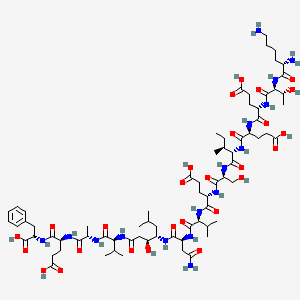
NH2-Lys-Thr-Glu-Glu-Ile-Ser-Glu-Val-Asn
Description
Significance of Peptides in Biomolecular Research
Peptides, typically comprising 2 to 50 amino acids, are pivotal in numerous physiological functions. They are involved in cell-to-cell communication, immune responses, and the regulation of enzymatic activity. In the context of research, synthetic peptides are crucial for:
Developing epitope-specific antibodies: Peptides are used to generate antibodies that can specifically recognize and bind to proteins, which is essential for a variety of diagnostic and research applications. particlepeptides.com
Studying protein-protein interactions: By synthesizing fragments of proteins, researchers can identify the specific domains responsible for their interactions.
Enzyme-substrate studies: Synthetic peptides are used to investigate the binding sites and mechanisms of enzymes, such as kinases and proteases, which are key players in cell signaling. particlepeptides.com
Drug discovery and development: Many peptides serve as lead compounds for the development of new drugs due to their high specificity and potency. nih.gov
The ability to chemically synthesize peptides offers significant advantages, including the incorporation of unnatural amino acids and modifications to enhance stability and activity. bachem.com
Overview of the Chemical Compound NH2-Lys-Thr-Glu-Glu-Ile-Ser-Glu-Val-Asn as a Research Entity
The peptide with the sequence this compound, also represented by the one-letter code KTEEISEVN, is a nonapeptide that has been a subject of scientific interest primarily as a constituent of a more complex synthetic molecule. This nonapeptide forms the core of a potent inhibitor of the enzyme β-secretase (BACE1).
This longer, modified peptide has the sequence Lys-Thr-Glu-Glu-Ile-Ser-Glu-Val-Asn-Sta-Val-Ala-Glu-Phe. peptide.co.jppeptanova.de A key feature of this extended peptide is the inclusion of Statine (B554654) (Sta), a non-proteinogenic amino acid, which is a common feature in the design of protease inhibitors. The investigation of this compound is particularly relevant in the field of neurodegenerative disease research, specifically Alzheimer's disease, where β-secretase plays a crucial role.
Table 1: Properties of the KTEEISEVN-Containing β-Secretase Inhibitor
| Property | Value |
| Full Sequence | Lys-Thr-Glu-Glu-Ile-Ser-Glu-Val-Asn-Sta-Val-Ala-Glu-Phe |
| Molecular Weight | 1651.6 g/mol |
| Primary Application | β-Secretase Inhibitor peptanova.de |
| Form | Powder |
| Storage Temperature | -20 °C |
Properties
Molecular Formula |
C73H118N16O27 |
|---|---|
Molecular Weight |
1651.8 g/mol |
IUPAC Name |
(4S)-4-[[(2S)-2-[[(2S)-2-[[(3S,4S)-4-[[(2S)-4-amino-2-[[(2S)-2-[[(2S)-4-carboxy-2-[[(2S)-2-[[(2S,3S)-2-[[(2S)-4-carboxy-2-[[(2S)-4-carboxy-2-[[(2S,3R)-2-[[(2S)-2,6-diaminohexanoyl]amino]-3-hydroxybutanoyl]amino]butanoyl]amino]butanoyl]amino]-3-methylpentanoyl]amino]-3-hydroxypropanoyl]amino]butanoyl]amino]-3-methylbutanoyl]amino]-4-oxobutanoyl]amino]-3-hydroxy-6-methylheptanoyl]amino]-3-methylbutanoyl]amino]propanoyl]amino]-5-[[(1S)-1-carboxy-2-phenylethyl]amino]-5-oxopentanoic acid |
InChI |
InChI=1S/C73H118N16O27/c1-11-37(8)59(88-66(108)45(23-27-56(101)102)79-63(105)43(21-25-54(97)98)81-72(114)60(39(10)91)89-62(104)41(75)19-15-16-28-74)71(113)85-49(33-90)68(110)80-44(22-26-55(99)100)65(107)87-58(36(6)7)70(112)83-47(31-51(76)93)67(109)82-46(29-34(2)3)50(92)32-52(94)86-57(35(4)5)69(111)77-38(9)61(103)78-42(20-24-53(95)96)64(106)84-48(73(115)116)30-40-17-13-12-14-18-40/h12-14,17-18,34-39,41-50,57-60,90-92H,11,15-16,19-33,74-75H2,1-10H3,(H2,76,93)(H,77,111)(H,78,103)(H,79,105)(H,80,110)(H,81,114)(H,82,109)(H,83,112)(H,84,106)(H,85,113)(H,86,94)(H,87,107)(H,88,108)(H,89,104)(H,95,96)(H,97,98)(H,99,100)(H,101,102)(H,115,116)/t37-,38-,39+,41-,42-,43-,44-,45-,46-,47-,48-,49-,50-,57-,58-,59-,60-/m0/s1 |
InChI Key |
CQTBDEGWLSDJEP-JMAXQNTPSA-N |
Isomeric SMILES |
CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(C)C)[C@H](CC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CCCCN)N |
Canonical SMILES |
CCC(C)C(C(=O)NC(CO)C(=O)NC(CCC(=O)O)C(=O)NC(C(C)C)C(=O)NC(CC(=O)N)C(=O)NC(CC(C)C)C(CC(=O)NC(C(C)C)C(=O)NC(C)C(=O)NC(CCC(=O)O)C(=O)NC(CC1=CC=CC=C1)C(=O)O)O)NC(=O)C(CCC(=O)O)NC(=O)C(CCC(=O)O)NC(=O)C(C(C)O)NC(=O)C(CCCCN)N |
Origin of Product |
United States |
Detailed Research Findings on the Kteeisevn Containing Peptide
Solid-Phase Peptide Synthesis Methodologies for the Compound
Solid-Phase Peptide Synthesis (SPPS) is the cornerstone for the artificial production of peptides like this compound. This methodology involves the stepwise addition of amino acids to a growing peptide chain that is covalently attached to an insoluble polymer resin. The Fmoc (9-fluorenylmethyloxycarbonyl) strategy is the most commonly employed approach for the synthesis of this peptide.
The synthesis commences from the C-terminus (Asparagine) and proceeds to the N-terminus (Lysine). The C-terminal amino acid (Asn) is first anchored to a solid support, such as a Wang or Rink Amide resin. The synthesis cycle for each subsequent amino acid consists of two main steps: the removal of the temporary Nα-Fmoc protecting group with a weak base (e.g., piperidine), followed by the coupling of the next Nα-Fmoc-protected amino acid. This coupling is facilitated by activating agents that promote the formation of the peptide bond.
Due to the presence of reactive side chains in several amino acids of the sequence (Lys, Thr, Glu, Ser, Asn), these functional groups must be protected with permanent protecting groups that are stable throughout the synthesis and are only removed during the final cleavage step.
Table 1: Amino Acids and Protecting Groups for the Synthesis of this compound
| Amino Acid | Nα-Protecting Group | Side-Chain Protecting Group |
| Lysine (B10760008) (Lys) | Fmoc | Boc (tert-butyloxycarbonyl) |
| Threonine (Thr) | Fmoc | tBu (tert-butyl) |
| Glutamic Acid (Glu) | Fmoc | OtBu (tert-butyl ester) |
| Isoleucine (Ile) | Fmoc | None |
| Serine (Ser) | Fmoc | tBu (tert-butyl) |
| Valine (Val) | Fmoc | None |
| Asparagine (Asn) | Fmoc | Trt (trityl) |
Once the entire peptide sequence is assembled on the resin, a final cleavage and deprotection step is performed. This is typically achieved by treating the peptide-resin with a strong acid cocktail, such as trifluoroacetic acid (TFA), which cleaves the peptide from the resin and simultaneously removes all the side-chain protecting groups. The crude peptide is then purified, commonly by reverse-phase high-performance liquid chromatography (RP-HPLC).
Isotope Labeling Techniques for Quantitative Research Applications
For quantitative studies, particularly in proteomics where the absolute or relative abundance of a peptide is measured, stable isotope labeling is an indispensable tool. nih.govbiosynth.com The synthesis of an isotopically heavy version of this compound allows it to be used as an internal standard in mass spectrometry-based assays. biosynth.comoup.com This is achieved by incorporating amino acids containing heavy isotopes of elements like carbon (¹³C) or nitrogen (¹⁵N) during SPPS. silantes.com
The synthetic process is identical to the one described for the unlabeled peptide, with the exception that one or more of the standard amino acid building blocks are replaced with their stable isotope-labeled counterparts. shoko-sc.co.jp For instance, a heavy version of the peptide can be synthesized by using Fmoc-L-Lysine(¹³C₆, ¹⁵N₂) or Fmoc-L-Valine(¹³C₅, ¹⁵N) instead of the corresponding unlabeled amino acids. The resulting labeled peptide is chemically identical to the native peptide but has a distinct, higher mass, allowing for its differentiation and quantification in a mass spectrometer. biosynth.com This technique, known as Stable Isotope Dilution (SID), is a gold standard for accurate peptide quantification. biosynth.com
Table 2: Common Stable Isotopes Used in Peptide Labeling
| Isotope | Natural Abundance (%) | Use in Peptide Labeling |
| Carbon-13 (¹³C) | 1.1 | Increases the mass of the amino acid. |
| Nitrogen-15 (¹⁵N) | 0.37 | Increases the mass of the amino acid. |
| Deuterium (²H) | 0.015 | Can be used but may have slight chromatographic shifts. |
| Oxygen-18 (¹⁸O) | 0.2 | Can be incorporated into the C-terminus. |
Design and Synthesis of Peptide Analogues Incorporating Non-Natural Amino Acids (e.g., Statine)
To investigate structure-activity relationships, improve metabolic stability, or modulate the biological activity of this compound, analogues can be designed and synthesized by incorporating non-natural amino acids. rsc.org These are amino acids that are not among the 20 common proteinogenic amino acids.
One such non-natural amino acid is Statine ((3S,4S)-4-amino-3-hydroxy-6-methylheptanoic acid), a γ-amino acid. wikipedia.org Statine is known for its role as a transition-state mimic in inhibitors of aspartic proteases. wikipedia.org The incorporation of statine into the peptide sequence, for example, in place of one of the natural amino acid residues, could confer protease resistance or alter the peptide's conformational properties. The synthesis of such an analogue would follow the standard SPPS protocol, with the statine building block being coupled at the desired position in the sequence. researchgate.net The hydroxyl group of statine may require protection during the synthesis. researchgate.net
The inclusion of non-natural amino acids can introduce novel chemical functionalities, steric constraints, or conformational biases that can lead to analogues with enhanced therapeutic potential or utility as research tools.
Table 3: Examples of Non-Natural Amino Acids for Peptide Analogue Design
| Non-Natural Amino Acid | Abbreviation | Potential Application in Analogue Design |
| Statine | Sta | Protease inhibition, transition-state mimicry. wikipedia.org |
| Aminoisobutyric Acid | Aib | Induces helical conformations. |
| D-Amino Acids | e.g., D-Lys | Increases resistance to enzymatic degradation. |
| N-methylated Amino Acids | e.g., N-Me-Val | Modifies conformation and improves cell permeability. |
Strategies for Modifying the Peptide Termini (e.g., N-terminal capping, C-terminal amidation)
N-terminal Capping: The free amino group at the N-terminus of this compound can be "capped" to remove its positive charge and increase its resistance to degradation by aminopeptidases. biosynth.com A common N-terminal modification is acetylation, where an acetyl group (CH₃CO-) is added. youtube.com This is typically performed as the final step on the solid support after the last amino acid (Lysine) has been coupled. The peptide-resin is treated with a mixture of acetic anhydride (B1165640) and a base, such as pyridine (B92270) or diisopropylethylamine (DIEA), in a suitable solvent. youtube.com
C-terminal Amidation: The C-terminal carboxylic acid can be replaced with a carboxamide group (-CONH₂). jpt.com This modification removes the negative charge at the C-terminus and can be crucial for the biological activity of many peptides, as it often mimics the native structure of peptide hormones. digitellinc.com C-terminal amidation also enhances the peptide's stability against carboxypeptidases. The synthesis of a C-terminally amidated version of the peptide is readily achieved by using a specific type of resin during SPPS, such as a Rink Amide or Sieber amide resin. peptide.comacs.org Upon cleavage from these resins with a strong acid like TFA, the peptide is released with a C-terminal amide. acs.org
Table 4: Common Peptide Termini Modifications and Their Rationale
| Modification | Location | Chemical Change | Purpose |
| Acetylation | N-terminus | Addition of CH₃CO- group | Neutralizes positive charge, increases stability, mimics native proteins. biosynth.com |
| Amidation | C-terminus | Conversion of -COOH to -CONH₂ | Neutralizes negative charge, increases stability, enhances biological activity. jpt.comnih.gov |
Biochemical Mechanisms and Interactions of Nh2 Lys Thr Glu Glu Ile Ser Glu Val Asn
Enzymatic Inhibition and Substrate Mimicry
The primary mechanism of action for NH2-Lys-Thr-Glu-Glu-Ile-Ser-Glu-Val-Asn involves enzymatic inhibition, specifically by mimicking the natural substrate of the target enzyme. This allows the peptide to bind to the enzyme's active site, blocking its normal catalytic function.
Role as a β-Secretase (BACE1) Inhibitor
The peptide this compound functions as an inhibitor of β-secretase, also known as Beta-site Amyloid Precursor Protein Cleaving Enzyme 1 (BACE1). BACE1 is an aspartic protease that plays a crucial role in the initial step of the amyloidogenic pathway, which leads to the production of amyloid-β (Aβ) peptides. researchgate.netnih.gov The inhibition of BACE1 is a primary therapeutic strategy aimed at reducing the formation of these Aβ peptides, which are a hallmark of Alzheimer's disease. researchgate.netnih.gov Peptide inhibitors are designed to mimic the sequence of the amyloid precursor protein (APP) at the cleavage site, allowing them to act as competitive inhibitors.
Characterization of Inhibitory Potency (IC50) in In Vitro Assays
The inhibitory potency of BACE1 peptide inhibitors is quantified using the half-maximal inhibitory concentration (IC50), which measures the concentration of the inhibitor required to reduce the enzyme's activity by 50% in laboratory assays. The development of potent BACE1 inhibitors often involves modifying peptide sequences to enhance their binding affinity and cellular activity. For example, the addition of lipid moieties or the incorporation of transition-state analogs like statine (B554654) can significantly improve potency. nih.gov While the specific IC50 for this compound is not detailed in the provided search results, related peptide inhibitors have demonstrated a wide range of potencies, from the micromolar to the low nanomolar and even picomolar range, depending on their specific composition and modifications. nih.govresearchgate.net
Below is an interactive table showcasing IC50 values for several example BACE1 peptide inhibitors, illustrating the structure-activity relationship and the impact of modifications on potency.
| Peptide Sequence | Modification | Cellular IC50 (Aβ lowering) |
|---|---|---|
| Glu-Val-Asn-Sta-Val-Ala-Glu-DPro-NH2 | None | Inactive (>40 µM) |
| Glu-Val-Asn-Sta-Val-Ala-Glu-DPro-Lys(ε-Chol'ester')-NH2 | Cholesterol Ester | 0.40 nM |
| Glu-Val-Asn-Sta-Val-Ala-Glu-DPro-Lys(ε-Palmitoyl)-NH2 | Palmitoyl | 6.0 nM |
| Tyr-Pro-Tyr-Phe-Ile-Pro-Leu-Gly-Gly-Gly-Glu-Val-Asn-Sta-Val-Ala-Glu-DPro-Lys(Chol'ester')-NH2 | Extended sequence with Cholesterol Ester | 0.027 nM |
| Tyr-Pro-Tyr-Phe-Ile-Pro-Leu-NH(CH2)5CO-Glu-Val-Asn-Sta-Val-Ala-Glu-DPro-Lys(Chol'ester')-NH2 | Linker and Cholesterol Ester | 0.075 nM |
Specificity of Interaction with BACE1 Active Site
The specificity of peptide inhibitors for BACE1 is determined by their interaction with the amino acid residues within the enzyme's active site. The BACE1 active site is characterized by an open and less hydrophobic pocket compared to other aspartic proteases and features two critical aspartic acid residues, Asp32 and Asp228, which are essential for its catalytic activity. nih.govamazonaws.com Peptide inhibitors are designed to fit within this active site and form strong interactions, such as hydrogen bonds and electrostatic interactions, with key residues. amazonaws.com Commonly interacting residues for peptide inhibitors include Gln73, Phe108, and Arg235. nih.gov The peptide's sequence is crucial for anchoring it correctly within the active site, thereby blocking substrate access and inhibiting the enzyme. amazonaws.com
Modulation of Proteolytic Processing Pathways
By inhibiting BACE1, the peptide this compound can modulate the proteolytic processing of BACE1's substrates, thereby altering cellular pathways.
Impact on Amyloid Precursor Protein (APP) Cleavage Pathways
The most significant impact of BACE1 inhibition is the alteration of Amyloid Precursor Protein (APP) processing. BACE1 performs the initial cleavage of APP in the amyloidogenic pathway. nih.gov By blocking this step, BACE1 inhibitors divert APP processing towards the non-amyloidogenic pathway, where it is cleaved by α-secretase. nih.gov This alternative cleavage prevents the formation of the Aβ peptide and instead produces a soluble, non-toxic fragment. nih.gov Therefore, the inhibition of BACE1 by peptides like this compound directly reduces the production of amyloidogenic species.
Influence on Sialyltransferase (ST6Gal I) Secretion Mediated by BACE1
Beyond APP, BACE1 is known to cleave other substrates, including the enzyme β-galactoside α2,6-sialyltransferase (ST6Gal I). nih.govnih.gov ST6Gal I is typically anchored in the Golgi apparatus, but it can be cleaved by BACE1 to release a soluble, active form of the enzyme into the culture media. nih.govnih.gov The inhibition of BACE1 has been shown to prevent this cleavage. nih.govresearchgate.net Consequently, treatment with a BACE1 inhibitor or knockdown of the BACE1 gene leads to an increase in the levels of the full-length, Golgi-anchored form of ST6Gal I and an increase in sialylation on the cell surface. nih.govresearchgate.net This demonstrates that BACE1 inhibitors can influence cellular processes beyond Aβ production by stabilizing other BACE1 substrates.
Peptide-Protein Interaction Dynamics and Specificity
The interaction between a peptide and its target protein is a highly dynamic process governed by a multitude of non-covalent interactions. The specificity of this interaction is crucial for biological function and therapeutic efficacy. For the peptide sequence , its role as part of a β-secretase inhibitor suggests a high degree of specificity for the active site of this enzyme.
Elucidation of Binding Determinants for Target Proteins
The binding of the parent peptide, and by extension the this compound sequence, to β-secretase is determined by the specific amino acid residues and their physicochemical properties. The active site of β-secretase is a cleft with distinct subpockets that accommodate the side chains of the substrate or inhibitor. The binding affinity and orientation of the peptide are dictated by a combination of hydrogen bonds, electrostatic interactions, and hydrophobic interactions.
The amino acid composition of the nonapeptide—comprising a mix of charged (Lys, Glu), polar (Thr, Ser, Asn), and hydrophobic (Ile, Val) residues—allows for a multifaceted interaction with the enzyme's active site. The positively charged lysine (B10760008) and negatively charged glutamic acid residues can form salt bridges with oppositely charged residues in the enzyme's binding pocket. The hydroxyl groups of threonine and serine, along with the amide group of asparagine, are capable of forming a network of hydrogen bonds. The hydrophobic isoleucine and valine residues are likely to engage in van der Waals interactions within the hydrophobic subpockets of the enzyme.
Table 1: Potential Intermolecular Interactions of this compound Residues with a Target Protein
| Amino Acid Residue | Position | Side Chain Property | Potential Interaction Type |
| Lysine (Lys) | 1 | Basic, Positively Charged | Ionic Bonding, Hydrogen Bonding |
| Threonine (Thr) | 2 | Polar, Uncharged | Hydrogen Bonding |
| Glutamic Acid (Glu) | 3 | Acidic, Negatively Charged | Ionic Bonding, Hydrogen Bonding |
| Glutamic Acid (Glu) | 4 | Acidic, Negatively Charged | Ionic Bonding, Hydrogen Bonding |
| Isoleucine (Ile) | 5 | Hydrophobic, Nonpolar | Hydrophobic Interactions, Van der Waals Forces |
| Serine (Ser) | 6 | Polar, Uncharged | Hydrogen Bonding |
| Glutamic Acid (Glu) | 7 | Acidic, Negatively Charged | Ionic Bonding, Hydrogen Bonding |
| Valine (Val) | 8 | Hydrophobic, Nonpolar | Hydrophobic Interactions, Van der Waals Forces |
| Asparagine (Asn) | 9 | Polar, Uncharged | Hydrogen Bonding |
This table is based on the general chemical properties of the amino acid side chains and represents potential interactions.
Investigation of Selective Recognition Mechanisms
Selective recognition is paramount for a peptide inhibitor to target a specific enzyme without affecting other related proteins, thereby minimizing off-target effects. The sequence and conformation of this compound play a crucial role in this selective recognition of β-secretase. The unique arrangement of its amino acid residues creates a specific three-dimensional shape and charge distribution that is complementary to the active site of β-secretase.
The flexibility of the peptide backbone allows it to adopt a conformation that fits snugly into the binding cleft of the target protein. This "induced fit" model of interaction can lead to a highly stable complex. The specificity is further enhanced by the cooperative nature of the multiple weak interactions. While a single hydrogen bond or van der Waals interaction is weak, the simultaneous formation of numerous such interactions across the peptide-protein interface leads to a strong and highly specific binding.
Research on similar peptide-based enzyme inhibitors has shown that even minor changes in the amino acid sequence can dramatically alter binding affinity and specificity. This underscores the importance of each residue within the this compound sequence for the selective recognition of its target. The presence of multiple glutamic acid residues, for instance, may be critical for interacting with specific positively charged patches within the target's active site, a feature that may be absent in other related proteins.
Computational Approaches and in Silico Analysis of Nh2 Lys Thr Glu Glu Ile Ser Glu Val Asn
Peptide Modeling and Simulation Techniques
Peptide modeling and simulation are powerful computational tools used to investigate the three-dimensional structure and dynamic behavior of peptides like NH2-Lys-Thr-Glu-Glu-Ile-Ser-Glu-Val-Asn. These techniques provide insights that are often difficult to obtain through experimental methods alone.
Conformer Generation and Structural Prediction
Understanding the three-dimensional shape, or conformation, of this compound is fundamental to understanding its biological activity. Conformer generation algorithms are employed to predict the ensemble of possible structures the peptide can adopt.
For a relatively short and flexible peptide like this nonapeptide, a variety of methods can be used for structural prediction:
Ab initio methods: These methods predict the peptide's structure from its amino acid sequence alone, without relying on experimentally determined homologous structures. They are computationally intensive but essential when no suitable templates are available.
Homology modeling: If a structurally similar peptide's conformation has been experimentally determined (e.g., through X-ray crystallography or NMR spectroscopy), it can be used as a template to build a model of this compound. This is a powerful technique, but its accuracy depends heavily on the degree of similarity between the target and template sequences.
Fragment-based assembly: This approach involves assembling the peptide structure from a library of known small peptide fragments. The conformations of these fragments are then pieced together and refined to generate a model of the full peptide.
The choice of method depends on factors such as the length of the peptide, the availability of homologous structures, and the desired level of accuracy. The resulting models provide a static picture of the peptide's potential shapes, which can then be used as starting points for more advanced simulations.
Molecular Dynamics Simulations for Conformational Analysis
While structural prediction provides static models, molecular dynamics (MD) simulations offer a dynamic view of a peptide's behavior over time. By simulating the movements of atoms and molecules, MD can reveal the conformational flexibility and preferred shapes of this compound in a simulated physiological environment.
In a typical MD simulation of this peptide, the following steps are taken:
A starting structure, often obtained from conformer generation methods, is placed in a simulation box.
The box is filled with solvent molecules (typically water) and ions to mimic physiological conditions.
The forces between all atoms are calculated using a force field, which is a set of parameters that describe the potential energy of the system.
Newton's equations of motion are solved iteratively to simulate the movement of each atom over a specific time period.
By analyzing the trajectory of the simulation, researchers can identify stable conformations, understand the transitions between different shapes, and calculate various properties of the peptide. This information is invaluable for understanding how the peptide might interact with its biological target.
Sequence and Structural Analysis
The amino acid sequence of this compound holds a wealth of information that can be unlocked through sequence and structural analysis. These methods help in understanding its properties and its relationship to other peptides.
Sequence Alignment and Homology-Based Analysis
Sequence alignment is a fundamental bioinformatic technique used to compare the sequence of this compound with other known peptide and protein sequences. This can reveal evolutionary relationships and identify functional motifs.
BLAST (Basic Local Alignment Search Tool): This widely used algorithm can be employed to search large sequence databases for sequences similar to KTEEISEVN. The results of a BLAST search can identify proteins or peptides that share a common ancestry or functional domains.
Pairwise and Multiple Sequence Alignment: These methods are used to align the peptide sequence with one or more other sequences to identify conserved regions and differences. For instance, aligning KTEEISEVN with the corresponding region of its target protein can provide insights into the binding mechanism.
Software packages like PepFun 2.0 offer functionalities for aligning both natural and modified peptide sequences, which is particularly relevant given that KTEEISEVN is part of a modified inhibitor. tandfonline.comresearchgate.net
Descriptors for Peptide Similarity and Property Prediction
To quantify the physicochemical properties of this compound and compare it to other peptides, a variety of molecular descriptors can be calculated. These descriptors are numerical representations of the peptide's structure and properties.
Commonly used peptide descriptors include:
Physicochemical Properties: These include molecular weight, net charge at a given pH, isoelectric point, and hydrophobicity. These can be calculated based on the amino acid composition.
Topological Descriptors: These are derived from the 2D representation of the peptide and can include measures of branching and connectivity.
3D-Descriptors: These are calculated from the 3D structure of the peptide and can include information about its shape, size, and surface properties.
Toolkits such as PepFuNN provide modules to calculate a range of these descriptors, including properties like topological polar surface area (TPSA), partition coefficient (LogP), and the number of rotatable bonds. nih.gov These descriptors are not only useful for similarity analysis but also form the basis for developing predictive models.
Below is an interactive table summarizing some calculated physicochemical properties for this compound.
| Property | Value |
| Molecular Weight (Da) | 1033.15 |
| Isoelectric Point (pI) | 4.09 |
| Net Charge at pH 7.4 | -2.99 |
| Hydrophobicity (Kyte-Doolittle) | -0.9 |
| Formula | C43H76N10O19 |
Note: These values are theoretical calculations and may vary slightly depending on the algorithm used.
Quantitative Structure-Activity Relationship (QSAR) Studies
Quantitative Structure-Activity Relationship (QSAR) is a computational modeling technique that aims to establish a mathematical relationship between the structural properties of a series of compounds and their biological activity. While no specific QSAR studies have been published for this compound, this methodology would be a powerful tool for optimizing its inhibitory activity against BACE1.
A typical QSAR study on this peptide and its analogs would involve the following steps:
Data Set Preparation: A series of peptides with variations in the KTEEISEVN sequence would be synthesized, and their inhibitory activity against BACE1 would be experimentally measured.
Descriptor Calculation: For each peptide in the series, a set of relevant molecular descriptors (as described in 4.2.2) would be calculated.
Model Development: Statistical methods, such as multiple linear regression or machine learning algorithms, would be used to build a mathematical model that correlates the calculated descriptors with the measured biological activity.
Model Validation: The predictive power of the QSAR model would be rigorously tested using statistical validation techniques.
Once a validated QSAR model is established, it can be used to predict the activity of new, unsynthesized peptide analogs. This allows for the in silico screening of large virtual libraries of peptides, prioritizing the most promising candidates for synthesis and experimental testing, thereby accelerating the drug discovery process.
Multivariate Approaches for Peptide QSAR
Quantitative Structure-Activity Relationship (QSAR) studies are fundamental in peptide research for correlating the physicochemical properties of amino acids with the biological activity of the peptide. mdpi.com For this compound, a multivariate QSAR approach would involve the characterization of each amino acid based on a set of descriptors. nih.govresearchgate.net These descriptors can be derived from the physicochemical properties of the amino acids, such as hydrophobicity, volume, and charge, which are then used to build predictive models. nih.govnih.gov
The variation in the amino acid sequence is described by principal properties (z-scales), which are derived from a principal components analysis of a wide range of physicochemical variables for the standard amino acids. nih.gov These z-scales (z1, z2, z3) represent hydrophobicity, steric properties, and electronic properties, respectively. By applying these scales to the peptide sequence, a quantitative description of its structure can be generated.
A hypothetical QSAR analysis for a series of analogs of this compound could be developed using the partial least squares (PLS) method. nih.govnih.gov This would allow for the prediction of the activity of new, unsynthesized peptide analogs, thereby guiding the design of more potent and selective compounds. nih.gov
| Amino Acid | Abbreviation | Hydrophobicity (Kyte-Doolittle) | Charge at pH 7.4 | Molecular Weight (g/mol) |
|---|---|---|---|---|
| Lysine (B10760008) | Lys (K) | -3.9 | Positive | 146.19 |
| Threonine | Thr (T) | -0.7 | Neutral | 119.12 |
| Glutamic Acid | Glu (E) | -3.5 | Negative | 147.13 |
| Isoleucine | Ile (I) | 4.5 | Neutral | 131.17 |
| Serine | Ser (S) | -0.8 | Neutral | 105.09 |
| Valine | Val (V) | 4.2 | Neutral | 117.15 |
| Asparagine | Asn (N) | -3.5 | Neutral | 132.12 |
Computational Methods for Identifying Structure-Activity Determinants
Identifying the key amino acid residues that determine the activity of this compound is crucial for its optimization. Computational modeling provides powerful tools to deconstruct the determinants of protein-peptide recognition. nih.gov Methods such as alanine (B10760859) scanning mutagenesis, where each residue is computationally mutated to alanine, can help in identifying "hotspot" residues that are critical for binding.
Molecular dynamics (MD) simulations can further elucidate the structural and dynamic determinants of the peptide's interaction with a target protein. nih.gov By simulating the behavior of the peptide-protein complex over time, it is possible to observe conformational changes and key interactions, such as hydrogen bonds and hydrophobic contacts, that stabilize the complex. nih.gov These simulations can reveal how the flexibility of both the peptide and the protein contributes to the binding affinity and specificity. nih.gov
Predictive Modeling of Peptide-Protein Interactions
Predicting how this compound will interact with its biological target is a key aspect of its computational analysis. Various in silico tools and methods are available for this purpose.
In Silico Prediction of Binding Sites
The initial step in modeling the interaction of this compound with a protein is to identify the potential binding site on the protein's surface. nih.gov Several computational methods can be used for this purpose, leveraging information from sequence conservation, geometric features, and physicochemical properties of the protein surface. nih.gov
Tools like PEP-SiteFinder can perform a blind search for peptide binding sites on a protein surface. oup.com This approach involves generating multiple 3D conformations of the peptide and then using rigid docking to scan the entire protein surface to identify residues that are likely to be part of the binding interface. oup.com Such methods are valuable when no prior information about the binding site is available. oup.com
Rational Design of Peptide-Based Modulators
The rational design of peptide-based modulators aims to create novel peptides with improved properties, such as enhanced binding affinity, specificity, and stability. researchgate.nettandfonline.com For this compound, this process would start with understanding its interaction with a target protein. frontiersin.orgnih.gov
Structure-based design is a powerful strategy where the three-dimensional structure of the peptide-protein complex is used to guide modifications. tandfonline.com For instance, if the structure reveals a key hydrophobic interaction, a residue in the peptide could be substituted with a more hydrophobic one to enhance binding. Similarly, introducing covalent bonds, such as disulfide bridges or hydrocarbon staples, can constrain the peptide into its bioactive conformation, leading to improved affinity and stability. researchgate.net
| Computational Tool/Method | Application in Peptide Analysis | Relevance to this compound |
|---|---|---|
| Multivariate QSAR | Correlates peptide structure with biological activity. mdpi.com | Predicting the activity of novel analogs. |
| Molecular Dynamics (MD) Simulations | Studies the dynamic behavior and interactions of peptide-protein complexes. nih.gov | Identifying key residues and conformational changes upon binding. |
| PEP-SiteFinder | Predicts peptide binding sites on protein surfaces. oup.com | Identifying potential protein targets and their interaction sites. |
| Rational Design | Guides the modification of peptides to improve their properties. researchgate.net | Designing more potent and stable modulators based on the peptide's sequence. |
| PepFun/PepFuNN | A suite of tools for peptide sequence analysis, library design, and structural analysis. github.comchemrxiv.orgnih.gov | Calculating physicochemical properties, designing analog libraries, and analyzing potential interactions. |
Integration of Bioinformatics and Cheminformatics Tools (e.g., PepFun, PepFuNN)
Tools like PepFun and its successor, PepFuNN, offer a comprehensive suite of functionalities for the in silico analysis of peptides. github.comchemrxiv.orgnih.gov These open-source Python packages integrate bioinformatics and cheminformatics approaches to study peptides at the sequence and structural levels. github.commdpi.com
For this compound, PepFun could be used to calculate a wide range of physicochemical properties, such as isoelectric point, charge at a specific pH, and hydrophobicity profile. mdpi.com It can also be employed to design libraries of peptide analogs by systematically substituting amino acids at different positions. github.commdpi.com
PepFuNN, the newer version, expands on these capabilities with enhanced functions for studying the chemical space of peptide libraries and performing detailed structure-activity relationship analyses. chemrxiv.org Its modular architecture allows for the calculation of physicochemical properties, similarity analysis using various peptide representations, clustering of peptides, and the design of peptide libraries based on specific criteria. chemrxiv.orgresearchgate.net These tools are invaluable for a systematic computational investigation of this compound and its derivatives. chemrxiv.org
Methodological Frameworks for Researching Nh2 Lys Thr Glu Glu Ile Ser Glu Val Asn
Spectroscopic and Chromatographic Characterization
A fundamental aspect of peptide research involves the rigorous confirmation of its identity, purity, and structural integrity. High-Performance Liquid Chromatography (HPLC) and Mass Spectrometry (MS) are indispensable tools for this purpose.
High-Performance Liquid Chromatography (HPLC) for Purity Assessment
HPLC is a cornerstone technique for assessing the purity of synthetic peptides like NH2-Lys-Thr-Glu-Glu-Ile-Ser-Glu-Val-Asn. Reversed-phase HPLC (RP-HPLC) is the most common modality for this application. The principle lies in the differential partitioning of the peptide between a nonpolar stationary phase (e.g., C18 silica (B1680970) gel) and a polar mobile phase, typically a gradient of water and an organic solvent like acetonitrile, often with an ion-pairing agent such as trifluoroacetic acid to improve peak shape.
The purity of the peptide is determined by integrating the area of the main peptide peak and comparing it to the total area of all peaks in the chromatogram. A high percentage for the main peak indicates a high degree of purity.
Table 1: Illustrative HPLC Purity Assessment Parameters for a Peptide Analog
| Parameter | Value |
|---|---|
| Column | C18 Reversed-Phase |
| Mobile Phase A | 0.1% Trifluoroacetic Acid in Water |
| Mobile Phase B | 0.1% Trifluoroacetic Acid in Acetonitrile |
| Gradient | 5% to 95% B over 30 minutes |
| Flow Rate | 1.0 mL/min |
| Detection | UV Absorbance at 214 nm |
| Retention Time | 15.2 minutes |
Mass Spectrometry for Structural Confirmation and Isotope Labeling Verification
Mass spectrometry is a powerful analytical technique used to confirm the molecular weight and sequence of this compound. Electrospray ionization (ESI) is a soft ionization technique commonly used for peptides, as it minimizes fragmentation and allows for the determination of the molecular mass of the intact molecule.
The process involves introducing the peptide solution into the mass spectrometer, where it is ionized. The mass-to-charge ratio (m/z) of the resulting ions is then measured. For a peptide of a known sequence, the experimentally determined molecular weight should match the theoretical calculated mass. High-resolution mass spectrometry can provide highly accurate mass measurements, further confirming the elemental composition.
Tandem mass spectrometry (MS/MS) can be employed to verify the amino acid sequence. In this technique, the parent ion corresponding to the peptide is selected and fragmented, and the masses of the resulting fragment ions are analyzed. The fragmentation pattern provides information about the amino acid sequence.
Enzyme Activity Assays
To investigate the functional activity of this compound as a potential BACE1 inhibitor, enzyme activity assays are crucial.
Fluorescence Resonance Energy Transfer (FRET) Based Assays for BACE1 Activity
FRET-based assays are a widely used method for monitoring BACE1 activity and screening for inhibitors. mdpi.com These assays utilize a synthetic peptide substrate that contains a fluorophore and a quencher molecule. In the intact substrate, the quencher is in close proximity to the fluorophore, suppressing its fluorescence signal through FRET. When BACE1 cleaves the peptide substrate, the fluorophore and quencher are separated, leading to an increase in fluorescence intensity.
The peptide sequence this compound is related to the Swedish mutation of the amyloid precursor protein, a known substrate for BACE1. A statine-modified version of this peptide, H-Lys-Thr-Glu-Glu-Ile-Ser-Glu-Val-Asn-Stat-Val-Ala-Glu-Phe-OH, is a known BACE1 inhibitor and is often used as a reference compound in these assays. nih.gov The inhibitory activity of the test peptide is determined by measuring the reduction in the rate of fluorescence increase in the presence of the compound.
Table 2: Example of BACE1 Inhibition Data for a Reference Peptide Inhibitor
| Compound | Concentration (nM) | % Inhibition |
|---|---|---|
| Reference Inhibitor | 1 | 15.2 |
| Reference Inhibitor | 10 | 48.5 |
| Reference Inhibitor | 100 | 89.7 |
Cell-Based Research Models for Functional Studies
To understand the effects of this compound in a more biologically relevant context, cell-based models are employed.
In Vitro Neuronal Cell Culture Systems for Investigating Peptide Effects
Neuronal cell lines, such as the human neuroblastoma cell line SH-SY5Y, are commonly used to study the cellular effects of potential BACE1 inhibitors. nih.gov These cells can be cultured and treated with the peptide to assess its impact on cellular processes related to Alzheimer's disease pathology.
Key parameters that can be investigated in these cell culture systems include the peptide's ability to reduce the production of amyloid-beta (Aβ) peptides (Aβ40 and Aβ42), the primary components of amyloid plaques. This is typically measured using techniques like enzyme-linked immunosorbent assay (ELISA). Furthermore, the effect of the peptide on cell viability and its potential to protect against Aβ-induced toxicity can be evaluated using assays such as the MTT assay. nih.gov
Studies with BACE1 inhibitors in primary cortical neurons have also been conducted to understand the impact on neuronal health and function. nih.gov Research has shown that BACE1 inhibition can affect dendritic spine density, highlighting the importance of investigating the neuronal effects of potential inhibitors. mdpi.comnih.gov
Table 3: Compounds Mentioned in this Article
| Compound Name | |
|---|---|
| This compound | |
| H-Lys-Thr-Glu-Glu-Ile-Ser-Glu-Val-Asn-Stat-Val-Ala-Glu-Phe-OH | |
| Trifluoroacetic Acid | |
| Acetonitrile | |
| Amyloid-beta (Aβ) | |
| Aβ40 |
Non-Neuronal Cell Lines in Comparative Studies
In the investigation of peptides with potential neurological activity, the use of non-neuronal cell lines is a critical component of a robust methodological framework. These cell lines serve multiple purposes, including acting as negative controls, assessing target specificity, and investigating off-target effects. For a peptide like this compound, which is a fragment of a larger protein with known inhibitory roles, comparative studies using non-neuronal cells are essential to delineate its specific biological interactions.
Researchers often employ common, well-characterized cell lines to express specific receptors or enzymes of interest ectopically. For example, Human Embryonic Kidney 293 (HEK293) cells are frequently used for their high transfection efficiency, allowing for the stable or transient expression of a target protein in a simplified, non-neuronal context. nih.gov This enables the study of direct peptide-protein interactions without the confounding variables present in complex neuronal cells. Comparing the peptide's effect on receptor-transfected HEK293 cells versus non-transfected (wild-type) cells can provide clear evidence of on-target activity.
Similarly, other non-neuronal lines can be used to explore potential interactions with ubiquitous cellular machinery or to confirm that the peptide's activity is restricted to its intended target. For instance, testing the peptide on epithelial or muscle cell lines could reveal unforeseen effects, contributing to a comprehensive understanding of its biological activity profile. nih.gov
Table 1: Examples of Non-Neuronal Cell Lines in Peptide Research This table illustrates the typical application of various non-neuronal cell lines in the comparative study of neurologically active peptides. Specific studies involving this compound in these exact cell lines are not detailed in the available literature but the principles apply.
| Cell Line | Type | Typical Application in Comparative Peptide Studies |
|---|---|---|
| HEK293 | Human Embryonic Kidney | Ectopic expression of neuronal receptors to isolate and study specific peptide-receptor interactions. nih.gov |
| CHO | Chinese Hamster Ovary | Used for stable expression of target proteins for binding affinity and functional assays. |
| HeLa | Human Cervical Cancer | General cytotoxicity assays and investigation of effects on basic cellular processes. |
| Fibroblasts | Connective Tissue Cells | Assessing peptide effects on cell proliferation, migration, and extracellular matrix interactions. |
High-Throughput Screening and Array Technologies
High-throughput screening (HTS) and array technologies have become indispensable tools in peptide research, enabling the rapid analysis of thousands of molecular interactions or enzymatic activities simultaneously. creative-peptides.com These methodologies are based on miniaturized assays, often in 96, 384, or 1536-well microplate formats, combined with automated liquid handling and sensitive detection systems. creative-peptides.com For a specific sequence like this compound, these platforms facilitate the efficient mapping of its binding partners and the screening of its potential inhibitory functions against a wide range of biological targets.
Peptide arrays are a powerful tool for identifying the binding partners of a specific peptide from a complex mixture of proteins, such as a cell lysate or serum. nih.gov The technology involves the chemical synthesis of peptides directly onto a solid support, like a cellulose (B213188) membrane or a glass slide, in a spatially defined pattern. researchgate.net
For the peptide this compound, it could be synthesized as one of many thousands of distinct peptides on a single array. This array is then incubated with a solution containing potential binding proteins. The proteins are typically labeled with a fluorescent tag or are later detected using a specific antibody. After washing away non-specific binders, the array is analyzed to identify the "spots" where a protein has bound to the synthesized peptide, thus mapping a specific molecular interaction. nih.gov This method is invaluable for discovering previously unknown receptors or interacting proteins, providing crucial leads for further functional studies. nih.govresearchgate.net
Table 2: Illustrative Data from a Hypothetical Peptide Array Screen This table represents the type of data generated from screening a peptide array containing the sequence KTEEISEVN against a protein library to identify potential binding partners.
| Peptide Sequence Immobilized | Interacting Protein Identified | Signal Intensity (Arbitrary Units) | Potential Significance |
|---|---|---|---|
| NH2-KTEEISEVN-COOH | Protein Kinase X | 15,432 | Suggests a role in a phosphorylation cascade. |
| NH2-KTEEISEVN-COOH | Receptor Subunit Y | 9,876 | Indicates potential binding to a cell surface receptor. |
| NH2-KTEEISEVN-COOH | Structural Protein Z | 1,205 | Low-affinity or non-specific interaction. |
High-throughput screening is widely used to test peptide libraries for inhibitory activity against specific enzymes. nih.gov Research has identified that a longer peptide containing the this compound sequence acts as a potent inhibitor of beta-secretase (BACE1), an enzyme implicated in Alzheimer's disease. peptanova.de The core sequence is part of a substrate-based inhibitor where the non-natural amino acid Statine (B554654) (Sta) is also included. peptanova.de
Biochemical assays to screen for such inhibitory activity are often based on principles like fluorescence resonance energy transfer (FRET). In a typical BACE1 FRET assay, a substrate peptide is engineered to have a fluorescent reporter and a quencher molecule at opposite ends. When the substrate is intact, the quencher suppresses the reporter's signal. Upon cleavage by BACE1, the reporter is separated from the quencher, resulting in a measurable increase in fluorescence.
When a potential inhibitor like this compound (or its derivatives) is added to the assay, it competes with the FRET substrate for the enzyme's active site. americanpeptidesociety.org Effective inhibition leads to a lower rate of substrate cleavage and thus a reduced fluorescent signal. By running thousands of such assays in parallel with different compounds, HTS can rapidly identify potent inhibitors. nih.gov The results are typically quantified by determining the half-maximal inhibitory concentration (IC50), which is the concentration of the inhibitor required to reduce the enzyme's activity by 50%. mdpi.com
Table 3: Research Findings on Inhibitory Activity of a Related Peptide
| Peptide Sequence | Target Enzyme | Assay Type | Key Finding | Reference |
|---|---|---|---|---|
| Lys-Thr-Glu-Glu-Ile-Ser-Glu-Val-Asn-Sta-Val-Ala-Glu-Phe | Beta-secretase (BACE1) | Biochemical Inhibition Assay | Identified as a potent inhibitor of the enzyme. | peptanova.de |
Emerging Research Perspectives and Future Directions for Nh2 Lys Thr Glu Glu Ile Ser Glu Val Asn Research
Advancements in Peptide Engineering and Rational Design
Rational design and chemical modification are pivotal for transforming native peptides into robust therapeutic candidates. For a peptide such as NH2-Lys-Thr-Glu-Glu-Ile-Ser-Glu-Val-Asn, which may possess inherent biological activity but suffer from poor stability or bioavailability, several engineering strategies can be employed.
One of the most promising techniques is peptide stapling . This method involves introducing a chemical brace, or "staple," to lock the peptide into its bioactive conformation, often an α-helix. nih.govcpcscientific.com By cross-linking the side chains of two amino acids, stapling can significantly enhance proteolytic resistance, increase target affinity, and improve cell permeability. nih.govnih.govacs.org For instance, an all-hydrocarbon staple could be introduced by replacing two amino acids at appropriate positions (e.g., i and i+4 or i and i+7) with non-natural amino acids that can be covalently linked. peptide.com This pre-organization of the peptide's structure reduces the entropic penalty upon binding to its target, often leading to a substantial increase in binding affinity. nih.govacs.org
Backbone modification offers another avenue for enhancing peptide stability. bachem.com Techniques such as N-methylation, where a methyl group is added to the backbone amide nitrogen, can disrupt hydrogen bonding and sterically hinder protease access, thereby increasing resistance to enzymatic degradation. peptide.comresearchgate.net Other modifications include the incorporation of D-amino acids or non-proteinogenic amino acids, which can alter the peptide's conformation and reduce its susceptibility to proteases. bachem.com
These engineering strategies are guided by rational design principles, where computational modeling and structural biology inform the precise placement and type of modification to achieve optimal therapeutic properties without compromising bioactivity.
| Engineering Strategy | Description | Potential Benefits for this compound | Key Considerations |
|---|---|---|---|
| Peptide Stapling | Introduction of a covalent cross-link (e.g., all-hydrocarbon) between amino acid side chains to enforce a specific secondary structure, typically an α-helix. cpcscientific.comacs.org | Increased proteolytic resistance, enhanced cell permeability, improved target affinity and specificity. nih.govacs.org | Requires incorporation of non-natural amino acids; position of the staple is critical for maintaining activity. |
| Backbone N-Methylation | Addition of a methyl group to the amide nitrogen of the peptide backbone. peptide.com | Increased resistance to proteolysis, improved membrane permeability. researchgate.net | Can disrupt necessary hydrogen bonds for target binding; may alter peptide conformation. |
| D-Amino Acid Substitution | Replacing one or more L-amino acids with their D-isomers. bachem.com | Significantly enhanced stability against enzymatic degradation. | Can dramatically alter the peptide's 3D structure and its interaction with the target protein. |
| Cyclization | Forming a cyclic structure via head-to-tail, sidechain-to-sidechain, or terminus-to-sidechain linkages. peptide.com | Improved stability, reduced conformational flexibility leading to higher affinity. slideshare.net | The optimal ring size and cyclization points must be determined to preserve bioactivity. |
Exploration of Novel Protein-Protein Interaction Targets for Peptide Modulators
Protein-protein interactions (PPIs) are fundamental to nearly all cellular processes, and their dysregulation is a hallmark of many diseases. ethz.ch Peptides are ideal candidates for modulating PPIs because they can mimic the binding epitopes of one of the protein partners, allowing for high specificity and potency. acs.orgnih.gov While some PPIs are well-established drug targets, a vast number of disease-relevant interactions remain unexplored and are considered "undruggable" by traditional small molecules due to their large, flat, and featureless interfaces. tandfonline.comnih.gov
Future research on this compound will likely involve screening it against a broader range of PPI targets implicated in various diseases, such as cancer, autoimmune disorders, and viral infections. tandfonline.com Computational methods are becoming indispensable for this exploration. nih.gov Structure-based and sequence-based algorithms can predict potential interactions between the peptide and proteins within the human interactome. nih.govnih.govmdpi.com Techniques like molecular docking and molecular dynamics simulations can model the binding of the peptide to novel protein targets, providing insights into binding affinity and mechanism of action before extensive experimental validation is undertaken. tandfonline.com
The identification of new PPI targets for this peptide could significantly expand its therapeutic applications. For example, if the peptide is found to disrupt a key interaction in a cancer signaling pathway or a virus-host interaction, it could be developed as a novel therapeutic for those conditions. tandfonline.com This exploratory approach, combining computational prediction with experimental validation, is a powerful strategy for unlocking the full potential of peptide modulators. purdue.edu
Integration of Artificial Intelligence and Machine Learning in Peptide Research Workflows
Artificial intelligence (AI) and machine learning (ML) are revolutionizing peptide-based drug discovery by accelerating the design, prediction, and optimization processes. polifaces.demdpi.com For this compound, AI can be integrated at multiple stages of the research workflow.
De novo design and optimization: Deep generative models, such as variational autoencoders (VAEs) and generative adversarial networks (GANs), can be trained on vast datasets of known peptide sequences and their properties. nih.govoup.comnih.gov These models can then generate novel peptide sequences, including variants of the original peptide, that are predicted to have enhanced properties like higher binding affinity, increased stability, or better selectivity. nih.govplos.org This allows for the rapid exploration of the vast chemical space around the lead peptide. arxiv.org
| AI/ML Application Area | Specific Models/Techniques | Impact on Peptide Research Workflow |
|---|---|---|
| De Novo Peptide Design | Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), Recurrent Neural Networks (RNNs). nih.govnih.gov | Generates novel peptide sequences with desired properties, expanding beyond known sequences. plos.org |
| Bioactivity Prediction | Support Vector Machines (SVM), Random Forests, Deep Neural Networks (DNNs). mdpi.com | Predicts the binding affinity and efficacy of peptides against specific biological targets. nih.gov |
| Toxicity & Safety Prediction | Quantitative Structure-Toxicity Relationship (QSTR) models, Large Language Models (LLMs). rsc.org | Assesses potential toxicity and adverse effects early in the design phase, reducing late-stage failures. researchgate.net |
| Lead Optimization | Reinforcement Learning, Iterative Screening Loops. arxiv.org | Systematically modifies peptide sequences to optimize multiple parameters simultaneously (e.g., affinity and stability). |
Development of Advanced In Vitro Models for Functional Characterization
To accurately assess the biological function and therapeutic potential of peptides like this compound, it is crucial to move beyond traditional two-dimensional (2D) cell cultures. Advanced in vitro models that better recapitulate human physiology are essential for generating more predictive data before moving to preclinical animal studies. nih.gov
Organoids and 3D Cell Cultures: Organoids are self-organizing 3D structures derived from stem cells that mimic the architecture and function of human organs. facellitate.commedium.com Using patient-derived organoids allows for the testing of peptide efficacy in a model that reflects the genetic and cellular complexity of a specific disease state. crownbio.comstemcell.com For example, tumor organoids can be used to screen the anti-cancer activity of the peptide, providing insights into its effectiveness that are more clinically relevant than data from 2D cell lines. 10xgenomics.com 3D spheroids and other scaffold-based cultures also provide a more realistic microenvironment, which is critical for evaluating factors like drug penetration and cell-cell interactions. cellgs.comrevvity.com
Microfluidic Devices: Microfluidics, or "lab-on-a-chip" technology, enables the precise manipulation of small fluid volumes to study biological processes in a controlled environment. news-medical.netnih.gov These devices can be used to perform high-throughput screening of the peptide's interaction with target proteins, measuring binding kinetics and affinity with minimal sample consumption. nih.govresearchgate.net Microfluidic systems can also be designed to mimic physiological conditions, such as blood flow or tissue interfaces, providing a dynamic environment for characterizing the peptide's behavior. acs.org
The integration of these advanced models into the drug discovery pipeline provides a more accurate and human-relevant assessment of a peptide's therapeutic potential, helping to bridge the gap between laboratory findings and clinical outcomes. 10xgenomics.comresearchgate.net
Q & A
Q. What protocols ensure reproducibility in animal studies evaluating its pharmacokinetics?
- Methodological Answer : Follow NIH guidelines for preclinical studies: use ≥6 animals/group, administer via IV/SC routes, and collect plasma at timed intervals. Quantify peptide levels via LC-MS/MS. Report parameters (t½, Cmax, AUC) using non-compartmental analysis (Phoenix WinNonlin) .
Data Analysis & Reporting
Q. How to statistically analyze dose-dependent effects in functional assays?
Q. What bioinformatics tools identify homologous sequences or conserved domains?
- Methodological Answer : Use BLASTP (NCBI) for sequence homology. Annotate domains via InterPro or SMART. For evolutionary analysis, construct phylogenetic trees (MEGA-X) with bootstrap values ≥1,000 .
Literature & Synthesis Guidance
Q. How to design a systematic review on this peptide’s functional roles?
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
