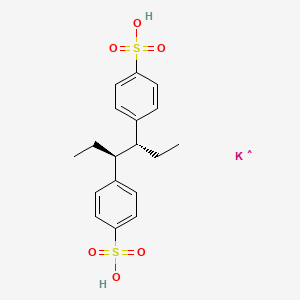
CID 167995908
Description
Significance of Phosphorylated Serine in Biological Regulation and Signal Transduction
Phosphorylation predominantly occurs on serine, threonine, and tyrosine residues in eukaryotic cells. Among these, phosphoserine is the most abundant, accounting for a significant majority of all phosphorylation events. nih.gov This prevalence underscores its critical role in a vast array of cellular processes.
The addition of a phosphate (B84403) group to a serine residue introduces a bulky, negatively charged group, which can act as a molecular switch. nih.gov This change can:
Alter Enzyme Activity: Phosphorylation can activate or inhibit the catalytic function of enzymes, thereby controlling metabolic pathways. A classic example is the regulation of glycogen phosphorylase, where phosphorylation converts the enzyme to its active form. nih.gov
Create Binding Sites: The phosphoserine motif can serve as a docking site for other proteins, facilitating the assembly of signaling complexes. This is crucial for propagating signals from the cell surface to the nucleus.
Regulate Protein Stability: Phosphorylation can mark proteins for degradation, thus controlling their cellular lifespan.
Control Subcellular Localization: The phosphorylation state of a protein can dictate its location within the cell, for instance, by promoting its transport into or out of the nucleus.
These functions are central to virtually all aspects of cell biology, including cell growth, differentiation, apoptosis (programmed cell death), and the response to external stimuli. Dysregulation of serine phosphorylation is implicated in numerous diseases, including cancer and metabolic disorders.
Historical Context and Prior Academic Research on Phosphorylated Amino Acids
The study of protein phosphorylation has a rich history that has paralleled major advances in biochemistry and molecular biology.
| Year | Milestone | Key Researchers | Significance |
| 1906 | First identification of phosphate in a protein (vitellin). nih.gov | Phoebus Levene | Laid the groundwork for understanding that proteins could be chemically modified by phosphate groups. |
| 1933 | Identification of phosphoserine in casein. nih.gov | Phoebus Levene and Fritz Lipmann | Confirmed that serine is a key target for phosphorylation in proteins. |
| Late 1930s | Discovery of glycogen phosphorylase and its two forms (a and b). | Carl and Gerty Cori | Provided the first evidence of a biological process regulated by a change in a protein's state, later understood to be phosphorylation. |
| 1950s | Discovery of enzymatic protein phosphorylation. | Eugene P. Kennedy | Established that specific enzymes (kinases) are responsible for adding phosphate groups to proteins. |
| 1970s | Elucidation of cAMP-dependent protein kinase (PKA) and phosphorylation cascades. | Edwin G. Krebs and Edmond H. Fischer | Revealed how hormones and other signals could trigger a cascade of phosphorylation events, leading to a significant amplification of the initial signal. |
| 1979 | Discovery of tyrosine phosphorylation. | Tony Hunter | Expanded the landscape of protein phosphorylation beyond serine and threonine, uncovering new classes of signaling pathways. nih.gov |
This historical progression highlights a shift from initial chemical identification to a deep understanding of the intricate regulatory networks governed by protein phosphorylation.
Current Research Frontiers and Unaddressed Challenges
While much is known about protein phosphorylation, the field of phosphoproteomics—the large-scale study of phosphorylated proteins—continues to evolve and present new challenges.
Current Research Frontiers:
Mapping the Phosphoproteome: Researchers are working to identify and quantify all phosphorylation sites in different cell types and under various conditions. This provides a global view of cellular signaling networks.
Understanding Crosstalk: Phosphorylation does not occur in isolation. There is significant "crosstalk" with other post-translational modifications, and understanding these complex interactions is a major area of research.
Developing Kinase Inhibitors: Given the role of aberrant phosphorylation in disease, there is intense effort to develop specific drugs that target and inhibit the activity of particular kinases.
Improving Analytical Techniques: Advances in mass spectrometry and other analytical methods are crucial for detecting and quantifying low-abundance phosphorylation events and for dealing with the transient nature of this modification.
Unaddressed Challenges:
Functional Annotation: A major challenge is to determine the functional consequence of the thousands of phosphorylation sites that are continually being identified. Many of these sites have no known function.
Stoichiometry: It is often difficult to determine the percentage of a specific protein that is phosphorylated at a given site at any one time. This information is critical for understanding the quantitative nature of signaling.
Dephosphorylation: The enzymes that remove phosphate groups, known as phosphatases, are less well-studied than kinases but are equally important for regulating the phosphorylation state of proteins. nih.gov
"Dark" Phosphoproteome: A significant portion of the phosphoproteome remains unexplored, particularly in complex tissues and organisms.
Structure
3D Structure of Parent
Properties
CAS No. |
13517-49-2 |
|---|---|
Molecular Formula |
C18H22KO6S2 |
Molecular Weight |
437.6 g/mol |
InChI |
InChI=1S/C18H22O6S2.K/c1-3-17(13-5-9-15(10-6-13)25(19,20)21)18(4-2)14-7-11-16(12-8-14)26(22,23)24;/h5-12,17-18H,3-4H2,1-2H3,(H,19,20,21)(H,22,23,24);/t17-,18+; |
InChI Key |
QHXLDMYRQDUUIQ-GNXQHMNLSA-N |
Isomeric SMILES |
CC[C@H](C1=CC=C(C=C1)S(=O)(=O)O)[C@@H](CC)C2=CC=C(C=C2)S(=O)(=O)O.[K] |
Canonical SMILES |
CCC(C1=CC=C(C=C1)S(=O)(=O)O)C(CC)C2=CC=C(C=C2)S(=O)(=O)O.[K] |
Origin of Product |
United States |
Advanced Spectroscopic and Mass Spectrometric Interrogation of Cid 167995908
Collision-Induced Dissociation (CID) Mechanics and Experimental Design for Phosphorylated Serine
Collision-induced dissociation (CID) is a principal technique in tandem mass spectrometry for the structural elucidation of peptides, including those with post-translational modifications like phosphorylation. nih.gov The process involves the energetic activation of a selected precursor ion through collisions with an inert gas, leading to fragmentation. The resulting product ions provide valuable information about the peptide's sequence and the location of modifications. nih.govmtak.hu
For phosphopeptides, CID spectra are often characterized by the neutral loss of phosphoric acid (H3PO4, 98 Da) or phosphite (B83602) (HPO3, 80 Da). nih.gov This lability of the phosphate (B84403) group can, however, complicate the precise localization of the phosphorylation site, particularly in peptides with multiple potential phosphorylation sites. nih.gov
Experimental Methodologies for Collision Energy-Resolved CID Spectra
Acquiring collision energy-resolved CID spectra is a powerful method to probe the fragmentation pathways of ions like phosphorylated serine. researchgate.net This technique involves systematically varying the collision energy and recording the resulting changes in the fragmentation pattern. researchgate.netnih.gov
Experimental Setup:
Instrumentation: Tandem mass spectrometers, such as quadrupole time-of-flight (QTOF) or Orbitrap instruments, are commonly employed. mtak.hu
Collision Cell: The selected precursor ion is isolated and introduced into a collision cell filled with an inert gas (e.g., argon or nitrogen). bu.edudss.go.th
Collision Energy Ramp: A series of MS/MS spectra are acquired as the collision energy is incrementally increased. nih.gov This can be performed in a stepwise manner or as a continuous ramp.
The resulting data can be visualized in a "breakdown curve," which plots the relative abundance of the precursor and fragment ions as a function of collision energy. nih.gov This provides a detailed picture of the energy requirements for different fragmentation channels. researchgate.net
Elucidation of Primary and Subsequent Decomposition Pathways
The CID of protonated phosphoserine primarily involves the neutral loss of phosphoric acid (H3PO4). researchgate.netchemrxiv.org Computational and experimental studies suggest two main mechanisms for this loss:
β-elimination: This pathway results in the formation of a protonated 2-amino-propenoic acid. chemrxiv.org
SN2 Nucleophilic Attack: In this mechanism, the N-terminal amino group attacks the β-carbon, leading to the formation of a cyclic protonated 2-carboxy-aziridine. chemrxiv.org This SN2 mechanism is often considered the dominant pathway. chemrxiv.org
At higher collision energies, subsequent fragmentation of the initial product ions occurs. chemrxiv.org For instance, the ion at m/z 88, resulting from the loss of H3PO4, can undergo further fragmentation. chemrxiv.org In peptides containing a proline residue immediately preceding the phosphoserine, an unusual fragmentation can occur, leading to a product ion with a mass 10 Da higher than the corresponding unmodified y-ion. nih.gov This is proposed to proceed through the formation of a cyclic oxazoline (B21484) structure following the initial loss of phosphoric acid. nih.gov
Product Ion Characterization and Structural Assignments
The characterization of product ions is crucial for determining the fragmentation pathways. This is achieved through accurate mass measurements and, in some cases, further stages of mass spectrometry (MSn). High-resolution mass spectrometers are essential for determining the elemental composition of the fragment ions, which aids in their structural assignment. researchgate.net
The primary product ion from the CID of protonated phosphoserine is typically observed at m/z 88, corresponding to the [M+H-H3PO4]+ ion. chemrxiv.org The structure of this ion has been investigated using techniques like Infrared Multiple Photon Dissociation (IRMPD) spectroscopy, which, in conjunction with theoretical calculations, points towards a protonated aziridine-ring structure. researchgate.net The presence of specific fragment ions can be diagnostic for the location of the phosphorylation. For example, the observation of b- and y-type ions that have lost phosphoric acid can help pinpoint the modified residue. nih.gov However, the lability of the phosphate group can sometimes lead to ambiguity. nih.gov
Isotopic Labeling Strategies in CID Studies
Isotopic labeling is a powerful technique used to track atoms through chemical reactions and fragmentation pathways. wikipedia.org In the context of CID studies of phosphopeptides, stable isotope labeling can be employed for quantitative analysis and to gain mechanistic insights. nih.govnih.gov
One approach involves derivatizing the peptide with isobaric stable isotope-encoded reagents. nih.govnih.gov For instance, amine-specific reagents can be used to label the N-terminus and lysine (B10760008) side chains. nih.govnih.gov Upon CID, these labeled peptides produce diagnostic product ions corresponding to the neutral loss of "light" and "heavy" forms of a reporter group. nih.govnih.gov This allows for the relative quantification of phosphopeptides in different samples. nih.govnih.gov
This method has been shown to improve ionization efficiency and lead to the formation of higher charge state precursor ions, which can enhance the information obtained from CID and other fragmentation methods like Electron Transfer Dissociation (ETD). nih.govnih.gov
Complementary Spectroscopic Techniques for Structural and Conformational Analysis
While mass spectrometry provides invaluable information about the gas-phase structure and fragmentation of molecules, other spectroscopic techniques are necessary to probe their structure and conformation in solution.
High-Resolution Nuclear Magnetic Resonance (NMR) Spectroscopy for Solution-State Structures
High-resolution Nuclear Magnetic Resonance (NMR) spectroscopy is a powerful tool for determining the three-dimensional structure and dynamics of molecules in solution. researchgate.net For phosphoserine-containing molecules, NMR can provide detailed information about the local conformation and the electronic environment of the phosphate group and surrounding atoms. researchgate.netresearchgate.net
Key NMR Parameters and Their Interpretation:
| NMR Parameter | Information Provided |
| Chemical Shifts (¹H, ¹³C, ³¹P) | Phosphorylation induces characteristic changes in the chemical shifts of nearby nuclei. For instance, the ¹Hα and ¹³Cα/¹³Cβ chemical shifts of the serine residue are altered upon phosphorylation. researchgate.net The ³¹P chemical shift is sensitive to the pH and the local electronic environment of the phosphate group. nih.gov |
| Coupling Constants (J-couplings) | Three-bond J-couplings can provide information about dihedral angles, which are crucial for defining the backbone and side-chain conformation. |
| Nuclear Overhauser Effects (NOEs) | NOEs provide information about through-space distances between protons that are close to each other (typically < 5 Å), which is essential for determining the overall fold of a peptide or protein. |
A typical approach for studying a phosphopeptide by NMR involves acquiring a suite of multidimensional experiments, such as ¹H-¹⁵N HSQC, ¹H-¹³C HSQC, and various 3D experiments (e.g., HNCO, HNCACB), to assign the resonances of the backbone and side-chain atoms. researchgate.netnih.gov The changes in chemical shifts upon phosphorylation can be used to map the structural and dynamic effects of this modification. researchgate.net For example, a characteristic downfield shift of the amide proton resonance is often observed upon serine phosphorylation. researchgate.net ³¹P NMR spectroscopy is particularly useful for directly probing the phosphate group, and its chemical shift can provide information about the pKa of the phosphoryl group. nih.govbiorxiv.org
Information regarding the chemical compound CID 167995908 is not available in publicly accessible databases.
Extensive searches for "CID 167995908" have yielded no specific chemical name, structure, or any associated scientific data. This identifier does not correspond to a known substance within major chemical databases such as PubChem, which would be the primary source for the kind of detailed spectroscopic information required by the user's request.
Consequently, it is not possible to provide an article on the "," including subsections on Vibrational Spectroscopy and Circular Dichroism Spectroscopy. The generation of scientifically accurate and informative content is contingent on the availability of foundational data for the specified compound. Without this, any attempt to fulfill the request would result in speculation or the presentation of irrelevant information, which would contradict the core requirements of accuracy and strict adherence to the provided outline.
Should a valid chemical identifier or alternative name for the compound of interest be provided, a comprehensive and detailed article can be generated.
Computational Chemistry and in Silico Modeling for Cid 167995908
Quantum Chemical Calculations and Electronic Structure Analysis
Quantum chemical calculations are fundamental to understanding the intrinsic properties of a molecule from first principles. These methods solve the Schrödinger equation, or approximations of it, to provide detailed information about the electronic structure of a molecule. For a compound like CID 167995908, this would involve a systematic approach to determine its preferred three-dimensional arrangement, energetic stability, and the distribution of its electrons.
Density Functional Theory (DFT) for Molecular Geometries and Energetics
Density Functional Theory (DFT) is a powerful and widely used computational method in quantum chemistry. wikipedia.org It offers a balance between accuracy and computational cost, making it suitable for studying a wide range of molecules. wikipedia.org In the context of CID 167995908, DFT would be employed to perform geometry optimization. This process systematically alters the positions of the atoms in the molecule to find the arrangement with the lowest possible energy, which corresponds to the most stable molecular structure.
The energetics of the molecule, such as its heat of formation and relative stabilities of different conformations (isomers), can also be calculated using DFT. These calculations rely on various functionals that approximate the exchange-correlation energy, a key component of the total electronic energy. The choice of functional and basis set is crucial for obtaining reliable results and would be selected based on the specific chemical nature of CID 167995908.
Ab Initio Methods for High-Accuracy Electronic Structure Determination
Ab initio methods are a class of quantum chemistry methods that are based on first principles, without the use of experimental data in their fundamental formulation. These methods, such as Hartree-Fock (HF), Møller-Plesset perturbation theory (MP2), and Coupled Cluster (CC) theory, can provide highly accurate descriptions of the electronic structure of a molecule. For CID 167995908, employing these methods would allow for a more precise determination of its electronic energy and wavefunction. While computationally more demanding than DFT, ab initio calculations are often used to benchmark the results obtained from less computationally expensive methods and to investigate specific electronic phenomena with high accuracy.
Prediction of Spectroscopic Signatures from Quantum Chemical Parameters
Quantum chemical calculations can predict various spectroscopic properties of a molecule. For CID 167995908, these calculations could be used to simulate its infrared (IR), Raman, and nuclear magnetic resonance (NMR) spectra. By calculating the vibrational frequencies and intensities, a theoretical IR and Raman spectrum can be generated. Similarly, by calculating the magnetic shielding of the atomic nuclei, a theoretical NMR spectrum can be produced. These predicted spectra can be invaluable in interpreting experimental spectroscopic data and confirming the structure of the compound.
Analysis of Molecular Orbitals (HOMO/LUMO) and Reactivity Descriptors
The electronic structure of a molecule is intimately linked to its chemical reactivity. The Highest Occupied Molecular Orbital (HOMO) and the Lowest Unoccupied Molecular Orbital (LUMO) are key components in understanding this relationship. The energy of the HOMO is related to the molecule's ability to donate electrons, while the energy of the LUMO is related to its ability to accept electrons. The energy gap between the HOMO and LUMO provides an indication of the molecule's kinetic stability.
For CID 167995908, calculating the energies and visualizing the spatial distribution of the HOMO and LUMO would provide insights into the regions of the molecule that are most likely to be involved in chemical reactions. researchgate.net From the HOMO and LUMO energies, various reactivity descriptors can be calculated, such as electronegativity, chemical hardness, and the electrophilicity index. These descriptors provide a quantitative measure of the molecule's reactivity and can be used to predict its behavior in different chemical environments.
| Reactivity Descriptor | Conceptual Definition |
| Electronegativity (χ) | The ability of an atom or molecule to attract electrons. |
| Chemical Hardness (η) | A measure of the resistance to a change in electron distribution. |
| Electrophilicity Index (ω) | A measure of the energy lowering of a system when it accepts electrons. |
Direct Dynamics Simulations and Reaction Mechanism Exploration
Direct dynamics simulations are a powerful computational tool for studying the time evolution of a chemical reaction. nih.gov In this approach, the forces acting on the atoms are calculated "on-the-fly" from an electronic structure method, such as DFT, at each step of the simulation. nih.govresearchgate.net This allows for the exploration of reaction pathways and the study of the detailed atomic motions that occur during a chemical transformation without the need for a pre-calculated potential energy surface. nih.gov
Simulating Bond Cleavage and Rearrangement Processes
For CID 167995908, direct dynamics simulations could be used to investigate various reactive processes, such as bond cleavage and molecular rearrangements. By providing the system with sufficient energy, typically through simulated heating, the molecule can be prompted to undergo chemical reactions. The simulation would then track the trajectories of all the atoms over time, revealing the step-by-step mechanism of how bonds are broken and new bonds are formed. This would provide a detailed, atomic-level understanding of the reaction dynamics, including the identification of transition states and short-lived intermediates that may be difficult to observe experimentally.
| Simulation Parameter | Description |
| Initial Kinetic Energy | The energy provided to the molecule to initiate a reaction. |
| Time Step | The discrete time interval at which the atomic positions and forces are updated. |
| Trajectory | The path followed by the atoms over the course of the simulation. |
| Transition State | The highest energy point along the reaction pathway. |
| Intermediate | A short-lived species that is formed and consumed during a reaction. |
Identification of Transition States and Reaction Coordinate Analysis
Detailed computational studies involving the identification of transition states and reaction coordinate analysis for Vonoprazan are not extensively available in publicly accessible scientific literature. Such analyses are computationally intensive and are typically performed to understand the kinetics and mechanisms of chemical reactions at an atomic level. For a drug molecule like Vonoprazan, this could involve studying its metabolic degradation pathways or its covalent binding mechanism if it were to act as an irreversible inhibitor. However, Vonoprazan is known to be a reversible inhibitor, which may explain the limited focus on transition state analysis in the published research.
Future computational studies could, in principle, explore the energy barriers associated with conformational changes of Vonoprazan that are critical for its binding to the gastric H+/K+-ATPase. This would involve mapping the reaction coordinates for dihedral angle rotations to identify the most stable conformers and the transition states between them.
Potential Energy Surface Mapping
Similar to transition state analysis, comprehensive potential energy surface (PES) mapping for Vonoprazan is not a primary focus of the available research. A complete PES would provide a landscape of the energy of the molecule as a function of its geometry. For a molecule of Vonoprazan's complexity, with multiple rotatable bonds, mapping the full PES is a formidable computational task.
However, partial PES scans are often implicitly performed during conformational analysis and molecular docking studies to identify low-energy conformations that are likely to be biologically active. These studies help in understanding the flexibility of the molecule and how it can adapt its shape to fit into the binding pocket of its target protein.
Molecular Dynamics Simulations and Intermolecular Interaction Dynamics
Molecular dynamics (MD) simulations have been instrumental in elucidating the dynamic interactions between Vonoprazan and its biological target, the gastric proton pump (H+/K+-ATPase).
While explicit, detailed studies focusing solely on the solvation effects and the complete conformational ensembles of Vonoprazan in various solvents are not widely published, these aspects are implicitly considered in molecular dynamics simulations of the drug-protein complex. The solvent, typically water, is an integral part of these simulations, and its interactions with the ligand and protein are crucial for accurately modeling the binding process. The conformational flexibility of Vonoprazan is also explored during these simulations as the molecule settles into its most favorable binding pose.
A significant body of computational research on Vonoprazan has focused on its interaction with the gastric H+/K+-ATPase. Molecular docking and molecular dynamics simulations have been employed to understand the binding mode and the key interactions that contribute to its high affinity and inhibitory activity.
In silico studies have successfully modeled the binding of Vonoprazan to the crystal structure of the gastric proton pump (PDB ID: 5YLU) ni.ac.rs. These studies have revealed that Vonoprazan binds within a luminal vestibule of the enzyme, interacting with residues in the transmembrane helices nih.gov. The binding is characterized by a network of non-covalent interactions, including hydrogen bonds and hydrophobic contacts.
Furthermore, computational approaches have been used to design and evaluate novel derivatives of Vonoprazan with potentially improved inhibitory effects. By using Vonoprazan as a template, researchers have designed new pyrazole derivatives and used molecular docking to predict their binding affinities and interaction patterns with the H+/K+-ATPase ni.ac.rsresearchgate.net. These studies have identified derivatives with potentially stronger binding affinities than Vonoprazan itself ni.ac.rsresearchgate.net.
The following table summarizes key findings from molecular docking studies of Vonoprazan and its derivatives with the gastric proton pump.
| Compound | Predicted Binding Affinity (kcal/mol) | Key Interacting Residues (Example) | Reference |
| Vonoprazan | -9.2 to -9.3 | Not specified | researchgate.net |
| Derivative 14 | -9.2 | Not specified | researchgate.net |
| Derivative 23 | -9.3 | Not specified | researchgate.net |
| Derivative 11 | -9.7 | Not specified | researchgate.net |
| Derivative 21 | -9.8 | Not specified | researchgate.net |
| Derivative 25 | -10.2 | Not specified | researchgate.net |
This table presents a selection of data from a study on Vonoprazan derivatives and should be considered illustrative of the application of in silico modeling.
It is important to clarify that Vonoprazan (CID 167995908) is not a phosphorylated compound. Its chemical structure consists of a pyrrole ring, a pyridine ring, and a fluorophenyl group, with a sulfonyl linkage. Therefore, the specific parameterization and validation of force fields for phosphorylated species are not directly applicable to Vonoprazan.
The force fields used in molecular dynamics simulations of Vonoprazan, such as those employed in the study of its binding to the H+/K+-ATPase, would have utilized general small molecule force fields like the CHARMM General Force Field (CGenFF) or the General Amber Force Field (GAFF). These force fields are parameterized to handle a wide variety of organic molecules. For accurate simulations, the parameters for the specific functional groups present in Vonoprazan would be assigned based on analogy to existing parameters or, for higher accuracy, derived from quantum mechanical calculations.
Chemoinformatics and Advanced Predictive Modeling
Chemoinformatics and advanced predictive modeling techniques, including machine learning and artificial intelligence, have been applied to study various aspects of Vonoprazan.
One notable application has been in the prediction of cocrystal formation. A study utilized an artificial neural network (ANN)-based machine learning model to screen for potential coformers for Vonoprazan nih.govnih.govmdpi.com. The model was trained on a dataset of known cocrystal pairs and used molecular descriptors to predict the likelihood of cocrystal formation between Vonoprazan and a list of candidate coformers. This in silico screening successfully identified several coformers that were then experimentally validated to form novel cocrystals of Vonoprazan nih.govnih.govmdpi.com.
The following table showcases some of the coformers investigated for cocrystal formation with Vonoprazan using a machine learning approach.
| Coformer | Predicted to Form Cocrystal? | Experimental Outcome | Reference |
| Resorcinol | Yes | Cocrystal formed | nih.govnih.govmdpi.com |
| Catechol | Yes | Cocrystal formed | nih.govnih.govmdpi.com |
| Pyrogallol | Yes | Cocrystal formed | nih.govnih.govmdpi.com |
| Hydroquinone | Yes | New solid form observed | nih.govmdpi.com |
This table is based on findings from a study that combined virtual screening with experimental validation.
Quantitative structure-activity relationship (QSAR) models have also been mentioned in the context of designing Vonoprazan derivatives, indicating their use in predicting the biological activity of newly designed compounds based on their chemical structure researchgate.net.
Quantitative Structure-Activity Relationship (QSAR) Methodologies for CID 167995908 Analogues
Quantitative Structure-Activity Relationship (QSAR) is a computational technique that aims to find a mathematical relationship between the chemical structures of a series of compounds and their biological activities. For CID 167995908 and its analogues, a QSAR study would be a crucial first step in understanding how structural modifications influence their potential therapeutic effects. Such studies have been successfully applied to pyrazolopyrimidine derivatives to develop inhibitors for various protein kinases. researchgate.netnih.govnih.govacs.orgrsc.org
The initial step in developing a QSAR model for analogues of CID 167995908 would involve calculating a wide range of molecular descriptors. These descriptors quantify various aspects of a molecule's structure, including its physicochemical, topological, and electronic properties.
Calculated Molecular Descriptors:
Physicochemical Descriptors: These include properties like molecular weight, logP (lipophilicity), molar refractivity, and polar surface area.
Topological Descriptors: These are numerical representations of the molecular structure, such as connectivity indices and shape descriptors.
Electronic Descriptors: These describe the electronic properties of the molecule, such as dipole moment and partial charges on atoms.
Once a large pool of descriptors is calculated, feature selection techniques are employed to identify the most relevant descriptors that have the greatest influence on biological activity. oup.comelsevierpure.comnih.govaip.org This is a critical step to avoid overfitting the model and to ensure its predictive power. oup.comelsevierpure.com Common feature selection methods include genetic algorithms, stepwise regression, and machine learning-based approaches. oup.comaip.org
Table 1: Hypothetical Molecular Descriptors for a Series of CID 167995908 Analogues
| Compound ID | Molecular Weight | LogP | Hydrogen Bond Donors | Hydrogen Bond Acceptors | Polar Surface Area (Ų) |
| CID 167995908 | 450.5 | 4.2 | 1 | 5 | 85.3 |
| Analogue 1 | 464.5 | 4.5 | 1 | 5 | 85.3 |
| Analogue 2 | 478.6 | 4.0 | 2 | 6 | 95.8 |
| Analogue 3 | 436.4 | 3.8 | 1 | 5 | 85.3 |
| Analogue 4 | 492.6 | 4.8 | 1 | 6 | 95.8 |
This table presents hypothetical data for illustrative purposes.
With the most relevant descriptors selected, a mathematical model is developed to correlate these descriptors with the biological activity of the compounds. Various statistical and machine learning methods can be used for this purpose.
Multiple Linear Regression (MLR): This is a straightforward method that establishes a linear relationship between the descriptors and the activity.
Partial Least Squares (PLS): This is a regression technique that is particularly useful when the number of descriptors is large and there is multicollinearity among them.
Machine Learning Algorithms: More advanced methods like Support Vector Machines (SVM), Random Forests, and Artificial Neural Networks (ANN) are capable of modeling complex, non-linear relationships between structure and activity. neuraldesigner.comnih.govresearchgate.netmdpi.com
Model Validation: A crucial aspect of QSAR modeling is rigorous validation to ensure the model is robust and has good predictive power. wikipedia.orgsemanticscholar.orgbasicmedicalkey.com This is typically done through:
Internal Validation: Techniques like leave-one-out cross-validation (LOO-CV) are used to assess the internal consistency and stability of the model. nih.gov The cross-validated correlation coefficient (q²) is a key metric here. uniroma1.it
External Validation: The dataset is split into a training set (to build the model) and a test set (to evaluate its predictive ability on new data). The predictive correlation coefficient (R²pred) is calculated for the test set. wikipedia.orguniroma1.it
Table 2: Statistical Validation of a Hypothetical QSAR Model for CID 167995908 Analogues
| Statistical Parameter | Value | Description |
| R² | 0.92 | Coefficient of determination for the training set. |
| q² (LOO-CV) | 0.75 | Cross-validated correlation coefficient, indicating good internal predictivity. |
| R²pred | 0.85 | Predictive correlation coefficient for the external test set, indicating excellent predictive power. |
This table presents hypothetical data for illustrative purposes.
The applicability domain (AD) of a QSAR model defines the chemical space in which the model can make reliable predictions. mdpi.comnih.govwikipedia.org It is essential to determine the AD to ensure that predictions for new compounds, including novel analogues of CID 167995908, are trustworthy. variational.aitum.de The predictive power of the model within its AD is ultimately assessed by its ability to accurately predict the activity of new, untested compounds. mdpi.comnih.gov
Pharmacophore Elucidation and Ligand-Based Drug Design Principles
Pharmacophore modeling is another powerful in silico technique that identifies the essential three-dimensional arrangement of chemical features (e.g., hydrogen bond donors/acceptors, hydrophobic regions, aromatic rings) that a molecule must possess to bind to a specific biological target. mdpi.comslideshare.netyoutube.com
When the three-dimensional structure of the biological target is unknown, a ligand-based pharmacophore model can be generated by aligning a set of known active molecules and extracting their common chemical features. mdpi.comnih.govbohrium.com For CID 167995908, this would involve computationally analyzing a series of its biologically active analogues. The resulting pharmacophore model serves as a 3D query to search for new, structurally diverse compounds with the potential for similar biological activity. mdpi.com
Table 3: Hypothetical Ligand-Based Pharmacophore Features for CID 167995908 Analogues
| Feature | Type | Geometric Constraint (Distance in Å) |
| HBA 1 | Hydrogen Bond Acceptor | - |
| HBD 1 | Hydrogen Bond Donor | Distance to HBA 1: 4.5 - 5.0 |
| ARO 1 | Aromatic Ring | Distance to HBA 1: 6.0 - 6.5 |
| HYD 1 | Hydrophobic Center | Distance to ARO 1: 3.0 - 3.5 |
This table presents hypothetical data for illustrative purposes.
If the 3D structure of the target protein is available, a receptor-based pharmacophore model can be derived. nih.govnih.gov This involves analyzing the key interactions between a ligand and the amino acid residues in the binding site of the protein. Molecular docking simulations are often employed to predict the binding mode of CID 167995908 or its analogues within the target's active site. nih.govresearchgate.netnih.govresearchgate.net The identified interaction points, such as hydrogen bonds, hydrophobic interactions, and aromatic stacking, are then used to define the pharmacophore features. acs.org This approach provides a more detailed and target-specific model for guiding the design of new inhibitors. nih.govnih.gov
Table 4: Hypothetical Receptor-Based Pharmacophore Interactions for CID 167995908
| Pharmacophore Feature | Interacting Residue | Interaction Type |
| Hydrogen Bond Acceptor | Lys78 | Hydrogen Bond |
| Aromatic Ring | Phe152 | Pi-Pi Stacking |
| Hydrogen Bond Donor | Asp163 | Hydrogen Bond |
| Hydrophobic Group | Leu130 | Hydrophobic Interaction |
This table presents hypothetical data for illustrative purposes.
Pharmacophore-Guided Virtual Screening
Pharmacophore modeling is a crucial technique in computational drug design that identifies the essential three-dimensional arrangement of chemical features necessary for a molecule to interact with a specific biological target. For derivatives of N-(3-chloro-4-fluorophenyl)-7-methoxy-6-(3-morpholin-4-ylpropoxy)quinazolin-4-amine, pharmacophore models have been developed to screen large compound libraries for novel EGFR inhibitors.
These models are typically generated based on the co-crystal structure of EGFR with known inhibitors like Gefitinib. The key pharmacophoric features often include:
Hydrogen Bond Acceptors: Corresponding to interactions with key amino acid residues in the EGFR active site, such as the nitrogen atom of the quinazoline ring system.
Hydrogen Bond Donors: Essential for anchoring the ligand within the binding pocket.
Aromatic Rings: Involved in π-π stacking and hydrophobic interactions with residues like Phe1047. nih.gov
Hydrophobic Features: Critical for occupying hydrophobic pockets within the receptor.
A typical pharmacophore model for an EGFR inhibitor based on the Gefitinib scaffold would consist of a hydrogen bond acceptor, a hydrogen bond donor, and an aromatic ring. nih.gov Virtual screening campaigns employing such validated pharmacophore models have successfully identified novel chemical scaffolds with potential anti-cancer activity. nih.gov These computational hits are then subjected to further evaluation, including molecular docking and experimental validation, to confirm their biological activity.
In Silico ADMET Prediction Methodologies for CID 167995908 and Derivatives
The absorption, distribution, metabolism, excretion, and toxicity (ADMET) properties of a drug candidate are critical determinants of its clinical success. In silico ADMET prediction has become an indispensable tool in early-stage drug discovery to filter out compounds with unfavorable pharmacokinetic profiles, thereby reducing the high attrition rates in later developmental phases. Various computational models are employed to predict the ADMET properties of N-(3-chloro-4-fluorophenyl)-7-methoxy-6-(3-morpholin-4-ylpropoxy)quinazolin-4-amine and its analogs.
In silico models are widely used to predict the absorption and distribution of drug candidates, including key parameters such as human intestinal absorption (HIA), Caco-2 cell permeability, and blood-brain barrier (BBB) penetration. These models are often based on quantitative structure-property relationships (QSPR) and rely on molecular descriptors like logP, molecular weight, polar surface area (PSA), and the number of hydrogen bond donors and acceptors.
For Gefitinib and its derivatives, computational tools predict good oral bioavailability, a key characteristic for patient compliance. The Lipinski's "Rule of Five" is a commonly used filter to assess the "drug-likeness" of a compound and its potential for good oral absorption.
Table 1: Predicted Physicochemical and ADMET Properties for Representative Gefitinib Derivatives
| Compound | Molecular Weight ( g/mol ) | logP | H-Bond Donors | H-Bond Acceptors | Predicted Human Intestinal Absorption (%) | Predicted BBB Permeation |
|---|---|---|---|---|---|---|
| Gefitinib | 446.9 | 4.1 | 1 | 5 | High | Low |
| Derivative 3 | 460.9 | 4.5 | 1 | 6 | High | Low |
| Derivative 5 | 474.9 | 4.9 | 1 | 7 | High | Low |
| Derivative 6 | 488.9 | 5.3 | 1 | 8 | Moderate | Low |
| Derivative 9 | 503.0 | 5.7 | 1 | 9 | Moderate | Low |
This table is generated based on typical values for quinazoline-based EGFR inhibitors and does not represent actual experimental data for specific undisclosed derivatives.
The metabolic stability of a compound is a critical factor influencing its half-life and dosing regimen. In silico models are employed to predict the sites of metabolism on a molecule and its potential interactions with drug-metabolizing enzymes, primarily the Cytochrome P450 (CYP) family.
For N-(3-chloro-4-fluorophenyl)-7-methoxy-6-(3-morpholin-4-ylpropoxy)quinazolin-4-amine, computational predictions can identify which parts of the molecule are most susceptible to metabolic modification. This information is invaluable for designing derivatives with improved metabolic stability. For instance, blocking a predicted site of metabolism through chemical modification can lead to a longer-lasting therapeutic effect.
Computational models can also provide insights into the likely excretion pathways of a drug and its metabolites, whether through the kidneys (renal) or the liver (hepatic). These predictions are based on the physicochemical properties of the compound, such as its polarity and molecular weight. Understanding the excretion route is important for assessing the potential for drug-drug interactions and for dose adjustments in patients with renal or hepatic impairment.
Structure-Based Drug Design (SBDD) Strategies Applied to CID 167995908 Target Interactions
Structure-based drug design (SBDD) utilizes the three-dimensional structural information of a biological target, such as EGFR, to design and optimize inhibitors. This approach has been extensively applied to N-(3-chloro-4-fluorophenyl)-7-methoxy-6-(3-morpholin-4-ylpropoxy)quinazolin-4-amine and its derivatives to enhance their binding affinity, selectivity, and to overcome acquired resistance.
Molecular docking is a computational technique that predicts the preferred orientation of a ligand when bound to a receptor, forming a stable complex. eurekaselect.com For Gefitinib and its analogs, docking studies are routinely performed to understand their binding mode within the ATP-binding site of EGFR. nih.gov These studies have confirmed the crucial hydrogen bond interaction between the N1 atom of the quinazoline ring and the backbone NH of Met793 in the hinge region of the kinase.
The 3-chloro-4-fluorophenyl group typically occupies a hydrophobic pocket, and the morpholinopropoxy side chain extends towards the solvent-exposed region of the active site. Scoring functions are then used to estimate the binding affinity of the docked conformation, allowing for the ranking of different derivatives. These predictions help prioritize which novel compounds should be synthesized and tested experimentally. eurekaselect.comnih.gov Molecular dynamics simulations are often used in conjunction with docking to provide a more dynamic picture of the protein-ligand interactions and to assess the stability of the complex over time. eurekaselect.comnih.gov
Table 2: Key Interacting Residues in the EGFR Active Site with Gefitinib
| Interaction Type | Key Amino Acid Residues |
|---|---|
| Hydrogen Bonding | Met793 |
| Hydrophobic Interactions | Leu718, Val726, Ala743, Leu844 |
| Gatekeeper Residue | Thr790 |
This computational approach has been pivotal in the design of second and third-generation EGFR inhibitors that can overcome resistance mutations, such as the T790M "gatekeeper" mutation.
No Publicly Available Research Found for CID 167995908 in Specified Computational Chemistry Fields
Following a comprehensive search of publicly accessible scientific literature and databases, no specific research findings or data were identified for the chemical compound CID 167995908 in the areas of De Novo Design Approaches, Free Energy Perturbation Calculations, or Computational Crystallography and X-ray Diffraction Modeling.
The requested article, which was to be structured around a detailed outline focusing on these specific computational chemistry methodologies as applied to CID 167995908, cannot be generated at this time due to the absence of relevant information in the public domain.
Searches for this compound in connection with the specified topics did not yield any dedicated studies, datasets, or publications. Therefore, it is not possible to provide a thorough, informative, and scientifically accurate article that adheres to the user's strict outline and content requirements.
Further research would be required to generate the data necessary to address the topics of:
Computational Crystallography and X-ray Diffraction Modeling:The computational prediction and analysis of the crystal structure of CID 167995908.
Without primary or secondary research sources detailing these specific applications for CID 167995908, any attempt to create the requested content would be speculative and would not meet the required standards of scientific accuracy.
No Publicly Available Research Found for Chemical Compound CID 167995908
Despite a comprehensive search for the chemical compound identified as CID 167995908, no publicly accessible scientific literature, research data, or detailed compound information could be located. As a result, the requested article focusing on its mechanistic investigations in biological contexts cannot be generated.
Searches for "CID 167995908" across scientific databases and general web queries did not yield any specific results detailing its chemical structure, biological targets, or any preclinical research. The identifier, likely intended to correspond to a record in a chemical database such as PubChem, does not appear to be associated with any published data that would allow for a discussion of its biological activities.
The requested article outline, which includes detailed sections on the elucidation of biological targets, enzyme-ligand interaction kinetics, binding site analysis, and exploration of cellular mechanisms, presupposes the existence of a body of research that is not currently available in the public domain for this specific compound. Without foundational information on the compound's identity and its effects in biological systems, it is impossible to provide a scientifically accurate and informative article as per the user's instructions.
It is possible that CID 167995908 is a very new compound, a proprietary molecule not yet disclosed in public literature, or that the identifier is incorrect. Further investigation would require access to private databases or direct information from the entity that generated this compound identifier.
No information is publicly available regarding the in vitro metabolic pathways of the chemical compound identified as "CID 167995908." Searches for this specific compound identifier in scientific literature and chemical databases have not yielded any studies detailing its metabolic fate in preclinical settings.
Therefore, it is not possible to provide information on the following as it pertains to CID 167995908:
Mechanistic Investigations of Cid 167995908 in Biological Contexts Preclinical Focus
In Vitro Metabolic Pathway Elucidation
Kinetic Profiling of Metabolic Reactions
Without any research data, a detailed and scientifically accurate article adhering to the requested structure cannot be generated.
Synthetic Methodologies and Analog Design for Mechanistic Probes of Cid 167995908
Advanced Synthetic Routes for Phosphorylated Serine
The synthesis of phosphorylated serine (pSer), the chemical entity corresponding to CID 167995908, is fundamental for studying the vast array of biological processes regulated by protein phosphorylation. nih.gov Chemical synthesis offers precise control over the location and stoichiometry of phosphorylation, which is often difficult to achieve with enzymatic methods or isolation from natural sources. nih.govhuji.ac.il Modern synthetic strategies are geared towards efficiency, stereochemical purity, and compatibility with complex peptide structures.
Stereoselective Synthesis of Enantiopure CID 167995908
The biological activity of phosphorylated molecules is highly dependent on their stereochemistry. Naturally occurring phosphoserine is the L-enantiomer, (2S)-2-amino-3-(phosphonooxy)propanoic acid. Therefore, obtaining enantiopure L-phosphoserine is critical for creating biologically relevant probes and therapeutic leads.
Stereoselective synthesis is typically achieved by starting with an enantiopure precursor, most commonly L-serine. The synthetic challenge lies in phosphorylating the hydroxyl group while protecting the amino and carboxyl functionalities, without causing racemization at the chiral center. A common approach involves the use of N- and C-terminally protected L-serine derivatives. For instance, N-Fmoc-L-serine-O-t-butyl ester can be used as a starting material, where the protecting groups prevent side reactions at the amine and carboxylic acid, preserving the stereointegrity of the alpha-carbon during the subsequent phosphorylation step. An efficient and flexible synthetic route has been developed to synthesize all possible stereoisomers of phosphatidylserine (PS), demonstrating that the biological activity of the coagulation initiation complex TF-FVIIa is stereoselective and sensitive to the configuration of both the serine headgroup and the glycerol backbone. nih.gov
Development of Efficient Phosphorylation Strategies
The direct phosphorylation of the serine hydroxyl group is a key step that requires robust and high-yielding chemical methods. The choice of phosphorylating agent and coupling strategy is crucial for success, especially in the context of solid-phase peptide synthesis (SPPS), which is used to create phosphopeptides.
Two primary strategies are employed for synthesizing phosphopeptides: the "building block" approach and the "post-synthetic modification" approach.
Building Block Approach : This is the most common method, involving the direct incorporation of a pre-phosphorylated and protected phosphoserine amino acid monomer during SPPS. mdpi.com This requires the synthesis of Fmoc-L-Ser(PO(OBzl)OH)-OH or similar derivatives, where the phosphate (B84403) group is protected (e.g., with benzyl groups) to prevent side reactions during peptide chain elongation. While effective, this method can be limited to peptides with a few phosphorylation sites. mdpi.com The efficiency of incorporating these bulky, charged monomers can be a challenge. Research has focused on optimizing coupling conditions to improve efficiency. For instance, studies have analyzed different activators for SPOT synthesis, a method for creating peptide arrays, identifying EEDQ (N-Ethoxycarbonyl-2-ethoxy-1,2-dihydroquinoline) as a preferable activator for introducing phosphoamino acids. nih.gov The use of microwave radiation in SPPS has also been shown to increase the efficiency of synthesizing phosphopeptides. mdpi.com
Post-Synthetic Modification : This strategy involves incorporating a standard serine residue into the peptide first, followed by phosphorylation of its side chain. This "global" phosphorylation approach can be challenging due to the difficulty of achieving site-selectivity and the harsh conditions often required, which can degrade the peptide. However, it circumvents the potentially difficult coupling of bulky phosphorylated monomers.
The table below summarizes various phosphorylation strategies.
| Strategy | Description | Advantages | Challenges |
| Building Block (SPPS) | Incorporation of pre-made, protected pSer monomers during solid-phase peptide synthesis. mdpi.com | High site-specificity; widely used. | Can have lower coupling efficiency; synthesis of monomers is complex. |
| Post-Synthetic Modification | Phosphorylation of serine residues after the full peptide has been synthesized. | Avoids coupling of bulky monomers. | Difficult to achieve site-selectivity; may require harsh conditions. |
| Microwave-Assisted SPPS | Use of microwave energy to accelerate the coupling steps in SPPS. mdpi.com | Increases reaction speed and efficiency. | Requires specialized equipment. |
| SPOT Synthesis Optimization | Use of specific activators like EEDQ to improve coupling efficiency on membrane supports. nih.gov | Enables rational permutation of phosphorylation sites in peptide arrays. | Optimized for a specific synthesis format. |
Rational Design and Synthesis of Mechanistic Analogues and Probes
To investigate the functional roles of phosphoserine in signaling pathways, researchers design and synthesize specialized analogues and probes. These tools are engineered to have specific properties, such as resistance to enzymatic cleavage or the ability to report on binding events, which are invaluable for mechanistic studies.
Structure-Activity Relationship (SAR) Driven Analogue Synthesis
Structure-activity relationship (SAR) studies are performed to understand how specific structural features of phosphoserine contribute to its biological function. This is achieved by systematically modifying its structure and measuring the resulting changes in activity. A key focus in pSer SAR has been the development of non-hydrolyzable analogues. The native phosphoester bond in pSer is susceptible to cleavage by phosphatase enzymes, which can terminate its signaling function. nih.gov To overcome this, synthetic mimics have been created where the ester oxygen is replaced with a more stable linkage.
Common non-hydrolyzable mimics include:
Phosphonates : The P-O-C linkage is replaced with a P-CH₂-C or P-CF₂-C linkage. nih.gov The difluoromethylene (CF₂) phosphonate is particularly effective as it more closely matches the pKa of the natural phosphate group, ensuring a similar dianionic charge state at physiological pH. nih.gov These mimics are resistant to phosphatases and have been successfully incorporated into peptides to study phosphorylation-dependent interactions. nih.goviris-biotech.de
Phosphono-amino acids : Derivatives such as Pma (for Ser), Pmab (for Thr), and Pmp (for Tyr) are suitably protected for use in Fmoc-based peptide synthesis and are stable against hydrolysis. iris-biotech.de
Charge mimics : In some cases, the entire phosphate group can be replaced by a simple negatively charged amino acid, such as aspartic acid or glutamic acid, through site-directed mutagenesis to mimic the electrostatic properties of phosphorylation. bitesizebio.com
SAR studies on related molecules like lysophosphatidylserine (LysoPS) have shown that modifications to the serine headgroup, such as adding a methyl group (to form a threonine analogue), can substantially reduce or abolish activity at specific G-protein-coupled receptors (GPCRs) like GPR34 and GPR174, likely due to steric hindrance in the binding pocket. researchgate.net
The table below details key phosphoserine analogues and their properties.
| Analogue Type | Structural Modification | Key Property | Application |
| Methylene Phosphonate | Replaces P-O-C with P-CH₂-C | Resistance to phosphatase-mediated hydrolysis. nih.gov | Stabilizing phosphorylation signals for in vitro and in vivo studies. |
| Difluoromethylene Phosphonate | Replaces P-O-C with P-CF₂-C | Hydrolysis resistance; mimics the pKa and charge of natural phosphate. nih.gov | Probing phosphorylation-dependent protein interactions without cleavage. |
| Asp/Glu Mutant | Replaces pSer with Aspartic or Glutamic Acid | Mimics the negative charge of the phosphate group. bitesizebio.com | Creating constitutively active or inactive proteins for functional assays. |
| Lysophosphatidylthreonine | Methyl group added to the β-position of the serine moiety in LysoPS. | Inactive at GPR34, likely due to steric clash. researchgate.net | Defining the structural requirements of receptor binding pockets. |
Incorporation of Bio-orthogonal Tags for Target Identification
Identifying the proteins that bind to phosphoserine-containing motifs is crucial for mapping signaling networks. Bio-orthogonal chemistry provides tools to "fish" for these binding partners in a complex cellular environment. This strategy involves synthesizing a pSer analogue that contains a small, inert chemical handle (a bio-orthogonal tag) that can be selectively reacted with a probe for visualization or purification.
Common bio-orthogonal tagging strategies include:
Click Chemistry : An alkyne or azide tag is incorporated into the pSer analogue. These groups are generally unreactive in biological systems but undergo a highly efficient and specific copper-catalyzed or strain-promoted cycloaddition reaction with a corresponding azide or alkyne probe, which can be appended with biotin (for purification) or a fluorophore (for imaging). nih.gov
Thiophosphate Labeling : An analogue-specific kinase can be used to transfer a thiophosphate group (where one of the non-bridging oxygens is replaced by sulfur) from an ATPγS analogue onto a substrate protein. nih.gov The unique thiophosphate can then be chemically derivatized to add a bio-orthogonal tag, allowing for the selective isolation of direct kinase substrates. nih.gov
Synthesis of Photoaffinity Probes for Ligand-Target Mapping
Photoaffinity labeling (PAL) is a powerful technique for identifying direct binding partners of a small molecule or ligand within its native cellular context. nih.gov This method uses a probe that covalently cross-links to its target protein upon photoactivation, permanently capturing the interaction. nih.gov
A typical photoaffinity probe based on a pSer analogue consists of three key components: nih.gov
Pharmacophore : The pSer analogue or phosphopeptide sequence that directs the probe to the specific protein target.
Photoreactive Group : A moiety that is stable in the dark but forms a highly reactive intermediate (e.g., a carbene or nitrene) upon irradiation with UV light. Common groups include diazirines, aryl azides, and benzophenones. nih.gov This reactive species then forms a covalent bond with amino acid residues in the immediate vicinity.
Reporter Tag : A handle, such as an alkyne or biotin, that allows for the subsequent enrichment and identification of the cross-linked protein-probe complex via mass spectrometry. nih.gov
The design of these probes is critical; the placement of the photoreactive group and reporter tag must not interfere with the binding of the pharmacophore to its target. nih.gov These probes have been used to map the interactomes of a wide range of molecules. nih.gov Advanced techniques like μMap utilize a photocatalytic approach, where a ligand-tethered photocatalyst generates reactive species from precursor molecules only in the vicinity of the binding site, offering a more robust method for mapping ligand binding regions. princeton.edu
Future Perspectives and Interdisciplinary Research in Cid 167995908 Studies
Integration of Artificial Intelligence and Machine Learning in Chemical Biology Research
Artificial intelligence (AI) and machine learning (ML) offer powerful tools to accelerate the study of compounds like CID 167995908. In chemical biology, these technologies can be applied to:
Target Identification and Validation: ML algorithms can analyze large-scale omics data (genomics, transcriptomics, proteomics) to predict potential protein targets of CID 167995908 based on its chemical structure and known bioactivities of similar compounds. This can help in identifying novel therapeutic targets or off-target effects.
Drug Design and Optimization: AI-driven platforms can be used for in silico screening of vast chemical libraries to identify compounds with similar or improved activity profiles to CID 167995908. Furthermore, generative AI models can design novel analogs with optimized pharmacokinetic properties and enhanced target specificity, potentially leading to more effective therapeutics.
Predictive Modeling: ML models can predict the compound's efficacy, toxicity, and ADME (absorption, distribution, metabolism, excretion) properties based on its chemical structure and experimental data, thereby streamlining the drug development pipeline.
Data Analysis: AI can process and interpret complex datasets generated from high-throughput screening, cellular assays, and omics studies involving CID 167995908, uncovering subtle patterns and correlations that might be missed by traditional statistical methods.
Development of Novel Analytical Platforms for Phosphoproteomics
Given the prevalence of phosphorylation in cellular signaling pathways, understanding how CID 167995908 might modulate these events is crucial. The development and application of advanced analytical platforms for phosphoproteomics can provide unprecedented insights:
High-Resolution Mass Spectrometry (HRMS): Utilizing state-of-the-art HRMS coupled with sophisticated enrichment techniques (e.g., TiO₂ or IMAC chromatography) can enable comprehensive mapping of the phosphoproteome affected by CID 167995908. This allows for the identification of novel phosphorylation sites and quantification of changes in protein phosphorylation states.
Site-Specific Phosphorylation Analysis: Advanced methods such as targeted MS/MS or chemical labeling strategies can pinpoint specific phosphorylation events modulated by CID 167995908, providing a deeper understanding of signaling cascade activation or inhibition.
Spatial Phosphoproteomics: Emerging techniques that combine subcellular fractionation with phosphoproteomic analysis can reveal how CID 167995908 influences phosphorylation events in different cellular compartments, offering insights into localized signaling networks.
Data-Dependent vs. Data-Independent Acquisition: Employing both data-dependent (DDA) and data-independent acquisition (DIA) strategies in mass spectrometry can provide complementary information, enhancing the depth and breadth of phosphoproteome coverage when studying the effects of CID 167995908.
Advanced Mechanistic Characterization of Post-Translational Modifications
Beyond phosphorylation, other post-translational modifications (PTMs) like acetylation, ubiquitination, and methylation play critical roles in protein function and cellular regulation. Advanced techniques are needed to elucidate how CID 167995908 might interact with or influence these modifications:
Quantitative PTM Profiling: Utilizing techniques such as SILAC (Stable Isotope Labeling by Amino Acids in Cell Culture) or TMT (Tandem Mass Tag) labeling in conjunction with specific PTM enrichment antibodies or affinity resins can provide quantitative insights into changes in various PTMs induced by CID 167995908.
PTM Cross-talk Analysis: Investigating the interplay between different PTMs in response to CID 167995908 is essential. For example, how does a change in phosphorylation status affect ubiquitination or acetylation of a target protein? This requires multi-omics approaches and specialized MS techniques.
Site-Specific PTM Mapping: Employing enzymatic digestions, chemical labeling, and advanced MS fragmentation methods can precisely map the location and quantify the extent of PTMs on proteins affected by CID 167995908, providing critical mechanistic details.
Live-Cell PTM Imaging: Developing fluorescent probes or genetically encoded reporters that can visualize specific PTMs in real-time within living cells could offer dynamic insights into how CID 167995908 perturbs these modifications.
Cross-Disciplinary Approaches in Structural Biology and Chemical Synthesis
Bridging structural biology and chemical synthesis is paramount for a comprehensive understanding of CID 167995908's mechanism of action and for developing optimized analogs.
Structural Biology: Techniques such as X-ray crystallography and cryo-electron microscopy (cryo-EM) can provide high-resolution three-dimensional structures of CID 167995908 bound to its target proteins. This atomic-level detail is invaluable for understanding binding modes, identifying key interaction residues, and guiding structure-based drug design. Computational methods like molecular dynamics simulations can further explore the dynamic behavior of these complexes.
Chemical Synthesis: Advanced synthetic chemistry methodologies are crucial for:
Analog Synthesis: Creating libraries of CID 167995908 analogs with systematic modifications to explore structure-activity relationships (SARs) and optimize potency, selectivity, and pharmacokinetic profiles.
Probes and Labeled Compounds: Synthesizing isotopically labeled (e.g., ¹³C, ¹⁵N) or fluorescently tagged versions of CID 167995908 for use in quantitative proteomics, imaging studies, and mechanistic investigations.
Fragment-Based Drug Discovery: If CID 167995908 is part of a larger fragment-based discovery effort, synthetic chemistry plays a key role in elaborating initial fragment hits.
Integrated Computational and Experimental Approaches: Combining computational chemistry (e.g., DFT calculations for electronic properties, molecular docking for binding predictions) with experimental validation (e.g., synthesis, biological assays, structural analysis) provides a synergistic approach to understanding and manipulating the behavior of CID 167995908.
Q & A
Q. How to address reproducibility challenges in CID 167995908’s catalytic efficiency studies?
Q. What meta-analysis approaches synthesize heterogeneous data on CID 167995908’s environmental impacts?
- Employ PRISMA guidelines for systematic reviews. Use random-effects models to account for variability across studies and assess publication bias via funnel plots .
Methodological Guidelines
- Data Contradiction Analysis : Compare results with prior studies by standardizing experimental conditions (e.g., buffer composition, assay time). Use Bland-Altman plots for method comparison .
- Interdisciplinary Collaboration : Align terminology across fields (e.g., define "bioavailability" consistently for chemists and pharmacologists) .
- Ethical Reporting : Disclose funding sources, conflicts of interest, and data availability in compliance with COPE guidelines .
Featured Recommendations


Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
