Protein (sartorilli)
Description
Contextualization within Modern Biochemistry and Molecular Biology
Proteins are fundamental macromolecules essential to virtually all biological processes. wikipedia.orgnih.gov In modern biochemistry and molecular biology, the study of proteins, or proteomics, is a central focus. Proteins are complex polymers composed of amino acid residues linked by peptide bonds. wikipedia.orgnewworldencyclopedia.org The specific sequence of these amino acids dictates the protein's unique three-dimensional structure, which in turn determines its function. wikipedia.orgnewworldencyclopedia.org
The functions of proteins are vast and varied, including:
Catalysis: Enzymes, a specialized class of proteins, catalyze most chemical reactions within cells. wikipedia.org
Structure: Proteins like collagen and keratin provide structural support to cells and tissues.
Transport: Hemoglobin, for instance, transports oxygen in the blood.
Signaling: Hormones such as insulin are proteins that transmit signals between cells.
Movement: Proteins like actin and myosin are crucial for muscle contraction.
Defense: Antibodies are proteins that protect the body from foreign pathogens.
The central dogma of molecular biology—that DNA is transcribed into RNA, which is then translated into protein—places proteins as the primary effectors of genetic information. Understanding protein structure and function is therefore critical to deciphering the mechanisms of life, health, and disease.
Historical Perspectives on Protein Discovery and Functional Elucidation
The recognition of proteins as a distinct class of biological molecules dates back to the 18th century, with early observations of substances like egg albumin coagulating with heat or acid. quora.com The term "protein" was first proposed in 1838 by Jöns Jacob Berzelius, derived from the Greek word "proteios," meaning "of the first rank," highlighting their perceived importance. newworldencyclopedia.orgquora.comyoutube.com
Key milestones in the history of protein research have shaped our current understanding:
| Year/Era | Discovery/Development | Significance |
| 1838 | Jöns Jacob Berzelius proposes the name "protein." quora.comyoutube.com | Established proteins as a distinct and important class of biological molecules. |
| Early 1900s | Emil Fischer proposes the "lock and key" model for enzyme-substrate interactions and identifies the peptide bond. quora.comyoutube.com | Provided foundational concepts for understanding protein specificity and structure. |
| 1950s | Frederick Sanger determines the complete amino acid sequence of insulin. quora.com | Demonstrated that proteins have a defined chemical structure, paving the way for sequencing other proteins. |
| 1958 | John Kendrew and Max Perutz solve the first three-dimensional structure of a protein, myoglobin, using X-ray crystallography. wikipedia.orgnewworldencyclopedia.org | Revealed the complex folded architecture of proteins, directly linking structure to function. |
| 1970s | The Protein Data Bank (PDB) is established. youtube.com | Created a public repository for protein structural data, accelerating research worldwide. |
| Late 20th/Early 21st Century | Advancements in techniques like NMR spectroscopy, cryo-electron microscopy, and mass spectrometry. | Expanded the toolkit for studying protein structure, dynamics, and interactions. |
Structure
3D Structure
Properties
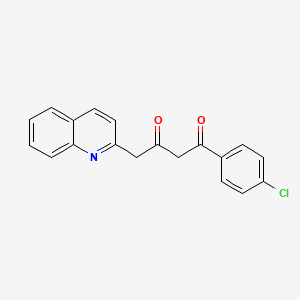
CAS No. |
26958-31-6 |
|---|---|
Molecular Formula |
C19H14ClNO2 |
Molecular Weight |
323.8 g/mol |
IUPAC Name |
1-(4-chlorophenyl)-4-quinolin-2-ylbutane-1,3-dione |
InChI |
InChI=1S/C19H14ClNO2/c20-15-8-5-14(6-9-15)19(23)12-17(22)11-16-10-7-13-3-1-2-4-18(13)21-16/h1-10H,11-12H2 |
InChI Key |
PWZYXHHXUXKCRA-UHFFFAOYSA-N |
Canonical SMILES |
C1=CC=C2C(=C1)C=CC(=N2)CC(=O)CC(=O)C3=CC=C(C=C3)Cl |
Origin of Product |
United States |
Molecular Architecture and Dynamics
Hierarchical Protein Structures and Folding Pathways
The structure of EZH2 is organized in a hierarchical manner, where the primary amino acid sequence dictates the formation of secondary structures, which in turn fold into a complex three-dimensional tertiary structure. The functional form of EZH2 is often achieved through its association with other proteins in a quaternary complex.
Each domain of EZH2 is characterized by a specific arrangement of secondary structural elements, primarily alpha-helices and beta-sheets. The catalytic SET domain, for example, has a characteristic fold where the core is formed by several β-strands, flanked by α-helices researchgate.net. The crystal structure of the EZH2-SET domain reveals a core of β-strands (β-3, 7, and 8) flanked by a three-stranded antiparallel β-sheet (β-4, 6, and 5) and an accessory α-helix (α-4) researchgate.net. The conformational propensities of these secondary structures are influenced by the primary amino acid sequence and post-translational modifications, which can alter the protein's folding and activity.
Table 1: Secondary Structure Composition of the EZH2 SET Domain
| Secondary Structure Element | Location within SET Domain | Function |
|---|---|---|
| β-strands 3, 7, and 8 | Core of the domain | Forms the central scaffold of the catalytic site. |
| Antiparallel β-sheet (β-4, 6, 5) | Flanking the core | Contributes to the structural integrity of the domain. |
| α-helix 4 | Accessory helix | Supports the overall fold of the SET domain. |
Table 2: Functional Domains of EZH2
| Domain | Function |
|---|---|
| EID (EED-binding) Domain | Interaction with the EED subunit of PRC2. |
| Domain II | Interaction with the SUZ12 subunit of PRC2. |
| SANT Domains | Histone binding. |
| CXC Domain | Contributes to methyltransferase activity. |
| SET Domain | The catalytic core responsible for histone methylation. |
EZH2 functions as part of the larger Polycomb Repressive Complex 2 (PRC2). The core of this complex is a heterotrimer consisting of EZH2, Embryonic Ectoderm Development (EED), and Suppressor of Zeste 12 (SUZ12) nih.govnih.gov. The assembly of this quaternary structure is essential for the catalytic activity of EZH2 nih.govnih.gov. EED and SUZ12 are not merely scaffolds but play active roles in regulating EZH2's function. The interaction between EZH2 and EED is mediated by a specific region on EZH2 that binds to the WD-repeat domain of EED nih.govresearchgate.net. This interaction is crucial for the allosteric activation of EZH2's methyltransferase activity.
Protein Dynamics and Conformational Transitions
The function of EZH2 is tightly regulated through its dynamic nature, involving conformational changes in response to various signals. These dynamics are central to its role as a regulated enzyme.
The catalytic activity of EZH2 is allosterically regulated. A key mechanism involves the binding of trimethylated H3K27 (H3K27me3) to the EED subunit of the PRC2 complex. This binding event induces a conformational change in EED, which is then transmitted to EZH2, leading to the activation of its methyltransferase activity. This positive feedback loop allows for the propagation of the H3K27me3 mark along the chromatin.
Furthermore, the binding of the histone substrate and the SAM cofactor to the active site of EZH2 involves an induced fit mechanism. In the absence of its binding partners in the PRC2 complex, the substrate and cofactor binding sites of EZH2 are in a closed or incomplete conformation plos.orgnih.gov. The assembly of the PRC2 complex induces a significant conformational change in EZH2, particularly in the I-SET and post-SET domains, which repositions key residues to form a catalytically competent active site nih.gov. This conformational plasticity is a hallmark of EZH2 regulation and ensures that its enzymatic activity is tightly controlled. X-ray crystallography has revealed that EZH2 possesses distinct pockets for substrate peptide and SAM binding, connected by a narrow catalytic channel researchgate.net. The proper formation of these pockets is dependent on the conformational state of the enzyme.
Unidentified Compound: "Protein (sartorilli)"
Initial research into the chemical compound specified as "Protein (sartorilli)" has yielded no identification of a substance with this name in publicly available scientific literature or databases. Consequently, a detailed article on its molecular architecture and dynamics as per the requested outline cannot be generated at this time.
Extensive searches for "Protein (sartorilli)" and variations of the term have not matched any known protein or chemical compound. This suggests several possibilities: the name may be a proprietary designation not yet disclosed in public research, a highly specific or internal project name, a significant misspelling of a known compound, or a term used in a context outside of formally recognized scientific nomenclature.
Without a verifiable identification of "Protein (sartorilli)," it is not possible to provide scientifically accurate and detailed information regarding its:
: Including any potential intrinsically disordered regions and their functional implications.
Ligand Binding Dynamics and Molecular Recognition: Elucidating the specifics of how it interacts with other molecules.
Further investigation is contingent upon the provision of a correct and recognized chemical name, CAS number, or other standard identifiers for the compound . Without such information, a scientifically rigorous article that adheres to the requested detailed outline cannot be produced.
Based on a comprehensive search of scientific literature, a specific chemical compound or protein designated as "Protein (sartorilli)" is not found. The term "Sartorilli" appears to be associated with Dr. Vittorio Sartorelli, a researcher noted for his work in the field of myogenesis and transcriptional regulation, rather than a specific protein.
Therefore, it is not possible to provide an article focusing solely on a compound named "Protein (sartorilli)" as no such entity is described in the current body of scientific knowledge. The detailed biological processes outlined in the request, such as biosynthesis, post-translational modifications, and proteostasis, are fundamental to all proteins. However, without a specific protein as the subject, a scientifically accurate and focused article as requested cannot be generated.
Biosynthesis, Post Translational Modifications, and Proteostasis
Proteostasis Network and Chaperone-Mediated Folding
The proteostasis network is a sophisticated and integrated system of cellular pathways that regulate the biogenesis, folding, trafficking, and degradation of proteins. wikipedia.org This network is essential for maintaining cellular health and function by ensuring the quality of the proteome. nih.gov At the core of this network are molecular chaperones, which play a pivotal role in assisting protein folding and preventing the aggregation of misfolded proteins.
Heat Shock Proteins and Folding Assistance
Heat Shock Proteins (HSPs) are a major class of molecular chaperones that are crucial for maintaining protein homeostasis. diva-portal.org They are named for their increased expression in response to cellular stress, such as elevated temperatures, but are also essential for normal cellular function. HSPs bind to unfolded or partially folded polypeptide chains, preventing them from aggregating and facilitating their correct folding into their native three-dimensional structures.
The Hsp70 family of chaperones is a key player in this process. nih.gov In conjunction with their co-chaperones, such as J-domain proteins (JDPs), Hsp70 chaperones recognize and bind to hydrophobic regions of unfolded proteins. nih.gov This interaction is an ATP-dependent process that helps to stabilize the protein in a folding-competent state. The Hsp70 system can either promote the refolding of misfolded proteins or, if the protein is irreparably damaged, target it for degradation. nih.gov
| Chaperone Family | Primary Function | Mechanism of Action |
| Hsp70 | Assists in the folding of newly synthesized proteins and the refolding of misfolded proteins. | Binds to exposed hydrophobic regions of unfolded polypeptides in an ATP-dependent manner. |
| Hsp60 (Chaperonins) | Provides a protected environment for the folding of a subset of cellular proteins. | Forms a barrel-shaped complex that encapsulates unfolded proteins, allowing them to fold in isolation. |
| Hsp90 | Facilitates the final maturation and activation of specific client proteins, such as steroid hormone receptors and protein kinases. | Binds to near-native protein conformations, often in the final stages of folding. |
| Small HSPs | Prevents the aggregation of denatured proteins. | Forms large oligomeric structures that bind to misfolded proteins, holding them in a state competent for refolding by other chaperones. |
Unfolded Protein Response Mechanisms
The endoplasmic reticulum (ER) is a major site of protein synthesis and folding for secreted and transmembrane proteins. When the folding capacity of the ER is overwhelmed by an influx of unfolded or misfolded proteins, a condition known as ER stress, the Unfolded Protein Response (UPR) is activated. frontiersin.org The UPR is a signaling pathway that aims to restore proteostasis by reducing the load of new proteins entering the ER, increasing the folding capacity of the ER, and enhancing the degradation of misfolded proteins.
In mammals, the UPR is mediated by three main ER-resident sensor proteins: IRE1 (Inositol-requiring enzyme 1), PERK (PKR-like ER kinase), and ATF6 (Activating transcription factor 6).
IRE1 Pathway: Upon activation, IRE1 splices the mRNA of the X-box binding protein 1 (XBP1). The spliced XBP1 mRNA is then translated into a potent transcription factor that upregulates the expression of genes involved in protein folding and degradation.
PERK Pathway: Activated PERK phosphorylates the eukaryotic initiation factor 2α (eIF2α), which leads to a general attenuation of protein synthesis, thereby reducing the protein load on the ER. However, the translation of certain mRNAs, such as that of the transcription factor ATF4, is paradoxically enhanced. ATF4 then drives the expression of genes involved in amino acid metabolism, antioxidant responses, and apoptosis.
ATF6 Pathway: When ER stress occurs, ATF6 is transported to the Golgi apparatus, where it is cleaved to release its N-terminal cytosolic domain. This fragment then translocates to the nucleus and acts as a transcription factor to increase the expression of ER chaperones and other components of the ER-associated degradation (ERAD) pathway.
Protein Turnover and Degradation Pathways
Protein turnover is a fundamental cellular process that involves the continuous degradation and synthesis of proteins. This dynamic process allows cells to adapt to changing conditions, remove damaged or misfolded proteins, and regulate the levels of key cellular proteins. There are two major pathways for protein degradation in eukaryotic cells: the lysosomal pathway and the ubiquitin-proteasome system.
Lysosomal and Autophagosomal Degradation
Lysosomes are acidic organelles that contain a wide array of hydrolytic enzymes capable of degrading various macromolecules, including proteins. Autophagy is a major cellular pathway that delivers cytoplasmic components, including proteins and organelles, to the lysosome for degradation. diva-portal.org
There are three main types of autophagy:
Macroautophagy: This is the most well-characterized form of autophagy. It involves the formation of a double-membraned vesicle, called an autophagosome, which engulfs a portion of the cytoplasm. The autophagosome then fuses with a lysosome to form an autolysosome, where the enclosed material is degraded.
Microautophagy: In this process, the lysosomal membrane itself invaginates to directly engulf small portions of the cytoplasm.
Chaperone-mediated autophagy (CMA): This is a more selective process where specific cytosolic proteins containing a KFERQ-like motif are recognized by the chaperone Hsc70 and its co-chaperones. This complex then binds to the lysosome-associated membrane protein 2A (LAMP-2A), leading to the unfolding and translocation of the substrate protein into the lysosomal lumen for degradation.
| Degradation Pathway | Substrate Selectivity | Key Machinery |
| Macroautophagy | Non-selective (bulk degradation) and selective (specific cargo) | Autophagosomes, Lysosomes |
| Microautophagy | Non-selective | Lysosomal membrane invagination |
| Chaperone-mediated autophagy | Selective for proteins with a KFERQ-like motif | Hsc70, LAMP-2A, Lysosomes |
Regulated Proteolysis in Cellular Processes
In addition to the bulk degradation of proteins, highly specific and regulated proteolysis is essential for a wide range of cellular processes. This controlled cleavage of proteins can activate or inactivate them, generate signaling molecules, or facilitate their degradation.
One of the most important systems for regulated proteolysis is the ubiquitin-proteasome system (UPS) . The UPS is the primary pathway for the degradation of most short-lived and regulatory proteins in the cytosol and nucleus. Proteins are targeted for degradation by the UPS through the covalent attachment of a polyubiquitin chain. This process, known as ubiquitination, is carried out by a cascade of three enzymes: E1 (ubiquitin-activating enzyme), E2 (ubiquitin-conjugating enzyme), and E3 (ubiquitin ligase). The specificity of the UPS is largely determined by the vast number of different E3 ligases, each of which recognizes specific substrate proteins.
Once a protein is tagged with a polyubiquitin chain, it is recognized by the 26S proteasome, a large multi-protein complex that functions as a cellular recycling machine. The proteasome unfolds the ubiquitinated protein, removes the ubiquitin tags for reuse, and degrades the protein into small peptides.
Regulated proteolysis by the UPS plays a critical role in:
Cell cycle control: The timely degradation of cyclins and other cell cycle regulators is essential for the proper progression through the cell cycle.
Signal transduction: The degradation of signaling proteins can terminate a signaling pathway.
Transcription regulation: The degradation of transcription factors can control gene expression.
Immune surveillance: The proteasome generates peptides from foreign proteins for presentation on MHC class I molecules.
Molecular Interactions and Complex Formation
Protein-Protein Interaction Networks (Interactomics)
The functions of myogenic regulatory factors are not dictated by solitary actions but rather by their participation in complex protein-protein interaction (PPI) networks. These networks, or interactomes, are dynamic and context-dependent, governing the assembly of transcriptional machinery on the promoters and enhancers of muscle-specific genes. Key players in myogenesis, such as the MyoD and Myocyte Enhancer Factor 2 (MEF2) families of proteins, operate within these intricate networks.
The interactions between myogenic proteins are characterized by a high degree of modularity and specificity, dictated by conserved structural domains.
MyoD and the bHLH Domain: MyoD and other myogenic regulatory factors (MRFs) belong to the basic helix-loop-helix (bHLH) superfamily of transcription factors. The bHLH domain is a highly conserved motif that mediates both DNA binding and dimerization. For transcriptional activity, MyoD must form heterodimers with ubiquitously expressed E-proteins (such as E12 and E47), which are also bHLH proteins. The specificity of this interaction is crucial, as MyoD homodimers have a lower affinity for their target DNA sequences, known as E-boxes, compared to MyoD/E-protein heterodimers. The basic region of the bHLH domain is primarily responsible for DNA recognition, while the helix-loop-helix region facilitates the dimerization that juxtaposes the basic domains for effective DNA binding wikipedia.org.
MEF2 and the MADS-box/MEF2 Domain: MEF2 proteins are characterized by a conserved MADS-box and an adjacent MEF2-specific domain at their N-terminus. These domains are essential for dimerization, DNA binding, and interaction with a multitude of co-regulatory proteins. The MEF2 domain, in particular, is a critical interface for interaction with co-repressors, such as class IIa histone deacetylases (HDACs), and co-activators. The interaction between MEF2 and its partners is highly specific; for instance, class IIa HDACs (HDAC4, -5, -7, and -9) are recruited to MEF2-containing transcriptional complexes, leading to the repression of muscle-specific genes in undifferentiated myoblasts nih.gov.
A summary of key interacting proteins for MyoD and MEF2 is presented in the table below.
| Primary Protein | Interacting Partner(s) | Interaction Domain(s) | Functional Consequence |
| MyoD | E-proteins (e.g., E12, E47) | Basic Helix-Loop-Helix (bHLH) | Formation of active heterodimers for DNA binding and transcriptional activation |
| MEF2 proteins | DNA-binding and dimerization motifs | Synergistic activation of myogenic gene expression nih.gov | |
| Pbx1-Meis1 | Cysteine-rich (H/C) region | Recruitment of chromatin remodelers to target gene loci | |
| Arp5 | Cysteine-rich (CR) region | Inhibition of MyoD's myogenic activity | |
| MEF2 | MyoD | DNA-binding and dimerization motifs | Cooperative activation of muscle-specific genes nih.gov |
| GATA4 | MEF2 DNA-binding domain and GATA4 C-terminal zinc finger | Synergistic activation of cardiac-specific genes, often independent of MEF2's DNA binding nih.gov | |
| Class IIa HDACs (HDAC4, 5, 7, 9) | MEF2 domain | Repression of myogenic differentiation in myoblasts | |
| p300/CBP | - | Co-activation of transcription through histone acetylation |
The stability and dynamics of protein complexes are governed by the binding affinities between their constituent proteins. These affinities are often expressed as the dissociation constant (Kd), which represents the concentration of a ligand at which half of the binding sites on a protein are occupied at equilibrium. A lower Kd value signifies a higher binding affinity.
Quantitative studies have begun to elucidate the binding affinities within myogenic protein complexes. For instance, fluorescence anisotropy has been used to measure the Gibb's free energy of dissociation (ΔG) for the binding of MyoD and E12 to DNA, which is related to the binding affinity. The heterodimer of MyoD with E12 binds to the muscle creatine kinase (MCK) enhancer with a ΔG of 21 kcal/mol, indicating a strong interaction acs.org. In contrast, MyoD homodimers bind with a lower affinity (ΔG = 19.6 kcal/mol) acs.org.
More direct measurements of protein-protein interaction affinities have also been reported. The interaction between Arp5 and MyoD, which is inhibitory to myogenesis, has been quantified with a Kd of 4.03 ± 0.72 µM. Arp5 also interacts with Pbx1, a MyoD cofactor, with a Kd of 1.69 ± 0.34 µM, while the interaction between Meis1 and MyoD is weaker, with a Kd of 10.48 ± 1.38 µM nih.gov. Furthermore, surface plasmon resonance (SPR) has been employed to determine the binding affinities between class IIa HDACs and MEF2A, revealing Kd values in the nanomolar range (3.5 nM to 19.1 nM), indicative of very tight binding nih.gov.
The table below summarizes available quantitative data on the binding affinities of key myogenic protein interactions.
| Interacting Proteins | Method | Binding Affinity (Kd) | Gibb's Free Energy of Dissociation (ΔG) |
| Arp5 - MyoD | Not specified | 4.03 ± 0.72 µM nih.gov | - |
| Arp5 - Pbx1 | Not specified | 1.69 ± 0.34 µM nih.gov | - |
| Meis1 - MyoD | Not specified | 10.48 ± 1.38 µM nih.gov | - |
| Class IIa HDACs - MEF2A | Surface Plasmon Resonance (SPR) | 3.5 - 19.1 nM nih.gov | - |
| MyoD/E12 - MCK Enhancer | Fluorescence Anisotropy | - | 21 kcal/mol acs.org |
| MyoD homodimer - MCK Enhancer | Fluorescence Anisotropy | - | 19.6 kcal/mol acs.org |
The assembly and disassembly of myogenic protein complexes are tightly regulated processes, responsive to cellular signaling pathways and the developmental stage of the muscle cell. This dynamic regulation ensures that muscle-specific genes are expressed at the appropriate time and level.
Phosphorylation: Post-translational modifications, particularly phosphorylation, play a critical role in modulating protein-protein interactions. For example, phosphorylation of MyoD can inhibit the DNA-binding activity of MyoD homodimers but does not affect the binding of MyoD-E12 heterodimers nih.gov. This differential effect suggests a mechanism for favoring the formation of transcriptionally active heterodimers over less active homodimers. Signaling pathways, such as the p38 mitogen-activated protein kinase (MAPK) pathway, are activated in response to differentiation cues and can influence the activity of both MyoD and MEF2, facilitating their binding to the regulatory regions of late-expressed muscle genes.
Co-factor Exchange: The transcriptional activity of MEF2 is regulated by its association with co-repressors and co-activators. In proliferating myoblasts, MEF2 is bound by class IIa HDACs, which repress myogenesis. Upon receiving differentiation signals, calcium-dependent signaling pathways, such as those involving CaM kinase, are activated. This leads to the phosphorylation of class IIa HDACs, their dissociation from MEF2, and their export from the nucleus. The now-unrepressed MEF2 can then associate with co-activators like p300/CBP, which possess histone acetyltransferase (HAT) activity, leading to chromatin remodeling and gene activation thebiogrid.org. This exchange of co-repressors for co-activators is a key step in the dynamic regulation of muscle gene expression.
Protein-Nucleic Acid Interactions
The ultimate function of myogenic regulatory factors is to control gene expression through direct interaction with DNA. Furthermore, recent research has highlighted the importance of RNA-binding proteins in the post-transcriptional regulation of these key factors.
MyoD and MEF2 are sequence-specific DNA-binding proteins that recognize distinct consensus sequences in the regulatory regions of their target genes.
MyoD and the E-box: MyoD/E-protein heterodimers bind to a DNA consensus sequence known as the E-box (CANNTG). The specificity of this binding is a primary determinant of which genes will be activated during myogenesis. The binding of MyoD to E-boxes in the promoters and enhancers of muscle-specific genes, such as muscle creatine kinase and myogenin, is a critical event for their transcriptional activation. The affinity of MyoD for different E-box sequences can vary, and this differential affinity may contribute to the temporal regulation of gene expression during differentiation.
MEF2 and the A/T-rich Element: MEF2 proteins bind to an A/T-rich DNA sequence [CTA(A/T)4TAR]. MEF2 binding sites are found in the regulatory regions of a vast number of muscle-specific genes, often in proximity to E-boxes. The cooperative binding of MEF2 and MyoD to these composite regulatory elements leads to a synergistic activation of transcription that is much greater than the sum of the activation by either factor alone nih.gov. In some cases, MEF2 can be recruited to promoters through its interaction with other DNA-bound transcription factors, such as GATA4, even in the absence of a high-affinity MEF2 binding site wikipedia.orgnih.gov. This highlights the versatility of MEF2 in gene regulation.
The expression and activity of myogenic regulatory factors are not only controlled at the transcriptional level but are also subject to post-transcriptional regulation by RNA-binding proteins (RBPs). RBPs can modulate the stability, localization, and translation of their target mRNAs, thereby fine-tuning the levels of key myogenic proteins.
HuR-mediated mRNA Stabilization: The RBP Hu antigen R (HuR) has been shown to play a crucial role in myogenesis by stabilizing the mRNAs of key myogenic factors. HuR binds to AU-rich elements (AREs) in the 3' untranslated region (3'-UTR) of mRNAs. During myoblast differentiation, HuR translocates from the nucleus to the cytoplasm, where it binds to and stabilizes the mRNAs of MyoD and myogenin, leading to their increased protein expression and promoting differentiation nih.govnih.gov. Furthermore, HuR can stabilize the mRNA of MEF2C, a member of the MEF2 family, thereby protecting it from degradation and ultimately enhancing the transcription of its target genes acs.orgthebiogrid.org.
KSRP-mediated mRNA Decay: In contrast to HuR, the K-homology splicing regulatory protein (KSRP) promotes the decay of myogenic factor mRNAs in proliferating myoblasts. KSRP binds to AREs and facilitates the degradation of MyoD and myogenin mRNAs nih.gov. Upon the induction of differentiation, KSRP is phosphorylated by the p38 MAPK pathway, which reduces its affinity for these target mRNAs. This, coupled with the stabilizing effect of cytoplasmic HuR, leads to a rapid accumulation of MyoD and myogenin, driving the cells into the differentiation program nih.gov.
The interplay between stabilizing and destabilizing RBPs provides a sophisticated mechanism for the rapid and precise control of myogenic regulatory factor expression during the transition from myoblast proliferation to terminal differentiation.
Based on a comprehensive search of available scientific literature, there is no identified chemical compound specifically named "Protein (sartorilli)". The name "Sartorelli" is associated with several prominent researchers in the fields of molecular biology, cancer pharmacology, and natural products chemistry, but it does not refer to a specific protein molecule.
The work of Vittorio Sartorelli, for instance, involves the study of various proteins and their interactions in the context of muscle cell differentiation and gene regulation. research.comgoogle.com His research has provided significant insights into the roles of proteins such as MyoD, Myogenin, and SIRT1 in these biological processes. research.comgrantome.com Similarly, the late Alan Sartorelli was a distinguished scientist in cancer pharmacology, with numerous publications on the mechanisms of action of cancer drugs. nih.gov Patricia Sartorelli is a researcher with expertise in the chemistry of natural products. resnetnpnd.org
However, none of the available data points to the existence of a compound named "Protein (sartorilli)". It is possible that this name is a misnomer, refers to a hypothetical molecule, or is a term used in a context not covered by publicly accessible scientific databases.
Due to the absence of any information regarding a chemical compound named "Protein (sartorilli)," it is not possible to provide an article detailing its molecular interactions, complex formation, or any of the other specific topics requested in the outline. Generating such an article would require fabricating information, which would be scientifically inaccurate.
Therefore, the requested article on "Protein (sartorilli)" cannot be generated.
Enzymatic and Catalytic Mechanisms
Enzyme Kinetics and Reaction Mechanisms
Enzymes are highly specialized proteins that accelerate the rate of biochemical reactions by lowering the activation energy. aklectures.com This is achieved through a series of intricate mechanisms involving the binding of substrates and the facilitation of their conversion into products. The study of the rates of these enzyme-catalyzed reactions is known as enzyme kinetics.
Substrate Binding and Catalytic Site Architecture
The catalytic activity of an enzyme is localized to a specific region known as the active site. This site is a three-dimensional cleft or crevice composed of amino acid residues that may be distant in the primary sequence but are brought into proximity by the protein's folded structure. saylor.org The active site's architecture is exquisitely complementary to the substrate, allowing for highly specific binding. creative-enzymes.com
Initially, the substrate binds to the active site through a combination of non-covalent interactions, such as hydrogen bonds, ionic bonds, and hydrophobic interactions. creative-enzymes.com This binding can induce conformational changes in the enzyme, a concept known as the "induced fit" model, which can enhance the binding and position the substrate optimally for catalysis. saylor.orgcreative-enzymes.com The active site contains catalytic groups, which are amino acid residues that directly participate in the breaking and forming of chemical bonds. saylor.org The microenvironment of the active site can also significantly influence the reactivity of these catalytic residues. acs.org
Key Features of Catalytic Site Architecture:
| Feature | Description |
| Specificity | The unique three-dimensional arrangement of amino acids in the active site allows for the recognition of specific substrates. |
| Catalytic Groups | Residues such as those of histidine, serine, aspartate, and cysteine often act as nucleophiles, electrophiles, acids, or bases in the catalytic mechanism. acs.org |
| Microenvironment | The polarity and charge distribution within the active site can alter the pKa values of amino acid side chains, enhancing their catalytic potential. acs.org |
| Proximity and Orientation | The active site binds substrates in a precise orientation that facilitates the reaction, effectively increasing the local concentration of reactants. |
Transition State Stabilization and Catalytic Efficiency
A fundamental principle of enzyme catalysis is the stabilization of the reaction's transition state. fiveable.menih.gov The transition state is a high-energy, transient molecular structure that is intermediate between the substrate and the product. saylor.org Enzymes have evolved to bind the transition state more tightly than the substrate, which effectively lowers the activation energy of the reaction. aklectures.comfiveable.melibretexts.org
This stabilization is achieved through various interactions within the active site, including electrostatic interactions and hydrogen bonding, that are more favorable with the transition state than with the initial substrate. fiveable.mewou.edu By providing a more stable environment for the transition state, the enzyme increases the probability that the reaction will proceed, thereby enhancing catalytic efficiency. fiveable.me The catalytic efficiency of an enzyme is often described by the ratio kcat/Km, where kcat is the turnover number (the number of substrate molecules converted to product per enzyme molecule per unit time) and Km is the Michaelis constant (a measure of the substrate concentration at which the reaction rate is half of the maximum).
Co-factor Dependence and Redox Chemistry
Many enzymes require non-protein chemical compounds, known as cofactors, for their catalytic activity. wikipedia.org An enzyme without its required cofactor is termed an apoenzyme, while the complete, active enzyme with its cofactor is called a holoenzyme. labxchange.org Cofactors can be broadly classified into two groups: metal ions and organic molecules known as coenzymes. wikipedia.orglibretexts.org
Metal ions, such as iron, magnesium, manganese, copper, and zinc, can play several roles in catalysis. libretexts.org They can help stabilize charged intermediates, participate in redox reactions by changing their oxidation state, and properly orient the substrate within the active site. labxchange.org For instance, magnesium ions are crucial for the function of DNA polymerase, where they stabilize the negative charges on the phosphate (B84403) backbone of DNA. labxchange.org
Coenzymes are often derived from vitamins. libretexts.org They can act as transient carriers of specific functional groups, atoms, or electrons. wikipedia.org Coenzymes that are loosely bound to the enzyme are sometimes referred to as cosubstrates, while those that are tightly or covalently bound are called prosthetic groups. wikipedia.org
In the context of redox chemistry, many oxidoreductase enzymes rely on cofactors to facilitate the transfer of electrons. portlandpress.com Coenzymes like nicotinamide (B372718) adenine (B156593) dinucleotide (NAD+) and flavin adenine dinucleotide (FAD) are common electron acceptors in catabolic pathways. wikipedia.orglibretexts.org These cofactors are reduced during the oxidation of a substrate and are subsequently reoxidized in other metabolic processes. wikipedia.org
Examples of Cofactors and Their Functions:
| Cofactor | Type | Function |
| Mg²⁺ | Metal Ion | Stabilizes negative charges on phosphate groups in ATP-dependent reactions and DNA synthesis. labxchange.org |
| Zn²⁺ | Metal Ion | Acts as a Lewis acid in enzymes like carbonic anhydrase and alcohol dehydrogenase. |
| Fe²⁺/Fe³⁺ | Metal Ion | Component of heme groups and iron-sulfur clusters; essential for electron transport in cytochromes. libretexts.orgportlandpress.com |
| NAD⁺/NADH | Coenzyme (Cosubstrate) | Electron carrier in redox reactions. wikipedia.orglibretexts.org |
| FAD/FADH₂ | Coenzyme (Prosthetic Group) | Electron carrier in redox reactions, often involved in the formation of carbon-carbon double bonds. libretexts.org |
| Heme | Coenzyme (Prosthetic Group) | Binds oxygen in hemoglobin and myoglobin; participates in electron transfer in cytochromes. wikipedia.orglabxchange.org |
Allosteric Regulation of Enzyme Activity
Allosteric regulation is a crucial mechanism for controlling metabolic pathways. wikipedia.org Allosteric enzymes possess, in addition to their active site, one or more regulatory sites where effector molecules (also called allosteric modulators) can bind. conductscience.com The binding of an effector to an allosteric site induces a conformational change in the enzyme that alters the shape of the active site, thereby modifying its activity. pw.live
Effectors can be either activators or inhibitors. wikipedia.org Allosteric activators increase the enzyme's activity, while allosteric inhibitors decrease it. wikipedia.orgpw.live A common form of allosteric regulation is feedback inhibition, where the end product of a metabolic pathway inhibits an enzyme that catalyzes an earlier step in that pathway. study.comteachmephysiology.com This prevents the overproduction of the final product. study.com
Allosteric enzymes are often multi-subunit proteins that exhibit cooperativity, meaning that the binding of a substrate or effector molecule to one subunit can influence the binding affinity of the other subunits. pw.live There are two primary models that describe the mechanism of allosteric regulation: the concerted model (or MWC model) and the sequential model. conductscience.compw.live
Examples of Allosteric Enzymes:
| Enzyme | Effector(s) | Function of Regulation |
| Aspartate Transcarbamoylase (ATCase) | ATP (activator), CTP (inhibitor) | Balances the biosynthesis of purine (B94841) and pyrimidine (B1678525) nucleotides. pw.livebyjus.com |
| Phosphofructokinase (PFK) | AMP (activator), ATP (inhibitor), Citrate (inhibitor) | Regulates the rate of glycolysis in response to the cell's energy state. wikipedia.orgconductscience.comteachmephysiology.com |
| Acetyl-CoA Carboxylase | Citrate (activator), Palmitoyl-CoA (inhibitor) | Controls the rate-limiting step in fatty acid synthesis. pw.livebyjus.com |
Enzyme Inhibition Strategies
Enzyme inhibition is the reduction of the catalytic activity of an enzyme by a specific molecule called an inhibitor. byjus.com Inhibition can be either reversible or irreversible. du.ac.in
Reversible Inhibition: Reversible inhibitors bind to enzymes through non-covalent interactions and can be removed, restoring enzyme activity. byjus.comwikipedia.org There are several types:
Competitive Inhibition: The inhibitor resembles the substrate and competes for binding to the active site. This type of inhibition can be overcome by increasing the substrate concentration. wikipedia.org
Non-competitive Inhibition: The inhibitor binds to a site on the enzyme other than the active site, causing a conformational change that reduces the enzyme's catalytic efficiency. The inhibitor can bind to both the free enzyme and the enzyme-substrate complex. byjus.com
Uncompetitive Inhibition: The inhibitor binds only to the enzyme-substrate complex, preventing the conversion of the substrate to product. byjus.com
Irreversible Inhibition: Irreversible inhibitors typically form a strong, often covalent, bond with the enzyme, permanently inactivating it. du.ac.inwikipedia.org These inhibitors can be highly specific for their target enzyme. "Suicide inhibitors" are a class of irreversible inhibitors that are converted to a reactive form by the enzyme's own catalytic mechanism, which then inactivates the enzyme. du.ac.in
Artificial Enzymes and Protein Engineering for Novel Catalysis
The principles of enzyme structure and function are being harnessed to design and create artificial enzymes with novel catalytic activities. nih.govstanford.edu This field, which combines protein engineering, computational design, and chemical synthesis, aims to develop catalysts for reactions not found in nature or to improve upon existing enzymes for industrial and therapeutic applications. nih.govbioengineer.org
Protein engineering techniques, such as directed evolution and rational design, allow scientists to modify the amino acid sequence of existing enzymes to alter their substrate specificity, enhance their stability, or introduce new catalytic functions. nih.gov Computational methods are increasingly used to design enzymes from scratch (de novo design), creating protein scaffolds that can support a desired active site. bioengineer.orgresearchgate.net
One approach involves introducing new catalytic functionalities into existing protein scaffolds. This can include incorporating non-canonical amino acids or synthetic metal complexes to create artificial metalloenzymes that can catalyze a wide range of chemical transformations. nih.govresearchgate.net These engineered biocatalysts hold promise for more sustainable and efficient chemical synthesis. stanford.edubioengineer.org For example, researchers have successfully designed artificial enzymes capable of sustaining life in living organisms, such as an artificial enzyme that can function in E. coli. princeton.edu
Regulatory Networks and Signaling Pathways
Protein Roles in Cellular Communication
We recommend verifying the name of the protein of interest. Should a recognized protein name be provided, a detailed and accurate article can be generated based on available scientific research.
Cellular and Subcellular Localization and Trafficking
Protein Targeting to Organelles (e.g., ER, Mitochondria, Nucleus)
The initial destination of Protein (sartorilli) following its synthesis on ribosomes is determined by specific targeting signals embedded within its amino acid sequence. These signals act as molecular "zip codes," directing the protein to the correct organelle for its function.
Endoplasmic Reticulum (ER) Targeting: If Protein (sartorilli) is destined for secretion, insertion into membranes, or for residence within the ER, Golgi apparatus, or lysosomes, its synthesis begins with an N-terminal signal sequence. This hydrophobic stretch of amino acids is recognized by the signal recognition particle (SRP), which transiently halts translation and guides the ribosome-mRNA-nascent protein complex to the ER membrane. There, the complex docks with the SRP receptor, and the nascent Protein (sartorilli) is translocated across or inserted into the ER membrane through a protein channel called the translocon.
Mitochondrial Targeting: Should Protein (sartorilli) function within the mitochondria, it would be synthesized with a mitochondrial targeting sequence, typically an N-terminal amphipathic helix. This sequence allows it to be recognized by receptor proteins on the outer mitochondrial membrane, such as the TOM (Translocase of the Outer Membrane) complex. The protein is then imported through the TOM complex and subsequently sorted to its specific mitochondrial compartment (outer membrane, intermembrane space, inner membrane, or matrix) by other protein complexes like the TIM (Translocase of the Inner Membrane) complexes.
Nuclear Targeting: For a role within the nucleus, such as in gene regulation, Protein (sartorilli) would possess a nuclear localization signal (NLS). The classic NLS is a short stretch of positively charged amino acids. This signal is recognized by importin proteins in the cytoplasm, which then mediate the transport of Protein (sartorilli) through the nuclear pore complex (NPC) into the nucleus in a process that requires the GTP-binding protein Ran.
The table below summarizes the key targeting signals and receptor complexes involved in directing Protein (sartorilli) to these organelles.
| Target Organelle | Targeting Signal | Key Recognition/Translocation Machinery |
| Endoplasmic Reticulum | N-terminal hydrophobic signal sequence | Signal Recognition Particle (SRP), SRP Receptor, Translocon |
| Mitochondria | N-terminal amphipathic helix (presequence) | TOM Complex, TIM Complex |
| Nucleus | Nuclear Localization Signal (NLS) (e.g., basic residues) | Importins, Nuclear Pore Complex (NPC), Ran GTPase |
Vesicular Transport and Secretory Pathways
Once Protein (sartorilli) enters the ER, it becomes part of the secretory pathway, a major trafficking route within the cell. Its journey through this pathway involves being packaged into small, membrane-bound sacs called transport vesicles.
From the ER, Protein (sartorilli) moves to the Golgi apparatus. This transport is mediated by COPII-coated vesicles, which bud from specific ER exit sites. Within the Golgi, the protein moves through a series of flattened sacs called cisternae, from the cis to the trans face. During this transit, it may undergo further post-translational modifications, such as glycosylation or phosphorylation, which are crucial for its final function and stability.
From the trans-Golgi network (TGN), Protein (sartorilli) is sorted into different types of vesicles for its final destination. If it is a secretory protein, it will be packaged into secretory vesicles that move to the plasma membrane and release their contents outside the cell via exocytosis. If it is destined for lysosomes, it is tagged with a mannose-6-phosphate (B13060355) signal that directs its packaging into clathrin-coated vesicles bound for the lysosome. Retrograde transport, moving proteins from the Golgi back to the ER, is mediated by COPI-coated vesicles.
Cytoskeletal Interactions and Protein Motility
The movement of Protein (sartorilli), either within vesicles or as part of larger complexes, is not a passive process. It relies on the cell's intricate network of protein filaments, the cytoskeleton, which acts as a system of highways. Motor proteins, which use the energy from ATP hydrolysis, act as the "vehicles" that transport cargo along these cytoskeletal tracks.
Microtubule-Based Transport: For long-range transport across the cell, Protein (sartorilli)-containing vesicles would likely utilize microtubules. Kinesin motor proteins typically move cargo towards the plus-end of microtubules (towards the cell periphery), while dynein motors move cargo towards the minus-end (towards the cell center). The specific motor protein recruited would depend on the direction of transport required.
Actin-Based Transport: For short-range movement, particularly in the cell periphery, Protein (sartorilli) transport would involve the actin cytoskeleton. Myosin motor proteins, such as myosin V, are known to move vesicles and organelles along actin filaments.
The interaction between the cargo (e.g., a vesicle containing Protein (sartorilli)) and the motor protein is often mediated by adaptor proteins that link the two together.
The following table details the cytoskeletal tracks and motor proteins involved in intracellular transport.
| Cytoskeletal Track | Motor Protein Family | Direction of Movement | Typical Role |
| Microtubules | Kinesins | Towards plus-end (anterograde) | Transport of vesicles/organelles to cell periphery |
| Microtubules | Dyneins | Towards minus-end (retrograde) | Transport of vesicles/organelles to cell center |
| Actin Filaments | Myosins | Variable (e.g., towards barbed end) | Short-range transport, particularly in the cortex |
Spatiotemporal Regulation of Protein Function
The function of Protein (sartorilli) is not only determined by its presence in a specific location but also by the precise timing of its localization. This spatiotemporal regulation is critical for responding to cellular signals and carrying out complex processes.
One key mechanism for regulating protein localization is post-translational modification. For example, the phosphorylation of Protein (sartorilli) by a specific kinase in response to an external signal could unmask a nuclear localization signal, triggering its rapid translocation from the cytoplasm to the nucleus to regulate gene expression. Conversely, dephosphorylation by a phosphatase could reverse this process.
Another level of regulation involves the controlled release or sequestration of the protein. Protein (sartorilli) might be held in an inactive state in one compartment, for instance, anchored to the ER membrane. Upon receiving a signal, a proteolytic cleavage event could release a soluble, active fragment of the protein that can then travel to its site of action.
The dynamic assembly and disassembly of protein complexes also play a role. The recruitment of Protein (sartorilli) to a specific subcellular structure, such as the leading edge of a migrating cell, could be dependent on local signaling events that promote its interaction with specific binding partners at that site, ensuring its function is executed precisely where and when it is needed.
Compound and Protein Table
| Name | Type |
| Protein (sartorilli) | Hypothetical Protein |
| Signal Recognition Particle (SRP) | Ribonucleoprotein complex |
| SRP Receptor | Protein |
| Translocon | Protein complex |
| TOM Complex | Protein complex |
| TIM Complex | Protein complex |
| Importin | Protein |
| Ran | GTP-binding protein |
| COPI | Protein complex |
| COPII | Protein complex |
| Clathrin | Protein |
| Kinesin | Motor protein |
| Dynein | Motor protein |
| Myosin | Motor protein |
| Mannose-6-phosphate | Modified sugar |
Information regarding the chemical compound "Protein (sartorilli)" is not available in the public domain, and as such, a detailed article on its roles in biological processes cannot be generated at this time.
Extensive searches for "Protein (sartorilli)" in reputable scientific databases and scholarly articles have yielded no results. This suggests that "Protein (sartorilli)" may be a term not yet described in scientific literature, a proprietary name not publicly disclosed, or a potential misnomer for another compound.
Without any verifiable scientific information, it is not possible to provide an accurate and informative article that adheres to the requested structure and content requirements. The generation of content for the following sections is therefore not feasible:
Roles in Biological Processes and Systems
Roles of Proteins in Inter-Organismal Interactions
Further investigation into the origin of the term "Protein (sartorilli)" is recommended to ascertain if it is a synonym for a known protein or a newly discovered compound that has not yet been documented in publicly accessible resources.
Unable to Identify "Protein (sartorilli)" in Scientific Literature
Following a comprehensive search of scientific databases and public information, the chemical compound specified as "Protein (sartorilli)" could not be identified. This term does not correspond to any known protein in established biological or chemical catalogs. It is possible that the name is a result of a misspelling, refers to a proprietary or internal code name not in the public domain, or is a misinterpretation of another term.
Notably, searches for the term "Sartorius" yield results for a major international biotechnology company that provides advanced equipment and services for protein analysis, including many of the sophisticated techniques requested in the article outline. It is conceivable that the user may have conflated the name of this company with a specific protein.
Due to the non-existence of "Protein (sartorilli)" as a verifiable scientific entity, it is not possible to generate the requested article focusing on the advanced methodologies for its investigation. An article detailing techniques such as advanced chromatography, mass spectrometry-based proteomics, X-ray crystallography, cryo-electron microscopy, and nuclear magnetic resonance spectroscopy requires a specific, known protein as its subject to provide accurate and scientifically valid information, including detailed research findings and data tables.
Without a valid protein subject, the creation of the requested content would be speculative and would not meet the required standards of scientific accuracy and authoritativeness. We recommend that the user verify the name of the chemical compound of interest and provide a correct and recognized protein name to enable the generation of the requested scientific article.
Advanced Methodologies for Protein Investigation
Biophysical Approaches for Protein Dynamics and Interactions
Surface Plasmon Resonance (SPR) and Isothermal Titration Calorimetry (ITC)
Surface Plasmon Resonance (SPR) is a real-time, label-free optical technique for monitoring biomolecular interactions. It measures the change in the refractive index at the surface of a sensor chip as molecules bind and dissociate. In a typical SPR experiment, a "ligand" protein is immobilized on the sensor surface, and a potential binding partner, the "analyte," flows over the surface. The binding event is detected as a change in the resonance angle of polarized light, which is proportional to the mass accumulating on the surface.
This technique provides a wealth of information, including:
Binding Affinity (KD): A measure of the strength of the interaction.
Kinetics: The association rate (ka) and dissociation rate (kd) of the interaction.
Specificity: Determining whether a protein interacts with one or multiple partners.
Isothermal Titration Calorimetry (ITC) is a thermodynamic technique that directly measures the heat change associated with a binding event. In an ITC experiment, a solution of one molecule (the ligand) is titrated into a solution containing the binding partner (the macromolecule) in a sample cell. The heat released or absorbed during the interaction is measured and plotted against the molar ratio of the reactants.
ITC is the gold standard for characterizing binding interactions as it provides a complete thermodynamic profile of the interaction in a single experiment, including:
Binding Affinity (KD)
Stoichiometry (n): The ratio of the binding partners in the complex.
Enthalpy (ΔH): The heat change upon binding.
Entropy (ΔS): The change in disorder of the system upon binding.
The table below summarizes typical data obtained from SPR and ITC experiments for a hypothetical protein interaction.
| Parameter | Surface Plasmon Resonance (SPR) | Isothermal Titration Calorimetry (ITC) |
| Binding Affinity (KD) | 10 nM | 12 nM |
| Association Rate (ka) | 1.5 x 105 M-1s-1 | Not Directly Measured |
| Dissociation Rate (kd) | 1.5 x 10-3 s-1 | Not Directly Measured |
| Stoichiometry (n) | Not Directly Measured | 1:1 |
| Enthalpy (ΔH) | Not Directly Measured | -8.5 kcal/mol |
| Entropy (ΔS) | Not Directly Measured | 5.2 cal/mol·K |
Fluorescence Spectroscopy and Single-Molecule Techniques
Fluorescence Spectroscopy is a highly sensitive technique that utilizes the fluorescence properties of intrinsic fluorophores (like the amino acids tryptophan and tyrosine) or extrinsic fluorescent probes attached to a protein. nih.gov Changes in the local environment of these fluorophores upon ligand binding, conformational changes, or protein unfolding can be monitored by measuring changes in fluorescence intensity, emission wavelength, or polarization. This method is widely used to study protein folding, stability, and binding interactions.
Single-Molecule Techniques , such as Single-Molecule Fluorescence Resonance Energy Transfer (smFRET), allow for the observation of individual protein molecules. In smFRET, two different fluorophores (a donor and an acceptor) are attached to a protein. The efficiency of energy transfer between the donor and acceptor is highly dependent on the distance between them. By measuring this energy transfer, researchers can monitor conformational changes and dynamics of a single protein molecule in real-time, providing insights that are often obscured in ensemble measurements.
Genetic and Cell-Based Systems for Protein Functional Analysis
Understanding the function of a protein ultimately requires studying it within its native biological context—the cell. Genetic and cell-based systems are indispensable for elucidating the physiological roles of proteins.
Gene Editing and Knockout Models
Gene Editing technologies, most notably CRISPR-Cas9, have revolutionized the study of protein function. These tools allow for precise modifications to the gene encoding a protein of interest within an organism's genome. This can include:
Gene Knockout: Completely inactivating the gene to study the consequences of the protein's absence.
Gene Knock-in: Introducing specific mutations to study the effect of those changes on protein function.
Gene Tagging: Fusing the gene with a tag (e.g., Green Fluorescent Protein) to track the protein's localization within the cell.
Knockout Models , typically in organisms like mice or cell lines, are created using gene editing techniques to lack a specific protein. By comparing the phenotype of the knockout model to its wild-type counterpart, researchers can infer the protein's function. For example, if a knockout of a particular kinase results in uncontrolled cell proliferation, it can be concluded that the kinase is involved in cell cycle regulation.
Reporter Assays and Live-Cell Imaging
Reporter Assays are used to measure the activity of a protein or a signaling pathway. In a typical reporter assay, the regulatory region of a gene that is controlled by the protein of interest is linked to a "reporter gene" that produces an easily measurable signal (e.g., luciferase, which produces light). The amount of signal produced by the reporter gene is proportional to the activity of the protein being studied.
Live-Cell Imaging techniques, often coupled with fluorescently tagged proteins, allow for the visualization of proteins in living cells in real-time. This provides invaluable information about a protein's:
Subcellular Localization: Where the protein is located within the cell (e.g., nucleus, mitochondria, cell membrane).
Dynamics: How the protein moves within the cell and how its localization changes in response to stimuli.
Interactions: Co-localization with other proteins can suggest a functional interaction.
The following table presents hypothetical data from a live-cell imaging experiment tracking a protein's localization in response to a cellular stimulus.
| Time Post-Stimulus | Predominant Cellular Localization |
| 0 minutes | Cytoplasm |
| 5 minutes | Cytoplasm and Nucleus |
| 15 minutes | Nucleus |
| 30 minutes | Nucleus |
| 60 minutes | Cytoplasm and Nucleus |
Theoretical and Computational Approaches in Protein Science
Computational Protein Structure Prediction and Modeling
The prediction of a protein's three-dimensional structure from its amino acid sequence is a fundamental challenge in computational biology. nih.govwikipedia.org Accurate structural models are crucial for understanding a protein's function, its interactions with other molecules, and for applications in drug design and biotechnology. wikipedia.orgpasteur.fr
Homology Modeling and De Novo Folding
For a newly identified protein like "Protein (sartorilli)," the initial step in structure prediction would be to search for homologous proteins with known structures.
Homology Modeling: This approach, also known as comparative modeling, is based on the principle that proteins with similar sequences adopt similar structures. nih.govnih.gov If a template protein with a sufficiently high sequence identity to "Protein (sartorilli)" exists in the Protein Data Bank (PDB), its structure can be used as a scaffold to build a model. The process involves sequence alignment, model building, and refinement. The accuracy of the resulting model is highly dependent on the sequence identity between the target ("sartorilli") and the template.
De Novo Folding (or Ab Initio Modeling): In the absence of a suitable template, de novo or ab initio methods are employed. nih.gov These methods predict the protein structure from the amino acid sequence alone, without relying on a known homologous structure. nih.gov This is often achieved by using physical principles to simulate the protein folding process or by using knowledge-based statistical potentials derived from known protein structures. Recent advancements in artificial intelligence, particularly deep learning methods like AlphaFold, have revolutionized de novo structure prediction, often achieving accuracy comparable to experimental methods. wikipedia.orgnih.govebi.ac.uk
| Method | Principle | Requirement for "Protein (sartorilli)" |
| Homology Modeling | Similar sequences fold into similar structures. nih.gov | A homologous protein with a known 3D structure. |
| De Novo Folding | Prediction based on physicochemical principles and statistical data from known structures. nih.gov | The amino acid sequence of "Protein (sartorilli)". |
Molecular Dynamics Simulations
Once a structural model of "Protein (sartorilli)" is obtained, molecular dynamics (MD) simulations can be used to study its dynamic behavior. MD simulations calculate the motion of atoms over time by solving Newton's equations of motion. nih.govarxiv.orgrsc.org This provides insights into the protein's flexibility, conformational changes, and interactions with other molecules, such as ligands or other proteins. rsc.orgbiorxiv.org For instance, MD simulations could reveal how "Protein (sartorilli)" changes its shape upon binding to a partner protein or a small molecule, which is crucial for its biological function. biorxiv.org
Protein-Protein Interaction Prediction and Network Analysis
Proteins rarely act in isolation; they form complex interaction networks to carry out their biological functions. sartorius.comcambridge.org Predicting the interaction partners of "Protein (sartorilli)" is essential to understand its role in cellular processes.
Computational methods for predicting protein-protein interactions (PPIs) can be broadly categorized into sequence-based, structure-based, and data-integration approaches. sartorius.com
Sequence-based methods look for co-evolutionary signals or conserved sequence motifs between interacting proteins.
Structure-based methods , such as protein docking, use the 3D structures of proteins to predict how they might bind to each other.
Data-integration approaches combine various sources of information, including genomic context, expression data, and functional annotations, to infer interactions. ucla.edu
Once potential interaction partners are identified, they can be used to construct a protein-protein interaction network around "Protein (sartorilli)." The analysis of this network's topology can reveal the protein's functional context and its importance within the cellular machinery. cambridge.org Mathematical models, such as the heterodimer model, can be used to describe the dynamics of these interactions. arxiv.org
In Silico Analysis of Protein Function and Evolution
Computational methods are invaluable for annotating the function of a new protein and understanding its evolutionary history. ucla.edu
For "Protein (sartorilli)," functional annotation would begin with sequence-based searches against protein databases like UniProt. cd-genomics.comnumberanalytics.com The presence of conserved domains or motifs can provide clues about its molecular function. For example, the identification of a kinase domain would suggest that "Protein (sartorilli)" is an enzyme that phosphorylates other proteins.
The evolutionary history of "Protein (sartorilli)" can be traced by constructing phylogenetic trees based on its sequence and the sequences of related proteins from different species. This can reveal its evolutionary origins and how its function may have diverged over time. pasteur.fr The study of how protein function evolves after events like gene duplication can be investigated by comparing the evolutionary properties of homologous sequences. pasteur.fr Recent computational approaches also allow for the simulation of protein fold evolution from random sequences, providing insights into the emergence of new protein structures and functions. biorxiv.org
Bioinformatics Tools for Proteome-Wide Analysis
To understand the broader context of "Protein (sartorilli)," it is necessary to consider its place within the entire proteome—the complete set of proteins expressed by an organism. numberanalytics.com Proteomics involves the large-scale analysis of proteins and requires sophisticated bioinformatics tools. numberanalytics.com
Mass spectrometry is a key technique in proteomics for identifying and quantifying proteins in a sample. numberanalytics.comnumberanalytics.com The vast amount of data generated by these experiments is analyzed using specialized software.
| Tool Category | Function | Example Tools |
| Database Search Algorithms | Match mass spectrometry data to protein sequence databases. numberanalytics.com | SEQUEST, Mascot numberanalytics.com |
| Protein Identification & Quantification | Facilitate the identification and quantification of proteins from processed data. numberanalytics.com | MaxQuant, Proteome Discoverer cd-genomics.comnumberanalytics.com |
| Pathway Analysis Tools | Help understand the biological pathways and networks in which proteins function. numberanalytics.com | Ingenuity Pathway Analysis (IPA), Reactome numberanalytics.com |
| Proteomics Data Repositories | Store and provide access to large-scale proteomics datasets. cd-genomics.com | PRIDE cd-genomics.com |
These tools would be essential to analyze experiments aimed at determining the expression levels of "Protein (sartorilli)" under different conditions or in different tissues, and to identify other proteins whose expression levels are correlated with it. dntb.gov.ua This proteome-wide perspective is crucial for building a comprehensive understanding of the biological significance of "Protein (sartorilli)".
Evolutionary and Comparative Protein Studies
Protein Family Evolution and Diversification
Protein families emerge and diversify through a variety of evolutionary mechanisms, primarily gene duplication and subsequent divergence. nih.gov When a gene duplicates, one copy is free to accumulate mutations and potentially acquire a new function, while the original copy retains its essential role. This process of neofunctionalization is a major driver of evolutionary innovation. Alternatively, the two duplicated genes can subdivide the original functions of the ancestral gene, a process known as subfunctionalization.
The diversification of the hypothetical "Sartorilli" protein family can be conceptualized through a model of gene duplication and functional shifts. Initially, an ancestral "Proto-Sartorilli" gene may have performed a general enzymatic function. Following a duplication event, one paralog could have evolved to specialize in a different substrate, leading to two distinct but related "Sartorilli" proteins. This divergence is driven by mutations that alter the protein's active site or regulatory domains. Over millions of years, repeated rounds of duplication and divergence can give rise to a large and functionally diverse protein family.
Recent research has highlighted that multifunctional ancestral proteins often give rise to more specialized descendants. nih.gov Ancestral protein reconstruction (APR) techniques allow scientists to infer the sequences of ancient proteins and experimentally test their properties. nih.gov Studies using APR have shown that the specific functions of many modern proteins were partitioned or enhanced from a common ancestor that had multiple functions. nih.gov
The evolution of new protein functions can also occur de novo following gene duplication, though this is considered a less frequent evolutionary path. nih.gov In some cases, low-level secondary activities of a protein can be optimized through mutation, leading to a new primary function without significantly compromising the original one. nih.gov
The table below illustrates a hypothetical evolutionary trajectory for the "Sartorilli" protein family, highlighting key duplication events and the emergence of new functions.
| Evolutionary Event | Ancestral Protein | Resulting Proteins | Change in Function |
| Initial State | Proto-Sartorilli | - | General metabolic enzyme |
| Duplication 1 | Proto-Sartorilli | Sartorilli-A, Sartorilli-B | Subfunctionalization: A & B specialize in different substrates |
| Duplication 2 (Sartorilli-B) | Sartorilli-B | Sartorilli-B1, Sartorilli-B2 | Neofunctionalization: B2 acquires a regulatory role |
| Divergence | Sartorilli-A | Sartorilli-A (variant) | Adaptation to new environmental conditions (e.g., temperature) |
Comparative Proteomics Across Species
Comparative proteomics involves the large-scale comparison of protein expression, modification, and interaction patterns between different species or conditions. This approach provides a snapshot of the functional state of an organism and can reveal how protein networks have evolved. By comparing the proteomes of organisms that possess "Sartorilli" proteins, researchers could infer the conserved and species-specific roles of these proteins.
For instance, a comparative proteomic study of a yeast species and a fruit fly, both containing a "Sartorilli-A" ortholog, might reveal that the protein is consistently involved in a core metabolic pathway in both organisms, indicating a conserved function. However, the study might also identify different interacting partner proteins in each species, suggesting that the regulatory network controlling "Sartorilli-A" has diverged.
Recent studies have utilized comparative proteomics to understand differences between old and modern wheat genotypes, revealing high similarity in their metabolic protein fractions. dtu.dk Another study used this approach to analyze the cellular response to Senecavirus A infection, identifying significant changes in cellular metabolism. nih.gov These examples demonstrate the power of comparative proteomics to uncover functional similarities and differences at the molecular level.
The following interactive data table summarizes hypothetical findings from a comparative proteomic analysis of "Sartorilli-B1" across three different species.
| Species | Expression Level (relative units) | Key Interacting Partner | Subcellular Localization |
| Saccharomyces cerevisiae | 1.0 | Protein-X | Cytosol |
| Drosophila melanogaster | 1.5 | Protein-Y | Mitochondria |
| Arabidopsis thaliana | 0.8 | Protein-Z | Chloroplast |
Evolutionary Constraints on Protein Structure and Function
Structural constraints are fundamental because a protein's function is intrinsically linked to its shape. sciencedaily.commdpi.com The hydrophobic core of a protein, for example, is typically under strong negative selection because mutations in this region can destabilize the entire structure. mdpi.com In contrast, residues on the protein surface are often more tolerant of mutations, unless they are part of a binding site. mdpi.com
Functional constraints arise from the need to maintain specific activities, such as catalysis or binding to other molecules. nih.gov Residues that are directly involved in these functions are highly conserved. The evolution of protein specificity, for instance, is often driven by changes in electrostatic complementarity at binding interfaces. nih.gov
Studies have shown that older proteins tend to be more stable and robust to mutations than younger proteins. plos.org This suggests that over evolutionary time, protein structures may acquire increased stability. plos.org The rate of protein evolution is influenced by a combination of intrinsic structural properties and historical factors like the protein's age. plos.org
The table below outlines the types of evolutionary constraints that would likely act on different regions of a hypothetical "Sartorilli" protein.
| Protein Region | Primary Constraint | Example of Conserved Feature | Likely Rate of Evolution |
| Active Site | Functional | Catalytic triad (B1167595) of amino acids | Very Slow |
| Hydrophobic Core | Structural | Non-polar amino acid composition | Slow |
| Surface Loop | Weaker Structural | General loop conformation | Moderate to Fast |
| Binding Interface | Functional | Specific charged and polar residues | Slow to Moderate |
Phylogenetics of Protein Domains and Modules
Proteins are often modular, composed of distinct structural and functional units called domains. nih.gov The evolution of proteins can be understood by tracing the history of these domains, which can be shuffled and combined in different ways to create new proteins with novel functions. nih.govfree.fr The presence or absence of specific protein domains across different genomes can be used to construct phylogenetic trees, offering insights into the evolutionary relationships between species. nih.gov
A phylogenetic analysis of the "Sartorilli" protein family would likely reveal the evolutionary relationships between its members based on the sequence and arrangement of their domains. For example, all members of the family would share a conserved catalytic domain, but some might have acquired additional regulatory domains over time.
The study of protein domain phylogenies can reveal that the evolutionary unit is often the domain itself, rather than the entire protein. nih.gov The combination of different domains through processes like gene fusion and recombination has been a major source of functional innovation throughout evolution. nih.gov
The following table presents a hypothetical domain architecture for different members of the "Sartorilli" family, which could be used to infer their phylogenetic relationships.
| Protein | N-terminal Domain | Central Domain | C-terminal Domain |
| Proto-Sartorilli | - | Catalytic Domain | - |
| Sartorilli-A | - | Catalytic Domain | - |
| Sartorilli-B1 | Regulatory Domain 1 | Catalytic Domain | - |
| Sartorilli-B2 | Regulatory Domain 1 | Catalytic Domain | Dimerization Domain |
Future Directions and Emerging Frontiers in Protein Research
Integration of Multi-Omics Data for Systems-Level Understanding
A comprehensive understanding of protein function requires looking beyond individual molecules to the complex networks in which they operate. The integration of multiple "omics" data streams—genomics, transcriptomics, proteomics, and metabolomics—is providing a holistic view of biological systems. azolifesciences.com This systems-level approach is crucial for deciphering the intricate networks of genes, proteins, and metabolites that drive cellular functions and organismal phenotypes. bioscipublisher.comnih.gov
By combining these diverse datasets, researchers can gain insights into complex biological phenomena that would not be apparent from a single omics approach alone. azolifesciences.commdpi.com For instance, integrating transcriptomics and proteomics data can reveal post-transcriptional regulation and provide a more accurate picture of protein abundance. mdpi.com Furthermore, combining proteomics and metabolomics can link protein activity to metabolic pathways, offering a more complete understanding of cellular responses to various stimuli. bioscipublisher.com
This integrative approach is particularly powerful in disease research, where it can help identify novel biomarkers and therapeutic targets. azolifesciences.combiorxiv.org For example, a multi-omics study on inborn errors of metabolism used proteomics and transcriptomics data to identify dysregulated protein complexes and pathways, revealing a new epigenetic dimension to these diseases. biorxiv.org
Key applications of multi-omics integration in protein research include:
Disease Subtyping and Biomarker Prediction: Identifying molecular signatures for more precise disease classification and diagnostics. azolifesciences.com
Understanding Complex Biological Processes: Unraveling the intricate regulatory networks that govern cellular function. azolifesciences.comnih.gov
Personalized Medicine: Tailoring therapeutic interventions based on an individual's unique multi-omics profile. azolifesciences.com
Challenges in data integration and interpretation remain, but advancements in bioinformatics and computational methods are continually improving our ability to extract meaningful biological insights from these large and complex datasets. azolifesciences.combioscipublisher.com
Artificial Intelligence and Machine Learning in Protein Design and Discovery
Artificial intelligence (AI) and machine learning (ML) are revolutionizing protein research, particularly in the areas of structure prediction, design, and drug discovery. mdpi.combetalifesci.compreprints.org These computational tools can analyze vast datasets of protein sequences and structures to identify patterns and relationships that are beyond human intuition. frontiersin.org
Impact of AI and ML on Protein Research:
| Application Area | Examples of AI/ML Contributions |
| Protein Structure Prediction | AlphaFold and similar models predict 3D protein structures from amino acid sequences with high accuracy. scielo.brnumberanalytics.com |
| De Novo Protein Design | Generative models are used to design entirely new proteins with specific functions. preprints.orgsynbiobeta.com |
| Drug Discovery | AI algorithms can screen vast libraries of compounds to identify potential drug candidates and predict their efficacy and toxicity. scielo.brnih.gov |
| Functional Annotation | Machine learning models can predict the function of uncharacterized proteins based on their sequence and structural features. frontiersin.orgfrontiersin.org |
The integration of AI and ML is shifting the paradigm of protein research from a largely experimental endeavor to one that is increasingly driven by computational design and prediction. preprints.org
Synthetic Biology Approaches to Protein Engineering
Synthetic biology combines principles from engineering and biology to design and construct new biological parts, devices, and systems. In the context of protein research, synthetic biology offers powerful tools for engineering proteins with novel or enhanced functions. betalifesci.comresearchgate.net
A key approach in synthetic biology is the "design-build-test-learn" cycle, which involves the iterative process of designing a protein, synthesizing the corresponding gene, expressing the protein, and then testing its function. researchgate.net This cycle is often accelerated by high-throughput screening methods and computational design tools.
Recent advancements in gene synthesis and editing technologies, such as CRISPR-Cas9, have made it easier and more precise to modify the genetic code that determines a protein's amino acid sequence. betalifesci.comresearchgate.net This allows researchers to make targeted changes to a protein's structure and function.
Applications of Synthetic Biology in Protein Engineering:
Therapeutic Proteins: Engineering proteins, such as antibodies and enzymes, for the treatment of diseases. betalifesci.com
Biocatalysts: Designing enzymes that can function under industrial conditions for applications in biofuels, pharmaceuticals, and food production. betalifesci.comresearchgate.net
Biosensors: Creating proteins that can detect specific molecules and signal their presence.
Novel Materials: Engineering proteins with unique structural properties for applications in materials science.
For example, researchers have successfully engineered enzymes for the biosynthesis of the anticancer drug Taxol in heterologous hosts, demonstrating the potential of synthetic biology to address challenges in drug production. frontiersin.org
Ethical Considerations in Protein Research (e.g., gain-of-function studies, genetic engineering)
As the power of protein engineering and genetic modification grows, so too do the ethical considerations surrounding this research. Two areas of particular concern are gain-of-function (GOF) research and germline genetic engineering.
Gain-of-Function Research: GOF research involves altering an organism in a way that enhances its biological functions, such as increasing the transmissibility or virulence of a pathogen. wikipedia.org The goal of such research is often to better understand disease mechanisms and develop countermeasures. nih.gov However, it also carries the risk of accidental release of a more dangerous pathogen, leading to a pandemic. wikipedia.orgnih.gov This has sparked intense debate within the scientific community about how to balance the potential benefits of this research against its risks. wikipedia.orgpitt.edu
Ethical Framework for Gain-of-Function Research:
| Ethical Principle | Consideration |
| Beneficence | The research should have the potential for significant societal benefit that cannot be achieved through less risky methods. researchgate.net |
| Non-maleficence | The risks of the research, including accidental release, must be minimized and managed. nih.gov |
| Justice | The benefits and risks of the research should be distributed fairly. |
| Transparency | There should be open discussion and public engagement in the oversight of such research. wikipedia.org |
Genetic Engineering: The ability to edit the human genome raises profound ethical questions, particularly when it comes to germline editing, which involves making changes to sperm, eggs, or embryos that can be passed down to future generations. yipinstitute.orgccne-ethique.fr While this technology has the potential to eradicate inherited diseases, there are concerns about its safety, the potential for unintended consequences, and the possibility of it being used for non-therapeutic "enhancements." yipinstitute.orgcsbsju.edunih.gov
Many countries have banned human germline editing for reproductive purposes, and there is a broad consensus that further public and scientific debate is needed before any clinical applications are considered. yipinstitute.orgccne-ethique.fr
Q & A
Basic Research Questions
Q. How should researchers design experiments to study the structural or functional properties of Protein (sartorilli) while ensuring reproducibility?
- Methodological Answer:
- Clearly define experimental variables (e.g., temperature, pH, concentration) and control groups. Use validated protocols for protein purification and characterization (e.g., SDS-PAGE, mass spectrometry).
- Include detailed descriptions of equipment, reagents, and statistical methods in the "Materials and Methods" section to enable replication. Limit primary manuscript data to critical findings (≤5 compounds), with supplementary materials for extended datasets .
- For novel proteins, provide spectroscopic evidence (e.g., NMR, X-ray crystallography) to confirm identity and purity .
Q. What frameworks are recommended for formulating hypothesis-driven research questions about Protein (sartorilli)?
- Methodological Answer:
- Apply the PICO framework (Population/Protein, Intervention/Condition, Comparison, Outcome) to narrow the scope. For example: "How does phosphorylation (Intervention) affect the binding affinity (Outcome) of Protein (sartorilli) compared to its wild-type form (Comparison)?"
- Evaluate feasibility using the FINER criteria (Feasible, Interesting, Novel, Ethical, Relevant). For instance, ensure access to specialized equipment (e.g., cryo-EM) before proposing structural studies .
Q. How can researchers ensure methodological rigor when analyzing Protein (sartorilli) interactions in vitro?
- Methodological Answer:
- Use orthogonal assays (e.g., surface plasmon resonance + isothermal titration calorimetry) to cross-validate binding kinetics.
- Report negative results (e.g., non-specific interactions) to avoid publication bias. Follow NIH guidelines for statistical reporting, including p-values, confidence intervals, and effect sizes .
Advanced Research Questions
Q. How should contradictory data about Protein (sartorilli)'s functional mechanisms be analyzed and resolved?
- Methodological Answer:
- Conduct a systematic error analysis : Compare experimental conditions (e.g., buffer composition, protein isoforms) across studies. Use tools like PRIDE Archive to re-analyze raw mass spectrometry data from conflicting publications .
- Engage in peer consultation to identify potential confounding variables (e.g., post-translational modifications not accounted for in prior studies) .
Q. What strategies are effective for integrating Protein (sartorilli) findings with existing literature on homologous proteins?
- Methodological Answer:
- Perform a phylogenetic analysis to identify conserved domains and functional motifs. Use databases like UniProt or Pfam to annotate sequence similarities.
- Critically evaluate prior methodologies (e.g., differences in assay sensitivity) that may explain divergent conclusions. Cite primary sources rather than reviews to maintain traceability .
Q. How can researchers address ethical considerations in studies involving Protein (sartorilli) derived from human or animal tissues?
- Methodological Answer:
- Document compliance with institutional review board (IRB) protocols for tissue sourcing. Include a "Participant Selection" section detailing donor consent processes and anonymization procedures.
- For animal studies, adhere to ARRIVE guidelines for reporting in vivo experiments .
Q. What statistical approaches are recommended for validating high-throughput datasets (e.g., proteomics) related to Protein (sartorilli)?
- Methodological Answer:
- Apply Benjamini-Hochberg correction to control false discovery rates in large datasets. Use tools like MaxQuant for label-free quantification with manual curation to remove low-confidence peptides.
- Validate findings through targeted experiments (e.g., Western blotting) and include raw data in repositories like ProteomeXchange .
Methodological Best Practices
- Literature Review: Use Boolean search strings (e.g., "Protein (sartorilli)" AND "kinetics") in PubMed/Scopus to identify primary studies. Avoid over-reliance on secondary sources .
- Data Presentation: Reference figures/tables in the main text only when critical to interpretation. Use SI units and IUPAC nomenclature for consistency .
- Peer Feedback: Pre-submit research questions to platforms like ResearchGate for community input, reducing the risk of post-hoc peer review criticisms .
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
