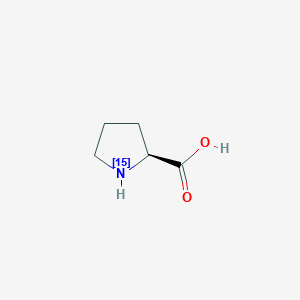
L-Proline-15N
Description
BenchChem offers high-quality this compound suitable for many research applications. Different packaging options are available to accommodate customers' requirements. Please inquire for more information about this compound including the price, delivery time, and more detailed information at info@benchchem.com.
Structure
3D Structure
Properties
Molecular Formula |
C5H9NO2 |
|---|---|
Molecular Weight |
116.12 g/mol |
IUPAC Name |
(2S)-(115N)azolidine-2-carboxylic acid |
InChI |
InChI=1S/C5H9NO2/c7-5(8)4-2-1-3-6-4/h4,6H,1-3H2,(H,7,8)/t4-/m0/s1/i6+1 |
InChI Key |
ONIBWKKTOPOVIA-JGTYJTGKSA-N |
Isomeric SMILES |
C1C[C@H]([15NH]C1)C(=O)O |
Canonical SMILES |
C1CC(NC1)C(=O)O |
Origin of Product |
United States |
Foundational & Exploratory
L-Proline-15N: An In-Depth Technical Guide to its Role in Protein Analysis
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive overview of L-Proline-15N, a stable isotope-labeled amino acid, and its critical applications in modern protein analysis. We will delve into its utility in Nuclear Magnetic Resonance (NMR) spectroscopy and mass spectrometry (MS)-based proteomics, offering detailed experimental protocols and data presentation to facilitate its integration into your research workflows.
Introduction to this compound
This compound is a non-radioactive, stable isotope-labeled form of the amino acid L-proline. In this molecule, the naturally abundant nitrogen-14 (¹⁴N) atom within the secondary amine group of the pyrrolidine ring is substituted with the heavier nitrogen-15 (¹⁵N) isotope. This subtle change in mass does not alter the chemical properties or biological activity of the amino acid, allowing it to be seamlessly incorporated into proteins during cellular protein synthesis. The key advantage of this isotopic enrichment lies in its ability to serve as a specific probe for tracking and quantifying proteins and their dynamics.
Chemical and Physical Properties
A clear understanding of the physicochemical characteristics of this compound is essential for its effective use in experimental design.
| Property | Value |
| Chemical Formula | C₅H₉¹⁵NO₂ |
| Molecular Weight | 116.12 g/mol |
| CAS Number | 59681-31-1 |
| Isotopic Purity | Typically ≥95 atom % ¹⁵N |
| Appearance | White to off-white solid |
| Melting Point | 228 °C (decomposes) |
| Solubility | Soluble in water |
The Role of this compound in Protein NMR Spectroscopy
Nuclear Magnetic Resonance (NMR) spectroscopy is a powerful technique for determining the three-dimensional structure and dynamics of proteins in solution. Isotopic labeling with ¹⁵N is a cornerstone of modern biomolecular NMR.
Overcoming the "Invisibility" of Proline in Standard NMR Experiments
In standard ¹H-¹⁵N Heteronuclear Single Quantum Coherence (HSQC) experiments, which are often the starting point for protein NMR studies, each amino acid residue in a protein typically gives rise to a unique signal, creating a "fingerprint" of the protein. However, proline residues are unique in that their nitrogen atom is part of a secondary amine within the rigid pyrrolidine ring and lacks a directly bonded amide proton. This absence of an amide proton makes proline residues "invisible" in conventional ¹H-¹⁵N HSQC spectra.
Despite this, ¹⁵N labeling of proline is highly valuable. Specialized NMR experiments that do not rely on the presence of an amide proton can be employed to specifically observe proline residues. The ¹⁵N chemical shifts of proline residues fall within a distinct and well-resolved region of the NMR spectrum, making them excellent probes, especially in intrinsically disordered proteins (IDPs) where prolines are often abundant.
Experimental Protocol: ¹⁵N Labeling of Recombinant Proteins in E. coli
This protocol outlines the general steps for producing a ¹⁵N-labeled protein in E. coli for NMR analysis.
Materials:
-
E. coli expression strain (e.g., BL21(DE3)) transformed with the plasmid encoding the protein of interest.
-
M9 minimal medium components.
-
¹⁵NH₄Cl (Ammonium Chloride-¹⁵N) as the sole nitrogen source.
-
Glucose (or other carbon source).
-
Trace elements solution.
-
MgSO₄ and CaCl₂ solutions.
-
Appropriate antibiotic.
-
IPTG (Isopropyl β-D-1-thiogalactopyranoside) for induction.
Procedure:
-
Starter Culture: Inoculate a single colony of the transformed E. coli into 5-10 mL of LB medium with the appropriate antibiotic. Grow overnight at 37°C with shaking.
-
Pre-culture in Minimal Medium: The next day, inoculate 100 mL of M9 minimal medium containing ¹⁴NH₄Cl with the overnight starter culture. Grow at 37°C with shaking until the OD₆₀₀ reaches 0.6-0.8. This step helps adapt the cells to the minimal medium.
-
Main Culture: Inoculate 1 L of M9 minimal medium, prepared with 1 g/L of ¹⁵NH₄Cl as the sole nitrogen source, with the pre-culture. Grow at 37°C with shaking.
-
Induction: When the OD₆₀₀ of the main culture reaches 0.6-0.8, induce protein expression by adding IPTG to a final concentration of 0.5-1 mM.
-
Expression: Reduce the temperature to 18-25°C and continue to grow the culture for another 12-16 hours.
-
Harvesting: Harvest the cells by centrifugation at 5,000 x g for 15 minutes at 4°C.
-
Protein Purification: Purify the ¹⁵N-labeled protein from the cell pellet using standard chromatography techniques (e.g., affinity, ion exchange, size exclusion).
-
Sample Preparation for NMR: Dialyze the purified protein into an NMR buffer (e.g., 20 mM sodium phosphate, 50 mM NaCl, pH 6.5) and concentrate to the desired concentration (typically 0.5-1 mM). Add 5-10% D₂O for the NMR lock.
L-Proline-15N: A Technical Guide to its Chemical Properties and Molecular Structure
For Researchers, Scientists, and Drug Development Professionals
This in-depth technical guide provides a comprehensive overview of the core chemical properties and molecular structure of L-Proline-15N, a stable isotope-labeled variant of the proteinogenic amino acid L-proline. This document is intended to serve as a valuable resource for researchers, scientists, and professionals in drug development and related fields who utilize labeled compounds in their work.
Chemical and Physical Properties
This compound is a non-essential amino acid distinguished by the isotopic labeling of its nitrogen atom with the heavy isotope ¹⁵N. This substitution provides a valuable tool for various analytical techniques, particularly in biomolecular Nuclear Magnetic Resonance (NMR) spectroscopy, metabolism studies, and proteomics.[1] The key chemical and physical properties of this compound are summarized in the tables below for easy reference and comparison.
Table 1: General Chemical Properties
| Property | Value | Reference(s) |
| Chemical Name | L-Proline-¹⁵N | [2] |
| Synonyms | (S)-Pyrrolidine-2-carboxylic acid-¹⁵N, (-)-2-Pyrrolidinecarboxylic acid-¹⁵N | [1][3] |
| CAS Number | 59681-31-1 | [2][4] |
| Molecular Formula | C₅H₉¹⁵NO₂ | [4] |
| Molecular Weight | 116.12 g/mol | [1][4] |
| Isotopic Purity | ≥95 atom % ¹⁵N | [4] |
| Chemical Purity | ≥98% | [1][4] |
| Mass Shift | M+1 | [4] |
| SMILES String | OC(=O)[C@@H]1CCC[15NH]1 | [4] |
| InChI Key | ONIBWKKTOPOVIA-JGTYJTGKSA-N | [4] |
Table 2: Physical Characteristics
| Property | Value | Reference(s) |
| Appearance | White to off-white powder or crystals | [3] |
| Melting Point | 228 °C (decomposes) | [4] |
| Optical Activity | [α]25/D -86.0°, c = 2 in H₂O | [4] |
| Storage Temperature | Refrigerated (+2°C to +8°C), protected from light | [1] |
Molecular Structure
L-Proline possesses a unique cyclic structure, making it the only proteinogenic amino acid with a secondary amine. This rigid five-membered ring significantly influences the secondary structure of proteins.[5] The nitrogen atom, labeled with ¹⁵N in this variant, is part of this pyrrolidine ring.
References
- 1. L-Proline (¹âµN, 98%) - Cambridge Isotope Laboratories, NLM-835-0.5 [isotope.com]
- 2. isotope-science.alfa-chemistry.com [isotope-science.alfa-chemistry.com]
- 3. L -Proline-13C5,15N 13C 98atom , 15N 98atom , 95 CP 202407-23-6 [sigmaaldrich.com]
- 4. This compound ≥95 atom % 15N, 98% (CP) | Sigma-Aldrich [sigmaaldrich.com]
- 5. L-Proline - American Chemical Society [acs.org]
Synthesis of ¹⁵N-Labeled L-Proline: An In-depth Technical Guide for Research Applications
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the synthesis of ¹⁵N-labeled L-Proline, a critical tool in metabolic research, structural biology, and drug development. The incorporation of the stable isotope ¹⁵N allows for the precise tracking and quantification of proline metabolism and its downstream products in various biological systems. This document details both chemical and enzymatic synthesis routes, providing in-depth experimental protocols, quantitative data, and visual representations of key pathways and workflows.
Introduction to ¹⁵N-Labeled L-Proline in Research
L-Proline, a unique cyclic amino acid, plays a crucial role in protein structure and function, collagen synthesis, and cellular stress responses. The ability to trace the metabolic fate of proline is essential for understanding these processes in both healthy and diseased states. ¹⁵N-labeled L-Proline serves as a powerful tracer for in vivo and in vitro studies, enabling researchers to monitor protein biosynthesis, elucidate metabolic pathways, and assess enzyme kinetics.[1] Its applications are particularly prominent in studies utilizing Nuclear Magnetic Resonance (NMR) spectroscopy and mass spectrometry, where the ¹⁵N isotope provides a distinct and measurable signal.[2][3]
Synthesis Methodologies
The synthesis of ¹⁵N-labeled L-Proline can be broadly categorized into two main approaches: chemical synthesis and enzymatic synthesis. The choice of method often depends on the desired isotopic enrichment, scale of production, and available starting materials.
Chemical Synthesis from ¹⁵N-Labeled L-Glutamic Acid
A common and effective method for the chemical synthesis of ¹⁵N-L-Proline involves the conversion of ¹⁵N-labeled L-Glutamic acid. This multi-step process leverages the structural similarity between the two amino acids and allows for high isotopic enrichment. The general synthetic scheme involves the ring closure of L-glutamic acid to form pyroglutamic acid (5-oxoproline), followed by a series of reduction steps.[4]
A key strategy for the selective reduction of the 5-amide function without affecting the 2-carboxylate function involves the conversion of the amide to a thioamide, which is then reduced to the amine using tributyltin hydride.[4]
Experimental Protocol: Chemical Synthesis
The following protocol is a generalized procedure based on established chemical synthesis routes. Researchers should optimize conditions based on their specific laboratory setup and safety protocols.
-
Cyclization of ¹⁵N-L-Glutamic Acid to ¹⁵N-L-Pyroglutamic Acid:
-
Suspend ¹⁵N-L-Glutamic acid in deionized water.
-
Heat the suspension at 130-140°C for 2-3 hours to induce cyclization.
-
Monitor the reaction by thin-layer chromatography (TLC).
-
Cool the reaction mixture and crystallize the resulting ¹⁵N-L-Pyroglutamic acid.
-
Filter and dry the product.
-
-
Thionation of ¹⁵N-L-Pyroglutamic Acid:
-
Dissolve the ¹⁵N-L-Pyroglutamic acid in an appropriate anhydrous solvent (e.g., dioxane).
-
Add a thionating agent, such as Lawesson's reagent, in stoichiometric amounts.
-
Reflux the mixture for several hours, monitoring the reaction by TLC.
-
Remove the solvent under reduced pressure.
-
Purify the resulting thioamide by column chromatography.
-
-
Reduction of the Thioamide to ¹⁵N-L-Proline:
-
Dissolve the purified thioamide in an appropriate solvent (e.g., toluene).
-
Add a reducing agent, such as tributyltin hydride, and a radical initiator (e.g., AIBN).
-
Heat the reaction mixture under an inert atmosphere.
-
Monitor the reaction by TLC.
-
Upon completion, quench the reaction and remove the solvent.
-
-
Purification of ¹⁵N-L-Proline:
-
The crude product is purified using ion-exchange chromatography.[5][6][7][8]
-
Dissolve the crude product in an appropriate buffer and load it onto a cation-exchange column.
-
Wash the column to remove impurities.
-
Elute the ¹⁵N-L-Proline using a suitable buffer gradient (e.g., aqueous ammonia).
-
Collect and pool the fractions containing the product.
-
Lyophilize the pooled fractions to obtain pure ¹⁵N-L-Proline.
-
Quantitative Data: Chemical Synthesis
| Parameter | Value | Reference |
| Starting Material | ¹⁵N-L-Glutamic Acid | [4] |
| Overall Yield | High | [4] |
| Isotopic Enrichment | >98% | [4] |
Enzymatic Synthesis
Enzymatic synthesis offers a highly specific and stereoselective route to ¹⁵N-L-Proline, mimicking the natural biosynthetic pathway. This method typically utilizes a cell-free system with purified enzymes to convert ¹⁵N-labeled precursors into the final product. The key enzymes in the proline biosynthesis pathway are Pyrroline-5-Carboxylate Synthetase (P5CS) and Pyrroline-5-Carboxylate Reductase (P5CR).[9]
P5CS is a bifunctional enzyme that first catalyzes the ATP-dependent phosphorylation of glutamate to γ-glutamyl phosphate, which is then reduced by NADPH to glutamate-γ-semialdehyde. This intermediate spontaneously cyclizes to form Δ¹-pyrroline-5-carboxylate (P5C). P5CR then reduces P5C to L-proline using NADH or NADPH as a cofactor.[10]
Experimental Protocol: Enzymatic Synthesis
This protocol outlines a general procedure for the in vitro enzymatic synthesis of ¹⁵N-L-Proline.
-
Enzyme Preparation:
-
Express and purify recombinant P5CS and P5CR enzymes from a suitable expression system (e.g., E. coli).
-
Ensure high purity and activity of the enzymes.
-
-
Reaction Setup:
-
Prepare a reaction buffer containing:
-
Tris-HCl buffer (pH 7.5-8.0)
-
MgCl₂
-
ATP
-
NADPH and/or NADH
-
¹⁵N-L-Glutamic acid (as the labeled precursor)
-
-
Add purified P5CS and P5CR to the reaction mixture.
-
-
Incubation:
-
Incubate the reaction mixture at an optimal temperature (e.g., 37°C) for several hours.
-
Monitor the progress of the reaction by analyzing small aliquots for proline formation using a suitable method (e.g., HPLC).
-
-
Reaction Termination and Product Purification:
Quantitative Data: Enzymatic Synthesis
| Parameter | Value | Reference |
| Starting Material | ¹⁵N-L-Glutamic Acid | [11] |
| Key Enzymes | P5CS, P5CR | [9] |
| Cofactors | ATP, NADPH, NADH | [10] |
| Isotopic Enrichment | >99% | [11] |
| Yield | High | [12] |
Characterization of ¹⁵N-L-Proline
The purity and isotopic enrichment of the synthesized ¹⁵N-L-Proline must be confirmed before its use in research applications. The following analytical techniques are commonly employed:
-
Nuclear Magnetic Resonance (NMR) Spectroscopy: ¹H and ¹³C NMR are used to confirm the chemical structure and purity of the L-Proline. ¹⁵N NMR is used to directly determine the position and extent of ¹⁵N labeling.[3][13]
-
Mass Spectrometry (MS): Mass spectrometry is used to confirm the molecular weight of the labeled compound and to accurately determine the isotopic enrichment by analyzing the mass-to-charge ratio of the molecular ion.[2]
Visualizing Key Pathways and Workflows
Proline Biosynthesis Pathway
The enzymatic synthesis of L-Proline from L-Glutamate is a fundamental metabolic pathway.
Caption: Enzymatic synthesis pathway of ¹⁵N-L-Proline from ¹⁵N-L-Glutamate.
General Experimental Workflow for Synthesis and Analysis
The following diagram illustrates a typical workflow for the synthesis, purification, and characterization of ¹⁵N-L-Proline.
Caption: General workflow for the synthesis and analysis of ¹⁵N-L-Proline.
Applications in Research
The availability of high-purity ¹⁵N-L-Proline is crucial for a variety of research applications:
-
Metabolic Flux Analysis: Tracing the incorporation of ¹⁵N from proline into other metabolites provides quantitative data on metabolic pathways.
-
Protein Synthesis and Turnover: Monitoring the incorporation of ¹⁵N-L-Proline into newly synthesized proteins allows for the determination of protein synthesis and degradation rates.[1]
-
Structural Biology: ¹⁵N-labeled proline is used in NMR studies to aid in the structural determination of proteins and to study protein dynamics.[3]
-
Drug Development: Understanding the role of proline metabolism in disease states can identify potential drug targets. ¹⁵N-L-Proline can be used to screen for compounds that modulate proline metabolic pathways.
Conclusion
The synthesis of ¹⁵N-labeled L-Proline is a well-established process that can be achieved through both chemical and enzymatic methods. The choice of synthesis route depends on the specific requirements of the research application. Careful purification and characterization are essential to ensure the quality of the final product. This in-depth guide provides researchers, scientists, and drug development professionals with the necessary information to produce and utilize ¹⁵N-L-Proline effectively in their studies, ultimately advancing our understanding of biological systems.
References
- 1. A comparison of 15N proline and 13C leucine for monitoring protein biosynthesis in the skin - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Mass spectrometry assisted assignment of NMR resonances in 15N labeled proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. researchgate.net [researchgate.net]
- 5. Using ion exchange chromatography to purify a recombinantly expressed protein - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. A unified method for purification of basic proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. A Specific and Sensitive Enzymatic Assay for the Quantitation of L-Proline - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Proline - Wikipedia [en.wikipedia.org]
- 11. researchgate.net [researchgate.net]
- 12. Enzymatic synthesis of some (15)N-labelled L-amino acids. | Sigma-Aldrich [merckmillipore.com]
- 13. mr.copernicus.org [mr.copernicus.org]
An In-depth Technical Guide to Isotopic Labeling with L-Proline-¹⁵N
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive overview of isotopic labeling using L-Proline-¹⁵N, a powerful technique for tracing proline metabolism, quantifying protein dynamics, and elucidating cellular signaling pathways. This document details experimental protocols, presents quantitative data, and visualizes key metabolic and signaling networks.
Core Concepts of L-Proline-¹⁵N Labeling
Isotopic labeling with L-Proline-¹⁵N involves the incorporation of the stable, non-radioactive isotope of nitrogen, ¹⁵N, into the proline amino acid structure. When cells or organisms are cultured in a medium containing L-Proline-¹⁵N, this "heavy" proline is utilized in protein synthesis and other metabolic pathways. The resulting ¹⁵N-labeled proteins and metabolites can be distinguished from their unlabeled ("light") counterparts by mass spectrometry (MS) and nuclear magnetic resonance (NMR) spectroscopy. This mass difference allows for the precise quantification of protein turnover, metabolic flux, and the identification of protein-protein interactions.
Key Applications:
-
Protein Turnover Analysis: Measuring the rates of protein synthesis and degradation.
-
Metabolic Flux Analysis: Tracing the metabolic fate of proline and its contribution to various biochemical pathways.
-
Quantitative Proteomics: Accurately quantifying changes in protein abundance between different experimental conditions (e.g., SILAC - Stable Isotope Labeling with Amino Acids in Cell Culture).
-
Structural Biology: Aiding in the determination of protein structure and dynamics using NMR spectroscopy.
-
Collagen Synthesis Studies: Specifically tracking the synthesis and turnover of collagen, a proline-rich protein crucial in tissue structure and disease.[1]
Quantitative Data Presentation
The efficiency of L-Proline-¹⁵N incorporation and its impact on protein turnover are critical parameters in labeling experiments. The following tables summarize quantitative data from representative studies.
| Cell Line/Organism | Labeling Method | ¹⁵N-Proline Concentration | Labeling Time | Incorporation Efficiency (%) | Reference |
| Human Embryonic Lung (HEL) Fibroblasts | SILAC | 50-350 mg/L | 4-7 days | >94 | [1] |
| Arabidopsis thaliana | ¹⁵N Metabolic Labeling | 1 g/L K¹⁵NO₃ | 14 days | ~94-97 | [2] |
| Pancreatic Cancer MIA PaCa Cells | ¹⁵N Amino Acid Mixture | 33-50% enriched medium | 72 hours | Not specified, but sufficient for mass shift | [3] |
Table 1: L-Proline-¹⁵N Incorporation Efficiency. This table presents the efficiency of ¹⁵N incorporation into the proteome of different biological systems, demonstrating the high level of labeling achievable with this technique.
| Protein | Cell Line/Organism | Labeling Method | Fractional Synthesis Rate (%/day) | Half-life (days) | Reference |
| Various Proteins | HeLa Cells | Dynamic SILAC | Varies | Average ~20 hours | [4] |
| Photosynthesis-related proteins | Barley Leaves | ¹⁵N Metabolic Labeling | Varies | Not specified | [5] |
| Bone Collagen | Rats | Deuterium Oxide (D₂O) Labeling | 0.027 - 0.203 | Varies | [6] |
| 40S ribosomal protein SA | Pancreatic Cancer MIA PaCa Cells | ¹⁵N Amino Acid Mixture | 44-76% (Fractional Synthesis) | Not specified | [3] |
Table 2: Protein Turnover Rates Determined by Stable Isotope Labeling. This table showcases the application of stable isotope labeling to measure the dynamics of protein synthesis and degradation for various proteins in different model systems.
Experimental Protocols
Detailed methodologies are crucial for the successful implementation of L-Proline-¹⁵N labeling experiments.
General ¹⁵N Metabolic Labeling in Cell Culture (SILAC)
This protocol outlines the general steps for performing a SILAC experiment using ¹⁵N-labeled amino acids.[7][8][9]
Materials:
-
Cell line of interest
-
SILAC-grade cell culture medium deficient in specific amino acids (e.g., DMEM, RPMI-1640)
-
"Light" amino acids (e.g., L-Arginine, L-Lysine)
-
"Heavy" ¹⁵N-labeled amino acids (e.g., L-Arginine-¹⁵N₄, L-Lysine-¹⁵N₂)
-
Dialyzed fetal bovine serum (dFBS)
-
Standard cell culture reagents and equipment
Procedure:
-
Cell Adaptation: Culture cells for at least five to six passages in the "heavy" SILAC medium to ensure complete incorporation of the ¹⁵N-labeled amino acids. A parallel culture is maintained in the "light" medium.
-
Experimental Treatment: Once fully labeled, expose the "heavy" and "light" cell populations to their respective experimental conditions.
-
Cell Harvesting and Lysis: Harvest both cell populations and lyse them using a suitable lysis buffer (e.g., RIPA buffer) containing protease and phosphatase inhibitors.
-
Protein Quantification: Determine the protein concentration of both lysates using a standard protein assay (e.g., BCA assay).
-
Sample Mixing: Mix equal amounts of protein from the "heavy" and "light" lysates.
-
Protein Digestion: Proceed with in-solution or in-gel digestion of the mixed protein sample.
In-Solution Protein Digestion for Mass Spectrometry
This protocol is a standard procedure for digesting protein samples into peptides for subsequent MS analysis.[10][11]
Materials:
-
Mixed protein lysate from SILAC experiment
-
Dithiothreitol (DTT)
-
Iodoacetamide (IAA)
-
Trypsin (mass spectrometry grade)
-
Ammonium bicarbonate buffer
-
Formic acid or Trifluoroacetic acid (TFA)
Procedure:
-
Reduction: Add DTT to the protein sample to a final concentration of 10 mM and incubate at 56°C for 1 hour to reduce disulfide bonds.
-
Alkylation: Add IAA to a final concentration of 55 mM and incubate in the dark at room temperature for 45 minutes to alkylate free cysteine residues.
-
Digestion: Dilute the sample with ammonium bicarbonate buffer to reduce the denaturant concentration. Add trypsin at a 1:50 to 1:100 (enzyme:protein) ratio and incubate overnight at 37°C.
-
Quenching: Stop the digestion by adding formic acid or TFA to a final concentration of 0.1-1%.
-
Desalting: Desalt the peptide mixture using a C18 StageTip or ZipTip before MS analysis.
Sample Preparation for NMR Spectroscopy
Proper sample preparation is critical for obtaining high-quality NMR spectra.[12][13][14][15]
Materials:
-
¹⁵N-labeled protein
-
NMR buffer (e.g., phosphate or Tris buffer with a low salt concentration)
-
Deuterium oxide (D₂O)
-
NMR tubes
Procedure:
-
Protein Purification: Purify the ¹⁵N-labeled protein to a high degree of homogeneity using standard chromatography techniques.
-
Buffer Exchange: Exchange the protein into the desired NMR buffer. The buffer should have a pH that is optimal for protein stability and NMR signal quality (typically pH 6.0-7.5).
-
Concentration: Concentrate the protein to the desired concentration for NMR analysis (typically 0.1-1 mM).
-
Addition of D₂O: Add D₂O to the sample to a final concentration of 5-10% for the NMR instrument's lock system.
-
Transfer to NMR Tube: Transfer the final sample to a clean, high-quality NMR tube, ensuring there are no air bubbles.
Visualization of Signaling Pathways and Workflows
The following diagrams, generated using the DOT language, illustrate key signaling pathways involving proline metabolism and a general experimental workflow for ¹⁵N labeling.
Conclusion
Isotopic labeling with L-Proline-¹⁵N is an indispensable tool in modern biological research. It provides a robust and versatile platform for the quantitative analysis of protein dynamics, metabolic pathways, and cellular signaling. The detailed protocols and data presented in this guide offer a solid foundation for researchers, scientists, and drug development professionals to design and execute sophisticated experiments, ultimately leading to a deeper understanding of complex biological systems and the development of novel therapeutic strategies.
References
- 1. pubs.acs.org [pubs.acs.org]
- 2. Frontiers | 15N Metabolic Labeling Quantification Workflow in Arabidopsis Using Protein Prospector [frontiersin.org]
- 3. Quantitative Proteomics: Measuring Protein Synthesis Using 15N Amino Acids Labeling in Pancreas Cancer Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 4. 15N Metabolic Labeling - TMT Multiplexing Approach to Facilitate the Quantitation of Glycopeptides Derived from Cell Lines - PMC [pmc.ncbi.nlm.nih.gov]
- 5. academic.oup.com [academic.oup.com]
- 6. A collagen extraction and deuterium oxide stable isotope tracer method for the quantification of bone collagen synthesis rates in vivo - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Using 15N-Metabolic Labeling for Quantitative Proteomic Analyses - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. sigmaaldrich.com [sigmaaldrich.com]
- 9. Metabolic Labeling (SILAC) | CK Isotopes [ckisotopes.com]
- 10. as.uky.edu [as.uky.edu]
- 11. UWPR [proteomicsresource.washington.edu]
- 12. pubs.acs.org [pubs.acs.org]
- 13. Using 15N-Metabolic Labeling for Quantitative Proteomic Analyses | Springer Nature Experiments [experiments.springernature.com]
- 14. Nuclear magnetic resonance spectroscopy of proteins - Wikipedia [en.wikipedia.org]
- 15. protein-nmr.org.uk [protein-nmr.org.uk]
L-Proline-15N in Biomolecular Research: An In-depth Technical Guide
For Researchers, Scientists, and Drug Development Professionals
L-Proline, a unique secondary amino acid, plays a critical role in protein structure and function, often found in turns and loops of proteins and integral to protein-protein interactions. The stable isotope-labeled counterpart, L-Proline-15N, has emerged as an indispensable tool in biomolecular research, providing high-resolution insights into protein structure, dynamics, and interactions. This technical guide delves into the core applications of this compound, offering detailed experimental protocols, quantitative data, and visual workflows to empower researchers in their scientific endeavors.
Core Applications of this compound
The primary application of this compound lies in Nuclear Magnetic Resonance (NMR) spectroscopy and mass spectrometry-based quantitative proteomics. Its unique structural properties make it a powerful probe for investigating challenging biological questions.
NMR Spectroscopy: Unraveling Protein Structure and Dynamics
In protein NMR, the lack of an amide proton in the proline ring makes it "invisible" in standard 2D 1H-15N HSQC spectra, which are the cornerstone of protein NMR analysis.[1][2] This presents a significant challenge in assigning and studying proline-rich regions or proteins where proline plays a key functional role. This compound labeling, often in conjunction with 13C labeling, provides a direct handle to overcome this limitation.
Key Advantages in NMR:
-
Sequential Assignment of Proline Residues: Specialized NMR experiments have been designed to correlate the 15N and 13C chemical shifts of proline with the alpha-protons of the preceding residue, enabling the sequential assignment of proline residues and even stretches of poly-proline.[3]
-
Probing Proline Cis/Trans Isomerism: The peptide bond preceding a proline residue can exist in both cis and trans conformations, a phenomenon crucial for protein folding and function. 15N NMR is highly sensitive to the local electronic environment, making this compound an excellent probe to study this isomerization.[4]
-
Characterizing Intrinsically Disordered Proteins (IDPs): IDPs are often enriched in proline residues. This compound labeling is instrumental in characterizing the conformational ensembles and dynamics of these challenging but biologically significant proteins.[2][5]
-
Studying Protein-Ligand and Protein-Protein Interactions: Changes in the 15N chemical shifts of labeled proline residues upon the addition of a ligand or binding partner can be used to map interaction interfaces and determine binding affinities.
Quantitative Proteomics: Metabolic Labeling with SILAC
Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) is a powerful technique for quantitative mass spectrometry.[6][7][8] While arginine and lysine are the most commonly used amino acids in SILAC, this compound can be employed in specific contexts, particularly when studying the metabolism of proline-rich proteins like collagen or investigating signaling pathways where proline metabolism is perturbed.
Workflow for SILAC using this compound:
-
Adaptation Phase: One population of cells is grown in a "light" medium containing the natural abundance of L-proline, while another is grown in a "heavy" medium where L-proline is replaced with this compound. Cells are cultured for several passages to ensure complete incorporation of the labeled amino acid.[9][10]
-
Experimental Phase: The two cell populations are subjected to different experimental conditions (e.g., drug treatment vs. control).
-
Sample Mixing and Analysis: The cell populations are combined, proteins are extracted and digested, and the resulting peptides are analyzed by mass spectrometry. The mass difference between the light and heavy proline-containing peptides allows for the relative quantification of protein abundance between the two conditions.
Quantitative Data
The efficiency of this compound incorporation is a critical parameter for the success of both NMR and mass spectrometry experiments. The following table summarizes typical incorporation efficiencies in common expression systems.
| Expression System | Labeling Method | Typical Incorporation Efficiency (%) | Reference |
| Escherichia coli | Minimal Media (M9) with 15NH4Cl as sole nitrogen source | > 95 | [11][12][13] |
| Escherichia coli | Selective labeling with this compound in minimal media | > 90 | [14] |
| Human Embryonic Kidney (HEK293) Cells | SILAC with this compound | > 95 | [1][15] |
| Arabidopsis thaliana | 15N metabolic labeling | 93-99 | [16] |
Table 1: this compound Incorporation Efficiencies. This table provides an overview of the expected labeling efficiencies for this compound in various commonly used expression systems.
In NMR-based structure determination, this compound labeling contributes to the generation of crucial distance and dihedral angle restraints.
| Type of NMR Constraint | Information Provided | Relevance of this compound |
| Nuclear Overhauser Effects (NOEs) | Inter-proton distances (< 5 Å) | Provides distance restraints involving proline protons, crucial for defining local and long-range structure. |
| Scalar Couplings (J-couplings) | Dihedral angles | Helps to restrain the backbone and sidechain torsion angles of proline residues. |
| Residual Dipolar Couplings (RDCs) | Orientation of inter-nuclear vectors | Provides long-range structural information and helps to refine the overall protein fold. |
| Chemical Shift Anisotropy (CSA) | Local electronic environment and dynamics | Sensitive to the unique electronic structure of the proline ring and its conformation. |
Table 2: NMR-Derived Constraints from this compound Labeled Proteins. This table outlines the types of structural information that can be obtained from NMR experiments on proteins labeled with this compound.
Experimental Protocols
Protocol 1: Uniform 15N-Labeling of Proteins in E. coli for NMR Studies
This protocol is adapted for the expression of proteins in E. coli using a minimal medium with 15NH4Cl as the sole nitrogen source, leading to the incorporation of 15N into all amino acids, including proline.
Materials:
-
M9 minimal medium components (Na2HPO4, KH2PO4, NaCl)
-
15NH4Cl (Cambridge Isotope Laboratories, Inc. or equivalent)
-
Glucose (or other carbon source)
-
MgSO4, CaCl2
-
Trace metals solution
-
Thiamine and Biotin
-
Appropriate antibiotic
-
E. coli expression strain (e.g., BL21(DE3)) transformed with the plasmid of interest
Procedure:
-
Prepare M9 Medium: Prepare a 10x M9 salt stock solution. For 1L of 1x M9 medium, use 100 mL of 10x M9 salts, 1g of 15NH4Cl, 20 mL of 20% glucose, 2 mL of 1M MgSO4, 100 µL of 1M CaCl2, 1 mL of trace metals solution, and 1 mL each of thiamine and biotin stock solutions.[11][12] Add the appropriate antibiotic.
-
Starter Culture: Inoculate 5-10 mL of LB medium with a single colony of the transformed E. coli and grow overnight at 37°C.
-
Pre-culture: The next day, inoculate 50-100 mL of M9 medium (containing natural abundance NH4Cl) with the overnight culture and grow until the OD600 reaches 0.6-0.8.
-
Main Culture and Induction: Pellet the pre-culture cells by centrifugation and resuspend them in 1L of M9 medium containing 15NH4Cl. Grow the culture at the optimal temperature for your protein until the OD600 reaches 0.6-0.8. Induce protein expression with IPTG (or other appropriate inducer) and continue to grow for the desired time (typically 4-16 hours).
-
Cell Harvesting and Protein Purification: Harvest the cells by centrifugation. The 15N-labeled protein can then be purified using standard chromatography techniques.
Protocol 2: Selective this compound Labeling in HEK293 Cells for NMR Studies
This protocol is for the selective incorporation of this compound into a protein expressed in mammalian HEK293 cells.
Materials:
-
HEK293 suspension cells (e.g., Expi293F™)
-
Custom amino acid-free culture medium (e.g., from Life Technologies)
-
This compound (Cambridge Isotope Laboratories, Inc. or equivalent)
-
Complete set of unlabeled amino acids
-
Fetal Bovine Serum (dialyzed)
-
Transfection reagent (e.g., PEI)
-
Expression plasmid
Procedure:
-
Cell Culture Adaptation: Adapt the HEK293 cells to a custom medium lacking proline but supplemented with all other amino acids and dialyzed FBS. This may take several passages.
-
Prepare Labeling Medium: Prepare the custom medium supplemented with all amino acids except proline. Add this compound to the desired final concentration (e.g., 100 mg/L).[1][15]
-
Transfection: When cells reach the desired density (e.g., 2-3 x 10^6 cells/mL), transfect them with the expression plasmid using a suitable transfection reagent.
-
Protein Expression and Harvesting: Allow the protein to be expressed for the desired period (typically 48-72 hours). Harvest the cells or the supernatant (for secreted proteins) by centrifugation.
-
Protein Purification: Purify the selectively labeled protein using appropriate chromatography methods.
Visualizations
The following diagrams, generated using the DOT language for Graphviz, illustrate key workflows and concepts related to the application of this compound.
Caption: Experimental workflow for NMR studies using this compound.
Caption: SILAC workflow for quantitative proteomics using this compound.
References
- 1. A comprehensive assessment of selective amino acid 15N-labeling in human embryonic kidney 293 cells for NMR spectroscopy - PMC [pmc.ncbi.nlm.nih.gov]
- 2. 15N-detected TROSY NMR experiments to study large disordered proteins in high-field magnets - PMC [pmc.ncbi.nlm.nih.gov]
- 3. A novel NMR experiment for the sequential assignment of proline residues and proline stretches in 13C/15N-labeled proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. mr.copernicus.org [mr.copernicus.org]
- 6. researchgate.net [researchgate.net]
- 7. Quantitative Proteomics Using SILAC | Springer Nature Experiments [experiments.springernature.com]
- 8. Quantitative Comparison of Proteomes Using SILAC - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. info.gbiosciences.com [info.gbiosciences.com]
- 11. www2.mrc-lmb.cam.ac.uk [www2.mrc-lmb.cam.ac.uk]
- 12. 15N labeling of proteins in E. coli – Protein Expression and Purification Core Facility [embl.org]
- 13. antibodies.cancer.gov [antibodies.cancer.gov]
- 14. Incorporation of proline analogs into recombinant proteins expressed in Escherichia coli - PMC [pmc.ncbi.nlm.nih.gov]
- 15. A comprehensive assessment of selective amino acid 15N-labeling in human embryonic kidney 293 cells for NMR spectroscopy - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. Frontiers | 15N Metabolic Labeling Quantification Workflow in Arabidopsis Using Protein Prospector [frontiersin.org]
The Core Principles of Nitrogen-15 Stable Isotope Labeling: An In-depth Technical Guide
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive overview of the fundamentals of nitrogen-15 (¹⁵N) stable isotope labeling, a powerful and versatile technique for quantitative analysis in biological systems. We will delve into the core principles, experimental methodologies, data interpretation, and key applications, with a particular focus on its relevance in drug development.
Introduction to Stable Isotope Labeling with ¹⁵N
Stable isotope labeling is a technique where an atom in a molecule is replaced by one of its non-radioactive (stable) isotopes. Nitrogen, a fundamental component of proteins, nucleic acids, and other essential biomolecules, naturally exists predominantly as ¹⁴N (99.63% abundance), with a small fraction of ¹⁵N (0.37% abundance). In ¹⁵N stable isotope labeling, organisms or cells are cultured in a medium where the primary nitrogen source is enriched with ¹⁵N. This leads to the incorporation of the heavier ¹⁵N isotope into newly synthesized biomolecules.
The key advantage of this technique lies in the mass difference between ¹⁴N and ¹⁵N. This mass shift can be accurately detected by analytical instruments such as mass spectrometers and nuclear magnetic resonance (NMR) spectrometers. By comparing the signals from the "light" (¹⁴N-containing) and "heavy" (¹⁵N-containing) molecules, researchers can gain valuable insights into various biological processes.[1][2][3]
Core Applications:
-
Quantitative Proteomics: Comparing protein expression levels between different states (e.g., healthy vs. diseased, treated vs. untreated).[4][5]
-
Metabolic Flux Analysis: Tracing the flow of nitrogen through metabolic pathways to understand cellular metabolism.[6][7][8]
-
Protein Structure and Dynamics: Utilizing NMR spectroscopy to determine the three-dimensional structure and dynamics of proteins.
-
Drug Development: Assessing drug efficacy, understanding mechanisms of action, and identifying biomarkers.
Methodologies for ¹⁵N Labeling
The choice of labeling strategy depends on the organism, the research question, and the analytical technique to be used. The most common approach is metabolic labeling, where the ¹⁵N-enriched nutrient is supplied during growth.
Labeling in Microorganisms (e.g., E. coli)
E. coli is a widely used host for recombinant protein expression, making ¹⁵N labeling in this system a routine procedure for structural biology and proteomics.
Experimental Protocol: ¹⁵N Labeling of Proteins in E. coli
-
Prepare Minimal Medium: A defined minimal medium (e.g., M9 medium) is prepared, where the standard nitrogen source, ammonium chloride (NH₄Cl), is replaced with ¹⁵N-labeled ammonium chloride (¹⁵NH₄Cl).[9][10]
-
Pre-culture: A starter culture of the E. coli strain carrying the plasmid for the protein of interest is grown overnight in a rich medium (e.g., LB) or a minimal medium containing natural abundance NH₄Cl.
-
Inoculation and Growth: The pre-culture is used to inoculate the M9 minimal medium containing ¹⁵NH₄Cl. The culture is grown at the appropriate temperature with shaking until it reaches the mid-logarithmic phase (OD₆₀₀ of 0.6-0.8).[10]
-
Induction of Protein Expression: Protein expression is induced by adding an appropriate inducer (e.g., IPTG for lac-based expression systems). The culture is then incubated for a further period (typically 3-16 hours) to allow for the expression of the ¹⁵N-labeled protein.[11]
-
Cell Harvesting and Protein Purification: The cells are harvested by centrifugation, and the ¹⁵N-labeled protein is purified using standard chromatography techniques.[9][11]
Labeling in Mammalian Cells
Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) is a popular metabolic labeling technique for quantitative proteomics in mammalian cells. While SILAC typically uses ¹³C- and ¹⁵N-labeled amino acids (like arginine and lysine), the principle of metabolic incorporation is the same. For complete proteome labeling with ¹⁵N, a specialized cell culture medium is required where all nitrogen-containing compounds are ¹⁵N-enriched.
Experimental Protocol: ¹⁵N-based SILAC in Mammalian Cells
-
Prepare SILAC Media: Two types of media are prepared: a "light" medium containing the natural abundance of amino acids and a "heavy" medium where specific essential amino acids (e.g., L-arginine and L-lysine) are replaced with their ¹⁵N-labeled counterparts.[3]
-
Cell Adaptation: Two populations of cells are cultured for at least five to six cell divisions in the "light" and "heavy" media, respectively, to ensure complete incorporation of the labeled amino acids into the proteome.[12]
-
Experimental Treatment: The two cell populations are subjected to different experimental conditions (e.g., one is treated with a drug, while the other serves as a control).
-
Cell Lysis and Protein Mixing: The cells are lysed, and the protein extracts from the "light" and "heavy" populations are mixed in a 1:1 ratio.[3]
-
Protein Digestion and Analysis: The mixed protein sample is digested with a protease (typically trypsin), and the resulting peptides are analyzed by mass spectrometry.
Labeling in Whole Organisms
¹⁵N labeling can also be performed in whole organisms, such as plants, mice, and rats, to study systemic effects and tissue-specific proteomes.
-
Plants: Plants are grown hydroponically or on solid media where the sole nitrogen source is a ¹⁵N-labeled salt like potassium nitrate (K¹⁵NO₃) or ammonium nitrate (¹⁵NH₄¹⁵NO₃).[5][13]
-
Rodents: Mice or rats are fed a specially formulated diet where the protein content is derived from a ¹⁵N-labeled source, such as spirulina grown in a ¹⁵N-enriched medium. This is often referred to as Stable Isotope Labeling in Mammals (SILAM).[14][15][16][17]
Data Presentation: Quantitative Insights
A key aspect of ¹⁵N labeling is the ability to generate precise quantitative data. This data is often presented in tables for clear comparison.
| Parameter | Typical Value/Range | Analytical Method | Reference |
| ¹⁵N Incorporation Efficiency | > 95% | Mass Spectrometry | [5][16] |
| ¹⁵N Enrichment in Commercial Reagents | > 98% | Manufacturer's Specification | [14] |
| Mass Shift per Nitrogen Atom | ~0.997 Da | Mass Spectrometry | Calculated |
| Reproducibility (SILAC) | High | Mass Spectrometry | [18] |
Table 1: Key Quantitative Parameters in ¹⁵N Labeling.
| Amino Acid | Number of Nitrogen Atoms | Mass Shift with Complete ¹⁵N Labeling (Da) |
| Alanine (Ala) | 1 | 0.997 |
| Arginine (Arg) | 4 | 3.988 |
| Asparagine (Asn) | 2 | 1.994 |
| Aspartic Acid (Asp) | 1 | 0.997 |
| Cysteine (Cys) | 1 | 0.997 |
| Glutamic Acid (Glu) | 1 | 0.997 |
| Glutamine (Gln) | 2 | 1.994 |
| Glycine (Gly) | 1 | 0.997 |
| Histidine (His) | 3 | 2.991 |
| Isoleucine (Ile) | 1 | 0.997 |
| Leucine (Leu) | 1 | 0.997 |
| Lysine (Lys) | 2 | 1.994 |
| Methionine (Met) | 1 | 0.997 |
| Phenylalanine (Phe) | 1 | 0.997 |
| Proline (Pro) | 1 | 0.997 |
| Serine (Ser) | 1 | 0.997 |
| Threonine (Thr) | 1 | 0.997 |
| Tryptophan (Trp) | 2 | 1.994 |
| Tyrosine (Tyr) | 1 | 0.997 |
| Valine (Val) | 1 | 0.997 |
Table 2: Number of Nitrogen Atoms and Corresponding Mass Shift for the 20 Standard Amino Acids.
Experimental Workflows and Data Analysis
The data generated from ¹⁵N labeling experiments require specialized analysis workflows to extract meaningful biological information.
Quantitative Proteomics Workflow
The general workflow for a quantitative proteomics experiment using ¹⁵N labeling is depicted below.
Determining Labeling Efficiency
Incomplete labeling can affect the accuracy of quantification. Therefore, it is crucial to determine the ¹⁵N incorporation efficiency. This is typically done by analyzing the isotopic pattern of several peptides from the ¹⁵N-labeled sample using mass spectrometry and comparing it to the theoretical isotopic distribution at different enrichment levels.[5][13][19] Software tools are available to facilitate this calculation.[13][20]
Applications in Drug Development
¹⁵N stable isotope labeling is a valuable tool in various stages of the drug development pipeline.
-
Target Identification and Validation: By comparing the proteomes of healthy versus diseased cells or tissues, ¹⁵N labeling can help identify proteins that are differentially expressed, providing potential new drug targets.
-
Mechanism of Action Studies: Researchers can investigate how a drug affects protein expression, post-translational modifications, or metabolic pathways. For example, by treating ¹⁵N-labeled cells with a compound, one can quantify changes in the proteome to understand the drug's cellular effects.
-
Biomarker Discovery: ¹⁵N labeling can be used to identify proteins that are up- or down-regulated in response to a drug, which can then serve as biomarkers for drug efficacy or patient stratification.
-
Pharmacokinetics and Pharmacodynamics (PK/PD): While less common for direct drug tracing (¹³C or ²H are often preferred), ¹⁵N labeling can be used to study the effect of a drug on the turnover of specific proteins or the flux through nitrogen-containing metabolic pathways.
Metabolic Pathway Tracing
¹⁵N-labeled substrates, such as amino acids, can be used to trace the flow of nitrogen through metabolic networks. This is particularly useful for studying amino acid metabolism, nucleotide biosynthesis, and other pathways that involve nitrogen-containing intermediates. By analyzing the incorporation of ¹⁵N into various metabolites, researchers can map out active pathways and identify metabolic reprogramming in diseases like cancer.[1][2][6][7][8][21][22][23]
Conclusion
Nitrogen-15 stable isotope labeling is a robust and powerful technique that provides quantitative insights into complex biological systems. Its applications in proteomics and metabolomics have significantly advanced our understanding of cellular processes and disease mechanisms. For researchers and professionals in drug development, ¹⁵N labeling offers a versatile platform for target discovery, mechanism of action studies, and biomarker identification, ultimately contributing to the development of more effective therapeutics.
References
- 1. Stable Isotope Labeled Tracers for Metabolic Pathway Elucidation by GC-MS and FT-MS - PMC [pmc.ncbi.nlm.nih.gov]
- 2. lirias.kuleuven.be [lirias.kuleuven.be]
- 3. chempep.com [chempep.com]
- 4. Using 15N-Metabolic Labeling for Quantitative Proteomic Analyses | Springer Nature Experiments [experiments.springernature.com]
- 5. biorxiv.org [biorxiv.org]
- 6. One‐shot 13C15N‐metabolic flux analysis for simultaneous quantification of carbon and nitrogen flux - PMC [pmc.ncbi.nlm.nih.gov]
- 7. embopress.org [embopress.org]
- 8. One-shot 13 C15 N-metabolic flux analysis for simultaneous quantification of carbon and nitrogen flux - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. www2.mrc-lmb.cam.ac.uk [www2.mrc-lmb.cam.ac.uk]
- 10. 15N labeling of proteins in E. coli – Protein Expression and Purification Core Facility [embl.org]
- 11. antibodies.cancer.gov [antibodies.cancer.gov]
- 12. Quantitative Comparison of Proteomes Using SILAC - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Frontiers | 15N Metabolic Labeling Quantification Workflow in Arabidopsis Using Protein Prospector [frontiersin.org]
- 14. buchem.com [buchem.com]
- 15. Using 15N-Metabolic Labeling for Quantitative Proteomic Analyses - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. 15N Metabolic Labeling of Mammalian Tissue with Slow Protein Turnover - PMC [pmc.ncbi.nlm.nih.gov]
- 17. labchem-wako.fujifilm.com [labchem-wako.fujifilm.com]
- 18. Comparing SILAC- and Stable Isotope Dimethyl-Labeling Approaches for Quantitative Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Method for the Determination of ¹⁵N Incorporation Percentage in Labeled Peptides and Proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 20. Isotope Enrichment Calculator | NIST [nist.gov]
- 21. Stable Isotope Tracers for Metabolic Pathway Analysis | Springer Nature Experiments [experiments.springernature.com]
- 22. researchgate.net [researchgate.net]
- 23. biorxiv.org [biorxiv.org]
A Technical Guide to L-Proline-¹⁵N: Suppliers, Purity, and Experimental Considerations
For researchers, scientists, and drug development professionals, the procurement of high-quality isotopically labeled compounds is a critical first step in ensuring the accuracy and reliability of experimental outcomes. L-Proline-¹⁵N, a stable isotope-labeled version of the amino acid proline, is a vital tool in a range of applications, from metabolic research to structural biology using Nuclear Magnetic Resonance (NMR) spectroscopy. This technical guide provides an in-depth overview of commercially available L-Proline-¹⁵N, including a comparative summary of suppliers and their purity specifications, alongside a discussion of the analytical methods used for its characterization and a workflow for selecting the appropriate grade of material for your research needs.
L-Proline-¹⁵N: Supplier and Purity Specifications
The selection of an L-Proline-¹⁵N supplier is a critical decision that can impact the quality of experimental data. The key specifications to consider are isotopic purity (the degree of ¹⁵N enrichment) and chemical purity. The following table summarizes the offerings of several prominent suppliers.
| Supplier | Product Name/Number | Isotopic Purity (¹⁵N atom %) | Chemical Purity | Additional Notes |
| Cambridge Isotope Laboratories (CIL) | L-Proline (¹⁵N, 98%) / NLM-835 | 98% | 98% | Also offer L-Proline (¹³C₅, 99%; ¹⁵N, 99%) and Fmoc-protected L-Proline-¹⁵N.[1][2][3][4] |
| Sigma-Aldrich (Merck) | L-Proline-¹⁵N / Product numbers may vary | ≥95% | 98% (CP) | Also provide dually labeled L-Proline-¹³C₅,¹⁵N.[5] |
| Isotope Science / Alfa Chemistry | L-Proline-¹⁵N / ACM59681311 | Not explicitly stated | 99%+ | [6] |
| Eurisotop | L-PROLINE (¹⁵N, 98%) / NLM-835 | 98% | 98% | A subsidiary of CIL.[7] |
| MedchemExpress | L-Proline-¹⁵N | Not explicitly stated | Not explicitly stated | Marketed for research use.[8] |
| Amsbio | L-Proline-¹⁵N / AMS.T203707 | Not explicitly stated | Not explicitly stated | Suitable for metabolic research.[9] |
| Anaspec | Fmoc-Pro-OH (U-¹³C₅, ¹⁵N) | Not explicitly stated | Not explicitly stated | Offers the Fmoc-protected version.[10] |
Note: (CP) denotes chemically pure. Isotopic and chemical purity levels can vary between batches, and it is always recommended to consult the Certificate of Analysis (CoA) for the specific lot you are purchasing.
Experimental Protocols for Purity Determination
Ensuring the purity of L-Proline-¹⁵N is paramount for its effective use. While suppliers provide a Certificate of Analysis, understanding the methodologies used for these assessments is crucial for the discerning researcher.
Isotopic Purity Determination by Mass Spectrometry
Methodology:
-
Sample Preparation: A small, accurately weighed sample of L-Proline-¹⁵N is dissolved in a suitable solvent, typically a mixture of water and an organic solvent like acetonitrile or methanol, compatible with the ionization technique.
-
Ionization: The sample is introduced into the mass spectrometer. Electron Impact (EI) or Electrospray Ionization (ESI) are common techniques. ESI is often preferred for its soft ionization, which minimizes fragmentation and preserves the molecular ion.
-
Mass Analysis: The ionized sample is guided into the mass analyzer (e.g., quadrupole, time-of-flight). The analyzer separates the ions based on their mass-to-charge ratio (m/z).
-
Detection: The detector records the abundance of each ion. For L-Proline-¹⁵N, the molecular ion peak will be at a higher m/z value compared to unlabeled L-Proline.
-
Data Analysis: The isotopic purity is calculated by comparing the peak intensity of the ¹⁵N-labeled L-Proline to that of the unlabeled L-Proline.
Chemical Purity Determination by High-Performance Liquid Chromatography (HPLC)
Methodology:
-
Sample Preparation: A standard solution of L-Proline-¹⁵N is prepared by dissolving a known amount of the substance in the mobile phase.
-
Chromatographic System: A C18 reversed-phase column is commonly used for the separation of amino acids.
-
Mobile Phase: An isocratic or gradient elution with a mixture of an aqueous buffer (e.g., phosphate buffer) and an organic modifier (e.g., acetonitrile or methanol) is employed.
-
Injection and Separation: A precise volume of the sample solution is injected into the HPLC system. The components of the sample are separated based on their differential partitioning between the stationary phase (the C18 column) and the mobile phase.
-
Detection: A UV detector is typically used, monitoring the absorbance at a specific wavelength (e.g., around 210 nm for the proline carboxyl group).
-
Data Analysis: The chemical purity is determined by integrating the area of the L-Proline-¹⁵N peak and expressing it as a percentage of the total area of all peaks in the chromatogram.
Logical Workflow for L-Proline-¹⁵N Selection
The selection of the appropriate L-Proline-¹⁵N for a given experiment involves a series of considerations beyond simply finding a supplier. The following diagram illustrates a logical workflow to guide this process.
Caption: A logical workflow for the selection of L-Proline-¹⁵N.
Applications of L-Proline-¹⁵N in Research
L-Proline-¹⁵N is a versatile tool in various scientific disciplines:
-
Metabolic Studies: As a tracer, L-Proline-¹⁵N allows researchers to follow the metabolic fate of proline in biological systems, providing insights into amino acid metabolism and protein biosynthesis.[9][11]
-
NMR Spectroscopy: In biomolecular NMR, ¹⁵N-labeling is essential for a wide range of experiments that elucidate the structure, dynamics, and interactions of proteins and other macromolecules. The ¹⁵N nucleus provides an additional dimension in NMR experiments, aiding in resonance assignment and the study of protein folding and function.[2][12][13]
-
Proteomics: In quantitative proteomics, stable isotope labeling with amino acids in cell culture (SILAC) can utilize L-Proline-¹⁵N to differentially label proteins, enabling the accurate quantification of protein abundance changes between different cell states.
By carefully considering the supplier, purity specifications, and the specific requirements of the experimental design, researchers can confidently employ L-Proline-¹⁵N to achieve high-quality, reproducible results.
References
- 1. L-Proline (¹³Câ , 99%; ¹âµN, 99%) - Cambridge Isotope Laboratories, CNLM-436-H-0.25 [isotope.com]
- 2. L-Proline (¹âµN, 98%) - Cambridge Isotope Laboratories, NLM-835-0.5 [isotope.com]
- 3. L-Proline-ð-Fmoc (¹³Câ , 99%; ¹âµN, 99%) | Cambridge Isotope Laboratories, Inc. [isotope.com]
- 4. L-Proline (¹âµN, 98%) | Cambridge Isotope Laboratories, Inc. [isotope.com]
- 5. This compound ≥95 atom % 15N, 98% (CP) | Sigma-Aldrich [sigmaaldrich.com]
- 6. isotope-science.alfa-chemistry.com [isotope-science.alfa-chemistry.com]
- 7. L-PROLINE | Eurisotop [eurisotop.com]
- 8. medchemexpress.com [medchemexpress.com]
- 9. amsbio.com [amsbio.com]
- 10. Proline (Pro) [anaspec.com]
- 11. A comparison of 15N proline and 13C leucine for monitoring protein biosynthesis in the skin - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. A comprehensive assessment of selective amino acid 15N-labeling in human embryonic kidney 293 cells for NMR spectroscopy - PMC [pmc.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
Methodological & Application
Application Notes and Protocols for L-Proline-¹⁵N in Protein Structure Determination by NMR
Audience: Researchers, scientists, and drug development professionals.
Introduction
Nuclear Magnetic Resonance (NMR) spectroscopy is a powerful technique for determining the three-dimensional structure and dynamics of proteins in solution. Isotopic labeling, particularly with ¹⁵N, is a cornerstone of modern biomolecular NMR. While standard ¹⁵N-labeling techniques are routine for most amino acids, proline presents a unique challenge due to its secondary amine structure, which lacks an amide proton. This makes it invisible in conventional ¹H-¹⁵N correlation experiments like the Heteronuclear Single Quantum Coherence (HSQC) spectroscopy, a primary tool for assessing protein folding and assigning backbone resonances.
This document provides detailed application notes and protocols for the use of L-Proline-¹⁵N in protein NMR studies. It covers methods for selective incorporation of ¹⁵N-labeled proline, specialized NMR experiments to overcome the absence of the amide proton, and approaches to study the functionally significant phenomenon of proline cis-trans isomerization.
Application Notes
The selective incorporation of L-Proline-¹⁵N is particularly valuable for:
-
Assignment of Proline-Rich Regions: In proteins with stretches of proline residues or in intrinsically disordered proteins (IDPs) where proline is abundant, standard assignment strategies often fail.[1][2][3] Specific labeling of proline provides unambiguous starting points for sequential assignment.
-
Studying Proline cis-trans Isomerization: Proline is the only natural amino acid where the peptide bond can exist in both cis and trans conformations. This isomerization can be a rate-limiting step in protein folding and is often crucial for biological function.[4][5][6] NMR is the sole method capable of characterizing these co-existing states at an atomic level.[5] ¹⁵N-labeling of proline enhances the detection of signals from both isomers.
-
Probing Protein Dynamics and Folding: The slow interconversion between cis and trans states provides a window into protein dynamics on the seconds-to-minutes timescale.[7] Real-time NMR experiments on ¹⁵N-Proline labeled samples can monitor folding events and conformational changes involving proline.[4]
-
Overcoming Spectral Crowding in IDPs: Proline's unique ¹⁵N chemical shift range (falling in a well-isolated spectral region) and the narrow linewidths of its nitrogen signals (due to the lack of a directly attached proton) can be exploited in specialized experiments to reduce spectral overlap, a common problem in IDPs.[2]
Experimental Protocols
Protocol 1: Selective ¹⁵N-Labeling of Proline Residues
This protocol describes the expression of a target protein in E. coli with ¹⁵N incorporated specifically at proline residues. This is achieved by growing the bacteria in a minimal medium containing ¹⁵NH₄Cl as the sole nitrogen source, and then supplementing it with a mixture of all unlabeled amino acids except for proline, which is added in its ¹⁵N-labeled form. A more cost-effective, though potentially less efficient, alternative is to add labeled proline to a rich medium just before induction. The "reverse labeling" approach is generally preferred for its higher incorporation efficiency.[8]
Materials:
-
E. coli expression strain (e.g., BL21(DE3)) transformed with the expression plasmid for the protein of interest.
-
M9 minimal medium components.
-
¹⁵NH₄Cl (Cambridge Isotope Laboratories, Inc. or equivalent).
-
Unlabeled amino acid kit (all 19 standard amino acids except proline).
-
L-Proline-¹⁵N.
-
Glucose (or ¹³C-glucose if dual labeling is desired).
-
Trace elements solution and vitamin mix.
-
Appropriate antibiotic.
-
IPTG (or other inducing agent).
Procedure:
-
Starter Culture: Inoculate 5-10 mL of a rich medium (e.g., LB) containing the appropriate antibiotic with a single colony of the transformed E. coli strain. Grow overnight at 37°C with shaking.
-
Adaptation Culture: The next morning, inoculate 100 mL of M9 minimal medium (containing standard ¹⁴NH₄Cl) with the overnight culture to an OD₆₀₀ of ~0.1. Grow until the OD₆₀₀ reaches 0.8-1.0. This step helps adapt the cells to the minimal medium.
-
Main Culture: Prepare 1 L of M9 minimal medium in a 2 L baffled flask. Crucially, omit NH₄Cl from the initial preparation.
-
Selective Labeling Supplementation:
-
Add 1 g of ¹⁵NH₄Cl to the 1 L of M9 medium.
-
Add all 19 unlabeled amino acids to a final concentration of 100 mg/L each.
-
Add 100-150 mg of L-Proline-¹⁵N.
-
Add glucose (2-4 g/L), vitamins, trace elements, MgSO₄ (2 mM), and the appropriate antibiotic.
-
-
Inoculation and Growth: Inoculate the 1 L supplemented M9 medium with the adaptation culture to a starting OD₆₀₀ of 0.1. Grow the cells at 37°C with vigorous shaking (220-250 rpm).
-
Induction: Monitor the cell growth. When the OD₆₀₀ reaches 0.6-0.8, lower the temperature (e.g., to 18-25°C) and induce protein expression by adding IPTG to a final concentration of 0.5-1.0 mM.
-
Harvesting: Continue to grow the culture for the desired expression time (typically 4-16 hours, depending on the protein and temperature). Harvest the cells by centrifugation (e.g., 6,000 x g for 15 minutes at 4°C).
-
Purification: Purify the labeled protein using standard protocols (e.g., affinity, ion-exchange, and size-exclusion chromatography).[9]
Protocol 2: NMR Data Acquisition for ¹⁵N-Proline Labeled Proteins
Since proline lacks an amide proton, standard ¹H-¹⁵N HSQC spectra will not show correlations for proline residues.[10] Specialized experiments are required to observe and assign these sites. This often requires a uniformly ¹³C,¹⁵N-labeled sample, but selective ¹⁵N-proline labeling can be used to confirm proline assignments in specific experiments.
Sample Preparation:
-
Protein Concentration: 0.5 – 1.0 mM.[9]
-
Buffer: Use buffer components lacking exchangeable protons (e.g., 25 mM sodium phosphate). Keep the pH below 6.5 to minimize the exchange rate of other backbone amide protons.[9]
-
Salt: Keep ionic strength low (e.g., 25-100 mM NaCl) to improve spectrometer performance.[9]
-
Solvent: 90-95% H₂O / 5-10% D₂O. The D₂O is required for the spectrometer's frequency lock.[9]
-
Volume: 400 - 600 µL.[9]
Key NMR Experiments:
-
(H)NCA-based Experiments for Proline Assignment:
-
Principle: Standard triple-resonance experiments like HNCA correlate the amide proton and nitrogen of one residue with the Cα of the same and the preceding residue. Proline breaks this chain. To bridge the gap, specific experiments are designed to correlate the Cα and Cδ chemical shifts of a proline residue with the Hα of the preceding residue (i-1).[1]
-
Experiment: A specialized 3D experiment, often a variant of an (H)CACON or similar pulse sequence, is used.[1][2] These experiments establish a magnetization transfer pathway that bypasses the proline amide and instead uses the ¹⁵N nucleus of proline.
-
Application: This directly links the spin system of the residue before proline to the proline itself, enabling sequential assignment through proline-rich regions.
-
-
¹⁵N-edited NOESY-HSQC:
-
Principle: While proline's ¹⁵N is not directly correlated to a proton in an HSQC, Nuclear Overhauser Effect (NOE) contacts can be observed between the proline's Hδ protons and the amide proton of the following residue (i+1).
-
Experiment: A 3D ¹⁵N-NOESY-HSQC experiment is recorded.
-
Application: The presence of NOE cross-peaks between the Hδ of proline and the Hɴ of residue i+1 can confirm sequential connectivity.
-
-
CON-based Experiments for IDPs:
-
Principle: For intrinsically disordered proteins, experiments that directly detect ¹³C or ¹⁵N can be advantageous. The 2D CON experiment correlates the carbonyl carbon (C') of the preceding residue with the nitrogen (N) of the current residue.[2] This works for all amino acids, including proline.
-
Experiment: A 2D CON or a proline-selective variant (CONPro) can be recorded. The proline-selective version uses band-selective ¹⁵N pulses to specifically excite the well-resolved proline ¹⁵N region.[2]
-
Application: Provides a direct fingerprint of proline residues and their preceding partners, which is extremely useful for assigning complex IDPs.[3]
-
Protocol 3: Monitoring Proline cis-trans Isomerization
The slow exchange between cis and trans isomers (on the order of 10⁻³–10⁻² s⁻¹) results in two distinct sets of NMR signals for the proline residue itself and for neighboring residues.[5]
Procedure:
-
Acquire High-Resolution 2D Spectra: Record a high-resolution 2D ¹H-¹⁵N HSQC (for residues neighboring proline) and/or a 2D ¹³C-¹⁵N or CON spectrum (for proline itself) on a uniformly ¹³C,¹⁵N-labeled protein.
-
Identify Paired Peaks: Look for pairs of peaks with unequal intensities in the vicinity of expected proline locations. The more intense peak typically corresponds to the major trans isomer, while the weaker peak represents the minor cis isomer.[6]
-
Confirm Isomer Identity: The most reliable indicator of the proline isomer form is the difference in the ¹³Cβ and ¹³Cγ chemical shifts of the proline residue itself, which can be measured from a 3D C(CO)NH or HNCACB experiment.[5] 2D ¹H-¹H NOESY can also be used, where a strong Hα(i-1)-Hα(i) NOE indicates a cis peptide bond.[5]
-
Quantify Populations: Integrate the volumes of the corresponding cross-peaks for the cis and trans states. The population of each state can be calculated as:
-
Population (%) = (Volume of isomer peak / Sum of volumes of both isomer peaks) x 100
-
-
Temperature Dependence (Thermodynamic Analysis):
-
Real-Time Exchange Studies:
-
Use techniques like Real-Time (RT) NMR or Exchange Spectroscopy (EXSY) to measure the kinetics of interconversion.[7] For RT-NMR, a perturbation (e.g., pressure jump, temperature jump, or addition of a denaturant) is applied, and a series of rapid 2D spectra are acquired to monitor the return to equilibrium.[11]
-
Data Presentation
Table 1: Typical NMR Parameters for ¹⁵N-Proline Studies
| Parameter | Typical Value/Range | Significance | Reference |
| ¹⁵N Chemical Shift | ~135-145 ppm (in IDPs) | Proline ¹⁵N chemical shifts are in a distinct, well-isolated region of the spectrum, aiding in selective experiments. | [2] |
| ¹³Cβ - ¹³Cγ Chemical Shift Difference (Δβγ) | trans: ~9-12 ppmcis: ~4-5 ppm | A reliable indicator to distinguish between cis and trans proline isomers. | [5] |
| cis-isomer Population | ~5-25% | The trans form is generally more stable, but the cis population can be significant and functionally important. | [6] |
| Isomerization Rate (kex) | 10⁻³ – 10⁻² s⁻¹ | The slow exchange rate allows for the observation of separate signals for each isomer in NMR spectra. | [5][7] |
Visualizations
Experimental Workflow for Selective ¹⁵N-Proline Labeling and NMR Analysis
Caption: Workflow for selective ¹⁵N-Proline labeling and subsequent NMR analysis.
Logical Flow for Proline Assignment in a Protein Backbone
Caption: Logic for assigning residues around a proline using specialized NMR.
Decision Tree for Investigating Proline Isomerization
Caption: Decision-making process for the NMR analysis of proline isomerization.
References
- 1. A novel NMR experiment for the sequential assignment of proline residues and proline stretches in 13C/15N-labeled proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. mr.copernicus.org [mr.copernicus.org]
- 3. 15N-detected TROSY NMR experiments to study large disordered proteins in high-field magnets - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Site-specific NMR monitoring of cis-trans isomerization in the folding of the proline-rich collagen triple helix - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Proline cis/trans Isomerization in Intrinsically Disordered Proteins and Peptides [imrpress.com]
- 6. Proline isomerization in the C-terminal region of HSP27 - PMC [pmc.ncbi.nlm.nih.gov]
- 7. An introduction to NMR-based approaches for measuring protein dynamics - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Specific isotopic labelling and reverse labelling for protein NMR spectroscopy: using metabolic precursors in sample preparation - PMC [pmc.ncbi.nlm.nih.gov]
- 9. www2.mrc-lmb.cam.ac.uk [www2.mrc-lmb.cam.ac.uk]
- 10. eprints.whiterose.ac.uk [eprints.whiterose.ac.uk]
- 11. researchgate.net [researchgate.net]
Application Notes and Protocols for Quantitative Proteomics using L-Proline-¹⁵N SILAC
For Researchers, Scientists, and Drug Development Professionals
Introduction
Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) is a powerful metabolic labeling technique for accurate quantitative proteomics.[1][2] This method involves the incorporation of stable isotope-labeled amino acids into the entire proteome of cultured cells.[2][3] By comparing the mass spectra of "heavy" and "light" isotope-labeled proteins, researchers can accurately quantify differences in protein abundance between different cell populations.[1]
A common challenge in traditional SILAC experiments that use labeled arginine is the metabolic conversion of arginine to proline, which can lead to inaccuracies in quantification.[1][2][4][5][6] This application note details a specialized SILAC workflow utilizing L-Proline-¹⁵N to circumvent this issue and enable precise and reliable quantitative proteomic analysis. Supplementing SILAC media with unlabeled L-proline has been shown to prevent the conversion of arginine to proline, thus improving the accuracy of quantification.[4][5][7] While less common, the direct use of labeled proline, such as L-Proline-¹⁵N, offers a direct approach to studying proline-rich proteins and specific metabolic pathways involving proline.
This document provides a detailed protocol for implementing an L-Proline-¹⁵N SILAC workflow, from cell culture and labeling to mass spectrometry analysis and data interpretation. It is intended for researchers, scientists, and drug development professionals seeking to perform high-accuracy quantitative proteomics studies.
Experimental Workflow
The overall experimental workflow for a quantitative proteomics experiment using L-Proline-¹⁵N SILAC is depicted below. This process begins with the metabolic labeling of two cell populations, one with the "light" (¹⁴N) L-Proline and the other with the "heavy" (¹⁵N) L-Proline. Following experimental treatment, the cell populations are combined, and the proteins are extracted, digested, and analyzed by mass spectrometry.
Figure 1: L-Proline-¹⁵N SILAC Experimental Workflow.
Experimental Protocols
Cell Culture and Metabolic Labeling
Objective: To achieve complete incorporation of "light" (¹⁴N) and "heavy" (¹⁵N) L-Proline into two separate cell populations.
Materials:
-
SILAC-grade cell culture medium deficient in L-Proline.
-
"Light" L-Proline (¹⁴N)
-
"Heavy" L-Proline-¹⁵N
-
Dialyzed Fetal Bovine Serum (dFBS)
-
Penicillin-Streptomycin solution
-
Cells of interest
Protocol:
-
Media Preparation: Prepare two types of SILAC media:
-
Light Medium: Supplement the proline-deficient medium with "light" L-Proline to a final concentration of 200 mg/L.[4][5]
-
Heavy Medium: Supplement the proline-deficient medium with "heavy" L-Proline-¹⁵N to a final concentration of 200 mg/L.
-
Add dFBS to a final concentration of 10% and Penicillin-Streptomycin to 1%.
-
-
Cell Adaptation:
-
Culture the cells in the "Light" and "Heavy" media for at least five to six cell divisions to ensure near-complete incorporation of the labeled amino acids.
-
Monitor cell morphology and growth rate to ensure that the labeling has no adverse effects.
-
-
Incorporation Check (Optional but Recommended):
-
After several passages, harvest a small aliquot of cells from the "Heavy" labeled population.
-
Extract proteins, digest them with trypsin, and analyze by mass spectrometry to confirm the incorporation efficiency of L-Proline-¹⁵N. The efficiency should ideally be >95%.
-
Experimental Treatment and Sample Collection
Objective: To apply the experimental conditions to the labeled cell populations and harvest them for analysis.
Protocol:
-
Once complete labeling is achieved, plate the "Light" and "Heavy" labeled cells for the experiment.
-
Apply the desired treatment to one population (e.g., drug treatment to the "Heavy" labeled cells) and a control treatment to the other (e.g., vehicle to the "Light" labeled cells).
-
After the treatment period, wash the cells with ice-cold PBS.
-
Harvest the cells by scraping or trypsinization.
-
Count the cells from each population and mix them at a 1:1 ratio.
-
Centrifuge the mixed cell suspension to obtain a cell pellet. The pellet can be stored at -80°C until further processing.
Protein Extraction and Digestion
Objective: To extract proteins from the mixed cell pellet and digest them into peptides suitable for mass spectrometry.
Materials:
-
Lysis buffer (e.g., RIPA buffer with protease and phosphatase inhibitors)
-
Dithiothreitol (DTT)
-
Iodoacetamide (IAA)
-
Trypsin (mass spectrometry grade)
-
Ammonium bicarbonate buffer (50 mM, pH 8.0)
Protocol:
-
Cell Lysis: Resuspend the cell pellet in lysis buffer and incubate on ice for 30 minutes with intermittent vortexing.
-
Protein Quantification: Centrifuge the lysate to pellet cell debris and collect the supernatant. Determine the protein concentration using a standard protein assay (e.g., BCA assay).
-
Reduction and Alkylation:
-
To a known amount of protein (e.g., 100 µg), add DTT to a final concentration of 10 mM and incubate at 56°C for 1 hour.
-
Cool the sample to room temperature and add IAA to a final concentration of 55 mM. Incubate in the dark at room temperature for 45 minutes.
-
-
Protein Digestion:
-
Dilute the protein sample with ammonium bicarbonate buffer to reduce the concentration of denaturants.
-
Add trypsin at a 1:50 (trypsin:protein) ratio and incubate overnight at 37°C.
-
-
Peptide Cleanup: Acidify the digest with formic acid to stop the reaction. Clean up the peptide mixture using a C18 solid-phase extraction (SPE) cartridge to remove salts and detergents.
LC-MS/MS Analysis
Objective: To separate the peptides by liquid chromatography and analyze them by tandem mass spectrometry to identify the peptides and quantify the relative abundance of the "light" and "heavy" forms.
Protocol:
-
Peptide Separation: Resuspend the cleaned peptides in a suitable solvent (e.g., 0.1% formic acid in water) and inject them into a reverse-phase liquid chromatography system coupled to a high-resolution mass spectrometer.
-
Mass Spectrometry: Operate the mass spectrometer in a data-dependent acquisition (DDA) or data-independent acquisition (DIA) mode.
-
Full Scan (MS1): Acquire high-resolution full scans to detect the "light" and "heavy" peptide pairs.
-
Fragmentation (MS2): Select the most intense precursor ions for fragmentation to obtain sequence information for peptide identification.
-
Data Analysis
Objective: To identify the peptides and proteins and to calculate the abundance ratios of the "heavy" to "light" forms for each protein.
Software: Use specialized proteomics software such as MaxQuant, Proteome Discoverer, or similar platforms.
Protocol:
-
Database Searching: Search the raw MS/MS data against a protein database (e.g., UniProt) to identify the peptides.
-
SILAC Quantification: The software will identify the "light" and "heavy" peptide pairs based on their mass difference (due to the ¹⁵N label in proline). It will then calculate the ratio of the intensities of the heavy and light forms for each peptide.
-
Protein Ratios: The software will aggregate the peptide ratios to calculate an overall abundance ratio for each protein.
-
Data Filtering and Visualization: Filter the results based on statistical significance (e.g., p-value, q-value) and fold change to identify proteins that are significantly up- or down-regulated in response to the treatment.
Quantitative Data Presentation
The quantitative output from a SILAC experiment is a list of identified proteins with their corresponding heavy/light (H/L) ratios. This data can be summarized in a table for easy comparison.
Table 1: Example of Quantified Proteins in a Drug Treatment Study
| Protein Accession | Gene Name | Protein Description | H/L Ratio | p-value | Regulation |
| P04637 | TP53 | Cellular tumor antigen p53 | 2.54 | 0.001 | Upregulated |
| P60709 | ACTB | Actin, cytoplasmic 1 | 1.02 | 0.95 | Unchanged |
| Q06830 | HSP90AA1 | Heat shock protein HSP 90-alpha | 0.45 | 0.005 | Downregulated |
| P10636 | GNB1 | Guanine nucleotide-binding protein subunit beta-1 | 1.10 | 0.88 | Unchanged |
| P31946 | YWHAZ | 14-3-3 protein zeta/delta | 3.12 | 0.0005 | Upregulated |
H/L Ratio > 1.5 and p-value < 0.05 is considered significantly upregulated. H/L Ratio < 0.67 and p-value < 0.05 is considered significantly downregulated.
Signaling Pathway Visualization
In many drug development applications, the goal is to understand how a drug affects specific signaling pathways. The quantitative proteomics data from an L-Proline-¹⁵N SILAC experiment can be used to map the observed protein expression changes onto known signaling pathways.
Below is an example of a simplified signaling pathway diagram where the nodes represent proteins and their colors indicate their regulation status based on the SILAC data.
Figure 2: Example Drug Response Signaling Pathway.
Conclusion
The L-Proline-¹⁵N SILAC workflow provides a robust and accurate method for quantitative proteomics, particularly in scenarios where the metabolic conversion of arginine to proline is a concern. By following the detailed protocols outlined in this application note, researchers can confidently identify and quantify thousands of proteins, enabling a deeper understanding of cellular processes, disease mechanisms, and drug modes of action. The high-quality quantitative data generated can be instrumental in identifying novel biomarkers and therapeutic targets.
References
- 1. chempep.com [chempep.com]
- 2. biocev.lf1.cuni.cz [biocev.lf1.cuni.cz]
- 3. researchgate.net [researchgate.net]
- 4. Prevention of Amino Acid Conversion in SILAC Experiments with Embryonic Stem Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Prevention of amino acid conversion in SILAC experiments with embryonic stem cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Effective correction of experimental errors in quantitative proteomics using stable isotope labeling by amino acids in cell culture (SILAC) - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
Unlocking Protein Dynamics: Application Notes and Protocols for L-Proline-15N Incorporation
For Researchers, Scientists, and Drug Development Professionals
Abstract
The unique cyclic structure of proline imposes significant conformational constraints on the polypeptide backbone, playing a pivotal role in protein folding, stability, and function. The slow cis-trans isomerization of the peptidyl-prolyl bond, in particular, can be a rate-limiting step in protein folding and can act as a molecular switch in various biological processes. Studying the dynamics of proline residues is therefore crucial for a comprehensive understanding of protein function and for the rational design of therapeutics. This document provides detailed application notes and protocols for the incorporation of L-Proline-15N into proteins for the investigation of their dynamics using Nuclear Magnetic Resonance (NMR) spectroscopy and Mass Spectrometry (MS).
Introduction
Isotope labeling with stable isotopes such as 15N is a powerful technique for elucidating the structure and dynamics of proteins at atomic resolution.[1] While uniform 15N labeling is a standard method for a variety of NMR experiments, selective labeling of specific amino acid types offers the advantage of reducing spectral complexity and allows for the focused study of particular residues or regions within a protein.[2]
L-Proline, being the only proteinogenic secondary amino acid, presents a unique case. Its nitrogen atom is part of a pyrrolidine ring and lacks an amide proton, rendering it invisible in conventional 1H-15N HSQC NMR experiments.[3][4] However, the 15N chemical shift of proline is highly sensitive to its local chemical environment and the cis-trans isomerization state of the X-Pro peptide bond.[5] By selectively incorporating this compound, researchers can leverage specialized NMR techniques and mass spectrometry to probe the dynamics of proline residues specifically.
This guide details the methodologies for selective this compound labeling in Escherichia coli, subsequent analysis by NMR and MS, and the interpretation of the resulting data to gain insights into protein dynamics.
Applications of this compound Incorporation
Selective incorporation of this compound enables a range of biophysical studies, including:
-
Probing Proline Cis-Trans Isomerization: The distinct 15N chemical shifts of the cis and trans conformers of the peptidyl-prolyl bond allow for the direct observation and quantification of these states and the kinetics of their interconversion.[6][7] This is critical for understanding conformational switches in proteins.
-
Characterizing the Dynamics of Proline-Rich Motifs: Many proteins involved in signaling and protein-protein interactions contain proline-rich domains that are often intrinsically disordered.[8][9] this compound labeling can provide residue-specific information on the conformational ensemble and dynamics of these important regions.
-
Simplifying Complex NMR Spectra: For large or complex proteins, selective labeling significantly reduces spectral overlap, facilitating resonance assignment and structural analysis.[2]
-
Validating Protein-Ligand Interactions: Changes in the 15N chemical shift of a proline residue upon ligand binding can provide evidence of interaction and report on conformational changes at the binding site.
-
Quantitative Proteomics: this compound can be used as a metabolic label in quantitative mass spectrometry-based proteomics to study changes in protein abundance or turnover.[10]
Experimental Protocols
Protocol 1: Selective this compound Labeling in E. coli
This protocol is adapted from general selective amino acid labeling procedures for expression in E. coli.[11] It is crucial to use a proline auxotrophic strain of E. coli to prevent the dilution of the 15N label from endogenously synthesized proline.
Materials:
-
E. coli expression strain (proline auxotroph recommended) containing the plasmid for the protein of interest.
-
Luria-Bertani (LB) medium.
-
M9 minimal medium components (see table below).
-
15N-L-Proline (Cambridge Isotope Laboratories, Inc. or equivalent).
-
Complete set of 19 unlabeled L-amino acids.
-
Inducing agent (e.g., IPTG).
-
Appropriate antibiotic(s).
M9 Minimal Medium Composition (per 1 Liter)
| Component | Amount | Final Concentration |
| 5x M9 salts | 200 mL | 1x |
| 20% (w/v) Glucose | 20 mL | 0.4% |
| 1 M MgSO4 | 2 mL | 2 mM |
| 1 M CaCl2 | 0.1 mL | 0.1 mM |
| 19 Amino Acid Mix (without Proline) | Varies | See below |
| 15N-L-Proline | 100 mg | 100 mg/L |
| Thiamine (1 mg/mL) | 1 mL | 1 µg/mL |
| Biotin (1 mg/mL) | 1 mL | 1 µg/mL |
| Antibiotic(s) | Varies | Varies |
19 Amino Acid Mix Preparation: Prepare a stock solution of the 19 unlabeled amino acids (excluding proline) at a concentration that provides sufficient nutrients for bacterial growth. A common starting point is 100 mg/L for each amino acid. To minimize isotope scrambling, the concentration of unlabeled amino acids that are metabolically close to proline (e.g., glutamate, arginine) can be increased.[1]
Procedure:
-
Starter Culture: Inoculate 5-10 mL of LB medium containing the appropriate antibiotic with a single colony of the E. coli expression strain. Grow overnight at 37°C with shaking.
-
Adaptation Culture (Optional but Recommended): Inoculate 50 mL of M9 minimal medium containing all 20 unlabeled amino acids with the overnight starter culture. Grow at 37°C until the OD600 reaches 0.6-0.8. This step helps the cells adapt to the minimal medium.
-
Main Culture: Inoculate 1 L of M9 minimal medium (prepared with the 19 amino acid mix and 15N-L-Proline) with the adaptation culture to an initial OD600 of ~0.05-0.1.
-
Growth: Grow the main culture at the optimal temperature for your protein expression (e.g., 37°C) with vigorous shaking until the OD600 reaches 0.6-0.8.
-
Induction: Induce protein expression by adding the appropriate concentration of the inducing agent (e.g., 1 mM IPTG).
-
Expression: Continue to grow the culture for the optimal time and temperature for your protein expression (e.g., 4-6 hours at 30°C or overnight at 18°C).
-
Harvesting: Harvest the cells by centrifugation (e.g., 6,000 x g for 15 minutes at 4°C).
-
Cell Lysis and Purification: Proceed with your standard protocol for cell lysis and protein purification.
Workflow for Selective this compound Labeling
Caption: Workflow for selective this compound labeling of proteins in E. coli.
Protocol 2: NMR Spectroscopy of this compound Labeled Proteins
Due to the absence of an amide proton, proline residues are not observed in standard 1H-15N correlation spectra. Therefore, 13C-detected or 15N-detected NMR experiments are required.[6][12]
Sample Preparation:
-
Concentration: 0.1 - 1 mM protein.
-
Buffer: A low-salt buffer is recommended (e.g., 20 mM Phosphate, 50 mM NaCl, pH 6.0-7.0).
-
Additives: 5-10% D2O for the field-frequency lock. A protease inhibitor cocktail may be added.
-
Volume: ~500-600 µL for a standard 5 mm NMR tube.
Recommended NMR Experiments:
-
2D 13C-15N Correlation (CON): This experiment directly correlates the carbonyl carbon (C') of the preceding residue with the nitrogen of the following residue, providing a fingerprint of the proline residues.[6]
-
3D (H)CBCACON: This experiment correlates the Cα and Cβ of the preceding residue with the C' and the 15N of the proline, providing sequential assignment information.[6]
-
15N-edited NOESY-HSQC: While proline itself is not directly observed, NOEs between the Hδ protons of proline and nearby amide protons can be observed in a uniformly 15N-labeled sample and can provide structural restraints. For a selectively labeled sample, this is less informative.
-
1D 15N-filtered 1H NMR: This can be used to observe protons directly attached to the 15N-labeled proline, although sensitivity may be low.
Data Acquisition and Processing:
-
Acquire spectra on a high-field NMR spectrometer (≥ 600 MHz) equipped with a cryoprobe for optimal sensitivity and resolution.
-
Process the data using appropriate software (e.g., TopSpin, NMRPipe).
-
Analyze the spectra to identify the resonances corresponding to the proline nitrogens and measure their chemical shifts, intensities, and line widths.
Signaling Pathway for Proline-Specific NMR Data Acquisition
Caption: Logical workflow for NMR analysis of this compound labeled proteins.
Protocol 3: Mass Spectrometry Analysis of this compound Labeled Proteins
Mass spectrometry is an essential tool to verify the incorporation of 15N-L-Proline and to quantify the labeling efficiency and the extent of any metabolic scrambling.
Sample Preparation:
-
Protein Digestion: Digest the purified 15N-Proline labeled protein with a protease such as trypsin.
-
Peptide Cleanup: Desalt the resulting peptide mixture using a C18 ZipTip or equivalent.
-
LC-MS/MS Analysis: Analyze the peptides by liquid chromatography-tandem mass spectrometry (LC-MS/MS) on a high-resolution mass spectrometer (e.g., Orbitrap or TOF).
Data Analysis:
-
Database Search: Search the acquired MS/MS data against the protein sequence database, specifying 15N as a variable modification on proline.
-
Quantification of Incorporation: Determine the percentage of 15N incorporation by comparing the intensities of the isotopic envelopes of peptides containing proline with their unlabeled counterparts.[4][5] Several software packages can perform this analysis.
-
Scrambling Analysis: Look for mass shifts corresponding to 15N incorporation in other amino acids. Scrambling is the metabolic conversion of the labeled proline into other amino acids. This can be minimized by using a proline auxotrophic strain and by adding an excess of unlabeled amino acids to the growth medium.[1]
Workflow for MS-based Quantification of 15N-Proline Incorporation
Caption: Workflow for verifying this compound incorporation using mass spectrometry.
Data Presentation and Interpretation
Quantitative Data Summary
The following table provides a template for summarizing the quantitative data obtained from the analysis of this compound labeled proteins.
| Parameter | Method | Result | Notes |
| Protein Yield | Bradford/BCA Assay | e.g., 5 mg/L | Yield from minimal medium is typically lower than from rich medium. |
| 15N-Proline Incorporation Efficiency | Mass Spectrometry | e.g., >95% | Calculated from the isotopic distribution of proline-containing peptides. |
| Metabolic Scrambling | Mass Spectrometry | e.g., <5% | Percentage of 15N label detected in other amino acids. |
| Proline Cis/Trans Isomer Ratio | NMR Spectroscopy | e.g., 90% trans, 10% cis | Determined from the relative intensities of the 15N resonances. |
| Cis-Trans Isomerization Rate | NMR (EXSY or line shape analysis) | e.g., 0.1 s⁻¹ | Provides information on the kinetics of the conformational change. |
Interpreting NMR Data for Protein Dynamics
-
Chemical Shift Perturbations: Changes in the 15N chemical shift of a proline residue upon perturbation (e.g., ligand binding, mutation, change in pH or temperature) indicate a change in its local environment and can be used to map interaction surfaces or conformational changes.
-
Multiple Resonances: The presence of two distinct 15N resonances for a single proline residue is a direct indication of slow cis-trans isomerization on the NMR timescale.[7] The relative populations of the two states can be determined from the peak integrals.
-
Line Broadening: An increase in the linewidth of a proline 15N resonance can indicate conformational exchange on the microsecond to millisecond timescale.
-
Relaxation Data: While more challenging to obtain for proline due to the lack of a directly attached proton, 15N T1, T2, and NOE measurements can provide information on the picosecond to nanosecond timescale dynamics of the proline ring.
Conclusion
Selective this compound labeling is a powerful tool for investigating the dynamics of proteins, particularly the conformational changes associated with proline residues. By combining specific labeling strategies with advanced NMR and mass spectrometry techniques, researchers can gain unique insights into the role of proline in protein function, folding, and regulation. The protocols and guidelines presented here provide a comprehensive framework for the successful application of this methodology in academic and industrial research settings.
References
- 1. pubs.acs.org [pubs.acs.org]
- 2. pubs.acs.org [pubs.acs.org]
- 3. www2.mrc-lmb.cam.ac.uk [www2.mrc-lmb.cam.ac.uk]
- 4. Method for the Determination of ¹⁵N Incorporation Percentage in Labeled Peptides and Proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. mr.copernicus.org [mr.copernicus.org]
- 7. 13C Direct Detected NMR for Challenging Systems - PMC [pmc.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. A rapid and robust method for selective isotope labeling of proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 10. UWPR [proteomicsresource.washington.edu]
- 11. 15N labeling of proteins in E. coli – Protein Expression and Purification Core Facility [embl.org]
- 12. 15N-detected TROSY NMR experiments to study large disordered proteins in high-field magnets - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for Analyzing L-Proline-15N Enrichment in Mass Spectrometry
For Researchers, Scientists, and Drug Development Professionals
Introduction
Stable isotope labeling with L-Proline-15N is a powerful technique used to trace the metabolic fate of proline and quantify its incorporation into proteins and other metabolites. This approach is critical in various research areas, including metabolic flux analysis, drug development, and understanding disease states where proline metabolism is significant. Mass spectrometry (MS) is the primary analytical method for accurately determining the enrichment of this compound in biological samples. These application notes provide detailed protocols for sample preparation and analysis using both Gas Chromatography-Mass Spectrometry (GC-MS) and Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS).
Overview of L-Proline Metabolism
L-proline is a non-essential amino acid synthesized in the body primarily from glutamate. It plays a crucial role in protein synthesis, collagen formation, and cellular signaling. The biosynthesis and degradation of proline are tightly regulated processes. This compound can be introduced into cellular systems to trace its path through these metabolic routes.
Below is a diagram illustrating the core metabolic pathways of L-proline, which can be traced using this compound.
Experimental Workflow for this compound Enrichment Analysis
The general workflow for analyzing this compound enrichment involves several key steps from sample collection to data analysis. The choice between GC-MS and LC-MS/MS will depend on the sample matrix, desired sensitivity, and available instrumentation.
Protocols
Sample Preparation
3.1.1. Metabolite Extraction from Cells
-
Aspirate the culture medium and wash the cells twice with ice-cold phosphate-buffered saline (PBS).
-
Add 1 mL of ice-cold 80% methanol (v/v) to each well (for a 6-well plate).
-
Scrape the cells and transfer the cell suspension to a microcentrifuge tube.
-
Vortex for 30 seconds and incubate at -20°C for 30 minutes to precipitate proteins.
-
Centrifuge at 14,000 x g for 10 minutes at 4°C.
-
Collect the supernatant containing the polar metabolites, including free L-proline.
-
Dry the supernatant under a stream of nitrogen or using a vacuum concentrator.
3.1.2. Protein Hydrolysis for Protein-Bound Proline Analysis
-
After metabolite extraction, wash the protein pellet with 1 mL of 80% methanol and centrifuge again.
-
Discard the supernatant and dry the protein pellet.
-
Add 500 µL of 6 M HCl to the protein pellet.
-
Incubate at 110°C for 24 hours in a sealed tube to hydrolyze the proteins into amino acids.
-
After hydrolysis, cool the sample and centrifuge to remove any insoluble material.
-
Transfer the supernatant to a new tube and dry it under a stream of nitrogen, resuspending in a suitable solvent for analysis.
GC-MS Analysis Protocol
For GC-MS analysis, derivatization of the amino acids is necessary to increase their volatility. A common method is silylation.
3.2.1. Derivatization
-
To the dried metabolite extract or protein hydrolysate, add 50 µL of N-tert-butyldimethylsilyl-N-methyltrifluoroacetamide (MTBSTFA) + 1% tert-butyldimethylchlorosilane (TBDMCS) and 50 µL of pyridine.
-
Seal the vial and heat at 70°C for 30 minutes.
-
Cool to room temperature before injection into the GC-MS.
3.2.2. GC-MS Instrumentation and Parameters
-
Gas Chromatograph: Agilent 7890B GC or equivalent.
-
Mass Spectrometer: Agilent 5977A MSD or equivalent.
-
Column: DB-5ms (30 m x 0.25 mm, 0.25 µm film thickness) or equivalent.
-
Inlet Temperature: 250°C.
-
Injection Volume: 1 µL (splitless mode).
-
Oven Program:
-
Initial temperature: 100°C, hold for 2 minutes.
-
Ramp to 280°C at 10°C/min.
-
Hold at 280°C for 5 minutes.
-
-
Ion Source Temperature: 230°C.
-
Quadrupole Temperature: 150°C.
-
Ionization Mode: Electron Ionization (EI) at 70 eV.
-
Acquisition Mode: Selected Ion Monitoring (SIM).
Table 1: SIM Parameters for GC-MS Analysis of TBDMS-derivatized Proline
| Analyte | Derivatized Formula | Monitored Ions (m/z) | Description |
| Unlabeled L-Proline | C18H37NO2Si2 | 258.2 | [M-57]+, characteristic fragment |
| This compound | C18H37¹⁵NO2Si2 | 259.2 | [M-57]+, labeled fragment |
LC-MS/MS Analysis Protocol
LC-MS/MS offers high sensitivity and specificity and does not typically require derivatization.
3.3.1. Sample Preparation
-
Reconstitute the dried metabolite extract or protein hydrolysate in 100 µL of the initial mobile phase (e.g., 0.1% formic acid in water).
-
Vortex and centrifuge to remove any particulates before transferring to an autosampler vial.
3.3.2. LC-MS/MS Instrumentation and Parameters
-
Liquid Chromatograph: Agilent 1290 Infinity II LC or equivalent.
-
Mass Spectrometer: Agilent 6470 Triple Quadrupole LC/MS or equivalent.
-
Column: Zorbax HILIC Plus (2.1 x 100 mm, 3.5 µm) or equivalent.
-
Mobile Phase A: 0.1% Formic Acid in Water.
-
Mobile Phase B: 0.1% Formic Acid in Acetonitrile.
-
Gradient:
-
0-1 min: 90% B
-
1-5 min: 90% to 50% B
-
5-6 min: 50% B
-
6-6.1 min: 50% to 90% B
-
6.1-9 min: 90% B
-
-
Flow Rate: 0.3 mL/min.
-
Column Temperature: 40°C.
-
Injection Volume: 5 µL.
-
Ion Source: Electrospray Ionization (ESI), Positive Mode.
-
Gas Temperature: 300°C.
-
Gas Flow: 8 L/min.
-
Nebulizer: 35 psi.
-
Capillary Voltage: 3500 V.
-
Acquisition Mode: Multiple Reaction Monitoring (MRM).
Table 2: MRM Transitions for LC-MS/MS Analysis of L-Proline
| Analyte | Precursor Ion (m/z) | Product Ion (m/z) | Collision Energy (V) |
| Unlabeled L-Proline | 116.1 | 70.1 | 15 |
| This compound | 117.1 | 71.1 | 15 |
Data Analysis: Calculating 15N Enrichment
The percentage of 15N enrichment in L-proline can be calculated from the peak areas of the labeled (M+1) and unlabeled (M) ions obtained from the mass spectrometer.
The fractional abundance of the labeled proline is calculated as:
Fractional Abundance = Area(M+1) / [Area(M) + Area(M+1)]
The percentage of 15N enrichment is then:
% Enrichment = Fractional Abundance * 100
It is important to correct for the natural abundance of ¹³C, which also contributes to the M+1 peak. The corrected peak area for the 15N-labeled proline can be calculated by subtracting the contribution of natural ¹³C from the unlabeled proline's M+1 peak. The natural abundance of ¹³C is approximately 1.1%. For proline (C5H9NO2), there are 5 carbon atoms, so the theoretical contribution to the M+1 peak from natural ¹³C is approximately 5 * 1.1% = 5.5% of the M peak intensity.
Corrected Area(M+1) = Measured Area(M+1) - (Measured Area(M) * 0.055)
The corrected enrichment is then calculated using the corrected M+1 area.
Conclusion
The methods described provide robust and reliable protocols for the analysis of this compound enrichment in various biological samples. The choice between GC-MS and LC-MS/MS will depend on specific experimental needs and available resources. Accurate determination of 15N incorporation is crucial for understanding the dynamics of proline metabolism and its role in health and disease. These protocols, when followed carefully, will yield high-quality, reproducible data for advanced metabolic research.
Application Notes and Protocols: L-Proline-15N in the Study of Intrinsically Disordered Proteins
For Researchers, Scientists, and Drug Development Professionals
Introduction
Intrinsically disordered proteins (IDPs) and intrinsically disordered regions (IDRs) challenge the traditional protein structure-function paradigm. Lacking a stable three-dimensional structure, these proteins are involved in a multitude of cellular processes, often through transient and dynamic interactions with various binding partners. Nuclear Magnetic Resonance (NMR) spectroscopy is a powerful technique for characterizing the structural ensembles and dynamics of IDPs at atomic resolution.
Proline residues are significantly enriched in IDP sequences and are critical to their function, in part by disrupting the formation of regular secondary structures.[1][2] However, the lack of an amide proton in the proline ring makes these residues invisible in conventional 1H-15N heteronuclear single quantum coherence (HSQC) NMR experiments, which are a cornerstone of protein NMR.[1][3] Isotopic labeling with L-Proline-15N provides a direct way to overcome this limitation, enabling the detailed investigation of proline-rich IDPs.
These application notes provide an overview and detailed protocols for the use of this compound in NMR-based studies of IDPs.
Applications of this compound in IDP Research
The incorporation of ¹⁵N-labeled proline into IDPs opens the door to a range of NMR experiments that provide critical insights into their structure, dynamics, and interactions.
-
Complete Backbone Resonance Assignment: A fundamental prerequisite for any detailed NMR study is the sequence-specific assignment of backbone resonances. Proline residues often act as breakers of sequential assignment walks in traditional proton-detected experiments. By specifically observing ¹⁵N-proline signals, researchers can complete the backbone assignments of IDPs, including proline-rich regions.[2]
-
Characterization of Proline cis/trans Isomerization: The peptide bond preceding a proline residue can exist in either a cis or trans conformation, and the slow exchange between these isomers can lead to conformational heterogeneity in the IDP ensemble.[4] NMR experiments on ¹⁵N-proline labeled samples can distinguish and quantify the populations of these two states, which can be crucial for understanding IDP function and interaction.[4][5]
-
Probing Local and Global Dynamics: NMR relaxation experiments on ¹⁵N-proline nuclei provide information on the dynamics of the protein backbone at proline positions. Parameters such as the longitudinal relaxation rate (R₁), transverse relaxation rate (R₂), and the heteronuclear Overhauser effect (hetNOE) can report on motions over a wide range of timescales (ps to ms).[4][6]
-
Mapping Binding Interfaces: Chemical shift perturbation (CSP) mapping is a widely used technique to identify the binding interface of a protein-ligand interaction. By monitoring the changes in the ¹⁵N-proline chemical shifts upon titration with a binding partner, the involvement of proline residues in the interaction can be mapped.
-
Investigating Post-Translational Modifications: Proline residues are subject to post-translational modifications, such as hydroxylation and phosphorylation, which can modulate the structure and function of IDPs. ¹⁵N-proline NMR can be used to study the structural consequences of these modifications.
Data Presentation: Quantitative NMR Parameters
The following tables summarize the key quantitative data that can be obtained from NMR experiments on this compound labeled IDPs.
Table 1: Proline ¹⁵N Chemical Shift Perturbations upon Ligand Binding
| Proline Residue | Chemical Shift (Free State, ppm) | Chemical Shift (Bound State, ppm) | Chemical Shift Perturbation (Δδ, ppm) |
| Pro-X | δ_free | δ_bound | |
| Pro-Y | δ_free | δ_bound | |
| Pro-Z | δ_free | δ_bound |
Note: The magnitude of the chemical shift perturbation is indicative of the residue's proximity to the binding interface.
Table 2: Proline Backbone Dynamics from ¹⁵N Relaxation Data
| Proline Residue | R₁ (s⁻¹) | R₂ (s⁻¹) | {¹H}-¹⁵N NOE |
| Pro-X | Value ± Error | Value ± Error | Value ± Error |
| Pro-Y | Value ± Error | Value ± Error | Value ± Error |
| Pro-Z | Value ± Error | Value ± Error | Value ± Error |
Note: Higher R₂ values can indicate slower motions (μs-ms timescale), often associated with conformational exchange or binding events. The NOE value provides information on fast motions (ps-ns timescale).
Table 3: Proline cis/trans Isomer Populations
| Proline Residue | Population of trans Isomer (%) | Population of cis Isomer (%) |
| Pro-X | Value ± Error | Value ± Error |
| Pro-Y | Value ± Error | Value ± Error |
| Pro-Z | Value ± Error | Value ± Error |
Note: The relative populations are determined from the integration of the corresponding peaks in the NMR spectrum.
Experimental Workflows
The following diagrams illustrate the general workflows for studying IDPs using this compound labeling.
Caption: General workflow for producing this compound labeled IDPs for NMR studies.
Caption: Workflow for NMR data acquisition and analysis of this compound labeled IDPs.
Experimental Protocols
Protocol 1: Expression and Labeling of IDPs with this compound
This protocol describes the expression of an IDP in E. coli in M9 minimal media for uniform ¹⁵N labeling, with the addition of unlabeled L-proline to ensure sufficient incorporation. For specific this compound labeling, ¹⁵N-labeled L-proline would be added to the media instead of unlabeled proline, and ¹⁴NH₄Cl would be used as the nitrogen source.
Materials:
-
E. coli strain (e.g., BL21(DE3)) transformed with the expression plasmid for the IDP of interest.
-
M9 minimal media components.
-
¹⁵NH₄Cl as the sole nitrogen source.
-
Glucose (or ¹³C-glucose for dual labeling).
-
L-proline.
-
Isopropyl β-D-1-thiogalactopyranoside (IPTG).
-
Appropriate antibiotic.
Procedure:
-
Starter Culture: Inoculate 50 mL of LB medium containing the appropriate antibiotic with a single colony of transformed E. coli. Grow overnight at 37°C with shaking.
-
Main Culture Inoculation: The next day, inoculate 1 L of M9 minimal media containing ¹⁵NH₄Cl, glucose, and the antibiotic with the overnight starter culture.
-
Cell Growth: Grow the main culture at 37°C with vigorous shaking until the optical density at 600 nm (OD₆₀₀) reaches 0.6-0.8.
-
Induction: Add L-proline to a final concentration of 100 mg/L. Induce protein expression by adding IPTG to a final concentration of 0.5-1 mM.
-
Expression: Reduce the temperature to 18-25°C and continue to grow the culture for 16-20 hours.
-
Harvesting: Harvest the cells by centrifugation at 5,000 x g for 20 minutes at 4°C.
-
Storage: The cell pellet can be stored at -80°C until purification.
Protocol 2: NMR Sample Preparation
Materials:
-
Purified, ¹⁵N-proline labeled IDP.
-
NMR buffer (e.g., 20 mM Sodium Phosphate, 50 mM NaCl, pH 6.5).
-
Deuterium oxide (D₂O).
-
DSS (4,4-dimethyl-4-silapentane-1-sulfonic acid) as an internal chemical shift reference.
Procedure:
-
Buffer Exchange: Exchange the purified protein into the desired NMR buffer using a desalting column or repeated concentration and dilution with a centrifugal filter device.
-
Concentration: Concentrate the protein to a final concentration of 0.1-1.0 mM.
-
Final Sample Preparation: In a final volume of 550 µL, add D₂O to 5-10% (v/v) and DSS to a final concentration of 0.1 mM.
-
Transfer to NMR Tube: Transfer the final sample to a clean, high-quality NMR tube.
Protocol 3: 2D ¹³C-¹⁵N CON Spectroscopy for Proline Fingerprinting
The 2D CON experiment is a ¹³C-detected experiment that correlates the amide nitrogen of a residue with the carbonyl carbon of the preceding residue.[1] This experiment is particularly useful for IDPs as it is not dependent on amide protons and provides a fingerprint of all residues, including prolines. The ¹⁵N resonances of proline residues fall in a distinct, isolated region of the 2D CON spectrum.[7][8]
NMR Spectrometer and Probe:
-
A high-field NMR spectrometer (e.g., 600 MHz or higher) equipped with a cryogenically cooled probe optimized for ¹³C-direct detection is recommended.[1]
Experimental Parameters (Example):
-
Temperature: 298 K
-
Acquisition Dimensions:
-
¹³C (direct): 1024 complex points
-
¹⁵N (indirect): 256 complex points
-
-
Spectral Widths:
-
¹³C: ~30 ppm
-
¹⁵N: ~35 ppm (a smaller spectral width can be used if only the proline region is of interest)
-
-
Number of Scans: 8-16 (dependent on sample concentration)
-
Inter-scan Delay: 1.5-2.0 seconds
Procedure:
-
Tune and match the probe for ¹H, ¹³C, and ¹⁵N frequencies.
-
Set up the 2D CON experiment using the manufacturer's pulse program.
-
Optimize the spectral widths in both dimensions to cover all expected resonances with adequate resolution.
-
Acquire the data.
-
Process the data using appropriate software (e.g., TopSpin, NMRPipe). This will involve Fourier transformation, phasing, and baseline correction.
-
The resulting 2D spectrum will show correlations between C'(i-1) and N(i). Proline residues will give rise to cross-peaks in a region of the ¹⁵N dimension that is distinct from the other amino acids.
This detailed approach, leveraging this compound labeling, provides a powerful toolkit for the comprehensive characterization of intrinsically disordered proteins, offering insights that are inaccessible through conventional methodologies.
References
- 1. news-medical.net [news-medical.net]
- 2. pnas.org [pnas.org]
- 3. Sequence-Specific Assignments for Intrinsically Disordered Proteins | Bruker [bruker.com]
- 4. discovery.ucl.ac.uk [discovery.ucl.ac.uk]
- 5. Proline cis/trans Isomerization in Intrinsically Disordered Proteins and Peptides [imrpress.com]
- 6. Predicting the sequence-dependent backbone dynamics of intrinsically disordered proteins | eLife [elifesciences.org]
- 7. researchgate.net [researchgate.net]
- 8. mr.copernicus.org [mr.copernicus.org]
Application Notes and Protocols for L-Proline-15N Labeling in Cell Culture
For Researchers, Scientists, and Drug Development Professionals
Introduction
Stable isotope labeling with amino acids in cell culture (SILAC) is a powerful technique for quantitative proteomics, enabling the accurate measurement of protein abundance and turnover. The incorporation of amino acids labeled with heavy isotopes, such as L-Proline-15N, allows for the differentiation of proteins from different cell populations by mass spectrometry. L-proline, a unique imino acid, plays a critical role in protein structure, particularly in collagen, and is involved in key cellular processes including metabolism and signaling pathways. These application notes provide a detailed guide to the preparation of cell culture media for this compound labeling, experimental protocols, and an overview of relevant biological pathways.
Data Presentation
Table 1: Standard L-Proline Concentrations in Common Cell Culture Media
| Media Formulation | Standard L-Proline Concentration (mg/L) | Molar Concentration (mM) |
| RPMI-1640 | 20.0 | 0.174 |
| DMEM (High Glucose, with NEAA) | 46.0 | 0.4 |
This table provides the standard concentrations of unlabeled L-proline in commonly used cell culture media. This information is crucial for calculating the required amount of this compound for complete replacement in labeling experiments.[1][2]
Table 2: Recommended this compound Labeling Parameters
| Parameter | Recommended Value | Notes |
| This compound Concentration | Match the concentration of the corresponding unlabeled medium (e.g., 20 mg/L for RPMI-1640) | Higher concentrations may be used, but cytotoxicity should be evaluated for the specific cell line. |
| Typical Labeling Efficiency | >95% | Labeling efficiency can be influenced by the cell line, passage number, and culture conditions. It is recommended to verify incorporation rates by mass spectrometry.[3][4] |
| Dialyzed Fetal Bovine Serum (FBS) | 10% (or as required by the cell line) | Dialysis is essential to remove unlabeled amino acids from the serum that would compete with the labeled this compound. |
| Adaptation Period | At least 5-6 cell doublings | This ensures near-complete incorporation of the labeled amino acid into the cellular proteome. |
Experimental Protocols
Protocol 1: Preparation of this compound Labeling Medium from Proline-Free Powdered Medium
This protocol describes the preparation of 1 liter of this compound labeling medium using proline-free RPMI-1640 as a base.
Materials:
-
Proline-free RPMI-1640 powder (e.g., from MyBioSource)[5]
-
This compound (≥98% isotopic purity)
-
Cell culture grade water (e.g., Milli-Q or equivalent)
-
Sodium Bicarbonate (NaHCO₃)
-
1N Hydrochloric Acid (HCl) and 1N Sodium Hydroxide (NaOH) for pH adjustment
-
Dialyzed Fetal Bovine Serum (dFBS)
-
Penicillin-Streptomycin solution (100x)
-
Sterile filtration unit (0.22 µm pore size)
-
Sterile storage bottles
Procedure:
-
Dissolve Powdered Medium: In a sterile container, dissolve the contents of the proline-free RPMI-1640 powder packet in approximately 900 mL of cell culture grade water. Stir gently until the powder is completely dissolved. Do not heat the water.[6]
-
Add this compound: Weigh out the appropriate amount of this compound to achieve the desired final concentration (e.g., 20 mg for a final concentration of 20 mg/L). Dissolve the this compound in a small amount of cell culture grade water and add it to the medium solution.
-
Add Sodium Bicarbonate: Add 2.0 g of sodium bicarbonate to the solution and stir until dissolved.[5]
-
Adjust pH: Adjust the pH of the medium to 7.2-7.4 using 1N HCl or 1N NaOH. Monitor the pH using a calibrated pH meter.
-
Bring to Final Volume: Add cell culture grade water to bring the total volume to 1 liter.
-
Sterile Filtration: Sterilize the medium by passing it through a 0.22 µm sterile filter into a sterile storage bottle.
-
Supplement the Medium: Aseptically add dFBS to a final concentration of 10% (or the desired concentration for your cell line) and Penicillin-Streptomycin to a final concentration of 1x.
-
Storage: Store the complete labeling medium at 2-8°C, protected from light.
Protocol 2: this compound Labeling of Adherent Mammalian Cells
Materials:
-
Healthy, actively dividing mammalian cells
-
Complete this compound labeling medium (prepared as in Protocol 1)
-
Complete standard (unlabeled) cell culture medium
-
Phosphate-Buffered Saline (PBS), sterile
-
Trypsin-EDTA solution
-
Cell culture flasks or plates
-
Hemocytometer or automated cell counter
Procedure:
-
Cell Seeding: Seed the cells in a new culture flask containing standard, unlabeled medium and allow them to attach and reach approximately 70-80% confluency.
-
Adaptation to Labeling Medium:
-
Aspirate the standard medium from the flask.
-
Wash the cell monolayer once with sterile PBS to remove any residual unlabeled medium.
-
Add the pre-warmed complete this compound labeling medium to the flask.
-
-
Cell Expansion and Labeling:
-
Culture the cells in the labeling medium for at least 5-6 cell doublings to ensure maximum incorporation of this compound.
-
Subculture the cells as needed, always using the this compound labeling medium.
-
-
Verification of Labeling Efficiency (Optional but Recommended):
-
After 5-6 doublings, harvest a small population of cells.
-
Extract proteins and analyze by mass spectrometry to determine the percentage of this compound incorporation. The efficiency should ideally be >95%.[3]
-
-
Experimental Procedure: Once the cells are fully labeled, they can be used for various experimental setups, such as comparing protein expression under different treatment conditions against a "light" (unlabeled) cell population.
Mandatory Visualizations
Signaling Pathways
Caption: L-Proline's role in collagen synthesis and mTOR signaling.
Experimental Workflow
Caption: Experimental workflow for this compound SILAC.
References
- 1. 11875 - RPMI 1640 | Thermo Fisher Scientific - SG [thermofisher.com]
- 2. 10938 - DMEM, high glucose, NEAA, no glutamine | Thermo Fisher Scientific - KG [thermofisher.com]
- 3. Frontiers | 15N Metabolic Labeling Quantification Workflow in Arabidopsis Using Protein Prospector [frontiersin.org]
- 4. researchgate.net [researchgate.net]
- 5. mybiosource.com [mybiosource.com]
- 6. Cell Culture Media Preparation from Powder | Thermo Fisher Scientific - KR [thermofisher.com]
Troubleshooting & Optimization
Technical Support Center: Overcoming Low L-Proline-15N Incorporation in Mammalian Cells
Welcome to the technical support center for troubleshooting issues related to the isotopic labeling of mammalian cells with L-Proline-15N. This resource is designed for researchers, scientists, and drug development professionals to diagnose and resolve common challenges encountered during their experiments.
Frequently Asked Questions (FAQs)
Q1: What is the primary reason for low this compound incorporation in my mammalian cell culture?
A1: Low incorporation of this compound is often not due to a direct failure of the cells to uptake the labeled proline, but rather a result of metabolic "scrambling" or dilution from other sources. The most common issue is the metabolic conversion of other amino acids, particularly L-Arginine, into proline.[1][2] Mammalian cells can synthesize proline from arginine, and if you are using a medium containing labeled arginine (as is common in SILAC experiments), the 15N label can be transferred to newly synthesized proline, diluting your intended this compound pool. Another significant factor can be the cells' own de novo synthesis of proline from glutamate, especially in cell lines that are proline prototrophs.
Q2: My cells are showing signs of toxicity after adding this compound. What could be the cause?
A2: While L-Proline itself is not typically toxic, high concentrations of any single amino acid can disrupt the overall amino acid balance in the cell, potentially leading to toxicity. More commonly, apparent toxicity may be related to the custom labeling medium rather than the this compound itself. Commercially available labeling media are often optimized for specific cell lines, and a custom formulation may lack essential nutrients or have an improper balance, leading to reduced cell viability and proliferation. It is also crucial to ensure the sterility of your this compound stock solution.
Q3: Are there cell-line-specific considerations I should be aware of?
A3: Yes, the genetic background of your mammalian cell line is critical. For instance, Chinese Hamster Ovary (CHO) cells are typically proline auxotrophs, meaning they cannot synthesize their own proline and are entirely dependent on external sources.[3] This makes them an excellent choice for this compound labeling as there is no endogenous proline synthesis to dilute the labeled pool. Conversely, cell lines like HEK293 are generally proline prototrophs and can synthesize proline, which can lead to lower incorporation efficiency of the exogenously supplied this compound.
Q4: How can I measure the incorporation efficiency of this compound?
A4: The most accurate method for determining incorporation efficiency is through mass spectrometry (MS).[4] This typically involves digesting a protein from your labeled cells with an enzyme like trypsin and then analyzing the resulting peptides by LC-MS/MS. By comparing the mass spectra of proline-containing peptides from labeled and unlabeled samples, you can determine the percentage of peptides that have incorporated the 15N isotope.[4]
Troubleshooting Guides
Issue 1: Low or Inconsistent this compound Incorporation
| Potential Cause | Recommended Solution |
| Metabolic Scrambling from L-Arginine-15N | If your labeling strategy involves labeled arginine, this is a likely culprit. To counteract this, supplement your culture medium with a high concentration of unlabeled L-Proline (e.g., 200 mg/L or higher). This excess of unlabeled proline will inhibit the enzymatic pathway that converts arginine to proline, thereby preventing the transfer of the 15N label.[1] |
| De novo Proline Synthesis | In proline prototrophic cell lines (e.g., HEK293), the cells' own synthesis of proline from glutamate will dilute the this compound pool. Consider using a proline auxotrophic cell line like CHO cells if possible. If you must use a prototrophic line, increasing the concentration of this compound in the medium can help to outcompete the endogenous synthesis. |
| Insufficient this compound Concentration | The concentration of this compound in the medium may be too low to achieve high incorporation. While there is no single optimal concentration for all cell lines, a starting point of 100-200 mg/L is common. You may need to perform a titration experiment to determine the optimal concentration for your specific cell line and experimental conditions. |
| Presence of Unlabeled Proline in Serum | If you are using fetal bovine serum (FBS) in your culture medium, it will contain unlabeled proline, which will compete with the this compound. Switch to a dialyzed FBS, which has had small molecules like amino acids removed. |
| Inadequate Adaptation Time | Cells need time to adapt to the new labeling medium and to turn over their existing unlabeled proteins. Ensure that cells are cultured in the labeling medium for a sufficient number of passages (typically at least 5-6) to allow for complete incorporation of the labeled amino acid. |
Issue 2: Poor Cell Growth or Viability in Labeling Medium
| Potential Cause | Recommended Solution |
| Nutrient-Deficient Medium | Custom labeling media can sometimes lack essential components found in standard growth media. Ensure your labeling medium is supplemented with all necessary amino acids (unlabeled, except for proline), vitamins, and glucose at appropriate concentrations. |
| Amino Acid Imbalance | High concentrations of a single amino acid can sometimes be detrimental. If you suspect this compound toxicity, try reducing the concentration and performing a dose-response experiment to find a balance between high incorporation and good cell health. |
| Serum Shock | If you have switched from a serum-containing to a serum-free labeling medium, cells may experience "serum shock." Gradually adapt your cells to the serum-free conditions over several passages before starting your labeling experiment. |
| Contamination | Poor cell health can be a sign of microbial contamination. Regularly test your cultures for mycoplasma and other common contaminants. |
Data Presentation
| Labeled Amino Acid(s) | Cell Line | Incorporation Efficiency (%) | Reference |
| 15N-Lysine, 15N-Glycine, 15N-Serine (KGS) | HEK293 | 52 ± 4 | [1] |
| 15N-Valine, 15N-Isoleucine, 15N-Leucine (VIL) | HEK293 | 30 ± 14 | [1] |
Note: The lower incorporation efficiency for VIL is attributed to significant metabolic scrambling.
Experimental Protocols
Protocol: this compound Labeling of Adherent Mammalian Cells (e.g., HEK293 or CHO)
This protocol provides a general framework. Optimization for specific cell lines and experimental goals is recommended.
Materials:
-
Adherent mammalian cell line (e.g., HEK293 or CHO-K1)
-
Standard growth medium (e.g., DMEM or F-12K)
-
Proline-free version of the standard growth medium
-
This compound (≥98% isotopic purity)
-
Dialyzed Fetal Bovine Serum (dFBS)
-
Penicillin-Streptomycin solution
-
Trypsin-EDTA solution
-
Phosphate-Buffered Saline (PBS)
-
Sterile culture flasks, plates, and other necessary labware
Procedure:
-
Cell Line Preparation:
-
Culture your chosen cell line in standard growth medium supplemented with 10% FBS and 1% Penicillin-Streptomycin.
-
If using CHO-K1 cells, ensure the standard medium contains proline.
-
For at least two passages before starting the labeling, switch to a medium containing 10% dialyzed FBS to begin depleting the pool of unlabeled amino acids.
-
-
Preparation of Labeling Medium:
-
Prepare the proline-free growth medium according to the manufacturer's instructions.
-
Supplement the proline-free medium with this compound to a final concentration of 100-200 mg/L.
-
Add 10% dFBS and 1% Penicillin-Streptomycin to the labeling medium.
-
Sterile-filter the complete labeling medium using a 0.22 µm filter.
-
-
Adaptation and Labeling:
-
When your cells are ready for passaging, detach them using Trypsin-EDTA and neutralize with standard medium.
-
Centrifuge the cells and resuspend the pellet in the prepared this compound labeling medium.
-
Seed the cells into a new culture flask at your standard seeding density.
-
Culture the cells in the labeling medium for at least 5-6 passages to ensure near-complete incorporation of the this compound. Monitor cell health and morphology during this adaptation period.
-
-
Harvesting and Sample Preparation for Mass Spectrometry:
-
Once sufficient incorporation is expected, harvest the cells.
-
Wash the cell pellet twice with ice-cold PBS to remove any residual medium.
-
The cell pellet can now be processed for protein extraction and subsequent analysis. For a typical bottom-up proteomics workflow:
-
Lyse the cells in a suitable lysis buffer containing protease inhibitors.
-
Quantify the protein concentration of the lysate.
-
Perform a protein digestion (e.g., in-solution or in-gel) using trypsin.
-
Desalt the resulting peptide mixture using a C18 desalting column.
-
The sample is now ready for LC-MS/MS analysis to determine this compound incorporation efficiency.
-
-
Visualizations
Experimental Workflow
References
- 1. A comprehensive assessment of selective amino acid 15N-labeling in human embryonic kidney 293 cells for NMR spectroscopy - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Effective Isotope Labeling of Proteins in a Mammalian Expression System - PMC [pmc.ncbi.nlm.nih.gov]
- 3. 15N Metabolic Labeling of Mammalian Tissue with Slow Protein Turnover - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Rapid mass spectrometric analysis of 15N-Leu incorporation fidelity during preparation of specifically labeled NMR samples - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Optimizing L-Proline-15N Labeling in Insect Cells
Welcome to the technical support center for optimizing L-Proline-15N labeling efficiency in insect cells. This resource provides troubleshooting guidance and answers to frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in achieving high-quality, specific labeling for their protein of interest.
Frequently Asked Questions (FAQs)
Q1: Why is my ¹⁵N-Proline labeling efficiency lower than expected?
A1: Several factors can contribute to low ¹⁵N-Proline incorporation:
-
Dilution by Unlabeled Proline: Residual unlabeled proline from the initial growth medium or components like yeastolate can dilute the ¹⁵N-labeled proline pool.
-
De Novo Biosynthesis: Insect cells can synthesize proline from unlabeled precursors present in the medium, primarily glutamate.[1][2] This newly synthesized, unlabeled proline will compete with the ¹⁵N-proline for incorporation into your target protein.
-
Suboptimal Cell Health: Poor cell viability at the time of infection and media exchange can lead to inefficient protein synthesis and, consequently, low label incorporation.
-
Incorrect Timing of Harvest: Harvesting the cells too early or too late can result in low yields of the labeled protein. Peak expression of recombinant proteins in the baculovirus expression vector system (BEVS) is typically transient.
-
Metabolic Scrambling: Although less prevalent in insect cells than in E. coli for essential amino acids, some metabolic conversion of proline to other amino acids (e.g., glutamate) can occur, which might be misinterpreted as low proline labeling if not all metabolic fates are considered.[3][4]
Q2: I see some ¹⁵N incorporation in Glutamate as well. Is this normal?
A2: Yes, this is a relatively common observation. Proline can be catabolized to glutamate in insect cells.[2] If you are providing ¹⁵N-Proline, it is metabolically possible for the ¹⁵N label to be transferred to glutamate. The extent of this "scrambling" can depend on the metabolic state of the cells and the specific media composition.
Q3: What is the recommended concentration of L-Proline-¹⁵N to use in the labeling medium?
A3: The optimal concentration can vary depending on the specific protein, expression levels, and media formulation. However, a common starting point is to supplement the medium with a concentration similar to that found in standard insect cell culture media. It is advisable to perform a titration experiment to determine the optimal concentration for your specific system.
Q4: How can I accurately measure the efficiency of ¹⁵N-Proline incorporation?
A4: The most accurate method for determining isotopic incorporation is mass spectrometry (MS). By analyzing the mass shift of peptides containing proline from your labeled protein compared to an unlabeled control, you can calculate the percentage of ¹⁵N incorporation. This can be done by analyzing the intact protein or, more commonly, by analyzing proteolytic digests of your protein (e.g., tryptic digest) followed by LC-MS/MS analysis.[5][6]
Troubleshooting Guide
Below are common issues encountered during L-Proline-¹⁵N labeling experiments and steps to resolve them.
Issue 1: Low or No ¹⁵N-Proline Incorporation
| Potential Cause | Troubleshooting Steps |
| Residual Unlabeled Proline | 1. Wash the cells thoroughly: Before resuspending the cells in the labeling medium, wash the cell pellet with a proline-free basal medium to remove any residual unlabeled growth medium. 2. Use a defined medium: If possible, adapt your cells to a chemically defined, proline-free medium for the labeling phase. 3. Optimize media components: If using yeastolate-containing media, consider using dialyzed yeastolate to reduce the concentration of free amino acids.[7] |
| De Novo Proline Synthesis | 1. Minimize unlabeled precursors: Use a labeling medium with minimal or no unlabeled glutamate, as this is a primary precursor for proline biosynthesis.[1][2] 2. Increase ¹⁵N-Proline concentration: A higher concentration of labeled proline can help to outcompete any endogenously synthesized unlabeled proline. |
| Suboptimal Expression Conditions | 1. Optimize expression before labeling: Determine the optimal Multiplicity of Infection (MOI) and harvest time for your protein in unlabeled medium first.[8] 2. Monitor cell viability: Ensure cell viability is high (>95%) at the time of infection and media exchange. |
Issue 2: Poor Protein Yield After Labeling
| Potential Cause | Troubleshooting Steps |
| Cell Stress During Media Exchange | 1. Handle cells gently: Centrifuge cells at low speed (e.g., 100-200 x g) to minimize cell damage. 2. Pre-warm the labeling medium: Ensure the labeling medium is at the optimal temperature (typically 27°C) before resuspending the cells. |
| Nutrient Limitation in Labeling Medium | 1. Ensure a complete medium: The labeling medium, even if lacking unlabeled proline, should contain all other essential nutrients for protein synthesis. 2. Supplement with essential amino acids: If using a minimal medium for labeling, ensure all other essential amino acids are present in sufficient quantities. |
| Incorrect Harvest Time | 1. Perform a time-course experiment: Collect and analyze samples at different time points post-infection to determine the peak of protein expression. |
Experimental Protocols
Protocol 1: General Workflow for L-Proline-¹⁵N Labeling in Insect Cells
This protocol provides a general outline. Optimization of cell density, MOI, and harvest time should be performed for each specific protein.
Materials:
-
Sf9 (or other suitable insect cell line) culture in logarithmic growth phase.
-
Complete, unlabeled growth medium (e.g., Sf-900™ II SFM).
-
Proline-free labeling medium.
-
L-Proline-¹⁵N (≥98% isotopic purity).
-
Recombinant baculovirus stock.
Procedure:
-
Grow a suspension culture of Sf9 cells in your standard, complete medium to a density of approximately 1.5-2.0 x 10⁶ cells/mL.
-
Harvest the cells by centrifugation at 100-200 x g for 10 minutes.
-
Gently discard the supernatant and wash the cell pellet once with a proline-free basal medium.
-
Centrifuge again and resuspend the cell pellet in the pre-warmed labeling medium supplemented with L-Proline-¹⁵N to the desired final concentration.
-
Infect the cell suspension with the recombinant baculovirus at the predetermined optimal MOI.
-
Incubate the culture at 27°C with shaking (e.g., 120 rpm).
-
Harvest the cells at the optimal time post-infection by centrifugation.
-
Store the cell pellet at -80°C until protein purification.
Protocol 2: Quantification of ¹⁵N-Proline Incorporation by Mass Spectrometry
Procedure:
-
Purify your target protein from both ¹⁵N-proline labeled and unlabeled control cultures.
-
Perform an in-solution or in-gel tryptic digest of both protein samples.
-
Analyze the resulting peptide mixtures by LC-MS/MS.
-
Identify peptides containing proline residues.
-
Compare the mass spectra of the proline-containing peptides from the labeled and unlabeled samples.
-
Calculate the incorporation efficiency based on the mass shift observed for the labeled peptides. The mass of a peptide will increase by approximately 1 Da for each ¹⁵N atom incorporated. Specialized software can be used for more precise quantification.[6][8][9]
Visualizations
Caption: Troubleshooting workflow for low ¹⁵N-Proline labeling efficiency.
Caption: Key metabolic pathways affecting ¹⁵N-Proline labeling.
References
- 1. Proline synthesis from glutamate in the mitochondria isolated from a blowfly, Aldrichina grahami - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. The Multifaceted Roles of Proline in Cell Behavior - PMC [pmc.ncbi.nlm.nih.gov]
- 3. A novel medium for expression of proteins selectively labeled with 15N-amino acids in Spodoptera frugiperda (Sf9) insect cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. The key role of glutamine for protein expression and isotopic labeling in insect cells - PMC [pmc.ncbi.nlm.nih.gov]
- 5. pubs.acs.org [pubs.acs.org]
- 6. Quantitative Proteomics: Measuring Protein Synthesis Using 15N Amino Acids Labeling in Pancreas Cancer Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 7. An improved protocol for amino acid type-selective isotope labeling in insect cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. 15N Metabolic Labeling Quantification Workflow in Arabidopsis Using Protein Prospector - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
Technical Support Center: Minimizing Isotopic Scrambling in ¹⁵N Metabolic Labeling
Welcome to the technical support center for minimizing isotopic scrambling in ¹⁵N metabolic labeling. This guide provides troubleshooting advice, frequently asked questions (FAQs), and detailed protocols to help researchers, scientists, and drug development professionals achieve high-quality labeling for their quantitative proteomics experiments.
Frequently Asked Questions (FAQs)
Q1: What is isotopic scrambling and why is it a problem in ¹⁵N metabolic labeling?
Isotopic scrambling is the metabolic conversion of a labeled amino acid into other amino acids, which leads to the unintended incorporation of the ¹⁵N isotope into amino acids that were not directly supplied in the labeled form.[1][2] This is problematic because it can complicate data analysis and lead to inaccuracies in protein quantification. For instance, the conversion of labeled arginine to labeled proline is a common issue in SILAC (Stable Isotope Labeling by Amino Acids in Cell Culture) experiments.[3][4]
Q2: Which amino acids are most susceptible to isotopic scrambling?
The susceptibility of an amino acid to scrambling depends on the expression system and its central metabolism.
-
In E. coli , amino acids like alanine, aspartate, glutamate, glutamine, isoleucine, leucine, and valine are highly prone to scrambling due to the activity of various transaminases.[2] Alanine, for example, can be converted to pyruvate, a precursor for other aliphatic amino acids.[2]
-
In mammalian cells (e.g., HEK293) , significant scrambling is observed for alanine, aspartate, glutamate, isoleucine, leucine, and valine.[5][6] Conversely, cysteine, phenylalanine, histidine, lysine, methionine, asparagine, arginine, tryptophan, and tyrosine show minimal scrambling.[5][6] Glycine and serine can interconvert.[5][6]
Q3: How can I detect and quantify isotopic scrambling in my samples?
Isotopic scrambling is typically detected and quantified using high-resolution mass spectrometry.[1] By analyzing the isotopic patterns of tryptic peptides, you can identify unexpected mass shifts corresponding to the incorporation of ¹⁵N in non-target amino acids.[1] The degree of enrichment and scrambling can be determined by comparing the experimental isotopic profile of a peptide against a series of theoretical profiles with different enrichment rates.[1]
Troubleshooting Guide
-
Cause: This is a classic sign of isotopic scrambling, where the host organism's metabolic pathways convert the labeled amino acid you provided into other amino acids.[1][2] This is particularly common for amino acids that are central to metabolic pathways, such as glutamate and alanine.
-
Solution 1: Use an Auxotrophic E. coli Strain: Employ an E. coli strain that is unable to synthesize the specific amino acid you are labeling with. This forces the organism to exclusively use the ¹⁵N-labeled amino acid from the media for protein synthesis, significantly reducing scrambling.
-
Solution 2: Adjust Cell Culture Conditions (for mammalian cells): For scrambling of amino acids like valine and isoleucine in HEK293 cells, reducing the concentration of the labeled amino acid in the culture medium can decrease the amount available for metabolic conversion into other amino acids.[5]
-
Solution 3: Use Metabolic Inhibitors (in cell-free systems): In cell-free protein synthesis systems, metabolic inhibitors can be added to block the enzymes responsible for amino acid conversions.
Problem 2: My SILAC experiment shows significant conversion of heavy arginine to heavy proline.
-
Cause: Some cell lines have high arginase activity, which leads to the metabolic conversion of arginine to proline.[3][4][7] This can lead to inaccurate quantification as the heavy isotope signal is split between arginine- and proline-containing peptides.
-
Solution: Supplement with Unlabeled Proline: Adding an excess of unlabeled L-proline to the SILAC media can suppress the conversion of labeled arginine to proline.[3][8] A concentration of 200 mg/L L-proline has been shown to be effective in preventing this conversion in embryonic stem cells.[8]
Quantitative Data on Isotopic Scrambling
The degree of isotopic scrambling can vary significantly between different expression systems and for different amino acids. The following tables provide a summary of expected scrambling behavior.
Table 1: Isotopic Scrambling of ¹⁵N-Labeled Amino Acids in HEK293 Cells
| Labeled Amino Acid | Scrambling Level | Notes |
| Alanine (A), Aspartate (D), Glutamate (E), Isoleucine (I), Leucine (L), Valine (V) | Significant | These amino acids are actively metabolized and their nitrogen can be incorporated into other amino acids.[5][6] |
| Glycine (G), Serine (S) | Interconversion | Glycine and Serine can be metabolically converted into each other.[5][6] |
| Cysteine (C), Phenylalanine (F), Histidine (H), Lysine (K), Methionine (M), Asparagine (N), Arginine (R), Tryptophan (W), Tyrosine (Y) | Minimal | These amino acids generally show low levels of metabolic scrambling.[5][6] |
Table 2: Susceptibility of Amino Acids to ¹⁵N Scrambling in E. coli
| Amino Acid | Susceptibility to Scrambling | Key Metabolic Pathways Involved |
| Alanine | High | Conversion to pyruvate by alanine transaminases.[2] |
| Isoleucine, Leucine, Valine | High | Action of various transaminases.[2] |
| Aspartate, Glutamate | High | Central roles in amino acid metabolism and transamination reactions. |
| Tyrosine, Phenylalanine | High | Aromatic amino acid transaminases cause nitrogen scrambling between them.[2] |
| Threonine | High | Connected to glycine, serine, cysteine, tryptophan, and isoleucine biosynthesis.[2] |
| Tryptophan | High | Tryptophanase can convert tryptophan to indole, pyruvate, and ammonia.[2] |
Experimental Protocols
Protocol 1: Uniform ¹⁵N Labeling of Proteins in E. coli
This protocol is adapted for expressing ¹⁵N-labeled proteins in E. coli using a minimal medium.
Materials:
-
M9 minimal medium (10x stock)
-
¹⁵NH₄Cl (as the sole nitrogen source)
-
Glucose (20% w/v stock)
-
1M MgSO₄
-
1M CaCl₂
-
Trace elements solution (100x)
-
Biotin (1 mg/mL)
-
Thiamin (1 mg/mL)
-
Appropriate antibiotic
-
E. coli expression strain transformed with the plasmid of interest
Procedure:
-
Prepare 1 liter of M9 minimal medium containing 1g of ¹⁵NH₄Cl.
-
Add the following sterile components: 20 mL of 20% glucose, 2 mL of 1M MgSO₄, 0.1 mL of 1M CaCl₂, 1 mL of trace elements solution, 1 mL of biotin, 1 mL of thiamin, and the appropriate antibiotic.[9]
-
Inoculate 5 mL of this medium with a single colony of the transformed E. coli and grow overnight at 37°C with shaking.[10]
-
Inoculate the 1 liter culture with the 5 mL overnight culture.
-
Grow the culture at the optimal temperature for your protein until the OD₆₀₀ reaches 0.6-0.8.
-
Induce protein expression with the appropriate inducer (e.g., IPTG).
-
Continue to culture for the desired time (typically 3-16 hours) at the optimal temperature.
-
Harvest the cells by centrifugation. The cell pellet can be stored at -80°C until purification.
Protocol 2: Minimizing Arginine-to-Proline Conversion in SILAC
This protocol provides a method to reduce the common issue of arginine-to-proline conversion in mammalian cell lines during SILAC experiments.
Materials:
-
SILAC-grade DMEM or RPMI-1640 medium lacking L-arginine and L-lysine
-
Dialyzed fetal bovine serum (dFBS)
-
"Heavy" ¹³C₆,¹⁵N₄-L-arginine
-
"Light" L-arginine
-
L-lysine
-
Unlabeled L-proline
-
Mammalian cell line of interest
Procedure:
-
Prepare "heavy" and "light" SILAC media. For the "heavy" medium, supplement with "heavy" arginine and the desired lysine isotope. For the "light" medium, supplement with "light" arginine and lysine.
-
To both "heavy" and "light" media, add unlabeled L-proline to a final concentration of at least 200 mg/L.[8]
-
Culture the cells in their respective SILAC media for at least 5-6 cell divisions to ensure complete incorporation of the labeled amino acids.
-
Proceed with your standard SILAC experimental workflow (e.g., cell treatment, lysis, protein digestion, and mass spectrometry analysis).
Visualizations
Caption: General overview of isotopic scrambling in ¹⁵N metabolic labeling.
Caption: Experimental workflow for ¹⁵N metabolic labeling and troubleshooting scrambling.
Caption: Glutamate metabolism and its role in ¹⁵N isotopic scrambling.
References
- 1. Measuring 15N and 13C Enrichment Levels in Sparsely Labeled Proteins Using High-Resolution and Tandem Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Specific isotopic labelling and reverse labelling for protein NMR spectroscopy: using metabolic precursors in sample preparation - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Prevention of Amino Acid Conversion in SILAC Experiments with Embryonic Stem Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 4. research-portal.uu.nl [research-portal.uu.nl]
- 5. A comprehensive assessment of selective amino acid 15N-labeling in human embryonic kidney 293 cells for NMR spectroscopy - PMC [pmc.ncbi.nlm.nih.gov]
- 6. A comprehensive assessment of selective amino acid 15N-labeling in human embryonic kidney 293 cells for NMR spectroscopy - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. SILAC Reagents and Sets â Cambridge Isotope Laboratories, Inc. [isotope.com]
- 8. researchgate.net [researchgate.net]
- 9. www2.mrc-lmb.cam.ac.uk [www2.mrc-lmb.cam.ac.uk]
- 10. 15N labeling of proteins in E. coli – Protein Expression and Purification Core Facility [embl.org]
Technical Support Center: Troubleshooting Proline Residue Assignment in 15N NMR Spectra
Welcome to the technical support center for researchers, scientists, and drug development professionals. This resource provides troubleshooting guides and frequently asked questions (FAQs) to address the specific challenges encountered during the assignment of proline residues in 15N NMR spectra.
Frequently Asked Questions (FAQs)
Q1: Why are my proline residues not visible in a standard 15N-HSQC spectrum?
Proline is unique among the 20 common amino acids because its side chain forms a cyclic structure by bonding back to the backbone nitrogen atom. This creates a secondary amine. In the predominant trans conformation of the peptide bond, this nitrogen is not directly bonded to a proton.[1][2][3][4] Standard 15N-HSQC (Heteronuclear Single Quantum Coherence) experiments rely on the scalar coupling between a 15N nucleus and its directly attached proton (¹H) for signal detection.[4][5] The absence of this N-H bond in proline means it will not generate a peak, rendering it "invisible" in these conventional spectra.[1][2][3][6]
Q2: I see multiple peaks for residues near a known proline. What is causing this peak doubling?
The peptide bond preceding a proline residue (the X-Pro bond) can exist in both cis and trans conformations. The energy barrier for the interconversion between these two isomers is high enough that the exchange is slow on the NMR timescale.[7][8][9] This slow isomerization results in distinct chemical environments for the residues neighboring the proline in both the cis and trans states, leading to the appearance of two separate sets of peaks for these residues.[7] The population of the minor cis conformer can be significant enough to be readily detected.[7]
Q3: What are the key NMR experiments to assign proline residues?
Several specialized NMR experiments are designed to overcome the challenges of proline assignment. These often involve detecting correlations through multiple bonds, rather than the direct one-bond N-H correlation.
-
Triple-Resonance Experiments (e.g., HNCA, HN(CO)CA, HNCACB): While not directly observing the proline nitrogen, these experiments are crucial for sequential backbone assignment. A "break" or interruption in the sequential walk (linking one amino acid to the next) is a strong indicator of a proline residue's location.[6]
-
13C-Detected Experiments: These experiments, which directly detect the 13C nucleus, are highly effective. For instance, a 2D 15N,13C CON spectrum can show correlations for proline residues, which appear in a distinct region of the spectrum.
-
Proline-Specific Pulse Sequences: Novel pulse sequences have been developed to establish sequential connectivities even in stretches of multiple prolines by correlating the Cδ and Cα chemical shifts of a proline with the Hα of the preceding residue.[10]
Troubleshooting Guide
This guide addresses common issues encountered during the assignment of proline residues.
| Problem | Potential Cause | Recommended Solution(s) |
| Missing Peaks in 15N-HSQC | The missing peak likely corresponds to one or more proline residues. | 1. Perform a full suite of 3D triple-resonance experiments (HNCA, HN(CO)CA, etc.) to carry out sequential backbone assignment. Identify breaks in the connectivity, which are hallmarks of proline residues.[6] 2. Acquire a 13C-detected experiment, such as a 15N,13C CON, to directly observe proline signals.[11] |
| Spectral Complexity (Peak Doubling) | Slow cis/trans isomerization of the X-Pro peptide bond is creating two sets of peaks for neighboring residues.[7] | 1. Acquire spectra at variable temperatures. If the peak doubling is due to conformational exchange, the peaks may broaden and coalesce at higher temperatures. 2. Use 2D ¹H,¹H-NOESY experiments to distinguish between cis and trans isomers based on the intensity of the Hα(i-1)-Hα(i) NOE peak.[7] |
| Break in Sequential Assignment Walk | A proline residue lacks the amide proton necessary to continue the standard sequential assignment pathway. | 1. Rely on through-space correlations from 3D 15N-edited NOESY-HSQC spectra to link residues on either side of the proline. 2. Utilize specialized experiments designed to "jump" over the proline by correlating residue i-1 with residue i+1. |
| Low Signal-to-Noise in Proline-Specific Experiments | These experiments often involve longer and more complex magnetization transfer pathways, leading to signal loss from relaxation. | 1. Optimize experimental parameters, including relaxation delays and the number of scans. 2. If available, use a higher-field NMR spectrometer and a cryoprobe to significantly enhance sensitivity. |
Experimental Protocols
Protocol: Identifying Proline Residues via Sequential Assignment Breaks
This protocol outlines a standard approach to pinpoint the location of proline residues in a protein backbone.
-
Sample Preparation: Prepare a uniformly ¹³C, ¹⁵N-labeled protein sample in an appropriate buffer for NMR analysis.
-
Data Acquisition: Acquire a standard set of 3D triple-resonance backbone assignment experiments. The minimal set typically includes:
-
3D HNCA
-
3D HN(CO)CA
-
3D HNCACB
-
3D CBCA(CO)NH
-
-
Data Processing: Process the acquired data using appropriate software (e.g., NMRPipe) to generate 3D spectra.
-
Sequential Linking:
-
Begin the assignment process by picking peaks in the 15N-HSQC as a reference.
-
Use the HNCA and HN(CO)CA (or HNCACB and CBCA(CO)NH) spectra to link the backbone atoms of one residue (i) to the next (i-1).
-
Systematically "walk" along the protein backbone by matching the Cα and Cβ chemical shifts.
-
-
Identifying Proline Locations:
-
A "break" in this sequential walk, where you can identify the atoms for a residue (i-1) but cannot find a corresponding HNCA correlation to link to residue i, strongly suggests that residue i is a proline.
-
Confirm this by observing that residue i+1 shows an HN(CO)CA correlation to the carbonyl carbon of residue i (the proline).
-
Visualizations
Caption: Identifying proline via breaks in the sequential assignment walk.
Caption: The effect of slow cis/trans isomerization on NMR spectra.
References
- 1. Exclusively heteronuclear NMR experiments for the investigation of intrinsically disordered proteins: focusing on proline residues - PMC [pmc.ncbi.nlm.nih.gov]
- 2. mr.copernicus.org [mr.copernicus.org]
- 3. Sequence-Specific Assignments for Intrinsically Disordered Proteins | Bruker [bruker.com]
- 4. chem.libretexts.org [chem.libretexts.org]
- 5. NMR Assignment through Linear Programming - PMC [pmc.ncbi.nlm.nih.gov]
- 6. marioschubert.ch [marioschubert.ch]
- 7. Proline cis/trans Isomerization in Intrinsically Disordered Proteins and Peptides [imrpress.com]
- 8. Proline Isomerization: From the Chemistry and Biology to Therapeutic Opportunities - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. A novel NMR experiment for the sequential assignment of proline residues and proline stretches in 13C/15N-labeled proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. sites.lsa.umich.edu [sites.lsa.umich.edu]
Technical Support Center: L-Proline-15N Labeled Protein NMR Resolution
This technical support center provides troubleshooting guidance and frequently asked questions to assist researchers, scientists, and drug development professionals in improving the resolution of NMR spectra for proteins labeled with L-Proline-15N.
Frequently Asked Questions (FAQs)
Q1: Why is achieving high resolution in NMR spectra of this compound labeled proteins often challenging?
A1: Several factors contribute to the challenges in obtaining high-resolution NMR spectra for proline-containing proteins. The most significant is the cis-trans isomerization of the peptide bond preceding a proline residue.[1][2][3] This isomerization occurs on a timescale that is often comparable to the NMR timescale, leading to line broadening and, in some cases, the appearance of two distinct sets of peaks for residues near the proline.[1] Additionally, proline residues lack an amide proton, which means they are not observable in standard 1H-15N HSQC experiments, requiring specialized NMR techniques for their direct detection.[4][5]
Q2: How does the cis-trans isomerization of proline affect NMR spectra?
A2: The peptide bond preceding a proline residue can exist in either a cis or a trans conformation. The energy barrier for interconversion between these two states is relatively low, allowing for exchange between the two forms.[3] If the rate of this exchange is slow on the NMR timescale, two separate peaks will be observed for each isomer. If the exchange is fast, a single, averaged peak will be seen. However, if the exchange rate is intermediate, significant line broadening will occur, potentially rendering the peaks undetectable. The ratio of cis to trans isomers can be influenced by the neighboring amino acid sequence, solvent conditions, and temperature.[2][6][7]
Q3: What are the best practices for preparing an this compound labeled protein sample for NMR?
A3: High-quality NMR spectra begin with a well-prepared sample. Key considerations include:
-
Concentration: Protein concentrations should ideally be between 0.2 and 1 mM.[8] For smaller proteins or peptides, concentrations of 2-5 mM may be achievable.[9]
-
Purity: The protein sample should be of high purity, free from contaminants and aggregates.
-
Buffer Conditions: Use a buffer with a pH that ensures protein stability and minimizes the exchange of amide protons. A pH below 7 is generally recommended.[10] The buffer concentration should be kept low (ideally around 20 mM) to reduce viscosity.[8] Phosphate buffers are a good, economical choice.[8]
-
Ionic Strength: Keep the ionic strength as low as possible to maintain protein solubility and stability, as high ionic strength can decrease the sensitivity of NMR experiments.[11] A salt concentration below 100 mM is advisable.[12]
-
Additives: The sample should contain 5-10% D2O for the spectrometer lock.[10][12]
Q4: Are there specific NMR experiments designed for observing proline residues?
A4: Yes, since prolines lack an amide proton, they are not visible in conventional 1H-15N correlation experiments. Specialized experiments that detect the 15N nucleus via its coupling to backbone and sidechain carbons are necessary. Examples include 13C-detected CON experiments and specialized 3D experiments like (H)CBCACONPro, which are designed to specifically observe proline resonances.[4][13] These experiments are crucial for obtaining complete backbone assignments of proline-rich proteins.
Troubleshooting Guide
Poor resolution in your this compound labeled protein NMR spectrum can arise from various factors. The following table outlines common problems, their potential causes, and suggested solutions.
| Problem | Potential Cause(s) | Suggested Solution(s) |
| Broad Peaks Throughout the Spectrum | - Protein aggregation- High sample viscosity- Suboptimal buffer conditions (pH, ionic strength) | - Optimize protein concentration.- Check for aggregation using dynamic light scattering (DLS).- Reduce buffer and salt concentrations.- Optimize pH for maximum protein stability. |
| Multiple Peaks or Severe Broadening for Residues Near Proline | - Intermediate exchange due to cis-trans isomerization of the X-Pro peptide bond. | - Vary the temperature of the NMR experiment. Lowering the temperature may slow the exchange enough to resolve separate cis and trans peaks. Conversely, increasing the temperature might accelerate the exchange into the fast regime, resulting in a single sharp peak.- Modify the solvent conditions (e.g., change pH, add organic co-solvents) to shift the cis-trans equilibrium. |
| Low Signal-to-Noise Ratio | - Low protein concentration- High salt concentration- Sample degradation | - Increase protein concentration if possible.- Reduce the ionic strength of the buffer.[11]- Ensure the protein is stable over the course of the experiment.[9] |
| Missing Proline Resonances | - Proline residues are not detectable in standard 1H-15N HSQC experiments. | - Utilize specialized NMR experiments such as 13C-detected CON or proline-specific 3D experiments.[4][13] |
Experimental Protocols
Protocol 1: Optimizing Sample Temperature to Resolve Proline Isomers
-
Initial Spectrum: Acquire a standard 2D 1H-15N HSQC spectrum at the standard experimental temperature (e.g., 298 K).
-
Temperature Titration: Incrementally decrease the temperature by 2-5 K and acquire a new spectrum at each temperature point. Monitor the line widths and chemical shifts of the peaks corresponding to residues near proline.
-
Analyze Spectra: Observe if the broad peaks begin to resolve into two distinct sets of resonances at lower temperatures, corresponding to the cis and trans isomers.
-
High-Temperature Experiment (Optional): If lowering the temperature does not improve resolution, incrementally increase the temperature above the initial setpoint. This may push the isomerization into the fast exchange regime, resulting in a single, sharp, averaged peak.
Protocol 2: Paramagnetic Relaxation Enhancement (PRE) for Structural Insights
For situations where line broadening is severe and prevents the determination of structural restraints from traditional NOE experiments, PRE can provide valuable long-range distance information.[14]
-
Site-Directed Mutagenesis: Introduce a cysteine residue at a specific, solvent-accessible location on the protein surface.
-
Spin Labeling: Attach a paramagnetic spin label, such as MTSL, to the cysteine residue.
-
NMR Data Acquisition: Acquire two sets of NMR spectra: one with the paramagnetic (oxidized) spin label and another with the diamagnetic (reduced) form. The reduction can be achieved by adding a twofold excess of a reducing agent like ascorbic acid.[14]
-
Data Analysis: Calculate the intensity ratio of the peaks in the paramagnetic versus the diamagnetic spectra (Ipara/Idia). This ratio is related to the distance between the paramagnetic center and the observed nucleus. PREs can provide distance restraints up to ~25 Å.[14]
Visualizations
Caption: Troubleshooting workflow for poor NMR resolution.
Caption: Cis-trans isomerization of the X-Pro peptide bond.
References
- 1. pubs.acs.org [pubs.acs.org]
- 2. 1H- and 13C-NMR investigations on cis-trans isomerization of proline peptide bonds and conformation of aromatic side chains in H-Trp-(Pro)n-Tyr-OH peptides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. article.imrpress.com [article.imrpress.com]
- 4. mr.copernicus.org [mr.copernicus.org]
- 5. 15N-detected TROSY NMR experiments to study large disordered proteins in high-field magnets - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Proline cis/trans Isomerization in Intrinsically Disordered Proteins and Peptides [imrpress.com]
- 7. researchgate.net [researchgate.net]
- 8. Sample Requirements - University of Birmingham [birmingham.ac.uk]
- 9. nmr-bio.com [nmr-bio.com]
- 10. Structure Biology by NMR [imserc.northwestern.edu]
- 11. scribd.com [scribd.com]
- 12. www2.mrc-lmb.cam.ac.uk [www2.mrc-lmb.cam.ac.uk]
- 13. Exclusively heteronuclear NMR experiments for the investigation of intrinsically disordered proteins: focusing on proline residues - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Paramagnetic relaxation enhancement‐assisted structural characterization of a partially disordered conformation of ubiquitin - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: L-Proline-15N In Vivo Enrichment
Welcome to the technical support center for L-Proline-15N enrichment in vivo. This resource is designed for researchers, scientists, and drug development professionals to provide troubleshooting guidance and frequently asked questions (FAQs) to enhance the success of your stable isotope labeling experiments.
Troubleshooting Guide
This guide addresses common issues encountered during in vivo this compound labeling experiments.
Question: We are observing low 15N enrichment in our target protein/tissue. What are the potential causes and solutions?
Answer:
Low 15N enrichment is a common challenge in in vivo labeling studies. Several factors can contribute to this issue. Below is a systematic guide to troubleshoot and enhance your this compound incorporation.
1. This compound Administration Strategy:
The route and timing of administration can significantly impact the bioavailability of the labeled proline.
-
Bolus Injection vs. Constant Infusion: A single high-dose bolus injection can lead to a rapid but transient peak in plasma 15N-proline concentration. In contrast, constant infusion maintains a steadier plasma concentration, which may be advantageous for achieving consistent labeling over a longer period. For proteins with slow turnover, a constant infusion or multiple bolus injections are recommended.
-
Route of Administration: Intravenous (IV) or intraperitoneal (IP) injections generally lead to more rapid and complete absorption compared to oral administration. For rodents, IP injection is a common and effective method. One study on glyproline peptides in rats suggested that intranasal administration was optimal for delivery to the central nervous system.[1]
2. Dietary Considerations:
The animal's diet is a critical factor that can dilute the 15N-labeled proline pool.
-
Unlabeled Proline in Diet: Standard chow contains unlabeled proline, which competes with the 15N-labeled proline for incorporation into proteins. To maximize enrichment, switch animals to a custom diet with a defined, low-proline content or a completely proline-free diet supplemented with this compound. For comprehensive labeling, consider diets where the sole nitrogen source is 15N-enriched, such as those containing 15N-Spirulina.
-
Acclimatization to Special Diets: Animals may require an acclimatization period to a new diet to avoid stress and ensure normal feeding behavior, which could otherwise affect metabolic rates.
-
Fasting: Short-term fasting prior to administration of this compound can lower the endogenous pool of unlabeled amino acids, potentially increasing the initial uptake and incorporation of the labeled tracer.
3. Host-Specific Factors:
The metabolic state of the animal can influence the uptake and utilization of L-proline.
-
Age and Growth Rate: Younger, growing animals generally have higher rates of protein synthesis and may incorporate this compound more rapidly than older, mature animals.
-
Tissue-Specific Turnover Rates: Different tissues have vastly different protein turnover rates. For example, liver proteins turn over more rapidly than brain proteins.[2] Consequently, achieving high enrichment in tissues with slow turnover, like the brain, requires longer labeling periods.[2]
-
Metabolic State: Pathological conditions or experimental manipulations that alter metabolism can affect proline utilization. For instance, some cancer cells exhibit altered proline metabolism.
4. Metabolic Scrambling and Dilution:
The body can synthesize proline de novo from other amino acids, primarily glutamate and arginine, which can dilute the 15N label.
-
Endogenous Synthesis: While L-proline is considered a non-essential amino acid in most adult mammals, endogenous synthesis can still contribute to the proline pool. In neonates, the capacity for endogenous proline synthesis is limited.
-
Metabolic Interconversion: The nitrogen from 15N-proline can potentially be transferred to other amino acids through transamination reactions, although this is less common for the imino acid proline compared to other amino acids.
5. Experimental Protocol and Sample Handling:
-
Purity of this compound: Ensure the isotopic purity of your this compound is high (ideally >98%).
-
Accurate Quantification: Use appropriate analytical methods, such as mass spectrometry, to accurately determine the percentage of 15N enrichment.
Summary of Troubleshooting Strategies
| Issue | Potential Cause | Recommended Solution |
| Low 15N Enrichment | Inefficient delivery of this compound. | Optimize administration route (IV or IP) and consider constant infusion for long-term studies. |
| Dilution from dietary unlabeled proline. | Switch to a low-proline or proline-free custom diet. Use a 15N-enriched diet for global labeling. | |
| Slow protein turnover in the target tissue. | Increase the duration of the labeling period, especially for tissues like the brain. | |
| Dilution from endogenous proline synthesis. | Consider the age and metabolic state of the animal. Short-term fasting may help. | |
| Inaccurate measurement of enrichment. | Validate your analytical methods (e.g., mass spectrometry) for quantifying 15N incorporation. |
Frequently Asked Questions (FAQs)
Q1: What is a realistic target for this compound enrichment in vivo?
A1: The achievable enrichment varies significantly depending on the tissue, the duration of labeling, and the experimental design. For tissues with high protein turnover like the liver, enrichment levels of over 90% can be achieved with a 15N-enriched diet over several weeks.[2] For tissues with slower turnover, such as the brain, achieving similar levels of enrichment will take longer.[2] For pulse-chase experiments with a single dose of this compound, the enrichment in specific proteins will be lower and will depend on the protein's synthesis rate. It is recommended to aim for a labeling efficiency of 97% or higher for high-quality quantitative data.[3]
Q2: How do I choose between a single bolus injection and continuous infusion of this compound?
A2: The choice depends on the goals of your study.
-
Bolus Injection: Best for pulse-chase studies where you want to track the fate of a single dose of proline over a short period. It is logistically simpler than continuous infusion.
-
Continuous Infusion: Ideal for studies aiming to achieve a steady-state labeling of proteins, especially those with slower turnover rates. It provides a more constant precursor pool enrichment.
Q3: Can I administer this compound orally?
A3: Oral administration is possible, but it may lead to lower and more variable bioavailability due to first-pass metabolism in the gut and liver. For precise and reproducible labeling, direct injection (IV or IP) is generally preferred.
Q4: Are there any known inhibitors of proline metabolism that could affect my experiment?
A4: Yes, there are compounds that can inhibit enzymes involved in proline metabolism. For example, L-tetrahydro-2-furoic acid is a known inhibitor of proline dehydrogenase (PRODH), the enzyme that catabolizes proline. While these are not typically used to enhance enrichment, it is important to be aware of any compounds in your experimental system that might interfere with proline metabolism.
Q5: How can I minimize the amount of expensive this compound I need to use?
A5: To use the labeled compound efficiently:
-
Optimize the Diet: Using a proline-free diet will reduce the amount of unlabeled proline competing for incorporation, meaning you may be able to use a lower dose of the labeled tracer.
-
Targeted Delivery: If you are interested in a specific organ, consider localized delivery methods if feasible, although this is often complex.
-
Pilot Studies: Conduct small-scale pilot studies to determine the optimal dose and time course for your specific model and experimental question before scaling up.
Experimental Protocols
Protocol 1: Bolus Intraperitoneal Injection of this compound in Mice
This protocol is suitable for pulse-chase experiments to measure protein synthesis rates.
Materials:
-
This compound (isotopic purity >98%)
-
Sterile phosphate-buffered saline (PBS)
-
Syringes and needles (e.g., 27-gauge)
-
Animal scale
Procedure:
-
Preparation of Dosing Solution:
-
Dissolve the this compound in sterile PBS to the desired concentration. A typical dose might range from 50 to 200 mg/kg body weight, but this should be optimized for your specific experiment.
-
Ensure the solution is sterile, for example, by filtering through a 0.22 µm syringe filter.
-
-
Animal Preparation:
-
Acclimatize mice to the housing conditions.
-
For some studies, a short fasting period (e.g., 4-6 hours) before injection can be beneficial to lower the endogenous amino acid pool. Ensure water is available at all times.
-
-
Administration:
-
Weigh the mouse immediately before injection to calculate the precise volume of the dosing solution.
-
Administer the this compound solution via intraperitoneal (IP) injection.
-
-
Time Course and Sample Collection:
-
Collect tissues or blood samples at predetermined time points after the injection. The timing will depend on the turnover rate of the protein or metabolite of interest. For rapidly synthesized proteins, time points within a few hours may be sufficient. For proteins with slower turnover, longer time points (e.g., 24, 48, 72 hours) will be necessary.
-
-
Sample Processing and Analysis:
-
Process the collected tissues to isolate proteins or metabolites of interest.
-
Determine the 15N enrichment using an appropriate analytical technique, such as mass spectrometry.
-
Protocol 2: Dietary Administration of 15N-Enriched Spirulina for Global Labeling in Rodents
This protocol is designed for achieving high, steady-state 15N enrichment across all tissues.
Materials:
-
15N-enriched Spirulina powder (>98% 15N)
-
Protein-free rodent chow powder
-
Water
-
Pellet maker (optional)
Procedure:
-
Preparation of 15N-Enriched Diet:
-
Mix the 15N-enriched Spirulina with the protein-free chow powder. A common ratio is 1 part Spirulina to 3 parts chow powder by weight.
-
To create pellets, add a small amount of water to the powder mixture to form a dough-like consistency.
-
Press the dough into pellets using a pellet maker or by hand and allow them to dry.
-
-
Animal Feeding:
-
For optimal enrichment, especially in tissues with slow turnover, it is best to start the 15N diet with pregnant dams, so the pups are exposed to the 15N source from birth.
-
Alternatively, start the diet with young, weanling animals.
-
Provide the 15N-enriched diet and water ad libitum.
-
-
Labeling Duration and Sample Collection:
-
The duration of the feeding will determine the level of enrichment. For tissues like the liver, high enrichment (>90%) can be achieved in a few weeks. For the brain, a longer period (e.g., several months) may be necessary to reach a similar level.
-
Collect tissues at the end of the labeling period.
-
-
Sample Processing and Analysis:
-
Process the tissues and analyze for 15N enrichment as described in Protocol 1.
-
Visualizations
Proline Metabolism and Transport Pathway
Caption: Overview of this compound uptake, incorporation, and catabolism.
Experimental Workflow for Enhancing In Vivo this compound Enrichment
Caption: A logical workflow for designing and executing in vivo this compound labeling experiments.
References
Validation & Comparative
L-Proline-15N vs. L-Proline-13C5: A Comparative Guide for Protein NMR Studies
For Researchers, Scientists, and Drug Development Professionals
In the realm of protein nuclear magnetic resonance (NMR) spectroscopy, isotopic labeling is a cornerstone technique for elucidating protein structure, dynamics, and interactions at an atomic level. Among the twenty common amino acids, proline presents unique challenges and opportunities due to its secondary amine and cyclic side chain. The choice between L-Proline-15N and L-Proline-13C5 labeling is not merely a matter of preference but a strategic decision dictated by the specific scientific questions being addressed. This guide provides an objective comparison of these two isotopic labeling strategies, supported by experimental data and detailed methodologies, to aid researchers in making informed decisions for their protein NMR studies.
Executive Summary
The fundamental difference between this compound and L-Proline-13C5 labeling lies in the specific nucleus that is made NMR-active. This compound introduces a spin-1/2 nitrogen isotope, while L-Proline-13C5 incorporates spin-1/2 carbon isotopes throughout the proline ring and carboxyl group. A critical consideration for proline is its lack of an amide proton in the peptide backbone. This renders it "invisible" in standard ¹H-¹⁵N Heteronuclear Single Quantum Coherence (HSQC) experiments, which are the workhorse of protein NMR for observing backbone amides.[1] Consequently, ¹⁵N labeling of proline alone is of limited utility for backbone resonance assignment using conventional methods.
Conversely, ¹³C labeling of proline, particularly uniform labeling as with L-Proline-¹³C5, enables the direct detection of proline's carbon signals. This allows for the unambiguous identification and assignment of proline residues, as well as the characterization of their unique conformational properties, such as cis-trans isomerization and ring puckering. Often, a combination of both ¹⁵N and ¹³C labeling is employed in advanced multi-dimensional NMR experiments to gain the most comprehensive insights into proline-containing proteins.
Data Presentation: Quantitative Comparison of Labeling Strategies
The following table summarizes the key quantitative and qualitative differences between this compound and L-Proline-13C5 labeling for protein NMR studies. It's important to note that often, for comprehensive proline analysis, double-labeling with both ¹³C and ¹⁵N is the most powerful approach.
| Feature | This compound Labeling | L-Proline-13C5 Labeling | Uniform ¹³C, ¹⁵N Double Labeling |
| Primary Nucleus Observed | ¹⁵N | ¹³C | ¹³C and ¹⁵N |
| Visibility in ¹H-¹⁵N HSQC | Not directly observed due to lack of amide proton. | Not applicable. | Proline ¹⁵N is not seen in ¹H-¹⁵N HSQC, but other residues are. |
| Visibility in ¹H-¹³C HSQC | Not applicable. | All five proline carbons (Cα, Cβ, Cγ, Cδ, C') can be observed. | All five proline carbons can be observed and correlated to protons. |
| Typical Chemical Shift Range (ppm) | Proline ¹⁵N: ~135-145 ppm (in specialized experiments) | Proline ¹³Cα: ~63 ppm, ¹³Cβ: ~32 ppm, ¹³Cγ: ~28 ppm, ¹³Cδ: ~50 ppm, ¹³C': ~177 ppm | Same as ¹³C5 labeling for carbons. |
| Information Gained | Limited for proline alone. Can be used in specialized ¹³C-detected experiments to correlate to the proline ¹⁵N. | - Proline identification and assignment- cis/trans isomerization state- Proline ring pucker analysis | - Sequential backbone assignment of residues preceding proline- Side-chain assignments of proline- Detailed structural and dynamic studies |
| Relative Sensitivity | Low for proline due to indirect detection methods. | Higher for direct ¹³C detection compared to indirect ¹⁵N detection of proline. | High, enables a wide range of triple-resonance experiments. |
| Cost Consideration | Generally less expensive than ¹³C-labeled amino acids. | Generally more expensive than ¹⁵N-labeled amino acids. | Most expensive option. |
| Primary Application | Used in conjunction with ¹³C labeling for advanced experiments. | - Studies of proline-rich motifs- Analysis of collagen and other proline-rich proteins- Investigating proline dynamics | - De novo protein structure determination- Detailed interaction studies involving proline residues |
Experimental Protocols
Protein Expression and Isotopic Labeling in E. coli
A standard method for producing isotopically labeled proteins for NMR studies is through overexpression in Escherichia coli grown in minimal media supplemented with the desired isotopes.
1. Preparation of M9 Minimal Media:
-
Prepare 1 L of 5x M9 salts solution (64 g Na₂HPO₄·7H₂O, 15 g KH₂PO₄, 2.5 g NaCl, 5.0 g NH₄Cl). For ¹⁵N labeling, substitute NH₄Cl with ¹⁵NH₄Cl.
-
Autoclave the M9 salts solution.
-
Separately prepare and autoclave solutions of:
-
20% (w/v) glucose (for ¹³C labeling, use ¹³C-glucose)
-
1 M MgSO₄
-
1 M CaCl₂
-
2. Culture Growth and Induction:
-
Inoculate a 50 mL starter culture of LB medium with a single colony of E. coli (e.g., BL21(DE3)) transformed with the expression plasmid for the protein of interest. Grow overnight at 37°C.
-
The next day, inoculate 1 L of M9 minimal medium (containing the appropriate isotopes) with the overnight starter culture.
-
Grow the culture at 37°C with shaking until the optical density at 600 nm (OD₆₀₀) reaches 0.6-0.8.
-
Induce protein expression by adding isopropyl β-D-1-thiogalactopyranoside (IPTG) to a final concentration of 0.5-1 mM.
-
For selective proline labeling, the growth medium can be supplemented with the desired isotopically labeled L-proline just before induction. This is particularly useful for avoiding metabolic scrambling of the isotopes.
-
Continue to grow the culture for 4-6 hours at a reduced temperature (e.g., 18-25°C) to improve protein folding and solubility.
3. Cell Harvesting and Protein Purification:
-
Harvest the cells by centrifugation.
-
Resuspend the cell pellet in a suitable lysis buffer and lyse the cells by sonication or high-pressure homogenization.
-
Clarify the lysate by centrifugation.
-
Purify the protein of interest from the supernatant using appropriate chromatography techniques (e.g., affinity chromatography, ion-exchange chromatography, size-exclusion chromatography).
NMR Spectroscopy of Proline Residues
1. ¹³C-detected 2D CON Experiment: This experiment is crucial for observing proline residues as it correlates the carbonyl carbon (C') of a residue with the nitrogen (N) of the following residue. For a residue preceding a proline, this will show a correlation to the proline ¹⁵N.
-
Sample Preparation: Purified, uniformly ¹³C, ¹⁵N-labeled protein at a concentration of 0.1-1.0 mM in a suitable NMR buffer (e.g., 20 mM sodium phosphate, 50 mM NaCl, pH 6.5) containing 10% D₂O.
-
Spectrometer: A high-field NMR spectrometer (≥600 MHz) equipped with a cryoprobe is recommended.
-
Pulse Sequence: A standard 2D CON pulse sequence.
-
Data Acquisition: Acquire a 2D spectrum with appropriate spectral widths in the ¹³C and ¹⁵N dimensions to cover the expected chemical shifts.
-
Data Processing: Process the data using software such as NMRPipe and analyze the spectra using programs like Sparky or CARA.
2. ¹³C-detected 3D (H)CBCACON Experiment: This triple-resonance experiment is a key tool for the sequential assignment of proline residues by linking the Cα and Cβ chemical shifts of a residue to the nitrogen of the subsequent residue.
-
Sample and Spectrometer: Same as for the 2D CON experiment.
-
Pulse Sequence: A standard 3D (H)CBCACON pulse sequence.
-
Data Acquisition and Processing: Acquire and process the 3D data to obtain correlations between Cα/Cβ and N chemical shifts.
Mandatory Visualization
Caption: Experimental workflow for producing and analyzing isotopically labeled proteins by NMR.
Signaling Pathway and Structural Context
Proline-rich motifs are crucial for mediating protein-protein interactions in a vast number of cellular signaling pathways.[2] SH3 (Src Homology 3) domains, for example, are small protein modules that specifically recognize and bind to proline-rich sequences, often containing a consensus PxxP motif.[2][3] The conformation of the proline residues within these motifs is critical for high-affinity binding. NMR spectroscopy, empowered by isotopic labeling, is an invaluable tool for characterizing these interactions.
Caption: SH3 domain recognition of a proline-rich motif in a signaling cascade.
The unique cyclic structure of proline also plays a critical role in the conformation of structural proteins like collagen. The stability of the collagen triple helix is highly dependent on the ring pucker of its abundant proline and hydroxyproline residues.[4][5][6] NMR studies utilizing ¹³C-labeled proline can directly probe the endo and exo pucker conformations of the pyrrolidine ring, providing insights into collagen stability and dynamics.[4]
Caption: The conformational equilibrium of proline ring pucker influencing protein stability.
Conclusion
The choice between L-Proline-¹⁵N and L-Proline-¹³C5 for protein NMR studies is determined by the experimental goals. Due to the absence of an amide proton, ¹⁵N-labeling of proline alone provides limited information through standard NMR techniques. In contrast, ¹³C5-labeling is essential for the direct observation and characterization of proline residues. For comprehensive structural and dynamic studies of proline-containing proteins, a dual ¹³C and ¹⁵N labeling strategy is often the most powerful approach, enabling a suite of advanced NMR experiments that can unravel the intricate roles of proline in protein function and interactions. Researchers should carefully consider the specific information required and the available instrumentation when designing their isotopic labeling strategy for proline-centric NMR investigations.
References
- 1. protein-nmr.org.uk [protein-nmr.org.uk]
- 2. Specificity and versatility of SH3 and other proline-recognition domains: structural basis and implications for cellular signal transduction - PMC [pmc.ncbi.nlm.nih.gov]
- 3. ucsf-cmp.github.io [ucsf-cmp.github.io]
- 4. Solid-state NMR Study Reveals Collagen I Structural Modifications of Amino Acid Side Chains upon Fibrillogenesis - PMC [pmc.ncbi.nlm.nih.gov]
- 5. pubs.acs.org [pubs.acs.org]
- 6. COLLAGEN STRUCTURE AND STABILITY - PMC [pmc.ncbi.nlm.nih.gov]
L-Proline-15N vs. L-Leucine-15N: A Comparative Guide for Metabolic Tracers
For Researchers, Scientists, and Drug Development Professionals
The use of stable isotope-labeled amino acids as metabolic tracers is a cornerstone of modern biomedical research, enabling the precise tracking and quantification of metabolic pathways in vivo and in vitro. Among these, L-Proline-15N and L-Leucine-15N are two of the most frequently utilized tracers for studying protein synthesis and other metabolic processes. This guide provides an objective comparison of their performance, supported by experimental data, to aid researchers in selecting the optimal tracer for their specific experimental needs.
At a Glance: Key Differences and Applications
| Feature | This compound | L-Leucine-15N |
| Primary Application | Collagen and skin protein synthesis, connective tissue metabolism. | Muscle protein synthesis, whole-body protein turnover. |
| Metabolic Fate | Primarily non-essential, readily synthesized and degraded. Catabolized to glutamate. | Essential amino acid, ketogenic. Catabolized to Acetyl-CoA and acetoacetate. |
| Precursor Pool Complexity | Can be complex due to intracellular synthesis and compartmentation, potentially complicating data interpretation. | Simpler precursor pool kinetics as it is an essential amino acid and not synthesized de novo in mammals. |
| mTOR Signaling | Can activate the mTORC1 signaling pathway. | Potent activator of the mTORC1 signaling pathway, a key regulator of protein synthesis. |
Performance in Key Research Areas
Collagen and Skin Protein Synthesis
L-Proline is a major constituent of collagen, the most abundant protein in mammals, making this compound an excellent tracer for studying its synthesis. A comparative study in rabbits investigating skin protein synthesis found that orally administered this compound was incorporated into skin proteins more rapidly and to a greater extent than L-[1-13C]-Leucine[1]. This suggests that for tissues rich in collagen, such as skin, this compound is the more sensitive and appropriate tracer.
However, studies in cultured fibroblasts have highlighted a potential complication with using isotopic proline. The intracellular precursor pool for protein synthesis may not readily equilibrate with the extracellular tracer, a phenomenon known as compartmentation[2]. This can lead to an underestimation of the true synthesis rate if not properly accounted for.
Muscle Protein Synthesis
L-Leucine is a branched-chain amino acid (BCAA) that not only serves as a building block for protein but also acts as a potent signaling molecule. It is a well-established activator of the mechanistic target of rapamycin complex 1 (mTORC1) pathway, a central regulator of muscle protein synthesis. Consequently, L-Leucine-15N is extensively used to measure muscle protein synthesis rates in various physiological and pathological conditions. Studies have shown that infusion of [15N]leucine can be used to estimate proteolysis and protein synthesis in humans[3]. The essential nature of leucine simplifies the modeling of its kinetics, as its intracellular pool is primarily derived from extracellular sources and protein breakdown.
Quantitative Data Summary
The following table summarizes quantitative data from studies utilizing L-Proline and L-Leucine as metabolic tracers. It is important to note that direct comparative studies using the 15N-labeled versions of both amino acids across various applications are limited. The data presented here is a compilation from different studies to provide a comparative overview.
| Parameter | This compound | L-Leucine-15N | Reference Study |
| Incorporation into Skin Proteins (rabbits, in vivo) | Higher incorporation observed | Lower incorporation observed | Doumit et al., 1999[1] |
| Plasma Clearance (rabbits, in vivo) | Cleared within 8 hours | Cleared within 8 hours | Doumit et al., 1999[1] |
| Precursor Pool Equilibration (cultured fibroblasts) | Does not readily equilibrate with tRNA-bound proline | Equilibrates with tRNA-leucine at 0.4 mM | Low et al., 1986[2] |
| Muscle Protein Synthesis Measurement | Not a primary tracer for this application | Widely used and validated | Various sources |
| Endogenous Nitrogen Flux Measurement (human jejunum) | Not directly measured in the cited study | Used to differentiate endogenous and exogenous nitrogen | Mariotti et al., 1998 |
Signaling Pathways
Both L-Proline and L-Leucine can influence the mTORC1 signaling pathway, a critical regulator of cell growth and protein synthesis. However, L-Leucine is recognized as a more potent and direct activator.
Caption: Activation of the mTORC1 pathway by L-Proline and L-Leucine.
Experimental Protocols
General Workflow for in vivo Metabolic Tracer Studies
The following diagram outlines a general experimental workflow for using 15N-labeled amino acids as metabolic tracers in in vivo studies. Specific details will vary based on the research question, model organism, and analytical method.
References
- 1. A comparison of 15N proline and 13C leucine for monitoring protein biosynthesis in the skin - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Comparison of the use of isotopic proline vs leucine to measure protein synthesis in cultured fibroblasts - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. journals.physiology.org [journals.physiology.org]
A Researcher's Guide to Validating Protein-Ligand Binding: 15N Chemical Shift Perturbation in Focus
For researchers, scientists, and drug development professionals, confirming the direct binding of a ligand to its target protein is a critical step in the discovery pipeline. Nuclear Magnetic Resonance (NMR) spectroscopy, specifically the monitoring of 15N chemical shift perturbations (CSPs), offers a powerful and detailed method for this validation. This guide provides an in-depth comparison of 15N CSP with other widely used biophysical techniques, supported by experimental data and detailed protocols, to aid in the selection of the most appropriate method for your research needs.
Introduction to Protein-Ligand Binding Validation
The interaction between a protein and a small molecule ligand is the fundamental basis for the therapeutic effect of most drugs. Validating this binding event and accurately quantifying its affinity are essential for structure-activity relationship (SAR) studies and lead optimization. A variety of biophysical techniques are available, each with its own set of advantages and limitations. This guide will focus on 15N HSQC-based chemical shift perturbation as a primary validation tool and provide a comparative analysis with Isothermal Titration Calorimetry (ITC), Surface Plasmon Resonance (SPR), Biolayer Interferometry (BLI), and Microscale Thermophoresis (MST).
15N Chemical Shift Perturbation (CSP): A Detailed Look
Principle: 15N CSP is an NMR-based technique that detects changes in the chemical environment of individual amino acids within a protein upon ligand binding. By isotopically labeling the protein with 15N, a 2D Heteronuclear Single Quantum Coherence (HSQC) spectrum can be acquired, which displays a peak for each backbone amide proton-nitrogen pair. When a ligand binds, it perturbs the local magnetic environment of nearby amino acid residues, causing a shift in the position of their corresponding peaks in the HSQC spectrum. These perturbations provide residue-specific information about the binding site and can be used to determine the dissociation constant (Kd) of the interaction.
Data Presentation: Quantitative Comparison of Biophysical Methods
The choice of a biophysical assay can be influenced by factors such as sample consumption, throughput, and the type of data required. The following table summarizes key quantitative parameters for 15N CSP and its alternatives. Note: The values presented are representative and can vary depending on the specific protein-ligand system and experimental conditions.
| Technique | Dissociation Constant (Kd) Range | Sample Consumption (Protein) | Throughput | Provides Kinetic Data (ka, kd) | Labeling Required |
| 15N CSP | µM to mM | mg | Low to Medium | No (qualitative information on exchange rate) | Yes (15N) |
| ITC | nM to µM | mg | Low | No | No |
| SPR | pM to mM | µg | Medium to High | Yes | No (one binding partner is immobilized) |
| BLI | nM to µM | µg | High | Yes | No (one binding partner is immobilized) |
| MST | nM to mM | µg | High | No | Yes (fluorescent label) or label-free (intrinsic tryptophan fluorescence) |
Experimental Protocols
15N Chemical Shift Perturbation (CSP) Experimental Protocol
-
Sample Preparation:
-
Express and purify the target protein with uniform 15N labeling using a minimal medium containing 15NH4Cl as the sole nitrogen source.
-
Prepare a concentrated stock solution of the ligand in a buffer compatible with the NMR experiment. The final DMSO concentration should be kept low (typically <5%) to avoid protein denaturation.
-
Prepare a series of NMR samples containing a constant concentration of the 15N-labeled protein (typically 50-200 µM) and increasing concentrations of the ligand. A control sample with protein only is essential.
-
Ensure the buffer conditions (pH, salt concentration, temperature) are identical across all samples to avoid chemical shift changes due to buffer effects.
-
-
NMR Data Acquisition:
-
Acquire a 2D 1H-15N HSQC spectrum for each sample on an NMR spectrometer equipped with a cryoprobe.
-
Standard pulse programs like hsqcetfpf3gpsi are commonly used.
-
Ensure consistent acquisition parameters (temperature, spectral width, number of scans) across all experiments.
-
-
Data Processing and Analysis:
-
Process the NMR spectra using software such as TopSpin, NMRPipe, or CCPNmr.
-
Overlay the HSQC spectra of the protein in the absence and presence of the ligand.
-
Identify and assign the backbone amide resonances that show significant chemical shift perturbations upon ligand titration.
-
Calculate the weighted average chemical shift difference (Δδ) for each perturbed residue using the following equation: Δδ = √[(ΔδH)^2 + (α * ΔδN)^2] where ΔδH and ΔδN are the chemical shift changes in the proton and nitrogen dimensions, respectively, and α is a weighting factor (typically around 0.14-0.2).
-
To determine the dissociation constant (Kd), plot the chemical shift perturbation (Δδ) of significantly affected residues as a function of the ligand concentration and fit the data to a suitable binding isotherm (e.g., a one-site binding model).
-
Alternative Biophysical Method Protocols
Detailed protocols for the alternative techniques are summarized below:
| Technique | Key Experimental Steps |
| Isothermal Titration Calorimetry (ITC) | 1. Prepare protein and ligand solutions in identical, degassed buffer. 2. Load the protein into the sample cell and the ligand into the titration syringe. 3. Perform a series of injections of the ligand into the protein solution while monitoring the heat change. 4. Integrate the heat pulses and plot them against the molar ratio of ligand to protein to determine Kd, stoichiometry (n), and enthalpy (ΔH). |
| Surface Plasmon Resonance (SPR) | 1. Immobilize the ligand (or protein) onto a sensor chip surface. 2. Flow a series of concentrations of the analyte (the binding partner in solution) over the sensor surface. 3. Monitor the change in the refractive index in real-time to generate sensorgrams. 4. Analyze the sensorgrams to determine association (ka) and dissociation (kd) rate constants, from which the Kd is calculated (Kd = kd/ka). |
| Biolayer Interferometry (BLI) | 1. Immobilize the ligand (or protein) onto a biosensor tip. 2. Dip the biosensor into wells containing a series of analyte concentrations. 3. Measure the change in the interference pattern of light reflected from the biosensor surface in real-time. 4. Analyze the resulting binding curves to determine ka, kd, and Kd. |
| Microscale Thermophoresis (MST) | 1. Label the protein with a fluorescent dye (or use intrinsic tryptophan fluorescence). 2. Prepare a series of samples with a constant concentration of the labeled protein and varying concentrations of the ligand. 3. Load the samples into capillaries and measure the movement of the fluorescently labeled protein in a microscopic temperature gradient. 4. Plot the change in thermophoresis against the ligand concentration to determine the Kd. |
Mandatory Visualizations
Experimental Workflow for 15N Chemical Shift Perturbation
Caption: Workflow for 15N CSP experiments.
Logical Relationship of Protein-Ligand Binding Validation Methods
L-Proline-15N in Protein Structure Determination: A Comparative Guide
For Researchers, Scientists, and Drug Development Professionals
The precise determination of protein three-dimensional structures is paramount for understanding biological function and for the rational design of therapeutics. Nuclear Magnetic Resonance (NMR) spectroscopy is a powerful technique for elucidating protein structures in solution, providing insights into their dynamic nature. The accuracy of NMR-derived structures is critically dependent on the quality and quantity of experimental restraints, which are in turn influenced by the isotopic labeling strategy employed. This guide provides a comparative analysis of the role and accuracy of using L-Proline-15N in determining the structure of proteins, particularly those rich in proline residues, compared to standard uniform 15N labeling methods for other proteins.
Proline residues present unique challenges in protein NMR due to the absence of an amide proton, which is the primary reporter in many standard NMR experiments. Selective or uniform labeling with this compound provides a crucial observable nucleus, enabling the acquisition of specific restraints that are otherwise inaccessible. This leads to a more accurate and complete structural depiction, especially in proline-rich regions that are often functionally significant in protein-protein interactions.
Quantitative Comparison of Structural Accuracy
The following table presents a summary of typical structural statistics for a proline-rich protein determined using 15N labeling, including this compound, and a standard globular protein of similar size determined with uniform 15N labeling. These values are representative of high-quality NMR structures and highlight the impact of specific labeling on resolving challenging structural features.
| Structural Statistic | Proline-Rich Protein (with this compound) | Standard Globular Protein (Uniform 15N) | Significance |
| PDB ID (Example) | 2L86 (Human Amylin) | 2JVD (GB1 domain) | Representative examples |
| Number of Residues | 37 | 56 | Size comparison |
| Total NOE Restraints | 458 | 852 | Density of distance information |
| Dihedral Angle Restraints | 52 | 104 | Constraints on backbone conformation |
| Backbone RMSD (Å) | 0.45 ± 0.12 | 0.35 ± 0.08 | Precision of the backbone fold |
| Heavy Atom RMSD (Å) | 0.89 ± 0.15 | 0.75 ± 0.10 | Precision of all non-hydrogen atoms |
| % Residues in Favored Ramachandran Regions | 95.2% | 97.8% | Stereochemical quality |
| % Residues in Allowed Ramachandran Regions | 4.8% | 2.2% | Stereochemical quality |
| % Residues in Outlier Ramachandran Regions | 0.0% | 0.0% | Stereochemical quality |
Note: The data presented are synthesized from typical values reported in the literature for well-resolved NMR structures and are intended for illustrative comparison. RMSD (Root Mean Square Deviation) values are for the ensemble of final structures.
Experimental Protocols
The determination of protein structures by NMR involves several key stages, from sample preparation to structure calculation and validation. The protocols outlined below highlight the specific considerations for incorporating this compound.
Protein Expression and Isotopic Labeling
Objective: To produce a protein sample uniformly labeled with 15N, including this compound.
Protocol for Uniform 15N Labeling (including this compound):
-
Expression System: Escherichia coli is a commonly used expression host. The protein of interest is typically cloned into an expression vector under the control of an inducible promoter (e.g., T7).
-
Growth Media: A minimal medium (e.g., M9) is used to ensure that the sole nitrogen source is the isotopically labeled compound.
-
Isotope Source: The medium is supplemented with ¹⁵NH₄Cl as the sole nitrogen source. For proline labeling, ¹⁵N-L-proline can be added to the growth medium, particularly for auxotrophic strains or to ensure high incorporation levels.
-
Cell Growth and Induction: Cells are grown at 37°C to an optimal density (OD₆₀₀ of 0.6-0.8). Protein expression is then induced by adding isopropyl β-D-1-thiogalactopyranoside (IPTG).
-
Harvesting and Purification: After several hours of induction, cells are harvested by centrifugation. The protein is then purified from the cell lysate using standard chromatographic techniques (e.g., affinity, ion exchange, and size-exclusion chromatography).
NMR Data Acquisition
Objective: To acquire a set of NMR spectra that provide through-bond and through-space correlations for resonance assignment and distance restraint generation.
Key Experiments:
-
2D ¹H-¹⁵N HSQC: This is the foundational experiment to visualize all the amide ¹H-¹⁵N correlations. For proline, which lacks an amide proton, its ¹⁵N resonance will not be visible in this spectrum.
-
3D HNCA & 3D HNCACB: These experiments correlate the amide ¹H and ¹⁵N of a residue with its own Cα and Cβ chemical shifts and those of the preceding residue, forming the basis for sequential backbone assignment.
-
3D CBCA(CO)NH: This experiment provides complementary information for sequential assignment.
-
Experiments for Proline Assignment:
-
3D (H)C(CO)NH-TOCSY: Can be used to identify residues preceding prolines.
-
3D ¹⁵N-edited NOESY-HSQC: This experiment is crucial for obtaining distance restraints (NOEs) between protons that are close in space. NOEs involving proline protons are essential for defining its conformation and its interactions with other residues. Specific NOEs to proline Hδ protons can help in assigning its ¹⁵N and other sidechain resonances.
-
Structure Calculation and Validation
Objective: To generate an ensemble of 3D structures that are consistent with the experimental restraints and to assess their quality.
Protocol:
-
Restraint Generation: NOE cross-peaks are identified, and their intensities are converted into upper distance limits. Dihedral angle restraints are often derived from backbone chemical shifts using programs like TALOS+.
-
Structure Calculation Software: Programs such as CNS (Crystallography & NMR System) or Xplor-NIH are commonly used.
-
Simulated Annealing: A simulated annealing protocol is employed to fold the protein from an extended conformation into a low-energy state that satisfies the experimental restraints.
-
Ensemble Generation: The calculation is repeated multiple times (typically 50-100) to generate an ensemble of structures.
-
Structure Refinement: The final ensemble of structures is often refined in a water box to improve packing and hydrogen bonding.
-
Validation: The quality of the final structures is assessed using programs like PROCHECK, which analyze stereochemical parameters (e.g., Ramachandran plot), and by evaluating the agreement with the experimental data (e.g., number of NOE violations). The precision of the structure is indicated by the RMSD of the ensemble.
Visualization of Experimental Workflow
The following diagram illustrates the general workflow for protein structure determination by NMR, highlighting the stages where this compound labeling is critical.
This diagram outlines the key stages from gene to final structure. The inclusion of this compound in the labeling step (c) enables the acquisition of crucial data in subsequent NMR experiments (g, h), which is essential for the accurate calculation and validation of the final protein structure (k, m).
Unlocking Cellular Insights: The Distinct Advantages of 15N-Labeled Proline in Research
For researchers, scientists, and drug development professionals, the precise tracking of molecular pathways is paramount. In the realm of stable isotope labeling, 15N-labeled proline emerges as a uniquely powerful tool, offering significant advantages over other amino acids in nuclear magnetic resonance (NMR) spectroscopy, metabolic flux analysis, and proteomics. Its distinct structural properties provide clarity and precision in complex biological systems, making it an invaluable asset in the quest for novel therapeutics and a deeper understanding of cellular function.
Proline's rigid, cyclic structure, which sets it apart from all other proteinogenic amino acids, is the foundation of its experimental advantages. This inherent rigidity, a consequence of its side chain forming a pyrrolidine ring with the backbone amide nitrogen, translates into unique spectroscopic and metabolic behaviors that can be expertly leveraged in experimental design.
Proline's Superiority in Protein NMR Spectroscopy
In the intricate world of protein structural analysis by NMR, 15N-labeled proline offers unparalleled clarity. The absence of a proton directly attached to the backbone nitrogen and its unique chemical environment result in distinct and easily interpretable signals.
One of the most significant advantages is the location of proline's 15N resonance in a well-isolated region of the NMR spectrum. This separation from the more crowded spectral regions where most other amino acid residues appear dramatically simplifies spectral analysis and reduces the likelihood of signal overlap, a common challenge in NMR studies of large proteins and intrinsically disordered proteins (IDPs).[1][2]
Furthermore, the lack of a directly bonded proton to the backbone nitrogen in proline leads to narrower 15N linewidths. This is because the primary relaxation mechanism for protonated nitrogens, dipolar coupling to the attached proton, is absent.[3] The result is sharper signals and enhanced spectral resolution, allowing for more precise measurements of structural and dynamic parameters.
Quantitative Comparison of NMR Properties
To illustrate these advantages, the following table summarizes key NMR properties for 15N-labeled proline in comparison to other representative 15N-labeled amino acids.
| Amino Acid | Typical ¹⁵N Chemical Shift Range (ppm) | Linewidth Characteristics | Key Advantages in NMR |
| Proline | ~135-145 | Narrow | Well-resolved signals in an uncrowded spectral region, reduced signal overlap, enhanced resolution. [1][2] |
| Glycine | ~105-115 | Broad | Prone to overlap with other residues. |
| Alanine | ~120-130 | Broad | Representative of many residues in the crowded central region of the spectrum. |
| Serine | ~115-125 | Broad | Susceptible to hydrogen exchange, which can broaden signals. |
| Leucine | ~120-130 | Broad | Resides in the congested spectral region. |
Note: Chemical shift ranges are approximate and can vary based on the local chemical environment within a protein.
Enhanced Precision in Metabolic Flux Analysis and Proteomics
The unique metabolic roles of proline, particularly in collagen synthesis, make its 15N-labeled counterpart an exceptional tracer for metabolic flux analysis. Collagen, the most abundant protein in mammals, is rich in proline and hydroxyproline (a post-translationally modified form of proline). Therefore, tracking the incorporation of 15N-proline provides a direct and sensitive measure of collagen biosynthesis and turnover. This is of particular interest in studies of wound healing, fibrosis, and other connective tissue disorders.[4]
A significant advantage of using a single 15N-labeled amino acid like proline in quantitative proteomics is the circumvention of metabolic conversion issues. For instance, in some organisms, arginine can be metabolically converted to proline, which can complicate the interpretation of data when using labeled arginine.[5] Using 15N-proline as the tracer ensures that the detected label originates solely from proline incorporation, leading to more accurate protein quantification.[5]
A comparative study on monitoring protein biosynthesis in the skin demonstrated the superiority of 15N-proline over 13C-leucine. The research found that a greater amount of proline was incorporated into skin proteins, indicating that it is a more effective tracer for studying protein metabolism in this collagen-rich tissue.[6]
Experimental Protocols
To fully harness the benefits of 15N-labeled proline, specific experimental approaches are required. Below are detailed methodologies for key experiments.
Experimental Protocol 1: Selective Observation of ¹⁵N-Proline Resonances in Proteins by NMR
This protocol is designed to selectively observe the well-resolved ¹⁵N signals of proline residues, which is particularly useful for large or intrinsically disordered proteins where spectral overlap is a major issue.
1. Protein Expression and Labeling:
-
Express the protein of interest in a minimal medium (e.g., M9) supplemented with ¹⁵NH₄Cl as the sole nitrogen source for uniform ¹⁵N labeling.
-
Alternatively, for selective proline labeling, supplement the minimal medium with all unlabeled amino acids except for ¹⁵N-proline.
2. NMR Sample Preparation:
-
Purify the ¹⁵N-labeled protein to homogeneity.
-
Prepare the NMR sample by dissolving the protein in a suitable buffer (e.g., 20 mM sodium phosphate, 50 mM NaCl, pH 6.5) to a final concentration of 0.1-1.0 mM. Add 5-10% D₂O for the spectrometer lock.
3. NMR Data Acquisition:
-
Utilize a ¹³C-detected 3D (H)CBCACONPro experiment. This experiment is specifically designed to exploit the unique ¹⁵N chemical shift of proline.[3]
-
The pulse sequence uses band-selective ¹⁵N pulses centered on the proline ¹⁵N region (~140 ppm). This selectively excites and detects signals from proline residues while suppressing signals from other amino acids.
-
Key parameters to optimize include the duration of the band-selective pulses and the inter-scan delay to ensure full relaxation.
4. Data Processing and Analysis:
-
Process the acquired 3D NMR data using appropriate software (e.g., NMRPipe, TopSpin).
-
The resulting spectrum will show correlations between the Cα and Cβ of the residue preceding the proline and the ¹⁵N of the proline, providing unambiguous assignment of proline residues and their preceding neighbors.
Experimental Protocol 2: Tracing Collagen Synthesis using ¹⁵N-Proline in Cell Culture
This protocol outlines a method to quantify the rate of new collagen synthesis in a cell culture model using ¹⁵N-proline as a metabolic tracer.
1. Cell Culture and Labeling:
-
Culture cells known to produce collagen (e.g., fibroblasts) in standard growth medium.
-
At the desired time point, switch the cells to a medium containing ¹⁵N-proline as the only source of proline. All other amino acid concentrations should be kept constant.
2. Time-Course Experiment:
-
Harvest cell lysates and the extracellular matrix at various time points after the introduction of the ¹⁵N-proline containing medium (e.g., 0, 2, 4, 8, 12, 24 hours).
3. Protein Extraction and Hydrolysis:
-
Separate the extracellular matrix from the cell lysate.
-
Hydrolyze the protein samples (e.g., using 6 M HCl at 110°C for 24 hours) to break them down into individual amino acids.
4. Mass Spectrometry Analysis:
-
Analyze the amino acid hydrolysates by gas chromatography-mass spectrometry (GC-MS) or liquid chromatography-mass spectrometry (LC-MS).
-
Quantify the ratio of ¹⁵N-proline to ¹⁴N-proline in the samples.
5. Data Analysis:
-
The rate of new collagen synthesis can be calculated from the rate of incorporation of ¹⁵N-proline into the protein hydrolysate over time. This provides a direct measure of metabolic flux through the collagen biosynthesis pathway.
Visualizing Key Pathways and Workflows
To further clarify the experimental logic and the central role of proline, the following diagrams, generated using the Graphviz DOT language, illustrate the collagen biosynthesis pathway and the workflow for selective NMR observation of proline.
Caption: Collagen Biosynthesis Pathway Traced with 15N-Proline.
References
- 1. kpwulab.com [kpwulab.com]
- 2. researchgate.net [researchgate.net]
- 3. mr.copernicus.org [mr.copernicus.org]
- 4. Proline Precursors and Collagen Synthesis: Biochemical Challenges of Nutrient Supplementation and Wound Healing - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Reprogramming of proline and glutamine metabolism contributes to the proliferative and metabolic responses regulated by oncogenic transcription factor c-MYC - PMC [pmc.ncbi.nlm.nih.gov]
- 6. A novel NMR experiment for the sequential assignment of proline residues and proline stretches in 13C/15N-labeled proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
A Researcher's Guide to High-Accuracy SILAC: The L-Proline Advantage
For researchers, scientists, and drug development professionals utilizing Stable Isotope Labeling by Amino acids in Cell culture (SILAC) for quantitative proteomics, achieving the highest level of accuracy is paramount. A common pitfall in SILAC experiments is the metabolic conversion of isotopically labeled arginine to proline, which can significantly skew quantification results. This guide provides a comprehensive comparison of SILAC data with and without the addition of unlabeled L-Proline to the culture medium, supported by experimental data and detailed protocols to help you mitigate this issue and enhance the reliability of your results.
The metabolic conversion of heavy arginine to heavy proline is a well-documented artifact in SILAC experiments that can lead to the underestimation of protein abundance.[1][2] This occurs because the mass shift intended for arginine-containing peptides is partially transferred to proline-containing peptides, complicating data analysis and compromising quantitative accuracy. This is a significant concern as it can affect up to half of all peptides in a proteomic experiment.[3] The addition of unlabeled L-proline to the SILAC growth medium is a simple and effective solution to suppress this conversion.
Quantitative Comparison: The Impact of L-Proline Supplementation
The addition of L-proline to the SILAC medium has a direct and measurable impact on the accuracy of protein quantification. The following table summarizes the key quantitative differences observed in SILAC experiments conducted with and without L-proline supplementation.
| Metric | SILAC without L-Proline | SILAC with L-Proline (≥200 mg/L) | Key Benefit of L-Proline |
| Arginine-to-Proline Conversion Rate | ~30-40% of proline-containing peptides show conversion.[2] | Conversion is completely undetectable.[3] | Prevents skewed peptide ratios. |
| Quantitative Accuracy | Inaccurate quantification for proline-containing peptides, with an average of 28% signal loss from the heavy arginine peptide.[1] | Accurate quantification of both proline and non-proline-containing peptides. | Increases confidence in quantitative data. |
| Data Complexity | Mass spectra are complicated by satellite peaks from converted heavy proline.[2] | Cleaner and more easily interpretable mass spectra. | Simplifies data analysis. |
| Number of Quantifiable Proteins | Potentially lower due to the exclusion of inaccurately quantified proline-containing peptides. | Higher number of accurately quantifiable proteins. | Improves proteome coverage. |
Experimental Protocols
To ensure the successful implementation of L-proline supplementation in your SILAC experiments, detailed methodologies for key experimental stages are provided below.
SILAC Media Preparation (for DMEM)
-
Start with DMEM for SILAC that is deficient in L-lysine and L-arginine.
-
Reconstitute the powdered medium in high-purity water according to the manufacturer's instructions.
-
For the "Light" medium, add unlabeled L-lysine and L-arginine to their normal physiological concentrations.
-
For the "Heavy" medium, add the desired isotopically labeled "heavy" L-lysine (e.g., ¹³C₆,¹⁵N₂) and L-arginine (e.g., ¹³C₆,¹⁵N₄).
-
Crucially, for both "Light" and "Heavy" media, add unlabeled L-proline to a final concentration of 200 mg/L.
-
Supplement both media with 10% dialyzed fetal bovine serum (FBS) to minimize the introduction of unlabeled amino acids.
-
Add penicillin/streptomycin to prevent bacterial contamination.
-
Sterile-filter the final media preparations using a 0.22 µm filter.
Cell Culture and Labeling
-
Culture your cells of interest (e.g., HeLa, HEK293T) in the prepared "Light" and "Heavy" SILAC media.
-
Passage the cells for at least five to six doublings to ensure complete incorporation of the labeled amino acids.
-
Monitor the incorporation efficiency by performing a small-scale mass spectrometry analysis of protein extracts from the "Heavy" labeled cells.
-
Once labeling is complete, cells are ready for the experimental treatment.
Protein Extraction, Digestion, and Mass Spectrometry
-
After experimental treatment, harvest the "Light" and "Heavy" labeled cell populations.
-
Combine the cell pellets at a 1:1 ratio based on cell number or total protein concentration.
-
Lyse the combined cell pellet using a suitable lysis buffer (e.g., RIPA buffer with protease and phosphatase inhibitors).
-
Quantify the total protein concentration of the lysate using a standard protein assay (e.g., BCA assay).
-
Perform in-solution or in-gel digestion of the proteins using trypsin.
-
Desalt the resulting peptide mixture using a C18 StageTip or equivalent.
-
Analyze the peptides by liquid chromatography-tandem mass spectrometry (LC-MS/MS) on a high-resolution mass spectrometer.
-
Analyze the acquired data using a software package that supports SILAC quantification (e.g., MaxQuant), ensuring that the software is configured to account for the specific heavy labels used.
Visualizing the Workflow and Underlying Biology
To further clarify the experimental process and the biochemical pathway at the heart of this issue, the following diagrams are provided.
Caption: SILAC experimental workflow with L-proline supplementation.
Caption: Metabolic conversion of heavy arginine to heavy proline.
Signaling Pathway Example: EGFR Signaling
SILAC is a powerful tool for studying dynamic cellular processes like signal transduction. The Epidermal Growth Factor Receptor (EGFR) signaling pathway, which is crucial in cell proliferation and is often dysregulated in cancer, is a common subject of SILAC-based investigations. By comparing the proteomes of cells stimulated with EGF to unstimulated cells, researchers can quantify changes in protein expression and phosphorylation, providing insights into the downstream effects of EGFR activation. The inclusion of L-proline in such studies is critical to ensure that the observed quantitative changes are not artifacts of arginine-to-proline conversion.
Caption: Simplified EGFR signaling pathway often studied by SILAC.
By implementing the straightforward and cost-effective measure of supplementing SILAC media with L-proline, researchers can significantly improve the accuracy and reliability of their quantitative proteomic data. This simple step helps to ensure that the biological insights gained from these powerful experiments are built on a solid and dependable foundation.
References
A Comparative Analysis of Isotopic Labeling Strategies for Quantitative Proteomics
For Researchers, Scientists, and Drug Development Professionals: An Objective Guide to Selecting the Optimal Protein Labeling Strategy
In the dynamic field of proteomics, the accurate quantification of protein abundance is paramount for unraveling complex biological processes, identifying disease biomarkers, and accelerating drug development. Isotopic labeling, coupled with mass spectrometry, has emerged as a powerful and widely adopted approach for precise and high-throughput protein quantification. This guide provides a comprehensive comparative analysis of the three most prominent isotopic labeling strategies: Stable Isotope Labeling by Amino acids in Cell culture (SILAC), isobaric Tags for Relative and Absolute Quantitation (iTRAQ), and Tandem Mass Tags (TMT). We will delve into their core principles, compare their performance based on experimental data, and provide detailed protocols to assist researchers in selecting the most suitable strategy for their specific experimental needs.
At a Glance: Comparing SILAC, iTRAQ, and TMT
| Feature | SILAC (Stable Isotope Labeling by Amino acids in Cell culture) | iTRAQ (isobaric Tags for Relative and Absolute Quantitation) | TMT (Tandem Mass Tags) |
| Labeling Principle | Metabolic labeling in vivo | Chemical labeling in vitro (on peptides) | Chemical labeling in vitro (on peptides) |
| Multiplexing Capacity | Typically 2-3 plex; up to 5-plex has been demonstrated.[1] | 4-plex or 8-plex.[2][3][4][5][6][7] | Up to 18-plex (TMTpro).[4] |
| Quantification Level | MS1 | MS2/MS3 | MS2/MS3 |
| Accuracy & Precision | High accuracy and precision, considered the "gold standard" for cultured cells.[8][9][10] | Good, but can be affected by ratio compression.[2][4] | Good, with potential for higher accuracy than iTRAQ, but also susceptible to ratio compression.[2] |
| Sample Type | Primarily for cultured cells that can undergo metabolic labeling.[4] | Applicable to a wide range of samples, including tissues and biofluids.[4][5] | Applicable to a wide range of samples, including tissues and biofluids.[2] |
| Workflow Complexity | Relatively simple labeling process during cell culture.[11] | Multi-step chemical labeling protocol post-protein extraction and digestion.[12][13] | Multi-step chemical labeling protocol post-protein extraction and digestion.[14][15] |
| Cost | Can be expensive due to the cost of stable isotope-labeled amino acids and media. | Reagents are a significant cost factor.[13] | Reagents are a significant cost factor.[2] |
In-Depth Comparison of Labeling Strategies
SILAC: The Metabolic Labeling Gold Standard
SILAC is an in vivo labeling technique where cells are cultured in media containing "heavy" stable isotope-labeled essential amino acids (e.g., ¹³C₆-lysine and ¹³C₆,¹⁵N₄-arginine).[16] This results in the incorporation of these heavy amino acids into all newly synthesized proteins. By comparing the mass spectra of heavy-labeled proteins with their "light" counterparts from a control cell population, precise relative quantification can be achieved at the MS1 level.
Advantages:
-
High Accuracy and Precision: SILAC is renowned for its high accuracy and reproducibility, as the labeling is introduced early in the experimental workflow, minimizing downstream quantitative errors.[8][9][10]
-
Physiologically Relevant: The labeling occurs within living cells, reflecting the true metabolic state of the proteome.
-
Reduced Sample Handling Errors: Samples are combined at the cellular level before protein extraction, reducing variability introduced during sample preparation.[17]
Disadvantages:
-
Limited Sample Type: Primarily applicable to actively dividing cultured cells.[4]
-
Lower Multiplexing: Typically limited to 2 or 3 samples, although higher plexing has been demonstrated.[1]
-
Cost: The expense of labeled amino acids and specialized media can be a limiting factor.
iTRAQ and TMT: High-Throughput Chemical Labeling
iTRAQ and TMT are in vitro chemical labeling methods that utilize isobaric tags. These tags have the same total mass, but upon fragmentation in the mass spectrometer, they yield unique reporter ions of different masses, allowing for the relative quantification of peptides at the MS2 or MS3 level.[3][6] The key difference between them lies in their chemical structure and multiplexing capacity, with TMT offering a higher number of tags for simultaneous analysis.[2]
Advantages:
-
High Multiplexing Capacity: TMT allows for the simultaneous analysis of up to 18 samples, significantly increasing throughput.[4] iTRAQ offers 4-plex and 8-plex capabilities.[3][4][5][6][7]
-
Broad Sample Applicability: Can be used to label proteins from virtually any source, including tissues, biofluids, and cell lysates.[4][5]
-
Comprehensive Proteome Coverage: Enables the identification and quantification of a large number of proteins in a single experiment.
Disadvantages:
-
Ratio Compression: Co-isolation of interfering ions can lead to an underestimation of quantitative differences between samples.[2][4]
-
Workflow Complexity: The multi-step labeling protocol can introduce variability.
-
Cost of Reagents: The isobaric tags are a significant experimental cost.[2][13]
Experimental Workflows
To provide a clear understanding of the practical application of these techniques, we have outlined their experimental workflows using Graphviz diagrams.
Case Study: EGFR Signaling Pathway Analysis
The Epidermal Growth Factor Receptor (EGFR) signaling pathway plays a crucial role in cell proliferation, differentiation, and survival, and its dysregulation is implicated in various cancers.[18] A systematic comparison of label-free, SILAC, and TMT techniques was conducted to study the early adaptation of colorectal cancer cells to EGFR inhibition.[8][9][10]
The study found that SILAC demonstrated the highest precision and was the most suitable method for quantifying changes in phosphorylation sites within the EGFR signaling network.[8][9][10] TMT, while offering higher multiplexing, showed lower coverage and more missing values, especially when replicates were distributed across multiple plexes.[8][9][10]
References
- 1. Development of a 5-plex SILAC Method Tuned for the Quantitation of Tyrosine Phosphorylation Dynamics - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Comparing iTRAQ, TMT and SILAC | Silantes [silantes.com]
- 3. iTRAQ in Proteomics: Principles, Differences, and Applications - Creative Proteomics [creative-proteomics.com]
- 4. Label-based Proteomics: iTRAQ, TMT, SILAC Explained - MetwareBio [metwarebio.com]
- 5. Label-based Protein Quantification Technology—iTRAQ, TMT, SILAC - Creative Proteomics [creative-proteomics.com]
- 6. creative-proteomics.com [creative-proteomics.com]
- 7. researchgate.net [researchgate.net]
- 8. pubs.acs.org [pubs.acs.org]
- 9. researchgate.net [researchgate.net]
- 10. Systematic Comparison of Label-Free, SILAC, and TMT Techniques to Study Early Adaption toward Inhibition of EGFR Signaling in the Colorectal Cancer Cell Line DiFi - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. biotech.cornell.edu [biotech.cornell.edu]
- 13. iTRAQ Introduction and Applications in Quantitative Proteomics - Creative Proteomics Blog [creative-proteomics.com]
- 14. TMT Sample Preparation for Proteomics Facility Submission and Subsequent Data Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 15. pubs.acs.org [pubs.acs.org]
- 16. sigmaaldrich.com [sigmaaldrich.com]
- 17. SILAC in Biomarker Discovery | Springer Nature Experiments [experiments.springernature.com]
- 18. EGF/EGFR Signaling Pathway Luminex Multiplex Assay - Creative Proteomics [cytokine.creative-proteomics.com]
Assessing the Structural Impact of L-Proline-15N Incorporation: A Comparative Guide
For Researchers, Scientists, and Drug Development Professionals
The site-specific incorporation of stable isotopes, such as 15N-labeled L-proline, is a cornerstone of modern structural biology, particularly in the field of Nuclear Magnetic Resonance (NMR) spectroscopy. This guide provides a comprehensive comparison of proteins containing L-Proline-15N versus their natural abundance counterparts. The central thesis, supported by decades of application in the field, is that the structural and functional impact of 15N incorporation in proline is minimal and far outweighed by the profound analytical advantages it offers.
The Isotope Effect: A Minimal Perturbation
The substitution of 14N with 15N in L-proline introduces a subtle change in mass. While isotope effects can influence reaction kinetics and vibrational modes, the impact on the static three-dimensional structure of a protein is generally considered negligible. The chemical properties and the geometry of the amino acid remain unchanged. The primary consequence of this substitution is the alteration of the nuclear spin, which is the very property exploited in NMR spectroscopy.
Comparative Performance: Unlabeled vs. 15N-Labeled L-Proline
The primary benefit of this compound incorporation lies in the ability to overcome the inherent challenges of studying proline residues in proteins. Proline, being an imino acid, lacks a backbone amide proton, rendering it invisible in standard 1H-15N heteronuclear single quantum coherence (HSQC) NMR experiments, which are often used as a protein's "fingerprint"[1][2]. Specific 15N labeling of proline allows for its direct observation using specialized NMR techniques.
| Feature | Unlabeled L-Proline | This compound | Supporting Data/Rationale |
| NMR Visibility (Standard ¹H-¹⁵N HSQC) | Invisible | Visible (in specialized experiments) | Proline lacks the amide proton necessary for standard ¹H-¹⁵N correlation experiments[1][3]. 15N-labeling enables detection through experiments that directly observe the 15N nucleus or correlate it with other nuclei like 13C. |
| Structural Perturbation | Baseline (Natural Abundance) | Negligible | The small increase in mass from 14N to 15N does not significantly alter bond lengths, angles, or the overall protein fold. This is implicitly supported by the widespread use of 15N labeling in high-resolution structure determination. |
| Protein Stability | Baseline | No significant change reported | Studies on the thermodynamic effects of proline substitutions (mutating other residues to proline) show measurable changes in stability[4][5][6]. However, there is a lack of evidence suggesting that isotopic labeling of proline itself significantly alters protein stability. |
| Protein Function/Activity | Baseline | No significant change reported | The conservation of structure and chemical properties suggests that protein function remains intact. This is a fundamental assumption for the validity of structural studies using isotopically labeled proteins. |
| Cost of Incorporation | Low (Natural Abundance) | High | The synthesis of 15N-labeled amino acids is a costly process. |
Key Experimental Protocols
Protocol for this compound Incorporation in E. coli
This protocol outlines the residue-specific labeling of a target protein with this compound using an E. coli expression system.
Materials:
-
E. coli expression strain (e.g., BL21(DE3)) transformed with the expression plasmid for the target protein.
-
Minimal medium (e.g., M9) with a suitable carbon source (e.g., glucose).
-
Amino acid mixture containing all 19 unlabeled amino acids (excluding proline).
-
This compound.
-
Inducing agent (e.g., IPTG).
Procedure:
-
Grow a starter culture of the E. coli expression strain overnight in a rich medium (e.g., LB).
-
Inoculate a larger volume of minimal medium with the overnight culture.
-
Grow the culture at 37°C with shaking until the optical density at 600 nm (OD600) reaches 0.6-0.8.
-
Pellet the cells by centrifugation and wash with minimal medium to remove any residual rich medium.
-
Resuspend the cell pellet in fresh minimal medium containing the 19 unlabeled amino acids and this compound. To prevent metabolic scrambling of the 15N label, it is often beneficial to use a 10-fold excess of the unlabeled amino acids relative to the labeled one[7].
-
Induce protein expression by adding the inducing agent (e.g., IPTG) to the desired final concentration.
-
Incubate the culture for the required time and temperature to allow for protein expression.
-
Harvest the cells by centrifugation and store the cell pellet at -80°C until purification.
-
Purify the labeled protein using standard chromatography techniques.
Protocol for Assessing Incorporation Efficiency by Mass Spectrometry
This protocol describes how to verify the successful and specific incorporation of this compound into the target protein.
Materials:
-
Purified 15N-proline labeled protein and an unlabeled control.
-
Protease (e.g., trypsin).
-
Mass spectrometer (e.g., MALDI-TOF or ESI-MS).
Procedure:
-
Digest a small amount of the purified labeled and unlabeled protein with a suitable protease to generate peptides.
-
Analyze the resulting peptide mixtures by mass spectrometry.
-
Compare the mass spectra of the labeled and unlabeled samples.
-
Identify peptides containing proline residues. The mass of these peptides in the labeled sample should be shifted by +1 for each incorporated 15N-proline compared to the unlabeled control.
-
The absence of mass shifts in non-proline-containing peptides and the expected mass shift in proline-containing peptides confirms high-fidelity incorporation and minimal metabolic scrambling[7]. The percentage of incorporation can be quantified by analyzing the isotopic distribution of the peptide peaks[8][9].
Visualizing Experimental Workflows and Concepts
Caption: Workflow for producing and analyzing this compound labeled proteins.
Caption: Comparison of NMR outcomes for unlabeled vs. 15N-labeled proline.
Conclusion
The incorporation of this compound is a powerful and essential technique for modern structural biology. While any isotopic substitution will theoretically induce minor perturbations, the available evidence and widespread application in the field strongly indicate that the structural and functional impact of 15N labeling of proline is negligible. The analytical benefits, particularly the ability to directly observe this unique imino acid in NMR experiments, provide invaluable insights into protein structure, dynamics, and function that would otherwise be unattainable. The focus for researchers should therefore be on ensuring high-fidelity incorporation of the label rather than on potential minor structural artifacts.
References
- 1. pubs.acs.org [pubs.acs.org]
- 2. biorxiv.org [biorxiv.org]
- 3. A comprehensive assessment of selective amino acid 15N-labeling in human embryonic kidney 293 cells for NMR spectroscopy - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Thermodynamic effects of proline introduction on protein stability - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. The contribution of proline residues to protein stability is associated with isomerization equilibrium in both unfolded and folded states - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Rapid mass spectrometric analysis of 15N-Leu incorporation fidelity during preparation of specifically labeled NMR samples - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Quantitative Proteomics: Measuring Protein Synthesis Using 15N Amino Acids Labeling in Pancreas Cancer Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 9. m.youtube.com [m.youtube.com]
A Guide to Validating NMR Assignments of Proline-Rich Proteins
For researchers, scientists, and drug development professionals, accurate Nuclear Magnetic Resonance (NMR) assignments are the bedrock of high-quality structural and functional studies of proline-rich proteins. These proteins, often intrinsically disordered, present unique challenges due to the conformational properties of proline residues. This guide provides a comprehensive comparison of methods for validating NMR assignments of proline-rich proteins, supported by experimental data and detailed protocols to ensure the reliability of your results.
Proline-rich regions are critical in a multitude of biological processes, including signal transduction and protein-protein interactions. Their inherent flexibility and the unique nature of the proline residue, which lacks an amide proton in the peptide backbone, complicate traditional NMR assignment approaches. Therefore, rigorous validation of resonance assignments is paramount. This guide explores several key methodologies for this purpose: traditional 3D heteronuclear NMR experiments, specialized techniques like the use of fluorinated prolines, and computational validation tools.
Comparison of Validation Methods
The validation of NMR assignments for proline-rich proteins can be approached through a combination of experimental and computational methods. While traditional triple-resonance experiments form the foundation of backbone assignment, their efficacy can be limited in proline-dense regions. Computational tools and specialized labeling techniques offer powerful alternatives and complementary approaches for robust validation.
| Method Category | Specific Technique | Principle | Advantages | Limitations |
| Experimental Validation | Traditional 3D Heteronuclear NMR | Sequential backbone assignment using through-bond scalar couplings (e.g., HNCA, HN(CO)CA, CBCANH, CBCA(CO)NH). | Well-established for structured proteins; provides direct experimental evidence of connectivity. | Lack of amide protons in proline breaks the sequential walk; spectral overlap in disordered regions. |
| Carbon-Detected NMR | Direct detection of 13C nuclei circumvents the need for proton detection, enabling direct observation of correlations involving proline residues. | Directly addresses the "proline problem"; can be optimized for disordered proteins. | Lower sensitivity compared to proton-detected experiments. | |
| Fluorinated Proline Labeling | Incorporation of 19F-labeled proline analogues introduces a unique NMR-active nucleus with high sensitivity and a large chemical shift dispersion. | Simplifies spectra; provides a sensitive probe for local environment and conformation; can be used to validate specific proline assignments. | Can potentially perturb protein structure and dynamics; requires chemical synthesis or specialized expression systems. | |
| Computational Validation | Probabilistic Approach for protein NMR Assignment Validation (PANAV) | A structure-independent method that compares observed chemical shifts to expected values based on residue-specific and secondary structure-specific chemical shift distributions from a database of correctly referenced proteins.[1][2] | Does not require a 3D structure; can identify and re-reference mis-referenced chemical shifts.[1][2] | Performance depends on the quality and completeness of the reference database. |
| Chemical Shift Prediction (e.g., SHIFTX2, ProCS15) | Predicts chemical shifts based on protein sequence and/or structure. The predicted shifts are then compared to the experimental assignments. | Can provide an independent check of assignment accuracy; SHIFTX2 is noted for its high accuracy.[3] | Accuracy can be lower for intrinsically disordered proteins and for proline residues specifically; prediction errors can complicate validation.[3] |
Experimental Protocols
Protocol 1: Isotopic Labeling and NMR Sample Preparation of Proline-Rich Intrinsically Disordered Proteins (IDPs)
This protocol is optimized for the expression and purification of 13C/15N-labeled proline-rich IDPs for NMR studies.
1. Expression:
-
Vector: Utilize an expression vector with a strong promoter (e.g., T7) and a fusion tag (e.g., His-tag or Npro) to enhance expression and solubility. The Npro fusion system has been shown to be effective for producing IDPs in E. coli inclusion bodies, protecting them from degradation.
-
Media: Grow E. coli in M9 minimal media supplemented with 15NH4Cl as the sole nitrogen source and 13C-glucose as the sole carbon source.
-
Induction: Induce protein expression with IPTG at a low temperature (e.g., 18-25 °C) to improve protein folding and solubility.
2. Purification:
-
Lysis: Lyse the cells using sonication or a French press in a buffer containing protease inhibitors.
-
Affinity Chromatography: If using a His-tag, purify the protein using a Ni-NTA column.
-
Npro Fusion Cleavage and Refolding: If using the Npro fusion system, refold the protein from inclusion bodies using dialysis. The Npro tag will auto-catalytically cleave, releasing the target IDP.
-
Size-Exclusion Chromatography (SEC): Perform a final polishing step using SEC to remove aggregates and ensure a monodisperse sample.
3. NMR Sample Preparation:
-
Buffer: Exchange the purified protein into an NMR buffer (e.g., 20 mM sodium phosphate, 50 mM NaCl, pH 6.0-7.0) containing 5-10% D2O.
-
Concentration: Concentrate the protein to a final concentration of 0.1-1.0 mM. For IDPs, lower concentrations may be necessary to prevent aggregation.
-
Additives: Consider adding a protease inhibitor cocktail and a reducing agent like DTT if cysteine residues are present.
Protocol 2: 3D Heteronuclear NMR for Proline-Rich Regions
Due to the absence of the amide proton in proline, traditional proton-detected triple resonance experiments are interrupted. Carbon-detected experiments are a powerful alternative.
Recommended Experiments:
-
(H)CbCaCON and (H)CbCaNCO: These experiments start with proton polarization to enhance sensitivity but detect 13C, allowing for the assignment of proline stretches.[4]
-
CON: A 2D experiment that correlates the amide nitrogen of a residue with the carbonyl carbon of the preceding residue. A proline-selective version can be used to reduce spectral crowding.[4]
Generic Experimental Parameters (for a 600 MHz spectrometer):
-
Temperature: 298 K
-
Sample Concentration: ~0.3 mM
-
Pulse Sequences: Utilize pulse sequences specifically designed for carbon detection.
-
Acquisition Times and Spectral Widths: These will need to be optimized for the specific protein and spectrometer.
Protocol 3: Validation using 19F-Labeled Proline
Incorporating fluorinated proline analogs provides a unique NMR handle for assignment validation.
1. Incorporation of Fluorinated Proline:
-
Use chemical synthesis for peptides or specialized in vivo expression systems for larger proteins to incorporate (4R)- or (4S)-fluoroproline.
2. NMR Data Acquisition:
-
Acquire a 1D 19F NMR spectrum. The high sensitivity and large chemical shift dispersion of 19F often provide resolved peaks for each fluorinated proline.
-
Acquire 2D 1H-19F HSQC or other correlation experiments to link the fluorine signal to the proton network of the protein.
3. Validation:
-
The number and chemical shifts of the 19F signals should correspond to the number and location of the incorporated fluoroprolines, providing a direct validation of their assignment.
-
Changes in 19F chemical shifts upon ligand binding or other perturbations can confirm the involvement of specific proline residues in these interactions.
Data Presentation
| Validation Tool | Principle | Input | Output | Performance on Proline-Rich Proteins |
| PANAV | Compares observed chemical shifts to a database of expected values. | Assigned chemical shift list. | Corrected chemical shifts, identification of potential mis-assignments. | Generally performs well for IDPs; its structure-independent nature is a significant advantage.[1][2] |
| SHIFTX2 | Predicts chemical shifts from protein sequence and structure. | Protein sequence and/or PDB file. | Predicted chemical shifts for comparison with experimental data. | High accuracy for structured proteins; performance may be reduced for the dynamic ensembles of proline-rich IDPs.[3] |
| ProCS15 | DFT-based chemical shift prediction. | Protein structure. | Predicted chemical shifts. | Can provide accurate predictions but is computationally intensive and sensitive to the quality of the input structure. |
Visualizing the Validation Workflow
The process of validating NMR assignments for proline-rich proteins can be visualized as a multi-step workflow.
This workflow illustrates the initial assignment process using various NMR techniques, followed by the crucial validation step using computational tools, leading to a refined and reliable set of assignments.
References
A Researcher's Guide to Internal Standards in Quantitative Proteomics: A Comparative Analysis of L-Proline-¹⁵N Metabolic Labeling, SILAC, TMT, and iTRAQ
For Researchers, Scientists, and Drug Development Professionals
In the pursuit of understanding complex biological systems and discovering novel therapeutic targets, the accurate quantification of protein expression is paramount. Quantitative proteomics relies on a variety of techniques to measure the relative or absolute abundance of proteins in a sample. A key component of many of these methods is the use of internal standards to improve accuracy and precision. This guide provides an objective comparison of several prominent internal standard strategies: general ¹⁵N metabolic labeling (which includes the labeling of L-Proline), Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC), Tandem Mass Tags (TMT), and Isobaric Tags for Relative and Absolute Quantitation (iTRAQ). We will delve into their principles, present comparative data, and provide detailed experimental protocols to aid in the selection of the most appropriate method for your research needs.
Comparison of Quantitative Proteomics Internal Standard Methods
The choice of an internal standard strategy depends on various factors, including the biological system under investigation, the desired level of multiplexing, and budget constraints. Below is a summary of the key characteristics of each method.
| Feature | ¹⁵N Metabolic Labeling | SILAC (Stable Isotope Labeling by Amino Acids in Cell Culture) | TMT (Tandem Mass Tags) | iTRAQ (Isobaric Tags for Relative and Absolute Quantitation) |
| Labeling Strategy | In vivo metabolic labeling with a ¹⁵N-enriched nitrogen source. All nitrogen-containing amino acids, including proline, are labeled. | In vivo metabolic labeling with "heavy" amino acids (e.g., ¹³C₆-L-Lysine, ¹³C₆¹⁵N₄-L-Arginine). | In vitro chemical labeling of peptides at the N-terminus and lysine residues with isobaric tags. | In vitro chemical labeling of peptides at the N-terminus and lysine residues with isobaric tags. |
| Applicability | Applicable to any organism or cell type that can be cultured with a ¹⁵N-enriched medium. Particularly useful for organisms where SILAC is not feasible.[1] | Primarily used for cultured cells that can incorporate the labeled amino acids over several cell divisions.[2][3] | Applicable to virtually any protein sample, including tissues and clinical specimens.[4] | Applicable to virtually any protein sample, including tissues and clinical specimens.[5][6] |
| Multiplexing | Typically 2-plex (light vs. heavy). | Typically 2-plex or 3-plex. | Up to 18-plex with TMTpro reagents, allowing for high-throughput analysis.[7] | 4-plex or 8-plex, enabling the simultaneous analysis of multiple samples.[5][8] |
| Quantification Level | MS1 level (precursor ion). | MS1 level (precursor ion). | MS2 or MS3 level (reporter ions). | MS2 level (reporter ions). |
| Accuracy & Precision | High accuracy as samples are mixed early in the workflow. Precision can be affected by incomplete labeling. | High accuracy and precision due to early mixing of samples.[2] | Good precision, but can be susceptible to ratio compression due to co-isolation of precursor ions.[4] | Good precision, but can also be affected by ratio compression.[4] |
| Cost | The cost of ¹⁵N-enriched media can be a significant factor, especially for labeling whole organisms.[1] | The cost of stable isotope-labeled amino acids can be high. | Reagent costs can be substantial, particularly for higher-plex experiments. | Reagent costs are a consideration. |
Experimental Workflows and Signaling Pathways
Visualizing the experimental workflow is crucial for understanding the intricacies of each quantitative proteomics strategy. The following diagrams, generated using the DOT language, illustrate the key steps involved in ¹⁵N metabolic labeling, SILAC, TMT, and iTRAQ.
Caption: Workflow for ¹⁵N metabolic labeling.
References
- 1. Quantitative Shotgun Proteomics Using a Uniform 15N-Labeled Standard to Monitor Proteome Dynamics in Time Course Experiments Reveals New Insights into the Heat Stress Response of Chlamydomonas reinhardtii - PMC [pmc.ncbi.nlm.nih.gov]
- 2. pubs.acs.org [pubs.acs.org]
- 3. Quantitative Comparison of Proteomes Using SILAC - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Comparing iTRAQ, TMT and SILAC | Silantes [silantes.com]
- 5. iTRAQ in Proteomics: Principles, Differences, and Applications - Creative Proteomics [creative-proteomics.com]
- 6. Robust workflow for iTRAQ-based peptide and protein quantification - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Label-based Proteomics: iTRAQ, TMT, SILAC Explained - MetwareBio [metwarebio.com]
- 8. iTRAQ Introduction and Applications in Quantitative Proteomics - Creative Proteomics Blog [creative-proteomics.com]
Safety Operating Guide
Proper Disposal of L-Proline-15N: A Guide for Laboratory Professionals
Essential Safety and Disposal Information for Researchers, Scientists, and Drug Development Professionals
This document provides comprehensive guidance on the proper disposal procedures for L-Proline-15N, a non-hazardous, stable isotope-labeled amino acid. Adherence to these protocols is essential for maintaining a safe laboratory environment and ensuring regulatory compliance.
Safety and Hazard Information
This compound is not classified as a hazardous substance.[1][2][3] Safety Data Sheets (SDS) from multiple suppliers indicate that it poses no significant risk of skin corrosion or irritation, serious eye damage, respiratory or skin sensitization, mutagenicity, carcinogenicity, or reproductive toxicity.[1] The National Fire Protection Association (NFPA) rating for L-Proline is 0 for health, fire, and reactivity hazards, signifying that it presents no hazard beyond that of ordinary combustible materials.[1]
While not hazardous, direct contact may cause mild irritation to the respiratory tract, skin, or eyes, and it may be harmful if ingested.[1] Therefore, standard laboratory personal protective equipment (PPE), including safety glasses, gloves, and a lab coat, should be worn when handling the compound.
Quantitative Data Summary
The following table summarizes key quantitative data for this compound, compiled from supplier safety data sheets.
| Property | Value |
| Chemical Purity | ≥98% |
| pH | 6 – 7 (at 115 g/l at 25 °C) |
| Melting Point/Range | 228 - 233 °C / 442.4 - 451.4 °F |
| Specific Gravity | 1.350 |
| Molecular Weight | 116.12 g/mol (for 15N labeled) |
Disposal Procedures for this compound
As a non-hazardous substance containing a stable, non-radioactive isotope, this compound does not require specialized hazardous or radioactive waste disposal.[] The disposal process should align with standard laboratory procedures for non-hazardous chemical waste and comply with local and national regulations.[1]
Step-by-Step Disposal Protocol:
-
Assess the Waste Form: Determine if the this compound waste is in solid form (e.g., unused powder, contaminated lab consumables) or in a liquid solution.
-
Solid Waste Disposal:
-
Unused or Surplus Material: Uncontaminated, solid this compound should be offered to a licensed disposal company for non-hazardous waste.
-
Contaminated Solids: Items such as contaminated gloves, weigh boats, or filter paper should be collected in a designated, clearly labeled container for non-hazardous solid chemical waste. This container should be a durable, sealable bag or a rigid, lidded container.
-
Final Disposal: Once the container is full, it can typically be disposed of in the regular laboratory trash that is sent to a sanitary landfill, unless institutional policy requires otherwise.[5]
-
-
Liquid Waste Disposal:
-
Aqueous Solutions: Dilute aqueous solutions of this compound can generally be disposed of down the sanitary sewer with copious amounts of water, provided the concentration is low and the solution does not contain any other hazardous materials.[5][6] Always check with your institution's Environmental Health and Safety (EHS) department for specific guidelines on sewer disposal.
-
Solutions with Hazardous Components: If the this compound is dissolved in a hazardous solvent, the entire solution must be treated as hazardous waste. It should be collected in a compatible, sealed, and properly labeled hazardous waste container for disposal by a licensed contractor.
-
-
Empty Container Disposal:
-
Decontamination: Empty containers that held this compound should be triple-rinsed with a suitable solvent (e.g., water).
-
Label Defacement: The original label on the container must be defaced or removed to prevent misidentification.[5]
-
Disposal: The rinsed and defaced container can typically be disposed of in the regular trash or recycling, in accordance with institutional policies.
-
Disposal Decision Workflow
The following diagram illustrates the decision-making process for the proper disposal of this compound waste.
Caption: Disposal decision workflow for this compound waste.
References
- 1. moravek.com [moravek.com]
- 2. 3.8 Disposal of Nonhazardous Laboratory Waste Chemicals | Environment, Health and Safety [ehs.cornell.edu]
- 3. sites.rowan.edu [sites.rowan.edu]
- 5. sfasu.edu [sfasu.edu]
- 6. In-Lab Disposal Methods: Waste Management Guide: Waste Management: Public & Environmental Health: Environmental Health & Safety: Protect IU: Indiana University [protect.iu.edu]
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
