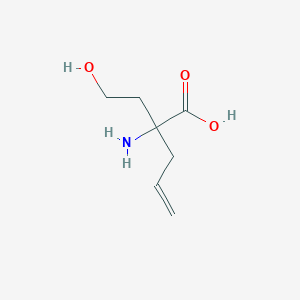
2-Prop-2-en-1-ylhomoserine
Description
Structure
3D Structure
Properties
CAS No. |
872983-37-4 |
|---|---|
Molecular Formula |
C7H13NO3 |
Molecular Weight |
159.18 g/mol |
IUPAC Name |
2-amino-2-(2-hydroxyethyl)pent-4-enoic acid |
InChI |
InChI=1S/C7H13NO3/c1-2-3-7(8,4-5-9)6(10)11/h2,9H,1,3-5,8H2,(H,10,11) |
InChI Key |
SPGMLVNLSSACNB-UHFFFAOYSA-N |
Canonical SMILES |
C=CCC(CCO)(C(=O)O)N |
Origin of Product |
United States |
Foundational & Exploratory
Technical Guide: Synthesis and Characterization of 2-Prop-2-en-1-ylhomoserine
For Researchers, Scientists, and Drug Development Professionals
Abstract
This technical guide outlines a proposed methodology for the synthesis and characterization of the novel, non-proteinogenic amino acid, 2-Prop-2-en-1-ylhomoserine, also known as 2-allylhomoserine. Due to the absence of established literature for this specific compound, this document provides a comprehensive, proposed multi-step synthetic pathway commencing from commercially available L-homoserine. The synthesis involves a sequence of protection, alkylation, and deprotection steps. Furthermore, this guide details the expected analytical characterization of the final compound, including predicted data for NMR spectroscopy and mass spectrometry, based on analogous chemical structures. All quantitative data is summarized for clarity, and detailed experimental protocols are provided. Visual diagrams generated using the DOT language are included to illustrate the synthetic workflow and a hypothetical biological signaling pathway.
Introduction
Non-proteinogenic amino acids are invaluable tools in drug discovery and chemical biology. Their incorporation into peptides can induce conformational constraints, enhance proteolytic stability, and introduce novel functionalities. The title compound, this compound, features an allyl group at the α-carbon, which can serve as a versatile chemical handle for further modifications, such as in peptide stapling or the attachment of fluorescent probes. This guide provides a robust, albeit proposed, framework for the synthesis and characterization of this promising research molecule.
Proposed Synthetic Pathway
The proposed synthesis of this compound is a multi-step process beginning with the protection of the amino and hydroxyl groups of L-homoserine, followed by α-alkylation, and concluding with deprotection.
dot
Caption: Proposed synthetic workflow for this compound.
Experimental Protocols
Step 1: N-Boc Protection of L-Homoserine
-
Procedure: L-homoserine (1 eq.) is dissolved in a 1:1 mixture of 1,4-dioxane and water. Sodium bicarbonate (2.5 eq.) is added, and the mixture is stirred until the solids dissolve. Di-tert-butyl dicarbonate (Boc₂O, 1.2 eq.) is added portion-wise at 0 °C. The reaction is allowed to warm to room temperature and stirred for 12-16 hours.
-
Work-up: The reaction mixture is concentrated under reduced pressure to remove the 1,4-dioxane. The aqueous residue is washed with ethyl acetate. The aqueous layer is then acidified to pH 2-3 with 1 M HCl at 0 °C. The product is extracted with ethyl acetate, and the combined organic layers are washed with brine, dried over anhydrous sodium sulfate, filtered, and concentrated in vacuo to yield N-Boc-L-homoserine as a white solid.
Step 2: Esterification and O-TBDMS Protection
-
Procedure (Esterification): N-Boc-L-homoserine (1 eq.) is dissolved in methanol and cooled to 0 °C. Thionyl chloride (1.2 eq.) is added dropwise, and the reaction is stirred at room temperature for 4-6 hours. The solvent is removed under reduced pressure to yield the methyl ester.
-
Procedure (O-TBDMS Protection): The crude methyl ester is dissolved in dry dichloromethane (DCM). Imidazole (2.5 eq.) and tert-butyldimethylsilyl chloride (TBDMSCl, 1.2 eq.) are added, and the reaction is stirred at room temperature for 8-12 hours.
-
Work-up: The reaction is quenched with water, and the product is extracted with DCM. The organic layer is washed with saturated aqueous sodium bicarbonate and brine, dried over anhydrous sodium sulfate, filtered, and concentrated. The crude product is purified by flash column chromatography.
Step 3: α-Alkylation
-
Procedure: A solution of lithium diisopropylamide (LDA) (1.1 eq.) in dry tetrahydrofuran (THF) is cooled to -78 °C under an inert atmosphere. A solution of the fully protected homoserine derivative (1 eq.) in dry THF is added dropwise, and the mixture is stirred for 1 hour at -78 °C. Allyl bromide (1.5 eq.) is then added, and the reaction is stirred for an additional 4-6 hours at -78 °C before being allowed to warm slowly to room temperature.
-
Work-up: The reaction is quenched with saturated aqueous ammonium chloride. The product is extracted with ethyl acetate. The combined organic layers are washed with brine, dried over anhydrous sodium sulfate, filtered, and concentrated. The crude product is purified by flash column chromatography.
Step 4: Deprotection
-
Procedure (N-Boc and O-TBDMS Deprotection): The protected 2-allylhomoserine derivative is dissolved in a 1:1 mixture of trifluoroacetic acid (TFA) and DCM and stirred at room temperature for 2 hours. The solvent is removed under reduced pressure. The residue is then dissolved in THF, and tetrabutylammonium fluoride (TBAF, 1 M in THF, 1.2 eq.) is added. The mixture is stirred for 2 hours.
-
Procedure (Ester Hydrolysis): The solution from the previous step is diluted with water, and lithium hydroxide (LiOH, 2 eq.) is added. The reaction is stirred at room temperature for 4-6 hours until the ester is fully hydrolyzed.
-
Work-up: The reaction mixture is neutralized with 1 M HCl and then purified by ion-exchange chromatography to yield the final product, this compound.
Predicted Characterization Data
The following table summarizes the predicted quantitative data for this compound.
| Parameter | Predicted Value |
| Appearance | White to off-white crystalline solid |
| Molecular Formula | C₇H₁₃NO₃ |
| Molecular Weight | 159.18 g/mol |
| Melting Point | 210-215 °C (decomposes) |
| Optical Rotation [α]²⁰D | -15° to -25° (c=1, H₂O) |
| ¹H NMR (500 MHz, D₂O) | δ 5.85-5.75 (m, 1H), 5.20-5.10 (m, 2H), 3.80-3.70 (m, 2H), 2.60-2.50 (m, 2H), 2.20-2.00 (m, 2H) |
| ¹³C NMR (125 MHz, D₂O) | δ 178.0, 132.5, 119.0, 63.0, 58.0, 35.0, 32.0 |
| HRMS (ESI+) [M+H]⁺ | Calculated for C₇H₁₄NO₃⁺: 160.0968; Found: [Predicted within 5 ppm] |
Hypothetical Biological Signaling Pathway
As a novel amino acid, this compound could potentially act as an inhibitor of enzymes involved in metabolic pathways. The allyl group could function as a reactive handle for covalent modification of an enzyme's active site.
dot
Caption: Hypothetical mechanism of enzyme inhibition by this compound.
Conclusion
This technical guide provides a comprehensive, albeit theoretical, framework for the synthesis and characterization of this compound. The proposed synthetic route utilizes well-established chemical transformations, and the predicted analytical data offers a benchmark for the characterization of this novel amino acid. This document is intended to serve as a valuable resource for researchers interested in the synthesis and application of new non-proteinogenic amino acids in the fields of medicinal chemistry, chemical biology, and drug development. Experimental validation of the proposed methods is encouraged to establish a definitive protocol for this compound.
The Enigmatic Allyl Moiety: A Technical Guide to the Anticipated Chemical Properties of N-Allyl Homoserine Derivatives
For Immediate Release
LATHAM, NY – October 26, 2025 – While the scientific community has extensively explored the landscape of N-acyl homoserine lactones (AHLs) as pivotal players in bacterial quorum sensing, a significant knowledge gap persists concerning their N-alkenyl counterparts. This technical guide delves into the anticipated chemical properties, potential synthetic routes, and hypothetical biological activities of N-allyl homoserine derivatives, a class of compounds that remains largely uncharted in peer-reviewed literature. Drawing upon analogous N-substituted homoserine lactones, this paper aims to provide a foundational resource for researchers, scientists, and drug development professionals interested in exploring this novel chemical space.
Introduction: The Unexplored Potential of N-Allyl Homoserine Lactones
N-acyl homoserine lactones are well-established signaling molecules in Gram-negative bacteria, regulating a host of collective behaviors, including biofilm formation and virulence factor production. The structural diversity of the N-acyl chain is a key determinant of their biological specificity and activity. However, the substitution of the acyl group with an allyl moiety introduces a unique chemical functionality—a reactive double bond—that could engender novel chemical and biological properties. The inherent reactivity of the allyl group could open avenues for covalent modification, click chemistry applications, and altered receptor binding kinetics. Despite this potential, a comprehensive review of scientific databases reveals a conspicuous absence of dedicated studies on N-allyl homoserine derivatives.
Proposed Synthesis and Chemical Properties
Based on established synthetic methodologies for structurally related N-substituted homoserine lactones, a plausible synthetic pathway for N-allyl homoserine lactone can be postulated. A promising approach involves the oxidative radical scission of an N-allyl-substituted hydroxyproline ester, followed by reduction and spontaneous in situ cyclization. This method has proven effective for a variety of N-substituents and is anticipated to be adaptable for the introduction of the N-allyl group.
The chemical properties of the putative N-allyl homoserine lactone would be largely influenced by the interplay between the homoserine lactone core and the N-allyl substituent. The lactone ring is susceptible to hydrolysis, a key inactivation mechanism for AHLs. The electron-donating nature of the allyl group, in comparison to an electron-withdrawing acyl group, may subtly alter the electrophilicity of the lactone carbonyl, potentially influencing its hydrolytic stability. Furthermore, the terminal double bond of the allyl group presents a reactive handle for a variety of chemical transformations, including but not limited to:
-
Electrophilic Addition: Reactions with halogens, hydrohalic acids, and other electrophiles.
-
Radical Addition: Thiol-ene coupling and other radical-mediated transformations.
-
Metathesis: Cross-metathesis with other olefins to introduce further structural diversity.
-
Oxidation: Epoxidation or dihydroxylation to introduce new functional groups.
These potential reactions offer exciting possibilities for the development of chemical probes and the synthesis of more complex derivatives for structure-activity relationship (SAR) studies.
Quantitative Data (Hypothetical)
In the absence of experimental data, the following table presents a hypothetical summary of the anticipated quantitative properties of N-allyl homoserine lactone, based on typical values for similar small molecules. These values should be considered as estimates pending empirical validation.
| Property | Anticipated Value | Method of Determination (Hypothetical) |
| Molecular Weight | 155.18 g/mol | Mass Spectrometry (e.g., ESI-MS) |
| Yield | 40-60% | Based on analogous syntheses |
| ¹H NMR (CDCl₃, 400 MHz) | δ 5.8 (m, 1H), 5.2 (m, 2H), 4.5 (m, 1H), 4.3 (m, 1H), 3.5 (d, 2H), 2.8 (m, 1H), 2.2 (m, 1H) | Nuclear Magnetic Resonance Spectroscopy |
| ¹³C NMR (CDCl₃, 100 MHz) | δ 175, 134, 118, 66, 55, 50, 30 | Nuclear Magnetic Resonance Spectroscopy |
| Infrared (IR) | ~3300 (N-H), ~1770 (C=O, lactone), ~1640 (C=C) cm⁻¹ | Infrared Spectroscopy |
| LogP | ~0.5 | Calculated (e.g., using ChemDraw) |
| IC₅₀ (Quorum Sensing Inhibition) | >100 µM | Based on data for small N-alkyl substituents |
Experimental Protocols (Proposed)
The following are proposed, high-level experimental protocols for the synthesis and characterization of N-allyl homoserine lactone. These protocols are adapted from established procedures for similar compounds and would require optimization.
Synthesis of N-Allyl-L-Homoserine Lactone
This proposed two-step synthesis starts from commercially available N-allyl-L-hydroxyproline methyl ester.
Step 1: Oxidative Radical Scission
-
To a solution of N-allyl-L-hydroxyproline methyl ester in a suitable solvent (e.g., dichloromethane), add a radical initiator (e.g., AIBN) and an oxidizing agent (e.g., lead tetraacetate) at room temperature.
-
Stir the reaction mixture under an inert atmosphere for 2-4 hours, monitoring the reaction progress by thin-layer chromatography (TLC).
-
Upon completion, quench the reaction and perform an aqueous workup.
-
Purify the crude product (the resulting N-allyl-β-aminoaldehyde) by column chromatography on silica gel.
Step 2: Reduction and In Situ Cyclization
-
Dissolve the purified aldehyde from Step 1 in a suitable solvent (e.g., methanol).
-
Add a reducing agent (e.g., sodium borohydride) portion-wise at 0 °C.
-
Allow the reaction to warm to room temperature and stir for 1-2 hours, monitoring by TLC.
-
Quench the reaction with a mild acid and perform an aqueous workup.
-
Purify the final N-allyl-L-homoserine lactone by column chromatography on silica gel.
Biological Activity Screening: Quorum Sensing Inhibition Assay
-
Utilize a reporter strain of bacteria (e.g., Chromobacterium violaceum or a genetically modified E. coli) that produces a detectable signal (e.g., violacein pigment or luminescence) in response to a specific AHL.
-
Culture the reporter strain in the presence of the cognate AHL to induce the signal.
-
In parallel, co-incubate the reporter strain with the cognate AHL and varying concentrations of the synthesized N-allyl homoserine lactone.
-
Include positive and negative controls (e.g., a known quorum sensing inhibitor and the vehicle solvent, respectively).
-
After a suitable incubation period, quantify the signal production in each condition.
-
Calculate the concentration of N-allyl homoserine lactone required to inhibit signal production by 50% (IC₅₀).
Signaling Pathway and Experimental Workflow Visualization
The following diagrams illustrate the general quorum sensing signaling pathway and a proposed experimental workflow for the synthesis and evaluation of N-allyl homoserine derivatives.
Caption: A generalized quorum sensing circuit in Gram-negative bacteria, adapted for a hypothetical N-allyl homoserine lactone.
Caption: A proposed workflow for the synthesis and evaluation of N-allyl homoserine lactone.
Conclusion and Future Directions
The study of N-allyl homoserine derivatives represents a compelling and unexplored frontier in the field of chemical biology and drug discovery. While this guide provides a theoretical framework based on analogous compounds, empirical research is critically needed to elucidate the true chemical properties and biological activities of these molecules. Future research should focus on the successful synthesis and rigorous characterization of N-allyl homoserine lactone, followed by a systematic evaluation of its stability, reactivity, and efficacy as a modulator of bacterial quorum sensing. The unique reactivity of the allyl group could be leveraged for the development of novel chemical probes to identify and characterize bacterial receptors, potentially paving the way for a new class of anti-virulence agents.
In-Depth Technical Guide on the Biological Activity of N-Allyl Amino Acids
For Researchers, Scientists, and Drug Development Professionals
Abstract
N-allyl amino acids, a class of modified amino acid derivatives, are emerging as compounds of significant interest in the fields of medicinal chemistry and drug development. The incorporation of an allyl group onto the nitrogen atom of an amino acid can confer unique biological properties, including potential anticancer, antimicrobial, and antifungal activities. This technical guide provides a comprehensive overview of the current understanding of the biological activities of N-allyl amino acids, with a focus on their synthesis, quantitative biological data, detailed experimental methodologies, and the molecular pathways they influence. This document is intended to serve as a valuable resource for researchers and professionals engaged in the discovery and development of novel therapeutic agents.
Introduction
The chemical modification of amino acids is a well-established strategy in drug discovery to enhance biological activity, improve pharmacokinetic properties, and reduce toxicity. The N-allylation of amino acids introduces a reactive allyl group, which can participate in various biological interactions and chemical transformations. This modification has been shown to impart a range of biological effects, making N-allyl amino acids attractive candidates for further investigation as potential therapeutic agents. This guide will delve into the synthesis of these compounds and their multifaceted biological activities.
Synthesis of N-Allyl Amino Acids
The synthesis of N-allyl amino acids can be achieved through several methods, with palladium-catalyzed N-allylation being a prominent and efficient approach.
Palladium-Catalyzed N-Allylation
A versatile method for the N-allylation of amino acids involves a palladium(0)-catalyzed reaction between an N-protected amino acid ester and an allylic carbonate under neutral conditions. This method is advantageous as it minimizes side reactions and prevents epimerization at the chiral center of the amino acid.[1][2]
Experimental Protocol: Palladium-Catalyzed N-Allylation of N-Tosyl-Protected Amino Acid Esters [1]
-
Materials:
-
N-Tosyl-protected amino acid ester (1.0 eq)
-
Allyl ethyl carbonate (1.5 eq)
-
Tris(dibenzylideneacetone)dipalladium(0)-chloroform (Pd₂(dba)₃·CHCl₃) (2.5 mol%)
-
1,2-Bis(diphenylphosphino)ethane (dppe) (10 mol%)
-
Anhydrous tetrahydrofuran (THF)
-
-
Procedure:
-
To a solution of the N-tosyl-protected amino acid ester in anhydrous THF, add allyl ethyl carbonate.
-
Add the palladium catalyst (Pd₂(dba)₃·CHCl₃) and the ligand (dppe) to the reaction mixture.
-
Stir the reaction mixture at room temperature under an inert atmosphere (e.g., argon) for 4-24 hours. The progress of the reaction can be monitored by thin-layer chromatography (TLC).
-
Upon completion, concentrate the reaction mixture under reduced pressure.
-
Purify the crude product by column chromatography on silica gel using an appropriate eluent system (e.g., hexane/ethyl acetate) to yield the N-allyl-N-tosyl amino acid ester.
-
The tosyl protecting group can be subsequently removed under standard conditions to yield the free N-allyl amino acid.
-
Anticancer Activity of N-Allyl Amino Acids
While specific quantitative data for simple N-allyl amino acids remains an active area of research, related S-allyl amino acid derivatives have demonstrated notable anticancer properties, suggesting a promising avenue for the investigation of their N-allyl counterparts. For instance, S-allyl-cysteine (SAC) has been shown to induce apoptosis in human bladder cancer cells.[3] Furthermore, the synthetic allyl derivative 17-allylamino-17-demethoxygeldanamycin (17-AAG) has undergone clinical trials for various cancers.[4]
Mechanism of Action: Apoptosis Induction and MAPK Pathway Modulation
One of the key mechanisms underlying the potential anticancer activity of allyl-containing amino acid derivatives is the induction of apoptosis. S-allyl-mercaptocysteine (SAMC), a derivative of S-allyl-cysteine, has been shown to induce apoptosis by activating the mitogen-activated protein kinase (MAPK) pathway.[4] This pathway is a critical signaling cascade that regulates a wide range of cellular processes, including proliferation, differentiation, and apoptosis.
Signaling Pathway: MAPK-Mediated Apoptosis
Caption: MAPK signaling pathway leading to apoptosis.
Experimental Protocol: MTT Assay for Cytotoxicity
The MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) assay is a colorimetric assay for assessing cell metabolic activity and is widely used to measure the cytotoxic effects of potential anticancer compounds.[5][6][7]
-
Cell Seeding:
-
Seed cancer cells in a 96-well plate at a density of 5,000-10,000 cells/well in 100 µL of complete culture medium.
-
Incubate the plate at 37°C in a humidified 5% CO₂ incubator for 24 hours to allow for cell attachment.
-
-
Compound Treatment:
-
Prepare a stock solution of the N-allyl amino acid in a suitable solvent (e.g., DMSO or PBS) and then prepare serial dilutions in culture medium.
-
Remove the old medium from the wells and add 100 µL of the medium containing different concentrations of the N-allyl amino acid. Include a vehicle control (medium with the solvent at the highest concentration used) and a positive control (a known anticancer drug).
-
Incubate the plate for 24, 48, or 72 hours.
-
-
MTT Addition and Incubation:
-
After the incubation period, add 10 µL of MTT solution (5 mg/mL in PBS) to each well.
-
Incubate the plate for another 2-4 hours at 37°C until a purple formazan precipitate is visible.
-
-
Formazan Solubilization and Absorbance Measurement:
-
Carefully remove the medium and add 100 µL of a solubilization solution (e.g., DMSO or a solution of 10% SDS in 0.01 M HCl) to each well to dissolve the formazan crystals.
-
Gently shake the plate for 15 minutes to ensure complete dissolution.
-
Measure the absorbance at 570 nm using a microplate reader.
-
-
Data Analysis:
-
Calculate the percentage of cell viability for each concentration compared to the vehicle control.
-
Plot a dose-response curve and determine the IC₅₀ value (the concentration of the compound that inhibits 50% of cell growth).
-
Antimicrobial and Antifungal Activity of N-Allyl Amino Acids
The allyl group is a key pharmacophore in several known antimicrobial and antifungal agents. While comprehensive studies on N-allyl amino acids are ongoing, the established activity of related compounds provides a strong rationale for their investigation in this area.
Potential Mechanism of Action: Squalene Epoxidase Inhibition
Allylamine antifungals, such as terbinafine, exert their effect by inhibiting the enzyme squalene epoxidase.[8] This enzyme is a key component of the fungal ergosterol biosynthesis pathway. Inhibition of squalene epoxidase leads to a deficiency of ergosterol, a vital component of the fungal cell membrane, and an accumulation of toxic squalene, ultimately resulting in fungal cell death. Given the structural similarity, it is hypothesized that N-allyl amino acids may also target this enzyme.
Signaling Pathway: Fungal Ergosterol Biosynthesis Inhibition
Caption: Inhibition of squalene epoxidase by N-allyl amino acids disrupts ergosterol biosynthesis.
Experimental Protocol: Determination of Minimum Inhibitory Concentration (MIC)
The minimum inhibitory concentration (MIC) is the lowest concentration of an antimicrobial agent that prevents the visible growth of a microorganism. The broth microdilution method is a standard procedure for determining MIC values.[9]
-
Preparation of Inoculum:
-
Culture the test microorganism (bacteria or fungi) in an appropriate broth medium overnight at the optimal temperature.
-
Dilute the culture to achieve a standardized inoculum density (e.g., 5 x 10⁵ CFU/mL for bacteria).
-
-
Preparation of Compound Dilutions:
-
Prepare a stock solution of the N-allyl amino acid in a suitable solvent.
-
Perform serial two-fold dilutions of the compound in a 96-well microtiter plate containing the appropriate growth medium.
-
-
Inoculation and Incubation:
-
Add the standardized inoculum to each well of the microtiter plate.
-
Include a positive control (medium with inoculum, no compound) and a negative control (medium only).
-
Incubate the plate under appropriate conditions (e.g., 37°C for 24 hours for bacteria, 25-30°C for 48-72 hours for fungi).
-
-
Determination of MIC:
-
After incubation, visually inspect the wells for turbidity. The MIC is the lowest concentration of the compound at which there is no visible growth.
-
The results can also be read using a microplate reader to measure absorbance.
-
Quantitative Data Summary
While a comprehensive dataset for a wide range of N-allyl amino acids is still under development in the scientific community, the following table summarizes representative data for related allyl compounds to provide a benchmark for future studies.
| Compound | Biological Activity | Target/Cell Line | IC₅₀ / MIC | Reference |
| S-Allyl-cysteine (SAC) | Anticancer | Human bladder cancer cells | Not specified | [3] |
| 17-AAG | Anticancer | Various cancer cell lines | Nanomolar to micromolar range | [4] |
| Terbinafine (Allylamine) | Antifungal | Candida albicans | Kᵢ = 0.03 µM (for squalene epoxidase) | [8] |
Conclusion and Future Directions
N-allyl amino acids represent a promising class of compounds with the potential for diverse biological activities. The preliminary evidence from related allyl derivatives suggests that these molecules may act as anticancer, antimicrobial, and antifungal agents through mechanisms such as apoptosis induction, MAPK pathway modulation, and inhibition of key enzymes like squalene epoxidase.
Future research should focus on the systematic synthesis and biological evaluation of a broader library of N-allyl amino acids to establish clear structure-activity relationships. The determination of specific IC₅₀ and MIC values against a wide panel of cancer cell lines and microbial strains is crucial for identifying lead compounds. Furthermore, detailed mechanistic studies are required to elucidate the precise molecular targets and signaling pathways affected by N-allyl amino acids. The development of this class of compounds holds significant promise for the discovery of novel therapeutic agents to address unmet medical needs in oncology and infectious diseases.
References
- 1. Application of the Palladium Catalyzed N-Allylation to the Modification of Amino Acids and Peptides [organic-chemistry.org]
- 2. thieme-connect.com [thieme-connect.com]
- 3. Anticancer effect of S-allyl-L-cysteine via induction of apoptosis in human bladder cancer cells - PMC [pmc.ncbi.nlm.nih.gov]
- 4. N-Acyl Amino Acids: Metabolism, Molecular Targets, and Role in Biological Processes [mdpi.com]
- 5. Palladium-catalyzed base- and solvent-controlled chemoselective allylation of amino acids with allylic carbonates [ccspublishing.org.cn]
- 6. Application of the Palladium Catalyzed N-Allylation to the Modification of Amino Acids and Peptides | Semantic Scholar [semanticscholar.org]
- 7. chemimpex.com [chemimpex.com]
- 8. Inhibition of squalene epoxidase by allylamine antimycotic compounds. A comparative study of the fungal and mammalian enzymes - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Synthesis and antitumor activity of amino acid ester derivatives containing 5-fluorouracil - PubMed [pubmed.ncbi.nlm.nih.gov]
The Unnatural Amino Acid 2-Prop-2-en-1-ylhomoserine: A Novel Building Block in Molecular Engineering
An In-depth Technical Guide for Researchers, Scientists, and Drug Development Professionals
Executive Summary
The field of synthetic biology and drug discovery is continually seeking novel molecular tools to expand the chemical diversity of proteins and peptides. Unnatural amino acids (UAAs) represent a powerful class of such tools, enabling the introduction of new functionalities, the enhancement of therapeutic properties, and the creation of novel biological pathways. This technical guide provides a comprehensive overview of 2-Prop-2-en-1-ylhomoserine, a promising yet under-documented UAA. Due to the limited availability of direct research on this compound, this paper will also draw parallels and provide detailed methodologies based on the closely related and well-studied UAA, L-Allylglycine, to offer a practical framework for its potential synthesis, incorporation, and application.
Introduction to this compound
This compound is a non-proteinogenic amino acid characterized by a homoserine backbone and an allyl group attached to the alpha-carbon. This unique structure offers a reactive handle—the terminal alkene of the allyl group—for bioorthogonal chemistry, allowing for site-specific modification of proteins. The homoserine scaffold provides a longer side chain compared to alanine or cysteine, potentially influencing protein folding and function in unique ways.
A Note on Availability: Extensive literature searches have revealed a significant lack of published data specifically on this compound. Therefore, this guide will leverage the extensive research on L-Allylglycine, an unnatural amino acid with a similar reactive allyl group, to provide a foundational understanding and practical protocols that can be adapted for the study and application of this compound.
Physicochemical Properties
While specific quantitative data for this compound is not available, the properties of the structurally similar L-Allylglycine are well-documented and can serve as a reasonable proxy for initial experimental design.
| Property | L-Allylglycine | Reference |
| Molecular Formula | C₅H₉NO₂ | [1] |
| Molar Mass | 115.13 g/mol | [1] |
| Appearance | White crystalline powder | [1] |
| Melting Point | 265 °C (decomposes) | [1] |
| Boiling Point | 231 °C | [1] |
| Density | 1.098 g/mL | [1] |
| Purity | Typically ≥97% | [2] |
Synthesis of L-Allylglycine: A Representative Protocol
The enantioselective synthesis of L-allylglycine is crucial for its biological applications. Several methods have been reported, with one common approach involving the alkylation of a chiral glycine enolate equivalent. Below is a generalized protocol based on established methods.[3][4]
Objective: To synthesize N-Boc-L-allylglycine methyl ester.
Materials:
-
N-(tert-butoxycarbonyl)-L-serine methyl ester
-
Triphenylphosphine
-
Imidazole
-
Iodine
-
Zinc dust
-
1,2-Dibromoethane
-
Chlorotrimethylsilane (TMS-Cl)
-
N,N-Dimethylformamide (DMF), dry
-
Vinyl bromide (1 M in THF)
-
Dichloromethane (DCM)
-
Ethyl acetate
-
Hexanes
-
Brine
-
Anhydrous sodium sulfate
-
Celite™
Procedure:
-
Preparation of Iodoalanine:
-
Dissolve triphenylphosphine and imidazole in dry DCM under an argon atmosphere.
-
Cool the solution to 0°C and add iodine portion-wise.
-
Add a solution of N-(tert-butoxycarbonyl)-L-serine methyl ester in DCM dropwise.
-
Allow the reaction to warm to room temperature and stir until completion (monitor by TLC).
-
Work up the reaction and purify by column chromatography to obtain tert-butyl (R)-1-(methoxycarbonyl)-2-iodoethylcarbamate.[3]
-
-
Zinc-mediated Cross-coupling:
-
Activate zinc dust by treating it with 1,2-dibromoethane in dry DMF at 60°C.
-
Cool the activated zinc suspension to room temperature and add TMS-Cl.
-
Add a solution of the iodoalanine derivative in dry DMF and heat to 35°C.
-
Cool the resulting organozinc reagent to -78°C.
-
Add a solution of vinyl bromide in THF dropwise.
-
Allow the reaction to warm to room temperature and stir for 12 hours.[3]
-
Quench the reaction with water and filter through Celite™.
-
Extract the aqueous layer with ethyl acetate.
-
Wash the combined organic layers with brine, dry over anhydrous sodium sulfate, and concentrate under reduced pressure.
-
Purify the crude product by column chromatography to yield N-(Boc)-L-allylglycine methyl ester.
-
Expected Yield: 65-75%
Site-Specific Incorporation of Unnatural Amino Acids into Proteins
The incorporation of UAAs like L-allylglycine into proteins at specific sites is typically achieved using an orthogonal aminoacyl-tRNA synthetase (aaRS)/tRNA pair that recognizes a nonsense codon, most commonly the amber stop codon (UAG).[5][6]
Experimental Workflow for UAA Incorporation:
Caption: Workflow for site-specific incorporation of an unnatural amino acid.
Detailed Protocol (General):
-
Plasmid Preparation:
-
Subclone the gene of interest (GOI) into an appropriate expression vector. Introduce an amber stop codon (TAG) at the desired site for UAA incorporation using site-directed mutagenesis.
-
Obtain or construct a plasmid encoding the orthogonal aaRS/tRNA pair specific for the desired UAA (e.g., a polyspecific synthetase that can recognize L-allylglycine).
-
-
Transformation and Expression:
-
Co-transform competent E. coli cells (e.g., BL21(DE3)) with the GOI plasmid and the aaRS/tRNA plasmid.
-
Grow the transformed cells in a minimal medium to an OD₆₀₀ of 0.6-0.8.
-
Induce protein expression with IPTG (isopropyl β-D-1-thiogalactopyranoside) and supplement the medium with the UAA (e.g., 1 mM L-allylglycine).
-
Continue to culture the cells at a reduced temperature (e.g., 18-25°C) for 12-16 hours.
-
-
Protein Purification and Verification:
-
Harvest the cells by centrifugation and lyse them using sonication or a French press.
-
Purify the protein of interest using an appropriate method, such as affinity chromatography (e.g., Ni-NTA for His-tagged proteins).
-
Verify the incorporation of the UAA by mass spectrometry (e.g., ESI-MS), which will show a mass shift corresponding to the mass of the incorporated UAA.
-
Biological Activity and Signaling Pathways of L-Allylglycine
L-Allylglycine is primarily known as an inhibitor of glutamate decarboxylase (GAD), the enzyme responsible for synthesizing the inhibitory neurotransmitter gamma-aminobutyric acid (GABA) from glutamate.[1][7][8] By inhibiting GAD, L-allylglycine reduces GABA levels in the brain, leading to an imbalance between excitatory and inhibitory neurotransmission, which can result in convulsions.[2] This property makes it a valuable tool in neuroscience research for studying epilepsy and the role of the GABAergic system.
Mechanism of Action of L-Allylglycine:
References
- 1. Single-site glycine-specific labeling of proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Site-Specific Incorporation of Unnatural Amino Acids into Proteins by Cell-Free Protein Synthesis | Springer Nature Experiments [experiments.springernature.com]
- 3. A General, Highly Enantioselective Method for the Synthesis of D and L α-Amino Acids and Allylic Amines [organic-chemistry.org]
- 4. Regional changes in cerebral GABA concentration and convulsions produced by D and by L-allylglycine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Efficient Incorporation of Unnatural Amino Acids into Proteins with a Robust Cell-Free System - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Incorporation of Unnatural Amino Acids - Profacgen [profacgen.com]
- 7. Evaluation and optimisation of unnatural amino acid incorporation and bioorthogonal bioconjugation for site-specific fluorescent labelling of proteins expressed in mammalian cells - PMC [pmc.ncbi.nlm.nih.gov]
- 8. mdpi.com [mdpi.com]
Spectroscopic Analysis of N-allyl Homoserine: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Predicted Spectroscopic Data
The following tables summarize the predicted ¹H and ¹³C NMR chemical shifts and the expected mass spectrometry fragmentation pattern for N-allyl homoserine. These predictions are derived from the known spectral data of L-homoserine, various allylic compounds, and N-acylated amino acids.
Predicted ¹H NMR Data
Table 1: Predicted ¹H NMR Chemical Shifts for N-allyl Homoserine
| Protons | Predicted Chemical Shift (ppm) | Predicted Multiplicity | Predicted Coupling Constant (J, Hz) | Notes |
| H-1' (allyl) | 5.7 - 5.9 | ddt | J ≈ 17, 10, 6 | Olefinic proton, complex splitting due to coupling with cis, trans, and allylic protons. |
| H-2'a (allyl) | 5.1 - 5.3 | dd | J ≈ 17, 1.5 | Olefinic proton, trans to H-1'. |
| H-2'b (allyl) | 5.0 - 5.2 | dd | J ≈ 10, 1.5 | Olefinic proton, cis to H-1'. |
| H-3' (allyl) | 3.2 - 3.4 | d | J ≈ 6 | Allylic protons attached to nitrogen. |
| H-2 (α-proton) | 3.5 - 3.7 | t | J ≈ 6 | Methine proton adjacent to the carboxylic acid and amine. |
| H-3 (β-protons) | 1.8 - 2.0 | m | - | Methylene protons. |
| H-4 (γ-protons) | 3.6 - 3.8 | t | J ≈ 6 | Methylene protons adjacent to the hydroxyl group. |
| OH | Variable | br s | - | Hydroxyl proton, chemical shift is concentration and solvent dependent. |
| NH | Variable | br s | - | Amine proton, chemical shift is concentration and solvent dependent. |
| COOH | Variable | br s | - | Carboxylic acid proton, chemical shift is concentration and solvent dependent. |
Note: Predicted values are for a deuterated solvent such as D₂O or MeOD. The exact chemical shifts and coupling constants can vary based on the solvent, pH, and temperature.
Predicted ¹³C NMR Data
Table 2: Predicted ¹³C NMR Chemical Shifts for N-allyl Homoserine
| Carbon | Predicted Chemical Shift (ppm) | Notes |
| C-1 (Carboxyl) | 175 - 180 | Carbonyl carbon of the carboxylic acid. |
| C-2 (α-carbon) | 55 - 60 | Methine carbon attached to the nitrogen and carboxyl group. |
| C-3 (β-carbon) | 30 - 35 | Methylene carbon. |
| C-4 (γ-carbon) | 60 - 65 | Methylene carbon attached to the hydroxyl group. |
| C-1' (allyl) | 130 - 135 | Olefinic methine carbon. |
| C-2' (allyl) | 115 - 120 | Terminal olefinic methylene carbon. |
| C-3' (allyl) | 50 - 55 | Allylic methylene carbon attached to nitrogen. |
Predicted Mass Spectrometry Data
For mass spectrometry, electrospray ionization (ESI) in positive ion mode would be a suitable method. The expected mass-to-charge ratios (m/z) for the parent ion and major fragments are outlined below.
Table 3: Predicted ESI-MS Fragmentation for N-allyl Homoserine
| m/z | Ion | Description |
| 160.0923 | [M+H]⁺ | Protonated molecular ion (C₇H₁₄NO₃) |
| 142.0817 | [M+H - H₂O]⁺ | Loss of water from the protonated parent ion. |
| 114.0919 | [M+H - H₂O - CO]⁺ | Subsequent loss of carbon monoxide. |
| 74.0606 | [C₃H₈NO]⁺ | Fragment corresponding to the homoserine backbone after loss of the allyl group and carboxyl group. |
| 41.0391 | [C₃H₅]⁺ | Allyl cation. |
Experimental Protocols
While a specific protocol for the synthesis of N-allyl homoserine is not explicitly detailed in the surveyed literature, a plausible synthetic route can be adapted from standard procedures for the N-alkylation of amino acids.
Synthesis of N-allyl Homoserine
This proposed synthesis involves the reaction of L-homoserine with an allyl halide under basic conditions.
Materials:
-
L-Homoserine
-
Allyl bromide
-
Sodium bicarbonate (NaHCO₃) or another suitable base
-
Solvent (e.g., a mixture of water and ethanol)
-
Diethyl ether or ethyl acetate for extraction
-
Hydrochloric acid (HCl) for pH adjustment
-
Anhydrous magnesium sulfate (MgSO₄) or sodium sulfate (Na₂SO₄) for drying
Procedure:
-
Dissolve L-homoserine in an aqueous solution of sodium bicarbonate.
-
Add a stoichiometric equivalent of allyl bromide to the solution. The reaction mixture is then stirred at room temperature or with gentle heating for several hours to overnight.
-
Monitor the reaction progress using thin-layer chromatography (TLC).
-
Once the reaction is complete, acidify the mixture with dilute HCl to a pH of approximately 6-7.
-
Extract the aqueous layer with an organic solvent such as diethyl ether or ethyl acetate to remove any unreacted allyl bromide and byproducts.
-
The aqueous layer containing the N-allyl homoserine can then be purified, for example, by ion-exchange chromatography.
-
The final product can be isolated by lyophilization or crystallization.
NMR Spectroscopy
Instrumentation:
-
A 400 MHz or higher field NMR spectrometer.
Sample Preparation:
-
Dissolve approximately 5-10 mg of the purified N-allyl homoserine in a suitable deuterated solvent (e.g., D₂O, MeOD).
Data Acquisition:
-
Acquire ¹H and ¹³C NMR spectra.
-
For structural confirmation, 2D NMR experiments such as COSY (Correlation Spectroscopy) and HSQC (Heteronuclear Single Quantum Coherence) should be performed to establish proton-proton and proton-carbon correlations, respectively.
Mass Spectrometry
Instrumentation:
-
A high-resolution mass spectrometer (e.g., Q-TOF or Orbitrap) equipped with an electrospray ionization (ESI) source.
Sample Preparation:
-
Prepare a dilute solution of the sample in a suitable solvent (e.g., methanol/water with 0.1% formic acid).
Data Acquisition:
-
Acquire a full scan mass spectrum in positive ion mode.
-
Perform tandem mass spectrometry (MS/MS) on the protonated parent ion ([M+H]⁺) to obtain fragmentation data for structural elucidation.
Logical and Pathway Diagrams
The following diagrams, generated using the DOT language, illustrate the experimental workflow for the analysis of N-allyl homoserine and a potential signaling pathway context.
Caption: Experimental workflow for the synthesis and spectroscopic analysis of N-allyl homoserine.
Caption: Analogous signaling pathway illustrating the potential role of N-allyl homoserine as a quorum sensing antagonist.
Discussion
N-allyl homoserine, as an analog of N-acyl homoserine lactones (AHLs), holds potential as a modulator of bacterial quorum sensing. AHLs are signaling molecules used by many Gram-negative bacteria to coordinate gene expression in a cell-density-dependent manner, controlling processes such as biofilm formation and virulence factor production.[1] The structural similarity of N-allyl homoserine to the core homoserine structure of AHLs suggests that it could act as a competitive inhibitor of AHL receptors, thereby disrupting quorum sensing pathways.
The spectroscopic data, once experimentally obtained, will be crucial for confirming the structure and purity of synthesized N-allyl homoserine. The predicted NMR and MS data in this guide provide a baseline for what to expect. The detailed experimental protocols offer a starting point for its synthesis and characterization.
Further research into N-allyl homoserine could involve biological assays to determine its efficacy as a quorum sensing inhibitor in various bacterial species. Such studies would be of significant interest to the drug development community in the search for novel anti-infective agents that target bacterial communication rather than viability, potentially reducing the selective pressure for antibiotic resistance.
References
In Silico Modeling of 2-Prop-2-en-1-ylhomoserine Interactions: A Technical Guide
This technical whitepaper presents a detailed guide to the in silico modeling of 2-Prop-2-en-1-ylhomoserine, a derivative of the amino acid homoserine. The methodologies outlined herein are designed to elucidate its potential protein interactions, binding affinities, and functional implications, which are critical for early-stage drug discovery and molecular research. This document provides standardized protocols for molecular docking and molecular dynamics simulations, summarizes hypothetical quantitative data in structured tables, and includes visual representations of key workflows and pathways to facilitate a deeper understanding of the computational analysis of this molecule.
Introduction to In Silico Modeling in Drug Discovery
In silico modeling has become an indispensable tool in modern drug discovery, offering a rapid and cost-effective means to screen and analyze potential drug candidates. By simulating molecular interactions computationally, researchers can predict the binding affinity of a ligand to a protein target, understand its mechanism of action, and refine its structure to improve efficacy and reduce off-target effects. The core of in silico modeling lies in two primary techniques: molecular docking, which predicts the preferred orientation of a molecule when bound to another, and molecular dynamics (MD) simulations, which provide insights into the dynamic behavior of the ligand-protein complex over time.
Potential Protein Targets for this compound
Given that this compound is a derivative of homoserine, its potential protein targets are likely to be enzymes involved in amino acid metabolism or signaling pathways where homoserine or its derivatives act as substrates or signaling molecules. A key enzyme in the biosynthesis pathway of several amino acids is Homoserine Dehydrogenase (HSD) , making it a prime candidate for interaction studies. In silico studies on HSD from various organisms, including pathogenic bacteria and fungi, have been conducted to identify potential inhibitors. For instance, studies have focused on identifying inhibitors for Homoserine Dehydrogenase from Paracoccidioides brasiliensis and Mycobacterium leprae as a strategy for developing novel antifungal and antibacterial agents.[1][2]
Another important class of proteins to consider are those involved in quorum sensing in bacteria, where N-acyl-homoserine lactones (AHLs) are key signaling molecules.[3][4] The homoserine lactone ring is a common feature of these molecules, and while this compound is not a lactone, its structural similarity to the homoserine backbone suggests potential interactions with AHL synthase or receptor proteins.
Quantitative Data Summary
The following tables summarize hypothetical quantitative data that could be generated from in silico modeling of this compound with a putative protein target, such as Homoserine Dehydrogenase. These values are illustrative and based on typical results from similar studies.
Table 1: Molecular Docking Results for this compound against Homoserine Dehydrogenase
| Parameter | Value | Unit | Description |
| Binding Affinity | -8.5 | kcal/mol | The estimated free energy of binding. A more negative value indicates a stronger binding interaction. |
| Inhibition Constant (Ki) | 0.5 | µM | The predicted concentration of the ligand required to inhibit 50% of the enzyme's activity. |
| Interacting Residues | ASP218, GLU224, LYS117 | - | Key amino acid residues in the protein's active site that form hydrogen bonds or hydrophobic interactions with the ligand. |
| Hydrogen Bonds | 3 | - | The number of hydrogen bonds formed between the ligand and the protein, indicating specific and strong interactions. |
Table 2: Molecular Dynamics Simulation Parameters and Results
| Parameter | Value | Unit | Description |
| Simulation Time | 100 | ns | The total time duration of the molecular dynamics simulation. |
| RMSD (Protein Backbone) | 1.5 | Å | Root Mean Square Deviation of the protein backbone atoms, indicating the stability of the protein structure during the simulation. |
| RMSF (Ligand) | 0.8 | Å | Root Mean Square Fluctuation of the ligand atoms, showing the flexibility of the ligand within the binding pocket. |
| MM-PBSA Binding Energy | -45.2 | kcal/mol | An end-point method to calculate the free energy of binding from the MD trajectory, providing a more accurate estimation than docking scores. |
Experimental Protocols
Molecular Docking Protocol
This protocol outlines the steps for performing molecular docking of this compound against a protein target using AutoDock Vina.
-
Protein Preparation:
-
Obtain the 3D structure of the target protein (e.g., Homoserine Dehydrogenase) from the Protein Data Bank (PDB).
-
Remove water molecules and any co-crystallized ligands from the PDB file.
-
Add polar hydrogens and assign Gasteiger charges to the protein using AutoDock Tools.
-
Save the prepared protein structure in the PDBQT format.
-
-
Ligand Preparation:
-
Generate the 3D structure of this compound using a chemical drawing tool like ChemDraw or Marvin Sketch.
-
Perform energy minimization of the ligand structure using a force field such as MMFF94.
-
Save the ligand structure in a MOL2 or SDF file format.
-
Convert the ligand file to the PDBQT format using AutoDock Tools, defining the rotatable bonds.
-
-
Grid Box Generation:
-
Identify the active site of the protein based on literature or by using site-finding tools.
-
Define a grid box that encompasses the entire active site to constrain the docking search space. The size of the grid box should be sufficient to allow the ligand to move and rotate freely within the binding pocket.
-
-
Docking Simulation:
-
Create a configuration file specifying the paths to the prepared protein and ligand files, the coordinates of the grid box center, and the dimensions of the grid.
-
Run the docking simulation using AutoDock Vina. The program will generate multiple binding poses of the ligand ranked by their binding affinity scores.
-
-
Analysis of Results:
-
Visualize the docked poses using molecular visualization software like PyMOL or VMD.
-
Analyze the interactions (hydrogen bonds, hydrophobic interactions) between the ligand and the protein for the best-scoring pose.
-
Molecular Dynamics Simulation Protocol
This protocol describes the steps for running a molecular dynamics simulation of the this compound-protein complex using GROMACS.
-
System Preparation:
-
Use the best-docked pose of the ligand-protein complex as the starting structure.
-
Generate the topology files for the protein and the ligand using a force field such as AMBER or CHARMM. Ligand parameterization can be done using tools like the Antechamber package.
-
Place the complex in a periodic box of appropriate size and solvate it with a chosen water model (e.g., TIP3P).
-
Add ions (e.g., Na+ or Cl-) to neutralize the system.
-
-
Energy Minimization:
-
Perform energy minimization of the solvated system to remove any steric clashes or unfavorable geometries. This is typically done using the steepest descent algorithm followed by the conjugate gradient algorithm.
-
-
Equilibration:
-
Perform a two-step equilibration process.
-
NVT Equilibration: Heat the system to the desired temperature (e.g., 300 K) while keeping the volume constant. This allows the solvent to equilibrate around the protein and ligand.
-
NPT Equilibration: Run a simulation at constant temperature and pressure to ensure the system reaches the correct density. Position restraints on the protein and ligand are gradually released during this phase.
-
-
-
Production MD Run:
-
Run the production simulation for the desired length of time (e.g., 100 ns) without any restraints. Save the trajectory and energy data at regular intervals.
-
-
Trajectory Analysis:
-
Analyze the trajectory to calculate metrics such as RMSD, RMSF, radius of gyration, and hydrogen bond occupancy.
-
Calculate the binding free energy using methods like MM-PBSA or MM-GBSA.
-
Visualizations
The following diagrams illustrate the key workflows and a hypothetical signaling pathway involving this compound.
References
- 1. Predicting of novel homoserine dehydrogenase inhibitors against Paracoccidioides brasiliensis: integrating in silico and in vitro approaches - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Exploring the Molecular Basis for Selective Binding of Homoserine Dehydrogenase from Mycobacterium leprae TN toward Inhibitors: A Virtual Screening Study [mdpi.com]
- 3. researchgate.net [researchgate.net]
- 4. ajbms.knu.edu.af [ajbms.knu.edu.af]
A Technical Guide to the Discovery of Naturally Occurring N-Acyl Homoserine Lactone Analogs
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the discovery, characterization, and significance of naturally occurring N-acyl homoserine lactone (AHL) analogs. AHLs are pivotal signaling molecules in quorum sensing (QS), a cell-to-cell communication process in Gram-negative bacteria that coordinates collective behaviors such as biofilm formation and virulence factor production.[1][2][3] The discovery of novel AHL analogs is crucial for advancing our understanding of bacterial communication and for developing new anti-infective strategies that disrupt these signaling pathways.
Introduction to N-Acyl Homoserine Lactones and Quorum Sensing
Quorum sensing allows bacteria to monitor their population density and collectively alter gene expression.[2] The canonical QS system, first identified in the marine bacterium Vibrio fischeri, involves two key proteins: a LuxI-family synthase that produces a specific AHL molecule, and a LuxR-family receptor protein that binds the AHL.[2][4] As the bacterial population grows, AHLs accumulate. Once a threshold concentration is reached, the AHLs bind to their cognate LuxR receptors, which then act as transcriptional regulators to control the expression of target genes.[5][6]
The basic structure of an AHL consists of a conserved homoserine lactone ring attached to an acyl side chain.[1][7] Variations in the length of this acyl chain (typically 4 to 14 carbons), along with modifications such as an oxo or hydroxyl group at the C-3 position, contribute to the diversity and specificity of these signaling molecules.[4][7]
Discovery of Novel Naturally Occurring AHL Analogs
While canonical AHL structures are well-documented, ongoing research continues to uncover a wide array of naturally occurring analogs with unconventional structures. These discoveries are expanding our knowledge of the chemical language used by bacteria.
Sources of Novel AHLs:
-
Marine Environments: Marine bacteria, particularly those from the families Flavobacteriaceae and Roseobacteraceae, have proven to be a rich source of novel AHLs and AHL-degrading enzymes.[8][9] For instance, a marine Mesorhizobium species was found to produce unprecedented long-chain AHLs, including 5-cis-3-oxo-C12-homoserine lactone.[8]
-
Plant-Associated Bacteria: Bacteria in the rhizosphere and other plant environments utilize AHL signaling for interactions with their plant hosts.[7][10] Some rhizobia, for example, produce a variety of AHLs that play a role in symbiotic processes.[7]
-
Plants as a Source of Mimics: Interestingly, plants themselves can produce substances that mimic the activity of bacterial AHLs, either stimulating or inhibiting QS-regulated behaviors.[11][12] These mimic compounds, found in exudates from plants like peas (Pisum sativum), represent a fascinating aspect of inter-kingdom communication and a potential source for novel QS modulators.[11][12]
Table 1: Examples of Naturally Occurring AHL Analogs and Mimics
| Molecule Name/Class | Source Organism/Environment | Key Structural Features / Activity | Reference(s) |
| 5-cis-3-oxo-C12-HSL and 5-cis-C12-HSL | Marine Mesorhizobium sp. | Unprecedented long-chain (C12) AHLs with a cis configuration. | [8] |
| 3-oxo-C7-HL | Erwinia carotovora, Pantoea stewartii | An uncommon AHL previously observed mainly in Serratia and Yersinia. | [13][14] |
| Poly-hydroxylated long-chain AHLs | Marine Rhodobacteraceae strain | Acyl side chains up to 19 carbons with multiple hydroxyl groups. | [15] |
| Halogenated Furanones | Marine red alga Delisea pulchra | Structurally similar to AHLs; act as antagonists to AHL signaling. | [3][7] |
| Uncharacterized AHL Mimics | Pea (Pisum sativum) seedling exudates | Stimulate or inhibit AHL-regulated behaviors in bacterial reporters. | [11][12] |
Experimental Protocols for Discovery and Characterization
The identification of novel AHL analogs involves a multi-step workflow that combines biological screening with advanced analytical techniques.
-
Bacterial Cultivation: The source bacterium is cultured in an appropriate liquid medium to a high cell density to ensure the production and accumulation of AHLs.
-
Solvent Extraction: The culture supernatant is typically extracted with an organic solvent, such as ethyl acetate, to separate the AHLs from the aqueous medium.
-
Solid-Phase Extraction (SPE): As an alternative or additional purification step, the supernatant can be passed through a solid-phase extraction column (e.g., C18) to concentrate the AHLs.[8]
-
Evaporation and Reconstitution: The organic solvent is evaporated, and the dried extract is reconstituted in a suitable solvent for further analysis.
Bacterial biosensors are genetically engineered strains that produce a detectable signal in response to the presence of AHLs. They are invaluable for the initial screening of extracts.[2][16][17]
-
Principle: These biosensors typically lack their own AHL synthase (a luxI homolog) but possess a functional AHL receptor (luxR homolog) linked to a reporter gene.[2][14] When an exogenous AHL binds to the LuxR protein, it activates the transcription of the reporter gene.[16]
-
Common Biosensor Strains:
-
Agrobacterium tumefaciens NTL4(pCF218)(pCF372): Detects a broad range of AHLs and produces β-galactosidase, leading to a blue color on plates containing X-Gal.[5][17]
-
Chromobacterium violaceum CV026: A mutant that has lost its ability to produce its native C6-HSL but will produce the purple pigment violacein in the presence of short-chain (C4-C8) AHLs.[16][17]
-
-
Methodology:
-
Thin-Layer Chromatography (TLC) Overlay: The crude extract is separated by TLC.
-
The TLC plate is then overlaid with a soft agar suspension of the biosensor strain.
-
The appearance of colored or luminescent spots on the plate indicates the presence of AHLs.
-
Once AHL activity is detected, the next step is to determine the precise chemical structure of the active molecules.
-
High-Performance Liquid Chromatography-Mass Spectrometry (HPLC-MS/MS): This is the primary tool for identifying both known and novel AHLs.[2][13][14][18]
-
Protocol: The extract is separated by HPLC, and the eluting compounds are ionized (commonly via electrospray ionization - ESI) and analyzed by a mass spectrometer.[19]
-
Identification of Novel AHLs: A non-targeted approach involves looking for the characteristic fragment ion of the homoserine lactone ring in MS/MS scans.[2][4][14] High-resolution mass spectrometry allows for the determination of the exact mass and elemental composition of the parent ion and its fragments.[19][20]
-
-
Nuclear Magnetic Resonance (NMR) Spectroscopy: For completely novel structures, purification of the compound is necessary, followed by NMR analysis to confirm the complete structural connectivity and stereochemistry.[17][21][22] NMR provides unambiguous structural information that is complementary to MS data.[20][22][23]
After structural identification, the biological activity of the novel AHL analog is assessed.
-
Virulence Factor Inhibition Assays: The ability of the analog to inhibit the production of QS-controlled virulence factors (e.g., proteases, pyoverdin) in pathogens like Pseudomonas aeruginosa is quantified.[8]
-
Biofilm Formation Assays: The effect of the analog on biofilm development is typically measured using a crystal violet staining method in microtiter plates.[24][25]
-
Gene Expression Analysis: Quantitative real-time PCR (qRT-PCR) can be used to measure how the analog affects the expression of key QS-regulated genes.[24][25]
Table 2: Key Experimental Techniques in AHL Analog Discovery
| Technique | Purpose | Key Information Obtained |
| Bacterial Biosensors | Initial screening and detection of AHL activity in extracts. | Presence and general class (e.g., short vs. long chain) of AHLs. |
| HPLC-MS/MS | Separation, identification, and quantification of AHLs. | Retention time, exact mass of parent and fragment ions, tentative structure. |
| NMR Spectroscopy | Definitive structural elucidation of purified novel compounds. | Complete chemical structure, including stereochemistry. |
| Bioassays | Functional characterization of the biological activity. | Agonistic or antagonistic activity, impact on virulence and biofilm formation. |
Visualizations of Key Pathways and Workflows
Caption: A diagram of the canonical LuxI/LuxR AHL-mediated quorum sensing pathway.
References
- 1. journals.asm.org [journals.asm.org]
- 2. Identification of Unanticipated and Novel N-Acyl L-Homoserine Lactones (AHLs) Using a Sensitive Non-Targeted LC-MS/MS Method | PLOS One [journals.plos.org]
- 3. mdpi.com [mdpi.com]
- 4. researchgate.net [researchgate.net]
- 5. Rapid Screening of Quorum-Sensing Signal N-Acyl Homoserine Lactones by an In Vitro Cell-Free Assay - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. courses.washington.edu [courses.washington.edu]
- 8. journals.asm.org [journals.asm.org]
- 9. Frontiers | MzmL, a novel marine derived N-acyl homoserine lactonase from Mesoflavibacter zeaxanthinifaciens that attenuates Pectobacterium carotovorum subsp. carotovorum virulence [frontiersin.org]
- 10. Importance of N-Acyl-Homoserine Lactone-Based Quorum Sensing and Quorum Quenching in Pathogen Control and Plant Growth Promotion - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. apsjournals.apsnet.org [apsjournals.apsnet.org]
- 13. Identification of Unanticipated and Novel N-Acyl L-Homoserine Lactones (AHLs) Using a Sensitive Non-Targeted LC-MS/MS Method - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. Identification of Unanticipated and Novel N-Acyl L-Homoserine Lactones (AHLs) Using a Sensitive Non-Targeted LC-MS/MS Method - PMC [pmc.ncbi.nlm.nih.gov]
- 15. researchgate.net [researchgate.net]
- 16. N-Acyl Homoserine Lactone-Mediated Quorum Sensing with Special Reference to Use of Quorum Quenching Bacteria in Membrane Biofouling Control - PMC [pmc.ncbi.nlm.nih.gov]
- 17. academic.oup.com [academic.oup.com]
- 18. researchgate.net [researchgate.net]
- 19. CURRENTA: Mass spectrometry for structural elucidation [currenta.de]
- 20. Recent Advances in Mass Spectrometry-Based Structural Elucidation Techniques - PMC [pmc.ncbi.nlm.nih.gov]
- 21. MicroCombiChem: Structure Elucidation, NMR, HPLC-MS Analytics [microcombichem.com]
- 22. researchgate.net [researchgate.net]
- 23. Advances in structure elucidation of small molecules using mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 24. Frontiers | Design, Synthesis, and Biological Evaluation of N-Acyl-Homoserine Lactone Analogs of Quorum Sensing in Pseudomonas aeruginosa [frontiersin.org]
- 25. Design, Synthesis, and Biological Evaluation of N-Acyl-Homoserine Lactone Analogs of Quorum Sensing in Pseudomonas aeruginosa - PMC [pmc.ncbi.nlm.nih.gov]
A Technical Guide to Homoserine Biosynthesis and Metabolic Engineering
For Researchers, Scientists, and Drug Development Professionals
Abstract
L-homoserine, a non-proteinogenic α-amino acid, is a key intermediate in the aspartate metabolic pathway, leading to the biosynthesis of essential amino acids such as threonine, methionine, and isoleucine. Its biotechnological production through microbial fermentation has garnered significant interest due to its applications as a chiral building block in the pharmaceutical and chemical industries. This guide provides an in-depth overview of the homoserine biosynthesis pathway, its regulation, and the metabolic engineering strategies employed to enhance its production in microbial hosts, primarily Escherichia coli and Corynebacterium glutamicum. Detailed experimental protocols for key genetic and fermentation techniques are provided, along with a comprehensive compilation of quantitative data from various studies. Furthermore, this guide explores the role of homoserine derivatives in bacterial quorum sensing, a critical cell-to-cell communication system.
The Homoserine Biosynthesis Pathway
The biosynthesis of L-homoserine from L-aspartate is a three-step enzymatic pathway conserved in bacteria, plants, and fungi.[1] In industrial microorganisms like E. coli and C. glutamicum, this pathway is a critical branch point for the synthesis of several essential amino acids.
The key enzymes and their corresponding genes in E. coli are:
-
Aspartate Kinase (AK): Catalyzes the phosphorylation of L-aspartate to β-aspartyl-phosphate. E. coli possesses three isoenzymes of AK:
-
AK I, encoded by thrA, is a bifunctional enzyme with both aspartate kinase and homoserine dehydrogenase activity and is feedback inhibited by threonine.
-
AK II, encoded by metL, is also a bifunctional enzyme and its expression is regulated by methionine.[2]
-
AK III, encoded by lysC, is feedback inhibited by lysine.[1]
-
-
Aspartate-Semialdehyde Dehydrogenase (ASD): Encoded by the asd gene, this enzyme catalyzes the reduction of β-aspartyl-phosphate to L-aspartate-β-semialdehyde.[3]
-
Homoserine Dehydrogenase (HDH): This enzyme reduces L-aspartate-β-semialdehyde to L-homoserine. In E. coli, this activity is carried out by the bifunctional enzymes AK I (thrA) and AK II (metL).[1]
The overall pathway can be visualized as follows:
Figure 1: The L-homoserine biosynthesis pathway from L-aspartate.
Regulation of Homoserine Biosynthesis
The flux through the homoserine biosynthesis pathway is tightly regulated at multiple levels to prevent the overproduction of downstream amino acids. The primary regulatory mechanism is allosteric feedback inhibition of the key enzymes.
-
Aspartate Kinase: As mentioned, the activities of AK I and AK III are inhibited by their respective end-products, threonine and lysine.[1] This is a major bottleneck for the overproduction of homoserine.
-
Homoserine Dehydrogenase: The HDH activity of AK I is also subject to feedback inhibition by threonine.
This feedback inhibition is a critical target for metabolic engineering efforts aimed at increasing homoserine production.
Figure 2: Feedback inhibition of the homoserine biosynthesis pathway.
Metabolic Engineering Strategies for Enhanced Homoserine Production
To overcome the tight regulation and divert carbon flux towards homoserine, several metabolic engineering strategies have been successfully implemented. These strategies often involve a combination of genetic modifications.[1][4]
3.1. Blocking Competing and Degradative Pathways
A primary strategy is to eliminate pathways that consume homoserine or its precursors. This involves knocking out key genes:
-
thrB (Homoserine Kinase): This gene encodes the enzyme that converts homoserine to O-phospho-L-homoserine, the first step in threonine biosynthesis. Deleting thrB is a crucial step to prevent the conversion of homoserine to threonine.[5]
-
metA (Homoserine O-succinyltransferase): This gene is responsible for the first step in methionine biosynthesis, converting homoserine to O-succinyl-L-homoserine. Its deletion prevents the channeling of homoserine into the methionine pathway.[5]
-
lysA (Diaminopimelate Decarboxylase): To increase the availability of the precursor L-aspartate-β-semialdehyde, the competing lysine biosynthesis pathway can be blocked by deleting lysA.
3.2. Overexpression of Key Biosynthetic Genes
To enhance the carbon flux towards homoserine, the genes encoding the key enzymes in the biosynthesis pathway are often overexpressed:
-
thrA : Overexpression of a feedback-resistant mutant of thrA (e.g., thrAfbr) is a common strategy to increase both aspartate kinase and homoserine dehydrogenase activities while bypassing threonine inhibition.[1]
-
asd : Increasing the expression of aspartate-semialdehyde dehydrogenase can further pull the metabolic flux from aspartate.
-
lysC : Overexpression of a feedback-resistant lysC mutant (lysCfbr) can also enhance the initial phosphorylation of aspartate.[1]
3.3. Enhancing Precursor Supply
Increasing the intracellular pool of the precursor L-aspartate is another effective strategy. This can be achieved by:
-
Overexpressing phosphoenolpyruvate carboxylase (ppc) or pyruvate carboxylase (pyc) to direct more carbon from the central metabolism towards oxaloacetate, the direct precursor of aspartate.[6]
-
Overexpressing aspartate aminotransferase (aspC) to facilitate the conversion of oxaloacetate to aspartate.
3.4. Modifying Transport Systems
Efficient export of homoserine from the cell is crucial to prevent feedback inhibition and potential toxicity at high intracellular concentrations.[1] This is often achieved by overexpressing exporter proteins such as RhtA and RhtB in E. coli or BrnFE in C. glutamicum.[7]
Figure 3: A typical workflow for the metabolic engineering of a homoserine-producing strain.
Quantitative Data on Homoserine Production
The following tables summarize key quantitative data from various metabolic engineering studies for L-homoserine production in E. coli and C. glutamicum.
Table 1: L-Homoserine Production in Engineered Escherichia coli
| Strain | Key Genetic Modifications | Fermentation Mode | Titer (g/L) | Yield (g/g glucose) | Productivity (g/L/h) | Reference |
| HS33 | ΔmetA, ΔthrB, ΔiclR, ↑thrA | Fed-batch | 37.57 | 0.31 | - | [5] |
| E. coli W3110 derivative | ΔmetA, ΔthrB, ΔlysA, ↑thrAfbr | Fed-batch | 60.1 | - | - | [1] |
| E. coli derivative | ΔmetA, ΔthrB, ↑thrAfbr, ↑asd, ↑lysCfbr | Fed-batch | 84.1 | 0.50 | 1.96 | [6] |
| E. coli derivative | Synthetic pathway engineering, cell division regulation | Fed-batch | 101.31 | 0.30 | 1.91 | [6] |
Table 2: L-Homoserine Production in Engineered Corynebacterium glutamicum
| Strain | Key Genetic Modifications | Fermentation Mode | Titer (g/L) | Yield (g/g mixed sugars) | Productivity (g/L/h) | Reference |
| C. glutamicum derivative | Redistribution of metabolic fluxes | Shake flask | 8.8 | - | - | [7] |
| C. glutamicum derivative | CRISPR genome editing | 5 L bioreactor | 22.1 | - | - | [6] |
| C. glutamicum derivative | Dual-channel glycolysis | 5 L bioreactor | 63.5 | - | - | [6] |
| C. glutamicum ATCC 13032 derivative | Mixed sugar co-utilization | Fed-batch bioreactor | 93.1 | 0.41 | 1.29 | [6] |
Table 3: Kinetic Parameters of Key Enzymes in the Homoserine Biosynthesis Pathway
| Enzyme | Organism | Substrate | Km (mM) | Vmax (μmol/min/mg) | Inhibitor | Ki (mM) | Reference |
| Aspartate Kinase I (thrA) | E. coli | L-Aspartate | - | - | L-Threonine | - | [8] |
| Aspartate Kinase I (thrA) | E. coli | ATP | 0.2 | - | - | - | [9] |
| Homoserine Dehydrogenase I (thrA) | E. coli | L-Homoserine | - | - | L-Threonine | - | [10] |
| Homoserine Kinase (thrB) | E. coli | L-Homoserine | 0.15 | - | L-Homoserine (substrate inhibition) | ~2 | [9] |
| Homoserine Dehydrogenase | Arthrobacter nicotinovorans | L-Homoserine | 6.30 | 180.70 | - | - | [11] |
Note: Specific kinetic parameters can vary depending on the experimental conditions.
Experimental Protocols
This section provides detailed methodologies for key experiments commonly performed in the metabolic engineering of homoserine-producing strains.
5.1. Gene Knockout using CRISPR/Cas9 in Corynebacterium glutamicum
This protocol is adapted for the deletion of a target gene in C. glutamicum using a two-plasmid CRISPR/Cas9 system.[12][13]
-
Design of sgRNA:
-
Identify a 20-bp target sequence in the gene of interest that is immediately upstream of a 5'-NGG-3' protospacer adjacent motif (PAM).
-
Design and synthesize two complementary oligonucleotides encoding the 20-bp target sequence.
-
-
Construction of the sgRNA Expression Plasmid:
-
Clone the annealed oligonucleotides into a suitable sgRNA expression vector (e.g., pgRNA-target).
-
-
Construction of the Editing Template Plasmid:
-
Amplify the upstream and downstream homologous arms (typically 500-1000 bp) flanking the target gene.
-
Assemble the two homologous arms into a suicide vector via Gibson assembly or restriction-ligation cloning.
-
-
Transformation and Gene Deletion:
-
Prepare electrocompetent C. glutamicum cells expressing the Cas9 nuclease.
-
Co-transform the sgRNA expression plasmid and the editing template plasmid into the competent cells.
-
Plate the transformed cells on selective agar plates (e.g., containing appropriate antibiotics).
-
Incubate at a permissive temperature to allow for plasmid replication and homologous recombination.
-
-
Verification of Gene Deletion:
-
Screen colonies by colony PCR using primers flanking the target gene. A smaller PCR product will be observed for successful deletions.
-
Confirm the deletion by Sanger sequencing of the PCR product.
-
5.2. Overexpression of His-tagged Enzymes in E. coli
This protocol describes the overexpression and purification of a His-tagged enzyme for in vitro characterization.[14][15]
-
Cloning of the Target Gene:
-
Amplify the gene of interest from the source organism's genomic DNA.
-
Clone the gene into an expression vector containing a T7 promoter and an N- or C-terminal 6xHis-tag (e.g., pET series).
-
-
Protein Expression:
-
Transform the expression plasmid into a suitable E. coli expression host (e.g., BL21(DE3)).
-
Grow the cells in LB medium at 37°C to an OD600 of 0.6-0.8.
-
Induce protein expression by adding IPTG to a final concentration of 0.1-1 mM.
-
Continue to grow the cells at a lower temperature (e.g., 16-25°C) for 4-16 hours to promote soluble protein expression.
-
-
Cell Lysis:
-
Harvest the cells by centrifugation.
-
Resuspend the cell pellet in lysis buffer (e.g., 50 mM NaH2PO4, 300 mM NaCl, 10 mM imidazole, pH 8.0).
-
Lyse the cells by sonication or high-pressure homogenization.
-
Clarify the lysate by centrifugation to remove cell debris.
-
-
Protein Purification using Immobilized Metal Affinity Chromatography (IMAC):
-
Equilibrate a Ni-NTA resin column with lysis buffer.
-
Load the cleared lysate onto the column.
-
Wash the column with wash buffer (e.g., 50 mM NaH2PO4, 300 mM NaCl, 20 mM imidazole, pH 8.0) to remove non-specifically bound proteins.
-
Elute the His-tagged protein with elution buffer (e.g., 50 mM NaH2PO4, 300 mM NaCl, 250 mM imidazole, pH 8.0).
-
Analyze the purified protein by SDS-PAGE.
-
5.3. Fed-Batch Fermentation for High-Density Culture and Homoserine Production
This protocol outlines a general procedure for fed-batch fermentation of engineered E. coli for high-titer homoserine production.[16][17]
-
Inoculum Preparation:
-
Inoculate a single colony of the production strain into a seed culture medium and grow overnight.
-
Use the seed culture to inoculate a larger volume of pre-culture medium and grow to a specific optical density.
-
-
Bioreactor Setup and Batch Phase:
-
Prepare the fermentation medium in a sterilized bioreactor. A typical medium contains a carbon source (e.g., glucose), nitrogen source (e.g., ammonium sulfate), phosphate source, and trace elements.
-
Inoculate the bioreactor with the pre-culture.
-
Maintain the temperature, pH, and dissolved oxygen (DO) at optimal levels (e.g., 37°C, pH 7.0, DO > 20%).
-
Run the batch phase until the initial carbon source is nearly depleted.
-
-
Fed-Batch Phase:
-
Initiate the feeding of a concentrated nutrient solution containing the carbon source and other necessary components.
-
The feeding rate can be controlled to maintain a constant low substrate concentration, which helps to avoid the formation of inhibitory byproducts like acetate.
-
Continue the fermentation until the desired homoserine titer is reached.
-
-
Sampling and Analysis:
-
Periodically take samples from the bioreactor to monitor cell growth (OD600), substrate consumption, and homoserine production.
-
5.4. Quantification of Homoserine by High-Performance Liquid Chromatography (HPLC)
This protocol describes a method for quantifying homoserine in fermentation broth.
-
Sample Preparation:
-
Centrifuge the fermentation broth sample to remove cells.
-
Filter the supernatant through a 0.22 µm syringe filter.
-
-
Derivatization (Optional but often required for UV detection):
-
Derivatize the amino acids in the sample with a reagent such as o-phthalaldehyde (OPA) or phenylisothiocyanate (PITC) to make them detectable by UV or fluorescence detectors.
-
-
HPLC Analysis:
-
Inject the prepared sample onto a reverse-phase C18 column.
-
Use a suitable mobile phase gradient (e.g., a gradient of acetonitrile and a buffer) to separate the amino acids.
-
Detect the derivatized homoserine at the appropriate wavelength.
-
Quantify the homoserine concentration by comparing the peak area to a standard curve prepared with known concentrations of L-homoserine.
-
Homoserine Derivatives in Signaling Pathways: Acyl-Homoserine Lactone (AHL) Quorum Sensing
Homoserine is a precursor to N-acyl-homoserine lactones (AHLs), which are signaling molecules used by many Gram-negative bacteria in a process called quorum sensing.[18] Quorum sensing allows bacteria to coordinate their gene expression in a population-density-dependent manner, regulating processes such as biofilm formation, virulence factor production, and bioluminescence.[19]
In the well-studied quorum-sensing systems of Pseudomonas aeruginosa, there are two main AHL-based systems: the las system and the rhl system.[20]
-
The las system: The LasI synthase produces the AHL signal N-(3-oxododecanoyl)-L-homoserine lactone (3-oxo-C12-HSL). At a critical concentration, this molecule binds to the transcriptional regulator LasR, which then activates the expression of target genes, including those for virulence factors and the rhl system.[19]
-
The rhl system: The RhlI synthase produces N-butanoyl-L-homoserine lactone (C4-HSL). This signal molecule binds to the RhlR transcriptional regulator, leading to the expression of another set of genes, including those involved in biofilm formation and the production of rhamnolipids.[19]
The biosynthesis of the homoserine lactone ring of AHLs is derived from S-adenosylmethionine (SAM), which in turn is synthesized from methionine, a downstream product of homoserine.
Figure 4: The hierarchical las and rhl acyl-homoserine lactone quorum-sensing systems in Pseudomonas aeruginosa.
Conclusion
The biosynthesis of L-homoserine represents a well-characterized metabolic pathway that is a prime target for metabolic engineering. Through a combination of rational and systems-level approaches, significant improvements in homoserine production have been achieved in microbial hosts. The detailed understanding of the pathway's regulation, coupled with the development of advanced genetic tools, has enabled the construction of highly efficient cell factories. The experimental protocols and quantitative data presented in this guide provide a valuable resource for researchers in academia and industry who are working on the production of homoserine and other valuable amino acids. Furthermore, the connection of homoserine metabolism to bacterial signaling pathways highlights the broader physiological importance of this key metabolite. Future research will likely focus on further optimizing production strains through synthetic biology and systems biology approaches, as well as exploring novel applications for L-homoserine and its derivatives.
References
- 1. Metabolic engineering strategies for L-Homoserine production in Escherichia coli - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. pubs.acs.org [pubs.acs.org]
- 4. researchgate.net [researchgate.net]
- 5. journals.asm.org [journals.asm.org]
- 6. pubs.acs.org [pubs.acs.org]
- 7. researchgate.net [researchgate.net]
- 8. An integrated study of threonine-pathway enzyme kinetics in Escherichia coli - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Homoserine kinase of Escherichia coli: kinetic mechanism and inhibition by L-aspartate semialdehyde - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Homoserine dehydrogenase-I (Escherichia coli): action of monovalent ions on catalysis and substrate association-dissociation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. biorxiv.org [biorxiv.org]
- 12. CRISPR/Cas9-mediated ssDNA Recombineering in Corynebacterium glutamicum - PMC [pmc.ncbi.nlm.nih.gov]
- 13. CRISPR/Cas9-mediated ssDNA Recombineering in Corynebacterium glutamicum [bio-protocol.org]
- 14. neb.com [neb.com]
- 15. Purification of His-Tagged Proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. eppendorf.com [eppendorf.com]
- 17. [PDF] Use of fed-batch cultivation for achieving high cell densities for the pilot-scale production of a recombinant protein (phenylalanine dehydrogenase) in Escherichia coli. | Semantic Scholar [semanticscholar.org]
- 18. youtube.com [youtube.com]
- 19. applications.emro.who.int [applications.emro.who.int]
- 20. pubs.acs.org [pubs.acs.org]
Methodological & Application
Application Notes and Protocols for Incorporating 2-Prop-2-en-1-ylhomoserine into Peptides
For Researchers, Scientists, and Drug Development Professionals
Introduction
The incorporation of unnatural amino acids into peptides is a powerful strategy in modern drug discovery and chemical biology, offering the potential to enhance peptide stability, potency, and conformational rigidity.[1][2] One such unnatural amino acid, 2-Prop-2-en-1-ylhomoserine, more commonly known as O-allyl-homoserine, provides a versatile tool for peptide modification due to the presence of a reactive allyl group in its side chain. This functional handle allows for subsequent chemical modifications, such as peptide stapling or the introduction of labels and other moieties, thereby expanding the chemical space and therapeutic potential of peptide-based molecules.[3][4]
These application notes provide a comprehensive overview and detailed protocols for the synthesis of Fmoc-protected O-allyl-homoserine and its incorporation into peptides via Solid-Phase Peptide Synthesis (SPPS).
Key Applications
The primary application of incorporating O-allyl-homoserine into peptides is to facilitate post-synthetic modifications, most notably peptide stapling . This technique involves covalently linking the side chains of two amino acid residues to create a cyclic peptide.[4] Stapled peptides often exhibit enhanced alpha-helical conformation, increased resistance to proteolytic degradation, and improved cell permeability, all of which are desirable properties for therapeutic peptides.[4]
The allyl group of O-allyl-homoserine serves as a precursor for various cross-linking chemistries, including ring-closing metathesis when paired with another olefin-containing amino acid. This approach allows for the generation of all-hydrocarbon staples that can mimic the natural alpha-helical structure of peptides involved in protein-protein interactions.[3]
Data Presentation
Table 1: Summary of Key Parameters for Fmoc-L-Homoserine(O-allyl)-OH Synthesis and Incorporation
| Parameter | Value/Range | Notes |
| Fmoc-L-Homoserine(O-allyl)-OH Synthesis Yield | 70-85% | Based on typical yields for similar amino acid derivatizations. |
| Coupling Efficiency in SPPS | >98% | Achievable with standard coupling reagents like HBTU/HOBt or HATU. Monitoring with a Kaiser test is recommended.[5] |
| Allyl Group Deprotection Yield | >95% | Using Pd(PPh₃)₄ and a scavenger like phenylsilane. Microwave-assisted methods can significantly reduce reaction time. |
| Purity of Crude Peptide | Variable | Dependent on peptide sequence and synthesis efficiency. |
| Purity of Final Stapled Peptide | >98% | Achievable after purification by reverse-phase HPLC.[6] |
Experimental Protocols
Protocol 1: Synthesis of Fmoc-L-Homoserine(O-allyl)-OH
This protocol describes the synthesis of the Fmoc-protected O-allyl-homoserine building block required for SPPS. The synthesis starts from commercially available Fmoc-L-homoserine.
Materials:
-
Fmoc-L-homoserine
-
Allyl bromide
-
Sodium hydride (NaH), 60% dispersion in mineral oil
-
Anhydrous N,N-Dimethylformamide (DMF)
-
Diethyl ether
-
Saturated aqueous sodium bicarbonate solution
-
Saturated aqueous sodium chloride solution (brine)
-
Anhydrous magnesium sulfate (MgSO₄)
-
Argon or Nitrogen gas
Procedure:
-
Preparation: Under an inert atmosphere (Argon or Nitrogen), suspend Fmoc-L-homoserine (1 equivalent) in anhydrous DMF.
-
Deprotonation: Cool the suspension to 0 °C in an ice bath. Add sodium hydride (1.2 equivalents) portion-wise over 15 minutes. Stir the mixture at 0 °C for 30 minutes, then allow it to warm to room temperature and stir for an additional hour.
-
Allylation: Cool the reaction mixture back to 0 °C and add allyl bromide (1.5 equivalents) dropwise. Allow the reaction to slowly warm to room temperature and stir overnight.
-
Quenching and Extraction: Carefully quench the reaction by the slow addition of water at 0 °C. Dilute the mixture with diethyl ether and wash sequentially with water, saturated aqueous sodium bicarbonate solution, and brine.
-
Drying and Concentration: Dry the organic layer over anhydrous magnesium sulfate, filter, and concentrate under reduced pressure to obtain the crude product.
-
Purification: Purify the crude product by flash column chromatography on silica gel using a suitable eluent system (e.g., a gradient of ethyl acetate in hexanes) to yield Fmoc-L-Homoserine(O-allyl)-OH as a white solid.
Expected Yield: 70-85%.
References
- 1. luxembourg-bio.com [luxembourg-bio.com]
- 2. A high-yielding solid-phase total synthesis of daptomycin using a Fmoc SPPS stable kynurenine synthon - Organic & Biomolecular Chemistry (RSC Publishing) [pubs.rsc.org]
- 3. Constraining and Modifying Peptides Using Pd‐Mediated Cysteine Allylation - PMC [pmc.ncbi.nlm.nih.gov]
- 4. mdpi.com [mdpi.com]
- 5. Bot Detection [iris-biotech.de]
- 6. Purification of therapeutic peptides using orthogonal methods to achieve high purity - American Chemical Society [acs.digitellinc.com]
Application Notes and Protocols for Solid-Phase Peptide Synthesis with 2-Prop-2-en-1-ylhomoserine
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive guide for the incorporation of the unnatural amino acid 2-Prop-2-en-1-ylhomoserine into peptides using Fmoc-based solid-phase peptide synthesis (SPPS). This versatile building block, featuring an allyl group, opens avenues for various peptide modifications, including hydrocarbon stapling for helix stabilization and subsequent functionalization via click chemistry.
Introduction
This compound, also known as 2-allylhomoserine, is a non-proteinogenic amino acid that serves as a valuable tool in peptide chemistry and drug discovery. Its terminal olefin functionality allows for post-synthetic modifications, most notably ring-closing metathesis (RCM) to create "stapled" peptides.[1][2] Stapled peptides are synthetic peptides with a reinforced alpha-helical structure, leading to enhanced proteolytic resistance, increased cell permeability, and improved target binding affinity.[2][3] These properties make them promising candidates for modulating intracellular protein-protein interactions (PPIs) that are often considered "undruggable."[1][4]
This document outlines the necessary protocols for the synthesis of the Fmoc-protected this compound monomer, its incorporation into a peptide sequence via automated or manual SPPS, and a representative application in creating a stapled peptide to modulate a key signaling pathway.
Synthesis of Fmoc-2-Prop-2-en-1-ylhomoserine-OH
The synthesis of the Fmoc-protected amino acid is a prerequisite for its use in SPPS. A plausible synthetic route, adapted from established procedures for similar unnatural amino acids, is presented below.
Protocol 2.1: Synthesis of Fmoc-2-Prop-2-en-1-ylhomoserine-OH
This protocol is based on the alkylation of a suitable precursor.
Materials:
-
Commercially available protected homoserine derivative (e.g., Boc-Hse(Trt)-OMe)
-
Allyl bromide
-
Sodium hydride (NaH)
-
Anhydrous Tetrahydrofuran (THF)
-
Reagents for deprotection of Boc, Trt, and methyl ester groups
-
9-fluorenylmethyloxycarbonyl succinimide (Fmoc-OSu)
-
Sodium bicarbonate
-
Dioxane
-
Water
-
Ethyl acetate
-
Hexanes
-
Dichloromethane (DCM)
-
Trifluoroacetic acid (TFA)
-
Triisopropylsilane (TIS)
Procedure:
-
Allylation: Dissolve the protected homoserine derivative in anhydrous THF under an inert atmosphere. Add NaH portion-wise at 0°C, followed by the dropwise addition of allyl bromide. Allow the reaction to warm to room temperature and stir overnight.
-
Work-up and Deprotection: Quench the reaction with water and extract the product with ethyl acetate. Dry the organic layer, concentrate, and proceed with the sequential deprotection of the Boc, Trt, and methyl ester protecting groups using standard literature procedures.
-
Fmoc Protection: Dissolve the resulting free amino acid in a 10% solution of sodium bicarbonate in water and dioxane. Add a solution of Fmoc-OSu in dioxane and stir at room temperature overnight.
-
Purification: Acidify the reaction mixture and extract the product with ethyl acetate. Wash the organic layer with brine, dry over sodium sulfate, and concentrate. Purify the crude product by flash column chromatography (silica gel, gradient of methanol in dichloromethane) to yield Fmoc-2-Prop-2-en-1-ylhomoserine-OH as a white solid.
Solid-Phase Peptide Synthesis (SPPS) Protocol
The following is a general protocol for the incorporation of Fmoc-2-Prop-2-en-1-ylhomoserine-OH into a peptide sequence using an automated peptide synthesizer. This protocol can be adapted for manual synthesis.[5]
Protocol 3.1: Automated SPPS of a Peptide Containing this compound
Materials and Equipment:
-
Automated peptide synthesizer
-
Rink Amide resin (or other suitable resin depending on the desired C-terminus)[5]
-
Fmoc-protected amino acids (standard and Fmoc-2-Prop-2-en-1-ylhomoserine-OH)
-
Coupling reagent: HBTU (2-(1H-benzotriazol-1-yl)-1,1,3,3-tetramethyluronium hexafluorophosphate) or HATU (1-[Bis(dimethylamino)methylene]-1H-1,2,3-triazolo[4,5-b]pyridinium 3-oxid hexafluorophosphate)[5]
-
Base: Diisopropylethylamine (DIPEA) or N-methylmorpholine (NMM)[5]
-
Deprotection agent: 20% piperidine in dimethylformamide (DMF)[5]
-
Solvents: DMF, DCM
-
Cleavage cocktail: e.g., 95% TFA, 2.5% water, 2.5% TIS
-
Cold diethyl ether
Procedure:
-
Resin Swelling: Swell the resin in DMF for 30-60 minutes in the reaction vessel.[5]
-
Fmoc Deprotection: Remove the Fmoc group from the resin-bound amino acid by treating with 20% piperidine in DMF.[5]
-
Washing: Thoroughly wash the resin with DMF to remove residual piperidine and byproducts.
-
Amino Acid Coupling:
-
Pre-activate a solution of the Fmoc-amino acid (3-5 equivalents relative to resin loading), coupling reagent (e.g., HBTU, 3-5 equivalents), and base (e.g., DIPEA, 6-10 equivalents) in DMF for 5-10 minutes.
-
Add the activated amino acid solution to the resin and allow to react for 30-60 minutes. For the sterically demanding this compound, a double coupling may be beneficial to ensure high coupling efficiency.
-
-
Washing: Wash the resin with DMF and DCM.
-
Repeat Cycle: Repeat steps 2-5 for each subsequent amino acid in the sequence.
-
Final Deprotection: After the final coupling step, remove the N-terminal Fmoc group.
-
Cleavage and Global Deprotection: Wash the resin with DCM and dry under vacuum. Treat the resin with the cleavage cocktail for 2-3 hours to cleave the peptide from the resin and remove side-chain protecting groups.
-
Peptide Precipitation and Purification: Precipitate the crude peptide in cold diethyl ether, centrifuge, and wash the pellet. Purify the peptide by reverse-phase high-performance liquid chromatography (RP-HPLC).
Table 1: Representative SPPS Cycle Parameters
| Step | Reagent/Solvent | Time |
| Swelling | DMF | 30-60 min |
| Fmoc Deprotection | 20% Piperidine in DMF | 2 x 10 min |
| Washing | DMF | 5 x 1 min |
| Coupling | Fmoc-AA, HBTU, DIPEA in DMF | 30-60 min |
| Washing | DMF, DCM | 5 x 1 min |
Application: Stapled Peptide for Targeting a Pro-Survival Protein
Peptides containing this compound can be used to create hydrocarbon-stapled peptides to mimic α-helical domains involved in critical protein-protein interactions. A prominent example is the interaction between the pro-apoptotic BH3 domain and pro-survival B-cell lymphoma 2 (Bcl-2) family proteins, a key signaling node in apoptosis regulation.[3]
Experimental Workflow: Synthesis and Evaluation of a Stapled BH3 Peptide
The following workflow describes the generation of a stapled peptide designed to bind to a pro-survival Bcl-2 family member, thereby inducing apoptosis.
Caption: Workflow for the synthesis and evaluation of a stapled peptide.
Signaling Pathway Modulation: Inhibition of Mcl-1
Myeloid cell leukemia 1 (Mcl-1) is a pro-survival Bcl-2 family protein often overexpressed in cancer, making it an attractive therapeutic target. A stapled peptide mimicking the BH3 domain of a pro-apoptotic protein can bind to the hydrophobic groove of Mcl-1, displacing its natural binding partners and triggering apoptosis.
Caption: Modulation of the Mcl-1 signaling pathway by a stapled peptide.
Quantitative Data
The efficiency of incorporating unnatural amino acids can vary. The following table provides expected outcomes based on similar studies. Actual results should be determined empirically.
Table 2: Expected Quantitative Data for SPPS with this compound
| Parameter | Expected Value | Method of Determination |
| Coupling Efficiency | >95% (with double coupling) | Kaiser Test or Fmoc-release UV monitoring |
| Crude Peptide Purity | 70-85% | RP-HPLC |
| Final Purity (post-HPLC) | >98% | RP-HPLC |
| Overall Yield | 15-30% | Based on initial resin loading |
Conclusion
The incorporation of this compound into peptides via SPPS provides a powerful tool for developing novel peptide-based therapeutics and research probes. The protocols and application examples provided herein offer a solid foundation for researchers to explore the potential of this versatile unnatural amino acid in their own work. Careful optimization of coupling and cleavage conditions will be key to achieving high yields and purity of the final peptide products.
References
- 1. Hydrocarbon-Stapled Peptides: Principles, Practice, and Progress: Miniperspective - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Hydrocarbon Stapled & Constrained Peptides | AnaSpec [anaspec.com]
- 3. Chemical Synthesis of Hydrocarbon-Stapled Peptides for Protein Interaction Research and Therapeutic Targeting - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Frontiers | Screening of Hydrocarbon-Stapled Peptides for Inhibition of Calcium-Triggered Exocytosis [frontiersin.org]
- 5. chem.uci.edu [chem.uci.edu]
Application Notes and Protocols: Utilizing 2-Prop-2-en-1-ylhomoserine for Advanced Protein Engineering
For Researchers, Scientists, and Drug Development Professionals
The site-specific incorporation of non-canonical amino acids (ncAAs) into proteins represents a powerful strategy in protein engineering, enabling the introduction of novel chemical functionalities for a wide range of applications in research, diagnostics, and therapeutics. Among the diverse array of ncAAs, 2-Prop-2-en-1-ylhomoserine, commonly known as allylhomoserine, provides a versatile chemical handle for bioorthogonal conjugation. The terminal allyl group allows for highly specific chemical modifications of proteins, facilitating the attachment of probes, drugs, or other biomolecules without interfering with native biological processes.
These application notes provide a comprehensive overview of the methodologies for incorporating allylhomoserine into proteins and its subsequent application in protein engineering and drug development. Due to the limited availability of specific data for this compound, this document leverages protocols and data from the closely related and more extensively studied analogue, S-allyl-homocysteine, to provide a practical guide for researchers.
Data Summary
Quantitative data for the incorporation efficiency of unnatural amino acids can vary significantly based on the specific amino acid, the expression system, the engineered aminoacyl-tRNA synthetase (aaRS), and the protein of interest. The following table summarizes typical incorporation efficiencies and characterization data for proteins containing ncAAs, providing a general reference for expected outcomes.
| Parameter | Typical Values | Analytical Method(s) | Reference |
| Incorporation Efficiency | |||
| - In vivo (E. coli) | 20 - 80% | Mass Spectrometry, Western Blot | [1][2] |
| - In vitro (Cell-free) | >95% | Mass Spectrometry, SDS-PAGE | [3] |
| Protein Yield | 1 - 10 mg/L | SDS-PAGE, BCA/Bradford Assay | [4] |
| Mass Shift Confirmation | Expected mass ± 1 Da | Mass Spectrometry (ESI-MS, MALDI-TOF) | [1][5] |
| Bioorthogonal Reaction Yield | 40 - 90% | SDS-PAGE, Fluorescence Imaging, Mass Spectrometry | [6] |
Experimental Protocols
General Workflow for Site-Specific Incorporation of Allylhomoserine
The successful incorporation of allylhomoserine into a target protein at a specific site relies on the use of an orthogonal translation system. This system consists of an engineered aminoacyl-tRNA synthetase (aaRS) that specifically recognizes allylhomoserine and charges it onto an orthogonal tRNA, which in turn recognizes a unique codon (typically an amber stop codon, UAG) introduced at the desired site in the gene of interest.
Protocol for In Vivo Incorporation of Allylhomoserine in E. coli
This protocol is adapted from methodologies for incorporating methionine analogues and provides a starting point for expressing proteins containing allylhomoserine.[4][7]
Materials:
-
E. coli expression strain (e.g., BL21(DE3))
-
Expression vector containing the gene of interest with an amber stop codon at the desired position.
-
Plasmid encoding the engineered allylhomoserine-tRNA synthetase (AlHS) and its cognate orthogonal tRNA.
-
LB medium and M9 minimal medium.
-
This compound.
-
Appropriate antibiotics.
-
IPTG (Isopropyl β-D-1-thiogalactopyranoside).
Procedure:
-
Transformation: Co-transform the E. coli expression strain with the plasmid containing your gene of interest and the plasmid for the orthogonal aaRS/tRNA pair. Plate on LB agar with appropriate antibiotics and incubate overnight at 37°C.
-
Starter Culture: Inoculate a single colony into 5 mL of LB medium with antibiotics and grow overnight at 37°C with shaking.
-
Expression Culture: Inoculate 1 L of M9 minimal medium with the overnight culture to an initial OD600 of 0.05. Add the appropriate antibiotics.
-
Growth: Grow the culture at 37°C with shaking until the OD600 reaches 0.6-0.8.
-
Induction: Add this compound to a final concentration of 1 mM. Induce protein expression by adding IPTG to a final concentration of 0.5 mM.
-
Expression: Reduce the temperature to 18-25°C and continue to shake for 16-20 hours.[7]
-
Harvesting: Pellet the cells by centrifugation at 6,000 x g for 15 minutes at 4°C. Discard the supernatant. The cell pellet can be stored at -80°C or used immediately for purification.[8]
Characterization by Mass Spectrometry
Confirmation of allylhomoserine incorporation is crucial and is typically achieved through mass spectrometry.[5][9]
Procedure:
-
Sample Preparation: Purify the expressed protein using a suitable method (e.g., Ni-NTA affinity chromatography for His-tagged proteins).
-
Intact Mass Analysis:
-
Desalt the purified protein.
-
Analyze by ESI-MS or MALDI-TOF to determine the molecular weight of the intact protein. The observed mass should correspond to the theoretical mass of the protein with the incorporated allylhomoserine.
-
-
Peptide Mapping (for site-specific confirmation):
-
Denature, reduce, and alkylate the purified protein.
-
Digest the protein with a specific protease (e.g., trypsin).
-
Analyze the resulting peptide mixture by LC-MS/MS.
-
Identify the peptide containing the modification and confirm the mass shift corresponding to the incorporation of allylhomoserine at the amber codon position.
-
Bioorthogonal Conjugation: Thiol-Ene Reaction
The allyl group of the incorporated allylhomoserine can be specifically modified using a variety of bioorthogonal reactions. The thiol-ene reaction is a common method for conjugating thiol-containing molecules (e.g., fluorescent dyes, biotin, drugs) to the protein.[10]
References
- 1. Coupling Bioorthogonal Chemistries with Artificial Metabolism: Intracellular Biosynthesis of Azidohomoalanine and Its Incorporation into Recombinant Proteins [mdpi.com]
- 2. Quantitative analysis of tryptophan analogue incorporation in recombinant proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Site-specific incorporation of an unnatural amino acid into proteins in mammalian cells - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Step-by-Step Protocol for Optimizing Recombinant Protein Expression [synapse.patsnap.com]
- 5. m.youtube.com [m.youtube.com]
- 6. A Minimal, Unstrained S‐Allyl Handle for Pre‐Targeting Diels–Alder Bioorthogonal Labeling in Live Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Strategies to Optimize Protein Expression in E. coli - PMC [pmc.ncbi.nlm.nih.gov]
- 8. youtube.com [youtube.com]
- 9. youtube.com [youtube.com]
- 10. mdpi.com [mdpi.com]
Application Notes and Protocols: 2-Prop-2-en-1-ylhomoserine as a Bioorthogonal Probe for Enzyme Activity
For Researchers, Scientists, and Drug Development Professionals
These application notes describe the use of 2-Prop-2-en-1-ylhomoserine, also known as O-allylhomoserine, as a versatile chemical probe for monitoring the activity of specific enzymes. This non-canonical amino acid serves as a substrate for certain enzymes and contains a bioorthogonal allyl group. This functional handle allows for the subsequent chemical ligation of a reporter molecule, enabling the detection and quantification of enzymatic activity.
Two primary applications are detailed below:
-
Monitoring the activity of O-acetylhomoserine sulfhydrylase (OAHS) , a key enzyme in the methionine biosynthesis pathway.
-
Assessing the activity of engineered methionyl-tRNA synthetase (MetRS) for the incorporation of non-canonical amino acids into proteins.
Principle of Detection
The core principle behind using this compound as an enzyme probe is a two-step process. First, the enzyme of interest recognizes and processes the molecule. In the case of OAHS, it is a direct substrate. For MetRS, it can be charged onto a tRNA molecule. The second step involves the bioorthogonal inverse-electron-demand Diels-Alder (IEDDA) reaction between the allyl group of this compound and a tetrazine-conjugated reporter molecule (e.g., a fluorophore). This reaction is highly specific and occurs rapidly under physiological conditions, allowing for the sensitive detection of the enzymatic product.
Data Presentation
The following tables present illustrative quantitative data for the application of this compound as an enzyme probe.
Table 1: Hypothetical Kinetic Parameters of E. coli O-acetylhomoserine sulfhydrylase (OAHS) with this compound
| Substrate | KM (µM) | kcat (s-1) | kcat/KM (M-1s-1) |
| O-acetylhomoserine (native) | 150 | 25 | 1.67 x 105 |
| This compound | 450 | 15 | 3.33 x 104 |
Table 2: Illustrative Labeling Efficiency of an Engineered Methionyl-tRNA Synthetase (MetRS*) with this compound in a Cell-Based Assay
| Amino Acid | Concentration (µM) | Reporter Fluorophore | Mean Fluorescence Intensity (Arbitrary Units) |
| Methionine (control) | 100 | Tetrazine-FITC | 10.5 |
| This compound | 100 | Tetrazine-FITC | 850.7 |
| No Amino Acid (background) | - | Tetrazine-FITC | 5.2 |
Mandatory Visualizations
Caption: General workflow for enzyme activity detection.
Caption: Comparative experimental workflows.
Experimental Protocols
Protocol 1: In Vitro Activity Assay for O-acetylhomoserine sulfhydrylase (OAHS)
This protocol describes a continuous kinetic assay to determine the activity of purified OAHS using this compound as a substrate.
Materials:
-
Purified OAHS enzyme
-
This compound stock solution (100 mM in water)
-
Assay Buffer: 50 mM Tris-HCl, pH 7.5, 100 mM NaCl
-
Tetrazine-fluorophore conjugate (e.g., Tetrazine-FITC), 10 mM stock in DMSO
-
96-well black microplate
-
Microplate reader with fluorescence detection capabilities
Procedure:
-
Prepare the reaction mixture: In each well of the 96-well plate, prepare a 90 µL reaction mixture containing assay buffer and varying concentrations of this compound (e.g., from 10 µM to 2 mM).
-
Add the reporter: To each well, add 5 µL of the Tetrazine-FITC stock solution to a final concentration of 500 µM.
-
Initiate the reaction: Add 5 µL of a solution containing the purified OAHS enzyme to each well to initiate the reaction. The final enzyme concentration should be in the nanomolar range and determined empirically.
-
Monitor fluorescence: Immediately place the microplate in the plate reader and monitor the increase in fluorescence over time (e.g., every 30 seconds for 30 minutes). Use excitation and emission wavelengths appropriate for the chosen fluorophore (e.g., 490 nm excitation and 525 nm emission for FITC).
-
Data Analysis:
-
Calculate the initial reaction rates (V0) from the linear portion of the fluorescence increase curves.
-
Plot V0 against the substrate concentration.
-
Fit the data to the Michaelis-Menten equation to determine the KM and Vmax. Calculate kcat from Vmax and the enzyme concentration.
-
Protocol 2: Cell-Based Assay for Engineered Methionyl-tRNA Synthetase (MetRS*) Activity
This protocol outlines a method to assess the ability of an engineered MetRS to incorporate this compound into proteins in a cellular context.
Materials:
-
Mammalian cells expressing the engineered MetRS (MetRS*)
-
Complete cell culture medium
-
Methionine-free cell culture medium
-
This compound stock solution (100 mM in water)
-
Lysis Buffer: RIPA buffer with protease inhibitors
-
Tetrazine-fluorophore conjugate (e.g., Tetrazine-Alexa Fluor 647), 10 mM stock in DMSO
-
BCA Protein Assay Kit
-
SDS-PAGE gels and running buffer
-
In-gel fluorescence scanner
Procedure:
-
Cell Culture and Labeling:
-
Plate the MetRS*-expressing cells and grow to 70-80% confluency.
-
Wash the cells twice with PBS and replace the complete medium with methionine-free medium.
-
Incubate the cells in methionine-free medium for 1 hour to deplete intracellular methionine.
-
Replace the medium with methionine-free medium supplemented with 100 µM this compound. As a negative control, use methionine-free medium without any amino acid supplement. As a positive control for protein synthesis, use medium supplemented with 100 µM methionine.
-
Incubate the cells for 4-16 hours.
-
-
Cell Lysis:
-
Wash the cells twice with cold PBS.
-
Add an appropriate volume of Lysis Buffer and incubate on ice for 30 minutes.
-
Scrape the cells and collect the lysate. Clarify the lysate by centrifugation at 14,000 x g for 15 minutes at 4°C.
-
-
Protein Quantification: Determine the total protein concentration of the supernatant using a BCA Protein Assay Kit.
-
Bioorthogonal Labeling:
-
To 50 µg of total protein from each sample, add the Tetrazine-Alexa Fluor 647 to a final concentration of 100 µM.
-
Incubate the reaction at room temperature for 1 hour in the dark.
-
-
SDS-PAGE and Fluorescence Detection:
-
Add SDS-PAGE loading buffer to the labeled lysates and boil for 5 minutes.
-
Separate the proteins on an SDS-PAGE gel.
-
Scan the gel using an in-gel fluorescence scanner with appropriate laser and emission filter settings for the chosen fluorophore (e.g., Alexa Fluor 647).
-
The intensity of the fluorescent bands corresponding to newly synthesized proteins will be proportional to the activity of the engineered MetRS with this compound.
-
Application Notes and Protocols for Metabolic Labeling of Proteins with Homoserine Analogs
Introduction
The ability to specifically label and track proteins within a complex cellular environment is a cornerstone of modern biological research. Metabolic labeling, a powerful technique where cells are supplied with modified amino acids that are incorporated into newly synthesized proteins, offers a non-invasive and highly specific method for studying proteomes. This document provides detailed application notes and protocols for the metabolic labeling of proteins using non-canonical amino acid analogs of homoserine.
While specific literature on 2-Prop-2-en-1-ylhomoserine is not widely available, the principles and protocols outlined here are based on well-established methods using analogous compounds, such as azidohomoalanine (AHA) and other "clickable" amino acids.[1][2] The "2-Prop-2-en-1-yl" group, an allyl moiety, provides a bioorthogonal handle that can be chemically modified for protein detection and enrichment, similar to the azide and alkyne groups used in click chemistry.[3][4][5] These methods are invaluable for researchers, scientists, and drug development professionals seeking to monitor protein synthesis, identify protein subpopulations, and visualize protein dynamics in living systems.
Principle of the Method
The metabolic labeling of proteins with homoserine analogs is a two-step process that combines cellular metabolism with bioorthogonal chemistry.
-
Metabolic Incorporation: A non-canonical amino acid, which is an analog of a natural amino acid (in this case, homoserine is a precursor to methionine), is introduced to the cell culture media.[6] The cellular translational machinery recognizes this analog and incorporates it into newly synthesized proteins in place of the corresponding canonical amino acid.[1] For this to be successful, the analog must be non-toxic to the cells and be a substrate for the cell's aminoacyl-tRNA synthetases.[4]
-
Bioorthogonal Ligation ("Click Chemistry"): The incorporated non-canonical amino acid carries a small, inert chemical handle (the "bioorthogonal" group), such as an azide, alkyne, or in the case of this compound, an allyl group. This handle does not interfere with cellular processes. Following labeling, the cells are lysed, and the proteome is treated with a probe molecule containing a complementary reactive group. This probe can be a fluorophore for imaging, a biotin tag for affinity purification, or another molecule for specific applications.[1][7] The reaction between the bioorthogonal handle on the protein and the probe is highly specific and occurs under biocompatible conditions, a concept known as "click chemistry".[3][5]
Visualizing the Workflow
Caption: A diagram illustrating the workflow of metabolic protein labeling.
Application Notes
Advantages of Metabolic Labeling with Homoserine Analogs:
-
High Specificity: Only newly synthesized proteins are labeled, allowing for the study of dynamic changes in the proteome.
-
Minimal Perturbation: The small size of the bioorthogonal handle is less likely to affect protein structure and function compared to larger tags like GFP.[5]
-
Versatility: A wide range of reporter tags can be attached, enabling various downstream applications from the same labeled sample.
-
Temporal Control: The labeling window can be precisely controlled by the duration of exposure to the non-canonical amino acid.
Experimental Considerations:
-
Choice of Analog: The ideal analog should be efficiently incorporated into proteins without significant toxicity. It is crucial to perform dose-response and viability assays.
-
Labeling Media: For efficient incorporation, it is often necessary to use media depleted of the corresponding natural amino acid (e.g., methionine-free media for AHA labeling).
-
Click Reaction Conditions: The copper catalyst used in the popular Copper-Catalyzed Azide-Alkyne Cycloaddition (CuAAC) can be toxic to cells, so this reaction is typically performed on fixed cells or cell lysates.[3] For live-cell imaging, Strain-Promoted Azide-Alkyne Cycloaddition (SPAAC), which does not require a copper catalyst, is preferred.[3] If using an allyl-containing amino acid, a suitable bioorthogonal reaction such as thiol-ene coupling would be employed, often initiated by UV light.
Applications in Research and Drug Development:
-
Monitoring Global Protein Synthesis: Quantifying the rate of new protein synthesis in response to stimuli, stress, or drug treatment.
-
Proteome Profiling: Identifying and quantifying newly synthesized proteins using mass spectrometry (a technique often referred to as BONCAT - Bioorthogonal Non-Canonical Amino Acid Tagging).[1]
-
Visualization of Protein Localization: Tracking the location of newly synthesized proteins within cells or tissues.
-
Target Engagement Studies: Assessing how a drug affects the synthesis of specific proteins.
Experimental Protocols
The following are generalized protocols for metabolic labeling in mammalian cell culture. These should be optimized for your specific cell line and experimental goals.
Protocol 1: Metabolic Labeling of Proteins in Cell Culture
-
Cell Seeding: Plate mammalian cells on an appropriate culture vessel (e.g., multi-well plates, coverslips for imaging) and grow to the desired confluency (typically 70-80%).
-
Media Preparation: Prepare methionine-free DMEM (or other appropriate base medium). For labeling, supplement this medium with dialyzed fetal bovine serum (dFBS) to minimize the concentration of free methionine.
-
Starvation (Optional but Recommended): Gently wash the cells with pre-warmed PBS. Replace the standard growth medium with methionine-free medium and incubate for 30-60 minutes to deplete intracellular methionine pools.
-
Labeling: Replace the starvation medium with freshly prepared labeling medium containing the desired concentration of the homoserine analog (e.g., 25-100 µM of AHA). The optimal concentration and labeling time (typically 1-24 hours) should be determined empirically.
-
Cell Lysis or Fixation:
-
For Lysis: Wash cells twice with cold PBS. Add lysis buffer (e.g., RIPA buffer with protease inhibitors) and incubate on ice for 30 minutes. Scrape the cells and centrifuge to pellet cell debris. Collect the supernatant containing the labeled proteome.
-
For Imaging: Wash cells with PBS and proceed with fixation using 4% paraformaldehyde in PBS for 15 minutes at room temperature.[7]
-
Protocol 2: Click Chemistry Reaction for Protein Visualization (on Fixed Cells)
This protocol assumes labeling with an azide-containing amino acid like AHA and detection with an alkyne-fluorophore.
-
Permeabilization: After fixation, wash the cells twice with PBS. Permeabilize with 0.25% Triton X-100 in PBS for 15 minutes.[7]
-
Click Reaction Cocktail Preparation: Prepare the click reaction cocktail immediately before use. For a 500 µL reaction, mix:
-
3 µM alkyne-fluorophore
-
1 mM CuSO₄
-
10 mM sodium ascorbate (prepare fresh)
-
Buffer (e.g., PBS)
-
-
Click Reaction: Wash the cells with 3% BSA in PBS. Add the click reaction cocktail to the cells and incubate for 30-60 minutes at room temperature, protected from light.
-
Washing and Staining: Wash the cells three times with PBS. If desired, counterstain nuclei with DAPI.
-
Imaging: Mount the coverslips and visualize using fluorescence microscopy.
Visualizing the Chemistry
References
- 1. info.gbiosciences.com [info.gbiosciences.com]
- 2. Synthesis of the functionalizable methionine surrogate azidohomoalanine using Boc-homoserine as precursor [authors.library.caltech.edu]
- 3. Click Chemistry in Proteomic Investigations - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Click Chemistry – Med Chem 101 [medchem101.com]
- 5. Frontiers | Specific and quantitative labeling of biomolecules using click chemistry [frontiersin.org]
- 6. Multiplex Design of the Metabolic Network for Production of l-Homoserine in Escherichia coli - PMC [pmc.ncbi.nlm.nih.gov]
- 7. documents.thermofisher.com [documents.thermofisher.com]
Application Notes and Protocols: Click Chemistry Applications of Allyl-Containing Amino Acids
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive overview of the use of allyl-containing amino acids in click chemistry, a powerful tool for bioconjugation, drug development, and materials science. The unique reactivity of the allyl group, particularly in thiol-ene "click" reactions, allows for efficient and specific modification of peptides and proteins under mild conditions.[1][2][3] This document details the synthesis of key building blocks, their incorporation into peptides, and various applications with detailed experimental protocols.
Introduction to Allyl-Containing Amino Acids in Click Chemistry
Allyl-containing amino acids are non-canonical amino acids that feature a terminal alkene functionality. This functional group serves as a versatile handle for a variety of chemical modifications, most notably the photoinitiated thiol-ene "click" reaction.[1][4] This reaction proceeds via a radical-mediated addition of a thiol to the alkene, forming a stable thioether linkage.[2] The reaction is characterized by its high efficiency, rapid kinetics, and orthogonality to many other functional groups found in biological systems, making it an ideal tool for bioconjugation.[2][5]
Commonly used allyl-containing amino acids include L-allylglycine and derivatives where the allyl group is attached to the side chain of other amino acids, such as through an allyloxycarbonyl (Alloc) protecting group on lysine.[4] These amino acids can be readily incorporated into peptide sequences using standard solid-phase peptide synthesis (SPPS) techniques.[6]
Applications
The versatility of the thiol-ene click reaction with allyl-containing amino acids has led to a wide range of applications in peptide and protein chemistry.
Peptide Cyclization
Cyclic peptides often exhibit enhanced metabolic stability and receptor binding affinity compared to their linear counterparts. The on-resin cyclization of peptides containing both a cysteine residue (as the thiol source) and an allyl-containing amino acid is a highly efficient method for creating cyclic peptides.[1][4][6] This intramolecular thiol-ene reaction can be initiated by UV light in the presence of a photoinitiator, leading to rapid and high-yielding cyclization.[4][7]
Bioconjugation and Surface Modification
The allyl group provides a specific site for the conjugation of various molecules to peptides, including fluorescent dyes, imaging agents, and drug molecules.[8][9][10] This allows for the targeted delivery of therapeutics and the development of diagnostic tools. Furthermore, peptides functionalized with allyl groups can be immobilized on surfaces modified with thiols, enabling the creation of bioactive materials for cell culture and biosensor applications.
Hydrogel Formation
Peptides containing multiple allyl groups can be crosslinked with dithiol-containing molecules to form hydrogels.[5][11] These hydrogels are useful for 3D cell culture, tissue engineering, and controlled drug release applications.[3][5][11][12] The formation of the hydrogel can be controlled by light, allowing for spatiotemporal control over its properties.[5][11]
Peptide Stapling
"Stapled" peptides are synthetic peptides in which the secondary structure (e.g., an alpha-helix) is constrained by a synthetic brace. This can enhance the peptide's cell permeability and target affinity. Thiol-ene click chemistry can be used to create this brace by reacting a cysteine residue with an allyl-containing amino acid incorporated at a specific distance within the peptide sequence.
Quantitative Data
The following tables summarize quantitative data from various studies on the efficiency of thiol-ene click reactions involving allyl-containing amino acids.
Table 1: On-Resin Peptide Cyclization Yields via Thiol-Ene Reaction
| Peptide Sequence | Alkene Source | Reaction Time | Yield (%) | Reference |
| Ac-Cys-Ala-Lys(Alloc)-Ala-Ala-NH2 | Lys(Alloc) | 20 min | 24 | [2] |
| Ac-Cys-Ala-Lys(Norbornene)-Ala-Ala-NH2 | Lys(Norbornene) | 20 min | 37 | [2] |
| H-Cys(Trt)-Ala-Gly-AllylGly-Ala-NH-Resin | Allylglycine | 1 h | ~70 | [7] |
| H-Cys(Trt)-Ala-Gly-A6c-Ala-NH-Resin | 6-aminohexenoic acid | 1 h | ~70 | [7] |
Table 2: Thiol-Ene Modification of Allylglycine-Containing Peptides
| Peptide | Thiol Reagent | Reaction Conditions | Conversion/Yield (%) | Reference |
| Ac-Ala-AllylGly-Ala-NH2 | Thioacetic acid | DPAP, UV (365 nm), DMF | >95 (Conversion) | [8] |
| Ac-Ala-AllylGly-Ala-NH2 | Boc-Cys-OH | DPAP, UV (365 nm), DMF | >90 (Yield) | [2] |
| GSH | Allyl alcohol | DPAP, UV, DMF/H2O | 81 (Isolated Yield) | [2] |
| RGD-peptide | Thiolated PEG | Irgacure 2959, UV, DES:H2O | 62 (Isolated Yield) | [13] |
Experimental Protocols
Synthesis of Fmoc-L-allylglycine
This protocol describes the synthesis of Fmoc-L-allylglycine, a key building block for incorporating an allyl group into peptides.
Materials:
-
L-allylglycine
-
9-fluorenylmethyl-N-succinimidyl carbonate (Fmoc-OSu)
-
Sodium bicarbonate (NaHCO3)
-
Acetone
-
Water
-
Concentrated hydrochloric acid (HCl)
-
Dichloromethane (DCM)
-
Magnesium sulfate (MgSO4)
Procedure:
-
Dissolve L-allylglycine and sodium bicarbonate in a mixture of acetone and water.
-
Add Fmoc-OSu to the solution while stirring.
-
Stir the resulting white suspension at room temperature for 20 hours.
-
Monitor the reaction completion by thin-layer chromatography (TLC).
-
Acidify the reaction mixture to pH 2 with concentrated HCl.
-
Remove acetone under reduced pressure.
-
Extract the aqueous suspension with DCM.
-
Combine the organic phases, wash with dilute HCl and water, and dry over MgSO4.
-
Concentrate the solution under reduced pressure to obtain Fmoc-L-allylglycine as a colorless solid.[14]
Solid-Phase Peptide Synthesis (SPPS) with Allylglycine
This protocol outlines the general workflow for incorporating allylglycine into a peptide sequence using Fmoc-based SPPS.
Workflow Diagram:
Caption: Standard Fmoc-SPPS workflow for peptide synthesis.
Procedure:
-
Resin Swelling: Swell the appropriate resin (e.g., Rink Amide resin) in dimethylformamide (DMF) for 1 hour.[15]
-
Fmoc Deprotection: Remove the Fmoc protecting group from the resin-bound amino acid by treating with 20% piperidine in DMF for 7 minutes.[15]
-
Washing: Wash the resin thoroughly with DMF to remove excess piperidine and byproducts.[15]
-
Amino Acid Coupling: Activate Fmoc-L-allylglycine with a coupling reagent (e.g., HCTU) and a base (e.g., DIPEA) in DMF and add it to the resin. Allow the coupling reaction to proceed for at least 4 hours.[15]
-
Washing: Wash the resin with DMF to remove unreacted reagents.
-
Repeat: Repeat steps 2-5 for each subsequent amino acid in the peptide sequence.
-
Cleavage and Deprotection: Once the synthesis is complete, cleave the peptide from the resin and remove the side-chain protecting groups using a cleavage cocktail, typically containing trifluoroacetic acid (TFA).[16]
-
Purification: Purify the crude peptide using reverse-phase high-performance liquid chromatography (RP-HPLC).
On-Resin Peptide Cyclization via Thiol-Ene Click Chemistry
This protocol describes the cyclization of a peptide containing both cysteine and an allyl-containing amino acid on the solid support.
Workflow Diagram:
References
- 1. On-resin peptide macrocyclization using thiol–ene click chemistry - Chemical Communications (RSC Publishing) [pubs.rsc.org]
- 2. Applications of Thiol-Ene Chemistry for Peptide Science - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Click Chemistry-Based Injectable Hydrogels and Bioprinting Inks for Tissue Engineering Applications - PMC [pmc.ncbi.nlm.nih.gov]
- 4. On-resin peptide macrocyclization using thiol-ene click chemistry - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Design of thiol–ene photoclick hydrogels using facile techniques for cell culture applications - Biomaterials Science (RSC Publishing) [pubs.rsc.org]
- 6. On-resin peptide macrocyclization using thiol-ene click chemistry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Frontiers | Applications of Thiol-Ene Chemistry for Peptide Science [frontiersin.org]
- 8. An Efficient Thiol‐ene Mediated Protocol for Thiolated Peptide Synthesis and On‐Resin Diversification - PMC [pmc.ncbi.nlm.nih.gov]
- 9. cpcscientific.com [cpcscientific.com]
- 10. qyaobio.com [qyaobio.com]
- 11. Design of thiol–ene photoclick hydrogels using facile techniques for cell culture applications - PMC [pmc.ncbi.nlm.nih.gov]
- 12. kinampark.com [kinampark.com]
- 13. researchgate.net [researchgate.net]
- 14. (S)-N-Fmoc-Allylglycine synthesis - chemicalbook [chemicalbook.com]
- 15. chem.uci.edu [chem.uci.edu]
- 16. mdpi.com [mdpi.com]
Protocols for N-Alkylation of Amino Acids in Peptide Synthesis: Application Notes
For Researchers, Scientists, and Drug Development Professionals
Introduction
N-alkylation of amino acids is a crucial modification in peptide synthesis, offering a powerful tool to enhance the therapeutic properties of peptide-based drugs. Introducing alkyl groups to the nitrogen atom of the peptide backbone can significantly improve metabolic stability, membrane permeability, and conformational rigidity, leading to peptides with increased oral bioavailability and enhanced biological activity. This document provides detailed application notes and protocols for several common methods of N-alkylation of amino acids used in peptide synthesis.
Reductive Amination
Reductive amination is a widely employed method for the N-alkylation of the N-terminal amino acid of a peptide on a solid support. This two-step process involves the formation of a Schiff base intermediate by reacting the primary amine of the peptide with an aldehyde or ketone, followed by reduction of the imine to a secondary amine.
Quantitative Data Summary
| Alkyl Group | Aldehyde/Ketone | Reducing Agent | Solvent | Reaction Time | Yield (%) | Purity (%) |
| Methyl | Formaldehyde | NaBH(OAc)₃ | 1% AcOH in DMF | 2 x 30 min | >90 | High |
| Isobutyl | Isobutyraldehyde | NaBH(OAc)₃ | 1% AcOH in DMF | 2 x 30 min | >90 | High |
| Benzyl | Benzaldehyde | NaBH(OAc)₃ | 1% AcOH in DMF | 2 x 30 min | >90 | High |
Experimental Protocol: On-Resin Reductive Amination
-
Resin Swelling: Swell the peptide-bound resin (e.g., Rink amide resin) in N,N-dimethylformamide (DMF) for 1 hour.
-
Fmoc-Deprotection: Remove the N-terminal Fmoc protecting group by treating the resin with 20% piperidine in DMF (2 x 10 min).
-
Washing: Wash the resin thoroughly with DMF (5 x 1 min) and dichloromethane (DCM) (3 x 1 min).
-
Schiff Base Formation and Reduction:
-
Prepare a solution of the aldehyde (10 equivalents) in 1% acetic acid in DMF.
-
Add the aldehyde solution to the resin, followed by the addition of sodium triacetoxyborohydride (NaBH(OAc)₃, 10 equivalents).
-
Shake the reaction mixture at room temperature for 30 minutes.
-
Repeat the addition of the aldehyde and reducing agent and shake for another 30 minutes.
-
-
Washing: Wash the resin with DMF (5 x 1 min), methanol (3 x 1 min), and DCM (3 x 1 min).
-
Confirmation of Alkylation: Perform a Kaiser test to confirm the absence of primary amines. A negative Kaiser test (yellow beads) indicates successful alkylation.
-
Peptide Elongation: Proceed with the coupling of the next amino acid.
Workflow Diagram
Caption: Workflow for on-resin reductive amination.
Alkylation with Alkyl Halides
Direct alkylation of the peptide backbone with alkyl halides is a classical approach. This method is often performed on a protected peptide to avoid side reactions with other nucleophilic side chains. The use of a suitable base is crucial for the deprotonation of the amide nitrogen.
Quantitative Data Summary
| Alkyl Halide | Base | Solvent | Temperature (°C) | Reaction Time (h) | Yield (%) |
| Methyl Iodide | Ag₂O | DMF | 25 | 24 | 93-98[1] |
| Ethyl Iodide | DBU | DMF | 25 | 1 | High[2][3] |
| Benzyl Bromide | K₂CO₃ | DMF | 25 | 12 | 86[1] |
Experimental Protocol: On-Resin N-Alkylation with Methyl Iodide
-
Resin Preparation: Start with the peptide-bound resin with the N-terminus protected (e.g., with a Boc group) and side chains protected as necessary.
-
Swelling: Swell the resin in DMF for 1 hour.
-
Alkylation Reaction:
-
Add a solution of methyl iodide (10 equivalents) in DMF to the resin.
-
Add silver oxide (Ag₂O, 5 equivalents) to the suspension.
-
Shake the reaction mixture at room temperature for 24 hours in the dark.
-
-
Washing: Wash the resin thoroughly with DMF (5 x 1 min), DCM (3 x 1 min), and methanol (3 x 1 min).
-
Deprotection and Cleavage: Proceed with the standard deprotection and cleavage protocols to obtain the N-alkylated peptide.
Logical Relationship Diagram
Caption: Key components for N-alkylation with alkyl halides.
Fukuyama-Mitsunobu Reaction
The Fukuyama-Mitsunobu reaction is a mild and efficient method for the N-alkylation of sulfonamides, which can be readily adapted for peptide synthesis on a solid support. This method involves the activation of an alcohol with a phosphine and a dialkyl azodicarboxylate to facilitate the alkylation of a 2-nitrobenzenesulfonyl (o-NBS) protected amine.
Quantitative Data Summary
| Alcohol | Phosphine | Azodicarboxylate | Solvent | Reaction Time | Yield (%) |
| Methanol | PPh₃ | DEAD | THF/DCM | 10 min | High[4] |
| Ethanol | PPh₃ | DEAD | THF/DCM | 10 min | High[4] |
| Isopropanol | PPh₃ | DEAD | THF/DCM | 20 min | Moderate[4] |
Experimental Protocol: On-Resin Fukuyama-Mitsunobu N-Alkylation
-
o-NBS Protection:
-
Mitsunobu Reaction:
-
Swell the o-NBS protected resin in a 1:1 mixture of tetrahydrofuran (THF) and DCM.
-
In a separate flask, dissolve triphenylphosphine (PPh₃, 5 equivalents) and the desired alcohol (10 equivalents) in THF/DCM.
-
Slowly add diethyl azodicarboxylate (DEAD, 5 equivalents) to the solution at 0°C.
-
Add the pre-activated solution to the resin and shake for 10-20 minutes at room temperature.[4]
-
-
Washing: Wash the resin with THF, DCM, and DMF.
-
o-NBS Deprotection:
-
Treat the resin with a solution of 2-mercaptoethanol (10 equivalents) and 1,8-diazabicyclo[5.4.0]undec-7-ene (DBU, 5 equivalents) in DMF for 2 x 5 minutes.
-
-
Washing: Wash the resin with DMF and DCM.
-
Peptide Elongation: Proceed with the coupling of the next amino acid.
Experimental Workflow Diagram
Caption: Workflow for on-resin Fukuyama-Mitsunobu N-alkylation.
Direct Catalytic N-Alkylation with Alcohols
A greener and more atom-economical approach to N-alkylation involves the direct coupling of unprotected amino acids with alcohols, catalyzed by transition metal complexes (e.g., Ruthenium or Iridium).[6][7] This method produces water as the only byproduct and often proceeds with high selectivity and retention of stereochemistry.[2][6][8][9][10][11]
Quantitative Data Summary
| Amino Acid | Alcohol | Catalyst | Solvent | Temperature (°C) | Reaction Time (h) | Yield (%) |
| Proline | Ethanol | Ru-complex | Neat | 90 | 18 | >99[6] |
| Glycine | 1-Nonanol | Ru-complex | Toluene | 110 | 18 | >90[6] |
| Phenylalanine | 1-Butanol | Ru-complex | Toluene | 110 | 18 | 85[6] |
Experimental Protocol: Catalytic N-Alkylation of an Unprotected Amino Acid
-
Reaction Setup: In a dry Schlenk tube under an argon atmosphere, add the unprotected amino acid (1 mmol), the Ruthenium catalyst (e.g., Shvo's catalyst, 0.01 mmol, 1 mol%), and the alcohol (10 mmol).
-
Reaction: Heat the reaction mixture at the specified temperature (e.g., 90-110°C) with stirring for 18 hours.
-
Work-up:
-
Cool the reaction mixture to room temperature.
-
If the alcohol is volatile, remove it under reduced pressure.
-
If the product precipitates, it can be isolated by filtration. Otherwise, standard purification techniques like column chromatography may be employed.
-
Signaling Pathway Analogy Diagram
References
- 1. research.rug.nl [research.rug.nl]
- 2. researchgate.net [researchgate.net]
- 3. researchgate.net [researchgate.net]
- 4. researchgate.net [researchgate.net]
- 5. researchgate.net [researchgate.net]
- 6. Direct N-alkylation of unprotected amino acids with alcohols - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Solid-Phase Synthesis of Diverse Peptide Tertiary Amides By Reductive Amination - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Synthesis of N-methylated peptides: on-resin methylation and microwave-assisted couplings - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Synthesis of N-Methylated Peptides: On-Resin Methylation and Microwave-Assisted Couplings | Springer Nature Experiments [experiments.springernature.com]
- 10. Direct N-alkylation of unprotected amino acids with alcohols - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. books.rsc.org [books.rsc.org]
Application Notes and Protocols: Site-Specific Incorporation of Unnatural Amino Acids into Proteins
Audience: Researchers, scientists, and drug development professionals.
Introduction
The ability to incorporate unnatural amino acids (Uaas) at specific sites within a protein sequence represents a powerful tool in protein engineering and drug development.[][2][3] This technology, often referred to as genetic code expansion, allows for the introduction of novel chemical functionalities, biophysical probes, and post-translational modifications into proteins.[3][4] By expanding the canonical 20 amino acid alphabet, researchers can enhance protein stability, modulate enzymatic activity, and create proteins with novel therapeutic properties.[][5]
The most established method for site-specific Uaa incorporation is through the use of an orthogonal aminoacyl-tRNA synthetase (aaRS) and its cognate transfer RNA (tRNA) pair.[6][7][8] This orthogonal system functions independently of the host cell's translational machinery and is engineered to recognize a specific Uaa and a unique codon, typically a nonsense or frameshift codon, that has been introduced into the gene of interest.[6][7] This application note will provide a detailed overview of the methodologies, key components, and applications of this technology, along with comprehensive experimental protocols.
Methodologies for Uaa Incorporation
Several methods have been developed for the site-specific incorporation of Uaas. The most common are amber suppression and frameshift suppression.
-
Amber Suppression: This technique utilizes the amber stop codon (UAG) to encode the Uaa.[7][9] An orthogonal aaRS/tRNA pair is introduced into the host cell, where the tRNA has been engineered to recognize the UAG codon (tRNACUA).[7][9] When the ribosome encounters the UAG codon in the mRNA, the acylated tRNACUA delivers the Uaa, allowing for the continuation of translation and the incorporation of the Uaa into the polypeptide chain.[7][9] A primary challenge with this method is the competition between the suppressor tRNA and the endogenous release factor 1 (RF1), which also recognizes the amber codon and can lead to premature termination of translation.[9]
-
Frameshift Suppression: This method employs a four-base (quadruplet) codon to direct the incorporation of the Uaa.[10][11] An orthogonal tRNA with a corresponding four-base anticodon reads the quadruplet codon, causing a ribosomal frameshift and allowing for the insertion of the Uaa.[10] This strategy is advantageous as it can be used to incorporate multiple different Uaas into the same protein by using distinct quadruplet codons and corresponding orthogonal pairs.[10][11]
Key Components of the Uaa Incorporation System
The successful site-specific incorporation of a Uaa relies on three key components:
-
Orthogonal Aminoacyl-tRNA Synthetase (aaRS): This enzyme is responsible for specifically recognizing and attaching the Uaa to its cognate tRNA.[6] The aaRS must be "orthogonal," meaning it does not recognize any of the host cell's endogenous tRNAs or amino acids.[6][8]
-
Orthogonal tRNA: This tRNA is engineered to be recognized exclusively by the orthogonal aaRS and to decode a specific codon (e.g., the amber codon UAG).[6][8] It should not be aminoacylated by any of the host's endogenous aaRSs.[6]
-
Target Protein Expression Vector: The gene encoding the protein of interest must be mutated to introduce the desired codon (e.g., an amber codon) at the site of Uaa incorporation.[12]
Quantitative Data Summary
The efficiency and fidelity of Uaa incorporation can vary depending on the specific Uaa, the orthogonal pair, the expression system, and the location of the incorporation site. The following tables summarize representative quantitative data from the literature.
Table 1: Comparison of Uaa Incorporation Efficiencies in E. coli
| Unnatural Amino Acid | Orthogonal System | Reporter Protein | Incorporation Efficiency (%) | Reference |
| p-Azido-L-phenylalanine (pAzF) | MjTyrRS/tRNATyrCUA | Superfolder GFP | ~50 | [13] |
| p-Benzoyl-L-phenylalanine (pBpa) | MjTyrRS/tRNATyrCUA | Myoglobin | ~40 | [14] |
| Nε-acetyl-L-lysine (AcK) | MbPylRS/tRNAPylCUA | sfGFP | ~60 | [15] |
Table 2: Comparison of Uaa Incorporation Efficiencies in Mammalian Cells
| Unnatural Amino Acid | Orthogonal System | Reporter Protein | Incorporation Efficiency (%) | Reference |
| 3-iodo-L-tyrosine | EcTyrRS/BsttRNATyrCUA | Ras protein | ~25 | [16] |
| p-Azido-L-phenylalanine (pAzF) | MjTyrRS/tRNATyrCUA | GFP | Up to 1 µg per 2x107 cells | [17][18] |
| Nε-tert-Boc-lysine (eBK) | MbPylRS/MmtRNAPylCUA | EGFP | High | [19] |
Experimental Protocols
Protocol 1: Site-Specific Incorporation of p-Azido-L-phenylalanine (pAzF) in E. coli
This protocol describes the incorporation of the photo-crosslinkable Uaa, p-Azido-L-phenylalanine (pAzF), into a target protein in E. coli using an evolved Methanocaldococcus jannaschii tyrosyl-tRNA synthetase (MjTyrRS)/tRNA pair.
Materials:
-
E. coli expression strain (e.g., BL21(DE3))
-
Expression plasmid for the target protein with an in-frame amber (TAG) codon at the desired position.
-
Plasmid encoding the orthogonal MjTyrRS-pAzF variant and the MjtRNATyrCUA (e.g., pEVOL-pAzF).
-
LB medium and agar plates with appropriate antibiotics.
-
p-Azido-L-phenylalanine (pAzF).
-
Isopropyl β-D-1-thiogalactopyranoside (IPTG).
-
Arabinose.
Methodology:
-
Transformation: Co-transform the E. coli expression strain with the target protein plasmid and the pEVOL-pAzF plasmid. Plate on LB agar with appropriate antibiotics and incubate overnight at 37°C.
-
Starter Culture: Inoculate a single colony into 5 mL of LB medium with antibiotics and grow overnight at 37°C with shaking.
-
Expression Culture: Inoculate 500 mL of LB medium with the overnight culture to an initial OD600 of 0.05. Add pAzF to a final concentration of 1 mM.
-
Induction: Grow the culture at 37°C with shaking to an OD600 of 0.6-0.8. Induce the expression of the orthogonal pair with 0.02% arabinose and the target protein with 1 mM IPTG.
-
Protein Expression: Reduce the temperature to 20-25°C and continue to shake for 16-20 hours.
-
Cell Harvesting and Lysis: Harvest the cells by centrifugation. Resuspend the cell pellet in lysis buffer and lyse the cells by sonication or high-pressure homogenization.
-
Protein Purification: Purify the target protein from the cell lysate using appropriate chromatography techniques (e.g., Ni-NTA affinity chromatography for His-tagged proteins).
-
Verification of Incorporation: Confirm the incorporation of pAzF by mass spectrometry.
Protocol 2: Site-Specific Incorporation of a Uaa in Mammalian Cells
This protocol outlines a general procedure for incorporating a Uaa into a target protein expressed in mammalian cells.[12]
Materials:
-
Mammalian cell line (e.g., HEK293T, CHO).
-
Expression vector for the target protein with an in-frame amber codon.
-
Expression vector for the orthogonal aaRS/tRNA pair.
-
Transfection reagent (e.g., Lipofectamine 2000).
-
Cell culture medium (e.g., DMEM) supplemented with fetal bovine serum (FBS) and antibiotics.
-
Unnatural amino acid.
Methodology:
-
Cell Seeding: Seed the mammalian cells in a multi-well plate or flask at an appropriate density to reach 70-90% confluency at the time of transfection.
-
Transfection: Co-transfect the cells with the target protein expression vector and the orthogonal pair expression vector using a suitable transfection reagent according to the manufacturer's protocol.[16]
-
Uaa Supplementation: After 4-6 hours of transfection, replace the medium with fresh medium containing the Uaa at a final concentration of 0.5-1 mM.
-
Protein Expression: Incubate the cells for 48-72 hours to allow for protein expression.
-
Cell Lysis: Wash the cells with PBS and lyse them using a suitable lysis buffer.
-
Protein Analysis: Analyze the expression of the full-length target protein containing the Uaa by Western blotting using an antibody against the protein or an epitope tag.
-
Protein Purification (Optional): For larger-scale expression, purify the protein using affinity chromatography.
-
Verification of Incorporation: Confirm the incorporation of the Uaa by mass spectrometry.
Visualizations
Caption: Workflow for site-specific Uaa incorporation.
Caption: Mechanism of amber suppression for Uaa incorporation.
References
- 2. Protein engineering with unnatural amino acids - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Reprogramming natural proteins using unnatural amino acids - RSC Advances (RSC Publishing) DOI:10.1039/D1RA07028B [pubs.rsc.org]
- 4. The use of unnatural amino acids to study and engineer protein function - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. portlandpress.com [portlandpress.com]
- 6. pnas.org [pnas.org]
- 7. mdpi.com [mdpi.com]
- 8. Rapid discovery and evolution of orthogonal aminoacyl-tRNA synthetase–tRNA pairs - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Frontiers | Unnatural amino acid incorporation in E. coli: current and future applications in the design of therapeutic proteins [frontiersin.org]
- 10. pubs.acs.org [pubs.acs.org]
- 11. In vivo incorporation of multiple unnatural amino acids through nonsense and frameshift suppression - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Site-specific incorporation of non-natural amino acids into proteins in mammalian cells with an expanded genetic code - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. Efficient Incorporation of Unnatural Amino Acids into Proteins with a Robust Cell-Free System - PMC [pmc.ncbi.nlm.nih.gov]
- 14. researchgate.net [researchgate.net]
- 15. pubs.acs.org [pubs.acs.org]
- 16. academic.oup.com [academic.oup.com]
- 17. Genetic incorporation of unnatural amino acids into proteins in mammalian cells | Springer Nature Experiments [experiments.springernature.com]
- 18. Genetic incorporation of unnatural amino acids into proteins in mammalian cells. [vivo.weill.cornell.edu]
- 19. Genetic Incorporation of Multiple Unnatural Amino Acids into Proteins in Mammalian Cells - PMC [pmc.ncbi.nlm.nih.gov]
Synthesis and Evaluation of N-Acyl-Homoserine Lactone (AHL) Analogs for Quorum Sensing Modulation
Application Notes and Protocols for Researchers in Microbiology and Drug Development
These application notes provide a comprehensive guide for the synthesis and biological evaluation of N-acyl-homoserine lactone (AHL) analogs as modulators of bacterial quorum sensing (QS). This document is intended for researchers, scientists, and drug development professionals interested in the discovery of novel anti-infective agents that target bacterial communication.
Introduction to Quorum Sensing and N-Acyl-Homoserine Lactones
Quorum sensing is a cell-to-cell communication process that bacteria use to coordinate gene expression in response to population density. In many Gram-negative bacteria, this communication is mediated by small signaling molecules called N-acyl-homoserine lactones (AHLs).[1] AHLs consist of a conserved homoserine lactone ring linked to an acyl side chain of varying length and substitution.[1] The biosynthesis of AHLs is catalyzed by LuxI-type synthases, and their detection is mediated by LuxR-type transcriptional regulators.[1] Upon binding to its cognate AHL, the LuxR-type receptor activates the transcription of target genes, often including those responsible for virulence factor production, biofilm formation, and antibiotic resistance. The disruption of QS signaling, a strategy known as quorum quenching, is a promising approach for the development of novel antimicrobial therapies that are less likely to induce resistance compared to traditional antibiotics.
Synthesis of N-Acyl-Homoserine Lactone Analogs
The synthesis of AHL analogs is a crucial step in the exploration of structure-activity relationships and the development of potent QS modulators. A common and effective method for synthesizing a diverse library of AHL analogs is the acylation of the L-homoserine lactone core.
General Protocol for the Synthesis of N-Acyl-Homoserine Lactone Analogs
This protocol describes a general method for the synthesis of AHL analogs by reacting L-homoserine lactone hydrobromide with an appropriate acylating agent, such as an acid chloride, under Schotten-Baumann conditions.[2][3]
Materials:
-
L-homoserine lactone hydrobromide
-
Desired acid chloride (e.g., 4-bromophenylacetyl chloride)
-
Sodium bicarbonate (NaHCO₃)
-
Dichloromethane (DCM)
-
Water (H₂O)
-
Magnesium sulfate (MgSO₄)
-
Silica gel for column chromatography
-
Ethyl acetate and hexanes for chromatography
Procedure:
-
Dissolution: Dissolve L-homoserine lactone hydrobromide (1 equivalent) in a saturated aqueous solution of sodium bicarbonate.
-
Addition of Acylating Agent: To the vigorously stirred solution, add a solution of the desired acid chloride (1.1 equivalents) in dichloromethane dropwise at 0 °C.
-
Reaction: Allow the reaction mixture to warm to room temperature and stir for 4-6 hours, or until the reaction is complete as monitored by thin-layer chromatography (TLC).
-
Work-up: Separate the organic layer. Wash the organic layer sequentially with 1 M HCl, saturated aqueous sodium bicarbonate, and brine.
-
Drying and Concentration: Dry the organic layer over anhydrous magnesium sulfate, filter, and concentrate under reduced pressure to obtain the crude product.
-
Purification: Purify the crude product by silica gel column chromatography using a suitable eluent system (e.g., a gradient of ethyl acetate in hexanes) to yield the pure N-acyl-homoserine lactone analog.
-
Characterization: Confirm the structure and purity of the synthesized analog using techniques such as Nuclear Magnetic Resonance (NMR) spectroscopy and Mass Spectrometry (MS).
Biological Evaluation of AHL Analogs
The biological activity of synthesized AHL analogs can be assessed using a variety of in vitro assays that measure their ability to inhibit or activate QS-regulated phenotypes.
Protocol 1: Violacein Inhibition Assay in Chromobacterium violaceum
Chromobacterium violaceum is a Gram-negative bacterium that produces a purple pigment called violacein, the synthesis of which is regulated by a C6-HSL-mediated QS system.[4][5] The mutant strain C. violaceum CV026 is unable to produce its own AHLs but will produce violacein in the presence of exogenous short-chain AHLs. This makes it an excellent reporter strain for screening QS inhibitors.
Materials:
-
Chromobacterium violaceum CV026
-
Luria-Bertani (LB) broth and agar
-
N-hexanoyl-L-homoserine lactone (C6-HSL)
-
Synthesized AHL analogs
-
Dimethyl sulfoxide (DMSO)
-
96-well microtiter plates
-
Spectrophotometer
Procedure:
-
Prepare Bacterial Culture: Grow an overnight culture of C. violaceum CV026 in LB broth at 30°C with shaking.
-
Prepare Assay Plate: In a 96-well microtiter plate, add LB broth containing a sub-micromolar concentration of C6-HSL (to induce violacein production).
-
Add Test Compounds: Add the synthesized AHL analogs to the wells at various concentrations. Include a positive control (C6-HSL only) and a negative control (LB broth only). Use DMSO as a solvent control.
-
Inoculate with Bacteria: Add the overnight culture of C. violaceum CV026 to each well to a final optical density at 600 nm (OD₆₀₀) of 0.1.
-
Incubation: Incubate the plate at 30°C for 24 hours with shaking.
-
Quantify Violacein: After incubation, quantify the violacein production. This can be done by lysing the cells and measuring the absorbance of the extracted violacein at 585 nm.
-
Data Analysis: Calculate the percentage inhibition of violacein production for each concentration of the AHL analog compared to the positive control. Determine the IC₅₀ value, which is the concentration of the analog that inhibits 50% of violacein production.
Protocol 2: Biofilm Inhibition Assay in Pseudomonas aeruginosa
Pseudomonas aeruginosa is an opportunistic human pathogen that relies on QS to regulate the formation of biofilms, which are communities of bacteria encased in a self-produced matrix that are highly resistant to antibiotics.[6][7] The crystal violet assay is a common method to quantify biofilm formation.
Materials:
-
Pseudomonas aeruginosa PAO1
-
LB broth
-
Synthesized AHL analogs
-
DMSO
-
96-well polystyrene microtiter plates
-
0.1% Crystal Violet solution
-
30% Acetic acid
-
Spectrophotometer
Procedure:
-
Prepare Bacterial Culture: Grow an overnight culture of P. aeruginosa PAO1 in LB broth at 37°C with shaking.
-
Prepare Assay Plate: Dilute the overnight culture 1:100 in fresh LB broth. In a 96-well microtiter plate, add the diluted bacterial culture to each well.
-
Add Test Compounds: Add the synthesized AHL analogs to the wells at various concentrations. Include a positive control (bacteria only) and a negative control (broth only). Use DMSO as a solvent control.
-
Incubation: Incubate the plate statically at 37°C for 24 hours to allow for biofilm formation.
-
Wash: Carefully discard the planktonic cells and wash the wells gently with sterile water or phosphate-buffered saline (PBS) to remove non-adherent cells.
-
Stain Biofilm: Add 0.1% crystal violet solution to each well and incubate at room temperature for 15 minutes.
-
Wash and Solubilize: Discard the crystal violet solution and wash the wells thoroughly with water until the wash water is clear. Air dry the plate. Solubilize the stained biofilm by adding 30% acetic acid to each well.
-
Quantify Biofilm: Transfer the solubilized crystal violet to a new flat-bottom 96-well plate and measure the absorbance at 550 nm using a microplate reader.[7]
-
Data Analysis: Calculate the percentage of biofilm inhibition for each concentration of the AHL analog compared to the positive control.
Quantitative Data of AHL Analog Activity
The following tables summarize the inhibitory activity of representative AHL analogs against QS-regulated phenotypes in C. violaceum and P. aeruginosa.
Table 1: Inhibition of Violacein Production in C. violaceum CV026 by N-Sulfonyl Homoserine Lactone Analogs [4]
| Compound | Substituent (R) | IC₅₀ (µM) |
| 5h | 4-Fluorophenyl | 1.64 |
| 5k | 4-Chlorophenyl | 1.66 |
| 5i | 4-Bromophenyl | 2.58 |
| 5j | 4-Iodophenyl | 3.12 |
| 5g | 3-Chlorophenyl | 5.25 |
| 5f | 2-Chlorophenyl | 10.5 |
| 5e | Phenyl | 25.3 |
| 5l | Naphthyl | 48.49 |
| 5a | Methyl | >50 |
| 5d | Propyl | >50 |
Table 2: Inhibition of Biofilm Formation in P. aeruginosa PAO1 by Phenylacetyl-HSL Analogs [8]
| Compound No. | R¹ | R² | Inhibition of Biofilm Formation (%) at 200 µM |
| 1 | H | 4-Br | ~20 |
| 2 | H | 2-Cl | ~30 |
| 3 | H | 4-Cl | ~65 |
| 4 | H | 2-F | ~25 |
| 5 | H | 4-F | ~40 |
| 6 | H | 4-NO₂ | ~0 |
| 7 | H | 4-CH₃ | ~35 |
| 8 | H | 4-OCH₃ | ~30 |
| 9 | CH₃ | 4-Br | ~55 |
| 10 | C₂H₅ | 4-Br | >60 |
Visualization of Signaling Pathways and Experimental Workflows
LuxR-AHL Signaling Pathway
The following diagram illustrates the canonical LuxR-AHL quorum sensing pathway in Gram-negative bacteria.
References
- 1. N-Acyl homoserine lactone - Wikipedia [en.wikipedia.org]
- 2. www-spring.ch.cam.ac.uk [www-spring.ch.cam.ac.uk]
- 3. researchgate.net [researchgate.net]
- 4. Design, Synthesis and Biological Evaluation of N-Sulfonyl Homoserine Lactone Derivatives as Inhibitors of Quorum Sensing in Chromobacterium violaceum - PMC [pmc.ncbi.nlm.nih.gov]
- 5. mdpi.com [mdpi.com]
- 6. mdpi.com [mdpi.com]
- 7. Microtiter Dish Biofilm Formation Assay - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Frontiers | Design, Synthesis, and Biological Evaluation of N-Acyl-Homoserine Lactone Analogs of Quorum Sensing in Pseudomonas aeruginosa [frontiersin.org]
Troubleshooting & Optimization
Technical Support Center: N-Allyl Amino Acid Synthesis
Welcome to the technical support center for N-allyl amino acid synthesis. This resource provides detailed troubleshooting guides, frequently asked questions (FAQs), and experimental protocols to assist researchers, scientists, and drug development professionals in overcoming common challenges encountered during their work.
Troubleshooting Guide
This guide addresses specific issues that may arise during the N-allylation of amino acids.
Question: My N-allylation reaction has a very low yield or is not proceeding. What are the common causes and how can I fix it?
Answer: Low or no yield is a frequent issue stemming from several factors related to reagents, conditions, or the substrate itself.
-
Insufficient Basicity: The amine nitrogen must be deprotonated to become sufficiently nucleophilic. If a weak base is used, the reaction may not proceed.
-
Solution: Switch to a stronger base. For amino acid esters, bases like potassium carbonate (K₂CO₃) in a polar aprotic solvent are common. For more challenging substrates, a stronger, non-nucleophilic base like sodium hydride (NaH) in an anhydrous solvent like DMF or THF can be effective.
-
-
Poor Reagent Reactivity: The chosen allylating agent may not be reactive enough.
-
Solvent Choice: The reaction medium significantly impacts reaction rates.
-
Solution: Use polar aprotic solvents such as Dimethylformamide (DMF), Dimethyl sulfoxide (DMSO), or acetonitrile (CH₃CN). These solvents effectively solvate the cation from the base while leaving the nucleophilic amine anion reactive.
-
-
Steric Hindrance: Bulky side chains on the amino acid can sterically hinder the approach of the allylating agent to the nitrogen atom.
-
Solution: Increase the reaction temperature or extend the reaction time. Microwave irradiation can sometimes overcome steric barriers by providing localized, rapid heating.[2]
-
Question: I am observing significant amounts of a di-allylated product. How can I promote mono-allylation?
Answer: Over-alkylation is a classic problem in amine alkylation because the mono-allylated product is often more nucleophilic than the starting primary amine.[3][4]
-
Control Stoichiometry: The most direct approach is to limit the amount of the allylating agent.
-
Solution 1: Use the amino acid as the excess reagent. A 2 to 5-fold excess of the amine component can statistically favor mono-allylation.
-
Solution 2: Add the allylating agent (e.g., allyl bromide) slowly to the reaction mixture using a syringe pump. This keeps the concentration of the alkylating agent low at all times, reducing the chance of the product reacting again.
-
-
Use of Protecting Groups: An alternative strategy is to use a protecting group that can be removed later.
-
Solution: N-alkylation can be achieved on sulfonamides (e.g., N-tosyl or N-nosyl protected amino acids), followed by deprotection. The sulfonamide nitrogen's acidity allows for selective alkylation.[5]
-
Question: My reaction is producing unwanted O-allylated byproducts. How can this be prevented?
Answer: Amino acids possess multiple nucleophilic sites, primarily the α-amino group and the carboxylate group. In amino acids with hydroxyl side chains (Ser, Thr, Tyr), the hydroxyl group is also a potential site for allylation.
-
Protecting Functional Groups: The most robust solution is to protect competing nucleophilic sites.
-
Carboxylic Acid: The carboxylic acid is typically protected as an ester (e.g., methyl, ethyl, or tert-butyl ester) prior to N-allylation. This removes the nucleophilic carboxylate.
-
Hydroxyl Groups: Side-chain hydroxyls should be protected with standard protecting groups (e.g., benzyl or silyl ethers) if O-allylation is a persistent issue.
-
-
Reaction Condition Control: In some cases, selectivity can be achieved by tuning the reaction conditions.
-
Solution: The choice of base and solvent can influence the chemoselectivity between N- and O-allylation. For instance, using sodium methoxide (NaOMe) in ethyl acetate (EtOAc) has been shown to favor O-allylation, suggesting that avoiding these conditions could suppress it.[1]
-
Question: How can I remove the N-allyl group after it has served its purpose as a protecting group?
Answer: The N-allyl group is valued for its stability but requires specific conditions for cleavage, which can be challenging, especially in complex molecules like peptides.[6]
-
Palladium-Catalyzed Cleavage: This is the most common and effective method.
-
Solution: A Pd(0) catalyst, typically tetrakis(triphenylphosphine)palladium(0) [Pd(PPh₃)₄], is used in the presence of an allyl scavenger (e.g., N-methylaniline, morpholine, or dimedone). The catalyst forms a π-allyl complex, which is then captured by the scavenger.[7]
-
-
Rhodium or Ruthenium-Based Methods: These offer alternative pathways for deallylation.
-
Solution: The reaction involves an initial isomerization of the N-allyl group to an enamine, catalyzed by a Rhodium or Ruthenium complex. The resulting enamine is then hydrolyzed or cleaved via ozonolysis to release the free amine.[6]
-
Frequently Asked Questions (FAQs)
Q1: What are the most common reagents for introducing an N-allyl group? A1: The most common laboratory reagents are allyl halides, such as allyl bromide, due to their high reactivity.[2] Allylic carbonates are also used, particularly in palladium-catalyzed reactions which offer high efficiency and control.[1]
Q2: Which solvents are optimal for N-allylation reactions? A2: Polar aprotic solvents are generally preferred. Dimethylformamide (DMF), dimethyl sulfoxide (DMSO), acetonitrile (MeCN), and tetrahydrofuran (THF) are excellent choices as they effectively dissolve the amino acid derivatives and promote the Sₙ2 reaction pathway.
Q3: How can I monitor the progress of my N-allylation reaction? A3: Reaction progress can be monitored by Thin-Layer Chromatography (TLC) to observe the consumption of the starting material and the appearance of the product spot. For more quantitative analysis, Liquid Chromatography-Mass Spectrometry (LC-MS) or Gas Chromatography (GC) can be used. ¹H NMR spectroscopy of an aliquot from the reaction mixture can also confirm the formation of the N-allyl group by identifying its characteristic signals.
Q4: What are the best methods for purifying N-allyl amino acids? A4: The purification method depends on the properties of the product.
-
Flash Column Chromatography: This is the most common method for purifying protected N-allyl amino acid esters. A silica gel stationary phase is used with a mobile phase gradient of ethyl acetate and hexanes.
-
Crystallization: If the product is a stable solid, crystallization can be an effective method for achieving high purity.
-
Acid-Base Extraction: For unprotected N-allyl amino acids, which are zwitterionic, purification can sometimes be achieved by careful pH-controlled extractions.
Q5: Can N-allylation cause racemization at the stereocenter? A5: Yes, racemization is a potential risk, especially under harsh basic conditions or elevated temperatures.[5] The α-proton can be abstracted by a strong base, leading to a loss of stereochemical integrity. It is crucial to use the mildest conditions possible and to verify the enantiomeric purity of the product, for example, by chiral HPLC.
Visual Guides & Workflows
Logical Troubleshooting Workflow
The following diagram outlines a decision-making process for troubleshooting a low-yield N-allylation reaction.
Caption: Troubleshooting decision tree for low-yield reactions.
General Experimental Workflow
This diagram illustrates the typical sequence of steps in an N-allylation experiment.
Caption: Standard workflow for N-allyl amino acid synthesis.
Data Summary
Table 1: Comparison of Selected N-Allylation Conditions
| Substrate Example | Allylating Agent | Base | Solvent | Temp. (°C) | Time (h) | Yield (%) | Reference |
|---|---|---|---|---|---|---|---|
| Diphenylamine | Allyl Bromide | KOH | DMSO | 70 | 12 | ~55% | [2] |
| Amino Alcohol | Allyl Bromide | NaH | DMF | RT | 16 | 88% (O-allyl) | |
| Amino Alcohol | Allyl Bromide | NaH | DMF | RT | 16 | 81% (N,O-bis) |
| N-Tosyl-t-butylglycine | Allyl Carbonate | NaOMe | EtOAc | RT | 5 | Good |[1] |
Table 2: Troubleshooting Quick Reference
| Problem | Common Cause(s) | Suggested Solution(s) |
|---|---|---|
| Low/No Yield | Inactive reagents, insufficient base, low temperature. | Check reagent purity, use a stronger base (e.g., NaH), increase temperature. |
| Di-allylation | Product is more nucleophilic, excess allylating agent. | Use a large excess of the amine, add allylating agent slowly. |
| O-allylation | Unprotected carboxyl or hydroxyl groups. | Protect functional groups (esterification, ether formation) before allylation. |
| Racemization | Harsh basic conditions. | Use milder bases (K₂CO₃), lower reaction temperature, minimize reaction time. |
| Deprotection Fails | Catalyst poisoning, wrong catalyst/scavenger system. | Use Pd(PPh₃)₄ with a suitable scavenger (e.g., morpholine). Consider Rh/Ru methods. |
Experimental Protocols
Protocol 1: General N-allylation of an Amino Acid Ester with Allyl Bromide
Materials:
-
Amino acid methyl ester hydrochloride (1.0 equiv)
-
Allyl bromide (1.1 - 2.2 equiv)
-
Potassium carbonate (K₂CO₃) (3.0 equiv)
-
Anhydrous Acetonitrile (CH₃CN) or Dimethylformamide (DMF)
-
Reaction flask, magnetic stirrer, condenser, and inert atmosphere setup (N₂ or Argon)
Procedure:
-
To a round-bottom flask under an inert atmosphere, add the amino acid methyl ester hydrochloride (1.0 equiv) and anhydrous acetonitrile (or DMF) to make a ~0.2 M solution.
-
Add potassium carbonate (3.0 equiv) to the suspension. The K₂CO₃ will neutralize the hydrochloride salt and act as the base for the N-allylation.
-
Stir the mixture vigorously for 15-20 minutes at room temperature.
-
Add allyl bromide (1.1 equiv for mono-allylation; may require optimization) dropwise to the stirring suspension.
-
Heat the reaction mixture to 50-70 °C and monitor its progress by TLC or LC-MS. The reaction may take anywhere from 6 to 24 hours.
-
Upon completion, cool the reaction to room temperature and filter off the inorganic salts.
-
Concentrate the filtrate under reduced pressure to remove the solvent.
-
Redissolve the residue in a suitable organic solvent (e.g., ethyl acetate) and wash with water and brine.
-
Dry the organic layer over anhydrous sodium sulfate (Na₂SO₄), filter, and concentrate.
-
Purify the crude product by flash column chromatography on silica gel to obtain the pure N-allyl amino acid ester.
Protocol 2: Palladium-Catalyzed Deprotection of an N-Allyl Group
Materials:
-
N-allyl protected amino acid/peptide (1.0 equiv)
-
Tetrakis(triphenylphosphine)palladium(0), Pd(PPh₃)₄ (0.05 - 0.1 equiv)
-
Allyl scavenger, e.g., Morpholine (20-30 equiv)
-
Anhydrous, degassed solvent (e.g., THF or Dichloromethane (DCM))
-
Inert atmosphere setup (N₂ or Argon)
Procedure:
-
Dissolve the N-allyl protected substrate (1.0 equiv) in the anhydrous, degassed solvent in a flask under an inert atmosphere.
-
Add the allyl scavenger (e.g., morpholine, 20 equiv) to the solution.
-
In a separate vial, weigh the Pd(PPh₃)₄ catalyst (0.05 equiv) and add it to the reaction mixture in one portion. The mixture may turn yellow or orange.
-
Stir the reaction at room temperature. The reaction is typically complete within 1-4 hours. Monitor by TLC or LC-MS until the starting material is fully consumed.
-
Once the reaction is complete, concentrate the mixture under reduced pressure.
-
The crude residue can be purified by flash column chromatography to remove the catalyst, scavenger, and byproducts, yielding the deprotected amine. An acidic wash during workup can also help remove the basic scavenger.
References
- 1. Palladium-catalyzed base- and solvent-controlled chemoselective allylation of amino acids with allylic carbonates [ccspublishing.org.cn]
- 2. DMSO–allyl bromide: a mild and efficient reagent for atom economic one-pot N-allylation and bromination of 2°-aryl amines, 2-aryl aminoamides, indoles and 7-aza indoles - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Amine alkylation - Wikipedia [en.wikipedia.org]
- 4. masterorganicchemistry.com [masterorganicchemistry.com]
- 5. research.monash.edu [research.monash.edu]
- 6. pubs.acs.org [pubs.acs.org]
- 7. US5777077A - Automated allyl deprotection in solid-phase synthesis - Google Patents [patents.google.com]
Technical Support Center: Optimizing Coupling of 2-Prop-2-en-1-ylhomoserine in SPPS
This technical support center provides researchers, scientists, and drug development professionals with troubleshooting guides and FAQs for optimizing the coupling efficiency of the unnatural amino acid 2-Prop-2-en-1-ylhomoserine during Solid-Phase Peptide Synthesis (SPPS).
Frequently Asked Questions (FAQs)
Q1: What are the potential challenges when incorporating this compound in SPPS?
The primary challenges are suspected to be related to the steric hindrance from the allyl group, which can slow down the coupling reaction. Additionally, the terminal double bond of the allyl group may be susceptible to side reactions under certain SPPS conditions, although this is not widely documented. As with many unnatural amino acids, aggregation of the growing peptide chain after its incorporation can also be a concern.
Q2: Which coupling reagents are recommended for this compound?
For sterically hindered amino acids, more potent coupling reagents are generally recommended. Urionium-based reagents like HATU, HBTU, and HDMC, or phosphonium-based reagents like PyBOP and PyAOP are often more effective than standard carbodiimides (e.g., DIC).[1] The choice of reagent may require empirical optimization for your specific peptide sequence.
Q3: Can the allyl group of this compound react with standard SPPS reagents?
While the allyl group is generally stable under standard Fmoc-SPPS conditions (piperidine for deprotection and TFA for cleavage), there is a theoretical potential for side reactions.[2][3] For instance, if palladium catalysts are used elsewhere in the synthesis (e.g., for the removal of Alloc protecting groups), they could potentially interact with the allyl side chain.[3][4] It is crucial to consider the full synthetic scheme for potential incompatibilities.
Q4: How can I monitor the coupling efficiency of this compound?
Standard qualitative tests like the Kaiser test or TNBS test can be used to check for the presence of unreacted primary amines after the coupling step.[5] For quantitative assessment, a small aliquot of the resin can be cleaved and the resulting peptide analyzed by HPLC and Mass Spectrometry to determine the ratio of the desired product to deletion sequences.[6]
Q5: What are the expected signs of poor coupling efficiency for this amino acid?
A positive Kaiser test (blue beads) after the coupling step is a primary indicator. Subsequent analysis of the crude peptide by HPLC may show a significant peak corresponding to the peptide lacking the this compound residue (a deletion sequence). Mass spectrometry will confirm the mass of this impurity.
Troubleshooting Guide
Issue 1: Low Coupling Efficiency (Positive Kaiser Test)
If you observe a positive Kaiser test after the coupling step for this compound, consider the following troubleshooting steps.
Workflow for Troubleshooting Low Coupling Efficiency:
References
- 1. Protocols for the Fmoc SPPS of Cysteine-Containing Peptides [sigmaaldrich.com]
- 2. Studies of peptide binding to allyl amine and vinyl acetic acid-modified polymers using matrix-assisted laser desorption/ionization mass spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. pubs.acs.org [pubs.acs.org]
- 4. researchgate.net [researchgate.net]
- 5. Bot Detection [iris-biotech.de]
- 6. Overview of peptide and protein analysis by mass spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
Technical Support Center: Purification of Peptides Containing 2-Prop-2-en-1-ylhomoserine
This guide provides researchers, scientists, and drug development professionals with detailed strategies, troubleshooting advice, and frequently asked questions for the successful purification of synthetic peptides incorporating the unnatural amino acid 2-Prop-2-en-1-ylhomoserine (also known as allylglycine).
Frequently Asked Questions (FAQs)
Q1: What is the standard purification method for peptides containing this compound?
A1: The industry-standard method for purifying synthetic peptides, including those with this compound, is Reversed-Phase High-Performance Liquid Chromatography (RP-HPLC).[1] This technique is highly effective due to its ability to separate peptides from a complex mixture based on their hydrophobicity.[1][2] A C18-modified silica stationary phase is most commonly used for this purpose.[1]
Q2: How does the this compound residue impact the purification process?
A2: The propargyl group (-CH2-CH=CH2) of this compound is non-polar, which increases the overall hydrophobicity of the peptide. This increased hydrophobicity typically leads to a longer retention time on an RP-HPLC column compared to a corresponding peptide without this residue. This characteristic is advantageous as it helps separate the target peptide from more polar impurities, such as truncated or deletion sequences, that are common by-products of solid-phase peptide synthesis (SPPS).[1]
Q3: What are the typical impurities I can expect in my crude peptide sample after synthesis?
A3: After solid-phase peptide synthesis and cleavage from the resin, the crude product is a heterogeneous mixture. Common impurities include deletion peptides (missing one or more amino acids), truncated peptides (incomplete sequences), incompletely deprotected peptides, and by-products from the cleavage and protecting group removal steps.[1]
Q4: Is it necessary to use an orthogonal purification method in addition to RP-HPLC?
A4: While RP-HPLC is very powerful, a single purification step may not be sufficient to achieve the high purity (>98%) required for therapeutic applications.[3] If impurities co-elute with the target peptide, an orthogonal method—one that separates based on a different principle—is recommended.[3] Ion-exchange chromatography (IEX), which separates based on net charge, is an excellent choice for a secondary purification step or a pre-purification capture step.[2][4]
Troubleshooting Guide
This section addresses specific issues that may arise during the RP-HPLC purification of your this compound-containing peptide.
Q: My peptide peak is broad or shows significant tailing. What is the cause and how can I fix it?
A: Poor peak shape can be caused by several factors.
-
Potential Cause 1: Secondary Interactions with Silica: Residual silanol groups on the silica backbone of the column can interact with basic residues in your peptide, causing peak tailing.
-
Potential Cause 2: Column Overload: Injecting too much crude peptide onto the column can exceed its binding capacity.
-
Solution: Reduce the sample load. For a standard analytical column (e.g., 4.6 mm ID), the load should be in the microgram range. For preparative columns, consult the manufacturer's guidelines.
-
-
Potential Cause 3: Peptide Aggregation: Hydrophobic peptides, especially those with multiple this compound residues, can aggregate.[7]
-
Solution: Try dissolving the crude peptide in a stronger solvent, such as a small amount of DMSO, before diluting it with the initial mobile phase. You can also try altering the mobile phase, for instance, by using formic acid instead of TFA or by adding a small percentage of isopropanol to the acetonitrile.
-
Q: My peptide elutes very early (in or near the void volume) or very late (at high acetonitrile concentration). How do I adjust the retention time?
A: Retention time is primarily controlled by the peptide's hydrophobicity and its interaction with the stationary phase.
-
Problem: Peptide Elutes Too Early (Low Retention): This is unlikely for a peptide containing the hydrophobic this compound unless the peptide is very short and highly charged.
-
Solution: Use a column with a different stationary phase, such as C8 or C4, which are less hydrophobic than C18. Alternatively, consider using a different ion-pairing agent that may increase retention.
-
-
Problem: Peptide Elutes Too Late (High Retention): This is a more common scenario, especially for longer peptides or those with multiple hydrophobic residues.
-
Solution: Adjust the gradient to be shallower, meaning the percentage of acetonitrile increases more slowly.[6] This will improve the separation between your target peptide and other closely eluting hydrophobic impurities. If retention is extreme, a more hydrophobic stationary phase like C8 or C4 could be beneficial.
-
Q: I am seeing low recovery of my peptide after lyophilization. What happened?
A: Low recovery can stem from issues during purification or post-purification workup.
-
Potential Cause 1: Irreversible Adsorption: The peptide may be irreversibly binding to the column or vials.
-
Solution: Passivating glass vials by rinsing with a solution of a blocking protein (like BSA) and then water can help for very "sticky" peptides. Ensure the collected fractions are processed for lyophilization as quickly as possible, as peptides can degrade or adsorb to surfaces when left in solution.[6]
-
-
Potential Cause 2: Incomplete Elution: A very hydrophobic peptide may not have fully eluted from the column at the end of the gradient.
-
Solution: Extend the gradient to a higher final percentage of acetonitrile (e.g., 95-100%) and hold it for several column volumes to ensure everything has eluted. Follow this with a column wash.
-
-
Potential Cause 3: Peptide Precipitation: The peptide may have precipitated in the collection tube if the concentration of acetonitrile was too high upon elution.
-
Solution: Dilute the collected fractions with water (without TFA) before freezing and lyophilizing. This reduces the organic solvent concentration and can help keep the peptide in solution.
-
Data Presentation: HPLC Parameter Comparison
The following table provides typical starting parameters for analytical and preparative RP-HPLC. These should be optimized for each specific peptide.
| Parameter | Analytical RP-HPLC | Preparative RP-HPLC |
| Column ID | 2.1 - 4.6 mm | 10 - 50 mm |
| Stationary Phase | C18, 3-5 µm particle size | C18, 5-10 µm particle size |
| Mobile Phase A | 0.1% TFA in Water | 0.1% TFA in Water |
| Mobile Phase B | 0.1% TFA in Acetonitrile | 0.1% TFA in Acetonitrile |
| Flow Rate | 0.5 - 1.5 mL/min | 5 - 100 mL/min |
| Typical Gradient | 5-65% B over 30 min | 20-50% B over 60 min (shallow) |
| Sample Load | 1 - 100 µg | 10 - 500 mg |
| Detection | 214 nm / 280 nm | 220 nm / 280 nm |
Experimental Protocols
Protocol 1: Standard Preparative RP-HPLC Purification
This protocol outlines a general procedure for purifying a crude peptide containing this compound.
-
Sample Preparation:
-
Dissolve the crude lyophilized peptide in a minimal amount of Mobile Phase A.
-
If solubility is poor, add a small volume of acetonitrile or DMSO, then dilute with Mobile Phase A.
-
Centrifuge the sample at high speed (>10,000 x g) for 5 minutes to pellet any insoluble material.
-
Filter the supernatant through a 0.45 µm syringe filter.
-
-
HPLC System Preparation:
-
Equilibrate the preparative C18 column with the starting mobile phase conditions (e.g., 95% A, 5% B) for at least 5 column volumes or until the baseline is stable.
-
-
Purification Run:
-
Inject the filtered sample onto the equilibrated column.
-
Run a shallow linear gradient. A good starting point is an increase of 0.5% to 1.0% Mobile Phase B per minute.
-
Monitor the elution profile at 220 nm.
-
-
Fraction Collection:
-
Collect fractions (e.g., 1-minute intervals) as peaks begin to elute.
-
It is crucial to collect fractions across the entire peak, including the rising and falling edges.
-
-
Analysis and Pooling:
-
Analyze each collected fraction using analytical RP-HPLC and Mass Spectrometry (MS) to determine which contain the pure target peptide.
-
Combine the fractions that meet the desired purity level (e.g., >98%).
-
-
Lyophilization:
-
Freeze the pooled fractions at -80°C.
-
Lyophilize the frozen solution until a dry, fluffy powder is obtained. Store the purified peptide at -20°C or -80°C.[6]
-
Visualizations
General Peptide Purification Workflow
References
- 1. bachem.com [bachem.com]
- 2. HPLC Analysis and Purification of Peptides - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Purification of therapeutic peptides using orthogonal methods to achieve high purity - American Chemical Society [acs.digitellinc.com]
- 4. Purification of peptides derived from proenkephalin A on Bio-Rex 70 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. hplc.eu [hplc.eu]
- 6. peptide.com [peptide.com]
- 7. blog.mblintl.com [blog.mblintl.com]
Technical Support Center: Enhancing Protein Stability with Unnatural Amino Acids
This technical support center provides researchers, scientists, and drug development professionals with comprehensive troubleshooting guides and frequently asked questions (FAQs) for improving protein stability through the incorporation of unnatural amino acids (UAAs).
Troubleshooting Guides
This section addresses specific issues that may arise during experiments involving the incorporation of unnatural amino acids to enhance protein stability.
Issue 1: Low Yield of the UAA-Containing Protein
-
Question: I am observing a very low yield of my target protein after inducing expression with the unnatural amino acid. What are the potential causes and how can I troubleshoot this?
-
Answer: Low protein yield is a common challenge when incorporating UAAs.[1][2] The issue often stems from inefficient suppression of the stop codon or problems with the orthogonal translation system.[3] Here are several factors to investigate:
-
Competition with Release Factor 1 (RF1): In E. coli, RF1 recognizes the UAG (amber) stop codon and terminates translation, competing with the suppressor tRNA that is meant to incorporate the UAA.[4]
-
Solution: Use an E. coli strain engineered with a genomic deletion of RF1. This significantly reduces premature termination and can substantially increase the yield of the full-length, UAA-containing protein.[5]
-
-
Suboptimal Concentrations of Orthogonal Translation System Components: The relative concentrations of the orthogonal aminoacyl-tRNA synthetase (aaRS), the suppressor tRNA, and the UAA are critical for efficient incorporation.
-
Solution: Titrate the concentrations of the UAA in the growth media. Additionally, optimizing the expression levels of the aaRS and tRNA, for instance by using plasmids with different copy numbers or promoters of varying strength, can improve yields.[3]
-
-
Toxicity of the Unnatural Amino Acid: Some UAAs can be toxic to the host cells, leading to poor growth and reduced protein expression.
-
Solution: Perform a toxicity assay by monitoring cell growth (OD600) at various concentrations of the UAA. If toxicity is observed, try using the lowest effective concentration of the UAA or switch to a less toxic analog if available.
-
-
Inefficient Transport of UAA into the Cell: The UAA must be efficiently taken up by the host cells to be available for incorporation.
-
Solution: If poor uptake is suspected, consider co-expressing a transporter protein known to facilitate the import of the specific UAA or a structurally similar molecule.
-
-
Issue 2: Protein Aggregation Upon UAA Incorporation
-
Question: My protein of interest is soluble in its wild-type form, but it aggregates and forms inclusion bodies when I incorporate an unnatural amino acid. How can I resolve this?
-
Answer: Protein aggregation upon UAA incorporation can occur if the UAA disrupts the native folding of the protein, often by exposing hydrophobic patches.[6][7] Here are some strategies to mitigate aggregation:
-
Optimize Expression Conditions:
-
Lower Temperature: Reducing the expression temperature (e.g., from 37°C to 18-25°C) can slow down protein synthesis, allowing more time for proper folding and reducing the likelihood of aggregation.[7]
-
Use a Weaker Promoter or Lower Inducer Concentration: This can also slow the rate of protein production, which may favor correct folding.
-
-
Co-expression of Chaperones: Molecular chaperones can assist in the proper folding of proteins. Co-expressing chaperones like GroEL/GroES or DnaK/DnaJ can help to prevent aggregation of the UAA-containing protein.
-
Buffer Optimization and Additives:
-
Solubilizing Agents: During purification, use buffers containing additives that promote solubility. Arginine and glutamate, for example, can help to prevent aggregation by interacting with exposed hydrophobic or charged regions.[8]
-
Detergents and Osmolytes: Low concentrations of non-denaturing detergents (e.g., Tween 20) or osmolytes like glycerol or sucrose can also stabilize the protein and prevent aggregation.[7][8]
-
-
Refolding from Inclusion Bodies: If the protein is still found in inclusion bodies, it may be necessary to purify the aggregated protein and then perform a refolding protocol. This typically involves solubilizing the inclusion bodies in a strong denaturant (e.g., urea or guanidinium hydrochloride) followed by a gradual removal of the denaturant to allow the protein to refold.
-
Issue 3: Misincorporation of Natural Amino Acids at the Target Codon
-
Question: Mass spectrometry analysis of my purified protein shows a significant amount of a natural amino acid (e.g., glutamine, tyrosine) at the position where the UAA was supposed to be incorporated. What causes this and how can I improve specificity?
-
Answer: Misincorporation of natural amino acids at the target codon indicates a lack of orthogonality in your system.[1] This means that either a native aaRS is charging the orthogonal tRNA with a natural amino acid, or the orthogonal aaRS is recognizing a natural amino acid.[9]
-
Improve Orthogonality of the aaRS/tRNA Pair:
-
Directed Evolution: The specificity of the orthogonal aaRS can be enhanced through directed evolution. This involves creating a library of aaRS mutants and selecting for variants that have higher specificity for the UAA and lower activity with all 20 canonical amino acids.[10]
-
Negative Selection: During the evolution of the aaRS, it is crucial to perform negative selection steps to eliminate variants that recognize natural amino acids. This can be done by expressing the aaRS library in the absence of the UAA and selecting against cells that survive due to misincorporation of a natural amino acid at a stop codon in a counter-selectable marker.
-
-
Check for Near-Cognate Suppression: In some cases, a natural tRNA in the host can recognize the stop codon, leading to the incorporation of its cognate amino acid. While less common for the amber (UAG) codon, it can contribute to background misincorporation. Using a genomically recoded organism where the target codon has been removed from the genome can eliminate this issue.
-
Frequently Asked Questions (FAQs)
Q1: How do unnatural amino acids increase protein stability?
A1: Unnatural amino acids can enhance protein stability through several mechanisms, primarily by introducing novel chemical properties not found in the 20 canonical amino acids.[11] These include:
-
Hydrophobic Effects: Incorporating highly hydrophobic UAAs, such as those with fluorinated side chains, into the core of a protein can increase the hydrophobic surface area buried upon folding, which is a major driving force for protein stability.[12]
-
Aromatic Stacking: UAAs with extended aromatic systems can form more stable stacking interactions within the protein structure compared to natural aromatic residues.
-
Conformational Rigidity: Introducing UAAs with conformationally restricted side chains can decrease the conformational entropy of the unfolded state, which thermodynamically favors the folded state.[13][14]
-
Novel Covalent Bonds: Some UAAs can be used to introduce novel intramolecular crosslinks (e.g., through click chemistry), which can significantly increase the thermal and chemical stability of the protein.
Q2: Which unnatural amino acids are best for increasing protein stability?
A2: The choice of UAA depends on the specific protein and the desired mechanism of stabilization. However, some classes of UAAs have been generally successful:
-
Fluorinated Amino Acids: Highly fluorinated versions of aliphatic and aromatic amino acids, such as hexafluoroleucine and pentafluorophenylalanine, are particularly effective at enhancing thermal stability.[15][16] The fluorine atoms increase the hydrophobicity of the side chain without significantly increasing its size, leading to better packing in the protein core.[12]
-
Aromatic Amino Acids with Extended Pi Systems: Analogs of tryptophan or phenylalanine with larger aromatic groups can enhance stability through improved aromatic stacking interactions.
-
Thioether-Containing Amino Acids: Replacing a methylene group with a sulfur atom in an aliphatic side chain can introduce favorable interactions and improve stability.
Q3: How do I choose the best site in my protein to substitute with an unnatural amino acid for stability enhancement?
A3: Rational selection of the mutation site is crucial for success. Key considerations include:
-
Target the Hydrophobic Core: The most significant stability gains are often achieved by replacing residues in the hydrophobic core of the protein. These sites are not solvent-exposed and are critical for the overall fold.
-
Computational Modeling: Use protein modeling software to predict the effects of UAA substitution at various positions. Tools that can calculate the change in Gibbs free energy of folding (ΔΔG) upon mutation can help prioritize candidate sites.[17]
-
Avoid the Active Site: Unless you are intentionally trying to modulate activity, avoid substituting residues in or near the active site or other functionally important regions, as this could compromise the protein's function.
-
Consider Structural Context: Analyze the local environment of potential mutation sites. For example, a site involved in a critical hydrogen bond network may not be a good candidate for a purely hydrophobic UAA.
Quantitative Data on Protein Stability Enhancement
The incorporation of fluorinated amino acids has been shown to significantly increase the thermal stability of proteins. The table below summarizes data from a study on the B1 domain of protein G (GB1), where various amino acids were incorporated at a solvent-exposed position.
| Amino Acid at Position 53 | Melting Temperature (Tm) in °C | Change in Gibbs Free Energy of Unfolding (ΔGu) in kcal/mol |
| Leucine (Leu) | 55.2 | 4.5 |
| (S)-5,5,5',5'-tetrafluoroleucine (Qfl) | 56.5 | 4.7 |
| (S)-5,5,5,5',5',5'-hexafluoroleucine (Hfl) | 57.1 | 4.8 |
| Phenylalanine (Phe) | 58.3 | 5.1 |
| (S)-pentafluorophenylalanine (Pff) | 60.1 | 5.4 |
| 2-aminobutyric acid (Abu) | 54.8 | 4.4 |
| (S)-2-amino-4,4,4-trifluorobutyric acid (Atb) | 55.9 | 4.6 |
Data adapted from studies on the effects of fluorinated amino acids on protein stability.[15][18] The data clearly show that increasing the fluorination of the amino acid side chain leads to a higher melting temperature and a more favorable Gibbs free energy of unfolding, indicating enhanced protein stability.
Experimental Protocols
Protocol 1: Site-Directed Mutagenesis for UAA Incorporation
This protocol outlines the steps for introducing a TAG (amber) stop codon at the desired position in the gene of interest using QuikChange mutagenesis.[17]
-
Primer Design: Design two complementary oligonucleotide primers, typically 25-45 bases in length, containing the desired TAG codon at the center. The primers should have a melting temperature (Tm) of ≥78°C.
-
PCR Reaction: Set up a PCR reaction containing the template plasmid DNA (encoding the wild-type protein), the designed primers, PfuUltra DNA polymerase, and dNTPs.
-
Thermal Cycling: Perform thermal cycling, typically consisting of an initial denaturation step, followed by 18-25 cycles of denaturation, annealing, and extension.
-
Digestion of Parental DNA: After the PCR, digest the parental, methylated template DNA with the DpnI restriction enzyme. DpnI specifically cleaves methylated and hemimethylated DNA, leaving the newly synthesized, unmethylated plasmid DNA containing the desired mutation.
-
Transformation: Transform the DpnI-treated plasmid DNA into competent E. coli cells (e.g., DH5α).
-
Verification: Isolate plasmid DNA from the resulting colonies and verify the presence of the TAG codon by DNA sequencing.
Protocol 2: Thermal Shift Assay (Differential Scanning Fluorimetry)
A thermal shift assay is used to determine the melting temperature (Tm) of a protein, which is a measure of its thermal stability.[19] An increase in Tm upon UAA incorporation indicates stabilization.[20]
-
Reagent Preparation:
-
Prepare a stock solution of your purified protein (both wild-type and UAA-containing variant) at a concentration of approximately 0.5-5 µM in a suitable assay buffer (e.g., 50 mM Tris, 150 mM NaCl, pH 7.5).[19]
-
Prepare a stock solution of a fluorescent dye that binds to hydrophobic regions of unfolded proteins, such as SYPRO Orange.[21][22] A 10x stock is typically prepared from the commercial 5000x stock.[21]
-
-
Assay Setup:
-
Data Acquisition:
-
Place the 96-well plate in a real-time PCR machine.[20]
-
Set up a melt curve experiment. This involves gradually increasing the temperature from a starting point (e.g., 25°C) to a final temperature (e.g., 95°C) with a ramp rate of approximately 1°C/minute.
-
Monitor the fluorescence of SYPRO Orange at each temperature increment.
-
-
Data Analysis:
-
Plot the fluorescence intensity as a function of temperature. As the protein unfolds, it will expose its hydrophobic core, causing the SYPRO Orange dye to bind and fluoresce.[23]
-
The resulting curve will be sigmoidal. The melting temperature (Tm) is the temperature at the midpoint of this transition, which can be determined by fitting the data to a Boltzmann equation or by finding the peak of the first derivative of the melt curve.
-
Compare the Tm of the UAA-containing protein to the wild-type protein. A higher Tm indicates increased thermal stability.
-
Visualizations
Caption: Experimental workflow for incorporating an unnatural amino acid to enhance protein stability.
References
- 1. Incorporation of non-standard amino acids into proteins: Challenges, recent achievements, and emerging applications - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. mdpi.com [mdpi.com]
- 4. Frontiers | Unnatural amino acid incorporation in E. coli: current and future applications in the design of therapeutic proteins [frontiersin.org]
- 5. Advances and Challenges in Cell-Free Incorporation of Unnatural Amino Acids Into Proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Protein aggregation - Wikipedia [en.wikipedia.org]
- 7. Protein aggregation - Protein Expression Facility - University of Queensland [pef.facility.uq.edu.au]
- 8. info.gbiosciences.com [info.gbiosciences.com]
- 9. biorxiv.org [biorxiv.org]
- 10. m.youtube.com [m.youtube.com]
- 11. Reprogramming natural proteins using unnatural amino acids - PMC [pmc.ncbi.nlm.nih.gov]
- 12. pnas.org [pnas.org]
- 13. Probing protein stability with unnatural amino acids - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. Probing protein stability with unnatural amino acids. (1992) | David Mendel | 157 Citations [scispace.com]
- 15. Effect of highly fluorinated amino acids on protein stability at a solvent-exposed position on an internal strand of protein G B1 domain - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. The Effect of Fluorine-Containing Amino Acids on Protein Secondary Structure Stability [acswebcontent.acs.org]
- 17. scholarsarchive.byu.edu [scholarsarchive.byu.edu]
- 18. pubs.acs.org [pubs.acs.org]
- 19. Thermal shift assay - Wikipedia [en.wikipedia.org]
- 20. Current Protocols in Protein Science: Analysis of protein stability and ligand interactions by thermal shift assay - PMC [pmc.ncbi.nlm.nih.gov]
- 21. bitesizebio.com [bitesizebio.com]
- 22. bio-rad.com [bio-rad.com]
- 23. documents.thermofisher.com [documents.thermofisher.com]
Troubleshooting aggregation in solid-phase peptide synthesis of hydrophobic peptides.
Welcome to our technical support center dedicated to addressing the challenges of synthesizing hydrophobic peptides via solid-phase peptide synthesis (SPPS). This resource provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in overcoming common issues, particularly peptide aggregation.
Frequently Asked Questions (FAQs)
Q1: What causes peptide aggregation during SPPS?
A1: Peptide aggregation during SPPS is primarily caused by the formation of intermolecular hydrogen bonds between growing peptide chains, leading to the formation of secondary structures like β-sheets.[1][2] This is particularly prevalent in sequences containing a high number of hydrophobic amino acids such as Valine, Leucine, Isoleucine, and Phenylalanine.[1] Additionally, certain amino acids like Gln, Ser, and Thr can form intra-chain hydrogen bonds, contributing to aggregation. This aggregation can lead to poor solvation of the peptide-resin complex, hindering the accessibility of reagents to the reactive sites and resulting in incomplete deprotection and coupling reactions.[1][3]
Q2: How can I detect if my peptide is aggregating on-resin?
A2: On-resin aggregation can be detected through several observational and analytical methods. In batch synthesis, a visible shrinking of the resin beads is a strong indicator of aggregation. For continuous flow synthesis, a broadening and flattening of the Fmoc-deprotection peak profile, as monitored by UV-Vis spectroscopy, suggests aggregation is occurring.[4][5] Additionally, performing a test cleavage on a small amount of resin followed by analysis (e.g., MALDI-TOF MS) can reveal the presence of deletion sequences or truncated peptides, which are common consequences of incomplete reactions due to aggregation.
Q3: What are the initial and simplest steps I can take to troubleshoot aggregation?
A3: When encountering aggregation, several initial strategies can be employed:
-
Solvent Choice: Switching from standard solvents like DMF to more polar, aprotic solvents such as N-methylpyrrolidone (NMP) or adding dimethyl sulfoxide (DMSO) can improve solvation of the peptide-resin complex.[6][7] A "magic mixture" of DCM/DMF/NMP (1:1:1) has also been shown to be effective.[1][8]
-
Resin Selection: Utilize resins with good swelling properties, such as those based on polyethylene glycol (PEG) like NovaSyn® TG, NovaPEG, or PEGA. Using a resin with a lower substitution level can also help by increasing the distance between peptide chains, thereby reducing intermolecular interactions.[6]
-
Longer Reaction Times: Increasing the coupling time or performing a double coupling can help drive the reaction to completion, especially when aggregation slows down reaction kinetics.[9]
Troubleshooting Guides
Guide 1: Modifying Synthesis Chemistry to Disrupt Aggregation
Problem: Standard synthesis protocols are failing for a known hydrophobic sequence, resulting in low yield and purity.
Solution: Implement chemical modifications to the peptide backbone to disrupt secondary structure formation.
-
Pseudoproline Dipeptides: Introduce pseudoproline dipeptides at strategic locations within your peptide sequence.[10][11] These dipeptides, derived from Ser, Thr, or Cys, create a "kink" in the peptide backbone, effectively disrupting the formation of β-sheets.[10][11] They are incorporated as a dipeptide unit and the native sequence is regenerated during the final cleavage.[10]
-
Backbone Protection: Utilize backbone-protecting groups like 2-hydroxy-4-methoxybenzyl (Hmb) or 2,4-dimethoxybenzyl (Dmb) on the α-nitrogen of amino acid residues.[6] These groups physically prevent the formation of hydrogen bonds between peptide chains. It is recommended to incorporate a protected residue every six to seven amino acids to effectively disrupt aggregation.[6]
Experimental Protocol: Incorporation of Pseudoproline Dipeptides
Objective: To incorporate a pseudoproline dipeptide into a peptide sequence during Fmoc-SPPS to mitigate on-resin aggregation.
Materials:
-
Fmoc-protected amino acids
-
Appropriate Fmoc-Xaa-Ser/Thr(ψPro)-OH pseudoproline dipeptide (5 equivalents relative to resin loading)
-
Coupling reagent (e.g., HBTU, HATU, PyBOP) (5 equivalents)
-
Base (e.g., DIPEA) (10 equivalents)
-
Fmoc-deprotected peptide-resin
-
DMF or NMP as solvent
Procedure (Manual Coupling):
-
Dissolve the pseudoproline dipeptide and the coupling reagent in a minimal volume of DMF or NMP.
-
Add the base (DIPEA) to the solution and mix thoroughly.
-
Immediately add the activated dipeptide solution to the vessel containing the Fmoc-deprotected peptide-resin.
-
Agitate the reaction mixture for 1-2 hours.
-
Monitor the completion of the coupling reaction using a qualitative test such as the TNBS (trinitrobenzenesulfonic acid) test. If the reaction is incomplete, extend the coupling time or repeat the coupling step with fresh reagents.
Q4: Can changing the physical conditions of the synthesis help with aggregation?
A4: Yes, modifying the physical parameters of the synthesis can significantly impact aggregation.
-
Elevated Temperature: Increasing the reaction temperature can disrupt hydrogen bonds and improve reaction kinetics.[6][12] Temperatures between 60°C and 86°C have been shown to be effective.[12][13]
-
Microwave-Assisted SPPS (MW-SPPS): The application of microwave energy can accelerate both the coupling and deprotection steps, often leading to higher purity and yield for difficult sequences.[14][15][16] Microwave energy helps to prevent the folding and aggregation of the growing peptide chains.[14]
Workflow for Troubleshooting Aggregation
Caption: A logical workflow for identifying and troubleshooting peptide aggregation.
Guide 2: Utilizing Additives to Overcome Aggregation
Problem: Aggregation persists even after optimizing solvents and temperature.
Solution: Introduce additives that disrupt non-covalent interactions responsible for aggregation.
-
Chaotropic Agents: These are salts that disrupt the structure of water and interfere with hydrogen bonding.[1] Adding chaotropic salts such as LiCl, KSCN, or NaClO4 to the coupling or washing steps can help to solubilize the aggregating peptide chains.[6][8]
-
Surfactants: Non-ionic detergents like Triton X-100 can be added to the reaction mixture to mimic a membrane-like environment, which can help to keep hydrophobic peptides solubilized.[8]
Data Summary
Table 1: Common Solvents and Additives for Mitigating Peptide Aggregation
| Category | Agent | Typical Concentration/Mixture | Mechanism of Action | Reference(s) |
| Solvents | N-Methylpyrrolidone (NMP) | Used as primary solvent | Increases solvation of peptide-resin | [7] |
| Dimethyl Sulfoxide (DMSO) | Often used as a co-solvent with DMF | Improves solvation | [17] | |
| "Magic Mixture" | DCM/DMF/NMP (1:1:1) | Enhanced solvation properties | [1][8] | |
| Chaotropic Agents | Lithium Chloride (LiCl) | - | Disrupts hydrogen bonding | [8] |
| Potassium Thiocyanate (KSCN) | 4 M in DMF for washing | Disrupts hydrogen bonding | [8] | |
| Sodium Perchlorate (NaClO4) | 0.8 M in DMF for washing | Disrupts hydrogen bonding | ||
| Surfactants | Triton X-100 | 1% in "Magic Mixture" | Mimics membrane environment | [8] |
Logical Relationship of Aggregation Factors
Caption: Relationship between causes, consequences, and solutions for aggregation.
Q5: Are there any sequence-specific considerations for using these troubleshooting techniques?
A5: Yes, the choice of strategy can be sequence-dependent.
-
Pseudoproline Dipeptides: These are only applicable at Ser, Thr, or Cys residues.[10][11] Therefore, their use is dictated by the presence of these amino acids in the sequence. For optimal results, it is recommended to space pseudoprolines 5-6 residues apart.[18]
-
Backbone Protection (Hmb/Dmb): While broadly applicable, the insertion of these bulky groups can sometimes be sterically hindered. They are particularly useful for breaking up stretches of hydrophobic residues.
-
Microwave SPPS: While generally effective, high temperatures used in microwave synthesis can increase the risk of racemization for sensitive amino acids like His and Cys.[13] Therefore, it is important to use optimized methods that control temperature precisely.[15]
By understanding the underlying causes of aggregation and employing the appropriate troubleshooting strategies, researchers can significantly improve the success rate of synthesizing challenging hydrophobic peptides.
References
- 1. Challenges and Perspectives in Chemical Synthesis of Highly Hydrophobic Peptides - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. academic.oup.com [academic.oup.com]
- 4. A robust data analytical method to investigate sequence dependence in flow-based peptide synthesis - Reaction Chemistry & Engineering (RSC Publishing) DOI:10.1039/D3RE00494E [pubs.rsc.org]
- 5. chemrxiv.org [chemrxiv.org]
- 6. peptide.com [peptide.com]
- 7. biotage.com [biotage.com]
- 8. cpcscientific.com [cpcscientific.com]
- 9. How to Optimize Peptide Synthesis? - Creative Peptides [creative-peptides.com]
- 10. Pseudoproline - Wikipedia [en.wikipedia.org]
- 11. chempep.com [chempep.com]
- 12. WO2018057470A1 - Rapid peptide synthesis at elevated temperatures - Google Patents [patents.google.com]
- 13. pubs.acs.org [pubs.acs.org]
- 14. Microwave-Assisted Solid-Phase Peptide Synthesis (MW-SPPS) Technology - Therapeutic Proteins & Peptides - CD Formulation [formulationbio.com]
- 15. Microwave-assisted solid-phase peptide synthesis based on the Fmoc protecting group strategy (CEM) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. Solid-phase peptide synthesis using microwave irradiation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. genscript.com [genscript.com]
- 18. Pseudoproline Product Spoltlight | Merck [merckmillipore.com]
Addressing low yield in the synthesis of modified peptides
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals address low yield in the synthesis of modified peptides.
Frequently Asked Questions (FAQs)
Q1: What are the most common causes of low yield in modified peptide synthesis?
A1: Low yields in solid-phase peptide synthesis (SPPS) can stem from a variety of factors, often related to the peptide sequence itself. "Difficult sequences," such as those that are long (over 30 amino acids), hydrophobic, or prone to aggregation, are a primary cause.[1][2] Aggregation of the growing peptide chain on the solid support can hinder reaction kinetics, leading to incomplete reactions.[3] Other common causes include inefficient coupling and deprotection steps, undesired side reactions like racemization and aspartimide formation, and issues during cleavage from the resin and final purification.[1][4]
Q2: How does the peptide sequence influence the synthesis yield?
A2: The amino acid sequence is a critical determinant of synthesis success. Peptides rich in hydrophobic residues (e.g., Val, Ile, Leu, Phe) have a higher tendency to aggregate via inter- or intramolecular hydrogen bonds, forming secondary structures like β-sheets on the resin.[3][5] This aggregation can physically block reactive sites, leading to failed coupling and deprotection steps and resulting in truncated or deletion sequences.[3] The presence of certain amino acid combinations can also predispose a sequence to side reactions, further reducing the yield of the desired product.
Q3: What is peptide aggregation and how can it be minimized?
A3: Peptide aggregation during SPPS is the self-association of growing peptide chains on the solid support, often driven by the formation of stable secondary structures.[3] This phenomenon is particularly prevalent with hydrophobic sequences.[3] Aggregation can lead to significant drops in yield by making the N-terminus of the peptide inaccessible for the next coupling reaction.
Several strategies can be employed to minimize aggregation:
-
Chaotropic Agents: The addition of salts like guanidinium chloride can disrupt hydrogen bonding and reduce aggregation.
-
Special Solvents: Using alternative solvents such as N-methyl-2-pyrrolidone (NMP) or adding a small percentage of dimethyl sulfoxide (DMSO) to the standard dimethylformamide (DMF) can improve solvation of the peptide chain.
-
Elevated Temperatures: Performing coupling reactions at higher temperatures, often facilitated by microwave irradiation, can help disrupt secondary structures and improve reaction rates.
-
Structure-Disrupting Amino Acid Derivatives: Incorporating pseudoproline dipeptides or 2,4-dimethoxybenzyl (DMB) or 2-hydroxy-4-methoxybenzyl (HMB) protected amino acids can introduce "kinks" in the peptide backbone, disrupting the formation of aggregates.[6][7][8]
Q4: When should I consider using modified amino acids with backbone protection?
A4: Modified amino acids with backbone protection, such as pseudoproline dipeptides, are highly recommended for sequences known to be difficult or prone to aggregation.[6][7][8] They are particularly beneficial when synthesizing long peptides or sequences containing stretches of hydrophobic residues. By temporarily altering the peptide backbone's conformation, they prevent the formation of the secondary structures that lead to aggregation, thereby improving coupling efficiency and overall yield.[6][8]
Troubleshooting Guide
Issue 1: Low Coupling Efficiency
Symptom: Incomplete reaction after a coupling step, as indicated by a positive Kaiser test or the presence of deletion sequences in the final product.
| Potential Cause | Recommended Solution | Expected Outcome |
| Steric Hindrance | Use a more potent coupling reagent such as HATU, HCTU, or COMU.[9][10] | Increased coupling efficiency and reduced deletion sequences. |
| Perform a "double coupling" by repeating the coupling step with fresh reagents. | Drives the reaction closer to completion. | |
| Peptide Aggregation | Switch to a more solubilizing solvent like NMP or a DMF/DMSO mixture. | Improved solvation of the peptide chain, making the N-terminus more accessible. |
| Increase the reaction temperature, potentially using a microwave peptide synthesizer.[11] | Disruption of secondary structures and faster reaction kinetics. | |
| Incorporate a pseudoproline dipeptide at a strategic position in the sequence.[6][7][8] | Disruption of aggregation and improved coupling. Can increase product yield by up to 10-fold in highly aggregated sequences.[6][7] | |
| Insufficient Reagent Excess | Increase the equivalents of amino acid and coupling reagent used. | Higher concentration drives the reaction forward. |
Issue 2: Incomplete Fmoc Deprotection
Symptom: The presence of Fmoc-protected peptides or deletion sequences in the final product.
| Potential Cause | Recommended Solution | Expected Outcome |
| Peptide Aggregation | Use a more effective deprotection solution, such as 20% piperidine in NMP. | Better swelling of the resin and improved access to the Fmoc group. |
| Increase the deprotection time or perform a second deprotection step. | More complete removal of the Fmoc group. | |
| Formation of a Stable Salt | Add a small amount of a chaotropic agent like 1% Triton X-100 to the deprotection solution. | Disruption of ionic interactions that may hinder deprotection. |
Issue 3: Significant Yield Loss During Cleavage and Purification
Symptom: Good synthesis on-resin, but low recovery of the final peptide.
| Potential Cause | Recommended Solution | Expected Outcome |
| Incomplete Cleavage | Ensure the correct cleavage cocktail is used for the specific resin and protecting groups. | Complete release of the peptide from the solid support. |
| Increase the cleavage time or repeat the cleavage step. | Maximized recovery of the crude peptide. | |
| Peptide Precipitation Issues | Optimize the precipitation solvent and temperature. Cold ether is commonly used. | Efficient precipitation of the cleaved peptide. |
| Poor Solubility of Crude Peptide | Dissolve the crude peptide in a minimal amount of a strong solvent (e.g., neat TFA, acetic acid) before purification. | Improved handling and injection onto the HPLC column. |
| Suboptimal HPLC Conditions | Optimize the HPLC gradient, column, and mobile phases for the specific peptide. | Better separation and recovery of the pure peptide. |
Experimental Protocols
Protocol 1: Standard HBTU/HOBt Coupling
-
Resin Preparation: Swell the peptide-resin in DMF for 30-60 minutes.
-
Fmoc Deprotection: Treat the resin with 20% piperidine in DMF for 5-10 minutes. Repeat this step once.
-
Washing: Wash the resin thoroughly with DMF (5-7 times) to remove all traces of piperidine.
-
Amino Acid Activation: In a separate vessel, dissolve the Fmoc-protected amino acid (3-5 equivalents relative to resin loading), HBTU (3-5 equivalents), and HOBt (3-5 equivalents) in a minimal amount of DMF. Add DIPEA (6-10 equivalents) and allow the mixture to pre-activate for 1-2 minutes.
-
Coupling: Add the activated amino acid solution to the resin. Agitate the mixture for 1-2 hours at room temperature.
-
Monitoring: Perform a Kaiser test to check for the presence of free primary amines. A negative result (yellow beads) indicates a complete reaction.
-
Washing: Wash the resin with DMF (3-5 times) to remove excess reagents.
Protocol 2: Fmoc Deprotection
-
Initial Treatment: Add a solution of 20% piperidine in DMF to the peptide-resin.
-
Agitation: Agitate the mixture for 5-10 minutes at room temperature.
-
Drain: Drain the deprotection solution.
-
Second Treatment: Add a fresh portion of 20% piperidine in DMF and agitate for another 5-10 minutes.
-
Washing: Drain the solution and wash the resin extensively with DMF (at least 5 times) to ensure complete removal of piperidine and the dibenzofulvene-piperidine adduct.
Protocol 3: Cleavage from Wang Resin
-
Resin Preparation: Wash the final peptide-resin with dichloromethane (DCM) and dry it under a high vacuum for at least 1 hour.
-
Cleavage Cocktail Preparation: Prepare a cleavage cocktail appropriate for the amino acid protecting groups. A common cocktail is 95% Trifluoroacetic Acid (TFA), 2.5% water, and 2.5% triisopropylsilane (TIS).
-
Cleavage Reaction: Add the cleavage cocktail to the dried resin (approximately 10 mL per gram of resin).
-
Incubation: Gently agitate the mixture at room temperature for 2-3 hours.
-
Filtration: Filter the resin and collect the filtrate containing the cleaved peptide.
-
Washing: Wash the resin with a small amount of fresh TFA to recover any remaining peptide.
-
Precipitation: Add the combined filtrate to a 10-fold volume of cold diethyl ether to precipitate the crude peptide.
-
Isolation: Centrifuge the mixture to pellet the peptide, decant the ether, and wash the peptide pellet with cold ether two more times.
-
Drying: Dry the crude peptide pellet under a vacuum.
Visualizations
Caption: A flowchart illustrating the key steps in a standard Fmoc-based solid-phase peptide synthesis workflow.
Caption: A decision tree to guide troubleshooting efforts when encountering low peptide synthesis yield.
References
- 1. gyrosproteintechnologies.com [gyrosproteintechnologies.com]
- 2. researchgate.net [researchgate.net]
- 3. youtube.com [youtube.com]
- 4. chempep.com [chempep.com]
- 5. Pseudoproline Product Spoltlight | Merck [merckmillipore.com]
- 6. Extending pseudoprolines beyond Ser and Thr | Merck [merckmillipore.com]
- 7. pubs.acs.org [pubs.acs.org]
- 8. bachem.com [bachem.com]
- 9. luxembourg-bio.com [luxembourg-bio.com]
- 10. Microwave-Assisted Peptide Synthesis: A Faster Approach - Creative Peptides [creative-peptides.com]
- 11. Solid-phase peptide synthesis using microwave irradiation - PubMed [pubmed.ncbi.nlm.nih.gov]
Minimizing racemization during N-alkyl amino acid synthesis.
Welcome to the technical support center for N-alkyl amino acid synthesis. This resource is designed for researchers, scientists, and drug development professionals to troubleshoot common issues and find answers to frequently asked questions related to minimizing racemization during their experiments.
Troubleshooting Guide
This section addresses specific problems you may encounter during the synthesis of N-alkyl amino acids, providing potential causes and actionable solutions to maintain stereochemical integrity.
Question: I am observing significant racemization in my N-alkylation reaction. What are the common causes and how can I minimize it?
Answer:
Racemization during N-alkylation of amino acids is a frequent challenge that can arise from several factors. The primary mechanism involves the deprotonation of the α-carbon, leading to a loss of stereochemistry. Here are the common culprits and strategies to mitigate them:
-
Strong Bases: The use of strong bases can readily abstract the α-proton of the amino acid ester, leading to racemization.[1]
-
Solution: Opt for weaker bases. For instance, in N-arylation reactions, switching from sodium tert-butoxide to a milder base is crucial for preserving stereochemical integrity.[1] Studies have also shown that using Na2CO3 as a base with a 50% excess of the amino acid anion can minimize racemization during the aminolysis of activated esters.[2] The basicity and steric hindrance of organic bases also play a significant role; weaker bases with greater steric hindrance, such as 2,4,6-collidine (TMP), often result in less racemization compared to stronger, less hindered bases like triethylamine.[3]
-
-
Prolonged Reaction Times and High Temperatures: Extended exposure to basic or acidic conditions, especially at elevated temperatures, can increase the likelihood of racemization.[2][4]
-
Solution: Optimize your reaction time and temperature. Aim for the shortest time and lowest temperature necessary for the reaction to proceed to completion. For example, an efficient synthesis of optically pure Z-L-Phe-D-Val-OH was achieved with a reaction time of just 15 minutes.[2]
-
-
Solvent Effects: The choice of solvent can influence the rate of racemization.[5]
-
Solution: The effect of the solvent on racemization rates can be significant. It is advisable to screen different solvents to find one that disfavors the formation of the planar enolate intermediate.
-
-
Inappropriate Protecting Groups: The nature of the N-protecting group can influence the acidity of the α-proton.
-
Solution: Employ protecting groups that are known to suppress racemization. Carbamate-based protecting groups like Boc (tert-Butoxycarbonyl) and Z (Benzyloxycarbonyl) are generally preferred as they are known to reduce the tendency for racemization during activation.[6]
-
Question: My reductive amination of an α-keto acid is resulting in a racemic mixture of the N-alkyl amino acid. How can I achieve better stereoselectivity?
Answer:
Reductive amination is a powerful tool for N-alkyl amino acid synthesis; however, achieving high enantioselectivity can be challenging.
-
Enzyme-Catalyzed Reductive Amination: Biocatalysis offers a highly stereospecific approach.
-
Solution: Employ imine reductases (IREDs) or reductive aminases (RedAms). These enzymes can catalyze the direct reductive coupling of α-ketoesters and amines to produce N-substituted α-amino esters with high conversion and excellent enantioselectivity under mild reaction conditions.[7][8] Dehydrogenase enzymes are also used in biochemistry to catalyze the reductive amination of α-keto acids to yield α-amino acids with high stereospecificity.[9]
-
-
Asymmetric Reductive Amination: The use of chiral catalysts can induce enantioselectivity.
-
Solution: Implement asymmetric reductive amination using a chiral catalyst. This method involves the condensation of a carbonyl compound with an amine in the presence of H₂ and a chiral catalyst to form an imine intermediate, which is then reduced to the desired chiral amine.[9]
-
Question: I am struggling with low yields and side reactions during the N-alkylation of amino acids with alcohols. What can I do to improve my synthesis?
Answer:
Direct N-alkylation using alcohols is an atom-economical method, but can be prone to side reactions like esterification.
-
Catalyst and Reaction Conditions: The choice of catalyst and reaction parameters is critical.
-
Solution: A robust method involves using a ruthenium catalyst, which is atom-economic and base-free, allowing for excellent retention of stereochemistry. The addition of diphenylphosphate as an additive can significantly enhance reactivity and product selectivity.[10] Another approach utilizes a catalytic "borrowing hydrogen" strategy, which involves the dehydrogenation of the alcohol to an aldehyde, followed by imine formation and hydrogenation.[11] This method is highly selective and produces water as the only byproduct.[11]
-
-
Competing Esterification: The carboxylic acid functionality can compete with the amine for reaction with the alcohol.
-
Solution: Keeping the reaction temperature controlled can help minimize competing esterification reactions. For instance, a reaction temperature of 90°C was found to be effective in minimizing this side reaction in one study.[11]
-
Frequently Asked Questions (FAQs)
Q1: What are the most common methods for synthesizing N-alkyl amino acids while minimizing racemization?
A1: Several methods are employed to synthesize N-alkyl amino acids with high optical purity:
-
Direct N-alkylation of unprotected amino acids: This sustainable approach uses alcohols as alkylating agents in the presence of a catalyst, producing water as the only byproduct and often with excellent retention of stereochemistry.[11]
-
Reductive Amination of α-Keto Acids: This method can be highly enantioselective, especially when using biocatalysts like imine reductases (IREDs).[7][8]
-
Alkylation of N-Protected Amino Acids: This classic approach involves protecting the amino group before alkylation. The choice of protecting group is crucial to prevent racemization.[6][12]
-
Use of Chiral Auxiliaries: Chiral auxiliaries can be used to control the stereochemistry during the synthesis of optically active amino acids.[13]
Q2: How do protecting groups help in preventing racemization?
A2: Protecting groups play a vital role in minimizing racemization by influencing the electronic properties of the amino acid.
-
Urethane-type protecting groups like Boc and Z (Cbz) are particularly effective. They decrease the acidity of the α-proton, making it less susceptible to abstraction by a base, which is the primary step in the racemization mechanism.[4][6]
-
Side-chain protection is also important for amino acids with reactive side chains like histidine and cysteine, which are especially prone to racemization.[14][15] For example, protecting the imidazole nitrogen of histidine can significantly reduce racemization.[15]
Q3: What is the mechanism of racemization during N-alkyl amino acid synthesis?
A3: The primary mechanism of racemization involves the formation of a planar carbanion or enolate intermediate. This occurs through the abstraction of the proton on the α-carbon by a base. Once this planar intermediate is formed, reprotonation can occur from either face with equal probability, leading to a mixture of enantiomers.[3][16] Another pathway, particularly in peptide synthesis, is through the formation of an oxazolone ring.[3]
Q4: Can the choice of base and solvent impact the level of racemization?
A4: Absolutely. The choice of base and solvent has a significant impact on the extent of racemization.
-
Base: Stronger bases and those with less steric hindrance are more likely to cause racemization by facilitating the deprotonation of the α-carbon.[3] For example, triethylamine is more prone to causing racemization than the bulkier and less basic N-methylmorpholine (NMM) or 2,4,6-collidine (TMP).[3]
-
Solvent: The solvent can influence the stability of the intermediates involved in racemization. The rates of racemization have been shown to vary significantly in different solvents.[5]
Quantitative Data Summary
The following tables summarize quantitative data from various studies on N-alkyl amino acid synthesis, focusing on conditions that minimize racemization.
Table 1: Enantiomeric Excess in Direct N-Alkylation of Unprotected Amino Acids with Alcohols
| Amino Acid | Alkylating Agent | Catalyst | Enantiomeric Excess (ee %) | Reference |
| Proline | Ethanol | Shvo Catalyst | 99 | [11] |
| Valine | Ethanol | Shvo Catalyst | 93 | [11] |
| Leucine | Ethanol | Shvo Catalyst | 99 | [11] |
| Phenylalanine | Ethanol | Shvo Catalyst | 99 | [11] |
| Serine | Ethanol | Shvo Catalyst | 86 | [11] |
| Alanine | Ethanol | Shvo Catalyst | 84 | [11] |
Table 2: Enantiomeric Excess in Cobalt-Catalyzed N-Alkylation
| Substrate | Enantiomeric Excess (ee %) | Reference |
| Chiral Substrates | 85-99 | [17] |
Experimental Protocols
Protocol 1: General Procedure for the N-alkylation of Amino Acids with Alcohols using a Shvo Catalyst [11]
-
An oven-dried 20-mL Schlenk tube equipped with a stirring bar is charged with the amino acid, catalyst (e.g., Cat 1), and the alcohol.
-
The Schlenk tube is connected to an argon line, and a vacuum-backfill cycle is performed three times.
-
The alcohol and any solvent (if indicated) are added under an argon stream.
-
The reaction mixture is then heated to the specified temperature (e.g., 90°C) for the required duration.
-
Upon completion, the excess alcohol can be removed under reduced pressure to yield the N-alkylated amino acid.
Protocol 2: Biocatalytic Reductive Amination of α-Ketoesters [7]
-
Prepare a reaction mixture containing the α-ketoester, the amine, and an imine reductase (IRED) enzyme in a suitable buffer.
-
Ensure the presence of a cofactor such as NAD(P)H.
-
Incubate the reaction under mild conditions (e.g., controlled temperature and pH) until completion.
-
The N-substituted amino ester product can then be isolated and purified.
Visualizations
Caption: Workflow for Direct N-Alkylation of Amino Acids.
Caption: Mechanism of Racemization via α-Proton Abstraction.
References
- 1. Development of a Method for the N-Arylation of Amino Acid Esters with Aryl Triflates - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Racemization during aminolysis of activated esters of N-alkoxycarbonylamino acids by amino acid anions in partially aqueous solvents and a tactic to minimize it - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. A Brief Introduction to the Racemization of Amino Acids in Polypeptide Synthesis [en.highfine.com]
- 4. researchgate.net [researchgate.net]
- 5. Amino-acids and peptides. Part XXXV. The effect of solvent on the rates of racemisation and coupling of some acylamino-acid p-nitro-phenyl esters; the base strengths of some amines in organic solvents, and related investigations - Journal of the Chemical Society, Perkin Transactions 1 (RSC Publishing) [pubs.rsc.org]
- 6. Protecting Groups in Peptide Synthesis: A Detailed Guide - Creative Peptides [creative-peptides.com]
- 7. Asymmetric Synthesis of N‐Substituted α‐Amino Esters from α‐Ketoesters via Imine Reductase‐Catalyzed Reductive Amination - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Asymmetric Synthesis of N-Substituted α-Amino Esters from α-Ketoesters via Imine Reductase-Catalyzed Reductive Amination - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Reductive amination - Wikipedia [en.wikipedia.org]
- 10. d-nb.info [d-nb.info]
- 11. Direct N-alkylation of unprotected amino acids with alcohols - PMC [pmc.ncbi.nlm.nih.gov]
- 12. research.monash.edu [research.monash.edu]
- 13. Chiral Auxiliary for the Synthesis of Optically Active Amino Acids | Tokyo Chemical Industry Co., Ltd.(APAC) [tcichemicals.com]
- 14. peptide.com [peptide.com]
- 15. peptide.com [peptide.com]
- 16. Elucidating the Racemization Mechanism of Aliphatic and Aromatic Amino Acids by In Silico Tools [mdpi.com]
- 17. pubs.acs.org [pubs.acs.org]
Technical Support Center: Chemical Synthesis of Hydrophobic Peptides
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in overcoming the challenges associated with the chemical synthesis of hydrophobic peptides.
Troubleshooting Guides
This section addresses specific issues encountered during the synthesis of hydrophobic peptides in a question-and-answer format.
Problem 1: Low Yield and Incomplete Coupling Reactions
Question: My solid-phase peptide synthesis (SPPS) of a hydrophobic peptide is resulting in a low yield of the target peptide, and I suspect incomplete coupling reactions. How can I troubleshoot this?
Answer: Low yields and incomplete couplings are common challenges when synthesizing hydrophobic peptides due to on-resin aggregation, which hinders reagent accessibility. Here are several strategies to address this issue:
1. Optimize Solvent Conditions: The choice of solvent is critical to disrupt peptide aggregation.
-
N-Methyl-2-pyrrolidone (NMP): NMP is an excellent solvent for peptide synthesis as it effectively dissolves a wide range of organic compounds, including amino acids and peptides. It can stabilize reactive intermediates during the coupling process and is also effective for removing protecting groups.[1]
-
"Magic Mixture": For particularly challenging sequences, a "magic mixture" can be employed. This solvent system is designed to increase the polarity of the reaction mixture and introduce hydrogen bond acceptors to compete with the formation of β-sheets between peptide chains.[2] A typical composition is a 1:1:1 mixture of DMF/DCM/NMP.[3]
2. Employ Aggregation-Disrupting Amino Acid Derivatives:
-
Pseudoproline Dipeptides: Incorporating pseudoproline dipeptides at strategic locations (every 5-6 residues is optimal) can disrupt the formation of secondary structures that lead to aggregation.[4][5][6] These dipeptides are introduced using standard coupling methods and the native serine or threonine residue is regenerated during the final cleavage from the resin.[4][5]
-
Backbone Protecting Groups (Hmb/Dmb): Utilizing 2-hydroxy-4-methoxybenzyl (Hmb) or 2,4-dimethoxybenzyl (Dmb) groups on the alpha-nitrogen of amino acid residues physically prevents hydrogen bonding between peptide chains.[7]
3. Adjust Coupling Reaction Conditions:
-
Elevated Temperature: Performing coupling reactions at a higher temperature can help to disrupt inter-chain hydrogen bonding and accelerate reaction rates.[7]
-
Alternative Coupling Reagents: For difficult couplings, more potent activating reagents such as HATU, HBTU, or PyBOP can be used.[5]
Troubleshooting Workflow for Low Yield
References
- 1. Development of the Schedule for Multiple Parallel “Difficult” Peptide Synthesis on Pins - PMC [pmc.ncbi.nlm.nih.gov]
- 2. pubcompare.ai [pubcompare.ai]
- 3. Challenges and Perspectives in Chemical Synthesis of Highly Hydrophobic Peptides - PMC [pmc.ncbi.nlm.nih.gov]
- 4. chempep.com [chempep.com]
- 5. merckmillipore.com [merckmillipore.com]
- 6. mesalabs.com [mesalabs.com]
- 7. peptide.com [peptide.com]
Technical Support Center: A Guide to Synthesizing Peptides with Modified Amino Acids
This technical support center is designed for researchers, scientists, and professionals in drug development who are navigating the complexities of synthesizing peptides that incorporate modified amino acids. Here, you will find practical troubleshooting advice and answers to frequently asked questions to help ensure the success of your experiments.
Troubleshooting Guides
This section addresses common issues encountered during the synthesis of modified peptides, offering potential causes and actionable solutions in a straightforward question-and-answer format.
1. Low Coupling Efficiency and Incomplete Reactions
Question: I'm experiencing low coupling efficiency or incomplete reactions when trying to incorporate a modified amino acid. What could be the problem and how can I fix it?
Answer:
Low coupling efficiency is a frequent hurdle, particularly when working with bulky or sterically hindered modified amino acids. The primary causes include:
-
Steric Hindrance: The sheer size of the modified amino acid's side chain, or the growing peptide chain itself, can physically obstruct the reaction sites.
-
Secondary Structure Formation: The peptide chain can fold into secondary structures like β-sheets on the resin, rendering the N-terminus inaccessible for the next coupling reaction.
-
Inadequate Resin Swelling: If the solid support does not swell properly, reagents cannot efficiently reach the peptide chain.
-
Insufficiently Potent Coupling Reagents: The selected coupling reagent may not be strong enough to drive the reaction to completion for these challenging residues.
Troubleshooting Strategies:
-
Optimize Coupling Reagents and Conditions:
-
Consider switching to a more powerful coupling reagent. For difficult couplings, uronium/aminium salts such as HATU, HCTU, and COMU are generally more effective than carbodiimides.[1] Phosphonium salts like PyAOP and PyBOP are also highly effective and are preferred for cyclization reactions to prevent guanidinylation side reactions.[1][2]
-
Increase the amount of the amino acid and coupling reagent used.
-
Extend the duration of the coupling reaction.
-
Perform a "double coupling," where the coupling step is repeated with a fresh batch of reagents before proceeding to the next deprotection step.
-
-
Disrupt Secondary Structures:
-
Employ solvents known to break up hydrogen bonds, such as N-methyl-2-pyrrolidone (NMP) or dimethyl sulfoxide (DMSO), either on their own or mixed with DMF.
-
Incorporate "structure-breaking" elements like pseudoproline dipeptides into your sequence just before the challenging coupling point.
-
-
Enhance Resin Swelling:
-
Ensure the resin is fully swelled in an appropriate solvent like DMF or NMP before beginning the synthesis.
-
For particularly difficult sequences, consider using a resin with a higher swelling capacity, such as a polyethylene glycol (PEG)-based resin.
-
2. Side Reactions and the Formation of Impurities
Question: My crude peptide product is showing a high level of impurities after cleavage. What are the common side reactions, and how can I minimize them?
Answer:
Side reactions can occur at multiple stages of peptide synthesis and are often influenced by the specific amino acid sequence and the nature of the modifications.
Common Side Reactions:
-
Racemization: During the activation and coupling steps, the stereochemistry of the amino acid can be inverted, leading to diastereomeric impurities. This is a known issue for amino acids such as histidine and cysteine.
-
Aspartimide Formation: Peptides containing aspartic acid can form a cyclic imide, which can then be hydrolyzed to a mixture of aspartic acid and isoaspartic acid residues.
-
Guanidinylation: Uronium-based coupling reagents like HBTU and HATU can react with the free N-terminus of the peptide, which terminates the chain extension.[1]
-
Protecting Group Instability: Side-chain protecting groups may be prematurely removed or altered, leading to unwanted reactions.
Strategies to Minimize Side Reactions:
-
Racemization:
-
Use coupling reagents that include additives known to suppress racemization, such as HOBt or OxymaPure.[3]
-
Keep activation times as short as possible.
-
For amino acids that are highly susceptible to racemization, consider using pre-activated derivatives like Fmoc-amino acid fluorides.
-
-
Aspartimide Formation:
-
Utilize protecting groups on the side chain of aspartic acid that are less prone to cyclization, for instance, 3-tert-butyl-aspartate.
-
Employ milder coupling conditions to reduce the risk of aspartimide formation.
-
-
Guanidinylation:
-
Opt for phosphonium-based coupling reagents such as PyBOP or PyAOP, which do not cause this side reaction.[1]
-
Avoid using a large excess of uronium-based coupling reagents.
-
-
Protecting Group Strategy:
-
It is crucial to use an orthogonal protecting group strategy, where the side-chain protecting groups remain stable under the conditions used for the removal of the Nα-Fmoc group.[4]
-
3. Challenges Associated with Specific Modifications
Phosphorylation:
-
Question: I'm encountering difficulties in synthesizing a phosphopeptide. What are the main challenges?
-
Answer: The primary challenges in synthesizing phosphopeptides are the instability of the phosphate group under standard cleavage conditions and the risk of side reactions like β-elimination. It is essential to use a phosphate protecting group, such as monobenzyl, that is stable throughout the synthesis and can be removed during the final cleavage step.[5] For the efficient incorporation of phosphorylated amino acids, a double coupling with a potent coupling reagent like HATU is often required.[6]
Glycosylation:
-
Question: What are the common problems when synthesizing glycopeptides?
-
Answer: The synthesis of glycopeptides is challenging due to the steric bulk of the glycan, which can result in low coupling yields.[7] The stability of the glycosidic bond, especially for O-linked glycans, to acidic cleavage conditions is another significant concern.[8] The most effective strategy is to use pre-formed glycosylated amino acid building blocks that are Fmoc-protected at the α-amino group.[4]
Fluorescent Labeling:
-
Question: My fluorescently labeled peptide is exhibiting poor solubility and is aggregating. What is the cause?
-
Answer: Many fluorescent dyes are hydrophobic and can cause the peptide to aggregate.[2] To minimize this, it is important to carefully choose the dye and the position of labeling. Attaching the label at the N-terminus or on a lysine side chain that is distant from the core binding sequence is often a good strategy. The use of a hydrophilic linker between the peptide and the dye can also enhance solubility.
Frequently Asked Questions (FAQs)
Q1: How do I select the most appropriate coupling reagent for my modified amino acid?
A1: The choice of coupling reagent should be based on the steric hindrance of the modified amino acid and the overall difficulty of the peptide sequence. For standard couplings, DIC/HOBt may be adequate. For more challenging couplings, such as those involving N-methylated amino acids or other bulky modifications, more powerful reagents like HATU, HCTU, PyAOP, or COMU are recommended.[9][10] Please refer to the data table below for a comparison of coupling efficiencies.
Q2: What is the most effective method for purifying my modified peptide?
A2: The gold standard for purifying synthetic peptides is reverse-phase high-performance liquid chromatography (RP-HPLC).[11] The selection of the column (e.g., C18) and the mobile phase gradient (usually a water/acetonitrile gradient containing 0.1% TFA) will depend on the hydrophobicity of your peptide. For peptides that are very hydrophobic or prone to aggregation, other purification techniques such as ion-exchange chromatography or size-exclusion chromatography may be necessary.
Q3: How can I verify the identity and purity of my final modified peptide?
A3: The identity of your peptide should be confirmed using mass spectrometry to ensure it has the correct molecular weight.[12] Purity is typically evaluated by analytical RP-HPLC, where the peak area of the desired peptide is compared to the total area of all peaks.[12] For more complex peptides or those with isomeric impurities, more advanced techniques like NMR or peptide mapping may be required for complete characterization.
Q4: I am getting a very low yield for my N-methylated peptide. What can I do to improve it?
A4: N-methylated amino acids are known to be difficult to couple due to their steric bulk and the reduced nucleophilicity of the N-methylated amine. The use of a powerful coupling reagent such as PyAOP or HATU is essential.[9] Double coupling and longer reaction times are often required. It is also advisable to monitor the coupling reaction with a colorimetric test like the bromophenol blue test, as the standard ninhydrin test is not effective for secondary amines.[9]
Q5: What are the main factors to consider when planning the synthesis of a long modified peptide (over 30 amino acids)?
A5: For long peptides, the cumulative effect of even minor inefficiencies in coupling can lead to a dramatic reduction in the final yield and purity. Key strategies to consider are:
-
Segmented Synthesis (Fragment Condensation): This involves synthesizing shorter peptide fragments and then ligating them together in solution.
-
Microwave-Assisted Peptide Synthesis (MAPS): The use of microwave energy can speed up coupling and deprotection steps, which can improve the efficiency of synthesizing long and difficult sequences.
-
Optimized Resin and Linker: Using a low-loading resin with a suitable linker can help to minimize aggregation and improve yields.
Data Presentation
Table 1: A Comparative Look at Coupling Reagent Efficiency for Difficult Couplings
| Amino Acid Type/Sequence | Coupling Reagent | Coupling Efficiency/Yield | Reference(s) |
| Sterically Hindered (e.g., Aib) | Fmoc-Aib-F | Quantitative | [7] |
| HATU/DIEA | >95% | [7] | |
| BOP-Cl | Good to excellent | [7] | |
| PyBroP | Good to excellent | [7] | |
| N-Methylated (e.g., MeLeu-MeVal) | HATU/DIEA | ~98-99% | [7] |
| PyAOP/DIEA | ~98-99% | ||
| PyBOP/HOAt/DIEA | ~95-98% | ||
| HBTU/DIEA | Lower yields | [9] | |
| Phosphorylated (pSer/pThr) | HATU/DIPEA | High | [6] |
| PyBOP/DIPEA | High | [6] | |
| Glycosylated (Bulky Glycan) | HATU/DIPEA | Moderate to High (sequence dependent) | [7] |
| DIC/HOBt | Lower yields | [7] |
Disclaimer: Coupling efficiencies are highly dependent on the specific peptide sequence. The values presented here are indicative and may vary depending on the experimental conditions.
Experimental Protocols
1. General Solid-Phase Peptide Synthesis (SPPS) Cycle (Fmoc/tBu Strategy)
This protocol details a single cycle of amino acid addition using the Fmoc/tBu strategy.
-
Resin Swelling: In the reaction vessel, swell the resin (e.g., Rink Amide resin) in DMF for a minimum of 30 minutes.
-
Fmoc Deprotection:
-
Drain the DMF from the resin.
-
Add a 20% solution of piperidine in DMF to the resin and agitate for 5-10 minutes at room temperature.
-
Drain the piperidine solution and repeat the treatment for another 5-10 minutes.
-
Thoroughly wash the resin with DMF (3-5 times).
-
-
Amino Acid Coupling:
-
In a separate container, dissolve the Fmoc-protected amino acid (3-5 equivalents relative to the resin loading) and the coupling reagent (e.g., HATU, 2.9 equivalents) in DMF.
-
Add a base (e.g., DIEA, 8 equivalents) to the amino acid solution and allow it to pre-activate for 1-2 minutes.
-
Add the activated amino acid solution to the deprotected resin and agitate for 30-60 minutes at room temperature.
-
Monitor the coupling reaction for completion using a suitable colorimetric test (e.g., the Kaiser test for primary amines or the bromophenol blue test for secondary amines). If the test indicates an incomplete reaction, repeat the coupling step.
-
-
Washing:
-
Drain the coupling solution.
-
Wash the resin thoroughly with DMF (3-5 times) and then with DCM (3-5 times) to prepare for the next cycle.
-
2. On-Resin Fluorescent Labeling
This protocol provides a method for labeling a peptide with a fluorescent dye while it is still attached to the solid support.
-
Peptide Synthesis: Synthesize the peptide on the resin following the general SPPS protocol, leaving the N-terminus Fmoc-protected.
-
Fmoc Deprotection: Perform the final Fmoc deprotection as described in the general SPPS protocol.
-
Dye Coupling:
-
Dissolve the fluorescent dye (e.g., FITC, 1.5-2 equivalents) and a base (e.g., DIEA, 3-4 equivalents) in DMF.
-
Add the dye solution to the deprotected peptide-resin.
-
Agitate the mixture in the dark to prevent photobleaching for 2-4 hours at room temperature.
-
Monitor the reaction by cleaving a small amount of the resin-bound peptide for analysis by HPLC-MS.
-
-
Washing:
-
Drain the dye solution and wash the resin extensively with DMF, DCM, and methanol to remove any unreacted dye.
-
-
Cleavage and Purification: Cleave the labeled peptide from the resin and purify it by RP-HPLC.
3. Peptide Cleavage from the Resin and Purification
This protocol describes the final steps of cleaving the peptide from the resin and purifying it.
-
Resin Preparation: Wash the final peptide-resin with DCM and dry it thoroughly under vacuum.
-
Cleavage:
-
Prepare a cleavage cocktail that is appropriate for the protecting groups used. For Fmoc/tBu chemistry, a common cocktail is 95% TFA, 2.5% water, and 2.5% triisopropylsilane (TIS).
-
Add the cleavage cocktail to the dried resin and agitate for 2-3 hours at room temperature.
-
-
Peptide Precipitation:
-
Filter the resin and collect the filtrate, which contains the cleaved peptide.
-
Precipitate the peptide by adding cold diethyl ether to the filtrate.
-
Centrifuge the mixture to form a peptide pellet.
-
Wash the pellet with cold diethyl ether twice more.
-
-
Purification by RP-HPLC:
-
Dissolve the crude peptide pellet in a suitable solvent (e.g., a mixture of water and acetonitrile with 0.1% TFA).
-
Filter the solution to remove any solid particles.
-
Inject the sample onto a preparative RP-HPLC column (e.g., C18).
-
Elute the peptide using a gradient of mobile phase B (acetonitrile with 0.1% TFA) in mobile phase A (water with 0.1% TFA).
-
Collect the fractions that correspond to the main peptide peak.
-
-
Characterization and Lyophilization:
-
Analyze the collected fractions by analytical RP-HPLC and mass spectrometry to confirm their purity and identity.
-
Pool the pure fractions and lyophilize them to obtain the final peptide as a white powder.
-
Visualizations
Caption: General workflow for Solid-Phase Peptide Synthesis (SPPS).
Caption: Troubleshooting decision tree for low coupling efficiency.
Caption: Workflow for peptide purification and characterization.
References
- 1. Peptide Coupling Reagents Guide [sigmaaldrich.com]
- 2. Bot Detection [iris-biotech.de]
- 3. merckmillipore.com [merckmillipore.com]
- 4. Choosing the Right Coupling Reagent for Peptides: A Twenty-Five-Year Journey | Semantic Scholar [semanticscholar.org]
- 5. cdnsciencepub.com [cdnsciencepub.com]
- 6. dacemirror.sci-hub.ru [dacemirror.sci-hub.ru]
- 7. peptide.com [peptide.com]
- 8. bachem.com [bachem.com]
- 9. Efficient peptide coupling involving sterically hindered amino acids - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. peptide.com [peptide.com]
- 11. Solid-phase synthesis and characterization of N-methyl-rich peptides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. gyrosproteintechnologies.com [gyrosproteintechnologies.com]
Validation & Comparative
A Comparative Guide to Novel Amino Acid-Based Molecular Assemblies for Drug Delivery
For Researchers, Scientists, and Drug Development Professionals
The self-assembly of amino acids and their derivatives into well-defined nanostructures offers a promising frontier in drug delivery. These biocompatible and chemically diverse building blocks can form a variety of architectures, including micelles, nanofibers, vesicles, and hydrogels, each with unique properties for encapsulating and delivering therapeutic agents. This guide provides a comparative overview of three distinct classes of novel amino acid-based molecular assemblies, presenting key performance data, detailed experimental protocols for their characterization, and visual workflows to aid in research and development.
Comparative Performance of Novel Amino Acid-Based Assemblies
The following tables summarize key quantitative data for three exemplary types of amino acid-based molecular assemblies, offering a baseline for comparison. It is important to note that performance metrics can vary significantly based on the specific amino acid sequence, environmental conditions, and the nature of the encapsulated drug.
Table 1: Physicochemical Properties
| Assembly Type | Predominant Morphology | Particle Size (nm) | Zeta Potential (mV) | Polydispersity Index (PDI) |
| Amphiphilic Peptide Nanomicelles | Spherical Micelles | 50 - 150 | -15 to +20 | < 0.2 |
| Dipeptide Nanofibers | Fibrillar Network | 10 - 30 (diameter) | -5 to +10 | > 0.3 |
| Bola-amphiphilic Vesicles | Vesicular (Hollow Spheres) | 100 - 300 | -25 to -5 | < 0.15 |
Table 2: Drug Loading and Release Characteristics
| Assembly Type | Model Drug | Encapsulation Efficiency (%) | Loading Capacity (%) | Release Profile |
| Amphiphilic Peptide Nanomicelles | Doxorubicin | 85 - 95 | 10 - 15 | pH-responsive (accelerated at pH 5.5) |
| Dipeptide Nanofibers | Curcumin | 70 - 85 | 5 - 10 | Sustained release over 72 hours |
| Bola-amphiphilic Vesicles | siRNA | 90 - 98 | 1 - 5 | Enzyme-triggered (MMP-2) |
Experimental Protocols
Detailed methodologies for the characterization of these assemblies are crucial for reproducible and comparative studies.
Transmission Electron Microscopy (TEM) for Morphological Analysis
Objective: To visualize the morphology and size of the self-assembled nanostructures.
Protocol:
-
Sample Preparation: A 5 µL aliquot of the aqueous solution of the amino acid-based assembly (typically 0.1-1 mg/mL) is drop-casted onto a carbon-coated copper grid.
-
Staining (for enhanced contrast): After 1-2 minutes of incubation, the excess solution is wicked away with filter paper. For negative staining, a 5 µL drop of a 2% (w/v) uranyl acetate or phosphotungstic acid solution is then added to the grid for 30-60 seconds. The excess staining solution is again removed with filter paper.
-
Drying: The grid is allowed to air-dry completely before being loaded into the TEM. For more sensitive structures, vitrification using a cryo-TEM approach is recommended to observe the morphology in a near-native state.[1]
-
Imaging: The sample is imaged using a transmission electron microscope operating at an accelerating voltage of 80-200 kV. Images are captured at various magnifications to observe both the overall morphology and fine structural details.
Dynamic Light Scattering (DLS) for Size Distribution and Stability
Objective: To determine the hydrodynamic diameter, polydispersity index (PDI), and zeta potential of the assemblies in solution.
Protocol:
-
Sample Preparation: The sample solution is diluted with deionized water or an appropriate buffer to a final concentration suitable for DLS analysis (typically 0.1-1 mg/mL) to avoid multiple scattering effects. The solution must be filtered through a 0.22 µm syringe filter to remove any dust or large aggregates.[2]
-
Instrument Setup: The DLS instrument is allowed to warm up and stabilize. The dispersant properties (viscosity and refractive index) and temperature are entered into the software.
-
Measurement: The filtered sample is pipetted into a clean cuvette, ensuring no air bubbles are present. The cuvette is placed in the instrument's sample holder.
-
Data Acquisition: For particle size and PDI, measurements are typically taken at a 90° or 173° scattering angle. For zeta potential, an electrode is inserted into the cuvette, and an electric field is applied. The instrument software calculates the size distribution and zeta potential from the correlation function of the scattered light intensity fluctuations.[3]
-
Analysis: The results are typically reported as the Z-average diameter and the PDI. A PDI value below 0.3 is generally considered indicative of a monodisperse population.
Circular Dichroism (CD) Spectroscopy for Secondary Structure Analysis
Objective: To characterize the secondary structure (e.g., α-helix, β-sheet, random coil) of the peptide-based assemblies.
Protocol:
-
Sample Preparation: The peptide assembly solution is prepared in a suitable buffer (e.g., phosphate buffer) that does not have a high absorbance in the far-UV region. The concentration should be adjusted to keep the absorbance below 1.0.[4]
-
Instrument and Cuvette: A CD spectrometer is used, and the sample is placed in a quartz cuvette with a short path length (typically 0.1-1 mm).[4]
-
Blank Measurement: A spectrum of the buffer alone is recorded and used as a baseline.
-
Sample Measurement: The CD spectrum of the sample is recorded in the far-UV region (typically 190-260 nm).[5]
-
Data Analysis: The baseline spectrum is subtracted from the sample spectrum. The resulting CD signal (in millidegrees) is often converted to molar ellipticity to normalize for concentration and path length. The shape of the spectrum is then analyzed to determine the predominant secondary structures. For instance, α-helices show characteristic negative bands around 208 and 222 nm, while β-sheets exhibit a negative band around 218 nm.[5]
Visualizing Workflows and Pathways
The following diagrams, generated using the DOT language, illustrate key processes in the characterization and application of amino acid-based molecular assemblies.
References
- 1. researchgate.net [researchgate.net]
- 2. research.cbc.osu.edu [research.cbc.osu.edu]
- 3. The principles of dynamic light scattering | Anton Paar Wiki [wiki.anton-paar.com]
- 4. youtube.com [youtube.com]
- 5. Time-Resolved Circular Dichroism in Molecules: Experimental and Theoretical Advances - PMC [pmc.ncbi.nlm.nih.gov]
A Comparative Analysis of Homoserine Derivatives: Exploring Function Beyond the Core Structure
A detailed examination of key homoserine derivatives reveals diverse functionalities, from bacterial communication to central roles in metabolic pathways. While direct comparative experimental data for 2-Prop-2-en-1-ylhomoserine (O-allyl-L-homoserine) is not available in the current scientific literature, this guide provides a comprehensive analysis of other well-characterized homoserine derivatives: N-Butanoyl-L-homoserine lactone, O-Acetyl-L-homoserine, and O-Succinyl-L-homoserine. This comparison serves as a valuable resource for researchers, scientists, and drug development professionals by highlighting the significant impact of side-chain modifications on the biological activity of the homoserine scaffold.
Introduction to Homoserine and its Derivatives
L-Homoserine is an alpha-amino acid that serves as a crucial intermediate in the biosynthesis of essential amino acids such as methionine and threonine.[1] Its core structure provides a versatile scaffold for the natural and synthetic generation of a wide array of derivatives. These derivatives exhibit a remarkable range of biological activities and applications, largely dictated by the nature of the chemical group attached to the homoserine backbone. This guide focuses on a comparative analysis of three key derivatives, each with distinct and significant roles in biological systems.
Comparative Data of Homoserine Derivatives
The following tables summarize the key physicochemical and biological properties of the selected homoserine derivatives, providing a clear basis for comparison.
| Physicochemical Properties | N-Butanoyl-L-homoserine lactone | O-Acetyl-L-homoserine | O-Succinyl-L-homoserine |
| IUPAC Name | (3S)-3-(butanoylamino)oxolan-2-one | (2S)-4-acetyloxy-2-aminobutanoic acid | (2S)-2-amino-4-[(3-carboxypropanoyl)oxy]butanoic acid |
| Molecular Formula | C₈H₁₃NO₃ | C₆H₁₁NO₄ | C₈H₁₃NO₆ |
| Molecular Weight ( g/mol ) | 171.19 | 161.16[2] | 219.19[3] |
| Structure | N-acylated and lactonized homoserine | O-acylated homoserine | O-acylated homoserine |
| Biological Role and Activity | N-Butanoyl-L-homoserine lactone | O-Acetyl-L-homoserine | O-Succinyl-L-homoserine |
| Primary Function | Bacterial quorum sensing signal molecule[4] | Intermediate in methionine biosynthesis[5][6] | Intermediate in methionine biosynthesis[7][8] |
| Key Biological Process | Regulation of gene expression in Gram-negative bacteria[4] | Precursor for cystathionine synthesis[5][6] | Precursor for cystathionine synthesis[7][8] |
| Mechanism of Action | Binds to and activates LuxR-type transcriptional regulators[9] | Substrate for O-acetylhomoserine sulfhydrylase[9] | Substrate for cystathionine gamma-synthase[10] |
| Therapeutic Potential | Target for anti-virulence therapies (as an inhibitor)[11] | Not a direct therapeutic target | Not a direct therapeutic target |
Signaling and Metabolic Pathways
The functional diversity of homoserine derivatives is best understood by examining their roles in specific biological pathways.
Figure 1: Quorum Sensing Signaling Pathway.
The N-acyl homoserine lactones (AHLs), such as N-butanoyl-L-homoserine lactone, are key signaling molecules in bacterial quorum sensing.[12] As depicted in Figure 1, these molecules are synthesized within the bacterial cell and, upon reaching a certain concentration threshold, bind to LuxR-type receptors. This complex then acts as a transcriptional regulator, modulating the expression of genes involved in processes like biofilm formation and virulence factor production.[11]
Figure 2: Homoserine Metabolic Pathway.
In contrast to the signaling role of AHLs, O-acetyl and O-succinyl-L-homoserine are key intermediates in the metabolic pathway leading to the synthesis of methionine (Figure 2).[13][14] L-homoserine, derived from aspartate, can be acylated to form either O-acetyl or O-succinyl-L-homoserine. These activated forms are then substrates for enzymes that incorporate sulfur to ultimately produce methionine.[7]
Experimental Protocols
The following sections provide detailed methodologies for key experiments related to the synthesis and evaluation of homoserine derivatives.
Synthesis of N-Butanoyl-L-homoserine lactone
This protocol describes a standard method for the synthesis of N-acylated homoserine lactones.
Materials:
-
L-homoserine lactone hydrobromide
-
Butyryl chloride
-
Sodium bicarbonate
-
Dichloromethane (DCM)
-
Magnesium sulfate
-
Silica gel for column chromatography
Procedure:
-
Dissolve L-homoserine lactone hydrobromide in a saturated aqueous solution of sodium bicarbonate.
-
Add an equivalent amount of butyryl chloride in DCM to the aqueous solution.
-
Stir the biphasic mixture vigorously at room temperature for 4-6 hours.
-
Separate the organic layer and wash it with water and brine.
-
Dry the organic layer over anhydrous magnesium sulfate, filter, and concentrate under reduced pressure.
-
Purify the crude product by silica gel column chromatography using a gradient of ethyl acetate in hexanes to yield pure N-butanoyl-L-homoserine lactone.
-
Confirm the structure and purity using ¹H NMR, ¹³C NMR, and mass spectrometry.
Quorum Sensing Inhibition Assay
This assay is used to screen for compounds that can inhibit AHL-mediated quorum sensing.
Materials:
-
Reporter bacterial strain (e.g., Chromobacterium violaceum CV026 or an E. coli biosensor)
-
Luria-Bertani (LB) agar and broth
-
Appropriate AHL (e.g., N-hexanoyl-L-homoserine lactone for CV026)
-
Test compounds (potential inhibitors)
-
96-well microtiter plates
-
Spectrophotometer
Procedure:
-
Grow the reporter strain overnight in LB broth.
-
Dilute the overnight culture in fresh LB broth.
-
In a 96-well microtiter plate, add the diluted bacterial culture to each well.
-
Add the specific AHL to induce the reporter system (e.g., violacein production in CV026).
-
Add the test compounds at various concentrations to the wells. Include positive (AHL only) and negative (no AHL, no compound) controls.
-
Incubate the plate at the optimal growth temperature for the reporter strain (e.g., 30°C for CV026) for 18-24 hours.
-
Quantify the reporter signal. For CV026, this can be done by extracting the violacein pigment with DMSO and measuring the absorbance at 585 nm. For fluorescent or luminescent reporters, measure the respective signal.
-
Determine the concentration of the test compound that causes a 50% reduction in the reporter signal (IC₅₀) to assess its inhibitory activity.
Production of O-Acetyl-L-homoserine in E. coli
This protocol outlines a method for the fermentative production of O-acetyl-L-homoserine.[5]
Materials:
-
Engineered E. coli strain overexpressing a feedback-resistant homoserine dehydrogenase and a homoserine O-acetyltransferase.
-
Minimal medium with glucose as the carbon source.
-
Appropriate antibiotics for plasmid maintenance.
-
Bioreactor for fed-batch fermentation.
Procedure:
-
Prepare a seed culture of the engineered E. coli strain in minimal medium overnight.
-
Inoculate the bioreactor containing the production medium with the seed culture.
-
Maintain the fermentation at a controlled temperature (e.g., 37°C) and pH (e.g., 7.0).
-
Implement a fed-batch strategy by feeding a concentrated glucose solution to maintain a constant, low glucose concentration in the bioreactor, which can help to avoid the accumulation of inhibitory byproducts.
-
Monitor cell growth (OD₆₀₀) and the concentration of O-acetyl-L-homoserine in the culture supernatant over time using HPLC.
-
Harvest the culture at the point of maximum O-acetyl-L-homoserine accumulation and purify the product from the supernatant.
Conclusion
The comparative analysis of N-Butanoyl-L-homoserine lactone, O-Acetyl-L-homoserine, and O-Succinyl-L-homoserine demonstrates the profound influence of side-chain modifications on the biological function of the homoserine scaffold. While AHLs act as crucial signaling molecules in bacterial communication, the O-acylated derivatives are central intermediates in essential amino acid biosynthesis. The lack of available data on this compound highlights a potential area for future research to explore the biological activities of other synthetic homoserine derivatives. The experimental protocols provided herein offer a foundation for researchers to further investigate these and other related compounds, potentially leading to the development of novel therapeutics and a deeper understanding of fundamental biological processes.
References
- 1. mdpi.com [mdpi.com]
- 2. Frontiers | Design, Synthesis, and Biological Evaluation of N-Acyl-Homoserine Lactone Analogs of Quorum Sensing in Pseudomonas aeruginosa [frontiersin.org]
- 3. digital.csic.es [digital.csic.es]
- 4. pnas.org [pnas.org]
- 5. Metabolic engineering and pathway construction for O-acetyl-L-homoserine production in Escherichia coli - PMC [pmc.ncbi.nlm.nih.gov]
- 6. scispace.com [scispace.com]
- 7. Screening strategies for quorum sensing inhibitors in combating bacterial infections - PMC [pmc.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. Structure-function analyses of the N-butanoyl L-homoserine lactone quorum-sensing signal define features critical to activity in RhlR - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Human Metabolome Database: Showing metabocard for O-Succinyl-L-homoserine (HMDB0255868) [hmdb.ca]
- 11. Design, Synthesis, and Biological Evaluation of N-Acyl-Homoserine Lactone Analogs of Quorum Sensing in Pseudomonas aeruginosa - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. Metabolic engineering strategies for L-Homoserine production in Escherichia coli - PMC [pmc.ncbi.nlm.nih.gov]
- 14. researchgate.net [researchgate.net]
A Comparative Analysis of the Biological Effects of L- and D-2-Prop-2-en-1-ylhomoserine Enantiomers
An Objective Guide for Researchers, Scientists, and Drug Development Professionals
Introduction
L-allylglycine is a well-documented inhibitor of glutamic acid decarboxylase (GAD), the enzyme responsible for the synthesis of the primary inhibitory neurotransmitter, gamma-aminobutyric acid (GABA), in the central nervous system.[1][2] Inhibition of GAD leads to a reduction in GABA levels, resulting in hyperexcitability and convulsions.[3] The biological activity of allylglycine is known to be stereospecific, with the L-enantiomer being significantly more potent than the D-enantiomer. This guide provides a summary of the available data comparing the biological effects of L- and D-allylglycine, along with relevant experimental protocols and pathway diagrams.
Data Presentation: A Comparative Summary
The following table summarizes the known biological effects of L- and D-allylglycine. Due to the limited availability of quantitative data for the individual enantiomers, data for the racemic mixture (DL-allylglycine) is also included where available.
| Biological Effect | L-Allylglycine | D-Allylglycine | DL-Allylglycine |
| Glutamate Decarboxylase (GAD) Inhibition | Potent inhibitor[1][2] | Inactive or significantly less active[4] | Inhibits GAD[3] |
| Convulsive Activity | Induces seizures[5] | Inactive as a convulsant[4] | ED50 for seizures in mice: 1.0 mmol/kg (i.p.)[6] |
| Effect on Heart Rate | Causes substantial increases[2] | No significant effect[2] | - |
| Effect on Blood Pressure | Causes slight increases[2] | No significant effect[2] | - |
Key Signaling Pathway: Inhibition of GABA Synthesis
The primary mechanism of action for the biological effects of L-allylglycine is the inhibition of GABA synthesis. This disruption of the major inhibitory neurotransmitter system in the brain leads to an imbalance in excitatory and inhibitory signals, resulting in neuronal hyperexcitability and seizures.
References
- 1. selleckchem.com [selleckchem.com]
- 2. L-Allylglycine | GABA Receptor | Dehydrogenase | TargetMol [targetmol.com]
- 3. medchemexpress.com [medchemexpress.com]
- 4. The Circumventricular Organs Form a Potential Neural Pathway for Lactate Sensitivity: Implications for Panic Disorder | Journal of Neuroscience [jneurosci.org]
- 5. researchgate.net [researchgate.net]
- 6. Seizures induced by allylglycine, 3-mercaptopropionic acid and 4-deoxypyridoxine in mice and photosensitive baboons, and different modes of inhibition of cerebral glutamic acid decarboxylase - PMC [pmc.ncbi.nlm.nih.gov]
Analysis of post-translational modifications on proteins.
A comprehensive guide to the analysis of post-translational modifications (PTMs) on proteins, this document provides a detailed comparison of key analytical techniques, experimental protocols, and visual representations of relevant signaling pathways. Tailored for researchers, scientists, and drug development professionals, this guide aims to facilitate the selection of appropriate methodologies for the investigation of protein PTMs.
Comparison of PTM Analysis Methods
The selection of an appropriate method for PTM analysis is critical and depends on the specific research question, the nature of the PTM, and the abundance of the target protein. The following tables provide a quantitative and qualitative comparison of the most common techniques: Mass Spectrometry, Western Blotting, and Enzyme-Linked Immunosorbent Assay (ELISA).
Quantitative Comparison of PTM Analysis Methods
| Feature | Mass Spectrometry | Western Blotting | ELISA |
| Sensitivity | High (fmol to amol range)[1][2] | Moderate to High (ng to pg range)[3][4] | High (pg to fg range)[5] |
| Limit of Detection | Low fmol range for phosphopeptides[2] | ~1-100 ng of target protein in a band[3] | As low as 0.625 µ g/well for total protein[5] |
| Dynamic Range | 4-5 orders of magnitude[1] | 1-2 orders of magnitude | 2-3 orders of magnitude[6][7] |
| Quantification | Relative and absolute quantification | Semi-quantitative to quantitative | Quantitative |
| Throughput | High | Low to Medium | High |
| Specificity | High (can pinpoint modification site) | Dependent on antibody specificity | Dependent on antibody specificity |
| Cost | High | Low to Moderate | Moderate |
Qualitative Comparison of PTM Analysis Methods
| Feature | Mass Spectrometry | Western Blotting | ELISA |
| Principle | Measures mass-to-charge ratio of ionized molecules. | Immunoassay to detect specific proteins in a sample separated by gel electrophoresis. | Immunoassay where an antigen is immobilized on a solid surface and detected with an antibody. |
| Advantages | - Unbiased discovery of novel PTMs- Precise identification of modification sites- High-throughput capabilities[8] | - Widely accessible- Relatively inexpensive- Provides information on protein size[9] | - Highly sensitive and specific- High-throughput format- Quantitative results |
| Disadvantages | - Requires specialized equipment and expertise- Data analysis can be complex- May have bias against certain protein types[10] | - Requires specific antibodies- Semi-quantitative without careful controls- Lower throughput[11] | - Requires specific antibody pairs- Does not provide information on protein size- Prone to matrix effects |
| Common PTMs Analyzed | Phosphorylation, Ubiquitination, Glycosylation, Acetylation, Methylation[12] | Phosphorylation, Ubiquitination, Acetylation[9] | Phosphorylation, Acetylation, Methylation |
Experimental Protocols
Detailed methodologies for the key PTM analysis techniques are provided below.
Mass Spectrometry-Based PTM Analysis (Bottom-Up Approach)
This protocol outlines a general workflow for the identification and quantification of PTMs using liquid chromatography-tandem mass spectrometry (LC-MS/MS).
1. Protein Extraction and Digestion:
-
Lyse cells or tissues in a buffer containing protease and phosphatase inhibitors to preserve PTMs.
-
Quantify the protein concentration of the lysate.
-
Reduce disulfide bonds with dithiothreitol (DTT) and alkylate cysteine residues with iodoacetamide.
-
Digest proteins into peptides using a specific protease, most commonly trypsin.[12]
2. Peptide Enrichment (for low abundance PTMs):
-
Phosphopeptide Enrichment: Use immobilized metal affinity chromatography (IMAC) or titanium dioxide (TiO2) chromatography.[11][13]
-
Ubiquitinated Peptide Enrichment: Employ antibodies that recognize the di-glycine remnant left on ubiquitinated lysine residues after tryptic digest.
-
Glycopeptide Enrichment: Utilize lectin affinity chromatography or hydrophilic interaction liquid chromatography (HILIC).
-
Acetylated Peptide Enrichment: Use antibodies specific for acetylated lysine residues.[14]
3. LC-MS/MS Analysis:
-
Separate the peptides by reverse-phase liquid chromatography.
-
Introduce the eluted peptides into the mass spectrometer.
-
Acquire mass spectra of the intact peptides (MS1 scan).
-
Select precursor ions for fragmentation (MS/MS or MS2 scan) using methods like collision-induced dissociation (CID) or higher-energy collisional dissociation (HCD).[12]
4. Data Analysis:
-
Search the acquired MS/MS spectra against a protein sequence database to identify the peptides.
-
Use specialized software to identify and localize the PTMs based on the mass shift of the modified amino acid.
-
Quantify the relative or absolute abundance of the modified peptides.[8]
Western Blotting for PTM Detection
This protocol describes the detection of a specific PTM on a target protein using Western blotting.
1. Sample Preparation:
-
Lyse cells or tissues in a buffer containing protease and phosphatase inhibitors.
-
Determine the protein concentration of the lysate.
-
Denature the protein samples by boiling in SDS-PAGE sample buffer.[3]
2. Gel Electrophoresis:
-
Separate the proteins by size using sodium dodecyl sulfate-polyacrylamide gel electrophoresis (SDS-PAGE).[15]
3. Protein Transfer:
-
Transfer the separated proteins from the gel to a membrane (e.g., PVDF or nitrocellulose).[15]
4. Blocking:
-
Block the membrane with a blocking agent (e.g., 5% BSA or non-fat milk in TBST) to prevent non-specific antibody binding.[3]
5. Antibody Incubation:
-
Incubate the membrane with a primary antibody specific for the PTM of interest on the target protein.
-
Wash the membrane to remove unbound primary antibody.
-
Incubate the membrane with a secondary antibody conjugated to an enzyme (e.g., HRP) or a fluorophore.[15]
6. Detection:
-
For HRP-conjugated antibodies, add a chemiluminescent substrate and detect the signal using an imager.
-
For fluorescently-labeled antibodies, detect the signal using a fluorescence imager.[15]
7. Data Analysis:
-
Quantify the band intensity using densitometry software. Normalize the signal of the PTM-specific antibody to a loading control (e.g., total protein or a housekeeping gene).
ELISA for PTM Quantification
This protocol outlines a sandwich ELISA for the quantitative measurement of a specific PTM on a target protein.
1. Plate Coating:
-
Coat the wells of a microplate with a capture antibody specific for the target protein.
-
Incubate and then wash the plate.[16]
2. Blocking:
-
Block the remaining protein-binding sites in the wells with a blocking buffer.[16]
3. Sample Incubation:
-
Add the protein samples (lysates) and standards to the wells.
-
Incubate to allow the target protein to bind to the capture antibody.
-
Wash the plate.[16]
4. Detection Antibody Incubation:
-
Add a detection antibody that is specific for the PTM of interest and is conjugated to an enzyme (e.g., HRP).
-
Incubate to allow the detection antibody to bind to the captured protein-PTM complex.
-
Wash the plate.[16]
5. Signal Development:
-
Add a substrate that is converted by the enzyme on the detection antibody into a detectable signal (e.g., colorimetric or fluorescent).
-
Stop the reaction.[16]
6. Data Acquisition and Analysis:
-
Measure the signal using a microplate reader.
-
Generate a standard curve from the standards and determine the concentration of the PTM-modified protein in the samples.
Immunoprecipitation (IP) for Enrichment of Modified Proteins
This protocol describes the enrichment of a protein with a specific PTM using immunoprecipitation.
1. Lysate Preparation:
-
Lyse cells or tissues in an IP-compatible lysis buffer containing protease and phosphatase inhibitors.
-
Clarify the lysate by centrifugation to remove cellular debris.[17]
2. Antibody-Bead Conjugation (Direct Method):
-
Incubate the antibody specific for the PTM or the target protein with protein A/G-conjugated beads to form an antibody-bead complex.[18]
3. Immunoprecipitation:
-
Add the antibody-bead complex to the cell lysate.
-
Incubate with gentle rotation to allow the antibody to bind to the target protein.[17]
4. Washing:
-
Wash the beads several times with wash buffer to remove non-specifically bound proteins.[17]
5. Elution:
-
Elute the bound proteins from the beads using an elution buffer (e.g., low pH buffer or SDS-PAGE sample buffer).[17]
6. Downstream Analysis:
-
The enriched protein can be further analyzed by Western blotting or mass spectrometry.
Signaling Pathway and Workflow Diagrams
The following diagrams, created using the DOT language for Graphviz, illustrate key signaling pathways and experimental workflows relevant to PTM analysis.
EGFR Signaling Pathway
This pathway highlights key phosphorylation and ubiquitination events following Epidermal Growth Factor Receptor (EGFR) activation.
Caption: EGFR signaling cascade initiated by EGF binding.
NF-κB Signaling Pathway (Canonical)
This diagram illustrates the role of phosphorylation and ubiquitination in the activation of the canonical NF-κB pathway.
Caption: Canonical NF-κB pathway activation via TNFα.
Akt Signaling Pathway
This diagram shows the activation of Akt through phosphorylation and its downstream effects.
Caption: PI3K/Akt signaling pathway promoting cell survival.
Experimental Workflow: PTM Analysis by Mass Spectrometry
This workflow outlines the major steps in a typical bottom-up proteomics experiment for PTM analysis.
References
- 1. escholarship.org [escholarship.org]
- 2. Improved Quantitative Mass Spectrometry Methods for Characterizing Complex Ubiquitin Signals - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Western blot for phosphorylated proteins | Abcam [abcam.com]
- 4. quora.com [quora.com]
- 5. bio-rad.com [bio-rad.com]
- 6. How to interpret the dynamic range of an ELISA | Abcam [abcam.com]
- 7. researchgate.net [researchgate.net]
- 8. Current Methods of Post-Translational Modification Analysis and Their Applications in Blood Cancers - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. Method for detecting acetylated PD-L1 in cell lysates [protocols.io]
- 11. m.youtube.com [m.youtube.com]
- 12. Methods for the analysis of histone H3 and H4 acetylation in blood - PMC [pmc.ncbi.nlm.nih.gov]
- 13. m.youtube.com [m.youtube.com]
- 14. researchgate.net [researchgate.net]
- 15. Comparison of Five Commonly Used Quantitative Proteomics Analysis Methods | by Prime Jones | Medium [medium.com]
- 16. Frontiers | Quantitative Analysis of Ubiquitinated Proteins in Human Pituitary and Pituitary Adenoma Tissues [frontiersin.org]
- 17. Strategies for Mass Spectrometry-based Phosphoproteomics using Isobaric Tagging - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Tips for detecting phosphoproteins by western blot | Proteintech Group [ptglab.com]
A Comparative Guide to the Misincorporation of Amino Acid Analogues into Proteins
The precise incorporation of amino acids is fundamental to protein synthesis. However, researchers have developed methods to intentionally misincorporate amino acid analogues, also known as non-canonical amino acids (ncAAs), into proteins. This technique offers a powerful toolkit for studying and engineering proteins by introducing novel chemical functionalities. This guide provides a comparative overview of the methods for ncAA incorporation, a look at commonly used analogues, and detailed experimental protocols for professionals in research and drug development.
Methods of Incorporation: A Comparative Overview
Two primary strategies exist for incorporating ncAAs into proteins: residue-specific and site-specific incorporation.[1]
Residue-specific incorporation relies on the cellular translational machinery recognizing an ncAA that is structurally similar to a canonical amino acid.[1] This approach leads to the replacement of a specific natural amino acid with its analogue at all its positions within the protein.[1][2] For high efficiency, this often requires using auxotrophic cell lines that cannot synthesize the natural amino acid, or providing the ncAA in much higher concentrations.[1]
Site-specific incorporation offers more precise control, inserting an ncAA at a single, predetermined location in the protein sequence.[3] This is achieved by engineering an orthogonal aminoacyl-tRNA synthetase/tRNA pair that recognizes a "blank" or reassigned codon, typically a stop codon like the amber codon (UAG), and inserts the ncAA in response.[1][3]
| Feature | Residue-Specific Incorporation | Site-Specific Incorporation |
| Principle | Competition with a canonical amino acid for the same tRNA synthetase.[1] | Use of an orthogonal tRNA/tRNA synthetase pair for a specific ncAA and a unique codon.[1] |
| Specificity | All instances of a particular amino acid are replaced.[1] | A single, genetically defined site is modified.[3] |
| Requirements | Often requires amino acid-depleted media or auxotrophic cell lines.[1] | Requires an orthogonal tRNA/synthetase pair and genetic modification of the target protein.[3] |
| Typical Applications | Global analysis of protein synthesis, turnover, and modification of global protein properties.[2] | Probing protein structure-function relationships at a specific site, introducing unique chemical handles.[3] |
| Advantages | Technically simpler, no genetic modification of the target protein is required.[2] | High specificity and control over the modification site.[3] |
| Limitations | Can alter global protein properties, potentially leading to toxicity or misfolding.[2] | Technically more complex, requiring genetic engineering and optimization of the orthogonal system.[3] |
Common Amino Acid Analogues: A Quantitative Comparison
Several methionine analogues are widely used for bioorthogonal non-canonical amino acid tagging (BONCAT) and fluorescent non-canonical amino acid tagging (FUNCAT).[4] These techniques allow for the visualization and purification of newly synthesized proteins.[4][5] The most common analogues include L-azidohomoalanine (AHA) and L-homopropargylglycine (HPG).[6]
| Analogue | Structure | Incorporation Efficiency | Key Features & Applications |
| L-azidohomoalanine (AHA) | Methionine analogue with a terminal azide group. | High, but can be lower than HPG in some systems.[7][8] In E. coli, incorporation can reach ~50% in auxotrophic strains.[6][9] | The azide group allows for "click" chemistry reactions with alkyne-bearing tags for protein labeling, purification, and visualization.[10][11] It is widely used in BONCAT and FUNCAT applications.[4] |
| L-homopropargylglycine (HPG) | Methionine analogue with a terminal alkyne group. | Generally high, with reported incorporation rates of 70-80% in both auxotrophic and prototrophic E. coli.[6][9] In some plant systems, HPG shows more efficient tagging than AHA.[8] | The alkyne group enables click chemistry with azide-bearing tags.[12] It can be used orthogonally with AHA for dual-labeling experiments.[12] |
| Photo-methionine (pMet) | Methionine analogue with a diazirine functional group. | Can range from 50-70% in auxotrophic E. coli.[6][9] | The diazirine group is photo-activatable, allowing for UV-light-induced crosslinking to study protein-protein interactions.[6] |
Experimental Protocols
Key Experiment: Residue-Specific Incorporation of Azidohomoalanine (AHA) for BONCAT
This protocol outlines the general steps for labeling newly synthesized proteins in mammalian cells with AHA, followed by detection.
1. Cell Culture and Labeling:
-
Seed mammalian cells in a 6-well plate to achieve 50-60% confluency.[13][14]
-
Optionally, to increase incorporation efficiency, starve cells in methionine-free DMEM for 30-60 minutes.[13][14]
-
Replace the medium with methionine-free DMEM supplemented with 1 mM AHA. As a negative control, use a well with methionine-free DMEM supplemented with 1 mM methionine.[13][14]
-
Incubate the cells for a desired period (e.g., 10 minutes to several hours) at 37°C in a CO2 incubator.[13][14]
-
Wash the cells with ice-cold PBS to stop the labeling process.[13][14]
2. Cell Lysis and Protein Extraction:
-
Harvest the cells and lyse them in a suitable lysis buffer containing protease inhibitors.
-
Quantify the protein concentration of the lysates.
3. Click Chemistry Reaction:
-
To a specific amount of protein lysate (e.g., 50 µg), add the click reaction cocktail. A typical cocktail includes an alkyne-biotin tag, a copper(I) catalyst (e.g., CuSO4 and a reducing agent like sodium ascorbate), and a copper chelator (e.g., TBTA).
-
Incubate the reaction for 30 minutes at room temperature, protected from light.[13]
4. Affinity Purification of Labeled Proteins:
-
Add streptavidin-coated magnetic beads to the reaction mixture to capture the biotinylated proteins.[11]
-
Incubate with gentle rotation to allow binding.
-
Wash the beads several times with a high-salt buffer to remove non-specifically bound proteins.
-
Elute the captured proteins from the beads using a suitable elution buffer (e.g., containing excess biotin or by boiling in SDS-PAGE sample buffer).
5. Downstream Analysis:
-
The enriched proteins can be analyzed by various methods, including Western blotting to detect a specific protein of interest or mass spectrometry for proteome-wide identification of newly synthesized proteins.[11]
Visualizing Workflows and Mechanisms
To better understand the processes involved in the misincorporation of amino acid analogues, the following diagrams illustrate key workflows.
Caption: General workflow for BONCAT (Bioorthogonal Non-Canonical Amino Acid Tagging).
Caption: Competition between Methionine and its analogue AHA for the same tRNA synthetase.
References
- 1. researchgate.net [researchgate.net]
- 2. Residue-specific incorporation of non�canonical amino acids into proteins: recent developments and applications - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Residue-specific Incorporation of Noncanonical Amino Acids into Model Proteins Using an Escherichia coli Cell-free Transcription-translation System - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Teaching old NCATs new tricks: using non-canonical amino acid tagging to study neuronal plasticity - PMC [pmc.ncbi.nlm.nih.gov]
- 5. UQ eSpace [espace.library.uq.edu.au]
- 6. Photo-Methionine, Azidohomoalanine and Homopropargylglycine Are Incorporated into Newly Synthesized Proteins at Different Rates and Differentially Affect the Growth and Protein Expression Levels of Auxotrophic and Prototrophic E. coli in Minimal Medium - PMC [pmc.ncbi.nlm.nih.gov]
- 7. biocompare.com [biocompare.com]
- 8. researchgate.net [researchgate.net]
- 9. Photo-Methionine, Azidohomoalanine and Homopropargylglycine Are Incorporated into Newly Synthesized Proteins at Different Rates and Differentially Affect the Growth and Protein Expression Levels of Auxotrophic and Prototrophic E. coli in Minimal Medium - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. genscript.com [genscript.com]
- 11. Bioorthogonal Non-Canonical Amino Acid Tagging (BONCAT) to detect newly synthesized proteins in cells and their secretome | PLOS One [journals.plos.org]
- 12. Defining the Translatome: Bioorthogonal Noncanonical Amino Acid Tagging (BONCAT) | Brandon S. Russell, Ph.D. [brandon-russell.com]
- 13. Measuring Protein Synthesis during Cell Cycle by Azidohomoalanine (AHA) Labeling and Flow Cytometric Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Measuring Protein Synthesis during Cell Cycle by Azidohomoalanine (AHA) Labeling and Flow Cytometric Analysis [bio-protocol.org]
A Researcher's Guide to Analyzing Protein Structural Changes Upon Modification
For researchers, scientists, and drug development professionals, understanding the subtle yet profound impact of post-translational modifications (PTMs) on protein structure is paramount. These modifications act as molecular switches, altering a protein's conformation, dynamics, and ultimately, its function. This guide provides a comparative analysis of key experimental techniques used to elucidate these structural changes, supported by experimental data and detailed protocols.
This guide will delve into the primary methodologies employed to study the structural consequences of phosphorylation, glycosylation, and ubiquitination. We will compare X-ray Crystallography, Cryo-Electron Microscopy (Cryo-EM), Nuclear Magnetic Resonance (NMR) Spectroscopy, and Hydrogen-Deuterium Exchange Mass Spectrometry (HDX-MS), providing a framework for selecting the most appropriate technique for your research question.
Comparative Analysis of Analytical Techniques
The choice of analytical technique depends on the specific research question, the nature of the protein, and the type of information sought. High-resolution static structures are best resolved by X-ray crystallography and Cryo-EM, while NMR and HDX-MS excel at capturing the dynamic changes a protein undergoes in solution.
Phosphorylation-Induced Structural Changes
Phosphorylation, the addition of a phosphate group, is a ubiquitous regulatory mechanism that can trigger significant conformational changes.[1] These alterations can range from localized shifts in loops to large-scale domain rearrangements, ultimately modulating protein activity and interaction networks.[1][2]
Table 1: Quantitative Comparison of Techniques for Analyzing Phosphorylation-Induced Structural Changes
| Technique | Protein Studied | Modification Site(s) | Key Findings & Quantitative Data | Resolution/Metric |
| X-ray Crystallography | Mitogen-activated protein kinase 2 (ERK2) | Thr183, Tyr185 | Phosphorylation induces refolding of the activation lip and domain rotation, leading to enzyme activation.[3][4] | 2.40 Å[3] |
| NMR Spectroscopy | WNK1 Kinase | Activation Loop | Phosphorylation stabilizes the activation loop, reducing its flexibility.[5] | Average Cα RMSD of A-loop: 4.7 Å (unphosphorylated) vs. 2.3 Å (phosphorylated)[5] |
| HDX-MS | Mitogen-activated protein kinase 2 (ERK2) | Thr183, Tyr185 | Phosphorylation alters backbone conformational mobility at sites more than 10 Å away from the modification.[2] | Differential deuterium uptake[2] |
Glycosylation-Induced Structural Changes
Glycosylation, the attachment of sugar moieties, can impact protein folding, stability, and recognition.[6] While often not inducing large-scale conformational changes, it can alter the protein's dynamics and surface properties.[7]
Table 2: Quantitative Comparison of Techniques for Analyzing Glycosylation-Induced Structural Changes
| Technique | Protein Studied | Modification Site(s) | Key Findings & Quantitative Data | Resolution/Metric |
| X-ray Crystallography | HIV-1 gp120 core | Asn262 and others | The glycan at Asn262 plays a role in protein folding and stabilization.[6] | 4.5 Å[6] |
| HDX-MS | Alpha-1-acid glycoprotein (AGP) | Multiple N-glycan sites | Removal of N-glycans alters the deuterium uptake profile, indicating changes in protein dynamics.[8] | Differential deuterium uptake[8] |
Ubiquitination-Induced Structural Changes
Ubiquitination, the addition of ubiquitin, can signal for protein degradation or modulate protein function through non-proteolytic mechanisms. The attachment of this relatively large protein modifier can induce significant conformational changes in the substrate protein.
Table 3: Quantitative Comparison of Techniques for Analyzing Ubiquitination-Induced Structural Changes
| Technique | Protein Studied | Modification Site(s) | Key Findings & Quantitative Data | Resolution/Metric |
| Cryo-EM | Cullin-RING E3 ligase (CRL) complex | Substrate-specific | Provides high-resolution structures of large, dynamic ubiquitinated complexes.[9] | Near-atomic resolution[9] |
| NMR Spectroscopy | Tau repeat domain | Site-specific | Ubiquitination affects the overall compaction of the intrinsically disordered tau protein.[10] | Changes in 15N relaxation rates[10] |
Visualizing Workflows and Pathways
To better illustrate the processes involved in analyzing protein structural changes and the biological context in which they occur, the following diagrams are provided.
Experimental Protocols
Detailed methodologies are crucial for reproducible research. Below are overviews of the typical workflows for the discussed techniques.
X-ray Crystallography Protocol
-
Protein Crystallization : The initial and often most challenging step is to obtain high-quality crystals of both the modified and unmodified protein. This involves screening a wide range of conditions (precipitants, pH, temperature) to induce crystallization.
-
Data Collection : Crystals are exposed to an X-ray beam, and the resulting diffraction patterns are recorded.
-
Structure Determination : The diffraction data is processed to determine the electron density map of the protein. This map is then used to build a 3D model of the protein's atomic structure.
-
Refinement : The initial model is refined against the experimental data to improve its accuracy.
-
Comparative Analysis : The structures of the modified and unmodified proteins are superimposed and analyzed to identify conformational changes.
Cryo-Electron Microscopy (Cryo-EM) Workflow
-
Sample Preparation : A purified protein solution is applied to an EM grid and rapidly frozen in liquid ethane to create a thin layer of vitrified ice, preserving the protein in its native state.[11]
-
Data Collection : The frozen grid is imaged in a transmission electron microscope, capturing thousands of 2D projection images of individual protein particles in different orientations.
-
Image Processing : The 2D images are computationally aligned and classified to generate 2D class averages. These are then used to reconstruct a 3D model of the protein.
-
Structure Refinement : The 3D model is refined to near-atomic resolution.
-
Comparative Analysis : 3D maps of the modified and unmodified protein complexes are compared to identify structural differences.
NMR Spectroscopy Protocol for Dynamics
-
Sample Preparation : Isotope-labeled (¹⁵N, ¹³C) protein is prepared to allow for the detection of specific nuclei.
-
Data Acquisition : A series of NMR experiments are performed on both the modified and unmodified protein. For studying dynamics, experiments like Carr-Purcell-Meiboom-Gill (CPMG) relaxation dispersion are used.[8]
-
Spectral Analysis : The resulting NMR spectra are analyzed to measure parameters such as chemical shift perturbations and relaxation rates for individual amino acids.[12][13]
-
Dynamics Analysis : Changes in these parameters between the modified and unmodified states are used to map regions of the protein that experience changes in conformation and flexibility on a microsecond to millisecond timescale.
Hydrogen-Deuterium Exchange Mass Spectrometry (HDX-MS) Protocol
-
Deuterium Labeling : The modified and unmodified proteins are incubated in a deuterated buffer (D₂O) for various time points. Backbone amide hydrogens exposed to the solvent will exchange with deuterium.[14]
-
Quenching : The exchange reaction is stopped by rapidly lowering the pH and temperature.[2]
-
Proteolysis : The protein is digested into smaller peptides, typically using an acid-stable protease like pepsin.[14]
-
LC-MS Analysis : The peptide mixture is separated by liquid chromatography and analyzed by mass spectrometry to measure the mass increase of each peptide due to deuterium incorporation.[2]
-
Data Analysis : The deuterium uptake levels for each peptide are compared between the modified and unmodified states. Regions with altered deuterium uptake indicate changes in solvent accessibility and/or hydrogen bonding, reflecting conformational changes.[15]
References
- 1. biorxiv.org [biorxiv.org]
- 2. Phosphorylation-Dependent Changes in Structure and Dynamics in ERK2 Detected by SDSL and EPR - PMC [pmc.ncbi.nlm.nih.gov]
- 3. rcsb.org [rcsb.org]
- 4. researchgate.net [researchgate.net]
- 5. pubs.acs.org [pubs.acs.org]
- 6. Crystal structure of a fully glycosylated HIV-1 gp120 core reveals a stabilizing role for the glycan at Asn262 - PMC [pmc.ncbi.nlm.nih.gov]
- 7. N-Glycosylation as a Modulator of Protein Conformation and Assembly in Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Hydrogen–Deuterium Exchange Epitope Mapping of Glycosylated Epitopes Enabled by Online Immobilized Glycosidase - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. pnas.org [pnas.org]
- 11. researchgate.net [researchgate.net]
- 12. Analysis of coordinated NMR chemical shifts to map allosteric regulatory networks in proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 13. chemical shift perturbations: Topics by Science.gov [science.gov]
- 14. Analysis of Structural Changes in the Protein near the Phosphorylation Site [mdpi.com]
- 15. researchgate.net [researchgate.net]
Unlocking the Arsenal: A Comparative Guide to Novel Unnatural Amino Acids in Antibiotic Polypeptides
For researchers, scientists, and drug development professionals at the forefront of combating antimicrobial resistance, the incorporation of unnatural amino acids (UAAs) into antibiotic polypeptides represents a promising frontier. This guide provides an objective comparison of the performance of such novel antibiotics, supported by experimental data and detailed methodologies, to aid in the rational design of next-generation antimicrobial agents.
The relentless rise of antibiotic-resistant bacteria necessitates innovative strategies to replenish our dwindling arsenal of effective drugs. Antimicrobial peptides (AMPs), a class of naturally occurring defense molecules, have long been recognized for their therapeutic potential. However, their clinical translation has been hampered by limitations such as susceptibility to proteolytic degradation and potential toxicity. The strategic incorporation of unnatural amino acids—amino acids not found among the 20 proteinogenic ones—offers a powerful approach to overcome these hurdles and enhance the therapeutic properties of AMPs.[1][2]
This guide delves into the design and synthesis of antibiotic polypeptides containing various classes of UAAs, presenting a comparative analysis of their antimicrobial efficacy, stability, and toxicity.
Performance Comparison of UAA-Containing Antibiotic Polypeptides
The introduction of UAAs can significantly impact the biological activity of antimicrobial peptides. The following tables summarize the quantitative data from various studies, comparing the performance of UAA-modified peptides with their natural counterparts or conventional antibiotics.
Table 1: Antimicrobial Activity (Minimum Inhibitory Concentration - MIC)
The Minimum Inhibitory Concentration (MIC) is a key measure of an antibiotic's potency, representing the lowest concentration required to inhibit the visible growth of a microorganism. Lower MIC values indicate higher antimicrobial activity.
| Peptide/Antibiotic | Unnatural Amino Acid(s) | Target Organism(s) | MIC (µM) | Reference Peptide/Antibiotic | MIC (µM) |
| E2-53R | Norvaline (Nva), 1,2,3,4-Tetrahydroisoquinoline-3-carboxylic acid (Tic) | Gram-negative bacteria (average) | ~16-32 | E2-35 (natural) | ~8-16 |
| Gram-positive bacteria (average) | ~4-8 | E2-35 (natural) | ~4-8 | ||
| LE-54R | Norvaline (Nva), 1,2,3,4-Tetrahydroisoquinoline-3-carboxylic acid (Tic) | Gram-negative bacteria (average) | ~8-16 | Tobramycin | >32 |
| Gram-positive bacteria (average) | ~2-4 | Tobramycin | >32 | ||
| D-MPI | D-amino acids (full substitution) | E. coli | 16 | Polybia-MPI (L-amino acids) | 32 |
| S. aureus | 8 | Polybia-MPI (L-amino acids) | 16 | ||
| d-lys-MPI | D-Lysine | E. coli | >128 | Polybia-MPI (L-amino acids) | 32 |
| S. aureus | >128 | Polybia-MPI (L-amino acids) | 16 | ||
| Aurein 1.2 Analogues | β-amino acids | C. albicans | 4-fold lower than Aurein 1.2 | Aurein 1.2 (natural) | - |
| Pep05 Derivatives | D-amino acids, Dab, Dap, Hor, Aib, L-thienylalanine | Gram-positive and Gram-negative bacteria | 0.5 to 2-fold change vs. Pep05 | Pep05 (natural) | - |
| C18G Analogues | Non-natural hydrophobic amino acids | A. baumannii, P. aeruginosa, S. aureus, E. coli | Maintained or increased activity | C18G (natural) | - |
| TA4(dK) | D-Lysine | P. aeruginosa | Similar to TA4 | TA4 (L-amino acids) | - |
| C10:0-A2(6-NMeLys) | N-methyl-Lysine | P. aeruginosa | Similar to C10:0-A2 | C10:0-A2 (unmodified) | - |
Data is compiled from multiple sources.[1][2][3][4][5][6][7] MIC values are often presented as a range or an average across different strains.
Table 2: Hemolytic Activity and Proteolytic Stability
A crucial aspect of antibiotic development is minimizing toxicity to host cells and enhancing stability in biological fluids. Hemolytic assays measure the ability of a compound to lyse red blood cells, a common indicator of cytotoxicity. Proteolytic stability assays assess the resistance of a peptide to degradation by proteases.
| Peptide | Unnatural Amino Acid(s) | Hemolytic Activity (% at a given concentration) | Proteolytic Stability |
| E2-53R & LE-54R | Norvaline, Tic | < 5% at 32 µM | Not explicitly stated, but designed for enhanced properties. |
| D-MPI | D-amino acids (full substitution) | Decreased compared to Polybia-MPI | Significantly increased |
| Aurein 1.2 Analogues | β-amino acids | < 5% at MIC | Enhanced |
| Pep05 Derivatives (DP06) | D-amino acids (full substitution) | Comparable to Pep05 | Remarkable stability in human plasma (>60% remaining after 24h) |
| Pep05 Derivatives (Unnatural a.a.) | Dab, Dap, Hor, Aib, L-thienylalanine | Significantly increased (except for UP07) | Enhanced |
| TA4(dK) | D-Lysine | Not explicitly stated | 100% remaining after 8h in serum |
| C10:0-A2(NMe-a.a.) | N-methyl amino acids | Not explicitly stated | Increased stability in serum (40-65% remaining after 1h) |
Data is compiled from multiple sources.[1][2][3][4][7]
Experimental Protocols
The synthesis and evaluation of UAA-containing antibiotic polypeptides involve a series of well-defined experimental procedures.
Peptide Synthesis: Solid-Phase Peptide Synthesis (SPPS)
Solid-phase peptide synthesis is the most common method for producing these modified peptides.[8][9]
-
Resin Selection: A suitable solid support, such as Rink amide or Wang resin, is chosen based on the desired C-terminal modification (amide or carboxylic acid).[10]
-
Amino Acid Coupling:
-
Fmoc Deprotection: The N-terminal Fmoc (9-fluorenylmethyloxycarbonyl) protecting group of the resin-bound amino acid is removed using a solution of 20% piperidine in a solvent like NMP (N-Methyl-2-pyrrolidone).[10]
-
Washing: The resin is thoroughly washed with solvents like NMP and DCM (Dichloromethane) to remove excess reagents.[10]
-
Coupling: The next Fmoc-protected amino acid (natural or unnatural) is activated using a coupling reagent such as HBTU (2-(1H-benzotriazol-1-yl)-1,1,3,3-tetramethyluronium hexafluorophosphate) and HOBt (Hydroxybenzotriazole) in the presence of a base like DIEA (N,N-Diisopropylethylamine) in DMF (Dimethylformamide). This activated amino acid is then added to the resin to form the peptide bond.[10]
-
Washing: The resin is washed again to remove unreacted reagents.
-
-
Cycle Repetition: These deprotection, washing, and coupling steps are repeated for each amino acid in the peptide sequence.
-
Cleavage and Deprotection: Once the peptide chain is fully assembled, it is cleaved from the resin, and the side-chain protecting groups are removed using a cleavage cocktail, typically containing a strong acid like trifluoroacetic acid (TFA) with scavengers such as water, triisopropylsilane (TIPS), and ethanedithiol.[5]
-
Purification and Characterization: The crude peptide is purified using reverse-phase high-performance liquid chromatography (RP-HPLC). The identity and purity of the peptide are confirmed by mass spectrometry (e.g., MALDI-TOF or ESI-MS) and analytical HPLC.[5][10]
Antimicrobial Susceptibility Testing: Minimum Inhibitory Concentration (MIC) Assay
The MIC of the synthesized peptides is determined using the broth microdilution method according to the guidelines of the Clinical and Laboratory Standards Institute (CLSI).[4][5]
-
Peptide Preparation: The lyophilized peptides are dissolved in a suitable solvent (e.g., 10 mM phosphate buffer) to create stock solutions.
-
Bacterial Inoculum Preparation: Bacterial colonies are grown in a suitable broth (e.g., Mueller-Hinton broth) to a specific optical density, corresponding to a known cell concentration (e.g., 5 x 10^5 CFU/mL).[5]
-
Serial Dilution: The peptide stock solution is serially diluted in a 96-well microtiter plate.
-
Inoculation: A standardized bacterial suspension is added to each well.
-
Incubation: The plate is incubated at 37°C for 18-24 hours.
-
MIC Determination: The MIC is determined as the lowest concentration of the peptide that completely inhibits visible bacterial growth.[11]
Proteolytic Stability Assay
The stability of the peptides against protease degradation is assessed by incubating them with proteases found in human serum or specific bacterial proteases.[4][11]
-
Incubation: The peptide is incubated with human plasma or a specific protease (e.g., trypsin, neutrophil elastase) at 37°C.[4][11][12]
-
Time-Course Sampling: Aliquots are taken at different time points (e.g., 0, 1, 4, 8, 24 hours).
-
Reaction Quenching: The enzymatic reaction in the aliquots is stopped, for example, by adding an acid like TFA.[11]
-
Analysis: The amount of intact peptide remaining at each time point is quantified using RP-HPLC. The degradation rate is then calculated.[4][11]
Visualizing the Workflow and Concepts
To better illustrate the processes involved in the development of UAA-containing antibiotic polypeptides, the following diagrams are provided.
References
- 1. Antimicrobial activity and stability of the d-amino acid substituted derivatives of antimicrobial peptide polybia-MPI - PMC [pmc.ncbi.nlm.nih.gov]
- 2. How Unnatural Amino Acids in Antimicrobial Peptides Change Interactions with Lipid Model Membranes - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Incorporation of β-amino acids enhances the antifungal activity and selectivity of the helical antimicrobial peptide aurein 1.2 - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Frontiers | D- and Unnatural Amino Acid Substituted Antimicrobial Peptides With Improved Proteolytic Resistance and Their Proteolytic Degradation Characteristics [frontiersin.org]
- 5. Effect of non-natural hydrophobic amino acids on the efficacy and properties of the antimicrobial peptide C18G - PMC [pmc.ncbi.nlm.nih.gov]
- 6. pubs.acs.org [pubs.acs.org]
- 7. D- and N-Methyl Amino Acids for Modulating the Therapeutic Properties of Antimicrobial Peptides and Lipopeptides - PMC [pmc.ncbi.nlm.nih.gov]
- 8. journals.asm.org [journals.asm.org]
- 9. Methods and protocols of modern solid phase Peptide synthesis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. rsc.org [rsc.org]
- 11. pubs.acs.org [pubs.acs.org]
- 12. Evaluation of Strategies for Improving Proteolytic Resistance of Antimicrobial Peptides by Using Variants of EFK17, an Internal Segment of LL-37 - PMC [pmc.ncbi.nlm.nih.gov]
Safety Operating Guide
Essential Safety and Logistical Information for Handling 2-Prop-2-en-1-ylhomoserine
Personal Protective Equipment (PPE)
Given the lack of specific toxicity data, a cautious approach is necessary. The recommended PPE is summarized in the table below.
| PPE Category | Recommended Protection | Rationale |
| Eye and Face Protection | Chemical safety goggles or a full-face shield. | Protects against potential splashes and airborne particles that could cause eye irritation or damage. |
| Skin Protection | Nitrile gloves and a lab coat. | Prevents skin contact, which may cause irritation or allergic reactions, as seen with some acrylic esters.[1] |
| Respiratory Protection | Use in a well-ventilated area. A NIOSH-approved respirator may be necessary if handling fine powders or creating aerosols. | Minimizes inhalation of the compound, which could irritate the respiratory system. |
Operational Plan
A systematic approach to handling 2-Prop-2-en-1-ylhomoserine is crucial to minimize exposure and ensure a safe laboratory environment.
1. Engineering Controls:
-
Always handle the compound in a certified chemical fume hood to control airborne exposures.
-
Ensure that an eyewash station and a safety shower are readily accessible and in good working order.
2. Handling Procedures:
-
Before beginning work, ensure all necessary PPE is correctly worn.
-
When weighing the solid compound, do so within the fume hood to contain any dust.
-
If preparing a solution, add the solid to the solvent slowly to prevent splashing.
-
Avoid eating, drinking, or smoking in the laboratory area.
-
After handling, thoroughly wash hands with soap and water.
3. Storage:
-
Store this compound in a tightly sealed container in a cool, dry, and well-ventilated area.
-
Keep it away from incompatible materials such as strong oxidizing agents.
Disposal Plan
Proper disposal of this compound and any contaminated materials is critical to prevent environmental contamination and ensure regulatory compliance.
-
Waste Segregation: All disposable items that have come into contact with the compound, such as gloves, weighing papers, and pipette tips, must be collected in a designated hazardous waste container.
-
Chemical Waste: Unused or waste quantities of the chemical should be disposed of as hazardous chemical waste. Do not pour down the drain or mix with general laboratory waste.
-
Institutional Guidelines: Follow all local, state, and federal regulations for hazardous waste disposal, and adhere to your institution's specific waste management protocols.
Experimental Workflow
The following diagram outlines the logical progression of steps for the safe handling of this compound, from preparation to disposal.
Caption: Safe handling workflow for this compound.
References
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
