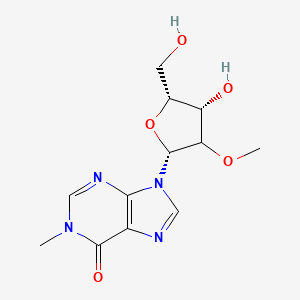
1-Methyl-2'-O-methylinosine
Description
BenchChem offers high-quality this compound suitable for many research applications. Different packaging options are available to accommodate customers' requirements. Please inquire for more information about this compound including the price, delivery time, and more detailed information at info@benchchem.com.
Properties
Molecular Formula |
C12H16N4O5 |
|---|---|
Molecular Weight |
296.28 g/mol |
IUPAC Name |
9-[(2R,4S,5R)-4-hydroxy-5-(hydroxymethyl)-3-methoxyoxolan-2-yl]-1-methylpurin-6-one |
InChI |
InChI=1S/C12H16N4O5/c1-15-4-14-10-7(11(15)19)13-5-16(10)12-9(20-2)8(18)6(3-17)21-12/h4-6,8-9,12,17-18H,3H2,1-2H3/t6-,8+,9?,12-/m1/s1 |
InChI Key |
JSRIPIORIMCGTG-HRLNAYTHSA-N |
Isomeric SMILES |
CN1C=NC2=C(C1=O)N=CN2[C@H]3C([C@H]([C@H](O3)CO)O)OC |
Canonical SMILES |
CN1C=NC2=C(C1=O)N=CN2C3C(C(C(O3)CO)O)OC |
Origin of Product |
United States |
Foundational & Exploratory
The Biological Significance of 1-Methyl-2'-O-methylinosine: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Abstract
1-Methyl-2'-O-methylinosine (m1Im) is a doubly modified nucleoside found in RNA, characterized by methylation at the N1 position of the inosine (B1671953) base and the 2'-O position of the ribose sugar. While direct experimental evidence elucidating the specific biological role of m1Im is currently limited, its significance can be inferred from the well-documented functions of its precursor modifications: 1-methylinosine (B32420) (m1I) and 2'-O-methylinosine (Im). These modifications are crucial for the proper structure and function of transfer RNA (tRNA), impacting translation efficiency and fidelity. This technical guide provides a comprehensive overview of the biological context of m1Im, focusing on its biosynthetic pathway and the roles of its constituent modifications. Detailed experimental protocols for the analysis of such RNA modifications and quantitative data are also presented to facilitate further research in this area.
Introduction to this compound (m1Im)
This compound, also known as 1,2'-O-dimethylinosine (m1Im), is a hypermodified nucleoside. Its structure combines two key post-transcriptional modifications: N1-methylation of inosine and 2'-O-methylation of the ribose moiety. These modifications individually play critical roles in RNA metabolism, particularly in tRNA.
-
1-methylinosine (m1I): This modification is found in the anticodon loop of specific tRNAs, at position 37, 3' to the anticodon. It is crucial for maintaining the correct reading frame during translation by preventing frameshifting.[1]
-
2'-O-methylinosine (Im): The 2'-O-methylation of the ribose sugar can enhance the structural stability of RNA molecules and can influence the interactions of RNA with proteins and other nucleic acids.[2]
The dual modification in m1Im suggests a synergistic or enhanced role in fine-tuning tRNA function, potentially impacting codon recognition, translational fidelity, and the overall stability of the tRNA molecule.
Biosynthesis of this compound
The MODOMICS database suggests that m1Im can be synthesized through two potential pathways involving the sequential modification of an inosine residue within an RNA molecule.[3][4]
Pathway 1: Inosine (I) -> 1-methylinosine (m1I) -> 1,2'-O-dimethylinosine (m1Im)
Pathway 2: Inosine (I) -> 2'-O-methylinosine (Im) -> 1,2'-O-dimethylinosine (m1Im)
The enzymes responsible for these individual methylation steps are key to understanding the formation of m1Im.
-
Trm5: The formation of m1I is catalyzed by the tRNA methyltransferase Trm5. This enzyme is responsible for the N1-methylation of guanosine (B1672433) and inosine at position 37 in tRNAs.[2][5]
-
FTSJ1: This protein is an RNA 2'-O-methyltransferase responsible for the 2'-O-methylation of various nucleosides at positions 32 and 34 in the anticodon loop of tRNAs.[3][6] While FTSJ1 has been shown to methylate cytidine (B196190) and guanosine, it is plausible that a similar 2'-O-methyltransferase is responsible for the formation of Im.
Below is a diagram illustrating the proposed biosynthetic pathways for this compound.
Biological Role and Significance
Due to the limited direct research on m1Im, its biological role is inferred from the functions of m1I and Im.
Role of 1-methylinosine (m1I)
1-methylinosine is a modified nucleotide found at position 37 in the tRNA, adjacent to the 3' end of the anticodon.[1] Its primary role is to act as a reading frame buffer. The methyl group at the N1 position prevents the formation of a standard Watson-Crick base pair, which in turn helps to prevent frameshift errors during protein synthesis. The absence of m1I has been linked to developmental defects and aberrant protein translation in plants.[4]
Role of 2'-O-methylinosine (Im)
2'-O-methylation is a common RNA modification that adds a methyl group to the 2' hydroxyl of the ribose sugar. This modification has several important functions:
-
Structural Stability: The 2'-O-methyl group locks the ribose into a C3'-endo conformation, which is characteristic of A-form helices found in double-stranded RNA. This contributes to the thermal stability of RNA duplexes.
-
Nuclease Resistance: The presence of a 2'-O-methyl group can protect the phosphodiester backbone of RNA from cleavage by nucleases.
-
Modulation of Interactions: 2'-O-methylation can influence the binding of proteins and other molecules to RNA, thereby regulating various cellular processes.[2]
The combination of these two modifications in m1Im likely provides a robust mechanism to ensure translational accuracy and tRNA stability, particularly under specific cellular conditions or in response to stress.
Quantitative Data
The following table summarizes key quantitative information related to the precursor modifications of m1Im. Data for m1Im itself is not currently available in the literature.
| Modification | Location in tRNA | Enzyme | Organism(s) | Effect of Deficiency | Reference |
| 1-methylinosine (m1I) | Position 37 | Trm5 | Eukaryotes | Impaired growth, developmental defects, aberrant protein translation | [4][5] |
| 2'-O-methylation | Positions 32, 34 | FTSJ1 | Humans, Mice | X-linked intellectual disability, reduced tRNA stability | [3][6] |
Experimental Protocols
Detection and Quantification of Modified Nucleosides by HPLC-Coupled Mass Spectrometry
This protocol outlines a general method for the analysis of modified nucleosides in tRNA, which can be adapted for the detection of m1I, Im, and potentially m1Im.
1. tRNA Isolation and Purification:
- Isolate total RNA from cells or tissues using a standard method (e.g., Trizol extraction).
- Purify tRNA from the total RNA pool using anion-exchange chromatography or size-exclusion chromatography.
2. Enzymatic Hydrolysis of tRNA:
- Digest the purified tRNA to single nucleosides using a cocktail of nuclease P1 and bacterial alkaline phosphatase.
- Incubate 1-5 µg of tRNA with 1 U of nuclease P1 in 10 mM ammonium (B1175870) acetate (B1210297) (pH 5.3) at 37°C for 2 hours.
- Add 1 U of bacterial alkaline phosphatase and continue incubation at 37°C for an additional 2 hours.
- Terminate the reaction by filtration through a 10-kDa molecular weight cutoff filter.
3. HPLC-MS/MS Analysis:
- Separate the resulting nucleosides using reversed-phase high-performance liquid chromatography (HPLC) on a C18 column.
- Use a gradient of a suitable mobile phase, such as water with 0.1% formic acid (solvent A) and acetonitrile (B52724) with 0.1% formic acid (solvent B).
- Couple the HPLC to a triple quadrupole mass spectrometer operating in positive ion mode with multiple reaction monitoring (MRM) for sensitive and specific detection of the target nucleosides.
- Identify and quantify the modified nucleosides based on their specific retention times and mass transitions.
Below is a workflow diagram for this protocol.
In Vitro tRNA Methylation Assay
This protocol can be used to study the activity of tRNA methyltransferases like Trm5.
1. Expression and Purification of Recombinant Enzyme:
- Clone the gene encoding the methyltransferase (e.g., TRM5) into an expression vector with an affinity tag (e.g., His-tag or GST-tag).
- Express the recombinant protein in a suitable host, such as E. coli.
- Purify the recombinant enzyme using affinity chromatography.
2. Preparation of tRNA Substrate:
- Synthesize an in vitro transcript of the target tRNA using T7 RNA polymerase. The tRNA should lack the modification of interest.
- Alternatively, use total tRNA isolated from a mutant strain deficient in the specific methyltransferase.
3. Methylation Reaction:
- Set up the reaction mixture containing:
- Purified recombinant methyltransferase
- tRNA substrate
- S-adenosyl-L-[methyl-³H]methionine (as a methyl donor)
- Reaction buffer (e.g., 50 mM Tris-HCl pH 7.5, 5 mM MgCl₂, 1 mM DTT)
- Incubate the reaction at the optimal temperature for the enzyme (e.g., 37°C) for a defined period.
4. Analysis of Methylation:
- Stop the reaction and precipitate the tRNA.
- Quantify the incorporation of the radiolabeled methyl group into the tRNA using scintillation counting.
- Alternatively, the reaction products can be analyzed by HPLC-MS/MS to confirm the identity and position of the modification.
Conclusion and Future Directions
This compound represents a fascinating, yet understudied, RNA modification. Its biosynthesis from the well-characterized modifications m1I and Im suggests a critical role in the fine-tuning of tRNA function and, consequently, the regulation of protein synthesis. The lack of direct experimental data on m1Im highlights a significant knowledge gap and presents an exciting opportunity for future research.
Future studies should focus on:
-
Identifying the specific tRNA species that contain the m1Im modification.
-
Characterizing the enzymes responsible for the sequential methylation steps leading to m1Im.
-
Elucidating the precise biological function of m1Im in translation and other cellular processes.
-
Investigating the potential involvement of m1Im in human diseases, given the known association of its precursor modifications with conditions like cancer and neurological disorders.
The development of more sensitive analytical techniques will be crucial for the detection and quantification of this rare modification. A deeper understanding of m1Im will undoubtedly provide valuable insights into the complex world of the epitranscriptome and its role in health and disease, potentially opening new avenues for therapeutic intervention.
References
- 1. Loss of Ftsj1 perturbs codon-specific translation efficiency in the brain and is associated with X-linked intellectual disability - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Quantitative analysis of tRNA modifications by HPLC-coupled mass spectrometry [dspace.mit.edu]
- 4. Quantitative analysis of tRNA modifications by HPLC-coupled mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Chemical manipulation of m1A mediates its detection in human tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
The Strategic Role of 1-Methyl-2'-O-methylinosine (m¹Im) in Archaeal tRNA: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Abstract
In the extreme environments inhabited by many archaea, the structural integrity of cellular machinery is paramount. Transfer RNA (tRNA), a central player in protein synthesis, is particularly vulnerable to thermal degradation. To counteract this, archaea have evolved a sophisticated arsenal (B13267) of post-transcriptional modifications. Among the most critical of these is the doubly modified nucleoside, 1-methyl-2'-O-methylinosine (m¹Im). This technical guide provides an in-depth exploration of the function, biosynthesis, and significance of m¹Im in archaeal tRNA, offering insights for researchers in the fields of molecular biology, extremophile biochemistry, and drug development.
Introduction: The Imperative of tRNA Stability in Archaea
Archaea, particularly hyperthermophiles, thrive in conditions of extreme temperature, pressure, and pH. At elevated temperatures, the canonical secondary and tertiary structures of nucleic acids, including tRNA, are prone to denaturation, which would be catastrophic for cellular function. Consequently, archaeal tRNAs are heavily modified to enhance their structural stability and ensure accurate and efficient translation. These modifications, ranging from simple methylations to complex multi-step additions, are crucial for maintaining the canonical L-shape of tRNA, which is essential for its interaction with ribosomes, aminoacyl-tRNA synthetases, and other components of the translational apparatus.
One of the key strategies employed by hyperthermophilic archaea to stabilize their tRNAs is the extensive 2'-O-methylation of ribose moieties. This modification rigidifies the sugar-phosphate backbone and protects the phosphodiester bonds from hydrolysis. The doubly modified nucleoside, this compound (m¹Im), represents a pinnacle of this stabilization strategy, combining both a base methylation and a ribose methylation at the same nucleoside.
The Function of m¹Im: A Guardian of Thermostability
The primary and most well-documented function of this compound in archaeal tRNA is its profound contribution to the thermostability of the molecule. The presence of m¹Im, along with other 2'-O-methylated nucleosides, significantly increases the melting temperature (Tm) of tRNA, allowing it to remain functional at the high growth temperatures of hyperthermophiles.
In the hyperthermophilic archaeon Pyrodictium occultum, which grows optimally at 105°C, the initiator tRNA (tRNAiMet) exhibits a melting temperature of over 100°C, a stark contrast to the 80°C Tm of its unmodified in vitro transcribed counterpart[1]. This remarkable increase of over 20°C in thermal stability is largely attributed to the presence of a variety of modified nucleosides, including m¹Im[1].
The stabilizing effect of the 2'-O-methyl group is attributed to its preference for the C3'-endo sugar pucker conformation, which is characteristic of A-form RNA helices. This pre-organizes the sugar-phosphate backbone into a more rigid and stable helical structure. The N1-methylation of the inosine (B1671953) base further contributes to the overall stability and specific structural context of the tRNA.
While the role of m¹Im in thermostability is clear, its direct impact on other aspects of translation, such as fidelity and efficiency, remains an area of active investigation. It is plausible that by ensuring the correct tRNA structure at extreme temperatures, m¹Im indirectly influences these processes.
Biosynthesis of m¹Im: A Multi-Step Modification Pathway
The precise enzymatic pathway for the synthesis of this compound in archaea has not been fully elucidated. However, based on the known biosynthesis of its constituent modifications, a putative pathway can be proposed. The formation of m¹Im likely involves a multi-step process, beginning with the modification of an adenosine (B11128) residue within the tRNA transcript.
The biosynthesis of 1-methylinosine (B32420) (m¹I) in the archaeon Haloferax volcanii has been shown to occur via a two-step enzymatic process at position 57 in the TΨC loop. The first step is the S-adenosylmethionine (SAM)-dependent methylation of adenosine (A) at the N1 position to form 1-methyladenosine (B49728) (m¹A), catalyzed by a tRNA methyltransferase. This is followed by the deamination of the 6-amino group of m¹A to yield m¹I.
It is hypothesized that the formation of m¹Im follows a similar initial pathway, with an additional 2'-O-methylation step. This 2'-O-methylation could occur either before or after the formation of m¹I.
The enzymes responsible for the 2'-O-methylation step in m¹Im formation have yet to be definitively identified. In archaea, 2'-O-methylation is carried out by two distinct mechanisms: site-specific 2'-O-methyltransferases and the C/D box small RNA (sRNA)-guided machinery[2]. Archaeal tRNA 2'-O-methyltransferases, such as aTrm56 and aTrmJ, have been characterized and show specificity for certain positions and nucleosides[3][4][5][6]. It is plausible that a yet-to-be-identified archaeal 2'-O-methyltransferase recognizes m¹I or a precursor as its substrate.
Location of m¹Im in Archaeal tRNA
While the presence of m¹Im has been confirmed in the total tRNA of hyperthermophilic archaea like Pyrodictium occultum, its precise location within specific tRNA molecules is not extensively documented. However, the location of the related modification, 1-methylinosine (m¹I), has been identified at position 57 in the TΨC loop of several archaeal tRNAs, including those from Haloferax volcanii. Given the structural and biosynthetic relationship between m¹I and m¹Im, it is highly probable that m¹Im also resides at or near position 57 in the TΨC loop of tRNAs in hyperthermophilic archaea. This region of the tRNA is critical for maintaining its tertiary structure through interactions with the D-loop.
Quantitative Data on the Impact of m¹Im
Direct quantitative data isolating the specific contribution of m¹Im to the thermodynamic stability of archaeal tRNA is limited. Most studies have focused on the collective effect of multiple 2'-O-methylations. The significant increase in the melting temperature of P. occultum tRNAiMet by over 20°C is a testament to the combined power of these modifications, including m¹Im[1].
| tRNA Species | Source Organism | Modification Status | Melting Temperature (Tm) | Reference |
| tRNAiMet | Pyrodictium occultum | Fully Modified (contains m¹Im) | > 100°C | [1] |
| tRNAiMet | In vitro transcript | Unmodified | 80°C | [1] |
Table 1: Comparison of Melting Temperatures of Modified and Unmodified Archaeal tRNA.
Further research employing techniques such as differential scanning calorimetry or UV-melting analysis on in vitro transcribed tRNAs with and without the enzymatic incorporation of m¹Im would be necessary to precisely quantify its individual contribution to tRNA stability.
Experimental Protocols
Isolation and Purification of Archaeal tRNA
-
Cell Lysis: Archaeal cells are harvested and lysed, typically by sonication or French press, in a buffer containing high salt concentrations to maintain the integrity of cellular components.
-
Phenol-Chloroform Extraction: The cell lysate is subjected to phenol-chloroform extraction to remove proteins and lipids.
-
Ethanol Precipitation: Total RNA is precipitated from the aqueous phase using ethanol.
-
Anion-Exchange Chromatography: The total RNA is fractionated using anion-exchange chromatography (e.g., DEAE-cellulose column) to separate tRNA from larger ribosomal RNA and smaller RNA fragments.
-
Size-Exclusion Chromatography: Further purification can be achieved using size-exclusion chromatography to obtain highly pure tRNA.
Analysis of Modified Nucleosides by HPLC-Mass Spectrometry
-
tRNA Hydrolysis: Purified tRNA is completely hydrolyzed to its constituent nucleosides using a combination of nucleases, such as nuclease P1 and bacterial alkaline phosphatase.
-
HPLC Separation: The resulting nucleoside mixture is separated by reverse-phase high-performance liquid chromatography (RP-HPLC).
-
Mass Spectrometry Detection: The eluting nucleosides are detected and identified by online electrospray ionization mass spectrometry (ESI-MS). The mass-to-charge ratio (m/z) of each nucleoside is determined, allowing for the identification of modified nucleosides based on their unique masses.
-
Quantification: The abundance of each nucleoside, including m¹Im, can be quantified by integrating the peak area from the HPLC chromatogram.
In Vitro tRNA Methyltransferase Assay
-
Substrate Preparation: An unmodified tRNA transcript is prepared by in vitro transcription using T7 RNA polymerase from a DNA template.
-
Enzyme Preparation: The candidate archaeal tRNA methyltransferase is overexpressed and purified.
-
Reaction Mixture: The reaction is set up in a buffer containing the unmodified tRNA substrate, the purified enzyme, and the methyl donor, S-adenosyl-L-methionine (SAM), often radioactively labeled ([³H]SAM or [¹⁴C]SAM) for detection.
-
Incubation: The reaction mixture is incubated at the optimal temperature for the enzyme.
-
Analysis: The incorporation of the methyl group into the tRNA is analyzed by methods such as scintillation counting of the precipitated tRNA or by HPLC-MS analysis of the digested tRNA to identify the specific methylated nucleoside formed.
Implications for Drug Development
The enzymes involved in archaeal tRNA modification pathways, including those responsible for the synthesis of m¹Im, represent potential targets for the development of novel antimicrobial agents. As many of these modifications and the corresponding enzymes are unique to archaea, inhibitors targeting these enzymes could offer high specificity with minimal off-target effects on eukaryotic hosts. Furthermore, understanding the mechanisms of tRNA stabilization in extremophiles can provide valuable insights for the design of thermostable RNA-based therapeutics and diagnostics.
Conclusion and Future Directions
This compound is a key post-transcriptional modification in the tRNA of hyperthermophilic archaea, playing a critical role in the structural stabilization of these essential molecules at extreme temperatures. While its primary function in thermostability is well-established, the precise enzymatic machinery responsible for its biosynthesis and its potential roles in other cellular processes remain to be fully elucidated. Future research should focus on:
-
The identification and characterization of the specific archaeal 2'-O-methyltransferase(s) involved in m¹Im formation.
-
The precise mapping of m¹Im in a wider range of archaeal tRNA species.
-
Quantitative studies to dissect the individual contribution of m¹Im to tRNA thermostability and translational fidelity.
-
Exploration of the potential regulatory roles of m¹Im in response to environmental stresses.
A deeper understanding of the biology of m¹Im will not only enhance our knowledge of life in extreme environments but also open new avenues for biotechnological and therapeutic applications.
References
- 1. Structural feature of the initiator tRNA gene from Pyrodictium occultum and the thermal stability of its gene product, tRNA(imet) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Two different mechanisms for tRNA ribose methylation in Archaea: a short survey - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Characterization of two homologous 2′-O-methyltransferases showing different specificities for their tRNA substrates - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Characterization of two homologous 2'-O-methyltransferases showing different specificities for their tRNA substrates - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. The Cm56 tRNA modification in archaea is catalyzed either by a specific 2'-O-methylase, or a C/D sRNP - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. The Cm56 tRNA modification in archaea is catalyzed either by a specific 2′-O-methylase, or a C/D sRNP - PMC [pmc.ncbi.nlm.nih.gov]
An In-depth Technical Guide to the Enzymes Involved in 1-Methyl-2'-O-methylinosine (m1Im) Synthesis
For Researchers, Scientists, and Drug Development Professionals
Introduction
1-Methyl-2'-O-methylinosine (m1Im) is a hypermodified nucleoside found in transfer RNA (tRNA), particularly in archaea. The intricate chemical structure of m1Im, featuring both a methyl group on the nitrogen-1 (N1) of the hypoxanthine (B114508) base and another on the 2'-hydroxyl group of the ribose sugar, suggests a sophisticated enzymatic synthesis pathway. This guide provides a comprehensive overview of the current understanding of the enzymes potentially involved in m1Im biosynthesis, drawing from research on tRNA modification pathways. While the complete pathway and the specific enzymes responsible for every step in all organisms are not yet fully elucidated, this document synthesizes the available evidence to propose a putative enzymatic cascade and details relevant experimental methodologies.
Proposed Biosynthetic Pathways of this compound (m1Im)
Based on the known enzymatic reactions involved in tRNA modification, two primary pathways for the synthesis of m1Im can be postulated. These pathways involve a series of sequential enzymatic modifications, including deamination and methylation events.
Pathway 1: Deamination Followed by Sequential Methylations
This pathway begins with the deamination of adenosine (B11128) (A) to inosine (B1671953) (I), followed by two successive methylation steps.
-
Adenosine Deamination: The initial step is the conversion of adenosine to inosine. This reaction is catalyzed by adenosine deaminases acting on tRNA (ADATs). In bacteria, the enzyme TadA is responsible for this modification, while in eukaryotes, a heterodimeric ADAT2/ADAT3 complex performs this function[1][2].
-
2'-O-methylation of Inosine: The next step would involve the methylation of the 2'-hydroxyl group of the inosine ribose to form 2'-O-methylinosine (Im). This reaction is catalyzed by a 2'-O-methyltransferase. Members of the FTSJ1/TRM7 family of enzymes are known to catalyze 2'-O-methylation of various nucleotides in tRNA[1][3][4][5][6]. While their activity on inosine has not been extensively characterized, it is plausible that an enzyme from this family, or a related methyltransferase, could perform this step.
-
N1-methylation of 2'-O-methylinosine: The final step is the methylation of the N1 position of the hypoxanthine base of Im to yield m1Im. This reaction would be catalyzed by an N1-methyltransferase. Enzymes from the Trm5 and Trm10 families are known to methylate the N1 position of purines in tRNA[7]. Trm5, for instance, has been shown to methylate inosine to form 1-methylinosine (B32420) (m1I)[8]. It is conceivable that a Trm5 or Trm10 homolog could recognize 2'-O-methylinosine as a substrate.
Pathway 2: N1-methylation, Deamination, and 2'-O-methylation
This alternative pathway initiates with the methylation of adenosine, followed by deamination and a final methylation step. This sequence of events has been observed in the biosynthesis of m1I in archaea[8].
-
N1-methylation of Adenosine: The first step is the methylation of adenosine at the N1 position to form 1-methyladenosine (B49728) (m1A). This reaction is catalyzed by tRNA (m1A) methyltransferases, such as members of the Trm family.
-
Deamination of 1-methyladenosine: The m1A intermediate is then deaminated to form 1-methylinosine (m1I). This reaction is carried out by a specific 1-methyladenosine deaminase.
-
2'-O-methylation of 1-methylinosine: The final step to produce m1Im would be the methylation of the 2'-hydroxyl group of the ribose of m1I. This reaction would be catalyzed by a 2'-O-methyltransferase, likely from the FTSJ1/TRM7 family.
Core Enzymes and Their Families
The biosynthesis of m1Im likely involves a consortium of enzymes from distinct families, each responsible for a specific chemical modification.
Adenosine Deaminases (ADATs/TadA)
-
Function: Catalyze the hydrolytic deamination of adenosine to inosine in tRNA.
-
Significance: This is a crucial initial step in Pathway 1 and is essential for generating the inosine base that is subsequently methylated.
N1-Methyltransferases (Trm5 and Trm10 Families)
-
Function: These S-adenosyl-L-methionine (SAM)-dependent methyltransferases catalyze the transfer of a methyl group to the N1 position of purine (B94841) bases (adenine and guanine) in tRNA. Trm5 has been shown to methylate inosine to m1I[8].
-
Significance: These enzymes are critical for the N1-methylation step in both proposed pathways. Their substrate specificity, particularly their ability to act on already modified nucleosides like 2'-O-methylinosine or to initiate the process by methylating adenosine, is a key area for further research.
2'-O-Methyltransferases (FTSJ1/TRM7 Family)
-
Function: This family of SAM-dependent enzymes catalyzes the transfer of a methyl group to the 2'-hydroxyl group of the ribose sugar of nucleotides within RNA molecules.[1][3][4][5][6]
-
Significance: These enzymes are responsible for the 2'-O-methylation step in both proposed pathways. Identifying the specific member of this family that can utilize inosine or 1-methylinosine as a substrate is crucial for fully elucidating the m1Im synthesis pathway.
Quantitative Data
Quantitative kinetic data for the specific enzymatic reactions involved in m1Im synthesis is currently limited in the scientific literature. The tables below are structured to present such data as it becomes available through future research.
Table 1: Kinetic Parameters of N1-Methyltransferases
| Enzyme | Substrate | Km (µM) | kcat (s-1) | kcat/Km (M-1s-1) | Organism | Reference |
| Data Not Currently Available | 2'-O-methylinosine | |||||
| Data Not Currently Available | Adenosine | |||||
| Trm5 | Inosine | Saccharomyces cerevisiae | [8] |
Table 2: Kinetic Parameters of 2'-O-Methyltransferases
| Enzyme | Substrate | Km (µM) | kcat (s-1) | kcat/Km (M-1s-1) | Organism | Reference |
| Data Not Currently Available | Inosine | |||||
| Data Not Currently Available | 1-methylinosine |
Table 3: Kinetic Parameters of Adenosine Deaminases
| Enzyme | Substrate | Km (µM) | kcat (s-1) | kcat/Km (M-1s-1) | Organism | Reference |
| ADAT2/ADAT3 | Adenosine in tRNA | Homo sapiens | [2] | |||
| TadA | Adenosine in tRNA | Escherichia coli | [1] |
Experimental Protocols
The following sections provide detailed methodologies for key experiments relevant to the study of enzymes involved in m1Im synthesis.
Protocol 1: Recombinant Expression and Purification of tRNA Methyltransferases
This protocol describes a general method for producing and purifying recombinant tRNA methyltransferases, which is a prerequisite for in vitro characterization.
1. Gene Cloning and Expression Vector Construction:
- The gene encoding the putative methyltransferase is amplified by PCR from the genomic DNA of the source organism.
- The PCR product is cloned into an expression vector (e.g., pET vector series) containing a suitable tag for purification (e.g., His6-tag, GST-tag).
- The construct is verified by DNA sequencing.
2. Protein Expression:
- The expression vector is transformed into a suitable E. coli expression strain (e.g., BL21(DE3)).
- A single colony is used to inoculate a starter culture in LB medium containing the appropriate antibiotic.
- The starter culture is used to inoculate a larger volume of culture medium.
- The culture is grown at 37°C with shaking until the optical density at 600 nm (OD600) reaches 0.6-0.8.
- Protein expression is induced by the addition of isopropyl β-D-1-thiogalactopyranoside (IPTG) to a final concentration of 0.1-1 mM.
- The culture is then incubated at a lower temperature (e.g., 16-25°C) for several hours to overnight to enhance soluble protein expression.
3. Cell Lysis and Protein Purification:
- Cells are harvested by centrifugation.
- The cell pellet is resuspended in lysis buffer (e.g., 50 mM Tris-HCl pH 8.0, 300 mM NaCl, 10 mM imidazole (B134444), 1 mM PMSF).
- Cells are lysed by sonication or using a French press.
- The lysate is clarified by centrifugation to remove cell debris.
- The supernatant containing the soluble protein is loaded onto an appropriate affinity chromatography column (e.g., Ni-NTA for His6-tagged proteins, Glutathione-agarose for GST-tagged proteins).
- The column is washed with wash buffer (lysis buffer with a slightly higher concentration of imidazole or with no glutathione).
- The recombinant protein is eluted from the column using an elution buffer containing a high concentration of imidazole or reduced glutathione.
- The purity of the eluted protein is assessed by SDS-PAGE.
- If necessary, further purification steps such as ion-exchange and size-exclusion chromatography can be performed.
Protocol 2: In Vitro tRNA Methyltransferase Assay using Radiolabeled S-adenosyl-L-methionine ([³H]-SAM)
This assay is a highly sensitive method to measure the activity of tRNA methyltransferases.
1. Reaction Setup:
- Prepare a reaction mixture containing:
- Reaction buffer (e.g., 50 mM Tris-HCl pH 8.0, 50 mM KCl, 5 mM MgCl2, 1 mM DTT)
- Purified recombinant methyltransferase (concentration to be optimized)
- tRNA substrate (unmodified or specifically prepared with the target nucleoside)
- [³H]-S-adenosyl-L-methionine (specific activity and concentration to be optimized)
- The final reaction volume is typically 20-50 µL.
2. Incubation:
- Incubate the reaction mixture at the optimal temperature for the enzyme (e.g., 37°C for mesophilic enzymes, higher for thermophilic enzymes) for a defined period (e.g., 30-60 minutes).
3. Termination of Reaction and Precipitation of tRNA:
- The reaction is stopped by the addition of an equal volume of phenol:chloroform (B151607):isoamyl alcohol (25:24:1).
- The mixture is vortexed and centrifuged to separate the phases.
- The aqueous phase containing the tRNA is transferred to a new tube.
- The tRNA is precipitated by adding 1/10 volume of 3 M sodium acetate (B1210297) (pH 5.2) and 2.5 volumes of cold ethanol (B145695).
- The mixture is incubated at -20°C for at least 1 hour.
4. Quantification of Incorporated Radioactivity:
- The precipitated tRNA is collected by centrifugation.
- The pellet is washed with 70% ethanol to remove unincorporated [³H]-SAM.
- The dried pellet is resuspended in a suitable buffer or water.
- The amount of incorporated radioactivity is measured using a liquid scintillation counter.
- The specific activity of the enzyme can be calculated based on the amount of incorporated radioactivity, the specific activity of the [³H]-SAM, and the amount of enzyme used.
Protocol 3: LC-MS/MS for the Identification and Quantification of this compound
Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is the gold standard for the sensitive and specific detection of modified nucleosides.
1. RNA Digestion to Nucleosides:
- Purified tRNA (or total RNA) is digested to single nucleosides.
- Incubate the RNA sample with nuclease P1 at 37°C for 2-4 hours.
- Then, add bacterial alkaline phosphatase and continue incubation at 37°C for another 1-2 hours to dephosphorylate the nucleosides.
- The enzymes are removed by filtration or chloroform extraction.
2. LC Separation:
- The resulting nucleoside mixture is separated by reverse-phase high-performance liquid chromatography (RP-HPLC).
- A C18 column is typically used with a gradient of mobile phases, such as water with 0.1% formic acid (mobile phase A) and acetonitrile (B52724) or methanol (B129727) with 0.1% formic acid (mobile phase B).
- The elution gradient is optimized to achieve good separation of the different nucleosides.
3. MS/MS Detection and Quantification:
- The eluent from the HPLC is directed to a tandem mass spectrometer equipped with an electrospray ionization (ESI) source.
- The mass spectrometer is operated in positive ion mode.
- For identification, a full scan MS analysis is performed to detect the protonated molecular ion of m1Im ([M+H]⁺).
- For confirmation and quantification, a product ion scan (MS/MS) is performed on the precursor ion of m1Im. The fragmentation pattern will be specific to the structure of m1Im.
- Quantification is typically achieved using multiple reaction monitoring (MRM), where specific precursor-to-product ion transitions for m1Im and an internal standard (a stable isotope-labeled version of m1Im) are monitored.
Signaling Pathways and Logical Relationships
The synthesis of m1Im is a fundamental process of tRNA maturation. The presence of this hypermodified nucleoside can have significant implications for the structure and function of tRNA, which in turn can affect the fidelity and efficiency of protein translation.
DOT Script for Proposed Biosynthetic Pathways
Proposed biosynthetic pathways for this compound (m1Im).
DOT Script for Experimental Workflow
General experimental workflow for characterizing enzymes in m1Im synthesis.
Conclusion
The synthesis of the hypermodified nucleoside this compound is a testament to the complexity and precision of the cellular machinery for tRNA modification. While the exact enzymatic pathway remains to be definitively established in any organism, the convergence of evidence points towards a multi-step process involving adenosine deaminases and at least two distinct types of methyltransferases. The proposed pathways and experimental protocols outlined in this guide provide a solid foundation for researchers to further investigate and ultimately unravel the complete biosynthesis of m1Im. Such knowledge will not only deepen our understanding of fundamental RNA biology but may also open new avenues for drug development, particularly in targeting the unique metabolic pathways of archaea and other organisms that utilize this complex modification.
References
- 1. Intellectual disability-associated gene ftsj1 is responsible for 2'-O-methylation of specific tRNAs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. GeneCards Commercial Trial - LifeMap Sciences [lifemapsc.com]
- 3. researchgate.net [researchgate.net]
- 4. FTSJ1 FtsJ RNA 2'-O-methyltransferase 1 [Homo sapiens (human)] - Gene - NCBI [ncbi.nlm.nih.gov]
- 5. tRNA 2′-O-methylation by a duo of TRM7/FTSJ1 proteins modulates small RNA silencing in Drosophila - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Intellectual disability‐associated gene ftsj1 is responsible for 2′‐O‐methylation of specific tRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Modomics - A Database of RNA Modifications [genesilico.pl]
- 8. Enzymatic conversion of adenosine to inosine and to N1-methylinosine in transfer RNAs: a review - PubMed [pubmed.ncbi.nlm.nih.gov]
The Natural Occurrence of 1-Methyl-2'-O-methylinosine (m1Im): A Technical Guide for Researchers
A comprehensive overview of the modified ribonucleoside 1-Methyl-2'-O-methylinosine (m1Im), detailing its presence in various organisms, methods for its detection and quantification, and its known biological context.
Introduction
Post-transcriptional modifications of RNA molecules are critical for regulating gene expression and cellular function. Among the vast array of known modifications, this compound (m1Im), also known as 1,2'-O-dimethylinosine, is a doubly methylated derivative of inosine (B1671953). This hypermodified nucleoside is found in the transfer RNA (tRNA) of certain organisms, particularly within the domain of Archaea. Its presence suggests a specialized role in the stabilization and function of tRNA, especially in organisms thriving in extreme environments. This technical guide provides an in-depth exploration of the natural occurrence of m1Im, detailed methodologies for its analysis, and a summary of its biological significance for researchers, scientists, and professionals in drug development.
Natural Occurrence and Distribution of m1Im
The primary occurrence of this compound is in the transfer RNA of Archaea, a domain of single-celled organisms known for their ability to inhabit extreme environments.[1][2] Specifically, m1Im has been identified at position 57 in the TΨC loop of several archaeal tRNAs.[2] This modification is a hallmark of archaeal tRNA, distinguishing it from bacterial and eukaryotic tRNA.[1]
The biosynthesis of m1Im begins with the methylation of adenosine (B11128) at the N1 position to form 1-methyladenosine (B49728) (m1A), followed by deamination to 1-methylinosine (B32420) (m1I), and finally, 2'-O-methylation of the ribose sugar to yield m1Im.
While the most well-documented occurrences of m1Im are in Archaea, the presence of its precursor, 1-methylinosine (m1I), is also noted in eukaryotic tRNA, specifically at position 37 of tRNAAla.[3] However, the subsequent 2'-O-methylation to form m1Im in eukaryotes is not as commonly observed as in Archaea. There is currently limited quantitative data on the abundance of m1Im across a wide range of organisms and tissues. The available data primarily focuses on its presence within specific archaeal species.
Table 1: Documented Occurrence of this compound (m1Im) and its Precursor (m1I)
| Organism Domain | RNA Type | Position | Modified Nucleoside | References |
| Archaea | tRNA | 57 | This compound (m1Im) | [2] |
| Eukaryota | tRNAAla | 37 | 1-methylinosine (m1I) | [3] |
Biosynthetic Pathway of this compound (m1Im)
The formation of m1Im is a multi-step enzymatic process. The pathway, particularly in Archaea, involves the sequential action of methyltransferases and a deaminase.
Biosynthetic pathway of this compound (m1Im).
Experimental Protocols for Detection and Quantification
The gold standard for the sensitive and accurate quantification of RNA modifications like m1Im is liquid chromatography-tandem mass spectrometry (LC-MS/MS).[4] This technique allows for the precise identification and measurement of modified nucleosides in a complex biological sample.
Workflow for LC-MS/MS Quantification of m1Im
Workflow for m1Im quantification by LC-MS/MS.
Detailed Methodology
1. RNA Isolation and Purification:
-
Isolate total RNA from the organism or tissue of interest using a standard method such as TRIzol reagent or a commercial kit.
-
To increase the sensitivity for tRNA modifications, consider enriching for small RNAs (<200 nt) using a specialized kit.
-
Assess RNA quality and quantity using a spectrophotometer and gel electrophoresis.
2. Enzymatic Digestion of RNA:
-
Digest 1-5 µg of total RNA to single nucleosides.
-
A common enzyme cocktail includes:
-
Nuclease P1: To digest RNA into 5'-mononucleotides.
-
Bacterial Alkaline Phosphatase (BAP): To dephosphorylate the mononucleotides to nucleosides.
-
-
Incubate the RNA with Nuclease P1 in a suitable buffer (e.g., 10 mM ammonium (B1175870) acetate, pH 5.3) at 37°C for 2 hours.
-
Add BAP and continue incubation at 37°C for another 2 hours.
-
Terminate the reaction by adding a solvent like acetonitrile (B52724) or by heat inactivation, followed by filtration through a 10 kDa molecular weight cutoff filter to remove the enzymes.
3. LC-MS/MS Analysis:
-
Liquid Chromatography (LC):
-
Use a reversed-phase C18 column for separation of the nucleosides.
-
Employ a gradient elution with a mobile phase consisting of:
-
Solvent A: Water with 0.1% formic acid.
-
Solvent B: Acetonitrile or methanol (B129727) with 0.1% formic acid.
-
-
A typical gradient might run from 0% to 40% Solvent B over 20-30 minutes.
-
-
Tandem Mass Spectrometry (MS/MS):
-
Operate the mass spectrometer in positive electrospray ionization (ESI) mode.
-
Use Multiple Reaction Monitoring (MRM) for targeted quantification of m1Im and the four canonical ribonucleosides (A, C, G, U).
-
The specific mass transitions for m1Im need to be determined empirically or from literature. Based on its structure, the precursor ion ([M+H]+) would be m/z 297.1. The product ion would correspond to the fragmented base, 1-methylhypoxanthine, with an m/z of 151.1.
-
Table 2: Exemplar LC-MS/MS Parameters for Nucleoside Analysis
| Analyte | Precursor Ion (m/z) | Product Ion (m/z) | Collision Energy (eV) |
| This compound (m1Im) | 297.1 | 151.1 | ~15-25 |
| Adenosine (A) | 268.1 | 136.1 | ~15-25 |
| Cytidine (C) | 244.1 | 112.1 | ~15-25 |
| Guanosine (G) | 284.1 | 152.1 | ~15-25 |
| Uridine (U) | 245.1 | 113.1 | ~15-25 |
| Note: Collision energies are instrument-dependent and require optimization. |
4. Quantification and Data Analysis:
-
For absolute quantification, a stable isotope-labeled internal standard for m1Im is required. If unavailable, relative quantification can be performed.
-
Generate a standard curve using known concentrations of unlabeled m1Im.
-
Calculate the amount of m1Im in the sample by comparing its peak area to the standard curve.
-
Normalize the quantity of m1Im to the total amount of one or all of the canonical nucleosides to account for variations in sample input.
Biological Function and Significance
The precise biological role of this compound is still under investigation, but its location in the TΨC loop of archaeal tRNA suggests a role in stabilizing the tertiary structure of the tRNA molecule.[2] This stabilization is particularly crucial for organisms living in high-temperature environments, where maintaining the correct tRNA fold is essential for efficient and accurate protein synthesis.
The precursor modification, 1-methyladenosine (m1A), is known to be involved in promoting translation.[5] The positive charge introduced by the N1-methylation of adenosine can influence RNA structure and its interaction with proteins.[5] It is plausible that the subsequent modifications to form m1Im further fine-tune these structural and functional properties.
Currently, there is no direct evidence linking m1Im to specific signaling pathways. However, as a component of the translational machinery, its presence and abundance could indirectly influence various cellular processes by modulating the efficiency and fidelity of protein synthesis. Further research is needed to elucidate the direct functional consequences of m1Im modification and its potential involvement in cellular signaling.
Conclusion
This compound represents a fascinating example of the chemical diversity of RNA modifications, particularly in the archaeal domain. While its presence is well-documented in archaeal tRNA, there is a need for more extensive quantitative studies to understand its distribution across a broader range of organisms and tissues. The detailed LC-MS/MS methodology provided in this guide offers a robust framework for researchers to pursue such investigations. Elucidating the precise biological function of m1Im and its potential role in cellular regulation will undoubtedly be a fruitful area for future research, with implications for our understanding of RNA biology, extremophile adaptation, and the evolution of the translation machinery.
References
- 1. Biosynthesis and function of tRNA modifications in Archaea - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. mdpi.com [mdpi.com]
- 3. hmdb.ca [hmdb.ca]
- 4. Global analysis by LC-MS/MS of N6-methyladenosine and inosine in mRNA reveal complex incidence - PMC [pmc.ncbi.nlm.nih.gov]
- 5. N1-methyladenosine formation, gene regulation, biological functions, and clinical relevance - PMC [pmc.ncbi.nlm.nih.gov]
The Physiological Significance of N1-methyladenosine (m1A) Modification in tRNA: An In-depth Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Executive Summary
N1-methyladenosine (m1A) is a critical post-transcriptional modification of transfer RNA (tRNA) that plays a pivotal role in a multitude of physiological and pathological processes. This modification, catalyzed by specific methyltransferases, occurs at several conserved positions within the tRNA molecule, profoundly influencing its structure, stability, and function. The m1A modification is not merely a static structural feature but a dynamic regulatory mark implicated in the fine-tuning of translation, mitochondrial function, and cellular stress responses. Dysregulation of m1A modification has been increasingly linked to a range of human diseases, including various cancers and mitochondrial disorders, making the enzymes that mediate this modification attractive targets for therapeutic intervention. This technical guide provides a comprehensive overview of the physiological significance of m1A modification in tRNA, detailing the enzymatic machinery, its functional consequences, and its role in disease. We present quantitative data, detailed experimental protocols for m1A detection and analysis, and visual representations of the key signaling pathways involved to serve as a valuable resource for researchers and professionals in the field.
Introduction to m1A Modification in tRNA
Post-transcriptional modifications of tRNA are essential for their proper function, expanding their chemical and functional diversity beyond the four canonical ribonucleosides.[1] Methylation is the most common type of tRNA modification, and N1-methyladenosine (m1A) is a conserved modification found across all domains of life.[2][3] The m1A modification involves the addition of a methyl group to the N1 position of adenosine, a reaction catalyzed by specific tRNA methyltransferases.[4] This modification is primarily found at positions 9, 14, 22, 57, and 58 of various tRNAs, with positions 9 and 58 being the most well-studied.[1][3] The presence of a methyl group at the N1 position introduces a positive charge under physiological conditions and disrupts the Watson-Crick base-pairing face of adenosine, leading to significant alterations in the local RNA structure and its interactions with other molecules.[5][6]
The Enzymatic Machinery of m1A tRNA Modification
The installation of the m1A modification is carried out by distinct families of S-adenosyl-L-methionine (SAM)-dependent methyltransferases (MTases). The primary enzymes responsible for m1A modification in tRNA are summarized in the table below.
| Modification Site | Enzyme/Complex | Organism/Location | Key Features |
| m1A9 | TRMT10C (MRPP1) | Human mitochondria | Part of the mitochondrial RNase P complex, also exhibits m1G9 MTase activity.[1][7] |
| Trm10 family | Archaea | Belongs to the SPOUT family of MTases.[7] | |
| m1A22 | TrmK | Bacteria | Essential for the survival of some pathogenic bacteria like Streptococcus pneumoniae.[1][7] |
| m1A57 | TrmI | Archaea | m1A57 is a transient intermediate that is subsequently deaminated to 1-methylinosine (B32420) (m1I).[1][8] |
| m1A58 | TRMT6/TRMT61A | Eukaryotic cytosol | A heterodimeric complex where TRMT61A is the catalytic subunit and TRMT6 is required for tRNA binding.[7][9] |
| TRMT61B | Human mitochondria | Responsible for m1A58 modification in mitochondrial tRNAs.[7] | |
| TrmI | Bacteria and Archaea | A homotetrameric enzyme.[7] |
Physiological Functions of m1A Modification
The m1A modification exerts its physiological effects through several key mechanisms, primarily by influencing tRNA structure and stability, which in turn impacts protein translation and other cellular processes.
tRNA Structure and Stability
The m1A modification is crucial for maintaining the correct three-dimensional L-shaped structure of tRNA.[1][10]
-
m1A9 : This modification in human mitochondrial tRNALys is essential for its correct folding. It disrupts a non-canonical Watson-Crick base pair between A9 and U64, which would otherwise lead to an extended hairpin structure, and promotes the formation of the functional L-shape.[1][3]
-
m1A58 : Located in the T-loop, m1A58 is critical for the thermostability of tRNAs.[1][3] The combination of m1A58 with other modifications, such as Gm18 and m5s2U54, has been shown to increase the melting temperature of tRNAs from Thermus thermophilus by approximately 10°C.[3] This increased stability is vital for tRNA function, especially in thermophilic organisms. The positive charge introduced by m1A58 can also stabilize the tRNA structure through electrostatic interactions with the negatively charged phosphate (B84403) backbone.[11]
Regulation of Translation
By ensuring the proper structure and stability of tRNAs, the m1A modification plays a significant role in the efficiency and fidelity of protein translation.
-
Translation Initiation and Elongation : The m1A58 modification, particularly in the initiator tRNAMet, is important for its maturation and stability, thereby influencing the initiation of translation.[3][12] In T-cell activation, the upregulation of TRMT6/TRMT61A and subsequent m1A58 modification of a subset of tRNAs enhances the translation of key proteins required for proliferation, such as MYC.[12][13]
-
Codon-Biased Translation : The level of m1A modification on specific tRNAs can influence the translation of mRNAs that are enriched in their corresponding codons. For example, in hepatocellular carcinoma, increased m1A levels on certain tRNAs promote the translation of peroxisome proliferator-activated receptor delta (PPARδ).[14][15]
Role of m1A Modification in Disease
The dysregulation of m1A tRNA modification has been implicated in a growing number of human diseases, highlighting the importance of this modification in maintaining cellular homeostasis.
Cancer
Aberrant m1A modification levels are frequently observed in various cancers and can contribute to tumorigenesis through multiple mechanisms.
-
Hepatocellular Carcinoma (HCC) : The TRMT6/TRMT61A complex is often overexpressed in HCC. This leads to increased m1A58 levels on a subset of tRNAs, which in turn enhances the translation of PPARδ.[14][15] Elevated PPARδ expression triggers cholesterol biosynthesis, activating the Hedgehog signaling pathway and promoting the self-renewal of liver cancer stem cells.[14][15]
-
Bladder Cancer : High expression of TRMT6/TRMT61A in bladder cancer leads to increased m1A modification of tRNA-derived fragments (tRFs).[1] This modification attenuates the gene-silencing activity of these tRFs, which are involved in the regulation of the unfolded protein response (UPR), thereby promoting cancer progression.[1][9]
-
T-cell Leukemia : The m1A58 modification is a critical regulator of T-cell activation and expansion.[16][17] The TRMT6/TRMT61A complex is upregulated upon T-cell activation, leading to increased m1A58 levels and enhanced translation of proteins like MYC, which are essential for proliferation.[13][18] This suggests that targeting the m1A pathway could be a therapeutic strategy for T-cell malignancies.
Mitochondrial Diseases
Given the prevalence of m1A modifications in mitochondrial tRNAs, it is not surprising that defects in m1A formation are associated with mitochondrial dysfunction.
-
Combined Oxidative Phosphorylation Deficiency : Mutations in the gene encoding the mitochondrial m1A9 methyltransferase, TRMT10C, have been linked to this rare and severe autosomal recessive disorder.[3] Patients exhibit symptoms such as lactic acidosis, hypotonia, and respiratory failure.[1] The deficiency in m1A9 modification impairs the proper folding and function of mitochondrial tRNAs, leading to defects in mitochondrial protein synthesis and respiratory chain function.[7]
Quantitative Data on the Effects of m1A Modification
The following tables summarize key quantitative findings from the literature on the impact of m1A modification.
Table 1: Impact of m1A Modification on Translation and Protein Expression
| Cell/System | Modification/Enzyme | Target Protein | Observed Effect | Quantitative Change | Reference |
| Hepatocellular Carcinoma (HCC) cells | TRMT6/TRMT61A (m1A58) | PPARδ | Increased translation | ~2-fold increase in protein levels upon TRMT6/61A overexpression | [15] |
| Mouse CD4+ T cells | Trmt61a (m1A58) | MYC | Decreased protein synthesis upon Trmt61a knockout | Significant reduction in MYC protein levels, leading to cell cycle arrest | [13][18] |
| Bladder Cancer cells | TRMT6/TRMT61A (m1A) | - | Reduced cell proliferation upon knockdown | Significant inhibitory effect on proliferation in HT1197 cells | [19] |
Table 2: Impact of m1A Modification on tRNA Stability
| tRNA | Modification | Experimental System | Observed Effect | Quantitative Change | Reference |
| Thermus thermophilus tRNAs | m1A58 (in combination with Gm18 and m5s2U54) | In vitro melting studies | Increased thermostability | ~10°C increase in melting temperature | [3] |
| Yeast tRNAiMet | m1A58 | Yeast genetics | Required for maturation and stability | - | [3] |
| Human mitochondrial tRNALys | m1A9 | In vitro structural studies | Promotes correct folding into the L-shape | Shifts the equilibrium from an extended hairpin to the L-shape conformation | [1][3] |
Experimental Protocols for the Study of m1A Modification
A variety of techniques are available for the detection, quantification, and functional analysis of m1A in tRNA. Below are detailed methodologies for some key experiments.
Quantification of m1A in tRNA by Mass Spectrometry (LC-MS/MS)
This protocol provides a general workflow for the quantitative analysis of m1A nucleosides in total tRNA.
Materials:
-
Total RNA or purified tRNA
-
Nuclease P1
-
Bacterial alkaline phosphatase
-
Acetonitrile
-
Formic acid
-
LC-MS/MS system
Procedure:
-
tRNA Isolation: Isolate total RNA from cells or tissues using a standard RNA extraction method (e.g., TRIzol). For higher sensitivity, purify the tRNA fraction using methods like PAGE or HPLC.[7][14]
-
Enzymatic Digestion:
-
To 1-5 µg of tRNA in a microcentrifuge tube, add 10X nuclease P1 buffer and nuclease P1 (e.g., 2 units).
-
Incubate at 37°C for 2 hours.
-
Add 10X bacterial alkaline phosphatase buffer and bacterial alkaline phosphatase (e.g., 1 unit).
-
Incubate at 37°C for another 2 hours to dephosphorylate the nucleosides.[1]
-
-
LC-MS/MS Analysis:
-
Centrifuge the digested sample to pellet any debris.
-
Inject the supernatant onto a reverse-phase C18 column for chromatographic separation.
-
Use a gradient of mobile phase A (e.g., 5 mM ammonium acetate in water) and mobile phase B (e.g., acetonitrile) to elute the nucleosides.
-
Perform mass spectrometry in positive ion mode using multiple reaction monitoring (MRM) to detect and quantify the transition from the protonated molecular ion of m1A to its characteristic fragment ion (the protonated base).
-
Quantify the amount of m1A relative to one of the canonical nucleosides (e.g., adenosine).[1][14]
-
Templated-Ligation based qPCR (TL-qPCR) for m1A Quantification
This method allows for the quantification of m1A at a specific site within a tRNA.[17][20]
Materials:
-
Total RNA
-
SplintR ligase and buffer
-
Two DNA oligonucleotides (a 5'-phosphorylated downstream probe and an upstream probe) that are complementary to the tRNA sequence flanking the m1A site
-
qPCR master mix with a fluorescent probe
-
Real-time PCR instrument
Procedure:
-
Probe Design: Design two DNA oligonucleotides that anneal to the target tRNA immediately adjacent to each other at the m1A site. The ligation junction should be directly at the position of the m1A modification.
-
Templated Ligation:
-
qPCR Quantification:
Nanopore Sequencing for m1A Detection
Direct RNA sequencing using nanopores can simultaneously identify the tRNA sequence and detect modifications.[3][21]
Materials:
-
Purified tRNA
-
Nanopore direct RNA sequencing kit
-
MinION or other nanopore sequencing device
Procedure:
-
Library Preparation:
-
Ligate a 3' adapter to the tRNA molecules.
-
Ligate a sequencing adapter with a motor protein to the 3' adapter.[3]
-
-
Nanopore Sequencing:
-
Load the prepared library onto the nanopore flow cell.
-
During sequencing, as the RNA molecule passes through the nanopore, it creates a characteristic disruption in the ionic current.
-
The raw signal data (squiggles) is recorded.[21]
-
-
Data Analysis:
-
Basecall the raw signal data to determine the nucleotide sequence.
-
Modifications like m1A cause a detectable deviation in the current signal compared to the canonical adenosine.
-
Use specialized software to analyze these deviations and identify the location and stoichiometry of m1A modifications.[3][21]
-
Signaling Pathways Involving m1A-modified tRNA
The functional consequences of m1A tRNA modification are often mediated through complex signaling pathways. Below are diagrams of key pathways implicated in the cellular response to changes in m1A levels.
Hedgehog Signaling Pathway in Hepatocellular Carcinoma
Caption: Hedgehog signaling pathway activated by m1A-mediated PPARδ translation in HCC.
Unfolded Protein Response (UPR) in Bladder Cancer
Caption: Attenuation of tRF-mediated gene silencing by m1A modification in the UPR pathway.
mTORC1 Signaling in T-cell Activation
Caption: Role of m1A modification in enhancing translation during T-cell activation via the mTORC1 pathway.
Conclusion and Future Perspectives
The N1-methyladenosine modification in tRNA is a fundamental regulatory mechanism with profound implications for cellular physiology and disease. Its role in maintaining tRNA structural integrity, ensuring translational fidelity, and responding to cellular cues underscores its importance in a wide range of biological processes. The growing body of evidence linking aberrant m1A modification to cancer and mitochondrial diseases has opened up new avenues for therapeutic intervention. The enzymes responsible for writing and erasing this mark, such as the TRMT6/TRMT61A complex, represent promising targets for the development of novel drugs.
Future research will likely focus on several key areas:
-
Expanding the m1A epitranscriptome: Identifying the full complement of tRNAs and other RNA species that are modified with m1A and understanding the specific contexts in which these modifications occur.
-
Deciphering the regulatory networks: Elucidating the upstream signals that regulate the activity of m1A methyltransferases and demethylases.
-
Developing selective inhibitors: Designing potent and specific small molecule inhibitors of m1A-modifying enzymes for therapeutic applications.
-
Clinical translation: Validating the use of m1A levels or the expression of m1A-related enzymes as biomarkers for disease diagnosis, prognosis, and response to therapy.
This in-depth technical guide provides a solid foundation for researchers, scientists, and drug development professionals to further explore the fascinating world of m1A tRNA modification and harness its potential for the advancement of human health.
References
- 1. Quantitative analysis of tRNA modifications by HPLC-coupled mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Sequence mapping of transfer RNA chemical modifications by liquid chromatography tandem mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 3. tRNA-seq logistics [rnabioco.github.io]
- 4. researchgate.net [researchgate.net]
- 5. researchgate.net [researchgate.net]
- 6. A comprehensive map of the mTOR signaling network - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Quantitative analysis of tRNA modifications by HPLC-coupled mass spectrometry [dspace.mit.edu]
- 8. researchgate.net [researchgate.net]
- 9. Unfolded protein response - Wikipedia [en.wikipedia.org]
- 10. researchgate.net [researchgate.net]
- 11. Beyond the Anticodon: tRNA Core Modifications and Their Impact on Structure, Translation and Stress Adaptation - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Quantitative analysis of tRNA abundance and modifications by nanopore RNA sequencing [immaginabiotech.com]
- 13. Hedgehog Signaling in Cancer: A Prospective Therapeutic Target for Eradicating Cancer Stem Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 14. tRNA Modification Analysis by MS - CD Genomics [rna.cd-genomics.com]
- 15. N1-methyladenosine methylation in tRNA drives liver tumourigenesis by regulating cholesterol metabolism - PMC [pmc.ncbi.nlm.nih.gov]
- 16. mTOR - Wikipedia [en.wikipedia.org]
- 17. Quantification of tRNA m1A modification by templated-ligation qPCR - PMC [pmc.ncbi.nlm.nih.gov]
- 18. tRNA-m1A modification promotes T cell expansion via efficient MYC protein synthesis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 19. Depletion of the m1A writer TRMT6/TRMT61A reduces proliferation and resistance against cellular stress in bladder cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 20. Quantification of tRNA m1A modification by templated-ligation qPCR - PubMed [pubmed.ncbi.nlm.nih.gov]
- 21. biorxiv.org [biorxiv.org]
The Stabilizing Influence of 1-Methyl-2'-O-methylinosine on RNA: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Executive Summary
The strategic modification of RNA molecules is a cornerstone of developing next-generation therapeutics and research tools. Among the vast array of known RNA modifications, 1-Methyl-2'-O-methylinosine (m1Im) represents a unique combination of two stability-enhancing modifications: methylation at the N1 position of the inosine (B1671953) base and 2'-O-methylation of the ribose sugar. While direct quantitative data on the cumulative effect of the m1Im modification on RNA stability is limited in publicly available literature, the well-documented impacts of its constituent modifications—1-methylinosine (B32420) (m1I) and 2'-O-methylation—provide a strong basis for understanding its role. This technical guide synthesizes the current understanding of these individual modifications to extrapolate the significant potential of m1Im in enhancing RNA stability, offering a valuable resource for researchers in drug development and RNA biology.
Introduction to RNA Stability and Modification
The inherent instability of RNA molecules, largely due to their susceptibility to enzymatic degradation by nucleases, presents a significant challenge in the development of RNA-based therapeutics and diagnostics. Chemical modifications are a key strategy to overcome this limitation. Post-transcriptional modifications are naturally occurring alterations to RNA nucleotides that play crucial roles in regulating RNA structure, function, and metabolism. The strategic incorporation of synthetic modifications can therefore enhance the therapeutic potential of RNA molecules by increasing their half-life and resistance to degradation.
The Role of 1-Methylinosine (m1I) and 2'-O-Methylation in RNA Stability
The this compound modification combines two key chemical alterations, each contributing to the overall stability of the RNA molecule.
1-Methylinosine (m1I): The methylation at the N1 position of the inosine base disrupts the Watson-Crick base-pairing face of the nucleobase. This modification can lead to localized changes in RNA secondary structure. While this disruption might seem destabilizing, in certain contexts, such as in transfer RNA (tRNA), m1A (a precursor to m1I) has been shown to be crucial for inducing correct tRNA folding and enhancing structural stability. The positive charge introduced by N1-methylation can also influence electrostatic interactions with other parts of the RNA molecule or with RNA-binding proteins, potentially modulating the accessibility of the RNA to degradation machinery.
2'-O-Methylation (2'-O-Me): The addition of a methyl group to the 2'-hydroxyl of the ribose sugar is a widely recognized and potent stabilizer of RNA. This modification provides steric hindrance, protecting the adjacent phosphodiester bond from nuclease-mediated cleavage. Furthermore, 2'-O-methylation pre-organizes the ribose into an A-form helical conformation, which is the preferred conformation for RNA duplexes. This conformational preference reduces the entropic penalty of duplex formation, thereby increasing the thermodynamic stability of the RNA.
Synergistic Effects of m1Im: By combining these two modifications, this compound is hypothesized to confer a multi-faceted stabilization to RNA molecules. The 2'-O-methyl group provides a direct shield against nucleases and enhances thermodynamic stability, while the N1-methylated inosine can modulate local structure and interactions, potentially further protecting the RNA from degradation.
Quantitative Data on RNA Stability
Table 1: Expected Impact of Individual Modifications on RNA Half-Life
| Modification | Expected Change in Half-Life vs. Unmodified RNA | Mechanism of Action |
| 1-Methylinosine (m1I) | Moderate Increase | Alteration of local RNA structure, potential disruption of nuclease recognition sites. |
| 2'-O-Methylation | Significant Increase | Steric hindrance of nucleases, increased thermodynamic stability. |
| This compound (m1Im) | High Increase (Hypothesized) | Combined effects of structural modulation and direct nuclease protection. |
Table 2: Expected Impact of Individual Modifications on RNA Melting Temperature (Tm)
| Modification | Expected Change in Tm (°C) vs. Unmodified RNA | Mechanism of Action |
| 1-Methylinosine (m1I) | Variable (Context-dependent) | Disruption of Watson-Crick pairing can locally decrease Tm, but overall structural stabilization can sometimes increase it. |
| 2'-O-Methylation | +1 to +2 °C per modification | Increased thermodynamic stability due to pre-organization of the ribose into an A-form helix. |
| This compound (m1Im) | Significant Increase (Hypothesized) | Dominant stabilizing effect of 2'-O-methylation, potentially modulated by the m1I modification. |
Experimental Protocols
The following are detailed methodologies for key experiments to assess the stability of RNA modified with this compound.
Protocol 1: Synthesis of m1Im-Containing RNA Oligonucleotides
The synthesis of RNA oligonucleotides containing m1Im requires the use of a corresponding phosphoramidite (B1245037) building block. While a specific protocol for the synthesis of this compound phosphoramidite is not widely published, it would generally follow established procedures for the synthesis of modified nucleoside phosphoramidites.
Workflow for Synthesis of m1Im Phosphoramidite and Oligonucleotide Synthesis:
Caption: Workflow for the synthesis of m1Im-modified RNA.
Detailed Steps for Oligonucleotide Synthesis (General):
-
Phosphoramidite Preparation: Synthesize or procure the this compound phosphoramidite.
-
Solid-Phase Synthesis: Utilize an automated DNA/RNA synthesizer.
-
Coupling: During the desired cycle, introduce the m1Im phosphoramidite for coupling to the growing oligonucleotide chain.
-
Standard Cycles: Continue with standard phosphoramidite chemistry cycles (capping, oxidation, deblocking) for the remaining unmodified nucleotides.
-
Cleavage and Deprotection: Treat the solid support with an appropriate cleavage and deprotection solution to release the oligonucleotide and remove protecting groups.
-
Purification: Purify the full-length m1Im-containing RNA oligonucleotide using high-performance liquid chromatography (HPLC) or polyacrylamide gel electrophoresis (PAGE).
-
Quality Control: Verify the identity and purity of the synthesized RNA using mass spectrometry and analytical HPLC or PAGE.
Protocol 2: In Vitro RNA Stability Assay (Actinomycin D Chase)
This protocol measures the half-life of an m1Im-modified RNA transcript in a cellular environment.
Workflow for In Vitro RNA Stability Assay:
Caption: Workflow for determining RNA half-life using an Actinomycin D chase.
Detailed Steps:
-
Cell Culture and Transfection: Plate cells at an appropriate density and transfect with equimolar amounts of either the m1Im-modified RNA or the corresponding unmodified control RNA.
-
Transcription Inhibition: After a suitable incubation period to allow for RNA uptake and expression (if applicable), add Actinomycin D to the culture medium to a final concentration of 5 µg/mL to block new transcription.
-
Time-Course Collection: Collect cell samples at various time points after the addition of Actinomycin D (e.g., 0, 2, 4, 6, and 8 hours).
-
RNA Isolation: Immediately lyse the cells at each time point and isolate total RNA using a standard protocol (e.g., TRIzol extraction or a column-based kit).
-
Reverse Transcription: Synthesize complementary DNA (cDNA) from the isolated RNA using a reverse transcriptase enzyme and random hexamers or gene-specific primers.
-
Quantitative PCR (qPCR): Perform qPCR using primers specific for the RNA of interest. Include a stable housekeeping gene as a reference for normalization.
-
Data Analysis: Determine the relative quantity of the target RNA at each time point, normalized to the reference gene. Plot the natural logarithm of the relative RNA quantity against time. The half-life (t½) can be calculated from the slope of the linear regression line (k) using the formula: t½ = ln(2) / -k.
Protocol 3: Nuclease Digestion Assay
This assay directly assesses the resistance of an m1Im-modified RNA to degradation by nucleases.
Workflow for Nuclease Digestion Assay:
Caption: Workflow for assessing nuclease resistance of modified RNA.
Detailed Steps:
-
Reaction Setup: Prepare reaction mixtures containing a fixed concentration of either m1Im-modified RNA or unmodified control RNA in a suitable buffer.
-
Nuclease Addition: Initiate the digestion by adding a specific concentration of a nuclease (e.g., RNase A, S1 nuclease, or cell lysate).
-
Time-Course Incubation: Incubate the reactions at an appropriate temperature (e.g., 37°C) and collect aliquots at various time points.
-
Reaction Quenching: Stop the digestion in each aliquot by adding a quenching solution, such as a strong denaturant or a specific nuclease inhibitor.
-
Analysis: Analyze the integrity of the RNA in each sample using denaturing polyacrylamide gel electrophoresis (PAGE) followed by staining (e.g., with SYBR Gold) or by capillary electrophoresis.
-
Quantification: Quantify the intensity of the band corresponding to the full-length RNA at each time point. Plot the percentage of intact RNA remaining versus time to compare the degradation rates of the modified and unmodified RNA.
Protocol 4: UV Thermal Denaturation Analysis
This method determines the melting temperature (Tm) of an RNA duplex containing the m1Im modification, providing insights into its thermodynamic stability.
Workflow for UV Thermal Denaturation Analysis:
Caption: Workflow for determining the melting temperature of RNA duplexes.
Detailed Steps:
-
Sample Preparation: Prepare solutions of the m1Im-modified RNA duplex and the unmodified control duplex at a known concentration in a buffer with a defined salt concentration (e.g., 10 mM sodium phosphate, 100 mM NaCl, pH 7.0).
-
Instrumentation: Use a UV-Vis spectrophotometer equipped with a Peltier temperature controller.
-
Melting Program: Equilibrate the samples at a low temperature (e.g., 20°C) and then slowly ramp the temperature up to a high temperature (e.g., 90°C) at a controlled rate (e.g., 0.5°C/minute).
-
Data Collection: Continuously monitor the absorbance of the sample at 260 nm throughout the temperature ramp.
-
Data Analysis: Plot the absorbance at 260 nm as a function of temperature to obtain the melting curve. The melting temperature (Tm) is the temperature at which 50% of the duplex has dissociated into single strands and is determined as the peak of the first derivative of the melting curve.
Signaling Pathways and Logical Relationships
The presence of RNA modifications can influence various cellular pathways by altering the interaction of RNA with RNA-binding proteins (RBPs) and the enzymatic machinery involved in RNA metabolism. While specific pathways directly regulated by m1Im are yet to be elucidated, a general model of how such modifications can impact RNA fate can be proposed.
Logical Relationship of RNA Modification and Stability:
Caption: Logical flow of how m1Im modification leads to increased RNA stability.
Conclusion
While direct experimental evidence for the role of this compound in RNA stability is still emerging, a strong theoretical framework based on the well-characterized effects of 1-methylinosine and 2'-O-methylation suggests its significant potential as a stabilizing modification. The combination of structural modulation and direct protection from nuclease degradation makes m1Im a highly promising candidate for enhancing the efficacy of RNA-based therapeutics. The experimental protocols provided in this guide offer a comprehensive toolkit for researchers to quantitatively assess the impact of m1Im and other novel modifications on RNA stability, thereby accelerating the development of the next generation of RNA medicines. Further research is warranted to fully elucidate the specific molecular interactions and cellular pathways influenced by this unique modification.
Navigating the Epitranscriptome: A Technical Guide to 1-Methyl-2'-O-methylinosine and its Precursor
An In-depth Technical Guide for Researchers, Scientists, and Drug Development Professionals
Foreword
The field of epitranscriptomics is rapidly advancing our understanding of gene regulation beyond the static sequence of RNA. Post-transcriptional modifications add a dynamic layer of control, influencing RNA stability, localization, and translation. While modifications like N6-methyladenosine (m6A) have been extensively studied, a vast landscape of other modifications remains to be fully explored. This technical guide focuses on a rare and relatively under-investigated modification, 1-Methyl-2'-O-methylinosine (m1Im) .
Due to the limited direct research on m1Im, this guide will primarily focus on its immediate and better-characterized precursor, 2'-O-methylinosine (Im) . By understanding the synthesis, function, and detection of Im, we can build a foundational knowledge base to infer the potential roles and significance of m1Im. This document will synthesize the current, albeit sparse, data on these modifications, provide detailed experimental considerations, and present conceptual frameworks for future research.
Introduction to 2'-O-methylinosine (Im) and this compound (m1Im)
Post-transcriptional modifications dramatically expand the functional capacity of RNA molecules. Among these, methylation is a common modification affecting both the base and the ribose sugar of nucleotides.
2'-O-methylinosine (Im) is a modified nucleoside characterized by the addition of a methyl group to the 2'-hydroxyl of the ribose sugar of inosine (B1671953).[1] Inosine itself is a deaminated form of adenosine. The 2'-O-methylation is a widespread modification found in various RNA species, where it is known to increase the stability of RNA duplexes and protect against nuclease degradation.[2][3]
This compound (m1Im) is a further modification of Im, involving the methylation at the N1 position of the inosine base. While its existence is documented in databases such as Modomics, its biological context, function, and the enzymes responsible for its formation are largely uncharacterized.
This guide will first delve into the known aspects of Im, laying the groundwork for a discussion on the potential properties and research directions for m1Im.
Biochemical Properties and Synthesis Pathway
The biochemical characteristics of these modified nucleosides are summarized below.
| Property | 2'-O-methylinosine (Im) | This compound (m1Im) |
| Full Name | 2'-O-methylinosine | 1,2'-O-dimethylinosine |
| Abbreviation | Im | m1Im |
| Chemical Formula | C11H14N4O5[4] | C12H16N4O5 |
| Monoisotopic Mass | 282.0964 Da[4] | 296.1121 Da |
| [M+H]+ | 283.1042 Da[4] | Not available |
| Key Product Ion (m/z) | 137[4] | Not available |
The synthesis of m1Im is believed to occur via a sequential modification pathway, starting from adenosine.
This proposed pathway highlights that m1Im can be synthesized from Im. The enzymes responsible for the 2'-O-methylation of inosine to Im in mRNA and the subsequent N1-methylation to m1Im are currently unknown. In tRNA, Trm5 is known to catalyze the N1-methylation of inosine.[5]
Biological Role and Function of 2'-O-methylinosine (Im)
The functional significance of Im is beginning to be unraveled, primarily through studies in yeast.
Presence in mRNA and Dynamic Regulation
A significant breakthrough was the identification and quantification of Im in the messenger RNA (mRNA) of Saccharomyces cerevisiae.[1] This finding is crucial as it suggests a role for Im in the regulation of gene expression at the level of mRNA.
The levels of Im in yeast mRNA are not static; they exhibit dynamic changes throughout different cellular growth phases.[1] Furthermore, the abundance of Im was observed to decrease significantly in response to oxidative stress induced by hydrogen peroxide (H2O2).[1] This suggests that the deposition or removal of Im on mRNA may be a component of the cellular stress response pathway.
| Condition | Change in Im level in yeast mRNA | Reference |
| Different growth stages | Dynamic changes observed | [1] |
| H2O2 treatment | Significant decrease | [1] |
Potential Functions of 2'-O-methylation
Based on the known properties of 2'-O-methylation in other contexts, we can infer the likely functions of Im in mRNA:
-
Increased RNA Stability: The 2'-O-methyl group provides protection against degradation by nucleases, which could increase the half-life of mRNAs containing this modification.[2][3]
-
Modulation of RNA Structure: 2'-O-methylation stabilizes the C3'-endo ribose conformation, which is characteristic of A-form RNA helices. This can influence the local secondary and tertiary structure of mRNA.[2]
-
Altered Protein-RNA Interactions: The presence of a methyl group in the major groove of the RNA helix can influence the binding of RNA-binding proteins (RBPs), potentially altering mRNA localization, splicing, or translation.
-
Regulation of Translation: By affecting mRNA stability and structure, Im could directly or indirectly influence the efficiency of protein translation.
The following diagram illustrates the potential consequences of Im deposition on an mRNA molecule.
Experimental Protocols for the Detection of 2'-O-methylinosine (Im)
The gold standard for the detection and quantification of modified nucleosides is liquid chromatography-tandem mass spectrometry (LC-MS/MS). The following is a generalized protocol adapted for the detection of Im, based on established methods for similar modifications like 2'-O-methyladenosine.[6]
RNA Isolation and Purification
High-purity RNA is essential for accurate quantification.
-
Homogenization: Homogenize cells or tissues in a suitable lysis reagent (e.g., TRIzol).
-
Phase Separation: Add chloroform (B151607) and centrifuge to separate the aqueous (RNA-containing) and organic phases.
-
RNA Precipitation: Transfer the aqueous phase to a new tube and precipitate the RNA with isopropanol.
-
Washing: Wash the RNA pellet with 75% ethanol (B145695) to remove impurities.
-
Resuspension: Resuspend the purified RNA in RNase-free water.
-
Quality Control: Assess RNA concentration and purity using a spectrophotometer (e.g., NanoDrop). An A260/A280 ratio of ~2.0 is indicative of pure RNA.
Enzymatic Digestion of RNA to Nucleosides
To analyze individual nucleosides, the RNA polymer must be completely digested.
-
Enzyme Cocktail: Use a combination of nucleases to ensure complete digestion. A common cocktail includes Nuclease P1 and bacterial alkaline phosphatase (BAP).
-
Digestion Reaction:
-
To 1-2 µg of purified RNA, add an appropriate amount of a stable isotope-labeled internal standard for Im (if available) for accurate quantification.
-
Add Nuclease P1 and its corresponding buffer. Incubate at 37°C for 2 hours.
-
Add BAP and its buffer. Incubate at 37°C for an additional 2 hours.
-
-
Sample Cleanup: After digestion, the sample may need to be filtered or subjected to solid-phase extraction to remove enzymes and other interfering substances before LC-MS/MS analysis.
LC-MS/MS Analysis
-
Chromatographic Separation: Use a reverse-phase C18 column to separate the nucleosides. A gradient of mobile phases (e.g., ammonium (B1175870) acetate (B1210297) and acetonitrile) is typically used.
-
Mass Spectrometry Detection:
-
Operate the mass spectrometer in positive ion mode.
-
Use multiple reaction monitoring (MRM) for quantification. The precursor ion for Im would be its [M+H]+ (m/z 283.1), and the product ion would be the base (m/z 137.0).
-
-
Quantification: The amount of Im in the sample is determined by comparing the peak area of endogenous Im to that of the known amount of the spiked internal standard.
The following diagram outlines the general workflow for Im detection.
Implications for Drug Development
The field of epitranscriptomics is a burgeoning area for therapeutic intervention. Targeting the enzymes that write, erase, or read RNA modifications presents a novel strategy for drug development.[1][6]
While there are no current drugs targeting Im or m1Im specifically, the general principles are applicable:
-
Targeting "Writer" Enzymes: Developing small molecule inhibitors of the yet-to-be-identified methyltransferases that produce Im and m1Im could be a viable strategy, particularly if these modifications are found to be upregulated in disease states.
-
2'-O-Methylated Oligonucleotides: The use of 2'-O-methylated nucleotides in antisense oligonucleotides and siRNAs is a well-established method to increase their stability and therapeutic efficacy.[3] Understanding the cellular machinery that processes 2'-O-methylated nucleosides could inform the design of more effective RNA-based drugs.
Future Directions and Unanswered Questions
The study of this compound is still in its infancy. The following are critical areas for future research:
-
Identification of Writer and Eraser Enzymes: The foremost priority is the identification of the methyltransferases responsible for the synthesis of Im and m1Im, as well as any potential demethylases.
-
Occurrence in Higher Eukaryotes: It is crucial to determine if Im and m1Im are present in the RNA of mammals and other higher eukaryotes, and if their levels are altered in disease.
-
Functional Characterization: Elucidating the precise functional roles of Im and m1Im in mRNA metabolism will require a combination of genetic, biochemical, and transcriptomic approaches.
-
Development of Specific Detection Methods: The development of antibodies specific to Im and m1Im would enable techniques like immunoprecipitation followed by sequencing (MeRIP-seq) to map their locations across the transcriptome.
Conclusion
This compound (m1Im) represents a frontier in the field of epitranscriptomics. While direct knowledge of this modification is scarce, the study of its precursor, 2'-O-methylinosine (Im), provides a valuable starting point. The discovery of Im in yeast mRNA and its dynamic regulation in response to cellular stress underscore its potential importance in gene expression. The methodologies and conceptual frameworks outlined in this guide are intended to provide researchers and drug development professionals with a solid foundation to explore the roles of Im and m1Im in biology and disease, ultimately paving the way for new diagnostic and therapeutic strategies.
References
- 1. pubs.acs.org [pubs.acs.org]
- 2. 2′-O-methylation (Nm) in RNA: progress, challenges, and future directions - PMC [pmc.ncbi.nlm.nih.gov]
- 3. 2'-O methyl Inosine Oligo Modifications from Gene Link [genelink.com]
- 4. Modomics - A Database of RNA Modifications [genesilico.pl]
- 5. A Quantitative Systems Approach Reveals Dynamic Control of tRNA Modifications during Cellular Stress - PMC [pmc.ncbi.nlm.nih.gov]
- 6. benchchem.com [benchchem.com]
The Evolutionary Conservation of 1-Methyl-2'-O-methylinosine (m1Im): A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Abstract
1-Methyl-2'-O-methylinosine (m¹Im) is a doubly modified nucleoside found in transfer RNA (tRNA), primarily in thermophilic archaea. This modification, characterized by methylation at the N1 position of the inosine (B1671953) base and the 2'-hydroxyl group of the ribose sugar, is believed to play a crucial role in stabilizing tRNA structure, particularly under extreme environmental conditions. This technical guide provides a comprehensive overview of the current understanding of m¹Im, focusing on its evolutionary conservation, biosynthesis, and the methodologies for its detection and analysis. While direct evidence for the widespread evolutionary conservation of m¹Im across all domains of life is limited, its presence in archaea suggests an ancient origin and a fundamental role in RNA biology. This document aims to serve as a valuable resource for researchers investigating the epitranscriptome and its implications for drug development.
Introduction
Post-transcriptional modifications of RNA molecules significantly expand the functional capacity of the transcriptome. Among the more than 170 known RNA modifications, methylation is a prevalent and functionally diverse modification. This compound (m¹Im) is a hypermodified nucleoside that combines two types of methylation: N1-methylation of the inosine base and 2'-O-methylation of the ribose moiety. Inosine itself is a modification derived from the deamination of adenosine (B11128).
The presence of 2'-O-methylation is known to increase the conformational rigidity of the ribose sugar, favoring an A-form helical structure and protecting the phosphodiester backbone from enzymatic cleavage.[1] N1-methylation of purines can alter base-pairing properties and tertiary interactions within the RNA molecule. The combination of these two modifications in m¹Im suggests a significant role in the structural integrity and function of the RNA molecules in which it is found.
Evolutionary Distribution and Conservation
The distribution of m¹Im appears to be most prominent in the domain of Archaea, particularly in species that thrive in high-temperature environments (hyperthermophiles). Its presence has been primarily documented in tRNA at position 57 in the TΨC loop.[2] This localization suggests a role in stabilizing the tertiary structure of tRNA, which is essential for its function in protein synthesis, especially at elevated temperatures.
While the presence of N1-methylinosine (m¹I) is known in eukaryotic tRNA (at position 37), the subsequent 2'-O-methylation to form m¹Im has not been widely reported in Eukarya or Bacteria.[3] The evolutionary conservation of m¹Im, therefore, appears to be lineage-specific, with a strong conservation within certain archaeal lineages. The enzymes responsible for the individual methylation steps provide further clues to its evolutionary history.
Table 1: Distribution of this compound (m¹Im) and Related Modifications
| Domain/Kingdom | Organism Type | Presence of m¹Im | Location in RNA | Related Modifications Present |
| Archaea | Hyperthermophiles | Yes | tRNA (position 57) | m¹I, Im |
| Bacteria | Various | Not definitively identified | - | m¹A, Im, Gm18 |
| Eukarya | Yeast, Human | Not definitively identified | - | m¹I (tRNA, position 37), Im |
Biosynthesis of this compound (m¹Im)
The biosynthetic pathway of m¹Im is a multi-step process involving both deamination and dual methylation. While the complete pathway and all the enzymes involved have not been fully elucidated for all organisms, a putative pathway can be constructed based on the known biosynthesis of its precursor modifications.
In archaea, the formation of N1-methylinosine (m¹I) at position 57 of tRNA follows a distinct pathway compared to eukaryotes. It is proposed that adenosine (A) at position 57 is first methylated by a tRNA (m¹A57) methyltransferase to form N1-methyladenosine (m¹A). Subsequently, m¹A is deaminated by a specific deaminase to yield m¹I.[3] The final step to produce m¹Im would then be the 2'-O-methylation of the ribose of m¹I, catalyzed by a yet-to-be-identified 2'-O-methyltransferase. S-adenosyl-L-methionine (SAM) is the universal methyl donor for these reactions.
Putative biosynthetic pathway of m1Im in archaeal tRNA.
Experimental Protocols
The gold-standard for the detection and quantification of modified nucleosides like m¹Im is liquid chromatography coupled with tandem mass spectrometry (LC-MS/MS). This technique offers high sensitivity and specificity, allowing for the identification and quantification of modifications from complex biological samples.
RNA Isolation and Purification
-
Sample Collection: Collect cells or tissues of interest. For archaea, cultivate under appropriate conditions (e.g., high temperature for hyperthermophiles).
-
Total RNA Extraction: Extract total RNA using a suitable method, such as TRIzol reagent or a commercial RNA extraction kit, following the manufacturer's instructions. Ensure all steps are performed under RNase-free conditions.
-
tRNA Enrichment (Optional but Recommended): For specific analysis of tRNA modifications, enrich for small RNAs (<200 nt) using a size-exclusion chromatography or a specialized kit. This step significantly improves the signal-to-noise ratio for tRNA-specific modifications.
Enzymatic Digestion of RNA to Nucleosides
-
RNA Denaturation: Resuspend 1-5 µg of purified RNA in nuclease-free water. Denature the RNA by heating at 95°C for 5 minutes, followed by rapid cooling on ice.
-
Nuclease P1 Digestion: Add Nuclease P1 (e.g., 2 units) and a suitable buffer (e.g., 10 mM ammonium (B1175870) acetate, pH 5.3). Incubate at 37°C for 2 hours. Nuclease P1 digests RNA into 5'-mononucleotides.
-
Dephosphorylation: Add bacterial alkaline phosphatase (BAP; e.g., 1 unit) and its corresponding buffer. Incubate at 37°C for an additional 2 hours to dephosphorylate the nucleoside monophosphates to nucleosides.
-
Sample Cleanup: Remove enzymes by protein precipitation (e.g., with cold acetonitrile) or using a molecular weight cutoff filter (e.g., 3 kDa). The resulting supernatant/filtrate contains the mixture of nucleosides.
LC-MS/MS Analysis
-
Chromatographic Separation:
-
Column: Use a reversed-phase C18 column suitable for nucleoside analysis.
-
Mobile Phase A: 0.1% formic acid in water.
-
Mobile Phase B: 0.1% formic acid in acetonitrile (B52724) or methanol.
-
Gradient: A linear gradient from a low percentage of mobile phase B to a higher percentage over a suitable time (e.g., 20-30 minutes) is typically used to separate the nucleosides.
-
Flow Rate: A flow rate of 200-400 µL/min is common.
-
-
Mass Spectrometry Detection:
-
Ionization: Use positive ion electrospray ionization (ESI).
-
Analysis Mode: Operate the mass spectrometer in Multiple Reaction Monitoring (MRM) mode for targeted quantification.
-
MRM Transitions: Specific precursor-to-product ion transitions for canonical and modified nucleosides need to be determined. For m¹Im, the precursor ion will be [M+H]⁺, and the product ion will correspond to the protonated base after the loss of the ribose moiety.
-
Inosine (I): m/z 269.1 → 137.1
-
1-Methylinosine (m¹I): m/z 283.1 → 151.1
-
2'-O-methylinosine (Im): m/z 283.1 → 137.1
-
This compound (m¹Im): m/z 297.1 → 151.1
-
-
Quantification: Use stable isotope-labeled internal standards for accurate quantification.
-
Experimental workflow for m1Im detection.
Functional Implications and Future Directions
The primary function attributed to m¹Im is the stabilization of tRNA structure. The 2'-O-methylation significantly contributes to the thermal stability of RNA, a critical feature for organisms living in extreme temperatures.[1] The N1-methylation at the "wobble" position can influence codon-anticodon interactions, although the functional consequence of this modification at position 57 is more likely related to maintaining the overall L-shaped structure of the tRNA.
Currently, there is no direct evidence linking m¹Im to specific signaling pathways. However, the broader field of epitranscriptomics is increasingly revealing how RNA modifications can act as dynamic regulators of gene expression in response to cellular signals and environmental stresses. Future research should focus on:
-
Expanding the search for m¹Im: Utilizing sensitive LC-MS/MS techniques to screen for m¹Im in a wider range of organisms from all three domains of life.
-
Identifying the m¹Im methyltransferase: The discovery of the enzyme responsible for the 2'-O-methylation of m¹I would be a significant breakthrough, allowing for genetic studies to probe its function and evolutionary conservation.
-
Investigating the role of m¹Im in translation: Elucidating how this modification affects tRNA stability, aminoacylation, and the fidelity of protein synthesis.
-
Exploring potential roles in signaling: Investigating whether the levels of m¹Im change in response to environmental stimuli, which could suggest a role in cellular signaling cascades.
Conclusion
This compound represents a fascinating example of RNA hypermodification, likely playing a critical role in the adaptation of life to extreme environments. While its known distribution is currently limited, the continuous advancement of analytical techniques promises to shed more light on its evolutionary conservation and functional significance. A deeper understanding of m¹Im and its biosynthetic pathway could open new avenues for research in RNA biology and potentially inform the development of novel therapeutic strategies targeting RNA-modifying enzymes.
References
Unveiling the Enigmatic Function of 1-Methyl-2'-O-methylinosine: A Technical Guide for Researchers
Disclaimer: Direct experimental studies on the biological function of 1-Methyl-2'-O-methylinosine (m¹Im) are not extensively available in current scientific literature. This guide provides a comprehensive overview based on the well-documented functions of its constituent modifications, 1-methylinosine (B32420) (m¹I) and 2'-O-methylation (Nm), to infer its potential roles and to propose a framework for its investigation.
Introduction: The Frontier of the Epitranscriptome
The field of epitranscriptomics has unveiled a complex landscape of over 170 chemical modifications to RNA, profoundly influencing gene expression and cellular function.[1] While modifications like N⁶-methyladenosine (m⁶A) have been studied extensively, many others remain enigmatic. This compound (m¹Im) represents one such frontier. This hyper-modified nucleoside, bearing both a methyl group on the N1 position of the inosine (B1671953) base and another on the 2'-hydroxyl of the ribose, is not yet characterized in terms of its biological role.
This technical guide is designed for researchers, scientists, and drug development professionals. It aims to consolidate the existing knowledge on the individual components of m¹Im—1-methylinosine (m¹I) and 2'-O-methylation (Nm)—to build a hypothetical framework for the function of m¹Im. Furthermore, it provides detailed experimental protocols and workflows that can be adapted to investigate this novel modification, thereby paving the way for future discoveries.
Functional Insights from Constituent Modifications
To hypothesize the function of m¹Im, we must first understand the established roles of its parent modifications.
1-Methylinosine (m¹I): A Key Player in Translation
1-methylinosine is a modified nucleoside derived from the deamination of 1-methyladenosine (B49728) (m¹A). It is predominantly found in transfer RNA (tRNA), particularly at position 37, adjacent to the anticodon, and at position 57 in the TΨC loop of some archaeal tRNAs.[2][3]
Key Functions of m¹I:
-
Codon Recognition and Reading Frame Maintenance: The m¹G modification, a precursor to m¹I in some pathways, is crucial for preventing +1 frameshifting during translation.[4] The presence of m¹I at position 37 (m¹I37) is thought to similarly stabilize the codon-anticodon interaction, ensuring translational fidelity.
-
tRNA Structure and Stability: Modifications in the anticodon loop, including m¹I, contribute to the proper folding and structural integrity of tRNA.[5] The positive charge introduced by N1-methylation can be critical for the overall tRNA structure and its interactions.[6]
2'-O-Methylation (Nm): The Guardian of RNA Integrity
2'-O-methylation is one of the most common RNA modifications, found in tRNA, ribosomal RNA (rRNA), messenger RNA (mRNA), and small nuclear RNA (snRNA).[7] It involves the addition of a methyl group to the 2'-hydroxyl of the ribose sugar.
Key Functions of 2'-O-Methylation:
-
Structural Stabilization: The 2'-O-methyl group restricts the ribose to a C3'-endo conformation, which is characteristic of A-form RNA helices. This stabilizes the local RNA structure, enhances the stability of RNA duplexes, and contributes to the proper folding of complex RNAs like tRNA and rRNA.[7][8]
-
Protection from Nuclease Degradation: The presence of a methyl group at the 2'-hydroxyl position provides steric hindrance, protecting the phosphodiester backbone from cleavage by many ribonucleases. This significantly increases the stability and half-life of RNA molecules.[9]
-
Modulation of RNA-Protein Interactions: 2'-O-methylation can influence the binding of proteins to RNA, either by creating a favorable interaction or by preventing the binding of factors that recognize unmodified RNA.
-
Innate Immunity Evasion: In the context of mRNA, 2'-O-methylation at the 5' cap helps the cell distinguish "self" RNA from foreign RNA (e.g., from viruses), thereby preventing the activation of the innate immune response.[7]
Quantitative Data Summary
While no quantitative data exists for m¹Im, the following tables summarize key characteristics of its constituent modifications.
Table 1: Properties and Functions of 1-Methylinosine (m¹I)
| Property | Description | References |
| Location in RNA | Primarily tRNA position 37 (eukaryotes) and 57 (archaea). | [2][3] |
| Primary Function | Enhances translational fidelity, prevents frameshifting. | [4][5] |
| Structural Impact | Stabilizes anticodon loop structure. | [5] |
| Biosynthesis | Formed from adenosine (B11128) via deamination (by ADAT enzymes) and methylation (by Trm5 enzymes). The order can vary. | [2][10][11] |
Table 2: Properties and Functions of 2'-O-Methylation (Nm)
| Property | Description | References |
| Location in RNA | Ubiquitous: tRNA, rRNA, mRNA, snRNA. | [7][8] |
| Primary Function | Increases RNA stability, protects from nuclease degradation. | [9][12] |
| Structural Impact | Stabilizes C3'-endo ribose pucker, favoring A-form helices. | [7][8] |
| Biosynthesis | Catalyzed by stand-alone methyltransferases or by fibrillarin in box C/D snoRNP complexes. | [13] |
Hypothetical Biosynthesis and Function of m¹Im
Based on the known enzymatic pathways, we can propose a potential route for m¹Im synthesis and infer its likely function.
Proposed Biosynthetic Pathway
The formation of m¹Im likely occurs on a precursor nucleoside within an RNA molecule, such as adenosine (A) or inosine (I). Two plausible pathways can be hypothesized, both involving a methyltransferase and a deaminase. The MODOMICS database indicates a reaction from 2'-O-methylinosine (Im) to 1,2'-O-dimethylinosine (m¹Im), though it notes no known enzyme for the final methylation step.
Inferred Function
Given the dual modifications, m¹Im could possess a synergistic or enhanced version of the functions of its parent modifications.
-
Extreme Structural Stabilization: The combination of the N1-methyl group's influence on base stacking and the 2'-O-methyl group's ribose puckering effect would likely create a highly rigid and stable local RNA structure. This could act as a critical structural anchor point in tRNAs or rRNAs, especially in organisms living in extreme environments (extremophiles).
-
Ultimate Nuclease Resistance: The 2'-O-methylation already confers significant protection against nucleases. The addition of the N1-methyl group might further alter the conformation to provide even greater resistance to enzymatic degradation, leading to an exceptionally long RNA half-life.
-
Fine-tuning of Translation: If located in the anticodon loop of a specific tRNA, m¹Im could be essential for the accurate decoding of a particularly difficult-to-read codon or for preventing frameshifting in specific contexts, acting as a master regulator of translational fidelity for a select group of genes.
Experimental Protocols for Investigation
Investigating a novel RNA modification requires a multi-step approach, from initial detection to functional characterization.
Experimental Workflow for Characterizing m¹Im
The following workflow outlines the key stages for studying the function of a novel RNA modification like m¹Im.
Protocol 1: Detection and Quantification by LC-MS/MS
This protocol describes the general method for analyzing the nucleoside composition of total RNA.[14][15]
1. RNA Isolation and Purification:
-
Isolate total RNA from cells or tissues using a standard Trizol or column-based method.
-
To analyze a specific RNA type (e.g., tRNA), purify the target RNA from the total RNA pool using size-exclusion chromatography or specific capture methods. Ensure high purity and integrity, as assessed by gel electrophoresis.
2. Enzymatic Hydrolysis to Nucleosides:
-
To 5-10 µg of purified RNA in a nuclease-free tube, add 2 units of nuclease P1 in a buffer of 20 mM ammonium (B1175870) acetate (B1210297) (pH 5.3).
-
Incubate at 42°C for 2 hours.
-
Add 1 unit of bacterial alkaline phosphatase and continue incubation at 37°C for an additional 2 hours to dephosphorylate the nucleotides to nucleosides.
-
Terminate the reaction by filtering through a 10-kDa molecular weight cutoff filter to remove the enzymes.
3. LC-MS/MS Analysis:
-
Chromatography: Separate the nucleoside mixture using a reversed-phase C18 column on an HPLC system. A typical gradient would be:
-
Mobile Phase A: 5 mM ammonium acetate in water, pH 5.3.
-
Mobile Phase B: Acetonitrile/water mixture (e.g., 60:40) with 5 mM ammonium acetate.
-
Run a gradient from 0% B to 50% B over 30-40 minutes at a flow rate of ~100-200 µL/min.[16]
-
-
Mass Spectrometry:
-
Couple the HPLC output to a triple quadrupole or high-resolution mass spectrometer (e.g., Q-TOF, Orbitrap) operating in positive ion mode with electrospray ionization (ESI).
-
Perform a full scan to detect the mass-to-charge ratio (m/z) of potential nucleosides. The expected [M+H]⁺ for m¹Im (C₁₂H₁₆N₄O₅) is approximately 297.12.
-
Use tandem mass spectrometry (MS/MS) for structural confirmation. The characteristic fragmentation pattern would involve the neutral loss of the ribose moiety (146 Da for a 2'-O-methylated ribose), resulting in a fragment ion corresponding to the 1-methylinosine base.
-
For quantification, use a Multiple Reaction Monitoring (MRM) method, monitoring the specific transition from the parent ion (m/z ~297.12) to the characteristic fragment ion. Compare peak areas to those of a synthetic m¹Im standard curve for absolute quantification.
-
Protocol 2: In Vitro Translation Assay
This protocol assesses the functional impact of m¹Im on protein synthesis using a reconstituted cell-free translation system.[17][18]
1. Template Preparation:
-
Synthesize two versions of a short mRNA encoding a reporter protein (e.g., Luciferase or a short peptide). One version will be the unmodified control, and the other will contain a single, site-specifically incorporated m¹Im nucleoside at a desired codon. This requires specialized chemical RNA synthesis.
-
Ensure both mRNAs have a 5' cap and a 3' poly(A) tail for efficient translation in eukaryotic systems.[19]
2. Assembling the Translation Reaction:
-
Use a commercially available or lab-prepared in vitro translation system (e.g., rabbit reticulocyte lysate or a fully reconstituted bacterial system).
-
For a typical 25 µL reaction, combine:
-
12.5 µL of lysate/translation mix.
-
1 µL of an amino acid mixture (minus methionine if radiolabeling).
-
1 µL of [³⁵S]-Methionine for radiolabeling (or use a non-radioactive detection method).
-
1-2 µg of the synthetic mRNA template (titrate for optimal concentration).[20]
-
Nuclease-free water to 25 µL.
-
3. Translation and Analysis:
-
Incubate the reactions at the recommended temperature (e.g., 30°C or 37°C) for 60-90 minutes.
-
Stop the reaction by placing it on ice or adding an RNase inhibitor.
-
Analysis of Translation Efficiency: Quantify the amount of synthesized protein. For radiolabeled products, this can be done by SDS-PAGE followed by autoradiography and densitometry. For luciferase reporters, measure luminescence using a luminometer.[21]
-
Analysis of Translational Fidelity: To assess frameshifting, design the mRNA template with a sequence prone to frameshifting at the site of modification. Analyze the protein products on a high-resolution gel to detect any larger-than-expected products resulting from a frameshift.
Conclusion and Future Directions
While the direct functional role of this compound remains to be elucidated, the established importance of its constituent modifications provides a strong foundation for hypothesizing its function. The combination of N1-methylation and 2'-O-methylation suggests a powerful role in RNA structural stabilization and the fine-tuning of translation, potentially critical for cellular function under specific conditions or in particular organisms.
The lack of current knowledge presents a significant opportunity for discovery. The experimental workflows and protocols outlined in this guide offer a clear path for researchers to pursue the identification, characterization, and functional analysis of m¹Im. Such studies will not only illuminate the role of this specific modification but also contribute to the broader understanding of the epitranscriptomic code and its impact on biology, from fundamental cellular processes to human disease. The development of novel chemoproteomic approaches, such as RNABPP, could also be instrumental in identifying the elusive enzymes responsible for m¹Im biosynthesis.[22][23]
References
- 1. Chemoproteomic approaches to study RNA modification-associated proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 2. A general LC-MS-based RNA sequencing method for direct analysis of multiple-base modifications in RNA mixtures - PMC [pmc.ncbi.nlm.nih.gov]
- 3. academic.oup.com [academic.oup.com]
- 4. The T. brucei TRM5 methyltransferase plays an essential role in mitochondrial protein synthesis and function - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Methylated nucleosides in tRNA and tRNA methyltransferases - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Reversible RNA Modification N1-methyladenosine (m1A) in mRNA and tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 7. 2′-O-methylation (Nm) in RNA: progress, challenges, and future directions - PMC [pmc.ncbi.nlm.nih.gov]
- 8. benchchem.com [benchchem.com]
- 9. researchgate.net [researchgate.net]
- 10. academic.oup.com [academic.oup.com]
- 11. AtTrm5a catalyses 1-methylguanosine and 1-methylinosine formation on tRNAs and is important for vegetative and reproductive growth in Arabidopsis thaliana - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. scholars.houstonmethodist.org [scholars.houstonmethodist.org]
- 13. academic.oup.com [academic.oup.com]
- 14. Quantitative analysis of tRNA modifications by HPLC-coupled mass spectrometry [dspace.mit.edu]
- 15. Protocol for preparation and measurement of intracellular and extracellular modified RNA using liquid chromatography-mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Automated Identification of Modified Nucleosides during HRAM-LC-MS/MS using a Metabolomics ID Workflow with Neutral Loss Detection - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Investigating the consequences of mRNA modifications on protein synthesis using in vitro translation assays - PMC [pmc.ncbi.nlm.nih.gov]
- 18. The Basics: In Vitro Translation | Thermo Fisher Scientific - HK [thermofisher.com]
- 19. A highly optimized human in vitro translation system - PMC [pmc.ncbi.nlm.nih.gov]
- 20. promegaconnections.com [promegaconnections.com]
- 21. A Streamlined In Vitro mRNA Production Evaluation for mRNA-Based Vaccines and Therapeutics | MDPI [mdpi.com]
- 22. chemistry.princeton.edu [chemistry.princeton.edu]
- 23. pubs.acs.org [pubs.acs.org]
An In-depth Technical Guide to the Cellular Localization of 1-Methyl-2'-O-methylinosine
For Researchers, Scientists, and Drug Development Professionals
Abstract
1-Methyl-2'-O-methylinosine (m1Im) is a modified nucleoside whose precise subcellular distribution remains to be definitively established in the scientific literature. However, based on the known localization of related RNA modifications and the enzymes responsible for their synthesis, an inferred localization can be proposed. This guide synthesizes the current understanding of closely related modified nucleosides to predict the probable cellular compartments harboring m1Im. Furthermore, it provides a comprehensive overview of the experimental methodologies that would be employed to empirically determine its exact subcellular localization. This document is intended to serve as a foundational resource for researchers investigating the epitranscriptome and its role in cellular function and disease.
Inferred Cellular Localization
Direct experimental evidence for the specific subcellular localization of this compound (m1Im) is not currently available in published literature. However, we can infer its likely distribution by examining the localization of its constituent modifications: N1-methylation of inosine (B1671953) (related to N1-methyladenosine, m1A) and 2'-O-methylation of the ribose moiety.
-
N1-methyladenosine (m1A): This modification is found in various RNA species across different cellular compartments. It is present in both nuclear and mitochondrial transfer RNAs (tRNAs) and ribosomal RNAs (rRNAs), as well as in messenger RNA (mRNA) in the cytoplasm.[1][2][3] The enzymes responsible for m1A formation have distinct localizations. For instance, the TRMT6/TRMT61A complex is active in the cytoplasm, TRMT61B and TRMT10C are mitochondrial, and RRP8/NML is found in the nucleolus.[2][3]
-
1-methylinosine (m1I): This modification is known to occur in tRNA.[1] Specifically, it has been identified at position 37 in the anticodon loop of eukaryotic tRNAAla.
-
2'-O-methylation (Nm): This is one of the most common RNA modifications and is found in all major classes of RNA, including tRNA, rRNA, mRNA, and small nuclear RNA (snRNA). 2'-O-methylation occurs in both the nucleus and mitochondria.
Given that the precursor modifications are present in the nucleus, mitochondria, and cytoplasm, it is plausible that This compound is present in both the nucleus and mitochondria , likely as a modification within tRNA or rRNA molecules.
Biosynthetic Pathway of this compound
The formation of m1Im likely proceeds through a series of enzymatic modifications of an adenosine (B11128) residue within an RNA molecule. The precise order of these steps can vary. Below is a diagram illustrating a potential biosynthetic pathway.
Caption: A potential biosynthetic pathway for this compound (m1Im).
Experimental Protocols for Determining Cellular Localization
To empirically determine the subcellular localization of m1Im, a combination of cellular fractionation and sensitive analytical techniques would be required.
Subcellular Fractionation
This is the initial step to separate major cellular compartments.
Protocol: Differential Centrifugation
-
Cell Lysis: Harvest cultured cells and resuspend them in a hypotonic lysis buffer. Homogenize the cells using a Dounce homogenizer or a similar method to disrupt the plasma membrane while keeping organelles intact.
-
Nuclear Fractionation: Centrifuge the cell lysate at a low speed (e.g., 1,000 x g for 10 minutes at 4°C). The resulting pellet contains the nuclei.
-
Mitochondrial Fractionation: Transfer the supernatant from the previous step to a new tube and centrifuge at a higher speed (e.g., 10,000 x g for 20 minutes at 4°C). The pellet will contain the mitochondria.
-
Cytoplasmic Fraction: The supernatant from the mitochondrial fractionation step represents the cytoplasmic fraction.
-
RNA Extraction: Extract total RNA from each fraction using a standard method such as TRIzol reagent or a commercial RNA purification kit.
Caption: Workflow for subcellular fractionation to isolate nuclear, mitochondrial, and cytoplasmic components.
Quantification of this compound
Once RNA is isolated from each subcellular fraction, a highly sensitive and specific method is required to detect and quantify m1Im.
Protocol: Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS)
-
RNA Digestion: Digest the purified RNA from each fraction into individual nucleosides using a cocktail of nucleases (e.g., nuclease P1) and phosphatases (e.g., alkaline phosphatase).
-
LC Separation: Separate the resulting nucleosides using reverse-phase high-performance liquid chromatography (HPLC).
-
MS/MS Detection: Introduce the separated nucleosides into a tandem mass spectrometer. The instrument will be set to specifically detect the mass-to-charge ratio (m/z) of m1Im and its characteristic fragmentation pattern.
-
Quantification: Quantify the amount of m1Im in each fraction by comparing its signal intensity to that of a known amount of a stable isotope-labeled internal standard of m1Im.
Caption: Workflow for the quantification of this compound using LC-MS/MS.
Data Presentation
The quantitative data obtained from the LC-MS/MS analysis of the subcellular fractions would be summarized in a table for clear comparison.
Table 1: Hypothetical Quantitative Distribution of this compound
| Cellular Fraction | m1Im Abundance (fmol/µg RNA) | Relative Distribution (%) |
| Nucleus | Value | Value |
| Mitochondria | Value | Value |
| Cytoplasm | Value | Value |
| Total | Value | 100% |
Note: The values in this table are placeholders and would be populated with experimental data.
Conclusion
While the precise cellular localization of this compound has yet to be experimentally determined, a strong inference can be made for its presence in the nucleus and mitochondria based on the known distribution of related RNA modifications and their biosynthetic enzymes. The experimental protocols outlined in this guide provide a clear roadmap for researchers to definitively identify and quantify the subcellular distribution of this intriguing modified nucleoside. Such studies will be crucial for elucidating the functional role of m1Im in RNA biology and its potential implications in health and disease.
References
The Cornerstone of Thermostability: A Technical Guide to 1-Methyl-2'-O-methylinosine in Hyperthermophilic Archaea
For Immediate Release
Pasadena, CA – December 19, 2025 – In the extreme environments inhabited by hyperthermophilic archaea, where temperatures can exceed the boiling point of water, the stability of essential biomolecules is paramount. Among the sophisticated adaptations that enable life to thrive under such conditions, the post-transcriptional modification of transfer RNA (tRNA) plays a critical and often underestimated role. This technical guide delves into the significance of a unique and complex modification, 1-methyl-2'-O-methylinosine (m¹Im), a cornerstone of tRNA thermostability in these remarkable organisms.
This document serves as an in-depth resource for researchers, scientists, and drug development professionals, providing a comprehensive overview of the current understanding of m¹Im. It covers its role in tRNA structure and function, its biosynthetic pathway, and the experimental methodologies used for its study.
Introduction: The Challenge of High-Temperature Life
Hyperthermophilic archaea, organisms that thrive at temperatures between 80°C and 122°C, have evolved intricate mechanisms to maintain the integrity of their cellular machinery. Transfer RNA, a central molecule in protein synthesis, is particularly vulnerable to thermal degradation. Unmodified RNA is prone to hydrolysis and loss of its crucial three-dimensional structure at high temperatures. To counteract this, hyperthermophiles employ extensive post-transcriptional modifications, with 2'-O-methylation being a key strategy to enhance tRNA stability. The doubly modified nucleoside, this compound, is a prime example of such an adaptation, contributing significantly to the structural resilience of tRNA in these organisms.
The Role of m¹Im in tRNA Thermostability
The presence of m¹Im and other "hypermodifications" in the tRNA of hyperthermophiles is strongly correlated with their ability to withstand extreme temperatures. The methylation at the 2'-hydroxyl group of the ribose sugar (2'-O-methylation) is a widespread strategy to stabilize RNA structure. This modification locks the ribose into the C3'-endo conformation, which is characteristic of A-form RNA helices, thereby rigidifying the phosphodiester backbone and increasing the melting temperature (Tm) of the tRNA.
While a precise quantitative value for the contribution of m¹Im alone is not yet available, the collective effect of extensive modifications is dramatic. For instance, the initiator tRNA from the hyperthermophilic archaeon Pyrodictium occultum, which contains a suite of modified nucleosides including m¹Im, exhibits a melting temperature of over 100°C. In stark contrast, its unmodified counterpart, synthesized in vitro, has a Tm of only 80°C.[1] This significant increase of more than 20°C underscores the critical role of these modifications in maintaining tRNA structural integrity at physiological growth temperatures for these organisms.
Quantitative Data on tRNA Thermostability
The following table summarizes the known quantitative data regarding the effect of modifications on the thermal stability of tRNA from hyperthermophilic archaea.
| Organism | tRNA Species | Modification Status | Melting Temperature (Tm) | Reference |
| Pyrodictium occultum | Initiator tRNAMet | Fully Modified (contains m¹Im) | >100°C | [1] |
| Pyrodictium occultum | Initiator tRNAMet | Unmodified (in vitro transcript) | 80°C | [1] |
Biosynthesis of this compound (m¹Im)
The biosynthetic pathway of m¹Im in hyperthermophilic archaea is not yet fully elucidated but can be inferred from the known mechanisms of inosine (B1671953) formation, N1-methylation, and 2'-O-methylation in archaeal tRNA. The pathway likely involves a multi-step enzymatic process.
It is hypothesized that adenosine (B11128) (A) within the tRNA transcript is first methylated at the N1 position to form 1-methyladenosine (B49728) (m¹A) by a tRNA (adenine-N1)-methyltransferase. Subsequently, the m¹A is deaminated at the C6 position by an adenosine deaminase to yield 1-methylinosine (B32420) (m¹I). Finally, the 2'-hydroxyl group of the ribose of m¹I is methylated by a tRNA (inosine-2'-O)-methyltransferase to produce the mature this compound (m¹Im). The methyl group for both methylation steps is provided by S-adenosyl-L-methionine (SAM).
Archaea are known to possess two distinct mechanisms for 2'-O-methylation of tRNA: site-specific tRNA 2'-O-methyltransferases and a guide RNA-dependent mechanism involving box C/D small ribonucleoproteins (sRNPs).[2] It remains to be determined which of these mechanisms is responsible for the 2'-O-methylation of inosine to form m¹Im.
Caption: Hypothetical biosynthetic pathway of this compound (m¹Im) in archaeal tRNA.
Experimental Protocols
Analysis of m¹Im in Archaeal tRNA by HPLC-Mass Spectrometry
This protocol outlines the general workflow for the identification and quantification of m¹Im from total tRNA isolated from hyperthermophilic archaea.
1. tRNA Isolation:
-
Cultivate hyperthermophilic archaea under optimal growth conditions.
-
Harvest cells by centrifugation.
-
Extract total RNA using a phenol-chloroform extraction method or a commercial RNA purification kit suitable for archaea.
-
Isolate the small RNA fraction, enriched in tRNA, by size-exclusion chromatography or polyacrylamide gel electrophoresis (PAGE).
2. tRNA Hydrolysis:
-
Digest the purified tRNA to nucleosides using a cocktail of nuclease P1 and bacterial alkaline phosphatase.
-
Incubate approximately 5-10 µg of tRNA with 1-2 units of nuclease P1 in a suitable buffer (e.g., 10 mM ammonium (B1175870) acetate (B1210297), pH 5.3) at 37°C for 2-4 hours.
-
Add alkaline phosphatase and continue incubation for another 1-2 hours at 37°C to dephosphorylate the nucleoside monophosphates.
-
Terminate the reaction by heating or by adding a compatible solvent.
3. HPLC Separation:
-
Separate the resulting nucleosides by reversed-phase high-performance liquid chromatography (RP-HPLC).
-
Use a C18 column with a gradient of a polar solvent (e.g., ammonium acetate buffer) and a less polar solvent (e.g., acetonitrile (B52724) or methanol).
-
Monitor the elution profile using a UV detector at 254 nm and 280 nm.
4. Mass Spectrometry Analysis:
-
Couple the HPLC system to a mass spectrometer (e.g., triple quadrupole or high-resolution mass spectrometer) for sensitive and specific detection.
-
Identify m¹Im based on its specific retention time and mass-to-charge ratio (m/z) in positive ion mode. The expected m/z for the protonated molecule [M+H]⁺ of m¹Im is 297.12.
-
Confirm the identity of m¹Im by tandem mass spectrometry (MS/MS) and comparison of the fragmentation pattern with that of a known standard, if available. Key fragments would correspond to the loss of the ribose moiety.
Caption: Experimental workflow for the analysis of m¹Im in archaeal tRNA.
In Vitro Synthesis of tRNA Containing m¹Im
The site-specific incorporation of m¹Im into a tRNA transcript for functional studies is a challenging endeavor. A chemo-enzymatic approach is generally employed.
1. Solid-Phase Synthesis of a Modified RNA Oligonucleotide:
-
Chemically synthesize an RNA oligonucleotide containing this compound at the desired position using phosphoramidite (B1245037) chemistry on a solid support. This requires the synthesis of the corresponding m¹Im phosphoramidite.
2. Synthesis of Unmodified tRNA Fragments:
-
Synthesize the remaining parts of the tRNA molecule as separate, unmodified RNA oligonucleotides, either by solid-phase synthesis or by in vitro transcription using T7 RNA polymerase.
3. Enzymatic Ligation:
-
Ligate the m¹Im-containing oligonucleotide with the other tRNA fragments using T4 RNA ligase. This often requires a DNA or RNA splint to bring the ends of the fragments into close proximity for efficient ligation.
-
Purify the full-length, site-specifically modified tRNA using denaturing PAGE.
4. Refolding and Functional Assays:
-
Refold the purified tRNA into its active conformation by heating and slow cooling in the presence of magnesium ions.
-
The functional competence of the modified tRNA can then be assessed in various assays, such as aminoacylation assays or in vitro translation systems.
Logical Relationships: m¹Im, tRNA Structure, and Cellular Function
The presence of m¹Im is part of a complex network of adaptations that ensure the fidelity and efficiency of protein synthesis at high temperatures. The logical flow from the genetic information to a functional, thermostable translational machinery is critically dependent on such modifications.
Caption: Logical relationship of m¹Im to tRNA function and archaeal survival.
Conclusion and Future Directions
This compound is a testament to the remarkable molecular adaptations that have evolved to support life in extreme environments. Its role in the thermostabilization of tRNA is crucial for the survival of hyperthermophilic archaea. While significant progress has been made in identifying and characterizing this and other complex tRNA modifications, several avenues for future research remain.
The precise enzymatic machinery responsible for the biosynthesis of m¹Im needs to be identified and characterized. Quantitative studies to dissect the specific thermodynamic contribution of m¹Im to tRNA stability are essential for a deeper understanding of its function. Furthermore, the development of more efficient methods for the site-specific incorporation of m¹Im and other hypermodifications into RNA will be invaluable for detailed structure-function analyses and for potential applications in RNA-based therapeutics and nanotechnology. The study of these intricate molecular solutions to life's challenges continues to provide fundamental insights into the boundaries of life and the versatility of RNA.
References
Methodological & Application
Application Note: Ultrasensitive Detection and Quantification of 1-Methyl-2'-O-methylinosine in Biological Samples by Liquid Chromatography-Mass Spectrometry (LC-MS/MS)
For Research Use Only. Not for use in diagnostic procedures.
Abstract
This application note describes a robust and sensitive method for the detection and quantification of the doubly modified ribonucleoside, 1-Methyl-2'-O-methylinosine (m1Im), in RNA from biological samples. The protocol employs enzymatic hydrolysis of RNA followed by analysis using liquid chromatography coupled to tandem mass spectrometry (LC-MS/MS). This method is intended for researchers, scientists, and drug development professionals investigating the role of RNA modifications in biological processes and as potential biomarkers. While this compound is a known modification, detailed analytical methods for its detection are not widely published. This protocol is based on established principles for the analysis of other modified nucleosides and provides a framework for the targeted analysis of m1Im.
Introduction
Post-transcriptional modifications of RNA add a significant layer of complexity to the regulation of gene expression. These modifications can influence RNA stability, localization, and translation.[1] this compound (m1Im) is a doubly modified nucleoside, featuring a methyl group on the N1 position of the inosine (B1671953) base and another on the 2'-hydroxyl group of the ribose sugar.[2] While the individual modifications, 1-methylinosine (B32420) (m1I) and 2'-O-methylinosine (Im), have been identified in various RNA species, the biological significance of the combined m1Im modification is still under investigation.[3] Accurate and sensitive detection methods are crucial for elucidating its distribution and function. LC-MS/MS has become the gold standard for the analysis of modified nucleosides due to its high sensitivity and specificity.[1] This application note provides a comprehensive protocol for the analysis of m1Im, from sample preparation to data acquisition and analysis.
Experimental Workflow
The overall experimental workflow for the detection of this compound is depicted below. It involves the isolation of total RNA from a biological sample, followed by purification to enrich for the RNA species of interest. The purified RNA is then enzymatically digested into its constituent nucleosides. These nucleosides are subsequently separated by liquid chromatography and analyzed by tandem mass spectrometry.
References
Application Note and Protocol for the Quantitative Analysis of 1-Methyl-2'-O-methylinosine using LC-MS/MS
Introduction
1-Methyl-2'-O-methylinosine (m¹Im) is a modified ribonucleoside that is a constituent of RNA. The study of such modifications is a key aspect of epitranscriptomics, with implications for understanding the regulation of gene expression and the pathogenesis of various diseases. Liquid chromatography coupled with tandem mass spectrometry (LC-MS/MS) is the gold standard for the sensitive and specific quantification of modified nucleosides in biological matrices.[1][2][3] This document provides a detailed protocol for the quantitative analysis of m¹Im in biological samples such as urine and cell culture media.
Modified nucleosides are products of RNA turnover and are released into the extracellular environment, making them potential biomarkers for various physiological and pathological states.[4][5] Accurate quantification of these molecules is crucial for their validation and clinical application. This protocol outlines the necessary steps from sample preparation to LC-MS/MS analysis and data interpretation.
Experimental Protocols
This section details the methodology for the quantification of this compound.
1. Sample Preparation: RNA Extraction and Enzymatic Hydrolysis
This protocol describes the extraction of total RNA from biological samples and its subsequent enzymatic digestion to individual nucleosides.
Materials:
-
TRIzol™ reagent or equivalent RNA isolation kit
-
Nuclease P1
-
Bacterial Alkaline Phosphatase
-
Ultrapure water
-
Centrifuge, microcentrifuge tubes, heat block
Protocol:
-
RNA Isolation: Isolate total RNA from the biological sample (e.g., cell pellets, tissue) using a commercial RNA extraction kit or TRIzol™ reagent according to the manufacturer's instructions.
-
RNA Quantification: Determine the concentration and purity of the extracted RNA using a UV-Vis spectrophotometer. An A260/A280 ratio of ~2.0 is indicative of pure RNA.
-
Enzymatic Digestion:
-
To 1-5 µg of total RNA, add Nuclease P1 in an ammonium acetate buffer.
-
Incubate at 37°C for 2 hours.
-
Add Bacterial Alkaline Phosphatase and incubate for an additional 2 hours at 37°C.
-
The resulting solution contains a mixture of nucleosides.
-
-
Sample Cleanup (Optional but Recommended): Use a solid-phase extraction (SPE) cartridge to remove proteins and other interfering substances.
-
Final Preparation: Dilute the digested sample in the initial mobile phase for LC-MS/MS analysis.
2. LC-MS/MS Analysis
This protocol provides the parameters for the chromatographic separation and mass spectrometric detection of this compound.
Instrumentation:
-
A high-performance liquid chromatography (HPLC) or ultra-high-performance liquid chromatography (UHPLC) system.
-
A triple quadrupole mass spectrometer with an electrospray ionization (ESI) source.
Chromatography Conditions:
| Parameter | Value |
| Column | Reversed-phase C18 column (e.g., 100 x 2.1 mm, 1.8 µm) |
| Mobile Phase A | 5 mM ammonium acetate in water |
| Mobile Phase B | Acetonitrile |
| Gradient | 0-2 min: 2% B; 2-8 min: 2-30% B; 8-8.1 min: 30-95% B; 8.1-10 min: 95% B; 10.1-12 min: 2% B (equilibration) |
| Flow Rate | 0.3 mL/min |
| Column Temp. | 40°C |
| Injection Vol. | 5 µL |
Mass Spectrometry Conditions:
The mass spectrometer should be operated in positive ion mode with multiple reaction monitoring (MRM). The characteristic fragmentation of nucleosides involves the loss of the ribose moiety.[2]
| Parameter | Value |
| Ionization Mode | Electrospray Ionization (ESI), Positive |
| MRM Transitions | See Table 1 |
| Spray Voltage | 4500 V |
| Source Temp. | 500°C |
| Collision Gas | Argon |
| Dwell Time | 100 ms |
Note: Source parameters and collision energies should be optimized for the specific instrument used.
Data Presentation
Quantitative data for this compound should be presented in a clear and organized manner.
Table 1: MRM Transitions for this compound
| Analyte | Precursor Ion (m/z) | Product Ion (m/z) | Collision Energy (eV) |
| This compound | 297.1 | 151.1 | 20 (Optimize) |
| Internal Standard (¹³C₅-m¹Im) | 302.1 | 156.1 | 20 (Optimize) |
Table 2: Method Validation Parameters (Hypothetical Data)
| Parameter | Result |
| Linear Range | 0.1 - 100 ng/mL |
| LLOQ | 0.1 ng/mL |
| Correlation (r²) | > 0.995 |
| Intra-day Precision | < 10% RSD |
| Inter-day Precision | < 15% RSD |
| Accuracy | 90 - 110% |
| Matrix Effect | < 15% |
Visualizations
Diagram 1: General Pathway of RNA Modification and Turnover
References
- 1. Quantification of Modified Nucleosides in the Context of NAIL-MS - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. nationalacademies.org [nationalacademies.org]
- 3. benchchem.com [benchchem.com]
- 4. LC/MS/MS Method Package for Modified Nucleosides : SHIMADZU (Shimadzu Corporation) [shimadzu.com]
- 5. LC-MS/MS Method Package for Modified Nucleosides : Shimadzu (Ãsterreich) [shimadzu.at]
Application Note: High-Performance Liquid Chromatography (HPLC) for the Separation of Modified Nucleosides
Audience: Researchers, scientists, and drug development professionals.
Introduction
Modified nucleosides, such as 1-methyladenosine (B49728) (m1A), are crucial components of various types of RNA and play significant roles in regulating gene expression and other cellular processes.[1][2][3] Accurate separation and quantification of these modified nucleosides are essential for understanding their biological functions and for the development of novel therapeutics. High-Performance Liquid Chromatography (HPLC) is a powerful and widely used technique for the analysis of these complex biological molecules.[2][4][5] This application note provides a detailed protocol for the separation of modified nucleosides using reversed-phase HPLC (RP-HPLC), a common and effective method for such analyses.
Experimental Workflow
The general workflow for the analysis of modified nucleosides by HPLC involves several key steps, from sample preparation to data analysis. The selection of the appropriate HPLC technique is critical and depends on the physicochemical properties of the target molecule, such as polarity.[6]
Caption: A typical experimental workflow for HPLC analysis of modified nucleosides.
Detailed Experimental Protocol: Reversed-Phase HPLC
This protocol details a robust method for the separation of modified nucleosides using a C18 reversed-phase column.
1. Sample Preparation (RNA Digestion)
To analyze modified nucleosides from an RNA sample, the RNA must first be digested into its constituent nucleosides.
-
Enzymatic Digestion: A common method involves a two-step enzymatic digestion.[7][8]
-
Sample Cleanup: After digestion, it is crucial to remove proteins and other potential interferents. This can be achieved by centrifugation at high speed (e.g., 30,000 x g) for 10 minutes.[7]
-
Filtration: Before injection into the HPLC system, filter the sample through a 0.22 µm syringe filter to remove any particulate matter that could clog the column.[6][9]
2. HPLC System and Conditions
The following table summarizes the recommended HPLC conditions for the separation of modified nucleosides.
| Parameter | Condition 1 | Condition 2 |
| HPLC System | Standard HPLC with UV-Vis or PDA detector | Agilent 1220 HPLC or similar |
| Column | Phenomenex C18 (150x4.6 mm)[4] | Thermo Scientific Hypersil ODS (C18), 250 mm length, 4.6 mm ID, 3 µm particle size[10] |
| Mobile Phase A | 50 mM Phosphate Buffer (pH 5.8)[4] | 20 mM Ammonium Acetate Buffer (pH 5.4)[10] |
| Mobile Phase B | Acetonitrile[4] | HPLC-grade Methanol[10] |
| Flow Rate | 0.5 mL/min[4] | 0.5 mL/min[10] |
| Column Temperature | 40 °C[6] | Maintained at a constant temperature (e.g., 35°C)[11] |
| Detection Wavelength | 254 nm[4] | 260 nm[9][10] |
| Injection Volume | 10 µL | 10 µL[10] |
3. Gradient Elution Program
A gradient elution is typically required to achieve optimal separation of the various nucleosides in a complex mixture.
| Time (minutes) | % Mobile Phase A | % Mobile Phase B |
| 0 - 3 | 95 | 5 |
| 3 - 15 | Gradient to 50 | Gradient to 50 |
| 15 - 18 | Gradient to 70 | Gradient to 30 |
| 18 - 30 | Gradient to 90 | Gradient to 10 |
| 30 - 35 | 95 | 5 |
Note: This is a representative gradient and may require optimization based on the specific sample and HPLC system. A common approach is to start with a high percentage of the aqueous mobile phase (A) and gradually increase the organic mobile phase (B) to elute the more hydrophobic compounds.[6]
4. Data Analysis and Quantification
-
Identification: Modified nucleosides are identified by comparing their retention times with those of known standards.
-
Quantification: The amount of each nucleoside can be quantified by integrating the area under the corresponding peak in the chromatogram.[12] A standard curve should be generated using known concentrations of the nucleoside of interest to ensure accurate quantification.[7][13]
Alternative and Complementary HPLC Methods
While reversed-phase HPLC is a versatile technique, other methods can be employed depending on the specific properties of the nucleosides of interest.
1. Hydrophilic Interaction Liquid Chromatography (HILIC)
HILIC is an excellent alternative for separating highly polar modified nucleosides that are not well-retained by RP-HPLC.[6] It utilizes a polar stationary phase and a mobile phase with a high concentration of organic solvent.[6]
| Parameter | Condition |
| Stationary Phase | Bare Silica or Zwitterionic (e.g., Merck SeQuant ZIC-cHILIC)[6] |
| Mobile Phase | 85% Acetonitrile, 1-9% Ammonium Acetate, Water[6] |
| Flow Rate | 0.5 mL/min[6] |
| Detection | UV at 240 nm or 254 nm[6] |
| Temperature | 22-25 °C[6] |
2. Ion-Exchange Chromatography (IEX)
IEX is suitable for separating charged nucleosides. The separation is based on the interaction of the charged molecules with a charged stationary phase.
| Parameter | Condition |
| Stationary Phase | Strong or weak anion-exchange (e.g., Q-type) or cation-exchange (e.g., S-type) column[6] |
| Mobile Phase A (Binding Buffer) | Low ionic strength buffer (e.g., 20 mM Tris-HCl)[6] |
| Mobile Phase B (Elution Buffer) | High ionic strength buffer (e.g., Binding Buffer + 1 M NaCl) |
| Detection | UV at 260 nm[6] |
Signaling Pathway Visualization
The accurate quantification of modified nucleosides like m1A is crucial for understanding their role in cellular signaling pathways. For instance, the levels of m1A can be dynamically regulated by "writer" (methyltransferase) and "eraser" (demethylase) enzymes, which in turn can impact mRNA stability and translation, thereby influencing downstream cellular processes.
Caption: Regulation and downstream effects of m1A RNA modification.
This application note provides a comprehensive guide for the separation and analysis of modified nucleosides using HPLC. The detailed protocols for reversed-phase HPLC, along with overviews of HILIC and IEX, offer researchers the necessary tools to accurately quantify these important biomolecules. The choice of method will ultimately depend on the specific nucleosides of interest and the sample matrix. Proper method development and validation are crucial for obtaining reliable and reproducible results in the study of RNA modifications.
References
- 1. benchchem.com [benchchem.com]
- 2. Research progress of N1-methyladenosine RNA modification in cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Chemical manipulation of m1A mediates its detection in human tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 4. thepharmajournal.com [thepharmajournal.com]
- 5. HPLC Analysis of tRNA‐Derived Nucleosides - PMC [pmc.ncbi.nlm.nih.gov]
- 6. benchchem.com [benchchem.com]
- 7. Detection of RNA Modifications by HPLC Analysis and Competitive ELISA - PMC [pmc.ncbi.nlm.nih.gov]
- 8. wormmine.nephrolab.uni-koeln.de [wormmine.nephrolab.uni-koeln.de]
- 9. protocols.io [protocols.io]
- 10. Nucleoside analysis with high performance liquid chromatography (HPLC) [protocols.io]
- 11. academic.oup.com [academic.oup.com]
- 12. Base composition analysis of nucleosides using HPLC - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. Use of high performance liquid chromatography-mass spectrometry (HPLC-MS) to quantify modified nucleosides - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes: Transcriptome-Wide Mapping of 2'-O-Methylation (Nm)
Introduction
2'-O-methylation (Nm) is a critical post-transcriptional modification of RNA where a methyl group is added to the 2' hydroxyl of the ribose sugar.[1][2] This modification is widespread, occurring on all four nucleotides (A, U, G, C) and is found in nearly all types of RNA, including messenger RNA (mRNA), ribosomal RNA (rRNA), transfer RNA (tRNA), and small nuclear RNA (snRNA).[3] Nm plays a crucial role in RNA stability, structure, and function.[4][5] For instance, it protects mRNA from degradation, influences rRNA translation efficiency, and is involved in innate immunity.[2][6] Dysregulation of Nm has been implicated in various human diseases, including cancer, neurodegenerative disorders, and viral infections, making it a significant area of interest for both basic research and therapeutic development.[1][3][7]
This document provides a detailed overview of current high-throughput sequencing methods for the transcriptome-wide mapping of 2'-O-methylation, complete with comparative data and experimental protocols for researchers, scientists, and drug development professionals.
Methods Based on Chemical & Enzymatic Properties
These methods exploit the unique chemical properties conferred by the 2'-O-methyl group, primarily its resistance to cleavage by specific chemical or enzymatic treatments.
RiboMeth-seq: Mapping by Resistance to Alkaline Hydrolysis
Principle: RiboMeth-seq is based on the principle that the phosphodiester bond 3' to a 2'-O-methylated nucleotide is resistant to alkaline hydrolysis.[8][9] Total RNA is randomly fragmented under alkaline conditions. The resulting RNA fragments are converted into a sequencing library. When the sequencing reads are mapped to a reference transcriptome, 2'-O-methylation sites are identified by a characteristic gap or a significant drop in the coverage of 5' and 3' read ends at the position immediately following the modified nucleotide.[8][10]
Applications & Considerations: RiboMeth-seq is highly effective for detecting and quantifying Nm sites in abundant RNA species like rRNA and tRNA.[9][11] It has been successfully used to provide quantitative analysis of rRNA modifications under various conditions.[11] However, the method is less sensitive for detecting sites with low modification stoichiometry or for analyzing low-abundance transcripts like most mRNAs, as it requires very deep sequencing to achieve sufficient coverage.[12] Furthermore, its accuracy can be compromised by RNA secondary structures that also inhibit random cleavage, potentially leading to false-positive signals.[8]
Nm-seq & RibOxi-seq: Mapping by Periodate (B1199274) Oxidation
Principle: These methods leverage the differential reactivity of 2'-O-methylated and unmodified 2'-hydroxyl groups to periodate oxidation.[13][14] The vicinal diol at the 3' end of an RNA strand with a free 2'-OH group can be oxidized by sodium periodate (NaIO₄), leading to a dialdehyde (B1249045) that can be subsequently removed. A 2'-O-methylated ribose lacks this diol and is therefore resistant to this reaction.[15]
-
Nm-seq uses iterative cycles of oxidation, β-elimination, and dephosphorylation (OED) to sequentially remove nucleotides from the 3' end of fragmented RNA until a resistant Nm site is exposed. These enriched fragments are then ligated to adapters and sequenced, creating a distinct signature where read ends pile up precisely at the Nm site.[15]
-
RibOxi-seq also uses periodate oxidation but in a different workflow. It oxidizes all non-methylated 3' ends within a pool of randomly fragmented RNA, rendering them incapable of ligation. Only fragments that happen to terminate with a 2'-O-methylated nucleotide (or are otherwise protected) can be ligated to a 3' adapter and subsequently sequenced. This creates a positive signal for methylation.[16]
Methods Based on Reverse Transcription Properties
This category of techniques relies on the ability of a 2'-O-methyl group to impede the activity of reverse transcriptase under specific reaction conditions.
2OMe-seq / RTL-P: Mapping by Reverse Transcription Arrest
Principle: A 2'-O-methyl group on the ribose can sterically hinder the progression of reverse transcriptase (RT). This effect is particularly pronounced at low concentrations of deoxynucleoside triphosphates (dNTPs).[12][20] Under these restrictive conditions, the RT enzyme tends to pause or dissociate from the RNA template at the Nm site, leading to truncated cDNA products.[20][21] When these cDNAs are sequenced, the 5' ends of the reads will accumulate at the nucleotide position corresponding to the modification site.
Applications & Considerations: This principle is often used in methods like 2OMe-seq or for site-specific validation using Reverse Transcription at Low dNTP followed by qPCR (RTL-P).[22] The approach is conceptually straightforward but can be less robust for transcriptome-wide discovery compared to chemical-based methods. The efficiency of the RT stop can be variable and influenced by the surrounding sequence context and RNA structure. Quantitative accuracy can be challenging, with some studies noting that RTL-P may only reliably detect sites with high modification levels (>40%).[5]
References
- 1. 2'-O-RNA Methylation Sequencing Service - CD Genomics [cd-genomics.com]
- 2. biorxiv.org [biorxiv.org]
- 3. The detection, function, and therapeutic potential of RNA 2’-O-methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 4. What Is 2'-O-Methylation and How to Detect It - CD Genomics [rna.cd-genomics.com]
- 5. An integrative platform for detection of RNA 2′-O-methylation reveals its broad distribution on mRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 6. 2'-O-Methylation Sequencing - CD Genomics [rna.cd-genomics.com]
- 7. The detection, function, and therapeutic potential of RNA 2'-O-methylation [the-innovation.org]
- 8. researchgate.net [researchgate.net]
- 9. Frontiers | Holistic Optimization of Bioinformatic Analysis Pipeline for Detection and Quantification of 2′-O-Methylations in RNA by RiboMethSeq [frontiersin.org]
- 10. academic.oup.com [academic.oup.com]
- 11. Next-Generation Sequencing-Based RiboMethSeq Protocol for Analysis of tRNA 2′-O-Methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 12. 2′-O-methylation (Nm) in RNA: progress, challenges, and future directions - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Nm-seq [protocols.io]
- 14. researchgate.net [researchgate.net]
- 15. Nm-seq maps 2′-O-methylation sites in human mRNA with base precision - PMC [pmc.ncbi.nlm.nih.gov]
- 16. High-throughput and site-specific identification of 2′-O-methylation sites using ribose oxidation sequencing (RibOxi-seq) - PMC [pmc.ncbi.nlm.nih.gov]
- 17. fpwr.org [fpwr.org]
- 18. Nm-seq maps 2′-O-methylation sites in human mRNA with base precision | Springer Nature Experiments [experiments.springernature.com]
- 19. Nm-seq maps 2′-O-methylation sites in human mRNA with base precision | Semantic Scholar [semanticscholar.org]
- 20. Detection and quantification of RNA 2′-O-methylation and pseudouridylation - PMC [pmc.ncbi.nlm.nih.gov]
- 21. Assessing 2’-O-methylation of mRNA Using Quantitative PCR - PMC [pmc.ncbi.nlm.nih.gov]
- 22. researchgate.net [researchgate.net]
Synthetic Routes for 1-Methyl-2'-O-methylinosine Phosphoramidite: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
Introduction
1-Methyl-2'-O-methylinosine is a modified nucleoside of significant interest in the development of therapeutic oligonucleotides. The N1-methylation of the inosine (B1671953) base can influence base pairing and stacking interactions, while the 2'-O-methylation of the ribose sugar confers increased nuclease resistance and enhanced binding affinity to target RNA sequences. These properties make it a valuable component in antisense oligonucleotides, siRNAs, and other RNA-based therapeutics. This document provides detailed application notes and protocols for the chemical synthesis of this compound phosphoramidite (B1245037), the key building block for its incorporation into synthetic oligonucleotides.
The synthesis of this compound phosphoramidite is a multi-step process that requires careful control of reaction conditions and purification of intermediates. The overall synthetic strategy can be divided into three key stages:
-
N1-Methylation of Inosine: Selective methylation of the N1 position of the inosine base.
-
2'-O-Methylation: Selective methylation of the 2'-hydroxyl group of the ribose sugar.
-
Phosphitylation: Introduction of the phosphoramidite moiety at the 3'-hydroxyl group.
This document will provide a detailed protocol for each of these stages, including information on necessary protecting groups, reaction conditions, and purification methods.
Synthetic Pathway Overview
A logical workflow for the synthesis of this compound phosphoramidite is outlined below. This pathway employs protecting groups to ensure regioselectivity in the methylation and phosphitylation steps.
Caption: Synthetic workflow for this compound phosphoramidite.
Experimental Protocols
Stage 1: Synthesis of 1-Methylinosine (B32420)
The synthesis of 1-methylinosine from inosine requires the protection of the ribose hydroxyl groups to ensure selective methylation at the N1 position of the purine (B94841) ring. A common strategy involves the use of silyl (B83357) protecting groups, which can be subsequently removed under mild conditions.
Protocol 1: Protection of Inosine Hydroxyl Groups
-
Materials:
-
Inosine
-
Anhydrous Pyridine (B92270)
-
tert-Butyldimethylsilyl chloride (TBDMSCl)
-
Anhydrous Dichloromethane (DCM)
-
Saturated aqueous sodium bicarbonate (NaHCO₃)
-
Brine
-
Anhydrous sodium sulfate (B86663) (Na₂SO₄)
-
Silica (B1680970) gel for column chromatography
-
-
Procedure:
-
Dissolve inosine in anhydrous pyridine.
-
Add TBDMSCl portion-wise at 0 °C with stirring.
-
Allow the reaction to warm to room temperature and stir for 12-16 hours.
-
Monitor the reaction progress by Thin Layer Chromatography (TLC).
-
Upon completion, quench the reaction with saturated aqueous NaHCO₃.
-
Extract the product with DCM.
-
Wash the organic layer with brine, dry over anhydrous Na₂SO₄, and concentrate under reduced pressure.
-
Purify the crude product by silica gel column chromatography to yield 2',3',5'-Tris-O-(tert-butyldimethylsilyl)inosine.
-
Protocol 2: N1-Methylation of Protected Inosine
-
Materials:
-
2',3',5'-Tris-O-(tert-butyldimethylsilyl)inosine
-
Anhydrous Dimethylformamide (DMF)
-
Sodium hydride (NaH, 60% dispersion in mineral oil)
-
Methyl iodide (MeI)
-
Saturated aqueous ammonium (B1175870) chloride (NH₄Cl)
-
Ethyl acetate (B1210297) (EtOAc)
-
Brine
-
Anhydrous sodium sulfate (Na₂SO₄)
-
Silica gel for column chromatography
-
-
Procedure:
-
Dissolve 2',3',5'-Tris-O-(tert-butyldimethylsilyl)inosine in anhydrous DMF.
-
Add NaH portion-wise at 0 °C under an inert atmosphere (e.g., Argon or Nitrogen).
-
Stir the mixture for 30 minutes at 0 °C.
-
Add methyl iodide dropwise and continue stirring at room temperature for 2-4 hours.
-
Monitor the reaction by TLC.
-
Carefully quench the reaction with saturated aqueous NH₄Cl at 0 °C.
-
Extract the product with EtOAc.
-
Wash the organic layer with brine, dry over anhydrous Na₂SO₄, and concentrate in vacuo.
-
Purify the product by silica gel column chromatography.
-
Protocol 3: Deprotection to Yield 1-Methylinosine
-
Materials:
-
N1-Methyl-2',3',5'-tris-O-(tert-butyldimethylsilyl)inosine
-
Tetrabutylammonium fluoride (B91410) (TBAF) solution (1 M in THF)
-
Anhydrous Tetrahydrofuran (THF)
-
Silica gel for column chromatography
-
-
Procedure:
-
Dissolve the protected 1-methylinosine in anhydrous THF.
-
Add TBAF solution and stir at room temperature for 2-4 hours.
-
Monitor the deprotection by TLC.
-
Concentrate the reaction mixture under reduced pressure.
-
Purify the crude product by silica gel column chromatography to obtain 1-methylinosine.
-
Quantitative Data Summary for Stage 1
| Step | Product | Typical Yield (%) | Purity (%) |
| Protection | 2',3',5'-Tris-O-(tert-butyldimethylsilyl)inosine | 85-95 | >95 |
| N1-Methylation | N1-Methyl-2',3',5'-tris-O-(tert-butyldimethylsilyl)inosine | 70-85 | >95 |
| Deprotection | 1-Methylinosine | 80-90 | >98 |
Stage 2: Synthesis of this compound
Selective 2'-O-methylation requires protection of the 5'- and 3'-hydroxyl groups. A common strategy involves the use of a dimethoxytrityl (DMT) group for the 5'-hydroxyl and a temporary protecting group for the 3'-hydroxyl, or exploiting the differential reactivity of the hydroxyl groups. A direct methylation approach can also be employed, though it may result in a mixture of 2'- and 3'-O-methylated isomers, requiring careful purification.
Protocol 4: Direct 2'-O-Methylation of 1-Methylinosine
This method is simpler but may result in a mixture of isomers.
-
Materials:
-
1-Methylinosine
-
Anhydrous Dimethylformamide (DMF)
-
Sodium hydride (NaH, 60% dispersion in mineral oil)
-
Methyl iodide (MeI)
-
Saturated aqueous ammonium chloride (NH₄Cl)
-
Ethyl acetate (EtOAc)
-
Brine
-
Anhydrous sodium sulfate (Na₂SO₄)
-
Silica gel for column chromatography or Reverse-Phase HPLC
-
-
Procedure:
-
Dissolve 1-methylinosine in anhydrous DMF.
-
Add NaH portion-wise at 0 °C under an inert atmosphere.
-
Stir for 30 minutes at 0 °C.
-
Add a stoichiometric amount of methyl iodide dropwise.
-
Stir the reaction at room temperature for 4-6 hours, monitoring by TLC or HPLC.
-
Quench the reaction carefully with saturated aqueous NH₄Cl at 0 °C.
-
Extract the products with EtOAc.
-
Wash the organic layer with brine, dry over Na₂SO₄, and concentrate.
-
Purify and separate the 2'-O-methyl and 3'-O-methyl isomers by silica gel column chromatography or reverse-phase HPLC.
-
Quantitative Data Summary for Stage 2 (Direct Methylation)
| Product | Isomer Ratio (2'-O- vs 3'-O-) | Typical Yield (2'-O-isomer, %) | Purity (%) |
| This compound | ~2:1 to 4:1 | 30-50 | >98 (after purification) |
Stage 3: Synthesis of this compound Phosphoramidite
The final step involves the phosphitylation of the 3'-hydroxyl group of this compound. This is typically achieved using 2-cyanoethyl N,N-diisopropylchlorophosphoramidite in the presence of a non-nucleophilic base.
Protocol 5: 5'-O-DMT Protection of this compound
-
Materials:
-
This compound
-
Anhydrous Pyridine
-
4,4'-Dimethoxytrityl chloride (DMT-Cl)
-
Anhydrous Dichloromethane (DCM)
-
Saturated aqueous sodium bicarbonate (NaHCO₃)
-
Brine
-
Anhydrous sodium sulfate (Na₂SO₄)
-
Silica gel for column chromatography
-
-
Procedure:
-
Co-evaporate this compound with anhydrous pyridine.
-
Dissolve the residue in anhydrous pyridine and add DMT-Cl.
-
Stir the reaction at room temperature for 2-4 hours, monitoring by TLC.
-
Quench the reaction with methanol.
-
Dilute with DCM and wash with saturated aqueous NaHCO₃ and brine.
-
Dry the organic layer over anhydrous Na₂SO₄ and concentrate.
-
Purify the crude product by silica gel column chromatography to yield 5'-O-DMT-1-Methyl-2'-O-methylinosine.
-
Protocol 6: Phosphitylation of 5'-O-DMT-1-Methyl-2'-O-methylinosine
-
Materials:
-
5'-O-DMT-1-Methyl-2'-O-methylinosine
-
Anhydrous Dichloromethane (DCM)
-
N,N-Diisopropylethylamine (DIPEA)
-
2-Cyanoethyl N,N-diisopropylchlorophosphoramidite
-
Saturated aqueous sodium bicarbonate (NaHCO₃)
-
Brine
-
Anhydrous sodium sulfate (Na₂SO₄)
-
Silica gel for column chromatography (pre-treated with triethylamine)
-
-
Procedure:
-
Dissolve 5'-O-DMT-1-Methyl-2'-O-methylinosine in anhydrous DCM under an inert atmosphere.
-
Add DIPEA and cool the solution to 0 °C.
-
Add 2-cyanoethyl N,N-diisopropylchlorophosphoramidite dropwise with stirring.
-
Allow the reaction to warm to room temperature and stir for 1-2 hours.
-
Monitor the reaction by TLC.
-
Quench the reaction with saturated aqueous NaHCO₃.
-
Separate the organic layer, wash with brine, dry over anhydrous Na₂SO₄, and concentrate.
-
Purify the crude product by silica gel column chromatography (eluting with a solvent system containing a small percentage of triethylamine) to afford the final this compound phosphoramidite as a white foam.
-
Quantitative Data Summary for Stage 3
| Step | Product | Typical Yield (%) | Purity (%) |
| 5'-O-DMT Protection | 5'-O-DMT-1-Methyl-2'-O-methylinosine | 80-90 | >95 |
| Phosphitylation | This compound phosphoramidite | 75-85 | >98 |
Characterization
The identity and purity of the intermediates and the final phosphoramidite product should be confirmed by standard analytical techniques, including:
-
Nuclear Magnetic Resonance (NMR) Spectroscopy: ¹H, ¹³C, and ³¹P NMR to confirm the structure and the presence of the phosphoramidite group.
-
Mass Spectrometry (MS): To verify the molecular weight of the products.
-
High-Performance Liquid Chromatography (HPLC): To assess the purity of the final product.
Application in Oligonucleotide Synthesis
The synthesized this compound phosphoramidite can be directly used in automated solid-phase oligonucleotide synthesizers. The 2'-O-methyl group provides nuclease resistance, while the N1-methylinosine modification can be used to modulate the binding properties and structural characteristics of the resulting oligonucleotide.
Caption: Automated solid-phase oligonucleotide synthesis cycle.
Conclusion
The synthetic route outlined in these application notes provides a comprehensive guide for the preparation of this compound phosphoramidite. By following these detailed protocols, researchers and drug development professionals can efficiently synthesize this valuable modified nucleoside for incorporation into therapeutic oligonucleotides. The enhanced properties conferred by this modification offer promising avenues for the development of next-generation RNA-based drugs.
Application Notes: Incorporating 1-Methyl-2'-O-methylinosine into Synthetic Oligonucleotides
Introduction
The strategic incorporation of modified nucleosides is a cornerstone of modern oligonucleotide therapeutic development. Chemical modifications are employed to enhance key characteristics such as nuclease resistance, binding affinity to target sequences, and pharmacokinetic properties, while mitigating off-target effects.[1][2][3] The 2'-O-methyl (2'-OMe) modification is a widely utilized alteration that confers significant resistance to nuclease degradation and increases the thermal stability (Tm) of duplexes with complementary RNA.[2][4]
Inosine (B1671953), a naturally occurring purine (B94841) nucleoside, is often used in synthetic oligonucleotides as a "universal base" due to its ability to pair with all four canonical bases, albeit with varying affinities (I-C > I-A > I-T ≈ I-G).[5] The addition of a methyl group at the N1 position of the hypoxanthine (B114508) base (1-methylinosine) alters its hydrogen-bonding capabilities, potentially disrupting canonical Watson-Crick pairing and introducing unique structural or recognition properties.
This document provides detailed protocols for the incorporation of 1-Methyl-2'-O-methylinosine ([2OMeI(Me)]) into synthetic oligonucleotides using standard phosphoramidite (B1245037) chemistry. It covers the entire workflow from solid-phase synthesis to purification and characterization, providing researchers and drug development professionals with the necessary methodology to explore the impact of this novel modification.
Key Features of this compound Modification:
-
Enhanced Nuclease Resistance : The 2'-OMe group provides steric hindrance, protecting the phosphodiester backbone from enzymatic degradation.[2][4]
-
Altered Base Pairing : The N1-methylation of the inosine base is expected to disrupt the standard hydrogen bonding pattern, which could be useful for applications requiring mismatched or wobble pairs, or for probing specific protein-RNA interactions.
-
Increased Duplex Stability : The 2'-OMe modification typically pre-organizes the sugar pucker into an A-form geometry, which generally increases the melting temperature (Tm) of the resulting duplex with an RNA target.[2]
Experimental Protocols
Automated Solid-Phase Oligonucleotide Synthesis
This protocol details a single coupling cycle for incorporating a this compound phosphoramidite into a growing oligonucleotide chain on an automated synthesizer. The synthesis proceeds in the 3' to 5' direction on a solid support, typically controlled pore glass (CPG).[6][7]
Table 1: Reagents and Equipment for Synthesis
| Reagent/Equipment | Purpose | Supplier Example |
|---|---|---|
| DNA/RNA Synthesizer | Automated solid-phase synthesis | Applied Biosystems, MerMade |
| This compound CE Phosphoramidite | Modified building block | Custom Synthesis |
| Standard A, G, C, U/T CE Phosphoramidites | Standard building blocks | Thermo Fisher Scientific, Glen Research |
| Controlled Pore Glass (CPG) Support | Solid support for synthesis | Glen Research |
| Anhydrous Acetonitrile (ACN) | Main solvent for synthesis | Sigma-Aldrich |
| Dichloroacetic Acid (DCA) in Dichloromethane (DCM) | Detritylation reagent | Thermo Fisher Scientific |
| 5-Ethylthio-1H-tetrazole (ETT) or DCI | Activator for coupling step | Glen Research |
| Acetic Anhydride (B1165640)/N-Methylimidazole/THF/Pyridine | Capping reagents (Cap A & B) | Sigma-Aldrich |
| Iodine/Water/Pyridine | Oxidizing agent | Thermo Fisher Scientific |
The standard phosphoramidite cycle is repeated for each nucleotide addition.[1]
Caption: Workflow of the four-step phosphoramidite cycle for oligonucleotide synthesis.
Protocol Steps:
-
Detritylation: The 5'-dimethoxytrityl (DMT) protecting group is removed from the support-bound nucleoside by treating the column with 3% Dichloroacetic Acid (DCA) in Dichloromethane (DCM). The column is then washed with anhydrous acetonitrile.[1]
-
Coupling: The this compound phosphoramidite (or any other amidite) is delivered to the synthesis column simultaneously with an activator, such as 5-Ethylthio-1H-tetrazole (ETT), to form a phosphite triester linkage with the free 5'-hydroxyl group.[8] The coupling time for modified amidites may be extended to ensure high efficiency.[8]
-
Capping: Any unreacted 5'-hydroxyl groups are acetylated using a capping solution (e.g., acetic anhydride and N-methylimidazole). This prevents the formation of deletion sequences.[1]
-
Oxidation: The unstable phosphite triester linkage is oxidized to a stable phosphotriester using a solution of iodine in water and pyridine.[1] The column is washed with acetonitrile, and the cycle is repeated until the full-length oligonucleotide is synthesized.
Table 2: Example Synthesis Cycle Parameters
| Step | Reagent | Wait Time |
|---|---|---|
| 1. Detritylation | 3% DCA in DCM | 60 seconds |
| 2. Coupling | 0.1 M Amidite + 0.25 M ETT | 180-600 seconds* |
| 3. Capping | Cap Mix A + Cap Mix B | 30 seconds |
| 4. Oxidation | 0.02 M I2 in THF/H2O/Pyridine | 30 seconds |
*Coupling times for modified phosphoramidites like this compound may require optimization and extension compared to standard amidites.[8]
Cleavage and Deprotection
Following synthesis, the oligonucleotide is cleaved from the CPG support, and all remaining protecting groups (from the bases and phosphate (B84403) backbone) are removed.
Protocol:
-
Transfer the CPG support containing the synthesized oligonucleotide to a 2 mL screw-cap vial.
-
Add 1.5 mL of a pre-mixed solution of Ammonium Hydroxide/40% Methylamine (AMA) (1:1, v/v).[9]
-
Seal the vial tightly and heat at 65°C for 15-20 minutes.
-
Cool the vial to room temperature and centrifuge briefly.
-
Carefully transfer the supernatant containing the cleaved and deprotected oligonucleotide to a new tube.
-
Evaporate the AMA solution to dryness using a centrifugal vacuum concentrator.
-
Resuspend the resulting oligonucleotide pellet in an appropriate volume of nuclease-free water for purification.
Purification by Reverse-Phase HPLC
Purification is essential to separate the full-length product from shorter failure sequences. Reverse-phase HPLC is a highly effective method.[10][11]
Caption: Standard workflow from crude oligonucleotide to purified, verified product.
Table 3: Typical RP-HPLC Purification Parameters
| Parameter | Setting |
|---|---|
| Column | C18 Reverse-Phase, e.g., XTerra® MS C18, 2.5 µm[10] |
| Mobile Phase A | 0.1 M Triethylammonium Acetate (TEAA), pH 7.0, in 5% Acetonitrile[11] |
| Mobile Phase B | 0.1 M TEAA, pH 7.0, in 30% Acetonitrile[10] |
| Flow Rate | 1.0 mL/min (for analytical scale)[10] |
| Column Temperature | 60°C[10] |
| Detection | UV Absorbance at 260 nm[10] |
| Gradient | 0-100% Mobile Phase B over 15-20 minutes |
Protocol:
-
Equilibrate the HPLC column with Mobile Phase A.
-
Inject the resuspended crude oligonucleotide sample.
-
Run the gradient method as specified. The full-length, DMT-on product (if synthesized trityl-on) will be the most retained, hydrophobic peak.[12]
-
Collect the fractions corresponding to the major product peak.
-
If purification was performed DMT-on, the collected fraction must be treated with 80% acetic acid to remove the DMT group, followed by neutralization.
-
Desalt the purified oligonucleotide using a suitable method like a Sep-Pak cartridge or size-exclusion chromatography.[13]
-
Lyophilize the final sample and store at -20°C.[6]
Quality Control and Characterization
A. Mass Spectrometry for Identity Confirmation
Mass spectrometry is used to confirm that the purified oligonucleotide has the correct molecular weight.[14] Electrospray Ionization (ESI-MS) is commonly used for this purpose.[15][16]
Protocol Outline:
-
Prepare a dilute solution (e.g., 5-10 µM) of the purified oligonucleotide in a suitable buffer, often containing an ion-pairing agent compatible with mass spectrometry.[15]
-
Infuse the sample into the ESI-MS instrument.
-
Acquire the mass spectrum in negative ion mode.
-
Deconvolute the resulting charge state series to obtain the molecular mass of the oligonucleotide.
-
Compare the experimentally determined mass to the calculated theoretical mass. The mass contribution of the this compound modification must be included in the calculation.[14]
B. Thermal Denaturation (Tm) for Duplex Stability
The melting temperature (Tm) is the temperature at which 50% of the oligonucleotide duplex dissociates into single strands. It is a direct measure of duplex stability.
Protocol Outline:
-
Anneal the modified oligonucleotide with its complementary RNA or DNA strand by heating to 95°C for 5 minutes and then cooling slowly to room temperature.
-
Prepare the sample in a buffered solution (e.g., 10 mM sodium phosphate, 100 mM NaCl, 0.1 mM EDTA, pH 7.0).[17]
-
Place the sample in a UV-Vis spectrophotometer equipped with a temperature controller.
-
Monitor the absorbance at 260 nm while slowly increasing the temperature (e.g., 0.5°C/minute) from a starting temperature (e.g., 20°C) to a final temperature (e.g., 90°C).[17]
-
The Tm is determined from the midpoint of the resulting melting curve (absorbance vs. temperature).
Table 4: Example of Biophysical Data Presentation
| Oligonucleotide Sequence (Modification in Bold) | Complement | Tm (°C) | ΔTm (°C) (vs. Unmodified) |
|---|---|---|---|
| 5'-CGA-UI A-GGC-3' (Unmodified Inosine) | 3'-GCU-AUC-CCG-5' | 55.2 | 0.0 |
| 5'-CGA-U**[2OMeI]A-GGC-3' (2'-OMe-Inosine) | 3'-GCU-AUC-CCG-5' | 58.7 | +3.5 |
| 5'-CGA-U[2OMeI(Me)]**A-GGC-3' (1-Me-2'-OMe-I) | 3'-GCU-AUC-CCG-5' | 53.1 | -2.1 |
(Note: Data are hypothetical and for illustrative purposes only.)
C. Circular Dichroism (CD) Spectroscopy for Conformation Analysis
CD spectroscopy provides information about the secondary structure (e.g., A-form, B-form) of the oligonucleotide duplex.
Protocol Outline:
-
Prepare an annealed duplex sample (typically 3-5 µM) in a suitable buffer (e.g., 10 mM sodium phosphate, 10 mM NaCl, pH 7.2).[9]
-
Place the sample in a quartz cuvette.
-
Record the CD spectrum from approximately 320 nm to 200 nm at a controlled temperature (e.g., 20°C).
-
An A-form helix, typical for RNA:RNA and 2'-OMe:RNA duplexes, is characterized by a strong positive peak around 260-270 nm and a strong negative peak around 210 nm.[4]
Caption: Logical flow of how the modification influences properties and applications.
References
- 1. benchchem.com [benchchem.com]
- 2. 2'-O methyl Inosine Oligo Modifications from Gene Link [genelink.com]
- 3. Biophysical and biological properties of splice-switching oligonucleotides and click conjugates containing LNA-phosphothiotriester linkages - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Characterization of fully 2'-modified oligoribonucleotide hetero- and homoduplex hybridization and nuclease sensitivity - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. 2'-O-Methylinosine, 2'-OMe-I Oligonucleotide Modification [biosyn.com]
- 6. alfachemic.com [alfachemic.com]
- 7. files01.core.ac.uk [files01.core.ac.uk]
- 8. Synthesis and properties of oligonucleotides modified with an N-methylguanidine-bridged nucleic acid (GuNA[Me]) bearing adenine, guanine, or 5-methylcytosine nucleobases - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Protocol for the Solid-phase Synthesis of Oligomers of RNA Containing a 2'-O-thiophenylmethyl Modification and Characterization via Circular Dichroism - PMC [pmc.ncbi.nlm.nih.gov]
- 10. mz-at.de [mz-at.de]
- 11. researchgate.net [researchgate.net]
- 12. atdbio.com [atdbio.com]
- 13. Large-scale purification of synthetic oligonucleotides and carcinogen-modified oligodeoxynucleotides on a reverse-phase polystyrene (PRP-1) column - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. sg.idtdna.com [sg.idtdna.com]
- 15. academic.oup.com [academic.oup.com]
- 16. Sequence confirmation of modified oligonucleotides using chemical degradation, electrospray ionization, time-of-flight, and tandem mass spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. Characterization of synthetic oligonucleotides containing biologically important modified bases by MALDI-TOF mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
Application Note and Protocol for Enzymatic Digestion of RNA for Nucleoside Analysis
For Researchers, Scientists, and Drug Development Professionals
Introduction
The analysis of nucleosides, the fundamental building blocks of RNA, is crucial for understanding various biological processes, including post-transcriptional modifications and their role in gene expression and disease.[1][2] This application note provides a detailed protocol for the enzymatic digestion of RNA into its constituent nucleosides, a critical preparatory step for subsequent quantitative analysis by techniques such as high-performance liquid chromatography-mass spectrometry (HPLC-MS).[3][4][5][6] Complete and accurate digestion is paramount for obtaining reliable data on the abundance of canonical and modified nucleosides.[7] This document outlines both a traditional two-step and a more streamlined one-step digestion protocol, along with considerations for sample preparation and data interpretation.
Core Principles
The enzymatic digestion of RNA to nucleosides is a multi-step process that requires the concerted action of several enzymes to break down the phosphodiester backbone and remove phosphate (B84403) groups.[8]
-
Endonucleases (e.g., Nuclease P1, Benzonase): These enzymes cleave the internal phosphodiester bonds within the RNA molecule, breaking it down into smaller fragments or individual 5'-mononucleotides.[8]
-
Phosphodiesterases (e.g., Snake Venom Phosphodiesterase I): These enzymes further hydrolyze the remaining phosphodiester linkages at the ends of RNA fragments, releasing 5'-mononucleotides.[8][9]
-
Phosphatases (e.g., Alkaline Phosphatase): The final step involves the removal of the 5'-phosphate group from the mononucleotides by a phosphatase, yielding the desired nucleosides for analysis.[4][8]
Experimental Protocols
Materials and Reagents
-
Purified RNA sample (1-5 µg)
-
Nuclease P1 (from Penicillium citrinum)
-
Bacterial Alkaline Phosphatase (BAP)
-
Snake Venom Phosphodiesterase I (optional, for some protocols)
-
Benzonase Nuclease (for one-step protocol)
-
Reaction Buffers (specific to each enzyme, or a combined buffer for one-step protocols)
-
Ammonium Acetate solution (pH 5.3)
-
HEPES buffer (pH 7.0 - 8.0)
-
RNase-free water
-
RNase inhibitors
-
Molecular weight cutoff filters (e.g., 10 kDa) for enzyme removal (optional)[3][7]
-
Stable-isotope labeled internal standards (SILIS) for absolute quantification[3][7]
Protocol 1: Two-Step Enzymatic Digestion
This traditional method involves sequential enzymatic reactions at different pH optima.[3][8]
Step 1: Nuclease P1 Digestion (pH 5.3)
-
In an RNase-free microcentrifuge tube, combine the following:
-
Purified RNA: 1-5 µg
-
Nuclease P1: 0.5 - 1 U
-
10X Nuclease P1 Reaction Buffer (e.g., 100 mM Ammonium Acetate, pH 5.3)
-
RNase-free water to a final volume of 20-25 µL.
-
-
Mix gently by pipetting.
-
Incubate at 37°C for 2 hours. Some protocols may recommend heating the RNA at 65°C for 2 minutes prior to adding the enzyme to disrupt secondary structures.[5]
Step 2: Alkaline Phosphatase Digestion (pH 7.0 - 8.0)
-
To the reaction mixture from Step 1, add:
-
Bacterial Alkaline Phosphatase (BAP): 0.5 U
-
1 M HEPES buffer (pH 7.0-8.0) to adjust the pH.
-
-
Mix gently.
-
Incubate at 37°C for an additional 1-3 hours.[10] For 2'-O-methylated nucleosides, which can be resistant to digestion, a prolonged incubation of up to 24 hours may be necessary.[10]
Protocol 2: One-Step Enzymatic Digestion
This streamlined protocol combines all enzymes in a single reaction, offering convenience and reduced sample handling.[8][11] Commercial kits are also available for this purpose.[3][11]
-
Prepare a master mix containing the digestion enzymes in a compatible reaction buffer (typically pH 7.5-8.5).
-
In an RNase-free microcentrifuge tube, combine the following:
-
Purified RNA: 1-5 µg
-
Nucleoside Digestion Mix (containing Benzonase, Phosphodiesterase I, and Alkaline Phosphatase)[9] or individual enzymes.
-
10X Reaction Buffer (e.g., 20 mM Tris-HCl, pH 7.5, 10 mM MgCl₂)
-
RNase-free water to a final volume of 20-50 µL.
-
-
Mix gently.
Post-Digestion Sample Preparation
-
(Optional) Enzyme Removal: To prevent interference with downstream analysis, enzymes can be removed using a molecular weight cutoff filter (e.g., 10 kDa).[3][7] Centrifuge the digested sample through the filter according to the manufacturer's instructions and collect the filtrate containing the nucleosides.
-
(For Absolute Quantification) Addition of Internal Standards: For accurate quantification, add a known amount of stable-isotope labeled internal standards (SILIS) to each sample.[3][7]
-
The sample is now ready for analysis by HPLC-MS/MS. If not analyzed immediately, store at -20°C or -80°C.
Data Presentation
Quantitative data from HPLC-MS/MS analysis should be summarized in tables for clear comparison.
Table 1: Abundance of Canonical Nucleosides
| Sample ID | Adenosine (A) (fmol/µg RNA) | Guanosine (G) (fmol/µg RNA) | Cytidine (C) (fmol/µg RNA) | Uridine (U) (fmol/µg RNA) |
| Control 1 | Value | Value | Value | Value |
| Control 2 | Value | Value | Value | Value |
| Treatment 1 | Value | Value | Value | Value |
| Treatment 2 | Value | Value | Value | Value |
Table 2: Quantification of Modified Nucleosides
| Sample ID | N6-methyladenosine (m6A) (fmol/µg RNA) | Pseudouridine (Ψ) (fmol/µg RNA) | 5-methylcytidine (m5C) (fmol/µg RNA) | Other Modification (fmol/µg RNA) |
| Control 1 | Value | Value | Value | Value |
| Control 2 | Value | Value | Value | Value |
| Treatment 1 | Value | Value | Value | Value |
| Treatment 2 | Value | Value | Value | Value |
Visualizations
Caption: General workflow for enzymatic digestion of RNA for nucleoside analysis.
Caption: Troubleshooting workflow for incomplete RNA digestion.
Troubleshooting
| Problem | Potential Cause | Recommendation |
| Incomplete Digestion | Degraded RNA starting material | Ensure high-quality, intact RNA is used. Work in an RNase-free environment. |
| Insufficient enzyme concentration or incubation time | Optimize enzyme concentration and/or increase incubation time. | |
| Presence of inhibitors in the RNA sample | Re-purify the RNA sample to remove any contaminants. | |
| RNA secondary structures | Heat-denature the RNA at 65-70°C for 2-3 minutes before adding enzymes.[5][10] | |
| Variable Results | Inconsistent pipetting | Use calibrated pipettes and ensure accurate reagent volumes. |
| Fluctuation in incubation temperature | Use a calibrated incubator or water bath. | |
| Loss of Hydrophobic Modified Nucleosides | Adsorption to filter materials during enzyme removal | Be aware that hydrophobic modifications may be lost during filtration with certain filter types.[7] |
| Inaccurate Quantification | Lack of appropriate internal standards | Use stable-isotope labeled internal standards for each analyte of interest for the most accurate quantification.[3][7] |
| Chemical instability of certain modified nucleosides | Be mindful of the stability of your target nucleosides and adjust sample handling and storage accordingly.[3][7] |
References
- 1. Quantitative Analysis of RNA Modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 2. mdpi.com [mdpi.com]
- 3. Pitfalls in RNA Modification Quantification Using Nucleoside Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 4. RNA Modifications [labome.com]
- 5. researchgate.net [researchgate.net]
- 6. Detection of ribonucleoside modifications by liquid chromatography coupled with mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 7. pubs.acs.org [pubs.acs.org]
- 8. benchchem.com [benchchem.com]
- 9. Complete enzymatic digestion of double-stranded RNA to nucleosides enables accurate quantification of dsRNA - Analytical Methods (RSC Publishing) DOI:10.1039/D0AY01498B [pubs.rsc.org]
- 10. Protocol for preparation and measurement of intracellular and extracellular modified RNA using liquid chromatography-mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
Developing Antibodies for 1-Methyl-2'-O-methylinosine (m1Am) Immunoprecipitation: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive overview and detailed protocols for the development and characterization of antibodies targeting 1-Methyl-2'-O-methylinosine (m1Am), and their application in m1Am-specific RNA immunoprecipitation (IP).
Introduction
This compound (m1Am) is a modified nucleoside found in RNA. To study its distribution, regulation, and biological function, the development of specific antibodies for techniques such as methylated RNA immunoprecipitation followed by sequencing (MeRIP-Seq) is crucial. This document outlines the necessary steps, from immunogen synthesis to antibody validation and use in m1Am IP.
Data Presentation
Successful antibody development requires rigorous quantitative assessment. The following tables summarize key data points that should be generated to characterize a novel anti-m1Am antibody.
Table 1: Antibody Titer and Affinity
| Parameter | Description | Result |
| Immunogen | Hapten-carrier conjugate used for immunization. | m1Am-succinyl-KLH |
| Antibody Type | Polyclonal or Monoclonal. | Monoclonal (Clone ID: X) |
| ELISA Titer | The reciprocal of the highest antibody dilution giving a positive signal. | 1:128,000 |
| Dissociation Constant (Kd) | A measure of the binding affinity of the antibody to m1Am. Determined by ELISA or Surface Plasmon Resonance (SPR).[1] | 5 nM |
Table 2: Antibody Specificity and Cross-Reactivity
| Modified Nucleoside | Description | Cross-Reactivity (%) |
| This compound (m1Am) | Target antigen. | 100% |
| N1-methyladenosine (m1A) | Structurally similar modified nucleoside. | < 0.1% |
| N6-methyladenosine (m6A) | Common internal mRNA modification. | < 0.1% |
| Inosine (I) | Unmodified inosine. | < 0.1% |
| 2'-O-methylinosine (Im) | Lacks the N1-methylation. | < 0.5% |
| Guanosine (G) | Purine nucleoside. | < 0.1% |
| Adenosine (A) | Purine nucleoside. | < 0.1% |
| 7-methylguanosine (m7G) cap analog | 5' cap structure of mRNA. | < 0.1% |
Experimental Protocols
Part 1: Anti-m1Am Antibody Development
The generation of a specific antibody against a small molecule like m1Am requires its conjugation to a larger carrier protein to elicit a robust immune response.
This protocol describes a plausible method for derivatizing m1Am to introduce a carboxyl group for protein conjugation.
Materials:
-
This compound (m1Am)
-
Succinic anhydride (B1165640)
-
Anhydrous Dimethylformamide (DMF)
-
Triethylamine (TEA)
-
Diethyl ether
-
Thin Layer Chromatography (TLC) supplies
-
NMR and Mass Spectrometry equipment for characterization
Procedure:
-
Dissolve m1Am in anhydrous DMF.
-
Add a 1.5 molar excess of succinic anhydride and triethylamine.
-
Stir the reaction at room temperature overnight.
-
Monitor the reaction progress by TLC.
-
Upon completion, precipitate the product by adding the reaction mixture to cold diethyl ether.
-
Collect the precipitate by centrifugation and wash with diethyl ether.
-
Dry the product under vacuum.
-
Characterize the structure of the resulting m1Am-succinyl hapten by NMR and Mass Spectrometry.
This protocol utilizes the carbodiimide (B86325) crosslinker EDC to couple the carboxyl group of the hapten to the primary amines on the carrier protein.
Materials:
-
m1Am-succinyl hapten
-
Keyhole Limpet Hemocyanin (KLH)
-
N-(3-Dimethylaminopropyl)-N'-ethylcarbodiimide hydrochloride (EDC)
-
N-hydroxysuccinimide (NHS)
-
Phosphate Buffered Saline (PBS), pH 7.4
-
Dialysis tubing (10 kDa MWCO)
Procedure:
-
Dissolve m1Am-succinyl hapten, EDC, and NHS in DMF.
-
Stir at room temperature for 1 hour to activate the carboxyl group.
-
Dissolve KLH in PBS.
-
Slowly add the activated hapten solution to the KLH solution.
-
Allow the reaction to proceed for 4 hours at room temperature with gentle stirring.
-
Purify the m1Am-KLH conjugate by dialysis against PBS to remove unreacted components.
-
Determine the conjugation efficiency using MALDI-TOF mass spectrometry or a spectrophotometric assay.
This protocol provides a general workflow for monoclonal antibody production using hybridoma technology.
Materials:
-
m1Am-KLH immunogen
-
Adjuvant (e.g., TiterMax Gold)
-
BALB/c mice
-
Myeloma cell line (e.g., SP2/0)
-
Hybridoma growth medium and supplements
-
ELISA plates coated with m1Am-BSA
Procedure:
-
Immunization: Emulsify the m1Am-KLH immunogen with an equal volume of adjuvant. Immunize BALB/c mice subcutaneously or intraperitoneally. Boost the immunization every 3-4 weeks.
-
Titer Monitoring: After each boost, collect a small amount of blood and determine the antibody titer by ELISA using plates coated with m1Am-BSA.
-
Fusion: Once a high titer is achieved, give a final intravenous boost. Three days later, sacrifice the mouse and isolate splenocytes. Fuse the splenocytes with myeloma cells using polyethylene (B3416737) glycol (PEG).
-
Selection and Screening: Select for fused hybridoma cells in HAT medium. Screen the supernatants of surviving hybridoma clones for the presence of anti-m1Am antibodies by ELISA.
-
Cloning and Expansion: Subclone the positive hybridomas by limiting dilution to ensure monoclonality. Expand the desired clones and cryopreserve them.
-
Antibody Purification: Purify the monoclonal antibody from the hybridoma supernatant using Protein A/G affinity chromatography.
Part 2: Antibody Characterization
A dot blot is a quick method to assess the specificity of the antibody against various modified nucleosides.[2][3][4][5][6]
Materials:
-
Nitrocellulose membrane
-
m1Am, m1A, m6A, I, Im, G, A, and m7G cap analog
-
Anti-m1Am antibody
-
HRP-conjugated secondary antibody
-
Chemiluminescent substrate
Procedure:
-
Spot 1 µL of each modified nucleoside (at a concentration of 1 mg/mL) onto a nitrocellulose membrane and let it air dry.
-
Block the membrane with 5% non-fat milk in TBST for 1 hour at room temperature.
-
Incubate the membrane with the anti-m1Am antibody (e.g., at 1 µg/mL) in blocking buffer for 1 hour.
-
Wash the membrane three times with TBST.
-
Incubate with an HRP-conjugated secondary antibody for 1 hour.
-
Wash the membrane three times with TBST.
-
Apply the chemiluminescent substrate and visualize the signal. A strong signal should only be observed for the m1Am spot.
Part 3: m1Am RNA Immunoprecipitation (m1Am-IP)
This protocol is adapted from established MeRIP-Seq protocols for m6A and should be optimized for m1Am.
Materials:
-
Total RNA from cells or tissues
-
Anti-m1Am antibody
-
Protein A/G magnetic beads
-
IP buffer (e.g., 50 mM Tris-HCl pH 7.4, 150 mM NaCl, 0.1% NP-40, with RNase inhibitor)
-
Wash buffer (e.g., high salt IP buffer)
-
Elution buffer (e.g., containing a high concentration of free m1Am or a denaturing agent)
-
RNA purification kit
Procedure:
-
RNA Fragmentation: Fragment total RNA to an average size of 100-200 nucleotides using enzymatic or chemical fragmentation.
-
Antibody-Bead Conjugation: Incubate the anti-m1Am antibody with Protein A/G magnetic beads in IP buffer for 1 hour at 4°C.
-
Immunoprecipitation: Add the fragmented RNA to the antibody-bead complexes. Reserve a small fraction of the fragmented RNA as an "input" control. Incubate for 2-4 hours at 4°C with rotation.
-
Washing: Wash the beads three to five times with wash buffer to remove non-specifically bound RNA.
-
Elution: Elute the bound RNA from the beads using the elution buffer.
-
RNA Purification: Purify the eluted RNA and the input RNA using an RNA purification kit.
Validation of enrichment of known m1Am-containing transcripts is essential.
Materials:
-
cDNA synthesis kit
-
SYBR Green qPCR master mix
-
Primers for a known m1Am-containing transcript (positive control) and a transcript known to lack m1Am (negative control).
Procedure:
-
Reverse transcribe the eluted RNA and a corresponding amount of input RNA into cDNA.
-
Perform qPCR using primers for the positive and negative control transcripts.
-
Calculate the enrichment of the target transcript in the IP sample relative to the input, normalized to the negative control transcript.[7][8][9]
Visualizations
Caption: Workflow for the development of anti-m1Am monoclonal antibodies.
Caption: Experimental workflow for m1Am RNA Immunoprecipitation (m1Am-IP).
References
- 1. [Study of the affinity characteristics of monoclonal antibodies by solid-phase immunoenzyme analysis] - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. 2024.sci-hub.se [2024.sci-hub.se]
- 3. Dot Blot: A Quick and Easy Method for Separation-Free Protein Detection [jacksonimmuno.com]
- 4. Dot Blot Protocol: A Simple and Quick Immunossay Technique: R&D Systems [rndsystems.com]
- 5. Dot blot protocol | Abcam [abcam.com]
- 6. Dot Blot Protocol & Troubleshooting Guide | Validated Antibody Collection - Creative Biolabs [creativebiolabs.net]
- 7. Frontiers | Identifying key m6A-methylated lncRNAs and genes associated with neural tube defects via integrative MeRIP and RNA sequencing analyses [frontiersin.org]
- 8. Validated Impacts of N6-Methyladenosine Methylated mRNAs on Apoptosis and Angiogenesis in Myocardial Infarction Based on MeRIP-Seq Analysis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. sigmaaldrich.com [sigmaaldrich.com]
Application Notes and Protocols for the Quantification of 1-Methylimidazole (1-MIM) using Stable Isotope Labeling
For Researchers, Scientists, and Drug Development Professionals
Introduction
1-Methylimidazole (B24206) (1-MIM), a heterocyclic organic compound, is a subject of growing interest in various fields, including its role as a building block in the synthesis of pharmaceuticals and ionic liquids. Accurate and precise quantification of 1-MIM in complex matrices is crucial for understanding its metabolic fate, toxicological profile, and for quality control in manufacturing processes. Stable isotope labeling, coupled with liquid chromatography-tandem mass spectrometry (LC-MS/MS), offers a highly sensitive and specific method for the robust quantification of 1-MIM.[1]
This document provides detailed application notes and protocols for the quantification of 1-MIM using a stable isotope dilution strategy. The use of a stable isotope-labeled internal standard (SIL-IS) is the gold standard for quantitative mass spectrometry as it corrects for variations in sample preparation, chromatography, and ionization efficiency, thereby ensuring high accuracy and precision.[1]
Principle of the Method
The quantification of 1-MIM is achieved by spiking a known amount of a stable isotope-labeled analogue of 1-MIM (e.g., d3-1-methylimidazole) into the sample as an internal standard. The SIL-IS is chemically identical to the analyte but has a different mass due to the incorporated stable isotopes (e.g., deuterium, ¹³C, ¹⁵N). The analyte and the SIL-IS are co-extracted and co-analyzed by LC-MS/MS. The ratio of the signal intensity of the analyte to that of the SIL-IS is used to calculate the concentration of the analyte in the sample, based on a calibration curve prepared with known concentrations of the analyte and a fixed concentration of the SIL-IS.
Experimental Workflow
The overall experimental workflow for the quantification of 1-MIM using stable isotope labeling is depicted in the following diagram.
Caption: Experimental workflow for 1-MIM quantification.
Protocols
Materials and Reagents
-
1-Methylimidazole (≥99% purity)
-
d3-1-Methylimidazole (d3-1-MIM, isotopic purity ≥98%)
-
LC-MS grade water
-
LC-MS grade acetonitrile (B52724)
-
LC-MS grade methanol (B129727)
-
Formic acid (LC-MS grade)
-
Ammonium (B1175870) formate (B1220265) (LC-MS grade)
-
Protein precipitation solvent (e.g., acetonitrile with 1% formic acid)
-
Solid Phase Extraction (SPE) cartridges (e.g., mixed-mode cation exchange)
-
Standard laboratory glassware and consumables
Preparation of Standards and Solutions
-
Stock Solutions (1 mg/mL):
-
Accurately weigh and dissolve 1-MIM and d3-1-MIM in methanol to prepare individual stock solutions of 1 mg/mL. Store at -20°C.
-
-
Working Standard Solutions:
-
Prepare a series of working standard solutions of 1-MIM by serial dilution of the stock solution with a 50:50 mixture of methanol and water. These will be used to create the calibration curve.
-
-
Internal Standard Spiking Solution (100 ng/mL):
-
Dilute the d3-1-MIM stock solution with a 50:50 mixture of methanol and water to a final concentration of 100 ng/mL.
-
Sample Preparation Protocol
This protocol is a general guideline and may need to be optimized for specific sample matrices.
-
Sample Collection: Collect 100 µL of the biological sample (e.g., plasma, urine).
-
Internal Standard Spiking: Add 10 µL of the 100 ng/mL d3-1-MIM internal standard spiking solution to each sample, calibrator, and quality control (QC) sample. Vortex briefly.
-
Protein Precipitation (for plasma/serum): Add 300 µL of ice-cold acetonitrile containing 1% formic acid. Vortex for 1 minute. Centrifuge at 10,000 x g for 10 minutes at 4°C.
-
Supernatant Transfer: Carefully transfer the supernatant to a new tube.
-
Solid Phase Extraction (SPE) - Optional but recommended for complex matrices:
-
Condition a mixed-mode cation exchange SPE cartridge with 1 mL of methanol followed by 1 mL of water.
-
Load the supernatant onto the SPE cartridge.
-
Wash the cartridge with 1 mL of water, followed by 1 mL of methanol.
-
Elute the analyte and internal standard with 1 mL of 5% ammonium hydroxide (B78521) in methanol.
-
-
Evaporation: Evaporate the eluate to dryness under a gentle stream of nitrogen at 40°C.
-
Reconstitution: Reconstitute the dried residue in 100 µL of the initial mobile phase (e.g., 95:5 water:acetonitrile with 0.1% formic acid). Vortex and transfer to an autosampler vial.
LC-MS/MS Analysis
Liquid Chromatography (LC) Conditions:
| Parameter | Value |
| Column | C18 reverse-phase column (e.g., 2.1 x 50 mm, 1.8 µm) |
| Mobile Phase A | 0.1% Formic acid in water |
| Mobile Phase B | 0.1% Formic acid in acetonitrile |
| Gradient | 5% B for 0.5 min, 5-95% B in 3 min, hold at 95% B for 1 min, return to 5% B in 0.1 min, hold for 1.4 min |
| Flow Rate | 0.4 mL/min |
| Column Temperature | 40°C |
| Injection Volume | 5 µL |
Mass Spectrometry (MS) Conditions:
| Parameter | Value |
| Ionization Mode | Positive Electrospray Ionization (ESI+) |
| Scan Type | Multiple Reaction Monitoring (MRM) |
| Capillary Voltage | 3.5 kV |
| Source Temperature | 150°C |
| Desolvation Temperature | 400°C |
| Desolvation Gas Flow | 800 L/hr |
| Cone Gas Flow | 50 L/hr |
MRM Transitions:
The following MRM transitions should be optimized for the specific instrument used.
| Analyte | Precursor Ion (m/z) | Product Ion (m/z) | Collision Energy (eV) |
| 1-Methylimidazole (1-MIM) | 83.1 | 56.1 | 15 |
| d3-1-Methylimidazole (d3-1-MIM) | 86.1 | 59.1 | 15 |
Data Presentation
The following table summarizes hypothetical quantitative data for 1-MIM in different biological matrices.
| Sample ID | Matrix | 1-MIM Concentration (ng/mL) | %RSD (n=3) |
| QC Low | Plasma | 5.2 | 4.5 |
| QC Mid | Plasma | 48.9 | 3.1 |
| QC High | Plasma | 495.1 | 2.5 |
| Sample 1 | Plasma | 15.7 | 3.8 |
| Sample 2 | Urine | 88.2 | 5.2 |
| Sample 3 | Tissue Homogenate | 25.4 | 4.1 |
Signaling Pathway and Logical Relationships
While 1-MIM is not typically involved in a classical signaling pathway, its metabolic fate can be represented. The following diagram illustrates a simplified metabolic pathway.
Caption: Simplified metabolic fate of 1-Methylimidazole.
Conclusion
The use of stable isotope labeling with LC-MS/MS provides a robust, sensitive, and specific method for the quantification of 1-methylimidazole in various complex matrices. The detailed protocol and application notes provided herein serve as a comprehensive guide for researchers, scientists, and drug development professionals to implement this methodology in their laboratories. The accuracy and precision afforded by this technique are essential for reliable pharmacokinetic, toxicological, and quality control studies involving 1-methylimidazole.
References
Application Notes and Protocols for the Computational Prediction of 1-Methyl-2'-O-methylinosine (m¹Im) Sites in RNA
Audience: Researchers, scientists, and drug development professionals.
Introduction
1-Methyl-2'-O-methylinosine (m¹Im) is a post-transcriptional RNA modification cataloged in the MODOMICS database.[1] As a doubly modified nucleoside, its biogenesis likely involves the N1-methylation of adenosine (B11128) (m¹A), followed by deamination to inosine (B1671953) and subsequent 2'-O-methylation of the ribose sugar. The presence of such complex modifications can have profound impacts on RNA structure, stability, and function, making their identification crucial for understanding gene regulation and disease pathogenesis.
Currently, the direct computational prediction of m¹Im sites is a nascent field with no dedicated, experimentally validated predictors publicly available. This is primarily due to the rarity of the modification and the lack of high-throughput sequencing methods specifically designed for its detection, which are necessary to generate the large datasets required for training machine learning models.
This document provides a practical guide for the computational inference of potential m¹Im sites by focusing on the prediction of its constituent modifications: N1-methyladenosine (m¹A) and 2'-O-methylation (Nm). We present a proposed computational workflow, detail relevant experimental validation protocols, and summarize the performance of existing prediction tools for m¹A and Nm.
Computational Prediction of m¹A and Nm Sites
The prediction of m¹Im can be approached by identifying sites that are likely to undergo both N1-methylation and 2'-O-methylation. This involves a two-step computational analysis using existing predictors for m¹A and Nm.
Predictors for N1-methyladenosine (m¹A) Sites
A variety of machine learning and deep learning models have been developed to identify m¹A sites from RNA sequences. These tools typically use sequence- and structure-based features to classify adenosine residues as either modified or unmodified.
Table 1: Summary of Selected Computational Tools for m¹A Site Prediction
| Tool Name | Organism(s) | Method | Features | Performance (Accuracy/AUC) | Reference |
| m1A-pred | Human, Mouse, Yeast | XGBoost | Position and composition-based properties, statistical moments | Not specified | |
| RAMPred | Human, Mouse, Yeast | SVM | Nucleotide chemical properties | 99.13% Accuracy, 0.98 MCC | |
| m1A-Ensem | Human | Ensemble (Blending, Boosting, Bagging) | Novel feature development mechanisms | Optimized scores reported | |
| DeepPromise | Human, Mouse | Deep Learning (CNN) | Enhanced nucleic acid composition, one-hot encoding, RNA embedding | ~43% higher AUROC for m¹A prediction compared to other methods | |
| Geo2vec | Human, Mouse | Deep Learning | Sub-molecular geographic information | Improved performance reported | [2] |
Predictors for 2'-O-methylation (Nm) Sites
Similarly, numerous computational tools are available for the prediction of 2'-O-methylation sites across all four nucleotides (Am, Cm, Gm, Um). These predictors are essential for the second step of our proposed m¹Im prediction workflow.
Table 2: Summary of Selected Computational Tools for 2'-O-methylation (Nm) Site Prediction
| Tool Name | Organism(s) | Method | Features | Performance (AUC) | Reference |
| NmSEER | Human | Random Forest | Not specified | Not specified | [3] |
| DeepOMe | Human | Hybrid CNN and BLSTM | Sequence-based | ~0.998 | [4] |
| 2OMe-LM | Human | Pre-trained RNA language model | Sequence-based | Not specified | [5] |
| H2Opred | Human | Hybrid Deep Learning | Sequence-based | High stability and excellence reported | [6] |
| iRNA-2OM | Human | SVM | Sequence-based | Not specified | [7] |
Proposed Computational Workflow for m¹Im Site Prediction
Given the absence of a direct m¹Im predictor, we propose a logical workflow to identify candidate sites by combining the predictions of m¹A and Nm tools. This workflow is designed to be a practical approach for generating hypotheses for experimental validation.
Caption: Proposed workflow for the computational prediction of m¹Im sites.
Experimental Protocols for Validation
The computational prediction of m¹Im sites must be followed by rigorous experimental validation. Below are detailed protocols for methods that can be adapted to detect and validate m¹Im sites.
Protocol 1: Nm-seq for the Detection of 2'-O-methylation Sites
Nm-seq is a method that leverages the resistance of 2'-O-methylated nucleotides to periodate (B1199274) oxidation and subsequent β-elimination to map Nm sites transcriptome-wide.[8]
Materials:
-
Total RNA
-
RNA Fragmentation Reagents
-
Sodium periodate (NaIO₄)
-
Lysine-HCl buffer
-
Shrimp Alkaline Phosphatase (SAP)
-
T4 RNA Ligase 1
-
3' adapter
-
Reverse transcriptase
-
PCR amplification reagents
-
Sequencing platform (e.g., Illumina)
Methodology:
-
RNA Fragmentation: Fragment total RNA to an average size of 100-200 nucleotides.
-
3' End Dephosphorylation: Treat fragmented RNA with Shrimp Alkaline Phosphatase (SAP) to remove 3' phosphates.
-
Oxidation-Elimination-Dephosphorylation (OED) Cycles:
-
Oxidation: Resuspend RNA in lysine-HCl buffer and add NaIO₄. Incubate to oxidize the 3'-terminal ribose of non-2'-O-methylated fragments.
-
Elimination: The oxidized ribose undergoes spontaneous β-elimination, removing the terminal nucleotide.
-
Dephosphorylation: Treat with SAP to remove the resulting 3'-phosphate.
-
Repeat the OED cycles to enrich for fragments with a 2'-O-methylated nucleotide at the 3' end.
-
-
3' Adapter Ligation: Ligate a 3' adapter to the enriched RNA fragments. Only fragments with a 3'-terminal 2'-O-methylated nucleotide will be efficiently ligated.
-
Reverse Transcription and PCR: Perform reverse transcription using a primer complementary to the 3' adapter, followed by PCR amplification to generate a sequencing library.
-
Sequencing and Data Analysis: Sequence the library and align reads to the reference transcriptome. The 5' ends of the reads will correspond to the position of the 2'-O-methylated nucleotide.
Caption: Experimental workflow for Nm-seq.
Protocol 2: m¹A-seq for the Detection of N1-methyladenosine Sites
m¹A-seq combines antibody-based enrichment of m¹A-containing RNA fragments with high-throughput sequencing.[9]
Materials:
-
Total RNA
-
Anti-m¹A antibody
-
Protein A/G magnetic beads
-
RNA fragmentation reagents
-
RNA ligation and library preparation kits
-
Sequencing platform
Methodology:
-
RNA Fragmentation: Fragment total RNA into ~100 nucleotide-long fragments.
-
Immunoprecipitation (IP):
-
Incubate the fragmented RNA with an anti-m¹A antibody.
-
Capture the antibody-RNA complexes using protein A/G magnetic beads.
-
Wash the beads to remove non-specifically bound RNA.
-
-
RNA Elution: Elute the m¹A-containing RNA fragments from the beads.
-
Library Preparation and Sequencing: Construct a sequencing library from the eluted RNA and an input control (a sample of fragmented RNA that did not undergo IP).
-
Data Analysis: Sequence both the IP and input libraries. Align the reads to a reference transcriptome and identify enriched regions (peaks) in the IP sample compared to the input, which correspond to m¹A sites.
Protocol 3: Mass Spectrometry for Direct Detection of m¹Im
Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is the gold standard for the unequivocal identification and quantification of RNA modifications.[10][11]
Methodology:
-
RNA Isolation and Digestion: Isolate the RNA of interest and digest it into individual nucleosides using a cocktail of nucleases.
-
Chromatographic Separation: Separate the resulting nucleosides using high-performance liquid chromatography (HPLC).
-
Mass Spectrometry Analysis:
-
The separated nucleosides are ionized and introduced into a mass spectrometer.
-
The mass-to-charge ratio of each nucleoside is measured, allowing for the identification of canonical and modified nucleosides based on their unique masses.
-
Tandem mass spectrometry (MS/MS) can be used to fragment the nucleosides, providing further structural confirmation.
-
Conclusion
The computational prediction of this compound (m¹Im) sites in RNA is a challenging but important area of epitranscriptomics. While direct predictors for m¹Im are not yet available, a combination of computational tools for m¹A and Nm sites can provide a valuable starting point for identifying candidate loci. The experimental protocols detailed in this document are essential for validating these computational predictions and for generating the necessary data to develop dedicated m¹Im prediction tools in the future. As high-throughput sequencing technologies for modified bases continue to evolve, we anticipate that the direct detection and computational prediction of complex RNA modifications like m¹Im will become more feasible, opening up new avenues for research and drug discovery.
References
- 1. Modomics - A Database of RNA Modifications [genesilico.pl]
- 2. Nm-seq maps 2′-O-methylation sites in human mRNA with base precision | Springer Nature Experiments [experiments.springernature.com]
- 3. Bioinformatics for Inosine: Tools and Approaches to Trace This Elusive RNA Modification - PMC [pmc.ncbi.nlm.nih.gov]
- 4. DeepOMe: A Web Server for the Prediction of 2′-O-Me Sites Based on the Hybrid CNN and BLSTM Architecture - PMC [pmc.ncbi.nlm.nih.gov]
- 5. 2OMe-LM: predicting 2′-O-methylation sites in human RNA using a pre-trained RNA language model - PMC [pmc.ncbi.nlm.nih.gov]
- 6. academic.oup.com [academic.oup.com]
- 7. livrepository.liverpool.ac.uk [livrepository.liverpool.ac.uk]
- 8. Nm-seq maps 2′-O-methylation sites in human mRNA with base precision - PMC [pmc.ncbi.nlm.nih.gov]
- 9. weizmann.elsevierpure.com [weizmann.elsevierpure.com]
- 10. LC-MS Analysis of Methylated RNA | Springer Nature Experiments [experiments.springernature.com]
- 11. nationalacademies.org [nationalacademies.org]
Application Notes and Protocols for 1-Methyl-2'-O-methylinosine in RNA Therapeutics
For Researchers, Scientists, and Drug Development Professionals
Introduction
The landscape of RNA therapeutics is rapidly evolving, with chemical modifications to ribonucleosides playing a pivotal role in enhancing the safety, stability, and efficacy of messenger RNA (mRNA)-based drugs and vaccines. While modifications such as N1-methylpseudouridine (m1Ψ) have become central to the success of COVID-19 mRNA vaccines, the exploration of novel or combined modifications continues to be a frontier of research. This document provides detailed application notes and experimental protocols for the hypothesized use of 1-Methyl-2'-O-methylinosine (m1Im), a doubly modified inosine (B1671953) nucleoside, in the development of RNA therapeutics.
Inosine itself is a naturally occurring purine (B94841) nucleoside that can be found in RNA and is known to alter the coding potential of mRNA. The addition of a methyl group at the N1 position (1-methylinosine, m1I) and another at the 2'-hydroxyl of the ribose sugar (2'-O-methylinosine, Im) is proposed to confer unique and advantageous properties to therapeutic RNA molecules. These properties are extrapolated from the known effects of each individual modification.
Application Notes
The incorporation of this compound into therapeutic RNA is anticipated to provide a multi-faceted approach to overcoming key challenges in the field, namely enzymatic degradation, innate immunogenicity, and translational control.
Enhanced Stability and Nuclease Resistance
The 2'-O-methylation of the ribose is a well-established modification for increasing the stability of RNA molecules.[1] By masking the 2'-hydroxyl group, the RNA backbone is protected from cleavage by ribonucleases, thereby extending the half-life of the mRNA therapeutic in the cellular environment. This modification enhances thermal stability by promoting a more rigid sugar conformation.[1] The N1-methylation of inosine may further contribute to the structural integrity of the RNA.
Reduced Innate Immunogenicity
Exogenously delivered RNA can be recognized by innate immune sensors such as Toll-like receptors 7 and 8 (TLR7/8), leading to the production of pro-inflammatory cytokines and type I interferons, which can impede therapeutic efficacy and cause adverse effects. 2'-O-methylation is known to be a potent suppressor of TLR7 and TLR8 activation.[2][3] The presence of the 2'-O-methyl group on the ribose of inosine is therefore expected to significantly dampen the innate immune response to the therapeutic RNA. The N1-methylation of the inosine base may also contribute to a reduction in immunogenicity by altering the RNA's interaction with immune sensors.
Modulation of Translational Efficiency
The N1-methylation of purine nucleosides can impact translation. For instance, N1-methyladenosine (m1A), a structurally related modification, has been shown to either enhance or repress translation depending on its location within the mRNA.[4][5] The presence of a positive charge on the N1-methylated base can alter the secondary structure of the mRNA and its interaction with the ribosomal machinery.[6] The strategic placement of this compound within the 5' untranslated region (UTR) or the coding sequence could therefore be a tool to fine-tune protein expression levels from the therapeutic mRNA.
Quantitative Data Summary
While direct quantitative data for this compound in RNA therapeutics is not yet available, the following table summarizes the expected effects based on studies of its constituent modifications.
| Modification Component | Property Assessed | Expected Quantitative Effect | Reference |
| 2'-O-methylation | RNA Duplex Stability | Increase in melting temperature (Tm) | [1] |
| Nuclease Resistance | Increased half-life in serum/cellular extracts | [1] | |
| TLR7/8 Activation | Significant reduction in IFN-α and other pro-inflammatory cytokine secretion | [2][3] | |
| N1-methylation (of Adenosine) | Translation Efficiency | Context-dependent increase or decrease in protein expression | [4][5] |
| RNA Structure | Can disrupt Watson-Crick base pairing and alter secondary structure | [6] |
Experimental Protocols
The following protocols provide a framework for the synthesis, purification, and evaluation of RNA containing this compound.
Protocol 1: In Vitro Transcription of RNA containing this compound
This protocol describes the synthesis of mRNA with complete or partial substitution of a standard nucleotide triphosphate with this compound triphosphate (m1ImTP).
Materials:
-
Linearized DNA template with a T7 promoter
-
T7 RNA Polymerase
-
10x Transcription Buffer
-
Ribonucleotide Triphosphate (NTP) solutions (ATP, CTP, GTP, UTP)
-
This compound triphosphate (m1ImTP)
-
RNase Inhibitor
-
DNase I (RNase-free)
-
Nuclease-free water
Procedure:
-
Reaction Setup: Assemble the following components at room temperature in a nuclease-free microcentrifuge tube. The example below is for a 20 µL reaction where GTP is being substituted.
-
Nuclease-free water: to 20 µL
-
10x Transcription Buffer: 2 µL
-
ATP, CTP, UTP (100 mM each): 2 µL of each
-
GTP (100 mM): 0.5 µL (adjust ratio as needed)
-
m1ImTP (10 mM): 5 µL (adjust ratio as needed)
-
Linearized DNA template (1 µg/µL): 1 µL
-
RNase Inhibitor (40 U/µL): 1 µL
-
T7 RNA Polymerase: 2 µL
-
-
Incubation: Mix gently by pipetting and incubate at 37°C for 2-4 hours. For transcripts containing a high percentage of modified nucleotides, a longer incubation time may be necessary.[7]
-
DNase Treatment: Add 1 µL of DNase I to the reaction mixture and incubate at 37°C for 15 minutes to digest the DNA template.
-
RNA Purification: Purify the synthesized RNA using a suitable method, such as lithium chloride precipitation or a spin column-based RNA purification kit, following the manufacturer's instructions.
-
Quantification and Quality Control: Determine the concentration and purity of the synthesized RNA using a spectrophotometer (e.g., NanoDrop). The A260/A280 ratio should be ~2.0. Analyze the integrity of the RNA transcript by gel electrophoresis.
Protocol 2: Assessment of Modified mRNA Stability in a Cell-Free System
This protocol outlines a method to evaluate the stability of the m1Im-containing mRNA in a cellular extract.
Materials:
-
m1Im-modified mRNA and unmodified control mRNA
-
HeLa cell S100 cytoplasmic extract (or other suitable cell extract)
-
Nuclease-free water
-
RNA purification kit
-
Reagents and equipment for RT-qPCR
Procedure:
-
Incubation with Cellular Extract:
-
Prepare reaction mixtures containing the S100 extract and either the modified or unmodified mRNA.
-
Incubate the reactions at 37°C.
-
-
Time-Course Sampling:
-
At various time points (e.g., 0, 30, 60, 120 minutes), take an aliquot of the reaction mixture and immediately stop the degradation by adding an RNA stabilization solution or by proceeding directly to RNA purification.
-
-
RNA Purification: Purify the RNA from each time point using an appropriate RNA purification kit.
-
RT-qPCR Analysis:
-
Perform reverse transcription followed by quantitative PCR (RT-qPCR) to determine the amount of remaining mRNA at each time point.
-
Calculate the mRNA half-life by plotting the percentage of remaining mRNA against time and fitting the data to a one-phase decay curve.[8]
-
Protocol 3: Evaluation of Innate Immune Response to Modified mRNA
This protocol describes the stimulation of human peripheral blood mononuclear cells (PBMCs) to measure the induction of pro-inflammatory cytokines.
Materials:
-
m1Im-modified mRNA and unmodified control mRNA
-
Lipofectamine or other suitable transfection reagent
-
Human PBMCs
-
RPMI-1640 medium supplemented with 10% FBS
-
ELISA kits for human IFN-α, TNF-α, and IL-6
Procedure:
-
Cell Culture: Culture human PBMCs in RPMI-1640 medium.
-
Transfection:
-
Complex the modified and unmodified mRNAs with a transfection reagent according to the manufacturer's protocol.
-
Add the RNA-lipid complexes to the PBMCs in a 96-well plate. Include a mock transfection control (transfection reagent only).
-
-
Incubation: Incubate the cells for 24 hours at 37°C in a 5% CO2 incubator.
-
Cytokine Measurement:
-
Data Analysis: Compare the cytokine concentrations induced by the m1Im-modified mRNA to those induced by the unmodified control mRNA.
Protocol 4: Quantification of this compound in RNA by LC-MS/MS
This protocol provides a method for the enzymatic digestion of RNA to nucleosides and subsequent analysis by liquid chromatography-tandem mass spectrometry (LC-MS/MS) to quantify the level of m1Im.[11][12]
Materials:
-
Purified m1Im-containing RNA
-
Nuclease P1
-
Bacterial alkaline phosphatase
-
LC-MS/MS system
Procedure:
-
RNA Digestion:
-
Digest the purified RNA to its constituent nucleosides by sequential treatment with nuclease P1 and bacterial alkaline phosphatase.
-
-
LC-MS/MS Analysis:
Visualizations
Caption: Workflow for synthesis and evaluation of m1Im-modified mRNA.
References
- 1. synoligo.com [synoligo.com]
- 2. 2'-O-Methylation within Bacterial RNA Acts as Suppressor of TLR7/TLR8 Activation in Human Innate Immune Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 3. 2'-O-Methylation within Bacterial RNA Acts as Suppressor of TLR7/TLR8 Activation in Human Innate Immune Cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Methyladenosine Modification in RNAs: Classification and Roles in Gastrointestinal Cancers - PMC [pmc.ncbi.nlm.nih.gov]
- 5. N1-methyladenosine modification in cancer biology: Current status and future perspectives - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Reversible RNA Modification N1-methyladenosine (m1A) in mRNA and tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 7. neb.com [neb.com]
- 8. mRNA Stability Assay Using transcription inhibition by Actinomycin D in Mouse Pluripotent Stem Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Approaches to Determine Expression of Inflammatory Cytokines - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Cell Culture and estimation of cytokines by ELISA [protocols.io]
- 11. Detection of ribonucleoside modifications by liquid chromatography coupled with mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. Protocol for preparation and measurement of intracellular and extracellular modified RNA using liquid chromatography-mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 14. discover.library.noaa.gov [discover.library.noaa.gov]
Application Notes: Single-Molecule Sequencing of RNA Containing 1-Methyl-2'-O-methylinosine (m1Im)
Audience: Researchers, scientists, and drug development professionals.
Introduction
1-Methyl-2'-O-methylinosine (m1Im) is a doubly modified ribonucleoside, and its detection and localization within RNA molecules are crucial for understanding its biological function. The advent of single-molecule direct RNA sequencing, particularly with Oxford Nanopore Technologies (ONT), provides a promising avenue for the direct detection of such modifications without the need for reverse transcription or amplification. This technology relies on the principle that as an RNA molecule passes through a nanopore, it creates a characteristic disruption in an ionic current. Modified bases alter this current signal in a distinct manner compared to their canonical counterparts, allowing for their identification.
These application notes provide a comprehensive overview and a detailed protocol for the development and validation of a workflow for sequencing RNA containing m1Im using Nanopore direct RNA sequencing. The protocol covers the preparation of synthetic m1Im-containing RNA standards, library preparation, sequencing, and a data analysis strategy for the de novo identification of this specific modification.
Principle of Detection
The detection of m1Im using Nanopore sequencing is based on the unique electrical signal it generates. The presence of both a methyl group on the inosine (B1671953) base (at the N1 position) and a methyl group on the 2'-hydroxyl of the ribose sugar is expected to produce a significant and distinct deviation in the ionic current compared to adenosine, guanosine, inosine, or singly methylated versions. By training a machine learning model on the raw signal data from synthetic RNAs with known m1Im locations, it is possible to develop a classifier that can identify m1Im sites in native RNA samples with high confidence.
Applications
-
Epitranscriptomics Research: Elucidating the prevalence and location of m1Im in different RNA species (e.g., tRNA, rRNA, mRNA) across various organisms and cell types.
-
Drug Development: Investigating the role of m1Im in disease pathogenesis and as a potential therapeutic target. Alterations in RNA modification patterns have been linked to various diseases, including cancer.
-
RNA Biology: Studying the impact of m1Im on RNA structure, stability, and its interaction with RNA-binding proteins and the translational machinery.
Challenges and Considerations
-
Lack of Pre-trained Models: As of now, there are no universally available pre-trained models specifically for the detection of m1Im. Therefore, the generation of high-quality training data is a critical first step.
-
Distinguishing Similar Modifications: The electrical signals from different RNA modifications can be similar, posing a challenge for accurate identification. High-resolution data and robust computational models are necessary to distinguish m1Im from other modifications.
-
Stoichiometry Quantification: While direct RNA sequencing can identify the presence of a modification on a single molecule, accurately quantifying the percentage of modification at a specific site across a population of RNA molecules requires sufficient sequencing depth and careful data analysis.
Data Presentation
The following tables present hypothetical quantitative data that could be expected from a successfully validated m1Im sequencing workflow.
Table 1: Performance of a Custom Machine Learning Model for m1Im Detection
| Metric | Value |
| Accuracy | 96.5% |
| Precision | 95.2% |
| Recall | 97.1% |
| F1-Score | 96.1% |
| Area Under ROC Curve (AUC) | 0.98 |
Table 2: Comparison of m1Im Stoichiometry at a Specific Site in Different Conditions
| Sample Condition | Sequencing Read Depth | Reads with m1Im | Stoichiometry (%) |
| Control | 1500 | 750 | 50.0 |
| Treatment A | 1450 | 362 | 25.0 |
| Treatment B | 1520 | 1216 | 80.0 |
Experimental Protocols
Protocol 1: Enzymatic Synthesis of m1Im-Containing RNA Standards
This protocol describes the generation of a synthetic RNA molecule with a site-specific m1Im modification, which is essential for training and validating the m1Im detection model. This is achieved through a combination of in vitro transcription and RNA ligation.
Materials:
-
T7 RNA Polymerase
-
NTPs (ATP, CTP, GTP, UTP)
-
Linearized DNA template for the 5' and 3' fragments of the target RNA
-
Chemically synthesized RNA oligonucleotide containing m1Im with 5'-phosphate and 3'-hydroxyl groups
-
T4 RNA Ligase 1
-
RNase Inhibitor
-
Nuclease-free water
-
Denaturing polyacrylamide gel (for purification)
Method:
-
In Vitro Transcription of RNA Fragments:
-
Set up two separate in vitro transcription reactions using the linearized DNA templates to generate the 5' and 3' fragments of the target RNA.
-
Incubate the reactions at 37°C for 2-4 hours.
-
Purify the transcribed RNA fragments using denaturing polyacrylamide gel electrophoresis (PAGE).
-
-
Ligation of RNA Fragments:
-
In a nuclease-free tube, combine the purified 5' RNA fragment, the chemically synthesized m1Im-containing RNA oligonucleotide, and the purified 3' RNA fragment in equimolar amounts.
-
Add T4 RNA Ligase 1 and the appropriate reaction buffer.
-
Incubate the reaction at 16°C overnight.
-
-
Purification of Full-Length m1Im-RNA:
-
Purify the full-length ligated RNA product using denaturing PAGE.
-
Elute the RNA from the gel slice and precipitate with ethanol.
-
Resuspend the purified m1Im-containing RNA in nuclease-free water.
-
-
Quality Control:
-
Verify the integrity and purity of the synthetic RNA using a Bioanalyzer.
-
Confirm the presence and location of the m1Im modification using liquid chromatography-tandem mass spectrometry (LC-MS/MS).
-
Protocol 2: Nanopore Direct RNA Library Preparation and Sequencing
This protocol outlines the preparation of a direct RNA sequencing library using the Oxford Nanopore Technologies Direct RNA Sequencing Kit (SQK-RNA004).[1]
Materials:
-
Purified RNA sample (either native RNA or the synthetic m1Im standard)
-
Oxford Nanopore Direct RNA Sequencing Kit (SQK-RNA004)[1]
-
Agencourt RNAClean XP beads
-
Nuclease-free water
-
Ethanol (70%)
-
MinION, GridION, or PromethION sequencing device
-
Nanopore flow cell (e.g., FLO-MIN106D)
Method:
-
RNA Sample Preparation:
-
Start with high-quality, intact RNA. For native RNA, a poly(A) selection or ribosomal RNA depletion is recommended.
-
Quantify the RNA using a Qubit fluorometer.
-
Assess RNA integrity using a Bioanalyzer or similar instrument.
-
-
Reverse Transcription and Adapter Ligation:
-
Follow the manufacturer's protocol for the Direct RNA Sequencing Kit (SQK-RNA004).[1] This typically involves:
-
Ligation of a reverse transcription adapter to the 3' end of the RNA.
-
A reverse transcription step to create an RNA/cDNA hybrid. This step is primarily for improving sequencing stability and does not erase the modification information from the native RNA strand that is sequenced.[1]
-
Ligation of sequencing adapters to the RNA/cDNA hybrid.
-
-
-
Library Purification:
-
Purify the final library using Agencourt RNAClean XP beads according to the kit's instructions.
-
Elute the library in the provided elution buffer.
-
-
Sequencing:
-
Prime the Nanopore flow cell according to the manufacturer's instructions.
-
Load the prepared library onto the flow cell.
-
Initiate the sequencing run using the MinKNOW software.
-
Protocol 3: Data Analysis for m1Im Detection
This protocol describes a general workflow for analyzing the raw Nanopore signal data to identify m1Im modifications. This requires the development of a custom machine learning model.
Software/Tools:
-
Oxford Nanopore's basecaller (e.g., Guppy)
-
Tools for raw signal alignment (e.g., Tombo)
-
A machine learning framework (e.g., TensorFlow, PyTorch)
-
Custom scripts for feature extraction and model training
Method:
-
Basecalling and Raw Signal Alignment:
-
Basecall the raw FAST5 files to generate FASTQ files.
-
Align the raw electrical signal data to a reference transcriptome using a tool like Tombo. This will map the signal to specific genomic coordinates.
-
-
Feature Extraction:
-
Using the aligned signal data from the synthetic m1Im-containing RNA standard, extract features from the raw signal at the known modified sites and at unmodified control sites.
-
Features can include mean signal intensity, standard deviation of the signal, and dwell time for each k-mer.
-
-
Model Training:
-
Use the extracted features and the known labels (m1Im or unmodified) to train a supervised machine learning model (e.g., a recurrent neural network or a random forest classifier).
-
The model will learn to distinguish the signal characteristics of m1Im from canonical bases.
-
-
Model Validation and Prediction:
-
Validate the trained model on a separate test set of synthetic RNA data to assess its accuracy, precision, and recall.
-
Apply the validated model to the raw signal data from native RNA samples to predict the locations of m1Im modifications.
-
-
Orthogonal Validation:
-
Validate a subset of the predicted m1Im sites in the native RNA sample using an orthogonal method, such as LC-MS/MS, to confirm the accuracy of the predictions.[2]
-
Visualizations
Caption: Experimental workflow for m1Im sequencing.
Caption: Potential role of m1Im in tRNA function and translation.
References
Application Notes and Protocols for Novel Sequencing Methods in N1-methylinosine (m1I) Detection
For Researchers, Scientists, and Drug Development Professionals
Introduction
N1-methylinosine (m1I) is a post-transcriptional RNA modification derived from the deamination of N1-methyladenosine (m1A). This modification plays a crucial role in maintaining the structural integrity of RNA molecules and modulating their biological functions. The accurate detection and quantification of m1I are essential for understanding its role in various cellular processes and its potential as a biomarker or therapeutic target in drug development. This document provides an overview of emerging sequencing methodologies for m1I detection, complete with detailed protocols and comparative data to guide researchers in selecting the most appropriate method for their studies.
Novel Sequencing Methods for m1I Detection
Several innovative sequencing techniques have been developed or adapted to identify and quantify m1I modifications in RNA. These methods primarily rely on three principles: antibody-based enrichment, chemical modification coupled with reverse transcription signatures, and direct sequencing of native RNA molecules.
m1I-MaP-seq: m1I-MeRIP-seq followed by mutational profiling
This method combines the specificity of antibody-based enrichment with the precision of mutational profiling. It is a variation of the m1A-MaP-seq technique adapted for m1I.
-
Principle: RNA is fragmented and immunoprecipitated using an antibody specific to m1I. The enriched RNA fragments are then subjected to a library preparation protocol that induces mutations at the modification site during reverse transcription. These mutations are subsequently identified by high-throughput sequencing.
Demethylase-Assisted m1I Sequencing
This approach leverages the enzymatic activity of demethylases to identify m1I sites.
-
Principle: An RNA sample is divided into two aliquots. One aliquot is treated with a demethylase enzyme, such as AlkB, which can remove the methyl group from m1I, converting it back to inosine. The other aliquot remains untreated. Both samples are then sequenced, and the m1I sites are identified by comparing the sequencing data from the treated and untreated samples. The removal of the methyl group often leads to a change in the reverse transcription signature at that position.
Direct RNA Sequencing using Nanopore Technology
Nanopore sequencing offers a direct way to detect RNA modifications without the need for reverse transcription or amplification.
-
Principle: Native RNA molecules are passed through a protein nanopore. As the RNA strand moves through the pore, it creates a characteristic disruption in the ionic current. RNA modifications like m1I cause slight alterations in this current signal compared to the canonical bases. These altered signals can be computationally decoded to identify the location of the modification.[1][2]
Quantitative Data Summary
The following table summarizes the key quantitative metrics for the described m1I detection methods. Please note that performance can vary depending on the specific experimental conditions and the bioinformatic analysis pipeline used.
| Method | Resolution | Sensitivity | Specificity | Quantitative Accuracy | Required RNA Input | Key Advantages | Key Limitations |
| m1I-MaP-seq | Single-nucleotide | High (with good antibody) | Dependent on antibody specificity | Semi-quantitative to quantitative | 1-10 µg of total RNA | High signal-to-noise ratio due to enrichment | Antibody cross-reactivity can be a concern |
| Demethylase-Assisted Sequencing | Single-nucleotide | Moderate to High | High | Quantitative | 1-5 µg of total RNA | Provides enzymatic validation of modification | Incomplete demethylation can lead to false negatives |
| Nanopore Direct RNA Sequencing | Single-nucleotide | Moderate | Moderate to High | Quantitative | 500 ng - 1 µg of poly(A) RNA | Direct detection, no amplification bias | Higher error rate for base calling compared to NGS |
Experimental Protocols
Protocol 1: m1I-MaP-seq
This protocol describes the general steps for performing m1I-MeRIP-seq followed by mutational profiling.
Materials:
-
Total RNA sample
-
m1I-specific antibody
-
Protein A/G magnetic beads
-
RNA fragmentation buffer
-
Immunoprecipitation buffer
-
Wash buffers
-
RNA extraction kit
-
Reverse transcriptase with read-through and misincorporation properties
-
Library preparation kit for high-throughput sequencing
Procedure:
-
RNA Fragmentation: Fragment 5-10 µg of total RNA to an average size of 100-200 nucleotides using RNA fragmentation buffer.
-
Immunoprecipitation:
-
Incubate the fragmented RNA with an m1I-specific antibody in immunoprecipitation buffer for 2 hours at 4°C.
-
Add Protein A/G magnetic beads and incubate for another 1 hour at 4°C to capture the antibody-RNA complexes.
-
Wash the beads three times with wash buffer to remove non-specifically bound RNA.
-
-
RNA Elution and Purification: Elute the m1I-containing RNA fragments from the beads and purify them using an RNA extraction kit.
-
Library Preparation and Sequencing:
-
Perform reverse transcription on the enriched RNA fragments using a reverse transcriptase that can read through the m1I modification while introducing mutations.
-
Prepare a sequencing library from the resulting cDNA.
-
Sequence the library on a high-throughput sequencing platform.
-
-
Data Analysis: Align the sequencing reads to the reference transcriptome and identify sites with a high frequency of mutations, which correspond to the m1I locations.
Protocol 2: Demethylase-Assisted m1I Sequencing
This protocol outlines the procedure for identifying m1I sites using a demethylase enzyme.
Materials:
-
Total RNA sample
-
AlkB demethylase and reaction buffer
-
RNase inhibitors
-
RNA purification kit
-
Library preparation kit for high-throughput sequencing
Procedure:
-
Sample Preparation: Aliquot the total RNA into two tubes.
-
Demethylase Treatment:
-
To one tube, add AlkB enzyme and reaction buffer. Incubate at 37°C for 1 hour to allow for demethylation.
-
To the control tube, add reaction buffer without the enzyme and incubate under the same conditions.
-
-
RNA Purification: Purify the RNA from both the treated and control reactions.
-
Library Preparation and Sequencing: Prepare sequencing libraries from both the demethylase-treated and control RNA samples and sequence them.
-
Data Analysis: Compare the sequencing data from the two samples. A reduction in the reverse transcription signature (e.g., stops or mutations) at specific sites in the treated sample compared to the control indicates the presence of an m1I modification.
Visualizations
Experimental Workflow Diagrams
References
Application Notes and Protocols for 1-Methyl-2'-O-methylinosine Analysis
For Researchers, Scientists, and Drug Development Professionals
Introduction
1-Methyl-2'-O-methylinosine (m¹Im) is a modified nucleoside that has been identified in RNA. The precise quantification and characterization of such modifications are crucial for understanding their biological roles and for the development of novel therapeutics. This document provides detailed application notes and protocols for the sample preparation of m¹Im from various biological matrices for analysis, primarily by liquid chromatography-tandem mass spectrometry (LC-MS/MS), a highly sensitive and specific analytical technique.[1][2][3][4] The protocols described herein cover the extraction of m¹Im from cellular RNA and urine, two common matrices in biomedical research.
Analytical Approaches
The analysis of modified nucleosides like m¹Im typically involves enzymatic digestion of RNA to release the individual nucleosides, followed by chromatographic separation and mass spectrometric detection.[1][2] LC-MS/MS is the method of choice due to its high sensitivity and specificity, allowing for the accurate quantification of low-abundance modifications.[3][4] For volatile and thermally stable derivatives, gas chromatography-mass spectrometry (GC-MS) can also be employed, though it often requires a derivatization step to increase analyte volatility.
Quantitative Data Summary
Accurate quantification of modified nucleosides is essential for meaningful biological interpretation. The following table summarizes key quantitative parameters for the analysis of modified nucleosides. While specific data for this compound is limited in the literature, representative data for other modified nucleosides are provided for reference.
| Parameter | Analyte/Method | Matrix | Value | Reference |
| Recovery | Strata-X SPE | Urine | 85-102% (for various nucleosides and nucleotides) | [5] |
| Liquid-Liquid Extraction | Urine | 98.04–114.01% (for various methylated nucleosides) | [6] | |
| Polymeric Reversed-Phase SPE | Plasma | ~85% (for morphine and clonidine) | [7] | |
| Limit of Detection (LOD) | LC-MS/MS | General | Determined by a signal-to-noise ratio (S/N) of at least 3 | [1] |
| Limit of Quantification (LOQ) | LC-MS/MS | Bivalve Mollusks | 0.79 - 1.51 ng/mL (for various cyanotoxins) | [8] |
| Concentration Range | Various Methylated Nucleosides | Human Urine | 0.09–4230.32 nmol/mmol creatinine | [6] |
Experimental Protocols
Protocol 1: Extraction of this compound from Cellular RNA
This protocol details the enzymatic digestion of total RNA to single nucleosides for subsequent LC-MS/MS analysis.
Materials:
-
Total RNA sample
-
Nuclease P1
-
Bacterial Alkaline Phosphatase (BAP)
-
200 mM HEPES buffer (pH 7.0)
-
Nuclease-free water
-
Heating block or PCR instrument
Procedure:
-
In a nuclease-free microcentrifuge tube, combine the following:
-
Up to 2.5 µg of total RNA
-
2 µL of Nuclease P1 solution (0.5 U/µL)
-
0.5 µL of Bacterial Alkaline Phosphatase (BAP)
-
2.5 µL of 200 mM HEPES (pH 7.0)
-
Nuclease-free water to a final volume of 25 µL
-
-
Incubate the reaction mixture at 37°C for 3 hours. For 2'-O-methylated nucleosides like m¹Im, which can be resistant to enzymatic digestion, a prolonged incubation of up to 24 hours may be beneficial to increase the yield.[9] To prevent evaporation during prolonged incubation, it is recommended to use a PCR instrument with a heated lid.[9]
-
After incubation, the sample is ready for direct LC-MS/MS analysis. No further purification is typically required.[10][11]
Protocol 2: Solid-Phase Extraction (SPE) of this compound from Urine
This protocol describes the enrichment and purification of modified nucleosides from urine using solid-phase extraction, a technique that separates analytes from the sample matrix.[12]
Materials:
-
Urine sample
-
Internal standard solution (e.g., stable isotope-labeled m¹Im)
-
Solid-Phase Extraction (SPE) cartridges (e.g., C18 or a mixed-mode cation exchange)
-
Ammonium (B1175870) acetate (B1210297) solution (pH 9)
-
Deionized water
-
Centrifuge
-
SPE manifold
Procedure:
-
Sample Pre-treatment:
-
Thaw the urine sample at room temperature.
-
Centrifuge the sample at 13,000 rpm for 15 minutes at 4°C to pellet any precipitates.[13]
-
Transfer a known volume of the supernatant (e.g., 100 µL) to a clean tube.
-
Spike the sample with an appropriate internal standard.
-
-
SPE Cartridge Conditioning:
-
Condition the SPE cartridge by passing methanol through it, followed by deionized water. This ensures the sorbent is activated and ready for sample loading.
-
-
Sample Loading:
-
Dilute the pre-treated urine sample with water and load it onto the conditioned SPE cartridge.
-
-
Washing:
-
Wash the cartridge with deionized water to remove unretained matrix components.
-
-
Elution:
-
Elute the retained nucleosides, including m¹Im, with a suitable solvent. For C18 cartridges, a solvent with a higher organic content (e.g., methanol) is used. For ion-exchange cartridges, a change in pH or ionic strength is employed for elution. An effective elution solution for some SPE cartridges is 10 mM ammonium acetate at pH 9.[5]
-
-
Solvent Evaporation and Reconstitution:
-
Evaporate the eluate to dryness under a gentle stream of nitrogen.
-
Reconstitute the dried residue in a small volume of the initial mobile phase for LC-MS/MS analysis.
-
Visualizations
Caption: Workflow for this compound analysis from RNA.
Caption: Workflow for this compound analysis from urine.
References
- 1. Detection of ribonucleoside modifications by liquid chromatography coupled with mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Global analysis by LC-MS/MS of N6-methyladenosine and inosine in mRNA reveal complex incidence - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Global analysis by LC-MS/MS of N6-methyladenosine and inosine in mRNA reveal complex incidence - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. Simultaneous Determination of Methylated Nucleosides by HILIC–MS/MS Revealed Their Alterations in Urine from Breast Cancer Patients - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Innovative Solid-Phase Extraction Strategies for Improving the Advanced Chromatographic Determination of Drugs in Challenging Biological Samples - PMC [pmc.ncbi.nlm.nih.gov]
- 8. LC-MS/MS Analysis of Cyanotoxins in Bivalve Mollusks—Method Development, Validation and First Evidence of Occurrence of Nodularin in Mussels (Mytilus edulis) and Oysters (Magallana gigas) from the West Coast of Sweden [mdpi.com]
- 9. Protocol for preparation and measurement of intracellular and extracellular modified RNA using liquid chromatography-mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 10. neb.com [neb.com]
- 11. researchgate.net [researchgate.net]
- 12. Analysis of Nucleosides and Nucleotides in Plants: An Update on Sample Preparation and LC–MS Techniques - PMC [pmc.ncbi.nlm.nih.gov]
- 13. HILIC-MS/MS for the Determination of Methylated Adenine Nucleosides in Human Urine - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for the Quantification of 1-Methyl-2'-O-methylinosine
Introduction
1-Methyl-2'-O-methylinosine (m¹Im) is a modified ribonucleoside that plays a role in various biological processes. Accurate quantification of m¹Im in biological samples such as total RNA, mRNA, and bodily fluids is crucial for understanding its physiological functions and its potential as a biomarker in disease. These application notes provide a detailed protocol for the quantification of m¹Im using Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS), a highly sensitive and specific analytical technique.[1][2] The methodology described herein is intended for researchers, scientists, and drug development professionals.
Principle
The quantification of this compound is achieved through a stable isotope dilution LC-MS/MS method.[3] This approach involves the extraction of total RNA from a biological sample, followed by enzymatic digestion of the RNA into its constituent nucleosides. The resulting nucleoside mixture is then separated by reverse-phase liquid chromatography and detected by a triple quadrupole mass spectrometer operating in Multiple Reaction Monitoring (MRM) mode. An isotopically labeled internal standard, such as [¹³C₅]-1-Methyl-2'-O-methylinosine, is spiked into the sample prior to digestion to correct for variations in sample preparation and instrument response, ensuring accurate quantification.[3]
Experimental Protocols
Materials and Reagents
-
This compound analytical standard
-
[¹³C₅]-1-Methyl-2'-O-methylinosine (or other suitable stable isotope-labeled internal standard)
-
Nuclease P1 (from Penicillium citrinum)
-
Antarctic Phosphatase
-
TRIzol™ Reagent or other RNA extraction kit
-
Acetonitrile (LC-MS grade)
-
Methanol (LC-MS grade)
-
Formic acid (LC-MS grade)
-
Ammonium (B1175870) acetate (B1210297) (LC-MS grade)
-
Ultrapure water (18.2 MΩ·cm)
-
Microcentrifuge tubes
-
Syringe filters (0.22 µm)
Sample Preparation: RNA Extraction and Digestion
-
RNA Extraction: Isolate total RNA from cells or tissues using TRIzol™ reagent or a commercial RNA extraction kit according to the manufacturer's instructions. Ensure the final RNA pellet is dissolved in RNase-free water. The quality and quantity of the extracted RNA should be assessed using a spectrophotometer (e.g., NanoDrop) and agarose (B213101) gel electrophoresis to ensure high purity.[4]
-
Internal Standard Spiking: To a 1-5 µg aliquot of total RNA, add a known amount of the [¹³C₅]-1-Methyl-2'-O-methylinosine internal standard. The amount of internal standard should be optimized based on the expected concentration of the analyte in the sample.
-
Enzymatic Digestion:
-
Add 1/10th volume of 10X Nuclease P1 buffer (100 mM ammonium acetate, pH 5.3).
-
Add 1-2 units of Nuclease P1.
-
Incubate the mixture at 37°C for 2 hours.
-
Add 1/10th volume of 10X Antarctic Phosphatase buffer (500 mM Bis-Tris-Propane-HCl, 10 mM MgCl₂, 1 mM ZnCl₂, pH 6.0).
-
Add 1-2 units of Antarctic Phosphatase.
-
Incubate at 37°C for an additional 2 hours.
-
-
Sample Cleanup: After digestion, centrifuge the sample at 14,000 x g for 10 minutes to pellet any undigested material or enzyme.[5] Transfer the supernatant to a new microcentrifuge tube. Filter the supernatant through a 0.22 µm syringe filter into an LC-MS vial.
LC-MS/MS Analysis
The analysis of the digested RNA samples is performed using a high-performance liquid chromatography (HPLC) system coupled to a triple quadrupole mass spectrometer.
a. Liquid Chromatography Conditions
-
Column: C18 reverse-phase column (e.g., 2.1 mm x 100 mm, 1.8 µm particle size)
-
Mobile Phase A: 0.1% formic acid in water
-
Mobile Phase B: 0.1% formic acid in acetonitrile
-
Gradient:
-
0-2 min: 2% B
-
2-10 min: 2-30% B
-
10-12 min: 30-95% B
-
12-14 min: 95% B
-
14-15 min: 95-2% B
-
15-20 min: 2% B (re-equilibration)
-
-
Flow Rate: 0.3 mL/min
-
Column Temperature: 40°C
-
Injection Volume: 5 µL
b. Mass Spectrometry Conditions
-
Ionization Mode: Positive Electrospray Ionization (ESI+)
-
Capillary Voltage: 3.5 kV
-
Source Temperature: 150°C
-
Desolvation Temperature: 350°C
-
Gas Flow (Desolvation): 800 L/hr
-
Gas Flow (Cone): 50 L/hr
-
MRM Transitions: The specific mass transitions for this compound and its labeled internal standard need to be determined by infusing the pure standards into the mass spectrometer. The precursor ion will be the [M+H]⁺ ion, and the product ion will be the protonated base fragment.
Data Analysis and Quantification
-
Calibration Curve: Prepare a series of calibration standards containing a fixed amount of the internal standard and varying concentrations of the this compound analytical standard. The concentration range should bracket the expected concentrations in the biological samples.
-
Quantification: The concentration of this compound in the samples is determined by calculating the peak area ratio of the analyte to the internal standard and interpolating this ratio against the calibration curve. The final concentration is typically expressed as a ratio to a canonical nucleoside (e.g., adenosine) to normalize for the total amount of RNA analyzed.[6]
Quantitative Data Summary
The following table provides an example of how to present the quantitative data for this compound in different biological samples. The values presented are hypothetical and should be replaced with experimental data.
| Sample ID | Sample Type | Replicate | m¹Im (fmol/µg RNA) | Standard Deviation | %RSD |
| Control-1 | HeLa Cells | 1 | 15.2 | 1.3 | 8.6% |
| Control-2 | HeLa Cells | 2 | 16.5 | ||
| Control-3 | HeLa Cells | 3 | 14.8 | ||
| Treated-1 | HeLa Cells + Drug X | 1 | 25.8 | 2.1 | 8.1% |
| Treated-2 | HeLa Cells + Drug X | 2 | 28.1 | ||
| Treated-3 | HeLa Cells + Drug X | 3 | 24.9 | ||
| Normal-1 | Human Plasma | 1 | 5.4 | 0.6 | 11.1% |
| Normal-2 | Human Plasma | 2 | 6.1 | ||
| Normal-3 | Human Plasma | 3 | 5.1 | ||
| Disease-1 | Human Plasma (Disease Y) | 1 | 12.3 | 1.1 | 8.9% |
| Disease-2 | Human Plasma (Disease Y) | 2 | 13.5 | ||
| Disease-3 | Human Plasma (Disease Y) | 3 | 11.9 |
Visualizations
References
- 1. Detection of ribonucleoside modifications by liquid chromatography coupled with mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 2. discover.library.noaa.gov [discover.library.noaa.gov]
- 3. Isotope-dilution mass spectrometry for exact quantification of noncanonical DNA nucleosides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. pubs.acs.org [pubs.acs.org]
- 5. On the Quest for Biomarkers: A Comprehensive Analysis of Modified Nucleosides in Ovarian Cancer Cell Lines - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Global analysis by LC-MS/MS of N6-methyladenosine and inosine in mRNA reveal complex incidence - PMC [pmc.ncbi.nlm.nih.gov]
Troubleshooting & Optimization
Technical Support Center: Detection of Rare RNA Modifications like m1Im
This technical support center provides troubleshooting guidance and frequently asked questions for researchers, scientists, and drug development professionals working on the detection of rare N1-methyladenosine (m1A) RNA modifications.
FAQs - General Questions
Q1: What is m1A and why is it considered a "rare" RNA modification?
N1-methyladenosine (m1A) is a post-transcriptional RNA modification that involves the methylation of the N1 position of adenosine.[1] It is considered "rare" compared to more abundant modifications like N6-methyladenosine (m6A), as it is estimated to be present at a lower frequency in messenger RNA (mRNA) and other RNA species.[2] However, its presence is critical for the structural stability and function of various RNAs, including transfer RNA (tRNA), ribosomal RNA (rRNA), and mRNA.[1]
Q2: What are the primary challenges in detecting m1A?
The detection of m1A is challenging due to several factors:
-
Low Abundance: The low stoichiometry of m1A in many RNA populations requires highly sensitive detection methods.[3]
-
Lack of Specific Tools: There is a limited number of highly specific antibodies and chemical methods for direct and unambiguous m1A detection.[3]
-
High Turnover: The dynamic nature of RNA modifications, where they can be added and removed by cellular enzymes, makes their detection and quantification complex.[3]
-
RNA Secondary Structure: Complex RNA secondary structures can mask m1A modifications, hindering their accessibility to antibodies or chemical probes.[2]
Q3: What are the common methods for detecting m1A?
Several methods are employed for m1A detection, each with its own advantages and limitations. These can be broadly categorized as:
-
Antibody-based methods: Techniques like methylated RNA immunoprecipitation followed by sequencing (m1A-seq or MeRIP-seq) utilize antibodies to enrich for m1A-containing RNA fragments.
-
Next-Generation Sequencing (NGS)-based methods: Some methods rely on the principle that m1A can induce mismatches or stalls during reverse transcription, which can then be identified by sequencing.
-
Mass Spectrometry (MS): Liquid chromatography-mass spectrometry (LC-MS/MS) can provide a direct and quantitative measurement of m1A levels but requires RNA hydrolysis into single nucleosides, thus losing sequence context.[4][5]
-
Nanopore Direct RNA Sequencing: This emerging technology allows for the direct detection of RNA modifications on single, native RNA molecules by analyzing disruptions in the ionic current as the RNA passes through a nanopore.[6][7][8]
Troubleshooting Guide
This guide addresses common issues encountered during m1A detection experiments.
| Problem | Potential Causes | Troubleshooting Steps |
| Low Signal-to-Noise Ratio in m1A-Seq | 1. Inefficient immunoprecipitation (IP).2. Low abundance of m1A in the sample.3. Poor antibody quality or specificity. | 1. Optimize IP conditions (antibody concentration, incubation time, washing steps).2. Increase the amount of starting RNA material.3. Validate antibody specificity using dot blots with known m1A-containing and unmodified RNA controls. Use a different, validated antibody if necessary. |
| High Background in Antibody-Based Assays | 1. Non-specific binding of the antibody to unmodified RNA or other cellular components.2. Inadequate washing steps during the IP protocol.3. Cross-reactivity of the antibody with other methylated bases. | 1. Include a non-specific IgG control to assess background levels.2. Increase the stringency and number of wash steps.3. Perform dot blot analysis with various modified nucleosides to check for cross-reactivity. |
| Inconsistent Results in RT-PCR Based Detection | 1. Incomplete reverse transcription (RT) due to RNA secondary structure.2. The specific reverse transcriptase used may not be sensitive to m1A.3. Variability in RNA sample quality. | 1. Optimize RT reaction conditions (e.g., use a higher temperature or additives to denature RNA secondary structures).2. Test different reverse transcriptases to find one that is effectively blocked or paused by m1A.3. Ensure high-quality, intact RNA is used for all experiments. |
| No Detectable m1A Signal in Mass Spectrometry | 1. Insufficient amount of starting material.2. Incomplete digestion of RNA to nucleosides.3. The m1A level is below the detection limit of the instrument. | 1. Increase the quantity of input RNA.2. Optimize the enzymatic digestion protocol to ensure complete hydrolysis.3. Use a more sensitive mass spectrometer or an enrichment strategy for m1A-containing RNAs prior to analysis. |
Experimental Protocols
Protocol 1: m1A-Seq (MeRIP-Seq)
This protocol provides a general overview of the methylated RNA immunoprecipitation sequencing workflow.
-
RNA Isolation and Fragmentation:
-
Isolate total RNA from the cells or tissues of interest using a standard method like TRIzol extraction.
-
Assess RNA quality and quantity using a Bioanalyzer or similar instrument.
-
Fragment the RNA to an average size of 100-200 nucleotides using chemical or enzymatic methods.
-
-
Immunoprecipitation (IP):
-
Incubate the fragmented RNA with an m1A-specific antibody.
-
Add protein A/G magnetic beads to the RNA-antibody mixture to capture the antibody-RNA complexes.
-
Wash the beads multiple times to remove non-specifically bound RNA.
-
Elute the m1A-containing RNA fragments from the beads.
-
-
Library Preparation and Sequencing:
-
Prepare a sequencing library from the eluted RNA fragments and an input control (a small fraction of the fragmented RNA saved before the IP step).
-
Perform high-throughput sequencing of the libraries.
-
-
Data Analysis:
-
Align the sequencing reads to the reference genome/transcriptome.
-
Use peak-calling algorithms to identify enriched regions in the m1A-IP sample compared to the input control. These peaks represent putative m1A sites.
-
Quantitative Data Summary
The following table compares different methods for m1A detection.
| Method | Principle | Sensitivity | Quantitative? | Sequence Context | Advantages | Disadvantages |
| m1A-Seq (MeRIP-Seq) | Antibody-based enrichment of m1A-containing RNA fragments followed by sequencing. | Moderate to High | Semi-quantitative | Yes | Transcriptome-wide mapping. | Relies on antibody specificity; resolution is limited to the fragment size. |
| RT-PCR Based Methods | m1A modification can cause reverse transcriptase to stall or misincorporate nucleotides. | High | Semi-quantitative | Yes | Site-specific validation of m1A sites. | Not suitable for transcriptome-wide discovery; can be influenced by RNA secondary structure. |
| LC-MS/MS | Separation and mass analysis of individual nucleosides after RNA hydrolysis.[4][5] | High | Yes | No | Highly accurate and quantitative. | Destroys the RNA sequence context; requires specialized equipment. |
| Nanopore Direct RNA Sequencing | Direct sequencing of native RNA molecules, where modifications cause characteristic changes in the ionic current.[6][7][8] | High | Yes | Yes | Single-molecule resolution; provides sequence context. | Data analysis is complex; technology is still evolving. |
Visual Guides
Caption: A generalized experimental workflow for the detection of m1A RNA modifications.
Caption: A decision tree for troubleshooting low signal issues in m1A detection experiments.
Caption: The principle of antibody-based enrichment for m1A-modified RNA fragments.
References
- 1. researchgate.net [researchgate.net]
- 2. Navigating the pitfalls of mapping DNA and RNA modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Challenges with Simulating Modified RNA: Insights into Role and Reciprocity of Experimental and Computational Approaches - PMC [pmc.ncbi.nlm.nih.gov]
- 4. mdpi.com [mdpi.com]
- 5. mdpi.com [mdpi.com]
- 6. nanoporetech.com [nanoporetech.com]
- 7. m.youtube.com [m.youtube.com]
- 8. nanoporetech.com [nanoporetech.com]
Technical Support Center: LC-MS Detection of 1-Methyl-2'-O-methylinosine
Welcome to the technical support center for the LC-MS analysis of 1-Methyl-2'-O-methylinosine. This resource provides troubleshooting guidance and answers to frequently asked questions to help researchers, scientists, and drug development professionals optimize their analytical methods for improved sensitivity and robust detection of this modified nucleoside.
Troubleshooting Guide: Enhancing Sensitivity
Low sensitivity is a common challenge in the analysis of modified nucleosides like this compound. This guide provides a systematic approach to identifying and resolving potential issues.
Question: I am observing a weak or no signal for this compound. Where should I start troubleshooting?
Answer: A weak or absent signal can originate from various stages of your workflow, from sample preparation to data acquisition. Follow this logical troubleshooting flow to pinpoint the issue:
Technical Support Center: Overcoming Matrix Effects in Nucleoside Mass Spectrometry
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals overcome matrix effects in the mass spectrometry of nucleosides.
Frequently Asked Questions (FAQs)
Q1: What are matrix effects in the context of nucleoside mass spectrometry?
A1: Matrix effects refer to the alteration of an analyte's ionization efficiency by co-eluting compounds from the sample matrix, such as plasma or urine.[1] These effects can manifest as ion suppression (a decrease in signal) or ion enhancement (an increase in signal), leading to inaccurate and imprecise quantification of nucleosides.[1][2] Common sources of matrix effects in biofluids include phospholipids, salts, proteins, and other endogenous metabolites.[1][3][4]
Q2: What are the common indicators of matrix effects in my nucleoside analysis?
A2: Several signs can point to the presence of matrix effects in your analysis. These include poor reproducibility between sample preparations, inaccurate quantification leading to high variability, non-linear calibration curves, reduced sensitivity with poor signal-to-noise ratios, and inconsistent peak areas for quality control (QC) samples.[5]
Q3: How can I assess the presence and magnitude of matrix effects in my assay?
A3: There are two primary methods to evaluate matrix effects:
-
Post-Column Infusion: This qualitative method involves infusing a constant flow of a nucleoside standard solution into the mass spectrometer post-column while a blank, extracted biofluid sample is injected.[6][7] A dip or rise in the baseline signal at the expected retention time of the nucleoside indicates ion suppression or enhancement, respectively.[1][7]
-
Post-Extraction Spike: This quantitative method compares the response of a nucleoside standard in a neat solution to the response of the same standard spiked into an extracted blank biofluid sample.[3][8] The matrix factor (MF) is calculated as the ratio of the peak area in the presence of the matrix to the peak area in the neat solution. An MF less than 1 indicates ion suppression, while an MF greater than 1 suggests ion enhancement.[1][8]
Q4: What is the most effective internal standard strategy to compensate for matrix effects during nucleoside analysis?
A4: The use of a stable isotope-labeled internal standard (SIL-IS) is widely considered the gold standard and most effective approach to compensate for matrix effects.[6][9][10] A SIL-IS is chemically identical to the analyte and will co-elute, experiencing the same matrix effects.[10] This allows for accurate correction of signal variations, leading to reliable quantification.[11][12][13]
Troubleshooting Guide
This guide provides a systematic approach to diagnosing and resolving common issues related to matrix effects during nucleoside analysis.
Issue 1: Poor Reproducibility and Inaccurate Quantification
Possible Cause: Significant matrix effects are likely present, causing inconsistent ion suppression or enhancement.
Troubleshooting Workflow:
Caption: Troubleshooting workflow for poor reproducibility.
Issue 2: Low Signal Intensity and Poor Sensitivity
Possible Cause: Ion suppression due to co-eluting matrix components.
Troubleshooting Steps:
-
Identify the Source of Suppression: Perform a post-column infusion experiment to determine the retention time regions where ion suppression occurs.
-
Optimize Chromatography: Adjust the LC gradient to separate the nucleoside analyte from the suppression zones.
-
Enhance Sample Cleanup: Implement a more rigorous sample preparation method to remove interfering compounds. Common techniques include Solid-Phase Extraction (SPE), Liquid-Liquid Extraction (LLE), and protein precipitation.[4]
Sample Preparation Method Comparison
| Sample Preparation Method | Principle | Pros | Cons |
| Protein Precipitation (PPT) | Addition of an organic solvent (e.g., acetonitrile) to precipitate proteins. | Simple, fast, and inexpensive. | Non-selective, may not remove other matrix components like phospholipids.[4] |
| Liquid-Liquid Extraction (LLE) | Partitioning of the analyte between two immiscible liquid phases. | More selective than PPT, can remove phospholipids.[4] | Can be labor-intensive and require larger solvent volumes. |
| Solid-Phase Extraction (SPE) | Analyte is retained on a solid sorbent while interferences are washed away. | Highly selective, provides excellent sample cleanup.[4][14] | Can be more expensive and require method development. |
Issue 3: Non-Linear Calibration Curve
Possible Cause: The matrix effect is concentration-dependent.
Troubleshooting Logic:
Caption: Troubleshooting logic for a non-linear curve.
Experimental Protocols
Protocol 1: Assessment of Matrix Effects using Post-Extraction Spike
Objective: To quantify the extent of ion suppression or enhancement.
Materials:
-
Blank biological matrix (e.g., plasma, urine) from at least six different sources.
-
Nucleoside standard solution of known concentration.
-
Reconstitution solvent.
-
LC-MS/MS system.
Procedure:
-
Sample Preparation:
-
Set A (Neat Solution): Prepare a standard solution of the nucleoside in the reconstitution solvent.
-
Set B (Post-Extraction Spike): Extract the blank biological matrix using your established sample preparation protocol. Spike the extracted matrix with the nucleoside standard to the same final concentration as Set A.
-
-
LC-MS/MS Analysis: Analyze both sets of samples under the same conditions.
-
Data Analysis:
-
Calculate the average peak area for the nucleoside in both Set A and Set B.
-
Calculate the Matrix Factor (MF) using the following formula:
-
MF = (Average Peak Area in Set B) / (Average Peak Area in Set A)
-
-
An MF < 1 indicates ion suppression.
-
An MF > 1 indicates ion enhancement.
-
Protocol 2: Isotope Dilution Mass Spectrometry for Nucleoside Quantification
Objective: To achieve accurate quantification of nucleosides by correcting for matrix effects.
Workflow Diagram:
Caption: Isotope dilution mass spectrometry workflow.
Procedure:
-
Sample Spiking: To a known volume or weight of your sample, add a precise amount of the corresponding SIL-IS for each nucleoside being analyzed.
-
Sample Preparation: Perform your optimized sample preparation protocol (e.g., protein precipitation, LLE, or SPE) on the spiked sample.
-
Calibration Curve: Prepare a series of calibration standards containing known concentrations of the unlabeled nucleoside and a constant concentration of the SIL-IS. These standards should be prepared in a matrix that closely mimics the actual samples if possible (matrix-matched calibration).[10]
-
LC-MS/MS Analysis: Analyze the prepared samples and calibration standards.
-
Quantification:
-
For each sample and calibrator, determine the peak area ratio of the native nucleoside to its corresponding SIL-IS.
-
Construct a calibration curve by plotting the peak area ratios of the calibrators against their known concentrations.
-
Determine the concentration of the nucleoside in your samples by interpolating their peak area ratios on the calibration curve.
-
References
- 1. benchchem.com [benchchem.com]
- 2. Overcoming matrix effects in liquid chromatography-mass spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Tracking Matrix Effects in the Analysis of DNA Adducts of Polycyclic Aromatic Hydrocarbons - PMC [pmc.ncbi.nlm.nih.gov]
- 4. chromatographyonline.com [chromatographyonline.com]
- 5. benchchem.com [benchchem.com]
- 6. chromatographyonline.com [chromatographyonline.com]
- 7. Compensate for or Minimize Matrix Effects? Strategies for Overcoming Matrix Effects in Liquid Chromatography-Mass Spectrometry Technique: A Tutorial Review - PMC [pmc.ncbi.nlm.nih.gov]
- 8. What is matrix effect and how is it quantified? [sciex.com]
- 9. pubs.acs.org [pubs.acs.org]
- 10. longdom.org [longdom.org]
- 11. Isotope-dilution mass spectrometry for exact quantification of noncanonical DNA nucleosides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Quantification of modified nucleotides and nucleosides by isotope dilution mass spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. semanticscholar.org [semanticscholar.org]
- 14. Matrix effect in bio-analysis of illicit drugs with LC-MS/MS: influence of ionization type, sample preparation, and biofluid - PubMed [pubmed.ncbi.nlm.nih.gov]
Technical Support Center: Quantification of 1-Methyl-2'-O-methylinosine (m1Am) in Complex Samples
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in the accurate quantification of 1-Methyl-2'-O-methylinosine (m1Am) in complex biological samples using liquid chromatography-tandem mass spectrometry (LC-MS/MS).
Frequently Asked Questions (FAQs) & Troubleshooting Guides
Q1: Why is the signal intensity for m1Am consistently low or undetectable in my samples?
A: Low or no signal for this compound (m1Am) can stem from several factors throughout the experimental workflow. A common issue is inefficient release of the modified nucleoside from the RNA backbone. Additionally, degradation of the target analyte during sample processing or suboptimal mass spectrometry settings can significantly impact signal intensity.
Troubleshooting Steps:
-
Optimize RNA Digestion: Ensure complete enzymatic digestion of your RNA samples. Incomplete digestion will fail to liberate m1Am, making it unavailable for detection.
-
Enzyme Choice: A combination of nucleases is crucial for complete RNA digestion to single nucleosides. A common and effective combination includes Nuclease P1 followed by Bacterial Alkaline Phosphatase (BAP) or a cocktail of Benzonase and Phosphodiesterase I.
-
Enzyme-to-Substrate Ratio: Ensure an adequate amount of enzyme is used for the quantity of RNA being digested. A typical starting point is 1-2 units of Nuclease P1 per 1 µg of RNA.
-
Incubation Time and Temperature: Follow the enzyme manufacturer's recommendations. Inadequate incubation times will result in incomplete digestion.
-
-
Assess Sample Integrity: Degraded RNA will lead to inaccurate quantification. Always assess RNA quality (e.g., using a Bioanalyzer) before proceeding with digestion.
-
Verify Mass Spectrometry Parameters: Ensure the mass spectrometer is set to monitor the correct mass transitions for m1Am.
-
Precursor and Product Ions: For m1Am, the protonated molecule [M+H]⁺ is expected at m/z 297.1. The most abundant product ion typically results from the cleavage of the glycosidic bond, yielding the modified base at m/z 151.1.
-
Ionization Source Conditions: Optimize the electrospray ionization (ESI) source parameters, including spray voltage, gas flows, and temperature, to ensure efficient ionization of m1Am.
-
-
Sample Cleanup: Complex biological matrices can cause ion suppression.[1] Incorporate a solid-phase extraction (SPE) step after digestion to remove interfering substances.
Q2: How can I mitigate matrix effects that are causing inconsistent quantification results?
A: Matrix effects, which are the suppression or enhancement of ionization of the analyte of interest by co-eluting compounds from the sample matrix, are a significant challenge in LC-MS/MS analysis.[1] The most effective strategy to correct for matrix effects is the use of a stable isotope-labeled internal standard (SILIS).[1][2]
Strategies to Minimize and Correct for Matrix Effects:
-
Stable Isotope-Labeled Internal Standard (SILIS): This is the gold standard for correcting matrix effects.[2][3] A SILIS for m1Am (e.g., ¹³C- or ¹⁵N-labeled m1Am) will co-elute with the analyte and experience the same ionization effects, allowing for accurate correction. The SILIS should be added to the sample as early as possible in the workflow.
-
Effective Sample Preparation: Reducing the complexity of the sample matrix before injection is crucial.
-
Solid-Phase Extraction (SPE): Utilize SPE cartridges that are appropriate for retaining and eluting nucleosides while washing away interfering components like salts and proteins.
-
Liquid-Liquid Extraction (LLE): This can also be an effective cleanup method.
-
-
Chromatographic Separation: Optimize the HPLC separation to resolve m1Am from matrix components that cause ion suppression.
-
Gradient Optimization: Adjust the gradient elution profile to maximize the separation between your analyte and any interfering peaks.
-
Column Chemistry: Test different column chemistries (e.g., C18, HILIC) to achieve the best separation.
-
-
Sample Dilution: If the analyte concentration is high enough, simply diluting the sample can reduce the concentration of interfering matrix components, thereby lessening their impact on ionization.[1]
Q3: My results show high variability between technical replicates. What are the likely causes?
A: High variability in quantitative results often points to inconsistencies in sample handling and preparation, or issues with the analytical instrument.
Troubleshooting High Variability:
-
Inconsistent Sample Preparation:
-
Pipetting Errors: Ensure pipettes are properly calibrated and that precise volumes are used, especially when adding the internal standard.
-
Incomplete Digestion: As mentioned in Q1, incomplete or variable digestion efficiency between samples will lead to inconsistent results.
-
Sample Evaporation: If samples are left uncapped for extended periods, solvent evaporation can concentrate the sample, leading to artificially high readings. Use autosampler vials with septa and keep samples cooled.
-
-
LC-MS/MS System Issues:
-
Injection Volume Precision: Check the autosampler for consistent injection volumes.
-
Column Performance: A deteriorating HPLC column can lead to peak shape distortion and shifting retention times, affecting integration and quantification.
-
MS Source Contamination: A dirty ion source can cause erratic signal intensity. Regular cleaning and maintenance are essential.
-
-
Data Processing:
-
Peak Integration: Ensure that the software is consistently and accurately integrating the chromatographic peaks for both the analyte and the internal standard. Manual review of peak integration is often necessary.
-
Experimental Protocols
Protocol 1: RNA Extraction and Digestion
This protocol describes the enzymatic digestion of total RNA to nucleosides for LC-MS/MS analysis.
-
RNA Isolation: Isolate total RNA from your biological sample using a commercially available kit or a TRIzol-based method. Ensure the final RNA pellet is dissolved in RNase-free water.
-
RNA Quantification and Quality Control: Quantify the RNA using a spectrophotometer (e.g., NanoDrop) and assess its integrity using an Agilent Bioanalyzer or similar capillary electrophoresis system.
-
Enzymatic Digestion: a. In an RNase-free microcentrifuge tube, combine 1-5 µg of total RNA with the stable isotope-labeled internal standard (e.g., ¹³C₅-¹⁵N₂-m1Am). b. Add Nuclease P1 buffer (e.g., 10 mM ammonium (B1175870) acetate, pH 5.3) and 2 units of Nuclease P1. c. Incubate at 37°C for 2 hours. d. Add Bacterial Alkaline Phosphatase (BAP) buffer (e.g., 50 mM Tris-HCl, pH 8.0) and 1 unit of BAP. e. Incubate at 37°C for an additional 2 hours.
-
Sample Cleanup (SPE): a. Condition a mixed-mode SPE cartridge with methanol (B129727) and then with water. b. Load the digested sample onto the cartridge. c. Wash the cartridge with water to remove salts and other polar impurities. d. Elute the nucleosides with a solution of 5% ammonium hydroxide (B78521) in methanol. e. Dry the eluate under a stream of nitrogen or in a vacuum concentrator. f. Reconstitute the sample in the initial mobile phase for LC-MS/MS analysis.
Protocol 2: LC-MS/MS Analysis of m1Am
This protocol provides a starting point for the development of an LC-MS/MS method for m1Am quantification.
-
Liquid Chromatography (LC):
-
Column: A reversed-phase C18 column (e.g., 2.1 x 100 mm, 1.8 µm) is a good starting point.
-
Mobile Phase A: 0.1% formic acid in water.
-
Mobile Phase B: 0.1% formic acid in acetonitrile.
-
Gradient: A linear gradient from 2% to 40% B over 10 minutes.
-
Flow Rate: 0.3 mL/min.
-
Injection Volume: 5 µL.
-
-
Mass Spectrometry (MS):
-
Ionization Mode: Positive Electrospray Ionization (ESI+).
-
Analysis Mode: Multiple Reaction Monitoring (MRM).
-
Scan Type: Monitor the specific mass transitions for m1Am and its SILIS.
-
Quantitative Data Tables
Table 1: Example LC-MS/MS Parameters for m1Am Quantification
| Analyte | Precursor Ion (m/z) | Product Ion (m/z) | Collision Energy (eV) | Dwell Time (ms) |
| This compound (m1Am) | 297.1 | 151.1 | 20 | 50 |
| ¹³C₅-¹⁵N₂-m1Am (SILIS) | 304.1 | 156.1 | 20 | 50 |
Note: Collision energy should be optimized for your specific instrument.
Table 2: Summary of Common Troubleshooting Issues and Solutions
| Issue | Potential Cause(s) | Recommended Solution(s) |
| No or Low Signal | Incomplete RNA digestion, analyte degradation, incorrect MS/MS parameters. | Optimize digestion protocol, check sample integrity, verify mass transitions. |
| High Variability | Inconsistent sample preparation, unstable spray, inconsistent peak integration. | Use a SILIS, perform regular instrument maintenance, manually review peak integration. |
| Poor Peak Shape | Column degradation, inappropriate mobile phase, sample solvent mismatch. | Replace column, ensure mobile phase compatibility, reconstitute sample in initial mobile phase. |
| Inaccurate Quantification | Matrix effects, lack of appropriate internal standard, non-linear calibration curve. | Use a SILIS, perform thorough sample cleanup, use a weighted calibration curve if necessary. |
Visualizations
Experimental Workflow for m1Am Quantification
Caption: Workflow for m1Am quantification from sample to result.
Troubleshooting Logic for Low Signal Intensity
Caption: Decision tree for troubleshooting low m1Am signal.
References
Technical Support Center: Optimizing HPLC Separation of 1-Methyl-2'-O-methylinosine Isomers
This technical support center is designed for researchers, scientists, and drug development professionals to provide troubleshooting guidance and frequently asked questions (FAQs) for the HPLC separation of 1-Methyl-2'-O-methylinosine isomers.
Troubleshooting Guide
This section addresses specific issues you may encounter during your experiments in a direct question-and-answer format.
Q1: My this compound isomers are co-eluting or showing poor resolution. What are the initial steps to improve separation?
A1: Co-elution of closely related isomers is a common challenge. A systematic approach to enhance column selectivity and efficiency is necessary.
Initial Troubleshooting Steps:
-
Optimize the Mobile Phase Gradient: A shallow gradient can increase the separation time between closely eluting peaks.
-
Modify the Mobile Phase Composition:
-
Adjust Organic Modifier Concentration: For reversed-phase HPLC, altering the ratio of the organic solvent (e.g., acetonitrile (B52724) or methanol) to the aqueous buffer can significantly impact retention and selectivity.
-
Switch Organic Modifier: Methanol and acetonitrile offer different selectivities. If one is not providing adequate separation, switching to the other is a valuable step.
-
Adjust pH: Since nucleosides have ionizable groups, modifying the mobile phase pH can alter their charge state and interaction with the stationary phase, leading to improved separation.[1]
-
-
Change the Column Temperature: Adjusting the column temperature can influence the thermodynamics of the separation and improve resolution.
Q2: I'm observing peak tailing for my isomer peaks. What are the likely causes and how can I fix it?
A2: Peak tailing is often caused by secondary interactions between the analyte and the stationary phase, particularly with acidic silanol (B1196071) groups on silica-based columns.
Solutions for Peak Tailing:
-
Use a Mobile Phase Additive: Adding a small amount of a competing base, such as triethylamine (B128534) (TEA), can mask the active silanol groups and improve peak shape for basic compounds.
-
Adjust Mobile Phase pH: Operating at a lower pH (e.g., around 3.0) can suppress the ionization of silanol groups, reducing unwanted interactions.
-
Employ an End-Capped Column: Modern, high-purity, end-capped columns have fewer exposed silanol groups and are less prone to causing peak tailing.
Q3: My retention times are drifting between injections. What could be the cause?
A3: Unstable retention times can compromise the reliability of your results. The issue can stem from the HPLC system, column, or mobile phase.
Troubleshooting Retention Time Instability:
-
Ensure Proper Column Equilibration: The column must be thoroughly equilibrated with the initial mobile phase conditions before each injection. A minimum of 10 column volumes is recommended.
-
Check for Leaks: Inspect the system for any leaks, as this can cause fluctuations in pressure and flow rate.
-
Mobile Phase Preparation: Ensure the mobile phase is well-mixed and degassed to prevent bubble formation in the pump.
-
Column Temperature Control: Use a column oven to maintain a stable temperature, as fluctuations can affect retention times.
Q4: After optimizing the mobile phase, the isomers are still not separating. What is the next step?
A4: If mobile phase optimization is insufficient, the stationary phase chemistry may not be suitable for the separation.
Advanced Troubleshooting:
-
Change the Stationary Phase:
-
Different Reversed-Phase Chemistry: If using a C18 column, consider a phenyl-hexyl or a polar-embedded column, which can offer different selectivities for aromatic and polar compounds.
-
Chiral Stationary Phase (CSP): Since this compound is a chiral molecule, its isomers may be enantiomers or diastereomers. For enantiomeric separation, a chiral column is necessary. Polysaccharide-based and macrocyclic glycopeptide chiral columns are commonly used for nucleoside analogs.[2]
-
Frequently Asked Questions (FAQs)
Q1: What is a good starting point for developing a reversed-phase HPLC method for this compound isomers?
A1: A good starting point is to use a C18 column with a mobile phase consisting of a buffered aqueous solution and an organic modifier like acetonitrile or methanol. A common approach is to run a scouting gradient (e.g., 5% to 95% organic solvent) to determine the approximate elution conditions. A volatile buffer like ammonium (B1175870) acetate (B1210297) or ammonium formate (B1220265) is often a good choice, especially if the method will be coupled with mass spectrometry.
Q2: How does the pH of the mobile phase affect the separation of nucleoside isomers?
A2: The pH of the mobile phase is a critical parameter as it influences the ionization state of the analytes.[1] For nucleosides, which contain basic and acidic functional groups, a change in pH can alter their hydrophobicity and interaction with the stationary phase, thereby affecting their retention time and the selectivity of the separation.
Q3: When should I consider using a chiral HPLC column?
A3: You should consider a chiral HPLC column when you are trying to separate enantiomers. Enantiomers have identical physical and chemical properties in an achiral environment, so they will not be separated on a standard achiral column. A chiral stationary phase provides a chiral environment that allows for differential interaction with the enantiomers, leading to their separation.[2]
Q4: Can I use the same method for both analytical and preparative separation?
A4: While the same chromatographic principles apply, preparative HPLC methods are typically scaled up from analytical methods. This involves using a larger column, a higher flow rate, and injecting a larger sample volume. The goal of preparative HPLC is to isolate a pure compound, so baseline separation is crucial. The analytical method is first optimized for the best resolution, and then the conditions are adapted for the preparative scale.
Data Presentation
Table 1: Recommended Starting Columns for Isomer Separation
| Column Type | Stationary Phase Chemistry | Particle Size (µm) | Dimensions (mm) | Recommended For |
| Reversed-Phase | C18 | 1.8 - 5 | 4.6 x 150/250 | General purpose, initial method development |
| Reversed-Phase | Phenyl-Hexyl | 1.8 - 5 | 4.6 x 150/250 | Aromatic and moderately polar isomers |
| Chiral | Polysaccharide-based (e.g., Cellulose or Amylose derivatives) | 3 - 5 | 4.6 x 150/250 | Enantiomeric separation |
| Chiral | Macrocyclic Glycopeptide (e.g., Teicoplanin or Vancomycin) | 3 - 5 | 4.6 x 150/250 | Enantiomeric separation |
Table 2: Mobile Phase Additives and Their Functions
| Additive | Typical Concentration | Mode of Chromatography | Function |
| Trifluoroacetic Acid (TFA) | 0.05 - 0.1% | Reversed-Phase | Ion-pairing agent, improves peak shape for basic compounds |
| Formic Acid | 0.1% | Reversed-Phase | Acidic modifier, good for LC-MS compatibility |
| Ammonium Acetate/Formate | 10 - 20 mM | Reversed-Phase | Buffer, volatile and LC-MS compatible |
| Triethylamine (TEA) | 0.1% | Reversed-Phase | Reduces peak tailing by masking silanols |
Experimental Protocols
Protocol 1: Recommended Starting Method for Reversed-Phase HPLC Separation of this compound Isomers
This protocol provides a starting point for method development. Optimization will likely be required to achieve baseline separation.
-
HPLC System: A standard HPLC or UHPLC system with a UV detector.
-
Column: C18 reversed-phase column (e.g., 4.6 x 150 mm, 3.5 µm).
-
Mobile Phase A: 10 mM Ammonium Acetate in water, pH 5.5.
-
Mobile Phase B: Acetonitrile.
-
Gradient:
-
0-2 min: 5% B
-
2-20 min: 5% to 40% B (linear gradient)
-
20-25 min: 40% B
-
25-26 min: 40% to 5% B (linear gradient)
-
26-30 min: 5% B (equilibration)
-
-
Flow Rate: 1.0 mL/min.
-
Column Temperature: 30 °C.
-
Detection: UV at 260 nm.
-
Injection Volume: 10 µL.
-
Sample Preparation: Dissolve the sample in a mixture of water and acetonitrile (e.g., 95:5 v/v) to a concentration of approximately 1 mg/mL. Filter through a 0.22 µm syringe filter before injection.
Protocol 2: Chiral HPLC Separation Screening
If reversed-phase separation is unsuccessful, a chiral screening approach is recommended.
-
HPLC System: A standard HPLC system with a UV detector.
-
Columns:
-
Cellulose-based chiral column (e.g., Chiralcel OD-H)
-
Amylose-based chiral column (e.g., Chiralpak AD-H)
-
-
Mobile Phases (Normal Phase):
-
Hexane/Isopropanol (90:10, v/v)
-
Hexane/Ethanol (90:10, v/v)
-
-
Mobile Phases (Reversed-Phase for Chiral Columns):
-
Acetonitrile/Water (e.g., 50:50, v/v)
-
Methanol/Water (e.g., 60:40, v/v)
-
-
Flow Rate: 0.5 - 1.0 mL/min.
-
Column Temperature: 25 °C.
-
Detection: UV at 260 nm.
-
Injection Volume: 10 µL.
-
Procedure:
-
Equilibrate the first chiral column with the first mobile phase.
-
Inject the sample and run isocratically.
-
If separation is not achieved, switch to the next mobile phase and re-equilibrate the column.
-
Repeat the process for the second chiral column.
-
Mandatory Visualization
Caption: Troubleshooting workflow for poor isomer separation.
Caption: General experimental workflow for HPLC method development.
References
minimizing RNA degradation during sample preparation for m1Im analysis
This technical support center provides researchers, scientists, and drug development professionals with comprehensive troubleshooting guides and frequently asked questions (FAQs) to minimize RNA degradation during sample preparation for N1-methyladenosine (m1A) analysis.
Troubleshooting Guides
This section addresses specific issues that may arise during your experimental workflow, leading to RNA degradation.
Problem 1: Low RNA Yield and Quality Post-Extraction
-
Question: I've just extracted my RNA, but the concentration is very low, and the A260/A280 and A260/A230 ratios are suboptimal. What could have gone wrong?
-
Answer: Low yield and poor purity are often the first indicators of RNA degradation or issues with the extraction protocol. Here are the potential causes and solutions:
-
Incomplete Cell Lysis: If cells are not completely lysed, the RNA will not be efficiently released, leading to low yields.
-
Solution: Ensure you are using the appropriate lysis method for your sample type. For difficult-to-lyse samples like microbial cells, consider combining chemical lysis with mechanical methods (e.g., bead beating) or enzymatic digestion (e.g., lysozyme, proteinase K).[1]
-
-
RNase Contamination: RNases are ubiquitous and can rapidly degrade RNA.[2][3] Contamination can be introduced from your hands, dust, or non-certified reagents and equipment.[2]
-
Solution: Always wear gloves and change them frequently, especially after touching any non-sterile surfaces.[2][4][5] Work in a designated RNase-free area and use certified RNase-free reagents, pipette tips, and tubes.[4][6] Clean your workspace and equipment with RNase decontamination solutions.[4][7]
-
-
Improper Sample Handling and Storage: RNA is inherently unstable and susceptible to degradation, especially at room temperature.[3][4]
-
Solution: Process your samples immediately after collection whenever possible. If immediate processing is not feasible, stabilize the RNA by either snap-freezing the sample in liquid nitrogen or by using a commercial RNA stabilization reagent.[1][5][8] Always keep your samples on ice during the extraction procedure.[5][7]
-
-
Guanidine (B92328) Salt or Organic Inhibitor Carryover: A low 260/230 ratio can indicate contamination with guanidine salts (used in many lysis buffers) or other organic compounds which can inhibit downstream enzymatic reactions.[8]
-
Solution: Ensure sufficient washing steps during the RNA purification process. For column-based kits, additional washes with 70-80% ethanol (B145695) can help remove residual salts.[8] If using a TRIzol-based method, a thorough ethanol wash of the RNA pellet is crucial.[8]
-
-
Problem 2: Evidence of RNA Degradation on Gel Electrophoresis
-
Question: I ran my RNA sample on a denaturing agarose (B213101) gel, and instead of sharp 28S and 18S rRNA bands, I see a smear. What does this indicate?
-
Answer: A smear on a denaturing gel is a classic sign of RNA degradation.[3] The well-defined ribosomal RNA (rRNA) bands should be distinct, with the 28S rRNA band appearing approximately twice as intense as the 18S rRNA band for high-quality eukaryotic RNA.
-
Causes of Degradation:
-
Troubleshooting Steps:
-
Sample Stabilization: The most critical step is to inactivate endogenous RNases immediately upon sample collection.[1][7] This can be achieved by:
-
Immediate Lysis: Homogenize the sample directly in a lysis buffer containing a strong denaturant like guanidinium (B1211019) thiocyanate (B1210189).[1]
-
Stabilization Reagents: Submerge the sample in an RNA stabilization solution.[1][4]
-
Snap Freezing: Immediately freeze the sample in liquid nitrogen and store it at -80°C.[5][8] Do not allow the sample to thaw before it is placed in lysis buffer.[8]
-
-
Maintain an RNase-Free Environment:
-
Incorporate RNase Inhibitors: Add a broad-spectrum RNase inhibitor to your lysis buffer and other solutions where RNases might be active.[2][9] Murine RNase inhibitors are often recommended as they are more resistant to oxidation than their human counterparts.[10]
-
-
Problem 3: Low Library Yields or Failure in Downstream m1A Analysis
-
Question: My RNA quality metrics (RIN, A260/280) looked good, but my m1A library preparation failed, or the sequencing results are poor. Why could this be?
-
Answer: Even if initial quality control metrics seem acceptable, subtle RNA degradation or the presence of inhibitors can significantly impact downstream applications like reverse transcription and library construction for m1A analysis.[9][11]
-
Potential Issues and Solutions:
-
RNA Fragmentation: While some protocols for m1A sequencing involve controlled RNA fragmentation, excessive degradation prior to this step can lead to a loss of library complexity and biased results.[12][13][14]
-
Solution: Adhere strictly to best practices for preventing RNA degradation throughout the entire workflow. Use high-quality, intact RNA as your starting material. The RNA Integrity Number (RIN) is a good metric to assess this, with a RIN value ≥ 7 being desirable for most sequencing applications.[15][16]
-
-
Inefficient Reverse Transcription: The presence of m1A modifications can cause reverse transcriptase to stall or misincorporate bases, which is a principle used for their detection.[17] However, contaminants in the RNA sample can further inhibit the reverse transcriptase enzyme, leading to low cDNA yield.
-
RNase Activity During Reactions: RNases can remain active during enzymatic reactions if not properly inactivated.
-
-
Frequently Asked Questions (FAQs)
Q1: What is the optimal storage condition for my RNA samples? A1: For long-term storage (up to a year), RNA should be stored at -80°C.[3] It can be stored as an ethanol precipitate at -20°C for long periods as well.[2] For short-term storage, -20°C or 4°C is acceptable for a few weeks, but storage in a buffered solution (e.g., TE buffer, pH 7.5 or sodium citrate, pH 6) is recommended over RNase-free water to prevent hydrolysis.[4] To minimize degradation from repeated freeze-thaw cycles, it is best practice to aliquot RNA samples into smaller volumes.[18]
Q2: How do I create an RNase-free work environment? A2:
-
Designated Area: Have a specific bench or area dedicated solely to RNA work.[6]
-
Decontamination: Regularly clean your benchtop, pipettes, and other equipment with commercially available RNase decontamination solutions or 70% ethanol.[5][7]
-
Personal Protective Equipment (PPE): Always wear clean gloves and a lab coat. Change gloves frequently, especially if you touch non-decontaminated surfaces like your face, skin, or door handles.[2][4][5] Consider wearing a face mask to prevent contamination from breathing over your samples.[5]
-
RNase-Free Consumables: Use certified RNase-free pipette tips (with filters), microcentrifuge tubes, and reagents.[5][6]
-
Treating Non-disposable Items: Treat non-disposable plasticware with 0.1 M NaOH/1 mM EDTA, followed by a thorough rinse with RNase-free water.[2] Glassware can be baked at a high temperature.
Q3: What are the key quality control checkpoints for my RNA sample before proceeding with m1A analysis? A3: There are three main quality control metrics to assess:
-
Purity: Measured using a spectrophotometer.
-
Integrity: Assessed to determine if the RNA is intact or degraded.
-
Denaturing Agarose Gel Electrophoresis: Visually inspect for sharp 28S and 18S rRNA bands and the absence of smearing.
-
Automated Capillary Electrophoresis (e.g., Agilent Bioanalyzer): Provides an RNA Integrity Number (RIN) on a scale of 1 (degraded) to 10 (intact).[16] For m1A sequencing, a RIN value of ≥ 7 is generally recommended.[15]
-
-
Quantity: The concentration of RNA is determined by spectrophotometry (at 260 nm) or more accurately by fluorometry (e.g., Qubit), which is less affected by contaminants.[11][16]
Q4: Can I use degraded RNA for m1A analysis? A4: The use of low-quality, degraded RNA is highly discouraged as it can lead to biased results and a loss of library complexity.[13][14] RNA degradation does not occur uniformly across all transcripts, meaning that some RNA species may be disproportionately lost, which would skew the quantification of m1A modifications.[13] While some computational methods can attempt to correct for degradation effects, starting with high-quality RNA is the best practice for reliable and reproducible results.[13][14]
Data Summary
Table 1: RNA Stability Under Different Storage Conditions
| Storage Condition | Buffer | Duration | Expected RNA Integrity |
| Room Temperature (25°C) | RNase-free Water | > 15 minutes | Significant Degradation[3] |
| Room Temperature (25°C) | TE or Citrate Buffer | 3 weeks | Largely Intact[4] |
| 4°C | RNase-free Water | 3 weeks | Intact[4] |
| -20°C | RNase-free Water/Buffer | At least 3 weeks | Stable[4] |
| -80°C | RNase-free Water/Buffer | Up to 1 year | Stable[2][3] |
Table 2: RNA Quality Control Metrics and Interpretation
| Metric | Instrument | Ideal Value | Indication of a Problem |
| A260/A280 Ratio | Spectrophotometer | ~2.0[16] | < 1.8 suggests protein contamination |
| A260/A230 Ratio | Spectrophotometer | > 1.8[16] | < 1.5 suggests salt or organic contamination |
| RNA Integrity Number (RIN) | Bioanalyzer/TapeStation | ≥ 7[15] | < 6 indicates significant degradation |
| 28S:18S rRNA Ratio | Gel/Bioanalyzer | ~2:1 | A ratio closer to 1:1 or smearing indicates degradation |
Experimental Protocols
Protocol 1: General RNA Extraction from Cultured Mammalian Cells
This protocol provides a general workflow. Always refer to the manufacturer's instructions for your specific RNA extraction kit.
-
Sample Collection:
-
Aspirate the cell culture medium.
-
Wash the cell monolayer once with cold, sterile PBS.
-
Harvest cells by either trypsinization or by scraping directly into the lysis buffer.
-
-
Cell Lysis:
-
Add the appropriate volume of lysis buffer (containing a chaotropic agent like guanidinium thiocyanate and often β-mercaptoethanol to inhibit RNases) directly to the cell pellet or plate.[8]
-
Homogenize the lysate by passing it through a syringe with a narrow-gauge needle or by vortexing.
-
-
RNA Purification (Column-Based Method):
-
Add an equal volume of 70% ethanol to the lysate and mix well.
-
Transfer the mixture to a spin column and centrifuge. Discard the flow-through.
-
Perform the recommended wash steps with the provided wash buffers. This is crucial for removing contaminants.
-
Perform an additional centrifugation step to completely dry the column and remove any residual ethanol.
-
-
RNA Elution:
-
Place the column in a clean collection tube.
-
Add RNase-free water or elution buffer to the center of the column membrane.
-
Incubate for 1-2 minutes at room temperature.
-
Centrifuge to elute the purified RNA.
-
-
Quality Control:
-
Immediately place the eluted RNA on ice.
-
Assess the RNA quantity and purity using a spectrophotometer.
-
Assess the RNA integrity using a Bioanalyzer or by running an aliquot on a denaturing agarose gel.
-
-
Storage:
-
Store the RNA at -80°C in small aliquots to avoid multiple freeze-thaw cycles.
-
Visualizations
Caption: Experimental workflow for high-quality RNA sample preparation.
Caption: Decision tree for troubleshooting RNA degradation issues.
Caption: Key players in the m1A RNA modification pathway.
References
- 1. zymoresearch.com [zymoresearch.com]
- 2. Working with RNA: Hints and Tips | Bioline | Meridian Bioscience [bioline.com]
- 3. m.youtube.com [m.youtube.com]
- 4. biotium.com [biotium.com]
- 5. Tips for Working with RNA - University of Mississippi Medical Center [umc.edu]
- 6. RNA Extraction, Handling, and Storage - Nordic Biosite [nordicbiosite.com]
- 7. Best practices for RNA storage and sample handling | QIAGEN [qiagen.com]
- 8. bitesizebio.com [bitesizebio.com]
- 9. stackwave.com [stackwave.com]
- 10. neb.com [neb.com]
- 11. How to Troubleshoot Sequencing Preparation Errors (NGS Guide) - CD Genomics [cd-genomics.com]
- 12. weizmann.elsevierpure.com [weizmann.elsevierpure.com]
- 13. RNA-seq: impact of RNA degradation on transcript quantification - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. dspace.mit.edu [dspace.mit.edu]
- 15. m1A Sequencing - CD Genomics [rna.cd-genomics.com]
- 16. RNA quantification and quality assessment techniques | QIAGEN [qiagen.com]
- 17. qian.human.cornell.edu [qian.human.cornell.edu]
- 18. benchchem.com [benchchem.com]
Technical Support Center: Dealing with Isobaric Interference in Mass Spectrometry
Welcome to the Technical Support Center for resolving isobaric interference in mass spectrometry. This guide is designed for researchers, scientists, and drug development professionals to provide troubleshooting strategies and answers to frequently asked questions.
Frequently Asked Questions (FAQs)
Q1: What is isobaric interference and why is it a problem in mass spectrometry?
A1: Isobaric interference occurs when two or more different molecules have the same nominal mass-to-charge ratio (m/z), making them difficult to distinguish using a low-resolution mass spectrometer. This overlap can lead to inaccurate quantification, false positives, and misidentification of the compound of interest. In complex samples, such as those from biological matrices, the likelihood of encountering isobaric interferences is high, posing a significant challenge to data accuracy.
Q2: My analysis of m1Im is showing a broader peak than expected. Could this be due to isobaric interference?
A2: Yes, peak broadening or splitting in a mass spectrum can be an indication of underlying isobaric interference.[1] When two or more species with very similar m/z values are not fully resolved by the mass spectrometer, their signals can merge, resulting in a single, wider peak. It is crucial to investigate this further to ensure the purity of the signal being measured for your analyte, which we will assume to be a modified imidazole (B134444) (m1Im) for the purpose of this guide.
Q3: What are the primary methods to identify and resolve isobaric interference?
A3: Several techniques can be employed to tackle isobaric interference:
-
High-Resolution Mass Spectrometry (HRMS): Instruments like Orbitrap and Fourier-transform ion cyclotron resonance (FT-ICR) mass spectrometers can differentiate between ions with very small mass differences.[2][3]
-
Tandem Mass Spectrometry (MS/MS): By isolating the ions of interest and fragmenting them, MS/MS can distinguish between isobaric compounds based on their unique fragmentation patterns.[3]
-
Ion Mobility Spectrometry (IMS): This technique separates ions based on their size, shape, and charge, providing an additional dimension of separation that can resolve isobars.[2]
-
Chemical Derivatization: Modifying the analyte of interest with a chemical tag can shift its mass, potentially separating it from the interfering isobar.[4]
-
Chromatographic Separation: Optimizing the liquid chromatography (LC) method can separate isobaric compounds before they enter the mass spectrometer.[3]
Troubleshooting Guides
Problem: I suspect isobaric interference is affecting the quantification of my target compound.
Solution Workflow:
This workflow outlines the steps to diagnose and resolve suspected isobaric interference.
Caption: Troubleshooting workflow for isobaric interference.
Experimental Protocols
Protocol 1: High-Resolution Mass Spectrometry (HRMS) for Isobaric Resolution
This protocol describes the use of an Orbitrap mass spectrometer to distinguish between two hypothetical isobaric compounds: m1Im-A (C5H5N3O) and an interfering compound Interferent-X (C6H7N3).
Table 1: Theoretical Masses of Isobaric Compounds
| Compound | Molecular Formula | Monoisotopic Mass (Da) |
| m1Im-A | C5H5N3O | 123.0433 |
| Interferent-X | C6H7N3 | 121.0639 |
Methodology:
-
Sample Preparation: Prepare a 1 µg/mL solution of the sample in a 50:50 mixture of acetonitrile (B52724) and water with 0.1% formic acid.
-
Instrumentation: Use an Orbitrap Fusion Lumos mass spectrometer (or equivalent) equipped with a heated electrospray ionization (HESI) source.
-
MS Settings:
-
Resolution: Set the Orbitrap resolution to 120,000.
-
Scan Range: Acquire data from m/z 100-1000.
-
AGC Target: Set the Automatic Gain Control (AGC) target to 4e5.
-
Maximum Injection Time: Set to 50 ms.
-
-
Data Analysis:
-
Acquire the full scan mass spectrum.
-
Extract the ion chromatogram for the theoretical exact mass of m1Im-A (123.0433 ± 5 ppm).
-
Examine the mass spectrum to see if a distinct peak for Interferent-X (121.0639) can be resolved.
-
Expected Outcome: The high resolving power of the instrument should allow for the baseline separation of the two isobaric peaks, enabling accurate quantification of m1Im-A.
Protocol 2: Tandem Mass Spectrometry (MS/MS) for Isobaric Differentiation
This protocol outlines how to use MS/MS to differentiate between m1Im-A and Interferent-X based on their fragmentation patterns.
Methodology:
-
Instrumentation: Use a triple quadrupole or Q-TOF mass spectrometer.
-
Precursor Ion Selection: Isolate the precursor ion at the nominal m/z where the isobaric interference is observed (e.g., m/z 122 for [M+H]+ of Interferent-X and m/z 124 for [M+H]+ of m1Im-A, assuming these are the ions of interest).
-
Collision-Induced Dissociation (CID): Apply a range of collision energies (e.g., 10-40 eV) to induce fragmentation.
-
Fragment Ion Scanning: Acquire the product ion spectra.
-
Data Analysis: Compare the fragmentation patterns. Isobaric compounds will typically produce different fragment ions.
Table 2: Expected MS/MS Transitions
| Compound | Precursor Ion (m/z) | Key Fragment Ions (m/z) |
| m1Im-A | 124.051 | 82.042, 68.029 |
| Interferent-X | 122.071 | 95.066, 78.050 |
Expected Outcome: By monitoring unique fragment ions for each compound, you can selectively quantify your analyte of interest without interference from the isobar.
Advanced Technique: Ion Mobility Spectrometry (IMS)
Ion Mobility Spectrometry (IMS) provides an orthogonal separation dimension based on the ion's size and shape (collisional cross-section, CCS). This can be particularly useful for separating isomers, which have the same exact mass and often similar fragmentation patterns.
Caption: Conceptual diagram of IMS resolving isobars.
For further assistance, please contact our technical support team.
References
improving the efficiency of 1-Methyl-2'-O-methylinosine chemical synthesis
This technical support center provides researchers, scientists, and drug development professionals with comprehensive troubleshooting guides and frequently asked questions (FAQs) to improve the efficiency of 1-Methyl-2'-O-methylinosine chemical synthesis.
Troubleshooting Guide
This guide addresses specific issues that may be encountered during the synthesis of this compound, presented in a question-and-answer format.
Q1: My overall yield of this compound is consistently low. What are the potential causes and how can I improve it?
A1: Low overall yield can stem from several factors throughout the multi-step synthesis. Here’s a breakdown of potential issues and solutions at each stage:
-
Incomplete Protection of Hydroxyl Groups: If the 3' and 5' hydroxyl groups of the starting material (e.g., 2'-O-methylinosine) are not fully protected, the subsequent N1-methylation step can lead to a mixture of undesired side products, significantly lowering the yield of the target molecule.
-
Solution: Ensure the complete protection of the 3' and 5' hydroxyls by using a sufficient excess of the protecting group reagent (e.g., TBDMS-Cl) and allowing adequate reaction time. Monitor the reaction progress using Thin Layer Chromatography (TLC) until the starting material is fully consumed.
-
-
Inefficient N1-Methylation: The methylation of the N1 position on the inosine (B1671953) ring can be challenging due to the presence of other potentially reactive sites.
-
Solution: Use a strong methylating agent like methyl iodide (CH₃I) or dimethyl sulfate (B86663) ((CH₃)₂SO₄) in an appropriate solvent. The choice of base is also critical; a strong, non-nucleophilic base like sodium hydride (NaH) is often used to deprotonate the N1 position, facilitating methylation. Ensure anhydrous conditions, as moisture can quench the base and hydrolyze the methylating agent.
-
-
Suboptimal Deprotection Conditions: Harsh deprotection conditions can lead to the degradation of the desired product.
-
Solution: Use a fluoride (B91410) source such as tetrabutylammonium (B224687) fluoride (TBAF) for the removal of silyl (B83357) protecting groups. This method is generally mild and efficient. Monitor the deprotection reaction closely by TLC to avoid prolonged exposure to the reagent.
-
-
Losses during Purification: The final product and intermediates can be lost during purification steps if the appropriate techniques are not employed.
-
Solution: Utilize column chromatography with a suitable solvent system to carefully separate the desired product from byproducts and unreacted starting materials. For the final product, recrystallization can be an effective method for obtaining high-purity this compound.
-
Q2: I am observing multiple spots on my TLC plate after the N1-methylation step. What are these side products and how can I minimize their formation?
A2: The presence of multiple spots on the TLC plate indicates the formation of side products. Common side products in the N1-methylation of a protected 2'-O-methylinosine include:
-
N7-methylated isomer: Methylation can sometimes occur at the N7 position of the purine (B94841) ring.
-
O6-methylated product: The oxygen at the 6-position of the inosine ring can also be methylated.
-
Unreacted starting material: Incomplete reaction will leave some of the protected 2'-O-methylinosine.
To minimize the formation of these side products:
-
Control Reaction Temperature: Perform the methylation reaction at a low temperature (e.g., 0 °C) to improve the selectivity for N1-methylation.
-
Choice of Base and Methylating Agent: The combination of a strong, non-nucleophilic base and a reactive methylating agent can favor N1-alkylation.
-
Slow Addition of Reagents: Add the methylating agent slowly to the reaction mixture to maintain better control over the reaction and reduce the formation of undesired isomers.
Q3: The purification of this compound by column chromatography is proving difficult, with poor separation between my product and impurities. What can I do?
A3: Poor separation during column chromatography can be addressed by optimizing several parameters:
-
Solvent System: Experiment with different solvent systems (e.g., dichloromethane/methanol (B129727), ethyl acetate (B1210297)/hexane with a methanol gradient) to find the optimal mobile phase that provides the best separation on the TLC plate before scaling up to a column.
-
Silica (B1680970) Gel: Ensure that the silica gel is properly packed and of a suitable particle size for good resolution.
-
Column Loading: Avoid overloading the column, as this can lead to broad peaks and poor separation. It is better to run multiple smaller columns if you have a large amount of crude product.
-
Alternative Purification Techniques: If column chromatography is not effective, consider other techniques such as preparative High-Performance Liquid Chromatography (HPLC) for a higher degree of purification.
Frequently Asked Questions (FAQs)
Q: What is a common synthetic strategy for preparing this compound?
A: A common and effective strategy involves a stepwise approach starting from inosine or, more conveniently, from commercially available 2'-O-methylinosine. The general synthetic pathway is as follows:
-
Protection: Selectively protect the 3' and 5' hydroxyl groups of 2'-O-methylinosine using a suitable protecting group like tert-butyldimethylsilyl (TBDMS).
-
N1-Methylation: Methylate the N1 position of the protected 2'-O-methylinosine using a methylating agent such as methyl iodide in the presence of a strong base.
-
Deprotection: Remove the protecting groups from the 3' and 5' hydroxyls to yield the final product, this compound.
Q: What are the key analytical techniques to confirm the successful synthesis and purity of this compound?
A: The following analytical techniques are essential for characterizing the final product:
-
Nuclear Magnetic Resonance (NMR) Spectroscopy: ¹H NMR and ¹³C NMR are crucial for confirming the chemical structure. The presence of two distinct methyl signals (one for N1-methyl and one for 2'-O-methyl) and the correct shifts for the ribose and purine protons will confirm the structure.
-
Mass Spectrometry (MS): High-resolution mass spectrometry (HRMS) is used to confirm the exact molecular weight of the synthesized compound, further validating its identity.
-
Thin Layer Chromatography (TLC) and High-Performance Liquid Chromatography (HPLC): These techniques are used to assess the purity of the final product. A single spot on a TLC plate or a single peak in an HPLC chromatogram indicates a high degree of purity.
Data Presentation
The following tables summarize typical quantitative data for the key steps in the synthesis of this compound, based on analogous reactions reported in the literature.
Table 1: Protection of 2'-O-methylinosine
| Reagent | Molar Equiv. | Solvent | Temp. (°C) | Time (h) | Typical Yield (%) |
| TBDMS-Cl | 2.5 | Pyridine | 25 | 12-16 | 85-95 |
| Imidazole (B134444) | 5.0 | DMF | 25 | 12-16 | 80-90 |
Table 2: N1-Methylation of Protected 2'-O-methylinosine
| Methylating Agent | Base | Molar Equiv. (Base) | Solvent | Temp. (°C) | Time (h) | Typical Yield (%) |
| CH₃I | NaH | 1.2 | THF | 0 - 25 | 2-4 | 60-75 |
| (CH₃)₂SO₄ | K₂CO₃ | 2.0 | DMF | 25 | 6-8 | 55-70 |
Table 3: Deprotection of 3',5'-O-TBDMS-1-Methyl-2'-O-methylinosine
| Reagent | Solvent | Temp. (°C) | Time (h) | Typical Yield (%) |
| TBAF (1M in THF) | THF | 25 | 1-2 | 90-98 |
| HF-Pyridine | Pyridine | 0 - 25 | 2-4 | 85-95 |
Experimental Protocols
Protocol 1: Synthesis of 3',5'-O-bis(tert-butyldimethylsilyl)-2'-O-methylinosine
-
Dissolve 2'-O-methylinosine (1.0 eq) in anhydrous pyridine.
-
Add imidazole (5.0 eq) to the solution and stir until dissolved.
-
Cool the reaction mixture to 0 °C in an ice bath.
-
Add tert-butyldimethylsilyl chloride (TBDMS-Cl, 2.5 eq) portion-wise to the stirred solution.
-
Allow the reaction to warm to room temperature and stir for 12-16 hours.
-
Monitor the reaction progress by TLC (e.g., 10% methanol in dichloromethane).
-
Once the starting material is consumed, quench the reaction by adding methanol.
-
Remove the solvent under reduced pressure.
-
Dissolve the residue in ethyl acetate and wash with saturated aqueous sodium bicarbonate solution and then with brine.
-
Dry the organic layer over anhydrous sodium sulfate, filter, and concentrate under reduced pressure.
-
Purify the crude product by silica gel column chromatography (e.g., ethyl acetate/hexane gradient) to afford the protected nucleoside.
Protocol 2: Synthesis of 1-Methyl-3',5'-O-bis(tert-butyldimethylsilyl)-2'-O-methylinosine
-
Dissolve the protected 2'-O-methylinosine (1.0 eq) in anhydrous tetrahydrofuran (B95107) (THF).
-
Cool the solution to 0 °C under an inert atmosphere (e.g., argon or nitrogen).
-
Add sodium hydride (NaH, 60% dispersion in mineral oil, 1.2 eq) portion-wise to the solution.
-
Stir the mixture at 0 °C for 30 minutes.
-
Add methyl iodide (CH₃I, 1.5 eq) dropwise to the reaction mixture.
-
Allow the reaction to warm to room temperature and stir for 2-4 hours.
-
Monitor the reaction progress by TLC.
-
Carefully quench the reaction by the slow addition of methanol.
-
Remove the solvent under reduced pressure.
-
Partition the residue between ethyl acetate and water.
-
Wash the organic layer with brine, dry over anhydrous sodium sulfate, filter, and concentrate.
-
Purify the crude product by silica gel column chromatography.
Protocol 3: Synthesis of this compound
-
Dissolve the N1-methylated protected nucleoside (1.0 eq) in THF.
-
Add tetrabutylammonium fluoride (TBAF, 1M solution in THF, 2.2 eq).
-
Stir the reaction mixture at room temperature for 1-2 hours.
-
Monitor the reaction by TLC until the starting material is consumed.
-
Concentrate the reaction mixture under reduced pressure.
-
Purify the crude product by silica gel column chromatography (e.g., methanol/dichloromethane gradient) to yield this compound.
-
Further purification can be achieved by recrystallization from a suitable solvent system (e.g., methanol/ether).
Visualizations
Caption: Synthetic workflow for this compound.
Caption: Troubleshooting logic for low yield in synthesis.
Technical Support Center: Troubleshooting Low Yields in Oligonucleotide Synthesis with Modified Bases
Welcome to the Technical Support Center for oligonucleotide synthesis. This resource is designed for researchers, scientists, and drug development professionals to address challenges encountered during the synthesis of oligonucleotides containing modified bases.
Frequently Asked Questions (FAQs)
Q1: We are experiencing significantly lower than expected yields when incorporating a modified base into our oligonucleotides compared to standard DNA/RNA synthesis. What are the potential causes?
A1: Low yields when incorporating modified bases are a common challenge and can stem from several factors throughout the synthesis process. The most frequent culprits are suboptimal coupling efficiency of the modified phosphoramidite (B1245037), issues during the deprotection steps, and degradation of the oligonucleotide.
Key potential causes include:
-
Reduced Coupling Efficiency: Modified phosphoramidites often exhibit lower coupling efficiencies than standard amidites due to factors like steric hindrance.[1][2]
-
Incomplete Deprotection: The protecting groups on modified bases may require specific deprotection conditions that differ from standard protocols.[3][4]
-
Degradation during Synthesis: Certain modifications can render the oligonucleotide more susceptible to degradation, such as depurination during the acidic detritylation step.[5][6]
-
Reagent Quality: The quality and freshness of all reagents, including the modified phosphoramidite, activator, and solvents, are critical.[1][7] Moisture contamination is a particularly common issue that can dramatically reduce coupling efficiency.[4][8]
-
Suboptimal Synthesis Protocol: Standard synthesis cycle parameters may not be suitable for all modified bases. Adjustments to coupling time, reagent concentration, or the choice of activator may be necessary.[1]
-
Purification Losses: The unique chemical properties of modified oligonucleotides can lead to lower recovery during purification.[4][8]
Q2: How can I determine if low coupling efficiency of my modified phosphoramidite is the cause of low yield?
A2: A systematic approach is key to diagnosing low coupling efficiency. You can monitor the trityl cation release during synthesis, which provides a real-time measure of coupling efficiency. A significant drop in the orange color of the trityl cation released after the introduction of the modified base is a strong indicator of a coupling problem.[1] Post-synthesis analysis of the crude product by HPLC or mass spectrometry can also reveal a higher than expected proportion of shorter, failure sequences (n-1, n-2, etc.), pointing to inefficient coupling at the modification site.
Q3: What strategies can I employ to improve the coupling efficiency of a sterically hindered modified phosphoramidite?
A3: For modified bases that are sterically hindered, several protocol modifications can be implemented to improve coupling efficiency:
-
Increase Coupling Time: Doubling the standard coupling time for the modified monomer is a common and effective starting point.[1][2] For particularly challenging modifications, a threefold increase may be necessary.
-
Increase Phosphoramidite Concentration: Using a higher concentration of the modified phosphoramidite solution (e.g., 0.15 M instead of the standard 0.1 M) can help drive the reaction towards completion.[1]
-
Use a Stronger Activator: If you are using a standard activator like 1H-Tetrazole, switching to a more potent activator such as 5-(Ethylthio)-1H-tetrazole (ETT) or 4,5-Dicyanoimidazole (DCI) can enhance the reaction rate.[1][6]
-
Perform a Double Coupling: This involves delivering the same modified phosphoramidite and activator twice in the same synthesis cycle.[2] This gives the reaction a second opportunity to go to completion.
Q4: My modified oligonucleotide is sensitive to standard deprotection conditions. What are my options?
A4: Many modified bases and linkers are not stable under standard deprotection conditions like concentrated ammonium (B1175870) hydroxide (B78521) at elevated temperatures.[9] It is crucial to review the technical specifications for your specific modification to determine its chemical sensitivities.[10]
Here are some alternative deprotection strategies:
-
UltraMILD Deprotection: For highly sensitive modifications, use of UltraMILD phosphoramidites (e.g., Pac-dA, Ac-dC, iPr-Pac-dG) in conjunction with deprotection using potassium carbonate in methanol (B129727) is a gentle option.[3][11]
-
Ammonium Hydroxide/Methylamine (AMA): This mixture can often allow for deprotection at lower temperatures or for shorter durations compared to ammonium hydroxide alone.[11]
-
Gas Phase Deprotection: For high-throughput applications, gas-phase deprotection with ammonia (B1221849) or other amines can be a viable, milder alternative.[11]
Always remember the primary rule of deprotection: "First, Do No Harm."[10][11] The deprotection strategy must be compatible with the most sensitive component in your oligonucleotide.
Q5: I suspect depurination is contributing to my low yield of full-length product. How can I minimize this?
A5: Depurination, the loss of purine (B94841) bases (A and G), is caused by the acidic conditions of the detritylation step and leads to chain cleavage during the final basic deprotection.[5][12] This is a more significant issue for longer oligonucleotides and for certain modified bases that destabilize the glycosidic bond.[5][6]
To mitigate depurination:
-
Use a Milder Deblocking Agent: Replace the standard trichloroacetic acid (TCA) in your deblocking solution with dichloroacetic acid (DCA), which is less acidic and reduces the rate of depurination.[6]
-
Use Depurination-Resistant Protecting Groups: For guanosine, using a dimethylformamidine (dmf) protecting group can help protect against depurination.[6]
-
Optimize Deblocking Time: Avoid excessively long exposure to the acidic deblocking reagent. Ensure the deblocking step is just long enough for complete removal of the DMT group.[10]
Troubleshooting Guides
Guide 1: Diagnosing the Cause of Low Yield
This guide provides a systematic workflow to identify the root cause of low yield when synthesizing oligonucleotides with modified bases.
Data Presentation
Table 1: Recommended Adjustments for Low Coupling Efficiency of Modified Bases
| Parameter | Standard Condition | Recommended Adjustment for Modified Bases | Rationale |
| Coupling Time | 30 - 180 seconds | Double or triple the standard time | Allows more time for sterically hindered phosphoramidites to react completely.[1] |
| Phosphoramidite Concentration | 0.1 M | 0.15 M or higher | Increases the concentration of the reactant to help drive the reaction to completion. |
| Activator | 1H-Tetrazole | 5-(Ethylthio)-1H-tetrazole (ETT) or 4,5-Dicyanoimidazole (DCI) | Stronger activators increase the rate of the coupling reaction.[1][6] |
| Coupling Strategy | Single Couple | Double Couple | Provides a second opportunity for the coupling reaction to occur, increasing overall efficiency.[2] |
Table 2: Deprotection Conditions for Sensitive Modified Oligonucleotides
| Deprotection Method | Reagent(s) | Typical Conditions | Suitable For |
| Standard | Concentrated Ammonium Hydroxide | 55 °C, 8-16 hours | Most standard DNA oligonucleotides. |
| AMA | Ammonium Hydroxide / 40% Methylamine (1:1) | Room Temp, 2 hours or 55 °C, 15 min | Faster deprotection; suitable for many common dyes and modifications.[11] |
| UltraMILD | 0.05 M Potassium Carbonate in Methanol | Room Temp, 4-24 hours | Very base-sensitive modifications (e.g., certain dyes, protected bases).[3][11] |
| Gas Phase | Gaseous Ammonia or Methylamine | Varies by instrument | High-throughput synthesis; can be milder than aqueous conditions.[11] |
Experimental Protocols
Protocol 1: Crude Product Analysis by HPLC
Objective: To assess the purity of the crude oligonucleotide product and identify potential issues such as low coupling efficiency or incomplete deprotection.
Methodology:
-
After synthesis and deprotection, dissolve a small aliquot of the crude oligonucleotide in an appropriate aqueous buffer (e.g., 100 mM TEAA).
-
Analyze the sample using Ion-Pairing Reverse-Phase High-Performance Liquid Chromatography (IP-RP-HPLC).
-
Column: A C18 column is typically used.
-
Mobile Phase A: An aqueous buffer containing an ion-pairing agent (e.g., 100 mM TEAA or a solution with a trialkylamine and hexafluoroisopropanol).
-
Mobile Phase B: Acetonitrile.
-
Gradient: A linear gradient from a low percentage of B to a higher percentage of B over 20-30 minutes.
-
Detection: UV absorbance at 260 nm.
-
-
Data Interpretation:
-
The main peak should correspond to the full-length product (FLP).
-
Peaks eluting before the main peak are typically shorter failure sequences (n-1, n-2, etc.). A large area for these peaks suggests low coupling efficiency.
-
Peaks eluting after the main peak often correspond to incompletely deprotected species, as the remaining hydrophobic protecting groups increase retention time.[3]
-
Protocol 2: Mass Spectrometry Analysis
Objective: To confirm the identity of the synthesized oligonucleotide and identify any modifications or impurities.
Methodology:
-
Prepare the crude or purified oligonucleotide sample by desalting it, as salts can interfere with ionization.
-
Analyze the sample using Electrospray Ionization Mass Spectrometry (ESI-MS).
-
Data Interpretation:
-
Compare the observed molecular weight to the theoretical molecular weight of the desired full-length product.
-
A mass corresponding to the FLP confirms successful synthesis.
-
Masses lower than the FLP indicate truncated sequences, potentially from low coupling efficiency or depurination.
-
Masses higher than the FLP can indicate incomplete deprotection (e.g., +114 Da for a remaining TBDMS group) or the formation of adducts.[3]
-
Protocol 3: Trityl Cation Assay (On-Synthesizer)
Objective: To monitor the stepwise coupling efficiency during synthesis.
Methodology:
-
During the synthesis, after the detritylation step of each cycle, the acidic deblocking solution containing the cleaved dimethoxytrityl (DMT) cation is collected.
-
The intense orange color of the DMT cation is measured spectrophotometrically at approximately 495 nm.
-
The absorbance is proportional to the number of successful coupling events in the previous cycle.
-
Data Interpretation:
-
A consistent absorbance reading from cycle to cycle indicates high and uniform coupling efficiency.
-
A sudden and significant drop in absorbance after the introduction of a modified phosphoramidite indicates a problem with its incorporation.[1]
-
References
- 1. benchchem.com [benchchem.com]
- 2. benchchem.com [benchchem.com]
- 3. benchchem.com [benchchem.com]
- 4. trilinkbiotech.com [trilinkbiotech.com]
- 5. glenresearch.com [glenresearch.com]
- 6. glenresearch.com [glenresearch.com]
- 7. benchchem.com [benchchem.com]
- 8. What affects the yield of your oligonucleotides synthesis [biosyn.com]
- 9. Designing Oligo With Multiple Modifications - ELLA Biotech [ellabiotech.com]
- 10. benchchem.com [benchchem.com]
- 11. glenresearch.com [glenresearch.com]
- 12. Synthesis of high-quality libraries of long (150mer) oligonucleotides by a novel depurination controlled process - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Site-Specific Analysis of N1-methylinosine (m1I)
This technical support center provides researchers, scientists, and drug development professionals with comprehensive guidance on the site-specific analysis of N1-methylinosine (m1I), a modified RNA nucleoside. Here you will find troubleshooting guides, frequently asked questions (FAQs), detailed experimental protocols, and visual workflows to assist in your research.
Frequently Asked Questions (FAQs)
Q1: What is N1-methylinosine (m1I)?
A1: N1-methylinosine (m1I) is a post-transcriptional modification of RNA, meaning it is a chemical change that occurs to the nucleoside after the RNA molecule has been synthesized. It is found in various types of RNA, including transfer RNA (tRNA) and messenger RNA (mRNA).[1][2] In tRNA, it is typically found at specific positions, such as position 37, adjacent to the anticodon.[1]
Q2: How is m1I formed in RNA?
A2: The formation of m1I can occur through two primary pathways. In some cases, an inosine (B1671953) (I) residue in the RNA is directly methylated by a specific methyltransferase enzyme. Alternatively, N1-methyladenosine (m1A) can be deaminated to form m1I.[1]
Q3: Why is the site-specific analysis of m1I important?
A3: The location of m1I within an RNA molecule is critical to its function. Site-specific analysis allows researchers to understand how this modification at a particular position affects RNA structure, stability, and its interactions with other molecules. This has implications for gene expression, protein translation, and the development of diseases such as cancer.[2][3]
Q4: What are the common challenges in detecting m1I?
A4: Challenges in m1I detection include its low abundance, the need for highly sensitive and specific methods to pinpoint its exact location, and potential interference from other RNA modifications. Distinguishing m1I from its precursor, m1A, can also be challenging.
Troubleshooting Guides
Difficulties can arise during the experimental process for m1I analysis. This section provides solutions to common problems encountered during sequencing and mass spectrometry-based methods.
Sanger Sequencing & Next-Generation Sequencing (NGS) Troubleshooting
| Problem | Possible Cause | Recommended Solution |
| No or Low Signal | Low concentration or poor quality of the input RNA/DNA template. | Verify template concentration and purity using spectrophotometry and gel electrophoresis. Ensure the A260/A280 ratio is ~1.8.[4] |
| Inefficient primer binding. | Check primer design, annealing temperature, and integrity. Ensure the primer sequence is correct and not degraded.[5] | |
| Messy Chromatogram / High Background Noise | Contaminants in the template DNA. | Re-purify the DNA template. Ethanol precipitation can help remove some impurities.[6] |
| Multiple priming events. | Optimize annealing temperature and consider using a higher fidelity polymerase. Redesign primers for better specificity.[6] | |
| Signal Drops Off Prematurely | Secondary structures in the template. | Use a polymerase with strand-displacing activity or add additives like betaine (B1666868) to the PCR reaction to reduce secondary structures.[6] |
| Low processivity of the reverse transcriptase. | Ensure the reverse transcriptase used is of high quality and suitable for templates with modifications. |
Liquid Chromatography-Mass Spectrometry (LC-MS/MS) Troubleshooting
| Problem | Possible Cause | Recommended Solution |
| Low Signal Intensity / Poor Ionization | Suboptimal mobile phase composition. | Optimize the mobile phase pH and organic solvent percentage to improve the ionization efficiency of m1I. |
| Matrix effects from co-eluting compounds. | Improve sample cleanup procedures. Use of immunoaffinity columns can help purify and concentrate the analyte.[7] Consider using a standard addition calibration curve to correct for matrix effects.[7] | |
| Poor Peak Shape | Inappropriate column chemistry or gradient. | Test different C18 columns with varying properties. Optimize the elution gradient to ensure proper separation and peak shape.[7] |
| Column overloading. | Reduce the amount of sample injected onto the column. | |
| Inconsistent Retention Times | Fluctuations in column temperature or mobile phase composition. | Use a column oven to maintain a stable temperature. Ensure the mobile phase is well-mixed and degassed. |
| Column degradation. | Replace the column if it has been used extensively or shows signs of performance loss. |
Experimental Protocols
Protocol 1: Site-Specific m1I Detection by Ligation-Assisted Differentiation and qPCR
This method relies on the principle that the methyl group in m1I can disrupt Watson-Crick base pairing, leading to lower ligation efficiency.
Methodology:
-
RNA Extraction: Isolate total RNA from cells or tissues using a standard Trizol-based protocol. Assess RNA quality and quantity.
-
RNA Fragmentation: Fragment the RNA to an appropriate size (e.g., 100-200 nucleotides) using enzymatic or chemical methods.
-
Splint Ligation: Design two DNA splint oligonucleotides that are complementary to the target RNA sequence flanking the potential m1I site. One splint should have a 5' phosphate (B84403) and the other a 3' hydroxyl group at the ligation junction.
-
Ligation Reaction: Hybridize the fragmented RNA with the DNA splints and perform ligation using a DNA ligase (e.g., T3 DNA ligase, which shows good discrimination between m1A and adenosine).[8] The presence of m1I will reduce the ligation efficiency compared to unmodified inosine or adenosine (B11128).
-
Reverse Transcription and qPCR: Reverse transcribe the ligated products into cDNA. Quantify the amount of ligated product using quantitative PCR (qPCR) with primers specific to the ligated sequence. A lower amount of qPCR product for a given site compared to a control suggests the presence of m1I.
Protocol 2: Global m1I Quantification by LC-MS/MS
This protocol allows for the quantification of the total amount of m1I in an RNA sample.
Methodology:
-
RNA Isolation and Purification: Isolate total RNA and purify mRNA using oligo(dT)-magnetic beads to reduce contamination from highly abundant rRNAs and tRNAs.
-
RNA Digestion: Digest the purified RNA into single nucleosides using a mixture of nucleases (e.g., nuclease P1) and phosphatases (e.g., bacterial alkaline phosphatase).
-
LC-MS/MS Analysis: Separate the resulting nucleosides using reverse-phase high-performance liquid chromatography (HPLC). The HPLC is coupled to a triple quadrupole mass spectrometer operating in multiple reaction monitoring (MRM) mode.
-
Quantification: Identify and quantify m1I based on its specific retention time and mass-to-charge (m/z) transitions. Use a standard curve generated from a pure m1I standard for absolute quantification.[9][10]
Visualizing Workflows and Pathways
Experimental Workflow for Site-Specific m1I Analysis
Caption: Workflow for m1I analysis using ligation-based and mass spectrometry methods.
Putative m1I Regulatory Pathway
Caption: Putative regulatory pathways involved in the formation and function of m1I.
References
- 1. Enzymatic conversion of adenosine to inosine and to N1-methylinosine in transfer RNAs: a review - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. N1-methyladenosine formation, gene regulation, biological functions, and clinical relevance - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Comprehensive of N1-Methyladenosine Modifications Patterns and Immunological Characteristics in Ovarian Cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 4. MGH DNA Core [dnacore.mgh.harvard.edu]
- 5. cdn.prod.website-files.com [cdn.prod.website-files.com]
- 6. ocimumbio.com [ocimumbio.com]
- 7. mdpi.com [mdpi.com]
- 8. pubs.acs.org [pubs.acs.org]
- 9. On the Quest for Biomarkers: A Comprehensive Analysis of Modified Nucleosides in Ovarian Cancer Cell Lines - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Global analysis by LC-MS/MS of N6-methyladenosine and inosine in mRNA reveal complex incidence - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: 1-Methyl-2'-O-methylinosine (m¹Im) Antibody Development
Welcome to the technical support center for the development of commercial antibodies targeting 1-Methyl-2'-O-methylinosine (m¹Im), also known as 1,2'-O-dimethylinosine. As a rare, modified ribonucleoside, the development of specific antibodies presents unique challenges. This resource provides researchers, scientists, and drug development professionals with comprehensive troubleshooting guides, frequently asked questions (FAQs), and detailed experimental protocols to navigate the complexities of antibody production and validation for this novel target.
Frequently Asked Questions (FAQs)
This section addresses common questions regarding the generation and validation of antibodies for this compound.
Q1: What is this compound (m¹Im) and why is it a challenging target for antibody development?
This compound is a modified purine (B94841) nucleoside. Developing antibodies against small molecules like m¹Im is inherently challenging due to their low immunogenicity.[1][2] These small molecules, or haptens, are typically not immunogenic on their own and require conjugation to a larger carrier protein to elicit a robust immune response.[1][3] The specificity of the resulting antibodies must be high enough to distinguish m¹Im from structurally similar nucleosides, such as inosine, 1-methylinosine, and 2'-O-methylinosine.
Q2: What is the best strategy for designing an immunogen for m¹Im?
The recommended strategy is to couple the this compound nucleoside to a carrier protein.[3] This process involves chemically modifying the nucleoside to introduce a reactive group that can be covalently linked to the carrier. Common carrier proteins include Keyhole Limpet Hemocyanin (KLH) and Bovine Serum Albumin (BSA). The choice of conjugation chemistry and the site of attachment on the nucleoside are critical for presenting the key epitopes of m¹Im to the immune system.
Q3: What are the key considerations when selecting an antibody development platform?
Both monoclonal and polyclonal antibodies can be developed. Monoclonal antibodies, produced from a single B-cell clone, offer high specificity and batch-to-batch consistency.[4] Recombinant monoclonal antibody technology, particularly from rabbit hosts, can yield antibodies with high affinity and the ability to recognize small epitopes.[2][5][6] Polyclonal antibodies, a mixture of antibodies recognizing different epitopes on the antigen, can provide a stronger signal in some applications but may have higher batch-to-batch variability.
Q4: How can I validate the specificity of a newly developed anti-m¹Im antibody?
A multi-tiered validation approach is crucial.[7][8] This should include:
-
ELISA-based screening: Use competitive ELISA to assess the antibody's ability to bind to the m¹Im-carrier conjugate and be inhibited by the free m¹Im nucleoside.
-
Cross-reactivity testing: Test the antibody's binding to other modified and unmodified nucleosides (e.g., inosine, 1-methylinosine, 2'-O-methylinosine) to ensure specificity.
-
Application-specific validation: Validate the antibody in the intended application (e.g., Western blot, immunoprecipitation, immunofluorescence) using appropriate positive and negative controls.[8][9]
Troubleshooting Guides
This section provides solutions to common problems encountered during the development and application of an anti-m¹Im antibody.
| Problem | Possible Cause | Solution |
| No or Low Titer in Polyclonal Sera | Poor immunogenicity of the m¹Im-carrier conjugate. | - Increase the hapten-to-carrier ratio in the conjugate.- Try a different carrier protein (e.g., switch from BSA to KLH).- Use a stronger adjuvant in the immunization protocol. |
| High Background in ELISA | Non-specific binding of the antibody. | - Increase the stringency of the wash steps.- Optimize the blocking buffer (e.g., increase the concentration of blocking agent).- Titer the primary and secondary antibodies to find the optimal concentrations. |
| Cross-reactivity with other Nucleosides | The antibody recognizes a shared epitope. | - If using polyclonal antibodies, affinity purification against the target m¹Im can help remove cross-reactive antibodies.- For monoclonal antibodies, this indicates a need to screen more clones to find one with higher specificity. |
| Antibody Works in ELISA but not in Western Blot | The antibody recognizes a conformational epitope that is lost upon protein denaturation. | - Since m¹Im is a modification on RNA, direct detection on a standard Western blot is not expected. For detecting m¹Im-containing RNA, techniques like dot blots or RNA immunoprecipitation followed by detection would be more appropriate. |
| Inconsistent Results Between Batches | Variation in polyclonal antibody production or monoclonal antibody instability. | - For polyclonal antibodies, pool sera from multiple animals to average out individual immune responses.- For monoclonal antibodies, ensure proper storage conditions and consider subcloning the hybridoma line to ensure stability. |
Experimental Protocols
Detailed methodologies for key experiments in the validation of an anti-m¹Im antibody are provided below.
Protocol 1: Competitive ELISA for Antibody Specificity
-
Coating: Coat a 96-well plate with 1 µg/mL of m¹Im-BSA conjugate in coating buffer (e.g., carbonate-bicarbonate buffer, pH 9.6) and incubate overnight at 4°C.
-
Washing: Wash the plate three times with wash buffer (e.g., PBS with 0.05% Tween-20).
-
Blocking: Block the plate with 200 µL/well of blocking buffer (e.g., 5% non-fat dry milk in wash buffer) for 1 hour at room temperature.
-
Competition:
-
Prepare serial dilutions of the free m¹Im nucleoside and competitor nucleosides (e.g., inosine, 1-methylinosine, 2'-O-methylinosine) in assay buffer.
-
In a separate plate, pre-incubate the anti-m¹Im antibody (at a pre-determined optimal dilution) with the serially diluted competitors for 30 minutes.
-
-
Incubation: Transfer the antibody-competitor mixtures to the coated and blocked plate and incubate for 2 hours at room temperature.
-
Washing: Repeat the wash step.
-
Secondary Antibody: Add a horseradish peroxidase (HRP)-conjugated secondary antibody diluted in blocking buffer and incubate for 1 hour at room temperature.
-
Washing: Repeat the wash step.
-
Detection: Add TMB substrate and incubate until a blue color develops. Stop the reaction with stop solution.
-
Analysis: Read the absorbance at 450 nm. A decrease in signal in the presence of the free m¹Im nucleoside indicates specific binding.
Protocol 2: RNA Dot Blot for m¹Im Detection
-
RNA Preparation: Prepare serial dilutions of in vitro transcribed RNA containing m¹Im and control RNA without the modification.
-
Membrane Application: Spot 1-2 µL of each RNA dilution onto a positively charged nylon membrane and allow it to air dry.
-
Crosslinking: UV crosslink the RNA to the membrane.
-
Blocking: Block the membrane in blocking buffer (e.g., 5% non-fat dry milk in TBST) for 1 hour at room temperature.
-
Primary Antibody Incubation: Incubate the membrane with the anti-m¹Im antibody (at an optimized dilution) overnight at 4°C.
-
Washing: Wash the membrane three times for 10 minutes each with TBST.
-
Secondary Antibody Incubation: Incubate with an HRP-conjugated secondary antibody for 1 hour at room temperature.
-
Washing: Repeat the wash step.
-
Detection: Use an enhanced chemiluminescence (ECL) substrate to detect the signal.
Visualizations
Logical Workflow for Custom Antibody Development
Caption: A logical workflow for the development and validation of a custom antibody against this compound.
Potential Role of m¹Im in RNA Regulation
Caption: A hypothetical pathway illustrating the synthesis and potential functional roles of this compound in RNA.
References
- 1. Antibodies specific for nucleic acid modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 2. fortislife.com [fortislife.com]
- 3. Validation strategies for antibodies targeting modified ribonucleotides - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Custom Monoclonal Antibody Services - Syd Labs [sydlabs.com]
- 5. Custom Monoclonal Antibody Against Small Molecules - Creative Diagnostics [creative-diagnostics.com]
- 6. genscript.com [genscript.com]
- 7. hellobio.com [hellobio.com]
- 8. cusabio.com [cusabio.com]
- 9. The ABCs of finding a good antibody: How to find a good antibody, validate it, and publish meaningful data - PMC [pmc.ncbi.nlm.nih.gov]
improving ligation efficiency for sequencing libraries with 2'-O-methylated RNA
This technical support center provides troubleshooting guidance and frequently asked questions for researchers encountering challenges with the ligation of 2'-O-methylated RNA during sequencing library preparation.
Frequently Asked Questions (FAQs)
Q1: What is 2'-O-methylation and why does it affect my library preparation?
A 2'-O-methylation (2'-O-Me) is a common post-transcriptional modification of RNA where a methyl group is added to the 2' hydroxyl group of the ribose sugar.[1] This modification is prevalent in various RNA species, including plant microRNAs (miRNAs), piwi-interacting RNAs (piRNAs), and small nucleolar RNAs (snoRNAs).[1][2][3] The presence of a 2'-O-methyl group at the 3'-terminal nucleotide of an RNA molecule can inhibit the activity of RNA ligases, which are essential enzymes for attaching adapters during sequencing library preparation.[4][5][6] This inhibition leads to lower ligation efficiency and can introduce significant bias into the sequencing data, potentially causing underrepresentation of 2'-O-methylated RNAs in the final library.[3][4]
Q2: Which RNA ligase should I use for 2'-O-methylated RNA?
For ligating adapters to 2'-O-methylated RNA, T4 RNA Ligase 2, truncated (T4 Rnl2tr) is generally more efficient than T4 RNA Ligase 1 (T4 Rnl1).[7] T4 Rnl1 shows a significant decrease in ligation efficiency when the 3'-terminal nucleotide of the RNA is 2'-O-methylated.[7] In contrast, T4 Rnl2tr, especially under optimized conditions, can achieve high ligation efficiency for both unmodified and 2'-O-methylated RNAs, thereby reducing capture bias.[7]
Q3: How can I improve the efficiency of 3' adapter ligation to 2'-O-methylated RNA?
Several strategies can be employed to enhance ligation efficiency:
-
Use T4 RNA Ligase 2, truncated (T4 Rnl2tr): As mentioned, this enzyme is more effective for ligating modified RNAs.[7]
-
Add Polyethylene Glycol (PEG): The inclusion of a crowding agent like PEG 8000 in the ligation reaction can dramatically increase ligation efficiency.[7] Concentrations around 25% (w/v) have been shown to yield nearly 100% ligation for both modified and unmodified RNAs.[7]
-
Optimize Reaction Conditions: Lower incubation temperatures (e.g., 16°C) with longer reaction times (e.g., overnight) can improve the ligation of 2'-O-methylated species.[5][7]
-
Increase Enzyme Concentration: For particularly difficult ligations, increasing the concentration of T4 Rnl2tr can help drive the reaction to completion.[7]
Q4: Are there commercial kits available that are optimized for 2'-O-methylated RNA?
Yes, several commercial kits are designed to reduce bias and improve the capture of modified RNAs. For example, the NEBNext Low-bias Small RNA Library Prep Kit from New England Biolabs is designed to generate libraries that accurately represent the RNA species in a sample and provides a single protocol for both standard and 2'-O-methylated samples.[8] Other protocols, like the "TS5" method, have also been developed to have less bias and better detection of 2'-O-methylated RNAs.[2][5]
Troubleshooting Guide
| Problem | Possible Cause(s) | Recommended Solution(s) |
| Low library yield with known 2'-O-methylated RNA samples | Inhibition of 3' adapter ligation due to 2'-O-methylation. | • Switch from T4 RNA Ligase 1 to T4 RNA Ligase 2, truncated (T4 Rnl2tr). • Add PEG 8000 to the ligation reaction to a final concentration of 20-25%.[7][9] • Increase the concentration of T4 Rnl2tr in the reaction.[7] • Optimize ligation incubation conditions: try 16°C overnight.[5][7] |
| Underrepresentation of certain small RNAs (e.g., plant miRNAs) in sequencing data | Ligation bias against 2'-O-methylated RNAs. | • Implement the optimized ligation conditions mentioned above (T4 Rnl2tr, PEG, optimized temperature/time). • Consider using a library preparation kit specifically designed for low bias and modified RNAs.[3][8] • The use of randomized adapters may also help to reduce sequence-specific ligation bias.[3] |
| No or very faint band corresponding to ligated product on a gel | Complete or near-complete failure of the ligation reaction. | • Verify the integrity and concentration of your RNA, adapters, and ligase. • Ensure the use of a pre-adenylated 3' adapter, as this is crucial for the ligation reaction with truncated T4 RNA Ligase 2 in the absence of ATP.[5] • Re-evaluate the entire protocol, paying close attention to buffer components and reaction setup. |
| High adapter-dimer formation | Excess adapter concentration relative to input RNA. Inefficient ligation of RNA to adapters. | • Optimize the molar ratio of adapter to insert.[10] • Consider using modified adapters that are designed to reduce adapter-dimer formation.[9] • Gel purification after ligation can help to remove adapter-dimers.[5] |
Quantitative Data Summary
Table 1: Effect of Ligase and PEG on Ligation Efficiency of Unmodified vs. 2'-O-Methylated RNA
| RNA Type | Ligase | PEG 8000 Concentration | Ligation Efficiency |
| Unmodified RNA | T4 Rnl1 | Standard Buffer | ~100% |
| 2'-O-Me RNA (terminating in U) | T4 Rnl1 | Standard Buffer | 36.0% ± 1.3% |
| Unmodified RNA | T4 Rnl2tr | 25% (w/v) | 94.2% ± 2.67% |
| 2'-O-Me RNA | T4 Rnl2tr | 25% (w/v) | 96.3% ± 0.17% |
| (Data adapted from a study optimizing enzymatic reaction conditions for small RNA.)[7] |
Table 2: Impact of T4 Rnl2tr Ligase Concentration on Ligation Efficiency
| RNA Type | T4 Rnl2tr Concentration (units) | Extent of Ligation |
| Unmodified small RNAs | 100 | Maximal |
| 2'-O-methyl-modified RNAs | 200 | Maximal |
| (Data based on experiments examining the effect of ligase concentration on small RNA ligation to adenylated DNA adapters.)[7] |
Experimental Protocols & Methodologies
Optimized 3' Adapter Ligation Protocol for 2'-O-Methylated RNA
This protocol is based on methodologies demonstrated to improve the ligation of 2'-O-methylated RNAs.[5][7]
-
Reaction Setup: In a 0.2 mL microcentrifuge tube, combine the following on ice:
-
Purified small RNA (~0.1-1 µM): 1 µL
-
Preadenylated 3' adapter (10 µM): 1 µL
-
-
Denaturation: Incubate the RNA and adapter mix at 72°C for 2 minutes, then immediately place on ice.
-
Ligation Master Mix: Prepare a master mix with the following components per reaction:
-
50% PEG 8000: 4 µL
-
10x T4 RNA Ligase Buffer: 1 µL
-
T4 RNA Ligase 2, truncated (e.g., 200 U/µL): 1 µL
-
RNase Inhibitor: 1 µL
-
Nuclease-free water: 1 µL
-
-
Ligation Reaction: Add 8 µL of the ligation master mix to the 2 µL of denatured RNA and adapter. Mix gently by pipetting.
-
Incubation: Incubate the reaction overnight at 16°C.
Following the 3' adapter ligation, proceed with subsequent steps of your library preparation protocol, such as 5' adapter ligation, reverse transcription, and PCR amplification.[5]
Visualizations
Caption: Standard workflow for small RNA sequencing library preparation.
Caption: Troubleshooting logic for improving 2'-O-methylated RNA ligation.
References
- 1. 2'-O-methylation - Wikipedia [en.wikipedia.org]
- 2. A Small RNA-Seq Protocol with Less Bias and Improved Capture of 2'-O-Methyl RNAs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. rna-seqblog.com [rna-seqblog.com]
- 4. mdpi.com [mdpi.com]
- 5. Improving Small RNA-seq: Less Bias and Better Detection of 2'-O-Methyl RNAs [jove.com]
- 6. Detection and Analysis of RNA Ribose 2′-O-Methylations: Challenges and Solutions - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Optimization of enzymatic reaction conditions for generating representative pools of cDNA from small RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 8. NEB Low-Bias Small RNA Lib Prep [bionordika.fi]
- 9. Small RNA Library Preparation Method for Next-Generation Sequencing Using Chemical Modifications to Prevent Adapter Dimer Formation - PMC [pmc.ncbi.nlm.nih.gov]
- 10. neb.com [neb.com]
Technical Support Center: Enrichment of RNAs Containing 1-Methyl-2'-O-methylinosine (m¹Im)
This technical support center provides researchers, scientists, and drug development professionals with strategies, troubleshooting guides, and frequently asked questions (FAQs) for the enrichment of RNAs containing the rare, doubly modified nucleoside, 1-methyl-2'-O-methylinosine (m¹Im).
Frequently Asked Questions (FAQs)
Q1: Is there a direct method to enrich for RNAs containing this compound (m¹Im)?
A: Currently, there are no commercially available antibodies that specifically recognize the combined this compound (m¹Im) modification. Therefore, a direct, single-step immunoprecipitation for m¹Im-containing RNA is not feasible. The recommended approach is a sequential immunoprecipitation strategy.
Q2: What is the proposed strategy for enriching m¹Im-containing RNAs?
A: We recommend a sequential RNA immunoprecipitation (RIP) approach. This involves two consecutive immunoprecipitation steps to isolate RNAs that possess both the 1-methylinosine (B32420) (m¹I) and the 2'-O-methylation (2'-OMe) modifications. The workflow involves first enriching for all RNAs with one modification (e.g., 2'-O-methylation), and then using the enriched RNA pool as the input for a second immunoprecipitation targeting the other modification (e.g., m¹I).
Q3: What are the critical controls for a sequential RNA immunoprecipitation experiment?
A: Several controls are essential for validating the results of a sequential RIP experiment. These include:
-
Isotype Control: A non-specific IgG from the same host species as the primary antibody should be used in parallel to the specific antibody IPs to control for non-specific binding to the beads and antibody.
-
Input Control: A small fraction of the initial and intermediate RNA samples should be set aside before each immunoprecipitation step. These "input" samples represent the total RNA population at that stage and are crucial for calculating enrichment efficiency.
-
Positive and Negative Control RNAs: If available, in vitro transcribed RNAs with and without the target modifications can be spiked into the sample to validate the immunoprecipitation efficiency and specificity.
Q4: How can I validate the final enriched RNA pool for the presence of m¹Im?
A: The most definitive method for validating the presence and quantifying the abundance of m¹Im in the final enriched RNA pool is liquid chromatography-tandem mass spectrometry (LC-MS/MS).[1][2][3] This technique can identify and quantify modified nucleosides with high sensitivity and specificity.
Q5: What is the expected yield from a sequential enrichment for a rare modification like m¹Im?
A: The final yield of m¹Im-containing RNA is expected to be very low. The efficiency of each immunoprecipitation step and the natural abundance of the m¹Im modification will significantly impact the final amount of enriched RNA. It is crucial to start with a sufficient amount of high-quality total RNA.
Experimental Protocols
Protocol 1: Sequential RNA Immunoprecipitation (RIP) for m¹Im Enrichment
This protocol outlines a two-step immunoprecipitation to enrich for RNAs containing both 1-methylinosine and 2'-O-methylation.
Workflow Diagram:
Caption: Sequential RNA immunoprecipitation workflow for m¹Im enrichment.
Materials:
-
Total RNA of high integrity
-
Anti-2'-O-methylated adenosine (B11128) antibody
-
Anti-1-methylinosine antibody[4]
-
Protein A/G magnetic beads
-
RIP wash and elution buffers
-
RNase inhibitors
-
Proteinase K
Procedure:
Part 1: First Immunoprecipitation (e.g., for 2'-O-methylation)
-
Antibody-Bead Conjugation: Incubate the anti-2'-O-methylated adenosine antibody with protein A/G magnetic beads to allow for antibody conjugation.
-
RNA Fragmentation: Fragment the total RNA to an appropriate size (e.g., 100-200 nucleotides) using enzymatic or chemical methods.
-
Immunoprecipitation: Incubate the fragmented RNA with the antibody-conjugated beads.
-
Washing: Perform a series of stringent washes to remove non-specifically bound RNA.
-
Elution: Elute the 2'-O-methylated RNA from the beads. This is your "first-pass enriched RNA."
Part 2: Second Immunoprecipitation (for 1-methylinosine)
-
Input for Second IP: Use the eluted RNA from the first step as the input for the second immunoprecipitation.
-
Antibody-Bead Conjugation: Prepare a fresh batch of antibody-conjugated beads with the anti-1-methylinosine antibody.
-
Second Immunoprecipitation: Incubate the first-pass enriched RNA with the anti-1-methylinosine antibody-conjugated beads.
-
Washing: Perform stringent washes as in the first step.
-
Elution: Elute the RNA from the beads. This is your final, m¹Im-enriched RNA pool.
Part 3: RNA Purification and Validation
-
Proteinase K Treatment: Treat the final eluate with Proteinase K to degrade any remaining antibody and proteins.
-
RNA Purification: Purify the RNA using a standard RNA clean-up kit.
-
Quantification and Validation: Quantify the final RNA yield. Proceed with LC-MS/MS analysis to confirm the presence of m¹Im.
Protocol 2: Validation of Enriched RNA by LC-MS/MS
Workflow Diagram:
Caption: Workflow for LC-MS/MS validation of m¹Im enrichment.
Procedure:
-
RNA Digestion: Digest the enriched RNA sample to individual nucleosides using a cocktail of nucleases (e.g., nuclease P1, snake venom phosphodiesterase, and alkaline phosphatase).
-
Chromatographic Separation: Separate the resulting nucleosides using high-performance liquid chromatography (HPLC).
-
Mass Spectrometry Analysis: Analyze the separated nucleosides using a tandem mass spectrometer to identify and quantify m¹Im based on its unique mass-to-charge ratio and fragmentation pattern.
Troubleshooting Guide
| Issue | Possible Cause | Recommended Solution |
| Low yield of enriched RNA | Insufficient starting material. | Increase the initial amount of total RNA. |
| Low abundance of the target modification. | Consider starting with a larger cell or tissue sample. | |
| Inefficient immunoprecipitation. | Optimize antibody concentration and incubation times. Ensure the antibody is validated for RIP.[5][6] | |
| RNA degradation. | Maintain a sterile, RNase-free environment. Use RNase inhibitors at all steps. | |
| High background/non-specific binding | Inadequate washing. | Increase the number and stringency of wash steps.[7] |
| Antibody cross-reactivity. | Use a highly specific monoclonal antibody if available. Perform dot blot analysis to check antibody specificity.[4] | |
| Non-specific binding to beads. | Pre-clear the RNA sample by incubating it with beads alone before adding the antibody. | |
| Inconsistent results between replicates | Variability in RNA quality. | Ensure consistent quality and quantity of starting RNA for all replicates. |
| Inconsistent antibody-bead conjugation. | Prepare a master mix of antibody-conjugated beads for all samples in an experiment. | |
| No detectable m¹Im in the final sample | The modification is absent or below the detection limit in the starting material. | Use a positive control with a known m¹Im-containing RNA if possible. |
| Inefficient second immunoprecipitation. | The first elution buffer may interfere with the second IP. Ensure proper buffer exchange or RNA purification between steps. |
Quantitative Data Summary
The efficiency of RNA immunoprecipitation can vary significantly depending on the antibody, the abundance of the modification, and the experimental conditions. The following table provides a general expectation for enrichment levels.
| Enrichment Step | Target Modification | Typical Enrichment Fold-Change (over input) | Reference |
| First IP | 2'-O-methylation | 5 to 50-fold | [8] |
| Second IP | 1-methylinosine | 10 to 100-fold (on pre-enriched RNA) | [5] |
Note: The fold-change for the second IP is relative to the already enriched RNA from the first step. The overall enrichment for m¹Im will be a product of the efficiencies of both steps and is expected to be substantial, but the final yield will be low due to the rarity of the double modification. Validation by quantitative methods like qRT-PCR on known target RNAs (if any are known) or absolute quantification by LC-MS/MS is crucial.[1]
References
- 1. Global analysis by LC-MS/MS of N6-methyladenosine and inosine in mRNA reveal complex incidence - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Modomics - A Database of RNA Modifications [genesilico.pl]
- 4. m1I Antibody Dot Blot (C15410366) | Diagenode [diagenode.com]
- 5. 1-methyladenosine Monoclonal Antibody | Diagenode [diagenode.com]
- 6. RNA Immunoprecipitation Chip (RIP) Assay [sigmaaldrich.com]
- 7. RNA immunoprecipitation to identify in vivo targets of RNA editing and modifying enzymes - PMC [pmc.ncbi.nlm.nih.gov]
- 8. 2′-O-Methylation at internal sites on mRNA promotes mRNA stability - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: 1-Methyl-2'-O-methylinosine (m1Am) Detection
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals avoid common artifacts during the detection and quantification of 1-Methyl-2'-O-methylinosine (m1Am).
Frequently Asked Questions (FAQs)
Q1: What are the most common sources of artifacts in m1Am detection?
A1: Artifacts in m1Am detection can arise from several stages of the experimental workflow. The most common sources include:
-
Sample Preparation: Incomplete enzymatic digestion of RNA can lead to the erroneous detection of dinucleotides as modified monomers.[1] Chemical instability of related modified nucleosides, such as decomposition under acidic conditions, suggests that pH control during sample preparation is critical.[2][3] Contamination with other RNA species that are rich in modifications can also lead to false positives.[4][5]
-
Chromatography and Mass Spectrometry (LC-MS/MS): Co-elution of isomeric or isobaric compounds can lead to misidentification. In-source fragmentation or the formation of adducts can complicate mass spectra and lead to inaccurate quantification.[6]
-
Antibody-Based Methods: Antibodies raised against one modified nucleoside may exhibit cross-reactivity with other, structurally similar modifications. For instance, antibodies for N1-methyladenosine (m1A) have been shown to cross-react with the 7-methylguanosine (B147621) (m7G) cap of mRNA, leading to false-positive signals.[7] This is a critical consideration for m1Am, which shares the N1-methylation with m1A.
Q2: How can I ensure complete digestion of my RNA sample to avoid dinucleotide artifacts?
A2: Incomplete RNA hydrolysis is a significant source of artifacts, particularly for 2'-O-methylated nucleosides which can be resistant to nucleases.[1] To ensure complete digestion:
-
Use a combination of enzymes: A common approach involves a two-step digestion, first with a nuclease like Nuclease P1, followed by a phosphodiesterase such as snake venom phosphodiesterase (SVP). The addition of a phosphatase like bacterial alkaline phosphatase (BAP) is also crucial to remove the 3'-phosphate group.
-
Optimize digestion conditions: Ensure optimal pH, temperature, and incubation time for each enzyme. It may be necessary to perform a time-course experiment to determine the optimal digestion time for your specific RNA samples.
-
Enzyme quality: Use high-quality, certified enzymes to avoid contamination with other nucleases or activities that could introduce artifacts.
Q3: What steps can I take to minimize artifacts during LC-MS/MS analysis?
A3: To minimize artifacts during LC-MS/MS analysis of m1Am:
-
High-resolution mass spectrometry (HRMS): Use of HRMS can help distinguish m1Am from other co-eluting compounds with similar mass-to-charge ratios.
-
Stable isotope-labeled internal standard: Incorporating a stable isotope-labeled version of m1Am into your samples allows for accurate quantification and can help to identify and correct for matrix effects and variations in instrument response.
-
Chromatographic separation: Optimize your liquid chromatography method to achieve baseline separation of m1Am from other known and potential RNA modifications. This is particularly important for distinguishing between isomers.
-
MS/MS fragmentation analysis: Careful analysis of the fragmentation pattern of your analyte and comparison with a synthetic m1Am standard is essential for confident identification.
Q4: How can I validate the specificity of an antibody for m1Am?
A4: Given the high potential for cross-reactivity with other methylated nucleosides, rigorous validation of anti-m1Am antibodies is essential.[7][8]
-
Dot blot analysis: Test the antibody against a panel of synthetic modified and unmodified nucleosides to assess its specificity and potential for cross-reactivity.
-
Competitive ELISA: Perform a competitive ELISA with a range of free modified nucleosides to quantify the antibody's binding affinity for m1Am and other modifications.
-
Immunoprecipitation followed by LC-MS/MS (IP-LC-MS/MS): This is a powerful method to confirm that the antibody specifically enriches for RNA fragments containing m1Am. The immunoprecipitated RNA is digested to nucleosides and analyzed by LC-MS/MS to confirm the presence and enrichment of m1Am.
Troubleshooting Guides
Issue 1: Unexpected peaks in my LC-MS/MS chromatogram.
| Potential Cause | Troubleshooting Step |
| Incomplete RNA digestion | Re-optimize the digestion protocol. Increase enzyme concentration or incubation time. Consider using a different combination of nucleases.[1] |
| Contamination from other RNA species (e.g., tRNA, rRNA) | Improve the purity of your mRNA sample. Use stringent purification methods like poly(A) selection or ribosomal RNA depletion.[4][5] |
| Formation of adducts (e.g., sodium, potassium) | Check the purity of your solvents and reagents. Use high-purity mobile phases. Optimize ESI source conditions to minimize adduct formation.[6] |
| In-source fragmentation | Optimize the electrospray ionization (ESI) source parameters, particularly the source voltage and temperature, to minimize fragmentation of the parent ion. |
| Presence of isomeric modifications | Use a high-resolution chromatography column and optimize the gradient to improve separation. Compare retention times with synthetic standards for all potential isomers. |
Issue 2: High background or false positives in antibody-based assays (e.g., MeRIP, dot blot).
| Potential Cause | Troubleshooting Step |
| Antibody cross-reactivity | Validate antibody specificity using dot blots with a panel of modified nucleosides. Perform competitive assays to determine binding affinities.[8][9] |
| Non-specific binding to the membrane or beads | Use appropriate blocking buffers (e.g., non-fat milk, BSA). Increase the stringency of wash steps. |
| Cross-reactivity with the m7G cap | This is a known issue for m1A antibodies and is highly probable for m1Am antibodies.[7] Consider enzymatic decapping of the RNA prior to immunoprecipitation to eliminate this artifact. |
| Poor antibody quality | Use a different batch or a different supplier for the antibody. Ensure proper storage and handling of the antibody. |
Experimental Protocols
Protocol 1: Enzymatic Digestion of RNA for LC-MS/MS Analysis
-
RNA Sample Preparation: Start with 1-5 µg of high-purity mRNA.
-
Denaturation: Denature the RNA by heating at 95°C for 5 minutes, then immediately place on ice.
-
Nuclease P1 Digestion:
-
Add Nuclease P1 (e.g., 2 units) in a buffer of 20 mM ammonium (B1175870) acetate, pH 5.3.
-
Incubate at 37°C for 2 hours.
-
-
Phosphatase and Phosphodiesterase Digestion:
-
Add bacterial alkaline phosphatase (BAP; e.g., 0.5 units) and snake venom phosphodiesterase (SVP; e.g., 0.002 units) in a buffer of 50 mM ammonium bicarbonate, pH 8.0.
-
Incubate at 37°C for an additional 2 hours.
-
-
Enzyme Removal:
-
Filter the reaction mixture through a 10 kDa molecular weight cutoff filter to remove the enzymes.
-
-
LC-MS/MS Analysis:
-
The resulting nucleoside mixture is ready for analysis by LC-MS/MS. A stable isotope-labeled m1Am internal standard should be added prior to injection for accurate quantification.
-
Visualizations
Caption: General experimental workflow for the detection of m1Am using LC-MS/MS.
Caption: A logical flowchart for troubleshooting common issues in m1Am detection.
References
- 1. Modomics - A Database of RNA Modifications [genesilico.pl]
- 2. chembk.com [chembk.com]
- 3. Methyl Effect on the Metabolism, Chemical Stability, and Permeability Profile of Bioactive N-Sulfonylhydrazones - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Cellular Metabolic and Autophagic Pathways: Traffic Control by Redox Signaling - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Protein purification and crystallization artifacts: The tale usually not told - PMC [pmc.ncbi.nlm.nih.gov]
- 6. creative-diagnostics.com [creative-diagnostics.com]
- 7. Antibody cross-reactivity accounts for widespread appearance of m1A in 5'UTRs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Validation strategies for antibodies targeting modified ribonucleotides - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Specificity and Cross-Reactivity - Immunology and Evolution of Infectious Disease - NCBI Bookshelf [ncbi.nlm.nih.gov]
Validation & Comparative
A Researcher's Guide to the Validation of 1-Methyl-2'-O-methylinosine LC-MS Results
For researchers, scientists, and professionals in drug development, the accurate quantification of modified nucleosides like 1-Methyl-2'-O-methylinosine (m¹Im) is crucial for understanding its biological roles and potential as a biomarker. Liquid chromatography-mass spectrometry (LC-MS) stands as the gold standard for this purpose due to its high sensitivity and selectivity. This guide provides a comprehensive comparison of LC-MS with other analytical techniques, supported by detailed experimental protocols and data to aid in the validation of your m¹Im research findings.
Quantitative Performance Comparison
The performance of any analytical method is paramount for generating reliable and reproducible data. The following table summarizes the typical quantitative performance characteristics of an LC-MS/MS method for the analysis of modified nucleosides. It is important to note that these values are representative and should be established specifically for this compound in your laboratory during method validation.
| Parameter | LC-MS/MS | 2D-Thin Layer Chromatography (2D-TLC) | Nanopore Sequencing |
| Limit of Detection (LOD) | Low fmol to pmol range | pmol to nmol range | Not directly quantitative |
| Limit of Quantitation (LOQ) | Low fmol to pmol range | pmol to nmol range | Not directly quantitative |
| **Linearity (R²) ** | > 0.99 | Semi-quantitative | Not applicable |
| Precision (%RSD) | < 15% | 15-30% | Not applicable |
| Accuracy (%Recovery) | 85-115% | Variable | Not applicable |
| Specificity | High | Moderate | High (sequence context) |
| Throughput | High | Low | High |
Experimental Protocols
A robust and well-documented experimental protocol is the foundation of reproducible research. Below is a detailed methodology for the analysis of this compound using LC-MS/MS.
Experimental Workflow for LC-MS/MS Analysis
Detailed Methodologies
1. RNA Isolation and Purification:
-
Isolate total RNA from cells or tissues using a commercial kit (e.g., RNeasy Mini Kit, Qiagen) or a TRIzol-based method, following the manufacturer's instructions.
-
Ensure all reagents and equipment are RNase-free to prevent RNA degradation.
2. RNA Quantification and Quality Control:
-
Determine the concentration and purity of the isolated RNA using a spectrophotometer (e.g., NanoDrop). A 260/280 ratio of ~2.0 is indicative of pure RNA.
-
Assess RNA integrity using an automated electrophoresis system (e.g., Agilent Bioanalyzer).
3. Enzymatic Digestion of RNA to Nucleosides:
-
To 1-5 µg of total RNA, add nuclease P1 (e.g., 2 Units) and incubate at 37°C for 2 hours in a buffer solution (e.g., 20 mM ammonium (B1175870) acetate (B1210297), pH 5.3).[1]
-
Add bacterial alkaline phosphatase (e.g., 1 Unit) and continue incubation at 37°C for another 2 hours to dephosphorylate the nucleotides to nucleosides.[1]
-
For 2'-O-methylated nucleosides, which can be resistant to digestion, a longer incubation time (up to 24 hours) may be necessary to improve the yield.[1]
4. Sample Cleanup:
-
Remove the enzymes from the digested sample. This can be achieved by protein precipitation with a solvent like acetonitrile (B52724) or by using a centrifugal filter with a molecular weight cutoff (e.g., 3 kDa).
-
Dry the sample in a vacuum centrifuge and reconstitute in a solvent compatible with the initial LC mobile phase (e.g., 95:5 water:acetonitrile with 0.1% formic acid).
5. LC-MS/MS Analysis:
-
Liquid Chromatography:
-
Column: A hydrophilic interaction liquid chromatography (HILIC) column (e.g., SeQuant ZIC-HILIC, 150 x 2.1 mm, 5 µm) is often preferred for the separation of polar modified nucleosides. Alternatively, a reversed-phase (RP) C18 column can be used.
-
Mobile Phase A: 10 mM ammonium acetate in water with 0.1% acetic acid.
-
Mobile Phase B: Acetonitrile.
-
Gradient: A typical gradient would start with a high percentage of mobile phase B, gradually decreasing to elute the polar analytes.
-
Flow Rate: 0.2-0.4 mL/min.
-
Injection Volume: 5-10 µL.
-
-
Mass Spectrometry:
-
Ionization: Electrospray ionization (ESI) in positive ion mode.
-
Detection: A triple quadrupole (QQQ) mass spectrometer operating in Multiple Reaction Monitoring (MRM) mode is ideal for quantification.
-
MRM Transitions: Specific precursor-to-product ion transitions for this compound need to be determined using a pure standard. Based on the Modomics database, the [M+H]⁺ for 1,2'-O-dimethylinosine (m¹Im) is m/z 297.1199, and a likely product ion from the loss of the ribose moiety would be the protonated base at m/z 151.
-
6. Data Analysis and Quantification:
-
Integrate the peak areas of the MRM transitions for this compound and an appropriate internal standard (e.g., a stable isotope-labeled version of the analyte).
-
Construct a calibration curve using a series of known concentrations of a pure this compound standard.
-
Quantify the amount of this compound in the samples by interpolating their peak area ratios from the calibration curve.
Comparison with Alternative Methods
While LC-MS/MS is the preferred method for the quantification of modified nucleosides, other techniques have been historically used and are still relevant in certain contexts.
-
2D-Thin Layer Chromatography (2D-TLC): This method involves the separation of radiolabeled nucleosides on a TLC plate in two different solvent systems.
-
Advantages: Relatively inexpensive and does not require sophisticated instrumentation.
-
Disadvantages: Labor-intensive, has lower sensitivity and specificity compared to LC-MS/MS, is semi-quantitative, and requires the use of radioactivity.
-
-
Nanopore Sequencing: This emerging technology allows for the direct sequencing of RNA molecules and has the potential to identify RNA modifications.[2]
Biological Context: The Role of tRNA Modifications in Stress Response
Modified nucleosides, including methylated inosines, are often found in transfer RNA (tRNA) and play a critical role in regulating protein translation, particularly under conditions of cellular stress.
Under oxidative stress, for example, the cell activates signaling pathways that can lead to changes in the expression and activity of tRNA modifying enzymes.[3] This results in a dynamic regulation of tRNA modifications, which can fine-tune the translation of specific mRNAs that are crucial for the stress response, ultimately promoting cellular adaptation and survival.[3] The presence and abundance of this compound could therefore be an important indicator of the cellular response to stress.
References
- 1. Protocol for preparation and measurement of intracellular and extracellular modified RNA using liquid chromatography-mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 2. tRNA structural and functional changes induced by oxidative stress - PMC [pmc.ncbi.nlm.nih.gov]
- 3. A Quantitative Systems Approach Reveals Dynamic Control of tRNA Modifications during Cellular Stress | PLOS Genetics [journals.plos.org]
A Comparative Analysis of 1-Methylinosine (m1I) and 1-Methyl-2'-O-methylinosine (m1Im): Structure, Function, and Experimental Analysis
For Researchers, Scientists, and Drug Development Professionals
This guide provides a detailed comparison of the functional and structural properties of two modified ribonucleosides: 1-methylinosine (B32420) (m1I) and its 2'-O-methylated counterpart, 1-methyl-2'-O-methylinosine (m1Im). Understanding the nuanced differences imparted by the 2'-O-methyl group is critical for researchers in RNA biology and for professionals engaged in the development of RNA-based therapeutics. This document synthesizes available experimental data to offer a clear, objective comparison.
Introduction to m1I and the Impact of 2'-O-Methylation
1-methylinosine (m1I) is a post-transcriptionally modified nucleoside found in transfer RNA (tRNA). It is formed by the methylation of the N1 position of inosine (B1671953). This modification is crucial for the proper functioning of tRNA, primarily by enhancing the accuracy and efficiency of protein translation through the stabilization of tRNA structure.
The addition of a methyl group to the 2'-hydroxyl of the ribose sugar, a process known as 2'-O-methylation , is a common modification in various RNA species. This modification is known to confer several key properties, including increased thermal stability of RNA duplexes, enhanced resistance to nuclease degradation, and the ability to modulate the innate immune response to RNA. The presence of a 2'-O-methyl group on m1I, forming This compound (m1Im) , is therefore expected to significantly alter its biochemical and functional characteristics.
Comparative Functional Analysis
The functional roles of m1I are well-documented, particularly in the context of tRNA. While direct experimental data exclusively comparing the functions of m1I and m1Im are limited, we can infer the functional implications of the additional 2'-O-methylation based on extensive studies of this modification on other nucleosides.
| Feature | 1-methylinosine (m1I) | This compound (m1Im) (Inferred) |
| Primary Role in tRNA | Stabilizes the anticodon loop, ensuring proper codon recognition and preventing frameshifting during translation. | Likely enhances the structural stability of tRNA to an even greater extent than m1I, potentially leading to increased translational fidelity. |
| Contribution to tRNA Structure | The N1-methylation of the inosine base contributes to the overall structural integrity of the tRNA molecule. | The 2'-O-methyl group is expected to favor the C3'-endo sugar pucker conformation, which is characteristic of A-form RNA helices, thereby further rigidifying the local RNA structure. |
| Nuclease Resistance | Offers some protection against nuclease degradation compared to unmodified inosine. | Expected to confer significantly higher resistance to degradation by single-strand specific ribonucleases due to the steric hindrance provided by the 2'-O-methyl group. |
| Thermal Stability of RNA Duplexes | Contributes to the overall thermal stability of the tRNA molecule. | The presence of the 2'-O-methyl group is known to increase the melting temperature (Tm) of RNA duplexes, suggesting that tRNAs containing m1Im would be more stable at higher temperatures. |
| Immunomodulatory Properties | As a modified nucleoside, it may contribute to the evasion of innate immune recognition of self-RNA. | 2'-O-methylation is a key modification for distinguishing self from non-self RNA, thereby reducing the activation of innate immune sensors like Toll-like receptors (TLRs). m1Im is therefore expected to have a more pronounced role in immune evasion. |
Biosynthetic Pathways
The biosynthesis of m1I occurs through distinct enzymatic pathways depending on its location within the tRNA molecule and the organism. The formation of m1Im would require an additional 2'-O-methylation step, likely catalyzed by a specific RNA methyltransferase.
Experimental Protocols
The analysis and comparison of m1I and m1Im in biological samples require sensitive and specific analytical techniques. The following section outlines key experimental protocols for the detection, quantification, and functional analysis of these modified nucleosides.
tRNA Isolation and Purification
Objective: To obtain high-purity tRNA from biological samples for downstream analysis.
Methodology:
-
Total RNA Extraction: Homogenize cells or tissues in a lysis buffer (e.g., TRIzol) to disrupt cells and denature proteins. Perform a phenol-chloroform extraction to separate RNA from DNA and proteins.
-
tRNA Enrichment: Isolate tRNA from the total RNA pool using one of the following methods:
-
Anion-exchange chromatography: Separate RNA species based on their size and charge.
-
Polyacrylamide gel electrophoresis (PAGE): Separate RNA based on size, allowing for the excision of the tRNA band.
-
-
Quality Control: Assess the purity and integrity of the isolated tRNA using a Bioanalyzer or similar capillary electrophoresis system.
Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS) for Nucleoside Analysis
Objective: To identify and quantify m1I and m1Im in isolated tRNA.
Methodology:
-
Enzymatic Digestion: Digest the purified tRNA to single nucleosides using a cocktail of nucleases (e.g., nuclease P1) and phosphatases (e.g., bacterial alkaline phosphatase).
-
LC Separation: Separate the resulting nucleosides using reversed-phase high-performance liquid chromatography (HPLC) or ultra-high-performance liquid chromatography (UHPLC).
-
MS/MS Detection: Detect and quantify the nucleosides using a tandem mass spectrometer operating in multiple reaction monitoring (MRM) mode. Specific parent-to-daughter ion transitions for m1I and m1Im are used for unambiguous identification and quantification against a standard curve of known concentrations.
tRNA Sequencing for Modification Mapping (e.g., Nano-tRNAseq)
Objective: To map the location of m1I and potentially m1Im within specific tRNA molecules.
Methodology:
-
Library Preparation: Ligate adapters to the 3' and 5' ends of the isolated tRNA molecules.
-
Nanopore Sequencing: Sequence the adapter-ligated tRNA directly using a nanopore sequencing platform. The passage of each native RNA molecule through a nanopore generates a characteristic electrical signal.
-
Data Analysis: Analyze the raw sequencing data. Modified bases, such as m1I and m1Im, will cause deviations in the electrical signal compared to their unmodified counterparts. These deviations can be used to identify the presence and location of the modifications.
Experimental Workflow
The following diagram illustrates a typical workflow for the comparative analysis of m1I and m1Im.
comparative analysis of tRNA modifications in different archaeal species
Transfer RNA (tRNA) modifications are crucial post-transcriptional alterations that ensure the structural integrity, decoding fidelity, and overall efficiency of protein synthesis.[1][2] In Archaea, these modifications are particularly vital for adaptation to extreme environments.[1][2][3] This guide provides a comparative analysis of tRNA modifications across different archaeal species, focusing on quantitative data, experimental methodologies, and the functional implications for researchers and drug development professionals.
I. Comparative Analysis of tRNA Modifications
The landscape of tRNA modifications varies significantly across different archaeal species, reflecting their diverse evolutionary paths and environmental niches.[1][2][3] Thermophilic archaea, for instance, often exhibit a higher degree and complexity of modifications compared to their mesophilic counterparts, which contributes to tRNA stability at high temperatures.[4][5][6]
Below is a summary of common and species-specific tRNA modifications found in three representative archaeal species: the mesophilic methanogen Methanococcus maripaludis, the hyperthermophile Pyrococcus furiosus, and the thermoacidophile Sulfolobus acidocaldarius.[4][5]
Table 1: Comparison of Key tRNA Modifications in Selected Archaeal Species
| Modification (Symbol) | Location(s) | M. maripaludis (Mesophile) | P. furiosus (Hyperthermophile) | S. acidocaldarius (Thermoacidophile) | Putative Function |
| Archaeosine (G+) | 15 | Present | Present | Present | Stabilizes D- and T-loops interaction, tRNA core structure[7] |
| N4-acetylcytidine (ac4C) | 12, 34 | Less Frequent | Frequent | Frequent | Stabilizes C-G base pairs, enhances thermal stability[4][5] |
| 1-methylguanosine (m1G) | 9, 37 | Present | Present | Present | Prevents frameshifting, ensures translational accuracy[8] |
| N2,N2-dimethylguanosine (m22G) | 10, 26 | Present | Present | Present | Facilitates correct tRNA folding and tertiary structure[2] |
| Wyosine derivatives (e.g., imG) | 37 | Present | Present | Present | Ensures correct decoding of specific codons[4][5] |
| Dihydrouridine (D) | D-loop | Present | Present | Present | Contributes to tRNA flexibility and recognition |
| Pseudouridine (Ψ) | Various | Present | Present | Present | Stabilizes tRNA structure through additional H-bonds |
| 2'-O-methylation (Nm) | Various | Less Frequent | Frequent | Frequent | Increases tRNA rigidity and thermal stability[6] |
| 7-methylguanosine (m7G) | 1, 10, 46 | Absent | Present (at 1, 10) | Present (at 46) | Contributes to tRNA stability and recognition[4][5][6] |
This table is a synthesis of data from multiple studies. The frequency is relative and based on findings from comparative analyses.[4][5]
II. Experimental Methodologies
The identification and quantification of tRNA modifications predominantly rely on mass spectrometry-based techniques, often coupled with liquid chromatography.[4][9][10]
Generalized Protocol for LC-MS/MS Analysis of tRNA Modifications:
-
tRNA Isolation and Purification:
-
Enzymatic Digestion:
-
The purified tRNA is completely hydrolyzed into individual nucleosides.
-
This is typically achieved using a cocktail of enzymes, such as nuclease P1 (to cleave phosphodiester bonds) followed by a phosphatase (e.g., bacterial alkaline phosphatase) to remove the 5'-phosphate.[10]
-
-
Chromatographic Separation:
-
The resulting mixture of nucleosides is separated using reversed-phase HPLC (RP-HPLC).[9]
-
This separation is based on the different polarities of the canonical and modified nucleosides.
-
-
Mass Spectrometry Analysis:
-
The separated nucleosides are introduced into a mass spectrometer, typically a triple quadrupole (QqQ) or a high-resolution instrument like an Orbitrap.[10]
-
The mass spectrometer identifies each nucleoside based on its unique mass-to-charge ratio.
-
Tandem mass spectrometry (MS/MS) is used to fragment the nucleosides, providing structural information that confirms their identity.[10][12]
-
-
Quantification:
III. Visualizing Experimental and Logical Workflows
To better understand the processes involved in tRNA modification analysis, the following diagrams illustrate the general experimental workflow and a classification of common archaeal modifications.
IV. Conclusion
The study of tRNA modifications in archaea is a rapidly evolving field that provides deep insights into the mechanisms of adaptation to extreme environments and the fundamental principles of translational regulation.[1][2] Comparative analyses reveal both conserved and lineage-specific modification patterns, highlighting the co-evolution of tRNAs and their modifying enzymes.[1][2][3] The methodologies outlined here, particularly LC-MS/MS, are powerful tools for researchers to quantitatively profile these modifications. For drug development professionals, understanding the unique archaeal tRNA modification enzymes and pathways could open avenues for novel antimicrobial strategies targeting these essential cellular processes.
References
- 1. The Landscape of tRNA Modifications in Archaea - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. biorxiv.org [biorxiv.org]
- 3. researchgate.net [researchgate.net]
- 4. Comparative patterns of modified nucleotides in individual tRNA species from a mesophilic and two thermophilic archaea - PMC [pmc.ncbi.nlm.nih.gov]
- 5. [PDF] Comparative patterns of modified nucleotides in individual tRNA species from a mesophilic and two thermophilic archaea | Semantic Scholar [semanticscholar.org]
- 6. mdpi.com [mdpi.com]
- 7. journals.asm.org [journals.asm.org]
- 8. journals.asm.org [journals.asm.org]
- 9. Quantitative analysis of tRNA modifications by HPLC-coupled mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Probing the diversity and regulation of tRNA modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 11. tRNA Modification Analysis by MS - CD Genomics [rna.cd-genomics.com]
- 12. pubs.acs.org [pubs.acs.org]
- 13. dspace.mit.edu [dspace.mit.edu]
cross-validation of sequencing and mass spectrometry for m1Im detection
A Comprehensive Guide to the Cross-Validation of Sequencing and Mass Spectrometry for N1-methyladenosine (m1A) Detection
For researchers, scientists, and drug development professionals investigating the epitranscriptome, accurate detection and quantification of RNA modifications are paramount. N1-methyladenosine (m1A), a reversible post-transcriptional modification, has emerged as a critical regulator of RNA stability and translation.[1][2] This guide provides an objective comparison of the two primary methodologies for m1A detection: high-throughput sequencing and mass spectrometry. We present supporting experimental data, detailed protocols, and visual workflows to aid in the selection and implementation of the most suitable method for your research needs.
Data Presentation: A Comparative Analysis
The choice between sequencing-based methods and mass spectrometry for m1A detection hinges on the specific research question, whether it's transcriptome-wide mapping at single-nucleotide resolution or precise global quantification. The following table summarizes the key performance characteristics of each approach.
| Feature | High-Throughput Sequencing (e.g., m1A-seq, m1A-MAP) | Mass Spectrometry (LC-MS/MS) |
| Principle | Immunoprecipitation of m1A-containing RNA fragments followed by high-throughput sequencing; detection is based on reverse transcription signatures (mutations or truncations) at m1A sites.[3][4] | Separation and identification of modified nucleosides based on their mass-to-charge ratio after enzymatic digestion of RNA.[5] |
| Resolution | Single-nucleotide.[4][6] | Provides global quantification of m1A in the total RNA pool; does not provide single-nucleotide resolution.[5] |
| Sensitivity | High, capable of detecting lowly abundant m1A sites.[4] | High, but can be challenging to detect and interpret low-abundance modifications.[5] |
| Specificity | Can be affected by antibody cross-reactivity, particularly with the m7G cap.[7] Chemical treatments (Dimroth rearrangement or AlkB demethylation) are often used to improve specificity.[3][4] | High specificity in identifying and quantifying m1A nucleosides.[5] |
| Quantification | Semi-quantitative to quantitative, often relies on the frequency of mutational events, which may not be linear with the modification level.[8] | Highly quantitative, providing precise measurements of the m1A/A ratio.[6] |
| Throughput | High, suitable for transcriptome-wide analysis. | Lower, typically used for global analysis or validation of specific targets.[9] |
| Strengths | - Transcriptome-wide mapping- Single-nucleotide resolution- Requires less starting material than some MS methods | - Gold standard for quantification- High specificity- Not susceptible to antibody cross-reactivity |
| Limitations | - Potential for antibody cross-reactivity- Indirect quantification based on RT signatures- Data analysis can be complex | - Does not provide sequence context- Requires enzymatic digestion, losing positional information- Can overestimate high-level modifications[5] |
Quantitative Cross-Validation Data
A direct comparison of m1A quantification by m1A-MAP (a sequencing method) and liquid chromatography-mass spectrometry (LC-MS/MS) for synthetic RNA oligonucleotides demonstrates the quantitative capabilities and limitations of sequencing-based approaches.
| RNA Oligo | m1A Modification Level (by LC-MS/MS) | Misincorporation Rate (by m1A-MAP) |
| Model 1 | ~97-98% | ~66-75% |
| Model 2 | ~50% | ~9-10% |
Data synthesized from a study by Li et al.[8]
This data highlights that while sequencing methods can detect m1A, the observed mutation rate is not always directly proportional to the actual modification level, suggesting that the quantification can be an underestimation.[8]
Experimental Protocols
Detailed methodologies are crucial for reproducible and reliable results. Below are generalized protocols for m1A detection using sequencing and mass spectrometry.
m1A-Specific Sequencing (m1A-seq/m1A-MAP) Protocol
This protocol combines antibody-based enrichment with the analysis of reverse transcription signatures.
-
RNA Isolation and Fragmentation: Isolate total RNA from the sample of interest. For mRNA analysis, perform poly(A) selection. Fragment the RNA to an appropriate size (e.g., ~100 nucleotides) using enzymatic or chemical methods.
-
Immunoprecipitation (IP): Incubate the fragmented RNA with an anti-m1A antibody to enrich for m1A-containing fragments.[4] Magnetic beads coupled to a secondary antibody are used to pull down the antibody-RNA complexes.
-
Elution and Control Treatment: Elute the enriched RNA fragments. A portion of the sample should be set aside as an "input" control (no IP). For improved specificity, a parallel IP sample can be treated with a demethylase like AlkB to remove m1A, or undergo Dimroth rearrangement to convert m1A to N6-methyladenosine (m6A), which is not read as a mutation by reverse transcriptase.[3][4]
-
Library Preparation: Prepare sequencing libraries from the IP, input, and control-treated RNA samples. This typically involves reverse transcription, second-strand synthesis, adapter ligation, and PCR amplification.
-
High-Throughput Sequencing: Sequence the prepared libraries on a high-throughput sequencing platform.
-
Data Analysis: Align the sequencing reads to a reference genome or transcriptome. Identify m1A sites by looking for characteristic mutation patterns (misincorporations) or an increase in truncations at specific adenosine (B11128) residues in the IP sample compared to the input and control samples.
Liquid Chromatography-Mass Spectrometry (LC-MS/MS) Protocol for Global m1A Quantification
This protocol provides a precise measurement of the overall m1A levels in an RNA sample.
-
RNA Isolation: Isolate total RNA from the sample. Ensure high purity and integrity of the RNA.
-
RNA Digestion: Digest the RNA into individual nucleosides using a cocktail of enzymes, such as nuclease P1 and alkaline phosphatase.
-
Liquid Chromatography (LC) Separation: Separate the resulting nucleosides using high-performance liquid chromatography (HPLC) or ultra-high-performance liquid chromatography (UHPLC). A hydrophilic interaction liquid chromatography (HILIC) column is often used for this purpose.
-
Tandem Mass Spectrometry (MS/MS) Analysis: Introduce the separated nucleosides into a tandem mass spectrometer. The instrument will ionize the nucleosides and fragment them, allowing for the specific detection and quantification of m1A and unmodified adenosine (A) based on their unique mass-to-charge ratios and fragmentation patterns.
-
Quantification: Determine the amount of m1A relative to the amount of unmodified adenosine to calculate the global m1A/A ratio. Stable isotope-labeled internal standards can be used for absolute quantification.
Mandatory Visualization
To further clarify the experimental processes and their relationship, the following diagrams have been generated using the DOT language.
Caption: Workflow for m1A detection by sequencing.
Caption: Workflow for m1A detection by mass spectrometry.
Caption: Cross-validation of sequencing and mass spectrometry.
References
- 1. qian.human.cornell.edu [qian.human.cornell.edu]
- 2. researchgate.net [researchgate.net]
- 3. pubs.acs.org [pubs.acs.org]
- 4. Chemical manipulation of m1A mediates its detection in human tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Research progress of N1-methyladenosine RNA modification in cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 6. m1A RNA Methylation Analysis - CD Genomics [cd-genomics.com]
- 7. pubs.acs.org [pubs.acs.org]
- 8. Base-resolution mapping reveals distinct m1A methylome in nuclear- and mitochondrial-encoded transcripts - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
The Subtle Architect: A Comparative Guide to the Effects of 2'-O-Methylation on RNA Structure
For researchers, scientists, and drug development professionals, understanding the intricate interplay of RNA modifications is paramount. Among the more than 170 known modifications, 2'-O-methylation (Nm), the addition of a methyl group to the 2'-hydroxyl of the ribose moiety, stands out as a critical regulator of RNA structure, stability, and function. This guide provides an objective comparison of the effects of different 2'-O-methylations on RNA structure, supported by experimental data and detailed methodologies.
The 2'-O-methylation is a widespread and highly conserved post-transcriptional modification found in various RNA species, including messenger RNA (mRNA), transfer RNA (tRNA), ribosomal RNA (rRNA), and small non-coding RNAs.[1][2] This seemingly minor alteration has profound implications for the structural integrity and biological activity of RNA molecules.
Enhanced Thermal Stability: A Quantitative Look
One of the most well-documented effects of 2'-O-methylation is the enhancement of RNA duplex stability. This stabilization is primarily attributed to the 2'-O-methyl group favoring a C3'-endo sugar pucker conformation, which is the characteristic conformation of nucleotides within an A-form RNA helix.[3] This pre-organization of the ribose moiety reduces the entropic penalty of duplex formation, leading to a more stable helical structure.[3][4]
The impact of 2'-O-methylation on the thermodynamic stability of RNA duplexes is typically quantified by measuring the change in melting temperature (Tm), the temperature at which half of the duplex molecules dissociate into single strands. An increase in Tm is indicative of greater stability. Further thermodynamic parameters, including the change in Gibbs free energy (ΔG°), enthalpy (ΔH°), and entropy (ΔS°), provide a more comprehensive understanding of these stabilizing effects.[3]
Below is a summary of quantitative data from studies on the effects of 2'-O-methylation on RNA duplex stability:
| RNA Duplex Sequence | Modification | ΔTm (°C) | ΔΔG° (kcal/mol) | Reference |
| U14/A14 | Fully 2'-O-methylated U-strand | +12 | - | [1] |
| U14/A14 | Fully 2'-O-methylated A-strand | 0 | - | [1] |
| HIV-1 TAR | Single Am35 | -0.1 (no Mg2+), +0.4 (with Mg2+) | ~ -0.1 (no Mg2+), ~ +0.4 (with Mg2+) | [5] |
| HIV-1 TAR | Triple Nm (C24, U25, A35) | - | ~ -0.3 (no Mg2+), ~ +0.6 (with Mg2+) | [5] |
Note: The exact quantitative changes are dependent on the specific sequence context, the number and position of modifications, and the experimental conditions.[3][5]
Beyond Stability: Structural and Functional Implications
The influence of 2'-O-methylation extends beyond simple duplex stabilization. This modification plays a crucial role in:
-
Nuclease Resistance: The methyl group at the 2' position sterically hinders the access of ribonucleases, thereby protecting the RNA from degradation and increasing its cellular half-life.[6]
-
RNA-Protein Interactions: 2'-O-methylation can either enhance or inhibit the binding of proteins to RNA, thereby modulating various cellular processes.
-
Splicing and Translation: In mRNA, internal 2'-O-methylation has been shown to regulate splicing and translation, highlighting its role in gene expression.[6][7]
-
Immune Evasion: In viral RNAs, 2'-O-methylation can help the virus evade the host's innate immune system.
Visualizing the Impact: Experimental Workflows and Logical Relationships
To better understand the processes involved in studying 2'-O-methylation and its effects, the following diagrams illustrate key experimental workflows and the logical relationships of its structural impact.
Caption: Workflow for analyzing 2'-O-methylation effects.
Caption: The structural consequences of 2'-O-methylation.
Experimental Protocols
Accurate and reproducible experimental methods are crucial for dissecting the effects of 2'-O-methylation. Below are detailed protocols for key experiments.
UV Thermal Denaturation for Tm Determination
This method measures the change in UV absorbance of an RNA duplex solution as the temperature is increased to determine its melting temperature (Tm).
1. Sample Preparation:
-
Synthesize and purify the unmodified and 2'-O-methylated RNA oligonucleotides using standard phosphoramidite (B1245037) chemistry.
-
Quantify the concentration of each RNA strand by measuring the absorbance at 260 nm (A260) at a high temperature (e.g., 90°C) where the RNA is single-stranded.
-
Prepare equimolar amounts of the complementary strands in a buffer solution (e.g., 10 mM sodium phosphate, 100 mM NaCl, 0.1 mM EDTA, pH 7.0).[5]
-
Anneal the duplexes by heating to 95°C for 5 minutes, followed by slow cooling to room temperature.[5]
2. Data Acquisition:
-
Use a spectrophotometer equipped with a temperature-controlled cuvette holder.
-
Place the RNA duplex solution in a quartz cuvette.
-
Monitor the absorbance at 260 nm while increasing the temperature at a controlled rate (e.g., 1°C/minute) from a low temperature (e.g., 15°C) to a high temperature (e.g., 95°C).[5]
3. Data Analysis:
-
Plot the absorbance at 260 nm as a function of temperature to obtain a melting curve.
-
The Tm is the temperature at which the absorbance is halfway between the lower (duplex) and upper (single-stranded) baselines.
-
Thermodynamic parameters (ΔG°, ΔH°, and ΔS°) can be derived from analyzing the shape of the melting curve using appropriate software.[8]
RiboMethSeq for Transcriptome-Wide 2'-O-Methylation Mapping
RiboMethSeq is a high-throughput sequencing method that identifies 2'-O-methylated sites based on their resistance to alkaline hydrolysis.[4][9][10][11][12]
1. RNA Fragmentation:
-
Subject total RNA or purified RNA species to random alkaline hydrolysis (e.g., using sodium carbonate buffer at 95°C for a defined time).[9]
-
The phosphodiester bond adjacent to a 2'-O-methylated nucleotide is protected from cleavage.
2. Library Preparation:
-
Repair the ends of the RNA fragments (dephosphorylation of 3'-ends and phosphorylation of 5'-ends).[9]
-
Ligate 3' and 5' adapters to the RNA fragments.
-
Perform reverse transcription to convert the RNA fragments into a cDNA library.
-
Amplify the cDNA library by PCR.
3. High-Throughput Sequencing:
-
Sequence the cDNA library using an Illumina platform.
4. Data Analysis:
-
Map the sequencing reads to the reference transcriptome.
-
A gap or a reduction in the number of read ends at a specific nucleotide position is indicative of the presence of a 2'-O-methylation at the preceding nucleotide, which has conferred protection from cleavage.[9]
RNase H Cleavage Assay for Site-Specific Analysis
This method utilizes RNase H, an enzyme that specifically cleaves the RNA strand of an RNA/DNA hybrid, to detect 2'-O-methylation, which inhibits this cleavage.[13][14][15]
1. Probe Design:
-
Design a DNA oligonucleotide probe that is complementary to the target RNA sequence spanning the suspected methylation site.
2. Hybridization:
-
Hybridize the DNA probe to the target RNA to form an RNA/DNA hybrid.
3. RNase H Digestion:
-
Treat the RNA/DNA hybrid with RNase H.
-
If the target site is unmethylated, RNase H will cleave the RNA strand.
-
If the site is 2'-O-methylated, cleavage will be inhibited.
4. Analysis:
-
Analyze the cleavage products using methods such as gel electrophoresis, quantitative PCR (qPCR), or northern blotting to determine the extent of cleavage and thus the methylation status of the target site.[15]
Conclusion
2'-O-methylation is a subtle yet powerful modification that significantly influences RNA structure and function. Its ability to enhance thermal stability, confer nuclease resistance, and modulate molecular interactions underscores its importance in a multitude of biological processes. The experimental techniques outlined in this guide provide a robust toolkit for researchers to further unravel the complexities of the epitranscriptome and leverage this knowledge for the development of novel RNA-based therapeutics and diagnostics.
References
- 1. pubs.acs.org [pubs.acs.org]
- 2. academic.oup.com [academic.oup.com]
- 3. benchchem.com [benchchem.com]
- 4. researchgate.net [researchgate.net]
- 5. 2′-O-Methylation can increase the abundance and lifetime of alternative RNA conformational states - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Assessing 2′-O-Methylation of mRNA Using Quantitative PCR | Springer Nature Experiments [experiments.springernature.com]
- 7. researchgate.net [researchgate.net]
- 8. Nearest-neighbor parameters for the prediction of RNA duplex stability in diverse in vitro and cellular-like crowding conditions - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Frontiers | Holistic Optimization of Bioinformatic Analysis Pipeline for Detection and Quantification of 2′-O-Methylations in RNA by RiboMethSeq [frontiersin.org]
- 10. Quantification of 2′-O-Me Residues in RNA Using Next-Generation Sequencing (Illumina RiboMethSeq Protocol) | Springer Nature Experiments [experiments.springernature.com]
- 11. Next-Generation Sequencing-Based RiboMethSeq Protocol for Analysis of tRNA 2′-O-Methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Illumina-based RiboMethSeq approach for mapping of 2'-O-Me residues in RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. neb.com [neb.com]
- 14. neb.com [neb.com]
- 15. Detection and quantitation of RNA base modifications - PMC [pmc.ncbi.nlm.nih.gov]
The Quest for Validating 1-Methyl-2'-O-methylinosine (m¹Am) Sites: A Guide to an Emerging Field
The validation of predicted 1-Methyl-2'-O-methylinosine (m¹Am) sites in RNA remains a significant challenge in the field of epitranscriptomics. While computational tools for predicting various RNA modifications are advancing, experimental verification, particularly through precise techniques like mutagenesis, is crucial for confirming their biological relevance. However, a comprehensive survey of the current scientific literature reveals a notable scarcity of studies specifically detailing the validation of predicted m¹Am sites using mutagenesis.
This guide aims to provide researchers, scientists, and drug development professionals with an objective overview of the current landscape, highlighting the existing knowledge gaps and outlining the methodologies that could be adapted for the validation of m¹Am sites. Due to the limited specific data on m¹Am validation, this guide will draw parallels from the more extensively studied N1-methyladenosine (m¹A) modification and provide a framework for future research in this emerging area.
The Challenge of m¹Am Detection and Validation
This compound (m¹Am) is a doubly modified ribonucleoside, and its identification and functional characterization are in the early stages. The presence of both a methyl group on the inosine (B1671953) base and another on the 2'-hydroxyl group of the ribose sugar makes its detection and the study of its functional impact complex.
Current high-throughput sequencing methods for RNA modifications are often optimized for more common modifications like N6-methyladenosine (m⁶A) and m¹A. While techniques like mass spectrometry can identify novel modifications, including potentially m¹Am, the validation of specific sites within the transcriptome and the elucidation of their functional consequences require targeted experimental approaches.
A Proposed Workflow for m¹Am Site Validation using Mutagenesis
Based on established protocols for other RNA modifications, a logical workflow for validating predicted m¹Am sites using mutagenesis can be proposed. This workflow would serve to systematically assess the functional importance of the predicted modification.
Figure 1. A proposed experimental workflow for the validation of predicted m¹Am sites using site-directed mutagenesis.
Experimental Protocols: Adapting Existing Methodologies
Site-Directed Mutagenesis
The core of the validation process involves mutating the target adenosine (B11128) nucleotide to another nucleotide (e.g., guanosine) to prevent methylation. This allows for a direct comparison between the wild-type (potentially modified) and mutant (unmodified) RNA.
Table 1: Comparison of Mutagenesis Approaches
| Technique | Principle | Advantages | Disadvantages |
| PCR-based Mutagenesis | Utilizes mutagenic primers in a polymerase chain reaction to introduce the desired mutation into a plasmid containing the RNA of interest. | Fast, efficient, and widely accessible. | Potential for off-target mutations, requires sequencing verification. |
| CRISPR-Cas9 Gene Editing | Employs a guide RNA to direct the Cas9 nuclease to a specific genomic locus to introduce a mutation. | Enables in vivo validation in a native cellular context. | More complex to design and implement, potential for off-target effects. |
Detailed Protocol: PCR-Based Site-Directed Mutagenesis
-
Primer Design: Design complementary forward and reverse primers (~25-45 nucleotides in length) containing the desired mutation in the middle. The primers should have a melting temperature (Tm) of ≥78°C.
-
PCR Amplification: Perform PCR using a high-fidelity DNA polymerase, the plasmid template containing the wild-type RNA sequence, and the mutagenic primers. The reaction cycles should be optimized for the specific plasmid and primers.
-
Template Digestion: Digest the parental, methylated template DNA using the DpnI restriction enzyme, which specifically cleaves methylated and hemimethylated DNA.
-
Transformation: Transform the mutated plasmid into competent E. coli cells for amplification.
-
Verification: Isolate the plasmid DNA from multiple colonies and verify the presence of the desired mutation and the absence of off-target mutations by Sanger sequencing.
Functional Assays
Following successful mutagenesis, the functional consequences of ablating the m¹Am site can be assessed through various assays.
Table 2: Potential Functional Assays for m¹Am Validation
| Assay | Purpose | Expected Outcome if m¹Am is Functional |
| Quantitative PCR (qPCR) | To measure changes in RNA stability. | Altered mRNA half-life in the mutant compared to the wild-type. |
| Reporter Assays (e.g., Luciferase) | To assess the impact on translation efficiency. | Changes in reporter protein expression levels. |
| RNA-Protein Interaction Assays (e.g., RIP-qPCR) | To determine if the modification affects protein binding. | Altered binding of specific RNA-binding proteins to the mutant RNA. |
| Cell-based Phenotypic Assays | To investigate the effect on cellular processes (e.g., proliferation, apoptosis). | Changes in cellular phenotype upon mutation of the m¹Am site. |
The Path Forward: A Call for Focused Research
The field of epitranscriptomics is rapidly expanding, and the discovery and characterization of new RNA modifications like m¹Am are at its forefront. The lack of specific studies on the validation of predicted m¹Am sites using mutagenesis represents a critical knowledge gap.
Future research should focus on:
-
Developing and optimizing detection methods specifically for m¹Am to enable accurate transcriptome-wide mapping.
-
Identifying the "writer" and "eraser" enzymes responsible for the deposition and removal of m¹Am, which will be crucial for understanding its regulation.
-
Conducting systematic validation studies of predicted m¹Am sites using the mutagenesis and functional assay frameworks outlined in this guide.
By addressing these research priorities, the scientific community can begin to unravel the functional significance of this intriguing RNA modification and its potential role in health and disease. This will ultimately pave the way for the development of novel therapeutic strategies targeting the epitranscriptome.
N1-methyladenosine (m1A) Levels Under Varied Growth Conditions: A Quantitative Comparison
For researchers, scientists, and professionals in drug development, understanding the nuanced cellular responses to environmental changes is paramount. Post-transcriptional modifications of RNA, such as N1-methyladenosine (m1A), are emerging as critical regulators in these adaptive processes.[1][2][3] This guide provides a quantitative comparison of m1A levels across different growth conditions, supported by experimental data and detailed methodologies.
Quantitative Analysis of m1A Levels
The abundance of m1A in cellular RNA is not static; it is a dynamic modification that responds to various physiological and stress stimuli.[4][5] Studies have demonstrated significant changes in global m1A levels in mRNA in response to nutrient deprivation and environmental stress.
Below is a summary of quantitative data from studies on mammalian cells, specifically HepG2 cells, illustrating the dynamic nature of m1A modification.
| Growth Condition | Fold Change in m1A Levels (relative to control) | Cell Type | Reference |
| Glucose Starvation (4 hours) | ~ 3-fold decrease | HepG2 | [4] |
| Amino Acid Starvation (4 hours) | ~ 2-fold decrease | HepG2 | [4] |
| Heat Shock (4 hours) | ~ 1.5-fold increase | HepG2 | [4] |
| Serum Starvation (4 hours) | Modest change | HepG2 | [4] |
Note: The data presented are based on liquid chromatography-tandem mass spectrometry (LC-MS/MS) quantification.
Experimental Protocols
Accurate quantification of m1A levels is crucial for understanding its regulatory roles. The primary methods employed in the cited studies are Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS) and specialized sequencing techniques.
Quantification of Global m1A Levels by LC-MS/MS
This method provides a precise measurement of the total amount of a specific RNA modification within a sample.
Protocol Outline:
-
RNA Isolation: Total RNA is extracted from cells grown under control and experimental conditions.
-
mRNA Purification: Poly(A) RNA is purified from the total RNA to isolate messenger RNA.
-
RNA Digestion: The purified mRNA is enzymatically digested into single nucleosides.
-
LC-MS/MS Analysis: The resulting nucleoside mixture is subjected to liquid chromatography to separate the different nucleosides, followed by tandem mass spectrometry for detection and quantification of m1A relative to unmodified adenosine.
Transcriptome-wide Mapping of m1A Sites
To identify the specific locations of m1A within transcripts, specialized sequencing methods have been developed.
Protocol Outline (m1A-seq):
-
RNA Fragmentation: Purified mRNA is fragmented into smaller pieces.
-
Immunoprecipitation: An antibody specific to m1A is used to enrich for RNA fragments containing the modification.
-
Library Preparation: The enriched RNA fragments are converted into a cDNA library for high-throughput sequencing.
-
Sequencing and Data Analysis: The library is sequenced, and the data is analyzed to identify peaks corresponding to m1A sites across the transcriptome. A key step in some protocols involves the Dimroth rearrangement, where m1A is chemically converted to N6-methyladenosine (m6A) under alkaline conditions, which can be identified by specific signatures during reverse transcription.[1][4]
Visualization of Experimental Workflow and Regulatory Pathways
The following diagrams illustrate the general workflow for m1A quantification and a simplified representation of the regulatory machinery involved in m1A modification.
Caption: Workflow for m1A quantification.
Caption: Regulation of m1A modification.
References
- 1. N1-methyladenosine formation, gene regulation, biological functions, and clinical relevance - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Research progress of N1-methyladenosine RNA modification in cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. N1-methyladenosine methylome in messenger RNA and non-coding RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. The dynamic N1-methyladenosine methylome in eukaryotic messenger RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 5. The Secret Life of N1-methyladenosine: A Review on its Regulatory Functions - PubMed [pubmed.ncbi.nlm.nih.gov]
A Comparative Guide to the Substrate Specificity of RNA Methyltransferases
For Researchers, Scientists, and Drug Development Professionals
This guide provides a detailed comparison of the substrate specificity of three key RNA methyltransferases: DNMT2 (an m5C methyltransferase), the METTL3/METTL14 complex (the primary m6A writer), and NSUN2 (another important m5C methyltransferase). Understanding the distinct substrate preferences of these enzymes is crucial for elucidating their biological roles and for the development of targeted therapeutics. This document summarizes quantitative data, details experimental methodologies, and provides visual representations of key processes to facilitate a comprehensive understanding.
Data Presentation: Quantitative Comparison of Substrate Specificity
The following table summarizes the kinetic parameters and substrate preferences for DNMT2, METTL3/METTL14, and NSUN2. Direct comparison of kinetic values should be approached with caution, as experimental conditions may vary between studies.
| Enzyme | Modification | Primary RNA Substrate(s) | Recognition Motif/Structural Features | K_m (RNA) | k_cat | k_cat/K_m | Reference(s) |
| DNMT2 | m5C | tRNA (specifically tRNA-Asp, tRNA-Gly, tRNA-Val)[1][2] | Anticodon stem-loop of tRNA, specifically targeting cytosine 38 (C38)[1][2] | ~6 µM (for tRNA-Asp) | N/A | N/A | [3] |
| METTL3/METTL14 | m6A | mRNA, lncRNAs | RRACH (R=G/A, H=A/C/U), typically near stop codons and in 3' UTRs[4] | 22 ± 2 nM (for ssRNA with GGACU) | 18 ± 2 h⁻¹ | 818 h⁻¹µM⁻¹ | [5] |
| ssDNA | GGACU | 7.7 µM | 1.98 min⁻¹ | 0.26 µM⁻¹min⁻¹ | [6] | ||
| NSUN2 | m5C | tRNA, mRNA, other non-coding RNAs[7][8][9] | 5'-CNGGG sequence, often in a hairpin loop structure[10] | N/A | N/A | N/A | [10] |
Note: "N/A" indicates that specific quantitative data was not available in the reviewed literature under comparable conditions. The kinetic parameters for METTL3/METTL14 on ssDNA are included to highlight its potential for off-target activity.
Key Differences in Substrate Recognition
-
DNMT2 exhibits high specificity for tRNAs, recognizing a specific structural context within the anticodon stem-loop.[1][2] Its activity is highly dependent on the overall tRNA structure.
-
The METTL3/METTL14 complex recognizes a linear sequence motif (RRACH) within mRNA and other long RNAs.[4] METTL14 is primarily responsible for RNA binding, while METTL3 provides the catalytic activity.[11]
-
NSUN2 also recognizes a sequence motif (5'-CNGGG), but often within a structured context like a hairpin loop.[10] It has a broader range of substrates compared to DNMT2, including various types of RNA.[7][8][9]
Experimental Protocols
Detailed methodologies for key experiments cited in this guide are provided below.
In Vitro RNA Methylation Assay
This assay is used to directly measure the catalytic activity of a purified RNA methyltransferase on a specific RNA substrate.[5]
Materials:
-
Purified recombinant RNA methyltransferase (e.g., METTL3/METTL14 complex)
-
In vitro transcribed or synthetic RNA substrate containing the recognition motif
-
S-adenosylmethionine (SAM), the methyl donor (can be radiolabeled, e.g., [³H]-SAM, for detection)
-
Reaction buffer (e.g., 50 mM Tris-HCl pH 7.5, 150 mM NaCl, 1 mM DTT)
-
Scintillation counter (if using radiolabeled SAM) or LC-MS/MS for product detection
Procedure:
-
Set up the methylation reaction on ice by combining the reaction buffer, purified enzyme, and RNA substrate.
-
Initiate the reaction by adding SAM.
-
Incubate the reaction at the optimal temperature for the enzyme (e.g., 37°C) for a defined period.
-
Stop the reaction (e.g., by adding EDTA or by heat inactivation).
-
Detect the methylated RNA. If using [³H]-SAM, this can be done by spotting the reaction mixture onto a filter paper, washing away unincorporated [³H]-SAM, and measuring the retained radioactivity using a scintillation counter. Alternatively, the formation of the methylated product can be quantified using LC-MS/MS.
-
For kinetic analysis, vary the concentration of the RNA substrate while keeping the enzyme and SAM concentrations constant, and measure the initial reaction velocity. Fit the data to the Michaelis-Menten equation to determine K_m and k_cat.[5][12]
Methylated RNA Immunoprecipitation followed by Sequencing (MeRIP-Seq)
MeRIP-Seq is a powerful technique to identify the transcriptome-wide locations of a specific RNA modification, such as m6A.
Materials:
-
Total RNA isolated from cells or tissues
-
Antibody specific to the RNA modification of interest (e.g., anti-m6A antibody)
-
Magnetic beads conjugated with Protein A/G
-
Fragmentation buffer
-
IP buffer
-
Wash buffers
-
RNA purification kits
-
Reagents for next-generation sequencing library preparation
Procedure:
-
Isolate total RNA and fragment it into smaller pieces (typically ~100 nucleotides).
-
Incubate the fragmented RNA with an antibody specific to the methylation mark.
-
Add Protein A/G magnetic beads to the RNA-antibody mixture to capture the antibody-RNA complexes.
-
Wash the beads to remove non-specifically bound RNA.
-
Elute the methylated RNA fragments from the beads.
-
Purify the eluted RNA.
-
Prepare a cDNA library from the enriched RNA fragments for next-generation sequencing.
-
Sequence the library and analyze the data to identify enriched regions, which correspond to the locations of the RNA modification.
RNA Bisulfite Sequencing
RNA bisulfite sequencing is used to detect m5C modifications at single-nucleotide resolution.
Materials:
-
Total RNA
-
Bisulfite conversion reagent
-
RNA purification kits
-
Reverse transcriptase and primers for cDNA synthesis
-
PCR amplification reagents
-
Reagents for next-generation sequencing library preparation
Procedure:
-
Treat the RNA sample with sodium bisulfite. This chemical treatment converts unmethylated cytosine residues to uracil, while 5-methylcytosine (B146107) remains unchanged.
-
Purify the bisulfite-converted RNA.
-
Perform reverse transcription to synthesize cDNA from the treated RNA. During this step, the uracils are read as thymines.
-
Amplify the cDNA by PCR.
-
Prepare a sequencing library from the amplified cDNA.
-
Sequence the library and align the reads to a reference genome/transcriptome.
-
Identify m5C sites by comparing the sequenced reads to the reference sequence. A C that was not converted to a T in the sequencing data represents a methylated cytosine.
Mandatory Visualization
The following diagrams illustrate key experimental workflows and conceptual relationships in the study of RNA methyltransferase specificity.
Caption: Experimental workflows for assessing RNA methyltransferase substrate specificity.
Caption: Impact of RNA methylation on RNA fate.
References
- 1. researchgate.net [researchgate.net]
- 2. Mechanism and biological role of Dnmt2 in Nucleic Acid Methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Human DNMT2 methylates tRNAAsp molecules using a DNA methyltransferase-like catalytic mechanism - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Frontiers | How Do You Identify m6 A Methylation in Transcriptomes at High Resolution? A Comparison of Recent Datasets [frontiersin.org]
- 5. researchgate.net [researchgate.net]
- 6. Human MettL3–MettL14 complex is a sequence-specific DNA adenine methyltransferase active on single-strand and unpaired DNA in vitro - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. Substrate diversity of NSUN enzymes and links of 5-methylcytosine to mRNA translation and turnover - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Frontiers | Unveiling the potential impact of RNA m5C methyltransferases NSUN2 and NSUN6 on cellular aging [frontiersin.org]
- 10. mRNA turnover dynamics are affected by cell differentiation and loss of the cytosine methyltransferase Nsun2 - PMC [pmc.ncbi.nlm.nih.gov]
- 11. The catalytic mechanism of the RNA methyltransferase METTL3 - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Human MettL3-MettL14 RNA adenine methyltransferase complex is active on double-stranded DNA containing lesions - PMC [pmc.ncbi.nlm.nih.gov]
assessing the accuracy of 1-Methyl-2'-O-methylinosine quantification methods
A comprehensive evaluation of analytical methodologies is crucial for the accurate quantification of 1-Methyl-2'-O-methylinosine (m1Am), a modified nucleoside with emerging significance in biological research and drug development. This guide provides a detailed comparison of common quantification techniques, supported by established analytical principles and experimental data, to assist researchers in selecting the most appropriate method for their studies.
Comparison of this compound Quantification Methods
The selection of a quantification method for m1Am is dependent on the specific requirements of the study, including the need for absolute versus relative quantification, the complexity of the sample matrix, and the required sensitivity and accuracy. The following table summarizes the key performance characteristics of prevalent analytical techniques.
| Method | Principle | Quantification Type | Reported Accuracy/Precision | Advantages | Disadvantages |
| LC-MS/MS with Stable Isotope Dilution (SIDA) | Chromatographic separation followed by mass spectrometric detection, using a stable isotope-labeled internal standard. | Absolute | High accuracy (recoveries often 88-105%) and high precision (RSD < 15%).[1][2][3] | Gold standard for quantification, corrects for matrix effects, high sensitivity and specificity.[4][5] | Requires specialized equipment, higher cost, and synthesis of a labeled internal standard.[1][3] |
| Liquid Chromatography-Mass Spectrometry (LC-MS/MS) | Separation of the analyte from a mixture by liquid chromatography and its subsequent detection by a mass spectrometer. | Relative or Absolute (with external calibration) | Good, but susceptible to matrix effects which can impact accuracy. | High throughput, high sensitivity, and specificity.[6][7] | Matrix effects can lead to ion suppression or enhancement, affecting accuracy without an internal standard.[1][3] |
| Immunoblotting (e.g., Dot Blot) | Use of a specific antibody to detect the target molecule immobilized on a membrane. | Semi-quantitative to Relative | Variable, generally lower precision and accuracy compared to MS-based methods.[8][9] | Relatively inexpensive, does not require a mass spectrometer. | Dependent on the availability and specificity of a primary antibody to m1Am, prone to cross-reactivity, and less precise.[8][10] |
| Next-Generation Sequencing (NGS) based methods | High-throughput sequencing to identify the location of modified bases in RNA. | Relative abundance of modification at specific sites | Not designed for absolute quantification of the total modified nucleoside pool. | Provides positional information of the modification within an RNA sequence.[11][12] | Indirect quantification method, complex data analysis, and can be expensive.[13][14] |
| Thin-Layer Chromatography (TLC) | Separation of components based on their differential partitioning between a stationary phase and a mobile phase. | Relative | Lower accuracy and precision compared to modern techniques. | Simple, low cost. | Low sensitivity and resolution, not suitable for complex samples.[15] |
Experimental Protocols
Quantification of m1Am using LC-MS/MS with Stable Isotope Dilution Analysis (SIDA)
This protocol provides a general framework. Specific parameters such as chromatographic conditions and mass transitions must be optimized for the specific instrumentation used.
a. Sample Preparation and RNA Hydrolysis:
-
Isolate total RNA from the biological sample of interest using a standard RNA extraction protocol.
-
Quantify the purified RNA using a spectrophotometer.
-
To an aliquot of RNA (e.g., 1 µg), add a known amount of stable isotope-labeled m1Am internal standard.
-
Hydrolyze the RNA to its constituent nucleosides by incubation with nuclease P1 and alkaline phosphatase.
-
Precipitate the enzymes by adding a solvent such as acetonitrile (B52724).
-
Centrifuge the sample and collect the supernatant containing the nucleosides.
-
Dry the supernatant under vacuum and reconstitute in the mobile phase for LC-MS/MS analysis.
b. LC-MS/MS Analysis:
-
Liquid Chromatography:
-
Use a C18 reverse-phase column suitable for nucleoside analysis.
-
Employ a gradient elution using a mobile phase consisting of, for example, water with 0.1% formic acid (A) and acetonitrile with 0.1% formic acid (B).
-
Optimize the gradient to achieve baseline separation of m1Am from other nucleosides.
-
-
Mass Spectrometry:
-
Operate the mass spectrometer in positive ion mode using electrospray ionization (ESI).
-
Use Multiple Reaction Monitoring (MRM) for quantification.
-
Determine the specific precursor-to-product ion transitions for both native m1Am and the stable isotope-labeled internal standard.
-
Optimize MS parameters such as collision energy and declustering potential for each transition.
-
c. Quantification:
-
Generate a calibration curve by analyzing a series of standards containing known concentrations of native m1Am and a fixed concentration of the internal standard.
-
Plot the ratio of the peak area of the native m1Am to the peak area of the internal standard against the concentration of the native m1Am.
-
Calculate the concentration of m1Am in the unknown samples by interpolating their peak area ratios on the calibration curve.
Semi-Quantitative Analysis of m1Am using Immunoblotting (Dot Blot)
This protocol assumes the availability of a specific primary antibody against m1Am.
a. Sample Preparation:
-
Isolate total RNA from the samples.
-
Denature the RNA by heating.
-
Serially dilute the RNA samples in a suitable buffer.
b. Dot Blotting:
-
Spot the serially diluted RNA samples onto a nitrocellulose or PVDF membrane.
-
Allow the spots to dry completely.
-
Cross-link the RNA to the membrane using UV irradiation.
c. Immunodetection:
-
Block the membrane with a suitable blocking buffer (e.g., 5% non-fat milk in TBST) for 1 hour at room temperature to prevent non-specific antibody binding.[16]
-
Incubate the membrane with the primary antibody specific for m1Am, diluted in blocking buffer, overnight at 4°C with gentle agitation.
-
Wash the membrane three times with TBST for 5-10 minutes each.[16]
-
Incubate the membrane with a horseradish peroxidase (HRP)-conjugated secondary antibody, diluted in blocking buffer, for 1 hour at room temperature.
-
Wash the membrane three times with TBST for 5-10 minutes each.
-
Detect the signal using an enhanced chemiluminescence (ECL) substrate and image the membrane using a chemiluminescence detector.
d. Analysis:
-
Quantify the dot intensities using densitometry software.
-
Compare the signal intensities between different samples to determine the relative abundance of m1Am.
Visualizations
References
- 1. Stable isotope dilution assay for the accurate determination of mycotoxins in maize by UHPLC-MS/MS - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Stable isotope dilution assay for the accurate determination of mycotoxins in maize by UHPLC-MS/MS - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. Liquid chromatography-tandem mass spectrometry methods for clinical quantitation of antibiotics - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Stable-isotope dilution LC–MS for quantitative biomarker analysis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. rsc.org [rsc.org]
- 7. How Does LC/MS Perform MS1 and MS2 Detection? | MtoZ Biolabs [mtoz-biolabs.com]
- 8. Considerations when quantitating protein abundance by immunoblot - PMC [pmc.ncbi.nlm.nih.gov]
- 9. External quality assessment of M-protein diagnostics: a realistic impression of the accuracy and precision of M-protein quantification - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. bio-rad.com [bio-rad.com]
- 11. bmglabtech.com [bmglabtech.com]
- 12. Next-Generation Sequencing (NGS) | Explore the technology [illumina.com]
- 13. Quantification of microRNA Expression with Next-Generation Sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Quantification of microRNA expression with next-generation sequencing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. mdpi.com [mdpi.com]
- 16. General Immunoblotting Protocol | Rockland [rockland.com]
Comparative Functional Analysis of m1A/m1I-Modified vs. Unmodified tRNA: A Guide for Researchers
For researchers, scientists, and drug development professionals, understanding the nuanced roles of post-transcriptional modifications in tRNA is critical for fields ranging from basic molecular biology to therapeutic development. This guide provides a detailed comparison of the functional characteristics of tRNAs with and without N1-methyladenosine (m1A) and its derivative, N1-methylinosine (m1I), supported by experimental data and detailed protocols.
The N1-methyladenosine (m1A) modification is a widespread and highly conserved post-transcriptional modification found in tRNA across all domains of life.[1][2][3] It is typically found at several key positions, most notably at position 58 in the T-loop (m1A58), which is crucial for tRNA stability and proper folding.[2][4] In archaea, m1A at position 57 serves as a precursor to 1-methylinosine (B32420) (m1I), another modification that plays a role in translation.[4][5] The presence of these modifications significantly impacts tRNA structure and function, thereby influencing the efficiency and fidelity of protein synthesis.[1] This guide compares the functional attributes of m1A/m1I-modified tRNAs with their unmodified counterparts.
Quantitative and Functional Comparison
The following tables summarize the key functional differences between m1A/m1I-modified and unmodified tRNAs based on available experimental evidence.
Table 1: Impact of m1A Modification on tRNA Function
| Functional Parameter | Unmodified tRNA | m1A-Modified tRNA | Key Findings & Citations |
| Structural Stability & Folding | Lower thermal stability, more flexible structure. May be targeted for degradation if misfolded. | Increased thermal stability and structural rigidity. The m1A58 modification is critical for the proper folding of certain tRNAs, such as the initiator tRNAMet in yeast.[4][6] | The combination of m1A58 with other modifications can increase the melting temperature of tRNA by approximately 10°C in thermophiles.[4] Lack of m1A58 can lead to thermosensitivity.[4] |
| Aminoacylation Efficiency | Generally lower affinity for its cognate aminoacyl-tRNA synthetase (aaRS). | Modification can alter the kinetic parameters of aminoacylation. While not always a direct enhancer, proper folding induced by m1A is a prerequisite for efficient aminoacylation. | Modifications in the anticodon loop have been shown to alter the kinetic parameters for aminoacylation.[7] Proper tRNA structure, stabilized by modifications like m1A, is essential for efficient recognition by aaRSs. |
| Codon Recognition & Ribosome Binding | Standard codon recognition as dictated by the anticodon sequence. | The m1A modification, particularly outside the anticodon loop, is not directly involved in codon reading but ensures the overall tRNA structure is optimal for ribosome binding. | tRNA modifications are crucial for shaping the anticodon loop to permit efficient codon reading.[8] |
| Translational Fidelity & Efficiency | May contribute to lower translational fidelity and efficiency due to structural instability. | Promotes translation initiation and elongation.[1][9] The m1A58 modification enhances the translation efficiency of mRNAs enriched in specific codons.[1][2] | Deficiency in m1A58 modification impairs the synthesis of key proteins like MYC in T-cells, indicating a role in codon-biased translation.[1] |
Table 2: Functional Role of m1I Modification in Archaeal tRNA
| Functional Parameter | Unmodified/m1A57 tRNA | m1I57-Modified tRNA | Key Findings & Citations |
| Biosynthesis | Adenosine at position 57 is methylated to m1A57 by a tRNA methyltransferase. | m1A57 is subsequently deaminated to form m1I57. | The biosynthesis of m1I at position 57 in archaeal tRNAs is a two-step enzymatic process starting with the formation of m1A57.[5] |
| Translational Role | The precursor m1A57-modified tRNA is an intermediate. | The precise functional role of m1I57 is still under investigation, but modifications in the T-loop are known to stabilize tRNA structure, which is crucial for function in the extreme environments inhabited by many archaea. | The TrmI enzyme in Pyrococcus abyssi can methylate both A57 and A58, with m1A57 serving as the substrate for a deaminase to produce m1I57.[5] |
Experimental Protocols
To facilitate further research, detailed methodologies for key comparative experiments are provided below.
In Vitro tRNA Aminoacylation Assay
This protocol measures the rate and extent to which a tRNA can be charged with its cognate amino acid, allowing for a comparison of the kinetic parameters between modified and unmodified tRNA.
Materials:
-
Purified unmodified and m1A-modified tRNA transcripts.
-
Purified cognate aminoacyl-tRNA synthetase (aaRS).
-
Radiolabeled amino acid (e.g., [³H]-Leucine or [³⁵S]-Methionine).
-
ATP and MgCl₂.
-
Aminoacylation buffer (e.g., 30 mM HEPES-KOH pH 7.5, 30 mM KCl, 10 mM MgCl₂).
-
Trichloroacetic acid (TCA).
-
Glass fiber filters.
-
Scintillation counter and fluid.
Procedure:
-
Reaction Setup: Prepare a reaction mixture containing the aminoacylation buffer, ATP, MgCl₂, the radiolabeled amino acid, and the aaRS enzyme.
-
Initiation: Start the reaction by adding either the unmodified or the m1A-modified tRNA to the mixture. Incubate at the optimal temperature for the enzyme (e.g., 37°C).
-
Time Points: At various time points (e.g., 0, 1, 2, 5, 10, 20 minutes), take aliquots of the reaction mixture and quench them by spotting onto glass fiber filters pre-soaked in cold 10% TCA.
-
Washing: Wash the filters three times with cold 5% TCA to remove unincorporated radiolabeled amino acids, followed by a final wash with ethanol.
-
Quantification: Dry the filters and place them in scintillation vials with scintillation fluid. Measure the radioactivity using a scintillation counter. The counts per minute (CPM) are proportional to the amount of aminoacyl-tRNA formed.
-
Data Analysis: Plot the CPM against time to determine the initial reaction velocity. By varying the tRNA concentration, Michaelis-Menten kinetic parameters (Km and kcat) can be determined for both modified and unmodified tRNAs.[10]
Ribosome Filter-Binding Assay for Codon Recognition
This assay measures the affinity of aminoacylated tRNA for its cognate codon on the ribosome.
Materials:
-
Purified ribosomes (70S for prokaryotes, 80S for eukaryotes).
-
Aminoacylated tRNA (charged with a radiolabeled amino acid), both modified and unmodified versions.
-
Synthetic mRNA trinucleotide codons.
-
Binding buffer (e.g., 80 mM K-cacodylate pH 7.2, 20 mM Mg(OAc)₂, 100 mM NH₄Cl).
-
Nitrocellulose filters.
-
Filter apparatus.
-
Scintillation counter.
Procedure:
-
Complex Formation: In a reaction tube, combine ribosomes, the synthetic mRNA codon, and the radiolabeled aminoacyl-tRNA (either modified or unmodified) in the binding buffer.
-
Incubation: Incubate the mixture at an appropriate temperature (e.g., 30°C) for a sufficient time (e.g., 20 minutes) to allow for the formation of the ribosome-mRNA-tRNA complex.
-
Filtering: Pass the reaction mixture through a nitrocellulose filter under vacuum. The ribosome and any bound molecules will be retained on the filter, while unbound tRNA will pass through.
-
Washing: Wash the filter with cold binding buffer to remove any non-specifically bound components.
-
Quantification: Dry the filter and measure the retained radioactivity using a scintillation counter.
-
Data Analysis: The amount of radioactivity on the filter corresponds to the amount of tRNA bound to the ribosome-mRNA complex. By performing the assay with varying concentrations of tRNA, the dissociation constant (Kd) can be calculated to compare the codon-binding affinity of modified versus unmodified tRNA.
In Vitro Translation Assay for Translational Fidelity
This assay assesses the accuracy of translation by measuring either the readthrough of a stop codon or the misincorporation of an amino acid using a reporter system.
Materials:
-
Cell-free translation system (e.g., rabbit reticulocyte lysate or a purified PURE system).
-
Reporter mRNA containing an in-frame stop codon or a near-cognate codon for a specific amino acid, upstream of a reporter gene (e.g., luciferase or GFP).
-
Unmodified and m1A-modified tRNA populations.
-
Amino acid mixture (with or without the specific amino acid being tested for misincorporation).
-
Luciferase assay reagent or a fluorescence plate reader for GFP.
Procedure:
-
Reaction Setup: Prepare the in vitro translation reactions containing the cell-free system, the reporter mRNA, and the amino acid mixture.
-
tRNA Addition: Supplement separate reactions with either the purified unmodified tRNA pool or the m1A-modified tRNA pool.
-
Incubation: Incubate the reactions at the optimal temperature (e.g., 30°C) for a set period (e.g., 60-90 minutes) to allow for protein synthesis.
-
Reporter Quantification: Measure the reporter protein activity. For luciferase, add the luciferase assay reagent and measure luminescence. For GFP, measure the fluorescence.
-
Data Analysis:
-
For stop-codon readthrough: A higher reporter signal indicates a higher rate of readthrough, suggesting lower fidelity.
-
For amino acid misincorporation: A higher reporter signal in the absence of the cognate amino acid indicates a higher rate of misincorporation by the tRNA being tested.
-
Compare the reporter signals from reactions with unmodified versus modified tRNAs to determine the effect of the m1A modification on translational fidelity. Misincorporation rates can be estimated by comparing the signal from the near-cognate codon to the wild-type codon.[11]
-
Visualizations
Experimental Workflow
The following diagram illustrates a typical workflow for the comparative functional analysis of modified and unmodified tRNA.
Caption: Workflow for comparing m1A-modified vs. unmodified tRNA function.
Signaling & Biosynthetic Pathway
This diagram illustrates the enzymatic pathway for the formation of m1A and m1I modifications on tRNA.
Caption: Biosynthesis of m1A and m1I modifications on tRNA.
References
- 1. The m1A modification of tRNAs: a translational accelerator of T-cell activation - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Reversible RNA Modification N1-methyladenosine (m1A) in mRNA and tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 3. m1A Post-Transcriptional Modification in tRNAs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. m1A Post-Transcriptional Modification in tRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 5. academic.oup.com [academic.oup.com]
- 6. Methods for Kinetic and Thermodynamic Analysis of Aminoacyl-tRNA Synthetases - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Alteration of the kinetic parameters for aminoacylation of Escherichia coli formylmethionine transfer RNA by modification of an anticodon base - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. biorxiv.org [biorxiv.org]
- 9. Chemical manipulation of m1A mediates its detection in human tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. The frequency of translational misreading errors in E. coli is largely determined by tRNA competition - PMC [pmc.ncbi.nlm.nih.gov]
Benchmarking New Detection Methods for 1-Methyl-2'-O-methylinosine: A Comparative Guide
For Researchers, Scientists, and Drug Development Professionals
The field of epitranscriptomics is rapidly advancing, with a growing interest in the diverse array of chemical modifications that adorn RNA molecules. Among these, 1-Methyl-2'-O-methylinosine (m1Am), also known as 1,2'-O-dimethylinosine (m1Im), is a lesser-studied but potentially significant modification. Accurately detecting and quantifying m1Am is crucial for elucidating its biological functions and its potential role in disease. This guide provides a comprehensive comparison of the current gold-standard method and emerging techniques for the detection of m1Am, supported by experimental protocols and performance data.
Data Presentation: A Comparative Analysis of Detection Methodologies
The selection of an appropriate detection method for this compound depends on the specific research question, available resources, and desired level of quantification and resolution. While Liquid Chromatography-Mass Spectrometry (LC-MS/MS) remains the established gold standard for its quantitative power, newer, sequencing-based methods, though not yet specifically validated for m1Am, offer the potential for high-throughput, transcriptome-wide mapping.
| Method | Principle | Resolution | Quantification | Sensitivity | Specificity | Throughput | Key Advantages | Key Limitations |
| Liquid Chromatography-Mass Spectrometry (LC-MS/MS) | Separation of enzymatically digested nucleosides by liquid chromatography followed by mass-to-charge ratio analysis for identification and quantification. | Not applicable (bulk analysis) | Absolute | High (pM to fM range) | High | Low to Medium | Gold standard for accurate quantification. Unambiguous identification based on mass. | Does not provide sequence context. Requires specialized equipment and expertise. |
| Antibody-based Enrichment and Sequencing (Hypothetical for m1Am) | Immunoprecipitation of RNA fragments containing m1Am using a specific antibody, followed by high-throughput sequencing. | ~100-200 nucleotides | Relative | Moderate to High | Dependent on antibody specificity | High | Enables transcriptome-wide mapping of m1Am sites. | Dependent on the availability of a highly specific antibody. Potential for off-target binding. |
| Nanopore Direct RNA Sequencing (Hypothetical for m1Am) | Direct sequencing of native RNA molecules through a nanopore. RNA modifications cause characteristic changes in the ionic current signal. | Single nucleotide | Relative | High | Moderate to High | High | Enables direct detection without reverse transcription. Provides long reads. | Requires sophisticated bioinformatic analysis to accurately call modifications. Higher error rates compared to other sequencing methods. |
Experimental Protocols: Methodologies for Key Experiments
Detailed and robust experimental protocols are essential for reproducible and reliable results. Below is a detailed protocol for the gold-standard LC-MS/MS method for the detection of modified nucleosides, which can be adapted for this compound.
Protocol 1: Quantitative Analysis of this compound by LC-MS/MS
This protocol is adapted from methodologies used for the sensitive detection of other RNA modifications.
1. RNA Isolation and Purification:
-
Isolate total RNA from the desired biological sample using a standard method (e.g., TRIzol extraction).
-
To enrich for mRNA and remove the majority of ribosomal RNA (rRNA), perform poly(A) selection using oligo(dT)-magnetic beads.
-
Assess the integrity and purity of the RNA using a Bioanalyzer or similar instrument.
2. Enzymatic Digestion of RNA to Nucleosides:
-
To 1-5 µg of purified RNA, add nuclease P1 (2U) in a buffer of 10 mM ammonium (B1175870) acetate (B1210297) (pH 5.3) and incubate at 42°C for 2 hours.
-
Subsequently, add bacterial alkaline phosphatase (1U) and incubate at 37°C for an additional 2 hours to dephosphorylate the nucleosides.
-
Centrifuge the sample at 10,000 x g for 5 minutes to pellet any debris.
3. LC-MS/MS Analysis:
-
Liquid Chromatography:
-
Use a C18 reversed-phase column for separation.
-
Employ a gradient elution with a mobile phase consisting of (A) 0.1% formic acid in water and (B) 0.1% formic acid in acetonitrile.
-
The gradient can be optimized but a typical run would be: 0-5% B over 5 min, 5-95% B over 10 min, hold at 95% B for 5 min, and re-equilibrate at 5% B for 10 min.
-
-
Mass Spectrometry:
-
Operate the mass spectrometer in positive ion mode using electrospray ionization (ESI).
-
Perform Multiple Reaction Monitoring (MRM) for the specific mass transition of this compound. The precursor ion ([M+H]+) for m1Am (C12H16N4O5) is m/z 297.1, and a characteristic product ion would need to be determined experimentally (e.g., the base, 1-methylhypoxanthine, at m/z 151.1).
-
Create a standard curve using a synthetic this compound standard of known concentrations to enable absolute quantification.
-
4. Data Analysis:
-
Integrate the peak areas of the MRM transitions for both the m1Am in the sample and the standards.
-
Quantify the amount of m1Am in the sample by interpolating its peak area onto the standard curve.
-
Normalize the quantity of m1Am to the total amount of RNA used in the assay.
Mandatory Visualizations: Pathways and Workflows
Visual representations are critical for understanding complex biological processes and experimental designs. The following diagrams were generated using the DOT language.
Unveiling the Presence of 1-Methyl-2'-O-methylinosine Across RNA Classes: A Comparative Guide
For researchers, scientists, and drug development professionals, understanding the landscape of RNA modifications is paramount. Among the more than 170 known modifications, 1-Methyl-2'-O-methylinosine (m1Im), a dually modified ribonucleoside, presents a complex analytical challenge. This guide provides a comparative analysis of m1Im in different RNA classes, supported by experimental data and detailed methodologies, to aid in its detection and functional characterization.
Abundance of this compound: An Indirect Comparison
Direct quantitative data comparing the absolute abundance of this compound (m1Im) across messenger RNA (mRNA), transfer RNA (tRNA), and ribosomal RNA (rRNA) is limited in current literature. However, based on the prevalence of its constituent modifications—N1-methylinosine (m1I) and 2'-O-methylation (Nm)—we can infer its relative distribution.
Both tRNA and rRNA are known to be heavily decorated with a variety of chemical modifications, including 2'-O-methylation, which contributes to their structural stability and function.[1][2] In contrast, mRNA modifications are generally less frequent. A recent study successfully identified 2'-O-methylinosine (another name for m1Im) in the mRNA of yeast for the first time, highlighting the technical challenge of purifying mRNA from the more abundant and heavily modified tRNA and rRNA species.[3] This finding suggests that while m1Im is present in mRNA, its concentration is likely significantly lower than in tRNA and rRNA.
Table 1: Inferred Comparison of this compound (m1Im) Across RNA Classes
| RNA Class | Inferred Relative Abundance of m1Im | Supporting Evidence |
| tRNA | High | High abundance of both 2'-O-methylation and inosine (B1671953) modifications.[1][4][5] |
| rRNA | High | Extensive 2'-O-methylation is a hallmark of rRNA, with many sites identified.[3][6][7][8] |
| mRNA | Low | Recently identified in yeast mRNA; purification challenges suggest lower abundance compared to tRNA and rRNA.[3][9] |
Functional Implications of m1Im and its Constituent Modifications
The functional role of the combined m1Im modification is still under investigation. However, the functions of its individual components provide clues to its potential impact on RNA metabolism.
-
N1-methylinosine (m1I): Inosine, the precursor to m1I, is formed by the deamination of adenosine (B11128) and is known to be present in the anticodon loop of tRNAs, where it expands decoding capabilities through wobble base pairing.[5][10][11] The N1-methylation of inosine further modulates these interactions.
-
2'-O-methylation (Nm): This modification is one of the most common in eukaryotic RNA and is crucial for the structural integrity and function of rRNA and tRNA.[1][2] In rRNA, 2'-O-methylation is thought to enhance translational fidelity.[12] In tRNA, it can inhibit innate immune activation by Toll-like receptors.[4][13][14] Within the coding sequence of mRNA, 2'-O-methylation can disrupt the decoding process during translation elongation.[12]
The presence of m1Im, therefore, likely plays a role in fine-tuning the structure and function of these RNA molecules, potentially impacting protein synthesis and cellular responses to foreign RNA.
Experimental Protocols for the Analysis of m1Im
The detection and quantification of m1Im require sensitive and specific analytical techniques. Liquid chromatography coupled with tandem mass spectrometry (LC-MS/MS) is the gold standard for this purpose.
Experimental Protocol: Quantification of m1Im in RNA by LC-MS/MS
This protocol is adapted from established methods for the analysis of modified ribonucleosides.[9][13]
1. RNA Isolation and Purification:
-
Isolate total RNA from the biological sample of interest using a standard method such as TRIzol extraction or a commercial kit.
-
To compare different RNA classes, further purify total RNA into mRNA, tRNA, and rRNA fractions.
-
mRNA can be isolated using oligo(dT) magnetic beads.[9]
-
tRNA and rRNA can be separated based on size using gel electrophoresis or specialized chromatography columns.
-
2. Enzymatic Digestion of RNA to Nucleosides:
-
To 1-5 µg of purified RNA in a nuclease-free tube, add a buffer solution (e.g., 20 mM Tris-HCl, pH 7.5).
-
Add a cocktail of nucleases to completely digest the RNA into individual nucleosides. A common combination includes:
-
Nuclease P1 (to digest RNA to 5'-mononucleotides)
-
Bacterial Alkaline Phosphatase (to remove the 5'-phosphate)
-
-
Incubate the reaction at 37°C for 2-4 hours.
-
Terminate the reaction and remove the enzymes, for example, by filtration through a 10 kDa molecular weight cutoff filter.
3. LC-MS/MS Analysis:
-
Separate the resulting nucleosides using a reversed-phase high-performance liquid chromatography (HPLC) column.
-
The separated nucleosides are then introduced into a tandem mass spectrometer for detection and quantification.
-
The mass spectrometer is operated in positive ion mode using multiple reaction monitoring (MRM) to specifically detect the transition from the parent ion of m1Im to its characteristic fragment ion (the protonated base).
-
Quantification is achieved by comparing the peak area of m1Im to a standard curve generated with a synthetic m1Im standard.
Diagram 1: General Workflow for LC-MS/MS-based quantification of m1Im in RNA.
Caption: Workflow for m1Im quantification.
The Enzymatic Machinery Behind m1Im Formation
The biosynthesis of m1Im is a two-step process involving two distinct types of modifications.
-
Adenosine-to-Inosine (A-to-I) Editing: The first step is the deamination of adenosine to inosine. This reaction is catalyzed by Adenosine Deaminases Acting on RNA (ADARs) .[10][11]
-
2'-O-methylation: The second step is the methylation of the 2'-hydroxyl group of the inosine ribose. The specific enzyme responsible for the 2'-O-methylation of inosine to form m1Im has not been definitively identified. However, 2'-O-methylation in RNA is generally carried out by two main classes of enzymes:
-
snoRNA-guided fibrillarin: In eukaryotes, the majority of 2'-O-methylations in rRNA and small nuclear RNAs (snRNAs) are directed by C/D box small nucleolar RNAs (snoRNAs) that guide the methyltransferase fibrillarin to specific sites.[12]
-
Standalone methyltransferases: Enzymes such as FTSJ1 (in humans) and its yeast ortholog TRM7 are responsible for 2'-O-methylation at specific positions in tRNA.[1][15]
-
It is plausible that one of these known 2'-O-methyltransferases is also responsible for the formation of m1Im.
Diagram 2: Putative Biosynthetic Pathway of this compound (m1Im).
Caption: Biosynthesis of m1Im.
Concluding Remarks
The analysis of this compound presents both a challenge and an opportunity in the field of epitranscriptomics. While direct quantitative comparisons of m1Im across different RNA classes are yet to be established, current evidence strongly suggests a higher abundance in structurally critical non-coding RNAs like tRNA and rRNA compared to mRNA. The established LC-MS/MS methodologies provide a robust framework for its quantification, paving the way for future studies to elucidate its precise distribution and functional significance. Unraveling the roles of m1Im and the enzymes that regulate its formation will undoubtedly provide deeper insights into the intricate layers of gene expression regulation and may open new avenues for therapeutic intervention.
References
- 1. 2'-O-methylation - Wikipedia [en.wikipedia.org]
- 2. 2′-O-methylation (Nm) in RNA: progress, challenges, and future directions - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Mapping 2'-O-methyl groups in ribosomal RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. 2'- O-methylation within prokaryotic and eukaryotic tRNA inhibits innate immune activation by endosomal Toll-like receptors but does not affect recognition of whole organisms - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Enzymatic conversion of adenosine to inosine and to N1-methylinosine in transfer RNAs: a review - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Constitutive and variable 2’-O-methylation (Nm) in human ribosomal RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 7. 2′-O-Methylation of Ribosomal RNA: Towards an Epitranscriptomic Control of Translation? - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Ribosomal RNA 2′-O-methylations regulate translation by impacting ribosome dynamics - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Global analysis by LC-MS/MS of N6-methyladenosine and inosine in mRNA reveal complex incidence - PMC [pmc.ncbi.nlm.nih.gov]
- 10. The Power of Inosine: How RNA Editing Shapes the Transcriptome - AlidaBio [alidabio.com]
- 11. Identification of Enzymes for Adenosine-to-Inosine Editing and Discovery of Cytidine-to-Uridine Editing in Nucleus-Encoded Transfer RNAs of Arabidopsis - PMC [pmc.ncbi.nlm.nih.gov]
- 12. 2′-O-methylation in mRNA disrupts tRNA decoding during translation elongation - PMC [pmc.ncbi.nlm.nih.gov]
- 13. 2′-O-methylation within prokaryotic and eukaryotic tRNA inhibits innate immune activation by endosomal Toll-like receptors but does not affect recognition of whole organisms - PMC [pmc.ncbi.nlm.nih.gov]
- 14. The 2′-O-methylation status of a single guanosine controls transfer RNA–mediated Toll-like receptor 7 activation or inhibition - PMC [pmc.ncbi.nlm.nih.gov]
- 15. tRNA 2′-O-methylation by a duo of TRM7/FTSJ1 proteins modulates small RNA silencing in Drosophila - PMC [pmc.ncbi.nlm.nih.gov]
Distinguishing 1-Methyl-2'-O-methylinosine: A Comparative Guide for Researchers
For researchers, scientists, and drug development professionals, the precise identification of modified nucleosides is paramount. This guide provides a comprehensive comparison of 1-Methyl-2'-O-methylinosine (m¹Im) with other closely related methylated inosines, namely 1-methylinosine (B32420) (m¹I) and 2'-O-methylinosine (Im). By detailing key analytical techniques and presenting comparative experimental data, this guide serves as a valuable resource for the unambiguous identification of these important molecules.
The structural distinction between these methylated inosines lies in the position of the methyl group(s). In 1-methylinosine (m¹I), a methyl group is attached to the N1 position of the hypoxanthine (B114508) base. In 2'-O-methylinosine (Im), the methyl group is located on the 2'-hydroxyl of the ribose sugar. This compound (m¹Im) is a doubly methylated nucleoside, featuring methyl groups at both the N1 position of the base and the 2'-O position of the ribose. These subtle structural differences give rise to distinct physicochemical properties that can be exploited for their differentiation using modern analytical techniques.
Comparative Analysis of Methylated Inosines
Distinguishing between m¹I, Im, and m¹Im requires high-resolution analytical methods. The primary techniques employed are Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS) and Nuclear Magnetic Resonance (NMR) Spectroscopy.
Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS)
LC-MS/MS is the gold standard for the identification and quantification of RNA modifications.[1] The separation of these isomers is achieved based on their differential retention times in a liquid chromatography column, followed by mass analysis for unambiguous identification.
Key Distinguishing Features in LC-MS/MS:
-
Retention Time: The polarity of the molecules dictates their retention time on a reverse-phase HPLC column. Generally, the addition of methyl groups can alter the hydrophobicity and, consequently, the retention time. While specific retention times are highly dependent on the exact chromatographic conditions (e.g., column type, mobile phase composition, gradient), a general trend can be observed where the retention time will differ between the singly and doubly methylated species.
-
Mass-to-Charge Ratio (m/z): While m¹I and Im are isomers and share the same precursor ion m/z, m¹Im will have a distinct, higher m/z due to the presence of an additional methyl group.
-
Fragmentation Pattern (MS/MS): Collision-induced dissociation (CID) of the precursor ions generates characteristic product ions. The key to distinguishing m¹I and Im lies in the fragmentation of the glycosidic bond between the base and the ribose sugar.
-
For base-methylated nucleosides like m¹I, the characteristic fragment will be the methylated base.
-
For ribose-methylated nucleosides like Im, the fragmentation will yield an unmodified base and a methylated ribose fragment.
-
This compound (m¹Im) will produce a fragment corresponding to the methylated base and a fragment corresponding to the methylated ribose.
-
Table 1: Comparative LC-MS/MS Data for Methylated Inosines
| Compound | Precursor Ion ([M+H]⁺) m/z | Key Fragment Ion(s) m/z | Description of Key Fragmentation |
| 1-methylinosine (m¹I) | 283.1 | 151.1 | Fragment corresponds to the methylated hypoxanthine base (m¹H) |
| 2'-O-methylinosine (Im) | 283.1 | 137.1 | Fragment corresponds to the unmodified hypoxanthine base (H) |
| This compound (m¹Im) | 297.1 | 151.1 | Fragment corresponds to the methylated hypoxanthine base (m¹H) |
Note: The exact m/z values may vary slightly depending on the instrument calibration and resolution. The key is the mass difference corresponding to the base and ribose moieties.
Nuclear Magnetic Resonance (NMR) Spectroscopy
NMR spectroscopy provides detailed structural information by probing the chemical environment of atomic nuclei. Both ¹H and ¹³C NMR are invaluable for distinguishing between methylated inosine (B1671953) isomers. The chemical shifts of the methyl protons and carbons are highly sensitive to their position on the nucleoside.
Key Distinguishing Features in NMR:
-
¹H NMR: The proton chemical shifts of the methyl groups in m¹I, Im, and m¹Im will be distinct. The N1-methyl group protons of m¹I and m¹Im will resonate in a different region compared to the O2'-methyl group protons of Im and m¹Im.
-
¹³C NMR: Similarly, the carbon chemical shifts of the methyl groups will provide clear evidence of their location. The N1-methyl carbon will have a characteristic chemical shift different from the O2'-methyl carbon.
-
2D NMR (HSQC, HMBC): Heteronuclear single quantum coherence (HSQC) and heteronuclear multiple bond correlation (HMBC) experiments can definitively link the methyl protons to their corresponding carbons and confirm their position within the molecule by observing correlations to other protons and carbons in the purine (B94841) ring or the ribose sugar.
Table 2: Comparative ¹H and ¹³C NMR Chemical Shifts (δ, ppm) for Methyl Groups of Inosine Derivatives
| Compound | Methyl Group | ¹H Chemical Shift (ppm) | ¹³C Chemical Shift (ppm) |
| 1-methylinosine (m¹I) | N1-CH₃ | ~3.6 | ~34.5 |
| 2'-O-methylinosine (Im) | O2'-CH₃ | ~3.5 | ~58.0 |
| This compound (m¹Im) | N1-CH₃ | Distinct from m¹I | Distinct from m¹I |
| O2'-CH₃ | Distinct from Im | Distinct from Im |
Note: Chemical shifts are approximate and can vary based on the solvent and other experimental conditions. Data for m¹Im is less commonly reported and would need to be determined experimentally and compared to the known values for m¹I and Im.
Experimental Protocols
LC-MS/MS Analysis of Methylated Inosines
A detailed protocol for the analysis of RNA modifications by LC-MS/MS is a critical component for reproducible results.
1. RNA Digestion:
- Start with purified RNA (e.g., total RNA, tRNA, or mRNA).
- Digest the RNA to nucleosides using a cocktail of enzymes, typically including nuclease P1, snake venom phosphodiesterase, and alkaline phosphatase. This ensures complete hydrolysis to individual nucleosides.
2. Chromatographic Separation:
- Use a reverse-phase C18 column for separation.
- The mobile phase typically consists of a gradient of an aqueous solution (e.g., water with 0.1% formic acid) and an organic solvent (e.g., acetonitrile (B52724) or methanol (B129727) with 0.1% formic acid).
- The gradient is optimized to achieve baseline separation of the different nucleosides, including the methylated inosine isomers.
3. Mass Spectrometry Detection:
- Employ a tandem mass spectrometer operating in positive ion mode with electrospray ionization (ESI).
- Set the instrument to perform selected reaction monitoring (SRM) or multiple reaction monitoring (MRM) for targeted quantification of the specific precursor-to-product ion transitions for m¹I, Im, and m¹Im as detailed in Table 1.
RNA_Sample [label="Purified RNA Sample"];
Digestion [label="Enzymatic Digestion\n(Nuclease P1, SVP, AP)"];
Nucleosides [label="Nucleoside Mixture"];
HPLC [label="Reverse-Phase HPLC"];
Separation [label="Separated Nucleosides"];
Mass_Spec [label="Tandem Mass Spectrometer (ESI+)"];
Data_Analysis [label="Data Analysis\n(Retention Time, m/z, Fragmentation)"];
RNA_Sample -> Digestion;
Digestion -> Nucleosides;
Nucleosides -> HPLC;
HPLC -> Separation;
Separation -> Mass_Spec;
Mass_Spec -> Data_Analysis;
}
NMR Spectroscopy Analysis
1. Sample Preparation:
- Dissolve the purified methylated inosine standard or the nucleoside digest in a suitable deuterated solvent (e.g., D₂O or DMSO-d₆).
- The concentration should be sufficient for obtaining a good signal-to-noise ratio, typically in the millimolar range.
2. NMR Data Acquisition:
- Acquire ¹H NMR spectra to observe the chemical shifts of the methyl protons.
- Acquire ¹³C NMR spectra (or use 2D HSQC) to determine the chemical shifts of the methyl carbons.
- Perform 2D NMR experiments like HSQC and HMBC to establish connectivity and confirm the position of the methyl groups.
Biological Significance and Signaling Pathways
Modified nucleosides, particularly those in transfer RNA (tRNA), play critical roles in regulating gene expression and cellular signaling.[2][3] Modifications in the anticodon loop of tRNA, where m¹I is often found, are crucial for decoding fidelity and efficiency during protein translation.[4][5][6]
While the specific signaling pathways directly involving this compound are still an active area of research, the presence of both a base and a ribose methylation suggests a role in fine-tuning tRNA structure and function. tRNA modifications can influence cellular responses to stress and are implicated in various signaling pathways that control cell growth and metabolism.[7][8][9] The intricate interplay of different modifications on a single tRNA molecule can act as a "modification network," allowing for a highly regulated response to cellular needs.
References
- 1. Nucleoside modifications in the regulation of gene expression: focus on tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 2. The emerging role of complex modifications of tRNALysUUU in signaling pathways [microbialcell.com]
- 3. royalsocietypublishing.org [royalsocietypublishing.org]
- 4. The emerging role of complex modifications of tRNALysUUU in signaling pathways - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. researchgate.net [researchgate.net]
- 7. tRNA Modifications and Modifying Enzymes in Disease, the Potential Therapeutic Targets - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Extracurricular Functions of tRNA Modifications in Microorganisms - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Importance of a tRNA anticodon loop modification and a conserved, noncanonical anticodon stem pairing in tRNACGGPro for decoding - PMC [pmc.ncbi.nlm.nih.gov]
A Comparative Guide to Validating the Role of Novel RNA Modifications in Cellular Stress Response
Introduction
The cellular stress response is a complex network of signaling pathways that enables cells to adapt to and survive various insults, including oxidative stress, nutrient deprivation, and proteotoxic stress. While transcriptional regulation of this response is well-understood, the field of epitranscriptomics is revealing a critical new layer of control governed by chemical modifications to RNA. Over 170 such modifications have been identified, but the functions of most, including novel species like 1-Methyl-2'-O-methylnosine (m1m2I), remain largely uncharacterized.
This guide provides a comparative framework for researchers seeking to validate the role of novel RNA modifications in the stress response. We objectively compare the established roles of two well-studied modifications, N6-methyladenosine (m6A) and N1-methyladenosine (m1A), with the canonical Integrated Stress Response (ISR) pathway. This comparison is supported by representative experimental data and detailed protocols, offering a roadmap for the investigation of new players in stress biology.
Comparative Analysis of Stress Response Pathways
Cellular adaptation to stress is managed by multiple overlapping mechanisms. Here, we compare two epitranscriptomic pathways (m6A and m1A) against the protein-based Integrated Stress Response.
The N6-methyladenosine (m6A) Pathway
N6-methyladenosine (m6A) is the most abundant internal modification on eukaryotic mRNA and is integral to the stress response.[1][2] It is dynamically regulated by "writer" enzymes (e.g., METTL3/14), "erasers" (e.g., FTO, ALKBH5), and "reader" proteins that dictate the fate of the modified transcript. Under stress, m6A modification intersects directly with the Integrated Stress Response. For example, during amino acid starvation, the translation of the key stress transcription factor ATF4 is regulated by m6A levels in its 5' untranslated region (UTR).[3][4] Depleting m6A demethylases (erasers) can repress ATF4 translation, while knocking down methyltransferases (writers) can enhance it, demonstrating that dynamic m6A modification fine-tunes the output of the ISR.[3][4] Furthermore, oxidative stress has been shown to significantly increase the number of m6A peaks on cellular mRNA, suggesting a broad role in reprogramming the transcriptome to cope with damage.[5][6]
The N1-methyladenosine (m1A) Pathway
N1-methyladenosine (m1A) is another critical RNA modification involved in protecting the transcriptome during acute stress.[7] During heat shock, the m1A-generating enzyme complex, TRMT6/61A, accumulates in stress granules (SGs)—cytoplasmic foci where mRNAs are sequestered to prevent irreversible damage.[7] Mass spectrometry has confirmed that RNA within these granules is enriched with m1A.[7] Functionally, the presence of an m1A motif in a transcript promotes a more efficient recovery of protein synthesis from that specific mRNA after the stress has subsided.[7] Like m6A, m1A levels are also dynamically regulated under stress conditions such as oxygen-glucose deprivation.[8] This pathway represents a mechanism for triaging and protecting specific transcripts to ensure rapid cellular recovery.
The Integrated Stress Response (ISR) Pathway (Alternative)
The ISR is a canonical, evolutionarily conserved signaling pathway that converges on the phosphorylation of the eukaryotic translation initiation factor 2 alpha (eIF2α).[9][10] Four different kinases (GCN2, PERK, PKR, HRI) respond to distinct stressors (e.g., amino acid starvation, ER stress, viral infection, heme deficiency) by phosphorylating eIF2α.[10][11] This event has two major consequences:
-
A global shutdown of cap-dependent translation, conserving cellular resources.[10]
-
The selective translation of a handful of mRNAs containing upstream open reading frames (uORFs), most notably the transcription factor ATF4.[3][10]
ATF4 then orchestrates a transcriptional program to restore homeostasis.[11] The ISR serves as a benchmark for comparing the effects of RNA modifications, as it represents a primary, protein-centric mechanism of translational control under stress.
Data Presentation: Comparing Pathway Outputs
The following tables summarize representative quantitative data comparing the functional outputs of the m6A, m1A, and ISR pathways in response to oxidative stress (e.g., induced by sodium arsenite).
Table 1: Effect of Pathway Modulation on Global and Specific Protein Synthesis
| Pathway Manipulated | Stress Condition | Global Protein Synthesis (% of Control) | ATF4 Protein Expression (Fold Change) |
| Control (No Inhibition) | No Stress | 100% | 1.0 |
| Control (No Inhibition) | Oxidative Stress | ~30% | ~8.0 |
| m6A Eraser (FTO/ALKBH5) Inhibition | Oxidative Stress | ~30% | ~3.5[3][4] |
| m1A Writer (TRMT6/61A) Knockdown | Oxidative Stress | ~30% | ~8.0 (post-stress recovery impaired)[7] |
| ISR Inhibition (eIF2α-P Blocker) | Oxidative Stress | ~85% | ~1.5[3] |
Table 2: Comparison of RNA Modification Levels Under Stress
| Modification | Stress Condition | Change in Global Modification Level | Localization |
| m6A | Oxidative Stress | Significant Increase[5][6] | Enriched in 5'UTRs of stress-related transcripts[5] |
| m1A | Heat Shock | Enriched in specific RNA populations | Accumulates in Stress Granules[7] |
Experimental Protocols
Protocol 1: Methylated RNA Immunoprecipitation followed by Sequencing (MeRIP-Seq)
This protocol is used to map m6A or m1A modifications across the transcriptome.
-
RNA Isolation & Fragmentation: Isolate total RNA from control and stressed cells. Purify mRNA and fragment it into ~100-nucleotide-long segments using RNA fragmentation buffer.
-
Immunoprecipitation (IP): Incubate the fragmented RNA with a highly specific anti-m6A or anti-m1A antibody coupled to magnetic beads. This will capture the RNA fragments containing the modification. A parallel "input" sample (without antibody IP) must be processed as a control.
-
Washing & Elution: Wash the beads extensively to remove non-specifically bound RNA. Elute the captured, methylated RNA fragments from the antibody/bead complex.
-
Library Preparation & Sequencing: Prepare sequencing libraries from both the eluted (IP) RNA and the input RNA. Sequence the libraries using a high-throughput sequencer.
-
Bioinformatic Analysis: Align sequencing reads to the reference genome/transcriptome. Use peak-calling algorithms (e.g., MACS2) to identify regions significantly enriched in the IP sample compared to the input, revealing the locations of the RNA modifications.[12]
Protocol 2: Polysome Profiling
This protocol assesses the translational status of specific mRNAs by separating mRNAs based on the number of associated ribosomes.
-
Cell Lysis: Lyse control and stressed cells in the presence of cycloheximide (B1669411) to "freeze" ribosomes on the mRNA transcripts they are actively translating.
-
Sucrose (B13894) Gradient Ultracentrifugation: Carefully layer the cell lysate onto a continuous sucrose gradient (e.g., 10-50%). Centrifuge at high speed for several hours. This separates cellular components by density, with heavier polysomes (mRNAs with many ribosomes) migrating further down the gradient than lighter monosomes or free mRNA.
-
Fractionation & RNA Isolation: Puncture the bottom of the centrifuge tube and collect fractions while continuously measuring absorbance at 254 nm to visualize the ribosomal peaks. Isolate RNA from each fraction.
-
Analysis (RT-qPCR or RNA-Seq): Use RT-qPCR or RNA-sequencing on the RNA from each fraction to determine the distribution of a specific mRNA of interest (e.g., ATF4). An increase in the proportion of an mRNA in the heavy polysome fractions indicates enhanced translation.
Mandatory Visualization
Signaling and Workflow Diagrams
References
- 1. Research Portal [weizmann.esploro.exlibrisgroup.com]
- 2. biorxiv.org [biorxiv.org]
- 3. N6-Methyladenosine Guides mRNA Alternative Translation during Integrated Stress Response - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. researchgate.net [researchgate.net]
- 6. A narrative review of the role of m6A in oxidative stress and inflammation - Chen - Biotarget [biotarget.amegroups.org]
- 7. The protective role of m1A during stress-induced granulation - PMC [pmc.ncbi.nlm.nih.gov]
- 8. N1-Methyladenosine modification of mRNA regulates neuronal gene expression and oxygen glucose deprivation/reoxygenation induction - PMC [pmc.ncbi.nlm.nih.gov]
- 9. mdpi.com [mdpi.com]
- 10. The integrated stress response - PMC [pmc.ncbi.nlm.nih.gov]
- 11. The integrated stress response in metabolic adaptation - PMC [pmc.ncbi.nlm.nih.gov]
- 12. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
Safety Operating Guide
A Guide to the Proper Disposal of 1-Methyl-2'-O-methylinosine for Laboratory Professionals
For researchers, scientists, and drug development professionals, the proper handling and disposal of laboratory chemicals is paramount to ensuring a safe and compliant work environment. This guide provides essential, step-by-step procedures for the safe disposal of 1-Methyl-2'-O-methylinosine, a modified nucleoside used in various research applications. By adhering to these protocols, laboratories can minimize risks, maintain regulatory compliance, and foster a culture of safety.
Safety and Hazard Assessment
Based on available Safety Data Sheets (SDS) for the closely related compound 2'-O-Methylinosine, this compound is not classified as a hazardous substance under the Globally Harmonized System (GHS) of Classification and Labelling of Chemicals. However, it is crucial to treat all laboratory chemicals with a degree of caution.
Key Safety Information:
-
Hazard Class: Not classified as hazardous.
-
Primary Routes of Exposure: Inhalation, ingestion, and skin or eye contact.
-
Handling Precautions: Always wear appropriate personal protective equipment (PPE), including safety glasses, gloves, and a lab coat, when handling this compound. Work in a well-ventilated area to minimize the potential for inhalation.
Quantitative Data Summary
The following table summarizes the key physical and chemical properties of 2'-O-Methylinosine, a compound structurally similar to this compound. This data is provided for informational purposes to guide handling and storage.
| Property | Value |
| CAS Number | 3881-21-8 |
| Molecular Formula | C₁₁H₁₄N₄O₅ |
| Molecular Weight | 282.25 g/mol |
| Appearance | White to off-white solid |
| Solubility | Soluble in water |
| Stability | Stable under normal laboratory conditions |
Step-by-Step Disposal Protocol
The disposal of this compound, as a non-hazardous chemical, should follow standard laboratory procedures for non-regulated waste. This ensures that the waste is managed in a safe, environmentally responsible, and compliant manner.
Experimental Protocol for Waste Segregation and Collection:
-
Waste Identification and Segregation:
-
Confirm that the waste contains only this compound and is not mixed with any hazardous substances.
-
If the compound has been used in experiments with hazardous materials (e.g., toxic solvents, radioactive isotopes), it must be treated as hazardous waste and segregated accordingly.
-
Keep solid and liquid waste streams separate.
-
-
Container Selection:
-
For solid waste (e.g., powder, contaminated labware), use a durable, leak-proof container with a secure lid. A clearly labeled, dedicated waste container is recommended.
-
For aqueous solutions, use a compatible, sealable container, such as a high-density polyethylene (B3416737) (HDPE) carboy.
-
-
Labeling:
-
Clearly label the waste container with the full chemical name: "this compound".
-
Indicate that the waste is "Non-Hazardous".
-
Include the name of the principal investigator or research group and the date of accumulation.
-
-
Storage:
-
Store the waste container in a designated, low-traffic area within the laboratory, away from incompatible chemicals.
-
Ensure the container is kept closed except when adding waste.
-
-
Arranging for Disposal:
-
Contact your institution's Environmental Health and Safety (EHS) office or the designated chemical waste management service to schedule a pickup.
-
Provide them with the necessary information about the waste, including its identity and non-hazardous nature.
-
Do not dispose of this compound down the drain or in the regular trash unless explicitly permitted by your institution's EHS guidelines.
-
Disposal Decision Pathway
The following diagram illustrates the decision-making process for the proper disposal of this compound.
Caption: Disposal workflow for this compound.
By following these established procedures, laboratories can ensure the safe and compliant disposal of this compound, contributing to a secure and responsible research environment. Always consult your institution's specific waste management policies for any additional requirements.
Personal protective equipment for handling 1-Methyl-2'-O-methylinosine
For Researchers, Scientists, and Drug Development Professionals
This guide provides crucial safety and logistical information for the handling and disposal of 1-Methyl-2'-O-methylinosine. Given the absence of a specific Safety Data Sheet (SDS) for this compound, a cautious approach is mandated, treating it as a potentially hazardous substance. The following procedures are based on the safety profile of the related compound N1-Methylinosine and general best practices for handling nucleoside analogs, which may exhibit biological activity.
Immediate Safety and Personal Protective Equipment (PPE)
While the Safety Data Sheet for the closely related N1-Methylinosine indicates it is not classified as a hazardous substance, the toxicological properties of this compound have not been fully investigated.[1][2] Therefore, comprehensive personal protective equipment is essential to minimize exposure.
Recommended Personal Protective Equipment (PPE)
| PPE Category | Item | Specifications |
| Eye and Face Protection | Safety Glasses with Side Shields | Minimum requirement for all laboratory work. |
| Chemical Splash Goggles | Wear when there is a risk of splashes or generating aerosols. | |
| Face Shield | To be worn in addition to goggles during procedures with a high risk of splashing. | |
| Hand Protection | Disposable Nitrile Gloves | Standard for handling chemicals. Check for compatibility. |
| Body Protection | Laboratory Coat | To protect skin and personal clothing. |
| Respiratory Protection | N95 Respirator or higher | Recommended if handling the compound as a powder or if aerosols may be generated. |
Operational Plan: Safe Handling Procedures
A systematic approach to handling this compound is critical to ensure personnel safety and prevent contamination.
Workflow for Handling this compound
Caption: A stepwise workflow for the safe handling of this compound.
Experimental Protocol for Safe Handling:
-
Preparation:
-
Designate a specific area for handling, preferably within a chemical fume hood or other ventilated enclosure.
-
Assemble all necessary PPE as outlined in the table above.
-
Gather all required laboratory equipment and reagents.
-
-
Handling:
-
Put on all required PPE before handling the compound.
-
If working with the solid form, perform all weighing and transfers within a chemical fume hood to minimize inhalation risk.
-
Avoid the formation of dust and aerosols.[1]
-
For dissolution, add the solvent to the solid slowly to prevent splashing.
-
-
Post-Handling:
-
Thoroughly decontaminate all work surfaces and equipment after use.
-
Segregate all waste materials as described in the disposal plan below.
-
Remove PPE in the designated area, avoiding contamination of skin and clothing.
-
Wash hands thoroughly with soap and water after removing gloves.
-
Disposal Plan
Proper disposal of this compound and associated waste is crucial to prevent environmental contamination and ensure regulatory compliance.
Disposal Workflow
Caption: A workflow outlining the proper segregation and disposal of waste.
Disposal Protocol:
-
Solid Waste:
-
Includes contaminated gloves, bench paper, and other disposable materials.
-
Collect in a designated, clearly labeled hazardous waste bag.
-
-
Liquid Waste:
-
Includes unused solutions of this compound and solvent rinses from decontamination.
-
Collect in a labeled, sealed, and chemically compatible hazardous waste container. Do not mix with incompatible waste streams.
-
-
Sharps Waste:
-
Includes any contaminated needles, syringes, or other sharp objects.
-
Dispose of immediately in a designated, puncture-resistant sharps container.
-
-
Final Disposal:
-
All waste streams must be disposed of through your institution's hazardous waste management program. Follow all local, state, and federal regulations.
-
By adhering to these safety and handling protocols, researchers can minimize risks and ensure a safe laboratory environment when working with this compound.
References
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
