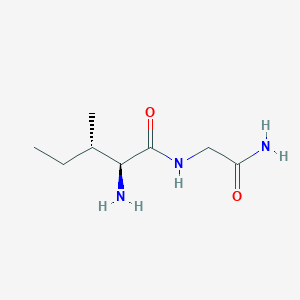
L-Isoleucylglycinamide
Description
Structure
3D Structure
Properties
CAS No. |
62307-15-7 |
|---|---|
Molecular Formula |
C8H17N3O2 |
Molecular Weight |
187.24 g/mol |
IUPAC Name |
(2S,3S)-2-amino-N-(2-amino-2-oxoethyl)-3-methylpentanamide |
InChI |
InChI=1S/C8H17N3O2/c1-3-5(2)7(10)8(13)11-4-6(9)12/h5,7H,3-4,10H2,1-2H3,(H2,9,12)(H,11,13)/t5-,7-/m0/s1 |
InChI Key |
OVQWCOOFHSLVEE-FSPLSTOPSA-N |
Isomeric SMILES |
CC[C@H](C)[C@@H](C(=O)NCC(=O)N)N |
Canonical SMILES |
CCC(C)C(C(=O)NCC(=O)N)N |
Origin of Product |
United States |
Synthetic Methodologies and Derivative Chemistry of L Isoleucylglycinamide
Advanced Strategies for L-Isoleucylglycinamide Synthesis
The synthesis of L-Isoleucylglycinamide involves the formation of a peptide bond between L-isoleucine and glycinamide (B1583983). This process requires careful control of protecting groups and coupling conditions to ensure high yield and stereochemical purity.
Solid-Phase Peptide Synthesis (SPPS) Protocols and Optimizations
Solid-phase peptide synthesis (SPPS) is a cornerstone of modern peptide chemistry, offering a streamlined approach to the synthesis of peptides like L-Isoleucylglycinamide. The process involves assembling the peptide chain on a solid support, which simplifies purification by allowing for the removal of excess reagents and by-products through simple filtration and washing steps. google.com
For the synthesis of a peptide with a C-terminal amide, a suitable resin such as Rink amide resin is typically employed. uci.edu The synthesis commences with the deprotection of the 9-fluorenylmethoxycarbonyl (Fmoc) group from the resin, commonly achieved using a 20% solution of piperidine (B6355638) in a solvent like N,N-dimethylformamide (DMF). uci.edu
The subsequent coupling of Fmoc-L-isoleucine is a critical step. Due to the steric hindrance of the isoleucine side chain, efficient coupling reagents are necessary. A common and effective method involves the use of activators like O-(Benzotriazol-1-yl)-N,N,N',N'-tetramethyluronium hexafluorophosphate (B91526) (HBTU) or O-(7-Azabenzotriazol-1-yl)-N,N,N',N'-tetramethyluronium hexafluorophosphate (HATU) in the presence of a base such as N,N-diisopropylethylamine (DIPEA). bachem.com The use of an additive like 1-hydroxybenzotriazole (B26582) (HOBt) or 1-hydroxy-7-azabenzotriazole (B21763) (HOAt) can further enhance coupling efficiency and minimize side reactions. americanpeptidesociety.org
The final step in SPPS is the cleavage of the completed dipeptide from the resin and the simultaneous removal of any side-chain protecting groups. This is typically accomplished by treating the resin-bound peptide with a strong acid cocktail, such as a mixture of trifluoroacetic acid (TFA), water, and a scavenger like triisopropylsilane (B1312306) (TIS) to prevent side reactions. sigmaaldrich.com
Table 1: Representative Protocol for Solid-Phase Synthesis of L-Isoleucylglycinamide
| Step | Procedure | Reagents/Solvents | Typical Duration |
| 1. Resin Swelling | Swell Rink amide resin in a suitable solvent. | DMF or Dichloromethane (DCM) | 30-60 min |
| 2. Fmoc Deprotection | Remove the Fmoc group from the resin. | 20% piperidine in DMF | 20-30 min |
| 3. Washing | Wash the resin to remove piperidine and by-products. | DMF, DCM | 5 x 1 min |
| 4. Coupling | Couple Fmoc-L-isoleucine to the deprotected resin. | Fmoc-L-isoleucine, HBTU/HATU, DIPEA, HOBt/HOAt in DMF | 1-2 hours |
| 5. Washing | Wash the resin to remove excess reagents. | DMF, DCM | 5 x 1 min |
| 6. Final Fmoc Deprotection | Remove the Fmoc group from the N-terminal isoleucine. | 20% piperidine in DMF | 20-30 min |
| 7. Washing | Wash the resin thoroughly. | DMF, DCM | 5 x 1 min |
| 8. Cleavage | Cleave the dipeptide from the resin. | TFA/TIS/H₂O (e.g., 95:2.5:2.5) | 2-3 hours |
| 9. Isolation | Precipitate the crude peptide in cold diethyl ether. | Diethyl ether | - |
Solution-Phase Synthetic Routes and Their Applicability
Solution-phase peptide synthesis, while often more labor-intensive than SPPS, offers advantages for large-scale production and for the synthesis of complex or modified peptides. ekb.eg In this approach, all reactions are carried out in a homogeneous solution, and intermediates are isolated and purified after each step. nih.gov
A common strategy for the solution-phase synthesis of L-Isoleucylglycinamide would involve the coupling of an N-terminally protected L-isoleucine derivative (e.g., Boc-L-isoleucine) with glycinamide hydrochloride. The carboxyl group of the protected isoleucine is activated using a coupling reagent like dicyclohexylcarbodiimide (B1669883) (DCC) or 1-ethyl-3-(3-dimethylaminopropyl)carbodiimide (B157966) (EDC), often in the presence of an additive like HOBt to improve efficiency and reduce racemization. americanpeptidesociety.orgpeptide.com The reaction is typically carried out in an organic solvent such as DCM or THF. peptide.com
Following the coupling reaction, the protected dipeptide is isolated, often through extraction and crystallization. The protecting group (e.g., Boc) is then removed under appropriate conditions (e.g., treatment with an acid like TFA) to yield the final L-Isoleucylglycinamide. nih.gov
Protecting Group Chemistry and Deprotection Techniques
The selection of appropriate protecting groups is crucial in peptide synthesis to prevent unwanted side reactions. For the synthesis of L-Isoleucylglycinamide, the primary amino group of L-isoleucine must be protected during the coupling step.
Commonly used N-terminal protecting groups include:
Fmoc (9-fluorenylmethoxycarbonyl): This is the standard protecting group for SPPS due to its base-lability. It is typically removed with a solution of piperidine in DMF. uci.edu
Boc (tert-butyloxycarbonyl): Often used in solution-phase synthesis and in Boc-based SPPS, this group is stable to many reaction conditions but is readily cleaved by strong acids like TFA. nih.gov
Z (Benzyloxycarbonyl): Another acid-labile group, it can be removed by catalytic hydrogenation or with strong acids.
Stereochemical Fidelity and Epimerization Control During Synthesis
Maintaining the stereochemical integrity of the chiral center in L-isoleucine is a significant challenge during peptide synthesis. Epimerization, the conversion of the L-isomer to the D-isomer, can occur at the α-carbon, particularly during the activation of the carboxyl group. nih.gov Sterically hindered amino acids like isoleucine are particularly susceptible to this side reaction. u-tokyo.ac.jp
Several strategies are employed to minimize epimerization:
Choice of Coupling Reagent: Uronium/aminium-based reagents like HBTU and HATU, when used with additives like HOBt or HOAt, are generally preferred over carbodiimides alone as they can suppress racemization. bachem.com
Reaction Conditions: Performing the coupling reaction at low temperatures can significantly reduce the rate of epimerization. u-tokyo.ac.jp The choice of solvent is also critical, with polar aprotic solvents like DMF sometimes increasing the risk of epimerization compared to less polar solvents like DCM. u-tokyo.ac.jp
Use of Additives: Additives like HOBt and HOAt react with the activated amino acid to form an active ester intermediate, which is less prone to racemization than the initial activated species. americanpeptidesociety.org The addition of copper(II) chloride (CuCl₂) has also been reported to suppress epimerization in certain coupling reactions. peptide.com
Isolation and Purity Assessment of Synthetic L-Isoleucylglycinamide
After synthesis, the crude L-Isoleucylglycinamide must be purified to remove by-products, unreacted starting materials, and any epimerized diastereomers. The most common method for the purification of peptides is Reversed-Phase High-Performance Liquid Chromatography (RP-HPLC) . nih.gov
In RP-HPLC, the crude peptide mixture is passed through a column containing a nonpolar stationary phase (typically C18-silica). A gradient of increasing organic solvent (e.g., acetonitrile) in an aqueous mobile phase (often containing 0.1% TFA as an ion-pairing agent) is used to elute the components. nih.gov The more hydrophobic the molecule, the longer it is retained on the column. The purity of the collected fractions is then assessed by analytical RP-HPLC.
The identity and purity of the final product are confirmed using analytical techniques such as:
Mass Spectrometry (MS): To verify the molecular weight of the dipeptide.
Nuclear Magnetic Resonance (NMR) Spectroscopy: To confirm the structure and stereochemistry of the molecule.
Table 2: Representative RP-HPLC Conditions for L-Isoleucylglycinamide Purification
| Parameter | Condition |
| Column | C18, 5 µm particle size, 100 Å pore size |
| Mobile Phase A | 0.1% TFA in Water |
| Mobile Phase B | 0.1% TFA in Acetonitrile (B52724) |
| Gradient | e.g., 5% to 50% B over 30 minutes |
| Flow Rate | 1.0 mL/min (analytical) or higher (preparative) |
| Detection | UV at 214 nm and 280 nm |
Rational Design and Preparation of L-Isoleucylglycinamide Derivatives
The chemical structure of L-Isoleucylglycinamide can be systematically modified to create derivatives with altered physicochemical properties or biological activities. This rational design approach is fundamental in medicinal chemistry and drug discovery.
One common strategy is the N-acylation of the N-terminal amino group of isoleucine. By introducing various acyl groups (e.g., fatty acids), the lipophilicity of the dipeptide can be modulated. This can be achieved by reacting L-Isoleucylglycinamide with an activated carboxylic acid (such as an acyl chloride or an active ester) under basic conditions. The synthesis of such N-acyl derivatives can be accomplished through both chemical and enzymatic methods. nih.gov For instance, N-lauroyl-L-glutamic acid is a commercially available N-acylated amino acid derivative. nih.gov
Another approach involves the creation of prodrugs . For example, the C-terminal amide or the N-terminal amine could be modified with a promoiety that is cleaved in vivo to release the active dipeptide. Lipid moieties can be attached to create lipid-based prodrugs, potentially enhancing absorption and altering distribution. nih.gov
The synthesis of these derivatives generally follows the fundamental principles of peptide chemistry, utilizing protecting groups and coupling reagents to selectively form the desired bonds while preserving the stereochemistry of the parent molecule. The specific synthetic route would be tailored based on the nature of the desired modification.
Structure-Guided Design Principles for Analogues and Mimetics
The design of analogues and mimetics of L-Isoleucylglycinamide is fundamentally based on understanding the structure-activity relationships (SAR) that govern its biological effects. While specific SAR studies on L-Isoleucylglycinamide are not extensively documented in publicly available literature, the principles of peptidomimetic design can be applied. The core strategy involves modifying the parent structure to enhance properties such as metabolic stability, receptor affinity, and bioavailability, while maintaining or improving its desired biological activity.
Key modifications often focus on several areas of the molecule:
The Isoleucine Side Chain: The bulky, hydrophobic sec-butyl side chain of isoleucine is a critical determinant of its interaction with biological targets. Analogues can be designed with altered alkyl groups to probe the size and steric requirements of the binding pocket. For instance, replacing the sec-butyl group with smaller (e.g., valine) or larger, more complex hydrophobic moieties could modulate binding affinity and selectivity.
The Peptide Bond: The amide bond between isoleucine and glycine (B1666218) is susceptible to enzymatic cleavage by proteases. To create more stable analogues, this bond can be replaced with non-hydrolyzable isosteres, such as a reduced amide bond (ψ[CH₂-NH]), a thioamide (ψ[CS-NH]), or a C-C bond.
The design process is often iterative, beginning with a pharmacophore model derived from the parent compound or a known active congener. This model highlights the essential functional groups and their spatial arrangement required for biological activity.
Chemical Synthesis of Functionally Modified L-Isoleucylglycinamide Analogues
The synthesis of L-Isoleucylglycinamide analogues typically follows established protocols of peptide chemistry, often involving the coupling of protected amino acid derivatives. A common approach starts with the N-protected L-isoleucine, which is then activated and coupled with glycinamide or a derivative thereof.
A representative synthetic route for preparing analogues of L-Isoleucylglycinamide can be adapted from the synthesis of other L-isoleucine amides. researchgate.net For instance, N-tert-butyloxycarbonyl (Boc)-L-isoleucine can be coupled with a desired amine (in this case, a modified glycinamide) using a coupling agent like N,N'-dicyclohexylcarbodiimide (DCC) in the presence of an activator such as hydroxybenzotriazole (B1436442) (HOBt). researchgate.net The Boc protecting group can then be removed under acidic conditions to yield the final dipeptide amide analogue.
Table 1: Synthetic Scheme for L-Isoleucylglycinamide Analogues
| Step | Reactants | Reagents | Product |
| 1 | N-Boc-L-isoleucine, Glycinamide derivative (H₂N-Gly-R) | DCC, HOBt | N-Boc-L-Isoleucylglycinamide derivative |
| 2 | N-Boc-L-Isoleucylglycinamide derivative | Trifluoroacetic acid (TFA) or HCl in dioxane | L-Isoleucylglycinamide derivative |
This methodology allows for the introduction of a wide variety of functional groups at the C-terminus by using different glycinamide derivatives (H₂N-Gly-R). For example, if R is a substituted phenyl group, a series of analogues with varying electronic and steric properties can be synthesized to probe the binding site.
Further modifications can be introduced at the N-terminus of the deprotected dipeptide amide. For example, acylation of the free amino group of the isoleucine residue with different carboxylic acid chlorides can introduce further diversity. researchgate.net
Table 2: Examples of Synthesized L-Isoleucine Amide Derivatives
| Compound | Structure | Synthetic Method | Reference |
| (2S,3S)-2-amino-N-benzyl-3-methylpentanamide | L-Ile-NH-CH₂-Ph | Coupling of N-Boc-L-isoleucine with benzylamine (B48309) followed by deprotection. | researchgate.net |
| (2S,3S)-2-amino-3-methyl-N-(naphthalen-1-yl)pentanamide | L-Ile-NH-Napthyl | Coupling of N-Boc-L-isoleucine with 1-naphthylamine (B1663977) followed by deprotection. | researchgate.net |
Mechanistic Implications of Structural Modifications on Molecular Activity
Each structural modification to the L-Isoleucylglycinamide scaffold has the potential to alter its interaction with its biological target and, consequently, its molecular activity.
Alterations to the Isoleucine Side Chain: Changes in the size, shape, and hydrophobicity of the isoleucine side chain directly impact van der Waals interactions and hydrophobic contacts within the binding pocket of a target protein. Increasing the bulkiness of the side chain may enhance binding affinity if the pocket is large enough to accommodate it, or it could introduce steric hindrance and reduce activity.
Peptide Bond Isosteres: The introduction of a non-hydrolyzable peptide bond isostere is primarily aimed at increasing the metabolic stability of the analogue. This modification can also alter the conformational preferences of the dipeptide backbone, which may lead to a more favorable or unfavorable binding conformation. For example, a reduced amide bond introduces greater flexibility, which could be beneficial or detrimental depending on the entropic cost of binding.
C-Terminal Modifications: Modifications at the C-terminal glycinamide can influence the molecule's solubility, membrane permeability, and hydrogen bonding interactions with the target. For instance, converting the terminal amide to a carboxylic acid would introduce a negative charge at physiological pH, potentially forming a salt bridge with a positively charged residue in the binding site. Conversely, N-alkylation of the amide could disrupt a critical hydrogen bond donor interaction.
Computational Approaches to Derivative Design and Virtual Screening
Computational chemistry plays a pivotal role in the modern drug discovery process, and the design of L-Isoleucylglycinamide derivatives can be significantly accelerated through these methods.
Molecular Docking: If the three-dimensional structure of the biological target is known, molecular docking can be used to predict the binding mode and affinity of designed analogues. This technique allows for the virtual screening of large libraries of compounds, prioritizing those with the highest predicted binding scores for synthesis and experimental testing. For instance, a library of virtual L-Isoleucylglycinamide derivatives with various side chains and C-terminal modifications could be docked into the active site of a target enzyme to identify promising candidates.
Quantitative Structure-Activity Relationship (QSAR): In the absence of a target structure, QSAR models can be developed based on the biological activities of a series of synthesized analogues. These models mathematically correlate the chemical structures of the compounds with their activities, allowing for the prediction of the activity of new, unsynthesized derivatives. Descriptors used in QSAR models can include physicochemical properties such as logP, molar refractivity, and electronic parameters.
Molecular Dynamics (MD) Simulations: MD simulations can provide insights into the dynamic behavior of the L-Isoleucylglycinamide analogues and their complexes with target proteins. These simulations can help to understand the stability of the binding interactions, the role of solvent molecules, and the conformational changes that occur upon binding.
These computational approaches, when used in conjunction with experimental synthesis and biological testing, provide a powerful platform for the rational design and optimization of novel L-Isoleucylglycinamide derivatives with desired therapeutic properties.
Biochemical Roles and Metabolic Pathways of L Isoleucylglycinamide
Endogenous Biosynthesis and Biotransformation Pathways
Identification of Precursors and Enzymatic Synthesis Routes
There is no information available in the scientific literature regarding the natural precursors or the specific enzymes involved in the synthesis of L-Isoleucylglycinamide within a biological system.
Catabolic and Anabolic Processes Involving L-Isoleucylglycinamide
Details regarding the breakdown (catabolism) or synthesis (anabolism) of L-Isoleucylglycinamide are not documented.
Kinetic and Mechanistic Studies of L-Isoleucylglycinamide-Enzyme Interactions
No studies on the kinetics or mechanisms of enzymes interacting with L-Isoleucylglycinamide have been found.
Regulation of Cellular Metabolic Fluxes by L-Isoleucylglycinamide
Influence on Key Metabolic Cycles and Pathways
There is no evidence to suggest that L-Isoleucylglycinamide influences key metabolic cycles such as glycolysis, the citric acid cycle, or others.
Modulatory Effects on Metabolic Enzyme Activities
No research has been published detailing any modulatory effects of L-Isoleucylglycinamide on the activity of metabolic enzymes.
Research on L-Isoleucylglycinamide and Cellular Responses Remains Undisclosed
Despite a thorough review of scientific literature and databases, no specific information is currently available regarding the adaptive cellular responses triggered by the chemical compound L-Isoleucylglycinamide.
The biochemical roles and metabolic pathways of this particular dipeptide, specifically its influence on how cells adapt to environmental or internal stressors, have not been documented in publicly accessible research.
Extensive searches for data on L-Isoleucylglycinamide's effects on cellular signaling, gene expression, or stress response pathways have yielded no relevant findings. Similarly, there is a lack of information on how this compound might be metabolized by cells and what, if any, downstream effects its metabolic byproducts may have.
While the individual amino acids that constitute L-Isoleucylglycinamide—L-isoleucine and glycine (B1666218)—are well-characterized in their biological roles, the specific functions of this dipeptide remain unelucidated in the context of adaptive cellular mechanisms. Scientific inquiry into the biological activity of countless peptides is ongoing, and it is possible that L-Isoleucylglycinamide is a compound that has not yet been a subject of detailed investigation or that the findings of such research have not been made public.
Therefore, the following sections on the biochemical roles and adaptive cellular responses of L-Isoleucylglycinamide cannot be populated with scientifically accurate and detailed information as per the user's request.
Molecular Interactions and Receptor Binding Studies of L Isoleucylglycinamide
Characterization of Ligand-Receptor Binding Mechanisms
A thorough understanding of a ligand's interaction with its receptor is paramount. This involves quantifying the binding affinity, analyzing the kinetics of the interaction, and determining the ligand's selectivity for various receptor subtypes.
Quantitative Assessment of Binding Specificity and Affinity
The specificity and affinity with which L-Isoleucylglycinamide binds to its target receptor(s) are fundamental parameters that dictate its biological activity. Binding affinity is typically quantified by the equilibrium dissociation constant (Kd) or the inhibition constant (Ki). A lower Kd or Ki value signifies a higher binding affinity.
As of the latest literature review, specific quantitative binding affinity data (e.g., Ki or Kd values) for L-Isoleucylglycinamide are not publicly available. In a typical study, these values would be determined through saturation or competition binding assays. For instance, a hypothetical competitive binding assay might involve incubating a fixed concentration of a radiolabeled ligand known to bind to a specific receptor with varying concentrations of L-Isoleucylglycinamide. The concentration of L-Isoleucylglycinamide that inhibits 50% of the specific binding of the radioligand is the IC50 value, which can then be converted to a Ki value using the Cheng-Prusoff equation.
Hypothetical Binding Affinity Data for L-Isoleucylglycinamide
| Receptor Target | Radioligand Used | L-Isoleucylglycinamide IC50 (nM) | L-Isoleucylglycinamide Ki (nM) |
|---|---|---|---|
| Receptor X | [3H]-Ligand A | Data Not Available | Data Not Available |
Kinetic Analysis of L-Isoleucylglycinamide-Receptor Association and Dissociation
The kinetics of a ligand-receptor interaction, described by the association rate constant (kon) and the dissociation rate constant (koff), provide a dynamic view of the binding process. The kon value reflects how quickly the ligand binds to the receptor, while the koff value indicates the stability of the ligand-receptor complex, or how quickly the ligand dissociates. The ratio of koff to kon also provides a measure of the equilibrium dissociation constant (Kd). excelleratebio.com
Currently, there are no published studies detailing the kinetic parameters of L-Isoleucylglycinamide's interaction with any specific receptor. Such studies would typically involve time-course experiments where the binding of a labeled form of L-Isoleucylglycinamide is measured at various time points to determine the kon. To determine koff, the dissociation of the pre-formed ligand-receptor complex would be initiated, often by the addition of an excess of an unlabeled competing ligand, and the amount of bound ligand remaining would be measured over time.
Hypothetical Kinetic Parameters for L-Isoleucylglycinamide
| Receptor Target | kon (M-1s-1) | koff (s-1) | Residence Time (1/koff) (s) |
|---|---|---|---|
| Receptor X | Data Not Available | Data Not Available | Data Not Available |
Subtype Selectivity and Receptor Profiling
Many receptors exist as multiple subtypes, and a ligand's selectivity for these subtypes can have significant functional implications. Receptor profiling involves testing the binding of a ligand against a panel of different receptor subtypes to determine its selectivity profile. A highly selective ligand will exhibit significantly higher affinity for one subtype over others. nih.gov
The receptor subtype selectivity of L-Isoleucylglycinamide has not been characterized in the available scientific literature. A comprehensive receptor profiling study would involve performing binding assays for L-Isoleucylglycinamide against a broad range of receptor subtypes, including those that are structurally related. The resulting data would reveal the compound's specificity and potential for off-target effects. For example, a compound might be tested against a panel of adrenergic or serotonergic receptor subtypes. nih.gov The selectivity is often expressed as a ratio of the Ki values for the different subtypes. nih.gov
Methodological Frameworks for Receptor Binding Analysis
The characterization of ligand-receptor interactions relies on a variety of robust and sensitive experimental techniques. Radioligand binding assays have long been the gold standard, though fluorescence-based and label-free methods are increasingly utilized.
Radioligand Binding Assays for Receptor Quantification
Radioligand binding assays are a powerful tool for quantifying receptor density (Bmax) and ligand affinity (Kd). researchgate.net These assays utilize a ligand that has been labeled with a radioactive isotope, such as tritium (B154650) (3H) or iodine-125 (B85253) (125I). nih.gov There are two primary types of radioligand binding assays:
Saturation Assays: In these experiments, increasing concentrations of a radioligand are incubated with a receptor preparation until equilibrium is reached. The amount of bound radioligand is then measured. The specific binding, which is the total binding minus the non-specific binding (determined in the presence of an excess of an unlabeled competing ligand), is plotted against the concentration of the radioligand. This allows for the determination of Bmax, representing the total number of receptors, and Kd, the concentration of radioligand at which 50% of the receptors are occupied. researchgate.net
Competition Assays: These assays are used to determine the affinity of an unlabeled compound (the competitor) for a receptor. A fixed concentration of a radioligand is incubated with the receptor preparation in the presence of varying concentrations of the unlabeled competitor. The ability of the competitor to displace the radioligand from the receptor is measured, and the IC50 value is determined. This value can then be used to calculate the inhibition constant (Ki) for the competitor. researchgate.net
The separation of bound from free radioligand is typically achieved through rapid filtration, where the receptor-bound radioligand is captured on a filter, or through centrifugation. nih.gov
Fluorescence-Based and Label-Free Receptor Binding Techniques
While radioligand assays are highly sensitive, concerns about the handling and disposal of radioactive materials have driven the development of alternative methods.
Fluorescence-Based Assays: These techniques utilize fluorescently labeled ligands. One common approach is Fluorescence Polarization (FP) . In FP, a small, fluorescently labeled ligand tumbles rapidly in solution, resulting in low polarization of emitted light when excited with polarized light. Upon binding to a larger receptor molecule, the tumbling rate slows significantly, leading to an increase in the polarization of the emitted light. This change in polarization can be used to monitor the binding event and determine binding affinity. Another method involves Förster Resonance Energy Transfer (FRET) , where energy is transferred from a donor fluorophore on the receptor to an acceptor fluorophore on the ligand upon binding.
Label-Free Techniques: These methods detect the binding event without the need to label the ligand or the receptor. Surface Plasmon Resonance (SPR) is a prominent example. In SPR, one of the binding partners (e.g., the receptor) is immobilized on a sensor chip. The binding of a ligand to the immobilized receptor causes a change in the refractive index at the sensor surface, which is detected in real-time. This allows for the direct measurement of the association and dissociation rates (kon and koff), providing a comprehensive kinetic profile of the interaction.
High-Throughput Screening Platforms for Binding Interactions
High-throughput screening (HTS) represents a powerful methodology for the rapid assessment of the binding of a vast number of compounds to a specific biological target. While detailed HTS campaigns specifically targeting L-Isoleucylglycinamide are not extensively documented in publicly available literature, the compound is recognized as a viable candidate for such screening efforts. The general principles of HTS can be applied to identify and characterize its binding interactions with potential protein targets.
These platforms typically rely on various detection methods, including fluorescence polarization (FP), surface plasmon resonance (SPR), and affinity chromatography, to measure the binding of a ligand to a receptor. In a hypothetical HTS campaign for L-Isoleucylglycinamide, a library of receptors could be screened for binding affinity. The results of such a screen would provide a "hit list" of receptors that interact with the dipeptide, which would then be subjected to more detailed biophysical and functional assays for validation.
Table 1: Illustrative High-Throughput Screening Data for L-Isoleucylglycinamide Binding
| Target Receptor | Assay Type | Signal Change | Hit Confidence |
| Receptor A | Fluorescence Polarization | +++ | High |
| Receptor B | Surface Plasmon Resonance | ++ | Medium |
| Receptor C | Affinity Chromatography | + | Low |
| Receptor D | Fluorescence Polarization | - | No Hit |
This table is illustrative and represents the type of data generated from an HTS campaign. Actual data would depend on the specific receptors and screening conditions.
Structure-Activity Relationship (SAR) in L-Isoleucylglycinamide-Receptor Interactions
The structure-activity relationship (SAR) of a molecule describes how its chemical structure correlates with its biological activity. For L-Isoleucylglycinamide, SAR studies are crucial for understanding which parts of the molecule are essential for receptor binding and for designing analogs with improved properties.
A pharmacophore is a three-dimensional arrangement of electronic and steric features that are necessary for a molecule to interact with a specific receptor. The identification of the pharmacophore for L-Isoleucylglycinamide would involve comparing its structure with other molecules that bind to the same receptor to identify common features. These features typically include hydrogen bond donors and acceptors, hydrophobic regions, and charged groups.
For L-Isoleucylglycinamide, the key pharmacophoric features are likely to include:
A hydrogen bond donor: The primary amine of the isoleucine residue.
Hydrogen bond acceptors: The carbonyl groups of the peptide bond and the C-terminal amide.
A hydrophobic region: The isobutyl side chain of the isoleucine residue.
A hydrogen bond donor/acceptor: The N-H of the peptide bond and the C-terminal amide.
Computational pharmacophore modeling can be employed to generate and validate these hypotheses. acs.orgnih.gov Such models serve as valuable tools in virtual screening campaigns to identify new ligands with similar binding properties. fip.org
Table 2: Putative Pharmacophore Features of L-Isoleucylglycinamide
| Pharmacophore Feature | Molecular Moiety | Potential Interaction |
| Hydrogen Bond Donor | Isoleucine α-amino group | Ionic interaction, H-bond |
| Hydrogen Bond Acceptor | Peptide carbonyl | Hydrogen bond |
| Hydrogen Bond Acceptor | Glycinamide (B1583983) carbonyl | Hydrogen bond |
| Hydrophobic Center | Isoleucine side chain | Van der Waals interactions |
| Hydrogen Bond Donor | Peptide N-H | Hydrogen bond |
| Hydrogen Bond Donor | Glycinamide -NH2 | Hydrogen bond |
The three-dimensional shape, or conformation, of L-Isoleucylglycinamide is a critical determinant of its ability to bind to a receptor. The flexibility of the peptide backbone and the rotation of the isoleucine side chain allow the molecule to adopt various conformations. However, it is likely that only a specific "bioactive" conformation is recognized by a given receptor.
Studies on the conformational preferences of related molecules, such as glycinamide, have shown that both intramolecular hydrogen bonding and interactions with the solvent play a significant role in determining the favored conformation. nih.gov For L-Isoleucylglycinamide, the steric bulk of the isoleucine side chain will further influence the accessible conformational space. The presence of the isoleucine residue can impact peptide-membrane interactions, a factor that is often related to the molecule's hydrophobicity and amphipathicity. nih.gov
The binding of a dipeptide to a transporter protein like PEPT1, for instance, is known to be influenced by charge, hydrophobicity, size, and the flexibility of the side chains. nih.gov While many dipeptides may bind, not all are transported, highlighting the importance of specific conformational and structural features for functional interaction. nih.gov
Computational methods, such as molecular dynamics simulations, can provide insights into the conformational landscape of L-Isoleucylglycinamide and help identify low-energy conformations that are likely to be relevant for receptor binding. The analysis of these conformations can reveal key dihedral angles and intramolecular distances that define the bioactive shape.
Mechanistic Investigations of L Isoleucylglycinamide in Biological Systems Non Human in Vitro and in Vivo
Modulation of Intracellular Signaling Pathways
Effects on PI3K/AKT/mTOR Pathway Dynamics
No research data is currently available on the effects of L-Isoleucylglycinamide on the PI3K/AKT/mTOR signaling pathway.
Interplay with MAPK Signaling Cascades
There is no available scientific literature detailing the interplay of L-Isoleucylglycinamide with MAPK signaling cascades.
Influence on NF-κB-Mediated Cellular Responses
The influence of L-Isoleucylglycinamide on NF-κB-mediated cellular responses has not been documented in published research.
Analysis of Crosstalk Between Signaling Networks
Due to the lack of data on its individual pathway interactions, no analysis of crosstalk between signaling networks in response to L-Isoleucylglycinamide is possible at this time.
Enzymatic Regulation and Downstream Functional Consequences
L-Isoleucylglycinamide as an Enzyme Modulator (Inhibitor or Activator)
There are no studies available that characterize L-Isoleucylglycinamide as an enzyme modulator.
Allosteric Effects and Cofactor Dependency
There is currently no available research to suggest or detail any allosteric modulatory roles of L-Isoleucylglycinamide on enzymes or receptors. An allosteric modulator would bind to a site on a protein distinct from the active site, altering the protein's activity. nih.govnih.gov However, no studies have been identified that investigate whether L-Isoleucylglycinamide acts in such a capacity. Similarly, information regarding any dependency on or interaction with cofactors for its potential biological activity is absent from the scientific record.
Impact on Protein Expression and Post-Translational Modifications
The influence of L-Isoleucylglycinamide on protein expression and post-translational modifications (PTMs) in non-human biological systems has not been documented. nih.gov PTMs are crucial for regulating protein function and cellular processes. nih.gov Research into whether this compound can alter the synthesis of proteins or induce modifications such as phosphorylation, acetylation, or ubiquitination is not present in the available literature. nih.gov
Mechanistic Studies in Model Systems
While various model systems are routinely used to elucidate the mechanisms of action of chemical compounds, none have been specifically reported in the context of L-Isoleucylglycinamide.
In Vitro Cellular Models for Pathway Elucidation
No studies utilizing in vitro cellular models to explore the signaling pathways affected by L-Isoleucylglycinamide have been published. Such models are fundamental in dissecting the molecular interactions of a compound within a cell.
Organotypic Cultures and Isolated Tissue Preparations
Organotypic cultures, which maintain the three-dimensional structure of tissues, and isolated tissue preparations are powerful tools for studying the effects of compounds in a more physiologically relevant context. nih.govnih.govnih.gov These methods are widely used in pharmacological and physiological research to assess the impact of substances on tissue function and cellular architecture. nih.govuah.esmonash.edu.au However, a review of existing literature reveals no studies where L-Isoleucylglycinamide has been investigated using these techniques.
Mechanistic Exploration in Non-Human In Vivo Models
Similarly, there is a lack of published research on the mechanistic exploration of L-Isoleucylglycinamide in non-human in vivo models. Such studies would be critical for understanding the compound's physiological effects within a whole organism. nih.gov
Computational Approaches in L Isoleucylglycinamide Research
Molecular Modeling and Dynamics Simulations
Molecular modeling and dynamics simulations are foundational computational tools that allow for the detailed exploration of L-Isoleucylglycinamide's structural and dynamic properties. These methods are crucial for understanding how the molecule adopts different shapes and interacts with its biological targets.
Conformational Space Exploration and Structural Prediction
The biological function of a molecule like L-Isoleucylglycinamide is intrinsically linked to its three-dimensional structure. Computational methods are employed to explore the vast conformational space available to this dipeptide. This involves identifying the various shapes, or conformers, the molecule can adopt by rotating around its single bonds. libretexts.org
Protein-Ligand Docking and Binding Energy Calculations
A primary application of computational modeling for L-Isoleucylglycinamide is to predict how it interacts with protein targets. Molecular docking is a technique used to forecast the preferred orientation of a ligand when it binds to a receptor to form a stable complex. youtube.comyoutube.com This process involves placing the L-Isoleucylglycinamide molecule into the binding site of a target protein and evaluating the fit using a scoring function. youtube.com Programs like AutoDock Vina are commonly used for this purpose. youtube.comnih.gov
Once a docked pose is obtained, binding energy calculations can provide a quantitative estimate of the binding affinity. These calculations can range from relatively simple scoring functions to more rigorous methods like Molecular Mechanics/Poisson-Boltzmann Surface Area (MM/PBSA) or Linear Interaction Energy (LIE) methods. nih.gov These calculations are crucial for understanding the strength of the interaction between L-Isoleucylglycinamide and its target protein. nih.govaps.org The calculated binding free energy, often expressed in kcal/mol, provides a valuable metric for comparing the affinity of L-Isoleucylglycinamide to different targets or for comparing it with other potential ligands. nih.gov
Dynamic Simulation of Molecular Interactions at Atomic Resolution
While molecular docking provides a static picture of the binding event, molecular dynamics (MD) simulations offer a dynamic view of the interactions between L-Isoleucylglycinamide and its environment over time. nih.gov MD simulations solve Newton's equations of motion for a system of atoms and molecules, allowing researchers to observe the molecule's behavior at an atomic level. nih.gov
These simulations can reveal how L-Isoleucylglycinamide and its target protein adapt to each other upon binding, the role of solvent molecules in the interaction, and the stability of the resulting complex. nih.gov By analyzing the trajectories from MD simulations, researchers can identify key intermolecular interactions, such as hydrogen bonds and hydrophobic contacts, that are critical for binding. This detailed understanding of the dynamic nature of the interaction is essential for rational drug design and for interpreting experimental data. nih.gov
Quantitative Structure-Activity Relationship (QSAR) and Cheminformatics Applications
QSAR and cheminformatics provide a bridge between the chemical structure of L-Isoleucylglycinamide and its biological activity, enabling the development of predictive models and facilitating the discovery of new, related compounds.
Development of Predictive Models for Biological Activity
Quantitative Structure-Activity Relationship (QSAR) studies aim to establish a mathematical relationship between the chemical structure of a series of compounds and their biological activity. nih.gov For L-Isoleucylglycinamide and its analogs, QSAR models can be developed to predict their activity based on various molecular descriptors. These descriptors can include physicochemical properties like lipophilicity, electronic properties, and steric parameters. nih.gov
The process typically involves compiling a dataset of compounds with known activities and then using statistical methods, such as multiple linear regression or machine learning algorithms, to build a predictive model. acs.orgnih.gov A successful QSAR model can then be used to predict the activity of new, untested compounds, thereby prioritizing synthetic efforts towards more potent molecules. nih.gov
Ligand-Based and Structure-Based Virtual Screening
Virtual screening is a computational technique used in drug discovery to search large libraries of small molecules to identify those that are most likely to bind to a drug target. mdpi.com This approach can be broadly categorized into ligand-based and structure-based methods.
In ligand-based virtual screening , a known active molecule, such as L-Isoleucylglycinamide, is used as a template to search for other molecules with similar properties. This is often done by comparing molecular fingerprints or 3D shapes.
Systems Biology and Network Analysis
In the study of L-Isoleucylglycinamide, computational approaches have evolved from analyzing the molecule in isolation to understanding its role within complex biological networks. Systems biology provides a framework for this by integrating diverse biological data to model and discover the emergent properties of the entire system upon interaction with the dipeptide. wikipedia.orgmdpi.com This holistic perspective is crucial because the biological effect of a simple dipeptide is not solely determined by its direct interactions but also by its influence on interconnected pathways and cellular modules. nih.gov
Network analysis is a key component of systems biology, allowing researchers to visualize and analyze the complex web of interactions that L-Isoleucylglycinamide may be involved in. These networks can represent various levels of biological organization, such as protein-protein interactions, gene regulatory networks, and metabolic pathways. mdpi.com By mapping the potential interaction partners of L-Isoleucylglycinamide—for instance, transporters, enzymes, or receptors—researchers can begin to predict its functional role. ebi.ac.uk Computational tools can identify central "hub" nodes or critical pathways within these networks that are perturbed by the presence of the dipeptide, offering insights into its mechanism of action. nih.gov This approach moves beyond a one-target, one-molecule view, embracing the complexity of cellular responses. nih.gov
Integration of Multi-Omics Data for Comprehensive Mechanistic Insights
To construct robust systems-level models, it is essential to integrate multiple layers of biological data, a practice known as multi-omics analysis. nih.gov This approach systematically combines data from genomics, transcriptomics, proteomics, and metabolomics to provide a comprehensive view of a cell's or organism's state in response to L-Isoleucylglycinamide. The integration of these datasets allows for a more complete understanding of the flow of biological information, from the genetic blueprint to functional protein and metabolic output. oup.com
For a compound like L-Isoleucylglycinamide, a multi-omics study would typically involve the following:
Transcriptomics (RNA-seq): Measures the changes in gene expression in response to the dipeptide, identifying which genes are up- or down-regulated. This can reveal the signaling pathways and cellular processes that are transcriptionally activated or suppressed. nih.gov
Proteomics: Quantifies changes in protein abundance, providing a closer link to cellular function than transcriptomics alone. This can identify changes in the levels of enzymes, structural proteins, or signaling molecules.
Metabolomics: Profiles the full range of small-molecule metabolites, including the administered dipeptide itself and any downstream products. This provides a direct readout of the biochemical activity and physiological state of the cell. nih.gov Research has shown that dipeptide profiles can be organ-specific, suggesting that integrating metabolomics data is key to understanding systemic effects. nih.gov
Epigenomics (e.g., ATAC-seq): Assesses changes in chromatin accessibility, revealing how L-Isoleucylglycinamide might influence the regulatory landscape of the genome, making certain genes more or less available for transcription. nih.gov
By integrating these data types, researchers can build a detailed, multi-layered network model. For example, an observed increase in the transcript for a specific metabolic enzyme (transcriptomics) can be correlated with an increase in the abundance of that enzyme (proteomics) and a subsequent change in related metabolite concentrations (metabolomics). This correlative analysis strengthens the evidence for the dipeptide's involvement in that specific pathway. oup.com
| Omics Layer | Data Acquired | Potential Insights for L-Isoleucylglycinamide | Integration Approach |
|---|---|---|---|
| Transcriptomics | mRNA expression levels | Identifies genes and pathways (e.g., cell stress, metabolism) transcriptionally altered by the dipeptide. | Quantitative integration using statistical models (e.g., network inference, correlation analyses) to link changes across layers and identify key regulatory nodes and pathways affected by the dipeptide. mdpi.comoup.com |
| Proteomics | Protein abundance and post-translational modifications | Confirms if transcriptional changes translate to the protein level; identifies functional protein changes. | |
| Metabolomics | Concentrations of small molecules (metabolites) | Tracks the fate of L-Isoleucylglycinamide, its breakdown products, and its effect on cellular metabolic pathways. nih.gov | |
| Epigenomics | Chromatin accessibility (e.g., ATAC-seq data) | Reveals changes in the gene regulatory landscape that precede transcriptional changes. nih.gov |
Predictive Modeling of Cellular and Systemic Responses to L-Isoleucylglycinamide
A major goal of computational research is to develop models that can predict the biological effects of a compound before it is tested in the lab. nih.gov For L-Isoleucylglycinamide, predictive modeling can forecast its bioactivity, cellular uptake, or its impact on specific cellular phenotypes. These models often leverage machine learning and deep learning algorithms trained on large datasets of known peptide sequences and their corresponding biological activities. nih.govresearchgate.net
The process typically involves several steps:
Feature Engineering: The L-Isoleucylglycinamide molecule is converted into a set of numerical descriptors (features). These can include physicochemical properties (e.g., molecular weight, charge, hydrophobicity), dipeptide composition, and structural information. nih.govbiorxiv.org
Model Training: A machine learning algorithm, such as a Random Forest or a neural network, is trained on a dataset where these features are linked to a known outcome (e.g., cell permeability, receptor binding affinity). researchgate.netnih.gov For instance, models have been successfully built to predict whether peptides can penetrate cell membranes based on their amino acid and dipeptide composition. biorxiv.org
Prediction: Once trained, the model can predict the outcome for L-Isoleucylglycinamide based on its specific features.
Recent advancements have led to sophisticated deep learning models, such as compositional perturbation autoencoders (CPA), that can predict single-cell transcriptional responses to new molecules. nih.gov While not yet applied specifically to L-Isoleucylglycinamide, such a model could theoretically predict how different cell types would respond to the dipeptide by integrating its chemical structure with basal gene expression data from those cells. nih.gov These models can even predict the effects of unseen dosages and combinations, significantly accelerating research and hypothesis generation.
| Model Type | Input Features | Predicted Outcome | Example Performance (from general peptide studies) |
|---|---|---|---|
| Random Forest Classifier | Dipeptide composition, amino acid frequencies, physicochemical properties (charge, molecular weight). biorxiv.org | Cell-penetrating potential (Yes/No). | Accuracy of ~95% on validation datasets. nih.gov |
| Support Vector Machine (SVM) | Structural descriptors, molecular fingerprints. | Enzyme inhibitory activity. | High correlation between predicted and experimental values (e.g., MCC > 0.8). nih.gov |
| Deep Neural Network (CNN) | Peptide sequence, MHC-binding data. | Immunogenicity of the peptide. nih.gov | Outperforms previous methods in identifying immunogenic epitopes. nih.gov |
By leveraging these predictive tools, researchers can prioritize experimental studies, design modified versions of L-Isoleucylglycinamide with enhanced properties, and generate testable hypotheses about its systemic effects, thereby guiding future research in a more efficient, data-driven manner.
Advanced Analytical Research Methodologies for L Isoleucylglycinamide
Spectroscopic and Chromatographic Techniques for High-Resolution Analysis
The precise identification and quantification of L-Isoleucylglycinamide are fundamentally reliant on the synergistic use of chromatography for separation and spectroscopy for detection. High-performance liquid chromatography (HPLC) and its variants, coupled with mass spectrometry (MS), represent the gold standard for the analysis of small peptides like L-Isoleucylglycinamide. taylorfrancis.com
High-performance liquid chromatography is a cornerstone technique for the separation of peptides from complex mixtures. taylorfrancis.com For a relatively polar compound such as L-Isoleucylglycinamide, reversed-phase HPLC (RP-HPLC) is a common approach. In this technique, a non-polar stationary phase is used with a polar mobile phase. The separation is achieved by gradually increasing the hydrophobicity of the mobile phase, typically by increasing the concentration of an organic solvent like acetonitrile (B52724) in an aqueous buffer. nih.gov
Another powerful chromatographic technique is hydrophilic interaction liquid chromatography (HILIC), which is particularly well-suited for the separation of polar and hydrophilic compounds. HILIC utilizes a polar stationary phase and a mobile phase with a high concentration of organic solvent. This method can provide alternative selectivity compared to RP-HPLC and may be advantageous for separating L-Isoleucylglycinamide from other polar metabolites.
Mass spectrometry is the definitive technique for the structural confirmation and quantification of L-Isoleucylglycinamide. When coupled with HPLC (LC-MS), it provides high sensitivity and specificity. nih.gov Electrospray ionization (ESI) is a soft ionization technique commonly used for peptides, which allows the molecule to be ionized intact, preserving its structure. The mass spectrometer then separates the ions based on their mass-to-charge ratio (m/z), providing a precise molecular weight of L-Isoleucylglycinamide.
Tandem mass spectrometry (MS/MS) further enhances the confidence in identification. In this technique, the parent ion of L-Isoleucylglycinamide is selected and fragmented, producing a characteristic pattern of daughter ions that is unique to its structure. This fragmentation pattern can be predicted and matched to confirm the amino acid sequence. nih.gov
Below is a table summarizing typical parameters for the HPLC-MS/MS analysis of a dipeptide like L-Isoleucylglycinamide.
| Parameter | Setting | Purpose |
| Chromatography | ||
| Column | C18 reversed-phase (e.g., 2.1 x 100 mm, 1.8 µm) | Separation based on hydrophobicity |
| Mobile Phase A | 0.1% Formic acid in water | Aqueous component of the mobile phase |
| Mobile Phase B | 0.1% Formic acid in acetonitrile | Organic component for elution |
| Gradient | 5% to 95% B over 10 minutes | To elute compounds with varying polarities |
| Flow Rate | 0.3 mL/min | Optimal flow for separation and detection |
| Column Temperature | 40 °C | To ensure reproducible retention times |
| Mass Spectrometry | ||
| Ionization Mode | Positive Electrospray Ionization (ESI+) | Efficient ionization of peptides |
| MS1 Scan Range | m/z 100-500 | To detect the precursor ion |
| Precursor Ion (m/z) | [M+H]⁺ for L-Isoleucylglycinamide | Selection of the target molecule |
| Fragmentation | Collision-Induced Dissociation (CID) | To generate fragment ions for identification |
| Monitored Transitions | Specific precursor-to-product ion pairs | For high-specificity quantification (MRM) |
Bioanalytical Methods for Detection and Quantification in Complex Matrices
The detection and quantification of L-Isoleucylglycinamide in biological samples such as plasma, serum, or tissue extracts present a significant challenge due to the complexity of these matrices. youtube.com Bioanalytical methods must be highly selective and sensitive to accurately measure what are often low concentrations of the analyte.
Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is the predominant bioanalytical method for the quantification of small molecules like L-Isoleucylglycinamide in complex biological fluids. cameca.comnih.gov The high specificity of multiple reaction monitoring (MRM) mode in tandem mass spectrometry minimizes interference from other matrix components. researchgate.net In an MRM experiment, a specific precursor ion (the molecular ion of L-Isoleucylglycinamide) is selected and fragmented, and only a specific fragment ion is monitored. This highly selective detection allows for accurate quantification even in the presence of a high background of other substances. researchgate.net
Sample preparation is a critical step to ensure the accuracy and reliability of the bioanalytical method. The goal is to remove interfering substances and concentrate the analyte. Common techniques include protein precipitation, liquid-liquid extraction, and solid-phase extraction (SPE). For a small peptide like L-Isoleucylglycinamide, SPE can be particularly effective in cleaning up the sample and improving the limit of quantification.
The development of a robust bioanalytical method requires careful validation to ensure its performance. This includes assessing linearity, accuracy, precision, selectivity, and stability of the analyte in the biological matrix. The use of a stable isotope-labeled internal standard of L-Isoleucylglycinamide is highly recommended to correct for matrix effects and variations in sample processing and instrument response. researchgate.net
The following table outlines key validation parameters for a bioanalytical LC-MS/MS assay for L-Isoleucylglycinamide.
| Validation Parameter | Acceptance Criteria | Rationale |
| Linearity | Correlation coefficient (r²) ≥ 0.99 | Demonstrates a proportional response to concentration |
| Accuracy | Within ±15% of the nominal concentration | Ensures the measured value is close to the true value |
| Precision | Coefficient of variation (CV) ≤ 15% | Measures the reproducibility of the method |
| Lower Limit of Quantification (LLOQ) | Signal-to-noise ratio ≥ 10; accuracy and precision within ±20% | The lowest concentration that can be reliably quantified |
| Selectivity | No significant interfering peaks at the retention time of the analyte | Confirms the method is specific for L-Isoleucylglycinamide |
| Matrix Effect | CV of the response in different matrix lots should be ≤ 15% | Assesses the influence of the biological matrix on ionization |
| Recovery | Consistent and reproducible | Measures the efficiency of the extraction process |
| Stability | Analyte concentration remains within ±15% of the initial value under various storage conditions | Ensures the integrity of the analyte during sample handling and storage |
Advanced Imaging and Microscopy Techniques for Subcellular Localization
Determining the subcellular location of L-Isoleucylglycinamide is crucial for understanding its biological function. However, imaging small, non-fluorescent molecules at high resolution within a cell is technically demanding. While traditional fluorescence microscopy is not directly applicable, advanced mass spectrometry imaging (MSI) techniques offer a pathway for the label-free visualization of small molecules in tissues and cells. nih.govacs.org
One of the most promising techniques for subcellular imaging of small molecules is Nanoscale Secondary Ion Mass Spectrometry (NanoSIMS). wikipedia.orgpnnl.govmpi-bremen.de NanoSIMS is a high-resolution mass spectrometry imaging technique that can map the elemental and isotopic distribution on a sample surface with a spatial resolution down to 50 nanometers. wikipedia.orgpnnl.gov To visualize L-Isoleucylglycinamide using NanoSIMS, it would be necessary to synthesize an isotopically labeled version of the dipeptide, for example, by incorporating ¹⁵N or ¹³C. mpi-bremen.de By introducing this labeled compound to cells, NanoSIMS can then be used to track its uptake and distribution within different organelles. nih.gov This approach provides a powerful tool to "see" where the molecule accumulates within the cell without the need for a bulky fluorescent tag that could alter its biological activity. springernature.com
Other MSI techniques, such as Matrix-Assisted Laser Desorption/Ionization (MALDI) imaging and Desorption Electrospray Ionization (DESI) imaging, can also provide spatial information on the distribution of small molecules in tissue sections, although typically with lower spatial resolution than NanoSIMS. youtube.com These methods are valuable for understanding the distribution of L-Isoleucylglycinamide at the tissue level. nih.gov
The table below compares key features of these advanced imaging techniques for the potential analysis of L-Isoleucylglycinamide.
| Imaging Technique | Principle | Spatial Resolution | Sample Preparation | Key Advantage for L-Isoleucylglycinamide |
| NanoSIMS | A focused primary ion beam sputters secondary ions from the sample surface, which are then analyzed by a mass spectrometer. mpi-bremen.de | Down to 50 nm wikipedia.orgpnnl.gov | Requires fixation and embedding; isotopic labeling of the analyte is necessary. springernature.com | High spatial resolution for subcellular localization. nih.gov |
| MALDI Imaging | A laser is used to desorb and ionize molecules from a tissue section coated with a matrix. nih.gov | 1-10 µm | Tissue sectioning and matrix application are required. | Good for mapping distribution in tissue sections. |
| DESI Imaging | A charged solvent spray desorbs and ionizes molecules from the sample surface under ambient conditions. youtube.com | ~50 µm | Minimal sample preparation is needed. acs.org | Analysis under ambient conditions without a matrix. |
Statistical and Bioinformatics Approaches for Data Interpretation
The data generated from high-resolution analytical techniques, particularly quantitative LC-MS/MS and MSI, require sophisticated statistical and bioinformatics tools for meaningful interpretation. nih.gov These approaches are essential for identifying significant changes in the abundance of L-Isoleucylglycinamide under different experimental conditions and for extracting patterns from complex datasets.
For quantitative studies, statistical analysis is used to determine if observed differences in L-Isoleucylglycinamide levels between experimental groups are statistically significant. This typically involves the use of t-tests or analysis of variance (ANOVA), depending on the number of groups being compared. It is also crucial to control for false discovery rates when multiple comparisons are being made. nih.gov Software packages like Prostar are designed for the statistical analysis of quantitative proteomics and peptidomics data and can be adapted for the analysis of dipeptide quantification. nih.gov
The statistical analysis of quantitative peptide data involves several key steps, as outlined in the table below.
| Statistical Step | Description | Common Methods |
| Data Preprocessing | Normalization, transformation, and handling of missing values to prepare the data for statistical testing. | Log transformation, quantile normalization, imputation. nih.gov |
| Differential Analysis | Application of statistical tests to identify significant differences in abundance between groups. | Student's t-test, ANOVA, Limma. nih.gov |
| False Discovery Rate (FDR) Control | Adjustment of p-values to account for multiple testing and reduce the number of false positives. | Benjamini-Hochberg procedure, q-value. nih.gov |
| Data Visualization | Creation of plots to visualize the results and identify patterns. | Volcano plots, heatmaps, box plots. |
In the context of mass spectrometry imaging, bioinformatics tools are used to process the large datasets generated and to identify regions of interest where L-Isoleucylglycinamide is localized. This can involve image segmentation, co-localization analysis with other molecular markers, and statistical comparisons of ion intensities across different regions of a tissue or cell. youtube.com
Bioinformatics databases and pathway analysis tools can also be employed to put the findings into a biological context. For example, if the levels of L-Isoleucylglycinamide are found to change in response to a particular stimulus, these tools can help to generate hypotheses about the metabolic pathways that may be affected.
Emerging Research Frontiers and Methodological Advancements for L Isoleucylglycinamide
Development of Novel Synthetic Strategies for Complex Peptide Architectures
The synthesis of peptides has evolved significantly beyond traditional solution-phase and solid-phase methods. Modern strategies focus on creating more complex, stable, and functionally diverse peptide-based molecules, where a dipeptide amide like L-Isoleucylglycinamide could serve as a fundamental building block. These novel strategies are crucial for exploring the full potential of peptide structures in materials science and therapeutics.
Key advancements include:
Hybrid Synthetic Approaches: Combining solid-phase peptide synthesis (SPPS) with solution-phase techniques allows for the efficient creation of large, complex peptide architectures. This enables the incorporation of non-standard amino acids, cyclization, and the attachment of moieties like polymers or lipids, which can enhance the properties of a base dipeptide.
Enzymatic Synthesis: The use of enzymes, such as ligases, offers a green chemistry approach to peptide bond formation. This method is highly specific, proceeds under mild conditions, and prevents racemization, which is a common challenge in chemical synthesis.
Click Chemistry: The copper-catalyzed azide-alkyne cycloaddition (CuAAC) and other click reactions provide a powerful tool for modifying peptide structures. A dipeptide like L-Isoleucylglycinamide could be functionalized with an azide (B81097) or alkyne group, allowing it to be "clicked" onto other molecules to create complex bioconjugates or peptidomimetics.
These advanced synthetic methods are enabling the construction of peptide libraries with unprecedented diversity, which is essential for discovering new functions.
| Synthetic Strategy | Description | Applicability to L-Isoleucylglycinamide Architectures |
| Automated Flow Chemistry | Continuous synthesis in a flowing stream, allowing for rapid optimization, scalability, and integration of reaction and purification steps. | Enables rapid production of L-Isoleucylglycinamide derivatives and analogues for screening. |
| Native Chemical Ligation (NCL) | A chemoselective reaction that ligates two unprotected peptide fragments, one with a C-terminal thioester and the other with an N-terminal cysteine. | Allows the incorporation of the L-Isoleucylglycinamide motif into larger protein and peptide scaffolds. |
| Multicomponent Reactions (MCRs) | Reactions where three or more reactants combine in a single step to form a new product, such as in the Ugi reaction. pnas.org | Facilitates the rapid generation of a diverse library of peptide-like molecules based on the core dipeptide structure for screening purposes. pnas.org |
Implementation of High-Throughput Screening Methodologies for Interaction Discovery
Identifying the biological targets and interaction partners of a compound is fundamental to understanding its function. High-throughput screening (HTS) allows for the rapid testing of thousands to millions of compounds against biological targets. uw.edu For a small molecule like L-Isoleucylglycinamide, HTS can be employed to uncover novel biological activities or binding partners, moving beyond its known structural role.
Modern HTS methodologies applicable to dipeptide amides include:
Affinity-Based Screening: Techniques such as affinity chromatography or surface plasmon resonance (SPR) can identify molecules that bind to a specific protein target. A library of compounds including L-Isoleucylglycinamide could be screened against a panel of proteins to find novel interactions.
Cell-Based Phenotypic Screening: This approach involves treating cultured cells with test compounds and using automated microscopy and image analysis to detect changes in cell morphology, viability, or the expression of specific markers. This can uncover unexpected biological effects without prior knowledge of a specific target.
Mass Spectrometry-Based HTS: Direct infusion mass spectrometry offers a label-free method for screening compound libraries against enzyme targets. rsc.org This technique can measure the enzymatic conversion of a substrate to a product, and its inhibition by compounds like L-Isoleucylglycinamide, with very high speed and sensitivity. rsc.orgnih.gov
The integration of robotics, microfluidics, and sensitive detection methods has made it possible to screen large and diverse chemical libraries efficiently, accelerating the pace of discovery. uw.edunih.gov
| HTS Method | Principle | Potential Finding for L-Isoleucylglycinamide |
| DNA-Encoded Libraries (DEL) | Large libraries of compounds are synthesized, each with a unique DNA tag. Screening involves binding to a target protein, followed by PCR amplification and sequencing of the DNA tags to identify hits. | Identification of novel protein targets that bind to the L-Isoleucylglycinamide structure with high affinity and specificity. |
| Fragment-Based Screening | Small, low-complexity molecules ("fragments") are screened for weak binding to a target. Hits are then optimized and linked to create more potent leads. | L-Isoleucylglycinamide itself could act as a fragment hit that is later elaborated into a more potent and specific modulator of a protein target. |
| High-Content Imaging (HCI) | An advanced form of cell-based screening that uses automated microscopy and sophisticated image analysis to quantify multiple phenotypic parameters simultaneously. | Discovery of effects on complex cellular processes, such as organelle function, cytoskeletal arrangement, or cell signaling pathways. |
Application of Machine Learning and Artificial Intelligence in Predictive Biology
Artificial intelligence (AI) and machine learning (ML) are revolutionizing drug discovery and computational biology. nih.govpolifaces.de These technologies can analyze vast datasets to identify patterns and make predictions about the properties and activities of molecules. nih.gov For L-Isoleucylglycinamide, AI and ML can be used to predict its physicochemical properties, potential biological activities, and toxicity, as well as to design novel, optimized analogues. nih.govresearchgate.net
Key applications in this area include:
Quantitative Structure-Activity Relationship (QSAR) Modeling: ML algorithms can build models that correlate the chemical structure of molecules with their biological activity. By training on a dataset of known peptides, a model could predict the potential activity of L-Isoleucylglycinamide.
ADMET Prediction: Predicting the Absorption, Distribution, Metabolism, Excretion, and Toxicity (ADMET) properties of a compound is crucial for drug development. nih.gov AI models, trained on large datasets of experimental data, can provide early estimates of the drug-likeness of L-Isoleucylglycinamide and its derivatives. nih.govarxiv.org
De Novo Peptide Design: Generative AI models, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs), can design entirely new peptide sequences with desired properties. nih.govpolifaces.de Starting with a scaffold like L-Isoleucylglycinamide, these models could suggest modifications to enhance a specific activity or improve stability.
The power of AI lies in its ability to navigate the immense chemical space of possible peptide modifications, guiding experimental work toward the most promising candidates. nih.govnih.gov
| AI/ML Application | Description | Example Input Descriptors for L-Isoleucylglycinamide | Predicted Output |
| Solubility Prediction | ML models trained on experimental solubility data predict how well a compound will dissolve in water or other solvents. | Molecular weight, LogP, number of hydrogen bond donors/acceptors, polar surface area. | Aqueous solubility (e.g., in mg/mL). |
| Binding Affinity Prediction | Deep learning models analyze the 3D structures of a ligand and a protein target to predict the strength of their interaction. | Atomic coordinates, electrostatic potential, hydrophobicity of the binding pocket and the ligand. | Binding free energy (ΔG) or inhibition constant (Ki). |
| Bioactivity Classification | Models classify a compound as active or inactive against a particular target (e.g., an enzyme or receptor) based on its structural features. | Chemical fingerprints (e.g., ECFP, MACCS keys), physicochemical properties. | Probability of being an inhibitor, agonist, or antagonist. |
Integrative Approaches for Multiscale Biological Understanding
Biological processes span multiple scales of length and time, from the quantum behavior of electrons to the interactions of whole organisms. nih.govescholarship.org Understanding the role of a simple molecule like L-Isoleucylglycinamide requires an integrative approach that connects its molecular properties to its effects at the cellular and systemic levels. nih.gov Multiscale modeling is a computational strategy that bridges these different scales. researchgate.netuvm.edu
This integrative framework involves:
All-Atom Molecular Dynamics (MD) Simulations: These simulations model the precise movements of every atom in a molecule and its surrounding environment (e.g., water). This can reveal the conformational flexibility of L-Isoleucylglycinamide and its detailed interactions with a target protein.
Coarse-Grained (CG) Simulations: To study larger systems or longer timescales, such as the self-assembly of peptides or their interaction with a cell membrane, CG models are used. nih.gov In these models, groups of atoms are represented as single beads, reducing computational cost while retaining essential physics. researchgate.netnih.gov
Systems Biology Modeling: At a higher level, the effects of L-Isoleucylglycinamide on a cellular pathway can be modeled using a network of differential equations. This can help predict how modulating one target might affect the entire cellular system.
By combining computational models from different scales with experimental data, researchers can build a more holistic and predictive understanding of a molecule's biological role. nih.govnih.gov
| Modeling Scale | Methodology | System Studied | Information Gained for L-Isoleucylglycinamide |
| Quantum Mechanical (QM) | Density Functional Theory (DFT) | The L-Isoleucylglycinamide molecule itself. | Electron distribution, bond energies, reaction mechanisms. |
| All-Atom (AA) | Molecular Dynamics (MD) | L-Isoleucylglycinamide in a solvent box or bound to a protein active site. | Conformational preferences, specific hydrogen bonds, binding free energy. |
| Coarse-Grained (CG) | Martini Force Field, etc. | Many L-Isoleucylglycinamide molecules interacting with a lipid bilayer. | Propensity to self-assemble, partitioning into membranes, membrane disruption. |
| Cellular/Systems Level | Ordinary Differential Equations (ODEs), Network Analysis | A metabolic or signaling pathway. | Impact on pathway flux, feedback loops, and overall cellular response. |
Q & A
Q. What standardized analytical methods are recommended for characterizing the purity and structural integrity of L-Isoleucylglycinamide?
- Methodological Answer : To ensure reproducibility, employ a combination of high-performance liquid chromatography (HPLC) for purity assessment, nuclear magnetic resonance (NMR) spectroscopy for structural confirmation, and mass spectrometry (MS) for molecular weight validation. Document solvent systems, column specifications, and calibration standards in detail. Cross-reference results with synthetic protocols to identify potential contaminants. Experimental details must align with guidelines for reporting compound characterization in peer-reviewed journals, including full spectral data and purity thresholds (e.g., ≥95%) .
Q. How should initial in vitro assays be designed to evaluate L-Isoleucylglycinamide’s biological activity?
- Methodological Answer : Begin with dose-response experiments using cell lines or enzymatic systems relevant to the compound’s hypothesized targets (e.g., peptide receptors). Include positive and negative controls, and validate assay conditions (pH, temperature, incubation time) through pilot studies. Use triplicate measurements to assess variability. For ligand-binding studies, employ radiolabeled or fluorescent probes with competitive binding protocols. Ensure transparency by adhering to the "ARRIVE guidelines" for preclinical research, which emphasize rigor in experimental design and data reporting .
Q. What critical parameters must be controlled during L-Isoleucylglycinamide synthesis in laboratory settings?
- Methodological Answer : Key parameters include reaction temperature, solvent polarity, catalyst concentration, and protecting group strategies. Monitor reaction progress via thin-layer chromatography (TLC) or real-time MS. Purification steps (e.g., recrystallization, column chromatography) should be optimized to minimize byproducts. Document deviations from published protocols and their impact on yield/purity. Refer to the Beilstein Journal’s experimental section guidelines for granular reporting, including raw data and failure analyses .
Advanced Research Questions
Q. How can researchers resolve discrepancies in reported bioactivity data for L-Isoleucylglycinamide across studies?
- Methodological Answer : Conduct a systematic review using PRISMA or Cochrane frameworks to identify methodological variations (e.g., assay type, cell lines, compound batches) . Perform meta-analyses to quantify heterogeneity, and validate findings through independent replication studies. Investigate potential confounding variables, such as impurities or stereochemical differences, using orthogonal analytical techniques. Engage in peer consultation to interpret conflicting results within the context of study limitations .
Q. What integrated strategies are effective for studying L-Isoleucylglycinamide’s metabolic stability and in vivo pharmacokinetics?
- Methodological Answer : Combine in vitro hepatocyte stability assays with in vivo pharmacokinetic (PK) profiling in rodent models. Use LC-MS/MS for quantifying plasma concentrations and metabolite identification. Apply compartmental modeling (e.g., non-linear mixed-effects modeling) to analyze absorption/distribution parameters. For translational relevance, align protocols with FDA guidelines for preclinical PK studies, including dose proportionality and sex-specific analyses. Statistical plans must be pre-registered to avoid post hoc bias .
Q. How can computational modeling enhance empirical studies of L-Isoleucylglycinamide’s receptor interactions?
- Methodological Answer : Use molecular docking (e.g., AutoDock Vina) to predict binding affinities against target receptors, followed by molecular dynamics simulations (e.g., GROMACS) to assess stability. Validate predictions with mutagenesis studies or surface plasmon resonance (SPR) binding assays. Cross-correlate computational and experimental data to refine force field parameters. Publish raw simulation trajectories and code to facilitate reproducibility, as recommended by open-science initiatives .
Methodological Frameworks and Tools
- Data Contradiction Analysis : Apply the FINER criteria (Feasible, Interesting, Novel, Ethical, Relevant) to evaluate study validity and contextualize contradictions .
- Literature Review : Use scoping studies to map evidence gaps and prioritize replication efforts, particularly for underpowered or methodologically flawed studies .
- Statistical Rigor : Pre-specify analysis plans (e.g., ANOVA, regression models) and power calculations to mitigate Type I/II errors. Consult statisticians during experimental design .
Data Reporting Standards
| Parameter | Reporting Requirement | Example Tools/Methods |
|---|---|---|
| Purity | HPLC chromatograms, integration thresholds | Agilent 1260 Infinity II HPLC |
| Structural Confirmation | NMR chemical shifts, coupling constants | Bruker 600 MHz NMR |
| Bioactivity | IC50/EC50 values, dose-response curves | GraphPad Prism |
| Pharmacokinetics | AUC, Cmax, half-life (t½) | Phoenix WinNonlin |
Table 1: Essential data reporting parameters for L-Isoleucylglycinamide studies, aligned with journal guidelines .
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
