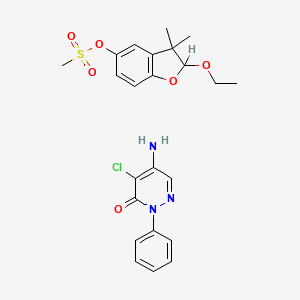
Magnum
Description
BenchChem offers high-quality Magnum suitable for many research applications. Different packaging options are available to accommodate customers' requirements. Please inquire for more information about Magnum including the price, delivery time, and more detailed information at info@benchchem.com.
Properties
CAS No. |
50641-63-9 |
|---|---|
Molecular Formula |
C23H26ClN3O6S |
Molecular Weight |
508.0 g/mol |
IUPAC Name |
5-amino-4-chloro-2-phenylpyridazin-3-one;(2-ethoxy-3,3-dimethyl-2H-1-benzofuran-5-yl) methanesulfonate |
InChI |
InChI=1S/C13H18O5S.C10H8ClN3O/c1-5-16-12-13(2,3)10-8-9(18-19(4,14)15)6-7-11(10)17-12;11-9-8(12)6-13-14(10(9)15)7-4-2-1-3-5-7/h6-8,12H,5H2,1-4H3;1-6H,12H2 |
InChI Key |
XQMVBICWFFHDNN-UHFFFAOYSA-N |
Canonical SMILES |
CCOC1C(C2=C(O1)C=CC(=C2)OS(=O)(=O)C)(C)C.C1=CC=C(C=C1)N2C(=O)C(=C(C=N2)N)Cl |
Origin of Product |
United States |
Magnum-PSI: A Technical Guide to Simulating Fusion Reactor Divertor Conditions
An in-depth exploration of the Magnum-PSI linear plasma generator, its core functionalities, and its pivotal role in advancing materials science for nuclear fusion energy.
Magnum-PSI, housed at the Dutch Institute for Fundamental Energy Research (DIFFER), stands as a unique and critical facility in the global quest for fusion energy. It is a linear plasma generator designed to replicate the extreme conditions anticipated at the divertor of future fusion reactors like ITER.[1][2] By providing a controlled yet representative environment, Magnum-PSI allows researchers to study the intricate plasma-surface interactions (PSI) that are fundamental to the long-term viability and success of fusion power.[1][3] This technical guide delves into the operational principles, experimental capabilities, and significant contributions of Magnum-PSI to fusion research.
The Crucial Role of Plasma-Surface Interaction in Fusion
In a fusion reactor, the divertor is the component responsible for exhausting heat and ash from the plasma. It is therefore subjected to immense heat and particle fluxes, creating one of the most challenging environments for materials to withstand.[2] Understanding how different materials behave under these extreme conditions—including erosion, redeposition, and fuel retention—is paramount for designing durable and efficient fusion power plants.[4] Magnum-PSI is the only laboratory experiment in the world capable of producing plasma conditions that mimic those at the ITER divertor, making it an indispensable tool for testing and qualifying candidate plasma-facing materials.[1][2]
Core Technical Specifications of Magnum-PSI
Magnum-PSI is engineered to generate a steady-state, high-flux, magnetized plasma beam that can be directed onto a target material.[4][5] Its key design parameters are meticulously chosen to align with the conditions projected for the ITER divertor's "detached" operational regime, which is characterized by high plasma density and low temperature.
| Parameter | Value | Reference |
| Plasma Source | Cascaded Arc | [1][3] |
| Magnetic Field | Up to 2.5 T (Superconducting Magnet) | [3][6] |
| Electron Density (n_e) | 10¹⁹ – 10²¹ m⁻³ | [3] |
| Electron Temperature (T_e) | 0.1 – 10 eV | [3] |
| Particle Flux | 10²³ - 10²⁵ m⁻² s⁻¹ | [3][6] |
| Heat Flux | > 10 MW m⁻² (steady state) | [3] |
| Transient Heat Loads | Up to 2 GW m⁻² | [3] |
| Target Area | Up to 100 cm² | [4] |
| Operational Mode | Steady-state and pulsed | [2][6] |
Experimental Capabilities and Protocols
Magnum-PSI is equipped with a sophisticated suite of diagnostics to analyze both the plasma and the target material in-situ and ex-situ.[1][3] This allows for a comprehensive understanding of the dynamic processes occurring at the plasma-material interface.
Key Experimental Areas:
-
Material Erosion and Redeposition: Studying the rate at which plasma-facing materials wear away and where the eroded material is redeposited.[4]
-
Hydrogen Isotope Retention: Investigating the absorption and trapping of hydrogen isotopes (deuterium and tritium) within the wall materials, which is crucial for fuel cycle management and safety.[4]
-
Transient Events: Simulating the effects of sudden, intense bursts of heat and particles, known as Edge Localized Modes (ELMs), on material surfaces.[1]
-
Liquid Metal Concepts: Testing innovative divertor concepts that utilize flowing liquid metals to handle the extreme heat loads.[1]
Generalized Experimental Workflow:
A typical experiment on Magnum-PSI follows a structured protocol to ensure data accuracy and reproducibility.
Detailed Methodologies of Key Experiments:
Erosion and Redeposition Studies:
-
Target Preparation: A sample of the material of interest (e.g., tungsten) is precisely weighed and its surface topography is characterized using techniques like scanning electron microscopy (SEM).
-
Plasma Exposure: The sample is mounted on a water-cooled target holder and inserted into the Magnum-PSI vacuum chamber.[1] It is then exposed to a plasma beam with specific parameters (density, temperature, flux) for a predetermined duration.
-
In-situ Monitoring: During exposure, optical emission spectroscopy is used to monitor the spectral lines of eroded material in the plasma, providing real-time information on erosion rates.
-
Post-exposure Analysis: After exposure, the sample is retracted into the Target Exchange and Analysis Chamber (TEAC) without breaking vacuum.[3] It is then transferred to an external facility for detailed surface analysis, including weight loss measurements and high-resolution microscopy to quantify the net erosion. The redeposited layers on surrounding surfaces are also analyzed.
Hydrogen Retention Studies:
-
Sample Preparation: The material sample is outgassed at high temperatures to remove any pre-existing trapped gases.
-
Plasma Exposure: The sample is exposed to a deuterium (B1214612) or hydrogen plasma beam for a set duration to simulate fuel implantation.
-
Thermal Desorption Spectroscopy (TDS): Following plasma exposure, the sample is transferred to a TDS system.[1] In the TDS chamber, the sample is heated at a controlled rate, causing the trapped deuterium to be released. A mass spectrometer measures the amount and rate of gas release as a function of temperature, providing insights into the trapping mechanisms and total retention.
Diagnostic Systems
Magnum-PSI is equipped with a comprehensive suite of diagnostic tools to characterize the plasma and the target material.
| Diagnostic Tool | Measured Parameter | Reference |
| Thomson Scattering | Electron temperature (T_e) and density (n_e) | [4][6] |
| High-Resolution Spectroscopy | Ion temperature, plasma composition | [4] |
| Langmuir Probes | Plasma potential, electron temperature, ion saturation current | [7][8] |
| Infrared (IR) Thermography | Target surface temperature | |
| Ion Beam Facility (IBF) | (Sub)surface material properties and processes | [1] |
| Thermal Desorption Spectroscopy (TDS) | Adsorbed molecules on the surface | [1] |
| Active Spectroscopy (TALIF, CARS, VUV-LIF) | Densities of atomic and molecular hydrogen | [9] |
Logical Relationships in Magnum-PSI Research
The research conducted at Magnum-PSI follows a logical progression, where fundamental understanding of plasma-material interactions is built upon to address engineering challenges for fusion reactors.
References
- 1. onderzoeksfaciliteiten.nl [onderzoeksfaciliteiten.nl]
- 2. Candidate fusion materials to be investigated at Magnum-PSI [iter.org]
- 3. Magnum-PSI | Dutch Institute for Fundamental Energy Research [differ.nl]
- 4. www-pub.iaea.org [www-pub.iaea.org]
- 5. impact.ornl.gov [impact.ornl.gov]
- 6. research.tue.nl [research.tue.nl]
- 7. researchgate.net [researchgate.net]
- 8. researchgate.net [researchgate.net]
- 9. Active spectroscopy on Magnum-PSI to characterize atomic and molecular hydrogen in detached conditions [inis.iaea.org]
An In-depth Technical Guide to MAGMA for Gene-Set Analysis
For Researchers, Scientists, and Drug Development Professionals
Introduction
MAGMA (Multi-marker Analysis of GenoMic Annotation) is a powerful and versatile tool for gene-set analysis of Genome-Wide Association Study (GWAS) data.[1][2][3] It addresses key challenges in the field, such as accounting for linkage disequilibrium (LD) between markers and detecting multi-marker effects, to provide enhanced statistical power in identifying genes and gene sets associated with complex traits and diseases.[2][3] This technical guide provides an in-depth overview of MAGMA's core methodologies, experimental protocols, and practical applications for researchers, scientists, and drug development professionals.
Core Principles of MAGMA
MAGMA's analytical framework is structured into three main stages: annotation, gene analysis, and gene-set analysis.[1][3][4] This layered approach offers flexibility, allowing for independent modifications and expansions of the gene and gene-set analysis steps.[2]
Annotation
The initial step in a MAGMA analysis is to map single nucleotide polymorphisms (SNPs) from a GWAS to their corresponding genes.[1][4][5] This is achieved by defining a genomic window around each gene's transcription region. For instance, a window can be set to include SNPs up to 35 kilobases (kb) upstream and 10kb downstream of a gene to capture regulatory variants.[6]
Gene Analysis
Following annotation, MAGMA calculates a gene-level association statistic (p-value) by aggregating the SNP-level associations within each gene.[1][3] This process accounts for the LD structure between SNPs. MAGMA offers several models for gene analysis:
-
SNP-wise Mean Model: This model calculates the mean of the chi-squared statistics of all SNPs within a gene.
-
SNP-wise Top Model: This approach uses the chi-squared statistic of the most significant SNP within a gene.
-
Multiple Linear Principal Components Regression: This model, unique to MAGMA, uses principal components analysis (PCA) to account for LD between SNPs within a gene and performs a multiple regression to test for the overall association of the gene with the phenotype.[4] This method requires access to the raw genotype data.
Gene-Set Analysis
The final stage involves testing for the association of predefined sets of genes (e.g., biological pathways, Gene Ontology terms) with the phenotype of interest. MAGMA performs two main types of gene-set analysis:
-
Self-contained Gene-Set Analysis: This tests the null hypothesis that the genes in a set are not, as a group, associated with the phenotype.
-
Competitive Gene-Set Analysis: This tests whether the genes within a specific set are more strongly associated with the phenotype than genes outside of that set.[4]
Experimental Protocols: A Step-by-Step Guide to MAGMA Analysis
This section provides a detailed methodology for conducting a gene-set analysis using MAGMA from the command line.
Prerequisites:
-
MAGMA software: Downloadable from the official website.
-
GWAS Summary Statistics: A text file containing SNP IDs, p-values, and sample size (N).
-
Gene Location File: A file defining the genomic coordinates of genes (e.g., from NCBI or Ensembl).
-
Gene Set File: A file where each line defines a gene set, starting with the set name followed by the gene IDs belonging to that set.
-
Reference Data (Optional but Recommended): Genotype data from a reference panel (e.g., 1000 Genomes) in PLINK binary format to estimate LD if raw GWAS data is unavailable.
Step 1: Annotation
This step maps SNPs to genes based on their genomic locations.
-
--annotate: Specifies the annotation step.
-
--snp-loc: Path to the file with SNP locations from your GWAS.
-
--gene-loc: Path to the gene location file.
-
--out: Prefix for the output files.
Step 2: Gene Analysis
This step computes gene-level p-values. The example below uses the SNP-wise mean model with pre-computed SNP p-values.
-
--bfile: Specifies the reference panel for LD estimation.
-
--pval: Path to the GWAS summary statistics file. The N= argument specifies the total sample size.
-
--gene-annot: The annotation file created in the previous step.
-
--out: Prefix for the gene analysis output files.
Step 3: Gene-Set Analysis
This final step performs the competitive gene-set analysis.
-
--gene-results: The raw gene analysis results file from Step 2.
-
--set-annot: The file containing the gene set definitions.
-
--out: Prefix for the final gene-set analysis results.
Quantitative Data Summary
MAGMA has demonstrated superior statistical power compared to other gene and gene-set analysis tools. The following tables summarize the findings from the original MAGMA publication by de Leeuw et al. (2015), which analyzed a Crohn's Disease (CD) GWAS dataset.
Table 1: Number of Significant Genes Identified at Different P-value Thresholds
| P-value Threshold | MAGMA (PC regression) | VEGAS | PLINK (mean) | PLINK (top) |
| < 2.5e-6 | 112 | 85 | 82 | 95 |
| < 1e-5 | 168 | 135 | 130 | 152 |
| < 1e-4 | 335 | 288 | 280 | 318 |
Table 2: Number of Significant Gene Sets Identified (Self-Contained Analysis)
| P-value Threshold | MAGMA | PLINK |
| < 0.05 | 105 | 98 |
| < 0.01 | 75 | 70 |
| < 0.001 | 42 | 38 |
Table 3: Number of Significant Gene Sets Identified (Competitive Analysis)
| P-value Threshold | MAGMA | ALIGATOR | INRICH | MAGENTA |
| < 0.05 | 15 | 8 | 10 | 9 |
| < 0.01 | 8 | 3 | 4 | 4 |
| < 0.001 | 3 | 1 | 1 | 1 |
These tables illustrate MAGMA's increased power to detect significant genes and gene sets in both self-contained and competitive analyses.[7]
Visualizations
MAGMA Analysis Workflow
The following diagram illustrates the core workflow of a MAGMA gene-set analysis.
Caption: A diagram illustrating the three main stages of a MAGMA analysis.
Logical Relationship of MAGMA's Analysis Models
This diagram shows the relationship between the different analysis models available in MAGMA.
Caption: The different gene analysis models available within MAGMA.
Example Signaling Pathway for Analysis: KEGG Ribosome Pathway
The following is a simplified representation of a signaling pathway that could be analyzed with MAGMA. If a GWAS study implicated variants associated with a ribosomal disorder, MAGMA could be used to test if the genes in the KEGG Ribosome pathway are enriched for association signals.
Caption: A simplified diagram of the KEGG Ribosome pathway.
Conclusion
MAGMA provides a robust and statistically powerful framework for conducting gene and gene-set analyses on GWAS data. Its ability to account for LD and its flexible, multi-stage approach make it an invaluable tool for uncovering the biological mechanisms underlying complex traits. By following the detailed protocols and understanding the core principles outlined in this guide, researchers can effectively leverage MAGMA to gain deeper insights from their GWAS results, ultimately aiding in the identification of novel therapeutic targets and the advancement of drug development.
References
- 1. Documentation [magma.maths.usyd.edu.au]
- 2. researchgate.net [researchgate.net]
- 3. Gene Set Analysis with MAGMA - OmicsBox User Manual [docs.omicsbox.biobam.com]
- 4. ibg.colorado.edu [ibg.colorado.edu]
- 5. ibg.colorado.edu [ibg.colorado.edu]
- 6. MAGMA: Generalized Gene-Set Analysis of GWAS Data | PLOS Computational Biology [journals.plos.org]
- 7. storage.googleapis.com [storage.googleapis.com]
The Avian Magnum: A Technical Guide to Albumen Synthesis and Secretion
For Researchers, Scientists, and Drug Development Professionals
Abstract
The magnum, the longest segment of the avian oviduct, is the principal site of egg white (albumen) protein synthesis and secretion. This intricate process is fundamental to avian reproduction, providing the developing embryo with essential nutrients and protection against microbial invasion. The synthesis and secretion of albumen are tightly regulated by a complex interplay of steroid hormones, primarily estrogen and progesterone (B1679170). Understanding the molecular mechanisms governing magnum function is crucial for optimizing poultry production and holds potential for the development of novel bioreactors for pharmaceutical protein production. This technical guide provides an in-depth overview of the magnum's core functions, presenting quantitative data on albumen composition, detailed experimental protocols for its study, and visualizations of key signaling pathways and experimental workflows.
Core Function of the Magnum: Albumen Synthesis and Secretion
The magnum is a highly glandular organ responsible for synthesizing and secreting the majority of the egg white proteins. As the ovulated yolk traverses the magnum, a journey that takes approximately three hours, it is enrobed in concentric layers of albumen. The primary cell types involved in this process are the tubular gland cells, which synthesize and store albumen proteins, and the ciliated and non-ciliated epithelial cells that line the lumen and facilitate the movement of the egg and the secretion of specific components.
The synthesis of albumen proteins is a continuous process in laying hens, but the rate of synthesis and secretion is significantly upregulated in the presence of a developing egg. This regulation is primarily under hormonal control, with estrogen stimulating the differentiation of the magnum and the synthesis of albumen proteins, and progesterone playing a role in the regulation of specific proteins and the timing of secretion.
Quantitative Data on Albumen Composition
The albumen is a complex aqueous solution of proteins, with ovalbumin being the most abundant. The precise composition can vary depending on the avian species, age, and diet of the hen. The following tables summarize the quantitative data on the protein composition of chicken egg white and the typical serum concentrations of key regulatory hormones during the laying cycle.
Table 1: Protein Composition of Chicken Egg White
| Protein | Percentage of Total Albumen Protein | Key Functions |
| Ovalbumin | ~54% | Nutrient source for the embryo |
| Ovotransferrin (Conalbumin) | ~12% | Iron-binding and antimicrobial properties |
| Ovomucoid | ~11% | Trypsin inhibitor, allergenic properties |
| Ovomucin | ~3.5% | Contributes to the gel-like consistency of thick albumen |
| Lysozyme | ~3.4% | Antimicrobial (hydrolyzes bacterial cell walls) |
| Avidin | ~0.05% | Binds biotin, antimicrobial |
| Other proteins | ~16% | Various enzymatic and structural roles |
Data compiled from various proteomic studies of chicken egg white.[1][2][3]
Table 2: Serum Steroid Hormone Concentrations in Laying Hens During the Ovulatory Cycle
| Hormone | Concentration Range | Peak Activity |
| Estrogen (Estradiol) | 6 - >11 pg/mL | 4-6 hours pre-ovulation |
| Progesterone | 0.67 - 9.60 ng/mL | 4-6 hours pre-ovulation |
Concentrations can vary based on the specific strain of hen and the timing of sample collection relative to ovulation.[4][5][6]
Experimental Protocols
The study of magnum function employs a variety of molecular and cellular biology techniques. Below are detailed methodologies for key experiments.
RNA Extraction from Magnum Tissue using TRIzol Reagent
This protocol is for the isolation of total RNA from avian magnum tissue, which can then be used for downstream applications such as quantitative real-time PCR (qPCR) to measure gene expression levels of albumen proteins.
Materials:
-
Fresh or frozen magnum tissue
-
TRIzol Reagent
-
75% Ethanol (B145695) (in RNase-free water)
-
RNase-free water
-
Homogenizer
-
Microcentrifuge
-
Pipettes and RNase-free tips
Procedure:
-
Homogenization:
-
Phase Separation:
-
Incubate the homogenate for 5 minutes at room temperature to permit the complete dissociation of nucleoprotein complexes.
-
Add 0.2 mL of chloroform per 1 mL of TRIzol Reagent used.
-
Cap the tube securely and shake vigorously by hand for 15 seconds.
-
Incubate at room temperature for 2-3 minutes.
-
Centrifuge the sample at 12,000 x g for 15 minutes at 4°C. The mixture will separate into a lower red, phenol-chloroform phase, an interphase, and a colorless upper aqueous phase. RNA remains exclusively in the aqueous phase.[9]
-
-
RNA Precipitation:
-
Carefully transfer the upper aqueous phase to a fresh tube.
-
Precipitate the RNA from the aqueous phase by adding 0.5 mL of isopropanol per 1 mL of TRIzol Reagent used.
-
Incubate samples at room temperature for 10 minutes.
-
Centrifuge at 12,000 x g for 10 minutes at 4°C. The RNA will form a gel-like pellet on the side and bottom of the tube.[10]
-
-
RNA Wash:
-
Remove the supernatant.
-
Wash the RNA pellet once with 1 mL of 75% ethanol per 1 mL of TRIzol Reagent used.
-
Mix the sample by vortexing and centrifuge at 7,500 x g for 5 minutes at 4°C.[11]
-
-
RNA Solubilization:
-
Briefly air-dry the RNA pellet for 5-10 minutes. Do not allow the pellet to dry completely as this will greatly decrease its solubility.
-
Resuspend the RNA in RNase-free water by passing the solution a few times through a pipette tip and incubating for 10 minutes at 55-60°C.
-
Western Blotting for Albumen Protein Detection
This protocol describes the detection and quantification of specific albumen proteins from magnum tissue lysates.
Materials:
-
Magnum tissue lysate
-
Laemmli sample buffer
-
SDS-PAGE gels
-
Transfer buffer
-
PVDF or nitrocellulose membrane
-
Blocking buffer (e.g., 5% non-fat dry milk or BSA in TBST)
-
Primary antibody specific to the target albumen protein
-
HRP-conjugated secondary antibody
-
Chemiluminescent substrate
-
Imaging system
Procedure:
-
Sample Preparation:
-
Prepare protein lysates from magnum tissue.
-
Determine protein concentration using a standard assay (e.g., BCA assay).
-
Mix a specific amount of protein (e.g., 20-30 µg) with Laemmli sample buffer and heat at 95-100°C for 5 minutes to denature the proteins.[12]
-
-
Gel Electrophoresis:
-
Load the denatured protein samples into the wells of an SDS-PAGE gel.
-
Run the gel at a constant voltage until the dye front reaches the bottom of the gel.[13]
-
-
Protein Transfer:
-
Transfer the separated proteins from the gel to a PVDF or nitrocellulose membrane using a wet or semi-dry transfer system.[14]
-
-
Blocking:
-
Incubate the membrane in blocking buffer for 1 hour at room temperature with gentle agitation to prevent non-specific antibody binding.[14]
-
-
Antibody Incubation:
-
Incubate the membrane with the primary antibody diluted in blocking buffer overnight at 4°C with gentle agitation.
-
Wash the membrane three times for 5-10 minutes each with TBST (Tris-buffered saline with 0.1% Tween 20).
-
Incubate the membrane with the HRP-conjugated secondary antibody diluted in blocking buffer for 1 hour at room temperature with gentle agitation.
-
Wash the membrane three times for 5-10 minutes each with TBST.[15]
-
-
Detection:
-
Incubate the membrane with a chemiluminescent substrate according to the manufacturer's instructions.
-
Capture the chemiluminescent signal using an imaging system.
-
Immunohistochemistry for Localization of Albumen Proteins
This protocol allows for the visualization of the cellular and subcellular localization of specific albumen proteins within the magnum tissue.
Materials:
-
Paraffin-embedded magnum tissue sections on slides
-
Xylene
-
Ethanol series (100%, 95%, 70%)
-
Antigen retrieval buffer (e.g., citrate (B86180) buffer, pH 6.0)
-
Blocking solution (e.g., 5% normal goat serum in PBS)
-
Primary antibody specific to the target albumen protein
-
Biotinylated secondary antibody
-
Streptavidin-HRP conjugate
-
DAB (3,3'-Diaminobenzidine) substrate
-
Hematoxylin (B73222) counterstain
-
Mounting medium
Procedure:
-
Deparaffinization and Rehydration:
-
Immerse slides in xylene to remove paraffin.
-
Rehydrate the tissue sections by sequential immersion in 100%, 95%, and 70% ethanol, followed by distilled water.
-
-
Antigen Retrieval:
-
Immerse slides in antigen retrieval buffer and heat (e.g., in a microwave or water bath) to unmask the antigenic epitopes. The optimal time and temperature will depend on the specific antibody and antigen.
-
-
Blocking:
-
Incubate the sections with a blocking solution for at least 30 minutes at room temperature to block non-specific binding sites.[16]
-
-
Primary Antibody Incubation:
-
Incubate the sections with the primary antibody at its optimal dilution overnight at 4°C in a humidified chamber.[17]
-
-
Secondary Antibody and Detection:
-
Wash the sections with PBS.
-
Incubate with a biotinylated secondary antibody for 30-60 minutes at room temperature.
-
Wash with PBS.
-
Incubate with streptavidin-HRP conjugate for 30 minutes at room temperature.
-
Wash with PBS.
-
Incubate with DAB substrate until the desired brown color intensity is reached.[18]
-
-
Counterstaining and Mounting:
-
Counterstain the sections with hematoxylin to visualize cell nuclei.
-
Dehydrate the sections through an ethanol series and clear in xylene.
-
Mount a coverslip over the tissue section using a permanent mounting medium.
-
Signaling Pathways and Experimental Workflows
The following diagrams, created using the DOT language for Graphviz, illustrate the key signaling pathways regulating albumen synthesis and a typical experimental workflow for studying magnum function.
Signaling Pathways
Experimental Workflow
Conclusion
The magnum of the avian oviduct is a highly specialized organ essential for reproduction. Its primary function, the synthesis and secretion of albumen, is a complex and finely tuned process regulated by steroid hormones. The information presented in this technical guide provides a comprehensive overview of the current understanding of magnum function, from the molecular composition of albumen to the signaling pathways that govern its production. The detailed experimental protocols offer a practical resource for researchers in the field. Further research into the intricate regulatory networks of the magnum will not only enhance our knowledge of avian reproductive biology but also pave the way for advancements in biotechnology and poultry science.
References
- 1. Differential proteomic analysis revealed crucial egg white proteins for hatchability of chickens - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Quantitative proteomic analysis of chicken egg white and its components - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. researchgate.net [researchgate.net]
- 5. researchgate.net [researchgate.net]
- 6. veterinariadigital.com [veterinariadigital.com]
- 7. science.smith.edu [science.smith.edu]
- 8. Tissue Homogenization and RNA + Protein Extraction using TRIzol reagent | Duke Department of Biostatistics and Bioinformatics [biostat.duke.edu]
- 9. immgen.org [immgen.org]
- 10. bowdish.ca [bowdish.ca]
- 11. animal.ifas.ufl.edu [animal.ifas.ufl.edu]
- 12. digitalcommons.unl.edu [digitalcommons.unl.edu]
- 13. bu.edu [bu.edu]
- 14. Western blot protocol | Abcam [abcam.com]
- 15. Detailed Western Blotting (Immunoblotting) Protocol [protocols.io]
- 16. ptglab.com [ptglab.com]
- 17. youtube.com [youtube.com]
- 18. bosterbio.com [bosterbio.com]
An In-depth Technical Guide to the Core Principles of Plasma-Surface Interaction in Magnum-PSI
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the fundamental principles governing plasma-surface interactions (PSI) within the Magnum-PSI (MAgnetized plasma Generator and NUMerical modeling for Plasma Surface Interactions) linear plasma device. Magnum-PSI is a world-leading facility designed to investigate the complex interplay between high-flux plasmas and various materials under conditions relevant to future fusion reactors like ITER. Understanding these interactions is crucial for the development of resilient plasma-facing components and has broader implications for materials science and process technology, including applications in drug development where plasma processes are utilized for surface modification and sterilization.
Core Principles of Plasma-Surface Interaction in Magnum-PSI
Plasma-surface interaction in Magnum-PSI is fundamentally governed by the exposure of a material target to a high-flux, low-temperature plasma beam confined by a strong magnetic field. The key phenomena at the plasma-material interface include sputtering, erosion, deposition, and implantation of plasma species. These processes are intricately linked and are influenced by the plasma parameters, the target material properties, and the magnetic field configuration. Magnum-PSI is specifically designed to create plasma conditions that mimic the harsh environment of a fusion reactor's divertor, characterized by high particle and heat fluxes.[1][2][3]
The primary plasma source in Magnum-PSI is a cascaded arc, which generates a dense and hot plasma that is then guided towards the target by a superconducting magnet.[4] This setup allows for long-duration, steady-state plasma exposures, enabling the study of material evolution over relevant timescales.[5][6] The main research areas include the investigation of erosion and re-deposition of wall materials, fuel (deuterium) retention, and the impact of transient events like Edge Localized Modes (ELMs) on material integrity.[3][7][8]
Data Presentation: Key Experimental Parameters and Results
The following tables summarize key quantitative data from various experimental campaigns conducted in Magnum-PSI, providing a basis for comparison across different studies and conditions.
| Parameter | Value | Unit | Reference(s) |
| Plasma Source | Cascaded Arc | - | [4] |
| Magnetic Field Strength | Up to 2.5 | T | [4] |
| Gases Used | H, D, He, Ne, Ar | - | [9][10] |
| Electron Density (n_e) | 10¹⁹ - 10²¹ | m⁻³ | [4][11] |
| Electron Temperature (T_e) | 0.1 - 10 | eV | [4][11] |
| Particle Flux | 10²³ - 10²⁵ | m⁻²s⁻¹ | [4][11] |
| Heat Flux | > 10 | MW/m² | [4][11] |
| Transient Heat Loading | Up to 2 | GW/m² | [4] |
| Longest Continuous Plasma Pulse | > 18 | hours | [6] |
| Experiment Type | Material | Plasma Species | Key Findings | Reference(s) |
| Sputtering/Erosion | Tungsten (W) | Ar | Significant surface roughening and re-deposition observed downstream. | [12] |
| Sputtering/Erosion | Tungsten (W) | H, Ar | Entrainment of Ar impurities leads to a large increase in their impact energy and sputtering yield. | [13] |
| Deuterium (B1214612) Retention | Tungsten (W) | D, N | Deuterium is implanted only within the ion penetration range at 300 K. | [14] |
| Deuterium Retention | W-B alloys | D | Higher boron concentration leads to higher initial deuterium retention. | [15] |
| Material Migration | Tungsten (W) | Ar | High re-deposition rates observed, with entrainment being a dominant mechanism. | [16] |
| Heat Load Effects | Graphite | H | Surface emissivity changes significantly with prolonged plasma exposure, affecting temperature measurements. | [17] |
Experimental Protocols: Detailed Methodologies
While specific, step-by-step standard operating procedures for every experiment in Magnum-PSI are proprietary to the research teams, the general methodologies can be synthesized from published research.
General Plasma Exposure Protocol
-
Target Preparation and Mounting: The material sample (target) is first characterized (e.g., surface roughness, composition) and then mounted on a water-cooled target holder. This assembly is introduced into the Magnum-PSI vacuum vessel.[18][19]
-
Vacuum Pump-Down: The vacuum vessel is pumped down to a base pressure typically in the range of 10⁻⁶ to 10⁻⁷ mbar to minimize impurities.
-
Gas Injection and Plasma Ignition: The working gas (e.g., Hydrogen, Deuterium, Argon) is introduced into the cascaded arc plasma source. A high voltage is applied to ignite the plasma.[10][20]
-
Plasma Confinement and Transport: The superconducting magnet is ramped up to the desired field strength to confine the plasma into a beam and guide it towards the target.[5]
-
Plasma Exposure: The target is exposed to the plasma for a predetermined duration, which can range from seconds to many hours for high-fluence studies.[6] During exposure, various in-situ diagnostics monitor the plasma and surface conditions.
-
Plasma Termination and Cool-Down: The plasma source is turned off, and the target is allowed to cool down.
-
Post-Exposure Analysis: The target is retracted into a separate analysis chamber (Target Exchange and Analysis Chamber - TEAC) under vacuum for in-vacuo surface analysis, or removed from the vessel for ex-situ characterization.[2]
Sputtering and Erosion/Deposition Studies
-
Methodology: These experiments often involve exposing a primary target material to a plasma of a specific species (e.g., Argon to enhance physical sputtering). Witness plates made of a different material are placed around the primary target to collect the sputtered particles.
-
Analysis: The thickness and composition of the deposited layers on the witness plates are analyzed post-exposure using techniques such as Rutherford Backscattering Spectrometry (RBS), Nuclear Reaction Analysis (NRA), and Scanning Electron Microscopy (SEM) to determine the sputtering yield and re-deposition patterns.[12][16][21] The erosion of the primary target can be quantified by profilometry.[17]
Deuterium Retention Measurements
-
Methodology: Samples are exposed to a deuterium plasma. The amount of deuterium retained in the material is a critical parameter for fusion research.
-
In-situ Analysis: Techniques like Nuclear Reaction Analysis (NRA) and Laser-Induced Breakdown Spectroscopy (LIBS) are used during or immediately after plasma exposure to measure the deuterium content in the near-surface region.[7][14][22]
-
Ex-situ Analysis: Thermal Desorption Spectroscopy (TDS) is a common ex-situ technique where the sample is heated after exposure, and the released deuterium is measured with a mass spectrometer to determine the total retained amount and the trapping energies.
Mandatory Visualization: Diagrams of Key Processes
The following diagrams, generated using the DOT language, illustrate key workflows and logical relationships in plasma-surface interaction studies in Magnum-PSI.
References
- 1. Advances in Magnum-PSI probe diagnosis in support of plasma-surface interaction studies | Dutch Institute for Fundamental Energy Research [differ.nl]
- 2. Redirecting [linkinghub.elsevier.com]
- 3. www-pub.iaea.org [www-pub.iaea.org]
- 4. Magnum-PSI | Dutch Institute for Fundamental Energy Research [differ.nl]
- 5. Conditioning of a superconducting Magnum-PSI | Dutch Institute for Fundamental Energy Research [differ.nl]
- 6. World record plasma exposure in Magnum-PSI | Dutch Institute for Fundamental Energy Research [differ.nl]
- 7. research.tue.nl [research.tue.nl]
- 8. Candidate fusion materials to be investigated at Magnum-PSI [iter.org]
- 9. researchgate.net [researchgate.net]
- 10. differ.nl [differ.nl]
- 11. research.tue.nl [research.tue.nl]
- 12. indico.euro-fusion.org [indico.euro-fusion.org]
- 13. researchgate.net [researchgate.net]
- 14. researchgate.net [researchgate.net]
- 15. repositum.tuwien.at [repositum.tuwien.at]
- 16. researchgate.net [researchgate.net]
- 17. researchgate.net [researchgate.net]
- 18. researchgate.net [researchgate.net]
- 19. Application form Magnum-PSI | Dutch Institute for Fundamental Energy Research [differ.nl]
- 20. First plasma beam on Magnum PSI [iter.org]
- 21. pure.tue.nl [pure.tue.nl]
- 22. researchgate.net [researchgate.net]
Unveiling the Engine of Discovery: A Technical Guide to the MAGMA Multiple Regression Model
For Researchers, Scientists, and Drug Development Professionals
In the landscape of post-Genome-Wide Association Study (GWAS) analysis, the Multi-marker Analysis of GenoMic Annotation (MAGMA) has emerged as a powerful and widely adopted tool.[1] At its core, MAGMA leverages a multiple regression framework to aggregate the effects of single nucleotide polymorphisms (SNPs) at the gene level, thereby enabling robust gene-set and pathway analyses. This guide provides an in-depth technical overview of the MAGMA multiple regression model, its applications, and the experimental protocols necessary for its implementation, tailored for professionals in genetic research and drug development.
The Core of MAGMA: A Multiple Principal Components Regression Model
MAGMA's primary gene analysis is built upon a multiple linear principal components regression model.[2][3] This approach is designed to address the challenges of multicollinearity arising from linkage disequilibrium (LD) between SNPs within a gene. Instead of directly regressing the phenotype on all SNPs in a gene, MAGMA first performs a Principal Component Analysis (PCA) on the SNP data for each gene. The resulting principal components (PCs), which are orthogonal linear combinations of the original SNP genotypes, are then used as predictors in a multiple linear regression model.
The fundamental model can be expressed as follows:
Y = β₀ + β₁PC₁ + β₂PC₂ + ... + βₖPCₖ + ε
Where:
-
Y represents the phenotype of interest.
-
PC₁ , PC₂ , ..., PCₖ are the selected principal components derived from the SNP genotype matrix for a given gene.
-
β₀ , β₁ , β₂ , ..., βₖ are the regression coefficients for the intercept and each principal component, respectively.
-
ε is the error term.
By default, MAGMA prunes away principal components that explain a very small fraction of the variance in the SNP data (typically less than 0.1%), which reduces the number of parameters in the model and improves statistical power.[2][3] The overall significance of the gene's association with the phenotype is then determined using an F-test on the full model.
Data Presentation: Quantitative Insights
To facilitate a clear understanding of the data involved and the results produced by MAGMA, the following tables summarize key quantitative information.
Table 1: MAGMA Input File Formats
| File Type | Description | Example Format |
| GWAS Summary Statistics | Contains SNP-level p-values from a GWAS. A plain text file with columns for SNP ID and p-value. | SNP Prs123 0.045rs456 0.871 |
| Gene Annotation File | Maps SNPs to genes based on their genomic coordinates. A plain text file with columns for Gene ID, Chromosome, Start Position, and End Position. | GENE CHR START ENDGENE1 1 10000 20000GENE2 1 25000 35000 |
| Gene Set File | Defines sets of genes, such as biological pathways. A plain text file where each line starts with the gene set name followed by the gene IDs in that set. | PathwayA GENE1 GENE3 GENE5PathwayB GENE2 GENE4 GENE6 |
| Linkage Disequilibrium (LD) Reference Panel | Used to estimate the correlation structure between SNPs. Typically in PLINK binary format (.bed, .bim, .fam). | Not applicable (binary format) |
Table 2: Example MAGMA Gene-Set Analysis Output
| VARIABLE | NGENES | BETA | BETA_STD | SE | P |
| KEGG_NOTCH_SIGNALING_PATHWAY | 45 | 0.253 | 0.189 | 0.067 | 0.0001 |
| REACTOME_JAK_STAT_SIGNALING | 123 | 0.198 | 0.152 | 0.051 | 0.0023 |
| GO_NEURON_DEVELOPMENT | 345 | 0.151 | 0.115 | 0.042 | 0.0156 |
-
VARIABLE : The name of the gene set.
-
NGENES : The number of genes in the gene set that were included in the analysis.
-
BETA : The estimated regression coefficient for the gene set.
-
BETA_STD : The standardized beta coefficient.
-
SE : The standard error of the beta coefficient.
-
P : The p-value for the association of the gene set with the phenotype.
Table 3: Performance Comparison of Gene-Set Analysis Methods
| Method | Analysis Type | Power | Type I Error Rate | Computational Time |
| MAGMA (PC Regression) | Self-contained | High | Well-controlled | Fast |
| PLINK (set-based) | Self-contained | Moderate | Well-controlled | Moderate |
| VEGAS | Gene-based p-value combination | Moderate-High | Well-controlled | Slow |
| GSEA | Competitive | Moderate | Variable | Moderate |
This table provides a qualitative comparison based on published studies. Actual performance may vary depending on the dataset and analysis parameters.
Experimental Protocols: A Step-by-Step Guide
The following protocol outlines the key steps for performing a gene-set analysis using MAGMA from the command line.
Step 1: Data Preparation
-
GWAS Summary Statistics: Ensure your summary statistics are in a plain text file with at least two columns: SNP identifiers and p-values.
-
Gene Annotation: Obtain a gene location file corresponding to the genome build of your summary statistics. These are available on the MAGMA website.
-
Gene Sets: Prepare a file containing your gene sets of interest (e.g., from MSigDB or KEGG).
-
LD Reference Panel: Download a suitable reference panel (e.g., from the 1000 Genomes Project) that matches the ancestry of your GWAS data.
Step 2: SNP Annotation
This step maps SNPs from your GWAS summary statistics to genes.
-
--snp-loc: Your file containing SNP locations (can be extracted from your GWAS results).
-
--gene-loc: The gene location file.
-
--out: The prefix for the output annotation file (.genes.annot).
-
Recommended Parameter: --annotate window=5,1.5 to include SNPs in a 5kb upstream and 1.5kb downstream window of each gene.
Step 3: Gene-Level Analysis
This step calculates gene-level p-values using the multiple principal components regression model.
-
--bfile: The prefix of your LD reference panel in PLINK binary format.
-
--pval: Your GWAS summary statistics file.
-
N: The sample size of your GWAS.
-
--gene-annot: The annotation file created in Step 2.
-
--out: The prefix for the gene analysis output files (.genes.raw and .genes.out).
Step 4: Gene-Set Analysis
This step performs the competitive gene-set analysis to identify pathways associated with the phenotype.
-
--gene-results: The .genes.raw file from the gene-level analysis.
-
--set-annot: Your gene set file.
-
--out: The prefix for the gene-set analysis output file (.gsa.out).
Visualizing Biological Context and Workflow
Visualizations are crucial for interpreting the complex relationships within biological pathways and understanding the analytical workflow. The following diagrams are generated using the DOT language for Graphviz.
MAGMA Experimental Workflow
References
Avian Magnum: A Comprehensive Technical Guide to its Histology and Anatomy
For Researchers, Scientists, and Drug Development Professionals
Introduction
The avian magnum, the longest and most secretory segment of the oviduct, plays a pivotal role in egg formation. It is responsible for the synthesis and secretion of the majority of the egg white proteins, collectively known as albumen. This intricate process is under precise hormonal control and involves a complex interplay of various cell types and signaling pathways. Understanding the detailed histology and anatomy of the magnum is crucial for research in avian reproductive biology, the development of transgenic avian bioreactors for pharmaceutical protein production, and for professionals in drug development concerned with reproductive toxicology. This guide provides an in-depth technical overview of the avian magnum, summarizing key quantitative data, detailing experimental protocols, and visualizing complex biological processes.
Anatomy of the Avian Magnum
The magnum is a highly coiled and glandular portion of the left oviduct, which is the functional oviduct in most bird species.[1] It is situated between the infundibulum, where fertilization occurs, and the isthmus, where the shell membranes are formed. The magnum's considerable length, which can be up to 40 centimeters in the domestic hen, provides a large surface area for the secretion of albumen.[2] The passage of the yolk through the magnum takes approximately 2-3 hours, during which it is coated with layers of albumen.[3]
Histology of the Avian Magnum
The wall of the magnum is composed of four distinct layers, or tunics: the tunica mucosa, tunica submucosa (often considered part of the lamina propria), tunica muscularis, and tunica serosa.[4][5]
-
Tunica Mucosa: This is the innermost layer and is characterized by prominent longitudinal folds, which are further divided into primary, secondary, and sometimes tertiary folds.[5][6] These folds significantly increase the secretory surface area. The mucosal epithelium is composed of two main cell types:
-
Ciliated Columnar Cells: These cells possess motile cilia on their apical surface which aid in the rotation and transport of the developing egg.[1][3]
-
Non-ciliated Secretory (Goblet) Cells: These cells are responsible for synthesizing and secreting specific components of the egg white, such as avidin, under the influence of progesterone (B1679170).[3]
-
-
Lamina Propria-Submucosa: This layer of connective tissue lies beneath the epithelium and is densely packed with branched, coiled tubular glands.[1][5] These glands are the primary sites of egg white protein synthesis, including ovalbumin, conalbumin, ovomucoid, and lysozyme.[7] The synthesis and secretion of these proteins are primarily stimulated by estrogen.[3] The lamina propria is also rich in blood vessels, which supply the necessary nutrients for the high metabolic activity of the glandular cells.[6]
-
Tunica Muscularis: This layer consists of an inner circular and an outer longitudinal layer of smooth muscle.[6] The coordinated contractions of these muscle layers propel the egg along the oviduct.
-
Tunica Serosa: This is the outermost layer, composed of a thin layer of loose connective tissue covered by a simple squamous epithelium (mesothelium).[4]
Cellular Ultrastructure
Transmission electron microscopy reveals the detailed ultrastructure of the magnum's secretory cells. The tubular gland cells are characterized by abundant rough endoplasmic reticulum and a prominent Golgi apparatus, indicative of their high protein synthesis and secretion activity.[8] Secretory granules containing egg white proteins are numerous in the apical cytoplasm of these cells, awaiting release into the lumen.
Quantitative Histological Data
The following tables summarize key quantitative data on the histology of the avian magnum from various studies. These values can vary depending on the species, age, and reproductive status of the bird.
Table 1: Thickness of Magnum Wall Layers in Quails (µm)
| Age (weeks) | Epithelial Height | Propria Submucosa Thickness | Tunica Muscularis Thickness | Tunica Serosa Thickness |
| 8 | - | - | 20.76 ± 7.27 | 3.72 ± 0.9 |
| 12 | - | - | 21.82 ± 5.63 | 3.62 ± 0.6 |
| 16 | - | - | 21.57 ± 3.82 | 3.97 ± 0.17 |
| 20 | - | - | 23.20 ± 4.19 | 4.28 ± 0.5 |
| 24 | - | - | 24.31 ± 6.17 | 4.67 ± 0.11 |
| 28 | - | - | 26.62 ± 5.53 | 5.38 ± 0.26 |
| 32 | - | - | 27.53 ± 6.98 | 5.43 ± 0.3 |
Data from Sukhadeve et al. (2021) on Punjab white quails.[4]
Table 2: Histomorphometrical Parameters in Japanese Quails (µm)
| Parameter | Measurement Range | Mean ± Standard Error |
| Height of Primary Folds | 234.84 - 515.88 | 378.23 ± 21.3 |
| Height of Luminal Epithelium | 15.72 - 31.51 | 22.98 ± 0.25 |
| Width of Glands | 22.99 - 49.12 | 33.96 ± 0.84 |
| Glandular Luminal Diameter | 2.04 - 23.12 | 11.47 ± 0.81 |
Data from a study on control Japanese quails.[9]
Table 3: Magnum Wall and Epithelial Thickness in Different Chicken Breeds at 48 weeks (µm)
| Breed | Magnum Wall Thickness | Epithelial Height |
| Kadaknath | 685.67 ± 1.71 | 17.56 ± 0.45 |
| White Leghorn | 448.54 ± 3.02 | 17.56 ± 0.45 |
Data from a comparative study on Kadaknath and White Leghorn fowl.[10]
Signaling Pathways in the Avian Magnum
The function of the avian magnum is primarily regulated by the steroid hormones estrogen and progesterone. These hormones bind to their respective receptors within the magnum's cells, initiating signaling cascades that control gene expression and protein synthesis.
Caption: Hormonal control of egg white protein synthesis in the avian magnum.
Recent transcriptomic studies have revealed other potential signaling pathways involved in magnum function, such as the relaxin signaling pathway, focal adhesion, and ECM-receptor interaction pathways, which may play roles in tissue remodeling and cell-to-cell communication during the egg formation cycle.
Experimental Protocols
This section provides detailed methodologies for key experiments commonly used in the study of the avian magnum.
Tissue Preparation for Histology
A standard workflow for preparing avian magnum tissue for histological analysis is outlined below.
Caption: Workflow for histological preparation of avian magnum tissue.
Protocol 1: Hematoxylin and Eosin (H&E) Staining
This is a standard staining method for observing the general morphology of the tissue.
-
Deparaffinization and Rehydration:
-
Xylene: 2 changes, 5 minutes each.
-
100% Ethanol: 2 changes, 3 minutes each.
-
95% Ethanol: 1 change, 3 minutes.
-
70% Ethanol: 1 change, 3 minutes.
-
Distilled water: rinse for 5 minutes.
-
-
Staining:
-
Harris' Hematoxylin: 5-10 minutes.
-
Rinse in running tap water: 5 minutes.
-
Differentiate in 1% Acid Alcohol (1% HCl in 70% ethanol): 3-10 seconds.
-
Rinse in running tap water: 1 minute.
-
Bluing in Scott's Tap Water Substitute or 0.2% ammonia (B1221849) water: 1-2 minutes.
-
Rinse in running tap water: 5 minutes.
-
Eosin Y: 1-3 minutes.
-
-
Dehydration and Clearing:
-
95% Ethanol: 2 changes, 2 minutes each.
-
100% Ethanol: 2 changes, 2 minutes each.
-
Xylene: 2 changes, 5 minutes each.
-
-
Coverslipping: Mount with a permanent mounting medium.
Protocol 2: Periodic Acid-Schiff (PAS) Staining for Glycoproteins
This method is used to detect neutral mucosubstances and glycogen, which are abundant in the secretory granules of the magnum.
-
Deparaffinization and Rehydration: Follow the same procedure as for H&E staining.
-
Staining:
-
0.5% Periodic Acid solution: 5 minutes.
-
Rinse in distilled water.
-
Schiff reagent: 15 minutes.
-
Wash in lukewarm tap water: 5 minutes.
-
Counterstain with Mayer's hematoxylin: 1 minute.
-
Wash in tap water: 5 minutes.
-
-
Dehydration, Clearing, and Coverslipping: Follow the same procedure as for H&E staining.
Protocol 3: Toluidine Blue Staining
This stain is useful for highlighting acidic components like proteoglycans and nucleic acids.
-
Deparaffinization and Rehydration: Follow the same procedure as for H&E staining.
-
Staining:
-
0.1% Toluidine Blue in 30% ethanol: 1-2 minutes.
-
Rinse briefly in distilled water.
-
-
Dehydration, Clearing, and Coverslipping:
-
Rapidly dehydrate through 95% and 100% ethanol.
-
Clear in xylene and mount.
-
Immunohistochemistry for Ovalbumin Detection
This protocol allows for the specific localization of ovalbumin, a major egg white protein, within the magnum tissue.
-
Antigen Retrieval: After deparaffinization and rehydration, immerse slides in a citrate (B86180) buffer (pH 6.0) and heat in a water bath or microwave.
-
Blocking: Incubate sections with a blocking solution (e.g., 3% bovine serum albumin in PBS) for 1 hour to prevent non-specific antibody binding.
-
Primary Antibody Incubation: Incubate with a primary antibody against ovalbumin overnight at 4°C.
-
Secondary Antibody Incubation: Wash slides and incubate with a biotinylated secondary antibody for 1 hour at room temperature.
-
Detection: Wash slides and incubate with a streptavidin-horseradish peroxidase (HRP) conjugate. Visualize with a chromogen such as diaminobenzidine (DAB), which produces a brown precipitate at the site of the antigen.
-
Counterstaining, Dehydration, and Mounting: Counterstain with hematoxylin, dehydrate, clear, and mount.
Gene Expression Analysis by qRT-PCR
This technique is used to quantify the mRNA levels of specific genes in the magnum.
Caption: Workflow for quantitative real-time PCR (qRT-PCR) analysis.
-
RNA Extraction: Isolate total RNA from magnum tissue using a commercial kit or a Trizol-based method.
-
cDNA Synthesis: Synthesize complementary DNA (cDNA) from the extracted RNA using a reverse transcriptase enzyme.
-
Quantitative PCR: Perform PCR using a real-time PCR system with gene-specific primers for the target gene (e.g., ovalbumin) and a reference gene (e.g., GAPDH or ACTB) for normalization.
-
Data Analysis: Analyze the amplification data to determine the relative expression levels of the target gene.
Conclusion
The avian magnum is a highly specialized and dynamic organ with a complex and fascinating histology and anatomy. Its efficient synthesis and secretion of massive amounts of egg white proteins are orchestrated by a fine-tuned interplay of hormonal signals and cellular machinery. The data and protocols presented in this guide offer a solid foundation for researchers, scientists, and drug development professionals to delve deeper into the intricacies of this vital component of the avian reproductive system. Further research into the molecular signaling pathways and the application of advanced imaging and analytical techniques will undoubtedly continue to unravel the complexities of the avian magnum, with significant implications for both fundamental science and applied biotechnology.
References
- 1. ndpublisher.in [ndpublisher.in]
- 2. RNA sequencing-based analysis of the magnum tissues revealed the novel genes and biological pathways involved in the egg-white formation in the laying hen - PMC [pmc.ncbi.nlm.nih.gov]
- 3. In situ detection of progesterone receptor mRNA in the chicken oviduct using probe-on slides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Immunohistochemical localization of progesterone receptor isoforms and estrogen receptor alpha in the chicken oviduct magnum during development - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. animbiosci.org [animbiosci.org]
- 6. veterinarypaper.com [veterinarypaper.com]
- 7. Magnal steroid hormone receptors during egg formation in the domestic hen - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Structural and histological characterization of oviductal magnum and lectin-binding patterns in Gallus domesticus - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. researchgate.net [researchgate.net]
Magnum Open Modification Mass Spectrometry Software: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
This in-depth technical guide provides a comprehensive overview of the Magnum open modification mass spectrometry (MS) software. Magnum is a powerful, open-source tool designed for the discovery of novel peptide adducts of unknown mass, a critical task in fields ranging from fundamental biology to drug development.[1] This guide will delve into the core functionalities of Magnum, detailing its operational workflow, data handling capabilities, and application in elucidating complex biological processes.
Introduction to Open Modification Searching and Magnum
Open modification searching (OMS) is a powerful mass spectrometry-based proteomics strategy that allows for the identification of peptides with any type of modification without prior specification.[2][3] Unlike traditional closed searches that are limited to a predefined set of modifications, OMS employs a wide precursor mass window to match experimental spectra against a protein sequence database, thereby enabling the discovery of unanticipated or unknown post-translational modifications (PTMs) and xenobiotic adducts.[2][3]
Magnum is a command-line-driven search algorithm optimized for open modification searches.[1][2] Written in C++, it is designed for high-throughput analysis and can be integrated into various data analysis pipelines.[1] A key feature of Magnum is its ability to not only detect adducts of unknown mass but also to localize these modifications to specific residues on a peptide, providing valuable insights into protein function and interaction.[1]
Key Features of Magnum:
-
Open Modification Identification: Identifies peptides with modifications of an unknown mass.[1]
-
Adduct Localization: Pinpoints the location of modifications on the peptide sequence.[1]
-
Support for Open Data Standards: Compatible with common MS data formats such as mzML, MGF, and mzXML.[1]
-
Flexible Output: Generates results in tab-delimited text and pepXML formats.[1]
-
Cross-Platform Compatibility: Available as pre-compiled binaries for both Windows and GNU/Linux operating systems.[1]
-
Open-Source: The source code is freely available under an Apache 2.0 license, fostering transparency and community-driven development.[1]
Data Presentation: Quantitative Performance
Table 1: General Performance Metrics for Open Modification Search Software
| Metric | Description | Typical Performance Range |
| Search Speed | Time taken to search a dataset against a protein database. | Minutes to hours, depending on dataset size and search parameters. |
| Sensitivity (Identifications) | Number of unique peptides or peptide-spectrum matches (PSMs) identified. | Varies significantly with sample complexity and instrument performance. |
| False Discovery Rate (FDR) | The percentage of incorrect identifications among the accepted results. | Typically controlled at 1-5% using target-decoy database strategies. |
| Modification Mass Accuracy | The precision with which the mass of the unknown modification is determined. | Dependent on the mass accuracy of the mass spectrometer (ppm level for high-resolution instruments). |
Table 2: Common Types of Modifications Investigated by Open Modification Searching
| Modification Type | Mass Shift (Da) | Biological/Chemical Relevance |
| Phosphorylation | +79.966 | Key regulator of cellular signaling. |
| Acetylation | +42.011 | Affects protein stability and function. |
| Methylation | +14.016 | Plays a role in epigenetics and protein regulation. |
| Ubiquitination (GlyGly) | +114.043 | Targets proteins for degradation. |
| Oxidation | +15.995 | Can be a biological modification or an artifact of sample preparation. |
| Drug Adducts | Variable | Covalent binding of drugs or their metabolites to proteins. |
Experimental Protocols
A typical experimental workflow using Magnum for open modification searching involves several key stages, from sample preparation to data analysis. The following protocol provides a detailed methodology based on best practices in the field.
Sample Preparation and Mass Spectrometry
-
Protein Extraction and Digestion: Proteins are extracted from cells or tissues using appropriate lysis buffers. The protein mixture is then typically reduced, alkylated, and digested into peptides using a protease such as trypsin.
-
Liquid Chromatography-Mass Spectrometry (LC-MS/MS): The resulting peptide mixture is separated by reverse-phase liquid chromatography and analyzed by tandem mass spectrometry. High-resolution mass spectrometers are recommended to achieve the mass accuracy necessary for confident identification of unknown modifications.
Magnum Open Modification Search
-
Configuration File Setup: Magnum is controlled via a text-based configuration file. Key parameters to define include:
-
database_name: Path to the protein sequence database in FASTA format. This should include both target and decoy sequences for FDR estimation.
-
spectra: Path to the mass spectrometry data file (e.g., in mzML format).
-
precursor_mass_tolerance: The mass tolerance for matching peptide masses, set to a wide range for open searches (e.g., 500 Da).
-
fragment_mass_tolerance: The mass tolerance for matching fragment ion masses.
-
mods_spec: Specification for known, fixed, and variable modifications.
-
blind_search: Enables the open modification search.
-
-
Executing the Search: The Magnum search is initiated from the command line, specifying the path to the configuration file.
-
Output Files: Magnum generates a tab-delimited text file and a pepXML file containing the search results. These files include information on peptide-spectrum matches, protein identifications, and details of any identified open modifications.
Downstream Data Analysis and Validation
The results from Magnum are typically processed further to validate the identifications and aid in their interpretation.
-
Percolator: The pepXML output from Magnum can be used as input for Percolator, a tool that uses a semi-supervised machine learning approach to improve the discrimination between correct and incorrect peptide-spectrum matches and to assign a q-value (a measure of the FDR) to each identification.
-
Limelight: Limelight is a web-based application designed for the analysis, visualization, and sharing of mass spectrometry data, including results from Magnum.[4] It allows for the comparison of multiple datasets and aids in the identification of interesting adducts.[4]
-
Trans-Proteomic Pipeline (TPP): The TPP is a suite of tools that can be used for the validation and statistical analysis of Magnum search results.[1]
Mandatory Visualization
Magnum Data Analysis Workflow
The following diagram illustrates the general workflow for an open modification search using Magnum, from raw mass spectrometry data to validated results.
Caption: A flowchart of the Magnum open modification search workflow.
Example Signaling Pathway: Drug-Target Interaction
Open modification searching is particularly powerful for identifying covalent drug-protein adducts, which can elucidate a drug's mechanism of action or off-target effects. The following diagram illustrates a hypothetical signaling pathway where an unknown drug metabolite covalently modifies a key signaling protein, which is then identified using an open modification search.
Caption: Drug-target identification via open modification mass spectrometry.
Conclusion
Magnum is a valuable open-source tool for the proteomics community, enabling the discovery of novel and uncharacterized protein modifications. Its command-line interface and support for open standards facilitate its integration into diverse bioinformatics pipelines. While the full potential of open modification searching is still being explored, tools like Magnum are paving the way for a deeper understanding of the complex landscape of the proteome and its modifications, with significant implications for both basic research and therapeutic development.
References
An In-depth Technical Guide to the Magnum-PSI Linear Plasma Generator
The Magnum-PSI (MAgnetized plasma Generator and NUMerical modeling for Plasma Surface Interaction) is a world-leading research facility dedicated to studying the complex interactions between plasma and materials under conditions relevant to future nuclear fusion reactors, such as ITER.[1][2][3] Located at the Dutch Institute for Fundamental Energy Research (DIFFER), this linear plasma generator is unique in its ability to produce high-flux, low-temperature plasmas in a steady state, mimicking the harsh environment of a fusion reactor's divertor.[2][4] This guide provides a technical overview of its core features, operational parameters, and experimental capabilities.
Core Technical Specifications
Magnum-PSI's design is centered around achieving ITER-relevant plasma conditions with maximum flexibility and diagnostic access.[1][5] This is accomplished through a combination of a powerful plasma source, a strong superconducting magnet, and a sophisticated vacuum system. The modular design allows for adaptation to new physics insights.[5]
| Feature | Specification | Source |
| Plasma Source | DC Cascaded Arc Discharge | [3][6][7] |
| Magnetic Field | Superconducting Magnet | [2][6] |
| Up to 2.5 T (Steady State) | [1][6] | |
| Vacuum System | 3-Stage Differentially Pumped | [1][8] |
| Target System | Water-cooled, inclinable (± 90°) targets | [6] |
| Target Exchange and Analysis Chamber (TEAC) | [6] | |
| Operational Mode | Steady State / Continuous Operation | [6][8] |
| Transient Capability | Pulsed Power System / High-Power Laser | [5][6][7] |
Plasma Generation and Confinement
The process begins with the generation of a hot, dense plasma in the cascaded arc source, which is then guided and confined by a powerful magnetic field towards a target material. The differentially pumped vacuum system is crucial for maintaining a low neutral pressure in the target region, ensuring that the plasma-surface interaction is dominated by the incoming ion flux.[1]
Achievable Plasma Parameters
Magnum-PSI is designed to replicate the high-density, low-temperature plasma conditions expected at the ITER divertor strike zones.[1] This allows for the study of material erosion, redeposition, and fuel retention under realistic and sustained fluxes.
| Parameter | Range | Source |
| Particle Flux | 10²³ - 10²⁵ ions m⁻²s⁻¹ | [1][4][6] |
| Heat Flux (Steady State) | > 10 MW m⁻² | [5][6] |
| Heat Flux (Transient) | Up to 2 GW m⁻² | [6] |
| Electron Density (nₑ) | 10¹⁹ - 10²¹ m⁻³ | [4][6] |
| Electron Temperature (Tₑ) | 0.1 - 10 eV (typically 1 - 5 eV) | [4][6][8] |
| Neutral Background Pressure | < 1 Pa | [6] |
| Plasma Beam Diameter | Up to 10 cm | [1] |
Experimental Workflow and Diagnostics
A typical experiment in Magnum-PSI involves exposing a material sample to the plasma beam while a suite of diagnostics monitors both the plasma and the material's response. The facility's design provides extensive diagnostic access through 16 radial ports.[1] After exposure, targets can be retracted into the Target Exchange and Analysis Chamber (TEAC) for in-vacuum surface analysis.[6]
Key Diagnostic Systems: Magnum-PSI is equipped with a comprehensive set of diagnostics to characterize the plasma and the target material.
-
Plasma Diagnostics:
-
Thomson Scattering: Measures electron density (nₑ) and temperature (Tₑ).[1][8]
-
Double Langmuir Probes: Provides local plasma parameter measurements.[1]
-
Optical Emission Spectroscopy (OES): Analyzes light emitted from the plasma to identify species.[9]
-
Active Spectroscopy (TALIF, CARS, VUV-LIF): Used to measure the properties of neutral particles like atomic and molecular hydrogen, which are crucial for understanding plasma detachment.[10]
-
-
Surface and Material Diagnostics:
-
Infrared (IR) Thermography: Monitors the surface temperature of the target during plasma exposure.[9]
-
Target Calorimetry: Measures the total heat flux delivered to the target.[1][9]
-
Ion Beam Facility (IBF): Connected to the TEAC, the IBF allows for detailed (sub)surface analysis of materials after plasma exposure to study morphology, composition, and fuel retention.[3][6]
-
Experimental Protocols and Capabilities
Magnum-PSI enables a wide range of experiments crucial for fusion research.
-
Steady-State High-Fluence Exposure: The superconducting magnet allows for long-duration experiments, accumulating high particle fluences (e.g., 10³⁰ m⁻² in ~30 hours) to test the lifetime of plasma-facing components.[8]
-
Detachment Studies: A key area of research is plasma detachment, a process where the plasma cools and recombines before reaching the divertor wall, reducing heat and particle loads. Experiments are conducted by systematically increasing the neutral gas pressure in the target chamber and observing the plasma's response.[11]
-
Transient Event Simulation: To study the effect of Edge Localized Modes (ELMs)—brief, intense bursts of energy from the core plasma—Magnum-PSI can superimpose power transients onto the steady-state plasma.[5] This is achieved either with a capacitor bank connected to the source or by using a high-power laser aimed at the target surface, simulating heat loads well in excess of 1 GW m⁻².[5][7]
-
Material Screening: The facility is used to expose various candidate materials, such as tungsten and liquid metals, to fusion-relevant conditions to evaluate their performance, erosion characteristics, and fuel retention properties.[2][3]
References
- 1. research.tue.nl [research.tue.nl]
- 2. Candidate fusion materials to be investigated at Magnum-PSI [iter.org]
- 3. onderzoeksfaciliteiten.nl [onderzoeksfaciliteiten.nl]
- 4. researchgate.net [researchgate.net]
- 5. nstx.pppl.gov [nstx.pppl.gov]
- 6. Magnum-PSI | Dutch Institute for Fundamental Energy Research [differ.nl]
- 7. differ.nl [differ.nl]
- 8. Redirecting [linkinghub.elsevier.com]
- 9. researchgate.net [researchgate.net]
- 10. Active spectroscopy on Magnum-PSI to characterize atomic and molecular hydrogen in detached conditions [inis.iaea.org]
- 11. cris.maastrichtuniversity.nl [cris.maastrichtuniversity.nl]
A Beginner's Technical Guide to MAGMA for Genetic Analysis
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive walkthrough of MAGMA (Multi-marker Analysis of GenoMic Annotation), a powerful tool for gene and gene-set analysis of Genome-Wide Association Study (GWAS) data. By aggregating the effects of multiple genetic markers, MAGMA can identify genes and gene sets associated with complex traits and diseases, offering crucial insights for target discovery and validation in drug development.[1][2][3]
Core Concepts of MAGMA
MAGMA's methodology is built upon a three-step process designed to transform SNP-level data into biologically interpretable gene-level and gene-set-level results.[2][4][5] This approach enhances the statistical power to detect associations that may be missed at the individual SNP level, a common challenge in the study of polygenic traits.[1][3]
The three core steps are:
-
Annotation: This initial step involves mapping single nucleotide polymorphisms (SNPs) to their corresponding genes based on their genomic locations.[2][5][6]
-
Gene Analysis: In the second step, MAGMA computes a single gene-level p-value by aggregating the association statistics of all SNPs mapped to that gene.[2][4] This step accounts for the linkage disequilibrium (LD) between SNPs.[1][3]
-
Gene-Set Analysis: The final step tests for the association of predefined sets of genes (e.g., biological pathways, Gene Ontology terms) with the phenotype of interest.[2][5]
The MAGMA Workflow: A Visual Overview
The following diagram illustrates the logical flow of a standard MAGMA analysis, from input data to the final gene-set enrichment results.
Experimental Protocols: A Step-by-Step Guide
This section details the command-line implementation of the core MAGMA workflow. It is assumed that you have MAGMA installed and the necessary input files are prepared.[4][7]
Step 1: Annotation
The annotation step maps SNPs from your GWAS summary statistics to genes based on their genomic coordinates.
Methodology: You will need a SNP location file (which can be derived from your GWAS results) and a gene location file.[4][6] The gene location file can be downloaded from the MAGMA website for various genome builds.[4] An optional window can be added upstream and downstream of genes to include regulatory variants.[5][8]
Command:
Input File Formats:
| File Type | Description | Format |
| SNP Location File | Contains the genomic coordinates of each SNP. | A text file with three columns: SNP ID, Chromosome, Base-pair Position. A PLINK .bim file can also be used.[4] |
| Gene Location File | Contains the genomic coordinates of each gene. | A text file with at least four columns: Gene ID, Chromosome, Start Position, Stop Position.[4] |
Step 2: Gene Analysis
This step calculates gene-level p-values from the SNP p-values, accounting for LD. MAGMA offers several models for this analysis.
Methodology: The gene analysis can be performed on raw genotype data or on SNP p-values from summary statistics, with the latter requiring a reference panel to estimate LD.[4] The snp-wise=mean model is a common choice when using summary statistics.[4][6]
Command (using SNP p-values):
Input File Formats:
| File Type | Description | Format |
| Reference Panel | Genotype data used to calculate LD (e.g., 1000 Genomes). | PLINK binary format (.bed, .bim, .fam).[4] |
| SNP P-value File | Contains the p-values for each SNP from the GWAS. | A text file with columns for SNP ID and P-value. MAGMA will look for headers named SNP and P.[4] |
| Annotation File | The output from the annotation step. | [OUTPUT_PREFIX].genes.annot |
Step 3: Gene-Set Analysis
The final step performs a competitive gene-set analysis to determine if genes within a given set are more strongly associated with the phenotype than other genes.
Methodology: This analysis is implemented as a linear regression model at the gene level.[6] It requires the .genes.raw file from the gene analysis step and a file defining the gene sets.
Command:
Input File Formats:
| File Type | Description | Format |
| Gene Results File | The raw output from the gene analysis step. | [GENE_ANALYSIS_PREFIX].genes.raw |
| Gene-Set File | Defines the gene sets to be tested. | A text file where each row represents a gene set, starting with the set name followed by the Gene IDs belonging to that set, separated by spaces.[6][9] |
Data Presentation: Understanding MAGMA Output
The primary output of a MAGMA gene-set analysis is a .gsa.out file. This file contains detailed statistics for each tested gene set.
Example Output Table Structure:
| Column | Description | Example Value |
| VARIABLE | The name of the gene set. | REACTOME_SIGNALING_BY_NOTCH |
| TYPE | The type of analysis (SET). | SET |
| NGENES | The number of genes in the set that were included in the analysis. | 120 |
| BETA | The regression coefficient for the gene set. | 0.25 |
| SE | The standard error of the regression coefficient. | 0.08 |
| Z | The Z-score for the gene set. | 3.125 |
| P | The p-value for the association of the gene set with the phenotype. | 0.0018 |
Advanced Analyses in MAGMA
MAGMA's framework also supports more complex analyses, such as conditional and interaction analyses.
Conditional Gene-Set Analysis
This analysis tests the association of a gene set while controlling for the effect of another gene set. This is useful for disentangling the effects of closely related pathways.
Gene Property Analysis
MAGMA can also be used to investigate the relationship between a continuous gene property (e.g., tissue-specific gene expression) and the gene's association with a phenotype.
Methodology: This analysis uses a regression model to test if the gene-level association with the phenotype is predicted by the continuous gene property.
Example: A positive association with brain-specific expression would suggest that genes more highly expressed in the brain tend to have stronger genetic associations with the phenotype under study.[10]
Conclusion
MAGMA provides a robust and flexible framework for moving from SNP-level GWAS results to actionable biological insights. By systematically performing annotation, gene analysis, and gene-set analysis, researchers can identify key biological pathways and prioritize genes for further investigation in the drug discovery pipeline. This guide offers a foundational understanding of the core principles and practical steps involved in conducting a MAGMA analysis. For more advanced applications and detailed options, users are encouraged to consult the official MAGMA documentation.[4][7]
References
- 1. MAGMA: Generalized Gene-Set Analysis of GWAS Data | PLOS Computational Biology [journals.plos.org]
- 2. Gene Set Analysis with MAGMA - OmicsBox User Manual [docs.omicsbox.biobam.com]
- 3. MAGMA: Generalized Gene-Set Analysis of GWAS Data - PMC [pmc.ncbi.nlm.nih.gov]
- 4. ibg.colorado.edu [ibg.colorado.edu]
- 5. Gene Set Analysis of GWAS data with MAGMA [biobam.com]
- 6. genomeanalysis / MAGMA analysis · GitLab [gitlab.lcsb.uni.lu]
- 7. MAGMA - CNCR [cncr.nl]
- 8. Gene/Gene-set tests by MAGMA - GWASTutorial [cloufield.github.io]
- 9. ibg.colorado.edu [ibg.colorado.edu]
- 10. ibg.colorado.edu [ibg.colorado.edu]
The Influence of Environmental Factors on the Avian Magnum: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Abstract
The avian magnum, a critical segment of the oviduct, is responsible for the synthesis and secretion of the majority of egg white proteins. Its function is intricately linked to a variety of environmental cues, which can significantly impact avian reproductive success and egg quality. This technical guide provides an in-depth exploration of how environmental factors such as photoperiod, temperature, nutrition, and toxins modulate the physiological and molecular processes within the avian magnum. Detailed experimental protocols for key analyses and visualizations of critical signaling pathways are presented to support further research and development in this field.
Introduction: The Avian Magnum
The magnum is the longest and most glandular portion of the avian oviduct. Its primary role is the synthesis and secretion of major egg white proteins, including ovalbumin, ovotransferrin, ovomucoid, and lysozyme. This process is under complex hormonal control, primarily regulated by estrogens and progesterone (B1679170). The development and function of the magnum are essential for producing viable eggs with the necessary nutritional and protective components for embryonic development. Environmental conditions can profoundly influence the delicate hormonal balance and cellular activities within the magnum, thereby affecting egg production and quality.
Impact of Key Environmental Factors
Photoperiod
Photoperiod, or the duration of light exposure, is a primary driver of reproductive activity in many avian species.[1][2] Increasing day length stimulates the hypothalamus to release Gonadotropin-Releasing Hormone (GnRH).[1][2] GnRH, in turn, acts on the pituitary gland to secrete Luteinizing Hormone (LH) and Follicle-Stimulating Hormone (FSH), which are crucial for ovarian development and steroid hormone production.[1] These hormones, particularly estrogen, are vital for the growth and functional differentiation of the magnum.
Table 1: Effect of Photoperiod on Laying Hen Performance and Hormone Levels
| Photoperiod (Light:Dark) | Egg Production (%) | Egg Mass ( g/day ) | Serum FSH (ng/mL) | Serum LH (ng/mL) |
| 12L:12D | 75.2 ± 2.1 | 48.9 ± 1.5 | 3.8 ± 0.4 | 2.5 ± 0.3 |
| 14L:10D | 82.5 ± 1.8 | 53.6 ± 1.2 | 4.5 ± 0.5 | 3.1 ± 0.4 |
| 16L:8D | 88.1 ± 1.5 | 57.3 ± 1.0 | 5.2 ± 0.6 | 3.8 ± 0.5 |
| 18L:6D | 87.5 ± 1.7 | 56.9 ± 1.1 | 5.1 ± 0.5 | 3.7 ± 0.4 |
Data synthesized from studies on laying ducks, indicating a general trend applicable to domestic fowl. Actual values may vary by species and breed.[3]
Temperature
Ambient temperature is a critical factor that can induce stress in birds, leading to physiological changes that affect reproduction. The optimal temperature for most laying hens is between 19-22°C. Temperatures outside this range can lead to heat or cold stress, activating the Hypothalamic-Pituitary-Adrenal (HPA) axis and increasing circulating corticosterone (B1669441) levels.[4] Elevated corticosterone can have inhibitory effects on the reproductive axis, reducing egg production and quality.
Table 2: Influence of Ambient Temperature on Laying Hen Performance
| Temperature (°C) | Feed Intake ( g/day ) | Egg Production (%) | Egg Weight (g) |
| 12 ± 4.5 | 133.7 ± 5.3 | 85.2 ± 4.1 | 64.0 ± 1.9 |
| 24 ± 3.0 | 112.7 ± 8.7 | 86.5 ± 3.5 | 65.3 ± 1.5 |
Data from a study on 36-week-old laying hens over a 4-week period.
Nutrition
Proper nutrition is fundamental for the structural and functional integrity of the magnum and for the synthesis of egg components. Key nutrients include:
-
Calcium: Essential for eggshell formation, but also plays a role in overall reproductive health. Inadequate calcium can lead to a compensatory increase in feed intake, potentially causing fatty liver and affecting overall hen health.[5]
-
Phosphorus: Works in conjunction with calcium for skeletal health, which is crucial for calcium mobilization for eggshell formation.
-
Vitamin D3: Necessary for proper calcium absorption and metabolism.
-
Trace Minerals (Manganese, Copper, Zinc): Act as cofactors for enzymes involved in the formation of the eggshell matrix.
Table 3: Effect of Dietary Calcium Levels on Aged Laying Hens (70-80 weeks)
| Dietary Calcium (%) | Egg Production (%) | Cracked Eggs (%) | Eggshell Strength ( kg/cm ²) | Eggshell Thickness (mm) |
| 3.5 | 88.5 ± 1.2 | 3.6 ± 0.4 | 3.2 ± 0.2 | 0.38 ± 0.01 |
| 3.8 | 88.9 ± 1.1 | 3.1 ± 0.3 | 3.4 ± 0.2 | 0.39 ± 0.01 |
| 4.1 | 89.2 ± 1.0 | 2.8 ± 0.3 | 3.6 ± 0.2 | 0.40 ± 0.01 |
| 4.4 | 88.7 ± 1.2 | 2.5 ± 0.2 | 3.7 ± 0.2 | 0.41 ± 0.01 |
| 4.7 | 88.1 ± 1.3 | 2.1 ± 0.2 | 3.8 ± 0.2 | 0.42 ± 0.01 |
This study showed that while egg production was not significantly affected, higher calcium levels improved eggshell quality in older hens.[6][7]
Toxins
Exposure to toxins can have detrimental effects on the magnum, leading to morphological damage and impaired function.
-
Mycotoxins: Produced by fungi in contaminated feed, mycotoxins like aflatoxin B1 and T-2 toxin can cause a reduction in egg production and quality.[8][9] Histopathological effects can include necrosis of hepatocytes and nephritis.[10][11][12]
-
Heavy Metals: Cadmium has been shown to negatively impact egg quality, although some of these effects may be ameliorated by supplementation with agents like calcium tetraborate.[13]
-
Pesticides and Industrial Chemicals: Organophosphorus insecticides and other environmental pollutants can disrupt endocrine function and impair reproduction.
Table 4: Pathological Effects of Mycotoxins on Poultry
| Mycotoxin | Target Organs | Observed Pathological Changes in Magnum and Related Tissues |
| Aflatoxin B1 | Liver, Kidneys | Reduced egg production and weight, fatty liver.[8] |
| T-2 Toxin | Liver, Kidneys, Immune System | Decreased egg production and quality, oral lesions, regression of the bursa of Fabricius.[8][9] |
| Ochratoxin A | Kidneys, Liver | Reduced egg production, poor feathering.[9] |
| Fumonisin B1 | Liver | Hepatocellular hyperplasia.[9] |
Key Signaling Pathways
Hypothalamic-Pituitary-Ovarian (HPO) Axis
The HPO axis is the central regulatory pathway for avian reproduction. Environmental cues, primarily photoperiod, initiate a signaling cascade that results in the secretion of steroid hormones from the ovary, which then act on the magnum.[1][2][14][15][16]
Hypothalamic-Pituitary-Adrenal (HPA) Axis and Stress Response
Environmental stressors activate the HPA axis, leading to the release of corticosterone.[4][17][18][19] Chronic elevation of corticosterone can suppress the HPO axis, thereby inhibiting magnum function and egg production.[20]
Experimental Protocols
Tissue Collection and Histological Analysis
This protocol outlines the steps for collecting and preparing avian magnum tissue for histological examination.
Workflow Diagram:
Methodology:
-
Tissue Collection: Immediately following euthanasia, expose the abdominal cavity and carefully dissect the entire oviduct. Identify the magnum section based on its anatomical location and appearance (thick-walled and glandular).
-
Trimming: Excise a small section of the magnum and trim it to a thickness of 2-3 mm to ensure proper fixative penetration.[21]
-
Fixation: Immediately immerse the trimmed tissue in at least 20 volumes of 10% neutral buffered formalin (NBF).[21][22] Fix for 6 to 72 hours at room temperature, depending on the tissue size.[21]
-
Processing: After fixation, dehydrate the tissue through a graded series of ethanol (B145695) (e.g., 70%, 95%, 100%). Clear the tissue with an agent like xylene. This can be done manually or using an automated tissue processor.[21][23]
-
Embedding: Infiltrate the tissue with molten paraffin wax and embed it in a paraffin block, ensuring correct orientation.[22][23][24]
-
Sectioning: Cut thin sections (5-10 µm) from the paraffin block using a microtome.[23]
-
Staining: Mount the sections on glass slides, deparaffinize, rehydrate, and stain with Hematoxylin (B73222) and Eosin (H&E) for morphological evaluation.
-
Analysis: Examine the stained sections under a light microscope to assess the magnum's morphology, including the integrity of the luminal epithelium and tubular glands.
RNA Extraction and Quantitative PCR (qPCR)
This protocol details the procedure for quantifying gene expression in the avian magnum.
Methodology:
-
Tissue Collection and Storage: Collect magnum tissue as described above and immediately snap-freeze it in liquid nitrogen or place it in an RNA stabilization solution (e.g., RNAlater®) to prevent RNA degradation. Store at -80°C until use.
-
RNA Extraction:
-
Homogenize the tissue (50-100 mg) in 1 mL of a lysis reagent like TRIzol.[25]
-
Perform phase separation by adding chloroform (B151607) and centrifuging. The RNA will remain in the upper aqueous phase.[25]
-
Precipitate the RNA from the aqueous phase using isopropanol.[25]
-
Wash the RNA pellet with 75% ethanol and resuspend it in RNase-free water.[25]
-
Assess RNA quality and quantity using a spectrophotometer (e.g., NanoDrop) and/or a bioanalyzer.
-
-
cDNA Synthesis (Reverse Transcription):
-
Treat the extracted RNA with DNase I to remove any contaminating genomic DNA.
-
Synthesize first-strand complementary DNA (cDNA) from the RNA template using a reverse transcriptase enzyme and primers (oligo(dT)s, random hexamers, or a mix).[26]
-
-
Quantitative PCR (qPCR):
-
Prepare a reaction mix containing SYBR Green master mix, forward and reverse primers for the gene of interest, and the synthesized cDNA template.[27][28]
-
Perform the qPCR reaction in a real-time PCR cycler. The cycling conditions typically include an initial denaturation step, followed by 40 cycles of denaturation, annealing, and extension.[26][27]
-
Include a melting curve analysis at the end of the run to verify the specificity of the amplified product.[26]
-
Analyze the data using the comparative Cq (ΔΔCq) method, normalizing the expression of the target gene to one or more stably expressed reference genes (e.g., GAPDH, ACTB).[27][29]
-
Immunohistochemistry (IHC) for Steroid Receptors
This protocol describes the localization of estrogen and progesterone receptors within the magnum tissue.[30][31][32]
Methodology:
-
Tissue Preparation: Use formalin-fixed, paraffin-embedded magnum sections as prepared for histology.
-
Deparaffinization and Rehydration: Deparaffinize the sections in xylene and rehydrate through a graded series of ethanol to water.
-
Antigen Retrieval: Perform heat-induced epitope retrieval by immersing the slides in a retrieval solution (e.g., citrate (B86180) buffer, pH 6.0) and heating them in a microwave, pressure cooker, or water bath. This step is crucial for unmasking the antigenic sites.[33]
-
Blocking: Block endogenous peroxidase activity with a hydrogen peroxide solution. Block non-specific antibody binding with a blocking serum (e.g., normal goat serum).
-
Primary Antibody Incubation: Incubate the sections with a primary antibody specific to the estrogen receptor (ERα) or progesterone receptor (PR) at an optimized dilution, typically overnight at 4°C.[30][34]
-
Secondary Antibody and Detection:
-
Wash the slides and incubate with a biotinylated secondary antibody that recognizes the primary antibody.
-
Incubate with a streptavidin-horseradish peroxidase (HRP) conjugate.
-
Apply a chromogen substrate (e.g., DAB) to visualize the antibody binding (typically a brown precipitate).
-
-
Counterstaining, Dehydration, and Mounting: Lightly counterstain the sections with hematoxylin to visualize cell nuclei. Dehydrate the sections, clear in xylene, and mount with a coverslip.
-
Analysis: Examine the slides under a microscope to determine the localization (nuclear, cytoplasmic) and intensity of receptor staining in different cell types of the magnum (e.g., luminal epithelium, tubular gland cells).[30]
Conclusion
The avian magnum is a highly dynamic organ whose function is tightly regulated by a complex interplay of hormonal signals that are, in turn, heavily influenced by environmental factors. Photoperiod, temperature, nutrition, and exposure to toxins can all significantly alter the magnum's physiology and its capacity to produce high-quality eggs. Understanding these interactions at a molecular level is crucial for optimizing poultry production, assessing the impacts of environmental change on wild bird populations, and for the development of novel therapeutics or management strategies. The protocols and pathway diagrams provided in this guide serve as a foundational resource for researchers dedicated to advancing our knowledge of avian reproductive biology.
References
- 1. mdpi.com [mdpi.com]
- 2. researchgate.net [researchgate.net]
- 3. Effects of photoperiod on performance, ovarian morphology, reproductive hormone level, and hormone receptor mRNA expression in laying ducks - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. Calcium and its relationship to excess feed consumption, body weight, egg size, fat deposition, shell quality, and fatty liver hemorrhagic syndrome - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Effects of Dietary Calcium Levels on Productive Performance, Eggshell Quality and Overall Calcium Status in Aged Laying Hens - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. Effects of supplemented multicomponent mycotoxin detoxifying agent in laying hens fed aflatoxin B1 and T2-toxin contaminated feeds - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Prevalence and effects of mycotoxins on poultry health and performance, and recent development in mycotoxin counteracting strategies - PMC [pmc.ncbi.nlm.nih.gov]
- 10. iijls.com [iijls.com]
- 11. researchgate.net [researchgate.net]
- 12. wvj.science-line.com [wvj.science-line.com]
- 13. abis-files.metu.edu.tr [abis-files.metu.edu.tr]
- 14. researchgate.net [researchgate.net]
- 15. Transcriptome Analysis of Hypothalamic-Pituitary-Ovarian Axis Reveals circRNAs Related to Egg Production of Bian Chicken - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Molecular mechanisms of hypothalamic-pituitary-ovarian/thyroid axis regulating age at first egg in geese - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Telencephalic regulation of the HPA axis in birds - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. Telencephalic regulation of the HPA axis in birds - PMC [pmc.ncbi.nlm.nih.gov]
- 19. researchgate.net [researchgate.net]
- 20. academic.oup.com [academic.oup.com]
- 21. Optimal FFPE Tissue Fixation, Processing, and Embedding: A Comprehensive Guide | CellCarta [cellcarta.com]
- 22. masseycancercenter.org [masseycancercenter.org]
- 23. molecular-machines.com [molecular-machines.com]
- 24. health.uconn.edu [health.uconn.edu]
- 25. stackscientific.nd.edu [stackscientific.nd.edu]
- 26. elearning.unite.it [elearning.unite.it]
- 27. Reference Genes for Quantitative Gene Expression Studies in Multiple Avian Species - PMC [pmc.ncbi.nlm.nih.gov]
- 28. Reference Genes for Quantitative Gene Expression Studies in Multiple Avian Species | PLOS One [journals.plos.org]
- 29. abdn.elsevierpure.com [abdn.elsevierpure.com]
- 30. Immunohistochemical localization of progesterone receptor isoforms and estrogen receptor alpha in the chicken oviduct magnum during development - PubMed [pubmed.ncbi.nlm.nih.gov]
- 31. Immunohistochemical localization of oestrogen receptor alpha in the various cell categories of chick embryo ovary - PubMed [pubmed.ncbi.nlm.nih.gov]
- 32. A study of the immunohistochemical localization of the progesterone and oestrogen receptors in the magnum of the immature ostrich, Struthio camelus - PubMed [pubmed.ncbi.nlm.nih.gov]
- 33. Optimized immunohistochemical detection of estrogen receptor beta using two validated monoclonal antibodies confirms its expression in normal and malignant breast tissues - PMC [pmc.ncbi.nlm.nih.gov]
- 34. Immunohistochemical Performance of Estrogen and Progesterone Receptor Antibodies on the Dako Omnis Staining Platform: Evaluation in Multicenter Studies - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for MAGMA in GWAS Data Analysis
These application notes provide researchers, scientists, and drug development professionals with a detailed guide to utilizing MAGMA (Multi-marker Analysis of GenoMic Annotation) for post-GWAS (Genome-Wide Association Study) analysis. MAGMA is a powerful tool for deriving gene-based and gene-set-based p-values from SNP-level GWAS summary statistics, which can help elucidate the biological mechanisms underlying complex traits and diseases.
Introduction to MAGMA
Genome-Wide Association Studies (GWAS) have successfully identified thousands of genetic variants associated with complex traits and diseases. However, interpreting these associations and understanding their biological context remains a significant challenge. MAGMA is a computational tool that addresses this by aggregating SNP-level associations to the level of genes and then testing for associations with gene sets or pathways. This approach increases statistical power and aids in the biological interpretation of GWAS findings.
The core functionalities of MAGMA include:
-
Gene Analysis: Calculating a single p-value for each gene, representing the combined effect of all SNPs within that gene.
-
Gene-Set Analysis: Testing whether predefined sets of genes (e.g., biological pathways) are enriched for genetic associations.
-
Gene-Property Analysis: Investigating the relationship between the genetic association of a gene and specific gene properties, such as tissue-specific expression levels.
Experimental Protocols
This section details the step-by-step protocols for performing the core analyses in MAGMA.
The first step in a typical MAGMA workflow is to compute gene-level p-values from SNP p-values. This involves two main stages: annotation and gene analysis.
Methodology:
-
Annotation Step:
-
Objective: To map SNPs from the GWAS summary statistics to the genes they are located in or near.
-
Input Files:
-
A file containing SNP p-values from a GWAS.
-
A gene location file.
-
A reference data file (e.g., from the 1000 Genomes Project) to account for Linkage Disequilibrium (LD).
-
-
Procedure: The magma --annotate command is used to create an annotation file. This file will specify which SNPs are located within or near each gene, based on a user-defined window.
-
-
Gene Analysis Step:
-
Objective: To calculate a single p-value for each gene based on the p-values of the SNPs mapped to it.
-
Input Files:
-
The annotation file created in the previous step.
-
The GWAS SNP p-value file.
-
The reference data to compute LD.
-
-
Procedure: The magma --bfile (for raw genotype data) or --pfile (for summary statistics) command is used in conjunction with --gene-annot and --pval to perform the gene analysis. The default analysis uses the mean of SNP associations as the test statistic for the gene.
-
A generalized workflow for MAGMA gene analysis is depicted below.
Once gene-level p-values have been calculated, MAGMA can test for the enrichment of genetic associations in predefined gene sets.
Methodology:
-
Objective: To determine if specific biological pathways or other defined sets of genes are significantly associated with the trait of interest.
-
Input Files:
-
The gene-level results file from Protocol 1 (.genes.out).
-
A gene-set file, where each line defines a set with a name followed by the gene IDs belonging to that set.
-
-
Procedure: The magma --gene-results command is used, specifying the output from the gene analysis. The --set-annot option is used to provide the gene-set file. MAGMA then performs a competitive gene-set analysis, which tests whether the genes in a set are more strongly associated with the trait than other genes.
The logical relationship in gene-set analysis is illustrated in the diagram below.
This analysis investigates the relationship between gene-level associations and continuous gene properties, such as tissue-specific gene expression.
Methodology:
-
Objective: To identify tissues or cell types where the genetic associations are concentrated, suggesting a role for those tissues in the trait's etiology.
-
Input Files:
-
The gene-level results file from Protocol 1 (.genes.out).
-
A gene-property file containing gene expression levels across different tissues. This is typically a matrix with genes as rows and tissues as columns.
-
-
Procedure: The analysis is performed using the --gene-results file and a specially formatted gene expression file provided via the --gene-covar option. MAGMA tests the relationship between the gene's p-value (or Z-score) and its expression level in a specific tissue, conditioning on the average expression across all tissues.
The workflow for gene-property analysis is shown below.
Data Presentation
The following tables summarize the key input files, MAGMA commands, and output files for easy reference.
Table 1: Summary of Input Files for MAGMA
| File Type | Description | Format |
| GWAS Summary Stats | Contains SNP IDs and their p-values from a GWAS. | A text file with columns for SNP ID and p-value. |
| Gene Location File | Defines the genomic coordinates for each gene. | A text file with columns for Gene ID, Chromosome, Start, and End position. |
| Reference Panel | Genotype data used to compute Linkage Disequilibrium (LD). | PLINK binary format (.bed, .bim, .fam). |
| Gene-Set File | Defines sets of genes (e.g., pathways). | A text file where each line starts with a set name followed by Gene IDs. |
| Gene-Property File | Contains continuous gene-level data (e.g., expression). | A text file with a Gene ID column followed by columns for each property (tissue). |
Table 2: Core MAGMA Commands and Parameters
| Command | Parameter | Description |
| magma | --annotate --snp-loc | Maps SNPs to genes based on their genomic locations. |
| magma | --bfile | Performs gene analysis using raw genotype data as the LD reference. |
| magma | --pfile | Performs gene analysis using a pre-computed reference panel. |
| magma | --gene-results | Conducts a gene-set (pathway) analysis. |
| magma | --gene-results | Performs a gene-property analysis (e.g., for tissue specificity). |
Table 3: Description of Key MAGMA Output Files
| File Suffix | Analysis Type | Description |
| .annot | Annotation | Contains the mapping of SNPs to genes. |
| .genes.out | Gene Analysis | Contains gene-level association statistics, including p-values. |
| .genes.raw | Gene Analysis | Contains details of the gene analysis, including the number of SNPs per gene. |
| .gsa.out | Gene-Set Analysis | Contains the results of the gene-set analysis, including the p-value for each set. |
| .gene.covar.out | Gene-Property Analysis | Contains the results of the gene-property analysis, showing the association for each property. |
Conclusion
MAGMA provides a flexible and powerful framework for moving from SNP-level GWAS results to more biologically interpretable gene and gene-set level findings. By following the protocols outlined in these application notes, researchers can effectively leverage MAGMA to gain deeper insights into the genetic architecture of complex traits and diseases, identify key biological pathways, and prioritize tissues and cell types for further investigation. This can ultimately accelerate the translation of GWAS findings into novel therapeutic strategies.
Application Notes: Analysis of Protein Expression in the Avian Magnum
For Researchers, Scientists, and Drug Development Professionals
Introduction
The magnum is the longest and most functionally significant segment of the avian oviduct, responsible for synthesizing and secreting the majority of egg white proteins, collectively known as albumen.[1][2] This intricate biological process is tightly regulated by steroid hormones, primarily estrogen, which governs the expression of key proteins like ovalbumin, ovotransferrin, and lysozyme.[1][2] Understanding the mechanisms of protein expression, regulation, and secretion in the magnum is crucial for advancements in avian reproductive biology, poultry science, and the development of avian bioreactor systems for producing therapeutic proteins.[3][4]
These application notes provide a comprehensive overview and detailed protocols for studying protein expression in the avian magnum. The methodologies cover tissue collection, protein extraction, quantification, and analysis using Western blotting and immunohistochemistry.
Quantitative Data Summary
The protein composition of egg white is well-characterized, with a few major proteins accounting for the bulk of the albumen. The relative abundance of these proteins, synthesized in the magnum, is summarized below.
| Protein | Abbreviation | Molecular Weight (kDa) | Relative Abundance (%) | Key Function(s) |
| Ovalbumin | OVA | ~45 | 54% | Nutrient source, protease inhibitor properties |
| Ovotransferrin | OTF | ~76 | 12% | Iron binding, antimicrobial |
| Ovomucoid | OVM | ~28 | 11% | Trypsin inhibitor, allergenic component |
| Lysozyme | LYS | ~14.3 | 3.5% | Antimicrobial (hydrolyzes bacterial cell walls) |
| Ovomucin | OVMU | High MW Glycoprotein Complex | 3.5% | Gel-forming property, viscosity |
| Ovoinhibitor | OIH | ~49 | 1.5% | Serine protease inhibitor |
| Ovoglycoprotein | ~24.4 | 1.0% | Glycoprotein of unknown primary function | |
| Flavoprotein | ~32 | 0.8% | Riboflavin binding | |
| Ovomacroglobulin | ~760 | 0.5% | Protease inhibitor | |
| Avidin | AVD | ~68.3 | 0.05% | Biotin binding |
| Cystatin | ~12.7 | 0.05% | Cysteine protease inhibitor |
Table 1: Relative abundance and characteristics of major proteins synthesized in the avian magnum. Data compiled from multiple sources.[2][5][6]
Experimental Workflow Overview
A typical workflow for analyzing protein expression in the avian magnum involves several key stages, from tissue collection to data interpretation. This process ensures the integrity of the samples and the reliability of the results.
Detailed Experimental Protocols
Protocol 1: Avian Magnum Tissue Collection and Preparation
Objective: To properly collect and preserve magnum tissue for subsequent protein analysis.
Materials:
-
Surgical scissors and forceps
-
Phosphate-buffered saline (PBS), ice-cold
-
For Western Blotting/Proteomics: Liquid nitrogen, cryovials
-
For Immunohistochemistry: 4% Paraformaldehyde (PFA) in PBS, histology cassettes
Procedure:
-
Euthanize the hen according to approved animal care protocols.
-
Expose the abdominal cavity and locate the oviduct. The magnum is the long, glandular segment located between the infundibulum and the isthmus.
-
Carefully dissect the magnum tissue, avoiding adjacent segments.
-
Wash the tissue immediately in ice-cold PBS to remove any yolk, albumen, or blood.
-
For Western Blotting/Proteomics:
-
Cut the magnum into small pieces (approx. 50-100 mg).
-
Immediately snap-freeze the tissue pieces in liquid nitrogen.
-
Store the frozen tissue in pre-labeled cryovials at -80°C until use.
-
-
For Immunohistochemistry:
-
Cut the magnum into small sections (approx. 0.5 cm thick).
-
Place the sections into a histology cassette.
-
Immerse the cassette in 4% PFA for 24 hours at 4°C for fixation.[7][8]
-
After fixation, transfer to 70% ethanol (B145695) for storage at 4°C before paraffin (B1166041) embedding.
-
Protocol 2: Protein Extraction from Magnum Tissue for Western Blotting
Objective: To lyse magnum tissue and extract total protein.
Materials:
-
Frozen magnum tissue
-
RIPA lysis buffer (supplemented with protease and phosphatase inhibitors)[9]
-
Dounce homogenizer or mechanical tissue homogenizer
-
Microcentrifuge
-
BCA or Bradford Protein Assay Kit
Procedure:
-
Place a frozen piece of magnum tissue (50-100 mg) in a pre-chilled tube.
-
Add 500-1000 µL of ice-cold RIPA buffer with inhibitors.
-
Homogenize the tissue on ice until no visible tissue clumps remain.
-
Incubate the homogenate on ice for 30 minutes, vortexing briefly every 10 minutes.
-
Centrifuge the lysate at 14,000 x g for 20 minutes at 4°C.
-
Carefully transfer the supernatant (containing the soluble proteins) to a new pre-chilled tube. Avoid the pellet and any lipid layer.
-
Determine the protein concentration of the lysate using a BCA or Bradford assay according to the manufacturer's instructions.
-
Aliquot the protein lysate and store at -80°C.
Protocol 3: Western Blotting for a Target Protein (e.g., Ovalbumin)
Objective: To separate proteins by size, transfer them to a membrane, and detect a specific protein using antibodies.
Materials:
-
Protein lysate from Protocol 2
-
Laemmli sample buffer
-
SDS-PAGE gels and running buffer
-
Transfer buffer and system (e.g., semi-dry or tank)[10]
-
PVDF or nitrocellulose membrane
-
Blocking buffer (e.g., 5% non-fat milk or BSA in TBST)
-
Primary antibody (e.g., anti-ovalbumin)
-
HRP-conjugated secondary antibody
-
Chemiluminescent substrate (ECL)
-
Imaging system
Procedure:
-
Sample Preparation: Mix protein lysate with Laemmli buffer to a final concentration of 1-2 µg/µL. Heat at 95°C for 5 minutes.
-
SDS-PAGE: Load 20-30 µg of protein per well into an SDS-PAGE gel. Include a protein ladder. Run the gel until the dye front reaches the bottom.
-
Protein Transfer: Transfer the separated proteins from the gel to a PVDF membrane.[10] Confirm transfer by Ponceau S staining.
-
Blocking: Block the membrane in blocking buffer for 1 hour at room temperature to prevent non-specific antibody binding.[6]
-
Primary Antibody Incubation: Incubate the membrane with the primary antibody (diluted in blocking buffer) overnight at 4°C with gentle agitation.
-
Washing: Wash the membrane three times for 10 minutes each with TBST.
-
Secondary Antibody Incubation: Incubate the membrane with the HRP-conjugated secondary antibody (diluted in blocking buffer) for 1 hour at room temperature.
-
Washing: Repeat the washing step (Step 6).
-
Detection: Apply the ECL substrate to the membrane and immediately capture the chemiluminescent signal using an imaging system.[11]
-
Analysis: Analyze band intensity using densitometry software. Normalize to a loading control (e.g., β-actin or GAPDH).
Protocol 4: Immunohistochemistry (IHC) for Protein Localization
Objective: To visualize the location of a specific protein within the magnum tissue architecture.
Materials:
-
Paraffin-embedded magnum tissue sections on slides
-
Xylene and graded ethanol series
-
Antigen retrieval buffer (e.g., citrate (B86180) buffer, pH 6.0)
-
Blocking solution (e.g., normal goat serum)
-
Primary antibody
-
Biotinylated secondary antibody and ABC reagent or polymer-based detection system
-
DAB substrate kit
-
Hematoxylin (B73222) counterstain
-
Mounting medium
Procedure:
-
Deparaffinization and Rehydration: Immerse slides in xylene, followed by a graded series of ethanol (100%, 95%, 70%) and finally water.
-
Antigen Retrieval: Heat slides in antigen retrieval buffer (e.g., using a microwave or pressure cooker) to unmask the antigen epitopes.
-
Blocking: Block endogenous peroxidase activity with a hydrogen peroxide solution. Then, block non-specific binding sites with a blocking solution for 1 hour.[12]
-
Primary Antibody Incubation: Apply the primary antibody and incubate overnight at 4°C in a humidified chamber.[12]
-
Washing: Wash slides with PBS or TBS buffer.
-
Secondary Antibody & Detection: Apply the biotinylated secondary antibody, followed by the ABC reagent or a polymer-based detection system, according to the manufacturer's protocol.
-
Visualization: Apply the DAB substrate, which will form a brown precipitate at the site of the target protein. Monitor the color development under a microscope.
-
Counterstaining: Lightly counterstain the tissue with hematoxylin to visualize cell nuclei.
-
Dehydration and Mounting: Dehydrate the slides through a graded ethanol series and xylene, then coverslip using a permanent mounting medium.
-
Imaging: Observe and capture images using a light microscope. The brown stain indicates the presence and location of the target protein.
Signaling Pathway Visualization
Protein synthesis in the avian magnum is predominantly under the control of steroid hormones, particularly estrogen. Estrogen stimulates the transcription of genes encoding egg white proteins.
This pathway illustrates how estrogen, a steroid hormone, can freely diffuse across the cell membrane to bind with its intracellular receptor.[13] This hormone-receptor complex then translocates to the nucleus, where it binds to specific DNA sequences known as Estrogen Response Elements (EREs).[13] This binding event initiates the transcription of target genes, leading to the synthesis of large quantities of egg white proteins, which are subsequently secreted into the magnum lumen.[1][2]
References
- 1. RNA sequencing-based analysis of the magnum tissues revealed the novel genes and biological pathways involved in the egg-white formation in the laying hen - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Regulation of egg formation in the oviduct of laying hen | World's Poultry Science Journal | Cambridge Core [cambridge.org]
- 3. Identification and use of magnum-specific promoters for production of target proteins in avian eggs - OHIO STATE UNIVERSITY [portal.nifa.usda.gov]
- 4. researchgate.net [researchgate.net]
- 5. Differential proteomic analysis revealed crucial egg white proteins for hatchability of chickens - PMC [pmc.ncbi.nlm.nih.gov]
- 6. scielo.br [scielo.br]
- 7. rep.bioscientifica.com [rep.bioscientifica.com]
- 8. researchgate.net [researchgate.net]
- 9. animbiosci.org [animbiosci.org]
- 10. nacalai.com [nacalai.com]
- 11. digitalcommons.unl.edu [digitalcommons.unl.edu]
- 12. Structural and histological characterization of oviductal magnum and lectin-binding patterns in Gallus domesticus - PMC [pmc.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
Step-by-step guide to setting up an experiment in Magnum-PSI.
A Step-by-Step Guide to Setting Up Plasma-Surface Interaction Experiments
This document provides a comprehensive guide for researchers, scientists, and drug development professionals on how to set up and conduct experiments using the Magnum-PSI (MAgnetized plasma Generator and NUMerical modeling for Plasma Surface Interactions) facility. These application notes and protocols are designed to streamline the experimental process, from initial planning to data acquisition and analysis.
Introduction to Magnum-PSI
Magnum-PSI is a linear plasma generator designed to study the complex interactions between plasmas and various materials under conditions relevant to fusion reactors, particularly the divertor region of ITER. It utilizes a cascaded arc plasma source to generate a high-density, low-temperature plasma that is confined by a powerful superconducting magnet. This allows for the investigation of material erosion, deposition, and fuel retention, as well as the testing of novel plasma-facing components.
The key operational parameters of Magnum-PSI are summarized in the table below, showcasing its capability to simulate the extreme environment of a fusion reactor's divertor.
Data Presentation: Key Experimental Parameters
A successful experiment in Magnum-PSI relies on the precise control and monitoring of various parameters. The following table summarizes the key operational and diagnostic parameters that can be achieved and measured.
| Parameter | Value | Units | Notes |
| Plasma Source | |||
| Gas Types | Hydrogen (H), Deuterium (D), Helium (He), Neon (Ne), Argon (Ar) | - | Other gases may be possible upon request. |
| Gas Flow Rate | Variable | sccm | Controls the plasma density and neutral pressure. |
| Arc Current | 40 - 160 | A | A primary control for plasma density and temperature.[1][2] |
| Magnetic Field | |||
| On-axis Magnetic Field | up to 2.5 | T | Confines the plasma beam and influences particle transport.[3] |
| Plasma Parameters at Target | |||
| Electron Density (n_e) | 10^19 - 10^21 | m^-3 | Measured by Thomson Scattering.[3] |
| Electron Temperature (T_e) | 0.1 - 10 | eV | Measured by Thomson Scattering.[3] |
| Particle Flux | 10^23 - 10^25 | m^-2s^-1 | A key parameter for studying material erosion and deposition rates.[3] |
| Heat Flux | > 10 | MW/m^2 | Simulates the high heat loads on divertor components.[3] |
| Vacuum System | |||
| Base Pressure | < 10^-7 | mbar | Achieved through a multi-stage differential pumping system. |
| Operational Pressure | Variable | Pa | Dependent on gas flow and pumping configuration. |
| Target and Sample | |||
| Target Temperature | Variable | °C | Can be actively cooled or heated. |
| Target Biasing | Variable | V | Allows for control of ion impact energy.[4][5][6] |
| Sample Size | Variable | - | Accommodates a range of sample sizes and geometries. |
Experimental Protocols
This section outlines the detailed methodologies for conducting a typical plasma-surface interaction experiment in Magnum-PSI.
Experimental Planning and Proposal
The initial step involves defining the scientific objectives and experimental plan. For external users, this culminates in the submission of a beam time application.
Protocol 1: Experimental Proposal Submission
-
Define Research Goals: Clearly articulate the scientific questions to be addressed. This could involve studying material erosion rates, hydrogen retention, or the performance of a new plasma-facing component.
-
Determine Experimental Conditions: Specify the required plasma parameters (gas type, density, temperature, flux), target material, target temperature, and any in-situ diagnostics needed.
-
Consult with Magnum-PSI Staff: It is highly recommended to discuss the feasibility of the proposed experiment with the Magnum-PSI facility manager and scientific staff.
-
Submit a Proposal: Complete and submit the official Magnum-PSI beam time application form, detailing the experimental plan, required resources, and safety considerations.
-
Proposal Review: The proposal will be reviewed by a scientific committee for feasibility and scientific merit.
Sample Preparation and Mounting
Proper preparation and mounting of the material sample are crucial for obtaining reliable and reproducible results.
Protocol 2: Material Sample Preparation and Mounting
-
Sample Cleaning: Thoroughly clean the sample to remove any surface contaminants. The cleaning procedure will depend on the material but typically involves ultrasonic cleaning in a series of solvents (e.g., acetone, isopropanol, ethanol).
-
Surface Characterization (Pre-exposure): Characterize the pristine surface of the sample using appropriate techniques such as Scanning Electron Microscopy (SEM), X-ray Photoelectron Spectroscopy (XPS), or Atomic Force Microscopy (AFM).
-
Mounting on Target Holder: Securely mount the sample onto the designated target holder. Ensure good thermal contact if temperature control is required. This may involve the use of specific clamps or conductive pastes.
-
Installation in the Target Exchange and Analysis Chamber (TEAC): The target holder with the mounted sample is introduced into the TEAC, which is then evacuated.[3]
Vacuum System Operation and Plasma Generation
Achieving and maintaining a high-quality vacuum is fundamental to any plasma experiment. The following protocol outlines the general procedure.
Protocol 3: Vacuum and Plasma Operation
-
Pump-down of the Main Chamber: The main vacuum vessel is pumped down to the base pressure using a series of roughing and high-vacuum pumps. This process can take several hours.
-
Gas Introduction: The desired working gas is introduced into the cascaded arc plasma source through a mass flow controller. The gas flow rate is a key parameter for controlling the plasma density.
-
Plasma Initiation: The cascaded arc discharge is initiated by applying a high voltage across the cathode and anode. The arc current is then ramped up to the desired level.
-
Magnetic Field Activation: The superconducting magnet is energized to the specified magnetic field strength to confine the plasma beam.
-
Plasma Stabilization: The plasma parameters are allowed to stabilize before the target is exposed. This is monitored using various diagnostics.
Diagnostic Setup and Calibration
Magnum-PSI is equipped with a suite of advanced diagnostics to characterize both the plasma and the material surface. Proper setup and calibration are essential for accurate measurements.
Protocol 4: Thomson Scattering System Setup and Calibration
-
Laser Alignment: The high-power laser beam for the Thomson scattering system is carefully aligned to pass through the center of the plasma and the collection optics.
-
Wavelength Calibration: The spectrometers are calibrated using a known light source (e.g., a calibration lamp or Rayleigh scattering from a neutral gas) to ensure accurate measurement of the scattered light spectrum.[7][8][9]
-
Intensity Calibration: The absolute sensitivity of the detection system is calibrated using Raman scattering from a known density of gas (e.g., nitrogen). This allows for the determination of the absolute electron density.[10]
-
Stray Light Minimization: Baffles and a beam dump are used to minimize the amount of stray laser light reaching the detectors, which can be a significant source of noise.[10]
Data Acquisition and Analysis
Data from all diagnostics are collected and stored centrally. A typical data acquisition workflow is described below.
Protocol 5: Data Acquisition and Analysis
-
Define Shot Sequence: An experimental run plan or "shot sheet" is created, detailing the sequence of plasma exposures and the corresponding parameter settings.
-
Initiate Data Acquisition System: The data acquisition system is configured to record data from all relevant diagnostics for the duration of the plasma exposure.
-
Plasma Exposure: The target is moved into the plasma beam for the specified duration.
-
Data Storage: At the end of the shot, all data is automatically saved to a central database with a unique shot number for identification.
-
Post-shot Analysis: Preliminary analysis of the data is often performed between shots to monitor the experiment's progress and make any necessary adjustments.[11]
-
Detailed Analysis: A more thorough analysis of the collected data is performed after the experimental campaign is complete. This may involve custom analysis scripts and modeling.
Mandatory Visualizations
The following diagrams illustrate key workflows and relationships in a Magnum-PSI experiment.
Caption: High-level workflow for a complete experiment in Magnum-PSI.
Caption: Relationship between control inputs and plasma generation.
Caption: Data flow from the experiment to analysis.
References
- 1. researchgate.net [researchgate.net]
- 2. researchgate.net [researchgate.net]
- 3. Magnum-PSI | Dutch Institute for Fundamental Energy Research [differ.nl]
- 4. researchgate.net [researchgate.net]
- 5. mdpi.com [mdpi.com]
- 6. researchgate.net [researchgate.net]
- 7. researchgate.net [researchgate.net]
- 8. pubs.aip.org [pubs.aip.org]
- 9. sbfisica.org.br [sbfisica.org.br]
- 10. plasma.physics.ucla.edu [plasma.physics.ucla.edu]
- 11. anl.gov [anl.gov]
Application Notes and Protocols for Magnum Software in Protein-Drug Interaction Studies
For Researchers, Scientists, and Drug Development Professionals
This document provides detailed application notes and protocols for utilizing the Magnum software in the study of protein-drug interactions. Magnum is a powerful, open-source command-line tool designed for the analysis of mass spectrometry data to identify uncharacterized protein adducts, making it particularly well-suited for investigating covalent protein-drug interactions.[1][2]
Introduction to Magnum for Protein-Drug Interaction Analysis
Magnum functions as an open modification search algorithm that analyzes tandem mass spectrometry (MS/MS) data to identify peptides that have been modified by adducts of an unknown mass.[1][3] This capability is crucial in drug discovery, especially when studying covalent inhibitors or reactive metabolites, where the precise mass of the modification to the target protein may not be known beforehand.[4][5][6]
The software is typically integrated within the Trans-Proteomic Pipeline (TPP), a suite of tools for proteomics data analysis.[7][8] Magnum's output is provided in standard formats like tab-delimited text and pepXML, which allows for downstream analysis and visualization with various other software tools, including Limelight for visualization and Percolator for statistical validation of peptide-spectrum matches (PSMs).[1][2]
Key Features of Magnum:
-
Open Modification Searching: Identifies peptides with unexpected mass shifts, enabling the discovery of novel drug-protein adducts.[1][2]
-
Adduct Localization: Can pinpoint the specific amino acid residues on a peptide where the drug molecule has formed a covalent bond.[1]
-
Versatile and Open-Source: As a free and open-source tool, it can be integrated into diverse bioinformatics pipelines.[1]
-
Standard Data Formats: Supports common mass spectrometry data formats (mzML, mzXML, MGF) and outputs results in pepXML and tab-delimited text for compatibility with other software.[1]
Experimental Workflows and Logical Relationships
The overall workflow for using Magnum in protein-drug interaction studies involves several key stages, from sample preparation to data analysis and interpretation.
General workflow for protein-drug interaction studies using Magnum.
Experimental Protocols
Protocol 1: Identification of Covalent Drug Adducts on a Target Protein
This protocol outlines the steps to identify if and where a covalent drug binds to a purified protein.
Methodology:
-
Incubation:
-
Prepare two sets of samples: a control with the target protein in a suitable buffer (e.g., PBS) and a treatment group with the target protein and the drug at various molar ratios (e.g., 1:1, 1:5, 1:10 protein-to-drug).
-
Incubate both sets of samples at a controlled temperature (e.g., 37°C) for a specific duration to allow for the covalent reaction to occur.
-
-
Sample Preparation for Mass Spectrometry:
-
Denaturation, Reduction, and Alkylation: Denature the proteins using a denaturing agent like urea. Reduce disulfide bonds with dithiothreitol (B142953) (DTT) and alkylate the resulting free thiols with iodoacetamide.
-
Protein Digestion: Digest the proteins into peptides using a protease such as trypsin.
-
-
LC-MS/MS Analysis:
-
Analyze the peptide mixtures using liquid chromatography-tandem mass spectrometry (LC-MS/MS). It is recommended to use a high-resolution mass spectrometer for accurate mass measurements.
-
Acquire the data in a data-dependent acquisition (DDA) mode.
-
-
Magnum Data Analysis:
-
Configuration: Create a Magnum configuration file (.conf). Key parameters to specify include the path to the MS data file (in mzML or mzXML format), the protein sequence database (in FASTA format, including decoy sequences), and the mass range for the open modification search.
-
Execution: Run Magnum from the command line, providing the configuration file as input.
-
Output: Magnum will generate a .pep.xml file containing the peptide-spectrum matches, including information on any identified mass shifts.
-
-
Data Validation and Interpretation:
-
Use a tool like Percolator to assess the statistical confidence of the PSMs from the Magnum output.
-
Analyze the validated results to identify peptides with mass shifts corresponding to the mass of the drug or its reactive metabolite.
-
Utilize visualization tools like Limelight or spectrum viewers within the TPP to manually inspect the MS/MS spectra of the modified peptides to confirm the modification site.
-
Protocol 2: Determining Binding Stoichiometry of a Covalent Drug
This protocol describes how to estimate the stoichiometry of drug binding to a target protein using a label-free quantitative approach.
Methodology:
-
Sample Preparation and MS Analysis:
-
Follow steps 1-3 from Protocol 1. It is crucial to have both the control (unmodified protein) and the drug-treated samples.
-
-
Magnum Search and Validation:
-
Perform the Magnum search and Percolator validation as described in Protocol 1 for both the control and treated samples.
-
-
Quantitative Analysis with Skyline:
-
Spectral Library Generation: Use the validated .pep.xml files from the Magnum search to build a spectral library in Skyline. This library will contain spectra for both the unmodified and drug-modified peptides.
-
Target List Creation: Create a target list in Skyline that includes the precursor ions for the unmodified peptide and its corresponding drug-adducted form.
-
MS1 Filtering: Import the raw MS1 data (in mzML or mzXML format) into Skyline. The software will extract the ion chromatograms for the targeted precursors.[7]
-
Peak Integration: Manually review and integrate the peak areas for the unmodified and modified peptides in both the control and treated samples.
-
-
Stoichiometry Calculation:
-
The binding stoichiometry can be estimated by calculating the ratio of the peak area of the modified peptide to the sum of the peak areas of the modified and unmodified peptides.
-
Formula: % Modified = [Peak Area (Modified Peptide) / (Peak Area (Modified Peptide) + Peak Area (Unmodified Peptide))] * 100
-
Protocol 3: Analysis of Protein-Drug Reaction Kinetics
This protocol outlines a time-course experiment to study the kinetics of a covalent protein-drug interaction.
Methodology:
-
Time-Course Incubation:
-
Prepare a reaction mixture of the target protein and the drug.
-
At various time points (e.g., 0, 5, 15, 30, 60 minutes), take an aliquot of the reaction mixture and quench the reaction (e.g., by adding a quenching agent or by rapid denaturation).
-
-
Sample Preparation and MS Analysis:
-
Process each time-point sample as described in steps 2 and 3 of Protocol 1.
-
-
Data Analysis and Quantification:
-
Analyze each time-point's data using the Magnum and Skyline workflow as detailed in Protocol 2 to determine the percentage of the modified peptide at each time point.
-
-
Kinetic Parameter Estimation:
-
Plot the percentage of the modified peptide as a function of time.
-
Fit the data to a suitable kinetic model (e.g., a single-exponential association model) to estimate the observed rate constant (k_obs).
-
By performing the experiment at different drug concentrations, the second-order rate constant (k_inact/K_i) can be determined.
-
Data Presentation
Table 1: Identification of Drug-Modified Peptides
| Peptide Sequence | Modification Mass (Da) | Modified Residue | Magnum E-value |
| VGVYAVDTK | 355.1 | K8 | 1.2e-5 |
| ... | ... | ... | ... |
Table 2: Quantitative Analysis of Binding Stoichiometry
| Peptide Sequence | Condition | Peak Area (Unmodified) | Peak Area (Modified) | % Modified |
| VGVYAVDTK | Control | 1.5e7 | 0 | 0 |
| VGVYAVDTK | Drug-Treated | 7.2e6 | 6.8e6 | 48.6 |
| ... | ... | ... | ... | ... |
Table 3: Kinetic Analysis of Drug-Protein Reaction
| Time (minutes) | % Modified |
| 0 | 0 |
| 5 | 25.3 |
| 15 | 58.1 |
| 30 | 82.4 |
| 60 | 95.2 |
| ... | ... |
Signaling Pathways and Logical Relationships
The interaction of a drug with its protein target can initiate or inhibit a signaling cascade. The identification of the direct target and the specific site of interaction using Magnum is the first step in elucidating the drug's mechanism of action.
Elucidation of a signaling pathway following drug-target interaction.
Conclusion
Magnum is a valuable tool for researchers studying protein-drug interactions, particularly for the identification of covalent adducts. By integrating Magnum into a broader quantitative proteomics workflow, it is possible to not only identify the site of drug binding but also to gain insights into the stoichiometry and kinetics of the interaction. The protocols and application notes provided here offer a framework for utilizing Magnum to its full potential in drug discovery and development.
References
- 1. Label-Free Quantitation of Protein Modifications by Pseudo Selected Reaction Monitoring with Internal Reference Peptides - PMC [pmc.ncbi.nlm.nih.gov]
- 2. A Method for Removing Effects of Nonspecific Binding on the Distribution of Binding Stoichiometries: Application to Mass Spectroscopy Data - PMC [pmc.ncbi.nlm.nih.gov]
- 3. New Methodology for Determining Plasma Protein Binding Kinetics Using an Enzyme Reporter Assay Coupling with High-Resolution Mass Spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. pubs.acs.org [pubs.acs.org]
- 5. Magnum Parameters [magnum-ms.org]
- 6. pubs.acs.org [pubs.acs.org]
- 7. Platform-independent and label-free quantitation of proteomic data using MS1 extracted ion chromatograms in skyline: application to protein acetylation and phosphorylation [research.bidmc.org]
- 8. researchgate.net [researchgate.net]
Gene-Set Analysis of Crohn's Disease Data Using MAGMA: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a detailed protocol for performing gene-set analysis on Crohn's Disease (CD) Genome-Wide Association Study (GWAS) data using the MAGMA (Multi-marker Analysis of GenoMic Annotation) software. This powerful tool allows researchers to move beyond single-variant associations and identify entire biological pathways or sets of functionally related genes associated with Crohn's Disease, offering deeper insights into its molecular underpinnings and highlighting potential therapeutic targets.
Introduction to Gene-Set Analysis and MAGMA
Gene-set analysis is a statistical method used to determine whether a pre-defined set of genes is enriched for genetic association with a particular trait or disease.[1] Instead of examining individual genetic markers, this approach aggregates the evidence of association across all genes within a set, increasing the power to detect polygenic signals that might be missed at the single-marker level.[1]
MAGMA is a widely used, versatile, and computationally efficient tool for gene-set analysis of GWAS data.[2][3] It operates in two main stages: first, it calculates gene-level association statistics from SNP p-values while accounting for linkage disequilibrium (LD); second, it performs a gene-set analysis to test for the enrichment of association signals within predefined gene sets.[1] MAGMA can perform both self-contained and competitive gene-set analyses.[3]
Data Acquisition and Preparation
A successful MAGMA analysis hinges on the quality and proper formatting of the input data. This section outlines the necessary files and where to obtain them.
Crohn's Disease GWAS Summary Statistics
For this protocol, we will use publicly available GWAS summary statistics for Crohn's Disease from the International IBD Genetics Consortium (IIBDGC). These datasets contain the results of large-scale meta-analyses, providing robust SNP-level association data.
Data Source:
-
International IBD Genetics Consortium (IIBDGC): The IIBDGC provides open access to several IBD-related GWAS datasets. A relevant dataset for this protocol is the Crohn's disease meta-analysis summary statistics.
File Format: The summary statistics file should be a plain text file with columns for SNP identifier (e.g., rsID), p-value, and sample size (N). The file should be formatted to be readable by MAGMA, typically with columns for SNP ID and p-value.
Reference Panel for Linkage Disequilibrium
MAGMA requires a reference panel to estimate the LD between SNPs. The 1000 Genomes Project data is a commonly used and appropriate reference for populations of European ancestry.
Data Source:
-
MAGMA website: Pre-formatted 1000 Genomes Phase 3 reference data for European populations can be downloaded directly from the MAGMA website.
Gene Location File
A gene location file is necessary to map SNPs to their corresponding genes. These files, based on different genome builds, are also available from the MAGMA website.
Data Source:
-
MAGMA website: Download the NCBI Build 37.3 gene location file.
Gene-Set Files
Gene sets can be obtained from various public databases. For this protocol, we will consider pathways from the Kyoto Encyclopedia of Genes and Genomes (KEGG) and molecular signatures from the Molecular Signatures Database (MSigDB).
Data Sources:
-
MSigDB: Provides curated gene sets for various biological processes, pathways, and experimental results.
-
KEGG: A database of molecular pathways.
File Format: A gene-set file for MAGMA is a text file where each line represents a gene set. The first column is the gene set name, followed by the Entrez Gene IDs of the genes in that set, separated by tabs or spaces.
Experimental Protocols: Step-by-Step MAGMA Analysis
This section provides a detailed, step-by-step protocol for performing a gene-set analysis of Crohn's Disease data using MAGMA from the command line.
Installation of MAGMA
Download the appropriate version of MAGMA for your operating system from the official website.
Step 1: Annotation - Mapping SNPs to Genes
The first step is to annotate the SNPs from your GWAS summary statistics to genes based on their genomic locations.
Command:
-
--annotate: This flag initiates the annotation step.
-
--snp-loc: Specifies the file containing the SNP locations from your GWAS data (a file with SNP ID, chromosome, and position).
-
--gene-loc: The path to the downloaded gene location file.
-
--out: The prefix for the output files.
This command will generate a cd_annot.genes.annot file, which contains the mapping of SNPs to genes.
Step 2: Gene Analysis - Calculating Gene-Level P-values
Next, MAGMA calculates gene-level p-values by aggregating the SNP p-values for all SNPs located within a gene, while accounting for LD.
Command:
-
--bfile: Specifies the 1000 Genomes reference panel.
-
--pval: The input file of GWAS summary statistics, with SNP IDs and p-values.
-
N: The total sample size of the GWAS.
-
--gene-annot: The annotation file generated in the previous step.
-
--out: The prefix for the output files.
This step will produce cd_gene_analysis.genes.raw (used for the next step) and cd_gene_analysis.genes.out (a more readable version of the gene-level results).
Step 3: Gene-Set Analysis - Testing for Enrichment
Finally, perform the gene-set analysis to identify pathways enriched for association with Crohn's Disease.
Command:
-
--gene-results: The raw gene-level results from the previous step.
-
--set-annot: The file containing your predefined gene sets (e.g., from KEGG or MSigDB).
-
--out: The prefix for the output files.
The primary output file will be cd_geneset_results.gsa.out, which contains the results of the gene-set analysis.
Data Presentation: Summarizing Quantitative Results
The results of the MAGMA gene-set analysis should be presented in a clear and structured table for easy interpretation and comparison.
Table 1: Top Enriched Gene Sets in Crohn's Disease
| Gene Set Name | Number of Genes | Beta Coefficient | Standard Error | P-value | Adjusted P-value |
| KEGG_INTESTINAL_IMMUNE_NETWORK_FOR_IGA_PRODUCTION | 45 | 0.452 | 0.098 | 3.8e-06 | 0.005 |
| REACTOME_INTERLEUKIN_10_SIGNALING | 62 | 0.398 | 0.085 | 1.2e-05 | 0.011 |
| BIOCARTA_IL17_PATHWAY | 38 | 0.512 | 0.115 | 2.5e-05 | 0.018 |
| KEGG_NOD_LIKE_RECEPTOR_SIGNALING_PATHWAY | 78 | 0.315 | 0.072 | 4.1e-05 | 0.025 |
| REACTOME_CYTOKINE_SIGNALING_IN_IMMUNE_SYSTEM | 254 | 0.289 | 0.068 | 8.9e-05 | 0.043 |
This table is a hypothetical example based on known Crohn's Disease biology and the structure of a typical MAGMA output file. The values are for illustrative purposes.
Visualization of Key Pathways and Workflows
Visualizing the experimental workflow and the implicated biological pathways can greatly enhance the understanding of the analysis and its results.
MAGMA Experimental Workflow
Caption: Workflow for gene-set analysis of Crohn's Disease GWAS data using MAGMA.
NF-κB Signaling Pathway in Crohn's Disease
The NF-κB signaling pathway is a crucial regulator of inflammation and is strongly implicated in the pathogenesis of Crohn's Disease.[2][4]
Caption: Simplified NF-κB signaling pathway in the context of Crohn's Disease.
MAPK Signaling Pathway in Crohn's Disease
The Mitogen-Activated Protein Kinase (MAPK) signaling cascade is another key pathway involved in the inflammatory response characteristic of Crohn's Disease.[2][4]
Caption: Overview of the MAPK signaling cascade in Crohn's Disease.
Conclusion
Gene-set analysis using MAGMA provides a powerful framework for interpreting GWAS data in the context of biological pathways. By following this protocol, researchers and drug development professionals can identify key molecular networks dysregulated in Crohn's Disease, paving the way for a deeper understanding of its pathogenesis and the development of novel therapeutic strategies. The visualization of workflows and signaling pathways further aids in the communication and interpretation of these complex analyses.
References
- 1. MAGMA: Generalized Gene-Set Analysis of GWAS Data | PLOS Computational Biology [journals.plos.org]
- 2. MAGMA: Generalized Gene-Set Analysis of GWAS Data - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Incorporating regulatory interactions into gene-set analyses for GWAS data: A controlled analysis with the MAGMA tool - PMC [pmc.ncbi.nlm.nih.gov]
- 4. MAGMA - CNCR [cncr.nl]
Application Notes and Protocols for Open Mass Modification Searches in Proteomics Using Magnum
Audience: Researchers, scientists, and drug development professionals.
Introduction:
Open mass modification (OMS) searches are a powerful tool in mass spectrometry-based proteomics for the discovery of unexpected or uncharacterized post-translational modifications (PTMs) and other chemical modifications of proteins.[1][2][3][4] Unlike traditional closed searches that are limited to a predefined list of modifications, OMS allows for the identification of peptides with any mass shift within a specified range.[4] This capability is particularly valuable in drug development for identifying protein-drug adducts, in cell signaling research for uncovering novel regulatory PTMs, and in toxicology for detecting modifications caused by xenobiotics.[5]
Magnum is a high-performance search engine specifically designed for open modification searches.[5] It can be operated via the command line and seamlessly integrated into various proteomics data analysis pipelines.[5] A key feature of Magnum is its ability to localize modifications to specific residues within a peptide sequence, providing valuable insights into the site of modification.[5][6] This document provides detailed application notes and protocols for utilizing Magnum to perform open mass modification searches.
I. Experimental Design and Workflow
A typical open mass modification search workflow using Magnum involves several key stages, from sample preparation to data validation. The overall process is depicted in the workflow diagram below.
Sample Preparation
Proper sample preparation is critical for the success of any proteomics experiment, and this is especially true for open modification searches where the goal is to detect a wide range of modifications.
-
Protein Extraction and Lysis: The choice of lysis buffer should be compatible with downstream enzymatic digestion and mass spectrometry. Buffers containing strong detergents may need to be removed or diluted prior to digestion.
-
Reduction and Alkylation: For standard bottom-up proteomics, disulfide bonds in proteins are typically reduced (e.g., with dithiothreitol, DTT) and the resulting free thiols are alkylated (e.g., with iodoacetamide, IAA) to prevent them from reforming. This is important for achieving complete digestion.
-
Proteolytic Digestion: Trypsin is the most commonly used protease as it generates peptides of a suitable length for mass spectrometry analysis. It is crucial to ensure complete digestion to minimize the number of missed cleavages, which can be misinterpreted as modifications in an open search.
-
Peptide Desalting: After digestion, peptides should be desalted using a C18 solid-phase extraction (SPE) column to remove salts and other contaminants that can interfere with LC-MS/MS analysis.
LC-MS/MS Analysis
The digested and desalted peptides are separated by liquid chromatography (LC) and analyzed by tandem mass spectrometry (MS/MS). High-resolution mass spectrometers are highly recommended for open modification searches to achieve accurate mass measurements of both precursor and fragment ions.
Data Conversion
Raw data files from the mass spectrometer need to be converted to an open standard format such as mzML or mzXML before they can be processed by Magnum.[5] Tools like msconvert from the ProteoWizard suite can be used for this purpose.
II. Magnum Open Mass Modification Search Protocol
This protocol outlines the steps for performing an open mass modification search using Magnum from the command line.
Prerequisites
-
Magnum executable installed.
-
Mass spectrometry data in mzML or mzXML format.
-
A protein sequence database in FASTA format, containing the sequences of the proteins expected in the sample, as well as decoy sequences for false discovery rate (FDR) estimation.
Magnum Configuration File
Magnum is controlled by a configuration file that specifies the input files, search parameters, and output options.[6] Below is an example of a configuration file for an open search for modifications on lysine (B10760008) residues.
Key Parameters for Open Searches:
-
min_adduct_mass and max_adduct_mass: These parameters define the mass range for the open search.
-
adduct_sites: This parameter restricts the open search to specific amino acid residues. For a global open search, all amino acids can be listed. Restricting the search space can significantly reduce search times and improve sensitivity for modifications on specific residues.[6]
Running Magnum
Once the configuration file is prepared, Magnum can be run from the command line:
Magnum will generate output files in tab-delimited text and, if specified in the configuration file, in pepXML and Percolator input formats.[5]
III. Downstream Data Analysis and Validation
The results from an open search require careful validation to distinguish between true modifications and false positives. The Trans-Proteomic Pipeline (TPP) is a suite of tools that can be used for this purpose.[7][8][9][10][11]
Peptide-Spectrum Match (PSM) Validation with PeptideProphet
PeptideProphet is a tool within the TPP that statistically validates the peptide-spectrum matches (PSMs) generated by search engines like Magnum.[7] It calculates a probability for each PSM being correct.
Protein Inference with ProteinProphet
ProteinProphet takes the validated PSMs from PeptideProphet and infers the set of proteins present in the sample.[7]
Visualization and Interpretation
Specialized tools like Limelight can be used to visualize and interpret the results of open modification searches.[5] These tools help in identifying novel modifications and comparing modification profiles across different samples.
IV. Quantitative Data Presentation
The performance of open modification search tools can be evaluated based on several metrics. The following tables summarize the performance of Magnum in comparison to other search engines from a published study.
Table 1: Comparison of Peptide-Spectrum Matches (PSMs) at 1% FDR
| Search Engine | Number of PSMs |
| Magnum (Lysine) | 3,101 |
| MSFragger | 1,760 |
| Comet (Closed) | 2,500 |
Data adapted from a study on xenobiotic-protein adduct discovery.[12]
Table 2: Precision and Recall for Adduct Mass Identification
| Search Engine | Precision | Recall |
| Magnum (Lysine) | 0.95 | 0.85 |
| MSFragger | 0.92 | 0.78 |
| Open-pFind | 0.88 | 0.82 |
Data derived from a precision-recall plot in a comparative study.[12]
V. Application Example: Studying the Ubiquitin-Proteasome System
Open mass modification searches are particularly well-suited for studying complex post-translational modifications like ubiquitination. Ubiquitination involves the covalent attachment of ubiquitin (a small protein) to lysine residues of target proteins, which can regulate a wide range of cellular processes.[13][14][15][16][17]
Upon tryptic digestion of ubiquitinated proteins, a characteristic diglycine (GG) remnant from ubiquitin remains attached to the modified lysine residue. This GG modification has a mass of 114.0429 Da and can be readily identified in an open search.
Ubiquitin-Proteasome Signaling Pathway
The following diagram illustrates the key steps in the ubiquitin-proteasome pathway.
VI. Application Example: Investigating MAPK Signaling
Mitogen-activated protein kinase (MAPK) signaling cascades are central to the regulation of numerous cellular processes, including cell proliferation, differentiation, and stress responses.[18][19][20][21] These pathways are regulated by reversible phosphorylation events, which can be investigated using open modification searches to identify both known and novel phosphorylation sites.
Generic MAPK Signaling Cascade
The diagram below shows a generalized MAPK signaling pathway.
Magnum, in conjunction with a robust data analysis pipeline, provides a powerful platform for the discovery-oriented analysis of protein modifications. The protocols and application notes presented here offer a comprehensive guide for researchers to effectively utilize open mass modification searches in their proteomics studies, leading to novel insights into cellular signaling, drug action, and disease mechanisms.
References
- 1. pubs.acs.org [pubs.acs.org]
- 2. Identification of Modified Peptides using Open and Conventional Search Engines | LUP Student Papers [lup.lub.lu.se]
- 3. Open search for PTM discovery with FragPipe | FragPipe [fragpipe.nesvilab.org]
- 4. Enhancing Open Modification Searches via a Combined Approach Facilitated by Ursgal - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Magnum [magnum-ms.org]
- 6. Magnum Configuration [magnum-ms.org]
- 7. A Guided Tour of the Trans-Proteomic Pipeline - PMC [pmc.ncbi.nlm.nih.gov]
- 8. deepblue.lib.umich.edu [deepblue.lib.umich.edu]
- 9. researchgate.net [researchgate.net]
- 10. providence.elsevierpure.com [providence.elsevierpure.com]
- 11. Trans-Proteomic Pipeline — The OpenSWATH Proteomics Workflow [openswath.org]
- 12. Discovery and Visualization of Uncharacterized Drug–Protein Adducts Using Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Ubiquitin/Proteasome | Cell Signaling Technology [cellsignal.com]
- 14. iris.univr.it [iris.univr.it]
- 15. researchgate.net [researchgate.net]
- 16. creative-diagnostics.com [creative-diagnostics.com]
- 17. Ubiquitin and Ubiquitin-Like Protein Resources | Cell Signaling Technology [cellsignal.com]
- 18. Identification of novel MAP kinase pathway signaling targets by functional proteomics and mass spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 19. researchgate.net [researchgate.net]
- 20. discovery.researcher.life [discovery.researcher.life]
- 21. Function and Regulation in MAPK Signaling Pathways: Lessons Learned from the Yeast Saccharomyces cerevisiae - PMC [pmc.ncbi.nlm.nih.gov]
Investigating Plasma-Wall Interactions with Magnum-PSI: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
This document provides a comprehensive overview of the Magnum-PSI linear plasma generator, detailing its capabilities for studying plasma-wall interactions (PWI) relevant to fusion energy research and other fields requiring high-flux plasma exposure. It includes key operational parameters, detailed experimental protocols for conducting PWI studies, and a description of the available diagnostics and data analysis procedures.
Introduction to Magnum-PSI
Magnum-PSI, located at the Dutch Institute for Fundamental Energy Research (DIFFER), is a unique laboratory facility designed to investigate the complex interactions between high-temperature plasmas and various materials.[1][2] It is the only experiment worldwide capable of generating plasma conditions that mimic those expected at the divertor region of the ITER fusion reactor.[2] This allows for crucial research into material erosion, deposition, and fuel retention, which are critical for the development of future fusion power plants.[3]
The core of Magnum-PSI is a cascaded arc plasma source that produces a dense, hot plasma.[1][3] This plasma is then guided and confined by a powerful superconducting magnet, creating a high-flux plasma beam that is directed onto a target material.[1][4] A key feature of Magnum-PSI is its steady-state capability, allowing for long-duration exposures to investigate the lifetime of materials under reactor-relevant conditions.[1]
Key Capabilities and Operational Parameters
Magnum-PSI offers a wide range of operational parameters, making it a versatile tool for various PWI studies.[5] The key design and performance parameters are summarized in the table below.
| Parameter | Value | Unit |
| Plasma Source | ||
| Plasma Composition | Hydrogen, Deuterium (B1214612), Helium, Neon, Argon | |
| Plasma Parameters | ||
| Electron Density (n_e) | 10¹⁹ - 10²¹ | m⁻³ |
| Electron Temperature (T_e) | 0.1 - 10 | eV |
| Plasma Fluxes | ||
| Particle Flux | 10²³ - 10²⁵ | m⁻²s⁻¹ |
| Heat Flux (steady-state) | > 10 | MW/m² |
| Heat Flux (transient) | up to 2 | GW/m² |
| Magnetic Field | ||
| Magnetic Field Strength | up to 2.5 | T |
| Target & Exposure | ||
| Target Inclination | ± 90 | degrees |
| Exposure Time | Steady-state (hours) | |
| Vacuum System | ||
| Neutral Background Pressure | < 1 | Pa |
Table 1: Key Operational Parameters of Magnum-PSI. [1][6]
Experimental Protocols
Conducting a successful experiment on Magnum-PSI involves a series of well-defined steps, from initial proposal to post-exposure analysis. The general workflow is outlined below, followed by a more detailed protocol for a typical tungsten erosion experiment.
General Experimental Workflow
The process of conducting an experiment at the Magnum-PSI user facility follows a structured path to ensure scientific excellence and technical feasibility.
Detailed Protocol: Tungsten Erosion Experiment
This protocol provides a step-by-step guide for investigating the erosion of a tungsten target under high-flux deuterium plasma exposure.
I. Pre-Exposure Phase
-
Proposal Submission: Submit a research proposal detailing the scientific motivation, experimental plan, required plasma conditions, and necessary diagnostics.[7]
-
Sample Preparation:
-
Procure tungsten samples of the desired purity and dimensions.
-
Characterize the pristine samples using surface analysis techniques such as Scanning Electron Microscopy (SEM) for surface morphology and X-ray Photoelectron Spectroscopy (XPS) for elemental composition.
-
Mount the samples on the appropriate target holder (single or multi-target).[7]
-
II. Experimental Phase
-
System Preparation:
-
Install the target holder in the Magnum-PSI vacuum vessel.
-
Pump down the vacuum vessel to the required base pressure.
-
Cool down the superconducting magnet to its operating temperature of 4 Kelvin, a process that takes several weeks.[4]
-
-
Plasma Generation and Exposure:
-
Set the desired magnetic field strength.
-
Introduce deuterium gas into the cascaded arc plasma source.
-
Ignite the plasma and ramp up the source current to achieve the target plasma density and temperature.
-
Expose the tungsten target to the plasma for the planned duration. A record-breaking experiment exposed tungsten to a deuterium ion fluence of 10³⁰ m⁻² over 18 hours.[3]
-
-
In-situ Diagnostics and Data Acquisition:
-
Monitor the plasma parameters (electron density and temperature) in front of the target using Thomson Scattering.
-
Use Optical Emission Spectroscopy to monitor plasma composition and impurity levels.[6]
-
Measure the surface temperature of the target using infrared thermography and pyrometry.[6]
-
Record all diagnostic data and machine parameters using the central Control, Data Acquisition, and Communication (CODAC) system.[6]
-
III. Post-Exposure Phase
-
Target Retraction and Sample Retrieval:
-
After the exposure, retract the target holder into the Target Exchange and Analysis Chamber (TEAC) under vacuum.[1]
-
Vent the TEAC and retrieve the samples.
-
-
Post-mortem Analysis:
-
Perform surface analysis on the exposed samples to characterize changes in morphology, composition, and microstructure. Common techniques include:
-
Scanning Electron Microscopy (SEM): To observe surface modifications like cracking, melting, and recrystallization.
-
X-ray Photoelectron Spectroscopy (XPS): To determine the elemental composition of the near-surface region and identify implanted species or deposited impurities.[8][9]
-
Ion Beam Analysis (IBA): Techniques like Rutherford Backscattering Spectrometry (RBS), Nuclear Reaction Analysis (NRA), and Elastic Recoil Detection (ERD) can be used to quantify the amount of retained deuterium and the erosion depth.[2]
-
Thermal Desorption Spectroscopy (TDS): To measure the amount and binding states of trapped deuterium.[2]
-
-
-
Data Analysis and Interpretation:
-
Analyze the in-situ diagnostic data to determine the plasma conditions during the exposure.
-
Correlate the post-mortem analysis results with the plasma exposure parameters to understand the erosion mechanisms and quantify the erosion yield.
-
Compare the experimental results with predictions from simulation codes like B2.5-Eunomia.[10][11]
-
Data Presentation: Example Experimental Data
The following table presents data from a landmark long-duration exposure experiment performed on Magnum-PSI, demonstrating its unique capabilities.
| Parameter | Value | Unit |
| Target Material | Tungsten | |
| Plasma Species | Deuterium | |
| Exposure Duration | 18 | hours |
| Ion Fluence | 10³⁰ | m⁻² |
| Power Load | ≥ 10 | MW/m² |
Table 2: Parameters from a Record-Breaking Long-Duration Exposure Experiment. [3]
Visualization of Experimental Logic
The following diagram illustrates the logical relationship between the main components of the Magnum-PSI facility and the key steps in a typical plasma-wall interaction experiment.
References
- 1. Magnum-PSI | Dutch Institute for Fundamental Energy Research [differ.nl]
- 2. research.tue.nl [research.tue.nl]
- 3. First plasma beam on Magnum PSI [iter.org]
- 4. Conditioning of a superconducting Magnum-PSI | Dutch Institute for Fundamental Energy Research [differ.nl]
- 5. impact.ornl.gov [impact.ornl.gov]
- 6. researchgate.net [researchgate.net]
- 7. Application form Magnum-PSI | Dutch Institute for Fundamental Energy Research [differ.nl]
- 8. pure.tue.nl [pure.tue.nl]
- 9. researchgate.net [researchgate.net]
- 10. cris.maastrichtuniversity.nl [cris.maastrichtuniversity.nl]
- 11. researchgate.net [researchgate.net]
A guide to interpreting MAGMA gene analysis results.
Application Notes and Protocols for Researchers, Scientists, and Drug Development Professionals
Introduction to MAGMA
MAGMA (Multi-marker Analysis of GenoMic Annotation) is a powerful tool for gene and gene-set analysis of Genome-Wide Association Study (GWAS) data.[1][2] It aggregates the effects of single nucleotide polymorphisms (SNPs) at the gene level and then examines the collective association of gene sets (e.g., biological pathways) with a particular trait or disease.[3][4] This approach increases statistical power to detect polygenic signals and aids in the biological interpretation of GWAS findings.[5][6]
This guide provides a comprehensive overview of the MAGMA analysis workflow, from input data preparation to the interpretation of results, with a focus on practical application for researchers in academia and industry.
The MAGMA Analysis Workflow
The MAGMA analysis pipeline consists of three main stages: Annotation, Gene Analysis, and Gene-Set Analysis. Each of these steps has specific input requirements and generates distinct output files that are used in subsequent analyses.
Visualizing the MAGMA Workflow
The following diagram illustrates the overall workflow of a typical MAGMA analysis.
References
- 1. MAGMA: Generalized Gene-Set Analysis of GWAS Data - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Software, Resources & GWAS Sumstats - CNCR [cncr.nl]
- 3. Gene Set Analysis with MAGMA - OmicsBox User Manual [docs.omicsbox.biobam.com]
- 4. rna-seqblog.com [rna-seqblog.com]
- 5. MAGMA: Generalized Gene-Set Analysis of GWAS Data | PLOS Computational Biology [journals.plos.org]
- 6. researchgate.net [researchgate.net]
Application Notes and Protocols for Histological Slide Preparation of the Avian Magnum
For Researchers, Scientists, and Drug Development Professionals
These application notes provide detailed protocols for the histological preparation of the avian magnum, the longest and most glandular portion of the avian oviduct responsible for albumen (egg white) secretion.[1][2] Proper preparation of magnum tissue is crucial for accurate morphological and immunohistochemical analysis in reproductive biology, toxicology, and drug development studies.
Application Notes
The avian magnum is a complex tissue composed of a mucosal layer with ciliated and non-ciliated columnar cells, and a thick lamina propria containing abundant branched tubular glands.[3] The histological approach must be tailored to the specific research question. For general morphology, standard fixation and staining methods are sufficient. However, for immunohistochemistry or electron microscopy, specific protocols are required to preserve antigenicity and ultrastructure, respectively.
Key Considerations:
-
Tissue Collection: Immediately after euthanasia, collect tissue to prevent postmortem autolysis.[4] Place the tissue into fixative immediately.[4] The ratio of fixative to tissue should be at least 20:1 to ensure proper fixation.[4]
-
Fixation: The choice of fixative is critical. 10% Neutral Buffered Formalin (NBF) is a good general-purpose fixative.[1] For immunohistochemistry, 4% buffered paraformaldehyde is often used.[5][6] For electron microscopy, a primary fixation with glutaraldehyde (B144438) followed by a secondary fixation with osmium tetroxide is required.[5][7]
-
Decalcification: While not always necessary for the magnum, if the tissue contains calcified areas, decalcification is essential for proper sectioning.[8][9][10] This step is performed after fixation and before processing.[8]
-
Processing and Embedding: Dehydration through a graded series of ethanol (B145695), clearing with an agent like xylene, and infiltration with paraffin (B1166041) wax are standard procedures. Automated tissue processors can standardize these steps.
-
Sectioning: Obtain thin sections (typically 4-6 µm) using a rotary microtome.[1]
-
Staining: Hematoxylin and Eosin (H&E) is the standard stain for observing general morphology.[11][12] Special stains can be used to identify specific components, such as Periodic acid-Schiff (PAS) for neutral mucopolysaccharides and Alcian blue for acidic mucopolysaccharides.[1]
Experimental Protocols
Protocol 1: Routine Histological Preparation (H&E Staining)
This protocol is suitable for the general morphological examination of the avian magnum.
Materials:
-
10% Neutral Buffered Formalin (NBF)[1]
-
Graded ethanol series (70%, 80%, 95%, 100%)
-
Xylene
-
Paraffin wax
-
Hematoxylin stain
-
Eosin stain
-
Microscope slides and coverslips
Procedure:
-
Fixation: Immediately immerse fresh avian magnum tissue samples in 10% NBF for 24-48 hours at room temperature.[13] The volume of fixative should be at least 20 times the volume of the tissue.[4]
-
Processing (Dehydration, Clearing, and Infiltration):
-
Wash the fixed tissue in running tap water.
-
Dehydrate the tissue through a graded series of ethanol:
-
70% ethanol for 1 hour
-
80% ethanol for 1 hour
-
95% ethanol for 1 hour
-
100% ethanol for 1 hour (2 changes)
-
-
Clear the tissue in xylene for 1 hour (2 changes).
-
Infiltrate the tissue with molten paraffin wax at 58-60°C for 2-4 hours.
-
-
Embedding: Embed the paraffin-infiltrated tissue in a paraffin block.
-
Sectioning: Cut 5-6 µm thick sections using a rotary microtome.[1]
-
Staining:
-
Deparaffinize the sections in xylene.
-
Rehydrate through a descending series of ethanol to water.
-
Stain with Hematoxylin.
-
Differentiate in acid alcohol.
-
'Blue' in running tap water.
-
Counterstain with Eosin.
-
Dehydrate through an ascending series of ethanol.
-
Clear in xylene.
-
-
Mounting: Mount the coverslip using a suitable mounting medium.
Protocol 2: Immunohistochemistry (IHC)
This protocol is designed to detect specific proteins within the avian magnum tissue.
Materials:
-
Phosphate-Buffered Saline (PBS)
-
Antigen retrieval solution (e.g., citrate (B86180) buffer, pH 6.0)
-
Blocking solution (e.g., 5% normal goat serum in PBS)
-
Primary antibody (specific to the target protein)
-
Biotinylated secondary antibody
-
Streptavidin-peroxidase complex
-
Chromogen substrate (e.g., DAB or AEC)[14]
-
Hematoxylin (for counterstaining)
Procedure:
-
Fixation and Processing: Fix magnum segments in 4% buffered paraformaldehyde.[5][6] Subsequently, embed the tissue in a paraffin block as described in Protocol 1.[6]
-
Sectioning: Cut 4 µm thick sections.[14]
-
Deparaffinization and Rehydration: As described in Protocol 1.
-
Antigen Retrieval: Perform heat-induced epitope retrieval by immersing slides in citrate buffer (pH 6.0) and heating in a water bath or microwave.
-
Blocking: Incubate sections with a blocking solution for 30-60 minutes to prevent non-specific antibody binding.
-
Primary Antibody Incubation: Incubate with the primary antibody at a specific dilution overnight at 4°C.[14]
-
Secondary Antibody Incubation: Apply a biotinylated secondary antibody and incubate for 1-2 hours at room temperature.[14]
-
Detection: Apply a streptavidin-peroxidase complex and incubate.
-
Visualization: Add the chromogen substrate to develop the color.
-
Counterstaining: Lightly counterstain with hematoxylin.
-
Dehydration, Clearing, and Mounting: As described in Protocol 1.
Quantitative Data Summary
| Parameter | Value | Technique | Reference |
| Fixation Time | 24 hours | Routine Histology | [15] |
| 48 hours | Routine Histology | [13] | |
| 2-4 hours | Electron Microscopy (Primary) | [5] | |
| Section Thickness | 5-6 µm | Routine Histology | [1] |
| 4 µm | Immunohistochemistry | [14] | |
| 10 µm | Cryostat Sectioning | [1] | |
| Primary Antibody Incubation (IHC) | Overnight at 4°C | Immunohistochemistry | [14] |
| 2 hours at 37°C | Immunohistochemistry | [14] | |
| Antigen Retrieval (IHC) | 10 minutes at 37°C (Enzyme-induced) | Immunohistochemistry | [14] |
Visualizations
Experimental Workflow for Histological Preparation
Caption: Workflow for avian magnum histological preparation.
Logical Relationship of Fixation Methods
Caption: Selection of fixatives for different histological applications.
References
- 1. luvas.edu.in [luvas.edu.in]
- 2. Reproductive system - Poultry Hub Australia [poultryhub.org]
- 3. Avian female reproductive tract – Veterinary Histology [ohiostate.pressbooks.pub]
- 4. masseycancercenter.org [masseycancercenter.org]
- 5. Structural and histological characterization of oviductal magnum and lectin-binding patterns in Gallus domesticus - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. animbiosci.org [animbiosci.org]
- 8. Decalcifying Tissue for Histological Processing - National Diagnostics [nationaldiagnostics.com]
- 9. An Introduction to Decalcification [leicabiosystems.com]
- 10. youtube.com [youtube.com]
- 11. avr.basu.ac.ir [avr.basu.ac.ir]
- 12. researchgate.net [researchgate.net]
- 13. Histomorphometrical and ultrastructural study of the effects of carbendazim on the magnum of the Japanese quail ( Coturnix coturnix japonica ) | Kimaro | Onderstepoort Journal of Veterinary Research [ojvr.org]
- 14. Tissue Tropism of H9N2 Low-Pathogenic Avian Influenza Virus in Broiler Chickens by Immunohistochemistry [mdpi.com]
- 15. bsu.edu.eg [bsu.edu.eg]
Common errors in MAGMA gene-set analysis and how to fix them.
Welcome to the technical support center for MAGMA (Multi-marker Analysis of GenoMic Annotation). This guide is designed to assist researchers, scientists, and drug development professionals in troubleshooting common errors and optimizing their MAGMA gene-set analyses.
Frequently Asked Questions (FAQs)
Q1: What is the general workflow for a MAGMA gene-set analysis?
A1: A standard MAGMA analysis involves three main stages:
-
Annotation: This initial step maps SNPs from your GWAS to their corresponding genes based on genomic location.[1][2][3] You will need a SNP location file and a gene location file for this stage.
-
Gene Analysis: In the second stage, MAGMA calculates gene-level p-values by aggregating the SNP-level association statistics for all SNPs located within a gene.[1][2][3] This can be done using either raw genotype data or summary statistics from a GWAS, in which case a reference genotype dataset is required to account for linkage disequilibrium (LD).
-
Gene-Set Analysis: The final stage involves testing whether genes within predefined sets (e.g., biological pathways) are more strongly associated with the phenotype of interest than other genes.[1][2][4] This is a competitive analysis that provides insights into the biological pathways underlying the studied trait.[2][4]
A visualization of the standard MAGMA workflow is provided below.
Troubleshooting Guides
Issue 1: "ERROR - reading p-value file: no valid p-values found for any SNPs in the data."
This is one of the most common errors encountered during the gene analysis step when using GWAS summary statistics. It indicates that MAGMA was unable to match the SNP identifiers in your p-value file with the SNP identifiers in the reference genotype data.
Common Causes and Solutions:
-
Mismatched SNP Identifiers: The most frequent cause is a discrepancy in the SNP naming convention between your GWAS summary file and the reference panel (e.g., using rsID in one file and chr:pos in the other).
-
Incorrect File Path: MAGMA may not be able to locate your p-value file if the provided path is incorrect.
-
Solution: Double-check that the file path specified with the --pval flag is correct and that the file exists at that location.
-
-
Incorrect Column Specification: MAGMA might be looking for SNP IDs and p-values in the wrong columns of your summary statistics file.
-
Solution: If your file has a header, ensure the columns containing SNP IDs and p-values are named "SNP" and "P" respectively. If there is no header, MAGMA assumes the first column contains SNP IDs and the second contains p-values.[4] You can use the use= modifier with the --pval flag to specify the correct columns by name or index (e.g., --pval my_gwas.txt use=rsID,PVAL).[4]
-
-
Insufficient SNP Overlap: Even with matching identifiers, there might be a very low overlap of SNPs between your summary statistics and the reference panel.
-
Solution: Always inspect the MAGMA log file (.log).[4] It provides detailed information on how many SNPs were read from your p-value file and how many of those were successfully mapped to the reference data. A very low mapping percentage indicates a significant mismatch between the two files.
-
Below is a troubleshooting flowchart to diagnose the "no valid p-values found" error.
Issue 2: "ERROR - reading gene annotation file: found no genes containing SNPs in genotype data."
This error occurs during the gene analysis step and indicates that after filtering, none of the SNPs in your dataset could be mapped to any of the genes in your annotation file.
Common Causes and Solutions:
-
Very Small Input SNP Set: If you are using a very small, pre-filtered set of SNPs, it's possible that none of them fall within the gene boundaries defined in your annotation file.
-
Solution: MAGMA is designed for genome-wide data. If you are analyzing a small subset of SNPs, it's possible none of them will map to genes. Consider using the full GWAS summary statistics for the annotation and gene analysis steps.
-
-
Incorrect Gene Window Size: The window size for mapping SNPs to genes might be too small, excluding nearby SNPs that could be relevant.
-
Solution: During the annotation step, you can specify a window around the gene transcription start and end sites to include nearby SNPs (e.g., --annotate window=5,1.5). The appropriate window size can be context-dependent, and you may need to experiment with different settings.
-
-
Mismatched Genome Builds: If your SNP locations and gene locations are from different genome builds (e.g., hg19 vs. hg38), the mapping will be incorrect.
-
Solution: Ensure that both your SNP location file and your gene location file are based on the same genome build. Gene location files for different builds are available on the MAGMA website.
-
Quantitative Data Summary
The choice of gene analysis model in MAGMA can impact the results. The table below summarizes the reported Type 1 error rates and power for different MAGMA models from a simulation study.
| Model Name | Analysis Type | Mean Type 1 Error Rate (SD) | Power (Isolated SNPs, Low LD) | Power (SNPs in High LD) | Power (Two-marker effect) |
| MAGMA-main | Raw Genotype Data | 0.049 (0.007) | 0.32 | 0.97 | 0.98 |
| MAGMA-mean | Summary Statistics | 0.049 (0.007) | 0.19 | 0.90 | 0.62 |
| MAGMA-top | Summary Statistics | 0.050 (0.007) | 0.38 | 0.99 | 0.63 |
Data is based on simulations and may vary depending on the dataset.[6]
Experimental Protocols
Standard MAGMA Protocol using GWAS Summary Statistics
This protocol outlines the standard procedure for performing a gene-set analysis using GWAS summary statistics and a reference genotype panel like the 1000 Genomes Project.
1. Prepare Input Files:
-
GWAS Summary Statistics File: A plain text file containing columns for SNP identifiers, p-values, and sample size for each SNP. Ensure the SNP IDs match the reference panel.
-
Reference Genotype Data: Download a suitable reference panel (e.g., 1000 Genomes European panel) from the MAGMA website. This should be in PLINK binary format (.bed, .bim, .fam).
-
Gene Location File: Download the appropriate gene location file for the correct genome build from the MAGMA website.
-
Gene Set File: A file defining your gene sets of interest. Each line should contain a gene set name followed by the Entrez gene IDs belonging to that set.
2. Annotation Step:
This step creates a file that maps each SNP in your reference panel to the genes it falls into.
-
[REFERENCE_DATA]: The prefix of your reference genotype files.
-
[GENE_LOCATION_FILE]: The path to your gene location file.
-
[OUTPUT_PREFIX]: A prefix for your output files. This will generate [OUTPUT_PREFIX].genes.annot.
3. Gene Analysis Step:
This step calculates gene-level p-values based on your GWAS summary statistics.
-
[GWAS_SUMMARY_FILE]: Your GWAS summary statistics file.
-
N=[SAMPLE_SIZE]: The sample size of your GWAS.
-
This will generate [OUTPUT_PREFIX].genes.out and [OUTPUT_PREFIX].genes.raw.
4. Gene-Set Analysis Step:
This final step performs the competitive gene-set analysis.
-
[GENE_SET_FILE]: Your custom gene set file.
-
This will generate [OUTPUT_PREFIX].gsa.out, which contains the results of the gene-set analysis.
Important Considerations:
-
Always inspect the .log file after each step to check for warnings and ensure the analysis is running as expected.[4]
-
The choice of reference panel is crucial and should match the ancestry of your GWAS population to accurately model LD.
-
Be aware of the MAGMA version you are using, as updates may include important changes to statistical models. For instance, the SNP-wise Mean model was updated in v1.08 to correct an issue with inflated Type 1 error rates.[7]
References
- 1. Developer Notes · Magma Documentation [magma.github.io]
- 2. google.com [google.com]
- 3. MAGMA: Generalized Gene-Set Analysis of GWAS Data - PMC [pmc.ncbi.nlm.nih.gov]
- 4. ibg.colorado.edu [ibg.colorado.edu]
- 5. Regarding MAGMA [groups.google.com]
- 6. storage.googleapis.com [storage.googleapis.com]
- 7. autoblog.com [autoblog.com]
Troubleshooting unexpected results in avian magnum research.
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals working with the avian magnum. The information is presented in a question-and-answer format to directly address common challenges encountered during experimentation.
I. FAQs: Hormone Stimulation and Protein Expression
Q1: We are not observing the expected increase in magnum weight and ovalbumin expression after estrogen administration. What are the possible causes and troubleshooting steps?
A1: Failure to induce magnum growth and ovalbumin expression with estrogen treatment can stem from several factors, from the hormone itself to the condition of the experimental animals.
Possible Causes & Troubleshooting Steps:
-
Hormone Inactivity:
-
Solution: Ensure the estrogen (e.g., 17β-estradiol or diethylstilbestrol) is properly stored and has not expired. Prepare fresh hormone solutions for each experiment. Consider using a different batch or supplier if the issue persists.
-
-
Incorrect Dosage or Administration:
-
Solution: Verify the calculated dosage and administration route. For immature chicks, a common protocol is daily administration of estrogen.[1] A single injection of oestradiol benzoate (B1203000) (1.5 mg/kg) has been shown to increase magnum wet weight in estrogen-withdrawn chickens.[2] Ensure consistent and accurate administration, whether through injection or other methods.
-
-
Animal-Related Factors:
-
Solution: The age, strain, and physiological state of the birds can influence their response to hormones.[3] Younger, sexually immature birds are typically more responsive to primary estrogen stimulation. Ensure the animals are healthy and not under stress, as stress can affect reproductive hormone levels and receptor expression.[4]
-
-
Estrogen Receptor (ER) Issues:
-
Solution: The presence and functionality of estrogen receptors are crucial for a response.[5] While less common, factors like genetic variations or prior treatments could potentially alter ER levels or sensitivity. Ensure that the experimental model is appropriate and has been previously characterized for estrogen responsiveness.
-
Q2: We are seeing high variability in gene expression (e.g., ovalbumin, avidin (B1170675) mRNA) between individual birds in the same treatment group. How can we reduce this variability?
A2: High inter-individual variability is a common challenge in animal research. In the context of avian magnum gene expression, this can be minimized by standardizing several experimental parameters.
Strategies to Reduce Variability:
-
Synchronize the Ovulation Cycle: The expression of genes in the magnum is tightly linked to the egg-laying cycle.[6] For laying hens, it is critical to collect magnum tissue at the same time point relative to ovulation for all individuals.
-
Standardize Age and Genetic Background: Use birds of the same age and from the same genetic strain to minimize variations in basal gene expression and hormonal sensitivity.
-
Control Environmental Conditions: House birds under consistent lighting, temperature, and nutritional conditions. Stressors can significantly impact hormone levels and gene expression.[4]
-
Increase Sample Size: A larger number of birds per group can help to mitigate the effects of individual outliers and increase the statistical power of your results.
II. FAQs: Molecular Biology Techniques
Q3: We are getting weak or no signal for our target protein (e.g., ovalbumin) on our Western blots. What are the common causes and solutions?
A3: A weak or absent signal on a Western blot can be frustrating. The issue can arise at multiple stages of the protocol, from sample preparation to antibody incubation and detection.
Troubleshooting Western Blot Signal Issues:
| Potential Cause | Troubleshooting Steps |
| Low Protein Concentration | Increase the amount of total protein loaded onto the gel. Include a positive control (e.g., purified ovalbumin or a magnum lysate from a fully stimulated bird) to verify the detection system.[7] |
| Inefficient Protein Extraction | Optimize your protein extraction protocol. Ensure the lysis buffer is appropriate for the target protein and that protease inhibitors are included to prevent degradation.[8] |
| Poor Protein Transfer | Verify successful transfer from the gel to the membrane by staining the membrane with Ponceau S after transfer. Optimize transfer time and voltage based on the molecular weight of your target protein. |
| Suboptimal Antibody Concentrations | Titrate your primary and secondary antibody concentrations to find the optimal dilution. A concentration that is too low will result in a weak signal. |
| Inactive Antibodies | Ensure antibodies have been stored correctly and have not expired. Consider using a fresh aliquot or a different antibody if activity is suspect. |
| Insufficient Blocking | Inadequate blocking can lead to high background, which can mask a weak signal. Ensure the blocking buffer is appropriate and the incubation time is sufficient. |
Q4: Our qPCR results for magnum-specific genes show inconsistent amplification or multiple peaks in the melt curve analysis. How can we troubleshoot this?
A4: Inconsistent qPCR results can invalidate your gene expression data. The key is to ensure the specificity and efficiency of your PCR reaction.
Troubleshooting qPCR Issues:
| Potential Cause | Troubleshooting Steps |
| Poor Primer Design | Re-design primers to ensure they are specific to your target gene and do not form primer-dimers. Verify primer specificity using tools like NCBI BLAST. |
| Suboptimal Annealing Temperature | Perform a temperature gradient PCR to determine the optimal annealing temperature for your primer set. |
| Poor Quality RNA/cDNA | Ensure your RNA is of high purity and integrity. Use a reliable reverse transcription kit to synthesize high-quality cDNA. |
| Genomic DNA Contamination | Treat RNA samples with DNase I before reverse transcription to remove any contaminating genomic DNA. |
| PCR Inhibitors | Ensure that the RNA purification method effectively removes PCR inhibitors. If inhibitors are suspected, try diluting the cDNA template. |
III. FAQs: Histology and Cell Culture
Q5: We are observing artifacts in our H&E stained magnum tissue sections, such as tissue folding and poor nuclear detail. What are the likely causes and how can we prevent them?
A5: Histological artifacts can obscure the true morphology of the tissue and lead to misinterpretation. Proper tissue handling from fixation to mounting is crucial.
Common Histological Artifacts and Prevention:
| Artifact | Potential Cause | Prevention/Solution |
| Tissue Folding | Improper placement of the tissue section on the slide. | Carefully flatten the tissue section on the water bath before picking it up with the slide. |
| Poor Nuclear Detail | Delayed or inadequate fixation. | Fix tissue immediately after collection in an appropriate fixative (e.g., 10% neutral buffered formalin). Ensure the fixative volume is at least 10-20 times the tissue volume.[9] |
| Shrinkage/Spaces between Tissue Layers | Over-dehydration during tissue processing. | Optimize the dehydration schedule in your tissue processor. Avoid prolonged exposure to high concentrations of alcohol. |
| Chatter/Venetian Blinds | A loose or dull microtome blade, or improperly processed tissue. | Ensure the microtome blade is sharp and securely clamped. Ensure tissue is properly infiltrated with paraffin (B1166041).[10] |
| Uneven Staining | Incomplete deparaffinization or contaminated staining solutions. | Ensure complete removal of paraffin wax before staining. Filter stains regularly and replace them as needed. |
Q6: We are having difficulty establishing a pure primary culture of avian magnum epithelial cells due to fibroblast contamination. What can we do?
A6: Fibroblast overgrowth is a common issue in primary epithelial cell culture. Several techniques can be employed to enrich for epithelial cells.
Strategies to Reduce Fibroblast Contamination:
-
Differential Trypsinization: Fibroblasts are generally more sensitive to trypsin than epithelial cells. A brief, partial trypsinization can be used to selectively detach and remove fibroblasts.
-
Percoll Gradient Centrifugation: This method separates cells based on their buoyant density. Epithelial cells and fibroblasts have different densities, allowing for their separation on a Percoll gradient.[11]
-
Selective Media Formulation: Some media formulations can be optimized to favor the growth of epithelial cells over fibroblasts.
-
Mechanical Removal: In the early stages of culture, it may be possible to mechanically scrape away colonies of fibroblasts under a microscope.
Experimental Protocols
Hormone Administration for Oviduct Growth (Immature Chicks)
-
Hormone Preparation: Prepare a stock solution of 17β-estradiol or diethylstilbestrol (B1670540) (DES) in a suitable vehicle (e.g., sesame oil).
-
Dosage: A common dosage for immature chicks is a daily subcutaneous or intramuscular injection. For example, a single injection of 1.5 mg/kg oestradiol benzoate can be used.[2]
-
Administration: Inject the hormone solution daily for a period of 5-10 days to induce magnum growth and differentiation.[1]
-
Control Group: Administer the vehicle only to a control group of chicks.
-
Tissue Collection: At the end of the treatment period, euthanize the chicks and dissect the oviduct. The magnum will be the longest, most glandular portion.
Protein Extraction from Magnum Tissue
-
Tissue Homogenization: Weigh the frozen magnum tissue and homogenize it in a suitable lysis buffer (e.g., RIPA buffer) containing a protease inhibitor cocktail on ice.
-
Lysis: Incubate the homogenate on ice for 30 minutes with occasional vortexing to ensure complete cell lysis.
-
Centrifugation: Centrifuge the lysate at high speed (e.g., 14,000 x g) for 15 minutes at 4°C to pellet cellular debris.
-
Supernatant Collection: Carefully collect the supernatant, which contains the soluble proteins.
-
Protein Quantification: Determine the protein concentration of the supernatant using a standard protein assay (e.g., Bradford or BCA assay).
-
Storage: Store the protein extract at -80°C until use.
Visualizations
Hormonal Regulation of Egg White Protein Synthesis
Caption: Hormonal control of egg white protein synthesis in the avian magnum.
Troubleshooting Workflow for Low Protein Yield
Caption: A logical workflow for troubleshooting low protein yield in Western blotting.
References
- 1. Interaction of estrogen and progesterone in chick oviduct development. I. Antagonistic effect of progesterone on estrogen-induced proliferation and differentiation of tubular gland cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Steroid receptors and effects of oestradiol and progesterone on chick oviduct proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Physiological factors influencing female fertility in birds - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Regulation of egg formation in the oviduct of laying hen | World's Poultry Science Journal | Cambridge Core [cambridge.org]
- 5. Estrogen receptors in the chick oviduct - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Changes in ovalbumin and protein synthesis in vivo in the magnum of laying hens during the egg formation cycle - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. ndpublisher.in [ndpublisher.in]
- 9. leicabiosystems.com [leicabiosystems.com]
- 10. Facts in artifacts - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Protocol to establish an oviduct epithelial cell line derived from Gallus gallus using Percoll for in vitro validation of recombinant proteins - PMC [pmc.ncbi.nlm.nih.gov]
Improving the statistical power of MAGMA analysis.
Welcome to the technical support center for MAGMA (Multi-marker Analysis of GenoMic Annotation). This guide provides troubleshooting advice and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals improve the statistical power of their MAGMA analyses.
Frequently Asked Questions (FAQs)
Q1: What is the primary factor that gives MAGMA greater statistical power compared to other gene-set analysis tools?
A1: MAGMA's enhanced statistical power primarily stems from its use of a multiple regression model at the gene-analysis stage.[1][2][3][4][5] This approach effectively accounts for the linkage disequilibrium (LD) between SNPs within a gene, which is a common issue that can reduce the power of other methods that aggregate single-marker associations.[1][2][5] By modeling the joint effect of all SNPs in a gene, MAGMA can detect multi-marker associations that might be missed by methods that rely on single-SNP p-values.[1][2]
Q2: Can the choice of gene analysis model in MAGMA impact statistical power?
A2: Yes, the choice of gene analysis model is critical and can significantly impact statistical power. MAGMA offers several models, and the optimal choice depends on the genetic architecture of the trait being studied. The principal components regression model is the default and is generally powerful across different scenarios.[6] However, the SNP-wise Mean and SNP-wise Top models can be more powerful under specific circumstances. For instance, the SNP-wise Top model is most sensitive when only a small proportion of SNPs in a gene are associated with the phenotype.[6]
Q3: How does the quality of the input GWAS summary statistics affect the power of a MAGMA analysis?
A3: The quality of the input GWAS summary statistics is paramount for a powerful MAGMA analysis. It is strongly recommended to use summary statistics that have undergone rigorous quality control.[6] Using imputed data with high imputation quality is also advisable.[6] Failure to adequately control for factors like population stratification in the original GWAS can lead to confounded results and reduced statistical power in the subsequent MAGMA analysis. Therefore, including principal components from the GWAS data as covariates in the MAGMA analysis is a recommended practice to correct for potential population stratification.[6]
Q4: What is the role of the reference panel in a MAGMA analysis, and how does it influence power?
A4: When using summary statistics, MAGMA requires a reference panel of genotypes to estimate the LD between SNPs.[6] The choice of this reference panel is crucial for accurate LD estimation and, consequently, for the statistical power of the analysis. The reference panel should be of the same ancestry as the GWAS cohort to ensure that the LD patterns are representative. Using an inappropriate reference panel can lead to inaccurate gene-level p-values and a loss of power.
Q5: Can the way SNPs are annotated to genes affect the results of a MAGMA analysis?
A5: Absolutely. The SNP-to-gene annotation step defines which SNPs are included in the analysis for each gene. This can be customized in MAGMA, for example, by defining a window around the gene's transcription start and end sites. A common approach is to include SNPs within a certain kilobase window upstream and downstream of the gene to capture regulatory variants.[7] The choice of this window size can impact the results, and it is important to consider the biological context when making this decision.
Troubleshooting Guide
| Issue | Possible Cause | Recommended Solution |
| Low number of significant genes or gene sets | Inadequate statistical power. | Review the choice of gene analysis model. Consider if the genetic architecture of your trait might be better captured by a different model (e.g., SNP-wise Top for traits driven by a few causal variants per gene).[6] Ensure your GWAS summary statistics have been properly quality-controlled.[6] Verify that the reference panel for LD estimation matches the ancestry of your GWAS cohort.[6] |
| "ERROR - reading p-value file: no valid p-values found for any SNPs in the data." | The SNP identifiers in your p-value file do not match the SNP identifiers in the reference panel. | Ensure that the SNP identifiers (e.g., rsIDs) are consistent between your summary statistics file and the LD reference panel. You may need to update the SNP IDs in your input file to match the reference panel. |
| Inflated or deflated gene-set p-values | Issues with the underlying gene-level p-values, potentially due to uncorrected population stratification or other confounders in the GWAS. | Include principal components from the GWAS data as covariates in your MAGMA analysis to correct for population stratification.[6] Re-examine the quality control steps of your GWAS summary statistics. |
| MAGMA run terminates with an error related to file paths. | Incorrect file paths specified in the command. | Double-check all file paths provided in your MAGMA command to ensure they are correct and that the files exist in the specified locations. |
Experimental Protocols
Protocol 1: Standard MAGMA Gene-Set Analysis with Summary Statistics
This protocol outlines the key steps for performing a gene-set analysis in MAGMA using GWAS summary statistics.
-
Annotation: Map SNPs to genes. This is a crucial first step where you define the genomic regions corresponding to each gene.
-
Command: magma --annotate --snp-loc
--gene-loc --out -
Note: You can use the --annotate window option to include SNPs in the upstream and downstream regions of genes.[7]
-
-
Gene Analysis: Calculate gene-level p-values from the SNP-level summary statistics.
-
Command: magma --bfile
--pval N= --gene-annot --out -
Note: The --bfile flag specifies the reference panel for LD calculation, and it is critical that this matches the ancestry of the GWAS cohort.[6]
-
-
Gene-Set Analysis: Test for the association of predefined gene sets with the phenotype.
-
Command: magma --gene-results
--set-annot --out -
Note: The gene-set file should contain the definitions of the gene sets you want to test.
-
Visualizations
Caption: A diagram illustrating the standard workflow for a MAGMA gene-set analysis.
References
- 1. MAGMA: Generalized Gene-Set Analysis of GWAS Data | PLOS Computational Biology [journals.plos.org]
- 2. MAGMA: Generalized Gene-Set Analysis of GWAS Data - PMC [pmc.ncbi.nlm.nih.gov]
- 3. MAGMA: generalized gene-set analysis of GWAS data - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. MAGMA: Generalized Gene-Set Analysis of GWAS Data - ProQuest [proquest.com]
- 5. researchgate.net [researchgate.net]
- 6. ibg.colorado.edu [ibg.colorado.edu]
- 7. Gene/Gene-set tests by MAGMA - GWASTutorial [cloufield.github.io]
Addressing challenges in long-term material exposure in Magnum-PSI.
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals conducting long-term material exposure experiments in the Magnum-PSI linear plasma device.
Frequently Asked Questions (FAQs)
Q1: What is Magnum-PSI and what are its key capabilities for long-term material exposure?
Magnum-PSI (Magnetized Plasma-Surface Interaction) is a linear plasma generator designed to study the interaction between plasmas and various materials under conditions relevant to future fusion reactors like ITER.[1][2] Its key capability lies in producing high-flux, steady-state plasmas that can expose material samples to extreme heat and particle loads for extended durations.[3][4] This allows for the investigation of long-term material performance and degradation in a controlled laboratory environment, simulating the harsh conditions inside a fusion reactor.[3][5] The facility is unique in its ability to achieve plasma conditions comparable to those at the surface of the sun.[5] A significant upgrade with a superconducting magnet allows for record-breaking long-term exposure of materials to these intense plasmas.[3][5]
Q2: What types of materials are typically tested in long-term exposure experiments in Magnum-PSI?
The primary materials investigated in Magnum-PSI are candidate plasma-facing components (PFCs) for fusion reactors. Tungsten and its alloys are a major focus due to their high melting point and low sputtering yield.[6] Experiments have been conducted on tungsten mock-ups of ITER reactor wall components.[6] The research program also addresses challenges related to other materials, including carbon substrates and mixed materials, focusing on issues like erosion, redeposition, and hydrogen retention.[1]
Q3: What are the typical plasma conditions achievable in Magnum-PSI for long-duration experiments?
Magnum-PSI can generate plasmas with a wide range of parameters to simulate different operational scenarios in a fusion reactor divertor.[2] Key parameters include:
| Parameter | Value | Reference |
| Ion Flux | Up to 1024 H+ ions m-2s-1 | [1][4] |
| Heat Flux | ≥ 10 MW/m² | [4][7] |
| Electron Temperature (Te) | 0.5 - 7 eV | [1] |
| Electron Density (ne) | 1019 - 1021 m-3 | [8] |
| Magnetic Field | Up to 3 T | [1] |
These conditions can be maintained in a steady state, enabling long-term exposure studies that were not previously possible.[3]
Q4: What are the primary plasma-material interaction (PMI) challenges investigated during long-term exposure?
Long-term exposure to high-flux plasma in Magnum-PSI allows for the study of a variety of complex and critical PMI phenomena.[9] These include:
-
Erosion and Redeposition: The removal of surface material due to plasma bombardment and its subsequent redeposition elsewhere on the surface.[1]
-
Material Damage and Transmutation: The formation of defects within the material's crystal structure and changes in its elemental composition due to neutron bombardment (simulated in other facilities).[10]
-
Fuel Retention: The trapping of hydrogen isotopes (deuterium and tritium) within the material, which has implications for fuel recycling and safety in a fusion reactor.[9]
-
Surface Morphology Changes: The evolution of the material's surface structure, including roughening, blistering, and the formation of nanostructures.[11]
-
Thermomechanical Property Degradation: Changes in material properties such as hardness, ductility, and thermal conductivity due to plasma and heat loads.[10]
Troubleshooting Guides
Problem: Unexpectedly High Material Erosion or Surface Damage
Q: My material sample shows significantly higher erosion than predicted. What are the potential causes and how can I troubleshoot this?
A: Unexpectedly high erosion can stem from several factors related to both the plasma conditions and the material itself. A systematic approach is necessary to identify the root cause.
Troubleshooting Workflow:
Caption: Troubleshooting workflow for high material erosion.
Detailed Steps:
-
Verify Plasma Parameters: Cross-check the requested plasma parameters with the actual measured values from diagnostics like Thomson Scattering for electron temperature (Te) and density (ne), and Langmuir probes for ion saturation current.[12][13] Higher than expected Te or ion flux can significantly increase sputtering yields.
-
Analyze for Plasma Impurities: Use optical emission spectroscopy to check for the presence of impurities in the plasma.[14] High-Z impurities, even in small concentrations, can dramatically increase the erosion of the target material.
-
Monitor Surface Temperature: Review infrared thermography data to ensure the surface temperature of the material remained within the expected range.[7] Elevated temperatures can lead to increased erosion and changes in material microstructure.
-
Inspect Material Properties: Before and after exposure, characterize the material's composition and microstructure. Inhomogeneities or pre-existing defects can lead to localized, accelerated erosion.
-
Investigate Transient Events: Analyze data for any transient events, such as plasma instabilities or Edge Localized Mode (ELM)-like pulses, which can cause short but intense bursts of heat and particle fluxes, leading to significant erosion.[7]
Problem: Inconsistent or Unstable Plasma Conditions During Long-Term Exposure
Q: I'm observing fluctuations in my plasma parameters during a long-duration experiment. What could be the cause, and how can I improve stability?
A: Maintaining stable plasma conditions over many hours is a key challenge.[6] Fluctuations can arise from the plasma source, the magnetic field, gas fueling, or interactions with the target itself.
Logical Relationship Diagram:
References
- 1. www-pub.iaea.org [www-pub.iaea.org]
- 2. impact.ornl.gov [impact.ornl.gov]
- 3. Candidate fusion materials to be investigated at Magnum-PSI [iter.org]
- 4. researchgate.net [researchgate.net]
- 5. First plasma in upgraded extreme materials-facility Magnum-PSI | Dutch Institute for Fundamental Energy Research [differ.nl]
- 6. World record plasma exposure in Magnum-PSI | Dutch Institute for Fundamental Energy Research [differ.nl]
- 7. differ.nl [differ.nl]
- 8. researchgate.net [researchgate.net]
- 9. Plasma surface interaction - Wikipedia [en.wikipedia.org]
- 10. info.ornl.gov [info.ornl.gov]
- 11. mdpi.com [mdpi.com]
- 12. Advances in Magnum-PSI probe diagnosis in support of plasma-surface interaction studies | Dutch Institute for Fundamental Energy Research [differ.nl]
- 13. researchgate.net [researchgate.net]
- 14. researchgate.net [researchgate.net]
Technical Support Center: Refining Immunohistochemistry Protocols for the Avian Magnum
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in refining their immunohistochemistry (IHC) protocols for the avian magnum. The unique protein-rich environment of the magnum, responsible for synthesizing a majority of the egg-white proteins, presents specific challenges that require careful optimization of standard IHC procedures.
Troubleshooting Guides
This section addresses common issues encountered during IHC of the avian magnum, offering potential causes and solutions in a structured question-and-answer format.
Issue 1: High Background Staining
High background staining can obscure the specific signal, making accurate interpretation of results difficult. This is a common challenge in the protein-rich environment of the avian magnum.
| Potential Cause | Recommended Solution |
| Non-specific antibody binding | Optimize the primary antibody concentration by performing a titration experiment.[1][2] A high concentration can increase non-specific interactions.[3] Consider incubating the primary antibody at 4°C overnight to reduce non-specific binding.[4][5] |
| Insufficient Blocking | Use a blocking serum from the same species as the secondary antibody to block non-specific binding sites.[6][7][8] Increase the serum concentration in the blocking buffer, potentially up to 10%.[3] Alternatively, use protein-based blockers like bovine serum albumin (BSA) or casein.[6][7] |
| Endogenous Enzyme Activity | If using an HRP-conjugated antibody, quench endogenous peroxidase activity by treating the tissue with 3% hydrogen peroxide (H₂O₂) before primary antibody incubation.[1][3] For alkaline phosphatase (AP) detection, use levamisole (B84282) to block endogenous AP activity.[7][9] |
| Endogenous Biotin (B1667282) | If using a biotin-based detection system, block endogenous biotin with an avidin/biotin blocking kit prior to incubation with the biotinylated antibody.[1][3][7][10] |
| Hydrophobic Interactions | The high protein content of the magnum can lead to hydrophobic interactions. Including a detergent like Triton X-100 or Tween 20 in the washing and antibody dilution buffers can help reduce this type of non-specific binding.[6] |
Troubleshooting Workflow for High Background Staining
Caption: A logical workflow for troubleshooting high background staining in avian magnum IHC.
Issue 2: Weak or No Staining
The absence of a clear signal can be equally frustrating. This section provides guidance on how to address weak or non-existent staining.
| Potential Cause | Recommended Solution |
| Improper Tissue Fixation | The choice of fixative and the duration of fixation are critical. Over-fixation can mask epitopes.[1][10] While paraformaldehyde (PFA) is common, trichloroacetic acid (TCA) fixation has also been shown to be effective for some antigens in avian embryos and may be worth considering.[11][12] Ensure fixation time is optimized for the magnum tissue. |
| Suboptimal Antigen Retrieval | Formalin fixation often requires an antigen retrieval step to unmask epitopes.[13] Heat-Induced Epitope Retrieval (HIER) is generally more successful than Protease-Induced Epitope Retrieval (PIER). Experiment with different HIER buffers (e.g., citrate (B86180) buffer pH 6.0 or Tris-EDTA pH 9.0) and optimize the heating time and temperature.[14][15][16] |
| Primary Antibody Issues | Confirm that the primary antibody is validated for use in IHC and is suitable for avian species.[4][17] Not all antibodies raised against mammalian proteins will cross-react with their avian counterparts.[17] Increase the primary antibody concentration or extend the incubation time (e.g., overnight at 4°C).[2][4] |
| Inactive Reagents | Ensure that antibodies and detection reagents have been stored correctly and are within their expiration dates.[2] Test the secondary antibody and detection system on a positive control to confirm their activity.[1] |
| Low Antigen Abundance | The target protein may be expressed at low levels in the magnum. Consider using a signal amplification system, such as a biotin-conjugated secondary antibody followed by a streptavidin-enzyme complex, to enhance the signal.[9][18] |
Troubleshooting Workflow for Weak or No Staining
Caption: A logical workflow for troubleshooting weak or absent staining in avian magnum IHC.
Frequently Asked Questions (FAQs)
Q1: What is the best fixative for avian magnum tissue?
A1: 4% buffered paraformaldehyde (PFA) is a commonly used and effective fixative for avian oviductal magnum tissue.[14] However, the optimal fixation method can be antigen-dependent.[11] Studies on chick embryos have shown that for certain antigens, trichloroacetic acid (TCA) fixation can improve signal intensity compared to PFA.[11][12] It is recommended to start with 4% PFA but consider testing other fixatives if you encounter issues with epitope masking.
Q2: How can I select a suitable primary antibody for use in the avian magnum?
A2: When selecting a primary antibody, it is crucial to verify that it has been validated for use in IHC and, ideally, in avian species.[4][17] Not all antibodies targeting mammalian proteins will recognize the avian homologue due to species differences in protein sequences.[17] Whenever possible, choose antibodies that have been previously cited in the literature for use in avian tissues. A study on 53 avian species found that an anti-CD3 antibody (clone F7.2.38) was effective for detecting T lymphocytes across all species tested, while the anti-PAX5 antibody (clone SP34) detected B lymphocytes in a majority of species.[17][19]
Q3: What are the key parameters to optimize for antigen retrieval in magnum tissue?
A3: For formalin-fixed, paraffin-embedded magnum tissue, Heat-Induced Epitope Retrieval (HIER) is generally recommended. The key parameters to optimize are the retrieval solution and the heating method.[13] Commonly used retrieval solutions include sodium citrate buffer (pH 6.0) and Tris-EDTA buffer (pH 9.0).[14][15] The optimal pH can be antibody-dependent. Heating can be performed using a microwave, pressure cooker, or water bath, and the duration and temperature of heating should be optimized for your specific antigen and antibody.[13][14]
Q4: What is a standard protocol for blocking non-specific binding in the avian magnum?
A4: A standard blocking protocol for the avian magnum involves incubating the tissue sections in a blocking solution for at least one hour at room temperature.[11] The blocking solution typically contains normal serum from the species in which the secondary antibody was raised (e.g., normal goat serum if using a goat anti-rabbit secondary antibody) diluted in a buffer such as PBS or TBS.[6][7][14] Adding a protein like BSA to the blocking buffer can also help reduce non-specific binding.[6]
Experimental Protocols
General Immunohistochemistry Protocol for Paraffin-Embedded Avian Magnum
This protocol provides a general framework. Optimization of specific steps, particularly antibody concentrations and incubation times, is essential.
-
Deparaffinization and Rehydration:
-
Immerse slides in xylene (or a xylene substitute) two times for 5 minutes each.
-
Hydrate sections by sequential immersion in 100%, 95%, and 70% ethanol (B145695) for 3 minutes each.
-
Rinse with distilled water.
-
-
Antigen Retrieval (HIER Method):
-
Immerse slides in a staining dish containing sodium citrate buffer (10 mM, pH 6.0).
-
Heat in a microwave oven for 10-15 minutes.[14] Do not allow the solution to boil dry.
-
Allow slides to cool in the buffer for at least 20 minutes at room temperature.[15]
-
Rinse slides in wash buffer (e.g., PBS with 0.05% Tween-20).
-
-
Blocking Endogenous Peroxidase (if using HRP detection):
-
Incubate sections in 3% H₂O₂ in methanol (B129727) or water for 15 minutes at room temperature.[3]
-
Rinse with wash buffer.
-
-
Blocking Non-Specific Binding:
-
Primary Antibody Incubation:
-
Dilute the primary antibody in an appropriate antibody diluent (e.g., PBS with 1% BSA).
-
Incubate sections with the diluted primary antibody overnight at 4°C in a humidified chamber.[5]
-
-
Secondary Antibody Incubation:
-
Rinse slides with wash buffer (3 times for 5 minutes each).
-
Incubate with a biotinylated secondary antibody (or other appropriate secondary) diluted according to the manufacturer's instructions for 1 hour at room temperature.
-
-
Detection:
-
Rinse slides with wash buffer (3 times for 5 minutes each).
-
Incubate with an enzyme-conjugated streptavidin (e.g., HRP-streptavidin) for 30-60 minutes at room temperature.
-
Rinse with wash buffer.
-
-
Chromogen Development:
-
Incubate sections with a suitable chromogen substrate (e.g., DAB for HRP) until the desired color intensity is reached. Monitor under a microscope.
-
Rinse with distilled water to stop the reaction.
-
-
Counterstaining, Dehydration, and Mounting:
-
Counterstain with hematoxylin.
-
Dehydrate sections through a graded series of ethanol and clear in xylene.
-
Mount with a permanent mounting medium.
-
General IHC Workflow Diagram
Caption: A standard workflow for immunohistochemistry on avian magnum tissue sections.
References
- 1. Ultimate IHC Troubleshooting Guide: Fix Weak Staining & High Background [atlasantibodies.com]
- 2. origene.com [origene.com]
- 3. IHCに関するトラブルシューティングガイド | Thermo Fisher Scientific - JP [thermofisher.com]
- 4. bosterbio.com [bosterbio.com]
- 5. Primary Antibody Selection for IHC: Monoclonal vs. Polyclonal : Novus Biologicals [novusbio.com]
- 6. IHC Blocking | Proteintech Group [ptglab.com]
- 7. Blocking in IHC | Abcam [abcam.com]
- 8. bio-rad-antibodies.com [bio-rad-antibodies.com]
- 9. bma.ch [bma.ch]
- 10. biossusa.com [biossusa.com]
- 11. Effectiveness of fixation methods for wholemount immunohistochemistry across cellular compartments in chick embryos - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Effectiveness of fixation methods for wholemount immunohistochemistry across cellular compartments in chick embryos - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. IHC antigen retrieval protocol | Abcam [abcam.com]
- 14. Structural and histological characterization of oviductal magnum and lectin-binding patterns in Gallus domesticus - PMC [pmc.ncbi.nlm.nih.gov]
- 15. IHC Antigen Retrieval | Proteintech Group [ptglab.com]
- 16. bosterbio.com [bosterbio.com]
- 17. Immunohistochemical identification of T and B lymphocytes in formalin-fixed, paraffin-embedded tissues of 53 avian species using commercial antibodies - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Immunohistochemical staining for the detection of the avian influenza virus in tissues - PubMed [pubmed.ncbi.nlm.nih.gov]
- 19. researchgate.net [researchgate.net]
Debugging pipeline integration with Magnum mass spectrometry software.
Welcome to the technical support center for the Magnum mass spectrometry software. This resource is designed for researchers, scientists, and drug development professionals to help troubleshoot issues and answer frequently asked questions related to pipeline integration and data analysis.
Troubleshooting Guides
This section provides detailed, step-by-step guides to resolve specific issues you may encounter while using Magnum in your data analysis pipeline.
Issue: Magnum execution fails with a "File not found" error.
This is one of the most common errors and typically points to a problem with how the input files are specified in the configuration file or the command-line execution.
Step 1: Verify the file paths in your Magnum.conf file.
Magnum relies on a configuration file (e.g., Magnum.conf) to locate your input files.[1] Ensure that the paths for MS_data_file and database are correct.[1]
-
Absolute vs. Relative Paths: It is best practice to use absolute paths to your files to avoid ambiguity. If you are using relative paths, ensure they are relative to the directory from which you are running the Magnum executable.
-
Check for Typos: Carefully inspect the file names and directory paths for any typographical errors.
Step 2: Ensure the files exist and have the correct permissions.
Navigate to the specified directories in your terminal or file explorer to confirm that the files are present. Additionally, verify that you have read permissions for the files. In a Unix-like environment, you can use the ls -l command to check permissions.
Step 3: Check your command-line execution.
When you run Magnum, you need to provide the path to your configuration file.[1]
If the path to the configuration file is incorrect, Magnum will not be able to find it and, consequently, won't be able to locate your data files.
Issue: Peptide identification is poor or results in no significant hits.
Low identification rates can be frustrating and may stem from several factors, from sample quality to incorrect search parameters.
Step 1: Evaluate the quality of your mass spectrometry data.
Garbage in, garbage out is a crucial concept in bioinformatics.[2] Poor quality MS data will inevitably lead to poor identification results.
-
Check Total Ion Chromatogram (TIC): A stable and consistent TIC suggests good LC-MS performance.
-
Inspect Spectra: Manually inspect some of your MS/MS spectra. Are they of good quality with clear isotopic envelopes and fragmentation patterns?
Step 2: Verify your search parameters in Magnum.conf.
Incorrectly specified parameters are a frequent cause of poor identification results.
-
Enzyme Specificity: Ensure the enzyme parameter matches the protease used for digestion (e.g., [KR]|{P} for Trypsin).[3]
-
Mass Tolerances: Check that the ppm_tolerance_pre (precursor mass tolerance) and fragment_bin_size (fragment mass tolerance) are appropriate for your instrument's resolution and mass accuracy.
-
Modifications: Verify that fixed_modification and modification parameters are correctly defined for your experimental conditions (e.g., Carbamidomethylation of Cysteine as a fixed modification).[4] The max_mods_per_peptide parameter should also be set to a reasonable number.[5]
-
Adduct Mass Range: If you are searching for unknown adducts, ensure the min_adduct_mass and max_adduct_mass range is appropriate for your expected modifications.
Step 3: Check your protein sequence database.
The database you search against is critical for successful peptide identification.
-
Correct Organism: Ensure the FASTA file contains the proteome of the correct organism.
-
Contaminants: It is good practice to include a list of common contaminants (e.g., keratin, trypsin) in your database.
-
Decoy Sequences: For reliable False Discovery Rate (FDR) estimation, your database should contain decoy sequences. Many tools can generate these for you.
Step 4: Post-search validation with Percolator.
Magnum is often used in conjunction with Percolator for post-search validation to improve the discrimination between correct and incorrect peptide-spectrum matches (PSMs). If Percolator exits with a non-zero status, it often means that no peptides passed the specified FDR threshold.[6] This can be an indication of the issues mentioned in the steps above.
Frequently Asked Questions (FAQs)
Q1: What input file formats does Magnum support?
Magnum supports open data standards for mass spectrometry data, including mzML, MGF, and mzXML.[7] For protein sequence databases, the FASTA format is required.
Q2: How do I specify variable modifications in my search?
You can specify variable modifications in the Magnum.conf file using the modification parameter. For example, to search for oxidation of methionine, you would add the line: modification = M 15.9949. You can have multiple modification lines for different modifications.[4]
Q3: My pipeline run completes, but the output file is empty or contains only headers. What could be the problem?
This typically indicates that no PSMs passed the scoring and FDR thresholds. Refer to the "Peptide identification is poor or results in no significant hits" troubleshooting guide above to diagnose the potential causes.
Q4: Can Magnum be integrated into any bioinformatics pipeline?
Yes, Magnum is a command-line tool, which makes it highly suitable for integration into various bioinformatics pipelines and workflow management systems like Nextflow or Snakemake.[7]
Q5: Where can I find more detailed information about all the configuration parameters?
A complete list and description of all parameters can be found on the official Magnum website. It is recommended to familiarize yourself with these options to optimize your searches.
Experimental Protocols & Data
Experimental Protocol: Protein Quantitation of Drug-Treated vs. Control Cells
This protocol outlines a typical bottom-up proteomics workflow to identify and quantify protein expression changes in response to drug treatment.
-
Cell Culture and Lysis:
-
Culture human cancer cells (e.g., HeLa) to ~80% confluency.
-
Treat one set of cells with the drug of interest at a specified concentration and duration. Treat a control set with a vehicle (e.g., DMSO).
-
Harvest cells, wash with PBS, and lyse in a urea-based buffer containing protease and phosphatase inhibitors.
-
Sonicate the lysate to shear DNA and clarify by centrifugation.
-
-
Protein Digestion:
-
Determine protein concentration using a BCA assay.
-
Take 100 µg of protein from each sample.
-
Reduce disulfide bonds with DTT at 56°C for 30 minutes.
-
Alkylate cysteine residues with iodoacetamide (B48618) in the dark at room temperature for 20 minutes.
-
Dilute the sample to reduce the urea (B33335) concentration.
-
Digest with sequencing-grade trypsin overnight at 37°C.
-
-
Peptide Cleanup and LC-MS/MS Analysis:
-
Desalt the resulting peptide mixture using a C18 solid-phase extraction cartridge.
-
Dry the peptides and resuspend in a buffer suitable for mass spectrometry.
-
Analyze the peptides by LC-MS/MS on a high-resolution mass spectrometer (e.g., an Orbitrap).
-
Data Presentation: Quantitative Proteomics Results
The following table summarizes hypothetical quantitative data from the experiment described above. Protein abundance is often represented as a log2 fold change of the treated sample relative to the control.
| Protein ID (UniProt) | Gene Name | Description | Log2 Fold Change (Treated/Control) | p-value |
| P04637 | TP53 | Cellular tumor antigen p53 | 2.1 | 0.001 |
| P31749 | BAX | Apoptosis regulator BAX | 1.8 | 0.005 |
| P10415 | BCL2 | Apoptosis regulator Bcl-2 | -1.5 | 0.012 |
| Q06609 | CDK1 | Cyclin-dependent kinase 1 | -1.9 | 0.003 |
Visualizations
Signaling Pathway Diagram
The diagram below illustrates a simplified p53 signaling pathway, which is often studied in the context of drug development for cancer. The proteins in the table above are part of or related to this pathway.
Caption: A simplified diagram of the p53 signaling pathway.
Experimental Workflow Diagram
The following diagram outlines the major steps in a typical proteomics experimental workflow.
References
- 1. Magnum Instructions [magnum-ms.org]
- 2. blog.omni-inc.com [blog.omni-inc.com]
- 3. Magnum Parameters - enzyme [magnum-ms.org]
- 4. Magnum Parameters - modification [magnum-ms.org]
- 5. Magnum Parameters - max_mods_per_peptide [magnum-ms.org]
- 6. support.proteomesoftware.com [support.proteomesoftware.com]
- 7. Magnum [magnum-ms.org]
Enhancing the accuracy of MAGMA by incorporating Hi-C data (H-MAGMA).
This technical support center provides troubleshooting guidance and answers to frequently asked questions for researchers, scientists, and drug development professionals using H-MAGMA (Hi-C-coupled MAGMA) to enhance the accuracy of gene-level association studies.
Frequently Asked Questions (FAQs)
Q1: What is H-MAGMA and how does it improve upon the original MAGMA?
A1: H-MAGMA is a computational tool that enhances the capabilities of MAGMA (Multi-marker Analysis of GenoMic Annotation) by integrating chromatin interaction data, such as that from Hi-C experiments.[1][2] While the original MAGMA assigns single nucleotide polymorphisms (SNPs) to their nearest genes based on genomic proximity, H-MAGMA utilizes 3D chromatin configuration to link non-coding SNPs to the genes they physically interact with, which can often be located at a considerable linear distance.[1][3] This approach allows for a more biologically relevant assignment of non-coding variants to their target genes, which is crucial given that a majority of disease-associated variants identified through genome-wide association studies (GWAS) are located in non-coding regions.[1][3]
Q2: What are the key advantages of using H-MAGMA?
A2: The primary advantages of H-MAGMA include:
-
Biologically informed gene mapping: By incorporating Hi-C data, H-MAGMA provides a more accurate mapping of non-coding SNPs to their cognate genes based on physical interactions.[1]
-
Identification of novel risk genes: H-MAGMA can identify disease-associated genes that are missed by conventional MAGMA, particularly when non-coding variants regulate distal genes.[1][3] Up to 60% of disorder risk genes have been found to be "H-MAGMA selective," meaning they were identified by H-MAGMA but not by conventional MAGMA.[1]
-
Tissue and cell-type specificity: The framework is versatile and can be adapted to specific biological contexts by using Hi-C data from the relevant tissue or cell type of interest for a given GWAS trait.[3][4]
-
Leveraging sub-threshold GWAS signals: H-MAGMA can utilize signals from SNPs that do not reach genome-wide significance, which collectively can explain a significant portion of heritability.[1]
Q3: What input files are required to run H-MAGMA?
A3: To perform an H-MAGMA analysis, you will need the following files:
-
GWAS summary statistics: A text file containing SNP p-values from your study.[3][5]
-
Hi-C data: Chromatin interaction data in BEDPE format for the tissue or cell type of interest.[3][6]
-
Reference genome data: A reference panel for the ancestry corresponding to your GWAS data (e.g., 1000 Genomes for European ancestry) in PLINK binary format (.bed, .bim, .fam).[3][5]
-
Gene, exon, and promoter coordinate files: BED files defining the genomic locations of genes, exons, and promoters.[6]
-
Gene annotation file: To convert ENSEMBL gene IDs to HGNC symbols.[3]
Q4: How does H-MAGMA compare to eQTL-based gene mapping methods?
A4: H-MAGMA and eQTL-based methods like TWAS and coloc can identify overlapping sets of risk genes. For instance, in a schizophrenia GWAS analysis, a significant proportion of genes identified by eQTL-based mapping were also detected by H-MAGMA.[1] However, H-MAGMA often identifies a larger number of associated genes that still explain a significant portion of heritability.[1] These methods can be seen as complementary, as they provide different lines of evidence for linking non-coding variants to gene function.
Troubleshooting Guide
| Problem | Possible Reason | Solution |
| No such file or directory error | The working directory is not set to the location of the downloaded input files. | Change the working directory to the correct path containing all necessary files.[3] |
| R crashes during the aggregate step (snpagg <- aggregate(...)) | This step can be memory-intensive, and your local machine may not have sufficient RAM. | If you encounter this issue, it is recommended to run the analysis on a high-performance computing cluster with more available memory.[7] |
| "The two combined objects have no sequence levels in common" error | Chromosome annotations (e.g., 'chr1' vs '1') are inconsistent between your input files (SNP, exon, promoter, or Hi-C data). | Ensure that the chromosome naming convention is consistent across all your input files.[3] |
| Discrepancies in the number of identified risk genes compared to published studies | A different, likely older, version of MAGMA was used which may have inflated Type I error rates. | It is recommended to use MAGMA v1.08 or newer, as it better controls for potential false positives.[5][8] Using an updated version may result in a smaller, but more robust, set of identified risk genes.[8] |
| Low number of significant genes identified | The statistical power of the input GWAS is low due to a small sample size. | The number of risk genes identified by H-MAGMA is impacted by the power of the GWAS. Be mindful of this limitation when interpreting the results.[3] |
| Uncertainty about the direction of effect of identified SNPs | H-MAGMA assigns SNPs to genes but does not determine if the variant upregulates or downregulates the gene. | To investigate the directionality of the effect, you can integrate eQTL datasets to analyze whether the associated variants influence gene expression levels.[6] |
Quantitative Data Summary
Table 1: Comparison of SNP-to-Gene Mapping between conventional MAGMA (cMAGMA) and H-MAGMA
| SNP Location | Percentage Mapped to Nearest Gene (cMAGMA) |
| Intronic SNPs | 20% |
| Intergenic SNPs | 5% |
| This table highlights that a large proportion of non-coding SNPs do not interact with their nearest gene, underscoring the importance of using chromatin interaction data for accurate gene mapping.[1] |
Table 2: Overlap of Schizophrenia (SCZ) Risk Genes Identified by H-MAGMA and eQTL-based Methods
| Method | Overlap with H-MAGMA | Odds Ratio (95% CI) | P-value |
| coloc | 74.9% | 4.34 (3.22–5.90) | 1.76x10⁻²⁶ |
| TWAS | 72.6% | 12.14 (10.20–14.49) | 3.94x10⁻²⁰⁶ |
| This table demonstrates a significant overlap between the risk genes identified by H-MAGMA and those identified by eQTL-based methods, while also showing that H-MAGMA identifies a substantial number of additional genes.[1] |
Experimental Protocols & Methodologies
H-MAGMA Workflow
The H-MAGMA process consists of two main stages:
-
Variant-Gene Annotation: This step generates an annotation file that links SNPs to their target genes.
-
Exonic and Promoter SNPs: These are directly assigned to the gene in which they are located or whose promoter they fall within.[1][3]
-
Intronic and Intergenic SNPs: These are mapped to genes based on Hi-C interaction data. A SNP is assigned to a gene if it physically interacts with the gene's promoter or exons.[1][3][6]
-
-
Gene Analysis: The generated annotation file is then used as input for MAGMA along with the GWAS summary statistics.
Generating the H-MAGMA Variant-Gene Annotation File
A detailed protocol for creating the necessary annotation file is available in Nature Protocols and on Zenodo.[3][4][10] The general steps involve:
-
Prepare Input Files: Load gene, exon, and promoter coordinate files, as well as the Hi-C data in BEDPE format.
-
Assign Exonic and Promoter SNPs: Directly map these SNPs to their respective genes.
-
Map Intronic and Intergenic SNPs:
-
Identify SNPs that do not fall within exons or promoters.
-
Use the Hi-C data to find physical interactions between these non-coding SNPs and gene promoters/exons.
-
-
Aggregate and Format: Combine the SNP-gene assignments from all steps into a single annotation file that is compatible with MAGMA.
Visualizations
Caption: The H-MAGMA workflow, from input data to the identification of risk genes.
Caption: Logical flow for assigning SNPs to genes in the H-MAGMA framework.
References
- 1. A computational tool (H-MAGMA) for improved prediction of brain disorder risk genes by incorporating brain chromatin interaction profiles - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Annotating genetic variants to target genes using H-MAGMA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Annotating genetic variants to target genes using H-MAGMA - PMC [pmc.ncbi.nlm.nih.gov]
- 4. cdr.lib.unc.edu [cdr.lib.unc.edu]
- 5. GitHub - thewonlab/H-MAGMA [github.com]
- 6. youtube.com [youtube.com]
- 7. RAM requirements for gene-variant workup · Issue #10 · thewonlab/H-MAGMA · GitHub [github.com]
- 8. biorxiv.org [biorxiv.org]
- 9. Item - H-MAGMA workflow. - Public Library of Science - Figshare [plos.figshare.com]
- 10. H-MAGMA Protocol [zenodo.org]
Technical Support Center: Mitigating Contamination Effects in Magnum-PSI Experiments
This technical support center provides researchers, scientists, and drug development professionals with comprehensive troubleshooting guides and FAQs to address contamination issues during Magnum-PSI experiments.
Frequently Asked Questions (FAQs)
Q1: What are the most common unintentional contaminants in the Magnum-PSI vacuum vessel?
A1: The most prevalent contaminants in high-vacuum systems like Magnum-PSI are water vapor (H₂O) desorbing from internal surfaces, hydrocarbons from pump oils, greases, and fingerprints, and atmospheric gases (N₂, O₂) that were not fully pumped out. Other potential sources include residues from cleaning solvents and outgassing of materials used in the experimental setup.[1][2][3]
Q2: How can I tell if my experiment is affected by contamination?
A2: Signs of contamination include:
-
Anomalous Plasma Behavior: Unexplained changes in plasma temperature or density, or the appearance of unexpected spectral lines in Optical Emission Spectroscopy (OES).
-
Inconsistent Results: Poor reproducibility of experimental outcomes under seemingly identical conditions.
-
Surface Analysis Discrepancies: Post-exposure surface analysis of the target in the Target Exchange and Analysis Chamber (TEAC) revealing unexpected elements (e.g., carbon, oxygen).
-
Pressure Issues: Difficulty in reaching the desired base pressure or a high residual gas analyzer (RGA) signal for masses corresponding to water (18 amu), nitrogen/CO (28 amu), or oxygen (32 amu).
Q3: What is outgassing and which materials are the worst offenders?
A3: Outgassing is the release of trapped or adsorbed gases from a material's surface or bulk when under vacuum.[1][2][3] This process can be a major source of contamination. Materials with high porosity and those that readily absorb water, such as certain plastics, elastomers (like Viton, when not properly baked), and unvented screws, are significant sources of outgassing. The most common outgassing product in vacuum systems is water.[1]
Q4: What is the purpose of a vacuum bakeout?
A4: A vacuum bakeout involves heating the vacuum chamber and its internal components to accelerate the desorption of volatile substances like water and hydrocarbons from the surfaces.[4][5] This process helps to achieve a lower ultimate base pressure and a cleaner environment for the experiment by driving off contaminants that would otherwise slowly outgas during the plasma exposure.
Q5: When should I perform an in-situ plasma cleaning?
A5: In-situ plasma cleaning is recommended:
-
Before starting a new experimental campaign to ensure a clean chamber environment.
-
After the system has been vented to atmosphere for an extended period.
-
When contamination is suspected to be affecting experimental results, particularly on the target surface.
-
To remove a specific coating or contaminant layer from the target or surrounding components without breaking the vacuum.[6][7]
Troubleshooting Guides
Issue 1: Unstable Plasma or Unexpected Spectral Lines
Symptoms:
-
Plasma parameters (density, temperature) fluctuate unexpectedly.
-
Optical Emission Spectroscopy (OES) shows lines from unknown species (e.g., strong C, O, or N lines in a pure hydrogen plasma).
Troubleshooting Workflow:
Caption: Troubleshooting workflow for unstable plasma.
Issue 2: Poor Base Pressure
Symptoms:
-
The vacuum system struggles to reach the desired base pressure (e.g., <10⁻⁴ Pa).[8]
-
The pressure rises quickly after the pumps are valved off.
Troubleshooting Workflow:
Caption: Troubleshooting workflow for poor base pressure.
Data Presentation
Table 1: Outgassing Rates of Common Vacuum Materials
| Material | TML (%) | CVCM (%) | Common Outgassing Species | Notes |
| Stainless Steel (304/316L) | < 0.1 | < 0.01 | H₂, CO, H₂O | Requires proper cleaning and bakeout for UHV. |
| Aluminum (6061) | < 0.1 | < 0.01 | H₂O | Can have a porous oxide layer that traps water. |
| Viton (baked) | < 1.0 | < 0.1 | H₂O, various organics | Must be baked under vacuum to reduce outgassing. |
| Teflon (PTFE) | ~0.01-0.1 | < 0.01 | Fluorocarbons | Generally good, but can have trapped gases. |
| Kapton (Polyimide) | ~0.6 | < 0.01 | H₂O, N₂ | Absorbs significant water. Requires bakeout. |
| Macor | < 0.1 | < 0.01 | H₂O | Stable ceramic, good for UHV applications. |
TML = Total Mass Loss, CVCM = Collected Volatile Condensable Material. Data compiled from NASA standards and general vacuum handbooks. Lower values are better.[2]
Table 2: Recommended In-Situ Plasma Cleaning Parameters (General Guidance)
| Contaminant Type | Primary Gas | Typical Pressure (Pa) | Typical Duration (min) | Mechanism |
| Light Hydrocarbons | Argon (Ar) | 1 - 10 | 10 - 30 | Sputtering (Physical Removal) |
| Heavy Organics/Polymers | Ar + Oxygen (O₂) | 1 - 10 | 20 - 60 | Chemical Etching & Sputtering |
| Surface Oxides | Argon (Ar) + Hydrogen (H₂) | 1 - 10 | 15 - 45 | Chemical Reduction & Sputtering |
| General Conditioning | Argon (Ar) | 1 - 5 | 30 - 60 | Sputter Cleaning |
Note: Optimal parameters are highly dependent on the specific material, system geometry, and severity of contamination. These should be used as starting points.[6][7]
Experimental Protocols
Protocol 1: Standard Vacuum System Bakeout
Objective: To reduce the partial pressure of water vapor and other volatile contaminants to achieve ultra-high vacuum conditions.
Methodology:
-
Preparation:
-
Ensure all sensitive components (e.g., certain diagnostics, electronics) are removed or protected.
-
Verify that all vacuum seals are bakeout-compatible (e.g., copper gaskets or baked Viton).
-
Wrap heating tapes around the vacuum vessel and any attached large-conductance tubing. Cover the tapes with aluminum foil to ensure uniform heat distribution.[4]
-
Place thermocouples at various points on the chamber to monitor temperature.
-
-
Execution:
-
Pump the system down to at least the high-vacuum range (<10⁻³ Pa).
-
Slowly ramp up the temperature using the heating tapes to the target temperature (typically 120-150°C for systems with Viton seals, higher for all-metal systems). The ramp rate should be slow enough to prevent rapid pressure bursts that could stall the turbo pumps.
-
Maintain the target temperature while the turbo pumps continue to evacuate the outgassed species. Monitor the RGA to observe the partial pressures of water and other contaminants decrease over time.
-
A typical bakeout lasts 24-72 hours. The bakeout is considered complete when the partial pressure of water (18 amu) has dropped significantly and stabilized at a low level.
-
-
Cooldown:
-
Turn off the heating tapes and allow the system to cool down slowly to room temperature while still under vacuum.
-
The base pressure of the system should be significantly lower after cooling than before the bakeout.
-
Protocol 2: In-Situ Plasma Cleaning for Hydrocarbon Removal
Objective: To remove surface hydrocarbon contamination from the target and chamber walls using an argon/oxygen plasma.
Methodology:
-
Preparation:
-
Pump the system down to its base pressure.
-
Retract or protect any sensitive diagnostics that could be damaged by the cleaning plasma.
-
Set up the gas supply for Argon and a small percentage of Oxygen (e.g., 95% Ar, 5% O₂).
-
-
Execution:
-
Establish a stable gas flow of the Ar/O₂ mixture into the chamber.
-
Adjust the pumping speed to achieve a stable operating pressure, typically between 1-10 Pa.
-
Ignite the plasma source. The plasma will generate energetic ions and reactive oxygen radicals.
-
The oxygen radicals chemically react with hydrocarbons to form volatile products like CO, CO₂, and H₂O, which are then pumped away.[6] The argon ions provide physical sputtering to assist in the removal process.[7]
-
Run the cleaning discharge for the desired duration (e.g., 30 minutes). Monitor the process with an RGA; a successful cleaning will show an initial increase in CO, CO₂, and H₂O signals, followed by a decrease as the contaminants are removed.
-
-
Post-Cleaning:
-
Turn off the plasma source and the cleaning gas flow.
-
Pump the system back down to its base pressure to remove all byproducts.
-
A short, pure Argon plasma may be run afterwards to remove any oxides formed on metallic surfaces during the cleaning process.
-
References
- 1. Vacuum - Wikipedia [en.wikipedia.org]
- 2. Kistler [kistler.com]
- 3. vaccoat.com [vaccoat.com]
- 4. safety.als.lbl.gov [safety.als.lbl.gov]
- 5. Vacuum bake out: its importance and implementation - Leybold USA [leybold.com]
- 6. vaccoat.com [vaccoat.com]
- 7. glowresearch.org [glowresearch.org]
- 8. ncsx.pppl.gov [ncsx.pppl.gov]
Overcoming Limitations in Positional Mapping with MAGMA: A Technical Support Center
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals using MAGMA for gene mapping. It specifically addresses common issues and limitations related to positional gene mapping and offers solutions and alternative approaches.
Frequently Asked Questions (FAQs)
General
Q1: What is MAGMA and what is its primary application?
A1: MAGMA (Multi-marker Analysis of GenoMic Annotation) is a command-line tool used for gene and gene-set analysis of Genome-Wide Association Study (GWAS) data.[1][2][3] Its primary application is to aggregate single-nucleotide polymorphism (SNP) association signals at the gene level and then to test for associations of gene sets (e.g., biological pathways) with a particular trait or disease.[1][2][3]
Q2: What are the core steps in a standard MAGMA analysis?
A2: A standard MAGMA analysis consists of three main steps:
-
Annotation: Mapping SNPs to genes based on their genomic coordinates.[1][2]
-
Gene Analysis: Calculating a single gene-level association statistic (p-value) from the SNP p-values within that gene, while accounting for linkage disequilibrium (LD).[1][4][5]
-
Gene-Set Analysis: Testing whether genes in a predefined set (e.g., a biological pathway) are more strongly associated with the phenotype than other genes.[1][4][5]
Positional Mapping
Q3: What is positional mapping in MAGMA and what are its main limitations?
A3: Positional mapping in MAGMA assigns SNPs to genes based on their physical proximity in the genome, typically by defining a window around the gene's transcription start and end sites.[3][6] While straightforward, this approach has limitations:
-
Ignores long-range regulation: It often fails to capture the effects of distal regulatory elements, such as enhancers, which can be located far from the gene they regulate.
-
Nearest gene is not always the target: The closest gene to a trait-associated SNP is not always the functionally relevant one.
-
Limited biological insight: It does not incorporate information about the functional consequences of genetic variants, such as their effect on gene expression.
Troubleshooting Guide
Annotation Step
Q1: I'm getting an error during the annotation step. What are the common causes?
A1: Errors during annotation often stem from issues with your input files. Here are some common problems and solutions:
| Problem | Possible Cause | Solution |
| "No such file or directory" | The path to your SNP location file or gene location file is incorrect. | Double-check the file paths and ensure the files are in the specified directory. |
| Mismatched genome builds | Your SNP location file and gene location file are based on different genome builds (e.g., hg19 vs. hg38).[6] | Ensure both files use the same genome build. You can download pre-formatted gene location files for common builds from the MAGMA website. |
| Incorrect file format | The SNP or gene location files are not in the format expected by MAGMA. | The SNP location file should have at least three columns: SNP ID, chromosome, and base-pair position. The gene location file requires at least four columns: Gene ID, chromosome, start position, and stop position.[6] |
Gene Analysis Step
Q2: My gene analysis is failing with an error about the p-value file. What should I check?
A2: Errors related to the p-value file (--pval) are common. Here’s what to look for:
| Problem | Possible Cause | Solution |
| "No valid p-values found for any SNPs in the data" | SNP IDs in your p-value file do not match the SNP IDs in your reference panel. This can be due to different naming conventions (e.g., rsID vs. chr:bp). | Ensure that the SNP identifiers are consistent between your p-value file and the LD reference panel. Use a consistent naming scheme. |
| Incorrect file format | The p-value file is not a plain text file or the columns are not correctly specified. | The file should be a simple text file with columns for SNP ID and p-value. If your column names are different from the default ('SNP' and 'P'), you must specify them using the snp-id and pval modifiers with the --pval flag. |
| Missing sample size information | You have not provided the sample size (N) for your GWAS summary statistics. | Specify the sample size using N= with the --pval flag. If the sample size varies per SNP, you can provide a column in your p-value file and specify it with ncol=. |
Q3: I am seeing a warning that a large number of SNPs are being excluded from the analysis. Why is this happening?
A3: This warning usually indicates a mismatch between your GWAS summary statistics and the LD reference panel.
| Problem | Possible Cause | Solution |
| Different SNP sets | Many SNPs in your GWAS data are not present in the reference panel. | Use a reference panel that is appropriate for the population of your GWAS and has good SNP coverage. The 1000 Genomes Project panels are commonly used. |
| Allele frequency differences | SNPs with very low minor allele frequency (MAF) in the reference panel might be excluded. | MAGMA has options to filter on MAF. Check the log file for details on filtering thresholds. |
| Inconsistent SNP identifiers | As mentioned above, differing SNP ID formats (e.g., with/without 'rs' prefix) can cause SNPs to be dropped. | Harmonize the SNP identifiers across all your input files. |
Overcoming Positional Mapping Limitations: Alternative Approaches
The primary limitation of positional mapping is its reliance on genomic proximity. More advanced methods that incorporate functional genomic data can provide a more biologically informed assignment of SNPs to genes.
eQTL-based Mapping (e-MAGMA)
Expression Quantitative Trait Loci (eQTLs) are genomic loci where variation is associated with gene expression levels. e-MAGMA is an extension of MAGMA that uses eQTL information to link SNPs to genes they are known to regulate, regardless of their physical distance.[7][8]
Advantages:
-
Provides a functional link between a SNP and a gene.
-
Can identify target genes that are far from the associated SNP.
-
Tissue-specific eQTL data can be used to investigate tissue-specific gene associations.
Chromatin Interaction-based Mapping (H-MAGMA)
H-MAGMA (Hi-C-coupled MAGMA) leverages chromatin conformation data (from techniques like Hi-C) to assign SNPs to genes. Hi-C identifies long-range physical interactions between different genomic regions, such as enhancers and promoters.
Advantages:
-
Captures long-range regulatory interactions that are missed by positional mapping.
-
Provides insight into the 3D organization of the genome and its role in gene regulation.
-
Can be particularly powerful for studying complex diseases with a strong regulatory component.
Quantitative Comparison of Mapping Strategies
The choice of mapping strategy can significantly impact the number of identified risk genes. The following table summarizes findings from studies that compared different mapping approaches for complex diseases.
| Disease | Positional Mapping (MAGMA) - Significant Genes | eQTL/Chromatin Interaction Mapping (e-MAGMA/H-MAGMA) - Significant Genes | Reference |
| Schizophrenia | ~150 | 254 (e-MAGMA) | [7] |
| Alzheimer's Disease | 31 (Discovery cohort), 7 (Extension cohort) | H-MAGMA identified a larger number of risk genes compared to positional mapping. | [9][10] |
| Major Depressive Disorder | Not specified | 119 (e-MAGMA) | [7] |
| Bipolar Disorder | Not specified | 32 (e-MAGMA) | [7] |
Experimental Protocols
Protocol 1: Standard MAGMA Gene-Based Analysis (Positional Mapping)
This protocol outlines the steps for a standard gene-based analysis using positional mapping.
1. Prepare Input Files:
- GWAS Summary Statistics: A text file containing SNP IDs, p-values, and sample size.
- SNP Location File: A file with SNP IDs, chromosome, and base-pair positions.
- Gene Location File: A file with gene IDs, chromosome, and start and end positions.
2. Annotation Step:
- Use the magma --annotate command to map SNPs to genes.
- Specify the SNP and gene location files using --snp-loc and --gene-loc.
- Define a window around genes to include nearby SNPs using --annotate window=
, (e.g., window=35,10 for 35kb upstream and 10kb downstream).[11] - Example Command: bash magma --annotate window=35,10 --snp-loc my_snps.loc --gene-loc NCBI37.3.gene.loc --out my_analysis
3. Gene Analysis Step:
- Use the magma --bfile ... --pval ... --gene-annot command to perform the gene analysis.
- --bfile: Specify the LD reference panel (e.g., g1000_eur).
- --pval: Provide your GWAS summary statistics file and sample size (e.g., my_gwas.txt N=10000).
- --gene-annot: Use the output file from the annotation step (my_analysis.genes.annot).
- Example Command: bash magma --bfile g1000_eur --pval my_gwas.txt N=10000 --gene-annot my_analysis.genes.annot --out my_gene_analysis
Protocol 2: eQTL-based Gene Analysis (e-MAGMA)
This protocol describes how to perform a gene-based analysis using eQTL mapping.
1. Prepare eQTL-based Annotation File:
- Instead of creating an annotation file based on genomic location, you will use a pre-computed annotation file where SNPs are mapped to genes based on significant eQTL associations for a specific tissue. These files can often be obtained from resources like the e-MAGMA tutorial GitHub repository.
2. Gene Analysis Step:
- The command is similar to the standard gene analysis, but you will provide the eQTL-based annotation file.
- Example Command (using a hypothetical brain eQTL annotation): bash magma --bfile g1000_eur --pval my_gwas.txt N=10000 --gene-annot brain_eqtl.genes.annot --out my_emagma_analysis
Visualizations
Logical Workflow for MAGMA Analysis
Caption: Standard MAGMA workflow from input data to gene-set results.
Conceptual Comparison of Mapping Strategies
Caption: Comparison of SNP-to-gene mapping strategies in MAGMA.
Example Signaling Pathway for Gene-Set Analysis (TGF-β Pathway)
Caption: Simplified TGF-β signaling pathway for gene-set analysis.
References
- 1. Gene Set Analysis with MAGMA - OmicsBox User Manual [docs.omicsbox.biobam.com]
- 2. rna-seqblog.com [rna-seqblog.com]
- 3. genomeanalysis / MAGMA analysis · GitLab [gitlab.lcsb.uni.lu]
- 4. MAGMA: Generalized Gene-Set Analysis of GWAS Data | PLOS Computational Biology [journals.plos.org]
- 5. MAGMA: Generalized Gene-Set Analysis of GWAS Data - PMC [pmc.ncbi.nlm.nih.gov]
- 6. ibg.colorado.edu [ibg.colorado.edu]
- 7. E-MAGMA: an eQTL-informed method to identify risk genes using genome-wide association study summary statistics - PMC [pmc.ncbi.nlm.nih.gov]
- 8. biorxiv.org [biorxiv.org]
- 9. A computational tool (H-MAGMA) for improved prediction of brain disorder risk genes by incorporating brain chromatin interaction profiles - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Identification of risk genes for Alzheimer’s disease by gene embedding - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Gene/Gene-set tests by MAGMA - GWASTutorial [cloufield.github.io]
A Head-to-Head Comparison of Gene-Set Analysis Tools: MAGMA vs. VEGAS vs. PLINK
In the landscape of post-GWAS analysis, gene-set analysis has emerged as a powerful approach to elucidate the collective effect of genetic variants on biological pathways. For researchers, scientists, and drug development professionals navigating this complex field, selecting the right tool is paramount. This guide provides an objective, data-driven comparison of three widely used gene-set analysis tools: MAGMA, VEGAS, and PLINK, focusing on their performance, methodologies, and practical application.
Core Methodologies: A Glimpse Under the Hood
At the heart of each tool lies a distinct statistical approach to aggregating SNP-level data to the gene and gene-set level. These differences can significantly impact the power to detect associations and the overall interpretation of results.
MAGMA (Multi-marker Analysis of GenoMic Annotation) distinguishes itself by employing a multiple linear regression model. This approach allows for the simultaneous analysis of all SNPs within a gene, accounting for linkage disequilibrium (LD) between them. By modeling the additive effects of SNPs, MAGMA aims to capture a greater proportion of the genetic signal within a gene.[1]
VEGAS (Versatile Gene-based Association Study) and PLINK, on the other hand, primarily utilize SNP-wise models. These methods first calculate a test statistic for each individual SNP within a gene (e.g., from single-marker association p-values) and then combine these statistics to generate a single gene-level p-value. While computationally efficient, this approach may not fully capture the joint effect of multiple SNPs in high LD.
| Feature | MAGMA (Multiple Regression) | VEGAS (SNP-wise) | PLINK (SNP-wise) |
| Core Model | Multiple linear regression of SNP effects on phenotype | Combines single-SNP p-values within a gene | Combines single-SNP test statistics within a gene |
| LD Handling | Explicitly modeled within the regression framework | Accounts for LD through simulations from a multivariate normal distribution or using a reference panel | Can account for LD through permutation or pruning |
| Input Data | Raw genotype data or summary statistics | Summary statistics (SNP p-values) | Raw genotype data |
| Analysis Types | Self-contained and competitive gene-set analysis | Gene-based association tests | Gene-set analysis (set-based tests) |
Performance Showdown: Evidence from Experimental Data
To provide a tangible comparison of these tools, we turn to a real-world application: a gene-set analysis of Crohn's Disease (CD) GWAS data, as presented in the original MAGMA publication. This analysis provides valuable insights into the relative power and computational efficiency of each tool.
Identification of Significant Genes and Gene Sets
In the analysis of the Crohn's Disease dataset, MAGMA demonstrated greater statistical power in identifying both individual genes and gene sets associated with the disease compared to VEGAS and PLINK.
Table 1: Number of Significant Genes Identified in Crohn's Disease Data
| Tool | Number of Significant Genes (Bonferroni corrected) |
| MAGMA (main) | 46 |
| VEGAS | 29 |
| PLINK (avg) | 25 |
| PLINK (top) | 30 |
Table 2: Number of Significant Gene Sets Identified in Crohn's Disease Data
| Tool | Number of Significant Gene Sets (FDR < 0.05) |
| MAGMA (main) | 13 |
| PLINK (prune) | 5 |
| PLINK (avg) | 3 |
Computational Efficiency
A key consideration in the era of large-scale genomic data is the computational time required to perform analyses. The MAGMA paper reports a significant advantage in speed over both VEGAS and PLINK.
Table 3: Computational Time for Gene and Gene-Set Analysis of Crohn's Disease Data
| Analysis | Tool | Computation Time (hh:mm:ss) |
| Gene Analysis | MAGMA (main) | 00:00:44 |
| VEGAS | 01:12:00 | |
| PLINK (avg) | 00:01:20 | |
| Gene-Set Analysis | MAGMA (main) | 00:00:02 |
| PLINK (avg) | 00:05:00 |
Note: The VEGAS gene-set analysis time is not directly reported in the same table but is noted to be substantially longer due to its reliance on permutations.
Statistical Rigor: Type I Error and Power
A crucial aspect of any statistical tool is its ability to control for false positives (Type I error) while maximizing the detection of true associations (statistical power).
Type I Error Rate
Simulations conducted as part of the MAGMA validation showed that it maintains a correct Type I error rate under various null models.[2]
Table 4: Mean Type I Error Rates for MAGMA Gene-Set Analysis
| Null Model | Gene-Set Type | Self-contained | Competitive |
| Global Null | MSigDB | 0.051 | 0.052 |
| Simulated (Size=10) | 0.050 | 0.051 | |
| Simulated (Size=100) | 0.051 | 0.053 | |
| Polygenic Null | MSigDB | 0.088 | 0.051 |
| Simulated (Size=10) | 0.073 | 0.051 | |
| Simulated (Size=100) | 0.131 | 0.052 |
Statistical Power
The multiple regression model employed by MAGMA is designed to have greater power to detect multi-marker effects compared to SNP-wise models. The results from the Crohn's Disease analysis support this, with MAGMA identifying a larger number of significant associations.[1]
Experimental Protocols: A Practical Workflow
To illustrate the practical application of these tools, we outline a generalized workflow for gene-set analysis of GWAS summary statistics.
Step 1: Data Preparation
-
GWAS Summary Statistics: A file containing SNP identifiers (e.g., rsIDs), p-values, and sample size for each SNP.
-
Gene and Gene-Set Definitions: Files defining the genomic coordinates of genes and the grouping of genes into sets (e.g., from KEGG or Gene Ontology).
-
Reference Panel (for MAGMA and VEGAS with summary statistics): A reference panel of genotypes (e.g., from 1000 Genomes) to estimate LD.
Step 2: Gene-Level Analysis
This step aggregates SNP-level data to derive a gene-level statistic.
-
MAGMA:
-
VEGAS: VEGAS is often run through a web interface or a command-line script that requires specific formatting of input files.
-
PLINK: PLINK's primary gene-set analysis functionality is through its set-based tests on raw genotype data.
Step 3: Gene-Set Analysis
This final step tests for the enrichment of association signals within predefined gene sets.
-
MAGMA:
Visualizing Biological Context: The TGF-beta Signaling Pathway
Gene-set analysis provides a bridge from statistical association to biological insight. Visualizing the implicated pathways is a critical step in interpreting the results. Below is a simplified representation of the KEGG TGF-beta signaling pathway, a crucial pathway in cellular processes, which could be identified as significant in a gene-set analysis.
Caption: Simplified TGF-beta signaling pathway.
Conclusion: Choosing the Right Tool for the Job
The choice between MAGMA, VEGAS, and PLINK will depend on the specific research question, available data, and computational resources.
-
MAGMA stands out for its statistical power, particularly in detecting multi-marker effects, and its computational efficiency. Its ability to work with both raw genotype data and summary statistics adds to its versatility. The robust control over Type I error makes it a reliable choice for rigorous statistical analysis.
-
VEGAS offers a user-friendly approach for researchers who primarily work with summary statistics and require a tool that accounts for LD through simulation.
-
PLINK remains a cornerstone for general GWAS quality control and basic association testing. Its gene-set analysis capabilities are most straightforwardly applied to raw genotype data and can be a good option for initial exploratory analyses.
For researchers seeking a powerful, fast, and statistically robust tool for in-depth gene-set analysis of GWAS data, MAGMA presents a compelling case. However, the specific context of the study and the nature of the available data should always guide the final decision.
References
Comparative anatomy of the magnum across different avian species.
The magnum is the longest and most glandular section of the avian oviduct, responsible for the synthesis and secretion of the majority of the egg white, or albumen. Its anatomical and histological characteristics, as well as the composition of the albumen it produces, exhibit significant variation across different avian species. This guide provides a comparative overview of the magnum's anatomy, details experimental protocols for its study, and explores the molecular pathways governing its function, offering valuable insights for researchers, scientists, and drug development professionals.
Gross and Histological Anatomy: A Species-Specific Perspective
The magnum's size and structure are intrinsically linked to the egg characteristics of a given species. Gross morphometric analysis reveals considerable diversity in magnum length and weight among different birds. Histologically, the magnum is characterized by a highly folded mucosa lined with ciliated and non-ciliated columnar epithelial cells, and a lamina propria packed with tubular glands that synthesize and secrete albumen proteins.
Table 1: Comparative Morphometrics of the Magnum in Different Avian Species
| Species | Magnum Length (cm) | Magnum Wall Thickness (µm) | Mucosal Fold Height (µm) | Glandular Density | Source(s) |
| Chicken | |||||
| White Leghorn (24 weeks) | 34.38 ± 1.07 | - | 27.38 ± 4.74 | Dense and large | [1][2] |
| Kadaknath (32 weeks) | 23.70 ± 0.94 | - | - | - | [3] |
| Kadaknath (48 weeks) | - | 685.67 ± 1.71 | 17.56 ± 0.45 | More glandular activity than White Leghorn | [1] |
| Uttara Fowl | 29.16 ± 0.66 | - | - | - | [4] |
| Boschveld Chicken | Longest oviduct segment | - | - | - | [5] |
| Duck | 45-50 | - | Long | Dense and large | [6] |
| Goose | - | - | Short | Few | [6] |
| Turkey | - | Thick | Short | Dense and large | [6] |
| Pigeon (Columba domestica) | 4.18 ± 0.09 (resting stage) | - | 2.44 ± 496 (primary folds, resting stage) | - | [7] |
| Japanese Quail (Coturnix coturnix japonica) | - | - | 378.23 ± 21.3 (primary folds) | - | [8] |
Note: Data is presented as mean ± standard deviation where available. "-" indicates data not found in the cited sources.
Histological comparisons reveal that chickens and ducks have long mucosal folds in the magnum, while turkeys and geese have shorter folds[6]. The density of the albumen-secreting tubular glands also varies, being dense and large in chickens, ducks, and turkeys, but sparse in geese[6].
Albumen Protein Composition: A Reflection of Functional Diversity
The albumen is a complex mixture of proteins, with ovalbumin being the most abundant, followed by ovotransferrin, ovomucoid, lysozyme, and others. The concentration of these proteins varies among species, likely reflecting different reproductive strategies and environmental pressures.
Table 2: Albumen Protein Concentration in Eggs of Different Avian Species
| Species | Total Albumen Protein (mg/mL) | Ovalbumin (% of total albumen protein) | Ovotransferrin (% of total albumen protein) | Source(s) |
| Quail | 2.99 ± 0.20 | - | - | [6] |
| Broiler Chicken | 2.97 ± 0.22 | ~54% | ~12-13% | [6][9][10] |
| Duck | 2.83 ± 0.22 | - | - | [6] |
| "Gavran" | 2.04 ± 0.08 | - | - | [6] |
Note: "Gavran" is not a recognized avian species and may refer to a local or specific strain of domestic chicken. Ovalbumin and ovotransferrin percentages are general estimates for chicken eggs.
Experimental Protocols
Histological Analysis of the Magnum
Objective: To visualize the morphology of the magnum, including the mucosal folds, epithelium, and tubular glands.
Protocol: Hematoxylin (B73222) and Eosin (B541160) (H&E) Staining [11][12][13][14][15]
-
Tissue Fixation: Immediately after dissection, fix magnum tissue samples in 10% neutral buffered formalin for 24-48 hours.
-
Dehydration: Dehydrate the fixed tissues through a graded series of ethanol (B145695) solutions (e.g., 70%, 80%, 95%, and 100% ethanol), typically for 1-2 hours at each concentration.
-
Clearing: Clear the dehydrated tissues in two changes of xylene for 1-2 hours each.
-
Infiltration and Embedding: Infiltrate the cleared tissues with molten paraffin (B1166041) wax in an oven at 58-60°C for 2-4 hours, followed by embedding in paraffin blocks.
-
Sectioning: Cut 4-5 µm thick sections from the paraffin blocks using a rotary microtome.
-
Deparaffinization and Rehydration: Deparaffinize the sections in xylene and rehydrate through a descending series of ethanol concentrations to water.
-
Hematoxylin Staining: Stain the nuclei by immersing the slides in Harris's hematoxylin solution for 3-5 minutes.
-
Differentiation: Briefly dip the slides in 1% acid alcohol to remove excess stain.
-
Bluing: "Blue" the nuclei by washing in running tap water or immersing in a bluing agent like Scott's tap water substitute.
-
Eosin Staining: Counterstain the cytoplasm and connective tissue by immersing the slides in eosin Y solution for 1-3 minutes.
-
Dehydration and Clearing: Dehydrate the stained sections through an ascending series of ethanol concentrations and clear in xylene.
-
Mounting: Mount the sections with a permanent mounting medium and a coverslip.
Analysis of Albumen Protein Composition
Objective: To separate and quantify the major proteins in avian egg albumen.
Protocol: Sodium Dodecyl Sulfate-Polyacrylamide Gel Electrophoresis (SDS-PAGE) [16][17][18][19]
-
Sample Preparation:
-
Separate the egg white (albumen) from the yolk.
-
Dilute the albumen 1:10 (v/v) with a sample buffer (containing SDS, glycerol, a tracking dye like bromophenol blue, and a reducing agent like β-mercaptoethanol or dithiothreitol).
-
Heat the diluted samples at 95-100°C for 5 minutes to denature the proteins.
-
-
Gel Preparation:
-
Cast a polyacrylamide gel with a lower separating gel (10-12% acrylamide (B121943) is suitable for resolving major albumen proteins) and an upper stacking gel (4-5% acrylamide).
-
-
Electrophoresis:
-
Load the prepared protein samples and a molecular weight marker into the wells of the stacking gel.
-
Run the gel in an electrophoresis chamber filled with running buffer at a constant voltage (e.g., 100-150V) until the tracking dye reaches the bottom of the gel.
-
-
Staining and Destaining:
-
Stain the gel with Coomassie Brilliant Blue R-250 solution for at least 1 hour to visualize the protein bands.
-
Destain the gel in a solution of methanol (B129727) and acetic acid until the background is clear and the protein bands are distinct.
-
-
Quantification:
-
Densitometric analysis of the stained gel can be performed using imaging software to quantify the relative abundance of each protein band.
-
Signaling Pathways and Experimental Workflows
The development and function of the magnum are primarily regulated by steroid hormones, particularly estrogen. The following diagrams illustrate a simplified estrogen signaling pathway and a general workflow for the comparative analysis of the avian magnum.
Simplified estrogen signaling pathway in the avian magnum.
Experimental workflow for comparative analysis of the avian magnum.
References
- 1. animalmedicalresearch.org [animalmedicalresearch.org]
- 2. researchgate.net [researchgate.net]
- 3. entomoljournal.com [entomoljournal.com]
- 4. tandfonline.com [tandfonline.com]
- 5. ndpublisher.in [ndpublisher.in]
- 6. ijsr.net [ijsr.net]
- 7. [PDF] Comparative histomorphometrical study of genital tract in adult laying hen and duck | Semantic Scholar [semanticscholar.org]
- 8. Histomorphometrical and ultrastructural study of the effects of carbendazim on the magnum of the Japanese quail ( Coturnix coturnix japonica ) | Kimaro | Onderstepoort Journal of Veterinary Research [ojvr.org]
- 9. Importance of albumen during embryonic development in avian species, with emphasis on domestic chicken | World's Poultry Science Journal | Cambridge Core [cambridge.org]
- 10. Natural Products of Plants and Animal Origin Improve Albumen Quality of Chicken Eggs - PMC [pmc.ncbi.nlm.nih.gov]
- 11. H&E Staining Method and Protocol - Harris - IHC WORLD [ihcworld.com]
- 12. Hematoxylin and Eosin (H&E) Staining Protocol - IHC WORLD [ihcworld.com]
- 13. a.storyblok.com [a.storyblok.com]
- 14. researchgate.net [researchgate.net]
- 15. researchgate.net [researchgate.net]
- 16. curresweb.com [curresweb.com]
- 17. Determination of yolk:white ratio of egg using SDS-PAGE - PMC [pmc.ncbi.nlm.nih.gov]
- 18. researchgate.net [researchgate.net]
- 19. researchgate.net [researchgate.net]
Validating MAGMA's Genetic Insights: A Guide to Functional Genomic Cross-Validation
A comparative guide for researchers on integrating functional genomics to validate and interpret findings from MAGMA gene-set analyses.
In the quest to unravel the genetic underpinnings of complex traits and diseases, Multi-marker Analysis of GenoMic Annotation (MAGMA) has emerged as a powerful tool for aggregating single-nucleotide polymorphism (SNP) data from genome-wide association studies (GWAS) into gene-level and gene-set associations.[1][2] However, the statistical associations identified by MAGMA require further biological validation to pinpoint causal genes and mechanisms. This guide provides a comparative overview of methodologies for cross-validating MAGMA results using functional genomics data, offering detailed protocols and performance comparisons to enhance the interpretability and biological relevance of your findings.
The Imperative of Functional Validation
The majority of genetic variants identified through GWAS are located in non-coding regions of the genome, making their functional interpretation a significant challenge.[3] These variants are often presumed to exert their effects by regulating gene expression. Therefore, integrating functional genomics data, which provides insights into gene regulation and function, is a critical step in moving from statistical association to biological mechanism. This guide focuses on three advanced approaches to either enhance standard MAGMA or to provide orthogonal validation of its results: eQTL-informed MAGMA (E-MAGMA), Chromatin Interaction-based MAGMA (H-MAGMA), and eQTL Colocalization analysis.
Comparative Overview of Validation Methodologies
The choice of a cross-validation strategy depends on the available data and the specific research question. While standard MAGMA relies on the genomic proximity of SNPs to genes, E-MAGMA and H-MAGMA incorporate functional data to make more biologically informed SNP-to-gene assignments.[4][5] eQTL colocalization, on the other hand, provides a statistical framework to assess whether a GWAS signal and a gene expression signal are driven by the same underlying causal variant.[6]
| Method | Principle | Functional Data Utilized | Key Advantage | Limitations |
| Standard MAGMA | Aggregates SNP p-values to genes based on physical proximity.[7][8] | None (relies on genomic coordinates) | Simple to implement; widely used baseline. | May misassign regulatory variants to the nearest gene, ignoring long-range interactions. |
| E-MAGMA | Assigns SNPs to genes based on significant SNP-gene expression associations (eQTLs) in specific tissues.[4][9] | Tissue-specific eQTL data (e.g., from GTEx) | Provides a functional link between a variant and gene expression in a disease-relevant tissue. | Limited by the availability and power of eQTL datasets for specific tissues and cell types. |
| H-MAGMA | Incorporates 3D chromatin interaction data (e.g., Hi-C) to link distal regulatory variants to their target genes.[3][5][10] | Chromatin conformation data (Hi-C) | Can identify long-range regulatory relationships missed by proximity-based methods. | Requires high-quality chromatin interaction data for the relevant cell type, which can be challenging to obtain. |
| eQTL Colocalization (e.g., with coloc) | Statistically tests whether a GWAS signal and an eQTL signal in the same genomic region share the same causal variant.[6][11] | GWAS summary statistics and eQTL summary statistics | Provides strong evidence for a causal relationship between a variant, gene expression, and the trait of interest. | Can be confounded by multiple independent causal variants in the same region (allelic heterogeneity). |
Performance Comparison in Gene Discovery
Integrating functional genomics data can significantly enhance the power to identify disease-relevant genes. The following table summarizes a comparison of the number of significant genes identified for Major Depressive Disorder (MDD) using different eQTL-informed methods.
| Method | Number of Significant Genes Identified for MDD |
| E-MAGMA | 158 |
| S-PrediXcan | 43 |
| FUSION | 24 |
| SMR | 18 |
Data synthesized from Gerring et al., 2019. This table illustrates that E-MAGMA can identify a substantially larger number of putative candidate genes compared to other eQTL-based methods.[8][9]
Experimental Protocols
Here, we provide detailed methodologies for implementing these cross-validation strategies.
Protocol 1: E-MAGMA - eQTL-informed Gene-Based Analysis
This protocol outlines the steps to perform an E-MAGMA analysis, which integrates tissue-specific eQTL data to inform SNP-to-gene mapping.
1. Data Preparation:
- GWAS Summary Statistics: A file containing SNP identifiers (rsIDs), p-values, and sample size.
- eQTL Annotation File: A pre-computed file that assigns SNPs to genes based on significant eQTLs in a specific tissue. These files for various tissues (e.g., from GTEx) are often provided with the E-MAGMA tutorial resources.[12]
- Reference Panel: A reference panel for linkage disequilibrium (LD) calculations, such as the 1000 Genomes Project data.
2. SNP Annotation:
- Use the magma --annotate command, providing the eQTL annotation file. This step maps the SNPs from your GWAS summary statistics to their target genes based on the eQTL data.
3. Gene-Based Analysis:
- Run MAGMA's gene-based analysis using the magma --bfile ... --pval ... --gene-annot ... --out ... command. This will calculate gene-level p-values based on the eQTL-informed SNP-to-gene mapping.
4. Gene-Set Analysis (Optional):
- The resulting gene-level p-values can be used for downstream gene-set and pathway analyses to identify biological processes enriched for association with the trait.[13]
Protocol 2: H-MAGMA - Chromatin Interaction-based Analysis
This protocol describes how to leverage 3D chromatin interaction data to link non-coding variants to their target genes.
1. Data Preparation:
- GWAS Summary Statistics: As in the E-MAGMA protocol.
- Hi-C Data: Chromatin interaction data in BEDPE format for a disease-relevant cell type.
- Gene Location File: A file with the genomic coordinates of genes.
- SNP Location File: A file with the genomic coordinates of SNPs.
2. Generate H-MAGMA Annotation File:
- This is the key step in H-MAGMA and involves overlapping the Hi-C interaction data with gene promoters and SNP locations to create a custom annotation file where SNPs are linked to genes they physically interact with. A detailed protocol and scripts for this step are provided by the developers of H-MAGMA.[9][14]
3. Run H-MAGMA:
- The procedure is similar to a standard MAGMA analysis but uses the custom-generated H-MAGMA annotation file. The command will be magma --bfile ... --pval ... --gene-annot H-MAGMA_annotation.annot --out ....[9]
Protocol 3: eQTL Colocalization Analysis with coloc
This protocol provides a step-by-step guide to performing a colocalization analysis to test if a GWAS hit and an eQTL share a common causal variant.
1. Data Preparation:
- GWAS Summary Statistics: For the genomic region of interest, you will need SNP rsIDs, p-values, effect allele frequency, and sample size.
- eQTL Summary Statistics: For the same genomic region and for a specific gene, you will need the same information as for the GWAS data.
2. Analysis in R using the coloc package:
- Load Data: Read the GWAS and eQTL summary statistics into R data frames.[6]
- Format Data: Create two lists, one for the GWAS data and one for the eQTL data, containing the required information (p-values, sample size, type of study - "cc" for case-control or "quant" for quantitative).
- Run Colocalization: Use the coloc.abf() function from the coloc package. This function calculates the posterior probabilities for five hypotheses (no association, association with trait 1 only, association with trait 2 only, two distinct causal variants, and a shared causal variant).[6]
3. Interpretation:
- The primary output of interest is the posterior probability for hypothesis 4 (H4), which represents the probability that the GWAS and eQTL signals are driven by a single shared causal variant. A high posterior probability for H4 (e.g., > 0.8) provides strong evidence for colocalization.
Visualizing Workflows and Biological Pathways
To further clarify these methodologies and their biological interpretations, the following diagrams illustrate the cross-validation workflow, a comparison of the different MAGMA-based approaches, and a hypothetical signaling pathway implicated by a MAGMA analysis.
Caption: Workflow for MAGMA cross-validation.
Caption: Comparison of SNP-to-gene mapping methods.
Caption: Dopamine signaling and MAGMA-implicated genes.
Conclusion
Cross-validating MAGMA results with functional genomics data is an essential step in translating genetic associations into biological insights. By employing methods such as E-MAGMA, H-MAGMA, and eQTL colocalization, researchers can build a stronger, more biologically plausible case for the involvement of specific genes and pathways in complex traits and diseases. This integrated approach not only enhances the confidence in MAGMA's findings but also provides a clearer path for downstream experimental validation and potential therapeutic targeting. The FUMA web platform is a valuable resource that integrates many of these functionalities, providing a user-friendly interface for MAGMA analysis and functional annotation.[12][15] As functional genomics datasets continue to grow in scale and resolution, the synergy between statistical genetics and functional genomics will be paramount in deciphering the complex genotype-phenotype map.
References
- 1. youtube.com [youtube.com]
- 2. MAGMA: Generalized Gene-Set Analysis of GWAS Data | PLOS Computational Biology [journals.plos.org]
- 3. A computational tool (H-MAGMA) for improved prediction of brain disorder risk genes by incorporating brain chromatin interaction profiles - PMC [pmc.ncbi.nlm.nih.gov]
- 4. magma.maths.usyd.edu.au [magma.maths.usyd.edu.au]
- 5. medium.com [medium.com]
- 6. GWAS-eQTL Colocalization Analysis Workflow | GWAS-eQTL-Colocalization [hanruizhang.github.io]
- 7. eMAGMA-tutorial/emagma_Amygdala_script at gtex_v8 · eskederks/eMAGMA-tutorial · GitHub [github.com]
- 8. ibg.colorado.edu [ibg.colorado.edu]
- 9. GitHub - thewonlab/H-MAGMA [github.com]
- 10. Software, Resources & GWAS Sumstats - CNCR [cncr.nl]
- 11. academic.oup.com [academic.oup.com]
- 12. GitHub - eskederks/eMAGMA-tutorial: A step by step guide on how to use eMAGMA, an approach to conducting eQTL informed gene-based tests. [github.com]
- 13. eMAGMA-tutorial/eMAGMA Tutorial PART_2.md at gtex_v8 · eskederks/eMAGMA-tutorial · GitHub [github.com]
- 14. cdr.lib.unc.edu [cdr.lib.unc.edu]
- 15. Functional Mapping and Annotation of Genome-wide association studies [fuma.ctglab.nl]
Benchmarking the performance of Magnum-PSI with other plasma generators.
For researchers, scientists, and drug development professionals navigating the complex landscape of plasma-material interaction, the choice of a plasma generator is paramount. This guide provides a comprehensive performance benchmark of the Magnum-PSI linear plasma generator against other leading alternatives, supported by experimental data and detailed methodologies.
Magnum-PSI (MAgnetized plasma Generator and NUMerical modeling for Plasma Surface Interactions) stands as a unique facility capable of producing plasma conditions relevant to the demanding environment of the ITER divertor.[1][2] This guide will delve into a quantitative comparison of Magnum-PSI with its forerunner, Pilot-PSI, and other significant linear plasma devices such as PSI-2, JULE-PSI, Proto-PISCES, and NAGDIS-II.
Performance Benchmark: A Quantitative Comparison
The performance of a plasma generator is primarily characterized by its ability to generate high-density, high-temperature plasmas, delivering high particle and heat fluxes to a target material. The following table summarizes the key performance parameters of Magnum-PSI and its counterparts.
| Parameter | Magnum-PSI | Pilot-PSI | PSI-2 | JULE-PSI | Proto-PISCES | NAGDIS-II |
| Electron Density (n_e) | 10¹⁹ - 10²¹ m⁻³[1] | ~ (0.1 - 10) x 10²⁰ m⁻³ | 10¹⁷ - 10¹⁹ m⁻³ | Modeled on PSI-2 | ~ 5 x 10¹⁸ m⁻³ | 10¹⁸ - 10¹⁹ m⁻³ |
| Electron Temperature (T_e) | 0.1 - 10 eV[1] | 1 - 5 eV | 3 - 20 eV | Modeled on PSI-2 | 5 - 20 eV | 1 - 10 eV |
| Particle Flux (Γ_p) | 10²³ - 10²⁵ m⁻²s⁻¹[1] | ~ 10²³ - 10²⁴ m⁻²s⁻¹ | 10²¹ - 10²³ m⁻²s⁻¹ | Modeled on PSI-2 | ~ 10²¹ m⁻²s⁻¹ | ~ 10²² m⁻²s⁻¹ |
| Heat Flux (q_h) | > 10 MW/m²[1] | Up to ~4 MW/m² | - | Modeled on PSI-2 | ~ 1 MW/m² | - |
| Magnetic Field (B) | Up to 2.5 T[1] | Up to 1.6 T[3] | ~ 0.1 T | Modeled on PSI-2 | ~ 0.2 T | ~ 0.1 T |
Experimental Protocols: Methodologies for Key Measurements
The data presented in this guide is primarily derived from two key diagnostic techniques: Thomson Scattering and Langmuir Probes. These methods are fundamental to characterizing the plasma conditions in linear devices.
Thomson Scattering
Thomson scattering is a non-invasive diagnostic technique used to measure electron temperature and density with high spatial and temporal resolution. The fundamental principle involves scattering a high-power laser beam off the electrons in the plasma. The scattered light is Doppler-shifted due to the thermal motion of the electrons. By analyzing the spectral broadening of the scattered light, the electron temperature can be determined. The total intensity of the scattered light is proportional to the electron density.
Experimental Procedure:
-
A high-energy pulsed laser (e.g., Nd:YAG) is directed into the plasma volume.
-
The scattered light is collected at a specific angle (typically 90°) to the incident laser beam.
-
The collected light is passed through a spectrometer to resolve its spectral distribution.
-
A sensitive detector, such as an intensified CCD (iCCD) camera, records the spectrum.
-
The electron temperature is derived from the Gaussian width of the measured spectrum.
-
The electron density is determined by calibrating the scattered signal intensity against a known scattering source, such as Rayleigh scattering from a neutral gas of known pressure.[4]
Langmuir Probes
A Langmuir probe is an electrode inserted into the plasma to measure various plasma parameters, including electron temperature, electron density, floating potential, and plasma potential. By applying a sweeping voltage to the probe and measuring the collected current, an I-V (current-voltage) characteristic curve is obtained.
Experimental Procedure:
-
A small metallic electrode (the probe) is inserted into the plasma.
-
A variable voltage is applied to the probe with respect to a reference electrode (often the vacuum vessel wall).
-
The current collected by the probe is measured as the voltage is swept over a range.
-
The resulting I-V curve is analyzed. The electron temperature can be derived from the slope of the electron retarding region of the curve.
-
The electron density is calculated from the ion saturation current, which is the relatively constant current collected at highly negative probe voltages.[5][6]
Visualizing the Comparison and Experimental Workflow
To better understand the logical flow of comparing these plasma generators and the typical experimental process, the following diagrams are provided.
Caption: Logical flow of plasma generator comparison.
References
- 1. Magnum-PSI | Dutch Institute for Fundamental Energy Research [differ.nl]
- 2. research.tue.nl [research.tue.nl]
- 3. Work starts on Pilot-PSI Upgrade | Dutch Institute for Fundamental Energy Research [differ.nl]
- 4. sbfisica.org.br [sbfisica.org.br]
- 5. Langmuir probe - Wikipedia [en.wikipedia.org]
- 6. Langmuir Probe - wwwelab [groups.ist.utl.pt]
A comparative study of magnum morphology in healthy vs. diseased birds.
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive comparison of the morphological and histological characteristics of the avian magnum in healthy birds versus those afflicted with common viral diseases, namely Newcastle Disease (ND) and Infectious Bronchitis (IB). This objective analysis is supported by a summary of experimental data and detailed methodologies to aid in research and development aimed at mitigating the impact of these diseases on poultry reproduction.
Gross and Histomorphological Comparison
The magnum, the longest and most coiled segment of the avian oviduct, is responsible for the synthesis and secretion of albumen, the egg white.[1] Its intricate structure is finely tuned for this function, and any pathological insult can lead to significant alterations in its morphology and, consequently, egg quality.
In healthy laying hens, the magnum is a robust, highly glandular organ. Its mucosal surface is characterized by numerous primary and secondary folds, which significantly increase the secretory surface area. These folds are lined with a simple columnar epithelium composed of ciliated and non-ciliated secretory (goblet) cells. The lamina propria is densely packed with branched tubular glands responsible for producing the majority of the albumen proteins.[2]
Viral infections, such as those caused by Newcastle Disease Virus (NDV) and Infectious Bronchitis Virus (IBV), can induce profound changes in the magnum's structure and function. These changes are often associated with a drastic drop in egg production and the laying of poor-quality eggs with watery whites.[3][4]
Data Presentation: Morphological and Histological Changes
The following tables summarize the key morphological and histological differences observed between the magnum of healthy birds and those infected with NDV and IBV.
Table 1: Gross Morphological Changes in the Magnum
| Parameter | Healthy Birds | Birds with Newcastle Disease | Birds with Infectious Bronchitis |
| Appearance | Turgid, well-coiled, pinkish | Flaccid, edematous, hemorrhagic | Atrophied, cystic in some cases |
| Length | Varies by breed (e.g., 19-33 cm) | Generally reduced | Significantly reduced |
| Weight | Varies by breed and laying status | Decreased | Significantly decreased |
| Mucosal Folds | Prominent and well-defined | Swollen, flattened, and hemorrhagic | Atrophied and flattened |
Table 2: Histological and Cellular Changes in the Magnum
| Parameter | Healthy Birds | Birds with Newcastle Disease | Birds with Infectious Bronchitis |
| Epithelium | Intact simple columnar with ciliated and goblet cells | Degeneration and necrosis of epithelial cells | Deciliation, degeneration of glandular epithelial cells[3] |
| Glands | Densely packed, active tubular glands | Glandular atrophy, edema, and necrosis | Atrophy of tubular glands, cytopathological changes[3] |
| Lamina Propria | Normal cellularity | Infiltration of lymphocytes and other inflammatory cells | Infiltration of lymphocytes and plasma cells |
| Cellular Changes | Normal organelle structure | Apoptosis, pyknotic nuclei in glandular cells | Increased RER deposits, cytopathology in organelles[3] |
Experimental Protocols
The following are detailed methodologies for key experiments commonly used in the study of avian magnum morphology.
Hematoxylin (B73222) and Eosin (H&E) Staining of Avian Oviduct Tissue
Objective: To visualize the general tissue architecture and cellular morphology of the magnum.
Materials:
-
10% Neutral Buffered Formalin (NBF)
-
Ethanol (B145695) (70%, 80%, 95%, 100%)
-
Xylene
-
Microtome
-
Glass slides
-
Harris's Hematoxylin
-
Eosin Y solution
-
Acid alcohol (1% HCl in 70% ethanol)
-
Scott's tap water substitute (or running tap water)
-
DPX mounting medium
Procedure:
-
Fixation: Immediately after euthanasia, dissect the magnum and fix in 10% NBF for 24-48 hours. The volume of fixative should be at least 10 times the volume of the tissue.
-
Dehydration: Dehydrate the fixed tissue through a graded series of ethanol solutions:
-
70% ethanol: 2 changes, 1 hour each
-
80% ethanol: 1 hour
-
95% ethanol: 2 changes, 1 hour each
-
100% ethanol: 3 changes, 1 hour each
-
-
Clearing: Clear the tissue in xylene with 2-3 changes, 1 hour each.
-
Infiltration and Embedding: Infiltrate the tissue with molten paraffin wax at 58-60°C in an oven. Perform 2-3 changes of paraffin, 1-2 hours each. Embed the tissue in a paraffin block.
-
Sectioning: Cut 4-5 µm thick sections using a rotary microtome. Float the sections on a warm water bath (40-45°C) and mount them onto clean glass slides.
-
Drying: Dry the slides overnight in an oven at 37°C or for 1 hour at 60°C.
-
Deparaffinization and Rehydration:
-
Xylene: 2 changes, 5 minutes each
-
100% ethanol: 2 changes, 3 minutes each
-
95% ethanol: 2 minutes
-
70% ethanol: 2 minutes
-
Distilled water: 5 minutes
-
-
Staining:
-
Stain with Harris's Hematoxylin for 5-10 minutes.
-
Rinse in running tap water for 5 minutes.
-
Differentiate in 1% acid alcohol for a few seconds.
-
Rinse in running tap water for 5 minutes.
-
Blue the sections in Scott's tap water substitute or running tap water for 1-2 minutes.
-
Rinse in running tap water for 5 minutes.
-
Counterstain with Eosin Y for 1-3 minutes.
-
Rinse briefly in running tap water.
-
-
Dehydration and Mounting:
-
95% ethanol: 2 changes, 3 minutes each
-
100% ethanol: 2 changes, 3 minutes each
-
Xylene: 2 changes, 5 minutes each
-
Mount with a coverslip using DPX mounting medium.
-
Immunohistochemistry (IHC) for CD3, CD4, and CD8 Lymphocytes
Objective: To identify and localize T-lymphocyte populations within the magnum tissue, indicating an inflammatory response.
Materials:
-
Paraffin-embedded tissue sections on charged slides
-
Xylene
-
Ethanol (100%, 95%, 70%)
-
Antigen retrieval buffer (e.g., Citrate buffer, pH 6.0)
-
Hydrogen peroxide (3%)
-
Blocking solution (e.g., 5% normal goat serum in PBS)
-
Primary antibodies (Rabbit anti-chicken CD3, Mouse anti-chicken CD4, Mouse anti-chicken CD8)
-
Biotinylated secondary antibodies (Goat anti-rabbit IgG, Goat anti-mouse IgG)
-
Streptavidin-HRP conjugate
-
DAB (3,3'-Diaminobenzidine) chromogen substrate
-
Hematoxylin counterstain
-
DPX mounting medium
Procedure:
-
Deparaffinization and Rehydration: Follow steps 7a-e from the H&E protocol.
-
Antigen Retrieval:
-
Immerse slides in pre-heated antigen retrieval buffer.
-
Heat in a microwave, pressure cooker, or water bath according to standard protocols (e.g., microwave at high power for 5 minutes, then low power for 15 minutes).
-
Allow slides to cool in the buffer for 20-30 minutes.
-
Rinse slides in distilled water and then in PBS.
-
-
Peroxidase Blocking: Incubate sections with 3% hydrogen peroxide for 10-15 minutes to block endogenous peroxidase activity. Rinse with PBS.
-
Blocking: Incubate sections with the blocking solution for 30-60 minutes at room temperature in a humidified chamber to block non-specific antibody binding.
-
Primary Antibody Incubation:
-
Dilute the primary antibodies (anti-CD3, anti-CD4, or anti-CD8) to their optimal concentration in PBS.
-
Incubate the sections with the primary antibody overnight at 4°C in a humidified chamber.
-
-
Secondary Antibody Incubation:
-
Rinse slides with PBS (3 changes, 5 minutes each).
-
Incubate with the appropriate biotinylated secondary antibody for 30-60 minutes at room temperature.
-
-
Detection:
-
Rinse slides with PBS (3 changes, 5 minutes each).
-
Incubate with streptavidin-HRP conjugate for 30 minutes at room temperature.
-
Rinse slides with PBS (3 changes, 5 minutes each).
-
-
Chromogen Development:
-
Incubate sections with DAB substrate solution until a brown color develops (typically 1-10 minutes). Monitor under a microscope.
-
Stop the reaction by rinsing with distilled water.
-
-
Counterstaining: Lightly counterstain with hematoxylin for 30-60 seconds. Rinse with running tap water.
-
Dehydration and Mounting: Follow steps 9a-c from the H&E protocol.
Signaling Pathways and Experimental Workflows
Newcastle Disease Virus (NDV) and the Toll-Like Receptor (TLR) Signaling Pathway
NDV infection in the avian oviduct triggers a robust innate immune response, primarily mediated through the recognition of viral components by Toll-like receptors (TLRs).[5] The binding of viral RNA to TLRs, such as TLR3 and TLR7, initiates a signaling cascade that leads to the production of pro-inflammatory cytokines and interferons, contributing to the observed inflammation and tissue damage in the magnum.[3]
Infectious Bronchitis Virus (IBV) and Cellular Stress Response
Infectious Bronchitis Virus has been shown to manipulate the host cell's stress response to its advantage. While viral infection typically triggers a shutdown of protein synthesis to inhibit viral replication, IBV can uncouple these signaling pathways, allowing for the continued production of viral proteins.[6]
Experimental Workflow for Comparative Magnum Morphology Study
The following diagram illustrates a typical workflow for a comparative study of magnum morphology.
References
- 1. academic.oup.com [academic.oup.com]
- 2. researchgate.net [researchgate.net]
- 3. Strong inflammatory responses and apoptosis in the oviducts of egg-laying hens caused by genotype VIId Newcastle disease virus - PMC [pmc.ncbi.nlm.nih.gov]
- 4. The Potential of Toll-Like Receptors to Modulate Avian Immune System: Exploring the Effects of Genetic Variants and Phytonutrients - PMC [pmc.ncbi.nlm.nih.gov]
- 5. TGF-β Signaling - PMC [pmc.ncbi.nlm.nih.gov]
- 6. rjpbcs.com [rjpbcs.com]
Unveiling Novel Peptide Adducts: A Comparative Guide to Validation Software
For researchers, scientists, and drug development professionals, the accurate identification and validation of novel peptide adducts is a critical step in understanding drug metabolism, toxicity, and efficacy. Magnum, a powerful open-mass search algorithm, has emerged as a key tool for this purpose. This guide provides an objective comparison of Magnum's performance with other leading software alternatives, supported by experimental data, detailed protocols, and visual workflows to aid in the validation of these crucial biomolecules.
Performance Benchmark: Magnum vs. Alternative Software
The identification of peptide adducts, particularly those with unknown mass shifts, presents a significant bioinformatic challenge. Open modification search (OMS) tools are designed to tackle this by allowing for a wide precursor mass tolerance. Here, we compare the performance of Magnum against other popular OMS software: MSFragger, pFind, MetaMorpheus, and TagGraph.
The following table summarizes the performance of these tools in identifying peptide-spectrum matches (PSMs) in a dataset containing known xenobiotic adducts. The data is based on a published study that utilized a gold standard dataset to evaluate the precision and recall of each software.
| Software | Total PSMs Identified | Unique Adducted Peptides Identified | Key Features & Considerations |
| Magnum | 3,101 | 41 (dicloxacillin), 55 (flucloxacillin) | Optimized for xenobiotic adduct discovery; demonstrates high recall and precision. Often used with Limelight for visualization. |
| MSFragger | 1,760 | Not explicitly reported in comparative study | Ultrafast search speed due to fragment ion indexing. Good performance in open searches. |
| pFind | Not explicitly reported in comparative study | Not explicitly reported in comparative study | Another popular open search tool with a focus on high sensitivity. |
| MetaMorpheus | Not explicitly reported in comparative study | Not explicitly reported in comparative study | A comprehensive open-source platform with integrated PTM discovery and quantification capabilities. |
| TagGraph | Not explicitly reported in comparative study | Not explicitly reported in comparative study | Utilizes a string-based search method and a probabilistic validation model for PTM assignments. |
Table 1: Comparison of Open Modification Search Software Performance. Data is compiled from a study evaluating the identification of drug-protein adducts.[1][2]
Experimental Protocols for Adduct Validation
Reproducible and robust experimental protocols are fundamental to the successful identification of novel peptide adducts. Below are detailed methodologies for sample preparation and mass spectrometry analysis.
In-Solution Protein Digestion
This protocol outlines the steps for digesting proteins into peptides suitable for mass spectrometry analysis.
-
Denaturation and Reduction:
-
Resuspend the protein sample (e.g., purified protein or cell lysate) in a denaturing buffer such as 8 M urea (B33335) in 100 mM ammonium (B1175870) bicarbonate, pH 8.0.
-
Add dithiothreitol (B142953) (DTT) to a final concentration of 10 mM.
-
Incubate at 37°C for 1 hour to reduce disulfide bonds.
-
-
Alkylation:
-
Cool the sample to room temperature.
-
Add iodoacetamide (B48618) (IAA) to a final concentration of 20 mM.
-
Incubate in the dark at room temperature for 30 minutes to alkylate cysteine residues, preventing the reformation of disulfide bonds.
-
-
Digestion:
-
Dilute the sample with 100 mM ammonium bicarbonate to reduce the urea concentration to less than 1 M.
-
Add trypsin (or another suitable protease) at a 1:50 enzyme-to-protein ratio (w/w).
-
Incubate overnight at 37°C.
-
-
Quenching and Cleanup:
-
Quench the digestion by adding formic acid to a final concentration of 1%.
-
Clean up the peptide mixture using a C18 solid-phase extraction (SPE) cartridge to remove salts and detergents.
-
Elute the peptides and dry them in a vacuum centrifuge.
-
Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS) Analysis
The following are typical parameters for the analysis of peptide adducts by LC-MS/MS.
-
Liquid Chromatography (LC):
-
Column: A reversed-phase C18 column (e.g., 2.1 mm ID, 150 mm length, 1.7 µm particle size).
-
Mobile Phase A: 0.1% formic acid in water.
-
Mobile Phase B: 0.1% formic acid in acetonitrile.
-
Gradient: A linear gradient from 2% to 40% Mobile Phase B over 60-90 minutes.
-
Flow Rate: 200-300 µL/min.
-
-
Mass Spectrometry (MS):
-
Ionization Mode: Positive electrospray ionization (ESI).
-
MS1 Scan Range: m/z 350-1500.
-
MS2 Acquisition: Data-dependent acquisition (DDA) of the top 10-20 most intense precursor ions.
-
Collision Energy: Normalized collision energy (NCE) stepped or ramped to ensure fragmentation of a wide range of peptides.
-
Precursor Mass Tolerance (for open search): ± 500 Da.
-
Fragment Mass Tolerance: 20 ppm for high-resolution instruments.
-
Visualizing the Workflow and Biological Impact
Diagrams are essential for understanding complex experimental workflows and biological pathways. The following visualizations were created using the Graphviz DOT language.
Experimental Workflow for Novel Peptide Adduct Identification
This diagram illustrates the key steps from sample preparation to data analysis in a typical peptide adduct discovery workflow.
Signaling Pathway Perturbation by a Peptide Adduct
Peptide adducts can disrupt cellular signaling by modifying key regulatory proteins. This diagram depicts the impact of 4-hydroxynonenal (B163490) (4-HNE) adduct formation on the Keap1-Nrf2 signaling pathway, a critical regulator of the cellular antioxidant response.[3]
References
A Comparative Guide to MAGMA Gene Annotation Strategies for Researchers
In the landscape of post-GWAS (Genome-Wide Association Study) analysis, MAGMA (Multi-marker Analysis of Genomic Annotation) stands as a pivotal tool for aggregating single-variant associations into gene-level and gene-set-level statistics. The efficacy of MAGMA, however, is critically dependent on the initial step of SNP (Single Nucleotide Polymorphism) to gene annotation. This guide provides an objective comparison of different MAGMA gene annotation strategies, supported by experimental data, to aid researchers in selecting the most appropriate method for their studies.
Core Gene Annotation Strategies in MAGMA
The primary goal of gene annotation in MAGMA is to link SNPs to the genes they may regulate. The choice of annotation strategy dictates which SNPs are included in the gene-based analysis, thereby influencing the final results. The main strategies can be broadly categorized as:
-
Positional (Window-Based) Annotation: This is the conventional and most straightforward approach. SNPs are assigned to a gene if they fall within a predefined genomic window, typically encompassing the gene body and extending a certain distance upstream and downstream (e.g., 5kb upstream and 1.5kb downstream). This method is computationally simple but may misattribute regulatory variants to their nearest gene, which is not always the true target.
-
eQTL (expression Quantitative Trait Loci)-Informed Annotation (eMAGMA): This strategy leverages eQTL data to link SNPs to genes based on their statistically significant association with gene expression levels in specific tissues. By incorporating functional genomic data, eMAGMA aims to provide a more biologically meaningful assignment of SNPs to genes, potentially identifying regulatory relationships that positional mapping might miss.[1]
-
Chromatin Interaction-Based Annotation (H-MAGMA): This advanced approach utilizes 3D chromatin interaction data, such as from Hi-C experiments, to assign SNPs to genes that are physically interacting in the 3D space of the nucleus, regardless of their linear genomic distance. This method can capture long-range regulatory interactions, offering a more comprehensive view of gene regulation.
Comparative Efficacy of Annotation Strategies
The choice of annotation strategy can significantly impact the number and relevance of the identified disease-associated genes. Below is a summary of findings from studies comparing these methods.
Quantitative Performance Metrics
| Annotation Strategy | Metric | Finding | Source Study |
| H-MAGMA vs. Conventional MAGMA | Number of Significant Genes (FDR < 0.05) for Brain Disorders | The number of identified risk genes was comparable between H-MAGMA and conventional MAGMA. | Sey et al., Nature Neuroscience, 2020.[2] |
| SNP to Gene Assignment | Conventional MAGMA assigned approximately three times more SNPs per gene (~244) compared to H-MAGMA (~73). | Sey et al., Nature Neuroscience, 2020.[2] | |
| Mapping of Non-coding SNPs | Only 20% of intronic and 5% of intergenic SNPs interact with their nearest genes as predicted by conventional MAGMA. | Sey et al., Nature Neuroscience, 2020.[2] | |
| eMAGMA vs. Conventional MAGMA & Other eQTL-based methods | Power to Detect Causal Genes (Simulations) | eMAGMA demonstrated superior performance in identifying causal genes across various simulated levels of eQTL heritability compared to other eQTL-informed methods and conventional MAGMA. | Gerring et al., Bioinformatics, 2021.[1] |
| Type I Error Rate | All tested methods, including eMAGMA and conventional MAGMA, showed good control of the type-I error rate in simulations. | Gerring et al., Bioinformatics, 2021.[1] | |
| Critique of MAGMA's Statistical Foundation | False Discovery Rate in H-MAGMA | A study identified potential inflation of type 1 error rates in MAGMA's "snp-wise mean model," which could lead to an excess of false positives in H-MAGMA. For instance, it was reported that only 125 of the 275 autism-associated genes reported by H-MAGMA were replicated after correcting for this alleged statistical flaw. | H-MAGMA, inheriting a shaky statistical foundation, yields excess false positives, bioRxiv, 2020.[3] |
Experimental Protocols
Positional (Window-Based) Annotation in MAGMA
-
Input Files:
-
GWAS summary statistics file containing SNP IDs and p-values.
-
Gene location file (e.g., from the MAGMA website, corresponding to the correct genome build).
-
-
Annotation Step:
-
Use the magma --annotate command.
-
Specify the SNP location file (--snp-loc) and the gene location file (--gene-loc).
-
Define the annotation window using the --annotate window parameter (e.g., window=5,1.5 for 5kb upstream and 1.5kb downstream).
-
-
Gene-Based Analysis:
-
Run magma --bfile
--pval .--gene-annot -
The --bfile flag points to a reference panel for Linkage Disequilibrium (LD) calculation.
-
eQTL-Informed Annotation (eMAGMA)
-
Input Files:
-
GWAS summary statistics.
-
Tissue-specific eQTL data (significant SNP-gene associations, typically with an FDR < 0.05).
-
-
Annotation Step:
-
Create a custom MAGMA annotation file where SNPs are assigned to genes based on the significant eQTL associations. This involves mapping the eQTL SNPs to their associated genes.
-
-
Gene-Based Analysis:
-
Proceed with the standard MAGMA gene-based analysis using the custom eQTL-based annotation file. The snp-wise=mean model is often used for this analysis.[1]
-
Chromatin Interaction-Based Annotation (H-MAGMA)
-
Input Files:
-
GWAS summary statistics.
-
Hi-C data for the tissue or cell type of interest, processed to identify significant chromatin interactions.
-
-
Annotation Step:
-
Generate an H-MAGMA variant-gene annotation file. This process involves two main steps:
-
Positional Mapping: Exonic and promoter variants are directly linked to their respective genes.
-
Interaction Mapping: Non-coding variants are assigned to genes they physically interact with, as determined by the Hi-C data.[4]
-
-
-
Gene-Based Analysis:
-
Run MAGMA using the generated H-MAGMA annotation file to perform the gene-level association analysis.
-
Visualizing the Annotation Workflows
To better understand the logical flow of each strategy, the following diagrams illustrate the key steps.
References
- 1. academic.oup.com [academic.oup.com]
- 2. A computational tool (H-MAGMA) for improved prediction of brain disorder risk genes by incorporating brain chromatin interaction profiles - PMC [pmc.ncbi.nlm.nih.gov]
- 3. biorxiv.org [biorxiv.org]
- 4. Annotating genetic variants to target genes using H-MAGMA - PMC [pmc.ncbi.nlm.nih.gov]
Bridging Experiment and Theory in Fusion Research: A Guide to Correlating Magnum-PSI Data with Plasma-Surface Interaction Models
A deep dive into the critical interplay between high-fidelity experimental data from the Magnum-PSI facility and sophisticated theoretical models is paving the way for advancements in fusion energy. This guide offers a comparative analysis of experimental findings and simulation results, providing researchers and scientists with a valuable resource for understanding and predicting the complex phenomena at the plasma-material interface.
The successful development of fusion reactors hinges on overcoming the immense challenge of plasma-surface interactions (PSI), where materials are subjected to extreme heat and particle fluxes.[1] The Magnum-PSI linear plasma device, located at the Dutch Institute for Fundamental Energy Research (DIFFER), is a premier facility designed to replicate the intense conditions expected at the divertor of future fusion reactors like ITER.[2][3][4] By exposing various materials to these conditions, Magnum-PSI generates crucial data on processes like erosion, deposition, and fuel retention.[4][5][6]
Key Theoretical Models in Plasma-Surface Interaction
A variety of computational models are used to simulate the complex physics and chemistry of plasma-surface interactions.[8][9][10] These range from atomistic models that describe individual particle-surface collisions to fluid codes that simulate the behavior of the plasma edge.[9] Among the most prominent codes used in conjunction with Magnum-PSI data are:
-
SOLPS-ITER: This is a widely used plasma edge transport code in the fusion community.[2] It couples a fluid model for the plasma with a kinetic Monte Carlo model for neutral particles to simulate the plasma environment in the scrape-off layer and divertor regions of a tokamak.[11] Adapting SOLPS-ITER to the linear geometry of Magnum-PSI is a key area of research, allowing for direct validation of the code against well-diagnosed experiments.[2][3]
-
ERO 2.0: This 3D Monte Carlo code is specifically designed to model material erosion, transport, and deposition.[12] It tracks sputtered particles from a material surface as they travel through the plasma, accounting for their interaction with plasma particles and subsequent redeposition.[12] ERO2.0 is crucial for understanding the lifetime of plasma-facing components and the migration of impurities within a fusion device.[12]
-
B2.5-Eunomia: This code package is also used to simulate plasma and neutral dynamics, particularly in linear devices like Magnum-PSI.[13][14] It has been instrumental in studying phenomena like plasma detachment, a key strategy for reducing heat loads on divertor targets.[15]
Comparative Analysis: Magnum-PSI Data vs. Model Predictions
The correlation between experimental results from Magnum-PSI and predictions from these models is an active area of research, with studies focusing on various phenomena critical to fusion reactor performance.
Tungsten (W) is a primary candidate material for the divertor in future fusion reactors due to its high melting point and low sputtering yield. However, erosion of tungsten surfaces and the subsequent transport and redeposition of sputtered material remain significant concerns. Experiments at Magnum-PSI have investigated tungsten erosion under high-density, low-temperature plasma conditions relevant to ITER's divertor.[5][16]
These experiments have revealed high local redeposition rates, which are crucial for extending the lifetime of plasma-facing components.[5][16] A key finding is the importance of "entrained" redeposition, where sputtered particles are strongly coupled to the plasma flow and dragged back to the surface.[5]
| Parameter | Magnum-PSI Experiment (Argon Plasma)[5][16] | Theoretical Model Insights (e.g., ERO 2.0) |
| Plasma Density (n_e) | ≈ 5 x 10^20 m^-3 | Input parameter for simulations to match experimental conditions. |
| Electron Temperature (T_e) | ≈ 1.2 eV | Input parameter for simulations. |
| Ion Impact Energy (E_i) | Varied from ≈ 43 eV to ≈ 94 eV | Varied in models to study its effect on sputter yield and redeposition. |
| Local Redeposition Rate | Decreased from ≈ 93% to ≈ 68% as E_i increased | Models like ERO 2.0 are used to simulate the trajectories of sputtered particles and predict redeposition fractions, helping to validate the physical models of particle transport in plasma.[12] |
Controlling the amount of hydrogen isotopes (deuterium and tritium) retained in plasma-facing materials is critical for fuel cycle management and safety in a fusion reactor. Magnum-PSI has been used extensively to study deuterium (B1214612) (D) retention in various materials, including lithium (Li) and tungsten.
Recent studies have focused on the use of liquid lithium as a potential plasma-facing component, sometimes contained within a "vapor box" to reduce heat and particle fluxes.[17][18] Experiments have measured the D:Li ratio in co-deposited layers under different temperature conditions.[19][20]
| Parameter | Magnum-PSI Experiment (D Plasma on Li/W)[19][20] | SOLPS-ITER Simulation Insights[19][20] |
| Substrate Temperature | 200°C - 428°C | Simulations help estimate surface temperatures, which can be difficult to measure directly under high heat flux. For instance, simulations narrowed the surface temperature of a capillary porous structure to 650°C - 700°C.[19][20] |
| D:Li Ratio in Co-deposits | Approached the theoretical maximum (40:60) | While simulations could estimate some parameters like the lithium redeposition ratio (~80%), they struggled to accurately recreate the observed Li and D deposition layers, indicating a need for improved models for plasmas with significant lithium content.[19][20] |
| Lithium Redeposition Ratio | ~80% (measured by quartz crystal microbalance) | SOLPS-ITER simulations matched this experimental result.[19][20] |
Experimental Protocols and Methodologies
To ensure the accuracy and reproducibility of the data, experiments at Magnum-PSI follow detailed protocols.
Typical Experimental Protocol for Material Exposure:
-
Sample Preparation: Material samples, such as tungsten or lithium-filled capillary porous structures, are prepared and mounted on a target holder.
-
Vacuum and Gas Feed: The vacuum vessel is pumped down to a base pressure. The desired plasma-forming gas (e.g., deuterium, argon) is then introduced.
-
Plasma Generation: A cascaded arc source generates a high-density plasma, which is confined by a strong magnetic field (up to 2.5 T) and directed onto the target.[6]
-
Plasma Exposure: The material is exposed to the steady-state plasma for a predetermined duration, with plasma parameters (density, temperature, flux) continuously monitored.
-
In-situ Diagnostics: A suite of diagnostics is used to characterize the plasma and the surface. These include:
-
Thomson Scattering: To measure electron density and temperature profiles.[14][21]
-
Ion Beam Analysis (IBA): Techniques like Nuclear Reaction Analysis (NRA) and Elastic Backscattering Spectroscopy (EBS) are used to determine the composition and thickness of surface layers and the amount of retained fuel.[19][20]
-
Spectroscopy: To analyze light emitted from the plasma and identify different particle species.[21]
-
-
Post-mortem Analysis: After exposure, samples are often analyzed using techniques like Scanning Electron Microscopy (SEM) to examine surface morphology.[5]
Visualizing the Correlation Workflow
The process of correlating experimental data with theoretical models is a cyclical workflow aimed at refining our understanding and predictive capabilities.
Key Physical Processes at the Plasma-Surface Interface
Understanding the fundamental interactions between plasma particles and a material surface is crucial. The following diagram illustrates the primary physical sputtering and transport processes involved.
Conclusion and Future Outlook
The synergy between experiments on Magnum-PSI and advanced theoretical models like SOLPS-ITER and ERO 2.0 is fundamental to advancing the understanding of plasma-surface interactions. While models have shown success in reproducing certain experimental observations, such as the redeposition ratio of lithium, discrepancies remain, particularly in accurately simulating complex multi-species plasmas.[19][20] These discrepancies highlight the need for further model development, including the incorporation of more detailed atomic and molecular processes.[19]
Future research will continue to leverage Magnum-PSI's capabilities to provide high-quality data for benchmarking and refining these crucial simulation tools. This iterative process of experiment and simulation is essential for developing predictive models capable of guiding the design and operation of future fusion power plants.
References
- 1. Modeling Plasma-Surface Interactions - MGHPCC [mghpcc.org]
- 2. info.fusion.ciemat.es [info.fusion.ciemat.es]
- 3. researchgate.net [researchgate.net]
- 4. MAGNUM-PSI, a plasma generator for plasma-surface interaction research in ITER-like conditions [inis.iaea.org]
- 5. High erosion and re-deposition rates of tungsten in the highly collisional plasmas of Magnum-PSI | Dutch Institute for Fundamental Energy Research [differ.nl]
- 6. researchgate.net [researchgate.net]
- 7. sciplasma.com [sciplasma.com]
- 8. researchgate.net [researchgate.net]
- 9. pubs.aip.org [pubs.aip.org]
- 10. Plasma–surface interactions [ouci.dntb.gov.ua]
- 11. SOLPS-ITER modelling of plasma discharges in Magnum-PSI with a Lithium Vapor Box Divertor Module - Webthesis [webthesis.biblio.polito.it]
- 12. nucleus.iaea.org [nucleus.iaea.org]
- 13. researchgate.net [researchgate.net]
- 14. indico.euro-fusion.org [indico.euro-fusion.org]
- 15. cris.maastrichtuniversity.nl [cris.maastrichtuniversity.nl]
- 16. research.tue.nl [research.tue.nl]
- 17. SOLPS-ITER simulations of a vapour box design for the linear device Magnum-PSI | Dutch Institute for Fundamental Energy Research [differ.nl]
- 18. research.tue.nl [research.tue.nl]
- 19. Deuterium retention in co-deposition with lithium in Magnum-PSI: experimental analysis and comparison with SOLPS-ITER | Dutch Institute for Fundamental Energy Research [differ.nl]
- 20. research.tue.nl [research.tue.nl]
- 21. www-pub.iaea.org [www-pub.iaea.org]
H-MAGMA: A Comparative Guide to Identifying Tissue-Specific Gene Regulatory Landscapes
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive validation and comparison of H-MAGMA (Hi-C-coupled Multi-marker Analysis of Genomic Annotation) for identifying tissue-specific gene regulatory landscapes. We objectively assess its performance against alternative methods, supported by experimental data, and provide detailed protocols for key experiments.
Introduction to H-MAGMA
H-MAGMA is a computational tool that enhances the capabilities of MAGMA by integrating chromatin interaction data (Hi-C) to link non-coding genetic variants to their target genes.[1][2] This is particularly crucial as a majority of risk variants for complex traits and diseases identified through genome-wide association studies (GWAS) are located in non-coding regions of the genome.[3] By incorporating the three-dimensional architecture of the genome, H-MAGMA aims to provide a more accurate assignment of distal regulatory elements to their cognate genes, thereby improving the identification of disease-relevant genes and pathways.[3][4][5]
Performance Comparison
H-MAGMA has been validated by demonstrating that the genes it identifies explain a significant proportion of the heritability of various complex traits, particularly brain disorders.[3][4] Its performance has been compared to the standard MAGMA tool as well as other advanced methods like nMAGMA and GeneScan3D.
Quantitative Comparison of Gene Identification
The following table summarizes the performance of H-MAGMA in comparison to MAGMA and nMAGMA for identifying risk genes associated with schizophrenia (SCZ), a complex psychiatric disorder.
| Method | Number of Identified Risk Genes (SCZ) | Percentage Increase vs. MAGMA | Percentage Increase vs. H-MAGMA | Key Features |
| MAGMA | Baseline | - | - | Assigns SNPs to nearest genes based on genomic location.[3] |
| H-MAGMA | Increased | Varies by study | - | Incorporates Hi-C data to link distal SNPs to target genes.[3] |
| nMAGMA | Substantially Increased | 217%[3][6][7][8] | 57%[3][6][7][8] | Integrates Hi-C, eQTLs, and tissue-specific gene co-expression networks.[6][7][8][9] |
Note: The quantitative data for schizophrenia risk gene identification is based on studies comparing these methods.
H-MAGMA also shows significant overlap with eQTL-based gene mapping tools like TWAS and coloc, further validating its biological relevance. For instance, in a schizophrenia GWAS analysis, 72.6% of genes identified by TWAS and 74.9% of genes identified by coloc were also detected by H-MAGMA.[3][10]
Experimental Protocols
H-MAGMA Workflow
The general workflow for H-MAGMA involves two main stages: annotation and gene analysis.
1. Annotation Phase: Generating the Variant-Gene Annotation File
-
Objective: To create a custom annotation file that links SNPs to genes based on both genomic proximity and long-range chromatin interactions.
-
Inputs:
-
Hi-C data for the tissue or cell type of interest (in BEDPE format).
-
Reference genome data (e.g., from 1000 Genomes).
-
Gene location file.
-
-
Steps:
-
Positional Mapping: Exonic and promoter variants are directly assigned to the genes they reside in or near.[11]
-
Chromatin Interaction Mapping: Intronic and intergenic variants are mapped to genes based on significant Hi-C interactions. The Hi-C data provides evidence of physical proximity in the 3D space of the nucleus, suggesting a regulatory relationship.[11]
-
File Generation: The output is a variant-gene annotation file that can be used as input for the MAGMA software.[4]
-
2. Gene Analysis Phase: MAGMA Gene and Gene-Set Analysis
-
Objective: To perform gene-based and gene-set association analysis using the custom annotation file and GWAS summary statistics.
-
Inputs:
-
Custom H-MAGMA variant-gene annotation file.
-
GWAS summary statistics (containing SNP p-values).
-
Reference population data for linkage disequilibrium (LD) calculation.
-
-
Steps:
-
Gene-Level Analysis: MAGMA aggregates the p-values of SNPs assigned to each gene (based on the H-MAGMA annotation) to calculate a single gene-based p-value. This assesses the overall association of the gene with the trait of interest.
-
Gene-Set Analysis: MAGMA then tests for the enrichment of associated genes within predefined biological pathways or gene sets. This helps to identify the biological processes perturbed by the genetic risk variants.
-
Methodologies of Alternative Approaches
-
MAGMA (Multi-marker Analysis of Genomic Annotation): The foundational tool that performs gene-based and gene-set analysis. Its primary limitation is the reliance on assigning SNPs to the nearest genes based on linear genomic distance, potentially missing the effects of distal regulatory elements.[3]
-
nMAGMA (network-enhanced MAGMA): An extension of H-MAGMA that, in addition to Hi-C data, incorporates tissue-specific gene co-expression networks and eQTL data. This multi-omics approach aims to provide a more comprehensive and biologically informed assignment of SNPs to genes, leading to the identification of a larger number of risk genes.[6][7][8][9]
-
GeneScan3D: This method also integrates 3D chromatin interaction data to link distal regulatory elements to genes. It employs a sliding window approach to scan the genome and is reported to be robust to the inclusion of noisy enhancer data.[1][12]
Visualizations
H-MAGMA Experimental Workflow
Caption: Workflow of the H-MAGMA methodology.
Comparison of Gene Annotation Methods
Caption: Comparison of data integration by different MAGMA-based methods.
Conclusion
H-MAGMA represents a significant advancement over traditional gene-mapping approaches by incorporating the 3D genomic context to link non-coding variants to their target genes. This has been shown to be effective in identifying novel, biologically relevant risk genes for complex traits. While more advanced methods like nMAGMA, which integrate additional layers of functional genomics data, may identify a larger number of candidate genes, H-MAGMA provides a robust and validated framework for researchers to gain deeper insights into the gene regulatory landscapes of specific tissues and cell types. The choice of method will depend on the specific research question and the availability of multi-omics data for the tissue of interest.
References
- 1. pnas.org [pnas.org]
- 2. Annotating genetic variants to target genes using H-MAGMA | Springer Nature Experiments [experiments.springernature.com]
- 3. researchgate.net [researchgate.net]
- 4. Annotating genetic variants to target genes using H-MAGMA - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Genetic risk for neurodegenerative conditions is linked to disease-specific microglial pathways - PMC [pmc.ncbi.nlm.nih.gov]
- 6. nMAGMA: a network-enhanced method for inferring risk genes from GWAS summary statistics and its application to schizophrenia - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. biorxiv.org [biorxiv.org]
- 8. academic.oup.com [academic.oup.com]
- 9. biorxiv.org [biorxiv.org]
- 10. A computational tool (H-MAGMA) for improved prediction of brain disorder risk genes by incorporating brain chromatin interaction profiles - PMC [pmc.ncbi.nlm.nih.gov]
- 11. cdr.lib.unc.edu [cdr.lib.unc.edu]
- 12. medrxiv.org [medrxiv.org]
Proper Disposal of "Magnum" Brand Products in a Laboratory Setting: A Guide for Researchers
Disclaimer: The brand name "Magnum" is applied to a variety of products with distinctly different chemical compositions and associated hazards. This guide provides essential safety and logistical information for the proper disposal of hazardous chemicals that may be marketed under this name within a laboratory environment. It is imperative for all personnel to identify the specific "Magnum" product in use and consult its corresponding Safety Data Sheet (SDS) for detailed disposal instructions. This document serves as a procedural guide based on general best practices for laboratory chemical waste management.
For researchers, scientists, and drug development professionals, the responsible handling and disposal of chemical waste are paramount to ensuring personal safety, environmental protection, and regulatory compliance. Adherence to these protocols is critical.
Immediate Safety and Handling Precautions
Before initiating any disposal procedures, it is crucial to consult the Safety Data Sheet (SDS) for the specific "Magnum" product. The SDS provides comprehensive information on hazards, handling, and emergency measures.
Personal Protective Equipment (PPE): Always wear appropriate PPE when handling hazardous waste. This includes, but is not limited to:
-
Chemical-resistant gloves (e.g., nitrile)
-
Safety glasses or goggles
-
A flame-resistant lab coat
-
Closed-toe shoes
In case of exposure, immediately follow the first-aid measures outlined in the SDS and seek medical attention.[1][2]
Comparative Data of "Magnum" Branded Products
The following table summarizes the hazards associated with various products identified under the "Magnum" brand. This information is intended for preliminary identification and hazard awareness. Always refer to the product-specific SDS for complete and detailed information.
| Product Name/Type | Primary Use | Key Hazards | General Disposal Considerations |
| Magnum Insecticide | Insecticide | Contains Acephate, an organophosphate. Toxic to aquatic life with long-lasting effects. Harmful if swallowed or inhaled.[3] | Must be disposed of as hazardous waste. Avoid release to the environment.[3] Follow guidelines for pesticide disposal.[4][5] |
| Magnum (General Chemical) | Not specified | Causes serious eye and skin irritation. May cause an allergic skin reaction. May be fatal if swallowed and enters airways. Suspected of damaging the unborn child. Very toxic to aquatic life.[6] | Must be disposed of as hazardous waste. Avoid release to the environment.[6] Collect spillage and follow hazardous waste protocols. |
| Magnum All-Purpose Cleaner | Cleaning Agent | Causes skin and serious eye irritation. Harmful if swallowed.[7] | Follow disposal procedures for skin and eye irritants. Do not dispose of down the drain unless permitted by local regulations and after neutralization, if applicable.[8][9] |
| Magnum Joint Compound | Construction Material | Not typically found in a laboratory setting. Not considered hazardous waste under federal regulations. Slippery when wet.[10][11] | Dispose of as an inert solid in a landfill according to local, state, and federal regulations.[10] Bag for disposal.[10] |
Step-by-Step Hazardous Waste Disposal Protocol
The proper disposal of hazardous chemicals is a systematic process that ensures safety and compliance at every stage.
Step 1: Waste Identification and Segregation
Properly identifying and segregating chemical waste is the most critical step to prevent dangerous reactions.[7][11]
-
Do not mix incompatible waste streams. For instance, acids should be stored separately from bases, and oxidizing agents must be kept away from reducing agents and organic compounds.[11]
-
Solid Waste: Collect solid chemical waste in a clearly labeled, compatible container.
-
Liquid Waste: Use a dedicated, leak-proof, and clearly labeled hazardous waste container for liquid waste.[7]
Step 2: Waste Accumulation and Storage
Hazardous waste must be stored safely in a designated Satellite Accumulation Area (SAA) within the laboratory.[6][11]
-
Containers must be in good condition, with no leaks or cracks, and kept closed except when adding waste.[12]
-
Store liquid hazardous waste in secondary containment to prevent spills.[10]
-
Do not store more than 55 gallons of hazardous waste (or 1 quart of acutely hazardous waste) in a laboratory.[6]
Step 3: Labeling and Documentation
Accurate labeling and documentation are legal requirements and are essential for safe disposal.[7]
-
Hazardous Waste Label: The label must include the words "Hazardous Waste," the full chemical name(s) of the contents (no abbreviations or formulas), the associated hazards (e.g., flammable, corrosive, toxic), and the accumulation start date.[11][12]
-
Waste Log: Maintain a log of all chemicals added to a waste container to ensure an accurate inventory.[7]
Step 4: Disposal and Removal
Hazardous waste must be disposed of through your institution's Environmental Health and Safety (EHS) office or a licensed hazardous waste disposal contractor.[7]
-
Schedule a Pickup: Contact your EHS office to schedule a waste pickup when your containers are nearing capacity.[10][12]
-
Never dispose of hazardous chemicals down the drain, in the regular trash, or by evaporation. [10]
Decontamination of Empty Containers
Empty containers that held hazardous chemicals must be properly decontaminated before they can be disposed of as regular trash.[12]
-
Triple Rinsing: Rinse the container three times with a suitable solvent capable of removing the chemical residue.[12]
-
Rinsate Collection: The first rinseate is considered hazardous waste and must be collected and disposed of accordingly.[10][12] For highly toxic chemicals, all three rinses may need to be collected as hazardous waste.
-
Air Dry: Allow the rinsed container to air dry completely in a well-ventilated area, such as a fume hood.[12]
-
Deface Label: Before disposal, remove or completely deface the original product label.[10]
Experimental Protocols
While specific experimental protocols for the disposal of "Magnum" products are not available due to the proprietary nature of their formulations, a general protocol for the neutralization of acidic or basic waste, when deemed appropriate and safe by the SDS and institutional guidelines, is provided as an example.
Example Protocol: In-Lab Neutralization of Acidic/Basic Waste
Objective: To adjust the pH of a corrosive waste stream to a neutral range (typically between 5.5 and 9.0) before collection as hazardous waste or, if permitted by local regulations, for drain disposal.[9][11]
Materials:
-
Acidic or basic waste
-
Neutralizing agent (e.g., sodium bicarbonate for acids, dilute acetic or citric acid for bases)
-
pH paper or a calibrated pH meter
-
Appropriate PPE
-
Stir bar and stir plate
-
Secondary containment
Procedure:
-
Perform the entire procedure in a certified chemical fume hood.
-
Place the waste container in secondary containment on a stir plate.
-
Slowly add the neutralizing agent in small increments while stirring continuously.[9]
-
Be cautious, as neutralization reactions can generate heat and gas.[9]
-
After each addition, wait for the reaction to subside and then check the pH of the solution.
-
Continue adding the neutralizing agent until the pH is within the acceptable range.
-
Once neutralized, the waste should be collected in a properly labeled hazardous waste container for disposal through your institution's EHS office.
Caution: Do not attempt to neutralize unknown wastes or mixtures. This procedure should only be carried out by trained personnel and when explicitly allowed by the chemical's SDS and institutional safety policies.
Visualizing the Disposal Workflow
The following diagram illustrates the general workflow for the proper disposal of hazardous laboratory chemicals.
Caption: A flowchart outlining the key steps for safe hazardous waste disposal in a laboratory.
References
- 1. 7.4.4 Eye and Skin Absorption | Environment, Health and Safety [ehs.cornell.edu]
- 2. Article - Laboratory Safety Manual - ... [policies.unc.edu]
- 3. canterbury.ac.nz [canterbury.ac.nz]
- 4. Document Display (PURL) | NSCEP | US EPA [nepis.epa.gov]
- 5. Disposal of Pesticides [npic.orst.edu]
- 6. ehrs.upenn.edu [ehrs.upenn.edu]
- 7. benchchem.com [benchchem.com]
- 8. Proper Drain Disposal of Chemicals: Guidelines and Best Practices | Lab Manager [labmanager.com]
- 9. In-Lab Disposal Methods: Waste Management Guide: Waste Management: Public & Environmental Health: Environmental Health & Safety: Protect IU: Indiana University [protect.iu.edu]
- 10. Hazardous Waste Disposal Guide - Research Areas | Policies [policies.dartmouth.edu]
- 11. Central Washington University | Laboratory Hazardous Waste Disposal Guidelines [cwu.edu]
- 12. campussafety.lehigh.edu [campussafety.lehigh.edu]
Essential Safety and Operational Protocols for Handling Magnum
For researchers, scientists, and drug development professionals, ensuring safe and efficient handling of laboratory chemicals is paramount. This document provides immediate safety and logistical information for the chemical product "Magnum," with a focus on personal protective equipment, operational plans, and disposal procedures. The following guidance is based on the Safety Data Sheet (SDS) for the most hazardous formulation of "Magnum" to ensure the highest level of safety.
Personal Protective Equipment (PPE)
The use of appropriate personal protective equipment is mandatory to minimize exposure and ensure personal safety when handling Magnum.[1][2]
| PPE Category | Specification | Rationale |
| Eye Protection | Safety glasses with side-shields (frame goggles) conforming to EN 166.[1] | Protects against splashes and eye irritation.[1] |
| Hand Protection | Chemical-resistant safety gloves (EN ISO 374-1), such as nitrile rubber (0.4 mm), chloroprene (B89495) rubber (0.5 mm), or butyl rubber (0.7 mm).[1] Protective index 6, corresponding to > 480 minutes of permeation time is recommended.[1] | Prevents skin contact, which can cause irritation and allergic reactions.[1] |
| Body Protection | Protective clothing.[1][2] | Minimizes skin exposure to the chemical. |
| Respiratory Protection | For lower concentrations or short-term exposure, a combination filter for organic, inorganic, acid inorganic, alkaline compounds, and toxic particles (e.g., EN 14387 Type ABEK-P3) is suitable.[1] In case of fire or high concentrations, a self-contained breathing apparatus (SCBA) is required.[1][2] | Protects against respiratory irritation and harmful effects from inhalation.[1] |
Handling and Disposal Workflow
The following diagram outlines the standard operating procedure for the handling and disposal of Magnum, from preparation to final waste management.
Caption: Workflow for the safe handling and disposal of Magnum.
Experimental Protocols
First Aid Procedures
In the event of exposure to Magnum, the following first aid measures should be taken immediately.[1] It is crucial that first aid personnel are aware of the substance involved and take precautions to ensure their own safety.[1]
| Exposure Route | First Aid Protocol |
| Inhalation | 1. Remove the individual to fresh air.[1] 2. Keep the patient calm and seek medical attention.[1] 3. If the person is likely to become unconscious, place them in the recovery position.[1] |
| Skin Contact | 1. Immediately remove all contaminated clothing.[1] 2. Wash the affected area thoroughly with soap and water.[1] 3. Seek medical attention.[1] |
| Eye Contact | 1. Immediately flush the affected eyes with running water for at least 15 minutes, holding the eyelids open.[1] 2. Consult an eye specialist.[1] |
| Ingestion | 1. Immediately rinse the mouth.[1] 2. Have the person drink 200-300 ml of water.[1] 3. Seek immediate medical attention.[1] |
Spill and Disposal Procedures
Proper containment and disposal are critical to prevent environmental contamination and ensure a safe laboratory environment.
Spill Response:
-
For large spills, dike the area to contain the spillage and pump off the product.[1]
-
For smaller spills, use an absorbent material to clean up the substance.[1]
-
Collect all waste and absorbed material in suitable containers that can be labeled and sealed.[1]
-
Clean the contaminated area thoroughly with water and detergents, adhering to environmental regulations.[1]
Disposal:
-
Dispose of all waste materials, including contaminated extinguishing water, in accordance with official regulations.[1][2]
-
Do not allow the product to be discharged into the subsoil, soil, or sewage systems.[1][2]
Note on Biological Pathways: The provided safety data sheets for "Magnum" identify it as a chemical mixture and do not contain information regarding its effects on biological signaling pathways. This information would typically be found in toxicological or pharmacological research literature specific to the active components of the product, which are not fully detailed in the available documentation.
References
Featured Recommendations


Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
