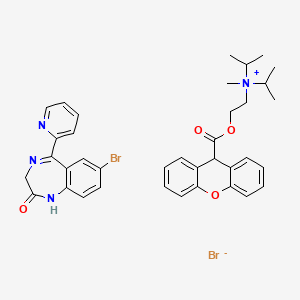
Lexil
Description
BenchChem offers high-quality Lexil suitable for many research applications. Different packaging options are available to accommodate customers' requirements. Please inquire for more information about Lexil including the price, delivery time, and more detailed information at info@benchchem.com.
Properties
CAS No. |
63280-97-7 |
|---|---|
Molecular Formula |
C37H40Br2N4O4 |
Molecular Weight |
764.5 g/mol |
IUPAC Name |
7-bromo-5-pyridin-2-yl-1,3-dihydro-1,4-benzodiazepin-2-one;methyl-di(propan-2-yl)-[2-(9H-xanthene-9-carbonyloxy)ethyl]azanium;bromide |
InChI |
InChI=1S/C23H30NO3.C14H10BrN3O.BrH/c1-16(2)24(5,17(3)4)14-15-26-23(25)22-18-10-6-8-12-20(18)27-21-13-9-7-11-19(21)22;15-9-4-5-11-10(7-9)14(17-8-13(19)18-11)12-3-1-2-6-16-12;/h6-13,16-17,22H,14-15H2,1-5H3;1-7H,8H2,(H,18,19);1H/q+1;;/p-1 |
InChI Key |
VJPXJCQAEYLZCE-UHFFFAOYSA-M |
SMILES |
CC(C)[N+](C)(CCOC(=O)C1C2=CC=CC=C2OC3=CC=CC=C13)C(C)C.C1C(=O)NC2=C(C=C(C=C2)Br)C(=N1)C3=CC=CC=N3.[Br-] |
Canonical SMILES |
CC(C)[N+](C)(CCOC(=O)C1C2=CC=CC=C2OC3=CC=CC=C13)C(C)C.C1C(=O)NC2=C(C=C(C=C2)Br)C(=N1)C3=CC=CC=N3.[Br-] |
Synonyms |
Lexil Ro 10-9618 |
Origin of Product |
United States |
The Theoretical Underpinnings of Lexile Measures: A Technical Guide
The Lexile® Framework for Reading, developed by MetaMetrics®, provides a scientific approach to measuring both a reader's ability and the difficulty of a text on the same scale. This allows for a more precise matching of readers with texts, aiming to optimize reading comprehension and growth. This in-depth technical guide explores the core theoretical basis of Lexile measures, designed for researchers, scientists, and professionals in drug development who require a thorough understanding of its psychometric and linguistic foundations.
Core Principles of the Lexile Framework
The fundamental concept behind the Lexile Framework is to place both reader ability and text complexity onto a single, developmental scale.[1][2][3][4][5][6][7] This shared scale enables a direct comparison between a reader's proficiency and a text's difficulty, facilitating the selection of appropriately challenging reading material.[1][8][9] The two key measures within this framework are:
-
Lexile Reader Measure: This quantifies a person's reading ability. It is determined through a reading comprehension test or program that has been linked to the Lexile Framework.[2][3][8][10][11] A higher Lexile reader measure signifies a greater reading ability.[8]
-
Lexile Text Measure: This indicates the reading demand of a text.[2][3][12] It is calculated by analyzing the semantic and syntactic characteristics of the text using the Lexile Analyzer®.[1][13][14] A higher Lexile text measure corresponds to a more challenging text.[8]
The Lexile scale is a developmental scale ranging from below 0L for beginning readers and texts (designated with a "BR" for Beginning Reader) to over 1600L for advanced readers and texts.[1][3][4]
Psychometric Foundation: The Rasch Model
The Lexile Framework is built upon a strong psychometric foundation, specifically the Rasch model.[1][15][16][17][18] The Rasch model is a form of conjoint measurement, which means it allows for the measurement of two different elements—in this case, reader ability and text difficulty—on the same scale and in the same units.[1] This is a crucial aspect of the framework, as it provides the theoretical basis for matching readers and texts.
The application of the Rasch model allows for the creation of a linear measurement scale where the difference between any two points on the scale has the same meaning, regardless of where on the scale it occurs. This is in contrast to raw scores on a test, where the difference in ability between scores at the extremes of the scale may not be the same as the difference between scores in the middle.[16]
Quantifying Text Complexity: The Lexile Analyzer®
The Lexile text measure is determined through a proprietary software called the Lexile Analyzer®.[1][12][13] This tool analyzes the full text to evaluate its complexity based on two well-established predictors of reading difficulty: syntactic complexity and semantic difficulty.[8][10][19][20]
-
Syntactic Complexity (Sentence Length): This is measured by the mean sentence length. Longer sentences are generally more grammatically complex and place a greater demand on a reader's short-term memory, thus indicating a higher level of syntactic difficulty.[1][10]
-
Semantic Difficulty (Word Frequency): This is determined by the frequency of words in a large corpus of text. The Lexile Framework uses the mean log word frequency.[1][13] Words that appear less frequently in the corpus are considered more challenging, indicating greater semantic difficulty.[10]
The combination of these two factors in the Lexile equation produces the Lexile measure for a text.[1][13] Longer sentences and lower-frequency words result in a higher Lexile measure, while shorter sentences and higher-frequency words lead to a lower measure.[1][14]
Experimental Protocol for Lexile Text Measurement
The process of analyzing a text with the Lexile Analyzer® follows a detailed protocol to ensure accuracy and consistency:
-
Text Preparation: The text must be in a plain text format. Any non-prose elements such as poetry, lists, or song lyrics are removed as they lack conventional punctuation and can skew the analysis.[1][12][14][21]
-
Slicing the Text: The text is divided into 125-word slices.[17][19]
-
Analysis of Slices: Each slice is analyzed for its sentence length and word frequency against the Lexile corpus, which contains nearly 600 million words from a wide variety of sources and genres.[17][19]
-
Application of the Lexile Equation: The calculations for sentence length and word frequency are input into the Lexile equation to determine a Lexile measure for each slice.
-
Rasch Model Application: The Lexile measures of all the slices are then applied to the Rasch psychometric model to calculate the final Lexile measure for the entire text.[17][19]
For texts intended for early readers (650L and below), the Lexile Analyzer® incorporates nine variables, including decoding, patterning, and structural variables, to provide a more nuanced assessment of text complexity.[22]
Data Presentation
The quantitative data associated with the Lexile Framework is summarized in the tables below for easy comparison.
| Lexile Scale Range | Reader/Text Description |
| BR (Beginning Reader) | Measures below 0L for emergent readers and texts.[3][4] |
| 200L - 1600L+ | The typical range of the Lexile scale.[18] |
| Above 1700L | Advanced readers and texts.[23] |
| Lexile Range for Optimal Reading | Forecasted Comprehension Rate | Description |
| Reader's Lexile Measure -100L to +50L | Approximately 75% | This range is considered the "sweet spot" for reading growth, providing enough challenge to encourage progress without causing frustration.[8][11][19][24] |
Visualizing the Lexile Framework
The following diagrams, created using the DOT language, illustrate the core concepts and workflows of the Lexile Framework.
References
- 1. metametricsinc.com [metametricsinc.com]
- 2. researchgate.net [researchgate.net]
- 3. Lexile Framework for Reading [partnerhelp.metametricsinc.com]
- 4. lexile.com [lexile.com]
- 5. youtube.com [youtube.com]
- 6. m.youtube.com [m.youtube.com]
- 7. youtube.com [youtube.com]
- 8. bjupresshomeschool.com [bjupresshomeschool.com]
- 9. scispace.com [scispace.com]
- 10. Understanding the Lexile Framework- the Pros & Cons — Reading Rev [readingrev.com]
- 11. Lexile Measures [help.turnitin.com]
- 12. Lexile Analyzer® [la-tools.lexile.com]
- 13. cdn.lexile.com [cdn.lexile.com]
- 14. help.activelylearn.com [help.activelylearn.com]
- 15. Using Lexile Reading Measures to Improve Literacy [rasch.org]
- 16. scribd.com [scribd.com]
- 17. renaissance.com [renaissance.com]
- 18. cdn.edmentum.com [cdn.edmentum.com]
- 19. cdn.lexile.com [cdn.lexile.com]
- 20. scholastic.com [scholastic.com]
- 21. youtube.com [youtube.com]
- 22. Lexile Reading and Text Measures [partnerhelp.metametricsinc.com]
- 23. files.eric.ed.gov [files.eric.ed.gov]
- 24. m.youtube.com [m.youtube.com]
what are the core principles of the Lexile framework
An In-depth Technical Guide on the Core Principles of the Lexile Framework
The Lexile® Framework for Reading provides a quantitative system for measuring text complexity and a reader's comprehension ability on the same developmental scale.[1][2][3] Developed by MetaMetrics, this framework is rooted in over 30 years of research and is widely used to match readers with texts that are appropriately challenging, thereby fostering reading growth.[4][5] The core of the framework lies in its ability to express both the difficulty of a text and the ability of a reader using a common metric: the Lexile.[5][6]
Core Principles: A Dual-Component System
The Lexile Framework is constructed upon two fundamental components: the Lexile Text Measure and the Lexile Reader Measure .[1][7][8] Both are reported on the Lexile scale, which typically ranges from below 0L for beginning readers (designated with a "BR" code) to over 1600L for advanced readers and complex texts.[2][4][9] This unified scale is a key principle, allowing for a direct comparison and matching between a reader's ability and a text's difficulty.[4][5] The goal is to find a "targeted reading experience" where the reader can comprehend approximately 75% of the material, a level considered optimal for skill development without causing frustration.[4][10]
The Scientific Foundation of Text Complexity
A Lexile text measure is derived from a quantitative analysis of two well-established predictors of text difficulty: syntactic complexity and semantic difficulty.[2][4][6][11] These factors are evaluated algorithmically, independent of qualitative aspects like age-appropriateness or the complexity of themes.[3][7]
-
Syntactic Complexity (Sentence Structure): The framework uses the average sentence length as a powerful and reliable proxy for syntactic complexity.[4][12] Longer sentences are generally more complex, containing more clauses and requiring the reader to process more information in short-term memory.[4][12]
-
Semantic Difficulty (Word Familiarity): This is determined by word frequency.[4][6][11] The framework assesses the familiarity of words based on their prevalence within a massive, nearly 600-million-word corpus of texts.[4][6][11] Words that appear less frequently in this corpus are considered more challenging. The specific metric used is the mean log word frequency, which had the highest correlation with text difficulty (r = -0.779) among the variables studied by MetaMetrics.[4][12]
These two variables—mean sentence length and mean log word frequency—are combined in a proprietary mathematical equation to calculate the final Lexile measure for a text.[4][12]
Methodologies and Protocols
The determination of Lexile measures for both texts and readers follows distinct, scientifically grounded protocols.
Experimental Protocol: Lexile Text Measure Determination
The Lexile text measure is calculated using an automated software program called the Lexile® Text Analyzer.[4][9] The protocol is as follows:
-
Text Slicing: The full text of a book or article is partitioned into 125-word slices.[3][6][11] This slicing method ensures that variations in complexity throughout the text are accounted for and prevents shorter, simpler sections from disproportionately influencing the overall measure.[4]
-
Syntactic and Semantic Analysis: Within each slice, the software calculates the two core variables:
-
Lexile Equation Application: The MSL and MLF values for each slice are entered into the Lexile equation to produce a Lexile measure for that slice.
-
Rasch Model Calibration: The Lexile measures from all the individual slices are then applied to the Rasch psychometric model.[6][11] This conjoint measurement model places the text's difficulty onto the common Lexile scale, resulting in a single, holistic Lexile measure for the entire text.[4][6][11]
For texts intended for early readers (generally below 650L), the analyzer also evaluates four "Early Reading Indicators": Structure, Syntactic, Semantic, and Decoding demands, to provide a more nuanced assessment.[9]
Protocol: Lexile Reader Measure Determination
A reader's Lexile measure is not determined by analyzing their speech or writing but is obtained from their performance on a standardized reading comprehension test that has been linked to the Lexile framework.[1][2] Many prominent educational assessments report student reading scores as Lexile measures.[1][13] The Rasch model is fundamental here as well, as it allows student abilities to be placed on the same scale as the text difficulties, providing a direct link between assessment performance and text complexity.[4][14][15]
Data Presentation
The quantitative nature of the Lexile framework is summarized in the following tables.
| Lexile Scale and Reader/Text Designations | |
| Lexile Measure | Description |
| Above 1600L | Advanced readers and texts.[2][9] |
| 900L - 1050L | The recommended reading range for a reader with a 1000L measure.[1][12] |
| Below 650L | Texts where Early Reading Indicators are applied for enhanced analysis.[9] |
| 0L and Below | Beginning Reader (BR). A higher number after BR indicates a less complex text (e.g., BR300L is easier than BR100L).[7][9] |
| AD | Adult Directed: Text is best read aloud to a student.[9] |
| NC | Non-Conforming: Content is age-appropriate for readers whose ability is lower than the text's complexity suggests.[9] |
| HL | High-Low: High-interest content at a lower reading level.[9] |
| GN | Graphic Novel.[9] |
| Key Variables in Lexile Text Analysis | |
| Variable | Description & Example Data |
| Mean Sentence Length (MSL) | A proxy for syntactic complexity.[4] Longer sentences increase the Lexile measure. |
| Example Text 1 (420L): MSL = 6.95[9] | |
| Example Text 2 (980L): MSL = 13.78[9] | |
| Mean Log Word Frequency (MLF) | A proxy for semantic difficulty, based on a ~600-million-word corpus.[4][6] Lower frequency words (and thus a lower MLF) increase the Lexile measure. |
| Example Text 1 (420L): MLF = 3.43[9] | |
| Example Text 2 (980L): MLF = 3.28[9] | |
| Correlation of MLF to Text Difficulty | r = -0.779[4][12] |
Visualized Workflows and Relationships
The logical and experimental processes of the Lexile Framework are illustrated below using Graphviz.
References
- 1. bjupresshomeschool.com [bjupresshomeschool.com]
- 2. Lexile Framework for Reading [schooldataleadership.org]
- 3. renaissance.com [renaissance.com]
- 4. metametricsinc.com [metametricsinc.com]
- 5. m.youtube.com [m.youtube.com]
- 6. usg.edu [usg.edu]
- 7. Lexile - Wikipedia [en.wikipedia.org]
- 8. Understanding the Lexile Framework- the Pros & Cons — Reading Rev [readingrev.com]
- 9. metametricsinc.com [metametricsinc.com]
- 10. youtube.com [youtube.com]
- 11. cdn.lexile.com [cdn.lexile.com]
- 12. cdn.lexile.com [cdn.lexile.com]
- 13. youtube.com [youtube.com]
- 14. Using Lexile Reading Measures to Improve Literacy [rasch.org]
- 15. scribd.com [scribd.com]
The Foundational Research Behind the Lexile Framework: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
This in-depth technical guide delves into the foundational research and core methodologies that underpin the Lexile Framework for Reading. Developed by MetaMetrics, the Lexile Framework provides a scientific approach to measuring reading ability and text complexity on the same scale. This allows for the precise matching of readers with texts, a critical component in educational and professional settings where clear comprehension of technical documents is paramount. This guide will explore the psychometric underpinnings, key experimental validations, and the analytical processes at the heart of the Lexile Framework.
Core Principles: The Rasch Model and Key Predictors
The Lexile Framework is built upon a strong psychometric foundation, primarily the Rasch model , a one-parameter logistic item response theory model.[1][2][3] This model establishes a common scale for both reader ability and text difficulty, allowing for a direct comparison between the two. The fundamental principle is that the probability of a reader correctly comprehending a text is a function of the difference between the reader's ability measure and the text's difficulty measure.
The difficulty of a text, its Lexile measure, is determined by two key linguistic features that have been consistently shown to be powerful predictors of text complexity:
-
Semantic Difficulty (Word Frequency): This refers to the novelty of the words in a text. The Lexile Framework operationalizes this by calculating the frequency of words against a massive corpus of written material.[4] Words that appear less frequently in the corpus are considered more challenging.
-
Syntactic Complexity (Sentence Length): This refers to the complexity of the sentence structures. The framework uses the length of sentences as a proxy for syntactic complexity, with longer sentences generally indicating more complex grammatical structures.[4]
The Lexile Analyzer: The Engine of Text Measurement
The Lexile Analyzer is the software that calculates the Lexile measure for a given text.[5] The process involves several key steps:
-
Text Preparation: The text is first prepared for analysis. This includes removing extraneous elements like titles, headings, and incomplete sentences that could skew the measurement.
-
Slicing: The entire text is divided into 125-word slices. This ensures that the analysis captures the complexity across the entire document and is not overly influenced by any single section.[6]
-
Analysis of Slices: Each 125-word slice is analyzed for its semantic and syntactic characteristics.
-
Application of the Lexile Equation: The data from the analysis of the slices are then input into a proprietary algebraic equation, known as the "Lexile specification equation," to determine the Lexile measure for the entire text.[1][4] While the exact formula is proprietary, it is a regression equation that combines the measures of word frequency and sentence length.[7]
The Lexile Corpus
A critical component of the Lexile Analyzer is its extensive corpus of text. Initially developed with a 600-million-word corpus, it has since expanded to over 1.4 billion words.[7] This corpus is compiled from thousands of published texts across a wide range of genres and subject areas, providing a robust baseline for determining word frequencies.[7]
Quantitative Data and Validation Studies
The validity of the Lexile Framework has been established through numerous studies that correlate Lexile measures with other established measures of reading comprehension and text difficulty.
| Validation Study Type | Key Finding | Source |
| Correlation with Text Difficulty | The mean log word frequency, a measure of semantic difficulty, was found to have a high correlation with text difficulty. | [4] |
| Correlation with Observed Item Difficulty | The mean log word frequency showed a high correlation with the rank order of reading comprehension test items. | [7] |
| Linking with Standardized Tests | A study combining nine standardized reading tests found a high correlation between the observed logit difficulties of reading passages and the theoretical calibrations from the Lexile equation after correction for range restriction and measurement error. | [7] |
| Internal Consistency | Analysis of basal reader series demonstrated that the Lexile Framework could consistently account for the sequential difficulty of the units within the series. | [8] |
Experimental Protocols
While detailed, step-by-step protocols for the initial development of the Lexile Analyzer are proprietary, the general methodologies for key validation and linking studies are available.
Protocol for Linking Standardized Tests to the Lexile Scale
The process of linking a standardized reading test to the Lexile Framework involves a rigorous psychometric study to establish a statistical relationship between the two scales.
-
Content Analysis: A thorough analysis of the content and format of the standardized test is conducted.
-
Development of a Linking Instrument: A custom reading assessment, often referred to as a "Lexile linking test," is developed. This test is designed to be content-neutral and to measure reading ability across a wide range of the Lexile scale.
-
Co-administration Study: A sample of students takes both the standardized test and the Lexile linking test.
-
Psychometric Analysis: The data from the co-administration study is analyzed using the Rasch model to place both the items from the standardized test and the linking test onto a common scale.
-
Development of Conversion Tables: Based on the analysis, a set of conversion tables or equations is created that allows for the translation of scores from the standardized test into Lexile measures.
Protocol for Lexile Analyzer Validation
The validation of the Lexile Analyzer is an ongoing process that involves multiple approaches:
-
Correlation with External Measures: Lexile measures of texts are correlated with other established readability formulas and with expert judgments of text difficulty.
-
Predictive Validity Studies: Studies are conducted to determine how well Lexile measures predict actual reader comprehension. This often involves having students read texts at various Lexile levels and then assessing their comprehension.
-
Analysis of Fit to the Rasch Model: The extent to which the data from reader-text interactions fit the predictions of the Rasch model is continuously evaluated.
Visualizing the Lexile Framework
The following diagrams, created using the DOT language, illustrate the core concepts and workflows of the Lexile Framework.
Caption: Core components of the Lexile Framework.
Caption: Workflow of the Lexile Analyzer.
Caption: Process of linking a standardized test to the Lexile Framework.
References
- 1. metametricsinc.com [metametricsinc.com]
- 2. Using Lexile Reading Measures to Improve Literacy [rasch.org]
- 3. scribd.com [scribd.com]
- 4. scispace.com [scispace.com]
- 5. m.youtube.com [m.youtube.com]
- 6. renaissance.com [renaissance.com]
- 7. metametricsinc.com [metametricsinc.com]
- 8. levelupreader.net [levelupreader.net]
The Application of Lexile Measures in Enhancing Clarity and Comprehension of Clinical and Pharmaceutical Documentation: A Technical Guide
For Immediate Release
DURHAM, NC – October 30, 2025 – This technical guide explores the application of Lexile® measures, a widely recognized framework for assessing text complexity, to the domain of scientific and drug development documentation. Primarily directed at researchers, scientists, and drug development professionals, this document outlines the imperative for clear, comprehensible technical literature and proposes a framework for the exploratory application of Lexile measures to enhance the efficacy of communication within the pharmaceutical industry.
The development of novel therapeutics is contingent on the precise and unambiguous communication of complex scientific and clinical information. From clinical trial protocols to regulatory submissions, the clarity of these documents can significantly impact the efficiency of drug development, the integrity of clinical trials, and ultimately, patient safety. While the Lexile framework has been extensively validated in educational settings, its application to the specialized and technical language of pharmaceutical science remains a nascent yet promising field of inquiry.
This guide will provide a comprehensive overview of the Lexile framework, detail methodologies for its application in a pharmaceutical context, present quantitative data from related fields, and propose workflows for integrating readability analysis into the drug development lifecycle.
The Lexile® Framework for Reading: A Primer
The Lexile Framework for Reading provides a quantitative measure of text complexity and reader ability on the same scale.[1] A Lexile text measure is calculated based on two key indicators of text difficulty:
-
Sentence Length: Longer sentences are generally more complex and place a higher demand on the reader's short-term memory.
-
Word Frequency: Words that appear less frequently in a large corpus of text are considered more challenging.
The resulting Lexile score is a number followed by an "L" (e.g., 1200L), which allows for the matching of readers with texts at an appropriate level of difficulty.
The Case for Readability in Drug Development
While the primary audience for much of the documentation in drug development consists of highly trained professionals, the clarity and readability of these materials are nonetheless critical. A discussion forum hosted by the Association for Applied Human Pharmacology (AGAH e.V.) underscored the need for improvement in the readability and comprehensibility of Investigator's Brochures (IBs) for meaningful risk assessment in early clinical trials.[2] The overall consensus was that an optimized presentation of data is crucial for the best possible understanding of a compound's characteristics and for safeguarding clinical trial participants.[2]
Complex or unclear language in documents such as clinical trial protocols can lead to misinterpretations, protocol deviations, and compromised data integrity. Similarly, the readability of regulatory submissions can impact the efficiency of the review process.
Exploratory Application of Lexile Measures in Pharmaceutical Documentation
While direct, published exploratory studies on the application of Lexile measures to internal drug development documentation are limited, the principles and methodologies are transferable from studies on patient-facing materials and other technical documents. The following sections outline a proposed approach for such exploratory studies.
Experimental Protocol: Assessing the Readability of Technical Documents
A proposed study to assess the readability of technical documents within a pharmaceutical setting would involve the following steps:
-
Document Selection: A representative sample of key documents from the drug development lifecycle would be selected. This could include:
-
Clinical Trial Protocols
-
Investigator's Brochures (IBs)
-
Informed Consent Forms (ICFs)
-
Standard Operating Procedures (SOPs)
-
Regulatory Submission Dossiers (e.g., sections of a New Drug Application)
-
-
Text Preparation: The selected documents would be converted to plain text format to be processed by the Lexile Analyzer®, a software tool that calculates the Lexile measure of a text.[3]
-
Lexile Analysis: Each document would be analyzed to determine its Lexile score. The analysis would also yield data on mean sentence length and word frequency.
-
Data Analysis and Benchmarking: The Lexile scores of the documents would be analyzed to establish a baseline readability level for different types of pharmaceutical documentation. This data could be compared to established Lexile benchmarks for other types of complex texts, such as scientific articles or legal documents.
-
Correlation with Outcomes (Exploratory): In a more advanced study, the Lexile scores of documents could be correlated with relevant outcomes. For example:
-
Clinical Trial Protocols: Correlation with the rate of protocol deviations or amendments.
-
Investigator's Brochures: Correlation with the time required for investigator training or the number of queries from clinical sites.
-
Regulatory Submissions: Correlation with the number of review cycles or requests for information from regulatory agencies.
-
Quantitative Data from Related Fields
While awaiting direct studies in the pharmaceutical industry, valuable insights can be drawn from research on the readability of patient-facing medical information. The following tables summarize quantitative data from studies that have used readability formulas, including Lexile, to assess such materials.
Table 1: Readability of Prescription Drug Warning Labels
| Warning Label Text | Lexile Score | Correct Interpretation Rate |
| Take with Food | Beginning | 83.7% |
| Do not take dairy products, antacids, or iron preparations within 1 hour of this medication | 1110L | 7.6% |
Source: Adapted from a study on the impact of low literacy on the comprehension of prescription drug warning labels.[4]
Table 2: Readability of Clinical Research Patient Information Leaflets/Informed Consent Forms (PILs/ICFs)
| Readability Metric | Mean Score/Level | Recommended Level |
| Flesch Reading Ease | 49.6 | 60-70 |
| Flesch-Kincaid Grade Level | 11.3 | 6th |
| Gunning Fog | 12.1 | <8 |
| Simplified Measure of Gobbledegook (SMOG) | 13.0 | <6 |
Source: Adapted from a retrospective quantitative analysis of clinical research PILs/ICFs in Ireland and the UK.[5]
These data clearly indicate a significant gap between the complexity of patient-facing medical documents and the recommended reading levels for the general public. A similar gap may exist for professional-facing documentation, hindering effective communication even among experts.
Proposed Workflow for Integrating Readability Analysis
The integration of readability analysis into the document development workflow can be a proactive step towards improving the clarity of scientific and clinical communications. The following diagram illustrates a proposed workflow.
Caption: A proposed workflow for integrating Lexile analysis into the technical document lifecycle.
This iterative process ensures that readability is considered a key quality attribute of the documentation, alongside scientific accuracy and regulatory compliance.
Signaling Pathway for Improved Comprehension and Efficiency
The application of readability metrics can be conceptualized as a signaling pathway that leads to improved comprehension and, consequently, enhanced efficiency in the drug development process.
Caption: A signaling pathway illustrating how readability analysis can lead to improved outcomes in drug development.
Conclusion and Future Directions
The application of Lexile measures to the internal documentation of the drug development process presents a significant opportunity to enhance communication, improve efficiency, and reduce errors. While the direct evidence base is still emerging, the foundational principles of readability and the methodologies for its assessment are well-established.
Future exploratory studies should focus on:
-
Establishing Lexile benchmarks for a wide range of internal pharmaceutical documents.
-
Investigating the correlation between the readability of these documents and key performance indicators in drug development.
-
Developing best practice guidelines for writing and formatting technical documents to optimize for clarity and comprehension.
By embracing a culture of clear communication, the pharmaceutical industry can streamline its processes, foster better collaboration, and ultimately, accelerate the delivery of safe and effective medicines to patients.
References
- 1. m.youtube.com [m.youtube.com]
- 2. How to Interpret an Investigator’s Brochure for Meaningful Risk Assessment: Results of an AGAH Discussion Forum - PMC [pmc.ncbi.nlm.nih.gov]
- 3. What is an Investigator’s Brochure (IB) in Clinical Trials? | Novotech CRO [novotech-cro.com]
- 4. Reliability of Wikipedia - Wikipedia [en.wikipedia.org]
- 5. Readability and understandability of clinical research patient information leaflets and consent forms in Ireland and the UK: a retrospective quantitative analysis - PMC [pmc.ncbi.nlm.nih.gov]
The Genesis of Text Complexity: A Technical Deep Dive into the Lexile Framework
Durham, NC - For researchers, scientists, and professionals in drug development, the precise and consistent communication of complex information is paramount. The texts they produce and consume demand a nuanced understanding of readability and comprehension. The Lexile Framework for Reading, a ubiquitous tool in education and publishing, offers a standardized approach to measuring text complexity. This technical guide delves into the origins of the Lexile scale, its foundational methodologies, and the empirical data that underpins its validity, providing a comprehensive resource for those who require a granular understanding of text measurement.
The Lexile Framework was developed by MetaMetrics, Inc., an educational measurement company, with its origins tracing back to the early 1980s and the work of its co-founders, A. Jackson Stenner and Malbert Smith III.[1][2] The development was significantly propelled by a series of Small Business Innovation Research (SBIR) grants from the National Institute of Child Health and Human Development (NICHD) starting in 1984.[3] The central goal was to create a scientific, universal scale for measuring both a reader's ability and the difficulty of a text, allowing for a more precise matching of readers to appropriate reading materials.[2][4]
At its core, the Lexile Framework is built upon the principle that text complexity can be quantified by analyzing two key linguistic features: syntactic complexity and semantic difficulty.[5][6] This dual-component model forms the basis of the proprietary "Lexile equation" or "Lexile specification equation" used to calculate the Lexile measure of a text.[5][6]
The Core Algorithm: Deconstructing the Lexile Equation
The Lexile Analyzer, a proprietary software, is the engine that calculates Lexile measures.[5] The process begins by breaking down a text into 125-word "slices."[5][7] This slicing method ensures that the analysis is not skewed by variations in sentence length across a long text. For each slice, the analyzer calculates the mean sentence length and the mean log word frequency.
Syntactic Complexity: The Role of Sentence Length
A primary and powerful indicator of the syntactic challenge a text presents is the average length of its sentences.[5] Longer sentences are more likely to contain multiple clauses and complex grammatical structures, placing a greater demand on a reader's short-term memory and information processing capabilities.[5] The Lexile model uses the mean sentence length as its measure of syntactic complexity.
Semantic Difficulty: The Power of Word Frequency
To quantify the semantic difficulty of a text, MetaMetrics turned to the concept of word frequency. The underlying theory is that words that appear more frequently in a language are more familiar to readers and therefore present less of a comprehension challenge.[5] After analyzing over 50 different semantic variables, researchers at MetaMetrics determined that the mean log word frequency had the highest correlation with text difficulty.[5]
The word frequency is not determined from the text being analyzed itself, but rather by comparing the words in the text to a massive, 600-million-word corpus of written material.[8] This extensive corpus provides a stable and representative baseline of word frequencies in the English language. The logarithm of the word frequency is used to account for the vast differences in the occurrences of common and rare words.
The Psychometric Foundation: The Rasch Model
A key innovation of the Lexile Framework is its ability to place both reader ability and text difficulty on the same measurement scale.[1][9] This is achieved through the application of the Rasch model, a psychometric model from the field of item response theory.[1] The Rasch model allows for the creation of a "conjoint measurement" system, where the probability of a particular outcome (in this case, a reader successfully comprehending a text) is a function of the difference between the person's ability and the item's difficulty.[1]
In the context of the Lexile Framework, the Rasch model was used to calibrate a common scale, the Lexile scale, where a reader's ability and a text's difficulty are both expressed in Lexile units (L).[9] The scale typically ranges from below 0L for beginning readers and texts (designated as BR for Beginning Reader) to over 1700L for advanced readers and complex texts. A key benchmark of the scale is that a reader is expected to have a 75% comprehension rate with a text that has the same Lexile measure as their reading ability.[5]
Experimental Validation
The validity of the Lexile Framework has been established through numerous studies that demonstrate a strong correlation between Lexile measures and other established measures of reading comprehension and text difficulty.[3] Initial validation efforts involved linking the Lexile scale to standardized reading tests such as The Iowa Tests of Basic Skills and the Stanford Achievement Test.[3] These studies consistently showed a strong positive relationship between a student's reading comprehension score on these tests and their Lexile measure.[3]
Further validation has been an ongoing process, with hundreds of independent research studies utilizing Lexile measures as a metric for text complexity.[10] One notable finding from the early research was the high negative correlation (r = -0.779) between mean log word frequency and text difficulty, underscoring the significance of this variable in the Lexile equation.[5][8]
Below is a summary of the core components of the Lexile Framework's development:
| Component | Description |
| Theoretical Basis | Text complexity is a function of syntactic and semantic difficulty. |
| Syntactic Variable | Mean Sentence Length |
| Semantic Variable | Mean Log Word Frequency (derived from a 600-million-word corpus) |
| Psychometric Model | Rasch Model for conjoint measurement of reader ability and text difficulty |
| Unit of Measurement | Lexile (L) |
| Target Comprehension | 75% comprehension when reader's Lexile measure matches the text's Lexile measure |
The Lexile Analysis Workflow
The process of determining a Lexile measure for a given text follows a structured workflow, which can be visualized as follows:
Logical Relationship of Core Components
The fundamental relationship between the core components of the Lexile Framework can be illustrated as follows:
References
- 1. metametricsinc.com [metametricsinc.com]
- 2. cdn.lexile.com [cdn.lexile.com]
- 3. metametricsinc.com [metametricsinc.com]
- 4. researchgate.net [researchgate.net]
- 5. cdn.lexile.com [cdn.lexile.com]
- 6. metametricsinc.com [metametricsinc.com]
- 7. cheshirelibraryblog.com [cheshirelibraryblog.com]
- 8. metametricsinc.com [metametricsinc.com]
- 9. advancebookreaders.com [advancebookreaders.com]
- 10. metametrics.com [metametrics.com]
A Technical Deep Dive: The Genesis and Funding of the Lexile Framework
A Whitepaper on the Foundational Development and Initial Financial Backing of the Lexile Framework for Reading
This technical guide provides an in-depth exploration of the initial development and funding of the Lexile Framework for Reading. It is intended for researchers, psychometricians, and educational technology professionals interested in the scientific underpinnings of widely adopted educational tools. This document details the core methodologies, the pivotal role of federal grant funding, and the early validation protocols that established the framework as a durable measure of reading ability and text complexity.
Introduction: The Scientific Pursuit of a Common Metric
The Lexile Framework for Reading was conceived to address a fundamental challenge in education: accurately matching readers with texts of appropriate difficulty to optimize learning and growth. Developed by Dr. A. Jackson Stenner and Dr. Malbert Smith III, co-founders of MetaMetrics, Inc., the framework introduced a common scale for measuring both reader ability and text complexity in the same units, known as Lexiles (L).[1][2][3] The core innovation was the application of a scientific, psychometric model to create an objective, scalable system, moving beyond traditional, often subjective, leveling methods.[3] This guide focuses on the seminal period of its creation, tracing its journey from a research concept to a validated, operational framework.
Initial Funding: The Role of Federal Research Grants
The foundational research and development of the Lexile Framework were substantially supported by the U.S. government, primarily through the Small Business Innovation Research (SBIR) program.[4] The National Institute of Child Health and Human Development (NICHD), a division of the National Institutes of Health (NIH), provided the critical early-stage funding that enabled MetaMetrics to pursue its long-term research agenda.[4]
Quantitative Funding Data
Between 1984 and 1996, MetaMetrics was the recipient of five separate SBIR grants from the NICHD. This sustained funding was instrumental in the multi-year research effort required to develop and validate the framework. While a comprehensive public database detailing the precise award dates and amounts for these specific historical grants is not readily accessible, the SBIR program operates in distinct phases, with Phase I grants focused on establishing technical merit and feasibility and Phase II grants supporting full-scale research and development.
| Funding Body | Grant Program | Number of Grants | Time Period | Stated Purpose |
| National Institute of Child Health and Human Development (NICHD) | Small Business Innovation Research (SBIR) | 5 | 1984–1996 | To develop a universal measurement system for reading and writing.[5] |
Core Methodology: A Psychometric Approach
The technical core of the Lexile Framework is its basis in psychometric theory, specifically the Rasch model—a one-parameter logistic model from Item Response Theory.[6][7] This model allows for the placement of both reader ability and text difficulty onto a single, equal-interval scale.[8][9] This conjoint measurement is the key feature that enables the direct comparison and matching of readers and texts.[8]
The initial Lexile equation was a regression formula designed to predict the difficulty of a text based on two core linguistic features that decades of readability research had identified as powerful and reliable predictors of text complexity.[1]
-
Syntactic Complexity (Sentence Length): This variable measures the average length of sentences in a text. Longer sentences are hypothesized to place a greater load on a reader's short-term memory, thereby increasing the cognitive demand of the reading task.[1]
-
Semantic Difficulty (Word Frequency): This variable is an indicator of vocabulary difficulty. The framework operates on the principle that words appearing less frequently in a large corpus of written language are less likely to be familiar to a reader, thus making the text more challenging.[1]
Experimental Protocol: Text Calibration
The process of assigning a Lexile measure to a text, known as calibration, follows a defined protocol.
-
Text Sampling: The text is first parsed into 125-word slices. If the 125th word falls mid-sentence, the slice is extended to the end of that sentence. This slicing method ensures that local variations in text complexity are accounted for and prevents shorter, simpler sentences from being disproportionately weighted against longer, more complex ones in the overall analysis.[9]
-
Variable Analysis: For each slice, the two core variables are measured:
-
The average sentence length is calculated.
-
The frequency of each word is determined by referencing a large, proprietary corpus of text. The initial development relied on the best available corpora of the time, which have since been expanded. The modern Lexile corpus contains over 600 million words.[1]
-
-
Application of the Lexile Equation: The values for mean sentence length and mean word frequency are entered into the Lexile equation to produce a Lexile measure for each slice.
-
Averaging: The Lexile measures of all slices are then averaged to determine the final Lexile measure for the entire text.
-
Rasch Modeling: The entire process is anchored by the Rasch model, which converts the raw text characteristics into measurements on a consistent, linear scale.[6]
Initial Validation Studies
A critical component of the framework's development was a series of validation studies to establish its construct validity. This involved demonstrating a strong correlation between the Lexile Framework's measurements and the difficulty of texts as determined by other established, independent measures, such as nationally normed reading comprehension tests.
Methodology
The primary validation protocol involved the following steps:
-
Selection of Standardized Tests: A set of widely used, nationally normed reading comprehension tests was selected.
-
Item Difficulty Analysis: The Rasch item difficulties for the reading passages on these tests were obtained, often from the test publishers themselves. This provided an empirical measure of each passage's difficulty based on actual student performance data.
-
Lexile Calibration: The text of each reading passage was then analyzed using the Lexile Analyzer to generate a "theory-based" Lexile measure.
-
Correlational Analysis: The empirical Rasch difficulties (observed difficulty) were correlated with the Lexile measures (predicted difficulty).
Quantitative Results
These studies demonstrated a very strong positive relationship between the Lexile measures and the observed difficulties of the test passages. A key 1987 study by Stenner, Smith, Horabin, and Smith analyzed 1,780 items from nine nationally normed tests.[9] The resulting correlation between the Lexile calibrations and the Rasch item difficulties was 0.93 after correcting for measurement error and range restriction, providing powerful evidence for the framework's validity.[1]
While a detailed breakdown of the correlations for each individual test from the initial studies is not available in the reviewed literature, the high overall correlation across a wide range of established assessments was a pivotal result. The table below summarizes the types of tests used in these linking studies over the years, illustrating the breadth of the validation effort.
| Standardized Test Type | Grades Studied | Typical Correlation with Lexile Measures |
| Norm-Referenced Reading Comprehension Tests | K-12 | Strong Positive (typically >0.70) |
| State-Mandated Achievement Tests | Various | Strong Positive |
| Interim/Benchmark Assessments | K-12 | Strong Positive |
Note: The correlations in Table 2 are representative of the strong positive relationships found in numerous linking studies reported in MetaMetrics' technical documents.[5] Specific values vary by test and student population.
Visualizing the Development and Workflow
The following diagrams illustrate the key relationships and processes in the initial development of the Lexile Framework.
Conclusion
The initial development of the Lexile Framework for Reading represents a significant application of psychometric principles to the field of literacy. Its creation was not an overnight endeavor but a deliberate, multi-year research and development effort made possible by crucial seed funding from the National Institute of Child Health and Human Development. By grounding the framework in the Rasch model and focusing on robust, objective indicators of text complexity—sentence length and word frequency—the developers created a scientifically defensible and highly scalable tool. The strong results of early validation studies provided the empirical evidence necessary for its widespread adoption by state departments of education, assessment publishers, and curriculum developers, fundamentally shaping the landscape of reading assessment and instruction.
References
- 1. metametricsinc.com [metametricsinc.com]
- 2. m.youtube.com [m.youtube.com]
- 3. levelupreader.net [levelupreader.net]
- 4. researchgate.net [researchgate.net]
- 5. cdn.lexile.com [cdn.lexile.com]
- 6. Home | RePORT [report.nih.gov]
- 7. scispace.com [scispace.com]
- 8. youtube.com [youtube.com]
- 9. partnerhelp.metametricsinc.com [partnerhelp.metametricsinc.com]
Utilizing the Lexile Framework for Advanced Reading Research: Application Notes and Protocols for Scientific and Clinical Contexts
For Immediate Release
These application notes provide a detailed guide for researchers, scientists, and drug development professionals on leveraging the Lexile Framework for Reading to enhance the clarity and effectiveness of scientific and clinical communication. By applying a standardized metric to text complexity, researchers can improve patient comprehension, ensure the accessibility of clinical trial materials, and contribute to more robust research outcomes in health literacy.
Introduction to the Lexile Framework in a Research Context
The Lexile Framework for Reading offers a scientific approach to measuring both the complexity of a text and the reading ability of an individual on the same scale.[1][2] A Lexile measure is a number followed by an "L" (e.g., 1000L), which indicates the reading demand of a text or a person's reading ability.[2] This framework is predicated on over three decades of research and is widely adopted for its accuracy in matching readers with appropriate texts.[3][4]
While traditionally used in educational settings, the principles of the Lexile Framework are increasingly relevant in scientific and clinical research. Ensuring that patient-facing materials, such as informed consent forms, patient education brochures, and drug information leaflets, are at an appropriate reading level is crucial for patient understanding, adherence, and informed decision-making.[5] Research has consistently shown that a significant portion of the adult population has limited health literacy, making the assessment of text complexity a critical component of ethical and effective research.
Core Principles of the Lexile Framework
The Lexile Framework is based on two primary predictors of text difficulty:
-
Semantic Difficulty (Word Frequency): This refers to the complexity of the vocabulary used. The Lexile Framework analyzes the frequency of words in a vast corpus of text; less frequent words are considered more challenging.[4]
-
Syntactic Complexity (Sentence Length): This relates to the structure of sentences. Longer, more complex sentence structures are more demanding for a reader to process.[6]
A proprietary algorithm combines these two factors to produce a single Lexile measure for a given text.[7]
Application in a Scientific and Drug Development Context
The Lexile Framework can be a valuable tool for:
-
Assessing the Readability of Clinical Trial Materials: Evaluating the complexity of informed consent forms, study protocols, and patient-reported outcome measures to ensure they are understandable to the target participant population.[5]
-
Developing Patient Education Materials: Creating patient-friendly content that aligns with the average reading ability of the general public, which is often cited as being around the 8th-grade level.[8]
-
Health Literacy Research: Investigating the relationship between the Lexile level of health information and patient comprehension, adherence to treatment, and health outcomes.
-
Standardizing Text Complexity in Research: Providing an objective measure of text complexity in studies that use written materials as part of the experimental design.
Experimental Protocols
Protocol for Assessing the Lexile Level of Research Materials
This protocol outlines the steps to determine the Lexile measure of written materials, such as informed consent forms or patient education documents.
Objective: To quantitatively assess the reading complexity of a text using the Lexile Framework.
Materials:
-
The text to be analyzed in a plain text format (.txt).
-
Access to the Lexile Analyzer® tool.
Procedure:
-
Prepare the Text: Convert the document into a plain text file. Ensure that any extraneous text not intended for the reader (e.g., version numbers, internal review notes) is removed.
-
Access the Lexile Analyzer: Navigate to the official Lexile website and access the Lexile Analyzer tool. This may require creating a free account.[9]
-
Upload the Text: Upload the prepared plain text file into the analyzer.
-
Analyze the Text: Initiate the analysis process. The tool will process the text based on its semantic and syntactic characteristics.[4]
-
Record the Lexile Measure: The Lexile Analyzer will output a Lexile measure for the text. Record this measure for your research records.
-
Interpret the Results: Compare the obtained Lexile measure to established benchmarks for different populations (see Table 1). For patient-facing materials in the United States, a target Lexile range is often recommended to align with the average adult reading level.
Protocol for a Comparative Readability Study
This protocol describes a methodology for comparing the readability of different versions of a document or documents from different sources.
Objective: To compare the Lexile measures of two or more texts to determine their relative readability.
Materials:
-
All text documents to be compared, each in a plain text format.
-
Access to the Lexile Analyzer®.
-
Statistical software for data analysis.
Procedure:
-
Text Selection: Clearly define the criteria for selecting the texts for comparison. For example, you might compare an original informed consent form with a revised, "plain language" version.
-
Lexile Measurement: Follow the protocol outlined in 4.1 to determine the Lexile measure for each document.
-
Data Tabulation: Record the Lexile measures for all documents in a structured table for easy comparison.
-
Statistical Analysis: If comparing groups of documents, consider using appropriate statistical tests (e.g., t-test, ANOVA) to determine if there are significant differences in the mean Lexile measures between the groups.
-
Reporting: Report the Lexile measures for each document or the mean and standard deviation for each group of documents. Clearly state the findings of your comparative analysis.
Data Presentation
Quantitative data from readability studies should be presented in a clear and organized manner.
Table 1: Example of Lexile Measures for Different Text Types
| Text Type | Sample Document | Lexile Measure |
| Academic Publication | Journal Article Abstract | 1400L |
| Standard Informed Consent | Original Clinical Trial Consent Form | 1250L |
| Plain Language Informed Consent | Revised Clinical Trial Consent Form | 950L |
| Patient Education Brochure | "Understanding Your Condition" | 800L |
Table 2: Fictional Data from a Comparative Study of Patient Information Leaflets
| Drug Class | Manufacturer A (Mean Lexile ± SD) | Manufacturer B (Mean Lexile ± SD) | p-value |
| Antihypertensives (n=10) | 1150L ± 85L | 980L ± 70L | <0.05 |
| Statins (n=10) | 1210L ± 92L | 1020L ± 80L | <0.05 |
| Anticoagulants (n=10) | 1300L ± 110L | 1050L ± 95L | <0.01 |
Visualizations
Workflow for Applying the Lexile Framework in Clinical Research
References
- 1. cdn.lexile.com [cdn.lexile.com]
- 2. youtube.com [youtube.com]
- 3. metametrics.com [metametrics.com]
- 4. metametricsinc.com [metametricsinc.com]
- 5. Assessing the Readability of Clinical Trial Consent Forms for Surgical Specialties - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. youtube.com [youtube.com]
- 7. scispace.com [scispace.com]
- 8. cdn.technologynetworks.com [cdn.technologynetworks.com]
- 9. education.udel.edu [education.udel.edu]
Unlocking Text Complexity: A Detailed Methodological Guide to Determining Lexile Scores
Application Notes and Protocols for Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive overview and detailed protocols for understanding and applying the methodology behind Lexile® scores, a widely used measure of text complexity. This guide is designed for researchers, scientists, and professionals who require a thorough understanding of the quantitative underpinnings and procedural steps involved in assigning Lexile measures to written texts.
Introduction to the Lexile Framework for Reading
The Lexile Framework for Reading is a scientific approach to measuring both the complexity of a text and a reader's ability on the same scale.[1][2][3] This allows for a precise matching of readers with texts that are appropriately challenging, fostering comprehension and skill development. The framework is underpinned by a proprietary algorithm that analyzes the semantic and syntactic characteristics of a text to produce a Lexile score.[1][2]
A Lexile text measure is a number followed by an "L" (e.g., 1050L), which represents the difficulty of a text. The Lexile scale is a developmental scale ranging from below 0L for beginning reader texts to over 1700L for advanced and complex materials.[1]
Core Principles of Lexile Text Measurement
The determination of a Lexile score for a text is based on two primary and well-established predictors of text difficulty:
-
Syntactic Complexity: This refers to the complexity of sentence structure. Longer, more complex sentences are generally more difficult to process and comprehend. In the Lexile framework, this is quantified by mean sentence length .[2]
-
Semantic Difficulty: This relates to the complexity of the vocabulary used in a text. Words that appear less frequently in a language are typically more challenging for a reader. This is quantified by mean log word frequency .[2]
The proprietary Lexile equation combines these two factors to calculate the final Lexile score. While the exact formula is not public, the relationship is such that longer sentences and lower frequency words result in a higher Lexile measure.[2]
Quantitative Data Summary
The following tables summarize the key quantitative parameters involved in the Lexile scoring methodology.
| Parameter | Description | Unit of Measurement | Role in Lexile Score |
| Mean Sentence Length | The average number of words per sentence in a given text sample. | Words | A primary indicator of syntactic complexity. Longer sentences increase the Lexile score. |
| Mean Log Word Frequency | The logarithm of the frequency with which words in the text appear in the MetaMetrics Corpus. | Logits | A primary indicator of semantic difficulty. Lower frequency words (and thus a lower mean log frequency) increase the Lexile score. |
| Lexile Score | The final calculated measure of text complexity. | Lexiles (L) | The output of the Lexile equation, representing the text's position on the Lexile scale. |
Table 1: Core Quantitative Parameters in Lexile Text Measurement
| Component | Description | Key Statistics |
| MetaMetrics Corpus | A large, curated body of written English text used as a reference for determining word frequencies. | Comprises over 1.4 billion words from a wide range of K-12 educational materials. |
| Lexile Analyzer | The proprietary software that performs the automated analysis of a text to determine its Lexile score. | Processes text to calculate mean sentence length and mean log word frequency. |
Table 2: Key Components of the Lexile Analysis Infrastructure
Experimental Protocols
The following protocols outline the standardized methodology for determining the Lexile score of a text.
Protocol for Text Preparation
Objective: To prepare a text file for analysis by the Lexile Analyzer.
Materials:
-
Digital text file (e.g., .txt, .doc, .pdf)
-
Word processing software (e.g., Microsoft Word, Google Docs)
Procedure:
-
Obtain Digital Text: Secure a digital version of the text to be analyzed.
-
Ensure Text Integrity: Verify that the digital text is a faithful representation of the original, with no significant omissions or additions of content.
-
Format as Plain Text:
-
Open the text in a word processor.
-
Remove any elements that are not part of the main body of the text, such as:
-
Tables of contents
-
Indexes
-
Bibliographies
-
Footnotes and endnotes
-
Page numbers and headers/footers
-
-
Save the cleaned text as a plain text file (.txt). This ensures that no formatting codes interfere with the analysis.
-
Protocol for Lexile Analysis using the Lexile Analyzer
Objective: To obtain a Lexile score for a prepared text using the Lexile Analyzer software.
Materials:
-
Prepared plain text file (.txt)
-
Access to the Lexile Analyzer software (typically through a licensed MetaMetrics product or service)
Procedure:
-
Initiate the Lexile Analyzer: Launch the Lexile Analyzer software.
-
Load the Text File: Import the prepared plain text file into the analyzer.
-
Execute Analysis: Initiate the analysis process. The software will perform the following automated steps:
-
Text Slicing: The text is divided into smaller, manageable segments for analysis.
-
Sentence Boundary Detection: The software identifies the beginning and end of each sentence.
-
Word Tokenization: The text is broken down into individual words (tokens).
-
Sentence Length Calculation: The number of words in each sentence is counted, and the mean sentence length for the entire text is calculated.
-
Word Frequency Analysis: Each word is compared against the MetaMetrics Corpus to determine its frequency of occurrence. The logarithm of this frequency is taken.
-
Mean Log Word Frequency Calculation: The average of the log word frequencies for all words in the text is calculated.
-
-
Lexile Score Calculation: The Lexile Analyzer applies the proprietary Lexile equation to the calculated mean sentence length and mean log word frequency to generate the final Lexile score.
-
Review Results: The output will display the Lexile score for the text, along with the mean sentence length and mean word frequency.
Visualizing the Methodology
The following diagrams, generated using the DOT language, illustrate the key workflows and relationships in the Lexile scoring methodology.
Caption: Workflow for determining the Lexile score of a text.
Caption: Conceptual relationship of factors influencing a Lexile score.
References
Applying Lexile Measures in Educational Research: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive guide for incorporating Lexile® measures into educational research studies. The Lexile Framework for Reading offers a scientific approach to measuring both a reader's ability and the complexity of a text on the same scale, making it a valuable tool for quantitative research in reading comprehension, literacy interventions, and educational program evaluation.
Introduction to the Lexile Framework
The Lexile Framework is a widely used methodology that quantifies both reader ability (Lexile reader measure) and text complexity (Lexile text measure) on a single, developmental scale.[1] Lexile measures are expressed as a number followed by an "L" (e.g., 850L). This dual-measurement system allows for the precise matching of readers with texts that are at an appropriate level of difficulty to foster reading growth.[2]
The determination of a text's Lexile measure is based on two key linguistic features:
-
Word Frequency: The prevalence of words in a large corpus of text.
-
Sentence Length: The number of words per sentence.
A reader's Lexile measure is typically determined through a standardized reading assessment that has been linked to the Lexile scale.[3]
Data Presentation
In educational research utilizing Lexile measures, clear and structured presentation of quantitative data is crucial for interpretation and comparison. The following tables are examples of how Lexile data can be presented in a research context.
Table 1: Participant Demographics and Baseline Lexile Measures
| Characteristic | Intervention Group (n=50) | Control Group (n=50) | Total (N=100) |
| Age (Mean ± SD) | 10.2 ± 1.5 | 10.1 ± 1.6 | 10.15 ± 1.55 |
| Gender (% Female) | 52% | 48% | 50% |
| Baseline Lexile (Mean ± SD) | 650L ± 50L | 645L ± 55L | 647.5L ± 52.5L |
Table 2: Pre- and Post-Intervention Lexile Measures by Group
| Group | Pre-Intervention Lexile (Mean ± SD) | Post-Intervention Lexile (Mean ± SD) | Mean Lexile Gain (L) |
| Intervention | 650L ± 50L | 780L ± 60L | 130L |
| Control | 645L ± 55L | 665L ± 58L | 20L |
Table 3: Longitudinal Lexile Growth Over Three Time Points
| Time Point | Intervention Group Lexile (Mean ± SD) | Control Group Lexile (Mean ± SD) |
| Baseline (T1) | 650L ± 50L | 645L ± 55L |
| Mid-Point (T2 - 6 months) | 715L ± 55L | 655L ± 56L |
| End-Point (T3 - 12 months) | 780L ± 60L | 665L ± 58L |
Experimental Protocols
The following are detailed methodologies for two common types of research studies that utilize Lexile measures: a reading intervention study and a longitudinal reading growth study.
Protocol for a Lexile-Based Reading Intervention Study
This protocol outlines a randomized controlled trial to assess the efficacy of a targeted reading intervention.
3.1.1. Participant Recruitment and Screening
-
Define Target Population: Specify the age or grade level of participants (e.g., 4th-grade students).
-
Inclusion Criteria:
-
Students within the defined age/grade range.
-
Students with a baseline Lexile measure within a specified range (e.g., 400L to 700L) as determined by a standardized reading assessment (e.g., MAP Growth Reading Test, STAR Reading Test).[3]
-
-
Exclusion Criteria:
-
Students with diagnosed learning disabilities that would require specialized instruction beyond the scope of the intervention.
-
Students who are not proficient in the language of the intervention.
-
-
Informed Consent: Obtain informed consent from parents or legal guardians and assent from the student participants.
3.1.2. Randomization and Blinding
-
Randomization: Randomly assign participants to either the intervention group or a control group using a random number generator.
-
Blinding: If possible, blind the assessors who administer the pre- and post-intervention reading assessments to the group allocation of the participants.
3.1.3. Intervention Design
-
Intervention Group:
-
Text Selection: Provide students with a collection of reading materials that are within their "Lexile range," which is typically defined as 100L below to 50L above their current Lexile reader measure.[1][3] This ensures the texts are challenging but not frustrating.
-
Intervention Delivery: Implement a structured reading program for a set duration (e.g., 30 minutes daily for 12 weeks). This could involve independent reading, small group instruction, or the use of a specific reading software program.
-
-
Control Group:
-
The control group will continue with the standard reading curriculum without the targeted Lexile-based intervention.
-
3.1.4. Data Collection
-
Baseline (Pre-Intervention): Administer a standardized reading assessment to all participants to obtain their initial Lexile reader measure.
3.1.5. Statistical Analysis
-
Descriptive Statistics: Calculate the mean and standard deviation for baseline and post-intervention Lexile scores for both groups.
-
Inferential Statistics:
-
Use an independent samples t-test to compare the mean Lexile gain (post-intervention score minus pre-intervention score) between the intervention and control groups.
-
Alternatively, use an Analysis of Covariance (ANCOVA) with the post-intervention Lexile score as the dependent variable, group (intervention vs. control) as the independent variable, and the pre-intervention Lexile score as a covariate to control for initial differences.
-
Protocol for a Longitudinal Study of Reading Growth
This protocol outlines a study to track the natural progression of reading ability over time using Lexile measures.
3.2.1. Participant Cohort
-
Define Cohort: Select a cohort of students at a specific starting point (e.g., the beginning of 3rd grade).
-
Recruitment: Recruit a representative sample of students from the target population. Obtain informed consent and assent.
3.2.2. Data Collection Timeline
-
Time Point 1 (Baseline): At the beginning of the academic year, administer a standardized reading assessment to obtain the initial Lexile reader measure for each participant.
-
Time Point 2: At the end of the same academic year, re-administer the same assessment to measure Lexile growth.
-
Subsequent Time Points: Continue to administer the assessment at regular intervals (e.g., annually at the beginning and end of each school year) for the duration of the study (e.g., three years).
3.2.3. Data Analysis
-
Descriptive Statistics: Calculate the mean and standard deviation of Lexile scores at each time point.
-
Growth Modeling:
-
Use repeated measures ANOVA to analyze the change in Lexile scores over time.
-
Employ hierarchical linear modeling (HLM) or latent growth curve modeling (LGCM) to model individual and group-level growth trajectories. These models can account for variability in initial reading ability and growth rates, and can also incorporate time-varying and time-invariant covariates (e.g., socioeconomic status, instructional practices).
-
Mandatory Visualizations
The following diagrams, created using Graphviz (DOT language), illustrate the experimental workflow and logical relationships described in the protocols.
Caption: Workflow for a Lexile-Based Reading Intervention Study.
Caption: Workflow for a Longitudinal Study of Reading Growth Using Lexile Measures.
Limitations and Considerations
While Lexile measures are a powerful tool for educational research, it is important to be aware of their limitations:
-
Quantitative Focus: The Lexile Framework is a quantitative measure of text complexity and does not account for qualitative factors such as text structure, genre, author's purpose, or the background knowledge of the reader.
-
Not a Diagnostic Tool: A Lexile score indicates a student's reading comprehension level but does not diagnose the underlying reasons for reading difficulties.[2]
-
Potential for Misuse: Lexile measures should not be used as the sole factor in determining what a student should read. Student interest and motivation are also critical components of reading development. The framework is intended to be a guide, not a prescription. The framework has been criticized for being overly simplistic and potentially limiting readers' choices.
References
Application Notes and Protocols: Utilizing the Lexile Framework for Differentiated Instruction in Research
For Researchers, Scientists, and Drug Development Professionals
Introduction
The Lexile framework measures text complexity based on two key predictors: sentence length and word frequency.[2][4] The resulting Lexile measure is a number followed by an "L" (e.g., 1200L), which indicates the reading demand of the text.[2][3] By understanding the Lexile measures of both scientific documents and the reading abilities of research personnel, organizations can create a more effective and efficient scientific communication ecosystem.
Application in a Research Context
Differentiated instruction in a research setting involves providing scientific information in multiple formats or at varying levels of complexity to accommodate the diverse expertise of the audience. This can range from providing onboarding materials for new scientists with lower Lexile measures to presenting highly complex data to seasoned principal investigators in texts with higher Lexile measures. The goal is to ensure that all personnel can effectively understand and act upon the information presented to them.
Quantitative Data Summary
To illustrate the potential impact of applying the Lexile framework in a research setting, the following tables summarize hypothetical data from studies assessing the effect of text complexity on researcher performance.
Table 1: Impact of Lexile-Adapted Protocols on Experimental Execution Time
| Researcher Experience Level | Average Lexile Measure of Original Protocols | Average Lexile Measure of Adapted Protocols | Average Completion Time for Original Protocols (minutes) | Average Completion Time for Adapted Protocols (minutes) | Percentage Improvement in Completion Time |
| New Hire (0-1 year) | 1650L | 1300L | 120 | 90 | 25.0% |
| Mid-Level (2-5 years) | 1650L | 1450L | 95 | 85 | 10.5% |
| Senior Scientist (5+ years) | 1650L | N/A | 75 | N/A | N/A |
Table 2: Effect of Text Complexity on Protocol Comprehension and Error Rates
| Document Lexile Measure | Target Audience Experience | Average Comprehension Score (%) | Average Rate of Critical Errors per Protocol |
| 1700L | New Hire | 65 | 4.2 |
| 1500L | New Hire | 85 | 1.5 |
| 1300L | New Hire | 95 | 0.5 |
| 1700L | Senior Scientist | 92 | 0.8 |
| 1500L | Senior Scientist | 98 | 0.2 |
Experimental Protocols
The following protocols provide a framework for implementing and evaluating the use of the Lexile framework for differentiated instruction within a research organization.
Experiment 1: Baseline Readability Assessment of Internal Scientific Documents
Objective: To determine the current range of text complexity for a sample of internal scientific and technical documents.
Methodology:
-
Document Sampling:
-
Randomly select a representative sample of 50 internal documents, including standard operating procedures (SOPs), research protocols, and internal reports.
-
-
Text Preparation:
-
For each document, extract the main body of text, excluding tables, figures, and references.
-
Save each text sample as a plain text file (.txt).
-
-
Lexile Analysis:
-
Utilize the Lexile® Analyzer tool to determine the Lexile measure for each text sample.
-
Record the Lexile measure, word count, and mean sentence length for each document.
-
-
Data Analysis:
-
Calculate the mean, median, and range of Lexile measures for the entire sample of documents.
-
Categorize the documents by type (e.g., SOP, protocol, report) and calculate the average Lexile measure for each category.
-
Experiment 2: Comprehension and Performance Study with Lexile-Adapted Protocols
Objective: To assess the impact of Lexile-adapted research protocols on comprehension, task performance, and error rates among scientists with varying levels of experience.
Methodology:
-
Participant Recruitment:
-
Recruit a cohort of 30 scientists: 10 new hires (<1 year experience), 10 mid-level scientists (2-5 years experience), and 10 senior scientists (>5 years experience).
-
-
Protocol Selection and Adaptation:
-
Select a standard laboratory protocol with a high baseline Lexile measure (e.g., 1600L).
-
Create two adapted versions of the protocol: one at a lower Lexile measure (e.g., 1400L) and one at a significantly lower measure (e.g., 1200L) by simplifying sentence structure and substituting less frequent words with more common synonyms where scientifically appropriate.
-
-
Experimental Design:
-
Randomly assign participants within each experience level to one of three groups, each receiving one version of the protocol (original, adapted 1, or adapted 2).
-
Each participant will be asked to perform the protocol.
-
-
Data Collection:
-
Measure the time taken to complete the protocol.
-
Record the number and severity of any errors made during the execution of the protocol.
-
Administer a post-task comprehension quiz consisting of 10 multiple-choice questions about the key steps and principles of the protocol.
-
-
Data Analysis:
-
Compare the average completion times, error rates, and comprehension scores across the different protocol versions for each experience level.
-
Use appropriate statistical tests (e.g., ANOVA) to determine the significance of any observed differences.
-
Experiment 3: Implementation of a Differentiated Scientific Communication Framework
Objective: To pilot a system for creating and disseminating scientific documents with differentiated Lexile measures.
Methodology:
-
Framework Development:
-
Establish target Lexile ranges for different audiences (e.g., new hires: 1200L-1400L; general scientific staff: 1400L-1600L; subject matter experts: 1600L+).
-
Develop guidelines for scientific writers on how to adapt text complexity without sacrificing scientific accuracy.
-
-
Pilot Program:
-
Select a specific research project or department for the pilot.
-
For all new documents generated within the pilot, require the creation of at least two versions with different Lexile measures.
-
Make both versions of the documents available to the relevant personnel.
-
-
Evaluation:
-
After a three-month pilot period, collect feedback from the participating scientists through surveys and focus groups.
-
Monitor key performance indicators, such as the frequency of requests for clarification on protocols and the number of reported errors in experimental execution.
-
Compare these metrics to pre-pilot data.
-
-
Refinement and Rollout:
-
Based on the evaluation, refine the framework and guidelines.
-
Develop a plan for a broader rollout of the differentiated communication framework across the organization.
-
Visualizations
The following diagrams illustrate key workflows and concepts related to the application of the Lexile framework in a research context.
References
Unlocking Reading Potential: Protocols for Tracking Student Reading Growth with the Lexile Framework
Application Notes and Protocols for Researchers, Scientists, and Drug Development Professionals
These application notes provide a detailed framework for researchers to design and implement studies tracking student reading growth using the Lexile® Framework for Reading. The protocols outlined below are intended to ensure rigorous and reproducible research in educational technology, curriculum development, and learning science.
Introduction to the Lexile Framework for Reading
The Lexile Framework for Reading is a scientific approach to measuring both reading ability and the complexity of texts on the same developmental scale.[1][2] A student's reading ability and the difficulty of a text are both reported as a Lexile measure, which is a number followed by an "L" (e.g., 850L).[1][3][4] This system allows for the precise matching of readers with texts that are at an appropriate level of challenge to foster reading growth.[1][3][5] The optimal range for reading growth is considered to be 100L below to 50L above a student's Lexile measure.[1][3]
Research Objectives and Applications
These protocols are designed for studies aiming to:
-
Track longitudinal reading growth in student populations.
-
Evaluate the efficacy of educational interventions on reading development.
-
Investigate the relationship between reading growth and other academic outcomes.
-
Develop and validate new educational technologies and curricula.
Experimental Protocols
Study Design
A longitudinal study design is recommended for tracking reading growth over time. This can be implemented as a single-group cohort study or a randomized controlled trial (RCT) to evaluate an intervention.
-
Single-Group Cohort Study: To track the natural progression of reading ability in a specific population over a defined period.
-
Randomized Controlled Trial (RCT): To compare the reading growth of an experimental group receiving a specific intervention against a control group.
Participant Recruitment and Selection
-
Define Target Population: Clearly define the characteristics of the student population to be studied (e.g., grade level, reading proficiency, demographic factors).
-
Inclusion and Exclusion Criteria: Establish clear criteria for including and excluding participants to ensure a homogenous study group.
-
Informed Consent: Obtain informed consent from parents or legal guardians and assent from student participants.
Data Collection
3.3.1 Obtaining Lexile Measures:
Student Lexile measures should be obtained using a validated, standardized assessment. Several assessments provide Lexile measures, including:
-
NWEA™ MAP® Growth™
-
Renaissance Star Reading®
-
Scholastic Reading Inventory™ (SRI)
-
i-Ready® Diagnostic
3.3.2 Data Collection Schedule:
To effectively track growth, Lexile measures should be collected at multiple time points. A typical schedule includes:
-
Baseline (T1): Beginning of the academic year (e.g., September).
-
Mid-point (T2): Middle of the academic year (e.g., January).
-
End-point (T3): End of the academic year (e.g., May).
For longer-term longitudinal studies, data should be collected at the same time points across multiple academic years.
Data Presentation
Quantitative data should be summarized in clearly structured tables to facilitate comparison and interpretation.
Table 1: Participant Demographics
| Characteristic | Experimental Group (n=) | Control Group (n=) | Total (N=) |
| Grade Level | |||
| 4th Grade | |||
| 5th Grade | |||
| Gender | |||
| Male | |||
| Female | |||
| Reading Proficiency (Baseline) | |||
| Below Grade Level | |||
| At Grade Level | |||
| Above Grade Level |
Table 2: Mean Lexile Scores and Growth Over Time
| Time Point | Experimental Group (Mean Lexile ± SD) | Control Group (Mean Lexile ± SD) | p-value |
| Baseline (T1) | |||
| Mid-point (T2) | |||
| End-point (T3) | |||
| Overall Growth (T3-T1) |
Table 3: Lexile Growth by Subgroup
| Subgroup | Experimental Group (Mean Lexile Growth ± SD) | Control Group (Mean Lexile Growth ± SD) | p-value |
| Grade 4 | |||
| Grade 5 | |||
| Below Grade Level (Baseline) | |||
| At/Above Grade Level (Baseline) |
Mandatory Visualizations
Experimental Workflow
The following diagram illustrates the workflow for a randomized controlled trial tracking reading growth with Lexile measures.
Experimental workflow for a Lexile-based reading growth study.
Logical Relationship of Key Concepts
This diagram illustrates the logical relationship between the core components of the Lexile Framework and their application in research.
Logical relationship of concepts in Lexile-based research.
References
Application Notes and Protocols for Obtaining Lexile Measures for a Corpus of Texts
For Researchers, Scientists, and Drug Development Professionals
Introduction
The Lexile® Framework for Reading is a widely used methodology for assessing the readability of a text. It provides a quantitative measure, known as a Lexile measure, which represents the complexity of a text based on its syntactic and semantic features.[1][2][3] For researchers, scientists, and professionals in drug development, applying Lexile measures to a corpus of texts—such as clinical trial documentation, scientific literature, patient-facing materials, or regulatory submissions—can provide valuable insights into text complexity, aiding in the assessment of document readability and comprehension by the intended audience.
These application notes provide detailed protocols for obtaining Lexile measures for a corpus of texts using the official MetaMetrics® tools and API.
Core Principles of the Lexile Framework
The Lexile measure of a text is calculated based on two primary linguistic features[3][4]:
-
Sentence Length: Longer sentences are generally more grammatically complex and require greater short-term memory to process.[5]
-
Word Frequency: The frequency of words in a large corpus of text is used as a proxy for vocabulary difficulty. Less frequent words are typically more challenging for a reader.[5]
These two variables are analyzed by a proprietary algorithm to produce a Lexile measure on the Lexile scale, which ranges from below 0L for beginning reader texts to above 1600L for advanced texts.[1][2]
Methodologies for Obtaining Lexile Measures
There are two primary methods for obtaining Lexile measures for a corpus of texts: manual analysis using the Lexile® Analyzer and programmatic analysis via the MetaMetrics® API.
Manual Analysis using the Lexile® Analyzer
The Lexile® Analyzer is a web-based tool that allows for the analysis of individual text files.[6][7] This method is suitable for smaller corpora or for initial exploratory analysis.
Experimental Protocol:
-
Account Registration: Register for a free account on the Lexile® & Quantile® Hub (hub.lexile.com).[6]
-
Text Preparation:
-
Ensure each text file is in plain text format (.txt).
-
Remove any extraneous formatting, headers, footers, and citations that are not part of the main body of the text.
-
For accurate measurement, each text should be at least 25 words long.
-
-
Accessing the Lexile Analyzer: Navigate to the Lexile® Analyzer tool within the Lexile & Quantile Hub.
-
Text Submission:
-
Copy and paste the text directly into the text box.
-
Alternatively, upload a plain text file.
-
-
Analysis and Data Extraction:
-
Initiate the analysis. The tool will return a Lexile measure for the submitted text.
-
Manually record the Lexile measure for each text in your corpus in a structured format (e.g., a spreadsheet).
-
Programmatic Analysis using the MetaMetrics® API
For large corpora, programmatic access via the MetaMetrics® API is the most efficient method. This requires obtaining an API key and using a programming language such as Python to send requests to the API.
Experimental Protocol:
-
API Key Acquisition: Contact MetaMetrics to inquire about API access for research purposes. This may involve a licensing agreement and associated fees.
-
API Documentation Review: Thoroughly review the MetaMetrics® API documentation to understand the request format, parameters, and response structure.
-
Environment Setup:
-
Install necessary libraries in your programming environment (e.g., requests in Python) to handle HTTP requests.
-
-
Corpus Preparation:
-
Organize your text corpus in a structured manner (e.g., a directory of text files or a database).
-
Ensure each text is properly encoded (e.g., UTF-8).
-
-
API Request Scripting:
-
Develop a script to iterate through your corpus.
-
For each text, the script should:
-
Read the content of the text file.
-
Format the text as required by the API (e.g., as a string in a JSON payload).
-
Send a POST request to the appropriate API endpoint, including your API key for authentication.
-
Receive and parse the JSON response containing the Lexile measure.
-
Store the Lexile measure and any other relevant data (e.g., word count, mean sentence length) in a structured format (e.g., CSV file, database).
-
-
-
Data Analysis: Once all texts in the corpus have been analyzed, you can perform quantitative analysis on the collected Lexile measures.
Data Presentation
The quantitative data obtained from the Lexile analysis should be summarized in a clear and structured format.
| Document ID | Word Count | Mean Sentence Length (MSL) | Mean Log Word Frequency (MLF) | Lexile Measure |
| CLIN-TRIAL-001 | 34,567 | 22.5 | 3.1 | 1350L |
| PATIENT-INFO-002 | 1,234 | 15.2 | 2.8 | 980L |
| REG-SUB-003 | 120,876 | 25.8 | 3.3 | 1550L |
| SCI-PAPER-004 | 8,912 | 21.1 | 3.0 | 1320L |
Table 1: Example of a structured table for summarizing Lexile measure data for a corpus of texts.
| Lexile Range | "Stretch" Text Complexity Band (Common Core) |
| 420L - 820L | Grades 2-3 |
| 740L - 940L | Grades 4-5 |
| 925L - 1070L | Grades 6-8 |
| 1050L - 1185L | Grades 9-10 |
| 1185L - 1385L | Grades 11-CCR |
Table 2: General correspondence between Lexile measures and grade-level text complexity bands.
Visualization of Workflows and Logical Relationships
Experimental Workflow for Obtaining Lexile Measures
Caption: Workflow for obtaining Lexile measures from a text corpus.
Logical Diagram of the Lexile Framework
Caption: Logical relationship of components in the Lexile Framework.
References
Implementing the Lexile Framework in Longitudinal Reading Studies: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
This document provides detailed application notes and protocols for the implementation of the Lexile® Framework for Reading in longitudinal studies. The Lexile framework offers a standardized, quantitative approach to measuring both reader ability and text complexity on the same scale, making it a valuable tool for tracking reading growth over time. These guidelines are designed to assist researchers in designing robust longitudinal studies to assess the impact of interventions on reading development.
Introduction to the Lexile Framework in Longitudinal Research
The Lexile Framework for Reading is a scientific approach to measuring reading ability and the complexity of texts. It is based on the principle of matching readers with texts that are at an appropriate level of difficulty to foster reading growth. In the context of longitudinal studies, the Lexile framework provides a consistent metric to track changes in reading ability within individuals and groups over extended periods.
A student's Lexile measure represents their reading ability on the Lexile scale. This measure is obtained through a variety of standardized reading assessments that have been linked to the Lexile framework. By administering these assessments at multiple time points, researchers can collect longitudinal data on reading growth.
Experimental Protocols
Participant Selection
The selection of participants is a critical step in designing a longitudinal reading study. The criteria for inclusion and exclusion should be clearly defined based on the research question.
General Population Studies:
-
Inclusion Criteria: Participants within a specific age or grade range (e.g., students in grades 3-8).
-
Exclusion Criteria: Students with pre-existing conditions that could significantly impact reading development and are not the focus of the study (e.g., severe, uncorrected vision or hearing impairments).
Studies on Specific Populations: For studies focusing on particular demographics, such as at-risk students, the selection criteria should be more specific.
-
Example: At-Risk Middle School Students [1]
Selection of Lexile-Linked Assessments
A variety of standardized assessments provide Lexile reader measures. The choice of assessment will depend on the age of the participants and the specific goals of the study. It is crucial to use the same or a vertically scaled assessment instrument throughout the study to ensure consistency and comparability of scores over time.
Commonly Used Lexile-Linked Assessments:
-
MAP® Growth™ Reading Test (NWEA)[2]
-
STAR Reading™ Test[2]
-
DIBELS® Next (Dynamic Indicators of Basic Early Literacy Skills)[2]
-
i-Ready® Diagnostic[2]
-
Achieve3000®
-
State-specific end-of-grade (EOG) tests, such as the North Carolina End-of-Grade Test in Reading.[3]
Data Collection Timeline
The frequency and timing of data collection are key considerations in a longitudinal study.
-
Frequency: Assessments should be administered at regular intervals to capture meaningful growth. Common frequencies include:
-
Annually: Typically at the beginning or end of the school year. This is suitable for tracking year-over-year growth.
-
Biannually: At the beginning and end of the school year to measure growth within a single academic year.
-
More Frequently: For studies on rapid interventions or with younger learners, more frequent assessments (e.g., every few months) may be appropriate.
-
-
Timing: Consistency in the timing of assessment administration is crucial to minimize variability due to instructional time. For example, if testing is done annually, it should be done in the same month each year.
Intervention and Control Groups
In studies evaluating the efficacy of an intervention, participants should be randomly assigned to an intervention group and a control group.
-
Intervention Group: Receives the specific reading program, pedagogical approach, or therapeutic agent being studied.
-
Control Group: Continues with the standard curriculum or a placebo. The activities of the control group should be well-documented.
Data Presentation
Quantitative data from longitudinal studies using the Lexile framework should be presented in a clear and structured format to allow for easy comparison.
| Study | Participant Population | Sample Size (n) | Duration | Assessment(s) Used | Key Findings on Lexile Growth |
| North Carolina Longitudinal Study [3] | Public school students | ~68,000 | 6 years (Grade 3 to Grade 8) | North Carolina End-of-Grade Test in Reading | On average, students' reading abilities tracked near the upper-difficulty levels of typical grade-level texts.[3] |
| At-Risk Middle School Student Study [1] | Urban middle school students (97% poverty rate, 87% minority, 75% English learners) | 2,485 | 5 years | Lexile-linked testing instrument | A distinct pattern of growth was observed, with readers at the kindergarten to second-grade reading levels showing the most significant Lexile growth.[1] |
Statistical Analysis Protocols
The analysis of longitudinal data requires statistical methods that can account for the nested nature of the data (i.e., repeated measures nested within individuals).
Growth Curve Modeling (GCM)
Growth curve modeling is a powerful statistical technique for analyzing change over time. It allows researchers to model individual growth trajectories and to identify predictors of that growth.
Protocol for Growth Curve Modeling of Lexile Data:
-
Data Structuring: Organize the data in a "long" format, where each row represents a single observation (a Lexile score at a specific time point) for a participant.
-
Model Specification:
-
Unconditional Model: Begin by fitting an unconditional growth model to determine the overall pattern of change in Lexile scores over time (e.g., linear, quadratic). This model estimates the average initial Lexile score (intercept) and the average rate of change (slope).
-
Conditional Model: Introduce time-invariant predictors (e.g., treatment group, demographic variables) to explain individual differences in the intercept and slope.
-
-
Software: Utilize statistical software packages such as R (with the lme4 or lavaan package), Mplus, or HLM to fit the models.
-
Interpretation: Interpret the model parameters to understand the average growth trajectory and the factors that influence individual differences in reading development.
Hierarchical Linear Modeling (HLM)
Hierarchical linear modeling (also known as multilevel modeling) is another appropriate method for analyzing longitudinal data. It explicitly models the two levels of the data structure: the repeated measures level (Level 1) and the individual participant level (Level 2).
Protocol for HLM Analysis of Lexile Data:
-
Level 1 Model: Define the within-person model of change. This model represents each individual's Lexile score as a function of time.
-
Level 2 Model: Model the between-person differences in the Level 1 parameters (intercept and slope). This allows for the examination of how individual characteristics predict the initial Lexile score and the rate of growth.
-
Model Building: Start with a null model (with no predictors) to partition the variance in Lexile scores into within-person and between-person components. Then, add predictors at both Level 1 (time-varying covariates) and Level 2 (time-invariant covariates).
-
Software: HLM, SAS (PROC MIXED), SPSS (MIXED), and R are commonly used for HLM analysis.
Visualizations
Diagrams are essential for visualizing the complex relationships and workflows in longitudinal reading studies.
Caption: Experimental workflow for a longitudinal reading study.
Caption: Logical relationship within the Lexile framework.
References
Applying Lexile Codes for Developmental Appropriateness in Research Studies: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
Introduction
The Lexile® Framework for Reading provides a scientific approach to measuring both text complexity and a reader's ability on the same scale.[1] While widely used in educational settings, the application of Lexile codes is increasingly relevant in research, particularly in clinical trials and drug development, to ensure that participant-facing materials are developmentally appropriate and easily understood. This is crucial for obtaining truly informed consent and ensuring patient comprehension of study-related information.
These application notes and protocols provide a framework for researchers, scientists, and drug development professionals to systematically apply Lexile codes to assess and improve the readability and developmental appropriateness of their study documents.
Understanding Lexile Measures and Codes
A Lexile measure is a number followed by an "L" (e.g., 880L) that indicates the reading demand of a text.[2][3] The Lexile scale is a developmental scale ranging from below 0L for beginning readers to above 1600L for advanced readers.[3] In addition to the numerical score, Lexile codes provide further context about a text's developmental appropriateness and intended use.[3]
Table 1: Description of Lexile Codes
| Code | Description | Application in a Research Context |
| AD | Adult Directed: The text is intended to be read aloud to the user.[3] | Useful for materials designed for pediatric participants where a parent or guardian will be reading the information. |
| NC | Non-Conforming: The text has a high Lexile measure but is appropriate for younger, advanced readers due to its content.[3] | Applicable for studies with gifted or advanced pediatric cohorts where the complexity of the language can be higher, but the subject matter must remain age-appropriate. |
| HL | High-Low: The text has a low Lexile measure but is suitable for older readers due to its mature themes and content.[3] | Valuable for materials intended for adult participants with lower literacy skills, ensuring the content is respectful and engaging. |
| IG | Illustrated Guide: The text consists of independent sections, like a manual or encyclopedia.[3] | Can be applied to patient diaries, device instructions, or other reference materials provided to study participants. |
| GN | Graphic Novel: The text is presented in a comic book format. | May be a useful format for assent documents for children or for patient education materials to enhance engagement and comprehension. |
| BR | Beginning Reader: The text is appropriate for emergent readers, with a Lexile measure below 0L.[3] | Essential for developing materials for very young pediatric participants or individuals with significant cognitive or literacy challenges. |
Quantitative Data: Lexile Framework for Reading
Understanding typical reading levels across different populations is essential for tailoring study materials appropriately. While individual reading abilities vary, the following tables provide a general guide to Lexile levels by grade and for the general adult population.
Table 2: Typical Lexile Ranges by Grade Level
| Grade | "Stretch" Lexile Band |
| 2-3 | 420L - 820L |
| 4-5 | 740L - 1010L |
| 6-8 | 925L - 1185L |
| 9-10 | 1050L - 1335L |
| 11-CCR | 1185L - 1385L |
Source: Adapted from Common Core State Standards' recommendations for text complexity grade bands.[4]
Table 3: Estimated Lexile Levels for Adult Literacy
| Literacy Level | Estimated Lexile Range | Characteristics & Implications for Research Materials |
| Below Basic | Below 400L | Individuals may have difficulty with simple, everyday literacy tasks. Materials should use very simple vocabulary, short sentences, and be heavily supported by visuals. The "AD" (Adult Directed) code may be appropriate. |
| Basic | 400L - 800L | Individuals can read and understand short, commonplace texts. Informed consent forms and other materials should be written in plain language, avoiding jargon. The "HL" (High-Low) code can be useful for engaging content. |
| Intermediate | 800L - 1200L | Individuals can read and understand moderately dense texts. Most patient-facing documents should be targeted within this range to be accessible to the general population. |
| Proficient | 1200L and above | Individuals can read and understand complex and abstract texts. While some study documents for scientific audiences will fall in this range, it is generally too high for materials intended for the average study participant. |
Note: These are estimations and should be used as a guide. The actual literacy level of a study population should be considered during the development of materials.
Experimental Protocols
Protocol for Assessing the Readability of Informed Consent Forms (ICFs)
Objective: To systematically assess and revise an Informed Consent Form (ICF) to ensure it is developmentally appropriate and readable for the target study population.
Methodology:
-
Define the Target Population: Clearly define the intended age range and expected literacy level of the study participants.
-
Initial Lexile Analysis:
-
Prepare the ICF text by removing all non-prose elements (e.g., tables, bulleted lists that are not complete sentences).
-
Use a certified Lexile Analyzer tool to determine the initial Lexile score of the ICF. The text can be split into 125-word slices for analysis.[5]
-
-
Content and Developmental Appropriateness Review:
-
A multidisciplinary team, including researchers, clinicians, and community representatives, should review the ICF for clarity, tone, and cultural sensitivity.
-
Evaluate the content to determine if any Lexile codes (e.g., HL for adults with low literacy, NC for advanced pediatric readers) are applicable.
-
-
Revision Based on Analysis:
-
If the initial Lexile score is too high for the target population, revise the text by:
-
Simplifying vocabulary.
-
Shortening sentence length.
-
Using an active voice.
-
Breaking down complex ideas into smaller, more manageable concepts.
-
-
-
Re-analysis and Iteration:
-
Re-run the revised text through the Lexile Analyzer.
-
Repeat the revision and re-analysis process until the target Lexile range is achieved.
-
-
User Testing (Qualitative Assessment):
-
Conduct user testing with a representative sample of the target population to assess their comprehension of the revised ICF.
-
Use think-aloud protocols or structured interviews to identify any remaining areas of confusion.
-
-
Finalization and Documentation:
-
Finalize the ICF based on the results of the Lexile analysis and user testing.
-
Document the entire process, including initial and final Lexile scores, revisions made, and user testing feedback, in the study documentation.
-
Visualizations
Signaling Pathway for Developmental Appropriateness
Caption: Signaling pathway for ensuring developmental appropriateness of study documents.
Experimental Workflow for Lexile-Based Readability Assessment
Caption: Experimental workflow for Lexile-based readability assessment.
Conclusion
The integration of the Lexile Framework into the development of research and clinical trial materials is a critical step towards enhancing participant comprehension and ensuring true informed consent. By systematically applying Lexile measures and codes, researchers can create documents that are not only scientifically accurate but also developmentally appropriate and accessible to their intended audience. This commitment to clear communication ultimately strengthens the ethical foundation of research and fosters greater trust between researchers and participants.
References
limitations of Lexile scores in analyzing text complexity
Lexile Score Analysis: Technical Support Center
Welcome to the Technical Support Center for Lexile score analysis. This resource is designed for researchers, scientists, and drug development professionals to understand the nuances and limitations of using Lexile scores for text complexity analysis in their work. Below you will find frequently asked questions and troubleshooting guides to address common issues encountered when relying on this metric.
Frequently Asked Questions (FAQs)
Q1: What are the fundamental inputs for calculating a Lexile score?
A1: The Lexile Framework for Reading determines a text's complexity based on two primary quantitative variables: word frequency and sentence length.[1][2][3] The underlying principle is that longer sentences and less common words increase the difficulty of a text.[4] The calculation does not incorporate any qualitative aspects of the text.[5]
Q2: We analyzed a research paper with a seemingly low Lexile score, but our team found it very difficult to comprehend. Why is there a discrepancy?
A2: This is a common issue. Lexile scores, being purely quantitative, do not account for factors like the complexity of ideas, abstract themes, or the need for specific background knowledge, all of which are critical for understanding scientific literature.[1][6][7] A text can use simple sentence structures and common words but convey highly sophisticated and challenging concepts.[2] For example, Elie Wiesel's "Night," a book with profound themes of loss and moral ambiguity, has a relatively low Lexile score.[6]
Q3: Can Lexile scores account for the diverse backgrounds and expertise levels within a research team?
A3: No. A significant limitation of the Lexile framework is its inability to consider reader-specific factors.[4][8][9] The score is static and does not adjust for a reader's prior knowledge, motivation, or interest in the subject matter.[3][4] A researcher with extensive experience in a particular field will find a relevant paper easier to comprehend than a colleague new to the area, regardless of the text's Lexile score.[8][9]
Q4: Are Lexile scores a reliable tool for selecting training materials for our scientific staff?
A4: While a Lexile score can be a starting point, it should be used with caution and as only one of multiple assessment tools.[3][6] Over-reliance on Lexile scores can narrow reading choices and exclude texts that are culturally or contextually relevant.[6] For training purposes, it is crucial to also consider qualitative measures and the specific learning objectives for your team.[2][6]
Q5: How can a text with complex, multi-clause sentences receive a lower Lexile score than a text with shorter, simpler sentences?
A5: This scenario is unlikely, as sentence length is a primary driver of the score. However, the other variable, word frequency, plays a crucial role. A text with long sentences might still get a lower score if the vocabulary is extremely common. Conversely, a text with short sentences but many rare, technical terms could receive a higher score. The final score is an average of the entire text's characteristics, and individual sections can vary in complexity.[8][9]
Troubleshooting Guide
Issue: A text's perceived difficulty does not align with its Lexile score.
This is the most common challenge users face. The discrepancy arises because the Lexile formula is limited to syntactic and semantic difficulty from a quantitative standpoint.
Methodology for Analysis:
The Lexile score for a text is calculated through the following steps:
-
The text is divided into 125-word segments.
-
Within each segment, the sentence lengths and the frequency of each word are measured.
-
Word frequency is determined by comparing the words in the text to a large corpus of English words.
-
These quantitative measurements are then entered into the Lexile equation to produce a score for each segment.
-
The scores of all segments are averaged to determine the final Lexile measure for the entire text.[5]
This methodology, by its nature, excludes the qualitative factors that are often paramount in scientific and technical documents.
Solution: Implement a Multi-Faceted Text Complexity Model
To get a more accurate assessment of a text's complexity, supplement the quantitative Lexile score with qualitative analysis. Consider the following factors:
-
Knowledge Demands: What prior knowledge is assumed?
-
Structure: Is the text logically organized? Does it use complex structures like nested hierarchies or non-linear arguments?
-
Language Conventionality and Clarity: Does the text use figurative, ironic, or ambiguous language?
-
Levels of Meaning: Does the text have multiple layers of meaning or require significant inference?
Data Presentation: Examples of Misleading Lexile Scores
The table below presents examples of texts where the Lexile score may not accurately reflect the text's true complexity for its intended audience.
| Title | Author | Lexile Score | Syntactic/Semantic Complexity | Qualitative Complexity |
| Of Mice and Men | John Steinbeck | 630L | Relatively simple sentence structure and common vocabulary. | Deals with mature themes of friendship, loneliness, and moral dilemmas.[1] |
| Night | Elie Wiesel | 570L | Straightforward language and sentence construction. | Profound and emotionally challenging themes of loss, trauma, and human nature.[6] |
| The Grapes of Wrath | John Steinbeck | 680L | Accessible vocabulary and sentence patterns. | Complex social and historical themes requiring significant background knowledge.[10] |
Visualization of Lexile Score Limitations
The following diagrams illustrate the inputs into the Lexile scoring system and the numerous factors that it fails to consider, which are often critical for a comprehensive analysis of text complexity.
Caption: Core inputs for the Lexile score calculation.
Caption: Factors influencing text complexity beyond Lexile scores.
References
- 1. Understanding the Lexile Framework- the Pros & Cons — Reading Rev [readingrev.com]
- 2. isbe.net [isbe.net]
- 3. m.youtube.com [m.youtube.com]
- 4. exclusive.multibriefs.com [exclusive.multibriefs.com]
- 5. cheshirelibraryblog.com [cheshirelibraryblog.com]
- 6. pernillesripp.com [pernillesripp.com]
- 7. youtube.com [youtube.com]
- 8. readingrockets.org [readingrockets.org]
- 9. To Lexile or Not to Lexile | Shanahan on Literacy [shanahanonliteracy.com]
- 10. youtube.com [youtube.com]
optimizing the Lexile framework for diverse student populations
Technical Support Center: Lexile Framework Optimization
Introduction for Clinical Researchers
This technical support center is designed for researchers, scientists, and drug development professionals utilizing the Lexile framework to assess text comprehension in clinical and experimental settings. While the Lexile framework is a powerful tool for measuring text difficulty based on word frequency and sentence length, its application to diverse patient populations—including multilingual individuals, those with varying socioeconomic backgrounds, and patients encountering conceptually dense medical texts—requires careful optimization to ensure data validity. This guide provides troubleshooting advice, FAQs, and standardized protocols to address common challenges encountered during these applications.
Troubleshooting and FAQs
Question 1: Why do patient cohorts with Limited English Proficiency (LEP) demonstrate poor comprehension of clinical trial materials that have a "simple" Lexile score?
Answer: This is a common issue stemming from the core limitations of the Lexile framework, which primarily measures syntactic complexity (sentence length) and word frequency[1][2][3]. It does not account for other critical factors:
-
Conceptual Density: Medical and consent documents often contain low-frequency, high-concept terms (e.g., "placebo," "randomized," "contraindication") that are not adequately weighted by the standard algorithm.
-
Cultural Context: The framework does not assess the cultural relevance of a text[4]. Materials lacking cultural context can impede comprehension, even if the language is syntactically simple[5]. For multilingual learners, cultural knowledge significantly impacts their understanding[4].
-
Thematic Complexity: A text can have a low Lexile score but be thematically complex and emotionally challenging, leading to cognitive burdens not reflected in the score[1][6][7].
Troubleshooting Steps:
-
Analyze Conceptual Load: Manually or computationally identify high-concept, domain-specific terms not captured by general word frequency lists.
-
Cultural Relevancy Audit: Engage a multicultural review panel to assess if analogies, examples, and phrasing are appropriate for the target patient populations.
-
Implement Protocol 1.1: Follow the detailed protocol for creating a "Context-Adjusted Lexile Score" to supplement the standard measure.
Question 2: We are observing high variance in reading comprehension gains within a patient cohort from a low socioeconomic status (SES) background, despite all participants being within the target Lexile range for the study materials. What could be the cause?
Answer: High variance in this cohort may be linked to factors outside the immediate experimental controls. Research has shown that individuals from low-SES backgrounds may have had less access to a wide variety of "just right" reading materials, potentially impacting their strategic reading skills and background knowledge[8]. The standard Lexile measure does not account for a reader's prior knowledge, motivation, or reading context[4]. A study on third graders from low-income families found that poor readers often had books at home with reading demands well above their reading levels, while good readers had books with minimal challenge[8]. This suggests that the "one-size-fits-all" Lexile range may not be equally effective for all participants.
Troubleshooting Steps:
-
Pre-study Assessment: Administer a baseline assessment of background knowledge on the specific topics covered in the study materials.
-
Adjust Target Range: For participants struggling, provide texts at the lower end of their Lexile range (-100L) to build confidence and fluency before introducing more challenging materials (+50L)[9][10].
-
Follow Protocol 2.1: Utilize the protocol for "Baseline Knowledge Normalization" to statistically account for these initial differences in your data analysis.
Question 3: Our internal review showed that a patient-facing document written in vernacular language to improve relatability received a very low Lexile score, flagging it as "too simple" for our target adult population. Is this score accurate?
Answer: This is a known limitation of algorithms that rely on standard word frequency databases[6]. The Lexile framework can misinterpret culturally rich or vernacular texts as being overly simple.
-
Algorithmic Bias: The formula penalizes texts that use non-standard English, verse, or translanguaged text, even if the cognitive and emotional load is significant[6]. For example, two books like To Kill a Mockingbird and The House on Mango Street can share an identical Lexile score (870L) but offer vastly different comprehension challenges and cultural relevance, especially for English Language Learners[5].
-
Punishment of Good Writing: The system can inadvertently reward convoluted writing with longer sentences and obscure words, while punishing clear, concise prose as "simple"[7].
Troubleshooting Steps:
-
Qualitative Analysis: Do not rely solely on the quantitative Lexile score. Use a qualitative rubric to score the text for clarity, engagement, and conceptual accuracy.
-
Reader-Task Assessment: Evaluate the text based on the specific reader and the task they need to perform. A low Lexile score may be appropriate if the goal is rapid, accurate comprehension of a critical instruction.
-
Execute Protocol 3.1: Follow the "Qualitative and Reader-Task Matrix" protocol to generate a more holistic difficulty rating.
Quantitative Data Summary
The following table represents hypothetical data from an experiment testing a standard clinical consent form against a version modified according to the protocols below.
| Participant Cohort | Document Version | Standard Lexile Score | Adjusted Lexile Score (Protocol 1.1) | Mean Comprehension Score (%) | Critical Error Rate (%) |
| Native English Speakers (n=50) | Standard | 1150L | 1350L | 92% | 3% |
| Native English Speakers (n=50) | Modified (Plain Language) | 950L | 1050L | 98% | 1% |
| Limited English Proficiency (n=50) | Standard | 1150L | 1350L | 65% | 28% |
| Limited English Proficiency (n=50) | Modified (Plain Language) | 950L | 1050L | 89% | 7% |
Experimental Protocols
Protocol 1.1: Generating a Context-Adjusted Lexile Score
-
Objective: To create a supplementary score that accounts for the conceptual density of specialized (e.g., medical) texts.
-
Methodology:
-
Standard Analysis: Process the document through a certified Lexile analyzer to obtain the baseline score.
-
Domain-Specific Lexicon Generation: Create a corpus of key terms and concepts essential for comprehension in your specific domain (e.g., "double-blind," "bioavailability," "adverse event").
-
Term Frequency Analysis: Use a script (e.g., Python with NLTK) to count the frequency of these domain-specific terms within the text.
-
Conceptual Density Index (CDI) Calculation: Define a CDI score as: CDI = (Number of Domain-Specific Terms / Total Words) * 100.
-
Score Adjustment: Apply a pre-defined weighting factor to the baseline Lexile score. For example: Adjusted Score = Baseline Lexile + (CDI * 50). The weighting factor (e.g., 50) should be validated and standardized for your research area.
-
Validation: Correlate the Adjusted Score with actual patient comprehension scores across multiple texts to refine the weighting factor.
-
Protocol 2.1: Baseline Knowledge Normalization
-
Objective: To control for the confounding variable of pre-existing background knowledge in a diverse patient cohort.
-
Methodology:
-
Develop Assessment: Create a short, non-technical quiz (5-10 multiple-choice questions) that assesses the core concepts of the research materials without using the exact terminology from the documents.
-
Administer Pre-Test: Administer this quiz to all participants before they are exposed to the study materials.
-
Score and Categorize: Score the quiz and categorize participants into tiers (e.g., Low, Medium, High background knowledge).
-
Statistical Analysis: Use the pre-test score as a covariate in your statistical analysis (e.g., ANCOVA) when comparing comprehension outcomes between different groups or interventions. This will allow you to mathematically adjust for the initial differences in knowledge.
-
Protocol 3.1: Qualitative and Reader-Task Matrix
-
Objective: To create a holistic text difficulty score that complements the quantitative Lexile measure.
-
Methodology:
-
Define Dimensions: Create a rubric with 3-5 key dimensions.
-
Clarity & Simplicity: How clear is the language? (1-5 scale)
-
Cultural Relevancy: How appropriate are examples/idioms for the target audience? (1-5 scale) .
-
Actionability: How easy is it for the reader to know what to do next? (1-5 scale)
-
Conceptual Load: How many new or complex ideas are introduced? (1-5 scale)
-
-
Panel Review: Assemble a review panel that includes subject matter experts, communication specialists, and representatives from the target patient population.
-
Independent Scoring: Have each panel member score the text independently using the rubric.
-
Aggregate and Finalize: Average the scores for each dimension to create a final qualitative profile for the document. This profile should be presented alongside the Lexile score in any analysis.
-
Visualizations
Caption: Troubleshooting workflow for addressing inconsistent Lexile data.
References
- 1. Understanding the Lexile Framework- the Pros & Cons — Reading Rev [readingrev.com]
- 2. teacher.scholastic.com [teacher.scholastic.com]
- 3. m.youtube.com [m.youtube.com]
- 4. hkedcity.net [hkedcity.net]
- 5. Reddit - The heart of the internet [reddit.com]
- 6. pernillesripp.com [pernillesripp.com]
- 7. The League of Extraordinary Writers: How the Lexile System Harms Students [leaguewriters.blogspot.com]
- 8. files.eric.ed.gov [files.eric.ed.gov]
- 9. metametricsinc.com [metametricsinc.com]
- 10. What is Lexile and is it important for heritage language learners? - Growing Global Citizens [growingglobalcitizens.com]
refining Lexile-based reading interventions for struggling readers
Technical Support Center: Lexile-Based Reading Interventions
This technical support center provides troubleshooting guidance, frequently asked questions (FAQs), and experimental protocols for researchers and educational scientists .
Frequently Asked Questions (FAQs)
Q1: What is the Lexile Framework for Reading?
A: The Lexile Framework for Reading is a scientific approach that places both readers and texts on the same measurement scale to match a reader's ability with the difficulty of a text.[1][2] It involves two types of measures: a Lexile reader measure, which quantifies a student's reading ability, and a Lexile text measure, which indicates the complexity of a text based on factors like sentence length and word frequency.[3][4][5] The scale ranges from below 0L (coded as BR for Beginning Reader) to over 1600L.[2][4]
Q2: What is the recommended Lexile range for selecting instructional texts?
A: The optimal range for fostering reading growth is typically considered to be from 100L below to 50L above a student's reported Lexile measure.[2][3][4] Texts within this "sweet spot" are challenging enough to stimulate growth without causing frustration, targeting a comprehension rate of about 75%.[5]
Q3: What are the primary limitations of using Lexile measures to guide interventions?
A: While useful, the Lexile framework is not a comprehensive measure of reading difficulty. Its primary limitations include:
-
Focus on Quantitative Factors: Lexile measures are based on sentence length and word frequency.[4][5][6]
-
Exclusion of Qualitative Factors: The framework does not account for qualitative aspects like the complexity of ideas, text structure, theme, age-appropriateness, or the background knowledge a reader brings to the text.[6][7]
-
Student Motivation and Interest: A student's interest in a topic can significantly impact their ability to comprehend a text, potentially allowing them to read above their measured Lexile range or struggle with texts within it.[6]
Q4: Can Lexile measures be used to monitor student progress over time?
A: Yes, a key application of Lexile measures is to monitor reading growth longitudinally.[2][3] By administering linked assessments at different time points, researchers can track a student's progress toward college and career readiness benchmarks.[3] However, it's important to be aware that scores can vary from test to test.[2]
Q5: How do Lexile-based assessments compare to norm-referenced assessments?
A: Lexile-based assessments (e.g., Scholastic Reading Inventory) are criterion-referenced, comparing a student's performance to the predetermined criteria of the Lexile scale.[8] Norm-referenced assessments (e.g., GRADE) compare a student's performance to that of a representative sample of peers. Educators should be cautious when comparing results, as strong performance on a Lexile-based assessment may not always transfer directly to performance on summative, norm-referenced tests.[8]
Troubleshooting Guides
This section addresses specific issues that may arise during the implementation of Lexile-based reading interventions.
Issue 1: Student comprehension is poor despite reading within their recommended Lexile range.
-
Possible Cause A: Mismatch in Qualitative Complexity. The text may contain complex themes, abstract language, or require specific background knowledge not captured by the Lexile score.[6][7]
-
Solution: Manually review the text for qualitative factors. Use a text complexity rubric to analyze dimensions like structure, language features, and knowledge demands. Supplement with texts that have similar Lexile measures but lower qualitative demands.
-
-
Possible Cause B: Low Student Interest or Motivation. The student may not be engaged with the text's topic.[6]
-
Possible Cause C: Underlying Foundational Skills Deficit. The student may have specific, unidentified gaps in foundational reading skills (e.g., phonics, fluency) that hinder comprehension even with syntactically simple texts.
Issue 2: A student's Lexile measure has plateaued and is not showing expected growth.
-
Possible Cause A: Insufficient Reading Volume. The student may not be engaging in enough reading practice to drive growth.
-
Possible Cause B: Lack of Instructional Scaffolding. The student may be reading independently but requires more direct instruction to tackle increasingly complex texts.
-
Solution: Introduce texts slightly above the student's comfort range (+50L to +100L) but provide explicit instruction on challenging vocabulary, complex sentence structures, and comprehension strategies before, during, and after reading.
-
-
Possible Cause C: The "Third Grade Slump." Research has shown that reading growth rates, measured in Lexiles, tend to be highest in early grades (K-2) and decrease significantly from third grade onward.[12]
-
Solution: Re-evaluate growth targets to align with realistic expectations for the student's grade level. Focus on deep comprehension of complex texts rather than solely on increasing the Lexile number.
-
Issue 3: Logistical challenges in finding appropriately leveled texts for a large, diverse group of struggling readers.
-
Possible Cause: Over-reliance on a limited physical library.
-
Solution: Leverage digital reading platforms and online databases. Many platforms (e.g., CommonLit, Newsela, LightSail) use Lexile measures to provide vast libraries of articles and books that can be personalized for each student.[1][11] These tools often have embedded assessments to continuously track progress and adjust text difficulty.[11][13]
-
Quantitative Data Presentation
When evaluating interventions, data should be structured to allow for clear analysis of student growth.
Table 1: Hypothetical Student Lexile Growth Over an Intervention Period
| Assessment Point | Date | Assessment Used | Lexile (L) Measure | Change from Baseline | Grade Level | Notes |
| Baseline | 2025-09-05 | LevelSet | 450L | - | 4 | Identified for intervention. |
| Checkpoint 1 | 2025-11-15 | SRI | 495L | +45L | 4 | Responding well to high-interest texts. |
| Checkpoint 2 | 2026-02-01 | LevelSet | 510L | +60L | 4 | Growth rate slowed. |
| Checkpoint 3 | 2026-04-10 | SRI | 560L | +110L | 4 | Intensive vocabulary support added. |
| Post-Intervention | 2026-06-05 | LevelSet | 590L | +140L | 4 | Met annual growth target of >100L. |
Note: A typical growth expectation for some interventions is a gain of 100L over a school year.[8]
Experimental Protocols
Protocol: Evaluating a Lexile-Based Intervention Using a Quasi-Experimental Design
This protocol outlines a methodology for assessing the efficacy of a targeted reading intervention for struggling readers in a middle school setting.
-
Participant Selection:
-
Administer a universal screener (e.g., a Lexile-linked benchmark assessment) to all students in grades 6-8 at the beginning of the school year.
-
Identify students scoring more than one grade level below expectations based on their Lexile measure. For this study, we will define this as students in the "Intensive Group" (n≈60).[12]
-
From this pool, select participants for the intervention group (n=30) and a control group (n=30) matched on baseline Lexile scores, grade level, and demographic data.
-
-
Intervention Design (Intervention Group):
-
Duration: 24 weeks, 4 sessions per week, 45 minutes per session.
-
Procedure:
-
Students receive targeted instruction in small groups.
-
Each student is assigned a personalized digital library of texts within their recommended Lexile range (-100L to +50L).
-
Instruction focuses on pre-teaching challenging vocabulary and comprehension strategies for assigned texts.
-
Students engage in 30 minutes of daily independent reading within a platform that provides embedded comprehension questions and tracks progress.[11]
-
Educators monitor real-time data on student performance to provide immediate, targeted feedback.
-
-
-
Control Group Condition:
-
The control group continues with the standard school-wide English Language Arts curriculum without the specialized intervention. They do not use the personalized reading platform.
-
-
Data Collection & Measures:
-
Primary Outcome Measure: Student Lexile scores, measured at baseline, mid-point (12 weeks), and post-intervention (24 weeks) using a consistent, linked assessment (e.g., Scholastic Reading Inventory).
-
Secondary Outcome Measure: A standardized, norm-referenced reading comprehension test to assess the transferability of skills.[8]
-
Qualitative Data: Student surveys and interest inventories to measure engagement and motivation.
-
-
Data Analysis:
-
An analysis of covariance (ANCOVA) will be used to compare the post-intervention Lexile scores of the intervention and control groups, with the baseline Lexile score as the covariate.
-
A repeated measures ANOVA will be used to analyze the pattern of Lexile growth over the three time points within the intervention group.
-
Visualizations (Graphviz)
The following diagrams illustrate key workflows and logical relationships in refining Lexile-based interventions.
References
- 1. Harnessing the Power of Lexile | Step-by-Step Reading Instruction Guide [capti.com]
- 2. lexile.com [lexile.com]
- 3. youtube.com [youtube.com]
- 4. youtube.com [youtube.com]
- 5. m.youtube.com [m.youtube.com]
- 6. m.youtube.com [m.youtube.com]
- 7. m.youtube.com [m.youtube.com]
- 8. textproject.org [textproject.org]
- 9. youtube.com [youtube.com]
- 10. metametricsinc.com [metametricsinc.com]
- 11. lightsailed.com [lightsailed.com]
- 12. researchgate.net [researchgate.net]
- 13. ReadTheory | Free Reading Comprehension Practice for Students and Teachers [readtheory.org]
troubleshooting inaccurate Lexile measures for specific text types
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals address challenges with inaccurate Lexile® measures for specific text types encountered in their work.
Troubleshooting Guides & FAQs
Q1: Why is the Lexile measure for my scientific research paper unexpectedly low?
A: An unexpectedly low Lexile measure for a scientific paper is a common issue. The Lexile framework primarily assesses text complexity based on sentence length and word frequency in a general corpus of text.[1][2][3] Scientific texts, while containing complex ideas, may use concise sentence structures. Additionally, highly specialized or technical terms, though difficult for a general audience, might not be flagged as complex if they are used frequently within the document. The Lexile Analyzer is optimized for standard prose and can misinterpret the complexity of specialized scientific writing.[4]
Q2: My technical report contains numerous lists, tables, and captions, and the Lexile score seems inaccurate. Why is this?
A: The Lexile Analyzer is designed to measure professionally edited, complete, and conventional prose.[4] It may not accurately process texts with a significant amount of non-prose elements like lists, tables, mathematical formulas, or extensive captions. These elements lack the conventional punctuation and sentence structure that the Lexile algorithm relies on, which can lead to an unreliable Lexile measure.[5]
Q3: Can the presence of extensive technical jargon and acronyms in my drug development documentation affect the Lexile score?
A: Yes. The Lexile framework determines word difficulty based on its frequency in a large body of general text.[6] Technical jargon and acronyms specific to a narrow field, such as drug development, will likely be considered low-frequency and therefore complex by the Lexile Analyzer. This can inflate the Lexile score, suggesting the text is more difficult than it might be for its intended expert audience who are familiar with the terminology.
Q4: I have a regulatory submission document with long, complex sentences. Will the Lexile measure be accurate?
A: The Lexile framework heavily weighs sentence length in its calculation of text complexity.[6] Documents with consistently long and complex sentences, which are common in regulatory and legal texts, will generally receive a higher Lexile measure. While this may accurately reflect the syntactic complexity, it's important to remember that this is only one aspect of readability. The score does not account for the clarity of the information presented or the reader's prior knowledge.[7]
Q5: Are there alternative readability formulas that might be more suitable for scientific and technical documents?
A: Yes, several other readability formulas can provide a different perspective on your text's complexity. Some alternatives include:
-
Flesch-Kincaid Grade Level: This formula also uses sentence length and word complexity (syllables per word) to estimate the U.S. grade level required to understand the text.[8]
-
Gunning Fog Index: This index estimates the years of formal education a person needs to understand the text on the first reading. It places more emphasis on complex words (those with three or more syllables).[8]
-
Dale-Chall Readability Formula: This formula is notable for using a list of words that are familiar to most fourth-grade students to determine the complexity of the vocabulary.[8]
It can be beneficial to use a consensus of multiple readability scores to get a more holistic view of your document's readability.[9]
Data Presentation
Table 1: Illustrative Comparison of Readability Scores for a Fictional Scientific Abstract
| Readability Formula | Estimated Score | Key Measurement Factors | Potential Interpretation for a Scientific Audience |
| Lexile® Framework | 1450L | Sentence Length, Word Frequency | High score due to technical terms, may overestimate difficulty for experts. |
| Flesch-Kincaid Grade Level | 16.5 | Sentence Length, Syllables per Word | Suggests a high level of education is needed, which is expected for the target audience. |
| Gunning Fog Index | 19.2 | Sentence Length, Complex Words | Indicates a very high complexity, aligning with postgraduate-level material. |
| Dale-Chall Readability Formula | 13.1 | Sentence Length, Unfamiliar Words | Score reflects the use of vocabulary outside a commonly understood word list. |
Note: This table presents hypothetical data for illustrative purposes.
Experimental Protocols
Methodology for Assessing and Addressing Inaccurate Lexile Measures in Technical Documents
-
Initial Lexile Analysis:
-
Qualitative Review:
-
Engage a subject matter expert (SME) from the target audience to review the text.
-
The SME should assess the text for clarity, comprehensibility, and the appropriateness of the terminology, ignoring the initial Lexile score.
-
Gather feedback on sections that are particularly dense, confusing, or overly simplistic.
-
-
Analysis with Alternative Formulas:
-
Process the same cleaned text through at least two other readability formulas (e.g., Flesch-Kincaid, Gunning Fog Index).
-
Record the scores from each formula.
-
-
Comparative Analysis:
-
Compare the Lexile measure with the scores from the alternative formulas and the qualitative feedback from the SME.
-
Identify discrepancies. For example, a high Lexile score might contrast with an SME's assessment of the text as clear and easy to follow for the intended audience.
-
-
Iterative Refinement and Re-analysis:
-
Based on the comparative analysis, revise the text to improve readability for the target audience. This may involve:
-
Simplifying sentence structures without sacrificing precision.
-
Defining key acronyms and jargon upon first use.
-
Breaking down complex concepts into more digestible paragraphs.
-
-
After revision, repeat steps 1, 3, and 4 to measure the impact of the changes on the readability scores.
-
-
Documentation of Findings:
-
Document the initial and final readability scores from all formulas used.
-
Summarize the qualitative feedback and the revisions made.
-
Conclude with a final assessment of the text's readability for the intended audience, considering both the quantitative scores and the qualitative review.
-
Mandatory Visualization
Caption: Troubleshooting workflow for inaccurate Lexile measures.
References
- 1. How accurate are lexile text measures? - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. youtube.com [youtube.com]
- 3. m.youtube.com [m.youtube.com]
- 4. Lexile Analyzer® [la-tools.lexile.com]
- 5. scispace.com [scispace.com]
- 6. How to Change the Lexile Level of a Text - Cathoven [cathoven.com]
- 7. youtube.com [youtube.com]
- 8. youtube.com [youtube.com]
- 9. Readability Scoring System PLUS with the Robert Gunning Editor [readabilityformulas.com]
Beyond the Numbers: A Technical Support Center for Accounting for Qualitative Factors Not Measured by Lexile
For Researchers, Scientists, and Drug Development Professionals
This technical support center provides guidance on selecting and evaluating texts for complexity by considering qualitative factors that are not captured by quantitative measures like the Lexile framework. For researchers, scientists, and professionals in drug development, ensuring the appropriate complexity of technical documents, research articles, and protocols is crucial for clear communication and accurate comprehension. This center offers troubleshooting guides and frequently asked questions (FAQs) to address specific issues you may encounter.
Frequently Asked Questions (FAQs)
Q1: What are the key limitations of relying solely on a Lexile score for technical and scientific documents?
While a Lexile score provides a useful starting point by measuring quantitative aspects of a text like word frequency and sentence length, it does not account for the nuanced and complex qualitative features inherent in scientific and technical writing.[1][2] Over-reliance on Lexile can be misleading as it fails to capture deeper comprehension challenges.[2][3]
Key limitations include:
-
Complexity of Ideas: Lexile does not measure the density, abstraction, or novelty of the concepts presented. A text with a low Lexile score could still be conceptually very difficult.[1][4]
-
Text Structure: Scientific papers have specific, often complex structures (e.g., IMRaD), which are not factored into Lexile scores. The logical flow and organization of arguments are critical for comprehension.[3]
-
Language Features: Technical language often includes discipline-specific vocabulary, acronyms, figurative language (e.g., metaphors to explain complex processes), and nuanced phrasing that Lexile's algorithm doesn't fully appreciate.[2][3]
-
Knowledge Demands: The reader's prior knowledge is a significant factor in comprehending technical texts. Lexile does not assess the level of background knowledge required to understand the material.[2]
-
Visual and Graphical Information: Scientific documents frequently rely on complex tables, graphs, and diagrams to convey information. The complexity of these visual elements is not measured by Lexile.
Q2: What are the primary qualitative factors I should consider when evaluating a technical document?
To gain a comprehensive understanding of a text's complexity, a qualitative analysis is essential. The following are key qualitative factors to consider:
-
Purpose and Levels of Meaning: Is the purpose of the document explicit or implicit? Are there multiple layers of meaning or is the information straightforward?
-
Text Structure: How is the text organized? Is it a conventional structure for the genre (e.g., a standard research paper format)? Are the connections between ideas clear or do they require significant inference?
-
Language Conventionality and Clarity: Is the language literal or does it employ figurative or ironic elements? Is the vocabulary highly specialized and dense?
-
Knowledge Demands: What level of prior subject matter knowledge is assumed? Are there many intertextual references to other research or theories?
Q3: How can I systematically assess these qualitative factors?
A systematic approach to qualitative analysis involves using a rubric to score the different dimensions of text complexity. This ensures a consistent and thorough evaluation. The process typically involves a close reading of the text by a subject-matter expert.
Troubleshooting Guides
Problem: A research paper has a "low" Lexile score, but junior researchers are struggling to understand it.
Cause: This common issue highlights the limitations of quantitative metrics. The difficulty likely lies in the qualitative aspects of the text.
Solution:
-
Conduct a Qualitative Analysis: Use a rubric (see the "Experimental Protocols" section for a detailed methodology) to assess the paper's structure, language features, knowledge demands, and purpose.
-
Identify Specific Barriers: Pinpoint the exact sources of complexity. Is it the assumed background knowledge? The density of new concepts? The way the methodology is described?
-
Provide Scaffolding: Based on your analysis, provide support for the readers. This could include:
-
A glossary of key terms.
-
A pre-reading guide that outlines the paper's structure and key arguments.
-
A discussion session to clarify complex concepts.
-
Problem: We need to select a training manual for a new laboratory procedure that is accessible to a team with diverse experience levels.
Solution:
-
Start with a Quantitative Filter: Use a readability formula to get an initial gauge of the text's difficulty. Aim for a score that corresponds to a level accessible to the less experienced members of your team.
-
Perform a Qualitative Assessment: Have an experienced team member evaluate the manual using a qualitative rubric. Pay close attention to the clarity of instructions, the logical flow of the procedures, and the use of diagrams and illustrations.
-
Consider the "Reader and Task": The final component of text complexity analysis is considering the specific readers and the task they need to perform. Will they be reading this for a general overview or to follow a step-by-step protocol? Their motivation and prior experience will influence how they interact with the text.[2]
Data Presentation
Comparison of Common Readability Formulas
While Lexile is widely known, several other quantitative formulas can provide additional perspectives on a text's readability. Each uses a different combination of variables to calculate a score, typically corresponding to a U.S. grade level.
| Formula | Key Variables | Output | Best Suited For |
| Lexile Framework | Word frequency and sentence length. | A numeric score (e.g., 1300L). | General reading material. |
| Flesch-Kincaid Grade Level | Average sentence length and average number of syllables per word. | U.S. grade level. | A wide range of texts. |
| Gunning Fog Index | Average sentence length and percentage of complex words (three or more syllables). | U.S. grade level. | Business and technical writing.[5] |
| Coleman-Liau Index | Average number of characters per 100 words and average number of sentences per 100 words. | U.S. grade level. | Texts where character count is a better proxy for word difficulty than syllable count. |
| SMOG Index | Number of polysyllabic words (three or more syllables) in a sample of 30 sentences. | U.S. grade level. | Healthcare and medical writing. |
| Automated Readability Index (ARI) | Average number of characters per word and average number of words per sentence. | U.S. grade level. | Technical manuals. |
Note: While these formulas can be a useful starting point, research has shown that there can be inconsistencies between them, and they do not always correlate strongly with a human reader's perception of difficulty.[6][7]
Experimental Protocols
Methodology for Qualitative Text Analysis
This protocol outlines a systematic approach for conducting a qualitative analysis of a technical or scientific text.
Objective: To assess the qualitative dimensions of text complexity that are not captured by quantitative readability formulas.
Materials:
-
The text to be analyzed.
-
Qualitative Analysis Rubric (see table below).
-
Subject-matter expert(s).
Procedure:
-
Initial Skim: The expert reader should first skim the text to get a general sense of its topic, structure, and purpose.
-
Close Reading and Annotation: The reader should then perform a close reading of the text, annotating specific examples that relate to the categories in the rubric (e.g., instances of complex language, unclear transitions, high knowledge demands).
-
Scoring with the Rubric: Using the annotations as evidence, the reader should score each of the qualitative dimensions on a scale from 1 (Slightly Complex) to 4 (Exceedingly Complex).
-
Synthesize Findings: The reader should write a brief summary of the qualitative analysis, highlighting the key areas of complexity and potential challenges for the target audience.
Qualitative Analysis Rubric for Informational Texts
| Dimension | 1: Slightly Complex | 2: Moderately Complex | 3: Very Complex | 4: Exceedingly Complex |
| Purpose/Levels of Meaning | Purpose is explicit and clear. | Purpose is implied but easy to infer. | Purpose is implicit and subtle. | Purpose is subtle, intricate, and difficult to determine. |
| Structure | Organization is clear and sequential. Connections between ideas are explicit. | Organization is evident, with some implicit connections. | Organization is complex with multiple pathways. Connections are often implicit. | Organization is intricate and discipline-specific. Connections are deep and often ambiguous. |
| Language Features | Language is literal and clear. Vocabulary is familiar. | Language is largely literal with some specialized vocabulary. | Language may be figurative or ironic. Vocabulary is often specialized. | Language is dense and complex, potentially abstract or ironic. Vocabulary is highly specialized and academic. |
| Knowledge Demands | Assumes minimal prior knowledge. Few, if any, external references. | Assumes some domain-specific knowledge. Some references to other texts or ideas. | Relies on significant discipline-specific knowledge. Many references to other texts or theories. | Relies on extensive, deep, and theoretical knowledge. Many complex and abstract concepts. |
Mandatory Visualization
Below are diagrams illustrating key concepts in accounting for qualitative factors in text complexity.
Caption: A model for comprehensive text complexity analysis.
Caption: Workflow for conducting a qualitative text analysis.
References
- 1. Readability | Technical Writing [courses.lumenlearning.com]
- 2. Why a Lexile Score Isn’t Enough: A Smarter Way to Choose Complex Texts [ebacademics.com]
- 3. ideals.illinois.edu [ideals.illinois.edu]
- 4. youtube.com [youtube.com]
- 5. apps.dtic.mil [apps.dtic.mil]
- 6. View of The Validity of Some Popular Readability Formulas [richtmann.org]
- 7. researchgate.net [researchgate.net]
Technical Support Center: The Impact of Student Motivation on Lexile-Based Predictions
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals who are utilizing Lexile-based predictions in their studies and encountering variability that may be attributed to student motivation.
Frequently Asked Questions (FAQs)
Q1: We are observing a significant discrepancy between our experimental group's predicted Lexile scores and their actual reading comprehension performance. Could student motivation be a contributing factor?
A1: Yes, it is highly probable. The Lexile Framework for Reading primarily measures text complexity based on sentence length and word frequency. While this provides a valuable baseline, it does not account for reader-specific variables such as motivation, interest in the topic, and background knowledge. Research has shown a strong correlation between student engagement and reading comprehension outcomes, which can lead to performance that deviates from initial Lexile-based predictions. Highly motivated students may perform above their predicted Lexile level, while unmotivated students may perform below.
Q2: What is the distinction between intrinsic and extrinsic motivation, and how might each uniquely affect Lexile score accuracy?
A2: Intrinsic motivation refers to a student's internal drive to read for pleasure, interest, or personal growth. Extrinsic motivation is driven by external factors such as rewards, grades, or praise.[1][2] Studies suggest that intrinsic motivation is more strongly linked to sustained reading engagement and deeper comprehension, which can lead to greater and more consistent Lexile growth over time.[3] Extrinsically motivated students might demonstrate performance spikes when rewards are present, but this may not translate to a stable or accurate reflection of their true reading abilities in the absence of those external motivators. Therefore, a heavy reliance on extrinsic motivators in an experimental setting could inflate or temporarily alter reading performance, leading to less reliable Lexile-based predictions.
Q3: Are there validated instruments to measure student motivation in the context of reading comprehension studies?
A3: Yes, several validated questionnaires and scales can be used to assess student reading motivation. The English Reading Motivation Questionnaire, which integrates Keller's ARCS Model (Attention, Relevance, Confidence, and Satisfaction), is one such instrument.[4] Another common approach is the use of self-report surveys that gauge students' attitudes and beliefs about reading. When designing your experiments, incorporating such tools can provide valuable data to correlate with reading comprehension performance and Lexile scores.
Q4: How can we mitigate the impact of motivational variance in our experimental design?
A4: To mitigate the impact of motivational variance, consider the following strategies:
-
Account for Topic Interest: Whenever possible, select reading materials that align with the known interests of your study population. Providing a choice of texts on a similar Lexile level can also enhance engagement.[1]
-
Control for Environmental Factors: Ensure a consistent and comfortable testing environment to minimize external distractions that could affect motivation and focus.
-
Measure Motivation: Administer a reading motivation questionnaire pre- and post-intervention to statistically account for motivation as a covariate in your analysis.
-
Incorporate a Control Group: A well-designed control group can help differentiate the effects of your intervention from baseline motivational levels.
Troubleshooting Guides
Issue 1: Inconsistent Lexile Growth in a Longitudinal Study
-
Symptom: Individual participants show erratic patterns of Lexile score progression, with unexpected plateaus or regressions.
-
Possible Cause: Fluctuations in student motivation and engagement over the course of the study. A student's interest in the reading materials may wane, or external factors could impact their motivation to perform well on assessments.
-
Troubleshooting Steps:
-
Review Engagement Data: If your platform tracks metrics like time spent reading or number of articles completed, analyze this data for correlations with Lexile score changes.
-
Conduct Qualitative Analysis: Implement short surveys or interviews to gauge student interest and motivation at different stages of the study.
-
Vary Content: If feasible within your experimental design, introduce new topics or genres of reading material to re-engage participants.
-
Analyze by Subgroups: Segment your data by initial motivation levels (as measured by a baseline questionnaire) to see if there are different growth patterns for high- and low-motivation groups.
-
Issue 2: Higher-than-Expected Lexile Growth in the Treatment Group
-
Symptom: The experimental group demonstrates Lexile gains that significantly exceed the expected growth for their demographic and baseline reading levels.
-
Possible Cause: The intervention may be inadvertently increasing extrinsic motivation, leading to inflated performance on reading assessments. This is particularly relevant if the intervention includes gamification, rewards, or frequent progress feedback.
-
Troubleshooting Steps:
-
Isolate Motivational Components: Analyze the components of your intervention. Are there elements specifically designed to be "engaging" that could be acting as powerful extrinsic motivators?
-
Assess Transferability: Design a follow-up assessment using a different format or context to see if the observed reading gains are transferable. A drop in performance might suggest the initial gains were context-dependent and driven by extrinsic factors.
-
Measure Intrinsic Motivation: Use a validated scale to assess whether the intervention is also fostering intrinsic motivation. An increase in intrinsic motivation is more likely to be associated with sustainable and generalizable reading skill improvement.
-
Data Presentation
Table 1: Impact of Engagement on Annual Lexile Growth
| Engagement Level | Average Number of Lessons Completed Weekly | Average First-Try Score on Comprehension Quizzes | Actual Lexile Growth | Expected Lexile Growth | Growth Multiple vs. Expected |
| High | 2 or more | ≥ 75% | 245L | 69L | 3.5X |
| Moderate | 1-2 | ≥ 75% | 173L | 69L | 2.5X |
| Low | Less than 1 | < 75% | 89L | 69L | 1.3X |
This table summarizes data from a national study on the Achieve3000 literacy platform, demonstrating the significant impact of student engagement on Lexile growth.[5]
Experimental Protocols
Protocol 1: Assessing the Impact of Intrinsic Motivation on Reading Comprehension and Lexile Measurement
-
Objective: To determine the extent to which intrinsic motivation influences reading comprehension performance on texts with a fixed Lexile level.
-
Methodology:
-
Participant Recruitment: Recruit a cohort of students within a similar Lexile range (e.g., +/- 50L).
-
Baseline Motivation Assessment: Administer a validated reading motivation scale to establish a baseline intrinsic motivation score for each participant.
-
Text Selection: Select two sets of reading passages at the same Lexile level. One set should cover topics of high interest to the target demographic (determined through a preliminary interest survey), and the other set should cover low-interest, neutral topics.
-
Reading Comprehension Assessment: Randomly assign participants to read either the high-interest or low-interest passages. Administer a standardized reading comprehension test immediately following the reading.
-
Data Analysis: Compare the comprehension scores of the two groups. A significant difference in scores between the high-interest and low-interest groups would indicate that motivation (driven by interest) impacts comprehension, even when the text difficulty (as measured by Lexile) is held constant.
-
Protocol 2: Evaluating the Influence of Extrinsic Motivators on Lexile Test Performance
-
Objective: To investigate the effect of external rewards on student performance on a Lexile-based reading assessment.
-
Methodology:
-
Participant Screening: Select a group of students and administer a pre-test to determine their current Lexile measure.
-
Group Assignment: Randomly divide the participants into a control group and an experimental group.
-
Intervention:
-
Control Group: Instruct the students to complete a series of reading passages and accompanying comprehension questions.
-
Experimental Group: Provide the same instructions but inform the students that they will receive a tangible reward (e.g., a gift card, extra credit) for each question answered correctly.
-
-
Post-Intervention Assessment: After the intervention period, administer a post-test to both groups to measure any changes in their Lexile scores.
-
Analysis: Compare the pre- and post-test Lexile scores for both groups. A significantly greater increase in the experimental group's scores would suggest that extrinsic motivation can inflate performance on Lexile assessments.
-
Mandatory Visualization
Caption: Logical relationship between motivation, engagement, and Lexile prediction accuracy.
References
- 1. m.youtube.com [m.youtube.com]
- 2. selfdeterminationtheory.org [selfdeterminationtheory.org]
- 3. the-contributions-of-intrinsic-and-extrinsic-reading-motivation-to-the-development-of-reading-competence-over-summer-vacation - Ask this paper | Bohrium [bohrium.com]
- 4. Frontiers | Enhancing English reading motivation and performance via the ARCS model: an empirical study using the ARCS motivation scale [frontiersin.org]
- 5. go.achieve3000.com [go.achieve3000.com]
Navigating the Nuances: A Technical Guide to Applying Lexile Measures in Poetry and Drama Research
Welcome to the Technical Support Center for Improving the Application of Lexile Measures for Poetry and Drama. This resource is designed for researchers, scientists, and drug development professionals who are exploring the complexities of textual analysis in non-traditional formats. Here, you will find troubleshooting guides and frequently asked questions (FAQs) to address the specific challenges encountered when applying quantitative readability measures, such as Lexile, to poetic and dramatic works.
Frequently Asked Questions (FAQs)
This section addresses common issues and foundational knowledge required for working with Lexile measures and non-prose texts.
| Question | Answer |
| 1. Why doesn't the Lexile Analyzer provide a standard score for my poem or play script? | The Lexile Framework is designed to measure professionally-edited, conventional prose.[1] Poetry and drama often lack standard punctuation and sentence structure, which are critical for the Lexile Analyzer's algorithm. As a result, these texts are typically assigned a "Non-Prose" (NP) code, indicating they cannot be accurately measured by the standard framework.[2][3] |
| 2. What specific features of poetry and drama make them incompatible with the Lexile Analyzer? | The Lexile Analyzer determines sentence length by recognizing conventional end-of-sentence punctuation (periods, question marks, exclamation points).[1] Poetry's use of line breaks for metrical or aesthetic purposes, and drama's reliance on dialogue format, disrupt this analysis. The analyzer may incorrectly interpret a series of short lines as a single, long, and complex sentence, leading to a skewed and invalid measure.[1] |
| 3. What is the "NP" (Non-Prose) code? | The NP code is assigned to any text where more than 50% is comprised of non-standard or non-conforming prose. This includes poems, plays, songs, and recipes. An NP code signifies that the text does not receive a numerical Lexile measure. |
| 4. Are there any "workarounds" to get a Lexile score for poetry or drama? | While it is technically possible to reformat a poem or script into a prose paragraph, this fundamentally alters the text and is not recommended. The resulting Lexile score would not reflect the true complexity of the original work, as it would ignore structural elements crucial to the text's meaning and challenge. Such a score would be considered invalid. |
| 5. How can I assess the complexity of poetry and drama if I can't use a standard Lexile score? | A multi-faceted approach is recommended, combining qualitative analysis with alternative quantitative methods. Qualitative rubrics provide a structured way to evaluate aspects like meaning, structure, language conventionality, and knowledge demands. For quantitative insights, various computational and Natural Language Processing (NLP) tools can analyze features beyond sentence length and word frequency. |
| 6. What are qualitative analysis rubrics? | These are frameworks that guide a human reader in evaluating the complexity of a text based on a set of criteria. For literary texts, these criteria often include the subtlety of the theme, the complexity of the structure (e.g., non-linear plot), the use of figurative language, and the assumed background knowledge required of the reader. |
| 7. What are some alternative quantitative tools for analyzing poetry and drama? | Several Natural Language Processing (NLP) libraries and tools can be used for a more nuanced quantitative analysis. These include: - NLTK (Natural Language Toolkit): A Python library for tasks like tokenization and sentiment analysis.[4] - spaCy: Another Python library that offers powerful tools for syntactic parsing and entity recognition. - Google Cloud Natural Language API: Provides pre-trained models for sentiment analysis, entity recognition, and syntax analysis.[4] |
Troubleshooting Guides
This section provides step-by-step guidance for specific issues you may encounter during your experiments.
Issue 1: The Lexile Analyzer returned an error or an unexpectedly high/low score for a reformatted text.
Question: I tried to get a Lexile score by removing the line breaks from a poem and formatting it as a single paragraph. The score seems inaccurate. What went wrong?
Answer:
-
Fundamental Incompatibility: The core issue is that the Lexile Analyzer's algorithm is calibrated for prose. By removing the deliberate line breaks and structure of the poem, you have created a text that the analyzer can process, but the resulting score is not a valid measure of the original poem's complexity.
-
Punctuation and Sentence Boundaries: Poetry often uses unconventional punctuation or omits it entirely. When you concatenate lines, the analyzer may either see one very long, run-on sentence or misinterpret punctuation, leading to an unreliable analysis of sentence length.
-
Figurative Language and Word Frequency: While the analyzer will still assess word frequency, it cannot account for the added cognitive load of figurative language, metaphor, and ambiguity, which are central to poetic complexity.
Recommended Protocol: Qualitative Analysis of a Poem
Instead of attempting to force a Lexile score, a more accurate assessment of a poem's complexity can be achieved through a structured qualitative analysis.
Methodology:
-
Initial Reading: Read the poem multiple times to gain a holistic understanding of its theme, mood, and overall message.
-
Structural Analysis:
-
Examine the poem's form (e.g., sonnet, haiku, free verse).
-
Note the use of stanzas, line length, and enjambment.
-
Consider the rhyme scheme and meter, and how they contribute to the poem's meaning and rhythm.
-
-
Language Analysis:
-
Identify and interpret figurative language (metaphors, similes, personification).
-
Analyze the diction (word choice), noting any archaic, ambiguous, or domain-specific vocabulary.
-
Evaluate the complexity of the syntax, even if it deviates from standard prose.
-
-
Meaning and Purpose:
-
Determine if the theme is explicit or implicit.
-
Consider if there are multiple layers of meaning or if the poem is open to various interpretations.
-
-
Knowledge Demands:
-
Assess the prior knowledge (historical, cultural, literary) required to fully understand the poem.
-
Note any allusions to other texts or events.
-
The following diagram illustrates the workflow for a qualitative analysis of poetry:
Issue 2: My quantitative analysis of a play script is yielding inconsistent results.
Question: I'm trying to use a script to analyze the complexity of dialogue in a play, but my results are not consistent. How should I prepare the text?
Answer:
-
Isolating Dialogue: A common error is to include stage directions, character names, and scene headings in the text being analyzed. These non-dialogue elements will skew any quantitative measure.
-
Character-Specific vs. Overall Complexity: Are you aiming to measure the complexity of the play as a whole, or the speech patterns of individual characters? Your preparation method will differ accordingly.
-
Formatting for Analysis: The structure of a screenplay, with character names preceding dialogue, requires pre-processing to be suitable for most analysis tools.
Recommended Protocol: Preparing a Play Script for Quantitative Analysis
Methodology:
-
Text Extraction:
-
Begin with a plain text version of the script.
-
Use a script or regular expressions to parse the text and separate the following elements:
-
Character names
-
Dialogue
-
Stage directions
-
-
-
Creating Datasets:
-
For Overall Play Complexity: Concatenate all dialogue from all characters into a single text file. Ensure that each line of dialogue is treated as a complete sentence or utterance for analysis.
-
For Character-Specific Complexity: Create separate text files for each character, containing only their dialogue.
-
-
Cleaning the Data:
-
Remove any parenthetical stage directions within the dialogue (e.g., "(angrily)").
-
Standardize character names to ensure consistency.
-
-
Quantitative Analysis:
-
Once the dialogue is isolated and cleaned, you can apply various quantitative measures, such as:
-
Average sentence length
-
Vocabulary richness (type-token ratio)
-
Readability indices (note that these will still be estimates)
-
Sentiment analysis
-
-
The following diagram illustrates the decision-making process for preparing a play script for analysis:
Data Presentation: A Comparative Look at Text Complexity Measures
While a direct Lexile comparison is often not feasible, the following table illustrates how different forms of the same narrative might be assessed using a combination of quantitative and qualitative measures. For this example, we will consider a hypothetical story presented as a prose novel and as a play script.
| Text Format | Lexile Measure | Alternative Quantitative Measures | Qualitative Complexity Assessment |
| Prose Novel | 880L | - Average Sentence Length: 15.2 words - Vocabulary Diversity (Type-Token Ratio): 0.45 | Moderate: Linear narrative, but with some figurative language and implicit themes. |
| Play Script | NP (Non-Prose) | - Average Dialogue Length per Turn: 12.5 words - Vocabulary Diversity (Type-Token Ratio): 0.48 | High: Subtext in dialogue, reliance on stage directions for context, and potential for multiple interpretations in performance. |
This table demonstrates that while the prose version receives a standard Lexile measure, the play script, despite having shorter average sentences in dialogue, can be considered more complex due to qualitative factors that are not captured by traditional readability formulas.
By utilizing the FAQs, troubleshooting guides, and methodologies outlined in this support center, researchers can adopt a more robust and nuanced approach to analyzing the complexity of poetry and drama, moving beyond the limitations of traditional readability metrics.
References
Technical Support Center: Overcoming Challenges with Lexile Measures for Culturally Diverse Literature
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals encountering challenges with applying Lexile measures to culturally diverse literature in their work.
Frequently Asked Questions (FAQs)
Q1: We are using Lexile measures to select texts for a literacy intervention study. However, a book with significant cultural relevance to our study population, The House on Mango Street, has a Lexile score of 870L, which is below the recommended grade band for our participants. Is this score an accurate reflection of the text's complexity?
A1: It is a common challenge that Lexile scores for culturally rich and thematically complex texts may not fully represent their true difficulty. The Lexile framework primarily measures text complexity based on sentence length and word frequency.[1] The House on Mango Street, for instance, uses accessible language and sentence structure, resulting in a lower Lexile score.[2][3] However, its complexity lies in its use of figurative language, non-linear narrative structure (vignettes), and the sophisticated themes of identity, poverty, and gender roles within a specific cultural context.[3][4] Therefore, the 870L score likely underestimates the cognitive load and interpretive demands placed on the reader.
Q2: A culturally relevant book for our adolescent participants, Ghost Boys, has a Lexile score of HL360L. What does the "HL" designation mean, and is this book appropriate for middle schoolers?
A2: The "HL" in a Lexile score stands for "High-Low," indicating that the text has high interest content but a lower reading difficulty.[5] While the syntactic and semantic difficulty of Ghost Boys is low, as reflected in the 360L score, the themes it addresses—police brutality, systemic racism, and historical injustice—are highly complex and emotionally charged, making it suitable for a middle-grade audience.[6][7] This is a prime example of why qualitative analysis is crucial; the Lexile score alone does not capture the book's thematic maturity.
Q3: How can we justify the inclusion of a culturally diverse book in our study when its Lexile measure is outside our predetermined range?
A3: To justify the inclusion of such a text, you should supplement the Lexile score with a qualitative text complexity analysis. This involves a systematic evaluation of the text's structure, language features, knowledge demands, and levels of meaning.[8] Presenting a detailed rationale that outlines the book's qualitative complexities, its cultural relevance to your participants, and its potential to engage readers and elicit rich data can be a powerful argument. You can also point to the limitations of relying solely on quantitative measures for culturally and linguistically diverse texts.
Q4: What are the primary limitations of using Lexile measures for culturally diverse literature?
A4: The primary limitations are:
-
Focus on Syntax and Semantics: Lexile scores are based on algorithms that analyze sentence length and word frequency, largely ignoring other dimensions of text complexity.[1]
-
Neglect of Qualitative Features: The framework does not account for the complexity of a text's structure (e.g., non-linear narratives, use of vignettes), the nuance of its language (e.g., figurative language, irony, dialect), the depth of its meaning, or the background knowledge it assumes.[9]
-
Cultural and Linguistic Bias: The algorithms may not adequately capture the complexity of texts that incorporate non-standard English, translanguaging, or culturally specific references, which can lead to an underestimation of their difficulty.
Troubleshooting Guides
Problem: A selected culturally diverse text has a Lexile score that seems too low, and stakeholders are questioning its appropriateness.
Solution:
-
Conduct a Qualitative Text Complexity Analysis: Use a systematic rubric to evaluate the text's qualitative features. (See Experimental Protocol below).
-
Provide Comparative Data: Present a table that contrasts the quantitative Lexile score with the qualitative analysis, highlighting the areas of complexity that the Lexile score misses. (See Data Presentation below).
-
Articulate the Rationale: Clearly explain why the text's cultural relevance, thematic depth, and other qualitative features make it a valuable and appropriately challenging resource for your specific audience.
Problem: Researchers need a standardized way to assess the complexity of culturally diverse literature beyond Lexile scores.
Solution:
-
Adopt a Multi-dimensional Approach: Implement a text complexity model that incorporates quantitative, qualitative, and reader and task considerations.
-
Utilize a Qualitative Analysis Protocol: Follow a standardized protocol to ensure consistent and thorough evaluation of qualitative features across different texts. (See Experimental Protocol below).
-
Document Findings: Maintain a record of the qualitative analyses to build a repository of vetted, culturally diverse texts for future research and application.
Data Presentation
The following table provides examples of culturally diverse young adult novels where the quantitative Lexile measure does not fully capture the text's complexity.
| Book Title | Author(s) | Lexile Measure | Qualitative Complexity Analysis |
| The House on Mango Street | Sandra Cisneros | 870L[2][10][11] | High Complexity: Features a non-linear vignette structure, extensive use of figurative and poetic language, and explores mature themes of poverty, identity, and sexism.[3][12][13] |
| Ghost Boys | Jewell Parker Rhodes | HL360L[5][7][14][15] | High Complexity: Deals with emotionally and thematically complex issues such as racial injustice, police brutality, and historical trauma through a ghost narrative.[6] |
| All American Boys | Jason Reynolds & Brendan Kiely | HL750L | High Complexity: Employs a dual-narrative structure to explore themes of racism, privilege, and activism from two different perspectives.[16] |
| The Hate U Give | Angie Thomas | HL890L | High Complexity: Addresses complex social issues, including systemic racism, code-switching, and activism, with a nuanced and emotionally mature narrative. |
Experimental Protocols
Protocol for Qualitative Text Complexity Analysis of Culturally Diverse Literature
This protocol outlines a systematic approach to evaluating the qualitative dimensions of a text.
1. Pre-analysis:
- Identify the intended audience and the purpose for which the text is being evaluated.
- Acknowledge the potential limitations of one's own cultural lens and strive for an objective analysis.
2. Analysis of Text Structure:
- Examine the genre and its conventions.
- Analyze the narrative point of view (e.g., single, multiple, unreliable).
- Evaluate the organization of the text (e.g., linear, non-linear, vignettes, flashbacks).
- Assess the complexity of the plot and the presence of subplots.
3. Analysis of Language Features:
- Evaluate the use of figurative language (e.g., metaphors, symbolism, irony).
- Assess the complexity of vocabulary, including academic and domain-specific terms.
- Analyze sentence structure and variety.
- Consider the use of dialect, non-standard English, or translanguaging and its impact on reader comprehension.
4. Analysis of Knowledge Demands:
- Determine the extent to which the text requires prior cultural, historical, or literary knowledge.
- Assess the complexity of the themes and ideas presented.
- Evaluate the intertextuality (references to other texts).
5. Analysis of Levels of Meaning:
- Determine if the text has a single, clear meaning or multiple, nuanced layers of meaning.
- Assess the ambiguity and subtlety of the author's purpose.
6. Synthesis and Final Placement:
- Synthesize the findings from each dimension of the analysis.
- Make a final judgment on the text's overall qualitative complexity.
- Write a rationale that explains the placement, citing specific evidence from the text.
Mandatory Visualization
Caption: Workflow for a comprehensive text complexity analysis.
Caption: The relationship between different measures of text complexity.
References
- 1. pernillesripp.com [pernillesripp.com]
- 2. lexile.com [lexile.com]
- 3. literacyandccss.wordpress.com [literacyandccss.wordpress.com]
- 4. teachersinstitute.yale.edu [teachersinstitute.yale.edu]
- 5. Ghost Boys~Jewell Parker Rhodes — Riley Reads [rileyreadsya.com]
- 6. helenaschools.org [helenaschools.org]
- 7. Ghost Boys (Paperback) [books4school.com]
- 8. isbe.net [isbe.net]
- 9. ccsoh.us [ccsoh.us]
- 10. lexile.com [lexile.com]
- 11. booksource.com [booksource.com]
- 12. resources.finalsite.net [resources.finalsite.net]
- 13. The House on Mango Street: Analysis of Setting | Research Starters | EBSCO Research [ebsco.com]
- 14. colorfulbookreviews.wordpress.com [colorfulbookreviews.wordpress.com]
- 15. booksource.com [booksource.com]
- 16. Character Analysis: All American Boys | ipl.org [ipl.org]
strategies for supplementing Lexile scores with other text complexity measures
Welcome to the support center for researchers, scientists, and drug development professionals. This resource provides guidance on moving beyond single metrics like Lexile scores to a more robust, multi-faceted approach for analyzing text complexity in scientific and technical documents.
Frequently Asked Questions (FAQs)
Q1: Why is the Lexile score insufficient for evaluating the complexity of our research articles and technical documents?
A1: Lexile scores are a quantitative measure based on two variables: word frequency and sentence length.[1][2] While useful as a preliminary screening tool, this formula does not account for critical dimensions of scientific texts.[3] For example, a research paper might have a deceptively low Lexile score due to short sentences and common words, yet be conceptually dense and require significant prior knowledge.[4] Qualitative factors such as the intricacy of the methodology, the novelty of the concepts, the use of specialized terminology, and the logical structure of the argument are not captured by Lexile scores alone.[5][6]
Q2: What is the recommended framework for a more comprehensive text complexity analysis?
A2: The consensus framework for text complexity involves a three-part model that integrates quantitative measures, qualitative dimensions, and considerations of the reader and task.[1][7] This "text complexity triangle" ensures a more holistic and accurate assessment.[4]
-
Quantitative Measures: Objective, computer-calculated scores based on features like sentence length and word frequency.[8]
-
Qualitative Measures: A human-led evaluation of a text's deeper characteristics, such as its structure, purpose, language features, and knowledge demands.[4][9]
-
Reader and Task Considerations: Analysis of the intended audience's background knowledge and motivation, as well as the purpose for which they are reading the text.[3][10]
Q3: What are some alternative quantitative tools we can use to supplement Lexile scores?
A3: Several quantitative tools are available, each with slightly different algorithms. Using multiple tools can provide a more nuanced quantitative perspective.[7] Some of these include the Flesch-Kincaid Grade Level, Gunning Fog Index, and Coh-Metrix, which analyzes cohesion and other linguistic features.[8][11]
Q4: How do we apply qualitative analysis to a highly technical document, like a clinical trial protocol or a research paper?
A4: Qualitative analysis for technical documents requires an expert reader to evaluate specific features.[4] Key areas to assess include:
-
Purpose and Levels of Meaning: Is the purpose explicitly stated or implied? Does the text contain intricate theoretical elements or subtle arguments?[9]
-
Structure: How is the information organized? Are the connections between ideas explicit or are they buried in a complex structure? Does it follow a conventional IMRaD (Introduction, Methods, Results, and Discussion) format, or is it a non-traditional structure like a technical manual?[5][12]
-
Language Conventionality: Does the text use dense, abstract, or figurative language? How specialized and academic is the vocabulary?[5]
-
Knowledge Demands: How much discipline-specific prior knowledge is assumed? Are there references to other complex texts or theories (intertextuality)?[6][11]
Troubleshooting Guides
Problem: Our team is struggling to select appropriate scientific literature for a new cross-disciplinary project. Lexile scores are misleading.
Solution: Implement an integrated text complexity protocol. This involves moving beyond a single quantitative score to a multi-faceted evaluation.
-
Step 1: Quantitative Baseline: Run the texts through several quantitative analyzers to get a grade-band approximation. See the comparison table below for options.
-
Step 2: Qualitative Deep Dive: Use a qualitative rubric (a template is provided in the "Experimental Protocols" section) to have a subject matter expert (SME) score the texts. This is crucial for identifying challenges related to conceptual density and methodological complexity.
-
Step 3: Reader and Task Analysis: Define your audience (e.g., biochemists, data scientists) and their task (e.g., literature review for hypothesis generation, protocol replication). A text that is moderately complex for a biochemist may be exceedingly complex for a data scientist if it assumes extensive biological knowledge.[10]
Problem: A standard operating procedure (SOP) has a low readability score, but new technicians are consistently making errors.
Solution: The issue likely lies in the qualitative dimensions or a mismatch with the reader and task.
-
Analyze Structure: Is the SOP organized sequentially and logically? Are steps unambiguous? Poor organization can increase complexity even with simple language.[5]
-
Evaluate Language Clarity: While the vocabulary may be common, is the language precise and free of ambiguity? In technical writing, clarity is paramount.
-
Consider Knowledge Demands: Does the SOP implicitly assume prior knowledge of certain equipment or techniques? This is a common issue where the writer, an expert, overlooks the knowledge gaps of the reader.[11]
-
Task Consideration: The task is to perform a procedure flawlessly. The cognitive load of the task itself must be considered. The text needs to minimize extraneous cognitive load by being as clear and direct as possible.
Data Presentation
Table 1: Comparison of Quantitative Text Complexity Measures
This table summarizes several common quantitative tools. For a given scientific abstract, the scores can vary, highlighting the need for a multi-tool approach.
| Measure | Primary Variables | Output | Best For | Limitations |
| Lexile Framework | Word Frequency, Sentence Length[1] | Numeric Score (e.g., 1300L) | General readability and grade-banding. | Ignores text structure, conceptual density, and cohesion.[4] |
| Flesch-Kincaid Grade Level | Syllables per Word, Words per Sentence[4] | U.S. Grade Level | Assessing general audience documents. | Can be misleading for technical texts with many polysyllabic but common terms. |
| Gunning Fog Index | Words per Sentence, Percentage of Complex Words | U.S. Grade Level | Quick assessment of text for educated adults. | "Complex word" definition (3+ syllables) may not be nuanced enough for scientific jargon. |
| Coh-Metrix | Over 100 indices including cohesion, syntactic complexity, and word concreteness[11] | Multiple scores across different dimensions | Detailed linguistic analysis of a text's properties. | Requires more expertise to interpret the various scores. |
| Reading Maturity Metric (Pearson) | Word rarity, sentence length, and syntactic complexity[7] | Numeric Score | Analyzing more complex texts for mature readers. | Proprietary algorithm; less transparent than other measures. |
Experimental Protocols
Protocol: Integrated Multi-dimensional Text Complexity Analysis
This protocol outlines a systematic approach to evaluating the complexity of a scientific research article.
Objective: To produce a comprehensive complexity profile of a target text that can inform its use in a specific research or development context.
Methodology:
-
Quantitative Analysis:
-
Select the target text (e.g., a published research paper).
-
Prepare the text for analysis by removing references, author information, and figure captions to isolate the main body.
-
Process the text through at least three different quantitative tools (e.g., Lexile Analyzer, Flesch-Kincaid calculator, Coh-Metrix).
-
Record the scores in a standardized log.
-
-
Qualitative Analysis:
-
Recruit at least two Subject Matter Experts (SMEs) in the text's domain.
-
Provide the SMEs with a qualitative analysis rubric (see example rubric elements below).
-
Each SME independently reads the text and scores it on a scale (e.g., 1-5) for each qualitative dimension:
-
Purpose/Levels of Meaning: How implicit, subtle, or theoretical is the purpose?
-
Structure: How intricate, dense, or discipline-specific is the organization?
-
Language Conventionality/Clarity: How abstract, dense, or academic is the language?
-
Knowledge Demands: How much specialized knowledge is assumed?
-
-
The SMEs then meet to discuss their ratings and arrive at a consensus score for each dimension.
-
-
Reader & Task Analysis:
-
Clearly define the intended reader profile (e.g., "early-career pharmacologist with a Ph.D.") and the primary task (e.g., "to evaluate the methodology for potential adoption in our lab").
-
Based on this profile, assess the likely match or mismatch with the text's identified knowledge demands.
-
Consider the task's complexity. A task requiring critical appraisal is more demanding than one requiring only a summary of findings.
-
-
Synthesis and Final Recommendation:
-
Synthesize the findings from the quantitative, qualitative, and reader/task analyses into a final report.
-
Assign a final complexity rating (e.g., "Highly complex; suitable for domain experts only") and provide specific recommendations for its use (e.g., "Requires pre-reading of foundational concepts for non-specialists").
-
Mandatory Visualization
Caption: Workflow for an integrated text complexity analysis.
Caption: The three-part model of text complexity.
References
- 1. Achievethecore.org :: Text Complexity [achievethecore.org]
- 2. teachthought.com [teachthought.com]
- 3. Helping Kids Slip the Surly Bonds of Leveled Reading - Education Next [educationnext.org]
- 4. isbe.net [isbe.net]
- 5. doe.louisiana.gov [doe.louisiana.gov]
- 6. achievethecore.org [achievethecore.org]
- 7. New Research Expands Thinking on Text Complexity [edweek.org]
- 8. Free Text Complexity Analysis Tool Online | Lumos Learning [lumoslearning.com]
- 9. mdek12.org [mdek12.org]
- 10. youtube.com [youtube.com]
- 11. fiveable.me [fiveable.me]
- 12. gpb.org [gpb.org]
A Comparative Analysis of the Lexile Framework and Other Readability Formulas for Scientific and Technical Texts
The Lexile Framework for Reading stands out by measuring both reader ability and text complexity on the same scale, offering a unique approach to matching readers with appropriate texts.[1] However, a variety of other formulas, each with its own algorithm and underlying linguistic assumptions, are also widely used. This guide will delve into a comparison of these methods, their applications, and their limitations in the context of scientific and drug development literature.
Overview of Readability Formulas
Readability formulas assess text difficulty based on syntactic and semantic factors. Most traditional formulas utilize variables such as sentence length and word complexity (often measured by the number of syllables or characters). Newer methods, leveraging natural language processing (NLP), incorporate more sophisticated linguistic features.
The Lexile Framework calculates a text's measure based on two main variables:
-
Syntactic Complexity: Measured by sentence length. Longer sentences are considered more complex as they require greater short-term memory to process.[2]
-
Semantic Difficulty: Determined by word frequency. Words that appear less frequently in a large corpus of text are considered more difficult.[2]
Lexile measures for texts are expressed as a number followed by an "L" (for Lexile), on a scale from below 0L for beginning reader materials to over 1700L for advanced texts. A key feature of the Lexile framework is its ability to also measure a reader's ability on the same scale, allowing for a targeted matching of reader to text.[1]
Other commonly used readability formulas include:
-
Flesch-Kincaid Grade Level: This formula is widely used and is integrated into popular word processing software. It calculates a U.S. school grade level based on the average number of syllables per word and words per sentence.[3]
-
Flesch Reading Ease: A related formula to Flesch-Kincaid, it scores a text on a 100-point scale, where a higher score indicates easier readability. A score of 60-70 is considered easily understandable by the general public.
-
SMOG (Simple Measure of Gobbledygook) Index: The SMOG grade is calculated based on the number of polysyllabic words (words with three or more syllables) in a sample of 30 sentences. It is often recommended for use in healthcare as it is believed to be more accurate for assessing technical documents.[4]
-
Gunning Fog Index: This formula estimates the years of formal education a person needs to understand a text on the first reading. It is based on the average sentence length and the percentage of "complex" words (those with three or more syllables).[3]
-
Coleman-Liau Index: Unlike formulas that rely on syllable counts, the Coleman-Liau Index uses character counts, which are easier for computer programs to calculate. It is based on the average number of letters per 100 words and the average number of sentences per 100 words.
-
Automated Readability Index (ARI): The ARI also uses character counts instead of syllable counts, making it computationally efficient. Its output is a U.S. grade level.
Quantitative Comparison of Readability Formulas
Direct quantitative comparisons of readability formulas on the same corpus of scientific or medical text are crucial for understanding their relative performance. While a single, universally accepted comparative study is elusive, the existing body of research highlights significant variability among these formulas.
One study that assessed written health information found that readability scores for the same text could vary by as much as five grade levels depending on the formula used.[5] Another study focusing on online health information discovered that automated readability calculators produced scores that varied by up to 12.9 grade levels for the same text, even when using the same formula.[6]
The following table summarizes the core variables and typical output of the discussed readability formulas.
| Readability Formula | Core Variables | Output |
| Lexile Framework | Sentence Length, Word Frequency | Lexile Scale (e.g., 1000L) |
| Flesch-Kincaid Grade Level | Average Syllables per Word, Average Words per Sentence | U.S. Grade Level |
| Flesch Reading Ease | Average Syllables per Word, Average Words per Sentence | 0-100 Scale (higher is easier) |
| SMOG Index | Number of Polysyllabic Words (≥3 syllables) | U.S. Grade Level |
| Gunning Fog Index | Average Sentence Length, Percentage of Complex Words (≥3 syllables) | U.S. Grade Level |
| Coleman-Liau Index | Average Characters per Word, Average Sentences per 100 Words | U.S. Grade Level |
| Automated Readability Index (ARI) | Average Characters per Word, Average Words per Sentence | U.S. Grade Level |
Research in the healthcare domain has suggested that the SMOG index often performs more consistently for medical texts.[7] This is attributed to its focus on polysyllabic words, which are common in scientific and medical terminology.
Experimental Protocols for Comparing Readability Formulas
A robust experimental protocol for comparing readability formulas on scientific and medical texts would typically involve the following steps:
-
Corpus Selection: A representative corpus of texts from the target domain (e.g., drug development literature, clinical trial documents, patient information leaflets) is selected.
-
Text Preparation: The selected texts are prepared for analysis. This may involve removing irrelevant elements such as references, figures, and tables, and standardizing formatting.[6]
-
Application of Formulas: Multiple readability formulas are applied to the prepared text corpus using either manual calculations or automated tools.
-
Human Readability Assessment: A panel of target audience members (e.g., researchers, clinicians, or patients) assesses the readability of the texts. This can be done through comprehension tests (such as the Cloze test), surveys, or direct feedback.[5]
-
Statistical Analysis: The scores from the different readability formulas are statistically compared with each other and with the results of the human readability assessment. Correlation analyses are often used to determine the level of agreement between the formulas and with human perception.[6]
Visualizing Readability Assessment Workflows
The following diagrams illustrate the conceptual workflows for evaluating text readability.
Caption: Factors influencing readability scores.
Caption: Workflow for comparing readability formulas.
Limitations and Considerations for Scientific Texts
While readability formulas can be useful for providing a general estimate of text difficulty, they have several limitations, particularly when applied to scientific and technical documents:
-
Focus on Surface Features: Traditional formulas primarily measure surface-level characteristics of a text and do not account for the complexity of the concepts being presented. A text can have a "good" readability score but still be conceptually difficult for a reader without the necessary background knowledge.
-
Handling of Jargon and Technical Terms: Scientific texts are inherently filled with specialized terminology. Formulas that heavily penalize long words or words not on a common word list may produce misleadingly high difficulty scores.
-
Lack of Context: Readability formulas do not consider the reader's prior knowledge, motivation, or interest in the topic, all of which can significantly influence comprehension.
-
Inconsistent Results: As noted earlier, different formulas can produce widely varying scores for the same text, making it difficult to determine the "true" readability level.[5][6]
A systematic review of readability formulas in health content concluded that there is limited evidence to support their accuracy and that they often do not correlate well with expert or user assessments of difficulty.
The Rise of Newer, NLP-Based Models
To address the limitations of traditional formulas, newer models based on natural language processing (NLP) and machine learning are being developed. These models can analyze a much wider range of linguistic features, including:
-
Lexical diversity: The variety of vocabulary used.
-
Syntactic complexity: The grammatical structure of sentences.
-
Discourse connectives: Words and phrases that signal relationships between different parts of the text.
Some research suggests that these newer formulas, such as CAREC (Crowdsourced Algorithm of Reading Comprehension), may be more reliable in representing text difficulty.[8] Another study introduced a new formula called NERF (New English Readability Formula) and recalibrated older formulas for better performance on medical texts.
Conclusion
The Lexile Framework offers a valuable approach to matching readers with texts by placing both on the same scale. However, like all readability formulas, it has its limitations, particularly when applied to the nuanced and jargon-rich domain of scientific and drug development literature.
For researchers and professionals in these fields, it is crucial to use readability formulas as a guide rather than an absolute measure. When selecting a formula, consider the specific context and audience. For healthcare-related materials, the SMOG index may offer greater consistency. It is also advisable to supplement the use of any readability formula with qualitative assessments, such as user testing with the intended audience, to gain a more holistic understanding of a document's readability.
As the field of natural language processing continues to advance, we can expect the development of even more sophisticated and accurate tools for assessing the readability of complex scientific and technical texts.
References
- 1. youtube.com [youtube.com]
- 2. google.com [google.com]
- 3. Readability Formulas and User Perceptions of Electronic Health Records Difficulty: A Corpus Study - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Readability Metrics in Patient Education: Where Do We Innovate? - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. Comparison of Readability Scores for Written Health Information Across Formulas Using Automated vs Manual Measures - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. Assessing Readability Formulas: A Comparison of Readability Formula Performance on the Classification of Simplified Texts | Semantic Scholar [semanticscholar.org]
The Accuracy of Lexile Measures: A Review of Validation Studies
Durham, NC - The Lexile® Framework for Reading, a widely used system for matching readers with appropriately challenging texts, has been the subject of numerous research studies to validate its accuracy. These studies generally support the reliability and validity of Lexile measures in predicting text difficulty and reader ability. This guide provides an objective comparison of Lexile measures with other readability formulas, supported by experimental data, to assist researchers, scientists, and professionals in the field of drug development in understanding the strengths and limitations of this tool.
The Lexile Framework, developed by MetaMetrics, quantifies both reader ability and text difficulty on the same developmental scale, measured in Lexile units (L). A reader's Lexile measure is obtained through a reading comprehension test, while a text's Lexile measure is determined by a proprietary algorithm that analyzes sentence length and word frequency.[1][2]
Quantitative Analysis of Lexile Measure Accuracy
Research validating the Lexile Framework has demonstrated a strong correlation between Lexile measures and other established metrics of reading comprehension and text difficulty. These studies provide quantitative data supporting the accuracy of Lexile measures.
A key aspect of validating a readability formula is to compare its output with the observed difficulty of a text, often determined by student performance on reading comprehension tests. MetaMetrics, the developer of the Lexile Framework, has conducted extensive research demonstrating high correlations between their theoretical text difficulty calibrations and the actual difficulties observed in standardized reading tests. In one study, the correlation between the predicted difficulty of reading passages from nine standardized tests and the observed difficulty was 0.93 after corrections for measurement error and range restriction.[3][4] Another study reported a correlation of 0.97 under similar conditions.[3][4]
A seminal study by Stenner, Burdick, Sanford, and Burdick (2006) estimated the standard deviation of Lexile text measures.[5] The study found that for a standard-length passage of approximately 125 words, the standard deviation was about 64L.[5] This indicates a high degree of accuracy, with the standard error decreasing significantly for longer texts.[5] For texts between 2,500 and 150,000 words, the uncertainty in the Lexile measure is in the single digits.[5]
| Metric | Finding | Source |
| Correlation with Observed Text Difficulty | 0.93 - 0.97 | [3][4] |
| Standard Deviation (125-word passage) | ~64L | [5] |
| Uncertainty for Longer Texts (2,500-150,000 words) | In the single digits | [5] |
Table 1: Summary of Quantitative Data on Lexile Measure Accuracy
Comparison with Other Readability Formulas
Lexile measures are often compared with other readability formulas, such as the Flesch-Kincaid Grade Level, ATOS, and the Dale-Chall Formula. While these formulas also aim to predict text difficulty, they utilize different variables and algorithms. For instance, the Flesch-Kincaid formula is based on the average number of syllables per word and words per sentence.[6][7] The ATOS formula, used in the Accelerated Reader program, considers average sentence length, average word length, vocabulary grade level, and the number of words in a book.
Studies comparing these formulas have shown a high degree of correlation, suggesting that they are measuring similar constructs. For example, a strong positive correlation has been found between Lexile and Flesch-Kincaid scores.
Experimental Protocols for Validation Studies
The validation of readability measures like the Lexile Framework typically involves a multi-step experimental protocol. While specific details may vary across studies, the general methodology follows a consistent pattern.
A core component of these validation studies is the use of the Rasch model, a psychometric model used to analyze categorical data from assessments to measure latent traits, such as reading ability.[8][9] The Lexile Framework uses the Rasch model to place both reader ability and text difficulty on a common scale.[8][9]
The following diagram illustrates a typical workflow for a Lexile validation study:
Key Steps in a Validation Study:
-
Selection of Reading Passages: A diverse set of reading passages is selected from various sources, including standardized tests and authentic texts.
-
Administration of Reading Tests: These passages are administered to a large and representative sample of students. Students' performance on comprehension questions associated with each passage is recorded.
-
Calculation of Lexile Measures: The selected passages are analyzed using the Lexile Analyzer to determine their Lexile text measures.
-
Scoring of Student Reading Comprehension: The students' responses to the comprehension questions are scored to determine the observed difficulty of each passage.
-
Correlation Analysis: Statistical analyses, such as regression analysis, are conducted to determine the correlation between the Lexile text measures and the observed passage difficulties derived from student performance.[3][4]
-
Model Refinement: The results of the correlation analysis are used to refine the Lexile equation to improve its predictive accuracy.[3][4]
References
- 1. Comparison of Readability Scores for Written Health Information Across Formulas Using Automated vs Manual Measures - PMC [pmc.ncbi.nlm.nih.gov]
- 2. mdpi.com [mdpi.com]
- 3. partnerhelp.metametricsinc.com [partnerhelp.metametricsinc.com]
- 4. levelupreader.net [levelupreader.net]
- 5. How accurate are lexile text measures? - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Readability Formulas: The Science Behind Reading Scales and Grade Scores – ReadabilityFormulas.com [readabilityformulas.com]
- 7. Flesch Reading Ease and the Flesch Kincaid Grade Level – Readable [readable.com]
- 8. aclanthology.org [aclanthology.org]
- 9. metametricsinc.com [metametricsinc.com]
A Comparative Analysis of Lexile and Flesch-Kincaid Readability Scores
In the landscape of textual analysis, the Lexile Framework for Reading and the Flesch-Kincaid Grade Level are two of the most widely recognized and utilized metrics for assessing text readability. While both aim to quantify the difficulty of a text, they employ distinct methodologies, resulting in different scoring scales and applications. This guide provides a detailed comparative analysis of these two readability scores, supported by quantitative data and experimental protocols, to assist researchers, scientists, and drug development professionals in selecting the appropriate tool for their specific needs.
Core Methodologies and Scoring
The fundamental difference between the Lexile and Flesch-Kincaid frameworks lies in the linguistic variables they measure.
The Lexile Framework for Reading , developed by MetaMetrics, evaluates text complexity based on two key predictors:
-
Semantic Difficulty (Word Frequency): This is determined by the frequency of words in a large corpus of text. Less frequent words are considered more challenging.
-
Syntactic Complexity (Sentence Length): The average length of sentences in a text is used as a measure of its grammatical complexity.
The Lexile Analyzer, a proprietary software, calculates a score on the Lexile scale, which ranges from below 0L for beginning reader materials (designated as BR for Beginning Reader) to over 2000L for advanced texts.[1] A key feature of the Lexile framework is that it measures both reader ability and text difficulty on the same scale, allowing for a direct matching of readers to appropriate texts.[1]
The Flesch-Kincaid Grade Level formula, on the other hand, is a public domain formula that also considers two main factors:
-
Word Complexity (Syllables per Word): Instead of word frequency, Flesch-Kincaid uses the average number of syllables per word as a proxy for word difficulty.
-
Sentence Complexity (Words per Sentence): Similar to Lexile, it measures the average sentence length.
The formula for the Flesch-Kincaid Grade Level is:
(0.39 × average sentence length) + (11.8 × average syllables per word) − 15.59
The resulting score corresponds to a U.S. grade level, indicating the number of years of education a person would need to comprehend the text. For example, a score of 8.0 suggests that the text is understandable to an average 8th-grade student.
Quantitative Comparison of Readability Scores
Direct comparisons of Lexile and Flesch-Kincaid scores on the same texts reveal a strong positive correlation, as both are influenced by sentence length. A study on patient education materials for Chronic Kidney Disease found a correlation of 0.89 between the two measures.[2] However, the different underlying variables for word complexity (word frequency vs. syllables per word) can lead to variations in scores for certain texts.
Below is a table summarizing the readability scores for a set of short texts from a psychometric validation study, illustrating the output of each formula on the same material.
| Text Title | Flesch-Kincaid Grade Level | Lexile Score |
| Titanic | 6.6 | 640L |
| Parrot | 4.9 | 1100L |
| Frog | 2.8 | 1440L |
| Dog | 5.1 | 690L |
Data sourced from a 2014 study on the psychometric validation of the Sentence Verification Technique.
Additionally, a comparative analysis of passages from the Progress in International Reading Literacy Study (PIRLS) and the National Assessment of Educational Progress (NAEP) provides a broader view of how the scores compare on average for assessment materials.
| Assessment | Average Flesch-Kincaid Grade Level | Average Lexile Score |
| PIRLS 2011 | 4.5 | 828L |
| NAEP 2011 | 5.9 | 913L |
Experimental Protocols for Comparative Analysis
To conduct a robust comparative analysis of Lexile and Flesch-Kincaid readability scores, a detailed experimental protocol is essential. The following methodology is a synthesis of approaches used in various readability studies.
1. Corpus Selection:
-
A diverse corpus of texts should be selected, representing a range of genres, topics, and difficulty levels relevant to the target audience (e.g., scientific articles, patient information leaflets, technical manuals).
-
The number of texts should be sufficient to ensure statistical power. For instance, studies have used corpora ranging from dozens to thousands of documents.[2]
2. Text Preparation:
-
Prior to analysis, texts should be cleaned to remove elements that could skew the results, such as headers, footers, tables, and lists.
-
Decisions on handling specific punctuation, such as semicolons and colons, should be made and applied consistently.
3. Score Calculation:
-
The Lexile score for each text should be calculated using the official Lexile Analyzer to ensure consistency and accuracy.
-
The Flesch-Kincaid Grade Level should be calculated using a standardized implementation, such as the one found in Microsoft Word or other reputable readability software. It is crucial to use the same tool for all texts to avoid variations in how sentences and syllables are counted.[2]
4. Statistical Analysis:
-
A Pearson correlation coefficient should be calculated to determine the strength and direction of the linear relationship between the Lexile and Flesch-Kincaid scores.
-
To compare the performance of the two formulas in classifying texts into predefined categories (e.g., "easy," "intermediate," "difficult"), a logistic regression analysis can be employed. The accuracy of each formula in correctly classifying the texts would then be compared.
-
For a more granular comparison, t-tests can be used to determine if there are statistically significant differences in the classification accuracy between the two formulas.
Logical Workflow for Readability Score Calculation
The following diagram illustrates the process of deriving Lexile and Flesch-Kincaid scores from a given text.
Conclusion
Both the Lexile Framework and the Flesch-Kincaid Grade Level provide valuable, albeit different, perspectives on text readability. Lexile's use of word frequency offers a measure of semantic difficulty based on real-world usage, and its unified scale for readers and texts is a significant advantage in educational settings. Flesch-Kincaid's reliance on syllable counting makes it a more transparent and easily replicable formula, providing an intuitive grade-level score that is widely understood.
For researchers and professionals in scientific and drug development fields, the choice between these tools may depend on the specific application. For materials intended for a broad, non-specialist audience, the Flesch-Kincaid Grade Level can provide a quick and understandable assessment of accessibility. For more nuanced applications, such as developing educational materials for professionals with varying levels of expertise, the Lexile Framework may offer a more precise way to match text complexity with reader ability. Ultimately, a comprehensive approach to assessing readability should consider the scores from these quantitative tools in conjunction with qualitative factors such as content, structure, and design.
References
Assessing the Reliability and Consistency of Lexile Text Measures: A Comparative Guide
For Researchers, Scientists, and Drug Development Professionals
The accurate assessment of text complexity is a critical component in various fields, from educational research to the dissemination of scientific and medical information. The Lexile Framework for Reading, a widely used metric, provides a quantitative measure of both reader ability and text difficulty. This guide offers an objective comparison of the Lexile Framework with other prominent readability formulas, supported by experimental data and detailed methodologies, to aid professionals in making informed decisions about their application.
The Lexile Framework: A Two-Factor Model
The Lexile Framework, developed by MetaMetrics, quantifies text complexity based on two primary linguistic features:
-
Syntactic Complexity: Measured by sentence length. Longer sentences are generally considered more syntactically complex.
-
Semantic Difficulty: Determined by word frequency. Words that appear less frequently in a large corpus of text are considered more semantically challenging.[1][2]
These two factors are analyzed by the Lexile Analyzer, a software program that processes text to generate a Lexile measure.[3] This measure places both the reader's ability and the text's difficulty on the same scale, ranging from below 0L for beginning readers and texts (designated as BR for Beginning Reader) to over 1600L for advanced readers and complex materials.[3]
Reliability and Consistency of Lexile Measures
The reliability of the Lexile Framework has been a subject of internal and external research. One key aspect of its consistency is the precision of its text measures. For a standard-length passage of approximately 125 words, the standard deviation of a Lexile text measure is estimated to be 64L due to the inherent variations in language that are not fully captured by the two-factor model.[4] However, for longer texts, such as those ranging from 2,500 to 150,000 words, the standard errors of the Lexile measures are reported to be in the single digits, suggesting a high degree of precision for substantial pieces of writing.[4]
The validity of the Lexile Framework is often established through "linking studies," which correlate Lexile measures with the results of standardized reading tests. These studies have demonstrated a strong relationship between reading comprehension ability as measured by the Lexile Framework and other established assessments.[5]
Comparison with Alternative Text Complexity Measures
While the Lexile Framework is widely adopted, several other readability formulas are also utilized to assess text complexity. This section compares Lexile measures with two prominent alternatives: the ATOS Readability Formula and the Flesch-Kincaid Grade Level formula.
| Metric | Core Principles | Output | Key Differentiators |
| Lexile Framework | Analyzes sentence length and word frequency against a large corpus. | A numerical score followed by "L" (e.g., 1000L). | Places both reader and text on the same developmental scale. |
| ATOS Readability Formula | Considers average sentence length, average word length, and word difficulty level. | A grade-level equivalent (e.g., 4.5 for a fourth-grade, fifth-month level). | Developed for the Accelerated Reader program and validated for the Common Core State Standards. |
| Flesch-Kincaid Grade Level | Based on the average number of syllables per word and the average number of words per sentence. | A U.S. school grade level. | Widely available in word processing software and easy to calculate. |
Quantitative Comparison of Readability Formulas
Studies comparing different readability formulas often report correlation coefficients to indicate the degree of agreement between the measures. While specific correlations can vary depending on the text corpus, research has generally found strong positive correlations between Lexile, ATOS, and Flesch-Kincaid scores, indicating that they tend to rank texts in a similar order of difficulty.
However, it is important to note that despite the high correlations, the different formulas can produce varying grade-level assignments for the same text. This is due to the different linguistic features each formula emphasizes.
Experimental Protocols
The methodologies employed in assessing the reliability and validity of text complexity measures are crucial for interpreting the resulting data.
Lexile Framework Validation Methodology
The validation of the Lexile Framework typically involves a multi-step process:
-
Corpus Development: A large and diverse corpus of texts is assembled to represent a wide range of topics and difficulty levels. The Lexile Framework currently utilizes a corpus of over 600 million words.[5]
-
Text Analysis: The Lexile Analyzer software processes the texts to determine the mean sentence length and the log of the mean word frequency.
-
Rasch Modeling: The Rasch model, a psychometric model, is used to place both reader ability and text difficulty on a common measurement scale. This allows for the direct comparison of a reader's proficiency with the complexity of a text.[4]
-
Linking Studies: To establish external validity, Lexile measures are correlated with scores from established standardized reading comprehension tests. This involves administering a Lexile-calibrated test and a standardized test to the same group of students and analyzing the statistical relationship between the two sets of scores.
Comparative Analysis of Readability Formulas
A typical experimental protocol for comparing different readability formulas includes the following steps:
-
Text Selection: A diverse set of texts representing various genres, topics, and difficulty levels is selected.
-
Readability Calculation: Each text in the sample is analyzed using the different readability formulas being compared (e.g., Lexile Analyzer, ATOS calculator, Flesch-Kincaid formula).
-
Human-Based Assessment (Optional but Recommended): Experienced educators or reading specialists may be asked to rate the difficulty of the texts based on their professional judgment. This provides a human benchmark against which to compare the formula-based scores.
-
Statistical Analysis: The scores from the different formulas are then statistically compared. This typically involves calculating correlation coefficients (e.g., Pearson's r) to determine the level of agreement between the formulas.
Visualizing the Methodologies
To further clarify the processes involved in assessing text complexity, the following diagrams illustrate the experimental workflows.
References
Critique of the Lexile Framework's Correlation with Standardized Tests: A Comparative Guide
For Researchers, Scientists, and Drug Development Professionals
The Lexile Framework for Reading, a widely used metric for assessing text difficulty and reader ability, has become a ubiquitous tool in educational settings. Its core principle lies in matching readers with texts that are at an appropriate level of challenge to foster reading growth. However, the framework's strong reliance on two core linguistic variables—sentence length and word frequency—has drawn criticism for potentially oversimplifying the complex nature of reading comprehension. This guide provides a critical examination of the Lexile framework's correlation with standardized tests, compares it with alternative readability formulas, and presents available data and the methodologies behind these assessments.
The Lexile Framework: A Two-Factor Model
Developed by MetaMetrics, the Lexile framework measures both text complexity and a reader's ability on the same scale, reported in Lexile units (L). The formula for calculating a text's Lexile measure is primarily based on two predictors:
-
Syntactic Complexity: Measured by sentence length.
-
Semantic Difficulty: Measured by word frequency, determined by the rarity of words in a large corpus of text.[1]
MetaMetrics reports a high correlation (r = -0.779) between the mean log word frequency and text difficulty, a cornerstone of their methodology.[1]
Correlation with Standardized Tests: A Closer Look
This lack of transparent, independently verified correlation data is a significant point of critique. Without it, it is challenging for researchers and educators to independently assess the predictive validity of Lexile scores for performance on these high-stakes assessments.
Limitations of the Lexile Framework
Critics of the Lexile framework point to several key limitations that stem from its two-factor model:
-
Neglect of Deeper Textual Features: The framework does not account for several factors that can significantly impact reading comprehension, such as:
-
Text Structure and Cohesion: How ideas are organized and connected.
-
Complexity of Ideas: The abstractness and sophistication of the concepts presented.
-
Author's Purpose and Tone: The subtle nuances of the author's intent.
-
Background Knowledge Requirements: The prior knowledge a reader needs to understand the text.
-
Figurative Language and Nuance: The use of metaphors, irony, and other literary devices.
-
-
Not a Diagnostic Tool: A low Lexile score indicates a student is struggling with reading but does not provide insight into the underlying reasons for that struggle.
-
Potential for "Gaming the System": The focus on sentence length and word frequency can lead to the creation of texts that achieve a certain Lexile level without being genuinely easy or difficult to comprehend. For instance, a text with short, choppy sentences and simple vocabulary might receive a low Lexile score but be conceptually dense and difficult to follow.
Comparison with Alternative Readability Formulas
Several other readability formulas exist, each with its own methodology for assessing text difficulty. While many also rely on sentence and word-level features, they often incorporate different variables.
| Readability Formula | Key Variables | Output |
| Lexile Framework | Mean sentence length, Mean log word frequency | Lexile Scale (e.g., 1000L) |
| Flesch-Kincaid Grade Level | Average sentence length, Average syllables per word | U.S. Grade Level (e.g., 8.5)[3][4] |
| Gunning Fog Index | Average sentence length, Percentage of "complex" words (3+ syllables) | U.S. Grade Level (e.g., 10.2)[3] |
| SMOG Grade | Number of polysyllabic words in 30 sentences | U.S. Grade Level (e.g., 9.8) |
| Coleman-Liau Index | Average number of letters per 100 words, Average number of sentences per 100 words | U.S. Grade Level (e.g., 7.9) |
| Automated Readability Index (ARI) | Average number of characters per word, Average number of words per sentence | U.S. Grade Level (e.g., 8.1) |
Performance Comparison
Direct, large-scale, independent studies comparing the predictive validity of Lexile scores against other readability formulas on standardized test performance are scarce. However, some studies have compared their outputs on the same texts. For instance, a moderate correlation has been found between Lexile scores and the Flesch-Kincaid Grade Level.
One study that did not include Lexile but compared four other popular formulas (Flesch Reading Ease, Gunning Fog, SMOG, and Flesch-Kincaid) against human evaluation of text readability found no significant correlation between the two.[5] This highlights a broader challenge in the field of readability assessment: the difficulty of capturing the nuances of human comprehension with purely quantitative formulas.
Experimental Protocols: A Methodological Overview
The methodologies employed in studies that correlate readability formulas with reading comprehension or compare different formulas generally follow a similar structure.
Typical Experimental Workflow for Readability Formula Validation
Caption: Workflow for validating readability formulas.
Key Methodological Steps:
-
Text Corpus Selection: A diverse set of texts is chosen, often including passages from standardized tests for which student performance data is available.
-
Readability Score Calculation: The selected texts are analyzed using the Lexile framework and one or more alternative readability formulas.
-
Human Comprehension Measurement: A group of readers is assessed on their comprehension of the selected texts. This can be done through various methods, such as:
-
Multiple-Choice Questions: Readers answer questions about the main idea, details, and inferences from the text.
-
Cloze Tests: Words are systematically removed from a text, and readers must fill in the blanks. The percentage of correctly filled words serves as a measure of comprehension.
-
Think-Aloud Protocols: Readers verbalize their thoughts as they read, providing qualitative data on their comprehension processes.
-
-
Statistical Analysis: The readability scores for each text are then statistically correlated with the average comprehension scores of the readers. Regression analysis may be used to determine how well each readability formula predicts comprehension.
Logical Relationships in Readability Assessment
The relationship between the core components of readability formulas and reading comprehension is not always straightforward. The following diagram illustrates the simplified, direct relationship assumed by many formulas versus the more complex, multifaceted nature of true reading comprehension.
Caption: Simplified vs. Comprehensive models of readability.
Conclusion
The Lexile framework offers a simple, standardized method for gauging text difficulty that has been widely adopted. Its correlation with standardized tests is a key part of its value proposition. However, the framework's reliance on a limited set of linguistic features is a significant drawback, as it fails to capture the full spectrum of factors that contribute to reading comprehension. While alternative formulas exist, they often share similar limitations.
For researchers, scientists, and professionals in drug development, where precise understanding of complex technical documents is paramount, it is crucial to recognize that no single readability formula can provide a complete picture of a text's difficulty. These formulas can serve as a useful first approximation, but they should be supplemented with qualitative analysis and consideration of the intended audience's background knowledge and the specific reading task. The absence of readily available, independent data directly correlating Lexile scores with performance on standardized tests like the SAT and ACT underscores the need for a more critical and nuanced approach to the use of such metrics.
References
Independent Evaluations of the Lexile Framework's Effectiveness: A Comparative Guide
The Lexile Framework for Reading, a widely used tool for assessing text difficulty and matching readers with appropriate materials, has been the subject of numerous independent evaluations. This guide provides a comprehensive comparison of the Lexile framework with other readability formulas, supported by experimental data and detailed methodologies, to offer researchers, scientists, and drug development professionals a clear understanding of its effectiveness.
At a Glance: Lexile and Its Alternatives
The Lexile framework, developed by MetaMetrics, determines a text's difficulty based on two primary factors: sentence length and word frequency. The resulting Lexile measure is a number followed by an "L" (e.g., 1000L), which is then used to match readers with texts within their optimal reading range.[1][2] While lauded for its simplicity and widespread adoption, the framework's reliance on only two variables has drawn criticism for its failure to account for the multifaceted nature of text complexity.[3]
To provide a comparative analysis, this guide will focus on the Flesch-Kincaid Grade Level, another popular readability formula, and discuss findings from studies that have either directly or indirectly compared its outputs with the Lexile framework.
Quantitative Comparison of Readability Formulas
While direct, independent, head-to-head experimental studies with detailed protocols are not abundant in the publicly available literature, existing research provides valuable insights into the comparative performance of the Lexile framework.
| Study/Report | Readability Formulas Compared | Key Findings | Correlation/Data Summary |
| Hiebert (Commissioned by CCSS Developers) | Lexile Framework, State Assessments, Norm-referenced assessment (SAT-9) | Weak correlation between Lexile levels and the grade band assigned to texts on state assessments. | Correlation of Lexiles to grade-level text assignments on a state assessment was approximately 0.26 for Grades 6–8 and 0.22 for Grades 9–11. For the SAT-9, the correlation was 0.24 for Grades 6-8 and dropped to 0.078 for Grades 9-11.[4] |
| Unnamed Study in Interpreting Intervention Outcomes | Lexile-based assessments | A 100L gain on a Lexile-based assessment does not guarantee improved performance on state assessments. | A grade level is identified as 50L, and a year of growth is a 100L gain.[4] |
| The Effect of Altered Lexile Levels of Informational Text on Reading Comprehension | Lexile Framework | No overall difference in reading comprehension for on-level and above-level readers across different Lexile versions of the same text. Below-level readers' scores improved only with significantly lower Lexile level texts. | A 3-way ANOVA showed no significant interaction between Reading Ability Level, Grade, and Text Level on comprehension scores (p = .507).[5] |
| The Relationship Between Reading Fluency and Lexile Measures | Lexile Framework (as a measure of comprehension) and Reading Fluency | A strong positive correlation exists between reading fluency and reading comprehension as measured by Lexile. | Specific correlation coefficients were not provided in the abstract. |
| Stenner, A. J., & Burdick, H. (MetaMetrics) | Lexile Framework | The standard deviation component associated with theory misspecification is estimated at 64L for a standard-length passage (approximately 125 words). | This indicates a level of inherent error in the Lexile text measure. |
| ResearchGate Study on CKD Patient Materials | Lexile and Flesch-Kincaid | A high correlation was found between the two measures. | Correlation between Lexile and Flesch-Kincaid was 0.89.[6] |
Critiques and Limitations of the Lexile Framework
A significant body of research highlights the limitations of the Lexile framework's purely quantitative approach. The primary critiques include:
-
Neglect of Qualitative Factors: The framework does not consider crucial elements of text complexity such as:
-
Levels of Meaning and Purpose: It cannot distinguish between a text with a single, literal meaning and one with multiple, nuanced layers of meaning.[3]
-
Text Structure: It does not account for the complexity of a text's organization, such as chronological versus non-linear narratives.[3]
-
Language Conventionality and Clarity: Figurative language, irony, and complex sentence structures are not directly measured.[3]
-
Knowledge Demands: The framework does not assess the amount of prior knowledge a reader needs to comprehend a text.[3]
-
-
Inadequate for Certain Text Types: The quantitative approach of the Lexile framework is not well-suited for all genres. For example, poetry and drama are not reliably measured due to their unique structures and styles.
-
Limited Predictive Power for Comprehension: Research has shown that a text's Lexile level is not always a strong predictor of how well a student will comprehend it, especially when compared to performance on more comprehensive state assessments.[4]
Experimental Methodologies: A Closer Look
While detailed independent experimental protocols are scarce, the methodologies employed in the cited studies provide a framework for understanding how the effectiveness of readability formulas is evaluated.
Correlation Studies
A common approach is to correlate the readability scores of different formulas with external measures of reading comprehension or text difficulty.
Caption: Workflow for a correlational study comparing readability formulas.
Protocol:
-
Text Selection: A diverse corpus of texts is selected.
-
Readability Analysis: The selected texts are analyzed using the Lexile framework and other readability formulas to generate scores.
-
Comprehension Data Collection: Student reading comprehension data for the selected texts is collected from sources such as standardized tests or state assessments.
-
Statistical Correlation: The readability scores from each formula are statistically correlated with the student comprehension data.
-
Analysis: The strength and significance of the correlations are analyzed to determine the predictive validity of each formula.
Experimental Studies on Text Simplification
Another approach involves manipulating the Lexile level of a text and measuring the impact on reading comprehension.
Caption: Workflow for an experimental study on text simplification.
Protocol:
-
Text Selection: An original text is chosen.
-
Text Manipulation: Several versions of the text are created at different Lexile levels, while attempting to control for other factors.
-
Participant Grouping: Students are randomly assigned to read one of the text versions.
-
Comprehension Assessment: After reading, all students take the same reading comprehension test.
-
Statistical Analysis: An analysis of variance (ANOVA) or other appropriate statistical test is used to determine if there are significant differences in comprehension scores among the groups who read the different text versions.
Conclusion
The Lexile framework is a widely accessible tool for providing a quantitative measure of text difficulty. Its simplicity, based on sentence length and word frequency, allows for the quick classification of a vast number of texts. However, independent evaluations consistently point to a significant limitation: the framework's inability to account for the qualitative dimensions of a text that are crucial for true comprehension.
Studies have shown a weak correlation between Lexile scores and student performance on comprehensive assessments, and that manipulating Lexile levels does not consistently impact the comprehension of on-level or advanced readers. While a high correlation with other quantitative formulas like Flesch-Kincaid exists, this primarily indicates that they are measuring similar surface-level text features.
For researchers, scientists, and drug development professionals who require a nuanced understanding of text complexity, relying solely on the Lexile framework may be insufficient. A more robust approach involves a three-part model that considers quantitative measures, qualitative dimensions, and the specific reader and task.[3] This integrated approach, which combines the data from tools like the Lexile framework with expert human judgment, will provide a more accurate and effective assessment of text difficulty.
References
A Comparative Analysis of the Lexile Framework and Fountas & Pinnell for Text Leveling
In the landscape of educational tools, the accurate assessment of text difficulty is paramount for fostering literacy and ensuring comprehension. Among the most prominent systems utilized for this purpose are the Lexile Framework for Reading and the Fountas & Pinnell Guided Reading Leveling System. This guide provides an objective comparison of these two methodologies, presenting quantitative data, experimental protocols, and visual representations of their respective workflows to aid researchers, scientists, and drug development professionals in understanding their applications and distinctions.
Core Methodologies: A Tale of Two Approaches
The fundamental difference between the Lexile Framework and the Fountas & Pinnell system lies in their methodological underpinnings. The Lexile Framework employs a quantitative, algorithmic approach, while Fountas & Pinnell utilizes a qualitative, teacher-driven method.
The Lexile Framework for Reading , developed by MetaMetrics, assigns a numerical "Lexile measure" to both texts and readers.[1][2] For texts, this measure is determined by a proprietary algorithm, the "Lexile Analyzer," which evaluates two key predictors of text difficulty:
-
Syntactic Complexity: The length of sentences. Longer sentences are generally more complex and require greater cognitive effort to process.
-
Semantic Difficulty: The frequency of words. Words that appear less frequently in a large corpus of text are considered more challenging.[3]
The Lexile scale is a developmental scale ranging from below 0L for beginning reader texts to over 1600L for advanced texts.[3][4]
In contrast, the Fountas & Pinnell Guided Reading Leveling System uses an alphabetic gradient, from A to Z+, to classify text difficulty. This system is rooted in a more holistic, qualitative assessment conducted by trained educators.[5] The leveling process involves a teacher observing a student's oral reading of a benchmark text, an assessment known as a "running record."[5][6] During a running record, the teacher notes the student's accuracy, fluency, and comprehension, analyzing the types of errors made to understand the reader's processing of the text.[5][6] Fountas and Pinnell's system considers a wider range of factors beyond just sentence length and word frequency, including:
-
Genre and Text Structure: The organizational patterns and literary devices used in the text.
-
Content and Themes: The complexity and abstractness of the ideas presented.
-
Language and Literary Features: The use of figurative language, dialogue, and other stylistic elements.
-
Illustrations and Print Features: The role of visuals and typography in supporting the text.
Quantitative Comparison: Correlation and Variability
A study conducted by MetaMetrics investigated the relationship between Lexile measures and Fountas & Pinnell reading levels.[7] The research found a strong positive correlation between the two systems, indicating that as the Fountas & Pinnell level increases, the corresponding Lexile measure also tends to increase.[7] However, the study also highlighted significant variability in Lexile measures within each Fountas & Pinnell level.[7] This suggests that while the systems are generally aligned, a direct one-to-one conversion is not always precise.[7]
Below is a summary of the quantitative data from the MetaMetrics study, illustrating the distribution of Lexile measures within Fountas & Pinnell's early reading levels (A-M).
| Fountas & Pinnell Level | Mean Lexile Measure | Standard Deviation | 25th Percentile | 50th Percentile (Median) | 75th Percentile |
| A | BR70L | 55 | BR110L | BR70L | BR30L |
| B | BR40L | 60 | BR80L | BR40L | 10L |
| C | 10L | 70 | BR30L | 10L | 50L |
| D | 80L | 75 | 30L | 80L | 130L |
| E | 160L | 80 | 110L | 160L | 210L |
| F | 240L | 85 | 180L | 240L | 300L |
| G | 310L | 80 | 260L | 310L | 360L |
| H | 370L | 75 | 320L | 370L | 420L |
| I | 430L | 70 | 390L | 430L | 470L |
| J | 490L | 65 | 450L | 490L | 530L |
| K | 540L | 60 | 500L | 540L | 580L |
| L | 590L | 55 | 550L | 590L | 630L |
| M | 640L | 50 | 600L | 640L | 680L |
Data sourced from the MetaMetrics research brief "The Relationship Between Lexile Text Measures and Early Grades Fountas & Pinnell Reading Levels." BR indicates a Beginning Reader score.
Experimental Protocols
Lexile Framework: The Lexile Analyzer
The determination of a Lexile text measure is a fully automated process. The experimental protocol for leveling a text using the Lexile Framework is as follows:
-
Text Input: A digital version of the text is fed into the Lexile Analyzer software.
-
Sentence Segmentation: The software identifies sentence boundaries.
-
Word Tokenization: The software breaks down the text into individual words (tokens).
-
Syntactic Analysis: The average sentence length is calculated.
-
Semantic Analysis: The frequency of each word is compared against the Lexile corpus, a large body of text, to determine its rarity.
-
Lexile Equation: The values for average sentence length and average word frequency are entered into a proprietary equation to calculate the final Lexile measure.
Fountas & Pinnell: The Running Record
The Fountas & Pinnell leveling process is an observational assessment performed by an educator. The protocol for a running record is as follows:
-
Text Selection: The teacher selects a benchmark text that is believed to be at or near the student's reading level.
-
Student Reading: The student reads the text aloud.
-
Teacher Observation and Notation: The teacher uses a standardized set of conventions to record the student's reading behaviors, including:
-
Correctly read words.
-
Errors (substitutions, omissions, insertions).
-
Self-corrections.
-
Use of meaning, structure, and visual cues.
-
-
Accuracy Rate Calculation: The percentage of words read correctly is calculated.
-
Comprehension Conversation: After the reading, the teacher engages the student in a conversation about the text to assess their understanding.
-
Level Determination: Based on the accuracy rate, fluency, and comprehension, the teacher determines if the text is at the student's independent, instructional, or frustrational level and assigns the corresponding Fountas & Pinnell letter grade.
Visualizing the Workflows
The following diagrams illustrate the distinct processes of the Lexile Framework and the Fountas & Pinnell system for text leveling.
Conclusion
The Lexile Framework for Reading and the Fountas & Pinnell Guided Reading Leveling System represent two distinct and valuable approaches to text leveling. The Lexile Framework offers a precise, quantitative measure based on syntactic and semantic features, allowing for a high degree of consistency and scalability. Its strength lies in its objectivity and the ability to match readers to a wide range of texts with a common metric.
Fountas & Pinnell, on the other hand, provides a more nuanced, qualitative assessment that considers a broader array of text characteristics and is deeply integrated with instructional practices. Its strength lies in the diagnostic power of the running record and the direct involvement of the teacher in the assessment process, allowing for a more holistic understanding of a student's reading behaviors.
Ultimately, the choice between or the combined use of these systems depends on the specific needs and goals of the educational or research context. For large-scale assessments and objective text-complexity analysis, the Lexile Framework is a powerful tool. For individualized instruction and in-depth diagnostic assessment of reading behaviors, the Fountas & Pinnell system offers a comprehensive framework. Understanding the methodologies and data presented in this guide can help professionals make informed decisions about which system, or combination of systems, is best suited for their purposes.
References
correlation between Lexile measures and student comprehension outcomes
The Lexile Framework for Reading is a widely adopted metric used to match reader ability with text difficulty. Developed by MetaMetrics, it aims to predict how well a student will comprehend a text, with the goal of targeting a 75% comprehension rate to optimize reading growth. This guide provides a comprehensive comparison of Lexile measures with student comprehension outcomes, supported by experimental data, and explores its relationship with other reading level systems.
Quantitative Data Summary
The correlation between Lexile measures and student reading comprehension has been the subject of numerous studies. The data presented below summarizes key quantitative findings from the research.
| Study/Report | Measure of Correlation | Finding |
| MetaMetrics | Correlation Coefficient | A strong positive correlation has been found between Lexile measures and various standardized reading comprehension tests. For instance, an average correlation of .99 was observed between the Lexile calibration of text comprehensibility and the rank order of basal reader units. |
| Stenner (1996) | Correlation Coefficient | A regression analysis based on word-frequency and sentence-length measures produced a regression equation that explained most of the variance found in the set of reading comprehension tasks. The resulting correlation between the observed |
Disclaimer: The following information is for a hypothetical substance, "Lexil."
The guidance provided below is an illustrative example of a comprehensive safety and handling plan for a potent research compound. You must consult the official Safety Data Sheet (SDS) and your institution's safety protocols for the specific chemical you are using. Never handle a chemical without first reviewing its official safety documentation.
Essential Safety and Handling Protocols for Lexil (Hypothetical Cytotoxic Agent)
This document provides essential, immediate safety and logistical information for the handling and disposal of the hypothetical cytotoxic agent, Lexil. The procedural, step-by-step guidance is designed to directly answer specific operational questions for researchers, scientists, and drug development professionals.
Personal Protective Equipment (PPE) for Handling Lexil
Appropriate PPE is mandatory to prevent exposure through inhalation, skin contact, or eye contact.[1][2] The required PPE can be found in section 8 of the SDS.[3] The following table summarizes the minimum PPE requirements for handling Lexil in a laboratory setting.
| PPE Component | Specification | Purpose | Standard Operating Procedure (SOP) |
| Gloves | Double-gloving with chemotherapy-rated nitrile gloves. | Prevents skin contact with Lexil. | Inner glove tucked under the lab coat cuff, outer glove over the cuff. Change outer glove every 30 minutes or immediately upon contamination. |
| Eye Protection | Chemical safety goggles or a full-face shield. | Protects eyes from splashes and aerosols. | Must be worn at all times when Lexil is being handled, even in a fume hood. |
| Lab Coat | Disposable, solid-front, back-closing gown. | Protects clothing and skin from contamination. | Must be fully fastened. Remove and dispose of as hazardous waste before leaving the designated work area. |
| Respiratory Protection | N95 or higher-rated respirator. | Prevents inhalation of Lexil aerosols or powders. | Required for handling powdered Lexil or when there is a risk of aerosol generation outside of a certified chemical fume hood. |
| Shoe Covers | Disposable, slip-resistant shoe covers. | Prevents tracking of contamination outside the work area. | To be worn in the designated Lexil handling area and disposed of as hazardous waste upon exiting. |
Experimental Workflow for Handling Lexil
The following diagram outlines the standard workflow for preparing a stock solution of Lexil. This workflow is designed to minimize exposure and ensure a safe and controlled process.
References
Featured Recommendations


Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
