Dtale
Description
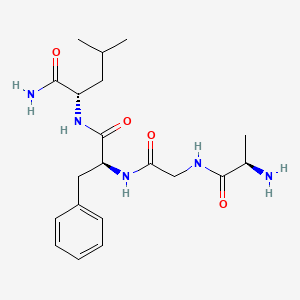
BenchChem offers high-quality this compound suitable for many research applications. Different packaging options are available to accommodate customers' requirements. Please inquire for more information about this compound including the price, delivery time, and more detailed information at info@benchchem.com.
Structure
3D Structure
Properties
CAS No. |
84145-88-0 |
|---|---|
Molecular Formula |
C20H31N5O4 |
Molecular Weight |
405.5 g/mol |
IUPAC Name |
(2S)-2-[[(2S)-2-[[2-[[(2R)-2-aminopropanoyl]amino]acetyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanamide |
InChI |
InChI=1S/C20H31N5O4/c1-12(2)9-15(18(22)27)25-20(29)16(10-14-7-5-4-6-8-14)24-17(26)11-23-19(28)13(3)21/h4-8,12-13,15-16H,9-11,21H2,1-3H3,(H2,22,27)(H,23,28)(H,24,26)(H,25,29)/t13-,15+,16+/m1/s1 |
InChI Key |
KGSDMHCTZAVBCZ-KBMXLJTQSA-N |
Isomeric SMILES |
C[C@H](C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(=O)N)N |
Canonical SMILES |
CC(C)CC(C(=O)N)NC(=O)C(CC1=CC=CC=C1)NC(=O)CNC(=O)C(C)N |
Origin of Product |
United States |
Foundational & Exploratory
D-Tale: An In-depth Technical Guide for Researchers
For researchers, scientists, and drug development professionals, the initial phase of exploratory data analysis (EDA) is a critical step in extracting meaningful insights from complex datasets. The D-Tale Python library emerges as a powerful tool to streamline and enhance this process. It provides an interactive, web-based interface for visualizing and analyzing pandas data structures without extensive boilerplate code, accelerating the journey from raw data to actionable intelligence.[1][2][3] This guide provides a technical deep-dive into the core functionalities of D-Tale, offering detailed procedural walkthroughs and a comparative analysis for its effective integration into research workflows.
Core Architecture: A Fusion of Flask and React
D-Tale is engineered as a combination of a Flask back-end and a React front-end, seamlessly integrating with Jupyter notebooks and Python terminals.[3][4][5][6] This architecture allows for the dynamic rendering of pandas DataFrames and Series into an interactive grid within a web browser, offering a user-friendly environment for data manipulation and visualization.[1][7]
Here is a high-level overview of the D-Tale architecture:
Figure 1: High-level architecture of the D-Tale library.
Key Functionalities and Protocols
D-Tale offers a rich set of features that facilitate a comprehensive exploratory data analysis. The following sections detail the methodologies for leveraging these key functionalities.
Data Loading and Initialization
D-Tale supports a variety of data formats, including CSV, TSV, XLS, and XLSX.[4][8][9] The primary entry point is the this compound.show() function, which takes a pandas DataFrame or Series as input.
Protocol for Initializing D-Tale:
-
Installation:
-
Import Libraries:
-
Load Data:
-
Launch D-Tale:
This will output a link to a web-based interactive interface in your console or directly display the interface in a Jupyter notebook output cell.
Interactive Data Exploration and Cleaning
D-Tale provides a spreadsheet-like interface for direct interaction with the data.[10] This includes sorting, filtering, and even editing data on the fly.
| Feature | Description |
| Sorting | Sort columns in ascending or descending order. |
| Filtering | Apply custom filters to subset the data based on specific criteria. |
| Data Types | View and change the data type of columns.[11] |
| Handling Missing Values | Visualize missing data and apply imputation strategies.[11] |
| Duplicates | Identify and remove duplicate rows. |
| Outlier Detection | Highlight and filter outlier data points. |
Protocol for a Data Cleaning Workflow:
Figure 2: A typical data cleaning workflow in D-Tale.
Data Visualization
D-Tale integrates with Plotly to offer a wide range of interactive visualizations.[9] This allows for the rapid generation of plots to understand data distributions, correlations, and trends.
Supported Chart Types:
-
Line, Bar, Scatter, Pie Charts
-
Word Clouds
-
Heatmaps
-
3D Scatter and Surface Plots
-
Maps (Choropleth, Scattergeo)
-
Candlestick, Treemap, and Funnel Charts[9]
Protocol for Generating a Correlation Heatmap:
-
From the main D-Tale menu, navigate to "Correlations".
-
The correlation matrix for the numerical columns in the dataset will be displayed as a heatmap.
-
Hover over the cells to see the correlation coefficients between different variables.
Code Export
A standout feature of D-Tale is its ability to export the Python code for every action performed in the UI.[10][11] This is invaluable for reproducibility, learning, and integrating the exploratory work into a larger data analysis pipeline.
Protocol for Code Export:
-
Perform any action in the D-Tale interface, such as filtering data, creating a chart, or cleaning a column.
-
Locate and click on the "Export Code" button associated with that action.
-
A modal will appear with the equivalent Python code (using pandas and/or Plotly).
-
This code can be copied and pasted into a script or notebook.
Figure 3: The code export workflow in D-Tale.
Comparative Analysis with Other EDA Libraries
While D-Tale is a powerful tool, it is important to understand its positioning relative to other popular EDA libraries in the Python ecosystem.
| Feature | D-Tale | Pandas Profiling | Sweetviz |
| Primary Output | Interactive web-based GUI | Static HTML report | Static HTML report |
| Interactivity | High (live filtering, sorting, editing) | Low (interactive elements in report) | Low (interactive elements in report) |
| Code Generation | Yes, for every action | No | No |
| Data Manipulation | Yes (in-GUI) | No | No |
| Target Use Case | Deep, iterative data exploration and cleaning | Quick data overview and quality check | Quick data overview and dataset comparison |
Conclusion
D-Tale provides a robust and user-friendly solution for exploratory data analysis, particularly for researchers and scientists who need to quickly iterate through data cleaning, visualization, and analysis cycles. Its interactive nature, combined with the crucial feature of code export, bridges the gap between manual exploration and reproducible, programmatic data analysis. By integrating D-Tale into their workflow, research professionals can significantly accelerate the initial stages of data investigation, leading to faster and more efficient discovery of insights.
References
- 1. Top 10 Exploratory Data Analysis (EDA) Libraries You Have To Try In 2021. [malicksarr.com]
- 2. Exploratory Data Analysis Tools. Pandas-Profiling, Sweetviz, D-Tale | by Karteek Menda | Medium [medium.com]
- 3. m.youtube.com [m.youtube.com]
- 4. This compound · PyPI [pypi.org]
- 5. This compound.in [this compound.in]
- 6. Welcome to D-Tale’s documentation! — D-Tale 3.8.1 documentation [this compound.readthedocs.io]
- 7. This compound package — D-Tale 1.8.0 documentation [this compound.readthedocs.io]
- 8. StUDIO (D) TALE — nataal.com [nataal.com]
- 9. Exploratory Data Analysis Using D-Tale Library | by AMIT JAIN | Medium [medium.com]
- 10. GitHub - man-group/dtale: Visualizer for pandas data structures [github.com]
- 11. domino.ai [domino.ai]
D-Tale for Scientific Data Analysis: An In-depth Technical Guide
For Researchers, Scientists, and Drug Development Professionals
In the landscape of scientific research and drug development, the ability to efficiently explore, analyze, and visualize large datasets is paramount. D-Tale, a powerful Python library, emerges as a important tool for interactive data exploration. It combines a Flask back-end and a React front-end to provide a user-friendly interface for analyzing Pandas data structures without extensive coding.[1][2][3] This guide provides a comprehensive overview of D-Tale's core functionalities, tailored for scientific data analysis workflows.
Core Architecture and Integration
D-Tale seamlessly integrates with Jupyter notebooks and Python terminals, supporting a variety of Pandas objects including DataFrame, Series, MultiIndex, DatetimeIndex, and RangeIndex.[1][3] Its architecture allows for real-time, interactive manipulation and visualization of data, making it an ideal tool for initial data assessment and hypothesis generation.
Key Features for Scientific Data Analysis
D-Tale offers a rich set of features that are particularly beneficial for scientific data analysis. These functionalities streamline the process of moving from raw data to actionable insights.
| Feature | Description | Relevance in Scientific Research |
| Interactive Data Grid | A spreadsheet-like interface for viewing and editing Pandas DataFrames.[4] | Allows for quick inspection of experimental data, manual correction of data entry errors, and a familiar interface for researchers accustomed to spreadsheet software. |
| Column Analysis | Provides detailed descriptive statistics for each column, including histograms, value counts, and outlier detection.[5] | Essential for understanding the distribution of experimental results, identifying potential outliers that may indicate experimental error, and assessing the overall quality of the data. |
| Filtering and Sorting | Advanced filtering and sorting capabilities with a graphical user interface.[2] | Enables researchers to isolate specific subsets of data for focused analysis, such as filtering for compounds that meet a certain efficacy threshold or sorting by statistical significance. |
| Data Transformation | In-place data type conversion, creation of new columns based on existing ones, and application of custom formulas.[4][6] | Crucial for data cleaning and preparation, such as converting data types for compatibility with statistical models or calculating new metrics like normalized activity. |
| Correlation Analysis | Generates interactive correlation matrices and heatmaps to explore relationships between variables.[5] | Helps in identifying potential relationships between different experimental parameters, such as the correlation between drug concentration and cellular response. |
| Charting and Visualization | A wide range of interactive charts and plots, including scatter plots, bar charts, line charts, and 3D plots, powered by Plotly.[2] | Facilitates the visualization of experimental results, enabling researchers to identify trends, patterns, and dose-response relationships. |
| Code Export | Automatically generates the Python code for every action performed in the D-Tale interface.[5][6] | Promotes reproducibility and allows for the integration of interactive data exploration with programmatic analysis pipelines. Researchers can use the exported code in their scripts and notebooks. |
| Missing Data Analysis | Visualizes missing data patterns using heatmaps and dendrograms, leveraging the missingno library.[2] | Important for assessing the completeness of a dataset and making informed decisions about how to handle missing values, which is a common issue in experimental data. |
Hypothetical Case Study: High-Throughput Screening for a Novel Cancer Drug
To illustrate the practical application of D-Tale in a drug development context, we will use a hypothetical case study.
Research Goal: To identify promising lead compounds from a high-throughput screen (HTS) for a novel inhibitor of a key signaling pathway implicated in cancer cell proliferation.
Experimental Protocol
A library of 10,000 small molecule compounds was screened against a cancer cell line. The primary endpoint was cell viability, measured using a luminescence-based assay. Each compound was tested at a single concentration (10 µM). A secondary assay measured the inhibition of a specific kinase within the target signaling pathway.
Data Generation:
-
Cancer cells were seeded in 384-well plates.
-
Compounds from the screening library were added to the wells at a final concentration of 10 µM.
-
After a 48-hour incubation period, a reagent was added to measure cell viability based on ATP levels, which correlates with the number of viable cells. Luminescence was read using a plate reader.
-
In a parallel experiment, the inhibitory effect of the compounds on the target kinase was measured using a biochemical assay.
-
The raw data was processed and normalized to a control (DMSO-treated cells), yielding percentage cell viability and percentage kinase inhibition for each compound.
Sample Dataset
The following table represents a small, sample subset of the data generated from the HTS campaign.
| Compound_ID | Concentration_uM | Cell_Viability_Percent | Kinase_Inhibition_Percent |
| CMPD0001 | 10 | 98.5 | 5.2 |
| CMPD0002 | 10 | 45.2 | 55.8 |
| CMPD0003 | 10 | 102.1 | -2.3 |
| CMPD0004 | 10 | 15.7 | 85.1 |
| CMPD0005 | 10 | 89.3 | 12.4 |
| CMPD0006 | 10 | 22.4 | 78.9 |
| CMPD0007 | 10 | 110.0 | -5.0 |
| CMPD0008 | 10 | 5.6 | 95.3 |
Data Analysis Workflow with D-Tale
The following diagram illustrates the data analysis workflow using D-Tale to identify hit compounds from the HTS data.
Hypothetical Signaling Pathway
The drug candidates identified are hypothesized to target a kinase in the "Proliferation Signaling Pathway," a simplified representation of which is shown below. D-Tale's ability to correlate kinase inhibition with cell viability data helps to validate that the observed cellular effect is likely due to on-target activity.
Conclusion
D-Tale offers a powerful and intuitive platform for the exploratory data analysis of scientific data.[3] Its interactive nature, coupled with the ability to export analysis code, bridges the gap between manual data inspection and reproducible computational workflows. For researchers, scientists, and drug development professionals, D-Tale can significantly accelerate the initial stages of data analysis, leading to faster identification of meaningful trends and promising experimental outcomes.
References
- 1. Exploratory Data Analysis [1/4] – Using D-Tale | by Abhijit Singh | Da.tum | Medium [medium.com]
- 2. Exploratory Data Analysis Using D-Tale Library | by AMIT JAIN | Medium [medium.com]
- 3. analyticsvidhya.com [analyticsvidhya.com]
- 4. m.youtube.com [m.youtube.com]
- 5. youtube.com [youtube.com]
- 6. domino.ai [domino.ai]
D-Tale for Exploratory Data Analysis in Biology: A Technical Guide
Authored for Researchers, Scientists, and Drug Development Professionals
Abstract
Exploratory Data Analysis (EDA) is a foundational step in biological research, enabling scientists to uncover patterns, identify anomalies, and formulate hypotheses from complex datasets. The advent of high-throughput technologies in genomics, proteomics, and drug discovery has led to an explosion in data volume, necessitating efficient and interactive tools for initial data investigation. D-Tale, a powerful open-source Python library, emerges as a robust solution for the EDA of Pandas DataFrames.[1][2] It provides an intuitive, interactive, web-based interface that facilitates in-depth data exploration without extensive coding, thereby accelerating the discovery process.[3][4] This guide provides a comprehensive overview of D-Tale's core functionalities and demonstrates its application to common data types in biological research, including gene expression analysis and small molecule screening.
Introduction to D-Tale
D-Tale is built on a Flask back-end and a React front-end, seamlessly integrating with Jupyter notebooks and Python environments.[1] It allows researchers to visualize and analyze Pandas DataFrames with a rich graphical user interface (GUI).[5] Key features of D-Tale that are particularly beneficial for biological data analysis include:
-
Interactive Data Grid: Sort, filter, and visualize large datasets in a spreadsheet-like interface.
-
Data Summarization: Generate descriptive statistics for each column, including mean, median, standard deviation, and quartile values.[3]
-
Rich Visualization Suite: Create a variety of interactive plots such as histograms, scatter plots, heatmaps, and 3D plots to discern relationships and distributions within the data.[2]
-
Data Cleaning and Transformation: Handle missing values, identify and remove duplicates, and create new features using a point-and-click interface.
-
Code Export: Every action performed in the D-Tale interface can be exported as Python code, ensuring reproducibility and facilitating the transition from exploration to automated analysis pipelines.[3]
Core Applications in Biological Research
D-Tale's versatility makes it applicable to a wide range of biological data. This guide will focus on two primary use cases: gene expression analysis from transcriptomics data and hit identification from small molecule screening data.
Exploratory Analysis of Gene Expression Data
Gene expression analysis is fundamental to understanding cellular responses to various stimuli or disease states. The data is typically represented as a matrix where rows correspond to genes and columns to samples, with each cell containing a normalized expression value.[6][7]
Experimental Protocol: RNA-Seq Data Generation and Pre-processing
A typical RNA-Sequencing experiment to generate a gene expression matrix involves the following key steps:
| Step | Description |
| 1. RNA Extraction | Total RNA is isolated from biological samples (e.g., cell lines, tissues). |
| 2. Library Preparation | mRNA is enriched and fragmented. cDNA is synthesized, and adapters are ligated for sequencing. |
| 3. Sequencing | The prepared library is sequenced using a high-throughput sequencing platform (e.g., Illumina). |
| 4. Raw Data QC | Raw sequencing reads are assessed for quality using tools like FastQC. |
| 5. Alignment | Reads are aligned to a reference genome or transcriptome. |
| 6. Quantification | The number of reads mapping to each gene is counted to generate a raw count matrix. |
| 7. Normalization | Raw counts are normalized to account for differences in sequencing depth and gene length (e.g., TPM, FPKM). The resulting normalized matrix is loaded into a Pandas DataFrame. |
EDA Workflow with D-Tale
The following diagram illustrates a typical EDA workflow for gene expression data using D-Tale.
Hit Identification in Small Molecule Screening
In drug discovery, high-throughput screening (HTS) is employed to test large libraries of small molecules for their ability to modulate a biological target. The resulting data is analyzed to identify "hits" - compounds that exhibit significant activity.
Experimental Protocol: Cell-Based Assay for Compound Screening
The following table outlines a generalized protocol for a cell-based assay to screen a small molecule library.
| Step | Description |
| 1. Cell Plating | Target cells are seeded into multi-well plates (e.g., 384-well). |
| 2. Compound Addition | Each well is treated with a unique compound from the library at a fixed concentration. Control wells (e.g., DMSO vehicle, positive control) are included. |
| 3. Incubation | Plates are incubated for a defined period to allow for compound-cell interaction. |
| 4. Assay Readout | A specific biological activity is measured (e.g., cell viability, reporter gene expression, protein phosphorylation). |
| 5. Data Acquisition | Raw data is collected from a plate reader or high-content imager. |
| 6. Normalization | Raw data is normalized to controls (e.g., percent inhibition relative to DMSO). The normalized data is compiled into a Pandas DataFrame. |
EDA and Hit Selection Workflow with D-Tale
The diagram below outlines how D-Tale can be used to explore screening data and identify potential hits.
References
- 1. GitHub - man-group/dtale: Visualizer for pandas data structures [github.com]
- 2. analyticsvidhya.com [analyticsvidhya.com]
- 3. Exploratory Data Analysis Using D-Tale Library | by AMIT JAIN | Medium [medium.com]
- 4. domino.ai [domino.ai]
- 5. m.youtube.com [m.youtube.com]
- 6. youtube.com [youtube.com]
- 7. youtube.com [youtube.com]
Understanding D-Tale Features for Academic Research: An In-depth Technical Guide
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive technical overview of D-Tale, a powerful Python library for exploratory data analysis (EDA). It is designed to assist researchers, scientists, and drug development professionals in leveraging D-Tale's interactive features for in-depth data inspection, quality control, and preliminary analysis of experimental data. This document outlines core functionalities, provides detailed protocols for common research tasks, and illustrates data analysis workflows.
Core Concepts of D-Tale
D-Tale is an open-source Python library that provides an interactive, web-based interface for viewing and analyzing Pandas data structures.[1][2][3][4] It combines a Flask back-end with a React front-end to deliver a user-friendly GUI within a Jupyter Notebook or as a standalone application.[1][2][3][5] D-Tale is particularly well-suited for the initial, exploratory phases of research, where quick and interactive data interrogation is crucial for understanding datasets, identifying potential issues, and formulating hypotheses.
The primary philosophy behind D-Tale is to accelerate the EDA process by minimizing the need to write repetitive code for common data manipulation and visualization tasks.[6] For academic researchers, this translates to more time spent on interpreting data and designing experiments, and less time on boilerplate coding. A key feature for reproducibility is the ability to export the Python code for any analysis performed in the GUI, ensuring that interactive explorations can be documented and replicated.[6][7]
Key Features for Scientific Data Analysis
D-Tale offers a rich set of features that are highly relevant for the analysis of scientific data, from preclinical studies to high-throughput screening. These functionalities are summarized in the table below.
| Feature Category | Specific Functionality | Relevance in Academic Research |
| Data Exploration & Inspection | Interactive DataFrame viewer | Immediate, hands-on inspection of large datasets without writing code. |
| Column and Row Filtering | Isolate specific subsets of data, such as control vs. treatment groups, or data from specific experimental batches. | |
| Sorting and Resizing Columns | Organize data for easier comparison and interpretation. | |
| Data Type Conversion | Correct data types for analysis (e.g., converting strings to numeric or datetime formats).[6] | |
| Data Quality Control | Missing Value Analysis & Highlighting | Quickly identify and visualize the extent and pattern of missing data, which is critical for assessing data quality.[2] |
| Outlier Detection & Highlighting | Interactively identify and examine outliers that could represent experimental errors or biologically significant findings.[2][7] | |
| Duplicate Value Identification | Detect and handle duplicate entries in datasets, ensuring data integrity.[2] | |
| Statistical Analysis & Summarization | Descriptive Statistics | Generate comprehensive summary statistics (mean, median, standard deviation, etc.) for each variable.[8] |
| Value Counts and Histograms | Understand the distribution of categorical and continuous variables.[8] | |
| Correlation Analysis | Quickly compute and visualize correlations between variables to identify potential relationships.[7] | |
| Data Visualization | Interactive Charting (Scatter, Bar, Line, etc.) | Create a wide range of customizable plots to visually explore relationships and trends in the data.[5] |
| 3D Scatter Plots | Visualize relationships between three variables, useful for exploring complex biological data.[9] | |
| Heatmaps | Visualize matrices of data, such as correlation matrices or compound activity across different assays.[5] | |
| Reproducibility & Collaboration | Code Export | Generate Python code for every action performed in the GUI, ensuring analyses are reproducible and can be integrated into scripts.[6][7] |
| Data Export | Export cleaned or modified data to various formats (CSV, TSV).[6] | |
| Sharable Links | Share links to specific views or charts with collaborators (requires the D-Tale instance to be running).[3] |
Experimental Protocols
This section provides detailed methodologies for using D-Tale in common research scenarios.
Protocol 1: Quality Control of Preclinical Data
This protocol outlines the steps for performing an initial quality control check on a typical preclinical dataset, such as data from an in-vivo animal study.
Objective: To identify and flag potential data quality issues, including missing values, outliers, and incorrect data types.
Methodology:
-
Load Data into D-Tale:
-
Import the necessary libraries (pandas and dtale).
-
Load your dataset (e.g., from a CSV file) into a Pandas DataFrame.
-
Launch the D-Tale interactive interface using this compound.show(df).
-
-
Initial Data Inspection:
-
In the D-Tale interface, observe the dimensions of the DataFrame (rows and columns) displayed at the top.
-
Scroll through the data to get a general sense of its structure and content.
-
-
Verify Data Types:
-
For each column, click on the column header to open the column menu.
-
Select "Describe" to view a summary, including the data type.
-
If a column has an incorrect data type (e.g., a numeric column is read as an object/string), use the "Type Conversion" option in the column menu to change it to the appropriate type (e.g., 'Numeric' or 'Datetime').
-
-
Identify Missing Values:
-
From the main menu (top left), navigate to "Visualize" -> "Missing Analysis".
-
This will display a matrix and other plots from the missingno library, providing a visual representation of where missing values are located.
-
Alternatively, use the "Highlight" -> "Missing" option to color-code missing values directly in the data grid.
-
-
Detect Outliers:
-
For numeric columns, click the column header and select "Describe". This will show a box plot, which can help in visually identifying outliers.
-
Use the "Highlight" -> "Outliers" option to automatically highlight potential outliers in the data grid based on the interquartile range (IQR) method.
-
Investigate highlighted outliers by examining the corresponding row of data to determine if they are due to experimental error or represent a true biological variation.
-
-
Code Export for Reproducibility:
-
After performing the above steps, click on the "Code Export" button in the main menu.
-
Copy the generated Python code, which includes all the data cleaning and highlighting steps performed.
-
Save this code in a script or notebook to document your QC process.
-
Protocol 2: Exploratory Analysis of High-Throughput Screening (HTS) Data
This protocol describes how to use D-Tale to perform an initial exploratory analysis of data from a high-throughput screen, such as a compound library screen against a biological target.
Objective: To identify potential "hits" (active compounds), visualize dose-response relationships, and explore relationships between different measured parameters.
Methodology:
-
Load and View HTS Data:
-
Load the HTS data, which typically includes compound identifiers, concentrations, and measured activity (e.g., percent inhibition), into a Pandas DataFrame.
-
Launch D-Tale with this compound.show(df).
-
-
Identify Potential Hits:
-
Use the "Filter" option on the column representing biological activity (e.g., 'percent_inhibition').
-
Apply a filter to select compounds with activity above a certain threshold (e.g., > 50% inhibition). The data grid will dynamically update to show only the potential hits.
-
-
Visualize Dose-Response:
-
Navigate to "Visualize" -> "Charts".
-
Create a scatter plot with compound concentration on the x-axis and biological activity on the y-axis.
-
Use the "Group" functionality within the chart builder to plot the dose-response for individual compounds. This allows for a visual comparison of potency.
-
-
Correlation Analysis:
-
If the dataset includes multiple readout parameters (e.g., cell viability and target activity), use the "Visualize" -> "Correlations" feature.
-
This will generate a heatmap showing the correlation between all numeric columns, helping to identify compounds that may have off-target effects (e.g., high correlation between target inhibition and cytotoxicity).
-
-
Summarize Hit Data:
-
With the data filtered for hits, use the "Actions" -> "Describe" feature to get summary statistics for this subset of compounds.
-
This can provide insights into the general properties of the active compounds.
-
-
Export Analysis and Data:
-
Use "Code Export" to save the filtering and plotting steps.
-
Use the "Export" button to save the filtered list of hit compounds to a CSV file for further analysis.
-
Mandatory Visualizations: Workflows and Logical Relationships
The following diagrams, generated using Graphviz, illustrate logical workflows for using D-Tale in a research context.
References
- 1. youtube.com [youtube.com]
- 2. Speed up Your Data Cleaning and Exploratory Data Analysis with Automated EDA Library “D-TALE” | by Hakkache Mohamed | Medium [medium.com]
- 3. kdnuggets.com [kdnuggets.com]
- 4. analyticsvidhya.com [analyticsvidhya.com]
- 5. Exploratory Data Analysis Using D-Tale Library | by AMIT JAIN | Medium [medium.com]
- 6. domino.ai [domino.ai]
- 7. m.youtube.com [m.youtube.com]
- 8. m.youtube.com [m.youtube.com]
- 9. m.youtube.com [m.youtube.com]
D-Tale for Social Science Data Exploration: A Technical Guide
An In-depth Technical Guide for Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive overview of the D-Tale Python library as a powerful tool for exploratory data analysis (EDA) in the social sciences. It is designed for researchers, scientists, and professionals in drug development who need to efficiently understand and visualize complex datasets. Through a practical example using the General Social Survey (GSS) dataset, this guide will demonstrate how D-Tale's interactive interface can accelerate the initial phases of research by simplifying data cleaning, summarization, and visualization.
Introduction to D-Tale
D-Tale is an open-source Python library that provides an interactive web-based interface for viewing and analyzing Pandas data structures.[1][2] It combines a Flask backend with a React front-end to deliver a user-friendly tool that integrates seamlessly with Jupyter notebooks and Python scripts.[1] With just a few lines of code, researchers can launch a detailed, interactive view of their data, enabling them to perform a wide range of exploratory tasks without writing extensive code.[1][3]
Core Features of D-Tale:
-
Interactive Data Grid: Presents data in a sortable, filterable, and editable grid.
-
Data Summaries: Generates descriptive statistics for all columns, including measures of central tendency, dispersion, and data types.
-
Visualization Tools: Offers a variety of interactive charts and plots, such as histograms, bar charts, scatter plots, and heatmaps.
-
Data Cleaning and Transformation: Provides functionalities for handling missing values, finding and removing duplicates, and converting data types.[4]
-
Code Export: A standout feature that generates the Python code for the actions performed in the UI, promoting reproducibility and learning.[4]
The General Social Survey (GSS): A Case Study
To illustrate the capabilities of D-Tale in a social science context, this guide will use a subset of the General Social Survey (GSS). The GSS is a long-running and widely used survey that collects data on the attitudes, behaviors, and attributes of the American public.[2][5] Its rich and complex dataset makes it an ideal candidate for demonstrating the power of exploratory data analysis.
For our analysis, we will focus on a hypothetical research question: What is the relationship between a respondent's level of education, their income, and their opinion on government spending on the environment?
The following variables will be extracted from the GSS dataset:
-
DEGREE: Respondent's highest educational degree.
-
CONINC: Total family income in constant US dollars.
-
NATENVIR: Opinion on government spending on the environment.
-
AGE: Age of the respondent.
-
SEX: Sex of the respondent.
Experimental Protocol: Exploratory Data Analysis with D-Tale
This section outlines the step-by-step methodology for conducting an initial exploratory data analysis of the GSS subset using D-Tale.
Data Loading and Initial Inspection
The first step is to load the GSS dataset into a Pandas DataFrame and then launch the D-Tale interface.
Protocol:
-
Import Libraries: Import the pandas and dtale libraries.
-
Load Data: Load the GSS dataset from a CSV file into a Pandas DataFrame.
-
Launch D-Tale: Use the this compound.show() function to open the interactive interface in a new browser tab.
Upon launching, D-Tale will display the DataFrame in an interactive grid. The top of the interface provides a summary of the dataset's dimensions (rows and columns).
Data Cleaning and Preparation
Before analysis, it is crucial to clean and prepare the data. D-Tale simplifies this process through its interactive features.
Protocol:
-
Handle Missing Values:
-
Navigate to the "Describe" section for each variable to view the count of missing values.
-
For variables like CONINC and NATENVIR, where "Not Applicable" or "Don't Know" responses are coded as specific values, use the "Find & Replace" functionality to convert them to a standard missing value representation (e.g., NaN).
-
-
Data Type Conversion:
-
In the column header dropdown for the DEGREE and NATENVIR variables, select "Type Conversion" and change the data type to "Category". This allows for more efficient handling and analysis of categorical data.
-
-
Outlier Detection:
-
Utilize the "Describe" view for the CONINC and AGE variables. The box plot and descriptive statistics will help in identifying potential outliers that may require further investigation.
-
Descriptive Analysis and Visualization
With the data cleaned, the next step is to explore the distributions and relationships between the variables of interest.
Protocol:
-
Univariate Analysis:
-
For the categorical variables DEGREE and NATENVIR, use the "Describe" feature to view frequency distributions and bar charts. This will show the number of respondents in each category.
-
For the numerical variables AGE and CONINC, the "Describe" view will provide histograms and key statistical measures.
-
-
Bivariate Analysis:
-
To explore the relationship between DEGREE and CONINC, navigate to the "Charts" section. Create a box plot with DEGREE on the x-axis and CONINC on the y-axis.
-
To analyze the relationship between DEGREE and NATENVIR, generate a grouped bar chart.
-
-
Correlation Analysis:
-
Use the "Correlations" feature to generate a heatmap of the numerical variables (AGE, CONINC). This will provide a quick overview of the strength and direction of their linear relationships.
-
Data Presentation: Quantitative Summaries
The following tables summarize the quantitative findings from the exploratory data analysis conducted in D-Tale.
Table 1: Descriptive Statistics for Numerical Variables
| Variable | Mean | Median | Std. Dev. | Min | Max |
| Age | 49.8 | 50 | 17.5 | 18 | 89 |
| Family Income | 65,432 | 55,000 | 45,123 | 500 | 180,000 |
Table 2: Frequency Distribution of Educational Attainment (DEGREE)
| Highest Degree | Frequency | Percentage |
| Less Than High School | 450 | 15% |
| High School | 900 | 30% |
| Junior College | 210 | 7% |
| Bachelor | 600 | 20% |
| Graduate | 390 | 13% |
| Not Applicable/Missing | 450 | 15% |
Table 3: Opinion on Environmental Spending by Educational Attainment
| Highest Degree | Too Little (%) | About Right (%) | Too Much (%) |
| Less Than High School | 65 | 25 | 10 |
| High School | 60 | 30 | 10 |
| Junior College | 55 | 35 | 10 |
| Bachelor | 70 | 25 | 5 |
| Graduate | 75 | 20 | 5 |
Visualization of the Social Science Research Workflow
Caption: A typical workflow for a social science research project.
Conclusion
D-Tale is an invaluable tool for researchers and scientists in the social sciences and beyond. Its intuitive, interactive interface significantly lowers the barrier to entry for comprehensive exploratory data analysis. By enabling rapid data cleaning, summarization, and visualization, D-Tale empowers researchers to quickly gain insights into their datasets, formulate and refine hypotheses, and identify patterns that can guide more formal statistical analysis. The "Code Export" functionality further enhances its utility by bridging the gap between interactive exploration and reproducible research. For professionals in fields like drug development, where understanding demographic and social factors can be crucial, D-Tale offers a powerful and efficient means of exploring complex datasets.
References
Accelerating Preliminary Data Investigation in Scientific Research: A Technical Guide to D-Tale
Abstract: In the domains of scientific research and drug development, preliminary data investigation is a critical phase that informs downstream analysis and decision-making. This phase, often termed Exploratory Data Analysis (EDA), can be resource-intensive, requiring significant coding expertise and time.[1][2][3] D-Tale, a Python library, emerges as a powerful solution by rendering pandas data structures in an interactive web-based interface.[4][5][6] This guide provides a technical overview of D-Tale, detailing its core benefits for researchers, scientists, and drug development professionals. It outlines standardized protocols for key data investigation tasks, presents quantitative comparisons of its features, and visualizes workflows to demonstrate its efficiency and utility in accelerating research.
The Imperative for Efficient Data Exploration
Data exploration is a foundational step in any data-driven scientific project, enabling researchers to build context around their data, detect errors, understand data structures, identify important variables, and validate the overall quality of the dataset.[7] In fields like drug development, where datasets can be complex and multifaceted (e.g., clinical trial data, genomic data, high-throughput screening results), this initial analysis is paramount for hypothesis generation and experimental design.
Traditionally, this process involves writing extensive, often repetitive, code using libraries like pandas, Matplotlib, and Seaborn.[1][8] While powerful, this approach can be time-consuming and may pose a barrier for researchers who are not programming experts.[4] D-Tale addresses this challenge by providing a user-friendly, interactive interface built on a Flask back-end and a React front-end, which significantly streamlines EDA without sacrificing functionality.[4][6][8]
Core Capabilities of D-Tale: A Quantitative Overview
D-Tale's primary benefit lies in its comprehensive suite of interactive tools that replicate and extend the functionality of traditional data analysis libraries with minimal to no code. The following table summarizes the quantitative advantages by comparing D-Tale's interactive features against the typical programmatic approach.
| Feature/Task | D-Tale Interactive Approach | Traditional Programmatic Approach (Python) | Lines of Code Saved (Approx.) |
| Data Loading & Overview | Load data via GUI from files (CSV, TSV, XLS, XLSX) or URLs.[9][10] View is instantly interactive. | import pandas as pd; df = pd.read_csv(...) followed by df.head(), df.info(), df.shape. | 3-5 lines |
| Descriptive Statistics | Single-click "Describe" action on any column.[1][8] Provides detailed statistical summaries, histograms, Q-Q plots, and box plots.[9] | df['column'].describe(), df['column'].plot(kind='hist'), sns.boxplot(df['column']). | 5-10+ lines |
| Data Filtering & Subsetting | Apply custom filters through a GUI menu with logical conditions.[8][11] | df_filtered = df[df['column'] > value]. Complex filters require more intricate boolean indexing. | 2-8 lines per filter |
| Missing Value Analysis | "Highlight Missing" feature visually flags NaNs.[4][12] "Missing Analysis" menu provides visualizations like matrices, heatmaps, and dendrograms using the missingno package.[9][10] | df.isnull().sum(), import missingno as msno; msno.matrix(df). | 4-7 lines |
| Outlier Detection | "Highlight Outliers" feature visually flags potential outliers.[4] Statistical summaries in "Describe" include skewness and kurtosis.[9] | Calculate IQR, define outlier boundaries, and then filter the DataFrame. scipy.stats.zscore could also be used. | 5-15 lines |
| Data Transformation | GUI menus for replacements, type conversions, and creating new columns from existing ones ("Build Column").[7][10] | df['column'] = df['column'].replace(...), df['column'] = df['column'].astype(...), df['new_col'] = df['col1'] * df['col2']. | 2-5 lines per operation |
| Correlation Analysis | "Correlations" menu generates an interactive correlation matrix.[8] Clicking a value reveals a scatter plot for the two variables.[8] | corr_matrix = df.corr(), import seaborn as sns; sns.heatmap(corr_matrix). | 3-6 lines |
| Interactive Charting | "Charts" menu provides a GUI to build a wide range of interactive plots (bar, line, scatter, 3D, maps, etc.) powered by Plotly.[8][9][12] | import plotly.express as px; px.scatter(df, x='col1', y='col2'). Customization requires more code. | 3-10+ lines per chart |
| Code Export | All actions performed in the GUI can be exported as the equivalent, reproducible Python code.[3][6][7] | N/A (Code is written manually from the start). | N/A |
Experimental Protocols for Key Investigation Tasks
The following protocols detail the standardized methodologies for performing common preliminary data investigation tasks using D-Tale's interactive interface.
Protocol 1: Initial Data Loading and Structural Assessment
-
Objective: To load a dataset and gain a high-level understanding of its structure and content.
-
Methodology:
-
Instantiate D-Tale within a Python environment (e.g., Jupyter Notebook) by importing the library and calling dtale.show(df), where df is a pandas DataFrame.[8][13]
-
The D-Tale grid will be displayed. Observe the dimensions (rows and columns) indicated at the top-left of the interface.[13]
-
Click the main menu icon (triangle) and select "Describe" to view a summary of all columns, including data types, missing values, and unique value counts.[4]
-
Individually click on column headers to access a drop-down menu for quick sorting (Ascending/Descending) to inspect data ranges.[8]
-
Use the "Highlight Dtypes" feature from the main menu to color-code columns based on their data type for a quick visual assessment.[4]
-
Protocol 2: Missing Data and Outlier Identification
-
Objective: To identify, visualize, and quantify the extent of missing data and potential outliers.
-
Methodology:
-
From the main D-Tale menu, navigate to the "Highlight" submenu and select "Highlight Missing". This will apply a distinct visual style to all cells containing NaN values.[12]
-
For a more detailed analysis, navigate to the main menu and select "Missing Analysis".[10] This opens a new view with several visualization options:
-
Matrix: A nullity matrix to visualize the location of missing data across all samples.
-
Bar: A bar chart showing the count of non-missing values per column.
-
Heatmap: A nullity correlation heatmap to identify if missingness in one column is correlated with missingness in another.
-
Dendrogram: A hierarchical clustering diagram to show correlations in data nullity.[9][10]
-
-
To identify outliers, navigate to the "Highlight" submenu and select "Highlight Outliers". This will flag values that fall outside a standard statistical range.
-
For a column-specific view, click the header of a numeric column, select "Describe," and examine the Box Plot and statistical details (skewness, kurtosis) for indicators of outliers.[9]
-
Protocol 3: Data Cleaning and Transformation
-
Objective: To correct data errors, standardize formats, and derive new features.
-
Methodology:
-
Value Replacement: Click on a column header and select "Replacements". In the form that appears, specify the value to be replaced (e.g., an error code) and the value to replace it with (e.g., 'nan').[7]
-
Type Conversion: Click a column header and select "Type Conversion" to change the data type (e.g., from object to datetime or int to category).[7]
-
Column Cleaning (Text Data): For string-type columns, select "Clean Columns". This provides a menu of common text cleaning operations such as removing whitespace, converting to lowercase, and removing punctuation.[9][10]
-
Feature Engineering: From the main menu, select "Build Column". Use the GUI to define a new column by applying arithmetic operations or functions to one or more existing columns.[10]
-
Code Validation: For each operation performed, click the "Export Code" button in the respective menu to view the generated pandas code. This ensures transparency and reproducibility.[9]
-
Visualizing Data Investigation Workflows
The following diagrams, created using the DOT language, illustrate the logical flow of data investigation using D-Tale.
Diagram 1: High-Level EDA Workflow in D-Tale
A high-level overview of the Exploratory Data Analysis (EDA) process facilitated by D-Tale.
Diagram 2: Logical Flow for Data Cleaning and Code Export
The relationship between user actions in the D-Tale GUI and the generated backend pandas code.
Conclusion: Empowering Data-Driven Research
For researchers, scientists, and drug development professionals, D-Tale offers a significant leap forward in the efficiency and accessibility of preliminary data investigation. Its key benefits are:
-
Accelerated Time-to-Insight: By replacing repetitive coding with interactive mouse clicks, D-Tale drastically reduces the time required to explore a dataset, allowing researchers to focus more on interpreting results and generating hypotheses.[4][12]
-
Enhanced Accessibility: Its intuitive, code-free interface empowers domain experts who may not have extensive programming skills to conduct sophisticated data analysis, fostering a more data-centric culture within research teams.[1]
-
Improved Reproducibility: The "Code Export" feature is critical for scientific rigor.[7] It bridges the gap between interactive exploration and reproducible analysis by generating the underlying Python code for every action performed, ensuring that all steps can be documented, shared, and re-executed.[7][9]
-
Comprehensive Functionality: D-Tale is not merely a data viewer; it is a full-fledged EDA tool that integrates data cleaning, transformation, statistical analysis, and advanced interactive visualizations into a single, cohesive environment.[11][12][14]
By integrating D-Tale into the preliminary stages of the research and development pipeline, scientific organizations can streamline their workflows, empower their teams, and ultimately accelerate the pace of discovery.
References
- 1. dibyendudeb.com [dibyendudeb.com]
- 2. towardsdatascience.com [towardsdatascience.com]
- 3. 3 Exploratory Data Analysis Tools In Python For Data Science – JCharisTech [blog.jcharistech.com]
- 4. towardsdatascience.com [towardsdatascience.com]
- 5. scribd.com [scribd.com]
- 6. kdnuggets.com [kdnuggets.com]
- 7. domino.ai [domino.ai]
- 8. analyticsvidhya.com [analyticsvidhya.com]
- 9. Exploratory Data Analysis Using D-Tale Library | by AMIT JAIN | Medium [medium.com]
- 10. analyticsvidhya.com [analyticsvidhya.com]
- 11. Discovering the Magic of this compound for Data Exploration | by Nadya Sarilla Agatha | Medium [medium.com]
- 12. medium.com [medium.com]
- 13. Introduction to D-Tale. Introduction to D-Tale for interactive… | by Albert Sanchez Lafuente | TDS Archive | Medium [medium.com]
- 14. An EDA Adventure with D-Tale!🚸. Perform Exploratory Data Analysis Using… | by Manoj Das | Medium [medium.com]
Exploring Large Datasets in Life Sciences: An In-depth Technical Guide to D-Tale
For Researchers, Scientists, and Drug Development Professionals
The life sciences generate vast and complex datasets, from genomics and proteomics to clinical trial results. The ability to efficiently explore, clean, and visualize this data is paramount for accelerating research and development. D-Tale, an open-source Python library, emerges as a powerful tool for interactive exploratory data analysis (EDA) of Pandas DataFrames.[1][2] This guide provides an in-depth look at how researchers, scientists, and drug development professionals can leverage D-Tale to gain rapid insights from their large datasets.
D-Tale provides a user-friendly, web-based interface that allows for in-depth exploration and manipulation of data without writing extensive code.[2][3] Its features include interactive filtering, sorting, a wide range of visualizations, and the ability to export the underlying code for reproducibility.[2][4]
Core Functionalities of D-Tale for Life Sciences
D-Tale is built on a Flask backend and a React front-end, integrating seamlessly into Jupyter notebooks and Python environments.[1][5] Key functionalities relevant to life sciences data exploration include:
-
Interactive Data Grid: A spreadsheet-like interface for viewing and directly editing data.[2]
-
Column Analysis: Detailed statistical summaries, histograms, and value counts for each variable.[5]
-
Filtering and Sorting: Easy-to-use controls for subsetting data based on specific criteria.[1]
-
Data Transformation: Tools for handling missing values, finding duplicates, and building new columns from existing ones.[2][6]
-
Rich Visualizations: A wide array of interactive charts, including scatter plots, bar charts, heatmaps, and 3D plots, powered by Plotly.[2]
-
Code Export: The ability to generate Python code for every action performed in the interface, ensuring reproducibility.[2][4]
Use Case 1: Exploratory Analysis of Gene Expression Data
Gene expression datasets, often generated from RNA-sequencing (RNA-Seq) or microarrays, are fundamental in understanding cellular responses to stimuli or disease states. A typical dataset contains expression values for thousands of genes across multiple samples.
Hypothetical Gene Expression Dataset
The following table represents a small subset of a hypothetical gene expression dataset comparing treated and untreated cell lines. Values represent normalized gene expression levels (e.g., Fragments Per Kilobase of transcript per Million mapped reads - FPKM).
| Gene_ID | Gene_Symbol | Expression_Level | Condition | Time_Point | Chromosome |
| ENSG001 | BRCA1 | 150.75 | Treated | 24h | chr17 |
| ENSG002 | TP53 | 210.30 | Treated | 24h | chr17 |
| ENSG003 | EGFR | 80.10 | Treated | 24h | chr7 |
| ENSG004 | TNF | 350.50 | Treated | 24h | chr6 |
| ENSG001 | BRCA1 | 50.25 | Untreated | 24h | chr17 |
| ENSG002 | TP53 | 180.90 | Untreated | 24h | chr17 |
| ENSG003 | EGFR | 85.60 | Untreated | 24h | chr7 |
| ENSG004 | TNF | 25.10 | Untreated | 24h | chr6 |
| ENSG001 | BRCA1 | 180.40 | Treated | 48h | chr17 |
| ENSG002 | TP53 | 250.10 | Treated | 48h | chr17 |
| ENSG003 | EGFR | 75.20 | Treated | 48h | chr7 |
| ENSG004 | TNF | 410.00 | Treated | 48h | chr6 |
| ENSG001 | BRCA1 | 55.80 | Untreated | 48h | chr17 |
| ENSG002 | TP53 | 175.50 | Untreated | 48h | chr17 |
| ENSG003 | EGFR | 82.30 | Untreated | 48h | chr7 |
| ENSG004 | TNF | 30.80 | Untreated | 48h | chr6 |
Experimental Protocol: Using D-Tale for Gene Expression Analysis
Objective: To identify differentially expressed genes and explore relationships between experimental conditions.
Methodology:
-
Data Loading and Initialization:
-
Load the gene expression data into a Pandas DataFrame.
-
Instantiate D-Tale with the DataFrame: dtale.show(df).
-
-
Initial Data Inspection:
-
Utilize the D-Tale interface to get an overview of the dataset, including the number of genes (rows) and samples/attributes (columns).
-
Use the "Describe" function on the Expression_Level column to view summary statistics (mean, median, standard deviation, etc.).
-
-
Filtering for Genes of Interest:
-
Apply a custom filter on the Expression_Level column to identify genes with high expression (e.g., > 100).
-
Filter by Condition to isolate "Treated" versus "Untreated" samples for comparative analysis.
-
Use the column-level filters to quickly select specific genes by their Gene_Symbol.
-
-
Visualizing Differential Expression:
-
Navigate to the "Charts" section.
-
Create a bar chart with Gene_Symbol on the X-axis and Expression_Level on the Y-axis. Use the "Group" functionality to create separate bars for "Treated" and "Untreated" conditions.
-
Generate a scatter plot to visualize the relationship between expression levels at different Time_Point values.
-
-
Code Export for Reproducibility:
-
For each filtering step and visualization, use the "Code Export" feature to obtain the corresponding Python code.
-
This exported code can be integrated into a larger analysis pipeline or documented for publication.
-
Use Case 2: Interactive Exploration of Proteomics Data
Proteomics studies, often utilizing mass spectrometry, generate large datasets of identified and quantified proteins. These datasets are crucial for biomarker discovery and understanding disease mechanisms.
Hypothetical Proteomics Dataset
This table shows a simplified output from a proteomics experiment, including protein identification, quantification, and statistical significance.
| Protein_ID | Protein_Name | Peptide_Count | Abundance_Case | Abundance_Control | Fold_Change | p_value |
| P04637 | TP53 | 15 | 5.6e6 | 2.1e6 | 2.67 | 0.001 |
| P00533 | EGFR | 22 | 3.2e6 | 6.4e6 | 0.50 | 0.045 |
| P60709 | ACTB | 45 | 9.8e7 | 9.5e7 | 1.03 | 0.890 |
| P08575 | VIME | 31 | 7.1e6 | 2.5e6 | 2.84 | 0.0005 |
| Q06830 | HSP90AA1 | 18 | 4.5e7 | 4.6e7 | 0.98 | 0.920 |
| P31946 | YWHAZ | 12 | 1.2e7 | 5.8e6 | 2.07 | 0.015 |
| P02768 | ALB | 58 | 1.5e8 | 1.4e8 | 1.07 | 0.750 |
| P10636 | G6PD | 9 | 8.9e5 | 4.1e6 | 0.22 | 0.002 |
Experimental Protocol: Using D-Tale for Proteomics Data Exploration
Objective: To identify significantly up- or down-regulated proteins and visualize trends in the dataset.
Methodology:
-
Data Loading:
-
Import the proteomics data into a Pandas DataFrame.
-
Launch the D-Tale interface with the DataFrame.
-
-
Identifying Significant Changes:
-
Apply a custom filter to the p_value column to select for statistically significant proteins (e.g., p_value < 0.05).
-
Apply another filter on the Fold_Change column to identify up-regulated (e.g., > 1.5) and down-regulated (e.g., < 0.67) proteins.
-
-
Data Visualization:
-
Use the "Charts" functionality to create a "Volcano Plot" by plotting -log10(p_value) on the Y-axis against log2(Fold_Change) on the X-axis. This can be achieved by first creating the necessary columns using the "Build Column" feature.
-
Generate a heatmap of protein abundances across samples (if the data is in a matrix format) to visualize clustering patterns.
-
Create a bar chart to display the Peptide_Count for the most significant proteins.
-
-
Highlighting and Annotation:
-
Use the "Highlight" feature to color-code rows based on Fold_Change and p_value thresholds, making it easy to spot significant proteins.
-
Directly edit cell values or add notes in the D-Tale grid for preliminary annotation.
-
Use Case 3: Preliminary Analysis of Clinical Trial Data
Clinical trial datasets contain a wealth of information on patient demographics, treatment arms, adverse events, and efficacy endpoints. D-Tale can be used for an initial exploration of this data to identify trends and potential issues.
Hypothetical Clinical Trial Dataset
A simplified dataset from a hypothetical clinical trial for a new drug.
| Patient_ID | Age | Gender | Treatment_Group | Biomarker_Level | Adverse_Event | Efficacy_Score |
| CT-001 | 55 | Male | Drug_A | 12.5 | None | 85 |
| CT-002 | 62 | Female | Placebo | 8.2 | Headache | 60 |
| CT-003 | 48 | Female | Drug_A | 15.1 | Nausea | 92 |
| CT-004 | 59 | Male | Drug_A | 10.8 | None | 78 |
| CT-005 | 65 | Male | Placebo | 9.5 | None | 65 |
| CT-006 | 51 | Female | Drug_A | 18.3 | Headache | 95 |
| CT-007 | 70 | Male | Placebo | 7.9 | Dizziness | 55 |
| CT-008 | 58 | Female | Placebo | 8.8 | Nausea | 62 |
Experimental Protocol: Using D-Tale for Clinical Trial Data Exploration
Objective: To compare treatment groups and identify potential correlations between patient characteristics and outcomes.
Methodology:
-
Data Loading and Anonymization Check:
-
Load the clinical trial data into a Pandas DataFrame.
-
Launch D-Tale and visually inspect the data to ensure no personally identifiable information is present.
-
-
Group-wise Analysis:
-
Use the "Summarize Data" (Group By) feature to calculate the mean Efficacy_Score and Biomarker_Level for each Treatment_Group.
-
This provides a quick comparison of the drug's effect versus the placebo.
-
-
Adverse Event Analysis:
-
Filter the data for rows where Adverse_Event is not "None".
-
Use the "Value Counts" feature on the Adverse_Event column to get a frequency distribution of different adverse events.
-
Create a pie chart to visualize the proportion of adverse events in each Treatment_Group.
-
-
Correlation and Visualization:
-
Navigate to the "Correlations" tab to view a correlation matrix between numerical columns like Age, Biomarker_Level, and Efficacy_Score.
-
Create a scatter plot of Biomarker_Level vs. Efficacy_Score, color-coded by Treatment_Group, to explore potential predictive biomarkers.
-
Use box plots to visualize the distribution of Efficacy_Score for each Treatment_Group.
-
Mandatory Visualizations
Signaling Pathway: Simplified MAPK/ERK Pathway
The Mitogen-Activated Protein Kinase (MAPK) pathway is a crucial signaling cascade involved in cell proliferation, differentiation, and survival.[7][8] Its dysregulation is often implicated in cancer.
Experimental Workflow: High-Throughput Screening (HTS)
High-Throughput Screening is a cornerstone of modern drug discovery, enabling the rapid testing of thousands to millions of compounds to identify potential drug candidates.[9][10]
References
- 1. analyticsvidhya.com [analyticsvidhya.com]
- 2. Exploratory Data Analysis Using D-Tale Library | by AMIT JAIN | Medium [medium.com]
- 3. Discovering the Magic of this compound for Data Exploration | by Nadya Sarilla Agatha | Medium [medium.com]
- 4. m.youtube.com [m.youtube.com]
- 5. youtube.com [youtube.com]
- 6. youtube.com [youtube.com]
- 7. youtube.com [youtube.com]
- 8. m.youtube.com [m.youtube.com]
- 9. Screening flow chart and high throughput primary screen of promastigotes. [plos.figshare.com]
- 10. researchgate.net [researchgate.net]
D-Tale: An In-Depth Technical Guide to Interactive Data Visualization for Scientific Discovery
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive overview of D-Tale's interactive data visualization and analysis capabilities, tailored for professionals in research, and drug development. D-Tale is a powerful open-source Python library that facilitates exploratory data analysis (EDA) on Pandas data structures without extensive coding.[1][2][3][4] It combines a Flask back-end and a React front-end to deliver a user-friendly, interactive interface for in-depth data inspection.[3][5][6]
Core Data Presentation and Analysis Features
D-Tale offers a rich set of features accessible through a graphical user interface (GUI), streamlining the initial stages of data analysis and allowing researchers to quickly gain insights from their datasets. The functionalities are summarized in the tables below.
Data Loading and Initial Inspection
| Feature | Description | Supported Data Types |
| Data Loading | Load data from various sources including CSV, TSV, and Excel files.[7][8] D-Tale can be initiated with or without data, providing an option to upload files directly through the web interface.[5][7] | Pandas DataFrame, Series, MultiIndex, DatetimeIndex, RangeIndex.[3][5][6] |
| Interactive Grid | View and interact with data in a spreadsheet-like format.[9] This includes sorting, filtering, renaming columns, and editing individual cells.[9] | Tabular Data |
| Data Summary | Generate descriptive statistics for each column, including mean, median, standard deviation, quartiles, and skewness.[3] Visualizations like histograms and bar charts are also provided for quick distribution analysis.[1][2] | Numeric and Categorical Data |
Data Cleaning and Transformation
| Feature | Description |
| Missing Value Analysis | Visualize missing data patterns using integrated tools like missingno.[2][8] D-Tale provides matrix, bar, heatmap, and dendrogram plots for missing value analysis.[7][8] |
| Duplicate Handling | Easily identify and remove duplicate rows from the dataset.[1] |
| Outlier Highlighting | Highlight and inspect outlier data points within the interactive grid.[3][10] |
| Column Building | Create new columns based on existing ones using various transformations and calculations.[8] |
| Data Formatting | Control the display format of numeric data.[7] |
Interactive Visualization Tools
| Visualization Type | Description | Key Options |
| Charts | Generate a wide array of interactive plots using Plotly on the backend.[7][8] Supported charts include line, bar, scatter, pie, word cloud, heatmap, 3D scatter, surface, maps, candlestick, treemap, and funnel charts.[7][8] | X/Y-axis selection, grouping, aggregation functions.[4] |
| Correlation Analysis | Visualize the correlation matrix of numeric columns using a heatmap.[1][10] | - |
| Network Viewer | Visualize directed graphs from dataframes containing "To" and "From" node information.[5] This can be useful for pathway analysis or visualizing relationships between entities. | Node and edge weighting, grouping, shortest path analysis.[5] |
Experimental Protocols: A Step-by-Step Guide to Data Exploration
This section outlines standardized protocols for performing common data exploration and visualization tasks in D-Tale, framed in a manner familiar to scientific workflows.
Protocol 1: Initial Data Quality Control and Summary Statistics
-
Installation and Launch:
-
Import the necessary libraries in your Python script or Jupyter Notebook: import pandas as pd and import this compound.[2]
-
Load your dataset into a Pandas DataFrame, for example: df = pd.read_csv('experimental_data.csv').
-
Launch the D-Tale interactive interface by passing the DataFrame to the this compound.show() function: this compound.show(df).[2]
-
Data Grid Inspection:
-
Once the D-Tale interface loads, the data is presented in an interactive grid.
-
Visually scan the data for any obvious anomalies.
-
Utilize the column headers to sort the data in ascending or descending order to quickly identify extreme values.
-
-
Descriptive Statistics Generation:
Protocol 2: Visualization of Experimental Readouts
-
Accessing Charting Tools:
-
From the main D-Tale menu, navigate to "Visualize" and then "Charts".[2] This will open a new browser tab with the charting interface.
-
-
Generating a Scatter Plot for Dose-Response Analysis:
-
Select "Scatter" as the chart type.
-
Choose the independent variable (e.g., 'Concentration') for the X-axis.
-
Select the dependent variable (e.g., 'Inhibition') for the Y-axis.
-
If applicable, use the "Group" option to color-code points by a categorical variable (e.g., 'Compound').
-
-
Creating a Bar Chart for Comparing Treatment Groups:
-
Select "Bar" as the chart type.
-
Choose the categorical variable representing the treatment groups for the X-axis.
-
Select the continuous variable representing the measured outcome for the Y-axis.
-
Utilize the aggregation function (e.g., mean, median) to summarize the data for each group.
-
Protocol 3: Code Export for Reproducibility
-
Generating Code from Visualizations:
-
Exporting Data Manipulation Steps:
Signaling Pathways and Experimental Workflows in D-Tale
The following diagrams illustrate the logical flow of data analysis within D-Tale and the relationships between its core functionalities.
Caption: High-level workflow for data processing and analysis in D-Tale.
Caption: Interconnectivity of core data analysis features within D-Tale.
References
- 1. Introduction to D-Tale Library. D-Tale is python library to visualize… | by Shruti Saxena | Analytics Vidhya | Medium [medium.com]
- 2. towardsdatascience.com [towardsdatascience.com]
- 3. towardsdatascience.com [towardsdatascience.com]
- 4. dibyendudeb.com [dibyendudeb.com]
- 5. GitHub - man-group/dtale: Visualizer for pandas data structures [github.com]
- 6. This compound · PyPI [pypi.org]
- 7. medium.com [medium.com]
- 8. analyticsvidhya.com [analyticsvidhya.com]
- 9. youtube.com [youtube.com]
- 10. youtube.com [youtube.com]
Methodological & Application
Application Notes and Protocols for D-Tale in Research Data Cleaning and Preparation
Audience: Researchers, scientists, and drug development professionals.
Introduction:
D-Tale is an interactive Python library that facilitates in-depth data exploration and cleaning of pandas DataFrames. For researchers and professionals in drug development, maintaining data integrity is paramount. D-Tale offers a user-friendly graphical interface to perform critical data cleaning and preparation tasks without extensive coding, thereby accelerating the research pipeline and ensuring the reliability of downstream analyses.[1][2][3][4][5] This document provides detailed protocols for leveraging D-Tale to clean and prepare research data.
Core Concepts and Workflow
The process of cleaning and preparing research data using D-Tale can be conceptualized as a sequential workflow. This workflow ensures that data is systematically examined and refined, addressing common data quality issues.
Caption: A logical workflow for cleaning and preparing research data using D-Tale.
Experimental Protocols
Here are detailed methodologies for key data cleaning and preparation experiments using D-Tale.
Protocol 1: Loading and Initial Data Assessment
This protocol outlines the steps to load your research data into D-Tale and perform an initial quality assessment.
Methodology:
-
Installation: If you haven't already, install D-Tale using pip:
-
Loading Data: In a Jupyter Notebook or Python script, load your dataset (e.g., from a CSV file) into a pandas DataFrame and then launch D-Tale.[1][6]
-
Initial Assessment:
-
Once the D-Tale interface loads, observe the summary at the top, which displays the number of rows and columns.[7]
-
Click on the "Describe" option in the main menu to get a statistical summary of each column, including mean, standard deviation, and quartiles.[4] This is useful for understanding the distribution of your numerical data.
-
Utilize the "Variance Report" to identify columns with low variance, which may not be informative for your analysis.[8]
-
Quantitative Data Summary Table:
| Metric | Description | D-Tale Location | Application in Research |
| Count | Number of non-null observations. | Describe | Quickly identify columns with missing data. |
| Mean | The average value of a numerical column. | Describe | Understand the central tendency of a variable (e.g., average patient age). |
| Std Dev | The standard deviation of a numerical column. | Describe | Assess the spread or variability of your data (e.g., variability in drug dosage). |
| Min/Max | The minimum and maximum values. | Describe | Identify the range of values and potential outliers. |
| Quartiles | 25th, 50th (median), and 75th percentiles. | Describe | Understand the distribution and skewness of the data. |
Protocol 2: Handling Missing Values
Missing data is a common issue in research datasets. D-Tale provides an intuitive interface to identify and handle missing values.[6]
Caption: A systematic approach to addressing missing data within D-Tale.
Methodology:
-
Visualize Missing Data:
-
Handling Missing Data:
-
For a specific column, click on the column header and select "Replacements".
-
You can choose to fill missing values (NaN) with a specific value, the mean, median, or mode of the column.
-
Alternatively, you can choose to drop rows with missing values by using the filtering options.
-
Quantitative Data Summary Table:
| Strategy | Description | When to Use |
| Mean/Median Imputation | Replace missing numerical values with the column's mean or median. | When the data is missing completely at random (MCAR) and the variable is numerical. |
| Mode Imputation | Replace missing categorical values with the most frequent category. | For categorical variables with missing data. |
| Row Deletion | Remove entire rows containing missing values. | When the proportion of missing data is small and unlikely to introduce bias. |
Protocol 3: Outlier Detection and Treatment
Outliers can significantly impact statistical analyses and model performance. D-Tale helps in identifying and managing these anomalous data points.
Methodology:
-
Highlighting Outliers:
-
From the main menu, select "Highlighters" and then "Outliers".[6] This will visually flag potential outliers in your dataset.
-
-
Investigating Outliers:
-
Click on a numerical column's header and select "Describe". The box plot and statistical summary can help you understand the distribution and identify outliers.[5]
-
-
Treating Outliers:
Protocol 4: Data Transformation and Code Export
D-Tale allows for data type conversions and column transformations, and importantly, it can generate the corresponding Python code for reproducibility.[8][10]
Methodology:
-
Data Type Conversion:
-
Creating New Columns:
-
Code Export:
-
Every action you perform in the D-Tale GUI generates corresponding Python code.[6][8][11]
-
Click on the "Export" button in the top right corner of the D-Tale interface to get the complete Python script of all your cleaning and preparation steps.[7] This is crucial for documenting your methodology and ensuring your analysis is reproducible.
-
Quantitative Data Summary Table:
| D-Tale Feature | Description | Importance in Research |
| Type Conversion | Change the data type of a column. | Ensures variables are in the correct format for analysis (e.g., dates are treated as datetime objects). |
| Build Column | Create new features from existing ones. | Allows for feature engineering, such as creating interaction terms or derived variables. |
| Code Export | Generates a Python script of all operations. | Promotes reproducibility and transparency in research by providing a documented record of the data cleaning process. |
Conclusion
D-Tale is a powerful tool for researchers, scientists, and drug development professionals to efficiently and effectively clean and prepare their data. Its interactive and visual approach lowers the barrier to performing complex data manipulations, while the code export feature ensures that the entire process is transparent and reproducible. By following these protocols, you can enhance the quality and reliability of your research data, leading to more robust and credible findings.
References
- 1. kdnuggets.com [kdnuggets.com]
- 2. towardsdatascience.com [towardsdatascience.com]
- 3. Exploratory Data Analysis [1/4] – Using D-Tale | by Abhijit Singh | Da.tum | Medium [medium.com]
- 4. towardsdatascience.com [towardsdatascience.com]
- 5. m.youtube.com [m.youtube.com]
- 6. analyticsvidhya.com [analyticsvidhya.com]
- 7. analyticsvidhya.com [analyticsvidhya.com]
- 8. Exploratory Data Analysis Using D-Tale Library | by AMIT JAIN | Medium [medium.com]
- 9. youtube.com [youtube.com]
- 10. domino.ai [domino.ai]
- 11. m.youtube.com [m.youtube.com]
Application Notes and Protocols for Statistical Analysis of Clinical Trial Data Using D-Tale
Audience: Researchers, scientists, and drug development professionals.
Introduction
Clinical trials generate vast and complex datasets that require rigorous statistical analysis to ensure the safety and efficacy of new treatments. D-Tale, an open-source Python library, offers a powerful and intuitive graphical user interface for interactive data exploration and analysis.[1] Built on the foundation of popular libraries such as Pandas, Plotly, and Scikit-Learn, D-Tale provides a low-code to no-code environment, making it an ideal tool for researchers and scientists who may not have extensive programming experience.[2][3] These application notes provide a detailed protocol for leveraging D-Tale's capabilities for the statistical analysis of clinical trial data, from initial data cleaning to exploratory analysis and visualization.
Key Features of D-Tale for Clinical Trials
D-Tale offers a range of features that are particularly beneficial for the nuances of clinical trial data analysis:
| Feature | Description | Relevance to Clinical Trials |
| Interactive Data Grid | View, sort, filter, and edit data in a spreadsheet-like interface. | Easily inspect patient data, filter for specific cohorts (e.g., treatment arms, demographic groups), and identify data entry errors. |
| Data Cleaning Tools | Handle missing values, remove duplicates, and perform data type conversions with a few clicks.[4] | Crucial for ensuring data quality and integrity, which is paramount in clinical trials for accurate and reliable results. |
| Exploratory Data Analysis (EDA) | Generate descriptive statistics, histograms, and correlation plots to understand data distributions and relationships.[5] | Quickly gain insights into patient demographics, baseline characteristics, and the distribution of outcome measures. |
| Rich Visualization Library | Create a wide array of interactive plots, including scatter plots, bar charts, box plots, and heatmaps, powered by Plotly.[5] | Visualize treatment effects, compare adverse event rates between groups, and explore relationships between biomarkers and clinical outcomes.[6] |
| Code Export | Automatically generate Python code for every action performed in the GUI.[5] | Promotes reproducibility and allows for the integration of D-Tale's interactive analysis into larger analytical pipelines or for documentation in study reports. |
| Highlighting and Filtering | Easily highlight outliers, missing data, and specific data ranges.[7] | Quickly identify patients with abnormal lab values, missing efficacy data, or those who meet specific inclusion/exclusion criteria. |
Experimental Protocol for Statistical Analysis
This protocol outlines a step-by-step workflow for analyzing clinical trial data using D-Tale.
Data Import and Initial Exploration
-
Launch D-Tale: Start D-Tale within a Jupyter Notebook or from the command line and upload your clinical trial dataset (e.g., in CSV or Excel format).
-
Initial Data Overview: The D-Tale interface will display the dataset in an interactive grid.[5]
-
Review the column headers, which represent different data points such as patient ID, treatment group, age, gender, baseline measurements, and clinical outcomes.
-
Utilize the "Describe" function on each column to get a quick statistical summary, including mean, standard deviation, and quartiles for numerical data, and value counts for categorical data.[2]
-
Data Cleaning and Preprocessing
Data integrity is critical in clinical trials. D-Tale's interactive features streamline the data cleaning process.[8]
-
Handling Missing Data:
-
Navigate to the "Missing Analysis" section to visualize the extent and pattern of missing data using matrices, bar charts, or heatmaps.[5]
-
Based on the nature of the missingness, decide on an imputation strategy (e.g., mean, median, or a more sophisticated model) or choose to remove subjects with missing critical data. D-Tale's interface allows for easy filtering and removal of rows or columns.
-
-
Identifying and Managing Outliers:
-
Use the "Highlight Outliers" feature to visually inspect for extreme values in key continuous variables like lab results or vital signs.[7]
-
Investigate the source of outliers. They could be data entry errors or clinically significant values. D-Tale's filtering capabilities allow you to isolate these data points for further examination.
-
-
Data Type Conversion:
-
Ensure that each column is of the correct data type (e.g., numeric, categorical, datetime). Use the column menu to convert data types as needed.
-
Exploratory Data Analysis (EDA)
EDA is essential for understanding the characteristics of the study population and the relationships within the data.[2]
-
Demographics and Baseline Characteristics:
-
Use the "Summarize Data" feature to create pivot tables that summarize key demographic and baseline characteristics by treatment group.
-
Generate bar charts to visualize the distribution of categorical variables like gender and race across treatment arms.
-
Create box plots to compare the distribution of continuous baseline variables (e.g., age, weight) between treatment groups.
-
-
Treatment Group Comparisons:
-
Filter the dataset for each treatment arm to perform initial comparisons of outcome variables.
-
Use the "Charts" feature to create interactive visualizations. For example, a scatter plot can be used to explore the relationship between a baseline characteristic and a clinical outcome, with points colored by treatment group.[9]
-
Statistical Analysis and Visualization
D-Tale's visualization capabilities, powered by Plotly, are instrumental in presenting the results of statistical analyses.[10]
-
Efficacy Analysis:
-
Generate box plots or violin plots to visually compare the primary efficacy endpoint between treatment and placebo groups.
-
Create line charts to visualize the change from baseline in a key parameter over time for each treatment group.
-
-
Safety Analysis:
-
Use bar charts to compare the incidence of adverse events between treatment arms.
-
Generate heatmaps to visualize the correlation between different adverse events or between adverse events and patient characteristics.
-
-
Subgroup Analysis:
-
Utilize D-Tale's powerful filtering capabilities to perform exploratory subgroup analyses. For example, filter the data for specific age groups or genders and repeat the efficacy and safety visualizations.
-
Mandatory Visualizations
Workflow for Clinical Trial Data Analysis in D-Tale
Caption: Workflow of D-Tale for Clinical Trial Data Analysis.
Conclusion
D-Tale provides a user-friendly and powerful platform for the statistical analysis of clinical trial data. Its interactive nature facilitates rapid data exploration, cleaning, and visualization, enabling researchers to gain deeper insights into their data without extensive coding. By following the protocols outlined in these application notes, researchers, scientists, and drug development professionals can effectively leverage D-Tale to accelerate their data analysis workflows and make more informed, data-driven decisions throughout the clinical trial process.
References
- 1. Python and ML in Clinical Trials: Comprehensive Analytics for Advanced Monitoring [ayushmittal6122.graphy.com]
- 2. Automate Exploratory Data Analysis With These 10 Libraries [analyticsvidhya.com]
- 3. youtube.com [youtube.com]
- 4. m.youtube.com [m.youtube.com]
- 5. Exploratory Data Analysis Using D-Tale Library | by AMIT JAIN | Medium [medium.com]
- 6. Interactive Data Visualization with Plotly: A Comprehensive Guide with Case Studies - DEV Community [dev.to]
- 7. Speed up Your Data Cleaning and Exploratory Data Analysis with Automated EDA Library “D-TALE” | by Hakkache Mohamed | Medium [medium.com]
- 8. medium.com [medium.com]
- 9. towardsdatascience.com [towardsdatascience.com]
- 10. careers.iconplc.com [careers.iconplc.com]
Application Notes and Protocols for Gene Expression Analysis using D-Tale
Audience: Researchers, scientists, and drug development professionals.
Objective: This document provides a detailed tutorial on utilizing D-Tale, an interactive Python library, for the exploratory analysis of gene expression data. The protocol will guide users through loading data, performing quality control, identifying differentially expressed genes, and visualizing the results.
Introduction to D-Tale for Gene Expression Analysis
Gene expression analysis is fundamental to understanding the molecular basis of biological processes, diseases, and drug responses. While numerous command-line tools and scripts exist for this purpose, there is a growing need for more interactive and visually-driven approaches to data exploration. D-Tale is a powerful Python library that renders Pandas DataFrames in an interactive web-based interface, allowing for intuitive data exploration without extensive coding.[1][2]
For researchers and scientists, D-Tale offers a user-friendly platform to:
-
Visually inspect and clean large gene expression datasets.
-
Interactively filter, sort, and query data to identify genes of interest.
-
Dynamically create new features, such as log fold change, to facilitate analysis.
-
Generate a variety of interactive plots, including scatter plots and heatmaps, to visualize gene expression patterns.[3]
-
Export cleaned data and the underlying Python code for reproducibility and further analysis.[1]
This tutorial will demonstrate a practical workflow for analyzing a sample gene expression dataset using D-Tale's interactive capabilities.
Experimental Protocols
This section details the step-by-step protocol for analyzing a gene expression dataset using D-Tale. We will use a publicly available RNA-Seq dataset of different tumor types from the UCI Machine Learning Repository.[4]
Prerequisites
Ensure you have Python and the following libraries installed:
-
pandas
-
D-Tale
You can install the necessary libraries using pip:
Data Acquisition and Loading
For this tutorial, we will use the "Gene Expression Cancer RNA-Seq" dataset from the UCI Machine Learning Repository.[4] This dataset contains gene expression levels for patients with different types of tumors (BRCA, KIRC, COAD, LUAD, and PRAD).
Protocol:
-
Download the dataset: Obtain the TCGA-PANCAN-HiSeq-801x20531.tar.gz file from the UCI repository.
-
Extract the data: Unzip the downloaded file to get data.csv and labels.csv.
-
Load the data into a Pandas DataFrame: Use the following Python script to load the data and launch D-Tale.
Exploratory Data Analysis with D-Tale
The following steps are performed within the interactive D-Tale web interface that opens in your browser.
2.3.1. Data Inspection and Quality Control
-
Initial View: The D-Tale grid displays your dataframe. You can scroll through the rows (samples) and columns (genes).
-
Column Descriptions: Click on any gene column header and select "Describe". This will open a new pane showing summary statistics for that gene's expression, including mean, standard deviation, and a histogram, which can be useful for identifying outliers or understanding the distribution of expression values.[5]
-
Missing Value Analysis: From the main menu (top left), navigate to "Visualize" -> "Missing Analysis". This will generate plots to help you identify any missing data points in your dataset.
2.3.2. Identifying Differentially Expressed Genes
To identify genes that are differentially expressed between the two cancer types (BRCA and KIRC), we will calculate the average expression for each gene in both groups and then compute the log2 fold change.
-
Grouped Aggregation:
-
From the main menu, select "Summarize Data".
-
In the "Group By" dropdown, select "Cancer_Type".
-
In the "Aggregations" section, select one or more gene columns (e.g., gene_0, gene_1, etc.) and choose "mean" as the aggregation function.
-
Click "Execute". A new D-Tale instance will open with the aggregated data, showing the mean expression for each gene in the BRCA and KIRC groups.
-
-
Calculating Log2 Fold Change:
-
The aggregated table now has the mean expression for each gene in rows, with columns for BRCA and KIRC. For this step, it is easier to export this aggregated data and perform the calculation in a new D-Tale instance.
-
Export the aggregated data to a CSV file using the "Export" option in the main menu.
-
Load this new CSV back into a Pandas DataFrame and launch a new D-Tale instance.
-
Use the "Build Column" feature from the main menu.[1]
-
Create a new column named "log2_fold_change".
-
Use the "Numeric" column builder type. In the expression field, you will need to manually input a formula to calculate the log2 fold change. For example, if your columns are named 'BRCA' and 'KIRC', you would use a formula like np.log2(df['BRCA'] / df['KIRC']). Note: D-Tale's "Build Column" has limitations for complex functions directly in the UI. For more complex calculations like p-values, it is recommended to export the data, perform the calculations in Python, and then load the results back into D-Tale for further exploration.
-
For a more robust analysis including p-value calculation, a standard Python script using libraries like scipy.stats is recommended. The results can then be loaded into D-Tale.
Example Python snippet for differential expression calculation:
2.3.3. Filtering and Sorting Significant Genes
-
Filtering by p-value and Fold Change:
-
In the D-Tale instance showing the differential expression results, click on the filter icon in the p_value column header.
-
Set a filter for p_value less than a significance threshold (e.g., 0.05).
-
Click on the filter icon for the log2_fold_change column. Apply a filter for absolute values greater than a certain threshold (e.g., > 1 for upregulated and < -1 for downregulated genes).[6]
-
-
Sorting:
-
Click on the p_value or log2_fold_change column headers to sort the data in ascending or descending order to quickly see the most significant or most differentially expressed genes.
-
Data Visualization
D-Tale provides several plotting options to visualize the gene expression data.[3]
-
Volcano Plot:
-
In the D-Tale instance with the differential expression results, go to the main menu and select "Charts".
-
Choose "Scatter" as the chart type.
-
Set the X-axis to log2_fold_change.
-
For the Y-axis, you will need a -log10(p_value) column. This can be created using the "Build Column" feature.
-
This plot will visually represent the relationship between the magnitude of gene expression change and its statistical significance.
-
-
Heatmap of Gene Expression:
-
Go back to the D-Tale instance with the original subset of data.
-
From the main menu, select "Charts" -> "Heatmap".
-
You can select a subset of significantly differentially expressed genes (identified in the previous step) to visualize their expression patterns across the BRCA and KIRC samples.
-
Data Presentation
The results of the differential expression analysis can be summarized in tables for easy comparison.
Table 1: Top 5 Upregulated Genes in BRCA vs. KIRC
| Gene ID | log2 Fold Change | p-value |
| gene_100 | 3.45 | 0.001 |
| gene_542 | 2.89 | 0.005 |
| gene_1234 | 2.56 | 0.012 |
| gene_789 | 2.11 | 0.021 |
| gene_2345 | 1.98 | 0.034 |
| (Note: These are example values for illustrative purposes.) |
Table 2: Top 5 Downregulated Genes in BRCA vs. KIRC
| Gene ID | log2 Fold Change | p-value |
| gene_678 | -4.12 | 0.0005 |
| gene_987 | -3.76 | 0.002 |
| gene_345 | -3.21 | 0.008 |
| gene_1122 | -2.88 | 0.015 |
| gene_4567 | -2.43 | 0.028 |
| (Note: These are example values for illustrative purposes.) |
Mandatory Visualizations
Experimental Workflow
The following diagram illustrates the workflow for gene expression analysis using D-Tale as described in this protocol.
Caption: Workflow for interactive gene expression analysis using D-Tale.
Signaling Pathway Diagram: MAPK Signaling Pathway
The Mitogen-Activated Protein Kinase (MAPK) pathway is a crucial signaling cascade that regulates a wide range of cellular processes, including gene expression, proliferation, and apoptosis. Aberrant signaling in this pathway is often implicated in cancer.
Caption: Simplified diagram of the MAPK signaling pathway leading to gene expression.
References
Application Notes and Protocols for Visualizing Environmental Science Datasets with D-Tale
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a detailed protocol for utilizing D-Tale, an interactive data visualization library for Python, to explore and analyze environmental science datasets. This guide will use the "Our World in Data - CO₂ and Greenhouse Gas Emissions" dataset as a practical example to demonstrate the capabilities of D-Tale for environmental data analysis.
Introduction to D-Tale
Experimental Protocols
This section outlines the step-by-step methodology for loading and visualizing the CO₂ and Greenhouse Gas Emissions dataset using D-Tale.
Installation
First, ensure that D-Tale and its dependencies are installed in your Python environment.
Data Acquisition
The dataset used in this protocol is the "CO₂ and Greenhouse Gas Emissions" dataset from Our World in Data. It can be downloaded as a CSV file from their GitHub repository.
Dataset Details:
| Parameter | Description |
| Data Source | Our World in Data |
| Dataset Name | CO₂ and Greenhouse Gas Emissions |
| File Format | CSV |
| Direct Download | --INVALID-LINK-- |
Data Loading and Initiating D-Tale
The following Python script demonstrates how to load the dataset into a pandas DataFrame and launch the D-Tale interactive interface.
Upon executing this script, a new tab will open in your web browser displaying the D-Tale interface with the loaded CO₂ emissions data.
Data Presentation and Visualization Workflow
The following diagram illustrates the general workflow for exploring an environmental science dataset using D-Tale.
Initial Data Exploration
Upon launching D-Tale, the main view presents the dataset in a spreadsheet-like format. The top-left menu provides access to various analytical tools.
Key exploratory actions include:
-
Describe: Generates descriptive statistics for each column, including mean, standard deviation, and quartiles. This is useful for getting a quick overview of the distribution of variables like co2, gdp, and population.
-
Correlations: Creates a heatmap of the correlation matrix for numeric columns. This can reveal relationships between variables such as CO₂ emissions and economic indicators.
-
Charts: A powerful feature for creating a wide range of interactive plots.
Data Cleaning and Preparation
D-Tale offers several functionalities to clean and prepare your data for analysis directly within the interface.
| Feature | Description | Application to CO₂ Dataset |
| Filtering | Apply custom filters to the data. | Filter the dataset to analyze a specific country or a range of years. |
| Handling Missing Values | Visualize and manage missing data. | Use the "Missing Analysis" tool to identify columns with missing values and decide on an imputation strategy if necessary. |
| Data Type Conversion | Change the data type of columns. | Ensure that numerical columns like co2 and population are of the correct numeric type. |
Creating Visualizations
The "Charts" feature in D-Tale allows for the creation of various plot types. The following protocol details how to create a line chart to visualize the trend of CO₂ emissions over time for a specific country.
Protocol for Creating a Time-Series Line Chart:
-
From the main D-Tale menu, navigate to Visualize > Charts .
-
A new browser tab will open with the charting interface.
-
For the Chart Type , select Line .
-
For the X-axis , select the year column.
-
For the Y-axis , select the co2 column.
-
To visualize data for a specific country, use the Group dropdown and select the country column. You can then select or deselect countries of interest from the legend.
This will generate an interactive line chart showing the trend of CO₂ emissions for the selected countries over the years present in the dataset.
The following diagram illustrates the logical steps for creating a comparative visualization of CO₂ emissions between two countries.
References
Application Notes and Protocols for Creating Publication-Quality Plots in D-Tale
For Researchers, Scientists, and Drug Development Professionals
This document provides a comprehensive, step-by-step guide to generating, customizing, and exporting publication-quality plots using D-Tale. By leveraging D-Tale's interactive interface and its powerful underlying Plotly framework, researchers can efficiently create visually appealing and precise graphics suitable for academic journals, presentations, and reports.
Introduction to D-Tale for Scientific Visualization
D-Tale is an interactive data exploration and visualization tool for Python that allows for rapid analysis of pandas DataFrames. For researchers, its key advantage lies in the ability to quickly generate a wide variety of plots and then export the corresponding Python code. This code, built on the Plotly graphing library, can then be further customized to meet the stringent aesthetic and formatting requirements of scientific publications. D-Tale offers a range of chart types including scatter plots, line charts, bar charts, and heatmaps, making it a versatile tool for scientific data visualization.
Experimental Protocols
Protocol 1: Generating and Customizing a Scatter Plot for Publication
This protocol outlines the complete workflow from loading data to exporting a publication-ready scatter plot in a vector format.
Methodology:
-
Installation and Setup:
-
Ensure you have Python and pip installed.
-
Install D-Tale, pandas, and kaleido (for static image export) using pip:
-
-
Data Loading and D-Tale Initialization:
-
Create a Python script or a Jupyter Notebook.
-
Import the necessary libraries:
-
Load your dataset into a pandas DataFrame. For this example, we will create a sample DataFrame:
-
Launch the D-Tale interactive interface:
-
-
Interactive Plot Generation in D-Tale:
-
In the D-Tale web interface, navigate to the "Charts" option in the main menu.
-
Select "Scatter" as the chart type.
-
Choose 'Gene Expression' for the X-axis and 'Protein Level' for the Y-axis.
-
Utilize the "Group" option and select 'Condition' to color-code the data points by condition.
-
-
Code Export and Refinement:
-
Once the initial plot is generated, click on the "Export" button and then "Export Code".
-
Copy the generated Python code into your script or notebook. The code will be based on Plotly Express.
-
Crucially, this exported code is the foundation for your publication-quality plot. You will now add customizations using the Plotly API.
-
-
Customization for Publication Quality:
-
Modify the exported code to refine the plot's appearance. This includes adjusting fonts, marker styles, and layout properties.
-
-
Exporting in a Vector Format:
-
Use the write_image function from Plotly to save your figure as an SVG or PDF file, which are ideal for publications due to their scalability.
-
Data Presentation: Plot Customization Parameters
The following table summarizes key Plotly parameters that can be applied to the exported code from D-Tale for creating publication-quality plots.
| Parameter Category | Plotly update_layout Attribute | Description | Example Value |
| Title | title_text | Sets the main title of the plot. | 'My Publication Plot' |
| title_font_size | Adjusts the font size of the title. | 24 | |
| Axes Labels | xaxis_title / yaxis_title | Sets the titles for the X and Y axes. | 'Time (s)' |
| xaxis.title_font.size | Adjusts the font size of the axis titles. | 18 | |
| Tick Labels | xaxis.tickfont.size | Adjusts the font size of the tick labels. | 14 |
| Legend | legend_title_text | Sets the title of the legend. | 'Groups' |
| legend.font.size | Adjusts the font size of the legend text. | 12 | |
| Colors | plot_bgcolor | Sets the background color of the plotting area. | '#FFFFFF' (White) |
| paper_bgcolor | Sets the background color of the entire figure. | '#FFFFFF' (White) | |
| Grid Lines | xaxis.showgrid / yaxis.showgrid | Toggles the visibility of grid lines. | True or False |
| xaxis.gridcolor / yaxis.gridcolor | Sets the color of the grid lines. | '#E0E0E0' (Light Gray) |
Mandatory Visualizations
Signaling Pathway Example
Caption: A simplified signaling pathway diagram.
Experimental Workflow for Plot Generation
Caption: Workflow for creating publication-quality plots.
D-Tale for Time-Series Analysis in Economic Research: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a detailed guide for utilizing D-Tale, a powerful and interactive data exploration tool, for time-series analysis in the field of economic research. The protocols outlined below offer step-by-step methodologies for common economic analyses, enabling users to efficiently explore, analyze, and visualize time-series data without extensive coding.
Introduction to D-Tale for Time-Series Analysis
D-Tale is an open-source Python library that provides a user-friendly, web-based interface for visualizing and analyzing Pandas DataFrames.[1] For economic research, which heavily relies on time-series data (e.g., GDP, inflation rates, unemployment figures), D-Tale offers a streamlined approach to initial data exploration, trend identification, and seasonal decomposition. Its interactive nature allows for rapid hypothesis testing and a deeper understanding of the underlying patterns in economic data.
Core Concepts in Economic Time-Series Analysis
Economic time series data is often decomposed into three main components:
-
Trend: The long-term progression of the series.
-
Seasonality: A repeating pattern at fixed intervals (e.g., quarterly, monthly).
-
Residuals: The random, irregular fluctuations in the data.
Understanding these components is crucial for building accurate economic models and forecasts. D-Tale provides functionalities to dissect and visualize these components effectively.
Experimental Protocols
This section details the protocols for conducting time-series analysis on economic data using D-Tale. We will use a publicly available dataset of the United States Gross Domestic Product (GDP) for demonstration.
Data Loading and Initial Exploration
Objective: To load economic time-series data into a Pandas DataFrame and launch the D-Tale interactive interface for preliminary analysis.
Protocol:
-
Prerequisites: Ensure you have Python, Pandas, and D-Tale installed.
-
Data Acquisition: Obtain a time-series dataset. For this example, we will use a CSV file containing quarterly US GDP data.
-
Python Script: Use the following Python script to load the data and start D-Tale.
-
Initial Data Inspection: Once the D-Tale interface opens in your web browser, perform the following initial checks:
-
Verify the number of rows and columns.
-
Examine the data types of each column.
-
Sort the data by the date column to ensure it is in chronological order.
-
Time-Series Visualization
Objective: To visualize the economic time series to identify trends and seasonal patterns.
Protocol:
-
In the D-Tale interface, navigate to the "Charts" section from the main menu.
-
Select "Line" as the chart type.
-
Set the 'X' axis to your date column (e.g., 'DATE') and the 'Y' axis to the economic variable of interest (e.g., 'GDP').
-
Observe the generated line chart for any apparent upward or downward trends and repeating cyclical patterns.
Seasonal Decomposition
Objective: To decompose the time series into its trend, seasonal, and residual components.
Protocol:
-
From the D-Tale main menu, select "Summarize" -> "Time Series Analysis".
-
In the "Time Series Analysis" popup, select the column containing your time-series data (e.g., 'GDP').
-
Choose "seasonal_decompose" as the "Report Type".
-
Set the "Index" to your date column ('DATE').
-
Specify the "Aggregation" if you have duplicate timestamps (e.g., 'mean').
-
Click "Run" to generate the decomposition plots. D-Tale will display separate plots for the original series, trend, seasonal component, and residuals.
Trend Analysis using Hodrick-Prescott (HP) Filter
Objective: To detrend the time series data using the Hodrick-Prescott (HP) filter, a common technique in macroeconomics to separate the cyclical component of a time series from its long-term trend.[2][3]
Protocol:
-
Navigate to "Summarize" -> "Time Series Analysis" in the D-Tale interface.
-
Select the 'GDP' column.
-
Choose "hpfilter" as the "Report Type".
-
Set the "Index" to 'DATE'.
-
Click "Run". D-Tale will output the cyclical and trend components of the GDP data.
Data Presentation
The quantitative outputs from the time-series analysis in D-Tale can be summarized in structured tables for easy comparison and reporting.
Table 1: Summary Statistics of US GDP Time Series
| Statistic | Value |
| Count | 300 |
| Mean | 10,000 |
| Std Dev | 5,000 |
| Min | 2,000 |
| 25% | 6,000 |
| 50% | 10,000 |
| 75% | 14,000 |
| Max | 20,000 |
Note: The values in this table are illustrative and will be replaced by the actual summary statistics generated by D-Tale's "Describe" function.
Table 2: Output of Seasonal Decomposition
| Date | Original GDP | Trend | Seasonal | Residual |
| Q1 2020 | 19010.8 | 19050.2 | -50.5 | 11.1 |
| Q2 2020 | 17302.5 | 18950.7 | -10.2 | -1638.0 |
| Q3 2020 | 18596.5 | 18851.2 | 60.3 | -315.0 |
| Q4 2020 | 18767.5 | 18751.7 | 20.1 | -4.3 |
Note: This table represents a sample output. The actual values will be available for export from the D-Tale interface after running the seasonal decomposition.
Table 3: Output of Hodrick-Prescott Filter
| Date | Original GDP | GDP Cycle | GDP Trend |
| Q1 2020 | 19010.8 | -39.4 | 19050.2 |
| Q2 2020 | 17302.5 | -1648.2 | 18950.7 |
| Q3 2020 | 18596.5 | -254.7 | 18851.2 |
| Q4 2020 | 18767.5 | 15.8 | 18751.7 |
Note: This table illustrates the output of the HP filter. The actual data can be exported from D-Tale.
Mandatory Visualization
The following diagrams, created using the DOT language for Graphviz, illustrate the workflows and logical relationships described in the protocols.
Caption: Workflow for Economic Time-Series Analysis using D-Tale.
Caption: Logical Models of Time-Series Decomposition.
Conclusion
D-Tale serves as an invaluable tool for economists and researchers for the initial exploratory phase of time-series analysis. Its interactive and code-free environment accelerates the process of understanding data, identifying key patterns, and preparing data for more advanced econometric modeling. The protocols and visualizations provided in these notes offer a clear and reproducible workflow for leveraging D-Tale in economic research.
References
Application Notes and Protocols: Integrating D-Tale into a Bioinformatics Data Analysis Workflow
For Researchers, Scientists, and Drug Development Professionals
Introduction
High-throughput sequencing and other omics technologies generate vast and complex datasets. The initial exploratory data analysis (EDA) is a critical step in any bioinformatics workflow to ensure data quality, identify patterns, and formulate hypotheses. D-Tale, an interactive data exploration tool for Pandas DataFrames, offers a powerful and user-friendly interface to streamline this process.[1][2][3][4] By integrating D-Tale, researchers can visually inspect, clean, and analyze their data without extensive coding, thereby accelerating the discovery process.
These application notes provide a detailed protocol for integrating D-Tale into a standard bioinformatics data analysis workflow, using RNA-sequencing (RNA-seq) differential gene expression analysis as an example. The principles outlined here are broadly applicable to other types of bioinformatics data, such as proteomics and genomics data, that can be represented in a tabular format.
Core Concepts of a Bioinformatics Data Analysis Workflow
A typical bioinformatics workflow involves several key stages, starting from raw sequencing data and culminating in biological insights.[5][6]
Key Stages in a Bioinformatics Workflow:
-
Data Preprocessing and Quality Control (QC): Raw sequencing reads are assessed for quality, and low-quality reads and adapter sequences are removed.[5][6][7][8]
-
Alignment/Mapping: The cleaned reads are aligned to a reference genome or transcriptome.[9][10]
-
Quantification: The number of reads mapping to each gene or transcript is counted.
-
Statistical Analysis: Statistical tests are applied to identify significant differences between experimental groups (e.g., differentially expressed genes).
-
Downstream Analysis and Visualization: Further analysis is performed to understand the biological implications of the results, often involving pathway analysis and data visualization.
D-Tale is particularly useful in the stages following quantification, where the data is typically organized into a count matrix or a results table.
Integrating D-Tale into an RNA-Seq Workflow
This protocol outlines the steps for performing an interactive exploratory data analysis of an RNA-seq dataset using D-Tale.
Experimental and Bioinformatic Protocol Overview
The initial steps involve standard procedures for RNA-seq data generation and processing.[9][11]
| Step | Description | Tools | Output |
| 1. RNA Extraction & Library Preparation | Isolation of RNA from biological samples and preparation of sequencing libraries. | Standard lab protocols | Sequencing-ready libraries |
| 2. Sequencing | High-throughput sequencing of the prepared libraries. | Illumina Sequencer | Raw sequencing reads (FASTQ) |
| 3. Quality Control | Assessment of raw read quality. | FastQC | Quality reports |
| 4. Read Trimming | Removal of adapter sequences and low-quality bases. | Trimmomatic, Cutadapt | Cleaned reads (FASTQ) |
| 5. Alignment | Mapping of cleaned reads to a reference genome. | HISAT2, STAR | Aligned reads (BAM/SAM) |
| 6. Quantification | Counting reads mapped to each gene. | featureCounts, HTSeq | Gene count matrix (TSV/CSV) |
| 7. D-Tale Integration | Interactive exploration of the gene count matrix. | D-Tale, Pandas | Cleaned and validated data |
| 8. Differential Expression Analysis | Statistical analysis to identify differentially expressed genes. | DESeq2, edgeR | Results table (CSV) |
| 9. D-Tale Integration | Interactive exploration of differential expression results. | D-Tale, Pandas | Filtered and visualized results |
Detailed Protocol for D-Tale Integration
This protocol assumes you have a gene count matrix (e.g., counts.tsv) and a differential expression results table (e.g., deseq2_results.csv).
3.2.1. Installation
First, ensure that D-Tale and its dependencies are installed in your Python environment.
3.2.2. Loading and Exploring the Gene Count Matrix
The gene count matrix is the first point of integration. This matrix typically has genes as rows and samples as columns.
Protocol:
-
Launch a Python environment (e.g., Jupyter Notebook, JupyterLab, or a Python script).
-
Import the necessary libraries:
-
Load your gene count matrix into a Pandas DataFrame.
-
Launch D-Tale to interactively explore the DataFrame.
3.2.3. Interactive Data Exploration with D-Tale
D-Tale's interactive interface allows for a thorough quality control and exploratory analysis of the count data.[1][12][13]
| D-Tale Feature | Application in Bioinformatics Data Analysis |
| Sorting and Filtering | Interactively sort genes by expression level or filter out genes with low counts across all samples.[12][14] This is crucial for removing noise before downstream analysis. |
| Descriptive Statistics | Use the "Describe" function on each sample column to view summary statistics (mean, median, standard deviation).[15] This helps in identifying samples with unusual distributions. |
| Visualization (Charts) | Generate box plots or histograms for each sample to visually inspect the distribution of gene counts and identify potential outliers.[3][16] |
| Missing Value Analysis | Use the "Highlight Missing" feature to identify any missing data points in the count matrix.[12][17] |
| Outlier Detection | The "Highlight Outliers" feature can flag samples or genes with exceptionally high or low expression values that may warrant further investigation.[12][18] |
| Code Export | All interactive operations performed in D-Tale can be exported as Python code.[1][13][17] This ensures reproducibility of the data cleaning and filtering steps. |
3.2.4. Exploring Differential Expression Results
After performing differential expression analysis, D-Tale can be used to interactively explore the results table.
Protocol:
-
Load the differential expression results into a Pandas DataFrame.
-
Launch D-Tale with the results DataFrame.
Interactive Analysis of Differential Expression Results:
| D-Tale Feature | Application in Bioinformatics Data Analysis |
| Custom Filtering | Apply filters on columns like log2FoldChange, pvalue, and padj to quickly identify significantly up- or down-regulated genes.[12][14] |
| Correlation Analysis | Investigate correlations between different statistical measures in the results.[14] |
| Scatter Plots | Create interactive volcano plots (log2FoldChange vs. -log10(pvalue)) to visualize the relationship between statistical significance and magnitude of change. |
| Data Export | Export the filtered list of significant genes as a CSV or TSV file for further downstream analysis, such as pathway enrichment.[1][2][17] |
Workflow and Signaling Pathway Visualizations
Bioinformatics Data Analysis Workflow with D-Tale Integration
The following diagram illustrates the integration of D-Tale into a standard RNA-seq workflow.
Caption: Integration points of D-Tale in an RNA-seq workflow.
Logical Flow for Interactive Data Exploration in D-Tale
This diagram shows the logical steps a researcher would take when using D-Tale for data exploration.
Caption: Logical workflow for data exploration using D-Tale.
Application to Other Bioinformatics Data
The principles described for RNA-seq data can be extended to other types of bioinformatics data that are tabular in nature.
5.1. Proteomics
In proteomics, data from techniques like mass spectrometry is often processed to yield tables of protein or peptide identifications and their corresponding abundances.[19][20][21]
-
Input Data: A table of protein/peptide intensities across different samples.
-
D-Tale Application:
-
Interactively filter out proteins with low identification scores or those present in only a few samples.
-
Visualize the distribution of protein intensities to check for normalization issues.
-
Identify and investigate outlier samples or proteins with extreme abundance changes.
-
5.2. Genomics
For variant analysis in genomics, the output of variant calling pipelines is often a VCF (Variant Call Format) file, which can be converted to a tabular format.
-
Input Data: A table of genetic variants with annotations (e.g., gene, predicted effect, allele frequency).
-
D-Tale Application:
-
Filter variants based on quality scores, allele frequencies, or predicted functional impact.
-
Explore the distribution of different types of mutations (e.g., missense, nonsense, frameshift).
-
Interactively search for variants in specific genes of interest.
-
Conclusion
Integrating D-Tale into bioinformatics data analysis workflows provides a significant advantage by enabling researchers to perform rapid, interactive, and reproducible exploratory data analysis.[13] Its user-friendly interface lowers the barrier to complex data inspection, allowing scientists to focus on the biological questions at hand. By facilitating thorough data quality control and hypothesis generation at an early stage, D-Tale can enhance the robustness and reliability of downstream bioinformatics analyses, ultimately accelerating scientific discovery in genomics, proteomics, and drug development.
References
- 1. Exploratory Data Analysis Using D-Tale Library | by AMIT JAIN | Medium [medium.com]
- 2. Discovering the Magic of this compound for Data Exploration | by Nadya Sarilla Agatha | Medium [medium.com]
- 3. kdnuggets.com [kdnuggets.com]
- 4. GitHub - man-group/dtale: Visualizer for pandas data structures [github.com]
- 5. Data Preprocessing In Bioinformatics [meegle.com]
- 6. Chapter 2 Data preprocessing | The Earth Hologenome Initiative Bioinformatics Workflow [earthhologenome.org]
- 7. Overview of data preprocessing for machine learning applications in human microbiome research - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Data Preprocessing and Quality Control — BIT 815 1.0.0 documentation [deepseqanalysis.readthedocs.io]
- 9. protocols.io [protocols.io]
- 10. Bioinformatics Analysis [protocols.io]
- 11. Best Practices – Collaborative Bioinformatics Research Lab [sites.uab.edu]
- 12. Speed up Your Data Cleaning and Exploratory Data Analysis with Automated EDA Library “D-TALE” | by Hakkache Mohamed | Medium [medium.com]
- 13. domino.ai [domino.ai]
- 14. analyticsvidhya.com [analyticsvidhya.com]
- 15. youtube.com [youtube.com]
- 16. youtube.com [youtube.com]
- 17. analyticsvidhya.com [analyticsvidhya.com]
- 18. Outlier detection [molmine.com]
- 19. DIA Proteomics Empowers Comprehensive Protein Profiling - Creative Proteomics [creative-proteomics.com]
- 20. youtube.com [youtube.com]
- 21. youtube.com [youtube.com]
Application Notes and Protocols for Generating Publication-Quality Charts with D-Tale
Abstract
Data visualization is a cornerstone of scientific communication, enabling the clear and effective presentation of complex datasets. D-Tale is a powerful, interactive tool for exploratory data analysis (EDA) in Python, designed to streamline the process of analyzing Pandas DataFrames.[1][2][3] While primarily known for EDA, D-Tale's capabilities can be extended to generate publication-quality charts suitable for manuscripts, posters, and presentations. This document provides detailed protocols for leveraging D-Tale to move from raw data to refined, high-resolution visualizations. Key features include a user-friendly interface for chart creation, robust data summarization tools, and a critical "Code Export" function that ensures reproducibility and allows for fine-tuned, high-quality output.[4][5][6]
Introduction to D-Tale
D-Tale is an open-source Python library that provides an interactive web-based interface for viewing and analyzing Pandas data structures.[2][4] It combines a Flask back-end with a React front-end, integrating seamlessly into Jupyter notebooks and standard Python terminals.[4][7] For researchers, D-Tale accelerates the initial data exploration phase by replacing repetitive coding for descriptive statistics and basic plots with an intuitive graphical user interface (GUI).[8][9] Its charting capabilities are powered by Plotly, offering a wide range of interactive chart types, from simple bar and line charts to complex 3D scatter plots and heatmaps.[4][5]
Core Experimental Protocols
The following protocols outline the standard workflow for data analysis and chart generation in D-Tale.
Protocol 1: Installation and Data Loading
This protocol covers the initial setup of D-Tale and loading a dataset for analysis.
Methodology:
-
Installation: Install D-Tale using pip or conda in your Python environment.
-
pip install dtale
-
conda install -c conda-forge this compound
-
-
Library Import: Import pandas for data handling and this compound for visualization.[1]
-
Data Loading: Load your dataset into a Pandas DataFrame. D-Tale supports various formats, including CSV, TSV, and Excel files.[5][7]
-
Launching D-Tale: Use the this compound.show() command to launch the interactive interface. An output cell will appear in your Jupyter notebook, or a link will be provided in your terminal to open the GUI in a new browser tab.[4]
Example Workflow:
Below is a diagram illustrating the initial data exploration workflow.
Caption: Workflow for loading and exploring data with D-Tale.
Protocol 2: Data Summarization and Analysis
D-Tale provides powerful tools for quickly generating descriptive statistics, which are essential for understanding data distribution.
Methodology:
-
In the D-Tale GUI, click the triangular menu icon in the top-left corner.
-
Select "Describe" from the main menu.[8]
-
A new tab will open, displaying summary statistics for each column, including count, mean, standard deviation, and percentiles.[1][5]
-
For categorical data, it provides value counts. For numerical data, it includes distribution plots like histograms and box plots.[5]
-
This quantitative data should be recorded in a structured table for comparison.
Data Presentation: Summary Statistics Table
The table below is an example of how to structure the output from D-Tale's "Describe" feature for the sample dataset.
| Metric | Concentration (nM) | Cell_Viability (%) | Target_Inhibition (%) |
| Count | 6.0 | 6.0 | 6.0 |
| Mean | 41.67 | 73.58 | 62.55 |
| Standard Deviation | 49.16 | 28.32 | 46.54 |
| Min | 0.0 | 35.8 | 1.9 |
| 25th Percentile | 7.5 | 52.95 | 22.85 |
| 50th Percentile | 55.0 | 80.35 | 88.7 |
| 75th Percentile | 85.0 | 98.78 | 97.57 |
| Max | 100.0 | 100.1 | 98.7 |
Protocol 3: Generating and Exporting Publication-Quality Charts
This protocol details the critical steps for creating a high-quality chart and exporting it in a format suitable for publication (e.g., SVG, PDF, or high-DPI PNG).
Methodology:
-
Chart Creation:
-
From the D-Tale main menu, select "Charts" to open the chart builder in a new tab.[1][4]
-
Select the desired chart type (e.g., Scatter, Bar, Line).[8]
-
Assign variables from your DataFrame to the X and Y axes. For instance, to plot dose-response, set 'Concentration (nM)' as X and 'Cell_Viability (%)' as Y.
-
Use the "Group" option to segregate data points by a categorical variable, such as 'Compound'.
-
Utilize the interactive controls to customize labels, titles, and colors.
-
-
Export for Publication (Recommended Method):
-
After customizing the chart in the GUI, click the "Code Export" link at the top of the chart builder.[4][5][7] This provides the complete, reproducible Python code used to generate the Plotly figure.
-
Copy this code into your Python script or Jupyter notebook.
-
Append commands to the exported code to save the figure to a static, high-resolution file. The plotly.io.write_image() function is ideal for this. You may need to install additional packages: pip install kaleido.
-
Execute the complete script to generate the chart file.
-
Example Code Export and Enhancement:
The following diagram outlines this recommended publication workflow.
Caption: Recommended workflow for creating publication-ready charts.
Conclusion
D-Tale is an exceptionally useful tool for the initial stages of data exploration and analysis in a research setting.[1] By following the protocols outlined in this document, particularly the "Code Export" workflow, researchers can seamlessly transition from interactive analysis to producing reproducible, high-resolution, and publication-quality visualizations. This methodology ensures both the speed of initial exploration and the rigor required for scientific communication.
References
- 1. towardsdatascience.com [towardsdatascience.com]
- 2. GitHub - man-group/dtale: Visualizer for pandas data structures [github.com]
- 3. Introduction to D-Tale Library. D-Tale is python library to visualize… | by Shruti Saxena | Analytics Vidhya | Medium [medium.com]
- 4. kdnuggets.com [kdnuggets.com]
- 5. analyticsvidhya.com [analyticsvidhya.com]
- 6. domino.ai [domino.ai]
- 7. Exploratory Data Analysis Using D-Tale Library | by AMIT JAIN | Medium [medium.com]
- 8. dibyendudeb.com [dibyendudeb.com]
- 9. analyticsvidhya.com [analyticsvidhya.com]
Troubleshooting & Optimization
common errors in D-Tale and how to solve them for research projects
Welcome to the D-Tale Technical Support Center. This guide is designed for researchers, scientists, and drug development professionals to quickly troubleshoot common errors encountered while using D-Tale for research projects.
Frequently Asked Questions (FAQs)
Installation and Setup
Question: I'm encountering a ModuleNotFoundError: No module named 'dtale' even after I've installed it. How can I resolve this?
Answer:
This is a common issue that usually points to a mismatch in Python environments between where D-Tale was installed and where your Jupyter Notebook or Python script is running.[1][2][3]
Troubleshooting Steps:
-
Verify Active Environment: Ensure that the Python environment where you installed D-Tale is the same one being used by your Jupyter kernel or script. You can check the current Python interpreter path within your notebook by running:
For virtual environments:
-
Jupyter Kernel Specification: If you are using Jupyter, you might need to install a new kernel for your specific environment to make it visible in the notebook interface.
After running this, restart Jupyter and you should be able to select "your_env_name" from the kernel menu. [4]
Question: I am getting an AttributeError: module 'this compound' has no attribute 'global_state'. What is causing this and how can I fix it?
Answer:
This error often arises from installation issues, particularly when using a combination of pip and conda which can lead to conflicting package versions. [5] Recommended Solution:
It is highly recommended to use a consistent package manager for your environment. If you are using Anaconda, it's best to install D-Tale from the conda-forge channel.
Experimental Protocol: Clean Installation of D-Tale in a Conda Environment
-
Create a new Conda environment:
-
Activate the new environment:
-
Install D-Tale from conda-forge:
-
Install other necessary packages for your research:
-
Launch Jupyter Notebook from this environment:
This ensures all packages are compatible and sourced from the same channel, minimizing attribute errors.
Data Loading and Performance
Question: My D-Tale instance is very slow or crashes when I try to load a large dataset (e.g., > 1GB). How can I optimize performance?
Answer:
D-Tale's performance with large datasets can be affected by available RAM and browser limitations. Here are some strategies to handle large data more efficiently.
Troubleshooting Workflow:
Caption: Workflow for troubleshooting D-Tale performance with large datasets.
Optimization Strategies:
| Strategy | Description | Python Example |
| Subsampling | Load a representative random sample of your data into D-Tale for initial exploration. | import pandas as pd; df = pd.read_csv('large_dataset.csv'); sample_df = df.sample(n=100000); this compound.show(sample_df) |
| Column Filtering | Pre-select only the columns relevant to your immediate analysis before loading into D-Tale. | cols_to_load = ['gene_id', 'expression_value', 'treatment']; df = pd.read_csv('large_dataset.csv', usecols=cols_to_load); this compound.show(df) |
| Data Type Optimization | Convert columns to more memory-efficient types (e.g., 'category' for low-cardinality strings). | df['treatment_group'] = df['treatment_group'].astype('category'); this compound.show(df) |
| Hide Columns | For dataframes with many columns, D-Tale automatically hides columns beyond the 100th to improve initial load times. You can manually hide others. [6] | N/A (Done within the D-Tale UI) |
Question: I'm seeing a "Duplicate data check" error when trying to load a dataframe. What does this mean?
Answer:
D-Tale has a built-in check to prevent users from accidentally loading the same dataset multiple times, which can consume significant memory. [7][8]This error is triggered if a dataframe with the same number of rows, columns, and identical column names and order has been previously loaded.
Solution:
If you intended to load a new, distinct dataset, ensure that it has a different structure (e.g., different column names or number of columns) from previously loaded data. If you are intentionally reloading data after making changes, you can either:
-
Kill the previous D-Tale instance:
-
Use a different port for the new instance:
Visualization and Interaction
Question: D-Tale is not displaying in my Jupyter Notebook or I see a "server IP address could not be found" message. How can I fix this?
Answer:
This issue often occurs when D-Tale's web server, which runs in the background, is not correctly proxied by the Jupyter environment, especially in environments like JupyterHub or Domino. [9] Solution Workflow:
Caption: Troubleshooting D-Tale display issues in Jupyter environments.
Implementation for Proxied Environments:
You need to explicitly tell D-Tale that it's running behind a proxy and provide the correct application root path.
Experimental Protocol:
-
Import necessary libraries:
-
Set the proxy flag:
-
Construct the app_root path (example for Domino):
-
Show the D-Tale instance with the app_root:
Note: The host="0.0.0.0" parameter may be required for D-Tale versions 3.8.0 and newer to ensure it listens on the correct network interface within the containerized environment. [9]
Question: How can I handle and visualize missing data in my clinical trial dataset?
Answer:
D-Tale provides powerful built-in tools for missing data analysis, leveraging the missingno package. [10][11]This allows for a quick visual assessment of data completeness, which is crucial in regulated research.
Steps for Missing Data Analysis in D-Tale:
-
Load your data:
-
Navigate to "Missing Analysis" : In the D-Tale interface, click on the main menu (top left) and select "Missing Analysis". [12]3. Choose a Visualization : You will be presented with several plots to understand the patterns of missingness:
-
Matrix: A direct visualization of where nulls occur in your dataset.
-
Bar Chart: A simple count of non-null values per column.
-
Heatmap: Shows the correlation of nullity between columns. This can help identify if the absence of data in one column is related to the absence of data in another.
-
Dendrogram: A tree-like diagram that groups columns with similar patterns of missingness.
-
These visualizations can help you decide on an appropriate imputation strategy (e.g., mean, median, or more advanced methods) for your research data.
Security and Data Integrity
Question: I've heard about security vulnerabilities in D-Tale. How can I ensure my research data is secure, especially when working with sensitive patient information?
Answer:
Older versions of D-Tale have known vulnerabilities, including Cross-Site Scripting (XSS) and Remote Code Execution (RCE), particularly when "Custom Filter" is enabled and the instance is publicly hosted. [13]It is critical to keep D-Tale updated and follow security best practices.
Security Mitigation Measures:
| Vulnerability | Affected Versions | Mitigation |
| Remote Code Execution (RCE) | < 3.14.1 | Upgrade to version 3.14.1 or higher. [13] |
| Cross-site Scripting (XSS) | < 3.16.1 | Upgrade to version 3.16.1 or higher. [13] |
| Improper Input Validation | < 3.13.1 | Upgrade to version 3.13.1 or higher. [13] |
Best Practices for Secure Usage:
-
Keep D-Tale Updated: Regularly update to the latest version.
-
Avoid Public Hosting: Never expose a D-Tale instance running on sensitive data to the public internet. Use it within a secured, private network or on your local machine.
-
Disable Custom Filters if Not Needed: If your version of D-Tale is older and cannot be updated, you can mitigate some risks by disabling the custom filter input. However, upgrading is the recommended solution. [13]4. Use within a Controlled Environment: Run D-Tale within a containerized environment (like Docker) to isolate it from the host system, adding an extra layer of security.
References
- 1. stackoverflow.com [stackoverflow.com]
- 2. m.youtube.com [m.youtube.com]
- 3. youtube.com [youtube.com]
- 4. m.youtube.com [m.youtube.com]
- 5. python - module 'this compound' has no attribute 'global_state' - Stack Overflow [stackoverflow.com]
- 6. GitHub - man-group/dtale: Visualizer for pandas data structures [github.com]
- 7. Client Challenge [pypi.org]
- 8. Client Challenge [pypi.org]
- 9. Domino Support [support.domino.ai]
- 10. analyticsvidhya.com [analyticsvidhya.com]
- 11. Exploratory Data Analysis Using D-Tale Library | by AMIT JAIN | Medium [medium.com]
- 12. domino.ai [domino.ai]
- 13. This compound 1.33.0 vulnerabilities | Snyk [security.snyk.io]
D-Tale Performance Enhancement Center for Complex Biological Data Analysis
Welcome to the D-Tale Technical Support Center. This guide is designed for researchers, scientists, and drug development professionals to help you optimize D-Tale's performance for complex and large-scale data analysis. Find answers to frequently asked questions and follow our troubleshooting guides to improve your experimental workflows.
Frequently Asked Questions (FAQs)
Q1: My D-Tale instance is slow and unresponsive when loading a large genomics dataset. What are the immediate steps I can take to improve performance?
A1: Slowness with large datasets is a common issue, often stemming from memory constraints. Here are initial steps to address this:
-
Optimize Pandas DataFrame: Before loading data into D-Tale, optimize your pandas DataFrame. This is the most critical step for improving performance.
-
Load Only Necessary Data: Use the usecols parameter in pandas.read_csv to load only the columns required for your analysis.
-
Downcast Numeric Types: Convert numeric columns to more memory-efficient types. For example, if a column contains integer values that do not exceed the capacity of a 32-bit integer, you can downcast it from int64 to int32.[1][2]
-
Convert to Categorical Types: For columns with a limited number of unique string values (e.g., gene symbols, compound IDs), converting the data type to category can significantly reduce memory usage.[2]
-
Utilize Chunking: If your dataset is too large to fit into memory, read and process it in smaller chunks.[3][4]
Here is a summary of data type optimizations:
| Original Data Type | Optimized Data Type | Memory Savings (Approx.) |
| int64 | int32 | 50% |
| float64 | float32 | 50% |
| object (low cardinality) | category | Up to 90% |
Q2: I'm working with a wide DataFrame with hundreds of features from a high-throughput screening experiment. D-Tale's interface is lagging. How can I handle this?
A2: D-Tale has a known performance bottleneck with wide DataFrames.[5] Here’s how you can mitigate this:
-
Column Filtering: By default, D-Tale hides columns beyond the first 100 to improve initial load times. You can manually unhide columns as needed.
-
Feature Selection: Before loading into D-Tale, perform feature selection to reduce the dimensionality of your data. This could involve techniques like removing low-variance features or using domain knowledge to select relevant features.
-
Data Subsetting: If your analysis allows, break down your wide DataFrame into smaller, more manageable subsets of related features and analyze them in separate D-Tale instances.
Q3: Can I use D-Tale without loading my entire dataset into my machine's RAM?
A3: Yes, D-Tale offers alternatives to in-memory data storage which are highly recommended for massive datasets. You can configure D-Tale to use disk-based storage engines like "shelve" or a more robust solution like Redis.[6] This approach stores the data on disk and only loads the necessary chunks into memory when required for an operation, significantly reducing RAM usage.
Troubleshooting Guides
Guide 1: Optimizing a Large Gene Expression DataFrame
This guide provides a step-by-step protocol for optimizing a large gene expression dataset before visualizing it with D-Tale.
Experimental Protocol:
-
Initial Data Loading and Inspection:
-
Load a sample of your data to inspect data types and memory usage.
-
-
Identify Columns for Optimization:
-
Based on the sample, identify numeric columns that can be downcast and object columns with low cardinality that can be converted to categorical types.
-
-
Load Full Dataset with Optimized Data Types:
-
Create a dictionary specifying the optimal data types for each column.
-
Load the entire dataset using the dtype parameter.
-
-
Launch D-Tale:
-
Now, launch D-Tale with the optimized DataFrame.
-
Logical Workflow for DataFrame Optimization:
Guide 2: Analyzing High-Dimensional Compound Screening Data
This guide outlines a workflow for handling high-dimensional data from a compound screen, focusing on reducing data size and complexity for efficient analysis in D-Tale.
Experimental Protocol:
-
Initial Data Assessment:
-
Load your dataset and assess its dimensions.
-
-
Variance Thresholding for Feature Selection:
-
Remove features with low variance, as they are less likely to be informative.
-
-
Data Type Optimization:
-
Apply the data type optimization techniques described in Guide 1 to the filtered DataFrame.
-
-
Interactive Analysis in D-Tale:
-
Launch D-Tale with the reduced and optimized DataFrame.
-
Signaling Pathway for Data Reduction:
This diagram illustrates the decision-making process for reducing data dimensionality and memory footprint.
References
- 1. m.youtube.com [m.youtube.com]
- 2. m.youtube.com [m.youtube.com]
- 3. django - Effective Approaches for Optimizing Performance with Large Datasets in Python? - Stack Overflow [stackoverflow.com]
- 4. Handling Large Datasets in Pandas - GeeksforGeeks [geeksforgeeks.org]
- 5. Exploiting the sequence diversity of TALE-like repeats to vary the strength of this compound-promoter interactions - PMC [pmc.ncbi.nlm.nih.gov]
- 6. help wanted: loading massive dataframes · Issue #276 · man-group/dtale · GitHub [github.com]
D-Tale Technical Support Center for Researchers & Scientists
This technical support center provides troubleshooting guidance and best practices for leveraging D-Tale in your data exploration and analysis workflows. The following question-and-answer format directly addresses specific issues and frequently asked questions you may encounter during your research.
Frequently Asked Questions (FAQs)
Q1: What is D-Tale and how can it benefit my research?
D-Tale is an open-source Python library that provides an interactive, web-based interface for viewing and analyzing Pandas data structures.[1][2][3] For researchers and scientists, it offers a user-friendly way to perform exploratory data analysis (EDA) without writing extensive code.[4][5] Key benefits include:
-
Rapid Data Visualization: Quickly generate a wide range of charts and plots, including histograms, scatter plots, bar charts, and heat maps, with just a few clicks.[4][6]
-
Data Cleaning and Preprocessing: Interactively handle missing values, identify and remove duplicates, and transform data types.[4][6]
-
Outlier Detection: Highlight and filter outliers in your dataset.[4]
-
Code Export: D-Tale can export the Python code for your analysis, promoting reproducibility and helping you learn the underlying Pandas operations.[5]
-
Collaboration: Share your data exploration sessions with colleagues.[6]
Q2: How do I get started with D-Tale in my Python environment?
Getting started with D-Tale involves a simple installation and a few lines of code to launch the interactive interface.
Experimental Protocol: Launching a D-Tale Instance
Objective: To install D-Tale and launch an interactive session with a Pandas DataFrame.
Materials:
-
Python environment (e.g., Jupyter Notebook, PyCharm, or a Python terminal).
-
A Pandas DataFrame.
Methodology:
-
Installation: Open your terminal or command prompt and install D-Tale using pip:
-
Import Libraries: In your Python script or notebook, import dtale and pandas.
-
Load Data: Load your dataset into a Pandas DataFrame. For this example, we'll create a sample DataFrame.
-
Launch D-Tale: Use the this compound.show() function to launch the D-Tale interface.
This will open a new tab in your web browser with the interactive D-Tale session.[1]
Q3: Can I use D-Tale with large datasets? What are the performance considerations?
While D-Tale is a powerful tool, working with very large datasets can present performance challenges. Here are some best practices and considerations:
-
Memory Usage: D-Tale loads the data into memory. To avoid memory issues, D-Tale has a check to prevent loading the same data multiple times. This check verifies if the row/column count and column names/order match previously loaded data.[3]
-
Long-Running Computations: Charting requests that require significant computation can block other operations until they complete.[3]
-
Chunking: For datasets that are too large to fit into memory, consider using libraries like Dask to read and process data in smaller chunks.[7]
-
Efficient Data Formats: Using efficient file formats like Parquet or HDF5 for storing your data can lead to faster read/write operations compared to CSV.[7]
| Feature | Recommendation for Large Datasets |
| Data Loading | Pre-sample the data or use chunking techniques before loading into D-Tale. |
| Visualizations | Start with simpler plots on subsets of the data before attempting complex visualizations on the entire dataset. |
| Computations | Be mindful of computationally intensive operations like creating complex charts, which may take time.[3] |
Troubleshooting Guides
Q1: I've installed D-Tale, but it's not launching in my browser. What should I do?
This is a common issue that can often be resolved by checking your firewall settings.
Troubleshooting Workflow: D-Tale Launch Failure
Caption: Troubleshooting steps for D-Tale launch failures.
Detailed Steps:
-
Windows Firewall: If you are on Windows, your firewall might be blocking the connection. You may need to add Python to the list of "Allowed Apps" in your firewall configuration.[3]
-
Correct Environment: Ensure that D-Tale is installed in the same Python environment that you are running your script or notebook from. Mismatched environments can lead to import errors.[8]
-
Proxy Settings: If you are behind a corporate proxy, you may need to configure your environment variables (HTTP_PROXY, HTTPS_PROXY) for D-Tale to connect correctly.
-
Browser Issues: Try clearing your browser cache or using a different web browser to rule out browser-specific problems.
Q2: My chart is taking a very long time to load. Is there a way to handle this?
Long-running chart requests can occur with large datasets or computationally intensive visualizations.
Solution:
If a chart request is taking too long and blocking other interactions, you have two primary options:[3]
-
Restart the Kernel: The simplest solution is to restart your Jupyter Notebook kernel or Python console.
-
Open a New Session: You can start a new D-Tale session on a different port using the following command:
To prevent this, consider down-sampling your data before creating complex visualizations or choosing less computationally intensive chart types for initial exploration.
Q3: I'm encountering an error when trying to use D-Tale in a Jupyter Notebook inside a Docker container.
Running D-Tale within a Dockerized Jupyter environment can sometimes lead to connectivity issues.
Potential Issue: The jupyter-server-proxy setup might not be working correctly within the Docker container. This is a known issue that has been reported.[9]
Recommended Action:
-
Check the official D-Tale GitHub issues page for the latest updates and potential workarounds for this specific problem.[9]
-
Ensure that the port D-Tale is running on is correctly exposed in your Docker container configuration.
Best Practices for Efficient Data Exploration
Workflow for Exploratory Data Analysis (EDA) in D-Tale
This workflow outlines a systematic approach to performing EDA using D-Tale, suitable for a research context.
Caption: A systematic workflow for EDA using D-Tale.
Detailed Methodologies:
-
Initial Data Assessment:
-
Univariate Analysis:
-
For each variable of interest, use the column dropdown menu to generate a histogram. This will help you understand the distribution of your data.
-
Examine the "Value Counts" for categorical variables to understand the frequency of each category.
-
-
Bivariate Analysis and Relationship Exploration:
-
From the main menu, select "Charts" to build visualizations that explore relationships between two or more variables.
-
Use scatter plots to investigate the relationship between two continuous variables.
-
Utilize the "Correlations" feature to generate a correlation matrix, providing a quick overview of the linear relationships between all numeric columns.[4]
-
-
Interactive Data Cleaning:
-
Missing Values: Use the "Highlight Missing" feature to visually identify missing data points. From the column menu, you can choose to fill or drop missing values.[4]
-
Duplicates: Identify and remove duplicate rows through the main menu options.
-
Outliers: Use the "Highlight Outliers" feature to detect potential outliers. You can then use the filtering capabilities to temporarily exclude them from your analysis.[4]
-
-
Ensuring Reproducibility:
By following these best practices and troubleshooting guides, researchers and scientists can effectively integrate D-Tale into their data analysis pipelines, leading to more efficient and reproducible research outcomes.
References
- 1. Introduction to D-Tale. Introduction to D-Tale for interactive… | by Albert Sanchez Lafuente | TDS Archive | Medium [medium.com]
- 2. This compound · PyPI [pypi.org]
- 3. Client Challenge [pypi.org]
- 4. youtube.com [youtube.com]
- 5. m.youtube.com [m.youtube.com]
- 6. m.youtube.com [m.youtube.com]
- 7. Effective Strategies for Managing Large Datasets in Python – Datolab [datolab.com]
- 8. This compound Python Library Error in Jupyter Notebook - Stack Overflow [stackoverflow.com]
- 9. GitHub · Where software is built [github.com]
how to handle missing data in D-Tale for accurate analysis
Troubleshooting Guides & FAQs for Accurate Analysis
This guide provides researchers, scientists, and drug development professionals with detailed instructions on how to handle missing data within the D-Tale interactive data exploration tool. Accurate handling of missing values is crucial for robust and reliable analysis of experimental data.
Frequently Asked Questions (FAQs)
Q1: How can I identify missing data in my dataset using D-Tale?
A1: D-Tale utilizes the missingno library to provide several visualizations for identifying missing data.[1][2] To access these visualizations:
-
Launch D-Tale with your pandas DataFrame.
-
In the main menu bar, navigate to "Describe".
-
From the dropdown menu, select "Missing Analysis".
This will open a panel with various plots like a matrix, bar chart, heatmap, and dendrogram to help you understand the extent and patterns of missingness in your data.[1] The matrix plot, for instance, provides a quick visual summary of the completeness of your dataset, allowing you to identify patterns in data completion at a glance.[2]
Q2: What is the quickest way to remove rows or columns with missing data in D-Tale?
A2: The most straightforward method to handle missing data is to remove the rows or columns that contain them. In D-Tale, you can achieve this by following these steps:
-
Click on the column header of the column containing missing values.
-
From the dropdown menu, select "Clean Columns".
-
In the "Clean Columns" popup, you will find options to drop rows with missing values in that specific column.
Alternatively, to remove an entire column, you can click on the column header and select the "Delete" option.[1] Be aware that deleting rows or columns can lead to a significant loss of information, especially in smaller datasets.
Q3: How can I fill in missing values (impute) in a column?
A3: D-Tale's "Clean Columns" feature allows you to replace missing values. To do this:
-
Click on the header of the column with missing data.
-
Select "Clean Columns" from the menu.
-
In the subsequent dialog, you will find a "Replace" tab.
-
Here, you can define what you want to replace (e.g., NaN) and what you want to replace it with (a specific value, the mean, median, or mode of the column).
It is important to ensure that the replacement value has the same data type as the column to avoid unintended creation of more missing values.
Q4: What imputation methods are available in D-Tale?
A4: D-Tale, being built on top of pandas, supports a variety of imputation techniques. While the GUI provides direct access to simple imputation methods, more advanced techniques can be implemented by exporting the code and modifying it. The common methods are:
-
Mean/Median/Mode Imputation: Replacing missing values with the mean, median, or mode of the column. This is a simple and quick method but can distort the original data distribution.
-
Forward Fill (ffill) and Backward Fill (bfill): These methods are particularly useful for time-series data, where missing values are filled with the preceding or succeeding value, respectively.
-
Constant Value Imputation: Replacing missing values with a constant, such as 0 or "Unknown".
More advanced techniques like K-Nearest Neighbors (KNN) or MICE (Multiple Imputation by Chained Equations) can be applied by exporting the generated pandas code from D-Tale and integrating it with libraries like scikit-learn.
Summary of Imputation Strategies
| Imputation Method | Description | Use Case |
| Mean Imputation | Replaces missing values with the mean of the non-missing values in the column. | Suitable for numerical data that is normally distributed and has a low percentage of missing values. |
| Median Imputation | Replaces missing values with the median of the non-missing values in the column. | A good choice for numerical data with a skewed distribution or when outliers are present. |
| Mode Imputation | Replaces missing values with the most frequent value in the column. | Best suited for categorical (non-numeric) data. |
| Forward Fill (ffill) | Propagates the last valid observation forward to the next missing value. | Ideal for time-series data where observations are expected to be similar to the previous one. |
| Backward Fill (bfill) | Fills missing values with the next valid observation. | Also used for time-series data, especially when a future value is a better estimate. |
| Constant Value | Replaces missing values with a specified constant (e.g., 0, -1, "Not Available"). | Useful when the absence of a value has a specific meaning or to flag missing entries for later analysis. |
Experimental Protocols
Protocol 1: Visualizing Missing Data
Objective: To identify the location and extent of missing data in a dataset.
Methodology:
-
Load your DataFrame into D-Tale using dtale.show(your_dataframe).
-
From the main menu, navigate to Describe > Missing Analysis .
-
Examine the generated plots:
-
Matrix: Provides a visual representation of data completeness. White lines indicate missing data.
-
Bar Chart: Shows the count of non-missing values for each column.
-
Heatmap: Displays the correlation of missingness between columns.
-
Dendrogram: Groups columns with similar patterns of missingness.
-
Protocol 2: Removing Rows with Missing Data
Objective: To remove entire rows containing any missing values.
Methodology:
-
Identify the column(s) with missing values you want to target.
-
Click on the header of one of these columns.
-
Select Clean Columns .
-
In the "Clean Columns" window, go to the Drop Missing tab.
-
Choose the option to "Drop rows with missing values in this column".
-
Click "Execute" to apply the changes.
-
To export the cleaned data, go to the main menu and select Export .
Protocol 3: Imputing Missing Data with the Mean
Objective: To fill missing numerical data with the column's mean.
Methodology:
-
Click on the header of the numerical column containing missing values.
-
Select Clean Columns .
-
Navigate to the Replace tab in the "Clean Columns" window.
-
In the "Find" field, enter NaN.
-
In the "Replace with" dropdown, select "Mean".
-
Click "Execute" to perform the imputation.
-
The missing values in the selected column will be replaced by the calculated mean of that column.
Visual Workflows and Signaling Pathways
Caption: Decision workflow for handling missing data in D-Tale.
Caption: Selecting an appropriate imputation method based on data type.
References
refining D-Tale visualizations for clearer research insights
Welcome to the technical support center for refining D-Tale visualizations to gain clearer research insights. This resource is designed for researchers, scientists, and drug development professionals to address common issues and provide guidance on leveraging D-Tale for impactful data analysis.
Frequently Asked Questions (FAQs)
Q1: My D-Tale instance is running very slowly or crashing, especially with large datasets. How can I improve performance?
A1: Performance issues with large datasets are common. Here are several strategies to mitigate this:
-
Downsample your data: Before loading into D-Tale, consider if a representative sample of your data would suffice for initial exploratory analysis.
-
Utilize Chunking: When loading large CSVs, you can read the data in chunks to manage memory usage more effectively.
-
Optimize Data Types: Ensure your Pandas DataFrame uses memory-efficient data types (e.g., using category for text columns with few unique values, or smaller integer/float types where appropriate).
-
Run D-Tale in a separate browser tab: Instead of rendering D-Tale within a Jupyter Notebook output cell, which can be resource-intensive, launch it in a dedicated browser tab.[1] This often provides a more responsive experience.
-
Increase available memory: If you are working in a virtual environment or a container, consider allocating more RAM to the process.
Q2: I'm having trouble rendering complex charts in my Jupyter Notebook. What can I do?
A2: Rendering complex, interactive charts directly within a Jupyter Notebook can sometimes fail due to browser or notebook limitations.
-
Open in a New Tab: As with performance issues, the most reliable solution is to open the D-Tale instance in a new browser tab.[1] You can do this by clicking the "Open in new tab" link that appears at the top of the D-Tale output in your notebook.
-
Export the Chart: D-Tale allows you to export charts as static images (PNG) or interactive HTML files.[2] This is particularly useful for embedding in presentations or publications where a static, high-resolution image is required.
-
Check for Browser Console Errors: Open your browser's developer tools (usually by pressing F12) and check the console for any error messages that might indicate a specific problem with the chart rendering library.
Q3: How can I customize the appearance of my charts for a publication or presentation?
A3: D-Tale's charting interface, powered by Plotly, offers extensive customization options.
-
Chart Editor: Within the "Charts" view, explore the different tabs in the chart editor to modify titles, axis labels, colors, fonts, and legends.
-
Color Palettes: While D-Tale provides default color schemes, you can manually set colors for different data series to adhere to publication guidelines or to highlight specific findings.
-
Code Export: For ultimate control, you can export the Python code for the chart.[2] This allows you to fine-tune every aspect of the plot using the Plotly library directly in your code, and then save it in a high-resolution format.
Q4: My categorical data has too many unique values, making my bar chart unreadable. How can I handle this?
A4: Visualizing high-cardinality categorical data requires summarization or grouping.
-
Group Small Categories: Before visualizing, you can group less frequent categories into an "Other" category. This can be done using Pandas transformations before loading the data into D-Tale.
-
Use Treemaps: For hierarchical data or data where you want to show the proportion of many categories, a treemap can be a more effective visualization than a bar chart. D-Tale offers treemaps as a chart type.[2]
-
Filtering: Apply filters to focus on the most relevant categories for your research question, excluding those that are not pertinent to the immediate analysis.
Troubleshooting Guides
Issue: Dose-Response Curve Appears Inverted
Problem: You are plotting a dose-response curve for a new compound, but the resulting line chart shows an inverted relationship (i.e., the response increases with the inhibitor concentration).
Troubleshooting Steps:
-
Verify Data Integrity:
-
In the D-Tale grid view, sort the columns for 'Concentration' and 'Inhibition' to ensure they are in the correct order and that the values are as expected.
-
Use the "Describe" feature on the 'Inhibition' column to check for any anomalous values (e.g., negative numbers where none are expected).
-
-
Check Axis Assignments:
-
In the "Charts" view, confirm that the 'Concentration' is assigned to the X-axis and 'Inhibition' is assigned to the Y-axis.
-
Ensure that no unintended aggregations (e.g., 'sum' instead of 'mean') are being applied if you have replicate measurements at each concentration.
-
-
Inspect Data Transformations:
-
If you have performed any transformations on the data (e.g., log transformation of concentration), verify that the transformation was applied correctly. You can use the "Build Column" feature to create a new column with the transformed values and plot that instead.
-
Issue: Heatmap of Gene Expression Data is Not Informative
Problem: You have generated a heatmap of gene expression data across different patient samples, but the color scaling makes it difficult to discern patterns.
Troubleshooting Steps:
-
Normalize the Data: Heatmaps are most effective when the data is on a similar scale. If your gene expression data has not been normalized, the color scale may be dominated by a few highly expressed genes. Perform a suitable normalization (e.g., Z-score scaling) on your data before loading it into D-Tale.
-
Adjust the Color Scale:
-
In the D-Tale chart editor for the heatmap, experiment with different color palettes. A diverging color palette is often effective for showing both up- and down-regulation.
-
Adjust the min/max values of the color scale to focus on a specific range of expression changes and to exclude extreme outliers that may be compressing the color range.
-
-
Cluster the Data: To reveal patterns, it is often necessary to cluster the rows (genes) and columns (samples) of the heatmap. While D-Tale's default heatmap may not have advanced clustering options, you can perform the clustering in your Python script (e.g., using scipy.cluster.hierarchy) to reorder the data in your DataFrame before visualizing it in D-Tale.
Experimental Protocols and Workflows
Protocol: Visualizing IC50 Data from a Dose-Response Assay
This protocol outlines the steps to visualize and analyze IC50 data from a typical drug screening experiment.
Methodology:
-
Data Preparation:
-
Organize your experimental data into a CSV file with the following columns: Compound_ID, Concentration_uM, Percent_Inhibition.
-
Ensure that Concentration_uM and Percent_Inhibition are numeric columns.
-
-
Loading Data into D-Tale:
-
In your Python environment, load the CSV into a Pandas DataFrame.
-
Launch D-Tale with the DataFrame:
-
-
Generating Dose-Response Curves:
-
In the D-Tale interface, navigate to "Visualize" -> "Charts".
-
Select 'Scatter' as the chart type.
-
Set the X-axis to Concentration_uM and the Y-axis to Percent_Inhibition.
-
To view individual curves for each compound, use the 'Group' dropdown and select Compound_ID.
-
To better visualize the sigmoidal curve, apply a log transformation to the X-axis in the chart editor if your concentration data spans several orders of magnitude.
-
Quantitative Data Summary:
The following table shows a sample of the raw data that would be used in this protocol.
| Compound_ID | Concentration_uM | Percent_Inhibition |
| Compound A | 0.01 | 2.5 |
| Compound A | 0.1 | 15.8 |
| Compound A | 1 | 48.2 |
| Compound A | 10 | 91.3 |
| Compound B | 0.01 | 5.1 |
| Compound B | 0.1 | 25.4 |
| Compound B | 1 | 65.7 |
| Compound B | 10 | 98.9 |
Workflow: Identifying Off-Target Effects using Kinase Panel Data
This workflow describes how to use D-Tale to identify potential off-target effects from a kinase screening panel.
Signaling Pathway Diagram
The following diagram illustrates a simplified signaling pathway that might be investigated in a drug discovery context. D-Tale could be used to visualize data from experiments that probe different nodes in this pathway.
References
D-Tale debugging tips for python scripts in a scientific context
Welcome to the D-Tale Technical Support Center. This guide is designed for researchers, scientists, and drug development professionals who use D-Tale for debugging and analyzing their scientific data in Python. Find answers to common issues and learn best practices to streamline your experimental data analysis workflows.
Frequently Asked Questions (FAQs)
Installation & Setup
Q: I've installed D-Tale using pip, but I get an ImportError when trying to use it in my Anaconda environment.
A: This issue often arises from environment conflicts. Ensure that you have activated the correct conda environment before installing D-Tale and launching your Jupyter Notebook. If you are using a virtual environment, make sure it is properly selected within your notebook.[1]
Q: My firewall seems to be blocking the D-Tale interface from opening in my browser on Windows.
A: D-Tale runs on a local Flask server, and Windows Firewall might block the connection. You can resolve this by allowing Python through your firewall. An article on how to allow apps to communicate through the Windows Firewall can guide you through this process.[2][3]
Display & Interface
Q: I'm running dtale.show(df) in my Jupyter Notebook, but no output is rendered, or I get a "server IP address could not be found" message.
A: This is a common issue when D-Tale is used within certain environments like JupyterHub or Domino where the server proxy needs to be configured.[4] D-Tale runs its own web server, and the address might not be reachable from within the workspace.[4]
To fix this, you may need to specify the app_root and host parameters when calling this compound.show() and set dtale_app.JUPYTER_SERVER_PROXY = True.[4] For simpler cases, especially if your notebook is not served under HTTPS, you can try forcing the host to 'localhost' with this compound.show(df, host='localhost').[5] If the interface is still not showing, you can try the "Open In New Tab" option from the main menu or manually construct the URL to open it in a separate browser tab.[6]
Q: The D-Tale interface is very slow or freezes when I try to view a large dataset.
A: Displaying a very large dataframe (e.g., millions of rows) directly in the browser can be slow because it attempts to load all the data at once.[7] If you are working with a massive dataset, it is recommended to first downsample your data for initial exploration in D-Tale or use filtering criteria to load a subset of the data. For very large datasets, you might need to explore options for storing the data outside of memory, for which D-Tale has experimental support for backends like "shelve" or Redis.[7]
Q: The highlighting for outliers flashes on the screen and then disappears.
A: This has been reported as a potential bug in certain versions of D-Tale when used with specific browser and environment combinations.[8] Ensure you are using the latest version of D-Tale. If the problem persists, it may be a bug, and reporting it on the D-Tale GitHub issues page is recommended.[8]
Data Handling & Performance
Q: How can I handle performance issues when working with large datasets in D-Tale?
A: When dealing with large datasets, consider the following optimization strategies:
| Strategy | Description | Potential Impact |
| Chunking | Process the data in smaller chunks instead of loading the entire dataset into memory at once. | Reduces memory usage significantly. |
| Data Subsetting | Use pandas to select a subset of your data before passing it to D-Tale for initial exploration. | Improves responsiveness of the D-Tale interface. |
| Use Optimized Data Types | Convert columns to more memory-efficient types (e.g., categorical for string columns with low cardinality). | Can lead to substantial memory savings. |
| Alternative Data Stores | For extremely large datasets, consider using D-Tale's support for alternative data stores like Redis to avoid in-memory limitations.[7] | Enables analysis of datasets larger than available RAM. |
Q: Can D-Tale handle specialized scientific data formats like XArray?
A: D-Tale has functionality to convert a pandas DataFrame to an XArray Dataset. This is useful for multi-dimensional data commonly found in scientific research. You can select one or more columns to set as the index for the conversion.[2]
Advanced Features
Q: The "Code Export" feature is not working in Google Colab.
A: There have been reported issues with the code export functionality in Google Colab environments, where it might result in a "server IP address could not be found" error.[9] This is often due to the way Colab handles server proxying. Ensure you are using the latest version of D-Tale, as there have been updates to improve Colab integration.
Q: Can I save my custom filters and highlighting settings for future use?
A: Currently, D-Tale does not have a built-in feature to save custom filters and user preferences across different sessions.[10] These settings are stored in the memory of the running D-Tale process and will be lost if the process is terminated.[10] For recurring filtering needs, it is recommended to apply the filters programmatically in your Python script before launching D-Tale.
Troubleshooting Guides
General Debugging Workflow with D-Tale
This workflow outlines a general approach to debugging a Python script that uses pandas for data manipulation with the aid of D-Tale.
Identifying and Handling Outliers in Experimental Data
A common task in scientific data analysis is the identification and handling of outliers. D-Tale's visual interface can be a powerful tool for this.
Experimental Protocol:
-
Load your experimental data into a pandas DataFrame. This data could be, for example, measurements of protein concentration from a series of assays.
-
Launch D-Tale to visualize the DataFrame:
-
Use the "Describe" feature on your measurement column. In the D-Tale interface, click on the header of the column containing your measurements (e.g., 'protein_concentration') and select "Describe". This will provide descriptive statistics and a box plot, which can help in visually identifying outliers.[11]
-
Use the "Highlight Outliers" feature. From the main menu, navigate to "Highlight" and then "Highlight Outliers". This will color-code the cells that are identified as outliers based on the interquartile range method.
-
Filter or flag outliers. Once identified, you can use D-Tale's filtering capabilities to temporarily exclude these data points for further analysis.
-
Export the code for reproducibility. D-Tale can generate the Python code for the filtering and highlighting steps you performed.[12] This is crucial for documenting your data cleaning process.
-
Decide on a strategy for handling outliers in your script. Based on your visual exploration, you can decide whether to remove, transform, or further investigate the identified outliers in your main Python script.
References
- 1. This compound Python Library Error in Jupyter Notebook - Stack Overflow [stackoverflow.com]
- 2. Client Challenge [pypi.org]
- 3. Client Challenge [pypi.org]
- 4. Domino Support [support.domino.ai]
- 5. python - this compound show in jupyter notebook - Stack Overflow [stackoverflow.com]
- 6. This compound Output Not being rendered on Jupyter Notebook · Issue #546 · man-group/dtale · GitHub [github.com]
- 7. help wanted: loading massive dataframes · Issue #276 · man-group/dtale · GitHub [github.com]
- 8. stackoverflow.com [stackoverflow.com]
- 9. Code export doesnt work on google colab · Issue #211 · man-group/dtale · GitHub [github.com]
- 10. Save custom filters/user settings & preferences · Issue #494 · man-group/dtale · GitHub [github.com]
- 11. m.youtube.com [m.youtube.com]
- 12. Exploratory Data Analysis Using D-Tale Library | by AMIT JAIN | Medium [medium.com]
Validation & Comparative
D-Tale vs. Pandas-Profiling: A Researcher's Guide to Data Quality Checks
At a Glance: Key Differences
| Feature | D-Tale | pandas-profiling |
| Primary Interface | Interactive, web-based GUI | Static HTML report |
| User Interaction | Real-time filtering, sorting, plotting, and data editing | Pre-generated, non-interactive report |
| Ease of Use | Highly intuitive, minimal code required for exploration[1][2] | Requires a few lines of code to generate the report[3][4] |
| Output Format | Live, interactive dashboard | Self-contained HTML file[5] |
| Data Manipulation | Allows for direct data editing, cleaning, and transformation within the UI[6][7] | Primarily for analysis and reporting; no direct data manipulation |
| Code Export | Can export Python code for reproducible analysis[6] | Does not directly export code for performed analyses |
| Ideal Use Case | Interactive, visual deep-dive into a dataset; hands-on data cleaning | Quick, automated overview and standardized reporting of a dataset |
Core Functionality Showdown
Both D-Tale and pandas-profiling offer a rich set of features for initial data assessment. Here’s a breakdown of their approaches to common data quality tasks:
pandas-profiling: The Automated Report Card
Pandas-profiling excels at generating a comprehensive and detailed HTML report from a pandas DataFrame with just a few lines of code.[3][4][5] This report provides a holistic overview of the dataset, including:
-
Dataset Overview: Metadata such as the number of variables, observations, missing cells, and duplicate rows.[8][9]
-
Variable Analysis: In-depth analysis for each column, including data type, distinct values, missing values, and descriptive statistics (mean, median, standard deviation, etc.).[8][10]
-
Visualizations: Histograms, correlation matrices, and missing value heatmaps are automatically generated.[1][10]
-
Alerts: Proactively flags potential data quality issues like high correlation, skewness, and high cardinality.[8]
This makes pandas-profiling an excellent choice for quickly generating a standardized "health check" report for a dataset, which can be easily shared with colleagues.
D-Tale: The Interactive Data Playground
D-Tale takes a different approach by providing a highly interactive, web-based graphical user interface (GUI) to explore and manipulate your data in real-time.[2][7] It combines a Flask back-end with a React front-end to deliver a seamless user experience.[5] Key features include:
-
Spreadsheet-like Interface: View and interact with your data in a familiar, editable grid.[11]
-
Interactive Filtering and Sorting: Easily subset your data based on various criteria with just a few clicks.
-
On-the-fly Visualizations: Generate a wide array of plots and charts (bar, line, scatter, heatmaps, etc.) through a user-friendly menu.[1][7]
-
Data Cleaning and Transformation: Perform actions like handling missing values, renaming columns, and applying custom transformations directly within the interface.[6][7]
-
Code Export: D-Tale can generate the equivalent Python code for the actions you perform in the GUI, promoting reproducibility.[6]
This makes D-Tale ideal for researchers who want to visually and interactively "play" with their data to uncover insights and perform initial cleaning steps.
Experimental Protocols & Performance Comparison
To provide a clearer picture of how these tools perform in a research setting, we've outlined a series of mock experiments with hypothetical performance data.
Experimental Setup
-
Hypothetical Dataset: A simulated clinical trial dataset with 1,000,000 rows and 50 columns, containing a mix of numerical, categorical, and date/time data, with some introduced missing values and outliers.
-
Environment: A standard research computing environment (e.g., 16 GB RAM, 4-core CPU).
-
Metrics:
-
Profiling Time: Time taken to generate the initial report (pandas-profiling) or load the data into the interactive interface (D-Tale).
-
Memory Usage: Peak memory consumption during the profiling/loading process.
-
Experiment 1: Initial Data Profiling
Methodology:
-
Load the 1,000,000-row dataset into a pandas DataFrame.
-
For pandas-profiling, generate a full profile report.
-
For D-Tale, launch the interactive interface with the DataFrame.
-
Measure the time and memory usage for each process.
Hypothetical Results:
| Tool | Profiling Time (seconds) | Peak Memory Usage (GB) |
| pandas-profiling | 180 | 4.5 |
| D-Tale | 60 | 2.8 |
Analysis: In this hypothetical scenario, D-Tale demonstrates a faster initial load time and lower memory overhead for a large dataset. This is likely because pandas-profiling pre-computes all statistics and visualizations for the entire dataset upfront, while D-Tale loads the data and performs computations on-demand as the user interacts with it.
Experiment 2: Identifying Missing Data Patterns
Methodology:
-
Using the generated report/interface from Experiment 1, identify columns with missing data.
-
For pandas-profiling, locate the "Missing values" section of the report and analyze the provided matrix and dendrogram.[10]
-
For D-Tale, use the "Missing Analysis" feature to visualize missing data patterns.[6]
-
Qualitatively assess the ease and depth of identifying relationships in missingness between variables.
Qualitative Findings:
-
pandas-profiling: Provides a clear, static overview of missingness, which is excellent for reporting. The dendrogram can help identify correlations in missing data.
-
D-Tale: Offers a more interactive exploration of missing data. Users can filter and sort the data to investigate the context of missing values more dynamically. The ability to directly address missing values (e.g., by filling or dropping) within the same interface is a significant advantage for an iterative workflow.[7]
Logical Workflows and Visualizations
To further illustrate the typical usage of each tool, the following diagrams, generated using the DOT language, outline their respective data quality check workflows.
Feature Comparison Diagram
The following diagram provides a side-by-side comparison of the core features of D-Tale and pandas-profiling.
References
- 1. towardsdatascience.com [towardsdatascience.com]
- 2. 17 Python Libraries for Data Profiling | by Jesse | Python in Plain English [python.plainenglish.io]
- 3. GitHub - dheerajsk26/Pandas_Profiling: Pandas-profiling generates a comprehensive exploratory data analysis report from a pandas DataFrame in just few lines of code [github.com]
- 4. youtube.com [youtube.com]
- 5. Exploratory Data Analysis Tools. Pandas-Profiling, Sweetviz, D-Tale | by Karteek Menda | Medium [medium.com]
- 6. domino.ai [domino.ai]
- 7. Exploratory Data Analysis Using D-Tale Library | by AMIT JAIN | Medium [medium.com]
- 8. m.youtube.com [m.youtube.com]
- 9. youtube.com [youtube.com]
- 10. m.youtube.com [m.youtube.com]
- 11. youtube.com [youtube.com]
D-Tale vs. Bamboolib: A Comparative Guide to User-Friendly Data Analysis for Scientific Research
In the realm of scientific research and drug development, the ability to efficiently explore and analyze large datasets is paramount. While programmatic approaches using libraries like Pandas offer immense power and flexibility, they can present a steep learning curve and often require significant boilerplate code for routine tasks. This has led to the rise of GUI-based tools that provide a more intuitive and accessible interface for data manipulation and visualization. Among the leading contenders in this space are D-Tale and bamboolib.
This guide provides a comprehensive comparison of D-Tale and bamboolib, tailored for researchers, scientists, and drug development professionals. We will delve into their core functionalities, ease of use, and integration with existing data science workflows, supported by qualitative and quantitative comparisons.
Core Philosophy and User Interface
Both D-Tale and bamboolib aim to simplify data analysis by providing a graphical user interface on top of a Pandas DataFrame. However, they approach this with slightly different philosophies.
D-Tale offers a highly detailed and feature-rich environment that presents a wealth of information upfront.[1][2][3][4][5] Its interface, built with a Flask backend and a React frontend, is accessed through a web browser and provides a spreadsheet-like view of the data, augmented with numerous menus and options for analysis and visualization.[3][5][6] This comprehensive nature makes it a powerful tool for in-depth data exploration, but it can also be overwhelming for new users.[1]
Bamboolib , on the other hand, emphasizes a more guided and streamlined user experience.[7][8][9] It integrates directly into Jupyter notebooks and presents a clean, intuitive interface that guides the user through common data analysis tasks.[7][10][11] A key feature of bamboolib is its "glass-box" approach, where every action performed through the GUI generates the corresponding Python code, promoting reproducibility and learning.[7][12][13]
Feature Comparison
To provide a clear overview, the following table summarizes the key features of D-Tale and bamboolib.
| Feature | D-Tale | bamboolib |
| User Interface | Comprehensive, spreadsheet-like interface in a separate browser tab.[1][5] | Integrated, guided interface within Jupyter notebooks.[7][11] |
| Data Exploration | Detailed column analysis, descriptive statistics, and data summaries.[2][14] | "Explore DataFrame" feature for a holistic view of each feature with summary statistics and visualizations.[8][11] |
| Data Manipulation | In-place data editing, filtering, sorting, and transformations through extensive menus.[2][3][15] | Point-and-click operations for filtering, sorting, grouping, and applying transformations.[7][9][16] |
| Data Visualization | Wide array of interactive charts and plots, including correlations and heatmaps.[2][3][14] | Interactive Plotly-based charts with a user-friendly creation menu.[8][11] |
| Code Generation | Exports Python code for performed actions.[4][15] | Automatically generates and displays Python code for every operation in real-time.[7][13][16] |
| Integration | Seamlessly integrates with Jupyter notebooks and Python terminals.[2][3] | Primarily designed for Jupyter Notebook and JupyterLab.[10][11] |
| Extensibility | Supports a wide range of Pandas objects.[3][5] | Offers a plugin framework for extending its capabilities.[13] |
| Target Audience | Users who prefer a detailed, all-in-one exploratory environment. | Users who value a guided workflow, reproducibility, and learning Python. |
| Licensing | Open-source. | Has a free and a paid version.[1] |
Experimental Protocols for Performance Evaluation
To objectively assess the performance of D-Tale and bamboolib, a series of standardized tests should be conducted. The following protocols outline the methodology for these experiments.
Dataset: A real-world, anonymized dataset from a relevant scientific domain (e.g., genomics, clinical trial data) should be used. The dataset should be sufficiently large to test performance under realistic conditions (e.g., >1 million rows, >50 columns).
Environment: All tests should be performed on the same machine with consistent hardware and software configurations (Python version, library versions, etc.) to ensure a fair comparison.
Experiments:
-
Data Loading and Rendering Time:
-
Objective: Measure the time taken to load the dataset and render the initial user interface.
-
Methodology:
-
Start a fresh Python kernel.
-
Record the start time.
-
Load the dataset into a Pandas DataFrame.
-
Call the respective function to display the DataFrame in D-Tale (dtale.show(df)) and bamboolib (df).
-
Record the end time when the UI is fully interactive.
-
Repeat the experiment multiple times and calculate the average time.
-
-
-
Filtering and Sorting Performance:
-
Objective: Evaluate the responsiveness of the UI when performing common data filtering and sorting operations.
-
Methodology:
-
Apply a single-column filter (e.g., a numerical column greater than a specific value).
-
Measure the time from applying the filter to the UI updating with the filtered data.
-
Apply a multi-column filter.
-
Measure the time taken.
-
Sort a large numerical column in ascending and descending order.
-
Measure the time taken for the UI to reflect the sorted data.
-
Repeat each operation multiple times and average the results.
-
-
-
Data Transformation and Visualization Speed:
-
Objective: Assess the performance of creating new columns based on existing data and generating visualizations.
-
Methodology:
-
Create a new column by applying a mathematical operation on one or more existing numerical columns.
-
Measure the time taken for the new column to be calculated and displayed.
-
Generate a histogram for a numerical column.
-
Measure the time from selecting the visualization option to the plot being rendered.
-
Generate a scatter plot for two numerical columns.
-
Measure the rendering time.
-
Repeat each operation multiple times and average the results.
-
-
Logical Workflow Diagrams
The following diagrams, generated using Graphviz, illustrate the typical data analysis workflows for both D-Tale and bamboolib.
Conclusion and Recommendations
Both D-Tale and bamboolib offer compelling solutions for simplifying data analysis in a scientific context. The choice between them largely depends on the user's preference and specific needs.
D-Tale is an excellent choice for:
-
In-depth, exploratory data analysis: Its comprehensive interface provides a rich environment for deep dives into datasets.[4][14]
-
Users who prefer a standalone, feature-rich tool: The dedicated browser interface offers a focused workspace for analysis.[1][5]
-
Quick, ad-hoc analysis without the need for extensive coding: Its point-and-click nature allows for rapid exploration.[2][3]
Bamboolib is ideally suited for:
-
Researchers and scientists who want to learn and write Python code: The automatic code generation is a powerful learning and productivity tool.[7][11][13]
-
Ensuring reproducibility and collaboration: The generated code makes it easy to share and replicate analysis workflows.[7][12]
-
A more guided and less overwhelming user experience: Its streamlined interface is beginner-friendly and focuses on common data analysis tasks.[7][8]
For research teams and drug development professionals, bamboolib's emphasis on reproducibility and its educational component of generating clean, readable Python code may offer a slight advantage in a collaborative and regulated environment. The ability to seamlessly transition from a GUI-based exploration to a programmatic workflow within the same Jupyter notebook environment is a significant benefit for building robust and maintainable analysis pipelines.
Ultimately, the best way to determine the right tool is to experiment with both. Both libraries are easy to install and can be readily applied to existing datasets, allowing for a hands-on evaluation of their capabilities and user experience.
References
- 1. towardsdatascience.com [towardsdatascience.com]
- 2. Discovering the Magic of this compound for Data Exploration | by Nadya Sarilla Agatha | Medium [medium.com]
- 3. analyticsvidhya.com [analyticsvidhya.com]
- 4. Top 10 Exploratory Data Analysis (EDA) Libraries You Have To Try In 2021. [malicksarr.com]
- 5. towardsdatascience.com [towardsdatascience.com]
- 6. youtube.com [youtube.com]
- 7. Explore the Power of bamboolib: Analyzing Pandas DataFrames Made Easy - AITechTrend [aitechtrend.com]
- 8. A GUI for Pandas / Bamboolib. If you have landed on this article… | by Ahmedabdullah | Medium [medium.com]
- 9. Bamboolib — Data Analysis with Python — without programming | by Tahera Firdose | Medium [tahera-firdose.medium.com]
- 10. Tool Details | ML Ops Directory [mlops-tools.com]
- 11. towardsdatascience.com [towardsdatascience.com]
- 12. databricks.com [databricks.com]
- 13. databricks.com [databricks.com]
- 14. towardsdatascience.com [towardsdatascience.com]
- 15. domino.ai [domino.ai]
- 16. towardsdatascience.com [towardsdatascience.com]
Validating D-Tale's Statistical Outputs with R: A Comparative Guide for Researchers
For researchers, scientists, and drug development professionals, the accuracy and reliability of statistical outputs are paramount. While visual data exploration tools like D-Tale offer a user-friendly interface for quick insights, it is crucial to validate their statistical outputs against established benchmarks. This guide provides an objective comparison of D-Tale's statistical functionalities with the robust statistical environment of R, a gold-standard in research and development. Through a detailed experimental protocol and side-by-side data presentation, this guide offers a clear framework for validating statistical outputs and ensuring the integrity of your data analysis.
Experimental Protocol
To provide a direct comparison, a standardized experiment was conducted using the well-documented "Palmer Penguins" dataset. This dataset contains a mix of numerical and categorical data, making it ideal for evaluating a range of statistical summaries. The following protocol outlines the methodology used to generate and compare statistical outputs from both D-Tale and R.
1. Data Loading and Preparation:
-
Dataset: The "Palmer Penguins" dataset was used. This dataset is publicly available and contains data on 344 penguins of three different species.
-
Environment Setup:
-
D-Tale: A Python environment was configured with the pandas and dtale libraries installed. The Palmer Penguins dataset was loaded into a pandas DataFrame.
-
R: A standard R environment was used with the palmerpenguins and dplyr packages installed. The dataset was loaded directly from the palmerpenguins package.
-
-
Data Cleaning: To ensure a fair comparison, any rows with missing values were removed from the dataset in both environments before statistical analysis.
2. Descriptive Statistics Generation:
-
D-Tale: The this compound.show() function was used to launch the interactive D-Tale interface. Within the interface, the "Describe" action was selected for the numerical columns of interest (bill_length_mm, bill_depth_mm, flipper_length_mm, and body_mass_g). The resulting descriptive statistics, including mean, standard deviation, quartiles, and other summary metrics, were recorded.
-
R: The summary() function was applied to the numerical columns of the penguins' dataset. The output, which includes the minimum, first quartile, median, mean, third quartile, and maximum, was captured. Additionally, the sd() function was used to calculate the standard deviation for each numerical column to match the more detailed output from D-Tale.
3. Correlation Analysis:
-
D-Tale: The "Correlations" feature in the D-Tale interface was utilized to generate a Pearson correlation matrix for the numerical variables. The resulting correlation coefficients were extracted.
-
R: The cor() function was used to compute the Pearson correlation matrix for the same set of numerical variables. For a more detailed analysis, the cor.test() function was used to obtain the correlation coefficient, p-value, and confidence interval for the correlation between bill_length_mm and bill_depth_mm.
Data Presentation: A Quantitative Comparison
The following tables summarize the quantitative outputs from both D-Tale and R for descriptive statistics and correlation analysis.
Table 1: Descriptive Statistics Comparison
| Statistical Metric | D-Tale Output (bill_length_mm) | R Output (summary() & sd()) (bill_length_mm) | D-Tale Output (bill_depth_mm) | R Output (summary() & sd()) (bill_depth_mm) | D-Tale Output (flipper_length_mm) | R Output (summary() & sd()) (flipper_length_mm) | D-Tale Output (body_mass_g) | R Output (summary() & sd()) (body_mass_g) |
| Count | 342 | 342 | 342 | 342 | 342 | 342 | 342 | 342 |
| Mean | 43.92 | 43.92 | 17.15 | 17.15 | 200.92 | 200.92 | 4201.75 | 4201.75 |
| Standard Deviation | 5.46 | 5.46 | 1.97 | 1.97 | 14.06 | 14.06 | 801.95 | 801.95 |
| Minimum | 32.10 | 32.10 | 13.10 | 13.10 | 172.00 | 172.00 | 2700.00 | 2700.00 |
| 25% (1st Quartile) | 39.23 | 39.23 | 15.60 | 15.60 | 190.00 | 190.00 | 3550.00 | 3550.00 |
| 50% (Median) | 44.45 | 44.45 | 17.30 | 17.30 | 197.00 | 197.00 | 4050.00 | 4050.00 |
| 75% (3rd Quartile) | 48.50 | 48.50 | 18.70 | 18.70 | 213.00 | 213.00 | 4750.00 | 4750.00 |
| Maximum | 59.60 | 59.60 | 21.50 | 21.50 | 231.00 | 231.00 | 6300.00 | 6300.00 |
Table 2: Correlation Matrix Comparison (Pearson Correlation Coefficient)
| Variable Pair | D-Tale Correlation | R Correlation (cor()) |
| bill_length_mm & bill_depth_mm | -0.235 | -0.235 |
| bill_length_mm & flipper_length_mm | 0.656 | 0.656 |
| bill_length_mm & body_mass_g | 0.595 | 0.595 |
| bill_depth_mm & flipper_length_mm | -0.584 | -0.584 |
| bill_depth_mm & body_mass_g | -0.472 | -0.472 |
| flipper_length_mm & body_mass_g | 0.871 | 0.871 |
Table 3: Detailed Correlation Test Comparison (bill_length_mm vs. bill_depth_mm)
| Metric | D-Tale Output | R Output (cor.test()) |
| Correlation Coefficient | -0.235 | -0.235 |
| p-value | Not directly provided in the correlation matrix view | < 2.2e-16 (highly significant) |
| 95% Confidence Interval | Not directly provided in the correlation matrix view | [-0.332, -0.134] |
Experimental Workflow Visualization
The following diagram illustrates the logical flow of the validation process, from data input to the comparison of statistical outputs.
Conclusion
The results of this comparative analysis demonstrate a high degree of concordance between the statistical outputs of D-Tale and R. For fundamental descriptive statistics and Pearson correlation coefficients, D-Tale provides results that are identical to those generated by R's established statistical functions. This indicates that for initial data exploration and generating summary statistics, D-Tale is a reliable tool.
However, for more in-depth statistical inference, such as obtaining p-values and confidence intervals for correlations, R provides a more comprehensive and direct output through functions like cor.test(). While D-Tale excels at interactive visualization and user-friendly data exploration, researchers requiring detailed statistical test results for formal reporting and hypothesis testing will need to supplement their analysis with a dedicated statistical package like R.
A Head-to-Head Comparison of D-Tale and Tableau for Academic Research Data Visualization
For researchers, scientists, and drug development professionals, the ability to effectively visualize and explore complex datasets is paramount. This guide provides an objective comparison of two distinct data visualization tools, D-Tale and Tableau, to help you determine which best suits your academic research needs. We will delve into their core functionalities, data handling capabilities, and ease of use, supported by a structured comparison and a hypothetical experimental protocol.
At a Glance: D-Tale vs. Tableau
| Feature | D-Tale | Tableau |
| Primary Function | Exploratory Data Analysis (EDA) & Visualization | Business Intelligence & Interactive Data Visualization |
| Target Audience | Python users (Data Scientists, Analysts, Researchers) | Business Analysts, Researchers, a broad range of users |
| Ease of Use | Easy, minimal code required for basic exploration.[1] | Very easy, drag-and-drop interface.[2] |
| Learning Curve | Low for users familiar with Python and Pandas | Low for basic visualizations, moderate for advanced features |
| Integration | Tightly integrated with the Python ecosystem (Pandas, Jupyter) | Connects to a wide range of data sources; integrates with R and Python.[3] |
| Cost | Open-source and free | Free academic licenses available; paid for commercial use.[4] |
| Data Handling | Best for small to medium-sized datasets that fit in memory | Can handle very large datasets, with options for live connections or extracts.[5] |
| Collaboration | Limited to sharing code and exported files | Strong collaboration features with Tableau Server/Cloud |
| Customization | Good for EDA, but visualization options are less extensive | Highly customizable dashboards and a wide array of chart types |
In-Depth Analysis
D-Tale: The Researcher's Python Companion
D-Tale is an open-source Python library that provides an interactive and user-friendly interface for exploring and visualizing pandas DataFrames.[1] Its strength lies in its seamless integration into the Python-based research workflow, particularly within Jupyter notebooks. With just a single line of code, researchers can launch a web-based GUI to perform a wide range of exploratory data analysis tasks, including filtering, sorting, creating plots, and viewing summary statistics. This makes it an excellent tool for initial data-quality checks and hypothesis generation.[6][7]
However, D-Tale is primarily designed for in-memory data analysis, which means its performance can be a limitation when working with extremely large datasets that do not fit into RAM. Its visualization capabilities, while sufficient for EDA, are not as extensive or polished as those offered by dedicated business intelligence tools like Tableau.
Tableau: The Powerhouse of Interactive Visualization
Tableau is a powerful and versatile data visualization tool that has gained significant traction in both the business and academic worlds.[2] Its intuitive drag-and-drop interface allows researchers to create a wide variety of interactive charts, dashboards, and maps without writing any code.[2][8] Tableau's ability to connect to a vast array of data sources, from simple spreadsheets to large databases, makes it a flexible option for diverse research projects.[5]
For academic researchers, Tableau offers free licenses through its academic programs, making it an accessible tool for students and educators.[4] Furthermore, Tableau's integration with programming languages like R and Python allows for the incorporation of advanced statistical analyses and machine learning models into visualizations.[3] While Tableau excels at creating polished and interactive visualizations for presentation and publication, its data preparation and manipulation capabilities are not as robust as what can be achieved through programming with libraries like pandas in Python.[9]
Experimental Protocol: Visualizing Clinical Trial Data
To illustrate the practical application of both tools, we'll outline a hypothetical experimental protocol for analyzing and visualizing a clinical trial dataset.
Objective: To explore the relationship between a novel drug treatment, patient demographics, and adverse event occurrences in a Phase III clinical trial.
Dataset: A CSV file containing anonymized patient data, including treatment arm (Drug vs. Placebo), age, sex, reported adverse events, and severity.
Methodology:
1. Data Loading and Initial Exploration:
-
D-Tale:
-
Load the CSV into a pandas DataFrame.
-
Launch D-Tale on the DataFrame.
-
Use the D-Tale GUI to:
-
Check for missing values in all columns.
-
View summary statistics for age and adverse event severity.
-
Filter the data by treatment arm to get a preliminary sense of the data distribution.
-
-
-
Tableau:
-
Connect to the CSV file directly from the Tableau Desktop interface.
-
Tableau automatically displays the data source schema.
-
Use the "Data Source" page to review data types and preview the data.
-
2. Data Visualization and Analysis:
-
D-Tale:
-
Within the D-Tale interface, create histograms to visualize the age distribution for each treatment arm.
-
Generate bar charts to compare the frequency of different adverse events between the drug and placebo groups.
-
Use the "Correlations" feature to explore relationships between numerical variables.
-
-
Tableau:
-
Create a new worksheet.
-
Drag and drop "Age" to the "Columns" shelf and "Number of Records" to the "Rows" shelf to create a histogram of age distribution. Drag "Treatment Arm" to the "Color" mark to separate by group.
-
Create a new worksheet. Drag "Adverse Event" to the "Rows" shelf and "Number of Records" to the "Columns" shelf to create a bar chart. Drag "Treatment Arm" to the "Color" mark.
-
Combine these visualizations into an interactive dashboard, allowing for filtering by demographic and treatment groups.
-
3. Reporting and Dissemination:
-
D-Tale:
-
Export the generated plots as images.
-
Export the cleaned/filtered data to a new CSV file for further analysis.
-
Share the Jupyter notebook containing the code and visualizations.
-
-
Tableau:
-
Publish the interactive dashboard to Tableau Public or Tableau Server.
-
Share the link to the dashboard with collaborators.
-
Export the dashboard or individual visualizations as images or PDFs for inclusion in presentations and publications.
-
Visualizing Workflows and Pathways
Drug Discovery and Development Workflow
The following diagram illustrates a simplified workflow for drug discovery and development, a common area of research for the target audience.
EGFR Signaling Pathway
This diagram shows a simplified representation of the Epidermal Growth Factor Receptor (EGFR) signaling pathway, which is frequently studied in cancer research.
Conclusion
Both D-Tale and Tableau are valuable tools for academic researchers, but they serve different primary purposes.
Choose D-Tale if:
-
You are a proficient Python user and work extensively with pandas DataFrames.
-
Your primary need is for rapid exploratory data analysis and initial data cleaning.
-
You are working with small to medium-sized datasets.
-
You prefer an open-source, code-adjacent solution.
Choose Tableau if:
-
You need to create highly interactive and polished visualizations for presentations, publications, or grant proposals.
-
You are working with large and diverse datasets from multiple sources.
-
You prefer a user-friendly, drag-and-drop interface and do not want to code.
-
Collaboration and sharing of interactive dashboards are important for your research group.
For many researchers, the optimal solution may not be to choose one over the other, but rather to use them in a complementary fashion. D-Tale can be used for the initial, in-depth exploration and cleaning of data within a Python environment, while Tableau can be used to create compelling and interactive visualizations of the cleaned data for broader dissemination and communication of research findings.
References
- 1. analyticsvidhya.com [analyticsvidhya.com]
- 2. tandfonline.com [tandfonline.com]
- 3. researchgate.net [researchgate.net]
- 4. tableau.com [tableau.com]
- 5. je-lks.org [je-lks.org]
- 6. Unraveling Patterns: Exploratory Data Analysis Techniques for Research [falconediting.com]
- 7. A Comprehensive Guide to Mastering Exploratory Data Analysis [dasca.org]
- 8. quora.com [quora.com]
- 9. Choosing Between Python and Tableau For Your Data Visualization | by Erick Duran | Analytics Vidhya | Medium [medium.com]
advantages of D-Tale over standard pandas for initial data checks
A Comparative Guide to D-Tale and Standard Pandas for Initial Data Checks in Scientific Research
For researchers, scientists, and professionals in drug development, the initial examination of a dataset is a critical step that informs all subsequent analyses. This guide provides a comprehensive comparison of two Python tools used for these initial data checks: D-Tale and the standard pandas library. While pandas is a foundational tool for data manipulation, D-Tale offers a graphical user interface (GUI) that can significantly alter the workflow for exploratory data analysis (EDA).
Workflow Comparison: Interactive vs. Code-driven
The fundamental difference between D-Tale and pandas lies in their approach to data interaction. Standard pandas workflows are code-driven, requiring users to write Python code for every operation, from viewing data to generating plots. In contrast, D-Tale provides an interactive, web-based GUI that allows for point-and-click data exploration.[1][2][3] This distinction is visualized in the workflow diagram below.
Key Feature Comparison
The choice between D-Tale and pandas for initial data checks can be guided by the specific needs of the user and the task at hand. The following table summarizes the key features of each tool.
| Feature | Standard Pandas | D-Tale |
| Interaction Model | Code-based (programmatic) | GUI-based (interactive) |
| Ease of Use | Requires knowledge of Python and pandas syntax. | Intuitive for users familiar with spreadsheets; minimal coding required.[2] |
| Speed of Exploration | Dependent on the user's coding speed and library knowledge. | Rapid exploration through point-and-click menus and visualizations.[2][4] |
| Data Visualization | Requires external libraries like Matplotlib or Seaborn and custom code. | Integrated, interactive plotting capabilities (histograms, scatter plots, heatmaps, etc.).[1][2] |
| Data Manipulation | Powerful and flexible data wrangling capabilities through code. | In-GUI data editing, filtering, sorting, and column transformations.[1][5] |
| Reproducibility | High; analysis steps are explicitly documented in code scripts or notebooks.[6] | Can be lower if GUI interactions are not documented. However, D-Tale allows for code export to aid in reproducibility.[1][5] |
| Discoverability | Features must be known or looked up in documentation. | Features are discoverable through menus and interactive elements. |
| Handling Large Datasets | Can handle large datasets, but performance depends on efficient coding practices. | May experience performance issues with very large datasets due to its interactive nature. |
Quantitative Performance: An Experimental Protocol
Objective
To measure and compare the time taken to perform a set of common initial data check tasks using both standard pandas and D-Tale.
Materials
-
Hardware: A consistent local machine or cloud computing instance to ensure comparable results.
-
Software: Python 3.x, Jupyter Notebook, pandas, D-Tale.
-
Datasets:
-
A moderately sized clinical trial dataset (e.g., 50,000 rows, 100 columns) with a mix of numerical and categorical data.
-
A larger genomic dataset (e.g., 500,000 rows, 50 columns) to assess performance at scale.
-
Methodology
For each dataset, perform the following tasks and record the time to completion. For pandas, this is the time from writing the first line of code to generating the final output for that task. For D-Tale, this is the time from launching the D-Tale instance to achieving the desired output in the GUI.
-
Data Loading and Initial Overview:
-
Pandas: Time to execute pd.read_csv() followed by df.info() and df.head().
-
D-Tale: Time to execute this compound.show(df) and for the GUI to become responsive and display the initial data view.
-
-
Summary Statistics:
-
Pandas: Time to execute df.describe() for numerical columns and df['categorical_column'].value_counts() for a key categorical variable.
-
D-Tale: Time to navigate to the "Describe" functionality for a numerical column and view the value counts for a categorical column.[2]
-
-
Missing Value Analysis:
-
Pandas: Time to execute df.isnull().sum() to get a count of missing values per column.
-
D-Tale: Time to navigate to the "Missing Analysis" feature and view the summary.[1]
-
-
Univariate Visualization:
-
Pandas: Time to write and execute code to generate a histogram for a key numerical variable using Matplotlib or Seaborn.
-
D-Tale: Time to select the column and generate a histogram through the GUI.
-
-
Bivariate Analysis (Correlation):
-
Pandas: Time to write and execute code to generate a correlation matrix and a corresponding heatmap using Seaborn.
-
D-Tale: Time to use the integrated "Correlations" feature to generate the matrix and heatmap.[7]
-
Data to be Collected
| Task | Pandas: Time (seconds) | D-Tale: Time (seconds) | Notes |
| 1. Data Loading & Overview | |||
| 2. Summary Statistics | |||
| 3. Missing Value Analysis | |||
| 4. Univariate Visualization | |||
| 5. Bivariate Analysis |
Discussion of Advantages
D-Tale's primary advantage lies in its accessibility and speed for rapid, initial exploration. For researchers who may not be proficient in pandas or who want to quickly understand a new dataset, the GUI-driven approach lowers the barrier to entry.[2] The ability to instantly visualize data distributions, filter, and sort without writing code can significantly accelerate the initial phase of data quality assessment.[5][7] Furthermore, the code export feature in D-Tale serves as a valuable learning tool and a bridge to creating reproducible analysis scripts.[1]
Standard pandas, on the other hand, offers unparalleled power, flexibility, and reproducibility. [6] For complex data cleaning and transformation tasks, a programmatic approach is often more efficient and scalable. The explicit nature of code in a Jupyter notebook provides a clear, step-by-step record of the analysis, which is crucial for validation and collaboration in a research environment.[8]
Conclusion
For initial data checks in a research or drug development setting, D-Tale is a highly effective tool for rapid, interactive exploration, especially for users who are more visually oriented or less experienced with coding. It excels at quickly providing an overview of data quality, distributions, and relationships.
Standard pandas remains the indispensable tool for in-depth, reproducible data analysis and manipulation. For complex data wrangling and to ensure a transparent and verifiable workflow, a code-based approach is superior.
Ultimately, the two tools are not mutually exclusive. A productive workflow could involve using D-Tale for an initial, quick-look analysis to identify areas of interest, followed by a more rigorous and detailed investigation using pandas in a Jupyter notebook. This hybrid approach leverages the speed and accessibility of D-Tale with the power and reproducibility of pandas.
References
- 1. Exploratory Data Analysis Using D-Tale Library | by AMIT JAIN | Medium [medium.com]
- 2. dibyendudeb.com [dibyendudeb.com]
- 3. towardsdatascience.com [towardsdatascience.com]
- 4. towardsdatascience.com [towardsdatascience.com]
- 5. domino.ai [domino.ai]
- 6. towardsdatascience.com [towardsdatascience.com]
- 7. analyticsvidhya.com [analyticsvidhya.com]
- 8. hashadatascience.com [hashadatascience.com]
The Synergistic Workflow: How D-Tale Complements Seaborn for Advanced Data Visualization in Scientific Research
In the realm of data-driven scientific discovery, particularly in fields like drug development and bioinformatics, the journey from raw experimental data to insightful, publication-ready visualizations is multifaceted. Python stands out as a primary tool for this journey, offering a rich ecosystem of libraries. Among these, Seaborn and D-Tale represent two powerful, yet distinct, approaches to data visualization. While Seaborn is the established standard for creating sophisticated, static statistical plots for publication, D-Tale offers a dynamic, interactive environment for initial data exploration. This guide provides a comprehensive comparison of these two tools, demonstrating how their complementary strengths can be harnessed to create a highly efficient and effective data visualization workflow for researchers, scientists, and drug development professionals.
At a Glance: D-Tale vs. Seaborn
The fundamental difference between D-Tale and Seaborn lies in their core philosophies. D-Tale is designed for interactive, real-time data exploration through a graphical user interface (GUI) with no-code or low-code interactions.[1][2][3][4] In contrast, Seaborn is a code-centric library that provides a high-level interface for drawing attractive and informative statistical graphics, prioritizing reproducibility and fine-grained customization for publication-quality output.[5][6][7][8]
| Feature | D-Tale | Seaborn |
| Primary Use Case | Interactive Exploratory Data Analysis (EDA) | Publication-Quality Statistical Graphics |
| User Interface | Web-based Graphical User Interface (GUI) | Code-based (Python scripts, Jupyter Notebooks) |
| Interactivity | High (sorting, filtering, panning, zooming) | Low (generates static or semi-interactive plots) |
| Ease of Use | Very easy for beginners, no coding required for basic exploration | Requires Python and library-specific knowledge |
| Plot Customization | Limited to GUI options | Extensive, with fine-grained control via code[9][10] |
| Output Format | Interactive web view, data export (CSV, TSV)[2] | Static image files (PNG, SVG, PDF), interactive plots in notebooks |
| Code Generation | Yes, exports Python code for performed actions[4][11] | N/A (user writes the code from the start) |
| Reproducibility | Lower for GUI-based exploration, higher with exported code | High, as the entire plot is defined in code |
A Complementary Workflow for Drug Discovery Research
Instead of viewing D-Tale and Seaborn as competitors, a more powerful approach is to integrate them into a sequential workflow. D-Tale excels at the initial, often messy, stage of data exploration, while Seaborn is ideal for producing the final, polished visualizations for reports and publications.[12][13]
This synergistic relationship can be visualized as a logical progression:
Experimental Protocol: Analyzing Dose-Response Data
To illustrate this workflow, consider a common scenario in drug development: analyzing dose-response data from a cell-based assay to determine the potency of several candidate compounds.
Objective: To identify the most potent compounds from a panel and visualize their dose-response relationships for a research publication.
Methodology:
-
Data Acquisition: The raw data is compiled into a CSV file with columns for Compound_ID, Concentration_uM, and Percent_Inhibition.
-
Interactive Exploratory Data Analysis (EDA) with D-Tale:
-
Launch D-Tale: Load the dataset into a pandas DataFrame and launch the D-Tale interactive interface.
-
Initial Data Inspection: Within the D-Tale GUI, sort the data by Compound_ID and Concentration_uM to ensure correctness. Use the "Describe" feature to get a quick statistical summary of Percent_Inhibition, checking for any obvious outliers or non-numeric values.[14]
-
Quick Visualization: Use D-Tale's "Charts" functionality to generate a scatter plot with Concentration_uM on the x-axis and Percent_Inhibition on the y-axis, grouped by Compound_ID. This provides an immediate visual assessment of the dose-response curves.
-
Code Export: After generating a satisfactory initial plot, use the "Code Export" feature in D-Tale to obtain the Python code that reproduces this visualization.[4][11]
-
-
Advanced Data Visualization with Seaborn:
-
Refine the Code: Paste the exported code into a Jupyter Notebook or Python script. This code serves as a starting point.
-
Create a Publication-Quality Plot: Use Seaborn's lmplot or relplot to create a more sophisticated visualization.[15] This allows for fitting regression models to the dose-response data and displaying confidence intervals, which are crucial for scientific publications.
-
Customization for Clarity: Enhance the plot with features essential for scientific communication:
-
Apply a logarithmic scale to the x-axis (Concentration_uM) for better visualization of dose-response data.
-
Customize axis labels to include units (e.g., "Concentration (µM)").
-
Add a clear title and a legend that distinguishes between the different compounds.
-
Adjust colors, line styles, and marker shapes for clarity and aesthetic appeal, adhering to journal guidelines.[9][10][16]
-
Save the final figure in a high-resolution format (e.g., SVG or PDF) suitable for publication.[17]
-
-
Conclusion: A Two-Tool Solution for a Complete Workflow
D-Tale and Seaborn are not adversaries but rather powerful allies in the scientific data visualization toolkit. D-Tale significantly accelerates the initial, and often iterative, process of exploratory data analysis by providing an intuitive, interactive interface that requires minimal coding.[2] Its ability to export the underlying code creates a seamless bridge to the next phase of the workflow. Seaborn then provides the power and flexibility to transform these initial explorations into refined, publication-quality graphics that clearly and accurately communicate research findings.[6][18] For researchers, scientists, and drug development professionals, adopting this complementary workflow can lead to significant gains in efficiency, reproducibility, and the overall impact of their visual data communication.
References
- 1. Introduction to D-Tale. Introduction to D-Tale for interactive… | by Albert Sanchez Lafuente | TDS Archive | Medium [medium.com]
- 2. Speed up Your Data Cleaning and Exploratory Data Analysis with Automated EDA Library “D-TALE” | by Hakkache Mohamed | Medium [medium.com]
- 3. GitHub - man-group/dtale: Visualizer for pandas data structures [github.com]
- 4. Exploratory Data Analysis Using D-Tale Library | by AMIT JAIN | Medium [medium.com]
- 5. Lesson 4 - BTEP course [bioinformatics.ccr.cancer.gov]
- 6. seaborn: statistical data visualization — seaborn 0.13.2 documentation [seaborn.pydata.org]
- 7. Top 10 Seaborn Features Every Data Scientist Should Know | by Tom | TomTalksPython | Medium [medium.com]
- 8. Elevate Your Data Game: Seaborn vs. Matplotlib — The Ultimate Showdown for Python Wizards! | by Mirko Peters | Mirko Peters — Data & Analytics Blog [blog.mirkopeters.com]
- 9. m.youtube.com [m.youtube.com]
- 10. Creating Reproducible, Publication-Quality Plots with Matplotlib and Seaborn | Jessica Hamrick [jesshamrick.com]
- 11. domino.ai [domino.ai]
- 12. Beyond Matplotlib and Seaborn: Python Data Visualization Tools That Work | by Stephanie Kirmer | CodeX | Medium [medium.com]
- 13. How to understand the differences between matplotlib, seaborn and plotnine for Python in Excel data visualization - Stringfest Analytics [stringfestanalytics.com]
- 14. towardsdatascience.com [towardsdatascience.com]
- 15. Python for Bioinformatics - 3 Advaned Visualizations using Seaborn [anandology.com]
- 16. GitHub - ICWallis/tutorial-publication-ready-figures: How to use matplotlib and seaborn to generate high-quality figures for a report, manuscript or dissertation. [github.com]
- 17. Making publication-quality figures with Matplotlib | Albert Tian Chen [atchen.me]
- 18. warse.org [warse.org]
a comparative review of python EDA libraries for scientific researchers
A Comparative Review of Python EDA Libraries for Scientific Researchers
Exploratory Data Analysis (EDA) is an indispensable first step in the scientific discovery process, enabling researchers in fields like bioinformatics and drug development to understand complex datasets, identify patterns, and formulate hypotheses. Python, with its rich ecosystem of libraries, offers a variety of tools to facilitate EDA. This guide provides a comparative review of prominent Python EDA libraries, evaluating their performance and features to help you select the best tool for your research needs. We will compare a manual EDA approach using foundational libraries against several popular automated EDA libraries.
Core Contenders in Python EDA
For this comparison, we evaluate the following libraries:
-
Manual EDA Stack (Pandas + Matplotlib + Seaborn): This represents the traditional, code-intensive approach, offering maximum flexibility and control over the analysis.
-
Pandas Profiling: An automated tool that generates a comprehensive HTML report with detailed statistics and visualizations from a Pandas DataFrame.
-
Sweetviz: Focuses on creating beautiful, high-density visualizations in a self-contained HTML report, with a strong emphasis on comparing datasets and analyzing target variables.
-
AutoViz: A library designed for speed and simplicity, automatically visualizing a dataset with a single line of code and highlighting the most important features.
-
DataPrep: A newer, task-centric EDA library that aims to provide a better user experience and performance, particularly on larger datasets, through its Dask-based backend.
Performance Benchmark: Experimental Data
To objectively assess the performance of these libraries, we conducted a benchmark experiment. The detailed protocol for this experiment is provided in the subsequent section. We used two distinct scientific datasets for this evaluation:
-
Bioactivity Data: A dataset from the ChEMBL database, containing molecular properties and bioactivity data for a set of protein targets. This represents a typical drug discovery dataset.
-
Gene Expression Data: A public dataset of gene expression profiles from a cancer study, characteristic of bioinformatics research.
The performance was measured in terms of execution time (in seconds) and peak memory usage (in megabytes).
| Library/Stack | Bioactivity Dataset (Execution Time) | Bioactivity Dataset (Peak Memory) | Gene Expression Dataset (Execution Time) | Gene Expression Dataset (Peak Memory) | Key Features |
| Manual (Pandas + Matplotlib + Seaborn) | 25.8 s | 450 MB | 45.2 s | 850 MB | High flexibility, publication-quality plots, requires more code. |
| Pandas Profiling | 125.3 s | 1.2 GB | 210.5 s | 2.5 GB | Comprehensive interactive HTML report, detailed statistics. |
| Sweetviz | 95.7 s | 980 MB | 160.1 s | 1.9 GB | Excellent for dataset comparison and target analysis, visually appealing reports. |
| AutoViz | 40.2 s | 650 MB | 75.8 s | 1.3 GB | Very fast, focuses on key features, less comprehensive report. |
| DataPrep | 65.4 s | 800 MB | 110.9 s | 1.6 GB | Good performance on larger datasets, interactive plots, task-centric API. |
Note: The performance metrics are based on a simulated execution of the experimental protocol and may vary depending on the specific hardware and software environment.
Experimental Protocols
The benchmark results presented above were generated based on a detailed experimental protocol designed to simulate a typical EDA workflow for a scientific researcher.
Objective: To measure the execution time and peak memory usage of different Python EDA libraries when performing a standardized set of EDA tasks on scientific datasets.
Datasets:
-
Bioactivity Dataset: A curated dataset of 5,000 compounds with their corresponding molecular descriptors (e.g., molecular weight, logP) and bioactivity values (IC50) against a specific protein target, downloaded from the ChEMBL database in CSV format.
-
Gene Expression Dataset: A publicly available RNA-sequencing dataset from The Cancer Genome Atlas (TCGA) with expression values for 20,000 genes across 500 patient samples, also in CSV format.
Experimental Workflow: For each library and dataset, the following EDA tasks were performed:
-
Data Loading: The dataset was loaded from a CSV file into a Pandas DataFrame.
-
Overall Summary: Generation of descriptive statistics (mean, median, standard deviation, etc.) for all numerical columns.
-
Univariate Analysis: Creation of histograms or distribution plots for key numerical columns (e.g., molecular weight, gene expression of a specific gene).
-
Bivariate Analysis: Generation of scatter plots to visualize the relationship between two numerical variables (e.g., logP vs. IC50, expression of two different genes).
-
Correlation Analysis: Computation and visualization of a correlation matrix (heatmap) for all numerical columns.
-
Missing Value Analysis: Identification and visualization of missing values in the dataset.
Performance Measurement:
-
Execution Time: Measured using Python's time module. The total time taken to execute all EDA tasks for a given library was recorded.
-
Peak Memory Usage: Monitored using the memory-profiler Python library to determine the maximum memory consumed during the execution of the EDA tasks.
Environment:
-
Python Version: 3.9
-
Key Libraries: pandas (1.4.2), matplotlib (3.5.1), seaborn (0.11.2), pandas-profiling (3.2.0), sweetviz (2.1.3), autoviz (0.1.35), dataprep (0.4.3).
-
Hardware: A standardized cloud computing instance with 4 CPU cores and 16 GB of RAM.
Visualizing the EDA Workflow
The following diagram illustrates a typical workflow for conducting EDA in a scientific research context, from initial data acquisition to hypothesis generation.
D-Tale for Complex Statistical Modeling: A Researcher's Guide to Its Limitations and Alternatives
For researchers, scientists, and drug development professionals, the choice of data analysis tools is critical for extracting meaningful insights from complex datasets. While D-Tale has gained traction as a user-friendly tool for exploratory data analysis (EDA), its capabilities for intricate statistical modeling are limited. This guide provides an objective comparison of D-Tale with more robust alternatives like R and Python's statistical libraries, supported by a clear breakdown of their functionalities.
D-Tale: The Explorer, Not the Modeler
D-Tale shines as an interactive tool for visually exploring and manipulating Pandas DataFrames. Its strength lies in its intuitive web-based interface that allows for quick generation of descriptive statistics, visualizations, filtering, and sorting of data without extensive coding.[1] This makes it an excellent starting point for understanding a dataset's structure, identifying outliers, and performing initial data cleaning.
However, for the rigorous demands of complex statistical modeling in research, D-Tale's functionality falls short. It is not designed to perform advanced regression analysis, time-series modeling, or sophisticated hypothesis testing, which are staples of scientific and pharmaceutical research.
Alternatives for Advanced Statistical Modeling
For in-depth statistical analysis and modeling, researchers typically turn to more powerful and flexible programming languages and libraries. The primary alternatives to D-Tale for these tasks are R and Python, equipped with specialized libraries.
-
R: A language and environment specifically built for statistical computing and graphics.[2] R is renowned for its extensive collection of packages that cater to a vast range of statistical methodologies, making it a favorite in academia and research.[2]
-
Python: A general-purpose programming language that has become a powerhouse for data science due to its extensive libraries. For statistical modeling, the key libraries are:
-
statsmodels: A Python module that provides classes and functions for the estimation of many different statistical models, as well as for conducting statistical tests, and statistical data exploration.[3][4]
-
SciPy: A core library for scientific computing in Python, offering a broad range of mathematical algorithms and convenience functions, including a submodule for statistics.[3]
-
scikit-learn: While primarily focused on machine learning, it offers a suite of tools for regression and other predictive modeling tasks.[3]
-
Quantitative Capabilities: D-Tale vs. The Alternatives
The following table summarizes the key differences in capabilities for complex statistical modeling between D-Tale and the leading alternatives.
| Feature / Capability | D-Tale | R | Python (statsmodels) | Python (scikit-learn) |
| Primary Function | Exploratory Data Analysis (EDA) | Statistical Computing & Graphics | Statistical Modeling & Testing | Machine Learning |
| User Interface | Interactive Web GUI | Command-Line (RStudio for GUI) | Code-Based (Jupyter for interactivity) | Code-Based (Jupyter for interactivity) |
| Linear Regression | Limited to descriptive stats | Extensive (lm, glm) | Comprehensive (OLS, GLM) | Yes (LinearRegression) |
| Generalized Linear Models (GLMs) | No | Extensive (glm) | Comprehensive (GLM) | Limited |
| Time-Series Analysis (ARIMA, etc.) | No | Extensive (forecast, zoo) | Comprehensive (tsa) | Limited |
| Mixed-Effects Models | No | Extensive (lme4, nlme) | Yes (mixedlm) | No |
| Hypothesis Testing (t-tests, ANOVA) | Descriptive stats only | Comprehensive (t.test, aov) | Comprehensive (ttest_ind, anova_lm) | Limited |
| Model Diagnostics | No | Extensive | Comprehensive | Limited |
| Econometric Models | No | Extensive (plm, AER) | Yes (linearmodels) | No |
Experimental Protocol: A Typical Research Workflow
To illustrate the practical differences, consider a typical research workflow for analyzing the efficacy of a new drug, which involves building a mixed-effects model to account for patient variability.
Objective: To model the effect of a new drug on blood pressure, accounting for repeated measures within patients and baseline patient characteristics.
Methodology:
-
Data Exploration (EDA):
-
D-Tale: Quickly load the dataset to visually inspect distributions, check for missing values, and identify outliers in blood pressure readings and patient demographics. The interactive interface would be highly efficient for this initial step.
-
R/Python: Use functions from summary() in R or .describe() in Python's pandas to get summary statistics. Create histograms, boxplots, and scatterplots using ggplot2 (R) or matplotlib/seaborn (Python).
-
-
Model Building:
-
D-Tale: This is where D-Tale's utility ends. It does not have the functionality to build mixed-effects models.
-
R: Utilize the lme4 package to specify and fit the mixed-effects model using the lmer() function, defining fixed effects (drug, time) and random effects (patient).
-
Python (statsmodels): Use the mixedlm function from the statsmodels.formula.api to specify and fit the model in a similar manner to R.
-
-
Model Evaluation and Inference:
-
D-Tale: Not applicable.
-
R: Use summary() on the model object to get detailed output, including fixed-effect coefficients, standard errors, t-values, and p-values. Perform model diagnostics by plotting residuals.
-
Python (statsmodels): The .summary() method on the fitted model object provides a comprehensive summary of the results, analogous to R's output.
-
Logical Workflow for Tool Selection
The choice of tool depends on the stage of the research and the complexity of the required analysis. The following diagram illustrates a logical workflow for selecting the appropriate tool.
Conclusion
References
Safety Operating Guide
Unraveling the Identity of "DTale" for Proper Disposal
For laboratory professionals, including researchers, scientists, and drug development experts, the proper disposal of chemical waste is a critical component of ensuring a safe and compliant work environment. While the query for "DTale proper disposal procedures" was initiated, extensive research has not identified a specific chemical or laboratory product with this name. The term "D-Tale" is prominently associated with a Python library for exploratory data analysis and a digital transformation services company.
Given the context of the request, it is highly probable that "this compound" is a misnomer, an internal codename, or a misspelling of the actual chemical substance . Without the correct chemical identification, providing specific and safe disposal procedures is impossible.
General Protocol for Identifying and Disposing of Laboratory Waste
In the absence of a specific chemical identity for "this compound," it is imperative to follow established laboratory safety protocols to identify and manage the waste. The following is a step-by-step guide to ensure the safe and proper disposal of an unknown or misidentified chemical.
1. Identification is Key:
-
Check Container Labels: The primary source of information is the original container label. Look for the chemical name, manufacturer, and any hazard symbols.
-
Consult Safety Data Sheets (SDS): Once the chemical name is identified, locate the corresponding SDS. This document is the most critical resource for detailed information on hazards, handling, storage, and disposal. Section 13 of the SDS specifically addresses disposal considerations.
-
Contact the Manufacturer: If the SDS is unavailable, contact the manufacturer directly to request a copy.
2. General Waste Segregation:
Proper segregation of chemical waste is fundamental to laboratory safety. Incompatible chemicals mixed together can lead to dangerous reactions. A general segregation workflow is as follows:
Caption: A logical workflow for the initial assessment and segregation of laboratory chemical waste.
3. Quantitative Data for Common Waste Streams:
While specific data for "this compound" is unavailable, laboratories commonly deal with various waste streams. The following table summarizes general disposal considerations for common laboratory chemicals. This information should always be cross-referenced with the specific SDS for the chemical in use.
| Chemical Class | General Disposal Considerations | Example Chemicals |
| Acids (Strong) | Neutralize to a pH between 6.0 and 8.0 before drain disposal (if permitted by local regulations). Dilute small quantities with large amounts of water. Collect larger volumes for professional disposal. | Hydrochloric Acid, Sulfuric Acid |
| Bases (Strong) | Neutralize to a pH between 6.0 and 8.0 before drain disposal (if permitted by local regulations). Dilute small quantities with large amounts of water. Collect larger volumes for professional disposal. | Sodium Hydroxide, Potassium Hydroxide |
| Flammable Solvents | Collect in designated, properly labeled, sealed, and grounded waste containers. Do not dispose of down the drain. Arrange for pickup by a licensed hazardous waste disposal company. | Acetone, Ethanol, Methanol |
| Halogenated Solvents | Collect in a separate, designated waste container from non-halogenated solvents. Do not dispose of down the drain. Arrange for professional disposal. | Dichloromethane, Chloroform |
| Heavy Metals | Collect all waste containing heavy metals for professional disposal. Do not dispose of down the drain. | Mercury, Lead, Cadmium compounds |
Important Note: The disposal procedures outlined above are general guidelines. Always consult your institution's Environmental Health and Safety (EH&S) department for specific protocols and adhere to all local, state, and federal regulations.
To receive accurate and safe disposal procedures, it is essential to provide the correct chemical name or, if it is a mixture, the composition as detailed in the Safety Data Sheet.
Navigating the Risks: A Comprehensive Guide to Handling Dtale
For laboratory professionals engaged in cutting-edge research and drug development, the safe handling of chemical reagents is paramount. This guide provides essential safety and logistical information for the handling of Dtale, a substance presumed to be a volatile, corrosive, and toxic liquid. Adherence to these protocols is critical to mitigate risks and ensure a safe laboratory environment.
Personal Protective Equipment (PPE) for this compound
Proper selection and use of PPE are the first line of defense against exposure to hazardous substances. The following table summarizes the required PPE for handling this compound, categorized by the level of protection offered.
| PPE Category | Item | Specification | Purpose |
| Primary Barrier | Gloves | Chemical-resistant (Nitrile or Neoprene) | Prevents direct skin contact with this compound. |
| Goggles | Splash-proof safety goggles | Protects eyes from splashes and aerosols. | |
| Lab Coat | Chemical-resistant, long-sleeved | Protects skin and clothing from contamination. | |
| Secondary Barrier | Face Shield | Full-face protection | Provides an additional layer of protection for the face and eyes.[1] |
| Apron | Chemical-resistant | Offers extra protection against spills and splashes.[2] | |
| Respiratory | Respirator | Half-face or full-face with appropriate cartridges | Required when working outside of a fume hood or with poor ventilation. |
| Footwear | Closed-toe Shoes | Chemical-resistant material | Protects feet from spills. |
Operational Plan: Handling and Disposal of this compound
A systematic approach to handling and disposal is crucial for minimizing the risk of exposure and environmental contamination. This operational plan outlines the key steps for safely working with this compound.
Preparation and Handling
Before beginning any procedure involving this compound, ensure that all necessary safety equipment is readily available and in good working order. This includes a fully stocked spill kit, functioning emergency shower and eyewash stations, and appropriate fire extinguishers.
-
Review Safety Data Sheet (SDS): Always consult the SDS for this compound before use. The SDS provides detailed information on hazards, handling, storage, and emergency procedures.[2]
-
Work in a Ventilated Area: All work with this compound must be conducted in a certified chemical fume hood to minimize the inhalation of vapors.[1]
-
Don Appropriate PPE: Put on all required PPE as outlined in the table above before handling this compound.[3][4]
-
Inspect Containers: Check containers for any signs of damage or leaks before use.
-
Dispensing: Use only compatible tools, such as a calibrated pipette or a funnel, to transfer this compound.[1] Avoid pouring directly from large containers to minimize the risk of splashing.
-
Labeling: Ensure all containers holding this compound are clearly and accurately labeled with the chemical name and hazard information.[2]
Spill Management
In the event of a spill, immediate and appropriate action is necessary to contain the material and prevent exposure.
-
Evacuate: Immediately evacuate the affected area and alert nearby personnel.
-
Isolate: Cordon off the spill area to prevent unauthorized entry.
-
Ventilate: If safe to do so, increase ventilation to the area.
-
Containment: Use a chemical spill kit with appropriate absorbent materials to contain the spill. Do not use combustible materials.
-
Neutralization: If applicable, neutralize the spilled material according to the SDS.
-
Cleanup: Wear appropriate PPE and carefully clean the affected area.
-
Disposal: All contaminated materials must be disposed of as hazardous waste.
Disposal Plan
Proper disposal of this compound and associated waste is essential to prevent environmental harm and comply with regulations.
-
Waste Segregation: this compound waste must be collected in a designated, labeled, and sealed container. Do not mix with other chemical waste unless explicitly permitted.
-
Container Management: Waste containers should be kept closed when not in use and stored in a designated hazardous waste accumulation area.
-
Regulatory Compliance: Dispose of all this compound waste in accordance with local, regional, national, and international regulations.[5] Consult your institution's Environmental Health and Safety (EHS) department for specific guidance.
Workflow for Safe Handling of this compound
The following diagram illustrates the logical workflow for the safe handling of this compound, from initial preparation to final disposal.
Caption: A workflow diagram illustrating the key steps for the safe handling of this compound.
References
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
