Spot the reaction mixture onto a DE81 filter paper.
-
Washing: Wash the filter paper three times with 5% TCA to remove unincorporated [³H]-SAM.
-
Drying: Wash the filter with ethanol (B145695) and let it air dry.
-
Quantification: Place the filter in a scintillation vial with a scintillation cocktail and measure the incorporated radioactivity using a scintillation counter.
MTase-Glo™ Bioluminescent Assay
This commercially available assay (Promega) measures the production of SAH, a universal byproduct of methylation reactions, through a coupled-enzyme system that generates a luminescent signal.[7][8][9][10]
Materials:
-
MTase-Glo™ Reagent and Detection Solution (Promega)
-
Purified DNMT enzyme
-
DNA substrate
-
SAM
-
White, opaque 96- or 384-well plates
-
Luminometer
Procedure:
-
Reaction Setup: In a well of a white assay plate, set up the methyltransferase reaction containing the DNMT enzyme, DNA substrate, and SAM in the appropriate reaction buffer. The final volume is typically 5-20 µL.
-
Incubation: Incubate the plate at the desired temperature (e.g., 37°C) for the desired time (e.g., 60 minutes).
-
SAH to ADP Conversion: Add an equal volume of MTase-Glo™ Reagent to each well. This reagent contains enzymes that convert SAH to ADP.
-
Incubation: Incubate at room temperature for 30 minutes.
-
ADP to ATP to Light Conversion: Add an equal volume of MTase-Glo™ Detection Solution to each well. This solution contains enzymes that convert ADP to ATP, which is then used by luciferase to generate light.
-
Incubation: Incubate at room temperature for 30 minutes.
-
Measurement: Measure the luminescence using a plate-reading luminometer. The light output is proportional to the amount of SAH produced, and thus to the DNMT activity.
In Vitro Methylation Followed by Bisulfite Sequencing
This method allows for the analysis of methylation patterns at single-nucleotide resolution on a specific DNA fragment after in vitro methylation by a DNMT.
Materials:
-
Purified DNMT enzyme
-
Unmethylated DNA substrate of interest (e.g., a PCR product or plasmid)
-
SAM
-
DNMT reaction buffer
-
Bisulfite conversion kit
-
PCR primers specific for the bisulfite-converted DNA
-
DNA polymerase suitable for PCR of bisulfite-treated DNA
-
Sanger or next-generation sequencing platform
Procedure:
-
In Vitro Methylation: Perform an in vitro methylation reaction as described in the radioactive assay protocol, but using non-radiolabeled SAM.
-
DNA Purification: Purify the methylated DNA to remove the enzyme and other reaction components.
-
Bisulfite Conversion: Treat the purified DNA with sodium bisulfite using a commercial kit or a standard protocol. This converts unmethylated cytosines to uracil, while 5mC remains unchanged.[11]
-
PCR Amplification: Amplify the region of interest from the bisulfite-converted DNA using primers designed to be specific for the converted sequence.
-
Sequencing: Sequence the PCR product.
-
Data Analysis: Align the sequencing reads to the original reference sequence. Unmethylated cytosines will appear as thymines, while methylated cytosines will remain as cytosines. The percentage of methylation at each CpG site can then be calculated.
Visualization of Key Molecular Interactions and Workflows
Visual representations of the catalytic mechanism and experimental procedures can aid in understanding the complex processes involved in DNMT function.
This guide provides a foundational understanding of the mechanism of this compound formation by DNMTs and practical guidance for its study in a research setting. For further details on specific applications and troubleshooting, consulting the original research articles and manufacturer's protocols is recommended.
References
- 1. researchgate.net [researchgate.net]
- 2. researchgate.net [researchgate.net]
- 3. dasher.wustl.edu [dasher.wustl.edu]
- 4. researchgate.net [researchgate.net]
- 5. researchgate.net [researchgate.net]
- 6. epigenome-noe.net [epigenome-noe.net]
- 7. promega.com [promega.com]
- 8. MTase-Glo™ Methyltransferase Assay [promega.com]
- 9. Filter binding assay - Wikipedia [en.wikipedia.org]
- 10. Methyltransferase-Glo: a universal, bioluminescent and homogenous assay for monitoring all classes of methyltransferases - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. files01.core.ac.uk [files01.core.ac.uk]
5-Methylcytosine Patterns in Embryonic Development: An In-depth Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Introduction
5-methylcytosine (B146107) (5mC) is a critical epigenetic modification that plays a fundamental role in regulating gene expression and maintaining genome stability during embryonic development. The dynamic patterns of 5mC, established and removed by a delicate interplay of enzymes, are essential for processes such as genomic imprinting, X-chromosome inactivation, and the silencing of transposable elements.[1] This technical guide provides a comprehensive overview of this compound dynamics during embryogenesis, details key experimental methodologies for its study, and visualizes the core signaling pathways involved.
Core Concepts: The Enzymatic Machinery of DNA Methylation
The landscape of 5mC is dynamically shaped by two key families of enzymes: DNA methyltransferases (DNMTs) and Ten-eleven translocation (TET) enzymes.
-
DNA Methyltransferases (DNMTs): These enzymes are responsible for establishing and maintaining DNA methylation patterns.
-
De novo methyltransferases (DNMT3A and DNMT3B): These enzymes establish new methylation patterns on unmethylated DNA, a crucial process during early embryonic development and gametogenesis.[2] DNMT3B is particularly active in early embryos and during implantation, while DNMT3A plays a more prominent role in later stages of development and cell differentiation.[2]
-
Maintenance methyltransferase (DNMT1): Following DNA replication, DNMT1 recognizes hemi-methylated DNA strands and methylates the newly synthesized strand, ensuring the faithful propagation of methylation patterns through cell divisions.[2]
-
-
Ten-eleven Translocation (TET) Enzymes: The TET family of dioxygenases (TET1, TET2, and TET3) are responsible for the oxidative demethylation of 5mC. This process occurs through a series of intermediates:
-
5-formylcytosine (5fC)
-
5-carboxylcytosine (5caC)
These oxidized forms can be passively diluted through DNA replication or actively excised by Thymine DNA Glycosylase (TDG) followed by base excision repair, ultimately leading to the restoration of an unmethylated cytosine.[2]
Dynamic Waves of this compound Reprogramming in Embryonic Development
Mammalian embryonic development is characterized by two major waves of genome-wide DNA demethylation and subsequent remethylation, which are critical for erasing epigenetic memory and establishing pluripotency.
First Wave: Pre-implantation Development
Following fertilization, the embryonic genome undergoes a massive reprogramming of 5mC.
-
Paternal Genome: The paternal pronucleus undergoes rapid and active demethylation, a process largely mediated by TET3.[3] This is characterized by a significant increase in 5hmC levels.
-
Maternal Genome: The maternal pronucleus undergoes a more gradual, passive demethylation over subsequent cell divisions.
This global demethylation reaches its lowest point at the blastocyst stage.[4] Following implantation, de novo methylation is initiated by DNMT3A and DNMT3B, re-establishing methylation patterns in the developing embryo.
Second Wave: Primordial Germ Cells (PGCs)
The second wave of demethylation occurs in primordial germ cells, the precursors to gametes. This process erases genomic imprints and ensures the totipotency of the germline. PGCs undergo a profound genome-wide demethylation, reaching the lowest levels of 5mC observed in any normal cell type.[4] This is followed by sex-specific de novo methylation during gametogenesis.
Quantitative Dynamics of 5mC and 5hmC During Embryonic Development
The following tables summarize the global levels of this compound and 5-hydroxymethylcytosine at key stages of mouse embryonic development, providing a quantitative overview of the epigenetic reprogramming waves.
| Developmental Stage | Global 5mC Level (% of total Cytosines) | Key Events | Reference |
| Sperm | ~75-80% | Highly methylated paternal genome. | [4] |
| Oocyte | ~50% | Moderately methylated maternal genome. | [4] |
| Zygote (10h post-fertilization) | ~40% decline from initial levels | Active demethylation of the paternal genome. | [5] |
| 8-cell Stage (Natural Mating) | Slight decrease from zygote | Gradual passive demethylation. | [1] |
| Blastocyst | ~20% | Global hypomethylation. | [4] |
| Post-implantation Epiblast | Increasing | De novo methylation wave. | [4] |
| Primordial Germ Cells (E10.5-13.5) | ~3-7% | Second wave of global demethylation. | [4] |
| Developmental Stage | Global 5hmC Level | Key Events | Reference |
| Zygote (Paternal Pronucleus) | High | TET3-mediated oxidation of 5mC. | [3] |
| Pre-implantation Embryo | Gradually decreasing | Passive dilution through cell division. | [3] |
| Primordial Germ Cells (E9.5-11.5) | Low initially, then peaks at E11.5 | TET1/TET2-mediated conversion of 5mC to 5hmC. | [6][7] |
| Primordial Germ Cells (E11.5-E13.5) | Gradually decreasing | Replication-dependent dilution. | [6][7] |
Signaling Pathways and Experimental Workflows
DNA Methylation and Demethylation Cycle
Epigenetic Reprogramming in Early Mammalian Development
Experimental Protocols
A variety of techniques are employed to study this compound and its derivatives. Below are overviews of the core methodologies.
Whole Genome Bisulfite Sequencing (WGBS)
WGBS is considered the "gold standard" for single-base resolution mapping of 5mC.
Principle: Treatment of genomic DNA with sodium bisulfite converts unmethylated cytosines to uracil, while 5-methylcytosines remain unchanged. During subsequent PCR amplification, uracils are read as thymines. Comparison of the sequenced bisulfite-treated DNA to a reference genome allows for the identification of methylated cytosines.
Protocol Outline:
-
Genomic DNA Extraction: Isolate high-quality genomic DNA from embryonic cells or tissues.
-
DNA Fragmentation: Shear the DNA to a desired fragment size (e.g., 200-500 bp) using sonication.
-
End Repair and A-tailing: Repair the ends of the fragmented DNA and add a single adenine (B156593) nucleotide to the 3' ends.
-
Adapter Ligation: Ligate methylated sequencing adapters to the DNA fragments. These adapters are necessary for sequencing and are methylated to protect them from bisulfite conversion.
-
Bisulfite Conversion: Treat the adapter-ligated DNA with sodium bisulfite.
-
PCR Amplification: Amplify the bisulfite-converted DNA using a polymerase that can read uracil.
-
Library Quantification and Sequencing: Quantify the final library and perform high-throughput sequencing.
Reduced Representation Bisulfite Sequencing (RRBS)
RRBS is a cost-effective alternative to WGBS that enriches for CpG-rich regions of the genome.
Principle: Genomic DNA is digested with a methylation-insensitive restriction enzyme (e.g., MspI) that cuts at CpG-containing sites. This enriches for fragments from CpG islands and promoter regions. The subsequent steps are similar to WGBS.
Protocol Outline:
-
Genomic DNA Extraction: Isolate genomic DNA.
-
Restriction Enzyme Digestion: Digest the DNA with MspI.
-
End Repair and A-tailing: Prepare the digested fragments for adapter ligation.
-
Adapter Ligation: Ligate methylated sequencing adapters.
-
Size Selection: Select a specific size range of fragments for sequencing.
-
Bisulfite Conversion: Treat the size-selected fragments with sodium bisulfite.
-
PCR Amplification: Amplify the library.
-
Library Quantification and Sequencing: Quantify and sequence the library.
Methylated DNA Immunoprecipitation Sequencing (MeDIP-seq)
MeDIP-seq is an antibody-based method for enriching methylated DNA regions.
Principle: Genomic DNA is fragmented, and an antibody specific to this compound is used to immunoprecipitate the methylated DNA fragments. The enriched DNA is then sequenced.
Protocol Outline:
-
Genomic DNA Extraction and Fragmentation: Isolate and sonicate genomic DNA.
-
Denaturation: Denature the DNA fragments to create single-stranded DNA.
-
Immunoprecipitation: Incubate the denatured DNA with an anti-5mC antibody. Pull down the antibody-DNA complexes using magnetic beads.
-
Washing: Wash the beads to remove non-specifically bound DNA.
-
Elution and DNA Purification: Elute the methylated DNA from the beads and purify it.
-
Library Preparation and Sequencing: Prepare a sequencing library from the enriched DNA and perform high-throughput sequencing.
Tet-Assisted Bisulfite Sequencing (TAB-seq)
TAB-seq is a method for the single-base resolution mapping of 5-hydroxymethylcytosine.
Principle: This technique distinguishes 5hmC from 5mC and C. First, 5hmC is protected by glucosylation. Then, TET enzymes are used to oxidize 5mC to 5-carboxylcytosine (5caC). Subsequent bisulfite treatment converts C and 5caC (originally 5mC) to U (read as T), while the protected 5hmC is resistant and read as C.
Protocol Outline:
-
Genomic DNA Extraction: Isolate high-quality genomic DNA.
-
5hmC Glucosylation: Use β-glucosyltransferase (β-GT) to transfer a glucose moiety to the hydroxyl group of 5hmC, protecting it from oxidation.
-
TET-mediated Oxidation of 5mC: Treat the DNA with a TET enzyme to convert 5mC to 5caC.
-
Bisulfite Conversion: Perform bisulfite treatment on the modified DNA.
-
Library Preparation and Sequencing: Prepare a sequencing library and perform high-throughput sequencing.
Conclusion
The dynamic regulation of this compound is a cornerstone of embryonic development. The waves of demethylation and remethylation are essential for establishing cellular identity and pluripotency. Understanding the intricate patterns of 5mC and the enzymes that govern them is crucial for research in developmental biology, regenerative medicine, and for the development of novel therapeutic strategies targeting epigenetic dysregulation in disease. The methodologies outlined in this guide provide powerful tools for dissecting these complex epigenetic landscapes.
References
- 1. Superovulation alters global DNA methylation in early mouse embryo development - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Quantitative assessment of Tet-induced oxidation products of this compound in cellular and tissue DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 3. The link between 5-hydroxymethylcytosine and DNA demethylation in early embryos - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. DNA methylation dynamics in mouse preimplantation embryos revealed by mass spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Dynamics of this compound and 5-hydroxymethylcytosine during germ cell reprogramming - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
The Influence of 5-Methylcytosine on Chromatin Structure: A Technical Guide for Researchers
An In-depth Technical Guide for Researchers, Scientists, and Drug Development Professionals
Abstract
5-Methylcytosine (5mC) is a pivotal epigenetic modification that plays a crucial role in regulating chromatin structure and gene expression. Its presence within the genome, particularly at CpG dinucleotides, serves as a key signaling hub, orchestrating the recruitment of a diverse cast of proteins that collectively shape the chromatin landscape. This technical guide provides a comprehensive overview of the intricate relationship between 5mC and chromatin architecture, detailing the molecular mechanisms, experimental methodologies for its study, and quantitative data illustrating its impact. This document is intended to serve as a valuable resource for researchers, scientists, and professionals in drug development seeking to understand and manipulate this fundamental epigenetic pathway.
The Core Mechanism: How this compound Sculpts Chromatin
This compound exerts its influence on chromatin structure through two primary, interconnected mechanisms: the direct modulation of DNA biophysical properties and, more significantly, the recruitment of specific protein complexes that interpret and translate the methylation signal into downstream effects on chromatin accessibility and gene transcription.
Direct Effects of 5mC on DNA Structure
The addition of a methyl group to the C5 position of cytosine subtly alters the local DNA structure. While 5mC can be accommodated within the B-form DNA double helix, it increases the rigidity of the DNA molecule.[1] This increased stiffness can influence the ability of DNA to wrap around the histone octamer, thereby affecting nucleosome positioning and stability.[1][2] Studies have shown that methylated DNA is more resistant to the spontaneous unwrapping from the histone core, which can contribute to a more stable and less dynamic chromatin state.[3]
Indirect Effects Mediated by 5mC-Binding Proteins ("Readers")
The major mechanism by which 5mC impacts chromatin is through the recruitment of methyl-CpG-binding domain (MBD) proteins, which act as "readers" of the epigenetic mark.[4][5] These proteins recognize and bind to methylated CpG sites, initiating a cascade of events that typically lead to transcriptional repression. The MBD family includes proteins such as MeCP2, MBD1, MBD2, and MBD4.[4][6]
Upon binding to 5mC, MBD proteins recruit larger co-repressor complexes that contain histone-modifying enzymes and chromatin remodelers.[7] A well-characterized example is the recruitment of histone deacetylases (HDACs) by MeCP2.[8][9] HDACs remove acetyl groups from histone tails, leading to a more positive charge on the histones and a tighter association with the negatively charged DNA, resulting in chromatin compaction.[10][11]
Furthermore, the interplay between 5mC and histone methylation is critical. For instance, the UHRF1 protein, which contains a domain that recognizes hemi-methylated DNA, also interacts with histone H3 trimethylated at lysine (B10760008) 9 (H3K9me3), a hallmark of heterochromatin.[12][13] This dual recognition is crucial for the faithful maintenance of both DNA methylation and repressive chromatin states during cell division.[12]
The following diagram illustrates the central role of 5mC in recruiting repressive machinery to chromatin.
Quantitative Impact of this compound on Chromatin and Gene Expression
The presence and density of 5mC have a quantifiable impact on various aspects of chromatin biology and gene regulation. The following tables summarize key quantitative data from the literature.
Table 1: Correlation between Promoter 5mC Levels and Gene Expression
| Gene Example | Promoter 5mC Percentage (%) | Fold Change in Gene Expression | Reference |
| Gene A | 10% | -1.5 | Fictional Example |
| Gene B | 50% | -5.2 | Fictional Example |
| Gene C | 80% | -12.8 | Fictional Example |
| Multiple Genes | Inverse correlation (Pearson R = -0.75) | Varies | [14] |
Note: The first three rows are illustrative examples. Real-world data shows a strong inverse correlation between promoter methylation and gene expression, though the exact fold change is gene- and context-dependent.
Table 2: Impact of 5mC on Chromatin Accessibility (ATAC-seq)
| Genomic Region | Change in 5mC Level | Change in ATAC-seq Peak Height | Reference |
| Enhancer 1 | Increase | Decrease | Fictional Example |
| Promoter 2 | Decrease | Increase | Fictional Example |
| Hyperaccessible Peaks in DKO cells | Loss of methylation | log2 fold change > 1 | [8] |
| Hypoaccessible Peaks in DKO cells | Loss of methylation | log2 fold change < -1 | [8] |
Note: DKO (DNMT1 and DNMT3b double knockout) cells exhibit a global loss of DNA methylation.
Table 3: Binding Affinities of 5mC Reader Proteins
| Protein | Ligand | Dissociation Constant (Kd) | Reference |
| MeCP2-MBD | unmethylated C-G | 398 nM | [15] |
| MeCP2-MBD | hemi-methylated CpG (C/mC) | 38.3 nM | [15] |
| MeCP2-MBD | hemi-hydroxymethylated CpG (C/hmC) | 187.9 nM | [15] |
| MeCP2 | mCG | 50 nM | [7] |
| MeCP2 | hmCG | >10-fold decrease from mCG | [7] |
| UHRF1 TTD | H3K9me3 peptide | 2.0 µM | [12] |
Experimental Protocols for Studying 5mC and Chromatin Structure
A variety of powerful techniques are employed to investigate the relationship between 5mC and chromatin. Below are detailed methodologies for three key experiments.
Bisulfite Sequencing for 5mC Mapping
Principle: Sodium bisulfite treatment of DNA converts unmethylated cytosines to uracils, while 5-methylcytosines remain unchanged. Subsequent PCR amplification and sequencing allow for the single-nucleotide resolution mapping of DNA methylation.[4][16][17]
Detailed Protocol:
-
DNA Extraction: Isolate high-quality genomic DNA from the cells or tissue of interest.
-
Bisulfite Conversion:
-
Quantify the genomic DNA and use 200-500 ng for conversion.
-
Use a commercial bisulfite conversion kit (e.g., Qiagen EpiTect Bisulfite Kit) and follow the manufacturer's instructions.[18]
-
The process involves denaturation of DNA, deamination with sodium bisulfite, and desulfonation.
-
-
PCR Amplification of Target Regions:
-
Design primers specific to the bisulfite-converted DNA sequence. Primers should ideally not contain CpG sites to avoid amplification bias.[17] The length of primers should be around 25-30 nucleotides.[16]
-
The PCR product size should be less than 400 bp due to potential DNA degradation during bisulfite treatment.[16]
-
Perform a nested or semi-nested PCR to increase sensitivity and yield.[17]
-
Typical PCR Conditions:
-
Initial denaturation: 95°C for 5 minutes.
-
40 cycles of: 95°C for 30 seconds, 55-60°C (optimized for specific primers) for 30 seconds, 72°C for 30-60 seconds.
-
Final extension: 72°C for 5 minutes.
-
-
-
Sequencing and Data Analysis:
-
Purify the PCR products.
-
Sequence the purified products using Sanger or next-generation sequencing methods.
-
Analyze the sequencing data by comparing the obtained sequence to the original reference sequence. A 'C' at a CpG site indicates methylation, while a 'T' indicates an unmethylated cytosine. The proportion of methylation can be quantified by the relative peak heights in the sequencing chromatogram.[4][16]
-
The following diagram outlines the workflow for bisulfite sequencing.
Chromatin Immunoprecipitation followed by Sequencing (ChIP-seq) for 5mC Readers and Histone Modifications
Principle: ChIP-seq is used to identify the genome-wide binding sites of specific proteins, such as 5mC readers (e.g., MeCP2) or the locations of specific histone modifications.[19][20]
Detailed Protocol:
-
Chromatin Cross-linking and Preparation:
-
Treat cells with 1% formaldehyde (B43269) for 10 minutes at room temperature to cross-link proteins to DNA.[21]
-
Quench the reaction with glycine.
-
Lyse the cells and isolate the nuclei.
-
Sonify the chromatin to shear the DNA into fragments of 200-500 bp.
-
-
Immunoprecipitation:
-
Incubate the sheared chromatin with an antibody specific to the protein of interest (e.g., anti-MeCP2 antibody, typically 4-10 µg/mL).[22]
-
Add protein A/G magnetic beads to capture the antibody-protein-DNA complexes.
-
Wash the beads to remove non-specific binding.
-
-
Elution and Reverse Cross-linking:
-
Elute the immunoprecipitated complexes from the beads.
-
Reverse the cross-links by incubating at 65°C overnight.
-
Treat with RNase A and Proteinase K to remove RNA and protein.
-
-
DNA Purification and Library Preparation:
-
Purify the DNA using phenol-chloroform extraction or a commercial kit.
-
Prepare a sequencing library from the purified DNA.
-
-
Sequencing and Data Analysis:
-
Sequence the library using a next-generation sequencing platform.
-
Align the sequencing reads to the reference genome.
-
Use peak-calling algorithms to identify regions of enrichment, which correspond to the binding sites of the protein of interest.
-
Assay for Transposase-Accessible Chromatin with Sequencing (ATAC-seq)
Principle: ATAC-seq utilizes a hyperactive Tn5 transposase to preferentially insert sequencing adapters into open, accessible regions of chromatin.[5][23]
Detailed Protocol:
-
Nuclei Isolation:
-
Start with 50,000 to 500,000 cells.
-
Lyse the cells with a non-ionic detergent to release the nuclei, while keeping the nuclear membrane intact.
-
-
Transposition Reaction:
-
Incubate the isolated nuclei with the Tn5 transposase loaded with sequencing adapters. The transposase will simultaneously fragment the DNA and ligate the adapters in accessible chromatin regions.
-
-
DNA Purification and Library Amplification:
-
Purify the transposed DNA.
-
Amplify the library using PCR with primers that recognize the ligated adapters. The number of PCR cycles should be minimized to avoid amplification bias.
-
-
Sequencing and Data Analysis:
-
Sequence the amplified library.
-
Align the reads to the reference genome.
-
Regions with a high density of reads (peaks) represent open chromatin regions.[24] The height and width of the peaks can provide quantitative information about the degree of accessibility.
-
Signaling Pathways and Logical Relationships
The interplay between 5mC, its readers, and chromatin modifying enzymes constitutes a complex signaling network that ultimately dictates gene expression states. The following diagram illustrates the logical flow from a methylated CpG site to the establishment of a repressive chromatin environment.
Conclusion
This compound is a fundamental epigenetic mark that profoundly influences chromatin structure and gene regulation. Its effects are mediated through a combination of direct biophysical alterations to DNA and the recruitment of a sophisticated machinery of protein complexes that modify chromatin. The quantitative relationship between 5mC and its downstream consequences is an area of active research, with techniques such as bisulfite sequencing, ChIP-seq, and ATAC-seq providing powerful tools for its investigation. A thorough understanding of these mechanisms is essential for researchers in basic science and for the development of novel therapeutic strategies targeting the epigenome. This guide provides a foundational resource for navigating this complex and dynamic field.
References
- 1. The Growing Complexity of UHRF1-Mediated Maintenance DNA Methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Distribution and regulatory roles of oxidized 5-methylcytosines in DNA and RNA of the basidiomycete fungi Laccaria bicolor and Coprinopsis cinerea - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Direct bisulfite sequencing for examination of DNA methylation patterns with gene and nucleotide resolution from brain tissues - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. Binding Analysis of Methyl-CpG Binding Domain of MeCP2 and Rett Syndrome Mutations - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Active Repression of Methylated Genes by the Chromosomal Protein MBD1 - PMC [pmc.ncbi.nlm.nih.gov]
- 8. methyl-ATAC-seq measures DNA methylation at accessible chromatin - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Recruitment of histone deacetylases HDAC1 and HDAC2 by the transcriptional repressor ZEB1 downregulates E-cadherin expression in pancreatic cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. The physiological roles of histone deacetylase (HDAC) 1 and 2: complex co-stars with multiple leading parts. | Semantic Scholar [semanticscholar.org]
- 11. Histone deacetylases (HDACs): characterization of the classical HDAC family - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. Examples — graphviz 0.21 documentation [graphviz.readthedocs.io]
- 14. Integrated Analysis of Gene Expression, CpG Island Methylation, and Gene Copy Number in Breast Cancer Cells by Deep Sequencing | PLOS One [journals.plos.org]
- 15. Analyzing the relationship of RNA and DNA methylation with gene expression - PMC [pmc.ncbi.nlm.nih.gov]
- 16. DNA methylation detection: Bisulfite genomic sequencing analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Bisulfite genomic sequencing to uncover variability in DNA methylation: Optimized protocol applied to human T cell differentiation genes | Inmunología [elsevier.es]
- 18. med.upenn.edu [med.upenn.edu]
- 19. discovery.researcher.life [discovery.researcher.life]
- 20. A Step-by-Step Guide to Successful Chromatin Immunoprecipitation (ChIP) Assays | Thermo Fisher Scientific - SG [thermofisher.com]
- 21. encodeproject.org [encodeproject.org]
- 22. Chromatin Immunoprecipitation Sequencing (ChIP-seq) Protocol - CD Genomics [cd-genomics.com]
- 23. academic.oup.com [academic.oup.com]
- 24. youtube.com [youtube.com]
The Impact of 5-Methylcytosine on Transcription Factor Binding: An In-depth Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Executive Summary
5-Methylcytosine (B146107) (5mC), the most well-characterized epigenetic modification of DNA, plays a critical role in gene regulation. Beyond its influence on chromatin structure, 5mC directly impacts the binding of transcription factors (TFs), the key proteins that control gene expression. This guide provides a comprehensive technical overview of the mechanisms by which 5mC modulates TF binding, presents quantitative data on these interactions, and details the experimental protocols used to study them. Understanding this intricate relationship is paramount for researchers in basic science and for professionals in drug development targeting epigenetic pathways. This document will explore both the inhibitory and, perhaps less intuitively, the enhancing effects of 5mC on TF-DNA interactions, providing a nuanced understanding of this fundamental biological process.
Introduction: The Dual Role of this compound in Transcriptional Regulation
DNA methylation, primarily occurring at the 5th position of cytosine in CpG dinucleotides, has long been associated with transcriptional repression. This silencing effect is mediated through two principal mechanisms: the recruitment of methyl-binding domain (MBD) proteins that initiate the formation of repressive chromatin structures, and the direct interference with the binding of specific transcription factors to their cognate DNA sequences[1].
However, a growing body of evidence reveals a more complex and dualistic role for 5mC. While it acts as a deterrent for many transcription factors, a significant number of TFs exhibit a preference for, or are unaffected by, methylated DNA. This selective binding landscape suggests that 5mC is not a universal "off" switch but rather a nuanced regulator that contributes to the precise control of gene expression patterns that define cellular identity and function.
This guide will delve into the molecular underpinnings of these differential effects, categorize transcription factors based on their sensitivity to 5mC, and provide the technical details necessary to investigate these phenomena in a laboratory setting.
Mechanisms of this compound-Mediated Modulation of TF Binding
The influence of a methyl group on TF binding is context-dependent and can be broadly categorized into two opposing effects: inhibition and enhancement.
Inhibition of Transcription Factor Binding
The most classically understood role of 5mC is the steric hindrance of TF binding. The addition of a methyl group into the major groove of the DNA can physically obstruct the amino acid residues of a transcription factor's DNA-binding domain from making the precise contacts required for stable interaction. This is a common mechanism for TFs with binding sites that contain a CpG dinucleotide at a critical position for recognition.
Several major classes of transcription factors are known to be inhibited by CpG methylation, including:
-
bHLH (basic Helix-Loop-Helix) family: e.g., MYC
-
bZIP (basic Leucine Zipper) family: e.g., CREB, AP-1 (Fos/Jun)[1][2]
-
ETS family
dot graph TD { graph [rankdir="LR", splines=true, nodesep=0.5, ranksep=1.2, fontname="Arial", fontsize=12, bgcolor="#FFFFFF"]; node [shape=box, style="rounded,filled", fontname="Arial", fontsize=10, margin=0.2]; edge [fontname="Arial", fontsize=10, color="#202124"];
} caption: Steric hindrance of TF binding by this compound.
Enhancement of Transcription Factor Binding
Contrary to the inhibitory model, a substantial number of transcription factors demonstrate enhanced binding to methylated DNA. This phenomenon can be attributed to favorable hydrophobic interactions between the methyl group of 5mC and specific nonpolar amino acid residues within the TF's DNA-binding domain. In this scenario, the methyl group acts as an additional recognition element, increasing the binding affinity and specificity.
Transcription factors that are known to prefer methylated DNA often play crucial roles in development and cell lineage specification. Examples include:
-
Homeodomain family: e.g., HOX proteins[5]
-
POU domain family
-
Some Zinc Finger proteins: e.g., ZFP57, KLF4 (context-dependent)[6]
-
CEBP family: e.g., CEBPA, CEBPB[7]
dot graph TD { graph [rankdir="LR", splines=true, nodesep=0.5, ranksep=1.2, fontname="Arial", fontsize=12, bgcolor="#FFFFFF"]; node [shape=box, style="rounded,filled", fontname="Arial", fontsize=10, margin=0.2]; edge [fontname="Arial", fontsize=10, color="#202124"];
} caption: Enhanced TF binding through hydrophobic interactions with 5mC.
Quantitative Analysis of this compound's Impact on TF Binding
The effect of 5mC on transcription factor binding affinity can be quantified using various biophysical and high-throughput sequencing techniques. The following tables summarize the observed effects for a selection of key transcription factors.
Table 1: Transcription Factors Inhibited by this compound
| Transcription Factor | Family | Model System | Method | Quantitative Change in Binding | Reference(s) |
| CREB | bZIP | In vitro | EMSA, Microarray | Universally detrimental to binding. | [2] |
| MYC | bHLH | In vitro | EMSA | Binding repressed by mCpG within the binding site. | [1] |
| NF-κB | Rel | In vitro | EMSA, DNaseI Footprinting | Methylation of the core CpG inhibits binding. | [3] |
| AP-2 | AP-2 | In vitro | Methylation Interference | Methylation at specific G residues interferes with binding. | [8] |
| p53 | p53 | In vitro | EpiSELEX-seq | Methylation at C4+G5+ reduces binding by ~20%. | [9] |
Table 2: Transcription Factors with Enhanced or Unaffected Binding by this compound
| Transcription Factor | Family | Model System | Method | Quantitative Change in Binding | Reference(s) |
| p53 | p53 | In vitro | EpiSELEX-seq | Methylation at C1+G2+ increases binding ~2-3 fold. | [9] |
| EGR1 | Zinc Finger | In vitro | Stopped-flow fluorescence | Affinity is unaffected by CpG methylation. | [10] |
| CEBPA | bZIP | Pediatric AML | Methylation-specific PCR | Aberrant promoter hypermethylation leads to silencing. | [11] |
| HOXA5 | Homeodomain | In vitro | Protein Microarray | Binds to at least 66 methylated motifs. | [5] |
| KLF4 | Zinc Finger | Mouse ES cells | In vitro | Binds to methylated CpG sites. | [12] |
Experimental Protocols for Studying 5mC-TF Interactions
A variety of in vitro and in vivo techniques are employed to dissect the relationship between DNA methylation and transcription factor binding. Below are detailed methodologies for key experiments.
Electrophoretic Mobility Shift Assay (EMSA) for Methylated Probes
EMSA, or gel shift assay, is a fundamental technique to study protein-DNA interactions in vitro. To assess the impact of methylation, complementary oligonucleotides with and without this compound are used as probes.
Detailed Methodology:
-
Probe Preparation:
-
Synthesize complementary single-stranded DNA oligonucleotides containing the TF binding site of interest. For the methylated probe, order oligonucleotides with this compound at the desired CpG sites. Companies such as Integrated DNA Technologies (IDT) or Metabion offer this modification.
-
Anneal the complementary strands to form double-stranded probes by heating to 95°C for 5 minutes and then slowly cooling to room temperature.
-
Label the 5' end of the probes with a radioactive isotope (e.g., ³²P) using T4 polynucleotide kinase or with a non-radioactive label such as biotin (B1667282) or a fluorescent dye.
-
Purify the labeled probes using a suitable column purification kit.
-
-
Binding Reaction:
-
In a final volume of 20 µL, combine the following in order:
-
Nuclease-free water
-
10x binding buffer (composition varies depending on the TF, but typically contains Tris-HCl, MgCl₂, EDTA, DTT, and glycerol)
-
Non-specific competitor DNA (e.g., poly(dI-dC)) to reduce non-specific binding.
-
Purified recombinant transcription factor or nuclear extract.
-
Labeled probe (typically 20-50 fmol).
-
-
For competition assays, add a 50-100 fold molar excess of unlabeled cold competitor (methylated or unmethylated) to the reaction before adding the labeled probe.
-
Incubate the reaction at room temperature for 20-30 minutes.
-
-
Electrophoresis:
-
Load the samples onto a native polyacrylamide gel (4-6%).
-
Run the gel in a cold room or at 4°C to prevent protein denaturation.
-
The electrophoresis buffer is typically 0.5x TBE.
-
Run the gel until the dye front has migrated approximately two-thirds of the way down.
-
-
Detection:
-
Dry the gel and expose it to X-ray film or a phosphorimager screen if using a radioactive probe.
-
For non-radioactive probes, transfer the DNA to a nylon membrane and detect using a streptavidin-HRP conjugate (for biotin) or by direct fluorescence imaging.
-
dot graph G { graph [fontname="Arial", fontsize=12, bgcolor="#FFFFFF"]; node [shape=box, style="rounded,filled", fontname="Arial", fontsize=10, margin=0.2, fillcolor="#F1F3F4", fontcolor="#202124"]; edge [fontname="Arial", fontsize=10, color="#202124"];
} caption: Workflow for Electrophoretic Mobility Shift Assay (EMSA).
Chromatin Immunoprecipitation Sequencing (ChIP-seq)
ChIP-seq is a powerful in vivo method to identify the genomic binding sites of a transcription factor. When combined with bisulfite sequencing, it can reveal whether a TF preferentially binds to methylated or unmethylated regions in the genome.
Detailed Methodology:
-
Cross-linking and Chromatin Preparation:
-
Treat cells with formaldehyde (B43269) to cross-link proteins to DNA.
-
Lyse the cells and isolate the nuclei.
-
Sonically shear the chromatin to obtain fragments of 200-600 bp.
-
-
Immunoprecipitation:
-
Incubate the sheared chromatin with an antibody specific to the transcription factor of interest.
-
Add protein A/G magnetic beads to capture the antibody-protein-DNA complexes.
-
Wash the beads extensively to remove non-specifically bound chromatin.
-
-
Elution and Reverse Cross-linking:
-
Elute the chromatin from the beads.
-
Reverse the cross-links by heating at 65°C in the presence of high salt.
-
Treat with RNase A and Proteinase K to remove RNA and protein.
-
-
DNA Purification and Library Preparation:
-
Purify the DNA using a column-based kit or phenol-chloroform extraction.
-
Prepare a sequencing library by end-repairing the DNA fragments, adding 'A' tails, and ligating sequencing adapters.
-
Amplify the library by PCR.
-
-
Sequencing and Data Analysis:
-
Sequence the library on a next-generation sequencing platform.
-
Align the reads to a reference genome.
-
Use peak-calling algorithms (e.g., MACS2) to identify regions of TF binding enrichment.
-
Integrate the peak data with whole-genome bisulfite sequencing (WGBS) data to determine the methylation status of the TF binding sites.
-
dot graph G { graph [fontname="Arial", fontsize=12, bgcolor="#FFFFFF"]; node [shape=box, style="rounded,filled", fontname="Arial", fontsize=10, margin=0.2, fillcolor="#F1F3F4", fontcolor="#202124"]; edge [fontname="Arial", fontsize=10, color="#202124"];
} caption: Workflow for Chromatin Immunoprecipitation Sequencing (ChIP-seq).
High-Throughput Systematic Evolution of Ligands by Exponential Enrichment (HT-SELEX) and Methyl-SELEX
HT-SELEX is an in vitro method used to determine the DNA binding specificity of a transcription factor. The "Methyl-SELEX" or "EpiSELEX-seq" variations incorporate a methylation step to specifically assess the impact of 5mC on binding preference.
Detailed Methodology:
-
Library Design and Synthesis:
-
Synthesize a library of oligonucleotides containing a central random region (e.g., 20-40 bp) flanked by constant primer binding sites.
-
-
Methylation (for Methyl-SELEX):
-
Treat the oligonucleotide library with a CpG methyltransferase (e.g., M.SssI) to methylate all CpG dinucleotides. A parallel unmethylated library is used as a control.
-
-
Binding and Selection:
-
Incubate the (methylated) oligonucleotide library with the purified transcription factor.
-
Capture the TF-DNA complexes, typically using an affinity tag on the TF and magnetic beads.
-
Wash away unbound oligonucleotides.
-
-
Amplification:
-
Elute the bound DNA.
-
Amplify the eluted DNA by PCR using primers corresponding to the constant regions of the library.
-
-
Iterative Cycles and Sequencing:
-
Repeat the binding, selection, and amplification steps for several cycles to enrich for high-affinity binding sequences.
-
Collect the enriched DNA from each cycle and prepare sequencing libraries.
-
Sequence the libraries using a high-throughput sequencing platform.
-
-
Data Analysis:
-
Analyze the sequence data to identify enriched motifs at each cycle.
-
Compare the enriched motifs from the methylated and unmethylated SELEX experiments to determine the TF's preference.
-
dot graph G { graph [fontname="Arial", fontsize=12, bgcolor="#FFFFFF"]; node [shape=box, style="rounded,filled", fontname="Arial", fontsize=10, margin=0.2, fillcolor="#F1F3F4", fontcolor="#202124"]; edge [fontname="Arial", fontsize=10, color="#202124"];
} caption: Workflow for HT-SELEX and Methyl-SELEX.
Conclusion and Future Directions
The interplay between this compound and transcription factor binding is a critical layer of epigenetic regulation. It is now clear that 5mC does not act as a simple binary switch for transcription but rather as a sophisticated modulator that can either repel or attract transcription factors, thereby fine-tuning gene expression programs. For researchers, understanding which TFs are sensitive to methylation is crucial for interpreting gene expression data in the context of a cell's epigenome. For drug development professionals, the enzymes that write, read, and erase DNA methylation marks, as well as the TFs that are influenced by them, represent promising therapeutic targets.
Future research will likely focus on a more comprehensive and quantitative mapping of the methylation sensitivity of the entire human "transcription factor-ome." The development of novel high-throughput technologies and computational models will be instrumental in achieving this goal. Furthermore, elucidating how the interplay between 5mC and TF binding is altered in disease states will open new avenues for diagnostic and therapeutic interventions. The continued exploration of this dynamic interface will undoubtedly deepen our understanding of gene regulation and its role in health and disease.
References
- 1. Sensitivity of transcription factors to DNA methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. DNA CpG methylation inhibits binding of NF-kappa B proteins to the HIV-1 long terminal repeat cognate DNA motifs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Frontiers | Inhibiting DNA Methylation Improves Survival in Severe Sepsis by Regulating NF-κB Pathway [frontiersin.org]
- 5. DNA methylation presents distinct binding sites for human transcription factors | eLife [elifesciences.org]
- 6. Examining the role of EGR1 during viral infections - PMC [pmc.ncbi.nlm.nih.gov]
- 7. CEBPA restricts alveolar type 2 cell plasticity during development and injury-repair - PMC [pmc.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. Quantitative analysis of the DNA methylation sensitivity of transcription factor complexes - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Potential role of DNA methylation as a facilitator of target search processes for transcription factors through interplay with methyl-CpG-binding proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Characterization of CEBPA mutations and promoter hypermethylation in pediatric acute myeloid leukemia - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Measuring quantitative effects of methylation on transcription factor–DNA binding affinity - PMC [pmc.ncbi.nlm.nih.gov]
The Role of 5-Methylcytosine in X-Chromosome Inactivation: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Abstract
X-chromosome inactivation (XCI) is a fundamental epigenetic process in female mammals that ensures dosage compensation for X-linked genes between XX females and XY males. This is achieved through the transcriptional silencing of one of the two X chromosomes. A key player in the establishment and maintenance of this silenced state is the epigenetic modification of DNA, specifically the methylation of cytosine at the 5th position (5-methylcytosine or 5mC). This technical guide provides an in-depth exploration of the role of This compound (B146107) in X-chromosome inactivation, detailing the molecular mechanisms, key enzymatic players, and the experimental methodologies used to study this phenomenon. Quantitative data on methylation differences between the active and inactive X chromosomes are summarized, and detailed protocols for cornerstone experimental techniques are provided. Furthermore, signaling pathways and experimental workflows are visualized using Graphviz to offer a clear and comprehensive understanding of this critical biological process.
Introduction to this compound and X-Chromosome Inactivation
X-chromosome inactivation is a complex process that involves a cascade of events, including the expression of the long non-coding RNA Xist, recruitment of chromatin-modifying complexes, and the establishment of a heterochromatic state on the inactive X chromosome (Xi).[1] this compound is a crucial epigenetic mark that contributes significantly to the stable, long-term silencing of genes on the Xi.[2]
DNA methylation is catalyzed by a family of enzymes called DNA methyltransferases (DNMTs). In the context of XCI, DNMT1 is primarily responsible for maintaining pre-existing methylation patterns after DNA replication, while DNMT3A and DNMT3B are involved in de novo methylation, establishing new methylation marks.[3][4] The inactive X chromosome is characterized by hypermethylation of CpG islands in the promoter regions of many genes that are subject to inactivation.[2][5] This hypermethylation is a critical factor in preventing the binding of transcription factors and recruiting repressive protein complexes, thus ensuring the silenced state is inherited through cell divisions.[6]
Quantitative Analysis of this compound in X-Chromosome Inactivation
The differential methylation between the active X chromosome (Xa) and the inactive X chromosome (Xi) is a hallmark of XCI. Quantitative studies have revealed significant differences in this compound levels, particularly at CpG islands of gene promoters.
| Feature | Active X Chromosome (Xa) | Inactive X Chromosome (Xi) | Reference |
| Promoter CpG Islands (Genes Subject to XCI) | Unmethylated or low methylation | Hypermethylated | [2][5] |
| Promoter CpG Islands (Genes Escaping XCI) | Unmethylated or low methylation | Unmethylated or low methylation | [2][7] |
| Gene Bodies | Variable methylation | Generally higher methylation | [8] |
| Intergenic Regions | Heavily methylated | Heavily methylated | [9] |
Table 1: Summary of this compound Distribution on Active and Inactive X Chromosomes. This table summarizes the general patterns of DNA methylation observed on the active and inactive X chromosomes.
| Gene Status | Mean log2 Methylation (46,XX vs. 45,X) | p-value | Reference |
| Genes Subject to XCI | 1.04 | 1.3 x 10⁻²³ | [2] |
| Genes Escaping XCI | 0.34 | 0.00013 | [2] |
Table 2: Quantitative Methylation Differences at Promoter CpG Islands. This table presents quantitative data on the mean difference in log2 methylation levels at promoter CpG islands between individuals with both an active and inactive X (46,XX) and individuals with only an active X (45,X), highlighting the significant hypermethylation of genes subject to XCI on the inactive X.
Molecular Mechanisms of this compound in X-Chromosome Inactivation
The establishment and maintenance of this compound patterns on the inactive X chromosome is a tightly regulated process involving a signaling cascade initiated by the Xist RNA.
Caption: Signaling pathway of this compound in X-chromosome inactivation.
The process begins with the expression of Xist RNA from the future inactive X chromosome.[1] The Xist RNA then coats the chromosome in cis, leading to the recruitment of Polycomb Repressive Complex 2 (PRC2).[6] PRC2 catalyzes the trimethylation of histone H3 at lysine (B10760008) 27 (H3K27me3), a repressive histone mark.[10] This histone modification is thought to be a key signal for the recruitment of the de novo DNA methyltransferase, DNMT3B, which establishes the initial this compound patterns on CpG islands.[11] Following DNA replication, the maintenance methyltransferase, DNMT1, recognizes the hemimethylated DNA and methylates the newly synthesized strand, ensuring the faithful propagation of the silenced state through cell division.[3]
Experimental Protocols
Studying the role of this compound in X-chromosome inactivation requires a combination of molecular biology techniques to analyze DNA methylation, histone modifications, and RNA localization.
Bisulfite Sequencing for DNA Methylation Analysis
Bisulfite sequencing is the gold standard for single-nucleotide resolution analysis of DNA methylation. The principle of this method is the chemical conversion of unmethylated cytosines to uracil (B121893) by sodium bisulfite, while methylated cytosines remain unchanged.[12][13] Subsequent PCR amplification and sequencing reveal the original methylation status.
Caption: Experimental workflow for bisulfite sequencing.
Detailed Protocol:
-
Genomic DNA Extraction: Isolate high-quality genomic DNA from the cells or tissues of interest.
-
Bisulfite Conversion:
-
Denature 1-2 µg of genomic DNA.
-
Incubate the denatured DNA with a sodium bisulfite solution at 50-55°C for 4-16 hours.[12] This reaction converts unmethylated cytosines to uracils.
-
Purify the bisulfite-treated DNA using a desalting column to remove excess bisulfite.
-
Perform desulfonation by adding a sodium hydroxide (B78521) solution to convert sulfonyl uracil adducts to uracil.[12]
-
Purify the final converted DNA.
-
-
PCR Amplification:
-
Design primers specific for the bisulfite-converted DNA sequence of the target region. Primers should not contain CpG dinucleotides.
-
Perform PCR to amplify the region of interest.
-
-
Sequencing Library Preparation:
-
Purify the PCR products.
-
Ligate sequencing adapters to the ends of the PCR products.
-
Perform a final round of PCR to enrich for the adapter-ligated fragments.
-
-
High-Throughput Sequencing: Sequence the prepared libraries on a next-generation sequencing platform.
-
Data Analysis:
-
Align the sequencing reads to a reference genome that has been computationally converted to reflect the bisulfite treatment (C-to-T conversion).
-
For each CpG site, calculate the methylation level as the percentage of reads with a C at that position out of the total reads covering that position.
-
Chromatin Immunoprecipitation Sequencing (ChIP-seq) for Histone Modifications
ChIP-seq is used to identify the genome-wide localization of specific histone modifications, such as H3K27me3, which is enriched on the inactive X chromosome.
Caption: Experimental workflow for ChIP-seq.
Detailed Protocol:
-
Crosslinking: Treat cells with formaldehyde (B43269) to crosslink proteins to DNA.
-
Chromatin Shearing: Lyse the cells and shear the chromatin into fragments of 200-600 bp using sonication or enzymatic digestion.
-
Immunoprecipitation:
-
Incubate the sheared chromatin with an antibody specific for the histone modification of interest (e.g., anti-H3K27me3).
-
Add protein A/G beads to pull down the antibody-histone-DNA complexes.
-
Wash the beads to remove non-specifically bound chromatin.
-
-
Reverse Crosslinking and DNA Purification:
-
Elute the chromatin from the beads.
-
Reverse the crosslinks by heating at 65°C.
-
Treat with RNase A and Proteinase K to remove RNA and protein.
-
Purify the DNA.
-
-
Sequencing Library Preparation and Sequencing: Prepare and sequence the DNA libraries as described for bisulfite sequencing.
-
Data Analysis:
-
Align the sequencing reads to the reference genome.
-
Use peak-calling algorithms to identify regions of the genome that are enriched for the histone modification.
-
Immunofluorescence for Visualization of XCI Markers
Immunofluorescence combined with fluorescence in situ hybridization (FISH) can be used to visualize the colocalization of Xist RNA and repressive histone marks like H3K27me3 on the inactive X chromosome.[14][15]
Caption: Experimental workflow for Immuno-FISH.
Detailed Protocol:
-
Cell Preparation: Grow cells on coverslips.
-
Fixation and Permeabilization:
-
Fix the cells with paraformaldehyde.
-
Permeabilize the cells with a detergent (e.g., Triton X-100) to allow antibody and probe entry.
-
-
Immunostaining:
-
Block non-specific antibody binding with a blocking solution (e.g., BSA).
-
Incubate with a primary antibody against the target protein (e.g., rabbit anti-H3K27me3).[14]
-
Wash to remove unbound primary antibody.
-
Incubate with a fluorophore-conjugated secondary antibody that recognizes the primary antibody (e.g., anti-rabbit IgG conjugated to a red fluorophore).[14]
-
-
Fluorescence In Situ Hybridization (FISH):
-
Incubate the cells with a fluorescently labeled probe specific for Xist RNA (e.g., a probe conjugated to a green fluorophore).
-
Wash to remove the unbound probe.
-
-
Mounting and Imaging: Mount the coverslips on microscope slides with an antifade mounting medium containing a nuclear counterstain (e.g., DAPI). Visualize the fluorescent signals using a fluorescence microscope.
Conclusion and Future Directions
This compound plays an indispensable role in the stable silencing of the inactive X chromosome. The intricate interplay between Xist RNA, histone modifications, and DNA methyltransferases establishes and maintains a repressive chromatin environment. The experimental techniques outlined in this guide provide powerful tools for dissecting the molecular details of this process.
Future research in this area will likely focus on several key questions. What are the precise mechanisms that target DNMT3B to the Xist-coated chromosome? How do genes that escape X-inactivation maintain a hypomethylated state in the midst of a generally hypermethylated chromosome? And how do alterations in DNA methylation on the X chromosome contribute to sex-biased diseases? Advances in single-cell sequencing and high-resolution imaging will undoubtedly provide further insights into the dynamic and complex role of this compound in X-chromosome inactivation, with potential implications for the development of novel therapeutic strategies for X-linked disorders.
References
- 1. X-inactivation - Wikipedia [en.wikipedia.org]
- 2. DNA methylation profiles of human active and inactive X chromosomes - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Mechanisms of DNA Methyltransferase Recruitment in Mammals - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Epigenetics - Wikipedia [en.wikipedia.org]
- 5. Methylation status of CpG-rich islands on active and inactive mouse X chromosomes - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. rcastoragev2.blob.core.windows.net [rcastoragev2.blob.core.windows.net]
- 8. Landscape of DNA methylation on the X chromosome reflects CpG density, functional chromatin state and X-chromosome inactivation - PMC [pmc.ncbi.nlm.nih.gov]
- 9. pnas.org [pnas.org]
- 10. researchgate.net [researchgate.net]
- 11. X inactivation-specific methylation of LINE-1 elements by DNMT3B: implications for the Lyon repeat hypothesis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Bisulfite Sequencing of DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Principles and Workflow of Whole Genome Bisulfite Sequencing - CD Genomics [cd-genomics.com]
- 14. Quick Fluorescent In Situ Hybridization Protocol for Xist RNA Combined with Immunofluorescence of Histone Modification in X-chromosome Inactivation [jove.com]
- 15. researchgate.net [researchgate.net]
Introduction to Genomic Imprinting and 5-Methylcytosine
References
- 1. Genomic imprinting - Wikipedia [en.wikipedia.org]
- 2. Mechanisms of Genomic Imprinting - PMC [pmc.ncbi.nlm.nih.gov]
- 3. geneticeducation.co.in [geneticeducation.co.in]
- 4. New themes in the biological functions of this compound and 5-hydroxymethylcytosine - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Genomic Imprinting - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Molecular mechanisms of genomic imprinting and clinical implications for cancer | Expert Reviews in Molecular Medicine | Cambridge Core [cambridge.org]
- 7. journals.biologists.com [journals.biologists.com]
- 8. Quantitative analysis of DNA methylation at all human imprinted regions reveals preservation of epigenetic stability in adult somatic tissue - PMC [pmc.ncbi.nlm.nih.gov]
- 9. This compound, a possible epigenetic link between ageing and ocular disease - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Quantitative analysis of DNA methylation at all human imprinted regions reveals preservation of epigenetic stability in adult somatic tissue - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. tandfonline.com [tandfonline.com]
- 12. Bisulfite Sequencing of DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 13. med.upenn.edu [med.upenn.edu]
- 14. Bisulfite Protocol | Stupar Lab [stuparlab.cfans.umn.edu]
- 15. bcm.edu [bcm.edu]
- 16. Using ChIP-Seq Technology to Generate High-Resolution Profiles of Histone Modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Chromatin Immunoprecipitation (ChIP) for Analysis of Histone Modifications and Chromatin-Associated Proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 18. chromosomedynamics.com [chromosomedynamics.com]
The Role of 5-Methylcytosine in Cellular Differentiation: An In-depth Technical Guide
Abstract: DNA methylation, specifically the addition of a methyl group to the fifth carbon of cytosine to form 5-methylcytosine (B146107) (5mC), is a pivotal epigenetic modification governing cellular differentiation. This technical guide provides a comprehensive overview of the molecular mechanisms orchestrated by 5mC that underpin cell fate determination and lineage specification. We delve into the enzymatic machinery responsible for the dynamic regulation of 5mC patterns, its profound impact on gene expression, and the quantitative changes observed during key differentiation processes. Detailed experimental protocols for the analysis of 5mC and illustrative diagrams of the associated signaling pathways and workflows are provided to support researchers, scientists, and drug development professionals in this field.
Introduction: The Epigenetic Landscape of Cellular Identity
Cellular differentiation is the process by which a less specialized cell becomes a more specialized cell type. This intricate process is not solely dictated by the DNA sequence itself, but by a layer of heritable chemical modifications collectively known as the epigenome. Among these, DNA methylation is one of the most studied and crucial mechanisms.[1][2] this compound, often referred to as the "fifth base" of DNA, plays a critical role in establishing and maintaining cellular identity by regulating gene expression programs that drive lineage commitment.[1]
The landscape of 5mC is dynamically remodeled during development, with distinct patterns being established in different cell lineages. These patterns are meticulously controlled by a set of "writer," "eraser," and "reader" proteins that add, remove, and interpret methylation marks, respectively. Dysregulation of these processes can lead to developmental abnormalities and is a hallmark of various diseases, including cancer.
The Enzymatic Machinery of DNA Methylation and Demethylation
The precise control of 5mC levels is orchestrated by two key families of enzymes: DNA methyltransferases (DNMTs) that establish and maintain methylation patterns, and Ten-Eleven Translocation (TET) enzymes that initiate demethylation.
DNA Methyltransferases (DNMTs): The Writers of the Methylome
DNMTs catalyze the transfer of a methyl group from S-adenosyl-L-methionine (SAM) to the C5 position of cytosine, primarily within CpG dinucleotides. In mammals, there are three main active DNMTs:
-
DNMT1: The "maintenance" methyltransferase, which preferentially recognizes hemi-methylated DNA strands during replication and copies the methylation pattern to the newly synthesized strand, ensuring the faithful inheritance of methylation patterns through cell division.
-
DNMT3A and DNMT3B: The de novo methyltransferases, which establish new methylation patterns during embryogenesis and cellular differentiation. Their expression and activity are tightly regulated to ensure proper lineage specification.
Ten-Eleven Translocation (TET) Enzymes: The Erasers of the Methylome
The removal of 5mC is not a passive process but is actively initiated by the TET family of dioxygenases (TET1, TET2, and TET3). These enzymes iteratively oxidize 5mC to 5-hydroxymethylcytosine (B124674) (5hmC), 5-formylcytosine (B1664653) (5fC), and 5-carboxylcytosine (5caC).[3] 5hmC is a relatively stable intermediate and is now considered an epigenetic mark in its own right, with distinct functions from 5mC.[4] The further oxidized forms, 5fC and 5caC, are recognized and excised by the base excision repair (BER) machinery, ultimately leading to the replacement with an unmethylated cytosine.
Quantitative Dynamics of this compound in Differentiation
The global levels and genomic distribution of 5mC undergo dramatic changes during cellular differentiation. Pluripotent embryonic stem cells (ESCs) are characterized by a globally hypomethylated genome with the exception of specific repressed regions. Upon differentiation, a wave of de novo methylation establishes lineage-specific patterns.
| Cell State/Lineage | Global 5mC Level (% of total Cytosines) | Key Observations | References |
| Human Embryonic Stem Cells (hESCs) | ~4% | Pluripotency-associated genes like OCT4 and NANOG are hypomethylated. | [2] |
| Differentiated Somatic Cells | Varies by tissue (e.g., Brain ~0.67% 5hmC of total C) | Lineage-specific genes show dynamic changes in methylation. Global 5mC levels generally increase upon differentiation, while 5hmC levels can be tissue-specific. | [5][6] |
| Neuronal Differentiation | Decreased global 5mC and 5hmC during initial differentiation from hESCs. | Neurogenesis-related genes acquire gene body 5hmC and are upregulated. Pluripotency genes acquire promoter 5mC and are downregulated. | [5][7] |
| Hematopoietic Differentiation | Distinct methylation patterns distinguish hematopoietic stem cells (HSCs) from different sources (fetal liver, cord blood, bone marrow). | Myeloid and lymphoid progenitors exhibit lineage-specific DNA methylation at enhancer regions. | [8][9][10][11] |
| Microglia vs. Neurons vs. Astrocytes | Microglia show significantly higher levels of 5mC compared to neurons and astrocytes. | Over half of microglia CpG sites have 80% or higher 5mC levels. | [12] |
Table 1: Quantitative Changes in this compound and 5-Hydroxymethylcytosine during Cellular Differentiation. This table summarizes the dynamic changes in the levels of 5mC and its oxidized form, 5hmC, across different cell states and lineages, highlighting the role of these epigenetic marks in defining cellular identity.
Impact of this compound on Gene Expression
The primary mechanism by which 5mC influences gene expression is by modulating the accessibility of chromatin and the binding of transcription factors.
-
Promoter Methylation: High levels of 5mC in gene promoter regions are classically associated with transcriptional repression. This can occur through two main mechanisms:
-
Direct Interference: The methyl group can directly block the binding of transcription factors to their cognate DNA sequences.
-
Indirect Repression: Methyl-CpG binding domain (MBD) proteins can specifically recognize and bind to methylated DNA, recruiting chromatin remodeling complexes that lead to a condensed, transcriptionally silent chromatin state.
-
-
Gene Body Methylation: The role of 5mC within the gene body is more complex and context-dependent. In some cases, it is associated with active transcription and may play a role in suppressing spurious transcription initiation from within the gene body.
-
Enhancer Methylation: Dynamic changes in methylation at distal regulatory elements, such as enhancers, are increasingly recognized as a key mechanism for controlling lineage-specific gene expression during differentiation.
Experimental Protocols for this compound Analysis
The accurate and quantitative analysis of 5mC is crucial for understanding its role in cellular differentiation. Here, we provide detailed methodologies for two key techniques.
Whole Genome Bisulfite Sequencing (WGBS)
WGBS is considered the gold standard for single-base resolution mapping of DNA methylation across the entire genome.[13]
Principle: Sodium bisulfite treatment of DNA converts unmethylated cytosines to uracil, while methylated cytosines remain unchanged. Subsequent PCR amplification replaces uracils with thymines. By comparing the sequenced DNA to a reference genome, methylated cytosines can be identified.
Detailed Protocol:
-
DNA Extraction and Fragmentation:
-
Extract high-quality genomic DNA from the cell population of interest.
-
Fragment the DNA to a desired size range (e.g., 200-500 bp) using sonication or enzymatic digestion.[14]
-
-
Library Preparation (Pre-Bisulfite):
-
Perform end-repair, A-tailing, and ligation of methylated sequencing adapters to the fragmented DNA. It is crucial to use methylated adapters to protect them from bisulfite conversion.[15]
-
-
Bisulfite Conversion:
-
Treat the adapter-ligated DNA with sodium bisulfite using a commercial kit (e.g., Zymo EZ DNA Methylation-Gold™ Kit) according to the manufacturer's instructions. This typically involves denaturation of the DNA followed by incubation with the bisulfite reagent at a specific temperature for a set duration.[16]
-
-
Library Amplification:
-
Amplify the bisulfite-converted library using PCR with primers that anneal to the adapter sequences. The number of PCR cycles should be minimized to avoid amplification bias.
-
-
Sequencing and Data Analysis:
-
Sequence the amplified library on a next-generation sequencing platform.
-
Align the sequencing reads to a reference genome and use specialized software (e.g., Bismark) to determine the methylation status of each cytosine.
-
Methylated DNA Immunoprecipitation Sequencing (MeDIP-seq)
MeDIP-seq is an enrichment-based method that allows for the genome-wide analysis of methylated regions.[17]
Principle: An antibody specific for this compound is used to immunoprecipitate methylated DNA fragments. These enriched fragments are then sequenced to identify methylated regions across the genome.
Detailed Protocol:
-
DNA Extraction and Fragmentation:
-
Extract and purify genomic DNA.
-
Sonicate the DNA to an average size of 200-800 bp.[18]
-
-
Denaturation:
-
Immunoprecipitation:
-
Washing and Elution:
-
DNA Purification and Library Preparation:
-
Purify the eluted DNA using phenol-chloroform extraction and ethanol (B145695) precipitation.[19]
-
Prepare a sequencing library from the enriched DNA.
-
-
Sequencing and Data Analysis:
-
Sequence the library and align the reads to a reference genome.
-
Identify enriched regions (peaks) which correspond to methylated regions of the genome.
-
Oxidative Bisulfite Sequencing (oxBS-seq)
To distinguish between 5mC and 5hmC, oxBS-seq can be employed.[20][21][22]
Principle: This method involves a chemical oxidation step prior to bisulfite treatment. Potassium perruthenate (KRuO4) oxidizes 5hmC to 5-formylcytosine (5fC), which is then susceptible to bisulfite-mediated conversion to uracil. 5mC remains resistant to oxidation. By comparing the results of oxBS-seq with standard BS-seq on the same sample, the levels of both 5mC and 5hmC can be determined at single-base resolution.[20]
Protocol Outline:
-
DNA Preparation: Genomic DNA is fragmented and purified.
-
Oxidation: The DNA is treated with an oxidizing agent (e.g., KRuO4) to convert 5hmC to 5fC.[20]
-
Bisulfite Conversion: The oxidized DNA is then subjected to standard bisulfite treatment.
-
Library Preparation and Sequencing: Sequencing libraries are prepared and sequenced.
-
Data Analysis: The sequencing data is compared to that from a parallel BS-seq experiment to deduce the locations and levels of 5mC and 5hmC.
Visualizing the Role of this compound
Diagrams illustrating the key molecular pathways and experimental workflows provide a clear conceptual framework for understanding the role of 5mC in cellular differentiation.
Caption: The dynamic cycle of DNA methylation and demethylation.
Caption: Experimental workflow for Whole Genome Bisulfite Sequencing (WGBS).
Caption: Experimental workflow for Methylated DNA Immunoprecipitation Sequencing (MeDIP-seq).
Caption: Logical relationship of this compound in gene regulation.
Conclusion and Future Directions
This compound is a fundamental epigenetic mark that plays a multifaceted role in the orchestration of cellular differentiation. The dynamic interplay between DNA methyltransferases and TET enzymes establishes and refines lineage-specific methylation patterns, which in turn regulate gene expression programs crucial for cell fate decisions. The advent of high-throughput sequencing technologies has revolutionized our ability to study 5mC at a genome-wide scale, providing unprecedented insights into its dynamic nature and functional consequences.
Future research will likely focus on several key areas:
-
Single-cell methylomics: Analyzing DNA methylation at the single-cell level will provide a higher resolution understanding of the heterogeneity within differentiating cell populations.
-
The "epigenetic clock": Further investigation into how DNA methylation patterns change with age and during disease progression will be crucial for developing novel diagnostic and therapeutic strategies.
-
Interplay with other epigenetic modifications: A deeper understanding of the crosstalk between DNA methylation, histone modifications, and non-coding RNAs will be essential for a holistic view of epigenetic regulation in development and disease.
The continued exploration of the dynamic world of this compound holds immense promise for advancing our understanding of fundamental biology and for the development of new approaches in regenerative medicine and disease treatment.
References
- 1. Epigenetics - Wikipedia [en.wikipedia.org]
- 2. DNA methylation in embryonic stem cells - PMC [pmc.ncbi.nlm.nih.gov]
- 3. 5-Hydroxymethylcytosine: generation, fate, and genomic distribution - PMC [pmc.ncbi.nlm.nih.gov]
- 4. DNA methylation and hydroxymethylation in stem cells - PMC [pmc.ncbi.nlm.nih.gov]
- 5. academic.oup.com [academic.oup.com]
- 6. Distribution of 5-Hydroxymethylcytosine in Different Human Tissues - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Dynamic changes in DNA methylation and hydroxymethylation when hES cells undergo differentiation toward a neuronal lineage - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. DNA Methylation Dynamics of Human Hematopoietic Stem Cell Differentiation - PMC [pmc.ncbi.nlm.nih.gov]
- 9. DNA Methylation Dynamics of Human Hematopoietic Stem Cell Differentiation [repository.cam.ac.uk]
- 10. researchgate.net [researchgate.net]
- 11. DNA Methylation Dynamics of Human Hematopoietic Stem Cell Differentiation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. biorxiv.org [biorxiv.org]
- 13. Principles and Workflow of Whole Genome Bisulfite Sequencing - CD Genomics [cd-genomics.com]
- 14. support.illumina.com [support.illumina.com]
- 15. lfz100.ust.hk [lfz100.ust.hk]
- 16. Whole-Genome Bisulfite Sequencing (WGBS) Protocol - CD Genomics [cd-genomics.com]
- 17. genetargetsolutions.com.au [genetargetsolutions.com.au]
- 18. MeDIP Application Protocol | EpigenTek [epigentek.com]
- 19. Methylated DNA Immunoprecipitation - PMC [pmc.ncbi.nlm.nih.gov]
- 20. Oxidative Bisulfite Sequencing: An Experimental and Computational Protocol - PubMed [pubmed.ncbi.nlm.nih.gov]
- 21. oxBS-seq - CD Genomics [cd-genomics.com]
- 22. Bisulfite Sequencing (BS-Seq)/WGBS [illumina.com]
The Double-Edged Sword: 5-Methylcytosine's Role in Cancer Development
An In-depth Technical Guide for Researchers, Scientists, and Drug Development Professionals
Abstract
5-Methylcytosine (B146107) (5mC), the most well-characterized epigenetic modification of DNA, plays a pivotal role in the regulation of gene expression and the maintenance of genome stability. In normal cellular physiology, 5mC is integral to processes such as X-chromosome inactivation and genomic imprinting.[1] However, the aberrant distribution of 5mC is a hallmark of carcinogenesis, contributing to tumor initiation and progression through a variety of mechanisms. This technical guide provides a comprehensive overview of the role of this compound in cancer development, detailing the enzymatic machinery that governs its deposition and removal, its impact on critical signaling pathways, and the experimental methodologies employed for its study. Quantitative data on 5mC levels and the expression of its regulatory enzymes across various cancers are summarized, and key signaling pathways affected by aberrant 5mC are visualized. This document is intended to serve as a detailed resource for researchers, scientists, and drug development professionals in the field of oncology and epigenetics.
The Core Machinery of DNA Methylation
The landscape of this compound is dynamically regulated by a set of key enzymes: the DNA methyltransferases (DNMTs) and the Ten-Eleven Translocation (TET) family of dioxygenases.
1.1. DNA Methyltransferases (DNMTs): The Writers of the Methyl Code
DNMTs are responsible for establishing and maintaining 5mC marks on DNA. This family of enzymes catalyzes the transfer of a methyl group from S-adenosyl-L-methionine (SAM) to the fifth carbon of a cytosine residue, primarily within CpG dinucleotides.[1] In mammals, there are three catalytically active DNMTs:
-
DNMT1: This enzyme is considered the "maintenance" methyltransferase. It preferentially recognizes hemi-methylated DNA strands during replication and copies the methylation pattern to the newly synthesized strand, ensuring the faithful propagation of epigenetic information through cell divisions.[2]
-
DNMT3A and DNMT3B: These are the "de novo" methyltransferases, responsible for establishing new methylation patterns during development and cellular differentiation.[2][3] Their expression and activity are tightly regulated.
Aberrant expression and activity of DNMTs are frequently observed in cancer.[2][3] Overexpression of all three DNMTs has been reported in various malignancies, including breast, colorectal, and lung cancers, often correlating with the hypermethylation and silencing of tumor suppressor genes.[2][4]
1.2. Ten-Eleven Translocation (TET) Enzymes: The Erasers of the Methyl Code
The TET family of enzymes (TET1, TET2, and TET3) initiates the process of DNA demethylation by oxidizing 5mC to 5-hydroxymethylcytosine (B124674) (5hmC).[5] This can be further oxidized to 5-formylcytosine (B1664653) (5fC) and 5-carboxylcytosine (5caC), which are then excised by the base excision repair (BER) pathway and replaced with an unmethylated cytosine. The TET enzymes are crucial for maintaining the dynamic nature of the methylome.
In many cancers, the expression and/or activity of TET enzymes are diminished.[5][6] This can be due to mutations in the TET genes themselves or through metabolic alterations, such as mutations in isocitrate dehydrogenase (IDH) which lead to the accumulation of 2-hydroxyglutarate, an oncometabolite that inhibits TET activity. Reduced TET function leads to a global decrease in 5hmC levels, a phenomenon observed in a wide range of solid and hematological malignancies.[4][7][8]
The Dichotomous Role of 5mC in Carcinogenesis
The role of 5mC in cancer is not monolithic; it contributes to tumorigenesis through two opposing, yet often concurrent, phenomena: hypermethylation and hypomethylation.
2.1. Hypermethylation: Silencing the Guardians
Focal hypermethylation, particularly in the CpG islands of gene promoters, is a common mechanism for the silencing of tumor suppressor genes.[9] By recruiting methyl-CpG binding proteins and chromatin-modifying complexes, dense methylation in promoter regions leads to a condensed chromatin state that is refractory to transcription. This epigenetic silencing can inactivate genes involved in critical cellular processes such as cell cycle control, DNA repair, and apoptosis, providing a selective advantage for tumor growth.
2.2. Hypomethylation: Unleashing the Instigators
Concurrently with focal hypermethylation, cancer genomes often exhibit global hypomethylation, a widespread reduction in 5mC content.[9] This loss of methylation primarily affects repetitive DNA sequences and gene bodies. The consequences of global hypomethylation are multifaceted and contribute to cancer progression by:
-
Genomic Instability: Hypomethylation of repetitive elements can lead to their reactivation and recombination, resulting in chromosomal instability, translocations, and aneuploidy.
-
Activation of Oncogenes: Loss of methylation in the promoter regions of oncogenes can lead to their aberrant expression, driving cell proliferation and survival.
-
Loss of Imprinting: Hypomethylation can disrupt the monoallelic expression of imprinted genes, leading to abnormal growth.
Quantitative Analysis of 5mC and its Regulators in Cancer
The following tables summarize the quantitative changes in global 5mC and 5hmC levels, as well as the expression of DNMT and TET enzymes in various cancers compared to normal tissues.
Table 1: Global this compound (5mC) and 5-Hydroxymethylcytosine (5hmC) Levels in Cancer
| Cancer Type | Change in Global 5mC | Change in Global 5hmC | References |
| Colorectal Cancer | Decreased | Significantly Decreased | [8] |
| Breast Cancer | Modest Decrease | Significantly Decreased | [8] |
| Prostate Cancer | Modest Decrease | Significantly Decreased | [8] |
| Clear Cell Renal Cell Carcinoma | - | Significantly Decreased | [4] |
| Urothelial Carcinoma | - | Significantly Decreased | [4] |
| Non-small Cell Lung Cancer | - | Significantly Decreased | [6] |
Table 2: Expression of DNA Methyltransferases (DNMTs) in Cancer
| Cancer Type | DNMT1 Expression | DNMT3A Expression | DNMT3B Expression | References |
| Breast Cancer | Increased | Increased (primarily in primary stage) | Increased (primarily in primary stage) | [4][10] |
| Ovarian Cancer | Increased | - | Increased | [3] |
| Pancreatic Cancer | Increased | - | - | [2] |
| Gastric Cancer | Increased | - | - | [2] |
| Multiple Cancers (TCGA) | Upregulated in most cancers | Upregulated in most cancers | Upregulated in most cancers | [11] |
Table 3: Expression of Ten-Eleven Translocation (TET) Enzymes in Cancer
| Cancer Type | TET1 Expression | TET2 Expression | TET3 Expression | References |
| Breast Cancer | Decreased | - | Increased in some contexts | [5][12] |
| Non-small Cell Lung Cancer | Significantly Decreased | Significantly Decreased | Significantly Decreased | [6] |
| Multiple Cancers (TCGA) | Downregulated in BRCA, KICH, KIRC, KIRP, THCA; Upregulated in CHOL, HNSC, LIHC, LUAD, LUSC | Downregulated in BRCA, COAD, HNSC, KIRP, READ, THCA; Upregulated in CHOL, GBM, KIRC, UCEC | Upregulated in most cancers | [13] |
5mC and Key Signaling Pathways in Cancer
Aberrant 5mC patterns directly impact critical signaling pathways that govern cell fate and behavior. Below are diagrams illustrating how 5mC-mediated epigenetic changes contribute to the dysregulation of these pathways in cancer.
The Wnt Signaling Pathway
The Wnt signaling pathway is crucial for development and tissue homeostasis. Its aberrant activation is a key driver in many cancers, particularly colorectal cancer. One of the primary mechanisms of aberrant Wnt activation is the epigenetic silencing of its negative regulators.
In colorectal cancer, promoter hypermethylation of genes encoding Wnt antagonists such as Secreted Frizzled-Related Proteins (SFRPs), Dickkopf (DKK), and Wnt Inhibitory Factor 1 (WIF1) is frequently observed.[9][14][15][16] This epigenetic silencing prevents these inhibitors from sequestering Wnt ligands or binding to their co-receptors, leading to constitutive activation of the Wnt pathway, accumulation of β-catenin in the nucleus, and transcription of pro-proliferative target genes.[9]
The PI3K/AKT Signaling Pathway
The PI3K/AKT pathway is a central regulator of cell growth, proliferation, and survival. Its hyperactivation is a common feature of many cancers. The tumor suppressor PTEN is a critical negative regulator of this pathway, and its inactivation can occur through promoter hypermethylation.
In breast cancer and other malignancies, the promoter of the PTEN gene is often hypermethylated, leading to its transcriptional silencing and loss of protein expression.[1][17][18][19][20] The absence of PTEN allows for the accumulation of PIP3 at the cell membrane, leading to constitutive activation of AKT and its downstream effectors, thereby promoting cell survival and proliferation and inhibiting apoptosis.
The p53 Signaling Pathway
The tumor suppressor p53 is a critical regulator of the cell cycle and apoptosis in response to cellular stress. The interplay between p53 and the DNA methylation machinery is complex and involves a feedback loop.
p53 can repress the expression of DNMT1, thereby influencing global methylation levels.[6] Conversely, DNA methylation can lead to the silencing of p53 target genes. For instance, the gene ZDHHC1, which encodes an enzyme that palmitoylates p53, a post-translational modification required for its nuclear translocation and tumor-suppressive function, can be silenced by promoter hypermethylation in cancer.[21] This creates a feedback loop where the loss of p53 function can lead to increased DNMT1 activity and subsequent hypermethylation and silencing of genes that are required for p53's own activity.
Experimental Protocols for this compound Analysis
The study of 5mC relies on a variety of sophisticated techniques. Below are detailed methodologies for three key experimental approaches.
Whole Genome Bisulfite Sequencing (WGBS)
WGBS is considered the gold standard for single-base resolution, genome-wide methylation analysis.
Methodology:
-
DNA Fragmentation: High-molecular-weight genomic DNA is fragmented to a desired size range (typically 200-500 bp) using sonication (e.g., Covaris) or enzymatic digestion.
-
End Repair and A-tailing: The fragmented DNA is end-repaired to create blunt ends, and a single adenine (B156593) nucleotide is added to the 3' ends.
-
Adapter Ligation: Methylated sequencing adapters are ligated to the A-tailed DNA fragments. The use of methylated adapters is crucial to protect them from subsequent bisulfite conversion.
-
Bisulfite Conversion: The adapter-ligated DNA is treated with sodium bisulfite, which deaminates unmethylated cytosines to uracils, while 5-methylcytosines remain unchanged.
-
PCR Amplification: The bisulfite-converted DNA is amplified by PCR using primers that target the ligated adapters. This step enriches for adapter-ligated fragments and generates a sufficient quantity of DNA for sequencing.
-
Sequencing: The amplified library is sequenced using a high-throughput sequencing platform (e.g., Illumina).
-
Data Analysis: Sequencing reads are aligned to a reference genome, and the methylation status of each cytosine is determined by comparing the sequenced base to the reference. A cytosine that is read as a thymine (B56734) was originally unmethylated, while a cytosine that remains as a cytosine was methylated.
Reduced Representation Bisulfite Sequencing (RRBS)
RRBS is a cost-effective alternative to WGBS that enriches for CpG-rich regions of the genome.
Methodology:
-
Restriction Enzyme Digestion: Genomic DNA is digested with a methylation-insensitive restriction enzyme, most commonly MspI, which recognizes and cleaves at CCGG sequences. This enriches for fragments with CpG dinucleotides at their ends.
-
End Repair and A-tailing: Similar to WGBS, the digested fragments are end-repaired and A-tailed.
-
Adapter Ligation: Methylated sequencing adapters are ligated to the fragments.
-
Size Selection: The adapter-ligated fragments are size-selected (typically 40-220 bp) using gel electrophoresis to further enrich for CpG-rich regions.
-
Bisulfite Conversion: The size-selected fragments are treated with sodium bisulfite.
-
PCR Amplification: The bisulfite-converted library is amplified by PCR.
-
Sequencing and Data Analysis: The library is sequenced, and the data is analyzed in a similar manner to WGBS.
Methylated DNA Immunoprecipitation Sequencing (MeDIP-Seq)
MeDIP-Seq is an enrichment-based method that uses an antibody to capture methylated DNA fragments.
Methodology:
-
DNA Fragmentation: Genomic DNA is fragmented by sonication.
-
Denaturation: The fragmented DNA is denatured to create single-stranded DNA.
-
Immunoprecipitation: The single-stranded DNA is incubated with an antibody that specifically recognizes this compound.
-
Capture of Antibody-DNA Complexes: The antibody-DNA complexes are captured using magnetic beads that are conjugated to a secondary antibody or protein A/G.
-
Washing and Elution: The beads are washed to remove non-specifically bound DNA, and the methylated DNA is then eluted.
-
Library Preparation and Sequencing: The enriched methylated DNA is used to prepare a sequencing library, which is then sequenced.
-
Data Analysis: Sequencing reads are aligned to a reference genome, and peaks of enrichment are identified, which correspond to methylated regions of the genome.
References
- 1. PTEN mutation, methylation and expression in breast cancer patients - PMC [pmc.ncbi.nlm.nih.gov]
- 2. DNA Methyltransferases in Cancer: Biology, Paradox, Aberrations, and Targeted Therapy - PMC [pmc.ncbi.nlm.nih.gov]
- 3. DNMT1, DNMT3A and DNMT3B gene variants in relation to ovarian cancer risk in the Polish population - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Global 5-Hydroxymethylcytosine Levels Are Profoundly Reduced in Multiple Genitourinary Malignancies - PMC [pmc.ncbi.nlm.nih.gov]
- 5. TET Enzymes and 5hmC Levels in Carcinogenesis and Progression of Breast Cancer: Potential Therapeutic Targets - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Evaluation of TET Family Gene Expression and 5-Hydroxymethylcytosine as Potential Epigenetic Markers in Non-small Cell Lung Cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 7. 5-Hydroxymethylcytosine: a key epigenetic mark in cancer and chemotherapy response - PMC [pmc.ncbi.nlm.nih.gov]
- 8. oncotarget.com [oncotarget.com]
- 9. Targeting Wnt signaling in colorectal cancer. A Review in the Theme: Cell Signaling: Proteins, Pathways and Mechanisms - PMC [pmc.ncbi.nlm.nih.gov]
- 10. DNMT3A and DNMT3B in Breast Tumorigenesis and Potential Therapy - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Systematic Characterization of DNA Methyltransferases Family in Tumor Progression and Antitumor Immunity - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. Pan-cancer analyses reveal the molecular and clinical characteristics of TET family members and suggests that TET3 maybe a potential therapeutic target - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Aberrant DNA methylation of WNT pathway genes in the development and progression of CIMP-negative colorectal cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Boosting Wnt activity during colorectal cancer progression through selective hypermethylation of Wnt signaling antagonists - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. Potential Epigenetic Modifiers Targeting the Alteration of Methylation in Colorectal Cancer [xiahepublishing.com]
- 17. Promoter methylation of the PTEN gene is a common molecular change in breast cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. The association of PTEN hypermethylation and breast cancer: a meta-analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 19. PTEN promoter is methylated in a proportion of invasive breast cancers - PubMed [pubmed.ncbi.nlm.nih.gov]
- 20. researchgate.net [researchgate.net]
- 21. Cancer cells escape p53’s tumor suppression through ablation of ZDHHC1-mediated p53 palmitoylation - PMC [pmc.ncbi.nlm.nih.gov]
Methodological & Application
Detecting 5-Methylcytosine in DNA: Application Notes and Protocols for Researchers
For researchers, scientists, and drug development professionals, understanding the landscape of 5-methylcytosine (B146107) (5mC) detection is crucial for advancing epigenetic studies. This document provides detailed application notes and protocols for the principal techniques used to identify 5mC, a key epigenetic mark involved in gene regulation, development, and disease.
This guide offers a comparative overview of four major methodologies: Whole Genome Bisulfite Sequencing (WGBS), Enzymatic Methyl-seq (EM-seq), Methylated DNA Immunoprecipitation Sequencing (MeDIP-seq), and Third-Generation Sequencing using Oxford Nanopore Technologies. Detailed protocols, quantitative comparisons, and visual workflows are provided to aid in the selection and implementation of the most suitable technique for your research needs.
Comparison of 5mC Detection Techniques
The choice of method for 5mC detection depends on various factors, including the desired resolution, the amount of starting material, and the specific biological question being addressed. The following tables summarize the key quantitative parameters of the four major techniques.
| Parameter | Whole Genome Bisulfite Sequencing (WGBS) | Enzymatic Methyl-seq (EM-seq) | Methylated DNA Immunoprecipitation (MeDIP-seq) | Third-Generation Sequencing (Nanopore) |
| Resolution | Single-base | Single-base | ~150-200 bp (fragment-dependent) | Single-base |
| DNA Input | 100 ng - 1 µg | 100 pg - 200 ng[1] | 100 ng - 1 µg | ≥ 1 µg[2] |
| Coverage | Genome-wide, but can have GC bias | Genome-wide, more uniform coverage[1] | Enriched in methylated regions | Genome-wide, less bias in difficult regions[3] |
| DNA Damage | High, due to harsh bisulfite treatment | Low, enzymatic conversion is gentle on DNA[4] | Low, involves sonication and immunoprecipitation | None, native DNA is sequenced |
| Distinguishes 5mC from 5hmC? | No, both are read as cytosine[5] | Can be adapted to distinguish with additional steps | Specific for 5mC, does not detect 5hmC[5] | Yes, with appropriate bioinformatic models |
| Performance Metric | Whole Genome Bisulfite Sequencing (WGBS) | Enzymatic Methyl-seq (EM-seq) | Methylated DNA Immunoprecipitation (MeDIP-seq) | Third-Generation Sequencing (Nanopore) |
| Sensitivity | High | High, potentially higher than WGBS[4] | Moderate to High (depends on antibody and methylation density) | High, but can be model-dependent[6] |
| Specificity | High (for C vs. modified C) | High | Moderate to High (potential for off-target binding) | High, with improving algorithms[6] |
| Cost per Sample | High | High | Moderate | Moderate to High (flow cell cost) |
| Bioinformatic Complexity | High | Moderate (can use WGBS pipelines)[4] | Moderate | High (requires specialized tools) |
Experimental Workflows
Visualizing the experimental process is key to understanding the nuances of each technique. The following diagrams, generated using the DOT language, illustrate the core workflows.
Detailed Experimental Protocols
The following sections provide detailed, step-by-step protocols for each of the four major 5mC detection methods.
Protocol 1: Whole Genome Bisulfite Sequencing (WGBS)
WGBS is considered the gold standard for DNA methylation analysis, providing single-nucleotide resolution across the entire genome.[7] The protocol involves bisulfite treatment of DNA, which converts unmethylated cytosines to uracil (B121893), while methylated cytosines remain unchanged.
Materials:
-
Genomic DNA (100 ng - 1 µg)
-
DNA fragmentation system (e.g., Covaris sonicator)
-
NEBNext® Ultra™ II DNA Library Prep Kit for Illumina®
-
Bisulfite conversion kit (e.g., Zymo Research EZ DNA Methylation-Gold™ Kit)
-
AMPure XP beads
-
Qubit fluorometer and Bioanalyzer
Procedure:
-
DNA Fragmentation:
-
Fragment genomic DNA to an average size of 200-400 bp using a Covaris sonicator or enzymatic digestion.
-
Verify the fragment size distribution using a Bioanalyzer.
-
-
Library Preparation (Pre-Bisulfite):
-
Perform end repair and A-tailing of the fragmented DNA using the NEBNext Ultra II kit reagents.
-
Ligate methylated sequencing adapters to the DNA fragments. These adapters contain 5mC instead of cytosine to protect them from bisulfite conversion.
-
Purify the adapter-ligated DNA using AMPure XP beads.
-
-
Bisulfite Conversion:
-
Treat the adapter-ligated DNA with sodium bisulfite according to the manufacturer's protocol (e.g., Zymo Research EZ DNA Methylation-Gold™ Kit). This step typically involves denaturation, conversion, and desulfonation.
-
Elute the converted DNA in nuclease-free water.
-
-
PCR Amplification:
-
Amplify the bisulfite-converted library using a polymerase that can read through uracil residues (e.g., PfuTurbo Cx Hotstart DNA Polymerase).
-
Use primers that are complementary to the ligated adapters.
-
The number of PCR cycles should be optimized to minimize amplification bias (typically 10-15 cycles).
-
Purify the final library using AMPure XP beads.
-
-
Quality Control and Sequencing:
-
Assess the library concentration using a Qubit fluorometer and the size distribution using a Bioanalyzer.
-
Sequence the library on an Illumina platform.
-
Protocol 2: Enzymatic Methyl-seq (EM-seq)
EM-seq is a newer method that uses a series of enzymatic reactions to achieve the same C-to-U conversion as bisulfite treatment but with significantly less DNA damage.[4] This results in higher quality libraries with more uniform coverage.
Materials:
-
Genomic DNA (100 pg - 200 ng)
-
NEBNext® Enzymatic Methyl-seq Kit (E7120)
-
AMPure XP beads
-
Qubit fluorometer and Bioanalyzer
Procedure:
-
DNA Fragmentation and Library Preparation:
-
Fragment genomic DNA to the desired size.
-
Perform end repair, A-tailing, and adapter ligation using the NEBNext Ultra II reagents included in the EM-seq kit.
-
-
Enzymatic Conversion:
-
Step 1: Oxidation: Incubate the adapter-ligated DNA with TET2 enzyme and an oxidation enhancer. TET2 oxidizes 5mC and 5-hydroxymethylcytosine (B124674) (5hmC).
-
Step 2: Deamination: Add APOBEC enzyme to the reaction. APOBEC deaminates unmethylated cytosines to uracils, while the oxidized 5mC and 5hmC are protected from deamination.[4]
-
-
PCR Amplification:
-
Amplify the converted library using the provided Q5U Master Mix, which is a uracil-tolerant polymerase.
-
Use the supplied primers for amplification.
-
Purify the final library using AMPure XP beads.
-
-
Quality Control and Sequencing:
-
Quantify the library and check its size distribution as described for WGBS.
-
Sequence the library on an Illumina platform.
-
Protocol 3: Methylated DNA Immunoprecipitation Sequencing (MeDIP-seq)
MeDIP-seq is an affinity-based method that enriches for methylated DNA fragments using an antibody specific to 5mC.[8] It does not provide single-base resolution but is a cost-effective way to identify methylated regions across the genome.
Materials:
-
Genomic DNA (100 ng - 1 µg)
-
Sonicator
-
Anti-5-methylcytosine antibody
-
Protein A/G magnetic beads
-
DNA library preparation kit for Illumina
-
AMPure XP beads
-
Qubit fluorometer and Bioanalyzer
Procedure:
-
DNA Fragmentation and Denaturation:
-
Sonicate genomic DNA to an average size of 150-300 bp.
-
Denature the fragmented DNA by heating to 95°C for 10 minutes, followed by rapid cooling on ice.
-
-
Immunoprecipitation:
-
Incubate the denatured DNA with an anti-5mC antibody overnight at 4°C with gentle rotation.
-
Add Protein A/G magnetic beads to the DNA-antibody mixture and incubate for 2 hours at 4°C to capture the antibody-DNA complexes.
-
Wash the beads several times to remove non-specifically bound DNA.
-
-
Elution and DNA Purification:
-
Elute the methylated DNA from the beads using an elution buffer.
-
Treat with Proteinase K to digest the antibody.
-
Purify the eluted DNA using phenol-chloroform extraction and ethanol (B145695) precipitation or a DNA purification kit.
-
-
Library Preparation and Sequencing:
-
Prepare a sequencing library from the enriched methylated DNA using a standard library preparation kit for Illumina.
-
Perform PCR amplification to generate a sufficient amount of library for sequencing.
-
Purify the final library.
-
-
Quality Control and Sequencing:
-
Assess the library quality and quantity.
-
Sequence the library on an Illumina platform.
-
Protocol 4: 5mC Detection with Oxford Nanopore Sequencing
Third-generation sequencing technologies, such as Oxford Nanopore, allow for the direct detection of DNA modifications on native DNA molecules, eliminating the need for conversion or enrichment steps.[9]
Materials:
-
High molecular weight genomic DNA (≥ 1 µg)
-
Ligation Sequencing Kit (e.g., SQK-LSK110) from Oxford Nanopore Technologies
-
Nanopore sequencing device (e.g., MinION, GridION)
-
Appropriate flow cell
Procedure:
-
DNA Extraction and Quality Control:
-
Extract high molecular weight genomic DNA. The quality of the input DNA is critical for long reads.
-
Quantify the DNA using a Qubit fluorometer and assess its integrity using a TapeStation or similar instrument.
-
-
Library Preparation:
-
Perform end repair and A-tailing of the genomic DNA.
-
Ligate sequencing adapters, which include a motor protein, to the prepared DNA.
-
Purify the adapter-ligated DNA using beads.
-
-
Sequencing:
-
Prime the Nanopore flow cell.
-
Load the prepared library onto the flow cell.
-
Start the sequencing run on the MinKNOW software.
-
-
Data Analysis:
-
Basecalling: Convert the raw electrical signal data into DNA sequences using a basecaller such as Guppy.
-
Modification Calling: Use specialized bioinformatic tools (e.g., Megalodon, DeepSignal) that employ deep learning models to detect 5mC and other modifications directly from the raw signal.[10]
-
Downstream Analysis: Align the basecalled reads to a reference genome and analyze the methylation patterns.
-
References
- 1. neb-online.de [neb-online.de]
- 2. Detection of DNA this compound (5mC) by Nanopore Sequencing Protocol - CD Genomics [cd-genomics.com]
- 3. scholarworks.indianapolis.iu.edu [scholarworks.indianapolis.iu.edu]
- 4. youtube.com [youtube.com]
- 5. academic.oup.com [academic.oup.com]
- 6. Collection - Benchmark of the Oxford Nanopore, EM-seq, and HumanMethylationEPIC BeadChip for the detection of the 5mC sites in cancer and normal samples - Frontiers in Epigenetics and Epigenomics - Figshare [frontiersin.figshare.com]
- 7. Whole-Genome Bisulfite Sequencing Protocol for the Analysis of Genome-Wide DNA Methylation and Hydroxymethylation Patterns at Single-Nucleotide Resolution - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Methylated DNA immunoprecipitation (MeDIP) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Nanopore Sequencing and Data Analysis for Base-Resolution Genome-Wide this compound Profiling | Springer Nature Experiments [experiments.springernature.com]
- 10. drpress.org [drpress.org]
Application Notes and Protocols for 5-Methylcytosine Analysis using Bisulfite Sequencing
For Researchers, Scientists, and Drug Development Professionals
Introduction
DNA methylation, a fundamental epigenetic modification, plays a crucial role in regulating gene expression, cellular differentiation, and development. The most prevalent form of DNA methylation in mammals is the addition of a methyl group to the 5th carbon of a cytosine residue, forming 5-methylcytosine (B146107) (5mC). Aberrant DNA methylation patterns are associated with various diseases, including cancer, making the study of 5mC a significant area of research for diagnostics and therapeutics.
Bisulfite sequencing is considered the gold-standard for single-base resolution analysis of DNA methylation.[1][2] This technique relies on the chemical treatment of DNA with sodium bisulfite, which deaminates unmethylated cytosines to uracil (B121893), while 5-methylcytosines remain unchanged.[3][4] Subsequent PCR amplification and sequencing allow for the precise identification of methylated sites. This document provides a detailed protocol for performing bisulfite sequencing for 5mC analysis, from DNA extraction to data interpretation.
Principle of Bisulfite Sequencing
The core principle of bisulfite sequencing lies in the differential chemical reactivity of cytosine and this compound with sodium bisulfite. The process involves three main chemical reactions: sulfonation, deamination, and desulfonation.[5][6]
-
Sulfonation: Sodium bisulfite adds to the 5-6 double bond of cytosine, forming a cytosine-6-sulfonate intermediate.[5]
-
Deamination: This intermediate is susceptible to hydrolytic deamination, converting it to a uracil-6-sulfonate.[6] this compound is resistant to this deamination due to the presence of the methyl group at the C5 position.
-
Desulfonation: Under alkaline conditions, the sulfonate group is removed from the uracil-6-sulfonate, yielding uracil.[5]
Following these reactions, unmethylated cytosines are effectively converted to uracils, which are then read as thymines during subsequent PCR and sequencing steps.[1][7] In contrast, 5-methylcytosines are not converted and are read as cytosines. By comparing the sequenced data of the bisulfite-treated DNA to a reference genome, the methylation status of each cytosine can be determined at a single-nucleotide resolution.[4]
Caption: Principle of bisulfite conversion for 5mC analysis.
Experimental Protocols
This section provides a detailed workflow for bisulfite sequencing, from sample preparation to data analysis.
Genomic DNA Extraction and Quantification
High-quality, pure genomic DNA is crucial for successful bisulfite sequencing.[3][8] Contaminants can inhibit the bisulfite conversion reaction and subsequent enzymatic steps.
Methodology:
-
Extract genomic DNA from the sample of interest using a commercial DNA extraction kit or a standard phenol-chloroform extraction protocol.
-
Treat the extracted DNA with RNase A to remove any contaminating RNA.
-
Assess the quality and quantity of the extracted DNA using a spectrophotometer (e.g., NanoDrop) and fluorometric quantification (e.g., Qubit).
-
An A260/A280 ratio of ~1.8 indicates pure DNA.
-
An A260/A230 ratio of >2.0 indicates minimal contamination with organic compounds.
-
| Parameter | Recommended Value |
| DNA Purity (A260/A280) | 1.8 - 2.0 |
| DNA Purity (A260/A230) | > 2.0 |
| DNA Input for Conversion | 100 ng - 1 µg |
Bisulfite Conversion of DNA
This is the most critical step in the workflow, and complete conversion of unmethylated cytosines is essential for accurate results.[2] Several commercial kits are available for bisulfite conversion, which are generally recommended for their reliability and ease of use.[9][10]
Methodology (using a commercial kit as an example):
-
DNA Denaturation: Mix the genomic DNA (typically 100 ng to 1 µg) with the provided denaturation buffer. Incubate at the temperature and time specified by the kit manufacturer (e.g., 37°C for 15 minutes).[9]
-
Bisulfite Treatment: Add the bisulfite conversion reagent to the denatured DNA. The incubation conditions are critical and typically involve long incubation times at a specific temperature in the dark (e.g., 50-70°C for 1-16 hours).[11][12] Some protocols may include thermal cycling to improve denaturation and conversion efficiency.[12]
-
Desalting: After incubation, the DNA is purified to remove bisulfite and other salts. This is typically done using a spin column provided in the kit.
-
Desulfonation: Add the desulfonation buffer and incubate at room temperature (e.g., 15-25 minutes).[9] This step removes the sulfonate group from the uracil bases.
-
Final Purification: Wash the DNA on the spin column and elute the purified, bisulfite-converted DNA in a low-salt buffer or nuclease-free water.
| Step | Parameter | Typical Condition |
| Denaturation | Temperature | 37°C or 97°C |
| Time | 1 - 15 minutes | |
| Bisulfite Incubation | Temperature | 50°C - 70°C |
| Time | 1 - 16 hours | |
| Desulfonation | Temperature | Room Temperature |
| Time | 15 - 25 minutes |
PCR Amplification of Bisulfite-Converted DNA
Bisulfite treatment leads to DNA degradation and creates a template that is rich in adenine, thymine, and guanine, which can be challenging for PCR amplification.[13]
Methodology:
-
Primer Design: Design PCR primers specific to the bisulfite-converted DNA sequence. Primers should not contain CpG sites to avoid methylation-biased amplification.[14] The target amplicon size should ideally be between 150-300 bp.[13]
-
PCR Reaction: Use a hot-start DNA polymerase that is capable of reading uracil-containing templates.[13][15]
-
PCR Cycling Conditions: Optimize the annealing temperature, as the AT-rich nature of the template can lead to non-specific amplification. Touchdown PCR can be an effective strategy.[14][15] A typical PCR program consists of an initial denaturation step, followed by 35-45 cycles of denaturation, annealing, and extension, and a final extension step.
| PCR Parameter | Recommended Condition |
| Template DNA | 1-2 µl of bisulfite-converted DNA |
| Polymerase | Hot-start, Uracil-tolerant |
| Amplicon Size | 150 - 300 bp |
| Cycling Number | 35 - 45 cycles |
Library Preparation and Sequencing
For genome-wide analysis, the bisulfite-converted DNA is used to prepare a library for next-generation sequencing (NGS).
Methodology:
-
Library Construction: Various commercial kits are available for preparing libraries from bisulfite-treated DNA.[16][17][18] The general steps include end-repair, A-tailing, and ligation of sequencing adapters. Some modern protocols perform library preparation after bisulfite conversion to minimize DNA loss.[18]
-
Library Amplification: The adapter-ligated library is amplified by PCR to generate sufficient material for sequencing.
-
Sequencing: The prepared library is sequenced on an NGS platform (e.g., Illumina).
Bioinformatic Analysis
The raw sequencing data needs to be processed through a specialized bioinformatic pipeline to determine the methylation status of each cytosine.[7][19]
Workflow:
-
Quality Control: Raw sequencing reads are assessed for quality, and adapter sequences and low-quality bases are trimmed.[3]
-
Alignment: The trimmed reads are aligned to an in-silico bisulfite-converted reference genome.[19] This involves aligning reads to both a C-to-T converted and a G-to-A converted reference genome to account for both strands.
-
Methylation Calling: For each cytosine in the reference genome, the number of reads reporting a 'C' (methylated) and the number of reads reporting a 'T' (unmethylated) are counted.[7]
-
Data Analysis: The methylation level for each cytosine is calculated as the ratio of 'C' reads to the total number of reads covering that site.[20] Downstream analysis includes identifying differentially methylated regions (DMRs) between samples and annotating these regions to genes and other genomic features.[19][20]
Caption: Experimental workflow for bisulfite sequencing.
Data Presentation
Quantitative data from bisulfite sequencing experiments should be summarized in a clear and structured manner to facilitate interpretation and comparison.
Table 1: Example of Methylation Call Summary
| Genomic Locus | Total Reads | Methylated Reads (C) | Unmethylated Reads (T) | Methylation Level (%) |
| chr1:10058 | 50 | 45 | 5 | 90.0 |
| chr1:10062 | 52 | 10 | 42 | 19.2 |
| chr1:10070 | 48 | 48 | 0 | 100.0 |
Table 2: Example of Differentially Methylated Region (DMR) Analysis
| DMR ID | Genomic Location | Length (bp) | Avg. Methylation (Control) | Avg. Methylation (Treatment) | p-value | Associated Gene |
| DMR_1 | chr5:150200-150500 | 300 | 85.2% | 25.6% | 1.2e-6 | Gene A |
| DMR_2 | chr12:897650-897800 | 150 | 12.5% | 78.9% | 3.5e-8 | Gene B |
Conclusion
Bisulfite sequencing remains a powerful and widely used technique for the analysis of this compound at single-base resolution. The detailed protocol and workflow presented in these application notes provide a comprehensive guide for researchers, scientists, and drug development professionals. Careful execution of each step, from DNA extraction to bioinformatic analysis, is critical for obtaining accurate and reliable DNA methylation profiles. The insights gained from bisulfite sequencing can significantly contribute to our understanding of gene regulation in health and disease, and aid in the discovery of novel epigenetic biomarkers and therapeutic targets.
References
- 1. neb.com [neb.com]
- 2. DNA methylation detection: Bisulfite genomic sequencing analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Bisulfite sequencing in DNA methylation analysis | Abcam [abcam.com]
- 4. Bisulfite sequencing - Wikipedia [en.wikipedia.org]
- 5. geneticeducation.co.in [geneticeducation.co.in]
- 6. The bisulfite genomic sequencing protocol [file.scirp.org]
- 7. DNA Methylation: Bisulfite Sequencing Workflow — Epigenomics Workshop 2025 1 documentation [nbis-workshop-epigenomics.readthedocs.io]
- 8. qiagen.com [qiagen.com]
- 9. oncodiag.fr [oncodiag.fr]
- 10. researchgate.net [researchgate.net]
- 11. Bisulfite Sequencing of DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Bisulfite Protocol | Stupar Lab [stuparlab.cfans.umn.edu]
- 13. epigenie.com [epigenie.com]
- 14. What should I do to optimize the bisulfite PCR conditions for amplifying bisulfite-treated material? | AAT Bioquest [aatbio.com]
- 15. researchgate.net [researchgate.net]
- 16. Methyl and Bisulfite Sequencing Library Preparation [genohub.com]
- 17. zymoresearch.de [zymoresearch.de]
- 18. sg.idtdna.com [sg.idtdna.com]
- 19. academic.oup.com [academic.oup.com]
- 20. Principles and Workflow of Whole Genome Bisulfite Sequencing - CD Genomics [cd-genomics.com]
Unmasking the Methylome: A Guide to Methylation-Specific PCR (MSP) for 5mC Detection
Application Notes & Protocols for Researchers, Scientists, and Drug Development Professionals
The study of DNA methylation, a key epigenetic modification, is crucial for understanding gene regulation in normal development and disease. One of the most widely used techniques for detecting 5-methylcytosine (B146107) (5mC) at specific gene loci is Methylation-Specific PCR (MSP). This powerful method offers a sensitive, cost-effective, and rapid approach to assess the methylation status of CpG islands, making it an invaluable tool in basic research, clinical diagnostics, and drug development.
Principle of Methylation-Specific PCR
MSP relies on the chemical modification of DNA with sodium bisulfite, followed by PCR amplification with two pairs of primers specifically designed to distinguish between methylated and unmethylated sequences.[1][2]
Sodium Bisulfite Treatment: This chemical treatment deaminates unmethylated cytosine residues to uracil, while methylated cytosines remain unchanged.[1]
Primer Design: Two sets of primers are designed for the target CpG-rich region:
-
Methylated (M) primers: These primers are complementary to the bisulfite-converted sequence where cytosines in CpG sites were methylated (and thus remained cytosine).
-
Unmethylated (U) primers: These primers are complementary to the bisulfite-converted sequence where cytosines in CpG sites were unmethylated (and thus converted to uracil, which is then read as thymine (B56734) during PCR).[1]
PCR Amplification and Detection: Two separate PCR reactions are performed on the bisulfite-treated DNA, one with the "M" primers and one with the "U" primers. The amplification products are then typically visualized using agarose (B213101) gel electrophoresis. The presence of a PCR product in the "M" reaction indicates methylation, while a product in the "U" reaction indicates a lack of methylation. The presence of products in both reactions suggests hemi-methylation or a heterogeneous population of methylated and unmethylated alleles.
Applications in Research and Drug Development
MSP is a versatile technique with broad applications in various fields:
-
Cancer Research: Aberrant DNA methylation is a hallmark of cancer. MSP is widely used to detect hypermethylation of tumor suppressor genes or hypomethylation of oncogenes, which can serve as biomarkers for early cancer detection, prognosis, and prediction of therapeutic response.[3] For example, methylation of the MGMT gene promoter is a key predictive biomarker for the response of glioblastoma to temozolomide (B1682018) therapy.[4][5]
-
Developmental Biology: DNA methylation plays a critical role in gene regulation during embryonic development and cell differentiation. MSP can be used to study the methylation dynamics of specific genes during these processes.
-
Neuroscience: Epigenetic modifications, including DNA methylation, are increasingly recognized for their role in brain function, learning, and memory, as well as in neurological disorders. MSP allows for the investigation of methylation changes in genes associated with these processes.
-
Drug Discovery and Development: MSP can be employed to:
-
Validate drug targets: Assess the methylation status of genes that are potential targets for epigenetic drugs.
-
Monitor drug efficacy: Evaluate the ability of demethylating agents to alter the methylation patterns of target genes.
-
Patient stratification: Identify patient populations that are more likely to respond to specific therapies based on their methylation profiles.
-
Quantitative Data Summary
The performance of MSP can be compared with other common DNA methylation analysis techniques. The following table summarizes key quantitative parameters, compiled from various studies. It is important to note that these values can vary depending on the specific gene, sample type, and experimental conditions.
| Method | Principle | Sensitivity | Specificity | DNA Input | Throughput | Cost per Sample (relative) | Resolution |
| Methylation-Specific PCR (MSP) | Bisulfite conversion followed by PCR with methylation-specific primers. | High (can detect <0.1% methylated alleles).[1] | High, but dependent on primer design.[6] | 10-100 ng | Low to Medium | Low | Locus-specific |
| Quantitative MSP (qMSP / MethyLight) | Real-time PCR version of MSP using fluorescent probes. | Very High | Very High | 10-100 ng | Medium | Low to Medium | Locus-specific |
| Pyrosequencing | Sequencing-by-synthesis of bisulfite-converted DNA. | High (detects ~5% methylation differences).[2] | High | 10-100 ng | Medium | Medium | Single CpG site |
| MassARRAY (EpiTYPER) | MALDI-TOF mass spectrometry of base-specifically cleaved bisulfite-converted DNA. | High | High | 10-100 ng | High | Medium to High | Single CpG site |
| Methylated DNA Immunoprecipitation (MeDIP-Seq) | Immunoprecipitation of methylated DNA fragments followed by sequencing. | Medium to High | Medium | 100 ng - 1 µg | High | High | ~150 bp |
| Whole Genome Bisulfite Sequencing (WGBS) | Bisulfite conversion of the entire genome followed by sequencing. | Very High | Very High | 100 ng - 1 µg | High | Very High | Single base |
Experimental Workflow and Signaling Pathways
The following diagrams illustrate the experimental workflow of Methylation-Specific PCR and the principle of sodium bisulfite conversion.
Caption: Experimental workflow for Methylation-Specific PCR (MSP).
Caption: Principle of sodium bisulfite conversion of DNA.
Experimental Protocols
Here, we provide detailed protocols for the key steps in a Methylation-Specific PCR experiment.
Protocol 1: Genomic DNA Extraction
High-quality genomic DNA is a prerequisite for successful bisulfite conversion and MSP. Standard DNA extraction kits are suitable for this purpose.
Materials:
-
Cell or tissue sample
-
Genomic DNA extraction kit (e.g., QIAamp DNA Mini Kit)
-
Microcentrifuge
-
Spectrophotometer (e.g., NanoDrop)
Procedure:
-
Follow the manufacturer's instructions for the chosen DNA extraction kit.
-
Elute the purified genomic DNA in nuclease-free water or the provided elution buffer.
-
Quantify the DNA concentration and assess its purity using a spectrophotometer. A 260/280 ratio of ~1.8 is indicative of pure DNA.
-
Store the extracted DNA at -20°C until further use.
Protocol 2: Sodium Bisulfite Conversion of Genomic DNA
This protocol describes the chemical conversion of unmethylated cytosines to uracils. Several commercial kits are available that streamline this process.
Materials:
-
Purified genomic DNA (200 ng - 1 µg)
-
Bisulfite conversion kit (e.g., EpiTect Bisulfite Kit)
-
Thermal cycler
-
Nuclease-free water
Procedure:
-
Follow the manufacturer's protocol for the bisulfite conversion kit. This typically involves:
-
Mixing the genomic DNA with the bisulfite reaction mixture.
-
Incubating the mixture in a thermal cycler for a specific time and temperature profile to allow for denaturation and conversion.
-
Purifying the bisulfite-converted DNA using the provided spin columns.
-
-
Elute the converted DNA in the supplied elution buffer.
-
The bisulfite-converted DNA is now ready for MSP or can be stored at -20°C for short-term storage or -80°C for long-term storage.
Protocol 3: Methylation-Specific PCR (MSP)
This protocol provides a general guideline for setting up and running the MSP reactions. Optimal conditions, particularly the annealing temperature, should be determined empirically for each primer set.
Materials:
-
Bisulfite-converted DNA
-
Methylated (M) primer pair
-
Unmethylated (U) primer pair
-
Hot-start Taq DNA polymerase and corresponding PCR buffer
-
dNTPs
-
Nuclease-free water
-
Methylated and unmethylated control DNA (commercially available or prepared in-house)
-
Thermal cycler
MSP Reaction Setup (for a 25 µL reaction):
| Component | Final Concentration | Volume |
| 10x PCR Buffer | 1x | 2.5 µL |
| dNTPs (10 mM) | 200 µM | 0.5 µL |
| Forward Primer (10 µM) | 0.4 µM | 1.0 µL |
| Reverse Primer (10 µM) | 0.4 µM | 1.0 µL |
| Hot-start Taq Polymerase (5 U/µL) | 1.25 U | 0.25 µL |
| Bisulfite-converted DNA | 1-2 µL | X µL |
| Nuclease-free water | - | to 25 µL |
Note: Set up two separate reactions for each sample, one with the "M" primers and one with the "U" primers.
MSP Cycling Conditions (example):
| Step | Temperature | Time | Cycles |
| Initial Denaturation | 95°C | 10-15 min | 1 |
| Denaturation | 95°C | 30-60 sec | \multirow{3}{}{35-40} |
| Annealing | 55-65°C | 30-60 sec | |
| Extension | 72°C | 30-60 sec | |
| Final Extension | 72°C | 5-10 min | 1 |
| Hold | 4°C | ∞ | 1 |
* The annealing temperature is critical and must be optimized for each primer set to ensure specificity.
Protocol 4: Agarose Gel Electrophoresis
Materials:
-
Agarose
-
1x TAE or TBE buffer
-
DNA loading dye
-
DNA ladder
-
Ethidium bromide or other DNA stain
-
Gel electrophoresis apparatus and power supply
-
UV transilluminator and gel documentation system
Procedure:
-
Prepare a 1.5-2.5% agarose gel in 1x TAE or TBE buffer containing a DNA stain.
-
Mix the MSP products with DNA loading dye.
-
Load the samples and a DNA ladder into the wells of the gel.
-
Run the gel at an appropriate voltage until the dye front has migrated sufficiently.
-
Visualize the DNA bands on a UV transilluminator and capture an image.
Interpretation of Results:
-
Methylated: A band is present in the lane with the "M" primers and absent in the "U" lane.
-
Unmethylated: A band is present in the lane with the "U" primers and absent in the "M" lane.
-
Hemi-methylated/Heterogeneous: Bands are present in both the "M" and "U" lanes.
-
No amplification: No bands in either lane may indicate poor DNA quality, failed bisulfite conversion, or PCR inhibition.
Conclusion
Methylation-Specific PCR is a robust and widely accessible technique for the analysis of DNA methylation at specific loci. Its high sensitivity and specificity, coupled with its relatively low cost and rapid turnaround time, make it an indispensable tool for researchers and clinicians in the field of epigenetics. By following standardized protocols and carefully designing primers, MSP can provide reliable and valuable insights into the role of DNA methylation in health and disease.
References
- 1. scienceopen.com [scienceopen.com]
- 2. DNA Methylation Analysis: Choosing the Right Method - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. MGMT promoter methylation status testing to guide therapy for glioblastoma: refining the approach based on emerging evidence and current challenges - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Optimization of Quantitative MGMT Promoter Methylation Analysis Using Pyrosequencing and Combined Bisulfite Restriction Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Specificity of Methylation Assays in Cancer Research: A Guideline for Designing Primers and Probes - PMC [pmc.ncbi.nlm.nih.gov]
Quantitative Analysis of 5-Methylcytosine Levels: A Guide for Researchers
Application Note: AN-5MC2025
Introduction
5-Methylcytosine (5mC) is a critical epigenetic modification in mammals, playing a pivotal role in regulating gene expression, genomic stability, and cellular differentiation.[1] The addition of a methyl group to the fifth carbon of a cytosine residue, typically within a CpG dinucleotide context, can lead to transcriptional repression.[2][3] Aberrant 5mC patterns are implicated in various diseases, including cancer, making the quantitative analysis of 5mC levels a crucial aspect of research and drug development.[4][5] This document provides detailed application notes and protocols for the quantitative analysis of 5mC, targeting researchers, scientists, and drug development professionals.
Core Methodologies for 5mC Quantification
Several techniques are available for the quantitative analysis of 5mC, each with distinct advantages and limitations. The choice of method depends on the specific research question, required resolution, sample availability, and budget. The primary methods covered in this guide are:
-
Whole-Genome Bisulfite Sequencing (WGBS): Considered the gold standard for comprehensive, single-base resolution analysis of genome-wide DNA methylation.[6]
-
Reduced Representation Bisulfite Sequencing (RRBS): A cost-effective alternative to WGBS that enriches for CpG-rich regions of the genome.[7]
-
Quantitative Methylation-Specific PCR (qMSP): A targeted approach for quantifying methylation at specific gene loci.[8][9]
-
Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS): A highly accurate method for determining global 5mC levels.[10][11]
Data Presentation: Comparison of 5mC Quantification Methods
The following table summarizes the key quantitative and qualitative features of the primary 5mC analysis methods to facilitate an informed choice for your research needs.
| Feature | Whole-Genome Bisulfite Sequencing (WGBS) | Reduced Representation Bisulfite Sequencing (RRBS) | Quantitative Methylation-Specific PCR (qMSP) | Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS) |
| Resolution | Single-base | Single-base | Locus-specific | Global (genome-wide average) |
| Coverage | Whole-genome | CpG islands and promoter regions | Specific target regions | Global |
| Sensitivity | High | High | High (can detect low levels of methylation)[9] | Very High (detection limits in the fmol range) |
| Specificity | High | High | Dependent on primer design | Very High |
| DNA Input | 100 ng - 1 µg[12] | 10 ng - 200 ng[13] | 10 - 25 ng[14] | 50 ng - 1 µg |
| Cost | High | Moderate | Low | Moderate to High |
| Throughput | Low to Moderate | Moderate to High | High | Moderate |
| Advantages | Comprehensive genome-wide data, unbiased.[6] | Cost-effective for CpG-rich regions, high throughput.[7] | Fast, cost-effective, suitable for clinical samples.[9] | Gold standard for global quantification, highly accurate and reproducible.[15] |
| Disadvantages | High cost, complex data analysis. | Biased towards CpG-rich regions, may miss other methylated sites. | Only provides information on targeted loci, primer design is critical. | Does not provide locus-specific information, requires specialized equipment. |
Mandatory Visualizations
Signaling Pathway: DNA Methylation and Gene Expression Regulation
Caption: DNA methylation's role in regulating gene expression.
Experimental Workflow: Whole-Genome Bisulfite Sequencing (WGBS)
Caption: Workflow for Whole-Genome Bisulfite Sequencing (WGBS).
Experimental Workflow: Reduced Representation Bisulfite Sequencing (RRBS)
References
- 1. DNA methylation - Wikipedia [en.wikipedia.org]
- 2. biomodal.com [biomodal.com]
- 3. DNA methylation and regulation of gene expression: Guardian of our health - PMC [pmc.ncbi.nlm.nih.gov]
- 4. This compound RNA modification and its roles in cancer and cancer chemotherapy resistance - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. Whole-Genome Bisulfite Sequencing Protocol for the Analysis of Genome-Wide DNA Methylation and Hydroxymethylation Patterns at Single-Nucleotide Resolution - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Reduced representation bisulfite sequencing - Wikipedia [en.wikipedia.org]
- 8. researchgate.net [researchgate.net]
- 9. Quantitative Methylation-Specific PCR: A Simple Method for Studying Epigenetic Modifications of Cell-Free DNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. benchchem.com [benchchem.com]
- 11. Quantification of Global DNA Methylation Status by LC-MS/MS [visikol.com]
- 12. lfz100.ust.hk [lfz100.ust.hk]
- 13. Reduced Representation Bisulfite Sequencing (RRBS) with NEB Reagents [protocols.io]
- 14. Development of a Quantitative Methylation-Specific Polymerase Chain Reaction Method for Monitoring Beta Cell Death in Type 1 Diabetes | PLOS One [journals.plos.org]
- 15. Comparison of Methods for Quantification of Global DNA Methylation | EpigenTek [epigentek.com]
Application Notes: Antibody-Based Detection of 5-Methylcytosine (5mC)
For Researchers, Scientists, and Drug Development Professionals
Introduction
DNA methylation, specifically the addition of a methyl group to the fifth carbon of cytosine to form 5-methylcytosine (B146107) (5mC), is a critical epigenetic modification involved in the regulation of gene expression, genomic imprinting, and cellular development.[1] Aberrant DNA methylation patterns are associated with various diseases, making the detection and quantification of 5mC a key area of research. Antibody-based methods offer specific and versatile tools for studying 5mC. These techniques rely on monoclonal antibodies that specifically recognize and bind to 5mC, enabling the enrichment and analysis of methylated DNA.[2][3] This document provides detailed protocols for the most common antibody-based 5mC detection methods: Methylated DNA Immunoprecipitation (MeDIP) followed by qPCR or Sequencing, Immunofluorescence (IF), and Enzyme-Linked Immunosorbent Assay (ELISA).
Key Applications
| Application | Description | Key Benefit |
| MeDIP-qPCR | Locus-specific analysis of DNA methylation at specific gene promoters or regions of interest. | Rapid and quantitative assessment of methylation changes at targeted genomic sites. |
| MeDIP-Seq | Genome-wide mapping of DNA methylation patterns.[2][4][5] | Provides a comprehensive view of the methylome, identifying differentially methylated regions across the entire genome.[4] |
| Immunofluorescence (IF) | In situ visualization of 5mC within cell nuclei or tissue sections.[6] | Offers spatial information on the distribution and localization of DNA methylation within the nuclear context.[6] |
| ELISA | Global quantification of 5mC levels in a given DNA sample.[7][8][9] | High-throughput and sensitive method for determining overall changes in DNA methylation. |
Antibody Specifications and Performance
The success of any antibody-based detection method for 5mC is highly dependent on the quality and specificity of the primary antibody. Several monoclonal antibodies have been developed that show high specificity for 5mC with minimal cross-reactivity to 5-hydroxymethylcytosine (B124674) (5hmC).[10][11]
| Parameter | Specification | Application | Source |
| Antibody Clone | 33D3 (Mouse Monoclonal) | MeDIP, IF, Dot Blot | [12][13] |
| Host Species | Mouse, Rabbit | MeDIP, IF, ELISA | [1][12][14] |
| Isotype | IgG1 | MeDIP, IF | [12][13] |
| Working Dilution (IF) | 1:500 | Immunofluorescence (HeLa cells) | [13] |
| Working Dilution (IHC-P) | 1:100 | Immunohistochemistry (pig embryo) | [12] |
| Specificity | Specific for 5-methylcytidine. Does not cross-react with other modified cytosines.[13] | All applications | [10][11][13] |
| ELISA Sensitivity | Detection limit of ≥0.5% 5-mC per 100 ng of DNA. | ELISA | [8] |
| ELISA Kit Sensitivity | Approximately 2.336 ng/ml. | Competitive ELISA | [7] |
Experimental Workflows and Protocols
Methylated DNA Immunoprecipitation (MeDIP)
MeDIP is a technique used to enrich for methylated DNA fragments from a larger pool of genomic DNA using an antibody specific for 5mC.[2][3][15] The enriched DNA can then be analyzed by quantitative PCR (MeDIP-qPCR) to assess methylation at specific loci or by next-generation sequencing (MeDIP-Seq) for genome-wide analysis.[2][4]
Caption: Workflow for Methylated DNA Immunoprecipitation (MeDIP).
Protocol: MeDIP
This protocol is a generalized procedure; optimization may be required based on the specific antibody and sample type.
1. DNA Preparation and Fragmentation: a. Isolate high-quality genomic DNA from cells or tissues. b. Fragment the DNA to an average size of 200-800 bp by sonication or enzymatic digestion (e.g., with MseI).[16] c. Purify the fragmented DNA.
2. Denaturation: a. Take 1-5 µg of fragmented DNA in a suitable buffer (e.g., TE buffer). b. Denature the DNA by heating at 95-98°C for 10 minutes.[11][17] c. Immediately transfer the tube to ice and chill for at least 5 minutes to keep the DNA single-stranded.[11][17]
3. Immunoprecipitation: a. Prepare the IP reaction by adding IP buffer (e.g., 10 mM Sodium Phosphate pH 7.0, 140 mM NaCl, 0.05% Triton X-100) and 2-5 µg of a high-specificity anti-5mC monoclonal antibody to the denatured DNA.[11][17] A non-specific IgG should be used as a negative control.[15] b. Incubate overnight at 4°C on a rotating platform.[17] c. Add pre-washed Protein A/G magnetic beads to the DNA/antibody mixture. d. Incubate for 2 hours at 4°C on a rotating platform to allow the beads to bind the antibody-DNA complexes.[2][17]
4. Washing: a. Place the tube on a magnetic rack to capture the beads and discard the supernatant. b. Wash the beads three times with 1 mL of cold IP buffer. For each wash, resuspend the beads, incubate for 1 minute on ice, and then recapture the beads on the magnetic rack.[2]
5. Elution and DNA Purification: a. Resuspend the washed beads in 250 µL of a digestion buffer containing Proteinase K.[2] b. Incubate at 55°C for 2-3 hours on a rotating platform to digest the antibody and release the DNA.[2] c. Purify the eluted DNA using a standard DNA purification kit or phenol-chloroform extraction followed by ethanol (B145695) precipitation.
6. Downstream Analysis:
-
For MeDIP-qPCR: Use the purified DNA as a template for qPCR with primers specific to the genomic regions of interest.
-
For MeDIP-Seq: Prepare a sequencing library from the purified DNA according to the manufacturer's protocol for your chosen sequencing platform.
Immunofluorescence (IF) for 5mC
Immunofluorescence allows for the visualization of 5mC distribution within the nucleus of cells or in tissue sections.[6] A critical step in this protocol is DNA denaturation, typically using HCl, to expose the 5mC epitopes within the double-stranded DNA.[13][18]
Caption: Workflow for 5mC Immunofluorescence.
Protocol: Immunofluorescence
1. Cell/Tissue Preparation: a. For cultured cells, grow them on glass coverslips. b. For tissues, prepare cryosections or paraffin-embedded sections.
2. Fixation and Permeabilization: a. Wash the samples with PBS. b. Fix with 4% paraformaldehyde (PFA) in PBS for 10-15 minutes at room temperature.[13][18] c. Wash three times with PBS. d. Permeabilize with 0.1-0.5% Triton X-100 in PBS for 10-20 minutes at room temperature.[13][18] e. Wash three times with PBS.
3. DNA Denaturation (Antigen Retrieval): a. Incubate the samples in 2N to 4N HCl for 15-30 minutes at room temperature.[13][18] b. Immediately neutralize the acid by washing with a neutralizing buffer (e.g., 100 mM Tris-HCl, pH 8.5) or by washing extensively with PBS.[18]
4. Blocking: a. Block non-specific antibody binding by incubating in a blocking solution (e.g., 1-3% BSA or 10% Normal Goat Serum in PBST) for 1 hour at room temperature.[12][19]
5. Antibody Incubation: a. Dilute the primary anti-5mC antibody in the blocking solution to its optimal concentration (e.g., 1:500). b. Incubate the samples with the primary antibody overnight at 4°C in a humidified chamber.[19][20] c. The next day, wash the samples three times with PBST (PBS + 0.1% Tween-20). d. Dilute the fluorophore-conjugated secondary antibody (e.g., Alexa Fluor 488 goat anti-mouse IgG) in the blocking solution. e. Incubate the samples with the secondary antibody for 1 hour at room temperature, protected from light.[19] f. Wash three times with PBST, protected from light.
6. Mounting and Imaging: a. Mount the coverslips onto glass slides using a mounting medium containing a nuclear counterstain like DAPI. b. Image the samples using a confocal or fluorescence microscope.
This compound DNA ELISA
The 5mC DNA ELISA is a high-throughput method for quantifying the global percentage of 5mC in a DNA sample. It is typically a competitive or direct assay performed in a 96-well plate format.[7][21]
Caption: General Workflow for a 5mC DNA ELISA Kit.
Protocol: 5mC DNA ELISA (Based on a typical kit)
This protocol is based on commercially available kits; always refer to the specific manufacturer's instructions.[8][9]
1. Standard and Sample Preparation: a. Prepare a standard curve by diluting a provided fully methylated DNA standard with a non-methylated DNA standard to create a range of known 5mC percentages.[9] b. Use 10-200 ng of your purified sample DNA per well. The protocol is often optimized for 100 ng.[8][9] c. Denature all standards and samples by heating at 98°C for 5 minutes, followed by immediate chilling on ice.[9]
2. DNA Coating: a. Add the denatured DNA (standards and samples) to the wells of the ELISA plate, which are pre-coated to bind single-stranded DNA. b. Incubate for 1 hour at 37°C to allow the DNA to bind to the plate.[8]
3. Blocking and Antibody Incubation: a. Wash the wells three times with the provided ELISA Wash Buffer. b. Add a blocking buffer to each well and incubate for 30 minutes at 37°C.[8][9] c. Wash the wells again. d. Add the anti-5mC primary antibody to each well and incubate for 1 hour at room temperature.[7]
4. Secondary Antibody and Detection: a. Wash the wells five times with Wash Buffer. b. Add an HRP-conjugated secondary antibody and incubate for 1 hour at room temperature.[7] c. Wash the wells five times with Wash Buffer. d. Add a TMB substrate to each well and incubate for 10-60 minutes at room temperature, or until sufficient color development is observed.[7][9]
5. Measurement and Quantification: a. Stop the reaction by adding a Stop Solution. b. Read the absorbance immediately at 450 nm using a microplate reader.[7] c. Generate a logarithmic standard curve from the absorbance readings of the standards. d. Calculate the percentage of 5mC in your samples by interpolating their absorbance values on the standard curve.[22]
Concluding Remarks
Antibody-based detection of this compound provides a powerful and accessible suite of tools for epigenetic research. The choice of method depends on the specific research question, whether it requires locus-specific data (MeDIP-qPCR), genome-wide mapping (MeDIP-Seq), cellular localization (Immunofluorescence), or global quantification (ELISA). For all applications, the use of a highly specific and validated anti-5mC antibody is paramount to obtaining accurate and reproducible results. Researchers should be aware that while highly specific, some antibodies might be biased towards regions with high densities of CpG methylation.[23][24] Careful experimental design, including appropriate controls, is essential for the robust interpretation of data.
References
- 1. This compound (5-mC) (D3S2Z) Rabbit Monoclonal Antibody | Cell Signaling Technology [cellsignal.com]
- 2. Genome-Wide Mapping of DNA Methylation 5mC by Methylated DNA Immunoprecipitation (MeDIP)-Sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Protocol for Methylated DNA Immunoprecipitation (MeDIP) Analysis | Springer Nature Experiments [experiments.springernature.com]
- 4. Overview of Methylated DNA Immunoprecipitation Sequencing (MeDIP-seq) - CD Genomics [cd-genomics.com]
- 5. Research Portal [rex.libraries.wsu.edu]
- 6. Antibody-Based Detection of Global Nuclear DNA Methylation in Cells, Tissue Sections, and Mammalian Embryos - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. raybiotech.com [raybiotech.com]
- 8. files.zymoresearch.com [files.zymoresearch.com]
- 9. bioscience.co.uk [bioscience.co.uk]
- 10. academic.oup.com [academic.oup.com]
- 11. Examination of the specificity of DNA methylation profiling techniques towards this compound and 5-hydroxymethylcytosine - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Anti-5-methylcytosine (5-mC) antibody [33D3] (ab10805) | Abcam [abcam.com]
- 13. bpsbioscience.com [bpsbioscience.com]
- 14. Anti-5-Methylcytosine Antibodies | Invitrogen [thermofisher.com]
- 15. Methylated DNA Immunopreciptation (MeDIP) Kit | Proteintech [ptglab.com]
- 16. Methylated DNA immunoprecipitation (MeDIP) assays [bio-protocol.org]
- 17. MeDIP Application Protocol | EpigenTek [epigentek.com]
- 18. pubs.acs.org [pubs.acs.org]
- 19. Immunofluorescence (IF) Protocol | EpigenTek [epigentek.com]
- 20. Immunohistochemical Detection of this compound and 5-Hydroxymethylcytosine in Developing and Postmitotic Mouse Retina - PMC [pmc.ncbi.nlm.nih.gov]
- 21. cellbiolabs.com [cellbiolabs.com]
- 22. zymoresearch.com [zymoresearch.com]
- 23. MeDIP [biomics.pasteur.fr]
- 24. MeDIP-Seq/DIP-Seq [illumina.com]
Application Notes and Protocols for Enzymatic 5-Methylcytosine Mapping
For researchers, scientists, and drug development professionals, accurately mapping 5-methylcytosine (B146107) (5mC) is crucial for understanding epigenetic regulation in normal development and disease. Traditional methods relying on bisulfite conversion cause significant DNA damage, leading to biased and less accurate results. Enzymatic methods offer a gentler, more precise alternative for generating high-quality methylomes. This document provides detailed application notes and protocols for key enzymatic 5mC mapping techniques.
I. Introduction to Enzymatic this compound (5mC) Mapping
DNA methylation, primarily the addition of a methyl group to the 5th carbon of cytosine (5mC), is a fundamental epigenetic modification.[1][2] It plays a critical role in regulating gene expression, maintaining cellular identity, and silencing transposable elements.[1] Dysregulation of 5mC patterns is a known hallmark of various diseases, including cancer.[1]
The gold-standard method for 5mC mapping, whole-genome bisulfite sequencing (WGBS), suffers from significant drawbacks. The harsh chemical treatment with sodium bisulfite leads to DNA degradation and fragmentation, resulting in library bias, particularly against GC-rich regions, and data loss.[3][4] Enzymatic methods circumvent these issues by using enzymes to selectively modify and identify cytosine variants, preserving DNA integrity and providing a more accurate representation of the methylome.[5][6]
Key enzymatic methods include:
-
Enzymatic Methyl-seq (EM-seq): A method that uses a series of enzymes to convert unmethylated cytosines to uracils, while protecting 5mC and 5-hydroxymethylcytosine (B124674) (5hmC).[4][5]
-
TET-assisted Bisulfite Sequencing (TAB-seq): A technique designed to specifically map 5hmC at single-base resolution, which allows for the inference of 5mC levels when compared with traditional bisulfite sequencing.[7][8][9]
-
APOBEC-Coupled Epigenetic Sequencing (ACE-seq): A bisulfite-free method that leverages APOBEC deaminases to differentiate and map 5hmC.[10][11][12]
II. Method 1: Enzymatic Methyl-seq (EM-seq)
Application Note:
EM-seq is rapidly becoming the new standard for whole-genome methylation analysis. It offers a clear advantage over WGBS by avoiding DNA-damaging chemical treatments.[4] The workflow involves two main enzymatic steps: protection of modified cytosines followed by deamination of unmodified cytosines.[4][5] First, TET2 enzyme oxidizes 5mC and 5hmC to 5-carboxylcytosine (5caC). An optional step includes using T4-BGT to glucosylate 5hmC, protecting it from TET2 oxidation if separate identification is desired.[6] Subsequently, the APOBEC enzyme deaminates only the unmodified cytosines to uracil.[4] During sequencing, these uracils are read as thymines, allowing for the direct identification of methylated sites, which remain as cytosines.
The gentle nature of EM-seq results in higher quality libraries with longer insert sizes, more uniform GC coverage, and higher mapping efficiency compared to WGBS.[3][13][14] This makes it particularly suitable for studies involving low DNA input, such as clinical samples (e.g., cfDNA, FFPE tissue) and single-cell analysis.[15]
Experimental Workflow Diagram:
Caption: Workflow for NEBNext® Enzymatic Methyl-seq (EM-seq).
Experimental Protocol (EM-seq):
This protocol is adapted from the NEBNext® Enzymatic Methyl-seq Kit.[16]
Part 1: Library Preparation (Pre-Conversion)
-
Fragmentation: Shear 10-200 ng of genomic DNA to a target size of ~300 bp using mechanical or enzymatic methods.
-
End Repair and dA-Tailing: In a single PCR tube, combine the sheared DNA, NEBNext Ultra II End Prep Reaction Buffer, and Enzyme Mix. Incubate at 20°C for 30 minutes, then 65°C for 30 minutes.
-
Adaptor Ligation: Add NEBNext EM-seq Adaptor and Ligation Master Mix. Incubate at 20°C for 15 minutes. Add Ligation Enhancer and mix.
-
Cleanup: Purify the adaptor-ligated DNA using sample purification beads.
Part 2: Enzymatic Conversion
-
Oxidation Step (TET2):
-
To the purified DNA, add TET2 Reaction Buffer, Oxidation Enhancer, and TET2 enzyme.
-
Incubate at 37°C for 1 hour.
-
Add Stop Reagent to halt the reaction.
-
-
Deamination Step (APOBEC):
-
Add APOBEC Reaction Buffer and APOBEC enzyme to the sample.
-
Incubate at 37°C for 3 hours.
-
-
Cleanup: Purify the converted DNA using sample purification beads.
Part 3: PCR Amplification and Sequencing
-
PCR Amplification:
-
Set up a PCR reaction using the converted DNA, NEBNext Q5U Master Mix, and appropriate indexed primers.
-
Perform PCR with the following cycling conditions: 98°C for 30s (initial denaturation), followed by 8-12 cycles of [98°C for 10s, 65°C for 75s], and a final extension at 65°C for 5 minutes.
-
-
Final Cleanup: Purify the amplified library using sample purification beads.
-
QC and Sequencing: Assess library quality and quantity. Sequence on an Illumina platform. Data can be analyzed using standard bisulfite analysis pipelines like Bismark.[3]
III. Method 2: TET-assisted Bisulfite Sequencing (TAB-seq)
Application Note:
TAB-seq is a specialized method designed to specifically map 5-hydroxymethylcytosine (5hmC) at single-base resolution.[7][8] While EM-seq and WGBS typically measure the sum of 5mC and 5hmC, TAB-seq can distinguish them.[17] The principle relies on protecting 5hmC while converting 5mC to a form that is susceptible to bisulfite treatment. First, 5hmC residues are glucosylated using β-glucosyltransferase (βGT), which shields them from further modification.[8] Next, the TET1 enzyme is used to oxidize all 5mC to 5-carboxylcytosine (5caC). In the final step, standard bisulfite treatment converts both unmodified cytosine and the newly formed 5caC to uracil, while the protected glucosylated 5hmC remains as cytosine.[18] By comparing TAB-seq data with standard WGBS data from the same sample, one can infer the locations of 5mC.
Experimental Workflow Diagram:
Caption: Workflow for TET-assisted Bisulfite Sequencing (TAB-seq).
Experimental Protocol (TAB-seq):
This protocol is a generalized summary based on published methods.[7][8][18]
-
DNA Preparation: Start with high-quality genomic DNA. Spike-in controls (unmethylated, methylated, and hydroxymethylated lambda DNA) are essential for assessing conversion efficiencies.[8]
-
Glucosylation of 5hmC:
-
Incubate the genomic DNA with β-glucosyltransferase (βGT) and UDP-glucose at 37°C for 1 hour. This converts 5hmC to β-glucosyl-5-hydroxymethylcytosine (5gmC).
-
Purify the DNA.
-
-
Oxidation of 5mC:
-
Treat the glucosylated DNA with a recombinant TET1 enzyme in a buffer containing necessary cofactors (Fe(II), 2-oxoglutarate).
-
Incubate at 37°C for 1-2 hours to convert 5mC to 5caC.
-
Purify the DNA.
-
-
Bisulfite Conversion:
-
Perform standard sodium bisulfite conversion on the TET-treated DNA. This will deaminate cytosine and 5caC to uracil.
-
-
Library Preparation and Sequencing:
-
Construct a sequencing library from the bisulfite-converted DNA.
-
Perform PCR amplification using a polymerase that can read uracil-containing templates.
-
Sequence the library on an Illumina platform.
-
-
Data Analysis: Align reads to a converted reference genome. Any remaining cytosines at CpG sites represent original 5hmC marks.
IV. Method 3: APOBEC-Coupled Epigenetic Sequencing (ACE-seq)
Application Note:
ACE-seq is a bisulfite-free method for mapping 5hmC at single-base resolution, requiring only nanogram quantities of input DNA.[10][11][19] The method leverages the ability of AID/APOBEC family DNA deaminases to discriminate between different cytosine modifications on single-stranded DNA.[12][19] In the ACE-seq protocol, DNA is first glucosylated to protect 5hmC. Then, the DNA is denatured, and an APOBEC3A enzyme is used to deaminate both cytosine and 5mC to uracil.[19] The protected 5hmC is resistant to this deamination. Consequently, after sequencing, sites that remain as cytosine correspond to the original 5hmC positions. This non-destructive enzymatic approach avoids the DNA damage associated with bisulfite treatment, making it ideal for scarce or precious samples.[12]
Experimental Workflow Diagram:
Caption: Workflow for APOBEC-Coupled Epigenetic Sequencing (ACE-seq).
Experimental Protocol (ACE-seq):
This protocol is a generalized summary based on published methods.[10][12]
-
Library Preparation: Start with adaptor-ligated, fragmented DNA.
-
Glucosylation: Incubate the library with βGT and UDP-glucose to protect 5hmC sites.
-
Denaturation: Denature the DNA to make it single-stranded, typically through heat or chemical means. This is a critical step for APOBEC activity.
-
APOBEC Deamination:
-
Incubate the single-stranded DNA with a highly active APOBEC3A fusion protein.
-
The reaction conditions are optimized to ensure complete deamination of C and 5mC while leaving the protected 5hmC untouched.
-
-
PCR Amplification: Amplify the library using a high-fidelity polymerase capable of reading uracil-containing templates.
-
Sequencing and Analysis: Sequence the library and align reads. Cytosines that were not converted to thymines are identified as 5hmC sites.
V. Quantitative Data Summary
The performance of enzymatic methods, particularly EM-seq, is demonstrably superior to WGBS across several key metrics.
Table 1: Comparison of EM-seq vs. WGBS Performance Metrics
| Metric | EM-seq | WGBS | Advantage of EM-seq | Reference |
| DNA Input | 10-200 ng (standard) | >100 ng | Requires less input DNA | [3][15] |
| DNA Damage | Minimal, gentle enzymatic steps | High, harsh bisulfite treatment | Preserves DNA integrity | [4][15] |
| Library Insert Size | Larger | Smaller | Enables longer reads, better mapping | [3] |
| GC Coverage Bias | Uniform coverage | Biased against high GC regions | More accurate methylation in CpG islands | [3][20] |
| Mapping Efficiency | High | Lower | More usable reads per run | [13] |
| Duplicate Rate | Lower | Higher | More complex libraries | [6][14] |
| CpG Coverage (≥10x) | Higher | Lower | More confident CpG calls | [13] |
| Methylation Overestimation | Low (~0%) in unmethylated controls | Higher (~2-3%) in controls | More accurate quantification | [13] |
Table 2: CpG Site Detection Comparison
| Method | Average Coverage | Total CpGs Called | Unique CpGs Detected | Reference |
| EM-seq | 41x | ~54 million | 850 K (1.5%) | [6] |
| WGBS | 46x | ~54 million | 622 K (1.1%) | [6] |
| ONT (Nanopore) | 34x | ~56 million | 5.31 M (9.5%) | [6] |
Data from a comparative study on human samples. "Unique CpGs" refers to sites not captured by the other two sequencing methods in the study.[6]
VI. TET Enzyme Signaling Pathway
The Ten-Eleven Translocation (TET) enzymes are central to many of these methods and are the key players in the biological pathway of active DNA demethylation. TET proteins (TET1, TET2, TET3) are dioxygenases that iteratively oxidize 5mC.[2][21][22] This process not only creates distinct epigenetic marks (5hmC, 5fC, 5caC) but also initiates the removal of the methyl group, returning the cytosine to its unmodified state.
DNA Demethylation Pathway Diagram:
Caption: The TET-mediated pathway for active DNA demethylation.
References
- 1. Direct enzymatic sequencing of this compound at single-base resolution - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Tet family proteins and 5-hydroxymethylcytosine in development and disease - PMC [pmc.ncbi.nlm.nih.gov]
- 3. neb-online.de [neb-online.de]
- 4. Enzymatic methyl-seq - Wikipedia [en.wikipedia.org]
- 5. biorxiv.org [biorxiv.org]
- 6. Comparison of current methods for genome-wide DNA methylation profiling - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Tet-Assisted Bisulfite Sequencing (TAB-seq) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Tet-Assisted Bisulfite Sequencing (TAB-seq) - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Tet-Assisted Bisulfite Sequencing (TAB-seq) | Springer Nature Experiments [experiments.springernature.com]
- 10. Bisulfite-Free Sequencing of 5-Hydroxymethylcytosine with APOBEC-Coupled Epigenetic Sequencing (ACE-Seq) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. Bisulfite-Free Sequencing of 5-Hydroxymethylcytosine with APOBEC-Coupled Epigenetic Sequencing (ACE-Seq) | Springer Nature Experiments [experiments.springernature.com]
- 12. researchgate.net [researchgate.net]
- 13. cegat.com [cegat.com]
- 14. researchgate.net [researchgate.net]
- 15. WGBS vs. EM-seq: Key Differences in Principles, Pros, Cons, and Applications - CD Genomics [cd-genomics.com]
- 16. neb.com [neb.com]
- 17. 5mC vs 5hmC Detection Methods: WGBS, EM-Seq, 5hmC-Seal - CD Genomics [cd-genomics.com]
- 18. researchgate.net [researchgate.net]
- 19. Nondestructive, base-resolution sequencing of 5-hydroxymethylcytosine using a DNA deaminase - PMC [pmc.ncbi.nlm.nih.gov]
- 20. Practical Case Studies for Comparison Between EM-seq and Other Methylation Sequencing Technologies - CD Genomics [cd-genomics.com]
- 21. Mechanisms and functions of Tet protein-mediated this compound oxidation - PMC [pmc.ncbi.nlm.nih.gov]
- 22. Enzymatic Analysis of Tet Proteins: Key Enzymes in the Metabolism of DNA Methylation - PMC [pmc.ncbi.nlm.nih.gov]
Unlocking the Epigenome: Computational Tools for 5-Methylcytosine Data Analysis
For Researchers, Scientists, and Drug Development Professionals
The study of 5-methylcytosine (B146107) (5mC), a key epigenetic modification, is fundamental to understanding gene regulation in health and disease. The advent of high-throughput sequencing technologies has generated vast amounts of 5mC data, necessitating robust computational tools for its analysis and interpretation. This document provides detailed application notes and protocols for a selection of widely used computational tools, offering a guide for researchers navigating the complex landscape of 5mC data analysis.
Application Notes: A Toolkit for 5mC Analysis
The analysis of 5mC data, primarily from whole-genome bisulfite sequencing (WGBS) and reduced representation bisulfite sequencing (RRBS), as well as long-read sequencing technologies, involves a multi-step workflow. Key stages include read alignment, methylation calling, differential methylation analysis, and visualization. Here, we highlight a curated set of tools for each stage.
1. Read Alignment: Mapping Bisulfite-Treated Reads
Bisulfite treatment converts unmethylated cytosines to uracils (read as thymines), creating a challenge for standard alignment algorithms. Specialized aligners are essential for accurate mapping.
-
Bismark: A popular and versatile tool that aligns bisulfite-treated reads to a reference genome and performs methylation calling simultaneously.[1] It uses a three-letter alphabet approach (C, T, and other bases) to align reads. Bismark is known for its accuracy and detailed reporting.[2]
-
BS-Seeker3: An ultrafast and versatile pipeline for mapping bisulfite-treated reads.[3] It is designed for efficiency and can handle large datasets, making it suitable for high-throughput studies.[3][4]
2. Methylation Calling and Quantification
Once reads are aligned, the methylation status of each cytosine needs to be determined.
-
MethGo: A comprehensive tool for analyzing post-alignment bisulfite sequencing data.[5] It not only calls methylation levels but also provides functionalities for downstream analyses, including coverage distribution, gene-centric methylation levels, and detection of single nucleotide polymorphisms (SNPs) and copy number variations (CNVs).[6][7]
3. Differential Methylation Analysis
A primary goal of many 5mC studies is to identify differentially methylated regions (DMRs) between different conditions (e.g., tumor vs. normal tissue).
-
methylKit: A comprehensive R package for the analysis of genome-wide DNA methylation profiles.[8] It provides functions for quality control, differential methylation analysis at single-base or regional levels, and various visualization capabilities.[9][10]
-
DiffMethylTools: A Python-based toolkit for the comprehensive analysis of DNA methylation differences.[11] It is designed to be a single-command solution for detecting, annotating, and visualizing DMLs and DMRs from both short-read and long-read sequencing data.[12][13]
4. Visualization of 5mC Data
Visual inspection of methylation patterns is crucial for interpreting results and generating hypotheses.
-
NanoMethViz: An R/Bioconductor package specifically designed for visualizing long-read methylation data from platforms like Oxford Nanopore.[14][15] It allows for the exploration of methylation patterns at various resolutions, from genome-wide to single-read level.[16][17]
Quantitative Data Summary
The performance of computational tools for 5mC analysis can vary. The following tables summarize key performance metrics from benchmarking studies to aid in tool selection.
Table 1: Comparison of Bisulfite Sequencing Aligners
| Tool | Uniquely Aligned Reads (%) | Speed (reads/sec) | Reference |
| Bismark | 42.2 | 1642 | [18] |
| BSMAP | 58.9 | 5.6 | [18] |
| RMAPBS | 65.1 | 119.6 | [18] |
| BWA-meth | High | High | [19] |
| BSBolt | High | Moderate | [20] |
| Walt | High | High | [20] |
Table 2: Performance of Differential Methylation Loci (DML) Detection Tools
| Tool | F1 Score | Precision | Reference |
| DiffMethylTools | 0.92 | 0.97 | [12] |
| DSS | 0.72 | 0.72 | [12] |
| MethylKit | 0.43 | 0.28 | [12] |
| MethylSig | 0.46 | 0.31 | [12] |
Experimental Workflows & Protocols
This section provides detailed protocols for a typical 5mC data analysis workflow using some of the tools mentioned above.
Workflow for Bisulfite Sequencing Data Analysis
The overall workflow for analyzing bisulfite sequencing data involves several sequential steps, from raw sequencing reads to the identification of biologically relevant differentially methylated regions.
Protocol 1: Alignment and Methylation Calling with Bismark
This protocol outlines the steps for aligning bisulfite-treated reads and extracting methylation calls using Bismark.
1. Genome Preparation:
Before alignment, the reference genome must be prepared for bisulfite mapping. This step only needs to be performed once per genome.
2. Read Alignment:
Align single-end or paired-end FASTQ files to the prepared genome. For paired-end reads:
3. Deduplication (Optional but Recommended):
PCR duplicates can introduce bias. Bismark provides a script to remove duplicate alignments.
4. Methylation Extraction:
Extract methylation calls from the aligned reads.
2. Filter and Unite Samples:
Filter for coverage and unite the samples into a single methylBase object.
3. Calculate Differential Methylation:
4. Identify DMCs and DMRs:
Signaling Pathway Visualization
DNA methylation plays a crucial role in regulating signaling pathways, particularly in the context of cancer. [21]Hypermethylation of promoter regions can lead to the silencing of tumor suppressor genes, while hypomethylation can activate oncogenes. [22]The calcium signaling pathway, for instance, has been shown to be frequently hypermethylated across various cancers, leading to the downregulation of genes involved in critical cellular processes. [23]
This document serves as a starting point for researchers and professionals working with 5mC data. The provided application notes, protocols, and visualizations are intended to facilitate a deeper understanding and more effective analysis of the methylome. As the field of epigenetics continues to evolve, so too will the computational tools and methodologies for its study.
References
- 1. Bismark [felixkrueger.github.io]
- 2. Genome methylation analysis with Bismark [genomespot.blogspot.com]
- 3. BS-Seeker3: ultrafast pipeline for bisulfite sequencing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. Welcome to MethGo’s documentation! — MethGo 1.0 documentation [methgo.readthedocs.io]
- 6. biorxiv.org [biorxiv.org]
- 7. MethGo [bioinformaticshome.com]
- 8. edoc.mdc-berlin.de [edoc.mdc-berlin.de]
- 9. DNA Methylation: Bisulfite Sequencing Workflow — Epigenomics Workshop 2025 1 documentation [nbis-workshop-epigenomics.readthedocs.io]
- 10. methylKit: User Guide v1.0.0 [bioconductor.statistik.tu-dortmund.de]
- 11. GitHub - qgenlab/DiffMethylTools [github.com]
- 12. DiffMethylTools: a toolbox of the detection, annotation and visualization of differential DNA methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 13. biorxiv.org [biorxiv.org]
- 14. NanoMethViz: An R/Bioconductor package for visualizing long-read methylation data | PLOS Computational Biology [journals.plos.org]
- 15. researchmgt.monash.edu [researchmgt.monash.edu]
- 16. NanoMethViz: An R/Bioconductor package for visualizing long-read methylation data - PMC [pmc.ncbi.nlm.nih.gov]
- 17. biorxiv.org [biorxiv.org]
- 18. Comparison of alignment software for genome-wide bisulphite sequence data - PMC [pmc.ncbi.nlm.nih.gov]
- 19. academic.oup.com [academic.oup.com]
- 20. Benchmarking DNA methylation analysis of 14 alignment algorithms for whole genome bisulfite sequencing in mammals - PubMed [pubmed.ncbi.nlm.nih.gov]
- 21. Regulation of Canonical Oncogenic Signaling Pathways in Cancer via DNA Methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 22. DNA methylation profiles in cancer: functions, therapy, and beyond | Cancer Biology & Medicine [cancerbiomed.org]
- 23. oncotarget.com [oncotarget.com]
Application Notes and Protocols: 5-Methylcytosine Profiling in Disease Research
For Researchers, Scientists, and Drug Development Professionals
Introduction: 5-methylcytosine (B146107) (5mC) is a critical epigenetic modification involving the addition of a methyl group to the C5 position of a cytosine residue, primarily within CpG dinucleotides.[1][2] This process, mediated by DNA methyltransferases (DNMTs), plays a fundamental role in regulating gene expression, genomic stability, and cellular differentiation.[3][4] Aberrant 5mC patterns are a hallmark of numerous diseases, including cancer, neurological disorders, and autoimmune conditions, making genome-wide 5mC profiling an invaluable tool for biomarker discovery, disease diagnosis, and the development of novel therapeutic strategies.[2][5][6]
Section 1: Applications of 5mC Profiling in Disease Research
The ability to map 5mC across the genome has revolutionized our understanding of disease pathogenesis. Altered methylation patterns can serve as highly specific biomarkers for early detection, prognosis, and monitoring treatment response.
Cancer Research
Abnormal DNA methylation is a well-established driver of tumorigenesis. This includes global hypomethylation, which can lead to genomic instability, and gene-specific hypermethylation, which can silence tumor suppressor genes.
-
Early Detection and Diagnosis: 5mC signatures in circulating cell-free DNA (cfDNA) from liquid biopsies show immense promise for non-invasive cancer screening.[7][8] For instance, distinct 5mC patterns can distinguish cancer patients from healthy individuals and even indicate the tissue of origin.[8] A new technique, Direct Methylation Sequencing (DM-Seq), allows for accurate 5mC mapping from very small DNA samples, enhancing its potential for liquid biopsies.[6][7]
-
Prognosis and Treatment Response: Specific methylation patterns have been linked to clinical outcomes. In glioblastoma, methylation levels at certain genomic sites can help predict patient prognosis.[6] Additionally, profiling 5mC can help predict response to epigenetic drugs that target the DNA methylation machinery.[3][9]
-
Therapeutic Targets: The enzymes that regulate DNA methylation, such as DNMTs and Ten-eleven translocation (TET) enzymes, are promising targets for cancer therapy.[3][4][10] Understanding the methylation landscape of a tumor can guide the use of hypomethylating agents and other targeted therapies.
Neurological Disorders
Epigenetic modifications, particularly 5mC, are crucial for normal brain development and function. Alterations in these patterns have been implicated in a range of neurodevelopmental and neurodegenerative diseases.[5][11]
-
Neurodegenerative Diseases: Studies have revealed significant changes in DNA methylation in conditions like Alzheimer's disease (AD), Parkinson's disease (PD), and Huntington's disease (HD).[5][12] For example, brain tissue from AD patients has shown evidence of DNA hypomethylation, potentially leading to increased expression of genes involved in amyloid-beta production.[5] Global 5mC levels are often significantly lower in brain disorders compared to healthy individuals.[13]
-
Neurodevelopmental Disorders: Alterations in 5mC have been linked to Rett syndrome, autism spectrum disorders, and schizophrenia.[12] These changes can affect genes critical for neurogenesis, neuronal activity, and survival.[5]
Autoimmune Diseases
Growing evidence suggests that DNA methylation plays a key role in the pathogenesis of autoimmune diseases by regulating the expression of immune-related genes.
-
Systemic Lupus Erythematosus (SLE) and Rheumatoid Arthritis (RA): A common finding in autoimmune diseases is the global hypomethylation of DNA in immune cells, particularly T-cells.[2][14] This can lead to the overexpression of genes that promote autoimmunity.[2] In patients with active SLE and RA, the mean percentage of 5mC has been found to be significantly lower than in healthy controls.[14] Therapy with certain drugs, such as cyclosporin (B1163) A, has been shown to affect 5mC levels.[14]
Section 2: Quantitative Data Summary
The following tables summarize quantitative findings from key studies, highlighting the potential of 5mC and its derivative, 5-hydroxymethylcytosine (B124674) (5hmC), as clinical biomarkers.
| Disease | Biomarker Type | Sample Type | Key Findings | Reference(s) |
| Colorectal Cancer (CRC) | 5mC & 5hmC | cfDNA (Liquid Biopsy) | Combined model showed 85% sensitivity at 95% specificity for early-stage cancer detection. | [15] |
| Colorectal Cancer (CRC) | 5mC | Blood Immune Cells | m5C levels were an independent risk factor with an odds ratio of 7.622 for CRC diagnosis. | [16] |
| Esophageal Cancer (EC) | 5hmC | cfDNA (Liquid Biopsy) | Classifier achieved 93.75% sensitivity and 85.71% specificity (AUC of 0.947). | [8] |
| Septic Cardiomyopathy | 5hmC | Extracellular Vesicles | Diagnostic model accuracy of 0.962 , with 92.3% sensitivity and 88.89% specificity . | [17] |
| Autoimmune Diseases (RA, SLE) | Global 5mC | Peripheral Blood | Mean percentage of 5mC was significantly lower in patients compared to controls. | [14] |
| Neurological Disorders (General) | Global 5mC | Blood Samples | Patients with clinical improvement showed a significant increase in 5mC levels (from 2.46% to 3.95% ). | [18] |
| Brain Disorders (AD, PD, DV) | Global 5hmC | Buffy Coat Samples | 5hmC values were significantly lower in all three pathologies compared to healthy subjects. | [13] |
Section 3: Key Experimental Protocols
Accurate 5mC profiling requires robust and reliable experimental methods. Below are detailed protocols for three key techniques: Whole-Genome Bisulfite Sequencing (WGBS), Reduced Representation Bisulfite Sequencing (RRBS), and Enzymatic Methyl-seq (EM-seq).
Protocol: Whole-Genome Bisulfite Sequencing (WGBS)
WGBS is considered the gold standard for single-base resolution, genome-wide methylation analysis.[19] However, the required bisulfite treatment can cause significant DNA degradation.[1][20]
1. Genomic DNA Preparation:
-
Extract high-quality genomic DNA (gDNA) using a suitable kit (e.g., QIAGEN DNeasy).[21]
-
Quantify gDNA using a fluorometric method (e.g., Qubit).
-
Spike in 0.1-0.5% (w/w) unmethylated lambda phage DNA as a control for bisulfite conversion efficiency.[20]
2. DNA Fragmentation:
-
Shear gDNA to a target size of ~250 bp using a Covaris sonicator.[22]
-
Verify the fragment size distribution using gel electrophoresis or a Fragment Analyzer.[22]
3. Library Preparation (Pre-Bisulfite Protocol):
-
End Repair and dA-Tailing: Perform end repair to create blunt ends and add a single 'A' nucleotide to the 3' ends of the fragments.[21]
-
Adapter Ligation: Ligate methylated adapters (which are resistant to bisulfite conversion) to the DNA fragments.[20][21]
-
Size Selection: Purify the ligation products of the desired size range using AMPure XP beads or agarose (B213101) gel extraction.[21][22]
4. Bisulfite Conversion:
-
Treat the adapter-ligated DNA with sodium bisulfite using a commercial kit (e.g., Zymo Research EZ DNA Methylation-Gold Kit).[23] This converts unmethylated cytosines to uracil (B121893), while 5mC remains unchanged.[1]
-
Purify the converted DNA according to the kit manufacturer's protocol.
5. PCR Amplification:
-
Amplify the bisulfite-converted library using a polymerase that can read uracil (e.g., PfuTurbo Cx Hotstart DNA Polymerase).[20][22] Use a minimal number of PCR cycles to avoid amplification bias.[20]
-
Purify the final PCR product using AMPure XP beads.[22]
6. Quality Control and Sequencing:
-
Quantify the final library using qPCR (e.g., KAPA Library Quantification Kit).[22]
-
Check the final library size distribution on a Fragment Analyzer or Bioanalyzer.[22]
-
Sequence the library on an Illumina platform, ensuring a sequencing depth of at least 30X coverage for each biological replicate.[24]
Protocol: Reduced Representation Bisulfite Sequencing (RRBS)
RRBS is a cost-effective method that enriches for CpG-rich regions of the genome by using a methylation-insensitive restriction enzyme, typically MspI.[25][26]
1. Genomic DNA Digestion:
-
Digest 100-200 ng of gDNA with the MspI restriction enzyme, which cleaves at 'CCGG' sites regardless of methylation status.[25][27]
-
Incubate at 37°C for at least 2 hours, up to overnight.[28]
2. Library Preparation:
-
End Repair and dA-Tailing: Use a kit like the NEBNext Ultra II End Prep to repair the MspI-generated sticky ends and add a 3' dA-tail.[28]
-
Adapter Ligation: Ligate methylated adapters to the DNA fragments.[29]
3. Size Selection (Optional but Recommended):
-
Select fragments in the desired size range (e.g., 180-2000 bp) to enrich for informative CpG-containing fragments.[28][29] This can be done using AMPure beads or gel extraction.
4. Bisulfite Conversion:
-
Perform bisulfite conversion on the purified, adapter-ligated DNA using a commercial kit (e.g., EZ Methylation Gold Kit).[27]
-
Follow the thermal cycling program for conversion (e.g., 98°C for 10 min, then 64°C for 150 min).[27]
5. PCR Amplification:
-
Amplify the library using a suitable polymerase. Typically, 9-15 cycles are required depending on the input amount.[25]
-
Purify the amplified library.
6. Quality Control and Sequencing:
-
Assess the library concentration and size distribution.
-
Sequence on an Illumina platform using single-end reads of at least 50 bases.[28]
Protocol: Enzymatic Methyl-seq (EM-seq)
EM-seq is a newer, less-damaging alternative to bisulfite sequencing that uses a series of enzymatic reactions to achieve cytosine conversion.[19][23][30] This results in higher library yields, more uniform coverage, and requires less input DNA.[19]
1. DNA Fragmentation and Library Preparation:
-
Shear 10-200 ng of gDNA to the desired fragment size (e.g., 300 bp).[23]
-
Perform end repair, dA-tailing, and ligate EM-seq specific adapters.[31][32]
2. Enzymatic Conversion (Two-Step Process):
-
Step 1: Protection of 5mC and 5hmC: Incubate the library with TET2 enzyme and an oxidation enhancer. TET2 oxidizes 5mC to 5-hydroxymethylcytosine (5hmC) and further derivatives.[31] This protects both modified cytosines from the subsequent deamination step.
-
Step 2: Deamination of Unmodified Cytosines: Add APOBEC enzyme to deaminate all unprotected, unmodified cytosines to uracil.[23][31]
3. PCR Amplification:
-
Amplify the final library using a uracil-tolerant DNA polymerase (e.g., Q5U).[31]
-
Purify the amplified library.
4. Quality Control and Sequencing:
-
Quantify the library and verify its size.
-
The resulting library is sequenced on an Illumina platform. The data is compatible with standard WGBS analysis pipelines.[23]
Section 4: Visualizations
The following diagrams illustrate key concepts and workflows related to this compound profiling.
Caption: The dynamic cycle of DNA methylation by DNMTs and active demethylation mediated by TET enzymes.
Caption: A high-level overview of the 5mC profiling workflow from sample collection to data analysis.
Caption: The experimental workflow for Reduced Representation Bisulfite Sequencing (RRBS).
Caption: The enzymatic conversion workflow for Enzymatic Methyl-seq (EM-seq).
References
- 1. Computational Workflow for Genome-Wide DNA Methylation Profiling and Differential Methylation Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Epigenetics and autoimmune diseases - Autoimmunity - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 3. Frontiers | this compound turnover: Mechanisms and therapeutic implications in cancer [frontiersin.org]
- 4. mdpi.com [mdpi.com]
- 5. The DNA Methylation in Neurological Diseases [mdpi.com]
- 6. A New Epigenetic Sequencing Method to Improve Cancer Detection | Clinical And Molecular Dx [labroots.com]
- 7. New DNA sequencing method may mean earlier cancer detection | Penn Medicine [pennmedicine.org]
- 8. Towards precision medicine: advances in 5-hydroxymethylcytosine cancer biomarker discovery in liquid biopsy - PMC [pmc.ncbi.nlm.nih.gov]
- 9. This compound turnover: Mechanisms and therapeutic implications in cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 10. 5-hydroxymethylcytosine: a potential therapeutic target in cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. 5-hydroxymethylcytosine: A new player in brain disorders? - PMC [pmc.ncbi.nlm.nih.gov]
- 12. The emerging role of 5-hydroxymethylcytosine in neurodegenerative diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 13. mdpi.com [mdpi.com]
- 14. This compound content of DNA in blood, synovial mononuclear cells and synovial tissue from patients affected by autoimmune rheumatic diseases - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. Synergistic Biomarkers for Early Colorectal Cancer Detection: 5-mC and 5-hmC | Technology Networks [technologynetworks.com]
- 16. This compound (m5C) modification in peripheral blood immune cells is a novel non-invasive biomarker for colorectal cancer diagnosis - PMC [pmc.ncbi.nlm.nih.gov]
- 17. 5-Hydroxymethylcytosine signatures as diagnostic biomarkers for septic cardiomyopathy - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. DNA Methylation as a Biomarker for Monitoring Disease Outcome in Patients with Hypovitaminosis and Neurological Disorders - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Whole Genome Methylation Sequencing via Enzymatic Conversion (EM-seq): Protocol, Data Processing, and Analysis | Springer Nature Experiments [experiments.springernature.com]
- 20. mdpi.com [mdpi.com]
- 21. support.illumina.com [support.illumina.com]
- 22. lfz100.ust.hk [lfz100.ust.hk]
- 23. neb-online.de [neb-online.de]
- 24. encodeproject.org [encodeproject.org]
- 25. Reduced Representation Bisulfite Sequencing (RRBS) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 26. Reduced representation bisulfite sequencing - Wikipedia [en.wikipedia.org]
- 27. Reduced Representation Bisulfite Sequencing (RRBS) Protocol - CD Genomics [cd-genomics.com]
- 28. Reduced Representation Bisulfite Sequencing (RRBS) with NEB Reagents [protocols.io]
- 29. What are the steps involved in reduced representation bisulfite sequencing (RRBS)? | AAT Bioquest [aatbio.com]
- 30. biorxiv.org [biorxiv.org]
- 31. researchgate.net [researchgate.net]
- 32. NGI Sweden » Enzymatic Methyl-seq (EM-seq) [ngisweden.scilifelab.se]
Application Notes and Protocols: 5-Methylcytosine as a Biomarker for Cancer
Audience: Researchers, scientists, and drug development professionals.
Introduction
DNA methylation, primarily occurring at the 5th position of cytosine (5-methylcytosine or 5mC), is a crucial epigenetic modification that plays a significant role in regulating gene expression, genomic stability, and cellular differentiation.[1][2][3] In normal cellular processes, 5mC patterns are meticulously maintained. However, the initiation and progression of cancer are often marked by profound disruptions to this epigenetic landscape.[4] These alterations typically manifest as genome-wide hypomethylation, leading to genomic instability, and region-specific hypermethylation, particularly at CpG islands in the promoter regions of tumor suppressor genes, resulting in their silencing.[4][5] This aberrant DNA methylation is a hallmark of many cancers and presents a valuable source of biomarkers for cancer detection, prognosis, and therapeutic response prediction.[6][7]
Signaling Pathways and a New Player: 5-Hydroxymethylcytosine (B124674) (5hmC)
The landscape of DNA methylation is dynamic, governed by the interplay of methylation and demethylation processes. DNA methyltransferases (DNMTs) are responsible for establishing and maintaining 5mC marks.[8] The demethylation pathway is not a simple reversal but involves the oxidation of 5mC by the Ten-Eleven Translocation (TET) family of enzymes.[1][8] This process converts 5mC into 5-hydroxymethylcytosine (5hmC), which can be further oxidized to 5-formylcytosine (B1664653) (5fC) and 5-carboxylcytosine (5caC).[6][8] These oxidized forms are then recognized and excised by the base excision repair (BER) machinery, leading to the restoration of an unmodified cytosine.[8]
The discovery of 5hmC, often termed the "sixth base," has added a new layer of complexity and opportunity in cancer epigenetics.[1] While global hypomethylation of 5mC is a known cancer characteristic, a widespread loss of 5hmC is also a common feature across many tumor types, including brain, lung, breast, and liver cancers.[2][9][10] This reduction in 5hmC is often linked to mutations in TET genes or the enzymes that regulate TET activity.[10] Consequently, both 5mC and 5hmC are now being investigated, sometimes synergistically, as potent biomarkers in oncology.[11][12][13]
Data Presentation: 5mC and 5hmC as Cancer Biomarkers
The utility of 5mC and its derivative 5hmC as biomarkers is being demonstrated across a wide range of cancers, particularly in the context of liquid biopsies using cell-free DNA (cfDNA).
Table 1: Comparison of Key 5mC/5hmC Detection Methodologies
| Method | Principle | Resolution | Advantages | Disadvantages |
| Whole-Genome Bisulfite Sequencing (WGBS) | Sodium bisulfite converts unmethylated cytosine to uracil, while 5mC and 5hmC remain unchanged.[14] | Single-base | Gold standard, comprehensive genome-wide coverage. | High cost, DNA degradation, cannot distinguish 5mC from 5hmC.[15][16] |
| Reduced Representation Bisulfite Sequencing (RRBS) | Similar to WGBS but enriches for CpG-rich regions using restriction enzymes before bisulfite treatment.[14] | Single-base | Cost-effective for CpG island analysis. | Biased towards CpG-rich regions, incomplete genome coverage. |
| Methylated DNA Immunoprecipitation (MeDIP-Seq) | Uses antibodies to enrich for DNA fragments containing 5mC.[14] | ~150-200 bp | Cost-effective for genome-wide screening. | Lower resolution, antibody-dependent bias. |
| Oxidative Bisulfite Sequencing (oxBS-Seq) | A two-step process involving oxidation of 5hmC to 5fC, followed by bisulfite treatment. Allows for direct quantification of 5mC.[17] | Single-base | Can distinguish 5mC from 5hmC. | Complex protocol, requires two separate experiments (BS-Seq and oxBS-Seq). |
| TET-Assisted Bisulfite Sequencing (TAB-Seq) | Protects 5hmC from TET oxidation, then TET enzymes convert 5mC to caC, which is read as thymine (B56734) after bisulfite treatment.[7] | Single-base | Direct, positive detection of 5hmC. | Technically challenging protocol. |
| 5hmC-Seal | Chemical labeling and enrichment of 5hmC-containing DNA fragments.[18] | Region-level | Highly sensitive for low-input samples like cfDNA.[18] | Does not provide single-base resolution. |
| Direct Methylation Sequencing (DM-Seq) | An enzymatic method that directly detects 5mC without DNA damage.[15] | Single-base | High sensitivity for small DNA amounts, avoids DNA damage.[15] | Newer technology, less widely adopted. |
Table 2: Quantitative Performance of 5mC and 5hmC as Cancer Biomarkers
| Cancer Type | Biomarker(s) | Sample Type | Key Finding / Performance Metric |
| Colorectal Cancer (CRC) | 5mC and 5hmC | cfDNA | Combined 5mC and 5hmC model achieved an AUC of 0.95 for detecting Stage I CRC, significantly outperforming models that do not distinguish the two marks (AUC = 0.66).[12][13] |
| Colorectal Cancer (CRC) | 5mC and 5hmC | cfDNA | A combined model showed 85% sensitivity at 95% specificity for early-stage cancer detection.[11] |
| Colorectal Cancer (CRC) | 5hmC | Pre-diagnostic Plasma | A 32-gene 5hmC model distinguished occult CRC cases from controls with an AUC of 72.8% in a validation set.[18] |
| Hepatocellular Carcinoma | 5mC | ctDNA | Showed better diagnostic and prognostic value than serum alpha-fetoprotein (AFP).[6] |
| Diffuse Large B-cell Lymphoma | 5mC (LINE-1 elements) | cfDNA | LINE-1 methylation levels were strongly associated with clinical outcomes.[6] |
| Pan-Cancer (Bladder, Breast, CRC, Kidney, Lung, Prostate) | 5hmC | cfDNA | A 24-5hmC-gene model distinguished cancer patients from healthy individuals.[19] |
| Papillary Thyroid Carcinoma (PTC) | 5hmC | Tissue | Significant loss of 5hmC was observed in PTC compared to benign thyroid disease, suggesting diagnostic value.[9] |
Experimental Protocols & Workflow
The analysis of 5mC as a cancer biomarker involves several key steps, from sample collection to data analysis. The choice of method depends on the specific research question, required resolution, and sample availability.
Protocol 1: Global 5mC Quantification using HPLC-MS
High-Performance Liquid Chromatography with Mass Spectrometry (HPLC-MS) is a highly sensitive and selective method for determining the total, genome-wide levels of 5mC.[17]
-
DNA Extraction: Isolate high-quality genomic DNA from tissue or cell samples using a standard kit.
-
DNA Hydrolysis: Digest 5-10 µg of genomic DNA into individual nucleosides using a DNA degradation enzyme mix (e.g., nuclease P1, followed by alkaline phosphatase).
-
HPLC Separation: Separate the resulting nucleosides using a reverse-phase HPLC column.
-
Mass Spectrometry: Introduce the separated nucleosides into a mass spectrometer operating in electrospray ionization (ESI) mode.
-
Quantification: Quantify the amount of 5mC relative to the amount of unmodified cytosine by comparing the area under the curve for their respective mass-to-charge ratios. This provides a global percentage of 5mC.
Protocol 2: Locus-Specific 5mC Analysis via Bisulfite Sequencing
Bisulfite sequencing remains the gold standard for single-base resolution methylation analysis.[14]
-
DNA Extraction: Isolate genomic DNA from the sample of interest.
-
Bisulfite Conversion: Treat 200-500 ng of DNA with sodium bisulfite using a commercial kit. This reaction converts unmethylated cytosines to uracil, while 5mC remains unchanged.
-
PCR Amplification: Amplify the specific genomic region of interest using primers designed to be specific for the bisulfite-converted DNA sequence.
-
Library Preparation & Sequencing: Prepare a sequencing library from the PCR products and perform next-generation sequencing.
-
Data Analysis:
-
Align the sequencing reads to an in silico bisulfite-converted reference genome.
-
For each CpG site, calculate the methylation level as the percentage of reads containing a cytosine versus the total number of reads (cytosine + thymine).
-
A read with a 'C' at a CpG site indicates methylation, while a 'T' indicates a lack of methylation.
-
Protocol 3: Genome-Wide 5mC Profiling using MeDIP-Seq
Methylated DNA Immunoprecipitation followed by Sequencing (MeDIP-Seq) is an enrichment-based method for surveying 5mC distribution across the genome.[14]
-
DNA Extraction and Fragmentation: Isolate genomic DNA and shear it to an average size of 200-500 bp using sonication.
-
Immunoprecipitation (IP): Incubate the fragmented DNA with a specific monoclonal antibody against 5mC.
-
Enrichment: Capture the antibody-DNA complexes using magnetic beads (e.g., Protein A/G beads).
-
Washing and Elution: Wash the beads to remove non-specifically bound DNA, then elute the enriched methylated DNA.
-
Library Preparation and Sequencing: Prepare a standard NGS library from the eluted DNA and perform high-throughput sequencing.
-
Data Analysis:
-
Align reads to the reference genome.
-
Identify peaks of enriched regions, which correspond to areas of high 5mC density.
-
Perform differential methylation analysis between sample groups by comparing peak heights or read counts within specific genomic regions.
-
Conclusion and Future Directions
The analysis of this compound is a powerful tool in cancer research and clinical diagnostics. Aberrant 5mC patterns are a fundamental characteristic of cancer, providing a rich source of biomarkers for early detection, prognosis, and patient stratification. The evolution of detection technologies, particularly those compatible with low-input cfDNA, is rapidly advancing the field of liquid biopsy.
Future efforts will likely focus on the integration of multiple epigenetic marks. As research has shown, distinguishing between 5mC and 5hmC can significantly improve the diagnostic accuracy for early-stage cancers.[12][13] The development of multi-omic approaches that simultaneously analyze genetic and multiple epigenetic alterations (including 5mC, 5hmC, and nucleosome positioning) from a single liquid biopsy sample holds the promise of delivering a new generation of highly sensitive and specific non-invasive cancer diagnostics, paving the way for true precision oncology.[6][20]
References
- 1. 5-hydroxymethylcytosine: A new insight into epigenetics in cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 2. The role of 5-hydroxymethylcytosine in human cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 3. mdpi.com [mdpi.com]
- 4. portlandpress.com [portlandpress.com]
- 5. researchgate.net [researchgate.net]
- 6. Towards precision medicine: advances in 5-hydroxymethylcytosine cancer biomarker discovery in liquid biopsy - PMC [pmc.ncbi.nlm.nih.gov]
- 7. 5-Hydroxymethylcytosine: a key epigenetic mark in cancer and chemotherapy response - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Frontiers | this compound turnover: Mechanisms and therapeutic implications in cancer [frontiersin.org]
- 9. 5-Hydroxymethylcytosine as a potential epigenetic biomarker in papillary thyroid carcinoma - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Regulation and Functional Significance of 5-Hydroxymethylcytosine in Cancer [mdpi.com]
- 11. Synergistic Biomarkers for Early Colorectal Cancer Detection: 5-mC and 5-hmC | Technology Networks [technologynetworks.com]
- 12. biorxiv.org [biorxiv.org]
- 13. aacrjournals.org [aacrjournals.org]
- 14. epigenie.com [epigenie.com]
- 15. New DNA sequencing method may mean earlier cancer detection | Penn Medicine [pennmedicine.org]
- 16. New sequencing methods for distinguishing DNA modifications — Oxford Cancer [cancer.ox.ac.uk]
- 17. Methods for Detection and Mapping of Methylated and Hydroxymethylated Cytosine in DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 18. 5-Hydroxymethylated biomarkers in cell-free DNA predict occult colorectal cancer up to 36 months prior to diagnosis in the PLCO Cancer Screening Trial - PMC [pmc.ncbi.nlm.nih.gov]
- 19. mdpi.com [mdpi.com]
- 20. 5-Hydroxymethylcytosine: a key epigenetic mark in cancer and chemotherapy response - PubMed [pubmed.ncbi.nlm.nih.gov]
Machine Learning Models for Predicting 5-Methylcytosine (5mC) Sites: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
This document provides a comprehensive overview of machine learning models designed to predict 5-methylcytosine (B146107) (5mC) sites in DNA. It includes detailed application notes, a comparison of various models, and step-by-step experimental protocols for generating the data used to train and validate these predictive tools.
Introduction to 5mC and its Importance
This compound (5mC) is a crucial epigenetic modification in mammals, playing a significant role in gene regulation, genomic imprinting, X-chromosome inactivation, and cellular differentiation.[1] Aberrant 5mC patterns are a hallmark of various diseases, most notably cancer, where hypermethylation of tumor suppressor gene promoters and global hypomethylation are common.[2][3] The precise identification of 5mC sites is therefore essential for understanding disease mechanisms and developing novel therapeutic strategies.
While experimental methods like bisulfite sequencing are considered the gold standard for detecting 5mC, they can be time-consuming and expensive.[4] This has spurred the development of computational methods, particularly machine learning models, to predict 5mC sites with high accuracy and efficiency.
Machine Learning Models for 5mC Site Prediction
A variety of machine learning and deep learning models have been developed to identify 5mC sites based on DNA sequence features. These models leverage different architectures, from deep neural networks to advanced transformer-based models, to learn the complex patterns surrounding methylated cytosines.
Data Presentation: Performance of 5mC Prediction Models
The performance of several state-of-the-art machine learning models for 5mC site prediction is summarized in the table below. The models were evaluated on independent test datasets using various metrics, including Accuracy (Acc), Specificity (Sp), Sensitivity (Sn), Matthews Correlation Coefficient (MCC), and the Area Under the Receiver Operating Characteristic Curve (AUC).
| Model | Accuracy (Acc) | Specificity (Sp) | Sensitivity (Sn) | MCC | AUC |
| DGA-5mC | 92.54% | 92.74% | 90.19% | 0.6464 | 0.9643 |
| BERT-5mC | 93.30% | 93.80% | N/A | 0.6560 | 0.9660 |
| iPromoter-5mC | 90.22% | 90.42% | 87.77% | 0.5771 | 0.9570 |
| BiLSTM-5mC | 93.03% | 93.74% | N/A | 0.6384 | 0.9635 |
| i5mC-DCGA | 96.58% | 96.52% | 97.02% | 0.8558 | 0.9866 |
Note: "N/A" indicates that the specific metric was not reported in the primary publication. Performance metrics are based on independent test sets as reported in the respective studies.[4][5][6][7][8]
Experimental Protocols for 5mC Data Generation
The following are detailed protocols for key experimental techniques used to generate the ground-truth data necessary for training and validating 5mC prediction models.
Whole-Genome Bisulfite Sequencing (WGBS)
WGBS is a comprehensive method for analyzing genome-wide methylation at single-nucleotide resolution.[9]
Protocol:
-
DNA Extraction:
-
DNA Fragmentation:
-
Fragment the genomic DNA to a desired size range (e.g., 200-300 bp) using sonication (e.g., Covaris).
-
-
End Repair, A-tailing, and Adaptor Ligation:
-
Perform end repair to create blunt-ended fragments.
-
Add a single 'A' nucleotide to the 3' ends of the fragments (A-tailing).
-
Ligate methylated sequencing adapters to the DNA fragments.
-
-
Bisulfite Conversion:
-
PCR Amplification:
-
Amplify the bisulfite-converted DNA using PCR to enrich for fragments with adapters on both ends.
-
-
Library Quantification and Sequencing:
-
Quantify the final library and perform high-throughput sequencing (e.g., Illumina platform).
-
-
Data Analysis:
-
Align the sequencing reads to a reference genome.
-
Determine the methylation status of each cytosine by comparing the sequenced reads to the reference. A cytosine that remains as a 'C' in the read was methylated, while one that is read as a 'T' was unmethylated.
-
Reduced Representation Bisulfite Sequencing (RRBS)
RRBS is a cost-effective method that enriches for CpG-rich regions of the genome.[13][14]
Protocol:
-
DNA Digestion:
-
End Repair, A-tailing, and Adaptor Ligation:
-
Similar to WGBS, perform end repair, A-tailing, and ligate methylated sequencing adapters.
-
-
Fragment Size Selection:
-
Select a specific size range of DNA fragments using gel electrophoresis or beads.[9]
-
-
Bisulfite Conversion:
-
Perform bisulfite conversion on the size-selected fragments as described for WGBS.
-
-
PCR Amplification and Sequencing:
-
Amplify the library and proceed with high-throughput sequencing.
-
Oxidative Bisulfite Sequencing (oxBS-Seq)
oxBS-Seq is a modification of WGBS that allows for the discrimination between 5mC and 5-hydroxymethylcytosine (B124674) (5hmC).
Protocol:
-
DNA Oxidation:
-
Chemically oxidize 5hmC to 5-formylcytosine (B1664653) (5fC) using an oxidizing agent like potassium perruthenate (KRuO4). 5mC remains unaffected.[16][17]
-
-
Bisulfite Conversion:
-
Perform standard bisulfite treatment. This converts unmethylated cytosines and 5fC to uracil, while 5mC is protected.
-
-
Library Preparation and Sequencing:
-
Prepare sequencing libraries and perform high-throughput sequencing as in WGBS.
-
-
Data Analysis:
-
By comparing the results of oxBS-Seq with a parallel standard BS-Seq experiment on the same sample, the levels of both 5mC and 5hmC can be inferred at single-base resolution.[18]
-
Tet-Assisted Bisulfite Sequencing (TAB-Seq)
TAB-Seq is another method to specifically map 5hmC at single-base resolution.
Protocol:
-
Protection of 5hmC:
-
Oxidation of 5mC:
-
Bisulfite Conversion:
-
Perform bisulfite treatment, which converts unmethylated cytosines and 5caC to uracil. The protected 5hmC remains as cytosine.
-
-
Library Preparation and Sequencing:
-
Prepare and sequence the library.
-
-
Data Analysis:
-
In the final sequence, any remaining cytosine represents a site that was originally 5hmC.
-
Signaling Pathways and Experimental Workflows
The following diagrams illustrate key biological pathways and experimental workflows related to 5mC prediction.
This pathway illustrates the enzymatic processes governing the addition and removal of methyl groups from cytosine. DNA methyltransferases (DNMTs) establish and maintain 5mC marks, while Ten-eleven translocation (TET) enzymes initiate the demethylation process through a series of oxidative reactions.[22][23] The base excision repair (BER) pathway, involving enzymes like Thymine DNA Glycosylase (TDG), completes the removal of the modified base.
This diagram outlines the major steps involved in preparing a WGBS library for sequencing. The key step is the bisulfite conversion, which chemically modifies unmethylated cytosines, allowing for their differentiation from methylated cytosines during sequencing and subsequent data analysis.
This diagram illustrates the fundamental process by which machine learning models predict 5mC sites. A DNA sequence is provided as input, from which relevant features are extracted. The trained machine learning model then processes these features to classify the central cytosine as either methylated or unmethylated.
Conclusion
Machine learning models are powerful tools for the high-throughput prediction of 5mC sites, complementing traditional experimental methods. The continued development of more accurate and robust models, trained on high-quality data generated through standardized protocols, will further enhance our understanding of the role of DNA methylation in health and disease and aid in the discovery of novel epigenetic biomarkers and therapeutic targets.
References
- 1. New themes in the biological functions of this compound and 5-hydroxymethylcytosine - PMC [pmc.ncbi.nlm.nih.gov]
- 2. iPromoter-5mC: A Novel Fusion Decision Predictor for the Identification of this compound Sites in Genome-Wide DNA Promoters - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. The role of 5-hydroxymethylcytosine in human cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 4. DGA-5mC: A this compound site prediction model based on an improved DenseNet and bidirectional GRU method - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. BiLSTM-5mC: A Bidirectional Long Short-Term Memory-Based Approach for Predicting this compound Sites in Genome-Wide DNA Promoters - PMC [pmc.ncbi.nlm.nih.gov]
- 6. iPromoter-5mC: A Novel Fusion Decision Predictor for the Identification of this compound Sites in Genome-Wide DNA Promoters - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. i5mC-DCGA: an improved hybrid network framework based on the CBAM attention mechanism for identifying promoter 5mC sites - PMC [pmc.ncbi.nlm.nih.gov]
- 9. An Introduction to Reduced Representation Bisulfite Sequencing (RRBS) - CD Genomics [cd-genomics.com]
- 10. encodeproject.org [encodeproject.org]
- 11. What are the basic steps of whole genome bisulfite sequencing (WGBS)? | AAT Bioquest [aatbio.com]
- 12. Principles and Workflow of Whole Genome Bisulfite Sequencing - CD Genomics [cd-genomics.com]
- 13. Reduced representation bisulfite sequencing - Wikipedia [en.wikipedia.org]
- 14. Intro to Reduced Representation Bisulfite Sequencing (RRBS) | EpigenTek [epigentek.com]
- 15. Reduced Representation Bisulfite Sequencing (RRBS) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. Oxidative Bisulfite Sequencing: An Experimental and Computational Protocol - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. epigenie.com [epigenie.com]
- 18. Bisulfite Sequencing (BS-Seq)/WGBS [illumina.com]
- 19. Tet-Assisted Bisulfite Sequencing Service, DNA Hydroxymethylation Analysis | CD BioSciences [epigenhub.com]
- 20. epigenie.com [epigenie.com]
- 21. Tet-Assisted Bisulfite Sequencing (TAB-seq) - PMC [pmc.ncbi.nlm.nih.gov]
- 22. researchgate.net [researchgate.net]
- 23. New Insights into 5hmC DNA Modification: Generation, Distribution and Function - PMC [pmc.ncbi.nlm.nih.gov]
Troubleshooting & Optimization
Technical Support Center: Troubleshooting Bisulfite Conversion of 5-Methylcytosine
Welcome to the technical support center for bisulfite conversion of 5-Methylcytosine. This guide is designed for researchers, scientists, and drug development professionals to provide clear and actionable solutions to common issues encountered during bisulfite conversion experiments.
Frequently Asked Questions (FAQs)
Q1: What is the principle behind bisulfite conversion?
Bisulfite sequencing is a method used to determine the methylation patterns in DNA.[1] The process involves treating DNA with sodium bisulfite, which chemically converts unmethylated cytosine (C) residues to uracil (B121893) (U), while methylated cytosines (5-mC) remain unchanged.[2][3] Subsequent PCR amplification replaces the uracils with thymines (T). By comparing the sequence of the bisulfite-treated DNA with the original untreated sequence, the methylation status of each cytosine can be determined at single-nucleotide resolution.[1]
Q2: What are the most common problems encountered during bisulfite conversion?
The most frequent challenges during bisulfite conversion are:
-
Incomplete Conversion: Failure to convert all unmethylated cytosines to uracil, leading to false-positive methylation results.[2][4]
-
DNA Degradation: The harsh chemical conditions of bisulfite treatment can cause significant DNA fragmentation, resulting in low yields and difficulty in amplifying larger DNA fragments.[5][6][7]
-
Low DNA Yield: A combination of DNA degradation and purification steps can lead to a substantial loss of sample material.[8][9]
Q3: How can I assess the success of my bisulfite conversion?
The efficiency of bisulfite conversion can be evaluated by sequencing a control DNA with a known methylation status or by analyzing the conversion of non-CpG cytosines, which are predominantly unmethylated in most mammalian genomes. A successful conversion should result in over 99% of unmethylated cytosines being converted to thymines.[4] Some commercial kits also include control reagents for assessing conversion efficiency.
Q4: What is the difference between bisulfite conversion and enzymatic conversion?
Enzymatic conversion is an alternative method that uses enzymes, such as APOBEC, to deaminate unmethylated cytosines to uracils. This method is generally milder than bisulfite treatment, resulting in less DNA degradation.[5][9] However, bisulfite conversion remains a widely used and well-established "gold standard" technique.[10]
Troubleshooting Guide
Issue 1: Incomplete Bisulfite Conversion
Symptoms:
-
High background of cytosine signals in non-CpG contexts after sequencing.
-
Sequencing results show unconverted cytosines in a control unmethylated DNA sample.
Potential Causes and Solutions:
| Cause | Recommended Solution |
| Poor DNA Quality | Ensure the starting DNA is of high quality and free from contaminants like proteins and RNA. Use purified, high molecular weight DNA.[11] |
| Incomplete Denaturation | Complete denaturation of the double-stranded DNA is critical for bisulfite to access the cytosines.[12] Ensure proper denaturation temperature and time as per the protocol. The presence of secondary structures in DNA can also inhibit conversion.[13] |
| Suboptimal Reagent Concentration | Use freshly prepared bisulfite and hydroquinone (B1673460) solutions.[11] An incorrect ratio of bisulfite to DNA can lead to incomplete conversion.[14] |
| Incorrect Incubation Time/Temperature | Optimize incubation time and temperature. Longer incubation times can improve conversion efficiency but may also increase DNA degradation.[13] Some protocols suggest cycling temperatures to enhance conversion. |
| Insufficient Desulfonation | Ensure the desulfonation step is carried out completely, as residual sulfonate groups can inhibit downstream PCR. Use freshly prepared desulfonation buffers.[13] |
Issue 2: Significant DNA Degradation and Low Yield
Symptoms:
-
Low concentration of DNA after purification.
-
Inability to amplify larger PCR products (>300 bp).[15]
-
Smearing of DNA on an agarose (B213101) gel, indicating fragmentation.[9]
Potential Causes and Solutions:
| Cause | Recommended Solution |
| Harsh Bisulfite Treatment Conditions | The combination of low pH, high temperature, and long incubation times inherently causes DNA degradation, with reports of 84-96% DNA loss.[6][7] Consider using a commercial kit with optimized reagents and protocols designed to minimize degradation. |
| Poor Starting DNA Quality | Fragmented starting DNA, such as that from FFPE tissues, is more susceptible to further degradation.[11][16] |
| Excessive Freeze-Thaw Cycles | Avoid repeated freezing and thawing of the bisulfite-converted DNA, as it is single-stranded and more fragile.[17] |
| Inefficient DNA Cleanup | Use a reliable method for DNA purification post-conversion, such as spin columns or magnetic beads, to maximize recovery. |
| High Bisulfite Concentration | While a sufficient concentration is needed for conversion, excessively high concentrations can exacerbate DNA degradation.[14] |
Issue 3: PCR Amplification Failure of Bisulfite-Converted DNA
Symptoms:
-
No PCR product or very faint bands on an agarose gel.
-
Non-specific PCR products.
Potential Causes and Solutions:
| Cause | Recommended Solution |
| Inappropriate Primer Design | Primers should be designed to be specific for the bisulfite-converted DNA sequence (where unmethylated Cs are now Ts). Avoid CpG sites within the primer sequence to prevent methylation bias.[17][18] Primer lengths of 24-32 nucleotides are often recommended.[11] |
| Low Amount of Template DNA | Due to degradation, the amount of intact template DNA may be very low. Try increasing the amount of converted DNA in the PCR reaction or performing a nested or semi-nested PCR to increase sensitivity.[17] |
| Suboptimal PCR Conditions | Use a hot-start DNA polymerase optimized for bisulfite-treated templates.[15] Optimize the annealing temperature, as the AT-rich nature of converted DNA can lead to non-specific binding. Touchdown PCR can be an effective strategy.[15][18] |
| Incorrect Polymerase Choice | Do not use proofreading polymerases as they cannot read through uracil. A hot-start Taq polymerase is recommended.[11] |
| Amplicon Size Too Large | Due to DNA fragmentation, it is advisable to design amplicons smaller than 300-400 bp.[1][15] |
Quantitative Data Summary
The following table summarizes the performance of different bisulfite conversion kits based on published comparative studies.
| Kit/Method | Conversion Efficiency (%) | DNA Recovery/Yield (%) | Key Findings |
| Premium Bisulfite Kit (Diagenode) | 99.0 ± 0.035 | ~80 (for 100bp fragments) | High recovery of short DNA fragments.[4][10] |
| EpiTect Bisulfite Kit (Qiagen) | 98.4 ± 0.013 | ~66 (for 200bp fragments) | Consistent results reported in multiple studies.[4][10][17] |
| MethylEdge Bisulfite Conversion System (Promega) | 99.8 ± 0.000 | - | Highest reported conversion efficiency in one study.[10] |
| EZ DNA Methylation-Direct Kit (Zymo Research) | - | 9-32 (mean range) | Allows for direct conversion from cell lysates.[4] |
| BisulFlash DNA Modification Kit (Epigentek) | 97.9 | - | One of the kits compared in a multi-kit analysis.[10] |
| Enzymatic Conversion (e.g., NEBNext Enzymatic Methyl-seq) | 99.0 - 99.8 | Lower than bisulfite | Results in significantly less DNA degradation.[9] |
Note: The values presented are compiled from different studies and may vary depending on the specific experimental conditions and input DNA.
Experimental Protocols
Detailed Protocol for Bisulfite Conversion of Genomic DNA
This protocol is a generalized procedure based on common practices. It is highly recommended to follow the specific instructions provided with your commercial kit.
Materials:
-
Purified genomic DNA (50-500 ng)
-
Sodium Bisulfite
-
Hydroquinone (antioxidant)
-
NaOH (for denaturation and desulfonation)
-
DNA purification columns or magnetic beads
-
Elution buffer
Procedure:
-
DNA Denaturation:
-
To your DNA sample, add freshly prepared NaOH to a final concentration of 0.2-0.3 M.
-
Incubate at 37-42°C for 10-15 minutes. This step denatures the double-stranded DNA.
-
-
Bisulfite Conversion Reaction:
-
Prepare the bisulfite conversion reagent by dissolving sodium bisulfite and hydroquinone in water. The exact concentrations will vary depending on the kit or protocol.
-
Add the bisulfite solution to the denatured DNA.
-
Incubate the reaction mixture in a thermal cycler. Incubation conditions can vary, for example, 16 hours at 50-55°C or shorter times at higher temperatures (e.g., 30 minutes at 70°C).[19] Some protocols use temperature cycling (e.g., 5 minutes at 95°C followed by 30 minutes at 60°C, repeated for several cycles).
-
-
DNA Cleanup (Desalting):
-
After incubation, the bisulfite-treated DNA needs to be purified from the conversion reagents. This is typically done using a spin column or magnetic beads according to the manufacturer's instructions.
-
-
Desulfonation:
-
Add a desulfonation buffer (containing NaOH) to the column-bound or bead-bound DNA.
-
Incubate at room temperature for 15-20 minutes. This step removes the sulfonate group from the uracil bases.
-
-
Final Purification and Elution:
-
Wash the DNA with a wash buffer to remove the desulfonation buffer.
-
Elute the purified, single-stranded, bisulfite-converted DNA in a small volume of elution buffer or nuclease-free water.
-
-
Storage:
-
It is best to use the converted DNA immediately in downstream applications. If storage is necessary, aliquot the DNA and store it at -20°C or -80°C to minimize degradation.[8]
-
Visualizations
Bisulfite Conversion Workflow
Caption: Workflow of bisulfite conversion for this compound analysis.
Troubleshooting Decision Tree for Bisulfite Conversion
Caption: A decision tree for troubleshooting common bisulfite conversion issues.
References
- 1. bisulfite Methods, Protocols and Troubleshootings [protocol-online.org]
- 2. Bisulfite Sequencing of DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Practical Guide to DOT Language (Graphviz) for Developers and Analysts · while true do; [danieleteti.it]
- 4. Comparative analysis of 12 different kits for bisulfite conversion of circulating cell-free DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Comparative performance evaluation of bisulfite- and enzyme-based DNA conversion methods - PMC [pmc.ncbi.nlm.nih.gov]
- 6. storage.prod.researchhub.com [storage.prod.researchhub.com]
- 7. Precision and Performance Characteristics of Bisulfite Conversion and Real-Time PCR (MethyLight) for Quantitative DNA Methylation Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 8. DOT Language | Graphviz [graphviz.org]
- 9. Comparison of enzymatic and bisulfite conversion of circulating cell-free tumor DNA for DNA methylation analyses - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Bisulfite Conversion of DNA: Performance Comparison of Different Kits and Methylation Quantitation of Epigenetic Biomarkers that Have the Potential to Be Used in Non-Invasive Prenatal Testing - PMC [pmc.ncbi.nlm.nih.gov]
- 11. DNA Methylation Analysis Support—Troubleshooting | Thermo Fisher Scientific - JP [thermofisher.com]
- 12. Bisulfite Protocol | Stupar Lab [stuparlab.cfans.umn.edu]
- 13. Frontiers | Bisulfite-Converted DNA Quantity Evaluation: A Multiplex Quantitative Real-Time PCR System for Evaluation of Bisulfite Conversion [frontiersin.org]
- 14. med.upenn.edu [med.upenn.edu]
- 15. reddit.com [reddit.com]
- 16. researchgate.net [researchgate.net]
- 17. bitesizebio.com [bitesizebio.com]
- 18. microsynth.com [microsynth.com]
- 19. Setting up bisulfite sequencing in lab - DNA Methylation and Epigenetics [protocol-online.org]
Technical Support Center: Optimizing PCR for Methylated DNA
Welcome to our technical support center for researchers, scientists, and drug development professionals. This resource provides troubleshooting guides and frequently asked questions (FAQs) to address common issues encountered when performing PCR on bisulfite-converted, methylated DNA.
Frequently Asked Questions (FAQs)
Q1: What is the fundamental principle behind PCR-based methylation analysis?
A1: The core principle lies in the chemical treatment of DNA with sodium bisulfite. This treatment converts unmethylated cytosine residues to uracil, while methylated cytosines remain unchanged.[1][2][3] Subsequent PCR amplification using specifically designed primers can then distinguish between the original methylated and unmethylated sequences. The uracils are read as thymines by the DNA polymerase during PCR.[4]
Q2: What are the main PCR-based methods for analyzing DNA methylation?
A2: The most common techniques are:
-
Methylation-Specific PCR (MSP): This method uses two pairs of primers. One pair is specific for the methylated sequence (containing CpGs), and the other is specific for the unmethylated sequence (containing TpGs post-bisulfite conversion).[5][6] The presence of a PCR product with a specific primer set indicates the methylation status.
-
Bisulfite Sequencing PCR (BSP): In this approach, primers are designed to amplify a bisulfite-converted region regardless of its methylation status.[7] The resulting PCR product is then sequenced to determine the methylation status of individual CpG sites within the amplified region.[1][4]
Q3: Why is my PCR amplification of bisulfite-treated DNA weak or absent?
A3: Several factors can contribute to poor amplification:
-
DNA Degradation: Bisulfite treatment is a harsh process that can lead to significant DNA degradation and fragmentation.[8] Shorter PCR amplicons (ideally under 300-400 bp) are generally more successful.[5]
-
Low DNA Input: The amount of available template DNA is reduced after bisulfite conversion and subsequent purification.[7] Consider starting with a higher initial amount of genomic DNA.
-
PCR Inhibition: Residual bisulfite or other chemicals from the conversion process can inhibit the DNA polymerase. Ensure thorough purification of the converted DNA.
-
Suboptimal PCR Conditions: Annealing temperature, primer concentration, and magnesium chloride concentration may not be optimal for the AT-rich sequences often resulting from bisulfite conversion.
Q4: I am seeing non-specific bands or a smear in my gel electrophoresis. What could be the cause?
A4: Non-specific amplification can be due to:
-
Low Annealing Temperature: An annealing temperature that is too low can allow primers to bind to non-target sequences. It is crucial to optimize the annealing temperature, often using a gradient PCR.
-
Primer-Dimers: The AT-rich nature of primers for bisulfite-converted DNA can sometimes promote the formation of primer-dimers.
-
Incomplete Bisulfite Conversion: If the bisulfite conversion is incomplete, primers may amplify the original, unconverted DNA sequence, leading to unexpected products.[7]
-
Excessive Template DNA or PCR Cycles: Too much template DNA or too many PCR cycles can lead to the accumulation of non-specific products.
Q5: How can I confirm that the bisulfite conversion was successful?
A5: To ensure complete conversion, you can:
-
Include Control DNA: Use commercially available or in-house prepared fully methylated and unmethylated control DNA in your bisulfite conversion and subsequent PCR.
-
Amplify a Control Region: Design primers for a region of DNA that is known to be unmethylated in your sample type. After bisulfite conversion and PCR, sequencing of this region should show complete conversion of cytosines to thymines.
-
Analyze Non-CpG Cytosines: When sequencing your target region, all cytosines that are not part of a CpG dinucleotide should be converted to thymines. The presence of remaining non-CpG cytosines indicates incomplete conversion.[7]
Troubleshooting Guides
Issue 1: No or Low PCR Product Yield
| Potential Cause | Recommended Solution |
| DNA Degradation | - Start with high-quality genomic DNA.- Limit the bisulfite treatment time as much as possible without compromising conversion efficiency.- Design primers to amplify shorter fragments (< 150-300 bp).[5] |
| Suboptimal Annealing Temperature | - Perform a gradient PCR to determine the optimal annealing temperature for your specific primers and template. |
| Incorrect Primer Design | - Ensure primers are designed for the bisulfite-converted sequence (all unmethylated Cs are treated as Ts).- For MSP, include at least one CpG site at the 3' end of the primers for maximum specificity.[5]- For BSP, design primers that do not contain CpG sites to avoid amplification bias. |
| PCR Inhibitors | - Use a high-quality kit for purifying the bisulfite-converted DNA to remove any residual reagents. |
| Insufficient Template DNA | - Increase the amount of bisulfite-converted DNA in the PCR reaction. |
Issue 2: Non-Specific Amplification (Smears or Multiple Bands)
| Potential Cause | Recommended Solution |
| Annealing Temperature Too Low | - Increase the annealing temperature in increments of 1-2°C. A gradient PCR is highly recommended. |
| Primer Concentration Too High | - Reduce the concentration of primers in the PCR reaction. |
| Magnesium Chloride (MgCl₂) Concentration | - Titrate the MgCl₂ concentration. While it can enhance yield, too much can reduce specificity. |
| Incomplete Bisulfite Conversion | - Ensure optimal denaturation of DNA before bisulfite treatment.- Use a reliable bisulfite conversion kit and follow the protocol carefully. |
| Primer Design Issues | - Check primers for potential self-dimerization or hairpin structures using primer design software. |
Quantitative Data for PCR Optimization
The following table provides recommended starting concentrations and ranges for key PCR components when working with bisulfite-converted DNA. Optimization is often necessary.
| Component | Recommended Starting Concentration | Typical Range for Optimization | Notes |
| Template DNA (Bisulfite-Converted) | 1-2 µL of eluate | 1-5 µL | The amount depends on the initial DNA concentration and the efficiency of the bisulfite conversion kit. |
| Forward & Reverse Primers | 0.2 µM | 0.1 - 0.5 µM | Higher concentrations can sometimes lead to non-specific products and primer-dimers. |
| dNTPs | 200 µM of each | 100 - 400 µM of each | Standard concentrations are usually effective. |
| MgCl₂ | 1.5 mM | 1.0 - 2.5 mM | This is a critical component to optimize. Higher concentrations can increase yield but may decrease specificity. |
| Taq Polymerase | 1.25 units / 50 µL reaction | 1.0 - 2.5 units / 50 µL reaction | Follow the manufacturer's recommendations for the specific polymerase used. Hot-start polymerases are highly recommended. |
Experimental Protocols
Protocol 1: Methylation-Specific PCR (MSP)
-
DNA Bisulfite Conversion:
-
Start with 500 ng to 1 µg of high-quality genomic DNA.
-
Use a commercial bisulfite conversion kit (e.g., Zymo Research EZ DNA Methylation-Gold™ Kit) and follow the manufacturer's protocol.
-
Elute the converted DNA in 10-20 µL of elution buffer.
-
-
PCR Amplification:
-
Prepare two separate PCR master mixes, one for the methylated-specific primer set (M-primers) and one for the unmethylated-specific primer set (U-primers).
-
For a 25 µL reaction, combine:
-
12.5 µL of 2x PCR Master Mix (containing Taq polymerase, dNTPs, MgCl₂)
-
1 µL of Forward Primer (10 µM)
-
1 µL of Reverse Primer (10 µM)
-
1-2 µL of bisulfite-converted DNA
-
Nuclease-free water to 25 µL
-
-
Include positive controls (fully methylated and unmethylated DNA) and a no-template control (NTC).
-
-
Thermocycling Conditions:
-
Initial Denaturation: 95°C for 10 minutes.
-
35-40 Cycles:
-
Denaturation: 95°C for 30 seconds.
-
Annealing: 55-65°C for 30 seconds (optimize with a gradient).
-
Extension: 72°C for 30 seconds.
-
-
Final Extension: 72°C for 5-10 minutes.
-
-
Analysis:
-
Run the PCR products on a 2% agarose (B213101) gel.
-
Visualize the bands under UV light. The presence of a band in the "M" lane indicates methylation, while a band in the "U" lane indicates an unmethylated status.
-
Protocol 2: Bisulfite Sequencing PCR (BSP)
-
DNA Bisulfite Conversion:
-
Follow the same procedure as for MSP.
-
-
PCR Amplification:
-
Design primers that flank the region of interest but do not contain any CpG sites.
-
Prepare a PCR master mix. For a 50 µL reaction, combine:
-
25 µL of 2x PCR Master Mix
-
2 µL of Forward Primer (10 µM)
-
2 µL of Reverse Primer (10 µM)
-
2-4 µL of bisulfite-converted DNA
-
Nuclease-free water to 50 µL
-
-
-
Thermocycling Conditions:
-
Follow the same cycling conditions as for MSP, adjusting the annealing temperature as needed based on the primer pair's melting temperature.
-
-
PCR Product Purification and Sequencing:
-
Run the entire PCR reaction on a 1.5% agarose gel.
-
Excise the band corresponding to the correct amplicon size.
-
Purify the DNA from the gel slice using a gel extraction kit.
-
Send the purified PCR product for Sanger sequencing.
-
-
Data Analysis:
-
Align the sequencing results with the original reference sequence (in silico converted for both methylated and unmethylated possibilities).
-
At each CpG site, a cytosine (C) peak indicates methylation, while a thymine (B56734) (T) peak indicates an unmethylated state.
-
Visualizations
Caption: Workflow of DNA bisulfite conversion for methylation analysis.
Caption: A decision tree for troubleshooting common PCR issues with methylated DNA.
References
- 1. youtube.com [youtube.com]
- 2. youtube.com [youtube.com]
- 3. researchgate.net [researchgate.net]
- 4. Direct bisulfite sequencing for examination of DNA methylation patterns with gene and nucleotide resolution from brain tissues - PMC [pmc.ncbi.nlm.nih.gov]
- 5. geneticeducation.co.in [geneticeducation.co.in]
- 6. news-medical.net [news-medical.net]
- 7. tandfonline.com [tandfonline.com]
- 8. The bisulfite genomic sequencing protocol [file.scirp.org]
Technical Support Center: 5-Methylcytosine Sequencing
Welcome to the technical support center for 5-Methylcytosine (5-mC) sequencing. This resource provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals address common artifacts and issues encountered during their experiments.
Frequently Asked Questions (FAQs)
Issue 1: Incomplete Bisulfite Conversion
Q1: My data suggests a high number of methylated cytosines, which is unexpected. Could this be an artifact?
A: This could be a result of incomplete bisulfite conversion, where unmethylated cytosines fail to be converted to uracil. This leads to them being incorrectly identified as methylated cytosines after sequencing, causing an overestimation of methylation levels.[1][2][3] The bisulfite conversion rate typically ranges from 95-98%.[1]
Q2: How can I assess the efficiency of my bisulfite conversion?
A: The conversion rate can be evaluated by examining the methylation levels of non-CpG cytosines, as these are generally unmethylated in most mammalian somatic cells.[4] A high percentage of non-CpG cytosines appearing as "methylated" indicates a poor conversion rate. Additionally, spiking your sample with unmethylated control DNA (like lambda phage DNA) before bisulfite treatment can help accurately determine the conversion efficiency.
Q3: What factors contribute to incomplete bisulfite conversion, and how can I improve it?
A: Several factors can lead to incomplete conversion:
-
Insufficient denaturation: DNA must be fully single-stranded for the bisulfite reagent to access and convert cytosines.[5] Ensure your denaturation protocol (thermal or chemical) is effective.
-
Suboptimal reaction conditions: Aggressive bisulfite treatment protocols, such as long incubation times, high temperatures, and high bisulfite molarity, can promote complete conversion.[6] However, these conditions must be balanced against the risk of DNA degradation.
-
Sample purity: Contaminants in the DNA sample can inhibit the conversion reaction. Ensure your DNA is of high purity before starting.
-
Reagent quality: Use fresh, high-quality bisulfite reagents for optimal performance.
Issue 2: PCR & Sequencing Biases
Q1: I'm observing uneven coverage across the genome, particularly in GC-rich or GC-poor regions. What could be the cause?
A: This is likely due to GC bias, a common artifact in whole-genome sequencing.[7] GC-rich regions can form stable secondary structures that impede polymerase activity, leading to underrepresentation.[7] Conversely, regions with very low GC content can also be challenging to amplify efficiently.[7] After bisulfite conversion, unmethylated regions become AT-rich, which can also lead to amplification bias.[8]
Q2: My data shows a high rate of duplicate reads. Is this a concern?
A: A high number of duplicate reads can be an artifact of PCR amplification, where certain DNA fragments are preferentially amplified over others.[7][9][10] These PCR duplicates do not represent independent biological molecules and can skew quantitative methylation analysis, leading to inaccurate results.[9][10] It is standard practice to identify and remove these duplicate reads during bioinformatic analysis.
Q3: How can I minimize PCR and sequencing biases?
A: To mitigate these biases:
-
Optimize PCR cycles: Use the minimum number of PCR cycles necessary to generate sufficient library material. Over-amplification can exacerbate biases.[8]
-
Choose the right polymerase: Select a polymerase designed for bisulfite-treated DNA, as these are better at amplifying uracil-containing templates and AT-rich sequences.[11]
-
Consider amplification-free protocols: For the least biased results, amplification-free library preparation methods are recommended where feasible.[12]
-
Bioinformatic correction: Utilize computational tools to identify and remove PCR duplicates and to correct for GC bias in your sequencing data.
Issue 3: DNA Degradation
Q1: My library yield is very low, and the fragment sizes are smaller than expected. What could be the problem?
A: This is a classic sign of DNA degradation, a significant side effect of bisulfite treatment. The harsh chemical conditions (low pH and high temperature) can cause DNA fragmentation, leading to a loss of sample material.[2][6][13] It has been reported that bisulfite treatment can degrade 80-96% of the initial DNA.[6][14]
Q2: How does DNA degradation affect my results?
A: DNA degradation can lead to:
-
Low library complexity: Fewer unique DNA molecules are available for sequencing, which can result in a higher proportion of PCR duplicates.
-
Biased representation: Shorter DNA fragments may be preferentially amplified, leading to uneven genome coverage.
-
Inability to amplify longer regions: If you are targeting specific longer amplicons, degradation can make it impossible to obtain a PCR product.[6]
Q3: What are the best practices for minimizing DNA degradation?
A: To reduce DNA degradation:
-
Start with high-quality DNA: Use intact, high-molecular-weight DNA. Samples from sources like formalin-fixed, paraffin-embedded (FFPE) tissues are often already degraded and may yield poor results.
-
Use optimized kits: Many commercial kits have been developed with modified reagents and protocols to reduce the severity of bisulfite treatment and protect the DNA from excessive degradation.[14] Some kits can reduce DNA loss to less than 10%.[14]
-
Limit incubation time: While sufficient incubation is needed for complete conversion, excessively long treatments should be avoided. Follow the recommendations of your chosen protocol or kit.
Quantitative Data Summary
The following table provides a summary of key quantitative metrics and potential issues in 5-mC sequencing.
| Parameter | Common Issue | Acceptable Range/Target | Potential Consequence of Deviation |
| Bisulfite Conversion Rate | Incomplete conversion | > 99% for unmethylated cytosines | False positives (unmethylated Cs appear methylated) |
| DNA Degradation | Excessive fragmentation | > 90% of DNA loss can be prevented with optimized kits[14] | Low library yield, biased representation, PCR failure |
| PCR Duplication Rate | High number of duplicates | Varies by application; as low as possible | Skewed methylation quantification, reduced library complexity |
| GC Bias | Uneven coverage | Normalized coverage close to 1 across GC content | Inaccurate methylation levels in GC-rich/poor regions |
Experimental Protocols & Workflows
Protocol: Assessing Bisulfite Conversion Efficiency Using Spike-in Controls
-
Prepare DNA Sample: Quantify your genomic DNA sample.
-
Add Spike-in Control: Add a known amount of unmethylated control DNA (e.g., lambda phage DNA) to your genomic DNA. The amount should be a small fraction of the total DNA (e.g., 0.1-0.5%).
-
Bisulfite Conversion: Perform bisulfite conversion on the mixed DNA sample using your standard protocol.
-
Library Preparation and Sequencing: Prepare a sequencing library and perform sequencing as usual.
-
Bioinformatic Analysis:
-
Align the sequencing reads to both the reference genome of your sample and the reference genome of the spike-in control.
-
For reads aligning to the spike-in control genome, calculate the percentage of cytosines that were converted to thymines.
-
This percentage represents your bisulfite conversion efficiency. For example: Conversion Rate = (Number of converted Cs / Total number of Cs) * 100.
-
Diagrams
Caption: Workflow for Whole-Genome Bisulfite Sequencing (WGBS) highlighting key stages where artifacts can be introduced.
Caption: Troubleshooting flowchart for diagnosing and addressing low bisulfite conversion efficiency.
References
- 1. researchgate.net [researchgate.net]
- 2. An Internal Control for Evaluating Bisulfite Conversion in the Analysis of Short Stature Homeobox 2 Methylation in Lung Cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Errors in the bisulfite conversion of DNA: modulating inappropriate- and failed-conversion frequencies - PMC [pmc.ncbi.nlm.nih.gov]
- 4. edoc.mdc-berlin.de [edoc.mdc-berlin.de]
- 5. qiagen.com [qiagen.com]
- 6. A new method for accurate assessment of DNA quality after bisulfite treatment - PMC [pmc.ncbi.nlm.nih.gov]
- 7. revvity.com [revvity.com]
- 8. Methylated DNA is over-represented in whole-genome bisulfite sequencing data - PMC [pmc.ncbi.nlm.nih.gov]
- 9. academic.oup.com [academic.oup.com]
- 10. researchgate.net [researchgate.net]
- 11. neb.com [neb.com]
- 12. Comparison of whole-genome bisulfite sequencing library preparation strategies identifies sources of biases affecting DNA methylation data - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Degradation of DNA by bisulfite treatment - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. Exploring DNA Methylation with Bisulfite Sequencing | EpigenTek [epigentek.com]
Technical Support Center: 5-methylcytosine (5mC) Immunoprecipitation
Welcome to the technical support center for 5-methylcytosine (B146107) (5mC) immunoprecipitation (MeDIP). This guide provides troubleshooting advice and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals improve the efficiency of their 5mC immunoprecipitation experiments.
Frequently Asked Questions (FAQs)
Q1: What is the optimal amount of starting genomic DNA for a MeDIP experiment?
A1: The optimal amount of starting DNA can vary depending on the sample type and the expected level of methylation. While early protocols often required micrograms of DNA, recent methods have been optimized for much lower inputs.[1][2] Successful MeDIP-qPCR has been performed with as little as 1 ng of genomic DNA.[2][3] For MeDIP-seq, starting amounts can range from 25 ng to several micrograms.[1][4] It is recommended to perform a titration experiment to determine the optimal input amount for your specific sample and antibody.[5]
Q2: How do I choose the right anti-5mC antibody?
A2: The choice of antibody is critical for a successful MeDIP experiment. It is essential to use a monoclonal antibody with high specificity for 5mC and minimal cross-reactivity with unmethylated cytosine or other modified bases like 5-hydroxymethylcytosine (B124674) (5hmC).[5][6] The specificity of the antibody should be verified, for example, by using spike-in controls with known methylation status.[2] Different antibodies may also show varying efficiency in immunoprecipitating DNA fragments with different CpG densities.[7]
Q3: What is the ideal size range for DNA fragments after sonication?
A3: For MeDIP-seq, the recommended DNA fragment size is typically between 200 and 800 base pairs (bp).[4][8] Smaller fragments can improve the resolution of the assay.[9] It is crucial to optimize sonication conditions for your specific cell type and equipment to achieve a consistent and desired fragment size distribution.[8][10] Over-sonication can lead to very small fragments that may be lost during purification, while under-sonication can result in large fragments that are inefficiently immunoprecipitated.
Q4: Should I use magnetic beads or agarose (B213101) beads for the immunoprecipitation?
A4: Both magnetic beads (e.g., Dynabeads) and agarose beads (e.g., Protein A/G) can be used effectively.[5] Magnetic beads are often preferred as they can make the washing steps more efficient and less prone to sample loss.[5] The choice may also depend on the isotype of your primary antibody and the bead's affinity for that isotype.
Troubleshooting Guide
This section addresses common problems encountered during 5mC immunoprecipitation and provides potential causes and solutions.
Problem 1: Low Yield of Immunoprecipitated DNA
Possible Causes & Solutions
| Possible Cause | Recommended Solution |
| Insufficient starting material | Increase the amount of input genomic DNA. If sample is limited, consider methods optimized for low-input MeDIP.[1][2] |
| Inefficient DNA fragmentation | Optimize sonication parameters to ensure the majority of fragments are within the 200-800 bp range. Verify fragmentation on an agarose gel or Bioanalyzer.[4][8] |
| Suboptimal antibody concentration | Perform an antibody titration experiment to determine the optimal concentration for your input DNA amount.[5] |
| Poor antibody quality | Use a highly specific and validated anti-5mC antibody. Check the antibody's datasheet for recommended applications and user reviews.[6] |
| Inefficient immunoprecipitation | Ensure proper incubation times and temperatures for antibody-DNA binding and bead capture. Gentle rotation or rocking during incubation is recommended.[5][8] |
| Loss of DNA during purification | Use spin columns or magnetic beads designed for DNA purification to minimize sample loss. Be cautious during washing and elution steps.[4] |
| DNA degradation | Handle DNA samples carefully to avoid nuclease contamination. Use nuclease-free reagents and consumables.[11] |
Problem 2: High Background (Non-specific Binding)
Possible Causes & Solutions
| Possible Cause | Recommended Solution |
| Insufficient washing | Increase the number and/or stringency of wash steps after immunoprecipitation to remove non-specifically bound DNA.[5] |
| Non-specific antibody binding | Include a pre-clearing step by incubating the sheared DNA with beads before adding the primary antibody. Use a non-specific IgG control to assess background levels. |
| Beads binding non-specifically | Block the beads with a blocking agent like BSA before adding the antibody-DNA complex. |
| Too much antibody | Using an excessive amount of antibody can lead to increased non-specific binding. Optimize the antibody concentration through titration.[5] |
| Contamination with unmethylated DNA | Ensure complete removal of the supernatant after each wash step. |
Quantitative Data Summary
Table 1: Effect of Input DNA Amount on MeDIP Enrichment
| Input DNA Amount | Relative Enrichment of Endogenous Methylated Region (IAP) | Relative Enrichment of Spiked-in Methylated Control |
| 100 ng | Low | High |
| 10 ng | Medium | Medium |
| 1 ng | High | Low |
This table summarizes findings where enrichment efficiency for endogenous methylated regions increased with decreasing input DNA, while it decreased for a constant amount of spiked-in control DNA. This is likely due to a higher antibody-to-methylated-DNA ratio at lower input concentrations for the endogenous targets.[3]
Table 2: Comparison of 5mC Antibody Specificity
| Antibody | Target | Relative Enrichment |
| Anti-5mC | 5mC-containing DNA | High |
| 5hmC-containing DNA | Low | |
| Unmethylated DNA | Very Low | |
| Anti-5hmC | 5hmC-containing DNA | High |
| 5mC-containing DNA | Low | |
| Unmethylated DNA | Very Low |
This table illustrates the high specificity of anti-5mC antibodies for this compound over 5-hydroxymethylcytosine and unmethylated cytosine, which is a critical factor for a successful MeDIP experiment.[6][12]
Experimental Protocols
Detailed MeDIP Protocol
This protocol is a compilation from several sources and may require optimization for your specific needs.[4][5][8][13]
1. DNA Fragmentation (Sonication)
-
Dilute 1-5 µg of genomic DNA in 1x TE buffer to a final volume of 130 µL in a sonication-appropriate microtube.
-
Sonicate the DNA to an average fragment size of 200-800 bp. Sonication conditions (power, duration, cycles) must be optimized for your specific instrument.
-
Verify the fragment size by running an aliquot on a 1.5% agarose gel alongside a DNA ladder.
2. DNA Denaturation and Antibody Incubation
-
Take the sonicated DNA and adjust the volume to 400 µL with 1x TE Buffer.
-
Denature the DNA by heating at 95°C for 10 minutes, then immediately place on ice for 10 minutes.
-
Add 100 µL of 5x IP Buffer and the optimized amount of anti-5mC antibody (typically 1-5 µg).
-
Incubate overnight at 4°C with gentle rotation.
3. Immunoprecipitation with Beads
-
Wash magnetic beads (e.g., Dynabeads M-280 Sheep anti-Mouse IgG) with 1x IP Buffer.
-
Add the washed beads to the DNA-antibody mixture and incubate at 4°C for 2 hours with gentle rotation.
4. Washing
-
Place the tube on a magnetic rack to capture the beads. Carefully remove and discard the supernatant.
-
Wash the beads three times with 1 mL of cold 1x IP Buffer. For each wash, resuspend the beads, incubate for 5 minutes on a rotator at 4°C, and then recapture the beads on the magnetic rack before removing the supernatant.
5. Elution and DNA Purification
-
Resuspend the beads in 250 µL of Digestion Buffer.
-
Add 3.5 µL of Proteinase K (20 mg/mL) and incubate at 55°C for 2-3 hours with rotation.
-
Place the tube on the magnetic rack and transfer the supernatant containing the eluted DNA to a new tube.
-
Purify the DNA using a standard phenol:chloroform extraction and ethanol (B145695) precipitation, or a suitable DNA purification kit.
-
Resuspend the purified DNA in nuclease-free water.
Buffer Recipes:
-
1x TE Buffer: 10 mM Tris-HCl (pH 8.0), 1 mM EDTA.
-
5x IP Buffer: 50 mM Sodium Phosphate (pH 7.0), 700 mM NaCl, 0.25% Triton X-100.
-
Digestion Buffer: 50 mM Tris-HCl (pH 8.0), 10 mM EDTA, 0.5% SDS.
Visualizations
Caption: Overview of the 5mC Immunoprecipitation (MeDIP) experimental workflow.
Caption: Logical workflow for troubleshooting common MeDIP issues.
References
- 1. mdpi.com [mdpi.com]
- 2. Methylated DNA immunoprecipitation and high-throughput sequencing (MeDIP-seq) using low amounts of genomic DNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. Optimized method for methylated DNA immuno-precipitation - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Genome-Wide Mapping of DNA Methylation 5mC by Methylated DNA Immunoprecipitation (MeDIP)-Sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Examination of the specificity of DNA methylation profiling techniques towards this compound and 5-hydroxymethylcytosine - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Comparison of methyl-DNA immunoprecipitation (MeDIP) and methyl-CpG binding domain (MBD) protein capture for genome-wide DNA methylation analysis reveal CpG sequence coverage bias - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. MeDIP Application Protocol | EpigenTek [epigentek.com]
- 9. Video: Methylated DNA Immunoprecipitation [jove.com]
- 10. content.abcam.com [content.abcam.com]
- 11. neb.com [neb.com]
- 12. researchgate.net [researchgate.net]
- 13. MeDIP Sequencing Protocol - CD Genomics [cd-genomics.com]
Technical Support Center: 5-Methylcytosine (5mC) vs. 5-Hydroxymethylcytosine (5hmC)
Welcome to the technical support center for distinguishing 5-Methylcytosine (B146107) (5mC) from 5-Hydroxymethylcytosine (B124674) (5hmC). This resource provides researchers, scientists, and drug development professionals with detailed troubleshooting guides, frequently asked questions (FAQs), and experimental protocols to navigate the complexities of identifying and quantifying these critical epigenetic marks.
Frequently Asked Questions (FAQs)
This section addresses common questions regarding the challenges and methodologies for differentiating 5mC and 5hmC.
Q1: What is the fundamental challenge in distinguishing 5mC from 5hmC?
A1: The primary challenge lies in their structural similarity. Both 5mC and 5hmC are modifications at the 5th position of the cytosine ring. Standard analytical methods, particularly traditional bisulfite sequencing, cannot differentiate between the two because both modifications are resistant to bisulfite-induced deamination. This leads to a combined signal, masking their distinct biological roles where 5mC is generally associated with transcriptional repression and 5hmC is often linked to active gene expression and demethylation pathways.
Q2: Why can't standard bisulfite sequencing differentiate between 5mC and 5hmC?
A2: Standard bisulfite sequencing relies on the chemical conversion of unmethylated cytosines to uracil, which is then read as thymine (B56734) during sequencing. Methylated cytosines (5mC) are protected from this conversion. However, 5-hydroxymethylcytosine (5hmC) is also resistant to this chemical reaction.[1] Consequently, both 5mC and 5hmC are read as cytosine, making them indistinguishable from each other with this method alone.[1] This inability to separate their signals can lead to incorrect interpretations of methylation data.[1]
Q3: What are the main methods available to distinguish 5mC from 5hmC?
A3: Several methods have been developed to overcome the limitations of standard bisulfite sequencing. The main approaches can be categorized as follows:
-
Sequencing-based methods with chemical or enzymatic pre-treatment: These provide single-base resolution.
-
Oxidative Bisulfite Sequencing (oxBS-Seq): This method uses a chemical oxidant to selectively convert 5hmC to 5-formylcytosine (B1664653) (5fC), which is then susceptible to bisulfite conversion.
-
Tet-assisted Bisulfite Sequencing (TAB-Seq): This enzymatic approach uses the TET enzyme to oxidize 5mC while protecting 5hmC, allowing for direct detection of 5hmC.
-
-
Affinity-based enrichment methods: These methods are suitable for identifying regions enriched with 5mC or 5hmC but offer lower resolution.
-
Methylated DNA Immunoprecipitation (MeDIP): Uses antibodies specific to 5mC.
-
Hydroxymethylated DNA Immunoprecipitation (hMeDIP): Employs antibodies specific to 5hmC.
-
Q4: What is the principle behind Oxidative Bisulfite Sequencing (oxBS-Seq)?
A4: OxBS-Seq introduces a chemical oxidation step prior to the standard bisulfite treatment.[2][3] A specific oxidizing agent, potassium perruthenate (KRuO4), converts 5hmC to 5-formylcytosine (5fC).[4] Unlike 5mC and 5hmC, 5fC is sensitive to bisulfite and is converted to uracil.[2][3] Therefore, after oxBS-Seq, only 5mC remains as cytosine. By comparing the results of an oxBS-Seq experiment with a parallel standard bisulfite sequencing (BS-Seq) experiment on the same sample, the levels of 5hmC can be inferred by subtraction (BS-Seq signal [5mC + 5hmC] - oxBS-Seq signal [5mC] = 5hmC signal).[3][5]
Q5: What is the principle behind Tet-assisted Bisulfite Sequencing (TAB-Seq)?
A5: TAB-Seq is an enzymatic method that provides a direct measurement of 5hmC. The workflow involves three key steps:
-
Protection of 5hmC: A β-glucosyltransferase (β-GT) enzyme is used to attach a glucose moiety to all 5hmC residues, protecting them from further modification.
-
Oxidation of 5mC: The Ten-eleven translocation (TET) enzyme is then used to oxidize all unprotected 5mC residues to 5-carboxylcytosine (5caC).[6][7]
-
Bisulfite Conversion: During the subsequent bisulfite treatment, both unmodified cytosine and 5caC are converted to uracil, while the protected (glucosylated) 5hmC remains as cytosine.[6][7] This allows for the direct identification of 5hmC as the only cytosine residue remaining after sequencing.
Q6: Are there non-sequencing-based methods to differentiate 5mC and 5hmC?
A6: Yes, affinity-based methods like hMeDIP-qPCR can be used to assess the enrichment of 5hmC at specific genomic loci. This method uses an antibody that specifically pulls down DNA fragments containing 5hmC, which can then be quantified by quantitative PCR (qPCR). While this approach does not provide single-base resolution, it can be a cost-effective way to validate findings from sequencing-based methods or to screen for changes in 5hmC enrichment at particular regions of interest.
Q7: How do I choose the right method for my experiment?
A7: The choice of method depends on your specific research question, available resources, and the nature of your samples. Key factors to consider include:
-
Resolution: Do you need single-base resolution (oxBS-Seq, TAB-Seq) or is regional enrichment information sufficient (MeDIP/hMeDIP-Seq)?
-
DNA Input: Affinity-based methods can often work with lower DNA input compared to sequencing-based approaches.
-
Cost and Throughput: Affinity-based methods are generally less expensive and higher throughput for targeted analysis. Whole-genome sequencing methods are more costly but provide a comprehensive view.
-
Primary target of interest: If you are only interested in 5hmC, TAB-Seq provides a direct measurement and can be more cost-effective than oxBS-Seq, which requires two parallel sequencing experiments.[6][7]
Method Comparison
The following table summarizes the key characteristics of the main techniques used to distinguish 5mC and 5hmC.
| Feature | Standard BS-Seq | oxBS-Seq | TAB-Seq | MeDIP/hMeDIP-Seq |
| Principle | Chemical conversion of C to U | Chemical oxidation of 5hmC, then bisulfite conversion | Enzymatic protection of 5hmC, oxidation of 5mC, then bisulfite conversion | Antibody-based enrichment of 5mC or 5hmC |
| Detected Mark(s) | 5mC + 5hmC (undistinguished) | 5mC (direct); 5hmC (inferred by subtraction) | 5hmC (direct) | 5mC or 5hmC (depending on antibody) |
| Resolution | Single-base | Single-base | Single-base | Low (~150-200 bp) |
| Typical DNA Input | 100 ng - 1 µg | 100 ng - 1 µg | 100 ng - 1 µg | 1 ng - 1 µg |
| Advantages | Gold standard for total methylation | Provides a direct readout of 5mC; does not require highly active enzymes.[2] | Directly measures 5hmC; can be more cost-effective if only 5hmC is of interest.[6][7] | Lower cost; suitable for low-input DNA; good for genome-wide screening of enriched regions. |
| Limitations | Cannot distinguish 5mC from 5hmC | Requires two parallel sequencing runs; subtractive analysis can compound errors.[2] | Relies on high enzyme activity, which can be expensive and variable.[6][7] | Low resolution; antibody specificity can be a concern; biased towards hypermethylated regions. |
Troubleshooting Guides
This section provides solutions to common problems encountered during experiments to differentiate 5mC and 5hmC.
Guide 1: Issues with Bisulfite-Based Methods (BS-Seq, oxBS-Seq, TAB-Seq)
| Problem | Possible Cause | Recommended Solution |
| Low Bisulfite Conversion Efficiency (<99%) | 1. Incomplete DNA denaturation. | Ensure complete denaturation of DNA before and during bisulfite treatment. Only single-stranded DNA is susceptible to conversion. |
| 2. Poor quality or old bisulfite reagent. | Use fresh, high-quality sodium bisulfite reagents. | |
| 3. Insufficient reaction time or incorrect temperature. | Optimize incubation time and temperature. Higher temperatures can improve conversion but may increase DNA degradation. | |
| 4. Protein contamination in the DNA sample. | Ensure DNA is free of protein contamination by performing a thorough purification. | |
| Ambiguous Sequencing Results (Mixed C/T peaks) | 1. Incomplete bisulfite conversion. | See "Low Bisulfite Conversion Efficiency" above. Use spike-in controls with known methylation status to assess conversion efficiency. |
| 2. PCR bias. | Use a polymerase suitable for bisulfite-treated DNA. Optimize PCR conditions, including annealing temperature and cycle number. | |
| 3. Heterogeneous methylation in the cell population. | This may be a true biological signal. Consider subcloning PCR products for sequencing to analyze individual alleles. | |
| Inefficient Oxidation in oxBS-Seq | 1. Degraded oxidant solution. | Ensure the oxidant (KRuO4) has not precipitated and is stored correctly. |
| 2. Contaminants in the DNA sample (e.g., ethanol). | Purify the DNA sample thoroughly before the oxidation step. | |
| Incomplete TET Enzyme Conversion in TAB-Seq | 1. Low TET enzyme activity. | Use a highly active and properly stored TET enzyme. Inefficient conversion of 5mC to 5caC is a major source of false-positive 5hmC signals.[7] |
| 2. Suboptimal reaction buffer or conditions. | Ensure all buffer components are at the correct concentration and the reaction is performed at the optimal temperature and time. |
Guide 2: Issues with Affinity-Based Methods (MeDIP/hMeDIP-Seq)
| Problem | Possible Cause | Recommended Solution |
| High Background Signal | 1. Non-specific antibody binding. | Titrate the antibody to find the optimal concentration. Include an IgG control to assess the level of non-specific binding. |
| 2. Insufficient washing. | Increase the number and/or stringency of wash steps after immunoprecipitation. | |
| 3. Too much starting material or antibody. | Optimize the ratio of DNA to antibody. | |
| Low Signal/Enrichment | 1. Poor antibody quality or low affinity. | Use a validated, high-specificity antibody for 5mC or 5hmC. |
| 2. Insufficient cross-linking (if applicable). | Optimize the cross-linking time to ensure efficient antibody-DNA interaction without masking the epitope. | |
| 3. DNA fragmentation is not optimal. | Ensure DNA is fragmented to the recommended size range (typically 150-500 bp) for efficient immunoprecipitation. | |
| Bias towards Hypermethylated Regions | 1. Inherent nature of the technique. | Be aware of this bias during data interpretation. Validate key findings with a single-base resolution method if possible. |
| 2. High antibody concentration. | Use the lowest effective concentration of the antibody to minimize this bias. |
Experimental Protocols
Protocol 1: Oxidative Bisulfite Sequencing (oxBS-Seq) Workflow
This protocol provides a general outline for performing oxBS-Seq. Specific reagent volumes and incubation times may need to be optimized based on the kit manufacturer's instructions and sample type.
-
DNA Preparation and Fragmentation:
-
Start with high-quality, purified genomic DNA (100 ng - 1 µg).
-
Fragment the DNA to the desired size for library preparation (e.g., 200-500 bp) using sonication or enzymatic methods.
-
Purify the fragmented DNA.
-
-
Sample Splitting:
-
Divide the fragmented DNA into two equal aliquots. One will be used for the oxBS-Seq workflow ("Oxidized") and the other for a parallel standard BS-Seq workflow ("Unoxidized").
-
-
Oxidation (for the "Oxidized" aliquot only):
-
Denature the DNA sample.
-
Add the oxidizing agent (e.g., potassium perruthenate) to the denatured DNA.
-
Incubate under specific conditions (e.g., temperature, time) to convert 5hmC to 5fC.
-
Purify the oxidized DNA to remove the oxidant.
-
-
Bisulfite Conversion (for both aliquots):
-
Perform bisulfite conversion on both the "Oxidized" and "Unoxidized" DNA samples using a commercial kit. This step converts unmethylated cytosines and 5fC (in the oxidized sample) to uracil.
-
Follow the kit's protocol for denaturation, conversion, and desulfonation.
-
Purify the bisulfite-converted DNA.
-
-
Library Preparation and Sequencing:
-
Prepare next-generation sequencing libraries from both the oxidized and unoxidized bisulfite-converted DNA.
-
Perform PCR amplification using a high-fidelity polymerase suitable for uracil-containing templates.
-
Quantify and pool the libraries.
-
Sequence the libraries on an appropriate platform.
-
-
Data Analysis:
-
Align reads from both sequencing runs to a reference genome using a bisulfite-aware aligner.
-
Call methylation levels for each CpG site.
-
Calculate 5hmC levels by subtracting the methylation level of the "Oxidized" sample from the "Unoxidized" sample at each site.
-
Protocol 2: Tet-assisted Bisulfite Sequencing (TAB-Seq) Workflow
This protocol outlines the general steps for TAB-Seq. As with oxBS-Seq, optimization may be required.
-
DNA Preparation and Fragmentation:
-
Begin with high-quality, purified genomic DNA (100 ng - 1 µg).
-
Fragment the DNA to the desired size and purify.
-
-
Glucosylation of 5hmC:
-
Incubate the fragmented DNA with β-glucosyltransferase (β-GT) and UDP-glucose. This will attach a glucose molecule to all 5hmC residues, protecting them.
-
Purify the DNA to remove the enzyme and reagents.
-
-
Oxidation of 5mC:
-
Incubate the glucosylated DNA with a highly active TET enzyme (e.g., mTet1) and necessary cofactors. This reaction oxidizes 5mC to 5caC.
-
Purify the DNA.
-
-
Bisulfite Conversion:
-
Perform bisulfite conversion on the TET-treated DNA. This will convert unmodified cytosines and 5caC to uracil, while the protected 5hmC remains as cytosine.
-
Purify the final converted DNA.
-
-
Library Preparation and Sequencing:
-
Prepare a sequencing library from the TAB-converted DNA.
-
Amplify the library using a suitable polymerase.
-
Quantify and sequence the library.
-
-
Data Analysis:
-
Align the sequencing reads using a bisulfite-aware aligner.
-
Call methylation levels. In TAB-Seq data, any remaining cytosine at a CpG site represents a 5hmC in the original sample.
-
Visualizations
The Core Challenge with Standard Bisulfite Sequencing
Caption: Standard bisulfite sequencing cannot distinguish 5mC from 5hmC.
Oxidative Bisulfite Sequencing (oxBS-Seq) Workflow
Caption: oxBS-Seq workflow for indirect 5hmC detection.
Tet-assisted Bisulfite Sequencing (TAB-Seq) Workflow
Caption: TAB-Seq workflow for direct 5hmC detection.
Method Selection Guide
Caption: Decision tree for selecting a 5mC/5hmC analysis method.
References
- 1. tandfonline.com [tandfonline.com]
- 2. epigenie.com [epigenie.com]
- 3. Oxidative Bisulfite Sequencing Service, DNA Hydroxymethylation Analysis | CD BioSciences [epigenhub.com]
- 4. Methods for Detection and Mapping of Methylated and Hydroxymethylated Cytosine in DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Oxidative bisulfite sequencing of this compound and 5-hydroxymethylcytosine - PMC [pmc.ncbi.nlm.nih.gov]
- 6. epigenie.com [epigenie.com]
- 7. Tet-Assisted Bisulfite Sequencing Service, DNA Hydroxymethylation Analysis | CD BioSciences [epigenhub.com]
Technical Support Center: 5-Methylcytosine (5mC) Analysis
Welcome to the technical support center for 5-Methylcytosine (B146107) (5mC) analysis. This resource is designed for researchers, scientists, and drug development professionals to provide guidance on quality control, troubleshooting, and experimental protocols.
Frequently Asked Questions (FAQs)
Q1: What is this compound (5mC) and why is it important?
A1: this compound (5mC) is a crucial epigenetic modification where a methyl group is added to the 5th carbon of the cytosine base in DNA.[1][2] This modification plays a vital role in regulating gene expression, cellular differentiation, and various developmental processes.[1][2] Aberrant 5mC patterns have been linked to numerous diseases, including cancer.[2]
Q2: What are the common methods for analyzing 5mC?
A2: Several techniques are available for 5mC analysis, each with its own advantages and limitations. The most common methods include:
-
Bisulfite Sequencing: Considered the gold standard, this method provides single-nucleotide resolution of methylation patterns.[1][3][4] It involves treating DNA with sodium bisulfite, which converts unmethylated cytosines to uracil, while 5mC remains unchanged.[3][4]
-
Enrichment-based Methods: These methods, such as Methylated DNA Immunoprecipitation (MeDIP), enrich for methylated DNA fragments, which are then sequenced.[1]
-
Enzyme-based Methods: These approaches use methylation-sensitive restriction enzymes to digest DNA at unmethylated sites.[1]
-
Nanopore Sequencing: This newer technology allows for the direct detection of DNA modifications, including 5mC, on native DNA molecules without the need for bisulfite conversion.[4][5]
-
Methylation Arrays: These are a high-throughput method for profiling methylation levels at hundreds of thousands of specific CpG sites across the genome.[5]
Q3: What is the difference between 5mC and 5-hydroxymethylcytosine (B124674) (5hmC)?
A3: 5-hydroxymethylcytosine (5hmC) is an oxidation product of 5mC, catalyzed by TET enzymes. While structurally similar, they have distinct biological roles. Standard bisulfite sequencing cannot distinguish between 5mC and 5hmC.[6] Specific techniques like oxidative bisulfite sequencing (oxBS-seq) or Tet-assisted bisulfite sequencing (TAB-seq) are required to differentiate them.[6][7]
Quality Control Metrics
Effective quality control is critical for reliable 5mC analysis. Below are key metrics to consider at different stages of a typical sequencing-based workflow.
Pre-Sequencing Quality Control
| Metric | Recommended Value | Method of Assessment |
| DNA Purity | A260/A280 ratio: ~1.8; A260/A230 ratio: 2.0-2.2 | UV-Vis Spectrophotometry (e.g., NanoDrop) |
| DNA Integrity | High molecular weight DNA with minimal degradation | Agarose (B213101) Gel Electrophoresis, Bioanalyzer |
| DNA Concentration | > 500 ng for most library preparation kits[8] | Fluorometric Quantification (e.g., Qubit, PicoGreen) |
Post-Bisulfite Conversion Quality Control
| Metric | Recommended Value | Method of Assessment |
| Bisulfite Conversion Rate | > 99% | Spiked-in unmethylated lambda DNA or analysis of unmethylated regions (e.g., mitochondrial DNA) |
| Converted DNA Yield | Sufficient for library preparation | qPCR-based assays targeting converted DNA sequences[8] |
Post-Sequencing Quality Control
| Metric | Recommended Value | Method of Assessment |
| Sequencing Read Quality | Phred Quality Score (Q30) > 80%[9] | FastQC, Illumina Sequencing Analysis Viewer (SAV)[9] |
| Sequencing Depth | Application-dependent (e.g., >10X for whole-genome analysis)[5] | Alignment statistics |
| Mapping Efficiency | > 70-80% | Alignment software reports (e.g., Bismark) |
| Duplication Rate | < 20% | Picard Tools, SAMtools |
Troubleshooting Guides
Issue 1: Low Bisulfite Conversion Efficiency
Symptoms:
-
High percentage of unconverted cytosines in unmethylated control DNA.
-
Inaccurate methylation calls.
Possible Causes and Solutions:
| Cause | Solution |
| Poor DNA Quality | Ensure input DNA is high quality and free of contaminants. Perform a DNA cleanup step if necessary. |
| Incomplete Denaturation | Ensure complete denaturation of DNA before bisulfite treatment as single-stranded DNA is required for the reaction. |
| Suboptimal Reaction Conditions | Follow the manufacturer's protocol for the bisulfite conversion kit precisely. Ensure correct incubation times and temperatures. |
| Degraded Bisulfite Reagent | Use fresh bisulfite reagent. Avoid repeated freeze-thaw cycles. |
Issue 2: PCR Amplification Failure After Bisulfite Conversion
Symptoms:
-
No or very faint bands on an agarose gel after PCR.
Possible Causes and Solutions:
| Cause | Solution |
| DNA Degradation | Bisulfite treatment is harsh and can degrade DNA.[10] Minimize incubation times and handle the DNA gently. Consider using a DNA repair kit before amplification. |
| Inappropriate Primers | Design primers specific to the bisulfite-converted sequence (all Cs converted to Ts, except at CpG sites).[10] Primer length should be 24-32 nucleotides.[10] |
| Incorrect Polymerase | Use a polymerase that can read uracil-containing templates, such as a hot-start Taq polymerase.[10] Proofreading polymerases are generally not recommended.[10] |
| Low Template Amount | Increase the amount of bisulfite-converted DNA in the PCR reaction.[10] |
Issue 3: Noisy Sequencing Data
Symptoms:
-
Low-quality base calls (low Phred scores).
-
High background signal in sequencing chromatograms.
Possible Causes and Solutions:
| Cause | Solution |
| Low Template Concentration | Ensure sufficient DNA template is used for library preparation and sequencing.[11] |
| Contaminants in the Library | Purify the sequencing library to remove contaminants like salts or phenol.[12] |
| Primer-Dimer Formation | Optimize primer design and PCR conditions to minimize the formation of primer-dimers.[11] |
| Over-clustering on Flow Cell | Adjust the library concentration for sequencing to achieve optimal cluster density. |
Experimental Protocols & Workflows
Whole Genome Bisulfite Sequencing (WGBS) Workflow
A generalized workflow for WGBS is outlined below. For detailed step-by-step instructions, please refer to specific kit manuals or published protocols.
Troubleshooting Logic for Failed Sequencing Reactions
This diagram illustrates a logical approach to troubleshooting failed sequencing reactions.
References
- 1. epigenie.com [epigenie.com]
- 2. 5mC/5hmC Sequencing - CD Genomics [cd-genomics.com]
- 3. researchgate.net [researchgate.net]
- 4. Analysis of DNA this compound Using Nanopore Sequencing [bio-protocol.org]
- 5. Whole human genome 5’-mC methylation analysis using long read nanopore sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 6. A Practical Guide to the Measurement and Analysis of DNA Methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. Quality control checkpoints for high throughput DNA methylation measurement using the human MethylationEPICv1 array: application to formalin-fixed paraffin embedded prostate tissue - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Our Top 5 Quality Control (QC) Metrics Every NGS User Should Know [horizondiscovery.com]
- 10. DNA Methylation Analysis Support—Troubleshooting | Thermo Fisher Scientific - ID [thermofisher.com]
- 11. base4.co.uk [base4.co.uk]
- 12. microsynth.com [microsynth.com]
Technical Support Center: Reducing Bias in Whole-Genome 5mC Profiling
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals address common issues related to bias in whole-genome 5-methylcytosine (B146107) (5mC) profiling experiments.
Frequently Asked Questions (FAQs)
Q1: What are the primary sources of bias in whole-genome bisulfite sequencing (WGBS)?
The main sources of bias in WGBS can be categorized into three main areas:
-
PCR Amplification Bias: During the PCR amplification step of library preparation, fragments with higher GC content tend to be amplified more efficiently than those with lower GC content. This leads to an over-representation of GC-rich regions and under-representation of AT-rich regions in the final sequencing data.
-
Bisulfite Conversion-Related Bias: Sodium bisulfite treatment, which converts unmethylated cytosines to uracils, can lead to DNA degradation and fragmentation. This degradation is not random and can introduce bias in the representation of certain genomic regions. Incomplete conversion can also lead to the false identification of methylated cytosines.
-
Library Preparation and Sequencing Bias: Biases can also be introduced during library construction, such as through adapter ligation and the inherent biases of the sequencing platform itself.
Q2: How can I detect if my WGBS data has significant bias?
Several quality control checks can help identify potential bias in your WGBS data:
-
GC Content Distribution: Analyze the GC content distribution of your sequencing reads. A significant deviation from the expected genomic GC content can indicate PCR bias.
-
Methylation Levels at Non-CpG sites: High methylation levels at non-CpG sites (CpH, where H = A, T, or C) in non-neural tissues can be an indicator of incomplete bisulfite conversion or other artifacts.
-
Coverage Uniformity: Examine the evenness of sequencing coverage across the genome. Large variations in coverage that correlate with GC content are a strong indicator of bias.
Troubleshooting Guides
Issue 1: Skewed GC content in sequencing reads.
Problem: The GC content distribution of my sequencing reads is shifted towards higher GC content compared to the reference genome, suggesting PCR amplification bias.
Solution:
-
Employ a PCR-free library preparation protocol. This is the most effective way to eliminate PCR-induced bias. Several commercial kits are available for PCR-free WGBS library preparation.
-
Optimize PCR conditions. If a PCR-free method is not feasible, optimizing the number of PCR cycles and using a high-fidelity, GC-tolerant polymerase can help mitigate bias. It is recommended to perform the minimum number of PCR cycles necessary to obtain sufficient library yield.
-
Use computational correction methods. Post-sequencing, computational tools can be used to correct for GC bias. These tools typically use statistical models to adjust read counts based on the GC content of the genomic region.
Issue 2: Low or uneven genome-wide coverage.
Problem: My WGBS data shows poor coverage in certain genomic regions, particularly AT-rich regions.
Solution:
-
Assess DNA quality and quantity. Start with high-quality, non-degraded genomic DNA. DNA degradation prior to bisulfite treatment can exacerbate coverage bias.
-
Optimize bisulfite conversion. Overly harsh bisulfite treatment can lead to excessive DNA degradation. Optimize the incubation time and temperature of the bisulfite conversion step.
-
Consider alternative library preparation methods. Methods that incorporate bisulfite treatment after adapter ligation can sometimes improve coverage uniformity.
Experimental Protocols
Protocol: PCR-Free Whole-Genome Bisulfite Sequencing
This protocol outlines a general workflow for preparing WGBS libraries without PCR amplification, which helps to minimize GC bias.
-
DNA Fragmentation: Fragment high-quality genomic DNA to the desired size range (e.g., 200-400 bp) using enzymatic or physical methods.
-
End Repair and A-tailing: Repair the ends of the fragmented DNA and add a single adenine (B156593) nucleotide to the 3' ends.
-
Adapter Ligation: Ligate methylated sequencing adapters to the A-tailed DNA fragments.
-
Size Selection: Perform size selection to remove adapter dimers and select the desired fragment size range.
-
Bisulfite Conversion: Treat the adapter-ligated DNA with sodium bisulfite to convert unmethylated cytosines to uracils.
-
Library Quantification and Quality Control: Quantify the final library and assess its quality using methods such as qPCR and capillary electrophoresis.
Quantitative Data Summary
| Bias Type | Mitigation Strategy | Expected Improvement in Coverage Uniformity | Reference |
| PCR Amplification Bias | PCR-free library preparation | Significant improvement, especially in AT-rich regions | |
| PCR Amplification Bias | Use of GC-tolerant polymerase | Moderate improvement | |
| Bisulfite Conversion Bias | Optimized bisulfite conversion protocol | Moderate improvement in coverage and data quality |
Visualizations
Caption: Workflow for WGBS with highlighted bias mitigation strategies.
Caption: Logical flow demonstrating the introduction of GC bias during PCR.
Technical Support Center: Troubleshooting Incomplete Bisulfite Conversion
Welcome to our technical support center. This guide provides troubleshooting information and frequently asked questions (FAQs) to help you address issues related to incomplete bisulfite conversion in your sequencing experiments.
Frequently Asked Questions (FAQs)
Q1: What is incomplete bisulfite conversion and why is it a problem?
A: Incomplete bisulfite conversion occurs when unmethylated cytosines (C) fail to be converted to uracils (U) during the bisulfite treatment process.[1] This is problematic because the subsequent PCR and sequencing steps will interpret these unconverted unmethylated cytosines as methylated cytosines, leading to false-positive results and an overestimation of DNA methylation levels.[2][3] A high conversion efficiency, ideally ≥98%, is crucial for accurate methylation analysis.[4]
Q2: What are the common causes of incomplete bisulfite conversion?
A: Several factors can contribute to incomplete bisulfite conversion. These include:
-
Poor DNA Quality: The presence of contaminants, such as proteins, can hinder the bisulfite reaction.[4] DNA must be free of protein to allow for full denaturation.[4]
-
Insufficient DNA Denaturation: Bisulfite can only react with single-stranded DNA.[5] Incomplete denaturation of the DNA is a critical factor that can lead to failed conversion.[2][5]
-
Suboptimal Bisulfite Reagent: The concentration and freshness of the sodium bisulfite solution are important. Oxidation of bisulfite to bisulfate can reduce its efficiency.[4]
-
Incorrect Incubation Time and Temperature: Both the duration and temperature of the incubation steps (denaturation and conversion) are critical for a complete reaction.[6]
-
Excessive DNA Input: Using too much starting DNA can lead to incomplete denaturation and subsequent incomplete conversion due to the re-annealing of complementary DNA strands.[4]
Q3: How can I assess the conversion efficiency of my experiment?
A: You can assess bisulfite conversion efficiency using several methods:
-
Analysis of Non-CpG Cytosines: In mammals, most methylation occurs at CpG sites. Therefore, the conversion rate of cytosines outside of the CpG context can be used to estimate the overall conversion efficiency.[3] A high conversion rate of these non-CpG cytosines to thymines (after PCR) indicates successful bisulfite treatment.[7]
-
Spike-in Controls: Adding a known unmethylated DNA sequence (like lambda DNA) to your sample before bisulfite treatment allows you to directly measure the conversion efficiency by sequencing this control DNA.[3][8]
-
PCR with Non-Bisulfite Specific Primers: After bisulfite conversion, attempting to amplify the original, unconverted DNA sequence using standard PCR primers should not yield a product if the conversion was successful.[7]
Troubleshooting Guide
Issue 1: High percentage of unconverted non-CpG cytosines.
This indicates a systemic issue with the bisulfite conversion chemistry or protocol.
| Potential Cause | Troubleshooting Recommendation |
| Poor DNA Quality | Ensure your DNA is of high purity. Consider performing a proteinase K digestion and re-purifying the DNA before bisulfite treatment.[9] |
| Insufficient Denaturation | Optimize the denaturation step. This may involve increasing the temperature or duration of the initial denaturation or using chemical denaturants like formamide (B127407).[10] |
| Suboptimal Bisulfite Reagent | Prepare fresh bisulfite solution for each experiment. Ensure proper storage of reagents to prevent oxidation. |
| Incorrect Incubation | Strictly adhere to the recommended incubation times and temperatures in your protocol. Consider optimizing these parameters for your specific DNA samples. A study showed complete cytosine conversion in 30 minutes at 70°C.[6] |
Issue 2: Variable or inconsistent conversion efficiency across samples.
This often points to inconsistencies in sample preparation or handling.
| Potential Cause | Troubleshooting Recommendation |
| Inaccurate DNA Quantification | Use a fluorometric method (e.g., Qubit) for accurate DNA quantification to ensure consistent input amounts for all samples. |
| Pipetting Errors | Calibrate your pipettes regularly and use proper pipetting techniques to ensure accurate reagent volumes. |
| Thermal Cycler Inaccuracy | Verify the temperature accuracy of your thermal cycler. Uneven heating can lead to variable conversion. |
Issue 3: Low DNA yield after conversion.
Significant DNA degradation is a known side effect of bisulfite treatment.
| Potential Cause | Troubleshooting Recommendation |
| Harsh Bisulfite Treatment | While complete conversion is essential, overly harsh conditions (prolonged incubation at high temperatures) can lead to excessive DNA degradation.[11] Consider using a commercial kit with DNA protection reagents. |
| Loss During Cleanup | Be meticulous during the DNA cleanup steps. Ensure complete binding to and elution from purification columns. |
| Starting with Degraded DNA | If your starting DNA is already fragmented (e.g., from FFPE tissues), expect lower recovery. Optimize protocols specifically for degraded DNA. |
Experimental Protocols
Protocol 1: Optimizing DNA Denaturation
This protocol provides a method to test different denaturation conditions.
-
Sample Preparation: Aliquot your purified genomic DNA into several tubes, each containing the same amount of DNA (e.g., 500 ng).
-
Denaturation Conditions:
-
Tube A (Control): Follow your standard denaturation protocol (e.g., 95°C for 5 minutes).
-
Tube B (Increased Time): Increase the denaturation time (e.g., 95°C for 10 minutes).
-
Tube C (Increased Temperature): Increase the denaturation temperature slightly if your thermal cycler allows (e.g., 98°C for 5 minutes).
-
Tube D (Chemical Denaturant): Add a chemical denaturant like formamide to the reaction mix before the heat denaturation step, following a validated protocol.[10]
-
-
Bisulfite Conversion: Proceed with the standard bisulfite conversion protocol for all tubes.
-
Analysis: Assess the conversion efficiency for each condition using one of the methods described in Q3 of the FAQ.
Protocol 2: Assessing Bisulfite Conversion Efficiency using Non-CpG Cytosine Conversion
-
Perform Bisulfite Sequencing: After your bisulfite sequencing experiment, align the reads to the reference genome.
-
Identify Non-CpG Cytosines: In your sequencing data, identify all cytosine positions that are not followed by a guanine (B1146940) (i.e., CHH and CHG contexts, where H can be A, C, or T).
-
Calculate Conversion Rate: For each non-CpG cytosine, count the number of reads that show a 'C' and the number of reads that show a 'T'. The conversion efficiency is calculated as: Conversion Efficiency = (Number of T reads) / (Number of C reads + Number of T reads) * 100%
-
Interpret Results: A conversion efficiency of >99% is generally considered good for most applications.[3]
Visualizations
Caption: Workflow of a typical bisulfite sequencing experiment.
Caption: Troubleshooting logic for incomplete bisulfite conversion.
References
- 1. Errors in the bisulfite conversion of DNA: modulating inappropriate- and failed-conversion frequencies - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Bisulfite sequencing - Wikipedia [en.wikipedia.org]
- 3. biorxiv.org [biorxiv.org]
- 4. Bisulfite Sequencing of DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 5. DNA methylation detection: Bisulfite genomic sequencing analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 6. An optimized rapid bisulfite conversion method with high recovery of cell-free DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Bisulfite Conversion of DNA: Performance Comparison of Different Kits and Methylation Quantitation of Epigenetic Biomarkers that Have the Potential to Be Used in Non-Invasive Prenatal Testing - PMC [pmc.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. documents.thermofisher.com [documents.thermofisher.com]
- 10. Formamide as a denaturant for bisulfite conversion of genomic DNA: Bisulfite sequencing of the GSTPi and RARbeta2 genes of 43 formalin-fixed paraffin-embedded prostate cancer specimens - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. qiagen.com [qiagen.com]
Technical Support Center: Optimizing Library Preparation for 5mC Sequencing
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals optimize their library preparation for 5-methylcytosine (B146107) (5mC) sequencing experiments.
Frequently Asked Questions (FAQs)
Q1: What is the recommended DNA input amount for 5mC sequencing library preparation?
The optimal DNA input amount can vary depending on the specific kit and protocol being used. However, here is a general guideline for different applications:
| Application | Recommended DNA Input | Typical Range |
| Whole-Genome Bisulfite Sequencing (WGBS) | 100 ng - 1 µg | 10 ng - 2 µg |
| Reduced Representation Bisulfite Sequencing (RRBS) | 10 ng - 100 ng | 1 ng - 500 ng |
| Targeted Methylation Sequencing | 10 ng - 200 ng | 1 ng - 1 µg |
Q2: How can I assess the quality of my input DNA?
DNA quality is critical for successful library preparation. It is highly recommended to assess the following:
-
Purity: Use a spectrophotometer (e.g., NanoDrop) to measure the A260/A280 and A260/A230 ratios. The ideal A260/A280 ratio is ~1.8, and the A260/A230 ratio should be between 2.0 and 2.2.
-
Integrity: Run an aliquot of the DNA on an agarose (B213101) gel or use an automated electrophoresis system (e.g., Agilent Bioanalyzer or TapeStation) to check for high molecular weight DNA with minimal degradation.
Q3: What are the critical steps in bisulfite conversion?
The bisulfite conversion step is crucial for accurately identifying 5mC. Key considerations include:
-
Complete Denaturation: Ensure the DNA is fully denatured to allow for efficient bisulfite reaction.
-
Optimal Reaction Time and Temperature: Follow the manufacturer's protocol precisely for incubation times and temperatures. Over-incubation can lead to DNA degradation, while under-incubation can result in incomplete conversion.
-
Efficient Desulfonation and Purification: Thoroughly desulfonate and purify the converted DNA to remove residual chemicals that can inhibit downstream enzymatic reactions.
Troubleshooting Guide
This guide addresses common issues encountered during 5mC sequencing library preparation.
| Issue | Possible Cause(s) | Recommended Solution(s) |
| Low Library Yield | - Insufficient DNA input- Poor DNA quality (degraded or impure)- Inefficient adapter ligation- Suboptimal PCR amplification | - Increase the amount of starting DNA- Assess DNA quality and perform cleanup if necessary- Optimize adapter-to-insert molar ratio- Increase PCR cycle number (with caution to avoid over-amplification) |
| Adapter Dimers | - Excessive adapter concentration- Inefficient ligation of adapters to DNA fragments | - Titrate the adapter concentration to find the optimal molar ratio- Ensure DNA fragments have been properly end-repaired and A-tailed |
| PCR Duplicates | - Over-amplification during PCR- Low library complexity | - Reduce the number of PCR cycles- Start with a higher amount of input DNA to increase library diversity |
| Incomplete Bisulfite Conversion | - Incomplete DNA denaturation- Suboptimal bisulfite reaction conditions (time, temperature)- Inefficient desulfonation | - Ensure complete denaturation of DNA before bisulfite treatment- Strictly follow the recommended incubation times and temperatures- Ensure complete removal of bisulfite and proper desulfonation |
| DNA Degradation | - Harsh DNA extraction methods- Excessive incubation time during bisulfite conversion- Multiple freeze-thaw cycles | - Use a gentle DNA extraction method- Adhere to the recommended bisulfite conversion protocol timelines- Aliquot DNA to avoid repeated freezing and thawing |
Experimental Workflows and Protocols
Overall 5mC Sequencing Library Preparation Workflow
Technical Support Center: Navigating DNA Integrity in Bisulfite Conversion
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals minimize DNA degradation during bisulfite treatment for methylation analysis.
Frequently Asked Questions (FAQs)
Q1: What are the primary causes of DNA degradation during bisulfite treatment?
DNA degradation during bisulfite treatment is a significant issue stemming from the harsh chemical and physical conditions required for the conversion of unmethylated cytosines to uracils. The primary culprits are the combination of low pH and high temperatures, which can lead to depurination or depyrimidination, resulting in DNA strand breaks.[1][2][3][4] This chemical treatment can result in the fragmentation of a substantial portion of the starting DNA, with some studies indicating that 84-96% of the DNA can be degraded.[1][5]
Q2: How does the quality of the starting DNA impact degradation?
The integrity of the initial DNA sample is a critical factor. Starting with high-quality, high molecular weight DNA is crucial for minimizing the extent of degradation.[6] DNA that is already fragmented, such as that extracted from formalin-fixed paraffin-embedded (FFPE) tissues, is significantly more vulnerable to further degradation during the aggressive bisulfite conversion process.[6][7] It is highly recommended to assess the quality of your DNA on an agarose (B213101) gel before proceeding with bisulfite treatment.[8]
Q3: My DNA yield is very low after bisulfite conversion and cleanup. What can I do to improve it?
Low DNA yield is a common problem due to the inherent DNA degradation during treatment.[6] Here are several factors and potential solutions to consider:
-
Starting DNA Amount: Ensure you are starting with a sufficient quantity of high-quality DNA. For fragmented or precious samples, consider using kits specifically designed for low-input DNA.[6]
-
Minimize Incubation Time: While complete conversion is essential, prolonged incubation can exacerbate DNA degradation.[9] Optimize your incubation time to balance conversion efficiency with DNA integrity.
-
Use a Commercial Kit with DNA Protectant: Many commercially available kits include proprietary reagents that act as DNA protectants, shielding the DNA from the harsh chemical environment and thereby reducing fragmentation.[10]
-
Purification Method: Inefficient purification can lead to the loss of smaller DNA fragments.[7] Consider using column-based or magnetic bead-based purification methods optimized for the recovery of bisulfite-converted DNA.[7][11]
Q4: My PCR amplification of bisulfite-converted DNA is failing or has very low yield. How can I troubleshoot this?
PCR failure with bisulfite-treated DNA is often linked to DNA degradation and the altered sequence composition. Here are some troubleshooting tips:
-
Amplify Shorter Fragments: Due to fragmentation, designing primers to amplify shorter amplicons (ideally less than 300 bp) can significantly improve PCR success rates.[9][12][13]
-
Increase PCR Cycle Number: Bisulfite-treated DNA is single-stranded and often present in low quantities. Increasing the number of PCR cycles to 40-45 can help amplify the target sequence.[12]
-
Optimize Annealing Temperature: The AT-rich nature of bisulfite-converted DNA can affect primer binding. Using a touchdown PCR protocol, starting with a higher annealing temperature and gradually decreasing it, can enhance specificity.[12]
-
Use a Hot-Start Polymerase: A hot-start DNA polymerase is recommended to reduce non-specific amplification and primer-dimer formation.[12]
-
Consider Nested PCR: For very low abundance templates, a nested PCR approach, using a second set of primers internal to the first amplicon, can increase sensitivity and specificity.[14]
Q5: Are there alternatives to traditional bisulfite conversion that cause less DNA damage?
Yes, alternative methods are being developed to circumvent the DNA-damaging effects of bisulfite treatment. One such method is enzymatic methyl-seq (EM-seq), which uses the APOBEC enzyme to convert unmethylated cytosines to uracils under milder reaction conditions, resulting in significantly less DNA degradation.[15] Another approach, termed Ultra-Mild Bisulfite Sequencing (UMBS-seq), refines the traditional bisulfite chemistry to minimize DNA damage while maintaining high conversion efficiency.[16]
Troubleshooting Guides
Issue 1: High DNA Degradation Observed on a Gel
Observation: Running bisulfite-converted DNA on an agarose gel shows a smear from approximately 100-200 bp up to 1-2 kb, indicating significant fragmentation.[11]
| Potential Cause | Recommended Solution |
| Harsh Reaction Conditions | Reduce incubation temperature or time. However, ensure conversion efficiency is not compromised.[1] |
| Poor Starting DNA Quality | Use high-quality, non-fragmented DNA as starting material. Assess DNA integrity before treatment.[6][8] |
| Oxidation of Reagents | Prepare bisulfite and hydroquinone (B1673460) solutions fresh before each use.[6][17] |
| Suboptimal pH | Ensure the pH of the bisulfite solution is correctly adjusted to 5.0.[1] |
Issue 2: Incomplete Bisulfite Conversion
Observation: Sequencing results show a high rate of non-conversion of unmethylated cytosines, leading to false-positive methylation calls.[15]
| Potential Cause | Recommended Solution |
| Insufficient Denaturation | Ensure complete denaturation of the DNA to a single-stranded form, as bisulfite only acts on single-stranded DNA.[13][15] This can be achieved through heat or chemical denaturation (e.g., NaOH).[11] |
| Insufficient Incubation Time | While aiming to reduce degradation, ensure the incubation time is sufficient for complete conversion. Refer to your kit's protocol or published literature for optimized times.[9] |
| Too Much Starting DNA | Using an excessive amount of starting DNA can lead to incomplete conversion.[18] Adhere to the recommended input amounts for your chosen protocol. |
| Reagent Quality | Use fresh, properly stored bisulfite reagents.[8] |
Experimental Protocols & Data
Generalized Bisulfite Conversion Protocol
This protocol provides a general outline. Always refer to the manufacturer's instructions provided with your specific kit for detailed procedures.
-
DNA Preparation: Start with 10 ng to 1 µg of high-quality genomic DNA.[1]
-
Denaturation: Chemically denature the DNA using a freshly prepared solution of NaOH (e.g., a final concentration of 0.3M) and incubate at a temperature such as 37°C for 15 minutes.[6]
-
Bisulfite Conversion: Add a freshly prepared solution of sodium bisulfite and hydroquinone to the denatured DNA.[6] Incubate the reaction in the dark. Incubation conditions can vary, for example, 16 hours at 50-55°C, or cycling temperatures (e.g., 5 minutes at 95°C followed by 3 hours at 55°C, repeated every 3 hours).[1][19]
-
DNA Cleanup (Desalting): Purify the bisulfite-treated DNA using a spin column or magnetic beads to remove bisulfite and other salts.[6]
-
Desulfonation: Add a desulfonation buffer (often containing NaOH) to the purified DNA and incubate to remove sulfonate groups from the uracil (B121893) bases.[6]
-
Final Purification: Perform a final purification and elute the converted DNA in a small volume of elution buffer.
Impact of Incubation Temperature on DNA Degradation and Conversion
| Incubation Temperature | Incubation Time | DNA Degradation (%) | Conversion Efficiency |
| 55°C | 4 hours | 84-96% | High |
| 55°C | 18 hours | >96% | Very High |
| 95°C | 1 hour | >96%[5] | High |
Note: The reported degradation rates are substantial even under optimized conditions, highlighting the importance of starting with sufficient high-quality DNA.
Visualizations
Caption: A workflow diagram illustrating the key steps in bisulfite sequencing.
Caption: The chemical pathways of bisulfite conversion and DNA degradation.
References
- 1. A new method for accurate assessment of DNA quality after bisulfite treatment - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Degradation of DNA by bisulfite treatment - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. academic.oup.com [academic.oup.com]
- 5. Bisulfite genomic sequencing: systematic investigation of critical experimental parameters - PMC [pmc.ncbi.nlm.nih.gov]
- 6. benchchem.com [benchchem.com]
- 7. epigenie.com [epigenie.com]
- 8. whatisepigenetics.com [whatisepigenetics.com]
- 9. scienceopen.com [scienceopen.com]
- 10. qiagen.com [qiagen.com]
- 11. epigenie.com [epigenie.com]
- 12. researchgate.net [researchgate.net]
- 13. DNA methylation detection: Bisulfite genomic sequencing analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Bisulfite Sequencing and PCR Troubleshooting - DNA Methylation and Epigenetics [protocol-online.org]
- 15. Bisulfite sequencing - Wikipedia [en.wikipedia.org]
- 16. biocompare.com [biocompare.com]
- 17. The bisulfite genomic sequencing protocol [file.scirp.org]
- 18. Bisulfite Sequencing of DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Bisulfite Protocol | Stupar Lab [stuparlab.cfans.umn.edu]
Validation & Comparative
Validating 5-Methylcytosine Sequencing: A Comparative Guide to Pyrosequencing
For researchers, scientists, and drug development professionals navigating the complexities of epigenetic analysis, accurate validation of 5-Methylcytosine (5mC) sequencing data is paramount. This guide provides an objective comparison of pyrosequencing as a validation method for high-throughput 5mC sequencing techniques, such as Whole-Genome Bisulfite Sequencing (WGBS), supported by experimental data and detailed protocols.
Introduction to this compound Analysis
This compound is a critical epigenetic modification involved in gene regulation, cellular differentiation, and disease.[1] High-throughput sequencing methods have revolutionized the study of genome-wide DNA methylation. However, the technical rigors of these approaches, particularly those involving sodium bisulfite treatment which can degrade DNA, necessitate robust validation of the sequencing results.[2] Pyrosequencing has emerged as a gold-standard technique for targeted, quantitative validation of 5mC levels at specific genomic loci identified by genome-wide analyses.[2][3]
The Role of Pyrosequencing in 5mC Validation
Pyrosequencing is a sequencing-by-synthesis method that provides real-time quantitative measurement of nucleotide incorporation.[4] For methylation analysis, genomic DNA is first treated with sodium bisulfite, which converts unmethylated cytosines to uracil (B121893), while 5-methylcytosines remain unchanged.[5] Subsequent PCR amplification replaces uracil with thymine (B56734). The region of interest is then sequenced, and the ratio of cytosine to thymine at specific CpG sites is quantified to determine the percentage of methylation.[6] This method offers a highly accurate and reproducible means to validate findings from genome-scale methylation studies.[3]
Experimental Workflow: From Genome-Wide Sequencing to Targeted Validation
The overall process involves an initial genome-wide analysis of 5mC, followed by targeted validation of key differentially methylated regions using pyrosequencing.
Comparative Analysis of Validation Methods
While pyrosequencing is a robust method, other techniques are also employed for targeted methylation analysis. A comparative overview is essential for selecting the most appropriate validation strategy. A study comparing various methods for DNA methylation analysis provided data on their performance for assessing highly, intermediately, and unmethylated loci.[7]
| Method | Principle | Accuracy | Throughput | Cost (Instrument) | Key Advantages | Key Disadvantages |
| Pyrosequencing | Sequencing-by-synthesis after bisulfite treatment.[8] | High, quantitative at single CpG resolution.[3] | High | High | Highly accurate and reproducible; analyzes multiple CpG sites in a single reaction.[7] | Requires specialized equipment; shorter read lengths (max ~350 bp).[7] |
| Methylation-Specific High-Resolution Melting (MS-HRM) | PCR-based melting curve analysis of bisulfite-treated DNA.[7] | High, semi-quantitative to quantitative.[9] | High | Low | Cost-effective, rapid, and simple PCR-based method.[7] | Provides an average methylation level across the amplicon, not single-CpG resolution.[9] |
| Quantitative Methylation-Specific PCR (qMSP) | Real-time PCR with primers specific for methylated or unmethylated sequences.[7] | Lower, often considered semi-quantitative.[7] | High | Moderate | Does not require sequencing. | Primer design is challenging and can introduce bias; less accurate than pyrosequencing.[7] |
| Methylation-Specific Restriction Endonuclease (MSRE) Analysis | Digestion of genomic DNA with methylation-sensitive restriction enzymes followed by qPCR.[7] | Moderate | Moderate | Low | Does not require bisulfite conversion. | Limited to the analysis of CpG sites within specific restriction enzyme recognition sequences; not suitable for intermediately methylated regions.[7] |
Experimental Protocols
Below are summarized protocols for Whole-Genome Bisulfite Sequencing (WGBS) for the discovery phase and pyrosequencing for the validation phase.
Whole-Genome Bisulfite Sequencing (WGBS) Protocol Summary
This protocol provides a general overview of the steps involved in preparing a WGBS library.
-
Genomic DNA Fragmentation: High-quality genomic DNA (1-5 µg) is fragmented to a desired size range (e.g., 200-300 bp) using sonication (e.g., Covaris).[10]
-
End Repair and A-tailing: The fragmented DNA is end-repaired to create blunt ends, and a single adenine (B156593) nucleotide is added to the 3' ends.[10]
-
Adapter Ligation: Methylated sequencing adapters are ligated to the DNA fragments. It is crucial to use methylated adapters to prevent their conversion during the subsequent bisulfite treatment.[11]
-
Bisulfite Conversion: The adapter-ligated DNA is treated with sodium bisulfite, which converts unmethylated cytosines to uracil. Commercial kits (e.g., EpiTect Bisulfite Kit) are often used for this step.[10]
-
PCR Amplification: The bisulfite-converted DNA is amplified by PCR using primers that anneal to the ligated adapters. This step enriches for fragments that have adapters on both ends and creates the final sequencing library.[11]
-
Sequencing: The library is sequenced on a high-throughput sequencing platform.
Pyrosequencing Protocol for 5mC Validation
This protocol outlines the key steps for validating 5mC levels at specific loci.
-
Primer Design: Design PCR and sequencing primers for the target region using specialized software (e.g., PyroMark Assay Design). One of the PCR primers must be biotinylated.[12]
-
Bisulfite Conversion of gDNA: Treat genomic DNA with sodium bisulfite as described in the WGBS protocol.[5]
-
PCR Amplification: Amplify the bisulfite-converted DNA using the designed primers. Typically, 25-100 ng of bisulfite-converted DNA is used per reaction.[5] Verify the PCR product on an agarose (B213101) gel.
-
Immobilization of PCR Product: The biotinylated PCR products are captured on streptavidin-coated Sepharose beads. The non-biotinylated strand is removed by denaturation, leaving a single-stranded DNA template bound to the beads.[7]
-
Sequencing Primer Annealing: The sequencing primer is annealed to the single-stranded template.[7]
-
Pyrosequencing Reaction: The pyrosequencing reaction is performed according to the manufacturer's instructions. Nucleotides are dispensed sequentially, and light is generated upon incorporation, which is detected by a CCD camera.[13]
-
Data Analysis: The pyrograms are analyzed using the appropriate software. The methylation percentage at each CpG site is calculated from the ratio of the peak heights for cytosine and thymine.[5]
Logical Framework for Data Interpretation
The validation process relies on a direct comparison of the methylation levels obtained from the genome-wide sequencing data and the targeted pyrosequencing results.
References
- 1. m.youtube.com [m.youtube.com]
- 2. elearning.unite.it [elearning.unite.it]
- 3. DSpace [diposit.ub.edu]
- 4. researchgate.net [researchgate.net]
- 5. Analysis of DNA Methylation by Pyrosequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 6. DNA Methylation Analysis [qiagen.com]
- 7. DNA Methylation Validation Methods: a Coherent Review with Practical Comparison - PMC [pmc.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. Comparison Study of MS-HRM and Pyrosequencing Techniques for Quantification of APC and CDKN2A Gene Methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 10. support.illumina.com [support.illumina.com]
- 11. lfz100.ust.hk [lfz100.ust.hk]
- 12. Protocol for single-base quantification of RNA m5C by pyrosequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 13. news-medical.net [news-medical.net]
A Head-to-Head Comparison: Bisulfite Sequencing vs. Enzymatic Methylation Analysis for DNA Methylation Studies
For researchers, scientists, and drug development professionals delving into the complexities of epigenetics, the accurate analysis of DNA methylation is critical. While whole-genome bisulfite sequencing (WGBS) has long been the gold standard, emerging enzymatic approaches, such as enzymatic methyl-seq (EM-seq), offer a compelling alternative. This guide provides an objective comparison of these two methods, supported by experimental data, to help you select the most suitable technique for your research.
The core principle of both methods is to distinguish between methylated and unmethylated cytosines. This is achieved by converting unmethylated cytosines into uracil, which is then read as thymine (B56734) during sequencing, while methylated cytosines (5mC) and hydroxymethylated cytosines (5hmC) remain unchanged.[1] The resulting sequencing data is compared to a reference genome to determine the methylation status of individual cytosine bases.
At a Glance: Key Performance Metrics
The decision between bisulfite and enzymatic methods often involves weighing the established nature of bisulfite sequencing against the promise of higher quality data and less sample degradation with enzymatic approaches.[2] The following table summarizes key performance metrics compiled from various studies.
| Performance Metric | Bisulfite Sequencing (e.g., WGBS) | Enzymatic Methyl-seq (e.g., EM-seq) | Key Advantage of Enzymatic Method |
| DNA Damage | High, due to harsh chemical treatment leading to significant DNA fragmentation and loss.[1][3][4] | Minimal, as the enzymatic reactions are gentler, preserving DNA integrity.[2][4][5] | Higher quality DNA, leading to more reliable and comprehensive sequencing data. |
| Library Yield | Lower, particularly with low-input or fragmented DNA samples.[2][3] | Significantly higher library yields from the same amount of starting material.[2][3] | More efficient use of precious or limited samples. |
| Library Complexity | Lower, with a higher percentage of PCR duplicate reads.[2][3] | Higher, with fewer PCR duplicates, resulting in the capture of more unique methylation events.[2][3] | A more comprehensive and accurate representation of the methylome. |
| GC Bias | Exhibits lower relative coverage over GC-rich regions due to DNA fragmentation and amplification bias.[3][5] | More uniform coverage across regions of varying GC content.[5][6] | Improved accuracy in methylation analysis of GC-rich areas like CpG islands. |
| Conversion Efficiency | High, but can be variable depending on the kit and protocol (typically >98.7%).[7][8] | High and consistent, with reported efficiencies often exceeding 99%.[9] | Reliable and uniform conversion across the genome. |
| Input DNA Amount | Typically requires higher amounts of DNA (e.g., >100 ng).[10] | Suitable for low-input samples, with protocols available for as little as 100 pg.[4][11] | Enables analysis of rare or difficult-to-obtain samples. |
| Read Mapping Efficiency | Lower, due to shorter fragment sizes and lower library complexity.[9] | Higher, due to longer and more intact library fragments.[9][12] | More efficient use of sequencing reads and improved data quality. |
Experimental Workflows: A Visual Comparison
The fundamental difference between the two methods lies in the process of converting unmethylated cytosines.
Bisulfite Sequencing Workflow
Bisulfite sequencing employs a harsh chemical treatment with sodium bisulfite to deaminate unmethylated cytosines to uracils.[13] This process, however, can lead to significant DNA degradation.[1]
Caption: Workflow of Whole-Genome Bisulfite Sequencing (WGBS).
Enzymatic Methyl-seq (EM-seq) Workflow
EM-seq utilizes a series of enzymatic reactions to achieve the same conversion of unmethylated cytosines to uracils, but under much milder conditions.[6] This enzymatic approach significantly reduces DNA damage.[1]
Caption: Workflow of Enzymatic Methyl-seq (EM-seq).
Detailed Methodologies
Whole-Genome Bisulfite Sequencing (WGBS) Protocol Outline
-
DNA Extraction and Fragmentation: High-quality genomic DNA is extracted and then fragmented to the desired size range (typically 150-250 bp) using methods like sonication.[10][14]
-
Library Preparation: Sequencing adapters are ligated to the fragmented DNA. It is crucial to use methylated adapters to prevent their conversion during the bisulfite treatment.[14]
-
Bisulfite Conversion: The adapter-ligated DNA is treated with sodium bisulfite, which converts unmethylated cytosines to uracils.[15] This step involves incubation at specific temperatures and for defined durations, which can vary between kits.[8]
-
PCR Amplification: The converted DNA is amplified by PCR to generate a sufficient quantity for sequencing. This step can introduce bias, as fragments with different GC content may amplify with varying efficiencies.[13]
-
Sequencing: The amplified library is sequenced using next-generation sequencing platforms.
-
Data Analysis: Sequencing reads are aligned to a reference genome, and the methylation status of each cytosine is determined by comparing the sequenced base to the reference.
Enzymatic Methyl-seq (EM-seq) Protocol Outline
-
DNA Extraction and Fragmentation: Similar to WGBS, high-quality genomic DNA is extracted and fragmented.[5]
-
Library Preparation: Sequencing adapters are ligated to the fragmented DNA.[5]
-
Enzymatic Conversion: This is a two-step process:
-
Protection of Methylated Cytosines: The TET2 enzyme oxidizes 5mC and 5hmC.[16] An oxidation enhancer can be used to protect these modified cytosines from subsequent deamination.[2]
-
Deamination of Unmethylated Cytosines: The APOBEC enzyme specifically deaminates the unprotected, unmethylated cytosines to uracils.[2][16]
-
-
PCR Amplification: The enzymatically converted DNA is amplified by PCR. Due to the reduced DNA damage, fewer PCR cycles are often required compared to WGBS, leading to lower duplication rates.[17]
-
Sequencing: The amplified library is sequenced.
-
Data Analysis: The data analysis pipeline is generally the same as for WGBS, as the resulting converted sequences are identical.[5]
Conclusion: Choosing the Right Method for Your Research
Both bisulfite sequencing and enzymatic methods are powerful tools for single-base resolution DNA methylation analysis.[2] While WGBS has been the long-standing benchmark, the harsh chemical treatment can introduce biases and lead to sample degradation.[1] Enzymatic methods like EM-seq have emerged as a superior alternative in several key performance areas.[3] The gentler, enzymatic approach results in higher quality data, particularly from challenging and low-input samples, offering a more accurate and comprehensive view of the methylome.[2][3] For researchers working with precious or limited samples, such as clinical biopsies or circulating cell-free DNA, the advantages of enzymatic methylation analysis are particularly compelling.[3][18]
References
- 1. Treat Your Sample Gently - Enzymatic Methyl-Sequencing vs. Bisulfite Methyl-Sequencing [cegat.com]
- 2. benchchem.com [benchchem.com]
- 3. Comprehensive comparison of enzymatic and bisulfite DNA methylation analysis in clinically relevant samples - PMC [pmc.ncbi.nlm.nih.gov]
- 4. WGBS vs. EM-seq: Key Differences in Principles, Pros, Cons, and Applications - CD Genomics [cd-genomics.com]
- 5. neb-online.de [neb-online.de]
- 6. twistbioscience.com [twistbioscience.com]
- 7. researchgate.net [researchgate.net]
- 8. karger.com [karger.com]
- 9. tandfonline.com [tandfonline.com]
- 10. What are the basic steps of whole genome bisulfite sequencing (WGBS)? | AAT Bioquest [aatbio.com]
- 11. Enzymatic methyl sequencing detects DNA methylation at single-base resolution from picograms of DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 12. assets.ctfassets.net [assets.ctfassets.net]
- 13. Bisulfite sequencing in DNA methylation analysis | Abcam [abcam.com]
- 14. lfz100.ust.hk [lfz100.ust.hk]
- 15. Whole-Genome Bisulfite Sequencing (WGBS) Protocol - CD Genomics [cd-genomics.com]
- 16. Enzymatic methyl-seq - Wikipedia [en.wikipedia.org]
- 17. neb.com [neb.com]
- 18. Comprehensive comparison of enzymatic and bisulfite DNA methylation analysis in clinically relevant samples. [vivo.weill.cornell.edu]
5-Methylcytosine vs. 5-Hydroxymethylcytosine: A Comparative Guide to Their Roles in Gene Regulation
In the intricate landscape of epigenetics, 5-methylcytosine (B146107) (5mC) and 5-hydroxymethylcytosine (B124674) (5hmC) stand out as two crucial, yet functionally distinct, modifications of the DNA base cytosine. While 5mC has long been recognized as a key player in gene silencing, the more recently discovered 5hmC has emerged as a significant mark associated with active gene expression and a key intermediate in DNA demethylation. This guide provides a comprehensive comparison of 5mC and 5hmC, offering researchers, scientists, and drug development professionals a detailed overview of their functions, the experimental methods to distinguish them, and their implications in health and disease.
Core Distinctions and Biological Significance
This compound is generated by the addition of a methyl group to the 5th carbon of cytosine, a reaction catalyzed by DNA methyltransferases (DNMTs).[1][2][3] This modification is a stable epigenetic mark predominantly found in CpG dinucleotides and is a cornerstone of long-term gene silencing, playing critical roles in genomic imprinting, X-chromosome inactivation, and the repression of transposable elements.[1][4]
In contrast, 5-hydroxymethylcytosine is formed through the oxidation of 5mC by the Ten-Eleven Translocation (TET) family of dioxygenases.[5][6][7] Initially considered merely an intermediate in the DNA demethylation pathway, 5hmC is now recognized as a stable epigenetic mark in its own right, with distinct biological functions.[8][9][10] It is particularly abundant in the brain and embryonic stem cells.[1][11][12] The presence of 5hmC is often correlated with active gene transcription and it is thought to counteract the repressive effects of 5mC.[8][12]
The TET enzymes can further oxidize 5hmC to 5-formylcytosine (B1664653) (5fC) and 5-carboxylcytosine (5caC), which are then excised by thymine-DNA glycosylase (TDG) as part of the base excision repair (BER) pathway, leading to the restoration of an unmodified cytosine.[5][6][11][13] This process represents a pathway for active DNA demethylation.
Comparative Analysis of 5mC and 5hmC
To facilitate a clear understanding of their distinct characteristics, the following tables summarize the key quantitative and qualitative differences between 5mC and 5hmC.
| Feature | This compound (5mC) | 5-Hydroxymethylcytosine (5hmC) |
| Enzymatic Formation | DNA methyltransferases (DNMTs)[1][3] | Ten-Eleven Translocation (TET) enzymes[5][6][7] |
| Primary Genomic Location | CpG islands in promoters, gene bodies, intergenic regions, and repetitive elements.[1][4][14] | Enriched in gene bodies, enhancers, and promoters of active genes.[1][7][12] |
| Primary Role in Gene Regulation | Generally associated with transcriptional repression and gene silencing.[1][14] | Generally associated with transcriptional activation and open chromatin states.[1][8][12] |
| Stability | Stable epigenetic mark. | Can be a stable mark or an intermediate in DNA demethylation.[8][9][10] |
| "Reader" Proteins | Recognized by Methyl-CpG binding domain (MBD) proteins, leading to recruitment of repressive complexes.[15] | Recognized by a distinct set of reader proteins that can influence chromatin structure and transcription. |
| Abundance | Generally more abundant than 5hmC in most somatic tissues. | Levels vary significantly across tissues, with high levels in the brain and embryonic stem cells.[1][16] |
Signaling Pathways and Experimental Workflows
Visualizing the intricate processes of DNA modification and the methods to study them is crucial for a deeper understanding. The following diagrams, generated using the DOT language, illustrate the enzymatic pathway of cytosine modification and a typical experimental workflow for distinguishing 5mC and 5hmC.
Experimental Protocols for Distinguishing 5mC and 5hmC
Accurate detection and quantification of 5mC and 5hmC are paramount for understanding their roles in gene regulation. Standard bisulfite sequencing cannot distinguish between the two.[12][17] Therefore, specialized techniques have been developed.
Oxidative Bisulfite Sequencing (oxBS-Seq)
This method provides a direct readout of 5mC levels, and by comparing with standard bisulfite sequencing data, the levels of 5hmC can be inferred.[17][18]
Methodology:
-
Sample Preparation: Isolate high-quality genomic DNA.
-
Oxidation: Treat the DNA with potassium perruthenate (KRuO₄), which specifically oxidizes 5hmC to 5-formylcytosine (5fC). 5mC remains unmodified.[17][19]
-
Bisulfite Conversion: Perform standard bisulfite treatment on the oxidized DNA. This converts unmethylated cytosines and 5fC to uracil, while 5mC remains as cytosine.[19]
-
PCR Amplification: Amplify the target regions using primers specific for the converted DNA.
-
Sequencing: Sequence the PCR products.
-
Data Analysis: Align the sequences to a reference genome. The percentage of 5mC at a specific site is determined by the ratio of C reads to the total C and T reads. 5hmC levels are then calculated by subtracting the 5mC percentage from the total methylation percentage obtained from a parallel standard bisulfite sequencing experiment (which detects both 5mC and 5hmC).[17][20]
TET-Assisted Bisulfite Sequencing (TAB-Seq)
TAB-Seq allows for the direct, single-base resolution sequencing of 5hmC.[21][22]
Methodology:
-
Protection of 5hmC: Genomic DNA is treated with β-glucosyltransferase (β-GT), which transfers a glucose moiety to the hydroxyl group of 5hmC, forming glycosylated 5hmC (g5hmC). This protects 5hmC from subsequent oxidation.[21][22][23]
-
Oxidation of 5mC: The DNA is then treated with a TET enzyme, which oxidizes 5mC to 5-carboxylcytosine (5caC).[21][22]
-
Bisulfite Conversion: Standard bisulfite treatment is performed. Unmethylated cytosines and 5caC are converted to uracil, while the protected g5hmC is resistant and remains as cytosine.[22]
-
PCR Amplification and Sequencing: The treated DNA is amplified and sequenced.
-
Data Analysis: In the resulting sequence data, cytosines represent the original locations of 5hmC.
Implications in Disease and Drug Development
Alterations in the patterns of both 5mC and 5hmC are increasingly being recognized as hallmarks of various diseases, particularly cancer.[16][24][25][26] A global loss of 5hmC is a common feature in many types of tumors and is often associated with mutations in TET enzymes or the IDH1/2 genes, which produce a metabolite that inhibits TET activity.[16][25][26] This widespread loss of 5hmC can lead to aberrant gene expression, contributing to tumorigenesis.[15]
The distinct roles and regulatory pathways of 5mC and 5hmC present novel opportunities for therapeutic intervention. For instance, drugs that can modulate the activity of DNMTs and TET enzymes are being explored as potential cancer therapies. Understanding the specific epigenetic landscape of a tumor, including the balance between 5mC and 5hmC, could lead to more targeted and effective treatments. Furthermore, the stability of these marks in circulating cell-free DNA makes them promising biomarkers for early cancer detection and monitoring treatment response.[16][20]
References
- 1. New themes in the biological functions of this compound and 5-hydroxymethylcytosine - PMC [pmc.ncbi.nlm.nih.gov]
- 2. DNA Methylation: What’s the Difference Between 5mC and 5hmC? - Genevia Technologies [geneviatechnologies.com]
- 3. This compound turnover: Mechanisms and therapeutic implications in cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 4. This compound - Wikipedia [en.wikipedia.org]
- 5. researchgate.net [researchgate.net]
- 6. Tet family proteins and 5-hydroxymethylcytosine in development and disease - PMC [pmc.ncbi.nlm.nih.gov]
- 7. TET Enzymes and 5hmC in Adaptive and Innate Immune Systems - PMC [pmc.ncbi.nlm.nih.gov]
- 8. 5-hydroxymethylcytosines regulate gene expression as a passive DNA demethylation resisting epigenetic mark in proliferative somatic cells - PMC [pmc.ncbi.nlm.nih.gov]
- 9. 5-Hydroxymethylcytosine: Far Beyond the Intermediate of DNA Demethylation - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. Frontiers | TET Enzymes and 5-Hydroxymethylcytosine in Neural Progenitor Cell Biology and Neurodevelopment [frontiersin.org]
- 12. epigenie.com [epigenie.com]
- 13. europeanreview.org [europeanreview.org]
- 14. Frontiers | this compound turnover: Mechanisms and therapeutic implications in cancer [frontiersin.org]
- 15. Decreased 5-hydroxymethylcytosine levels correlate with cancer progression and poor survival: a systematic review and meta-analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 16. 5-Hydroxymethylcytosine: a key epigenetic mark in cancer and chemotherapy response - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Oxidative Bisulfite Sequencing: An Experimental and Computational Protocol - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. Oxidative bisulfite sequencing of this compound and 5-hydroxymethylcytosine - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Methods for Detection and Mapping of Methylated and Hydroxymethylated Cytosine in DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 20. tandfonline.com [tandfonline.com]
- 21. Tet-Assisted Bisulfite Sequencing (TAB-seq) - PMC [pmc.ncbi.nlm.nih.gov]
- 22. Tet-assisted bisulfite sequencing of 5-hydroxymethylcytosine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 23. epigenie.com [epigenie.com]
- 24. This compound and 5-Hydroxymethylcytosine Signatures Underlying Pediatric Cancers - PMC [pmc.ncbi.nlm.nih.gov]
- 25. The role of 5-hydroxymethylcytosine in human cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 26. Regulation and Functional Significance of 5-Hydroxymethylcytosine in Cancer [mdpi.com]
A Researcher's Guide to Cross-Validation of 5-Methylcytosine Data from Diverse Platforms
An in-depth comparison of leading technologies for the analysis of 5-Methylcytosine (5mC), this guide provides researchers, scientists, and drug development professionals with a comprehensive overview of the performance and methodologies of key platforms. We present a synthesis of experimental data to facilitate informed decisions for study design and data integration.
The accurate detection of this compound (5mC), a key epigenetic modification, is crucial for understanding its role in health and disease. A variety of platforms are available for 5mC analysis, each with its own strengths and limitations. This guide offers a comparative analysis of four major platforms: Whole-Genome Bisulfite Sequencing (WGBS), Enzymatic Methyl-seq (EM-seq), Illumina Infinium MethylationEPIC BeadChip (EPIC Array), and Oxford Nanopore Technologies (ONT).
Quantitative Performance Comparison
The selection of a 5mC analysis platform is often a trade-off between coverage, accuracy, and cost. The following tables summarize key performance metrics to aid in this decision-making process.
| Metric | WGBS | EM-seq | EPIC Array | ONT | References |
| CpG Coverage (Human Genome) | ~28 million | ~28 million | ~850,000 to ~935,000 | ~28 million | [1][2] |
| Concordance with WGBS (Pearson r) | N/A | High (0.826 - 0.906) | High (0.92) | Moderate to High | [2][3] |
| GC Bias | Present, especially in GC-rich regions | Reduced compared to WGBS | Present in high GC regions | Minimal | [3][4] |
| DNA Input Requirement | High (microgram range) | Low (nanogram to picogram range) | Moderate (nanogram range) | Low (nanogram range) | [3] |
| DNA Degradation | Significant due to bisulfite treatment | Minimal | N/A (requires bisulfite conversion) | None (native DNA) | [3] |
| Performance Metric | WGBS | EM-seq | ONT | References |
| Accuracy | High | High | N/A | High (>99% for 5mC on synthetic DNA) |
| Precision | High | High | N/A | High (>99% for 5mC on synthetic DNA) |
| Recall | High | High | N/A | High (>99% for 5mC on synthetic DNA) |
| F1-Score | High | High | N/A | High (>99% for 5mC on synthetic DNA) |
Experimental Protocols
Detailed methodologies are critical for the reproducibility and comparison of results across different studies and platforms. Below are generalized protocols for each of the discussed 5mC analysis platforms.
Whole-Genome Bisulfite Sequencing (WGBS)
-
DNA Extraction and Fragmentation: High-quality genomic DNA is extracted and fragmented to a desired size range (e.g., 200-400 bp) using sonication or enzymatic digestion.
-
End Repair, A-tailing, and Adapter Ligation: Fragmented DNA is end-repaired to create blunt ends, followed by the addition of a single adenine (B156593) nucleotide to the 3' ends. Methylated sequencing adapters are then ligated to the DNA fragments.
-
Bisulfite Conversion: The adapter-ligated DNA is treated with sodium bisulfite, which converts unmethylated cytosines to uracils, while methylated cytosines remain unchanged. This step can lead to significant DNA degradation.
-
PCR Amplification: The bisulfite-converted DNA is amplified by PCR to generate a sufficient quantity of library for sequencing.
-
Sequencing: The amplified library is sequenced on a high-throughput sequencing platform.
-
Data Analysis: Sequencing reads are aligned to a reference genome, and the methylation status of each cytosine is determined based on the C-to-T conversion rate.
Enzymatic Methyl-seq (EM-seq)
-
DNA Fragmentation and Library Preparation: Genomic DNA is fragmented, end-repaired, A-tailed, and ligated to sequencing adapters.
-
Enzymatic Conversion:
-
Step 1: Oxidation: TET2 enzyme oxidizes 5mC and 5-hydroxymethylcytosine (B124674) (5hmC) to protect them from deamination.
-
Step 2: Deamination: APOBEC enzyme deaminates unmethylated cytosines to uracils. This enzymatic process is less harsh on the DNA compared to bisulfite treatment.
-
-
PCR Amplification: The enzymatically converted library is amplified by PCR.
-
Sequencing: The library is sequenced on a high-throughput sequencing platform.
-
Data Analysis: The data analysis pipeline is similar to that of WGBS, involving alignment and methylation calling.
Illumina Infinium MethylationEPIC BeadChip (EPIC Array)
-
DNA Extraction: Genomic DNA is extracted from the sample.
-
Bisulfite Conversion: The genomic DNA is treated with sodium bisulfite to convert unmethylated cytosines to uracils.
-
Whole-Genome Amplification: The bisulfite-converted DNA is amplified to increase the amount of DNA for hybridization.
-
Hybridization: The amplified DNA is hybridized to the EPIC array, which contains probes targeting over 850,000 CpG sites.
-
Single-Base Extension and Staining: Single-base extension with labeled nucleotides is performed to determine the methylation status of the target CpG sites. The array is then stained.
-
Scanning and Data Extraction: The array is scanned, and the fluorescence intensity data is extracted to determine the methylation level (beta value) for each CpG site.
-
Data Analysis: The raw data is normalized and analyzed to identify differentially methylated positions and regions.
Oxford Nanopore Technologies (ONT)
-
DNA Extraction: High-molecular-weight genomic DNA is extracted.
-
Library Preparation: A sequencing library is prepared by ligating sequencing adapters to the ends of the native DNA fragments. No bisulfite conversion or PCR amplification is required.
-
Sequencing: The library is loaded onto a nanopore flow cell. As individual DNA molecules pass through the nanopores, changes in the ionic current are measured. These changes are characteristic of the nucleotide sequence, including base modifications like 5mC.
-
Basecalling and Methylation Calling: The raw electrical signal is basecalled to determine the DNA sequence. Specialized algorithms are then used to detect the presence of 5mC at single-nucleotide resolution directly from the raw signal.
-
Data Analysis: The methylation calls are mapped to a reference genome for downstream analysis.
Visualizing the Cross-Validation Workflow
To effectively compare and validate 5mC data from different platforms, a structured workflow is essential. The following diagrams illustrate a typical experimental workflow and the logical process of data comparison.
Caption: Experimental workflow for cross-platform 5mC data validation.
Caption: Logical flow for the comparison of 5mC data from different platforms.
References
- 1. Comparison of current methods for genome-wide DNA methylation profiling - PMC [pmc.ncbi.nlm.nih.gov]
- 2. BoostMe accurately predicts DNA methylation values in whole-genome bisulfite sequencing of multiple human tissues - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Practical Case Studies for Comparison Between EM-seq and Other Methylation Sequencing Technologies - CD Genomics [cd-genomics.com]
- 4. Comparing methylation levels assayed in GC-rich regions with current and emerging methods - PMC [pmc.ncbi.nlm.nih.gov]
A Comparative Guide to 5-methylcytosine (5mC) Patterns Across Eukaryotic Species
Introduction: Cytosine DNA methylation (5mC) is a fundamental epigenetic modification found across the eukaryotic tree of life, playing crucial roles in processes ranging from transcriptional regulation and transposon silencing to genomic imprinting.[1][2] While the core machinery for DNA methylation has ancient evolutionary roots, its application, genomic distribution, and regulatory mechanisms have diverged remarkably between species.[2][3] This guide provides a comparative analysis of 5mC patterns in different species, details the experimental protocols used for their detection, and illustrates the key enzymatic pathways involved. It is intended for researchers, scientists, and drug development professionals seeking to understand the evolutionary diversity of the DNA methylome.
Section 1: Comparative Overview of 5mC Patterns
The distribution and density of 5mC across the genome vary significantly among eukaryotes. In vertebrates, genomes are typically heavily methylated, a pattern referred to as global or hypermethylation.[4][5] This contrasts sharply with many invertebrates, which exhibit a "mosaic" pattern where methylation is targeted primarily to the bodies of specific genes, leaving the rest of the genome largely unmethylated.[4] Plants display yet another distinct pattern, with methylation occurring not only at CpG sites, as is common in mammals, but also in CHG and CHH contexts (where H is A, C, or T).[6][7] This non-CpG methylation is often associated with silencing transposable elements.[6] In the fungal kingdom, 5mC patterns are exceptionally diverse; some species lack methylation entirely, while others show significant levels, often concentrated in repeats.[8]
This diversity challenges the once-held view that genome hypermethylation is an exclusive trait of vertebrates and highlights the evolutionary lability of epigenetic systems.[1][9]
Quantitative Comparison of 5mC Characteristics Across Major Eukaryotic Groups
The following table summarizes key quantitative and qualitative features of 5mC patterns in representative species.
| Feature | Mammals (e.g., Homo sapiens, Mus musculus) | Plants (e.g., Arabidopsis thaliana) | Fungi (e.g., Neurospora crassa) | Invertebrates (e.g., Apis mellifera) |
| Overall Methylation Level | High (60-80% of all CpGs)[10] | Moderate (5-25% of all cytosines)[11] | Highly Variable (from none to ~1.8% of cytosines in some species)[8][12] | Low to Moderate ("Mosaic")[4] |
| Primary Sequence Context(s) | Almost exclusively CpG[10][13] | CpG, CHG, and CHH[6][7] | Varies; often CpG or non-CG depending on the species[8][14] | Primarily CpG[4] |
| Predominant Genomic Location | Genome-wide, including gene bodies, intergenic regions, and repetitive elements[6][15] | Primarily transposable elements and repetitive sequences[6][15] | Repetitive elements and transposons[8] | Primarily within gene bodies (exons)[4] |
| Primary Function(s) | Gene regulation, transposon silencing, genomic imprinting, X-chromosome inactivation[4] | Transposon silencing, gene regulation[6][16] | Genome defense against transposable elements[8] | Regulation of gene expression, including alternative splicing[1] |
Section 2: The Machinery of DNA Methylation and Demethylation
The establishment, maintenance, and removal of 5mC are governed by specific families of enzymes that have also evolved differently across lineages.
DNA Methylation (The "Writers"):
-
DNA Methyltransferases (DNMTs) are responsible for catalyzing the addition of a methyl group to cytosine.[17]
-
In mammals, DNMT1 is the primary "maintenance" methyltransferase, ensuring the faithful copying of methylation patterns to daughter strands after DNA replication.[10][18] DNMT3A and DNMT3B act as de novo methyltransferases, establishing new methylation patterns during development.[10][18]
-
Plants possess homologs of DNMT1 (MET1) as well as distinct families, such as Chromomethylase 3 (CMT3) for CHG methylation and Domains Rearranged Methyltransferase (DRM) for CHH methylation.[6][14]
-
DNA Demethylation (The "Erasers"): The pathways for active DNA demethylation show a stark divergence between animals and plants.
-
In animals , demethylation is primarily an oxidative process initiated by the Ten-Eleven Translocation (TET) family of enzymes .[19] TET proteins iteratively oxidize 5mC to 5-hydroxymethylcytosine (B124674) (5hmC), 5-formylcytosine (B1664653) (5fC), and 5-carboxylcytosine (5caC).[18] These modified bases are then recognized and excised by Thymine DNA Glycosylase (TDG) as part of the Base Excision Repair (BER) pathway, ultimately restoring an unmodified cytosine.[12][18]
-
In plants , demethylation occurs via a direct excision pathway. A family of DNA glycosylases (e.g., ROS1, DME) recognizes and directly removes the 5mC base from the DNA backbone.[12] The resulting abasic site is then repaired by the BER pathway.[12][18]
Section 3: Experimental Protocols for 5mC Analysis
The genome-wide, single-base resolution analysis of 5mC is primarily achieved through bisulfite sequencing. Two common strategies are Whole-Genome Bisulfite Sequencing (WGBS) and Reduced Representation Bisulfite Sequencing (RRBS).
Protocol 1: Whole-Genome Bisulfite Sequencing (WGBS)
WGBS is considered the gold standard for DNA methylation analysis, providing comprehensive coverage of nearly every cytosine in the genome.[20][21]
-
Principle: Genomic DNA is treated with sodium bisulfite, which deaminates unmethylated cytosines to uracil, while methylated cytosines remain unchanged.[22] During subsequent PCR amplification, uracils are replaced with thymines. By comparing the sequenced reads to a reference genome, the original methylation status of each cytosine can be determined.[22]
-
Key Experimental Steps:
-
DNA Extraction: High-quality genomic DNA is isolated from the sample.
-
Fragmentation: DNA is fragmented to a suitable size for sequencing (e.g., via sonication).
-
Library Preparation: Sequencing adapters are ligated to the DNA fragments. This can be done before or after bisulfite treatment. Pre-bisulfite ligation protocols are common but require methylated adapters to protect them from conversion.[16]
-
Bisulfite Conversion: The adapter-ligated DNA is treated with sodium bisulfite. This step is harsh and can lead to DNA degradation.[23]
-
PCR Amplification: The converted DNA is amplified to generate sufficient material for sequencing. High-fidelity polymerases are used to minimize bias.[23]
-
Sequencing: The library is sequenced using next-generation sequencing platforms.
-
Data Analysis: Reads are aligned to a specially converted reference genome (e.g., using software like Bismark), and the methylation level at each cytosine site is calculated.[16][24]
-
-
Advantages: Provides the most comprehensive and unbiased view of the entire methylome.[21]
-
Disadvantages: Higher cost per sample and requires higher DNA input compared to targeted methods.[20]
Protocol 2: Reduced Representation Bisulfite Sequencing (RRBS)
RRBS is a cost-effective alternative that enriches for CpG-rich genomic regions, such as promoters and CpG islands, thereby reducing sequencing costs.[20]
-
Principle: The method uses a methylation-insensitive restriction enzyme, typically MspI, which cuts at CCGG sites regardless of methylation status.[20] This digestion enriches for fragments that are dense in CpG sites. The subsequent steps of bisulfite conversion and sequencing are similar to WGBS.
-
Key Experimental Steps:
-
DNA Extraction: High-quality genomic DNA is isolated.
-
Enzymatic Digestion: DNA is digested with the MspI restriction enzyme.
-
End Repair & Adapter Ligation: The digested fragments are end-repaired, A-tailed, and ligated to methylated sequencing adapters.
-
Size Selection: Fragments of a specific size range (e.g., 40-220 bp) are selected to enrich for CpG-rich regions.
-
Bisulfite Conversion: The size-selected, adapter-ligated fragments are treated with sodium bisulfite.
-
PCR Amplification: The converted library is amplified.
-
Sequencing & Data Analysis: The library is sequenced and analyzed similarly to WGBS, with the understanding that the data represents CpG-rich regions rather than the entire genome.
-
-
Advantages: Highly cost-effective and efficient for analyzing methylation in functionally important CpG islands and promoters.
-
Disadvantages: Provides a biased view of the methylome, missing information from CpG-poor regions.[21]
References
- 1. Evolution of DNA Methylome Diversity in Eukaryotes - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Encyclopaedia of eukaryotic DNA methylation: from patterns to mechanisms and functions - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Evolutionary transition between invertebrates and vertebrates via methylation reprogramming in embryogenesis - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. Genes and Transposons Are Differentially Methylated in Plants, but Not in Mammals - PMC [pmc.ncbi.nlm.nih.gov]
- 7. m.youtube.com [m.youtube.com]
- 8. Diversity of cytosine methylation across the fungal tree of life - PMC [pmc.ncbi.nlm.nih.gov]
- 9. research-repository.uwa.edu.au [research-repository.uwa.edu.au]
- 10. Genetic studies on mammalian DNA methyltransferases - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Evidence for novel epigenetic marks within plants - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Cross-Kingdom DNA Methylation Dynamics: Comparative Mechanisms of 5mC/6mA Regulation and Their Implications in Epigenetic Disorders - PMC [pmc.ncbi.nlm.nih.gov]
- 13. academic.oup.com [academic.oup.com]
- 14. Frontiers | Diversity of Fungal DNA Methyltransferases and Their Association With DNA Methylation Patterns [frontiersin.org]
- 15. researchgate.net [researchgate.net]
- 16. How to Design a Whole-Genome Bisulfite Sequencing Experiment [mdpi.com]
- 17. mdpi.com [mdpi.com]
- 18. Mechanisms of DNA Methyltransferases (DNMTs) and DNA Demethylases | EpigenTek [epigentek.com]
- 19. The Role of DNMT Methyltransferases and TET Dioxygenases in the Maintenance of the DNA Methylation Level - PMC [pmc.ncbi.nlm.nih.gov]
- 20. Intro to Reduced Representation Bisulfite Sequencing (RRBS) | EpigenTek [epigentek.com]
- 21. Principles and Workflow of Whole Genome Bisulfite Sequencing - CD Genomics [cd-genomics.com]
- 22. Bisulfite Sequencing (BS-Seq)/WGBS [illumina.com]
- 23. Comparison of whole-genome bisulfite sequencing library preparation strategies identifies sources of biases affecting DNA methylation data - PMC [pmc.ncbi.nlm.nih.gov]
- 24. Reduced-Representation Bisulfite Sequencing (RRBS) Service - Creative Biolabs [creative-biolabs.com]
A Researcher's Guide to the Functional Validation of Differentially Methylated Regions
For researchers, scientists, and drug development professionals, understanding the functional consequences of changes in DNA methylation is crucial for deciphering disease mechanisms and identifying novel therapeutic targets. This guide provides a comprehensive comparison of key experimental methods used to validate the functional role of differentially methylated regions (DMRs), with a focus on reporter assays and CRISPR-based epigenome editing.
Differentially methylated regions (DMRs) are genomic regions with altered DNA methylation patterns between different biological states, such as in cancerous versus normal tissues. While identifying DMRs is a critical first step, determining their functional impact on gene regulation is paramount. This guide offers a side-by-side comparison of two powerful techniques: the traditional reporter assay and the more recent CRISPR-based epigenome editing technologies. We provide quantitative data, detailed experimental protocols, and visual workflows to aid in the selection and implementation of the most appropriate method for your research needs.
Comparison of Functional Validation Methods
The choice of a functional validation method depends on the specific research question, the genomic context of the DMR, and the available resources. Here, we compare the widely used luciferase reporter assay with the versatile CRISPR-dCas9 system for both targeted demethylation (using dCas9-TET1) and targeted methylation-mediated gene silencing (using dCas9-KRAB).
| Feature | Luciferase Reporter Assay | CRISPR-dCas9-TET1 (Demethylation) | CRISPR-dCas9-KRAB (Gene Silencing) |
| Principle | The DMR sequence is cloned into a plasmid upstream of a reporter gene (e.g., luciferase). The effect of the DMR's methylation status on reporter gene expression is measured. | A catalytically inactive Cas9 (dCas9) fused to the TET1 enzyme is guided to the DMR to induce targeted demethylation, and the effect on endogenous gene expression is measured.[1][2][3] | A dCas9 fused to the KRAB repressor domain is targeted to the DMR to induce methylation and subsequent silencing of the endogenous gene.[4][5][6] |
| Readout | Quantitative measure of light output (luminescence), indicating promoter/enhancer activity.[7][8][9] | Change in endogenous gene expression (mRNA or protein levels) and methylation status of the target locus.[1][2] | Decrease in endogenous gene expression (mRNA or protein levels).[5][6] |
| Typical Quantitative Data | Fold change in luciferase activity (e.g., 2-fold, 5-fold increase/decrease).[8] | Percentage decrease in methylation; fold change in gene expression. | Percentage of gene expression knockdown (e.g., 50-90% reduction).[5][6] |
| Strengths | - Highly sensitive and quantitative.[9] - Well-established and widely used. - Relatively straightforward to set up. | - Allows for the study of the DMR in its native genomic context. - Can directly assess the causal link between methylation and gene expression.[1][2] | - Highly specific and potent gene silencing.[4][6] - Reversible and does not alter the underlying DNA sequence.[6] |
| Limitations | - The DMR is studied outside of its native chromatin environment (episomal). - May not fully recapitulate the complex regulatory interactions present in the genome. | - Off-target effects are a potential concern. - Efficiency of demethylation can be variable. | - Off-target effects need to be carefully evaluated. - Delivery of the CRISPR components can be challenging in some cell types. |
| Best Suited For | - High-throughput screening of the regulatory potential of multiple DMRs. - Validating enhancer or promoter activity of a DMR. | - Confirming the functional role of a specific hypermethylated DMR in gene silencing. - Investigating the direct impact of methylation on gene expression in the native context. | - Validating the functional consequence of DMR hypermethylation by mimicking the silenced state. - Studying the role of a specific gene regulated by a DMR. |
Experimental Protocols
Detailed methodologies are crucial for reproducible and reliable results. Below are summarized protocols for the discussed functional validation techniques.
Dual-Luciferase Reporter Assay
This assay utilizes two luciferases: a primary reporter (e.g., Firefly luciferase) driven by the DMR of interest and a secondary, constitutively expressed reporter (e.g., Renilla luciferase) for normalization.[10][11][12][13][14]
Materials:
-
pGL3 or similar luciferase reporter vector
-
pRL-TK or similar Renilla luciferase control vector
-
Restriction enzymes for cloning
-
T4 DNA ligase
-
Mammalian cell line of interest
-
Transfection reagent
-
Dual-Luciferase® Reporter Assay System (Promega or similar)
-
Luminometer
Protocol:
-
Cloning: Clone the DMR of interest into the multiple cloning site of the pGL3 vector, upstream of the luciferase gene.
-
Cell Culture and Transfection: Seed cells in a 24-well plate. Co-transfect the cells with the DMR-luciferase construct and the Renilla luciferase control vector using a suitable transfection reagent.
-
Cell Lysis: After 24-48 hours of incubation, wash the cells with PBS and lyse them using the provided lysis buffer.
-
Luciferase Assay:
-
Add Luciferase Assay Reagent II (LAR II) to a sample of the cell lysate and measure the Firefly luciferase activity using a luminometer.
-
Add Stop & Glo® Reagent to the same sample to quench the Firefly reaction and simultaneously activate the Renilla luciferase. Measure the Renilla luciferase activity.
-
-
Data Analysis: Calculate the ratio of Firefly to Renilla luciferase activity to normalize for transfection efficiency and cell number. Express the results as a fold change relative to a control vector (e.g., an empty pGL3 vector).[15]
CRISPR-dCas9-TET1 Mediated Demethylation
This protocol describes the targeted demethylation of a specific DMR using a dCas9-TET1 fusion protein.[1][2][3][16][17]
Materials:
-
dCas9-TET1 expression vector
-
sgRNA expression vector
-
Cell line of interest
-
Transfection reagent
-
Genomic DNA extraction kit
-
Bisulfite conversion kit
-
Pyrosequencing or other methylation analysis platform
-
RNA extraction kit and reagents for qRT-PCR
Protocol:
-
sgRNA Design and Cloning: Design and clone sgRNAs targeting the DMR of interest into the sgRNA expression vector.
-
Cell Transfection: Co-transfect the cells with the dCas9-TET1 and sgRNA expression vectors.
-
Genomic DNA and RNA Extraction: After 48-72 hours, harvest the cells and extract genomic DNA and total RNA.
-
Methylation Analysis: Perform bisulfite conversion of the genomic DNA followed by pyrosequencing or targeted deep bisulfite sequencing to quantify the methylation levels at the target DMR.
-
Gene Expression Analysis: Perform qRT-PCR to measure the expression level of the gene associated with the DMR.
-
Data Analysis: Compare the methylation levels and gene expression in dCas9-TET1/sgRNA-treated cells to control cells (e.g., transfected with a non-targeting sgRNA).
CRISPR-dCas9-KRAB Mediated Gene Silencing
This method utilizes a dCas9-KRAB fusion protein to induce methylation and silence a target gene.[4][5][6]
Materials:
-
dCas9-KRAB expression vector
-
sgRNA expression vector
-
Cell line of interest
-
Transfection or transduction reagents (e.g., lentivirus)
-
RNA extraction kit and reagents for qRT-PCR
-
Protein extraction reagents and antibodies for Western blotting (optional)
Protocol:
-
sgRNA Design and Cloning: Design and clone sgRNAs targeting the promoter region of the gene associated with the DMR.
-
Cell Transfection/Transduction: Deliver the dCas9-KRAB and sgRNA constructs into the cells. For stable silencing, lentiviral delivery is often preferred.
-
RNA and Protein Extraction: After an appropriate incubation period (e.g., 72 hours for transient transfection, or after selection for stable lines), extract RNA and protein from the cells.
-
Gene Expression Analysis: Quantify the mRNA levels of the target gene using qRT-PCR.
-
Protein Level Analysis (Optional): Analyze the protein levels of the target gene by Western blotting.
-
Data Analysis: Calculate the percentage of gene expression knockdown compared to control cells.
Visualizing the Concepts: Pathways and Workflows
To better illustrate the biological processes and experimental procedures, we provide diagrams generated using the Graphviz DOT language.
Gene Silencing by Promoter Hypermethylation
This diagram illustrates the mechanism by which hypermethylation of a gene's promoter region can lead to gene silencing.[18][19][20][21][22]
Caption: Mechanism of gene silencing via promoter hypermethylation.
Experimental Workflow for DMR Functional Validation
This diagram outlines the typical workflow from the discovery of DMRs to their functional validation.[23][24][25]
Caption: A typical workflow for the functional validation of DMRs.
References
- 1. CRISPR/dCas9-Tet1-Mediated DNA Methylation Editing [bio-protocol.org]
- 2. CRISPR/dCas9-Tet1-Mediated DNA Methylation Editing - PMC [pmc.ncbi.nlm.nih.gov]
- 3. CRISPR/dCas9-Tet1-Mediated DNA Methylation Editing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Highly Specific Epigenome Editing by CRISPR/Cas9 Repressors for Silencing of Distal Regulatory Elements - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Unlock the Power of CRISPRi: a Robust Gene Silencing Alternative to dCas9-KRAB [horizondiscovery.com]
- 6. medium.com [medium.com]
- 7. A Dual Luciferase System for Analysis of Post-Transcriptional Regulation of Gene Expression in Leishmania - PMC [pmc.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. m.youtube.com [m.youtube.com]
- 10. assaygenie.com [assaygenie.com]
- 11. kirschner.med.harvard.edu [kirschner.med.harvard.edu]
- 12. Dual-Luciferase® Reporter Assay System Protocol [promega.com]
- 13. youtube.com [youtube.com]
- 14. Dual-Luciferase® Reporter Assay System [worldwide.promega.com]
- 15. researchgate.net [researchgate.net]
- 16. Editing of DNA Methylation Using dCas9-Peptide Repeat and scFv-TET1 Catalytic Domain Fusions | Springer Nature Experiments [experiments.springernature.com]
- 17. en.bio-protocol.org [en.bio-protocol.org]
- 18. researchgate.net [researchgate.net]
- 19. researchgate.net [researchgate.net]
- 20. researchgate.net [researchgate.net]
- 21. Molecular Mechanisms of Gene Silencing Mediated by DNA Methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 22. Gene silencing | PPTX [slideshare.net]
- 23. researchgate.net [researchgate.net]
- 24. researchgate.net [researchgate.net]
- 25. researchgate.net [researchgate.net]
A Comparative Analysis of the Stability of 5-Methylcytosine and Other Key DNA Modifications
For Researchers, Scientists, and Drug Development Professionals: An Objective Comparison of the Stability of 5-Methylcytosine, 5-Hydroxymethylcytosine, 5-Formylcytosine, 5-Carboxylcytosine, and N6-Methyladenine.
This guide provides a comprehensive comparison of the chemical and biological stability of this compound (5mC) and other significant DNA modifications, including 5-Hydroxymethylcytosine (5hmC), 5-Formylcytosine (5fC), 5-Carboxylcytosine (5caC), and N6-Methyladenine (6mA). Understanding the relative stability of these epigenetic marks is crucial for research in gene regulation, cancer biology, and the development of novel therapeutics. This document summarizes key quantitative data, details relevant experimental protocols, and provides visual representations of the underlying biological pathways.
Data Summary: Comparative Stability of DNA Modifications
The stability of a DNA modification is a critical determinant of its biological function, influencing its persistence as an epigenetic mark and its role in dynamic regulatory processes. The following table summarizes the known stability characteristics of five key DNA modifications. It is important to note that stability can be context-dependent, varying with the local DNA sequence, the presence of specific proteins, and the cellular environment.
| Modification | Chemical Stability | Thermal Stability | Biological Stability (Half-life) | Primary Degradation/Removal Pathway |
| This compound (5mC) | High. The C-C bond is strong. Susceptible to deamination to thymine, especially at high temperatures. | Generally increases the thermal stability of the DNA duplex. | Considered a stable epigenetic mark, maintained through DNA replication by DNMT1. However, turnover can be rapid in specific genomic contexts. | Passive dilution during DNA replication; Active removal via the TET-TDG pathway. |
| 5-Hydroxymethylcytosine (5hmC) | Less stable than 5mC. The hydroxymethyl group can be further oxidized. | Generally decreases the thermal stability of the DNA duplex compared to 5mC. | Can be a stable epigenetic mark, particularly abundant in neurons, or a transient intermediate in the demethylation pathway.[1][2] | Further oxidation by TET enzymes to 5fC and 5caC; Passive dilution during DNA replication.[1][3] |
| 5-Formylcytosine (5fC) | Chemically reactive due to the aldehyde group. | Destabilizes the DNA duplex more than 5hmC. | Generally considered a transient intermediate with a short half-life. | Efficiently recognized and excised by Thymine-DNA Glycosylase (TDG) as part of the Base Excision Repair (BER) pathway.[1][3] |
| 5-Carboxylcytosine (5caC) | Chemically quite stable, though the carboxyl group can influence local DNA structure.[1] | Significantly destabilizes the DNA duplex. | A transient intermediate in the active demethylation pathway. | Recognized and excised by Thymine-DNA Glycosylase (TDG) and the Base Excision Repair (BER) pathway.[1][3] |
| N6-Methyladenine (6mA) | The N-C bond is generally stable under physiological conditions. | The N6-methyl group can increase the stability of the B-DNA conformation. | Dynamically regulated by specific methyltransferases and demethylases. Its role in genome stability is an active area of research.[4][5] | Enzymatic demethylation by specific demethylases (e.g., ALKBH family). |
Experimental Protocols
Accurate assessment of the stability of DNA modifications is essential for understanding their biological roles. Below are detailed methodologies for key experiments used to quantify and compare the stability of these epigenetic marks.
Protocol 1: In Vitro Stability Assay of Modified Oligonucleotides in Biological Matrices
This protocol assesses the enzymatic stability of oligonucleotides containing specific DNA modifications when exposed to biological fluids like serum or tissue homogenates.
1. Materials:
- Synthetic DNA oligonucleotides (20-30 bases) containing a single, site-specific 5mC, 5hmC, 5fC, 5caC, or 6mA modification.
- Control unmodified oligonucleotide of the same sequence.
- Fetal Bovine Serum (FBS) or prepared tissue homogenate (e.g., liver S9 fraction).
- Phosphate-Buffered Saline (PBS), pH 7.4.
- Incubator at 37°C.
- Quenching solution (e.g., EDTA to chelate divalent cations and inhibit nucleases).
- HPLC system with a C18 column or LC-MS/MS system.
- Nuclease P1 and Alkaline Phosphatase for DNA digestion.
2. Procedure:
- Prepare stock solutions of the modified and unmodified oligonucleotides in nuclease-free water.
- In separate microcentrifuge tubes, mix the oligonucleotide solution with either FBS (e.g., 50% v/v) or tissue homogenate in PBS to a final oligonucleotide concentration of 10 µM.
- Incubate the reactions at 37°C.
- At various time points (e.g., 0, 1, 2, 4, 8, 24 hours), withdraw an aliquot of the reaction and immediately add quenching solution.
- Digest the oligonucleotide samples to individual nucleosides by treating with Nuclease P1 followed by Alkaline Phosphatase.
- Analyze the digested samples by HPLC or LC-MS/MS to quantify the amount of the remaining modified nucleoside and any degradation products.
- Plot the concentration of the intact modified nucleoside against time to determine the degradation kinetics and calculate the half-life.
Protocol 2: Thermal Denaturation Analysis of Modified DNA Duplexes
This protocol measures the melting temperature (Tm) of DNA duplexes containing modified bases, providing insights into their effect on thermal stability.
1. Materials:
- Complementary synthetic DNA oligonucleotides, with one strand containing the modification of interest.
- Annealing buffer (e.g., 10 mM sodium phosphate, 100 mM NaCl, pH 7.0).
- UV-Vis spectrophotometer with a temperature controller or a Differential Scanning Calorimeter (DSC).
- Nuclease-free water.
2. Procedure:
- Resuspend the complementary oligonucleotides in the annealing buffer to a final concentration of 2-5 µM.
- Anneal the strands by heating to 95°C for 5 minutes and then slowly cooling to room temperature to form duplex DNA.
- Transfer the annealed DNA solution to a quartz cuvette.
- Place the cuvette in the spectrophotometer and monitor the absorbance at 260 nm as the temperature is increased from a starting temperature (e.g., 25°C) to a final temperature (e.g., 95°C) at a controlled rate (e.g., 1°C/minute).
- The melting temperature (Tm) is the temperature at which 50% of the DNA is denatured. This is determined by finding the maximum of the first derivative of the melting curve (dA260/dT vs. T).
- Compare the Tm values of the modified DNA duplexes to that of the unmodified control duplex.
Protocol 3: Quantitative Analysis of DNA Modifications by LC-MS/MS
This protocol provides a highly sensitive and specific method for the absolute quantification of global levels of DNA modifications in genomic DNA.
1. Materials:
- Genomic DNA sample.
- Stable isotope-labeled internal standards for each modification (e.g., [¹⁵N₅]-dC, [d₃]-5mC).
- Nuclease P1, snake venom phosphodiesterase, and alkaline phosphatase.
- LC-MS/MS system with a triple quadrupole mass spectrometer.
- C18 reversed-phase LC column.
- Mobile phases (e.g., 0.1% formic acid in water and 0.1% formic acid in acetonitrile).
2. Procedure:
- Quantify the genomic DNA concentration accurately.
- Spike the DNA sample with a known amount of the stable isotope-labeled internal standards.
- Enzymatically digest the genomic DNA to single nucleosides using a cocktail of Nuclease P1, snake venom phosphodiesterase, and alkaline phosphatase.
- Inject the digested nucleoside mixture onto the LC-MS/MS system.
- Separate the nucleosides using a gradient elution on the C18 column.
- Detect and quantify the modified and unmodified nucleosides using multiple reaction monitoring (MRM) in positive ion mode. Specific precursor-to-product ion transitions are monitored for each analyte and its corresponding internal standard.
- Generate a calibration curve using known concentrations of unlabeled standards.
- Calculate the absolute amount of each modification relative to the total amount of deoxycytidine or deoxyadenosine (B7792050) in the sample.
Visualizing the Dynamics of DNA Modifications
The following diagrams, generated using the DOT language for Graphviz, illustrate the key pathways and relationships governing the stability of these DNA modifications.
Caption: The enzymatic pathway of cytosine methylation and active demethylation.
Caption: A generalized experimental workflow for assessing DNA modification stability.
Caption: A conceptual hierarchy of the biological stability of DNA modifications.
References
- 1. 5-hydroxymethylcytosine: a stable or transient DNA modification? - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. New Insights into 5hmC DNA Modification: Generation, Distribution and Function - PMC [pmc.ncbi.nlm.nih.gov]
- 4. N6-methyladenosine in DNA promotes genome stability - PMC [pmc.ncbi.nlm.nih.gov]
- 5. N6-methyladenosine in DNA promotes genome stability | eLife [elifesciences.org]
A Researcher's Guide to the Validation of 5-Methylcytosine Biomarkers in Clinical Samples
For researchers, scientists, and drug development professionals, the accurate validation of 5-Methylcytosine (5-mC) biomarkers is a critical step in translating epigenetic discoveries into clinical applications. This guide provides a comparative overview of common techniques used for 5-mC validation in clinical samples, supported by experimental data and detailed protocols.
The landscape of DNA methylation analysis has evolved significantly, offering a range of methodologies each with distinct advantages and limitations. The choice of a validation method is crucial and depends on factors such as the required sensitivity, the number of CpG sites to be analyzed, sample availability, and budget. Aberrant DNA methylation patterns, specifically the methylation of cytosine at the 5' position (5-mC), are established hallmarks of many diseases, including cancer.[1][2] Consequently, 5-mC is a promising biomarker for diagnosis, prognosis, and monitoring treatment response.[3][4]
This guide focuses on locus-specific validation techniques that are commonly employed to confirm findings from genome-wide discovery studies.
Comparative Analysis of 5-mC Validation Methods
The performance of different 5-mC validation methods varies in terms of sensitivity, specificity, limit of detection, cost, and the type of data they generate. The following table summarizes the key quantitative and qualitative features of several widely used techniques.
| Method | Principle | Sensitivity | Specificity | Limit of Detection | Throughput | Cost per Sample (Relative) | Key Advantages | Key Limitations |
| qMSP (quantitative Methylation-Specific PCR) | qPCR with primers specific for bisulfite-converted methylated and unmethylated DNA.[1][4] | Moderate to High | High | ~0.1% methylated alleles | High | Low | Cost-effective, high throughput, good for screening large sample sets.[1][3] | Prone to primer bias, provides information only on primer binding sites, can be less accurate than sequencing methods.[1][5] |
| MS-HRM (Methylation-Specific High-Resolution Melting) | PCR followed by melting curve analysis to distinguish between methylated and unmethylated sequences based on sequence differences after bisulfite treatment.[1] | High | High | ~0.1-1% methylated alleles | High | Low | Simple, rapid, and cost-effective screening tool.[1] | Provides semi-quantitative results, may not be suitable for complex methylation patterns.[1] |
| Pyrosequencing | Sequencing-by-synthesis method that quantitatively determines the methylation level of individual CpG sites in a region of interest after bisulfite conversion.[1][6] | High | High | ~1-5% methylated alleles | Medium | Medium | Provides quantitative methylation levels for each CpG site, highly reproducible.[6][7] | Limited to short DNA regions (<100 bp), instrument cost can be a limitation.[5][8] |
| MSRE-qPCR (Methylation-Sensitive Restriction Enzyme qPCR) | Digestion of genomic DNA with a methylation-sensitive restriction enzyme followed by qPCR to quantify the amount of undigested (methylated) DNA.[1] | Moderate | High | Dependent on enzyme efficiency | Medium | Low to Medium | Does not require bisulfite conversion, simple workflow.[1] | Only interrogates CpG sites within the enzyme's recognition sequence, not suitable for intermediately methylated regions.[1] |
| (Oxidative) Bisulfite Sequencing | Gold-standard for single-base resolution methylation analysis. Bisulfite treatment converts unmethylated cytosines to uracils, while 5-mC remains unchanged. Oxidative bisulfite sequencing (oxBS-seq) can distinguish 5-mC from 5-hydroxymethylcytosine (B124674) (5-hmC).[9][10] | Very High | Very High | Single-molecule level | Low to High (depending on platform) | High | Provides the most comprehensive and accurate methylation data at single-nucleotide resolution.[9] | Can be costly and time-consuming for large sample numbers, bisulfite treatment can degrade DNA.[11] |
Experimental Protocols
Detailed and optimized experimental protocols are fundamental for reproducible and reliable biomarker validation. Below are outlines for three key techniques.
Quantitative Methylation-Specific PCR (qMSP)
This method involves two sets of primers: one specific for the methylated and another for the unmethylated bisulfite-converted DNA sequence.
a. Bisulfite Conversion:
-
Start with 100-500 ng of genomic DNA from clinical samples (e.g., tissue biopsies, plasma-derived cell-free DNA).
-
Use a commercial bisulfite conversion kit following the manufacturer's instructions. This step is critical as incomplete conversion can lead to false-positive results.[4]
b. Primer Design:
-
Design two pairs of primers for the target region.
-
"M" primers are designed to be complementary to the sequence where methylated cytosines are retained as cytosines after bisulfite treatment.
-
"U" primers are designed to be complementary to the sequence where unmethylated cytosines are converted to uracils (read as thymines in PCR).
-
Primers should be 20-30 bp in length with a melting temperature of 55-65°C.[4]
c. qPCR Reaction:
-
Set up two separate qPCR reactions for each sample, one with the "M" primers and one with the "U" primers.
-
Include a standard curve of known methylated and unmethylated DNA for quantification.
-
Use a SYBR Green or probe-based qPCR master mix.
-
Typical cycling conditions: 95°C for 10 min, followed by 40 cycles of 95°C for 15 sec and 60°C for 1 min.
d. Data Analysis:
-
Determine the Cq (quantification cycle) values for both "M" and "U" reactions.
-
Calculate the percentage of methylation using the following formula: % Methylation = 100 / (1 + 2^(Cq_methylated - Cq_unmethylated))
Pyrosequencing
This technique provides quantitative methylation analysis at single CpG resolution.
a. Bisulfite Conversion and PCR Amplification:
-
Perform bisulfite conversion of genomic DNA as described for qMSP.
-
Amplify the target region using PCR with one of the primers being biotinylated. The primers are designed to be methylation-unbiased.
b. Single-Strand Preparation:
-
Capture the biotinylated PCR product on streptavidin-coated beads.
-
Wash and denature the captured DNA to obtain a single-stranded template.
c. Sequencing Reaction:
-
Anneal a sequencing primer to the single-stranded template.
-
Perform pyrosequencing using a dedicated instrument. The system dispenses one dNTP at a time, and light is generated upon nucleotide incorporation, which is proportional to the number of incorporated nucleotides.[12]
d. Data Analysis:
-
The software generates a pyrogram, and the methylation percentage at each CpG site is calculated as the ratio of the signal for cytosine to the sum of the signals for cytosine and thymine.[7]
Oxidative Bisulfite Sequencing (oxBS-seq)
This method allows for the differentiation between 5-mC and 5-hmC.[9]
a. Oxidation and Bisulfite Conversion:
-
Split the genomic DNA sample into two aliquots.
-
One aliquot is subjected to standard bisulfite conversion (BS-seq), which detects both 5-mC and 5-hmC.
-
The other aliquot undergoes an initial oxidation step (e.g., using potassium perruthenate) that converts 5-hmC to 5-formylcytosine (B1664653) (5fC).[9][11] Subsequent bisulfite treatment converts 5fC to uracil, while 5-mC remains unchanged.[11]
b. Library Preparation and Sequencing:
-
Prepare sequencing libraries from both the BS-treated and oxBS-treated DNA.
-
Perform next-generation sequencing.
c. Data Analysis:
-
Align the sequencing reads to a reference genome.
-
The methylation level at each CpG site is determined for both libraries.
-
The level of 5-mC is directly obtained from the oxBS-seq data.
-
The level of 5-hmC is calculated by subtracting the 5-mC level (from oxBS-seq) from the total modified cytosine level (from BS-seq).
Visualizing Key Processes
Understanding the underlying biological pathways and experimental workflows is crucial for proper experimental design and data interpretation.
Caption: A generalized workflow for the validation of 5-mC biomarkers in clinical samples.
The biological relevance of 5-mC is intrinsically linked to the dynamic process of DNA demethylation, which is mediated by the Ten-eleven translocation (TET) family of enzymes.
Caption: The active DNA demethylation pathway mediated by TET enzymes.
Conclusion
The validation of 5-mC biomarkers is a multifaceted process that requires careful consideration of the available technologies. While sequencing-based methods offer the highest resolution, techniques like qMSP, MS-HRM, and pyrosequencing provide robust and cost-effective alternatives for validating specific genomic loci in large clinical cohorts. The choice of method should be guided by the specific research question and the intended clinical application. By employing rigorous and well-documented validation protocols, the scientific community can accelerate the translation of promising 5-mC biomarkers from the laboratory to the clinic.
References
- 1. oxBS-seq - CD Genomics [cd-genomics.com]
- 2. TET enzymes - Wikipedia [en.wikipedia.org]
- 3. geneticeducation.co.in [geneticeducation.co.in]
- 4. tandfonline.com [tandfonline.com]
- 5. DNA Methylation Validation Methods: a Coherent Review with Practical Comparison - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Analysis of DNA Methylation by Pyrosequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 7. DNA Methylation Analysis [qiagen.com]
- 8. tandfonline.com [tandfonline.com]
- 9. Oxidative Bisulfite Sequencing: An Experimental and Computational Protocol - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Bisulfite Sequencing (BS-Seq)/WGBS [illumina.com]
- 11. oxBS-Seq, An Epigenetic Sequencing Method for Distinguishing 5mC and 5mhC - CD Genomics [cd-genomics.com]
- 12. news-medical.net [news-medical.net]
A Researcher's Guide to Distinguishing 5-mC and 5-hmC in Single-Cell Assays
A detailed comparison of leading methodologies for single-base resolution of cytosine modifications, enabling researchers to navigate the complexities of epigenetic heterogeneity.
The ability to distinguish between 5-methylcytosine (B146107) (5-mC) and 5-hydroxymethylcytosine (B124674) (5-hmC) at the single-cell level is crucial for unraveling the intricate epigenetic landscapes that govern cellular identity and function. While traditional bisulfite sequencing methods cannot differentiate between these two modifications, a new generation of assays has emerged to provide this critical resolution. This guide offers a comprehensive comparison of the leading single-cell technologies, providing researchers, scientists, and drug development professionals with the necessary information to select the most appropriate method for their experimental needs.
Performance Comparison of Single-Cell 5-mC and 5-hmC Sequencing Methods
The selection of an appropriate assay depends on various factors, including the required sensitivity, specificity, genomic coverage, and cell throughput. The following table summarizes the key quantitative performance metrics of the most prominent methods currently available.
| Method | Principle | 5-mC Detection | 5-hmC Detection | Mapping Efficiency | Genomic CpG Coverage | Cell Throughput | Key Advantages | Limitations |
| Joint-snhmC-seq | Bisulfite-based with enzymatic deamination | Indirect (5mC+5hmC) - 5hmC | Direct | ~60-65%[1] | 0.43% to 7.1% per cell[2] | Scalable | Simultaneous profiling from the same cell, quantitative. | Requires physical splitting of the sample, bisulfite-induced DNA damage. |
| Cabernet & Cabernet-H | Bisulfite-free, enzymatic conversion | Indirect (Cabernet: 5mC+5hmC) | Direct (Cabernet-H) | Higher than scBS-seq[3] | ~50% (double that of scBS-seq)[3] | High | High sensitivity and genomic coverage, avoids bisulfite damage.[3] | Requires two separate experiments to resolve 5-mC and 5-hmC. |
| scTAPS & scCAPS+ | Bisulfite-free, chemical conversion | Indirect (scTAPS: 5mC+5hmC) | Direct (scCAPS+) | ~90%[4] | 8-11% per cell[4] | Plate-based (96 cells) | High mapping efficiency, avoids bisulfite damage.[4] | Two separate assays are needed to distinguish 5-mC from 5-hmC. |
| DARESOME | Restriction enzyme-based | Direct | Direct | Not explicitly stated | Restricted to CCGG sites | Low to moderate | Simultaneous detection in a single assay, reveals strand bias.[5] | Limited to restriction enzyme recognition sites (CCGG), not genome-wide.[5] |
| SIMPLE-seq | Bisulfite-free, sequential chemical labeling | Direct | Direct | >90%[6] | Lower than other methods | High (thousands of cells) | Simultaneous, base-resolution analysis from the same molecule.[7] | Lower conversion rates may require data adjustment. |
Experimental Workflows and Methodologies
A detailed understanding of the experimental protocol is essential for successful implementation. Below are the conceptual workflows of the compared methods, followed by detailed experimental protocols.
Joint-snhmC-seq Workflow
The Joint-snhmC-seq method enables the simultaneous profiling of 5-hmC and true 5-mC from the same single nucleus. This is achieved by first treating the nuclear DNA with bisulfite, which converts cytosine to uracil (B121893) but protects 5-hmC as cytosine-5-methylenesulfonate (CMS). The sample is then split. One aliquot is processed with an enzyme (APOBEC3A) that deaminates 5-mC to thymine (B56734), leaving only the protected 5-hmC as a cytosine for sequencing (snhmC-seq2). The other aliquot is sequenced directly to detect both 5-mC and 5-hmC (snmC-seq2). The true 5-mC profile is then determined by subtracting the 5-hmC signal from the combined signal.[2][6]
Cabernet & Cabernet-H Workflow
Cabernet is a bisulfite-free method that relies on a series of enzymatic reactions to determine methylation status. For the detection of both 5-mC and 5-hmC (Cabernet), TET2 and BGT enzymes are used to protect these modifications, while APOBEC deaminates unmodified cytosines to uracil. To specifically detect 5-hmC (Cabernet-H), the TET2 oxidation step is omitted. This results in the protection of only 5-hmC by BGT, while both unmodified cytosine and 5-mC are deaminated by APOBEC.[3]
scTAPS & scCAPS+ Workflow
scTAPS and scCAPS+ are bisulfite-free methods that utilize chemical conversion to identify cytosine modifications. In scTAPS, TET-assisted pyridine (B92270) borane (B79455) sequencing converts 5-mC and 5-hmC to dihydrouracil (B119008) (DHU), which is read as thymine during sequencing. Unmodified cytosines remain as cytosines. For scCAPS+, a chemical-assisted approach specifically converts 5-hmC to DHU, while 5-mC and unmodified cytosines are unaffected. This allows for the specific detection of 5-hmC.[4]
DARESOME Workflow
DARESOME (DNA Analysis by Restriction Enzyme for Simultaneous detection of Multiple Epigenomic states) employs a series of modification-sensitive restriction enzymes to distinguish between unmodified cytosine, 5-mC, and 5-hmC at CCGG sites. The workflow involves sequential digestion with different enzymes and ligation of specific adapters to tag the different modification states, allowing for their simultaneous detection in a single sequencing run.[5]
SIMPLE-seq Workflow
SIMPLE-seq (Simultaneous Profiling of Epigenetic Cytosine Modifications by Sequencing) is a bisulfite-free method that uses a sequential chemical labeling strategy to jointly analyze 5-mC and 5-hmC in single cells. The method involves orthogonal labeling of 5-mC and 5-hmC, which are then recorded as C-to-T mutations during sequencing, allowing for their simultaneous detection from the same DNA molecule.[7]
Detailed Experimental Protocols
The following sections provide a more detailed, step-by-step overview of the key experimental procedures for each method. These are intended as a guide and should be supplemented with the detailed protocols provided in the primary publications.
Joint-snhmC-seq Protocol
-
Single Nucleus Isolation: Isolate single nuclei from the sample of interest using fluorescence-activated nucleus sorting (FANS) or other appropriate methods.
-
Lysis and Bisulfite Conversion: Lyse the sorted single nuclei and perform bisulfite conversion on the genomic DNA. This step converts unmethylated cytosines to uracil and protects 5-hmC by forming cytosine-5-methylenesulfonate (CMS).
-
Sample Splitting: Divide the bisulfite-converted single-stranded DNA from each nucleus into two separate reactions.
-
Differential Enzymatic Treatment:
-
Aliquot 1 (snhmC-seq2): Treat with APOBEC3A enzyme to deaminate 5-mC to thymine. The CMS-protected 5-hmC remains as cytosine.
-
Aliquot 2 (snmC-seq2): This aliquot receives no further enzymatic treatment and contains both 5-mC and protected 5-hmC as cytosines.
-
-
Library Preparation: Prepare sequencing libraries for both aliquots. This typically involves random priming for first-strand synthesis, followed by adapter ligation and PCR amplification.
-
Sequencing: Perform next-generation sequencing on both libraries.
-
Data Analysis:
-
Align reads from the snhmC-seq2 library to determine the genome-wide locations of 5-hmC.
-
Align reads from the snmC-seq2 library to identify the locations of both 5-mC and 5-hmC.
-
Computationally subtract the 5-hmC signal (from snhmC-seq2) from the combined (5-mC + 5-hmC) signal (from snmC-seq2) to derive the "true" 5-mC map.[2][6]
-
Cabernet & Cabernet-H Protocol
-
Single-Cell Lysis and DNA Fragmentation: Lyse single cells and fragment the genomic DNA, often using Tn5 transposase which simultaneously fragments and adds adapters.
-
Enzymatic Conversion (Parallel Reactions):
-
Cabernet (for 5-mC + 5-hmC):
-
Treat the DNA with TET2 dioxygenase to oxidize 5-mC and its derivatives.
-
Add β-glucosyltransferase (BGT) to glycosylate and protect 5-hmC and its oxidized forms.
-
Treat with APOBEC deaminase to convert unprotected cytosines to uracil.
-
-
Cabernet-H (for 5-hmC):
-
Omit the TET2 oxidation step.
-
Treat with BGT to specifically glycosylate and protect 5-hmC.
-
Treat with APOBEC deaminase to convert unprotected cytosines and 5-mC to uracil.
-
-
-
Library Amplification: Perform PCR to amplify the libraries.
-
Sequencing: Sequence the prepared libraries.
-
Data Analysis:
-
Analyze the Cabernet-H data to map the locations of 5-hmC.
-
Analyze the Cabernet data to map the combined locations of 5-mC and 5-hmC.
-
Subtract the 5-hmC map from the combined map to determine the 5-mC locations.[3]
-
scTAPS & scCAPS+ Protocol
-
Single-Cell Lysis and Tagmentation: Lyse single cells and use Tn5 transposase for DNA fragmentation and adapter ligation.
-
Chemical Conversion (Parallel Reactions):
-
scTAPS (for 5-mC + 5-hmC):
-
Perform TET-assisted pyridine borane sequencing chemistry. This involves TET-mediated oxidation of 5-mC and 5-hmC to 5-carboxylcytosine (5-caC), followed by pyridine borane reduction to dihydrouracil (DHU).
-
-
scCAPS+ (for 5-hmC):
-
Perform chemical-assisted pyridine borane sequencing plus chemistry. This specifically converts 5-hmC to DHU.
-
-
-
Library Preparation and Sequencing: Amplify the converted DNA and perform next-generation sequencing. During sequencing, DHU is read as thymine.
-
Data Analysis:
-
In scTAPS data, C-to-T conversions indicate the original positions of either 5-mC or 5-hmC.
-
In scCAPS+ data, C-to-T conversions indicate the original positions of 5-hmC.
-
Compare the results from both assays to distinguish 5-mC from 5-hmC.[4]
-
DARESOME Protocol
-
Genomic DNA Digestion (HpaII): Digest single-cell genomic DNA with the HpaII restriction enzyme, which cleaves at unmethylated CCGG sites.
-
U-tag Ligation: Ligate a specific adapter (U-tag) to the ends generated by HpaII digestion.
-
MspI Digestion: Digest the DNA with MspI, which cleaves at all CCGG sites regardless of methylation status (except for glucosylated 5-hmC).
-
H-tag Ligation: Ligate a different adapter (H-tag) to the ends generated by MspI.
-
Glucosylation: Treat the DNA with BGT to glucosylate 5-hmC, which protects it from subsequent MspI digestion.
-
Second MspI Digestion: Perform another round of MspI digestion. This time, only 5-mC-containing CCGG sites will be cleaved.
-
M-tag Ligation: Ligate a third unique adapter (M-tag) to the newly generated ends.
-
Library Preparation and Sequencing: Amplify the DNA with primers that recognize the ligated adapters and perform sequencing.
-
Data Analysis: The identity of the ligated adapter at each CCGG site reveals its original modification state: U-tag for unmodified, H-tag for 5-hmC, and M-tag for 5-mC.[5]
SIMPLE-seq Protocol
-
Single-Cell Tagmentation: Perform Tn5 tagmentation on single cells to fragment the DNA and add barcodes.
-
hmC-CATCH Chemistry:
-
Perform ruthenate (VI) oxidation to convert 5-hmC to 5-formylcytosine (B1664653) (5-fC).
-
Label the 5-fC with indanedione.
-
-
Primer Extension: Carry out a primer extension reaction to mark the position of the labeled 5-fC on the complementary strand.
-
TAPS Chemistry:
-
Perform TET-mediated oxidation of 5-mC to 5-caC.
-
Reduce the 5-caC to DHU using borane.
-
-
PCR Amplification and Sequencing: Amplify the library. During PCR, both the indanedione-labeled 5-fC and the DHU will result in a C-to-T transition in the sequencing reads.
-
Data Analysis: The sequencing data will contain C-to-T conversions at the original sites of both 5-mC and 5-hmC. The specific chemical labeling allows for their differentiation during data analysis.[7]
Conclusion
The field of single-cell epigenomics is rapidly advancing, offering powerful tools to dissect the roles of 5-mC and 5-hmC in health and disease. The choice of method will depend on the specific biological question, available resources, and desired balance between genome-wide coverage, sensitivity, and throughput. Bisulfite-free methods like Cabernet and scTAPS/scCAPS+ offer the advantage of reduced DNA damage and higher mapping efficiency, while methods like Joint-snhmC-seq and SIMPLE-seq provide the benefit of simultaneous detection from the same cell or molecule. DARESOME, although not genome-wide, offers a unique approach for simultaneous detection at specific genomic loci. As these technologies continue to evolve, they will undoubtedly provide deeper insights into the dynamic interplay of epigenetic modifications in defining the cellular state.
References
- 1. GitHub - cxzhu/SIMPLE-seq: Joint analysis of 5mC and 5hmC from single cells [github.com]
- 2. Joint single-cell profiling resolves 5mC and 5hmC and reveals their distinct gene regulatory effects - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Single-cell bisulfite-free 5mC and 5hmC sequencing with high sensitivity and scalability - PMC [pmc.ncbi.nlm.nih.gov]
- 4. biorxiv.org [biorxiv.org]
- 5. researchgate.net [researchgate.net]
- 6. Advances in the joint profiling technologies of 5mC and 5hmC - PMC [pmc.ncbi.nlm.nih.gov]
- 7. epigenie.com [epigenie.com]
A Researcher's Guide to 5-Methylcytosine: A Comparative Analysis of Genome-Wide Detection Methods
For researchers, scientists, and drug development professionals navigating the complex landscape of epigenetic modifications, understanding the nuances of 5-methylcytosine (B146107) (5mC) is paramount. This guide provides an objective comparison of the leading methodologies for genome-wide 5mC analysis, supported by experimental data and detailed protocols. We delve into the strengths and limitations of each technique to empower you in selecting the most appropriate approach for your research questions.
DNA methylation, primarily the addition of a methyl group to the fifth carbon of cytosine to form 5mC, is a critical epigenetic modification involved in gene regulation, development, and disease.[1] The accurate, genome-wide mapping of 5mC is therefore essential for unraveling its biological significance. A variety of powerful techniques have been developed for this purpose, each with distinct principles, advantages, and drawbacks.[2] This guide focuses on a comparative analysis of the most widely adopted methods: Whole-Genome Bisulfite Sequencing (WGBS), Reduced Representation Bisulfite Sequencing (RRBS), Enzymatic Methyl-seq (EM-seq), and affinity-based enrichment methods such as Methylated DNA Immunoprecipitation Sequencing (MeDIP-seq).
Comparative Analysis of 5mC Detection Methods
The choice of a 5mC profiling method depends on various factors, including the desired resolution, genomic coverage, DNA input amount, and budget. The following table summarizes the key performance metrics of the most common techniques to facilitate an informed decision.
| Method | Principle | Resolution | Coverage | DNA Input | Advantages | Disadvantages |
| WGBS | Bisulfite conversion of unmethylated cytosines to uracil, followed by sequencing.[3] | Single-base | Whole-genome (>95% of CpGs)[4] | High (µg range, though protocols for lower inputs exist)[5] | Gold standard, comprehensive, quantitative at single-site level.[6][7] | High cost, potential DNA degradation from bisulfite treatment, cannot distinguish 5mC from 5hmC.[8][9] |
| RRBS | Restriction enzyme (MspI) digestion to enrich for CpG-rich regions, followed by bisulfite sequencing.[10] | Single-base | CpG islands, promoters, and other CpG-rich regions (~10-15% of CpGs).[4] | Low (ng range) | Cost-effective for targeting key regulatory regions, high sequencing depth in enriched areas.[10] | Biased towards CpG-rich regions, limited information on intergenic and low-CpG density regions.[11] |
| EM-seq | Enzymatic protection of 5mC and 5hmC, followed by enzymatic deamination of unmodified cytosines to uracils.[12] | Single-base | Whole-genome | Low (as low as 10 ng)[7] | Less DNA damage than WGBS, higher library yields, and more uniform coverage.[7] | Newer technology with potentially higher reagent costs, does not distinguish 5mC and 5hmC. |
| MeDIP-seq | Immunoprecipitation of methylated DNA fragments using an antibody specific to 5mC.[13] | Low (~100-300 bp) | Genome-wide, but biased by antibody affinity and CpG density.[11] | Moderate (ng to µg range) | Cost-effective for genome-wide screening, does not require bisulfite conversion.[14] | Indirect measure of methylation, resolution limited by fragment size, potential for antibody-related bias.[10] |
Experimental Workflows and Signaling Pathways
To visualize the distinct workflows of these key methodologies, the following diagrams have been generated using Graphviz.
Detailed Experimental Protocols
For researchers planning to implement these techniques, the following sections provide detailed, step-by-step protocols for three key methods: WGBS, EM-seq, and MeDIP-seq.
Whole-Genome Bisulfite Sequencing (WGBS) Protocol
This protocol outlines the major steps for generating WGBS libraries compatible with Illumina sequencing platforms.[15]
-
DNA Extraction and Fragmentation:
-
Isolate high-quality genomic DNA from the sample of interest. The required amount is typically in the microgram range, with a concentration of at least 50 ng/µl and an OD260/280 ratio between 1.8 and 2.0.[5]
-
Fragment the genomic DNA to a desired size range (e.g., 200-400 bp) using sonication (e.g., Covaris).
-
-
End Repair, A-tailing, and Adapter Ligation:
-
Perform end-repair on the fragmented DNA to create blunt ends.
-
Add a single 'A' nucleotide to the 3' ends of the DNA fragments (A-tailing).
-
Ligate methylated sequencing adapters to the A-tailed DNA fragments. These adapters are necessary for subsequent amplification and sequencing.
-
-
Bisulfite Conversion:
-
PCR Amplification:
-
Amplify the bisulfite-converted, adapter-ligated DNA using a proofreading DNA polymerase that can read through uracils. This step enriches for the library fragments that will be sequenced.
-
-
Library Quantification and Sequencing:
-
Quantify the final library using a fluorometric method (e.g., Qubit) and assess the size distribution using a bioanalyzer.
-
Sequence the library on an Illumina platform.
-
-
Data Analysis:
-
Align the sequencing reads to a reference genome that has been computationally converted (C-to-T and G-to-A) to account for the bisulfite conversion.
-
Determine the methylation status of each CpG site by comparing the sequenced bases to the reference genome.
-
Enzymatic Methyl-seq (EM-seq) Protocol
This protocol describes the workflow for EM-seq, which uses a series of enzymatic reactions to achieve the conversion of unmethylated cytosines.[16]
-
DNA Fragmentation and Library Preparation:
-
Fragment genomic DNA to the desired size.
-
Perform end repair, A-tailing, and ligate sequencing adapters. This initial library preparation is similar to WGBS.
-
-
Enzymatic Conversion (Two-Step Process):
-
Step 1: Oxidation. Treat the DNA with the TET2 enzyme, which oxidizes 5mC to 5-hydroxymethylcytosine (B124674) (5hmC), and subsequently to 5-formylcytosine (B1664653) (5fC) and 5-carboxylcytosine (5caC). 5hmC is also protected by glucosylation. This step effectively protects both 5mC and 5hmC from subsequent deamination.
-
Step 2: Deamination. Use the APOBEC enzyme to deaminate only the unmodified cytosines, converting them to uracils.[12]
-
-
PCR Amplification:
-
Amplify the enzymatically converted library using a uracil-tolerant DNA polymerase.
-
-
Library Quantification and Sequencing:
-
Quantify and quality control the final library.
-
Perform sequencing on an appropriate platform.
-
-
Data Analysis:
-
The data analysis pipeline for EM-seq is identical to that of WGBS, as the resulting sequence files have the same C-to-T conversion pattern for unmethylated cytosines.[12]
-
Methylated DNA Immunoprecipitation Sequencing (MeDIP-seq) Protocol
This protocol details the MeDIP-seq procedure, which relies on antibody-based enrichment of methylated DNA.[14]
-
DNA Extraction and Fragmentation:
-
Isolate high-quality genomic DNA.
-
Fragment the DNA into a size range of approximately 100-500 bp by sonication.
-
-
Immunoprecipitation (IP):
-
Denature the fragmented DNA to create single-stranded fragments.
-
Incubate the denatured DNA with a monoclonal antibody that specifically binds to this compound.
-
Capture the antibody-DNA complexes using magnetic beads coupled to a secondary antibody.
-
Wash the beads to remove non-specifically bound DNA fragments.
-
-
Elution and Library Preparation:
-
Elute the enriched methylated DNA from the antibody-bead complexes.
-
Perform end repair, A-tailing, and ligate sequencing adapters to the enriched DNA fragments.
-
-
PCR Amplification:
-
Amplify the adapter-ligated library to generate sufficient material for sequencing.
-
-
Library Quantification and Sequencing:
-
Quantify and validate the final library.
-
Sequence the library.
-
-
Data Analysis:
-
Align the sequencing reads to the reference genome.
-
Identify regions of the genome that are enriched for sequencing reads, as these correspond to methylated regions. Peak-calling algorithms are used for this purpose.
-
Conclusion
The field of comparative epigenomics of this compound is rapidly evolving, with a range of powerful technologies available to researchers. The "gold standard" WGBS provides a comprehensive and quantitative view of the methylome at single-base resolution, but at a higher cost and with the potential for DNA damage. RRBS offers a cost-effective alternative for focused analysis of CpG-rich regulatory regions. The newer EM-seq technology presents a promising alternative to WGBS with less DNA degradation and more uniform genome coverage. For researchers interested in a more cost-effective, genome-wide survey of methylation patterns, MeDIP-seq provides a valuable, albeit lower-resolution, approach. The selection of the most suitable method will ultimately depend on the specific research question, available resources, and the desired balance between resolution, coverage, and cost. This guide provides the foundational knowledge and practical protocols to aid in this critical decision-making process.
References
- 1. MeDIP‑Seq / hMeDIP‑Seq - CD Genomics [cd-genomics.com]
- 2. opus.lib.uts.edu.au [opus.lib.uts.edu.au]
- 3. Principles and Workflow of Whole Genome Bisulfite Sequencing - CD Genomics [cd-genomics.com]
- 4. What are the basic steps of whole genome bisulfite sequencing (WGBS)? | AAT Bioquest [aatbio.com]
- 5. Benchmarking DNA methylation analysis of 14 alignment algorithms for whole genome bisulfite sequencing in mammals - PMC [pmc.ncbi.nlm.nih.gov]
- 6. WGBS vs. EM-seq: Key Differences in Principles, Pros, Cons, and Applications - CD Genomics [cd-genomics.com]
- 7. Methods for Detection and Mapping of Methylated and Hydroxymethylated Cytosine in DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 8. MeDIP-seq vs. RRBS vs. WGBS - CD Genomics [cd-genomics.com]
- 9. tandfonline.com [tandfonline.com]
- 10. biorxiv.org [biorxiv.org]
- 11. Overview of Methylated DNA Immunoprecipitation Sequencing (MeDIP-seq) - CD Genomics [cd-genomics.com]
- 12. mdpi.com [mdpi.com]
- 13. encodeproject.org [encodeproject.org]
- 14. NGI Sweden » Enzymatic Methyl-seq (EM-seq) [ngisweden.scilifelab.se]
- 15. neb-online.de [neb-online.de]
- 16. commonfund.nih.gov [commonfund.nih.gov]
The Complex Dance of Gene Expression: A Guide to 5-Methylcytosine and Its Epigenetic Counterparts
For researchers, scientists, and drug development professionals, understanding the intricate mechanisms that govern gene expression is paramount. Among the key players in this regulatory ballet is 5-methylcytosine (B146107) (5mC), a well-studied epigenetic modification with a profound impact on cellular function and disease. This guide provides a comprehensive comparison of the correlation between 5mC and gene expression, juxtaposed with other critical epigenetic marks. We delve into the experimental data that underpins our current understanding and provide detailed protocols for the essential techniques in this field.
This compound: A Tale of Two Locations
The influence of this compound on gene expression is not a simple on-or-off switch; its effect is intricately tied to its genomic location. DNA methylation, the process of adding a methyl group to the cytosine base, predominantly occurs at CpG dinucleotides. While the majority of CpGs in the genome are methylated, CpG islands—regions with a high density of CpG sites—are often found in gene promoter regions and are typically unmethylated in active genes.[1]
The prevailing model, supported by extensive research, demonstrates a bimodal role for 5mC:
-
Promoter Methylation: The Silencer. High levels of 5mC within promoter regions and CpG islands are strongly associated with transcriptional repression.[1] This silencing can occur through two primary mechanisms. Firstly, the methyl groups can directly hinder the binding of transcription factors to their DNA recognition sites. Secondly, methylated DNA can be recognized by methyl-CpG-binding domain (MBD) proteins, which in turn recruit chromatin-remodeling complexes and histone deacetylases, leading to a more condensed chromatin structure that is inaccessible to the transcriptional machinery.[2] Aberrant hypermethylation of promoter regions of tumor suppressor genes is a well-established hallmark of many cancers.[3]
-
Gene Body Methylation: The Enigma. In contrast to its role in promoters, the presence of 5mC within the body of a gene is often positively correlated with gene expression.[1] The precise function of gene body methylation is still an area of active investigation, but several hypotheses have been proposed. It may play a role in suppressing transcription from cryptic start sites within the gene body, ensuring the fidelity of transcription. Additionally, it has been implicated in the regulation of alternative splicing.
Beyond 5mC: A Spectrum of Epigenetic Regulation
To fully appreciate the role of 5mC, it is crucial to consider it within the broader context of the epigenome. Other key epigenetic modifications work in concert with, or in opposition to, DNA methylation to fine-tune gene expression.
5-Hydroxymethylcytosine (5hmC): An Intermediate with a Distinct Role
5-Hydroxymethylcytosine is an oxidation product of 5mC, generated by the Ten-Eleven Translocation (TET) family of enzymes.[4] While structurally similar to 5mC, 5hmC is now recognized as a distinct epigenetic mark with its own set of reader proteins and functions. It is often considered an intermediate in the process of DNA demethylation.
Like 5mC, 5hmC is enriched in the gene bodies of actively transcribed genes and is generally associated with active gene expression.[5] Distinguishing between 5mC and 5hmC is critical for a precise understanding of epigenetic regulation, as traditional bisulfite sequencing cannot differentiate between the two. Techniques like oxidative bisulfite sequencing are required for this distinction.[4]
Histone Modifications: The Chromatin Code
The "histone code" refers to the vast array of post-translational modifications that occur on histone proteins, the spools around which DNA is wound. These modifications alter chromatin structure and accessibility, thereby influencing gene expression. Two well-characterized histone modifications with opposing effects are:
-
H3K4me3 (Trimethylation of Histone H3 at Lysine 4): The Activator. This mark is predominantly found at the transcription start sites of active genes and is a strong indicator of active transcription.[6][7]
-
H3K27me3 (Trimethylation of Histone H3 at Lysine 27): The Repressor. This modification is associated with transcriptionally silenced genes and is deposited by the Polycomb Repressive Complex 2 (PRC2).[6][8]
Quantitative Comparison of Epigenetic Marks and Gene Expression
The following tables summarize the general correlations and provide illustrative quantitative data from various studies. It is important to note that the precise quantitative relationship can vary depending on the cell type, genomic context, and the specific gene.
| Epigenetic Mark | Genomic Location | General Correlation with Gene Expression | Illustrative Quantitative Data |
| This compound (5mC) | Promoter/CpG Island | Negative | Hypermethylation of tumor suppressor gene promoters can lead to complete gene silencing. |
| Gene Body | Positive | Positive correlation observed between gene body 5mC levels and gene expression in various cell types. | |
| 5-Hydroxymethylcytosine (5hmC) | Gene Body/Enhancers | Positive | Strong positive correlation between gene body 5hmC levels and gene expression in human tissues.[9] |
| H3K4me3 | Transcription Start Site | Positive | High levels of H3K4me3 are a hallmark of actively transcribed genes. |
| H3K27me3 | Promoter/Gene Body | Negative | Enrichment of H3K27me3 is a key feature of Polycomb-repressed developmental genes. |
Visualizing the Interplay: Pathways and Workflows
To better illustrate the concepts discussed, the following diagrams were generated using the DOT language.
Detailed Experimental Protocols
Reproducibility and rigor are the cornerstones of scientific advancement. The following sections provide detailed methodologies for the key experiments cited in the analysis of this compound and gene expression.
Whole-Genome Bisulfite Sequencing (WGBS)
Objective: To determine the methylation status of every cytosine in the genome at single-base resolution.
Principle: Sodium bisulfite treatment of DNA converts unmethylated cytosines to uracil, while methylated cytosines remain unchanged. Subsequent PCR amplification replaces uracils with thymines. By comparing the sequenced DNA to the reference genome, methylated cytosines can be identified.
Protocol:
-
DNA Extraction and Fragmentation:
-
Extract high-quality genomic DNA from the biological sample.
-
Fragment the DNA to the desired size range (typically 200-500 bp) using sonication or enzymatic digestion.
-
-
Library Preparation:
-
Perform end-repair and A-tailing of the DNA fragments.
-
Ligate methylated sequencing adapters to the DNA fragments. These adapters are methylated to protect them from bisulfite conversion.
-
-
Bisulfite Conversion:
-
Treat the adapter-ligated DNA with sodium bisulfite. This step is critical and requires optimization to ensure complete conversion of unmethylated cytosines. Commercial kits are widely available and recommended for consistency.[10]
-
-
PCR Amplification:
-
Amplify the bisulfite-converted DNA library using primers that bind to the ligated adapters. Use a high-fidelity polymerase that can read through uracils.
-
-
Sequencing:
-
Sequence the amplified library on a next-generation sequencing platform.
-
-
Data Analysis:
-
Align the sequencing reads to a reference genome using a bisulfite-aware aligner (e.g., Bismark).
-
Determine the methylation level at each CpG site by calculating the ratio of reads with a 'C' to the total number of reads covering that site.
-
RNA-Sequencing (RNA-Seq)
Objective: To quantify the abundance of all RNA transcripts in a sample.
Principle: RNA is reverse transcribed into complementary DNA (cDNA), which is then sequenced. The number of reads mapping to a particular gene or transcript is proportional to its expression level.
Protocol:
-
RNA Extraction:
-
Extract total RNA from the biological sample using a method that preserves RNA integrity.
-
Assess RNA quality and quantity using a spectrophotometer and a bioanalyzer.
-
-
RNA Library Preparation:
-
rRNA Depletion or Poly(A) Selection: Ribosomal RNA (rRNA) constitutes the majority of total RNA. It is typically removed to enrich for messenger RNA (mRNA) and other non-coding RNAs. This can be achieved through rRNA depletion kits or by selecting for polyadenylated transcripts.
-
Fragmentation: Fragment the enriched RNA to a suitable size for sequencing.
-
cDNA Synthesis: Reverse transcribe the fragmented RNA into first-strand cDNA using random primers or oligo(dT) primers. Synthesize the second cDNA strand.
-
End-Repair and Adapter Ligation: Perform end-repair, A-tailing, and ligate sequencing adapters to the cDNA fragments.
-
-
PCR Amplification:
-
Amplify the cDNA library to generate sufficient material for sequencing.
-
-
Sequencing:
-
Sequence the amplified library on a next-generation sequencing platform.
-
-
Data Analysis:
-
Perform quality control on the raw sequencing reads.
-
Align the reads to a reference genome or transcriptome.
-
Quantify gene or transcript expression levels (e.g., as Fragments Per Kilobase of transcript per Million mapped reads - FPKM, or Transcripts Per Million - TPM).
-
Perform differential gene expression analysis between different conditions.
-
Chromatin Immunoprecipitation followed by Sequencing (ChIP-Seq) for Histone Modifications
Objective: To identify the genome-wide localization of specific histone modifications.
Principle: An antibody specific to the histone modification of interest is used to immunoprecipitate cross-linked DNA-protein complexes. The associated DNA is then purified and sequenced.
Protocol:
-
Cross-linking:
-
Treat cells or tissues with formaldehyde (B43269) to cross-link proteins to DNA.
-
-
Chromatin Preparation:
-
Lyse the cells and isolate the nuclei.
-
Shear the chromatin into fragments of 200-600 bp by sonication or enzymatic digestion.
-
-
Immunoprecipitation:
-
Incubate the sheared chromatin with an antibody specific to the target histone modification (e.g., H3K4me3 or H3K27me3).
-
Use protein A/G beads to pull down the antibody-chromatin complexes.
-
-
Washing and Elution:
-
Wash the beads to remove non-specifically bound chromatin.
-
Elute the immunoprecipitated chromatin from the antibody-bead complex.
-
-
Reverse Cross-linking and DNA Purification:
-
Reverse the formaldehyde cross-links by heating.
-
Treat with proteinase K to digest proteins.
-
Purify the DNA.
-
-
Library Preparation and Sequencing:
-
Prepare a sequencing library from the purified DNA.
-
Sequence the library on a next-generation sequencing platform.
-
-
Data Analysis:
-
Align the sequencing reads to a reference genome.
-
Identify regions of enrichment (peaks) for the histone modification.
-
Annotate the peaks to genomic features (e.g., promoters, enhancers, gene bodies).
-
Conclusion
The correlation of this compound with gene expression is a cornerstone of epigenetic research. Its location-dependent role as both a silencer and a potential facilitator of transcription highlights the complexity of gene regulation. By comparing 5mC with other key epigenetic marks like 5hmC and histone modifications, and by employing robust experimental techniques such as WGBS, RNA-seq, and ChIP-seq, researchers can unravel the intricate epigenetic landscapes that define cellular identity and contribute to health and disease. This guide serves as a foundational resource for professionals seeking to navigate this dynamic and rapidly evolving field.
References
- 1. This compound turnover: Mechanisms and therapeutic implications in cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Comparative Analyses of H3K4 and H3K27 Trimethylations Between the Mouse Cerebrum and Testis - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Bisulfite Sequencing of DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 4. youtube.com [youtube.com]
- 5. New Insights into 5hmC DNA Modification: Generation, Distribution and Function - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Profiling of H3K4me3 and H3K27me3 and Their Roles in Gene Subfunctionalization in Allotetraploid Cotton - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. Deciphering RNA-seq Library Preparation: From Principles to Protocol - CD Genomics [cd-genomics.com]
- 9. researchgate.net [researchgate.net]
- 10. Expression of 5‐methylcytosine regulators is highly associated with the clinical phenotypes of prostate cancer and DNMTs expression predicts biochemical recurrence - PMC [pmc.ncbi.nlm.nih.gov]
Safety Operating Guide
Proper Disposal of 5-Methylcytosine: A Guide for Laboratory Professionals
Ensuring the safe and environmentally responsible disposal of 5-Methylcytosine is a critical component of laboratory safety and chemical management. This guide provides detailed procedures for researchers, scientists, and drug development professionals to handle and dispose of this compound in accordance with general safety protocols.
Immediate Safety and Handling Precautions
Before beginning any disposal procedure, it is essential to handle this compound with appropriate personal protective equipment (PPE) to minimize exposure risks. While some safety data sheets (SDS) indicate no particular hazard associated with this compound, others classify it as hazardous under the 2012 OSHA Hazard Communication Standard.[1][2] Therefore, exercising caution is paramount.
Key Handling Advice:
-
Handle in a well-ventilated area to avoid dust formation and inhalation.[3][4]
-
Wear appropriate safety apparel, including safety glasses with side shields or goggles, protective gloves, and a lab coat or other protective clothing.[1][5]
-
If dust formation is likely or if exposure limits are exceeded, NIOSH/MSHA-approved respiratory protection should be worn.[1]
-
Avoid contact with skin, eyes, and clothing.[5]
-
Wash hands thoroughly after handling.[2]
Step-by-Step Disposal Procedure
The recommended method for the disposal of this compound is to engage a licensed professional waste disposal service.[4][6] On-site treatment, such as neutralization, is generally not recommended without specific, validated protocols.
1. Waste Collection and Storage:
-
Collect waste this compound, including any contaminated materials, in a suitable and clearly labeled, closed container.[3][4]
-
Store the waste container in a dry, cool, and well-ventilated place, away from incompatible materials such as strong oxidizing agents.[1][4]
2. Spill Management: In the event of a spill, follow these steps to ensure safety and proper cleanup:
-
Evacuate and Ventilate: Immediately clear the area and ensure adequate ventilation.
-
Contain the Spill: For solid this compound, carefully sweep up the material, taking care to avoid generating dust.[5] A wet cloth can also be used to collect the material.[2]
-
Collect and Dispose: Place the collected material and any contaminated cleaning supplies into a suitable, sealed container for disposal as chemical waste.[3][5]
-
Clean the Area: Thoroughly clean the contaminated surface.[1]
3. Professional Disposal:
-
Contact your institution's Environmental Health and Safety (EHS) department or a licensed chemical waste management company to arrange for pickup and disposal.[6]
-
Ensure that the disposal of this compound waste complies with all applicable local, state, and federal regulations for hazardous waste.[6]
-
Crucially, do not discharge this compound or its solutions into the sewer system or waterways. [3][6]
Summary of Safety and Disposal Information
| Parameter | Recommendation | Source |
| Hazard Classification | Considered hazardous by some sources under OSHA 2012 standard. | [1] |
| Personal Protective Equipment (PPE) | Safety glasses, protective gloves, protective clothing. Respiratory protection if dust is present. | [1][4][5] |
| Spill Cleanup | Sweep up solid material, avoid dust. Place in a closed container for disposal. | [1][2][5] |
| Primary Disposal Method | Engage a licensed professional waste disposal service. | [4][6] |
| Environmental Precautions | Should not be released into the environment. Do not dispose of in drains or waterways. | [3][4][5][6] |
| Storage of Waste | Keep in a tightly closed, suitable container in a dry, cool, and well-ventilated area. | [1][3] |
Disposal Workflow
The following diagram illustrates the logical workflow for the proper disposal of this compound.
Caption: Workflow for the safe disposal of this compound.
References
Essential Safety and Operational Protocols for Handling 5-Methylcytosine
For researchers, scientists, and drug development professionals, ensuring safe and efficient handling of chemical compounds is paramount. This guide provides immediate, essential safety and logistical information for the handling of 5-Methylcytosine, a critical compound in epigenetic research. The following procedural steps and data are designed to ensure user safety and operational integrity from acquisition to disposal.
Personal Protective Equipment (PPE)
When handling this compound, a comprehensive approach to personal protection is crucial to minimize exposure risk. The following table summarizes the required and recommended PPE.
| PPE Category | Specification | Rationale |
| Hand Protection | Nitrile or neoprene gloves are preferred. For handling hazardous products, consider double gloving with chemotherapy gloves meeting ASTM D6978 standard.[1] | Prevents direct skin contact. Gloves must be inspected before use and hands should be washed and dried after handling.[2] |
| Eye Protection | Tightly fitting safety goggles with side-shields conforming to EN 166 (EU) or NIOSH (US) standards.[2] A face shield can offer additional protection against splashes.[1][3] | Protects eyes from dust particles and potential splashes. |
| Body Protection | A disposable gown made of polyethylene-coated polypropylene (B1209903) or a clean lab coat is recommended.[1] For activities with a higher risk of contamination, fire/flame resistant and impervious clothing should be worn.[2] | Protects skin and personal clothing from contamination. Gowns should be changed regularly or immediately after a spill.[4] |
| Respiratory Protection | A full-face respirator should be used if exposure limits are exceeded or if irritation is experienced.[2] For compounding hazardous products, respiratory protection is necessary.[1] | Prevents inhalation of dust particles. |
| Head and Foot Protection | Disposable head, hair, and shoe covers are recommended, especially in cleanroom environments.[1][3] | Minimizes the risk of contamination of the work area and the product. |
Handling and Storage Procedures
Proper handling and storage are critical for maintaining the integrity of this compound and ensuring a safe laboratory environment.
Receiving and Storage:
-
Upon receipt, inspect the container for any damage or leaks.
-
Store the container in a tightly closed, dry, cool, and well-ventilated place.[2]
-
Keep apart from foodstuff containers or incompatible materials.[2]
Handling:
-
Handle in a well-ventilated area, preferably in a chemical fume hood to avoid dust formation and inhalation.[2]
-
Use non-sparking tools to prevent fire caused by electrostatic discharge.[2]
-
Wash hands thoroughly after handling.[5]
Spill Management and First Aid
In the event of a spill or exposure, immediate and appropriate action is critical.
| Situation | Procedure |
| Skin Contact | Take off contaminated clothing immediately. Wash off with soap and plenty of water. Consult a doctor.[2] |
| Eye Contact | Rinse with pure water for at least 15 minutes. Consult a doctor.[2] |
| Ingestion | Rinse mouth with water. Do not induce vomiting. Call a doctor or Poison Control Center immediately.[2] |
| Inhalation | Move the person into fresh air. If breathing is difficult, give oxygen. Consult a doctor. |
| Small Spill | Evacuate the area and ensure adequate ventilation. Wear appropriate PPE. For solid this compound, carefully sweep up the material, avoiding dust generation. For solutions, absorb with an inert material.[6] |
| Large Spill | Evacuate the area immediately. Inform your institution's Environmental Health and Safety (EHS) department.[7] |
Disposal Plan
The disposal of this compound and any contaminated materials must comply with local, state, and federal regulations for hazardous waste.[6]
-
Solid Waste: Collect swept-up material from spills or unused product in a labeled, sealed container for waste disposal.[6]
-
Contaminated Materials: All materials used for cleanup, including gloves, gowns, and absorbent pads, should be treated as hazardous waste and disposed of accordingly.[6]
-
Professional Disposal: It is highly recommended to engage a licensed chemical waste management company for the disposal of this compound waste.[6]
-
Do not discharge this compound or its solutions into the sewer system or waterways.[6]
Experimental Workflow for Handling this compound
The following diagram outlines the standard workflow for handling this compound in a laboratory setting, from preparation to disposal.
References
- 1. Personal protective equipment in your pharmacy - Alberta College of Pharmacy [abpharmacy.ca]
- 2. targetmol.com [targetmol.com]
- 3. pppmag.com [pppmag.com]
- 4. 8 Types of PPE to Wear When Compounding Hazardous Drugs | Provista [provista.com]
- 5. ruixibiotech.com [ruixibiotech.com]
- 6. benchchem.com [benchchem.com]
- 7. mdanderson.org [mdanderson.org]
Retrosynthesis Analysis
AI-Powered Synthesis Planning: Our tool employs the Template_relevance Pistachio, Template_relevance Bkms_metabolic, Template_relevance Pistachio_ringbreaker, Template_relevance Reaxys, Template_relevance Reaxys_biocatalysis model, leveraging a vast database of chemical reactions to predict feasible synthetic routes.
One-Step Synthesis Focus: Specifically designed for one-step synthesis, it provides concise and direct routes for your target compounds, streamlining the synthesis process.
Accurate Predictions: Utilizing the extensive PISTACHIO, BKMS_METABOLIC, PISTACHIO_RINGBREAKER, REAXYS, REAXYS_BIOCATALYSIS database, our tool offers high-accuracy predictions, reflecting the latest in chemical research and data.
Strategy Settings
| Precursor scoring | Relevance Heuristic |
|---|---|
| Min. plausibility | 0.01 |
| Model | Template_relevance |
| Template Set | Pistachio/Bkms_metabolic/Pistachio_ringbreaker/Reaxys/Reaxys_biocatalysis |
| Top-N result to add to graph | 6 |
Feasible Synthetic Routes





Featured Recommendations
| Most viewed |
|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
