IAB15
Description
BenchChem offers high-quality this compound suitable for many research applications. Different packaging options are available to accommodate customers' requirements. Please inquire for more information about this compound including the price, delivery time, and more detailed information at info@benchchem.com.
Properties
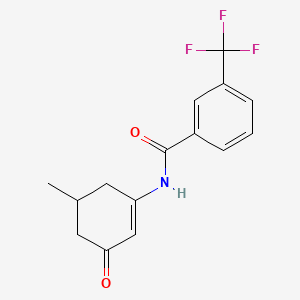
Molecular Formula |
C15H14F3NO2 |
|---|---|
Molecular Weight |
297.27 g/mol |
IUPAC Name |
N-(5-methyl-3-oxocyclohexen-1-yl)-3-(trifluoromethyl)benzamide |
InChI |
InChI=1S/C15H14F3NO2/c1-9-5-12(8-13(20)6-9)19-14(21)10-3-2-4-11(7-10)15(16,17)18/h2-4,7-9H,5-6H2,1H3,(H,19,21) |
InChI Key |
VRHFJCNAIWFYLN-UHFFFAOYSA-N |
Canonical SMILES |
CC1CC(=CC(=O)C1)NC(=O)C2=CC(=CC=C2)C(F)(F)F |
Origin of Product |
United States |
Foundational & Exploratory
What are the latest breakthroughs in [specific field of science e.g., molecular biology]?
The field of molecular biology is in a constant state of rapid evolution, with new discoveries fundamentally altering our understanding of life at the molecular level. This technical guide provides an in-depth exploration of two of the most significant recent breakthroughs: the advent of AlphaFold 3 for predictive structural biology and the elucidation of neural circuits that regulate the immune system. This document is intended for researchers, scientists, and drug development professionals, offering a detailed look at the core concepts, experimental methodologies, and quantitative data associated with these transformative advances.
AlphaFold 3: Redefining Structural Prediction of Biomolecular Complexes
The ability to accurately predict the three-dimensional structure of proteins and their interactions with other molecules is a cornerstone of modern drug discovery and molecular biology. Google DeepMind's AlphaFold 3 represents a paradigm shift in this area, extending the capabilities of its highly successful predecessor to model a wide range of biomolecules and their interactions with unprecedented accuracy.[1][2]
AlphaFold 3's architecture is a significant advancement, building upon the Evoformer module of AlphaFold 2 and incorporating a diffusion network to generate 3D structures.[3] This innovative approach allows it to predict the structures of proteins, DNA, RNA, and small molecule ligands, as well as their complex interactions.[3] The model takes a list of molecules as input and outputs their joint 3D structure, providing critical insights into how they fit together.[3]
Quantitative Data Presentation
The performance of AlphaFold 3 has been rigorously benchmarked against existing methods, demonstrating a significant improvement in prediction accuracy, particularly for protein-ligand and antibody-antigen interactions.[3] The confidence of these predictions is assessed using several key metrics.
| Metric | Description | Interpretation of High Confidence |
| pLDDT (predicted Local Distance Difference Test) | A per-atom estimate of confidence on a scale of 0-100.[3][4][5][6] | Scores > 90 indicate high confidence in the local atomic positions.[4][6] |
| pTM (predicted Template Modeling score) | A measure of the overall structural similarity between the prediction and the true structure, ranging from 0 to 1.[4][5] | A pTM score > 0.5 suggests the overall fold of the complex is likely correct.[5] |
| ipTM (interface predicted Template Modeling score) | Measures the accuracy of the predicted interfaces between different molecules in a complex, ranging from 0 to 1.[4][5][7] | An ipTM score > 0.8 indicates a high-quality prediction of the interaction interface.[5][7] |
| PAE (Predicted Aligned Error) | An estimate of the error in the relative positions and orientations of pairs of tokens (atoms or groups of atoms).[4][5] | Lower PAE values (closer to 0) indicate higher confidence in the relative positioning of different parts of the structure. |
Experimental Protocol: Predicting a Protein-Ligand Complex using the AlphaFold Server
The following protocol outlines the steps for predicting the structure of a protein in complex with a small molecule ligand using the user-friendly AlphaFold Server.[8][9]
Objective: To generate a 3D structural model of a protein-ligand complex.
Materials:
-
A computer with internet access.
-
The amino acid sequence of the target protein in FASTA format.
-
The canonical name or SMILES string of the ligand.
Procedure:
-
Access the AlphaFold Server: Navigate to the AlphaFold Server website.
-
Input Protein Sequence:
-
In the input field, paste the FASTA sequence of the protein of interest.
-
Alternatively, if you have a multi-chain protein, you can paste a multi-FASTA file, and the server will automatically recognize the separate chains.[9]
-
-
Add a Ligand:
-
Click on the "+ Add molecule" button and select "Ligand".
-
In the ligand input field, you can either type the common name of the molecule (e.g., "ATP") and select it from the dropdown menu, or you can input a SMILES string for the molecule.
-
-
Specify Stoichiometry:
-
If your complex contains multiple copies of the protein or ligand, adjust the "Copies" number accordingly.[9]
-
-
Initiate the Prediction:
-
Once all molecules and their stoichiometries are correctly entered, click the "Predict" button.
-
The server will queue the job and provide an estimated completion time.
-
-
Analyze the Results:
-
Upon completion, the results page will display an interactive 3D viewer of the predicted structure, colored by pLDDT scores to indicate local confidence.[8][9]
-
The page will also show the overall pTM and ipTM scores for the complex.[8][9]
-
A PAE plot will be provided, allowing for a detailed analysis of the confidence in the relative positions of different domains and molecules.[8][9]
-
-
Download the Prediction:
-
The predicted structure can be downloaded in PDB or mmCIF format for further analysis in molecular visualization software.
-
Signaling Pathways and Experimental Workflows
The logical workflow of an AlphaFold 3 prediction can be visualized as follows:
Caption: A high-level workflow of the AlphaFold 3 prediction process.
Neural Regulation of Immunity: A New Frontier in Neuroimmunology
A groundbreaking discovery has revealed a direct neural circuit in the brainstem that actively regulates the body's immune response. This finding fundamentally changes our understanding of the interplay between the nervous and immune systems and opens up new avenues for therapeutic intervention in inflammatory and autoimmune diseases.
Research has shown that the brain can sense and modulate inflammation throughout the body.[10] This regulation is mediated by a specific neural circuit located in the brainstem, which includes the caudal nucleus of the solitary tract (cNST), the vagal complex, and the parabrachial nucleus.[11][12] Sensory information about peripheral inflammation, carried by the vagus nerve, is integrated in the brainstem.[13] In response, the brainstem can then fine-tune the immune response, dialing down pro-inflammatory signals and ramping up anti-inflammatory ones to maintain homeostasis.[10][12]
Quantitative Data Presentation
Optogenetic manipulation of specific neuronal populations within this immunoregulatory circuit has provided quantitative evidence of their causal role in controlling inflammation. The table below summarizes representative data on how neuronal activation can modulate cytokine levels.
| Cytokine | Change upon Optogenetic Stimulation of cNST Neurons | Method of Measurement |
| Tumor Necrosis Factor-alpha (TNF-α) | Decreased | ELISA, Quantitative Real-Time PCR |
| Interleukin-1β (IL-1β) | Decreased | ELISA, Quantitative Real-Time PCR[11] |
| Interleukin-6 (IL-6) | Decreased | ELISA, Quantitative Real-Time PCR |
| Anti-inflammatory Cytokines (e.g., IL-10) | Increased | ELISA, Quantitative Real-Time PCR |
Experimental Protocol: Optogenetic Activation of cNST Neurons and Measurement of Cytokine Levels in Mice
This protocol describes a method for investigating the in vivo role of a specific neuronal population in the cNST in regulating systemic inflammation using optogenetics.
Objective: To determine the effect of activating cNST neurons on circulating cytokine levels in a mouse model of inflammation.
Materials:
-
Transgenic mice expressing Cre recombinase under a neuron-specific promoter.
-
Adeno-associated virus (AAV) vector encoding a light-sensitive channelrhodopsin (e.g., AAV-hSyn-DIO-ChR2-mCherry).
-
Stereotaxic surgery setup.
-
Fiber optic cannula and patch cord.
-
Laser for optogenetic stimulation (e.g., 473 nm blue laser).
-
Lipopolysaccharide (LPS) for inducing inflammation.
-
Blood collection supplies.
-
ELISA kits for quantifying cytokines.
Procedure:
-
Stereotactic Virus Injection:
-
Anesthetize the mouse and secure it in a stereotaxic frame.
-
Perform a craniotomy to expose the skull over the brainstem.
-
Using precise coordinates for the cNST, slowly inject the AAV-hSyn-DIO-ChR2-mCherry vector.[14][15] This ensures that only the targeted neurons will express the light-sensitive channel.
-
Implant a fiber optic cannula just above the injection site.
-
Allow several weeks for viral expression and recovery.
-
-
Optogenetic Stimulation:
-
Habituate the mouse to being connected to the fiber optic patch cord.
-
Induce systemic inflammation by intraperitoneal injection of LPS.
-
Connect the implanted cannula to the laser via the patch cord.
-
Deliver blue light stimulation in a predefined pattern (e.g., pulses at a specific frequency and duration) to activate the ChR2-expressing cNST neurons.
-
-
Blood Collection and Cytokine Measurement:
-
At specific time points after LPS injection and optogenetic stimulation, collect blood samples from the mice.
-
Separate the plasma from the blood samples.
-
Use ELISA kits to quantify the concentrations of pro-inflammatory (e.g., TNF-α, IL-1β, IL-6) and anti-inflammatory (e.g., IL-10) cytokines in the plasma.[16][17]
-
-
Data Analysis:
-
Compare the cytokine levels between mice that received optogenetic stimulation and control groups (e.g., mice injected with a control virus or mice that did not receive light stimulation).
-
Statistically analyze the data to determine the significance of any observed changes in cytokine concentrations.
-
Signaling Pathways and Experimental Workflows
The signaling pathway from the periphery to the brain and back to modulate the immune response, along with the experimental workflow, can be visualized as follows:
Caption: The neuro-immune signaling pathway for inflammation regulation.
Caption: Experimental workflow for optogenetic immunomodulation in vivo.
References
- 1. How to predict structures with AlphaFold - Proteopedia, life in 3D [proteopedia.org]
- 2. AlphaFold 3 and AlphaFold Server | AlphaFold [ebi.ac.uk]
- 3. How to interpret AlphaFold confidence scores? | LifeSciencesHub [lifescienceshub.ai]
- 4. How to assess the quality of AlphaFold 3 predictions | AlphaFold [ebi.ac.uk]
- 5. AlphaFold Server [alphafoldserver.com]
- 6. m.youtube.com [m.youtube.com]
- 7. biorxiv.org [biorxiv.org]
- 8. AlphaFold Server [alphafoldserver.com]
- 9. A step-by-step guide to generating predictions with AlphaFold Server | AlphaFold [ebi.ac.uk]
- 10. Optogenetic control of T cells for immunomodulation - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Optogenetic activation of spinal microglia triggers chronic pain in mice - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Intracranial Stereotactic Injection of Adeno-Associated Viral Vectors Protocol - Creative Biogene [creative-biogene.com]
- 13. AlphaFold 3 | SCINet | USDA Scientific Computing Initiative [scinet.usda.gov]
- 14. AAV-mediated gene transfer to the mouse CNS - PMC [pmc.ncbi.nlm.nih.gov]
- 15. A Single Injection of an Adeno-Associated Virus Vector into Nuclei with Divergent Connections Results in Widespread Vector Distribution in the Brain and Global Correction of a Neurogenetic Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Measurement of Cytokine Secretion, Intracellular Protein Expression, and mRNA in Resting and Stimulated Peripheral Blood Mononuclear Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Detection and Quantification of Cytokines and Other Biomarkers - PMC [pmc.ncbi.nlm.nih.gov]
The Vanguard of Cancer Treatment: An In-depth Guide to Emerging Immunotherapy Research
For Immediate Release
A comprehensive analysis of the evolving landscape of cancer immunotherapy reveals three burgeoning areas of research poised to redefine clinical practice: Adoptive Cell Therapy, particularly Chimeric Antigen Receptor (CAR) T-cell therapy; personalized Cancer Vaccines; and the modulation of the gut Microbiome. This technical guide offers researchers, scientists, and drug development professionals a detailed exploration of these frontiers, complete with experimental protocols and quantitative data to inform and accelerate future research and development.
Adoptive Cell Therapy: Engineering T-Cells for Precision Oncology
Adoptive cell therapy (ACT) represents a paradigm shift in cancer treatment, utilizing the patient's own immune cells to fight malignancies. Among ACT approaches, CAR T-cell therapy has shown remarkable success in treating hematological cancers.[1][2] This therapy involves genetically modifying a patient's T-cells to express chimeric antigen receptors (CARs) that recognize and bind to specific antigens on tumor cells, leading to their destruction.[1]
Core Mechanism of CAR T-Cell Therapy
The fundamental principle of CAR T-cell therapy is to reprogram a patient's T-cells to identify and eliminate cancer cells. This is achieved by introducing a synthetic CAR gene into the T-cells. The CAR is typically composed of an extracellular antigen-binding domain (usually a single-chain variable fragment, scFv), a transmembrane domain, and an intracellular signaling domain that activates the T-cell upon antigen binding.[1] Second-generation CARs, which have demonstrated significant clinical efficacy, incorporate a costimulatory domain (e.g., CD28 or 4-1BB) in addition to the primary signaling domain (CD3ζ), enhancing T-cell proliferation, persistence, and cytotoxic activity.[3]
Upon infusion back into the patient, the engineered CAR T-cells circulate through the body. When a CAR T-cell encounters a cancer cell expressing the target antigen, the CAR binds to it, triggering a signaling cascade that activates the T-cell. This activation leads to the release of cytotoxic granules containing perforin and granzymes, which induce apoptosis in the tumor cell.[1] The activated CAR T-cells also proliferate, creating a larger army of cancer-fighting cells.
Figure 1: CAR T-Cell Activation and Effector Function.
Clinical Efficacy of CAR T-Cell Therapies
The clinical success of CAR T-cell therapy has been most prominent in B-cell malignancies. Several CAR T-cell products have received FDA approval for the treatment of acute lymphoblastic leukemia (ALL), diffuse large B-cell lymphoma (DLBCL), and multiple myeloma.[1][4]
| Therapy (Target Antigen) | Disease | Overall Response Rate (ORR) | Complete Remission (CR) Rate | Reference |
| Tisagenlecleucel (CD19) | Relapsed/Refractory Pediatric ALL | 81% | 60% | [4] |
| Axicabtagene Ciloleucel (CD19) | Relapsed/Refractory Large B-Cell Lymphoma | 72% | 51% | [3] |
| Idecabtagene Vicleucel (BCMA) | Relapsed/Refractory Multiple Myeloma | 73% | 33% | FDA Approval Data |
| Ciltacabtagene Autoleucel (BCMA) | Relapsed/Refractory Multiple Myeloma | 97% | 67% | FDA Approval Data |
Table 1: Clinical Trial Data for FDA-Approved CAR T-Cell Therapies
Experimental Protocol: Manufacturing of CAR T-Cells for Research Use
The production of CAR T-cells is a complex, multi-step process that begins with the collection of a patient's T-cells and ends with the infusion of the engineered cells.[5][6]
-
T-Cell Isolation:
-
T-Cell Activation:
-
Gene Transfer:
-
The CAR-encoding gene is introduced into the activated T-cells.
-
Lentiviral or retroviral vectors are the most common methods for stable gene integration.[5] Electroporation is an emerging non-viral alternative.
-
Cells are incubated with the viral vector at a specific multiplicity of infection (MOI) to ensure efficient transduction.[7]
-
-
Ex Vivo Expansion:
-
Quality Control and Cryopreservation:
-
Throughout the process, quality control tests are performed to assess cell viability, purity, identity, and potency.
-
The final CAR T-cell product is cryopreserved until it is ready to be infused into the patient.[5]
-
References
- 1. Chimeric Antigen Receptor T-Cells: An Overview of Concepts, Applications, Limitations, and Proposed Solutions - PMC [pmc.ncbi.nlm.nih.gov]
- 2. cancerresearchuk.org [cancerresearchuk.org]
- 3. Frontiers | From bench to bedside: the history and progress of CAR T cell therapy [frontiersin.org]
- 4. CAR T Cells: Engineering Immune Cells to Treat Cancer - NCI [cancer.gov]
- 5. Optimizing Manufacturing Protocols of Chimeric Antigen Receptor T Cells for Improved Anticancer Immunotherapy - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. miltenyibiotec.com [miltenyibiotec.com]
- 8. youtube.com [youtube.com]
Unraveling the Engram: A Technical Guide to Key Unanswered Questions in Memory Consolidation
For Researchers, Scientists, and Drug Development Professionals
Introduction: The transformation of fragile, short-term memories into stable, long-term forms, a process known as memory consolidation, is a cornerstone of neurobiology. This process involves a complex interplay of molecular signaling cascades and structural changes at the synaptic level, ultimately leading to the physical instantiation of a memory trace, or "engram." Despite decades of research, fundamental questions about how memories are selected, stabilized, and integrated into the vast network of the brain remain unanswered. This guide delves into the core challenges and outstanding questions in the field of memory consolidation, providing an overview of the quantitative data, key experimental methodologies, and the intricate signaling pathways that govern this critical cognitive function.
Key Unanswered Questions in Memory Consolidation
The journey from a fleeting experience to an enduring memory is fraught with complexities that continue to challenge neuroscientists. While the general framework of synaptic plasticity and systems consolidation is well-established, the specific mechanisms and regulatory principles are still under intense investigation.
-
The Engram Allocation Problem: How Are Memories Tagged for Storage? A significant question in memory research is how specific populations of neurons are allocated to a particular memory trace.[1] It is known that only a sparse population of neurons encodes a specific memory.[2] For instance, in the dentate gyrus of the hippocampus, as few as 2-4% of granule cells are activated in a given context.[2][3] Similarly, only 10-30% of principal neurons in the lateral amygdala are involved in the auditory fear memory trace.[1] What are the molecular and cellular rules that determine which neurons become part of an engram while their neighbors do not? Is it a stochastic process, or is it governed by the intrinsic excitability of neurons at the time of encoding?
-
Synaptic vs. Systems Consolidation: What is the Nature of the Dialogue? Memory consolidation occurs at two distinct levels: synaptic consolidation, which involves the stabilization of synaptic changes over hours, and systems consolidation, where memories are gradually reorganized across different brain regions over days to years, becoming less dependent on the hippocampus.[4][5] A key unanswered question is how these two processes interact. How do the molecular events at the synapse during early consolidation instruct the large-scale reorganization of the memory trace at the systems level? What are the precise neural mechanisms, such as neural replay during sleep, that facilitate this dialogue between the hippocampus and the neocortex?[5]
-
The Persistence Problem: How are Memories Maintained for a Lifetime? Long-term potentiation (LTP), a persistent strengthening of synapses, is a primary cellular mechanism underlying memory formation.[6] However, the molecular components of the synapse, such as proteins and lipids, are in a constant state of turnover. How, then, can a memory trace be maintained for years or even a lifetime? This question points to the need for a deeper understanding of the structural and molecular mechanisms that confer long-term stability to synaptic changes. It is hypothesized that structural changes, such as the enlargement of dendritic spines and the formation of new synaptic connections, play a crucial role.[7][8]
-
The Role of Immediate-Early Genes: From Activity to Plasticity? The expression of immediate-early genes (IEGs) like Arc/Arg3.1 and c-fos is rapidly induced by neuronal activity and is critical for long-term memory.[9][10] Arc, for example, is involved in the trafficking of AMPA receptors and the regulation of the actin cytoskeleton, both of which are essential for synaptic plasticity.[10][11] However, the precise mechanisms by which these IEGs translate neuronal activity into lasting synaptic changes are not fully understood. How is the expression of different IEGs coordinated to support different forms of plasticity and memory? What are the downstream effectors of these proteins that ultimately lead to the stabilization of the engram?
Quantitative Data in Memory Consolidation
The study of memory consolidation benefits from a range of quantitative measures that help to characterize the underlying processes. The following table summarizes some key quantitative data points in the field.
| Parameter | Value | Brain Region/Context | Source |
| Neuronal Population in Engram | 2-4% of granule cells | Mouse Dentate Gyrus (contextual memory) | [2][3] |
| 10-30% of principal neurons | Rat Lateral Amygdala (auditory fear memory) | [1] | |
| Dendritic Length Density (ρd) | 0.48 μm⁻² | Mouse Occipital Cortex | [12] |
| 0.59 μm⁻² | Rat Hippocampus (CA1) | [12] | |
| 0.47 μm⁻² | Monkey Primary Visual Cortex (V1) | [12] | |
| 0.42 μm⁻² | Human Temporal Cortex | [12] | |
| Adult Neurogenesis Rate | >5000 new neurons/day | Human Hippocampus | [13] |
| Time Course of LTP Phases | Early-LTP (E-LTP) | 1-3 hours | Hippocampus |
| Late-LTP (L-LTP) | >3 hours to months | Hippocampus |
Key Experimental Protocols
The investigation of memory consolidation relies on a sophisticated toolkit of experimental techniques. Below are detailed methodologies for two of the most powerful approaches in the field.
Protocol 1: Optogenetic Manipulation of Memory Engrams
This protocol allows for the labeling and subsequent reactivation of neurons that were active during a specific memory-forming event.[2][14]
Objective: To demonstrate that the artificial reactivation of a specific neuronal ensemble (engram) is sufficient to elicit a memory-related behavior.
Materials:
-
c-fos-tTA transgenic mice.[2]
-
Adeno-associated virus (AAV) vector carrying a tetracycline-responsive element (TRE) driving the expression of a channelrhodopsin (e.g., ChR2) fused to a fluorescent reporter (e.g., EYFP).[2]
-
Doxycycline (Dox) in the animals' diet.
-
Stereotaxic surgery setup.
-
Fiber optic cannula and patch cord.
-
Laser for optogenetic stimulation.
-
Behavioral testing apparatus (e.g., fear conditioning chamber).
Procedure:
-
Viral Injection and Cannula Implantation:
-
Anesthetize a c-fos-tTA mouse and place it in a stereotaxic frame.
-
Inject the AAV9-TRE-ChR2-EYFP virus into the target brain region (e.g., dentate gyrus of the hippocampus).[2]
-
Implant a fiber optic cannula directly above the injection site.
-
Allow the animal to recover for several weeks to ensure robust viral expression.
-
-
Engram Labeling:
-
Maintain the mouse on a Dox diet to suppress ChR2-EYFP expression.
-
To open a window for labeling, remove the Dox from the diet.
-
Expose the mouse to a specific learning event (e.g., contextual fear conditioning in context A). Neurons that are active during this event will express tTA, which will drive the expression of ChR2-EYFP.[2]
-
Return the mouse to the Dox diet to close the labeling window and prevent further expression of the channelrhodopsin.
-
-
Memory Recall Testing:
-
Place the mouse in a neutral context (context B) where it has no prior experience.
-
Connect the fiber optic cannula to a laser via a patch cord.
-
Deliver light stimulation (e.g., blue light for ChR2) to activate the labeled engram cells.
-
Measure the behavioral response (e.g., freezing behavior as a measure of fear memory recall).[3]
-
-
Control Experiments:
-
Perform the same procedure on control groups, such as mice that were not fear-conditioned but received light stimulation, or fear-conditioned mice that were injected with a virus expressing only the fluorescent reporter without the channelrhodopsin.[2]
-
Protocol 2: Induction and Measurement of Long-Term Potentiation (LTP) in Hippocampal Slices
This ex vivo electrophysiological technique is a cornerstone for studying the synaptic mechanisms of memory.[15][16][17]
Objective: To induce and record LTP at synapses in the hippocampus, providing a cellular model of memory formation.
Materials:
-
Rodent (mouse or rat).
-
Vibrating microtome (vibratome).
-
Dissection microscope.
-
Artificial cerebrospinal fluid (ACSF) continuously bubbled with 95% O2 / 5% CO2.
-
Recording chamber for brain slices (submerged or interface type).
-
Glass microelectrodes for stimulation and recording.
-
Micromanipulators.
-
Amplifier and digitizer for electrophysiological recordings.
-
Stimulator for delivering electrical pulses.
-
Data acquisition and analysis software.
Procedure:
-
Hippocampal Slice Preparation:
-
Anesthetize and decapitate the animal.
-
Rapidly dissect the brain and place it in ice-cold, oxygenated ACSF.
-
Isolate the hippocampi and cut transverse slices (typically 300-400 µm thick) using a vibratome.
-
Transfer the slices to a holding chamber with oxygenated ACSF and allow them to recover for at least 1 hour at room temperature or a slightly elevated temperature (e.g., 32°C).[17]
-
-
Electrophysiological Recording:
-
Transfer a single slice to the recording chamber, which is continuously perfused with oxygenated ACSF.
-
Using a microscope and micromanipulators, place a stimulating electrode in the Schaffer collateral pathway and a recording electrode in the stratum radiatum of the CA1 region to record field excitatory postsynaptic potentials (fEPSPs).[16]
-
Adjust the stimulation intensity to elicit a baseline fEPSP that is approximately 30-50% of the maximum response.
-
-
LTP Induction:
-
Record a stable baseline of fEPSPs for at least 20-30 minutes by delivering single pulses at a low frequency (e.g., 0.05 Hz).
-
Induce LTP using a high-frequency stimulation (HFS) protocol, such as one or more trains of 100 pulses at 100 Hz.[17] An alternative is the more physiologically relevant theta-burst stimulation (TBS).[16]
-
-
Post-Induction Recording and Analysis:
-
Continue to record fEPSPs at the baseline frequency for at least 1-2 hours after the HFS.
-
Analyze the data by measuring the slope of the fEPSP. A persistent increase in the fEPSP slope after HFS is indicative of LTP. The magnitude of LTP is typically expressed as the percentage increase in the fEPSP slope relative to the pre-HFS baseline.[15]
-
Visualizing the Molecular Machinery of Memory
The following diagrams, created using the DOT language for Graphviz, illustrate a key signaling pathway and an experimental workflow central to memory consolidation research.
Caption: Signaling cascade for late-phase long-term potentiation (L-LTP).
Caption: Experimental workflow for optogenetic memory engram manipulation.
References
- 1. Memory allocation at the neuronal and synaptic levels [bmbreports.org]
- 2. researchgate.net [researchgate.net]
- 3. Optogenetic stimulation of a hippocampal engram activates fear memory recall - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Memory consolidation - Wikipedia [en.wikipedia.org]
- 5. Memory Consolidation - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Long-term potentiation - Wikipedia [en.wikipedia.org]
- 7. Molecular Mechanisms of Synaptic Plasticity Underlying Long-Term Memory Formation - Neural Plasticity and Memory - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 8. m.youtube.com [m.youtube.com]
- 9. Arc/Arg3.1: linking gene expression to synaptic plasticity and memory - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Arc/Arg3.1 function in long-term synaptic plasticity: Emerging mechanisms and unresolved issues - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. Statistical Traces of Long-Term Memories Stored in Strengths and Patterns of Synaptic Connections | Journal of Neuroscience [jneurosci.org]
- 13. Memory traces of trace memories: neurogenesis, synaptogenesis and awareness - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Frontiers | Identification and optogenetic manipulation of memory engrams in the hippocampus [frontiersin.org]
- 15. pubcompare.ai [pubcompare.ai]
- 16. Long-Term Potentiation by Theta-Burst Stimulation using Extracellular Field Potential Recordings in Acute Hippocampal Slices - PMC [pmc.ncbi.nlm.nih.gov]
- 17. The characteristics of LTP induced in hippocampal slices are dependent on slice-recovery conditions - PMC [pmc.ncbi.nlm.nih.gov]
The Evolution of an Idea: A Technical Guide to the Historical Development of the Central Dogma of Molecular Biology
Audience: Researchers, scientists, and drug development professionals.
This guide traces the historical and experimental journey that shaped one of the most fundamental principles in molecular biology: the Central Dogma. Originally a simple, linear concept, it has been tested, refined, and expanded over decades of research, revealing a far more intricate and nuanced flow of genetic information. We will explore the key experiments, present the quantitative data that provided the evidence, and visualize the evolving understanding of this core theory.
The Original Postulation: A Unidirectional Flow
The term "Central Dogma" was first coined by Francis Crick in 1958. In its initial form, it was a bold and simple declaration about the flow of genetic information. It posited that information moves from nucleic acids to proteins, and crucially, it cannot flow from protein back to nucleic acid. This established a foundational framework for understanding gene expression. At this stage, the model was based more on logical inference from the known structures of DNA and proteins than on direct experimental evidence for the transfer mechanisms.
The dogma distinguished between three types of information transfer:
-
General Transfers (believed to occur in all cells): DNA → DNA (Replication), DNA → RNA (Transcription), RNA → Protein (Translation).
-
Special Transfers (believed to occur only in specific cases): RNA → RNA, RNA → DNA, DNA → Protein.
-
Unknown Transfers (believed never to occur): Protein → Protein, Protein → RNA, Protein → DNA.
Caption: Crick's original 1958 model of the Central Dogma.
The Search for the Messenger: The Role of RNA
A critical question in the late 1950s was how the genetic information encoded in DNA within the nucleus was transported to the cytoplasm, where protein synthesis occurs. The "messenger hypothesis" proposed the existence of an unstable RNA molecule that acted as a transient copy of a gene.
Key Experiment: The PaJaMo Experiment (1961)
The experiment by Arthur Pardee, François Jacob, and Jacques Monod provided strong evidence for a short-lived messenger. They studied the induction of the β-galactosidase enzyme in E. coli following the transfer of a functional lacI gene into a mutant recipient cell.
Experimental Protocol:
-
Bacterial Strains: An Hfr donor strain of E. coli (possessing functional lacZ and lacI genes) and a recipient F- strain (with non-functional lacZ and lacI genes) were used.
-
Conjugation: The two strains were mixed to allow conjugation, initiating the transfer of the donor's genetic material into the recipient.
-
Induction: At specific time points, the synthesis of the β-galactosidase enzyme was induced by adding an inducer (IPTG).
-
Measurement: The activity of the β-galactosidase enzyme was measured over time using a colorimetric assay (e.g., with ONPG as a substrate).
-
Observation: They observed that the enzyme was synthesized almost immediately after the lacZ gene entered the recipient cell, but this synthesis could be repressed shortly after the corresponding repressor gene (lacI) entered. This indicated the presence of an unstable messenger molecule that was rapidly synthesized and degraded, and a separate, stable repressor molecule.
Caption: Workflow of the PaJaMo experiment demonstrating the messenger hypothesis.
A Challenge to the Dogma: Reverse Transcription
The original dogma stated that information transfer from RNA to DNA was a "special transfer" that was not thought to be a general mechanism. This view was dramatically overturned by the discovery of reverse transcriptase. In 1970, Howard Temin and David Baltimore independently discovered an enzyme in certain RNA viruses (retroviruses) that could synthesize DNA from an RNA template.
Key Experiment: Discovery of Reverse Transcriptase
The key experiments involved incubating purified virions of Rous sarcoma virus (Temin) and Rauscher murine leukemia virus (Baltimore) with the four deoxynucleoside triphosphates (dNTPs), including a radioactively labeled one ([³H]TTP), and observing the incorporation of the label into an acid-insoluble product that was sensitive to DNase but resistant to RNase and protease.
Experimental Protocol:
-
Virus Purification: Retroviruses were purified from infected cell cultures.
-
Permeabilization: The viral envelopes were permeabilized with a non-ionic detergent (e.g., Triton X-100) to allow dNTPs to enter the virion core.
-
Reaction Mixture: The permeabilized virions were incubated in a reaction buffer containing all four dNTPs (dATP, dGTP, dCTP, and TTP), with one being radioactively labeled (e.g., [³H]TTP).
-
Incubation: The mixture was incubated at 37°C for a set period (e.g., 60 minutes).
-
Product Analysis: The reaction was stopped, and the product was precipitated with trichloroacetic acid (TCA). The radioactivity of the acid-insoluble precipitate was measured.
-
Nuclease Digestion: To confirm the product's identity, the precipitate was treated with DNase, RNase, or protease before measurement. The radioactivity was lost only after DNase treatment, confirming the product was DNA.
Quantitative Data Summary:
The table below represents typical results from such an experiment, demonstrating the requirements for the polymerase activity.
| Reaction Condition | [³H]TTP Incorporation (cpm) | Interpretation |
| Complete (All 4 dNTPs) | 25,000 | Robust DNA synthesis occurs. |
| Minus dATP, dCTP, dGTP | 850 | Synthesis requires all four dNTPs. |
| Plus RNase A (pre-incubation) | 1,200 | The template is RNA. |
| Plus DNase (post-incubation) | 950 | The product is DNA. |
| No Virus | 300 | The enzyme is viral in origin. |
This discovery was a paradigm shift, proving that genetic information could, in fact, flow "backward" from RNA to DNA. This updated the Central Dogma to explicitly include this pathway, which is now critical for understanding retroviruses like HIV and for molecular biology tools like RT-PCR.
Caption: The Central Dogma, updated to include Reverse Transcription.
The Modern View: A Complex Web of Information
Decades of subsequent research have revealed an even more complex network of information flow. The Central Dogma remains the core principle, but it is now understood within a broader context that includes many exceptions and additional layers of regulation.
-
Non-coding RNAs (ncRNAs): Many RNA molecules are not translated into protein but have critical regulatory, structural, or catalytic functions (e.g., rRNA, tRNA, siRNA, miRNA). This highlights RNA's central role not just as a messenger, but as a key functional molecule in its own right.
-
Prions: These are infectious agents composed solely of protein. A misfolded prion protein can induce a conformational change in its normally folded counterparts, propagating a disease state. This represents a form of protein-to-protein information transfer, a pathway Crick thought impossible.
-
Epigenetic Inheritance: Modifications to DNA (like methylation) and histone proteins can alter gene expression and be heritably passed down without changing the underlying DNA sequence itself. This represents a layer of information existing "above" the genetic sequence.
Caption: The modern, expanded view of biological information flow.
This historical journey shows that the Central Dogma, while simple in its original form, has been a remarkably robust and productive framework. Its evolution reflects the progress of science itself: a core idea is proposed, rigorously tested by experiment, and refined to accommodate new discoveries, leading to a deeper and more accurate understanding of the complex machinery of life. For drug development, this detailed understanding is critical, as it reveals numerous points of potential therapeutic intervention, from transcription and translation inhibitors to the emerging fields of RNA-based therapies and epigenetic drugs.
The Convergence of Cancer Biology and Immunology: A Technical Guide to Immuno-Oncology
An In-depth Technical Guide for Researchers, Scientists, and Drug Development Professionals
The historic divergence of cancer biology and immunology has given way to a powerful convergence, creating the field of immuno-oncology. This interdisciplinary approach, which harnesses the body's own immune system to fight cancer, has led to revolutionary therapeutic breakthroughs.[1][2] Understanding the intricate connections between these two fields is now paramount for the development of next-generation cancer therapies. This guide provides a technical overview of a cornerstone of immuno-oncology: the programmed cell death protein 1 (PD-1) and its ligand (PD-L1) signaling pathway, a critical immune checkpoint that cancer cells exploit to evade immune destruction.[3][4][5][6]
The PD-1/PD-L1 Immune Checkpoint: A Key Interdisciplinary Axis
Under normal physiological conditions, the immune system can recognize and eliminate cancerous cells.[5] However, tumors can evolve mechanisms to suppress or evade this immune surveillance.[6][7] One of the most significant of these is the upregulation of PD-L1 on the surface of cancer cells.[6]
PD-1 is a receptor expressed on the surface of activated T cells, which are crucial for killing cancerous cells.[6] When PD-L1 on a tumor cell binds to PD-1 on a T cell, it triggers an inhibitory signal that effectively "turns off" the T cell, preventing it from attacking the tumor.[3][4][5] This interaction allows the cancer to grow unchecked by the immune system. The development of immune checkpoint inhibitors, specifically monoclonal antibodies that block the PD-1/PD-L1 interaction, has been a major breakthrough in cancer treatment, restoring the anti-tumor immune response.[4][6][8]
Quantitative Analysis of the PD-1/PD-L1 Axis
The expression of PD-L1 varies significantly across different tumor types and even within a single tumor, a phenomenon known as heterogeneity.[9][10][11] Quantifying PD-L1 expression is a critical step in predicting a patient's potential response to anti-PD-1/PD-L1 therapies.[12]
| Tumor Type | Method | PD-L1 Positivity (Various Cutoffs) | Reference |
| Non-Small Cell Lung Cancer (NSCLC) | IHC (22C3 clone) | 29.6% (Tumor Proportion Score ≥50%) | [12] |
| Melanoma | IHC | 46-50% in responding patients | [13] |
| Diffuse Large B-cell Lymphoma (DLBCL) | IHC | High plasma PD-L1 associated with poor survival | [3] |
| Multiple Tumor Types (Pooled Analysis) | Various | Overall Response Rate (ORR) of 20.21% to inhibitors | [14] |
This table summarizes representative data on PD-L1 expression and response rates. Actual values can vary significantly based on the specific antibody clone, staining platform, and scoring criteria used.[9][11][15]
Therapeutic Intervention: PD-1/PD-L1 Blockade
Monoclonal antibodies that block either PD-1 or PD-L1 have shown significant clinical efficacy across a wide range of cancers.[3][4] These therapies prevent the "off" signal from being delivered to T cells, thereby allowing them to recognize and attack cancer cells.
| Agent | Target | Select Approved Indications | Representative Overall Response Rate (ORR) | Reference |
| Pembrolizumab (Keytruda) | PD-1 | Melanoma, NSCLC, Head and Neck Squamous Cell Carcinoma | 45.2% in high PD-L1 NSCLC | [13][16] |
| Nivolumab (Opdivo) | PD-1 | Melanoma, NSCLC, Renal Cell Carcinoma | 34% recurrence/mortality reduction in adjuvant melanoma | [16][17] |
| Atezolizumab (Tecentriq) | PD-L1 | Urothelial Carcinoma, NSCLC, Triple-Negative Breast Cancer | Varies by indication | [17] |
This table provides a summary of major PD-1/PD-L1 inhibitors. The list of indications and response rates is not exhaustive and continues to expand.
Key Experimental Methodologies
The study of the PD-1/PD-L1 pathway and the broader tumor microenvironment relies on a variety of sophisticated experimental techniques.
Experimental Protocol: Immunohistochemistry (IHC) for PD-L1
Objective: To detect and quantify the expression of PD-L1 protein in formalin-fixed, paraffin-embedded (FFPE) tumor tissue.
Principle: This technique uses a primary antibody that specifically binds to PD-L1. A secondary antibody, linked to an enzyme, then binds to the primary antibody. The addition of a chromogenic substrate results in a colored precipitate at the site of antigen expression, which can be visualized under a microscope.
Methodology:
-
Sample Preparation: 4-5 µm thick sections of FFPE tumor tissue are cut and mounted on positively charged slides. The slides are baked to adhere the tissue.[18]
-
Deparaffinization and Rehydration: Slides are incubated in xylene to remove paraffin, followed by a series of graded ethanol washes to rehydrate the tissue.[18]
-
Antigen Retrieval: Heat-induced epitope retrieval is performed by incubating the slides in a target retrieval solution (e.g., low-pH buffer) at high temperature (e.g., >90°C) to unmask the antigen epitopes.[18]
-
Peroxidase Block: Endogenous peroxidase activity is blocked to prevent non-specific staining.[19]
-
Primary Antibody Incubation: The slides are incubated with a primary antibody specific for PD-L1 (e.g., clones 22C3, 28-8, SP142, or SP263).[15][19]
-
Secondary Antibody and Detection: A linker antibody and a polymer-based detection system conjugated with horseradish peroxidase are sequentially applied.[19]
-
Chromogen Application: A chromogen such as 3,3'-diaminobenzidine (DAB) is added, which produces a brown precipitate in the presence of the enzyme, indicating PD-L1 expression.[19]
-
Counterstaining: The tissue is lightly counterstained with hematoxylin to visualize cell nuclei.
-
Dehydration and Mounting: The slides are dehydrated through graded ethanol and xylene and then coverslipped for microscopic examination.
-
Scoring: A pathologist scores the percentage of viable tumor cells showing partial or complete membrane staining (Tumor Proportion Score - TPS) or the percentage of tumor area occupied by PD-L1-staining tumor cells and immune cells (Combined Positive Score - CPS).[12]
Experimental Protocol: Flow Cytometry for Immune Cell Profiling
Objective: To identify and quantify different immune cell populations within the tumor microenvironment or peripheral blood.
Principle: Flow cytometry is a laser-based technology that measures the physical and chemical characteristics of cells in a fluid stream. Cells are stained with fluorescently labeled antibodies specific to cell surface or intracellular markers. As the cells pass through the laser, they scatter light and emit fluorescence, which is detected and analyzed to identify different cell populations.
Methodology:
-
Single-Cell Suspension Preparation:
-
Solid Tumors: Tissues are mechanically dissociated and enzymatically digested to release individual cells. The resulting suspension is filtered to remove clumps.[20]
-
Peripheral Blood: Peripheral blood mononuclear cells (PBMCs) are isolated from whole blood using density gradient centrifugation (e.g., with Ficoll-Paque).[21]
-
-
Cell Staining:
-
Cells are washed and resuspended in a staining buffer.
-
A cocktail of fluorescently labeled antibodies targeting specific cell surface markers (e.g., CD3 for T cells, CD8 for cytotoxic T cells, CD4 for helper T cells, CD45 for all leukocytes, and PD-1) is added to the cells.
-
The cells are incubated with the antibodies, typically on ice and protected from light.[21]
-
-
Washing: Excess, unbound antibodies are removed by washing the cells with staining buffer.
-
Data Acquisition: The stained cells are run on a flow cytometer. The instrument measures forward scatter (related to cell size), side scatter (related to cell granularity/complexity), and the fluorescence intensity for each antibody used.
-
Data Analysis:
-
Software is used to "gate" on specific cell populations based on their scatter properties and fluorescence.
-
For example, lymphocytes can be identified based on their forward and side scatter, and then T cells can be further identified as CD3-positive. Within the T cell population, cytotoxic (CD8+) and helper (CD4+) subsets can be distinguished. The expression of PD-1 can then be quantified on these specific T cell subsets.
-
Visualizing the Interdisciplinary Connection
The following diagrams illustrate the core concepts and workflows at the intersection of cancer biology and immunology.
Caption: PD-1/PD-L1 signaling pathway leading to T-cell inhibition.
Caption: Experimental workflow for PD-L1 Immunohistochemistry (IHC).
Caption: Mechanism of action of PD-1/PD-L1 checkpoint inhibitors.
Conclusion
The synergy between cancer biology and immunology has ushered in a new era of cancer treatment. The PD-1/PD-L1 pathway serves as a prime example of this successful interdisciplinary connection, where a fundamental understanding of immune regulation has been translated into life-saving therapies. For drug development professionals, a deep, technical knowledge of these intersecting pathways, along with the quantitative and experimental methods used to study them, is essential for innovating the next generation of immuno-oncology treatments. Continued research at the nexus of these fields holds the promise of even more effective and personalized cancer therapies in the future.
References
- 1. Immunology Research to Fight Cancer and Autoimmunity – Bristol Myers Squibb [bms.com]
- 2. hopkinsmedicine.org [hopkinsmedicine.org]
- 3. PD-1/PD-L1 pathway: current researches in cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 4. A snapshot of the PD-1/PD-L1 pathway [jcancer.org]
- 5. Frontiers | PD-1 and PD-L1: architects of immune symphony and immunotherapy breakthroughs in cancer treatment [frontiersin.org]
- 6. Cancer immunotherapy and the PD-1/PD-L1 checkpoint pathway | Abcam [abcam.com]
- 7. Immunosuppressive Signaling Pathways as Targeted Cancer Therapies - PMC [pmc.ncbi.nlm.nih.gov]
- 8. mdpi.com [mdpi.com]
- 9. Quantitative Assessment of the Heterogeneity of PD-L1 Expression in Non-Small-Cell Lung Cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. Quantitative Assessment of the Heterogeneity of PD-L1 Expression in Non-small Cell Lung Cancer (NSCLC) - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Quantifying PD-L1 Expression to Monitor Immune Checkpoint Therapy: Opportunities and Challenges - PMC [pmc.ncbi.nlm.nih.gov]
- 13. onclive.com [onclive.com]
- 14. Efficacy of PD-1/PD-L1 blockade monotherapy in clinical trials - PMC [pmc.ncbi.nlm.nih.gov]
- 15. PD-L1 Immunohistochemistry Comparability Study in Real-Life Clinical Samples: Results of Blueprint Phase 2 Project - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Research Status and Outlook of PD-1/PD-L1 Inhibitors for Cancer Therapy - PMC [pmc.ncbi.nlm.nih.gov]
- 17. oncotarget.com [oncotarget.com]
- 18. meridian.allenpress.com [meridian.allenpress.com]
- 19. Development of an Automated PD-L1 Immunohistochemistry (IHC) Assay for Non–Small Cell Lung Cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 20. clinicallab.com [clinicallab.com]
- 21. research.pasteur.fr [research.pasteur.fr]
Review of foundational principles in [specific field of science e.g., organic chemistry]
This guide provides an in-depth overview of the core principles governing T-cell activation, a critical process in the adaptive immune response. Tailored for researchers, scientists, and drug development professionals, this document details the essential signaling events, quantitative parameters, and key experimental methodologies used to study this fundamental aspect of immunology.
Core Principles of T-Cell Activation
T-cell activation is a tightly regulated process that initiates an adaptive immune response against pathogens and malignant cells. The activation of a naive T-cell requires a multi-signal process to ensure specificity and prevent autoimmunity.
Signal 1: Antigen Recognition The primary signal is delivered through the T-cell receptor (TCR) recognizing a specific antigenic peptide presented by a Major Histocompatibility Complex (MHC) molecule on the surface of an antigen-presenting cell (APC).[1][2][3] CD4+ helper T-cells recognize peptides on MHC class II molecules, while CD8+ cytotoxic T-cells recognize peptides on MHC class I molecules.[4] This initial interaction ensures the high specificity of the immune response.
Signal 2: Co-stimulation For full activation, a T-cell must receive a second, co-stimulatory signal from the APC.[1][2][5] The most prominent co-stimulatory interaction involves the CD28 receptor on the T-cell binding to B7 molecules (CD80/CD86) on the APC.[1][2] This second signal confirms that the antigen is presented in the context of inflammation or danger, preventing T-cell activation against self-antigens. The absence of co-stimulation during TCR engagement can lead to a state of unresponsiveness known as anergy.[5]
Signal 3: Cytokine Signaling Following the first two signals, cytokines in the local environment direct T-cell differentiation into various effector subtypes (e.g., Th1, Th2, Th17). Interleukin-2 (IL-2) is a critical cytokine that promotes T-cell proliferation and survival.[6]
Quantitative Data in T-Cell Activation
The study of T-cell activation relies on the quantification of various cellular and molecular parameters. The following tables summarize key quantitative data relevant to this process.
| Parameter | Typical Value Range | Description |
| T-Cell Population in Human PBMCs | ||
| CD3+ T-Cells | 45 - 70% | Percentage of total Peripheral Blood Mononuclear Cells (PBMCs).[7][8][9] |
| CD4+ T-Cells | 25 - 60% | Percentage of total PBMCs, typically in a 2:1 ratio with CD8+ T-cells.[5][7][8][9] |
| CD8+ T-Cells | 5 - 30% | Percentage of total PBMCs.[7][8][9] |
| TCR-pMHC Binding Affinity | ||
| Dissociation Constant (KD) | 1 - 100 µM | The typical affinity range for TCR binding to its peptide-MHC ligand is in the micromolar range, which is considered relatively weak.[4][10][11] |
| High-Affinity Engineered TCRs | < 1 µM (nM range) | Engineered TCRs used in immunotherapies can have significantly higher affinities.[4][11] |
| Cytokine Production Post-Activation (In Vitro) | ||
| Interleukin-2 (IL-2) | 50 - 500 IU/mL | Optimal concentrations for in vitro T-cell expansion.[6][12] Higher concentrations do not always lead to significantly more expansion.[6] |
| Interferon-gamma (IFN-γ) | 100 - 5000 pg/mL | Concentration in cell culture supernatants after stimulation, highly variable depending on donor and stimulus. |
Key Signaling Pathways
Upon successful antigen recognition and co-stimulation, a cascade of intracellular signaling events is initiated within the T-cell, leading to cellular activation, proliferation, and differentiation.
T-Cell Receptor (TCR) Signaling Pathway
Engagement of the TCR-CD3 complex with a pMHC molecule triggers the phosphorylation of Immunoreceptor Tyrosine-based Activation Motifs (ITAMs) within the CD3 cytoplasmic tails by the kinase Lck. This creates docking sites for another kinase, ZAP-70, which is subsequently activated.[7] ZAP-70 then phosphorylates several downstream adaptor proteins, including LAT and SLP-76, leading to the activation of multiple signaling cascades, such as the PLCγ1 pathway, which results in calcium flux and activation of transcription factors like NFAT.[7]
CD28 Co-stimulatory Pathway
The binding of CD28 to CD80/CD86 initiates a separate signaling cascade that synergizes with TCR signaling. A key event is the recruitment and activation of Phosphoinositide 3-kinase (PI3K).[13] PI3K activation leads to the production of PIP3, which serves as a docking site for proteins with PH domains, such as Akt and PDK1. This pathway is crucial for promoting cell survival, metabolism, and proliferation, partly through the activation of the mTOR pathway and by enhancing the stability of IL-2 mRNA.[13][14]
Experimental Protocols
Several key experimental techniques are routinely used to measure the outcomes of T-cell activation, including proliferation, cytokine production, and the expression of activation markers.
T-Cell Proliferation Assay (CFSE-based)
This protocol uses Carboxyfluorescein succinimidyl ester (CFSE), a fluorescent dye that is progressively diluted with each cell division, allowing for the tracking of cell proliferation via flow cytometry.[2][15]
Methodology:
-
Cell Preparation: Isolate human PBMCs from whole blood using Ficoll-Paque density gradient centrifugation.
-
CFSE Labeling:
-
Resuspend 10-20 million cells/mL in 0.1% FBS/PBS.
-
Add CFSE to a final concentration of 1-5 µM. Vortex gently and incubate for 8-10 minutes at room temperature, protected from light.[16]
-
Stop the reaction by adding an equal volume of cold, 100% FBS and incubate for 5-10 minutes on ice to allow for efflux of unbound dye.[16]
-
Wash the cells three times with complete RPMI medium to remove excess CFSE.
-
-
Cell Culture and Stimulation:
-
Flow Cytometry Analysis:
-
Harvest cells and stain with fluorescently-conjugated antibodies against surface markers (e.g., CD3, CD4, CD8).
-
Acquire data on a flow cytometer, using the 488 nm laser for CFSE excitation.
-
Analyze the CFSE histogram of the gated T-cell populations. Each peak of decreasing fluorescence intensity represents a successive generation of divided cells.
-
Cytokine Quantification (ELISA)
The Enzyme-Linked Immunosorbent Assay (ELISA) is a plate-based assay for quantifying secreted proteins, such as IFN-γ, in cell culture supernatants.
Methodology (Sandwich ELISA):
-
Plate Coating: Coat a 96-well high-binding plate with a capture antibody specific for the cytokine of interest (e.g., anti-human IFN-γ) overnight at 4°C.
-
Blocking: Wash the plate and block non-specific binding sites with a blocking buffer (e.g., 1% BSA in PBS) for 1-2 hours at room temperature.
-
Sample Incubation: Wash the plate and add cell culture supernatants and a serial dilution of a known standard to the wells. Incubate for 2 hours at room temperature.[17]
-
Detection Antibody: Wash the plate and add a biotinylated detection antibody specific for a different epitope on the cytokine. Incubate for 1 hour at room temperature.[17]
-
Enzyme Conjugate: Wash the plate and add Streptavidin-Horseradish Peroxidase (SA-HRP). Incubate for 30 minutes at room temperature.[1]
-
Substrate Addition: Wash the plate and add a chromogenic substrate (e.g., TMB). A color change will develop in proportion to the amount of cytokine bound.
-
Stopping Reaction & Reading: Stop the reaction with a stop solution (e.g., 2N H₂SO₄) and read the absorbance at 450 nm using a microplate reader.
-
Quantification: Generate a standard curve from the known standards and calculate the concentration of the cytokine in the samples.
Intracellular Cytokine Staining (Flow Cytometry)
This method allows for the identification and quantification of cytokine-producing cells at a single-cell level.
Methodology:
-
Cell Stimulation: Stimulate PBMCs (e.g., with PMA and Ionomycin or specific antigen) for 4-6 hours. In the final hours of stimulation, add a protein transport inhibitor (e.g., Brefeldin A or Monensin) to trap cytokines within the cell.[18]
-
Surface Staining: Harvest the cells and stain for cell surface markers (e.g., CD4, CD8) with fluorescently-conjugated antibodies. This is typically done on live cells before fixation.[18]
-
Fixation: Wash the cells and resuspend them in a fixation buffer (e.g., 4% paraformaldehyde) for 20 minutes at room temperature to cross-link proteins and preserve cell morphology.[13]
-
Permeabilization: Wash the cells and resuspend them in a permeabilization buffer (e.g., containing saponin or Triton X-100). This allows antibodies to access intracellular targets.[13][19]
-
Intracellular Staining: Add a fluorescently-conjugated antibody specific for the intracellular cytokine of interest (e.g., anti-human IFN-γ) to the permeabilized cells. Incubate for 30 minutes at room temperature in the dark.
-
Washing and Analysis: Wash the cells to remove unbound antibody and resuspend them in FACS buffer for analysis on a flow cytometer.
Experimental Workflow
The following diagram illustrates a typical workflow for studying T-cell activation in vitro.
References
- 1. stemcell.com [stemcell.com]
- 2. agilent.com [agilent.com]
- 3. Structure-based prediction of T cell receptor:peptide-MHC interactions | eLife [elifesciences.org]
- 4. Evaluation of TCR-pMHC affinity and its implications for T cell responsiveness | Quality Assistance [quality-assistance.com]
- 5. Peripheral Blood Mononuclear Cells - The Impact of Food Bioactives on Health - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 6. Optimizing interleukin-2 concentration, seeding density and bead-to-cell ratio of T-cell expansion for adoptive immunotherapy - PMC [pmc.ncbi.nlm.nih.gov]
- 7. sanguinebio.com [sanguinebio.com]
- 8. miltenyibiotec.com [miltenyibiotec.com]
- 9. miltenyibiotec.com [miltenyibiotec.com]
- 10. HIGH-AFFINITY T CELL RECEPTOR DIFFERENTIATES COGNATE PEPTIDE-MHC AND ALTERED PEPTIDE LIGANDS WITH DISTINCT KINETICS AND THERMODYNAMICS - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Interplay between T Cell Receptor Binding Kinetics and the Level of Cognate Peptide Presented by Major Histocompatibility Complexes Governs CD8+ T Cell Responsiveness - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. Intracellular Cytokine Staining Protocol [anilocus.com]
- 14. CFSE dilution to study human T and NK cell proliferation in vitro - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. researchgate.net [researchgate.net]
- 16. bu.edu [bu.edu]
- 17. bdbiosciences.com [bdbiosciences.com]
- 18. Intracellular Flow Cytometry Staining Protocol [protocols.io]
- 19. (IC) Intracellular Staining Flow Cytometry Protocol Using Detergents: R&D Systems [rndsystems.com]
Impact of [a specific technology] on [a scientific field]
An In-Depth Technical Guide to the Impact of CRISPR-Cas9 on Cancer Immunotherapy
For: Researchers, Scientists, and Drug Development Professionals
Abstract
The advent of the CRISPR-Cas9 gene-editing technology has initiated a paradigm shift in cancer immunotherapy, offering unprecedented precision and versatility in reprogramming immune cells to combat malignancies.[1][2] This technical guide provides a comprehensive overview of the core applications of CRISPR-Cas9 in the field, with a particular focus on enhancing Adoptive Cell Therapy (ACT), such as Chimeric Antigen Receptor (CAR) T-cell therapy. We will delve into the detailed methodologies for key experiments, present quantitative data from pivotal preclinical and clinical studies, and visualize complex biological pathways and experimental workflows to provide a thorough understanding of this transformative technology's impact.
Introduction: Revolutionizing T-Cell Engineering
Cancer immunotherapy harnesses the body's immune system to fight cancer.[2] Adoptive cell therapies, where immune cells are engineered to recognize and attack tumor cells, have shown remarkable success, particularly in hematological cancers.[3][4] However, challenges such as T-cell exhaustion, the immunosuppressive tumor microenvironment (TME), and limitations in autologous T-cell manufacturing have hindered broader efficacy, especially against solid tumors.[4][5]
The CRISPR-Cas9 system, a powerful and adaptable genome-editing tool, provides a robust platform to address these challenges.[1][3] By enabling precise gene knockouts, knock-ins, and multiplexed edits, CRISPR-Cas9 is being used to create next-generation therapeutic immune cells with enhanced potency, persistence, and safety.[4][6] Key applications include disrupting immune checkpoint pathways, generating "universal" allogeneic T-cells, and identifying novel therapeutic targets through large-scale genetic screens.[3][4][7]
Core Applications of CRISPR-Cas9 in Cancer Immunotherapy
Enhancing CAR T-Cell Potency by Disrupting Inhibitory Pathways
A primary strategy for improving T-cell function is the elimination of inhibitory signals that lead to T-cell exhaustion. The Programmed cell death protein 1 (PD-1) is a key immune checkpoint receptor on activated T-cells that, when engaged by its ligand (PD-L1) on tumor cells, suppresses T-cell activity.
CRISPR-Cas9 can be used to knock out the gene encoding PD-1 (PDCD1) in T-cells before their administration to patients.[8] This renders the engineered T-cells resistant to the immunosuppressive signals from the tumor, enhancing their anti-tumor activity and persistence.[8][9][10] Preclinical studies have consistently shown that PD-1 knockout in CAR-T cells leads to improved clearance of tumor xenografts in animal models.[8]
Creating Universal "Off-the-Shelf" Allogeneic CAR T-Cells
Current CAR-T therapies are autologous, meaning they are manufactured on a patient-by-patient basis, which is time-consuming and expensive.[6] Using T-cells from healthy donors (allogeneic) could create "off-the-shelf" therapies. However, this approach carries the risk of Graft-versus-Host Disease (GvHD), where the donor T-cells attack the recipient's tissues, and rejection of the CAR-T cells by the host's immune system.
CRISPR-Cas9 enables the creation of universal CAR-T cells by simultaneously knocking out the endogenous T-cell receptor (TCR) and the Beta-2 microglobulin (B2M) gene, which is essential for the expression of Major Histocompatibility Complex (MHC) class I molecules.[9][11] Disrupting the TCR prevents GvHD, while eliminating MHC class I expression helps the CAR-T cells evade rejection by the host's immune system.[9]
Discovery of Novel Immunotherapy Targets via CRISPR Screens
Genome-wide CRISPR screens are a powerful tool for identifying novel genes that regulate the interaction between immune cells and cancer cells.[7][12] In these screens, a library of guide RNAs targeting thousands of genes is introduced into cancer cells or immune cells. By observing which gene knockouts make cancer cells more susceptible to T-cell killing, or which knockouts enhance T-cell function, researchers can uncover new therapeutic targets.[7][13] This approach has already identified novel regulators of antigen presentation and cytokine signaling as promising targets to overcome resistance to existing immunotherapies.[7]
Quantitative Data from Preclinical and Clinical Studies
The following tables summarize key quantitative outcomes from studies utilizing CRISPR-Cas9-engineered immune cells.
Table 1: Preclinical Efficacy of CRISPR-Edited CAR-T Cells
| Target Gene(s) Disrupted | Cancer Model | Key Finding | Outcome Metric | Result | Reference |
| PDCD1 (PD-1) | Human Glioblastoma (in vitro) | Enhanced cytotoxicity of CAR-T cells | Increased cancer cell death | Statistically significant increase in lysis of PD-L1+ tumor cells | |
| PDCD1 (PD-1) | Tumor Xenografts (in vivo) | Increased anti-tumor efficacy | Enhanced tumor clearance | Significantly improved survival and reduced tumor volume | [8] |
| CD70 | Multiple Antigens (in vitro) | Improved potency and persistence | Increased CAR-T cell function | CD70 knockout performed better than other checkpoint knockouts | [14] |
| TRAC, B2M | Acute Myeloid Leukemia (in vivo) | Eradication of tumors by allogeneic CAR-T cells | Tumor eradication | AML tumors eradicated without long-term myelosuppression | [11] |
Table 2: Clinical Trial Data for CRISPR-Edited T-Cells
| Study Identifier | Cancer Type | CRISPR Edits | Number of Patients | Key Findings & Outcomes | Reference |
| First-in-human Phase I (UPenn) | Refractory Cancers (Myeloma, Sarcoma) | TRAC, TRBC, PDCD1 Knockout; NY-ESO-1 TCR Knock-in | 3 | Feasibility & Safety: Multiplex editing was safe and feasible. Persistence: Engineered T-cells persisted for up to 9 months. Clinical Response: Tumors stabilized in some patients, but disease progression occurred. | [8][15][16] |
| PACT Pharma Phase I | Solid Tumors (Colon, Breast, Lung) | Patient-specific TCR knock-in | 16 | Safety: Minimal and manageable side effects. Clinical Response: Tumors stabilized in 5 of 16 patients. | [17] |
| CARBON Trial (CTX110) | Relapsed/Refractory B-cell Malignancies | Allogeneic CAR-T targeting CD19 | N/A | Efficacy: Positive results reported from the Phase 1 trial. | [11] |
Experimental Protocols
Protocol: CRISPR-Cas9 Mediated Knockout of PDCD1 in Human Primary T-Cells
This protocol provides a representative methodology for generating PD-1 knockout T-cells using Cas9 ribonucleoprotein (RNP) delivery, which has been shown to be efficient in primary human T-cells.[18]
1. T-Cell Isolation and Activation: a. Isolate Peripheral Blood Mononuclear Cells (PBMCs) from a healthy donor's blood using density gradient centrifugation. b. Isolate primary T-cells from PBMCs using a negative selection kit (e.g., EasySep™ Human T Cell Isolation Kit).[19] c. Activate isolated T-cells using anti-CD3/CD28 magnetic beads at a 1:1 bead-to-cell ratio in T-cell culture medium supplemented with IL-2. d. Culture the cells at 37°C and 5% CO₂ for 2-3 days. Activation can be confirmed by observing cell clustering and expression of activation markers.[19][20]
2. Preparation of Cas9 Ribonucleoprotein (RNP) Complex: a. Synthesize or procure a chemically modified single guide RNA (sgRNA) targeting an early exon of the PDCD1 gene. b. Resuspend lyophilized sgRNA in RNase-free buffer. c. Mix recombinant Cas9 protein (e.g., TrueCut Cas9 Protein v2) with the sgRNA at a 1:1 molar ratio.[21] d. Incubate the mixture at room temperature for 10-20 minutes to allow the formation of the RNP complex.[21]
3. Electroporation of T-Cells with RNP Complex: a. After 2-3 days of activation, harvest the T-cells and wash them to remove beads and culture medium. b. Resuspend 1-2 million T-cells in an electroporation buffer. c. Add the pre-formed Cas9 RNP complex to the cell suspension. d. Electroporate the cells using a system like the Neon™ Transfection System with a pre-optimized pulse protocol (e.g., 1600 V, 10 ms, 3 pulses).[21] e. Immediately transfer the electroporated cells into a pre-warmed culture plate containing fresh T-cell medium with IL-2.[21]
4. Post-Electroporation Culture and Validation: a. Culture the cells for 48-72 hours. b. Validation of Knockout Efficiency: i. Flow Cytometry: Stain a sample of cells with an anti-PD-1 antibody to quantify the loss of surface protein expression. Compare with a non-electroporated control.[18][20] ii. Genomic Analysis: Extract genomic DNA from a cell sample. Use a mismatch cleavage assay (e.g., T7 Endonuclease I assay) or sequencing to detect the presence of insertions/deletions (indels) at the target locus.[20]
5. Functional Assay: a. Co-culture the PD-1 knockout T-cells with a cancer cell line that expresses PD-L1. b. Use a control group of unedited T-cells. c. Measure the cytotoxic activity of the T-cells against the cancer cells using a chromium release assay or similar cytotoxicity assay. An increase in cancer cell lysis by the PD-1 knockout T-cells indicates enhanced function.[19][22]
Visualizations: Pathways and Workflows
Diagram 1: Simplified PD-1/PD-L1 Immune Checkpoint Pathway
Caption: CRISPR-Cas9 knockout of the PD-1 receptor prevents inhibitory signaling, enhancing T-cell function.
Diagram 2: Experimental Workflow for Generating CRISPR-Enhanced CAR-T Cells
Caption: A streamlined workflow for producing gene-edited CAR-T cells for adoptive cell therapy.
Diagram 3: Logic of Creating Universal Allogeneic CAR-T Cells
Caption: Multiplex CRISPR editing to prevent GvHD and host rejection in allogeneic CAR-T therapy.
Conclusion and Future Outlook
CRISPR-Cas9 has unequivocally emerged as a cornerstone technology for advancing cancer immunotherapy.[1][3] Its ability to precisely edit the genome of immune cells is overcoming critical barriers that have limited the efficacy of treatments like CAR-T cell therapy.[5][9] The generation of T-cells resistant to exhaustion, the development of universal allogeneic therapies, and the discovery of new therapeutic targets are just the beginning.
While the initial clinical data demonstrates safety and feasibility, further research is required to optimize editing efficiency and long-term persistence of engineered cells.[6] The combination of CRISPR with other emerging technologies, such as base and prime editing, promises even more sophisticated control over T-cell fate and function.[6] As this technology matures, CRISPR-engineered immune cells are poised to become a mainstream, potent, and more accessible therapeutic modality for a wider range of cancers.
References
- 1. Applications and advances of CRISPR-Cas9 in cancer immunotherapy - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. A review on CRISPR-Cas9 and its role in cancer immunotherapy | European Journal of Biological Research [journals.tmkarpinski.com]
- 3. Frontiers | CRISPR/Cas9 Gene-Editing in Cancer Immunotherapy: Promoting the Present Revolution in Cancer Therapy and Exploring More [frontiersin.org]
- 4. academic.oup.com [academic.oup.com]
- 5. CRISPR/Cas9: A Powerful Strategy to Improve CAR-T Cell Persistence - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Better living through chemistry: CRISPR/Cas engineered T cells for cancer immunotherapy - PMC [pmc.ncbi.nlm.nih.gov]
- 7. CRISPR Screens to Identify Regulators of Tumor Immunity - PMC [pmc.ncbi.nlm.nih.gov]
- 8. CRISPR-engineered T cells in patients with refractory cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 9. CRISPR/Cas9: A Powerful Strategy to Improve CAR-T Cell Persistence - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Frontiers | The Application of CRISPR/Cas9 Technology for Cancer Immunotherapy: Current Status and Problems [frontiersin.org]
- 11. cgtlive.com [cgtlive.com]
- 12. twistbioscience.com [twistbioscience.com]
- 13. Novel CRISPR-Cas9 screening enables discovery of new targets to aid cancer immunotherapy - ecancer [ecancer.org]
- 14. CRISPR Therapeutics Presents Preclinical Data… | CRISPR Therapeutics [crisprtx.com]
- 15. researchgate.net [researchgate.net]
- 16. CRISPR-engineered T cells in patients with refractory cancer - BSGCT [bsgct.org]
- 17. inverse.com [inverse.com]
- 18. pnas.org [pnas.org]
- 19. corning.com [corning.com]
- 20. researchgate.net [researchgate.net]
- 21. documents.thermofisher.com [documents.thermofisher.com]
- 22. CRISPRCas9-mediated PD-1 Knock-out In Human Primary T Cells Shows Enhanced Cytotoxicity Against Cancer Cells [cellandgene.com]
Future Directions in CAR T-Cell Research: A Technical Guide for Advanced Cancer Immunotherapy
Introduction
Chimeric Antigen Receptor (CAR) T-cell therapy has emerged as a transformative treatment for hematological malignancies, achieving remarkable success where traditional therapies have failed.[1][2][3] This innovative approach involves genetically modifying a patient's own T-cells to express CARs that recognize and eliminate cancer cells.[4] Despite its success in blood cancers, the application of CAR T-cell therapy to solid tumors has been met with significant challenges, including the immunosuppressive tumor microenvironment (TME), antigen heterogeneity, and limited T-cell persistence.[2][3][5] This technical guide provides an in-depth overview of the future directions of CAR T-cell research, focusing on next-generation strategies to overcome current limitations and expand the therapeutic reach of this promising immunotherapy. We will delve into novel CAR designs, combination therapies, and innovative manufacturing processes, presenting quantitative data, detailed experimental protocols, and pathway visualizations to inform researchers, scientists, and drug development professionals.
Key Future Research Directions
The next wave of CAR T-cell therapy is focused on enhancing efficacy against solid tumors, improving safety profiles, and increasing accessibility. Key areas of innovation include:
-
"Armored" CAR T-Cells: To counteract the immunosuppressive TME, researchers are engineering CAR T-cells to secrete immunomodulatory molecules, such as cytokines (e.g., IL-12, IL-15, IL-18) or checkpoint inhibitors.[2][5] These "armored" CARs can reshape the tumor landscape, promoting a more robust and sustained anti-tumor immune response.
-
Multi-Antigen Targeting: To address tumor antigen escape, where cancer cells downregulate the target antigen to evade CAR T-cell recognition, dual- and tandem-CAR designs are being developed.[6][7] These constructs can recognize two or more tumor-associated antigens simultaneously, reducing the likelihood of relapse due to antigen loss.
-
Logic-Gated CARs: To improve safety and minimize "on-target, off-tumor" toxicities, where CAR T-cells attack healthy tissues that express the target antigen at low levels, logic-gated CARs are being explored. These designs require the presence of two distinct antigens on the target cell for full activation, thereby increasing the specificity of the anti-tumor response.
-
Allogeneic "Off-the-Shelf" CAR T-Cells: Current autologous CAR T-cell manufacturing is a complex and lengthy process.[8] The development of allogeneic CAR T-cells from healthy donor T-cells could provide an "off-the-shelf" product, significantly reducing cost and waiting times for patients. Gene-editing technologies like CRISPR-Cas9 are being utilized to overcome the challenges of allogeneic T-cell rejection.
-
Modulating the Tumor Microenvironment: Strategies to overcome the physical and chemical barriers of the TME are a major focus. This includes engineering CAR T-cells to express enzymes that degrade the extracellular matrix or to be resistant to inhibitory signals within the tumor. Combination therapies with radiotherapy or chemotherapy are also being investigated to enhance CAR T-cell infiltration and function.[3]
Quantitative Data from Clinical Trials of Next-Generation CAR T-Cell Therapies
The following tables summarize recent clinical trial data for emerging CAR T-cell therapies in solid tumors, highlighting the objective response rates (ORR) and disease control rates (DCR).
| Target Antigen | Cancer Type | CAR T-Cell Therapy | Phase | Number of Patients | ORR (%) | DCR (%) | Key Findings | Citation |
| Claudin18.2 (CLDN18.2) | Gastrointestinal Cancers | Satri-cel (autologous CAR T) | I | 98 | 38.8 | 91.8 | Well-tolerated with manageable side effects. Responses were transient, attributed to heterogeneous antigen expression. | [5][9] |
| Glypican-3 (GPC3) | Solid Tumors | IL-15-armored GPC3-CAR T | I | N/A | 33 | 66 | Favorable safety profile. | [10] |
| Mesothelin | Malignant Pleural Mesothelioma | Mesothelin-targeted CAR T + Pembrolizumab | I/II | 18 | N/A (2 complete metabolic responses) | N/A (8 with stable disease ≥ 6 months) | Combination with checkpoint inhibition shows promise. 1-year overall survival rate of 83%. | [7][9] |
| GD2 | H3K27M-mutated Diffuse Midline Gliomas | GD2-CART | I | 11 | N/A (4 major tumor reductions, 1 complete response) | N/A | Intracerebroventricular infusions showed promise in a difficult-to-treat brain tumor. | [9] |
| Guanylate Cyclase 2C (GUCY2C) | Metastatic Colorectal Cancer | GCC19CART | I | 13 | 60 | 80 | Dose-dependent clinical activity with an acceptable safety profile. | [10] |
| Multi-Antigen Targeting Strategy | Cancer Type | CAR T-Cell Therapy | Phase | Number of Patients | ORR (%) | CR (%) | Key Findings | Citation |
| CD19/CD20 Bispecific | Non-Hodgkin Lymphoma (r/r) | Autologous bispecific CAR T | I | N/A | 90 | 70 | Safe and demonstrated strong efficacy. | [7] |
| BCMA/CD19 Dual | Multiple Myeloma | Sequential infusion of two CAR T products | I | N/A | N/A | N/A | Manageable cytokine release syndrome with no neurological toxicity. | [11] |
| BCMA/CD38 Tandem | Multiple Myeloma | BM38 CAR | Preclinical | N/A | N/A | N/A | Evaluated for anti-myeloma activity in vitro. | [6] |
Experimental Protocols
Generation of CAR T-Cells by Lentiviral Transduction
This protocol outlines the basic steps for generating CAR T-cells for research purposes using lentiviral vectors.
Materials:
-
Human Peripheral Blood Mononuclear Cells (PBMCs)
-
T-cell isolation kit (e.g., CD4+ and CD8+ enrichment kits)
-
T-cell activation reagent (e.g., anti-CD3/CD28 antibodies or beads)
-
Recombinant human cytokines (e.g., IL-2, IL-7, IL-15)
-
Lentiviral vector encoding the CAR construct
-
T-cell culture medium (e.g., RPMI-1640) with supplements
-
24-well tissue culture plates
Procedure:
-
Isolation of T-Cells: Isolate PBMCs from healthy donor blood using Ficoll-Paque density gradient centrifugation. Subsequently, enrich for CD4+ and CD8+ T-cell populations using magnetic-activated cell sorting (MACS) or fluorescence-activated cell sorting (FACS).[12][13]
-
T-Cell Activation: Activate the isolated T-cells by culturing them in a plate pre-coated with anti-CD3 and anti-CD28 antibodies, or by using anti-CD3/CD28-coated beads. Add IL-2 to the culture medium to promote T-cell proliferation.[12][14]
-
Lentiviral Transduction: On day 2 or 3 post-activation, transduce the T-cells with the lentiviral vector carrying the CAR construct at a multiplicity of infection (MOI) of 10.[12] Centrifugation of the plates (spinoculation) can enhance transduction efficiency.
-
Expansion of CAR T-Cells: Expand the transduced T-cells for 10-14 days in culture medium supplemented with IL-7 and IL-15.[12][13] Monitor cell viability and expansion regularly.
-
Confirmation of CAR Expression: After the expansion period, confirm the surface expression of the CAR on the T-cells using flow cytometry with an anti-Fab antibody or a recombinant target protein.[12]
In Vivo Assessment of CAR T-Cell Efficacy in a Xenograft Mouse Model
This protocol describes a general workflow for evaluating the anti-tumor efficacy of CAR T-cells in an immunodeficient mouse model.
Materials:
-
Immunodeficient mice (e.g., NSG mice)
-
Human tumor cell line expressing the target antigen (and preferably a reporter like luciferase)
-
Generated CAR T-cells and control T-cells
-
Bioluminescence imaging system (if using luciferase-expressing tumor cells)
-
Calipers for tumor measurement
-
Flow cytometry equipment and antibodies for immunophenotyping
Procedure:
-
Tumor Engraftment: Subcutaneously or orthotopically inject the human tumor cell line into the immunodeficient mice.[15][16][17] Allow the tumors to establish and reach a palpable size (e.g., 50-100 mm³).[16]
-
CAR T-Cell Infusion: Once tumors are established, intravenously inject the CAR T-cells into the mice.[15][16] Include control groups receiving non-transduced T-cells or saline. A typical dose is 5-10 x 10⁶ CAR+ T-cells per mouse.
-
Monitoring Tumor Growth: Monitor tumor growth over time using calipers to measure tumor volume or through bioluminescence imaging to quantify tumor burden.[15][17]
-
Assessment of CAR T-Cell Persistence and Function: At the end of the experiment, or at various time points, collect blood, spleen, and tumor tissue to assess the persistence, proliferation, and phenotype of the CAR T-cells using flow cytometry.[15]
-
Evaluation of Efficacy: The primary endpoint is typically a significant reduction in tumor growth or complete tumor regression in the CAR T-cell treated group compared to the control groups. Survival analysis can also be performed.
Mandatory Visualizations
Signaling Pathway of a Fourth-Generation "Armored" CAR T-Cell
Caption: Signaling cascade of a 4th-gen CAR T-cell expressing IL-12 to remodel the TME.
Experimental Workflow for CAR T-Cell Manufacturing and In Vivo Testing
Caption: Workflow from patient T-cell collection to in vivo efficacy assessment.
Logical Relationships for Overcoming CAR T-Cell Therapy Challenges in Solid Tumors
Caption: Strategies to mitigate key obstacles for CAR T-cell efficacy in solid tumors.
References
- 1. researchgate.net [researchgate.net]
- 2. Advances in CAR T cell therapy: antigen selection, modifications, and current trials for solid tumors - PMC [pmc.ncbi.nlm.nih.gov]
- 3. The current landscape of CAR T-cell therapy for solid tumors: Mechanisms, research progress, challenges, and counterstrategies - PMC [pmc.ncbi.nlm.nih.gov]
- 4. novartis.com [novartis.com]
- 5. Advancing CAR-T Therapy for Solid Tumors: From Barriers to Clinical Progress [mdpi.com]
- 6. Frontiers | Tandem CAR-T cell therapy: recent advances and current challenges [frontiersin.org]
- 7. mdpi.com [mdpi.com]
- 8. researchgate.net [researchgate.net]
- 9. onclive.com [onclive.com]
- 10. ascopubs.org [ascopubs.org]
- 11. Frontiers | Dual Targeting to Overcome Current Challenges in Multiple Myeloma CAR T-Cell Treatment [frontiersin.org]
- 12. inmuno-oncologia.ciberonc.es [inmuno-oncologia.ciberonc.es]
- 13. miltenyibiotec.com [miltenyibiotec.com]
- 14. rupress.org [rupress.org]
- 15. inmuno-oncologia.ciberonc.es [inmuno-oncologia.ciberonc.es]
- 16. How to Test Human CAR T cells in Solid Tumors, The Next Frontier of CAR T Cell Therapy - PMC [pmc.ncbi.nlm.nih.gov]
- 17. In vivo CAR T cell tumor control assay [protocols.io]
Methodological & Application
CRISPR-Cas9 Gene Editing: A Comprehensive Guide for Researchers and Drug Development Professionals
Introduction: The CRISPR-Cas9 system has emerged as a revolutionary gene-editing tool, offering unprecedented precision and efficiency in modifying DNA sequences.[1][2][3] This technology, adapted from a bacterial immune system, allows for targeted gene knockouts, insertions, and alterations, with wide-ranging applications in basic research, drug discovery, and the development of novel therapeutics.[1][4][5] This document provides a detailed guide to the CRISPR-Cas9 workflow, including experimental protocols and data presentation, tailored for researchers, scientists, and drug development professionals.
Principle of CRISPR-Cas9 Mediated Gene Editing
The CRISPR-Cas9 system consists of two key components: the Cas9 nuclease, which acts as a pair of "molecular scissors" to cut DNA, and a guide RNA (gRNA) that directs the Cas9 to a specific genomic location.[3][6] The gRNA is a synthetic RNA molecule that contains a user-defined ~20 nucleotide spacer sequence complementary to the target DNA sequence.[3][7] For the Cas9 nuclease to bind and cleave the DNA, the target sequence must be immediately followed by a short DNA sequence known as a protospacer adjacent motif (PAM).[6][7]
Once the Cas9-gRNA complex binds to the target DNA, the Cas9 protein induces a double-strand break (DSB).[6] The cell's natural DNA repair mechanisms are then activated to mend this break. The two primary repair pathways are:
-
Non-Homologous End Joining (NHEJ): This pathway is error-prone and often results in small insertions or deletions (indels) at the cut site. These indels can disrupt the reading frame of a gene, leading to a functional knockout.[2]
-
Homology-Directed Repair (HDR): In the presence of a DNA template with homology to the targeted locus, the HDR pathway can be utilized to introduce precise edits, such as single nucleotide polymorphisms (SNPs), insertions, or gene replacements.[2]
Experimental Workflow: A Step-by-Step Guide
The successful implementation of a CRISPR-Cas9 experiment involves a series of well-defined steps, from the initial design to the final validation of the genetic modification.[8][9][10]
Caption: A generalized workflow for a CRISPR-Cas9 gene-editing experiment.
Phase 1: Design
2.1.1. sgRNA Design and Selection:
The design of the single guide RNA (sgRNA) is a critical step that dictates the specificity and efficiency of the gene-editing experiment.[11][12] Several factors should be considered:
-
Target Site Selection: The target sequence should be unique within the genome to minimize off-target effects.[13] It is also crucial that the target sequence is immediately upstream of a Protospacer Adjacent Motif (PAM), which is typically 'NGG' for the commonly used Streptococcus pyogenes Cas9 (SpCas9).[9][14]
-
On-Target Activity Prediction: Various online tools and algorithms are available to predict the on-target efficiency of different sgRNA sequences. These tools often consider factors like GC content (ideally 40-80%) and the absence of secondary structures.[11][15]
-
Off-Target Minimization: It is recommended to select sgRNAs with minimal predicted off-target sites.[11]
Table 1: Key Considerations for sgRNA Design
| Parameter | Recommendation | Rationale |
| Target Sequence Length | 17-23 nucleotides | Balances specificity and on-target activity.[15] |
| PAM Sequence | NGG (for SpCas9) | Essential for Cas9 recognition and binding.[9][14] |
| GC Content | 40-80% | Contributes to the stability of the sgRNA-DNA complex.[15] |
| Genomic Location | Early exon for knockout | Increases the likelihood of a frameshift mutation leading to a non-functional protein.[16] |
| Off-Target Sites | Minimal | Reduces the risk of unintended mutations at other genomic locations.[11] |
2.1.2. In Silico Off-Target Analysis:
Before proceeding with the experiment, it is crucial to perform a thorough in silico analysis to identify potential off-target sites.[17] Several bioinformatics tools can scan the genome for sequences with high similarity to the chosen sgRNA.[18] This analysis helps in selecting the most specific sgRNA and in designing primers for subsequent off-target validation.
Phase 2: Delivery
2.2.1. Preparation of CRISPR Components:
The CRISPR-Cas9 components can be delivered into cells in three main formats:
-
Plasmid DNA: Plasmids encoding the Cas9 nuclease and the sgRNA. This method is cost-effective but may lead to prolonged expression of the Cas9 protein, increasing the risk of off-target effects.[19][20]
-
mRNA and sgRNA: In vitro transcribed Cas9 mRNA and sgRNA. This approach results in transient expression of the editing machinery.[20]
-
Ribonucleoprotein (RNP) complexes: Purified Cas9 protein pre-complexed with the sgRNA. This method offers the most transient expression and has been shown to have high editing efficiency and reduced off-target effects.[8][20]
2.2.2. Delivery into Target Cells:
The choice of delivery method depends on the cell type and experimental goals.[21] Common methods include:
-
Lipid-Mediated Transfection (Lipofection): Uses lipid-based reagents to deliver nucleic acids or RNPs into cells.[9][10]
-
Electroporation: Applies an electrical field to temporarily increase cell membrane permeability, allowing the entry of CRISPR components. This method is effective for a wide range of cell types, including those that are difficult to transfect.[19][22]
-
Viral Transduction: Utilizes viral vectors, such as adeno-associated viruses (AAV) or lentiviruses, for efficient delivery, particularly for in vivo applications or stable expression.[23]
Table 2: Comparison of Common CRISPR-Cas9 Delivery Methods
| Delivery Method | Components Delivered | Advantages | Disadvantages |
| Lipofection | Plasmid DNA, mRNA/sgRNA, RNP | Easy to perform, suitable for many cell lines.[10] | Lower efficiency in some cell types, potential for cytotoxicity. |
| Electroporation | Plasmid DNA, mRNA/sgRNA, RNP | High efficiency in a broad range of cells, including primary and stem cells.[19][22] | Can cause significant cell death.[19] |
| Viral Transduction | DNA (integrated into the host genome) | High efficiency, suitable for in vivo and stable expression.[23] | Potential for immunogenicity and insertional mutagenesis.[23] |
Phase 3: Editing & Selection
2.3.1. Genomic Cleavage and Repair:
Following successful delivery, the Cas9-gRNA complex will locate and cleave the target DNA sequence, inducing a double-strand break. The cell's repair machinery will then mend the break, leading to the desired genetic modification through either NHEJ or HDR.
Caption: The core mechanism of CRISPR-Cas9 gene editing.
2.3.2. Selection of Edited Cells:
Depending on the experimental setup, it may be necessary to select or enrich for the cells that have been successfully edited. This can be achieved through various methods, such as:
-
Antibiotic Selection: If a selection marker is co-delivered with the CRISPR components.[9]
-
Fluorescence-Activated Cell Sorting (FACS): If a fluorescent reporter is used to indicate successful transfection or editing.
-
Single-Cell Cloning: To isolate and expand individual clones for downstream analysis.
Phase 4: Validation
2.4.1. On-Target Validation:
It is essential to verify that the desired genetic modification has occurred at the target locus.[24] Several methods can be used to assess on-target editing efficiency:
-
Mismatch Cleavage Assays (e.g., T7 Endonuclease I assay): These assays detect heteroduplex DNA formed between wild-type and edited DNA strands.[25]
-
Sanger Sequencing: Sequencing of the target region from a population of cells can be used to detect the presence of indels.[9][26]
-
Next-Generation Sequencing (NGS): Provides a more comprehensive and quantitative analysis of the types and frequencies of different edits within a cell population.[26]
Table 3: Methods for Assessing On-Target Editing Efficiency
| Method | Principle | Advantages | Disadvantages |
| T7 Endonuclease I Assay | Enzyme cleaves mismatched DNA heteroduplexes.[25] | Rapid and relatively inexpensive. | Semi-quantitative, can underestimate editing efficiency. |
| Sanger Sequencing with TIDE/ICE analysis | Deconvolution of Sanger sequencing chromatograms to identify and quantify indels.[27][28] | Quantitative, provides information on indel types. | Less sensitive for low-frequency edits. |
| Next-Generation Sequencing (NGS) | Deep sequencing of the target locus.[26] | Highly sensitive and quantitative, provides detailed information on all edits. | More expensive and time-consuming. |
2.4.2. Off-Target Validation:
A major concern with CRISPR-Cas9 technology is the potential for off-target mutations at unintended genomic sites.[17][29] It is crucial to assess off-target effects, especially for therapeutic applications. Methods for off-target analysis include:
-
Targeted Sequencing: PCR amplification and sequencing of predicted off-target sites identified through in silico analysis.[30]
-
Unbiased Genome-Wide Methods: Techniques like GUIDE-seq, Digenome-seq, and SITE-seq can identify off-target sites across the entire genome.[18]
-
Whole-Genome Sequencing (WGS): Provides the most comprehensive assessment of off-target mutations but can be costly and computationally intensive.[29]
2.4.3. Functional Analysis:
The final step is to assess the functional consequences of the genetic modification. This can involve a variety of assays depending on the gene and the intended outcome, such as:
-
Quantitative PCR (qPCR): To measure changes in gene expression.[9]
-
Western Blotting: To assess changes in protein levels.[9]
-
Phenotypic Assays: To evaluate changes in cellular function, such as proliferation, apoptosis, or drug sensitivity.
Applications in Drug Development
The CRISPR-Cas9 system has numerous applications in the field of drug development:[4][5][31]
-
Target Identification and Validation: CRISPR-based screens can be used to identify novel drug targets by systematically knocking out genes and assessing the impact on disease-related phenotypes.[4][31]
-
Disease Modeling: Creating more accurate cellular and animal models of human diseases by introducing specific disease-causing mutations.[4][31]
-
Understanding Drug Resistance: Investigating the genetic basis of drug resistance by introducing or reverting mutations in cancer cells.[1]
-
Development of Gene and Cell Therapies: Directly correcting disease-causing mutations or engineering therapeutic cells, such as CAR-T cells, for cancer immunotherapy.[1][4]
Conclusion
The CRISPR-Cas9 system is a powerful and versatile tool for genome editing that is revolutionizing biological research and drug development. By following a well-designed and rigorously validated experimental workflow, researchers can harness the full potential of this technology to advance our understanding of disease and develop novel therapeutic strategies. Careful consideration of sgRNA design, delivery methods, and on- and off-target analysis is paramount to ensure the accuracy and reliability of CRISPR-based experiments.
References
- 1. researchgate.net [researchgate.net]
- 2. synthego.com [synthego.com]
- 3. What is CRISPR-Cas9? | How does CRISPR-Cas9 work? [yourgenome.org]
- 4. Cornerstones of CRISPR-Cas in drug development and therapy - PMC [pmc.ncbi.nlm.nih.gov]
- 5. The Pharmaceutical Applications of CRISPR-Cas9 and Its Development Trends | MedScien [lseee.net]
- 6. Mechanism and Applications of CRISPR/Cas-9-Mediated Genome Editing - PMC [pmc.ncbi.nlm.nih.gov]
- 7. CRISPR/Cas9 Editing Technology | All about this solution | genOway [genoway.com]
- 8. idtdna.com [idtdna.com]
- 9. assaygenie.com [assaygenie.com]
- 10. cd-genomics.com [cd-genomics.com]
- 11. Tips to optimize sgRNA design - Life in the Lab [thermofisher.com]
- 12. acresbiosciences.com [acresbiosciences.com]
- 13. genscript.com [genscript.com]
- 14. sg.idtdna.com [sg.idtdna.com]
- 15. synthego.com [synthego.com]
- 16. sbsbio.com [sbsbio.com]
- 17. Comprehensive Analysis of CRISPR Off-Target Effects - CD Genomics [cd-genomics.com]
- 18. lifesciences.danaher.com [lifesciences.danaher.com]
- 19. Delivery Strategies of the CRISPR-Cas9 Gene-Editing System for Therapeutic Applications - PMC [pmc.ncbi.nlm.nih.gov]
- 20. biotechacademy.dk [biotechacademy.dk]
- 21. CRISPR gene editing - Wikipedia [en.wikipedia.org]
- 22. synthego.com [synthego.com]
- 23. mdpi.com [mdpi.com]
- 24. portlandpress.com [portlandpress.com]
- 25. neb.com [neb.com]
- 26. Verification of CRISPR Gene Editing Efficiency | Thermo Fisher Scientific - SG [thermofisher.com]
- 27. mdpi.com [mdpi.com]
- 28. researchgate.net [researchgate.net]
- 29. Off-target effects in CRISPR/Cas9 gene editing - PMC [pmc.ncbi.nlm.nih.gov]
- 30. An analysis of possible off target effects following CAS9/CRISPR targeted deletions of neuropeptide gene enhancers from the mouse genome - PMC [pmc.ncbi.nlm.nih.gov]
- 31. Frontiers | CRISPR/Cas9 technology in tumor research and drug development application progress and future prospects [frontiersin.org]
Best Practices for CRISPR-Cas9 Mediated Gene Knockout in CAR-T Cell Therapy
Topic: Best practices for CRISPR-Cas9 mediated gene knockout in Chimeric Antigen Receptor (CAR)-T cell therapy.
Audience: Researchers, scientists, and drug development professionals.
Application Notes
The integration of CRISPR-Cas9 technology into CAR-T cell therapy represents a significant advancement in cancer immunotherapy.[1][2] This powerful gene-editing tool allows for precise genetic modifications to enhance the safety and efficacy of CAR-T cells.[2] One of the most promising applications is the knockout of specific genes to overcome limitations of current CAR-T therapies, such as T-cell exhaustion and the manufacturing of "off-the-shelf" allogeneic CAR-T cells.[2][3]
Key gene targets for knockout in CAR-T cells include:
-
Immune checkpoint inhibitors: Genes like PD-1 (Programmed Cell Death Protein 1) can be knocked out to prevent T-cell exhaustion and enhance the persistence and anti-tumor activity of CAR-T cells.[2][4][5]
-
Endogenous T-cell receptor (TCR): Knocking out the TCR is crucial for the development of allogeneic, or "universal," CAR-T cells. This prevents the graft-versus-host disease (GvHD) that can occur when donor T-cells recognize the recipient's tissues as foreign.[3]
-
Beta-2 microglobulin (B2M): B2M is a component of the major histocompatibility complex (MHC) class I molecules. Knocking out B2M can help to prevent the rejection of allogeneic CAR-T cells by the host's immune system.
Best Practices for CRISPR-Cas9 Gene Knockout in CAR-T Cells:
-
sgRNA Design and Optimization: The design of the single guide RNA (sgRNA) is critical for the success of the gene knockout.[6] Factors to consider include PAM compatibility, GC content (ideally 40-60%), and potential off-target effects.[6][7] It is recommended to use validated sgRNA design tools and consider chemical modifications to the sgRNA to improve knockout efficiency.[1][6]
-
Delivery of CRISPR-Cas9 Components: The efficient delivery of Cas9 and sgRNA into primary T-cells is a major challenge.[3] While viral vectors can be used, non-viral methods like electroporation of Cas9 ribonucleoprotein (RNP) complexes are often preferred due to safety concerns and high editing efficiency.[8][9][10]
-
Off-Target Analysis: A thorough analysis of off-target effects is essential to ensure the safety of the engineered CAR-T cells.[3] This can be achieved through a combination of in silico prediction tools and experimental methods like GUIDE-seq, CIRCLE-seq, or whole-genome sequencing (WGS).[11][12][13]
-
Functional Validation: After gene knockout, it is crucial to validate the functional consequences for the CAR-T cells. This includes assessing knockout efficiency, cell viability, proliferation, cytokine production, and cytotoxic activity against target cancer cells.
Experimental Protocols
Protocol 1: CRISPR-Cas9 Mediated Knockout of PD-1 in Primary Human T-Cells
This protocol outlines the general steps for knocking out the PD-1 gene in primary human T-cells using CRISPR-Cas9 RNP electroporation.
Materials:
-
Primary human T-cells
-
T-cell activation reagents (e.g., anti-CD3/CD28 beads)
-
TrueCut Cas9 Protein v2
-
TrueGuide Modified Synthetic sgRNA targeting PD-1
-
Neon™ Transfection System
-
Flow cytometer
-
PE Anti-Human α/β TCR Antibody
Methodology:
-
T-Cell Isolation and Activation: Isolate primary T-cells from peripheral blood mononuclear cells (PBMCs). Activate the T-cells using anti-CD3/CD28 beads for 2-3 days.[14]
-
Preparation of Cas9 RNP Complex:
-
Electroporation:
-
Post-Electroporation Culture:
-
Immediately transfer the electroporated cells to a pre-warmed culture medium.
-
Incubate the cells at 37°C in a humidified CO2 incubator for 48-72 hours.[15]
-
-
Validation of Knockout Efficiency:
Protocol 2: In Vitro Cytotoxicity Assay
This assay is used to evaluate the anti-tumor activity of the PD-1 knockout CAR-T cells.
Materials:
-
PD-1 knockout CAR-T cells (effector cells)
-
Target cancer cells expressing the CAR target antigen (e.g., CD19-positive Raji cells)
-
Luciferase-based cytotoxicity assay kit
Methodology:
-
Cell Preparation:
-
Culture the PD-1 knockout CAR-T cells and the target cancer cells.
-
On the day of the assay, harvest and count the cells.
-
-
Co-culture:
-
Plate the target cancer cells in a 96-well plate.
-
Add the PD-1 knockout CAR-T cells at different effector-to-target (E:T) ratios (e.g., 10:1, 5:1, 1:1).
-
Include control wells with target cells only (no effector cells) and effector cells only (no target cells).
-
-
Incubation: Incubate the co-culture plate at 37°C for a specified period (e.g., 4, 24, or 48 hours).
-
Cytotoxicity Measurement:
-
Follow the manufacturer's instructions for the luciferase-based cytotoxicity assay kit.
-
Measure the luminescence in each well using a plate reader.
-
-
Data Analysis: Calculate the percentage of specific lysis for each E:T ratio.
Data Presentation
Table 1: Representative Data for PD-1 Knockout in CAR-T Cells
| Parameter | Control CAR-T | PD-1 KO CAR-T |
| PD-1 Knockout Efficiency (%) | N/A | > 90% |
| Cell Viability (%) | > 85% | > 80% |
| In Vitro Cytotoxicity (% Lysis at 10:1 E:T ratio) | 60% | 85% |
| IFN-γ Secretion (pg/mL) | 800 | 1500 |
| In Vivo Tumor Regression (Xenograft model) | Moderate | Significant |
Mandatory Visualization
References
- 1. CRISPR/Cas-based CAR-T cells: production and application - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Optimizing cancer treatment: the synergistic potential of CAR-T cell therapy and CRISPR/Cas9 - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Advancing CAR T Therapies with CRISPR/Cas9, Novus Biologicals [novusbio.com]
- 4. PD-1 silencing impairs the anti-tumor function of chimeric antigen receptor modified T cells by inhibiting proliferation activity - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Frontiers | Revolutionizing cancer treatment: enhancing CAR-T cell therapy with CRISPR/Cas9 gene editing technology [frontiersin.org]
- 6. Tips to optimize sgRNA design - Life in the Lab [thermofisher.com]
- 7. lifesciences.danaher.com [lifesciences.danaher.com]
- 8. stemcell.com [stemcell.com]
- 9. rupress.org [rupress.org]
- 10. academic.oup.com [academic.oup.com]
- 11. idtdna.com [idtdna.com]
- 12. CRISPR Genome Editing & NGS | Off-target analysis and knockout confirmation [illumina.com]
- 13. Summary of CRISPR-Cas9 off-target Detection Methods - CD Genomics [cd-genomics.com]
- 14. Efficient CRISPR/Cas9-Mediated Mutagenesis in Primary Murine T Lymphocytes: CRISPR-mediated gene-disruption in murine T cells - PMC [pmc.ncbi.nlm.nih.gov]
- 15. documents.thermofisher.com [documents.thermofisher.com]
Application Note: Determining Drug Potency using Dose-Response Analysis in GraphPad Prism
Audience: Researchers, scientists, and drug development professionals.
Introduction: Dose-response analysis is a cornerstone of pharmacology and drug development, enabling the quantification of a drug's effect on a biological system as a function of its concentration. A key parameter derived from this analysis is the half-maximal inhibitory or effective concentration (IC50 or EC50), which represents the concentration of a drug required to elicit a 50% response. This value is a critical measure of a drug's potency. GraphPad Prism is a powerful software tool that simplifies the process of fitting dose-response curves using non-linear regression and calculating these potency values. This document provides a detailed protocol for conducting a cell-based assay to generate dose-response data and a step-by-step guide for analyzing this data in GraphPad Prism.
Experimental Protocol: Cell Viability Assay (MTT)
This protocol describes a common method for assessing the effect of a compound on cell viability, which can be used to determine its IC50 value.
A. Materials:
-
Human cancer cell line (e.g., HeLa)
-
Complete growth medium (e.g., DMEM with 10% FBS)
-
Test compound (solubilized in DMSO)
-
Phosphate-Buffered Saline (PBS)
-
MTT reagent (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide), 5 mg/mL in PBS
-
Solubilization solution (e.g., DMSO or a solution of 10% SDS in 0.01 M HCl)
-
96-well cell culture plates
-
Multichannel pipette
-
Plate reader (570 nm absorbance)
B. Methodology:
-
Cell Seeding: Plate cells in a 96-well plate at a density of 5,000-10,000 cells per well in 100 µL of complete growth medium. Incubate for 24 hours at 37°C and 5% CO2 to allow for cell attachment.
-
Compound Preparation: Prepare a serial dilution of the test compound in complete growth medium. A common starting point is a 10-point, 3-fold serial dilution starting from a high concentration (e.g., 100 µM). Remember to include a "vehicle control" (medium with DMSO, no compound) and a "no-cell" control (medium only, for background subtraction).
-
Cell Treatment: Carefully remove the medium from the wells and add 100 µL of the prepared compound dilutions to the respective wells.
-
Incubation: Incubate the plate for 48-72 hours at 37°C and 5% CO2.
-
MTT Addition: Add 20 µL of the 5 mg/mL MTT reagent to each well and incubate for another 4 hours. Viable cells with active metabolism will convert the yellow MTT into purple formazan crystals.
-
Solubilization: Carefully remove the medium and add 100 µL of solubilization solution to each well to dissolve the formazan crystals. Gently pipette to ensure complete dissolution.
-
Data Acquisition: Measure the absorbance of each well at 570 nm using a microplate reader.
Data Analysis Protocol in GraphPad Prism
A. Data Entry:
-
Open GraphPad Prism and select "XY" from the "New Table & Graph" dialog.
-
For the X-axis, choose "Numbers" and for the Y-axis, select "Enter and plot a single Y value for each point."
-
Enter your data:
-
X-Column: Enter the concentrations of your test compound. It is crucial to enter the actual concentrations (e.g., 100, 33.3, 11.1) and not the log of the concentration.
-
Y-Column: Enter the corresponding absorbance readings. If you have replicates, enter them in adjacent subcolumns (Y1, Y2, Y3, etc.).
-
B. Data Transformation and Normalization:
-
Click the "Analyze" button in the toolbar and select "Transform concentrations (X)" from the "XY analyses" section.
-
In the dialog box, choose "Transform X values using X=Log(X)". This will create a new results sheet with log-transformed concentration values.
-
To normalize the data, click "Analyze" again, and from the "XY analyses" section, select "Normalize."
-
In the normalize dialog, define your 0% and 100% response levels. The 100% level typically corresponds to your vehicle control (no inhibition), and the 0% level can be defined by a positive control or left as the lowest response value. This will generate a new results table with Y values expressed as a percentage response.
C. Non-Linear Regression for Curve Fitting:
-
Navigate to your normalized data table.
-
Click "Analyze" and select "Nonlinear regression (curve fit)" from the "XY analyses" section.
-
In the "Dose-Response - Inhibition" family of equations, select "log(inhibitor) vs. normalized response -- Variable slope."
-
Click "OK" to run the analysis. Prism will generate a results sheet containing the best-fit values for key parameters, including the LogIC50. The IC50 value itself will also be calculated and displayed.
Data Presentation
Quantitative results from the non-linear regression analysis should be tabulated for clarity and ease of comparison, especially when evaluating multiple compounds.
| Parameter | Compound A | Compound B |
| IC50 (µM) | 1.25 | 15.8 |
| LogIC50 | -5.90 | -4.80 |
| Hill Slope | -0.98 | -1.12 |
| Top | 99.8% | 101.2% |
| Bottom | 2.1% | 5.4% |
| R² | 0.995 | 0.989 |
| 95% CI of IC50 | (0.95 µM to 1.64 µM) | (12.1 µM to 20.6 µM) |
Table 1: Summary of dose-response parameters for two hypothetical compounds. Data represents the mean of three independent experiments. R² indicates the goodness of fit, and the 95% Confidence Interval (CI) indicates the precision of the IC50 estimate.
Visualizations
Diagrams help to visualize complex workflows and relationships, ensuring clarity in experimental design and data interpretation.
Caption: Experimental workflow for a cell-based MTT viability assay.
Caption: Logical relationship in a dose-response inhibition curve.
Caption: Example MAPK signaling pathway modulated by a kinase inhibitor.
Application Note: Detection of Apoptosis in Drosophila melanogaster Imaginal Discs using the TUNEL Assay
Audience: Researchers, scientists, and drug development professionals.
Introduction
Apoptosis, or programmed cell death, is a crucial process for tissue homeostasis, and its misregulation is implicated in various diseases, including cancer and neurodegeneration.[1][2] The TUNEL (Terminal deoxynucleotidyl transferase dUTP Nick End Labeling) assay is a widely used method to detect apoptosis by identifying DNA fragmentation, a key hallmark of this process.[3][4] This technique utilizes the enzyme Terminal deoxynucleotidyl transferase (TdT) to incorporate labeled dUTPs onto the 3'-hydroxyl termini of fragmented DNA.[3][4][5] These labeled nucleotides can then be visualized using fluorescence microscopy, allowing for the identification and quantification of apoptotic cells within a tissue.[1] This application note provides a detailed protocol for performing a TUNEL assay on imaginal discs from third-instar Drosophila melanogaster larvae, a powerful model organism for studying developmental and disease processes.[1][2]
Apoptosis Signaling Pathway in Drosophila
The intrinsic apoptotic pathway in Drosophila is initiated by various developmental cues or cellular stress. This leads to the activation of pro-apoptotic proteins which in turn inhibit the function of DIAP1 (Drosophila Inhibitor of Apoptosis Protein 1). The subsequent activation of initiator caspases, such as Dronc, triggers a caspase cascade, leading to the activation of effector caspases like Drice and Dcp-1. These effector caspases are responsible for the cleavage of cellular substrates, resulting in the characteristic morphological and biochemical changes of apoptosis, including DNA fragmentation.
References
- 1. researchgate.net [researchgate.net]
- 2. Protocol to study cell death using TUNEL assay in Drosophila imaginal discs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Detection of Cell Death in Drosophila Tissues - PMC [pmc.ncbi.nlm.nih.gov]
- 4. public-pages-files-2025.frontiersin.org [public-pages-files-2025.frontiersin.org]
- 5. researchgate.net [researchgate.net]
Application Notes & Protocols: Fluorescence Polarization for High-Throughput Screening of Protein-Ligand Interactions
Audience: Researchers, scientists, and drug development professionals.
Application Notes
Introduction to Fluorescence Polarization (FP)
Fluorescence Polarization (FP) is a robust, solution-based, and homogeneous technique used to monitor molecular binding events in real-time.[1][2][3] It has been widely adopted for high-throughput screening (HTS) in drug discovery due to its simplicity and quantitative nature.[1][3] The core principle of FP lies in detecting changes in the rotational speed of a fluorescently labeled molecule (a "tracer") upon binding to a larger partner.[2][4]
When a small fluorescent tracer is excited with plane-polarized light, it tumbles rapidly in solution before it emits light. This rapid rotation causes the emitted light to be largely depolarized.[2][5] However, when the tracer binds to a much larger molecule (e.g., a protein), its tumbling is significantly slowed. Consequently, the emitted light remains highly polarized.[2][5] This change in polarization is measured by a microplate reader and is directly proportional to the fraction of the tracer that is bound.[3]
Principle of the FP Assay
The degree of polarization (P) is a ratiometric measurement, calculated from the fluorescence intensities measured parallel (I∥) and perpendicular (I⊥) to the plane of the excitation light.[6] This makes the assay less susceptible to interferences like compound fluorescence that can affect simple fluorescence intensity assays.[3][6] The value is typically expressed in millipolarization (mP) units.[3][6]
-
Low mP Value: Indicates the fluorescent tracer is small and rotating freely in solution.
-
High mP Value: Indicates the tracer is bound to a larger molecule, slowing its rotation.
Applications in High-Throughput Screening
FP is exceptionally well-suited for HTS campaigns to identify small molecule inhibitors of biomolecular interactions.[2][5] Common applications include:
-
Protein-Protein Interactions (PPIs): Screening for compounds that disrupt the binding of a fluorescently labeled peptide or small protein to its larger protein partner.[1][6]
-
Receptor-Ligand Binding: Identifying antagonists that compete with a fluorescently labeled ligand for binding to a receptor, such as a GPCR.[1][2]
-
Enzyme Assays: Detecting inhibitors that block the binding of a fluorescent substrate to an enzyme's active site.[1][6]
-
Protein-Nucleic Acid Interactions: Screening for molecules that interfere with the binding of proteins to fluorescently labeled DNA or RNA probes.[6]
Advantages and Limitations
Advantages:
-
Homogeneous Format: The "mix-and-read" protocol requires no separation or wash steps, which simplifies automation and reduces variability.[2][3][5]
-
Real-Time Data: Allows for the measurement of binding events at equilibrium and can be adapted to study association/dissociation kinetics.[3][5]
-
Low Volume & Cost-Effective: The assay is highly miniaturizable (to 384- and 1536-well formats), reducing reagent consumption.[6][7]
-
Robust: The ratiometric nature of FP minimizes interference from colored compounds and fluctuations in lamp intensity.[3]
Limitations:
-
Size Differential Required: The assay is most effective when there is a significant size difference between the tracer and its binding partner (ideally ≥5-fold).[3][5]
-
Labeling Requirement: The smaller binding partner must be fluorescently labeled, which can sometimes alter its binding activity.[5]
-
Potential for Interference: Fluorescent compounds or light scattering can still interfere with the assay, requiring careful data analysis and counter-screens.
Experimental Protocols
Protocol 1: Direct Binding Saturation Assay
Objective: To determine the dissociation constant (Kd) of the interaction between a target protein and a fluorescent tracer.
Materials:
-
Target Protein
-
Fluorescent Tracer (e.g., FITC-labeled peptide)
-
Assay Buffer (e.g., PBS, 0.01% Tween-20, pH 7.4)
-
Microplate Reader with FP capabilities
-
Low-volume, black, 384-well assay plates
Methodology:
-
Prepare Reagents:
-
Prepare a 2X stock solution of the fluorescent tracer in assay buffer at a fixed concentration (typically low nM, e.g., 4 nM). This concentration should be well below the expected Kd and provide a stable fluorescence signal.
-
Prepare a serial dilution series of the target protein in assay buffer, starting from a concentration well above the expected Kd (e.g., 10 µM down to 0 µM). This will be the 2X protein solution.
-
-
Assay Setup (384-well plate):
-
Add 10 µL of each concentration of the 2X protein solution to triplicate wells.
-
Include "Reference" or "Low FP" control wells containing 10 µL of assay buffer instead of protein solution.[5]
-
Initiate the binding reaction by adding 10 µL of the 2X tracer solution to all wells. The final volume is 20 µL.
-
The "High FP" control should contain tracer and a saturating concentration of the binding partner.[5]
-
-
Incubation and Measurement:
-
Mix the plate gently on a plate shaker for 1 minute.
-
Incubate the plate at room temperature for a predetermined time (e.g., 30-60 minutes) to allow the binding to reach equilibrium. Protect the plate from light.
-
Measure the fluorescence polarization (mP) of each well using a microplate reader.
-
-
Data Analysis:
-
Subtract the mP value of blank wells (buffer only) from all measurements.[5]
-
Plot the change in mP as a function of the protein concentration.
-
Fit the data to a one-site binding (hyperbola) equation using graphing software (e.g., GraphPad Prism) to calculate the Kd.
-
Protocol 2: Competitive Inhibition Assay for HTS
Objective: To screen a compound library for inhibitors that displace the fluorescent tracer from the target protein and to determine their IC50 values.
Methodology:
-
Prepare Reagents:
-
Prepare a 2X solution of the target protein in assay buffer. The optimal concentration is typically the Kd value determined from the direct binding assay.
-
Prepare a 2X solution of the fluorescent tracer in assay buffer at the same concentration used in the direct binding assay.
-
Prepare a serial dilution of test compounds in DMSO, then dilute into assay buffer.
-
-
Assay Setup (384-well plate):
-
Dispense a small volume (e.g., 100 nL) of compound solutions into the assay plate wells.
-
Controls:
-
Negative Control (High mP): Wells with DMSO only (no inhibitor). This represents 0% inhibition.
-
Positive Control (Low mP): Wells with a known potent unlabeled inhibitor or no protein. This represents 100% inhibition.
-
-
Add 10 µL of the 2X target protein solution to all wells (except positive controls that lack protein). Mix and pre-incubate for 15-30 minutes.
-
Add 10 µL of the 2X fluorescent tracer solution to all wells to start the competition reaction. Final volume is ~20 µL.
-
-
Incubation and Measurement:
-
Mix the plate gently and incubate at room temperature (protected from light) for the predetermined equilibrium time.
-
Measure the mP value of each well.
-
-
Data Analysis:
-
Calculate the percent inhibition for each compound concentration using the following formula: % Inhibition = 100 * (1 - [(mP_sample - mP_positive) / (mP_negative - mP_positive)])
-
Plot percent inhibition versus the logarithm of the compound concentration.
-
Fit the data to a dose-response curve (e.g., log(inhibitor) vs. response -- variable slope) to determine the IC50 value for each active compound.
-
Data Presentation
Quantitative data from FP assays are typically summarized to compare the potencies of different compounds.
Table 1: Summary of Competitive Inhibition Assay Results. This table shows example data for compounds screened against the Bfl-1/FITC-Bid BH3 peptide interaction, a target in cancer therapy.[6] A lower IC50 value indicates a more potent inhibitor.
| Compound ID | Description | IC50 (µM) | Max Inhibition (%) | Z'-factor |
| Control-1 | Known Bfl-1 Inhibitor | 0.85 | 98.2 | 0.83 |
| Test-Cmpd-A | Screened Hit | 2.5 | 95.1 | N/A |
| Test-Cmpd-B | Screened Hit | 15.7 | 88.4 | N/A |
| Test-Cmpd-C | Inactive Compound | >100 | 5.3 | N/A |
The Z'-factor is a measure of assay quality, calculated from the high and low controls; a value > 0.5 indicates an excellent assay.[6]
References
- 1. Fluorescence Polarization Assays in Small Molecule Screening - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Fluorescence Polarization (FP) | Molecular Devices [moleculardevices.com]
- 3. bmglabtech.com [bmglabtech.com]
- 4. Analysis of fluorescence polarization competition assays with affinimeter [blog.affinimeter.com]
- 5. bpsbioscience.com [bpsbioscience.com]
- 6. Fluorescence polarization assays in high-throughput screening and drug discovery: a review - PMC [pmc.ncbi.nlm.nih.gov]
- 7. pubs.acs.org [pubs.acs.org]
Application Notes & Protocols: A Comparative Analysis of CRISPR-Cas9 for In Vitro and In Vivo Gene Editing
Introduction
The CRISPR-Cas9 system, derived from a bacterial adaptive immune mechanism, has emerged as a transformative technology for genome editing.[1][2][3][4] Its precision, efficiency, and versatility have revolutionized research in molecular biology, enabling targeted modification of DNA sequences in a wide array of organisms and cell types.[1][2][3] This technology consists of two primary components: the Cas9 nuclease, which acts as a pair of "molecular scissors" to create a double-strand break (DSB) in the DNA, and a guide RNA (gRNA) that directs the Cas9 to a specific genomic locus.[3][5] Following the DNA cut, the cell's natural repair mechanisms—either the error-prone non-homologous end joining (NHEJ) pathway or the high-fidelity homology-directed repair (HDR) pathway—are harnessed to introduce desired genetic changes, such as gene knockouts, knock-ins, or specific point mutations.[5][6][7][8]
These application notes provide a detailed comparison of CRISPR-Cas9 methodologies for two distinct contexts: in vitro (in cultured cells) and in vivo (in living organisms). We will explore the unique applications, quantitative benchmarks, and experimental protocols for each, offering researchers, scientists, and drug development professionals a comprehensive guide to leveraging this powerful tool.
Section 1: In Vitro Applications of CRISPR-Cas9
In vitro applications of CRISPR-Cas9 primarily involve the genetic modification of mammalian cell lines or primary cells in a controlled laboratory setting. This approach is fundamental for investigating gene function, modeling diseases, performing large-scale genetic screens, and validating drug targets.[9][10][11] The ability to rapidly and cost-effectively generate precise genetic alterations in cells makes CRISPR-Cas9 an indispensable tool for preclinical research.[9]
Data Presentation: Quantitative Analysis of In Vitro Editing
The following table summarizes representative quantitative data from various in vitro CRISPR-Cas9 experiments, highlighting key parameters such as cell type, delivery method, and editing efficiency.
| Cell Line | Target Gene | Delivery Method | Editing Efficiency (Indel %) | Application | Reference |
| HEK293T | AAVS1 | Plasmid Transfection | ~25-40% | Safe Harbor Gene Knock-in | (Not explicitly cited) |
| Mouse ESCs | Evx1 | Plasmid Transfection | >90% (in selected clones) | Gene Function Study | [12] |
| Human iPSCs | Various | Electroporation | ~30-80% | Disease Modeling | [13] |
| HeLa | SHIP164 | Plasmid Transfection | High (clonal selection) | Gene Knockout | [14] |
| Various | Genome-wide | Lentiviral Transduction | Variable (library-dependent) | High-Throughput Screening | [15][16] |
Diagram: CRISPR-Cas9 Mechanism of Action
The fundamental mechanism of CRISPR-Cas9 involves gRNA-guided DNA cleavage followed by cellular repair.
Caption: The CRISPR-Cas9 system recognizes and cleaves target DNA, which is then repaired by NHEJ or HDR.
Experimental Protocol: Generating a Knockout Human Cell Line
This protocol provides a generalized workflow for creating a gene knockout in a common cell line like HEK293T using plasmid transfection.[14][17][18]
1. gRNA Design and Plasmid Construction:
- Objective: Design a gRNA specific to an early exon of the target gene to induce a frameshift mutation.
- Procedure:
- Use an online design tool (e.g., CHOPCHOP) to identify candidate 20-bp gRNA sequences that precede a Protospacer Adjacent Motif (PAM) and have low predicted off-target activity.[14]
- Synthesize two complementary oligonucleotides encoding the chosen gRNA sequence with appropriate overhangs for cloning.
- Anneal the oligos and ligate them into a Cas9 expression plasmid (e.g., pX458, which co-expresses Cas9 and a fluorescent marker like GFP) that has been linearized with a compatible restriction enzyme (e.g., BbsI).[14]
- Transform the ligated plasmid into competent E. coli, select for positive colonies, and confirm the correct gRNA insertion via Sanger sequencing.
2. Transfection of Cultured Cells:
- Objective: Deliver the CRISPR-Cas9 plasmid into the target cells.
- Procedure:
- One day before transfection, seed 2.0 x 10^5 HEK293T cells per well in a 6-well plate. Cells should be ~90% confluent at the time of transfection.[18]
- On the day of transfection, prepare the DNA-lipid complex. For one well, dilute 2.5 µg of the endotoxin-free CRISPR plasmid into a serum-free medium.[18]
- In a separate tube, add a suitable lipid-based transfection reagent (e.g., Lipofectamine) to a serum-free medium according to the manufacturer's protocol.
- Combine the diluted DNA and transfection reagent, incubate for 15-20 minutes at room temperature to allow complex formation, and add the mixture dropwise to the cells.[18]
- Incubate the cells for 48-72 hours.
3. Clonal Isolation of Edited Cells:
- Objective: Isolate single cells to grow into clonal populations with a homogenous genetic background.
- Procedure:
- 48 hours post-transfection, detach the cells using trypsin.
- Resuspend the cells in media and filter them to create a single-cell suspension.
- Use Fluorescence-Activated Cell Sorting (FACS) to sort single GFP-positive cells (indicating successful transfection) into individual wells of a 96-well plate containing conditioned media.[17]
- Alternatively, perform serial dilution to seed an average of 0.5 cells per well.
- Culture the plates for 2-3 weeks, monitoring for the growth of single-cell-derived colonies.
4. Verification of Gene Knockout:
- Objective: Screen clonal populations to identify those with the desired knockout mutation.
- Procedure:
- When colonies are sufficiently large, aspirate the media and wash with PBS. Lyse the cells and extract genomic DNA.
- Amplify the genomic region surrounding the gRNA target site using PCR.
- Screening: Use a mismatch cleavage assay (e.g., T7 Endonuclease I) to detect the presence of insertions or deletions (indels).[17]
- Confirmation: Send the PCR products from positive clones for Sanger sequencing to confirm the presence of a frameshift-inducing indel. Analyze the sequencing chromatogram for overlapping peaks downstream of the cut site, which indicates a heterozygous or biallelic mutation.
Diagram: In Vitro CRISPR Screening Workflow
Pooled CRISPR screens are a powerful method to assess the function of thousands of genes simultaneously.[16]
Caption: Workflow for a pooled in vitro CRISPR screen to identify genes related to a specific phenotype.
Section 2: In Vivo Applications of CRISPR-Cas9
In vivo applications involve editing the genome of a whole, living organism. This is critical for creating animal models that faithfully recapitulate human diseases, studying gene function in the context of a complex biological system, and developing gene therapies to correct genetic disorders directly within the patient.[6][19][20] Delivery of CRISPR components into the target tissues is a major consideration and often relies on viral vectors (like Adeno-Associated Virus, AAV) or physical methods like microinjection.[19][21][22]
Data Presentation: Quantitative Analysis of In Vivo Editing
The following table summarizes key data from representative in vivo CRISPR-Cas9 studies.
| Animal Model | Target Gene/Disease | Delivery Method | Target Tissue | Editing Efficiency | Therapeutic Outcome | Reference |
| Mouse | Fah / Tyrosinemia | Hydrodynamic Injection | Liver | ~0.4% correction | Rescue of weight loss and liver damage | [23] |
| Mouse | Dmd / Muscular Dystrophy | AAV9 | Muscle, Heart | ~2-50% (tissue dependent) | Partial restoration of dystrophin expression | [22] |
| Rhesus Macaque | SIV (Simian HIV) | AAV9 | Blood, Tissues | 37-92% (in blood) | 38-95% decline in SIV viral DNA | [19] |
| Mouse | Pcsk9 / Hypercholesterolemia | Lipid Nanoparticles | Liver | >60% | ~40% reduction in plasma cholesterol | (Not explicitly cited) |
| Mouse | mPer1/mPer2 | Zygote Microinjection | Germline | Significantly higher than in MEFs | Generation of knock-in mice | [24] |
Experimental Protocol: Generating a Knockout Mouse via Zygote Microinjection
This protocol outlines the standard method for creating a germline knockout mouse model.[25][26][27][28]
1. Preparation of CRISPR Components:
- Objective: Prepare high-quality Cas9 and gRNA for microinjection.
- Procedure:
- Design and validate gRNAs in vitro as described in the previous protocol to ensure high cleavage efficiency.
- Synthesize the gRNA using an in vitro transcription kit. Purify the resulting RNA.
- Obtain purified, injection-ready Cas9 protein or synthesize Cas9 mRNA. The use of Cas9 protein to form a ribonucleoprotein (RNP) complex with the gRNA is often preferred for higher efficiency and reduced off-target effects.
- Dilute Cas9 protein/mRNA and gRNA in an injection buffer to the desired final concentrations (e.g., 50 ng/µl Cas9 and 25 ng/µl gRNA).
2. Superovulation and Zygote Collection:
- Objective: Obtain fertilized one-cell embryos for injection.
- Procedure:
- Hormonally superovulate female mice and mate them with stud males.
- The following morning, check for copulation plugs to confirm mating.
- Euthanize the plugged female mice and harvest fertilized zygotes (one-cell embryos) from the oviducts.
3. Microinjection:
- Objective: Inject the CRISPR-Cas9 components directly into the mouse zygotes.[26]
- Procedure:
- Using an inverted microscope equipped with micromanipulators, hold a zygote with a holding pipette.
- Load the CRISPR-Cas9 mixture into a fine-tipped injection needle.
- Carefully insert the needle into the pronucleus of the zygote and inject a small volume of the mixture.[26][27]
- Repeat for all collected zygotes.
4. Embryo Transfer and Generation of Founders:
- Objective: Transfer the injected embryos into a surrogate mother to develop to term.
- Procedure:
- Surgically transfer the microinjected zygotes into the oviducts of pseudopregnant female mice.
- Allow the surrogate mothers to carry the embryos to term and give birth (~19-21 days). The resulting offspring are called founder (F0) mice.
5. Genotyping and Breeding:
- Objective: Identify founder mice carrying the desired mutation and establish a stable knockout line.
- Procedure:
- At weaning age, take tail snips or ear punches from the F0 pups for genomic DNA extraction.
- Use PCR and Sanger sequencing to screen for founders that have indel mutations at the target locus. F0 mice are often genetic mosaics.
- Breed the founder mice that carry the desired mutation with wild-type mice to transmit the mutation through the germline.
- Genotype the F1 offspring to confirm germline transmission and establish heterozygous and homozygous knockout lines for future experiments.[22][25]
Diagram: In Vivo Knockout Mouse Generation Workflow
This diagram illustrates the key steps in creating a genetically engineered mouse model.
Caption: Workflow for generating a knockout mouse model using CRISPR-Cas9 microinjection of zygotes.
References
- 1. CRISPR gene editing - Wikipedia [en.wikipedia.org]
- 2. Applications of CRISPR-Cas9 as an Advanced Genome Editing System in Life Sciences - PMC [pmc.ncbi.nlm.nih.gov]
- 3. What is CRISPR-Cas9? | How does CRISPR-Cas9 work? [yourgenome.org]
- 4. integra-biosciences.com [integra-biosciences.com]
- 5. Mechanism and Applications of CRISPR/Cas-9-Mediated Genome Editing - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Frontiers | Revolutionizing in vivo therapy with CRISPR/Cas genome editing: breakthroughs, opportunities and challenges [frontiersin.org]
- 7. researchgate.net [researchgate.net]
- 8. researchgate.net [researchgate.net]
- 9. Frontiers | Applications of CRISPR-Cas9 for advancing precision medicine in oncology: from target discovery to disease modeling [frontiersin.org]
- 10. dovepress.com [dovepress.com]
- 11. researchgate.net [researchgate.net]
- 12. A high-throughput screening strategy for detecting CRISPR-Cas9 induced mutations using next-generation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 13. arep.med.harvard.edu [arep.med.harvard.edu]
- 14. Generation of knock-in and knock-out CRISPR/Cas9 editing in mammalian cells [protocols.io]
- 15. researchgate.net [researchgate.net]
- 16. resources.revvity.com [resources.revvity.com]
- 17. Video: Genome Editing in Mammalian Cell Lines using CRISPR-Cas [jove.com]
- 18. genecopoeia.com [genecopoeia.com]
- 19. In vivo delivery of CRISPR-Cas9 therapeutics: Progress and challenges - PMC [pmc.ncbi.nlm.nih.gov]
- 20. In vivo and in vitro disease modeling with CRISPR/Cas9 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 21. In Vivo | CRISPR Therapeutics [crisprtx.com]
- 22. Three CRISPR Approaches for Mouse Genome Editing [jax.org]
- 23. epigenie.com [epigenie.com]
- 24. biorxiv.org [biorxiv.org]
- 25. Simple Protocol for Generating and Genotyping Genome-Edited Mice With CRISPR-Cas9 Reagents - PubMed [pubmed.ncbi.nlm.nih.gov]
- 26. Genome Editing in Mice Using CRISPR/Cas9 Technology - PMC [pmc.ncbi.nlm.nih.gov]
- 27. Gene Knockout Mouse Generation - Creative Biogene CRISPR/Cas9 Platform [creative-biogene.com]
- 28. blog.addgene.org [blog.addgene.org]
Data analysis pipeline for [a type of large-scale dataset e.g., genomic data]
Audience: Researchers, scientists, and drug development professionals.
Introduction
The advent of high-throughput sequencing technologies has revolutionized genomic research, enabling the comprehensive analysis of entire genomes and transcriptomes. This has profound implications for drug discovery and development, allowing for the identification of novel therapeutic targets, the elucidation of disease mechanisms, and the development of personalized medicine approaches. This document provides a detailed guide to a standard data analysis pipeline for large-scale genomic data, with a focus on RNA sequencing (RNA-Seq) for differential gene expression analysis and subsequent pathway analysis. The protocols provided herein are intended to be a practical guide for researchers, scientists, and drug development professionals.
Data Analysis Pipeline Overview
A typical genomic data analysis pipeline consists of several key stages, starting from raw sequencing data and culminating in biological interpretation. The overall workflow is designed to ensure data quality, accurately identify biological signals, and provide meaningful insights.
A visual representation of this workflow is provided below.
Experimental Protocols
Protocol 1: Quality Control and Pre-processing of Raw Sequencing Data
Objective: To assess the quality of raw sequencing reads and remove low-quality bases and adapter sequences.
Tools:
Methodology:
-
Initial Quality Assessment with FastQC:
-
Run FastQC on the raw FASTQ files to generate a quality report.[1][5]
-
Examine the FastQC report for key metrics such as:
-
Per base sequence quality: Look for a drop in quality towards the 3' end of the reads.
-
Per sequence quality scores: A high average quality score is desirable.
-
Adapter Content: Presence of adapter sequences that need to be removed.[1]
-
Per base GC content: Deviations from the expected distribution may indicate contamination.[1]
-
-
-
Adapter and Quality Trimming with Trimmomatic:
-
Use Trimmomatic to remove adapter sequences and low-quality bases from the reads. The following is an example command for paired-end reads:[3][4]
-
Parameter Explanation:
-
PE: Specifies paired-end reads.
-
ILLUMINACLIP: Removes adapter sequences.
-
LEADING:3: Removes low-quality bases from the beginning of a read.
-
TRAILING:3: Removes low-quality bases from the end of a read.
-
SLIDINGWINDOW:4:15: Scans the read with a 4-base wide sliding window, cutting when the average quality per base drops below 15.[2]
-
MINLEN:36: Discards reads that are shorter than 36 bases after trimming.
-
-
-
Post-trimming Quality Assessment:
-
Run FastQC on the trimmed FASTQ files to verify the improvement in read quality.[5]
-
Compare the new report with the initial one to ensure that quality issues have been addressed.
-
Protocol 2: Alignment and Quantification
Objective: To align the cleaned reads to a reference genome and quantify the number of reads mapping to each gene.
Tools:
-
STAR (Spliced Transcripts Alignment to a Reference): For aligning RNA-Seq reads.
-
featureCounts (from Subread package): For counting reads per gene.
Methodology:
-
Genome Indexing (to be performed once per reference genome):
-
Before alignment, an index of the reference genome must be created.
-
-
Read Alignment with STAR:
-
Align the trimmed, paired-end reads to the indexed reference genome.
-
The output will be a BAM file containing the aligned reads.
-
-
Read Quantification with featureCounts:
-
Count the number of reads that map to each gene using the generated BAM file and a gene annotation file (GTF/GFF).
-
This will produce a tab-delimited text file with gene IDs and their corresponding read counts.
-
Protocol 3: Differential Gene Expression Analysis
Objective: To identify genes that are significantly up- or down-regulated between different experimental conditions.
Tool:
-
DESeq2 (R package): A popular tool for differential expression analysis of count data.[6]
Methodology (R script):
References
- 1. beam.cloud [beam.cloud]
- 2. A Beginner’s Guide to Genomic Data Analysis: Quality Control and Data Preprocessing of Raw Reads using FastQC and Trimmomatic | by Muhammad Abdullah Nabeel | Medium [medium.com]
- 3. Trimming and Filtering – Data Wrangling and Processing for Genomics [sbc.shef.ac.uk]
- 4. Data Wrangling and Processing for Genomics: Trimming and Filtering [datacarpentry.github.io]
- 5. Pre-processing and QC – NGS Analysis [learn.gencore.bio.nyu.edu]
- 6. reneshbedre.com [reneshbedre.com]
Application Note: Visualizing Membrane Protein Dynamics Using Fluorescence Recovery After Photobleaching (FRAP)
Audience: Researchers, scientists, and drug development professionals.
Introduction: The Principle of FRAP
Fluorescence Recovery After Photobleaching (FRAP) is a widely used microscopy technique to quantify the mobility of fluorescently labeled molecules within a living cell.[1][2] The core principle of FRAP lies in observing the redistribution of mobile fluorescent molecules into a small, selectively photobleached region of interest (ROI).[1] Photobleaching is an irreversible process where a high-intensity laser pulse permanently extinguishes the fluorescence of fluorophores within the ROI.[1][3] Following this bleaching event, the rate at which fluorescence recovers in the ROI is monitored over time using low-intensity illumination. This recovery is due to the movement of unbleached, fluorescent molecules from the surrounding area into the bleached region.[4][5]
The analysis of the fluorescence recovery curve provides quantitative data on two key parameters:
-
Mobile Fraction (Mf): The percentage of the total fluorescently labeled protein population that is free to move. The extent of fluorescence recovery indicates the proportion of mobile molecules.[1]
-
Diffusion Coefficient (D): A measure of the speed at which molecules are moving, calculated from the rate of fluorescence recovery.[1][6]
FRAP is a powerful tool in cell biology and drug discovery for studying membrane dynamics, protein trafficking, and molecular interactions in real-time.[2][4]
Key Applications in Research and Drug Development
-
Membrane Fluidity and Protein Dynamics: Assessing the lateral diffusion of membrane-associated proteins and lipids is a primary application of FRAP.[3]
-
Protein-Protein Interactions: Changes in the mobility of a protein can indicate binding to larger, less mobile complexes or structures.[4]
-
Cytoskeletal and Organelle Dynamics: Studying the movement of proteins within or between different cellular compartments.[2][3]
-
Drug Efficacy Screening: Evaluating how a compound affects the mobility of a target protein, which can provide insights into its mechanism of action.
Experimental Protocol: FRAP for Membrane Protein Dynamics
This protocol outlines the steps for analyzing the mobility of a GFP-tagged membrane protein in cultured mammalian cells using a laser scanning confocal microscope.
Materials and Reagents
-
Cells: Mammalian cell line (e.g., COS-7, HEK293) cultured on 35-mm glass-bottom dishes.
-
Expression Vector: Plasmid DNA encoding the membrane protein of interest fused to a fluorescent protein (e.g., GFP, YFP).
-
Transfection Reagent: (e.g., Lipofectamine).
-
Cell Culture Medium: Standard growth medium (e.g., DMEM with 10% FBS).
-
Imaging Medium: Phenol red-free medium supplemented with serum and HEPES buffer to maintain pH.
-
Microscope: A laser scanning confocal microscope equipped for live-cell imaging with temperature and CO2 control.[5]
Step-by-Step Methodology
Step 1: Cell Culture and Transfection
-
Seed cells onto 35-mm glass-bottom dishes to achieve 60-80% confluency on the day of transfection.
-
Transfect cells with the fluorescent protein expression vector according to the manufacturer's protocol.
-
Allow 24-48 hours for protein expression. Select cells with moderate, uniform expression on the plasma membrane for FRAP experiments to avoid artifacts from overexpression.[7][8]
Step 2: Microscope Configuration
-
Turn on the microscope, laser lines, and environmental chamber at least 30-60 minutes before the experiment to ensure system stability.[5] Set the temperature to 37°C.
-
Place the dish on the microscope stage and select a healthy, transfected cell. Focus on the basal plasma membrane, which is in contact with the coverslip.
-
Define a circular Region of Interest (ROI) with a diameter of approximately 2-5 µm on a flat, uniform area of the plasma membrane.[9]
-
Define a control ROI in an unbleached area of the cell to correct for acquisitional photobleaching and a background ROI outside the cell to measure background noise.
Step 3: Image Acquisition Parameters
-
Pre-Bleach Imaging: Acquire 5-10 images at a low laser power (e.g., 1-5% transmission) to establish the baseline fluorescence intensity. The imaging frequency should be fast enough to capture the recovery kinetics but slow enough to minimize photobleaching during acquisition.[5]
-
Photobleaching: Use a high-intensity laser pulse (e.g., 100% power for the 488 nm line for GFP) for a short duration to bleach the ROI. Aim for a 70-80% reduction in fluorescence intensity within the ROI.[5]
-
Post-Bleach Imaging: Immediately after the bleach pulse, acquire a time-lapse series of images using the same low laser power settings as the pre-bleach phase. The duration and frequency of this phase depend on the recovery speed of the protein of interest.
Data Analysis
-
Intensity Measurement: Measure the mean fluorescence intensity of the bleached ROI, the control ROI, and the background ROI for each time point.
-
Data Normalization: Correct the fluorescence intensity of the bleached ROI for background and acquisitional photobleaching using the control ROI.[8] Normalize the data so that the pre-bleach intensity is 1 and the intensity immediately after bleaching is 0.
-
Curve Fitting: Plot the normalized fluorescence intensity over time. The recovery curve is typically fitted to a single or double exponential function to extract kinetic parameters.[10]
-
Mobile Fraction (Mf): Calculated from the plateau of the recovery curve.
-
Half-maximal Recovery (t½): The time it takes for the fluorescence to recover to half of its final intensity.
-
-
Diffusion Coefficient (D): The diffusion coefficient can be calculated from the half-maximal recovery time and the radius of the bleached ROI using established mathematical models.[6][11]
Quantitative Data Presentation
The results from FRAP experiments are often summarized to compare the mobility of different proteins or the effect of various treatments.
| Protein/Condition | Mobile Fraction (Mf) | Half-Maximal Recovery (t½) (seconds) | Diffusion Coefficient (D) (µm²/s) |
| Control Protein A | 0.85 ± 0.05 | 5.2 ± 0.4 | 0.45 ± 0.03 |
| Protein A + Drug X | 0.45 ± 0.07 | 15.8 ± 1.1 | 0.12 ± 0.02 |
| Mutant Protein B | 0.90 ± 0.04 | 2.1 ± 0.3 | 0.98 ± 0.05 |
| Immobile Control | < 0.10 | N/A | < 0.01 |
Table 1: Example FRAP data comparing the mobility of a membrane protein under different conditions. Values are represented as mean ± standard deviation.
Diagrams and Workflows
Conceptual Diagram of the FRAP Process
Caption: The three key phases of a FRAP experiment.
Experimental Workflow for FRAP Analysis
Caption: A step-by-step workflow from sample preparation to data interpretation.
References
- 1. picoquant.com [picoquant.com]
- 2. ibidi.com [ibidi.com]
- 3. Fluorescence Recovery After Photobleaching - FluoroFinder [fluorofinder.com]
- 4. Fluorescence Recovery After Photobleaching (FRAP) | Teledyne Vision Solutions [teledynevisionsolutions.com]
- 5. Measuring Membrane Protein Dynamics in Neurons Using Fluorescence Recovery after Photobleach - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Simplified equation to extract diffusion coefficients from confocal FRAP data - PMC [pmc.ncbi.nlm.nih.gov]
- 7. doaj.org [doaj.org]
- 8. Fluorescence Recovery after Photobleaching (FRAP) Assay to Measure the Dynamics of Fluorescence Tagged Proteins in Endoplasmic Reticulum Membranes of Plant Cells [bio-protocol.org]
- 9. Analysis of protein and lipid dynamics using confocal fluorescence recovery after photobleaching (FRAP) - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Transport between im/mobile fractions shapes the speed and profile of cargo distribution in neurons - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Analysis of protein and lipid dynamics using confocal fluorescence recovery after photobleaching (FRAP) - PubMed [pubmed.ncbi.nlm.nih.gov]
Application Note: Raman Spectroscopy for Pharmaceutical Solid-State Characterization
Introduction
In pharmaceutical development, the solid-state properties of an Active Pharmaceutical Ingredient (API) are critical quality attributes that can significantly influence the final drug product's performance, including its stability, solubility, and bioavailability.[1] Raman spectroscopy has emerged as a preeminent analytical tool for characterizing these properties due to its non-destructive, rapid, and information-rich nature.[2][3][4][5] This vibrational spectroscopy technique requires minimal to no sample preparation and can analyze materials directly through transparent packaging like glass vials or plastic bags, making it ideal for applications ranging from raw material inspection to final product quality control.[6][3][7]
Raman spectroscopy works by detecting the inelastic scattering of monochromatic light (from a laser) as it interacts with a sample. The resulting energy shifts in the scattered photons correspond to the specific vibrational modes of the molecules within the material.[4] These vibrational modes are highly sensitive to the molecule's chemical structure and its local environment, providing a unique spectral "fingerprint."[2] Consequently, different crystalline forms (polymorphs) or the presence of an amorphous state can be clearly distinguished and quantified.[6][2][7][8] Low-frequency Raman spectroscopy, in particular, is effective for polymorph identification as it can probe the lattice vibrations related to the physical structure of the crystal.[6][8][9]
Key Applications in Drug Development
-
Polymorph and Salt Screening: Polymorphism, the ability of a compound to exist in multiple crystalline forms, is a major concern in the pharmaceutical industry.[1][2] Different polymorphs of the same API can exhibit different physicochemical properties. Raman spectroscopy is a powerful tool for identifying and differentiating these forms in real-time during development and manufacturing.[2][10]
-
Crystallinity Analysis: The degree of crystallinity versus the amorphous content in an API is a critical parameter, as amorphous forms are typically more soluble but less stable than their crystalline counterparts.[11] Raman spectroscopy can quantify the degree of crystallinity, providing crucial data for formulation and stability studies.
-
Content Uniformity: Ensuring that the API is uniformly distributed throughout a solid dosage form, such as a tablet, is essential for therapeutic efficacy. Raman mapping is a technique that can visualize the spatial distribution of the API and excipients on a tablet surface, providing a detailed assessment of blend homogeneity.
-
Process Analytical Technology (PAT): The speed and non-invasive nature of Raman spectroscopy make it an ideal PAT tool.[4] It can be used for in-line, real-time monitoring of critical processes like crystallization, granulation, and blending to ensure process understanding and control.[9]
Quantitative Data Presentation
The ability to differentiate polymorphs is based on subtle but distinct differences in their Raman spectra. Carbamazepine (CBZ) is a well-studied API known to exhibit multiple polymorphic forms. The table below summarizes the key distinguishing Raman peaks for two anhydrous polymorphs (Form I and Form III) and the dihydrate form.
Table 1: Characteristic Raman Peaks for Carbamazepine (CBZ) Polymorphs
| Polymorph | Key Distinguishing Raman Peaks (cm⁻¹) | Vibrational Mode Assignment |
| CBZ Form III | 183, 1565, 1600, 1624 | Lattice vibrations, Aromatic C=C stretch, N-H bend, Non-aromatic C=C stretch[12] |
| CBZ Form I | 40, 167, 1040 | Lattice vibrations[6][9], C-H bend (aromatic)[2] |
| CBZ Dihydrate | 19, 115, 171 | Lattice vibrations[9] |
Note: Peak positions can vary slightly based on instrumentation and calibration. The low-frequency region (< 200 cm⁻¹) is particularly useful for distinguishing these forms.[9]
Experimental Protocols and Workflows
Logical Relationship: Solid-State Properties to Drug Performance
The physical form of an API directly impacts its clinical performance. This diagram illustrates the critical relationship between the solid-state characteristics measured by Raman spectroscopy and the ultimate bioavailability of the drug.
General Workflow for Polymorph Identification
This workflow outlines the typical steps involved in using Raman spectroscopy for identifying and quantifying polymorphs in a pharmaceutical sample.
Protocol: Quantitative Analysis of Polymorphic Mixtures
This protocol provides a detailed methodology for quantifying the polymorphic content of an API sample, such as Carbamazepine, using Raman spectroscopy and multivariate analysis.
1. Objective: To determine the relative percentage of Polymorph Form I and Form III in an unknown bulk sample of Carbamazepine.
2. Materials & Equipment:
-
Raman Spectrometer (e.g., equipped with a 785 nm laser).
-
Microscope attachment with appropriate objectives (e.g., 20x or 50x).
-
Pure reference standards for Carbamazepine Form I and Form III (verified by a primary technique like XRPD).
-
Glass microscope slides or well plates.
-
Spatula.
-
Chemometrics software (e.g., for Principal Component Analysis - PCA or Partial Least Squares - PLS regression).
3. Reference Standard Preparation & Spectral Library Creation:
-
Step 3.1: Prepare a series of calibration standards by accurately weighing and physically mixing the pure Form I and Form III references to create mixtures with known compositions (e.g., 0%, 5%, 10%, 25%, 50%, 75%, 90%, 95%, 100% of Form I).
-
Step 3.2: For each calibration standard, place a small amount of the powder onto a microscope slide.
-
Step 3.3: Acquire Raman spectra from multiple (e.g., 5-10) different spots for each standard to ensure representative sampling. Use consistent acquisition parameters (laser power, exposure time, accumulations).
-
Step 3.4: Average the spectra for each concentration level and compile them into a spectral library.
4. Sample Preparation:
-
Step 4.1: Place a small, representative amount of the unknown Carbamazepine sample onto a clean microscope slide. Gently flatten the powder to create a level surface for analysis.
5. Data Acquisition:
-
Step 5.1: Instrument Setup:
-
Power on the laser and spectrometer, allowing them to stabilize.
-
Select the appropriate laser wavelength (e.g., 785 nm to minimize fluorescence).
-
Calibrate the spectrometer using a certified standard (e.g., silicon).
-
Set the acquisition parameters. A typical starting point could be 10-50 mW laser power, 1-10 second exposure time, and 2-5 accumulations. Caution: High laser power can sometimes induce polymorphic transformations.
-
-
Step 5.2: Spectral Collection:
-
Focus the laser on the surface of the unknown sample powder.
-
Acquire spectra from at least 10-15 random locations on the sample to account for any heterogeneity.
-
6. Data Analysis & Quantification:
-
Step 6.1: Pre-processing: Apply necessary spectral pre-processing steps to both the calibration library and the unknown sample spectra. This may include cosmic ray removal, baseline correction, and normalization.
-
Step 6.2: Model Building: Using the pre-processed spectral library of the calibration standards, build a multivariate quantitative model (e.g., PLS regression). The model will correlate the changes in the Raman spectra with the known concentrations of the polymorphs.
-
Step 6.3: Model Validation: Validate the PLS model using cross-validation or a separate validation set to ensure its predictive accuracy. The model should have a high coefficient of determination (R²) and a low Root Mean Square Error of Prediction (RMSEP).
-
Step 6.4: Prediction: Apply the validated PLS model to the spectra obtained from the unknown sample. The model will predict the percentage of Form I and Form III in the unknown sample.
-
Step 6.5: Reporting: Report the average predicted concentration and standard deviation from the multiple measurements taken on the unknown sample. A study has shown that this method can achieve a limit of quantitation of less than 2% for polymorphic impurities.
References
- 1. spectroscopyonline.com [spectroscopyonline.com]
- 2. europeanpharmaceuticalreview.com [europeanpharmaceuticalreview.com]
- 3. journals.library.ualberta.ca [journals.library.ualberta.ca]
- 4. lbt-scientific.com [lbt-scientific.com]
- 5. alfatestlab.com [alfatestlab.com]
- 6. azom.com [azom.com]
- 7. spectroscopyonline.com [spectroscopyonline.com]
- 8. Exploring the Solid-State Landscape of Carbamazepine during Dehydration: A Low Frequency Raman Spectroscopy Perspective - PMC [pmc.ncbi.nlm.nih.gov]
- 9. documents.thermofisher.com [documents.thermofisher.com]
- 10. spiedigitallibrary.org [spiedigitallibrary.org]
- 11. Polymorphism of Carbamazepine Pharmaceutical Cocrystal: Structural Analysis and Solubility Performance - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
Troubleshooting & Optimization
Common pitfalls to avoid in [a specific experimental technique]
Welcome to the technical support center for CRISPR-Cas9 gene editing. This resource is designed for researchers, scientists, and drug development professionals to provide troubleshooting guidance and answer frequently asked questions to help ensure the success of your experiments.
Troubleshooting Guide
This guide addresses common issues encountered during CRISPR-Cas9 experiments in a question-and-answer format.
Question: Why am I observing low or no editing efficiency in my CRISPR experiment?
Answer: Low editing efficiency is a frequent challenge in CRISPR experiments and can arise from several factors throughout the workflow.[1][2] A primary reason for low efficiency is the suboptimal design of the single-guide RNA (sgRNA).[1] An improperly designed sgRNA can lead to inefficient binding to the target DNA, resulting in reduced cleavage by the Cas9 enzyme.[1] Another critical factor is the efficiency of delivering the CRISPR components (Cas9 and sgRNA) into the target cells.[1][2] Inefficient transfection or transduction means that only a small fraction of cells receive the necessary machinery for gene editing.[1] Additionally, the choice of cell line can significantly impact editing efficiency, as different cell lines exhibit varying responses to CRISPR-based editing.[1]
To troubleshoot low editing efficiency, consider the following:
-
Optimize sgRNA Design: Ensure your sgRNA has a high on-target score and low off-target potential. The GC content should ideally be between 40-80% for stability.[3] There are several online tools available to predict sgRNA efficacy.[3][4]
-
Enhance Delivery Method: The method of delivering Cas9 and sgRNA is a critical variable.[2] Options include plasmid transfection, RNA transfection, ribonucleoprotein (RNP) electroporation, and viral transduction.[5][6] RNP delivery often results in higher efficiency and lower off-target effects due to the transient presence of the Cas9 protein.[5][6]
-
Verify Cas9 Expression: Confirm that the Cas9 nuclease is being expressed in the target cells. This can be checked by Western blot or by using a reporter system.
-
Assess Target Site Accessibility: The chromatin state of the target locus can influence Cas9 binding. If the target site is in a heterochromatic region, it may be less accessible.
-
Test Multiple sgRNAs: It is recommended to test 2-3 different sgRNAs for your target gene to identify the one that provides the best editing efficiency.[7]
Question: How can I minimize off-target effects in my CRISPR experiment?
Answer: Off-target effects, where the Cas9 nuclease cuts at unintended genomic locations, are a significant concern in CRISPR experiments as they can lead to unwanted mutations.[8][9][10] Several strategies can be employed to minimize these effects. The design of the sgRNA is crucial; using tools that predict potential off-target sites can help in selecting highly specific sgRNAs.[11] Truncated sgRNAs (17-18 nucleotides) have also been shown to decrease off-target cleavage.[10][12]
The choice and delivery of the Cas9 nuclease also play a vital role. Using a high-fidelity Cas9 variant, such as eSpCas9 or Cas9-HF1, can significantly reduce off-target activity.[12] The delivery format of the CRISPR components is another key consideration.[9] Delivering the Cas9 as a ribonucleoprotein (RNP) complex leads to rapid clearance from the cell, reducing the time available for off-target cleavage to occur compared to plasmid-based delivery which results in prolonged expression.[9][10][13] Optimizing the concentration of the delivered CRISPR components is also important; using the lowest effective concentration can help reduce off-target events.[2]
Frequently Asked Questions (FAQs)
What is the role of the Protospacer Adjacent Motif (PAM) sequence?
The Protospacer Adjacent Motif (PAM) is a short DNA sequence (typically 2-6 base pairs) that is essential for the Cas nuclease to recognize and bind to the target DNA.[14][15] For the commonly used Streptococcus pyogenes Cas9 (SpCas9), the PAM sequence is 5'-NGG-3', where 'N' can be any nucleotide.[15] The Cas9 enzyme will not bind and cleave the target DNA if the PAM sequence is not present immediately downstream of the sgRNA binding site.[10][14]
Should I use a single plasmid or a two-plasmid system for my CRISPR experiment?
A single plasmid system, which contains both the Cas9 nuclease and the sgRNA expression cassettes, is convenient for delivery.[6][16] However, a two-plasmid system, with Cas9 and sgRNA on separate vectors, offers more flexibility for experiments where you might want to use different sgRNAs with the same Cas9 or vice versa. The choice depends on the specific requirements of your experiment.
What is the difference between Non-Homologous End Joining (NHEJ) and Homology-Directed Repair (HDR)?
NHEJ and HDR are two distinct DNA repair pathways that are hijacked by the CRISPR-Cas9 system to introduce genetic modifications.[2][17]
-
NHEJ is the more common and error-prone pathway.[2] It often results in small random insertions or deletions (indels) at the double-strand break site, which can disrupt gene function and is typically used for gene knockouts.[2][18]
-
HDR is a less frequent but more precise pathway that requires a donor DNA template with sequences homologous to the regions flanking the break.[2] This pathway can be used to introduce specific point mutations or to insert new genetic material.[2]
How do I verify that my gene has been successfully edited?
After performing the CRISPR experiment, it is essential to verify the editing event. Common methods include:
-
Mismatch cleavage assays: These assays, such as the T7 Endonuclease I (T7E1) assay, can detect indels.
-
Sanger sequencing: Sequencing the target region of the genome can confirm the presence of mutations.
-
Next-Generation Sequencing (NGS): For a more comprehensive analysis of on-target and off-target mutations, NGS is the preferred method.[19]
Quantitative Data Summary
The choice of delivery method for CRISPR-Cas9 components significantly impacts the editing efficiency. The following table summarizes a comparison of common delivery methods.
| Delivery Method | Cargo | Typical In Vitro Efficiency | Advantages | Disadvantages |
| Plasmid Transfection | DNA | 5-30% | Simple, low cost | Lower efficiency, prolonged Cas9 expression can increase off-target effects, potential for genomic integration.[5][6] |
| mRNA Transfection | RNA | 20-60% | Faster than plasmid (no transcription needed), transient expression reduces off-target effects.[6] | RNA can be less stable than DNA. |
| Ribonucleoprotein (RNP) Electroporation | Protein/RNA complex | 40-90% | High efficiency, rapid action, transient presence minimizes off-target effects, no risk of genomic integration.[5][6] | Requires specialized equipment (electroporator), can be toxic to some cell types. |
| Lentiviral Transduction | Virus | 30-80% | High efficiency in a wide range of cell types, including hard-to-transfect cells; stable integration for long-term expression.[6][19] | Potential for insertional mutagenesis, more complex to produce. |
| Adeno-Associated Virus (AAV) Transduction | Virus | 20-70% | Low immunogenicity, can transduce non-dividing cells. | Limited cargo capacity (~4.7 kb), which can be a challenge for packaging both Cas9 and sgRNA.[6] |
Experimental Protocols
Protocol: Designing and Cloning a single guide RNA (sgRNA) into lentiCRISPRv2
This protocol outlines the steps for cloning a target-specific sgRNA into the lentiCRISPRv2 plasmid, which allows for both Cas9 expression and sgRNA delivery.[16]
1. Design sgRNA Oligonucleotides:
-
Identify a 20-nucleotide target sequence in your gene of interest that is immediately upstream of a 5'-NGG-3' PAM sequence.[16]
-
Use online design tools to minimize potential off-target effects.[3][4]
-
Synthesize two complementary oligonucleotides with appropriate overhangs for cloning into the BsmBI-digested lentiCRISPRv2 vector.[16][20]
-
Oligo 1 (Top strand): 5'- CACCG[20-nt target sequence] -3'
-
Oligo 2 (Bottom strand): 5'- AAAC[Reverse complement of 20-nt target]C -3'
-
2. Anneal Oligonucleotides:
-
Resuspend the lyophilized oligos in sterile water to a final concentration of 100 µM.[20]
-
Set up the annealing reaction in a PCR tube:
-
Oligo 1 (100 µM): 1 µl
-
Oligo 2 (100 µM): 1 µl
-
10x T4 Ligation Buffer: 1 µl
-
Nuclease-free water: 7 µl
-
-
Incubate in a thermocycler with the following program: 95°C for 5 minutes, then ramp down to 25°C at a rate of 5°C/minute.[21]
3. Digest lentiCRISPRv2 Plasmid:
-
Set up the restriction digest reaction:
-
lentiCRISPRv2 plasmid (1 µg)
-
BsmBI restriction enzyme
-
Appropriate reaction buffer
-
Nuclease-free water to the final volume
-
-
Incubate at the recommended temperature for the enzyme (typically 37°C or 55°C) for 1-2 hours.
-
Run the digested plasmid on an agarose gel. You should see two bands: the larger vector backbone and a smaller ~2kb filler piece.[16][21]
-
Excise the larger band and purify the DNA using a gel extraction kit.[16][21]
4. Ligate Annealed Oligos into Digested Vector:
-
Dilute the annealed oligo duplex 1:200 in sterile water.[21]
-
Set up the ligation reaction:
-
Digested and purified lentiCRISPRv2 (50 ng)
-
Diluted annealed oligo duplex (1 µl)
-
T4 DNA Ligase and buffer
-
Nuclease-free water to the final volume
-
-
Incubate at room temperature for 10 minutes or at 16°C overnight.
5. Transform into Competent E. coli:
-
Transform the ligation product into competent E. coli (e.g., Stbl3).[20][22]
-
Plate on ampicillin-containing agar plates and incubate overnight at 37°C.
6. Verify Clones:
-
Pick several colonies and grow them in liquid culture.
-
Isolate the plasmid DNA using a miniprep kit.
-
Verify the insertion of the sgRNA sequence by Sanger sequencing using a suitable primer (e.g., U6 promoter primer).[21]
Visualizations
References
- 1. Troubleshooting Low Knockout Efficiency in CRISPR Experiments - CD Biosynsis [biosynsis.com]
- 2. benchchem.com [benchchem.com]
- 3. synthego.com [synthego.com]
- 4. Bioinformatics 101: How to Design sgRNA - CD Genomics [bioinfo.cd-genomics.com]
- 5. CRISPR/Cas9 Delivery Systems to Enhance Gene Editing Efficiency [mdpi.com]
- 6. CRISPR This Way: Choosing Between Delivery System | VectorBuilder [en.vectorbuilder.com]
- 7. idtdna.com [idtdna.com]
- 8. Recent Advancements in Reducing the Off-Target Effect of CRISPR-Cas9 Genome Editing - PMC [pmc.ncbi.nlm.nih.gov]
- 9. documents.thermofisher.com [documents.thermofisher.com]
- 10. CRISPR - what can go wrong and how to deal with it | siTOOLs Biotech Blog [sitoolsbiotech.com]
- 11. Troubleshooting Guide for Common CRISPR-Cas9 Editing Problems [synapse.patsnap.com]
- 12. spiedigitallibrary.org [spiedigitallibrary.org]
- 13. academic.oup.com [academic.oup.com]
- 14. Tips to optimize sgRNA design - Life in the Lab [thermofisher.com]
- 15. lifesciences.danaher.com [lifesciences.danaher.com]
- 16. media.addgene.org [media.addgene.org]
- 17. researchgate.net [researchgate.net]
- 18. CRISPR gene editing - Wikipedia [en.wikipedia.org]
- 19. assaygenie.com [assaygenie.com]
- 20. static1.squarespace.com [static1.squarespace.com]
- 21. protocols.io [protocols.io]
- 22. Cloning sgRNA in lentiCRISPR v2 plasmid [protocols.io]
How to troubleshoot [a specific experimental problem e.g., PCR contamination]
This technical support center provides researchers, scientists, and drug development professionals with comprehensive guidance on troubleshooting and preventing PCR contamination.
Frequently Asked Questions (FAQs)
Q1: What is PCR contamination?
A1: PCR (Polymerase Chain Reaction) contamination refers to the unintentional introduction of extraneous DNA or RNA into a PCR experiment, leading to the amplification of non-target sequences. This can result in false-positive results, inaccurate quantification, and misinterpreted data. The high sensitivity of PCR makes it particularly susceptible to contamination from even minute amounts of unwanted genetic material.[1]
Q2: How do I know if my PCR is contaminated?
A2: The most reliable indicator of PCR contamination is the presence of an amplification product in your No-Template Control (NTC). The NTC contains all the PCR reaction components except for the DNA template. Therefore, any amplification observed in the NTC signifies the presence of contaminating nucleic acids in one or more of the reagents or the laboratory environment.[1][2]
Q3: What are the common sources of PCR contamination?
A3: PCR contamination can arise from several sources, broadly categorized as:
-
Product Carryover: This is the most frequent source, where PCR products (amplicons) from previous reactions contaminate new experiments. Aerosols generated when opening and closing tubes are a primary mode of transmission.[1][3][4][5]
-
Cross-Contamination: The transfer of nucleic acids between samples, often due to improper handling, shared reagents, or contaminated pipettes.[1][3]
-
Contaminated Reagents and Consumables: Reagents such as Taq polymerase, dNTPs, primers, and even the water used in the reaction can be sources of DNA contamination. Plasticware like tubes and pipette tips can also be contaminated.[1][3]
-
Environmental DNA: DNA from the laboratory environment, including bacteria, fungi, and human cells (from skin or hair), can be introduced into PCR reactions.[1][3]
-
Operator-Derived Contamination: Contamination can be introduced from the person performing the experiment through skin cells, hair, or aerosols from breathing.
Troubleshooting Guides
Guide 1: Identifying the Source of Contamination
If you observe a band in your No-Template Control (NTC), it is crucial to systematically identify the source of the contamination.
Step 1: Confirm the Contamination First, repeat the PCR, including a new NTC, to rule out a one-time error. If the NTC is still positive, proceed to the next step.[1]
Step 2: Isolate the Contaminated Reagent The most effective way to pinpoint a contaminated reagent is through a process of elimination. Set up a series of PCR reactions, each with a fresh, unopened aliquot of one of the following components, while keeping the others the same:
-
PCR-grade water
-
PCR buffer
-
dNTPs
-
Forward primer
-
Reverse primer
-
Taq polymerase
If replacing a specific reagent results in a clean NTC, you have identified the source of contamination. Discard the contaminated reagent immediately.[1][2]
Step 3: Assess the Laboratory Environment If all reagents are ruled out, the contamination is likely environmental. This could originate from your workbench, pipettes, or other laboratory equipment. To identify the specific source, a "wipe test" can be performed (see Experimental Protocols section).
Guide 2: Decontamination Procedures
Once the source of contamination is identified, or as a routine preventative measure, the following decontamination methods can be employed.
| Decontamination Method | Target | Efficacy & Notes |
| 10% Bleach (Sodium Hypochlorite) Solution | Work surfaces, pipettes, equipment | Highly effective at destroying DNA. Must be freshly prepared. Can be corrosive to metal surfaces.[2] |
| UV Irradiation | Work surfaces (inside a PCR hood) | Cross-links DNA, rendering it unamplifiable. Effectiveness is limited to surfaces and is not suitable for decontaminating liquids or equipment with crevices.[1] |
| DNA-destroying commercial reagents (e.g., DNAZap™) | Work surfaces, equipment | Reported to have high decontamination efficiency. |
| Uracil-DNA Glycosylase (UDG/UNG) with dUTP | Carryover amplicon contamination | An enzymatic method that degrades uracil-containing DNA from previous PCRs. A study reported a 10,000,000-fold reduction in amplicon concentration.[6] This method is highly effective for preventing carryover contamination but does not eliminate contamination from genomic DNA or other non-dUTP containing sources.[1] |
Quantitative Analysis of Contamination Sources
A study by Urban C, et al. provided a quantitative analysis of background DNA in a PCR setting:
| Contamination Source | Estimated Frequency | Average Amount of Contaminating DNA |
| Chemicals and Equipment | 65% | 2.5 pg per mL of sample |
| Operator Handling | 35% | 8.9 pg per mL of sample |
Data from: Urban C, Gruber F, Kundi M, Falkner FG, Dorner F, Hämmerle T. A systematic and quantitative analysis of PCR template contamination. J Forensic Sci 2000;45(6):1307–1311.[3][7]
Experimental Protocols
Protocol 1: Wipe Test for Environmental Contamination
This protocol is designed to identify the presence of contaminating DNA on laboratory surfaces.
Materials:
-
Sterile, DNA-free swabs
-
Sterile 1.5 mL microcentrifuge tubes
-
PCR-grade water
-
Vortex mixer
-
Microcentrifuge
-
PCR reagents for your target of interest (or a common housekeeping gene)
Procedure:
-
Label sterile 1.5 mL microcentrifuge tubes for each area to be tested (e.g., benchtop, pipette barrel, centrifuge rotor, door handle).
-
Add 50 µL of PCR-grade water to each tube.
-
Moisten a sterile swab with the water from its corresponding tube.
-
Firmly wipe a defined area (e.g., 10x10 cm) of the surface to be tested.
-
Place the head of the swab back into the tube containing the remaining water and break off the shaft.
-
Cap the tube and vortex vigorously for 30 seconds to elute the collected material.
-
Centrifuge the tube briefly to collect the liquid at the bottom.
-
Use 1-5 µL of the supernatant from each tube as the template in a PCR reaction.
-
Include a positive control (your target DNA) and a negative control (NTC with fresh reagents).
-
Analyze the PCR products by gel electrophoresis. The presence of a band in a lane corresponding to a specific location indicates DNA contamination at that site.
Protocol 2: Uracil-DNA Glycosylase (UDG) for Carryover Contamination Prevention
This protocol utilizes UDG to eliminate carryover contamination from previous PCRs.
Principle: By substituting deoxyuridine triphosphate (dUTP) for deoxythymidine triphosphate (dTTP) in the PCR master mix, all amplicons will contain uracil. A pre-incubation step with UDG in the subsequent PCR setup will degrade any uracil-containing DNA (from previous amplicons), leaving the new template DNA (which contains thymine) intact. The UDG is then heat-inactivated during the initial denaturation step of the PCR.[6]
Procedure:
-
Prepare a PCR master mix substituting dUTP for dTTP. A common ratio is a mix of dUTP and dTTP, for example, 175µM dUTP and 25µM dTTP in the final reaction.[8]
-
Add 1 unit of UDG to the PCR master mix just before adding the template DNA.
-
Incubate the reaction mixture at 37°C for 10-30 minutes. This allows the UDG to degrade any contaminating uracil-containing amplicons.[9]
-
Proceed with your standard thermal cycling protocol. The initial denaturation step (e.g., 95°C for 2-10 minutes) will inactivate the UDG, preventing it from degrading the newly synthesized PCR products.[9][10]
Visualizing Workflows and Relationships
References
- 1. clyte.tech [clyte.tech]
- 2. bitesizebio.com [bitesizebio.com]
- 3. A systematic and quantitative analysis of PCR template contamination - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. [PDF] A systematic and quantitative analysis of PCR template contamination. | Semantic Scholar [semanticscholar.org]
- 5. assets.fishersci.com [assets.fishersci.com]
- 6. biocompare.com [biocompare.com]
- 7. archive.gfjc.fiu.edu [archive.gfjc.fiu.edu]
- 8. Minimizing PCR Cross-Contamination using GoTaq® DNA Polymerase with dUTP and UNG [promega.jp]
- 9. google.com [google.com]
- 10. assaybiotechnology.com [assaybiotechnology.com]
Technical Support Center: Optimizing Signaling Pathway Inhibitor Concentration for Selective Cell Viability Reduction
This technical support center provides researchers, scientists, and drug development professionals with troubleshooting guides and frequently asked questions (FAQs) to address common issues encountered when optimizing the concentration of a signaling pathway inhibitor to achieve selective reduction in cell viability.
Troubleshooting Guide
This guide is designed to help you navigate common experimental challenges in a question-and-answer format.
Issue 1: No or weak inhibition of cell viability at expected concentrations.
-
Question: I'm not observing the expected decrease in cell viability even at concentrations reported in the literature. What should I do?
-
Answer: This is a common issue that can arise from several factors.[1] Here's a step-by-step approach to troubleshoot:
-
Verify Target Expression: Confirm that your cell line expresses the target protein of the inhibitor. This can be done using Western Blotting.
-
Check Compound Integrity and Solubility: Ensure your inhibitor stock solution is prepared correctly and has not degraded.[2] It's advisable to prepare fresh dilutions from a new aliquot for each experiment to avoid issues from repeated freeze-thaw cycles.[1][2] Also, visually inspect your stock solution and the final concentration in your media for any signs of precipitation, as this would lower the effective concentration.[2]
-
Optimize Incubation Time: The inhibitory effect may require a longer duration to manifest.[1] Perform a time-course experiment (e.g., 24, 48, 72 hours) to determine the optimal incubation period.
-
Assess Cell Permeability: If the inhibitor targets an intracellular protein, it must be able to cross the cell membrane. If permeability is low, the compound may not be reaching its target.[2]
-
Consider Cell Confluency: Ensure that cells are in the logarithmic growth phase and not overly confluent, as high cell density can sometimes impact inhibitor efficacy.[1]
-
Issue 2: High levels of cell death or cytotoxicity at all tested concentrations.
-
Question: I'm observing significant cytotoxicity even at very low inhibitor concentrations, which I suspect is not due to the intended mechanism of action. How can I investigate this?
-
Answer: Distinguishing between targeted anti-proliferative effects and general cytotoxicity is crucial.[2]
-
Evaluate Solvent Toxicity: High concentrations of solvents like DMSO can be toxic to cells.[2][3] Ensure the final solvent concentration in your culture medium is low (typically <0.5%) and include a vehicle-only control in your experiments.[2][4]
-
Perform a Cytotoxicity Assay: Use a standard cytotoxicity assay, such as an LDH release assay, to determine the 50% cytotoxic concentration (CC50). This will help you differentiate between specific inhibition and general toxicity.[2]
-
Assess for Off-Target Effects: At high concentrations, inhibitors can have off-target effects.[1][5] Consider using a lower concentration range and confirm that the observed phenotype correlates with the inhibition of your target protein (e.g., via Western Blot).
-
Issue 3: High variability between replicate wells.
-
Question: My results are inconsistent across replicate wells. What could be causing this?
-
Answer: High variability can obscure real biological effects.[4] Here are some common causes and solutions:
-
Uneven Cell Seeding: Ensure you have a single-cell suspension before seeding and that the cell number is consistent across all wells.[4][6]
-
Pipetting Errors: Calibrate your pipettes regularly and use consistent pipetting techniques.[4][6]
-
Edge Effects: Wells on the perimeter of a microplate are prone to evaporation, which can alter concentrations.[4] To mitigate this, you can avoid using the outer wells or fill them with sterile PBS or media.
-
Compound Precipitation: As mentioned earlier, if the inhibitor precipitates in the culture media, its effective concentration will be inconsistent.[4]
-
Frequently Asked Questions (FAQs)
Q1: How do I determine a starting concentration range for a new inhibitor?
A1: For a novel compound, it's recommended to start with a broad, logarithmic dilution series, for instance, from 1 nM to 100 µM.[6] This wide range helps to identify a window where the compound shows biological activity without causing excessive cytotoxicity.
Q2: What is an IC50 value and how is it determined?
A2: The half-maximal inhibitory concentration (IC50) is a measure of the potency of a substance in inhibiting a specific biological or biochemical function.[7] It indicates the concentration of an inhibitor required to reduce the activity of a biological process by 50%.[7][8] To determine the IC50, a dose-response curve is constructed by measuring the effect of different inhibitor concentrations on cell viability.[7]
Q3: What are off-target effects and how can I minimize them?
A3: Off-target effects are unintended interactions of a drug with proteins other than its intended target.[5] These are more likely to occur at higher concentrations.[1] To minimize them, use the lowest effective concentration of your inhibitor. You can also compare the effects of your inhibitor with another inhibitor that has a different chemical scaffold but targets the same protein.[5] Techniques like kinome profiling can also be used to assess the selectivity of your inhibitor.[5]
Q4: How should I prepare and store my inhibitor stock solutions?
A4: Proper handling and storage are critical for reproducibility.[2]
-
Solubility: Determine the best solvent for your inhibitor. DMSO is common, but always check for solubility issues.[2]
-
Stock Concentration: Prepare a high-concentration stock solution (e.g., 10 mM) to minimize the volume of solvent added to your experiments.[2]
-
Storage: Store stock solutions in small aliquots at -20°C or -80°C to prevent degradation from repeated freeze-thaw cycles.[1][2]
Data Presentation
Table 1: Example Dose-Response Data for a PI3K Inhibitor (Compound X) on a Cancer Cell Line.
| Compound X Concentration (µM) | % Cell Viability (Mean ± SD) |
| 0 (Vehicle Control) | 100 ± 4.5 |
| 0.01 | 98.2 ± 5.1 |
| 0.1 | 85.7 ± 6.2 |
| 1 | 52.3 ± 4.8 |
| 10 | 15.1 ± 3.9 |
| 100 | 5.4 ± 2.1 |
Table 2: IC50 Values of Common Kinase Inhibitors in Various Cell Lines.
| Inhibitor | Target Pathway | Cell Line | IC50 (µM) |
| Gefitinib | EGFR | A549 | > 10 |
| Erlotinib | EGFR | H3255 | 0.008 |
| LY294002 | PI3K | U87 MG | 12.5 |
| Wortmannin | PI3K | MCF-7 | 0.004 |
Experimental Protocols
Protocol 1: Cell Viability Assessment using PrestoBlue™ Assay
This protocol outlines the steps to measure cell viability, which is indicative of metabolic activity.
Materials:
-
Cells in culture
-
PrestoBlue™ Cell Viability Reagent
-
96-well plates (opaque-walled recommended for fluorescence)[9]
-
Phosphate-buffered saline (PBS)
-
Fluorescence or absorbance microplate reader[10]
Methodology:
-
Cell Seeding: Seed cells into a 96-well plate at a predetermined optimal density and allow them to adhere overnight in a 37°C incubator.[2]
-
Compound Preparation and Treatment: Prepare a serial dilution of the inhibitor in culture medium.[2] Remove the old medium from the cells and add the medium containing different concentrations of the inhibitor. Include vehicle-only and untreated controls.[2]
-
Incubation: Incubate the plate for the desired time period (e.g., 24, 48, or 72 hours).[6]
-
Assay: Add PrestoBlue™ reagent to each well (typically 10% of the well volume).[10]
-
Incubation with Reagent: Incubate at 37°C for 1 to 4 hours, protected from light.[9][10]
-
Measurement: Measure fluorescence (Ex/Em ~560/590 nm) or absorbance (~570 nm) using a microplate reader.[10][11]
-
Data Analysis: Normalize the data to the vehicle control to determine the percent cell viability.[2] Plot the percent viability against the log of the inhibitor concentration to determine the IC50 value.[2][12]
Protocol 2: Target Engagement Confirmation by Western Blot
This protocol is used to verify that the inhibitor is engaging its intended target by assessing the phosphorylation status of the target protein or its downstream effectors.
Materials:
-
Treated and untreated cell lysates
-
Protein quantification assay (e.g., BCA)
-
SDS-PAGE gels and running buffer
-
Transfer apparatus and buffer
-
PVDF or nitrocellulose membrane
-
Blocking buffer (e.g., 5% non-fat milk or BSA in TBST)
-
Primary antibodies (total and phosphorylated forms of the target protein, and a loading control like β-actin or GAPDH)
-
HRP-conjugated secondary antibodies
-
Chemiluminescent substrate[13]
-
Imaging system
Methodology:
-
Cell Lysis: After treatment with the inhibitor for the desired time, wash cells with cold PBS and lyse them in an appropriate lysis buffer containing protease and phosphatase inhibitors.[14]
-
Protein Quantification: Determine the protein concentration of each lysate using a BCA assay.[15]
-
Sample Preparation: Normalize the protein concentrations of all samples and add Laemmli sample buffer. Boil the samples at 95-100°C for 5-10 minutes.[15]
-
SDS-PAGE: Load equal amounts of protein (e.g., 20-30 µg) into the wells of an SDS-PAGE gel and run the gel to separate the proteins by size.[14][15]
-
Protein Transfer: Transfer the separated proteins from the gel to a PVDF or nitrocellulose membrane.[14][15]
-
Blocking: Block the membrane with blocking buffer for 1 hour at room temperature to prevent non-specific antibody binding.[15]
-
Primary Antibody Incubation: Incubate the membrane with primary antibodies against the target protein (total and phosphorylated forms) and a loading control overnight at 4°C.[14][15]
-
Secondary Antibody Incubation: Wash the membrane and then incubate with the appropriate HRP-conjugated secondary antibodies for 1 hour at room temperature.[15]
-
Detection: After further washing, add a chemiluminescent substrate to the membrane and visualize the protein bands using an imaging system.[15]
-
Analysis: Densitometric analysis of the bands can be performed to quantify the change in protein phosphorylation.
Mandatory Visualization
Caption: Workflow for determining inhibitor IC50 using a cell viability assay.
Caption: Simplified PI3K/Akt signaling pathway with targeted inhibition.
Caption: Logical workflow for troubleshooting unexpected experimental results.
References
- 1. benchchem.com [benchchem.com]
- 2. benchchem.com [benchchem.com]
- 3. benchchem.com [benchchem.com]
- 4. benchchem.com [benchchem.com]
- 5. benchchem.com [benchchem.com]
- 6. benchchem.com [benchchem.com]
- 7. IC50 - Wikipedia [en.wikipedia.org]
- 8. courses.edx.org [courses.edx.org]
- 9. Cell Viability Assays - Assay Guidance Manual - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 10. PrestoBlue Cell Viability Reagent for Microplates Protocol | Thermo Fisher Scientific - HK [thermofisher.com]
- 11. youtube.com [youtube.com]
- 12. Star Republic: Guide for Biologists [sciencegateway.org]
- 13. Western Blot Protocols and Recipes | Thermo Fisher Scientific - US [thermofisher.com]
- 14. pubcompare.ai [pubcompare.ai]
- 15. benchchem.com [benchchem.com]
Technical Support Center: Improving Signal-to-Noise Ratio in Fluorescence Microscopy Imaging
This technical support center is designed for researchers, scientists, and drug development professionals to provide targeted solutions for improving the signal-to-noise ratio (SNR) in fluorescence microscopy experiments. Below you will find troubleshooting guides and frequently asked questions in a direct question-and-answer format to address specific issues you may encounter.
Frequently Asked Questions (FAQs)
Q1: What are the primary sources of noise in my fluorescence microscopy images?
A: Noise in fluorescence microscopy images can be broadly categorized into two main types:
-
Photon Shot Noise: This is a fundamental type of noise resulting from the inherent statistical variation in the arrival of photons at the detector.[1][2][3] It follows a Poisson distribution, meaning that the noise is proportional to the square root of the signal intensity.[1][4] Therefore, brighter regions of your image will inherently have more shot noise.[1]
-
Detector Noise: This noise originates from the electronic components of the microscope's detector, such as the camera or photomultiplier tube (PMT).[1][2] It is generally independent of the signal intensity and includes:
Q2: My images have a high background. How can I reduce it?
A: High background fluorescence is a common issue that can significantly lower your SNR. Here are several strategies to mitigate it:
-
Sample Preparation:
-
Autofluorescence Reduction: Biological samples often contain endogenous molecules (e.g., NADH, FAD, lipofuscin) that fluoresce, creating a diffuse background signal. Consider using an autofluorescence quenching protocol.[8]
-
Staining Optimization: Use the lowest possible concentration of your fluorescent dye or antibody that still provides a detectable signal.[8] Ensure thorough washing steps to remove unbound fluorophores.[8]
-
Blocking: Use an appropriate blocking solution to prevent non-specific antibody binding.[8]
-
-
Instrumental Adjustments:
-
Confocal Pinhole: In confocal microscopy, reducing the pinhole size can effectively reject out-of-focus light and background.[7][9] However, an excessively small pinhole will also reduce your signal. The optimal size is typically around 1 Airy unit.[8]
-
Excitation Intensity: Lower the excitation light intensity to the minimum required for a good signal to reduce background excitation and phototoxicity.[8][10]
-
-
Image Acquisition & Processing:
-
Background Subtraction: Acquire an image of a region with no sample and subtract this background from your experimental images using image analysis software.[8]
-
Q3: How can I increase my signal intensity without increasing the noise?
A: Increasing the signal is a direct way to improve the SNR. Here are some approaches:
-
Fluorophore Selection: Choose bright, photostable fluorophores with high quantum yields.
-
Optical Components: Use high numerical aperture (NA) objectives to collect more light. Ensure all optical components are clean and correctly aligned.
-
Detector Settings: Increase the detector gain or exposure time.[10] However, be aware that excessively high gain can amplify detector noise, and long exposure times can lead to photobleaching.[7][10]
-
Signal Amplification: Consider using signal amplification techniques, such as secondary antibodies conjugated to multiple fluorophores or tyramide signal amplification (TSA).
Q4: What is a good signal-to-noise ratio for my images?
A: The acceptable SNR can vary depending on the application. However, here are some general guidelines for different microscopy techniques:
| Microscopy Technique | Low SNR | Average SNR | High SNR |
| Widefield (slide scanners) | 5-15 | - | > 40 |
| Widefield (cooled CCD) | - | - | 50-100 |
| Confocal / STED | 5-10 | 15-20 | > 30 |
Data sourced from Scientific Volume Imaging.[6]
Troubleshooting Guide
| Issue | Possible Causes | Recommended Solutions |
| Grainy or "Noisy" Image | Low photon count (weak signal). | Increase excitation power (with caution for phototoxicity).[7] Increase exposure time.[10] Use a brighter fluorophore. Use a higher NA objective. |
| High detector gain. | Reduce gain and increase exposure time if possible. | |
| Shot noise is dominant. | Increase the overall signal intensity. | |
| High Background Fluorescence | Autofluorescence from the sample. | Use an autofluorescence quenching protocol (see Protocol 1). Choose fluorophores in the red or far-red spectrum to avoid common autofluorescence. |
| Non-specific antibody/dye binding. | Optimize antibody/dye concentration and washing steps.[8] Use an appropriate blocking buffer.[8] | |
| Out-of-focus light (in widefield). | Use a confocal or deconvolution microscope. | |
| Weak Signal | Low fluorophore concentration or labeling efficiency. | Optimize your staining protocol. |
| Photobleaching. | Use an anti-fade mounting medium.[8] Minimize exposure time and excitation intensity.[8] | |
| Mismatched filter sets. | Ensure your excitation and emission filters are appropriate for your fluorophore.[8] | |
| Signal Bleed-through (Multi-color Imaging) | Spectral overlap between fluorophores. | Choose fluorophores with minimal spectral overlap using a spectra viewer.[8] Perform sequential image acquisition for each channel.[8] |
Experimental Protocols
Protocol 1: Autofluorescence Quenching with Sudan Black B
This protocol is effective for reducing lipofuscin-based autofluorescence in fixed tissue sections.[8]
Materials:
-
Sudan Black B powder
-
70% Ethanol
-
0.2 µm filter
-
Phosphate-buffered saline (PBS) or Tris-buffered saline (TBS)
-
Aqueous anti-fade mounting medium
Procedure:
-
Deparaffinize and Rehydrate: For paraffin-embedded sections, deparaffinize with xylene and rehydrate through a graded series of ethanol to distilled water.
-
Antigen Retrieval (if required): Perform antigen retrieval according to your standard protocol.
-
Immunostaining: Proceed with your standard immunofluorescence staining protocol for primary and secondary antibodies.
-
Sudan Black B Incubation: a. Prepare a 0.1% (w/v) solution of Sudan Black B in 70% ethanol. b. Filter the solution through a 0.2 µm filter. c. Incubate the stained slides in the Sudan Black B solution for 10-20 minutes at room temperature in the dark.
-
Destaining: a. Briefly rinse the slides in 70% ethanol to remove excess Sudan Black B. b. Wash thoroughly with PBS or TBS.
-
Mounting: Mount the coverslip with an aqueous anti-fade mounting medium.
Visualizations
Caption: General workflow for a fluorescence microscopy experiment.
Caption: Troubleshooting workflow for low signal-to-noise ratio.
References
- 1. Imaging in focus: An introduction to denoising bioimages in the era of deep learning - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Noise — Introduction to Bioimage Analysis [bioimagebook.github.io]
- 3. mural.maynoothuniversity.ie [mural.maynoothuniversity.ie]
- 4. olympusconfocal.com [olympusconfocal.com]
- 5. Noise · Analyzing fluorescence microscopy images with ImageJ [petebankhead.gitbooks.io]
- 6. Signal to Noise Ratio | Scientific Volume Imaging [svi.nl]
- 7. bitesizebio.com [bitesizebio.com]
- 8. benchchem.com [benchchem.com]
- 9. Signal-to-Noise Considerations [evidentscientific.com]
- 10. portlandpress.com [portlandpress.com]
Technical Support Center: Cre-Lox Recombination Model
Welcome to the technical support center for the Cre-Lox recombination system. This guide is designed for researchers, scientists, and drug development professionals to troubleshoot common issues, provide standardized protocols, and offer clear visual guides for experimental workflows.
Troubleshooting and FAQs
This section addresses specific issues that users may encounter during their experiments using a question-and-answer format.
Q1: Why am I observing low or no recombination efficiency in my target tissue?
A: Low recombination efficiency is a common challenge that can stem from several factors.[1][2][3] A primary reason is the Cre driver itself; its expression might be weaker than anticipated or exhibit mosaic (patchy) expression within the target cell population.[1][2] Additionally, the accessibility of the loxP sites within the chromatin can vary, making some "floxed" alleles inherently more difficult to recombine than others.[1] For inducible systems like Cre-ERT2, suboptimal tamoxifen dosage, administration route, or timing can lead to incomplete induction.[4]
Q2: I'm seeing recombination in unexpected tissues or without induction (leaky expression). What is the cause?
A: Leaky expression occurs when Cre recombinase is active in non-target cells or, in inducible systems, without the inducing agent (e.g., tamoxifen).[5][6] This can be due to the promoter driving Cre not being entirely specific to your target tissue.[7] Many promoters are active in other tissues at different developmental stages, including the germline.[8][9] Germline expression can lead to the "deleted" allele being passed on to all offspring, converting a conditional knockout into a constitutive one.[9][10] For inducible Cre-ERT2 systems, some Cre-ER fusion proteins can translocate to the nucleus even without tamoxifen, causing background recombination.[1][5]
Q3: My Cre-expressing mice show an abnormal phenotype, even without a floxed allele. Why?
A: This phenomenon can be attributed to two main causes. First, if the Cre transgene was inserted randomly into the genome, it might have disrupted an endogenous gene, causing an unexpected phenotype.[1] Second, high levels of Cre recombinase expression can be toxic to cells, potentially by recognizing and cutting cryptic loxP-like sequences in the genome, leading to DNA damage.[1][11] It is crucial to maintain a control group of mice that express Cre but are wild-type for the floxed allele to account for any Cre-specific effects.[12]
Q4: How can I reliably confirm that Cre-mediated recombination has occurred?
A: Confirmation should be performed at the DNA, mRNA, and protein levels.
-
DNA Level: Use PCR with primers flanking the floxed region. A successful recombination will produce a smaller PCR product corresponding to the deleted allele.[13][14] This is the most direct way to confirm excision.
-
mRNA Level: Quantitative RT-PCR (qRT-PCR) can be used to measure the transcript levels of the target gene. Ensure your primers are designed within the excised region to avoid detecting truncated, non-functional transcripts.[15]
-
Protein Level: Western blotting or immunohistochemistry (IHC) can confirm the absence or reduction of the target protein in the specific cell type.[15][16]
-
Reporter Lines: Crossing your Cre line with a reporter mouse (e.g., Rosa26-LSL-tdTomato) is an excellent strategy to visualize the spatial and temporal activity of Cre recombinase.[12][16][17]
Q5: What are the best breeding strategies for generating conditional knockout (cKO) mice?
A: A standard and efficient strategy involves a two-step process. First, cross a mouse homozygous for the floxed allele (fl/fl) with a mouse carrying the Cre transgene (Cre/+).[18] This will produce offspring that are heterozygous for the floxed allele and carry the Cre transgene (Cre/+; fl/+).[18] In the second step, cross these offspring back to the homozygous floxed (fl/fl) mice. This cross will generate the desired experimental animals (Cre/+; fl/fl) and littermate controls (+/+; fl/fl) in a predictable Mendelian ratio.[18] It is often recommended to use Cre-positive males for breeding when possible to avoid potential germline recombination that can occur in oocytes.[12]
Troubleshooting Summary Table
| Problem | Potential Causes | Recommended Solutions |
| Low/No Recombination | Weak Cre promoter activity; Mosaic Cre expression[1][2]; Inaccessible loxP sites[1]; Insufficient tamoxifen induction[4] | Validate Cre expression pattern with a reporter line; Increase tamoxifen dose or change administration route; Generate a compound heterozygote (fl/null) to require only one allele excision[12] |
| Leaky/Ectopic Recombination | Non-specific promoter activity[7]; Germline Cre expression[8][9]; Basal activity of Cre-ERT2 fusion protein[5] | Cross Cre line with a reporter to map activity precisely; Use Cre-positive males for breeding[12]; Screen breeders for germline deletion; Use newer generation, tighter Cre-ERT2 systems |
| Cre-Alone Phenotype | Insertional mutagenesis by Cre transgene[1]; Cre toxicity from high expression[1] | Use hemizygous Cre mice instead of homozygous[1]; Always include Cre-positive, flox-negative mice as controls[12] |
| Inconsistent Results Among Littermates | Mosaic Cre expression[2]; Parent-of-origin effects on Cre activity[1][2] | Screen multiple animals for recombination efficiency; Test if maternal vs. paternal inheritance of Cre affects recombination and maintain consistency[2] |
Comparison of Common Cre Reporter Alleles
| Reporter Allele | Reporter Protein | Detection Method | Advantages | Considerations |
| ROSA26-LSL-LacZ | β-galactosidase | X-gal staining, IHC | Robust, well-established, good for fixed tissue histology | Requires substrate, not suitable for live imaging |
| ROSA26-LSL-tdTomato (Ai9/Ai14) | tdTomato (red fluorescent) | Fluorescence Microscopy, Flow Cytometry | Very bright signal, excellent for live imaging and lineage tracing[17] | Potential for low-level expression before recombination[17] |
| ROSA26-LSL-eGFP/ZsGreen (Ai6) | eGFP/ZsGreen (green fluorescent) | Fluorescence Microscopy, Flow Cytometry | Bright signal, good for live imaging[17] | Autofluorescence in some tissues can interfere with signal |
| ROSA26-mT/mG | tdTomato -> eGFP | Fluorescence Microscopy | Membrane-targeted fluorescence clearly outlines cell morphology; acts as its own internal control (red cells are non-recombined, green are recombined)[17][19] | Requires dual-channel fluorescence imaging |
Experimental Protocols
Protocol 1: Multiplex PCR for Genotyping and Recombination Analysis
This protocol allows for the simultaneous detection of the wild-type (WT), floxed (fl), and recombined/deleted (Δ) alleles in a single PCR reaction from genomic DNA.
Methodology:
-
Primer Design: Design three primers:
-
Forward Primer 1 (F1): Located upstream of the 5' loxP site.
-
Reverse Primer 1 (R1): Located within the region to be excised (between the loxP sites).
-
Reverse Primer 2 (R2): Located downstream of the 3' loxP site.
-
-
Expected Products:
-
WT Allele: F1 + R2 will produce a band.
-
Floxed Allele: F1 + R2 will produce a slightly larger band than WT due to the inserted loxP sites. F1 + R1 will also produce a product.
-
Deleted Allele (Δ): F1 + R2 will produce a much smaller band, as the intervening sequence has been excised.
-
-
PCR Reaction Mix (25 µL total):
-
5 µL 5x PCR Buffer
-
1 µL 10 mM dNTPs
-
1.5 µL 25 mM MgCl₂
-
0.5 µL of each primer (10 µM stock)
-
0.25 µL Taq Polymerase
-
2 µL Genomic DNA (~50-100 ng)
-
14.25 µL Nuclease-free water
-
-
PCR Cycling Conditions:
-
Initial Denaturation: 95°C for 3 min
-
35 Cycles:
-
95°C for 30 sec
-
58-62°C (optimize for primers) for 30 sec
-
72°C for 60 sec (adjust based on largest expected product size)
-
-
Final Extension: 72°C for 5 min
-
-
Analysis: Run the entire PCR product on a 1.5-2.0% agarose gel to resolve the different band sizes.
Protocol 2: Tamoxifen Preparation and Administration for Cre-ERT2 Induction
This protocol describes the standard method for preparing and administering tamoxifen to induce Cre activity in Cre-ERT2 mouse models.
Methodology:
-
Preparation of Tamoxifen Stock (20 mg/mL):
-
Warning: Tamoxifen is a hazardous substance. Handle with appropriate personal protective equipment (PPE) in a chemical fume hood.
-
Weigh 500 mg of Tamoxifen (Sigma-Aldrich, T5648) into a 50 mL conical tube.
-
Add 25 mL of sterile corn oil.
-
Protect from light by wrapping the tube in aluminum foil.
-
Incubate and shake at 37°C overnight until the tamoxifen is completely dissolved.[5][20]
-
Store the solution at 4°C for up to two weeks.[4]
-
-
Dosage Calculation: The optimal dose must be determined empirically for each Cre line and experiment.[4][20] A common starting point is 75-100 mg/kg of mouse body weight.[20] For a 25g mouse, a 100 µL injection of a 20 mg/mL solution delivers 2 mg of tamoxifen, which corresponds to an 80 mg/kg dose.
-
Administration via Intraperitoneal (IP) Injection:
-
Warm the tamoxifen/oil solution to room temperature before injection.
-
Gently restrain the mouse, exposing the abdomen.
-
Using a 1 mL syringe with a 26-gauge needle, inject the calculated volume into the intraperitoneal cavity.
-
Administer one injection daily for 5 consecutive days.[20]
-
-
Post-Injection Monitoring:
-
Monitor mice for any adverse reactions during the injection period.
-
Wait for a designated period (e.g., 7 days) after the final injection before tissue collection to allow for maximal recombination and target protein turnover.[20]
-
Visual Guides
References
- 1. 12 things you don't know about Cre-lox [jax.org]
- 2. bitesizebio.com [bitesizebio.com]
- 3. How Does Cre-Lox Recombination Work in Conditional Knockouts? [synapse.patsnap.com]
- 4. Generating Tamoxifen-Inducible Cre Alleles to Investigate Myogenesis in Mice - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Tamoxifen Administration for Aldh1l1-CreERT2, Drp1 flox mice [protocols.io]
- 6. researchgate.net [researchgate.net]
- 7. Be mindful of potential pitfalls when using the Cre-LoxP system in cancer research - PMC [pmc.ncbi.nlm.nih.gov]
- 8. search-library.ucsd.edu [search-library.ucsd.edu]
- 9. Detecting and Avoiding Problems When Using the Cre/lox System - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Cre/loxP Recombination System: Applications, Best Practices, and Breeding Strategies | Taconic Biosciences [taconic.com]
- 11. addgene.org [addgene.org]
- 12. Are your Cre-lox mice deleting what you think they are? [jax.org]
- 13. researchgate.net [researchgate.net]
- 14. tandfonline.com [tandfonline.com]
- 15. youtube.com [youtube.com]
- 16. 4 essential steps to verify your Cre-lox model [jax.org]
- 17. JAXMice Search [mice.jax.org]
- 18. Cre Lox Breeding for Beginners, Part 1 [jax.org]
- 19. Overview of the reporter genes and reporter mouse models - PMC [pmc.ncbi.nlm.nih.gov]
- 20. Intraperitoneal Injection of Tamoxifen for Inducible Cre-Driver Lines [jax.org]
Technical Support Center: Suzuki-Miyaura Cross-Coupling
Welcome to the technical support center for the Suzuki-Miyaura cross-coupling reaction. This guide is designed for researchers, scientists, and drug development professionals to provide in-depth troubleshooting, frequently asked questions (FAQs), and optimized protocols to increase the yield of this essential C-C bond-forming reaction.
Troubleshooting Guide: Low & No Yield Issues
This section addresses specific issues that can lead to poor or failed reaction outcomes. Use the diagnostic workflow below to systematically identify and resolve the problem.
Diagram: Troubleshooting Workflow
Caption: A logical workflow for diagnosing the root cause of low product yield.
Question: My reaction shows no product, and I've recovered my starting materials. What's the likely cause?
Answer: This issue most commonly points to an inactive catalytic system or improper reaction conditions.
-
Inactive Catalyst: The palladium(0) catalyst is the engine of the reaction. If it is not active, the first step, oxidative addition, will not occur.[1] Ensure your palladium source is from a reliable vendor. Some Pd(0) sources, like those complexed with dba (dibenzylideneacetone), can degrade over time, forming inactive palladium black.[2]
-
Insufficient Temperature: The oxidative addition step can be demanding, especially for less reactive aryl halides like chlorides.[3] Ensure your reaction is heated to the appropriate temperature, and verify the temperature with an external thermometer.[4]
-
Ligand Issues: The ligand's role is to stabilize the palladium center and facilitate the reaction steps. For challenging substrates, bulky, electron-rich phosphine ligands are often necessary to promote the catalytic cycle.[2][3] An incorrect or degraded ligand can lead to catalyst deactivation.
Question: My yield is low, and I see several byproducts on my TLC or LC-MS. What are the common side reactions?
Answer: The presence of multiple byproducts suggests that competing side reactions are consuming your starting materials. The three most common are:
-
Homocoupling of the Boronic Acid: This forms a symmetrical biaryl byproduct from the boronic acid coupling with itself. It is often caused by the presence of oxygen in the reaction mixture.[1][4]
-
Protodeboronation: This is the replacement of the boron group on your organoboron reagent with a hydrogen atom from water or solvent.[4][5] This side reaction is a very common reason for low yields as it consumes the nucleophile.[2] It can be promoted by excess water or high temperatures.[7]
-
Dehalogenation/Reduction of the Aryl Halide: The aryl halide can be reduced, replacing the halogen with a hydrogen atom. This is less common but can occur if there are hydride sources present in the reaction mixture.[4]
Frequently Asked Questions (FAQs)
Q1: How critical is the choice of base for the Suzuki-Miyaura coupling?
A1: The base is absolutely critical and serves multiple roles. Its primary function is to activate the organoboron species by forming a more nucleophilic borate anion, which is necessary for the transmetalation step.[8][9][10] The choice of base can significantly impact the reaction yield.[11]
-
Common Bases: Inorganic bases like potassium carbonate (K₂CO₃), sodium carbonate (Na₂CO₃), cesium carbonate (Cs₂CO₃), and potassium phosphate (K₃PO₄) are frequently used.[6][11]
-
Base Strength: The optimal base often depends on the specific substrates. For example, stronger bases may be needed for less reactive coupling partners.[3] However, very strong bases can promote side reactions.
-
Solubility: The base must have some solubility in the reaction medium to be effective. The presence of water in biphasic systems (e.g., Toluene/Water) helps to dissolve inorganic bases.
Q2: Can I run the reaction open to the air?
A2: It is strongly discouraged. The active Pd(0) catalyst is sensitive to oxygen and can be oxidized to an inactive state.[5] Oxygen also promotes the unwanted homocoupling of the boronic acid reagent.[4] For reproducible and high-yielding results, the reaction should always be performed under an inert atmosphere (e.g., Argon or Nitrogen).[1]
Q3: My aryl halide is an aryl chloride, and the reaction is not working. What should I do?
A3: Aryl chlorides are the least reactive of the aryl halides (Reactivity: I > Br > OTf >> Cl).[3][10] Their C-Cl bond is strong, making the initial oxidative addition step difficult. To achieve success with aryl chlorides, you typically need more forcing conditions:
-
Specialized Ligands: Use bulky, electron-rich phosphine ligands (e.g., SPhos, XPhos, RuPhos) or N-heterocyclic carbene (NHC) ligands. These ligands facilitate the challenging oxidative addition step.[2][3]
-
Higher Temperatures: Higher reaction temperatures are often required.[12]
-
Stronger Base: A stronger base might be necessary to accelerate the catalytic cycle.[3]
Q4: How much catalyst loading should I use?
A4: Catalyst loading is a balance between reaction efficiency and cost/ease of purification.
-
Screening: For initial screenings, a catalyst loading of 1-5 mol% is common.
-
Optimization: For large-scale synthesis, optimization aims to reduce the catalyst loading significantly. With highly active catalyst systems, loadings can be reduced to parts-per-million (ppm) levels.[13] Reducing catalyst loading is crucial in pharmaceutical development to minimize residual palladium in the final product.[14]
Data on Yield Optimization
Optimizing a Suzuki-Miyaura coupling involves screening multiple parameters. The tables below summarize the effects of different catalysts, bases, and solvents on the yield of model reactions.
Table 1: Effect of Different Bases on Yield (Reaction: 4-iodotoluene with phenylboronic acid)
| Entry | Base (2.0 equiv) | Solvent | Temperature (°C) | Yield (%) |
| 1 | Na₂CO₃ | Toluene | 85 | 98 |
| 2 | K₂CO₃ | Toluene | 85 | 95 |
| 3 | K₃PO₄ | Toluene | 85 | 92 |
| 4 | Cs₂CO₃ | Toluene | 85 | 97 |
| 5 | KOH | Toluene | 85 | 85 |
| 6 | TEA (Triethylamine) | Toluene | 85 | 45 |
Data adapted from studies on base screening, demonstrating that inorganic bases are generally superior for this transformation.[11]
Table 2: Effect of Palladium Catalyst/Ligand System on Yield (Reaction: 4-chloroanisole with phenylboronic acid)
| Entry | Pd Source (2 mol%) | Ligand (4 mol%) | Solvent | Temperature (°C) | Yield (%) |
| 1 | Pd(OAc)₂ | PPh₃ | Dioxane | 100 | 25 |
| 2 | Pd₂(dba)₃ | SPhos | Dioxane | 100 | 95 |
| 3 | Pd₂(dba)₃ | XPhos | Dioxane | 100 | 97 |
| 4 | PdCl₂(dppf) | - | Dioxane | 100 | 68 |
| 5 | Pd(PPh₃)₄ | - | Dioxane | 100 | 35 |
Illustrative data based on the principle that challenging substrates like aryl chlorides require specialized, bulky phosphine ligands for high yields.[2][3]
Experimental Protocols & Key Mechanisms
General Experimental Protocol
This protocol provides a standard procedure for a small-scale Suzuki-Miyaura coupling reaction.
-
Reagent Preparation: To an oven-dried Schlenk tube or reaction vial equipped with a magnetic stir bar, add the aryl halide (1.0 mmol, 1.0 equiv), the organoboron reagent (1.1-1.5 equiv), and the base (e.g., K₂CO₃, 2.0-3.0 equiv).[5][15]
-
Inert Atmosphere: Seal the vessel with a septum or cap, then evacuate and backfill with an inert gas (e.g., Argon) three times to ensure an oxygen-free environment.[1]
-
Solvent Addition: Add the degassed anhydrous solvent (e.g., 1,4-dioxane, toluene, or DMF, ~0.1-0.2 M concentration) via syringe.[5] If using a biphasic system, add degassed water at this stage.
-
Catalyst Addition: Under a positive flow of inert gas, add the palladium catalyst and ligand (or a pre-catalyst complex like PdCl₂(dppf)) to the reaction mixture.
-
Reaction: Place the sealed vessel in a preheated oil bath or heating block and stir vigorously at the desired temperature (typically 80-110 °C) for the required time (2-24 hours).[1][16]
-
Monitoring: Monitor the reaction's progress by TLC or LC-MS until the limiting starting material is consumed.[5]
-
Work-up: Cool the reaction to room temperature. Dilute the mixture with an organic solvent (e.g., ethyl acetate) and wash with water and brine to remove the inorganic base and salts.[1]
-
Purification: Dry the organic layer over anhydrous sodium sulfate (Na₂SO₄), filter, and concentrate under reduced pressure. Purify the crude product by flash column chromatography on silica gel.[1][5]
Diagram: The Suzuki-Miyaura Catalytic Cycle
Caption: The three key steps of the Suzuki-Miyaura catalytic cycle.
References
- 1. benchchem.com [benchchem.com]
- 2. Yoneda Labs [yonedalabs.com]
- 3. chem.libretexts.org [chem.libretexts.org]
- 4. benchchem.com [benchchem.com]
- 5. benchchem.com [benchchem.com]
- 6. researchgate.net [researchgate.net]
- 7. pubs.acs.org [pubs.acs.org]
- 8. Role of the Base and Control of Selectivity in the Suzuki–Miyaura Cross‐Coupling Reaction | Semantic Scholar [semanticscholar.org]
- 9. wwjmrd.com [wwjmrd.com]
- 10. Suzuki reaction - Wikipedia [en.wikipedia.org]
- 11. researchgate.net [researchgate.net]
- 12. mdpi.com [mdpi.com]
- 13. Pd-Catalysed Suzuki–Miyaura cross-coupling of aryl chlorides at low catalyst loadings in water for the synthesis of industrially important fungicides - Green Chemistry (RSC Publishing) [pubs.rsc.org]
- 14. pubs.acs.org [pubs.acs.org]
- 15. A General and Efficient Method for the Suzuki-Miyaura Coupling of 2-Pyridyl Nucleophiles - PMC [pmc.ncbi.nlm.nih.gov]
- 16. youtube.com [youtube.com]
Technical Support: Reducing Background Noise in Immunofluorescence (IF) Microscopy
High background noise is a common challenge in immunofluorescence (IF) microscopy that can obscure specific signals, leading to false positives and complicating data interpretation. This guide provides detailed troubleshooting strategies, experimental protocols, and answers to frequently asked questions to help researchers achieve a high signal-to-noise ratio for publication-quality images.
Troubleshooting Guide
This section addresses specific issues users may encounter during their IF experiments in a question-and-answer format.
Question 1: My entire sample, including the negative control where I omitted the primary antibody, shows a high, uniform background signal. What is the likely cause?
Answer: This issue typically points to problems with the secondary antibody or the blocking step.
-
Non-Specific Secondary Antibody Binding: The fluorescently-conjugated secondary antibody may be binding non-specifically to components in your sample.[1]
-
Solution: Run a control with only the secondary antibody. If staining persists, the secondary antibody is binding non-specifically.[1] Consider using a pre-adsorbed secondary antibody, which has been purified to remove antibodies that cross-react with proteins from other species.
-
-
Insufficient Blocking: The blocking buffer may not be adequately preventing non-specific protein interactions.[2][3]
-
Solution: Increase the blocking incubation time (e.g., to 60 minutes) and ensure the blocking agent is appropriate.[2][4] A common and effective blocking buffer includes 5-10% normal serum from the same species that the secondary antibody was raised in.[5] For example, if you are using a goat anti-mouse secondary antibody, you should use normal goat serum.
-
Question 2: I see a speckled or punctate background pattern across my sample. What could be causing this?
Answer: This type of background often results from antibody aggregates or issues with reagents.
-
Antibody Aggregates: The primary or secondary antibody may have formed aggregates.
-
Solution: Centrifuge the antibody solution at high speed (e.g., >10,000 x g) for 1-5 minutes before diluting it. You can also filter the diluted antibody solution using a 0.22 µm syringe filter.
-
-
Precipitates in Buffers: Buffers, especially those containing BSA, may have precipitates.
-
Solution: Ensure all buffers are freshly made and filtered if any particulates are visible.
-
Question 3: My unstained control sample is fluorescent. How can I reduce this autofluorescence?
Answer: This is known as autofluorescence, which is intrinsic fluorescence from the biological specimen itself.[6][7]
-
Source of Autofluorescence: It can be caused by various endogenous molecules like collagen, elastin, NADH, and lipofuscin, or it can be induced by aldehyde fixatives like formaldehyde.[6][7][8]
-
Solution 1 - Perfusion: If working with tissues, perfuse the animal with PBS before fixation to remove red blood cells, which contain autofluorescent heme groups.[9]
-
Solution 2 - Quenching Agents: Treat samples with a quenching agent. For lipofuscin (common in aged tissues), Sudan Black B can be effective.[9] For aldehyde-induced autofluorescence, treatment with sodium borohydride (0.1% in PBS for 10-30 minutes) can help.[7][9]
-
Solution 3 - Fluorophore Choice: Shift to fluorophores in the far-red or near-infrared spectrum (e.g., Alexa Fluor 647 or 750), as autofluorescence is typically weaker at longer wavelengths.[10]
-
Question 4: The background is generally high, and my specific signal is weak. How can I improve my signal-to-noise ratio?
Answer: This common problem requires optimizing antibody concentrations and washing procedures to enhance the specific signal while minimizing background.
-
Suboptimal Antibody Concentration: Using too high a concentration of either the primary or secondary antibody is a frequent cause of high background.[1][11][12]
-
Solution: Titrate your antibodies to find the optimal dilution that provides the best signal-to-noise ratio.[13] This involves testing a range of dilutions to find the one that maximizes the specific signal while keeping background low.
-
-
Inadequate Washing: Insufficient washing will fail to remove unbound and loosely-bound antibodies.[2][11]
Frequently Asked Questions (FAQs)
What is the most common cause of high background in IF? The most frequent cause is an overly high concentration of the primary or secondary antibody, leading to non-specific binding.[1][11][12] It is essential to perform a titration experiment for every new antibody to determine its optimal working concentration.[13]
How do I choose the right blocking buffer? The ideal blocking buffer prevents non-specific interactions without masking the antigen of interest. A widely used and effective blocking buffer contains 5-10% normal serum from the host species of the secondary antibody, supplemented with a detergent like 0.3% Triton X-100 in PBS.[4] Using serum from the secondary antibody's host prevents the secondary antibody from binding to the blocking proteins themselves.[5]
What are the best practices for washing steps? Thorough washing is critical. Use a buffer like PBS containing a small amount of detergent (e.g., 0.05% Tween 20) to help remove non-specifically bound antibodies. Perform at least three washes of 5-10 minutes each after both primary and secondary antibody incubations, preferably with gentle agitation.[2][14]
How can I be sure my secondary antibody isn't the problem? Always include a "secondary-only" control in your experiment. In this control, you perform the entire staining protocol but omit the primary antibody. If you observe fluorescence in this sample, it indicates that your secondary antibody is binding non-specifically.[1][3]
Data Presentation
Optimizing antibody concentration is the most critical step for reducing background. The goal is to find a dilution that maximizes the signal-to-noise ratio. Below is an example of data from a primary antibody titration experiment.
| Primary Antibody Dilution | Mean Fluorescence Intensity (MFI) - Positive Cells | Mean Fluorescence Intensity (MFI) - Negative Control | Signal-to-Noise Ratio (Positive MFI / Negative MFI) |
| 1:50 | 9500 | 1500 | 6.3 |
| 1:100 | 8200 | 800 | 10.3 |
| 1:250 | 7100 | 350 | 20.3 |
| 1:500 | 4500 | 250 | 18.0 |
| 1:1000 | 2100 | 200 | 10.5 |
Table 1: Example of an antibody titration experiment. The 1:250 dilution provides the optimal signal-to-noise ratio, with a strong specific signal and low background fluorescence.
Experimental Protocols
Protocol 1: Primary Antibody Titration
This protocol is essential for determining the optimal antibody concentration to maximize the signal-to-noise ratio.
-
Prepare Samples: Prepare multiple identical samples (e.g., cells on coverslips or tissue sections on slides). Include a positive control (known to express the target) and a negative control (does not express the target).[13]
-
Fix, Permeabilize, and Block: Process all samples according to your standard protocol for fixation, permeabilization, and blocking.
-
Prepare Antibody Dilutions: Prepare a series of dilutions for your primary antibody in antibody dilution buffer (e.g., PBS with 1% BSA and 0.3% Triton X-100).[4] A good starting range is 1:50, 1:100, 1:250, 1:500, and 1:1000.[16]
-
Primary Antibody Incubation: Apply each dilution to a separate sample. Incubate according to your protocol (e.g., 1 hour at room temperature or overnight at 4°C).[4]
-
Wash: Wash all samples thoroughly three times for 5 minutes each in wash buffer (e.g., PBS with 0.05% Tween 20).
-
Secondary Antibody Incubation: Apply the secondary antibody (at its own pre-determined optimal concentration) to all samples. Incubate in the dark.
-
Final Washes & Mounting: Perform final washes and mount the samples with an antifade mounting medium.
-
Imaging and Analysis: Image all samples using the exact same microscope settings (e.g., laser power, gain, exposure time). Quantify the mean fluorescence intensity of the specific signal and the background. Calculate the signal-to-noise ratio for each dilution and select the dilution that provides the highest ratio.[13]
Protocol 2: Autofluorescence Quenching with Sodium Borohydride
This protocol is used to reduce background caused by aldehyde fixation.
-
Fix and Permeabilize: Fix and permeabilize your samples as usual (e.g., with 4% paraformaldehyde).
-
Wash: Rinse the samples twice with PBS for 5 minutes each.
-
Prepare Quenching Solution: Freshly prepare a 0.1% (w/v) solution of sodium borohydride (NaBH₄) in ice-cold PBS. Caution: Sodium borohydride will bubble upon contact with liquid. Prepare in a fume hood.
-
Incubation: Incubate the samples in the sodium borohydride solution for 30 minutes at room temperature.
-
Thorough Washing: Wash the samples extensively, at least three to four times for 5 minutes each with PBS, to remove all traces of the quenching agent.
-
Blocking: Proceed with the blocking step and the rest of your immunofluorescence protocol.
Visualizations
A troubleshooting workflow for diagnosing high background noise.
Diagram illustrating specific vs. non-specific antibody binding.
References
- 1. stjohnslabs.com [stjohnslabs.com]
- 2. hycultbiotech.com [hycultbiotech.com]
- 3. Immunofluorescence staining | Abcam [abcam.com]
- 4. Immunofluorescence Formaldehyde Fixation Protocol | Cell Signaling Technology [cellsignal.com]
- 5. Blocking Buffers in Immunofluorescence Workflows [visikol.com]
- 6. vectorlabs.com [vectorlabs.com]
- 7. Autofluorescence [jacksonimmuno.com]
- 8. vectorlabs.com [vectorlabs.com]
- 9. How to reduce autofluorescence | Proteintech Group [ptglab.com]
- 10. benchchem.com [benchchem.com]
- 11. ibidi.com [ibidi.com]
- 12. benchchem.com [benchchem.com]
- 13. blog.cellsignal.com [blog.cellsignal.com]
- 14. ICC/IF Troubleshooting | Antibodies.com [antibodies.com]
- 15. m.youtube.com [m.youtube.com]
- 16. 9 Tips to optimize your IF experiments | Proteintech Group [ptglab.com]
Technical Support Center: Flow Cytometer Calibration & Troubleshooting
This technical support center provides researchers, scientists, and drug development professionals with comprehensive guidance on calibrating a flow cytometer for accurate measurements. It includes troubleshooting guides and frequently asked questions in a direct question-and-answer format to address specific issues encountered during experiments.
Frequently Asked Questions (FAQs)
Q1: Why is daily calibration or Quality Control (QC) necessary for my flow cytometer?
A1: Daily quality control is crucial for ensuring the consistency and reliability of your data.[1][2][3] It verifies that the instrument's lasers, fluidics, and detectors are performing within established specifications.[4] This process helps to identify any instrument drift or performance shifts over time, allowing for adjustments before acquiring critical experimental data.[3][5] Tracking QC data, often with Levey-Jennings plots, provides a longitudinal record of instrument performance and aids in troubleshooting.[3][4][5]
Q2: What are the essential components of a daily QC procedure?
A2: A comprehensive daily QC protocol typically involves running standardized fluorescent beads to check several key parameters.[1][5] These include:
-
Optical Alignment: Ensuring the lasers are correctly focused on the sample stream.[1][6]
-
Fluidics Stability: Checking for consistent sample flow and the absence of clogs.[1][7]
-
Detector Performance: Verifying the linearity and sensitivity of the photomultiplier tubes (PMTs).[5]
-
Fluorescence Intensity: Confirming that the instrument can detect a known fluorescence signal at a consistent level.[4]
Q3: What is fluorescence compensation and why is it critical for multi-color experiments?
A3: Fluorescence compensation is a mathematical correction for spectral overlap, which occurs when the fluorescence emission of one fluorochrome is detected in another fluorochrome's designated detector.[8][9][10] This "spillover" can lead to false positive signals and incorrect data interpretation.[9] Proper compensation is absolutely essential for accurate analysis in multi-color flow cytometry, especially when identifying distinct cell populations.[8] For each fluorochrome in your experiment, a single-stained control (cells or beads) must be prepared to calculate the correct compensation matrix.[9][10]
Q4: Can I use the same compensation settings for all my experiments?
A4: No, compensation settings are specific to a particular set of fluorochromes and instrument settings (e.g., PMT voltages).[11] If you change any fluorochrome in your panel or adjust the detector voltages, you must run new single-stain controls and recalculate the compensation matrix.[12] It's a best practice to run compensation controls for each experiment to ensure the most accurate results.[6]
Troubleshooting Guides
Issue 1: Weak or No Fluorescence Signal
Q: My stained cells are showing a very weak or no signal. What are the possible causes and solutions?
A: This is a common issue with several potential causes. Refer to the table below for a systematic approach to troubleshooting.
| Possible Cause | Recommended Solution |
| Reagent Issues | Verify antibody storage conditions and expiration date.[6] Titrate the antibody to determine the optimal staining concentration.[6][13] For intracellular targets, ensure the fixation and permeabilization protocol is appropriate for the antibody and target location.[6][14] |
| Instrument Settings | Ensure the correct lasers and filters are selected for the fluorochromes being used.[12][14] Check that PMT voltages are set appropriately; they may be too low. Use a positive control to optimize settings.[15] |
| Low Target Expression | Confirm that your cell type expresses the target antigen.[6][16] If expression is known to be low, consider using a brighter fluorochrome or a signal amplification strategy (e.g., biotinylated primary antibody with a fluorescent streptavidin secondary).[12][16] |
| Sample Preparation | Whenever possible, use freshly isolated cells, as freezing can sometimes affect antigen expression.[14][16] Ensure your cell stimulation protocol (if any) is optimized to induce target expression.[14] |
Issue 2: High Background or Non-Specific Staining
Q: I'm observing high fluorescence background in my negative control or unstained cells. How can I resolve this?
A: High background can obscure real signals and lead to incorrect gating. The following table outlines common causes and solutions.
| Possible Cause | Recommended Solution |
| Non-Specific Antibody Binding | This can occur if the antibody binds to Fc receptors on cells like monocytes or macrophages.[14][16] Pre-incubate cells with an Fc blocking reagent or normal serum from the same species as your secondary antibody.[13][14][16] Ensure you are using an appropriate isotype control to identify non-specific binding.[13][16] |
| Excess Antibody | Too much antibody can lead to non-specific binding.[13] Titrate your antibody to find the concentration that gives the best signal-to-noise ratio.[6][15] |
| Inadequate Washing | Increase the number of wash steps after antibody incubation to remove any unbound antibody.[14][16] Consider adding a small amount of detergent (e.g., Tween-20) to the wash buffer.[6] |
| Cell Autofluorescence | Some cell types are naturally autofluorescent. Analyze an unstained sample to determine the level of autofluorescence.[16] If it's problematic, choose fluorochromes that emit in the far-red spectrum where autofluorescence is typically lower, or use brighter fluorochromes to raise the signal above the background.[16] |
| Dead Cells | Dead cells can non-specifically bind antibodies and exhibit high autofluorescence.[17] Use a viability dye (e.g., 7-AAD, Propidium Iodide, DAPI) to exclude dead cells from your analysis.[12] |
Issue 3: High Coefficient of Variation (CV) or Broad Peaks
Q: My data peaks are very broad (high CVs), making it difficult to resolve populations. What should I check?
A: High CVs reduce the resolution and sensitivity of your measurements. Here are the primary factors to investigate.
| Possible Cause | Recommended Solution |
| High Flow Rate | Running samples at a high flow rate can increase the core stream diameter, leading to greater variance in illumination and detection.[14] Always run samples at the lowest flow rate setting for optimal resolution.[14] |
| Instrument Misalignment | A misaligned laser can cause inconsistent illumination of cells. Run alignment beads to check and, if necessary, correct the optical alignment.[6] |
| Clogged Fluidics | A partial clog in the flow cell or tubing can disrupt the laminar flow, causing cells to pass through the laser beam inconsistently.[13] Perform cleaning cycles as recommended by the manufacturer (e.g., running cleaning solution or bleach).[7] |
| Improperly Mixed Sample | Ensure cells are in a single-cell suspension and well-mixed before acquisition. Clumps or doublets can create broad signals. Filter the sample if necessary.[15] |
Data Presentation
Table 1: Typical Flow Cytometer Laser and Fluorochrome Compatibility
This table provides a summary of common lasers found in flow cytometers and some compatible fluorochromes.
| Laser Line | Wavelength (nm) | Common Fluorochromes |
| Violet | 405 | Brilliant Violet™ 421, DAPI, eFluor™ 450 |
| Blue | 488 | FITC, PE, PerCP, PE-Cy7, Propidium Iodide |
| Yellow-Green | 561 | PE, PE-Dazzle™ 594, PE-Cy5, mCherry |
| Red | 640 | APC, Alexa Fluor® 647, APC-Cy7 |
Table 2: Daily QC Performance Log (Example)
Use a log like this to track daily instrument performance. Levey-Jennings plots are recommended for visualizing trends over time.[4][5]
| Date | Parameter | Target Value | Measured Value | % Deviation | Pass/Fail |
| 2025-10-27 | FITC MFI (Peak 4) | 150,000 | 152,300 | +1.5% | Pass |
| 2025-10-27 | FITC CV (%) | < 3.0 | 2.5 | N/A | Pass |
| 2025-10-28 | FITC MFI (Peak 4) | 150,000 | 148,900 | -0.7% | Pass |
| 2025-10-28 | FITC CV (%) | < 3.0 | 2.6 | N/A | Pass |
| 2025-10-29 | FITC MFI (Peak 4) | 150,000 | 143,500 | -4.3% | Pass |
| 2025-10-29 | FITC CV (%) | < 3.0 | 2.9 | N/A | Pass |
Experimental Protocols
Protocol 1: Daily Instrument Quality Control (QC) using Standardized Beads
This protocol outlines the standard procedure for performing daily QC to ensure consistent instrument performance.[1][18]
Materials:
-
QC Beads (e.g., multi-peak rainbow beads with a defined fluorescence intensity).[5]
-
Sheath Fluid
-
Flow Cytometer Tubes
Procedure:
-
Instrument Start-up: Follow the manufacturer's recommended start-up sequence. Ensure sheath fluid is full and waste is empty.
-
Prepare QC Beads: Vortex the bead vial for 30-60 seconds to ensure a homogenous suspension.[19]
-
Dilute Beads: Add 1-2 drops of the bead suspension to a flow cytometer tube containing 1 mL of sheath fluid or PBS.[19] Mix gently.
-
Load Baseline Settings: Open the instrument software and load the baseline or daily QC settings profile. These settings should have pre-defined target values for bead peak channels.[4]
-
Acquire Bead Data: Load the bead tube onto the instrument and begin acquisition. Collect a sufficient number of events (typically 5,000-10,000).[20]
-
Analyze Performance: Check that the Mean Fluorescence Intensity (MFI) and Coefficient of Variation (CV) for each bead peak are within the acceptable ranges defined by the bead manufacturer or your laboratory's established limits.[5]
-
Record Results: Record the MFI and CV values in your instrument's QC log.[4] If values are outside the acceptable range, do not proceed with experiments. Initiate troubleshooting procedures.
Protocol 2: Staining for Cell Surface Immunophenotyping
This protocol provides a general workflow for staining cells with fluorescently-conjugated antibodies for surface markers.
Materials:
-
Single-cell suspension of your sample (e.g., PBMCs, cultured cells)
-
Staining Buffer (e.g., PBS with 1-2% BSA or FBS)
-
Fc Blocking Reagent (optional, but recommended)
-
Fluorochrome-conjugated antibodies
-
Viability Dye
-
Flow Cytometer Tubes
Procedure:
-
Cell Preparation: Start with a single-cell suspension. Count cells and adjust the concentration to 1x10^6 cells per tube in 100 µL of staining buffer.
-
Fc Block (Optional): Add Fc blocking reagent to the cell suspension and incubate for 10 minutes at 4°C. This step helps to reduce non-specific antibody binding.[16]
-
Antibody Staining: Add the pre-titrated amount of each fluorochrome-conjugated antibody to the appropriate tubes. Vortex gently.
-
Incubation: Incubate for 20-30 minutes at 4°C in the dark to prevent photobleaching of fluorochromes.[21]
-
Washing: Add 2 mL of staining buffer to each tube and centrifuge at 300-400 x g for 5 minutes. Carefully decant the supernatant. Repeat the wash step.
-
Viability Staining: Resuspend the cell pellet in 200-400 µL of staining buffer. Add the viability dye according to the manufacturer's instructions.
-
Acquisition: Analyze the samples on the flow cytometer as soon as possible. Keep samples at 4°C and protected from light until acquisition.
Mandatory Visualizations
Caption: Troubleshooting workflow for high Coefficients of Variation (CVs).
Caption: Standard workflow for cell surface immunophenotyping.
Caption: The principle of fluorescence spillover and compensation.
References
- 1. bangslabs.com [bangslabs.com]
- 2. Quality control in flow cytometry (Chapter 4) - Cytometric Analysis of Cell Phenotype and Function [cambridge.org]
- 3. The Importance Of Quality Control And Quality Assurance In Flow Cytometry (Part 4 Of 6) [expertcytometry.com]
- 4. Flow Cytometry Quality Requirements for Monitoring of Minimal Disease in Plasma Cell Myeloma - PMC [pmc.ncbi.nlm.nih.gov]
- 5. How To Create A Flow Cytometry Quality Assurance Protocol For Your Lab - ExpertCytometry [expertcytometry.com]
- 6. hycultbiotech.com [hycultbiotech.com]
- 7. scribd.com [scribd.com]
- 8. medschool.cuanschutz.edu [medschool.cuanschutz.edu]
- 9. bio-rad-antibodies.com [bio-rad-antibodies.com]
- 10. Compensation in Flow Cytometry - FluoroFinder [fluorofinder.com]
- 11. 3 Requirements For Accurate Flow Cytometry Compensation - ExpertCytometry [expertcytometry.com]
- 12. Flow Cytometry Troubleshooting Tips [elabscience.com]
- 13. Flow Cytometry Troubleshooting Guide [sigmaaldrich.com]
- 14. Flow Cytometry Troubleshooting Guide | Cell Signaling Technology [cellsignal.com]
- 15. biocompare.com [biocompare.com]
- 16. bosterbio.com [bosterbio.com]
- 17. Recommended controls for flow cytometry | Abcam [abcam.com]
- 18. biocompare.com [biocompare.com]
- 19. takarabio.com [takarabio.com]
- 20. Calibration of Flow Cytometry for Quantitative Quantum Dot Measurements - PMC [pmc.ncbi.nlm.nih.gov]
- 21. mdpi.com [mdpi.com]
Artifacts in [a specific type of data] and how to identify them
Welcome to the technical support center for flow cytometry data analysis. This resource is designed for researchers, scientists, and drug development professionals to help identify and troubleshoot common artifacts encountered during flow cytometry experiments.
Troubleshooting Guides
This section provides answers to specific issues you may encounter with your flow cytometry data.
Q: My scatter plot shows a population of events with very low forward scatter (FSC) and side scatter (SSC). What are these events?
A: This population is likely cellular debris or electronic noise.[1] Debris consists of small particles and fragments from dead or damaged cells, which exhibit low scatter signals.[2][3] It is crucial to exclude this population, as it can interfere with the analysis of your target cells.
-
Identification: Debris typically appears as a dense cluster in the lower-left corner of an FSC vs. SSC plot.
-
Solution: Draw a gate around the distinct cell populations of interest on the FSC vs. SSC plot, effectively excluding the low-scatter debris from all subsequent analyses.[1] For samples with significant debris, consider filtering the cell suspension through a nylon mesh before acquisition.[4]
Q: I see a "tail" or diagonal population extending from my main cell cluster on plots of signal area (FSC-A) vs. signal height (FSC-H). What does this indicate?
A: This pattern is the classic signature of doublets or cell aggregates.[5][6] A doublet occurs when two cells pass through the laser interrogation point so close together that the cytometer registers them as a single event.[7][8] This artifact is problematic because it can lead to false positives (e.g., a fluorescent-positive cell stuck to a negative cell) and incorrect cell cycle analysis.[6]
-
Identification: On a plot of pulse area versus pulse height (e.g., FSC-A vs. FSC-H), single cells form a tight diagonal line because their area and height are proportional.[5] Doublets will have a similar height to single cells but approximately double the area, causing them to deviate from this diagonal.[6]
-
Solution: Use a "singlet gate" to isolate the linear population of single cells. Plot FSC-A vs. FSC-H and draw a gate around the main diagonal population.[5] Apply this gate to all downstream analyses to ensure you are only evaluating single-cell events. You can also use other parameter combinations like FSC-W (width) vs. FSC-H.[5]
Q: After staining, my "negative" population appears to have a signal in a channel where it should be negative, creating a diagonal spread on my bivariate plots. What is wrong?
A: This is a strong indication of improper fluorescence compensation.[9][10] When the emission spectra of two fluorochromes overlap, the signal from one can "spill over" into the detector for the other. Without proper correction, this spectral overlap leads to data that suggests cells are positive for markers they do not express.[9][11]
-
Identification: Uncompensated or under-compensated data shows a diagonal "smear" of populations on a bivariate plot instead of distinct, orthogonal clusters.[9] The median fluorescence intensity of the positive population in the spillover channel will not be equal to the median of the negative population.
-
Solution: You must perform compensation using single-stained controls for every fluorochrome in your panel.[9][12] The goal is to mathematically subtract the spillover signal.[9] Ensure your single-stain controls are at least as bright as the corresponding signal in your fully stained sample.[11] Most modern software can calculate a compensation matrix automatically from these controls.
Q: My data looks unstable when plotted against the "Time" parameter, showing gaps or sudden shifts in event rate. How should I interpret this?
A: Plotting your data against the time parameter is a critical quality control step to assess the stability of the fluidics during acquisition.[13] Gaps, drifts, or sudden changes in signal intensity over time can indicate a clog, air bubbles in the system, or that the sample ran out.[14]
-
Identification: On a plot with "Time" on the x-axis and any scatter or fluorescence parameter on the y-axis, the events should appear as a consistent, even band.[14] Any deviations from this pattern suggest a fluidics issue.
-
Solution: If you identify an unstable region, you can gate on the stable portion of the acquisition to salvage the data.[14] To prevent this, ensure your samples are well-filtered and properly vortexed before running.[4] If clogs persist, perform cleaning cycles on the instrument.
Frequently Asked Questions (FAQs)
Q: What are the most common artifacts in flow cytometry?
A: The most frequently encountered artifacts include:
-
Cell Aggregates/Doublets: Two or more cells passing through the laser as a single event.[1][7]
-
Debris and Dead Cells: Fragments of cells or non-viable cells that can non-specifically bind antibodies and increase background noise.[1][4]
-
Spectral Overlap (Spillover): The detection of fluorescence from one fluorochrome in a detector intended for another, requiring compensation.[9]
-
Autofluorescence: Natural fluorescence from cells that can obscure signals from dim markers.[15][16]
-
Fluidic Instability: Issues like clogs or air bubbles that cause inconsistent data acquisition over time.[14]
Q: How do I distinguish a G2/M phase cell from a doublet in cell cycle analysis?
A: This is a critical distinction, as both will have approximately double the DNA content (and thus double the fluorescence from a DNA dye) compared to a G1 cell. A true G2/M cell is a single event, while a doublet is two G1 cells stuck together.[6] You can differentiate them by plotting the area of the DNA dye signal (e.g., PI-A) against its height (PI-H) or width (PI-W). A G2/M cell will have roughly double the area and double the height of a G1 cell, keeping it on the same diagonal in an Area vs. Height plot. A doublet of two G1 cells will have double the area but only the height of a single G1 cell, causing it to shift off the diagonal.[6]
Q: Why is it important to use a viability dye?
A: Dead cells can compromise data quality significantly. Their membranes are often permeable, leading to non-specific binding of antibodies and high autofluorescence, which creates false-positive signals and high background.[4][15][17] Relying on FSC and SSC alone is not always sufficient to exclude all dead cells. A viability dye allows for the clear identification and exclusion of dead cells from the analysis, dramatically improving data accuracy.[4]
Q: What are compensation beads and when should I use them?
A: Compensation beads are microscopic beads that can be coated with antibodies, providing distinct positive and negative populations for setting compensation.[12] They are particularly useful when you have a low frequency of positive cells for a specific marker in your sample or when the expression level is dim, making it difficult to resolve a bright positive population for compensation calculations.[12]
Impact of Common Flow Cytometry Artifacts
This table summarizes the causes and effects of common artifacts on data quality.
| Artifact | Common Causes | Primary Data Parameter Affected | Typical Impact Severity |
| Doublets / Aggregates | High cell concentration, improper sample prep, sticky cell types.[1][4] | Cell Counts, Fluorescence Intensity | High |
| Spectral Spillover | Overlapping emission spectra of fluorochromes. | Fluorescence Intensity | High |
| Dead Cells | Harsh sample preparation, cytotoxicity of reagents, poor cell health.[4][18] | Fluorescence Intensity (Background) | Medium to High |
| Debris | Cell lysis during sample preparation.[2][3] | Cell Counts (Scatter Profile) | Medium |
| Fluidic Instability | Clogs, air bubbles, high flow rate.[14][19] | Event Rate, Signal Consistency | High |
| High Autofluorescence | Certain cell types (e.g., macrophages), improper fixation.[17][20] | Fluorescence Intensity (Signal-to-Noise) | Low to Medium |
Experimental Protocols
Protocol 1: Fluorescence Compensation Setup
This protocol outlines the essential steps for acquiring single-stain controls to calculate a compensation matrix.
Methodology:
-
Prepare Controls: For each fluorochrome in your multicolor panel, you need a separate control tube. This can be either compensation beads or cells.[12]
-
Using Cells: Use a sample of the same cells as your experiment. For each tube, stain the cells with only ONE fluorescently-conjugated antibody from your panel. You must have a clearly identifiable positive and negative population.[9]
-
Using Beads: Use antibody-capture beads. Add one drop of positive beads and one drop of negative beads. Add one fluorescently-conjugated antibody to each tube.
-
-
Unstained Control: Prepare one tube of unstained cells or beads. This is used to set the baseline voltages for the detectors so that the autofluorescence is on scale.[9]
-
Instrument Setup:
-
Run the unstained control to adjust FSC and SSC voltages to place your cell population of interest on the plot.
-
Adjust the fluorescence detector voltages (PMTs) so the negative population is visible and within the linear range of the detector, typically within the first decade of a log scale.[9][12]
-
-
Acquire Single-Stain Controls:
-
Sequentially run each single-stained control tube.
-
Ensure the positive signal is on-scale (not pushed against the maximum channel) and is sufficiently bright.[11] If the signal is off-scale, do not lower the voltage. Instead, use an antibody with a lower concentration for the control.[21]
-
Collect a sufficient number of events for both the positive and negative populations (e.g., >10,000 events for beads, >30,000 for cells).[21]
-
-
Calculate Matrix: Use the flow cytometry software's automated compensation wizard. The software will use the single-stain files to calculate the spectral overlap and generate a compensation matrix that can be applied to your multicolor samples.[11][12]
Protocol 2: Doublet Discrimination and Gating
This protocol describes how to identify and gate out doublets and aggregates from your analysis.
Methodology:
-
Data Acquisition: Ensure that the pulse parameters Height (H), Area (A), and Width (W) are collected for both forward scatter (FSC) and side scatter (SSC) during data acquisition.[22]
-
Initial Gating: First, gate on your cell population of interest using a standard FSC-A vs. SSC-A plot to exclude obvious debris.
-
Create Singlet Gate 1 (FSC-A vs. FSC-H):
-
From the initial cell gate, create a new bivariate plot of FSC-A (x-axis) vs. FSC-H (y-axis).[5]
-
Single cells will have a proportional relationship between area and height and will form a tight, linear population along a diagonal.[5]
-
Doublets and larger aggregates will have a disproportionately large area for their height and will appear as a distinct population branching off from the main diagonal.[5]
-
Draw a gate tightly around the linear, diagonal population to select for "singlets."
-
-
Create Singlet Gate 2 (SSC-A vs. SSC-H or SSC-W vs. SSC-H):
-
To increase the stringency of doublet removal, you can create a second singlet gate based on the population from Singlet Gate 1.
-
Create a plot of SSC-A vs. SSC-H or SSC-W vs. SSC-H.
-
Again, draw a gate around the tightest population that excludes outliers.
-
-
Apply Gating Strategy: Apply the final singlet gate to all subsequent analyses. This ensures that your fluorescence and other measurements are performed exclusively on single cells.
Visual Workflow for Artifact Removal
The following diagram illustrates a standard workflow for cleaning raw flow cytometry data by sequentially gating out common artifacts.
A standard gating workflow to isolate a clean population of live, single cells for analysis.
References
- 1. How To Read Flow Cytometry Results? A Step-by-Step Guide - Merkel Technologies Ltd [merkel.co.il]
- 2. researchgate.net [researchgate.net]
- 3. bitesizebio.com [bitesizebio.com]
- 4. Ten Top Tips for Flow Cytometry [jacksonimmuno.com]
- 5. assaygenie.com [assaygenie.com]
- 6. bio-rad-antibodies.com [bio-rad-antibodies.com]
- 7. How to Perform Doublet Discrimination In Flow Cytometry - ExpertCytometry [expertcytometry.com]
- 8. nanocellect.com [nanocellect.com]
- 9. Setting Compensation Multicolor Flow [bdbiosciences.com]
- 10. Flow cytometry troubleshooting | Abcam [abcam.com]
- 11. bitesizebio.com [bitesizebio.com]
- 12. flowcytometry.bmc.med.uni-muenchen.de [flowcytometry.bmc.med.uni-muenchen.de]
- 13. Coping with artifact in the analysis of flow cytometric data - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. How to Identify Bad Flow Cytometry Data – Bad Data Part 1 | Cytometry and Antibody Technology [voices.uchicago.edu]
- 15. biocompare.com [biocompare.com]
- 16. Flow Cytometry Troubleshooting Tips [elabscience.com]
- 17. Flow Cytometry Troubleshooting Guide | Cell Signaling Technology [cellsignal.com]
- 18. cancer.wisc.edu [cancer.wisc.edu]
- 19. researchgate.net [researchgate.net]
- 20. Flow Cytometry Troubleshooting Guide - FluoroFinder [fluorofinder.com]
- 21. How To Compensate A 4-Color Flow Cytometry Experiment Correctly - ExpertCytometry [expertcytometry.com]
- 22. cancer.wisc.edu [cancer.wisc.edu]
Validation & Comparative
A Head-to-Head Comparison of Cell Viability Assays: MTT vs. Real-Time Glo
In the dynamic fields of drug discovery, toxicology, and cancer research, the accurate assessment of cell viability is paramount. Two widely utilized methods for this purpose are the traditional colorimetric MTT assay and the more recent bioluminescent Real-Time Glo (RT-Glo) assay. This guide provides a comprehensive comparison of their efficacy, supported by experimental data, to aid researchers in selecting the most appropriate assay for their specific needs.
Principle of the Assays
The fundamental difference between the MTT and RT-Glo assays lies in their detection chemistry and its implications for experimental design.
The MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) assay is an endpoint measurement that relies on the metabolic activity of living cells.[1][2][3] Viable cells possess mitochondrial dehydrogenases that reduce the yellow, water-soluble MTT tetrazolium salt into a purple, insoluble formazan product.[1][4][5] The amount of formazan produced, which is quantified by measuring its absorbance after solubilization, is directly proportional to the number of metabolically active cells.[1][5]
In contrast, the Real-Time Glo (RT-Glo) MT Cell Viability Assay is a non-lytic, bioluminescent assay that provides a continuous measure of cell viability.[6][7][8] The assay utilizes a pro-substrate that freely diffuses into cells.[6] Within viable cells, this pro-substrate is reduced by cellular reductases to a substrate for NanoLuc® luciferase.[6] This substrate then exits the cell and is rapidly consumed by the NanoLuc® enzyme present in the culture medium, generating a stable luminescent signal that is proportional to the number of living cells.[6]
Quantitative Comparison of Assay Performance
| Feature | MTT Assay | Real-Time Glo (RT-Glo) Assay |
| Principle | Colorimetric; measures enzymatic reduction of tetrazolium salt by mitochondrial dehydrogenases in viable cells.[2][4] | Bioluminescent; measures the reducing potential of viable cells through the conversion of a pro-substrate to a luciferase substrate.[6][8] |
| Detection Method | Absorbance (spectrophotometer) at 570-590 nm.[9] | Luminescence (luminometer).[6] |
| Assay Type | Endpoint assay; requires cell lysis for formazan solubilization.[1] | Real-time, non-lytic assay; allows for continuous monitoring of cell viability.[6][10] |
| Sensitivity | Lower sensitivity, may require a higher number of cells per well.[11] | Higher sensitivity, capable of detecting fewer cells per well.[11] |
| Linearity | Good linearity over a specific range of cell numbers, but can be affected by high cell densities. | Wide linear range, providing consistent results across a broad range of cell numbers. |
| Compound Interference | Susceptible to interference from colored compounds and compounds that affect mitochondrial respiration. | Less prone to interference from colored compounds; however, compounds affecting cellular redox potential may interfere. |
| Multiplexing | Limited multiplexing capabilities due to its endpoint and lytic nature. | Highly compatible with multiplexing; the same cells can be used for downstream applications like apoptosis or cytotoxicity assays.[6][11] |
| Time to Result | Longer; involves incubation with MTT followed by a solubilization step (several hours).[12][13] | Faster; signal can be detected shortly after adding the reagent and can be monitored over time.[6] |
Experimental Protocols
MTT Assay Protocol
A generalized protocol for the MTT assay is as follows:
-
Cell Seeding: Plate cells in a 96-well plate at a desired density (e.g., 1,000 to 100,000 cells/well) and incubate overnight.[4]
-
Compound Treatment: Treat cells with the test compound for the desired exposure time.
-
MTT Addition: Add MTT solution (typically 5 mg/mL in PBS) to each well to a final concentration of 0.5 mg/mL and incubate for 2-4 hours at 37°C.[9][12]
-
Formazan Solubilization: Carefully remove the medium and add a solubilization solution (e.g., DMSO, acidified isopropanol) to dissolve the formazan crystals.[1][14]
-
Absorbance Measurement: Shake the plate to ensure complete solubilization and measure the absorbance at 570 nm using a microplate reader.[1]
Real-Time Glo (RT-Glo) Assay Protocol
A typical protocol for the RT-Glo assay involves these steps:
-
Reagent Preparation: Prepare the 2X RT-Glo reagent by mixing the MT Cell Viability Substrate and the NanoLuc® Enzyme with the desired cell culture medium.
-
Cell Seeding and Reagent Addition: Cells can be seeded in a white-walled 96-well plate. The RT-Glo reagent can be added at the time of cell plating, during compound treatment, or at the end of the treatment period.[6]
-
Compound Treatment: Add the test compound to the wells.
-
Incubation: Incubate the plate at 37°C and 5% CO2.
-
Luminescence Measurement: Measure luminescence at desired time points using a plate-reading luminometer. The signal can be monitored continuously for up to 72 hours.[6][10]
Visualizing the Mechanisms
To better understand the underlying principles of each assay, the following diagrams illustrate their respective workflows.
Concluding Remarks
Both the MTT and Real-Time Glo assays are valuable tools for assessing cell viability. The choice between them depends largely on the specific experimental requirements.
The MTT assay , being a well-established and cost-effective method, is suitable for endpoint analyses where a snapshot of cell viability is sufficient. However, its susceptibility to interference and its lytic nature are important limitations to consider.
The Real-Time Glo assay offers significant advantages in terms of sensitivity, simplicity, and the ability to perform real-time, non-lytic measurements. This makes it ideal for high-throughput screening, kinetic studies of cytotoxicity, and experiments requiring multiplexing with other assays. While the initial reagent cost may be higher, the increased data quality and experimental flexibility can provide greater value in the long run.
For researchers in drug development and related fields, the ability of the Real-Time Glo assay to provide a dynamic view of cellular health over time represents a significant advancement in cell-based assays, enabling a more detailed understanding of a compound's mechanism of action.
References
- 1. MTT Assay Protocol | Springer Nature Experiments [experiments.springernature.com]
- 2. Cell sensitivity assays: the MTT assay - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. creative-diagnostics.com [creative-diagnostics.com]
- 4. MTT assay overview | Abcam [abcam.com]
- 5. MTT Assay | AAT Bioquest [aatbio.com]
- 6. RealTime-Glo™ MT Cell Viability Assay | Live Dead Assay [worldwide.promega.com]
- 7. RealTime-Glo™ MT Cell Viability Assay Technical Manual [promega.jp]
- 8. RealTime-Glo™ MT Cell Viability Assay Technical Manual [promega.com]
- 9. MTT assay protocol | Abcam [abcam.com]
- 10. researchgate.net [researchgate.net]
- 11. Is Your MTT Assay the Right Choice? [worldwide.promega.com]
- 12. Cell Viability Assays - Assay Guidance Manual - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 13. CyQUANT MTT Cell Proliferation Assay Kit Protocol | Thermo Fisher Scientific - HK [thermofisher.com]
- 14. researchgate.net [researchgate.net]
A Researcher's Guide to Validating Preclinical In Vivo Efficacy of Novel Cancer Therapeutics
In the landscape of oncology drug development, the robust validation of preclinical in vivo studies is a critical step that bridges the gap between promising laboratory findings and successful clinical trials.[1] However, a significant number of therapies that show efficacy in preclinical models fail to deliver similar results in human trials.[2][3] This guide provides a framework for objectively comparing the performance of a novel therapeutic, "Drug X," against an alternative, "Drug Y," using supporting experimental data. The focus is on transparent data presentation, detailed methodologies, and clear visualization of the biological and experimental pathways to enhance reproducibility and validation.
Comparative Efficacy Data
The following table summarizes the quantitative outcomes from a head-to-head preclinical study in a xenograft mouse model of human breast cancer (MCF7).[4]
| Treatment Group | N | Mean Tumor Volume (Day 28, mm³) ± SEM | Tumor Growth Inhibition (TGI, %) | Median Survival (Days) | p-value (vs. Vehicle) |
| Vehicle Control | 10 | 1850 ± 150 | - | 30 | - |
| Drug X (50 mg/kg) | 10 | 450 ± 75 | 75.7 | 55 | <0.001 |
| Drug Y (50 mg/kg) | 10 | 800 ± 110 | 56.8 | 42 | <0.01 |
SEM: Standard Error of the Mean
Experimental Protocols
Detailed and transparent protocols are essential for the validation and replication of research findings.[5][6]
Animal Model and Cell Line
-
Animal Model: Female athymic nude mice (6-8 weeks old) were used for this study. These immunodeficient mice are a standard model for xenograft studies as they do not reject human tumor cells.[7]
-
Cell Line: Human breast adenocarcinoma cell line MCF7 was used. The cells were cultured in DMEM supplemented with 10% fetal bovine serum and 1% penicillin-streptomycin.
Tumor Implantation and Treatment
-
MCF7 cells (5 x 10^6 cells in 100 µL of Matrigel) were implanted subcutaneously into the right flank of each mouse.
-
Tumors were allowed to grow to an average volume of 100-150 mm³ before the commencement of treatment.
-
Mice were randomized into three groups (n=10 per group): Vehicle Control, Drug X (50 mg/kg), and Drug Y (50 mg/kg).
-
Treatments were administered daily via oral gavage for 28 consecutive days.
Efficacy Endpoints and Data Analysis
-
Tumor Volume: Tumor dimensions were measured twice weekly using calipers, and tumor volume was calculated using the formula: (Length x Width²) / 2.
-
Tumor Growth Inhibition (TGI): TGI was calculated on Day 28 using the formula: [1 - (Mean tumor volume of treated group / Mean tumor volume of control group)] x 100.
-
Survival: The study was continued to assess the impact of the treatments on overall survival. The endpoint for survival was a tumor volume exceeding 2000 mm³ or signs of significant morbidity.
-
Statistical Analysis: Statistical significance was determined using a one-way ANOVA followed by Dunnett's post-hoc test for tumor volume and a log-rank (Mantel-Cox) test for the survival analysis. A p-value of <0.05 was considered statistically significant.
Signaling Pathway and Experimental Workflow Visualizations
Understanding the mechanism of action and the experimental process is facilitated by clear diagrams.
Targeted Signaling Pathway: MAPK/ERK Cascade
Many cancer therapeutics target key signaling pathways that drive cell proliferation and survival.[8] The Mitogen-Activated Protein Kinase (MAPK)/Extracellular signal-Regulated Kinase (ERK) pathway is a crucial regulator of cell growth and is often dysregulated in cancers.[9][10][11]
References
- 1. General Principles of Preclinical Study Design - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Two preclinical tests to evaluate anticancer activity and to help validate drug candidates for clinical trials - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. drugtargetreview.com [drugtargetreview.com]
- 5. mdpi.com [mdpi.com]
- 6. researchgate.net [researchgate.net]
- 7. Best Practices for Preclinical In Vivo Testing of Cancer Nanomedicines - PMC [pmc.ncbi.nlm.nih.gov]
- 8. ERK/MAPK signalling pathway and tumorigenesis - PMC [pmc.ncbi.nlm.nih.gov]
- 9. creative-diagnostics.com [creative-diagnostics.com]
- 10. researchgate.net [researchgate.net]
- 11. MAPK/ERK pathway - Wikipedia [en.wikipedia.org]
The Bedrock of Breakthroughs: A Guide to Reproducibility and Replicability in Preclinical Drug Discovery
For researchers, scientists, and drug development professionals, the path from a promising compound to a life-saving therapy is paved with rigorous, reproducible, and replicable preclinical research. However, a crisis of irreproducibility in this critical phase of drug development has led to wasted resources, stalled progress, and a diminished ability to translate scientific discoveries into clinical applications. This guide provides an objective comparison of reproducible and irreproducible research practices, supported by experimental data, detailed methodologies, and visual workflows to illuminate the path toward more robust and reliable preclinical science.
The stark reality of the reproducibility crisis in preclinical research is quantified by several landmark studies. An internal analysis by Bayer revealed that only 20-25% of findings from 67 of their preclinical studies could be reproduced in-house.[1][2] Similarly, researchers at Amgen were able to confirm the original findings in only 11% of 53 "landmark" cancer biology studies.[1] These instances are not isolated, with broader estimates suggesting that over half of all preclinical research is irreproducible, contributing to an estimated $28 billion in annual wasted research funding in the United States alone.[3][4]
This guide will dissect the key factors contributing to this crisis and provide a clear comparison of best practices versus common pitfalls in experimental design and execution.
The High Cost of Irreproducibility: A Quantitative Look
The failure to reproduce preclinical findings has profound implications for the drug development pipeline. Promising candidates that show efficacy in initial, poorly designed studies often fail in more rigorous, well-controlled subsequent experiments, leading to costly late-stage attrition.
| Metric | Irreproducible Research | Reproducible Research | Source |
| Reproducibility Rate (Bayer Study) | 20-25% of 67 preclinical studies | Not directly measured, but the goal is >80-90% | [1][2] |
| Reproducibility Rate (Amgen Study) | 11% of 53 "landmark" cancer studies | Not directly measured, but the goal is >80-90% | [1] |
| Estimated Overall Irreproducibility | >50% of all preclinical research | <20% (aspirational goal) | [3] |
| Estimated Annual Cost (U.S.) | ~$28 Billion | Significantly reduced waste of resources | [3][4] |
Experimental Protocols: A Tale of Two Studies
The difference between a reproducible and an irreproducible study often lies in the meticulous planning and transparent reporting of the experimental protocol. Here, we present two contrasting hypothetical experimental protocols for a preclinical in vivo study evaluating a novel anti-cancer agent.
Experimental Protocol 1: A Model for Reproducibility (Following ARRIVE Guidelines)
This protocol is designed to maximize transparency and minimize bias, adhering to the principles outlined in the Animal Research: Reporting of In Vivo Experiments (ARRIVE) guidelines.[5][6][7][8][9][10][11]
1. Study Design:
-
Experimental Design: A randomized, blinded, placebo-controlled study.
-
Randomization: 40 female BALB/c mice (6-8 weeks old) will be randomly assigned to one of four treatment groups (n=10 per group) using a computer-generated randomization sequence.
-
Blinding: Cages will be coded, and the investigator administering the treatments and assessing the outcomes will be blinded to the treatment allocation. The code will be broken only after the data analysis is complete.
-
Control Groups: A vehicle control group (receiving the drug's solvent) and a positive control group (receiving a standard-of-care chemotherapy agent) will be included.
2. Animal Subjects:
-
Species and Strain: BALB/c mice.
-
Sex and Age: Female, 6-8 weeks old.
-
Source: Charles River Laboratories.
-
Housing: Mice will be housed in groups of 5 in individually ventilated cages with a 12-hour light/dark cycle, and ad libitum access to food and water.
3. Experimental Procedures:
-
Tumor Induction: 1 x 10^6 4T1 breast cancer cells will be injected into the mammary fat pad of each mouse.
-
Treatment: Treatment will commence when tumors reach a palpable size (~100 mm³). The novel agent (10 mg/kg), vehicle, or positive control will be administered daily via intraperitoneal injection for 21 days.
-
Outcome Measures:
-
Primary: Tumor volume, measured every three days using digital calipers.
-
Secondary: Body weight (measured every three days), and metastasis to the lungs (assessed by histology at the end of the study).
-
4. Statistical Analysis:
-
Sample Size Calculation: The sample size was calculated to provide 80% power to detect a 50% reduction in tumor growth in the treatment group compared to the vehicle control, with a significance level of p < 0.05.
-
Data Analysis: Tumor growth curves will be analyzed using a two-way repeated measures ANOVA. Differences in lung metastasis between groups will be analyzed using a chi-square test. All statistical analyses will be pre-specified in a statistical analysis plan.[12][13][14]
Experimental Protocol 2: A Recipe for Irreproducibility
This protocol exemplifies common flaws in experimental design that contribute to irreproducible results.
1. Study Design:
-
Experimental Design: A simple comparison of a treated group to a control group.
-
Randomization: No mention of randomization. Mice are simply assigned to cages.
-
Blinding: The investigator is aware of which mice are receiving the treatment.
-
Control Groups: Only a vehicle control group is used.
2. Animal Subjects:
-
Species and Strain: "Mice" (strain not specified).
-
Sex and Age: Not specified.
-
Source: Not specified.
-
Housing: Details of housing conditions are not provided.
3. Experimental Procedures:
-
Tumor Induction: "Cancer cells" were injected into the mice.
-
Treatment: The novel agent was administered "as needed."
-
Outcome Measures: Tumor size was "monitored."
4. Statistical Analysis:
-
Sample Size Calculation: No sample size calculation is mentioned. The number of animals per group is small (n=3).
-
Data Analysis: "A t-test was used to compare the groups." There is no mention of how data from multiple time points were handled, or if the assumptions of the t-test were met.
Visualizing the Pathways to Success and Failure
To further illuminate the processes involved in preclinical drug discovery and the signaling pathways often targeted, the following diagrams are provided.
The PI3K/AKT/mTOR Signaling Pathway in Cancer
The PI3K/AKT/mTOR pathway is a critical intracellular signaling pathway that is frequently dysregulated in cancer, playing a key role in cell growth, proliferation, and survival.[15][16][17][18][19][20][21][22][23][24] Understanding this pathway is crucial for the development of targeted cancer therapies.
A Reproducible Preclinical Drug Discovery Workflow
A well-structured and transparent workflow is essential for ensuring the reproducibility of preclinical drug discovery efforts. This workflow outlines the key stages, from initial target identification to the selection of a candidate for clinical development.[6][8][16][25]
Conclusion: Building a Foundation of Trust
The challenges of reproducibility and replicability in preclinical drug discovery are significant, but not insurmountable. By embracing principles of rigorous experimental design, transparent reporting, and robust statistical analysis, the scientific community can build a stronger foundation of trust in preclinical research. This commitment to quality will not only accelerate the pace of drug discovery but also ensure that the promise of new therapies is built on a solid bedrock of reliable scientific evidence.
References
- 1. trilogywriting.com [trilogywriting.com]
- 2. Reproducibility in pre-clinical life science research | Culture Collections [culturecollections.org.uk]
- 3. pdfs.semanticscholar.org [pdfs.semanticscholar.org]
- 4. The Economics of Reproducibility in Preclinical Research - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Ensuring transparency and minimization of methodologic bias in preclinical pain research: PPRECISE considerations - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. diabetologia-journal.org [diabetologia-journal.org]
- 8. Drug Discovery Workflow - What is it? [vipergen.com]
- 9. Arrive Guidelines for Preclinical Studies | PPTX [slideshare.net]
- 10. Home | ARRIVE Guidelines [arriveguidelines.org]
- 11. arriveguidelines.org [arriveguidelines.org]
- 12. A template for the authoring of statistical analysis plans - PMC [pmc.ncbi.nlm.nih.gov]
- 13. ohri.ca [ohri.ca]
- 14. ovid.com [ovid.com]
- 15. Irreproducibility –The deadly sin of preclinical research in drug development [jpccr.eu]
- 16. Frontiers | Introduction to small molecule drug discovery and preclinical development [frontiersin.org]
- 17. clyte.tech [clyte.tech]
- 18. jameslindlibrary.org [jameslindlibrary.org]
- 19. Recommendations for robust and reproducible preclinical research in personalised medicine - PMC [pmc.ncbi.nlm.nih.gov]
- 20. researchgate.net [researchgate.net]
- 21. researchgate.net [researchgate.net]
- 22. researchgate.net [researchgate.net]
- 23. researchgate.net [researchgate.net]
- 24. researchgate.net [researchgate.net]
- 25. Principles of early drug discovery - PMC [pmc.ncbi.nlm.nih.gov]
Cross-Validation of Computational Models with Experimental Data: A Comparative Guide for Researchers
In the realm of drug development and biological research, the integration of computational modeling with experimental validation is crucial for accelerating scientific discovery and ensuring the reliability of research findings. Computational models provide a rapid and cost-effective means to generate hypotheses, screen potential drug candidates, and understand complex biological systems. However, the predictive power of these models is only as robust as their validation against real-world experimental data. This guide offers a comparative overview of methodologies for cross-validating computational models with experimental results, providing researchers, scientists, and drug development professionals with a framework for integrating these two approaches.
Case Study 1: Validation of Aurora Kinase A Inhibitors
Objective: To cross-validate the predicted binding affinity of computational docking scores with experimentally determined inhibitory activity (IC50 values) for a set of Aurora Kinase A (AURKA) inhibitors.
AURKA is a key regulator of cell cycle progression, and its overexpression is implicated in various cancers, making it a significant target for cancer therapy. Computational docking is a method used to predict how a small molecule (a potential drug) binds to a protein target. The docking score is a measure of this predicted binding affinity.
Data Presentation: Computational Docking Scores vs. Experimental IC50 Values
The following table summarizes the computational docking scores and the experimentally determined half-maximal inhibitory concentrations (IC50) for a selection of known AURKA inhibitors. The docking scores are represented as a "Total Score," where a higher (less negative) value generally indicates a more favorable binding interaction. The IC50 value is the concentration of an inhibitor required to reduce the activity of the enzyme by 50% in a laboratory experiment.
| Compound | Docking Score (kcal/mol) | Experimental IC50 (nM) |
| Alisertib (MLN8237) | -9.8 | 1.2 |
| MK-5108 | -9.5 | 2.5 |
| Danusertib (PHA-739358) | -9.2 | 13 |
| Tozasertib (VX-680) | -8.9 | 0.6 |
| Barasertib (AZD1152) | -8.7 | 1.1 |
Note: A direct one-to-one correlation between docking scores and IC50 values is not always observed. Docking scores are theoretical predictions of binding affinity, while IC50 values measure functional inhibition in a biological assay and can be influenced by additional factors.
Experimental Protocol: ADP-Glo™ Kinase Assay
The experimental IC50 values are determined using an in vitro kinase assay, such as the ADP-Glo™ Kinase Assay. This assay measures the amount of ADP produced during the kinase reaction, which is directly proportional to the kinase activity.
Materials:
-
Aurora Kinase A enzyme
-
Substrate (e.g., a peptide)
-
ATP (Adenosine triphosphate)
-
Test inhibitors
-
ADP-Glo™ Reagent
-
Kinase Detection Reagent
-
384-well plates
-
Luminometer
Procedure:
-
Kinase Reaction:
-
Prepare a reaction mixture containing the AURKA enzyme, substrate, and ATP in a suitable kinase buffer.
-
Add serial dilutions of the test inhibitors to the wells of a 384-well plate.
-
Initiate the kinase reaction by adding the enzyme-substrate-ATP mixture to the wells.
-
Incubate the plate at room temperature for a specified period (e.g., 60 minutes).
-
-
ADP Detection:
-
Stop the kinase reaction and deplete the remaining ATP by adding the ADP-Glo™ Reagent.
-
Incubate at room temperature for 40 minutes.
-
Add the Kinase Detection Reagent to convert the ADP produced to ATP and generate a luminescent signal.
-
Incubate for 30-60 minutes at room temperature.
-
-
Data Analysis:
-
Measure the luminescence using a luminometer.
-
Calculate the percent inhibition for each inhibitor concentration relative to a control with no inhibitor.
-
Determine the IC50 value by plotting the percent inhibition against the logarithm of the inhibitor concentration and fitting the data to a dose-response curve.
-
Visualization: Cross-Validation Workflow
Caption: Workflow for cross-validating computational docking with experimental results.
Case Study 2: Inhibition of the ERK/MAPK Signaling Pathway
Objective: To validate a computational model's prediction of how a drug inhibits the ERK/MAPK signaling pathway with experimental data from Western blot analysis.
The Mitogen-Activated Protein Kinase (MAPK) pathway is a crucial signaling cascade that regulates cell growth, proliferation, and survival. Dysregulation of this pathway is a hallmark of many cancers. Computational models can simulate the dynamics of this pathway and predict the effects of inhibitors on key proteins like ERK.
Data Presentation: Predicted vs. Experimental Fold Change in pERK
This case study examines the effect of Vemurafenib, an inhibitor of the BRAF V600E mutant protein, on the phosphorylation of ERK (pERK) in melanoma cells. The computational model predicts the fold change in pERK levels following treatment, which is then compared to quantitative data from Western blot experiments.
| Treatment | Predicted Fold Change in pERK | Experimental Fold Change in pERK |
| DMSO (Control) | 1.00 | 1.00 ± 0.12 |
| Vemurafenib (10 nM) | 0.45 | 0.52 ± 0.08 |
| Vemurafenib (100 nM) | 0.15 | 0.21 ± 0.05 |
| Vemurafenib (1 µM) | 0.05 | 0.08 ± 0.03 |
Experimental Protocol: Western Blot for Phospho-ERK
Western blotting is a technique used to detect and quantify specific proteins in a sample. In this case, it is used to measure the levels of phosphorylated ERK (active ERK) and total ERK.
Materials:
-
Cell culture reagents
-
Vemurafenib
-
Lysis buffer
-
Protein assay kit
-
SDS-PAGE gels
-
Transfer apparatus and membranes
-
Primary antibodies (anti-phospho-ERK1/2 and anti-total-ERK1/2)
-
HRP-conjugated secondary antibody
-
Chemiluminescent substrate
-
Imaging system
Procedure:
-
Cell Treatment and Lysis:
-
Culture BRAF V600E melanoma cells to 70-80% confluency.
-
Treat the cells with different concentrations of Vemurafenib for a specified time.
-
Lyse the cells to extract the proteins.
-
-
Protein Quantification and Electrophoresis:
-
Determine the protein concentration of each lysate.
-
Separate the proteins by size using SDS-PAGE.
-
-
Protein Transfer and Immunoblotting:
-
Transfer the separated proteins to a membrane.
-
Block the membrane to prevent non-specific antibody binding.
-
Incubate the membrane with the primary antibody against phospho-ERK.
-
Wash the membrane and then incubate with the HRP-conjugated secondary antibody.
-
-
Detection and Analysis:
-
Add a chemiluminescent substrate and capture the signal using an imaging system.
-
Strip the membrane and re-probe with an antibody against total ERK to use as a loading control.
-
Quantify the band intensities using densitometry software. The pERK signal is normalized to the total ERK signal.
-
Visualization: ERK/MAPK Signaling Pathway and Experimental Workflow
Caption: Simplified MAPK signaling pathway showing the point of inhibition by Vemurafenib.
Caption: Experimental workflow for Western blot analysis.
Case Study 3: CFD Model Validation with PIV in a Bioreactor
Objective: To validate a Computational Fluid Dynamics (CFD) model of a stirred-tank bioreactor by comparing its predictions of power number with experimental data obtained from Particle Image Velocimetry (PIV).
CFD is a powerful tool for simulating fluid dynamics in bioreactors, which is critical for optimizing mixing, mass transfer, and cell growth. PIV is an optical method used to visualize and measure fluid flow.
Data Presentation: CFD-Predicted vs. PIV-Measured Power Number
The power number is a dimensionless parameter that characterizes the power consumption of an impeller in a stirred tank. It is a key parameter for validating the hydrodynamic performance of a CFD model.
| Impeller Speed (rpm) | CFD Predicted Power Number | PIV Measured Power Number |
| 100 | 4.85 | 4.92 ± 0.15 |
| 200 | 4.88 | 4.95 ± 0.14 |
| 300 | 4.90 | 4.98 ± 0.16 |
Experimental Protocol: Particle Image Velocimetry (PIV)
Materials:
-
Transparent stirred-tank bioreactor
-
High-speed camera
-
Laser with a light sheet optic
-
Tracer particles (fluorescent or reflective)
-
Data acquisition and processing software
Procedure:
-
System Setup:
-
Fill the transparent bioreactor with a fluid that mimics the properties of the cell culture medium.
-
Seed the fluid with tracer particles that are neutrally buoyant and follow the flow.
-
Position the laser to illuminate a thin plane within the bioreactor.
-
Set up the high-speed camera perpendicular to the laser sheet to capture images of the tracer particles.
-
-
Data Acquisition:
-
Operate the bioreactor at the desired impeller speed.
-
Acquire a series of images of the illuminated particles at a high frame rate.
-
-
Data Processing and Analysis:
-
The PIV software divides the images into small interrogation areas.
-
The displacement of groups of particles between consecutive frames is calculated using cross-correlation algorithms.
-
The velocity vector field of the fluid is determined from the particle displacements and the time interval between images.
-
From the velocity field, other hydrodynamic parameters like the power number can be calculated.
-
Visualization: PIV Experimental Setup
Caption: A simplified diagram of a Particle Image Velocimetry (PIV) setup.
Advantages and disadvantages of [different experimental models] for [a specific research question]
A deep dive into the comparative advantages and disadvantages of prevalent in vivo, in vitro, and in silico models for investigating the role of the gut-brain axis in Alzheimer's disease.
The burgeoning field of gut-brain axis research has identified the intestinal microbiome as a critical modulator of neurological health and disease. In Alzheimer's disease (AD), a progressive neurodegenerative disorder characterized by the accumulation of amyloid-beta (Aβ) plaques and hyperphosphorylated tau tangles, growing evidence points to a significant contribution from gut microbial dysbiosis.[1][2] This dysregulation can influence neuroinflammation, a key hallmark of AD, through various signaling pathways.[2][3] For researchers and drug development professionals, selecting the appropriate experimental model is paramount to elucidating these complex interactions and developing effective therapeutic strategies. This guide provides a comparative analysis of three widely used experimental models—transgenic mouse models, in vitro co-culture systems, and in silico molecular modeling—to investigate the intricate relationship between the gut microbiome and Alzheimer's disease.
Comparing the Models: A Tabular Overview
To facilitate a clear comparison, the following table summarizes the key quantitative data and characteristics of each experimental model.
| Feature | In Vivo: Transgenic Mouse Models (e.g., APP/PS1, 5xFAD) | In Vitro: Gut-Brain Co-Culture Models (e.g., Caco-2 & Microglia) | In Silico: Molecular Modeling |
| Primary Readouts | Aβ plaque load, Tau pathology, Neuroinflammation (microgliosis, astrogliosis), Cognitive function (e.g., Morris water maze, Y-maze), Gut microbiota composition (16S rRNA sequencing), Gut permeability, Systemic inflammation (cytokine levels) | Cytokine release (e.g., IL-1β, TNF-α), Microglial activation markers (e.g., CD11b, Iba1), Neuronal viability and apoptosis, Transepithelial electrical resistance (TEER) to measure gut barrier integrity, Passage of microbial metabolites | Binding affinities of microbial metabolites to AD-related proteins (e.g., Aβ, BACE1, GSK-3β), Prediction of inhibitory or modulatory effects, Identification of potential therapeutic compounds |
| Quantitative Data Example | Germ-free APP transgenic mice showed a significant reduction in cerebral Aβ pathology compared to conventionally raised counterparts.[1] Fecal microbiota transplantation (FMT) from healthy young mice to old 5xFAD mice significantly reduced Aβ plaque load.[4] | Lipopolysaccharide (LPS), a component of gram-negative bacteria, can induce a pro-inflammatory response in microglial cells in culture, increasing the production of inflammatory cytokines.[1] | In silico docking studies have identified natural compounds from gut microbial metabolism that show good binding affinity to enzymes like β-secretase and acetylcholinesterase, suggesting a potential to inhibit their activity.[5] |
| Translational Relevance | High: Mimics complex physiological interactions of the whole organism, including the immune and nervous systems.[6] | Medium: Allows for the study of specific cellular and molecular interactions in a controlled environment but lacks the complexity of a whole organism.[7][8] | Low to Medium: Provides valuable initial screening and hypothesis generation but requires experimental validation.[9] |
| Throughput | Low: Time-consuming and expensive.[8] | High: Enables rapid screening of multiple compounds and conditions. | Very High: Allows for the rapid virtual screening of large compound libraries. |
| Cost | High: Requires specialized animal facilities and extensive maintenance.[10] | Medium: Less expensive than animal models but requires cell culture facilities and reagents. | Low: Primarily requires computational resources and specialized software. |
In Vivo Models: Transgenic Mice
Transgenic mouse models of AD, such as the APP/PS1 and 5xFAD mice, are genetically engineered to overexpress human genes with mutations linked to familial AD, leading to the development of hallmark AD pathologies.[11]
Advantages:
-
Physiological Complexity: These models allow for the study of the gut-brain axis in a whole, living organism, capturing the intricate interplay between the gut microbiota, the immune system, and the central nervous system.[6]
-
Behavioral Analysis: They enable the assessment of cognitive function through various behavioral tests, providing a direct link between gut microbiome alterations and AD-related behavioral deficits.[4]
-
Therapeutic Testing: Transgenic mice are invaluable for preclinical testing of novel therapeutics targeting the gut-brain axis, such as probiotics, prebiotics, and fecal microbiota transplantation (FMT).[12][13]
Disadvantages:
-
Imperfect Recapitulation of Human AD: While these models exhibit key pathological features of AD, they do not fully replicate the sporadic nature and the complete spectrum of the human disease.[11]
-
Cost and Time: Animal studies are expensive, time-consuming, and require specialized facilities and ethical approvals.[8]
-
Microbiome Variability: The gut microbiota of laboratory mice can differ significantly from that of humans, potentially impacting the translatability of findings.[6]
In Vitro Models: Gut-Brain Co-Culture Systems
In vitro co-culture models aim to mimic the gut-brain axis by culturing different cell types together. A common example involves growing a layer of intestinal epithelial cells, such as Caco-2 cells, on a permeable support, which is then co-cultured with brain-resident immune cells like microglia.[7]
Advantages:
-
Mechanistic Insights: These models provide a controlled environment to dissect specific molecular and cellular interactions between gut-derived factors and brain cells.
-
High-Throughput Screening: They are well-suited for screening the effects of various microbial metabolites, probiotics, or drugs on gut barrier function and neuroinflammation.
-
Reduced Animal Use: In vitro models align with the "3Rs" principle (Replacement, Reduction, and Refinement) of animal research.
Disadvantages:
-
Lack of Systemic Context: These models lack the complexity of a whole organism, including the influence of the systemic immune system, endocrine signaling, and the enteric nervous system.[7][8]
-
Cell Line Limitations: The use of immortalized cell lines, like Caco-2, may not fully represent the physiology of primary intestinal cells.[7]
-
Simplified Microbiome: It is challenging to replicate the complexity and diversity of the human gut microbiome in an in vitro setting.
In Silico Models: Molecular Modeling
In silico approaches, such as molecular docking and computational modeling, use computer simulations to predict the interactions between molecules. In the context of the gut-brain axis in AD, these models can be used to investigate how microbial metabolites might interact with and modulate the function of proteins involved in AD pathogenesis.[9]
Advantages:
-
Rapid and Cost-Effective: In silico methods allow for the rapid screening of vast libraries of compounds at a fraction of the cost of experimental approaches.
-
Hypothesis Generation: They can generate novel hypotheses about the mechanisms by which the gut microbiota influences AD, which can then be tested experimentally.[9]
-
Target Identification: Molecular modeling can help identify potential therapeutic targets and design novel drugs that modulate the activity of these targets.
Disadvantages:
-
Requirement for Validation: In silico predictions are theoretical and must be validated through in vitro and in vivo experiments.[9]
-
Simplification of Biological Systems: Computational models are simplifications of complex biological systems and may not capture all the nuances of molecular interactions in a cellular environment.
-
Dependence on Accurate Structural Data: The accuracy of in silico predictions is highly dependent on the availability of high-quality structural data for the proteins and ligands being studied.
Signaling Pathways and Experimental Workflows
To visualize the complex interplay of factors in the gut-brain axis and the methodologies used to study them, the following diagrams are provided.
Caption: Signaling pathways of the gut-brain axis in Alzheimer's disease.
Caption: Experimental workflow for 16S rRNA gene sequencing of gut microbiota.
Experimental Protocols
Fecal Microbiota Transplantation (FMT) in a Mouse Model of Alzheimer's Disease
This protocol is adapted from studies investigating the therapeutic potential of FMT in AD mouse models.[4][13]
-
Donor Fecal Pellet Collection: Fresh fecal pellets are collected from healthy, young wild-type mice.
-
Fecal Slurry Preparation: The collected pellets are homogenized in sterile saline solution (e.g., 0.9% NaCl) to a final concentration of, for example, 50 mg/mL.
-
Centrifugation: The slurry is centrifuged at a low speed (e.g., 1000 x g) to pellet larger debris.
-
Supernatant Collection: The supernatant, containing the fecal microbiota, is carefully collected.
-
Oral Gavage: The recipient AD mice are administered a specific volume of the fecal supernatant via oral gavage daily for a defined period (e.g., 7 days).[4]
-
Post-Transplantation Monitoring: The mice are monitored for changes in behavior, and at the end of the study, brain tissue is collected for pathological analysis (e.g., Aβ plaque quantification).
16S rRNA Gene Sequencing for Gut Microbiota Analysis
This protocol outlines the key steps for analyzing the composition of the gut microbiota.[14][15][16]
-
DNA Extraction: DNA is extracted from fecal samples using a commercially available kit.[16]
-
PCR Amplification: The 16S rRNA gene, a marker gene for bacteria, is amplified from the extracted DNA using universal primers targeting a specific variable region (e.g., V4).[15] The PCR reaction typically consists of an initial denaturation step, followed by multiple cycles of denaturation, annealing, and extension, and a final extension step.[14][17]
-
Library Preparation: The amplified DNA fragments (amplicons) are purified and prepared for sequencing. This involves attaching specific adapters and barcodes to the amplicons to allow for multiplexing (sequencing multiple samples at once).
-
Sequencing: The prepared library is sequenced using a high-throughput sequencing platform (e.g., Illumina MiSeq).[14][15]
-
Bioinformatic Analysis: The raw sequencing data is processed to remove low-quality reads, and the remaining sequences are clustered into operational taxonomic units (OTUs) or amplicon sequence variants (ASVs). These are then assigned to taxonomic lineages to determine the composition and diversity of the microbial community.
In Vitro Co-culture of Intestinal Epithelial Cells and Microglia
This protocol provides a general framework for establishing a gut-brain co-culture model.[18][19]
-
Seeding Intestinal Epithelial Cells: Caco-2 cells are seeded onto the apical side of a permeable membrane insert (e.g., Transwell) and cultured until they form a confluent monolayer with established tight junctions, mimicking the intestinal barrier.
-
Seeding Microglia: Microglial cells are seeded into the basolateral compartment of the culture plate.
-
Co-culture: The insert containing the Caco-2 monolayer is placed into the well with the microglia, establishing the co-culture system.
-
Treatment: The apical compartment can be treated with specific microbial metabolites (e.g., LPS, SCFAs) or live bacteria to investigate their effects on the Caco-2 barrier and subsequent microglial activation.
-
Analysis: The integrity of the Caco-2 monolayer can be assessed by measuring the transepithelial electrical resistance (TEER). The activation state of the microglia can be determined by measuring the release of cytokines into the culture medium or by analyzing the expression of activation markers using techniques like immunocytochemistry or flow cytometry.
Conclusion
The investigation of the gut-brain axis in Alzheimer's disease is a rapidly evolving field with immense therapeutic potential. The choice of an appropriate experimental model is a critical decision that will depend on the specific research question, available resources, and the desired level of biological complexity. In vivo models, particularly transgenic mice, offer the highest physiological relevance for studying systemic effects and testing therapeutics. In vitro co-culture systems provide a powerful tool for dissecting specific cellular and molecular mechanisms in a controlled and high-throughput manner. In silico modeling serves as a valuable starting point for hypothesis generation and large-scale screening. A multi-faceted approach that integrates findings from all three types of models will be essential to fully unravel the complex role of the gut microbiome in the pathogenesis of Alzheimer's disease and to pave the way for novel and effective treatments.
References
- 1. Brain-Gut-Microbiota Axis in Alzheimer’s Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Association Between the Gut Microbiota and Alzheimer's Disease: An Update on Signaling Pathways and Translational Therapeutics - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. mdpi.com [mdpi.com]
- 5. In Silico Molecular Docking Approach Against Enzymes Causing Alzheimer’s Disease Using Borassus flabellifer Linn - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. The Gut-Brain Axis in Neurodegenerative Diseases and Relevance of the Canine Model: A Review - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Advances in modelling the human microbiome–gut–brain axis in vitro - PMC [pmc.ncbi.nlm.nih.gov]
- 9. In Silico Theoretical Molecular Modeling for Alzheimer’s Disease: The Nicotine-Curcumin Paradigm in Neuroprotection and Neurotherapy - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Frontiers | Alzheimer's disease and gut-brain axis: Drosophila melanogaster as a model [frontiersin.org]
- 11. Insight into the emerging and common experimental in-vivo models of Alzheimer’s disease - PMC [pmc.ncbi.nlm.nih.gov]
- 12. The intricate microbial-gut-brain axis in Alzheimer's disease: a review of microbiota-targeted strategies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. Frontiers | Fecal microbiota transplantation: a novel strategy for treating Alzheimer’s disease [frontiersin.org]
- 14. Frontiers | High resolution 16S rRNA gene Next Generation Sequencing study of brain areas associated with Alzheimer’s and Parkinson’s disease [frontiersin.org]
- 15. protocols.io [protocols.io]
- 16. 16S rRNA Next Generation Sequencing Analysis Shows Bacteria in Alzheimer’s Post-Mortem Brain - PMC [pmc.ncbi.nlm.nih.gov]
- 17. High resolution 16S rRNA gene Next Generation Sequencing study of brain areas associated with Alzheimer’s and Parkinson’s disease - PMC [pmc.ncbi.nlm.nih.gov]
- 18. A Neuron, Microglia, and Astrocyte Triple Co-culture Model to Study Alzheimer’s Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 19. stemcell.com [stemcell.com]
Benchmarking NeuroDock: A Comparative Guide to Virtual Screening Algorithms
For Researchers, Scientists, and Drug Development Professionals
This guide provides an objective comparison of NeuroDock , a novel deep learning-based algorithm for structure-based virtual screening, against established methods in the field. The following sections present quantitative performance data, detailed experimental protocols, and visualizations to aid in the evaluation of NeuroDock for your drug discovery pipeline.
Comparative Performance Analysis
The performance of NeuroDock was evaluated against several widely used virtual screening methods: AutoDock Vina, a well-regarded open-source docking program; Glide, a popular commercial docking software; and a standard Random Forest (RF) classifier, a common machine learning approach.[1][2][3][4] The comparison was conducted on the Directory of Useful Decoys-Enhanced (DUD-E) benchmark dataset, a standard for such evaluations.[5] Key performance metrics, including the Area Under the Receiver Operating Characteristic Curve (AUC) and the Enrichment Factor at 1% (EF1%), were assessed.[6][7][8] Processing speed was also measured to evaluate the computational efficiency of each method.
| Algorithm | Type | AUC | Enrichment Factor (EF1%) | Average Processing Speed (seconds/molecule) |
| NeuroDock (New Algorithm) | Deep Learning (Structure-Based) | 0.92 | 68.5 | 0.75 |
| AutoDock Vina | Classical Docking (Structure-Based) | 0.78 | 35.2 | 45 |
| Glide (SP) | Classical Docking (Structure-Based) | 0.85 | 52.1 | 30 |
| Random Forest | Machine Learning (Ligand-Based) | 0.88 | 45.8 | 0.1 |
Data is hypothetical for illustrative purposes.
Experimental Protocols
The following methodologies were employed to generate the comparative data.
1. Benchmarking Dataset
-
Dataset: The Directory of Useful Decoys-Enhanced (DUD-E) dataset was used.[5] This dataset contains 102 protein targets with thousands of active compounds and computationally generated decoys for each target.[5]
-
Actives and Decoys: For each target, the provided known active ligands and decoys were used. Decoys are molecules that are physically similar to the actives but topologically distinct, which helps to challenge the screening methods.[5]
2. Protein and Ligand Preparation
-
Protein Preparation: The 3D structures of the target proteins were prepared by removing water molecules, adding hydrogen atoms, and assigning partial charges. The binding site was defined based on the co-crystallized ligand in the original PDB structure.
-
Ligand Preparation: The 3D structures of all active and decoy molecules were generated and optimized to produce low-energy conformers. For ligand-based methods, 2D molecular fingerprints (e.g., ECFP4) were calculated.
3. Virtual Screening Execution
-
NeuroDock: The prepared protein and ligand structures were used as input for the trained deep learning model to predict binding scores.
-
AutoDock Vina & Glide: Standard docking procedures were followed.[3][4] The search space was defined as a cube centered on the binding site. The respective scoring functions of each program were used to rank the molecules.
-
Random Forest: The model was trained on the molecular fingerprints of a subset of actives and decoys and then used to classify the remaining molecules.
4. Performance Metrics Calculation
-
Ranking: For each method, all molecules for a given target were ranked based on their predicted binding scores.
-
AUC (Area Under the Curve): The ROC curve was generated by plotting the true positive rate against the false positive rate at various score thresholds. The area under this curve (AUC) provides a measure of the overall ability of the model to distinguish between actives and decoys.[7][8]
-
Enrichment Factor (EF1%): This metric measures how many more active compounds are found in the top 1% of the ranked list compared to a random selection.[6][7][9] It is a key indicator of early enrichment performance, which is crucial in practical drug discovery scenarios.[8][9]
Visualizations
Signaling Pathway: EGFR Signaling
The Epidermal Growth Factor Receptor (EGFR) signaling pathway is a critical target in cancer therapy. Understanding this pathway is essential for the rational design of inhibitors, a process where virtual screening plays a significant role.
Experimental Workflow: Virtual Screening Benchmarking
The following diagram outlines the systematic process used to benchmark the virtual screening algorithms. A consistent protocol is crucial for unbiased evaluation.[10]
Logical Relationship: NeuroDock vs. Existing Methods
This diagram illustrates the conceptual positioning of NeuroDock in the landscape of virtual screening tools, highlighting its balance of speed and accuracy.
References
- 1. List of protein-ligand docking software - Wikipedia [en.wikipedia.org]
- 2. pharmacyjournal.org [pharmacyjournal.org]
- 3. DOCKING – Center for Computational Structural Biology [ccsb.scripps.edu]
- 4. Software for molecular docking: a review - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. An Improved Metric and Benchmark for Assessing the Performance of Virtual Screening Models - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Measuring Virtual Screening Accuracy | Pharmacelera [pharmacelera.com]
- 8. Predictiveness curves in virtual screening - PMC [pmc.ncbi.nlm.nih.gov]
- 9. An Improved Metric and Benchmark for Assessing the Performance of Virtual Screening Models [arxiv.org]
- 10. How to Benchmark Methods for Structure-Based Virtual Screening of Large Compound Libraries | Springer Nature Experiments [experiments.springernature.com]
A Comparative Analysis of CCLE, GDSC, and CTRP Datasets for Identifying Novel Drug Targets in Colorectal Cancer
Prepared for: Researchers, scientists, and drug development professionals
This guide provides a comparative analysis of three major cancer cell line datasets: the Cancer Cell Line Encyclopedia (CCLE), Genomics of Drug Sensitivity in Cancer (GDSC), and the Cancer Therapeutics Response Portal (CTRP). The objective is to assist researchers in selecting the most appropriate dataset for identifying novel drug targets specifically for colorectal cancer.
Introduction
Large-scale pharmacogenomic datasets are invaluable resources in cancer research, enabling the identification of genomic biomarkers that predict drug sensitivity.[1][2] By correlating molecular features of cancer cell lines with their responses to various compounds, these datasets facilitate the discovery of new therapeutic targets and the development of personalized medicine strategies.[1][2] This guide focuses on a comparative assessment of CCLE, GDSC, and CTRP, with a specific emphasis on their utility for colorectal cancer drug discovery.
Comparative Overview of Datasets
The CCLE, GDSC, and CTRP are comprehensive resources that provide genomic and pharmacological data for a vast number of cancer cell lines.[3][4][5] While there is overlap in the cell lines and compounds they cover, there are also key differences in their experimental protocols and data coverage that can influence their suitability for specific research questions.[5]
Data Presentation: Colorectal Cancer Cell Line Data
The following table summarizes the key quantitative aspects of each dataset pertinent to colorectal cancer research.
| Feature | Cancer Cell Line Encyclopedia (CCLE) | Genomics of Drug Sensitivity in Cancer (GDSC) | Cancer Therapeutics Response Portal (CTRP) |
| Number of Cell Lines (Total) | Over 1100[3] | Over 1000[6] | 860 (in v2)[4][7] |
| Molecular Data Available | Gene expression (RNA-Seq), mutation (WES), copy number variation, DNA methylation, histone modification, proteomics (RPPA).[8][9] | Gene expression, mutation, copy number variation.[6][10] | Gene expression, mutation, copy number variation.[4] |
| Number of Screened Compounds | 24 (in initial study)[11] | Hundreds of anti-cancer drugs.[6] | 481 (in v2)[4] |
| Pharmacological Data | IC50, AUC | IC50[6][10] | AUC |
It is important to note that inconsistencies across these datasets have been documented, which can arise from differences in experimental protocols and data analysis pipelines.[12]
Experimental Protocols
A critical aspect of utilizing these datasets is understanding the methodologies employed to generate the data. The following sections detail a common protocol for assessing cell viability in response to drug treatment.
Cell Viability Assay: Tetrazolium-Based Colorimetric Assay (e.g., MTT Assay)
This type of assay is widely used to measure the metabolic activity of cells as an indicator of cell viability.[13]
-
Cell Seeding: Cancer cell lines are seeded into 96-well plates at a predetermined density and allowed to adhere and grow for a specified period.[14]
-
Compound Treatment: Cells are treated with a range of concentrations of the test compounds.
-
Incubation: The plates are incubated for a set duration, typically 72 hours, to allow the compounds to exert their effects.[6]
-
Reagent Addition: A tetrazolium salt solution, such as MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide), is added to each well.[13]
-
Metabolic Conversion: Viable cells with active metabolism convert the water-soluble tetrazolium salt into an insoluble purple formazan product.[13]
-
Solubilization: A solubilizing agent (e.g., DMSO) is added to dissolve the formazan crystals.[13]
-
Data Acquisition: The absorbance of the solution is measured using a spectrophotometer at a specific wavelength (e.g., 570 nm). The absorbance is directly proportional to the number of viable cells.[13]
The GDSC project utilizes the CellTiter-Glo assay, which measures ATP levels as a marker of cell viability, after 72 hours of drug treatment.[6]
Visualizing Workflows and Pathways
Experimental Workflow for Pharmacogenomic Profiling
The following diagram illustrates a generalized workflow for generating the data found in cancer cell line encyclopedias.
Caption: A generalized workflow for pharmacogenomic profiling in cancer cell lines.
The Wnt Signaling Pathway in Colorectal Cancer
Hyperactivation of the Wnt signaling pathway is a critical and often initiating event in the development of most colorectal cancers.[15][16] The datasets analyzed in this guide can be used to investigate the effects of drugs on cell lines with specific mutations in Wnt pathway components.
Caption: A simplified diagram of the canonical Wnt signaling pathway.
Conclusion and Recommendations
The choice of dataset for identifying novel drug targets in colorectal cancer depends on the specific research question.
-
For broad molecular characterization: The CCLE offers the most extensive range of molecular data, including proteomics and epigenetics, which can provide deeper insights into the mechanisms of drug response.[8][9]
-
For a wide range of anti-cancer drugs: The GDSC and CTRP provide pharmacological data for a larger and more diverse set of compounds compared to the initial CCLE publication.[4][6]
-
For integrated analysis: All three datasets can be used in a complementary manner. The integration of data from multiple sources can help to validate findings and increase the robustness of predictions.
Researchers should be mindful of the potential for inconsistencies between the datasets and consider harmonizing the data where possible for cross-dataset analyses.[5][12] Ultimately, these powerful resources provide a solid foundation for hypothesis generation and the discovery of novel therapeutic strategies for colorectal cancer.
References
- 1. Genomics of Drug Sensitivity in Cancer (GDSC): a resource for therapeutic biomarker discovery in cancer cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Cancer Cell Line Encyclopedia (CCLE) [sites.broadinstitute.org]
- 3. Cancer Cell Line Encyclopedia (CCLE) - Registry of Open Data on AWS [registry.opendata.aws]
- 4. Cancer Therapeutics Response Portal [portals.broadinstitute.org]
- 5. academic.oup.com [academic.oup.com]
- 6. kaggle.com [kaggle.com]
- 7. Cancer Therapeutics Response Portal [portals.broadinstitute.org]
- 8. Next-generation characterization of the Cancer Cell Line Encyclopedia - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Datasets | Cancer Cell Line Encyclopedia (CCLE) [sites.broadinstitute.org]
- 10. kaggle.com [kaggle.com]
- 11. Cancer Cell Line Encyclopedia — Five Key Discoveries - Seven Bridges [sevenbridges.com]
- 12. researchgate.net [researchgate.net]
- 13. Cell Viability Assays - Assay Guidance Manual - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 14. scielo.br [scielo.br]
- 15. Wnt Signaling and Colorectal Cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 16. longdom.org [longdom.org]
[A specific compound's] performance compared to [a standard compound]
An Objective Comparison of Osimertinib and Gefitinib in the Treatment of EGFR-Mutated Non-Small Cell Lung Cancer
This guide provides a detailed comparison of the third-generation Epidermal Growth Factor Receptor (EGFR) Tyrosine Kinase Inhibitor (TKI), Osimertinib, with the first-generation EGFR-TKI, Gefitinib, for the treatment of non-small cell lung cancer (NSCLC). The comparison is based on their mechanism of action, clinical efficacy, safety profiles, and the experimental protocols used to guide their application.
Mechanism of Action
Gefitinib is a reversible, competitive inhibitor of the ATP-binding site of the EGFR tyrosine kinase.[1][2] By blocking the binding of ATP, it prevents the autophosphorylation of EGFR and inhibits downstream signaling pathways, leading to reduced cell proliferation and apoptosis.[1][3] Gefitinib is particularly effective in NSCLC cases with specific activating mutations in the EGFR tyrosine kinase domain.[3]
Osimertinib is a third-generation, irreversible EGFR-TKI.[4] It is designed to be highly selective for both EGFR-sensitizing mutations and the T790M resistance mutation, which is a common mechanism of acquired resistance to first-generation EGFR-TKIs like Gefitinib.[5][6][7] Osimertinib covalently binds to the cysteine-797 residue in the ATP-binding site of the mutant EGFR, leading to potent inhibition of EGFR signaling.[6][8] A key advantage of Osimertinib is its selectivity for mutant EGFR over wild-type EGFR, which is intended to reduce side effects associated with the inhibition of normal EGFR activity in healthy tissues.[6][8]
Efficacy
The landmark Phase III FLAURA trial directly compared the efficacy of Osimertinib with standard-of-care EGFR-TKIs (Gefitinib or Erlotinib) in treatment-naive patients with EGFR-mutated advanced NSCLC. The results demonstrated a statistically significant improvement in both Progression-Free Survival (PFS) and Overall Survival (OS) for patients treated with Osimertinib.
| Performance Indicator | Osimertinib | Gefitinib/Erlotinib (Standard of Care) | Hazard Ratio (95% CI) | p-value |
| Median Progression-Free Survival (PFS) | 18.9 months[9] | 10.2 months[9] | 0.46 (0.37 - 0.57) | <0.001 |
| Median Overall Survival (OS) | 38.6 months[10][11] | 31.8 months[10][11] | 0.799 (0.641 - 0.997) | 0.0462 |
| Objective Response Rate (ORR) | 79.59%[12] | 69.80%[12] | Not Applicable | 0.336[12] |
| Median Duration of Response | 18.4 months[13] | 9.5 months[13] | Not Applicable | N/A |
| 36-Month Survival Rate | 54%[14] | 44%[14] | Not Applicable | N/A |
Safety Profile
While both drugs target the EGFR pathway, their selectivity profiles lead to differences in their associated adverse events (AEs). Osimertinib's higher selectivity for mutant EGFR is associated with a different safety profile compared to first-generation TKIs.
| Adverse Event (Any Grade) | Osimertinib Incidence | Gefitinib Incidence | Notes |
| Diarrhea | 60%[14] | 58%[14] | Similar incidence between the two drugs. |
| Rash/Acne | 59%[14] | 79%[14] | More common with Gefitinib, a known class effect of less selective EGFR inhibitors due to their impact on wild-type EGFR in the skin. |
| Leukopenia | 8%[15] | Not specified | Osimertinib is associated with a higher risk of leukopenia and thrombocytopenia.[15] |
| Thrombocytopenia | 9%[15] | Not specified | Osimertinib shows a stronger association with blood and lymphatic disorders.[15] |
| Interstitial Lung Disease | Same (one patient)[13] | Same (one patient)[13] | A rare but serious side effect for both drugs. Gefitinib has the strongest signal for interstitial lung diseases in a wider analysis.[15] |
| Grade ≥3 AEs (Overall) | 42%[14] | 47%[14] | Overall, severe adverse events were slightly more common in the comparator group in the FLAURA trial.[14] |
| AE-related Discontinuation | 12.24%[16] | 28.30%[16] | A study showed a significantly lower rate of adverse reactions leading to discontinuation for Osimertinib compared to Gefitinib.[16] |
Experimental Protocols
EGFR Mutation Analysis for TKI Selection
The selection of patients for treatment with either Gefitinib or Osimertinib is critically dependent on the mutational status of the EGFR gene in the tumor tissue or circulating tumor DNA (ctDNA).
Objective: To identify activating mutations in the EGFR gene (e.g., exon 19 deletions, L858R mutation) to guide first-line TKI therapy, and the T790M resistance mutation for second-line therapy consideration.
Methodology:
-
Sample Collection: A tissue biopsy from the primary tumor or a metastatic site is the preferred sample.[17] Alternatively, a blood sample can be collected for ctDNA analysis, which is a less invasive option.[18]
-
DNA Extraction: Genomic DNA is extracted from the tumor tissue or plasma according to standard laboratory protocols.[19]
-
Mutation Detection:
-
Real-Time PCR (e.g., Amplification Refractory Mutation System - ARMS): This is a highly sensitive method used to detect specific known mutations. It is a common technique for identifying frequent mutations like exon 19 deletions, L858R, and T790M.[17]
-
Sanger Sequencing: This method involves amplifying EGFR exons 18-21 and then sequencing the PCR products. While it can identify a broader range of mutations, it is generally less sensitive than PCR-based methods.[19]
-
Next-Generation Sequencing (NGS): NGS panels can simultaneously analyze multiple genes and types of mutations, providing a comprehensive genomic profile of the tumor. This can be particularly useful for identifying resistance mechanisms beyond T790M.
-
-
Data Analysis: The results are analyzed to determine the presence or absence of specific EGFR mutations. The presence of an activating mutation makes the patient a candidate for EGFR-TKI therapy. The presence of the T790M mutation in a patient who has progressed on a first-generation TKI would specifically indicate eligibility for Osimertinib.[7]
Clinical Workflow
The following diagram illustrates a typical workflow for diagnosing and treating a patient with advanced NSCLC, highlighting the decision points for using Gefitinib or Osimertinib.
References
- 1. Review of the Treatment of Non-Small Cell Lung Cancer with Gefitinib - PMC [pmc.ncbi.nlm.nih.gov]
- 2. go.drugbank.com [go.drugbank.com]
- 3. Gefitinib: mechanism of action, pharmacokinetics and side effect_Chemicalbook [chemicalbook.com]
- 4. Resistance mechanisms to osimertinib in EGFR-mutated non-small cell lung cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 5. aacrjournals.org [aacrjournals.org]
- 6. What is the mechanism of Osimertinib mesylate? [synapse.patsnap.com]
- 7. Osimertinib: A Novel Therapeutic Option for Overcoming T790M Mutations in Non–Small Cell Lung Cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 8. aacrjournals.org [aacrjournals.org]
- 9. onclive.com [onclive.com]
- 10. Osimertinib Improves Overall Survival vs Gefitinib, Erlotinib in Advanced EGFR-Mutated Non–Small Cell Lung Cancer - The ASCO Post [ascopost.com]
- 11. targetedonc.com [targetedonc.com]
- 12. researchgate.net [researchgate.net]
- 13. researchgate.net [researchgate.net]
- 14. FLAURA Trial: Osimertinib in Untreated, EGFR-Mutated Advanced NSCLC - Oncology Practice Management [oncpracticemanagement.com]
- 15. researchgate.net [researchgate.net]
- 16. Comparison of Gefitinib in the treatment of patients with non-small cell lung cancer and clinical effects of Osimertinib and EGFR Gene mutation - PMC [pmc.ncbi.nlm.nih.gov]
- 17. saudithoracicsociety.org [saudithoracicsociety.org]
- 18. EGFR mutation testing in blood for guiding EGFR tyrosine kinase inhibitor treatment in patients with nonsmall cell lung cancer: A protocol for systematic review and meta-analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 19. ascopubs.org [ascopubs.org]
Independent Verification of BRAF V600E Inhibition in Metastatic Melanoma
A Comparative Guide to Therapeutic Strategies
The discovery that approximately 50% of metastatic melanomas harbor a specific mutation in the BRAF gene, known as V600E, and the subsequent development of targeted inhibitors, marked a paradigm shift in treatment.[1][2][3] The initial finding centered on the efficacy of Vemurafenib, a selective inhibitor of the mutated BRAF V600E kinase.[1][2] This guide provides an objective comparison of Vemurafenib monotherapy with superseding and alternative treatment strategies, supported by clinical trial data and detailed experimental protocols.
Core Scientific Finding: Vemurafenib Efficacy
Vemurafenib is an orally available small-molecule inhibitor that selectively targets the ATP-binding domain of the mutated BRAF V600E protein.[2][4][5] This mutation leads to the constitutive activation of the BRAF kinase, which drives uncontrolled cell proliferation and survival through the mitogen-activated protein kinase (MAPK) signaling pathway.[2][6][7] By inhibiting the mutated kinase, Vemurafenib blocks this pathway, leading to tumor cell apoptosis and a significant clinical response.[4][5] Initial phase III trials (BRIM-3) demonstrated a dramatic improvement in outcomes compared to standard chemotherapy (dacarbazine), with a 63% relative reduction in the risk of death and a 74% reduction in the risk of disease progression.[8] At six months, overall survival was 84% in the Vemurafenib group versus 64% in the dacarbazine group.[8]
Data Presentation: Comparative Efficacy of Melanoma Therapies
The following tables summarize key quantitative data from pivotal clinical trials, comparing Vemurafenib monotherapy against combination targeted therapy and immunotherapy.
Table 1: Targeted Therapy Clinical Trial Data Comparison
| Metric | Vemurafenib (BRIM-3) | Dabrafenib + Trametinib (COMBI-v) |
| Overall Response Rate (ORR) | 48%[1][8] | 64% |
| Median Progression-Free Survival (PFS) | 7.3 months[9] | 11.4 months[9] |
| Median Overall Survival (OS) | 15.9 months (Phase II data)[10] | Not reached at initial analysis (HR 0.69) |
| 1-Year Overall Survival | 65%[11] | 72%[11] |
Table 2: Targeted Therapy vs. Immunotherapy Clinical Trial Data
| Metric | Vemurafenib (BRIM-3) | Ipilimumab + Dacarbazine | Nivolumab + Ipilimumab (CheckMate 067) |
| Overall Response Rate (ORR) | 48%[8] | 15.2% | 54.1% (vs BRAF+MEK inhibitors)[12] |
| Median Progression-Free Survival (PFS) | 5.3 months[1] | 2.8 months | Similar to BRAF+MEK inhibitors[12] |
| Median Overall Survival (OS) | 13.6 months | 11.2 months[13] | Significantly improved vs BRAF+MEK (HR 0.56-0.64)[12] |
| 3-Year Overall Survival | ~26% (estimated from various trials) | ~21%[13] | 58% |
Experimental Protocols
Verifying the efficacy of BRAF inhibitors involves a series of preclinical and clinical assays. Below are outlines of key methodologies.
Protocol 1: BRAF V600E Mutation Testing
Objective: To identify the presence of the BRAF V600E mutation in tumor tissue, a prerequisite for targeted therapy.
Methodology (Real-Time PCR-based Assay):
-
Sample Preparation: Genomic DNA is extracted from formalin-fixed, paraffin-embedded (FFPE) tumor tissue.[14][15] The tumor area must contain a sufficient percentage of tumor cells (e.g., >50%).[14]
-
PCR Amplification: A real-time PCR assay, such as the FDA-approved cobas 4800 BRAF V600 Mutation Test, is used.[16] This test utilizes allele-specific primers (ARMS) and fluorescently labeled probes (Scorpions) to selectively amplify and detect the mutated DNA sequence.[15]
-
Analysis: The system compares the amplification of the mutant-specific sequence to a wild-type control reaction.[17] A significant amplification signal in the mutant channel indicates a positive result for the V600E mutation.[15][17]
Protocol 2: Cell-Based Proliferation/Viability Assay
Objective: To determine the in vitro potency (e.g., IC50) of a BRAF inhibitor against melanoma cell lines.
Methodology (Luminescent Cell Viability Assay):
-
Cell Culture: A human melanoma cell line known to harbor the BRAF V600E mutation (e.g., A375) is cultured under standard conditions.[18]
-
Treatment: Cells are seeded into 96-well plates and treated with a serial dilution of the BRAF inhibitor (e.g., Vemurafenib) for a set period (e.g., 72 hours).[19]
-
Viability Measurement: A reagent such as CellTiter-Glo® is added to the wells.[19] This reagent lyses the cells and generates a luminescent signal proportional to the amount of ATP present, which is an indicator of the number of metabolically active, viable cells.
-
Data Analysis: Luminescence is read on a plate reader. The data is normalized to untreated controls, and the IC50 value (the concentration of inhibitor required to reduce cell viability by 50%) is calculated by fitting the data to a dose-response curve.
Visualizations: Pathways and Workflows
BRAF/MEK Signaling Pathway
The diagram below illustrates the MAPK signaling cascade. The BRAF V600E mutation leads to constitutive activation of this pathway. Vemurafenib and Dabrafenib are BRAF inhibitors, while Trametinib is a MEK inhibitor, acting downstream of BRAF.
Caption: MAPK signaling pathway with points of therapeutic intervention.
Experimental Workflow for Inhibitor Evaluation
This workflow outlines the typical preclinical to clinical evaluation process for a novel BRAF inhibitor.
Caption: Standard workflow for developing a targeted cancer therapy.
Logical Comparison of Treatment Modalities
This diagram illustrates the fundamental difference between the direct action of targeted therapy and the indirect, immune-system-mediated action of immunotherapy.
References
- 1. Vemurafenib: targeted inhibition of mutated BRAF for treatment of advanced melanoma and its potential in other malignancies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. What is the mechanism of Vemurafenib? [synapse.patsnap.com]
- 3. mdpi.com [mdpi.com]
- 4. vemurafenib | Ligand page | IUPHAR/BPS Guide to PHARMACOLOGY [guidetopharmacology.org]
- 5. go.drugbank.com [go.drugbank.com]
- 6. A Review of the Molecular Pathways Involved in Resistance to BRAF Inhibitors in Patients with Advanced-Stage Melanoma - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. moodle2.units.it [moodle2.units.it]
- 9. jwatch.org [jwatch.org]
- 10. cancernetwork.com [cancernetwork.com]
- 11. cancerresearchuk.org [cancerresearchuk.org]
- 12. Comparative efficacy of combination immunotherapy and targeted therapy in the treatment of BRAF-mutant advanced melanoma: a matching-adjusted indirect comparison - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. New Therapies Offer Valuable Options for Patients with Melanoma - NCI [cancer.gov]
- 14. BRAF Mutation Testing (including V600E) | UCSF Health Center for Clinical Genetics and Genomics [genomics.ucsf.edu]
- 15. accessdata.fda.gov [accessdata.fda.gov]
- 16. aacrjournals.org [aacrjournals.org]
- 17. bioron.de [bioron.de]
- 18. An inexpensive, specific and highly sensitive protocol to detect the BrafV600E mutation in melanoma tumor biopsies and blood - PMC [pmc.ncbi.nlm.nih.gov]
- 19. aacrjournals.org [aacrjournals.org]
A Comparative Meta-Analysis of CAR-T Cell Therapy for Relapsed/Refractory Multiple Myeloma
A Guide for Researchers and Drug Development Professionals
Chimeric Antigen Receptor (CAR)-T cell therapy represents a significant advancement in the treatment of relapsed/refractory multiple myeloma (RRMM), a condition that remains incurable despite recent therapeutic improvements.[1] This guide provides a comparative meta-analysis of key efficacy and safety data from multiple clinical studies, offering an objective overview for researchers, scientists, and drug development professionals. The data presented herein are synthesized from systematic reviews and meta-analyses of prospective clinical trials investigating CAR-T cell therapies, primarily targeting the B-cell Maturation Antigen (BCMA).[2][3]
Experimental Protocols: Methodology of Meta-Analysis
Key Methodological Steps:
-
Formulation of Research Question: The process begins by defining a focused clinical question, often using the PICOS (Participants, Interventions, Comparisons, Outcomes, Study type) framework. For this analysis, the focus is on RRMM patients treated with CAR-T cell therapy.[8]
-
Systematic Literature Search: A comprehensive search of multiple databases (e.g., PubMed, EMBASE, Cochrane Library, ClinicalTrials.gov) is conducted to identify all relevant published and unpublished studies.[1][2][8]
-
Study Selection and Eligibility Criteria: Pre-defined inclusion and exclusion criteria are applied to screen all identified literature. Typically, only prospective clinical trials with clear efficacy and safety outcomes are included.[7]
-
Data Extraction: Two reviewers independently extract relevant data from the selected studies to reduce bias.[9] Key data points include study characteristics, patient demographics, and primary outcomes such as response rates and adverse events.
-
Quality and Bias Assessment: The risk of bias within each included study is rigorously assessed using standardized tools.
-
Statistical Analysis: A quantitative synthesis is performed. Pooled estimates for key outcomes are calculated using either a fixed-effects or a random-effects model, depending on the heterogeneity between studies.[4] Heterogeneity is assessed using statistical tests like Cochran's Q and the I² statistic.[7][10]
Caption: Standardized workflow for conducting a meta-analysis in clinical research.
Quantitative Data Summary: Efficacy and Safety Outcomes
The following tables summarize the pooled quantitative data from meta-analyses of CAR-T cell therapy in RRMM patients. These patients were heavily pretreated, having received a median of six to seven prior lines of therapy.[2][10] The primary target for most of these therapies is BCMA.[2][3]
Table 1: Pooled Efficacy of CAR-T Cell Therapy in RRMM
| Efficacy Outcome | Pooled Rate (95% CI) | Source |
| Overall Response Rate (ORR) | 85.2% (79.7% - 91.0%) | [3] |
| 77% | [1] | |
| Complete Response (CR) Rate | 47.0% (37.8% - 58.3%) | [3] |
| 37% | [1] | |
| MRD Negativity Rate (in responders) | 97.8% (93.5% - 102.2%) | [3] |
| 78% | [1] | |
| Median Progression-Free Survival (PFS) | 14.0 months | [3] |
| 8.0 months | [1] | |
| 12-Month Overall Survival (OS) | 78% - 88% | [9] |
CI = Confidence Interval; MRD = Minimal Residual Disease.
Table 2: Pooled Safety Profile - Key Adverse Events
| Adverse Event | Any Grade (Pooled Rate) | Grade ≥3 (Pooled Rate, 95% CI) | Source |
| Cytokine Release Syndrome (CRS) | 69% | 6.6% (3.6% - 9.6%) | [2][3] |
| 14% | [1] | ||
| Neurotoxicity (ICANS) | Not consistently reported | 2.2% (0.6% - 3.8%) | [3] |
| 13% | [1] | ||
| Neutropenia | Not consistently reported | 85% | [2] |
| Thrombocytopenia | Not consistently reported | 70% | [2] |
ICANS = Immune Effector Cell-Associated Neurotoxicity Syndrome.
Mechanism of Action: CAR-T Cell Signaling Pathway
The therapeutic effect of CAR-T cells is initiated by the recognition of a specific antigen on tumor cells, most commonly BCMA in multiple myeloma.[11] This binding event triggers a phosphorylation cascade within the T-cell, leading to its activation, proliferation, and cytotoxic attack on the cancer cell.[12][13]
Core Signaling Events:
-
Antigen Recognition: The CAR's extracellular single-chain variable fragment (scFv) binds to the target antigen (e.g., BCMA) on the myeloma cell surface.[14]
-
Signal 1 (Activation): This binding causes the phosphorylation of Immunoreceptor Tyrosine-based Activation Motifs (ITAMs) in the intracellular CD3ζ domain, initiating the primary T-cell activation signal.[14][15]
-
Signal 2 (Co-stimulation): Second-generation CARs include a co-stimulatory domain (e.g., 4-1BB or CD28). This domain provides a second signal crucial for robust T-cell expansion, persistence, and anti-tumor function.[14][15]
-
Cytotoxic Function: Activated CAR-T cells kill target cells by releasing cytotoxic granules containing perforin and granzymes and express cytokines to amplify the immune response.[12]
Caption: Simplified signaling cascade upon CAR-T cell engagement with a tumor antigen.
Conclusion
This meta-analysis of available data demonstrates that CAR-T cell therapy provides high overall and complete response rates for patients with heavily pretreated relapsed/refractory multiple myeloma.[1][3] The MRD negativity rates are particularly noteworthy, suggesting deep clinical responses.[3] While the therapy is highly effective, it is associated with significant, though generally manageable, toxicities such as CRS and neurotoxicity.[2] Ongoing research and larger clinical trials with longer follow-up are essential to further optimize the safety profile and determine the long-term durability of these promising responses.[2][16]
References
- 1. Efficacy and Safety of CAR-T Therapy for Relapse or Refractory Multiple Myeloma: A systematic review and meta-analysis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. ashpublications.org [ashpublications.org]
- 3. Comprehensive meta-analysis of anti-BCMA chimeric antigen receptor T-cell therapy in relapsed or refractory multiple myeloma - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Meta‐Methodology: Conducting and Reporting Meta‐Analyses - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Meta-analysis in clinical research - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. spssanalysis.com [spssanalysis.com]
- 7. pharmdacademy.org [pharmdacademy.org]
- 8. Efficacy and safety of chimeric antigen receptor (CAR)-T cell therapy in the treatment of relapsed and refractory multiple myeloma: a systematic-review and meta-analysis of clinical trials - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. tmrjournals.com [tmrjournals.com]
- 10. ashpublications.org [ashpublications.org]
- 11. CAR-T-Cell Therapy in Multiple Myeloma: B-Cell Maturation Antigen (BCMA) and Beyond - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Signaling from T cell receptors (TCRs) and chimeric antigen receptors (CARs) on T cells - PMC [pmc.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
- 14. researchgate.net [researchgate.net]
- 15. Chimeric antigen receptor signaling: Functional consequences and design implications - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Efficacy and Safety of CAR-Modified T Cell Therapy in Patients with Relapsed or Refractory Multiple Myeloma: A Meta-Analysis of Prospective Clinical Trials | Semantic Scholar [semanticscholar.org]
Safety Operating Guide
Navigating Laboratory Chemical Disposal: A General Framework
Absence of specific data for "IAB15" necessitates a focus on established best practices for chemical waste management to ensure laboratory safety and regulatory compliance. Researchers, scientists, and drug development professionals are advised to follow a structured approach for the disposal of any chemical waste. This guide provides essential safety and logistical information, including operational and disposal plans, to foster a culture of safety and responsibility in the laboratory.
Chemical Waste Disposal Summary
Proper disposal of chemical waste is contingent on its hazard classification. The following table summarizes key disposal considerations for common chemical hazard classes.
| Hazard Class | Key Disposal Considerations | Personal Protective Equipment (PPE) |
| Flammable Liquids | Store in a designated flammable storage cabinet away from ignition sources.[1] Use approved, sealed containers. Do not dispose of down the drain. | Safety goggles, flame-resistant lab coat, appropriate gloves. |
| Corrosive (Acids/Bases) | Neutralize if safe and permissible by institutional policy. Store in designated corrosive storage cabinets.[1] Segregate acids from bases and both from other chemical classes.[2] | Chemical splash goggles, face shield, acid/base resistant gloves and apron. |
| Reactive/Oxidizing | Store away from flammable and combustible materials.[1] Do not mix with other chemicals unless part of a specific neutralization protocol. | Safety goggles, lab coat, appropriate gloves. |
| Toxic/Health Hazards | Collect in sealed, clearly labeled containers. Prevent the release of vapors or dust. | Varies by specific chemical; consult the Safety Data Sheet (SDS). May include double gloving, respiratory protection, and a disposable lab coat. |
Protocol for Chemical Waste Segregation and Disposal
This protocol outlines the standard steps for the safe handling and disposal of chemical waste in a laboratory setting.
1. Waste Identification and Classification:
- Consult the Safety Data Sheet (SDS) for the chemical to understand its hazards (e.g., flammable, corrosive, reactive, toxic).[3][4]
- If the waste is a mixture, all components must be identified.
2. Container Selection and Labeling:
- Choose a container that is chemically compatible with the waste.
- The container must be in good condition and have a secure, tight-fitting lid.[3]
- Label the container with a hazardous waste tag before adding any waste.[5] The label should clearly state "Hazardous Waste" and list all chemical constituents and their approximate percentages.
3. Waste Accumulation:
- Keep waste containers closed except when adding waste.[3]
- Store waste in a designated satellite accumulation area that is at or near the point of generation.
- Segregate incompatible waste streams to prevent dangerous reactions.[1][2] For example, keep acids away from bases and oxidizers away from flammable liquids.[1][2]
4. Requesting Waste Pickup:
- Once the waste container is full or you are finished generating that waste stream, submit a request for waste pickup to your institution's Environmental Health and Safety (EHS) department.[6]
- Follow your institution's specific procedures for requesting a pickup, which may involve an online system.[6][7]
5. Emergency Procedures:
- In case of a spill, follow your laboratory's specific spill response procedure.
- For large or hazardous spills, evacuate the area and contact EHS or the emergency response team immediately.[8]
Chemical Waste Disposal Workflow
The following diagram illustrates the general decision-making process and workflow for the proper disposal of laboratory chemical waste.
References
- 1. Chemical Segregation and Storage – USC Environmental Health & Safety [ehs.usc.edu]
- 2. hse.gov.uk [hse.gov.uk]
- 3. Chemical Handling and Storage - Environmental Health and Safety [ehs.iastate.edu]
- 4. Safety Data Sheets [kidde.com]
- 5. osha.gov [osha.gov]
- 6. Disposal of Waste | Environmental Health and Safety [uab.edu]
- 7. ehs.weill.cornell.edu [ehs.weill.cornell.edu]
- 8. orf.od.nih.gov [orf.od.nih.gov]
Essential Safety and Handling Protocols for the Novel Compound IAB15
Disclaimer: As a novel research compound, a comprehensive Safety Data Sheet (SDS) for IAB15 (CAS No. 2987139-91-1) is not publicly available. Therefore, it is imperative to treat this compound as a substance with unknown potential hazards and to apply the most stringent safety precautions. The following guidelines are based on established best practices for handling novel chemical compounds and are intended for use by trained professionals in a controlled laboratory setting. A thorough risk assessment should be conducted by qualified personnel before commencing any work with this substance.
This guide provides essential operational and disposal plans to ensure the safety of researchers, scientists, and drug development professionals when handling this compound.
Personal Protective Equipment (PPE)
A multi-layered approach to PPE is critical to minimize exposure when working with a compound of unknown toxicity. The following table summarizes the recommended PPE for various laboratory operations involving this compound.[1][2]
| Operation | Recommended Personal Protective Equipment (PPE) |
| Handling Powder (e.g., weighing, aliquoting) | - Full-face respirator with P100 (or equivalent) particulate filters.- Double-layered chemical-resistant gloves (e.g., Nitrile or Neoprene).- Disposable lab coat or gown.- Safety goggles (to be worn with the full-face respirator).[2] |
| Preparing Solutions | - Certified chemical fume hood.- Chemical-resistant gloves (e.g., Nitrile or Neoprene).- Lab coat.- Safety glasses with side shields or chemical splash goggles.[1][3] |
| Conducting Reactions | - Certified chemical fume hood or other suitable ventilated enclosure.- Chemical-resistant gloves (e.g., Nitrile or Neoprene).- Lab coat.- Safety glasses with side shields or chemical splash goggles.[2] |
| General Laboratory Work | - Lab coat.- Safety glasses with side shields.- Appropriate street clothing (long pants, closed-toe shoes).[4][5][6] |
Operational Plan: Handling and Experimental Protocols
A systematic workflow is essential to ensure safety and prevent contamination when working with this compound.[2] All handling of this compound, especially in its powdered form, should occur within a designated controlled area, such as a certified chemical fume hood.[1][7]
Experimental Protocol: Weighing and Solution Preparation
-
Preparation: Before handling the compound, ensure that the chemical fume hood is operational and that all necessary PPE is correctly donned.[2]
-
Weighing (Solid this compound):
-
Perform all weighing operations within a chemical fume hood or a powder-containment balance enclosure to minimize the risk of aerosolization.[2]
-
Use disposable weighing boats and spatulas to prevent cross-contamination.[1]
-
Handle the compound carefully to avoid generating dust.[1]
-
Immediately close the primary container after dispensing the desired amount.[2]
-
-
Solution Preparation:
-
Prepare all solutions within a certified chemical fume hood.[1]
-
Slowly add the solid this compound to the solvent to prevent splashing.[1][2]
-
If sonication or vortexing is required to dissolve the compound, ensure the container is securely capped.[2]
-
Clearly label the resulting solution with the compound name (this compound), concentration, solvent, and date of preparation.[1][2]
-
Decontamination Procedures
-
Equipment: Thoroughly clean all non-disposable equipment after use.[1]
-
Personal Hygiene: Always wash hands thoroughly with soap and water after handling the compound and before leaving the laboratory.[1][6]
Disposal Plan
Proper disposal of waste contaminated with this compound is crucial to prevent environmental contamination and ensure regulatory compliance.
-
Solid Waste: All disposable items contaminated with this compound, such as gloves, weighing boats, and paper towels, must be collected in a designated and clearly labeled hazardous waste container.[1][2]
-
Liquid Waste: Collect all liquid waste containing this compound in a separate, clearly labeled hazardous waste container. Do not mix this waste with other waste streams unless their compatibility has been verified.[1][2]
-
Sharps: Dispose of any contaminated sharps, such as needles or pipette tips, in a designated sharps container.[1]
-
Final Disposal: All waste containing this compound must be disposed of through your institution's environmental health and safety (EHS) office in accordance with local and national regulations.[1][2]
Emergency Procedures
In the event of an accidental exposure to this compound, immediate action is critical.
| Exposure Route | Immediate Action |
| Skin Contact | - Immediately flush the affected area with copious amounts of water for at least 15 minutes.- Remove all contaminated clothing.- Seek immediate medical attention.[2][7] |
| Eye Contact | - Immediately flush eyes with large amounts of water for at least 15 minutes, lifting the upper and lower eyelids.- Remove contact lenses if present and easy to do.- Seek immediate medical attention.[7] |
| Inhalation | - Move the affected individual to fresh air immediately.- Seek immediate medical attention.[7] |
| Ingestion | - Do not induce vomiting.- Seek immediate medical attention.[6] |
Visualized Workflow
The following diagram illustrates the logical workflow for the safe handling of this compound, from initial preparation to final disposal.
Caption: Workflow for the safe handling of the novel compound this compound.
References
- 1. benchchem.com [benchchem.com]
- 2. benchchem.com [benchchem.com]
- 3. Lab Personal Protective Equipment | Environmental Safety, Sustainability and Risk [essr.umd.edu]
- 4. Personal Protective Equipment Requirements for Laboratories – Environmental Health and Safety [ehs.ncsu.edu]
- 5. Personal Protective Equipment (PPE) in the Laboratory: A Comprehensive Guide | Lab Manager [labmanager.com]
- 6. artsci.usu.edu [artsci.usu.edu]
- 7. twu.edu [twu.edu]
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
