
4-Aminophenylalanine
Description
p-Aminophenylalanine has been reported in Vigna vexillata, Vigna angivensis, and other organisms with data available.
RN given refers to cpd without isomeric designation
Structure
2D Structure
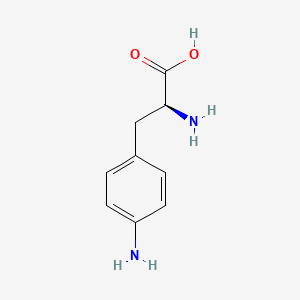
3D Structure
Properties
IUPAC Name |
(2S)-2-amino-3-(4-aminophenyl)propanoic acid |
Source


|
|---|---|---|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI |
InChI=1S/C9H12N2O2/c10-7-3-1-6(2-4-7)5-8(11)9(12)13/h1-4,8H,5,10-11H2,(H,12,13)/t8-/m0/s1 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI Key |
CMUHFUGDYMFHEI-QMMMGPOBSA-N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Canonical SMILES |
C1=CC(=CC=C1CC(C(=O)O)N)N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Isomeric SMILES |
C1=CC(=CC=C1C[C@@H](C(=O)O)N)N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Formula |
C9H12N2O2 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
DSSTOX Substance ID |
DTXSID90178828 |
Source
|
| Record name | 4-Aminophenylalanine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID90178828 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
Molecular Weight |
180.20 g/mol |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
CAS No. |
943-80-6, 2410-24-4 |
Source
|
| Record name | 4-Amino-L-phenylalanine | |
| Source | CAS Common Chemistry | |
| URL | https://commonchemistry.cas.org/detail?cas_rn=943-80-6 | |
| Description | CAS Common Chemistry is an open community resource for accessing chemical information. Nearly 500,000 chemical substances from CAS REGISTRY cover areas of community interest, including common and frequently regulated chemicals, and those relevant to high school and undergraduate chemistry classes. This chemical information, curated by our expert scientists, is provided in alignment with our mission as a division of the American Chemical Society. | |
| Explanation | The data from CAS Common Chemistry is provided under a CC-BY-NC 4.0 license, unless otherwise stated. | |
| Record name | 4-Aminophenylalanine | |
| Source | ChemIDplus | |
| URL | https://pubchem.ncbi.nlm.nih.gov/substance/?source=chemidplus&sourceid=0002410244 | |
| Description | ChemIDplus is a free, web search system that provides access to the structure and nomenclature authority files used for the identification of chemical substances cited in National Library of Medicine (NLM) databases, including the TOXNET system. | |
| Record name | 4-Aminophenylalanine | |
| Source | ChemIDplus | |
| URL | https://pubchem.ncbi.nlm.nih.gov/substance/?source=chemidplus&sourceid=0000943806 | |
| Description | ChemIDplus is a free, web search system that provides access to the structure and nomenclature authority files used for the identification of chemical substances cited in National Library of Medicine (NLM) databases, including the TOXNET system. | |
| Record name | 4-Aminophenylalanine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID90178828 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
| Record name | 4-Amino-L-phenylalanine hydrate | |
| Source | European Chemicals Agency (ECHA) | |
| URL | https://echa.europa.eu/information-on-chemicals | |
| Description | The European Chemicals Agency (ECHA) is an agency of the European Union which is the driving force among regulatory authorities in implementing the EU's groundbreaking chemicals legislation for the benefit of human health and the environment as well as for innovation and competitiveness. | |
| Explanation | Use of the information, documents and data from the ECHA website is subject to the terms and conditions of this Legal Notice, and subject to other binding limitations provided for under applicable law, the information, documents and data made available on the ECHA website may be reproduced, distributed and/or used, totally or in part, for non-commercial purposes provided that ECHA is acknowledged as the source: "Source: European Chemicals Agency, http://echa.europa.eu/". Such acknowledgement must be included in each copy of the material. ECHA permits and encourages organisations and individuals to create links to the ECHA website under the following cumulative conditions: Links can only be made to webpages that provide a link to the Legal Notice page. | |
| Record name | 4-AMINOPHENYLALANINE | |
| Source | FDA Global Substance Registration System (GSRS) | |
| URL | https://gsrs.ncats.nih.gov/ginas/app/beta/substances/1567B560CH | |
| Description | The FDA Global Substance Registration System (GSRS) enables the efficient and accurate exchange of information on what substances are in regulated products. Instead of relying on names, which vary across regulatory domains, countries, and regions, the GSRS knowledge base makes it possible for substances to be defined by standardized, scientific descriptions. | |
| Explanation | Unless otherwise noted, the contents of the FDA website (www.fda.gov), both text and graphics, are not copyrighted. They are in the public domain and may be republished, reprinted and otherwise used freely by anyone without the need to obtain permission from FDA. Credit to the U.S. Food and Drug Administration as the source is appreciated but not required. | |
Foundational & Exploratory
An In-depth Technical Guide on the Chemical Properties of 4-Amino-L-phenylalanine
For Researchers, Scientists, and Drug Development Professionals
Introduction
4-Amino-L-phenylalanine (L-4-APhe) is a non-proteinogenic amino acid, a derivative of L-phenylalanine containing an amino group at the para position of the phenyl ring.[1] This structural modification imparts unique chemical properties, making it a valuable building block in various scientific and pharmaceutical applications. It serves as a crucial intermediate in the biosynthesis of certain antibiotics and is increasingly utilized in peptide synthesis to create novel therapeutics with enhanced stability and functionality.[2][3][4] This guide provides a comprehensive overview of the core chemical properties of 4-Amino-L-phenylalanine, detailed experimental protocols for its synthesis, and a visualization of its synthetic pathway.
Physicochemical Properties
4-Amino-L-phenylalanine is typically an off-white crystalline powder.[3][5] Its key physicochemical properties are summarized in the tables below, providing a consolidated reference for laboratory use.
General and Physical Properties
| Property | Value | Source(s) |
| Appearance | White to off-white crystalline powder | [3][5][6] |
| Melting Point | 232 - 240 °C | [3] |
| Optical Rotation | [α]D20 = -42 ±4° (c=1 in water) | [3] |
| Solubility | Soluble in water. Insoluble in DMSO and EtOH. | [2][5][7] |
Chemical and Molecular Identifiers
| Property | Value | Source(s) |
| Molecular Formula | C₉H₁₂N₂O₂ | [3][8][9] |
| Molecular Weight | 180.20 g/mol | [8] |
| CAS Number | 943-80-6 | [3][5][8] |
| IUPAC Name | (2S)-2-amino-3-(4-aminophenyl)propanoic acid | [8] |
| SMILES | C1=CC(=CC=C1C--INVALID-LINK--N)N | [8] |
| InChIKey | CMUHFUGDYMFHEI-QMMMGPOBSA-N | [8] |
Experimental Protocols
The following sections detail common laboratory-scale synthesis procedures for 4-Amino-L-phenylalanine, starting from L-phenylalanine.
Synthesis of 4-Nitro-L-phenylalanine (Intermediate)
This protocol outlines the nitration of L-phenylalanine, a necessary precursor for the synthesis of 4-Amino-L-phenylalanine.
-
Materials:
-
L-phenylalanine (4.139 g, 25.1 mmol)
-
Concentrated Sulfuric Acid (H₂SO₄, 98%, 12.5 mL)
-
Nitrating acid mixture (e.g., a mixture of nitric acid and sulfuric acid)
-
Ammonium Hydroxide (NH₄OH)
-
Acetonitrile (B52724) (CH₃CN)
-
Deionized water
-
-
Procedure:
-
A solution of L-phenylalanine is prepared in 12.5 mL of 98% H₂SO₄.
-
The nitrating acid mixture (3.5 mL portion) is added dropwise to the L-phenylalanine solution with continuous stirring. The reaction temperature is maintained at 10 °C.[5]
-
The reaction mixture is stirred at 10 °C for 2.5 hours.[5]
-
Upon completion, the pH of the solution is carefully adjusted to 5 using NH₄OH, which will cause a precipitate to form.[5]
-
The resulting light yellow precipitate is collected by filtration.
-
The collected solid is washed sequentially with a small amount of water and acetonitrile (CH₃CN).[5]
-
The product, 4-nitro-L-phenylalanine, is dried to yield a yellow powder (Expected yield: ~90%).[5]
-
Synthesis of 4-Amino-L-phenylalanine via Hydrogenation
This protocol describes the reduction of the nitro group of 4-Nitro-L-phenylalanine to an amino group.
-
Materials:
-
4-Nitro-L-phenylalanine (2.006 g, 9.54 mmol)
-
5% Palladium-Barium Sulfate (B86663) catalyst (Pd/BaSO₄, 0.2 g)
-
Deionized water (35 mL)
-
Acetonitrile (CH₃CN)
-
Diatomaceous earth
-
-
Procedure:
-
4-Nitro-L-phenylalanine is suspended in 35 mL of water.[5]
-
0.2 g of 5% palladium-barium sulfate catalyst is added to the suspension.[5]
-
The hydrogenation reaction is carried out for 3 hours at room temperature under a hydrogen atmosphere.[5]
-
The reaction solution is filtered through a diatomaceous earth pad to remove the catalyst.[5]
-
The filtrate is concentrated under reduced pressure to yield a light brown residue.[5]
-
The residue is washed with CH₃CN to afford the final product as a light brown solid (Expected yield: ~85%).[5]
-
Synthetic Pathway Visualization
The chemical synthesis of 4-Amino-L-phenylalanine from L-phenylalanine is a two-step process involving nitration followed by catalytic hydrogenation. This workflow is critical for the laboratory-scale production of this non-canonical amino acid.
Caption: Workflow for the synthesis of 4-Amino-L-phenylalanine.
Applications in Research and Development
4-Amino-L-phenylalanine is a versatile molecule with significant applications in several research domains:
-
Peptide and Protein Synthesis: It is used as a building block to synthesize peptides and proteins with novel properties.[3] The additional amino group can be used for bioconjugation or to alter the charge and binding characteristics of the resulting peptide.[10]
-
Drug Development: The compound plays a role in developing drugs, particularly those targeting neurological disorders, by potentially influencing neurotransmitter synthesis and function.[3] It is also a component of certain antibiotics like Pristinamycin I.[2]
-
Biochemical Research: It serves as a tool to study enzyme activity and protein folding.[3] For instance, it has been studied as an allosteric activator for phenylalanine hydroxylase, although it is less potent than L-phenylalanine itself.[11]
Conclusion
4-Amino-L-phenylalanine possesses a unique combination of chemical properties stemming from the additional amino group on its phenyl ring. These characteristics make it an invaluable tool for chemists and pharmacologists. The synthetic protocols provided herein are reliable methods for its laboratory preparation, enabling further research into its applications in peptide chemistry, drug discovery, and materials science. As the demand for sophisticated biomolecules grows, the utility of non-canonical amino acids like 4-Amino-L-phenylalanine will continue to expand.
References
- 1. CAS 2922-41-0: 4-Amino-DL-phenylalanine | CymitQuimica [cymitquimica.com]
- 2. medchemexpress.com [medchemexpress.com]
- 3. chemimpex.com [chemimpex.com]
- 4. nbinno.com [nbinno.com]
- 5. 4-Amino-L-phenylalanine | 943-80-6 [chemicalbook.com]
- 6. usbio.net [usbio.net]
- 7. apexbt.com [apexbt.com]
- 8. 4-Aminophenylalanine | C9H12N2O2 | CID 151001 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 9. 4-Amino-L-phenylalanine, 95% | Fisher Scientific [fishersci.ca]
- 10. chemimpex.com [chemimpex.com]
- 11. The Amino Acid Specificity for Activation of Phenylalanine Hydroxylase Matches the Specificity for Stabilization of Regulatory Domain Dimers - PMC [pmc.ncbi.nlm.nih.gov]
synthesis of 4-Aminophenylalanine from 4-Nitro-L-phenylalanine
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides an in-depth overview of the synthesis of 4-Amino-L-phenylalanine, a non-proteinogenic amino acid of significant interest in pharmaceutical and biotechnological applications. The primary focus is on the reduction of its precursor, 4-Nitro-L-phenylalanine. This document outlines the prevalent synthetic methodologies, provides detailed experimental protocols, and presents key data in a structured format to aid researchers in the efficient and safe production of this valuable compound.
Introduction
4-Amino-L-phenylalanine (4-Am-Phe) serves as a versatile building block in drug development and as a tool in chemical biology. Its applications include the synthesis of peptidomimetics, the introduction of a reactive amino group for bioconjugation, and the production of therapeutic agents. The most common and efficient route to 4-Am-Phe is the reduction of the nitro group of 4-Nitro-L-phenylalanine (4-NO2-Phe). This guide will focus on the prevalent methods for this transformation, particularly catalytic hydrogenation.
Synthetic Pathways
The synthesis of 4-Amino-L-phenylalanine from 4-Nitro-L-phenylalanine is a straightforward reduction of an aromatic nitro group to an amine. Several methods are available for this transformation, with catalytic hydrogenation being the most widely used due to its high efficiency and clean reaction profile.[1][2]
The overall reaction is depicted below:
Caption: General reaction scheme for the synthesis of 4-Amino-L-phenylalanine.
Alternative reducing agents for aromatic nitro compounds include metals in acidic media (e.g., iron in acetic acid), sodium hydrosulfite, or tin(II) chloride.[1] However, catalytic hydrogenation is often preferred for its milder reaction conditions and avoidance of stoichiometric metal waste.
Experimental Protocols
This section provides detailed experimental protocols for the synthesis of the precursor, 4-Nitro-L-phenylalanine, and its subsequent reduction to 4-Amino-L-phenylalanine.
Synthesis of 4-Nitro-L-phenylalanine
The starting material, 4-Nitro-L-phenylalanine, is typically synthesized by the nitration of L-phenylalanine.[3]
Experimental Workflow:
Caption: Workflow for the synthesis of 4-Nitro-L-phenylalanine.
Protocol:
-
In a flask equipped with a magnetic stirrer and cooled in an ice bath, dissolve L-phenylalanine in concentrated sulfuric acid.
-
Slowly add concentrated nitric acid dropwise to the stirred solution, maintaining the temperature at 0°C.
-
After the addition is complete, continue stirring the reaction mixture at 0°C for a specified time (e.g., 1-3 hours).
-
Pour the reaction mixture onto crushed ice.
-
Neutralize the solution with a suitable base, such as lead (II) carbonate.
-
Filter the resulting precipitate.
-
Treat the filtrate with hydrogen sulfide (B99878) gas to precipitate any remaining lead ions as lead (II) sulfide.
-
Filter the lead sulfide precipitate.
-
Concentrate the filtrate under reduced pressure.
-
Recrystallize the crude product from hot water to yield pure 4-Nitro-L-phenylalanine.
Synthesis of 4-Amino-L-phenylalanine via Catalytic Hydrogenation
The reduction of 4-Nitro-L-phenylalanine is most commonly achieved by catalytic hydrogenation using palladium on carbon (Pd/C) or Raney Nickel as the catalyst.[2][4] The following protocol is a general procedure adapted from the hydrogenation of similar aromatic nitro compounds.[4]
Experimental Workflow:
Caption: Workflow for the catalytic hydrogenation of 4-Nitro-L-phenylalanine.
Protocol with Palladium on Carbon (Pd/C):
-
Inerting the Reaction Vessel: In a fume hood, equip a round-bottom flask with a magnetic stir bar and a gas inlet. Purge the flask with nitrogen gas for 10-15 minutes to establish an inert atmosphere.
-
Catalyst and Substrate Addition: Under a gentle stream of nitrogen, carefully add 5-10% palladium on carbon (typically 1-5 mol% relative to the substrate). Dissolve the 4-Nitro-L-phenylalanine in a suitable solvent such as methanol (B129727) or ethanol (B145695) and add it to the reaction flask.
-
Hydrogenation: Evacuate the flask and backfill with hydrogen gas from a balloon or a regulated cylinder. Repeat this evacuation-backfill cycle 3-5 times to ensure the atmosphere is saturated with hydrogen.
-
Reaction: Stir the reaction mixture vigorously at room temperature. Monitor the reaction progress by thin-layer chromatography (TLC) or high-performance liquid chromatography (HPLC) until the starting material is consumed.
-
Work-up: Once the reaction is complete, carefully purge the flask with nitrogen gas to remove all hydrogen.
-
Catalyst Filtration: Filter the reaction mixture through a pad of Celite® to remove the Pd/C catalyst. Caution: The used Pd/C catalyst can be pyrophoric. Do not allow the filter cake to dry completely. Keep it wet with the solvent and handle it according to safety protocols.
-
Product Isolation: Remove the solvent from the filtrate under reduced pressure to obtain the crude 4-Amino-L-phenylalanine. The product can be further purified by recrystallization if necessary.
Data Presentation
The following tables summarize key quantitative data for the starting material and the final product, as well as typical reaction parameters for the synthesis.
Table 1: Physicochemical Properties
| Property | 4-Nitro-L-phenylalanine | 4-Amino-L-phenylalanine |
| Molecular Formula | C₉H₁₀N₂O₄ | C₉H₁₂N₂O₂ |
| Molecular Weight | 210.19 g/mol | 180.20 g/mol [5] |
| Appearance | White to off-white powder | White or cream to brown crystals or powder[6] |
| Melting Point | 245-251 °C (dec.)[7] | - |
| Optical Rotation | [α]²⁵/D +6.8° (c=1.3 in 3 M HCl)[7] | -42° to -45° (c=2, water)[6] |
| Purity (Typical) | ≥98%[7] | ≥94.0%[6] |
Table 2: Synthesis Parameters and Expected Outcomes
| Parameter | Synthesis of 4-Nitro-L-phenylalanine | Synthesis of 4-Amino-L-phenylalanine |
| Key Reagents | L-phenylalanine, Conc. H₂SO₄, Conc. HNO₃ | 4-Nitro-L-phenylalanine, H₂, Pd/C or Raney Ni |
| Solvent | Sulfuric Acid | Methanol, Ethanol |
| Reaction Temperature | 0 °C[3] | Room Temperature |
| Reaction Time | 1-3 hours[3] | 1-12 hours (monitor by TLC/HPLC) |
| Typical Yield | 65-81%[3] | High (typically >90%) |
Conclusion
The synthesis of 4-Amino-L-phenylalanine from 4-Nitro-L-phenylalanine via catalytic hydrogenation is a robust and high-yielding process. This technical guide provides researchers, scientists, and drug development professionals with a comprehensive overview of the synthetic methodology, including detailed experimental protocols and key data. Adherence to the described procedures and safety precautions will enable the successful and safe synthesis of this important amino acid derivative for a wide range of applications.
References
- 1. benchchem.com [benchchem.com]
- 2. Nitro Reduction - Common Conditions [commonorganicchemistry.com]
- 3. researchgate.net [researchgate.net]
- 4. benchchem.com [benchchem.com]
- 5. scbt.com [scbt.com]
- 6. RaneyNi/Formic Acid Nitro Reduction - [www.rhodium.ws] [chemistry.mdma.ch]
- 7. 4-Nitro- L -phenylalanine 98 207591-86-4 [sigmaaldrich.com]
A Technical Guide to the Spectroscopic Properties of 4-Amino-L-phenylalanine
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the core spectroscopic data for 4-Amino-L-phenylalanine, a non-canonical aromatic amino acid. Its unique structure makes it a valuable tool in pharmaceutical development, biochemical research, and protein engineering, where it can be used as a fluorescent probe or a building block for novel peptides and proteins.[1] This document outlines key quantitative data, detailed experimental protocols for its characterization, and logical workflows for its analysis.
Spectroscopic Data Summary
Nuclear Magnetic Resonance (NMR) Spectroscopy
NMR spectroscopy is fundamental for elucidating the chemical structure of 4-Amino-L-phenylalanine. The addition of an amino group to the phenyl ring significantly influences the chemical shifts of the aromatic protons and carbons compared to L-phenylalanine.
Table 1: ¹H NMR Spectroscopic Data (Data for L-phenylalanine is from a 500 MHz spectrum in H₂O)
| Proton Assignment | 4-Amino-L-phenylalanine (Estimated δ, ppm) | L-phenylalanine (δ, ppm) | Multiplicity |
| Hα | ~3.9 - 4.1 | 3.98 | Doublet of doublets (dd) |
| Hβ | ~3.0 - 3.3 | 3.11, 3.27 | Multiplet (m) |
| Aromatic H (ortho to -CH₂) | ~7.0 - 7.2 | 7.37 | Multiplet (m) |
| Aromatic H (ortho to -NH₂) | ~6.6 - 6.8 | 7.37 | Multiplet (m) |
Note: Specific, high-resolution peak assignments for 4-Amino-L-phenylalanine were not available in the cited literature. The estimated shifts are based on general principles of substituent effects on aromatic rings.
Table 2: ¹³C NMR Spectroscopic Data (Data for L-phenylalanine is from a 125 MHz spectrum in H₂O)
| Carbon Assignment | 4-Amino-L-phenylalanine (Expected δ, ppm) | L-phenylalanine (δ, ppm) |
| C=O (Carboxyl) | ~175 - 178 | 174.3 |
| Cα | ~55 - 58 | 56.1 |
| Cβ | ~37 - 40 | 37.9 |
| Aromatic C (quaternary, C-CH₂) | ~125 - 128 | 137.2 |
| Aromatic C (quaternary, C-NH₂) | ~145 - 148 | - |
| Aromatic C (ortho to -CH₂) | ~130 - 132 | 129.3 |
| Aromatic C (ortho to -NH₂) | ~115 - 118 | 128.5 |
| Aromatic C (para to -CH₂) | - | 126.9 |
Note: Specific experimental data for 4-Amino-L-phenylalanine was not found. Expected shifts are predicted based on the known electronic effects of an amino substituent.
Mass Spectrometry (MS)
Mass spectrometry confirms the molecular weight and provides structural information through fragmentation analysis.
Table 3: Mass Spectrometry Data
| Parameter | Value | Source |
| Molecular Formula | C₉H₁₂N₂O₂ | [1] |
| Molecular Weight | 180.20 g/mol | [1] |
| Monoisotopic Mass | 180.089877630 Da | [1] |
| Key Fragments (m/z) | 180 [M]⁺, 136 [M-COOH]⁺, 107 [C₇H₉N]⁺, 106 [C₇H₈N]⁺ | Predicted based on Phenylalanine fragmentation[2] |
Infrared (IR) Spectroscopy
IR spectroscopy is used to identify the key functional groups present in the molecule. The spectrum of an amino acid is characterized by vibrations of the amino group (NH₃⁺), carboxylate group (COO⁻), and the side chain.
Table 4: Key IR Absorption Bands (Comparative data from L-phenylalanine)[3][4]
| Vibrational Mode | Expected Wavenumber (cm⁻¹) | Functional Group |
| N-H Stretch | 3200 - 3400 (m) | Primary amine (-NH₂) |
| N-H Stretch (zwitterion) | 3000 - 3200 (s, br) | Ammonium (-NH₃⁺) |
| C-H Stretch (aromatic) | 3000 - 3100 (m) | Aromatic Ring |
| C-H Stretch (aliphatic) | 2850 - 3000 (m) | -CH₂- and -CH- |
| C=O Stretch (zwitterion) | 1580 - 1610 (s) | Carboxylate (COO⁻), asymmetric |
| N-H Bend (zwitterion) | 1500 - 1550 (s) | Ammonium (-NH₃⁺) |
| C=C Stretch | 1500 - 1600 (m) | Aromatic Ring |
| C-O Stretch | 1300 - 1420 (s) | Carboxylate (COO⁻), symmetric |
| C-N Stretch | 1250 - 1335 (s) | Aromatic Amine |
| C-H "oop" Bend | 800 - 860 (s) | para-disubstituted aromatic |
UV-Visible Spectroscopy
The aromatic ring in 4-Amino-L-phenylalanine acts as a chromophore. The presence of the electron-donating amino group on the phenyl ring causes a significant red-shift (bathochromic shift) in the absorption maxima compared to L-phenylalanine.
Table 5: UV-Visible Absorption Data
| Parameter | 4-Amino-L-phenylalanine | L-phenylalanine (for comparison) |
| λmax | ~230-240 nm and ~280 nm (predicted) | ~198 nm, ~258 nm[5] |
Note: The predicted absorption maxima are based on the known red-shift effect of an amino substituent on the phenyl ring, similar to the shift observed between phenylalanine and tyrosine.[6] The electronic transitions for a related compound, 4-cyanophenylalanine, are red-shifted compared to phenylalanine, supporting this prediction.[7]
Experimental Protocols
The following sections provide detailed methodologies for acquiring the spectroscopic data presented above. These protocols are based on established techniques for amino acid analysis.
NMR Spectroscopy Protocol (¹H and ¹³C)
-
Sample Preparation : Dissolve 10-50 mg of 4-Amino-L-phenylalanine in 0.5-0.7 mL of deuterium (B1214612) oxide (D₂O).[8] For enhanced solubility or to study pH effects, small aliquots of DCl or NaOD can be used to adjust the pH.[8]
-
Internal Standard : For quantitative NMR (qNMR), add a known concentration of an internal standard such as terephthalic acid or sulfoisophthalic acid.[9]
-
Data Acquisition : Transfer the solution to a 5 mm NMR tube. Acquire spectra on a spectrometer (e.g., 400 MHz or higher).
-
¹H NMR : Typical parameters include a spectral width of 10-15 ppm, a relaxation delay of 1-2 seconds, and a sufficient number of scans (e.g., 16-64) to achieve a good signal-to-noise ratio.
-
¹³C NMR : Use a standard 1D pulse program with proton decoupling.[8] Typical parameters include a spectral width of 0-200 ppm, a relaxation delay of 2 seconds, and a larger number of scans (e.g., 1024 or more) due to the low natural abundance of ¹³C.[8]
-
-
Data Processing : Process the raw data (FID) with Fourier transformation. Reference the spectra using the residual solvent peak or an internal standard.
Mass Spectrometry Protocol (ESI-MS)
-
Sample Preparation : Prepare a stock solution of the sample in an organic solvent like methanol (B129727) or acetonitrile, or in water, at a concentration of approximately 1 mg/mL.[10]
-
Dilution : Take a small aliquot (e.g., 10 µL) of the stock solution and dilute it to a final concentration of 1-10 µg/mL in a solvent mixture suitable for electrospray ionization (ESI), such as 50:50 acetonitrile:water with 0.1% formic acid.[10][11]
-
Instrumentation : Use a mass spectrometer equipped with an ESI source.
-
Data Acquisition : Infuse the sample directly or via liquid chromatography (LC). Acquire data in positive ion mode. For fragmentation analysis (MS/MS), select the precursor ion (m/z 181.1 for [M+H]⁺) and apply collision-induced dissociation (CID).[12]
FT-IR Spectroscopy Protocol
-
Sample Preparation : For solid-state analysis, mix a small amount of the sample with dry potassium bromide (KBr) and press it into a thin pellet. Alternatively, use an Attenuated Total Reflectance (ATR) accessory, which requires placing a small amount of the powder directly onto the crystal.[13]
-
Background Collection : Record a background spectrum of the empty sample compartment (for KBr pellet) or the clean ATR crystal.
-
Data Acquisition : Place the sample in the spectrometer and collect the spectrum. Typically, 16-32 scans are co-added to improve the signal-to-noise ratio over a range of 4000 to 400 cm⁻¹.
-
Data Processing : The final spectrum is presented in terms of transmittance or absorbance after automatic background subtraction by the instrument software.
UV-Visible Spectroscopy Protocol
-
Sample Preparation : Prepare a stock solution of 4-Amino-L-phenylalanine in a UV-transparent solvent, typically deionized water or a buffer solution (e.g., phosphate (B84403) buffer).[14][15] Dilute the stock solution to a concentration that results in an absorbance reading between 0.1 and 1.0.
-
Instrumentation : Use a dual-beam UV-Vis spectrophotometer.
-
Blanking : Fill a quartz cuvette with the solvent used for sample preparation and use it to zero the instrument (set the baseline).[14]
-
Data Acquisition : Replace the blank cuvette with the sample cuvette. Scan a wavelength range from approximately 200 nm to 400 nm to identify all absorption maxima.[16]
Visualization of Workflows and Pathways
The following diagrams, generated using Graphviz, illustrate key logical workflows and conceptual pathways relevant to the analysis and application of 4-Amino-L-phenylalanine.
Spectroscopic Characterization Workflow
This diagram outlines the systematic process for the complete spectroscopic identification and characterization of 4-Amino-L-phenylalanine.
References
- 1. 4-Aminophenylalanine | C9H12N2O2 | CID 151001 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. researchgate.net [researchgate.net]
- 4. researchgate.net [researchgate.net]
- 5. UV-Vis Spectrum of Phenylalanine | SIELC Technologies [sielc.com]
- 6. Aromatic amino acid - Wikipedia [en.wikipedia.org]
- 7. Investigation of an unnatural amino acid for use as a resonance Raman probe: Detection limits, solvent and temperature dependence of the νC≡N band of 4-cyanophenylalanine - PMC [pmc.ncbi.nlm.nih.gov]
- 8. benchchem.com [benchchem.com]
- 9. Quantitative 1H Nuclear Magnetic Resonance (qNMR) of Aromatic Amino Acids for Protein Quantification - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Sample Preparation Protocol for ESI Accurate Mass Service | Mass Spectrometry Research Facility [massspec.chem.ox.ac.uk]
- 11. ctdp.org [ctdp.org]
- 12. benchchem.com [benchchem.com]
- 13. Self-assembly of l -phenylalanine amino acid: electrostatic induced hindrance of fibril formation - RSC Advances (RSC Publishing) DOI:10.1039/C9RA00268E [pubs.rsc.org]
- 14. scribd.com [scribd.com]
- 15. iosrjournals.org [iosrjournals.org]
- 16. documents.thermofisher.com [documents.thermofisher.com]
A Technical Guide to the Investigation of p-Aminophenylalanine in Vigna vexillata
<
Audience: Researchers, scientists, and drug development professionals.
Abstract: p-Aminophenylalanine (p-APA) is a non-proteinogenic amino acid with known bioactivity, making it a compound of interest for pharmaceutical research. While its presence has been confirmed in Vigna vexillata, detailed quantitative data and established experimental protocols for its analysis within this specific plant matrix are not widely consolidated.[1][2] This technical guide provides a comprehensive framework for the investigation of p-APA in Vigna vexillata. It outlines a proposed biosynthetic pathway, details robust experimental protocols for extraction, separation, quantification, and structural confirmation, and presents the necessary visualizations and data structures to guide researchers in this endeavor.
Introduction
Vigna vexillata (L.) A. Rich, commonly known as the wild cowpea or zombi pea, is a pan-tropical legume recognized for its edible tubers and protein-rich seeds.[3] The genus Vigna is a known source of various phytochemicals, including non-proteinogenic amino acids (NPAAs), which can serve as defense compounds and are of interest for their potential pharmacological activities.[4][5][6] Among these is p-aminophenylalanine (4-aminophenylalanine, p-APA), an analogue of phenylalanine. The biosynthesis of p-APA has been demonstrated in Vigna vexillata to originate from shikimic acid via a pathway distinct from that of phenylalanine and tyrosine.[2] Given the established bioactivity of NPAAs and the potential of p-APA as a precursor in drug synthesis, a rigorous and standardized approach to its study in V. vexillata is warranted. This document serves as a technical guide for researchers, providing the foundational knowledge and detailed methodologies required to investigate the natural occurrence, biosynthesis, and properties of p-APA in this plant species.
Proposed Biosynthesis of p-Aminophenylalanine
The biosynthesis of p-aminophenylalanine in Vigna vexillata proceeds from chorismic acid, a key branch-point intermediate in the shikimate pathway.[2] Unlike phenylalanine and tyrosine, which are formed via prephenate, p-APA synthesis involves a distinct amination and rearrangement sequence. The proposed pathway involves the conversion of chorismic acid to an aminated intermediate, which then undergoes rearrangements to form 4-aminophenylpyruvic acid, the direct precursor that is finally transaminated to yield p-aminophenylalanine.[2]
Caption: Proposed biosynthetic pathway of p-Aminophenylalanine from Chorismic Acid.
Experimental Protocols
A systematic approach is required to accurately isolate, identify, and quantify p-APA from Vigna vexillata. The following sections detail a comprehensive workflow.
Overall Experimental Workflow
The process begins with the careful preparation of plant material, followed by extraction of the target analyte. The resulting extract is then subjected to high-performance analytical techniques for separation and quantification, with definitive structural confirmation as the final step.
Caption: General experimental workflow for p-Aminophenylalanine analysis.
Sample Preparation and Extraction
-
Plant Material: Collect fresh samples from different tissues of Vigna vexillata (e.g., seeds, tubers, leaves).[3] Freeze-dry (lyophilize) the material to preserve chemical integrity and facilitate grinding.
-
Grinding: Grind the lyophilized tissue into a fine, homogenous powder using a mortar and pestle or a cryogenic grinder.
-
Extraction:
-
Weigh approximately 1 g of powdered sample into a centrifuge tube.
-
Add 10 mL of an extraction solvent (e.g., 70% (v/v) aqueous ethanol or 0.1% formic acid in methanol).
-
Vortex thoroughly and sonicate for 30 minutes in a water bath.
-
Centrifuge at 10,000 x g for 15 minutes.
-
Collect the supernatant. Repeat the extraction on the pellet and pool the supernatants.
-
Filter the pooled supernatant through a 0.22 µm syringe filter prior to analysis.
-
Separation and Quantification: LC-MS/MS
Liquid Chromatography coupled with Tandem Mass Spectrometry (LC-MS/MS) is the gold standard for quantifying trace levels of specific molecules in complex biological matrices due to its high sensitivity and selectivity.[7][8]
Protocol:
-
Instrumentation: Utilize a standard UPLC or HPLC system coupled to a triple quadrupole mass spectrometer.[9]
-
Chromatography: Separate the analyte using a reversed-phase C18 column.
-
Mass Spectrometry: Operate the mass spectrometer in positive electrospray ionization (ESI+) mode using Multiple Reaction Monitoring (MRM) for highest sensitivity and specificity.[10]
Table 1: Suggested LC-MS/MS Parameters
| Parameter | Recommended Setting |
| LC Column | Reversed-Phase C18 (e.g., 100 x 2.1 mm, 1.8 µm) |
| Mobile Phase A | 0.1% Formic Acid in Water |
| Mobile Phase B | 0.1% Formic Acid in Acetonitrile |
| Flow Rate | 0.3 mL/min |
| Injection Volume | 5 µL |
| Gradient | Start at 2% B, ramp to 95% B over 8 min, hold 2 min |
| Ionization Mode | ESI Positive |
| Capillary Voltage | 3.0 kV[9] |
| Source Temperature | 150 °C[9] |
| MRM Transition | Precursor Ion (Q1): m/z 181.1, Product Ion (Q3): m/z 164.1 |
Note: MRM transitions must be optimized by infusing a pure p-APA standard.
Structural Elucidation: NMR Spectroscopy
While LC-MS/MS provides quantitative data, Nuclear Magnetic Resonance (NMR) spectroscopy offers definitive structural confirmation. This requires isolating a larger quantity of the compound.
Protocol:
-
Isolation: Perform large-scale extraction and use preparative HPLC to isolate several milligrams of the putative p-APA.
-
Analysis: Dissolve the purified compound in a suitable deuterated solvent (e.g., D₂O or Methanol-d₄).
-
Data Acquisition: Acquire 1D (¹H, ¹³C) and 2D (e.g., COSY, HSQC, HMBC) NMR spectra.
-
Confirmation: Compare the acquired spectra with published data for p-aminophenylalanine or a certified reference standard. The characteristic aromatic signals in the ¹H NMR spectrum are key identifiers.[11]
Table 2: Expected ¹H NMR Chemical Shifts for p-Aminophenylalanine
| Proton | Expected Chemical Shift (δ, ppm) in D₂O | Multiplicity |
| H-α | ~3.9 - 4.1 | Doublet of doublets (dd) |
| H-β | ~3.0 - 3.2 | Multiplet (m) |
| Aromatic (ortho to NH₂) | ~6.8 - 7.0 | Doublet (d) |
| Aromatic (ortho to CH₂) | ~7.2 - 7.4 | Doublet (d) |
Note: Exact chemical shifts can vary based on solvent and pH.
Data Presentation and Interpretation
Quantitative data should be meticulously organized to allow for clear interpretation and comparison across different plant tissues or experimental conditions.
Table 3: Example Data Table for p-APA Quantification in Vigna vexillata
| Plant Tissue | Sample Replicate | Peak Area (LC-MS/MS) | Concentration (µg/g dry weight) | Standard Deviation |
| Seed | 1 | 150,450 | 12.5 | 0.8 |
| 2 | 162,300 | 13.4 | ||
| 3 | 148,900 | 12.3 | ||
| Tuber | 1 | 45,600 | 3.8 | 0.3 |
| 2 | 51,200 | 4.2 | ||
| 3 | 48,750 | 4.0 | ||
| Leaf | 1 | 10,890 | 0.9 | 0.1 |
| 2 | 12,100 | 1.0 | ||
| 3 | 13,300 | 1.1 |
Significance and Drug Development Pathway
The identification and quantification of novel or uncommon natural products like p-APA is the first step in a potential drug development pipeline. Its presence in an edible plant like V. vexillata suggests a favorable toxicity profile. As a non-proteinogenic amino acid, it can serve as a valuable chiral building block for the synthesis of more complex pharmaceutical agents.
Caption: From natural product discovery to clinical application.
Conclusion
This technical guide provides a robust, methodology-driven framework for the scientific investigation of p-aminophenylalanine in Vigna vexillata. By following the detailed protocols for extraction, LC-MS/MS quantification, and NMR confirmation, researchers can generate high-quality, reproducible data. Such research is crucial for understanding the phytochemistry of underutilized legumes and for identifying novel natural products that can serve as lead compounds in future drug development efforts.
References
- 1. This compound | C9H12N2O2 | CID 151001 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 2. Biosynthesis of p-aminophenylalanine: part of a general scheme for the biosynthesis of chorisimic acid derivatives - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Nutritional status of Zombi pea (Vigna vexillata) as influenced by plant density and deblossoming - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Plant proteins, peptides, and non-protein amino acids: Toxicity, sources, and analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Vigna vexillata var. vexillata | PlantZAfrica [pza.sanbi.org]
- 6. Frontiers | Editorial: Physiological Aspects of Non-proteinogenic Amino Acids in Plants [frontiersin.org]
- 7. A highly accurate mass spectrometry method for the quantification of phenylalanine and tyrosine on dried blood spots: Combination of liquid chromatography, phenylalanine/tyrosine-free blood calibrators and multi-point/dynamic calibration - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Determination of phenylalanine in human serum by isotope dilution liquid chromatography/tandem mass spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. benchchem.com [benchchem.com]
- 10. mdpi.com [mdpi.com]
- 11. Proton NMR observation of phenylalanine and an aromatic metabolite in the rabbit brain in vivo - PubMed [pubmed.ncbi.nlm.nih.gov]
An In-depth Technical Guide on the Optical Rotation and Chirality of L-4-aminophenylalanine
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the optical rotation and chirality of L-4-aminophenylalanine, a non-proteinogenic amino acid of significant interest in pharmaceutical research and development. This document details the quantitative chiral properties, experimental protocols for their determination, and the biological significance of its stereochemistry.
Core Concepts: Chirality and Optical Rotation
Chirality is a fundamental property of molecules that exist in two non-superimposable mirror-image forms, known as enantiomers. L-4-aminophenylalanine and its counterpart, D-4-aminophenylalanine, are enantiomers. While they share the same chemical formula and connectivity, their three-dimensional arrangement is different, leading to distinct interactions with other chiral molecules, such as biological receptors and enzymes.
Optical rotation is a characteristic physical property of chiral molecules. When plane-polarized light is passed through a solution containing a chiral compound, the plane of the light is rotated. The direction and magnitude of this rotation are unique to each enantiomer. The specific rotation, [α], is a standardized measure of this optical activity.
Quantitative Chiral Properties
The optical rotation of L-4-aminophenylalanine and its derivatives is a key parameter for its identification and quality control. The following table summarizes the available quantitative data.
| Compound | Specific Rotation [α] | Conditions |
| L-4-aminophenylalanine | -42° to -45° | c=2, water |
| Fmoc-4-amino-L-phenylalanine | -9 ± 2° | c=1, in Dimethylformamide (DMF) |
Table 1: Specific Rotation of L-4-aminophenylalanine and its N-Fmoc derivative.
Experimental Protocols
Accurate determination of the optical and chiral properties of L-4-aminophenylalanine is crucial for its application in research and drug development. Below are detailed methodologies for key experiments.
Determination of Optical Rotation by Polarimetry
This protocol outlines the procedure for measuring the specific rotation of L-4-aminophenylalanine.
Objective: To determine the specific rotation of L-4-aminophenylalanine using a polarimeter.
Materials:
-
L-4-aminophenylalanine sample
-
Distilled water (or appropriate solvent)
-
Volumetric flask
-
Analytical balance
-
Polarimeter
-
Polarimeter cell (1 dm)
Procedure:
-
Sample Preparation:
-
Accurately weigh approximately 200 mg of L-4-aminophenylalanine.
-
Dissolve the sample in distilled water in a 10 mL volumetric flask.
-
Ensure the sample is completely dissolved and the solution is homogeneous.
-
-
Instrument Calibration:
-
Turn on the polarimeter and allow the sodium lamp to warm up.
-
Calibrate the instrument with a blank solvent (distilled water) and set the reading to zero.
-
-
Measurement:
-
Rinse the polarimeter cell with a small amount of the sample solution.
-
Fill the cell with the sample solution, ensuring there are no air bubbles in the light path.
-
Place the filled cell in the polarimeter.
-
Record the observed optical rotation (α) at a constant temperature (e.g., 20°C) and a specific wavelength (e.g., 589 nm, the sodium D-line).
-
-
Calculation of Specific Rotation:
-
The specific rotation [α] is calculated using the following formula: [α] = α / (c × l) Where:
-
α = observed rotation in degrees
-
c = concentration of the solution in g/mL
-
l = path length of the polarimeter cell in decimeters (dm)
-
-
Chiral Purity Determination by High-Performance Liquid Chromatography (HPLC)
This method describes the separation of L- and D-enantiomers of 4-aminophenylalanine to determine enantiomeric purity.
Objective: To resolve and quantify the enantiomers of this compound using chiral HPLC.
Instrumentation and Materials:
-
HPLC system with a UV detector
-
Chiral stationary phase (CSP) column (e.g., a macrocyclic glycopeptide-based column like ristocetin (B1679390) A)
-
Mobile phase: Methanol/Acetic Acid (e.g., 100:0.1 v/v)
-
This compound sample
-
Solvent for sample preparation (e.g., mobile phase)
Procedure:
-
System Preparation:
-
Equilibrate the chiral column with the mobile phase at a constant flow rate (e.g., 1.0 mL/min) until a stable baseline is achieved.
-
Set the column temperature (e.g., 25°C).
-
-
Sample Preparation:
-
Dissolve a known amount of the this compound sample in the mobile phase.
-
Filter the sample through a 0.45 µm syringe filter before injection.
-
-
Chromatographic Analysis:
-
Inject a specific volume of the prepared sample (e.g., 10 µL) onto the column.
-
Monitor the elution of the enantiomers using a UV detector at an appropriate wavelength (e.g., 254 nm).
-
-
Data Analysis:
-
Identify the peaks corresponding to the L- and D-enantiomers based on their retention times (comparison with standards if available).
-
Calculate the enantiomeric excess (% ee) using the peak areas of the two enantiomers: % ee = [ (Area_L - Area_D) / (Area_L + Area_D) ] × 100
-
Structural Elucidation by Vibrational Circular Dichroism (VCD) Spectroscopy
VCD provides detailed information about the three-dimensional structure and absolute configuration of chiral molecules in solution.
Objective: To obtain the VCD spectrum of L-4-aminophenylalanine to confirm its absolute configuration and study its conformational properties.
Instrumentation and Materials:
-
VCD Spectrometer (FTIR-based with VCD accessory)
-
Infrared (IR) transparent sample cell (e.g., BaF₂)
-
L-4-aminophenylalanine sample
-
Appropriate solvent (e.g., D₂O to avoid interference from O-H and N-H vibrations)
Procedure:
-
Sample Preparation:
-
Dissolve the L-4-aminophenylalanine sample in the chosen deuterated solvent to an appropriate concentration.
-
-
Data Acquisition:
-
Acquire the VCD and IR spectra of the sample solution.
-
Acquire a background spectrum of the solvent in the same cell.
-
-
Data Processing:
-
Subtract the solvent spectrum from the sample spectrum.
-
The resulting VCD spectrum will show both positive and negative bands, which are characteristic of the molecule's specific enantiomer and conformation.
-
-
Spectral Interpretation:
-
Compare the experimental VCD spectrum with theoretical spectra calculated using quantum chemistry methods (e.g., Density Functional Theory - DFT) for the L- and D-enantiomers.
-
A good match between the experimental and calculated spectra allows for the unambiguous assignment of the absolute configuration.
-
Biological Significance and Signaling Pathways
The chirality of this compound is critical for its biological activity. The L-enantiomer interacts differently with enzymes and receptors compared to the D-enantiomer, leading to distinct physiological effects.
Allosteric Activation of Phenylalanine Hydroxylase (PAH)
L-4-aminophenylalanine is an analog of the essential amino acid L-phenylalanine and can act as an allosteric activator of Phenylalanine Hydroxylase (PAH).[1] PAH is a key enzyme in phenylalanine metabolism, and its dysregulation can lead to phenylketonuria (PKU). L-4-aminophenylalanine binds to a regulatory site on the enzyme, distinct from the active site, inducing a conformational change that enhances the enzyme's catalytic activity. This activation is achieved through the stabilization of regulatory domain dimers.[2] However, the activation by L-4-aminophenylalanine is reported to be at a lower level compared to L-phenylalanine itself.[1]
Caption: Allosteric activation of Phenylalanine Hydroxylase (PAH) by L-4-aminophenylalanine.
Inhibition of Dipeptidyl Peptidase IV (DPP-4)
Derivatives of L-4-aminophenylalanine have been developed as potent and selective inhibitors of Dipeptidyl Peptidase IV (DPP-4).[3] DPP-4 is a serine protease that inactivates incretin (B1656795) hormones, such as glucagon-like peptide-1 (GLP-1), which are crucial for regulating blood glucose levels.[4] By inhibiting DPP-4, these L-4-aminophenylalanine-based compounds prevent the degradation of GLP-1, thereby prolonging its action and leading to enhanced insulin (B600854) secretion and improved glucose control. This mechanism is a cornerstone of treatment for type 2 diabetes.
Caption: Mechanism of DPP-4 inhibition by L-4-aminophenylalanine derivatives.
Experimental Workflow
The following diagram illustrates a typical workflow for the synthesis, purification, and chiral analysis of L-4-aminophenylalanine.
Caption: General workflow for the preparation and analysis of L-4-aminophenylalanine.
Conclusion
The chirality of L-4-aminophenylalanine is a defining feature that governs its physical properties and biological functions. Its specific optical rotation is a critical parameter for its characterization, and reliable experimental protocols, such as polarimetry, chiral HPLC, and VCD, are essential for ensuring its enantiomeric purity and confirming its absolute configuration. The distinct biological activities of its L-enantiomer, particularly in the allosteric activation of PAH and the development of DPP-4 inhibitors, underscore the importance of stereochemistry in drug design and development. This guide provides a foundational resource for researchers and scientists working with this important chiral molecule.
References
- 1. A Computational Protocol for Vibrational Circular Dichroism Spectra of Cyclic Oligopeptides - PMC [pmc.ncbi.nlm.nih.gov]
- 2. spectroscopyeurope.com [spectroscopyeurope.com]
- 3. Frontiers | Inhibition of Dipeptidyl Peptidase-4 by Flavonoids: Structure–Activity Relationship, Kinetics and Interaction Mechanism [frontiersin.org]
- 4. hou.usra.edu [hou.usra.edu]
An In-depth Technical Guide to the Solubility of 4-Aminophenylalanine in Aqueous and Organic Solvents
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the solubility characteristics of 4-Aminophenylalanine, a non-canonical amino acid of significant interest in pharmaceutical and biotechnological research. Understanding its solubility in various solvent systems is critical for applications ranging from peptide synthesis to the development of novel therapeutics. This document compiles available quantitative data, outlines standard experimental protocols for solubility determination, and presents a visual workflow for clarity.
Core Physicochemical Properties
4-Amino-L-phenylalanine is an amino acid derivative with the molecular formula C₉H₁₂N₂O₂ and a molecular weight of approximately 180.2 g/mol [1][2]. It typically appears as a white to off-white or pale beige crystalline powder[3][4][5]. Its structure, featuring both a hydrophilic amino acid backbone and a more hydrophobic aminophenyl side chain, results in a varied solubility profile.
Quantitative Solubility Data
The solubility of this compound has been reported in several common laboratory solvents. The data, collated from various chemical suppliers and databases, is summarized below. It is important to note that solubility can be significantly influenced by factors such as temperature, pH, the specific enantiomeric form (L- or D-), and whether the compound is a free base or a salt. The data presented here should be considered as a guide, with experimental conditions noted where available.
| Solvent System | Compound Form | Temperature | Solubility | Method/Notes | Citation |
| Water | L-Form | Not Specified | Soluble | Qualitative assessment | [3][6] |
| Water | L-Form | 60°C | 3.33 mg/mL (18.48 mM) | Requires sonication, warming, and heating | [7] |
| Water | L-HCl Salt | Not Specified | ~50 mg/mL | Based on 0.1g in 2 mL yielding a clear solution | [4] |
| Phosphate-Buffered Saline (PBS) | L-Form | Not Specified | 10 mg/mL (55.49 mM) | Requires sonication | [7] |
| Dimethyl Sulfoxide (DMSO) | L-Form | Not Specified | < 1 mg/mL | Insoluble or slightly soluble | [7] |
| Methanol | L-Form | Not Specified | Slightly Soluble | Requires sonication | [3] |
| Acetonitrile | D-Form | Not Specified | 0.1 - 1 mg/mL | Slightly soluble | [8] |
Generally, the solubility of amino acids is highest in pure water and tends to decrease in semi-polar organic solvents[9]. The presence of both an acidic carboxylic group and a basic amino group means that solubility is highly dependent on pH. In aqueous systems, solubility typically increases significantly at pH values above and below the isoelectric point due to the formation of soluble salts[9].
Experimental Workflow for Solubility Determination
A common and reliable method for determining the solubility of a compound like this compound is the isothermal shake-flask method, followed by gravimetric or spectroscopic analysis. The following diagram illustrates a typical workflow for this process.
Caption: Experimental workflow for solubility determination.
Experimental Protocols
The following section details a standard protocol for determining the solubility of this compound using the shake-flask method, a technique widely applied for amino acid solubility studies[9][10].
Objective: To determine the equilibrium solubility of this compound in a specific solvent at a controlled temperature.
Materials:
-
This compound (powder)
-
Solvent of interest (e.g., deionized water, ethanol)
-
Thermostatic shaker or water bath
-
Analytical balance
-
Vials with airtight caps
-
Syringe filters (e.g., 0.22 µm PTFE or PVDF)
-
Pipettes and volumetric flasks
-
Vacuum oven or evaporator
-
(For spectroscopic analysis) HPLC or UV-Vis spectrophotometer and appropriate standards
Procedure:
-
Preparation: Add an excess amount of this compound solid to a known volume of the selected solvent in a sealed vial. The presence of undissolved solid is essential to ensure saturation is reached.
-
Equilibration: Place the vial in a thermostatic shaker set to the desired temperature (e.g., 25°C). The mixture should be agitated for a sufficient period to ensure equilibrium is reached. For amino acids, this can take between 24 to 72 hours[10].
-
Phase Separation: After equilibration, cease agitation and allow the vial to rest in the thermostatic bath for at least 12 hours to allow the excess solid to settle[10]. Alternatively, the sample can be centrifuged at the controlled temperature to facilitate separation.
-
Sampling: Carefully withdraw a precise volume of the clear supernatant using a pipette. To ensure no solid particulates are transferred, the supernatant should be immediately filtered through a syringe filter pre-conditioned to the experimental temperature.
-
Quantification (Gravimetric Method):
-
Dispense the filtered aliquot into a pre-weighed sample bottle[10].
-
Evaporate the solvent completely using a vacuum oven at a low temperature to prevent decomposition of the amino acid[10].
-
Once a constant mass is achieved, weigh the bottle containing the solid residue.
-
The mass of the dissolved this compound is the final mass minus the initial mass of the bottle.
-
-
Quantification (Spectrophotometric Method):
-
This method, also used for amino acid solubility, involves creating a calibration curve with known concentrations of this compound in the solvent.
-
The filtered aliquot is appropriately diluted, and its absorbance or chromatographic peak area is measured.
-
The concentration is then determined by comparing the measurement against the calibration curve.
-
-
Calculation: The solubility is calculated based on the mass of the solute and the initial volume of the solvent, typically expressed in mg/mL or mol/L. The process should be replicated multiple times to ensure accuracy[10].
References
- 1. This compound | C9H12N2O2 | CID 151001 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 2. 4-Amino-L-phenylalanine | CAS#:943-80-6 | Chemsrc [chemsrc.com]
- 3. 4-Amino-L-phenylalanine | 943-80-6 [chemicalbook.com]
- 4. usbio.net [usbio.net]
- 5. chemimpex.com [chemimpex.com]
- 6. 4-Amino-L-phenylalanine, 95% | Fisher Scientific [fishersci.ca]
- 7. medchemexpress.com [medchemexpress.com]
- 8. caymanchem.com [caymanchem.com]
- 9. "The Solubility of Amino Acids in Various Solvent Systems" by Thomas E. Needham [digitalcommons.uri.edu]
- 10. researchgate.net [researchgate.net]
The Elusive Crystalline Architecture of 4-Aminophenylalanine: A Guide to a Molecule of Interest
For researchers, scientists, and drug development professionals, understanding the solid-state properties of a molecule is paramount. This guide delves into the known characteristics of 4-Aminophenylalanine, a non-canonical amino acid of significant interest, while also highlighting the current gaps in our knowledge regarding its precise crystal structure and morphology.
While this compound is a commercially available compound utilized in various research applications, a comprehensive, publicly available, and fully determined crystal structure remains elusive. Searches of prominent crystallographic databases have not yielded a definitive single-crystal X-ray diffraction study complete with unit cell parameters, space group, and atomic coordinates. This absence of foundational crystallographic data presents a significant challenge in fully characterizing its solid-state behavior and predicting its properties.
Molecular Structure and Known Properties
This compound, also known as para-aminophenylalanine, is an analogue of the essential amino acid phenylalanine. Its structure is characterized by an amino group substituted at the para position of the phenyl ring. This modification introduces unique chemical properties that are leveraged in protein engineering and drug design.
Below is a representation of the molecular connectivity of this compound.
Caption: A 2D representation of the molecular structure of this compound.
The Path Forward: Experimental Determination of Crystal Structure
The lack of a published crystal structure necessitates experimental work to elucidate these fundamental properties. The typical workflow for such a study is outlined below. This process is crucial for understanding polymorphism, solubility, and stability, which are critical parameters in drug development.
Caption: A generalized workflow for the experimental determination of a compound's crystal structure and morphology.
Hypothetical Experimental Protocols
While specific, optimized protocols for this compound are not available in the literature, the following sections outline general methodologies that would be applied in its study.
Crystallization
The initial and often most challenging step is the growth of high-quality single crystals suitable for X-ray diffraction. A common approach for amino acids is slow evaporation from an aqueous solution.
Protocol for Slow Evaporation Crystallization:
-
Solution Preparation: Prepare a saturated or near-saturated solution of this compound in a suitable solvent. Water is a logical starting point. Gentle heating may be required to facilitate dissolution.
-
Filtration: Filter the solution through a fine-pored filter (e.g., 0.22 µm) to remove any particulate matter that could act as unwanted nucleation sites.
-
Crystallization Vessel: Transfer the filtered solution to a clean crystallization dish or beaker.
-
Evaporation Control: Cover the vessel with a perforated lid or parafilm with small pinholes to allow for slow evaporation of the solvent. The rate of evaporation is a critical parameter influencing crystal quality.
-
Incubation: Place the vessel in a vibration-free environment at a constant temperature.
-
Crystal Harvesting: Once crystals of sufficient size have formed, carefully remove them from the solution and dry them.
Single-Crystal X-ray Diffraction (SC-XRD)
This is the definitive technique for determining the three-dimensional arrangement of atoms within a crystal.
Protocol for SC-XRD Data Collection:
-
Crystal Selection: Under a microscope, select a well-formed single crystal with sharp edges and no visible defects.
-
Mounting: Mount the selected crystal on a goniometer head.
-
Data Collection: Place the mounted crystal on the diffractometer. A beam of X-rays is directed at the crystal, and the diffraction pattern is recorded as the crystal is rotated.
-
Data Processing: The collected diffraction data is processed to determine the unit cell dimensions and space group.
-
Structure Solution and Refinement: The processed data is used to solve the crystal structure, yielding the atomic coordinates. The structural model is then refined to best fit the experimental data.
Powder X-ray Diffraction (PXRD)
PXRD is used to analyze the bulk crystalline material and can be used to identify crystalline phases and assess purity.
Protocol for PXRD Analysis:
-
Sample Preparation: A small amount of the crystalline powder is gently packed into a sample holder.
-
Data Collection: The sample is placed in a powder diffractometer, and an X-ray beam is scanned over a range of angles (2θ).
-
Pattern Analysis: The resulting diffraction pattern, a plot of intensity versus 2θ, is a fingerprint of the crystalline phase.
Crystal Morphology Analysis
The external shape of a crystal, its morphology, is a consequence of its internal structure and the conditions of its growth.
Protocol for Scanning Electron Microscopy (SEM) Analysis:
-
Sample Mounting: Crystals are mounted on an SEM stub using conductive adhesive.
-
Coating: To prevent charging, the samples are typically coated with a thin layer of a conductive material, such as gold or palladium.
-
Imaging: The sample is placed in the SEM chamber, and a focused beam of electrons is scanned across the surface to generate high-resolution images of the crystal morphology.
Conclusion and Future Directions
The complete crystal structure and a detailed understanding of the morphology of this compound remain important unanswered questions for the scientific community. The experimental determination of these properties would provide invaluable data for researchers in fields ranging from materials science to pharmacology. The protocols outlined above provide a roadmap for future studies that will undoubtedly shed light on the solid-state landscape of this intriguing molecule. The publication and deposition of such data in publicly accessible databases are strongly encouraged to advance the collective understanding of this compound.
An In-depth Guide to the pKa Values of 4-Aminophenylalanine's Ionizable Groups
This technical guide provides a comprehensive overview of the acid-base dissociation constants (pKa values) for the ionizable groups of the non-proteinogenic amino acid, 4-Aminophenylalanine. This document is intended for researchers, scientists, and professionals in the field of drug development who require a thorough understanding of the physicochemical properties of this compound.
Estimated pKa Values
Due to the limited availability of direct experimental data for this compound in publicly accessible literature, the following table presents estimated pKa values. These estimations are derived from the known pKa values of its structural analogs, Phenylalanine and Aniline. The pKa of the α-carboxyl and α-amino groups are approximated from Phenylalanine, while the pKa of the aromatic amino group is based on that of Aniline.
| Ionizable Group | Estimated pKa | Basis for Estimation |
| α-Carboxyl Group | ~1.83 - 2.58 | Based on the pKa of the α-carboxyl group of Phenylalanine.[1][2][3][4] |
| α-Amino Group | ~9.13 - 9.24 | Based on the pKa of the α-amino group of Phenylalanine.[2][3][4] |
| 4-Amino Group (Aromatic) | ~4.6 | Based on the pKa of the anilinium ion (the conjugate acid of aniline).[5][6][7] |
Note: These values are estimations and may vary depending on experimental conditions such as temperature, ionic strength, and solvent. For precise values, experimental determination is highly recommended.
Experimental Protocols for pKa Determination
The determination of pKa values is crucial for understanding the ionization state of a molecule at a given pH, which in turn influences its solubility, lipophilicity, and biological activity. The following are detailed methodologies for two common experimental techniques used to determine the pKa values of amino acids.
Potentiometric Titration
Potentiometric titration is a widely used and accessible method for determining pKa values. It involves the gradual addition of a titrant (a strong acid or base) to a solution of the analyte while monitoring the pH.
Materials and Equipment:
-
This compound sample
-
Standardized 0.1 M Hydrochloric Acid (HCl) solution
-
Standardized 0.1 M Sodium Hydroxide (NaOH) solution
-
High-precision pH meter with a combination glass electrode
-
Magnetic stirrer and stir bar
-
Burette (50 mL)
-
Beaker (100 mL)
-
Volumetric flasks and pipettes
-
Deionized water (degassed)
-
Inert gas (Nitrogen or Argon)
Procedure:
-
Sample Preparation: Accurately weigh a known amount of this compound and dissolve it in a specific volume of deionized water to prepare a solution of known concentration (e.g., 0.01 M).
-
Initial Acidification: To determine the pKa of the carboxyl and aromatic amino groups, the solution is first acidified by adding a known excess of standardized HCl to protonate all ionizable groups.
-
Titration with Base: The acidified solution is then titrated with a standardized NaOH solution. The titrant is added in small, precise increments (e.g., 0.1 mL).
-
pH Measurement: After each addition of NaOH, the solution is stirred thoroughly to ensure homogeneity, and the pH is recorded once the reading stabilizes.
-
Titration Curve: The titration is continued until the pH reaches a value where all ionizable protons have been removed (typically around pH 11-12).
-
Data Analysis: A titration curve is generated by plotting the measured pH against the volume of NaOH added. The pKa values correspond to the pH at the midpoints of the buffering regions (the flat portions of the curve). The equivalence points (the steepest parts of the curve) indicate the complete deprotonation of each ionizable group. The pKa values can be more accurately determined from the first derivative of the titration curve, where the pKa is the pH at the half-equivalence point.
NMR Spectroscopy
Nuclear Magnetic Resonance (NMR) spectroscopy is a powerful technique for determining pKa values by monitoring the chemical shift changes of specific nuclei (typically ¹H or ¹³C) as a function of pH.
Materials and Equipment:
-
This compound sample
-
A series of buffer solutions with known pH values spanning the range of interest
-
NMR spectrometer
-
NMR tubes
-
Deuterated solvent (e.g., D₂O)
-
pH meter
Procedure:
-
Sample Preparation: A series of NMR samples is prepared, each containing the same concentration of this compound dissolved in a buffer of a specific pH. D₂O is typically used as the solvent to avoid a large water signal in the ¹H NMR spectrum.
-
NMR Data Acquisition: ¹H NMR (or ¹³C NMR) spectra are acquired for each sample in the pH series.
-
Chemical Shift Monitoring: The chemical shifts of protons (or carbons) adjacent to the ionizable groups are monitored. As the ionization state of a group changes with pH, the electronic environment of the nearby nuclei is altered, leading to a change in their chemical shifts.
-
Data Analysis: A plot of the chemical shift of a specific nucleus versus pH will generate a sigmoidal curve.
-
pKa Determination: The pKa value is the pH at the inflection point of this sigmoidal curve. This can be determined by fitting the data to the Henderson-Hasselbalch equation.
Visualization of Experimental Workflow
The following diagram illustrates the logical workflow for the determination of pKa values using the potentiometric titration method.
Caption: Workflow for pKa determination via potentiometric titration.
References
- 1. homework.study.com [homework.study.com]
- 2. Ch27 pKa and pI values [chem.ucalgary.ca]
- 3. iscabiochemicals.com [iscabiochemicals.com]
- 4. Star Republic: Guide for Biologists [sciencegateway.org]
- 5. Aniline - Wikipedia [en.wikipedia.org]
- 6. alfa-chemistry.com [alfa-chemistry.com]
- 7. pKa of Aniline [vcalc.com]
Thermal Stability and Decomposition of 4-Aminophenylalanine: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Disclaimer: Direct experimental data on the thermal stability and decomposition of 4-Aminophenylalanine is limited in publicly available literature. This guide provides an in-depth analysis based on the well-studied analogous compound, L-phenylalanine, and general principles of amino acid thermal decomposition. The presence of the para-amino group is expected to influence the decomposition profile, and the information presented herein should be considered as a predictive guide for experimental design.
Introduction
This compound (4-AP) is a non-proteinogenic amino acid that serves as a versatile building block in medicinal chemistry and drug development. Its incorporation into peptides and other molecules can impart unique biological activities and properties. Understanding the thermal stability and decomposition profile of 4-AP is critical for its synthesis, purification, storage, and formulation, particularly in processes involving elevated temperatures. This technical guide summarizes the expected thermal behavior of 4-AP, outlines relevant experimental protocols for its analysis, and proposes potential decomposition pathways.
Thermal Analysis Data
Table 1: Thermal Decomposition Data for L-Phenylalanine (for reference)
| Parameter | Value | Technique | Reference Compound |
| Decomposition Onset Temperature | ~220 - 260 °C | TGA/DSC | L-Phenylalanine |
| Major Decomposition Stage | 260 - 300 °C | TGA | L-Phenylalanine |
| Endothermic Peaks (Melting/Decomposition) | 262.1, 276.8, 292.4 °C | DSC | Anhydrous L-Phenylalanine[1] |
Note: The decomposition of amino acids is often a complex process involving simultaneous melting and decomposition, making the interpretation of thermal events challenging.[1][2] The presence of the para-amino group in this compound could potentially lower the decomposition temperature compared to phenylalanine due to electronic effects influencing bond strengths.
Proposed Thermal Decomposition Pathways
The thermal decomposition of amino acids typically proceeds through several key pathways, including decarboxylation, deamination, and condensation reactions. For this compound, the following pathways are proposed based on the known behavior of phenylalanine and other aromatic amino acids.[3][4]
Primary Decomposition Pathways
Two primary competing pathways are anticipated for the initial decomposition of this compound:
-
Decarboxylation: The loss of carbon dioxide from the carboxylic acid group is a common thermal decomposition route for amino acids. This would lead to the formation of 4-(2-aminoethyl)aniline.
-
Deamination: The removal of the alpha-amino group as ammonia (B1221849), potentially followed by decarboxylation, would result in the formation of substituted cinnamic acid derivatives or other aromatic compounds.
Secondary Decomposition and Products
The initial decomposition products can undergo further reactions, leading to a complex mixture of smaller molecules. The phenyl ring itself is relatively stable but can undergo reactions at higher temperatures. Gaseous products expected from the decomposition include ammonia (NH₃), carbon dioxide (CO₂), carbon monoxide (CO), and water (H₂O).[3]
Visualization of Proposed Pathways and Workflows
Proposed Decomposition Pathways of this compound
References
A Technical Guide to the Historical Chemical Synthesis of 4-Aminophenylalanine
For Researchers, Scientists, and Drug Development Professionals
This in-depth technical guide explores the foundational chemical methodologies developed for the synthesis of 4-aminophenylalanine, a non-proteinogenic amino acid of significant interest in peptidomimetics and drug design. The following sections detail the core historical strategies, providing both comparative data and explicit experimental protocols to offer a practical understanding of these seminal synthetic routes.
Introduction
This compound (4-APhe), also known as p-aminophenylalanine, is a valuable building block in medicinal chemistry. Its unique structure, featuring a primary aromatic amine, allows for a wide range of chemical modifications, making it a versatile component in the design of novel peptides, enzyme inhibitors, and other therapeutic agents. The historical synthesis of this amino acid has primarily revolved around two main strategies: the reduction of a nitro precursor and the construction of the amino acid backbone via the Erlenmeyer-Plöchl synthesis. This guide will provide a detailed examination of these classical methods.
Method 1: Reduction of 4-Nitrophenylalanine
One of the most direct and historically significant routes to this compound involves the reduction of the corresponding 4-nitrophenylalanine. This precursor is readily accessible through the nitration of L-phenylalanine. The subsequent reduction of the nitro group has been accomplished using various reagents and conditions, with catalytic hydrogenation and metal-based chemical reductions being the most prominent.
Synthesis of the Precursor: Nitration of L-Phenylalanine
The initial step in this synthetic pathway is the introduction of a nitro group at the para position of the phenyl ring of L-phenylalanine.
Experimental Protocol: Nitration of L-Phenylalanine
-
Materials: L-phenylalanine, concentrated sulfuric acid (H₂SO₄, 95-98%), concentrated nitric acid (HNO₃, 90%), lead carbonate (PbCO₃), hydrogen sulfide (B99878) (H₂S) gas, 95% ethanol (B145695).
-
Procedure:
-
10.0 g (60.6 mmol) of L-phenylalanine is dissolved in 16 mL of concentrated H₂SO₄ at 0°C.
-
3.0 mL of 90% HNO₃ is added dropwise to the stirring solution while maintaining the temperature at approximately 0°C.
-
After the addition is complete, the solution is stirred for an additional 10-15 minutes.
-
The reaction mixture is then poured over approximately 200 mL of ice and diluted to about 700 mL with water.
-
The solution is heated to a boil and neutralized with approximately 80 g of PbCO₃.
-
The resulting precipitate is filtered, and the supernatant is treated with H₂S gas to precipitate any remaining lead ions.
-
The solution is filtered again, and the filtrate is reduced to one-third of its original volume.
-
The solid that forms is filtered and washed with 95% ethanol.
-
Recrystallization from boiling water yields p-nitrophenylalanine.
-
-
Yield: 50-55%
Reduction of 4-Nitrophenylalanine to this compound
The reduction of the nitro group can be achieved through several historical methods, each with its own advantages and disadvantages in terms of yield, selectivity, and reaction conditions.
Catalytic hydrogenation is a widely used and generally high-yielding method for the reduction of nitroarenes.
Experimental Protocol: Catalytic Hydrogenation with Palladium on Carbon (Pd/C)
-
Materials: (S)-N-Acetyl-4-Nitrophenylalanine methyl ester, 10% w/w Palladium on Carbon (Pd/C), ethyl acetate (B1210297), hydrogen gas.
-
Procedure:
-
(S)-N-Acetyl-4-Nitrophenylalanine methyl ester (3.73g, 14.0mmol) and 10% w/w Pd/C (0.18g) are mixed with ethyl acetate (37ml).
-
The mixture is stirred under a hydrogen atmosphere for 2 hours.
-
The catalyst is removed by filtration.
-
The solution is concentrated to yield (S)-N-Acetyl-4-Aminophenylalanine methyl ester. Subsequent hydrolysis of the ester and acetyl groups would yield this compound.
-
Stannous chloride is a classic and effective reagent for the chemoselective reduction of nitro groups in the presence of other reducible functionalities.
Experimental Protocol: Reduction with Stannous Chloride
-
Materials: 4-Nitrophenylalanine, stannous chloride dihydrate (SnCl₂·2H₂O), ethanol, ethyl acetate, 2M potassium hydroxide (B78521) (KOH).
-
Procedure:
-
To a solution of 4-nitrophenylalanine (1 equivalent) in ethanol (5 mL), add SnCl₂·2H₂O (approximately 10 equivalents).
-
The reaction mixture is stirred at room temperature or with gentle heating. The progress of the reaction can be monitored by Thin Layer Chromatography (TLC).
-
Once the reaction is complete, the solvent is removed under reduced pressure.
-
The crude residue is partitioned between ethyl acetate and 2M KOH to precipitate tin salts and extract the product into the organic layer.
-
The organic layer is washed, dried, and concentrated to yield this compound.[1]
-
Data Presentation: Comparison of Reduction Methods
| Method | Reducing Agent/Catalyst | Solvent | Temperature | Typical Yield (%) | Notes |
| Catalytic Hydrogenation | H₂ / Pd/C | Ethyl Acetate / Alcohols | Room Temperature | >90 | Generally clean and high-yielding, but may require pressure equipment. |
| Catalytic Hydrogenation | H₂ / Raney Ni | Alcohols | Room Temperature | >85 | An alternative to Pd/C, sometimes offering different selectivity. |
| Chemical Reduction | SnCl₂·2H₂O | Ethanol | Room Temp. to Reflux | 70-95 | A mild and chemoselective method.[1] |
| Chemical Reduction | Fe / Acid (e.g., HCl, Acetic Acid) | Water / Ethanol | Reflux | 80-95 | A classic, cost-effective, and selective method. |
Method 2: Erlenmeyer-Plöchl Synthesis
The Erlenmeyer-Plöchl synthesis is a classical method for the preparation of α-amino acids.[2][3] The core of this synthesis involves the condensation of an N-acylglycine (typically hippuric acid or N-acetylglycine) with an aldehyde in the presence of acetic anhydride (B1165640) to form an azlactone (an oxazolone (B7731731) derivative). This intermediate can then be converted to the desired amino acid through reduction and hydrolysis. For the synthesis of this compound, a protected 4-aminobenzaldehyde (B1209532) would be the required starting material.
General Workflow of the Erlenmeyer-Plöchl Synthesis for this compound
Due to the reactivity of the free amino group, a protecting group strategy is essential for the 4-aminobenzaldehyde starting material. A common protecting group would be an acetyl or a carbobenzyloxy (Cbz) group.
Conceptual Experimental Workflow
-
Protection of 4-Aminobenzaldehyde: The amino group of 4-aminobenzaldehyde is protected, for example, by acetylation with acetic anhydride to yield 4-acetamidobenzaldehyde.
-
Azlactone Formation: The protected 4-aminobenzaldehyde is condensed with N-acetylglycine in the presence of acetic anhydride and sodium acetate to form the corresponding azlactone.
-
Reduction of the Azlactone: The double bond of the azlactone is reduced. This can be achieved through various methods, including catalytic hydrogenation or with reducing agents like sodium amalgam.
-
Hydrolysis: The resulting saturated azlactone is hydrolyzed, typically under acidic or basic conditions, to cleave the oxazolone ring and the protecting groups, yielding this compound.
Visualizations of Synthetic Pathways
The following diagrams, generated using the DOT language, illustrate the logical flow of the historical synthetic methods described.
Caption: Synthetic pathway for this compound via nitration and subsequent reduction.
Caption: General workflow for the Erlenmeyer-Plöchl synthesis of this compound.
Conclusion
The historical synthesis of this compound has been predominantly achieved through two robust chemical strategies. The reduction of a 4-nitrophenylalanine precursor offers a more direct route, with catalytic hydrogenation providing high yields and chemoselective methods like SnCl₂ reduction offering compatibility with sensitive functional groups. The Erlenmeyer-Plöchl synthesis, while more convergent, provides a classical and versatile platform for the de novo construction of the amino acid from simpler building blocks. Understanding these foundational methods provides valuable context for the development of modern, more efficient, and stereoselective synthetic approaches to this important unnatural amino acid.
References
The Biosynthesis of p-Aminophenylalanine as a Gateway to Quinone Moieties: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Introduction
The non-proteinogenic amino acid p-aminophenylalanine (PAPA) serves as a crucial building block in the biosynthesis of a variety of natural products, including the antitumor agent dnacin B1. A key feature of these molecules is the presence of a quinone moiety, which is often essential for their biological activity. This technical guide provides an in-depth overview of the biosynthetic pathway of PAPA and its subsequent conversion to a quinone structure, with a focus on the enzymatic machinery and available quantitative data. The information presented herein is intended to support research and development efforts in metabolic engineering, synthetic biology, and drug discovery.
The Biosynthetic Pathway of p-Aminophenylalanine (PAPA) from Chorismic Acid
The biosynthesis of PAPA originates from the central metabolite chorismic acid, a key branch-point intermediate in the shikimate pathway. In the context of dnacin B1 biosynthesis in Actinosynnema pretiosum, the pathway is encoded by the din gene cluster, specifically the genes dinV, dinE, and dinF. The transformation from chorismic acid to PAPA proceeds through three enzymatic steps, followed by a final transamination.
Step 1: Formation of 4-amino-4-deoxychorismate (ADC)
The initial step is the conversion of chorismic acid to 4-amino-4-deoxychorismate (ADC). This reaction is catalyzed by aminodeoxychorismate synthase (ADCS) , a two-component enzyme complex encoded by dinV in the dnacin B1 gene cluster, which is homologous to pabA and pabB in other bacteria.[1]
-
DinV (PabA/PabB homolog): This enzyme complex consists of a glutamine amidotransferase subunit (PabA) and a synthase subunit (PabB). PabA hydrolyzes L-glutamine to provide ammonia, which is then channeled to the PabB subunit. PabB catalyzes the replacement of the C4 hydroxyl group of chorismate with the amino group from ammonia, forming ADC.[1]
Step 2: Conversion of ADC to 4-amino-4-deoxyprephenate (ADP)
The second step involves the rearrangement of ADC to 4-amino-4-deoxyprephenate (ADP). This Claisen rearrangement is catalyzed by 4-amino-4-deoxychorismate mutase , encoded by the dinE gene (a papB homolog).
Step 3: Formation of p-aminophenylpyruvic acid (PAPP)
The final enzyme in this initial sequence is 4-amino-4-deoxyprephenate dehydrogenase , encoded by dinF (a papC homolog). This enzyme catalyzes the oxidative decarboxylation of ADP to yield p-aminophenylpyruvic acid (PAPP).
Step 4: Transamination to p-Aminophenylalanine (PAPA)
The biosynthesis of PAPA is completed by the transamination of PAPP. This reaction is catalyzed by an aminotransferase . In Actinosynnema pretiosum, several potential PAPA aminotransferases (APATs) have been identified, with APAT4 and APAT9 showing significant activity.[2] Endogenous aminotransferases in heterologous hosts like E. coli can also catalyze this final step.[3]
Quantitative Data
Quantitative understanding of the PAPA biosynthetic pathway is crucial for metabolic engineering and optimization of production. The following tables summarize available data on enzyme kinetics and production yields.
Table 1: Kinetic Parameters of Aminodeoxychorismate Synthase (PabB) from Escherichia coli
| Substrate | Km (µM) | Vmax (relative) | Conditions | Reference |
| Chorismate (with L-glutamine) | 4.2 ± 1.4 | 100% | pH 7.5, with PabA | [4] |
| L-glutamine | 1.60 ± 0.4 | 100% | pH 7.5, with PabB | [4] |
| Chorismate (with NH3) | 18.6 ± 7.5 | 39% | pH 7.5, with PabA | [4] |
Note: Kinetic data for DinE and DinF from Actinosynnema pretiosum are not currently available in the public literature.
Table 2: Production of p-Aminophenylalanine in Metabolically Engineered E. coli
| Strain | Carbon Source | Titer (g/L) | Yield (g/g) | Reference |
| Engineered E. coli | Glucose | - | 0.54 (theoretical max) | |
| Engineered E. coli | Sorghum hydrolysate | 5.7 | - |
Hypothetical Pathway for Quinone Formation from PAPA
The enzymatic conversion of PAPA to a quinone moiety is a critical yet less understood part of the overall biosynthetic pathway. Based on the biosynthesis of other quinone-containing natural products, such as saframycin A, a plausible hypothetical pathway can be proposed. Saframycin A biosynthesis involves the condensation of two tyrosine molecules to form its quinone skeleton.[5] Given the structural similarity between PAPA and tyrosine, a similar enzymatic logic may apply.
The proposed pathway likely involves the following steps:
-
Hydroxylation of the Aromatic Ring: An initial hydroxylation of PAPA, ortho to the amino group, would form a p-aminophenol derivative.
-
Oxidation to a Quinone Imine: The p-aminophenol intermediate could then be oxidized by a dehydrogenase or an oxidase to form a quinone imine.
-
Hydrolysis to a Benzoquinone: Finally, hydrolysis of the quinone imine would yield the final benzoquinone structure.
Further biochemical and genetic studies are required to elucidate the specific enzymes and intermediates involved in this transformation.
Experimental Protocols
The following sections provide generalized protocols for key experiments related to the biosynthesis of PAPA. These should be optimized for specific experimental conditions.
Protocol 1: Heterologous Expression and Purification of Biosynthetic Enzymes
This protocol describes the general workflow for producing and purifying the DinV, DinE, and DinF enzymes in E. coli.
-
Gene Cloning: The dinV, dinE, and dinF genes from Actinosynnema pretiosum are amplified by PCR and cloned into an appropriate expression vector (e.g., pET series) with a purification tag (e.g., His6-tag).
-
Transformation: The resulting plasmids are transformed into a suitable E. coli expression strain (e.g., BL21(DE3)).
-
Culture and Induction: A single colony is used to inoculate a starter culture in LB medium with the appropriate antibiotic. The starter culture is then used to inoculate a larger volume of expression medium. The culture is grown at 37°C to an OD600 of 0.6-0.8. Protein expression is then induced by the addition of IPTG (isopropyl β-D-1-thiogalactopyranoside) to a final concentration of 0.1-1 mM, and the culture is incubated at a lower temperature (e.g., 16-25°C) for 12-18 hours.
-
Cell Lysis: Cells are harvested by centrifugation, resuspended in lysis buffer (e.g., 50 mM Tris-HCl pH 8.0, 300 mM NaCl, 10 mM imidazole (B134444), 1 mM PMSF, and lysozyme), and lysed by sonication on ice.
-
Purification: The cell lysate is clarified by centrifugation. The supernatant containing the soluble His-tagged protein is loaded onto a Ni-NTA affinity chromatography column. The column is washed with a wash buffer (lysis buffer with a slightly higher imidazole concentration, e.g., 20 mM). The target protein is then eluted with an elution buffer containing a high concentration of imidazole (e.g., 250 mM).
-
Dialysis and Storage: The purified protein is dialyzed against a storage buffer (e.g., 50 mM Tris-HCl pH 7.5, 150 mM NaCl, 10% glycerol) and stored at -80°C.
Protocol 2: Enzyme Assay for Aminotransferase Activity
This assay measures the activity of aminotransferases that convert PAPP to PAPA.
-
Reaction Mixture: Prepare a reaction mixture containing:
-
100 mM Tris-HCl buffer (pH 8.0)
-
10 mM PAPP (substrate)
-
10 mM L-glutamate (amino donor)
-
0.1 mM Pyridoxal 5'-phosphate (PLP) (cofactor)
-
Purified aminotransferase enzyme
-
-
Incubation: Incubate the reaction mixture at 30°C for a defined period (e.g., 30 minutes).
-
Reaction Termination: Stop the reaction by adding an equal volume of 1 M HCl.
-
Analysis: The formation of PAPA can be quantified by HPLC analysis.
-
Column: C18 reverse-phase column.
-
Mobile Phase: A gradient of acetonitrile (B52724) in water with 0.1% trifluoroacetic acid.
-
Detection: UV absorbance at 280 nm.
-
Quantification: Compare the peak area of the product with a standard curve of known PAPA concentrations.
-
Visualizations
Diagram 1: Biosynthesis Pathway of p-Aminophenylalanine (PAPA)
Caption: Enzymatic conversion of chorismic acid to p-aminophenylalanine.
Diagram 2: Experimental Workflow for Enzyme Production and Assay
Caption: General workflow for recombinant enzyme production and activity assay.
Diagram 3: Hypothetical Quinone Formation from PAPA
Caption: Hypothetical enzymatic pathway for the conversion of PAPA to a benzoquinone.
Conclusion
The biosynthesis of p-aminophenylalanine represents a key metabolic pathway for the production of quinone-containing natural products. While the enzymatic steps leading to PAPA are relatively well-understood, the subsequent transformation into a quinone moiety remains an area of active investigation. This guide provides a comprehensive summary of the current knowledge, including available quantitative data and experimental protocols, to aid researchers in this exciting field. Further characterization of the enzymes involved in this pathway, particularly those responsible for quinone formation, will be critical for the rational design of novel bioactive compounds and the development of efficient biocatalytic production platforms.
References
- 1. Aminodeoxychorismate synthase - Wikipedia [en.wikipedia.org]
- 2. Characterization of the Saframycin A Gene Cluster from Streptomyces lavendulae NRRL 11002 Revealing a Nonribosomal Peptide Synthetase System for Assembling the Unusual Tetrapeptidyl Skeleton in an Iterative Manner - PMC [pmc.ncbi.nlm.nih.gov]
- 3. p-Aminophenylalanine Involved in the Biosynthesis of Antitumor Dnacin B1 for Quinone Moiety Formation - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Kinetic characterization of 4-amino 4-deoxychorismate synthase from Escherichia coli - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Biosynthetic studies on saframycin A, a quinone antitumor antibiotic produced by Streptomyces lavendulae - PubMed [pubmed.ncbi.nlm.nih.gov]
A Technical Guide to Fmoc-Protected 4-Amino-L-phenylalanine in Peptide Synthesis
For Researchers, Scientists, and Drug Development Professionals
Introduction
Fmoc-4-Amino-L-phenylalanine is a non-natural amino acid derivative that has become an invaluable tool in the field of peptide synthesis, particularly for applications in drug discovery and development.[1] The presence of the fluorenylmethoxycarbonyl (Fmoc) protecting group on the alpha-amino group allows for its seamless integration into standard solid-phase peptide synthesis (SPPS) workflows.[1] The unique feature of this building block is the amino group at the para position of the phenyl ring, which provides a site for further chemical modification, enabling the creation of peptides with enhanced stability, novel functionalities, and improved therapeutic potential. This guide provides an in-depth overview of the properties, synthesis protocols, and applications of Fmoc-4-Amino-L-phenylalanine.
Physicochemical Properties
A comprehensive understanding of the physicochemical properties of Fmoc-4-Amino-L-phenylalanine is crucial for its effective use in peptide synthesis. Key properties are summarized in the table below.
| Property | Value | Reference |
| Synonyms | Fmoc-L-Phe(4-NH2)-OH, Fmoc-p-amino-L-Phe-OH, (S)-Fmoc-2-amino-3-(4-aminophenyl)propionic acid | [1] |
| CAS Number | 95753-56-3 | [1] |
| Molecular Formula | C₂₄H₂₂N₂O₄ | [1] |
| Molecular Weight | 402.5 g/mol | [1] |
| Appearance | Off-white to light yellow powder | [1] |
| Melting Point | 190-205 °C | [1] |
| Purity | ≥ 98% (HPLC) | [1] |
| Optical Rotation | [a]D20 = -9 ± 2º (c=1 in DMF) | [1] |
| Storage Conditions | 0-8 °C | [1] |
Solid-Phase Peptide Synthesis (SPPS) Workflow
The incorporation of Fmoc-4-Amino-L-phenylalanine into a peptide sequence follows the standard Fmoc-based solid-phase peptide synthesis protocol. The general workflow involves the sequential addition of amino acids to a growing peptide chain that is covalently attached to a solid support (resin).
Figure 1: General workflow for solid-phase peptide synthesis.
Experimental Protocols
Fmoc Deprotection
The removal of the Fmoc protecting group from the N-terminus of the growing peptide chain is a critical step to allow for the coupling of the next amino acid.
Reagents:
-
20% (v/v) Piperidine in N,N-Dimethylformamide (DMF)
Procedure:
-
Swell the peptide-resin in DMF for 30 minutes.
-
Drain the DMF.
-
Add the 20% piperidine in DMF solution to the resin.
-
Agitate the mixture for 5 minutes and drain.
-
Add a fresh portion of the 20% piperidine in DMF solution.
-
Agitate for an additional 15 minutes.
-
Drain the solution and wash the resin thoroughly with DMF (5-7 times) to remove all traces of piperidine and the cleaved Fmoc-adduct.
Coupling of Fmoc-4-Amino-L-phenylalanine
The efficiency of the coupling reaction is crucial for the successful synthesis of the target peptide. The choice of coupling reagent can significantly impact the yield and purity. For sterically hindered or difficult couplings, more potent activating reagents are recommended.
Reagents:
-
Fmoc-4-Amino-L-phenylalanine(Boc)-OH (Note: The side-chain amino group is typically protected with a Boc group to prevent side reactions)
-
Coupling Reagent (e.g., HATU, HBTU, DIC)
-
Base (e.g., N,N-Diisopropylethylamine - DIPEA)
-
Anhydrous DMF
Coupling Protocol using HATU:
-
In a separate vessel, dissolve Fmoc-4-Amino-L-phenylalanine(Boc)-OH (3 equivalents relative to resin loading) and HATU (2.9 equivalents) in DMF.
-
Add DIPEA (6 equivalents) to the solution and allow it to pre-activate for 2-5 minutes at room temperature.
-
Add the activated amino acid solution to the deprotected peptide-resin.
-
Agitate the reaction mixture for 1-2 hours at room temperature.
-
Perform a Kaiser test to monitor the completion of the coupling reaction. A negative result (yellow beads) indicates a complete reaction.
-
If the Kaiser test is positive (blue beads), indicating incomplete coupling, the coupling step can be repeated ("double coupling").
-
Once the coupling is complete, wash the resin thoroughly with DMF.
Comparative Coupling Efficiency:
| Coupling Reagent | Typical Coupling Time (hours) | Reported Efficiency Range | Notes |
| HATU | 1-4 | 90-98% | Highly reactive, suitable for sterically hindered amino acids. |
| HBTU | 2-6 | 85-95% | Good balance of reactivity and cost-effectiveness. |
| DIC/HOBt | 2-8 | 80-90% | Carbodiimide-based, generally less reactive than uronium/aminium salts. |
Data is based on general observations for difficult couplings and may vary depending on the specific peptide sequence and reaction conditions.
Cleavage and Deprotection
Once the peptide synthesis is complete, the peptide is cleaved from the solid support, and the side-chain protecting groups are removed.
Reagents:
-
Trifluoroacetic acid (TFA)
-
Scavengers (e.g., Triisopropylsilane (TIS), water, 1,2-ethanedithiol (B43112) (EDT)) - the choice of scavengers depends on the amino acid composition of the peptide. A common cocktail is 95% TFA, 2.5% TIS, and 2.5% water.
Procedure:
-
Wash the peptide-resin with dichloromethane (B109758) (DCM) and dry it thoroughly under vacuum.
-
Add the cleavage cocktail to the dried resin.
-
Gently agitate the mixture at room temperature for 2-3 hours.
-
Filter the resin and collect the filtrate containing the cleaved peptide.
-
Precipitate the crude peptide by adding it to cold diethyl ether.
-
Centrifuge to pellet the peptide, decant the ether, and repeat the ether wash.
-
Dry the crude peptide pellet under vacuum.
Purification and Analysis
The crude peptide is typically purified by reverse-phase high-performance liquid chromatography (RP-HPLC). The purity and identity of the final peptide are confirmed by analytical RP-HPLC and mass spectrometry (MS).
Representative Analytical Data:
Table 1: HPLC Analysis of a Purified Peptide containing 4-Amino-L-phenylalanine
| Parameter | Value |
| Column | C18, 5 µm, 4.6 x 250 mm |
| Mobile Phase A | 0.1% TFA in Water |
| Mobile Phase B | 0.1% TFA in Acetonitrile |
| Gradient | 5-95% B over 30 minutes |
| Flow Rate | 1.0 mL/min |
| Detection | 220 nm |
| Retention Time | 15.8 minutes |
| Purity | >98% |
Table 2: Mass Spectrometry Analysis of a Peptide containing 4-Amino-L-phenylalanine
| Parameter | Value |
| Ionization Mode | Electrospray Ionization (ESI+) |
| Calculated Mass (Monoisotopic) | 1254.6 Da |
| Observed Mass [M+H]⁺ | 1255.6 Da |
Application in Drug Discovery: Inhibition of Dipeptidyl Peptidase IV (DPP-4)
Peptides and peptidomimetics containing 4-Amino-L-phenylalanine have been investigated as inhibitors of dipeptidyl peptidase IV (DPP-4).[2] DPP-4 is a therapeutic target for type 2 diabetes as it is responsible for the degradation of incretin (B1656795) hormones like GLP-1, which potentiate insulin (B600854) secretion. Inhibition of DPP-4 prolongs the action of GLP-1, leading to improved glycemic control.
The workflow for identifying a peptide-based DPP-4 inhibitor incorporating 4-Amino-L-phenylalanine can be visualized as follows:
Figure 2: Workflow for the development of a peptide-based DPP-4 inhibitor.
Conclusion
Fmoc-4-Amino-L-phenylalanine is a versatile and valuable building block for the synthesis of modified peptides with a wide range of applications in research and drug development. Its compatibility with standard Fmoc-SPPS protocols, combined with the potential for post-synthesis modification of the side-chain amino group, allows for the creation of novel peptide structures with tailored properties. The successful incorporation and application of this non-natural amino acid, as demonstrated in the context of DPP-4 inhibition, highlights its potential for advancing the field of peptide-based therapeutics. Rigorous adherence to optimized synthesis, purification, and analytical protocols is essential to ensure the quality and integrity of the final peptide products.
References
understanding the zwitterionic form of 4-Aminophenylalanine
An In-depth Technical Guide to the Zwitterionic Form of 4-Aminophenylalanine
Authored for: Researchers, Scientists, and Drug Development Professionals December 19, 2025
Abstract
This compound (4-APhe), a non-proteinogenic amino acid, serves as a critical building block in medicinal chemistry and peptide synthesis. Its unique structure, featuring an additional basic amino group on the phenyl ring, imparts distinct chemical properties. Understanding its zwitterionic form—the electrically neutral state with localized positive and negative charges—is fundamental to its application in physiological environments. This guide provides a comprehensive technical overview of the physicochemical and acid-base properties of zwitterionic 4-APhe, detailed experimental protocols for its synthesis and characterization, and a summary of its key quantitative data.
Physicochemical and Acid-Base Properties
Like all amino acids, this compound exists predominantly as a zwitterion in the solid state and in aqueous solutions near neutral pH. This internal salt is formed by the protonation of the α-amino group by the α-carboxylic acid group. The presence of a third ionizable group, the aromatic para-amino group, classifies 4-APhe as a basic amino acid and influences its acid-base behavior.
General Properties
The fundamental properties of L-4-Aminophenylalanine are summarized in the table below.
| Property | Value | Reference(s) |
| Molecular Formula | C₉H₁₂N₂O₂ | [1][2] |
| Molecular Weight | 180.20 g/mol | [1][2] |
| CAS Number | 943-80-6 (L-isomer) | [1][2] |
| IUPAC Name | (2S)-2-amino-3-(4-aminophenyl)propanoic acid | [1] |
| Appearance | Pale beige to beige solid | [1] |
| Solubility | Soluble in water | [1] |
Zwitterionic Structure
At its isoelectric point, the α-carboxylic acid group is deprotonated (pKa₁), and the α-amino group is protonated (pKa₂). The aromatic amino group (pKa₃) is largely unprotonated, resulting in a molecule with a net charge of zero.
Caption: Chemical structure of this compound in its zwitterionic form.
Acid-Base Equilibria and Isoelectric Point (pI)
This compound has three ionizable groups: the α-carboxyl group, the α-amino group, and the para-amino group on the phenyl ring. The equilibrium between its different ionic forms is pH-dependent.
| Ionizable Group | pKa (Estimated) | Description |
| α-Carboxyl (-COOH) | ~2.2 | Deprotonates to form a carboxylate (-COO⁻). |
| p-Amino (-NH₂) | ~4.6 | Protonates to form an anilinium ion (-NH₃⁺). |
| α-Amino (-NH₃⁺) | ~9.4 | Deprotonates to form an amino group (-NH₂). |
The isoelectric point (pI) is the pH at which the molecule has no net electrical charge. For a basic amino acid, the pI is calculated as the average of the pKa values of the two protonated amino groups.[3] However, at the pI, the aromatic p-amino group (pKa ~4.6) will be predominantly in its neutral form (-NH₂), while the α-amino group (pKa ~9.4) will be protonated (-NH₃⁺) and the carboxyl group will be deprotonated (-COO⁻). Therefore, the zwitterion is the major species at a pH between pKa₁ and pKa₃. The pI for an amino acid with an ionizable basic side chain is calculated by averaging the pKa values of the two ammonium (B1175870) groups.[3]
Calculation of Isoelectric Point (pI): pI = (pKa₂ + pKa₃) / 2 = (~9.4 + ~4.6) / 2 ≈ 7.0
Caption: pH-dependent equilibrium of this compound ionization states.
Experimental Protocols and Characterization
Synthesis of L-4-Aminophenylalanine
A common and effective method for synthesizing L-4-Aminophenylalanine is through the catalytic hydrogenation of its precursor, L-4-nitrophenylalanine.[4]
Experimental Protocol:
-
Dissolution: L-4-nitrophenylalanine is suspended in an aqueous solvent, such as water or an ethanol/water mixture.
-
Catalyst Addition: A hydrogenation catalyst, typically 5-10% Palladium on carbon (Pd/C) or Palladium-barium sulfate, is added to the suspension. The catalyst loading is usually around 5-10 mol% relative to the substrate.
-
Hydrogenation: The mixture is subjected to a hydrogen atmosphere (typically from a balloon or a pressurized reactor) and stirred vigorously at room temperature.
-
Reaction Monitoring: The reaction progress is monitored by techniques like Thin Layer Chromatography (TLC) or High-Performance Liquid Chromatography (HPLC) until the starting material is fully consumed (typically 3-6 hours).
-
Filtration: Upon completion, the reaction mixture is filtered through a pad of Celite or diatomaceous earth to remove the palladium catalyst.
-
Purification: The filtrate is concentrated under reduced pressure to yield the crude product. The product can be further purified by recrystallization from a suitable solvent system (e.g., water/ethanol) to afford L-4-Aminophenylalanine as a solid.
Caption: Workflow for the synthesis of L-4-Aminophenylalanine via hydrogenation.
Determination of pKa Values by Potentiometric Titration
Potentiometric titration is a standard method for determining the pKa values of amino acids.[5][6]
Experimental Protocol:
-
Sample Preparation: Accurately weigh a sample of this compound hydrochloride and dissolve it in a known volume of deionized water. The hydrochloride salt ensures all ionizable groups are fully protonated at the start.
-
Titration Setup: Place the solution in a beaker with a magnetic stirrer. Calibrate a pH meter and immerse the electrode in the solution.
-
Titration: Slowly add a standardized solution of a strong base (e.g., 0.1 M NaOH) in small, precise increments using a burette.
-
Data Collection: Record the pH of the solution after each addition of titrant, allowing the reading to stabilize. Continue the titration until the pH is above 11 to ensure all protons have been titrated.
-
Data Analysis: Plot the pH (y-axis) versus the volume of NaOH added (x-axis) to generate a titration curve. The curve will show two or three inflection points corresponding to the equivalence points. The pKa values are determined from the midpoints of the buffering regions (the flattest parts of the curve). Specifically, pKa₁ is the pH at which half of the first equivalent of NaOH has been added, and so on. The pI can be visually identified as the pH at the second equivalence point.
Spectroscopic Characterization
2.3.1. Nuclear Magnetic Resonance (NMR) Spectroscopy NMR spectroscopy provides detailed information about the chemical environment of each atom in the molecule. For the zwitterionic form in D₂O:
-
¹H NMR: The spectrum is expected to show signals for the α-proton (CH), the β-protons (CH₂), and the aromatic protons. The aromatic protons will appear as two doublets (an AA'BB' system) due to the para-substitution. The acidic proton of the -NH₃⁺ group will exchange with deuterium (B1214612) and typically will not be observed.
-
¹³C NMR: The spectrum will show distinct signals for the carboxylate carbon (~175-180 ppm), the α-carbon (~55-60 ppm), the β-carbon (~35-40 ppm), and the four unique aromatic carbons.
2.3.2. Fourier-Transform Infrared (FTIR) Spectroscopy FTIR spectroscopy is used to identify the functional groups present in a molecule. The zwitterionic form of 4-APhe exhibits characteristic vibrational bands.[7][8]
| Wavenumber (cm⁻¹) | Vibrational Mode | Functional Group |
| ~3000-3200 | N-H stretching | -NH₃⁺ (Ammonium) |
| ~1610-1660 | N-H asymmetric deformation (bending) | -NH₃⁺ (Ammonium) |
| ~1580-1600 | C=O asymmetric stretching | -COO⁻ (Carboxylate) |
| ~1500-1550 | N-H symmetric deformation (bending) | -NH₃⁺ (Ammonium) |
| ~1400-1420 | C=O symmetric stretching | -COO⁻ (Carboxylate) |
| ~1510, ~830 | Aromatic C=C stretching and C-H out-of-plane bend | Phenyl Ring |
X-ray Crystallography
Applications and Significance
The zwitterionic nature of this compound is central to its utility in drug development and biochemical research.
-
Peptide Synthesis: As a building block, its zwitterionic form allows it to behave like other natural amino acids in solid-phase and solution-phase peptide synthesis.[11]
-
Drug Development: The para-amino group provides a reactive handle for chemical modification, allowing 4-APhe to be incorporated into peptidomimetics or conjugated to other molecules. It has been used in the design of inhibitors for enzymes like dipeptidyl peptidase IV (DPP-4).
Conclusion
The zwitterionic form of this compound is its most biologically and chemically relevant state. Its characterization is defined by the interplay of its three ionizable groups, leading to a net neutral charge at physiological pH. A thorough understanding of its acid-base properties, supported by synthesis and spectroscopic analysis, is essential for its effective application by researchers in the design of novel peptides, therapeutics, and other advanced biomaterials.
References
- 1. This compound | C9H12N2O2 | CID 151001 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 2. scbt.com [scbt.com]
- 3. masterorganicchemistry.com [masterorganicchemistry.com]
- 4. researchgate.net [researchgate.net]
- 5. scribd.com [scribd.com]
- 6. Development of Methods for the Determination of pKa Values - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. researchgate.net [researchgate.net]
- 9. The self-assembling zwitterionic form of L-phenylalanine at neutral pH - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. pubs.rsc.org [pubs.rsc.org]
molecular weight and formula of 4-Aminophenylalanine HCl salt
An In-depth Technical Guide to 4-Aminophenylalanine HCl Salt
This technical guide provides comprehensive information on the molecular properties, experimental protocols, and applications of this compound hydrochloride salt, a key building block in pharmaceutical research and development. The data and methodologies presented are intended for researchers, scientists, and professionals in the field of drug development.
Molecular Profile
This compound, particularly in its L-enantiomeric form, is a non-proteinogenic amino acid derivative. Its hydrochloride salt is frequently used in synthesis due to its enhanced stability and solubility in aqueous solutions.
Quantitative Data
The molecular formula and weight for this compound and its common salt forms are summarized in the table below for easy reference and comparison.
| Compound Name | Molecular Formula | Molecular Weight ( g/mol ) | Form |
| 4-Amino-L-phenylalanine | C₉H₁₂N₂O₂ | 180.20[1][2][3] | Free Base |
| 4-Amino-L-phenylalanine Hydrochloride | C₉H₁₂N₂O₂·HCl | 216.67[4][5] | Anhydrous Salt |
| 4-Amino-L-phenylalanine Hydrochloride Hemihydrate | C₉H₁₂N₂O₂·HCl·½H₂O | 225.67[6] | Hydrated Salt |
Experimental Protocols
Detailed methodologies for the synthesis and analysis of this compound HCl salt are crucial for its effective application in research.
Synthesis of this compound Derivatives
A common route to synthesize this compound derivatives involves the reduction of the corresponding 4-nitrophenylalanine precursor. The following protocol is a representative example.
Objective: To synthesize (S)-N-Acetyl-4-Aminophenylalanine methyl ester from (S)-N-Acetyl-4-Nitrophenylalanine methyl ester.
Materials:
-
(S)-N-Acetyl-4-Nitrophenylalanine methyl ester
-
10% Palladium on Carbon (Pd/C) catalyst
-
Ethyl acetate (B1210297)
-
Hydrogen gas supply
-
Filtration apparatus
-
Rotary evaporator
Procedure:
-
Combine (S)-N-Acetyl-4-Nitrophenylalanine methyl ester and a catalytic amount (e.g., 0.05 wt equivalent) of 10% Pd/C in a reaction vessel containing ethyl acetate (10 volumes).[7]
-
Stir the mixture under a hydrogen atmosphere. The reaction progress can be monitored by techniques such as Thin Layer Chromatography (TLC) or Liquid Chromatography-Mass Spectrometry (LC-MS).
-
Upon completion of the reaction (typically after several hours), remove the catalyst by filtration through a pad of celite.[7]
-
Concentrate the filtrate under reduced pressure using a rotary evaporator to yield the crude product, (S)-N-Acetyl-4-Aminophenylalanine methyl ester.[7]
-
Further purification can be achieved by recrystallization or column chromatography if necessary.
Analytical Characterization
To ensure the identity and purity of this compound HCl salt, a combination of spectroscopic and chromatographic methods is employed.
Purity Determination by High-Performance Liquid Chromatography (HPLC):
-
Method: Reversed-phase HPLC is a standard method to assess the purity of the compound, which is often reported to be ≥99%.[4][5]
-
Mobile Phase: A typical mobile phase could consist of a gradient of acetonitrile (B52724) and water containing a small amount of an ion-pairing agent like trifluoroacetic acid (TFA).
-
Column: A C18 stationary phase is commonly used.
-
Detection: UV detection at a wavelength where the aromatic ring absorbs, typically around 254 nm.
Identity Confirmation by Spectroscopy:
-
Nuclear Magnetic Resonance (NMR) Spectroscopy: ¹H NMR spectroscopy is used to confirm the chemical structure by analyzing the chemical shifts, integration, and coupling patterns of the protons.[4]
-
Mass Spectrometry (MS): Mass spectrometry provides information about the mass-to-charge ratio of the molecule, confirming its molecular weight.[4]
Qualitative Test for Hydrochloride Salt:
-
Dissolve a small amount of the sample in deionized water.
-
Acidify the solution with a few drops of dilute nitric acid.
-
Add a few drops of silver nitrate (B79036) (AgNO₃) solution.
-
The formation of a curdy white precipitate (AgCl) indicates the presence of chloride ions, confirming the hydrochloride salt.[8]
Logical and Application Diagrams
The following diagrams, generated using the DOT language, illustrate key workflows and applications relevant to this compound HCl salt.
Caption: A logical workflow for the synthesis of a this compound derivative.
Caption: General workflow for the analysis of this compound HCl salt.
Caption: Key research applications of 4-Amino-L-phenylalanine HCl.
References
- 1. This compound | C9H12N2O2 | CID 151001 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 2. 4-Amino-L-phenylalanine - CAS:943-80-6 - Sunway Pharm Ltd [3wpharm.com]
- 3. Thermo Scientific Chemicals 4-Amino-DL-phenylalanine | Fisher Scientific [fishersci.ca]
- 4. usbio.net [usbio.net]
- 5. chemimpex.com [chemimpex.com]
- 6. 4-Amino- L -phenylalanine 98 312693-79-1 [sigmaaldrich.com]
- 7. WO2003068725A2 - Process for the preparation of 4-hetero-substituted phenylalanine derivatives - Google Patents [patents.google.com]
- 8. scribd.com [scribd.com]
Methodological & Application
Application Notes and Protocols for Site-Specific Incorporation of 4-Aminophenylalanine in E. coli
Audience: Researchers, scientists, and drug development professionals.
Introduction
The site-specific incorporation of non-canonical amino acids (ncAAs) into proteins represents a powerful tool in protein engineering and drug development. This technology, known as genetic code expansion, allows for the introduction of novel chemical functionalities, such as bio-orthogonal handles, fluorescent probes, and post-translational modifications, at precise locations within a protein's structure. 4-aminophenylalanine (pAF) is a particularly useful ncAA, as its amino group can be used for various chemical modifications.
This document provides a detailed protocol for the site-specific incorporation of pAF into a target protein in Escherichia coli. The methodology relies on an orthogonal aminoacyl-tRNA synthetase (aaRS)/tRNA pair that recognizes the amber stop codon (UAG) and directs the insertion of pAF at that position.
Principle of the Method
The central components for the site-specific incorporation of pAF are:
-
An Engineered E. coli Strain: Typically a strain like BL21(DE3) is used, which is suitable for recombinant protein expression.[1]
-
An Expression Plasmid for the Target Protein: This plasmid contains the gene of interest with an in-frame amber (TAG) codon at the desired site for pAF incorporation.
-
A Plasmid Encoding the Orthogonal System: This plasmid carries the genes for the engineered aminoacyl-tRNA synthetase (aaRS) specific for pAF and its cognate suppressor tRNA that recognizes the UAG codon.[1][2] The aaRS and tRNA must be "orthogonal," meaning they do not cross-react with the host cell's endogenous synthetases and tRNAs.[2]
-
This compound (pAF): The ncAA is supplied in the culture medium and is actively transported into the cell.
During protein synthesis, the ribosome pauses at the UAG codon. The orthogonal suppressor tRNA, charged with pAF by the orthogonal aaRS, recognizes the UAG codon and incorporates pAF into the growing polypeptide chain, allowing translation to continue.
Data Presentation
The efficiency and yield of pAF incorporation can be influenced by several factors, including the expression system, the specific protein, and the culture conditions. The following table summarizes typical quantitative data gathered from studies involving the incorporation of pAF and structurally similar ncAAs.
| Parameter | Typical Value | Notes | Source |
| Protein Yield (with ncAA) | 3.1 mg/L - >500 µg/mL | Yield is highly dependent on the protein and expression system (in vivo vs. cell-free). In some cell-free systems, yields can reach 50-120% of the wild-type protein. | [3][4][5][6] |
| Incorporation Efficiency | Up to 55% | This represents the percentage of full-length protein produced from the amber-containing transcript. | [3][5] |
| Incorporation Fidelity | >99% | Fidelity is high, with minimal misincorporation of natural amino acids. Background amber suppression in common strains like BL21 is around 3%. | [7] |
| pAF Concentration in Medium | 0.5 g/L - 1.1 mM | The optimal concentration can vary depending on the specific orthogonal pair and expression conditions. | [1][8] |
| Inducer Concentration (IPTG) | 0.05 - 1 mM | Lower concentrations are often optimal at higher temperatures to reduce metabolic burden. | [1][9][10] |
| Induction Temperature | 16 - 37°C | Lower temperatures (e.g., 18-25°C) often improve protein solubility and folding. | [11][12] |
| Induction Duration | 3 hours - overnight | Shorter inductions at higher temperatures or longer inductions at lower temperatures. | [9][11][12] |
Experimental Protocols
Plasmid Preparation and Transformation
-
Gene of Interest Cloning: Subclone the gene for your protein of interest into a suitable E. coli expression vector (e.g., a pET vector).
-
Site-Directed Mutagenesis: Introduce an amber stop codon (TAG) at the desired position in your gene of interest using a standard site-directed mutagenesis protocol. Verify the mutation by DNA sequencing.
-
Co-transformation: Transform competent E. coli cells (e.g., BL21(DE3)) with both the plasmid containing your gene of interest and the plasmid encoding the pAF-specific orthogonal aaRS/tRNA pair (e.g., pEVOL-pAF). Use a dual antibiotic selection strategy corresponding to the resistance markers on both plasmids.
-
Plating: Plate the transformed cells on LB agar (B569324) plates containing the appropriate antibiotics. Incubate overnight at 37°C.
Protein Expression
-
Starter Culture: Inoculate a single colony from the transformation plate into 5-10 mL of LB medium containing the appropriate antibiotics. Grow overnight at 37°C with shaking.
-
Main Culture: The next day, inoculate 1 L of LB medium containing the same antibiotics with the overnight starter culture (typically a 1:100 dilution).
-
Addition of pAF: Add this compound to the culture medium to a final concentration of 0.5 g/L.
-
Cell Growth: Grow the culture at 37°C with shaking until the optical density at 600 nm (OD600) reaches 0.6-0.8.
-
Induction: Induce protein expression by adding Isopropyl β-D-1-thiogalactopyranoside (IPTG) to a final concentration of 0.5 mM. If the orthogonal system plasmid is under the control of an arabinose-inducible promoter, also add L-arabinose (e.g., to 0.02%).
-
Expression: Reduce the temperature to 25°C and continue to shake the culture for 16-18 hours.
-
Harvesting: Harvest the cells by centrifugation at 5,000 x g for 15 minutes at 4°C. Discard the supernatant. The cell pellet can be stored at -80°C or used immediately for purification.
Protein Purification
This protocol assumes the target protein has been engineered with a hexahistidine (His6) tag for affinity purification.
-
Cell Lysis: Resuspend the cell pellet in lysis buffer (50 mM Tris-HCl pH 8.0, 300 mM NaCl, 10 mM imidazole, 1 mg/mL lysozyme, and protease inhibitors). Incubate on ice for 30 minutes. Sonicate the cell suspension on ice to ensure complete lysis and to shear the genomic DNA.
-
Clarification: Centrifuge the lysate at 15,000 x g for 30 minutes at 4°C to pellet the cell debris. Collect the supernatant, which contains the soluble protein fraction.
-
Affinity Chromatography:
-
Equilibrate a Ni-NTA affinity column with wash buffer (50 mM Tris-HCl pH 8.0, 300 mM NaCl, 20 mM imidazole).
-
Load the clarified lysate onto the column.
-
Wash the column with several column volumes of wash buffer to remove non-specifically bound proteins.
-
Elute the target protein with elution buffer (50 mM Tris-HCl pH 8.0, 300 mM NaCl, 250 mM imidazole). Collect the fractions.
-
-
Verification and Analysis:
-
Analyze the collected fractions by SDS-PAGE to check for protein purity and the expected molecular weight.
-
Confirm the incorporation of pAF by mass spectrometry. The mass of the protein will be increased by the mass of the pAF residue minus the mass of water, relative to the wild-type protein or a version where a natural amino acid is at the target position.
-
-
Buffer Exchange (Optional): If necessary, exchange the elution buffer for a suitable storage buffer using dialysis or a desalting column.
Visualizations
Experimental Workflow
Caption: Overview of the workflow for pAF incorporation in E. coli.
Mechanism of pAF Incorporation
Caption: Mechanism of orthogonal translation for pAF incorporation.
References
- 1. biochemistry.ucla.edu [biochemistry.ucla.edu]
- 2. Suppression of amber codons in vivo as evidence that mutants derived from Escherichia coli initiator tRNA can act at the step of elongation in protein synthesis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Enhanced yield of recombinant proteins with site-specifically incorporated unnatural amino acids using a cell-free expression system - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Enhanced Yield of Recombinant Proteins with Site-Specifically Incorporated Unnatural Amino Acids Using a Cell-Free Expression System - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. Biosynthesis and Genetic Incorporation of 3,4-Dihydroxy-L-Phenylalanine into Proteins in Escherichia coli - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Near-cognate suppression of amber, opal and quadruplet codons competes with aminoacyl-tRNAPyl for genetic code expansion - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Unraveling Complex Local Protein Environments with 4-Cyano-L-Phenylalanine - PMC [pmc.ncbi.nlm.nih.gov]
- 9. IPTG Induction Protocol - Biologicscorp [biologicscorp.com]
- 10. Optimizing recombinant protein expression via automated induction profiling in microtiter plates at different temperatures - PMC [pmc.ncbi.nlm.nih.gov]
- 11. neb.com [neb.com]
- 12. Strategies to Optimize Protein Expression in E. coli - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for Site-Specific Incorporation of 4-Aminophenylalanine in Mammalian Cells via Amber Codon Suppression
For Researchers, Scientists, and Drug Development Professionals
Introduction
The expansion of the genetic code to include non-canonical amino acids (ncAAs) offers a powerful tool for protein engineering and the development of novel therapeutics. By repurposing the UAG amber stop codon, ncAAs with unique chemical functionalities can be site-specifically incorporated into proteins of interest within mammalian cells. This technology relies on an orthogonal aminoacyl-tRNA synthetase/tRNA pair that is specific for the ncAA and does not cross-react with the host cell's translational machinery.
4-Aminophenylalanine (4-AP) is a particularly valuable ncAA, as its amino group can serve as a versatile chemical handle for various bioconjugation reactions, enabling the site-specific labeling of proteins with probes, the study of protein-protein interactions, and the development of antibody-drug conjugates. This document provides detailed application notes and protocols for the efficient incorporation of 4-AP into target proteins in mammalian cells.
Principle of Amber Codon Suppression
The site-specific incorporation of 4-AP is achieved through the amber suppression methodology. This process involves the introduction of a "blank" UAG codon at the desired position in the gene of interest. An orthogonal aminoacyl-tRNA synthetase (aaRS), specifically evolved to recognize 4-AP, charges a cognate suppressor tRNA (tRNACUA) with 4-AP. This charged tRNA then recognizes the UAG codon during translation and incorporates 4-AP into the growing polypeptide chain, leading to the production of the full-length protein containing the ncAA.
Quantitative Data Summary
| Non-Canonical Amino Acid | Orthogonal System | Reporter System | Cell Line | Suppression Efficiency (%) | Reference |
| This compound (4-AP) | Evolved E. coli Tyrosyl-tRNA Synthetase (EcTyrRS) Mutant / B. stearothermophilus tRNATyrCUA | mCherry-TAG-eGFP | HEK293 | Data Not Available | |
| p-azido-L-phenylalanine (AzF) (Example) | Evolved E. coli Tyrosyl-tRNA Synthetase (eAzFRS) / E. coli tRNATyrCUA | Dual-fluorescence reporter | CHO | ~25-50 | [4][5] |
| p-azido-L-phenylalanine (AzF) (Example) | TyrRS*/tRNACUA | eGFP(TAG) | HEK293 | ~40-60 | [6] |
Experimental Protocols
Protocol 1: Plasmid Construction for 4-AP Incorporation
This protocol describes the generation of the necessary plasmids for 4-AP incorporation: one encoding the orthogonal aaRS/tRNA pair and another for the target protein with an amber codon.
1.1. Orthogonal System Plasmid:
-
Synthetase Gene: Obtain a mammalian expression vector containing a mutant E. coli tyrosyl-tRNA synthetase (EcTyrRS) gene that has been evolved to be specific for 4-AP. If a pre-existing synthetase is unavailable, one can be evolved using directed evolution techniques.[7][8][9]
-
tRNA Gene: Synthesize the gene for the Bacillus stearothermophilus tyrosyl amber suppressor tRNA (BstYam).[10] To enhance expression, place the tRNA gene under the control of a U6 promoter. It is highly recommended to use a construct with multiple tandem repeats (e.g., four copies) of the tRNA expression cassette to increase intracellular tRNA levels.[6][10]
-
Cloning: Clone the synthetase and tRNA cassettes into a single mammalian expression vector. A common configuration is to have the synthetase expressed from a constitutive promoter like PGK, and the tRNAs from U6 promoters.[10]
1.2. Target Protein Plasmid:
-
Site-Directed Mutagenesis: Introduce an amber stop codon (TAG) at the desired site within the gene of your protein of interest (POI) using site-directed mutagenesis. The choice of the incorporation site can significantly impact suppression efficiency.[1][11]
-
Cloning: Clone the mutagenized POI gene into a mammalian expression vector with a suitable promoter (e.g., CMV) and a C-terminal tag (e.g., His6 or FLAG) for purification and detection.
Protocol 2: Mammalian Cell Culture and Transfection for 4-AP Incorporation
This protocol outlines the procedure for introducing the plasmids into mammalian cells and culturing them in the presence of 4-AP. HEK293 cells are commonly used for their high transfection efficiency.[6][10][12]
2.1. Materials:
-
HEK293 cells
-
Dulbecco's Modified Eagle's Medium (DMEM) with high glucose, supplemented with 10% Fetal Bovine Serum (FBS), 100 units/mL penicillin, and 100 µg/mL streptomycin
-
This compound (4-AP) stock solution (e.g., 100 mM in 1 M HCl, neutralized with NaOH)
-
Transfection reagent (e.g., Lipofectamine™ 3000 or Polyethylenimine (PEI))
-
6-well plates
2.2. Procedure:
-
Cell Seeding: Seed HEK293 cells in 6-well plates at a density of approximately 5 x 105 cells per well in 2 mL of complete growth medium.
-
Incubation: Incubate the cells at 37°C in a 5% CO2 atmosphere overnight.
-
4-AP Supplementation: One hour prior to transfection, add 4-AP to the growth medium to a final concentration of 500 µM.[10]
-
Transfection:
-
Prepare the plasmid mixture: For each well, mix 1 µg of the orthogonal system plasmid and 1 µg of the target protein plasmid.
-
Follow the manufacturer's protocol for your chosen transfection reagent. For example, using Lipofectamine™ 3000, dilute the plasmids and the reagent in Opti-MEM, incubate, and then add the complex to the cells.[12]
-
-
Expression: Incubate the transfected cells for 48-72 hours at 37°C in a 5% CO2 atmosphere.
Protocol 3: Protein Expression, Purification, and Verification
This protocol details the harvesting of cells, purification of the 4-AP containing protein, and verification of its expression.
3.1. Cell Lysis:
-
Aspirate the culture medium and wash the cells with ice-cold PBS.
-
Lyse the cells in a suitable lysis buffer (e.g., RIPA buffer) containing protease inhibitors.
-
Incubate on ice for 30 minutes, then centrifuge to pellet cell debris.
-
Collect the supernatant containing the protein lysate.
3.2. Protein Purification (for His-tagged proteins):
-
Equilibrate a Ni-NTA affinity chromatography column with binding buffer.
-
Load the cell lysate onto the column.
-
Wash the column with wash buffer to remove non-specifically bound proteins.
-
Elute the His-tagged protein with elution buffer containing imidazole.
-
Desalt the purified protein using a desalting column.
3.3. Western Blot Analysis:
-
Separate the purified protein and cell lysate by SDS-PAGE.
-
Transfer the proteins to a PVDF membrane.
-
Probe the membrane with an antibody against the C-terminal tag (e.g., anti-His or anti-FLAG) to confirm the expression of the full-length protein.
Protocol 4: Dual-Fluorescence Reporter Assay for Suppression Efficiency
This protocol allows for the quantification of amber suppression efficiency using a reporter construct.[3][4][13]
4.1. Reporter Plasmid:
-
Construct a plasmid expressing a fusion protein of two fluorescent proteins (e.g., mCherry and eGFP) separated by a linker containing an amber stop codon (mCherry-TAG-eGFP). Expression of the second fluorescent protein (eGFP) is dependent on the successful suppression of the amber codon.
4.2. Procedure:
-
Co-transfect HEK293 cells with the dual-fluorescence reporter plasmid and the orthogonal system plasmid as described in Protocol 2.
-
Culture one set of cells with 4-AP and a control set without 4-AP.
-
After 48 hours, lyse the cells and measure the fluorescence of both mCherry and eGFP using a plate reader.
-
Calculate the suppression efficiency as the ratio of eGFP to mCherry fluorescence in the presence of 4-AP, normalized to the ratio observed for a wild-type control construct (mCherry-eGFP without a TAG codon).
Protocol 5: Mass Spectrometry Analysis for 4-AP Incorporation Confirmation
This protocol provides a general workflow for preparing the purified protein for mass spectrometry to definitively confirm the incorporation of 4-AP.[14][15][16][17]
5.1. In-solution Digestion:
-
Denature the purified protein in a buffer containing urea (B33335) or guanidinium (B1211019) hydrochloride.
-
Reduce disulfide bonds with DTT and alkylate cysteine residues with iodoacetamide.
-
Digest the protein into peptides using a protease such as trypsin.
5.2. Peptide Cleanup:
-
Desalt the peptide mixture using a C18 desalting column or tip to remove salts and detergents that can interfere with mass spectrometry analysis.
5.3. LC-MS/MS Analysis:
-
Analyze the peptide mixture by liquid chromatography-tandem mass spectrometry (LC-MS/MS).
-
The mass spectrometer will measure the mass-to-charge ratio of the peptides and their fragments.
5.4. Data Analysis:
-
Use proteomics software to search the fragmentation data against the sequence of the target protein.
-
Identify the peptide containing the amber codon position and confirm the mass shift corresponding to the incorporation of this compound (molecular weight: 180.20 g/mol ) instead of a canonical amino acid. The expected mass of a peptide containing 4-AP will be different from the mass of the same peptide with a canonical amino acid at that position.[18]
Visualizations
Caption: Experimental workflow for 4-AP incorporation.
Caption: Mechanism of amber codon suppression for 4-AP.
Caption: Principle of the dual-fluorescence reporter assay.
References
- 1. Rapid discovery and evolution of orthogonal aminoacyl-tRNA synthetase–tRNA pairs - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Using genetically incorporated unnatural amino acids to control protein functions in mammalian cells - PMC [pmc.ncbi.nlm.nih.gov]
- 3. academic.oup.com [academic.oup.com]
- 4. A CHO-Based Cell-Free Dual Fluorescence Reporter System for the Straightforward Assessment of Amber Suppression and scFv Functionality - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Frontiers | Cell Engineering and Cultivation of Chinese Hamster Ovary Cells for the Development of Orthogonal Eukaryotic Cell-free Translation Systems [frontiersin.org]
- 6. Development of mammalian cell logic gates controlled by unnatural amino acids - PMC [pmc.ncbi.nlm.nih.gov]
- 7. An Evolved Aminoacyl-tRNA Synthetase with Atypical Polysubstrate Specificity - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Fine-tuning Interaction between Aminoacyl-tRNA Synthetase and tRNA for Efficient Synthesis of Proteins Containing Unnatural Amino Acids - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Evolution of Amber Suppressor tRNAs for Efficient Bacterial Production of Unnatural Amino Acid-Containing Proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 10. academic.oup.com [academic.oup.com]
- 11. Identification of permissive amber suppression sites for efficient non-canonical amino acid incorporation in mammalian cells - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Protocol for cell preparation and gene delivery in HEK293T and C2C12 cells - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Research Collection | ETH Library [research-collection.ethz.ch]
- 14. documents.thermofisher.com [documents.thermofisher.com]
- 15. massspec.unm.edu [massspec.unm.edu]
- 16. info.gbiosciences.com [info.gbiosciences.com]
- 17. Sample Preparation for Mass Spectrometry | Thermo Fisher Scientific - US [thermofisher.com]
- 18. benchchem.com [benchchem.com]
Application Notes & Protocols: Incorporating BODIPY-Conjugated 4-Aminophenylalanine for FRET Analysis
Introduction
The site-specific incorporation of fluorescent non-canonical amino acids (ncAAs) into proteins is a powerful technique for studying protein structure, function, and dynamics.[1][2] BODIPY (boron-dipyrromethene) dyes are a class of fluorophores well-suited for biological applications due to their high molar absorption coefficients, excellent fluorescence quantum yields, sharp emission peaks, and relative insensitivity to solvent polarity.[3][4][5][6] By conjugating a BODIPY dye to 4-aminophenylalanine (AmF), a fluorescent ncAA is created that can be genetically encoded into a protein of interest at a specific site.
This application note provides a detailed overview and protocols for incorporating BODIPY-conjugated this compound (BODIPY-AmF) into proteins and its subsequent use as a donor fluorophore in Förster Resonance Energy Transfer (FRET) analysis. FRET is a spectroscopic technique that can detect the proximity between two fluorophores—a donor and an acceptor—on the nanometer scale (typically 1-10 nm), making it an ideal tool for monitoring conformational changes and intermolecular interactions.[7][][9] The methods described herein utilize amber stop codon (UAG) suppression technology for the site-specific incorporation of BODIPY-AmF in E. coli.[10]
Principle of FRET with BODIPY-AmF
FRET is a non-radiative energy transfer process where an excited donor fluorophore transfers energy to a proximal acceptor chromophore through dipole-dipole interactions.[][11] The efficiency of this transfer (E) is highly dependent on the distance (r) between the donor and acceptor, as described by the Förster equation:
E = 1 / (1 + (r/R₀)⁶)
Where R₀ is the Förster distance, the specific distance at which FRET efficiency is 50%.[11] R₀ is determined by the spectral overlap between the donor's emission and the acceptor's absorption, the quantum yield of the donor, and the relative orientation of the two dipoles.[9]
By incorporating BODIPY-AmF as the donor and labeling a second site (on the same or a different protein) with a suitable acceptor, changes in the distance between these two points can be measured as changes in FRET efficiency. For example, BODIPY-FL-aminophenylalanine can be paired with an acceptor like BODIPY-558 to analyze protein conformational changes.[7]
Core Applications
-
Protein Conformational Changes: Monitoring dynamic changes in protein structure upon ligand binding, substrate turnover, or post-translational modification.[7][12]
-
Protein-Protein Interactions: Quantifying the association and dissociation of protein complexes in real-time.
-
High-Throughput Screening: Developing biosensors for drug discovery by detecting ligand-induced conformational shifts.[12]
-
Enzyme Kinetics: Studying the dynamics of enzyme mechanisms by placing probes at or near the active site.
Data Presentation: Spectroscopic Properties and FRET Parameters
Quantitative analysis requires a thorough understanding of the fluorophores' properties. The tables below summarize key data for a representative donor (BODIPY-FL) and potential acceptors.
Table 1: Spectroscopic Properties of a Representative BODIPY-AmF FRET Pair
| Fluorophore | Type | Excitation Max (nm) | Emission Max (nm) | Molar Extinction Coefficient (M⁻¹cm⁻¹) | Quantum Yield |
|---|---|---|---|---|---|
| BODIPY-FL-AmF | Donor | ~503 | ~512 | ~80,000 | > 0.90 |
| BODIPY TMR | Acceptor | ~544 | ~570 | ~100,000 | ~0.40 |
| Cy3 | Acceptor | ~550 | ~570 | ~150,000 | ~0.31 |
| BODIPY-558 | Acceptor | ~558 | ~568 | ~100,000 | ~0.20 |
| Alexa Fluor 594 | Acceptor | ~590 | ~617 | ~73,000 | ~0.66 |
Note: Exact spectroscopic values can vary depending on the local chemical environment, conjugation, and buffer conditions. Data is compiled from representative values.[4][6][7][]
Table 2: Calculated Förster Distances (R₀) for Common FRET Pairs
| Donor | Acceptor | R₀ (Å) |
|---|---|---|
| BODIPY FL | BODIPY R6G | 57 |
| BODIPY FL | BODIPY TMR | 54 |
| Alexa Fluor 488 | Alexa Fluor 594 | 56 |
| Cy3 | Cy5 | 50 |
Note: R₀ values are estimates and depend on the orientation factor κ², which is often assumed to be 2/3 for freely rotating fluorophores.[][9]
Experimental Workflow & Key Methodologies
The overall process involves genetic manipulation, protein expression with the ncAA, purification, and subsequent spectroscopic analysis.
Caption: High-level workflow for FRET analysis using BODIPY-AmF.
Protocol 1: Site-Specific Incorporation of BODIPY-AmF via Amber Suppression
This protocol outlines the expression and purification of a target protein containing BODIPY-AmF at a single, defined site in E. coli. It relies on a co-expressed orthogonal aminoacyl-tRNA synthetase and its cognate suppressor tRNA (tRNACUA).[10]
Caption: Mechanism of BODIPY-AmF incorporation via amber suppression.
Materials:
-
E. coli strain (e.g., BL21(DE3) or an RF1-deficient strain to reduce termination at the UAG codon).[13]
-
Expression plasmid for the target protein with an in-frame amber (TAG) codon at the desired position.
-
Plasmid encoding the orthogonal aminoacyl-tRNA synthetase/tRNACUA pair (e.g., pEVOL-pBpF).
-
BODIPY-FL-4-aminophenylalanine (or other desired BODIPY conjugate).
-
LB media and appropriate antibiotics.
-
IPTG (Isopropyl β-D-1-thiogalactopyranoside).
-
Standard protein purification reagents (e.g., Ni-NTA resin for His-tagged proteins).
Methodology:
-
Transformation: Co-transform the E. coli host strain with the target protein plasmid and the orthogonal synthetase/tRNA plasmid. Select for colonies on LB agar (B569324) plates containing the appropriate antibiotics.
-
Starter Culture: Inoculate a single colony into 5-10 mL of LB media with antibiotics and grow overnight at 37°C with shaking.
-
Expression Culture: Inoculate 1 L of LB media (with antibiotics) with the overnight starter culture. Grow at 37°C with shaking until the OD₆₀₀ reaches 0.6-0.8.
-
Supplementation: Add BODIPY-AmF to a final concentration of 1 mM. Note: BODIPY-AmF may need to be dissolved in a small amount of DMSO or NaOH before adding to the culture.
-
Induction: Induce protein expression by adding IPTG to a final concentration of 0.5-1 mM. If using the pEVOL plasmid, also add L-arabinose to induce the synthetase.
-
Expression: Reduce the temperature to 20-25°C and continue to shake for 12-18 hours. Lower temperatures often improve protein folding and ncAA incorporation efficiency.
-
Harvesting: Harvest the cells by centrifugation (e.g., 5,000 x g for 15 min at 4°C).
-
Purification: Resuspend the cell pellet in lysis buffer and purify the protein using standard affinity chromatography (e.g., Ni-NTA for His-tagged proteins), followed by size-exclusion chromatography to remove aggregates and non-incorporated ncAA. Confirm incorporation via mass spectrometry.
Protocol 2: FRET Measurement by Sensitized Emission
This protocol describes how to measure FRET efficiency by exciting the donor and measuring the resulting fluorescence from both the donor and the acceptor.
References
- 1. Site-Specific Incorporation of Non-canonical Amino Acids by Amber Stop Codon Suppression in Escherichia coli | Springer Nature Experiments [experiments.springernature.com]
- 2. In vitro incorporation of nonnatural amino acids into protein using tRNACys-derived opal, ochre, and amber suppressor tRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Synthesis and spectroscopic properties of some novel BODIPY dyes - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Amine-Reactive BODIPY Dye: Spectral Properties and Application for Protein Labeling - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. BODIPY Dye Series—Section 1.4 | Thermo Fisher Scientific - SG [thermofisher.com]
- 7. FRET analysis of protein conformational change through position-specific incorporation of fluorescent amino acids - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Basics of FRET Microscopy | Nikon’s MicroscopyU [microscopyu.com]
- 10. academic.oup.com [academic.oup.com]
- 11. The fluorescence laboratory. - Calculate Resonance Energy Transfer (FRET) Efficiencies [fluortools.com]
- 12. Position-specific incorporation of fluorescent non-natural amino acids into maltose-binding protein for detection of ligand binding by FRET and fluorescence quenching - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
Application Notes and Protocols for Cell-Free Protein Synthesis of Proteins Containing 4-Aminophenylalanine using the PURE System
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a detailed overview and experimental protocols for the site-specific incorporation of the non-canonical amino acid 4-Aminophenylalanine (4-APhe) into proteins using the PURE (Protein synthesis Using Recombinant Elements) cell-free system. This advanced in vitro translation system, composed of purified essential components for transcription and translation, offers a highly controlled environment ideal for protein engineering and the production of proteins with novel functionalities.
Introduction
The incorporation of non-canonical amino acids (ncAAs) into proteins allows for the introduction of novel chemical groups, enabling a wide range of applications from protein labeling and imaging to the development of therapeutic proteins with enhanced properties. This compound, with its reactive amino group, serves as a valuable tool for site-specific protein modification, including cross-linking and conjugation to other molecules. The PURE system, being a reconstituted cell-free protein synthesis platform, is particularly well-suited for ncAA incorporation due to the absence of competing cellular machinery and the ability to precisely control the reaction components.[1][2][3]
The methodology relies on the amber stop codon (UAG) suppression strategy.[4][5][6] An orthogonal aminoacyl-tRNA synthetase (aaRS) specifically charges a cognate suppressor tRNA (tRNA CUA ) with 4-APhe. This charged tRNA then recognizes the UAG codon in the mRNA sequence and incorporates 4-APhe into the growing polypeptide chain.
Key Components and Considerations
Successful incorporation of 4-APhe into a target protein using the PURE system requires the following key components:
-
PURE System Kit: A commercially available PURE system (e.g., PUREfrex® or PURExpress®) provides the core machinery for transcription and translation. These kits typically contain ribosomes, tRNAs, aminoacyl-tRNA synthetases for the 20 canonical amino acids, and other necessary protein factors.
-
DNA Template: A linear or plasmid DNA template encoding the gene of interest with an in-frame amber (TAG) codon at the desired incorporation site.
-
Orthogonal tRNA CUA : A suppressor tRNA that recognizes the UAG codon. The most commonly used is the Methanocaldococcus jannaschii tyrosyl-tRNA (Mj-tRNA Tyr CUA ).
-
This compound (4-APhe): The non-canonical amino acid to be incorporated.
Experimental Workflow
The overall experimental workflow for the cell-free synthesis of a protein containing 4-APhe is depicted below.
Caption: Experimental workflow for 4-APhe incorporation.
Detailed Protocols
Protocol 1: Cell-Free Protein Synthesis of a Model Protein (e.g., sfGFP) with this compound
This protocol describes the synthesis of a superfolder Green Fluorescent Protein (sfGFP) with a 4-APhe residue incorporated at a specific site via amber codon suppression in the PURE system.
Materials:
-
PURE System Kit (e.g., PUREfrex® 2.0)
-
Plasmid DNA encoding sfGFP with a TAG codon at the desired position (e.g., sfGFP-Y39TAG)
-
Purified orthogonal tRNA CUA (Mj-tRNA Tyr CUA )
-
Purified orthogonal 4-APheRS (an engineered MjTyrRS)
-
This compound (4-APhe) solution (10 mM in water, pH 7.5)
-
Nuclease-free water
Procedure:
-
Thaw PURE System Components: On ice, thaw the PURE system solutions (Solution I, II, and III, or equivalent components depending on the manufacturer).
-
Prepare the Reaction Mixture: In a nuclease-free microcentrifuge tube on ice, combine the following components in the order listed. The final reaction volume is 20 µL.
| Component | Stock Concentration | Volume to Add | Final Concentration |
| Nuclease-free water | - | to 20 µL | - |
| PURE System Solution I | - | 10 µL | 1x |
| PURE System Solution II | - | 2 µL | 1x |
| PURE System Solution III | - | 4 µL | 1x |
| sfGFP-Y39TAG DNA | 100 ng/µL | 1 µL | 5 ng/µL |
| This compound | 10 mM | 0.4 µL | 0.2 mM |
| Orthogonal tRNA CUA | 1 mg/mL | 0.5 µL | 25 µg/mL |
| 4-APheRS | 1 mg/mL | 0.5 µL | 25 µg/mL |
-
Incubation: Gently mix the reaction by pipetting up and down. Incubate the reaction mixture at 37°C for 2-4 hours.
-
Analysis of Protein Expression:
-
SDS-PAGE: Analyze a 5 µL aliquot of the reaction mixture by SDS-PAGE. The full-length sfGFP containing 4-APhe should be visible as a band of the expected molecular weight. A control reaction without 4-APhe or the orthogonal components should show a truncated product.
-
Fluorescence: If a fluorescent protein is expressed, measure the fluorescence to quantify the yield of the full-length protein.
-
Protocol 2: Validation of this compound Incorporation by Mass Spectrometry
This protocol outlines the steps to confirm the successful and site-specific incorporation of 4-APhe into the target protein using mass spectrometry.
Materials:
-
Cell-free protein synthesis reaction containing the purified protein with 4-APhe
-
Trypsin (mass spectrometry grade)
-
Dithiothreitol (DTT)
-
Iodoacetamide (IAM)
-
Ammonium (B1175870) bicarbonate buffer (50 mM, pH 8.0)
-
Formic acid
-
Acetonitrile
-
C18 desalting column
-
Mass spectrometer (e.g., ESI-Q-TOF)
Procedure:
-
Protein Purification: Purify the synthesized protein containing 4-APhe from the cell-free reaction mixture using an appropriate method (e.g., Ni-NTA affinity chromatography if the protein has a His-tag).
-
In-solution Digestion: a. Denature the purified protein in 50 mM ammonium bicarbonate buffer with 6 M urea (B33335). b. Reduce the disulfide bonds by adding DTT to a final concentration of 10 mM and incubating at 37°C for 1 hour. c. Alkylate the cysteine residues by adding IAM to a final concentration of 55 mM and incubating in the dark at room temperature for 45 minutes. d. Dilute the urea concentration to less than 1 M with 50 mM ammonium bicarbonate buffer. e. Add trypsin at a 1:50 (w/w) ratio of trypsin to protein and incubate overnight at 37°C.
-
Sample Preparation for Mass Spectrometry: a. Stop the digestion by adding formic acid to a final concentration of 0.1%. b. Desalt the peptide mixture using a C18 column according to the manufacturer's protocol. c. Elute the peptides and dry them in a vacuum centrifuge. d. Reconstitute the peptides in 0.1% formic acid for mass spectrometry analysis.
-
Mass Spectrometry Analysis: a. Analyze the peptide mixture by LC-MS/MS. b. Search the acquired spectra against a database containing the sequence of the target protein. c. Look for a peptide fragment containing the site of the original TAG codon with a mass shift corresponding to the incorporation of 4-APhe instead of a canonical amino acid. The mass of 4-APhe is approximately 180.22 Da.[3]
Data Presentation
Table 1: Expected Mass Shifts for Validation of 4-APhe Incorporation
| Amino Acid | Molecular Weight (Da) | Expected Mass Shift relative to Phenylalanine (Da) |
| Phenylalanine (Phe) | 165.19 | 0 |
| This compound (4-APhe) | 180.22 | +15.03 |
Table 2: Troubleshooting Guide for 4-APhe Incorporation in the PURE System
| Problem | Possible Cause | Suggested Solution |
| Low or no protein yield | Inactive PURE system components | Ensure proper storage and handling of the PURE system kit. |
| Degraded DNA template | Use high-quality, nuclease-free DNA. | |
| Suboptimal concentration of 4-APhe or orthogonal components | Titrate the concentrations of 4-APhe, tRNA CUA , and 4-APheRS. | |
| High level of truncated product | Inefficient amber suppression | Increase the concentration of tRNA CUA and 4-APheRS. |
| Depletion of 4-APhe | Increase the initial concentration of 4-APhe. | |
| Mis-incorporation of canonical amino acids | Polyspecificity of the 4-APheRS | Further engineer the 4-APheRS for higher specificity. |
| Contamination with canonical amino acids | Use highly pure 4-APhe. |
Signaling Pathways and Logical Relationships
The core of this technology is the establishment of an orthogonal translation system that operates in parallel with the endogenous translation machinery without cross-reactivity.
Caption: Orthogonal translation system for 4-APhe.
Applications in Research and Drug Development
The ability to site-specifically incorporate 4-APhe into proteins opens up numerous possibilities:
-
Bioconjugation: The primary amino group on the phenyl ring of 4-APhe can be used for specific chemical ligation to attach fluorescent probes, polyethylene (B3416737) glycol (PEG), or cytotoxic drugs for the development of antibody-drug conjugates (ADCs).
-
Protein-Protein Interaction Studies: 4-APhe can be used to introduce photo-crosslinkers to map protein interaction interfaces.
-
Enzyme Engineering: The introduction of 4-APhe can alter the catalytic activity or substrate specificity of enzymes.
-
Biomaterials: The unique properties of 4-APhe can be exploited to create novel protein-based biomaterials.
By providing a robust and controlled environment, the PURE system, coupled with an efficient orthogonal translation system for this compound, is a powerful platform for advancing protein engineering and therapeutic protein development.
References
- 1. Engineered Aminoacyl-tRNA Synthetases with Improved Selectivity toward Noncanonical Amino Acids - PMC [pmc.ncbi.nlm.nih.gov]
- 2. High-yield cell-free protein synthesis for site-specific incorporation of unnatural amino acids at two sites - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. benchchem.com [benchchem.com]
- 4. Amber Suppression Technology for Mapping Site-specific Viral-host Protein Interactions in Mammalian Cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Improved amber and opal suppressor tRNAs for incorporation of unnatural amino acids in vivo. Part 1: Minimizing misacylation - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Unnatural amino acid mutagenesis of GPCRs using amber codon suppression and bioorthogonal labeling - PubMed [pubmed.ncbi.nlm.nih.gov]
Application Notes and Protocols for Solid-Phase Peptide Synthesis (SPPS) using Fmoc-4-Amino-L-phenylalanine
For Researchers, Scientists, and Drug Development Professionals
Introduction
The incorporation of non-proteinogenic amino acids into peptide sequences is a powerful strategy in medicinal chemistry and drug development. 4-Amino-L-phenylalanine, a derivative of L-phenylalanine, offers a unique functional handle—a primary amino group on the phenyl ring—that can be leveraged to enhance peptide stability, modulate biological activity, and enable further chemical modifications.[1][2] This document provides detailed application notes and protocols for the successful solid-phase peptide synthesis (SPPS) of peptides containing 4-Amino-L-phenylalanine using Fluorenylmethyloxycarbonyl (Fmoc) chemistry.
Fmoc-SPPS is the predominant method for peptide synthesis, favored for its mild deprotection conditions and compatibility with a wide range of amino acid derivatives.[][4] When incorporating Fmoc-4-Amino-L-phenylalanine, a key consideration is the protection of the side-chain amino group to prevent unwanted branching and side reactions during peptide elongation. This is typically achieved using an orthogonal protecting group, such as tert-butyloxycarbonyl (Boc), which is stable to the basic conditions used for Fmoc removal and is cleaved during the final acidic cleavage from the resin.
These notes are intended to guide researchers through the nuances of utilizing Fmoc-4-Amino-L-phenylalanine, from understanding its impact on synthesis outcomes to providing robust protocols for its incorporation and the subsequent handling of the modified peptide.
Data Presentation: Synthesis Parameters and Expected Outcomes
The successful incorporation of Fmoc-4-Amino-L-phenylalanine into a peptide sequence is dependent on several factors, including the choice of coupling reagents and the nature of the peptide sequence itself. While comprehensive comparative data is often sequence-dependent, the following tables provide typical performance metrics based on established Fmoc-SPPS methodologies.
Table 1: Typical Purity of Commercially Available Fmoc-4-Amino-L-phenylalanine Derivatives
| Derivative | Purity (by HPLC) | Reference |
| Fmoc-4-(Boc-amino)-L-phenylalanine | ≥ 97% | [5] |
Table 2: General Performance Metrics in Fmoc-SPPS
| Parameter | Typical Value/Range | Notes |
| Coupling Efficiency (per step) | >99% | High efficiency is crucial for the synthesis of long peptides. Monitoring with a qualitative test like the Kaiser test is recommended.[] |
| Overall Crude Peptide Purity | 50-95% | Highly sequence-dependent. The presence of hydrophobic or bulky residues, including modified phenylalanine, can impact purity. |
| Final Peptide Yield (after purification) | 10-50% | Dependent on synthesis scale, peptide length, sequence difficulty, and purification efficiency. |
Experimental Protocols
The following protocols provide a detailed methodology for the key steps in the solid-phase synthesis of a peptide containing 4-Amino-L-phenylalanine.
Protocol 1: Resin Swelling and Fmoc Deprotection
-
Resin Swelling: Place the desired amount of resin (e.g., Rink Amide resin for C-terminal amides or Wang resin for C-terminal acids) in a reaction vessel. Add a sufficient volume of N,N-dimethylformamide (DMF) to swell the resin for at least 30 minutes.
-
Solvent Removal: Drain the DMF from the swollen resin.
-
Fmoc Deprotection: Add a solution of 20% piperidine (B6355638) in DMF to the resin. Agitate the mixture for 5-10 minutes. Drain the solution. Repeat the 20% piperidine in DMF treatment for another 5-10 minutes.
-
Washing: Thoroughly wash the resin with DMF (5-7 times) to remove all traces of piperidine and the Fmoc-piperidine adduct.
Protocol 2: Coupling of Fmoc-4-(Boc-amino)-L-phenylalanine
This protocol utilizes HBTU as the coupling reagent, which is known for its efficiency in coupling sterically hindered or unusual amino acids.
-
Amino Acid Preparation: In a separate vial, dissolve Fmoc-4-(Boc-amino)-L-phenylalanine (3 equivalents relative to the resin loading) and O-(Benzotriazol-1-yl)-N,N,N',N'-tetramethyluronium hexafluorophosphate (B91526) (HBTU) (2.9 equivalents) in DMF.
-
Activation: Add N,N-Diisopropylethylamine (DIPEA) (6 equivalents) to the amino acid/HBTU solution. Allow the mixture to pre-activate for 1-2 minutes.
-
Coupling Reaction: Add the activated amino acid solution to the deprotected resin in the reaction vessel. Agitate the mixture at room temperature for 1-2 hours. For difficult couplings, the reaction time can be extended.
-
Monitoring: Perform a Kaiser test on a small sample of resin beads. A negative result (yellow beads) indicates complete coupling. If the test is positive (blue/purple beads), the coupling step should be repeated.
-
Washing: After complete coupling, drain the reaction solution and wash the resin thoroughly with DMF (3-5 times) and then with dichloromethane (B109758) (DCM) (3-5 times).
Protocol 3: Peptide Cleavage and Deprotection
This protocol is for cleavage from an acid-labile resin (e.g., Rink Amide or Wang) and simultaneous removal of the Boc side-chain protecting group.
-
Resin Preparation: After the final Fmoc deprotection and washing of the fully assembled peptide-resin, wash the resin with DCM (3-5 times) and dry it under a stream of nitrogen or in a vacuum desiccator.
-
Cleavage Cocktail Preparation: Prepare a cleavage cocktail appropriate for the peptide sequence. A common general-purpose cocktail is Reagent K: Trifluoroacetic acid (TFA)/Water/Phenol/Thioanisole/1,2-Ethanedithiol (EDT) in a ratio of 82.5:5:5:5:2.5.
-
Cleavage Reaction: Add the cleavage cocktail to the dried peptide-resin (approximately 10 mL per gram of resin). Agitate the mixture at room temperature for 2-4 hours.
-
Peptide Precipitation: Filter the resin and collect the filtrate containing the cleaved peptide. Precipitate the peptide by adding the filtrate to a 10-fold volume of cold diethyl ether.
-
Peptide Isolation: Centrifuge the ether suspension to pellet the crude peptide. Carefully decant the ether.
-
Washing and Drying: Wash the peptide pellet with cold diethyl ether two more times. After the final wash, allow the crude peptide to air-dry or dry under vacuum to remove residual ether.
-
Purification: Purify the crude peptide using reverse-phase high-performance liquid chromatography (RP-HPLC).
Visualizations
Experimental Workflow
Caption: General workflow for solid-phase peptide synthesis (SPPS) incorporating Fmoc-4-(Boc)-Amino-L-phenylalanine.
Signaling Pathway
The incorporation of modified amino acids like 4-Amino-L-phenylalanine can be used to develop peptide-based kinase inhibitors that target key signaling pathways involved in cell proliferation and survival, such as the PI3K/Akt pathway. Phenylalanine-based molecules have been designed as covalent inactivators of Akt kinase, demonstrating the potential for peptides containing this modified residue to modulate this critical pathway.[6][7]
Caption: Simplified PI3K/Akt signaling pathway and a potential point of inhibition by a peptide containing 4-Amino-L-phenylalanine.
References
- 1. nbinno.com [nbinno.com]
- 2. nbinno.com [nbinno.com]
- 4. Fmoc Solid Phase Peptide Synthesis: Mechanism and Protocol - Creative Peptides [creative-peptides.com]
- 5. luxembourg-bio.com [luxembourg-bio.com]
- 6. Phenylalanine-Based Inactivator of AKT Kinase: Design, Synthesis, and Biological Evaluation - PMC [pmc.ncbi.nlm.nih.gov]
- 7. pubs.acs.org [pubs.acs.org]
Metabolic Labeling of Proteins with 4-Aminophenylalanine Analogs: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
This document provides detailed application notes and protocols for the metabolic labeling of proteins using analogs of 4-Aminophenylalanine (4-AP). This powerful technique enables the introduction of bioorthogonal functional groups into proteins, allowing for their subsequent visualization, identification, and quantification. These methods are invaluable for a wide range of applications in basic research and drug development, including the study of protein synthesis and turnover, post-translational modifications, protein-protein interactions, and target engagement.
Introduction
Metabolic labeling with non-canonical amino acids (ncAAs) is a versatile strategy to introduce unique chemical handles into proteins in living cells and organisms.[1] Analogs of this compound (4-AP), featuring bioorthogonal functional groups such as azides, alkynes, and ketones, are of particular interest. These analogs are structurally similar to the natural amino acid phenylalanine and can be incorporated into proteins by the cell's own translational machinery.[2] Once incorporated, the bioorthogonal handle can be specifically and efficiently modified with a probe of interest (e.g., a fluorophore, biotin (B1667282), or a drug molecule) through highly selective chemical reactions that do not interfere with biological processes.[3][4] This approach offers a powerful alternative to traditional methods of protein labeling, such as genetic fusion to fluorescent proteins or antibody-based detection, providing a smaller, less perturbing tag for studying protein dynamics in their native context.[2]
Overview of the Workflow
The general workflow for metabolic labeling of proteins with 4-AP analogs involves several key steps, from the introduction of the analog into the cellular environment to the final analysis of the labeled proteins.
Key this compound Analogs and Their Applications
Several 4-AP analogs have been developed, each with a unique bioorthogonal handle that dictates its subsequent chemical modification. The choice of analog depends on the specific research question and the desired downstream application.
| 4-AP Analog | Bioorthogonal Handle | Corresponding Reaction | Key Applications |
| 4-Azido-L-phenylalanine (pAzF) | Azide (-N₃) | Staudinger Ligation, Copper(I)-catalyzed Azide-Alkyne Cycloaddition (CuAAC), Strain-Promoted Azide-Alkyne Cycloaddition (SPAAC) | Protein-protein interaction studies, in vivo imaging, protein enrichment.[1][5] |
| p-Acetyl-L-phenylalanine (pAcF) | Ketone (-COCH₃) | Oxime/Hydrazone Ligation | Site-specific spin labeling for structural studies, protein engineering.[6][7] |
| 4-Alkynyl-L-phenylalanine | Alkyne (-C≡CH) | Copper(I)-catalyzed Azide-Alkyne Cycloaddition (CuAAC), Strain-Promoted Azide-Alkyne Cycloaddition (SPAAC) | Fluorescent imaging, peptide-based probes. |
| 4-Propargyloxy-L-phenylalanine (pPa) | Propargyloxy (-OCH₂C≡CH) | Copper(I)-catalyzed Azide-Alkyne Cycloaddition (CuAAC) | Enzyme inhibitor design, peptide synthesis.[8][9] |
Table 1: Common this compound Analogs and Their Applications.
Experimental Protocols
This section provides detailed protocols for the metabolic labeling of proteins in mammalian cells using 4-azido-L-phenylalanine (pAzF) and p-acetyl-L-phenylalanine (pAcF), followed by bioorthogonal ligation and sample preparation for mass spectrometry.
Protocol 1: Metabolic Labeling with 4-Azido-L-phenylalanine (pAzF)
This protocol is adapted for the incorporation of pAzF into cellular proteins for subsequent analysis by click chemistry.
Materials:
-
Mammalian cell line of interest
-
Complete cell culture medium (e.g., DMEM or RPMI-1640)
-
Phenylalanine-free medium
-
Dialyzed fetal bovine serum (dFBS)
-
4-Azido-L-phenylalanine (pAzF)
-
Phosphate-buffered saline (PBS)
-
Lysis buffer (e.g., RIPA buffer supplemented with protease inhibitors)
Procedure:
-
Cell Culture and Adaptation:
-
Culture cells in complete medium to ~80% confluency.
-
For stable isotope labeling by amino acids in cell culture (SILAC) experiments, adapt two populations of cells to "light" (containing natural phenylalanine) and "heavy" (containing a stable isotope-labeled phenylalanine) media for at least five passages to ensure full incorporation.[2]
-
-
Labeling:
-
Wash cells twice with pre-warmed PBS.
-
Replace the medium with phenylalanine-free medium supplemented with 10% dFBS and pAzF (typically 1-4 mM).
-
Incubate cells for the desired period (e.g., 4-24 hours) to allow for pAzF incorporation into newly synthesized proteins.
-
-
Cell Harvest and Lysis:
-
Wash cells twice with ice-cold PBS.
-
Lyse the cells directly on the plate by adding ice-cold lysis buffer.
-
Scrape the cells and transfer the lysate to a microcentrifuge tube.
-
Incubate on ice for 30 minutes, vortexing occasionally.
-
Clarify the lysate by centrifugation at 14,000 x g for 15 minutes at 4°C.
-
Collect the supernatant containing the pAzF-labeled proteome.
-
Protocol 2: Bioorthogonal Ligation via Click Chemistry (CuAAC)
This protocol describes the copper-catalyzed azide-alkyne cycloaddition (CuAAC) reaction to conjugate an alkyne-containing probe (e.g., alkyne-biotin or a fluorescent alkyne) to pAzF-labeled proteins.
Materials:
-
pAzF-labeled protein lysate
-
Alkyne-probe (e.g., Alkyne-Biotin)
-
Tris(2-carboxyethyl)phosphine (TCEP)
-
Tris[(1-benzyl-1H-1,2,3-triazol-4-yl)methyl]amine (TBTA)
-
Copper(II) sulfate (B86663) (CuSO₄)
-
Sodium ascorbate (B8700270)
Procedure:
-
Prepare Click Chemistry Reaction Mix:
-
In a microcentrifuge tube, combine the pAzF-labeled protein lysate (e.g., 1 mg of protein).
-
Add the alkyne-probe to a final concentration of 100 µM.
-
Add TCEP to a final concentration of 1 mM.
-
Add TBTA to a final concentration of 100 µM.
-
-
Initiate Reaction:
-
Add CuSO₄ to a final concentration of 1 mM.
-
Add freshly prepared sodium ascorbate to a final concentration of 1 mM to reduce Cu(II) to the catalytic Cu(I) species.
-
-
Incubation:
-
Incubate the reaction at room temperature for 1-2 hours with gentle rotation.
-
-
Protein Precipitation (Optional but Recommended):
-
Precipitate the proteins to remove excess reagents. A methanol/chloroform precipitation is effective.[10]
-
Resuspend the protein pellet in a buffer suitable for downstream applications (e.g., SDS-PAGE sample buffer for in-gel fluorescence or a denaturing buffer for protein digestion).
-
Protocol 3: Enrichment of Labeled Proteins
This protocol describes the enrichment of biotinylated proteins using streptavidin-agarose beads.
Materials:
-
Biotin-labeled protein lysate
-
Streptavidin-agarose beads
-
Wash buffers (e.g., PBS with 0.1% SDS, 6M Urea, and PBS)
-
Elution buffer (e.g., SDS-PAGE sample buffer containing biotin)
Procedure:
-
Bead Preparation:
-
Wash the streptavidin-agarose beads three times with lysis buffer.
-
-
Binding:
-
Add the biotin-labeled protein lysate to the washed beads.
-
Incubate for 1-2 hours at 4°C with gentle rotation.
-
-
Washing:
-
Pellet the beads by centrifugation and discard the supernatant.
-
Wash the beads sequentially with:
-
Lysis buffer containing 1% SDS
-
6 M Urea
-
PBS
-
-
-
Elution:
-
Elute the bound proteins by boiling the beads in SDS-PAGE sample buffer supplemented with 2-5 mM biotin for 10 minutes. The free biotin will compete with the biotinylated proteins for binding to streptavidin.
-
Protocol 4: Sample Preparation for Mass Spectrometry
This protocol outlines the in-solution digestion of enriched proteins for subsequent analysis by LC-MS/MS.
Materials:
-
Enriched and eluted protein sample
-
Dithiothreitol (DTT)
-
Iodoacetamide (IAA)
-
Trypsin (mass spectrometry grade)
-
Ammonium (B1175870) bicarbonate buffer (50 mM, pH 8.0)
-
Formic acid
Procedure:
-
Reduction and Alkylation:
-
Add DTT to the protein sample to a final concentration of 10 mM and incubate at 56°C for 30 minutes.
-
Cool the sample to room temperature.
-
Add IAA to a final concentration of 20 mM and incubate in the dark at room temperature for 30 minutes.
-
-
Digestion:
-
Dilute the sample with ammonium bicarbonate buffer to reduce the SDS concentration to less than 0.1%.
-
Add trypsin at a 1:50 (trypsin:protein) ratio and incubate overnight at 37°C.
-
-
Desalting:
-
Acidify the digest with formic acid to a final concentration of 0.1%.
-
Desalt the peptides using a C18 StageTip or ZipTip.
-
Elute the peptides with a solution of 50-80% acetonitrile (B52724) in 0.1% formic acid.
-
-
LC-MS/MS Analysis:
-
Dry the eluted peptides in a vacuum centrifuge and resuspend in a small volume of 0.1% formic acid for injection into the LC-MS/MS system.
-
Data Presentation and Analysis
Quantitative proteomics data obtained from metabolic labeling experiments with 4-AP analogs can be presented in tables to clearly summarize the results. This allows for easy comparison of protein abundance changes between different experimental conditions.
| Protein ID | Gene Name | Description | Log₂ Fold Change (Treated/Control) | p-value |
| P04637 | TP53 | Cellular tumor antigen p53 | 1.58 | 0.001 |
| P06213 | HBA1 | Hemoglobin subunit alpha | -1.25 | 0.015 |
| Q9Y6K9 | PARK7 | Parkinson disease protein 7 | 2.10 | 0.0005 |
| P62258 | PPIA | Peptidyl-prolyl cis-trans isomerase A | -0.89 | 0.042 |
Table 2: Example of Quantitative Proteomics Data. This table shows simulated data for illustrative purposes, demonstrating how changes in protein abundance can be quantified and statistically evaluated.
Visualizing Signaling Pathways and Workflows
Graphviz diagrams can be used to visualize the complex relationships in signaling pathways and experimental workflows.
EGFR Signaling Pathway
The epidermal growth factor receptor (EGFR) signaling pathway is a crucial regulator of cell proliferation, survival, and differentiation.[11][12] Metabolic labeling with 4-AP analogs can be used to study the dynamics of EGFR and its downstream signaling partners.
Bioorthogonal Ligation Schemes
Different bioorthogonal reactions can be employed for labeling proteins containing 4-AP analogs. The choice of reaction depends on factors such as reaction kinetics, biocompatibility, and the availability of reagents.[3]
Troubleshooting
| Problem | Possible Cause | Suggested Solution |
| Low incorporation of 4-AP analog | - Analog toxicity- Insufficient concentration of analog- Competition with natural amino acid | - Perform a dose-response curve to determine the optimal, non-toxic concentration.- Ensure complete removal of the natural amino acid from the medium.- Increase the incubation time. |
| High background in bioorthogonal reaction | - Non-specific binding of the probe- Impure reagents | - Include a no-analog control to assess background.- Perform protein precipitation after ligation to remove excess probe.- Use freshly prepared reagents. |
| Low yield of enriched proteins | - Inefficient bioorthogonal reaction- Incomplete binding to affinity resin- Harsh washing steps | - Optimize ligation reaction conditions (time, temperature, reagent concentrations).- Increase incubation time with the affinity resin.- Use less stringent wash buffers. |
| Poor peptide identification in MS | - Inefficient digestion- Sample loss during preparation- Inappropriate MS parameters | - Ensure complete denaturation and reduction before digestion.- Use low-binding tubes and tips.- Optimize fragmentation energy and include the mass shift of the modified amino acid in the database search. |
Table 3: Troubleshooting common issues.
Conclusion
Metabolic labeling with this compound analogs is a robust and versatile technology for the site-specific modification of proteins in living systems. The detailed protocols and application notes provided herein offer a comprehensive guide for researchers to implement these powerful techniques in their own studies. By enabling the precise introduction of bioorthogonal handles, this methodology opens up new avenues for investigating protein function, dynamics, and interactions in the complex cellular environment, with significant implications for both fundamental biology and drug discovery.
References
- 1. Protein turnover information provides new insights and may guide researchers to more accurate Alzheimer's disease models | St. Jude Research [stjude.org]
- 2. benchchem.com [benchchem.com]
- 3. Unnatural amino acid mutagenesis of GPCRs using amber codon suppression and bioorthogonal labeling - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. documents.thermofisher.com [documents.thermofisher.com]
- 6. Genetic Incorporation of the Unnatural Amino Acid p-Acetyl Phenylalanine into Proteins for Site-Directed Spin Labeling - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Genetic Incorporation of the Unnatural Amino Acid p-Acetyl Phenylalanine into Proteins for Site-Directed Spin Labeling - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Selective Enrichment and Identification of Azide-tagged Cross-linked Peptides Using Chemical Ligation and Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Site-specific incorporation of p-propargyloxyphenylalanine in a cell-free environment for direct protein-protein click conjugation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. biorxiv.org [biorxiv.org]
- 11. A comprehensive pathway map of epidermal growth factor receptor signaling - PMC [pmc.ncbi.nlm.nih.gov]
- 12. creative-diagnostics.com [creative-diagnostics.com]
Application Notes and Protocols: 4-Aminophenylalanine Derivatives as Dipeptidyl Peptidase IV (DPP-4) Inhibitors
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive overview of 4-aminophenylalanine derivatives as potent and selective inhibitors of Dipeptidyl Peptidase IV (DPP-4). This document includes detailed experimental protocols for their synthesis and evaluation, quantitative data on their inhibitory activity, and diagrams illustrating the relevant biological pathways and experimental workflows.
Introduction
Dipeptidyl peptidase-4 (DPP-4) is a serine protease that plays a crucial role in glucose homeostasis. It is responsible for the inactivation of incretin (B1656795) hormones, such as glucagon-like peptide-1 (GLP-1) and glucose-dependent insulinotropic polypeptide (GIP), which are key regulators of insulin (B600854) secretion.[1] By inhibiting DPP-4, the levels of active incretins are increased, leading to enhanced glucose-dependent insulin release and suppressed glucagon (B607659) secretion. This mechanism makes DPP-4 a validated therapeutic target for the treatment of type 2 diabetes mellitus.[2]
A novel series of this compound derivatives has been designed and evaluated as potent and selective DPP-4 inhibitors.[3] Certain derivatives have demonstrated significant potency and improved pharmacokinetic profiles, making them promising candidates for further drug development.[4]
Data Presentation
The following tables summarize the quantitative data for representative this compound and 4-aminocyclohexylalanine derivatives as DPP-4 inhibitors.
Table 1: In Vitro DPP-4 Inhibitory Activity
| Compound ID | Chemical Scaffold | DPP-4 IC50 (nM) | DPP-8 IC50 (nM) | DPP-9 IC50 (nM) | Selectivity vs. DPP-8 | Selectivity vs. DPP-9 |
| 10 | This compound derivative | 28 | >10,000 | >10,000 | >357x | >357x |
| 25 | 4-Aminocyclohexylalanine derivative | 4.8 | >10,000 | >10,000 | >2083x | >2083x |
| Sitagliptin | Reference Compound | 18 | 4800 | >100,000 | 267x | >5555x |
Data compiled from literature.[3][4]
Table 2: Pharmacokinetic Properties of a Representative 4-Aminocyclohexylalanine Derivative (Compound 25)
| Species | Route of Administration | Dose (mg/kg) | Oral Bioavailability (%) | Half-life (t½) (h) |
| Mouse | Oral | 10 | 45 | 1.5 |
| Rat | Oral | 2 | Not Reported | Not Reported |
| Dog | Oral | 1 | 70 | 2.5 |
Pharmacokinetic data for this compound derivatives is limited in publicly available literature. The data for compound 25, a cyclohexylalanine derivative, is presented to illustrate the improved pharmacokinetic profile achieved with this structural modification.[3][4]
Experimental Protocols
Protocol 1: General Synthesis of a this compound Derivative
This protocol describes a representative synthetic route for a this compound-based DPP-4 inhibitor.
Step 1: Protection of this compound
-
Dissolve this compound in a suitable solvent (e.g., a mixture of dioxane and water).
-
Add a base (e.g., sodium bicarbonate) to the solution.
-
Slowly add a protecting group reagent, such as di-tert-butyl dicarbonate (B1257347) (Boc)2O, to protect the amino group.
-
Stir the reaction mixture at room temperature for several hours until the reaction is complete (monitored by TLC).
-
Extract the Boc-protected this compound and purify it using column chromatography.
Step 2: Amide Coupling
-
Dissolve the Boc-protected this compound in a suitable solvent (e.g., dichloromethane).
-
Add a coupling agent, such as HATU (1-[Bis(dimethylamino)methylene]-1H-1,2,3-triazolo[4,5-b]pyridinium 3-oxid hexafluorophosphate), and a base (e.g., diisopropylethylamine).
-
Add the desired amine component to the reaction mixture.
-
Stir the reaction at room temperature overnight.
-
Wash the reaction mixture with an acidic solution, a basic solution, and brine.
-
Dry the organic layer over sodium sulfate, filter, and concentrate under reduced pressure.
-
Purify the coupled product by column chromatography.
Step 3: Deprotection
-
Dissolve the Boc-protected intermediate in a suitable solvent (e.g., dichloromethane).
-
Add a deprotecting agent, such as trifluoroacetic acid (TFA).
-
Stir the reaction at room temperature for 1-2 hours.
-
Remove the solvent and TFA under reduced pressure to obtain the final this compound derivative.
Protocol 2: In Vitro DPP-4 Inhibition Assay
This protocol outlines a fluorometric assay to determine the in vitro inhibitory activity of the synthesized compounds against DPP-4.
Materials:
-
Human recombinant DPP-4 enzyme
-
DPP-4 substrate: Gly-Pro-7-amino-4-methylcoumarin (Gly-Pro-AMC)
-
Assay Buffer: Tris-HCl buffer (pH 7.5) containing NaCl and EDTA
-
Test compounds dissolved in DMSO
-
Positive control (e.g., Sitagliptin)
-
96-well black microplate
-
Fluorometric microplate reader (Excitation: 360 nm, Emission: 460 nm)
Procedure:
-
Prepare serial dilutions of the test compounds and the positive control in DMSO.
-
In a 96-well plate, add 25 µL of the assay buffer to all wells.
-
Add 25 µL of the test compound solution or positive control to the respective wells. For the control (100% activity) and blank (no enzyme) wells, add 25 µL of DMSO.
-
Add 25 µL of the human recombinant DPP-4 enzyme solution to all wells except the blank wells. Add 25 µL of assay buffer to the blank wells.
-
Incubate the plate at 37°C for 10 minutes.
-
Initiate the enzymatic reaction by adding 25 µL of the Gly-Pro-AMC substrate solution to all wells.
-
Immediately measure the fluorescence intensity at 37°C in kinetic mode for 30 minutes, with readings taken every minute.
-
Calculate the rate of reaction (slope of the linear portion of the fluorescence vs. time curve).
-
Determine the percent inhibition using the following formula: % Inhibition = [1 - (Rate of sample / Rate of control)] x 100
-
Calculate the IC50 value by plotting the percent inhibition against the logarithm of the inhibitor concentration and fitting the data to a sigmoidal dose-response curve.
Protocol 3: In Vivo Oral Glucose Tolerance Test (OGTT) in a Murine Model
This protocol describes an in vivo experiment to evaluate the efficacy of a this compound derivative in improving glucose tolerance in mice.
Animals:
-
Male C57BL/6 mice (8-10 weeks old)
-
Animals are fasted overnight (12-16 hours) with free access to water before the experiment.
Procedure:
-
Randomly divide the mice into vehicle control and treatment groups.
-
Administer the test compound or vehicle (e.g., 0.5% methylcellulose (B11928114) in water) orally (p.o.) to the respective groups.
-
After 30 minutes, collect a baseline blood sample (t=0) from the tail vein.
-
Administer a glucose solution (2 g/kg body weight) orally to all mice.
-
Collect blood samples at 15, 30, 60, 90, and 120 minutes post-glucose administration.
-
Measure the blood glucose concentration in each sample using a glucometer.
-
Plot the blood glucose concentration over time for each group.
-
Calculate the area under the curve (AUC) for the glucose excursion from t=0 to t=120 minutes for each animal.
-
Statistically compare the AUC values between the vehicle and treatment groups to determine the effect of the compound on glucose tolerance.
Visualizations
Caption: DPP-4 Signaling Pathway in Glucose Homeostasis.
Caption: Experimental Workflow for DPP-4 Inhibitor Development.
References
- 1. The Role of DPP-4 Inhibitors in the Treatment Algorithm of Type 2 Diabetes Mellitus: When to Select, What to Expect - PMC [pmc.ncbi.nlm.nih.gov]
- 2. diabetesjournals.org [diabetesjournals.org]
- 3. This compound and 4-aminocyclohexylalanine derivatives as potent, selective, and orally bioavailable inhibitors of dipeptidyl peptidase IV - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
Application Notes and Protocols for Enzymatic Ligation of Peptides Containing 4-Aminophenylalanine
For Researchers, Scientists, and Drug Development Professionals
Introduction
The site-specific incorporation of unnatural amino acids into peptides and proteins is a powerful tool for advancing drug discovery and development. 4-Aminophenylalanine (4-APhe), with its reactive aniline (B41778) side chain, offers a versatile handle for bioconjugation, enabling the attachment of various functionalities such as imaging agents, polyethylene (B3416737) glycol (PEG), or cytotoxic drugs. Enzymatic ligation methods provide a highly specific and efficient means to conjugate peptides containing 4-APhe to other molecules under mild, biocompatible conditions. This document provides an overview and detailed protocols for the enzymatic ligation of peptides containing this compound using Sortase A, a well-characterized transpeptidase.
Overview of Enzymatic Ligation with Sortase A
Sortase A (SrtA), a transpeptidase from Staphylococcus aureus, recognizes the pentapeptide motif LPXTG (where X can be any amino acid) at the C-terminus of a substrate peptide.[1][2][3] The enzyme cleaves the peptide bond between threonine (T) and glycine (B1666218) (G), forming a covalent acyl-enzyme intermediate.[2][4] This intermediate is then resolved by a nucleophilic attack from the N-terminal amine of an oligoglycine (Gly)n nucleophile, resulting in the formation of a new peptide bond.[2][4] This highly specific reaction allows for the precise ligation of a peptide containing the LPXTG motif to any molecule bearing an N-terminal oligoglycine tag.
The versatility of Sortase A extends to the ligation of peptides containing unnatural amino acids.[5] The presence of this compound within the peptide sequence, outside of the recognition motif, is generally well-tolerated and allows for the site-specific introduction of this valuable functional handle into larger protein constructs or onto surfaces.
Experimental Workflows and Signaling Pathways
The enzymatic ligation of a 4-APhe-containing peptide can be a critical step in various experimental workflows, particularly in the development of targeted therapeutics and biological probes.
Caption: General workflow for producing functionalized bioconjugates using Sortase A-mediated ligation of a 4-APhe containing peptide.
Key Applications
-
Antibody-Drug Conjugates (ADCs): A peptide containing 4-APhe and a C-terminal LPXTG motif can be ligated to an antibody engineered with an N-terminal oligoglycine tag. The exposed amine of the 4-APhe can then be selectively conjugated to a cytotoxic drug.
-
Targeted Imaging Agents: A fluorescent probe or other imaging moiety can be attached to the 4-APhe of a targeting peptide that has been enzymatically ligated to a protein or nanoparticle.
-
Protein PEGylation: Site-specific PEGylation can be achieved by ligating a PEGylated oligoglycine to a protein of interest containing 4-APhe and the sortase recognition sequence, with the 4-APhe available for further modification if desired.
Experimental Protocols
Materials
-
Peptide containing this compound and a C-terminal LPXTG motif (Peptide-4APhe-LPXTG)
-
Oligoglycine-functionalized molecule of interest ((Gly)n-Molecule)
-
Recombinant Sortase A (e.g., pentamutant for higher activity)
-
Sortase Ligation Buffer (50 mM Tris-HCl, 150 mM NaCl, 10 mM CaCl₂, pH 7.5)
-
Quenching Solution (e.g., 0.1% Trifluoroacetic acid)
-
Analytical and Preparative Reverse-Phase High-Performance Liquid Chromatography (RP-HPLC) system
-
Mass Spectrometer (e.g., ESI-MS)
Protocol: Sortase A-Mediated Ligation of a 4-APhe Peptide
-
Peptide Preparation:
-
Synthesize the Peptide-4APhe-LPXTG using standard solid-phase peptide synthesis (SPPS). The this compound residue should be incorporated at the desired position within the peptide sequence. The C-terminus must have the LPXTG recognition sequence.
-
Synthesize or procure the (Gly)n-Molecule. A triglycine (B1329560) (GGG) is often sufficient for efficient ligation.[6]
-
Purify both peptides by RP-HPLC to >95% purity and confirm their identity by mass spectrometry.
-
Dissolve the lyophilized peptides in an appropriate solvent (e.g., water or a minimal amount of DMSO for hydrophobic peptides) to create stock solutions. Determine the precise concentration by UV-Vis spectrophotometry or another suitable method.
-
-
Enzymatic Ligation Reaction:
-
In a microcentrifuge tube, combine the following reagents in the specified order:
-
Sortase Ligation Buffer
-
Peptide-4APhe-LPXTG (final concentration, e.g., 100 µM)
-
(Gly)n-Molecule (final concentration, e.g., 200-500 µM; a 2-5 fold molar excess is recommended to drive the reaction forward)
-
-
Initiate the reaction by adding Sortase A (final concentration, e.g., 10-20 µM).
-
Incubate the reaction mixture at room temperature (or 37°C for potentially faster kinetics) for 1-4 hours. The optimal reaction time should be determined empirically by monitoring the reaction progress.
-
-
Reaction Monitoring and Quenching:
-
At various time points (e.g., 0, 1, 2, 4 hours), take a small aliquot of the reaction mixture and quench the reaction by adding an equal volume of quenching solution.
-
Analyze the quenched aliquots by analytical RP-HPLC and mass spectrometry to monitor the formation of the ligated product and the consumption of the starting materials.
-
-
Purification of the Ligated Product:
-
Once the reaction has reached the desired conversion, quench the entire reaction mixture.
-
Purify the ligated product from unreacted starting materials and Sortase A using preparative RP-HPLC.
-
Lyophilize the pure fractions containing the desired product.
-
-
Characterization:
-
Confirm the identity and purity of the final ligated product by analytical RP-HPLC and mass spectrometry.
-
Quantitative Data Summary
While specific data for the ligation of peptides containing this compound is not extensively published, the general efficiency of Sortase A-mediated ligation is high. The yields are dependent on substrate concentrations, enzyme concentration, and reaction time.
| Enzyme | Substrate 1 | Substrate 2 | Molar Ratio (Substrate 2:1) | Enzyme Conc. | Time (hr) | Yield (%) | Reference |
| Sortase A | GFP-LPETG-6His | GGG-Peptide | 5:1 | ~10 µM | 24 | >90 | [6] |
| Sortase A | Peptide-LPETG | (Gly)3-TAMRA | - | - | 3-12 | - | [7] |
Note: The table presents general Sortase A ligation data. Yields for specific 4-APhe containing peptides may vary and should be determined empirically.
Logical Relationships in Sortase A Catalysis
Caption: Simplified logical diagram of the Sortase A catalytic mechanism.
Conclusion
Enzymatic ligation using Sortase A offers a robust and highly specific method for the conjugation of peptides containing the versatile unnatural amino acid this compound. The mild reaction conditions and high efficiency make this an attractive strategy for the construction of complex bioconjugates for research, diagnostics, and therapeutic applications. The provided protocol serves as a general guideline, and optimization of reaction parameters for specific substrates is recommended to achieve maximal yields.
References
- 1. Employing unnatural promiscuity of sortase to construct peptide macrocycle libraries for ligand discovery - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Sortase-Mediated Ligation of Purely Artificial Building Blocks - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Reprogramming natural proteins using unnatural amino acids - RSC Advances (RSC Publishing) DOI:10.1039/D1RA07028B [pubs.rsc.org]
- 4. researchgate.net [researchgate.net]
- 5. Frontiers | Natural Occurring and Engineered Enzymes for Peptide Ligation and Cyclization [frontiersin.org]
- 6. academic.oup.com [academic.oup.com]
- 7. static1.squarespace.com [static1.squarespace.com]
Application Notes: Bioconjugation Strategies Utilizing the Amino Group of 4-Aminophenylalanine
Introduction
4-Aminophenylalanine (pAF) is a non-canonical amino acid that has garnered significant interest in bioconjugation, drug development, and materials science.[1][2][3] Its unique structure, featuring a primary aromatic amino group, offers a versatile handle for site-specific modification of peptides, proteins, and other biomolecules. This amino group provides a reactive site for a variety of chemical and enzymatic ligation strategies, enabling the attachment of reporter molecules, therapeutic agents, and other functionalities. These application notes provide an overview of key bioconjugation strategies targeting the amino group of pAF, complete with detailed protocols and quantitative data to guide researchers in this field.
Key Bioconjugation Strategies
Two primary approaches for modifying the amino group of this compound are chemical and enzymatic methods.
-
Chemical Ligation: Diazotization and Azo Coupling
A well-established method for modifying aromatic amines is through diazotization followed by azo coupling.[4] The primary amino group of pAF can be converted to a diazonium salt under acidic conditions using a nitrite (B80452) source.[1][5] This highly reactive diazonium intermediate can then be coupled with electron-rich aromatic compounds, such as phenols, naphthols, or anilines, to form stable azo bonds.[3][4][6] The resulting azo linkage is a chromophore, which can be useful for colorimetric labeling and detection. The stability of the diazonium salt is a critical factor, and reactions are typically performed at low temperatures (0-5 °C) to prevent its decomposition.[1][5][7]
-
Enzymatic Ligation Strategies
Enzymatic methods offer high specificity and mild reaction conditions, making them attractive for bioconjugation. Enzymes such as horseradish peroxidase (HRP) and tyrosinase can be employed to modify the aromatic amino group of pAF.
-
Horseradish Peroxidase (HRP) Catalyzed Cross-Linking: HRP, in the presence of hydrogen peroxide, can catalyze the oxidation of anilines to form radical intermediates.[8][9] These radicals can then couple with other molecules, leading to the formation of cross-linked products. This strategy can be used to conjugate pAF-containing proteins to surfaces or other biomolecules.[10]
-
Tyrosinase-Mediated Modification: Tyrosinase is an enzyme that catalyzes the oxidation of phenols to reactive o-quinones.[11][12][13] While its primary substrates are phenols, it has been shown to mediate the coupling of aniline (B41778) derivatives.[14] This approach can be harnessed for the site-specific modification of pAF residues in proteins.
-
Quantitative Data Summary
The following table summarizes representative yields for azo coupling reactions with various aniline derivatives, which can serve as an estimate for the efficiency of bioconjugation with this compound. The actual yield will depend on the specific reaction conditions and the coupling partner used.
| Aniline Derivative | Coupling Partner | Reaction Conditions | Yield (%) | Reference |
| Aniline | 1-Naphthol | Diazotization followed by coupling | 96 | [15] |
| Aniline | 2-Naphthol | Diazotization followed by coupling | 81 | [15] |
| Aniline | Phenol | Diazotization followed by coupling | 58 | [15] |
| p-Toluidine | - (Homocoupling) | CuCo2O4 catalyst, air, 85 °C | 95 | [16] |
| Halogenated Anilines | - (Homocoupling) | CuCo2O4 catalyst, air, 85 °C | High | [17] |
| p-Nitroaniline | Barbituric Acid | Grinding with p-TsA and NaNO2, 0 °C | 50-80 | [2] |
Experimental Protocols
Protocol 1: Diazotization of this compound and Azo Coupling
This protocol describes a general procedure for the diazotization of pAF and subsequent azo coupling with an electron-rich partner (e.g., 2-naphthol). This protocol is adapted from established methods for other aromatic amines.[1][4][18]
Materials:
-
This compound (pAF)
-
Hydrochloric acid (HCl), concentrated
-
Sodium nitrite (NaNO₂)
-
2-Naphthol (or other electron-rich coupling partner)
-
Sodium hydroxide (B78521) (NaOH)
-
Ice
-
Distilled water
-
Stir plate and stir bar
-
Beakers and flasks
Procedure:
-
Preparation of the pAF Solution:
-
In a beaker, dissolve a specific molar equivalent of pAF in a solution of distilled water and concentrated hydrochloric acid (typically 2.5-3 molar excess of HCl relative to the amine).
-
Cool the solution to 0-5 °C in an ice-water bath with continuous stirring. Some of the pAF salt may precipitate, which is acceptable.[18][19]
-
-
Diazotization:
-
In a separate beaker, prepare a solution of sodium nitrite (a slight molar excess, e.g., 1.1 equivalents) in a minimal amount of cold distilled water.
-
Slowly add the sodium nitrite solution dropwise to the cold pAF solution with vigorous stirring. Ensure the temperature remains below 5 °C.[1][5]
-
After the addition is complete, continue stirring for an additional 15-20 minutes to ensure the diazotization is complete. The resulting solution contains the pAF-diazonium salt and should be kept cold and used immediately.[7][20]
-
-
Preparation of the Coupling Partner Solution:
-
In a separate beaker, dissolve the electron-rich coupling partner (e.g., 2-naphthol, 1 equivalent) in a dilute solution of sodium hydroxide.
-
Cool this solution in an ice-water bath.
-
-
Azo Coupling:
-
Slowly add the cold pAF-diazonium salt solution to the cold solution of the coupling partner with vigorous stirring.
-
A brightly colored precipitate of the azo-pAF conjugate should form immediately.[4]
-
Continue stirring the mixture in the ice bath for an additional 30-60 minutes to ensure the reaction goes to completion.
-
-
Isolation and Purification:
-
Collect the precipitated azo-pAF conjugate by vacuum filtration.
-
Wash the solid with cold water to remove any unreacted salts.
-
The product can be further purified by recrystallization from an appropriate solvent (e.g., ethanol).
-
Protocol 2: Horseradish Peroxidase (HRP)-Catalyzed Bioconjugation of pAF
This protocol provides a general framework for the HRP-catalyzed cross-linking of a pAF-containing protein to another molecule. This is based on the known ability of HRP to oxidize anilines.[8][9]
Materials:
-
pAF-containing protein
-
Horseradish Peroxidase (HRP)
-
Hydrogen peroxide (H₂O₂)
-
Phosphate-buffered saline (PBS), pH 7.4
-
The molecule to be conjugated (e.g., another protein, a surface with available nucleophiles)
-
Stir plate and stir bar or shaker
-
Reaction tubes
Procedure:
-
Reaction Setup:
-
In a reaction tube, dissolve the pAF-containing protein and the molecule to be conjugated in PBS.
-
Add HRP to the solution to a final concentration of 1-10 µM.
-
Initiate the reaction by adding a stock solution of H₂O₂ to a final concentration of 100-500 µM.
-
-
Incubation:
-
Incubate the reaction mixture at room temperature with gentle shaking for 1-4 hours.
-
-
Quenching the Reaction:
-
The reaction can be stopped by adding a quenching agent such as sodium azide (B81097) or by removing the HRP through purification.
-
-
Purification and Analysis:
-
Purify the conjugate using standard protein purification techniques (e.g., size-exclusion chromatography, affinity chromatography) to remove unreacted components and HRP.
-
Analyze the conjugate by SDS-PAGE, mass spectrometry, or other relevant techniques to confirm the successful conjugation.
-
Protocol 3: Tyrosinase-Mediated Bioconjugation of pAF
This protocol outlines a general approach for the tyrosinase-mediated modification of a pAF-containing protein. This is based on the ability of tyrosinase to oxidize phenolic and anilinic compounds.[13][14]
Materials:
-
pAF-containing protein
-
Tyrosinase (e.g., from mushroom)
-
Phosphate (B84403) buffer, pH 6.5-7.5
-
The molecule to be conjugated (containing a nucleophilic group like a thiol or amine)
-
Stir plate and stir bar or shaker
-
Reaction tubes
Procedure:
-
Reaction Setup:
-
In a reaction tube, dissolve the pAF-containing protein and the molecule to be conjugated in the phosphate buffer.
-
Add tyrosinase to the solution to a final concentration of 100-500 U/mL.
-
-
Incubation:
-
Incubate the reaction mixture at room temperature with gentle shaking. The reaction is initiated by the presence of molecular oxygen dissolved in the buffer. The reaction time can range from 1 to 24 hours.
-
-
Monitoring and Stopping the Reaction:
-
Monitor the progress of the reaction by a suitable analytical method (e.g., HPLC, LC-MS).
-
The reaction can be stopped by adding an inhibitor of tyrosinase, such as kojic acid, or by heat inactivation.
-
-
Purification and Analysis:
-
Purify the conjugate using standard protein purification techniques to remove unreacted components and tyrosinase.
-
Analyze the conjugate by SDS-PAGE, mass spectrometry, or other relevant techniques to confirm the successful conjugation.
-
Visualizations
Caption: Diazotization and Azo Coupling of this compound.
Caption: HRP-Catalyzed Bioconjugation Workflow.
Caption: Tyrosinase-Mediated Bioconjugation Workflow.
References
- 1. benchchem.com [benchchem.com]
- 2. pccc.icrc.ac.ir [pccc.icrc.ac.ir]
- 3. benchchem.com [benchchem.com]
- 4. benchchem.com [benchchem.com]
- 5. Diazotization of Aniline Derivatives: Nitrous Acid Test [chemedx.org]
- 6. researchgate.net [researchgate.net]
- 7. chemguide.co.uk [chemguide.co.uk]
- 8. Mechanistic aspects of the horseradish peroxidase-catalysed polymerisation of aniline in the presence of AOT vesicles as templates - RSC Advances (RSC Publishing) [pubs.rsc.org]
- 9. researchgate.net [researchgate.net]
- 10. Cross-linking of horseradish peroxidase adsorbed on polycationic films: utilization for direct dye degradation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. Expanding the Substrate Scope and Applications of Tyrosinase-Mediated Oxidative Coupling Bioconjugation [escholarship.org]
- 12. researchgate.net [researchgate.net]
- 13. Structure–function correlations in tyrosinases - PMC [pmc.ncbi.nlm.nih.gov]
- 14. pubs.acs.org [pubs.acs.org]
- 15. researchgate.net [researchgate.net]
- 16. Direct Oxidative Azo Coupling of Anilines Using a Self-Assembled Flower-like CuCo2O4 Material as a Catalyst under Aerobic Conditions - PMC [pmc.ncbi.nlm.nih.gov]
- 17. researchgate.net [researchgate.net]
- 18. cuhk.edu.hk [cuhk.edu.hk]
- 19. benchchem.com [benchchem.com]
- 20. amyd.quimica.unam.mx [amyd.quimica.unam.mx]
Application Notes: Using 4-Aminophenylalanine to Study Protein-Protein Interactions
For Researchers, Scientists, and Drug Development Professionals
Introduction
The study of protein-protein interactions (PPIs) is fundamental to understanding cellular processes, disease mechanisms, and for the development of novel therapeutics. Photo-crosslinking, a technique that uses light to induce covalent bonds between interacting molecules, has emerged as a powerful tool for capturing both stable and transient PPIs in their native environment. This is often achieved by incorporating unnatural amino acids (UAAs) with photoreactive moieties into proteins.
While UAAs like p-azido-L-phenylalanine (pAzF) and p-benzoyl-L-phenylalanine (pBpa) are widely used, they can present challenges. The azide (B81097) group of pAzF, for instance, is susceptible to reduction to an amine by the cellular environment, leading to a heterogeneous protein population and reduced crosslinking efficiency.[1][2]
This application note details a robust, two-stage strategy that leverages 4-Amino-L-phenylalanine (pAF) as a stable, genetically encoded precursor that is subsequently converted into the photoreactive pAzF immediately before a crosslinking experiment. The primary amine of the pAF side chain serves as a versatile chemical handle for post-translational modification, allowing for the quantitative and chemoselective installation of a photo-activatable azide group.[2][3] This approach ensures a homogenous population of photoreactive proteins, maximizing the potential for capturing interacting partners.
Principle of the Method
The workflow involves three main stages:
-
Genetic Incorporation of pAF: The non-canonical amino acid 4-aminophenylalanine is site-specifically incorporated into a protein of interest (the "bait" protein) using amber stop codon (TAG) suppression technology with an evolved, orthogonal aminoacyl-tRNA synthetase/tRNA pair.
-
Chemical Conversion to pAzF: The chemically stable amine on the incorporated pAF residue is converted into a photoreactive azide using a highly selective, pH-tunable diazotransfer reaction. This creates the photo-crosslinker p-azido-L-phenylalanine (pAzF) in situ.[2]
-
Photo-Crosslinking and Analysis: Upon exposure to UV light, the newly formed azide group on pAzF becomes highly reactive, forming a covalent crosslink with nearby interacting proteins (the "prey"). The resulting covalent complex can then be isolated and analyzed using techniques such as SDS-PAGE and mass spectrometry to identify the interacting partner and the site of interaction.
Experimental Protocols
Protocol 1: Site-Specific Incorporation of this compound (pAF)
This protocol describes the expression of a target protein containing pAF at a specific site in E. coli.
Materials:
-
E. coli expression strain (e.g., BL21(DE3)).
-
Expression plasmid for the target gene with a TAG amber stop codon at the desired incorporation site.
-
Plasmid encoding the orthogonal aminoacyl-tRNA synthetase/tRNA pair for pAF/pAzF (e.g., pEVOL-pAzF).
-
4-Amino-L-phenylalanine (pAF).
-
Luria-Bertani (LB) medium and appropriate antibiotics.
-
Isopropyl β-D-1-thiogalactopyranoside (IPTG) and L-arabinose for induction.
Procedure:
-
Transformation: Co-transform the E. coli expression strain with the plasmid containing your gene of interest (with the TAG codon) and the pEVOL plasmid containing the synthetase/tRNA pair.
-
Starter Culture: Inoculate a single colony into 5-10 mL of LB medium with the appropriate antibiotics. Grow overnight at 37°C with shaking.
-
Expression Culture: The following day, inoculate 1 L of LB medium (with antibiotics) with the starter culture. Grow at 37°C with shaking until the optical density at 600 nm (OD600) reaches 0.6-0.8.
-
Induction: Add pAF to a final concentration of 1 mM. Induce protein expression by adding IPTG (final concentration ~1 mM) and L-arabinose (final concentration ~0.02%) to induce the expression of the synthetase/tRNA pair.
-
Expression: Shake the culture overnight at a reduced temperature (e.g., 25-30°C) to improve protein folding and solubility.
-
Harvest and Purification: Harvest the cells by centrifugation. Purify the pAF-containing protein using standard chromatography techniques (e.g., Ni-NTA affinity chromatography if His-tagged, size-exclusion chromatography). Confirm incorporation and purity via SDS-PAGE and mass spectrometry.
Protocol 2: Post-Translational Conversion of pAF to pAzF
This protocol details the chemoselective conversion of the amine group of pAF to an azide using a pH-dependent diazotransfer reaction.[2]
Materials:
-
Purified pAF-containing protein in a suitable buffer (e.g., Phosphate-Buffered Saline, PBS).
-
Imidazole-1-sulfonyl azide hydrochloride (ISAz).
-
Copper(II) sulfate (B86663) (CuSO₄).
-
Buffer solutions to maintain specific pH (e.g., sodium phosphate (B84403) buffers).
Procedure:
-
Reaction Setup: In a microcentrifuge tube, combine the purified pAF-containing protein (e.g., to a final concentration of 20-50 µM) with 200 molar equivalents of ISAz.
-
Catalyst Addition: Add CuSO₄ to a final concentration that is 10% of the ISAz concentration.
-
pH Adjustment: Adjust the reaction buffer to pH 7.2. This pH maximizes the conversion of pAF while minimizing off-target reactions with lysine (B10760008) residues and the protein's N-terminus (see Table 1).[2]
-
Incubation: Incubate the reaction at 20°C for 72 hours with gentle mixing.
-
Purification: Remove excess reagents and byproducts by buffer exchange using a desalting column or dialysis.
-
Verification: Confirm the successful conversion of pAF to pAzF by mass spectrometry. A successful conversion will result in a mass increase of +26 Da (N₃ - NH₂ = (14*3) - (14+2) = 42 - 16 = 26).
Protocol 3: Photo-Crosslinking of Protein Complexes
Materials:
-
Purified protein with pAzF incorporated.
-
Interacting partner protein(s) or cell lysate.
-
UV lamp (365 nm).
-
Quartz cuvette or microplate.
Procedure:
-
Complex Formation: Mix the pAzF-containing "bait" protein with its putative "prey" protein partner(s) in a suitable interaction buffer. Allow the components to incubate for 30-60 minutes at an appropriate temperature (e.g., 4°C or room temperature) to allow the protein complex to form.
-
UV Irradiation: Transfer the sample to a quartz cuvette or plate. Irradiate the sample with 365 nm UV light for 5-60 minutes on ice. The optimal irradiation time should be determined empirically.
-
Quenching (Optional): The reaction can be quenched by adding a scavenger like DTT.
-
Analysis by SDS-PAGE: Analyze the reaction products by SDS-PAGE. A successful crosslink will result in a new, higher molecular weight band corresponding to the bait-prey complex. The gel can be visualized by Coomassie staining or Western blotting using antibodies against the bait or prey proteins.
Protocol 4: Mass Spectrometry Analysis of Cross-linked Products
Procedure:
-
Band Excision: Excise the high molecular weight band corresponding to the cross-linked complex from the SDS-PAGE gel.
-
In-Gel Digestion: Perform an in-gel digest of the protein complex using a protease such as trypsin.
-
Peptide Extraction: Extract the resulting peptides from the gel matrix.
-
LC-MS/MS Analysis: Analyze the extracted peptides by liquid chromatography-tandem mass spectrometry (LC-MS/MS).
-
Data Analysis: Use specialized crosslink identification software (e.g., StavroX, pLink) to search the MS/MS data. The software will identify inter- and intra-protein cross-linked peptides, revealing the specific residues at the interaction interface.
Data Presentation
The success of the pAF-to-pAzF conversion is highly dependent on the reaction pH. The data below, adapted from published studies, illustrates the selectivity of the diazotransfer reaction.[2]
| pH | pAF Conversion (%) | N-Terminus Conversion (%) | Lysine Conversion (%) |
| 6.2 | ~75% | <5% | <1% |
| 7.2 | >95% | ~10% | <2% |
| 8.2 | >95% | ~60% | ~20% |
| Table 1: pH-Dependent Selectivity of Diazotransfer Reaction. Reaction conditions: 200 equivalents of ISAz, 20°C, 72 hours. The data shows that pH 7.2 provides the optimal balance of high conversion efficiency for pAF with minimal off-target modification of other primary amines. |
Visualizations
Caption: Overall experimental workflow for PPI studies using pAF.
Caption: Chemical conversion of pAF to the photoreactive pAzF.
Caption: Capturing a protein-protein interaction via photo-crosslinking.
References
Application Notes and Protocols for 4-Aminophenylalanine in Targeted Drug Delivery Systems
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive overview of the use of 4-Aminophenylalanine (4-APhe) as a targeting moiety in drug delivery systems. The focus is on leveraging the L-type amino acid transporter 1 (LAT1), which is frequently overexpressed on the surface of cancer cells and the blood-brain barrier, to achieve targeted delivery of therapeutic agents.
Introduction
Targeted drug delivery aims to enhance the therapeutic efficacy of drugs while minimizing off-target side effects. One promising strategy involves utilizing endogenous transport systems to ferry drugs into specific cells. The L-type amino acid transporter 1 (LAT1) is an attractive target due to its high expression in various cancer types and its role in transporting large neutral amino acids, like phenylalanine, across the blood-brain barrier.[1][2][3] this compound, a synthetic analog of phenylalanine, can be recognized by LAT1, making it an effective ligand for targeted drug delivery. By conjugating cytotoxic drugs to 4-APhe, it is possible to create prodrugs that are selectively taken up by LAT1-expressing cells.[4][5]
Principle of LAT1-Mediated Targeting
The core principle of this targeting strategy is the molecular mimicry of 4-APhe to natural amino acids that are substrates for the LAT1 transporter. This transporter is crucial for rapidly dividing cells, such as cancer cells, which have a high demand for amino acids to support protein synthesis and metabolism. By exploiting this dependency, 4-APhe-drug conjugates can be preferentially internalized into tumor cells, leading to a localized increase in drug concentration at the site of action.
Caption: Mechanism of LAT1-mediated uptake of a 4-APhe-drug conjugate into a cancer cell.
Quantitative Data Summary
The following tables summarize key quantitative data for phenylalanine-based drug conjugates targeting the LAT1 transporter. This data is crucial for evaluating the potential of new drug candidates.
Table 1: In Vitro Cytotoxicity of Phenylalanine-Drug Conjugates
| Conjugate/Drug | Cell Line | IC50 (µM) | Reference |
| Phenylalanine-Probenecid Conjugate | MCF-7 | >100 | [4] |
| Phenylalanine-Valproic Acid Conjugate | HEK-hLAT1 | Not specified, but showed high uptake | [4] |
| Phenylalanine-Salicylic Acid Conjugate | HEK-hLAT1 | Not specified, but showed highest uptake | [4] |
| Phenylalanine-Ketoprofen Conjugate | BV2 | 15.9 ± 7.8 | [6] |
| Free Doxorubicin (B1662922) | 4T1 | ~1 | [7] |
| Free Paclitaxel (B517696) | MDA-MB-231 | ~0.01 | [8] |
Table 2: Cellular Uptake and LAT1 Affinity
| Compound | Cell Line | Uptake/Binding Parameter | Value | Reference |
| Phenylalanine-Probenecid Conjugate | MCF-7 | Vmax | 111 pmol/min/mg | [4] |
| Phenylalanine-Probenecid Conjugate | MCF-7 | Km | 15.16 µM | [4] |
| Various Phenylalanine Prodrugs | HEK-hLAT1 | Km | 1-7 µM | [5] |
| L-Valyl-Acyclovir | Caco-2/hPEPT1 | Cellular Uptake vs. Acyclovir | ~10-fold higher | [9] |
Table 3: In Vivo Efficacy of Targeted Conjugates
| Treatment | Animal Model | Tumor Type | Outcome | Reference |
| NT4-Paclitaxel | Athymic Nude Mice | Orthotopic Breast Cancer (MDA-MB-231) | Tumor regression | [8][10] |
| PG-[3H]TXL | C3Hf/Kam Mice | Ovarian OCa-1 | 5-fold greater tumor exposure than free Paclitaxel | [11] |
| PTX-loaded micelles | CD-1 Nude Mice | A431 Epidermoid Carcinoma | Complete tumor regression | [12] |
Experimental Protocols
Detailed methodologies for the synthesis and evaluation of 4-APhe targeted drug delivery systems are provided below.
Protocol 1: Synthesis of a this compound-Doxorubicin Conjugate
This protocol describes a general method for conjugating doxorubicin to the amino group of this compound using a linker.
Materials:
-
This compound (Boc-protected at the alpha-amino group)
-
Doxorubicin hydrochloride
-
Succinimidyl 4-(N-maleimidomethyl)cyclohexane-1-carboxylate (SMCC) linker
-
N,N-Diisopropylethylamine (DIPEA)
-
Dimethylformamide (DMF), anhydrous
-
Trifluoroacetic acid (TFA)
-
Dichloromethane (DCM)
-
Coupling agents (e.g., HBTU, HOBt)[13]
Procedure:
-
Immobilization of Boc-4-APhe on Resin:
-
Swell the Merrifield resin in DCM.
-
Couple the carboxyl group of Boc-4-APhe to the resin using a suitable activation method (e.g., cesium salt method).[13]
-
-
Deprotection of the 4-Amino Group (if protected):
-
If the 4-amino group of phenylalanine is protected, selectively deprotect it while the alpha-amino group remains Boc-protected.
-
-
Activation of Doxorubicin:
-
Dissolve doxorubicin HCl and an excess of DIPEA in anhydrous DMF.
-
In a separate flask, dissolve the SMCC linker in DMF.
-
Slowly add the doxorubicin solution to the SMCC solution and stir at room temperature for 2-4 hours to form the maleimide-activated doxorubicin.
-
-
Conjugation to Resin-Bound 4-APhe:
-
Wash the resin with DMF.
-
Add the maleimide-activated doxorubicin solution to the resin.
-
Allow the reaction to proceed overnight at room temperature with gentle agitation.
-
-
Cleavage and Final Deprotection:
-
Wash the resin thoroughly with DMF, DCM, and methanol (B129727) to remove unreacted reagents.
-
Treat the resin with a cleavage cocktail (e.g., 95% TFA, 2.5% water, 2.5% triisopropylsilane) for 2-3 hours to cleave the conjugate from the resin and remove the Boc protecting group.[13]
-
Precipitate the crude conjugate in cold diethyl ether.
-
-
Purification:
-
Purify the crude conjugate using reverse-phase high-performance liquid chromatography (RP-HPLC).
-
Lyophilize the pure fractions to obtain the final 4-APhe-Doxorubicin conjugate.
-
Caption: General workflow for the solid-phase synthesis of a 4-APhe-drug conjugate.
Protocol 2: In Vitro Cytotoxicity Assay (MTT Assay)
This protocol determines the concentration of the 4-APhe-drug conjugate that inhibits cell growth by 50% (IC50).
Materials:
-
LAT1-positive cancer cell line (e.g., MCF-7, A549) and a LAT1-negative control cell line.
-
Complete cell culture medium.
-
96-well plates.
-
4-APhe-drug conjugate, unconjugated drug, and 4-APhe alone.
-
MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) solution.
-
Solubilization buffer (e.g., DMSO or a solution of SDS in HCl).
-
Microplate reader.
Procedure:
-
Cell Seeding:
-
Seed cells in a 96-well plate at a density of 5,000-10,000 cells per well and incubate for 24 hours to allow for attachment.
-
-
Treatment:
-
Prepare serial dilutions of the 4-APhe-drug conjugate, the free drug, and 4-APhe in culture medium.
-
Remove the old medium from the wells and add 100 µL of the different drug concentrations. Include untreated cells as a control.
-
Incubate the plate for 48-72 hours.
-
-
MTT Addition:
-
Add 10 µL of MTT solution (5 mg/mL in PBS) to each well and incubate for 4 hours at 37°C.
-
-
Solubilization:
-
Add 100 µL of solubilization buffer to each well and mix thoroughly to dissolve the formazan (B1609692) crystals.
-
-
Measurement:
-
Read the absorbance at 570 nm using a microplate reader.
-
-
Data Analysis:
-
Calculate the percentage of cell viability for each concentration relative to the untreated control.
-
Plot the cell viability against the drug concentration and determine the IC50 value using a suitable software.
-
Protocol 3: Cellular Uptake Study
This protocol quantifies the uptake of the 4-APhe-drug conjugate into cells.
Materials:
-
LAT1-positive and LAT1-negative cell lines.
-
24-well plates.
-
4-APhe-drug conjugate.
-
Hank's Balanced Salt Solution (HBSS).
-
Lysis buffer.
-
LC-MS/MS system for quantification.
Procedure:
-
Cell Seeding:
-
Seed cells in 24-well plates and grow to confluence.[4]
-
-
Uptake Experiment:
-
Wash the cells with pre-warmed HBSS.
-
Add HBSS containing a known concentration of the 4-APhe-drug conjugate to the wells.
-
Incubate for various time points (e.g., 5, 15, 30, 60 minutes) at 37°C.[4]
-
To determine LAT1-specific uptake, run parallel experiments in the presence of a LAT1 inhibitor (e.g., BCH).
-
-
Cell Lysis:
-
At each time point, aspirate the drug solution and wash the cells three times with ice-cold HBSS.
-
Add lysis buffer to each well and incubate on ice for 30 minutes.
-
-
Quantification:
-
Collect the cell lysates and determine the protein concentration (e.g., using a BCA assay).
-
Quantify the concentration of the internalized conjugate in the lysates using a validated LC-MS/MS method.[4]
-
-
Data Analysis:
-
Normalize the amount of internalized conjugate to the total protein content and the incubation time to determine the uptake rate (e.g., in pmol/mg protein/min).
-
Protocol 4: In Vivo Antitumor Efficacy Study
This protocol evaluates the therapeutic efficacy of the 4-APhe-drug conjugate in a tumor-bearing animal model.
Materials:
-
Immunocompromised mice (e.g., nude or SCID mice).
-
LAT1-positive human cancer cells (e.g., A431, MDA-MB-468).[12]
-
4-APhe-drug conjugate, free drug, and vehicle control.
-
Calipers for tumor measurement.
Procedure:
-
Tumor Xenograft Implantation:
-
Subcutaneously inject a suspension of cancer cells into the flank of each mouse.
-
Allow the tumors to grow to a palpable size (e.g., 100 mm³).[12]
-
-
Treatment:
-
Randomly assign the mice to treatment groups (e.g., vehicle control, free drug, 4-APhe-drug conjugate at different doses).
-
Administer the treatments intravenously or intraperitoneally according to a predetermined schedule (e.g., twice a week for 3 weeks).
-
-
Monitoring:
-
Measure the tumor volume with calipers every 2-3 days. Tumor volume can be calculated using the formula: (length × width²) / 2.
-
Monitor the body weight of the mice as an indicator of toxicity.
-
-
Endpoint:
-
At the end of the study, euthanize the mice and excise the tumors for weighing and further analysis (e.g., histology, immunohistochemistry).
-
-
Data Analysis:
-
Plot the mean tumor volume over time for each treatment group.
-
Compare the tumor growth inhibition between the different groups to evaluate the efficacy of the targeted conjugate.
-
Caption: Logical flow illustrating the advantages of using 4-APhe for targeted drug delivery.
Conclusion
The use of this compound as a targeting ligand for the LAT1 transporter represents a promising strategy for the development of novel anticancer therapeutics. The provided data and protocols offer a framework for the synthesis, in vitro evaluation, and in vivo testing of 4-APhe-drug conjugates. Further research in this area, including the optimization of linkers and the selection of appropriate drug payloads, will be crucial for translating this approach into clinical applications.
References
- 1. jscimedcentral.com [jscimedcentral.com]
- 2. chemistry.du.ac.in [chemistry.du.ac.in]
- 3. LAT1-targeted prodrugs in brain and cancer drug delivery [morressier.com]
- 4. Structural Features Affecting the Interactions and Transportability of LAT1-Targeted Phenylalanine Drug Conjugates - PMC [pmc.ncbi.nlm.nih.gov]
- 5. L-Type amino acid transporter 1 (LAT1)-utilizing prodrugs are carrier-selective despite having low affinity for organic anion transporting polypeptides (OATPs) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Comparison of Experimental Strategies to Study l-Type Amino Acid Transporter 1 (LAT1) Utilization by Ligands - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. Tumor-selective peptide-carrier delivery of Paclitaxel increases in vivo activity of the drug - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Cellular uptake mechanism of amino acid ester prodrugs in Caco-2/hPEPT1 cells overexpressing a human peptide transporter - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. Biodistribution of paclitaxel and poly(L-glutamic acid)-paclitaxel conjugate in mice with ovarian OCa-1 tumor - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Complete Regression of Xenograft Tumors upon Targeted Delivery of Paclitaxel via Π-Π Stacking Stabilized Polymeric Micelles - PMC [pmc.ncbi.nlm.nih.gov]
- 13. benchchem.com [benchchem.com]
Application Notes and Protocols: Creating Fluorescent Protein Sensors with 4-Aminophenylalanine
For Researchers, Scientists, and Drug Development Professionals
Introduction
The site-specific incorporation of unnatural amino acids (UAAs) into proteins offers a powerful tool for creating novel biosensors with tailored functionalities. 4-Aminophenylalanine (pAF), a non-canonical amino acid, provides a unique chemical handle—a primary aromatic amine—that can be post-translationally modified to generate a fluorescent reporter. This allows for the creation of fluorescent protein sensors that can monitor a variety of biological processes, from enzyme activity to protein-protein interactions, with high specificity.
This document provides detailed application notes and protocols for the design, creation, and implementation of fluorescent protein sensors based on the genetic incorporation of this compound. The core principle involves the site-specific introduction of pAF into a protein of interest, followed by a chemical reaction to convert the amino group into a fluorescent azo dye. This process can be engineered to be dependent on a specific biological event, thereby creating a "turn-on" or ratiometric fluorescent sensor.
Principle of pAF-Based Fluorescent Sensors
The creation of a fluorescent sensor using pAF generally follows a two-step process:
-
Genetic Incorporation of pAF: Using the amber stop codon (TAG) suppression methodology, pAF is site-specifically incorporated into a target protein in a host organism (typically E. coli). This requires an orthogonal aminoacyl-tRNA synthetase/tRNA pair that is specific for pAF and does not recognize any of the canonical amino acids.
-
Post-Translational Azo-Coupling: The primary amine of the incorporated pAF is chemically converted to a diazonium salt. This reactive intermediate can then undergo an azo-coupling reaction with an electron-rich aromatic residue, such as tyrosine, that is either naturally present or engineered to be in close proximity within the protein. The resulting azo linkage creates a new chromophore with distinct fluorescent properties. The efficiency of this reaction can be modulated by conformational changes in the protein, forming the basis of the biosensor.
Applications
Fluorescent protein sensors created with this compound have a wide range of potential applications in research and drug development:
-
Enzyme Activity Assays: By designing the sensor protein to undergo a conformational change upon phosphorylation, cleavage, or other enzymatic modifications, the proximity of the pAF and a tyrosine residue can be altered, leading to a change in fluorescence upon azo-coupling. This is particularly useful for monitoring the activity of kinases, proteases, and other modifying enzymes.[1][2][3][4]
-
Analyte Detection: The sensor protein can be engineered to bind a specific small molecule or ion, triggering a conformational change that enables the azo-coupling reaction. This allows for the development of sensors for metabolites, second messengers, or metal ions.
-
Protein-Protein Interaction Studies: By incorporating pAF into one protein and a tyrosine residue into its binding partner, the formation of the protein complex can be monitored by the appearance of fluorescence upon azo-coupling. This can also be adapted for Förster Resonance Energy Transfer (FRET) applications by creating an azo-dye that acts as a FRET acceptor or donor.[5][6][7][8]
-
High-Throughput Screening: The fluorescence-based readout of these sensors is amenable to high-throughput screening platforms for the discovery of enzyme inhibitors or modulators of protein interactions.
Data Presentation
The photophysical properties of the resulting azo-dye fluorescent reporter are critical for its application. Below is a summary of expected quantitative data for a fluorescent protein sensor generated by azo-coupling of a diazotized pAF with a tyrosine residue.
| Property | Description | Representative Value |
| Excitation Maximum (λex) | The wavelength of light that is most effective at exciting the fluorophore. | ~330-360 nm |
| Emission Maximum (λem) | The wavelength of light at which the fluorophore emits the most photons. | ~420-450 nm |
| Quantum Yield (Φ) | The ratio of photons emitted to photons absorbed. A measure of the fluorophore's brightness. | 0.1 - 0.3 |
| Extinction Coefficient (ε) | A measure of how strongly the fluorophore absorbs light at a given wavelength. | 10,000 - 20,000 M⁻¹cm⁻¹ |
| Fluorescence Lifetime (τ) | The average time the fluorophore stays in the excited state before returning to the ground state. | 1 - 5 ns |
Note: These values are estimates and can vary depending on the local protein environment of the azo-tyrosine linkage.
Experimental Protocols
Protocol 1: Site-Specific Incorporation of this compound (pAF)
This protocol describes the expression of a target protein containing pAF at a specific site using amber codon suppression in E. coli.
Materials:
-
E. coli expression strain (e.g., BL21(DE3))
-
Expression plasmid for the gene of interest with a TAG codon at the desired incorporation site.
-
pEVOL plasmid encoding the orthogonal aminoacyl-tRNA synthetase/tRNA pair for pAF.
-
This compound (pAF)
-
Luria-Bertani (LB) medium
-
Appropriate antibiotics
-
Isopropyl β-D-1-thiogalactopyranoside (IPTG)
-
L-arabinose
Procedure:
-
Co-transform the E. coli expression strain with the target protein expression plasmid and the pEVOL-pAF plasmid.
-
Plate the transformed cells on an LB agar (B569324) plate containing the appropriate antibiotics and incubate overnight at 37°C.
-
Inoculate a single colony into 5 mL of LB medium with antibiotics and grow overnight at 37°C with shaking.
-
The next day, inoculate 1 L of LB medium containing antibiotics with the overnight culture.
-
Grow the culture at 37°C with shaking until the optical density at 600 nm (OD600) reaches 0.6-0.8.
-
Add pAF to a final concentration of 1 mM.
-
Induce the expression of the orthogonal tRNA synthetase/tRNA pair by adding L-arabinose to a final concentration of 0.02% (w/v).
-
Induce the expression of the target protein by adding IPTG to a final concentration of 0.2 mM.
-
Incubate the culture at 18-20°C for 16-20 hours with shaking.
-
Harvest the cells by centrifugation at 5,000 x g for 15 minutes at 4°C.
-
Purify the pAF-containing protein using standard chromatography techniques (e.g., Ni-NTA affinity chromatography if the protein is His-tagged).
Protocol 2: In-situ Formation of the Azo-Tyrosine Fluorescent Reporter
This protocol describes the chemical modification of the incorporated pAF to form a fluorescent azo-tyrosine linkage.
Materials:
-
Purified protein containing pAF and a proximal tyrosine residue.
-
Sodium nitrite (B80452) (NaNO₂)
-
Hydrochloric acid (HCl)
-
Phosphate-buffered saline (PBS), pH 7.4
-
Reaction buffer (e.g., 100 mM sodium phosphate, pH 6.0)
-
Ice bath
Procedure:
-
Diazotization of pAF:
-
Prepare a fresh 100 mM solution of NaNO₂ in water.
-
Prepare a 100 mM solution of HCl.
-
Dilute the purified pAF-containing protein to a concentration of 10-50 µM in the reaction buffer.
-
Cool the protein solution on an ice bath for 10 minutes.
-
To initiate the diazotization, add the NaNO₂ solution to a final concentration of 1 mM and the HCl solution to adjust the pH to ~3-4.
-
Incubate the reaction on ice for 30 minutes in the dark. The solution may turn a pale yellow color.
-
-
Azo-Coupling with Tyrosine:
-
To initiate the azo-coupling, raise the pH of the reaction mixture to ~8-9 by adding a basic buffer (e.g., 1 M Tris-HCl, pH 9.0).
-
The proximity of a tyrosine residue to the newly formed diazonium salt will facilitate an intramolecular coupling reaction.
-
Allow the coupling reaction to proceed at room temperature for 1-2 hours. A color change to orange or red may be observed.
-
-
Purification and Characterization:
-
Remove excess reagents by buffer exchange using a desalting column or dialysis into PBS, pH 7.4.
-
Characterize the formation of the azo-tyrosine linkage by UV-Vis spectroscopy, looking for the characteristic absorbance of the azo-dye (~330-360 nm).
-
Measure the fluorescence properties (excitation and emission spectra, quantum yield) of the modified protein using a fluorometer.
-
Visualizations
Experimental Workflow for Creating a pAF-Based Fluorescent Sensor
Caption: Workflow for pAF-based fluorescent sensor creation.
Signaling Pathway for a Kinase Activity Sensor
This diagram illustrates a hypothetical signaling pathway for a pAF-based fluorescent biosensor designed to detect the activity of a specific protein kinase.
Caption: Kinase activity detection using a pAF-based sensor.
Logical Relationship for FRET-Based Sensor
This diagram shows the principle of a FRET-based sensor where the formation of the azo-dye creates a FRET acceptor.
Caption: Principle of a pAF-based FRET sensor.
References
- 1. Seeing is believing: peptide-based fluorescent sensors of protein tyrosine kinase activity - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. scilit.com [scilit.com]
- 3. scispace.com [scispace.com]
- 4. Shining Light on Protein Kinase Biomarkers with Fluorescent Peptide Biosensors - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Genetically encoded FRET sensors using a fluorescent unnatural amino acid as a FRET donor - RSC Advances (RSC Publishing) [pubs.rsc.org]
- 6. FRET Based Biosensor: Principle Applications Recent Advances and Challenges - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Application of FRET Biosensors in Mechanobiology and Mechanopharmacological Screening - PMC [pmc.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
Application Notes: Site-Specific C-Terminal Labeling of α-Tubulin with 4-Aminophenylalanine using Tubulin Tyrosine Ligase
Introduction
Microtubules, dynamic polymers of α- and β-tubulin heterodimers, are fundamental components of the eukaryotic cytoskeleton, playing crucial roles in cell division, intracellular transport, and motility.[1] The C-terminal tails of tubulin subunits are subject to a variety of post-translational modifications (PTMs) that constitute a "tubulin code," regulating microtubule functions.[2][3] Site-specific labeling of tubulin with unnatural amino acids provides a powerful tool to investigate the effects of these modifications and to introduce novel functionalities for imaging and drug development. This protocol details a chemoenzymatic method for the site-specific incorporation of 4-Aminophenylalanine (4-AP) onto the C-terminus of α-tubulin.
Principle of the Method
The method leverages the enzymatic activity of Tubulin Tyrosine Ligase (TTL), an enzyme that naturally re-attaches a tyrosine residue to the C-terminus of detyrosinated α-tubulin (Glu-tubulin).[4][5] TTL exhibits a broad substrate tolerance, accepting various tyrosine and phenylalanine analogs.[6][7] This protocol utilizes TTL to catalyze the ligation of this compound to the C-terminal glutamate (B1630785) of α-tubulin in a highly specific, ATP-dependent reaction. The incorporated 4-AP introduces a primary amine group, which can serve as a chemical handle for subsequent bioorthogonal conjugation reactions.
Applications
-
Probing Microtubule Dynamics: The introduction of 4-AP can be used to study how modifications at the C-terminus of α-tubulin affect microtubule polymerization, depolymerization, and interactions with microtubule-associated proteins (MAPs).
-
Site-Specific Conjugation: The primary amine of 4-AP can be specifically targeted for the attachment of fluorophores, biotin, or drug molecules, enabling advanced imaging studies and the development of novel therapeutic agents.
-
Drug Discovery: This method can be employed to screen for compounds that modulate the activity of TTL or to investigate the effects of C-terminal modifications on the binding of anti-cancer drugs that target the tubulin cytoskeleton.
Experimental Protocols
Protocol 1: Preparation of Detyrosinated Tubulin (Glu-Tubulin)
This protocol describes the removal of the C-terminal tyrosine from α-tubulin using carboxypeptidase A, generating the substrate for the TTL-catalyzed reaction.
Materials:
-
Purified tubulin (e.g., from bovine brain)
-
PME Buffer: 100 mM PIPES, 1 mM MgSO₄, 2 mM EGTA, pH 6.9
-
Carboxypeptidase A (CPA)
-
Dithiothreitol (DTT)
-
Sephadex G-50 desalting column
-
Liquid nitrogen
Procedure:
-
Thaw purified tubulin on ice. Dilute the tubulin to a final concentration of 3 mg/mL (approximately 30 µM) in pre-warmed PME buffer.
-
Add Carboxypeptidase A to a final concentration of 0.1 mg/mL.
-
Incubate the reaction mixture at 37°C for 30 minutes.
-
Stop the reaction by adding DTT to a final concentration of 20 mM.
-
Remove the cleaved tyrosine and exchange the buffer to PME by passing the reaction mixture through a Sephadex G-50 desalting column pre-equilibrated with PME buffer.
-
Determine the concentration of the detyrosinated tubulin (Glu-tubulin) using a Bradford assay or by measuring absorbance at 280 nm.
-
Aliquot the Glu-tubulin, flash-freeze in liquid nitrogen, and store at -80°C until use.
-
Confirm the removal of the C-terminal tyrosine by Western blot using antibodies specific for tyrosinated and detyrosinated tubulin.
Protocol 2: TTL-Catalyzed Ligation of this compound
This protocol details the enzymatic reaction to attach 4-AP to the C-terminus of detyrosinated α-tubulin.
Materials:
-
Detyrosinated tubulin (from Protocol 1)
-
Recombinant Tubulin Tyrosine Ligase (TTL)
-
This compound (4-AP)
-
ATP solution (100 mM)
-
MgCl₂ solution (1 M)
-
TTL Reaction Buffer: 50 mM HEPES, 100 mM KCl, pH 7.5
-
DTT (1 M)
Procedure:
-
On ice, prepare the reaction mixture in the following order:
-
TTL Reaction Buffer
-
Detyrosinated tubulin to a final concentration of 10 µM.
-
This compound to a final concentration of 1 mM.
-
ATP to a final concentration of 2 mM.
-
MgCl₂ to a final concentration of 5 mM.
-
DTT to a final concentration of 1 mM.
-
-
Initiate the reaction by adding TTL to a final concentration of 1 µM.
-
Incubate the reaction at 37°C for 1 to 2 hours.
-
The reaction can be stopped by proceeding directly to the purification step or by adding EDTA to a final concentration of 20 mM to chelate Mg²⁺.
Protocol 3: Purification of 4-AP Labeled Tubulin
This protocol describes the purification of the labeled tubulin from the reaction mixture using a polymerization/depolymerization cycle. This method also selects for assembly-competent tubulin.
Materials:
-
GTP solution (100 mM)
-
Polymerization Buffer (BRB80): 80 mM PIPES, 1 mM MgCl₂, 1 mM EGTA, pH 6.9
-
Warm Cushion Buffer: BRB80 containing 60% glycerol
-
Ice-cold Depolymerization Buffer: BRB80
Procedure:
-
To the reaction mixture from Protocol 2, add GTP to a final concentration of 1 mM and glycerol to a final concentration of 33% (v/v).
-
Incubate at 37°C for 30-60 minutes to induce microtubule polymerization.
-
Layer the polymerized microtubule solution onto an equal volume of warm (37°C) Cushion Buffer in an ultracentrifuge tube.
-
Pellet the microtubules by ultracentrifugation at 100,000 x g for 30 minutes at 35°C.
-
Carefully remove the supernatant containing TTL, unreacted 4-AP, and other reaction components.
-
Wash the pellet gently with warm Polymerization Buffer.
-
Resuspend the microtubule pellet in a minimal volume of ice-cold Depolymerization Buffer.
-
Incubate on ice for 30 minutes to induce depolymerization of the microtubules.
-
Clarify the solution by ultracentrifugation at 100,000 x g for 10 minutes at 4°C to remove any aggregates.
-
Collect the supernatant containing the purified 4-AP labeled tubulin.
-
Determine the final concentration, aliquot, flash-freeze in liquid nitrogen, and store at -80°C.
Protocol 4: Characterization of 4-AP Labeled Tubulin
A. Mass Spectrometry for Confirmation of Labeling
-
Digest a small aliquot of the purified 4-AP labeled tubulin with a suitable protease (e.g., trypsin or CNBr) to generate peptides.[8]
-
Analyze the resulting peptide mixture by LC-MS/MS.
-
Identify the C-terminal peptide of α-tubulin and confirm the mass shift corresponding to the replacement of glutamate with this compound.
B. Tubulin Polymerization Assay for Functional Assessment
This assay determines if the 4-AP labeled tubulin retains its ability to polymerize into microtubules.[9][10]
Materials:
-
4-AP labeled tubulin
-
Unlabeled tubulin (as a control)
-
Polymerization Buffer (BRB80)
-
GTP solution (100 mM)
-
Glycerol
-
Temperature-controlled spectrophotometer or plate reader capable of measuring absorbance at 340 nm.
Procedure:
-
On ice, prepare reaction mixtures containing 3 mg/mL tubulin (either 100% unlabeled or a mixture with 4-AP labeled tubulin) in Polymerization Buffer.
-
Add GTP to a final concentration of 1 mM and glycerol to 10% (v/v).
-
Transfer the reaction mixtures to a pre-warmed (37°C) 96-well plate.
-
Immediately begin monitoring the change in absorbance at 340 nm every minute for 60 minutes at 37°C. An increase in absorbance indicates microtubule polymerization.
-
Plot absorbance versus time to generate polymerization curves. Compare the kinetics (lag time, Vmax, and plateau) of the 4-AP labeled tubulin with the unlabeled control.
Data Presentation
Table 1: Summary of TTL-Catalyzed Ligation Reaction
| Parameter | Value |
| Substrate | Detyrosinated Tubulin |
| Amino Acid | This compound |
| Enzyme | Tubulin Tyrosine Ligase (TTL) |
| Tubulin Concentration | 10 µM |
| 4-AP Concentration | 1 mM |
| TTL Concentration | 1 µM |
| ATP Concentration | 2 mM |
| MgCl₂ Concentration | 5 mM |
| Reaction Temperature | 37°C |
| Reaction Time | 1-2 hours |
| Expected Labeling Efficiency | > 80% |
Table 2: Quantitative Analysis of Tubulin Polymerization
| Sample | Lag Time (min) | Vmax (mOD/min) | Plateau OD₃₄₀ |
| Unlabeled Tubulin | Value | Value | Value |
| 4-AP Labeled Tubulin | Value | Value | Value |
| Paclitaxel Control | Value | Value | Value |
| Nocodazole Control | Value | Value | Value |
*Values to be determined experimentally.
Mandatory Visualization
Caption: Overall experimental workflow for labeling tubulin with 4-AP.
Caption: TTL-catalyzed ligation of this compound to α-tubulin.
References
- 1. benchchem.com [benchchem.com]
- 2. bsw3.naist.jp [bsw3.naist.jp]
- 3. pnas.org [pnas.org]
- 4. Tubulin tyrosine ligase structure reveals adaptation of an ancient fold to bind and modify tubulin - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Tubulin—tyrosine ligase - Wikipedia [en.wikipedia.org]
- 6. Broad substrate tolerance of tubulin tyrosine ligase enables one-step site-specific enzymatic protein labeling - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. Methods in Tubulin Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 9. abscience.com.tw [abscience.com.tw]
- 10. search.cosmobio.co.jp [search.cosmobio.co.jp]
Application Notes: Synthesis and Application of Photoactivatable Proteins Using Caged 4-Aminophenylalanine
For Researchers, Scientists, and Drug Development Professionals
Introduction
The ability to control protein function with high spatiotemporal precision is a transformative tool in biological research and therapeutic development. Photoactivatable proteins, engineered to remain inert until activated by a pulse of light, offer an unparalleled level of control. This is achieved by incorporating a "caged" amino acid bearing a photolabile protecting group (PPG) into the protein's polypeptide chain. Upon irradiation with a specific wavelength of light, the PPG is cleaved, uncaging the amino acid and restoring the protein's native function.[1]
This document provides a detailed guide to the synthesis of photoactivatable proteins using N-para-(6-Nitroveratryloxycarbonyl)-4-amino-L-phenylalanine (NVOC-4-APhe), a caged derivative of 4-aminophenylalanine. We outline the chemical synthesis of this unnatural amino acid (UAA), its site-specific incorporation into recombinant proteins in Escherichia coli using the amber codon suppression technique, and the subsequent photoactivation and characterization of the modified protein.
The core technology relies on an orthogonal translation system, comprising an engineered aminoacyl-tRNA synthetase (aaRS) and its cognate transfer RNA (tRNA), which uniquely recognizes the amber stop codon (UAG) and inserts the caged UAA during protein synthesis.[2][3] This method enables the precise installation of a light-sensitive switch into virtually any protein of interest, opening new avenues for studying dynamic cellular processes and developing light-guided therapeutics.[4][5]
Synthesis of Caged this compound (NVOC-4-APhe)
The synthesis of N-para-(6-Nitroveratryloxycarbonyl)-4-amino-L-phenylalanine is a multi-step process. The strategy involves the protection of the alpha-amino group of 4-nitrophenylalanine, followed by the reduction of the nitro group to an amine, which is then "caged" with a photolabile NVOC group.
// Nodes A [label="N-α-Boc-4-nitro-L-phenylalanine", fillcolor="#F1F3F4", fontcolor="#202124"]; B [label="Reduction of Nitro Group\n(e.g., H₂, Pd/C)", fillcolor="#FFFFFF", fontcolor="#202124", shape=ellipse]; C [label="N-α-Boc-4-amino-L-phenylalanine", fillcolor="#F1F3F4", fontcolor="#202124"]; D [label="Caging Reaction\n(NVOC-Cl, Base)", fillcolor="#FFFFFF", fontcolor="#202124", shape=ellipse]; E [label="Fully Protected Intermediate", fillcolor="#F1F3F4", fontcolor="#202124"]; F [label="Deprotection of α-amino\n(e.g., TFA)", fillcolor="#FFFFFF", fontcolor="#202124", shape=ellipse]; G [label="NVOC-4-APhe\n(Final Product)", fillcolor="#4285F4", fontcolor="#FFFFFF"];
// Edges A -> B [label="Step 1"]; B -> C; C -> D [label="Step 2"]; D -> E; E -> F [label="Step 3"]; F -> G; } dot Caption: Workflow for the synthesis of NVOC-caged this compound.
Experimental Protocol: Synthesis of NVOC-4-APhe
Materials:
-
N-α-Boc-4-nitro-L-phenylalanine
-
Palladium on carbon (10% Pd/C)
-
Hydrogen (H₂) gas
-
Methanol (MeOH), Anhydrous
-
4,5-Dimethoxy-2-nitrobenzyl chloroformate (NVOC-Cl)
-
N,N-Diisopropylethylamine (DIPEA)
-
Dichloromethane (DCM), Anhydrous
-
Trifluoroacetic acid (TFA)
-
Ethyl acetate (B1210297) (EtOAc)
-
Hexanes
-
Saturated aqueous sodium bicarbonate (NaHCO₃)
-
Brine
Procedure:
-
Step 1: Reduction of the Nitro Group
-
Dissolve N-α-Boc-4-nitro-L-phenylalanine (1 eq.) in anhydrous MeOH in a flask suitable for hydrogenation.
-
Carefully add 10% Pd/C catalyst (approx. 10% by weight of the starting material).
-
Purge the flask with H₂ gas and maintain a hydrogen atmosphere (e.g., using a balloon) with vigorous stirring.
-
Monitor the reaction by Thin Layer Chromatography (TLC) until the starting material is consumed.
-
Once complete, carefully filter the reaction mixture through a pad of Celite to remove the Pd/C catalyst.
-
Concentrate the filtrate under reduced pressure to yield N-α-Boc-4-amino-L-phenylalanine as a solid, which can be used in the next step without further purification.
-
-
Step 2: Caging of the para-Amino Group
-
Dissolve the product from Step 1 (1 eq.) in anhydrous DCM.
-
Cool the solution to 0 °C in an ice bath.
-
Add DIPEA (2.5 eq.) to the solution.
-
Slowly add a solution of NVOC-Cl (1.1 eq.) in anhydrous DCM dropwise.
-
Allow the reaction to warm to room temperature and stir overnight.
-
Monitor the reaction by TLC. Upon completion, dilute the mixture with DCM and wash sequentially with saturated aqueous NaHCO₃ and brine.
-
Dry the organic layer over anhydrous sodium sulfate, filter, and concentrate under reduced pressure.
-
Purify the crude product by flash column chromatography (e.g., using a gradient of EtOAc in hexanes) to yield the fully protected intermediate.
-
-
Step 3: Deprotection of the α-Amino Group
-
Dissolve the purified product from Step 2 in DCM.
-
Add TFA (typically 20-50% v/v in DCM) and stir at room temperature.
-
Monitor the reaction by TLC until the starting material is consumed (usually 1-2 hours).
-
Concentrate the reaction mixture under reduced pressure. Co-evaporate with toluene (B28343) or DCM several times to remove residual TFA.
-
The resulting solid is the TFA salt of N-para-(NVOC)-4-amino-L-phenylalanine (NVOC-4-APhe). Store under inert gas at -20 °C.
-
Genetic Incorporation of NVOC-4-APhe into Proteins
The site-specific incorporation of NVOC-4-APhe is achieved in an E. coli expression system engineered for amber codon suppression. This requires two plasmids: an expression vector for the target protein containing an in-frame amber (TAG) codon at the desired modification site, and a second plasmid that constitutively expresses an orthogonal aminoacyl-tRNA synthetase/tRNA pair. For bulky phenylalanine derivatives, an evolved Pyrrolysyl-tRNA Synthetase (PylRS) from Methanosarcina mazei (e.g., a mutant like N346A/C348A) and its cognate tRNACUAPyl are highly effective.[5][6]
Experimental Protocol: Protein Expression and Purification
Materials:
-
E. coli BL21(DE3) cells
-
Plasmid for target protein with a C-terminal His₆-tag and a TAG codon at the desired site.
-
pEVOL plasmid encoding the engineered PylRS and tRNACUAPyl.[2]
-
Luria-Bertani (LB) agar (B569324) plates and broth with appropriate antibiotics (e.g., Kanamycin for the target plasmid, Chloramphenicol for pEVOL).
-
NVOC-4-APhe
-
Isopropyl β-D-1-thiogalactopyranoside (IPTG)
-
Ni-NTA Lysis Buffer (50 mM NaH₂PO₄, 300 mM NaCl, 10 mM imidazole, pH 8.0)
-
Ni-NTA Wash Buffer (50 mM NaH₂PO₄, 300 mM NaCl, 20 mM imidazole, pH 8.0)
-
Ni-NTA Elution Buffer (50 mM NaH₂PO₄, 300 mM NaCl, 250 mM imidazole, pH 8.0)
-
Ni-NTA Agarose (B213101) resin[7][8]
Procedure:
-
Transformation and Culture Growth:
-
Co-transform E. coli BL21(DE3) cells with the target plasmid and the pEVOL plasmid.
-
Plate on LB agar with both antibiotics and incubate overnight at 37 °C.
-
Inoculate a single colony into LB broth with both antibiotics and grow overnight at 37 °C with shaking.
-
The next day, use the overnight culture to inoculate a larger volume of LB broth (with antibiotics) and grow at 37 °C with shaking to an OD₆₀₀ of 0.6-0.8.
-
-
Protein Expression:
-
Add NVOC-4-APhe to a final concentration of 1 mM.
-
Induce protein expression by adding IPTG to a final concentration of 0.5-1 mM.
-
Reduce the temperature to 18-25 °C and continue shaking for 16-20 hours.
-
-
Cell Lysis:
-
Harvest the cells by centrifugation (e.g., 6,000 x g for 15 min at 4 °C).
-
Resuspend the cell pellet in ice-cold Ni-NTA Lysis Buffer.
-
Lyse the cells by sonication on ice.
-
Clarify the lysate by centrifugation (e.g., 20,000 x g for 30 min at 4 °C) to pellet cell debris.
-
-
Protein Purification (Ni-NTA Chromatography): [9][10]
-
Equilibrate a column of Ni-NTA agarose resin with Ni-NTA Lysis Buffer.
-
Load the clarified supernatant onto the column.
-
Wash the column with several column volumes of Ni-NTA Wash Buffer to remove non-specifically bound proteins.
-
Elute the His₆-tagged protein with Ni-NTA Elution Buffer.
-
Collect fractions and analyze by SDS-PAGE to identify those containing the purified protein.
-
Pool the pure fractions and dialyze into a suitable storage buffer (e.g., PBS, pH 7.4).
-
Quantitative Data: Synthesis and Incorporation
The yield and efficiency of producing photoactivatable proteins can vary depending on the target protein, the position of the UAA, and the specific orthogonal system used. The following table provides expected quantitative data based on published results for similar systems.
| Parameter | Metric | Typical Value/Range | Reference |
| UAA Synthesis | Chemical Yield (NVOC-Cl) | 95-98% | [11] |
| Protein Expression | Purified Protein Yield | 0.5 - 2.0 mg / L of culture | [12] |
| Incorporation | Suppression Efficiency | 50 - 88% | [12] |
| Photolysis | Uncaging Quantum Yield (Φ) | 0.01 - 0.05 (for NVOC) | [13] |
| Function | Activity Recovery | >90% (system dependent) | N/A |
Photoactivation and Characterization
The final steps involve activating the protein with light and confirming both its structural integrity and the restoration of its biological function.
Experimental Protocol: Photoactivation (Uncaging)
Materials:
-
Purified, caged protein in a suitable buffer.
-
UV-transparent cuvette or plate (e.g., quartz).
-
UV light source (e.g., 365 nm LED, mercury arc lamp with a filter, or a pulsed laser).[14]
-
Photodiode power meter to calibrate the light source.
Procedure:
-
Light Source Calibration:
-
Measure the power density (mW/cm²) of your UV light source at the sample position. This is critical for reproducible experiments.
-
-
Sample Preparation:
-
Place the purified caged protein solution in a UV-transparent container. The concentration will depend on the downstream application.
-
-
Irradiation:
-
Expose the sample to UV light (peak wavelength ~365 nm).
-
The optimal exposure time depends on the light source intensity, the quantum yield of the caging group, and the sample concentration. Start with short exposure times (e.g., 30-60 seconds) and titrate upwards as needed, monitoring the uncaging progress via mass spectrometry or a functional assay.
-
Avoid excessive exposure to prevent potential photodamage to the protein.
-
// Nodes CagedProtein [label="Purified Caged Protein\n(Inactive)", fillcolor="#F1F3F4", fontcolor="#202124"]; UV_Light [label="UV Light (365 nm)", shape=ellipse, fillcolor="#FBBC05", fontcolor="#202124"]; ActiveProtein [label="Active Protein", fillcolor="#34A853", fontcolor="#FFFFFF"]; MassSpec [label="Mass Spectrometry\n(Verification)", fillcolor="#FFFFFF", fontcolor="#202124", shape=invhouse]; FunctionalAssay [label="Functional Assay\n(Activity)", fillcolor="#FFFFFF", fontcolor="#202124", shape=invhouse]; MassShift [label="Mass Shift Confirmed\n(-NVOC byproduct)", fillcolor="#F1F3F4", fontcolor="#202124"]; ActivityRestored [label="Biological Activity\nRestored", fillcolor="#F1F3F4", fontcolor="#202124"];
// Edges CagedProtein -> UV_Light [label="Irradiation"]; UV_Light -> ActiveProtein [label="Uncaging"]; ActiveProtein -> MassSpec [label="Analysis"]; ActiveProtein -> FunctionalAssay [label="Analysis"]; MassSpec -> MassShift; FunctionalAssay -> ActivityRestored; } dot Caption: Workflow for photo-uncaging and subsequent protein analysis.
Protocol: Mass Spectrometry Characterization
Mass spectrometry is used to confirm the successful incorporation of the caged amino acid and its subsequent cleavage upon photoactivation.
Procedure:
-
Sample Preparation:
-
Take aliquots of the protein before and after UV irradiation.
-
For intact mass analysis, desalt the protein samples.
-
For peptide mapping, denature, reduce, alkylate, and digest the protein with a protease (e.g., trypsin).[15]
-
-
LC-MS/MS Analysis:
-
Analyze the samples using liquid chromatography coupled to a high-resolution mass spectrometer (e.g., Q-TOF or Orbitrap).[16][17]
-
Intact Mass Analysis: Compare the deconvoluted mass spectra of the caged and uncaged protein. A successful uncaging event will result in a predictable mass shift corresponding to the loss of the NVOC protecting group.
-
Peptide Mapping: Search the MS/MS data against the protein sequence. Identify the peptide containing the UAA modification and confirm the mass of the caged side chain before irradiation and the mass of the native this compound side chain after irradiation.
-
Application Example: Light-Activated Control of a Signaling Pathway
Photoactivatable proteins are powerful tools for dissecting complex signaling networks. By caging a critical residue in a kinase, for example, its activity can be switched on with light, allowing researchers to study the immediate downstream consequences independent of upstream signaling events.
A prime example is the MAP Kinase (MAPK) pathway, where a kinase like MEK1 could be controlled.[12] By replacing a key functional residue (e.g., a lysine (B10760008) in the ATP-binding pocket) with NVOC-4-APhe, the kinase would be rendered inactive. A pulse of UV light would uncage the residue, restore ATP binding, and initiate the phosphorylation of its downstream target, ERK, triggering a signaling cascade.
// Nodes UV [label="UV Light (365 nm)", shape=ellipse, fillcolor="#FBBC05", fontcolor="#202124"]; MEK_caged [label="MEK1 (Caged)\nInactive", fillcolor="#EA4335", fontcolor="#FFFFFF"]; MEK_active [label="MEK1 (Active)", fillcolor="#34A853", fontcolor="#FFFFFF"]; ERK [label="ERK", fillcolor="#F1F3F4", fontcolor="#202124"]; pERK [label="p-ERK\n(Active)", fillcolor="#4285F4", fontcolor="#FFFFFF"]; Cytoplasm [label="Cytoplasm", shape=plaintext, fontcolor="#5F6368"]; Nucleus [label="Nucleus", shape=plaintext, fontcolor="#5F6368"]; Transcription [label="Gene Transcription\n(Proliferation, Differentiation)", shape=note, fillcolor="#FFFFFF", fontcolor="#202124"];
// Edges UV -> MEK_caged [style=dashed, arrowhead=none]; MEK_caged -> MEK_active [label="Uncaging", color="#EA4335"]; MEK_active -> ERK [label="Phosphorylation", color="#34A853"]; ERK -> pERK [style=invis]; // for positioning pERK -> Nucleus [label="Translocation"]; Nucleus -> Transcription [label="Activates\nTranscription Factors"];
// Positioning {rank=same; MEK_caged; MEK_active;} {rank=same; Cytoplasm; Nucleus;} Cytoplasm -> MEK_caged [style=invis]; } dot Caption: Photoactivation of MEK1 to study downstream ERK signaling.
References
- 1. Efficient Amber Suppression via Ribosomal Skipping for In Situ Synthesis of Photoconditional Nanobodies - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Site-Specific Incorporation of Unnatural Amino Acids into Escherichia coli Recombinant Protein: Methodology Development and Recent Achievement - PMC [pmc.ncbi.nlm.nih.gov]
- 3. elsaesserlab.wordpress.com [elsaesserlab.wordpress.com]
- 4. Rethinking Uncaging: A New Antiaromatic Photocage Driven by a Gain of Resonance Energy - PMC [pmc.ncbi.nlm.nih.gov]
- 5. mdpi.com [mdpi.com]
- 6. Genetic Incorporation of Twelve meta-Substituted Phenylalanine Derivatives Using A Single Pyrrolysyl-tRNA Synthetase - PMC [pmc.ncbi.nlm.nih.gov]
- 7. iba-lifesciences.com [iba-lifesciences.com]
- 8. Purification of Polyhistidine-Containing Recombinant Proteins with Ni-NTA Purification System | Thermo Fisher Scientific - DE [thermofisher.com]
- 9. Nickel-NTA Protein Purification [protocols.io]
- 10. med.upenn.edu [med.upenn.edu]
- 11. CN1803758A - Method for synthesizing 4-nitrobenzyl chloroformate - Google Patents [patents.google.com]
- 12. Light-Activated Kinases Enable Temporal Dissection of Signaling Networks in Living Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
- 14. 4-Nitrobenzyl chloroformate | 4457-32-3 | Benchchem [benchchem.com]
- 15. Phenylalanine Modification in Plasma-Driven Biocatalysis Revealed by Solvent Accessibility and Reactive Dynamics in Combination with Protein Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Unraveling Complex Local Protein Environments with 4-Cyano-L-Phenylalanine - PMC [pmc.ncbi.nlm.nih.gov]
- 17. benchchem.com [benchchem.com]
Troubleshooting & Optimization
Technical Support Center: Improving Low Incorporation Efficiency of 4-Aminophenylalanine
Welcome to the technical support center for the incorporation of the non-canonical amino acid 4-Aminophenylalanine (pAF). This resource is designed for researchers, scientists, and drug development professionals to troubleshoot and optimize experiments involving pAF.
Frequently Asked Questions (FAQs)
Q1: What is this compound (pAF) and why is it used in research?
This compound (pAF) is an unnatural amino acid (UAA) that is structurally similar to the natural amino acids phenylalanine and tyrosine.[1][2] Its unique property is the presence of an amino group on the phenyl ring, which can serve as a biocompatible nucleophilic catalyst and a versatile chemical handle for protein engineering and drug development.[3] This allows for site-specific modifications of proteins, enabling the introduction of novel functionalities.
Q2: What are the primary challenges associated with pAF incorporation?
The main challenge is often low incorporation efficiency, leading to low yields of the desired protein. This can be due to several factors, including:
-
Inefficient charging of the tRNA with pAF by the aminoacyl-tRNA synthetase (aaRS).[4]
-
Competition with endogenous amino acids.
-
Toxicity of pAF at high concentrations to the host cells.[5]
-
Suboptimal expression and concentration of the orthogonal translation system components (aaRS and tRNA).[6][7]
Q3: How can I verify the successful incorporation of pAF into my target protein?
The most definitive method for verifying UAA incorporation is mass spectrometry.[8] By analyzing the intact protein or digested peptide fragments, you can detect the mass shift corresponding to the incorporation of pAF instead of the canonical amino acid at the target site. Other methods like click chemistry (if a reactive handle is introduced via pAF) followed by fluorescent labeling can also be used for confirmation.[8]
Q4: What is an orthogonal translation system (OTS) and why is it crucial for pAF incorporation?
An orthogonal translation system is a set of an aminoacyl-tRNA synthetase (aaRS) and its cognate tRNA that functions independently of the host cell's own translational machinery.[4][9] For pAF incorporation, a specific aaRS is engineered to exclusively charge pAF onto an orthogonal tRNA, which recognizes a "blank" codon (often the amber stop codon, UAG) engineered into the gene of the protein of interest.[6][9] This ensures that pAF is incorporated only at the desired site.
Troubleshooting Guides
This section provides solutions to common problems encountered during pAF incorporation experiments.
Issue: Low or No Yield of the Target Protein
Possible Cause 1: Inefficient Aminoacyl-tRNA Synthetase (aaRS)
-
Q: My protein yield is very low. How do I know if the aaRS is the problem? A: The engineered aaRS may have low activity or specificity for pAF. Consider testing different published aaRS variants or performing directed evolution to improve its catalytic efficiency.[7][10]
-
Q: What are some strategies to improve aaRS performance? A: You can introduce mutations in the amino acid binding pocket to enhance affinity and selectivity for pAF.[10] Additionally, optimizing the expression level of the aaRS can have a significant impact.
Possible Cause 2: Suboptimal Concentrations of pAF and Inducers
-
Q: What is the optimal concentration of pAF to use? A: The optimal concentration can vary between expression systems. It's crucial to perform a titration experiment to determine the best concentration that maximizes protein yield without causing significant cell toxicity. High concentrations of some UAAs can be detrimental to cell health.[5]
-
Q: How do I optimize the concentration of inducers like Arabinose? A: If the expression of your aaRS is under the control of an inducible promoter (e.g., pBAD), the concentration of the inducer (e.g., L-arabinose) is a critical parameter. A titration of the inducer should be performed in conjunction with pAF titration to find the optimal balance for protein expression.
Possible Cause 3: Poor Cell Health or Toxicity
-
Q: My cells are growing poorly or lysing after the addition of pAF. What should I do? A: This indicates pAF toxicity.[5] Try reducing the concentration of pAF. You can also try supplementing the growth media with a mixture of natural amino acids to see if this alleviates the toxic effects. Monitor cell morphology and viability after induction.
Issue: High Background of Wild-Type Protein
Possible Cause 1: Leaky Expression of the Target Protein
-
Q: I am getting a significant amount of wild-type protein (without pAF). How can I reduce this? A: This is likely due to "leaky" expression of your protein of interest before the addition of pAF and the induction of the orthogonal system. Ensure that the promoter controlling your target gene is tightly regulated. Using a different expression vector with a tighter promoter or a different host strain can help.
Possible Cause 2: Read-through of the Amber (UAG) Codon
-
Q: Why is the stop codon being read as a natural amino acid? A: In some cases, host release factors can compete with the pAF-loaded tRNA, leading to premature termination of translation. Alternatively, a natural tRNA can be mis-acylated and suppress the UAG codon. Overexpressing the orthogonal tRNA and aaRS can help outcompete these off-target effects.[9] Increasing the copy number of the tRNA gene has been shown to be effective.[9]
Quantitative Data Summary
The following tables summarize key quantitative data from various studies on unnatural amino acid incorporation.
Table 1: Reported Concentrations for pAF Incorporation
| Parameter | Concentration Range | Organism | Reference |
| pAF in media | 1 mM - 10 mM | E. coli | [1][11] |
| L-Arabinose | 0.002% - 0.2% | E. coli | - |
| IPTG | 0.1 mM - 1 mM | E. coli | [12] |
Table 2: Factors Influencing Incorporation Efficiency
| Factor | Observation | Impact on Efficiency | Reference |
| aaRS Engineering | Directed evolution of aaRS | 45-fold improvement in catalytic efficiency | |
| tRNA Expression | Quadrupling the tRNA cassette | Significant improvement | [6] |
| Codon Usage | Use of quadruplet codons | Can increase the number of available codons | [9][13] |
| Cellular Health | Suboptimal labeling conditions | Can lead to weak or no signal |
Experimental Protocols
Protocol 1: Optimizing pAF and L-Arabinose Concentrations
This protocol outlines a method for determining the optimal concentrations of pAF and L-arabinose for maximizing the yield of your target protein.
Materials:
-
Expression strain containing your target protein with an amber codon and the orthogonal aaRS/tRNA pair.
-
Growth media (e.g., LB or M9 minimal media).
-
pAF stock solution (e.g., 100 mM in 1M HCl, neutralized with NaOH).
-
L-arabinose stock solution (e.g., 20% w/v).
-
IPTG stock solution (e.g., 1 M).
-
96-well deep well plate.
-
Plate shaker with incubator.
Procedure:
-
Inoculate a starter culture of your expression strain and grow overnight.
-
The next day, dilute the starter culture into fresh media in a 96-well deep well plate.
-
Create a 2D titration matrix in the plate. Vary the concentration of pAF along the rows (e.g., 0, 0.1, 0.5, 1, 2, 5 mM) and the concentration of L-arabinose along the columns (e.g., 0, 0.0002%, 0.002%, 0.02%, 0.2%).
-
Grow the cells at 37°C with shaking until they reach an OD600 of 0.6-0.8.
-
Induce protein expression by adding a fixed concentration of IPTG (e.g., 0.5 mM) to all wells.
-
Continue to grow the cells for a set amount of time (e.g., 4-6 hours) at an optimal temperature for your protein's expression (e.g., 30°C).
-
Harvest the cells by centrifugation.
-
Lyse the cells and analyze the protein yield in each well by SDS-PAGE and Western blot.
-
The combination of pAF and L-arabinose that gives the highest protein yield with minimal toxicity is the optimal condition.
Protocol 2: Verifying pAF Incorporation via Mass Spectrometry
This protocol provides a general workflow for confirming the incorporation of pAF using mass spectrometry.
Materials:
-
Purified protein sample.
-
Trypsin (or another suitable protease).
-
Digestion buffer (e.g., 50 mM ammonium (B1175870) bicarbonate).
-
Reducing agent (e.g., DTT).
-
Alkylating agent (e.g., iodoacetamide).
-
LC-MS/MS system.
Procedure:
-
Protein Digestion:
-
Denature, reduce, and alkylate your purified protein sample.
-
Digest the protein into smaller peptides using trypsin overnight at 37°C.[8]
-
-
LC Separation:
-
Separate the resulting peptide mixture using liquid chromatography (LC) based on hydrophobicity.[8]
-
-
Mass Spectrometry Analysis:
-
Analyze the separated peptides in a mass spectrometer.
-
Perform a full scan (MS1) to detect the precursor ions of the peptides.[8]
-
Identify the peptide containing the amber codon site and look for a mass corresponding to the incorporation of pAF. The expected mass will be different from the mass of the peptide with any of the 20 canonical amino acids at that position.
-
Perform tandem mass spectrometry (MS/MS) on the parent ion of interest to fragment the peptide and confirm the sequence, which will definitively identify the location of pAF incorporation.[8]
-
Visualizations
Caption: Workflow for site-specific incorporation of pAF.
Caption: A logical guide for troubleshooting low pAF incorporation.
References
- 1. pubs.acs.org [pubs.acs.org]
- 2. This compound | C9H12N2O2 | CID 151001 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 3. This compound as a biocompatible nucleophilic catalyst for hydrazone ligations at low temperature and neutral pH - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Engineering aminoacyl-tRNA synthetases for use in synthetic biology - PMC [pmc.ncbi.nlm.nih.gov]
- 5. benchchem.com [benchchem.com]
- 6. Optimized genetic code expansion technology for time‐dependent induction of adhesion GPCR‐ligand engagement - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. benchchem.com [benchchem.com]
- 9. Improving the Efficiency and Orthogonality of Genetic Code Expansion - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Engineered Aminoacyl-tRNA Synthetases with Improved Selectivity toward Noncanonical Amino Acids - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Synthesis and explosion hazards of 4-Azido-L-phenylalanine - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Biosynthesis and Genetic Incorporation of 3,4-Dihydroxy-L-Phenylalanine into Proteins in Escherichia coli - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Frontiers | Biochemistry of Aminoacyl tRNA Synthetase and tRNAs and Their Engineering for Cell-Free and Synthetic Cell Applications [frontiersin.org]
Technical Support Center: Optimizing Codon Context for Amber Suppression of 4-Aminophenylalanine
This technical support center provides researchers, scientists, and drug development professionals with troubleshooting guides, frequently asked questions (FAQs), and detailed experimental protocols for optimizing the incorporation of 4-Aminophenylalanine (pAF) via amber suppression.
Troubleshooting Guides
This section addresses specific issues that may be encountered during experiments involving the incorporation of this compound.
Q: I am observing very low or no expression of my full-length protein containing this compound. What are the potential causes and how can I troubleshoot this?
A: Low or no expression of the target protein is a common issue in non-canonical amino acid incorporation experiments. Several factors could be contributing to this problem. Here’s a step-by-step troubleshooting guide:
-
Verify the Integrity of Your Expression System:
-
Plasmids: Sequence verify your expression plasmid containing the gene of interest with the amber (TAG) codon and the plasmid encoding the orthogonal aminoacyl-tRNA synthetase (aaRS) and suppressor tRNA (tRNA CUA). Ensure that all components are correct and in-frame.
-
Cell Line: If using a specific cell line for amber suppression, ensure its viability and proper maintenance. For E. coli, consider using strains engineered for enhanced amber suppression, such as those with a knockout of release factor 1 (RF1).[1]
-
-
Optimize the Codon Context:
-
The nucleotides flanking the amber codon significantly influence suppression efficiency.[2] Review the codon context of your TAG codon. In mammalian cells, a cytosine at the +4 position (the nucleotide immediately following the TAG codon) is often favorable.[2] For E. coli, purines at the +4 position have been shown to enhance incorporation.[2]
-
Consider using a predictive tool like iPASS (Identification of Permissive Amber Sites for Suppression) for mammalian systems to assess the permissiveness of your chosen site.[2][3] If the predicted efficiency is low, consider synonymous mutations in the flanking codons to improve the context.
-
-
Assess this compound Concentration and Uptake:
-
Ensure that you are using an adequate concentration of pAF in your culture medium.
-
In some cases, the non-canonical amino acid may not be efficiently transported into the cells. If you suspect this is an issue, you may need to explore alternative delivery methods or use cell lines with enhanced permeability.
-
-
Check for Protein Degradation or Aggregation:
-
The incorporation of a non-canonical amino acid can sometimes lead to protein misfolding and subsequent degradation or formation of inclusion bodies.
-
Troubleshooting Steps:
-
Perform a Western blot on both the soluble and insoluble fractions of your cell lysate to determine if the protein is being expressed but is insoluble.
-
Lower the expression temperature (e.g., 18-25°C for E. coli) to slow down protein synthesis and promote proper folding.[4]
-
Include protease inhibitors in your lysis buffer.
-
Consider co-expressing molecular chaperones.
-
-
Q: My Western blot shows a band at the expected size for the full-length protein, but also a prominent lower molecular weight band corresponding to the truncated product. How can I increase the ratio of full-length to truncated protein?
A: The presence of a significant amount of truncated product indicates inefficient amber suppression, where the ribosome terminates translation at the TAG codon instead of incorporating this compound. Here are some strategies to improve suppression efficiency:
-
Enhance the Competitiveness of the Suppressor tRNA:
-
Increase the copy number of the suppressor tRNA plasmid. In mammalian cells, high expression levels of the suppressor tRNA are often crucial for efficient suppression.[2]
-
Ensure that your orthogonal aaRS is efficiently charging the suppressor tRNA with this compound.
-
-
Reduce Termination Efficiency at the Amber Codon:
-
Release Factor 1 (RF1): In E. coli, RF1 is responsible for recognizing the UAG stop codon and terminating translation.[1] Using an E. coli strain with a knockout of the prfA gene (which encodes RF1) can dramatically increase the efficiency of amber suppression.[1][5]
-
In Mammalian Cells: Depletion of the eukaryotic release factor 1 (eRF1) can also enhance readthrough of stop codons.[6][7] This can be achieved using techniques like siRNA or shRNA.
-
-
Optimize the Codon Context:
-
As mentioned previously, the sequence context surrounding the amber codon is critical. A non-permissive context can favor termination over suppression. If possible, modify the codons flanking the TAG codon to create a more favorable environment for suppression.
-
Q: I am concerned about the misincorporation of natural amino acids at the amber codon site. How can I assess and minimize this?
A: Misincorporation of canonical amino acids, also known as near-cognate suppression, can be a significant issue, leading to a heterogeneous protein population.[8]
-
Assessing Misincorporation:
-
Mass Spectrometry: The most definitive way to identify and quantify misincorporation is through mass spectrometry analysis of the purified protein. By analyzing the peptide fragment containing the amber codon site, you can determine the identity and relative abundance of the incorporated amino acids.[9]
-
-
Minimizing Misincorporation:
-
Optimize this compound Concentration: Ensure that a sufficient concentration of pAF is available to outcompete endogenous amino acids for charging onto the suppressor tRNA.
-
Use a Highly Specific Orthogonal aaRS: The engineered aminoacyl-tRNA synthetase should have a strong preference for this compound over any of the 20 canonical amino acids. If you suspect off-target charging, you may need to perform further engineering of your synthetase.
-
Consider the Host Strain: Some E. coli strains have higher levels of natural amber suppression than others.[8] Strains like TOP10 generally exhibit lower background suppression compared to BL21 or MG1655.[8]
-
Frequently Asked Questions (FAQs)
Q1: What is the optimal codon context for this compound incorporation?
A1: The optimal codon context is dependent on the expression system.
-
In Mammalian Cells: Studies have shown that the nucleotides both upstream and downstream of the amber codon synergistically influence suppression efficiency.[2] A consensus motif for efficient amber suppression in mammalian cells has been identified, and a predictive tool called iPASS is available to guide the selection of permissive sites.[2][3] Generally, a cytosine at the +4 position is favorable.
-
In E. coli: Research suggests that purines (A or G) at the +4 position tend to promote higher suppression efficiencies.[2] The identity of the -1 and +1 codons (immediately preceding and following the TAG codon) also plays a significant role.
Q2: How does the position of the amber codon within the protein affect incorporation efficiency?
A2: The location of the amber codon can influence suppression efficiency. Some studies suggest that suppression efficiency may be lower for TAG codons located very early in the coding sequence. It is advisable to place the amber codon at a site that is known to be structurally tolerant to substitution.
Q3: Can I incorporate multiple this compound residues into a single protein?
A3: Yes, it is possible to incorporate multiple pAF residues. However, the efficiency of suppression at each site will be multiplicative, leading to a significant decrease in the yield of the full-length protein with each additional amber codon. Using an RF1 knockout E. coli strain can significantly improve the efficiency of multi-site incorporation.[1][5]
Q4: What concentration of this compound should I use in my culture medium?
A4: The optimal concentration can vary depending on the cell type and the efficiency of the orthogonal synthetase. A typical starting concentration is 1 mM. It is recommended to perform a titration experiment to determine the optimal concentration for your specific system.
Q5: Are there any specific considerations for purifying proteins containing this compound?
A5: The purification procedure is generally the same as for the wild-type protein. The addition of a single this compound residue is unlikely to significantly alter the overall biochemical properties of the protein. However, it is always good practice to monitor the purification process carefully, for example, by running SDS-PAGE gels of fractions from each purification step.
Data Presentation
The following tables provide a summary of representative data on the influence of codon context on amber suppression efficiency. Note that this data is generalized from studies on various non-canonical amino acids and should be used as a guideline. The actual efficiencies for this compound may vary.
Table 1: Influence of the +4 Nucleotide on Amber Suppression Efficiency in Mammalian Cells (Generalized)
| +4 Nucleotide | Relative Suppression Efficiency |
| C | High |
| G | Moderate-High |
| A | Moderate |
| U | Low-Moderate |
This table is based on the general findings that a cytosine at the +4 position is often favorable for amber suppression in mammalian cells.[2]
Table 2: Influence of Flanking Codons on Amber Suppression Efficiency in E. coli (Generalized)
| -1 Codon | +1 Codon | Relative Suppression Efficiency |
| Gln (CAG) | Ser (AGC) | High |
| Asn (AAC) | Tyr (UAU) | High |
| Lys (AAG) | Ala (GCU) | Moderate |
| Arg (CGU) | Leu (CUG) | Low |
This table illustrates that the identity of the codons immediately preceding and following the amber codon can have a significant impact on suppression efficiency in prokaryotic systems.
Experimental Protocols
Protocol 1: Quantification of this compound Incorporation Efficiency using a Dual-Luciferase Reporter Assay
This protocol describes a method to quantify the relative efficiency of this compound incorporation at a specific codon context using a dual-luciferase reporter system.
Materials:
-
Mammalian cell line (e.g., HEK293T)
-
Transfection reagent
-
Dual-luciferase reporter plasmid containing your codon context of interest upstream of a Firefly luciferase gene with an in-frame amber codon, and a Renilla luciferase gene for normalization.
-
Plasmid encoding the orthogonal aaRS for pAF and the suppressor tRNA
-
This compound (pAF)
-
Dual-Luciferase® Reporter Assay System (e.g., from Promega)
-
Luminometer
Procedure:
-
Cell Seeding: Seed cells in a 96-well plate at a density that will result in 70-90% confluency at the time of transfection.
-
Transfection: Co-transfect the cells with the dual-luciferase reporter plasmid and the aaRS/tRNA plasmid using your preferred transfection reagent. Include a control group that is not transfected with the aaRS/tRNA plasmid.
-
Addition of this compound: 24 hours post-transfection, replace the medium with fresh medium containing 1 mM pAF. For the negative control wells, use medium without pAF.
-
Cell Lysis: 48 hours post-transfection, wash the cells with PBS and lyse them according to the manufacturer's protocol for the Dual-Luciferase® Reporter Assay System.[10][11]
-
Luminescence Measurement: Measure the Firefly and Renilla luciferase activities sequentially using a luminometer according to the assay kit's instructions.
-
Data Analysis:
-
For each well, calculate the ratio of Firefly to Renilla luciferase activity.
-
The amber suppression efficiency is calculated as the (Firefly/Renilla ratio in the presence of pAF and aaRS/tRNA) / (Firefly/Renilla ratio of a control construct with a sense codon instead of the amber codon).
-
Protocol 2: Confirmation of this compound Incorporation by Western Blot
This protocol outlines the steps to confirm the expression of the full-length protein containing this compound.
Materials:
-
Cell lysate containing the expressed protein
-
SDS-PAGE gels
-
Transfer buffer
-
PVDF or nitrocellulose membrane
-
Blocking buffer (e.g., 5% non-fat milk or BSA in TBST)
-
Primary antibody specific to your protein of interest or an epitope tag
-
HRP-conjugated secondary antibody
-
Chemiluminescent substrate
-
Imaging system
Procedure:
-
Sample Preparation: Prepare cell lysates from cultures grown in the presence and absence of this compound. Quantify the total protein concentration of each lysate to ensure equal loading.[12]
-
SDS-PAGE: Separate the proteins by SDS-polyacrylamide gel electrophoresis.[13][14]
-
Protein Transfer: Transfer the separated proteins from the gel to a PVDF or nitrocellulose membrane.[15][16]
-
Blocking: Block the membrane with blocking buffer for 1 hour at room temperature to prevent non-specific antibody binding.
-
Primary Antibody Incubation: Incubate the membrane with the primary antibody diluted in blocking buffer overnight at 4°C.
-
Secondary Antibody Incubation: Wash the membrane with TBST and then incubate with the HRP-conjugated secondary antibody for 1 hour at room temperature.
-
Detection: After further washing, add the chemiluminescent substrate and visualize the protein bands using an imaging system.
-
Analysis: A band corresponding to the full-length protein should be present in the lane from the culture grown with this compound and the orthogonal expression machinery. The intensity of this band can be compared to the truncated product band to qualitatively assess suppression efficiency.
Mandatory Visualization
Caption: Workflow for quantifying this compound incorporation efficiency.
Caption: Troubleshooting decision tree for low protein expression.
References
- 1. RF1 Knockout Allows Ribosomal Incorporation of Unnatural Amino Acids at Multiple Sites - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Identification of permissive amber suppression sites for efficient non-canonical amino acid incorporation in mammalian cells - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Identification of permissive amber suppression sites for efficient non-canonical amino acid incorporation in mammalian cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Bacteria Expression Support—Troubleshooting | Thermo Fisher Scientific - JP [thermofisher.com]
- 5. Cell-free protein synthesis from a release factor 1 deficient Escherichia coli activates efficient and multiple site-specific nonstandard amino acid incorporation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. The effect of eukaryotic release factor depletion on translation termination in human cell lines - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Stop codon suppression via inhibition of eRF1 expression - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Near-cognate suppression of amber, opal and quadruplet codons competes with aminoacyl-tRNAPyl for genetic code expansion - PMC [pmc.ncbi.nlm.nih.gov]
- 9. MS-READ: Quantitative Measurement of Amino Acid Incorporation - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Dual-Luciferase® Reporter Assay System Protocol [promega.jp]
- 11. kirschner.med.harvard.edu [kirschner.med.harvard.edu]
- 12. origene.com [origene.com]
- 13. Western blot protocol | Abcam [abcam.com]
- 14. ptglab.com [ptglab.com]
- 15. cytivalifesciences.com [cytivalifesciences.com]
- 16. bio-rad.com [bio-rad.com]
Technical Support Center: Strategies to Improve the Solubility of 4-Aminophenylalanine Derivatives
This technical support center provides researchers, scientists, and drug development professionals with practical guidance for addressing solubility challenges encountered with 4-aminophenylalanine derivatives. The following sections offer troubleshooting guides, frequently asked questions (FAQs), detailed experimental protocols, and comparative data to facilitate your research and development efforts.
Frequently Asked Questions (FAQs)
Q1: What are the primary reasons for the poor aqueous solubility of my this compound derivative?
A1: The limited aqueous solubility of this compound derivatives often stems from a combination of factors related to their molecular structure. The presence of the aromatic phenyl ring imparts significant hydrophobicity. While the amino and carboxylic acid groups are ionizable and thus capable of interacting with water, their contribution to overall solubility can be minimal, particularly at or near the isoelectric point (pI). At the pI, the molecule exists as a zwitterion with a net neutral charge, which can lead to strong intermolecular electrostatic interactions and the formation of a stable, less soluble crystal lattice.
Q2: What are the main strategies I can employ to improve the solubility of my compound?
A2: Several effective strategies can be employed to enhance the solubility of this compound derivatives. These can be broadly categorized as chemical and physical modifications:
-
pH Adjustment: Modifying the pH of the solution to move away from the isoelectric point is often the simplest and most effective initial strategy. By creating a net positive or negative charge on the molecule, its interaction with water is significantly enhanced.
-
Salt Formation: Converting the acidic (carboxylic acid) or basic (amino group) functionalities into a salt can dramatically improve aqueous solubility. Hydrochloride salts are a common and effective choice for amine-containing compounds.
-
Prodrug Synthesis: Masking the carboxylic acid or amino group with a more soluble promoiety can enhance solubility. A common approach is the formation of amino acid esters, which can improve aqueous solubility and may be cleaved in vivo by esterases to release the active drug.
-
Use of Co-solvents: The addition of a water-miscible organic solvent, such as ethanol (B145695) or propylene (B89431) glycol, can increase the solubility of hydrophobic compounds by reducing the polarity of the solvent system.
-
Complexation with Cyclodextrins: Encapsulating the hydrophobic phenyl ring within the cavity of a cyclodextrin (B1172386) molecule can increase the apparent water solubility of the derivative by presenting a more hydrophilic exterior to the bulk solvent.
Q3: How do I choose the best solubility enhancement strategy for my specific derivative?
A3: The optimal strategy depends on the physicochemical properties of your specific derivative and its intended application.
-
For early-stage in vitro assays, pH adjustment or the use of co-solvents might be sufficient and are straightforward to implement.
-
For in vivo studies and formulation development, salt formation or a prodrug approach are often more suitable as they can also improve bioavailability and offer better stability in a physiological environment.
-
Cyclodextrin complexation is a valuable technique when the hydrophobicity of the phenyl ring is the primary contributor to poor solubility and when altering the chemical structure of the parent molecule is not desirable.
It is highly recommended to begin with a comprehensive solubility assessment under various pH conditions to inform your selection of the most appropriate and effective strategy.
Troubleshooting Guide
This guide addresses common issues encountered during the solubilization of this compound derivatives.
| Problem | Possible Cause | Suggested Solution |
| Compound precipitates out of solution when I adjust the pH. | You may have crossed the isoelectric point (pI), where the compound's solubility is at its minimum. | Determine the pI of your derivative. To maintain a net charge and improve solubility, work at a pH at least 2 units above or below the pI. |
| My hydrochloride salt is not as soluble as expected or precipitates over time. | The salt may be disproportionating back to the less soluble free form. The pH of the solution may not be optimal to maintain the salt form. | Screen a variety of pharmaceutically acceptable counter-ions. Ensure the pH of the final solution is sufficiently acidic to maintain the protonated amine and prevent precipitation of the free base. |
| My ester prodrug is not releasing the active this compound derivative. | The enzymatic or chemical cleavage of the promoiety is not occurring under the experimental conditions. | Ensure the appropriate enzymes (e.g., esterases for ester prodrugs) are present and active in your in vitro or in vivo system. For chemical cleavage (hydrolysis), verify that the pH and temperature conditions are suitable. |
| The use of a co-solvent is interfering with my biological assay. | The organic solvent may be denaturing proteins, inhibiting enzymes, or causing cell toxicity. | Use the lowest effective concentration of the co-solvent. If possible, choose a more biocompatible co-solvent (e.g., DMSO, ethanol). Always include a vehicle control in your assay to assess the impact of the solvent alone. |
| The compound forms an oil or amorphous precipitate instead of crystalline material during salt formation or crystallization. | The rate of supersaturation is too high, or the chosen solvent system is not optimal for crystal lattice formation. This is a common issue with zwitterionic compounds. | Reduce the rate of supersaturation by slowing down the cooling process or the rate of anti-solvent addition. Screen a wider range of solvent systems, including binary or tertiary mixtures, to find conditions that favor crystallization over "oiling out". Seeding with a small amount of crystalline material can also be effective. |
| I observe a cloudy solution even after attempting to dissolve my compound. | The compound may be forming fine, insoluble aggregates. | Try gentle warming (not exceeding 40°C) or sonication to aid in the dissolution of aggregates. For highly hydrophobic derivatives, dissolving the compound in a minimal amount of an organic solvent like DMSO before adding the aqueous buffer can be an effective strategy. |
Quantitative Data on Solubility Enhancement
The following tables summarize solubility data for this compound and demonstrate the potential for solubility enhancement using various strategies. Data for specific derivatives are often not publicly available; therefore, data for the parent compound and analogous structures are provided as a reference.
Table 1: Aqueous Solubility of 4-Amino-L-phenylalanine and its Hydrochloride Salt
| Compound | Form | Solvent | Solubility | Reference |
| 4-Amino-L-phenylalanine | Free Base | Water | ~20 mg/mL | [1] |
| 4-Amino-L-phenylalanine | Free Base | Water | 3.33 mg/mL (with heating and sonication) | [2] |
| 4-Amino-L-phenylalanine | Free Base | PBS | 10 mg/mL | [3] |
| 4-Amino-L-phenylalanine | Hydrochloride Salt | Water | ≥ 50 mg/mL (0.1g in 2ml) | [4][5] |
Table 2: Illustrative Solubility Enhancement with Prodrug and Cyclodextrin Strategies (Data from analogous compounds)
| Parent Compound | Strategy | Derivative/Complex | Solubility Improvement | Reference |
| 2-(4-aminophenyl) benzothiazoles | Amino Acid Prodrug (Amide) | L-lysyl-amide prodrug | Good water solubility in weak acid | [3] |
| 3-Carboranyl Thymidine (B127349) Analogues | Amino Acid Prodrug (Ester) | L-valine, L-glutamate, and glycine (B1666218) esters | 48 to 6,600-fold increase in PBS | [6][7] |
| Praziquantel | Cyclodextrin Complexation | Praziquantel/HP-β-CD | ~4.5-fold increase | [8] |
Detailed Experimental Protocols
Protocol 1: Determination of pH-Solubility Profile
This protocol outlines the steps to determine the aqueous solubility of a this compound derivative at various pH values.
Materials:
-
This compound derivative
-
Buffer solutions (e.g., citrate, phosphate, borate) covering a pH range from 2 to 10
-
Vials with screw caps
-
Shaker or agitator at a constant temperature (e.g., 25°C or 37°C)
-
Centrifuge
-
HPLC or UV-Vis spectrophotometer for concentration analysis
Procedure:
-
Preparation of Buffers: Prepare a series of buffers at the desired pH values with a fixed ionic strength.
-
Sample Preparation: Add an excess amount of the powdered this compound derivative to a vial containing a known volume of each buffer. Ensure enough solid is present to maintain a saturated solution throughout the experiment.
-
Equilibration: Seal the vials and agitate them at a constant temperature for a sufficient time to reach equilibrium (typically 24-48 hours).
-
Phase Separation: Centrifuge the samples at high speed to pellet the undissolved solid.
-
Sample Analysis: Carefully withdraw a known volume of the supernatant, dilute it with an appropriate solvent, and determine the concentration of the dissolved compound using a validated analytical method (e.g., HPLC, UV-Vis spectrophotometry).
-
Data Analysis: Plot the measured solubility (in mg/mL or mM) against the pH of the buffer to generate the pH-solubility profile.
Protocol 2: Synthesis and Isolation of a Hydrochloride Salt
This protocol provides a general method for the preparation of the hydrochloride (HCl) salt of a this compound derivative.
Materials:
-
This compound derivative (free base)
-
Hydrochloric acid (e.g., 2M solution in diethyl ether or concentrated aqueous HCl)
-
Anhydrous organic solvent (e.g., diethyl ether, ethyl acetate, or isopropanol)
-
Stir plate and magnetic stir bar
-
Filtration apparatus (e.g., Büchner funnel)
Procedure:
-
Dissolution: Dissolve the this compound derivative free base in a minimal amount of a suitable anhydrous organic solvent.
-
Acidification: While stirring, slowly add a stoichiometric amount (or a slight excess) of the hydrochloric acid solution.
-
Precipitation: The hydrochloride salt will typically precipitate out of the solution. Continue stirring for 1-2 hours to ensure complete precipitation. If precipitation does not occur, the solution can be cooled or an anti-solvent can be slowly added.
-
Isolation: Collect the precipitated salt by vacuum filtration.
-
Washing: Wash the collected solid with a small amount of cold, anhydrous solvent to remove any unreacted starting material or excess acid.
-
Drying: Dry the salt under vacuum to remove residual solvent.
-
Characterization: Confirm the formation of the salt and its purity using techniques such as NMR, FTIR, and melting point analysis.
Protocol 3: Preparation of an Amino Acid Ester Prodrug (Example: Ethyl Ester)
This protocol describes a general method for the synthesis of an ethyl ester prodrug of a this compound derivative.
Materials:
-
This compound derivative
-
Anhydrous ethanol
-
Thionyl chloride (SOCl₂) or acetyl chloride
-
Anhydrous reaction vessel with a reflux condenser and drying tube
-
Stir plate and magnetic stir bar
-
Rotary evaporator
Procedure:
-
Reaction Setup: Suspend the this compound derivative in anhydrous ethanol in a reaction vessel under an inert atmosphere (e.g., nitrogen or argon).
-
Esterification: Cool the suspension in an ice bath. Slowly and carefully add thionyl chloride or acetyl chloride dropwise. This will react with ethanol to form HCl in situ, which catalyzes the esterification.
-
Reaction: After the addition is complete, remove the ice bath and heat the reaction mixture to reflux for several hours, monitoring the reaction progress by TLC or LC-MS.
-
Solvent Removal: Once the reaction is complete, cool the mixture to room temperature and remove the solvent under reduced pressure using a rotary evaporator.
-
Purification: The crude product, often obtained as the hydrochloride salt of the ester, can be purified by recrystallization or column chromatography.
-
Characterization: Confirm the structure and purity of the final ethyl ester prodrug using NMR, mass spectrometry, and HPLC.
Protocol 4: Preparation of a Cyclodextrin Inclusion Complex
This protocol describes the co-precipitation method for forming an inclusion complex between a this compound derivative and a cyclodextrin (e.g., β-cyclodextrin or hydroxypropyl-β-cyclodextrin).
Materials:
-
This compound derivative
-
Cyclodextrin (e.g., HP-β-CD)
-
Deionized water
-
Water-miscible organic solvent (e.g., ethanol)
-
Stir plate and magnetic stir bar
-
Filtration apparatus
-
Freeze-dryer or vacuum oven
Procedure:
-
Dissolution: Dissolve the cyclodextrin in deionized water, gently warming if necessary to achieve complete dissolution. In a separate container, dissolve the this compound derivative in a minimal amount of a suitable organic solvent.
-
Complexation: With constant stirring, slowly add the solution of the derivative to the aqueous cyclodextrin solution.
-
Precipitation/Equilibration: Continue stirring the mixture for an extended period (several hours to overnight) to allow for complex formation. The solution may become cloudy as the complex forms.
-
Isolation: If a precipitate forms, collect the solid by filtration. If no precipitate forms, the complex is likely soluble, and the solution can be lyophilized (freeze-dried) to obtain the solid complex.
-
Washing and Drying: If filtered, wash the collected solid with a small amount of cold water or the organic solvent used, and then dry it under vacuum or by freeze-drying.
-
Characterization: Confirm the formation of the inclusion complex using techniques such as DSC, FTIR, and NMR spectroscopy. A phase solubility diagram can also be constructed to determine the stoichiometry and stability constant of the complex.
Visualizing Experimental Workflows and Logical Relationships
General Troubleshooting Workflow for Solubility Issues
Caption: A logical workflow for troubleshooting solubility issues with this compound derivatives.
Experimental Workflow for Salt Formation and Screening
Caption: A step-by-step workflow for the synthesis and evaluation of salts of this compound derivatives.
Relationship Between Solubility Enhancement Strategies
Caption: The logical relationships between different strategies for enhancing the solubility of this compound derivatives.
References
- 1. 4-Amino-L-phenylalanine | CAS#:102281-45-8 | Chemsrc [chemsrc.com]
- 2. medchemexpress.com [medchemexpress.com]
- 3. Antitumor benzothiazoles. 16. Synthesis and pharmaceutical properties of antitumor 2-(4-aminophenyl)benzothiazole amino acid prodrugs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. usbio.net [usbio.net]
- 5. chemimpex.com [chemimpex.com]
- 6. Synthesis, Chemical and Enzymatic Hydrolysis, and Aqueous Solubility of Amino Acid Ester Prodrugs of 3-Carboranyl Thymidine Analogues for Boron Neutron Capture Therapy of Brain Tumors - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Synthesis, chemical and enzymatic hydrolysis, and aqueous solubility of amino acid ester prodrugs of 3-carboranyl thymidine analogs for boron neutron capture therapy of brain tumors - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Stabilization of Zwitterionic Versus Canonical Glycine by DMSO Molecules - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Minimizing 4-Aminophenylalanine Toxicity in Bacterial Expression Systems
This technical support center provides researchers, scientists, and drug development professionals with comprehensive troubleshooting guides and frequently asked questions (FAQs) to address challenges associated with the toxicity of 4-Aminophenylalanine (pAF) in bacterial protein expression systems.
Frequently Asked Questions (FAQs)
Q1: What are the primary causes of this compound (pAF) toxicity in E. coli expression systems?
A1: The toxicity associated with this compound (pAF) incorporation in E. coli can stem from several factors. A primary cause is the metabolic burden placed on the host cell by the overexpression of the heterologous protein and the components of the unnatural amino acid (UAA) incorporation machinery, such as the aminoacyl-tRNA synthetase (aaRS) and suppressor tRNA.[1] This can disrupt normal cellular processes and lead to reduced growth or cell death. Additionally, intermediate metabolites in pAF biosynthesis pathways, if producing pAF endogenously, can sometimes be toxic to the cells.[2] The diversion of chorismate, a crucial metabolic precursor, towards pAF production can also starve the cell of essential aromatic amino acids, impairing growth.[2]
Q2: How does the choice of expression vector influence pAF-related toxicity?
A2: The expression vector is a critical component in managing toxicity. Using a single-plasmid system (like pEVOL or pUltra) that contains both the aaRS and multiple copies of the suppressor tRNA gene can be more efficient and less burdensome than using multiple plasmids.[3][4][5] The choice of promoter is also crucial. Tightly regulated promoters, such as the arabinose promoter (PBAD), are often preferred over "leaky" promoters like the T7 promoter to prevent basal expression of a potentially toxic pAF-containing protein before induction.[6][7] For very toxic proteins, using vectors with multiple layers of repression, such as those containing the lacIq gene for overexpression of the lac repressor, can be beneficial.[8][9] The copy number of the plasmid also plays a role; lower copy number plasmids can help to better regulate expression and reduce metabolic load.[6]
Q3: Can the E. coli host strain be engineered to better tolerate pAF?
A3: Yes, several host strain modifications can improve tolerance and incorporation efficiency of pAF. Strains like C41(DE3) and C43(DE3) have been shown to be useful for expressing some toxic proteins, including membrane proteins.[6] For systems using the T7 promoter, host strains like BL21(DE3)pLysS, which express T7 lysozyme, can reduce basal T7 RNA polymerase activity and minimize pre-induction toxicity.[6][7] Furthermore, genomically recoded E. coli strains, where all instances of the amber stop codon (TAG) are replaced with another stop codon (e.g., TAA), can significantly improve UAA incorporation efficiency by eliminating competition with release factor 1 (RF1).[5]
Q4: What is the role of the orthogonal aminoacyl-tRNA synthetase (aaRS) and suppressor tRNA in pAF toxicity?
A4: The efficiency and orthogonality of the aaRS/tRNA pair are paramount. An inefficient aaRS can lead to poor charging of the tRNA with pAF, resulting in low protein yields and potential mis-incorporation of natural amino acids. A non-orthogonal pair might cross-react with endogenous amino acids or tRNAs, disrupting normal protein synthesis and contributing to cellular stress.[4] Evolving the aaRS to have higher specificity and activity for pAF is a key strategy. The number of copies of the suppressor tRNA gene can also be optimized; while multiple copies can increase suppression efficiency, they can also contribute to metabolic burden.[10] Some studies have shown that using a single copy of an optimized tRNA can reduce toxicity and improve expression compared to multiple copies of the wild-type tRNA.[10]
Troubleshooting Guides
Issue 1: High Cell Toxicity and Poor Growth After Induction
This is a common issue when expressing proteins containing pAF. The following troubleshooting workflow can help identify and resolve the problem.
Caption: Troubleshooting workflow for high cell toxicity.
Detailed Steps:
-
Check for Basal (Leaky) Expression: Before induction, run a small sample of your culture on an SDS-PAGE gel and perform a Western blot for your protein of interest. If you detect your protein, you have leaky expression. To mitigate this, add 1% glucose to the culture medium to repress the lac promoter, or switch to a host strain with tighter control, like BL21(DE3)pLysS.[6][7]
-
Reduce Inducer Concentration: High concentrations of inducers (e.g., IPTG) can lead to a rapid and overwhelming production of the toxic protein. Try a titration of the inducer concentration. For IPTG, concentrations in the range of 0.01 - 0.1 mM are often effective for toxic proteins, compared to the standard 1.0 mM.[6]
-
Lower Induction Temperature: Reducing the temperature after induction (e.g., from 37°C to 18-25°C) slows down protein synthesis. This can give the cell more time to fold the protein correctly and manage the metabolic stress, often increasing the yield of soluble protein.[6]
-
Switch to a Tightly Regulated Promoter: If using a T7-based system, consider switching to a vector with a PBAD (arabinose-inducible) promoter, which has very low basal expression.[7]
-
Use a Different Host Strain: Strains like C41(DE3) or C43(DE3) are mutated to be more tolerant of toxic protein expression.[6]
-
Optimize pAF Concentration: While pAF itself is generally not highly toxic at typical concentrations used for incorporation (1-2 mM), very high concentrations could be detrimental.[2] Ensure you are not adding an excessive amount to your culture medium.
Issue 2: Low Yield of pAF-Containing Protein
Low yields can be due to inefficient incorporation of pAF, toxicity leading to cell death, or protein degradation.
Caption: Troubleshooting workflow for low protein yield.
Detailed Steps:
-
Verify pAF Incorporation: Purify a small amount of your protein and analyze it by mass spectrometry to confirm that pAF is being incorporated at the correct site. This will rule out issues with the fidelity of the system.
-
Optimize the Suppression System: The efficiency of the orthogonal aaRS/tRNA pair is critical. Ensure you are using a validated and efficient pair for pAF. Consider using a plasmid system like pUltra or pEVOL, which have been optimized for UAA incorporation.[4] Using a vector with multiple copies of the suppressor tRNA under a strong promoter like proK can enhance suppression efficiency.[3][11]
-
Check Codon Usage: While the amber codon (TAG) is the most commonly used for UAA incorporation, ensure that the gene for your protein of interest does not have internal TAG codons that are not intended for suppression. The amber codon is the least used stop codon in E. coli, which is why it is typically chosen.[5][10]
-
Optimize Culture Conditions: In addition to inducer concentration and temperature, ensure the growth medium is optimal. Supplementing with all 20 natural amino acids can help alleviate the metabolic burden on the cell.
-
Use a Genomically Recoded Strain: For the highest efficiency, use an E. coli strain where all genomic TAG codons have been replaced (e.g., C321.ΔA). This eliminates competition from Release Factor 1 and dedicates the amber codon exclusively to pAF incorporation.[5]
Data and Parameters for Optimization
The following tables provide a summary of key parameters that can be adjusted to minimize toxicity and improve the yield of pAF-containing proteins.
Table 1: Comparison of Expression Systems and Components
| Parameter | Low Toxicity Option | High Yield Option | Rationale |
| Promoter | PBAD (Arabinose) | T7 | PBAD has very tight regulation, preventing leaky expression of toxic proteins.[7] T7 is a very strong promoter leading to high expression levels. |
| Plasmid Copy # | Low (e.g., p15A ori) | Medium (e.g., ColE1 ori) | Lower copy number reduces metabolic burden from plasmid replication and basal expression.[6] |
| Host Strain | BL21(DE3)pLysS, C41(DE3) | Genomically Recoded E. coli | pLysS reduces T7 leakage; C41(DE3) is tolerant to toxic proteins.[6][7] Recoded strains eliminate RF1 competition.[5] |
| aaRS/tRNA Vector | Single Optimized tRNA | Multiple tRNA copies | A single, highly efficient tRNA can be less burdensome than multiple copies of a less optimal one.[10] Multiple copies can increase suppression.[3] |
Table 2: Optimization of Culture Conditions
| Condition | Range for Toxic Proteins | Standard Condition | Rationale |
| Induction Temperature | 18 - 25 °C | 30 - 37 °C | Lower temperatures slow protein synthesis, reduce aggregation, and decrease metabolic stress.[6] |
| Inducer (IPTG) Conc. | 0.01 - 0.1 mM | 0.5 - 1.0 mM | Lower inducer levels result in slower, more controlled expression, which can be crucial for toxic proteins.[6] |
| pAF Concentration | 1 - 2 mM | 1 - 2 mM | This is the typical effective range; higher concentrations rarely improve yield and may contribute to toxicity. |
| Media Additives | 1% Glucose (pre-induction) | None | Glucose represses the lac promoter, preventing leaky expression from T7-based systems.[6] |
Key Experimental Protocols
Protocol 1: Optimizing Inducer Concentration and Temperature
This protocol is designed to find the optimal balance between protein expression and cell viability.
-
Prepare Cultures: Inoculate several 10 mL cultures of your expression strain transformed with the pAF incorporation plasmids in a suitable medium (e.g., LB or M9 minimal medium) supplemented with the appropriate antibiotics and 1 mM pAF.
-
Grow Cells: Grow the cultures at 37°C with shaking until they reach an OD600 of 0.6-0.8.
-
Set Up Induction Matrix: Create a matrix of conditions. For example, set up three different temperatures (e.g., 20°C, 25°C, 30°C) and for each temperature, test four different IPTG concentrations (e.g., 0.01 mM, 0.05 mM, 0.1 mM, 0.5 mM). Include a no-inducer control for each temperature.
-
Induce Expression: Add the specified concentration of IPTG to each culture and move them to shakers at their designated temperatures.
-
Monitor Growth and Harvest: Continue to monitor the OD600 of each culture for 4-6 hours post-induction. A significant drop in OD after induction is a strong indicator of toxicity. Harvest 1 mL of each culture.
-
Analyze Results: Lyse the cells and run the lysates on an SDS-PAGE gel. Stain with Coomassie blue or perform a Western blot to visualize the expression level of your target protein.
-
Select Optimal Conditions: Choose the temperature and inducer concentration that provides the highest yield of soluble protein with the least impact on cell growth.
Signaling Pathways and Workflows
The metabolic burden of expressing a pAF-containing protein involves diverting cellular resources from essential processes.
Caption: Metabolic burden from pAF-protein expression.
This diagram illustrates how the synthesis of the pAF-containing protein, the specific aaRS, and the suppressor tRNA all draw from the same limited pool of cellular resources (energy, amino acids, ribosomes) as essential processes like cell growth and native protein synthesis. This competition and resource diversion is a primary source of toxicity.
References
- 1. “Metabolic burden” explained: stress symptoms and its related responses induced by (over)expression of (heterologous) proteins in Escherichia coli - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Computational design and engineering of an Escherichia coli strain producing the nonstandard amino acid para-aminophenylalanine - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Efficient incorporation of unnatural amino acids into proteins in Escherichia coli | Semantic Scholar [semanticscholar.org]
- 4. Frontiers | Unnatural amino acid incorporation in E. coli: current and future applications in the design of therapeutic proteins [frontiersin.org]
- 5. mdpi.com [mdpi.com]
- 6. biologicscorp.com [biologicscorp.com]
- 7. Strategies to Optimize Protein Expression in E. coli - PMC [pmc.ncbi.nlm.nih.gov]
- 8. How can I express toxic protein in E. coli? [qiagen.com]
- 9. neb.com [neb.com]
- 10. Optimized incorporation of an unnatural fluorescent amino acid affords measurement of conformational dynamics governing high-fidelity DNA replication - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
Technical Support Center: 4-Aminophenylalanine in Solid-Phase Peptide Synthesis (SPPS)
Welcome to the technical support center for the use of 4-Aminophenylalanine (4-AP) in Solid-Phase Peptide Synthesis (SPPS). This resource provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals overcome common challenges and prevent side reactions during their experiments.
Frequently Asked Questions (FAQs)
Q1: What is the primary challenge when incorporating this compound (4-AP) into a peptide sequence during SPPS?
The main challenge is the presence of the additional primary amino group on the phenyl ring (the para-amino group). This group is nucleophilic and can lead to undesired side reactions, such as branching of the peptide chain, if it is not appropriately protected during synthesis.[1][2] An unprotected p-amino group will compete with the N-terminal α-amino group for the activated amino acid during the coupling step, resulting in a complex mixture of peptide products that are difficult to purify.[2]
Q2: What is the recommended protecting group strategy for the side-chain amino group of 4-AP in Fmoc-based SPPS?
The most common and recommended strategy is to use an acid-labile protecting group that is orthogonal to the base-labile Fmoc group used for α-amino protection.[2][3] The standard commercially available building block is Fmoc-L-p-aminophenylalanine(Boc)-OH.[2] The tert-butoxycarbonyl (Boc) group is stable under the basic conditions (e.g., piperidine (B6355638) in DMF) used for Fmoc deprotection but is cleanly removed during the final cleavage from the resin with strong acids like trifluoroacetic acid (TFA).[2]
Q3: Can I use this compound without any side-chain protection?
It is strongly discouraged. An unprotected para-amino group will react with the activated carboxyl group of the incoming amino acid, leading to the formation of branched peptides. This results in significant impurities and a low yield of the target peptide.[2][3]
Q4: How is the Boc protecting group from the 4-AP side chain removed?
The Boc group is removed simultaneously with other acid-labile side-chain protecting groups (e.g., tBu, Trt) and during the cleavage of the peptide from the resin. This is typically achieved by treating the peptide-resin with a cleavage cocktail containing a high concentration of trifluoroacetic acid (TFA).[2]
Q5: My peptide solution turns yellow or brown after cleavage. What is the likely cause and how can I prevent it?
A yellow or brown color in the peptide solution after cleavage often indicates oxidation of the aniline-like para-amino group of 4-AP.[2] This is more likely to occur after the Boc group is removed during TFA cleavage, exposing the free amino group to air and light.[2]
To prevent this:
-
Use Scavengers: Ensure your cleavage cocktail contains appropriate scavengers. A common mixture is 95% TFA, 2.5% water, and 2.5% triisopropylsilane (B1312306) (TIS). For residues particularly sensitive to oxidation, adding a thiol scavenger like 1,2-ethanedithiol (B43112) (EDT) can be beneficial.[2]
-
Minimize Cleavage Time: Avoid unnecessarily long cleavage times. For most peptides, 1.5 to 2 hours is sufficient.[2]
-
Inert Atmosphere: Handle the crude peptide under an inert atmosphere (e.g., nitrogen or argon) after cleavage and precipitation to minimize air oxidation.[2]
-
Proper Storage: Store the lyophilized peptide protected from light at low temperatures (-20°C or -80°C).[2]
Troubleshooting Guides
Issue 1: Low Yield and/or Presence of Higher Mass Impurities
Symptom: The final crude product shows a low yield of the target peptide and multiple peaks in the HPLC chromatogram, some with a higher mass than the expected product.
Potential Cause: Unwanted acylation of the para-amino group on the 4-AP side chain. This can occur if an unprotected version of 4-AP was used, or if the Boc protecting group was compromised or prematurely removed. The free para-amino group can react with the activated amino acid in the coupling step, leading to branched peptides.[2]
Troubleshooting Workflow:
Caption: Troubleshooting workflow for low yield and impurities.
Preventative Measures:
-
Always use Fmoc-4-AP(Boc)-OH for Fmoc-based SPPS.[2]
-
Perform a quality check on incoming amino acid derivatives to ensure their integrity.[2]
-
For long peptides, consider a test cleavage of a small amount of resin mid-synthesis to check for the accumulation of side products.[2]
Issue 2: Incomplete Coupling of this compound
Symptom: A positive Kaiser test (blue or purple beads) after the coupling step for Fmoc-4-AP(Boc)-OH indicates the presence of unreacted free amines on the resin.[4]
Potential Cause: The bulky nature of the protected 4-AP can sterically hinder the coupling reaction, leading to incomplete incorporation.[4] Peptide aggregation on the resin can also block reactive sites.
Recommended Solutions:
| Strategy | Description |
| Double Coupling | Repeat the coupling step with a fresh solution of activated Fmoc-4-AP(Boc)-OH.[4] |
| Extend Coupling Time | Increase the coupling time from the standard 1-2 hours to 2-4 hours or longer.[4] |
| Use a More Potent Coupling Reagent | Switch from standard reagents like HBTU/DIPEA to more potent activators such as HATU. |
| Increase Reagent Equivalents | Increase the equivalents of the activated amino acid and coupling reagents from 3 to 5 equivalents. |
| Modify Synthesis Conditions | To disrupt peptide aggregation, consider coupling at a higher temperature (e.g., 40-50°C) or switching the solvent from DMF to NMP. |
Experimental Protocols
Protocol 1: Standard Coupling of Fmoc-4-AP(Boc)-OH
This protocol outlines the standard steps for coupling Fmoc-4-AP(Boc)-OH during manual or automated Fmoc SPPS.
-
Fmoc Deprotection: Treat the resin-bound peptide with 20% piperidine in DMF for 5-10 minutes to remove the N-terminal Fmoc group. Wash the resin thoroughly with DMF.[2]
-
Activation Mixture Preparation: In a separate vessel, dissolve Fmoc-4-AP(Boc)-OH (3 equivalents), HBTU (2.9 equivalents), and HOBt (3 equivalents) in DMF. Add N,N-diisopropylethylamine (DIPEA) (6 equivalents) to the mixture and allow it to pre-activate for 1-2 minutes.[5]
-
Coupling: Add the activated amino acid solution to the deprotected peptide-resin. Agitate the reaction vessel for 1-2 hours at room temperature.[2]
-
Washing: Wash the resin thoroughly with DMF.
-
Monitoring: Perform a Kaiser test to confirm the completion of the coupling (absence of free primary amines). If the test is positive, a second coupling may be necessary.[2][4]
Protocol 2: Cleavage and Deprotection
This protocol removes the side-chain protecting groups (including Boc from 4-AP) and cleaves the peptide from the resin.
-
Resin Preparation: Wash the final peptide-resin with DCM and dry it under a vacuum.[2]
-
Cleavage Cocktail Preparation: Prepare a cleavage cocktail. A standard cocktail is 95% TFA, 2.5% TIS, and 2.5% H₂O.[1][2]
-
Cleavage Reaction: Add the cleavage cocktail to the resin and incubate for 1.5-2 hours at room temperature with agitation.[2]
-
Peptide Collection: Filter the resin to collect the peptide solution.
-
Precipitation: Precipitate the peptide by adding the filtrate to cold diethyl ether.
-
Isolation: Centrifuge the mixture to pellet the peptide.
-
Washing: Wash the peptide pellet with cold diethyl ether.
-
Drying: Dry the crude peptide under a vacuum.[2]
Visualizations
Caption: Standard workflow for SPPS incorporating this compound.
References
optimizing pH for 4-Aminophenylalanine catalyzed bioconjugation reactions
Welcome to the technical support center for bioconjugation reactions utilizing 4-Aminophenylalanine (4-AP) as a catalyst. This resource is designed for researchers, scientists, and drug development professionals to provide troubleshooting guides, frequently asked questions (FAQs), and detailed protocols to address common challenges, specifically focusing on the optimization of reaction pH.
Troubleshooting Guide
This section provides a systematic approach to troubleshooting common problems encountered during this compound catalyzed bioconjugation experiments.
| Problem | Possible Cause(s) | Recommended Solution(s) |
| Low or No Product Yield | Suboptimal Reaction pH: The reaction rate is highly dependent on pH. At neutral pH, the uncatalyzed reaction is significantly slow.[1][2][3] 4-AP requires a specific pH range to be an effective nucleophilic catalyst. | Verify the pH of your reaction buffer. For 4-AP catalyzed reactions, a pH around 6.9-7.0 is often used.[4] If your biomolecule is stable at a lower pH, an uncatalyzed reaction might be more efficient in the pH 4.0-5.0 range.[1][2][5] |
| Ineffective Catalysis: The concentration of 4-AP may be too low, or the catalyst may be protonated and rendered non-nucleophilic if the pH is too acidic.[6] | Ensure you are using an effective concentration of 4-AP (e.g., 10 mM).[4] Confirm the pH is near neutral to ensure the aromatic amine of 4-AP is available for catalysis. | |
| Low Reactant Concentration: The kinetics of the ligation are dependent on the concentration of the reactants.[1] | If possible, increase the concentration of one or both of your reactants. | |
| Reactant Instability: The aminooxy or hydrazine (B178648) group can be susceptible to degradation. The carbonyl group on the binding partner may also be unstable. | Use high-purity, fresh solvents and reagents. Ensure all components have been stored properly according to the manufacturer's instructions.[2] | |
| Slow Reaction Rate | Non-Optimal Temperature: Unlike many reactions, 4-AP catalyzed hydrazone ligations can be faster at lower temperatures.[4][7][8] | The formation of the reactive imine intermediate between 4-AP and the carbonyl is an exothermic process.[4][7][8] Consider running the reaction at a lower temperature (e.g., 4°C or room temperature) instead of 37°C to increase the concentration of this key intermediate.[4] |
| Inherently Slow Kinetics: Hydrazone and oxime formation at neutral pH can be slow, even with catalysis.[3][7] | Increase the reaction time and monitor progress at various time points (e.g., 1, 4, 12, and 24 hours).[2] If feasible, consider a more potent catalyst like p-phenylenediamine (B122844), which has been shown to be more efficient than aniline (B41778) across the pH range of 4-7.[3][5] | |
| Protein Aggregation or Denaturation | Incompatible Catalyst: While 4-AP is designed to be biocompatible, high concentrations of any catalyst can sometimes affect sensitive proteins.[4][7] | 4-AP is generally less detrimental to protein structure than aniline.[4][7][9] However, if aggregation occurs, try reducing the 4-AP concentration or reaction temperature. Ensure the buffer composition is optimal for your specific protein's stability. |
Troubleshooting Workflow for Low Bioconjugation Yield
Caption: A decision tree for troubleshooting low bioconjugation yield.
Frequently Asked Questions (FAQs)
Q1: Why is pH so critical for bioconjugation reactions like oxime and hydrazone ligations?
The pH of the reaction buffer is a critical parameter because it influences both the nucleophilicity of the amine and the electrophilicity of the carbonyl group.[6] For uncatalyzed reactions, a slightly acidic pH (4.0-5.0) is optimal because it provides sufficient protonation of the carbonyl oxygen, making the carbonyl carbon more electrophilic, without excessively protonating the aminooxy/hydrazine nucleophile.[1][2][5]
Q2: How does this compound (4-AP) work as a catalyst at neutral pH?
At neutral pH, the uncatalyzed reaction is slow. 4-AP, like aniline, acts as a nucleophilic catalyst. It first reacts with the aldehyde or ketone on the target molecule to form a protonated Schiff base (or imine) intermediate.[2][4][7] This intermediate is significantly more reactive towards the aminooxy or hydrazine-functionalized molecule than the original carbonyl, thereby accelerating the overall rate of the bioconjugation reaction.[2][3]
pH Effect on Reaction Components
Caption: Logical diagram of pH effects on reaction components.
Q3: Is 4-AP a better catalyst than aniline?
4-AP is a highly effective and biocompatible alternative to aniline. Studies have shown it maintains approximately 70% of the catalytic efficacy of aniline.[4][7][9] Its main advantage is that it is less detrimental to the native structure of sensitive proteins, making it a superior choice for applications where protein stability is a primary concern.[4][7][8][9] For maximum reaction rates, other derivatives like p-phenylenediamine have been reported to be even more efficient than aniline.[3][10][5]
Q4: Can I perform a 4-AP catalyzed reaction at acidic pH?
It is not recommended. The aromatic amine side chain of 4-AP, which is responsible for its catalytic activity, will become protonated at acidic pH. This neutralizes its nucleophilicity, rendering it an ineffective catalyst.[6] Catalysis with 4-AP is specifically intended for reactions at or near neutral pH (6.5-7.5) where the catalyst remains active.[4]
Q5: How stable is the final oxime or hydrazone bond?
Oxime and hydrazone bonds are generally stable at physiological pH.[2] However, they can be susceptible to hydrolysis under strongly acidic conditions.[2]
Data Summary Tables
Table 1: Recommended pH Conditions for Bioconjugation
| Reaction Type | Catalyst | Optimal pH Range | Rationale |
| Aldehyde/Ketone + Aminooxy/Hydrazine | None (Uncatalyzed) | 4.0 - 5.0 | Balances carbonyl activation with nucleophile availability.[1][2][3][5] |
| Aldehyde/Ketone + Aminooxy/Hydrazine | This compound | 6.5 - 7.5 | Maintains catalyst nucleophilicity; crucial for pH-sensitive biomolecules.[4] |
| Aldehyde/Ketone + Aminooxy/Hydrazine | Aniline / p-Phenylenediamine | 6.5 - 7.5 | Effective catalysis at neutral pH for biomolecule stability.[1][10][5] |
Table 2: Relative Catalyst Efficiency at Neutral pH
| Catalyst | Fold Rate Increase (vs. Uncatalyzed) | Notes |
| Aniline | Up to 40-fold | A common nucleophilic catalyst.[1][3] |
| This compound | ~70% of Aniline's efficacy | More biocompatible; less detrimental to protein structure.[4][7][9] |
| p-Phenylenediamine | Up to 120-fold | Reported to be more efficient than aniline.[10][5] |
Experimental Protocols
Protocol: pH Optimization for 4-AP Catalyzed Bioconjugation
This protocol provides a general framework for determining the optimal pH for your specific bioconjugation reaction using 4-AP as a catalyst.
1. Reagent Preparation:
-
Buffer Solutions: Prepare a series of 0.1 M buffers with different pH values (e.g., Sodium Phosphate for pH 6.0, 6.5, 7.0, 7.5, and 8.0).[2] Verify the final pH of each buffer after preparation.
-
Biomolecule Stock: Prepare a concentrated stock solution of your carbonyl-containing biomolecule (e.g., protein, peptide) in a suitable, non-amine-containing buffer (like PBS or HEPES).
-
Conjugation Partner Stock: Prepare a concentrated stock solution of your aminooxy- or hydrazine-functionalized molecule in a compatible solvent (e.g., water, DMSO).
-
4-AP Catalyst Stock: Prepare a 100 mM stock solution of this compound in water. Gentle warming may be required to fully dissolve.
2. Reaction Setup:
-
For each pH to be tested, set up a reaction in a microcentrifuge tube.
-
Add the appropriate buffer.
-
Add the biomolecule stock to the desired final concentration (e.g., 1 mg/mL).
-
Add the 4-AP catalyst stock solution to a final concentration of 10 mM.[4]
-
Initiate the reaction by adding the stock solution of your conjugation partner to the desired final molar excess.
-
Vortex briefly to ensure thorough mixing.
-
Control: Set up a reaction at the optimal pH (e.g., 7.0) without the 4-AP catalyst to confirm its effect.
3. Incubation and Monitoring:
-
Incubate all reactions at a constant temperature. Based on literature, room temperature or 4°C may be more effective than 37°C.[4][7]
-
At various time points (e.g., 1, 2, 4, 8, and 24 hours), take an aliquot of each reaction mixture.[2]
-
Quench the reaction in the aliquot if necessary (e.g., by adding an excess of a quenching reagent like acetone (B3395972) or by immediate freezing).
-
Analyze the aliquots by a suitable method (e.g., SDS-PAGE, HPLC, mass spectrometry) to determine the extent of product formation.
4. Analysis:
-
Compare the product yield at each pH and time point to determine the optimal reaction conditions.
pH Optimization Workflow
Caption: Experimental workflow for pH optimization.
References
- 1. benchchem.com [benchchem.com]
- 2. benchchem.com [benchchem.com]
- 3. Oximes and Hydrazones in Bioconjugation: Mechanism and Catalysis - PMC [pmc.ncbi.nlm.nih.gov]
- 4. This compound as a Biocompatible Nucleophilic Catalyst for Hydrazone-Ligations at Low Temperature and Neutral pH - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. quora.com [quora.com]
- 7. pubs.acs.org [pubs.acs.org]
- 8. researchgate.net [researchgate.net]
- 9. This compound as a biocompatible nucleophilic catalyst for hydrazone ligations at low temperature and neutral pH - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. pubs.acs.org [pubs.acs.org]
Technical Support Center: 4-Aminophenylalanine in Cell Culture
This technical support center provides researchers, scientists, and drug development professionals with troubleshooting guides and frequently asked questions (FAQs) regarding the stability and use of 4-Aminophenylalanine (4-APF) in cell culture media.
FAQs and Troubleshooting Guide
This section addresses common issues and questions that may arise during the use of this compound in cell culture experiments.
Frequently Asked Questions (FAQs)
Q1: What is the recommended solvent and storage condition for a this compound stock solution?
A1: It is recommended to dissolve this compound (hydrochloride salt) in sterile water or a buffer such as PBS to prepare a stock solution.[1][2] For short-term use, the stock solution can be stored at 4°C. For long-term storage, it is advisable to aliquot the stock solution and store it at -20°C to minimize degradation from repeated freeze-thaw cycles.[1][2]
Q2: Is this compound stable in powder form?
A2: this compound as a dry powder is generally stable when stored correctly. However, it is a white solid that can darken upon exposure to air, suggesting potential oxidation.[3] Therefore, it is crucial to store it in a tightly sealed container in a cool, dark, and dry place.
Q3: Can I autoclave cell culture medium containing this compound?
A3: No, it is not recommended to autoclave cell culture medium after the addition of this compound. Like many amino acids, 4-APF can be sensitive to the high temperatures and pressures of autoclaving, which can lead to its degradation. It is best to sterile-filter the medium after adding 4-APF from a sterile stock solution.
Q4: What are the potential degradation products of this compound in cell culture media?
A4: While specific studies on 4-APF degradation in cell culture media are limited, its chemical structure, an aniline (B41778) derivative, suggests susceptibility to oxidation. Aromatic amines can oxidize to form colored compounds, and p-phenylenediamine, a related molecule, is known to oxidize into quinone-like structures.[4][5] Therefore, potential degradation products could include oxidized forms of 4-APF, which may have a brownish color.
Q5: How might the degradation of this compound affect my cell culture experiments?
A5: The degradation of 4-APF can have several adverse effects. Firstly, the actual concentration of 4-APF will decrease over time, potentially impacting experiments that rely on a specific concentration. Secondly, the degradation products themselves could be cytotoxic or have off-target effects on cellular processes, including signaling pathways.
Troubleshooting Guide
Problem 1: My cell culture medium containing 4-APF turns a brownish color after a short period.
-
Possible Cause: This is likely due to the oxidation of this compound. Aromatic amines are known to be susceptible to oxidation, which can result in the formation of colored compounds.[3][4] This process may be accelerated by exposure to light, oxygen, and certain components of the cell culture medium.
-
Solution:
-
Prepare fresh medium with 4-APF immediately before use.
-
Protect the medium from light by using amber bottles or wrapping the container in foil.
-
Minimize the exposure of the medium to air.
-
Consider using a cell culture medium with antioxidants if compatible with your experimental setup.
-
Problem 2: I am observing unexpected cytotoxicity or a decrease in cell viability after adding 4-APF.
-
Possible Cause 1: High Concentration of 4-APF. While some cell lines may tolerate certain concentrations, high levels of any non-canonical amino acid can be toxic.
-
Solution 1: Perform a dose-response experiment to determine the optimal, non-toxic concentration of 4-APF for your specific cell line.
-
Possible Cause 2: Cytotoxicity of Degradation Products. As 4-APF degrades, its byproducts could be more toxic to the cells than the parent compound.
-
Solution 2: Monitor the stability of 4-APF in your media over the course of your experiment. If significant degradation is observed, replenish the medium with fresh 4-APF at regular intervals.
-
Possible Cause 3: Contamination. As with any cell culture experiment, microbial contamination can lead to cell death.
-
Solution 3: Ensure aseptic techniques are strictly followed during the preparation and handling of the 4-APF stock solution and the cell culture medium.
Problem 3: Inconsistent experimental results when using 4-APF.
-
Possible Cause: Inconsistent concentration of 4-APF due to degradation. The rate of degradation can be influenced by factors such as the age of the stock solution and the time the prepared medium is stored before use.
-
Solution:
-
Use a freshly prepared 4-APF stock solution for each experiment.
-
Prepare the complete cell culture medium containing 4-APF on the day of the experiment.
-
Quantify the concentration of 4-APF in your medium at the start and end of your experiment to assess its stability under your specific conditions.
-
Data on this compound Stability
Table 1: Hypothetical Stability of this compound (1 mM) in Common Cell Culture Media at 37°C, 5% CO₂
| Time (hours) | DMEM (% Remaining) | RPMI-1640 (% Remaining) |
| 0 | 100 | 100 |
| 24 | 92 | 88 |
| 48 | 83 | 75 |
| 72 | 74 | 62 |
Table 2: Factors Influencing the Stability of this compound in Solution
| Factor | Effect on Stability | Recommendation |
| Temperature | Higher temperatures accelerate degradation. | Store stock solutions at 4°C for short-term and -20°C for long-term use.[1] |
| pH | Deviations from neutral pH may affect stability. Phenylalanine is generally stable between pH 5.0 and 11.0.[6] | Maintain the pH of the cell culture medium within the optimal range for your cells. |
| Light Exposure | Can promote photo-oxidation. | Protect solutions from light by using opaque containers. |
| Oxygen | The presence of oxygen can lead to oxidation. | Minimize headspace in storage containers and avoid vigorous shaking. |
Experimental Protocols
Protocol 1: Preparation of this compound Stock Solution
-
Weigh out the desired amount of this compound hydrochloride powder in a sterile environment.
-
Dissolve the powder in sterile, high-purity water or PBS to a final concentration of 100 mM.
-
Ensure complete dissolution, gentle warming or vortexing may be applied.
-
Sterile-filter the stock solution through a 0.22 µm filter into a sterile, light-protected container.
-
Aliquot the stock solution into smaller, single-use volumes to avoid repeated freeze-thaw cycles.
-
Store the aliquots at -20°C for long-term storage.
Protocol 2: Quantification of this compound in Cell Culture Media using HPLC-UV
This protocol provides a general guideline for the analysis of 4-APF. Method optimization and validation are essential for accurate quantification.
-
Sample Preparation:
-
Collect a sample of the cell culture medium at specified time points.
-
Centrifuge the sample at 10,000 x g for 10 minutes to remove cells and debris.
-
Collect the supernatant. For protein-containing media, a protein precipitation step (e.g., with acetonitrile (B52724) or methanol) may be necessary.
-
Filter the supernatant through a 0.22 µm syringe filter before injection.[4]
-
-
HPLC Conditions (Example):
-
Column: C18 reversed-phase column (e.g., 4.6 mm x 150 mm, 5 µm).[4]
-
Mobile Phase: A gradient of an aqueous buffer (e.g., 20 mM ammonium (B1175870) formate, pH 3) and an organic solvent (e.g., acetonitrile).[7]
-
Flow Rate: 1.0 mL/min.[4]
-
Column Temperature: 25°C.[4]
-
Detection: UV detector at 254 nm or 280 nm.[4]
-
Injection Volume: 10 µL.[4]
-
-
Quantification:
-
Prepare a standard curve of 4-APF in the same type of cell culture medium used in the experiment.
-
Analyze the standards and samples using the established HPLC method.
-
Determine the concentration of 4-APF in the samples by comparing their peak areas to the standard curve.
-
Visualizations
Caption: Experimental workflow for monitoring 4-APF stability.
Caption: Logic diagram for troubleshooting common 4-APF issues.
Caption: Potential effects of 4-APF on the mTOR signaling pathway.
References
effect of release factor 1 (RF1) on 4-Aminophenylalanine amber suppression efficiency
This technical support center provides researchers, scientists, and drug development professionals with comprehensive troubleshooting guides and frequently asked questions (FAQs) regarding the effect of release factor 1 (RF1) on 4-Aminophenylalanine (pAF) amber suppression efficiency.
Frequently Asked Questions (FAQs)
Q1: What is the role of Release Factor 1 (RF1) in protein translation?
A1: Release Factor 1 (RF1) is a protein in prokaryotes, such as E. coli, that recognizes the UAG (amber) and UAA stop codons in the mRNA sequence during protein synthesis. When a ribosome encounters one of these stop codons, RF1 binds to the ribosome and facilitates the termination of translation, leading to the release of the newly synthesized polypeptide chain.
Q2: How does RF1 affect the efficiency of this compound (pAF) incorporation at an amber (UAG) codon?
A2: RF1 acts as a direct competitor to the pAF-loaded suppressor tRNA (tRNA CUA) at the amber codon. The amber suppression system relies on the suppressor tRNA outcompeting RF1 for binding to the ribosome when a UAG codon is present. The inherent competition from RF1 leads to premature termination of translation, resulting in a truncated protein product and thereby reducing the overall yield of the full-length protein containing pAF. This competition is a major limiting factor for the efficiency of unnatural amino acid incorporation.[1]
Q3: What is the primary strategy to improve pAF incorporation efficiency in the context of RF1?
A3: The most effective strategy is to eliminate the competition from RF1. This is typically achieved by knocking out or knocking down the prfA gene, which encodes RF1, in the E. coli expression host.[1][2][3] By removing RF1, the UAG codon is no longer efficiently recognized as a stop signal, allowing the suppressor tRNA to incorporate pAF with significantly higher efficiency.[1]
Q4: Are there any commercially available E. coli strains that lack RF1?
A4: Yes, several research groups have developed and reported on RF1-deficient E. coli strains. A notable example is the JX33 strain, which is an RF1 knockout strain that has been shown to be stable and highly efficient for unnatural amino acid incorporation at multiple UAG sites.[1] Researchers can inquire about the availability of such strains from the respective research labs or commercial vendors specializing in synthetic biology tools.
Q5: Besides RF1, what other factors can influence pAF amber suppression efficiency?
A5: Several other factors can impact the efficiency of pAF incorporation:
-
mRNA Sequence Context: The nucleotides immediately surrounding the UAG codon can significantly influence suppression efficiency.[4][5][6]
-
Expression Levels of the Orthogonal Pair: The intracellular concentrations of the engineered aminoacyl-tRNA synthetase for pAF (pAF-RS) and the suppressor tRNA are crucial. Optimal expression levels are necessary to ensure a sufficient supply of pAF-charged tRNA.[7][8]
-
pAF Concentration: The concentration of pAF in the growth medium must be optimized to ensure it is readily available for charging the suppressor tRNA.
-
Promoter Strength and Plasmid Copy Number: The choice of promoters and plasmid copy numbers for expressing the target protein and the orthogonal components can affect the overall protein yield.
Troubleshooting Guide
| Problem | Possible Cause(s) | Recommended Solution(s) |
| Low yield of full-length protein containing pAF | Competition from RF1: The host strain expresses RF1, leading to premature translation termination at the UAG codon. | Use an E. coli strain with a knockout or knockdown of the prfA gene (encoding RF1).[1][9] |
| Suboptimal mRNA context: The nucleotides flanking the UAG codon are unfavorable for suppressor tRNA binding. | If possible, modify the codons upstream and downstream of the UAG site through silent mutations to create a more favorable context. Purine-rich sequences downstream of the UAG have been reported to enhance suppression.[6] | |
| Insufficient expression of the pAF-RS/tRNA pair: Low levels of the synthetase or suppressor tRNA can limit the amount of charged tRNA available for incorporation. | Optimize the expression of the pAF-RS and suppressor tRNA by using stronger promoters or higher copy number plasmids. Ensure that the expression of these components is well-balanced.[7] | |
| Low intracellular concentration of pAF: Inadequate uptake or availability of pAF in the cell. | Increase the concentration of pAF in the growth medium. Ensure the pAF is of high purity. | |
| High levels of truncated protein | Dominant RF1 activity: RF1 is outcompeting the suppressor tRNA at the UAG codon. | This strongly indicates the need to use an RF1-deficient expression host. |
| Low efficiency of the orthogonal pair: The pAF-RS may not be efficiently charging the suppressor tRNA, or the suppressor tRNA may have poor activity. | Sequence verify your pAF-RS and suppressor tRNA genes. Consider using a previously validated and optimized orthogonal pair. | |
| No incorporation of pAF observed | Lethal effect of RF1 knockout: In some genetic backgrounds, the deletion of RF1 can be detrimental to cell growth if not properly compensated. | Ensure the RF1 knockout strain used has compensatory mutations or modifications, such as in RF2, to maintain viability.[1] |
| Inactive pAF-RS or suppressor tRNA: Mutations in the synthetase or tRNA genes can render them non-functional. | Sequence verify the plasmids encoding the pAF-RS and suppressor tRNA. Test the activity of the orthogonal pair using a reporter protein like GFP with an amber codon. | |
| Degradation of pAF: pAF may be unstable under the experimental conditions. | Ensure proper storage and handling of the pAF stock solution. |
Data Presentation
Table 1: Effect of RF1 on Amber Suppression Efficiency
This table summarizes the quantitative impact of RF1 on the efficiency of unnatural amino acid (Uaa) incorporation at a single UAG codon. The data is based on studies using reporter proteins in E. coli.
| Strain | RF1 Status | Reporter Protein | Uaa Incorporation Efficiency (%) | Fold Increase in Efficiency | Reference |
| Parental Strain | Present | GFP | ~30% (Estimated) | - | [1] |
| JX33 | Knockout | GFP | >60% (Estimated) | >2-fold | [1] |
| DH10B | Present | GFP (Position Y39) | 51.2 ± 1.9 | - | [5] |
| C321.ΔA.exp | Knockout | GFP (Position Y39) | 75.5 ± 4.9 | 1.47-fold | [5] |
Note: The efficiencies are relative to the expression of the wild-type protein without a stop codon and can vary depending on the specific unnatural amino acid, the position of the UAG codon, and the quantification method.
Experimental Protocols
Protocol 1: RF1 Knockout in E. coli using Lambda Red Recombinase
This protocol provides a general workflow for deleting the prfA gene (encoding RF1) from the E. coli chromosome.
-
Preparation of the Antibiotic Resistance Cassette:
-
Design PCR primers to amplify an antibiotic resistance cassette (e.g., chloramphenicol (B1208) or kanamycin (B1662678) resistance).
-
The primers should have 40-50 base pair overhangs that are homologous to the regions immediately upstream and downstream of the prfA gene in the E. coli genome.
-
Perform PCR to amplify the resistance cassette with the homology arms. Gel purify the PCR product.
-
-
Preparation of Electrocompetent Cells:
-
Grow the target E. coli strain (e.g., a strain carrying the lambda Red recombinase system on a temperature-sensitive plasmid) at 30°C to an OD600 of 0.4-0.6.
-
Induce the expression of the lambda Red genes by shifting the temperature to 42°C for 15 minutes.
-
Immediately chill the cells on ice and make them electrocompetent by washing them multiple times with ice-cold sterile water or 10% glycerol.
-
-
Electroporation and Recombination:
-
Electroporate the purified PCR product (the resistance cassette with homology arms) into the electrocompetent cells.
-
Recover the cells in SOC medium at 37°C for 1-2 hours.
-
-
Selection and Verification:
-
Plate the transformed cells on agar (B569324) plates containing the appropriate antibiotic to select for colonies where the resistance cassette has integrated into the genome.
-
Verify the correct integration and deletion of the prfA gene by colony PCR using primers that flank the prfA locus. A successful knockout will result in a PCR product of a different size than the wild-type locus.
-
Further verify the knockout by sequencing the PCR product and by Western blot analysis to confirm the absence of the RF1 protein.
-
Protocol 2: Quantification of pAF Incorporation by Western Blot
This method provides a semi-quantitative estimation of pAF incorporation efficiency by comparing the amount of full-length protein to the truncated product.
-
Protein Expression and Sample Preparation:
-
Grow the E. coli expression host carrying the plasmid for the target protein with a UAG codon, the pAF-RS, and the suppressor tRNA in the presence of pAF.
-
As a control, grow the same strain without pAF.
-
Harvest the cells and prepare total cell lysates.
-
Determine the total protein concentration of each lysate using a BCA or Bradford assay.
-
-
SDS-PAGE and Western Blotting:
-
Load equal amounts of total protein from each sample onto an SDS-PAGE gel. Include a lane with a purified standard of the full-length protein if available.
-
Separate the proteins by electrophoresis.
-
Transfer the separated proteins to a nitrocellulose or PVDF membrane.
-
-
Immunodetection:
-
Block the membrane to prevent non-specific antibody binding.
-
Incubate the membrane with a primary antibody that specifically recognizes the target protein (e.g., an anti-His-tag antibody if the protein is His-tagged).
-
Wash the membrane and incubate with a horseradish peroxidase (HRP)-conjugated secondary antibody.
-
Wash the membrane again to remove unbound secondary antibody.
-
-
Signal Detection and Quantification:
-
Add an enhanced chemiluminescence (ECL) substrate to the membrane.
-
Capture the chemiluminescent signal using a CCD camera-based imager.
-
Using image analysis software, quantify the band intensities for the full-length protein and the truncated product (if visible).
-
The incorporation efficiency can be estimated as: (Intensity of full-length protein) / (Intensity of full-length protein + Intensity of truncated protein) * 100%.
-
Protocol 3: Quantification of pAF Incorporation by Mass Spectrometry
This is the most accurate method for confirming and quantifying pAF incorporation.
-
Protein Expression and Purification:
-
Express the target protein containing pAF as described above.
-
Purify the full-length protein using an appropriate chromatography method (e.g., Ni-NTA affinity chromatography for His-tagged proteins).
-
-
In-gel or In-solution Digestion:
-
Run the purified protein on an SDS-PAGE gel and excise the band corresponding to the full-length protein. Perform in-gel digestion with a protease like trypsin.
-
Alternatively, perform in-solution digestion of the purified protein.
-
-
LC-MS/MS Analysis:
-
Analyze the resulting peptide mixture by liquid chromatography-tandem mass spectrometry (LC-MS/MS).
-
The mass spectrometer will measure the mass-to-charge ratio of the peptides. The peptide containing pAF will have a specific mass shift compared to the corresponding peptide with the canonical amino acid.
-
The MS/MS fragmentation pattern will confirm the amino acid sequence of the peptide and the precise location of pAF.
-
-
Data Analysis and Quantification:
-
Use specialized software to analyze the mass spectrometry data.
-
For quantitative analysis, compare the peak areas or spectral counts of the pAF-containing peptide to a corresponding internal standard peptide or to the same peptide from a wild-type protein control. This allows for a precise determination of the incorporation efficiency.[10][11][12]
-
Visualizations
Caption: Mechanism of translation termination at a UAG codon in the presence of RF1.
References
- 1. RF1 Knockout Allows Ribosomal Incorporation of Unnatural Amino Acids at Multiple Sites - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Release Factor One Is Nonessential in Escherichia coli - PMC [pmc.ncbi.nlm.nih.gov]
- 3. academic.oup.com [academic.oup.com]
- 4. Identification of permissive amber suppression sites for efficient non-canonical amino acid incorporation in mammalian cells - PMC [pmc.ncbi.nlm.nih.gov]
- 5. mdpi.com [mdpi.com]
- 6. Large-scale analysis of mRNA sequences localized near the start and amber codons and their impact on the diversity of mRNA display libraries - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Therapeutic promise of engineered nonsense suppressor tRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Frontiers | Suppressor tRNAs at the interface of genetic code expansion and medicine [frontiersin.org]
- 9. RF1 attenuation enables efficient non-natural amino acid incorporation for production of homogeneous antibody drug conjugates - PMC [pmc.ncbi.nlm.nih.gov]
- 10. benchchem.com [benchchem.com]
- 11. Genetic Incorporation of Unnatural Amino Acids into Proteins in Yeast - PMC [pmc.ncbi.nlm.nih.gov]
- 12. MS-READ: Quantitative Measurement of Amino Acid Incorporation - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: N-Terminal 4-Aminophenylalanine (pAF) Tagging via Ribosomal Skipping
This technical support center provides researchers, scientists, and drug development professionals with a comprehensive guide to the challenges and troubleshooting strategies associated with N-terminal 4-Aminophenylalanine (pAF) tagging using ribosomal skipping technology.
Troubleshooting Guides
This section addresses specific issues that may arise during your experiments, offering potential causes and solutions in a question-and-answer format.
Issue 1: Low or no expression of the pAF-tagged protein of interest (POI).
-
Question: I am not observing any or very low levels of my pAF-tagged protein after inducing expression. What could be the problem?
-
Answer: Low or absent expression of the downstream protein of interest (POI) is a common challenge. Several factors could be contributing to this issue:
-
Ribosome Drop-off: The 2A peptide sequence can cause the ribosome to terminate translation after the synthesis of the upstream protein, a phenomenon known as "ribosome drop-off."[1] This leads to a molar excess of the upstream product and significantly less of the downstream POI.[2]
-
Inefficient Ribosomal Skipping: The efficiency of the ribosomal skipping event itself can be low, resulting in a majority of the translated product being a fusion protein of the upstream protein and your POI.
-
Protein Instability: The N-terminus of the downstream protein will have a proline residue added after the pAF, a remnant of the 2A peptide sequence.[1] This N-terminal proline, especially in combination with other adjacent amino acids introduced during cloning, can act as a degradation signal, leading to rapid proteasomal degradation of your pAF-tagged protein.[2][3]
-
Codon Usage for pAF: The codon used to incorporate pAF (typically an amber stop codon, TAG) may be inefficiently suppressed by the orthogonal tRNA/aminoacyl-tRNA synthetase system, leading to premature termination.
-
-
Troubleshooting Steps:
-
Optimize the 2A Peptide: Different 2A peptides have varying skipping efficiencies. P2A and T2A are generally the most efficient, while F2A is the least.[1] Consider switching to a more efficient 2A peptide.
-
Incorporate a Linker: Adding a flexible linker, such as Gly-Ser-Gly (GSG), immediately upstream of the 2A peptide sequence can improve skipping efficiency.[1]
-
Analyze Gene Order: The order of the genes in your polycistronic construct can influence expression levels. Consider placing your pAF-tagged POI as the upstream element, although this will result in a C-terminal 2A tag on your POI.
-
Stabilize the N-terminus: To counteract the destabilizing effect of the N-terminal proline, consider adding charged or hydrophilic amino acids (like glutamate (B1630785) or lysine) immediately after the pAF and proline.[2][3] This can be achieved through site-directed mutagenesis of your construct.
-
Codon Optimization: Ensure that the codon usage of your entire construct, particularly for the upstream protein and the 2A peptide, is optimized for your expression system.
-
Issue 2: A significant amount of uncleaved fusion protein is observed.
-
Question: My Western blot shows a prominent band at the expected size of the fusion protein (upstream protein + 2A + pAF-POI). How can I improve the skipping efficiency?
-
Answer: The presence of a significant amount of uncleaved fusion protein indicates inefficient ribosomal skipping. This can be influenced by the choice of 2A peptide and the surrounding amino acid context.
-
Troubleshooting Steps:
-
Switch to a More Efficient 2A Peptide: As mentioned previously, P2A and T2A peptides generally exhibit higher skipping efficiencies than E2A and F2A.[1][4]
-
Add a GSG Linker: The addition of a GSG linker at the N-terminus of the 2A peptide is a well-established method to enhance skipping efficiency.[4]
-
Consider the Upstream Protein's C-terminus: The nature of the amino acids immediately preceding the 2A peptide can impact its function. If the C-terminus of your upstream protein is structured or bulky, it may interfere with the proper functioning of the 2A peptide within the ribosome exit tunnel.[5] Introducing a flexible linker can help insulate the 2A peptide.
-
Verify Construct Sequence: Ensure there are no mutations in the 2A peptide sequence, as even single amino acid changes can abolish its activity.[6]
-
Issue 3: My purified pAF-tagged protein is unstable and degrades quickly.
-
Question: I can express and purify my pAF-tagged protein, but it is not stable. What can I do?
-
Answer: Instability of the purified protein is likely due to the N-terminal proline remnant, which can make the protein susceptible to degradation.
-
Troubleshooting Steps:
-
N-terminal Amino Acid Modification: As a primary strategy, introduce stabilizing amino acids (e.g., glutamate, lysine) immediately following the pAF-Proline sequence at the N-terminus of your protein of interest.[2][3]
-
Purification with Protease Inhibitors: During purification, always include a cocktail of protease inhibitors to minimize degradation by co-purifying proteases.
-
Optimize Buffer Conditions: Experiment with different buffer pH and salt concentrations to find conditions that enhance the stability of your specific protein.
-
Rapid Purification and Storage: Minimize the time the protein spends in cell lysate and during purification steps. Store the purified protein at -80°C in a suitable cryoprotectant (e.g., glycerol).
-
Frequently Asked Questions (FAQs)
Q1: What is ribosomal skipping and how do 2A peptides work?
A1: Ribosomal skipping is a translational effect mediated by short (18-22 amino acids) 2A peptide sequences derived from viruses.[1] When a ribosome translating an mRNA encounters a 2A sequence, it "skips" the formation of a peptide bond between the C-terminal glycine (B1666218) of the 2A peptide and the following proline.[1] This results in the release of the upstream polypeptide and the continuation of translation from the proline, yielding two separate proteins from a single mRNA transcript.[7]
Q2: Which 2A peptide is the best to use?
A2: The efficiency of ribosomal skipping varies among different 2A peptides. Porcine teschovirus-1 2A (P2A) and Thosea asigna virus 2A (T2A) are generally considered the most efficient, with skipping efficiencies often reported to be high in many contexts.[1] Foot-and-mouth disease virus 2A (F2A) is typically the least efficient.[1] The optimal choice can be system-dependent, and it is advisable to test different 2A peptides if high skipping efficiency is critical.
Q3: Will the pAF at the N-terminus interfere with ribosomal skipping?
A3: While direct studies on the effect of N-terminal pAF on 2A peptide efficiency are limited, the general mechanism of ribosomal skipping is primarily influenced by the 2A peptide sequence itself and the immediate upstream amino acids. The incorporation of an unnatural amino acid at the N-terminus of the downstream protein should not directly inhibit the skipping event. However, the efficiency of pAF incorporation via amber suppression can be a limiting factor for the overall yield of the tagged protein.
Q4: What are the remnants left on the proteins after ribosomal skipping?
A4: The upstream protein will have the 2A peptide sequence (minus the C-terminal proline) attached to its C-terminus. The downstream protein of interest will have an additional proline residue at its N-terminus, immediately following the incorporated pAF.[1]
Q5: How can I confirm successful N-terminal pAF tagging and ribosomal skipping?
A5: A combination of techniques is recommended:
-
Western Blotting: Use an antibody against your protein of interest to detect both the cleaved pAF-tagged protein and any uncleaved fusion protein. You can also use an antibody against the upstream protein to verify its expression.
-
Mass Spectrometry: This is the most definitive method. Analysis of the purified protein can confirm the presence of pAF at the N-terminus and determine the exact N-terminal sequence, including the additional proline.
Quantitative Data
The efficiency of ribosomal skipping is highly dependent on the specific 2A peptide, the genetic construct, and the expression system used. The following table summarizes the generally reported relative efficiencies of commonly used 2A peptides.
| 2A Peptide | Originating Virus | Relative Skipping Efficiency |
| P2A | Porcine teschovirus-1 | Very High |
| T2A | Thosea asigna virus | High |
| E2A | Equine rhinitis A virus | Medium |
| F2A | Foot-and-mouth disease virus | Low to Medium |
Note: These are general trends, and the actual efficiency can vary. The presence of an N-terminal unnatural amino acid on the downstream protein may influence the overall yield but is not expected to directly alter the intrinsic skipping efficiency of the 2A peptide.
Experimental Protocols
Protocol: Expression and Analysis of N-terminal pAF-tagged Protein using a P2A-based Bicistronic Vector
This protocol provides a general framework. Optimization of specific steps for your protein of interest and expression system is recommended.
1. Vector Construction:
-
Design a bicistronic expression vector with the following arrangement: [Promoter] - [Upstream Gene] - [GSG linker] - [P2A sequence] - [Amber Codon (TAG)] - [Gene of Interest] - [Terminator].
-
The upstream gene can be a fluorescent reporter (e.g., mCherry) to visually monitor expression and estimate skipping efficiency.
-
Ensure the amber codon (TAG) is in-frame with your gene of interest.
-
Codon-optimize the entire open reading frame for your chosen expression system (e.g., E. coli, mammalian cells).
2. Expression:
-
Co-transform your expression host with the bicistronic vector and a plasmid encoding the orthogonal aminoacyl-tRNA synthetase/tRNA pair for pAF incorporation.
-
Grow the cells in a suitable medium to the desired density.
-
Induce protein expression and supplement the medium with this compound. Optimal pAF concentration should be determined empirically (typically in the range of 1-5 mM).
-
Incubate for the appropriate time and temperature to allow for protein expression.
3. Cell Lysis and Protein Extraction:
-
Harvest the cells by centrifugation.
-
Resuspend the cell pellet in a lysis buffer containing a complete protease inhibitor cocktail.
-
Lyse the cells using an appropriate method (e.g., sonication, French press).
-
Clarify the lysate by centrifugation to remove cell debris.
4. Western Blot Analysis:
-
Separate the protein lysate by SDS-PAGE.
-
Transfer the proteins to a PVDF or nitrocellulose membrane.
-
Probe the membrane with a primary antibody specific to your protein of interest.
-
Use a secondary antibody conjugated to an appropriate enzyme (e.g., HRP) for detection.
-
Develop the blot to visualize the bands corresponding to the pAF-tagged protein and any uncleaved fusion protein.
5. Protein Purification (if required):
-
If your protein of interest has a purification tag (e.g., His-tag), use the appropriate affinity chromatography to purify it from the cell lysate.
-
Elute the purified protein and analyze it by SDS-PAGE and Coomassie staining to assess purity.
6. Mass Spectrometry Analysis:
-
Submit the purified protein for mass spectrometry analysis to confirm the identity and the presence of the N-terminal pAF tag.
Visualizations
Caption: Experimental workflow for N-terminal pAF tagging via ribosomal skipping.
Caption: Mechanism of 2A peptide-mediated ribosomal skipping.
References
- 1. 2A peptides - Wikipedia [en.wikipedia.org]
- 2. N-Terminal Amino Acids Determine KLF4 Protein Stability in 2A Peptide-Linked Polycistronic Reprogramming Constructs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. N-Terminal Amino Acids Determine KLF4 Protein Stability in 2A Peptide-Linked Polycistronic Reprogramming Constructs - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Cleavage efficient 2A peptides for high level monoclonal antibody expression in CHO cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Inhibition of 2A-mediated ‘cleavage’ of certain artificial polyproteins bearing N-terminal signal sequences - PMC [pmc.ncbi.nlm.nih.gov]
- 6. 2A peptides provide distinct solutions to driving stop-carry on translational recoding - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Highly efficient genome editing via 2A-coupled co-expression of two TALEN monomers - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Overcoming Aggregation of Peptides Containing 4-Aminophenylalanine
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in overcoming challenges associated with the aggregation of peptides containing the non-canonical amino acid 4-Aminophenylalanine (4-Aph).
Frequently Asked Questions (FAQs)
Q1: What is peptide aggregation and why is it a problem for peptides containing this compound?
A1: Peptide aggregation is a process where individual peptide molecules self-associate to form larger, often insoluble, structures. This can be a significant issue for peptides containing this compound (4-Aph) due to the aromatic and hydrophobic nature of this amino acid. The phenyl ring in 4-Aph can participate in π-π stacking interactions, which, along with hydrophobic interactions, can promote the formation of ordered structures like β-sheets, leading to aggregation.[1] Aggregation can result in poor peptide solubility, loss of biological activity, and difficulties during synthesis and purification.
Q2: How does the position of this compound in the peptide sequence affect aggregation?
A2: The position of 4-Aph can significantly influence a peptide's tendency to aggregate. Aromatic amino acids, like 4-Aph, have a greater impact on aggregation when located towards the C-terminus of the peptide chain.[1] This is thought to be due to the increased flexibility of the C-terminus, which may facilitate the necessary conformational changes for aggregation to occur.
Q3: Can the charge of my 4-Aph-containing peptide influence its aggregation?
A3: Yes, the overall net charge of your peptide plays a crucial role in its solubility and aggregation. Peptides are generally least soluble and most prone to aggregation at their isoelectric point (pI), where the net charge is zero.[2] By adjusting the pH of the solution to be at least one unit away from the pI, you can increase the net charge of the peptide, leading to greater electrostatic repulsion between molecules and reduced aggregation.
Q4: Are there any computational tools that can predict the aggregation propensity of my 4-Aph-containing peptide?
A4: Yes, there are computational methods available that can predict the solubility and aggregation potential of peptides containing non-canonical amino acids like 4-Aph.[3] These tools analyze the physicochemical properties of the amino acids in your sequence to provide a solubility score.[3] Using such tools during the design phase can help in identifying potentially problematic sequences and exploring modifications to improve solubility.
Troubleshooting Guides
Problem: My lyophilized peptide containing 4-Aph will not dissolve.
Possible Cause: The peptide has formed stable aggregates.
Solutions:
-
Initial Solvent Selection:
-
Start with a small amount of sterile, distilled water.[4]
-
If the peptide is basic (net positive charge), try dissolving it in a small amount of 0.1M acetic acid.
-
If the peptide is acidic (net negative charge), try a small amount of 0.1M ammonium (B1175870) bicarbonate.
-
-
Use of Organic Solvents:
-
For highly hydrophobic peptides, dissolve the peptide in a minimal amount of an organic solvent such as dimethyl sulfoxide (B87167) (DMSO), dimethylformamide (DMF), or acetonitrile (B52724) (ACN).[5]
-
Slowly add this solution dropwise into your aqueous buffer with constant stirring to prevent precipitation.[5]
-
-
Sonication:
-
Briefly sonicate the sample in a water bath to help break up small aggregates and facilitate dissolution.[6] Avoid excessive heating.
-
Problem: My 4-Aph-containing peptide precipitates out of solution during an experiment.
Possible Cause: A change in experimental conditions (e.g., pH, temperature, salt concentration) is inducing aggregation.
Solutions:
-
pH Adjustment:
-
Ensure the pH of your buffer is at least one unit away from the peptide's calculated isoelectric point (pI).
-
-
Inclusion of Additives:
-
Chaotropic Agents: Add agents like guanidine (B92328) hydrochloride (Gdn-HCl) or urea (B33335) to the buffer to disrupt hydrogen bonding and hydrophobic interactions. Start with a low concentration and optimize as needed.
-
Amino Acids: Incorporating certain amino acids like arginine and glutamic acid into the buffer can sometimes improve solubility.[7]
-
Surfactants: Low concentrations of non-ionic surfactants, such as Tween 20 or Triton X-100, can help to solubilize hydrophobic peptides.[7]
-
Quantitative Data on Factors Affecting Aggregation
The following table summarizes the effect of pH on the secondary structure of a homopolymer of 4-amino-L-phenylalanine (P4APhe), which provides insight into how environmental pH can influence the aggregation-prone conformations of peptides containing this amino acid. A decrease in molar ellipticity at 220 nm is indicative of a change in chain conformation, potentially leading to structures that are more prone to aggregation.
| pH | Molar Ellipticity [θ] at 220 nm (deg cm²/dmol) | Interpretation |
| < 3.5 | Higher values | Suggests a certain chain conformation. |
| > 3.5 | Lower, plateaued values | Indicates a change in chain conformation, which may be associated with the formation of β-sheet structures that can lead to aggregation.[8] |
Key Experimental Protocols
Protocol 1: Solubilization of a Hydrophobic 4-Aph-Containing Peptide
This protocol outlines a general procedure for dissolving a hydrophobic peptide containing 4-Aph.
Materials:
-
Lyophilized peptide
-
Dimethyl sulfoxide (DMSO)
-
Sterile, distilled water or desired aqueous buffer
-
Vortex mixer
-
Sonicator bath
Procedure:
-
Allow the lyophilized peptide to warm to room temperature before opening the vial.
-
Add a minimal volume of DMSO to the peptide to create a concentrated stock solution. Vortex briefly.
-
If the peptide is not fully dissolved, sonicate the vial in a water bath for 5-10 minutes.
-
Once the peptide is completely dissolved in DMSO, slowly add the concentrated peptide solution dropwise to your chilled aqueous buffer while gently vortexing.
-
Visually inspect the solution for any signs of precipitation. If the solution remains clear, it is ready for use.
-
If precipitation occurs, you may need to try a different co-solvent or add a solubilizing agent to your buffer (see Troubleshooting Guides).
Protocol 2: On-Resin Disruption of Aggregation during Solid-Phase Peptide Synthesis (SPPS)
This protocol can be used during SPPS if you observe signs of peptide aggregation on the resin (e.g., poor swelling, slow reaction kinetics).
Materials:
-
Peptide-resin
-
Dimethylformamide (DMF)
-
Chaotropic salt solution (e.g., 0.8 M LiCl in DMF)
Procedure:
-
After the deprotection step, wash the peptide-resin thoroughly with DMF.
-
Add the chaotropic salt solution to the resin and agitate for 15-30 minutes.
-
Drain the chaotropic salt solution.
-
Wash the resin extensively with DMF (at least 5-7 times) to completely remove the chaotropic salt.
-
Proceed with the next coupling step.
Visualizing Experimental Workflows and Logical Relationships
Caption: A flowchart outlining the systematic approach to solubilizing a peptide containing this compound.
Caption: A diagram illustrating the intrinsic and extrinsic factors that contribute to the aggregation of peptides containing this compound.
References
- 1. drugtargetreview.com [drugtargetreview.com]
- 2. wolfson.huji.ac.il [wolfson.huji.ac.il]
- 3. biorxiv.org [biorxiv.org]
- 4. A Robust and Efficient Production and Purification Procedure of Recombinant Alzheimers Disease Methionine-Modified Amyloid-β Peptides - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Solubility Guidelines for Peptides [sigmaaldrich.com]
- 6. A Screening Methodology for Purifying Proteins with Aggregation Problems | Springer Nature Experiments [experiments.springernature.com]
- 7. biozentrum.unibas.ch [biozentrum.unibas.ch]
- 8. researchgate.net [researchgate.net]
selecting scavengers to prevent side reactions during peptide cleavage
This technical support center provides guidance for researchers, scientists, and drug development professionals on selecting the appropriate scavengers to prevent common side reactions during the trifluoroacetic acid (TFA)-mediated cleavage of peptides from solid-phase resins.
Frequently Asked Questions (FAQs)
Q1: What is the primary role of a cleavage cocktail in solid-phase peptide synthesis (SPPS)?
A1: In SPPS, the cleavage cocktail has two main functions.[1] First, it cleaves the synthesized peptide from the solid support resin.[1] Second, it removes the side-chain protecting groups from the amino acid residues in a process known as global deprotection.[1] The most common method for this is using a strong acid, typically trifluoroacetic acid (TFA).[1]
Q2: Why are scavengers essential during peptide cleavage?
A2: During the cleavage and deprotection process, reactive carbocations are generated from the acid-labile protecting groups (e.g., tert-butyl cations from Boc or tBu groups) and the resin linker.[1][2][3][4][5] These electrophilic species can react with nucleophilic side chains of certain amino acids, leading to undesirable modifications and the formation of impurities.[1][6] Scavengers are nucleophilic reagents added to the cleavage cocktail to "trap" or quench these reactive cations, thereby preventing these side reactions and protecting the integrity of the synthesized peptide.[1][2][7]
Q3: Which amino acid residues are most susceptible to side reactions during TFA cleavage?
A3: Amino acid residues with nucleophilic side chains are the most vulnerable to modification by carbocations generated during TFA deprotection.[4] These include:
-
Tryptophan (Trp): The indole (B1671886) ring is highly nucleophilic and prone to alkylation (e.g., tert-butylation).[1][4][8]
-
Methionine (Met): The thioether side chain can be alkylated to form a sulfonium (B1226848) salt and is also susceptible to oxidation to methionine sulfoxide (B87167).[4][8][9]
-
Cysteine (Cys): The thiol group is highly nucleophilic and can be readily alkylated.[10] It is also prone to oxidation, which can lead to the formation of undesired disulfide bonds.[10][11]
-
Tyrosine (Tyr): The electron-rich phenol (B47542) side chain is susceptible to alkylation by carbocations.[6]
-
Asparagine (Asn) and Glutamine (Gln): These residues can undergo dehydration of the side-chain amide to form nitriles under strong acidic conditions.[4][7]
Q4: How do I select the right scavenger or cleavage cocktail for my peptide?
A4: The choice of cleavage cocktail is critical and depends on the amino acid composition of your peptide.[5][7][12] For peptides without sensitive residues, a simple mixture of TFA, triisopropylsilane (B1312306) (TIS), and water is often sufficient.[3][7][13] However, for peptides containing sensitive residues like Cysteine, Methionine, or Tryptophan, a more complex cocktail with additional scavengers is necessary.[7] The following decision-making workflow can help guide your selection.
Troubleshooting Guide
Problem 1: My peptide has an unexpected +16 Da mass shift, and it contains Methionine.
-
Possible Cause: This mass shift is characteristic of the oxidation of a methionine residue to methionine sulfoxide (Met(O)).[9] The thioether side chain of methionine is susceptible to oxidation during the final acidic cleavage step.[9]
-
Solution: Incorporate antioxidants or reducing agents into your cleavage cocktail.[9]
-
Reagent H is specifically designed to prevent methionine oxidation.[9][14]
-
The addition of Ammonium Iodide (NH₄I) and Dimethylsulfide (DMS) to the cleavage cocktail can significantly reduce or eliminate the formation of methionine sulfoxide.[9]
-
If the peptide is already synthesized, methionine sulfoxide can often be reduced back to methionine post-cleavage.[9]
-
Problem 2: My peptide contains Tryptophan and shows a +56 Da or +72 Da mass shift.
-
Possible Cause: The highly nucleophilic indole ring of Tryptophan is prone to alkylation by carbocations generated during cleavage, most commonly tert-butylation (+56 Da).[1][4]
-
Solution: Use a scavenger cocktail effective at trapping these carbocations.
-
Triisopropylsilane (TIS) is a general and effective scavenger for trityl and tert-butyl cations.[1][15]
-
1,2-Ethanedithiol (EDT) is also effective at scavenging trityl groups and preventing oxidation.[1][8]
-
Using Fmoc-Trp(Boc)-OH during synthesis can help suppress alkylation and reattachment of C-terminal Trp residues to the resin.[8]
-
Problem 3: My peptide contains Cysteine and I'm observing dimerization or a +56 Da adduct.
-
Possible Cause: The thiol group of Cysteine is highly nucleophilic and can be S-alkylated by tert-butyl cations (+56 Da).[10][16] It is also easily oxidized to form disulfide-bridged dimers or oligomers.[10]
-
Solution: A reducing agent is critical in the cleavage cocktail.
Problem 4: My peptide contains Tyrosine and shows unexpected adducts.
-
Possible Cause: The primary side reaction is the alkylation of the tyrosine phenol side chain by carbocations generated during deprotection.[6]
-
Solution: Use scavengers that effectively trap carbocations.
Data Presentation: Common Cleavage Cocktails
The following tables summarize the compositions of common cleavage cocktails and their effectiveness in preventing specific side reactions.
Table 1: Composition of Common Cleavage Cocktails
| Reagent Name | Composition | Primary Application |
| Standard | 95% TFA, 2.5% TIS, 2.5% H₂O | General purpose, good for peptides without highly sensitive residues.[1][5] |
| Reagent K | 82.5% TFA, 5% Phenol, 5% Water, 5% Thioanisole, 2.5% EDT | A general cleavage reagent suitable for peptides with sensitive residues like Cys, Met, Trp, and Tyr.[6][14][17] |
| Reagent H | 81% TFA, 5% Phenol, 5% Thioanisole, 3% Water, 2.5% EDT, 2% DMS, 1.5% NH₄I | Specifically designed to prevent methionine oxidation.[14][17] |
| Reagent R | 90% TFA, 5% Thioanisole, 3% EDT, 2% Anisole | Recommended for sequences containing Trp, His, Met, Cys, and Arg(Mtr/Pmc).[14] |
| Reagent B | 88% TFA, 5% Phenol, 5% Water, 2% TIS | An "odorless" cocktail where TIS replaces pungent thiols. Useful for trityl-based protecting groups but does not prevent Met oxidation.[17] |
Table 2: Scavenger Performance in Preventing S-tert-butylation of Cysteine
| Scavenger Added to TFA/TIS/H₂O | % S-tBu Side Product |
| None | 18.6% |
| Dithiothreitol (DTT) | 3.9% |
| Thioanisole | 4.8% |
| Dimethyl Sulfide (DMS) | 5.2% |
| m-Cresol | 11.2% |
| Anisole | 11.8% |
| (Data adapted from[5]) |
Experimental Protocols
Protocol 1: General Peptide Cleavage and Deprotection
This protocol is a general method for cleaving peptides from the resin and removing side-chain protecting groups.
Materials:
-
Peptide-resin (dried)
-
Cleavage Cocktail (freshly prepared, see tables above)
-
Dichloromethane (DCM)
-
Cold diethyl ether (-20°C)
-
Centrifuge tubes
Procedure:
-
Place the dried peptide-resin into a suitable reaction vessel.
-
Wash the resin with DCM to swell it, then drain the DCM.[18]
-
Add the freshly prepared cleavage cocktail to the resin (approximately 10 mL per gram of resin).[18]
-
Agitate the mixture at room temperature for 1.5 to 4 hours. The optimal time depends on the peptide sequence and protecting groups used.[12][18] For peptides with multiple arginine residues, longer cleavage times may be necessary.
-
Filter the resin and collect the filtrate containing the cleaved peptide.[18]
-
Wash the resin with a small amount of fresh cleavage cocktail or TFA and combine the filtrates.[9][17]
-
Precipitate the peptide by adding the filtrate dropwise to a 10-fold volume of cold diethyl ether.[12][18]
-
Incubate the mixture at a low temperature (e.g., 4°C) to maximize precipitation.[1]
-
Centrifuge the mixture to pellet the precipitated peptide.[18]
-
Carefully decant the ether supernatant.
-
Wash the peptide pellet with cold diethyl ether two more times to remove residual scavengers and TFA.[1][18]
-
Dry the final peptide pellet under a stream of nitrogen or in a vacuum desiccator.[1][18]
Mechanism Visualization
The diagram below illustrates the tert-butylation of a Tryptophan residue, a common side reaction, and how a scavenger like Triisopropylsilane (TIS) intervenes to prevent it.
References
- 1. benchchem.com [benchchem.com]
- 2. benchchem.com [benchchem.com]
- 3. WO2015028599A1 - Cleavage of synthetic peptides - Google Patents [patents.google.com]
- 4. benchchem.com [benchchem.com]
- 5. benchchem.com [benchchem.com]
- 6. benchchem.com [benchchem.com]
- 7. benchchem.com [benchchem.com]
- 8. Fmoc Resin Cleavage and Deprotection [sigmaaldrich.com]
- 9. benchchem.com [benchchem.com]
- 10. benchchem.com [benchchem.com]
- 11. biotage.com [biotage.com]
- 12. benchchem.com [benchchem.com]
- 13. Fmoc Resin Cleavage and Deprotection [sigmaaldrich.com]
- 14. benchchem.com [benchchem.com]
- 15. researchgate.net [researchgate.net]
- 16. pubs.acs.org [pubs.acs.org]
- 17. peptide.com [peptide.com]
- 18. benchchem.com [benchchem.com]
Technical Support Center: Enhancing Membrane Crossing of 4-Aminophenylalanine with Methyl Esters
This technical support center provides researchers, scientists, and drug development professionals with comprehensive guidance on utilizing methyl esters to improve the membrane permeability of 4-Aminophenylalanine. Below you will find troubleshooting guides, frequently asked questions (FAQs), detailed experimental protocols, and illustrative diagrams to support your experimental work.
Frequently Asked Questions (FAQs)
Q1: Why is enhancing the membrane crossing of this compound important?
A1: this compound is a non-proteinogenic amino acid with potential applications in drug development and as a biochemical probe. However, its inherent polarity can limit its ability to passively diffuse across cellular membranes, such as the intestinal epithelium or the blood-brain barrier. Enhancing its membrane permeability is crucial for improving its oral bioavailability and enabling its use in targeting intracellular processes.
Q2: How does methyl esterification enhance the membrane permeability of this compound?
A2: Methyl esterification is a common prodrug strategy used to increase the lipophilicity of molecules containing carboxylic acid groups. By converting the polar carboxylic acid of this compound into a less polar methyl ester, the overall lipophilicity of the molecule is increased. This enhanced lipophilicity facilitates its partitioning into the lipid bilayer of cell membranes, thereby increasing its rate of passive diffusion across the membrane.
Q3: What is the general expectation for the increase in permeability after methyl esterification?
A3: While the exact fold-increase is compound-specific and depends on the assay system, it is generally expected that converting a polar carboxylic acid to a methyl ester will significantly increase membrane permeability. The increase is attributed to the masking of the negative charge and the addition of a lipophilic methyl group.
Q4: Can the methyl ester of this compound be converted back to the active parent drug?
A4: Yes, the methyl ester is designed to be a prodrug. Once inside the cell, it can be hydrolyzed back to the active this compound by intracellular esterase enzymes. The rate of this conversion can vary depending on the cell type and its esterase activity.
Q5: What are the key in vitro assays to measure the permeability of this compound and its methyl ester?
A5: The most common in vitro assays for assessing passive permeability are the Parallel Artificial Membrane Permeability Assay (PAMPA) and cell-based assays like the Caco-2 permeability assay. PAMPA provides a measure of passive diffusion across an artificial lipid membrane, while Caco-2 assays use a monolayer of human intestinal cells to model intestinal absorption, which includes both passive diffusion and active transport mechanisms.
Troubleshooting Guides
This section addresses common issues that may arise during experiments aimed at evaluating the enhanced membrane crossing of this compound methyl ester.
| Issue | Potential Cause(s) | Recommended Solution(s) |
| Low or no detectable permeability for this compound methyl ester in PAMPA. | 1. Compound instability: The methyl ester may be hydrolyzing back to the parent amino acid in the aqueous donor solution. 2. Low compound solubility: The compound may not be fully dissolved in the donor buffer. 3. Incorrect pH of the donor buffer: The pH may be promoting ionization of the amino group, reducing lipophilicity. 4. Issues with the artificial membrane: The lipid layer may be compromised or of an inappropriate composition. | 1. Prepare fresh solutions immediately before the assay. Consider using a buffer with lower pH to slow hydrolysis if compatible with the assay. 2. Use a co-solvent like DMSO (typically up to 1-2%) to aid dissolution. Ensure the final concentration is below the solubility limit. 3. Use a donor buffer with a pH that ensures the primary amine is largely in its neutral form, if possible, to maximize lipophilicity. However, be mindful of the compound's pKa. 4. Use a fresh, pre-coated PAMPA plate or ensure proper coating of the filter plate with the lipid solution. Verify the integrity of the membrane using a known control compound. |
| High variability in permeability measurements between replicates. | 1. Inconsistent pipetting: Inaccurate or inconsistent volumes of donor or acceptor solutions. 2. Edge effects on the 96-well plate: Evaporation from the outer wells can concentrate the solutions. 3. Incomplete dissolution of the compound. 4. Cell monolayer integrity issues (for Caco-2 assays): Inconsistent cell growth or tight junction formation. | 1. Use calibrated pipettes and ensure careful and consistent pipetting technique. 2. Avoid using the outermost wells of the plate or fill them with buffer to create a humidity barrier. 3. Visually inspect the donor wells to ensure the compound is fully dissolved before starting the assay. 4. Monitor the transepithelial electrical resistance (TEER) of the Caco-2 monolayers to ensure their integrity and consistency across the plate. |
| Permeability of the methyl ester is not significantly higher than the parent amino acid. | 1. Rapid hydrolysis of the ester: The methyl ester may be converting back to this compound in the donor well before it has a chance to permeate. 2. Active transport of the parent amino acid: If using a cell-based assay, this compound might be a substrate for an amino acid transporter, leading to an overestimation of its passive permeability. 3. Assay conditions are not optimal for observing passive diffusion. | 1. Analyze the donor solution at the end of the experiment to quantify the extent of hydrolysis. Consider a shorter incubation time. 2. Compare the results with a PAMPA assay, which only measures passive diffusion. If the Caco-2 permeability of the parent is much higher than in PAMPA, transporter involvement is likely. 3. Ensure the pH of the buffers and the composition of the artificial membrane are appropriate for measuring the passive diffusion of your compounds. |
| Low recovery of the compound at the end of the experiment. | 1. Compound binding to the plate material: Lipophilic compounds can adsorb to the plastic of the 96-well plates. 2. Compound retention in the artificial membrane. 3. Compound degradation (other than hydrolysis). | 1. Use low-binding plates. Quantify the amount of compound in both the donor and acceptor wells at the end of the experiment to calculate mass balance. 2. This is a known phenomenon, especially for highly lipophilic compounds. The amount retained can be estimated by subtracting the amounts in the donor and acceptor wells from the initial amount. 3. Analyze the stability of the compound in the assay buffer under the experimental conditions in a separate experiment. |
Data Presentation
The following table presents hypothetical, yet representative, quantitative data for the permeability of this compound and its methyl ester derivative, as would be determined by a Parallel Artificial Membrane Permeability Assay (PAMPA). This illustrates the expected outcome of enhanced membrane crossing due to methyl esterification.
| Compound | Structure | Apparent Permeability (Papp) (10-6 cm/s) | Permeability Class |
| This compound |  | 0.5 ± 0.1 | Low |
| This compound methyl ester |  | 8.2 ± 0.9 | High |
Note: The structures are illustrative. The Papp values are hypothetical and serve for comparative purposes to demonstrate the expected increase in permeability.
Experimental Protocols
Synthesis of this compound Methyl Ester Hydrochloride
This protocol describes a general method for the esterification of an amino acid using thionyl chloride in methanol (B129727).
Materials:
-
This compound
-
Methanol (anhydrous)
-
Thionyl chloride (SOCl₂)
-
Diethyl ether
-
Round-bottom flask
-
Magnetic stirrer and stir bar
-
Ice bath
-
Rotary evaporator
-
Buchner funnel and filter paper
Procedure:
-
Suspend this compound (1 equivalent) in anhydrous methanol in a round-bottom flask equipped with a magnetic stir bar.
-
Cool the suspension in an ice bath to 0°C.
-
Slowly add thionyl chloride (1.2 equivalents) dropwise to the stirred suspension. Caution: This reaction is exothermic and releases HCl gas. Perform in a well-ventilated fume hood.
-
After the addition is complete, remove the ice bath and allow the reaction mixture to stir at room temperature for 12-24 hours. The reaction progress can be monitored by thin-layer chromatography (TLC).
-
Once the reaction is complete, remove the methanol under reduced pressure using a rotary evaporator.
-
Add diethyl ether to the residue to precipitate the product as a hydrochloride salt.
-
Collect the solid product by vacuum filtration using a Buchner funnel.
-
Wash the solid with cold diethyl ether and dry under vacuum to obtain this compound methyl ester hydrochloride.
-
Characterize the product by NMR and mass spectrometry to confirm its identity and purity.
Parallel Artificial Membrane Permeability Assay (PAMPA)
This protocol provides a general procedure for assessing the passive permeability of this compound and its methyl ester.
Materials:
-
PAMPA plate (e.g., a 96-well microtiter plate with a filter membrane)
-
Acceptor plate (96-well)
-
Donor plate (96-well)
-
Lipid solution (e.g., 2% (w/v) lecithin (B1663433) in dodecane)
-
Phosphate-buffered saline (PBS), pH 7.4
-
Test compounds (this compound and this compound methyl ester) dissolved in a suitable solvent (e.g., DMSO)
-
UV-Vis microplate reader or LC-MS/MS system
-
Control compounds (e.g., a high permeability and a low permeability standard)
Procedure:
-
Prepare the Artificial Membrane: Carefully coat the filter membrane of the PAMPA donor plate with the lipid solution (e.g., 5 µL per well). Allow the solvent to evaporate completely.
-
Prepare the Acceptor Plate: Fill each well of the acceptor plate with 300 µL of PBS (pH 7.4).
-
Prepare the Donor Solutions: Prepare stock solutions of the test and control compounds in DMSO. Dilute the stock solutions with PBS to the final desired concentration (e.g., 100 µM), ensuring the final DMSO concentration is low (e.g., <1%).
-
Start the Assay: Add 200 µL of the donor solutions to the corresponding wells of the coated donor plate.
-
Assemble the PAMPA Sandwich: Carefully place the donor plate on top of the acceptor plate, ensuring the bottom of the filter membrane is in contact with the acceptor solution.
-
Incubation: Incubate the plate assembly at room temperature for a defined period (e.g., 4-18 hours) in a sealed container with a wet paper towel to minimize evaporation.
-
Sample Analysis: After incubation, carefully separate the plates. Determine the concentration of the compound in the donor and acceptor wells using a suitable analytical method (e.g., UV-Vis spectrophotometry or LC-MS/MS).
-
Calculate Apparent Permeability (Papp): The apparent permeability coefficient (Papp) can be calculated using the following equation: Papp = (-VD * VA / ((VD + VA) * A * t)) * ln(1 - CA(t) / Cequilibrium) Where:
-
VD = volume of the donor well
-
VA = volume of the acceptor well
-
A = area of the filter membrane
-
t = incubation time
-
CA(t) = concentration in the acceptor well at time t
-
Cequilibrium = equilibrium concentration
-
Visualizations
Caption: Experimental workflow for enhancing and evaluating the membrane permeability of this compound.
Caption: Logical relationship between methyl esterification and enhanced membrane permeability.
Technical Support Center: Managing Metabolic Burden from Orthogonal Translation System (OTS) Overexpression
This technical support center provides troubleshooting guidance and frequently asked questions to help researchers, scientists, and drug development professionals manage the metabolic burden associated with the overexpression of orthogonal translation systems (OTS).
Troubleshooting Guides
This section addresses specific issues that may arise during experiments involving OTS overexpression.
Issue 1: Reduced Cell Growth and Viability After OTS Induction
Question: We observe a significant decrease in cell growth rate and viability after inducing the expression of our orthogonal translation system. What are the potential causes and how can we troubleshoot this?
Answer:
Reduced cell growth and viability are common indicators of metabolic burden imposed by the overexpression of OTS components. The primary sources of this cytotoxicity can be attributed to several factors:
-
High-level expression of the orthogonal aminoacyl-tRNA synthetase (o-aaRS): Overexpression of o-aaRS can deplete cellular energy resources and precursor molecules. This can activate a cellular stress response similar to the heat shock response and amino acid limitation, leading to a general reduction in both host and heterologous protein synthesis.
-
Imbalance of the orthogonal tRNA (o-tRNA) in the cellular tRNA pool: High concentrations of o-tRNA can interfere with the host's translational machinery and regulatory processes, contributing to toxicity. A high copy number of the o-tRNA expression plasmid can be inversely proportional to the relative fitness of the host cell.
-
High plasmid maintenance burden: The use of high-copy-number plasmids for expressing OTS components requires significant cellular resources for replication and maintenance, further straining the cell's metabolism.
-
Reduced orthogonality: Cross-reactivity of the o-aaRS with endogenous amino acids or the charging of endogenous tRNAs by the o-aaRS can lead to the synthesis of misacylated tRNAs, disrupting the fidelity of protein translation and inducing stress.
Troubleshooting Workflow:
Caption: Troubleshooting workflow for reduced cell growth.
Recommended Solutions:
-
Optimize OTS Component Expression Levels:
-
Use weaker, constitutive promoters or inducible promoters that allow for titration of expression levels for both the o-aaRS and o-tRNA.
-
Systematically evaluate different promoter strengths to find a balance that minimizes toxicity while maintaining sufficient OTS activity.
-
-
Reduce Plasmid Copy Number:
-
Subclone the OTS components into lower-copy-number plasmids (e.g., p15A origin) to decrease the metabolic load associated with plasmid replication.
-
-
Genomically Integrate OTS Components:
-
For stable, long-term expression and to eliminate the burden of plasmid maintenance, consider integrating the o-aaRS and o-tRNA genes into the host chromosome. This often leads to more stable and reproducible results.
-
-
Balance the o-aaRS and o-tRNA Ratio:
-
The optimal ratio of o-aaRS to o-tRNA can vary. Experimentally determine the ratio that results in the best target protein yield with minimal impact on cell growth.
-
Issue 2: Low Yield of the Target Protein Containing the Non-Canonical Amino Acid (ncAA)
Question: Our OTS appears to be functional, but the final yield of our target protein containing the ncAA is very low. How can we improve this?
Answer:
Low protein yield in the context of ncAA incorporation can stem from several bottlenecks in the orthogonal translation process.
-
Inefficient ncAA Incorporation: The efficiency of the o-aaRS in charging the o-tRNA with the ncAA and the subsequent decoding of the repurposed codon by the ribosome can be limiting factors.
-
Suboptimal Expression Conditions: The concentration of the ncAA in the growth medium, the timing of induction, and the growth temperature can all significantly impact the final protein yield.
-
Competition with Release Factors: When using stop codons (e.g., the amber stop codon UAG) for ncAA incorporation, there is competition between the ncAA-charged o-tRNA and cellular release factors that terminate translation.
-
Cellular Stress Responses: As discussed previously, metabolic burden can lead to a global reduction in protein synthesis, affecting the yield of the target protein.
Recommended Solutions:
-
Optimize ncAA Concentration and Supplementation:
-
Titrate the concentration of the ncAA in the culture medium to find the optimal level that supports efficient incorporation without causing toxicity.
-
Ensure the ncAA is stable in the medium and readily transported into the cells.
-
-
Fine-Tune Induction Conditions:
-
Optimize the cell density at the time of induction.
-
Vary the concentration of the inducer (e.g., IPTG, arabinose).
-
Experiment with different post-induction temperatures, as lower temperatures can sometimes improve protein folding and solubility.
-
-
Enhance Orthogonality and Efficiency of OTS Components:
-
If possible, use an evolved o-aaRS/o-tRNA pair with improved kinetics and specificity for the desired ncAA.
-
In bacterial systems, consider using a host strain with a modified genome, such as one lacking release factor 1 (RF1), to reduce competition at the amber stop codon.
-
-
Codon Optimization of the Target Gene:
-
Ensure that the codon usage of the target gene is optimized for the expression host to prevent translational pausing at rare codons, which can lead to premature termination or misincorporation.
-
Issue 3: Low Fidelity of ncAA Incorporation (Contamination with Canonical Amino Acids)
Question: Mass spectrometry analysis of our purified protein reveals significant incorporation of canonical amino acids at the target site instead of the desired ncAA. What causes this and how can we improve fidelity?
Answer:
Low fidelity of ncAA incorporation compromises the homogeneity of the final protein product and is a critical issue to address.
-
Cross-Reactivity of the o-aaRS: The o-aaRS may recognize and activate one or more of the 20 canonical amino acids, leading to their incorporation at the target codon.
-
Misacylation of the o-tRNA by Endogenous Synthetases: An endogenous aaRS might recognize and charge the o-tRNA with its cognate canonical amino acid.
-
Read-through of the Stop Codon: In the absence of efficient ncAA incorporation, near-cognate tRNAs can suppress the stop codon, leading to the insertion of a canonical amino acid.
Recommended Solutions:
-
Improve o-aaRS Specificity:
-
Employ directed evolution or rational design strategies to engineer an o-aaRS with higher specificity for the ncAA and reduced affinity for all 20 canonical amino acids.
-
Perform negative selection during the evolution process to select against synthetases that recognize canonical amino acids.
-
-
Enhance o-tRNA Orthogonality:
-
Ensure that the o-tRNA lacks the recognition elements for endogenous aaRSs. This can be achieved by mutating specific nucleotides in the tRNA sequence.
-
-
Optimize Expression and Growth Conditions:
-
Ensure a saturating concentration of the ncAA in the medium to outcompete any low-level recognition of canonical amino acids by the o-aaRS.
-
In some cases, depleting the medium of a competing canonical amino acid (if known) can improve fidelity, though this can also impact cell health.
-
Data Summary
Table 1: Impact of OTS Optimization on Host Cell Fitness and Protein Yield
| OTS Variant | Plasmid Copy Number | Promoter System | Relative Fitness (%) | Target Protein Yield (mg/L) | Reference |
| Original pSerOTS | High (ColE1) | Constitutive (glnS) | 50 | ~50 | |
| Optimized [P1] | Low (p15a) | Constitutive (glnS) | 80 | ~60 | |
| Optimized [C1] | High (ColE1) | Constitutive (glnS) | 65 | ~330 | |
| Optimized [C1] | High (ColE1) | Constitutive (glnS*) | 70 | ~380 |
Experimental Protocols
Protocol 1: Measuring Cell Growth Rate
Objective: To determine the growth rate of cells expressing an OTS to quantify metabolic burden.
Materials:
-
Spectrophotometer or plate reader capable of measuring optical density at 600 nm (OD600).
-
Culture tubes or microplates.
-
Appropriate growth medium with and without the ncAA.
-
Inducer (if applicable).
Methodology:
-
Inoculate a starter culture of the host strain containing the OTS plasmid(s) and grow overnight.
-
The next day, dilute the overnight culture into fresh medium to a starting OD600 of 0.05-0.1. Prepare replicate cultures for each condition (e.g., with and without inducer, with and without ncAA).
-
Incubate the cultures at the desired temperature with shaking.
-
At regular intervals (e.g., every hour), take a sample from each culture and measure the OD600.
-
Plot the OD600 values (on a logarithmic scale) against time (on a linear scale).
-
Identify the exponential growth phase and calculate the specific growth rate (μ) using the formula: μ = (ln(OD2) - ln(OD1)) / (t2 - t1), where OD1 and OD2 are the optical densities at times t1 and t2, respectively.
Protocol 2: Quantifying Target Protein Yield
Objective: To determine the concentration of the purified target protein containing the ncAA.
Materials:
-
Purified target protein.
-
Protein quantification assay kit (e.g., BCA or Bradford assay).
-
Spectrophotometer or plate reader.
-
Protein standard (e.g., BSA).
Methodology:
-
Prepare a series of dilutions of the protein standard to generate a standard curve.
-
Prepare dilutions of your purified protein sample to ensure the concentration falls within the linear range of the assay.
-
Follow the manufacturer's instructions for the chosen protein quantification assay to prepare the standards and samples.
-
Measure the absorbance of the standards and samples at the appropriate wavelength.
-
Generate a standard curve by plotting the absorbance of the standards against their known concentrations.
-
Use the standard curve to determine the concentration of your purified protein sample.
-
Calculate the total yield in mg/L of culture.
Protocol 3: Assessing ncAA Incorporation Fidelity by Mass Spectrometry
Objective: To determine the fidelity of ncAA incorporation at a specific site in the target protein.
Materials:
-
Purified target protein.
-
Protease (e.g., trypsin).
-
Mass spectrometer (e.g., LC-MS/MS).
Methodology:
-
In-solution or In-gel Digestion:
-
Denature, reduce, and alkylate the purified protein sample.
-
Digest the protein into smaller peptides using a specific protease like trypsin.
-
-
Liquid Chromatography-Mass Spectrometry (LC-MS) Analysis:
-
Separate the resulting peptides by reverse-phase liquid chromatography.
-
Analyze the eluted peptides by mass spectrometry to determine their mass-to-charge ratio (m/z).
-
-
Tandem Mass Spectrometry (MS/MS) Analysis:
-
Select the peptide of interest (containing the ncAA incorporation site) for fragmentation.
-
Analyze the fragmentation pattern to determine the amino acid sequence of the peptide.
-
-
Data Analysis:
-
Search the MS/MS data against a protein database containing the sequence of the target protein with the expected ncAA modification.
-
Quantify the relative abundance of the peptide containing the ncAA versus the peptide containing any misincorporated canonical amino acids by comparing the peak areas from the LC-MS data.
-
FAQs
Q1: What is metabolic burden in the context of OTS?
A1: Metabolic burden refers to the diversion of the host cell's resources (energy, amino acids, nucleotides, etc.) from essential cellular processes, such as growth and division, to the maintenance and expression of the heterologous orthogonal translation system. This can lead to a variety of stress responses and a reduction in overall cellular fitness.
Q2: How does the choice of non-canonical amino acid affect metabolic burden?
A2: The specific ncAA used can influence metabolic burden in several ways. Some ncAAs may be toxic to the cell at high concentrations. Others may be structurally similar to canonical amino acids, increasing the likelihood of cross-reactivity with endogenous enzymes. The efficiency of cellular uptake and the metabolic stability of the ncAA are also important factors.
Q3: Are there host strains that are better suited for OTS overexpression?
A3: Yes, engineered host strains can significantly improve the performance of an OTS. For example, E. coli strains with a deleted or modified release factor 1 (RF1) are commonly used to improve the efficiency of ncAA incorporation at the amber stop codon. Additionally, strains engineered for improved protein folding or reduced protease activity can also be beneficial.
Q4: What are the primary cellular stress responses activated by OTS overexpression?
A4: Overexpression of OTS components can trigger several stress response pathways, including:
-
The Heat Shock Response: This is often activated by the accumulation of misfolded or aggregated proteins, which can result from high-level heterologous protein expression or the incorporation of an ncAA that perturbs protein folding.
-
The Unfolded Protein Response (UPR): In eukaryotic cells, the UPR is triggered by an accumulation of unfolded proteins in the endoplasmic reticulum.
-
The Stringent Response: In bacteria, this response is triggered by amino acid starvation or the accumulation of uncharged tRNAs, which can occur due to the high demand for amino acids for o-aaRS synthesis or inefficient charging of the o-tRNA.
Caption: Cellular stress response to OTS overexpression.
Validation & Comparative
Confirming 4-Aminophenylalanine Incorporation: A Mass Spectrometry-Based Comparative Guide
For researchers, scientists, and drug development professionals, the precise incorporation of non-canonical amino acids (ncAAs) like 4-Aminophenylalanine (4-APF) is crucial for engineering proteins with novel functions. Mass spectrometry (MS) is the gold standard for verifying the successful and site-specific incorporation of these amino acids. This guide provides an objective comparison of MS-based techniques and other alternatives, supported by experimental data and detailed protocols, to ensure the structural integrity of your engineered proteins.
Comparative Analysis of Validation Techniques
A multi-faceted approach is often necessary for the unambiguous confirmation of 4-APF incorporation. High-resolution mass spectrometry (HRMS) can confirm the mass of the modified protein or peptide, while tandem mass spectrometry (MS/MS) is essential for pinpointing the exact location of the incorporated amino acid.[1] For applications where the stereochemistry is critical, other analytical techniques may be required.
| Analytical Technique | Information Provided | Advantages | Limitations |
| High-Resolution Mass Spectrometry (HRMS) | Confirms the accurate molecular weight of the peptide or protein, indicating the incorporation of the 4-APF residue.[1] | High mass accuracy provides strong evidence of successful incorporation.[1] | Does not confirm the location of the amino acid in the sequence or its stereochemistry (D/L isomer).[1] |
| Tandem Mass Spectrometry (MS/MS) | Provides peptide sequence information through fragmentation analysis, confirming the precise location of the 4-APF residue.[1] | Pinpoints the exact position of the modification within the peptide chain.[1] | Fragmentation patterns can be complex. The presence of the amino group on the phenyl ring of 4-APF may influence fragmentation patterns compared to standard phenylalanine.[1] |
| Chiral Amino Acid Analysis | Determines the stereochemistry (D or L) of the incorporated amino acid after peptide hydrolysis. | Directly confirms the presence of the desired isomer. | Is destructive to the peptide sample and does not provide sequence information.[1] |
| Nuclear Magnetic Resonance (NMR) Spectroscopy | Provides detailed 3D structural information and can confirm the presence of the 4-APF through characteristic chemical shifts.[2] | Offers unambiguous structural information.[2] | Has lower sensitivity compared to MS, requires larger sample amounts, and data analysis can be complex.[2] |
Quantitative Data Presentation
The successful incorporation of 4-APF results in a predictable mass shift. Phenylalanine has a molecular weight of approximately 165.19 g/mol , while this compound's molecular weight is around 180.22 g/mol .[3] This mass difference can be precisely measured by mass spectrometry.
Table 1: Expected Mass Shifts for a Hypothetical Peptide (Ac-G-X-A-K-NH2) with 4-APF Incorporation [3]
| Peptide Variant (X) | Monoisotopic Mass (Da) | Mass Shift from Phe (Da) |
| Phenylalanine (Phe) | 505.27 | 0 |
| This compound (4-APF) | 520.28 | +15.01 |
Quantitative proteomics techniques, such as Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC), can be adapted to determine the efficiency of 4-APF incorporation.[4] By comparing the signal intensities of peptides containing 4-APF to their counterparts with the canonical amino acid, a quantitative measure of incorporation can be achieved.
Experimental Protocols
Below are detailed protocols for the confirmation of 4-APF incorporation using mass spectrometry.
Protocol 1: Protein Digestion
This protocol is designed for proteins expressed in cell culture that have incorporated 4-APF.
-
Protein Denaturation, Reduction, and Alkylation:
-
Denature the protein containing 4-APF in a buffer with 8 M urea (B33335).
-
Reduce disulfide bonds by adding 10 mM dithiothreitol (B142953) (DTT) and incubating at 56°C for 30 minutes.
-
Alkylate cysteine residues with 20 mM iodoacetamide (B48618) in the dark at room temperature for 20 minutes.[1]
-
-
Digestion:
-
Dilute the solution 10-fold with 50 mM ammonium (B1175870) bicarbonate to lower the urea concentration.
-
Add trypsin at a 1:50 enzyme-to-protein ratio and incubate overnight at 37°C.[1]
-
-
Desalting:
-
Acidify the peptide digest with 0.1% trifluoroacetic acid (TFA).
-
Desalt the peptides using a C18 solid-phase extraction (SPE) cartridge.
-
Elute the peptides with a solution of 50-80% acetonitrile (B52724) and 0.1% formic acid.
-
Dry the eluted peptides in a vacuum centrifuge.[1]
-
-
Reconstitution:
-
Reconstitute the dried peptides in a solution of 0.1% formic acid in water for the subsequent LC-MS analysis.[1]
-
Protocol 2: LC-MS/MS Analysis
-
Liquid Chromatography (LC) Separation:
-
Column: Use a reversed-phase C18 column (e.g., 1.7 µm particle size, 100 Å pore size, 75 µm ID x 150 mm length).[3]
-
Mobile Phase A: 0.1% formic acid in water.[3]
-
Mobile Phase B: 0.1% formic acid in acetonitrile.[3]
-
Gradient: A typical gradient would be a linear increase from 2% to 40% mobile phase B over 60 minutes.[3]
-
Flow Rate: 300 nL/min.[3]
-
-
Mass Spectrometry (MS) and MS/MS:
-
Ionization: Use electrospray ionization (ESI) in positive ion mode.[3]
-
Full Scan MS: Acquire spectra in the m/z range of 350-1800 to detect precursor ions.[3]
-
MS/MS: Use data-dependent acquisition (DDA) to select the most intense precursor ions for fragmentation by collision-induced dissociation (CID) or higher-energy collisional dissociation (HCD).[3]
-
Mandatory Visualizations
Caption: Experimental workflow for confirming 4-APF incorporation.
Caption: Logical workflow for data analysis to confirm 4-APF incorporation.
References
Sequencing Peptides with 4-Aminophenylalanine: A Comparative Guide to Edman Degradation and Mass Spectrometry
For researchers, scientists, and drug development professionals, the precise sequencing of peptides containing unnatural amino acids (UAAs) is critical for verifying structure and ensuring function. This guide provides an objective comparison of traditional Edman degradation and modern mass spectrometry techniques for sequencing peptides incorporating 4-Aminophenylalanine (4-APF), supported by experimental data and detailed protocols.
The incorporation of this compound, a non-canonical aromatic amino acid, into peptides can confer unique properties, including altered biological activity and novel functionalities for drug development. However, its presence presents a challenge for standard peptide sequencing methodologies. This guide will explore the utility and limitations of Edman degradation for this specific application and compare its performance with the powerful alternative of mass spectrometry.
Methodological Overview
Edman Degradation Sequencing
Developed by Pehr Edman, this classical method determines the amino acid sequence of a peptide in a stepwise manner from the N-terminus.[1] The core of the process involves three key chemical reactions per cycle:
-
Coupling: The N-terminal amino acid reacts with phenyl isothiocyanate (PITC) under alkaline conditions to form a phenylthiocarbamyl (PTC) derivative.[1][2]
-
Cleavage: The PTC-derivatized N-terminal residue is selectively cleaved from the peptide chain using a strong acid, typically trifluoroacetic acid (TFA), to form an anilinothiazolinone (ATZ)-amino acid.[3]
-
Conversion and Identification: The unstable ATZ-amino acid is converted to a more stable phenylthiohydantoin (PTH)-amino acid derivative, which is then identified by chromatography, usually high-performance liquid chromatography (HPLC).[1]
This cycle is repeated to sequentially identify the amino acids.[1] For peptides containing UAAs like 4-APF, the success of Edman degradation hinges on the reactivity of the UAA with PITC and the stability and chromatographic behavior of the resulting PTH-UAA derivative.
Mass Spectrometry-Based Sequencing
Mass spectrometry (MS) has become a dominant technique for peptide sequencing due to its high sensitivity, throughput, and ability to handle complex mixtures and post-translational modifications.[3][4] The most common approach is tandem mass spectrometry (MS/MS) coupled with liquid chromatography (LC-MS/MS). In this "bottom-up" workflow, the peptide is first fragmented, typically by collision-induced dissociation (CID), and the resulting fragment ions (mainly b- and y-ions) are measured with high mass accuracy.[4] The amino acid sequence is then deduced from the mass differences between these fragment ions.[4]
Performance Comparison: Edman Degradation vs. Mass Spectrometry for 4-APF Peptides
The choice between Edman degradation and mass spectrometry for sequencing peptides containing 4-APF depends on several factors, including the specific research question, sample purity, and available instrumentation. While specific experimental data on the Edman degradation of 4-APF is limited in publicly available literature, a comparison can be constructed based on the known principles of each technique and data from similar modified amino acids.
| Parameter | Edman Degradation | Mass Spectrometry (LC-MS/MS) |
| Principle | Stepwise chemical degradation from the N-terminus.[1] | Fragmentation of peptide ions and mass analysis.[4] |
| Compatibility with 4-APF | Potentially challenging. The primary amine of the 4-APF side chain could potentially react with PITC, leading to side products or incomplete reactions. The resulting PTH-4-APF would require a standard for HPLC identification. | Generally high. The mass shift introduced by 4-APF is readily detected. Fragmentation patterns may be influenced by the aromatic side chain. |
| Repetitive Yield | Typically >95% for standard amino acids.[5] The yield for 4-APF is not well-documented and may be lower due to potential side reactions. | Not applicable in the same sense. Sequence coverage depends on fragmentation efficiency. |
| Sample Requirement | 1-10 picomoles.[3] | High sensitivity, often in the femtomole to low picomole range.[4] |
| Throughput | Low; one sample at a time with cycle times of 30-60 minutes per residue.[4] | High; compatible with autosamplers for analyzing multiple samples. |
| Sequence Coverage | Typically limited to the first 30-50 N-terminal residues.[1] | Can provide full sequence coverage, including internal sequences. |
| Handling of Mixtures | Not suitable for complex mixtures. | Can analyze and sequence multiple peptides in a single run.[4] |
| De Novo Sequencing | Straightforward, direct readout of the N-terminal sequence. | Possible, but can be complex for novel UAAs without specialized software. |
Experimental Protocols
Edman Degradation of a Peptide Containing 4-APF
This protocol is a generalized procedure and may require optimization for specific peptides and instrumentation.
1. Sample Preparation:
-
Approximately 5-10 picomoles of the purified peptide containing 4-APF are loaded onto a Polyvinylidene Fluoride (PVDF) membrane.[4]
-
The membrane is allowed to dry completely before being placed in the reaction chamber of an automated protein sequencer.
2. Automated Sequencing Cycle:
-
Coupling: The peptide on the PVDF membrane is treated with a solution of phenyl isothiocyanate (PITC) in a basic buffer (e.g., N-methylpiperidine/methanol/water) at 40-50°C to form the PTC-peptide.[2][4]
-
Washing: The excess PITC and by-products are removed by washing with appropriate solvents like ethyl acetate.
-
Cleavage: The N-terminal PTC-amino acid is cleaved by treatment with an anhydrous acid, such as trifluoroacetic acid (TFA), releasing the ATZ-amino acid derivative.[4]
-
Extraction: The ATZ-amino acid is extracted with an organic solvent (e.g., butyl chloride).[4]
-
Conversion: The extracted ATZ-amino acid is converted to the more stable PTH-amino acid derivative by heating in an aqueous acid solution (e.g., 25% TFA).[5]
3. HPLC Analysis of PTH-Amino Acids:
-
The PTH-amino acid derivative from each cycle is injected into a reverse-phase HPLC system.
-
Identification of the PTH-amino acid is achieved by comparing its retention time with that of known PTH-amino acid standards. For 4-APF, a custom PTH-4-APF standard would be necessary for unambiguous identification.
Mass Spectrometry Sequencing of a Peptide Containing 4-APF
This protocol outlines a general workflow for LC-MS/MS analysis.
1. Sample Preparation:
-
The peptide sample is dissolved in a suitable solvent for mass spectrometry, typically a mixture of water and acetonitrile (B52724) with a small amount of formic acid (e.g., 0.1%).
2. LC-MS/MS Analysis:
-
Instrumentation: A high-resolution mass spectrometer (e.g., Q-TOF or Orbitrap) coupled to a liquid chromatography system is used.
-
Chromatography: The peptide is loaded onto a reverse-phase column (e.g., C18) and eluted with a gradient of increasing organic solvent (e.g., acetonitrile with 0.1% formic acid).
-
Ionization: Electrospray ionization (ESI) in positive ion mode is typically used to generate protonated peptide ions.
-
MS1 Scan: The mass spectrometer scans for the mass-to-charge ratio (m/z) of the intact peptide ions.
-
MS2 Fragmentation: The most abundant peptide ions are selected for fragmentation using collision-induced dissociation (CID) or higher-energy collisional dissociation (HCD).
-
MS2 Scan: The m/z of the resulting fragment ions is measured.
3. Data Analysis:
-
The fragmentation spectra are analyzed to determine the amino acid sequence. This can be done manually or using specialized software. The mass of 4-APF (monoisotopic mass of the residue: 164.09 Da) must be included in the search parameters.
-
The presence of characteristic b- and y-ions will confirm the peptide sequence. The fragmentation of the aromatic side chain of 4-APF may also produce unique reporter ions.
Visualizing the Edman Degradation Workflow
Caption: Workflow of a single cycle of Edman degradation for N-terminal peptide sequencing.
Conclusion
Both Edman degradation and mass spectrometry are valuable techniques for the analysis of peptides containing this compound. Edman degradation offers a direct, albeit slower, method for unambiguously determining the N-terminal sequence, which can be particularly useful for validating the identity and integrity of a synthetic peptide. However, its application to 4-APF may be complicated by the reactivity of the side chain and the need for a custom standard.
In contrast, mass spectrometry provides a highly sensitive, high-throughput, and versatile approach that is generally more tolerant of amino acid modifications. It can provide full sequence coverage and is well-suited for analyzing complex samples. For comprehensive characterization of peptides containing 4-APF, a complementary approach utilizing both techniques may be optimal: Edman degradation to confirm the N-terminal sequence and mass spectrometry to verify the full sequence and identify any other modifications. The choice of the primary method will ultimately depend on the specific analytical needs, sample availability, and the resources at hand.
References
- 1. Edman degradation - Wikipedia [en.wikipedia.org]
- 2. 4 Steps of Edman Degradation | MtoZ Biolabs [mtoz-biolabs.com]
- 3. 26.6 Peptide Sequencing: The Edman Degradation – Organic Chemistry: A Tenth Edition – OpenStax adaptation 1 [ncstate.pressbooks.pub]
- 4. benchchem.com [benchchem.com]
- 5. ehu.eus [ehu.eus]
A Functional Comparison of 4-Aminophenylalanine and 4-Aminocyclohexylalanine in Drug Discovery
A detailed examination of their roles as bioactive scaffolds, focusing on enzyme inhibition and pharmacokinetic properties.
In the landscape of drug discovery and peptide design, the use of non-natural amino acids is a critical strategy for optimizing the therapeutic potential of lead compounds. Among these, 4-Aminophenylalanine (4-AP) and 4-Aminocyclohexylalanine (4-ACHA) represent two structurally related yet functionally distinct building blocks. This guide provides an objective comparison of their functional characteristics, supported by experimental data, to inform researchers, scientists, and drug development professionals in their molecular design endeavors. The core difference—an aromatic phenyl ring in 4-AP versus a saturated cyclohexyl ring in 4-ACHA—drives significant variations in biological activity, metabolic stability, and pharmacokinetic profiles.
Core Structural and Functional Differences
This compound is an aromatic amino acid that can be incorporated into peptides and other small molecules to introduce specific functionalities.[1] Its aromatic ring can participate in π-π stacking and other electronic interactions, while the amino group provides a site for further chemical modification.[1] 4-Aminocyclohexylalanine, as a saturated cyclic analogue of 4-AP, offers a more rigid and lipophilic scaffold. This substitution of an aromatic ring with a cyclohexyl group is a common strategy in medicinal chemistry to enhance metabolic stability and improve the pharmacokinetic properties of a peptide or small molecule drug.[2][3]
A prime example of the functional divergence between these two amino acids is demonstrated in the development of Dipeptidyl Peptidase IV (DPP-4) inhibitors for the treatment of type 2 diabetes.[4]
Case Study: Inhibition of Dipeptidyl Peptidase IV (DPP-4)
DPP-4 is a serine protease that plays a crucial role in glucose metabolism by inactivating incretin (B1656795) hormones like glucagon-like peptide-1 (GLP-1).[5][6] Inhibition of DPP-4 prolongs the action of GLP-1, leading to enhanced insulin (B600854) secretion and improved glucose control.[6] A study directly comparing derivatives of 4-AP and 4-ACHA as DPP-4 inhibitors revealed key differences in their potency and bioavailability.[4]
Quantitative Comparison of DPP-4 Inhibitors
The following table summarizes the in vitro potency (IC50) of representative compounds from the this compound and 4-aminocyclohexylalanine series against DPP-4.
| Compound Series | Representative Compound | DPP-4 IC50 (nM) |
| This compound | Compound 10 | 28 |
| 4-Aminocyclohexylalanine | Compound 25 | 16 |
Data sourced from a study on potent, selective, and orally bioavailable inhibitors of dipeptidyl peptidase IV.[4]
While both series yielded potent inhibitors, the 4-aminocyclohexylalanine derivatives demonstrated comparable or slightly improved potency. However, the most significant difference was observed in their pharmacokinetic profiles. The this compound series exhibited limited oral bioavailability, whereas the 4-aminocyclohexylalanine derivatives showed improved pharmacokinetic exposure and efficacy in an oral glucose tolerance test in mice.[4] This highlights the key advantage of the cyclohexyl scaffold in improving the drug-like properties of the molecule.
Experimental Protocols
DPP-4 Inhibition Assay
This protocol outlines a typical fluorescence-based assay to determine the in vitro inhibitory activity of test compounds against DPP-4.
1. Reagents and Materials:
-
Human recombinant DPP-4 enzyme
-
DPP-4 substrate: Gly-Pro-7-amino-4-methylcoumarin (Gly-Pro-AMC)
-
Assay Buffer: Tris-HCl buffer (pH 7.5)
-
Test compounds (4-AP and 4-ACHA derivatives) dissolved in DMSO
-
96-well black microplate
-
Fluorescence plate reader (Excitation: 360 nm, Emission: 460 nm)
2. Assay Procedure:
-
Add 20 µL of the test compound at various concentrations to the wells of the 96-well plate.
-
Add 30 µL of the DPP-4 enzyme solution to each well and incubate for 10 minutes at room temperature.
-
Initiate the reaction by adding 50 µL of the Gly-Pro-AMC substrate solution to each well.
-
Incubate the plate at 37°C for 30 minutes, protected from light.
-
Measure the fluorescence intensity using a plate reader.
-
The percent inhibition is calculated relative to a control without any inhibitor. IC50 values are then determined by plotting the percent inhibition against the logarithm of the inhibitor concentration.
Oral Glucose Tolerance Test (OGTT) in Mice
This protocol describes an in vivo experiment to assess the efficacy of DPP-4 inhibitors.
1. Animals:
-
Male C57BL/6 mice, fasted overnight.
2. Procedure:
-
Administer the test compound (e.g., a 4-ACHA derivative) or vehicle control orally (p.o.).
-
After 30 minutes, administer a glucose solution (2 g/kg) orally.
-
Collect blood samples from the tail vein at 0, 15, 30, 60, and 120 minutes post-glucose administration.
-
Measure blood glucose levels using a glucometer.
-
The efficacy of the compound is determined by its ability to reduce the glucose excursion compared to the vehicle control.
Signaling Pathways and Workflows
DPP-4 Signaling in Glucose Homeostasis
The following diagram illustrates the role of DPP-4 in the incretin pathway and how its inhibition leads to improved glucose control.
Caption: The DPP-4 signaling pathway in glucose metabolism.
Workflow for Evaluating 4-AP vs. 4-ACHA Derivatives
This diagram outlines the logical workflow for the comparative evaluation of 4-AP and 4-ACHA derivatives in a drug discovery context.
Caption: Workflow for the comparative evaluation of 4-AP and 4-ACHA.
Conclusion
The functional comparison between this compound and 4-Aminocyclohexylalanine clearly illustrates the impact of substituting an aromatic ring with a saturated cyclic system. While both can be used to design potent enzyme inhibitors, as demonstrated in the case of DPP-4, the 4-aminocyclohexylalanine scaffold offers a distinct advantage in terms of metabolic stability and oral bioavailability.[4] This makes 4-ACHA a more favorable building block for developing orally administered drugs. The choice between 4-AP and 4-ACHA will ultimately depend on the specific therapeutic goal, with 4-AP being suitable for applications where its electronic properties are desired and metabolic stability is less of a concern, while 4-ACHA is a superior choice for enhancing the drug-like properties of a lead compound. This guide underscores the importance of such strategic modifications in modern medicinal chemistry.
References
- 1. nbinno.com [nbinno.com]
- 2. researchgate.net [researchgate.net]
- 3. pharmaexcipients.com [pharmaexcipients.com]
- 4. This compound and 4-aminocyclohexylalanine derivatives as potent, selective, and orally bioavailable inhibitors of dipeptidyl peptidase IV - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. mdpi.com [mdpi.com]
- 6. Dipeptidyl-peptidase 4 Inhibition: Linking Metabolic Control to Cardiovascular Protection - PMC [pmc.ncbi.nlm.nih.gov]
A Comparative Analysis of the Catalytic Efficiency: 4-Aminophenylalanine vs. Aniline
For Researchers, Scientists, and Drug Development Professionals
This guide provides a detailed comparison of the catalytic roles and efficiencies of 4-Aminophenylalanine and aniline (B41778) in biological and synthetic systems. While direct enzymatic kinetic comparisons are scarce due to their distinct roles, this document synthesizes available data to offer a comprehensive overview of their catalytic potential. Aniline is typically encountered as a substrate for various enzymes, whereas this compound, a non-canonical amino acid, often functions as a catalytic residue within engineered enzymes or as an allosteric modulator.
Quantitative Data Summary
The following table summarizes the available quantitative data on the catalytic performance of aniline as an enzyme substrate and the catalytic effects of this compound.
| Compound | Enzyme/System | Role | Key Parameters | Value | Reference |
| Aniline | Horseradish Peroxidase C | Substrate | k_cat (catalytic constant) | Varies with substrate | [1] |
| K_M (Michaelis constant) | Varies with substrate | [1] | |||
| This compound | Phenylalanine Hydroxylase | Allosteric Activator | Fold Activation | Lower than L-phenylalanine | [2][3] |
| Designer Enzyme (LmrR variant) | Catalytic Residue | Rate Enhancement | ~3 orders of magnitude | [4] | |
| Hydrazone Ligation (chemical catalysis) | Catalyst | Relative Catalytic Efficacy | ~70% of aniline | [5] |
Experimental Protocols
Detailed methodologies for key experiments cited in this guide are provided below.
Enzymatic Assay for Aniline Oxidation by Horseradish Peroxidase
This protocol is based on the study of the steady-state reaction velocities of horseradish peroxidase C with aniline derivatives.
Objective: To determine the catalytic constant (k_cat) and Michaelis constant (K_M) of horseradish peroxidase C for aniline.
Materials:
-
Horseradish Peroxidase C (HRPC)
-
Aniline
-
Hydrogen peroxide (H₂O₂)
-
Appropriate buffer solution (e.g., phosphate (B84403) buffer at a specific pH)
-
Spectrophotometer
Procedure:
-
Prepare a series of aniline solutions of varying concentrations in the buffer.
-
Prepare a solution of HRPC and a separate solution of H₂O₂ in the same buffer.
-
In a cuvette, mix the HRPC solution with an aniline solution.
-
Initiate the reaction by adding the H₂O₂ solution.
-
Immediately measure the change in absorbance at a specific wavelength corresponding to the product formation over time using a spectrophotometer.
-
The initial reaction velocity (V₀) is calculated from the linear portion of the absorbance vs. time plot.
-
Repeat steps 3-6 for each concentration of aniline.
-
Plot the initial velocities (V₀) against the corresponding aniline concentrations ([S]).
-
Fit the data to the Michaelis-Menten equation to determine V_max and K_M.
-
Calculate k_cat using the equation: k_cat = V_max / [E], where [E] is the total enzyme concentration.[1]
Enzyme Activation Assay for this compound with Phenylalanine Hydroxylase
This protocol is adapted from studies on the allosteric activation of phenylalanine hydroxylase.
Objective: To measure the activation of phenylalanine hydroxylase by this compound.
Materials:
-
Phenylalanine Hydroxylase (PheH)
-
L-phenylalanine (substrate)
-
This compound (activator)
-
Tetrahydrobiopterin (BH₄) (cofactor)
-
Buffer solution (e.g., HEPES)
-
Fluorescence spectrophotometer
Procedure:
-
Pre-incubate the PheH enzyme with a specific concentration of this compound for a set period (e.g., 10 minutes) at a controlled temperature.[2]
-
Prepare an assay mixture containing the substrate L-phenylalanine and the cofactor BH₄ in the buffer.
-
Initiate the reaction by adding the pre-incubated enzyme-activator solution to the assay mixture.
-
Monitor the enzyme activity by measuring the rate of product (tyrosine) formation. This can be done by detecting the increase in tyrosine's intrinsic fluorescence.
-
The fold activation is calculated by comparing the enzyme activity in the presence of this compound to the basal activity in its absence.[2][3]
Visualizations
Michaelis-Menten Kinetics
The following diagram illustrates the fundamental model of enzyme kinetics, defining the key parameters V_max (maximum reaction velocity) and K_M (Michaelis constant), which is the substrate concentration at half V_max. The catalytic efficiency of an enzyme is often expressed as the k_cat/K_M ratio.
Caption: Michaelis-Menten model of enzyme catalysis.
Aniline as a Substrate for Horseradish Peroxidase
This diagram depicts the role of aniline as a reducing substrate in the catalytic cycle of horseradish peroxidase. The enzyme is first oxidized by hydrogen peroxide, and then aniline reduces the enzyme back to its resting state in a two-step process, generating an aniline radical product.
Caption: Aniline as a substrate in the HRP catalytic cycle.
This compound as a Catalytic Residue
This workflow illustrates how the unnatural amino acid this compound can be incorporated into a protein scaffold to create a designer enzyme. The aniline side chain of this compound then acts as a nucleophilic catalyst to promote a specific chemical reaction, such as hydrazone formation.[4][6]
Caption: Workflow for creating a designer enzyme with 4-APhe.
References
- 1. Differential substrate behaviour of phenol and aniline derivatives during oxidation by horseradish peroxidase: kinetic evidence for a two-step mechanism - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. The Amino Acid Specificity for Activation of Phenylalanine Hydroxylase Matches the Specificity for Stabilization of Regulatory Domain Dimers - PMC [pmc.ncbi.nlm.nih.gov]
- 3. The Amino Acid Specificity for Activation of Phenylalanine Hydroxylase Matches the Specificity for Stabilization of Regulatory Domain Dimers - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Designer enzyme uses unnatural amino acid for catalysis | EurekAlert! [eurekalert.org]
- 5. This compound as a biocompatible nucleophilic catalyst for hydrazone ligations at low temperature and neutral pH - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
A Head-to-Head Battle for Bioorthogonality: 4-Aminophenylalanine vs. p-Azidophenylalanine in Click Chemistry
For researchers, scientists, and drug development professionals navigating the landscape of bioorthogonal chemistry, the choice of non-canonical amino acid is a critical design parameter. This guide provides a comprehensive, data-driven comparison of two key players: 4-Aminophenylalanine (4-AmPhe) and p-azidophenylalanine (p-AzPhe), focusing on their applications in click chemistry for protein labeling and modification.
While p-azidophenylalanine (p-AzPhe) is a well-established tool for introducing azides into proteins for subsequent click chemistry, its in vivo instability presents a significant challenge. The azide (B81097) moiety of p-AzPhe is often reduced by cellular machinery to an amine, yielding this compound (4-AmPhe) and resulting in heterogeneous protein populations.[1] This guide explores a powerful strategy that embraces this conversion, utilizing 4-AmPhe as a stable precursor that can be efficiently and chemoselectively converted back to p-AzPhe post-translationally, enabling robust click chemistry applications.
Performance Characteristics at a Glance
| Feature | This compound (4-AmPhe) | p-Azidophenylalanine (p-AzPhe) |
| Primary Click Chemistry Functionality | Amine (precursor to azide) | Azide |
| Bioorthogonal Reaction | Post-translational diazotransfer followed by azide-alkyne cycloaddition | Direct azide-alkyne cycloaddition (CuAAC or SPAAC) |
| In Vivo Stability | High | Prone to reduction to 4-AmPhe[1] |
| Homogeneity of Labeled Protein | Potentially higher (post-conversion) | Can be heterogeneous due to in vivo reduction[1] |
| Protein Incorporation Yield (E. coli) | Generally good, can be optimized. | Variable, can be affected by cell permeability and toxicity.[2] |
| Protein Incorporation Yield (Mammalian Cells) | Feasible with appropriate orthogonal translation systems. | Feasible, but reduction to 4-AmPhe is also observed.[1] |
| Key Advantage | In vivo stability allows for production of homogenous protein populations prior to chemical conversion. | Direct incorporation of the click handle, simplifying the workflow if reduction is not a major issue. |
| Key Disadvantage | Requires an additional chemical conversion step. | In vivo reduction leads to a mixed population of proteins, complicating downstream applications.[1] |
The Two Strategies: A Visual Workflow
The fundamental difference in applying these two amino acids for click chemistry lies in the workflow. The direct incorporation of p-AzPhe is a more straightforward approach, while the use of 4-AmPhe involves a two-step post-translational modification strategy.
Quantitative Data Summary
A significant challenge with the direct incorporation of p-AzPhe is the intracellular reduction of the azide group to an amine, resulting in a heterogeneous population of proteins containing both p-AzPhe and 4-AmPhe. This can significantly impact the efficiency of subsequent click chemistry reactions. A study has shown that this reduction can lead to a 50-60% decrease in the yield of p-AzPhe residues per azide incorporated.[1]
The strategy of incorporating 4-AmPhe and then converting it to p-AzPhe in situ aims to overcome this limitation. A pH-tunable diazotransfer reaction using imidazole-1-sulfonyl azide (ISAz) has been demonstrated to convert 4-AmPhe to p-AzPhe with over 95% efficiency in proteins.[1]
| Parameter | 4-AmPhe (with in situ conversion) | p-AzPhe (direct incorporation) | Reference |
| Protein Incorporation Yield | Varies with expression system and protein, but generally robust. | Can be lower due to cellular uptake issues and potential toxicity.[2] | [2][3] |
| Azide Availability for Click Chemistry | >95% (after conversion) | 40-50% (due to in vivo reduction) | [1] |
| Homogeneity of Final Azide-Containing Protein | High | Low to moderate | [1] |
Experimental Protocols
Genetic Incorporation of Unnatural Amino Acids
The site-specific incorporation of both 4-AmPhe and p-AzPhe into proteins relies on the use of orthogonal translation systems, which consist of an orthogonal aminoacyl-tRNA synthetase (aaRS) and its cognate tRNA. These systems are designed to recognize a specific codon (typically an amber stop codon, UAG) and insert the desired non-canonical amino acid at that position.[4][5]
General Protocol for Unnatural Amino Acid Incorporation in E. coli
-
Plasmid Preparation: Co-transform E. coli cells (e.g., BL21(DE3)) with two plasmids:
-
Cell Culture: Grow the transformed cells in a suitable medium (e.g., LB or minimal medium) containing the appropriate antibiotics for plasmid selection.
-
Induction: When the cell culture reaches the mid-log phase (OD600 ≈ 0.6-0.8), induce protein expression with IPTG and supplement the medium with the non-canonical amino acid (typically 1-2 mM).
-
Expression: Continue to grow the cells at a reduced temperature (e.g., 18-25 °C) for 12-16 hours to allow for protein expression and incorporation of the unnatural amino acid.
-
Harvesting and Purification: Harvest the cells by centrifugation and purify the protein of interest using standard chromatography techniques.
In Situ Conversion of this compound to p-Azidophenylalanine
This protocol is based on the work of Arranz-Gibert et al. (2021) and utilizes a pH-dependent diazotransfer reaction.[1]
Materials:
-
Purified protein containing 4-AmPhe.
-
Imidazole-1-sulfonyl azide hydrogen sulfate (B86663) (ISAz·H₂SO₄) - a safer alternative to the hydrochloride salt.[8]
-
Phosphate (B84403) buffer (e.g., 100 mM sodium phosphate, pH 7.4).
Procedure:
-
Reaction Setup: Dissolve the purified protein containing 4-AmPhe in the phosphate buffer to a final concentration of 10-50 µM.
-
Reagent Preparation: Prepare a fresh stock solution of ISAz·H₂SO₄ in an appropriate organic solvent (e.g., DMSO).
-
Diazotransfer Reaction: Add the ISAz·H₂SO₄ solution to the protein solution to a final concentration of 1-5 mM (a 20- to 100-fold molar excess over the protein).
-
Incubation: Incubate the reaction mixture at room temperature for 1-4 hours. The optimal pH for the selective conversion of 4-AmPhe over other primary amines like lysine (B10760008) is around 7.4.[1]
-
Quenching and Purification: The reaction can be stopped by buffer exchange to remove excess reagent. The resulting protein now contains p-AzPhe at the desired position and is ready for click chemistry.
Click Chemistry Reactions
Once the protein contains the azide handle (either through direct incorporation of p-AzPhe or conversion of 4-AmPhe), it can be labeled using either copper-catalyzed azide-alkyne cycloaddition (CuAAC) or strain-promoted azide-alkyne cycloaddition (SPAAC).
General Protocol for Copper-Catalyzed Azide-Alkyne Cycloaddition (CuAAC):
-
Reaction Mixture: In a microcentrifuge tube, combine the azide-containing protein (typically at 10-100 µM) in a suitable buffer (e.g., PBS), the alkyne-functionalized probe (1.5-5 molar excess), a copper(I) source (e.g., CuSO₄), a reducing agent (e.g., sodium ascorbate), and a copper-chelating ligand (e.g., THPTA or TBTA) to stabilize the Cu(I) and improve reaction efficiency.[1]
-
Incubation: Incubate the reaction at room temperature for 1-2 hours.
-
Analysis: The labeled protein can be analyzed by SDS-PAGE, mass spectrometry, or other relevant techniques.
General Protocol for Strain-Promoted Azide-Alkyne Cycloaddition (SPAAC):
-
Reaction Mixture: Combine the azide-containing protein with a strained alkyne probe (e.g., DBCO, BCN) in a suitable buffer.
-
Incubation: Incubate the reaction at room temperature. Reaction times can vary from minutes to hours depending on the specific strained alkyne used.
-
Analysis: Analyze the labeled protein as described for CuAAC.
Signaling Pathways and Logical Relationships
The choice between 4-AmPhe and p-AzPhe can be guided by considering the experimental context, particularly the cellular environment and the desired homogeneity of the final product.
Conclusion
Both this compound and p-azidophenylalanine are valuable tools for the site-specific modification of proteins using click chemistry. While the direct incorporation of p-AzPhe offers a more streamlined workflow, the challenge of its in vivo reduction to 4-AmPhe can lead to significant heterogeneity in the labeled protein population.
The strategy of incorporating the stable precursor, 4-AmPhe, followed by a highly efficient in situ conversion to p-AzPhe, provides a powerful solution to this problem. This two-step approach allows for the production of a homogeneous population of amine-containing proteins, which can then be quantitatively converted to the azide form immediately prior to the click reaction. This method ultimately offers greater control over the final labeled product, which is particularly crucial for applications requiring precise stoichiometry and quantitative analysis, such as in drug development and detailed biophysical studies. The choice between these two amino acids will ultimately depend on the specific experimental requirements, including the expression system, the desired level of protein homogeneity, and the tolerance for an additional chemical modification step.
References
- 1. Chemoselective restoration of para-azido-phenylalanine at multiple sites in proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Efficient incorporation of p-azido-l-phenylalanine into the protein using organic solvents - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Metabolic engineering of Escherichia coli for 4-nitrophenylalanine production via the this compound synthetic pathway - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Optimized orthogonal translation of unnatural amino acids enables spontaneous protein double-labelling and FRET - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Genetic Incorporation of the Unnatural Amino Acid p-Acetyl Phenylalanine into Proteins for Site-Directed Spin Labeling - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Site-specific incorporation of biophysical probes into NF-κB with non-canonical amino acids - PMC [pmc.ncbi.nlm.nih.gov]
- 7. biochemistry.ucla.edu [biochemistry.ucla.edu]
- 8. Sensitivities of some imidazole-1-sulfonyl azide salts - PubMed [pubmed.ncbi.nlm.nih.gov]
A Comparative Guide to Fluorescent Assays for Quantifying 4-Aminophenylalanine Incorporation Efficiency
For Researchers, Scientists, and Drug Development Professionals
The site-specific incorporation of unnatural amino acids (UAAs) like 4-Aminophenylalanine (4-APF) into proteins is a powerful tool in protein engineering and drug development. The primary amino group of 4-APF serves as a chemical handle for subsequent bioconjugation. Accurately quantifying the incorporation efficiency of 4-APF is crucial for optimizing expression systems and ensuring the homogeneity of the final protein product. This guide provides a comparative overview of fluorescent assay methodologies that can be employed to determine 4-APF incorporation efficiency, complete with experimental protocols and supporting data.
Introduction to Methodologies
Quantifying this compound (4-APF) incorporation hinges on leveraging its unique chemical properties or the impact of its incorporation on a reporter system. The primary strategies involve either direct chemical modification of the introduced amino group with a fluorescent probe or the use of a reporter protein whose fluorescence is dependent on the successful incorporation of the UAA. This guide will compare two main approaches:
-
Post-Translational Labeling Assay: This method involves the chemical conjugation of an amine-reactive fluorescent dye to the primary amine of the incorporated 4-APF. The resulting fluorescence is directly proportional to the amount of incorporated 4-APF.
-
Fluorescent Reporter Assay: This strategy utilizes a reporter protein, such as Superfolder Green Fluorescent Protein (sfGFP), with an amber stop codon (TAG) engineered at a permissive site. Successful incorporation of 4-APF at this site allows for the translation of a full-length, functional fluorescent protein. The intensity of the fluorescence serves as a proxy for incorporation efficiency.[1][2][3]
Performance Comparison
The choice of assay depends on factors such as the desired sensitivity, the need for high-throughput screening, and the context of the protein of interest. Below is a summary of the key performance metrics for each approach.
| Feature | Post-Translational Labeling Assay | Fluorescent Reporter Assay |
| Principle | Chemical ligation of a fluorescent dye to the amine group of 4-APF. | Read-through of an amber stop codon in a fluorescent reporter gene. |
| Specificity | High, targets the unique primary amine of 4-APF. | Indirect; measures full-length protein expression, not direct UAA incorporation. |
| Sensitivity | Dependent on the quantum yield of the chosen fluorophore. | High, due to the inherent brightness of fluorescent proteins. |
| Throughput | Moderate to high, adaptable to plate-based formats. | High, well-suited for library screening in multi-well plates. |
| Key Advantage | Directly quantifies the incorporated 4-APF in the protein of interest. | Simple, no post-expression modification required.[4] |
| Key Disadvantage | Requires protein purification and a separate labeling step; potential for incomplete labeling. | Incorporation efficiency can be context-dependent and may not reflect efficiency in the actual protein of interest. |
| Typical Fluorophores | NHS Ester Dyes (e.g., Atto, Cy dyes), FITC, TRITC.[5][6] | Genetically encoded sfGFP. |
Experimental Protocols
Detailed methodologies for the key experiments are provided below.
Post-Translational Labeling of 4-APF with Amine-Reactive Dyes
This protocol outlines the steps for labeling a purified protein containing 4-APF with an NHS-ester functionalized fluorescent dye.
1. Protein Expression and Purification:
- Express the target protein containing the amber codon at the desired position in an E. coli strain co-expressing the orthogonal aminoacyl-tRNA synthetase/tRNA pair for 4-APF.
- Supplement the growth media with 4-APF.
- Purify the protein of interest using standard chromatographic techniques (e.g., Ni-NTA affinity chromatography if His-tagged).
- Determine the protein concentration using a BCA or Bradford assay.
2. Fluorescent Labeling Reaction:
- Prepare a stock solution of the amine-reactive dye (e.g., Atto 488 NHS ester) in anhydrous DMSO.
- In a microcentrifuge tube, mix the purified protein (typically at 1-5 mg/mL in a suitable buffer, e.g., PBS pH 7.4) with a 5- to 10-fold molar excess of the dye.
- Incubate the reaction for 1 hour at room temperature or overnight at 4°C, protected from light.
- Quench the reaction by adding a small molecule with a primary amine (e.g., Tris or glycine) to a final concentration of 50-100 mM.
3. Removal of Unreacted Dye:
- Separate the labeled protein from the unreacted dye using a desalting column (e.g., PD-10) or dialysis.
4. Quantification:
- Measure the absorbance of the labeled protein at 280 nm and the absorbance maximum of the dye.
- Calculate the degree of labeling (DOL) using the Beer-Lambert law, correcting for the dye's absorbance at 280 nm.
- The incorporation efficiency can be estimated by comparing the concentration of the dye to the concentration of the protein.
Fluorescent Reporter Assay using sfGFP
This protocol describes a high-throughput method to assess 4-APF incorporation efficiency by measuring the fluorescence of a reporter protein.
1. Plasmid Construction:
- Introduce an amber stop codon (TAG) at a permissive site within the coding sequence of a fluorescent reporter protein, such as superfolder GFP (sfGFP).[1] A common site is position 150.
- The sfGFP construct should be on a plasmid that is compatible with the plasmid carrying the orthogonal synthetase/tRNA pair.
2. Protein Expression:
- Co-transform E. coli cells with the sfGFP reporter plasmid and the 4-APF synthetase/tRNA plasmid.
- Grow the cells in a 96-well plate format in media with and without 4-APF.
- Induce protein expression with IPTG.
3. Fluorescence Measurement:
- After a suitable expression period (e.g., 16-24 hours), measure the fluorescence of the cultures directly in the 96-well plate using a plate reader (e.g., excitation at 485 nm and emission at 510 nm for sfGFP).
- Measure the optical density at 600 nm (OD600) to normalize for cell growth.
4. Data Analysis:
- Calculate the normalized fluorescence (Fluorescence / OD600).
- The incorporation efficiency is proportional to the normalized fluorescence of the culture grown with 4-APF compared to the background fluorescence of the culture grown without 4-APF.
- For a more quantitative measure, a standard curve can be generated using purified sfGFP. The fluorescence can then be related to the amount of full-length protein produced.[1]
Visualization of Experimental Workflows
The following diagrams illustrate the workflows for the described fluorescent assays.
Caption: Workflow for Post-Translational Labeling Assay.
Caption: Workflow for Fluorescent Reporter Assay.
Conclusion
Both post-translational labeling and fluorescent reporter assays offer robust methods for quantifying 4-APF incorporation efficiency. The choice between them will be guided by the specific experimental needs. For direct and accurate quantification of 4-APF in a specific protein of interest, the post-translational labeling method is superior, albeit more labor-intensive. For high-throughput screening of mutant libraries of orthogonal synthetases or for optimizing expression conditions, the fluorescent reporter assay provides a rapid and scalable solution. For ultimate confidence, a combination of a high-throughput reporter screen followed by validation of lead candidates with the post-translational labeling method on the actual protein of interest is recommended. Furthermore, mass spectrometry can be used as a complementary technique to confirm the fidelity of 4-APF incorporation.[1]
References
- 1. Tuning phenylalanine fluorination to assess aromatic contributions to protein function and stability in cells - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Crystal structures of green fluorescent protein with the unnatural amino acid 4-nitro-L-phenylalanine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Expanding the utility of 4-cyano-L-phenylalanine as a vibrational reporter of protein environments - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Probing unnatural amino acid integration into enhanced green fluorescent protein by genetic code expansion with a high-throughput screening platform - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Fluorescent Amine Protein Labeling - Jena Bioscience [jenabioscience.com]
- 6. Peptide fluorescent labeling - SB-PEPTIDE - Peptide engineering [sb-peptide.com]
comparative analysis of 4-Aminophenylalanine and 4-iodophenylalanine in protein engineering
Authored for: Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive, data-supported comparison of two pivotal non-canonical amino acids (ncAAs), 4-Aminophenylalanine (4-APF) and 4-Iodophenylalanine (4-IPF), in the context of protein engineering. We delve into their incorporation efficiencies, unique chemical reactivities, and distinct applications, offering a clear framework for selecting the optimal tool for your research needs.
Overview and Physicochemical Properties
4-APF and 4-IPF are structural analogs of tyrosine that can be site-specifically incorporated into proteins using engineered aminoacyl-tRNA synthetase/tRNA pairs, most commonly by reassigning the amber (TAG) stop codon.[1] Their true value lies in the unique chemical handles they introduce into a protein's structure: a reactive primary aromatic amine (4-APF) and a versatile aryl iodide (4-IPF). These handles serve as platforms for a diverse range of subsequent chemical modifications.
Table 1: Physicochemical Properties of 4-APF and 4-IPF
| Property | This compound (4-APF) | 4-Iodophenylalanine (4-IPF) |
| Chemical Structure |  |  |
| IUPAC Name | (2S)-2-amino-3-(4-aminophenyl)propanoic acid[2] | (2S)-2-amino-3-(4-iodophenyl)propanoic acid |
| Molecular Formula | C₉H₁₂N₂O₂[3] | C₉H₁₀INO₂ |
| Molecular Weight | 180.20 g/mol [3] | 291.09 g/mol |
| Key Functional Group | Primary Aromatic Amine (-NH₂) | Aryl Iodide (-I) |
| Primary Reactivity | Diazotization, Amide Bond Formation, Precursor for other groups | Palladium-Catalyzed Cross-Coupling, Heavy Atom Phasing |
Genetic Incorporation and Protein Expression
The most established method for incorporating both 4-APF and 4-IPF into proteins in Escherichia coli relies on an evolved Methanocaldococcus jannaschii tyrosyl-tRNA synthetase (MjTyrRS) and its cognate suppressor tRNA.[1] While both can be incorporated with high fidelity, their expression yields can vary depending on the protein, the specific synthetase used, and the expression conditions.
Table 2: Comparison of Incorporation and Expression
| Parameter | This compound (4-APF) | 4-Iodophenylalanine (4-IPF) |
| Typical Yields | Generally moderate to high; yields of several milligrams of purified protein per liter of culture are commonly reported. | Can be slightly lower than other ncAAs due to potential toxicity or metabolic effects, but still yields sufficient for most applications.[4] |
| Incorporation Fidelity | High, with minimal off-target incorporation when using a well-evolved, specific synthetase/tRNA pair. | High; the iodo-group is sterically distinct, leading to good selectivity by the engineered synthetase.[5][6] |
| Cellular Toxicity | Generally low, well-tolerated by E. coli expression systems.[7] | Can exhibit higher toxicity compared to 4-APF, potentially impacting cell growth and final protein yields.[8] |
| Synthetase Evolution | Several evolved MjTyrRS variants exist for efficient incorporation. | Robust and well-characterized MjTyrRS variants are widely available for its incorporation.[5][6] |
Core Applications and Chemical Reactivity
The fundamental differences between 4-APF and 4-IPF emerge in their post-incorporation utility. Their distinct functional groups open doors to entirely different classes of bioorthogonal and chemical biology applications.
This compound (4-APF): A Versatile Nucleophilic Handle
The primary aromatic amine of 4-APF is a versatile nucleophile that can undergo several specific chemical transformations.
-
Diazotization: The amine can be converted into a diazonium salt, which is a highly reactive intermediate. This can then be used in reactions like Sandmeyer or Heck coupling, or more commonly, for creating stable azo-dyes by coupling with electron-rich aromatic compounds, enabling protein labeling.
-
Amide Coupling: The amine can be acylated to form stable amide bonds, allowing for the attachment of various probes, drugs, or polymers.
-
Precursor for other ncAAs: The amino group serves as a chemical handle for synthesizing other useful ncAAs. For instance, it is a common starting point for the synthesis of 4-azidophenylalanine (4-AzF), a widely used ncAA for click chemistry, via a diazotransfer reaction.[9]
4-Iodophenylalanine (4-IPF): A Gateway for Carbon-Carbon Bonds and Phasing
The aryl iodide of 4-IPF is relatively inert in a biological context but is highly reactive under specific catalytic conditions, making it a powerful tool for protein modification and structural biology.
-
Palladium-Catalyzed Cross-Coupling: This is the flagship application of 4-IPF. The carbon-iodine bond readily participates in palladium-catalyzed reactions such as Suzuki , Sonogashira , and Heck couplings .[10][11] These reactions form new, stable carbon-carbon or carbon-heteroatom bonds under mild, often aqueous conditions, allowing for the site-specific attachment of a vast array of chemical moieties, including fluorescent dyes, biotin (B1667282) tags, and complex organic molecules.[10][12]
-
X-Ray Crystallography: The iodine atom is electron-rich and exhibits significant anomalous scattering of X-rays. Incorporating 4-IPF provides a heavy atom at a specific site in the protein, which can be invaluable for solving the phase problem in X-ray crystallography using techniques like single-wavelength anomalous dispersion (SAD).[5] The iodoPhe residue is often well-tolerated within the hydrophobic core of a protein without significantly perturbing the native structure.[5]
Caption: Comparative reaction pathways for 4-APF and 4-IPF.
Experimental Workflow and Protocols
The successful incorporation of 4-APF or 4-IPF requires a robust experimental setup. The general workflow involves co-transformation of E. coli with two plasmids: one containing the gene of interest with an in-frame amber (TAG) codon at the desired site, and a second plasmid (e.g., pEVOL or pSUP) encoding the orthogonal aminoacyl-tRNA synthetase/tRNA pair.[13]
Caption: General workflow for ncAA incorporation in E. coli.
Generalized Protocol for ncAA Incorporation in E. coli
This protocol provides a general framework. Optimization of ncAA concentration, inducer levels, and growth temperature is recommended for each target protein.
-
Plasmid Preparation:
-
Introduce an amber stop codon (TAG) at the desired site in your gene of interest (GOI) on an expression vector (e.g., pBAD, pET) using site-directed mutagenesis.[13]
-
Prepare high-quality plasmid DNA for both the GOI vector and the pEVOL/pSUP vector containing the engineered synthetase for 4-APF or 4-IPF.
-
-
Transformation:
-
Co-transform chemically competent or electrocompetent E. coli cells (e.g., BL21(DE3)) with both the GOI plasmid and the pEVOL/pSUP plasmid.[13]
-
Plate on LB-agar plates containing the appropriate antibiotics for both plasmids (e.g., ampicillin (B1664943) and chloramphenicol). Incubate overnight at 37°C.
-
-
Starter Culture:
-
Inoculate a single colony into 10-20 mL of LB medium containing both antibiotics.
-
Grow overnight at 37°C with shaking.
-
-
Expression Culture:
-
Inoculate 1 L of LB medium (containing antibiotics) with the overnight starter culture.
-
Grow at 37°C with shaking until the optical density at 600 nm (OD₆₀₀) reaches 0.6–0.8.[14]
-
Add the non-canonical amino acid (4-APF or 4-IPF) to a final concentration of 1-2 mM.
-
Induce protein expression by adding the appropriate inducers (e.g., 1 mM IPTG for pET vectors and 0.02% L-arabinose for pEVOL/pBAD vectors).[13]
-
-
Protein Expression and Harvest:
-
Reduce the temperature to 18-30°C and continue shaking for 16-20 hours.
-
Harvest the cells by centrifugation (e.g., 6,000 x g for 15 minutes at 4°C).
-
-
Purification and Verification:
-
Resuspend the cell pellet and lyse the cells (e.g., by sonication or microfluidization).
-
Purify the protein of interest using standard chromatography techniques (e.g., Ni-NTA affinity chromatography for His-tagged proteins).
-
Verify the incorporation of the ncAA using mass spectrometry (ESI-MS or MALDI-TOF).
-
Conclusion: Making the Right Choice
The choice between this compound and 4-Iodophenylalanine is dictated entirely by the intended downstream application.
-
Choose this compound (4-APF) when your goal is to leverage the reactivity of a primary amine for bioconjugation via diazotization or acylation, or when you need a synthetic precursor to generate other functional groups like azides.
-
Choose 4-Iodophenylalanine (4-IPF) when your primary objective is to perform palladium-catalyzed cross-coupling reactions to form stable carbon-carbon bonds for sophisticated protein labeling, or when you require a site-specific heavy atom for facilitating protein structure determination by X-ray crystallography.
Both ncAAs are powerful additions to the protein engineering toolkit. By understanding their distinct chemical personalities, researchers can design more precise, functional, and insightful experiments to probe and manipulate biological systems.
References
- 1. mdpi.com [mdpi.com]
- 2. plantaedb.com [plantaedb.com]
- 3. This compound | C9H12N2O2 | CID 151001 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 4. Site-specific incorporation of 4-iodo-L-phenylalanine through opal suppression - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. The site-specific incorporation of p-iodo-L-phenylalanine into proteins for structure determination - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. The Amino Acid Specificity for Activation of Phenylalanine Hydroxylase Matches the Specificity for Stabilization of Regulatory Domain Dimers - PMC [pmc.ncbi.nlm.nih.gov]
- 8. An Alternative and Expedient Synthesis of Radioiodinated 4-Iodophenylalanine - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Synthesis and explosion hazards of 4-Azido-L-phenylalanine - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Site-specific functionalization of proteins by organopalladium reactions - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. researchgate.net [researchgate.net]
- 13. biochemistry.ucla.edu [biochemistry.ucla.edu]
- 14. Efficient Incorporation of Unnatural Amino Acids into Proteins with a Robust Cell-Free System - PMC [pmc.ncbi.nlm.nih.gov]
evaluating protein stability after substitution with 4-Aminophenylalanine vs wild type
In the realm of protein engineering and drug development, the strategic substitution of natural amino acids with non-canonical counterparts offers a powerful tool for modulating protein structure and function. This guide provides a comparative analysis of protein stability following the substitution of a wild-type amino acid with 4-Aminophenylalanine (4-AmPhe). The introduction of 4-AmPhe, a phenylalanine analog containing an amino group on the phenyl ring, can introduce novel electrostatic interactions and alter the local environment, thereby influencing the overall stability of the protein.
This guide presents a summary of hypothetical, yet plausible, quantitative data to illustrate the potential effects of such a substitution. It also provides detailed experimental protocols for the key techniques used to assess protein stability, offering researchers a practical framework for their own investigations.
Data Presentation: A Comparative Analysis of Protein Stability
The following table summarizes representative data from biophysical assays comparing a wild-type protein to a variant where a phenylalanine residue has been substituted with this compound. This substitution can potentially lead to an increase in thermal stability, as reflected by a higher melting temperature (Tm).
| Parameter | Wild-Type Protein | This compound Substituted Protein |
| Melting Temperature (Tm) by DSC | 65.2 °C | 68.9 °C |
| Enthalpy of Unfolding (ΔH) by DSC | 450 kJ/mol | 475 kJ/mol |
| Change in Heat Capacity (ΔCp) by DSC | 8.5 kJ/(mol·K) | 8.2 kJ/(mol·K) |
| Secondary Structure (α-helix) by CD | 42% | 43% |
| Enzyme Activity (kcat/Km) | 1.2 x 10^5 M⁻¹s⁻¹ | 1.1 x 10^5 M⁻¹s⁻¹ |
Note: The data presented in this table is a hypothetical representation to illustrate the potential impact of this compound substitution and is not derived from a single specific study.
Experimental Protocols
Detailed methodologies for the key experiments cited in the data table are provided below. These protocols are synthesized from established biophysical techniques.
Site-Directed Mutagenesis and Protein Expression with this compound
This protocol outlines the incorporation of the non-canonical amino acid this compound at a specific site in a target protein using an amber suppression-based method.
a. Plasmid Preparation:
-
A plasmid encoding the target protein with an amber stop codon (TAG) at the desired substitution site is required.
-
A second plasmid encoding an orthogonal aminoacyl-tRNA synthetase/tRNA pair specific for this compound is also needed.
b. Protein Expression:
-
Co-transform E. coli expression strains (e.g., BL21(DE3)) with both the target protein plasmid and the synthetase/tRNA plasmid.
-
Grow the transformed cells in minimal medium supplemented with the appropriate antibiotics at 37°C with shaking.
-
When the optical density at 600 nm (OD600) reaches 0.6-0.8, induce protein expression with IPTG (e.g., 1 mM final concentration).
-
Simultaneously, supplement the culture medium with this compound (e.g., 1 mM final concentration).
-
Continue to grow the culture at a reduced temperature (e.g., 18-25°C) for 12-16 hours.
-
Harvest the cells by centrifugation and store the cell pellet at -80°C.
c. Protein Purification:
-
Resuspend the cell pellet in a suitable lysis buffer (e.g., containing Tris-HCl, NaCl, and protease inhibitors).
-
Lyse the cells by sonication or high-pressure homogenization.
-
Clarify the lysate by centrifugation.
-
Purify the target protein from the supernatant using appropriate chromatography techniques (e.g., affinity chromatography, ion-exchange chromatography, and size-exclusion chromatography).
-
Verify the incorporation of this compound by mass spectrometry.[1]
Differential Scanning Calorimetry (DSC)
DSC is used to measure the thermal stability of a protein by detecting the heat change associated with its thermal denaturation.[2][3]
-
Prepare samples of the wild-type and 4-AmPhe substituted proteins at a concentration of 1-2 mg/mL in a suitable buffer (e.g., PBS, pH 7.4).
-
Dialyze both protein samples against the same buffer to ensure identical buffer conditions.
-
Use the dialysis buffer as the reference solution.
-
Load the protein sample and the reference solution into the sample and reference cells of the DSC instrument, respectively.[2]
-
Pressurize the cells to prevent boiling at high temperatures.[3]
-
Scan the samples from a starting temperature (e.g., 20°C) to a final temperature (e.g., 100°C) at a constant scan rate (e.g., 1°C/min).[3]
-
Record the differential heat capacity as a function of temperature.
-
The melting temperature (Tm) is the temperature at the peak of the denaturation curve. The enthalpy of unfolding (ΔH) is calculated by integrating the area under the peak.
Circular Dichroism (CD) Spectroscopy
CD spectroscopy is used to assess the secondary structure of the proteins and monitor its change with temperature.
-
Prepare protein samples at a concentration of 0.1-0.2 mg/mL in a low-salt buffer (e.g., 10 mM phosphate (B84403) buffer, pH 7.4).
-
Use a quartz cuvette with a path length of 1 mm.
-
Record CD spectra in the far-UV region (e.g., 190-260 nm) at a controlled temperature (e.g., 25°C).
-
To determine thermal stability, monitor the CD signal at a specific wavelength (e.g., 222 nm for α-helical proteins) while increasing the temperature at a controlled rate (e.g., 1°C/min).
-
The resulting data can be fitted to a sigmoidal curve to determine the melting temperature (Tm).
-
The percentage of secondary structure elements can be estimated from the CD spectrum using deconvolution software.
Mandatory Visualization
The following diagrams illustrate the experimental workflow and the conceptual basis for the observed changes in protein stability.
Caption: Experimental workflow for comparing wild-type and 4-AmPhe substituted protein stability.
Caption: Logic of how 4-AmPhe substitution can alter protein stability.
References
- 1. Unraveling Complex Local Protein Environments with 4-Cyano-l-phenylalanine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Differential Scanning Calorimetry - Overview | Malvern Panalytical [malvernpanalytical.com]
- 3. Differential Scanning Calorimetry — A Method for Assessing the Thermal Stability and Conformation of Protein Antigen - PMC [pmc.ncbi.nlm.nih.gov]
X-ray Crystallography of Proteins Containing 4-Aminophenylalanine: A Comparative Guide
In the realm of structural biology and drug development, the site-specific incorporation of unnatural amino acids (UAAs) into proteins offers a powerful tool to probe and engineer protein structure and function. Among these, 4-Aminophenylalanine (pAF) presents a unique chemical functionality—an amino group—that can be leveraged for various bioconjugation strategies, mimicking post-translational modifications, or introducing novel catalytic activities. This guide provides a comparative overview of the X-ray crystallography of proteins containing pAF, supported by experimental data from closely related analogs, and details the methodologies required for successful structure determination.
Performance Comparison: Minimal Structural Perturbation
A critical consideration when introducing a UAA is its impact on the native protein structure. While crystallographic data for pAF-containing proteins are not extensively published, studies on structurally similar para-substituted phenylalanine analogs, such as 4-nitro-L-phenylalanine (B556529) (pNO2F) and 4-cyano-L-phenylalanine (pCNF), consistently demonstrate that their incorporation results in minimal structural perturbation. This makes them excellent probes for studying protein environments without disrupting the native fold.
Alignments of superfolder Green Fluorescent Protein (sfGFP) variants containing these UAAs with the wild-type structure reveal very small root-mean-square deviations (RMSD) of the Cα atoms, indicating that the overall protein architecture is well-preserved.[1][2] This low level of structural disturbance is a key advantage, suggesting that pAF would similarly serve as a non-perturbative probe.
Table 1: Crystallographic Data for sfGFP Variants with Unnatural Amino Acids
| Protein Construct | PDB Entry | Resolution (Å) | Space Group | Unit Cell Parameters (a, b, c in Å; α, β, γ in °) | Rwork / Rfree (%) | RMSD (Cα) vs. Wild-Type (Å) |
| sfGFP (Wild-Type) | 2B3P | 1.50 | P212121 | 52.4, 63.9, 68.1; 90, 90, 90 | 17.5 / 20.9 | - |
| Asp133pNO2F sfGFP | 6DQ0 | 2.05 | P3221 | 86.8, 86.8, 114.7; 90, 90, 120 | 18.5 / 21.9 | 0.229[1] |
| Asn149pNO2F sfGFP | 6DQ1 | 1.60 | P4122 | 77.9, 77.9, 101.4; 90, 90, 90 | 16.1 / 19.1 | 0.180[3] |
| Tyr74pCNF sfGFP | 6P3G | 1.51 | P212121 | 52.6, 64.0, 68.3; 90, 90, 90 | 16.8 / 19.4 | 0.227[2] |
Experimental Protocols
The successful determination of the crystal structure of a protein containing pAF relies on a systematic workflow encompassing gene mutagenesis, protein expression and purification, and crystallization. The following protocols are adapted from successful studies on proteins containing similar unnatural amino acids.[1]
Site-Directed Mutagenesis and Plasmid Preparation
To incorporate pAF at a specific site, the corresponding codon in the gene of interest is mutated to the amber stop codon (TAG). This is typically achieved using site-directed mutagenesis techniques like PCR with mutagenic primers. The mutated gene is then cloned into an expression vector. A second plasmid carrying the engineered orthogonal aminoacyl-tRNA synthetase/tRNA pair specific for pAF is also required.
Protein Expression and Purification
This protocol outlines the expression of a pAF-containing protein in E. coli using the amber codon suppression methodology.
-
Transformation: Co-transform the expression plasmid containing the gene of interest with the amber codon and the plasmid encoding the pAF-specific tRNA/synthetase pair into a suitable E. coli strain (e.g., DH10B).
-
Starter Culture: Inoculate a 5 mL starter culture of non-inducing medium with the co-transformed cells and grow overnight at 37°C with shaking.
-
Expression Culture: Inoculate 250 mL of autoinduction medium with the starter culture. Add this compound to a final concentration of 1 mM.
-
Incubation: Incubate the culture at 37°C with shaking for 24-30 hours.
-
Cell Harvesting: Harvest the cells by centrifugation and store the pellet at -80°C.
-
Lysis: Resuspend the cell pellet in lysis buffer (e.g., 50 mM Tris-HCl pH 8.0, with protease inhibitors) and lyse the cells by sonication.
-
Clarification: Centrifuge the lysate to remove cell debris.
-
Affinity Chromatography: If the protein is tagged (e.g., with a His-tag), purify the protein from the supernatant using an appropriate affinity chromatography resin (e.g., TALON cobalt affinity resin).[1]
-
Desalting and Tag Removal: Elute the protein and desalt it into a suitable buffer (e.g., 20 mM HEPES pH 7.5). If necessary, remove the affinity tag using a specific protease (e.g., trypsin).[1]
-
Final Purification: Concentrate the protein to a high concentration (e.g., 35-45 mg/mL) for crystallization trials.
Protein Crystallization
-
Crystallization Screening: Screen for initial crystallization conditions using commercial screens (e.g., Crystal Screens I and II, Index Screen) in 96-well sitting-drop vapor diffusion plates. The drops typically consist of 1 µL of protein solution mixed with 1 µL of the reservoir solution.
-
Optimization: Optimize the initial hits by varying the precipitant concentration, pH, and additives in hanging-drop or sitting-drop vapor diffusion plates.
Table 2: Example Crystallization Conditions for sfGFP Variants
| Protein Construct | Crystallization Method | Protein Concentration (mg/mL) | Reservoir Solution |
| Asp133pNO2F sfGFP | Sitting-drop vapor diffusion | 35-45 | 0.2 M ammonium (B1175870) citrate (B86180) tribasic pH 7.0, 18% PEG 3350[3] |
| Asn149pNO2F sfGFP | Sitting-drop vapor diffusion | 35-45 | 1.2 M malic acid[3] |
Data Collection and Structure Determination
-
Crystal Mounting and Cryo-protection: Mount the crystals on a loop and flash-cool them in liquid nitrogen. A cryoprotectant may be necessary to prevent ice formation.
-
X-ray Diffraction: Collect diffraction data using a synchrotron or in-house X-ray source.
-
Data Processing: Process the diffraction data using software like HKL2000 or XDS to determine the space group and unit cell parameters and to integrate the reflection intensities.
-
Structure Solution and Refinement: Solve the structure by molecular replacement using a known structure of the wild-type protein as a search model. Refine the model against the experimental data using software like PHENIX or REFMAC5, and manually build the structure in Coot.
Visualizing the Workflow
The following diagrams illustrate the key workflows in the X-ray crystallography of proteins containing this compound.
Caption: Experimental workflow for X-ray crystallography of pAF-containing proteins.
Caption: Amber codon suppression for pAF incorporation.
References
A Head-to-Head Battle of Bioorthogonal Handles: 4-Aminophenylalanine vs. p-Acetylphenylalanine for Precise Protein Labeling
For researchers, scientists, and drug development professionals, the site-specific modification of proteins is a cornerstone of modern biological inquiry. The ability to attach probes, drugs, or other functional moieties to a specific location on a protein provides unparalleled insights into its function, localization, and interactions. Genetically encoding non-canonical amino acids (ncAAs) with bioorthogonal reactive groups has emerged as a powerful strategy for achieving this precision. This guide provides a comprehensive comparison of two prominent ncAAs used for this purpose: a tetrazine-modified derivative of 4-aminophenylalanine and p-acetylphenylalanine.
While this compound itself can act as a biocompatible nucleophilic catalyst, its utility as a direct bioorthogonal handle for protein labeling is significantly enhanced through derivatization with a tetrazine moiety. This guide will focus on comparing this tetrazine derivative, herein referred to as Tet-4aPhe, with the widely used p-acetylphenylalanine (pAcPhe). We will delve into their respective bioorthogonal chemistries, labeling efficiencies, reaction kinetics, and the experimental workflows for their incorporation and conjugation.
At a Glance: Key Performance Metrics
To facilitate a direct comparison, the following table summarizes the key quantitative data for protein labeling using Tet-4aPhe and pAcPhe.
| Feature | This compound Derivative (Tet-4aPhe) | p-Acetylphenylalanine (pAcPhe) |
| Bioorthogonal Reaction | Inverse-Electron-Demand Diels-Alder (IEDDA) Cycloaddition | Oxime Ligation |
| Reaction Partner | Strained Alkenes (e.g., trans-cyclooctene (B1233481), TCO) | Hydroxylamine/Oxyamine Probes |
| Second-Order Rate Constant (k₂) | High (up to 10⁶ M⁻¹s⁻¹)[1][2] | Moderate (10¹ - 10³ M⁻¹s⁻¹)[3] |
| Labeling Efficiency / Yield | > 95%[4][5][6] | > 95%[7] |
| Typical Reaction Time | Quantitative within 5 minutes at room temperature[4][5][6] | 18-24 hours at 37°C (uncatalyzed) or ~24 hours at room temperature (catalyzed)[7] |
| Typical Protein Expression Yield | ~80 - 200 mg/L in E. coli[4][5][6][8] | Varies depending on the protein and expression system |
| Reaction Conditions | Physiological pH (e.g., pH 7.4)[4][5] | Mildly acidic (pH 4.0-4.5) or neutral pH with aniline-based catalyst[7][9] |
| Catalyst Required | No | Yes (for neutral pH reaction) |
The Chemistry of Precision: Bioorthogonal Reactions
The fundamental difference between Tet-4aPhe and pAcPhe lies in their bioorthogonal reaction partners and mechanisms.
Tet-4aPhe participates in an Inverse-Electron-Demand Diels-Alder (IEDDA) cycloaddition with a strained alkene, most commonly a trans-cyclooctene (TCO) derivative.[10][11] This reaction is exceptionally fast and proceeds without the need for a catalyst, making it highly suitable for in vivo applications.[11][12] The reaction is driven by the release of nitrogen gas, forming a stable dihydropyridazine (B8628806) linkage.[11]
pAcPhe , on the other hand, contains a ketone group that undergoes an oxime ligation with a hydroxylamine- or oxyamine-functionalized probe.[7] This reaction is typically acid-catalyzed, requiring mildly acidic conditions (pH 4.0-4.5) for optimal performance.[7] However, the development of aniline-based catalysts allows the reaction to proceed efficiently at neutral pH, expanding its applicability to acid-sensitive proteins.[7][9]
Experimental Workflows: From Gene to Labeled Protein
The overall workflow for labeling proteins with either Tet-4aPhe or pAcPhe involves two main stages: genetic incorporation of the ncAA into the protein of interest and the subsequent bioorthogonal labeling reaction.
Detailed Experimental Protocols
Genetic Incorporation of Tet-4aPhe and pAcPhe in E. coli
The site-specific incorporation of both Tet-4aPhe and pAcPhe is typically achieved through the suppression of an amber stop codon (TAG) introduced at the desired location in the gene of interest. This requires an orthogonal aminoacyl-tRNA synthetase (aaRS)/tRNA pair that is specific for the respective ncAA.
1. Plasmid Preparation and Transformation:
-
Plasmid 1: Contains the gene of interest with an in-frame amber (TAG) codon at the desired labeling site. This plasmid also carries a selectable marker (e.g., ampicillin (B1664943) resistance).
-
Plasmid 2: Encodes the orthogonal aaRS/tRNA pair specific for either Tet-4aPhe or pAcPhe. This plasmid typically has a different selectable marker (e.g., chloramphenicol (B1208) resistance). For pAcPhe, the pEVOL plasmid is often used.[7] For Tet-4aPhe, an optimized system like pAJE-E7 can be employed.[4][5][6]
-
Co-transform a suitable E. coli expression strain (e.g., BL21(DE3)) with both plasmids and select for dual antibiotic resistance.
2. Protein Expression:
-
Inoculate a starter culture in LB medium containing both antibiotics and grow overnight.
-
The following day, inoculate a larger volume of expression medium (e.g., Terrific Broth or auto-induction medium) containing both antibiotics.
-
Add the respective ncAA to the culture medium. A typical concentration is 1 mM.
-
Grow the culture at 37°C to an OD₆₀₀ of 0.6-0.8.
-
Induce protein expression with IPTG (and arabinose if using a pBAD promoter) and continue to grow the culture at a reduced temperature (e.g., 18-30°C) for 16-24 hours.
-
Harvest the cells by centrifugation.
3. Protein Purification:
-
Lyse the cells using standard methods (e.g., sonication, French press).
-
Purify the protein of interest using an appropriate chromatography technique (e.g., Ni-NTA affinity chromatography for His-tagged proteins).
Bioorthogonal Labeling Reactions
Labeling of Tet-4aPhe-containing Protein with a TCO-Probe:
-
Reactant Preparation:
-
Prepare the purified Tet-4aPhe-containing protein in a suitable buffer at physiological pH (e.g., PBS, pH 7.4).
-
Dissolve the TCO-functionalized probe (e.g., a fluorescent dye) in a compatible solvent like DMSO to create a stock solution.
-
-
Ligation Reaction:
-
Removal of Excess Probe:
-
Remove the unreacted probe using a desalting column or dialysis.
-
Labeling of pAcPhe-containing Protein with a Hydroxylamine-Probe:
Method A: Acidic Conditions
-
Buffer Exchange:
-
Exchange the purified pAcPhe-containing protein into a mildly acidic buffer (e.g., 100 mM sodium acetate, pH 4.0-4.5).
-
-
Ligation Reaction:
-
Add a 10-50 fold molar excess of the hydroxylamine-functionalized probe.
-
Incubate the reaction at 37°C for 18-24 hours.[7]
-
-
Removal of Excess Probe:
-
Remove the unreacted probe via desalting or dialysis.
-
Method B: Neutral pH with Aniline (B41778) Catalysis
-
Reactant Preparation:
-
Prepare the purified pAcPhe-containing protein in a buffer at neutral pH (e.g., PBS, pH 7.0).
-
Prepare a stock solution of an aniline-based catalyst (e.g., p-methoxyaniline) in an organic solvent.
-
-
Ligation Reaction:
-
Add the aniline catalyst to the protein solution to a final concentration of 10-50 mM.
-
Add a molar excess of the hydroxylamine-functionalized probe.
-
Incubate at room temperature for approximately 24 hours.[7]
-
-
Removal of Excess Probe:
-
Remove the unreacted probe and catalyst using a desalting column or dialysis.
-
Considerations for Choosing a Labeling Strategy
The choice between Tet-4aPhe and pAcPhe depends on the specific requirements of the experiment.
Choose Tet-4aPhe for:
-
Rapid labeling: The extremely fast kinetics of the IEDDA reaction are ideal for applications requiring quick labeling, such as in vivo imaging of dynamic processes.[11]
-
Labeling at low concentrations: The high reaction rate allows for efficient labeling even when the protein of interest is present at low concentrations.
-
Strictly physiological conditions: The reaction proceeds efficiently at neutral pH without the need for a catalyst.
-
In vivo applications: The high stability of the reactants and the rapid, catalyst-free nature of the reaction make it well-suited for labeling in living cells and organisms.[11]
Choose pAcPhe for:
-
Cost-effectiveness: p-Acetylphenylalanine is generally more commercially available and less expensive than tetrazine-derivatized amino acids.
-
When longer reaction times are acceptable: If the experimental workflow allows for overnight incubation, the oxime ligation provides a reliable method for protein labeling.
-
Acid-stable proteins: For proteins that are stable at mildly acidic pH, the uncatalyzed oxime ligation is a straightforward procedure.
-
Flexibility in reaction conditions: The availability of aniline catalysis provides an option for labeling acid-sensitive proteins at neutral pH.[7][9]
Potential Effects on Cellular Processes and Protein Function
The introduction of any non-canonical amino acid has the potential to affect cellular processes and protein function.
-
Toxicity: While both Tet-4aPhe and pAcPhe are generally well-tolerated by expression hosts, high concentrations of any ncAA can potentially be toxic. The tetrazine moiety in Tet-4aPhe is designed for stability in the cellular environment.[11][13][14]
-
Protein Structure and Function: The steric bulk of the ncAA and the attached probe can potentially perturb the structure and function of the target protein. Tet-4aPhe, with its larger tetrazine group, may be more perturbing than the smaller acetyl group of pAcPhe. However, the subsequent ligation product of pAcPhe with a probe can also be bulky. Careful selection of the incorporation site is crucial to minimize such effects.
-
Cellular Pathways: The introduction of an orthogonal translation system (aaRS/tRNA pair) and the suppression of a stop codon can potentially interfere with endogenous translation. However, these systems are designed to be orthogonal and generally have minimal off-target effects.
No specific signaling pathways are universally described as being affected by the incorporation of these ncAAs. However, as with any genetic modification, it is prudent to perform appropriate controls to ensure that the observed effects are due to the intended protein modification and not an artifact of the labeling system itself.
Conclusion
Both the tetrazine derivative of this compound and p-acetylphenylalanine are powerful tools for the site-specific labeling of proteins. Tet-4aPhe, with its exceptionally fast, catalyst-free IEDDA ligation, offers a significant advantage for applications requiring rapid labeling under strictly physiological conditions, particularly in living systems. On the other hand, pAcPhe provides a robust and more established method with the flexibility of performing the oxime ligation under either acidic or catalyzed neutral conditions. The choice between these two excellent bioorthogonal handles will ultimately be guided by the specific demands of the research question, including the required reaction speed, the sensitivity of the protein to reaction conditions, and the experimental setting.
References
- 1. benchchem.com [benchchem.com]
- 2. benchchem.com [benchchem.com]
- 3. Rapid Oxime and Hydrazone Ligations with Aromatic Aldehydes for Biomolecular Labeling - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Tetrazine Amino Acid Encoding for Rapid and Complete Protein Bioconjugation [bio-protocol.org]
- 5. en.bio-protocol.org [en.bio-protocol.org]
- 6. Tetrazine Amino Acid Encoding for Rapid and Complete Protein Bioconjugation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Genetic Incorporation of the Unnatural Amino Acid p-Acetyl Phenylalanine into Proteins for Site-Directed Spin Labeling - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Access To Faster Eukaryotic Cell Labeling With Encoded Tetrazine Amino Acids - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Ketoxime coupling of p-acetylphenylalanine at neutral pH for site-directed spin labeling of human sulfite oxidase - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. benchchem.com [benchchem.com]
- 11. Genetically Encoded Tetrazine Amino Acid Directs Rapid Site-Specific In Vivo Bioorthogonal Ligation with trans-Cyclooctenes - PMC [pmc.ncbi.nlm.nih.gov]
- 12. The Tetrazine Ligation: Fast Bioconjugation based on Inverse-electron-demand Diels-Alder Reactivity - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Tetrazine-Containing Amino Acid for Peptide Modification and Live Cell Labeling | PLOS One [journals.plos.org]
- 14. Tetrazine-Containing Amino Acid for Peptide Modification and Live Cell Labeling - PMC [pmc.ncbi.nlm.nih.gov]
Decoding Expression: A Researcher's Guide to Confirming 4-Aminophenylalanine-Containing Proteins
For researchers, scientists, and drug development professionals venturing into the world of unnatural amino acid incorporation, confirming the successful expression of proteins containing 4-Aminophenylalanine (pAF) is a critical checkpoint. This guide provides a comprehensive comparison of available methods for Western blot analysis of pAF-containing proteins, offering objective insights and supporting experimental data to inform your selection of the most suitable technique.
The site-specific incorporation of pAF, an unnatural amino acid with a reactive primary aromatic amine, opens up a myriad of possibilities for protein engineering, including novel drug conjugation strategies and the introduction of unique biophysical probes. However, the absence of commercially available antibodies that specifically recognize the pAF residue necessitates alternative approaches for its detection in a Western blot format. This guide will compare the leading methods: a chemical labeling approach targeting the unique functionality of pAF and mass spectrometry as the gold standard for confirmation.
Comparison of Detection Methods
The primary challenge in detecting pAF-containing proteins lies in distinguishing them from their wild-type counterparts. While traditional Western blotting relies on specific antibody-antigen recognition, the subtle difference of a single amino acid substitution makes the development of pAF-specific antibodies difficult. Therefore, researchers have turned to methods that either exploit the unique chemical reactivity of the pAF side chain or provide definitive mass-based evidence of its incorporation.
| Method | Principle | Pros | Cons | Throughput | Quantitative Capability |
| Chemical Labeling (Diazotization-based) | The primary aromatic amine of pAF is chemically modified (e.g., via diazotization) to introduce a reporter molecule (e.g., biotin) for subsequent detection with streptavidin-HRP. | High sensitivity, relatively low cost, compatible with standard Western blot workflow. | Requires chemical labeling steps on the membrane, potential for non-specific labeling if conditions are not optimized. | High | Semi-quantitative to quantitative with proper controls. |
| Mass Spectrometry (LC-MS/MS) | The protein of interest is excised from a gel or analyzed in solution to determine its precise mass, confirming the incorporation of pAF by the corresponding mass shift. | Unambiguous confirmation of incorporation and localization, highly accurate and sensitive. | Low throughput, requires specialized equipment and expertise, not a blotting technique but a confirmatory method. | Low | Highly quantitative (with isotopic labeling). |
| Anti-His/FLAG/etc. Tag Western Blot | A standard Western blot is performed to detect an epitope tag (e.g., His-tag, FLAG-tag) fused to the protein of interest. | Simple, uses readily available antibodies, confirms expression of the full-length tagged protein. | Does not directly confirm pAF incorporation; a full-length protein could be expressed with a natural amino acid at the target site. | High | Semi-quantitative. |
Visualizing the Workflow: From Expression to Detection
The process of expressing and confirming a pAF-containing protein involves several key stages. The following diagram illustrates the general workflow, highlighting the point at which different detection methods are employed.
Assessing Natural Amino Acid Misincorporation at the Amber Codon: A Comparative Guide
For Researchers, Scientists, and Drug Development Professionals
The deliberate incorporation of non-canonical amino acids (ncAAs) at amber (UAG) stop codons is a powerful tool in protein engineering and drug development. However, a critical aspect of validating these systems is to assess the misincorporation of natural amino acids at the target codon, a phenomenon known as amber codon readthrough. This guide provides an objective comparison of common methods used to quantify this misincorporation, complete with experimental data, detailed protocols, and workflow diagrams to aid in selecting the most appropriate technique for your research needs.
Comparison of Key Assessment Methods
The selection of an appropriate method for assessing misincorporation depends on the specific experimental goals, required sensitivity, and available resources. The following table summarizes the key quantitative parameters of the most common techniques.
| Method | Principle | Typical Readthrough Detection Limit | Throughput | Quantitative Precision | Key Advantages | Key Disadvantages |
| Dual-Fluorescence Reporter Assay | Ratiometric measurement of two fluorescent proteins separated by an amber codon.[1][2] | ~0.1-1% suppression efficiency[3][4] | High (96- or 384-well plates, flow cytometry) | Moderate to High | High-throughput, single-cell analysis possible, relatively low cost.[5] | Indirect measurement, potential for artifacts from reporter protein folding. |
| Mass Spectrometry (MS) | Direct identification and quantification of peptides with misincorporated amino acids.[6][7] | As low as 1 in 10,000 events (MS-READ method).[8] | Low to Medium | High | Direct detection and identification of misincorporated amino acids, high sensitivity and specificity.[6] | Lower throughput, higher cost, complex data analysis.[9] |
| tRNA Aminoacylation Fidelity Assay | Measures the extent to which an orthogonal tRNA is charged with natural amino acids. | N/A (Measures charging fidelity, not readthrough directly) | Medium | High | Directly assesses the source of potential misincorporation by the orthogonal pair.[10][11] | Does not directly measure readthrough at the ribosome. |
| Western Blotting | Immunodetection of full-length protein resulting from amber codon readthrough.[12][13] | ~1-5% suppression efficiency | Low | Low (Semi-quantitative) | Simple, widely available technique. | Low sensitivity, not ideal for precise quantification. |
Experimental Workflows and Signaling Pathways
Understanding the experimental workflow is crucial for implementing these assessment methods. The following diagrams, generated using Graphviz, illustrate the key steps in the dual-fluorescence reporter assay and mass spectrometry-based misincorporation analysis.
Caption: Workflow for assessing amber suppression using a dual-fluorescence reporter.
Caption: Workflow for direct detection of amino acid misincorporation by mass spectrometry.
Experimental Protocols
Dual-Fluorescence Reporter Assay Protocol
This protocol is adapted from studies utilizing reporters like mCherry-TAG-EGFP.[2][4]
1. Cell Culture and Transfection:
-
Seed mammalian cells (e.g., HEK293T) in a 24-well plate at a density that will result in 70-80% confluency at the time of transfection.
-
Co-transfect the cells with a plasmid encoding the dual-fluorescence reporter (e.g., pReporter-RFP-TAG-GFP) and, if applicable, plasmids for the orthogonal tRNA/aminoacyl-tRNA synthetase pair. Use a standard transfection reagent according to the manufacturer's instructions.
-
As a control, transfect a construct with a wild-type codon instead of the TAG codon to determine the maximum fluorescence ratio.
-
Culture the cells for 24-48 hours post-transfection to allow for reporter expression.
2. Flow Cytometry Analysis:
-
Harvest the cells by trypsinization and resuspend them in a suitable buffer for flow cytometry (e.g., PBS with 2% FBS).
-
Analyze the cells using a flow cytometer equipped with lasers and filters appropriate for the chosen fluorescent proteins (e.g., blue laser for GFP, yellow-green laser for RFP).
-
For each sample, collect data from at least 10,000 single-cell events.
-
Gate the cell population to exclude debris and doublets.
3. Data Analysis:
-
For each cell, determine the fluorescence intensity for both fluorescent proteins.
-
Calculate the ratio of the second fluorescent protein (downstream of the TAG codon, e.g., GFP) to the first fluorescent protein (upstream of the TAG codon, e.g., RFP).
-
The readthrough efficiency is calculated by normalizing the GFP/RFP ratio of the TAG-containing construct to the GFP/RFP ratio of the wild-type control construct.
Mass Spectrometry-Based Misincorporation Analysis Protocol
This protocol provides a general workflow for identifying misincorporated amino acids.[8][14]
1. Sample Preparation:
-
Express the protein of interest containing an amber codon in the desired expression system.
-
Lyse the cells and purify the protein of interest using affinity chromatography (e.g., His-tag purification) to enrich the sample.
-
Perform a buffer exchange to a buffer compatible with enzymatic digestion (e.g., ammonium (B1175870) bicarbonate).
-
Reduce and alkylate the protein to denature it and prevent disulfide bond reformation.
-
Digest the protein into peptides using a specific protease, such as trypsin.
2. LC-MS/MS Analysis:
-
Separate the resulting peptides using reverse-phase liquid chromatography (LC).
-
Elute the peptides from the LC column directly into the mass spectrometer.
-
The mass spectrometer will perform data-dependent acquisition, alternating between full MS scans to detect peptide ions and MS/MS scans to fragment selected peptide ions.
3. Data Analysis:
-
Search the acquired MS/MS spectra against a protein database that includes the sequence of the target protein.
-
To identify misincorporation events, perform an "open" or "unrestricted" search that allows for any amino acid substitution at the position of the amber codon.
-
Alternatively, create a custom database containing all 20 possible natural amino acid substitutions at the target site.
-
Quantify the relative abundance of the misincorporated peptide(s) to the wild-type (or intended non-canonical) peptide by comparing the peak areas of their respective extracted ion chromatograms.
tRNA Aminoacylation Fidelity Assay (tRNA Extension - tREX) Protocol
This protocol is a simplified overview of the tREX method.[8]
1. tRNA Isolation and Oxidation:
-
Isolate total tRNA from cells expressing the orthogonal tRNA/synthetase pair.
-
Treat the tRNA sample with sodium periodate (B1199274) (NaIO₄) at a slightly acidic pH. This will oxidize the 3'-ribose of uncharged tRNAs, rendering them unable to be extended by a polymerase. Aminoacylated tRNAs are protected from this oxidation.
2. Probe Annealing and Extension:
-
Anneal a fluorescently labeled DNA probe that is complementary to the 3' end of the tRNA of interest.
-
Add a DNA polymerase (e.g., Klenow fragment) and dNTPs. The polymerase will extend the probe only if the tRNA was initially aminoacylated (and thus not oxidized).
3. Gel Electrophoresis and Analysis:
-
Separate the reaction products on a denaturing polyacrylamide gel.
-
Visualize the fluorescently labeled DNA. An extended probe indicates that the tRNA was aminoacylated.
-
The intensity of the band corresponding to the extended product can be used to quantify the fraction of aminoacylated tRNA.
References
- 1. researchgate.net [researchgate.net]
- 2. Identification of permissive amber suppression sites for efficient non-canonical amino acid incorporation in mammalian cells - PMC [pmc.ncbi.nlm.nih.gov]
- 3. assaygenie.com [assaygenie.com]
- 4. A Label-Free Assay for Aminoacylation of tRNA | MDPI [mdpi.com]
- 5. User Guide — graphviz 0.21 documentation [graphviz.readthedocs.io]
- 6. graphviz.org [graphviz.org]
- 7. Expanding a tyrosyl-tRNA synthetase assay to other aminoacyl-tRNA synthetases - PMC [pmc.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. academic.oup.com [academic.oup.com]
- 10. Frontiers | A CHO-Based Cell-Free Dual Fluorescence Reporter System for the Straightforward Assessment of Amber Suppression and scFv Functionality [frontiersin.org]
- 11. Protocols | Mass Spectrometry Research Facility [massspec.chem.ox.ac.uk]
- 12. researchgate.net [researchgate.net]
- 13. researchgate.net [researchgate.net]
- 14. Development of Assay Systems for Amber Codon Decoding at the Steps of Initiation and Elongation in Mycobacteria - PMC [pmc.ncbi.nlm.nih.gov]
A Comparative Guide to the Functional Differences Between L- and D-Isomers of 4-Aminophenylalanine
For Researchers, Scientists, and Drug Development Professionals
The incorporation of unnatural amino acids into peptides and proteins is a powerful strategy in drug discovery and chemical biology, offering the potential to enhance therapeutic properties and probe biological systems. Among these, 4-aminophenylalanine, a synthetic analog of phenylalanine, exists as two stereoisomers, L-4-aminophenylalanine and D-4-aminophenylalanine. The chirality of this amino acid plays a pivotal role in its biological activity, influencing its interactions with enzymes, receptors, and its overall metabolic fate. This guide provides a comprehensive comparison of the known functional differences between the L- and D-isomers of this compound, supported by available experimental data and detailed methodologies.
Biochemical and Biological Activity: A Tale of Two Isomers
The spatial arrangement of the amino and carboxyl groups around the α-carbon dictates the interaction of each isomer with the chiral environment of biological systems. While L-amino acids are the canonical building blocks of proteins in nature, the strategic use of D-isomers can confer unique advantages, such as increased resistance to enzymatic degradation.
Enzyme Interactions
One of the most well-documented functional differences between L- and D-amino acid isomers lies in their interaction with enzymes. The active sites of enzymes are exquisitely stereospecific, typically favoring one enantiomer over the other.
Phenylalanine Hydroxylase Activation:
A study on the allosteric activation of phenylalanine hydroxylase (PheH), a key enzyme in phenylalanine metabolism, revealed that L-4-aminophenylalanine can act as an activator, albeit with lower efficacy compared to the natural substrate, L-phenylalanine. In this study, L-4-aminophenylalanine exhibited a lower level of activation compared to the approximately 7-fold activation observed with L-phenylalanine and D-phenylalanine.[1][2][3] Unfortunately, the study did not include data on the D-isomer of this compound for a direct comparison.
| Compound | Concentration for Preincubation | Relative Activation of PheH |
| L-Phenylalanine | 1 mM | ~7-fold |
| D-Phenylalanine | 10 mM | ~7-fold |
| L-4-Aminophenylalanine | 10 mM | Lower than L- and D-phenylalanine |
| Table 1: Activation of Phenylalanine Hydroxylase by Phenylalanine Analogs. Data sourced from a study on the amino acid specificity for PheH activation.[1][2][3] |
Experimental Protocol: Phenylalanine Hydroxylase Activity Assay
To assess the activation of phenylalanine hydroxylase, the following protocol was employed:
-
Enzyme Preparation: Purified phenylalanine hydroxylase is prepared in a suitable buffer (e.g., 200 mM HEPES, pH 7.0).
-
Preincubation: The enzyme is preincubated with the test compound (L- or D-4-aminophenylalanine) at a specific concentration for a defined period (e.g., 10 minutes at 23°C).
-
Assay Initiation: The preincubation mixture is added to an assay mixture containing the substrate (L-phenylalanine), the cofactor tetrahydrobiopterin (B1682763) (BH4), catalase, dithiothreitol, and ferrous ammonium (B1175870) sulfate (B86663) in a buffered solution.
-
Quenching and Analysis: The reaction is stopped after a set time (e.g., 30 seconds) by adding a strong acid (e.g., 2 M HCl). The amount of product (tyrosine) formed is then quantified using a suitable analytical method, such as high-performance liquid chromatography (HPLC).
Figure 1: General workflow for assessing the activation of phenylalanine hydroxylase by test compounds.
Applications in Drug Design and Peptide Chemistry
The distinct properties of L- and D-isomers of this compound make them valuable tools in drug design and the synthesis of novel peptides with enhanced therapeutic potential.
L-4-Aminophenylalanine in Peptide Synthesis
L-4-Aminophenylalanine is utilized as a building block in peptide synthesis to introduce a functional handle for further modifications. The amino group on the phenyl ring can be used for conjugation, labeling, or to modulate the electronic properties of the peptide. Derivatives of L-4-aminophenylalanine have been explored as components of potent and selective inhibitors for enzymes like dipeptidyl peptidase IV (DPP-4) and as antagonists for receptors such as VLA-4.[4][5][6]
D-4-Aminophenylalanine for Enhanced Stability and Bioactivity
Cellular Uptake and Toxicity
The stereochemistry of this compound is expected to influence its transport across cell membranes and its potential cytotoxicity. Amino acid transporters often exhibit stereoselectivity, favoring the L-isomers.
While direct comparative data on the cellular uptake and toxicity of the individual L- and D-isomers of this compound are limited, research on related compounds provides some insights. For instance, studies on peptides containing D-amino acids have shown that they can be effectively internalized by cells, although the specific uptake mechanisms may differ from their L-counterparts.
Regarding toxicity, the available information for this compound (without specifying the isomer) indicates that it may cause skin and eye irritation and respiratory irritation.[11] A comprehensive comparative toxicological assessment of the L- and D-isomers is needed to fully understand their safety profiles.
Signaling Pathways
Currently, there is a lack of specific research detailing signaling pathways that are differentially modulated by the L- and D-isomers of this compound. The biological effects of these isomers are likely to be mediated through their incorporation into peptides that interact with specific receptors or enzymes, thereby influencing downstream signaling cascades. The nature of these interactions would be highly dependent on the specific peptide sequence and the target protein.
To elucidate the differential effects on signaling pathways, a systematic approach would be required:
Figure 2: A proposed experimental workflow to identify signaling pathways differentially affected by peptides containing L- or D-4-aminophenylalanine.
Conclusion
The functional differences between L- and D-isomers of this compound stem from the fundamental principles of stereochemistry and their differential recognition by biological macromolecules. While L-4-aminophenylalanine serves as a versatile building block for creating novel peptides and enzyme inhibitors, the D-isomer holds promise for enhancing the stability and bioavailability of peptide-based therapeutics.
Further direct comparative studies are warranted to fully elucidate the distinct pharmacological and toxicological profiles of these two isomers. Such research will be invaluable for the rational design of more effective and safer therapeutic agents and for advancing our understanding of the role of chirality in biological systems. Researchers are encouraged to employ rigorous analytical methods for chiral separation and to conduct parallel in vitro and in vivo studies to comprehensively characterize the functional differences between these two important unnatural amino acids.
References
- 1. benchchem.com [benchchem.com]
- 2. The Amino Acid Specificity for Activation of Phenylalanine Hydroxylase Matches the Specificity for Stabilization of Regulatory Domain Dimers - PMC [pmc.ncbi.nlm.nih.gov]
- 3. The Amino Acid Specificity for Activation of Phenylalanine Hydroxylase Matches the Specificity for Stabilization of Regulatory Domain Dimers - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. benchchem.com [benchchem.com]
- 5. solubilityofthings.com [solubilityofthings.com]
- 6. This compound and 4-aminocyclohexylalanine derivatives as potent, selective, and orally bioavailable inhibitors of dipeptidyl peptidase IV - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. benchchem.com [benchchem.com]
- 8. benchchem.com [benchchem.com]
- 9. benchchem.com [benchchem.com]
- 10. Introduction of D-phenylalanine enhanced the receptor binding affinities of gonadotropin-releasing hormone peptides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. This compound | C9H12N2O2 | CID 151001 - PubChem [pubchem.ncbi.nlm.nih.gov]
Safety Operating Guide
Safeguarding Your Laboratory: Proper Disposal of 4-Aminophenylalanine
For researchers, scientists, and professionals in drug development, meticulous adherence to safety protocols is paramount, extending beyond the bench to the proper disposal of all chemical reagents. This guide provides essential, immediate safety and logistical information for the operational disposal of 4-Aminophenylalanine, ensuring the protection of laboratory personnel and the environment.
Immediate Safety and Handling
Before initiating any disposal procedure, it is crucial to consult the Safety Data Sheet (SDS) for this compound. This compound is classified as a skin and eye irritant.[1][2][3] Therefore, appropriate personal protective equipment (PPE) must be worn at all times.
Required Personal Protective Equipment (PPE):
-
Gloves: Wear chemical-resistant gloves.[1]
-
Eye Protection: Use safety glasses or goggles.[1]
-
Lab Coat: A standard lab coat is necessary to prevent skin contact.[1]
In the event of a spill, avoid generating dust. For small spills, the material should be dampened with water and transferred to a sealed, suitable container for disposal.[1] The affected area should then be cleaned with soap and water.[1]
Quantitative Data Summary
The following table summarizes key data for this compound for easy reference.
| Property | Value |
| CAS Number | 943-80-6[1][2] |
| Molecular Formula | C₉H₁₂N₂O₂[1][2] |
| Molecular Weight | 180.20 g/mol [1][2] |
| Primary Hazards | Skin Irritation, Eye Irritation[1][2][3] |
Step-by-Step Disposal Procedure
Chemical waste generators are responsible for determining if a chemical is classified as hazardous waste and must adhere to local, regional, and national regulations for complete and accurate classification and disposal.[1] The following procedure outlines the recommended steps for the proper disposal of this compound.
-
Characterization: Determine if the this compound waste is contaminated with other hazardous materials. If it is, the entire mixture must be treated as hazardous waste.[1]
-
Segregation: Keep this compound waste separate from other chemical waste streams to prevent unintended reactions.[1]
-
Labeling: Clearly label the waste container with "this compound" and list any other contaminants present.[1]
-
Storage: Store the sealed waste container in a designated, well-ventilated area, away from incompatible materials.[1]
-
Licensed Disposal: Arrange for the collection and disposal of the waste through a licensed hazardous waste disposal company.[1] Contact your institution's Environmental Health and Safety (EHS) office for established procedures.[1]
Disposal Workflow
The following diagram illustrates the decision-making process for the proper disposal of this compound.
Caption: Disposal workflow for this compound.
Experimental Protocols
Currently, there are no widely established experimental protocols for the in-lab neutralization or deactivation of this compound for disposal purposes. The standard and recommended procedure is to manage it as hazardous waste through a licensed disposal service. Attempting to neutralize the compound without a validated protocol could lead to unforeseen hazardous reactions. Always consult with your institution's EHS office before attempting any chemical treatment of waste.
References
Personal protective equipment for handling 4-Aminophenylalanine
For researchers, scientists, and drug development professionals, the paramount concern when handling chemical compounds like 4-Aminophenylalanine is safety. Adherence to rigorous safety protocols and the use of appropriate personal protective equipment (PPE) are critical to minimizing exposure risks and ensuring a safe laboratory environment. While 4-Amino-DL-phenylalanine is not classified as a hazardous substance under the 2012 OSHA Hazard Communication Standard, the toxicological properties of its isomers may not be fully investigated, warranting a cautious approach.[1] This guide provides essential safety and logistical information for handling this compound, covering recommended PPE, step-by-step operational procedures, and disposal plans.
Personal Protective Equipment (PPE)
A comprehensive suite of PPE is crucial to protect against potential hazards when handling this compound. The following table summarizes the recommended equipment.
| PPE Category | Item | Specifications and Recommendations |
| Eye and Face Protection | Safety Glasses with Side Shields | Must conform to EN 166 (EU) or ANSI Z87.1 (US) standards.[1] |
| Face Shield | Recommended when there is a significant risk of splashing or dust generation.[1] | |
| Hand Protection | Chemical-Resistant Gloves | Nitrile or neoprene gloves are recommended. For extended contact, it is crucial to consult the glove manufacturer's chemical resistance data. Double gloving is advised for enhanced protection.[1] |
| Body Protection | Laboratory Coat | A standard, fully buttoned laboratory coat should be worn to prevent skin contact.[1][2] |
| Chemical Apron | A splash-resistant chemical apron is recommended for procedures with a higher risk of splashes.[1] | |
| Respiratory Protection | Dust Mask/Respirator | If handling procedures are likely to generate dust, a NIOSH-approved N95 (US) or P1 (EN 143) dust mask should be used.[1] It is recommended to work in a well-ventilated area or under a fume hood.[1] For higher exposures or if irritation is experienced, a full-face respirator may be necessary.[3] |
Operational Plan: Step-by-Step Handling Protocol
A strict operational workflow is essential for minimizing the risk of exposure and contamination. The following diagram and steps outline the recommended procedure for handling this compound.
1. Preparation:
-
Area Preparation: Ensure the work area, preferably a chemical fume hood, is clean and uncluttered.
-
PPE: Don the appropriate personal protective equipment as outlined in the table above. Double gloving is recommended.[1]
2. Handling:
-
Weighing: If weighing the solid compound, do so in a ventilated balance enclosure or a fume hood to minimize dust inhalation.
-
Solution Preparation: When preparing solutions, slowly add the this compound solid to the solvent to avoid splashing. If the dissolution process is exothermic, use an ice bath to control the temperature.[1] Ensure the final container is clearly labeled.
3. Post-Handling and Disposal:
-
Decontamination: Thoroughly decontaminate all work surfaces and equipment that came into contact with the chemical.
-
PPE Removal and Disposal: Carefully remove and dispose of contaminated gloves and other disposable PPE in a designated waste container.[1] Contaminated clothing should be removed and washed before reuse.[3][4]
-
Hand Washing: Wash hands thoroughly with soap and water after completing the work.[1]
-
Waste Disposal: All waste containing this compound should be collected in a suitable, sealed container and disposed of as chemical waste according to your institution's environmental health and safety (EHS) guidelines.[2] The container must be clearly labeled.[2]
Emergency Procedures
In the event of an accidental exposure, follow these first-aid measures immediately:
-
If Inhaled: Move the individual to fresh air. If breathing is difficult, provide respiratory support and seek medical attention.[3][4]
-
In Case of Skin Contact: Immediately remove contaminated clothing and wash the affected skin area with plenty of soap and water.[3][5] If skin irritation occurs, seek medical help.[3][4]
-
In Case of Eye Contact: Rinse cautiously with water for several minutes.[3][4] If present, remove contact lenses and continue rinsing for at least 15 minutes.[3] Seek immediate medical attention.
-
If Swallowed: Rinse the mouth with water. Do not induce vomiting. Call a poison control center or doctor for guidance.[3]
By strictly adhering to these safety protocols, researchers can significantly mitigate the risks associated with handling this compound and maintain a safe and productive laboratory environment. Always consult your institution's specific safety guidelines and the material's Safety Data Sheet (SDS) before beginning any work.
References
Retrosynthesis Analysis
AI-Powered Synthesis Planning: Our tool employs the Template_relevance Pistachio, Template_relevance Bkms_metabolic, Template_relevance Pistachio_ringbreaker, Template_relevance Reaxys, Template_relevance Reaxys_biocatalysis model, leveraging a vast database of chemical reactions to predict feasible synthetic routes.
One-Step Synthesis Focus: Specifically designed for one-step synthesis, it provides concise and direct routes for your target compounds, streamlining the synthesis process.
Accurate Predictions: Utilizing the extensive PISTACHIO, BKMS_METABOLIC, PISTACHIO_RINGBREAKER, REAXYS, REAXYS_BIOCATALYSIS database, our tool offers high-accuracy predictions, reflecting the latest in chemical research and data.
Strategy Settings
| Precursor scoring | Relevance Heuristic |
|---|---|
| Min. plausibility | 0.01 |
| Model | Template_relevance |
| Template Set | Pistachio/Bkms_metabolic/Pistachio_ringbreaker/Reaxys/Reaxys_biocatalysis |
| Top-N result to add to graph | 6 |
Feasible Synthetic Routes



Featured Recommendations
| Most viewed |
|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
