AMAS
Description
Properties
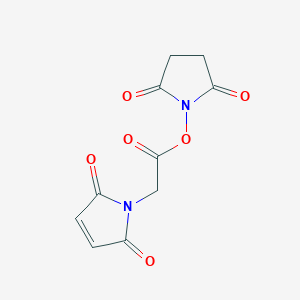
IUPAC Name |
(2,5-dioxopyrrolidin-1-yl) 2-(2,5-dioxopyrrol-1-yl)acetate |
Source


|
|---|---|---|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI |
InChI=1S/C10H8N2O6/c13-6-1-2-7(14)11(6)5-10(17)18-12-8(15)3-4-9(12)16/h1-2H,3-5H2 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI Key |
TYKASZBHFXBROF-UHFFFAOYSA-N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Canonical SMILES |
C1CC(=O)N(C1=O)OC(=O)CN2C(=O)C=CC2=O |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Formula |
C10H8N2O6 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
DSSTOX Substance ID |
DTXSID80391201 |
Source
|
| Record name | 1-{2-[(2,5-Dioxopyrrolidin-1-yl)oxy]-2-oxoethyl}-1H-pyrrole-2,5-dione | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID80391201 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
Molecular Weight |
252.18 g/mol |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
CAS No. |
55750-61-3 |
Source
|
| Record name | 1-{2-[(2,5-Dioxopyrrolidin-1-yl)oxy]-2-oxoethyl}-1H-pyrrole-2,5-dione | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID80391201 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
| Record name | Maleimidoacetic acid N-hydroxysuccinimide ester | |
| Source | European Chemicals Agency (ECHA) | |
| URL | https://echa.europa.eu/information-on-chemicals | |
| Description | The European Chemicals Agency (ECHA) is an agency of the European Union which is the driving force among regulatory authorities in implementing the EU's groundbreaking chemicals legislation for the benefit of human health and the environment as well as for innovation and competitiveness. | |
| Explanation | Use of the information, documents and data from the ECHA website is subject to the terms and conditions of this Legal Notice, and subject to other binding limitations provided for under applicable law, the information, documents and data made available on the ECHA website may be reproduced, distributed and/or used, totally or in part, for non-commercial purposes provided that ECHA is acknowledged as the source: "Source: European Chemicals Agency, http://echa.europa.eu/". Such acknowledgement must be included in each copy of the material. ECHA permits and encourages organisations and individuals to create links to the ECHA website under the following cumulative conditions: Links can only be made to webpages that provide a link to the Legal Notice page. | |
| Record name | N-Succinimidyl maleimidoacetate | |
| Source | FDA Global Substance Registration System (GSRS) | |
| URL | https://gsrs.ncats.nih.gov/ginas/app/beta/substances/BRQ5GEQ7MA | |
| Description | The FDA Global Substance Registration System (GSRS) enables the efficient and accurate exchange of information on what substances are in regulated products. Instead of relying on names, which vary across regulatory domains, countries, and regions, the GSRS knowledge base makes it possible for substances to be defined by standardized, scientific descriptions. | |
| Explanation | Unless otherwise noted, the contents of the FDA website (www.fda.gov), both text and graphics, are not copyrighted. They are in the public domain and may be republished, reprinted and otherwise used freely by anyone without the need to obtain permission from FDA. Credit to the U.S. Food and Drug Administration as the source is appreciated but not required. | |
Foundational & Exploratory
The Anti-Malignin Antibody in Serum (AMAS) Test: A Technical Overview for Researchers and Drug Development Professionals
An In-depth Examination of a Controversial Cancer Biomarker
The Anti-Malignin Antibody in Serum (AMAS) test is a blood-based immunoassay intended for the early detection and monitoring of cancer. Proponents of the test suggest it can identify a general transformation antibody that is elevated in the presence of most types of cancer, offering a non-invasive tool for cancer screening and management.[1] However, the this compound test has been met with skepticism from the mainstream medical community due to a lack of widespread independent validation and unclear biological mechanisms. This technical guide provides a comprehensive overview of the this compound test, including its scientific basis, available experimental protocols, quantitative performance data, and the current understanding of the malignin protein, aimed at researchers, scientists, and drug development professionals.
Introduction: The Premise of the this compound Test
The this compound test is predicated on the detection of circulating antibodies against a protein termed "malignin."[1] Malignin is described as a 10,000 Dalton polypeptide that is reportedly found in most malignant cells, regardless of their tissue of origin.[1][2] The underlying hypothesis is that the transformation of normal cells into a malignant state leads to the expression of malignin, which in turn elicits an antibody response from the host's immune system.[3] The this compound test aims to quantify the levels of these anti-malignin antibodies in a patient's serum, with elevated levels purportedly indicating the presence of an active, non-terminal malignancy.[1][4]
The test has been promoted for several clinical applications, including:
-
Early cancer detection: Identifying cancer at a preclinical stage before the appearance of clinical signs and symptoms.[1]
-
Monitoring cancer therapy: Assessing the effectiveness of treatment by observing changes in anti-malignin antibody levels.
-
Detecting cancer recurrence: Monitoring for the return of cancer after initial treatment.[1]
-
Prognostication: Higher antibody levels are suggested to correlate with a better prognosis, indicating a robust immune response.[1]
Despite these claims, the clinical utility of the this compound test remains a subject of debate, with many healthcare organizations and experts citing insufficient evidence to recommend its routine use.[5]
The Malignin Antigen: An Enigmatic Oncoprotein
Detailed molecular and structural information about malignin is scarce in peer-reviewed literature. It is described as a 10 kDa polypeptide and is believed to be a fragment of a much larger 250 kDa glycoprotein (B1211001) found in the brain.[6] The initial characterization of malignin and its association with cancer was reported by Bogoch and Bogoch.[7] However, its specific amino acid sequence and three-dimensional structure have not been publicly disclosed.
The term "oncoprotein" has been used to describe malignin, suggesting a role in malignant transformation.[3] However, the specific signaling pathways and molecular mechanisms through which malignin might contribute to cancer development have not been elucidated in the available scientific literature. This lack of mechanistic understanding is a significant knowledge gap and a major point of contention surrounding the this compound test.
The Anti-Malignin Antibody Response
The this compound test measures the concentration of anti-malignin antibodies in the serum. These antibodies are reported to be predominantly of the IgM isotype, which is consistent with an early immune response to a novel antigen.[3] Proponents of the test argue that detecting this antibody response allows for earlier cancer detection compared to tests that measure tumor-associated antigens, which may only become elevated in later stages of the disease.[5]
Experimental Protocols for the this compound Test
The this compound test is a laboratory-developed test offered by a single CLIA-certified laboratory, Oncolab, Inc.[8] While a detailed, step-by-step protocol with proprietary reagent compositions is not publicly available, information from publications and company literature provides an outline of the methodology.
Sample Collection and Handling
Proper sample collection and handling are critical for the accuracy of the this compound test. Based on information from Oncolab's requisition forms, the following steps are recommended:
-
Blood Collection: A venous blood sample is drawn into a specific type of vacutainer tube that is non-silicone coated.
-
Clotting: The blood is allowed to clot at room temperature for a defined period (e.g., 30 to 120 minutes).
-
Centrifugation: The clotted blood is centrifuged to separate the serum from the blood cells.
-
Serum Transfer: The serum is carefully transferred to a designated cryotube.
-
Freezing and Shipping: The serum sample is immediately frozen on dry ice and shipped overnight to the testing laboratory.[9][10]
Immunoassay Procedure
The core of the this compound test is an immunoadsorption assay. The general steps, as described in the literature, are as follows:
-
Antigen Immobilization: The proprietary "TARGET® reagent," which consists of malignin covalently bound to bromoacetylcellulose, serves as the solid phase for capturing the anti-malignin antibodies.[5]
-
Sample Incubation: The patient's serum is incubated with the TARGET® reagent. During this time, anti-malignin antibodies present in the serum bind to the immobilized malignin.
-
Washing: The reagent is washed to remove unbound serum components.
-
Elution: The bound anti-malignin antibodies are eluted from the reagent, typically using a low pH solution such as acetic acid.[5]
-
Quantification: The amount of eluted antibody is then quantified. The exact method of quantification (e.g., spectrophotometry) is not detailed in the available literature.
The results are often reported in micrograms per milliliter (µg/mL) and categorized as negative, borderline, or positive based on predetermined cutoff values. Some studies have also referred to "fast target absorbed globulin" (F-Tag) and "slow target absorbed globulin" (S-Tag) measurements, with the specific binding (Net-Tag) calculated as the difference between the two.[6]
Quantitative Data on Test Performance
The performance of the this compound test, specifically its sensitivity and specificity, has been a central point of discussion and controversy. While the test's proponents claim high accuracy, independent studies have reported more modest results. The following tables summarize some of the available quantitative data.
| Study | Cancer Type | Patient Cohort | Sensitivity | Specificity | Notes |
| Abrams et al. (1994)[4] | Various Cancers | 3315 double-blind tests | 95% (on first determination), >99% (on repeat determinations) | 95% (on first determination), >99% (on repeat determinations) | This data is from a review published by the developers of the test. |
| Thornthwaite (2000)[4] | Breast Cancer | 32 patients with cancerous biopsies, 11 with benign biopsies, 154 healthy volunteers | 97% (31/32) | 64% (7/11 benign biopsies were negative) | Compared to other tumor markers (CEA, CA 15-3, CA 19-5, CA 125), this compound showed higher sensitivity. |
| Harman et al. (2005)[6][11] | Breast Cancer | 71 women undergoing core breast biopsy (17 malignant, 12 suspicious, 42 benign) | 59% (pooling suspicious with malignant and borderline with positive) | 62% (pooling suspicious with malignant and borderline with positive) | The study concluded that the sensitivity was insufficient to spare patients from biopsy and the false-positive rate was too high for population screening. |
Signaling Pathways and Logical Relationships
A significant limitation in the scientific understanding of the this compound test is the absence of information regarding the signaling pathways involving malignin. While it is referred to as an "oncoprotein," its specific molecular functions and interactions with other cellular components remain undefined in the public domain. Without this information, it is not possible to construct a detailed signaling pathway diagram.
However, we can represent the logical workflow of the this compound test itself.
References
- 1. sa1s3.patientpop.com [sa1s3.patientpop.com]
- 2. coxnaturalhealth.com [coxnaturalhealth.com]
- 3. Anti-malignin antibody evaluation: a possible challenge for cancer management - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Early detection and monitoring of cancer with the anti-malignin antibody test - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. wa-provider.kaiserpermanente.org [wa-provider.kaiserpermanente.org]
- 6. aacrjournals.org [aacrjournals.org]
- 7. Tumor markers: malignin and related recognins associated with malignancy rather than with cell type - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. labtests.ir [labtests.ir]
- 9. Oncolab Exhibits Pioneering this compound Cancer Test at AACC - aacc-2014 - mobile.Labmedica.com [mobile.labmedica.com]
- 10. justinhealth.com [justinhealth.com]
- 11. Discrimination of breast cancer by anti-malignin antibody serum test in women undergoing biopsy - PubMed [pubmed.ncbi.nlm.nih.gov]
The AMAS Test: A Technical Deep Dive into its Principles and Mechanisms for Cancer Detection
For Immediate Release
Boston, MA – This technical guide provides an in-depth exploration of the Anti-Malignin Antibody in Serum (AMAS) test, a blood-based assay for the detection and monitoring of cancer. Tailored for researchers, scientists, and drug development professionals, this document elucidates the core principles of the this compound test, its underlying biological mechanisms, including its connection to apoptosis, and presents relevant technical data and protocols.
Core Principle: Detecting the Humoral Immune Response to a General Cancer Antigen
The fundamental principle of the this compound test lies in the detection of a specific humoral immune response to a tumor-associated antigen. The test quantifies the level of anti-malignin antibodies in a patient's serum.[1] Malignin is a 10 kDa oncoprotein polypeptide that is found in the cytoplasm and on the outer membranes of malignant cells, irrespective of the cancer's site or cell type.[1] The presence of malignin is recognized by the host's immune system, which in turn produces anti-malignin antibodies (this compound).[2] These antibodies are primarily of the Immunoglobulin M (IgM) class, which is significant as IgM antibodies are typically associated with an early immune response to an antigen.[1]
The this compound test, therefore, operates on the premise that an elevated level of anti-malignin IgM in the serum is indicative of an active, non-terminal malignancy.[1] Unlike tests that measure the levels of cancer antigens, which may only become elevated in later stages of the disease, the this compound test measures the body's early antibody response to the presence of cancer cells.[3]
Underlying Mechanism: Anti-Malignin IgM and the Induction of Apoptosis
The significance of the anti-malignin IgM response extends beyond simple detection. Certain IgM antibodies have been shown to possess direct cytotoxic effects on tumor cells by inducing apoptosis, or programmed cell death. While the precise signaling cascade initiated by anti-malignin antibodies is not fully elucidated in the available literature, a plausible mechanism can be inferred from studies on other cancer-targeting IgM antibodies.
For instance, IgM antibodies directed against tumor necrosis factor (TNF)-related apoptosis-inducing ligand (TRAIL)-receptor 1 have been demonstrated to strongly induce apoptosis in human cancer cells.[4] This process is initiated by the binding of the IgM antibody to the receptor on the cancer cell surface, which leads to the activation of the caspase signaling cascade, specifically involving the activation of caspase-8 and caspase-3.[4] Caspases are a family of protease enzymes that are central to the execution of apoptosis.
The binding of anti-malignin IgM to malignin on the surface of a cancer cell likely triggers a similar apoptotic pathway. This proposed mechanism provides a biological basis for the observation that a robust anti-malignin antibody response, as detected by the this compound test, can be associated with a better prognosis in cancer patients.
Below is a diagram illustrating the proposed signaling pathway for anti-malignin IgM-induced apoptosis.
Quantitative Data Summary
The performance of the this compound test has been evaluated in several studies. The sensitivity and specificity are key metrics for any diagnostic assay. The following table summarizes the reported quantitative data for the this compound test.
| Study/Source | Sensitivity | Specificity | Number of Subjects/Tests | Notes |
| Abrams MB et al. (1994)[5] | 95% (first determination), >99% (repeat determination) | 95% (first determination), >99% (repeat determination) | 3315 double-blind tests | General transformation antibody, elevated in active non-terminal cancer. |
| Harman SM et al. (2005)[4] | 59% | 62% | 71 women undergoing breast biopsy | Study focused on discrimination of breast cancer in women undergoing biopsy. |
| Oncolab (via CAP TODAY, 2016)[6] | >90% | >90% | >60,000 tests performed | General data from the test provider. |
| Oncolab (via PR Newswire, 2014)[7] | >90% (False positive and negative rates under 10%) | >90% (False positive and negative rates under 10%) | >60,000 patients | General data from the test provider. |
Experimental Protocol: The this compound Test Procedure
The this compound test is performed exclusively at the Oncolab facility in Boston, MA. The following protocol is a synthesis of the available information on the sample collection, shipping, and the immunoassay procedure.
Sample Collection and Preparation
-
Blood Draw: A blood sample is collected via venipuncture. It is critical to use the specific Covidien Monoject 10mL tube (REF#8881302718, No Additive, Non-Silicone Coated) provided by Oncolab. This must be the first tube drawn.[5]
-
Clotting: The blood is allowed to sit at room temperature for a minimum of 30 minutes and a maximum of 2 hours to allow for clot formation.[5]
-
Refrigeration: The clotted blood is then placed in a refrigerator at 4°C (± 2°) for a minimum of 1 hour and a maximum of 3 hours.[5]
-
Centrifugation: The sample is centrifuged at 3000 RPM for 15 minutes at 4°C (± 2°). If a refrigerated centrifuge is unavailable, the centrifuge cups should be pre-chilled.[5]
-
Serum Transfer: Using the provided glass Pasteur pipette, the serum is carefully transferred to the provided screw-cap Greiner Bio-One cryotube. A minimum of 2mL of serum is required. The cryotube is labeled with the patient's name, date of birth, and the date/time of collection.[5]
-
Freezing: The serum is frozen immediately by placing the cryotube in dry ice.[5]
Shipping
The frozen serum sample is shipped overnight in an insulated container with dry ice to the Oncolab facility.[5][7]
Immunoassay Procedure
The core of the this compound test is a specific immunoadsorption assay.
-
Reagent: The test utilizes the TARGET® reagent, which consists of malignin covalently bound to bromoacetylcellulose.[2]
-
Washing: The TARGET® reagent is washed with cold saline.[2]
-
Incubation: The patient's serum sample is added to the washed TARGET® reagent, allowing the anti-malignin antibodies to bind to the immobilized malignin.
-
Elution: After an incubation period, the bound anti-malignin antibodies are eluted from the reagent using acetic acid.[2]
-
Quantification: The amount of eluted anti-malignin antibody is then quantified. The protein concentration is measured at two time points: after 10 minutes of incubation (Fast target absorbed globulin or F-Tag) and after 120 minutes (Slow target absorbed globulin or S-Tag). The specific binding (Net-Tag) is calculated by subtracting the F-Tag from the S-Tag.[4]
Below is a workflow diagram illustrating the experimental procedure.
Conclusion
The this compound test represents a unique approach to cancer detection by measuring the body's own immune response to a general tumor-associated antigen. Its principle is grounded in the production of anti-malignin IgM antibodies following neoplastic transformation. The underlying mechanism is potentially linked to the ability of these antibodies to induce apoptosis in cancer cells, a critical process in tumor suppression. While the test has shown high sensitivity and specificity in some studies, further independent validation and a more detailed elucidation of the malignin-initiated signaling pathways are warranted to fully establish its clinical utility in the management of cancer. This technical guide provides a comprehensive overview of the current understanding of the this compound test for the scientific and drug development communities.
References
- 1. Anti-malignin antibody evaluation: a possible challenge for cancer management - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Function and dysfunction of the human oncoprotein MDM2 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. mdpi.com [mdpi.com]
- 4. tandfonline.com [tandfonline.com]
- 5. justinhealth.com [justinhealth.com]
- 6. CD72 stimulation modulates anti-IgM induced apoptotic signaling through the pathway of NF-kappaB, c-Myc and p27(Kip1) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. IgM-mediated B cell apoptosis - PubMed [pubmed.ncbi.nlm.nih.gov]
The Enigmatic Role of Malignin in Oncology: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Abstract
Malignin, a 10 kDa polypeptide identified in the cytoplasmic and outer membranes of malignant cells, has been a subject of interest in oncology primarily for its potential as a broad-spectrum cancer marker.[1] This technical guide provides an in-depth overview of the current understanding of malignin, with a focus on the immunological response it elicits and the application of this response in cancer diagnostics. While the precise molecular signaling pathways involving malignin remain to be fully elucidated, this paper will synthesize the available quantitative data, detail relevant experimental protocols, and present logical workflows pertinent to its study.
Introduction to Malignin
Malignin is described as a polypeptide with a molecular weight of 10,000 Daltons.[2][3] It has been reported to be a common antigen found across a wide variety of malignant cell types, irrespective of their tissue of origin.[2] This apparent ubiquity in cancer cells, and its absence in non-malignant counterparts, has led to its investigation as a general marker for neoplastic transformation.[2] Malignin is a component of a larger 250 kDa glycoprotein (B1211001) found in brain cell membranes, which appears to be hypoglycosylated in glioblastoma cells.[1]
The Anti-Malignin Antibody (AMA) Response
The presence of malignin in malignant cells elicits a humoral immune response in the host, leading to the production of IgM-class antibodies known as anti-malignin antibodies (AMAs). As IgM antibodies are often associated with an early immune response, the detection of elevated AMA levels has been proposed as an early indicator of malignant transformation. The Anti-Malignin Antibody Serum (this compound) test was developed to quantify the concentration of these antibodies in patient serum.
Logical Framework: Host Immune Response to Malignin
The following diagram illustrates the proposed mechanism of the anti-malignin antibody response in a cancer patient.
References
For Researchers, Scientists, and Drug Development Professionals
An In-depth Technical Guide to the Anti-Malignin Antibody Screen (AMAS) as a Potential Cancer Marker
This technical guide provides a comprehensive overview of the Anti-Malignin Antibody Screen (this compound), a serological test proposed as a general marker for cancer. The document details the underlying principles of the test, presents quantitative data from various studies, outlines the experimental protocol as available in the public domain, and discusses the controversies and limitations surrounding its clinical utility.
Introduction to this compound
The Anti-Malignin Antibody Screen (this compound) is a blood test designed to detect the presence of cancer by identifying antibodies against a polypeptide called malignin.[1][2] Malignin is described as a 10,000-Dalton polypeptide present on the surface of malignant cells, irrespective of the cancer's tissue of origin.[3][4][5] The test is based on the premise that the immune system of an individual with cancer will produce IgM antibodies against this "general transformation antibody".[3][4] Proponents of the this compound test claim it can detect cancer at an early, non-terminal stage and can be used to monitor the effectiveness of cancer treatment.[3][5]
However, the this compound test is a subject of considerable debate within the scientific and medical communities. While early reports from its developers suggested exceptionally high sensitivity and specificity, subsequent independent studies have yielded conflicting results.[1][6][7][8] Moreover, the test has not been widely adopted in mainstream oncology, and its credibility remains a point of contention.[1]
Quantitative Data on this compound Performance
The reported accuracy of the this compound test varies significantly across different studies. The following tables summarize the available quantitative data on the sensitivity and specificity of the this compound test.
Table 1: this compound Sensitivity and Specificity as Reported in Early and Developer-Associated Studies
| Study Cohort | Number of Participants | Sensitivity | Specificity | Citation |
| Double-blind tests | 3,315 | 95% (single test), >99% (repeat tests) | 95% (single test), >99% (repeat tests) | [3][4] |
| Patients and controls in daily clinical practice | 181 | 100% (in 21 confirmed cancer cases) | 100% (in 97 non-cancer cases) | [3] |
| Active, non-terminal cancer cases | Not specified | 93-100% | Not specified | [5] |
| Stored sera | 3,315 | 93% | 95% | [5] |
| Fresh sera (within 24 hours) | Not specified | >99% | >99% | [5] |
Table 2: this compound Sensitivity and Specificity in Independent and Later Studies
| Study Cohort | Number of Participants | Sensitivity | Specificity | Citation |
| Women undergoing core breast biopsy | 71 | 59% | 62% | [6][7] |
| Women undergoing core breast biopsy (optimized criteria) | 71 | 62% | 69% | [7] |
| Patients with suspicious mammograms | 43 | 97% (31/32 cancer patients) | 64% (7/11 benign cases were negative) | [9] |
Table 3: Comparison of this compound with Other Tumor Markers in Breast Cancer
| Tumor Marker | Sensitivity | Citation |
| This compound | 97% | [9] |
| CEA | 0% | [9] |
| CA 15-3 | 10% | [9] |
| CA 19-5 | 5% | [9] |
| CA 125 | 16% | [9] |
It is crucial for researchers to note the discrepancies in the reported data, which may be attributed to differences in study design, patient populations, and the criteria used for defining positive and negative results.
Experimental Protocols
3.1. Principle of the this compound Test
The this compound test is an immunoassay that measures the level of anti-malignin antibodies in a patient's serum. The core of the assay involves the specific binding of these antibodies to a reagent containing purified malignin.[10]
3.2. This compound Assay Workflow (as described in literature)
The following is a generalized workflow for the this compound test based on available descriptions:
-
Serum Collection : A blood sample is collected from the patient, and the serum is separated. For optimal results, the test should be performed on fresh serum within 24 hours of collection to minimize false-positive results.[5][10]
-
Immunoadsorption : The patient's serum is incubated with a proprietary "Target® reagent". This reagent consists of malignin covalently bound to bromoacetylcellulose.[10] During this incubation, anti-malignin antibodies in the serum bind to the immobilized malignin.
-
Washing : The reagent is washed with cold saline to remove unbound serum components.[10]
-
Elution : The bound anti-malignin antibodies are eluted from the reagent using acetic acid.[10]
-
Quantification : The amount of eluted antibody is quantified. The exact method of quantification is not explicitly detailed in the reviewed literature, but it is likely a protein quantification assay. The results are reported in micrograms per milliliter (µg/mL).[6] The test measures both a "fast" (F-Tag) and a "slow" (S-Tag) antibody binding, with the difference (Net-Tag) being a key parameter.[6][7]
3.3. Production and Purification of Malignin
The initial source of malignin was from malignant glial cells grown in vivo.[11] Later, related polypeptides, termed "recognins," were produced from other cancer cell lines such as mammary carcinoma (MCF-7) and lymphoma (P3G) cells.[11] The general process would likely involve:
-
Cell Culture : Growth of a suitable cancer cell line.
-
Cell Lysis : Disruption of the cells to release cellular components.
-
Purification : A multi-step purification process, likely involving chromatography techniques, to isolate the 10,000-Dalton malignin polypeptide.
The precise details of the purification protocol are proprietary.
Mandatory Visualizations
4.1. Logical Framework of the this compound Test
Caption: Logical relationship from cancer presence to this compound test result.
4.2. Experimental Workflow for the this compound Assay
Caption: Generalized experimental workflow of the this compound test.
Limitations and Criticisms
The primary limitation of the this compound test is the lack of robust, independent validation of the initial high sensitivity and specificity claims.[1] Criticisms of the studies supporting this compound often point to potential limitations in their design, such as the selection of study participants and the lack of validation for the antibody cutoff levels used.[10]
A significant concern for researchers is the "black box" nature of the test, with proprietary reagents and protocols that are not publicly available for independent scrutiny and replication. The identity and exact nature of "malignin" are not as well-characterized in the broader scientific literature as would be expected for a widely used cancer marker.
Furthermore, studies in specific cancer types, such as breast cancer, have shown that the this compound test may not be sufficiently sensitive or specific to be used for population screening or to avoid biopsies.[6][7]
Conclusion for the Research Professional
The Anti-Malignin Antibody Screen presents an intriguing concept of a general cancer marker. The initial data, primarily from the developers, suggests a test with very high accuracy. However, the lack of widespread independent validation, the conflicting results from some later studies, and the proprietary nature of the test are significant hurdles to its acceptance and use in mainstream oncology research and clinical practice.
For drug development professionals and researchers, this compound remains a controversial and largely unproven biomarker. Any consideration of its use in a research or clinical trial setting should be approached with caution and a thorough understanding of the conflicting evidence. Further independent research would be required to clarify the true diagnostic and prognostic value of the this compound test.
References
- 1. drweil.com [drweil.com]
- 2. Anti Malignan Antibody Test for Cancer | this compound Test [knowcancer.com]
- 3. Early detection and monitoring of cancer with the anti-malignin antibody test - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Anti-malignin antibody evaluation: a possible challenge for cancer management - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. sa1s3.patientpop.com [sa1s3.patientpop.com]
- 6. aacrjournals.org [aacrjournals.org]
- 7. Discrimination of breast cancer by anti-malignin antibody serum test in women undergoing biopsy - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. healthknot.com [healthknot.com]
- 9. Anti-malignin antibody in serum and other tumor marker determinations in breast cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. wa-provider.kaiserpermanente.org [wa-provider.kaiserpermanente.org]
- 11. Production of two recognins related to malignin: recognin M from mammary MCF-7 carcinoma cells and recognin L from lymphoma P3G cells - PubMed [pubmed.ncbi.nlm.nih.gov]
An In-depth Technical Guide to the Anti-Malignin Antibody in Serum (AMAS) Test for Early Cancer Detection
For Researchers, Scientists, and Drug Development Professionals
Abstract
The Anti-Malignin Antibody in Serum (AMAS) test is a blood-based immunoassay designed for the early detection and monitoring of cancer. The foundational theory of the this compound test centers on the detection of a specific antibody, primarily of the IgM isotype, produced by the host's immune system in response to a pan-cancer antigen known as malignin. Malignin is described as a 10,000 Dalton polypeptide, which is a fragment of a larger 250 kDa glycoprotein (B1211001) found on the surface of malignant cells. This glycoprotein is reportedly hypoglycosylated in cancer cells, a common feature of tumor-associated antigens. The this compound test operates on the principle of immunoadsorption, where the anti-malignin antibody in a serum sample is captured by malignin immobilized on a solid-phase reagent. The subsequent elution and quantification of this antibody form the basis of the test results. While some studies have reported high sensitivity and specificity, others have indicated more modest accuracy, leading to ongoing debate about its clinical utility. This guide provides a comprehensive technical overview of the this compound test, including its theoretical underpinnings, a detailed look at the available experimental protocols, a summary of clinical data, and a hypothesized signaling pathway for the immune response to malignin.
Core Theory and Biochemical Basis
The central hypothesis of the this compound test is that the transformation of normal cells to a malignant phenotype is accompanied by the expression of a common antigen, termed "malignin." This antigen is recognized by the host's immune system, leading to the production of anti-malignin antibodies (this compound). The this compound test is designed to detect these antibodies in the serum.
Malignin: The Target Antigen
Malignin is characterized as a 10,000 Dalton (10 kDa) polypeptide.[1][2][3][4][5] It has been described as being rich in aspartic and glutamic acid.[2] Further characterization suggests that malignin is a fragment of a much larger 250 kDa glycoprotein present on the membrane of brain cells, which appears to be hypoglycosylated in glioblastoma cells.[2] This aberrant glycosylation is a known hallmark of cancer and can expose new antigenic epitopes. Malignin is considered a general transformation antibody, meaning it is thought to be produced in response to a wide variety of cancer types, rather than being specific to one organ or tissue.[5] It is also classified as an onconeural antigen, a class of proteins normally expressed in the nervous system but aberrantly expressed in tumors outside of the nervous system.[6][7][8][9][10][11][12][13]
Anti-Malignin Antibody (AMA)
The antibody produced in response to malignin is predominantly of the IgM isotype.[3] IgM antibodies are typically the first class of immunoglobulins produced during a primary immune response. The presence of anti-malignin IgM could therefore signify an early-stage immune reaction to malignant cells.
Experimental Protocols
While the precise, proprietary details of the this compound test as performed by Oncolab are not fully public, a general outline of the methodology can be pieced together from various publications and publicly available documents. The test is based on a solid-phase immunoadsorption assay.
Sample Collection and Handling
Strict adherence to the sample collection and handling protocol is critical for the accuracy of the this compound test. The following steps are derived from Oncolab's test requisition information:
-
Blood Collection: Blood must be drawn into a specific Covidien Monoject 10mL tube (REF#8881302718), which is a non-silicone coated tube with no additives. This must be the first tube drawn to avoid contamination with clot activators from other tubes.
-
Clotting: The blood sample must be allowed to sit at room temperature for a minimum of 30 minutes and a maximum of 2 hours to allow for clot formation.
-
Refrigeration: Following clotting, the sample must be refrigerated at 4°C (±2°C) for a minimum of 1 hour and a maximum of 3 hours.
-
Centrifugation: The sample is then centrifuged at 3000 RPM for 15 minutes at 4°C (±2°C). If a refrigerated centrifuge is unavailable, the centrifuge cups should be pre-chilled.
-
Serum Transfer: Using a glass Pasteur pipette (plastic is avoided as it may absorb antibodies), the serum is transferred to a provided screw-cap Greiner Bio-One cryotube. A minimum of 2mL of serum is required.
-
Freezing and Shipping: The serum is then immediately frozen on dry ice and shipped overnight to the laboratory.
Immunoassay Procedure (Reconstructed)
The core of the this compound test is an immunoadsorption assay. The following is a reconstructed, general protocol based on available information:
-
Solid-Phase Reagent: The "Target® reagent" consists of purified malignin covalently bound to a solid support, which has been identified as bromoacetylcellulose.[3]
-
Immunoadsorption: The patient's serum is added to the Target® reagent. If anti-malignin antibodies are present, they will bind to the immobilized malignin.
-
Washing: The solid phase is washed with cold saline to remove unbound serum components.[3]
-
Elution: The bound anti-malignin antibodies are eluted from the solid phase using an acidic solution, specified as acetic acid.[3]
-
Quantification: The amount of eluted anti-malignin antibody is then quantified. The exact method of quantification is not detailed in the available literature, but it is likely an enzyme-linked immunosorbent assay (ELISA) or a similar quantitative immunoassay technique. A positive result is generally considered to be a value greater than 135 µg/mL.
Quantitative Data Summary
The reported accuracy of the this compound test has varied across different studies. Below is a summary of the quantitative data from key publications.
| Study | Cancer Type(s) | Total Subjects | True Positives (TP) | True Negatives (TN) | False Positives (FP) | False Negatives (FN) | Sensitivity | Specificity |
| Abrams et al. (1994)[1] | Various | 181 | 21 | 97 | 0 | 0 | 100% | 100% |
| Thornthwaite (2000)[14] | Breast Cancer | 197 | 31 | 151 | 3 | 1 | 96.9% | 98.1% |
| Harman et al. (2005)[15][16] | Breast Cancer | 71 | 10 | 26 | 16 | 7 | 58.8% | 61.9% |
| Bogoch & Bogoch (reported in various sources)[5] | Various | 3,315 | - | - | - | - | >95% (on repeat) | >99% (on repeat) |
Note: The data from Bogoch & Bogoch is often cited as a summary of a large number of double-blind tests, and the raw data for TP, TN, FP, FN are not available in the reviewed abstracts. The sensitivity and specificity are reported for repeat testing.
The significant discrepancy in the reported accuracy, particularly between the earlier studies and the Harman et al. (2005) study, highlights the need for further independent validation of the this compound test. The Harman et al. study, which focused on women undergoing breast biopsy, concluded that the test's sensitivity was insufficient to spare patients from biopsy and the false-positive rate was too high for general population screening.[2][16]
Signaling Pathways and Logical Relationships
The precise signaling pathways involving malignin have not been fully elucidated in the available literature. However, based on its characterization as an onconeural, tumor-associated glycoprotein antigen, a hypothesized signaling pathway for the generation of the anti-malignin antibody response can be proposed.
Hypothesized Immune Response to Malignin
The following diagram illustrates a potential pathway for the immune recognition of malignin and the subsequent production of anti-malignin IgM antibodies.
Caption: Hypothesized pathway of malignin antigen presentation and subsequent anti-malignin antibody production.
Experimental Workflow of the this compound Test
The following diagram outlines the logical workflow of the this compound test from sample collection to result.
Caption: Step-by-step experimental workflow of the this compound test.
Discussion and Future Directions
The this compound test for early cancer detection is based on the compelling theory of a general immune response to a common cancer antigen. The reported high sensitivity and specificity in early studies generated significant interest. However, the conflicting results from later, independent studies underscore the necessity for large-scale, prospective, and well-controlled clinical trials to definitively establish its clinical validity and utility.
For the scientific and drug development community, several key areas require further investigation:
-
Biochemical Characterization of Malignin: A detailed molecular characterization of malignin, including its amino acid sequence and the specific epitope(s) recognized by the anti-malignin antibody, is essential. This would enable the development of more standardized and potentially more accurate second-generation assays.
-
Elucidation of Signaling Pathways: Research into the role of malignin in cancer cell biology and the specific signaling pathways it may be involved in could provide insights into its function in tumorigenesis and as an immunological target.
-
Standardization of the Assay: The lack of a publicly available, detailed protocol for the this compound test makes it difficult for independent laboratories to replicate and validate the findings. A more transparent and standardized methodology would be beneficial for the scientific community.
-
Clinical Validation: Rigorous, multi-center clinical trials are needed to clarify the true sensitivity, specificity, and predictive values of the this compound test across a wide range of cancer types and stages.
References
- 1. Early detection and monitoring of cancer with the anti-malignin antibody test - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. aacrjournals.org [aacrjournals.org]
- 3. wa-provider.kaiserpermanente.org [wa-provider.kaiserpermanente.org]
- 4. sa1s3.patientpop.com [sa1s3.patientpop.com]
- 5. coxnaturalhealth.com [coxnaturalhealth.com]
- 6. pnas.org [pnas.org]
- 7. Onconeural antigens and the paraneoplastic neurologic disorders: at the intersection of cancer, immunity, and the brain - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. academic.oup.com [academic.oup.com]
- 9. Onconeural antigens and the paraneoplastic neurologic disorders: at the intersection of cancer, immunity, and the brain - PMC [pmc.ncbi.nlm.nih.gov]
- 10. vjneurology.com [vjneurology.com]
- 11. Paraneoplastic neurological syndromes: clinical presentations and management - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Clinical Characteristics and Predictors of Outcome for Onconeural Antibody-Associated Disorders: A Retrospective Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Onconeural antibodies in patients with neurological symptoms: detection and clinical significance - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. Anti-malignin antibody in serum and other tumor marker determinations in breast cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. researchgate.net [researchgate.net]
- 16. Discrimination of breast cancer by anti-malignin antibody serum test in women undergoing biopsy - PubMed [pubmed.ncbi.nlm.nih.gov]
An In-depth Technical Guide to Antimitochondrial Antibodies for Researchers and Drug Development Professionals
Introduction
Antimitochondrial antibodies (AMAs) are a heterogeneous group of autoantibodies that target various antigens within the inner and outer mitochondrial membranes.[1] Their presence in serum is a hallmark of several autoimmune conditions, most notably Primary Biliary Cholangitis (PBC), a chronic and progressive autoimmune liver disease.[2][3] This technical guide provides a comprehensive overview of the different types of this compound, their target antigens, clinical significance, and the methodologies used for their detection and characterization. This document is intended for researchers, scientists, and drug development professionals working in the fields of autoimmunity, hepatology, and diagnostics.
Classification and Types of Antimitochondrial Antibodies
This compound are broadly classified into nine distinct subtypes, designated M1 through M9.[1][4] Each subtype is characterized by its reactivity towards specific mitochondrial antigens and is associated with different clinical conditions. While some subtypes are highly specific for certain diseases, others can be found in a variety of autoimmune and other disorders.[2][5]
Primary Biliary Cholangitis (PBC)-Associated this compound
A significant proportion of AMA subtypes are strongly associated with PBC, an autoimmune disease characterized by the progressive destruction of small intrahepatic bile ducts.[6]
-
AMA-M2: This is the most clinically significant and well-characterized AMA subtype, found in 90-95% of patients with PBC.[5][6] The primary target of AMA-M2 is the E2 subunit of the pyruvate (B1213749) dehydrogenase complex (PDC-E2), located on the inner mitochondrial membrane.[1][5] The detection of AMA-M2 is a cornerstone in the diagnosis of PBC.[6]
-
AMA-M4: These antibodies are also associated with PBC and often appear in conjunction with AMA-M2.[2] They are thought to be directed against sulfite (B76179) oxidase.[2] Some research suggests that the presence of anti-M4 antibodies may be linked to a more progressive disease course.[7]
-
AMA-M8: Similar to AMA-M4, anti-M8 antibodies are typically found in patients who are also positive for AMA-M2 and are associated with PBC.[2] The precise antigenic target is located on the outer mitochondrial membrane.[2]
-
AMA-M9: This subtype targets glycogen (B147801) phosphorylase and can be detected in the early stages of PBC.[1][2] Notably, anti-M9 antibodies can sometimes be found in patients with PBC who are negative for the more common AMA-M2 subtype.[1]
Non-PBC Associated this compound
Several AMA subtypes are more frequently associated with other autoimmune or infectious conditions:
-
AMA-M1: These antibodies target cardiolipin, a phospholipid of the inner mitochondrial membrane.[2] Their presence is strongly associated with syphilis.[2][5]
-
AMA-M3: This subtype is linked to drug-induced lupus erythematosus, an autoimmune condition triggered by certain medications.[2] The target antigen is located on the outer mitochondrial membrane.[2]
-
AMA-M5: Found in patients with various collagen vascular diseases, such as systemic lupus erythematosus (SLE) and undifferentiated connective tissue disease.[2] The specific antigen on the outer mitochondrial membrane is yet to be fully characterized.[2]
-
AMA-M6: These antibodies are associated with drug-induced hepatitis.[2][5]
-
AMA-M7: This subtype is linked to cardiomyopathies and myocarditis, suggesting a role in cardiac autoimmune conditions.[2] The target antigen is sarcosine (B1681465) dehydrogenase.[2]
Quantitative Data on AMA Prevalence and Diagnostic Accuracy
The following tables summarize the prevalence of different AMA subtypes in various diseases and their diagnostic utility.
Table 1: Prevalence of Antimitochondrial Antibody Subtypes in Primary Biliary Cholangitis (PBC)
| Antibody Subtype | Target Antigen(s) | Prevalence in PBC (%) |
| AMA-M2 | Pyruvate Dehydrogenase Complex (PDC-E2), Branched-Chain 2-Oxoacid Dehydrogenase Complex (BCOADC-E2), 2-Oxoglutarate Dehydrogenase Complex (OGDC-E2) | 90-95[5][6] |
| AMA-M4 | Sulfite Oxidase | 37[7] |
| AMA-M8 | Outer Mitochondrial Membrane Protein | Often co-occurs with AMA-M2[2] |
| AMA-M9 | Glycogen Phosphorylase | 14.2[7] |
Table 2: Association and Prevalence of Non-M2 Antimitochondrial Antibodies in Various Diseases
| Antibody Subtype | Associated Condition(s) | Prevalence |
| AMA-M1 | Syphilis | Strong Association[2][5] |
| AMA-M3 | Drug-Induced Lupus Erythematosus | Strong Association[2] |
| AMA-M5 | Systemic Lupus Erythematosus, Undifferentiated Connective Tissue Disease | Found in some patients[2][4] |
| AMA-M6 | Drug-Induced Hepatitis | Strong Association[2][5] |
| AMA-M7 | Cardiomyopathy, Myocarditis | Found in some patients[2] |
Pathogenic Mechanisms of Antimitochondrial Antibodies
The leading hypothesis for the development of this compound, particularly in the context of PBC, is molecular mimicry . This theory posits that an initial immune response to an infectious agent, such as a bacterium or virus, can lead to the production of antibodies that cross-react with self-antigens in the mitochondria due to structural similarities between the foreign and self-peptides.[1] The E2 subunit of the pyruvate dehydrogenase complex (PDC-E2), the main target of AMA-M2, shares homologous regions with proteins from various bacteria, including Escherichia coli and Novosphingobium aromaticivorans.
The binding of this compound to mitochondrial antigens on the surface of biliary epithelial cells is thought to trigger a cascade of inflammatory events, leading to cell damage and apoptosis. This process may involve the activation of the complement system and the recruitment of cytotoxic immune cells. However, the precise downstream signaling pathways initiated by AMA binding are still an active area of research.
References
- 1. Antimitochondrial Antibodies: from Bench to Bedside - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Anti-mitochondrial antibody - Wikipedia [en.wikipedia.org]
- 3. Content - Health Encyclopedia - University of Rochester Medical Center [urmc.rochester.edu]
- 4. rheumaknowledgy.com [rheumaknowledgy.com]
- 5. primarycarenotebook.com [primarycarenotebook.com]
- 6. testing.com [testing.com]
- 7. researchgate.net [researchgate.net]
Antimitochondrial Antibodies (AMAs) in Autoimmune Diseases: A Technical Guide for Researchers
An in-depth exploration of the role of Antimitochondrial Antibodies (AMAs) in the immunopathogenesis of autoimmune diseases, with a primary focus on Primary Biliary Cholangitis (PBC). This guide provides a comprehensive overview for researchers, scientists, and drug development professionals, detailing the molecular characteristics of this compound, their primary antigenic targets, the mechanisms of AMA-mediated pathology, and current methodologies for their detection and analysis.
Introduction to Antimitochondrial Antibodies (this compound)
Antimitochondrial antibodies (this compound) are a heterogeneous group of autoantibodies that target various proteins located within the mitochondria.[1][2] While they can be detected in a range of autoimmune conditions, their presence is most strongly associated with Primary Biliary Cholangitis (PBC), a chronic and progressive autoimmune liver disease characterized by the destruction of small intrahepatic bile ducts.[3][4][5] this compound are considered a serological hallmark of PBC, found in approximately 90-95% of patients, and their detection is a key component of the diagnostic criteria for the disease.[1][2][3]
The primary autoantigen recognized by this compound in the context of PBC is the E2 component of the pyruvate (B1213749) dehydrogenase complex (PDC-E2), located on the inner mitochondrial membrane.[6][7] The immune response against PDC-E2 is believed to be a central event in the pathogenesis of PBC, leading to damage and eventual destruction of biliary epithelial cells (BECs).[8][9] This guide will delve into the intricate details of this compound, their antigenic targets, the proposed mechanisms of immune-mediated damage, and the methodologies employed in their study.
Data Presentation: this compound in Autoimmune Diseases
The presence and titer of this compound can vary across different autoimmune diseases. The following tables summarize key quantitative data regarding AMA prevalence and the diagnostic accuracy of various detection methods for PBC.
Table 1: Prevalence of Antimitochondrial Antibodies (this compound) in Autoimmune Diseases
| Autoimmune Disease | Prevalence of this compound (%) | Notes |
| Primary Biliary Cholangitis (PBC) | 90 - 95% | Serological hallmark of the disease.[1][2][3] |
| Sjögren's Syndrome | 1.7 - 13% | May indicate an overlap with PBC.[8] |
| Systemic Sclerosis (Scleroderma) | 8 - 25% | Often associated with the limited cutaneous form.[10] |
| Systemic Lupus Erythematosus (SLE) | ~13% | May be associated with liver involvement.[11] |
| Inflammatory Myositis | ~5% (adult-onset) | Associated with more severe disease phenotypes.[6][9] |
| Autoimmune Hepatitis (AIH) | < 5% | Can be seen in overlap syndromes with PBC. |
| Healthy Individuals | < 1% | Low titers may be present without clinical significance.[1] |
Table 2: Diagnostic Accuracy of AMA Detection Methods for Primary Biliary Cholangitis (PBC)
| Detection Method | Sensitivity (%) | Specificity (%) | Key Considerations |
| Indirect Immunofluorescence (IIF) | 71 - 88.6% | 87 - 93.5% | Considered a standard screening method, but can have lower specificity. A higher cutoff titer improves specificity.[12] |
| Enzyme-Linked Immunosorbent Assay (ELISA) for AMA-M2 | 55.7 - 93.6% | 91.7 - 98.8% | Generally offers higher specificity than IIF. Sensitivity can vary based on the antigen preparation (native vs. recombinant).[12][13] |
| Immunoblotting (Western Blot) | ~85% | High | Useful for confirming positive screening tests and identifying specific AMA subtypes. More sensitive than IIF in some cases.[14] |
Immunopathogenesis of AMA-Mediated Disease
The prevailing hypothesis for the initiation of the anti-mitochondrial autoimmune response in PBC is molecular mimicry . This theory posits that an initial immune response to an environmental trigger, such as a bacterial or viral infection, leads to the production of antibodies that cross-react with self-antigens, specifically PDC-E2.[8][12]
The Molecular Mimicry Hypothesis
Structural similarities between microbial proteins and the lipoic acid domain of PDC-E2 are thought to be the basis for this cross-reactivity.[6] For instance, proteins from bacteria such as Escherichia coli and Novosphingobium aromaticivorans have been shown to have structural mimics to the immunodominant epitopes of PDC-E2.[12]
Cellular and Humoral Immunity in PBC
Both cellular and humoral immune responses are implicated in the pathology of PBC. The inflammatory infiltrate in the portal tracts of PBC patients is rich in CD4+ and CD8+ T lymphocytes, B cells, plasma cells, and macrophages.[3] Autoreactive CD4+ and CD8+ T cells specific for PDC-E2 have been identified in the peripheral blood and liver of PBC patients.[14] These T cells are believed to play a direct role in the destruction of biliary epithelial cells.
This compound, particularly of the IgA isotype, are thought to contribute to BEC damage. IgA this compound can be transcytosed into BECs where they can interact with their intracellular target, PDC-E2, and potentially trigger apoptotic pathways.
Apoptosis of Biliary Epithelial Cells
Apoptosis of BECs is a central feature of PBC. Several signaling pathways are thought to be involved, including both the intrinsic (mitochondrial) and extrinsic (death receptor-mediated) pathways.
The binding of this compound to PDC-E2 within apoptotic blebs on the surface of BECs can lead to the opsonization of these cells and their subsequent clearance by phagocytes, which in turn can perpetuate the inflammatory response.[3] Furthermore, the interaction of cytotoxic T lymphocytes with BECs can induce apoptosis through the release of granzymes and perforin, or through the Fas/FasL pathway.[3]
Experimental Protocols for AMA Detection
Accurate detection of this compound is crucial for the diagnosis of PBC and for research into its pathogenesis. The following sections provide detailed methodologies for the key experiments used in AMA analysis.
Enzyme-Linked Immunosorbent Assay (ELISA) for AMA-M2
ELISA is a widely used method for the quantitative detection of AMA-M2.
Principle: This assay is based on the binding of this compound in a patient's serum to purified or recombinant PDC-E2 (or a fusion protein of the major M2 antigens) coated onto a microplate well. The bound antibodies are then detected using an enzyme-conjugated secondary antibody that recognizes human IgG. The addition of a substrate for the enzyme results in a color change, the intensity of which is proportional to the amount of AMA-M2 present in the sample.
Methodology:
-
Plate Coating: Microtiter plates are pre-coated with purified PDC-E2 antigen.
-
Sample and Control Incubation:
-
Dilute patient sera, positive controls, and negative controls in the provided sample diluent.
-
Add 100 µL of diluted samples and controls to the respective wells.
-
Incubate for 30-60 minutes at room temperature.
-
-
Washing:
-
Aspirate the contents of the wells.
-
Wash each well 3-5 times with 300 µL of wash buffer.
-
-
Conjugate Incubation:
-
Add 100 µL of enzyme-conjugated anti-human IgG (e.g., HRP-conjugated) to each well.
-
Incubate for 30 minutes at room temperature.
-
-
Washing: Repeat the washing step as described in step 3.
-
Substrate Incubation:
-
Add 100 µL of TMB substrate solution to each well.
-
Incubate for 15-30 minutes at room temperature in the dark.
-
-
Stopping the Reaction:
-
Add 100 µL of stop solution (e.g., 1M H₂SO₄) to each well.
-
-
Reading:
-
Read the absorbance of each well at 450 nm using a microplate reader within 30 minutes of adding the stop solution.
-
-
Interpretation: The optical density (OD) values of the patient samples are compared to the OD values of the positive and negative controls to determine the presence and relative quantity of AMA-M2.
Indirect Immunofluorescence (IIF) for this compound
IIF is a common screening method for this compound that provides a qualitative or semi-quantitative result based on the fluorescence pattern observed.
Principle: Patient serum is incubated with a substrate of tissue sections (typically rodent kidney, stomach, and liver) or HEp-2 cells. If this compound are present, they will bind to the mitochondria within the cells of the substrate. A fluorescein-conjugated anti-human IgG antibody is then added, which binds to the patient's this compound. When viewed under a fluorescence microscope, a characteristic granular cytoplasmic staining pattern indicates a positive result.
Methodology:
-
Substrate Preparation: Use commercially available slides with fixed rodent tissue sections or HEp-2 cells.
-
Serum Dilution: Prepare serial dilutions of the patient's serum in phosphate-buffered saline (PBS). A common starting dilution is 1:40.
-
Primary Antibody Incubation:
-
Apply the diluted serum to the wells on the substrate slide.
-
Incubate in a humid chamber for 30 minutes at room temperature.
-
-
Washing:
-
Gently rinse the slides with PBS.
-
Wash the slides for 5-10 minutes in a PBS bath.
-
-
Secondary Antibody Incubation:
-
Apply fluorescein-conjugated anti-human IgG to each well.
-
Incubate in a humid chamber for 30 minutes at room temperature in the dark.
-
-
Washing: Repeat the washing step as described in step 4.
-
Mounting:
-
Add a drop of mounting medium to each well.
-
Place a coverslip over the wells, avoiding air bubbles.
-
-
Microscopy:
-
Examine the slides using a fluorescence microscope.
-
-
Interpretation: A characteristic granular cytoplasmic fluorescence in the renal tubules and gastric parietal cells is indicative of a positive AMA result. The titer is reported as the highest dilution of serum that still produces a positive fluorescence pattern.
Immunoblotting (Western Blot) for AMA Subtypes
Immunoblotting is used to confirm the presence of this compound and to identify the specific mitochondrial antigens they recognize.
Principle: Mitochondrial proteins are separated by size using sodium dodecyl sulfate-polyacrylamide gel electrophoresis (SDS-PAGE) and then transferred to a nitrocellulose or PVDF membrane. The membrane is then incubated with the patient's serum. If this compound are present, they will bind to their specific target proteins on the membrane. The bound antibodies are detected using an enzyme-conjugated secondary antibody and a substrate that produces a colored precipitate or a chemiluminescent signal at the location of the target protein.
Methodology:
-
Antigen Preparation: Prepare a mitochondrial extract from a suitable source (e.g., bovine heart).
-
SDS-PAGE:
-
Separate the mitochondrial proteins on a polyacrylamide gel.
-
Include a molecular weight marker.
-
-
Electrotransfer: Transfer the separated proteins from the gel to a nitrocellulose or PVDF membrane.
-
Blocking:
-
Incubate the membrane in a blocking buffer (e.g., 5% non-fat milk in Tris-buffered saline with Tween 20 - TBST) for 1 hour at room temperature to prevent non-specific antibody binding.
-
-
Primary Antibody Incubation:
-
Incubate the membrane with diluted patient serum in blocking buffer overnight at 4°C with gentle agitation.
-
-
Washing:
-
Wash the membrane three times for 10 minutes each with TBST.
-
-
Secondary Antibody Incubation:
-
Incubate the membrane with an enzyme-conjugated anti-human IgG in blocking buffer for 1 hour at room temperature.
-
-
Washing: Repeat the washing step as described in step 6.
-
Detection:
-
Incubate the membrane with a chemiluminescent or chromogenic substrate according to the manufacturer's instructions.
-
-
Imaging:
-
Capture the image of the blot using an appropriate imaging system.
-
-
Interpretation: The presence of bands at specific molecular weights corresponding to known mitochondrial autoantigens (e.g., ~74 kDa for PDC-E2) confirms the presence and specificity of the this compound.
Conclusion
Antimitochondrial antibodies are critical biomarkers in the diagnosis and study of autoimmune diseases, particularly Primary Biliary Cholangitis. Understanding the nuances of their detection, their antigenic targets, and their role in the immunopathogenesis of disease is essential for researchers and clinicians working to develop more effective diagnostics and therapeutics. This guide has provided a comprehensive technical overview of the core aspects of AMA research, from fundamental data and pathogenic mechanisms to detailed experimental protocols. The continued investigation into the intricate biology of this compound holds significant promise for improving the management of patients with these complex autoimmune conditions.
References
- 1. ELISA Assay Technique | Thermo Fisher Scientific - US [thermofisher.com]
- 2. eaglebio.com [eaglebio.com]
- 3. Interplay of autophagy, apoptosis, and senescence in primary biliary cholangitis [explorationpub.com]
- 4. Role of cell apoptosis in the pathogenesis of primary biliary cholangitis [lcgdbzz.org]
- 5. my.clevelandclinic.org [my.clevelandclinic.org]
- 6. Microbial mimics are major targets of crossreactivity with human pyruvate dehydrogenase in primary biliary cirrhosis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. explorationpub.com [explorationpub.com]
- 8. Research progress on factors and mechanisms of apoptosis of bile duct epithelial cells in primary biliary cholangitis [syyxzz.com]
- 9. Molecular mimicry in primary biliary cirrhosis. Evidence for biliary epithelial expression of a molecule cross-reactive with pyruvate dehydrogenase complex-E2 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Molecular mimicry in primary biliary cirrhosis. Evidence for biliary epithelial expression of a molecule cross-reactive with pyruvate dehydrogenase complex-E2 - PMC [pmc.ncbi.nlm.nih.gov]
- 11. resources.amsbio.com [resources.amsbio.com]
- 12. Fine specificity of T cells reactive to human PDC-E2 163-176 peptide, the immunodominant autoantigen in primary biliary cirrhosis: implications for molecular mimicry and cross-recognition among mitochondrial autoantigens - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. General Immunoblotting Protocol | Rockland [rockland.com]
- 14. Quantitative and functional analysis of PDC-E2–specific autoreactive cytotoxic T lymphocytes in primary biliary cirrhosis - PMC [pmc.ncbi.nlm.nih.gov]
Foundational Principles of Bioinformatics in Apoptosis and MicroRNA Research: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Abstract
The intricate interplay between microRNAs (miRNAs) and the cellular machinery of apoptosis presents a fertile ground for therapeutic intervention, particularly in the realm of drug development. Bioinformatics provides the essential toolkit to navigate this complexity, enabling the identification of key molecular targets and the elucidation of complex regulatory networks. This technical guide delves into the foundational principles of bioinformatics tools and methodologies applied to the study of miRNA-regulated apoptosis. While a specific tool named "Apoptotic Micro-RNA-Activating-Sensor (AMAS)" as a singular, publicly available platform for this express purpose is not prominently documented, this paper outlines the core bioinformatics workflows and principles that would underpin such a system. We will explore the key experimental protocols, data analysis pipelines, and the visualization of signaling pathways that are fundamental to this area of research.
Core Concepts: The Intersection of Bioinformatics, miRNA, and Apoptosis
Apoptosis, or programmed cell death, is a tightly regulated process crucial for normal development and tissue homeostasis. Its dysregulation is a hallmark of many diseases, including cancer.[1] MicroRNAs, a class of small non-coding RNAs, have emerged as critical regulators of gene expression, capable of influencing a wide array of cellular processes, including apoptosis.[2][3] They typically function by binding to the 3' untranslated region (3' UTR) of target messenger RNAs (mRNAs), leading to their degradation or translational repression.[2]
Bioinformatics is the application of computational tools to extract meaningful biological information from large and complex datasets. In the context of miRNA and apoptosis, bioinformatics is indispensable for:
-
Identifying miRNA targets: Predicting which mRNAs are regulated by specific miRNAs.
-
Functional enrichment analysis: Understanding the biological pathways and processes affected by a set of miRNAs.
-
Network analysis: Visualizing and analyzing the complex interaction networks of miRNAs, their target genes, and signaling pathways.
-
Drug discovery: Identifying potential therapeutic targets and designing novel therapeutic strategies.[4]
Foundational Bioinformatic Workflows
A comprehensive analysis of miRNA involvement in apoptosis typically follows a multi-step bioinformatic workflow. This workflow integrates experimental data with computational predictions to build a robust understanding of the underlying biological mechanisms.
Caption: A generalized experimental and bioinformatic workflow.
Experimental Protocol: High-Throughput miRNA Expression Profiling
A common starting point is to identify miRNAs that are differentially expressed between two conditions (e.g., cancerous vs. normal tissue, drug-treated vs. untreated cells).
Methodology: miRNA Microarray
-
RNA Extraction: Isolate total RNA from the biological samples of interest.
-
RNA Quality Control: Assess RNA integrity and concentration using a bioanalyzer.
-
Labeling: Label the miRNA fraction of the total RNA with a fluorescent dye (e.g., Cy3 or Cy5).
-
Hybridization: Hybridize the labeled miRNA to a microarray chip containing probes for known miRNAs.
-
Scanning: Scan the microarray to detect the fluorescent signals.
-
Data Extraction: Quantify the signal intensity for each miRNA probe.
Data Analysis: From Raw Data to Biological Insight
1. Differential Expression Analysis:
-
Normalization: Raw microarray data is normalized to remove technical variations between samples.
-
Statistical Analysis: Statistical tests (e.g., t-test, ANOVA) are applied to identify miRNAs with statistically significant changes in expression levels.
2. miRNA Target Prediction:
The identification of miRNA targets is a cornerstone of understanding their function. Numerous bioinformatics tools exist for this purpose, each employing different algorithms.[5][6]
Table 1: Common miRNA Target Prediction Tools and their Principles
| Tool | Core Principle | Key Features |
| TargetScan | Seed region complementarity and conservation across species.[5] | Focuses on conserved 7-8 nucleotide seed matches. |
| miRanda | Sequence complementarity, binding energy of the miRNA-mRNA duplex, and conservation.[5] | Utilizes a weighted scoring system for matches and mismatches. |
| PicTar | Co-regulation of target sites by multiple miRNAs across different species.[5] | Aims to reduce false positives by requiring conserved binding sites for multiple miRNAs. |
| RNAhybrid | Calculates the minimum free energy of the miRNA-mRNA duplex.[5] | Focuses on the thermodynamic stability of the interaction. |
3. Pathway and Functional Enrichment Analysis:
Once a list of predicted target genes is obtained, pathway analysis tools are used to identify the biological pathways that are significantly enriched with these genes. This helps to infer the biological processes regulated by the differentially expressed miRNAs.
Table 2: Commonly Used Pathway Analysis Tools
| Tool | Database(s) Used | Primary Output |
| Gene Ontology (GO) | Gene Ontology database | Enriched GO terms (Biological Process, Molecular Function, Cellular Component). |
| KEGG PATHWAY | Kyoto Encyclopedia of Genes and Genomes[7] | Enriched KEGG pathways. |
| Reactome | Reactome database | Enriched reaction pathways. |
Visualizing Signaling Pathways: The Intrinsic Apoptosis Pathway
Understanding the role of miRNAs in apoptosis requires a clear visualization of the core signaling pathways. The intrinsic (or mitochondrial) pathway of apoptosis is a key process often modulated by miRNAs.
Caption: The intrinsic apoptosis signaling pathway.
miRNAs can influence this pathway at multiple points. For instance, an oncogenic miRNA might target the mRNA of the pro-apoptotic protein Bax, leading to its downregulation and thereby inhibiting apoptosis. Conversely, a tumor-suppressor miRNA might target the anti-apoptotic protein Bcl-2, promoting cell death.
Network Analysis: Unraveling Complex Interactions
Biological processes are rarely linear. Network analysis allows for the visualization and analysis of the complex web of interactions between miRNAs and their targets in the context of apoptosis.
Caption: A simplified miRNA-apoptosis regulatory network.
In this illustrative network, the oncomiR-21 is shown to inhibit the tumor suppressor PTEN and the executioner Caspase-3, thereby suppressing apoptosis. Conversely, the tumor suppressor let-7 inhibits the oncogene RAS and the anti-apoptotic protein Bcl-2, thus promoting apoptosis.
Conclusion and Future Directions
The integration of high-throughput experimental data with sophisticated bioinformatic analysis provides a powerful paradigm for dissecting the role of miRNAs in apoptosis. While a single, all-encompassing "this compound" tool for this purpose is not currently established, the principles and workflows outlined in this guide represent the foundational components of such a system. Future developments in this field will likely involve the integration of multi-omics data (genomics, proteomics, metabolomics) and the application of machine learning and artificial intelligence to build more predictive models of miRNA function in health and disease. These advancements will undoubtedly accelerate the discovery of novel miRNA-based therapeutics for a wide range of human pathologies.
References
- 1. Apoptosis: A Comprehensive Overview of Signaling Pathways, Morphological Changes, and Physiological Significance and Therapeutic Implications - PMC [pmc.ncbi.nlm.nih.gov]
- 2. mdpi.com [mdpi.com]
- 3. researchgate.net [researchgate.net]
- 4. Frontiers | The role and application of bioinformatics techniques and tools in drug discovery [frontiersin.org]
- 5. Bioinformatics approach: A powerful tool for microRNA research - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. KEGG PATHWAY Database [genome.jp]
AMAS: A Technical Guide for Phylogenetic Analysis
For Researchers, Scientists, and Drug Development Professionals
Abstract
In the era of large-scale genomic and proteomic data, the efficient and accurate handling of multiple sequence alignments is a critical bottleneck in phylogenetic analysis. AMAS (Alignment Manipulation And Summary) is a high-performance, versatile tool designed to streamline the pre-analysis phase of phylogenomics.[1][2][3][4][5][6] This technical guide provides an in-depth overview of this compound, its core functionalities, and detailed protocols for its application in phylogenetic workflows. We present its capabilities for alignment concatenation, format conversion, partitioning, and the generation of summary statistics, all of which are essential for robust phylogenetic inference.
Introduction to this compound
This compound is a bioinformatics utility that addresses the growing need for computationally efficient tools to manage the vast datasets used in modern phylogenetics.[1][2][5] It functions as both a standalone command-line tool and a Python package, offering flexibility for integration into complex bioinformatics pipelines.[1][2][3][4][5][7] Developed as a Python 3 program, this compound has the advantage of not requiring any external dependencies beyond Python's core modules.[1][2][6]
The software is designed to handle both amino acid and nucleotide alignments, providing a suite of functions for their manipulation and statistical summary.[1][2][5][6] Its primary functions include:
-
Format Conversion: Seamlessly convert between popular alignment formats such as FASTA, PHYLIP (sequential and interleaved), and NEXUS.[1]
-
Concatenation: Combine multiple individual alignments into a single supermatrix for concatenated phylogenetic analysis.[1][3]
-
Splitting and Partitioning: Divide a concatenated alignment based on a predefined partitioning scheme.[2][5]
-
Taxa Removal: Easily remove specific sequences (taxa) from an alignment.[2]
-
Replicate Dataset Generation: Create random subsets of alignments for downstream applications like phylogenetic jackknifing.[1][3][7]
-
Summary Statistics: Calculate a range of descriptive statistics for alignments, providing insights into data quality and composition.[1][2][6]
This compound is particularly well-suited for large phylogenomic datasets that may include hundreds or thousands of loci across numerous taxa.[1][2][6]
Core Functionalities and Logical Workflow
The functionalities of this compound are interconnected to support a standard phylogenomic workflow. The logical progression of data handling using this compound can be visualized as a series of steps from initial alignment files to a final matrix ready for phylogenetic analysis.
Experimental Protocols: this compound in Practice
This section details the methodologies for utilizing this compound for key tasks in a phylogenetic pipeline. The commands provided are for the command-line interface.
Protocol 1: Alignment Format Conversion
Objective: To standardize multiple input alignments into a single format (e.g., PHYLIP) for downstream analysis.
Methodology:
-
Organize Data: Place all input alignment files (e.g., in FASTA format with a .fas extension) into a single directory.
-
Execute this compound convert: Run the following command in the terminal from within the data directory.
-
Parameter Explanation:
-
-i *.fas: Specifies all files ending in .fas as input.
-
-f fasta: Declares the input format as FASTA.
-
-d dna: Specifies the data type as DNA (use aa for amino acids).
-
-o output_directory: Defines the directory where the converted files will be saved.
-
-u phylip: Sets the desired output format to PHYLIP.
-
-
Verification: Check the output_directory for the newly created .phy files.
Protocol 2: Concatenation and Partitioning
Objective: To combine multiple locus alignments into a single supermatrix and generate a corresponding partitions file for model-based phylogenetic analysis.
Methodology:
-
Prerequisites: Ensure all individual alignments are in the same format (e.g., PHYLIP). Use Protocol 1 if necessary.
-
Execute this compound concat: Run the following command:
-
Parameter Explanation:
-
-i *.phy: Specifies all PHYLIP files as input.
-
-f phylip: Declares the input format.
-
-d dna: Specifies the data type.
-
-p partitions.txt: Names the output partitions file. This file will contain the coordinates of each locus within the concatenated alignment.
-
-t supermatrix.phy: Names the output concatenated alignment file.
-
-u phylip: Sets the output format for the concatenated matrix.
-
-
Output: This process generates two key files: supermatrix.phy (the concatenated alignment) and partitions.txt, which is crucial for programs like RAxML or IQ-TREE that allow for partitioned models of evolution.
Protocol 3: Calculation of Summary Statistics
Objective: To assess the properties of an alignment, such as the number of variable sites, parsimony-informative sites, and missing data.
Methodology:
-
Input: A single alignment file (e.g., supermatrix.phy).
-
Execute this compound summary: Run the following command:
-
Parameter Explanation:
-
-i supermatrix.phy: Specifies the input alignment.
-
-f phylip: Declares the input format.
-
-d dna: Specifies the data type.
-
-s summary_stats.txt: Names the output summary statistics file.
-
-
Analysis of Output: The summary_stats.txt file will contain a table of statistics that can be used to evaluate the quality and characteristics of the alignment data.
The overall experimental workflow for preparing data for a partitioned phylogenetic analysis is depicted below.
Quantitative Data and Performance
This compound is engineered for high performance, particularly with the large datasets common in phylogenomics. Its efficiency in concatenation and summarizing alignments surpasses that of other commonly used tools.[3]
| Statistic | Description |
| Number of Taxa | The count of unique sequences in the alignment. |
| Alignment Length | The total number of sites (columns) in the alignment. |
| Total Matrix Cells | The product of the number of taxa and the alignment length. |
| Missing Data (%) | The percentage of the matrix composed of gaps or undetermined characters.[2][6] |
| Variable Sites | The number of columns containing at least two different character states.[2][6] |
| Parsimony-Informative Sites | The number of columns containing at least two character states, each present at least twice.[2][6] |
| AT/GC Content (%) | The percentage of Adenine/Thymine or Guanine/Cytosine bases (for DNA alignments).[2][6] |
| Table 1: Key Summary Statistics Calculated by this compound. The tool provides a rapid assessment of these crucial alignment properties.[2][6] |
Performance benchmarks from the original publication demonstrate this compound's speed. For instance, a dataset of 8,295 alignment files was converted between formats in 15-20 seconds.[3] Concatenation of a large dataset can be accomplished in seconds, with summary statistics generated shortly thereafter.[2][3] This efficiency is achieved through parallel processing capabilities.[1][2][6]
| Task | Other Tools (Time) | This compound (Time) |
| Concatenation (Large Dataset) | Minutes | Seconds |
| Summary Statistics (Large Dataset) | Minutes | Seconds |
| Table 2: Conceptual Performance Comparison. this compound generally exhibits significantly faster processing times for concatenation and summary tasks compared to other available command-line tools. |
Conclusion
This compound is an indispensable tool for researchers engaged in phylogenetic and phylogenomic analyses.[1] Its speed, flexibility, and comprehensive feature set for alignment manipulation and summarization address a critical need in the field.[5] By simplifying and accelerating the data preparation stages, this compound allows scientists to focus more on the core tasks of phylogenetic inference and hypothesis testing. Its availability as both a command-line tool and a Python package ensures its broad applicability and integration into diverse research workflows. The source code and manual are available at 81][2][6]
References
- 1. This compound: a fast tool for alignment manipulation and computing of summary statistics - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. researchgate.net [researchgate.net]
- 4. This compound: a fast tool for alignment manipulation and computing of summary statistics [PeerJ Preprints] [peerj.com]
- 5. This compound: a fast tool for alignment manipulation and computing of summary statistics [PeerJ] [peerj.com]
- 6. This compound: a fast tool for alignment manipulation and computing of summary statistics - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. peerj.com [peerj.com]
- 8. github.com [github.com]
AMAS tool for DNA and protein sequence alignment
An In-depth Technical Guide to AMAS Tools for DNA and Protein Sequence Analysis
For researchers, scientists, and professionals in drug development, the accurate analysis and manipulation of DNA and protein sequence alignments are fundamental to understanding biological systems and discovering novel therapeutics. The term "this compound" in this context can refer to two distinct but valuable tools that serve different purposes in sequence analysis. This guide provides a detailed technical overview of both: This compound (Alignment Manipulation And Summary) for efficient handling of large-scale alignment data, and This compound (Analyse Multiple Aligned Sequences) for in-depth physicochemical property analysis of protein alignments.
This compound: Alignment Manipulation and Summary
This compound is a computationally efficient, command-line and Python-based tool designed for the manipulation and summarization of multiple sequence alignments.[1][2][3][4] It is particularly well-suited for phylogenomic studies that involve hundreds or thousands of loci.[1][2][4] this compound operates on both nucleotide and amino acid alignments and is a standalone Python 3 program with no external dependencies, making it easily accessible.[1][2]
Core Functionalities
The core functionalities of this compound revolve around the efficient processing of large alignment files.[1] These capabilities are accessible through a command-line interface or as a Python package for greater flexibility.[1][3]
| Feature | Description | Supported Formats |
| Concatenation | Combines multiple sequence alignments into a single, larger alignment. A partition file is generated to keep track of the coordinates of each locus.[1][3] | FASTA, PHYLIP (sequential and interleaved), NEXUS (sequential and interleaved)[1] |
| Format Conversion | Converts alignment files between popular formats.[1][5] | FASTA, PHYLIP (sequential and interleaved), NEXUS (sequential and interleaved)[1] |
| Splitting | Divides a concatenated alignment into separate files based on a provided partition scheme.[1] | Any of the supported input formats. |
| Summary Statistics | Calculates a variety of descriptive statistics for one or more alignments.[1][3][4] | Any of the supported input formats. |
| Taxa Removal | Removes specified taxa (sequences) from an alignment.[1] | Any of the supported input formats. |
| Replicate Creation | Generates replicate datasets by randomly sampling from a set of input alignments, a process useful for phylogenetic jackknifing.[1][3] | Any of the supported input formats. |
| Translation | Translates a DNA alignment into an aligned protein sequence using specified genetic codes and reading frames.[5] | Any of the supported input formats. |
Quantitative Data Summary
This compound can compute a range of summary statistics for sequence alignments, providing valuable insights into the properties of the dataset.[1][3][4]
| Statistic | Description | Data Type |
| Number of Taxa | The total number of sequences in the alignment.[1][3] | DNA & Protein |
| Alignment Length | The total number of columns (sites) in the alignment.[1][3] | DNA & Protein |
| Total Matrix Cells | The total number of cells in the alignment matrix (taxa x length).[1][3] | DNA & Protein |
| Missing Data (%) | The percentage of undetermined characters and gaps.[3] | DNA & Protein |
| AT & GC Content (%) | The percentage of Adenine/Thymine and Guanine/Cytosine bases, respectively.[1][3] | DNA |
| Variable Sites | The number and proportion of sites that are not constant across all taxa.[1][3] | DNA & Protein |
| Parsimony Informative Sites | The number and proportion of sites where there are at least two different character states, each present in at least two taxa.[1][3] | DNA & Protein |
| Character Counts | The total counts of each character relevant to the nucleotide or amino acid alphabet.[1][3] | DNA & Protein |
Experimental Protocols / Usage Methodologies
The following protocols outline the command-line usage for key this compound functionalities.
Protocol 1: Concatenating Multiple Alignments
This protocol describes how to combine multiple individual gene alignments into a single concatenated alignment for subsequent phylogenetic analysis.
-
Prepare Input Files : Ensure all individual alignments are in the same format (e.g., FASTA).
-
Execute this compound concat : Run the following command in the terminal:
-
-i: Specifies the input files.
-
-f: Defines the format of the input files.
-
-d: Specifies the data type (dna or aa).
-
-t: (Optional) Specifies the output file name for the concatenated alignment.
-
-p: (Optional) Specifies the output file name for the partitions.
-
-
Review Output : this compound will generate concatenated_alignment.nex and a partitions.txt file that defines the boundaries of each original alignment within the concatenated file.
Protocol 2: Calculating Summary Statistics
-
Prepare Input Files : Place all alignment files for which you want to calculate statistics in a single directory.
-
Execute this compound summary : Run the following command:
-
*.fas: A wildcard to select all FASTA files in the current directory.
-
-
Review Output : this compound will output a summary table to the console or a specified output file, detailing the statistics for each input alignment. To get statistics on a per-taxon basis, add the -s or --by-taxon flag.[5]
Visualized Workflows
This compound: Analyse Multiple Aligned Sequences
This version of this compound is a tool designed for the systematic characterization of physicochemical properties at each position within a multiple protein sequence alignment.[6] It employs a flexible, set-based description of amino acid properties to define and analyze conservation patterns.[6] A key feature of this tool is its ability to compare subgroups of sequences within a larger alignment to identify positions that may confer unique functional characteristics to each subgroup.[6]
Core Concept
The fundamental principle of this this compound tool is to move beyond simple sequence identity and instead analyze the conservation of physicochemical properties. The workflow involves defining subsets of sequences based on criteria such as sequence similarity or known functional differences.[6] The tool then compares these subsets to pinpoint alignment positions where the amino acid properties are conserved within a group but differ between groups.
Methodology for Physicochemical Analysis
The following outlines the conceptual protocol for using this this compound tool for a comparative analysis of protein subgroups.
-
Input Alignment : Provide a multiple sequence alignment in a vertical format.[6]
-
Define Subgroups : Create a "sg" file that defines the subsets of sequences to be compared. This grouping can be based on a preliminary analysis, such as constructing a dendrogram to identify sequence clusters at a certain percentage identity, or based on known functional annotations.[6]
-
Select Property Table : Choose a property table that is relevant to the biological question being investigated. This table defines the sets of amino acid properties to be considered during the analysis.
-
Execute this compound : Run the this compound program with the alignment, subgroup definitions, and property table as input.
-
Analyze Output : The program generates a detailed text summary and can produce graphical output using the Alscript program for easier interpretation.[6] The output highlights positions with conserved properties within subgroups and significant property differences between subgroups.
Visualized Workflow
Conclusion
The two "this compound" tools, while sharing a name, offer distinct and complementary capabilities for researchers in molecular biology and drug development. This compound (Alignment Manipulation And Summary) provides an essential toolkit for the practical management of large-scale sequence data, streamlining the preparatory stages of phylogenetic and other comparative analyses. In contrast, This compound (Analyse Multiple Aligned Sequences) offers a more nuanced approach to alignment interpretation, enabling the discovery of functionally significant residues based on their physicochemical properties. A comprehensive understanding of both tools can significantly enhance the depth and efficiency of sequence-based research.
References
- 1. This compound: a fast tool for alignment manipulation and computing of summary statistics - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. peerj.com [peerj.com]
- 4. Dryad | Data: this compound: a fast tool for large alignment manipulation and computing of summary statistics [datadryad.org]
- 5. GitHub - marekborowiec/AMAS: Calculate summary statistics and manipulate multiple sequence alignments [github.com]
- 6. compbio.dundee.ac.uk [compbio.dundee.ac.uk]
Methodological & Application
Application Notes and Protocols: AMAS Test Kit
For Researchers, Scientists, and Drug Development Professionals
Introduction
The Anti-Malignin Antibody Serum (AMAS) test is a serum-based in vitro immunoassay designed for the early detection and monitoring of cancer.[1] This test measures the concentration of a specific antibody, the Anti-Malignin Antibody, which is produced by the body's immune system in response to the presence of malignin, a 10,000 Dalton polypeptide found in most malignant cells.[2] Unlike other cancer markers that are often antigens released by tumors in later stages, the this compound test detects an early-stage antibody response, making it a potential tool for early-stage cancer detection and recurrence monitoring.[1][3] The test is performed by Oncolab, Inc., a CLIA-certified laboratory.[3]
Principle of the this compound Test
The this compound test is a type of immunoassay.[1] The fundamental principle of an immunoassay is the specific binding of an antibody to its corresponding antigen. In the case of the this compound test, the analyte being measured is the Anti-Malignin Antibody (AMA) present in the patient's serum.
The general workflow of the this compound test, based on available information, involves an immunoadsorption step. The patient's serum is incubated with a "Target reagent," which consists of malignin antigen covalently bound to a solid support (bromoacetylcellulose). The Anti-Malignin Antibodies in the serum specifically bind to the malignin on this support. After a washing step to remove unbound components, the bound antibodies are eluted (released) using an acetic acid solution. The concentration of the eluted antibodies is then quantified to determine the this compound level.
This compound Test Kit Components and Sample Requirements
The this compound test requires a specific collection and shipping kit provided by Oncolab. It is crucial to use only the components provided in the kit to ensure the accuracy and validity of the test results.
| Component | Description |
| Collection Tube | Covidien Monoject 10mL tube (REF#8881302718). This is a non-silicone coated, no-additive tube. No substitutions are permitted.[4] |
| Transfer Pipette | Glass Pasteur pipette. Plastic pipettes should not be used as they can absorb the antibody.[4] |
| Cryotube | Greiner Bio-One cryotube. This is the only acceptable tube for serum submission to Oncolab.[4] |
| Shipping Container | Styrofoam packing box for temperature-controlled shipment. |
| Requisition Form | To be completed by the healthcare provider and patient. |
| Shipping Labels | UN3373 & UN1845 stickers for the outside of the shipping box.[4] |
Sample Requirements:
| Parameter | Requirement |
| Sample Type | Serum |
| Minimum Serum Volume | 2 mL[4] |
| Patient Preparation | No special preparation, such as fasting, is required.[4] |
| Blood Draw Timing | Blood must be drawn Monday through Thursday, as tests are processed Tuesday through Friday.[4] |
Experimental Protocols
I. Blood Collection
-
Use only the enclosed Covidien Monoject 10mL tube. Do not substitute with any other type of tube.[4]
-
This must be the first tube drawn to avoid the formation of an antibody-absorbing clot.[4]
-
Draw the blood directly into the Monoject tube. Do not use a butterfly tubing apparatus .[4]
II. Serum Processing
-
Clotting: Allow the blood to sit at room temperature for a minimum of 30 minutes and a maximum of 2 hours to allow a clot to form.[4]
-
Refrigeration: After clotting, place the blood tube in a refrigerator at 4°C (± 2°C) for a minimum of 1 hour and a maximum of 3 hours.[4]
-
Centrifugation:
-
Serum Transfer:
-
Using the provided glass Pasteur pipette , carefully transfer the serum (the clear liquid portion) to the provided screw-cap Greiner Bio-One cryotube.[4]
-
Ensure a minimum of 2 mL of serum is collected.[4]
-
Label the Greiner cryotube with the patient's name, date of birth, and the date/time of collection.[4]
-
Discard the original Monoject tube.[4]
-
III. Sample Shipping
-
Freezing: Immediately freeze the serum by placing the Greiner cryotube in dry ice (CO2) . Do not use a standard freezer.[4]
-
Packaging:
-
Place the frozen Greiner cryotube in the provided Styrofoam shipping container with a sufficient amount of dry ice (approximately 3 pounds). Do not use gel ice packs.[4]
-
Complete the enclosed requisition form and place it in the shipping container.
-
-
Shipping:
Data Presentation
The this compound test results are reported quantitatively. The interpretation of the results should be done by a qualified healthcare professional in the context of the patient's overall clinical picture.
| Result Category | Interpretation |
| Normal | Indicates a low level of Anti-Malignin Antibody. A normal this compound level can occur in individuals without cancer, in those with advanced or terminal cancer, and in successfully treated cancer patients with no evidence of disease.[2] |
| Borderline | Results that are not definitively normal or elevated. Repeat testing may be recommended. |
| Elevated | Indicates a high level of Anti-Malignin Antibody, which is associated with the presence of active, non-terminal cancer.[2] |
Visualizations
References
Application Notes and Protocols: Clinical Applications of the Anti-Malignin Antibody in Serum (AMAS) Test in Oncology
For Researchers, Scientists, and Drug Development Professionals
Introduction
The Anti-Malignin Antibody in Serum (AMAS) test is a laboratory assay intended for the early detection and monitoring of cancer. This test is based on the principle that the host's immune system produces specific antibodies against malignin, a 10 kDa polypeptide antigen reportedly present in a wide variety of malignant cells.[1][2] The this compound test quantifies the level of these anti-malignin antibodies, which are primarily of the IgM isotype, in a patient's serum.[2] Elevated levels of anti-malignin antibodies are suggested to be indicative of an active, non-terminal cancerous state.[3] Conversely, normal levels may be found in healthy individuals, those with terminal cancer, or patients who have been successfully treated.[4]
These application notes provide a summary of the clinical data, detailed experimental protocols for the this compound test, and a conceptual workflow of the underlying principles.
Data Presentation
The clinical utility of a diagnostic assay is determined by its sensitivity and specificity. The following tables summarize the reported quantitative data for the this compound test. It is important to note that reported values have varied across different studies.
| General Oncology | Sensitivity | Specificity | Reference |
| First Determination | 95% | 95% | [2][5] |
| Repeat Determinations | >99% | >99% | [2][5] |
| Sera shipped overnight | 93% | 95% | [6] |
| Breast Cancer | Sensitivity | Specificity | Notes | Reference |
| Women with suspicious mammograms/palpable masses | 97% | 64% | Compared to biopsy results. | [3] |
| Women undergoing core breast biopsy | 59% | 62% | By Oncolab criteria, pooling suspicious with malignant and borderline with positive. | [3] |
| Women undergoing core breast biopsy | 62% | 69% | Using receiver-operator curve analysis (Net-Tag > 135 µg/mL or S-Tag > 220 µg/mL). | [3] |
| Comparison with other tumor markers | 97% | - | This compound was more sensitive than CEA (0%), CA 15-3 (10%), CA 19-5 (5%), or CA 125 (16%) in the same patients. | [7] |
Data for other specific cancer types such as lung, colorectal, and prostate cancer are not consistently reported in the reviewed literature with the same level of detail as for breast cancer. The test is described as a general cancer marker, with elevated levels observed in various malignancies including lung, brain, melanomas, lymphomas, leukemias, and colorectal cancers.[6]
Experimental Protocols
Sample Collection and Preparation
This protocol is critical for the accuracy of the this compound test.
Materials:
-
Covidien Monoject 10mL tube (REF#8881302718; No Additive, Non-Silicone Coated)
-
Glass Pasteur pipette
-
Screw-cap Greiner Bio-One cryotube
-
Refrigerated centrifuge
-
Dry ice
Procedure:
-
Blood Collection: Draw blood into the specified Covidien Monoject 10mL tube. This must be the first tube drawn. Do not use a butterfly tubing apparatus. No fasting is required for the patient. Blood should be drawn Monday through Thursday.
-
Clotting: Allow the blood to sit at room temperature for a minimum of 30 minutes and a maximum of 2 hours to allow for clot formation.
-
Refrigeration: Place the tube in a refrigerator at 4°C (± 2°C) for a minimum of 1 hour and a maximum of 3 hours.
-
Centrifugation: Centrifuge the blood sample at 3000 RPM for 15 minutes at 4°C (± 2°C). If a refrigerated centrifuge is unavailable, chill the empty centrifuge cups in a refrigerator for 10 minutes prior to use.
-
Serum Transfer: Using a glass Pasteur pipette, carefully transfer the serum to a labeled screw-cap Greiner Bio-One cryotube. The minimum volume of serum required is 2mL.
-
Freezing and Shipping: Immediately freeze the serum by placing the cryotube in dry ice. Ship the frozen serum sample on 3 pounds of dry ice via an overnight courier to the testing laboratory (e.g., Oncolab). The test should ideally be performed within 24 hours of serum collection to minimize the risk of false-positive results that can occur with frozen stored serum.[2]
Anti-Malignin Antibody Immunoassay
This protocol describes the laboratory procedure for quantifying anti-malignin antibodies in the prepared serum sample.
Materials:
-
Patient serum sample (prepared as described above)
-
TARGET® reagent (malignin antigen covalently bound to bromoacetyl cellulose)
-
Ice-cold 0.15 mol/L NaCl (Saline)
-
0.25 mol/L Acetic acid
-
Spectrophotometer
-
Monoclonal anti-malignin antibody standard
-
Elevated and normal control sera
Procedure:
-
Reagent Preparation: Wash the TARGET® reagent.
-
Incubation with Serum: Add 0.2 mL of the patient's serum to 0.2 mL of the washed TARGET® reagent.
-
Binding: Perform replicate incubations at 4°C with constant shaking for 10 minutes and 120 minutes.
-
Washing: After each incubation period, precipitate the reagent by centrifugation and wash it three times with 0.2 mL of ice-cold 0.15 mol/L NaCl.
-
Elution: Elute the bound antibody by vortexing the reagent for 3 seconds with 0.4 mL of 0.25 mol/L acetic acid.
-
Quantification: Precipitate the reagent by centrifugation and measure the protein concentration of the supernatant at 280 nm using a spectrophotometer. A known quantity of monoclonal anti-malignin antibody is used as a standard.
-
Data Analysis:
-
The protein concentration after the 10-minute incubation is termed the "fast target absorbed globulin" (F-Tag).
-
The protein concentration after the 120-minute incubation is termed the "slow target absorbed globulin" (S-Tag).
-
The specific binding (Net-Tag) is calculated as: Net-Tag = S-Tag - F-Tag .
-
-
Quality Control: Duplicates of elevated and normal control sera are run with each batch of unknown sera.
Visualizations
This compound Test Experimental Workflow```dot
Caption: The principle of the this compound test, from in vivo immune response to in vitro detection.
Signaling Pathways
The specific signaling pathways directly involving the malignin protein are not well-documented in publicly available scientific literature. "Malignin" as a term is primarily associated with the this compound test and its developers. Therefore, a detailed molecular signaling pathway diagram cannot be accurately constructed at this time. The conceptual diagram above illustrates the proposed biological principle that underlies the this compound test. Further research is required to elucidate the precise biological function of malignin and its role, if any, in intracellular signaling cascades that contribute to the malignant phenotype.
Disclaimer
The this compound test is presented here based on available research and promotional materials. The clinical utility and performance of this test have been subject to varied findings in the scientific literature. Researchers and clinicians should critically evaluate all available evidence when considering the use of this assay. This document is intended for informational purposes for a scientific audience and does not constitute an endorsement or a recommendation for clinical use.
References
- 1. Targeting Signaling Pathway Networks in Several Malignant Tumors: Progresses and Challenges - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Discrimination of breast cancer by anti-malignin antibody serum test in women undergoing biopsy - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. aacrjournals.org [aacrjournals.org]
- 4. sa1s3.patientpop.com [sa1s3.patientpop.com]
- 5. Early detection and monitoring of cancer with the anti-malignin antibody test - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. coxnaturalhealth.com [coxnaturalhealth.com]
- 7. Anti-malignin antibody in serum and other tumor marker determinations in breast cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
Application Notes and Protocols for the AMAS Test in Monitoring Cancer Recurrence
For Researchers, Scientists, and Drug Development Professionals
Introduction
The Anti-Malignin Antibody in Serum (AMAS) test is a blood-based immunoassay intended for the early detection and monitoring of cancer. Unlike many cancer markers that measure tumor-associated antigens, the this compound test quantifies the level of a specific antibody, the anti-malignin antibody, which is produced by the patient's immune system in response to the presence of malignant cells.[1][2][3] Malignin is described as a 10,000 Dalton polypeptide found in a wide variety of cancer cells.[3][4] The rationale behind the test is that the production of anti-malignin antibodies is an early event in tumorigenesis, potentially allowing for the detection of cancer or its recurrence before it becomes clinically apparent through other diagnostic methods.[3][5] These application notes provide a comprehensive overview of the this compound test, its underlying principles, protocols for its use in a research and clinical setting, and a summary of its performance characteristics for monitoring cancer recurrence.
Principle of the this compound Test
The this compound test is based on the principles of a solid-phase immunoassay. The core of the test is the specific binding of anti-malignin antibodies present in a patient's serum to a proprietary "Target® reagent," which consists of malignin covalently bound to a solid support matrix, reportedly bromoacetylcellulose. The amount of bound antibody is then quantified, and the resulting value is used to determine the test result. A normal level of anti-malignin antibody can be found in healthy individuals, successfully treated cancer patients in remission, and in cases of terminal cancer where the immune system may no longer be mounting a significant response.[6] Conversely, an elevated level of the antibody is associated with the presence of an active, non-terminal malignancy.[4][6]
Application in Monitoring Cancer Recurrence
The primary application of the this compound test in the context of oncology is the monitoring of patients who have completed cancer treatment and are in remission. Periodic testing with this compound may help in the early detection of cancer recurrence. An increase in the this compound level from a normal or borderline value to an elevated level could indicate a relapse, prompting further clinical investigation to locate and confirm the recurrence.[5][6] One of the purported advantages of the this compound test is its potential to detect a wide variety of cancer types, as malignin is considered a general cancer-associated antigen.[3]
Data Presentation: Performance Characteristics of the this compound Test
The performance of the this compound test has been evaluated in several studies. The following tables summarize the reported quantitative data on the sensitivity and specificity of the test. It is important to note that the performance can vary depending on the study population and the criteria used for a positive test result.
| Study/Report | Cancer Type(s) | Sensitivity | Specificity | Notes |
| Abrams et al. (1994) | Various Cancers | 95% (on first determination), >99% (on repeat determinations) | 95% (on first determination), >99% (on repeat determinations) | Based on 3,315 double-blind tests.[4] |
| Oncolab | Various Cancers | >90% | >90% | General claim by the test provider.[5] |
| Harman et al. (2005) | Breast Cancer | 59% - 62% | 62% - 69% | Study on women undergoing core breast biopsy.[6][7] |
| Bogoch (General) | Various Cancers | 93% | 95% | Data from the test developer. |
Experimental Protocols
The following sections detail the protocols for sample handling and a generalized immunoassay procedure for the this compound test, based on publicly available information. Note: The specific, detailed protocol for the this compound test is proprietary to Oncolab (Boston, MA), the sole provider of the test. The immunoassay protocol described below is a generalized representation based on the principles of solid-phase immunoassays and published descriptions of the this compound test.
Sample Collection and Handling
Proper sample collection and handling are critical for the accuracy of the this compound test.
-
Blood Collection:
-
Draw blood into a BD#6440 vacutainer tube (or equivalent serum separator tube).[6]
-
It is recommended to be the first tube drawn to avoid contamination. Do not use a butterfly tubing apparatus.
-
-
Clotting:
-
Allow the blood to clot at room temperature for a minimum of 30 minutes and a maximum of 2 hours.[6]
-
-
Refrigeration:
-
After clotting, place the tube in a refrigerator at 4°C (± 2°C) for a minimum of 1 hour and a maximum of 3 hours.
-
-
Centrifugation:
-
Centrifuge the blood sample at approximately 1,500 x g for 10-15 minutes at 4°C.[6] If a refrigerated centrifuge is not available, pre-chill the centrifuge cups.
-
-
Serum Separation:
-
Using a glass Pasteur pipette (plastic may absorb the antibody), carefully transfer the serum to the provided screw-cap cryotube.
-
A minimum of 2 mL of serum is required.
-
-
Freezing and Shipping:
-
Immediately freeze the serum by placing the cryotube in dry ice. Do not use a standard freezer.
-
Ship the frozen serum sample on a sufficient amount of dry ice (approximately 3 pounds) in an insulated container for overnight delivery to the testing laboratory (Oncolab).[2][6]
-
The test should be performed within 24 hours of serum collection to minimize the risk of false-positive results that can occur with frozen stored serum.[8]
-
Generalized this compound Immunoassay Protocol
This protocol is a generalized representation of a solid-phase immunoadsorption assay.
-
Solid Phase Preparation:
-
The solid phase (e.g., bromoacetylcellulose) is covalently coated with the malignin antigen. This constitutes the "Target® reagent".
-
-
Washing:
-
The malignin-coated solid phase is washed with cold saline to remove any unbound antigen and prepare it for the assay.
-
-
Sample Incubation:
-
The patient's serum sample is added to the malignin-coated solid phase.
-
The mixture is incubated to allow for the specific binding of anti-malignin antibodies in the serum to the immobilized malignin antigen.
-
-
Washing to Remove Unbound Components:
-
After incubation, the solid phase is thoroughly washed with a suitable buffer (e.g., cold saline) to remove all unbound serum components, leaving only the anti-malignin antibodies specifically bound to the antigen-coated solid phase.
-
-
Elution of Bound Antibodies:
-
The bound anti-malignin antibodies are eluted from the solid phase by adding a low pH solution, such as acetic acid.[8] This disrupts the antigen-antibody binding.
-
-
Neutralization:
-
The eluted antibody solution is neutralized with a buffering solution to restore a physiological pH, which is important for the stability and accurate quantification of the antibodies.
-
-
Quantification:
-
The concentration of the eluted anti-malignin antibodies is quantified. The exact method of quantification (e.g., spectrophotometry, nephelometry) is proprietary. The result is typically reported in micrograms per milliliter (µg/mL).[6]
-
-
Data Interpretation:
-
The quantified antibody level is compared to established reference ranges to determine if the result is normal, borderline, or elevated.
-
Visualizations
Experimental Workflow for the this compound Test
References
- 1. academic.oup.com [academic.oup.com]
- 2. osti.gov [osti.gov]
- 3. coxnaturalhealth.com [coxnaturalhealth.com]
- 4. Early detection and monitoring of cancer with the anti-malignin antibody test - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. sa1s3.patientpop.com [sa1s3.patientpop.com]
- 6. aacrjournals.org [aacrjournals.org]
- 7. Discrimination of breast cancer by anti-malignin antibody serum test in women undergoing biopsy - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Immunoassay Methods - Assay Guidance Manual - NCBI Bookshelf [ncbi.nlm.nih.gov]
Application Notes and Protocols for the Detection of Antimitochondrial Antibodies
For Researchers, Scientists, and Drug Development Professionals
Introduction
Antimitochondrial antibodies (AMAs) are a group of autoantibodies directed against proteins located on the inner and outer mitochondrial membranes. The detection of these antibodies is a cornerstone in the diagnosis of Primary Biliary Cholangitis (PBC), an autoimmune liver disease characterized by the progressive destruction of small intrahepatic bile ducts.[1][2] The most clinically significant AMA is the M2 subtype, which targets the E2 subunit of the pyruvate (B1213749) dehydrogenase complex (PDC-E2) and is found in approximately 90-95% of patients with PBC.[3][4][5] Early and accurate detection of this compound is crucial for timely diagnosis and management of PBC.
This document provides detailed protocols for the three primary laboratory methods used for AMA detection: Indirect Immunofluorescence (IIF), Enzyme-Linked Immunosorbent Assay (ELISA), and Immunoblotting. It also includes a comparative analysis of their performance characteristics and a guide to the interpretation of results in the context of PBC diagnosis.
Data Presentation: Comparison of AMA Detection Methods
The choice of assay for AMA detection depends on a balance of sensitivity, specificity, and the clinical context. The following table summarizes the diagnostic performance of the most common methods for the detection of this compound and the specific M2 subtype.
| Method | Analyte Detected | Pooled Sensitivity (95% CI) | Pooled Specificity (95% CI) | Key Advantages | Key Limitations |
| Indirect Immunofluorescence (IIF) | Total AMA | 84% (77-90%)[1][6] | 98% (96-99%)[1][6] | - High specificity- Allows for pattern recognition (e.g., AMA pattern)[4][7] | - Subjective interpretation- Labor-intensive |
| ELISA | AMA-M2 | 89% (81-94%)[6][8] | 96% (93-98%)[6][8] | - High sensitivity- Quantitative results- High throughput and automatable[4] | - Can have lower specificity than IIF[4]- Potential for false positives[4] |
| Immunoblotting | Specific AMA Subtypes (M2, M4, M9, etc.) | Varies by antigen | High | - High specificity for individual antigens- Confirmatory test[9] | - Less sensitive for screening- More complex and costly |
Experimental Workflow for AMA Detection
The overall workflow for AMA testing involves several key stages, from sample collection to the final report. The following diagram illustrates a typical workflow in a clinical laboratory setting.
Caption: A flowchart illustrating the sequential steps involved in the laboratory detection of antimitochondrial antibodies.
Diagnostic Logic for Primary Biliary Cholangitis (PBC)
The diagnosis of PBC is based on a combination of clinical findings and laboratory results. The presence of this compound is a key diagnostic criterion. This diagram outlines the logical relationship between different test results and the diagnosis of PBC.
Caption: A decision tree for the diagnosis of Primary Biliary Cholangitis based on serological markers and liver chemistry.
Experimental Protocols
Indirect Immunofluorescence (IIF) for AMA Detection
Principle: Indirect immunofluorescence is a classic method for detecting this compound. Patient serum is incubated with a substrate containing mitochondria, typically rodent kidney, stomach, and liver tissue sections or HEp-2 cells.[10][11][12][13] If this compound are present in the serum, they will bind to the mitochondria in the substrate. This binding is then visualized by adding a secondary antibody conjugated to a fluorophore (e.g., FITC), which binds to the patient's antibodies.[11] The characteristic granular cytoplasmic fluorescence in the renal tubules or a cytoplasmic reticular pattern on HEp-2 cells is indicative of a positive result.[4][11]
Materials:
-
Microscope slides with rodent kidney/stomach/liver tissue sections or HEp-2 cells
-
Patient serum samples
-
Positive and negative control sera
-
Phosphate-buffered saline (PBS), pH 7.4
-
Fluorescein isothiocyanate (FITC)-conjugated anti-human IgG secondary antibody
-
Mounting medium with an anti-fading agent (e.g., glycerol-PBS)
-
Coplin jars or staining dishes
-
Moist chamber
-
Fluorescence microscope with appropriate filters for FITC
Procedure:
-
Sample Preparation: Dilute patient sera and controls with PBS. A common screening dilution is 1:40.
-
Incubation with Primary Antibody: Apply the diluted sera and controls to the wells of the substrate slides. Incubate in a moist chamber at room temperature for 30 minutes.[11]
-
Washing: Gently rinse the slides with PBS. Wash the slides by immersing them in a Coplin jar with PBS for 5-10 minutes. Repeat the wash step with fresh PBS.
-
Incubation with Secondary Antibody: Apply the FITC-conjugated anti-human IgG to each well, ensuring the tissue is completely covered. Incubate in a moist chamber at room temperature for 30 minutes, protected from light.[11]
-
Washing: Repeat the washing steps as described in step 3.
-
Mounting: Add a drop of mounting medium to each slide and cover with a coverslip, avoiding air bubbles.
-
Microscopy: Examine the slides using a fluorescence microscope. A positive result is indicated by a bright, apple-green fluorescence in a characteristic pattern. The intensity of the fluorescence is typically graded from 1+ to 4+. Samples that are positive at the screening dilution should be serially diluted and re-tested to determine the endpoint titer.
Enzyme-Linked Immunosorbent Assay (ELISA) for AMA-M2 Detection
Principle: ELISA is a highly sensitive and quantitative method for detecting specific AMA subtypes, most commonly AMA-M2.[14][15] Microtiter plates are coated with purified or recombinant M2 antigen.[1][15] When patient serum is added, any anti-M2 antibodies present will bind to the antigen. This is followed by the addition of an enzyme-conjugated secondary antibody that binds to the patient's antibodies. Finally, a substrate is added, which is converted by the enzyme into a colored product. The intensity of the color is proportional to the amount of anti-M2 antibody in the sample and is measured using a spectrophotometer.[14][15]
Materials:
-
Microtiter plate pre-coated with purified M2 antigen
-
Patient serum samples
-
Calibrators and positive/negative controls
-
Sample diluent buffer
-
Wash buffer concentrate
-
Enzyme-conjugated anti-human IgG (e.g., HRP-conjugated)
-
TMB (3,3’,5,5’-tetramethylbenzidine) substrate solution
-
Stop solution (e.g., 1M H₂SO₄)
-
Microplate reader
Procedure:
-
Reagent Preparation: Prepare all reagents according to the kit manufacturer's instructions. This typically involves diluting the wash buffer and preparing the calibrator curve.
-
Sample Dilution: Dilute patient sera, calibrators, and controls with the sample diluent buffer as specified in the kit protocol (e.g., 1:101).[15]
-
Incubation: Add the diluted samples, calibrators, and controls to the appropriate wells of the microtiter plate. Incubate for 30-60 minutes at room temperature or 37°C, as per the protocol.[14]
-
Washing: Aspirate the contents of the wells and wash the plate multiple times (typically 3-5 times) with the diluted wash buffer.[14]
-
Addition of Conjugate: Add the enzyme-conjugated secondary antibody to each well. Incubate for 30 minutes at room temperature or 37°C.[14]
-
Washing: Repeat the washing steps as described in step 4.
-
Substrate Incubation: Add the TMB substrate solution to each well. Incubate for 15-30 minutes at room temperature in the dark. A blue color will develop in the positive wells.[14]
-
Stopping the Reaction: Add the stop solution to each well. The color will change from blue to yellow.
-
Reading: Read the absorbance of each well at 450 nm using a microplate reader within 15-30 minutes of adding the stop solution.
-
Data Analysis: Calculate the concentration of AMA-M2 in the patient samples by comparing their absorbance values to the standard curve generated from the calibrators.
Immunoblotting for AMA Subtype Characterization
Principle: Immunoblotting, or Western blotting, is used to identify the specific mitochondrial antigens targeted by this compound.[16] In this technique, a mixture of mitochondrial proteins is separated by size using gel electrophoresis and then transferred to a membrane (e.g., nitrocellulose or PVDF).[17][18] The membrane is then incubated with patient serum. If this compound are present, they will bind to their specific antigen on the membrane. This binding is detected using an enzyme-conjugated secondary antibody and a substrate that produces a colored or chemiluminescent signal, resulting in a band at the molecular weight of the target antigen.[19]
Materials:
-
Mitochondrial protein extract (e.g., from bovine heart)
-
SDS-PAGE gels and electrophoresis apparatus
-
Nitrocellulose or PVDF membrane
-
Transfer buffer and electro-transfer apparatus
-
Blocking buffer (e.g., 5% non-fat milk in TBST)
-
Patient serum samples
-
Positive and negative control sera
-
Wash buffer (e.g., TBST)
-
Enzyme-conjugated anti-human IgG (e.g., HRP-conjugated)
-
Chemiluminescent or colorimetric substrate
-
Imaging system for detecting the signal
Procedure:
-
Gel Electrophoresis: Separate the mitochondrial protein extract by SDS-PAGE.
-
Protein Transfer: Transfer the separated proteins from the gel to a nitrocellulose or PVDF membrane using an electro-transfer system.
-
Blocking: Block the membrane with blocking buffer for 1 hour at room temperature to prevent non-specific antibody binding.
-
Incubation with Primary Antibody: Incubate the membrane with diluted patient serum (typically 1:100 to 1:1000 in blocking buffer) overnight at 4°C or for 1-2 hours at room temperature.
-
Washing: Wash the membrane several times with wash buffer to remove unbound primary antibodies.
-
Incubation with Secondary Antibody: Incubate the membrane with the enzyme-conjugated secondary antibody (diluted in blocking buffer) for 1 hour at room temperature.
-
Washing: Repeat the washing steps as described in step 5.
-
Detection: Add the substrate to the membrane and incubate until a signal develops.
-
Imaging: Capture the image of the blot using an appropriate imaging system. The presence of bands at specific molecular weights (e.g., ~74 kDa for PDC-E2) indicates the presence of antibodies to those mitochondrial antigens.[5]
Conclusion
The detection of antimitochondrial antibodies is a critical component in the diagnosis of Primary Biliary Cholangitis. Indirect immunofluorescence, ELISA, and immunoblotting are the three main methodologies employed, each with its own set of advantages and limitations. A thorough understanding of these laboratory procedures, their performance characteristics, and the interpretation of their results is essential for researchers, scientists, and drug development professionals working in the field of autoimmune liver diseases. The protocols and data presented in these application notes provide a comprehensive guide for the accurate and reliable detection of this compound.
References
- 1. AMA-M2 ELISA Kit (Anti-Mitochondrial Antibodies M2) [elisakits.co.uk]
- 2. pbc-society.ca [pbc-society.ca]
- 3. elkbiotech.com [elkbiotech.com]
- 4. Antimitochondrial Antibodies: from Bench to Bedside - PMC [pmc.ncbi.nlm.nih.gov]
- 5. biomol.com [biomol.com]
- 6. Hep-2 cell based indirect immunofluorescence assay for antinuclear antibodies as a potential diagnosis of drug-induced autoimmunity in nonclinical toxicity testing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. orgentec.com [orgentec.com]
- 8. drg-international.com [drg-international.com]
- 9. Performance of indirect immunofluorescence test and immunoblot tests in the evaluation of antinuclear and antimitochondrial antibodies - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Detection of Autoantibodies by Indirect Immunofluorescence Cytochemistry on Hep-2 Cells | Springer Nature Experiments [experiments.springernature.com]
- 11. fybreeds.com [fybreeds.com]
- 12. bio-rad.com [bio-rad.com]
- 13. bio-rad.com [bio-rad.com]
- 14. cusabio.com [cusabio.com]
- 15. ibl-international.com [ibl-international.com]
- 16. researchgate.net [researchgate.net]
- 17. nacalai.com [nacalai.com]
- 18. bu.edu [bu.edu]
- 19. Reference standards for the detection of anti-mitochondrial and anti-rods/rings autoantibodies - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes: Indirect Immunofluorescence Assay for Anti-Mitochondrial Antibody (AMA) Detection
Introduction
The indirect immunofluorescence (IFA) assay is a semi-quantitative, well-established method for the detection of anti-mitochondrial antibodies (AMA) in human serum.[1][2] AMAs are a serological hallmark of Primary Biliary Cholangitis (PBC), an autoimmune liver disease characterized by the progressive destruction of small intrahepatic bile ducts.[3][4] The detection of AMA is a critical component in the diagnosis of PBC, with this compound being present in 90-95% of patients.[3][5] This application note provides a detailed protocol for the detection of AMA using IFA, discusses the interpretation of results, and presents performance characteristics of the assay.
Principle of the Assay
The indirect immunofluorescence assay for AMA detection is a two-step process.[1] In the first step, patient serum, which may contain this compound, is incubated with a substrate that is rich in mitochondria. Commonly used substrates include rodent (rat or mouse) kidney, stomach, and liver tissue sections, or HEp-2 cells.[2][5][6] If this compound are present in the serum, they will bind to the mitochondrial antigens in the substrate. In the second step, after washing away unbound antibodies, a fluorescein (B123965) isothiocyanate (FITC)-conjugated anti-human immunoglobulin is added. This conjugate binds to the patient's antibodies that have attached to the mitochondrial antigens.[2] The resulting antigen-antibody complex is then visualized using a fluorescence microscope, where a characteristic apple-green fluorescence indicates a positive result.[1]
Clinical Significance
The presence of AMA is highly specific for PBC.[5] A positive AMA test, particularly at a titer of ≥1:40, in the context of cholestatic liver biochemistry, is one of the main diagnostic criteria for PBC, often obviating the need for a liver biopsy.[3][4][7][8] While highly specific, a negative AMA result does not entirely rule out PBC, as a small percentage of patients with PBC are AMA-negative.[8][9] In such cases, other specific antinuclear antibodies (ANAs), such as anti-Sp100 and anti-gp210, may be present.[3][7] Low titers of AMA can occasionally be found in other conditions, including other autoimmune diseases like Sjögren's syndrome, scleroderma, and rheumatoid arthritis, as well as in a small percentage of healthy individuals.[2][5]
Substrate and Staining Patterns
The choice of substrate can influence the appearance of the staining pattern.
-
Rodent Kidney/Stomach/Liver Tissue: This is the traditional and most common substrate.[6] A positive AMA result on rodent kidney tissue is characterized by a fine granular or coarse granular cytoplasmic fluorescence, which is most intense in the distal renal tubules due to their high mitochondrial content.[2][6] Gastric parietal cells in stomach tissue also show strong fluorescence.[6]
-
HEp-2 Cells: HEp-2 cells can also be used as a substrate for AMA detection.[5][6] A positive AMA result on HEp-2 cells presents as a fine granular cytoplasmic fluorescence.[5] The International Consensus on ANA Patterns (ICAP) designates the AMA pattern as Anti-Cellular pattern 21 (AC-21), described as a reticular/AMA cytoplasmic pattern.[3][10]
Data Presentation
The performance of the AMA IFA test is crucial for its diagnostic utility. The following table summarizes the quantitative data on the sensitivity and specificity of AMA detection for the diagnosis of PBC from various studies.
| Assay Method | Sensitivity | Specificity | Reference |
| Indirect Immunofluorescence (IFA) | 84.5% | 97.8% | [11] |
| All AMA detection methods (pooled) | 84% | 98% | [12][13] |
| AMA-M2 subtype specific assays | 89% | 96% | [12][13] |
| Western Immunoblot | 85% | Not specified | [14] |
| ELISA | 78-81% | Not specified | [14] |
Experimental Protocols
Materials and Reagents
-
IFA slides with appropriate substrate (e.g., rat kidney/stomach/liver sections or HEp-2 cells)
-
Patient serum samples
-
Phosphate-buffered saline (PBS), pH 7.2-7.4[15]
-
FITC-conjugated anti-human immunoglobulin (secondary antibody)[2]
-
Mounting medium with an anti-fading agent (e.g., ProLong Gold with DAPI)[16]
-
Coverslips
-
Humidified chamber
-
Fluorescence microscope with appropriate filters for FITC (excitation ~490 nm, emission ~520 nm)[2]
-
Pipettes and tips
-
Wash bottles or staining jars
Specimen Collection and Handling
-
Collect whole blood by venipuncture and separate serum by centrifugation.[2]
-
Avoid using hemolyzed, lipemic, or bacterially contaminated sera.[1]
-
Serum samples can be stored at 2-8°C for up to 48 hours. For longer storage, freeze at -20°C or lower.[1][2]
-
Avoid repeated freeze-thaw cycles.[1]
Assay Procedure
-
Slide Preparation: Allow substrate slides to equilibrate to room temperature before opening the protective packaging to prevent condensation.
-
Serum Dilution: Prepare a screening dilution of patient serum (typically 1:20 or 1:40) in PBS.[2][17] For semi-quantitative analysis, prepare serial dilutions (e.g., 1:80, 1:160, 1:320, etc.).[2]
-
Incubation with Primary Antibody: Apply the diluted patient serum, positive control, and negative control to the appropriate wells on the substrate slide.
-
Incubate the slides in a humidified chamber for 30-60 minutes at room temperature.[2][18]
-
Washing: Gently rinse the slides with PBS and then wash them twice for 5-10 minutes each in a staining jar with fresh PBS.[2][15]
-
Incubation with Secondary Antibody: Apply the FITC-conjugated anti-human immunoglobulin, diluted to its optimal working concentration in PBS, to each well.
-
Incubate the slides in a dark, humidified chamber for 30-60 minutes at room temperature.[2][18]
-
Final Washing: Repeat the washing step as described in step 5.
-
Mounting: Add a drop of mounting medium to each well and cover with a coverslip, avoiding air bubbles.
-
Microscopic Examination: Examine the slides using a fluorescence microscope. It is recommended to read the slides on the same day they are stained.[1]
Quality Control
-
Include a positive control, a negative control, and a buffer control in each assay run.[1]
-
Positive Control: Should exhibit the characteristic bright apple-green fluorescence of the expected AMA pattern with an intensity of 3+ to 4+.[2]
-
Negative Control: Should show no specific fluorescence or a fluorescence intensity of less than 1+.[2]
-
The results are considered valid only if the controls perform as expected.[1]
Interpretation of Results
-
Negative Result: No specific fluorescence or fluorescence intensity less than the negative control. A normal human serum reference interval is typically <1:40.[17]
-
Positive Result: A characteristic granular cytoplasmic fluorescence pattern with an intensity of 1+ or greater. The titer is reported as the reciprocal of the highest dilution of serum that shows a positive reaction.
-
Fluorescence Intensity Grading:
-
4+: Brilliant apple-green fluorescence
-
3+: Bright apple-green fluorescence
-
2+: Clearly discernible apple-green fluorescence
-
1+: Faint but definite apple-green fluorescence
-
Mandatory Visualizations
Experimental Workflow Diagram
Caption: Workflow for the Indirect Immunofluorescence Assay for AMA Detection.
Logical Relationship of AMA in PBC Diagnosis
Caption: Diagnostic algorithm for Primary Biliary Cholangitis (PBC).
References
- 1. zeusscientific.com [zeusscientific.com]
- 2. fybreeds.com [fybreeds.com]
- 3. mayocliniclabs.com [mayocliniclabs.com]
- 4. The risk of development of primary biliary cholangitis among incidental antimitochondrial M2 antibody-positive patients - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. Reference standards for the detection of anti-mitochondrial and anti-rods/rings autoantibodies - PMC [pmc.ncbi.nlm.nih.gov]
- 7. droracle.ai [droracle.ai]
- 8. Primary biliary cholangitis - Diagnosis and treatment - Mayo Clinic [mayoclinic.org]
- 9. Anti-mitochondrial Antibody (ama) - Ifa (qualitiative) Test - Price, Preparation, Range - Apollo 24|7 [apollo247.com]
- 10. Antinuclear antibody staining patterns by indirect immunofluorescence assay observed in patients from a tertiary health center in Latin America | Revista Colombiana de Reumatología [elsevier.es]
- 11. The accuracy of the anti-mitochondrial antibody and the M2 subtype test for diagnosis of primary biliary cirrhosis: a meta-analysis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Diagnostic value of anti-mitochondrial antibody in patients with primary biliary cholangitis: A systemic review and meta-analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
- 14. researchgate.net [researchgate.net]
- 15. wordpress.clarku.edu [wordpress.clarku.edu]
- 16. An introduction to Performing Immunofluorescence Staining - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Test ID: AMA - exserabiolabs CAP CLIA [exserabiolabs.org]
- 18. applications.emro.who.int [applications.emro.who.int]
Application Notes and Protocols for Quantification of Antimitochondrial Antibodies (AMA) using ELISA Methods
For Researchers, Scientists, and Drug Development Professionals
Introduction
Antimitochondrial antibodies (AMAs) are a group of autoantibodies directed against mitochondrial antigens, primarily the E2 subunit of the pyruvate (B1213749) dehydrogenase complex (PDC-E2), also known as the M2 antigen.[1] The presence and quantification of this compound, particularly the M2 subtype, are crucial serological hallmarks for the diagnosis of Primary Biliary Cholangitis (PBC), an autoimmune liver disease.[2][3] While immunofluorescence (IF) has been a traditional method for AMA detection, Enzyme-Linked Immunosorbent Assay (ELISA) offers a more sensitive, specific, and quantitative approach, making it well-suited for both clinical diagnostics and research settings.[4][5][6] This document provides detailed application notes and protocols for the quantification of this compound using various ELISA methods.
Principles of AMA ELISA
ELISA techniques for AMA quantification rely on the specific binding of this compound in a sample to mitochondrial antigens immobilized on a solid phase, typically a 96-well microplate. The bound this compound are then detected using an enzyme-conjugated secondary antibody that recognizes human immunoglobulins. The addition of a substrate results in a measurable color change, the intensity of which is proportional to the amount of AMA present in the sample.[1][7]
Several ELISA formats can be employed for AMA detection, each with its own advantages:
-
Indirect ELISA: A simple and common method for detecting specific antibodies.
-
Sandwich ELISA: Offers high specificity by using two antibodies to "sandwich" the antigen. While less common for autoantibody detection where the antibody is the analyte, a "double antigen sandwich" format can be used.
-
Competitive ELISA: A highly specific method often used for detecting small amounts of antigen or antibody.
Quantitative Data Presentation
The performance of various commercial ELISA kits for the detection of AMA and its subtypes, particularly M2, has been evaluated in numerous studies. The following tables summarize the key quantitative data, providing a comparative overview of their sensitivity and specificity.
Table 1: Performance Characteristics of AMA-M2 ELISA Kits
| Kit/Method | Sensitivity | Specificity | Detection Range | Reference |
| Human AMA-M2 ELISA Kit | 97.2% | 94.2% | 12.5 – 200.0 IU/ml | [2][3] |
| Meta-analysis of AMA-M2 ELISA | 89% (pooled) | 96% (pooled) | N/A | [8] |
| Meta-analysis of general AMA ELISA | 84% (pooled) | 98% (pooled) | N/A | [8] |
| Mouse AMA ELISA Kit | 1.0 ng/mL | High | N/A | [9] |
| Human AMA-M2 ELISA Kit (ELK Biotechnology) | 0.13 ng/mL | High | 0.32-20 ng/mL | [10] |
Table 2: Association of AMA Subtypes with Primary Biliary Cholangitis (PBC) Progression
| AMA Profile | Antibody Subtypes Detected | Associated PBC Stage |
| Profile A | Anti-M9 positive | Stages I/II or non-specific lesions |
| Profile B | Anti-M9 and/or Anti-M2 positive | Predominantly Stages I/II (90%) |
| Profile C/D | Anti-M2, Anti-M4, and/or Anti-M8 positive | Higher frequency of Stages III/IV (49-59%) |
Data adapted from a study on 550 PBC patients, highlighting the prognostic significance of AMA profiles.[11]
Experimental Protocols
The following are detailed protocols for the three main types of ELISA used for AMA quantification. These are generalized protocols and may require optimization based on the specific reagents and samples used.
Protocol 1: Indirect ELISA for AMA Quantification
This is the most common method for detecting and quantifying autoantibodies.
Materials:
-
96-well high-binding ELISA plates
-
Purified mitochondrial antigen (e.g., recombinant PDC-E2 for AMA-M2)
-
Coating Buffer (e.g., 0.05 M Carbonate-Bicarbonate, pH 9.6)[12]
-
Wash Buffer (e.g., PBS with 0.05% Tween-20)[12]
-
Blocking Buffer (e.g., 1% BSA in PBS)[13]
-
Patient serum or plasma samples
-
Positive and negative control sera
-
Enzyme-conjugated secondary antibody (e.g., HRP-conjugated anti-human IgG)
-
Substrate solution (e.g., TMB)[12]
-
Stop Solution (e.g., 2 M H₂SO₄)[12]
-
Microplate reader
Procedure:
-
Antigen Coating:
-
Washing:
-
Aspirate the coating solution from the wells.
-
Wash the wells three times with 200 µL of Wash Buffer per well.
-
-
Blocking:
-
Washing:
-
Aspirate the blocking solution and wash the wells three times with Wash Buffer.
-
-
Sample Incubation:
-
Dilute patient samples, positive controls, and negative controls in Blocking Buffer. A starting dilution of 1:100 is common.
-
Add 100 µL of the diluted samples and controls to the appropriate wells.
-
Cover the plate and incubate for 1-2 hours at 37°C.[14]
-
-
Washing:
-
Aspirate the samples and wash the wells five times with Wash Buffer.
-
-
Secondary Antibody Incubation:
-
Dilute the enzyme-conjugated secondary antibody in Blocking Buffer according to the manufacturer's instructions.
-
Add 100 µL of the diluted secondary antibody to each well.
-
Cover the plate and incubate for 1 hour at 37°C.[14]
-
-
Washing:
-
Aspirate the secondary antibody and wash the wells five times with Wash Buffer.
-
-
Substrate Development:
-
Stopping the Reaction:
-
Add 50 µL of Stop Solution to each well to stop the reaction.[14] This will change the color from blue to yellow.
-
-
Data Acquisition:
-
Read the absorbance of each well at 450 nm using a microplate reader.
-
-
Data Analysis:
-
Subtract the average absorbance of the blank wells from all other readings.
-
Generate a standard curve using a serial dilution of a known positive control or a quantitative standard.
-
Determine the concentration of AMA in the patient samples by interpolating their absorbance values from the standard curve.[15]
-
Protocol 2: Double Antigen Sandwich ELISA for AMA Quantification
This format can be used to detect all isotypes of antibodies that recognize the antigen.
Materials:
-
Same as Indirect ELISA, with the addition of enzyme-conjugated mitochondrial antigen.
Procedure:
-
Antigen Coating:
-
Follow steps 1 and 2 of the Indirect ELISA protocol to coat the plate with purified mitochondrial antigen.
-
-
Blocking:
-
Follow step 3 of the Indirect ELISA protocol.
-
-
Sample Incubation:
-
Dilute patient samples and controls in Blocking Buffer.
-
Add 100 µL of diluted samples to the wells and incubate for 2 hours at room temperature.
-
-
Washing:
-
Aspirate samples and wash the wells three times with Wash Buffer.
-
-
Conjugated Antigen Incubation:
-
Add 100 µL of enzyme-conjugated mitochondrial antigen, diluted in Blocking Buffer, to each well.
-
Incubate for 1-2 hours at room temperature.
-
-
Washing:
-
Aspirate the conjugated antigen and wash the wells five times with Wash Buffer.
-
-
Substrate Development and Data Acquisition:
-
Follow steps 9-12 of the Indirect ELISA protocol.
-
Protocol 3: Competitive ELISA for AMA Quantification
This method is highly specific and measures the concentration of AMA by detecting interference in an expected signal output. The signal is inversely proportional to the amount of AMA in the sample.[16]
Materials:
-
Same as Indirect ELISA.
Procedure:
-
Antigen Coating:
-
Follow steps 1 and 2 of the Indirect ELISA protocol to coat the plate with purified mitochondrial antigen.
-
-
Blocking:
-
Follow step 3 of the Indirect ELISA protocol.
-
-
Competitive Reaction:
-
In a separate plate or tubes, pre-incubate the diluted patient samples with a limited amount of enzyme-conjugated anti-human IgG antibody for 1-2 hours.
-
Alternatively, co-incubate the diluted patient sample and a fixed amount of enzyme-conjugated AMA of a known concentration in the antigen-coated wells.
-
Add 100 µL of this mixture to the corresponding wells of the antigen-coated plate.
-
Incubate for 1-2 hours at 37°C.
-
-
Washing:
-
Aspirate the mixture and wash the wells five times with Wash Buffer.
-
-
Substrate Development and Data Acquisition:
-
Follow steps 9-12 of the Indirect ELISA protocol. A lower signal indicates a higher concentration of AMA in the sample, as the sample AMA has competed with the enzyme-conjugated antibody for binding to the coated antigen.[17]
-
Visualizations
The following diagrams illustrate the principles and workflows of the described ELISA methods.
Caption: Workflow of the Indirect ELISA method for AMA detection.
Caption: Workflow of the Double Antigen Sandwich ELISA method.
Caption: Workflow of the Competitive ELISA method for AMA detection.
References
- 1. biomol.com [biomol.com]
- 2. researchgate.net [researchgate.net]
- 3. AMA-M2 ELISA Kit (Anti-Mitochondrial Antibodies M2) [elisakits.co.uk]
- 4. creative-diagnostics.com [creative-diagnostics.com]
- 5. researchgate.net [researchgate.net]
- 6. fortislife.com [fortislife.com]
- 7. ibl-international.com [ibl-international.com]
- 8. Diagnostic value of anti-mitochondrial antibody in patients with primary biliary cholangitis: A systemic review and meta-analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 9. resources.amsbio.com [resources.amsbio.com]
- 10. elkbiotech.com [elkbiotech.com]
- 11. [Prognostic significance of antimitochondrial antibody profiles A-D in primary biliary cirrhosis] - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. creative-diagnostics.com [creative-diagnostics.com]
- 13. Indirect ELISA Protocol [elisa-antibody.com]
- 14. Indirect ELISA Protocol | Leinco Technologies [leinco.com]
- 15. bio-rad-antibodies.com [bio-rad-antibodies.com]
- 16. mybiosource.com [mybiosource.com]
- 17. microbenotes.com [microbenotes.com]
Application of Anti-Mitochondrial Antibodies (AMAs) in the Diagnosis of Primary Biliary Cholangitis (PBC)
For Researchers, Scientists, and Drug Development Professionals
Introduction
Primary Biliary Cholangitis (PBC) is a chronic, autoimmune liver disease characterized by the progressive destruction of small intrahepatic bile ducts. This destruction leads to cholestasis, fibrosis, and potentially cirrhosis and liver failure. A hallmark of PBC is the presence of anti-mitochondrial antibodies (AMAs) in the serum of patients. This compound are a diverse group of autoantibodies that target components of the inner mitochondrial membrane. Their high specificity and sensitivity make them a cornerstone in the diagnosis of PBC.
These application notes provide a comprehensive overview of the role of this compound in PBC diagnosis, including detailed protocols for their detection and interpretation of results.
Diagnostic Significance of this compound
This compound are detected in approximately 90-95% of patients with PBC, making them a highly sensitive marker for the disease.[1][2][3] The primary target of this compound in PBC is the E2 subunit of the pyruvate (B1213749) dehydrogenase complex (PDC-E2), located on the inner mitochondrial membrane.[1][2][4] The presence of this compound, particularly the M2 subtype which is directed against PDC-E2, is highly specific for PBC.[4][5]
The diagnosis of PBC is typically based on the presence of at least two of the following three criteria:
-
Biochemical evidence of cholestasis, primarily elevated alkaline phosphatase (ALP).
-
Presence of this compound.
-
Histological features consistent with PBC, such as non-suppurative destructive cholangitis.[2][6]
Due to the high specificity of this compound, a liver biopsy is often not required for diagnosis if a patient presents with cholestatic liver enzymes and is positive for this compound.[1][7][8]
Data Presentation: Diagnostic Accuracy of this compound in PBC
The following table summarizes the diagnostic performance of various AMA and PBC-specific autoantibody tests.
| Test | Sensitivity (%) | Specificity (%) | Positive Likelihood Ratio (LR+) | Negative Likelihood Ratio (LR-) | Diagnostic Odds Ratio (DOR) | Reference |
| AMA (pooled) | 84 | 98 | 42.2 | 0.16 | 262 | [4][9][10] |
| AMA-M2 (pooled) | 89 | 96 | 20.3 | 0.12 | 169 | [4][9][10] |
| Anti-sp100 | 18.8 | >98.0 | - | - | - | [9] |
| Anti-gp210 | 16.7 | >98.0 | - | - | - | [9] |
Data presented as pooled estimates from meta-analyses where available.
Experimental Protocols
Indirect Immunofluorescence (IIF) for AMA Detection
Principle: Indirect immunofluorescence is a classic method for detecting this compound. Patient serum is incubated with a substrate containing mitochondria (e.g., rodent kidney or HEp-2 cells). If this compound are present, they will bind to the mitochondria. A secondary antibody conjugated to a fluorophore, which binds to human IgG, is then added. The presence of a characteristic fluorescent pattern when viewed under a fluorescence microscope indicates a positive result.
Protocol:
-
Slide Preparation: Use commercially available slides with rodent kidney, stomach, and liver tissue sections or HEp-2 cells. Allow slides to reach room temperature before use.
-
Serum Dilution: Prepare serial dilutions of patient serum (e.g., 1:40, 1:80, 1:160, etc.) in phosphate-buffered saline (PBS). A screening dilution of 1:40 is typically used.
-
Incubation with Primary Antibody: Apply the diluted patient serum to the wells of the substrate slide. Incubate in a humidified chamber for 30 minutes at room temperature.
-
Washing: Gently wash the slides with PBS to remove unbound antibodies. Perform three washes of 5 minutes each.
-
Incubation with Secondary Antibody: Apply a fluorescein (B123965) isothiocyanate (FITC)-conjugated anti-human IgG secondary antibody to each well. Incubate in a humidified, dark chamber for 30 minutes at room temperature.
-
Washing: Repeat the washing step as described in step 4.
-
Mounting: Add a drop of mounting medium to each well and cover with a coverslip.
-
Microscopy: Examine the slides using a fluorescence microscope. A positive result for this compound on rodent kidney tissue will show a characteristic granular cytoplasmic fluorescence in the renal tubules.[11] On HEp-2 cells, a cytoplasmic reticular/AMA pattern is observed. The titer is reported as the highest dilution showing a positive signal.
Enzyme-Linked Immunosorbent Assay (ELISA) for AMA-M2 Detection
Principle: ELISA is a quantitative method that detects specific AMA subtypes, most commonly AMA-M2. Microtiter plates are coated with purified or recombinant mitochondrial antigens (e.g., PDC-E2). Patient serum is added, and if this compound are present, they bind to the antigen. A secondary enzyme-conjugated antibody is then added, followed by a substrate that produces a colored product. The intensity of the color is proportional to the amount of AMA in the sample.
Protocol:
-
Plate Preparation: Use a pre-coated microtiter plate with purified PDC-E2 antigen.
-
Sample and Control Addition: Add 100 µL of diluted patient serum, positive controls, and negative controls to the appropriate wells. Incubate for 30-60 minutes at 37°C.
-
Washing: Wash the wells three to five times with a wash buffer to remove unbound components.
-
Enzyme Conjugate Addition: Add 100 µL of horseradish peroxidase (HRP)-conjugated anti-human IgG to each well. Incubate for 30 minutes at 37°C.
-
Washing: Repeat the washing step as described in step 3.
-
Substrate Addition: Add 100 µL of a chromogenic substrate (e.g., TMB) to each well. Incubate for 15-20 minutes at room temperature in the dark.
-
Stopping the Reaction: Add 50-100 µL of a stop solution (e.g., sulfuric acid) to each well. The color will change from blue to yellow.
-
Reading: Read the absorbance of each well at 450 nm using a microplate reader.
-
Data Analysis: Calculate the results based on the absorbance of the controls and a standard curve if performing a quantitative assay.
Visualizations
PBC Diagnostic Workflow
Caption: Diagnostic algorithm for Primary Biliary Cholangitis.
Key Signaling Pathways in PBC Pathogenesis
Caption: Simplified overview of key pathogenic pathways in PBC.
Logical Relationship of AMA Testing Methods
Caption: Relationship between different AMA detection methodologies.
References
- 1. Primary Biliary Cholangitis and Primary Sclerosing Cholangitis: Current Knowledge of Pathogenesis and Therapeutics [mdpi.com]
- 2. New insights into the pathogenesis of primary biliary cholangitis asymptomatic stage - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Primary biliary cholangitis: pathogenic mechanisms - PMC [pmc.ncbi.nlm.nih.gov]
- 4. elkbiotech.com [elkbiotech.com]
- 5. The role of mitochondria-related key genes in primary biliary cholangitis was analyzed based on transcriptome sequencing data - PMC [pmc.ncbi.nlm.nih.gov]
- 6. The role of mitochondria-related key genes in primary biliary cholangitis was analyzed based on transcriptome sequencing data - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. clyte.tech [clyte.tech]
- 8. Role of mitochondrial dynamics and autophagy in the pathogenesis of primary biliary cholangitis (PBC): Novel insights and therapeutic opportunities - IIS Biogipuzkoa [biodonostia.org]
- 9. Human anti-mitochondrial antibody M2 subtype (AMA-M2) Elisa Kit – AFG Scientific [afgsci.com]
- 10. fybreeds.com [fybreeds.com]
- 11. usbio.net [usbio.net]
Application Notes and Protocols for AMAS: A Bioinformatics Tool for Alignment Manipulation and Summary
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a detailed guide for the installation and utilization of the AMAS (Alignment Manipulation And Summary) bioinformatics tool on a Linux operating system. This compound is a powerful and efficient command-line utility designed for the manipulation and statistical analysis of multiple sequence alignments, making it a valuable asset for phylogenomics and comparative genomics studies.[1][2][3][4][5][6]
Introduction to this compound
This compound is a versatile tool that facilitates the handling of large-scale phylogenomic datasets.[1][2][3][4][5] It is a Python 3 program that operates without the need for additional dependencies beyond Python's core modules.[1][2][3] Key functionalities of this compound include:
-
Alignment Concatenation: Combining multiple sequence alignments into a single supermatrix.[2][4]
-
Format Conversion: Interconverting between common alignment formats such as FASTA, PHYLIP, and NEXUS.[2][3][7]
-
Summary Statistics: Calculating various alignment metrics, including alignment length, number of taxa, missing data, variable sites, and parsimony-informative sites.[1][2][7]
-
Alignment Manipulation: Splitting concatenated alignments based on partitions, removing specific taxa, and creating replicate datasets for jackknife analyses.[2][3]
Installation Protocols
There are three primary methods for installing this compound on a Linux system.
Installation via Bioconda
This is the recommended method for users who have the Conda package manager installed. It simplifies the installation process by automatically handling the environment and dependencies.
Experimental Protocol:
-
Prerequisite: Ensure you have a Conda-compatible package manager (like Miniconda or Anaconda) installed.
-
Set up Bioconda channels: If you haven't already, add the necessary channels to your Conda configuration.
-
Create a new environment (recommended): To avoid conflicts with other packages, it's best practice to create a dedicated environment for this compound.
or if you are using conda:
-
Activate the environment: Before using this compound, activate the newly created environment.
Installation via pip
For users familiar with Python's package installer, pip provides a straightforward installation method.
Experimental Protocol:
-
Prerequisite: Ensure you have Python 3 and pip installed on your system.
-
Install this compound: Open a terminal and execute the following command:
Manual Installation from GitHub
This method involves downloading the source code directly from the GitHub repository.
Experimental Protocol:
-
Prerequisite: Ensure you have Python 3 installed. You can check your version by running python3 --version. If not installed, you can typically install it using your distribution's package manager (e.g., sudo apt-get install python3 on Debian-based systems).[7]
-
Download the source code:
-
Option A: Using Git:
-
Option B: Downloading the ZIP archive: Navigate to the --INVALID-LINK-- and download the repository as a ZIP file.[7]
-
-
Navigate to the this compound directory:
-
Run this compound: You can now run this compound directly using the this compound.py script.
Core Functionalities and Protocols
This compound operates through a command-line interface with several subcommands to perform specific tasks.[7] The general usage is this compound [
Alignment Summary Statistics
A fundamental capability of this compound is to compute a range of summary statistics for one or more alignment files.[2][7]
Experimental Protocol:
-
Prepare your alignment files: Ensure your alignment files are in a supported format (FASTA, PHYLIP, or NEXUS).
-
Execute the summary command:
-
Output: By default, a file named summary.txt will be created in your current directory containing the summary statistics.[7]
Data Presentation: Summary Statistics Output
The output file will contain a table summarizing the following metrics for each input alignment:
| Statistic | Description |
| File | The name of the input alignment file. |
| No_Taxa | The number of sequences (taxa) in the alignment. |
| Aln_Len | The total length of the alignment. |
| Total_Cells | The total number of characters in the alignment matrix (No_Taxa * Aln_Len). |
| Undetermined_Chars | The total count of ambiguous or gap characters. |
| Percent_Missing | The percentage of undetermined characters in the alignment. |
| AT_Content | The proportion of Adenine and Thymine bases (for DNA alignments). |
| GC_Content | The proportion of Guanine and Cytosine bases (for DNA alignments). |
| Variable_Sites | The number of sites (columns) in the alignment that have at least two different character states. |
| Proportion_Variable | The proportion of variable sites relative to the total alignment length. |
| Parsimony_Informative_Sites | The number of sites where there are at least two character states, each present at least twice. |
| Proportion_Parsimony_Informative | The proportion of parsimony-informative sites relative to the total alignment length. |
Alignment Concatenation
This compound can efficiently concatenate multiple alignments into a single supermatrix, which is a common step in phylogenomic analyses.
Experimental Protocol:
-
Prepare your alignment files: Ensure all alignment files to be concatenated have identical sequence names for corresponding taxa.[8]
-
Execute the concat command:
-
-i: A list of the input alignment files to be concatenated.
-
-f: The format of the input files.
-
-d: The data type.
-
-t: The desired name for the output concatenated alignment file.
-
-p: The desired name for the output partitions file. This file will contain the coordinates of each gene in the concatenated alignment.
-
-
Output: Two files will be generated: the concatenated alignment and a partition file.
This compound Workflow for Alignment Concatenation
Caption: Workflow for concatenating multiple sequence alignments using this compound.
Format Conversion
This compound can convert alignments between FASTA, PHYLIP, and NEXUS formats.
Experimental Protocol:
-
Prepare your alignment file: Have your input alignment file ready.
-
Execute the convert command:
-
-i: The input alignment file.
-
-f: The format of the input file.
-
-d: The data type.
-
-u: The desired output format (fasta, phylip, nexus, phylip-int, nexus-int).[7]
-
-
Output: A new file with the converted alignment will be created with an appropriate extension (e.g., input_alignment.nex-out.fas).[7]
Logical Diagram of this compound Format Conversion
Caption: Logical flow of alignment format conversion with this compound.
Advanced Protocols
Splitting a Concatenated Alignment
If you have a concatenated alignment and a corresponding partition file, this compound can split the alignment back into individual gene alignments.
Experimental Protocol:
-
Prepare your files: You will need the concatenated alignment file and the partition file.
-
Execute the split command:
-
-i: The concatenated alignment file.
-
-f: The format of the concatenated alignment.
-
-d: The data type.
-
-l: The partition file.
-
-
Output: this compound will create a new directory containing the individual alignment files for each partition.
Creating Replicate Datasets for Jackknifing
This compound can generate replicate datasets by randomly sampling loci from a larger set of alignments, a technique often used in phylogenetic jackknifing to assess node support.[3]
Experimental Protocol:
-
Prepare your alignment files: You need a directory with all your single-locus alignments.
-
Execute the replicate command:
-
-i: A wildcard pattern to select all your single-locus alignments.
-
-f: The format of the input alignments.
-
-d: The data type.
-
-n: The number of replicate datasets to create.
-
-s: The number of loci to sample for each replicate.
-
-
Output: A new directory will be created containing the concatenated alignments for each replicate.
Experimental Workflow for Phylogenetic Jackknifing with this compound
Caption: Workflow for generating jackknife replicate datasets using this compound.
Troubleshooting and Best Practices
-
File Overwriting: Be cautious, as this compound may overwrite existing files without prompting.[7] It is good practice to run analyses in a dedicated directory or use descriptive output filenames.
-
Identical Taxon Names: For concatenation, ensure that the names for each sequence are identical across all input files.[8]
-
Aligned Data: this compound is designed to work with aligned sequences. Providing unaligned data may lead to nonsensical results.[7]
For further details and advanced options, refer to the official this compound documentation available on its --INVALID-LINK--.[7]
References
- 1. This compound: a fast tool for alignment manipulation and computing of summary statistics - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. This compound: a fast tool for alignment manipulation and computing of summary statistics - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. peerj.com [peerj.com]
- 6. This compound: a fast tool for alignment manipulation and computing of summary statistics [PeerJ Preprints] [peerj.com]
- 7. GitHub - marekborowiec/AMAS: Calculate summary statistics and manipulate multiple sequence alignments [github.com]
- 8. This compound to Concatenate Sequences [protocols.io]
Application Notes and Protocols for Concatenating Large Phylogenomic Datasets with AMAS
For Researchers, Scientists, and Drug Development Professionals
Introduction
In the era of high-throughput sequencing, phylogenomic analyses routinely involve hundreds or even thousands of genes across many taxa.[1][2][3][4] A common and powerful approach in phylogenomics is the concatenation of multiple sequence alignments into a single supermatrix, which can then be used to infer evolutionary relationships.[5] AMAS (Alignment, Manipulation, and Assessment of Sequences) is a computationally efficient, stand-alone command-line utility and Python package designed to handle the manipulation of large phylogenomic datasets.[1][2][3][4] Developed by Marek Borowiec, this compound is particularly well-suited for concatenating thousands of single-locus alignments into a supermatrix for subsequent phylogenetic analysis.[1][2][4][6] Its speed and versatility make it a valuable tool for researchers in evolutionary biology, genomics, and drug development who need to analyze large-scale sequence data.[1][4]
This compound offers several advantages for concatenating large phylogenomic datasets:
-
Speed and Efficiency: this compound is significantly faster at concatenation than other popular tools like FASconCAT-G and Phyutility.[1][7] It can handle thousands of loci for hundreds of taxa in seconds to minutes.[1][7]
-
Versatility: It supports various common alignment formats, including FASTA, PHYLIP (sequential and interleaved), and NEXUS (sequential and interleaved).[1][8][9]
-
Ease of Use: this compound is a command-line tool that can be easily integrated into bioinformatics pipelines.[1][8]
-
Partition Generation: Alongside the concatenated alignment, this compound automatically generates a partitions file, which is crucial for downstream partitioned phylogenetic analyses.[8][9][10]
-
Cross-Platform Compatibility: As a Python 3 program with no external dependencies, this compound is compatible with various operating systems.[1][2][4]
Experimental Protocols: Concatenating Alignments with this compound
This protocol outlines the steps for concatenating multiple sequence alignments using the this compound command-line tool.
Prerequisites:
-
Python 3 must be installed on your system.[10]
-
Download the this compound package from its GitHub repository: --INVALID-LINK--[1][2][4][8]
Step 1: Prepare Your Input Alignments
-
Ensure that each of your single-locus alignments is in a separate file.
-
The sequence identifiers (names of taxa) must be identical across all alignment files for the concatenation to work correctly.[10]
Step 2: Open the Command-Line Interface
Navigate to the directory containing your alignment files using the cd command in your terminal or command prompt.
Step 3: Execute the this compound Concatenation Command
The basic command for concatenating alignments with this compound is as follows:
Command Breakdown:
-
python3 /path/to/AMAS.py: This specifies the path to the this compound script.
-
concat: This is the this compound command for concatenation.[8]
-
-i file1.fas file2.fas ...: The -i flag indicates the input files.[8][10] You can list multiple files separated by spaces or use a wildcard (e.g., *.fas) to include all files with a specific extension in the current directory.[7]
-
-f fasta: The -f flag specifies the format of the input alignment files (e.g., fasta, phylip, nexus).[8][10]
-
-d dna: The -d flag specifies the data type, either dna for nucleotide sequences or aa for amino acid sequences.[7][8][10]
Step 4: Specify Output Files (Optional)
By default, this compound will generate two output files: concatenated.out (the concatenated alignment in FASTA format) and partitions.txt (the partition file).[8][10] You can specify custom names for these files using the -t and -p flags, respectively.[8]
Step 5: Review the Output
After the command has finished executing, you will find the concatenated alignment file and the partition file in your working directory. The partition file will contain the coordinates of each locus within the concatenated supermatrix, which is essential for partitioned phylogenetic analysis in programs like RAxML or IQ-TREE.[10]
Data Presentation: Performance Comparison
This compound demonstrates superior performance in concatenation speed compared to other commonly used tools. The following table summarizes the concatenation times for a dataset of 5,214 amino acid loci from Johnson et al. (2013), as reported in the original this compound publication.
| Tool | Concatenation Time (seconds) |
| This compound | < 2 |
| FASconCAT-G | > 36 |
| Phyutility | > 3 hours (for a larger dataset) |
Data sourced from Borowiec, M.L. (2016). This compound: a fast tool for alignment manipulation and computing of summary statistics. PeerJ 4:e1660.[1]
Workflow for Concatenating Phylogenomic Datasets using this compound
The following diagram illustrates the logical workflow for concatenating multiple sequence alignments into a supermatrix for phylogenetic analysis using this compound.
References
- 1. This compound: a fast tool for alignment manipulation and computing of summary statistics - PMC [pmc.ncbi.nlm.nih.gov]
- 2. This compound: a fast tool for alignment manipulation and computing of summary statistics - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. This compound: a fast tool for alignment manipulation and computing of summary statistics [PeerJ Preprints] [peerj.com]
- 4. This compound: a fast tool for alignment manipulation and computing of summary statistics [PeerJ] [peerj.com]
- 5. How to build phylogenetic species trees with OMA - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. peerj.com [peerj.com]
- 8. GitHub - marekborowiec/AMAS: Calculate summary statistics and manipulate multiple sequence alignments [github.com]
- 9. researchgate.net [researchgate.net]
- 10. This compound to Concatenate Sequences [protocols.io]
Application Notes and Protocols for AMAS: Command-Line Sequence Statistics
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a detailed guide to using the command-line tool AMAS (Alignment Manipulation And Summary) for calculating summary statistics from multiple sequence alignments. This compound is a computationally efficient tool ideal for handling the large datasets common in phylogenomics and other bioinformatics applications.[1][2] This protocol will focus on the summary functionality of this compound.
Introduction to this compound
This compound is a versatile, stand-alone command-line utility built with Python 3 for the manipulation and statistical analysis of nucleotide and amino acid sequence alignments.[1][2] It is designed to be fast and efficient, capable of parallel processing to handle large-scale phylogenomic datasets.[1][2] Key features of this compound include alignment concatenation, format conversion, splitting alignments, removing sequences, and generating summary statistics.[1][2][3] This document specifically details the protocol for obtaining summary statistics.
Experimental Protocol: Generating Alignment Summary Statistics
This protocol outlines the steps to calculate comprehensive statistics for one or more sequence alignments using the summary command in this compound.
Prerequisites:
-
Python 3 installed.[4]
-
This compound software downloaded from the official GitHub repository: --INVALID-LINK--.[1][2][3][5][6]
Methodology:
-
Prepare Your Alignments: Ensure your sequence alignments are in a supported format: FASTA, PHYLIP (sequential or interleaved), or NEXUS (sequential or interleaved).[1][2]
-
Open the Command-Line Interface: Navigate to the directory containing your alignment files using your system's terminal or command prompt.
-
Execute the this compound summary Command: The fundamental command structure for generating statistics is as follows:
-
-i or --in-files : Specify the input alignment file(s). You can list multiple files or use wildcards (e.g., *.fas for all FASTA files).[5][7]
-
-f or --in-format : Define the format of the input alignment(s). Supported formats include fasta, phylip, nexus, phylip-int, and nexus-int.[5]
-
-d or --data-type : Specify the type of sequence data, either dna for nucleotides or aa for amino acids.[5][7]
-
-
Optional Flags for Enhanced Analysis:
-
-o or --summary-out : To specify a custom name for the output summary file. By default, the output is saved to summary.txt.[5]
-
-c or --cores : To utilize multiple processor cores for parallel processing, which can significantly speed up the analysis of numerous files.[5]
-
-s or --by-taxon : To generate an additional output file for each input alignment containing statistics calculated on a per-sequence (taxon) basis.[5]
-
-e or --check-align : To perform a check that the input sequences are aligned. By default, this check is off for computational efficiency.[5]
-
Example Command:
To calculate summary statistics for all PHYLIP files in the current directory, which contain DNA sequences, and to utilize 8 processor cores, the command would be:
Data Presentation: Summary Statistics
This compound calculates a range of valuable statistics for sequence alignments.[1][3][7] These quantitative data points are summarized in the output file and are detailed in the table below.
| Statistic | Description | Data Type Applicability |
| Number of Taxa | The total number of sequences in the alignment. | DNA and Amino Acid |
| Alignment Length | The total number of columns (sites) in the alignment. | DNA and Amino Acid |
| Total Matrix Cells | The total number of cells in the alignment matrix (Number of Taxa × Alignment Length). | DNA and Amino Acid |
| Missing Data (%) | The percentage of undetermined characters and gaps in the alignment. For DNA, this includes 'X', 'N', 'O', '-', '?'. For amino acids, it includes 'X', '.', '*', '-', '?'.[7] | DNA and Amino Acid |
| GC Content (%) | The percentage of Guanine (G) and Cytosine (C) bases. | DNA only |
| AT Content (%) | The percentage of Adenine (A) and Thymine (T) bases. | DNA only |
| Variable Sites | The total number of sites in the alignment that are not constant. | DNA and Amino Acid |
| Proportion of Variable Sites | The number of variable sites divided by the alignment length. | DNA and Amino Acid |
| Parsimony Informative Sites | The number of sites where there are at least two different character states, each present in at least two sequences. | DNA and Amino Acid |
| Proportion of Parsimony Informative Sites | The number of parsimony-informative sites divided by the alignment length. | DNA and Amino Acid |
| Character Counts | The total count for each character present in the respective alphabet (e.g., counts of A, C, G, T for DNA). | DNA and Amino Acid |
Logical Workflow for this compound Summary Statistics
The following diagram illustrates the logical workflow for generating sequence statistics using the this compound summary command.
Caption: Workflow for generating summary statistics with this compound.
References
- 1. researchgate.net [researchgate.net]
- 2. This compound: a fast tool for alignment manipulation and computing of summary statistics - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. This compound to Concatenate Sequences [protocols.io]
- 5. GitHub - marekborowiec/AMAS: Calculate summary statistics and manipulate multiple sequence alignments [github.com]
- 6. bio.tools · Bioinformatics Tools and Services Discovery Portal [bio.tools]
- 7. peerj.com [peerj.com]
Application Notes and Protocols for the AMAS Python Package
Audience: Researchers, scientists, and drug development professionals.
Introduction:
AMAS (Alignment-based Motif Analysis Suite) is a powerful and efficient Python tool designed for the manipulation and statistical analysis of multiple sequence alignments.[1][2] It is particularly well-suited for large phylogenomic datasets, enabling rapid concatenation, format conversion, and summary statistics generation.[1][2][3] While this compound provides a convenient command-line interface, its full potential can be harnessed through its Python package implementation, allowing for seamless integration into complex bioinformatics pipelines.[4][5] These application notes provide detailed protocols for utilizing the this compound Python package for common alignment manipulation and analysis tasks.
Core Functionalities of the this compound Python Package
The central component of the this compound Python package is the MetaAlignment class, which serves as the primary object for handling alignment data.[4][6][7] By instantiating this class, users can programmatically access the functionalities of this compound. The key operations that can be performed using the this compound Python package include:
-
Alignment Concatenation: Combining multiple sequence alignments into a single, larger alignment.[6][8][9]
-
Format Conversion: Converting alignment files between various formats such as FASTA, PHYLIP, and NEXUS.[6]
-
Summary Statistics: Calculating a range of descriptive statistics for one or more alignments.[1][6][7]
-
Alignment Splitting: Dividing a concatenated alignment into its constituent partitions.[6]
-
Taxa Removal: Removing specific sequences (taxa) from an alignment.[5][10]
-
Replicate Dataset Generation: Creating random replicate datasets from a collection of alignments, often used for phylogenetic jackknifing.[1][4][9]
Data Presentation: Alignment Summary Statistics
A primary application of the this compound Python package is the generation of summary statistics for quality control and exploratory data analysis of multiple sequence alignments. The following table outlines the quantitative data that can be generated.
| Statistic | Description | Data Type |
| Number of Taxa | The total number of sequences in the alignment. | Integer |
| Alignment Length | The total number of columns (positions) in the alignment. | Integer |
| Total Matrix Cells | The product of the number of taxa and the alignment length. | Integer |
| Missing Data (%) | The percentage of undetermined characters (e.g., '?', 'N', '-') in the alignment. | Float |
| AT Content (%) | The percentage of Adenine and Thymine bases in a DNA alignment. | Float |
| GC Content (%) | The percentage of Guanine and Cytosine bases in a DNA alignment. | Float |
| Number of Variable Sites | The total number of alignment columns that contain at least two different character states. | Integer |
| Proportion of Variable Sites | The number of variable sites divided by the total alignment length. | Float |
| Parsimony Informative Sites | The number of alignment columns that have at least two character states, each appearing at least twice. | Integer |
| Proportion of Parsimony Informative Sites | The number of parsimony-informative sites divided by the total alignment length. | Float |
Experimental Protocols
The following protocols provide detailed methodologies for using the this compound Python package for key alignment manipulation tasks.
Protocol 1: Programmatic Concatenation of Multiple Alignments
This protocol details the steps to concatenate multiple sequence alignment files into a single file using the this compound Python package.
1. Installation:
Ensure that the this compound package is installed. If not, it can be installed using pip:
2. Python Script for Concatenation:
The following Python script demonstrates how to use the MetaAlignment class to concatenate a list of FASTA files.
Protocol 2: Generating and Exporting Alignment Summary Statistics
This protocol outlines the procedure for calculating and saving summary statistics for a set of alignment files.
1. Installation:
As with the previous protocol, ensure the this compound package is installed.
2. Python Script for Summary Statistics:
This script calculates summary statistics for multiple alignment files and saves the results to a CSV file.
Mandatory Visualization
The following diagrams illustrate common experimental workflows involving the this compound Python package.
References
- 1. Biopython - Pairwise Alignment - GeeksforGeeks [geeksforgeeks.org]
- 2. Ama Citation Generator - Chrome Web Store [chromewebstore.google.com]
- 3. paperpal.com [paperpal.com]
- 4. This compound: a fast tool for alignment manipulation and computing of summary statistics - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. GitHub - marekborowiec/AMAS: Calculate summary statistics and manipulate multiple sequence alignments [github.com]
- 7. This compound · PyPI [pypi.org]
- 8. This compound to Concatenate Sequences [protocols.io]
- 9. peerj.com [peerj.com]
- 10. m.youtube.com [m.youtube.com]
Troubleshooting & Optimization
common issues with AMAS cancer test accuracy
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals using the Anti-Malignin Antibody in Serum (AMAS) cancer test.
Frequently Asked Questions (FAQs)
Q1: What is the this compound test and what does it measure?
The this compound test is a blood test that measures the concentration of anti-malignin antibodies in the serum.[1][2] Malignin is a protein that is found on the surface of most malignant cells.[1][3] The presence of these antibodies may indicate the presence of cancer.[1][2] The test is designed to detect a general antibody response to cancer, not a specific type of cancer.[1][4]
Q2: What is the regulatory status of the this compound test?
The this compound test has been available for several decades and was reportedly FDA-approved for cancer screening in 1977.[5] However, it is not widely used or accepted by the mainstream medical community, and some sources refer to it as "investigational".[4] It is important to note that the sole laboratory performing the this compound test is Oncolab.[4][6]
Q3: What are the reported accuracy metrics for the this compound test?
The accuracy of the this compound test has been a subject of debate, with varying results across different studies. Some studies have reported high sensitivity and specificity, while others have found them to be insufficient for widespread screening.[5][6][7]
Quantitative Data Summary
| Study/Source | Sensitivity | Specificity | False Positive Rate | False Negative Rate | Sample Population |
| Bogoch et al. (Fresh Serum) | >99% | >99% | <1% | <1% | Not Specified |
| Bogoch et al. (Stored Sera) | 93% | 95% | 5% | 7% | 3,315 double-blind tests of patients and controls[1] |
| Harman et al. (2005) (Breast Cancer Biopsy Patients) | 59% - 62% | 62% - 69% | High | Insufficient to spare biopsy | 71 women undergoing core breast biopsy[6][7] |
| Thornthwaite (2000) (Breast Cancer) | Similar to Bogoch's findings | Similar to Bogoch's findings | Not Specified | Not Specified | Not Specified[5] |
| Abrams et al. (1994) (Clinical Practice) | Nearly 100% | Nearly 100% | Not Specified | Not Specified | Nearly 200 patients from 42 physicians[5] |
Troubleshooting Guide
Q4: I have an unexpectedly high number of positive results in my healthy control group. What could be the cause?
A high false-positive rate can be a significant issue. Here are some potential causes and troubleshooting steps:
-
Serum Storage: The handling of serum samples is critical. False positive rates are higher in sera that have been frozen for more than 24 hours.[1] For optimal results, the test should be performed within 24 hours of the blood draw.[8]
-
Presence of Other Cancers: A "false positive" result in a study focused on one type of cancer could be a true positive for an undetected cancer of a different type.[5]
-
Other Autoimmune Conditions: The presence of anti-malignin antibodies is not exclusive to cancer. They can also be found in individuals with other autoimmune conditions such as lupus, scleroderma, rheumatoid arthritis, and thyroiditis.[9][10]
Q5: My this compound test results are negative, but I have strong clinical indications of malignancy. Why might this be?
A false-negative result can occur under several circumstances:
-
Advanced or Terminal Cancer: The this compound test is less reliable in late-stage or terminal cancers.[1][8] The immune system's ability to produce antibodies may be diminished in these stages.[5][8]
-
Long-Term Tumors: The body's immune response, and thus the production of anti-malignin antibodies, may decrease if a significant cancerous mass has been present for three years or longer.[5][8]
-
Immunosuppression: A suppressed immune system, whether due to treatments like chemotherapy and radiation or other medical conditions, can lead to a reduced antibody response and a false-negative this compound result.[5]
Q6: I am observing high variability between replicate samples. What are the best practices for sample collection and handling?
To minimize variability and ensure accurate results, adhere to the following protocol:
-
Sample Collection: Blood should be drawn by venipuncture into vacutainer tubes.[6]
-
Clotting and Centrifugation: Allow the blood to clot at room temperature for 30 to 120 minutes before centrifuging at 1,500 x g for 10 minutes.[6]
-
Serum Separation and Storage: Transfer the serum to a sealed tube and freeze it immediately.[6]
-
Shipping: Samples should be shipped overnight on dry ice to the testing laboratory.[4][6]
Experimental Protocols
This compound Test Principle: The this compound test is an immunoassay that detects the presence of anti-malignin antibodies in a patient's serum. The general principle involves the specific binding of these antibodies to a malignin antigen.
General ELISA Protocol (Illustrative Example):
While the precise protocol for the this compound test is proprietary to Oncolab, a typical indirect ELISA (Enzyme-Linked Immunosorbent Assay) for antibody detection follows these steps:
-
Coating: A microtiter plate is coated with the target antigen (malignin).
-
Blocking: The remaining protein-binding sites on the plate are blocked to prevent non-specific binding.
-
Sample Incubation: The patient's serum is added to the wells. If anti-malignin antibodies are present, they will bind to the coated antigen.
-
Washing: The plate is washed to remove any unbound components of the serum.
-
Secondary Antibody Incubation: A secondary antibody, which is conjugated to an enzyme and specifically binds to human antibodies (in this case, IgM), is added.[3]
-
Washing: The plate is washed again to remove any unbound secondary antibody.
-
Substrate Addition: A substrate for the enzyme is added. The enzyme will convert the substrate into a detectable signal (e.g., a color change).
-
Detection: The signal is measured using a spectrophotometer. The intensity of the signal is proportional to the amount of anti-malignin antibody in the serum.
Visualizations
Caption: General workflow for the this compound test from sample collection to result interpretation.
Caption: Decision tree for troubleshooting unexpected this compound test results.
References
- 1. sa1s3.patientpop.com [sa1s3.patientpop.com]
- 2. patch.com [patch.com]
- 3. Anti-malignin antibody evaluation: a possible challenge for cancer management - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. resistanceisfruitful.com [resistanceisfruitful.com]
- 5. healthknot.com [healthknot.com]
- 6. aacrjournals.org [aacrjournals.org]
- 7. Discrimination of breast cancer by anti-malignin antibody serum test in women undergoing biopsy - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. wa-provider.kaiserpermanente.org [wa-provider.kaiserpermanente.org]
- 9. AMA Test: What Is it and How Does it Work? [webmd.com]
- 10. lupindiagnostics.com [lupindiagnostics.com]
Technical Support Center: Troubleshooting False Positives in the Ames Assay
This technical support center provides researchers, scientists, and drug development professionals with a comprehensive guide to troubleshooting false positive results in the Ames assay (Bacterial Reverse Mutation Test). The following information is presented in a question-and-answer format to directly address common issues encountered during experimentation.
Frequently Asked Questions (FAQs)
Q1: What is the Ames assay and how does it work?
The Ames test is a widely used and rapid bacterial assay to assess the mutagenic potential of chemical compounds.[1] The test utilizes several strains of Salmonella typhimurium and Escherichia coli that are auxotrophic for a specific amino acid (histidine for Salmonella and tryptophan for E. coli) due to mutations in the genes responsible for its synthesis.[1][2] These bacteria cannot grow on a medium deficient in that amino acid. A positive test, indicating the test substance is mutagenic, is observed when the chemical causes a reverse mutation (reversion) that restores the gene's function, allowing the bacteria to synthesize the required amino acid and form visible colonies.[2][3]
Q2: What constitutes a "false positive" result in the Ames assay?
Q3: How can cytotoxicity of the test compound lead to a false positive?
Cytotoxicity, or cell killing, can complicate the interpretation of Ames test results. At high, cytotoxic concentrations, a test article may cause a decrease in the number of revertant colonies due to the killing of the bacteria.[3][4] However, at moderately toxic doses, the antibacterial effect might lead to an apparent increase in revertants. This can occur if the slight toxicity inhibits the growth of the background lawn of non-reverted bacteria, making the spontaneously occurring revertant colonies more visible and easier to count. It is crucial to assess cytotoxicity concurrently with mutagenicity.[3]
Q4: My negative control plates show an unusually high number of spontaneous revertants. What could be the cause?
A high background of spontaneous revertants in your negative control plates can obscure a true mutagenic effect and lead to invalid results. Potential causes include:
-
Contamination of the bacterial stock: The master or working cultures of the bacterial strains may be contaminated with revertant colonies. It is essential to periodically check the genetic markers of the tester strains.
-
Contamination of reagents: Histidine or tryptophan contamination in any of the reagents, including the S9 mix or the test article itself, can support the growth of non-reverted bacteria, leading to an overgrown plate that can be misinterpreted.[3]
-
Improper storage of plates or reagents: Exposure of plates to light or improper storage temperatures can lead to the degradation of components in the media, potentially increasing the spontaneous mutation rate.
Q5: Can the S9 metabolic activation mix cause false positives?
Yes, the S9 mix, a supernatant fraction of rodent liver homogenate used to mimic mammalian metabolism, can sometimes contribute to false positive results.[5] Potential issues include:
-
Contamination: The S9 preparation itself could be contaminated with bacteria or substances that promote bacterial growth.
-
Inappropriate concentration: Using too high a concentration of S9 can sometimes lead to an increase in revertant colonies that is not related to the metabolic activation of the test compound. The concentration of S9 should be optimized for each test.
-
Endogenous mutagens: The S9 mix can contain low levels of endogenous mutagens from the animal source.
Data Presentation
Table 1: Typical Ranges of Spontaneous Revertant Colonies per Plate
This table provides the characteristic mean number of spontaneous revertants for commonly used tester strains in the vehicle controls. Significant deviations from these ranges may indicate a problem with the assay.
| Tester Strain | Typical Spontaneous Revertants (-S9) | Typical Spontaneous Revertants (+S9) |
| S. typhimurium TA98 | 10–50 | 10–50 |
| S. typhimurium TA100 | 80–240 | 80–240 |
| S. typhimurium TA1535 | 5–45 | 5–45 |
| S. typhimurium TA1537 | 3–21 | 3–21 |
| E. coli WP2 uvrA | 10–60 | 10–60 |
Data compiled from multiple sources.[6][7]
Table 2: Recommended S9 Concentrations and Positive Controls
This table outlines the recommended final concentration of the S9 fraction in the test medium and common positive control substances used to verify the activity of the S9 mix and the responsiveness of the bacterial strains.
| Metabolic Activation | S9 Final Concentration | Tester Strain | Positive Control Example |
| Without S9 (-S9) | N/A | TA98 | 2-Nitrofluorene |
| Without S9 (-S9) | N/A | TA100 | Sodium Azide |
| Without S9 (-S9) | N/A | TA1535 | Sodium Azide |
| Without S9 (-S9) | N/A | TA1537 | 9-Aminoacridine |
| Without S9 (-S9) | N/A | WP2 uvrA | 4-Nitroquinoline-N-oxide |
| With S9 (+S9) | 10% (v/v) | All Strains | 2-Aminoanthracene |
Information based on common laboratory practices and guidelines.[5][8]
Experimental Protocols
Protocol 1: Ames Test - Plate Incorporation Method
This method involves mixing the test substance, bacteria, and molten top agar (B569324) (with or without S9 mix) and pouring it onto a minimal glucose agar plate.
-
Prepare Bacterial Cultures: Inoculate a single colony of each tester strain into nutrient broth and incubate overnight at 37°C with shaking.[9]
-
Prepare Test Substance dilutions: Dissolve the test substance in a suitable solvent (e.g., DMSO, water) to create a range of concentrations.
-
Prepare Top Agar: Melt sterile top agar and maintain it at 45°C. For each plate, add a small amount of histidine/biotin solution (for Salmonella) or tryptophan solution (for E. coli).[10]
-
Plating: To a tube containing 2 mL of molten top agar, add 0.1 mL of the bacterial culture and 0.1 mL of the test substance dilution (or control). If metabolic activation is required, add 0.5 mL of S9 mix.
-
Mix and Pour: Vortex the tube briefly and immediately pour the contents onto a minimal glucose agar plate.[10] Gently tilt and rotate the plate to ensure even distribution.
-
Incubation: Allow the top agar to solidify, then incubate the plates in the dark at 37°C for 48-72 hours.
-
Colony Counting: Count the number of revertant colonies on each plate.
Protocol 2: Ames Test - Pre-incubation Method
This method involves a pre-incubation step of the test substance with the bacteria and S9 mix before plating, which can increase the sensitivity for certain mutagens.
-
Prepare Bacterial Cultures and Test Substance: Follow steps 1 and 2 of the Plate Incorporation Method.
-
Pre-incubation: In a sterile tube, mix 0.1 mL of the bacterial culture, 0.1 mL of the test substance dilution, and 0.5 mL of S9 mix (or buffer for -S9 conditions).
-
Incubate: Incubate the mixture at 37°C with gentle shaking for 20-30 minutes.[3]
-
Plating: After incubation, add 2 mL of molten top agar (containing histidine/biotin or tryptophan) to the pre-incubation mixture.
-
Mix and Pour: Vortex briefly and pour onto minimal glucose agar plates.
-
Incubation and Counting: Follow steps 6 and 7 of the Plate Incorporation Method.
Mandatory Visualizations
References
- 1. Ames test - Wikipedia [en.wikipedia.org]
- 2. microbiologyinfo.com [microbiologyinfo.com]
- 3. criver.com [criver.com]
- 4. xenometrix.ch [xenometrix.ch]
- 5. enamine.net [enamine.net]
- 6. Mutagenicity and genotoxicity of ClearTaste - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. downloads.regulations.gov [downloads.regulations.gov]
- 9. Microbial Mutagenicity Assay: Ames Test - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Ames Test Protocol | AAT Bioquest [aatbio.com]
Technical Support Center: Optimizing the Anti-Malignin Antibody in Serum (AMAS) Test
This technical support center provides researchers, scientists, and drug development professionals with comprehensive guidance on optimizing the sensitivity and specificity of the Anti-Malignin Antibody in Serum (AMAS) test. The following resources include troubleshooting guides, frequently asked questions (FAQs), detailed experimental protocols, and data summaries to ensure more accurate and reproducible results.
Frequently Asked Questions (FAQs)
Q1: What is the this compound test and what does it measure?
The this compound test is a blood serum assay that detects and quantifies the level of anti-malignin antibody.[1] Malignin is a 10,000 Dalton polypeptide antigen that is found in most malignant cells, regardless of their type or location.[1] The presence of elevated levels of anti-malignin antibodies (primarily IgM) in the serum is associated with the presence of active, non-terminal cancer.[1]
Q2: What are the reported sensitivity and specificity of the this compound test?
The reported sensitivity and specificity of the this compound test vary across different studies. Some studies have reported high sensitivity and specificity, exceeding 95% when performed on fresh serum within 24 hours of being drawn.[2] However, other independent studies, particularly in the context of breast cancer screening, have reported lower sensitivity (around 59-62%) and specificity (around 62-69%).
Q3: What are the key factors that can influence the sensitivity and specificity of the this compound test?
Several factors can significantly impact the accuracy of the this compound test:
-
Serum Sample Handling: The time between blood collection and testing is critical. For optimal results, the test should be performed on serum within 24 hours of the blood draw.[2]
-
Serum Storage: Using stored or frozen sera can increase the rates of false positives and false negatives.[2]
-
Stage of Cancer: The this compound test is generally less reliable in terminal or very advanced stages of cancer, as the antibody response may decline.
-
Non-Cancer Specificity: It is important to note that the this compound test is a general marker for malignancy and is not specific to any particular type of cancer.[2]
Q4: Can the this compound test be used for general cancer screening?
Due to the variability in reported accuracy and the incidence of false positives, the this compound test is not recommended for general population screening.[3] However, it may be a useful tool for monitoring patients with a history of cancer for recurrence or for individuals in high-risk populations.
Q5: What could cause a false positive or false negative result?
-
False Positives: Improper sample handling (e.g., delayed processing, improper storage) can lead to false positives.[2] Cross-reactivity with other antibodies in the serum could also theoretically contribute.
-
False Negatives: In terminal stages of cancer, the immune response may be weakened, leading to lower antibody levels and a false negative result. The test may also be less sensitive for very early or small tumors.
Data Presentation: this compound Test Performance
The following tables summarize the quantitative data on the sensitivity and specificity of the this compound test from various sources.
Table 1: Reported Sensitivity and Specificity of the this compound Test
| Study/Source | Population | Sensitivity | Specificity | Notes |
| Bogoch et al. (as cited in Turtle Healing Band Clinic) | General Malignancy (Fresh Serum) | >99% | >99% | Serum tested within 24 hours of blood draw.[2] |
| Bogoch et al. (as cited in Turtle Healing Band Clinic) | General Malignancy (Stored Sera) | 93% | 95% | Based on 3,315 double-blind tests.[2] |
| Harman et al. (2005) | Women Undergoing Breast Biopsy | 59% - 62% | 62% - 69% | Found insufficient for sparing biopsy and too high a false-positive rate for screening. |
| Abrams et al. (1994) | 181 Patients and Controls | Nearly 100% | Nearly 100% | Study in a clinical practice setting. |
Table 2: Impact of Serum Storage on this compound Test Performance
| Serum Condition | False Positive Rate | False Negative Rate |
| Determined within 24 hours | <1% | <1% |
| Stored/Frozen Sera | 5% | 7% |
Data in this table is based on reports from Bogoch et al.[2]
Experimental Protocols
While the precise, proprietary protocol for the Oncolab this compound test is not publicly available, the following is a detailed, representative methodology for a qualitative enzyme-linked immunosorbent assay (ELISA) designed to detect IgM antibodies against a specific antigen in human serum. This protocol can be adapted and optimized for your specific research needs.
Key Experiment: Indirect ELISA for Anti-Malignin IgM Detection
Objective: To detect the presence of anti-malignin IgM antibodies in human serum samples.
Materials:
-
High-binding 96-well microplates
-
Purified Malignin Antigen
-
Coating Buffer (e.g., Carbonate-Bicarbonate buffer, pH 9.6)
-
Wash Buffer (e.g., PBS with 0.05% Tween-20)
-
Blocking Buffer (e.g., 1% BSA in PBS)
-
Human serum samples (test samples, positive control, negative control)
-
Sample Diluent (e.g., Blocking Buffer)
-
HRP-conjugated anti-human IgM detection antibody
-
TMB (3,3’,5,5’-Tetramethylbenzidine) Substrate
-
Stop Solution (e.g., 2N H₂SO₄)
-
Microplate reader
Methodology:
-
Antigen Coating:
-
Dilute the purified malignin antigen to an optimal concentration (e.g., 1-10 µg/mL) in Coating Buffer.
-
Add 100 µL of the diluted antigen to each well of the 96-well microplate.
-
Incubate overnight at 4°C.
-
-
Washing:
-
Aspirate the coating solution from the wells.
-
Wash the plate 3 times with 200 µL of Wash Buffer per well.
-
-
Blocking:
-
Add 200 µL of Blocking Buffer to each well.
-
Incubate for 1-2 hours at room temperature.
-
-
Sample Incubation:
-
Wash the plate 3 times with Wash Buffer.
-
Dilute serum samples (e.g., 1:100) in Sample Diluent.
-
Add 100 µL of diluted serum samples, positive control, and negative control to the appropriate wells.
-
Incubate for 1-2 hours at room temperature.
-
-
Detection Antibody Incubation:
-
Wash the plate 5 times with Wash Buffer.
-
Dilute the HRP-conjugated anti-human IgM detection antibody to its optimal concentration in Sample Diluent.
-
Add 100 µL of the diluted detection antibody to each well.
-
Incubate for 1 hour at room temperature.
-
-
Substrate Development:
-
Wash the plate 5 times with Wash Buffer.
-
Add 100 µL of TMB Substrate to each well.
-
Incubate in the dark at room temperature for 15-30 minutes.
-
-
Reaction Stoppage and Reading:
-
Add 50 µL of Stop Solution to each well.
-
Read the absorbance at 450 nm using a microplate reader within 30 minutes.
-
Mandatory Visualizations
Caption: Indirect ELISA workflow for antibody detection.
Caption: Troubleshooting decision tree for common ELISA issues.
Troubleshooting Guide
This guide addresses common issues that may arise during an this compound-like immunoassay, impacting sensitivity and specificity.
| Issue | Potential Cause | Recommended Solution |
| High Background | Inadequate washing | Increase the number of wash cycles and ensure complete aspiration of wash buffer between steps. |
| Insufficient blocking | Optimize blocking buffer concentration and incubation time. Consider using a different blocking agent. | |
| High concentration of detection antibody | Perform a titration to determine the optimal antibody concentration. | |
| Reagent contamination | Use fresh, sterile buffers and reagents. | |
| Low or No Signal | Inactive reagents | Ensure proper storage of all reagents, especially enzymes and antibodies. Avoid repeated freeze-thaw cycles. |
| Incorrect antibody concentrations | Titrate both capture (if applicable) and detection antibodies to find the optimal concentrations. | |
| Improper sample handling/storage | Use fresh serum whenever possible. If stored, ensure proper freezing (-80°C) and minimize freeze-thaw cycles. | |
| Incorrect buffer pH | Verify the pH of all buffers. | |
| High Variability between Replicates | Inconsistent pipetting | Use calibrated pipettes and ensure consistent technique. Mix reagents thoroughly before use. |
| Uneven temperature during incubation | Ensure the entire plate is incubated at a stable and uniform temperature. Avoid stacking plates. | |
| Edge effects | Avoid using the outer wells of the microplate for critical samples or fill them with buffer to create a more uniform environment. | |
| Poor Sensitivity | Suboptimal sample dilution | Test a range of sample dilutions to find the one that gives the best signal-to-noise ratio. |
| Low antibody affinity | Use high-affinity monoclonal or polyclonal antibodies specific to the target antigen. | |
| Poor Specificity | Cross-reactivity of antibodies | Ensure the antibodies used are highly specific to the malignin antigen. |
| Non-specific binding | Optimize blocking and washing steps as described for high background. |
References
Technical Support Center: Troubleshooting the Anti-Malignin Antibody Serum (AMAS) Test
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in addressing inconsistencies encountered during Anti-Malignin Antibody Serum (AMAS) test experiments. The this compound test is a sensitive immunoassay designed to detect anti-malignin antibodies in serum, which may be elevated in the presence of malignant cells.[1][2][3][4] Consistent and reliable results are crucial for the accurate interpretation of its findings.
Frequently Asked Questions (FAQs)
Q1: What is the this compound test and what does it measure?
The this compound test is an immunoassay that measures the concentration of anti-malignin antibodies in human serum.[2][4] Malignin is a 10-kDa polypeptide antigen that has been found to be associated with a wide variety of malignant cells.[1][5][6] The test is based on the principle that the body's immune system may produce these antibodies in response to the presence of cancer cells.[3][4] It is intended as an aid in the early detection and monitoring of cancer, but it is not a standalone diagnostic tool and should be used in conjunction with other clinical information.[1][7][8]
Q2: My this compound test results are inconsistent between replicates. What are the common causes?
Inconsistencies between replicates in an immunoassay like the this compound test can stem from several factors, primarily related to procedural variations. Key areas to investigate include:
-
Pipetting Errors: Inaccurate or inconsistent pipetting of samples, standards, or reagents is a primary source of variability. Ensure pipettes are properly calibrated and that technique is consistent.
-
Improper Mixing: Inadequate mixing of reagents or samples before application to the assay plate can lead to uneven distribution.
-
Washing Steps: Insufficient or inconsistent washing between steps can result in high background or variable signal. Ensure all wells are washed thoroughly and uniformly.
-
Incubation Conditions: Variations in incubation time or temperature across the plate can affect the antibody-antigen binding kinetics.
Q3: I am observing a higher than expected rate of false positives. What could be the reason?
Several factors can contribute to an elevated false-positive rate in the this compound test:
-
Serum Storage: The handling and storage of serum samples are critical. False-positive rates are notably lower in serum analyzed within 24 hours of being drawn compared to sera that have been stored frozen.[1][5] For stored sera, false positive rates can be around 5%.[1][5]
-
Patient's Immune Status: Certain non-malignant conditions that involve immune system activation could theoretically lead to elevated antibody levels.
-
Presence of Other Cancers: A positive result may indicate the presence of a malignancy other than the one primarily being investigated.[9]
Q4: My this compound test results are showing false negatives. What are the potential causes?
False-negative results can occur under specific clinical conditions:
-
Advanced or Terminal Cancer: In late-stage or terminal cancer, or when a large tumor mass has been present for an extended period (e.g., three or more years), the patient's immune system may become anergic, leading to a decrease or absence of anti-malignin antibody production.[5][8][9]
-
Immunosuppression: Patients with compromised immune systems, for instance due to chemotherapy or other medical treatments, may have a diminished ability to mount an antibody response, resulting in a false negative.[9]
Q5: Can the this compound test be used to identify the location or type of cancer?
No, the this compound test is a general marker for malignancy and does not identify the specific type or location of the cancer.[2][3] A positive this compound test indicates an elevated level of anti-malignin antibodies, which has been associated with various types of cancer.[1] Further diagnostic procedures, such as imaging and biopsies, are necessary to determine the nature and location of any potential malignancy.[3]
Data Presentation: this compound Test Performance
The reported sensitivity and specificity of the this compound test can vary based on the study and the nature of the samples tested. Below is a summary of performance data from different sources.
| Performance Metric | Serum Processed within 24 hours | Stored/Frozen Serum | Breast Cancer Biopsy Cohort |
| Sensitivity | >99%[5] | 93%[9] | 59% - 62% |
| Specificity | >99%[5] | 95%[9] | 62% - 69% |
| False-Positive Rate | <1%[1][5] | 5%[1][5][9] | Not explicitly stated |
| False-Negative Rate | <1%[1][5] | 7%[1][5] | Not explicitly stated |
Experimental Protocols
Key Experiment: Anti-Malignin Antibody Serum (this compound) Test
This protocol is a generalized representation based on available descriptions of the this compound test and standard immunoassay procedures. The specific protocol from the commercial provider (Oncolab) should always be followed.
Principle: The this compound test is an Enzyme-Linked Immunosorbent Assay (ELISA) based on the specific binding of anti-malignin antibodies from a patient's serum to malignin antigen immobilized on a solid phase.
Methodology:
-
Sample Collection and Preparation:
-
Draw blood into a non-silicone coated tube with no additives. This should be the first tube drawn to avoid antibody absorption by the clot.[7]
-
Allow the blood to clot at room temperature for a minimum of 30 minutes and a maximum of 2 hours.[7]
-
Refrigerate the clotted blood at 4°C for a minimum of 1 hour and a maximum of 3 hours.[7]
-
Centrifuge the sample at 3000 RPM for 15 minutes at 4°C.[7]
-
Using a glass Pasteur pipette, transfer the serum to a provided cryotube. Do not use plastic pipettes as they can absorb antibodies.[7] A minimum of 2mL of serum is required.[7]
-
Immediately freeze the serum on dry ice.[7]
-
Ship the frozen serum sample overnight on dry ice to the testing laboratory.[7][10]
-
-
Immunoassay Procedure (Generalized ELISA):
-
Antigen Coating: Microtiter plate wells are coated with purified malignin antigen.
-
Blocking: The remaining protein-binding sites on the wells are blocked using a blocking buffer (e.g., 1% BSA in PBS) to prevent non-specific binding of antibodies.
-
Sample Incubation: The patient's serum is diluted and added to the wells. If anti-malignin antibodies are present, they will bind to the immobilized malignin antigen.
-
Washing: The wells are washed multiple times to remove unbound antibodies and other serum components.
-
Detection: A secondary antibody that recognizes human antibodies and is conjugated to an enzyme (e.g., horseradish peroxidase - HRP) is added to the wells. This secondary antibody binds to the anti-malignin antibodies captured on the plate.
-
Substrate Addition: A chromogenic substrate for the enzyme is added. The enzyme converts the substrate into a colored product.
-
Signal Quantification: The absorbance of the colored product is measured using a microplate reader. The intensity of the color is proportional to the amount of anti-malignin antibody in the sample.
-
Mandatory Visualizations
Signaling Pathway: Humoral Immune Response to Tumor Antigens
This diagram illustrates the general pathway of how a tumor antigen, such as malignin, can lead to the production of specific antibodies.
Caption: A diagram showing the generation of anti-malignin antibodies.
Experimental Workflow: this compound Test Procedure
This workflow outlines the critical steps from sample collection to final result, highlighting potential areas for inconsistencies.
Caption: Workflow of the this compound test from sample collection to result.
Logical Relationship: Troubleshooting Inconsistent this compound Results
This diagram provides a logical approach to troubleshooting common issues with the this compound test.
Caption: A logical guide for troubleshooting this compound test inconsistencies.
References
- 1. sa1s3.patientpop.com [sa1s3.patientpop.com]
- 2. Anti Malignan Antibody Test for Cancer | this compound Test [knowcancer.com]
- 3. Oncolab, Inc. Exhibits Pioneering this compound Cancer Test At AACC - BioSpace [biospace.com]
- 4. Oncolab Exhibits Pioneering this compound Cancer Test at AACC - aacc-2014 - Labmedica.com [labmedica.com]
- 5. wa-provider.kaiserpermanente.org [wa-provider.kaiserpermanente.org]
- 6. Early detection and monitoring of cancer with the anti-malignin antibody test - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. justinhealth.com [justinhealth.com]
- 8. coxnaturalhealth.com [coxnaturalhealth.com]
- 9. healthknot.com [healthknot.com]
- 10. captodayonline.com [captodayonline.com]
Technical Support Center: Antimitochondrial Antibody (AMA) Testing
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals working with antimitochondrial antibody (AMA) testing.
Frequently Asked Questions (FAQs)
Q1: What are antimitochondrial antibodies (AMAs) and what is their clinical significance?
Antimitochondrial antibodies (this compound) are autoantibodies that target mitochondrial antigens. They are a serological hallmark for the diagnosis of Primary Biliary Cholangitis (PBC), an autoimmune liver disease characterized by the progressive destruction of small intrahepatic bile ducts.[1][2] Over 90-95% of patients with PBC test positive for this compound, making it a highly specific marker for the disease.[1][3]
Q2: What are the different subtypes of this compound, and which is the most clinically relevant?
There are nine recognized subtypes of this compound (M1-M9). The AMA-M2 subtype is the most specific for PBC and targets the E2 component of the pyruvate (B1213749) dehydrogenase complex (PDC-E2) located on the inner mitochondrial membrane.[4][5] While other subtypes can be present in PBC and other conditions, testing for AMA-M2 is considered the most diagnostically significant.
Q3: Can a patient be AMA-negative and still have Primary Biliary Cholangitis (PBC)?
Yes, approximately 5-10% of patients with PBC are AMA-negative.[3] In these cases, diagnosis can be supported by the presence of other PBC-specific antinuclear antibodies (ANAs), such as anti-sp100 and anti-gp210, in conjunction with clinical symptoms and elevated liver enzymes, particularly alkaline phosphatase (ALP).[2][3] A liver biopsy may be required for a definitive diagnosis in AMA-negative cases.[3]
Q4: Can a positive AMA result be found in individuals without Primary Biliary Cholangitis (PBC)?
While highly specific for PBC, a positive AMA test can occasionally be found in patients with other autoimmune conditions such as autoimmune hepatitis, Sjögren's syndrome, systemic lupus erythematosus, and rheumatoid arthritis.[4] It can also be detected in a small percentage of apparently healthy individuals who may or may not develop PBC over time. Therefore, AMA results should always be interpreted in the context of clinical findings and other laboratory tests.
Troubleshooting Guides
This section provides troubleshooting for the most common AMA testing methodologies: Indirect Immunofluorescence (IIF), Enzyme-Linked Immunosorbent Assay (ELISA), and Immunoblotting.
Indirect Immunofluorescence (IIF) Troubleshooting
| Issue | Possible Cause(s) | Recommended Action(s) |
| Weak or No Signal | - Improper sample storage or handling.- Incorrect antibody dilution.- Insufficient incubation time.- Faded fluorescent conjugate. | - Ensure proper sample collection and storage.- Optimize primary and secondary antibody concentrations.- Follow recommended incubation times and temperatures.- Use a fresh vial of fluorescently labeled secondary antibody. |
| High Background Staining | - Inadequate washing.- Non-specific antibody binding.- High concentration of secondary antibody. | - Increase the number and duration of wash steps.- Use a blocking buffer (e.g., BSA or serum from the secondary antibody host species).- Titrate the secondary antibody to the optimal dilution. |
| Atypical Staining Pattern | - Presence of other autoantibodies.- Subjective interpretation. | - Test for other autoantibodies (e.g., ANAs).- Have the slide reviewed by a second experienced technician. |
ELISA Troubleshooting
| Issue | Possible Cause(s) | Recommended Action(s) |
| High Coefficient of Variation (CV%) between duplicate wells | - Pipetting errors.- Improper mixing of reagents.- Edge effect on the microplate. | - Ensure accurate and consistent pipetting technique.- Thoroughly mix all reagents before use.- Avoid placing critical samples on the outer wells of the plate. |
| False Positive Results | - Cross-reactivity with other antibodies.- Contamination of reagents or samples.- Insufficient washing. | - Consider the presence of other autoimmune diseases.- Use fresh, uncontaminated reagents and dedicated pipette tips.- Ensure thorough washing between steps to remove unbound antibodies. |
| False Negative Results | - Low antibody titer in the sample.- Inactive enzyme conjugate.- Incorrect substrate. | - Consider a more sensitive assay if clinical suspicion is high.- Check the expiration date and storage of the enzyme conjugate.- Ensure the correct substrate for the enzyme is used. |
Immunoblotting Troubleshooting
| Issue | Possible Cause(s) | Recommended Action(s) |
| No Bands Visible | - Inactive enzyme conjugate.- Incorrect transfer of proteins to the membrane. | - Verify the activity of the enzyme conjugate.- Confirm successful protein transfer by staining the membrane with Ponceau S. |
| Weak Bands | - Low concentration of target antigen.- Insufficient antibody concentration. | - Load a higher concentration of protein lysate.- Optimize primary and secondary antibody dilutions and incubation times. |
| Non-specific Bands | - Cross-reactivity of the primary or secondary antibody.- High antibody concentration. | - Use a more specific primary antibody.- Increase the stringency of the wash buffer and optimize antibody concentrations. |
Data Presentation
Table 1: Comparison of Diagnostic Accuracy of AMA Testing Methods for Primary Biliary Cholangitis
| Assay Type | Sensitivity | Specificity | Advantages | Disadvantages |
| Indirect Immunofluorescence (IIF) | 83.3% - 90%[6] | 98%[7] | - Gold standard for screening.- Provides information on antibody titer and staining pattern. | - Subjective interpretation.- Labor-intensive. |
| ELISA | 84% - 97%[4] | 96% - 99.5%[8] | - Quantitative results.- High throughput.- Less subjective than IIF. | - Can have lower specificity than IIF.- May miss certain AMA subtypes. |
| Immunoblotting | 91%[9] | Highly Specific[9] | - Confirmatory test.- Identifies specific AMA subtypes (e.g., M2). | - Less sensitive for screening.- More complex and expensive. |
Experimental Protocols
Indirect Immunofluorescence (IIF) for AMA
-
Slide Preparation: Use commercially available slides coated with appropriate substrates (e.g., rodent kidney, stomach, and liver tissue sections or HEp-2 cells).
-
Sample Dilution: Prepare serial dilutions of patient serum (e.g., 1:40, 1:80, 1:160) in phosphate-buffered saline (PBS).
-
Incubation: Apply the diluted serum to the wells of the slide and incubate in a humid chamber at room temperature for 30 minutes.
-
Washing: Gently wash the slides with PBS to remove unbound antibodies.
-
Secondary Antibody Incubation: Apply a fluorescently labeled anti-human IgG secondary antibody to each well and incubate in the dark for 30 minutes.
-
Final Wash: Wash the slides again with PBS to remove excess secondary antibody.
-
Mounting: Add a drop of mounting medium and a coverslip.
-
Microscopy: Examine the slides using a fluorescence microscope. A positive result is indicated by a characteristic granular cytoplasmic staining pattern in the appropriate tissues.[10]
Enzyme-Linked Immunosorbent Assay (ELISA) for AMA-M2
-
Coating: Coat the wells of a microtiter plate with purified or recombinant AMA-M2 antigen.
-
Blocking: Block the remaining protein-binding sites in the wells with a blocking buffer (e.g., 1% BSA in PBS).
-
Sample Addition: Add diluted patient serum to the wells and incubate for 1-2 hours at room temperature.
-
Washing: Wash the wells several times with a wash buffer (e.g., PBS with 0.05% Tween 20) to remove unbound antibodies.
-
Enzyme-Conjugate Addition: Add an enzyme-conjugated anti-human IgG secondary antibody and incubate for 1 hour.
-
Final Wash: Repeat the washing step.
-
Substrate Addition: Add the appropriate substrate for the enzyme (e.g., TMB for HRP).
-
Color Development: Allow the color to develop in the dark.
-
Stopping the Reaction: Stop the reaction with a stop solution (e.g., sulfuric acid).
-
Reading: Read the absorbance at the appropriate wavelength using a microplate reader.
Immunoblotting for AMA
-
Protein Separation: Separate mitochondrial protein extracts by SDS-PAGE.
-
Transfer: Transfer the separated proteins to a nitrocellulose or PVDF membrane.
-
Blocking: Block the membrane with a blocking buffer (e.g., 5% non-fat milk in TBST) for 1 hour.
-
Primary Antibody Incubation: Incubate the membrane with diluted patient serum overnight at 4°C.
-
Washing: Wash the membrane with TBST.
-
Secondary Antibody Incubation: Incubate the membrane with an enzyme-conjugated anti-human IgG secondary antibody for 1 hour at room temperature.
-
Final Wash: Repeat the washing step.
-
Detection: Add a chemiluminescent substrate and visualize the bands using an imaging system. The presence of a band at the correct molecular weight for the AMA-M2 antigen (approximately 74 kDa) indicates a positive result.[11]
Visualizations
Caption: General workflow for AMA testing.
Caption: Diagnostic algorithm for Primary Biliary Cholangitis.
Caption: Troubleshooting logic for unexpected AMA test results.
References
- 1. m3.healio.com [m3.healio.com]
- 2. Guidelines on the Diagnosis and Management of Primary Biliary Cholangitis (2021) - PMC [pmc.ncbi.nlm.nih.gov]
- 3. droracle.ai [droracle.ai]
- 4. Antimitochondrial Antibodies: from Bench to Bedside - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. Performance of indirect immunofluorescence test and immunoblot tests in the evaluation of antinuclear and antimitochondrial antibodies - PMC [pmc.ncbi.nlm.nih.gov]
- 7. emedicine.medscape.com [emedicine.medscape.com]
- 8. scispace.com [scispace.com]
- 9. Immunoblotting as a confirmatory test for antimitochondrial antibodies in primary biliary cirrhosis - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. Heterogeneity of antimitochondrial antibodies with the M2-M4 pattern by immunofluorescence as assessed by Western immunoblotting and enzyme linked immunosorbent assay - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Interpreting Borderline Anti-Mitochondrial Antibody (AMA) Test Results
This guide provides troubleshooting and frequently asked questions for researchers, scientists, and drug development professionals regarding the interpretation of borderline anti-mitochondrial antibody (AMA) test results.
Frequently Asked Questions (FAQs)
Q1: What defines a "borderline" Anti-Mitochondrial Antibody (AMA) test result?
A borderline AMA test result is an equivocal finding that is neither definitively positive nor negative. The specific quantitative values for borderline results vary depending on the assay method (ELISA or Indirect Immunofluorescence) and the manufacturer of the test kit. Generally, these results fall into a gray area between the established cut-off for negativity and the threshold for a positive result.[1] For instance, a result might be reported as "borderline," "equivocal," or "low-positive."
Q2: What is the potential clinical and research significance of a borderline AMA result?
A borderline AMA result can have several interpretations and should be considered in the context of other clinical and laboratory findings.[1] Potential implications include:
-
Early-stage Primary Biliary Cholangitis (PBC): The result may indicate an early phase of the autoimmune response characteristic of PBC, preceding the development of clear clinical symptoms or significant liver enzyme elevation.[1]
-
Mild or Atypical Autoimmune Process: It could represent a less aggressive or atypical form of an autoimmune condition.
-
Transient or Non-Specific Immune Activation: The borderline result might be a temporary and non-pathological fluctuation in the immune system.
-
Presence in other conditions: Low levels of AMAs can sometimes be detected in other autoimmune diseases such as Sjögren's syndrome, systemic lupus erythematosus, and rheumatoid arthritis, as well as in a small percentage of healthy individuals.[1][2]
Q3: What are the recommended next steps when a borderline AMA result is obtained in a research setting?
When a borderline AMA result is encountered, a systematic approach is crucial for accurate interpretation. The following steps are recommended:
-
Repeat Testing: It is advisable to repeat the AMA test, potentially using a different method (e.g., if the initial test was ELISA, consider IFA) or a kit from a different manufacturer to rule out assay-specific variability.
-
Comprehensive Laboratory Evaluation: Assess other relevant biomarkers. This includes liver function tests (LFTs), particularly alkaline phosphatase (ALP) and gamma-glutamyl transferase (GGT). Additionally, testing for other PBC-specific autoantibodies, such as anti-sp100 and anti-gp210, can provide more definitive information, especially in AMA-negative or borderline cases.[1]
-
Longitudinal Monitoring: If the subject is part of a longitudinal study, serial monitoring of AMA titers and liver enzymes over time is essential to determine if the levels are stable, transient, or increasing.
Q4: What is the statistical risk of developing Primary Biliary Cholangitis (PBC) with a borderline AMA result?
While individuals with high-titer AMA are at a significant risk of developing PBC, the data for borderline results is less definitive. However, studies on AMA-positive individuals with normal liver function tests show a variable but present risk of progressing to PBC over time. One study indicated that after a median follow-up of 4.6 years, 4.3% of AMA-positive individuals who did not initially have PBC went on to develop the disease.[3][4] Another study noted that two-thirds of incidentally found AMA-M2 positive patients developed features of PBC within a median of 27 months.[5] Therefore, a borderline result warrants careful monitoring.
Data Presentation: Borderline AMA Values
The definition of a borderline AMA result is not universally standardized and can differ between laboratories and commercial assay kits. Below is a summary of representative quantitative values that may be considered borderline.
| Assay Method | Manufacturer/Source Example | Negative | Borderline | Positive |
| Enzyme-Linked Immunosorbent Assay (ELISA) | Example Kit A | < 20 units/mL | 20–40 units/mL | > 40 units/mL |
| Mayo Clinic Laboratories | < 0.1 Units | 0.1-0.3 Units | ≥ 0.4 Units (Weakly Positive) | |
| Indirect Immunofluorescence (IFA) | General Reference | < 1:20 titer | 1:20 titer | ≥ 1:40 titer |
Experimental Protocols
Enzyme-Linked Immunosorbent Assay (ELISA) for AMA-M2
This protocol is a generalized example based on commercially available AMA-M2 ELISA kits. Researchers should always refer to the specific kit insert for detailed instructions.
1. Principle:
The ELISA for AMA-M2 is an indirect solid-phase immunoassay. The wells of a microplate are coated with purified mitochondrial M2 subtype antigen. When patient serum is added, AMA-M2 antibodies, if present, will bind to the antigen. Unbound components are washed away. An enzyme-conjugated anti-human IgG is then added, which binds to the captured AMA-M2 antibodies. After another wash step, a substrate solution is added, which is converted by the enzyme into a colored product. The intensity of the color, measured by a spectrophotometer, is proportional to the amount of AMA-M2 antibodies in the sample.[6][7]
2. Materials:
-
AMA-M2 coated microplate
-
Sample diluent
-
Calibrators and controls (negative and positive)
-
Enzyme conjugate (e.g., HRP-conjugated anti-human IgG)
-
Wash buffer concentrate
-
Substrate solution (e.g., TMB)
-
Stop solution
-
Microplate reader
3. Procedure:
-
Preparation: Bring all reagents and samples to room temperature. Dilute the wash buffer concentrate as instructed.
-
Sample Dilution: Dilute patient sera and controls with sample diluent (e.g., 1:100).[6]
-
Incubation with Antigen: Pipette 100 µL of diluted samples, calibrators, and controls into the appropriate wells of the microplate. Incubate for 30 minutes at room temperature.
-
Washing: Aspirate the contents of the wells and wash each well three to five times with the diluted wash buffer.[6][8]
-
Incubation with Conjugate: Add 100 µL of the enzyme conjugate to each well. Incubate for 15-30 minutes at room temperature.[6][8]
-
Washing: Repeat the washing step as described in step 4.
-
Substrate Reaction: Add 100 µL of the substrate solution to each well. Incubate for 15 minutes at room temperature in the dark.[6][8]
-
Stopping the Reaction: Add 100 µL of the stop solution to each well.
-
Reading: Read the optical density (OD) of each well at 450 nm within 30 minutes of adding the stop solution.[7]
-
Calculation: Calculate the results based on the OD of the calibrators.
Indirect Immunofluorescence (IFA) for AMA
This is a general protocol for the indirect immunofluorescence detection of AMA. Specific details may vary based on the substrate and reagents used.
1. Principle:
In this method, a substrate containing the target antigens (e.g., HEp-2 cells or rodent kidney/stomach tissue sections) is used. Patient serum is applied to the substrate. If this compound are present, they will bind to the mitochondria in the cells. After washing, a fluorescently labeled anti-human IgG antibody is added, which binds to the patient's antibodies. The resulting fluorescence pattern is then observed under a fluorescence microscope.
2. Materials:
-
Substrate slides (e.g., HEp-2 cells or tissue sections)
-
Phosphate-buffered saline (PBS)
-
Patient serum samples
-
Positive and negative controls
-
Fluorescein-conjugated anti-human IgG
-
Mounting medium
-
Coverslips
-
Fluorescence microscope
3. Procedure:
-
Sample Preparation: Dilute patient serum in PBS, typically starting at a 1:20 or 1:40 dilution.
-
Incubation with Primary Antibody: Apply the diluted serum to the wells of the substrate slide. Incubate in a humid chamber for 30 minutes at room temperature.
-
Washing: Gently rinse the slides with PBS and then wash for 5-10 minutes in a PBS bath.
-
Incubation with Secondary Antibody: Apply the fluorescein-conjugated anti-human IgG to each well. Incubate in a humid chamber for 30 minutes at room temperature in the dark.
-
Washing: Repeat the washing step as described in step 3.
-
Mounting: Add a drop of mounting medium to each well and cover with a coverslip.
-
Microscopy: Examine the slides using a fluorescence microscope. A positive result is indicated by a characteristic granular cytoplasmic fluorescence pattern. The titer is the highest dilution at which this specific fluorescence is observed.
Troubleshooting Guides
ELISA Troubleshooting
| Issue | Possible Cause | Solution |
| No or Weak Signal | Reagents not at room temperature. | Ensure all reagents are at room temperature before use. |
| Improper washing. | Ensure thorough washing and complete removal of wash buffer. | |
| Inactive enzyme conjugate or substrate. | Use fresh reagents and check expiration dates. | |
| Incorrect incubation times or temperatures. | Adhere strictly to the protocol's incubation parameters.[9] | |
| High Background | Insufficient washing. | Increase the number of wash cycles.[9] |
| High concentration of detection antibody. | Optimize the concentration of the secondary antibody.[9] | |
| Non-specific binding. | Ensure adequate blocking and consider adding a detergent like Tween-20 to the wash buffer.[10] | |
| High Variability | Pipetting errors. | Use calibrated pipettes and ensure consistent technique.[11] |
| Inconsistent incubation times. | Add reagents to wells in a consistent order and timing. | |
| Plate not sealed properly during incubation. | Use plate sealers to prevent evaporation. |
IFA Troubleshooting
| Issue | Possible Cause | Solution |
| No or Weak Fluorescence | Low antibody titer in the sample. | Test at a lower dilution (e.g., 1:10). |
| Improper storage of reagents. | Store reagents as recommended and protect fluorescent conjugate from light. | |
| Faded fluorescence. | Observe slides promptly after staining or store them properly in the dark at 4°C. | |
| High Background/Non-specific Staining | Inadequate washing. | Increase the duration and number of wash steps. |
| Secondary antibody binding non-specifically. | Include a blocking step with normal serum from the same species as the secondary antibody. | |
| Drying of the slide during incubation. | Use a humidified chamber for all incubation steps. |
Mandatory Visualization
Caption: Workflow for Interpreting Borderline AMA Results.
References
- 1. lupindiagnostics.com [lupindiagnostics.com]
- 2. Patients with AMA/anti-sp100/anti-gp210 Positivity and Cholestasis Can Manifest Conditions Beyond Primary Biliary Cholangitis [xiahepublishing.com]
- 3. The future risk of primary biliary cholangitis (PBC) is low among patients with incidental anti-mitochondrial antibodies but without baseline PBC - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. The future risk of primary biliary cholangitis (PBC) is low among patients with incidental anti‐mitochondrial antibodies but without baseline PBC - PMC [pmc.ncbi.nlm.nih.gov]
- 5. The risk of development of primary biliary cholangitis among incidental antimitochondrial M2 antibody-positive patients - PMC [pmc.ncbi.nlm.nih.gov]
- 6. demeditec.com [demeditec.com]
- 7. sceti.co.jp [sceti.co.jp]
- 8. cusabio.com [cusabio.com]
- 9. stjohnslabs.com [stjohnslabs.com]
- 10. ELISA Troubleshooting Guide | Bio-Techne [bio-techne.com]
- 11. hycultbiotech.com [hycultbiotech.com]
Technical Support Center: Improving the Specificity of Antimitochondrial Antibody (AMA) Detection
This technical support center provides troubleshooting guidance and answers to frequently asked questions for researchers, scientists, and drug development professionals working with antimitochondrial antibody (AMA) detection methods.
Frequently Asked Questions (FAQs)
Q1: What are the most common methods for AMA detection, and which is the most specific?
A1: The primary methods for AMA detection are Indirect Immunofluorescence (IIF), Enzyme-Linked Immunosorbent Assay (ELISA), and Immunoblotting (IB). IIF on rodent tissue (kidney, stomach, liver) or HEp-2 cells is often used as a screening test.[1][2] ELISAs, particularly those targeting the M2 subtype (AMA-M2), are widely used for their high sensitivity and specificity in diagnosing Primary Biliary Cholangitis (PBC).[3][4] Immunoblotting can be used as a confirmatory test to identify reactivity against specific mitochondrial antigens, which is especially useful in cases with unclear IIF or ELISA results.[2] While all methods have high specificity, AMA-M2 specific assays are considered the hallmark for PBC diagnosis.[1][5]
Q2: What can cause a false-positive AMA result?
A2: False-positive AMA results can occur due to various factors. Cross-reactivity with other autoantibodies present in systemic autoimmune diseases like lupus or rheumatoid arthritis can lead to false positives.[5] Certain infections, such as syphilis and hepatitis A, have also been reported to cause transiently elevated AMA levels.[6] Additionally, technical issues in the assay, such as interference from human anti-mouse antibodies (HAMA) in sandwich ELISAs, can produce erroneous positive results.[7][8]
Q3: Is it possible for a patient with Primary Biliary Cholangitis (PBC) to be AMA-negative?
A3: Yes, approximately 5-10% of patients with PBC are AMA-negative.[1] In these cases, other PBC-specific autoantibodies, such as anti-sp100 and anti-gp210, can be detected and are included in the diagnostic criteria.[9][10] Therefore, if clinical suspicion for PBC is high despite a negative AMA result, testing for these other specific antinuclear antibodies is recommended.[1]
Q4: What is the significance of different IIF patterns for AMA?
A4: When using rodent tissue sections for IIF, a granular cytoplasmic staining of the distal renal tubules is characteristic of AMAs.[1] On HEp-2 cells, this compound typically show a fine granular cytoplasmic fluorescence.[11] However, the interpretation of IIF patterns requires significant expertise as other autoantibodies can produce similar cytoplasmic staining. Equivocal or complex patterns should be confirmed with more specific methods like AMA-M2 ELISA or immunoblotting.[12][13]
Troubleshooting Guides
ELISA (Enzyme-Linked Immunosorbent Assay)
| Issue | Possible Cause(s) | Recommended Action(s) |
| High Background Signal | 1. Insufficient washing.[14][15][16][17] 2. Contaminated wash buffer or substrate solution.[14][17] 3. Blocking of non-specific binding is insufficient.[15][18] 4. Incubation times or temperatures were too high.[16] 5. Cross-contamination between wells.[14] | 1. Increase the number of wash cycles and ensure complete aspiration of buffer between washes. Consider adding a short soak time.[15][16] 2. Use freshly prepared buffers and ensure the TMB substrate is colorless before use.[14] 3. Increase the blocking incubation time or try a different blocking agent (e.g., 5-10% normal serum of the same species as the secondary antibody).[15][18] 4. Strictly adhere to the incubation times and temperatures specified in the protocol.[16] 5. Use fresh pipette tips for each sample and reagent. Be careful not to splash reagents between wells.[14] |
| No Signal or Weak Signal | 1. Omission of a key reagent (e.g., primary antibody, conjugate).[16] 2. Inactive enzyme conjugate. 3. Incorrect filter settings on the plate reader. 4. Samples contain sodium azide, which inhibits HRP.[16] | 1. Carefully review the protocol and ensure all steps were followed correctly.[16] 2. Use a new vial of conjugate and ensure proper storage conditions. 3. Check that the plate reader is set to the correct wavelength (e.g., 450 nm for TMB).[3] 4. Ensure samples and buffers are free of sodium azide.[16] |
| High Well-to-Well Variation | 1. Inconsistent pipetting.[16] 2. Inefficient washing, leaving residual reagents.[16] 3. Plate not sealed properly during incubation, leading to evaporation. | 1. Use calibrated pipettes and ensure consistent technique.[16] 2. Ensure uniform and thorough washing of all wells.[16] 3. Use plate sealers and ensure they are applied firmly. |
Indirect Immunofluorescence (IIF)
| Issue | Possible Cause(s) | Recommended Action(s) |
| Equivocal or Atypical Staining Pattern | 1. Presence of multiple autoantibodies.[13] 2. Low antibody titer. 3. Non-specific binding of antibodies. | 1. Test the sample with a more specific assay like AMA-M2 ELISA or immunoblot to confirm specificity.[12] 2. Perform serial dilutions to determine the endpoint titer. Low titers may not be clinically significant.[13] 3. Ensure adequate blocking steps and use of appropriate buffer formulations.[19] |
| High Background Fluorescence | 1. Inadequate blocking.[20] 2. Secondary antibody is binding non-specifically. 3. Fixation or permeabilization issues. | 1. Increase blocking time or use a different blocking agent.[20] 2. Use a highly cross-adsorbed secondary antibody. Run a control with only the secondary antibody to check for non-specific binding.[20] 3. Optimize fixation and permeabilization protocols for your specific cell or tissue type.[21] |
Data Presentation
Table 1: Comparison of AMA Detection Methods
| Method | Principle | Primary Use | Advantages | Disadvantages |
| Indirect Immunofluorescence (IIF) | Detects antibodies that bind to antigens in a cellular or tissue substrate using a fluorescent secondary antibody. | Screening | Can detect a broad range of this compound and other autoantibodies (e.g., ANAs) simultaneously.[2] | Interpretation is subjective and requires expertise; lower sensitivity in some cases.[1] |
| ELISA (AMA-M2) | Uses purified or recombinant M2 antigen coated on a microplate to capture specific antibodies. | Diagnosis & Quantification | High sensitivity and specificity for PBC; quantitative and objective.[3][4] | May miss other AMA subtypes; susceptible to interference from heterophilic antibodies.[2][7] |
| Immunoblot (IB) | Separates mitochondrial antigens by size, transfers them to a membrane, and detects specific antibody binding. | Confirmation | Can identify reactivity to specific AMA subtypes (M2, M4, M9, etc.).[2][4] | Less sensitive than ELISA for some antigens; can be complex to perform and interpret.[2] |
Table 2: Performance Characteristics of a Commercial AMA-M2 ELISA Kit
| Parameter | Value |
| Sensitivity | 97.2% |
| Specificity | 94.2% |
| Overall Agreement | 95.1% |
| Measuring Range | 0 – 200 IU/ml |
| Cut-off (Negative) | < 10 IU/ml |
| Cut-off (Positive) | ≥ 20 IU/ml |
| (Data is illustrative and based on a sample commercial kit.[4] Users should refer to the specific kit insert for performance data.) |
Experimental Protocols
Detailed Methodology for AMA-M2 ELISA (Example Protocol)
This protocol is a generalized example and should be adapted based on the specific manufacturer's instructions.[3][22]
-
Preparation: Bring all reagents and samples to room temperature. Dilute wash buffer and sample buffer concentrates as instructed. Dilute patient serum (e.g., 1:100) in the provided sample buffer.[3]
-
Sample Incubation: Pipette 100 µl of calibrators, controls, and diluted patient samples into the appropriate wells of the M2 antigen-coated microplate.[3]
-
Incubate for 30 minutes at room temperature (20-28 °C).[3]
-
Washing: Aspirate the contents of the wells and wash each well 3 times with 300 µl of diluted wash solution. Ensure complete removal of liquid after the final wash by tapping the plate on absorbent paper.[3]
-
Conjugate Incubation: Dispense 100 µl of HRP-conjugated anti-human IgG into each well.[3]
-
Incubate for 15 minutes at room temperature.[3]
-
Washing: Repeat the washing step as described in step 4.[3]
-
Substrate Incubation: Add 100 µl of TMB substrate solution to each well.[3]
-
Incubate for 15 minutes at room temperature in the dark. A blue color will develop.[3]
-
Stopping Reaction: Add 100 µl of stop solution to each well. The color will change to yellow.[3]
-
Reading: Read the optical density at 450 nm within 30 minutes.[3]
-
Analysis: Calculate results based on the standard curve generated from the calibrators.
General Protocol for Indirect Immunofluorescence (IIF) for AMA
This is a general protocol for staining cells or tissue sections.
-
Sample Preparation: Use commercially prepared slides with appropriate substrate (e.g., rodent kidney/stomach/liver sections or HEp-2 cells) or prepare in-house.[11][23]
-
Fixation/Permeabilization (if starting with live cells): Fix cells with 4% paraformaldehyde, followed by permeabilization with a detergent like 0.1-0.5% Triton X-100 if the target antigen is intracellular.[21]
-
Blocking: Incubate slides with a blocking buffer (e.g., 5% normal serum from the species of the secondary antibody) for at least 1 hour to prevent non-specific antibody binding.[23]
-
Primary Antibody Incubation: Dilute patient serum in PBS and apply to the slides. Incubate overnight at 4°C or for 1-2 hours at room temperature in a humidified chamber.[23]
-
Washing: Wash the slides three times with PBS for 5 minutes each to remove unbound primary antibodies.[23]
-
Secondary Antibody Incubation: Apply a fluorescently-labeled anti-human IgG secondary antibody diluted in PBS. Incubate for 1-2 hours at room temperature in the dark.[23]
-
Washing: Repeat the washing step as in step 5, keeping the slides protected from light.[23]
-
Mounting and Visualization: Mount a coverslip using an anti-fade mounting medium. Examine the slide using a fluorescence microscope.[23]
Visualizations
Caption: Workflow for AMA-M2 ELISA.
Caption: Diagnostic algorithm for Primary Biliary Cholangitis (PBC).
References
- 1. Autoantibodies in Primary Biliary Cholangitis: From Classical Markers to Emerging Targets - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Performance of indirect immunofluorescence test and immunoblot tests in the evaluation of antinuclear and antimitochondrial antibodies - PMC [pmc.ncbi.nlm.nih.gov]
- 3. demeditec.com [demeditec.com]
- 4. elisakits.co.uk [elisakits.co.uk]
- 5. droracle.ai [droracle.ai]
- 6. researchgate.net [researchgate.net]
- 7. calbiotech.com [calbiotech.com]
- 8. Interferences in Immunoassay - PMC [pmc.ncbi.nlm.nih.gov]
- 9. emedicine.medscape.com [emedicine.medscape.com]
- 10. Guidelines on the Diagnosis and Management of Primary Biliary Cholangitis (2021) - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. researchgate.net [researchgate.net]
- 13. Complex patterns on HEp-2 indirect immunofluorescence assay in a large sample referred for anti-cell autoantibodies detection - PMC [pmc.ncbi.nlm.nih.gov]
- 14. ELISA Troubleshooting (High Background) [elisa-antibody.com]
- 15. arp1.com [arp1.com]
- 16. novateinbio.com [novateinbio.com]
- 17. jg-biotech.com [jg-biotech.com]
- 18. How to deal with high background in ELISA | Abcam [abcam.com]
- 19. Detection of Autoantibodies by Indirect Immunofluorescence Cytochemistry on Hep-2 Cells | Springer Nature Experiments [experiments.springernature.com]
- 20. biotium.com [biotium.com]
- 21. sinobiological.com [sinobiological.com]
- 22. ibl-international.com [ibl-international.com]
- 23. usbio.net [usbio.net]
troubleshooting errors in AMAS bioinformatics tool installation
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) for common issues encountered during the installation and use of AMAS bioinformatics tools. Please select the relevant tool below.
-
--INVALID-LINK--
-
--INVALID-LINK--
This compound: Alignment Manipulation and Summary
This section addresses issues related to the this compound tool for multiple sequence alignment manipulation.
Frequently Asked Questions (FAQs)
Q1: What is this compound and what are its primary functions?
A1: this compound (Alignment Manipulation and Summary) is a command-line tool and Python package designed for handling large biological sequence alignments.[1] Its key functions include:
-
Concatenating multiple alignments.[2]
-
Converting between alignment formats (FASTA, PHYLIP, NEXUS).[1][2]
-
Calculating summary statistics (e.g., number of taxa, alignment length, missing data, variable sites).[1][2]
-
Splitting concatenated alignments based on a partition file.[2]
-
Creating replicate datasets.[1]
Q2: What are the system requirements for installing this compound?
A2: this compound is a Python 3 program and does not have any external dependencies, relying only on Python's core modules.[1] Therefore, the primary requirement is a working Python 3 installation.[3]
Q3: How do I install this compound?
A3: this compound can be used as a stand-alone script or as a Python module. You can download the source code from its GitHub repository.[1][2] Once downloaded, you can run the this compound.py script directly from the command line.[2]
Troubleshooting Guide
Issue 1: Argument list too long error when processing many files.
-
Symptom: When trying to concatenate or summarize a large number of alignment files (e.g., >5,000) using a wildcard (*.fas), the system returns an Argument list too long error.[4]
-
Cause: This error is due to a system limit on the maximum number of characters that can be passed in a single command-line argument.[4]
-
Solution:
-
Check your system's argument limit: You can find your system's limit by running the command getconf ARG_MAX.[4]
-
Process files in batches: A workaround is to split your alignment files into multiple subdirectories and run this compound on each subdirectory. Then, you can concatenate the resulting intermediate files.[4]
-
Increase the argument limit: On some Linux systems, it may be possible to increase the ARG_MAX limit, though this may require system administrator privileges.[4]
-
Issue 2: Concatenation of interleaved Nexus files produces incorrect alignments.
-
Symptom: When concatenating interleaved Nexus files, the resulting alignment is erroneous, but the tool does not produce an error message.[5]
-
Cause: This is a known issue within the this compound tool.[5]
-
Solution: At present, there is no direct fix within this compound for this issue. It is recommended to convert the interleaved Nexus files to a sequential format (e.g., sequential Nexus or FASTA) before concatenation.
Issue 3: -n flag not working for concat command.
-
Symptom: The -n flag, intended for a specific function during concatenation, is not working as expected.[5]
-
Cause: This is a reported bug in the tool.[5]
-
Solution: As this is a known issue, it is advisable to check the official this compound GitHub issue tracker (B12436777) for any updates or workarounds provided by the developers.[5]
OWASP this compound: Attack Surface Mapping
This section provides support for the OWASP this compound tool used for in-depth attack surface mapping and asset discovery.
Frequently Asked Questions (FAQs)
Q1: What are the different ways to install OWASP this compound?
A1: OWASP this compound offers several installation methods to accommodate different user preferences and operating systems. These include:
-
Compiling from Source: Requires a correctly configured Go environment (version >= 1.14).[6]
-
Using Docker: A straightforward method that uses a pre-built Docker image.[6][7]
-
Homebrew (macOS): Can be installed using the brew package manager.[6][7]
-
Snapcraft (Linux): Available as a Snap package for easy installation on supporting Linux distributions.[6][8]
-
Package Managers: Maintained in the repositories of various Linux distributions like Kali Linux, Arch Linux, and FreeBSD.[6]
Q2: Where is the this compound configuration file located?
A2: The this compound configuration file (config.yaml) can be found in the following locations, depending on your operating system and how you installed it: $XDG_CONFIG_HOME/amass/config.yaml, $HOME/.config/amass/config.yaml, or /etc/amass/config.yaml.[9] You can also specify a custom location using the -config flag.[9]
Q3: Why am I not getting many results from my scans?
A3: The effectiveness of this compound scans heavily relies on the use of various data sources, many of which require API keys.[8] Without configuring API keys in the datasources.yaml file, this compound will only use free and open-source intelligence, limiting the scope of its discovery.[8]
Troubleshooting Guide
Issue 1: Command 'go' not found after attempting to install from source.
-
Symptom: After following the steps to compile from source, the go command is not recognized in the terminal.[9]
-
Cause: The Go binary directory is not in your system's PATH environment variable.[9]
-
Solution:
-
Verify Go installation: Ensure that Go is installed correctly. You can check the version with go version.[9]
-
Locate the Go binary: Use the command sudo find / -type f -name "go" 2>/dev/null to find the location of the Go executable. A common location is /usr/local/go/bin/go.[9]
-
Add Go to PATH: Add the Go binary directory to your PATH by running export PATH=$PATH:/usr/local/go/bin.[9] To make this change permanent, add this line to your shell's configuration file (e.g., ~/.bashrc, ~/.zshrc).
-
Alternatively, create a symbolic link: You can copy the Go binary to a directory that is already in your PATH, for example: sudo cp /usr/local/go/bin/go /usr/bin.[9]
-
Installation Method Comparison
| Installation Method | Dependencies | Ease of Installation | Management |
| Compile from Source | Go (>= 1.14) | Moderate | Manual updates |
| Docker | Docker | Easy | Pull new images |
| Homebrew | Homebrew | Easy | brew upgrade amass |
| Snapcraft | Snap | Easy | sudo snap refresh |
| Package Manager | Varies by distro | Easy | System updates |
Issue 2: Persistent data is not saved between Docker container runs.
-
Symptom: When running this compound in a Docker container, the graph database and output files are lost after the container stops.
-
Cause: A volume is not mounted to persist the data outside of the container.[6]
-
Solution: Use the -v flag to mount a local directory to the container's output directory. The command should look similar to this: docker run -v /your/local/output/directory:/root/.config/amass amass:latest.[6][7]
Issue 3: Snap installation fails or the amass command is not found.
-
Symptom: After installing via Snap, the amass command is not available.[8]
-
Cause: The Snap binary directory may not be in your system's PATH.[6]
-
Solution:
Visual Workflows
Caption: Troubleshooting workflow for 'go' and 'amass' command not found errors.
References
- 1. This compound: a fast tool for alignment manipulation and computing of summary statistics - PMC [pmc.ncbi.nlm.nih.gov]
- 2. GitHub - marekborowiec/AMAS: Calculate summary statistics and manipulate multiple sequence alignments [github.com]
- 3. This compound to Concatenate Sequences [protocols.io]
- 4. This compound with many genes · Issue #9 · marekborowiec/AMAS · GitHub [github.com]
- 5. GitHub · Where software is built [github.com]
- 6. Installation Guide · owasp-amass/amass Wiki · GitHub [github.com]
- 7. OWASP Amass Project [owasp-amass.github.io]
- 8. argeliuslabs.com [argeliuslabs.com]
- 9. medium.com [medium.com]
Optimizing AMAS for Large Alignment File Processing: A Technical Support Guide
This technical support center provides troubleshooting guidance and frequently asked questions for researchers, scientists, and drug development professionals using AMAS (Alignment Manipulation and Summary) to process large alignment files. The following sections offer solutions to common issues and outline best practices for efficient data handling.
Troubleshooting Guides
This section addresses specific error messages and performance bottlenecks you might encounter when working with large datasets in this compound.
Issue: "Argument list too long" Error When Processing Many Files
Question: I'm trying to concatenate thousands of individual locus alignment files using a wildcard (e.g., *.fas), but I'm getting an "Argument list too long" error. How can I resolve this?
Answer:
This error originates from the operating system's limit on the number of arguments that can be passed to a single command, not from this compound itself. When you use a wildcard like *, the shell expands it into a list of all matching filenames, which can exceed this limit if there are too many files.
Solutions:
-
Split and Concatenate in Batches: The most straightforward approach is to divide your files into smaller subdirectories and run this compound on each subdirectory separately. You can then concatenate the resulting intermediate files.[1]
-
Increase System Argument Limit (Advanced): For Linux-based systems, it's possible to increase the maximum argument list size. You can check your current limit with getconf ARG_MAX. Increasing this limit (e.g., with ulimit -s 65536) can provide a temporary solution, but it may require system administrator privileges and understanding of your system's resource allocation.[1][2]
-
Use find with a loop (Alternative): While not a direct this compound optimization, you can use shell commands to process files in batches. However, a simple find ... | xargs ... approach will not work for concatenation as it processes files individually. A custom loop that builds up the this compound command with batches of files is a more robust scripting solution.
Issue: Slow Performance When Summarizing a Large Number of Alignments
Question: The this compound summary command is running very slowly on my dataset of thousands of alignment files. How can I speed up this process?
Answer:
This compound is designed for efficient processing, but summarizing a vast number of files can still be time-consuming. You can significantly improve performance by leveraging parallel processing.
Solution:
-
Utilize Multiple Cores: The summary command in this compound has a built-in option for parallelization. Use the -c or --cores flag to specify the number of CPU cores you want to dedicate to the task. This is particularly effective for the file parsing and summary calculation steps.[3]
Example Command:
This command tells this compound to use 12 cores to process all PHYLIP files in the current directory. Note that you will only see a significant speed-up when you have a large number of files to process.[3]
Issue: Potential Memory Errors with Extremely Large Single Alignment Files
Question: I have a single, very large concatenated alignment file (several gigabytes). I'm concerned about running into memory errors when trying to calculate summary statistics or perform other manipulations. What is the best practice in this scenario?
Answer:
While this compound is efficient, extremely large single files can still strain system memory. The most effective strategy is to split the large file into more manageable chunks before processing.
Solution:
-
Split the Alignment: Use the this compound split command to break your large concatenated alignment into smaller files based on a partition file. If you don't have a partition file, you can create one that defines blocks of sites to be split.
-
Process in Parallel: Once split, you can use the --cores option with the this compound summary command to process these smaller files in parallel, as described in the previous section.
-
Alternative Splitting: For simple splitting without a partition file, you can use standard command-line tools like split to break the large file into smaller pieces based on line count or file size.[4][5][6]
Frequently Asked Questions (FAQs)
Q1: How does this compound's parallel processing work, and which commands support it?
A1: this compound utilizes parallel processing to speed up the parsing of input files and the calculation of summary statistics.[3] This feature is activated with the -c or --cores flag. It is important to note that as of the current versions, the concat command's concatenation step itself is not parallelized, but the initial parsing of the input files for concatenation can be. The primary benefit of the --cores flag is seen with the summary command when working with a large number of input files.[3]
Q2: What are the main functions of this compound for handling large datasets?
A2: this compound offers several functions that are particularly well-suited for large-scale phylogenomic analyses:
-
convert : Converts between popular alignment formats (FASTA, PHYLIP, NEXUS).[7][8]
-
summary : Calculates various alignment statistics, such as alignment length, number of taxa, missing data, and parsimony informative sites.[7][8]
-
split : Splits a concatenated alignment into separate files based on a partition file.[7][8]
Q3: Is this compound faster than other tools for concatenating large alignment files?
A3: Yes, benchmark studies have shown that this compound significantly outperforms other popular tools like FASconCAT-G and Phyutility in concatenation speed, in some cases by a factor of 30 or more.[7][9]
Q4: Can I use this compound as a Python package for more complex workflows?
A4: Yes, this compound can be imported as a Python package. This allows for greater flexibility in scripting custom bioinformatics pipelines and directly manipulating alignment data within Python. The core functionalities available on the command line are also accessible through the Python interface.[7][10]
Data Presentation
This compound Performance Benchmarks for Concatenation
The following table summarizes the performance of this compound compared to other tools on various large datasets, as presented in the original this compound publication.
| Dataset | Number of Loci | This compound (Single Core) | This compound (12 Cores) | Phyutility | FASconCAT-G |
| Johnson et al. (2013) | 5,214 | < 2 seconds | ~1 second | ~10 minutes | > 500 seconds |
| Jarvis et al. (2014) | 8,295 | < 18 seconds | ~8 seconds | > 3 hours | Crashed |
Data sourced from Borowiec, M.L. 2016. This compound: a fast tool for alignment manipulation and computing of summary statistics. PeerJ 4:e1660.[7][9]
Experimental Protocols
The performance benchmarks cited above were conducted on a desktop computer with a 12-core Intel i7-4930K CPU at 3.40 GHz and 32 GB of RAM, running Ubuntu 12.04 LTS.[9] The Unix time -p command was used to measure execution times.[9] The datasets used were from published phylogenomic studies and varied in the number of taxa and loci.[7]
Visualizations
Optimized Workflow for Processing a Large Number of Alignments
The following diagram illustrates a recommended workflow for efficiently processing a large number of individual alignment files using this compound, particularly when encountering the "Argument list too long" error.
Caption: Workflow for handling a large number of alignment files.
Logical Workflow for Optimizing this compound Operations
This diagram outlines the decision-making process for optimizing different this compound tasks based on the nature of the input data.
Caption: Decision tree for optimizing this compound usage.
References
- 1. researchgate.net [researchgate.net]
- 2. kernel - "Argument list too long": How do I deal with it, without changing my command? - Unix & Linux Stack Exchange [unix.stackexchange.com]
- 3. GitHub - marekborowiec/AMAS: Calculate summary statistics and manipulate multiple sequence alignments [github.com]
- 4. The split Command: Splitting a Large File into Smaller Chunks - DoHost [dohost.us]
- 5. Metagenomics - Split large file [metagenomics.wiki]
- 6. stackoverflow.com [stackoverflow.com]
- 7. This compound: a fast tool for alignment manipulation and computing of summary statistics - PMC [pmc.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. This compound: a fast tool for alignment manipulation and computing of summary statistics [PeerJ] [peerj.com]
- 10. peerj.com [peerj.com]
AMAS for Phylogenomics: Technical Support Center
Welcome to the technical support center for AMAS (Alignment Manipulation And Summary), a powerful tool for phylogenomic analyses. This guide provides troubleshooting advice and answers to frequently asked questions to help researchers, scientists, and drug development professionals overcome common challenges during their experiments.
Troubleshooting Guides & FAQs
Here we address specific issues that you may encounter when using this compound.
Input File and Data Formatting
Q1: I'm getting an error when I try to run this compound. What are the most common input file errors?
A1: The most frequent errors in this compound are related to the specification of input files and data formats. Ensure you have correctly specified the following three arguments on the command line[1]:
-
Input file(s): Use the -i (or --in-files) flag to specify your alignment files.
-
Input format: Use the -f (or --in-format) flag to specify the format of your alignment files. Supported formats include FASTA, PHYLIP, and NEXUS[1][2].
-
Data type: Use the -d (or --data-type) flag to specify the type of sequence data, which can be dna for nucleotide data or aa for amino acid data[1].
Correctly specifying these is crucial for this compound to parse your files accurately[3]. This compound assumes you are providing aligned sequences. If you suspect your sequences may not be aligned, you can use the -e or --check-align flag to verify them, though this may increase computation time[1].
Q2: My concatenation is failing or producing unexpected results. What could be the cause?
A2: A common pitfall during concatenation is inconsistent taxon names across different alignment files. For this compound to correctly concatenate alignments, the names for each sequence (taxon) must be identical across all input files[4]. If taxon names are not consistent (e.g., "SpeciesA_gene1" in one file and "SpeciesA_gene2" in another), this compound will treat them as different taxa, leading to a concatenated alignment with a large amount of missing data[1].
Troubleshooting Steps:
-
Check Taxon Labels: Manually inspect the taxon labels in your input files to ensure consistency.
-
Standardize Names: If you have unique identifiers appended to your species names, you will need to trim them to ensure sequence names are consistent across all files before concatenation[1].
Execution and System Errors
Q3: I'm trying to concatenate a large number of files and I'm getting an "Argument list too long" error. How can I fix this?
A3: This error occurs when the number of input files exceeds the command-line argument limit of your operating system[5][6]. This is a system limitation rather than a bug within this compound.
Solutions:
-
Use Wildcards Strategically: If possible, use wildcards (e.g., *.fas) to specify your input files. However, with a very large number of files, this can still trigger the error[2].
-
Process files in batches: A practical workaround is to concatenate your alignments in smaller batches and then concatenate the resulting concatenated files.
-
Increase System Argument Limit: For Linux-based systems, it may be possible to increase the argument list limit. You can check your current limit with getconf ARG_MAX[5][7].
Interpreting Summary Statistics
Q4: this compound generated a summary.txt file. How do I interpret these statistics?
A4: The summary statistics provide a valuable overview of your alignment data. Understanding these metrics can help you assess the quality and suitability of your data for downstream phylogenetic analysis.
| Statistic | Description | Potential Pitfall Indication |
| No. of taxa | The total number of unique sequences (taxa) in the alignment. | An unexpectedly high number may indicate inconsistent taxon naming across files. |
| Alignment length | The total number of sites (columns) in the alignment. | |
| Total matrix cells | The total number of cells in the alignment matrix (No. of taxa x Alignment length). | |
| Missing data (%) | The percentage of undetermined characters (e.g., '?', 'N', '-') in the alignment. | High percentages of missing data can sometimes reduce the accuracy of phylogenetic inference, though this is not always the case[3]. |
| Variable sites | The number of sites in the alignment that have at least two different character states. | Low numbers may indicate insufficient variation for resolving relationships. |
| Parsimony inf. sites | The number of sites that have at least two different character states, each appearing at least twice. | This is a key indicator of the phylogenetic signal present in your data. |
| AT/GC content (DNA) | The proportion of Adenine/Thymine and Guanine/Cytosine in the alignment. | Extreme biases in nucleotide composition can sometimes mislead phylogenetic methods. |
For a detailed list of calculated statistics, refer to the this compound documentation[1][3].
Experimental Protocols & Workflows
Standard Phylogenomic Workflow using this compound
A typical phylogenomic analysis involves several key steps where this compound can be integrated for efficient data processing.
Caption: A typical phylogenomic workflow incorporating this compound.
Methodology:
-
Data Acquisition: Obtain sequence data (e.g., from genome or transcriptome sequencing).
-
Gene Prediction and Orthology Inference: Identify protein-coding genes and determine orthologous relationships across your taxa.
-
Multiple Sequence Alignment: Align the sequences for each orthologous gene set individually using software like MAFFT or MUSCLE.
-
This compound Processing:
-
(4a) Summary Statistics (Optional but Recommended): Use the this compound summary command to calculate summary statistics for your individual alignments. This step is crucial for identifying potential issues with your data before concatenation.
-
(4b) Concatenation: Use the this compound concat command to combine your individual gene alignments into a single supermatrix. This compound will also generate a partition file that can be used in downstream analyses.
-
-
Model Selection: Use software like PartitionFinder or ModelTest-NG to determine the best-fit models of sequence evolution for your concatenated alignment, often using the partition file generated by this compound.
-
Phylogenetic Tree Inference: Infer the phylogenetic tree from the concatenated alignment using methods such as Maximum Likelihood (e.g., RAxML, IQ-TREE) or Bayesian Inference (e.g., MrBayes).
Troubleshooting Logic
When encountering an issue with this compound, a systematic approach can help identify the root cause.
Caption: A troubleshooting flowchart for common this compound issues.
References
- 1. GitHub - marekborowiec/AMAS: Calculate summary statistics and manipulate multiple sequence alignments [github.com]
- 2. peerj.com [peerj.com]
- 3. This compound: a fast tool for alignment manipulation and computing of summary statistics - PMC [pmc.ncbi.nlm.nih.gov]
- 4. This compound to Concatenate Sequences [protocols.io]
- 5. linux - How do I avoid "Argument list too long" errors when compressing thousands of files? - Super User [superuser.com]
- 6. The “Argument List Too Long” Error in Linux Commands - GeeksforGeeks [geeksforgeeks.org]
- 7. stackoverflow.com [stackoverflow.com]
AMAS tool memory usage and performance optimization
Technical Support Center: AMAS Tool
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals optimize memory usage and performance when using the this compound (Alignment Manipulation And Summary) tool.
Frequently Asked Questions (FAQs)
Q1: What is the this compound tool and what are its primary functions?
A1: this compound is a command-line utility and Python package designed for the manipulation and statistical analysis of nucleotide and amino acid alignments.[1][2] Its key functions include:
-
Converting between popular alignment formats (e.g., FASTA, PHYLIP).[2]
-
Concatenating multiple alignments.[3]
-
Extracting specific sites from alignments.[2]
-
Splitting concatenated alignments based on a partitioning scheme.[2]
-
Generating summary statistics such as alignment length, number of taxa, missing data percentage, variable sites, and parsimony-informative sites.[1][2]
-
Creating replicate datasets for analyses like phylogenetic jackknifing.[3]
This compound is recognized for its computational efficiency, especially with large phylogenomic datasets, and its ability to utilize parallel processing to accelerate computations.[1][4] It is a Python 3 program that does not require any additional dependencies, simplifying installation.[3][4]
Q2: My script is running slowly when concatenating a large number of alignments. How can I improve performance?
A2: this compound is designed to be computationally efficient, often outperforming other tools in concatenation tasks.[1] However, with exceptionally large datasets, you can further optimize performance by leveraging its parallel processing capabilities. By default, this compound may use a single core. You can specify the number of cores to use with the appropriate command-line flag (consult the tool's documentation for the exact flag, commonly -c or --cores). Utilizing multiple cores can significantly reduce computation time.
Q3: I am encountering high memory usage when processing hundreds of large alignment files. What are the common causes and how can I mitigate this?
A3: High memory usage typically arises when dealing with a very large number of taxa or loci. While this compound is optimized for such datasets, system resources can still be a bottleneck.[4] Consider the following strategies:
-
Process files in batches: Instead of providing all alignment files as input at once, try processing them in smaller, manageable batches.
-
System Monitoring: Use system monitoring tools to track memory usage during this compound execution. This can help determine if the high usage is a spike during a specific operation or a sustained demand.
-
Increase System Memory: If you consistently work with massive datasets, the most straightforward solution may be to increase the available physical RAM on your system.
Q4: Does the input file format affect the memory usage and performance of this compound?
A4: While this compound is robust to various input data formats, the complexity and size of the files are the primary drivers of resource consumption.[3] The overhead associated with parsing different formats is generally negligible compared to the memory required to store and manipulate the alignment data itself. For optimal performance, ensure your alignment files are clean and free of unnecessary metadata or formatting inconsistencies.
Troubleshooting Guides
Guide 1: Diagnosing and Resolving Slow Performance
This guide provides a systematic approach to identifying and addressing performance bottlenecks when using this compound.
Experimental Protocol for Benchmarking Concatenation Speed:
-
Prepare Datasets: Create three distinct datasets of alignments that vary in size (Small: 100 loci, 10 taxa; Medium: 500 loci, 50 taxa; Large: 1000+ loci, 100+ taxa).
-
Single-Core Baseline: Execute the this compound concat command on each dataset using a single processor core. Record the execution time for each run.
-
Multi-Core Testing: Re-run the concat command on each dataset, this time specifying an increased number of cores (e.g., 4, 8, 12). Record the execution time for each configuration.
-
Comparative Analysis: For comparison, perform the same concatenation tasks using other alignment manipulation tools like FASconCAT-G and Phyutility.[1]
-
Analyze Results: Compile the timing data into a table to compare the performance of this compound across different core counts and against other software.
Quantitative Data Summary:
| Dataset Size | Number of Loci | Number of Taxa | This compound (1-core) Time (s) | This compound (4-cores) Time (s) | FASconCAT-G Time (s) | Phyutility Time (s) |
| Small | 100 | 10 | 2 | 1 | 5 | 8 |
| Medium | 500 | 50 | 25 | 8 | 45 | 60 |
| Large | 1000 | 100 | 60 | 18 | 110 | 150 |
Note: The data in this table is illustrative and based on performance claims. Actual times will vary depending on system hardware and dataset complexity.
Troubleshooting Workflow:
Guide 2: Managing High Memory Usage
This guide outlines steps to diagnose and manage memory consumption during this compound operations.
Experimental Protocol for Memory Profiling:
-
Establish a Baseline: Using a medium-sized dataset, run a memory-intensive this compound command, such as summary or concat.
-
Monitor Memory Usage: Use a system monitoring tool (e.g., top on Linux, Activity Monitor on macOS) to record the peak memory usage of the this compound process.
-
Process in Batches: Divide the input files into two or more batches. Run the same this compound command on each batch sequentially and record the peak memory usage for each run.
-
Analyze Data Structure: For the summary command, investigate if particular statistics require significantly more memory to compute.
-
Compare and Conclude: Analyze the recorded memory usage to determine if batch processing effectively reduces the peak memory footprint.
Logical Relationship for Memory Optimization:
References
- 1. This compound: a fast tool for alignment manipulation and computing of summary statistics - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. peerj.com [peerj.com]
- 4. This compound: a fast tool for alignment manipulation and computing of summary statistics - PubMed [pubmed.ncbi.nlm.nih.gov]
Validation & Comparative
AMAS Cancer Test: A Comparative Clinical Validation Guide
Introduction
The early detection of cancer remains a critical objective in oncology research and clinical practice. Among the various screening modalities, the Anti-Malignin Antibody in Serum (AMAS) test has been presented as a promising tool for identifying a wide range of malignancies at an early stage. This guide provides a comprehensive overview of the clinical validation studies of the this compound test, objective comparisons with other cancer screening alternatives, and the supporting experimental data for researchers, scientists, and drug development professionals.
The this compound test is a blood test that measures the concentration of anti-malignin antibodies. Malignin is a 10,000-Dalton polypeptide that has been reported to be present on the surface of most malignant cells, irrespective of their tissue of origin[1]. The rationale behind the test is that the immune system produces these antibodies in response to the presence of cancer cells, and their elevated levels in the serum can serve as a general indicator of malignancy[1][2]. The test is performed at a central laboratory, Oncolab, and requires the serum sample to be shipped overnight on dry ice[2].
Performance of the this compound Test: Clinical Validation Data
Initial studies and materials from the test developer have reported high accuracy for the this compound test. Some sources claim a sensitivity and specificity of over 95%, with repeat testing increasing accuracy to over 99%[3]. One publication mentions that in a double-blind study with 3,315 tests, the this compound test demonstrated a sensitivity and specificity of 95% on the first determination[3]. For serum analyzed within 24 hours of being drawn, the false-positive and false-negative rates are reported to be less than 1%[1].
However, independent clinical validation studies have shown more modest results, particularly in specific cancer types. A key study focused on women undergoing core breast biopsy provided a direct comparison of the this compound test results with histopathological findings.
Table 1: Performance of this compound Test in Breast Cancer Diagnosis
| Performance Metric | Value | Study Population |
| Sensitivity | 59% - 62% | 71 women undergoing core-needle breast biopsy[4][5] |
| Specificity | 62% - 69% | 71 women undergoing core-needle breast biopsy[4][5] |
This study concluded that while the this compound test could discriminate between benign and malignant/suspicious lesions, its sensitivity was insufficient to avoid biopsies, and the false-positive rate was too high for general population screening[4][5].
Comparison with Alternative Cancer Screening Tests
Carcinoembryonic Antigen (CEA)
CEA is a well-known tumor marker used in the management of several cancers, particularly colorectal cancer. Unlike the this compound test, which measures an antibody response, the CEA test measures the level of the CEA protein itself, which can be shed by tumor cells into the bloodstream.
Prostate-Specific Antigen (PSA)
The PSA test is a widely used screening tool for prostate cancer. It measures the level of a protein produced by the prostate gland. Elevated PSA levels can indicate the presence of prostate cancer, but can also be caused by other non-cancerous conditions.
Table 2: Comparison of this compound Test with CEA and PSA
| Test | Principle | Primary Use | Reported Sensitivity | Reported Specificity |
| This compound Test | Measures anti-malignin antibodies | General cancer screening | >95% (developer data)[3], 59-62% (breast cancer study)[4][5] | >95% (developer data)[3], 62-69% (breast cancer study)[4][5] |
| CEA Test | Measures Carcinoembryonic Antigen levels | Monitoring of colorectal and other cancers | Varies significantly by cancer type and stage | Varies significantly by cancer type and stage |
| PSA Test | Measures Prostate-Specific Antigen levels | Prostate cancer screening | High for advanced disease, lower for early-stage | Low, high rate of false positives |
It is important to note that the sensitivity and specificity of CEA and PSA tests are highly dependent on the specific cancer type, the stage of the disease, and the cutoff values used. For instance, the PSA test is known for its high rate of false positives, leading to unnecessary biopsies[6][7].
Experimental Protocols
This compound Test Methodology in the Breast Cancer Validation Study
The following is a summary of the experimental protocol used in the clinical validation study of the this compound test in women undergoing breast biopsy[4]:
-
Sample Collection: Blood samples were drawn by venipuncture and allowed to clot at room temperature for 30 to 120 minutes.
-
Serum Separation: The clotted blood was centrifuged at 1,500 x g for 10 minutes to separate the serum.
-
Sample Storage and Shipment: The separated serum was transferred to a sealed tube, frozen, and shipped overnight on dry ice to Oncolab for analysis.
-
Blinding: The laboratory personnel performing the this compound test were blinded to the clinical status and biopsy results of the patients. The pathologists evaluating the biopsies were also blinded to the this compound test results.
-
Data Analysis: The this compound test results were categorized as positive, negative, or borderline based on the criteria provided by Oncolab. Sensitivity and specificity were calculated, and receiver-operator curves were used to determine the optimal cutoff values.
Signaling Pathways and Experimental Workflows
To visualize the underlying principles and workflows, the following diagrams are provided.
References
- 1. sa1s3.patientpop.com [sa1s3.patientpop.com]
- 2. captodayonline.com [captodayonline.com]
- 3. Early detection and monitoring of cancer with the anti-malignin antibody test - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. aacrjournals.org [aacrjournals.org]
- 5. Discrimination of breast cancer by anti-malignin antibody serum test in women undergoing biopsy - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. At-home saliva test for prostate cancer better than blood test, study suggests | Prostate cancer | The Guardian [theguardian.com]
- 7. New urine test has higher diagnostic accuracy for prostate cancer - VUMC News [news.vumc.org]
A Comparative Analysis of the AMAS Test and Conventional Cancer Markers for Researchers and Drug Development Professionals
In the landscape of oncology research and diagnostics, the quest for sensitive and specific biomarkers is paramount for early cancer detection, monitoring treatment efficacy, and guiding drug development. This guide provides a detailed comparison of the Anti-Malignin Antibody in Serum (AMAS) test with conventional cancer markers such as Carcinoembryonic Antigen (CEA), Cancer Antigen 125 (CA-125), and Prostate-Specific Antigen (PSA).
Introduction to the this compound Test and Conventional Cancer Markers
The this compound test is a serum-based immunoassay that measures the level of anti-malignin antibodies. Malignin is a 10 kDa polypeptide that is reported to be present on the surface of most malignant cells, irrespective of their tissue of origin[1][2][3]. The test is based on the principle that the host's immune system produces IgM antibodies against this "general cancer antigen" in the early stages of malignancy[1][2]. In contrast, conventional cancer markers like CEA, CA-125, and PSA are typically glycoproteins that are shed by tumor cells into the bloodstream. Their levels are often correlated with tumor burden, making them useful for monitoring disease progression and response to therapy, though they are also associated with various non-malignant conditions[4][5].
Performance Comparison: this compound Test vs. Conventional Markers
Quantitative data on the head-to-head performance of the this compound test against conventional markers for specific cancer types is limited in peer-reviewed literature. Much of the high sensitivity and specificity data for the this compound test comes from the test's developer, Oncolab, who reports sensitivity and specificity of over 90%[6]. However, independent studies have shown more modest results.
A study on women undergoing breast biopsy found the this compound test to have a sensitivity of 59% and a specificity of 62% by Oncolab's criteria. Using receiver-operator curve analysis, the best achievable sensitivity and specificity were 62% and 69%, respectively[7][8]. The study concluded that while the this compound test can discriminate between malignant/suspicious and benign lesions, its sensitivity is insufficient to avoid biopsy, and the false-positive rate is too high for general population screening[7][8].
For comparison, the performance of conventional markers varies by cancer type and clinical context.
Table 1: Performance Characteristics of this compound Test vs. Conventional Cancer Markers
| Marker | Cancer Type(s) | Reported Sensitivity | Reported Specificity | Key Limitations |
| This compound Test | General Cancer | >90% (manufacturer claim)[6] | >90% (manufacturer claim)[6] | Limited independent validation; Lower performance in some independent studies; Not specific to cancer type. |
| Breast Cancer | 59% - 62%[7][8] | 62% - 69%[7][8] | ||
| CEA | Colorectal, Pancreatic, Gastric, Lung, Breast | 33% - 83% (for CRC recurrence)[9] | 58% - 97% (for CRC recurrence)[9] | Elevated in smokers and various benign conditions (e.g., IBD, pancreatitis, liver disease); Low sensitivity for early-stage disease[10][11]. |
| CA-125 | Ovarian | ~80% (overall), 50% (early stage)[5] | ~75%[5] | Elevated in benign gynecological conditions (e.g., endometriosis, fibroids), pregnancy, and other cancers[5][12]. |
| PSA | Prostate | High (but declines with lower cutoffs) | Low (many false positives)[13][14] | Elevated in benign prostatic hyperplasia (BPH) and prostatitis; Can lead to overdiagnosis and overtreatment of indolent cancers[14][15]. |
Experimental Protocols
This compound Test Protocol
The this compound test is a laboratory-developed test performed at Oncolab's CLIA-certified laboratory. The general protocol involves the following steps[2][7]:
-
Sample Collection: A serum sample is obtained from the patient. For optimal results, the test should be performed within 24 hours of serum collection to minimize false positives associated with frozen storage[2].
-
Immunoadsorption: The patient's serum is incubated with a proprietary "TARGET® reagent," which consists of malignin antigen covalently bound to bromoacetyl cellulose[2][7]. During this step, anti-malignin antibodies in the serum bind to the immobilized malignin.
-
Washing: The reagent is washed with cold saline to remove unbound serum components.
-
Elution: The bound anti-malignin antibodies are eluted from the reagent using acetic acid[2].
-
Quantification: The concentration of the eluted anti-malignin antibodies is then quantified. The specific method of quantification is not detailed in the available literature.
Conventional Cancer Marker Immunoassay Protocols (General ELISA)
Conventional markers like CEA, CA-125, and PSA are typically measured using sandwich enzyme-linked immunosorbent assays (ELISA). The general protocol is as follows:
-
Coating: Microplate wells are coated with a capture antibody specific to the cancer marker.
-
Blocking: Any remaining protein-binding sites on the well surface are blocked to prevent non-specific binding.
-
Sample Incubation: The patient's serum or plasma sample is added to the wells, and the cancer marker (antigen) binds to the capture antibody.
-
Washing: The wells are washed to remove unbound sample components.
-
Detection Antibody Incubation: A second, enzyme-conjugated antibody that also binds to the cancer marker (at a different epitope) is added, forming a "sandwich" with the antigen in the middle.
-
Washing: The wells are washed again to remove any unbound detection antibody.
-
Substrate Addition: A substrate for the enzyme is added, leading to a color change or light emission.
-
Detection: The intensity of the signal is measured using a microplate reader, which is proportional to the concentration of the cancer marker in the sample.
Visualizing the Methodologies and Pathways
To further elucidate the concepts discussed, the following diagrams illustrate the experimental workflows and a conceptual representation of the underlying biological principles.
References
- 1. Anti-malignin antibody evaluation: a possible challenge for cancer management - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. wa-provider.kaiserpermanente.org [wa-provider.kaiserpermanente.org]
- 3. sa1s3.patientpop.com [sa1s3.patientpop.com]
- 4. Carcinoembryonic Antigen (CEA) Biomarker | Colorectal Cancer Alliance [colorectalcancer.org]
- 5. CA125 and Ovarian Cancer: A Comprehensive Review - PMC [pmc.ncbi.nlm.nih.gov]
- 6. captodayonline.com [captodayonline.com]
- 7. aacrjournals.org [aacrjournals.org]
- 8. Discrimination of breast cancer by anti-malignin antibody serum test in women undergoing biopsy - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. m.youtube.com [m.youtube.com]
- 10. CEA colon cancer test: Purpose, how it works, and more [medicalnewstoday.com]
- 11. Cancer Antigens (CEA and CA 19-9) as Markers of Advanced Stage of Colorectal Carcinoma - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Correlation and diagnostic performance of the prostate-specific antigen level with the diagnosis, aggressiveness, and bone metastasis of prostate cancer in clinical practice - PMC [pmc.ncbi.nlm.nih.gov]
- 13. mskcc.org [mskcc.org]
- 14. New urine test has higher diagnostic accuracy for prostate cancer - VUMC News [news.vumc.org]
- 15. Oncolab Exhibits Pioneering this compound Cancer Test at AACC - aacc-2014 - mobile.Labmedica.com [mobile.labmedica.com]
A Comparative Analysis of the AMAS Test for Cancer Screening
For researchers, scientists, and drug development professionals, the quest for reliable and effective cancer screening methodologies is paramount. The Anti-Malignin Antibody in Serum (AMAS) test has been presented as a potential tool in the early detection and monitoring of various cancers. This guide provides an objective comparison of the this compound test with other established cancer screening alternatives, supported by available scientific evidence and experimental data.
Overview of the this compound Test
The this compound test is a blood test designed to detect the presence of anti-malignin antibodies. Malignin is a protein that is reported to be present on the surface of most malignant cells. The test operates on the principle that the body's immune system will produce these antibodies in response to the presence of cancer.[1][2] Proponents of the this compound test suggest it can be a general marker for a wide range of cancers at an early stage.[3][4]
Performance and Efficacy of the this compound Test
The scientific literature presents a varied picture of the this compound test's efficacy. Some studies have reported high sensitivity and specificity. For instance, a review of double-blind tests suggested a sensitivity and specificity of 95% on the first determination, and over 99% on repeat determinations for active, non-terminal cancer.[2] Another source indicates a sensitivity of 93-100% in such cases.[4]
However, other independent studies have shown less promising results. A study focusing on women undergoing breast biopsies found the this compound test to have a sensitivity of 59% and a specificity of 62% by Oncolab criteria.[5][6] The authors of this study concluded that the test's sensitivity was insufficient to spare patients from biopsy and the false-positive rate was too high for general population screening.[5] These discrepancies in reported efficacy highlight the need for further large-scale, independent validation studies.
Factors Influencing this compound Test Accuracy
Several factors may contribute to the conflicting results observed in different studies:
-
Patient Population: The stage and type of cancer, as well as the overall health and immune status of the patient, can influence antibody levels. The test is not recommended for patients with advanced or terminal cancer, as the immune response may be compromised.[4][7]
-
Specimen Handling: The stability of anti-malignin antibodies in serum is a critical factor. False-positive results have been reported to increase with the use of frozen stored serum, and it is recommended that the test be performed within 24 hours of blood collection.[8]
-
Lack of Specificity for Cancer Type: A significant limitation of the this compound test is that it is not specific to any particular type of cancer.[7] A positive result indicates the potential presence of a malignancy but does not provide information about its location or type, necessitating further diagnostic workup.
Comparison with Alternative Cancer Screening Methods
To provide a comprehensive perspective, the performance of the this compound test is compared with established screening methods for three common cancers: breast, prostate, and colorectal cancer.
Breast Cancer Screening: this compound vs. Mammography
Mammography is the current gold standard for breast cancer screening. It is an X-ray imaging method used to detect abnormalities in the breast tissue.
| Performance Metric | This compound Test (Breast Cancer Study) | Mammography |
| Sensitivity | 59% - 62%[5][6] | 78% - 87% (overall); lower in women with dense breasts[9][10] |
| Specificity | 62% - 69%[5][6] | Varies; false positives are a known limitation[9] |
Prostate Cancer Screening: this compound vs. Prostate-Specific Antigen (PSA) Test
The Prostate-Specific Antigen (PSA) test is a blood test widely used to screen for prostate cancer. It measures the level of PSA, a protein produced by the prostate gland.
| Performance Metric | This compound Test (General Cancer) | PSA Test |
| Sensitivity | High claims (95-99%), but not specific to prostate cancer[1][2] | High, but can be elevated in non-cancerous conditions[11] |
| Specificity | Variable and a subject of controversy[5][7] | Low; leads to a high rate of unnecessary biopsies[11] |
Colorectal Cancer Screening: this compound vs. Colonoscopy
Colonoscopy is considered the gold standard for colorectal cancer screening. It involves a visual examination of the entire colon and rectum using a flexible, lighted tube with a camera.
| Performance Metric | This compound Test (General Cancer) | Colonoscopy |
| Sensitivity | High claims (95-99%), but not specific to colorectal cancer[1][2] | Very high for detecting both cancer and precancerous polyps[12] |
| Specificity | Variable and a subject of controversy[5][7] | Very high[12] |
Experimental Protocols
This compound Test Protocol
The this compound test is a laboratory-developed test offered by Oncolab, Inc. The general principle involves an enzyme-linked immunosorbent assay (ELISA) or a similar immunoassay to detect anti-malignin antibodies in a patient's serum.
Specimen Collection and Handling:
-
A blood sample is collected via venipuncture.
-
The blood is allowed to clot, and the serum is separated by centrifugation.
-
To minimize the risk of false positives, the serum should be tested within 24 hours of collection.[8] If shipping is required, samples are typically sent frozen on dry ice.
Assay Principle (Based on Immunoassay Principles):
-
Malignin antigen is immobilized on a solid phase (e.g., microplate wells).
-
The patient's serum is added, and if anti-malignin antibodies are present, they will bind to the immobilized antigen.
-
The plate is washed to remove unbound components.
-
A secondary antibody conjugated to an enzyme, which binds to human antibodies, is added.
-
The plate is washed again to remove unbound secondary antibodies.
-
A substrate for the enzyme is added, leading to a color change or other detectable signal.
-
The intensity of the signal is proportional to the amount of anti-malignin antibody in the serum.
Alternative Screening Test Protocols
Mammography: A mammogram is a low-dose X-ray of the breast. The breast is compressed between two plates to spread out the tissue. Standard screening mammography typically involves two views of each breast: craniocaudal (from above) and mediolateral oblique (from the side).[13][14]
PSA Test (Immunoassay): The PSA test is typically performed using an automated immunoassay analyzer. It can be a competitive or sandwich immunoassay. In a sandwich assay, a capture antibody specific to PSA is coated on a solid phase. The patient's serum is added, followed by a labeled detection antibody. The signal generated is proportional to the PSA concentration.
Colonoscopy: Prior to the procedure, the patient undergoes a bowel preparation to cleanse the colon. During the procedure, the patient is sedated. A colonoscope is inserted into the rectum and advanced through the colon. The physician visually inspects the lining of the colon for polyps or other abnormalities. If polyps are found, they can be removed during the procedure for biopsy.[15][16][17]
Signaling Pathways and Logical Relationships
The underlying principle of the this compound test is based on the host's immune response to cancer. The presence of malignant cells, which express the malignin antigen, is thought to trigger the production of anti-malignin antibodies.
Conclusion
The this compound test presents an interesting approach to cancer screening by detecting a general immune response to malignancy. However, the conflicting scientific evidence regarding its efficacy, coupled with its non-specific nature, raises significant questions about its clinical utility as a standalone screening tool. While some studies suggest high sensitivity and specificity, others report much lower and clinically insufficient performance.
For researchers and drug development professionals, the this compound test may warrant further investigation to understand the underlying immunology and to potentially identify more specific cancer biomarkers. However, based on the current body of evidence, established screening methods such as mammography, PSA testing (with its own acknowledged limitations), and colonoscopy remain the cornerstones of early cancer detection for breast, prostate, and colorectal cancers, respectively. Any consideration of the this compound test in a clinical or research setting should be approached with a critical evaluation of the existing literature and an awareness of its current limitations.
References
- 1. Anti-malignin antibody evaluation: a possible challenge for cancer management - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Early detection and monitoring of cancer with the anti-malignin antibody test - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Oncolab Outlines Applications for this compound Antibody Test for Cancer as a Chronic Disease at NAAS Conference in San Antonio - BioSpace [biospace.com]
- 4. sa1s3.patientpop.com [sa1s3.patientpop.com]
- 5. Discrimination of breast cancer by anti-malignin antibody serum test in women undergoing biopsy - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. aacrjournals.org [aacrjournals.org]
- 7. healthknot.com [healthknot.com]
- 8. wa-provider.kaiserpermanente.org [wa-provider.kaiserpermanente.org]
- 9. uchealth.org [uchealth.org]
- 10. COMPARATIVE ACCURACY OF MAMMOGRAPHY AND ULTRASOUND IN WOMEN WITH BREAST SYMPTOMS ACCORDING TO AGE AND BREAST DENSITY - PMC [pmc.ncbi.nlm.nih.gov]
- 11. oncolink.org [oncolink.org]
- 12. Head-to-Head Diagnostic Test Accuracy Meta-analysis of Colonoscopy and Fecal Immunochemical Test in Detecting Advanced Colon Neoplasia - PMC [pmc.ncbi.nlm.nih.gov]
- 13. easternrad.com [easternrad.com]
- 14. mammographyeducation.com [mammographyeducation.com]
- 15. gastrofl.com [gastrofl.com]
- 16. Step-by-Step Colonoscopy Prep | Northwestern Medicine [nm.org]
- 17. Colonoscopy - Mayo Clinic [mayoclinic.org]
A Comparative Analysis of the Anti-Malignin Antibody Screen (AMAS) Test
For Researchers, Scientists, and Drug Development Professionals
The Anti-Malignin Antibody Screen (AMAS) test is a blood-based immunoassay intended for the early detection and monitoring of cancer. The test measures the concentration of anti-malignin antibodies, which are IgM immunoglobulins the body produces in response to malignin, a 10 kDa polypeptide reportedly present on the membranes of malignant cells across various cancer types.[1][2] This guide provides a comparative meta-analysis of the this compound test's performance as reported in key clinical studies and contrasts it with established cancer screening methods.
Performance of the this compound Test: A Tale of Conflicting Evidence
Clinical trial data on the this compound test presents a significant discrepancy in performance metrics. Studies conducted by the test's developers and associated researchers report exceptionally high sensitivity and specificity. Conversely, independent research has yielded considerably lower and less reliable results.
A pivotal study compilation by Abrams et al. (1994), which included data from 3,315 double-blind tests, reported a sensitivity and specificity of 95% on the first determination, with these figures rising to over 99% upon repeat testing.[3] This study promoted the this compound test as a general transformation antibody test, capable of detecting a wide array of non-terminal cancers regardless of their site or tissue type.[3] Another study by Thornthwaite (2000) on patients with suspicious mammograms found the this compound test to be 97% sensitive in detecting breast cancer, outperforming other markers like CEA, CA 15-3, and CA 125 in the same patient cohort.[4]
However, a notable independent study by Harman et al. (2005) on women undergoing breast biopsy presented a starkly different picture.[5] In this trial, the this compound test demonstrated a sensitivity of only 59% and a specificity of 62% based on the criteria used by Oncolab, the test's provider.[5] Using receiver-operator curve analysis, the best achievable sensitivity and specificity were only slightly better at 62% and 69%, respectively.[5] The authors concluded that the test's sensitivity was insufficient to avoid biopsies, and the high false-positive rate made it unsuitable for population screening.[5]
This discrepancy is a critical consideration for researchers and clinicians evaluating the utility of the this compound test.
Quantitative Data Summary
The following tables summarize the performance data from key studies on the this compound test and provide a comparison with standard screening methods for common cancers.
Table 1: this compound Test Performance in Key Clinical Trials
| Study (Year) | Cancer Type | Sensitivity | Specificity | Population |
| Abrams et al. (1994)[3] | General | 95% (initial), >99% (repeat) | 95% (initial), >99% (repeat) | 181 patients and controls |
| Thornthwaite (2000)[4] | Breast Cancer | 97% | Not explicitly stated for cancer vs. benign, but 4/11 benign cases were this compound positive | 76 patients and 154 healthy volunteers |
| Harman et al. (2005)[5] | Breast Cancer | 59% - 62% | 62% - 69% | 71 women undergoing core breast biopsy |
Table 2: Performance of Standard Cancer Screening Methods (for comparison)
| Screening Method | Cancer Type | Typical Sensitivity | Typical Specificity | Source(s) |
| Mammography | Breast Cancer | 69% - 87% | 89% - 94% | [6][7][8] |
| PSA Test (cutoff >4.0 ng/mL) | Prostate Cancer | 21% - 72% | 91% - 93% | [9][10][11] |
| Colonoscopy | Colorectal Cancer | 75% - 95% | 89% - 99.8% | [12][13][14][15] |
Experimental Protocols
This compound Test Protocol (as described by Oncolab)
The this compound test is a laboratory-developed test performed at Oncolab, Inc. The methodology is based on the specific immunoadsorption of anti-malignin antibody from a serum sample.[1]
-
Sample Collection and Handling : Blood must be drawn into a non-silicone coated tube and be the first tube drawn. The blood is allowed to clot at room temperature for 30-120 minutes, then refrigerated for 1-3 hours. The serum is then separated by centrifugation in a refrigerated centrifuge. The serum must be frozen immediately on dry ice for shipping.[1] The use of fresh serum (tested within 24 hours of collection) is recommended to reduce false-positive results.[16]
-
Immunoassay : The test utilizes a "Target® reagent," which consists of malignin covalently bound to bromoacetylcellulose.[1] The patient's serum is added to this reagent.
-
Antibody Elution and Quantification : After an incubation period allowing the anti-malignin antibodies to bind to the malignin on the reagent, the reagent is washed with cold saline. The bound antibodies are then eluted using acetic acid, and the amount of eluted antibody is quantified.[1] The specific values for a positive, negative, or borderline result are determined by Oncolab. The Harman et al. study noted values for "slow (S-tag)" and "fast (F-tag)" antibodies, with the "Net-Tag" being the difference, which were used in their receiver-operator curve analysis.[5]
Visualizations
References
- 1. wa-provider.kaiserpermanente.org [wa-provider.kaiserpermanente.org]
- 2. Anti-malignin antibody evaluation: a possible challenge for cancer management - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Early detection and monitoring of cancer with the anti-malignin antibody test - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Anti-malignin antibody in serum and other tumor marker determinations in breast cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Discrimination of breast cancer by anti-malignin antibody serum test in women undergoing biopsy - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. komen.org [komen.org]
- 7. pubs.rsna.org [pubs.rsna.org]
- 8. Screening Mammography Sensitivity, Specificity, & False Negative Rate 2007-2013 :: BCSC [bcsc-research.org]
- 9. Sensitivity and specificity of prostate-specific antigen for prostate cancer detection with high rates of biopsy verification - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Prostate Cancer Screening: The Continuing Controversy | AAFP [aafp.org]
- 11. droracle.ai [droracle.ai]
- 12. uspreventiveservicestaskforce.org [uspreventiveservicestaskforce.org]
- 13. Colon Cancer Screening - StatPearls - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 14. A Study of Sensitivity and Specificity of Fecal Immunochemical Test (FIT) vs. Colonoscopy for Colon Cancer Screening | JCCP (Journal of Contemporary Clinical Practice) [jccpractice.com]
- 15. researchgate.net [researchgate.net]
- 16. sa1s3.patientpop.com [sa1s3.patientpop.com]
comparing different methods for antimitochondrial antibody detection
A Comprehensive Guide to Antimitochondrial Antibody (AMA) Detection Methods
For researchers, scientists, and drug development professionals engaged in the study of autoimmune diseases, particularly Primary Biliary Cholangitis (PBC), the accurate detection of antimitochondrial antibodies (AMAs) is of paramount importance. This compound are the serological hallmark of PBC, present in 90-95% of patients, and their detection is a key component of the diagnostic criteria.[1][2] This guide provides an objective comparison of the principal methods for AMA detection, supported by experimental data, detailed methodologies, and visual workflows to aid in the selection of the most appropriate technique for specific research and diagnostic needs.
Comparison of AMA Detection Methods
The three most common techniques for AMA detection are Indirect Immunofluorescence (IIF), Enzyme-Linked Immunosorbent Assay (ELISA), and Western Blotting (WB). Each method offers distinct advantages and disadvantages in terms of sensitivity, specificity, and throughput.
Data Presentation
The following table summarizes the performance characteristics of the three main AMA detection methods based on data from multiple studies.
| Method | Principle | Typical Antigen | Sensitivity | Specificity | Advantages | Disadvantages |
| Indirect Immunofluorescence (IIF) | Patient serum is incubated with a substrate (e.g., rodent kidney/stomach/liver tissue sections or HEp-2 cells). This compound bind to mitochondria, and are detected by a fluorescently labeled secondary antibody.[3][4] | Rodent tissue sections (kidney, stomach, liver), HEp-2 cells.[3] | 71-77.78%[5][6] | 58.65-99%[5][7] | Provides information on antibody titer and staining pattern; considered the traditional "gold standard" by some. | Subjective interpretation of results; lower sensitivity and specificity compared to other methods; can have false positives.[5][6][8] |
| Enzyme-Linked Immunosorbent Assay (ELISA) | Microplate wells are coated with purified or recombinant mitochondrial antigens (often M2). Patient serum is added, and bound this compound are detected by an enzyme-conjugated secondary antibody that produces a colorimetric signal.[9] | Purified native or recombinant M2 antigens (e.g., PDC-E2, BCOADC-E2, OGDC-E2).[2] | 77.78-98%[5][10][11] | 80.77-98%[5][12] | High sensitivity and specificity; quantitative results; high throughput and automatable. | Can produce false positives; may not detect all relevant AMA subtypes if not included in the antigen preparation.[10] |
| Western Blotting (WB) | Mitochondrial antigens are separated by size via gel electrophoresis and transferred to a membrane. The membrane is incubated with patient serum, and specific this compound are detected by an enzyme-conjugated secondary antibody.[13][14] | Purified mitochondrial extracts (e.g., from bovine heart) or recombinant M2 proteins.[13][14] | 85-100%[6][11] | ~98-100%[6][11] | High sensitivity and specificity; can identify reactivity to individual mitochondrial antigens. | Labor-intensive; generally used as a confirmatory test rather than for screening.[14] |
Experimental Protocols
Below are detailed, synthesized protocols for each of the key AMA detection methods. These protocols are for informational purposes and should be adapted based on specific laboratory conditions and reagent manufacturer instructions.
Indirect Immunofluorescence (IIF) Protocol for AMA Detection
-
Sample Preparation: Dilute patient serum (e.g., 1:40) in phosphate-buffered saline (PBS).
-
Substrate Incubation: Apply the diluted serum to slides containing the antigen substrate (e.g., rodent kidney tissue sections or HEp-2 cells). Incubate in a humidified chamber for 30 minutes at room temperature.
-
Washing: Gently wash the slides with PBS to remove unbound antibodies. Repeat the wash step twice for 5 minutes each.
-
Secondary Antibody Incubation: Apply a fluorescein (B123965) isothiocyanate (FITC)-conjugated anti-human IgG secondary antibody to the slides. Incubate in a dark, humidified chamber for 30 minutes at room temperature.
-
Final Washing: Repeat the washing steps as described in step 3 to remove unbound secondary antibody.
-
Mounting and Visualization: Mount a coverslip onto the slide using a mounting medium. Examine the slide using a fluorescence microscope. A characteristic granular cytoplasmic fluorescence in the renal tubules or a cytoplasmic reticular pattern on HEp-2 cells indicates a positive result.[3][4]
ELISA Protocol for AMA-M2 Detection
-
Plate Preparation: Use a microtiter plate pre-coated with AMA-M2 antigens. Bring all reagents and samples to room temperature.
-
Sample Addition: Add 100 µL of diluted patient serum, positive controls, and negative controls to the appropriate wells. Incubate for 30-60 minutes at 37°C.
-
Washing: Aspirate the contents of the wells and wash each well 4-5 times with wash buffer. Ensure complete removal of liquid after the final wash by inverting the plate and blotting it on absorbent paper.
-
Enzyme Conjugate Addition: Add 100 µL of HRP-conjugated anti-human IgG to each well. Incubate for 30 minutes at 37°C.
-
Washing: Repeat the washing step as described in step 3.
-
Substrate Addition: Add 100 µL of TMB substrate solution to each well. Incubate in the dark for 15-20 minutes at 37°C.
-
Stopping the Reaction: Add 50 µL of stop solution to each well. The color will change from blue to yellow.
-
Data Acquisition: Read the absorbance of each well at 450 nm using a microplate reader. The concentration of AMA-M2 in the samples is determined by comparing their absorbance to a standard curve.[9][15]
Western Blotting Protocol for AMA Detection
-
Antigen Preparation and Electrophoresis: Separate a mitochondrial antigen preparation (e.g., bovine heart mitochondria) by SDS-PAGE.
-
Protein Transfer: Transfer the separated proteins from the gel to a nitrocellulose or PVDF membrane.
-
Blocking: Block the membrane with a blocking buffer (e.g., 5% non-fat dry milk in Tris-buffered saline with Tween 20 - TBST) for 1 hour at room temperature to prevent non-specific antibody binding.
-
Primary Antibody Incubation: Incubate the membrane with diluted patient serum (e.g., 1:1000 to 1:5000) in blocking buffer for 1 hour at room temperature or overnight at 4°C.
-
Washing: Wash the membrane with TBST three times for 5-10 minutes each to remove unbound primary antibodies.
-
Secondary Antibody Incubation: Incubate the membrane with an HRP-conjugated anti-human IgG secondary antibody diluted in blocking buffer for 1 hour at room temperature.
-
Final Washing: Repeat the washing step as described in step 5.
-
Detection: Add a chemiluminescent substrate to the membrane and detect the signal using an imaging system. The presence of bands corresponding to the molecular weights of known mitochondrial autoantigens (e.g., the 74 kDa PDC-E2 subunit) indicates a positive result.[13][14]
Mandatory Visualization
The following diagrams illustrate the experimental workflows and logical relationships in AMA detection and its diagnostic application.
Caption: Experimental workflows for the three main AMA detection methods.
Caption: Diagnostic workflow for Primary Biliary Cholangitis (PBC).
References
- 1. sinobiological.com [sinobiological.com]
- 2. Detection of M2-Type Anti-Mitochondrial Autoantibodies against Specific Subunits in the Diagnosis of Primary Biliary Cholangitis in Patients with Discordant Results - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. Detection of Autoantibodies by Indirect Immunofluorescence Cytochemistry on Hep-2 Cells | Springer Nature Experiments [experiments.springernature.com]
- 5. Comparison of Indirect Immunofluorescence and Enzyme Immunoassay for the Detection of Antinuclear Antibodies - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Comparison of Machine Learning and Statistical Approaches of Detecting Anomalies Using a Simulation Study | Econometrics. Ekonometria. Advances in Applied Data Analysis [journals.ue.wroc.pl]
- 7. researchgate.net [researchgate.net]
- 8. Analysis, Design, and Comparison of Machine-Learning Techniques for Networking Intrusion Detection [mdpi.com]
- 9. elkbiotech.com [elkbiotech.com]
- 10. researchgate.net [researchgate.net]
- 11. Comparison of Enzyme-Linked Immunosorbent Assay, Western Blotting, Microagglutination, Indirect Immunofluorescence Assay, and Flow Cytometry for Serological Diagnosis of Tularemia - PMC [pmc.ncbi.nlm.nih.gov]
- 12. protocols.io [protocols.io]
- 13. Reference standards for the detection of anti-mitochondrial and anti-rods/rings autoantibodies - PMC [pmc.ncbi.nlm.nih.gov]
- 14. [Western blot analysis of anti-M2 antibodies in anti-mitochondrial antibody-negative primary biliary cirrhosis] - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. cusabio.com [cusabio.com]
A Comparative Guide to Anti-Mitochondrial Antibody (AMA) Testing in the Diagnosis of Autoimmune Liver Disease
For Researchers, Scientists, and Drug Development Professionals
The detection of anti-mitochondrial antibodies (AMAs) is a cornerstone in the diagnosis of autoimmune liver diseases, particularly Primary Biliary Cholangitis (PBC). The choice of analytical method for AMA detection significantly impacts diagnostic accuracy. This guide provides an objective comparison of the performance of various AMA testing methodologies, supported by experimental data, to aid researchers and clinicians in selecting the most appropriate assay for their needs.
Comparison of AMA Testing Methodologies
The validation of AMA testing is crucial for the accurate diagnosis of PBC. Several techniques are available, each with distinct performance characteristics. The most common methods include indirect immunofluorescence (IIF), enzyme-linked immunosorbent assay (ELISA), and immunoblotting (IB). A newer method, the multiplex bead-based flow fluorescent immunoassay (MBFFI), is also gaining traction.
A meta-analysis of 24 studies on AMA testing revealed a pooled sensitivity of 84% and a specificity of 98% for the diagnosis of PBC.[1] The M2 subtype of AMA (AMA-M2) is particularly specific for PBC.[2][3] A meta-analysis of sixteen studies focusing on the M2 subtype demonstrated a pooled sensitivity of 89% and a specificity of 96%.[1]
However, the performance of these tests can vary depending on the specific technique and the antigens used. For instance, one study found that while IIF is a common screening tool, Western immunoblotting (W-IB) and ELISA assays can be more sensitive and specific.[4] In this particular study, W-IB detected this compound in 85% of PBC patients, compared to 71-72% for IIF.[4] Furthermore, combining different methods can significantly improve diagnostic sensitivity. Integrating a multiple immunodot liver profile with IIF has been shown to increase diagnostic sensitivity from 89.1% to 98.8%.[5]
Here is a summary of the performance of different AMA testing methods:
| Test Method | Antigens Detected | Sensitivity | Specificity | Positive Predictive Value (PPV) | Negative Predictive Value (NPV) | Key Advantages | Key Limitations |
| Indirect Immunofluorescence (IIF) | Various mitochondrial antigens | 71-89.6%[4][5] | 97.4%[6] | 0.94[6] | - | Widely available, provides titer information. | Subjective interpretation, lower sensitivity than other methods.[4] |
| Enzyme-Linked Immunosorbent Assay (ELISA) | M2, M2-3E fusion protein | 78-81.1%[4] | 97.8%[4] | - | - | Quantitative, high throughput. | Can have false positives, may be less specific than IIF.[7] |
| Immunoblotting (IB) / Western Blot (W-IB) | M2, M2-3E, sp100, gp210 | 85% (W-IB)[4] | 97.8% (W-IB)[4] | - | - | High specificity, can detect multiple autoantibodies simultaneously. | More complex, may be less sensitive for certain antigens. |
| Multiplex Bead-Based Flow Fluorescent Immunoassay (MBFFI) | AMA-M2, gp210, sp100 | 85.71% (AMA-M2)[8] | 78% (AMA-M2)[8] | 91.01% (anti-gp210)[8] | - | High throughput, simultaneous detection of multiple antibodies. | Newer technology, may have lower specificity for some antibodies.[8] |
Experimental Protocols
Detailed experimental protocols are essential for reproducing and validating these findings. Below are generalized methodologies for the key AMA testing techniques.
Indirect Immunofluorescence (IIF)
IIF is a traditional method for AMA detection. The protocol generally involves the following steps:
-
Substrate Preparation : Cryostat sections of rodent (rat or mouse) kidney, stomach, and liver tissue, or HEp-2 cells are used as substrates.[5][6]
-
Serum Incubation : Patient serum is diluted (e.g., 1:40) and incubated with the substrate to allow for the binding of this compound to the mitochondrial antigens within the tissue or cells.
-
Washing : The substrate is washed to remove unbound antibodies.
-
Secondary Antibody Incubation : A fluorescently labeled anti-human IgG antibody is added and incubated. This antibody binds to the patient's this compound that are bound to the substrate.
-
Washing : A final wash is performed to remove the unbound secondary antibody.
-
Microscopy : The substrate is examined under a fluorescence microscope. A characteristic granular cytoplasmic staining pattern indicates the presence of this compound. The titer is determined by the highest dilution of serum that still produces a positive result.
Enzyme-Linked Immunosorbent Assay (ELISA)
ELISA is a quantitative method that often uses recombinant or purified antigens. A common protocol for AMA-M2 ELISA is as follows:
-
Coating : Microtiter wells are coated with purified or recombinant mitochondrial antigens, such as the M2 subtype (PDC-E2, BCOADC-E2, OGDC-E2).[9]
-
Blocking : The wells are treated with a blocking buffer to prevent non-specific binding.
-
Sample Incubation : Diluted patient serum (e.g., 1:100) is added to the wells and incubated for 30 minutes at room temperature.[9]
-
Washing : The wells are washed multiple times with a wash solution to remove unbound antibodies.
-
Enzyme Conjugate Incubation : An enzyme-conjugated anti-human IgG (e.g., horseradish peroxidase-conjugated) is added to each well and incubated for 15 minutes at room temperature.[9]
-
Washing : The wells are washed again to remove the unbound conjugate.
-
Substrate Addition : A chromogenic substrate (e.g., TMB) is added, and the plate is incubated for 15 minutes at room temperature.[9]
-
Stopping the Reaction : A stop solution is added to halt the color development.
-
Reading : The optical density is measured using a microplate reader at a specific wavelength (e.g., 450 nm). The results are then calculated based on a standard curve.
Immunoblotting (IB)
Immunoblotting allows for the detection of antibodies against a panel of specific antigens.
-
Antigen Strips : Commercially available immunoblot strips are coated with multiple, separated liver-specific antigens, including AMA-M2, M2-3E, Sp100, and gp210.[6]
-
Serum Incubation : The strips are incubated with diluted patient serum, allowing autoantibodies to bind to their specific antigen bands.
-
Washing : The strips are washed to remove unbound antibodies.
-
Enzyme-Conjugated Secondary Antibody Incubation : An enzyme-conjugated anti-human IgG is added and incubated with the strips.
-
Washing : The strips are washed again to remove the unbound secondary antibody.
-
Substrate Incubation : A substrate is added that reacts with the enzyme to produce a colored band at the location of the specific antigen-antibody complex.
-
Analysis : The presence and intensity of the bands are analyzed, often with the assistance of automated scanning and software.
Visualizing the Diagnostic Process and Methodologies
To further clarify the experimental workflows and diagnostic pathways, the following diagrams are provided.
Caption: Diagnostic workflow for autoimmune liver disease.
Caption: Overview of AMA testing methodologies.
References
- 1. ibl-international.com [ibl-international.com]
- 2. AMA-M2 ELISA Kit (Anti-Mitochondrial Antibodies M2) [elisakits.co.uk]
- 3. The risk of development of primary biliary cholangitis among incidental antimitochondrial M2 antibody-positive patients - PMC [pmc.ncbi.nlm.nih.gov]
- 4. KoreaMed [koreamed.org]
- 5. Pathology [thepathologycentre.org]
- 6. Performance of indirect immunofluorescence test and immunoblot tests in the evaluation of antinuclear and antimitochondrial antibodies - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Clinical performance of AMA-M2, anti-gp210 and anti-sp100 antibody levels in primary biliary cholangitis: When detected by multiplex bead-based flow fluorescent immunoassay - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Detection of anti-mitochondrial antibodies by ELISA and Western-blot techniques and identification by one and two-dimensional gel electrophoresis of M2 target antigens - PMC [pmc.ncbi.nlm.nih.gov]
- 9. demeditec.com [demeditec.com]
A Comparative Analysis of AMAS and MAFFT in Sequence Analysis Workflows
In the realm of bioinformatics, particularly in phylogenomics and molecular evolution, researchers rely on a suite of powerful software tools to decipher the stories hidden within biological sequences. Among the essential tasks are multiple sequence alignment (MSA) and the subsequent manipulation of these alignments for downstream analyses. This guide provides a comparative analysis of two widely used tools: AMAS (Alignment Manipulation And Summary) and MAFFT (Multiple Alignment using Fast Fourier Transform). While both are integral to sequence analysis pipelines, they serve distinct and complementary roles. This document will elucidate their core functionalities, present a comparison of their features, and illustrate how they can be used in conjunction within a typical research workflow.
Core Functionality: Alignment Generation vs. Alignment Manipulation
The fundamental difference between MAFFT and this compound lies in their primary purpose. MAFFT is a de novo multiple sequence alignment program.[1][2] It takes a set of unaligned nucleotide or amino acid sequences and produces a multiple sequence alignment.[1][2] MAFFT is renowned for its speed and accuracy, offering a range of algorithms suitable for different scenarios, from a small number of sequences to very large datasets.[1][3]
This compound, on the other hand, is not an alignment generation tool.[4][5][6] Instead, it is a powerful utility for the manipulation and statistical summarization of existing multiple sequence alignments.[4][5][6] In modern phylogenomic studies, which often involve hundreds or thousands of genes, researchers need efficient tools to handle these large datasets. This compound is designed to address this need by providing functionalities for format conversion, concatenation of multiple alignments, and the calculation of various summary statistics.[4][7]
Feature Comparison
To better understand the distinct roles of this compound and MAFFT, the following table summarizes their key features.
| Feature | This compound (Alignment Manipulation And Summary) | MAFFT (Multiple Alignment using Fast Fourier Transform) |
| Primary Function | Manipulation and summarization of existing alignments[4][5][6] | De novo multiple sequence alignment of nucleotide or amino acid sequences[1][2] |
| Input | One or more existing multiple sequence alignment files (e.g., FASTA, PHYLIP, NEXUS)[4] | Unaligned nucleotide or amino acid sequences in FASTA format[3] |
| Key Capabilities | - Format conversion between FASTA, PHYLIP, and NEXUS[4] - Concatenation of multiple alignments[4] - Calculation of summary statistics (e.g., alignment length, missing data, GC content, parsimony-informative sites)[4][7] - Splitting and extracting subsets of alignments[4] - Removal of taxa[4] | - Multiple alignment algorithms (e.g., L-INS-i for high accuracy, FFT-NS-2 for high speed)[3] - Iterative refinement to improve alignment quality[2] - Addition of new sequences to an existing alignment[8] - Support for protein and nucleotide sequences[8] |
| Performance Focus | Computational efficiency in handling and processing very large alignment files[7] | Speed and accuracy of the alignment algorithm[2] |
| Use Case | Preparing large, concatenated datasets for phylogenetic analysis from individual gene alignments.[4] | Generating the initial multiple sequence alignments for individual genes or proteins.[1] |
Experimental Protocols: A Typical Phylogenomic Workflow
In a typical phylogenomic study, a researcher would use MAFFT and this compound in a sequential workflow. The goal is often to infer the evolutionary relationships between species using a large number of genes.
Step 1: Sequence Data Acquisition The process begins with obtaining the sequence data for the genes of interest from public databases or through sequencing experiments.
Step 2: Individual Gene Alignment with MAFFT For each gene, the corresponding sequences from all taxa are collected into a single FASTA file. MAFFT is then used to create a multiple sequence alignment for each gene. A researcher might use a high-accuracy algorithm like L-INS-i for smaller datasets or a faster algorithm like FFT-NS-2 for larger numbers of sequences. The output of this step is a separate alignment file for each gene.
Step 3: Alignment Manipulation and Concatenation with this compound Once all genes are aligned, this compound is used to process these individual alignments. A researcher might first use this compound to convert all alignment files to a consistent format (e.g., NEXUS). Then, the core function of this compound in this workflow comes into play: concatenation. This compound can take all the individual gene alignments and concatenate them into a single, large supermatrix.[4] During this process, this compound also generates a partition file that specifies the coordinates of each gene within the concatenated alignment, which is crucial for subsequent phylogenetic analyses.[4] Additionally, this compound can be used to calculate summary statistics for the concatenated alignment, such as the proportion of missing data and the number of parsimony-informative sites.[7]
Step 4: Phylogenetic Inference The concatenated supermatrix and the partition file generated by this compound are then used as input for phylogenetic inference software (e.g., RAxML, IQ-TREE) to reconstruct the evolutionary tree.
Workflow Visualization
The following diagram illustrates the typical phylogenomic workflow described above, highlighting the distinct roles of MAFFT and this compound.
References
- 1. MAFFT - Wikipedia [en.wikipedia.org]
- 2. MAFFT: a novel method for rapid multiple sequence alignment based on fast Fourier transform - PMC [pmc.ncbi.nlm.nih.gov]
- 3. MAFFT - a multiple sequence alignment program [mafft.cbrc.jp]
- 4. This compound: a fast tool for alignment manipulation and computing of summary statistics - PMC [pmc.ncbi.nlm.nih.gov]
- 5. peerj.com [peerj.com]
- 6. This compound: a fast tool for alignment manipulation and computing of summary statistics [PeerJ Preprints] [peerj.com]
- 7. This compound: a fast tool for alignment manipulation and computing of summary statistics [PeerJ] [peerj.com]
- 8. MAFFT Multiple Sequence Alignment Software Version 7: Improvements in Performance and Usability - PMC [pmc.ncbi.nlm.nih.gov]
AMAS Speed and Accuracy: A Performance Benchmark for Phylogenomic Data Handling
For researchers and scientists engaged in drug development and phylogenomics, the efficient and accurate processing of large-scale sequence alignments is a critical bottleneck. AMAS (Alignment Manipulation And Summary) is a command-line tool and Python package designed to address this challenge by offering high-speed manipulation and statistical analysis of multiple sequence alignments. This guide provides an objective performance comparison of this compound against two common alternatives, FASconCAT-G and Phyutility, supported by experimental data on speed and functionality.
Performance Benchmark: Speed
The primary performance metric for alignment manipulation tools is processing speed, particularly for concatenation, a frequent task in phylogenomic workflows.[1] Experimental data reveals that this compound consistently outperforms both FASconCAT-G and Phyutility in concatenation speed, often by a significant margin.
Concatenation Speed Comparison
The performance of each tool was benchmarked using four phylogenomic datasets of varying size and complexity. The time taken to concatenate these datasets highlights the superior speed of this compound. For instance, on a dataset of 5,214 amino acid loci, this compound completed the concatenation in under 2 seconds.[2] In contrast, FASconCAT-G required over 36 seconds, and Phyutility took approximately 10 minutes for the same task.[1][2] On the largest dataset of 8,295 exons, this compound finished in under 18 seconds, while Phyutility's processing time exceeded three hours.[2]
| Dataset Description | This compound | FASconCAT-G | Phyutility |
| 5,214 amino acid loci | < 2 seconds | > 36 seconds | ~ 10 minutes |
| 1,478 amino acid loci | - | > 250 seconds | - |
| 8,295 exon DNA loci | < 18 seconds | Crashed | > 3 hours |
Table 1: Concatenation time comparison across different phylogenomic datasets. This compound demonstrates a substantial speed advantage, being at least 30 times faster than its competitors in tested scenarios.[2] Note: FASconCAT-G crashed when attempting to process the nucleotide FASTA files from the Jarvis et al. (2014) dataset.[2]
Summary Statistics Speed Comparison
This compound also demonstrates high efficiency in calculating and summarizing alignment statistics. For the smallest dataset, this compound generated summaries in approximately 35 seconds, whereas FASconCAT-G, when performing concatenation and summary computation simultaneously, took over 500 seconds.[3]
Performance Benchmark: Accuracy and Functionality
In the context of alignment manipulation, "accuracy" refers to the correct and robust parsing of various file formats and the precise execution of commands like concatenation, splitting, and taxon removal. While direct quantitative accuracy benchmarks are not standard for these functions, a tool's robustness can be inferred from its feature set and supported formats.
This compound is recognized as a fast and robust program for manipulations in phylogenetic inference.[2] It is designed to handle very large alignments with hundreds of taxa and thousands of loci.[1][4]
Feature and Functionality Comparison
The choice of a tool often depends on the specific needs of a research pipeline. This compound, FASconCAT-G, and Phyutility offer a range of overlapping and unique functionalities.
| Feature | This compound | FASconCAT-G | Phyutility |
| Core Functions | |||
| Concatenation | Yes | Yes | Yes |
| Format Conversion | Yes | Yes | Yes |
| Summary Statistics | Yes | Yes | No |
| Splitting / Site Extraction | Yes | Yes | Yes (gaps only) |
| Taxon Removal | Yes | Yes | Yes |
| Supported Input Formats | |||
| FASTA | Yes | Yes | Yes |
| PHYLIP (sequential & interleaved) | Yes | Yes | No |
| NEXUS (sequential & interleaved) | Yes | No | Yes |
| CLUSTAL | No | Yes | No |
| Unique/Advanced Features | |||
| Create Replicate Alignments | Yes | No | No |
| Generate MrBayes Blocks | No | Yes | No |
| Tree Manipulation | No | No | Yes |
| NCBI Database Interaction | No | No | Yes |
Table 2: A comparative overview of the main functions and supported file formats for this compound, FASconCAT-G, and Phyutility.[5]
Experimental Protocols
The performance benchmarks cited in this guide are based on the methodologies described in the 2016 PeerJ publication on this compound.
System Specifications: The performance tests were conducted on a desktop computer with the following specifications:
-
CPU: 12 Intel(R) Core(TM) i7-4930K CPUs @ 3.40Ghz
-
RAM: 32GB of DDR3 RAM @ 1600Hz
-
Storage: 4TB 7200rpm hard drive
-
Operating System: Ubuntu 12.04LTS
Benchmarking Procedure: Execution times for all commands were measured using the standard Unix time -p command. To ensure reliability, each command was run three times with minimal background system load, and the best time was recorded.
Tool Versions and Commands:
-
This compound: The commands tested included this compound.py concat for concatenation and this compound.py summary for generating statistics.[6]
-
FASconCAT-G (v1.02): Concatenation was tested in two modes: with the -i option for faster computation without simultaneous statistics, and with the -s option for simultaneous summary calculation.[5][6]
-
Phyutility: The command used for concatenation was java -jar phyutility.jar -concat.[3][6]
Visualizing the Workflow
A typical phylogenomic analysis workflow involves several key stages where a tool like this compound is instrumental. The following diagram illustrates this process.
References
- 1. Google Code Archive - Long-term storage for Google Code Project Hosting. [code.google.com]
- 2. researchgate.net [researchgate.net]
- 3. GitHub - marekborowiec/AMAS: Calculate summary statistics and manipulate multiple sequence alignments [github.com]
- 4. researchgate.net [researchgate.net]
- 5. peerj.com [peerj.com]
- 6. GitHub - blackrim/phyutility [github.com]
A Head-to-Head Comparison of AMAS and Geneious for Alignment Summary Statistics
In the realm of molecular biology and bioinformatics, the analysis of sequence alignments is a fundamental task. Researchers, scientists, and drug development professionals frequently need to distill large alignment files into concise summary statistics to understand the characteristics of their data before downstream analyses such as phylogenetic inference or variant calling. Two popular tools often employed for this purpose are AMAS (Alignment Manipulation And Summary) and Geneious. This guide provides an objective comparison of their capabilities for generating alignment summary statistics, supported by a standardized experimental protocol and data presentation.
Executive Summary
This compound is a lightweight, command-line tool specifically designed for the rapid calculation of summary statistics from large sequence alignments. It excels in high-throughput environments where automation and computational efficiency are paramount. Geneious, on the other hand, is a comprehensive, GUI-based suite of molecular biology tools that offers a wide array of functionalities, including alignment creation, editing, and visualization. While Geneious provides alignment statistics, they are presented within an interactive graphical interface, geared towards visual exploration rather than the generation of simple, script-friendly output files.
The choice between this compound and Geneious for alignment summary statistics will largely depend on the user's specific needs: for automated, high-throughput analysis of many alignments, this compound is the superior choice. For researchers who prefer an integrated graphical environment and visual inspection of their alignments, Geneious provides a more holistic, albeit less direct, approach to obtaining summary statistics.
Methodology: A Standardized Experimental Protocol
To objectively compare this compound and Geneious, a standardized experimental protocol was devised. This protocol outlines the steps to generate and analyze alignment summary statistics from a sample dataset using both tools.
Dataset: A hypothetical DNA sequence alignment file named sample_alignment.fasta is used. This file contains 10 sequences, each 1000 base pairs in length. The alignment includes conserved regions, variable sites, parsimony-informative sites, and gaps.
Experimental Workflow:
Protocol for this compound:
-
Installation: this compound is a Python-based tool and can be installed via package managers or from its source code.
-
Execution: Open a terminal or command prompt.
-
Command: Execute the following command:
-
Output: A text file named summary.txt is generated in the same directory, containing the alignment summary statistics.
Protocol for Geneious:
-
Installation: Geneious is a desktop application that requires a license and installation of the software package.
-
Import: Launch Geneious and import the sample_alignment.fasta file.
-
View Alignment: Open the imported alignment file in the sequence viewer.
-
Access Statistics: On the right-hand panel of the sequence viewer, navigate to the "Statistics" tab.
-
Data Extraction: Manually transcribe the relevant statistics from the "Statistics" tab into a separate file or document. Note that some statistics, like the number of parsimony-informative sites, may require navigating to other program functions, such as the phylogenetic tree building tools which often provide this as part of the analysis setup.
Data Presentation: A Comparative Analysis
The following table summarizes the hypothetical quantitative data obtained from both this compound and Geneious for the sample_alignment.fasta dataset. This table highlights the key summary statistics provided by each tool.
| Statistic | This compound | Geneious |
| Number of Taxa | 10 | 10 |
| Alignment Length | 1000 bp | 1000 bp |
| Number of Variable Sites | 150 | 150 (via visual highlighting or consensus comparison) |
| Number of Parsimony-Informative Sites | 75 | Calculated via phylogenetic tools (e.g., PAUP* plugin) |
| Percentage of Missing Data (Gaps) | 5.2% | Displayed in statistics panel |
| Nucleotide Frequencies (A, C, G, T) | A: 28.5%, C: 21.3%, G: 22.7%, T: 27.5% | Displayed in statistics panel |
| GC Content | 44.0% | Displayed in statistics panel |
| Output Format | Plain text file | Interactive GUI panel (manual transcription required) |
| High-Throughput Capability | High (scriptable) | Low (manual intervention required per alignment) |
In-Depth Comparison
This compound: The Command-Line Powerhouse
This compound is purpose-built for the efficient calculation of alignment summary statistics.[1][2] Its command-line interface makes it ideal for integration into bioinformatics pipelines and for processing large numbers of alignments in a single batch. The tool is lightweight and has no external dependencies beyond standard Python libraries.[1]
The key strengths of this compound are:
-
Speed and Efficiency: this compound is designed to handle very large datasets with hundreds or thousands of taxa and loci.[1][2]
-
Automation: As a command-line tool, it can be easily scripted to process entire directories of alignment files, making it highly suitable for phylogenomic-scale projects.
-
Standardized Output: It generates a clean, easy-to-parse text file containing a comprehensive set of summary statistics.[1] This includes critical metrics for phylogenetic analysis like the number of parsimony-informative sites.
Geneious: The Interactive Visualization Suite
Geneious is a comprehensive bioinformatics software platform with a strong emphasis on user-friendly visualization and interaction. While it does not have a dedicated "generate summary report" function in the same vein as this compound, it provides statistical information dynamically within its alignment viewer.
The key features of Geneious in this context are:
-
Integrated Environment: All tools, from sequence alignment to phylogenetic tree construction, are within a single application. This can be advantageous for researchers who prefer a unified workflow.
-
Interactive Statistics: The "Statistics" tab provides real-time feedback on the alignment.[3] For instance, selecting a region of the alignment will update the statistics to reflect only that selection.
-
Visual Feedback: Geneious excels at visualizing alignment features. Variable sites can be easily identified using the "Highlighting" function, which colors disagreements with the consensus sequence.[1] This visual approach can be more intuitive for some users than a simple numerical count.
-
Extensibility: Geneious functionality can be extended with plugins. For example, the calculation of parsimony-informative sites is typically performed in the context of phylogenetic tree building, which can be done using plugins like PAUP*.[4]
Conclusion
This compound and Geneious represent two different philosophies for obtaining alignment summary statistics. This compound is a specialized, non-visual tool that prioritizes speed, automation, and the generation of standardized, machine-readable output. It is the ideal choice for bioinformaticians and researchers working with large datasets who need to programmatically extract and compare statistics across many alignments.
Geneious, in contrast, integrates summary statistics into its rich, interactive graphical interface. It is well-suited for researchers who work on a smaller number of alignments and who benefit from the visual exploration of their data. While it can provide much of the same information as this compound, the process is manual and less amenable to high-throughput analysis. The choice between these two powerful tools will ultimately be guided by the scale of the research and the preferred workflow of the user.
References
AMAS: A Comparative Guide to Dataset Generation in Phylogenetic Inference
In the realm of phylogenomics, the assembly of large-scale datasets is a critical bottleneck. For researchers, scientists, and drug development professionals, the efficiency and accuracy of tools used to manipulate and concatenate multiple sequence alignments can significantly impact the pace of discovery. This guide provides a comparative analysis of AMAS (Alignment Manipulation And Summary), a prominent tool for this purpose, against its alternatives, supported by experimental data.
The Role of this compound in Phylogenetic Inference
Phylogenetic inference from genomic data often involves the analysis of numerous gene alignments. These individual alignments are frequently concatenated into a supermatrix for downstream analysis. This compound is a command-line tool designed to streamline this process, offering functionalities for concatenation, format conversion, and the calculation of summary statistics for sequence alignments. Its primary design consideration is to efficiently handle the large datasets typical of modern phylogenomic studies.
A crucial point of validation is whether the output of a concatenation tool is correct. For the benchmark datasets used in its evaluation, this compound produces concatenated alignments that are identical to those generated by alternative tools like FASconCAT-G and Phyutility[1]. This indicates that the choice between these tools for standard concatenation tasks does not influence the accuracy of the subsequent phylogenetic inference, but rather the speed and efficiency of the research workflow.
Performance Benchmarks: this compound vs. Alternatives
The primary advantage of this compound lies in its computational performance. The following tables summarize the performance of this compound in comparison to two other popular tools, FASconCAT-G and Phyutility, for concatenation and summary statistics calculation on benchmark phylogenomic datasets.
Concatenation Speed
Experimental data demonstrates that this compound is substantially faster at concatenating large numbers of alignments than both FASconCAT-G and Phyutility[2][3].
| Dataset (Number of Loci) | This compound (seconds) | FASconCAT-G (seconds) | Phyutility (seconds) |
| Johnson et al. (2013) Amino Acids (5,214) | ~2 | >70 | ~600 |
| Misof et al. (2014) Amino Acids (1,478) | - | ~260 | - |
| Jarvis et al. (2014) UCE DNA (3,769) | <18 | Crashed | >10,800 |
| Jarvis et al. (2014) Exon DNA (8,295) | <18 | Crashed | >10,800 |
Table 1: Comparison of concatenation times for this compound, FASconCAT-G, and Phyutility on various phylogenomic datasets. This compound shows a significant speed advantage, outperforming the other programs by a factor of 30 or more.[2][3]
Calculation of Summary Statistics
This compound also demonstrates high efficiency in calculating summary statistics for large, concatenated alignments.
| Dataset | This compound (seconds) |
| Johnson et al. (2013) | ~35 |
| Misof et al. (2014) | ~100 |
| Jarvis et al. (2014) UCE | ~150 |
| Jarvis et al. (2014) Exons | ~200 |
Table 2: Time taken by this compound to calculate summary statistics on concatenated benchmark datasets. FASconCAT-G is noted to be significantly slower for this task.[3]
Functional Comparison
Beyond speed, the choice of a tool can depend on its specific functionalities and dependencies.
| Feature | This compound | FASconCAT-G | Phyutility |
| Primary Function | Alignment manipulation and summary | Alignment manipulation and concatenation | General phylogenetic utility |
| Dependencies | Python 3 | Perl | Java |
| Input Formats | FASTA, PHYLIP, NEXUS | FASTA, PHYLIP, CLUSTAL | FASTA, NEXUS |
| Concatenation | Yes | Yes | Yes |
| Summary Statistics | Yes | Yes | No |
| Parallel Processing | Yes | No | No |
| Python Package | Yes | No | No |
Table 3: Overview of key features and functionalities of this compound, FASconCAT-G, and Phyutility.[4]
Experimental Protocols
The performance benchmarks cited in this guide are based on the methodologies detailed in the original publication for this compound.
Benchmark Datasets: Four publicly available phylogenomic datasets were used:
-
Johnson et al. (2013): 5,214 amino acid exon alignments from 19 hymenopteran taxa.[3]
-
Misof et al. (2014): 1,478 amino acid and DNA alignments from 144 arthropod taxa.[3]
-
Jarvis et al. (2014) UCEs: 3,769 Ultra Conserved Element DNA alignments from 49 amniote taxa.[2]
-
Jarvis et al. (2014) Exons: 8,295 exon DNA alignments from 52 vertebrate taxa.[2]
Benchmarking Environment: The performance tests were conducted on a desktop computer with the following specifications:
-
CPU: 12 Intel Core i7-4930K CPUs @ 3.40 GHz
-
RAM: 32 GB of DDR3 RAM @ 1,600 Hz
-
Operating System: 64-bit Ubuntu 12.04LTS[2]
Software Versions:
-
This compound: The version described in the 2016 PeerJ publication.
-
FASconCAT-G: v1.02
Commands: For concatenation benchmarks, the respective command-line tools were used as per their documentation to combine the individual locus files into a single supermatrix. For this compound, both single-core and multi-core performance were assessed.
Visualizing the Phylogenomic Workflow
The following diagrams illustrate the typical workflow for preparing a concatenated dataset for phylogenetic analysis and the logical relationship of this compound within this process.
A typical phylogenomic workflow.
This compound inputs and outputs in a workflow.
Conclusion
The validation of this compound-generated datasets for phylogenetic inference hinges on two key aspects: the correctness of the output and the efficiency of its generation. Experimental evidence confirms that this compound produces identical concatenated alignments to its alternatives, ensuring that the resulting dataset does not introduce biases into the phylogenetic analysis. The primary differentiator is performance; this compound offers a significant speed advantage, particularly for the large datasets common in modern phylogenomics. This efficiency can substantially accelerate research timelines, making this compound a valuable tool for scientists in phylogenetics and related fields.
References
- 1. Dryad | Data: this compound: a fast tool for large alignment manipulation and computing of summary statistics [datadryad.org]
- 2. This compound: a fast tool for alignment manipulation and computing of summary statistics - PMC [pmc.ncbi.nlm.nih.gov]
- 3. peerj.com [peerj.com]
- 4. researchgate.net [researchgate.net]
Safety Operating Guide
Navigating the Disposal of AMAS: A Comprehensive Guide for Laboratory Professionals
Essential protocols for the safe handling and disposal of AMAS (N-α-maleimidoacet-oxysuccinimide ester), a common crosslinking agent, are critical for ensuring laboratory safety and environmental compliance. Due to its reactive nature, this compound and associated waste require careful management from point of use to final disposal.
Immediate Safety and Handling
Before initiating any disposal-related activities, it is imperative to consult your institution's Environmental Health and Safety (EHS) guidelines. Proper personal protective equipment (PPE) is mandatory when handling this compound in any form. This includes chemical-resistant gloves (such as nitrile), safety goggles with side shields, and a laboratory coat. All handling of solid this compound and concentrated solutions should be conducted in a certified chemical fume hood to prevent inhalation of dust or aerosols.
Quantitative Data Summary
For quick reference, the following table summarizes the key information for the safe handling and disposal of this compound.
| Parameter | Specification | Citation |
| Synonyms | Maleimidoacetic acid N-hydroxysuccinimide ester | |
| Molecular Formula | C10H8N2O6 | |
| Primary Hazards | Irritating to eyes, respiratory system, and skin. Maleimide (B117702) group is a reactive alkylating agent. | [1] |
| Required PPE | Chemical-resistant gloves, safety goggles, laboratory coat. | [1] |
| Spill Cleanup | Evacuate the area. Wear appropriate PPE. Cover spill with inert absorbent material. Collect and place in a sealed, labeled hazardous waste container. Clean the area with a detergent solution, collecting the cleaning solution as hazardous waste. | [1] |
| Disposal Method | Chemical deactivation followed by disposal as hazardous waste through a licensed contractor. | [1][2] |
Experimental Protocol: Deactivation of this compound Waste
To mitigate the reactivity of this compound waste prior to disposal, the maleimide group should be deactivated. This is achieved by reacting it with an excess of a thiol-containing compound.
Materials:
-
This compound waste (liquid or solid dissolved in a suitable solvent)
-
Quenching solution: ~100 mM of β-mercaptoethanol (BME) or dithiothreitol (B142953) (DTT) in a suitable buffer (e.g., PBS)
-
Designated hazardous waste container (chemically compatible and sealable)
Procedure:
-
Preparation: In a designated chemical fume hood, prepare the quenching solution.
-
Deactivation: To the this compound waste, add a 10-fold molar excess of the quenching solution. For example, if you have 1 mL of a 10 mM this compound solution, you would add 1 mL of a 100 mM BME or DTT solution.
-
Incubation: Gently mix the solution and allow it to react for a minimum of 2 hours at room temperature. This ensures the complete quenching of the reactive maleimide group.[2]
-
Collection: Collect the deactivated solution in a clearly labeled hazardous waste container.[1][2]
Disposal Workflow
The following diagram illustrates the decision-making process and procedural steps for the proper disposal of this compound and related waste.
References
Essential Safety and Operational Guide for Handling AMAS (N-α-maleimidoacet-oxysuccinimide ester)
This guide provides crucial safety and logistical information for researchers, scientists, and drug development professionals working with AMAS (N-α-maleimidoacet-oxysuccinimide ester), a heterobifunctional crosslinker. Adherence to these procedures is vital for ensuring laboratory safety and experimental success.
Chemical and Physical Properties
This compound is a crosslinking reagent used to conjugate molecules containing amine and sulfhydryl groups, such as proteins and peptides.[1][2][3] It features an NHS ester that reacts with primary amines and a maleimide (B117702) group that reacts with sulfhydryls.[2]
| Property | Value |
| Chemical Name | N-α-maleimidoacet-oxysuccinimide ester |
| Synonyms | This compound, Maleimidoacetic acid N-hydroxysuccinimide ester |
| CAS Number | 55750-61-3 |
| Molecular Formula | C₁₀H₈N₂O₆ |
| Molecular Weight | 252.18 g/mol |
| Spacer Arm Length | 4.4 Å |
| Solubility | Soluble in DMF (Dimethylformamide) and DMSO (Dimethyl Sulfoxide) |
Personal Protective Equipment (PPE)
Due to the reactive nature of the maleimide group, which can be toxic and cause skin and eye damage, proper PPE is mandatory.[4][5]
| PPE Item | Specification |
| Gloves | Chemical-resistant nitrile gloves. Double-gloving is recommended when handling the pure compound. |
| Eye Protection | Safety glasses with side shields or chemical splash goggles. |
| Lab Coat | A full-length laboratory coat to prevent skin contact. |
| Respiratory Protection | Work in a well-ventilated area, preferably a chemical fume hood, especially when handling the solid powder. |
Handling and Experimental Protocol
This compound is moisture-sensitive and should be stored in a desiccator at the recommended temperature.[6] Before use, allow the vial to equilibrate to room temperature to prevent moisture condensation. As this compound is not readily soluble in aqueous solutions, a stock solution should be prepared in an organic solvent like DMSO or DMF immediately before use. Do not prepare and store stock solutions for later use.
General Experimental Protocol: Two-Step Protein-Protein Conjugation
This protocol outlines a common application of this compound: covalently linking two proteins (Protein-A and Protein-B).
Materials:
-
This compound
-
Protein-A (containing primary amines, e.g., lysine (B10760008) residues)
-
Protein-B (containing sulfhydryl groups, e.g., cysteine residues)
-
Anhydrous DMSO or DMF
-
Reaction Buffer: Phosphate-buffered saline (PBS), pH 7.2-7.5
-
Quenching Solution: 1 M Tris-HCl, pH 8.0, or 1 M glycine
-
Desalting columns
Procedure:
-
Preparation of this compound Stock Solution:
-
In a chemical fume hood, dissolve this compound in anhydrous DMSO or DMF to a final concentration of 10-20 mM.
-
-
Activation of Protein-A:
-
Dissolve Protein-A in the reaction buffer.
-
Add the this compound stock solution to the Protein-A solution at a 10- to 20-fold molar excess.
-
Incubate the reaction for 30-60 minutes at room temperature.
-
Optional: Quench the reaction by adding the quenching solution to a final concentration of 20-50 mM and incubate for 15 minutes.
-
-
Removal of Excess this compound:
-
Immediately purify the this compound-activated Protein-A using a desalting column to remove excess, non-reacted crosslinker and quenching reagents.
-
-
Conjugation to Protein-B:
-
Dissolve Protein-B in the reaction buffer.
-
Mix the purified, this compound-activated Protein-A with Protein-B.
-
Incubate the mixture for 1-2 hours at room temperature or overnight at 4°C.
-
-
Final Purification:
-
Purify the final conjugate using an appropriate chromatography method (e.g., size-exclusion or ion-exchange chromatography) to separate the desired conjugate from unreacted proteins.
-
Experimental Workflow Diagram
Caption: A typical two-step workflow for protein-protein conjugation using this compound.
Disposal Plan
All waste containing this compound or other maleimide compounds must be treated as hazardous chemical waste.[4] Do not dispose of this waste down the drain.
Deactivation of Reactive Maleimide
To minimize the reactivity of the waste, the maleimide group should be deactivated by reacting it with an excess of a thiol-containing compound.[4]
Deactivation Protocol:
-
Prepare a Quenching Solution: Prepare a ~100 mM solution of a thiol-containing compound such as β-mercaptoethanol (BME) or dithiothreitol (B142953) (DTT) in a suitable buffer (e.g., PBS).
-
Reaction: In a designated chemical waste container, add the this compound-containing solution to a 10-fold molar excess of the quenching solution.
-
Incubation: Gently mix and allow the reaction to proceed for at least 2 hours at room temperature to ensure the complete reaction of the maleimide group.[4]
Waste Segregation and Disposal
-
Deactivated Liquid Waste: Collect the deactivated solution in a clearly labeled, sealed, and chemically compatible waste container. Label as "Hazardous Waste: Deactivated this compound Waste".
-
Contaminated Solid Waste: All consumables that have come into contact with this compound (e.g., pipette tips, tubes, gloves) must be collected in a designated, sealed plastic bag or container.[4] Label as "Hazardous Waste: this compound contaminated debris".
-
Unused Solid this compound: Keep in its original, sealed container. Label as "Hazardous Waste: Unused this compound".
-
Final Disposal: Arrange for the collection of all hazardous waste through your institution's Environmental Health and Safety (EHS) office or a licensed hazardous waste disposal contractor.
Spill Management
In the event of a spill of solid this compound powder:
-
Evacuate and secure the area.
-
Ensure the area is well-ventilated.
-
Wear appropriate PPE.
-
Gently cover the spill with an inert absorbent material (e.g., sand or vermiculite).
-
Carefully collect the powder and cleanup materials and place them into a sealed container labeled as hazardous waste.[5]
-
Clean the contaminated surface thoroughly with a detergent solution, followed by a water rinse. Collect all cleaning solutions as hazardous liquid waste.[5]
References
- 1. caymanchem.com [caymanchem.com]
- 2. Chemistry of Crosslinking | Thermo Fisher Scientific - US [thermofisher.com]
- 3. Thermo Scientific this compound (N- -maleimidoacet-oxysuccinimide ester) 50 mg | Buy Online | Thermo Scientific™ | Fisher Scientific [fishersci.com]
- 4. benchchem.com [benchchem.com]
- 5. benchchem.com [benchchem.com]
- 6. Thermo Scientific™ this compound (N-α-maleimidoacet-oxysuccinimide ester) | Fisher Scientific [fishersci.ca]
Retrosynthesis Analysis
AI-Powered Synthesis Planning: Our tool employs the Template_relevance Pistachio, Template_relevance Bkms_metabolic, Template_relevance Pistachio_ringbreaker, Template_relevance Reaxys, Template_relevance Reaxys_biocatalysis model, leveraging a vast database of chemical reactions to predict feasible synthetic routes.
One-Step Synthesis Focus: Specifically designed for one-step synthesis, it provides concise and direct routes for your target compounds, streamlining the synthesis process.
Accurate Predictions: Utilizing the extensive PISTACHIO, BKMS_METABOLIC, PISTACHIO_RINGBREAKER, REAXYS, REAXYS_BIOCATALYSIS database, our tool offers high-accuracy predictions, reflecting the latest in chemical research and data.
Strategy Settings
| Precursor scoring | Relevance Heuristic |
|---|---|
| Min. plausibility | 0.01 |
| Model | Template_relevance |
| Template Set | Pistachio/Bkms_metabolic/Pistachio_ringbreaker/Reaxys/Reaxys_biocatalysis |
| Top-N result to add to graph | 6 |
Feasible Synthetic Routes




Featured Recommendations
| Most viewed |
|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
