
MCAT
Description
BenchChem offers high-quality this compound suitable for many research applications. Different packaging options are available to accommodate customers' requirements. Please inquire for more information about this compound including the price, delivery time, and more detailed information at info@benchchem.com.
Structure
2D Structure
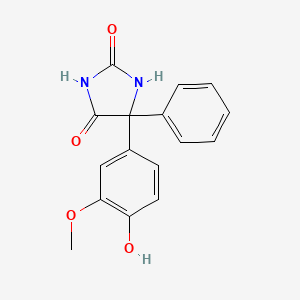
3D Structure
Properties
CAS No. |
36653-52-8 |
|---|---|
Molecular Formula |
C16H14N2O4 |
Molecular Weight |
298.29 g/mol |
IUPAC Name |
5-(4-hydroxy-3-methoxyphenyl)-5-phenylimidazolidine-2,4-dione |
InChI |
InChI=1S/C16H14N2O4/c1-22-13-9-11(7-8-12(13)19)16(10-5-3-2-4-6-10)14(20)17-15(21)18-16/h2-9,19H,1H3,(H2,17,18,20,21) |
InChI Key |
SVDVJBWDBYSQLO-UHFFFAOYSA-N |
SMILES |
COC1=C(C=CC(=C1)C2(C(=O)NC(=O)N2)C3=CC=CC=C3)O |
Canonical SMILES |
COC1=C(C=CC(=C1)C2(C(=O)NC(=O)N2)C3=CC=CC=C3)O |
Synonyms |
5-(4-hydroxy-3-methoxyphenyl)-5-phenylhydantoin |
Origin of Product |
United States |
Foundational & Exploratory
what are the fundamental principles of general chemistry on the MCAT
An In-Depth Guide to the Fundamental Principles of General Chemistry on the MCAT
This technical guide provides a comprehensive overview of the core general chemistry principles tested on the this compound, designed for researchers, scientists, and drug development professionals. The content is structured to facilitate a deep understanding of foundational concepts, with quantitative data presented in clear tables, detailed experimental methodologies, and visual representations of key relationships.
Atomic and Molecular Structure
A thorough understanding of the atom is foundational to chemistry. Key concepts include atomic number, mass number, isotopes, and electron configuration. Periodic trends are a high-yield topic, describing patterns in atomic properties across the periodic table.
Data Presentation: Periodic Trends
The following table summarizes the key periodic trends that are essential for the this compound. These trends are crucial for predicting the behavior and reactivity of elements.[1][2][3][4][5]
| Trend | Across a Period (Left to Right) | Down a Group (Top to Bottom) | Rationale |
| Atomic Radius | Decreases | Increases | Across a period, increasing nuclear charge pulls electrons closer. Down a group, the addition of electron shells increases the radius.[4][5] |
| Ionization Energy | Increases | Decreases | It becomes harder to remove an electron as the nuclear charge increases across a period. Down a group, the outermost electron is further from the nucleus and more easily removed.[1][3][4][5] |
| Electronegativity | Increases | Decreases | Atoms with a stronger pull on bonding electrons are found towards the right of a period. Down a group, increased atomic size reduces the nucleus's ability to attract bonding electrons.[1][2][3] |
| Electron Affinity | Generally Increases | Generally Decreases | Atoms on the right side of the periodic table more readily accept an electron. This trend is less consistent than the others. |
| Metallic Character | Decreases | Increases | Elements on the left of the periodic table are more likely to lose electrons and exhibit metallic properties. |
Chemical Bonding and Interactions
The nature of chemical bonds dictates the structure and properties of molecules. The this compound emphasizes understanding ionic and covalent bonds, Lewis structures, and molecular geometry (VSEPR theory).
Chemical Reactions and Stoichiometry
This area focuses on the quantitative relationships in chemical reactions. Mastery of concepts like the mole, balancing chemical equations (including redox reactions), and determining limiting reactants and theoretical yields is critical.
Thermodynamics and Energetics
Thermodynamics governs the energy changes that accompany chemical and physical transformations. Key concepts include the laws of thermodynamics, enthalpy (ΔH), entropy (ΔS), and Gibbs free energy (ΔG).
Data Presentation: Standard Thermodynamic Data
The following table provides standard thermodynamic values for selected substances at 25°C.[6][7][8][9][10]
| Substance | Formula | State | ΔH°f (kJ/mol) | ΔS° (J/mol·K) | ΔG°f (kJ/mol) |
| Water | H₂O | (l) | -285.8 | 69.9 | -237.1 |
| Carbon Dioxide | CO₂ | (g) | -393.5 | 213.8 | -394.4 |
| Methane | CH₄ | (g) | -74.8 | 186.3 | -50.8 |
| Ammonia | NH₃ | (g) | -46.1 | 192.8 | -16.5 |
| Glucose | C₆H₁₂O₆ | (s) | -1274.5 | 212.1 | -910.4 |
Visualization: Gibbs Free Energy Relationship
The relationship between Gibbs free energy, enthalpy, and entropy determines the spontaneity of a reaction. This relationship is described by the equation: ΔG = ΔH - TΔS.[11][12]
References
- 1. Periodic trends - Wikipedia [en.wikipedia.org]
- 2. Revision Notes - Periodic trends: Atomic radius, ionization energy, electronegativity | Structure: Classification of Matter | Chemistry HL | IB DP | Sparkl [sparkl.me]
- 3. chem.libretexts.org [chem.libretexts.org]
- 4. Periodic Table Trends | Texas Gateway [texasgateway.org]
- 5. byjus.com [byjus.com]
- 6. drjez.com [drjez.com]
- 7. srd.nist.gov [srd.nist.gov]
- 8. chem.pg.edu.pl [chem.pg.edu.pl]
- 9. chem.libretexts.org [chem.libretexts.org]
- 10. webassign.net [webassign.net]
- 11. Gibbs free energy - Wikipedia [en.wikipedia.org]
- 12. chem.libretexts.org [chem.libretexts.org]
An In-depth Technical Guide to Atomic and Molecular Structure for the MCAT
This guide provides a comprehensive overview of the fundamental principles of atomic and molecular structure, tailored for researchers, scientists, and drug development professionals preparing for the MCAT. It covers core concepts from atomic theory and quantum mechanics to molecular geometry and intermolecular forces, with a focus on the application of these principles in a biomedical context.
The Atom: Fundamental Concepts
The atom is the basic unit of a chemical element.[1] Understanding its structure is crucial for comprehending the behavior of matter.
Subatomic Particles and Atomic Structure
Atoms are composed of three primary subatomic particles: protons, neutrons, and electrons.[1][2] Protons carry a positive charge, neutrons have no charge, and electrons are negatively charged. The protons and neutrons are located in the central nucleus of the atom, while electrons occupy a surrounding "electron cloud."[2] The atomic number (Z) of an element is defined by the number of protons in its nucleus, which determines the element's identity.[1] The mass number is the sum of protons and neutrons in the nucleus.[2] Atoms of the same element with different numbers of neutrons are known as isotopes.[1]
The Quantum Mechanical Model of the Atom
The Bohr model, a foundational concept, depicts electrons orbiting the nucleus in discrete energy levels or shells.[2][3] While a simplified model, it introduces the idea of quantized electron energies.[3]
The more sophisticated quantum mechanical model describes the probability of finding an electron in a specific region of space, known as an orbital.[2][4] The behavior and location of an electron are characterized by a set of four quantum numbers:
-
Principal Quantum Number (n): This number describes the main energy level or shell of an electron and can have integer values (1, 2, 3, etc.).[2][5][6] Higher values of n correspond to higher energy levels.[3]
-
Azimuthal (Angular Momentum) Quantum Number (l): This number defines the shape of the orbital and has values ranging from 0 to n-1.[2][4][6] These values correspond to the s, p, d, and f subshells.[2][6]
-
Magnetic Quantum Number (ml): This number specifies the orientation of the orbital in space and can take integer values from -l to +l, including 0.[2][4][6]
-
Spin Quantum Number (ms): This describes the intrinsic angular momentum of an electron, which has two possible spin states: +½ or -½.[2][4][6]
The Pauli Exclusion Principle states that no two electrons in an atom can have the same set of four quantum numbers.[4] The Aufbau Principle dictates that electrons fill the lowest energy orbitals first, and Hund's Rule states that every orbital in a subshell is singly occupied with one electron before any one orbital is doubly occupied.[5]
Periodic Trends
The periodic table arranges elements based on their atomic number and recurring chemical properties.[1] Several key atomic properties exhibit predictable trends across the periodic table.
Atomic Radius
The atomic radius is a measure of the size of an atom.[2] It generally decreases from left to right across a period due to increasing effective nuclear charge, which pulls the electrons closer to the nucleus.[7][8] Atomic radius increases down a group as the number of electron shells increases.[7][8][9]
Ionization Energy
Ionization energy is the energy required to remove an electron from an atom in its gaseous state. It generally increases from left to right across a period because of the stronger pull of the nucleus on the electrons.[1][7][9] Ionization energy decreases down a group because the outermost electrons are further from the nucleus and are more easily removed.[7][9]
Electron Affinity
Electron affinity is the energy change that occurs when an electron is added to a neutral atom. Generally, electron affinity becomes more negative (more energy is released) from left to right across a period.[9]
Electronegativity
Electronegativity is a measure of the ability of an atom to attract shared electrons in a chemical bond. It increases from left to right across a period and decreases down a group.[7][9] Fluorine is the most electronegative element.[7]
Chemical Bonding and Molecular Structure
Chemical bonds are the forces that hold atoms together in molecules and compounds.
Covalent and Ionic Bonding
Covalent bonds are formed by the sharing of electrons between atoms.[10] These can be single, double, or triple bonds. A sigma (σ) bond is the first bond formed between two atoms and results from the direct overlap of orbitals.[11][12] Pi (π) bonds are formed from the sideways overlap of p-orbitals and are present in double and triple bonds.[11][12][13]
Ionic bonds result from the electrostatic attraction between oppositely charged ions, formed by the transfer of one or more electrons from one atom to another.
VSEPR Theory and Molecular Geometry
The Valence Shell Electron Pair Repulsion (VSEPR) theory is a model used to predict the three-dimensional geometry of molecules.[11][14] It is based on the principle that electron pairs in the valence shell of a central atom will arrange themselves to minimize repulsion.[14][15] This theory helps in determining both the electronic geometry , which considers all electron pairs (bonding and lone pairs), and the molecular geometry , which only considers the arrangement of the bonded atoms.[10]
Hybridization
Hybridization is the concept of mixing atomic orbitals to form new hybrid orbitals that are suitable for bonding.[11] The type of hybridization determines the geometry of the molecule:
-
sp3 hybridization results in a tetrahedral geometry with bond angles of approximately 109.5°.[11][12]
-
sp2 hybridization leads to a trigonal planar geometry with 120° bond angles.[11][12]
-
sp hybridization results in a linear geometry with 180° bond angles.[11][12]
Intermolecular Forces
Intermolecular forces are the attractive or repulsive forces that exist between molecules.[14] These forces are weaker than intramolecular forces (chemical bonds) but are crucial in determining the physical properties of substances, such as boiling point and melting point.[14][16]
The main types of intermolecular forces are:
-
London Dispersion Forces: These are the weakest intermolecular forces and are present in all molecules. They arise from temporary fluctuations in electron distribution.[14][17]
-
Dipole-Dipole Interactions: These forces occur between polar molecules that have permanent dipoles.[17][18]
-
Hydrogen Bonds: This is a particularly strong type of dipole-dipole interaction that occurs when hydrogen is bonded to a highly electronegative atom, such as nitrogen, oxygen, or fluorine.[16][17][18]
Data Presentation
Atomic Radii of Selected Elements
| Element | Symbol | Atomic Radius (pm)[3][11][12] |
| Hydrogen | H | 120 |
| Helium | He | 140 |
| Lithium | Li | 182 |
| Beryllium | Be | 153 |
| Boron | B | 87 |
| Carbon | C | 67 |
| Nitrogen | N | 56 |
| Oxygen | O | 152 |
| Fluorine | F | 147 |
| Neon | Ne | 154 |
| Sodium | Na | 227 |
| Magnesium | Mg | 173 |
| Aluminum | Al | 184 |
| Silicon | Si | 210 |
| Phosphorus | P | 180 |
| Sulfur | S | 180 |
| Chlorine | Cl | 175 |
| Argon | Ar | 188 |
Average Bond Lengths and Energies
| Bond | Bond Length (pm)[4][19] | Bond Energy (kJ/mol)[4][19] |
| H-H | 74 | 436 |
| C-H | 109 | 414 |
| C-C | 154 | 347 |
| C=C | 134 | 611 |
| C≡C | 120 | 837 |
| C-O | 143 | 360 |
| C=O | 120 | 736 |
| C-N | 147 | 305 |
| O-H | 97 | 464 |
| N-H | 100 | 389 |
| Cl-Cl | 199 | 243 |
| H-Cl | 127 | 431 |
| 799 in CO2 |
Experimental Protocols
Infrared (IR) Spectroscopy for Functional Group Identification
Principle: Infrared spectroscopy is a technique used to identify functional groups in a molecule.[7] It works on the principle that bonds within a molecule absorb infrared radiation at specific frequencies, causing them to vibrate.[5][20] The frequencies of these vibrations are characteristic of the types of bonds and functional groups present.[7]
Methodology:
-
Sample Preparation: The sample is prepared, which can be a solid, liquid, or gas. For solids, a common method is to create a KBr pellet or a mull. Liquids can be analyzed neat or in a solution.
-
Instrumentation: An IR spectrometer is used, which passes a beam of infrared light through the sample.
-
Data Acquisition: The detector measures the amount of light that passes through the sample at each frequency. The resulting data is plotted as absorbance or transmittance versus wavenumber (cm⁻¹).
-
Spectral Analysis: The resulting IR spectrum is analyzed by identifying characteristic absorption peaks. The region above 1500 cm⁻¹ is known as the functional group region, where characteristic stretching vibrations for common functional groups appear.[14][21] The region below 1500 cm⁻¹ is the fingerprint region, which is unique to each molecule.[21]
Mass Spectrometry for Molecular Weight and Structure Determination
Principle: Mass spectrometry is an analytical technique that measures the mass-to-charge ratio (m/z) of ionized molecules.[10][22] It is used to determine the molecular weight of a compound and can also provide information about its structure through fragmentation patterns.[23][24]
Methodology:
-
Ionization: The sample is introduced into the mass spectrometer and is ionized, typically by bombarding it with a beam of high-energy electrons (electron ionization).[23][24] This process forms a positively charged molecular ion (parent ion).[23]
-
Fragmentation: The molecular ions are often unstable and break down into smaller, charged fragments (daughter ions).[23]
-
Acceleration: The ions are accelerated by an electric field.
-
Deflection: The accelerated ions then pass through a magnetic field, which deflects them based on their mass-to-charge ratio.[6] Lighter ions are deflected more than heavier ions.
-
Detection: A detector records the abundance of ions at each m/z value, generating a mass spectrum.
-
Analysis: The peak with the highest m/z value usually corresponds to the molecular ion, providing the molecular weight of the compound. The fragmentation pattern can be analyzed to deduce the structure of the molecule.
X-ray Crystallography for 3D Molecular Structure Elucidation
Principle: X-ray crystallography is a powerful technique for determining the three-dimensional atomic and molecular structure of a crystal.[17][18] It relies on the diffraction of an X-ray beam by the ordered arrangement of atoms in a crystalline solid.[17][18]
Methodology:
-
Crystallization: A high-quality, single crystal of the substance of interest must be grown. This is often the most challenging step.
-
X-ray Diffraction: The crystal is mounted and exposed to a focused beam of X-rays.[15] The crystal diffracts the X-rays in specific directions.
-
Data Collection: The intensities and angles of the diffracted X-rays are measured using a detector.[18] This produces a diffraction pattern.
-
Electron Density Map Calculation: The diffraction data is used to calculate a three-dimensional electron density map of the crystal.[15]
-
Model Building and Refinement: A model of the molecule is built to fit the electron density map. This model is then refined to best match the experimental data, yielding a detailed three-dimensional structure of the molecule.[15]
Visualizations
Caption: A simplified model of atomic structure.
References
- 1. researchgate.net [researchgate.net]
- 2. Atomic radius - Wikipedia [en.wikipedia.org]
- 3. Atomic Radius | Periodic Table of Elements - PubChem [pubchem.ncbi.nlm.nih.gov]
- 4. profpaz.com [profpaz.com]
- 5. amherst.edu [amherst.edu]
- 6. quora.com [quora.com]
- 7. bellevuecollege.edu [bellevuecollege.edu]
- 8. chem.libretexts.org [chem.libretexts.org]
- 9. people.bu.edu [people.bu.edu]
- 10. Mass Spectrometry Protocols and Methods | Springer Nature Experiments [experiments.springernature.com]
- 11. Atomic radii of the elements (data page) - Wikipedia [en.wikipedia.org]
- 12. Atomic Radius for all the elements in the Periodic Table [periodictable.com]
- 13. chem.libretexts.org [chem.libretexts.org]
- 14. copbela.org [copbela.org]
- 15. x Ray crystallography - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Common Bond Energies (D [wiredchemist.com]
- 17. X-ray Determination Of Molecular Structure | Research Starters | EBSCO Research [ebsco.com]
- 18. X-ray crystallography - Wikipedia [en.wikipedia.org]
- 19. genchem1.chem.okstate.edu [genchem1.chem.okstate.edu]
- 20. personal.utdallas.edu [personal.utdallas.edu]
- 21. Infrared Spectra: Identifying Functional Groups [sites.science.oregonstate.edu]
- 22. Mass Spectrometry Coupled Experiments and Protein Structure Modeling Methods - PMC [pmc.ncbi.nlm.nih.gov]
- 23. SPECTROSCOPY AND STRUCTURE DETERMINATION [sydney.edu.au]
- 24. Advances in structure elucidation of small molecules using mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
The Nexus of Stability and Speed: An In-depth Technical Guide to Thermodynamics and Kinetics for the MCAT
A Whitepaper for Researchers, Scientists, and Drug Development Professionals
In the landscape of drug discovery and development, a profound understanding of the fundamental principles of thermodynamics and kinetics is not merely academic; it is the bedrock upon which successful therapeutic interventions are built. For professionals in this demanding field, the concepts tested on the Medical College Admission Test (MCAT) serve as a crucial foundation. This technical guide provides an in-depth exploration of these core principles, moving beyond rote memorization to a practical application-focused understanding. We will delve into the quantitative data that governs biochemical reactions, detail the experimental protocols used to obtain this data, and visualize the intricate interplay of these concepts in a key signaling pathway relevant to cancer therapeutics.
I. The Two Pillars of a Reaction: Thermodynamics and Kinetics
At its core, any chemical or biological process can be analyzed through two distinct yet interconnected lenses: thermodynamics and kinetics.
Thermodynamics addresses the stability of a system and the spontaneity of a reaction. It is governed by three key state functions:
-
Enthalpy (ΔH): The change in heat content of a system. A negative ΔH indicates an exothermic reaction that releases heat, while a positive ΔH signifies an endothermic reaction that absorbs heat.
-
Entropy (ΔS): A measure of the disorder or randomness of a system. An increase in entropy (positive ΔS) is generally favorable.
-
Gibbs Free Energy (ΔG): The ultimate arbiter of spontaneity. It integrates enthalpy and entropy into a single value that represents the maximum amount of non-expansion work that can be extracted from a closed system.
The relationship between these is elegantly captured by the Gibbs free energy equation: ΔG = ΔH - TΔS . A negative ΔG indicates a spontaneous (exergonic) reaction, a positive ΔG indicates a non-spontaneous (endergonic) reaction, and a ΔG of zero signifies that the system is at equilibrium.[1]
Kinetics , on the other hand, is concerned with the rate at which a reaction occurs. It is independent of the thermodynamic favorability of the reaction. A reaction can be thermodynamically spontaneous but proceed at an imperceptibly slow rate if it has a high activation energy (Ea). Enzymes, as biological catalysts, function by lowering the activation energy of a reaction, thereby increasing the reaction rate without altering the overall thermodynamics.[2]
The distinction between thermodynamic and kinetic control is paramount in drug development. A drug may bind to its target with high affinity (a favorable thermodynamic property), but if the rate of binding (kinetics) is too slow, it may not be therapeutically effective.
II. Quantitative Insights: Thermodynamic and Kinetic Parameters
To move from conceptual understanding to practical application, we must quantify these principles. The following tables summarize key thermodynamic and kinetic data for reactions and enzymes of biomedical significance.
A. Thermodynamics of ATP Hydrolysis
Adenosine triphosphate (ATP) is the primary energy currency of the cell. Its hydrolysis to adenosine diphosphate (ADP) and inorganic phosphate (Pi) is a highly exergonic reaction that drives many cellular processes.[3] The thermodynamic parameters for this crucial reaction are sensitive to conditions such as pH, temperature, and ionic strength.[4]
| Parameter | Value at Standard Conditions (pH 7, 25°C, 1M concentrations) | Physiological Conditions (approximate) |
| ΔG°' (kJ/mol) | -30.5 | -50 to -65 |
| ΔH°' (kJ/mol) | -20.1 | Not readily available, but contributes to ΔG |
| ΔS°' (J/mol·K) | +33.5 | Not readily available, but contributes to ΔG |
Note: Physiological concentrations of ATP, ADP, and Pi are in the millimolar range, which significantly impacts the actual Gibbs free energy change.[5]
B. Enzyme Kinetics: Vmax and Km
The Michaelis-Menten model is a cornerstone of enzyme kinetics, describing the relationship between the initial reaction velocity (V₀), the substrate concentration ([S]), the maximum velocity (Vmax), and the Michaelis constant (Km).[6]
Vmax represents the maximum rate of the reaction when the enzyme is saturated with substrate, and it is proportional to the enzyme concentration. Km is the substrate concentration at which the reaction rate is half of Vmax and is an inverse measure of the enzyme's affinity for its substrate; a lower Km indicates a higher affinity.[7]
| Enzyme | Substrate | Km (μM) | Vmax (units vary) |
| Hexokinase | Glucose | 100 | Low |
| Glucokinase | Glucose | 10,000 | High |
| Chymotrypsin | N-Acetyl-L-phenylalanine p-nitrophenyl ester | 5,000 | 100 s⁻¹ |
| Carbonic Anhydrase | CO₂ | 8,000 | 600,000 s⁻¹ |
| Penicillinase | Benzylpenicillin | 50 | 2,000 s⁻¹ |
Data for Hexokinase and Glucokinase from[8][9][10]. Data for other enzymes from[6].
III. Experimental Protocols: Measuring the Fundamentals
The quantitative data presented above is obtained through rigorous experimental methodologies. For researchers and drug development professionals, a working knowledge of these techniques is essential.
A. Isothermal Titration Calorimetry (ITC)
ITC is a powerful technique used to directly measure the heat changes that occur during a binding event, providing a complete thermodynamic profile of the interaction in a single experiment.[11] It is considered the gold standard for characterizing binding affinity, enthalpy, entropy, and stoichiometry.[12]
Detailed Methodology:
-
Sample Preparation:
-
The macromolecule (e.g., protein) is placed in the sample cell of the calorimeter.
-
The ligand (e.g., drug candidate) is loaded into a titration syringe.
-
Both the macromolecule and ligand must be in the same buffer to minimize heat of dilution effects.
-
-
Titration:
-
A series of small, precise injections of the ligand are made into the sample cell.
-
The heat released or absorbed upon each injection is measured by the instrument.
-
-
Data Analysis:
-
The heat change per injection is plotted against the molar ratio of ligand to macromolecule.
-
This binding isotherm is then fitted to a binding model to determine the binding affinity (Kd), stoichiometry (n), and enthalpy of binding (ΔH).
-
The Gibbs free energy (ΔG) and entropy (ΔS) of binding can then be calculated using the equation: ΔG = -RTln(Ka) = ΔH - TΔS , where Ka is the association constant (1/Kd).[4]
-
B. Enzyme Kinetic Assays
Enzyme kinetic assays are performed to determine the Vmax and Km of an enzyme-catalyzed reaction.
Detailed Methodology:
-
Assay Setup:
-
A series of reaction mixtures are prepared with a constant concentration of the enzyme and varying concentrations of the substrate.
-
The reaction is initiated by the addition of either the enzyme or the substrate.
-
The reaction is carried out under controlled conditions of temperature and pH.
-
-
Measurement of Initial Velocity (V₀):
-
The rate of product formation or substrate consumption is measured over a short period of time where the reaction rate is linear. This can be done using various detection methods, such as spectrophotometry or fluorescence.[13]
-
-
Data Analysis:
-
The initial velocities (V₀) are plotted against the corresponding substrate concentrations ([S]).
-
The resulting data points are fitted to the Michaelis-Menten equation to determine Vmax and Km.
-
Alternatively, the data can be linearized using a Lineweaver-Burk plot (a double reciprocal plot of 1/V₀ versus 1/[S]), where the y-intercept is 1/Vmax and the x-intercept is -1/Km.[1]
-
C. Differential Scanning Calorimetry (DSC)
DSC is a technique used to measure the thermal stability of a protein by monitoring the heat capacity of the sample as it is heated at a constant rate. This provides information on the protein's melting temperature (Tm) and the enthalpy of unfolding (ΔH).[6][14]
Detailed Methodology:
-
Sample Preparation:
-
A solution of the protein of interest is prepared in a suitable buffer.
-
A reference sample containing only the buffer is also prepared.
-
Protein concentration should be accurately determined.[15]
-
-
Thermal Scanning:
-
Both the sample and reference cells are heated at a constant scan rate.
-
The instrument measures the difference in heat required to raise the temperature of the sample and reference cells.
-
-
Data Analysis:
-
The resulting thermogram plots the excess heat capacity as a function of temperature.
-
The peak of the thermogram corresponds to the melting temperature (Tm), the temperature at which 50% of the protein is unfolded.
-
The area under the peak is the calorimetric enthalpy of unfolding (ΔH).[16]
-
IV. Visualizing the Concepts: EGFR Signaling in Cancer Therapeutics
The Epidermal Growth Factor Receptor (EGFR) signaling pathway is a critical regulator of cell growth and proliferation, and its dysregulation is a hallmark of many cancers. Small molecule tyrosine kinase inhibitors (TKIs), such as gefitinib, are a class of drugs that target the ATP-binding site of the EGFR kinase domain, inhibiting its activity. The development and optimization of these inhibitors rely heavily on understanding the thermodynamics and kinetics of their interaction with the EGFR protein.
A. The EGFR Signaling Pathway
The following diagram illustrates a simplified EGFR signaling cascade leading to cell proliferation.
B. Drug-Target Interaction: Thermodynamics and Kinetics
The efficacy of an EGFR inhibitor like gefitinib is determined by its ability to outcompete ATP for binding to the kinase domain. This is a classic example of competitive inhibition.
-
Thermodynamics: Isothermal Titration Calorimetry (ITC) can be used to measure the binding affinity (Kd) of gefitinib to the EGFR kinase domain, providing a quantitative measure of its potency.[1] The enthalpy (ΔH) and entropy (ΔS) of binding provide further insights into the molecular forces driving the interaction.
-
Kinetics: Enzyme kinetic assays are used to determine how gefitinib affects the Vmax and Km of the EGFR kinase for ATP. As a competitive inhibitor, gefitinib will increase the apparent Km for ATP but will not affect the Vmax. The inhibition constant (Ki), which can be derived from these experiments, is a crucial parameter for drug optimization.
The following diagram illustrates the competitive inhibition of EGFR by gefitinib.
C. Experimental Workflow for Drug Screening
The integration of thermodynamic and kinetic assays is fundamental to a modern drug discovery workflow. The following diagram outlines a typical process for screening and characterizing potential enzyme inhibitors.
V. Conclusion
The principles of thermodynamics and kinetics, while foundational to the this compound, are far from being mere academic hurdles. For researchers, scientists, and drug development professionals, a deep and quantitative understanding of these concepts is indispensable. By leveraging experimental techniques such as ITC, DSC, and enzyme kinetic assays, we can dissect the intricate interplay of stability and speed that governs biological processes. This knowledge empowers the rational design and optimization of novel therapeutics, ultimately paving the way for more effective treatments for a myriad of diseases. The continued application of these fundamental principles will undoubtedly remain at the forefront of biomedical innovation.
References
- 1. researchgate.net [researchgate.net]
- 2. Epidermal growth factor receptor tyrosine kinase inhibitors for non-small cell lung cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. researchgate.net [researchgate.net]
- 5. » How much energy is released in ATP hydrolysis? [book.bionumbers.org]
- 6. Enzyme Kinetics [www2.chem.wisc.edu]
- 7. solubilityofthings.com [solubilityofthings.com]
- 8. biologydiscussion.com [biologydiscussion.com]
- 9. Graphviz [graphviz.org]
- 10. Mutation and drug-specific intracellular accumulation of EGFR predict clinical responses to tyrosine kinase inhibitors - PMC [pmc.ncbi.nlm.nih.gov]
- 11. biochemistry - Gibbs free energy and its change for the hydrolysis of ATP - Biology Stack Exchange [biology.stackexchange.com]
- 12. A comprehensive pathway map of epidermal growth factor receptor signaling - PMC [pmc.ncbi.nlm.nih.gov]
- 13. What Is Enzyme Kinetics? Understanding Km and Vmax in Biochemical Reactions [synapse.patsnap.com]
- 14. researchgate.net [researchgate.net]
- 15. creative-diagnostics.com [creative-diagnostics.com]
- 16. Physicochemical properties of EGF receptor inhibitors and development of a nanoliposomal formulation of gefitinib - PMC [pmc.ncbi.nlm.nih.gov]
overview of acids and bases in a biological context for the MCAT
An In-Depth Technical Guide to Acids and Bases in a Biological Context for the MCAT
Introduction
A comprehensive understanding of acid-base chemistry is fundamental to the study of biological systems and a cornerstone of the this compound. For researchers, scientists, and drug development professionals, these principles are not merely academic; they are critical to understanding physiological homeostasis, enzyme function, and the pharmacokinetic and pharmacodynamic properties of therapeutic agents. This guide provides an in-depth overview of acids and bases from a biological perspective, tailored to the high-yield topics on the this compound, while also delving into the practical applications relevant to scientific research and drug development. We will explore the theoretical foundations of acid-base chemistry, the critical role of buffer systems in maintaining physiological pH, the acid-base properties of amino acids, and the significance of these concepts in a clinical and pharmaceutical context.
Fundamental Concepts of Acids and Bases
The behavior of acids and bases in biological systems is most effectively described by the Brønsted-Lowry and Lewis theories.
The Brønsted-Lowry Theory
The Brønsted-Lowry theory defines acids and bases based on the transfer of protons (H⁺ ions).[1]
-
A Brønsted-Lowry acid is a species that donates a proton.[2][3][4]
-
A Brønsted-Lowry base is a species that accepts a proton.[2][3][4]
This theory introduces the concept of conjugate acid-base pairs . When an acid donates a proton, it forms its conjugate base. Conversely, when a base accepts a proton, it forms its conjugate acid.[2][4] A strong acid will have a weak conjugate base, and a strong base will have a weak conjugate acid.[4]
Water is a classic example of an amphoteric species, meaning it can act as both a Brønsted-Lowry acid and a base.[3][4]
The Lewis Theory
The Lewis theory offers a broader definition that is not limited to proton transfer but focuses on electron pairs.[1][4]
-
A Lewis acid is a species that accepts an electron pair to form a covalent bond.[4][5]
-
A Lewis base is a species that donates an electron pair to form a covalent bond.[4][5]
All Brønsted-Lowry bases are also Lewis bases, but the reverse is not always true.[4] The Lewis definition is particularly useful in organic chemistry and for describing reactions in non-aqueous environments.
pH, pKa, and the Henderson-Hasselbalch Equation
The acidity or basicity of an aqueous solution is quantified using the pH scale.
-
pH : The negative logarithm of the hydrogen ion concentration, pH = -log[H⁺].[6] A pH below 7 is acidic, a pH above 7 is basic, and a pH of 7 is neutral.[6]
-
pKa : The negative logarithm of the acid dissociation constant (Ka). The pKa is a measure of the strength of an acid; a lower pKa corresponds to a stronger acid.[7]
The Henderson-Hasselbalch equation is a critical tool for calculating the pH of a buffer solution and for determining the protonation state of a molecule at a given pH.[8][9] The equation is expressed as:
pH = pKa + log ([A⁻]/[HA])
Where:
-
[A⁻] is the molar concentration of the conjugate base.
-
[HA] is the molar concentration of the weak acid.
This equation reveals that when the concentrations of the weak acid and its conjugate base are equal ([A⁻] = [HA]), the pH of the solution is equal to the pKa of the acid.[9][10] This point is the center of the buffering region for a weak acid.[11]
Buffer Systems in a Biological Context
Buffer solutions are aqueous systems that resist changes in pH upon the addition of small amounts of acid or base.[12] They are crucial for maintaining homeostasis in biological systems, where many enzymes and processes are highly sensitive to pH fluctuations.[12] A buffer consists of a weak acid and its conjugate base or a weak base and its conjugate acid.[12]
The Bicarbonate Buffer System
The primary buffer system in the blood is the bicarbonate buffer system, which maintains blood pH between 7.35 and 7.45.[10][13] This system involves the equilibrium between carbonic acid (H₂CO₃) and bicarbonate (HCO₃⁻).[14]
CO₂ (g) + H₂O (l) ⇌ H₂CO₃ (aq) ⇌ H⁺ (aq) + HCO₃⁻ (aq)[15]
The concentration of carbon dioxide is managed by the respiratory system through changes in breathing rate, while the kidneys control the concentration of bicarbonate by excreting or reabsorbing it from the urine.[13][14]
Amino Acids as Acids and Bases
Amino acids are the building blocks of proteins and are classic examples of amphoteric molecules.[4][16] Each amino acid has a central alpha-carbon bonded to an amino group (-NH₂), a carboxyl group (-COOH), a hydrogen atom, and a variable side chain (R-group).
At physiological pH (~7.4), the amino group is protonated (-NH₃⁺) and the carboxyl group is deprotonated (-COO⁻), forming a dipolar ion called a zwitterion .[17]
-
In acidic solutions (low pH), the carboxyl group is protonated (-COOH), and the amino acid has a net positive charge.[18][19]
-
In basic solutions (high pH), the amino group is deprotonated (-NH₂), and the amino acid has a net negative charge.[18][19]
The isoelectric point (pI) is the pH at which an amino acid has no net electrical charge.[17][18] For amino acids with non-ionizable side chains, the pI can be calculated by averaging the pKa values of the carboxyl and amino groups.
Titration of Amino Acids
Titrating an amino acid with a strong base reveals its buffering regions and pKa values. A titration curve for an amino acid like glycine will show two buffering regions, corresponding to the deprotonation of the carboxyl group and the amino group.[20] Amino acids with ionizable side chains, such as aspartic acid or lysine, will have a third buffering region.[21]
Quantitative Data Summary
The pKa values of amino acids and common buffers are essential for experimental design in biochemistry and pharmacology.
Table 1: pKa Values of Standard Amino Acids at 25°C
| Amino Acid | α-Carboxyl Group (pKa₁) | α-Amino Group (pKa₂) | Side Chain (pKaR) | Isoelectric Point (pI) |
| Alanine | 2.34 | 9.69 | - | 6.00 |
| Arginine | 2.17 | 9.04 | 12.48 | 10.76 |
| Asparagine | 2.02 | 8.80 | - | 5.41 |
| Aspartic Acid | 1.88 | 9.60 | 3.65 | 2.77 |
| Cysteine | 1.96 | 10.28 | 8.18 | 5.07 |
| Glutamic Acid | 2.19 | 9.67 | 4.25 | 3.22 |
| Glutamine | 2.17 | 9.13 | - | 5.65 |
| Glycine | 2.34 | 9.60 | - | 5.97 |
| Histidine | 1.82 | 9.17 | 6.00 | 7.59 |
| Isoleucine | 2.36 | 9.60 | - | 6.02 |
| Leucine | 2.36 | 9.60 | - | 5.98 |
| Lysine | 2.18 | 8.95 | 10.53 | 9.74 |
| Methionine | 2.28 | 9.21 | - | 5.74 |
| Phenylalanine | 1.83 | 9.13 | - | 5.48 |
| Proline | 1.99 | 10.60 | - | 6.30 |
| Serine | 2.21 | 9.15 | - | 5.68 |
| Threonine | 2.09 | 9.10 | - | 5.60 |
| Tryptophan | 2.83 | 9.39 | - | 5.89 |
| Tyrosine | 2.20 | 9.11 | 10.07 | 5.66 |
| Valine | 2.32 | 9.62 | - | 5.96 |
Table 2: Common Biological Buffers
| Buffer | pKa at 25°C | Useful pH Range |
| Phosphate (H₂PO₄⁻/HPO₄²⁻) | 7.20 | 6.2 - 8.2 |
| MES | 6.15 | 5.5 - 6.7 |
| PIPES | 6.80 | 6.1 - 7.5 |
| MOPS | 7.20 | 6.5 - 7.9 |
| HEPES | 7.55 | 6.8 - 8.2 |
| Tris | 8.10 | 7.1 - 9.1 |
| Bicine | 8.35 | 7.6 - 9.0 |
Experimental Protocol: Potentiometric Titration of an Amino Acid
This protocol outlines the determination of the pKa values of an unknown amino acid using a pH meter.
Objective: To determine the pKa values and the isoelectric point (pI) of an amino acid by titration with a strong base (NaOH).
Materials:
-
pH meter with a combination electrode
-
Magnetic stirrer and stir bar
-
Buret (25 mL or 50 mL)
-
Beaker (150 mL)
-
Volumetric flasks and pipettes
-
Amino acid solution (e.g., 0.1 M Glycine)
-
Standardized sodium hydroxide (NaOH) solution (e.g., 0.1 M)
-
Standard pH buffers (pH 4.00, 7.00, 10.00) for calibration
Procedure:
-
Calibrate the pH meter: Calibrate the pH meter using the standard buffers according to the manufacturer's instructions.
-
Prepare the sample: Pipette a known volume (e.g., 50.0 mL) of the amino acid solution into a 150 mL beaker. Add a magnetic stir bar.
-
Initial pH measurement: Place the beaker on the magnetic stirrer and immerse the pH electrode in the solution. Turn on the stirrer at a slow, steady speed. Record the initial pH of the amino acid solution.
-
Set up the buret: Rinse and fill the buret with the standardized NaOH solution. Record the initial volume.
-
Perform the titration:
-
Add the NaOH solution in small increments (e.g., 0.5 mL).
-
After each addition, allow the pH reading to stabilize and record the pH and the total volume of NaOH added.
-
As the pH begins to change more rapidly (approaching a pKa), reduce the increment size (e.g., 0.1 mL) to obtain more data points in the buffering region and near the equivalence point.
-
Continue the titration until the pH has risen significantly past the second buffering region (e.g., to pH 11-12).
-
-
Data Analysis:
-
Plot a titration curve with pH on the y-axis and the volume of NaOH added on the x-axis.
-
Determine the equivalence points, which are the points of steepest slope on the curve (inflection points).
-
The pKa values are the pH values at the midpoints of the buffering regions (the flattest parts of the curve). Specifically, pKa₁ is the pH at which half of the first equivalence volume of NaOH has been added, and pKa₂ is the pH at the midpoint between the first and second equivalence volumes.
-
Calculate the pI by averaging the pKa values of the ionizable groups that bracket the zwitterionic form.
-
Applications in Drug Development and Research
The acid-base properties of a drug molecule, quantified by its pKa, are a critical determinant of its absorption, distribution, metabolism, and excretion (ADME) profile.[22][23] The charge state of a drug affects its ability to cross biological membranes, its solubility, and its binding to target receptors.[22][23][24][25]
Most drugs are weak acids or weak bases. According to the pH-partition hypothesis, only the un-ionized (neutral) form of a drug can readily diffuse across lipid cell membranes. The degree of ionization depends on the drug's pKa and the pH of the surrounding environment.
-
Weakly Acidic Drugs (HA): More lipid-soluble in the acidic environment of the stomach (low pH), where they exist primarily in the protonated, neutral form (HA).
-
Weakly Basic Drugs (B): More lipid-soluble in the more alkaline environment of the small intestine (high pH), where they exist primarily in the deprotonated, neutral form (B).
This principle is fundamental to designing orally bioavailable drugs and predicting their behavior in different physiological compartments.
Conclusion
The principles of acid-base chemistry are deeply integrated into the fabric of biology and medicine. For the this compound, a firm grasp of Brønsted-Lowry and Lewis definitions, pH, pKa, buffers, and the behavior of amino acids is essential. For scientists and professionals in drug development, these concepts transcend examination requirements, forming the basis for understanding physiological regulation, designing effective therapeutics, and predicting their biological fate. The ability to apply the Henderson-Hasselbalch equation, interpret titration curves, and appreciate the role of pKa in pharmacokinetics is a critical skill set in modern biomedical research.
References
- 1. jackwestin.com [jackwestin.com]
- 2. solubilityofthings.com [solubilityofthings.com]
- 3. Khan Academy [khanacademy.org]
- 4. Acids and Bases for the this compound: Everything You Need to Know — Shemmassian Academic Consulting [shemmassianconsulting.com]
- 5. Lewis acids and bases - Wikipedia [en.wikipedia.org]
- 6. This compound-review.org [this compound-review.org]
- 7. youtube.com [youtube.com]
- 8. microbenotes.com [microbenotes.com]
- 9. chem.libretexts.org [chem.libretexts.org]
- 10. 20.3 Biological Acids and the HendersonâHasselbalch Equation - Organic Chemistry | OpenStax [openstax.org]
- 11. med.unc.edu [med.unc.edu]
- 12. ⚗️ Buffer Solutions: Definition & Function for the this compound — King of the Curve [kingofthecurve.org]
- 13. This compound Biology - Respiratory System - Free Practice Question - 11956 [varsitytutors.com]
- 14. jackwestin.com [jackwestin.com]
- 15. reddit.com [reddit.com]
- 16. youtube.com [youtube.com]
- 17. Amino Acids for the this compound â Medistudents [medistudents.com]
- 18. This compound-review.org [this compound-review.org]
- 19. m.youtube.com [m.youtube.com]
- 20. m.youtube.com [m.youtube.com]
- 21. medicalschoolhq.net [medicalschoolhq.net]
- 22. The Significance of Acid/Base Properties in Drug Discovery - PMC [pmc.ncbi.nlm.nih.gov]
- 23. The significance of acid/base properties in drug discovery - Chemical Society Reviews (RSC Publishing) [pubs.rsc.org]
- 24. The therapeutic importance of acid-base balance - PMC [pmc.ncbi.nlm.nih.gov]
- 25. research.monash.edu [research.monash.edu]
The Critical Role of Stereochemistry in Organic Chemistry and Drug Development
An In-depth Technical Guide for Researchers, Scientists, and Drug Development Professionals
Stereochemistry, the three-dimensional arrangement of atoms and molecules, is a cornerstone of organic chemistry and a critical consideration in the fields of pharmacology and drug development. For professionals in these areas, a deep understanding of stereoisomerism is not merely academic; it dictates the efficacy, safety, and metabolic profile of pharmaceutical agents. This guide explores the core principles of stereochemistry as they relate to the MCAT syllabus, and extends these concepts to their practical applications in modern drug design and analysis.
Foundational Concepts: Isomerism
Isomers are compounds that share the same molecular formula but differ in the arrangement of their atoms.[1] They are broadly classified into two main categories: constitutional isomers and stereoisomers.[2] Constitutional isomers have different atomic connectivity, while stereoisomers share the same connectivity but differ in the spatial arrangement of their atoms.[3]
Stereoisomers are further divided into enantiomers and diastereomers.[3]
-
Enantiomers are non-superimposable mirror images of each other.[3] A molecule that is not superimposable on its mirror image is termed "chiral."[1][3] Enantiomers possess identical physical properties, such as boiling point and melting point, but differ in their interaction with plane-polarized light and other chiral molecules.[4][5]
-
Diastereomers are stereoisomers that are not mirror images of one another.[3] They have different physical properties and can be separated by conventional laboratory techniques like chromatography.
Caption: Logical relationship of isomer classification.
Chirality and Biological Systems: The Principle of Stereospecificity
The significance of stereochemistry is most profound in biological systems, which are inherently chiral.[5] Enzymes, receptors, and other biological macromolecules are composed of L-amino acids and D-sugars, creating chiral environments.[1] Consequently, the interaction between a chiral drug and its biological target is often stereospecific; the enantiomers of a drug can exhibit markedly different pharmacological and toxicological profiles.[5][6]
This stereoselectivity is often explained by the "three-point attachment" model, which posits that for a chiral molecule to bind effectively to a receptor, it must have at least three points of interaction.[5][7] One enantiomer (the eutomer) will fit perfectly into the binding site, eliciting the desired therapeutic response, while the other (the distomer) may bind weakly, not at all, or even to a different receptor, causing side effects or toxicity.[8]
Caption: Three-point attachment model for chiral recognition.
Case Studies in Drug Development
The differential effects of enantiomers are well-documented and have profound implications for drug safety and efficacy.
-
Thalidomide: This is the most infamous example of stereochemistry's role in drug safety.[9] Thalidomide was prescribed as a racemic mixture (a 1:1 mixture of both enantiomers) to treat morning sickness.[10] It was later discovered that while the (R)-enantiomer has the desired sedative effect, the (S)-enantiomer is a potent teratogen, causing severe birth defects.[10][11] A critical complication is that the enantiomers can interconvert in vivo, meaning that administering the pure (R)-enantiomer does not eliminate the risk.[10][11]
-
Ibuprofen: A common non-steroidal anti-inflammatory drug (NSAID), ibuprofen is often sold as a racemate.[8] The pharmacological activity resides almost exclusively with the S(+)-enantiomer.[12] The R(-)-enantiomer is not inactive, however; it acts as a pro-drug, as it is metabolically inverted to the active S(+) form in the body.[12][13] This chiral inversion means the potency of a racemic dose can be dependent on the rate of absorption.[14]
Table 1: Comparison of Enantiomeric Properties for Selected Drugs
| Drug | Enantiomer | Primary Biological Activity | Notes |
| Thalidomide | (R)-thalidomide | Sedative[10][11] | Enantiomers interconvert in the body.[11] |
| (S)-thalidomide | Teratogenic[10][11] | Interferes with fetal development.[15] | |
| Ibuprofen | (S)-ibuprofen | Anti-inflammatory (Eutomer)[12] | Over 100-fold more potent than the (R)-form as a COX-1 inhibitor.[8] |
| (R)-ibuprofen | Pro-drug (Distomer)[13] | Undergoes unidirectional metabolic inversion to (S)-ibuprofen.[12][13] | |
| Ethambutol | (S,S)-ethambutol | Tuberculostatic (Eutomer) | 500 times more potent than the (R,R)-enantiomer.[9] |
| (R,R)-ethambutol | Can cause optic neuritis (blindness)[9] | The racemate was switched to the pure (S,S)-enantiomer for clinical use.[9] | |
| Penicillamine | (S)-penicillamine | Antiarthritic (Eutomer)[9] | |
| (R)-penicillamine | Highly toxic[9] |
Assigning Absolute Configuration: The Cahn-Ingold-Prelog (CIP) System
To unambiguously describe the three-dimensional arrangement of atoms at a chiral center, the Cahn-Ingold-Prelog (CIP) priority rules are used to assign an absolute configuration of either R (from the Latin rectus, for right) or S (from the Latin sinister, for left).[16][17]
Protocol for Assigning R/S Configuration:
-
Assign Priorities: Rank the four substituents attached to the chiral center based on atomic number. The atom with the highest atomic number receives the highest priority (1), and the lowest receives the lowest priority (4).[16][17]
-
Handle Ties: If two atoms are identical, move to the next atoms along their respective chains until a point of difference is found. The substituent with the atom of higher atomic number at the first point of difference gets higher priority.[17][18]
-
Treat Multiple Bonds: Double and triple bonds are treated as if the atom is bonded to two or three of the same atom, respectively.[18]
-
Orient the Molecule: Position the molecule so that the lowest-priority group (usually hydrogen) is pointing away from the viewer.
-
Determine Configuration: Trace the path from priority 1 to 2 to 3.
-
If the path is clockwise , the configuration is R .
-
If the path is counter-clockwise , the configuration is S .
-
Experimental Protocols for Stereochemical Analysis
The separation and analysis of enantiomers are critical tasks in drug development and quality control.
Chiral molecules are optically active, meaning they rotate the plane of plane-polarized light.[3] A polarimeter is used to measure this rotation.[19]
Experimental Protocol for Polarimetry:
-
Calibration: Fill the polarimeter tube with a pure achiral solvent (e.g., water or ethanol) to establish a baseline reading of 0°.[20][21]
-
Sample Preparation: Prepare a solution of the chiral compound with a precisely known concentration (c), typically in g/mL.[21]
-
Measurement: Fill the sample tube of a known path length (l), measured in decimeters (dm), with the solution. Place the tube in the polarimeter.[19][21]
-
Observation: Rotate the analyzer until the light intensity is at a minimum or the field of view is uniformly dark. The angle of rotation is the observed rotation (α).[20][22]
-
Calculation of Specific Rotation: The specific rotation [α] is a standardized physical constant for a given chiral molecule under specific conditions (temperature and wavelength, often the D-line of a sodium lamp). It is calculated using the formula:[23][24][25] [α] = α / (c * l)
Enantiomers will rotate light by the same magnitude but in opposite directions. A dextrorotatory (+) enantiomer rotates light clockwise, while a levorotatory (-) enantiomer rotates it counter-clockwise.[4] A racemic mixture is optically inactive because the rotations of the two enantiomers cancel each other out.[5]
Since enantiomers have identical physical properties in an achiral environment, they cannot be separated by standard chromatographic techniques.[26] Chiral chromatography utilizes a chiral stationary phase (CSP) that interacts differently with each enantiomer, allowing for their separation.[27][28]
Experimental Protocol for Chiral HPLC:
-
Column Selection: Choose a suitable chiral column. Common CSPs are based on polysaccharides (cellulose, amylose), proteins, or Pirkle-type phases.[28][29] The selection is often empirical and requires screening different columns and mobile phases.[28]
-
Mobile Phase Preparation: Prepare an appropriate mobile phase (e.g., a mixture of hexane and isopropanol). The composition is critical for achieving resolution.
-
Sample Injection: Dissolve the racemic mixture in the mobile phase and inject it into the HPLC system.
-
Elution and Detection: The mobile phase carries the sample through the chiral column. The enantiomers form transient, diastereomeric complexes with the CSP, leading to different interaction strengths and retention times.[28] A detector (e.g., UV-Vis) records the elution profile, showing two separate peaks for the two enantiomers.
-
Quantification: The area under each peak corresponds to the amount of each enantiomer in the mixture.
Caption: Experimental workflow for chiral chromatography.
References
- 1. med-pathway.com [med-pathway.com]
- 2. Introduction to Isomers - Free Sketchy this compound Lesson [sketchy.com]
- 3. jackwestin.com [jackwestin.com]
- 4. youtube.com [youtube.com]
- 5. Stereochemistry in Drug Action - PMC [pmc.ncbi.nlm.nih.gov]
- 6. taylorandfrancis.com [taylorandfrancis.com]
- 7. Stereoselectivity of drug-receptor interactions - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Chirality in Pharmaceuticals: The Impact of Molecular Handedness on Medicine – Chiralpedia [chiralpedia.com]
- 9. Chiral drugs - Wikipedia [en.wikipedia.org]
- 10. Thalidomide - American Chemical Society [acs.org]
- 11. Thalidomide - Wikipedia [en.wikipedia.org]
- 12. The relationship between the pharmacokinetics of ibuprofen enantiomers and the dose of racemic ibuprofen in humans - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. mdpi.com [mdpi.com]
- 14. Pharmacokinetics of ibuprofen enantiomers in humans following oral administration of tablets with different absorption rates - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. The Asymmetry of Harm: Thalidomide and the Power of Molecular Shape | OpenOChem Learn [learn.openochem.org]
- 16. fiveable.me [fiveable.me]
- 17. Cahn–Ingold–Prelog priority rules - Wikipedia [en.wikipedia.org]
- 18. vanderbilt.edu [vanderbilt.edu]
- 19. chem.libretexts.org [chem.libretexts.org]
- 20. Chemistry Online @ UTSC [utsc.utoronto.ca]
- 21. cts.iitkgp.ac.in [cts.iitkgp.ac.in]
- 22. Polarimeter - Wikipedia [en.wikipedia.org]
- 23. masterorganicchemistry.com [masterorganicchemistry.com]
- 24. youtube.com [youtube.com]
- 25. 5.4 Optical Activity – Organic Chemistry I [kpu.pressbooks.pub]
- 26. Chiral chromatography – Chiralpedia [chiralpedia.com]
- 27. The Secrets to Mastering Chiral Chromatography [rotachrom.com]
- 28. Chiral column chromatography - Wikipedia [en.wikipedia.org]
- 29. chem.libretexts.org [chem.libretexts.org]
An In-depth Guide to Enzyme Structure and Function: Core Concepts for Researchers and Drug Development Professionals
This guide provides a comprehensive overview of the principles of enzymology, tailored for professionals in scientific research and pharmaceutical development. While grounded in the core concepts relevant to the Medical College Admission Test (MCAT), the content is presented with the depth and technical detail required by an audience of researchers and scientists.
Enzyme Structure: The Foundation of Catalytic Activity
Enzymes are highly specialized proteins, and in some cases RNA molecules (ribozymes), that function as biological catalysts. Their catalytic prowess is intrinsically linked to their intricate three-dimensional structure. This structure is organized into four hierarchical levels:
-
Primary Structure: The linear sequence of amino acids linked by peptide bonds.
-
Secondary Structure: Local folding of the polypeptide chain into regular structures, primarily α-helices and β-pleated sheets, stabilized by hydrogen bonds.
-
Tertiary Structure: The overall three-dimensional shape of a single polypeptide chain, determined by interactions between the amino acid R-groups, including hydrophobic interactions, ionic bonds, hydrogen bonds, and disulfide bridges.
-
Quaternary Structure: The arrangement of multiple polypeptide subunits to form a functional protein complex.
The function of an enzyme is dictated by its structure; even a minor change in structure can lead to a significant alteration in function.[1] Key to this function are specific regions on the enzyme's surface.
The Active Site and Allosteric Site
Enzymes possess two critical sites that govern their activity:
-
The Active Site: This is the region of the enzyme where the substrate binds and the chemical reaction is catalyzed.[2] The active site is composed of a unique combination of amino acid residues that create a specific chemical environment, conferring substrate specificity.[2]
-
The Allosteric Site: A distinct site on the enzyme, separate from the active site, where regulatory molecules (effectors) can bind.[3] This binding event induces a conformational change in the enzyme, which can either enhance or inhibit its activity.[4]
Models of Enzyme-Substrate Interaction
Two primary models describe the interaction between an enzyme and its substrate:
-
Lock and Key Model: This earlier model postulates that the active site of the enzyme has a rigid, pre-formed shape that is perfectly complementary to the shape of its substrate.[1][5]
-
Induced Fit Model: A more contemporary and widely accepted model, which suggests that the active site is flexible.[2] The binding of the substrate induces a conformational change in the active site, leading to a more precise and optimal fit that facilitates catalysis.[2] This dynamic interaction maximizes the enzyme's ability to stabilize the reaction's transition state.
Mechanism of Catalysis
Enzymes accelerate biochemical reactions by lowering the activation energy (Ea), which is the energy required to reach the transition state.[2][6] They achieve this by providing an alternative reaction pathway. It is crucial to note that enzymes do not alter the overall free energy change (ΔG) or the equilibrium constant (Keq) of a reaction; they only affect the reaction kinetics, not the thermodynamics.[1]
Enzyme Kinetics
Enzyme kinetics is the study of the rates of enzyme-catalyzed reactions.[6] The Michaelis-Menten equation is a fundamental model that describes the relationship between the initial reaction velocity (V₀), the substrate concentration ([S]), the maximum reaction velocity (Vmax), and the Michaelis constant (Km).[6][7]
Michaelis-Menten Equation: V₀ = (Vmax * [S]) / (Km + [S])
-
Vmax (Maximum Velocity): The reaction rate when the enzyme is fully saturated with substrate.[7][8] Vmax is directly proportional to the enzyme concentration.[7]
-
Km (Michaelis Constant): The substrate concentration at which the reaction velocity is half of Vmax.[6][8] Km is an inverse measure of the enzyme's affinity for its substrate; a low Km indicates high affinity, while a high Km suggests lower affinity.[6][8]
A Lineweaver-Burk plot, or double-reciprocal plot, is a graphical representation of the Michaelis-Menten equation (1/V₀ vs. 1/[S]) that is useful for determining Vmax and Km.[7]
Enzyme Inhibition
Enzyme inhibitors are molecules that bind to enzymes and decrease their activity.[6][9] The study of enzyme inhibition is central to pharmacology and drug design. Inhibition can be broadly classified as reversible or irreversible.
Reversible Inhibition
In reversible inhibition, the inhibitor binds non-covalently and can be removed, restoring enzyme activity. There are three main types:
-
Competitive Inhibition: The inhibitor is structurally similar to the substrate and competes for binding at the active site.[9][10] This type of inhibition can be overcome by increasing the substrate concentration. It increases the apparent Km but does not affect Vmax.[10][11]
-
Uncompetitive Inhibition: The inhibitor binds only to the enzyme-substrate [ES] complex, at a site distinct from the active site.[10][11] This type of inhibition is most effective at high substrate concentrations and decreases both Vmax and Km.[11]
-
Non-competitive (Mixed) Inhibition: The inhibitor binds to an allosteric site, and can bind to either the free enzyme or the ES complex.[6][9] It decreases Vmax.[11] Its effect on Km varies; if the inhibitor has the same affinity for the enzyme and the ES complex, it is pure non-competitive inhibition and Km is unchanged. If affinities differ, it is termed mixed inhibition, and Km can either increase or decrease.[6][9]
Summary of Reversible Inhibition Effects
The following table summarizes the kinetic effects of reversible inhibitors, a critical concept for both theoretical understanding and practical application in drug screening.
| Inhibition Type | Binds To | Vmax | Km |
| Competitive | Active Site (Free Enzyme) | Unchanged | Increases |
| Uncompetitive | Enzyme-Substrate (ES) Complex | Decreases | Decreases |
| Non-competitive | Allosteric Site (Enzyme or ES Complex) | Decreases | Unchanged (Pure) or Variable (Mixed) |
Regulation of Enzyme Activity
Cellular metabolism is precisely controlled through the regulation of enzyme activity. Several mechanisms exist to modulate enzyme function in response to the cell's needs.[6]
-
Allosteric Regulation: As previously mentioned, the binding of an allosteric effector to the allosteric site can either activate or inhibit the enzyme.[4][6] This is a rapid method of regulation.
-
Feedback Inhibition: A common biological control mechanism where the end product of a metabolic pathway acts as an allosteric inhibitor of an enzyme that functions early in the pathway.[3][6] This prevents the overproduction of the product.[6]
-
Covalent Modification: The activity of an enzyme can be altered by the covalent attachment or removal of chemical groups, such as phosphate (phosphorylation/dephosphorylation), methyl, or acetyl groups.[4][6] Phosphorylation, for instance, can activate or inactivate an enzyme, thereby regulating its function.[4]
-
Zymogen Activation: Some enzymes, particularly digestive enzymes like pepsin, are synthesized as inactive precursors called zymogens (e.g., pepsinogen).[4] They are activated by irreversible proteolytic cleavage when they reach the appropriate cellular location, ensuring they are active only when and where needed.[4]
Key Experimental Methodologies
The characterization of enzymes relies on a suite of established laboratory techniques. Understanding these protocols is essential for research and development.
Protocol: General Spectrophotometric Enzyme Assay
This protocol outlines a common method for determining enzyme activity by measuring the change in absorbance of a substrate or product over time.
Objective: To measure the initial reaction rate of an enzyme.
Materials:
-
Purified enzyme solution of known concentration.
-
Substrate solution.
-
Reaction buffer (to maintain optimal pH).
-
Spectrophotometer.
-
Cuvettes.
-
Micropipettes and tips.
-
Timer.
Methodology:
-
Preparation: Set the spectrophotometer to the wavelength of maximum absorbance for the product or substrate being monitored. Equilibrate all solutions (buffer, substrate, enzyme) to the desired reaction temperature.
-
Reaction Mixture Setup: In a cuvette, combine the reaction buffer and the substrate solution. Mix gently.
-
Blank Measurement: Place the cuvette containing the buffer and substrate into the spectrophotometer and zero the instrument (this is the "blank").
-
Initiation of Reaction: Remove the cuvette. Add a small, precise volume of the enzyme solution to initiate the reaction. Mix immediately but gently by inverting the cuvette.
-
Data Collection: Immediately place the cuvette back into the spectrophotometer and begin recording the absorbance at regular time intervals (e.g., every 15 seconds) for a set period (e.g., 3-5 minutes).
-
Analysis: Plot absorbance versus time. The initial reaction velocity (V₀) is determined from the slope of the linear portion of the curve. This rate can be converted to concentration per unit time using the Beer-Lambert law (A = εbc).
Protocol: Protein Crystallography for Structure Determination
This protocol provides a high-level overview of the workflow used to determine the three-dimensional structure of an enzyme.
Objective: To produce a high-resolution 3D model of an enzyme.
Methodology:
-
Protein Purification: The target enzyme must be purified to a very high degree (>95% homogeneity).[12] Purity is assessed using techniques like SDS-PAGE and mass spectrometry.[12] The protein is concentrated to 10-20 mg/mL.[12]
-
Crystallization: The purified protein is subjected to a wide range of conditions (e.g., varying pH, salt concentration, temperature, precipitating agents) in an attempt to induce the formation of well-ordered crystals.[13] The hanging drop vapor diffusion method is commonly used.[12] This is often the most challenging and time-consuming step.
-
X-ray Diffraction Data Collection: A suitable crystal is selected, mounted, and cryo-cooled. It is then exposed to a high-intensity X-ray beam (often from a synchrotron source). The crystal diffracts the X-rays, producing a distinct pattern of spots that is recorded by a detector.[14]
-
Structure Solution (Phasing): The diffraction pattern provides information about the amplitudes of the scattered X-rays, but the phase information is lost. The "phase problem" must be solved using methods like Molecular Replacement (if a similar structure is known) or experimental phasing techniques.
-
Model Building and Refinement: Once initial phases are obtained, an electron density map is calculated.[14] A computational model of the enzyme's amino acid sequence is built into this map. This model is then iteratively refined to improve its fit with the experimental diffraction data.
-
Structure Validation: The final model is rigorously checked for stereochemical quality and consistency with known biochemical principles before being deposited in a public database like the Protein Data Bank (PDB).
References
- 1. This compound-review.org [this compound-review.org]
- 2. jackwestin.com [jackwestin.com]
- 3. jackwestin.com [jackwestin.com]
- 4. jackwestin.com [jackwestin.com]
- 5. app.achievable.me [app.achievable.me]
- 6. Enzymes for the this compound | What You Need to Know [inspiraadvantage.com]
- 7. jackwestin.com [jackwestin.com]
- 8. Enzyme Kinetics on the this compound: Vmax, Km, and Competitive Inhibition Simplified — King of the Curve [kingofthecurve.org]
- 9. jackwestin.com [jackwestin.com]
- 10. medschoolcoach.com [medschoolcoach.com]
- 11. youtube.com [youtube.com]
- 12. Protein XRD Protocols - Crystallization of Proteins [sites.google.com]
- 13. enzymology.insightconferences.com [enzymology.insightconferences.com]
- 14. Protein crystallography for aspiring crystallographers or how to avoid pitfalls and traps in macromolecular structure determination - PMC [pmc.ncbi.nlm.nih.gov]
An In-depth Technical Guide to Carbohydrate and Lipid Chemistry for the MCAT
Abstract: This guide provides a comprehensive overview of the core principles of carbohydrate and lipid chemistry as they pertain to the Medical College Admission Test (MCAT). While the this compound is a pre-medical examination, this document is structured to deliver a technically in-depth review suitable for an audience with a strong scientific background. It covers fundamental structures, classifications, and key reactions. The guide includes quantitative data summarized in tabular format, detailed experimental protocols for foundational assays, and visualizations of key pathways and classifications using the DOT language to facilitate a deeper understanding of the molecular logic.
Introduction to Macromolecules
In the context of cellular biology and biochemistry, lipids and carbohydrates represent two of the four major classes of macromolecules essential for life, the others being proteins and nucleic acids.[1][2] Carbohydrates primarily serve as a source of energy and as structural components.[3] Lipids are highly diverse in structure and function, playing critical roles in energy storage, membrane structure, and cell signaling.[4][5] A thorough understanding of their chemistry is fundamental to comprehending cellular function, metabolism, and pathophysiology—topics heavily weighted on the this compound.
Carbohydrate Chemistry
Carbohydrates are organic compounds with the general empirical formula Cn(H₂O)n.[2][3] They are polyhydroxy aldehydes or ketones, or substances that hydrolyze to yield them.[6] Functionally, they are the primary source of metabolic energy and form structural components of cells, such as cellulose in plant cell walls.[3][7]
Classification of Carbohydrates
Carbohydrates are broadly classified based on the number of sugar units they contain: monosaccharides, disaccharides, and polysaccharides.[8][9]
-
Monosaccharides: These are the simplest sugars and serve as the monomeric building blocks for more complex carbohydrates.[8] They are classified by the number of carbon atoms (e.g., triose, pentose, hexose) and by the nature of their carbonyl group (aldose or ketose).[10][11]
-
Disaccharides: Composed of two monosaccharide units joined by a covalent glycosidic linkage.[2]
-
Polysaccharides: Long polymers of monosaccharides linked by glycosidic bonds.[9] They can be linear or branched and serve in energy storage (e.g., starch, glycogen) or as structural components (e.g., cellulose, chitin).[8]
Structure of Monosaccharides
Monosaccharides with five or more carbons, such as glucose and fructose, exist predominantly in cyclic forms in aqueous solutions.[2] This cyclization occurs through the reaction of the carbonyl group with a hydroxyl group in the same molecule, forming a hemiacetal or hemiketal. The formation of this ring creates a new chiral center at the anomeric carbon (the original carbonyl carbon), resulting in two possible diastereomers, designated α and β.[2]
Quantitative Data for Common Monosaccharides
The physical properties of monosaccharides are critical to their biological function and detection.
| Monosaccharide | Formula | Molar Mass ( g/mol ) | Type | # of Carbons |
| D-Glucose | C₆H₁₂O₆ | 180.16 | Aldohexose | 6 |
| D-Fructose | C₆H₁₂O₆ | 180.16 | Ketohexose | 6 |
| D-Galactose | C₆H₁₂O₆ | 180.16 | Aldohexose | 6 |
| D-Ribose | C₅H₁₀O₅ | 150.13 | Aldopentose | 5 |
| D-Glyceraldehyde | C₃H₆O₃ | 90.08 | Aldotriose | 3 |
Table 1: Properties of Common Monosaccharides.[12][13]
Lipid Chemistry
Lipids are a heterogeneous group of organic molecules characterized by their insolubility in water and solubility in nonpolar organic solvents.[1][5] This property arises from their predominantly hydrocarbon nature. Lipids serve diverse and critical functions, including long-term energy storage, formation of cell membranes, and as signaling molecules.[14][15]
Classification of Lipids
Lipids can be broadly categorized based on their structure and function.
-
Fatty Acids: Carboxylic acids with long hydrocarbon chains, which can be saturated or unsaturated.[16] They are the fundamental building blocks of many complex lipids.[15]
-
Triacylglycerols (Triglycerides): Composed of a glycerol molecule esterified to three fatty acids.[1] They are the primary form of energy storage in animals.[14]
-
Phospholipids: Comprise a glycerol or sphingosine backbone, two fatty acid tails, and a phosphate-containing head group.[17] Their amphipathic nature is critical for forming the lipid bilayer of cell membranes.[4]
-
Steroids: Characterized by a four-ring carbon structure known as the steroid nucleus.[14] Cholesterol is a key steroid that modulates membrane fluidity and serves as a precursor to steroid hormones.[5]
-
Terpenes: Built from isoprene (C₅H₈) units and are precursors to steroids and other lipid signaling molecules.[18]
Quantitative Data for Common Fatty Acids
The physical properties of fatty acids, such as melting point, are determined by the length of the carbon chain and the degree of unsaturation.[16] Saturated fatty acids have higher melting points than unsaturated fatty acids of the same length due to more efficient van der Waals packing.
| Fatty Acid | Abbreviated Notation | Type | Melting Point (°C) |
| Lauric Acid | 12:0 | Saturated | 44 |
| Myristic Acid | 14:0 | Saturated | 58 |
| Palmitic Acid | 16:0 | Saturated | 63 |
| Stearic Acid | 18:0 | Saturated | 70 |
| Oleic Acid | 18:1 (cis-9) | Monounsaturated | 16 |
| Linoleic Acid | 18:2 (cis-9,12) | Polyunsaturated | -5 |
| α-Linolenic Acid | 18:3 (cis-9,12,15) | Polyunsaturated | -11 |
Table 2: Properties of Common Fatty Acids.[16]
Key Metabolic Pathways
Glycolysis
Glycolysis is a central metabolic pathway that converts glucose into pyruvate, generating ATP and NADH in the process.[19] It consists of ten enzyme-catalyzed reactions that occur in the cytoplasm and can proceed under both aerobic and anaerobic conditions.[7] The pathway is divided into an energy investment phase and an energy payoff phase.[19]
Experimental Protocols
Benedict's Test for Reducing Sugars
Objective: To detect the presence of reducing sugars, which include all monosaccharides and some disaccharides that possess a free aldehyde or ketone group.[20]
Principle: In the presence of an alkaline solution and heat, reducing sugars reduce the cupric ions (Cu²⁺) in Benedict's reagent to cuprous ions (Cu⁺).[20] These are precipitated as red copper(I) oxide. The color of the precipitate gives a semi-quantitative measure of the amount of reducing sugar present.[21]
Methodology:
-
Preparation: Pipette 2 mL of Benedict's reagent into a clean test tube.[22]
-
Sample Addition: Add approximately 1 mL of the sample solution to the test tube.[22]
-
Heating: Place the test tube in a boiling water bath for 3-5 minutes.[21][22]
-
Observation: Remove the test tube and observe any color change. The color can range from green (low concentration) to yellow, orange, and finally to brick-red (high concentration), indicating a positive result. A blue color indicates a negative result.[22]
Saponification of a Triglyceride
Objective: To hydrolyze a triglyceride (fat or oil) using a strong base to produce glycerol and fatty acid salts (soap).[23]
Principle: Saponification is the base-catalyzed hydrolysis of an ester. The ester linkages in a triglyceride are cleaved by the hydroxide ions, yielding glycerol and the corresponding carboxylate salts of the fatty acids.[24]
Methodology:
-
Reagent Preparation: In a suitable reaction vessel (e.g., a 150 mL beaker), combine approximately 10 g of a fat or oil (e.g., vegetable oil) with 20 mL of a 20% sodium hydroxide (NaOH) solution.[23] Add 10 mL of ethanol to act as a solvent to homogenize the mixture.[23]
-
Heating: Add boiling chips and gently heat the mixture using a hot plate or water bath. Stir continuously. The reaction should be heated for approximately 20-30 minutes.[25]
-
Completion Check: To check for completion, add a few drops of the reaction mixture to a test tube of cold water. If oily droplets form, the reaction is incomplete and requires further heating.[23]
-
Isolation: Once the reaction is complete, cool the mixture. Add a concentrated sodium chloride (NaCl) solution to precipitate the soap, a process known as "salting out."
-
Purification: The precipitated soap can be collected by vacuum filtration and washed with cold water to remove excess NaOH, glycerol, and NaCl.
References
- 1. jackwestin.com [jackwestin.com]
- 2. jackwestin.com [jackwestin.com]
- 3. jackwestin.com [jackwestin.com]
- 4. Lipids and Membranes for the this compound: Everything You Need to Know — Shemmassian Academic Consulting [shemmassianconsulting.com]
- 5. Lipid | Definition, Structure, Examples, Functions, Types, & Facts | Britannica [britannica.com]
- 6. alevelbiology.co.uk [alevelbiology.co.uk]
- 7. Biochemistry, Glycolysis - StatPearls - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 8. lndcollege.co.in [lndcollege.co.in]
- 9. Carbohydrate Classification - Free Sketchy this compound Lesson [sketchy.com]
- 10. This compound-review.org [this compound-review.org]
- 11. III. Carbohydrates, Structures and Types – A Guide to the Principles of Animal Nutrition [open.oregonstate.education]
- 12. Monosaccharide - Wikipedia [en.wikipedia.org]
- 13. microbenotes.com [microbenotes.com]
- 14. uomustansiriyah.edu.iq [uomustansiriyah.edu.iq]
- 15. jackwestin.com [jackwestin.com]
- 16. chem.libretexts.org [chem.libretexts.org]
- 17. LIPID MAPS [lipidmaps.org]
- 18. Lipids for this compound Biochemistry [brainscape.com]
- 19. Glycolysis - Wikipedia [en.wikipedia.org]
- 20. mlsu.ac.in [mlsu.ac.in]
- 21. savemyexams.com [savemyexams.com]
- 22. microbiologyinfo.com [microbiologyinfo.com]
- 23. chem.latech.edu [chem.latech.edu]
- 24. webassign.net [webassign.net]
- 25. Chemistry 102 - Experiment 8 [home.miracosta.edu]
Methodological & Application
Application Notes: Applying Gas Laws to MCAT Practice Problems
Introduction
A thorough understanding of the behavior of gases is critical for success on the MCAT, as these principles underpin numerous physiological and chemical processes. Gas laws describe the relationships between pressure, volume, temperature, and the number of moles of a gas. For professionals in research and drug development, a fundamental mastery of these concepts is essential for interpreting experimental data related to gaseous reactants or products and understanding physiological gas exchange. These notes provide a systematic protocol for analyzing and solving this compound-style problems involving gas laws.
Protocol I: Foundational Principles and Key Equations
The behavior of ideal gases is governed by a set of fundamental laws. An ideal gas is a theoretical gas whose particles have negligible volume and no intermolecular forces.[1] While no real gas is truly ideal, most gases behave nearly ideally under the conditions of high temperature and low pressure commonly encountered on the this compound.[2][3] The core relationships are derived from the Ideal Gas Law and are summarized below.
Data Presentation: Summary of Key Gas Laws
| Law | Equation | Constants | Relationship Described |
| Ideal Gas Law | PV = nRT | R (Ideal Gas Constant) | Relates the four macroscopic properties of a gas at a static state.[3] |
| Combined Gas Law | (P₁V₁)/(n₁T₁) = (P₂V₂)/(n₂T₂) | R | Relates the properties of a gas under two different sets of conditions. |
| Boyle's Law | P₁V₁ = P₂V₂ | n, T | Pressure is inversely proportional to Volume.[2][4] |
| Charles's Law | V₁/T₁ = V₂/T₂ | n, P | Volume is directly proportional to Temperature (in Kelvin).[2][5] |
| Gay-Lussac's Law | P₁/T₁ = P₂/T₂ | n, V | Pressure is directly proportional to Temperature (in Kelvin).[4] |
| Avogadro's Law | V₁/n₁ = V₂/n₂ | P, T | Volume is directly proportional to the number of moles.[2] |
| Dalton's Law | P_total = P_A + P_B + ...P_A = X_A * P_total | V, T | The total pressure of a gas mixture is the sum of the partial pressures of its components.[6][7] |
Key Constants and Conditions:
-
Ideal Gas Constant (R): 0.0821 L·atm/(mol·K) or 8.314 J/(mol·K). The value used depends on the units of pressure and volume given in the problem.
-
Standard Temperature and Pressure (STP): 273.15 K (0°C) and 1 atm.[4]
-
Molar Volume at STP: One mole of an ideal gas occupies 22.4 L at STP.[8]
Logical Workflow for Problem Solving
A systematic approach is crucial for efficiently and accurately solving gas law problems on the this compound. The following logical workflow guides the selection of the appropriate law and ensures all parameters are correctly handled.
Caption: A flowchart detailing the logical steps to solve this compound gas law problems.
Application Protocol: Step-by-Step Methodology
1. System Identification and Variable Tabulation:
-
Carefully read the problem to determine the initial and final states of the gaseous system.
-
Identify all known variables (Pressure, Volume, moles, Temperature) and the unknown variable the question asks for.
-
Organize this information in a table. This is especially useful for problems involving changing conditions.
2. Unit Conversion (Mandatory):
-
Temperature: Always convert temperature from Celsius (°C) to Kelvin (K) using the formula: K = °C + 273.15.[8] Gas law calculations are invalid with Celsius temperatures.[3]
-
Pressure and Volume: Ensure the units for pressure (e.g., atm, kPa, mmHg) and volume (e.g., L, mL) are consistent with the chosen value of the ideal gas constant, R.
3. Selection of the Appropriate Gas Law:
-
Use the workflow (Diagram 1) to select the correct formula.
-
If the problem involves a change in conditions (e.g., a piston moving, a change in temperature), the Combined Gas Law is the most robust starting point.[9]
-
If any variables are held constant, they can be canceled from the Combined Gas Law to yield the simpler laws (Boyle's, Charles's, etc.). For instance, if temperature and moles are constant, (P₁V₁)/(n₁T₁) = (P₂V₂)/(n₂T₂) simplifies to P₁V₁ = P₂V₂.
4. Algebraic Solution and Conceptual Verification:
-
Rearrange the chosen equation to solve for the unknown variable.
-
Substitute the known values and calculate the result.
-
Conceptual Check: Verify if the answer is logical. For example, according to Boyle's law, if you increase the pressure on a gas, its volume should decrease.[2] If your calculation shows an increase, re-check your work.
Relationships Among Gas Laws
The simpler gas laws are special cases of the Ideal Gas Law where certain variables are held constant. Understanding this hierarchy simplifies memorization and application.
Caption: Relationship between the Ideal Gas Law and its derivatives.
Experimental Protocols & Practice Problems
Experiment 1: Isobaric Expansion of a Gas (Charles's Law)
Protocol: A sample of 2.0 L of an ideal gas is contained within a cylinder fitted with a frictionless piston that maintains a constant pressure of 1 atm. The initial temperature of the gas is 27°C. The cylinder is heated until the volume expands to 4.0 L. Determine the final temperature of the gas in Celsius.
Data Table:
| Variable | Initial State (1) | Final State (2) | Constant |
| Pressure (P) | 1 atm | 1 atm | Yes |
| Volume (V) | 2.0 L | 4.0 L | No |
| Temperature (T) | 27°C | ? | No |
| Moles (n) | Constant | Constant | Yes |
Solution:
-
System Identification: A fixed amount of gas (n is constant) is heated at constant pressure (isobaric process). Conditions are changing.
-
Unit Conversion: Convert the initial temperature to Kelvin.
-
T₁ = 27°C + 273.15 = 300.15 K.
-
-
Law Selection: Since n and P are constant, we use Charles's Law: V₁/T₁ = V₂/T₂.[5]
-
Solve for Unknown: Rearrange to solve for T₂.
-
T₂ = T₁ * (V₂ / V₁)
-
T₂ = 300.15 K * (4.0 L / 2.0 L) = 600.3 K.
-
-
Final Conversion: Convert the final temperature back to Celsius as requested.
-
T₂ = 600.3 K - 273.15 = 327.15°C.
-
-
Conceptual Check: The volume doubled, so the absolute temperature should also double, which it did (300 K to 600 K). The result is logical.
Experiment 2: Gas Mixture in a Rigid Container (Dalton's Law)
Protocol: A rigid 10 L container at 298 K holds a mixture of 0.2 moles of Oxygen (O₂) and 0.8 moles of Nitrogen (N₂). Calculate the partial pressure of O₂ and the total pressure inside the container.
Data Table:
| Component | Moles (n) | Mole Fraction (X) | Partial Pressure (P) |
| Oxygen (O₂) ** | 0.2 mol | ? | ? |
| Nitrogen (N₂) ** | 0.8 mol | ? | ? |
| Total | 1.0 mol | 1.0 | ? |
Solution:
-
System Identification: A static mixture of non-reacting gases in a container of fixed volume and temperature.
-
Calculate Mole Fractions (X): The mole fraction of a gas is the moles of that gas divided by the total moles.[7]
-
X_O₂ = n_O₂ / n_total = 0.2 mol / 1.0 mol = 0.2
-
X_N₂ = n_N₂ / n_total = 0.8 mol / 1.0 mol = 0.8
-
-
Calculate Total Pressure (P_total): Use the Ideal Gas Law for the total mixture.
-
P_total = (n_total * R * T) / V
-
P_total = (1.0 mol * 0.0821 L·atm/(mol·K) * 298 K) / 10 L
-
P_total ≈ 2.45 atm.
-
-
Calculate Partial Pressure (P_O₂): Use Dalton's Law: P_A = X_A * P_total.[10]
-
P_O₂ = X_O₂ * P_total = 0.2 * 2.45 atm = 0.49 atm.
-
-
Conceptual Check: The mole fraction of oxygen is 20% of the total, so its partial pressure should be 20% of the total pressure. 0.49 atm is indeed 20% of 2.45 atm. The result is consistent.
Experiment 3: Scuba Diving Application (Combined Gas Law)
Protocol: A scuba diver's lungs hold 6.0 L of air at a depth where the pressure is 3.0 atm and the temperature is 20°C. If the diver ascends to the surface where the pressure is 1.0 atm and the water temperature is 27°C, what is the new volume of air in the lungs, assuming the diver holds their breath?
Data Table:
| Variable | Initial State (1) | Final State (2) | Constant |
| Pressure (P) | 3.0 atm | 1.0 atm | No |
| Volume (V) | 6.0 L | ? | No |
| Temperature (T) | 20°C | 27°C | No |
| Moles (n) | Constant | Constant | Yes |
Solution:
-
System Identification: A fixed amount of gas (air in the lungs) is subjected to changing pressure and temperature.
-
Unit Conversion: Convert both temperatures to Kelvin.
-
T₁ = 20°C + 273.15 = 293.15 K.
-
T₂ = 27°C + 273.15 = 300.15 K.
-
-
Law Selection: Since n is constant, the Combined Gas Law (P₁V₁)/T₁ = (P₂V₂)/T₂ is appropriate.
-
Solve for Unknown: Rearrange to solve for V₂.
-
V₂ = V₁ * (P₁/P₂) * (T₂/T₁)
-
V₂ = 6.0 L * (3.0 atm / 1.0 atm) * (300.15 K / 293.15 K)
-
V₂ ≈ 6.0 L * 3 * 1.024 ≈ 18.4 L.
-
-
Conceptual Check: The pressure decreased by a factor of three, which would cause the volume to triple (to 18 L). The temperature increased slightly, which would cause a slight additional increase in volume. The final answer of 18.4 L is logical and highlights the danger of ascending too quickly while diving.
References
- 1. youtube.com [youtube.com]
- 2. jackwestin.com [jackwestin.com]
- 3. m.youtube.com [m.youtube.com]
- 4. jackwestin.com [jackwestin.com]
- 5. varsitytutors.com [varsitytutors.com]
- 6. jackwestin.com [jackwestin.com]
- 7. jackwestin.com [jackwestin.com]
- 8. youtube.com [youtube.com]
- 9. reddit.com [reddit.com]
- 10. varsitytutors.com [varsitytutors.com]
Application Notes: A Strategic Approach to MCAT Solution Chemistry
These application notes provide a comprehensive overview of the principles and problem-solving strategies essential for mastering solution chemistry on the MCAT. The content is tailored for researchers, scientists, and professionals preparing for the exam, focusing on a systematic and protocol-driven approach to common problem types.
Foundational Concepts in Solution Chemistry
A solution is a homogeneous mixture composed of a solute (the substance being dissolved) and a solvent (the substance in which the solute dissolves).[1] Understanding the quantitative relationships between these components is critical for a wide range of applications, from biochemical reactions to pharmacological preparations. The this compound emphasizes a strong conceptual and quantitative understanding of these principles.
Key Concentration Units
Quantifying the amount of solute in a solution is fundamental.[1][2][3] The this compound requires fluency in converting between and applying various concentration units. The most common units are summarized below.
| Concentration Unit | Formula | Description |
| Molarity (M) | Moles of Solute / Liters of Solution | The most common unit of concentration, useful for stoichiometry in aqueous solutions.[2] |
| Molality (m) | Moles of Solute / Kilograms of Solvent | Temperature-independent, making it crucial for studying colligative properties.[2][4] |
| Mole Fraction (Χ) | Moles of Component / Total Moles of All Components | A unitless measure used in the context of vapor pressure and gas mixtures.[4] |
| Mass Percent (%) | (Mass of Solute / Mass of Solution) x 100% | Often used in commercial and consumer products. |
| Normality (N) | Number of Equivalents / Liters of Solution | Relates the molarity to the number of reactive species (e.g., H+ ions) per molecule.[5] |
Solubility Principles
Solubility describes the maximum amount of a solute that can be dissolved in a solvent at a given temperature. The core principle is "like dissolves like," meaning polar solutes dissolve in polar solvents, and nonpolar solutes dissolve in nonpolar solvents. For the this compound, a key skill is predicting the solubility of ionic compounds in water.
| Rule | Soluble Salts | Insoluble Salts (Exceptions) |
| 1 | All salts containing Group 1 alkali metals (Li+, Na+, K+, etc.) and ammonium (NH₄⁺). | --- |
| 2 | All salts containing nitrate (NO₃⁻) and acetate (CH₃COO⁻). | --- |
| 3 | Most salts containing chlorides (Cl⁻), bromides (Br⁻), and iodides (I⁻). | Salts of silver (Ag⁺), lead (Pb²⁺), and mercury(I) (Hg₂²⁺). |
| 4 | Most salts containing sulfate (SO₄²⁻). | Salts of calcium (Ca²⁺), strontium (Sr²⁺), barium (Ba²⁺), and lead (Pb²⁺). |
| 5 | --- | Most salts containing hydroxides (OH⁻) and sulfides (S²⁻). Exceptions include salts of Group 1 metals and ammonium. |
| 6 | --- | Most salts containing carbonates (CO₃²⁻) and phosphates (PO₄³⁻). Exceptions include salts of Group 1 metals and ammonium. |
Key Solution Chemistry Formulas
A set of core equations governs the quantitative aspects of solutions. Mastery of these formulas is essential for efficient problem-solving.
| Concept | Formula | Variables |
| Dilution | M₁V₁ = M₂V₂ | M = Molarity, V = Volume. |
| Solubility Product | Ksp = [A⁺]ⁿ[B⁻]ᵐ for AₙBₘ(s) ⇌ nA⁺(aq) + mB⁻(aq) | Ksp = Solubility Product Constant, [ ] = Molar Concentration.[5] |
| Freezing Point Depression | ΔTf = i * Kf * m | ΔTf = Change in freezing point, i = van 't Hoff factor, Kf = Cryoscopic constant, m = Molality.[2] |
| Boiling Point Elevation | ΔTb = i * Kb * m | ΔTb = Change in boiling point, i = van 't Hoff factor, Kb = Ebullioscopic constant, m = Molality.[2] |
| Osmotic Pressure | Π = i * M * R * T | Π = Osmotic pressure, i = van 't Hoff factor, M = Molarity, R = Ideal gas constant, T = Temperature (K). |
Experimental Protocols for Problem Solving
This section details standardized protocols for approaching the most common types of solution chemistry problems encountered on the this compound.
Protocol: Concentration and Stoichiometry Calculations
Objective: To determine the concentration of a solution or use concentration to find the mass or moles of a solute.
Methodology:
-
Identify Given Information: List all known values from the problem statement (e.g., mass of solute, volume of solution).
-
Determine the Required Unit: Identify the target concentration unit (Molarity, Molality, etc.).
-
Convert Units:
-
Convert the mass of the solute to moles using its molar mass.
-
Ensure the volume of the solution is in Liters (for Molarity) or the mass of the solvent is in kilograms (for Molality).
-
-
Apply Formula: Substitute the converted values into the appropriate concentration formula from Table 1.1.
-
Verify Result: Check that the final units are correct and the magnitude of the answer is reasonable.
Protocol: Dilution Calculations
Objective: To calculate the volume or concentration of a solution before or after dilution.
Methodology:
-
Assign Variables: Identify the initial molarity (M₁), initial volume (V₁), final molarity (M₂), and final volume (V₂). One of these will be the unknown.
-
Apply Dilution Equation: Set up the equation M₁V₁ = M₂V₂.
-
Isolate the Unknown: Algebraically rearrange the formula to solve for the target variable.
-
Calculate and Verify: Substitute the known values and calculate the result. Ensure that if the solution was diluted (solvent added), the final concentration is lower than the initial concentration.
Protocol: Colligative Properties Analysis
Objective: To determine the change in a solvent's physical properties due to the presence of a solute.
Methodology:
-
Identify the Property: Determine if the problem involves freezing point depression, boiling point elevation, or osmotic pressure.[2]
-
Determine the van 't Hoff Factor (i):
-
For non-electrolytes (e.g., glucose, sucrose), i = 1.
-
For strong electrolytes (e.g., NaCl, MgCl₂), i equals the number of ions produced upon dissociation (i=2 for NaCl, i=3 for MgCl₂).
-
-
Calculate Molality (m) or Molarity (M): Use the protocol in section 2.1 to find the concentration of the solution in the correct units (molality for freezing/boiling point, molarity for osmotic pressure).
-
Apply the Correct Formula: Select the appropriate equation from Table 1.3.
-
Calculate the Property Change: Substitute the values for i, m (or M), and the given constant (Kf, Kb, or R) to find ΔT or Π.
-
Determine the Final Value: For freezing point, subtract ΔTf from the solvent's normal freezing point. For boiling point, add ΔTb to the solvent's normal boiling point.
Logical Workflow for Solution Chemistry Problems
A systematic approach is crucial for efficiently and accurately solving this compound problems. The following workflow diagram illustrates a logical pathway from problem identification to solution.
Figure 1. A logical workflow for solving this compound solution chemistry problems.
References
- 1. Solutions and Gases for the this compound: Everything You Need to Know — Shemmassian Academic Consulting [shemmassianconsulting.com]
- 2. jackwestin.com [jackwestin.com]
- 3. Solutions - Magoosh this compound [this compound.magoosh.com]
- 4. bemoacademicconsulting.com [bemoacademicconsulting.com]
- 5. This compound-review.org [this compound-review.org]
Application of Le Chatelier's Principle in MCAT Questions: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
This document provides a detailed overview of the application of Le Chatelier's principle in the context of the Medical College Admission Test (MCAT). It is designed to be a valuable resource for researchers, scientists, and professionals in drug development by offering a comprehensive understanding of how this fundamental concept in chemistry is applied to biological systems. The content includes detailed application notes, experimental protocols for demonstrating the principle, and visualizations of key concepts.
I. Application Notes
Le Chatelier's principle states that if a change of condition is applied to a system in equilibrium, the system will shift in a direction that relieves the stress. For the this compound, this principle is not merely a theoretical concept but a critical tool for analyzing and predicting the behavior of physiological and biochemical systems. Understanding its application is essential for answering a significant portion of questions in the "Biological and Biochemical Foundations of Living Systems" and "Chemical and Physical Foundations of Biological Systems" sections of the exam.
A. The Bicarbonate Buffer System: Maintaining Blood pH Homeostasis
One of the most frequently tested applications of Le Chatelier's principle on the this compound is the bicarbonate buffer system in the blood. This system is crucial for maintaining blood pH within a narrow range (7.35-7.45). The primary equilibrium involved is:
CO₂ + H₂O ⇌ H₂CO₃ ⇌ H⁺ + HCO₃⁻
-
Stress 1: Increased CO₂ (e.g., during hypoventilation or intense exercise)
-
An increase in blood CO₂ shifts the equilibrium to the right to consume the excess CO₂.
-
This leads to an increase in the concentration of carbonic acid (H₂CO₃), which in turn dissociates to produce more hydrogen ions (H⁺) and bicarbonate ions (HCO₃⁻).
-
The increase in [H⁺] leads to a decrease in blood pH, a condition known as acidosis.[1] To counteract this, the respiratory rate may increase to expel more CO₂.[1]
-
-
Stress 2: Decreased CO₂ (e.g., during hyperventilation)
-
A decrease in blood CO₂ shifts the equilibrium to the left to produce more CO₂.
-
This consumes H⁺ and HCO₃⁻, leading to a decrease in [H⁺] and an increase in blood pH, a condition known as alkalosis.
-
-
Stress 3: Addition of Acid (e.g., lactic acid from anaerobic metabolism)
-
An increase in [H⁺] from an external source will shift the equilibrium to the left.
-
Bicarbonate ions (HCO₃⁻) will combine with the excess H⁺ to form carbonic acid (H₂CO₃), which can then be converted to CO₂ and exhaled. This buffers the blood against a drastic drop in pH.[2]
-
-
Stress 4: Addition of Base
-
A decrease in [H⁺] (due to the addition of a base) will shift the equilibrium to the right.
-
Carbonic acid will dissociate to replenish the H⁺ ions, thus resisting a significant increase in pH.
-
B. Hemoglobin and Oxygen Transport: The Bohr and Haldane Effects
The binding and release of oxygen by hemoglobin are also governed by Le Chatelier's principle and are frequently tested on the this compound. The simplified equilibrium is:
Hb + O₂ ⇌ HbO₂
-
In the Lungs (High pO₂): The high partial pressure of oxygen drives the equilibrium to the right, favoring the formation of oxyhemoglobin (HbO₂).
-
In Respiring Tissues (Low pO₂): The lower partial pressure of oxygen shifts the equilibrium to the left, promoting the release of oxygen from hemoglobin to the tissues.
Le Chatelier's principle also explains the Bohr effect , which describes the decrease in hemoglobin's affinity for oxygen in the presence of increased CO₂ and H⁺ concentrations.
-
Increased CO₂ and H⁺ in Tissues: In metabolically active tissues, the concentrations of CO₂ and H⁺ are higher.
-
CO₂ can bind to hemoglobin (forming carbaminohemoglobin), and H⁺ can protonate hemoglobin. Both of these actions stabilize the deoxygenated "tense" (T) state of hemoglobin, which has a lower affinity for oxygen.[3]
-
This shifts the oxygen-binding equilibrium to the left, facilitating the release of oxygen where it is most needed.
-
The Haldane effect is the converse: the deoxygenation of blood increases its ability to carry carbon dioxide. In the tissues, as hemoglobin releases oxygen, it has a higher affinity for H+, which in turn shifts the bicarbonate buffer equilibrium to the right, allowing more CO2 to be transported as bicarbonate.
C. Metabolic Pathways: Product Inhibition and Regulation
Le Chatelier's principle is also fundamental to the regulation of metabolic pathways.
-
Product Inhibition: In many enzymatic reactions, the accumulation of the product can inhibit the enzyme's activity. This can be viewed as an application of Le Chatelier's principle. An increase in the concentration of the product shifts the equilibrium of the enzyme-catalyzed reaction to the left, slowing down the forward reaction.
-
Driving Unfavorable Reactions: A thermodynamically unfavorable reaction (positive ΔG) can be driven forward by coupling it to a highly favorable reaction. This is often achieved by the immediate consumption of the product of the unfavorable reaction in a subsequent, highly exergonic step. By keeping the concentration of the product low, Le Chatelier's principle dictates that the equilibrium of the first reaction will shift to the right, favoring product formation. A classic example is the oxidation of malate to oxaloacetate in the Krebs cycle, which is driven forward by the rapid consumption of oxaloacetate in the subsequent reaction with acetyl-CoA.[4]
II. Data Presentation
The following tables provide quantitative data illustrating the principles discussed above.
Table 1: The Bicarbonate Buffer System's Response to Changes in Blood pH
| pH | Bicarbonate Ion (HCO₃⁻) Concentration (mmol/L) | Condition |
| 7.0 | 11 | Acidosis |
| 7.2 | 16 | Acidosis |
| 7.4 | 24 | Normal |
| 7.6 | 30 | Alkalosis |
| 7.8 | 38 | Alkalosis |
This data demonstrates that as the blood becomes more acidic (lower pH), the concentration of bicarbonate ion decreases as it is consumed to buffer the excess H⁺, shifting the equilibrium to the left. Conversely, in alkalosis, the bicarbonate concentration is higher.
Table 2: Effect of CO₂ Partial Pressure (pCO₂) on Hemoglobin's Oxygen Saturation
| Partial Pressure of O₂ (mmHg) | % Hemoglobin Saturation (pCO₂ = 20 mmHg) | % Hemoglobin Saturation (pCO₂ = 40 mmHg) | % Hemoglobin Saturation (pCO₂ = 80 mmHg) |
| 20 | 55% | 40% | 25% |
| 40 | 85% | 75% | 60% |
| 60 | 95% | 90% | 80% |
| 80 | 98% | 96% | 92% |
| 100 | 99% | 98% | 95% |
This table illustrates the Bohr effect. At any given partial pressure of oxygen, an increase in the partial pressure of carbon dioxide leads to a decrease in hemoglobin's oxygen saturation, indicating a rightward shift in the oxygen-hemoglobin dissociation curve and enhanced oxygen delivery to tissues.
III. Experimental Protocols
The following protocols describe experiments that can be used to demonstrate Le Chatelier's principle in a laboratory setting, with relevance to the concepts tested on the this compound.
A. Protocol 1: Demonstration of the Bicarbonate Buffer System
Objective: To visually demonstrate the buffering capacity of a bicarbonate solution compared to water.
Materials:
-
Sodium bicarbonate (NaHCO₃)
-
Distilled water
-
0.1 M Hydrochloric acid (HCl)
-
0.1 M Sodium hydroxide (NaOH)
-
Universal indicator solution or a pH meter
-
Beakers (250 mL)
-
Graduated cylinders
-
Pipettes or droppers
Procedure:
-
Prepare a bicarbonate buffer solution: Dissolve approximately 4.2 g of sodium bicarbonate in 500 mL of distilled water to create a 0.1 M solution.
-
Set up the experiment:
-
Label two 250 mL beakers as "Water" and "Buffer".
-
Add 100 mL of distilled water to the "Water" beaker.
-
Add 100 mL of the 0.1 M sodium bicarbonate solution to the "Buffer" beaker.
-
-
Add indicator: Add a few drops of universal indicator to each beaker and note the initial color and corresponding pH. Alternatively, measure the initial pH of each solution with a calibrated pH meter.
-
Stress the system with acid:
-
Add 1 mL of 0.1 M HCl to the "Water" beaker, stir, and observe the color change/measure the pH.
-
Add 1 mL of 0.1 M HCl to the "Buffer" beaker, stir, and observe the color change/measure the pH.
-
Continue adding HCl in 1 mL increments to both beakers, recording the observations after each addition, until a significant pH change is observed in the buffer solution.
-
-
Stress the system with base:
-
Repeat step 4 using 0.1 M NaOH instead of HCl with fresh solutions of water and buffer.
-
-
Analyze the results: Compare the change in pH of the water versus the bicarbonate buffer upon the addition of acid and base. The buffer solution will show a much smaller change in pH, demonstrating its ability to resist pH changes by shifting the equilibrium of the bicarbonate buffer system.
B. Protocol 2: Observing the Effect of Temperature on an Equilibrium
Objective: To demonstrate the effect of temperature on a reversible reaction, illustrating that heat can be treated as a reactant or product.
Materials:
-
Cobalt(II) chloride hexahydrate (CoCl₂·6H₂O)
-
Concentrated hydrochloric acid (HCl)
-
Distilled water
-
Test tubes
-
Beakers for hot and cold water baths
-
Hot plate
-
Ice
Procedure:
-
Establish the equilibrium:
-
Dissolve a small amount of CoCl₂·6H₂O in a test tube with a minimal amount of distilled water to form a pink solution. The pink color is due to the hydrated cobalt complex, [Co(H₂O)₆]²⁺.
-
Carefully add concentrated HCl dropwise until the solution turns a violet or blue color. This color is due to the formation of the tetrachlorocobaltate(II) complex, [CoCl₄]²⁻. The equilibrium established is: [Co(H₂O)₆]²⁺ (aq) + 4Cl⁻ (aq) ⇌ [CoCl₄]²⁻ (aq) + 6H₂O (l) (Pink)(Blue)
-
-
Stress the system with temperature changes:
-
Prepare a hot water bath by heating water in a beaker on a hot plate.
-
Prepare a cold water bath by mixing ice and water in a beaker.
-
Place the test tube containing the equilibrium mixture into the hot water bath. Observe and record any color change. A shift towards blue indicates the forward reaction is endothermic (heat is a reactant).
-
Move the test tube to the cold water bath. Observe and record any color change. A shift towards pink indicates the forward reaction is endothermic.
-
-
Analyze the results: Based on the color changes observed with heating and cooling, determine whether the forward reaction is endothermic or exothermic. This demonstrates that a change in temperature will shift the equilibrium to favor the endothermic or exothermic direction to counteract the temperature change.
IV. Mandatory Visualization
The following diagrams, created using the DOT language, illustrate key concepts related to the application of Le Chatelier's principle in this compound-relevant systems.
Caption: The Bicarbonate Buffer System Equilibrium.
Caption: Hemoglobin and Oxygen Transport Equilibrium Shifts.
Caption: Experimental Workflow for Bicarbonate Buffer Demonstration.
References
Application Notes and Protocols for Solving MCAT Electrochemistry Problems
For Researchers, Scientists, and Drug Development Professionals
This document provides a detailed guide to understanding and applying electrochemical concepts to solve problems typically encountered in the Medical College Admission Test (MCAT). A strong grasp of these principles is essential for comprehending various biological processes and the mechanisms of certain pharmaceuticals.
Fundamental Electrochemical Concepts
Electrochemistry explores the relationship between chemical energy and electrical energy through oxidation-reduction (redox) reactions. For the this compound, a key focus is the application of these principles in electrochemical cells.
1.1. Oxidation-Reduction (Redox) Reactions
Redox reactions involve the transfer of electrons from one species to another.
-
Oxidation: The loss of electrons, resulting in an increase in oxidation state.
-
Reduction: The gain of electrons, resulting in a decrease in oxidation state.
A helpful mnemonic to remember this is OIL RIG : O xidation I s L oss, R eduction I s G ain of electrons.[1][2]
1.2. Electrochemical Cells
Electrochemical cells are devices that convert chemical energy into electrical energy or vice versa.[3] They consist of two half-cells, each containing an electrode immersed in an electrolyte solution.[3][4]
Electrons always flow from the anode to the cathode.[4][5] A helpful mnemonic is AN OX (Anode Oxidation) and a RED CAT (Reduction at the Cathode).[2][5]
There are two main types of electrochemical cells: galvanic (voltaic) cells and electrolytic cells.
Galvanic (Voltaic) Cells
Galvanic cells, also known as voltaic cells, are electrochemical cells in which spontaneous redox reactions generate an electric current.[3][6] Think of them as batteries.
Key Characteristics:
-
Spontaneous Reaction: The overall redox reaction has a negative Gibbs Free Energy (ΔG < 0) and a positive electromotive force (EMF) or cell potential (E°cell > 0).[7]
-
Energy Conversion: They convert chemical energy into electrical energy.[3]
-
Anode and Cathode Charges: In a galvanic cell, the anode is negatively charged, and the cathode is positively charged.[3][8]
-
Salt Bridge: They require a salt bridge to maintain charge neutrality in the half-cells, allowing the reaction to continue.[4]
Experimental Protocol: Solving Galvanic Cell Problems
-
Identify the Half-Reactions: Determine the oxidation and reduction half-reactions. The species with the more positive standard reduction potential will be reduced at the cathode.
-
Determine the Anode and Cathode: The half-reaction with the lower reduction potential will be the site of oxidation (anode), and the one with the higher reduction potential will be the site of reduction (cathode).
-
Calculate the Standard Cell Potential (E°cell): E°cell = E°cathode - E°anode Note: Use the standard reduction potentials as given in the table. Do not flip the sign of the anode's potential.
-
Write the Overall Balanced Equation: Ensure the number of electrons lost in oxidation equals the number of electrons gained in reduction.
-
Determine the Direction of Electron Flow: Electrons flow from the anode to the cathode.
Electrolytic Cells
Electrolytic cells use an external power source to drive a non-spontaneous redox reaction.[1][8][9] This process is called electrolysis.
Key Characteristics:
-
Non-Spontaneous Reaction: The overall redox reaction has a positive Gibbs Free Energy (ΔG > 0) and a negative electromotive force (EMF) or cell potential (E°cell < 0).[5][7]
-
Energy Conversion: They convert electrical energy into chemical energy.[3]
-
Anode and Cathode Charges: In an electrolytic cell, the anode is positively charged, and the cathode is negatively charged.[8][9] This is the opposite of a galvanic cell.
-
External Power Source: An external voltage source (like a battery) is required to force the reaction to occur.[8][9]
Experimental Protocol: Solving Electrolytic Cell Problems
-
Identify the Components: Recognize the presence of an external power source, which indicates an electrolytic cell.
-
Determine the Anode and Cathode: The electrode connected to the positive terminal of the power source is the anode, and the electrode connected to the negative terminal is the cathode.
-
Identify the Half-Reactions: Determine the species that will be oxidized at the anode and reduced at the cathode based on the applied voltage.
-
Calculate the Minimum Voltage Required: The external voltage applied must be greater than the absolute value of the negative E°cell to drive the non-spontaneous reaction.
The Nernst Equation
The Nernst equation is used to calculate the cell potential (Ecell) under non-standard conditions (i.e., when the concentrations of reactants and products are not 1 M).[10][11]
Equation:
Ecell = E°cell - (RT/nF) * ln(Q)
Where:
-
E°cell: Standard cell potential
-
R: Gas constant (8.314 J/(mol·K))
-
T: Temperature in Kelvin
-
n: Number of moles of electrons transferred in the balanced redox reaction
-
F: Faraday's constant (approximately 96,500 C/mol e⁻)
-
Q: Reaction quotient, which is the ratio of the concentrations of products to reactants, raised to their stoichiometric coefficients.
A simplified version of the Nernst equation at standard temperature (298 K or 25°C) is:
Ecell = E°cell - (0.0592/n) * log(Q)[11]
Protocol for Applying the Nernst Equation
-
Determine the Standard Cell Potential (E°cell): Calculate this as you would for a standard cell.
-
Determine the Number of Electrons Transferred (n): Find the least common multiple of electrons in the balanced half-reactions.
-
Calculate the Reaction Quotient (Q): Use the given concentrations of the aqueous species. Remember that solids and liquids do not appear in the Q expression.
-
Substitute the Values into the Nernst Equation: Solve for the non-standard cell potential (Ecell).
Data Presentation: Standard Reduction Potentials
The following table summarizes the standard reduction potentials (E°) for common half-reactions at 25°C. A more positive E° indicates a greater tendency for the species to be reduced.
| Half-Reaction | Standard Reduction Potential (E°), Volts |
| F₂(g) + 2e⁻ → 2F⁻(aq) | +2.87 |
| Au³⁺(aq) + 3e⁻ → Au(s) | +1.50 |
| Cl₂(g) + 2e⁻ → 2Cl⁻(aq) | +1.36 |
| O₂(g) + 4H⁺(aq) + 4e⁻ → 2H₂O(l) | +1.23 |
| Br₂(l) + 2e⁻ → 2Br⁻(aq) | +1.07 |
| Ag⁺(aq) + e⁻ → Ag(s) | +0.80 |
| Fe³⁺(aq) + e⁻ → Fe²⁺(aq) | +0.77 |
| I₂(s) + 2e⁻ → 2I⁻(aq) | +0.54 |
| Cu²⁺(aq) + 2e⁻ → Cu(s) | +0.34 |
| 2H⁺(aq) + 2e⁻ → H₂(g) | 0.00 |
| Pb²⁺(aq) + 2e⁻ → Pb(s) | -0.13 |
| Sn²⁺(aq) + 2e⁻ → Sn(s) | -0.14 |
| Ni²⁺(aq) + 2e⁻ → Ni(s) | -0.25 |
| Co²⁺(aq) + 2e⁻ → Co(s) | -0.28 |
| Fe²⁺(aq) + 2e⁻ → Fe(s) | -0.44 |
| Zn²⁺(aq) + 2e⁻ → Zn(s) | -0.76 |
| 2H₂O(l) + 2e⁻ → H₂(g) + 2OH⁻(aq) | -0.83 |
| Al³⁺(aq) + 3e⁻ → Al(s) | -1.66 |
| Mg²⁺(aq) + 2e⁻ → Mg(s) | -2.37 |
| Na⁺(aq) + e⁻ → Na(s) | -2.71 |
| K⁺(aq) + e⁻ → K(s) | -2.93 |
| Li⁺(aq) + e⁻ → Li(s) | -3.05 |
Visualizations
Caption: Diagram of a Galvanic (Voltaic) Cell.
Caption: Diagram of an Electrolytic Cell.
Caption: Logical Workflow for Solving this compound Electrochemistry Problems.
References
- 1. blog.blueprintprep.com [blog.blueprintprep.com]
- 2. Electrochemistry for the this compound: Everything You Need to Know — Shemmassian Academic Consulting [shemmassianconsulting.com]
- 3. Galvanic Electrochemical Cells - Free Sketchy this compound Lesson [sketchy.com]
- 4. jackwestin.com [jackwestin.com]
- 5. This compound-review.org [this compound-review.org]
- 6. jackwestin.com [jackwestin.com]
- 7. m.youtube.com [m.youtube.com]
- 8. google.com [google.com]
- 9. jackwestin.com [jackwestin.com]
- 10. jackwestin.com [jackwestin.com]
- 11. blog.blueprintprep.com [blog.blueprintprep.com]
Applying Reaction Mechanisms in Organic Chemistry for the MCAT: A Guide for Scientists and Drug Development Professionals
Abstract: The Medical College Admission Test (MCAT) assesses a pre-medical student's grasp of foundational scientific concepts, with organic chemistry reaction mechanisms being a cornerstone of the Chemical and Physical Foundations of Biological Systems section. For researchers, scientists, and drug development professionals, understanding the this compound's perspective on these mechanisms can provide valuable insights into the fundamental principles that govern molecular transformations relevant to biological systems. This document provides detailed application notes on key reaction mechanisms, protocols for their analysis, and quantitative data for comparative purposes, all framed within the context of the this compound.
Application Notes: Core Reaction Mechanisms
A strong understanding of reaction mechanisms is more critical for the this compound than memorizing a vast number of specific reactions.[1] The focus is on applying fundamental principles to predict reaction outcomes. Key mechanisms frequently tested include substitution, elimination, addition, and reactions involving carbonyl groups.
Nucleophilic Substitution Reactions (SN1 and SN2)
Nucleophilic substitution is a high-yield topic on the this compound.[2] These reactions involve a nucleophile replacing a leaving group on an electrophilic carbon atom. The two main pathways are the SN1 and SN2 reactions.
-
SN1 (Substitution Nucleophilic Unimolecular): This is a two-step reaction. The first and rate-determining step is the formation of a carbocation intermediate after the leaving group departs. The second step is the rapid attack of the nucleophile on the carbocation.
-
Substrate: Favored by tertiary > secondary substrates due to the stability of the resulting carbocation.
-
Nucleophile: The concentration and strength of the nucleophile do not affect the reaction rate, so weak nucleophiles are common.
-
Solvent: Favored by polar protic solvents, which can stabilize the carbocation intermediate and the leaving group through hydrogen bonding.[3][4]
-
Stereochemistry: Results in a racemic mixture of products as the nucleophile can attack the planar carbocation from either side.
-
-
SN2 (Substitution Nucleophilic Bimolecular): This is a one-step reaction where the nucleophile attacks the electrophilic carbon at the same time as the leaving group departs. This is a concerted mechanism.
-
Substrate: Favored by methyl > primary > secondary substrates. Tertiary substrates do not undergo SN2 reactions due to steric hindrance.
-
Nucleophile: The rate is dependent on the concentration of both the substrate and the nucleophile, so strong, non-bulky nucleophiles are preferred.
-
Solvent: Favored by polar aprotic solvents, which solvate the cation but not the anion of the nucleophile, thus increasing its reactivity.
-
Stereochemistry: Results in an inversion of stereochemistry at the chiral center (Walden inversion).
-
Elimination Reactions (E1 and E2)
Elimination reactions involve the removal of two substituents from a molecule, typically resulting in the formation of a double bond.
-
E1 (Elimination Unimolecular): This is a two-step reaction that proceeds through a carbocation intermediate, similar to the SN1 reaction. It often competes with the SN1 mechanism.
-
Substrate: Favored by tertiary > secondary substrates.
-
Base: The rate is independent of the base concentration, so weak bases are sufficient.
-
Stereochemistry: Follows Zaitsev's rule, where the more substituted alkene is the major product.
-
-
E2 (Elimination Bimolecular): This is a one-step, concerted reaction where a strong base removes a proton, and the leaving group departs simultaneously to form a double bond.
-
Substrate: Favored by tertiary > secondary > primary substrates.
-
Base: Requires a strong, sterically hindered base.
-
Stereochemistry: Requires an anti-periplanar arrangement of the proton and the leaving group. The regioselectivity can be controlled by the choice of base (Zaitsev's rule with smaller bases, Hofmann's rule with bulky bases).
-
Addition Reactions
Addition reactions occur when two or more molecules combine to form a larger one. For the this compound, this often involves the addition to double and triple bonds.[5]
-
Electrophilic Addition to Alkenes: The pi bond of an alkene acts as a nucleophile, attacking an electrophile. This typically proceeds through a carbocation intermediate.
-
Markovnikov's Rule: In the addition of a protic acid (H-X) to an unsymmetrical alkene, the hydrogen atom attaches to the carbon with more hydrogen substituents, and the halide attaches to the more substituted carbon, proceeding through the more stable carbocation.
-
Anti-Markovnikov Addition: Occurs in the presence of peroxides for HBr addition, proceeding through a radical mechanism. Hydroboration-oxidation is another common anti-Markovnikov addition.[3]
-
Carbonyl Chemistry
Reactions involving the carbonyl group are a major focus. The carbonyl carbon is electrophilic due to the electronegativity of the oxygen atom.[4][6]
-
Nucleophilic Addition: Aldehydes and ketones undergo nucleophilic addition at the carbonyl carbon.[3] This can lead to the formation of hemiacetals, hemiketals, acetals, ketals, imines, and enamines.[3][7]
-
Enolate Chemistry: The alpha-protons of carbonyl compounds are acidic and can be removed by a base to form an enolate. Enolates are nucleophilic and are key intermediates in reactions like the aldol condensation.[2]
-
Redox Reactions: Aldehydes can be oxidized to carboxylic acids, while both aldehydes and ketones can be reduced to alcohols.[3][7] Primary alcohols can be oxidized to aldehydes or carboxylic acids, and secondary alcohols can be oxidized to ketones.[7]
Protocols for Reaction Mechanism Analysis
General Protocol for Predicting the Predominant Reaction Mechanism
This protocol outlines a systematic approach to determining the likely reaction pathway (SN1, SN2, E1, E2) for a given set of reactants and conditions.
-
Analyze the Substrate:
-
Determine if the carbon bearing the leaving group is primary, secondary, or tertiary.
-
Tertiary substrates favor SN1 and E1 (and E2 with a strong base).
-
Primary substrates favor SN2.
-
Secondary substrates can undergo all pathways, and the other conditions must be carefully considered.
-
-
Evaluate the Nucleophile/Base:
-
Categorize the reagent as a strong/weak nucleophile and a strong/weak base.
-
Strong nucleophiles (e.g., I-, Br-, RS-) favor SN2.
-
Strong, sterically hindered bases (e.g., t-BuOK) favor E2.
-
Weak nucleophiles/weak bases (e.g., H2O, ROH) favor SN1 and E1, especially with tertiary substrates.
-
-
Consider the Solvent:
-
Identify the solvent as polar protic (e.g., water, ethanol) or polar aprotic (e.g., acetone, DMSO).
-
Polar protic solvents stabilize carbocations and favor SN1/E1.
-
Polar aprotic solvents enhance the reactivity of nucleophiles and favor SN2.
-
-
Assess the Leaving Group:
-
Good leaving groups are weak bases (the conjugate bases of strong acids, e.g., I-, Br-, Cl-, OTs). A good leaving group is essential for both substitution and elimination reactions.
-
-
Synthesize the Information:
-
Combine the analyses from steps 1-4 to predict the major product and mechanism. For example, a tertiary substrate with a weak nucleophile in a polar protic solvent will predominantly undergo an SN1/E1 reaction.
-
Conceptual Experimental Protocol: Distinguishing SN1 from SN2
This protocol describes a conceptual experiment to determine whether a reaction proceeds via an SN1 or SN2 mechanism.
-
Hypothesis: The reaction of 2-bromobutane with sodium iodide proceeds via an SN2 mechanism, while the reaction with ethanol proceeds via an SN1 mechanism.
-
Experimental Design:
-
Reaction A (SN2): React (R)-2-bromobutane with a high concentration of sodium iodide in acetone (a polar aprotic solvent).
-
Reaction B (SN1): React (R)-2-bromobutane with ethanol (a weak nucleophile and polar protic solvent) at a low concentration.
-
-
Data Collection:
-
Kinetics: Measure the initial reaction rate for both reactions. For Reaction A, repeat the experiment with double the concentration of sodium iodide and, separately, double the concentration of (R)-2-bromobutane. For Reaction B, repeat the experiment with double the concentration of ethanol and, separately, double the concentration of (R)-2-bromobutane.
-
Stereochemistry: Analyze the stereochemical outcome of the products for both reactions using a polarimeter.
-
-
Expected Results and Interpretation:
-
Reaction A (SN2): The reaction rate should double when the concentration of either the substrate or the nucleophile is doubled, indicating a second-order rate law (rate = k[substrate][nucleophile]). The product should be exclusively (S)-2-iodobutane, showing a complete inversion of stereochemistry.
-
Reaction B (SN1): The reaction rate should double only when the concentration of the substrate is doubled and should be independent of the nucleophile concentration, indicating a first-order rate law (rate = k[substrate]). The product should be a racemic mixture of (R)- and (S)-2-ethoxybutane, showing loss of stereochemical information.
-
Quantitative Data Summary
| Feature | SN1 Reaction | SN2 Reaction | E1 Reaction | E2 Reaction |
| Substrate | 3° > 2° | Methyl > 1° > 2° | 3° > 2° | 3° > 2° > 1° |
| Rate Law | rate = k[Substrate] | rate = k[Substrate][Nuc] | rate = k[Substrate] | rate = k[Substrate][Base] |
| Nucleophile/Base | Weak Nucleophile | Strong Nucleophile | Weak Base | Strong Base |
| Solvent | Polar Protic | Polar Aprotic | Polar Protic | Varies |
| Stereochemistry | Racemization | Inversion | Zaitsev's Rule | Anti-periplanar |
| Leaving Group | Good | Good | Good | Good |
Visualizations
References
- 1. This compound Organic Chemistry Study Guide: Everything You Need to Ace the Exam | Sipath Blog [sipath.com]
- 2. blog.blueprintprep.com [blog.blueprintprep.com]
- 3. This compound Organic Chemistry - Chemistry Steps [chemistrysteps.com]
- 4. This compound Organic Chemistry: Everything You Need to Know — Shemmassian Academic Consulting [shemmassianconsulting.com]
- 5. jackwestin.com [jackwestin.com]
- 6. This compound Organic Chemistry Quiz – Kaplan Test Prep [kaptest.com]
- 7. This compound Organic Chemistry Mechanisms [this compound-prep.com]
Application Notes and Protocols for Compound Identification using Spectroscopy in MCAT Questions
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive overview and detailed protocols for utilizing Nuclear Magnetic Resonance (NMR) and Infrared (IR) spectroscopy to identify unknown organic compounds, with a specific focus on the types of molecules and data interpretation relevant to the Medical College Admission Test (MCAT).
Introduction
Spectroscopic techniques are fundamental analytical tools in chemistry, providing detailed information about molecular structure.[1][2] For the this compound, a foundational understanding of IR and ¹H NMR spectroscopy is crucial for elucidating the structures of organic molecules.[1][3][4] IR spectroscopy is primarily used to identify the functional groups present in a molecule by measuring the absorption of infrared light, which causes molecular vibrations.[4][5][6] NMR spectroscopy provides information about the carbon-hydrogen framework of a molecule by observing the behavior of atomic nuclei in a magnetic field.[3][7][8]
Data Presentation: Characteristic Spectroscopic Data
For efficient compound identification, a systematic comparison of experimental data with known characteristic values is essential. The following tables summarize the key quantitative data for IR and NMR spectroscopy frequently encountered in this compound-level organic chemistry.
Table 1: Infrared (IR) Spectroscopy - Characteristic Absorption Frequencies
| Functional Group | Bond | Characteristic Absorption (cm⁻¹) | Appearance of Peak |
| Alcohol/Phenol | O-H | 3200-3600 | Broad and strong[5] |
| Carboxylic Acid | O-H | 2500-3300 | Very broad and strong[5] |
| Amine | N-H | 3300-3500 | Medium (primary amines have two peaks) |
| Alkane | C-H | 2850-3000 | Strong and sharp[5] |
| Alkene | =C-H | 3000-3100 | Medium |
| Alkyne | ≡C-H | ~3300 | Sharp, strong |
| Aldehyde | (O=)C-H | 2700-2900 | Two weak to medium peaks |
| Carbonyl (C=O) | C=O | 1680-1750 | Sharp and strong[5][6] |
| - Ketone | ~1715 | ||
| - Aldehyde | ~1725[5] | ||
| - Carboxylic Acid | ~1700-1725[5] | ||
| - Ester | ~1735 | ||
| - Amide | ~1650-1690 | ||
| Alkene | C=C | 1600-1680 | Variable |
| Alkyne | C≡C | 2100-2260 | Variable |
| Nitrile | C≡N | 2220-2260 | Medium, sharp |
The region below 1500 cm⁻¹ is known as the fingerprint region and is unique for each compound, though it is less commonly used for functional group identification on the this compound.[5][6]
Table 2: ¹H Nuclear Magnetic Resonance (NMR) Spectroscopy - Approximate Chemical Shifts (δ)
| Type of Proton | Chemical Shift (ppm) | Notes |
| Alkyl (R-CH₃, R₂CH₂, R₃CH) | 0.9 - 1.8 | Shielded protons, appear "upfield"[8] |
| Alkyne (RC≡CH) | 2.0 - 3.0 | |
| Ketone (α-proton) | 2.0 - 2.5[8] | |
| Alcohol/Ether (α-proton) | 3.3 - 4.5 | Deshielded by electronegative oxygen |
| Alkene (vinylic) | 4.5 - 6.5 | Deshielded by the double bond's π electrons |
| Aromatic | 6.5 - 8.5[8] | Highly deshielded due to ring current |
| Aldehyde | 9.0 - 10.0[8] | Very deshielded |
| Carboxylic Acid | 10.0 - 13.0 | Most deshielded, often a broad singlet |
| Alcohol (O-H) | 2.0 - 5.0 (variable) | Position and appearance depend on concentration and solvent |
Key Concepts in ¹H NMR Interpretation:
-
Chemical Shift (δ): The position of a signal along the x-axis, indicating the electronic environment of the protons.[3][7]
-
Integration: The area under a signal is proportional to the number of equivalent protons giving rise to that signal.[3][7][8]
-
Splitting (Multiplicity): The splitting of a signal into multiple peaks (e.g., doublet, triplet) is caused by the influence of neighboring, non-equivalent protons. The number of peaks is given by the n+1 rule, where 'n' is the number of adjacent, non-equivalent protons.[3][8]
Experimental Protocols
Protocol 1: Identification of an Unknown Organic Compound
This protocol outlines a systematic approach to elucidating the structure of an unknown organic compound using a combination of IR and NMR spectroscopy.
1. Sample Preparation
-
For IR Spectroscopy:
-
Liquid Samples: A drop of the neat liquid is placed between two salt plates (e.g., NaCl or KBr).
-
Solid Samples: The solid is finely ground with KBr powder and pressed into a thin pellet, or dissolved in a suitable solvent (e.g., CCl₄) to be analyzed in a liquid cell.
-
-
For NMR Spectroscopy:
-
Approximately 5-10 mg of the sample is dissolved in 0.5-1.0 mL of a deuterated solvent (e.g., CDCl₃, D₂O, DMSO-d₆). The use of deuterated solvents prevents the solvent's proton signals from overwhelming the sample's signals.
-
A small amount of a reference standard, typically tetramethylsilane (TMS), is added to the solvent to provide a reference signal at 0 ppm.
-
2. Data Acquisition
-
IR Spectrum:
-
Record a background spectrum of the empty spectrometer.
-
Place the prepared sample in the spectrometer's sample holder.
-
Acquire the IR spectrum over the range of approximately 4000 cm⁻¹ to 400 cm⁻¹.
-
-
¹H NMR Spectrum:
-
Place the prepared NMR tube into the NMR spectrometer.
-
The instrument is tuned and shimmed to optimize the magnetic field homogeneity.
-
Acquire the ¹H NMR spectrum.
-
3. Spectral Analysis and Structure Elucidation
-
IR Spectrum Analysis:
-
¹H NMR Spectrum Analysis:
-
Number of Signals: Determine the number of distinct signals, which corresponds to the number of sets of non-equivalent protons.
-
Chemical Shift: Analyze the chemical shift of each signal to infer the electronic environment of the protons using Table 2.
-
Integration: Determine the relative ratio of protons for each signal from the integration curves.
-
Splitting Pattern: Analyze the multiplicity of each signal to determine the number of neighboring protons.
-
-
Structure Proposal and Verification:
-
Based on the functional groups identified from the IR spectrum and the structural fragments deduced from the ¹H NMR data, propose a plausible structure for the unknown compound.
-
Verify the proposed structure by ensuring it is consistent with all the spectroscopic data. For example, check if the predicted chemical shifts, integration, and splitting patterns for the proposed structure match the experimental NMR spectrum.
-
Mandatory Visualization
The following diagram illustrates the logical workflow for identifying an unknown compound using the combined spectroscopic approach.
Caption: Logical workflow for compound identification.
This structured approach, combining the functional group information from IR spectroscopy with the detailed connectivity data from NMR spectroscopy, provides a powerful methodology for the unambiguous identification of unknown organic compounds, a critical skill for success on the this compound and in scientific research.
References
- 1. ocw.mit.edu [ocw.mit.edu]
- 2. youtube.com [youtube.com]
- 3. pubs.acs.org [pubs.acs.org]
- 4. moorparkcollege.edu [moorparkcollege.edu]
- 5. chem.libretexts.org [chem.libretexts.org]
- 6. m.youtube.com [m.youtube.com]
- 7. pubs.acs.org [pubs.acs.org]
- 8. Organic Spectroscopy Laboratory: Utilizing IR and NMR in the Identification of an Unknown Substance - Dialnet [dialnet.unirioja.es]
Application of Laboratory Techniques in MCAT Chemistry Passages: Application Notes and Protocols
Introduction
The Medical College Admission Test (MCAT) frequently assesses a candidate's understanding of fundamental laboratory techniques within the context of complex chemistry and biochemistry passages. For professionals in research, science, and drug development, a sophisticated grasp of these methods is paramount. This document provides detailed application notes and protocols for key laboratory techniques commonly featured on the this compound, with a focus on their practical applications and the interpretation of experimental data.
Chromatography Techniques
Chromatography is a powerful set of laboratory techniques used to separate mixtures.[1][2] The separation is based on the differential partitioning of components between a mobile phase and a stationary phase.[2][3]
Thin-Layer Chromatography (TLC)
Application Notes: Thin-Layer Chromatography (TLC) is a rapid and inexpensive analytical technique used to monitor the progress of a reaction, identify compounds in a mixture, and determine the purity of a substance. In a drug development setting, TLC is often used for high-throughput screening of potential drug candidates or to quickly assess the success of a synthetic step. This compound passages may present a TLC plate and ask for the identification of a compound based on its retention factor (Rf) or relative polarity.[4] The stationary phase is typically a polar adsorbent like silica gel, and the mobile phase is a less polar organic solvent.[4] More polar compounds will have a stronger affinity for the stationary phase and will travel a shorter distance up the plate, resulting in a lower Rf value.[4]
Experimental Protocol:
-
Preparation of the TLC Plate: A small spot of the sample mixture is applied to the baseline of the TLC plate (a sheet of glass, plastic, or aluminum foil coated with a thin layer of adsorbent material).
-
Development of the Chromatogram: The bottom edge of the TLC plate is submerged in a developing chamber containing a shallow pool of a solvent (the mobile phase). The solvent is drawn up the plate via capillary action.[5]
-
Separation: As the solvent moves up the plate, it carries the sample mixture with it. The components of the mixture separate based on their differential affinities for the stationary and mobile phases.[2]
-
Visualization: After the solvent front has reached the top of the plate, the plate is removed and dried. The separated spots are visualized, often using a UV lamp if the compounds are UV-active, or by staining with an appropriate reagent.
-
Analysis: The retention factor (Rf) for each spot is calculated.
Data Presentation:
| Compound | Distance Traveled by Compound (cm) | Distance Traveled by Solvent Front (cm) | Retention Factor (Rf) | Relative Polarity |
| A | 2.5 | 10.0 | 0.25 | High |
| B | 5.0 | 10.0 | 0.50 | Medium |
| C | 7.5 | 10.0 | 0.75 | Low |
Rf = (Distance traveled by the compound) / (Distance traveled by the solvent front)[2]
Visualization:
Column Chromatography
Application Notes: Column chromatography is a purification technique used to separate individual chemical compounds from a mixture.[1] It is often used in drug synthesis to isolate the desired product from unreacted starting materials and byproducts. The principle is similar to TLC, but on a larger scale.[4] The stationary phase is packed into a vertical glass column, and the mobile phase is added to the top and flows down through the column.[2] Compounds with a lower affinity for the stationary phase will travel through the column more quickly and be collected first.
Experimental Protocol:
-
Column Packing: A glass column is packed with the stationary phase (e.g., silica gel or alumina) as a slurry with the mobile phase.[2]
-
Sample Loading: The mixture to be separated is carefully loaded onto the top of the stationary phase.[2]
-
Elution: The mobile phase (eluent) is passed through the column continuously.
-
Fraction Collection: As the separated components exit the bottom of the column, they are collected in a series of fractions.
-
Analysis: The composition of each fraction is typically analyzed by TLC to determine which fractions contain the desired compound in its pure form.
Visualization:
Spectroscopy Techniques
Spectroscopy is the study of the interaction between matter and electromagnetic radiation. It is a powerful tool for elucidating the structure of unknown compounds.
Infrared (IR) Spectroscopy
Application Notes: Infrared (IR) spectroscopy is used to identify the functional groups present in a molecule.[6] It works on the principle that covalent bonds vibrate at specific frequencies, and these frequencies are in the infrared region of the electromagnetic spectrum.[7] When a molecule is irradiated with infrared light, it will absorb the frequencies that correspond to its vibrational modes.[7] In an this compound passage, you may be given an IR spectrum and asked to identify a molecule based on the presence or absence of key absorption bands.
Experimental Protocol:
-
Sample Preparation: The sample (neat liquid, solid mulled in Nujol, or solid pressed into a KBr pellet) is placed in the sample holder of an IR spectrometer.
-
Data Acquisition: A beam of infrared light is passed through the sample. A detector measures the amount of light that is transmitted at each frequency.
-
Spectrum Generation: The data is plotted as percent transmittance versus wavenumber (cm⁻¹).[7] Absorptions are represented as downward peaks.[7]
Data Presentation:
| Functional Group | Bond | Characteristic Absorption (cm⁻¹) |
| Alcohol/Phenol | O-H | 3200-3600 (broad) |
| Carboxylic Acid | O-H | 2500-3300 (very broad) |
| Amine | N-H | 3300-3500 (sharp) |
| Alkane | C-H | 2850-3000 |
| Alkyne (terminal) | C-H | ~3300 |
| Carbonyl | C=O | 1680-1750 (sharp) |
| Alkene | C=C | 1600-1680 |
| Alkyne | C≡C | 2100-2260 |
Visualization:
Nuclear Magnetic Resonance (NMR) Spectroscopy
Application Notes: Nuclear Magnetic Resonance (NMR) spectroscopy is an analytical technique used to determine the carbon-hydrogen framework of an organic molecule.[6] It is based on the principle that certain atomic nuclei with a property called "spin" will align with an applied magnetic field. When these nuclei are irradiated with radio waves, they can absorb energy and "flip" to a higher energy spin state. The precise frequency required for this transition is influenced by the local electronic environment of the nucleus. An NMR spectrum provides information about the number of different types of protons (or carbons), their chemical environment, and how they are connected to each other.
Experimental Protocol:
-
Sample Preparation: A small amount of the sample is dissolved in a deuterated solvent (to avoid signals from the solvent) and placed in a thin glass tube.
-
Data Acquisition: The sample tube is placed inside a powerful magnet. The sample is irradiated with a pulse of radiofrequency energy.
-
Signal Detection: As the nuclei relax back to their lower energy state, they emit a signal that is detected and recorded.
-
Spectrum Generation: A Fourier transform is applied to the raw data to generate the NMR spectrum, which plots signal intensity versus chemical shift (in ppm).
Data Presentation:
| Type of Proton | Approximate Chemical Shift (δ, ppm) |
| Alkyl (R-CH₃, R₂-CH₂, R₃-CH) | 0.9 - 1.7 |
| Alkyne (R-C≡C-H) | 2.0 - 3.0 |
| Alkene (C=C-H) | 4.5 - 6.0 |
| Aromatic (Ar-H) | 6.5 - 8.0 |
| Aldehyde (R-CHO) | 9.0 - 10.0 |
| Carboxylic Acid (R-COOH) | 10.0 - 13.0 |
| Alcohol (R-OH) | 1.0 - 5.0 (variable) |
Visualization:
Separation and Purification Techniques
Distillation
Application Notes: Distillation is a technique used to separate components of a liquid mixture based on differences in their boiling points.[8][9] It is widely used in the chemical industry for purifying solvents and separating reaction products.
-
Simple Distillation: Used to separate liquids with significantly different boiling points (typically >25 °C difference).[4][9]
-
Fractional Distillation: Used to separate liquids with closer boiling points. A fractionating column provides a large surface area for repeated vaporization and condensation cycles, leading to a better separation.[4][9]
-
Vacuum Distillation: Used for compounds with very high boiling points that might decompose at atmospheric pressure. Lowering the pressure reduces the boiling point.[8]
Experimental Protocol (Simple Distillation):
-
Apparatus Setup: A distillation flask containing the liquid mixture, a condenser, and a receiving flask are assembled. A heat source is placed under the distillation flask.
-
Heating: The mixture is heated to its boiling point. The component with the lower boiling point will vaporize first.[9]
-
Condensation: The vapor travels into the condenser, where it is cooled by circulating water and condenses back into a liquid.
-
Collection: The purified liquid (distillate) is collected in the receiving flask.[9]
Visualization:
Extraction
Application Notes: Liquid-liquid extraction is a technique used to separate compounds based on their differential solubilities in two immiscible liquids, typically an aqueous phase and an organic phase.[4] This method is fundamental in work-up procedures following chemical reactions to isolate the product of interest. By manipulating the pH of the aqueous layer, acidic or basic compounds can be converted into their ionic (water-soluble) forms and thus separated from neutral organic compounds.
Experimental Protocol:
-
Combine Solvents: The mixture to be separated is dissolved in an appropriate solvent, and this solution is added to a separatory funnel along with an immiscible solvent.[4]
-
Mixing: The funnel is stoppered and shaken to allow for the transfer of the solute from one solvent to the other. The funnel is vented periodically to release pressure.
-
Separation of Layers: The funnel is allowed to stand until the two liquid layers have completely separated.
-
Draining: The lower layer is drained through the stopcock at the bottom of the funnel. The upper layer can then be drained or poured out from the top.
Visualization:
Electrophoresis and Blotting Techniques
These techniques are crucial for the separation and identification of macromolecules like proteins and nucleic acids.
Gel Electrophoresis and Western Blotting
Application Notes: Gel electrophoresis separates macromolecules based on size and/or charge.[10] For proteins, SDS-PAGE (sodium dodecyl sulfate-polyacrylamide gel electrophoresis) is commonly used. SDS denatures the proteins and coats them with a uniform negative charge, so separation is based almost exclusively on size.[11]
Western blotting is a technique used to detect a specific protein in a sample.[12] After separating proteins by SDS-PAGE, they are transferred to a membrane, which is then probed with an antibody specific to the protein of interest.[13] This is a highly specific and sensitive method used extensively in diagnostics and molecular biology research.
Experimental Protocol (Western Blot):
-
SDS-PAGE: Protein samples are loaded into a polyacrylamide gel and separated by size using an electric field.[13]
-
Transfer (Blotting): The separated proteins are transferred from the gel to a nitrocellulose or PVDF membrane.[13]
-
Blocking: The membrane is incubated with a blocking solution (e.g., milk or bovine serum albumin) to prevent non-specific binding of antibodies.[12]
-
Primary Antibody Incubation: The membrane is incubated with a primary antibody that specifically binds to the protein of interest.
-
Secondary Antibody Incubation: The membrane is washed and then incubated with a secondary antibody that is conjugated to an enzyme (e.g., horseradish peroxidase). This secondary antibody binds to the primary antibody.
-
Detection: A substrate is added that reacts with the enzyme on the secondary antibody to produce a detectable signal (e.g., chemiluminescence or color).
Visualization:
References
- 1. Chromatography - Free Sketchy this compound Lesson [sketchy.com]
- 2. jackwestin.com [jackwestin.com]
- 3. blog.blueprintprep.com [blog.blueprintprep.com]
- 4. blog.blueprintprep.com [blog.blueprintprep.com]
- 5. google.com [google.com]
- 6. Spectroscopy on the this compoundï½Key Info & Sample Questions [inspiraadvantage.com]
- 7. Spectroscopy for the this compound: Everything You Need to Know — Shemmassian Academic Consulting [shemmassianconsulting.com]
- 8. This compound-review.org [this compound-review.org]
- 9. jackwestin.com [jackwestin.com]
- 10. Biochemistry Lab Techniques for the this compound: Everything You Need to Know — Shemmassian Academic Consulting [shemmassianconsulting.com]
- 11. m.youtube.com [m.youtube.com]
- 12. jackwestin.com [jackwestin.com]
- 13. jackwestin.com [jackwestin.com]
Application Notes and Protocols for Analyzing and Interpreting Experimental Data in MCAT Chemistry
Audience: Researchers, scientists, and drug development professionals.
Objective: This document provides a detailed guide on how to analyze and interpret experimental data commonly encountered in the MCAT chemistry section. It includes structured data presentation, detailed experimental protocols, and logical workflow diagrams to facilitate understanding and application.
Acid-Base Titration: Determining Analyte Concentration
Application Note:
Acid-base titrations are a fundamental quantitative analysis technique used to determine the concentration of an unknown acidic or basic solution (the analyte) by reacting it with a solution of known concentration (the titrant). The reaction is monitored, typically by a pH meter or a colorimetric indicator, to identify the equivalence point, where the moles of titrant added are stoichiometrically equal to the moles of the initial analyte. The data from a titration experiment, when plotted as a titration curve (pH vs. volume of titrant added), provides critical information about the analyte, including its concentration and whether it is a strong or weak acid/base.
A key feature of a titration curve is the equivalence point, which is the steepest point of the curve. For the titration of a strong acid with a strong base, the equivalence point is at pH 7. For weak acid/strong base or weak base/strong acid titrations, the equivalence point is above or below pH 7, respectively. Another important feature for weak acid/base titrations is the half-equivalence point, where the pH equals the pKa of the weak acid or the pOH equals the pKb of the weak base.[1]
Experimental Protocol: Potentiometric Titration of a Weak Acid
-
Preparation:
-
Rinse a burette with a small amount of the standard titrant solution (e.g., 0.1 M NaOH).
-
Fill the burette with the titrant, ensuring no air bubbles are present in the tip. Record the initial volume.
-
Pipette a known volume (e.g., 25.0 mL) of the weak acid solution (the analyte) into a beaker.
-
Add a few drops of a suitable indicator (e.g., phenolphthalein) or place a calibrated pH electrode in the beaker.
-
-
Titration:
-
Place the beaker on a magnetic stirrer and begin gentle stirring.
-
Slowly add the titrant from the burette to the analyte solution in small increments (e.g., 1.0 mL).
-
After each addition, record the total volume of titrant added and the corresponding pH of the solution.
-
As the pH begins to change more rapidly, reduce the volume of the titrant increments (e.g., 0.1 mL) to accurately determine the equivalence point.
-
-
Data Analysis:
-
Continue adding titrant until the pH of the solution plateaus well past the equivalence point.
-
Plot the recorded pH values (y-axis) against the volume of titrant added (x-axis) to generate a titration curve.
-
Identify the equivalence point (the point of inflection) and the half-equivalence point from the graph.
-
Use the volume of titrant at the equivalence point to calculate the concentration of the analyte using the formula: M₁V₁ = M₂V₂, where M₁ and V₁ are the molarity and volume of the analyte, and M₂ and V₂ are the molarity and volume of the titrant.
-
Data Presentation:
Table 1: Titration of 25.0 mL of Acetic Acid (CH₃COOH) with 0.10 M Sodium Hydroxide (NaOH)
| Volume of NaOH Added (mL) | Measured pH |
| 0.0 | 2.87 |
| 5.0 | 4.14 |
| 10.0 | 4.57 |
| 12.5 (Half-Equivalence) | 4.74 (pKa) |
| 20.0 | 5.35 |
| 24.0 | 6.12 |
| 25.0 (Equivalence Point) | 8.72 |
| 26.0 | 11.29 |
| 30.0 | 11.96 |
Logical Workflow:
Caption: Workflow for performing and analyzing an acid-base titration.
Thin-Layer Chromatography (TLC): Separation and Identification of Compounds
Application Note:
Thin-Layer Chromatography (TLC) is a rapid and efficient separation technique used to separate components of a mixture based on their differential partitioning between a stationary phase and a mobile phase.[2] The stationary phase is typically a polar adsorbent like silica gel coated on a plate. The mobile phase, a solvent or solvent mixture, moves up the plate by capillary action. Nonpolar compounds, having weaker interactions with the polar stationary phase, travel further up the plate with the nonpolar mobile phase, resulting in a higher Retention Factor (Rf) value. Conversely, polar compounds interact more strongly with the stationary phase and have lower Rf values.[2] The Rf value is a characteristic property of a compound under specific conditions (stationary phase, mobile phase, temperature) and is calculated as the ratio of the distance traveled by the spot to the distance traveled by the solvent front.
Experimental Protocol: Separation of Analgesics by TLC
-
Preparation:
-
Obtain a TLC plate (e.g., silica gel on aluminum backing). Handle the plate by the edges to avoid contamination.
-
Using a pencil, gently draw a faint origin line about 1 cm from the bottom of the plate.
-
Prepare dilute solutions of the analgesic standards (e.g., aspirin, acetaminophen, caffeine) and the unknown mixture in a suitable solvent (e.g., ethyl acetate).
-
-
Spotting:
-
Using separate capillary tubes, spot small amounts of each standard and the unknown mixture onto the origin line, keeping the spots small and well-separated.
-
-
Development:
-
Pour a small amount of the developing solvent (mobile phase, e.g., a 95:5 mixture of ethyl acetate to acetic acid) into a developing chamber (a beaker with a watch glass cover).
-
Place the spotted TLC plate into the chamber, ensuring the origin line is above the solvent level.
-
Cover the chamber and allow the solvent to ascend the plate until it is about 1 cm from the top.
-
-
Visualization and Analysis:
-
Remove the plate from the chamber and immediately mark the solvent front with a pencil.
-
Allow the plate to dry.
-
Visualize the spots under a UV lamp and circle them with a pencil.
-
Measure the distance from the origin to the center of each spot and the distance from the origin to the solvent front.
-
Calculate the Rf value for each spot.
-
Identify the components of the unknown mixture by comparing their Rf values to those of the standards.
-
Data Presentation:
Table 2: Rf Values of Analgesic Compounds
| Compound | Distance Traveled by Spot (cm) | Distance Traveled by Solvent Front (cm) | Retention Factor (Rf) |
| Acetaminophen | 2.5 | 8.0 | 0.31 |
| Aspirin | 4.8 | 8.0 | 0.60 |
| Caffeine | 1.2 | 8.0 | 0.15 |
| Unknown Spot 1 | 2.5 | 8.0 | 0.31 |
| Unknown Spot 2 | 1.2 | 8.0 | 0.15 |
Experimental Workflow:
Caption: Step-by-step workflow for Thin-Layer Chromatography.
UV-Visible Spectroscopy: Quantifying Solute Concentration
Application Note:
UV-Visible spectroscopy is an analytical technique that measures the absorption of ultraviolet or visible light by a substance in solution. The amount of light absorbed is directly proportional to the concentration of the absorbing species, a relationship described by the Beer-Lambert Law (A = εbc), where A is absorbance, ε is the molar absorptivity (a constant for a given substance at a specific wavelength), b is the path length of the cuvette, and c is the concentration of the solution. By measuring the absorbance of a series of solutions with known concentrations, a calibration curve can be generated. The concentration of an unknown sample can then be determined by measuring its absorbance and interpolating from the calibration curve.
Experimental Protocol: Determining the Concentration of an Unknown KMnO₄ Solution
-
Preparation of Standards:
-
Prepare a stock solution of potassium permanganate (KMnO₄) of a known concentration (e.g., 0.01 M).
-
Perform a series of serial dilutions to prepare at least four standard solutions of lower, known concentrations.
-
-
Spectrophotometer Setup:
-
Turn on the UV-Vis spectrophotometer and allow it to warm up.
-
Set the wavelength to the λ_max (wavelength of maximum absorbance) for KMnO₄ (approximately 525 nm).
-
-
Calibration:
-
Fill a cuvette with the blank solution (the solvent used to prepare the standards, e.g., deionized water).
-
Place the cuvette in the spectrophotometer and zero the absorbance.
-
-
Measurement:
-
Measure the absorbance of each of the standard solutions, rinsing the cuvette with the next standard before filling.
-
Measure the absorbance of the unknown KMnO₄ solution.
-
-
Data Analysis:
-
Record the absorbance for each standard solution.
-
Plot a calibration curve of Absorbance (y-axis) vs. Concentration (x-axis).
-
Perform a linear regression to obtain the equation of the line (y = mx + b) and the R² value.
-
Use the absorbance of the unknown solution and the equation of the line to calculate its concentration.
-
Data Presentation:
Table 3: Calibration Data for KMnO₄ at 525 nm
| Concentration (M) | Absorbance |
| 0.0001 | 0.245 |
| 0.0002 | 0.491 |
| 0.0003 | 0.734 |
| 0.0004 | 0.980 |
| Unknown | 0.612 |
Linear Regression: y = 2455.5x + 0.0001; R² = 0.9999 Calculated Unknown Concentration: 0.00025 M
Signaling Pathway (Logical Flow):
Caption: Logical flow for concentration determination via UV-Vis Spectroscopy.
References
Troubleshooting & Optimization
common mistakes in MCAT general chemistry and how to avoid them
MCAT General Chemistry Troubleshooting Center
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals avoid common pitfalls in this compound General Chemistry. The content is designed to address specific issues encountered during problem-solving and experimental data interpretation.
Frequently Asked Questions (FAQs)
Q1: What is the most common reason for incorrect answers in the this compound General Chemistry section?
Q2: Are calculation errors a major concern, and if so, in which areas?
Yes, calculation errors are a prevalent issue. They are most common in topics requiring multi-step calculations, such as stoichiometry, acid-base chemistry (especially pH and buffer calculations), and thermodynamics. Specific mathematical mistakes include improper handling of scientific notation, incorrect unit conversions, and rounding numbers too early in the calculation process.[3][4][5]
Q3: How important is it to memorize the properties of all twenty amino acids for the general chemistry section?
Extremely important. While it may seem like a biochemistry topic, questions related to the acidic and basic properties of amino acids, their structures, and their functional groups are frequently tested in the general chemistry section.[1] You should be able to draw the structures and know the one- and three-letter codes, as well as the chemical properties of the side chains.
Q4: Is it more effective to do more practice problems or to thoroughly review a smaller number?
Thoroughly reviewing a smaller number of practice problems is generally more effective than simply completing a large volume of questions. The key to improvement is to understand the reasoning behind both correct and incorrect answers. For every question you get wrong, you should be able to explain why the correct answer is right and why your chosen answer was wrong.[1]
Troubleshooting Guides
This section provides detailed guides to troubleshoot common errors in key this compound General Chemistry topics.
Topic: Acid-Base Chemistry
Issue: Consistently miscalculating pH or misinterpreting acid/base strength.
Troubleshooting Protocol:
-
Verify the pH Scale Assumption: A common myth is that the pH scale is strictly from 0 to 14. For highly concentrated strong acid or base solutions, the pH can be negative or greater than 14, respectively.[1]
-
Correctly Apply the K_a and K_b Relationship: The relationship K_w = K_a * K_b only applies to a conjugate acid-base pair. A frequent mistake is to apply it to the same species (e.g., K_a of H₂PO₄⁻ and K_b of H₂PO₄⁻). The correct relationship is K_a(H₂PO₄⁻) * K_b(HPO₄²⁻) = K_w.[1]
-
Refine Understanding of Conjugate Strengths: Avoid the oversimplification that "strong acids have weak conjugate bases and weak acids have strong conjugate bases." A more accurate understanding is that stronger acids have weaker conjugate bases. Weak acids have weak conjugate bases, and strong acids have inert conjugate bases.[2]
-
Account for Temperature Effects on Neutrality: The pH of a neutral solution is 7 only at 25°C. At higher temperatures, the autoionization of water increases, leading to a K_w greater than 10⁻¹⁴ and a neutral pH below 7.[1]
Topic: Thermodynamics
Issue: Confusion with sign conventions and the concept of spontaneity.
Troubleshooting Protocol:
-
Clarify the First Law of Thermodynamics Sign Convention: The this compound typically uses the convention ΔU = Q - W, where W is the work done by the system on the surroundings. Be consistent with this convention. Work done on the system is negative, and work done by the system is positive.[6]
-
Distinguish Spontaneity from Reaction Rate: A negative Gibbs Free Energy (ΔG) indicates a spontaneous reaction, but it provides no information about the rate of the reaction. Do not assume that a spontaneous reaction is a fast reaction.[7]
-
Deepen Understanding of Entropy (ΔS): While entropy can be thought of as a measure of disorder, a more precise definition is the measure of the dispersion of energy. Reactions that increase the number of moles of gas or involve a phase change from solid to liquid or liquid to gas generally have a positive ΔS.[7]
Topic: Electrochemistry
Issue: Difficulty identifying anode/cathode and calculating cell potential.
Troubleshooting Protocol:
-
Systematically Identify Anode and Cathode: Remember the mnemonic "AN OX, RED CAT." Oxidation occurs at the Anode, and Reduction occurs at the Cathode. Electrons always flow from the anode to the cathode.[8][9]
-
Determine the Direction of Electron Flow: In a galvanic (voltaic) cell, the spontaneous reaction drives electron flow. In an electrolytic cell, an external power source forces electrons to flow in the non-spontaneous direction.[9]
-
Calculate Cell Potential (E_cell) Correctly: E°_cell = E°_reduction (cathode) - E°_reduction (anode). A common mistake is to change the sign of the anode's reduction potential and add it. Using the subtraction formula with both potentials as reduction potentials is a more reliable method. A positive E°_cell indicates a spontaneous reaction (galvanic cell), while a negative E°_cell indicates a non-spontaneous reaction (electrolytic cell).[8][10]
Quantitative Data Summary
The following table summarizes common quantitative mistakes made in this compound General Chemistry, their underlying causes, and recommended avoidance strategies.
| Error Type | Common Cause | Avoidance Strategy |
| Scientific Notation Errors | Incorrectly adding exponents when multiplying or dividing numbers in scientific notation. | Multiply the base numbers first, then add the exponents for multiplication or subtract them for division.[3] |
| Unit Conversion Mistakes | Forgetting to convert units to a consistent system (e.g., Joules vs. kilojoules, liters vs. milliliters). | Always write out units for all values and use dimensional analysis to ensure they cancel correctly.[3][5] |
| Rounding Errors | Rounding intermediate calculation steps too early. | Keep at least two to three significant figures throughout the calculation and only round the final answer.[3] |
| Logarithm Approximations | Difficulty estimating logarithms for pH and pKa calculations without a calculator. | Memorize and practice the approximation rule: If [H⁺] = a x 10⁻ᵇ, then pH ≈ b - 0.a. For example, if [H⁺] = 3 x 10⁻⁵, pH ≈ 5 - 0.3 = 4.7.[3] |
Experimental Protocols
This section provides detailed methodologies for approaching complex problems, treating the problem-solving process as a structured experiment.
Protocol 1: Stoichiometry Problem Solving
Objective: To accurately determine the limiting reactant and theoretical yield in a chemical reaction.
Methodology:
-
Balance the Chemical Equation: Ensure the law of conservation of mass is obeyed by having an equal number of atoms of each element on both the reactant and product sides of the equation.[11]
-
Convert Given Masses to Moles: Use the molar mass of each reactant to convert the given mass in grams to moles.
-
Determine the Limiting Reactant:
-
For each reactant, divide the number of moles by its stoichiometric coefficient from the balanced equation.
-
The reactant with the smallest resulting value is the limiting reactant.
-
-
Calculate the Theoretical Yield of the Product:
-
Use the number of moles of the limiting reactant.
-
Apply the mole ratio from the balanced equation between the limiting reactant and the desired product to find the moles of the product that can be formed.
-
Convert the moles of the product to grams using its molar mass. This is the theoretical yield.
-
-
Calculate Percent Yield (if required):
-
Percent Yield = (Actual Yield / Theoretical Yield) * 100%.
-
Protocol 2: Acid-Base Titration Analysis
Objective: To correctly interpret a titration curve and determine the pKa of a weak acid.
Methodology:
-
Identify the Key Points on the Titration Curve:
-
Starting Point: The initial pH of the analyte.
-
Half-Equivalence Point: The point where half of the analyte has been neutralized by the titrant.
-
Equivalence Point: The point where the moles of titrant added are equal to the initial moles of the analyte.
-
Buffer Region: The relatively flat region of the curve around the half-equivalence point.
-
-
Determine the pKa:
-
At the half-equivalence point, the concentrations of the weak acid and its conjugate base are equal.
-
According to the Henderson-Hasselbalch equation (pH = pKa + log([A⁻]/[HA])), when [A⁻] = [HA], the log term is zero, and pH = pKa.
-
Therefore, the pH at the half-equivalence point is equal to the pKa of the weak acid.
-
-
Analyze the Equivalence Point:
-
For a strong acid-strong base titration, the equivalence point is at pH 7.
-
For a weak acid-strong base titration, the equivalence point is at a pH > 7 due to the presence of the conjugate base.
-
For a strong acid-weak base titration, the equivalence point is at a pH < 7 due to the presence of the conjugate acid.
-
Visualizations
The following diagrams illustrate key logical workflows for avoiding common errors in this compound General Chemistry.
Caption: A stepwise workflow for solving stoichiometry problems.
References
- 1. blog.blueprintprep.com [blog.blueprintprep.com]
- 2. Reddit - The heart of the internet [reddit.com]
- 3. blog.blueprintprep.com [blog.blueprintprep.com]
- 4. reddit.com [reddit.com]
- 5. transformationtutoring.com [transformationtutoring.com]
- 6. reddit.com [reddit.com]
- 7. magoosh.com [magoosh.com]
- 8. Electrochemistry for the this compound: Everything You Need to Know — Shemmassian Academic Consulting [shemmassianconsulting.com]
- 9. This compound-review.org [this compound-review.org]
- 10. m.youtube.com [m.youtube.com]
- 11. m.youtube.com [m.youtube.com]
strategies for improving speed and accuracy on MCAT chemistry questions
MCAT Chemical & Physical Foundations: Performance Optimization Center
Welcome to the Technical Support Center for the this compound's Chemical and Physical Foundations of Biological Systems section. This guide is designed for researchers and scientists preparing for this critical examination. Here, we treat the this compound not as a test of memorization, but as a complex experimental system. Your performance is a function of key variables: processing speed (timing) and output purity (accuracy). This document provides troubleshooting guides and standard operating procedures (SOPs) to optimize these variables.
Frequently Asked Questions (FAQs)
This section addresses common error states and performance bottlenecks encountered during MC-AT system analysis.
Q1: System Throughput Error - My processing rate for passage-based questions is slow, leading to incomplete experiments (running out of time). What is the protocol for optimizing throughput?
A: This is a common bottleneck. The primary cause is often an inefficient data intake protocol. Instead of a linear read-through, we recommend a tiered approach. First, quickly scan the passage to identify the main subject—is it about thermodynamics, acid-base chemistry, or reaction kinetics? Briefly examine figures, noting only the axes and general trends. Read the first question before deeply analyzing the passage. This primes your analytical framework to search for specific, relevant data points, increasing both speed and efficiency. Many questions may be answerable from your foundational knowledge with only a quick reference to the passage, saving valuable time.[1][2]
Q2: Reagent Identification Failure - I frequently misidentify reactants and functional groups in organic chemistry problems, leading to incorrect reaction pathway predictions. What is the SOP for rapid and accurate identification?
A: This error stems from a failure in pattern recognition. Do not attempt to memorize every reaction. Instead, focus on understanding the fundamental principles of reaction mechanisms, such as nucleophilic attack, electrophilic substitution, and leaving group stability.[3][4][5] A recommended SOP involves:
-
Identify Functional Groups: Immediately classify the primary functional groups of the reactants (e.g., alcohol, ketone, carboxylic acid).[3][4]
-
Characterize Reagents: Determine if the other reagents are nucleophiles, electrophiles, acids, bases, oxidizing agents, or reducing agents.
-
Predict Reactivity: Based on electron density (rich vs. poor), predict the most likely site of interaction. For example, a nucleophile will attack an electrophilic carbonyl carbon.[5] This systematic approach is more reliable than rote memorization.
Q3: Calibration Error - My calculations in general chemistry problems (e.g., stoichiometry, titrations) are consistently inaccurate. How can I improve precision?
A: This indicates a procedural flaw. The key is rigorous adherence to the "Dimensional Analysis Calibration" protocol (see SOP-03 below). Before performing any calculation, write out the entire equation with all units. Ensure units cancel appropriately to yield the desired output unit. This methodical process catches most setup errors. Also, become proficient in scientific notation and estimation to quickly verify if a calculated answer is reasonable without a calculator. Many incorrect answer choices are off by an order of magnitude, making estimation a powerful tool for elimination.
Quantitative Analysis & Performance Metrics
To effectively allocate resources, it is crucial to understand the distribution of topics within the Chemical and Physical Foundations of Biological Systems section. The following table summarizes the approximate content distribution as specified by the AAMC.
| Discipline | Approximate Percentage of Section | Key High-Yield Topics |
| General Chemistry | 30% | Acids and Bases, Equilibrium (Keq, Le Chatelier's), Thermochemistry (Enthalpy, Entropy, Gibbs Free Energy), Electrochemistry, Kinetics.[6] |
| First-Semester Biochemistry | 25% | Amino Acids & Protein Structure, Enzyme Kinetics, Metabolism (Glycolysis, etc.).[6] |
| Introductory Physics | 25% | Kinematics, Fluids, Circuits, Light and Optics, Sound. |
| Organic Chemistry | 15% | Functional Groups, Reaction Mechanisms (SN1/SN2), Stereochemistry, Spectroscopy (NMR, IR).[3][6] |
| Introductory Biology | 5% | Primarily molecular and cellular biology relevant to biochemistry.[6] |
| Table 1: Distribution of Foundational Concepts in the Chem/Phys Section.[6] |
Standard Operating Procedures (SOPs) & Experimental Protocols
Follow these validated protocols to enhance performance and minimize systemic error.
SOP-01: The Passage-Based Problem Deconstruction Protocol
-
Initial Skim (30 seconds): Read the passage quickly to identify the core scientific subject. Do not get bogged down in details.
-
Analyze Figures (15-20 seconds per figure): Examine graphs, tables, and diagrams. Read the title, axes, and legend. Identify the independent and dependent variables and note any obvious trends or relationships. Do not attempt a deep interpretation yet.[7]
-
Address the First Question: Read the first question associated with the passage. Identify the specific information it requires.
-
Targeted Data Extraction: Return to the passage or figures with a clear objective. Scan for the specific keywords, data, or concepts needed to answer the question. This transforms reading from a passive act to an active search.[8]
-
Iterate: Repeat steps 3 and 4 for each subsequent question. Many questions can be treated as "pseudo-discrete," requiring minimal passage information once the overall context is understood.
SOP-02: The Discrete Question Triage Algorithm
-
Initial Assessment (5 seconds): Upon reading a discrete (non-passage) question, immediately classify it by topic (e.g., "This is an acid-base buffer question").
-
Knowledge Retrieval: Access the relevant foundational knowledge. If it involves a formula, write it down immediately.
-
Execute or Flag:
-
If the solution pathway is clear and can be executed in under 60-90 seconds, proceed.
-
If the pathway is unclear or you recognize it as a known area of weakness, make an educated guess, flag the question, and move on. Do not allow a single difficult question to consume disproportionate time.[9]
-
-
Review Phase: If time permits at the end of the section, return only to flagged questions.
SOP-03: "Dimensional Analysis Calibration" for Quantitative Problems
-
Identify the Target: Determine the final unit required for the answer (e.g., moles, Joules, Molarity).
-
List Given Values: Write down all numerical values provided in the question, each with its associated units.
-
Construct the Equation: Arrange the given values as a series of fractions. Use conversion factors (e.g., molar mass in g/mol , density in g/mL) as needed.
-
Unit Cancellation: Methodically cross out units that appear in both the numerator and denominator.
-
Verification: Before calculating, ensure that the only remaining unit is the target unit identified in Step 1. If not, the equation is constructed incorrectly.
-
Calculation: Perform the arithmetic only after the setup is verified.
System Workflows & Pathway Diagrams
The following diagrams illustrate key logical workflows for optimizing your experimental approach to the this compound.
Caption: Workflow for troubleshooting and correcting experimental errors (incorrect answers).
Caption: Logical pathway connecting a general chemistry principle to a physiological response.
References
- 1. reddit.com [reddit.com]
- 2. reddit.com [reddit.com]
- 3. This compound Organic Chemistry Study Guide: Everything You Need to Ace the Exam | Sipath Blog [sipath.com]
- 4. jackwestin.com [jackwestin.com]
- 5. Reddit - The heart of the internet [reddit.com]
- 6. Chemical and Physical Foundations of Biological Systems Section: Overview | Students & Residents [students-residents.aamc.org]
- 7. m.youtube.com [m.youtube.com]
- 8. m.youtube.com [m.youtube.com]
- 9. m.youtube.com [m.youtube.com]
how to overcome challenges in organic chemistry for the MCAT
MCAT Organic Chemistry: Technical Support Center
This support center provides troubleshooting guides, frequently asked questions (FAQs), and standardized protocols to address common challenges encountered during preparation for the organic chemistry sections of the this compound.
Troubleshooting Guide
This section addresses common issues and provides systematic solutions to improve performance and understanding.
Question: My study protocol involves memorizing reactions, but retention is low and application to novel problems is difficult. What is the procedural flaw?
Answer: The primary issue is a reliance on rote memorization rather than a conceptual understanding of reaction mechanisms.[1][2] The this compound prioritizes the application of fundamental principles to solve problems.[2]
-
Corrective Action: Shift focus from memorizing specific reactions to understanding the underlying principles.
-
Identify Nucleophiles and Electrophiles: The core of most organic chemistry reactions involves a nucleophile (electron-rich species) attacking an electrophile (electron-deficient species).[3][4][5] Consistently identifying these roles allows you to predict reaction outcomes even in unfamiliar scenarios.[1][6]
-
Understand Functional Group Properties: A functional group's structure dictates its reactivity.[1][7] For example, the partial positive charge on a carbonyl carbon makes it an electrophile, a frequent target for nucleophilic attack.[3]
-
Focus on Reaction Mechanisms: Instead of memorizing dozens of reactions, learn the key mechanisms like S_N1, S_N2, and aldol condensation.[4][8][9] This provides a framework to analyze a wide range of problems.
-
Question: I consistently make errors on questions involving stereochemistry. How can I troubleshoot this?
Answer: Difficulties with stereochemistry often stem from a non-systematic approach. A standardized protocol is required to correctly assign configurations and identify relationships between isomers.
-
Corrective Action: Implement the "Experimental Protocol for Assigning R/S Configuration" detailed below. This ensures all variables (atomic number, priority, orientation of the lowest-priority group) are accounted for. Practice is critical for improving speed and accuracy in identifying chiral centers and differentiating between enantiomers and diastereomers.[8]
Question: Spectroscopy problems are a recurring challenge. How can I improve my analytical procedure?
Answer: A common error is attempting to interpret spectra without a clear methodology. The solution is to focus on high-yield, diagnostic features first.
-
Corrective Action: Use a systematic approach to spectral interpretation. For IR spectroscopy, memorize key peaks for common functional groups, such as the broad peak for an O-H group (3100-3700 cm⁻¹) and the sharp peak for a carbonyl group (around 1700 cm⁻¹).[3] For ¹H NMR, focus on chemical shifts and splitting patterns to identify the electronic environment and neighboring protons.[8]
Frequently Asked Questions (FAQs)
Question: What are the most frequently tested, high-yield topics in this compound organic chemistry?
Answer: Analysis indicates that a specific subset of topics appears with high frequency. Prioritizing these concepts is an efficient study strategy.[10] Core areas include understanding functional groups, stereochemistry, reaction mechanisms, and interpreting experimental techniques like spectroscopy.[1][8]
Data Presentation: High-Yield this compound Organic Chemistry Topics
| Category | High-Yield Concepts |
|---|---|
| Structure & Bonding | Functional Groups (names, structures, properties), Stereochemistry (R/S configuration, enantiomers, diastereomers).[7][8] |
| Reactions & Mechanisms | Substitution (S_N1, S_N2), Addition, Elimination, Oxidation-Reduction, Aldol Condensation.[4][7][8][11] |
| Acids & Bases | Lewis and Brønsted-Lowry theories; predicting acidity/basicity of functional groups.[7] |
| Analytical Techniques | Spectroscopy (¹H NMR, IR), Separations (extraction, chromatography).[1][3] |
| Biologically Relevant | Amino Acids (structure, properties), Carbohydrates, Lipids.[9] |
Question: What is an effective logic for differentiating between substitution (S_N1/S_N2) and elimination (E1/E2) reactions?
Answer: A decision-making flowchart can systematically resolve this common point of confusion. The key variables are the structure of the substrate (primary, secondary, tertiary), the strength of the nucleophile/base, and the solvent. S_N2 reactions, for example, are favored by strong nucleophiles and hindered by steric bulk, while S_N1 reactions involve a carbocation intermediate and are favored by polar protic solvents.[4][8]
Question: What are the critical oxidizing and reducing agents tested on the this compound?
Answer: A small set of reagents is consistently tested. Understanding their function is more important than memorizing a comprehensive list. For example, PCC is known as a mild oxidizing agent that converts a primary alcohol to an aldehyde, whereas KMnO₄ is a strong oxidizing agent.[8][12]
Data Presentation: Common this compound Reagents and Their Functions
| Reagent | Class | Function |
|---|---|---|
| LiAlH₄ | Strong Reducing Agent | Reduces carboxylic acids, esters, aldehydes, and ketones to alcohols.[8][12] |
| NaBH₄ | Mild Reducing Agent | Reduces aldehydes and ketones to alcohols.[8] |
| PCC | Mild Oxidizing Agent | Oxidizes primary alcohols to aldehydes; secondary alcohols to ketones.[6][8][12] |
| KMnO₄ | Strong Oxidizing Agent | Oxidizes primary alcohols and aldehydes to carboxylic acids.[8] |
Experimental Protocols
Protocol 1: Systematic Approach to Problem Solving
This workflow provides a standardized method for analyzing any this compound organic chemistry question to minimize errors and improve efficiency.
Caption: General workflow for analyzing this compound organic chemistry problems.
Protocol 2: Assigning R/S Configuration
This protocol outlines the Cahn-Ingold-Prelog system for unambiguously assigning the absolute configuration at a chiral center.
-
Identify the Chiral Center: Locate the carbon atom bonded to four different substituents.
-
Assign Priority: Prioritize the four substituents based on atomic number. The atom with the highest atomic number gets the highest priority (1).
-
Orient the Molecule: Position the molecule so that the lowest-priority group (4) is pointing away from the viewer.
-
Determine Direction: Trace the path from priority 1 to 2 to 3.
-
If the path is clockwise , the configuration is R (Rectus).
-
If the path is counter-clockwise , the configuration is S (Sinister).
-
Mandatory Visualizations
Diagram 1: S_N2 Reaction Pathway
This diagram illustrates the concerted, single-step mechanism of a bimolecular nucleophilic substitution (S_N2) reaction, a high-yield topic.[4]
Caption: The concerted mechanism of an S_N2 reaction.
Diagram 2: Substitution vs. Elimination Decision Pathway
This flowchart provides a logical framework for predicting the major reaction pathway based on key molecular and environmental factors.
Caption: Decision logic for S_N1/S_N2 vs. E1/E2 pathways.
References
- 1. This compound Organic Chemistry: Everything You Need to Know — Shemmassian Academic Consulting [shemmassianconsulting.com]
- 2. This compound Organic Chemistry Study Guide: Everything You Need to Ace the Exam | Sipath Blog [sipath.com]
- 3. m.youtube.com [m.youtube.com]
- 4. blog.blueprintprep.com [blog.blueprintprep.com]
- 5. medicmind.us [medicmind.us]
- 6. Reddit - The heart of the internet [reddit.com]
- 7. jackwestin.com [jackwestin.com]
- 8. m.youtube.com [m.youtube.com]
- 9. This compound® Organic Chemistry: Topics, Practice Questions, and Study Strategies [gradschool.uworld.com]
- 10. medschoolcoach.com [medschoolcoach.com]
- 11. forums.studentdoctor.net [forums.studentdoctor.net]
- 12. m.youtube.com [m.youtube.com]
tips for mastering difficult biochemistry concepts for the MCAT
Welcome to the Technical Support Center for advanced MCAT biochemistry preparation. This resource is designed for aspiring medical professionals to troubleshoot and master the most challenging biochemical concepts.
Frequently Asked Questions (FAQs) & Troubleshooting Guides
General Troubleshooting
Question: I am consistently struggling with retaining complex biochemical pathways and concepts. What is a systematic approach to mastering them?
Answer: A systematic approach involves active learning and structured review rather than passive memorization. We recommend implementing a multi-faceted strategy that breaks down complex topics into manageable parts.[1]
Experimental Protocol: The Concept Deconstruction & Integration Method
-
Isolate the Concept: Identify a single, challenging concept (e.g., competitive enzyme inhibition, oxidative phosphorylation).
-
Break It Down: Deconstruct the concept into its fundamental principles. For a pathway, list the substrates, enzymes, products, and regulators for each step.[1]
-
Active Recall with Flashcards: Create flashcards for key terms, structures, and enzymes. Utilize spaced repetition software to enhance long-term memory.[2][3]
-
Apply the Feynman Technique: Explain the concept in simple terms, as if teaching it to someone with no prior knowledge. This process quickly reveals gaps in your understanding.[1][2]
-
Visualize and Connect: Draw the pathway or concept from memory. Create mind maps to link the concept to other topics, such as how metabolic pathways are regulated by hormones.[1]
-
Problem-Based Learning: Immediately apply your knowledge by working through this compound-style practice questions related to the concept.[1]
Below is a workflow diagram illustrating this systematic approach.
Caption: A workflow for mastering difficult biochemistry concepts.
Topic: Enzyme Kinetics
Question: I have trouble distinguishing between competitive, non-competitive, and uncompetitive enzyme inhibition on Lineweaver-Burk plots. How can I troubleshoot this?
Answer: This is a common high-yield topic on the this compound that requires visual and conceptual understanding. The key is to understand how each inhibitor type affects the enzyme's substrate affinity (Km) and maximum velocity (Vmax).
Data Presentation: Enzyme Inhibition Characteristics
| Inhibition Type | Binds to | Effect on Vmax | Effect on Km | Lineweaver-Burk Plot Appearance |
| Competitive | Active Site | No Change | Increases | Lines intersect at the y-axis |
| Non-competitive | Allosteric Site | Decreases | No Change | Lines intersect at the x-axis |
| Uncompetitive | Enzyme-Substrate Complex | Decreases | Decreases | Parallel lines |
Troubleshooting Guide: Interpreting Inhibition
-
Competitive Inhibition: The inhibitor directly competes with the substrate for the active site. This effect can be overcome by adding more substrate. Therefore, Vmax is unchanged, but Km (the substrate concentration at half Vmax) increases.
-
Non-competitive Inhibition: The inhibitor binds to an allosteric site on the enzyme, changing its conformation. This reduces the number of effective enzyme molecules, lowering Vmax. It does not affect substrate binding, so Km remains unchanged.
-
Uncompetitive Inhibition: The inhibitor binds only to the enzyme-substrate (ES) complex, effectively locking the substrate in place. This lowers both Vmax and Km.
Topic: Metabolic Pathways
Question: How can I effectively learn and recall the steps of glycolysis, gluconeogenesis, and the citric acid cycle, including their regulation?
Answer: Learning metabolic pathways is a significant memorization challenge. The most effective strategy is to focus on the connections, regulation, and physiological relevance rather than rote memorization of every intermediate.[4]
Experimental Protocol: Pathway Integration and Regulation Analysis
-
Draw the Pathways: Repeatedly draw the core pathways from memory. Do not initially focus on enzyme names, but on the carbon flow and key molecules (e.g., Glucose -> G6P -> ... -> Pyruvate).[4]
-
Identify Key Regulatory Steps: For each pathway, pinpoint the irreversible, rate-limiting enzymes (e.g., Phosphofructokinase-1 in glycolysis). These are the primary points of regulation.
-
Overlay Hormonal Control: Visualize how hormones like insulin and glucagon act as signals to control these key enzymes. Insulin signals a high-energy state (promotes glycolysis), while glucagon signals a low-energy state (promotes gluconeogenesis).[4]
-
Connect the Pathways: Create a larger map showing how the pathways intersect. For example, visualize how pyruvate is a branch point that can be converted to acetyl-CoA (for the citric acid cycle) or oxaloacetate (for gluconeogenesis).
The following diagram illustrates the high-level hormonal regulation of glucose metabolism.
Caption: Opposing effects of insulin and glucagon on key enzymes.
Topic: Laboratory Techniques
Question: What is a logical workflow for understanding common biochemical lab techniques like Western blotting?
Answer: Understanding the purpose and sequence of steps is crucial for interpreting experimental results presented in this compound passages. The Western blot is used to detect a specific protein in a sample.
Experimental Protocol: Western Blot Workflow
-
Protein Separation (SDS-PAGE): Proteins are denatured and separated by size using gel electrophoresis. Smaller proteins migrate faster.
-
Transfer: The separated proteins are transferred from the gel to a solid membrane.
-
Blocking: The membrane is incubated with a blocking agent (e.g., milk protein) to prevent non-specific antibody binding.
-
Primary Antibody Incubation: A primary antibody, which is specific to the target protein, is added and binds to the protein of interest.
-
Secondary Antibody Incubation: A secondary antibody, which binds to the primary antibody and is linked to a reporter enzyme (e.g., HRP), is added.
-
Detection: A substrate is added that reacts with the reporter enzyme to produce a detectable signal (e.g., light), revealing the location and quantity of the target protein.
This workflow is visualized in the diagram below.
Caption: The sequential steps of a Western blot experiment.
References
improving understanding of enzyme inhibition for the MCAT
This technical support center is designed to assist researchers, scientists, and drug development professionals in improving their understanding and execution of enzyme inhibition experiments, with a focus on concepts relevant to the MCAT.
Frequently Asked Questions (FAQs)
Q1: What is the fundamental difference between competitive, non-competitive, and uncompetitive inhibition?
A1: The primary distinction lies in where the inhibitor binds to the enzyme and how it affects the enzyme's interaction with its substrate.
-
Competitive Inhibition: The inhibitor molecule is structurally similar to the substrate and binds to the active site of the enzyme.[1][2] This prevents the substrate from binding. This type of inhibition can be overcome by increasing the substrate concentration.[3]
-
Non-competitive Inhibition: The inhibitor binds to an allosteric site (a site other than the active site) on the enzyme.[1][4] This binding event causes a conformational change in the enzyme that reduces its catalytic activity, but it does not prevent the substrate from binding. Increasing substrate concentration cannot overcome this type of inhibition.[2][3]
-
Uncompetitive Inhibition: The inhibitor binds only to the enzyme-substrate (ES) complex, at a site distinct from the active site.[1][5] This type of inhibition is most effective at high substrate concentrations when there is a higher concentration of the ES complex.
Q2: How do the different types of inhibitors affect Vmax and Km?
A2: Each type of inhibitor has a unique effect on the maximal velocity (Vmax) and the Michaelis constant (Km), which reflects the enzyme's affinity for the substrate.
-
Competitive inhibitors increase the apparent Km but do not change the Vmax.[6]
-
Non-competitive inhibitors decrease the Vmax but do not change the Km.[7][8]
-
Uncompetitive inhibitors decrease both the Vmax and the Km.[6][7]
-
Mixed inhibitors affect both Vmax and Km, but the changes in Km can vary.[1][4]
Q3: What is the significance of a Lineweaver-Burk plot in analyzing enzyme inhibition?
A3: The Lineweaver-Burk plot, a double reciprocal graph of the Michaelis-Menten equation, is a valuable tool for distinguishing between different types of enzyme inhibition.[9][10][11] By plotting 1/V (velocity) versus 1/[S] (substrate concentration), the resulting straight line makes it easier to visualize the changes in Km and Vmax.[10][11] The x-intercept of the plot is equal to -1/Km, and the y-intercept is equal to 1/Vmax.[12]
Troubleshooting Experimental Issues
Q1: My initial reaction rate is not leveling off at high substrate concentrations in my control experiment (no inhibitor). What could be the issue?
A1: This suggests that the enzyme is not reaching saturation under the tested conditions. Here are a few potential reasons and solutions:
-
Insufficient Substrate Concentration: The Km of your enzyme for the substrate may be higher than the concentrations you are using.[13] Solution: Increase the range of substrate concentrations in your experiment.
-
Enzyme Instability: The enzyme may be losing activity over the course of the assay. Solution: Check the stability of your enzyme at the assay temperature and pH. Consider using fresh enzyme preparations.
-
Substrate Depletion: The reaction may be proceeding so quickly that the substrate is being significantly consumed, leading to a non-linear initial rate. Solution: Measure the reaction velocity at earlier time points or use a lower enzyme concentration.
Q2: I've added a known competitive inhibitor, but I'm not seeing the expected increase in Km. Why might this be?
A2: Several factors could lead to this observation:
-
Inhibitor Concentration is Too Low: The concentration of the inhibitor may not be high enough to effectively compete with the substrate. Solution: Increase the inhibitor concentration in your assays.
-
Incorrect Inhibitor Type: The inhibitor may not be purely competitive. It could be a mixed inhibitor, which can also cause changes in Vmax. Solution: Re-evaluate the inhibitor's mechanism of action.
-
Experimental Error: Inaccuracies in pipetting or concentration calculations can lead to misleading results. Solution: Carefully review your experimental protocol and ensure all reagents are at the correct concentrations.
Q3: My Lineweaver-Burk plot is showing a lot of scatter in the data points, especially at low substrate concentrations. How can I improve this?
A3: The double reciprocal nature of the Lineweaver-Burk plot can amplify errors in measurements at low substrate concentrations.[14]
-
Measurement Precision: Small errors in measuring low reaction velocities at low substrate concentrations are magnified when you take the reciprocal. Solution: Ensure your assay is sensitive enough to accurately measure low levels of product formation. Take multiple readings at each substrate concentration to improve precision.
-
Data Weighting: Consider using non-linear regression analysis of the Michaelis-Menten equation directly, as this method is generally less prone to distortion by experimental error.[14]
Data Presentation: Effects of Reversible Inhibitors on Kinetic Parameters
| Inhibition Type | Effect on Vmax | Effect on Km | Lineweaver-Burk Plot Interpretation |
| Competitive | Unchanged | Increases | Lines intersect at the y-axis (same 1/Vmax).[7] |
| Non-competitive | Decreases | Unchanged | Lines intersect at the x-axis (same -1/Km).[7] |
| Uncompetitive | Decreases | Decreases | Lines are parallel.[7] |
| Mixed | Decreases | Increases or Decreases | Lines intersect to the left of the y-axis.[4][7] |
Experimental Protocols
Determining the Type of Enzyme Inhibition
This protocol outlines the general steps to determine the type of inhibition a compound exerts on an enzyme-catalyzed reaction.
1. Materials:
-
Purified enzyme solution of known concentration.
-
Substrate solution of known concentration.
-
Inhibitor solution of known concentration.
-
Reaction buffer at optimal pH and temperature for the enzyme.
-
Spectrophotometer or other detection instrument to measure product formation or substrate depletion.
-
Microplate reader and microplates (for high-throughput analysis).
2. Methodology:
-
Step 1: Determine Initial Velocity without Inhibitor (Control).
-
Prepare a series of reaction mixtures with a fixed enzyme concentration and varying substrate concentrations.
-
Initiate the reaction by adding the enzyme.
-
Measure the rate of product formation (or substrate consumption) over a short, linear period. This is the initial velocity (V₀).[15]
-
Plot V₀ versus substrate concentration ([S]) to generate a Michaelis-Menten curve and determine Vmax and Km for the uninhibited enzyme.
-
-
Step 2: Determine Initial Velocity with a Fixed Inhibitor Concentration.
-
Repeat the series of experiments from Step 1, but include a fixed concentration of the inhibitor in each reaction mixture.
-
Measure the initial velocities (V₀) at each substrate concentration in the presence of the inhibitor.
-
Plot the new V₀ versus [S] data on the same graph as the control data.
-
-
Step 3: Data Analysis using Lineweaver-Burk Plot.
-
Transform the data from both the control and inhibitor experiments by taking the reciprocal of the velocity (1/V₀) and substrate concentration (1/[S]).
-
Plot 1/V₀ versus 1/[S] for both datasets on the same graph.[10]
-
Analyze the resulting lines to determine the type of inhibition based on the changes in the x- and y-intercepts as described in the table above.[7][11]
-
Mandatory Visualizations
Caption: Signaling pathways for different types of enzyme inhibition.
Caption: Experimental workflow for determining enzyme inhibition type.
Caption: Lineweaver-Burk plots for different inhibition types.
References
- 1. jackwestin.com [jackwestin.com]
- 2. byjus.com [byjus.com]
- 3. microbenotes.com [microbenotes.com]
- 4. jackwestin.com [jackwestin.com]
- 5. medschoolcoach.com [medschoolcoach.com]
- 6. Enzymes on the this compound: Function, Inhibition, and High-Yield Kinetics — King of the Curve [kingofthecurve.org]
- 7. Enzyme Inhibition Types: Competitive vs Noncompetitive & Beyond (this compound Focus) — King of the Curve [kingofthecurve.org]
- 8. knyamed.com [knyamed.com]
- 9. 2minutemedicine.com [2minutemedicine.com]
- 10. superchemistryclasses.com [superchemistryclasses.com]
- 11. Khan Academy [khanacademy.org]
- 12. medschoolcoach.com [medschoolcoach.com]
- 13. researchgate.net [researchgate.net]
- 14. Lineweaver–Burk plot - Wikipedia [en.wikipedia.org]
- 15. prospectivedoctor.com [prospectivedoctor.com]
Technical Support Center: MCAT Chemistry Passage Analysis
This guide provides a systematic approach to deconstructing and solving complex chemistry passages on the MCAT. The methodologies outlined are designed for professionals in scientific fields, leveraging analytical and research-oriented skills to treat each passage as a discrete problem set.
Frequently Asked Questions (FAQs)
Q1: What is the most effective initial approach to a complex passage?
There are several validated strategies, and the optimal choice can depend on individual preference. One common recommendation is to quickly skim the passage to identify the main topic and locate important keywords, figures, and italicized terms. An alternative approach is to read the questions first to frame your reading of the passage, allowing you to focus on finding the specific information needed.[1] For particularly dense material, an "active reading" strategy, which involves summarizing key points and taking notes, can be highly effective.[1] It is recommended to experiment with these methods during practice to determine what works best for you.
Q2: How should I handle unfamiliar terminology or complex molecular structures?
The test is designed to include complex terms to challenge you.[2] The primary strategy is to focus on the concepts and terms you do recognize and use context to understand the overall experiment. Often, a complex molecule is less important than the class of compounds it belongs to or the functional groups it contains.[3][4] Do not spend excessive time trying to understand every unfamiliar word; instead, focus on the experimental procedure and the data presented.[2]
Q3: What are the most critical content areas to have mastered beforehand?
A strong foundation in specific high-yield topics is essential. It is practically guaranteed that questions about amino acids—including their structures, properties, and one- and three-letter codes—will appear.[5] Equally important is a thorough knowledge of functional groups, as their structures dictate their reactive properties, which is a frequently tested concept.[3][5] Mastery of fundamental experimental techniques, such as separations, purifications, and spectroscopy, is also critical for interpreting passage information.[3]
Q4: How do I manage time effectively on these passages?
Effective time management is crucial. It's important to periodically check the time to avoid getting fixated on a single difficult question. If a figure or table appears overly complicated, avoid a deep analysis unless a question directs you to it, which can be a significant time-saver.[1] Practicing with a large volume of passages helps to build speed and the ability to quickly identify relevant information.
Troubleshooting Guides & Experimental Protocols
These protocols provide a structured methodology for navigating this compound chemistry passages.
Protocol 1: The Passage Triage Protocol
This protocol is designed for the initial 60-90 seconds upon encountering a new passage to efficiently map its structure and key elements.
Methodology:
-
Initial Skim: Quickly read the passage to grasp the main scientific question or experiment.
-
Keyword Tagging: As you skim, highlight key scientific terms, names of molecules, units of measurement, and any words that are bolded or italicized.[6] This creates a quick reference map.
-
Identify Passage Structure: Mentally or with light notation, label the purpose of each paragraph (e.g., "Introduction," "Methods," "Results"). Pay special attention to paragraphs describing experimental procedures.[2]
-
Figure Assessment: Briefly examine the title and axes of all figures and tables to understand what is being measured.[2] Defer in-depth analysis until a question requires it.[1]
Protocol 2: The Question Deconstruction Protocol
This protocol details the process of breaking down a question to its core components before returning to the passage.
Methodology:
-
Identify the Core Task: Read the question carefully, multiple times if necessary, to fully understand what is being asked.[7]
-
Locate Keywords: Identify the key terms in the question stem. These terms will be your primary search query when you return to the passage.
-
Predict an Answer: Before looking at the options, try to formulate a potential answer based on your understanding of the passage and your outside content knowledge.[7]
-
Return to the Passage: Use the keywords from the question to locate the relevant section of the passage or figure that contains the necessary information to confirm your prediction.[7]
-
Execute Process of Elimination: Systematically evaluate each answer choice. Use the passage to find evidence that actively disproves the incorrect options. This significantly increases confidence in the correct answer.[7]
Data Presentation & Visualization
Quantitative Data Summary
The following tables summarize key quantitative and qualitative data relevant to passage analysis.
Table 1: Prioritization Matrix for Passage Elements
| Passage Element | Typical Information Value | Recommended Time Allocation | Key Focus Area |
|---|---|---|---|
| Title/Abstract | Low-Moderate | < 10 seconds | General Topic Identification |
| Introduction | Moderate | 20-30 seconds | Hypothesis, Experimental Goal |
| Methods/Procedure | High | 45-60 seconds | Reactants, Catalysts, Steps, Controls[2][4] |
| Figures/Graphs | Very High (Question Dependent) | 15 seconds (initial); 60+ seconds (if questioned) | Title, Axes, Units, Trends[2] |
| Tables | High (Question Dependent) | 15 seconds (initial); 45+ seconds (if questioned) | Column/Row Headers, Units, Significant Values |
| Results/Discussion | High | 30-45 seconds | Relationship Between Variables, Conclusions |
| Complex Names | Very Low | < 5 seconds | Ignore unless central to a question |
Table 2: High-Yield Infrared (IR) Spectroscopy Data
| Functional Group | Wavenumber (cm⁻¹) | Peak Characteristics |
|---|---|---|
| O-H (Alcohol) | 3200-3600 | Broad, U-shaped |
| O-H (Carboxylic Acid) | 2500-3300 | Very Broad |
| N-H | 3300-3500 | Sharp (one peak for -NH, two for -NH₂) |
| C=O (Carbonyl) | 1700-1750 | Sharp, Strong[4] |
| C≡N (Nitrile) | 2210-2260 | Sharp, Medium |
Mandatory Visualization
The following diagram illustrates the recommended workflow for approaching any complex science passage on the this compound.
Caption: A workflow diagram illustrating the four-phase approach to this compound chemistry passages.
References
Amino Acid Memorization & Application: Technical Support Center
Welcome to the Technical Support Center for amino acid memorization and application. This resource is designed for researchers, scientists, and drug development professionals to provide clear, actionable strategies for mastering amino acid structures and properties, along with practical experimental context.
Frequently Asked Questions (FAQs)
Q1: What is the most effective way to begin memorizing the 20 common amino acids?
A1: The most effective initial approach is to group the amino acids by their physicochemical properties rather than attempting to memorize them alphabetically.[1] This method allows you to associate structures with functions, which is more conceptually intuitive. The primary groups are:
-
Nonpolar, Aliphatic
-
Nonpolar, Aromatic
-
Polar, Uncharged
-
Positively Charged (Basic)
-
Negatively Charged (Acidic)
Q2: Are there any recommended mnemonic devices for these groups?
A2: Yes, mnemonic devices are a highly effective method for memorizing the amino acids within their respective groups.[1][2][3] Here are some commonly used mnemonics based on the one-letter codes:
-
Nonpolar, Aliphatic: G randma A lways V isits L ondon I n M ay P arties. (Glycine, Alanine, Valine, Leucine, Isoleucine, Methionine, Proline).[1][3]
-
Aromatic: The "W iF e" (Y ) is aromatic. (Tryptophan, Phenylalanine, Tyrosine). Some mnemonics classify Tyrosine as polar.
-
Polar, Uncharged: S anta's T eam C rafts N ew Q uilts Y early. (Serine, Threonine, Cysteine, Asparagine, Glutamine, Tyrosine).[1][3]
-
Positively Charged (Basic): L ysine, A rginine, H istidine are basic. (Lysine, Arginine, Histidine).
-
Negatively Charged (Acidic): As a mnemonic, consider that Aspartate and Glutamate are "A ciD ic" and "E lectronegative". (Aspartic Acid, Glutamic Acid).
Q3: How can I efficiently memorize the one-letter and three-letter codes?
A3: For the three-letter codes, most are simply the first three letters of the amino acid's name. The exceptions to focus on are Asparagine (Asn), Glutamine (Gln), Isoleucine (Ile), and Tryptophan (Trp).
Memorizing the one-letter codes requires more direct effort. Many are intuitive (e.g., A for Alanine, G for Glycine). For the non-intuitive ones, creating associations can be helpful:
-
F for Phenylalanine ("F enylalanine")
-
W for Tryptophan (the large, double-ring structure looks like a "W ")
-
Y for Tyrosine (contains a hY droxyl group)
-
D for Aspartate (asparD ate)
-
E for Glutamate (gluE tamate)
-
N for Asparagine (asparagiN e)
-
Q for Glutamine (Q -tamine)
-
K for Lysine (K is near L in the alphabet)
-
R for Arginine (R -ginine)
Regular practice with flashcards or online quizzes is highly recommended to solidify these codes.[4][5]
Q4: What is the best way to learn the structures?
A4: Repetitive drawing is the most effective technique.[5] Start with the basic backbone structure (N-Cα-C) and then add the unique side chain (R-group) for each amino acid. As you draw, say the name, codes, and properties out loud. This multi-modal approach (visual, kinesthetic, and auditory) enhances retention. You can also find patterns in the structures, such as Phenylalanine being an Alanine with a phenyl group attached.[5][6]
Troubleshooting Guides
Problem: I keep confusing the structures of similarly named amino acids (e.g., Aspartate/Asparagine, Glutamate/Glutamine).
Solution:
-
Focus on the key difference: Asparagine and Glutamine are the amide versions of Aspartic Acid and Glutamic Acid, respectively. Visually, the acids have a carboxyl group (-COOH) on their side chain, while the amides have a carboxamide group (-CONH2).
-
Structural Elongation: Notice that Glutamate and Glutamine each have an additional methylene group (-CH2-) in their side chain compared to Aspartate and Asparagine, making them longer.
-
Mnemonic Association: Think of "Gluta -" as being "longer" than "Asparta-".
Problem: I can't remember which amino acids are essential vs. non-essential.
Solution: Focus on memorizing the essential amino acids, and the rest are non-essential.
-
Mnemonic: P rivate T im H all. (Phenylalanine, Valine, Threonine, Tryptophan, Isoleucine, Methionine, Histidine, Arginine, Leucine, Lysine). Note that Arginine is considered semi-essential.
Quantitative Data Summary
For researchers, having quantitative data on amino acid properties is crucial for experimental design and data interpretation.
Table 1: pKa Values of the 20 Common Amino Acids
| Amino Acid | 3-Letter Code | 1-Letter Code | pKa (α-carboxyl) | pKa (α-amino) | pKa (Side Chain) | pI |
| Alanine | Ala | A | 2.34 | 9.69 | - | 6.00 |
| Arginine | Arg | R | 2.17 | 9.04 | 12.48 | 10.76 |
| Asparagine | Asn | N | 2.02 | 8.80 | - | 5.41 |
| Aspartic Acid | Asp | D | 1.88 | 9.60 | 3.65 | 2.77 |
| Cysteine | Cys | C | 1.96 | 10.28 | 8.18 | 5.07 |
| Glutamic Acid | Glu | E | 2.19 | 9.67 | 4.25 | 3.22 |
| Glutamine | Gln | Q | 2.17 | 9.13 | - | 5.65 |
| Glycine | Gly | G | 2.34 | 9.60 | - | 5.97 |
| Histidine | His | H | 1.82 | 9.17 | 6.00 | 7.59 |
| Isoleucine | Ile | I | 2.36 | 9.60 | - | 6.02 |
| Leucine | Leu | L | 2.36 | 9.60 | - | 5.98 |
| Lysine | Lys | K | 2.18 | 8.95 | 10.53 | 9.74 |
| Methionine | Met | M | 2.28 | 9.21 | - | 5.74 |
| Phenylalanine | Phe | F | 1.83 | 9.13 | - | 5.48 |
| Proline | Pro | P | 1.99 | 10.60 | - | 6.30 |
| Serine | Ser | S | 2.21 | 9.15 | - | 5.68 |
| Threonine | Thr | T | 2.09 | 9.10 | - | 5.60 |
| Tryptophan | Trp | W | 2.83 | 9.39 | - | 5.89 |
| Tyrosine | Tyr | Y | 2.20 | 9.11 | 10.07 | 5.66 |
| Valine | Val | V | 2.32 | 9.62 | - | 5.96 |
| Data sourced from multiple consistent biochemical references.[7][8][9][10] |
Table 2: Amino Acid Hydrophobicity Index (Kyte-Doolittle Scale)
| Amino Acid | 3-Letter Code | 1-Letter Code | Hydrophobicity Index |
| Isoleucine | Ile | I | 4.5 |
| Valine | Val | V | 4.2 |
| Leucine | Leu | L | 3.8 |
| Phenylalanine | Phe | F | 2.8 |
| Cysteine | Cys | C | 2.5 |
| Methionine | Met | M | 1.9 |
| Alanine | Ala | A | 1.8 |
| Glycine | Gly | G | -0.4 |
| Threonine | Thr | T | -0.7 |
| Serine | Ser | S | -0.8 |
| Tryptophan | Trp | W | -0.9 |
| Tyrosine | Tyr | Y | -1.3 |
| Proline | Pro | P | -1.6 |
| Histidine | His | H | -3.2 |
| Asparagine | Asn | N | -3.5 |
| Glutamine | Gln | Q | -3.5 |
| Aspartic Acid | Asp | D | -3.5 |
| Glutamic Acid | Glu | E | -3.5 |
| Lysine | Lys | K | -3.9 |
| Arginine | Arg | R | -4.5 |
| The Kyte-Doolittle scale is widely used for predicting transmembrane helices and surface-exposed regions.[11] |
Experimental Protocols
1. Determination of Amino Acid pKa Values via Titration
Objective: To experimentally determine the pKa values of an amino acid's ionizable groups.
Methodology:
-
Preparation of Amino Acid Solution: Prepare a solution of the amino acid of known concentration (e.g., 20 mM) in deionized water.
-
Initial pH Adjustment: Add a strong acid (e.g., 60 mM HCl) to the amino acid solution to lower the pH to around 1.5-2.0, ensuring all ionizable groups are fully protonated.
-
Titration Setup: Place the solution in a beaker with a calibrated pH meter and a magnetic stirrer. Use a burette to dispense a strong base of known concentration (e.g., 50 mM NaOH).
-
Titration Procedure: Add the strong base in small, precise increments (e.g., 1.000 mL aliquots). After each addition, allow the pH to stabilize and record the pH value and the total volume of base added.[12]
-
Data Plotting: Plot the pH (y-axis) against the equivalents of base added (x-axis) to generate a titration curve.
-
pKa Determination: The pKa values correspond to the pH at the midpoints of the buffering regions (the flat portions of the curve). The isoelectric point (pI) is the pH at the equivalence point, where the amino acid has a net zero charge.[13]
2. Determination of Amino Acid Hydrophobicity using the Kyte-Doolittle Method
Objective: To calculate the hydropathic character of a protein to predict transmembrane domains and surface regions.
Methodology: This is a computational method based on experimentally derived hydrophobicity values.
-
Assign Hydrophobicity Values: Each amino acid in the protein sequence is assigned a hydrophobicity value from the Kyte-Doolittle scale (see Table 2).[11]
-
Define a Window Size: A "window" of a specific number of amino acids (e.g., 9, 19, or 21 residues) is selected. The choice of window size affects the plot's resolution; a larger window is better for identifying transmembrane domains.
-
Calculate Average Hydrophobicity: The algorithm moves along the protein sequence, calculating the average hydrophobicity for each window. This average value is assigned to the central amino acid of that window.
-
Plot the Data: The average hydropathy scores are plotted against the amino acid position in the sequence.
-
Interpretation: Peaks with high positive scores (typically > 1.6 for a 19-residue window) are indicative of hydrophobic regions, likely to be transmembrane domains.[11][14] Valleys with negative scores suggest hydrophilic regions, which are likely to be on the protein's surface.
Visualizations
Caption: Logical grouping of amino acids by side chain properties.
Caption: A cyclical workflow for effective amino acid memorization.
References
- 1. rapidnovor.com [rapidnovor.com]
- 2. scribd.com [scribd.com]
- 3. Determination of Amino Acids’ pKa: Importance of Cavity Scaling within Implicit Solvation Models and Choice of DFT Functionals - PMC [pmc.ncbi.nlm.nih.gov]
- 4. novor.cloud [novor.cloud]
- 5. Hydrophobicity scales - Wikipedia [en.wikipedia.org]
- 6. Kyte-Doolittle Hydropathy Plots [gcat.davidson.edu]
- 7. creative-biolabs.com [creative-biolabs.com]
- 8. Protein pKa calculations - Wikipedia [en.wikipedia.org]
- 9. Amino Acid Hydrophobicity for Structural Prediction of Peptides and Proteins [biosyn.com]
- 10. A simple method for displaying the hydropathic character of a protein - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. resources.qiagenbioinformatics.com [resources.qiagenbioinformatics.com]
- 12. repository.stcloudstate.edu [repository.stcloudstate.edu]
- 13. Titration Curve of Amino Acids - Experiment, Significance, pKa - GeeksforGeeks [geeksforgeeks.org]
- 14. Plots - Justbio [justbio.com]
how to effectively review and learn from MCAT chemistry practice questions
MCAT Chemistry Practice Question Review: A Technical Support Center
Welcome to the technical support center for optimizing your this compound chemistry study sessions. This resource provides troubleshooting guides and frequently asked questions (FAQs) to help you effectively review and learn from your practice questions, turning mistakes into opportunities for score improvement.
Frequently Asked Questions (FAQs)
Q1: I'm finishing my practice sets, but my score isn't improving. What am I doing wrong?
A: Simply completing practice questions is only half the battle; the significant score increases come from a structured and active review process.[1][2] Many students glance at the correct answer and move on, which is a passive form of learning.[3][4] To see real improvement, you must shift your focus from what the correct answer was to why you got the question wrong and how to prevent similar errors in the future.[3][5][6][7]
Q2: How much time should I dedicate to reviewing a practice test or question set?
A: A thorough review is time-intensive but essential. For a full-length practice exam, expect the review process to take a minimum of 4 to 8 hours, and sometimes even longer.[8] As a general rule, you should spend at least as much time reviewing a set of questions as you spent answering them.[2]
Q3: How can I distinguish between a content gap and a reasoning error?
A: This is a critical step in effective review. After identifying an incorrect answer, ask yourself the following:
-
Content Gap: Did I simply not know the formula, definition, or concept required to answer the question? If you look at the correct answer and the underlying concept is completely unfamiliar, it's a content gap.[6][7]
-
Reasoning/Application Error: Did I know the content but fail to apply it correctly to the passage or question stem?[6][7] This can include misreading a graph, misunderstanding the question, falling for a trap answer, or making a calculation mistake.[5][6]
Q4: What is the most effective way to track my mistakes?
A: Keeping a detailed error log, often in a spreadsheet or notebook, is a highly effective strategy.[5][8] This log allows you to identify recurring patterns in your mistakes over time, such as struggling with a specific topic (e.g., electrochemistry) or a particular question type (e.g., interpreting experimental data).[5][6][7] Your log should track the question, the topic, the type of error, and a brief note on how to fix it.[8]
Q5: I guessed on a question and got it right. How should I handle this during review?
A: Treat any question you were not 100% confident about as if you got it wrong.[8][9] Review it carefully to understand the underlying logic.[1] This ensures you didn't just get lucky and that you can reliably answer a similar question in the future.[9]
Troubleshooting Guides
Issue: I consistently run out of time on the Chem/Phys section.
Solution:
-
Timed Practice: From day one, strictly time yourself during practice to simulate real exam conditions and build endurance.[9]
-
Identify Bottlenecks: During review, analyze the questions that took you the longest. Was it complex math, passage interpretation, or an unfamiliar topic? Pacing comes from being comfortable with the material.[10]
-
Master High-Yield Skills: Get comfortable with fundamental skills like unit conversions, scientific notation, and rounding to speed up calculations. This compound math is often simple; if you find yourself in a multi-step calculation that takes more than a minute, you should reassess your approach.
-
Question Triage: Practice skipping and flagging difficult questions to maximize points on easier ones first.[11] You can always return to the harder questions if time permits.
Issue: The passages are overwhelming, and I miss details.
Solution:
-
Active Reading Strategy: Instead of passively reading the passage, try an active approach. Some students find success by reading the questions first to know what to look for, while others prefer to skim the passage to get the main idea before tackling the questions.[10][12] Experiment to see what works for you.[9]
-
Flowcharting: For complex experimental passages, try creating a simple flowchart as you read. This active reading technique forces you to engage with the material and helps you keep track of the experimental setup and key findings.[13]
-
Focus on Data: Pay close attention to figures, graphs, and tables. The this compound often tests your ability to interpret data presented in the passage.[3]
Data Presentation
Table 1: this compound Chemistry/Physics Section At-a-Glance
| Metric | Value | Source |
| Number of Questions | 59 | [14] |
| Time Allotted | 95 minutes | [14] |
| Average Time per Question | ~1 minute 36 seconds | |
| Recommended Review Time (Full-Length) | 4 - 8 hours | [8] |
Table 2: Sample Error Log Structure
| Question # | Topic | Error Type | Root Cause Analysis | Actionable Fix |
| 23 | Thermodynamics | Content Gap | Forgot the formula for Gibbs Free Energy. | Create an Anki card with the formula and its variables. |
| 41 | Enzyme Kinetics | Reasoning | Misinterpreted the y-axis on the Lineweaver-Burk plot. | Redo the passage untimed. Write down the trap I fell for.[6] |
| 55 | Redox Reactions | Calculation | Rushed the calculation and made a simple math error. | Slow down on calculation questions; write out all steps. |
Experimental Protocols
Protocol 1: Systematic this compound Question Review
Objective: To systematically analyze performance on practice questions to identify weaknesses and create a targeted study plan for improvement.
Methodology:
-
Initial Reflection (10 minutes): Immediately after completing a practice set or exam, and before seeing your score, reflect on the experience.[7] Note your timing, confidence level, and any passages or questions that felt particularly challenging.
-
Error Categorization:
-
Go through each question you answered incorrectly.
-
For each error, classify it into one of three categories: 1) Content Gap, 2) Application/Reasoning Error, or 3) Test-Taking Error (e.g., misread question, time pressure).[6]
-
-
Uncertainty Analysis:
-
Root Cause Analysis:
-
For each error, dig deeper to understand the "why."
-
If Content Gap: Pinpoint the specific fact, formula, or concept you were missing.
-
If Reasoning Error: Explain in your own words why the correct answer is right and why the answer you chose was wrong.[3] Identify the logical trap or misinterpretation that led you astray.[6]
-
-
Create Actionable Fixes:
-
Based on the root cause, create a specific, actionable task.
-
For Content Gaps: Create targeted flashcards (e.g., using Anki) for the specific piece of information you were missing.[1][15]
-
For Reasoning Errors: Redo the question or passage untimed to walk through the logic.[6] Write down the principle or strategy you will use next time.
-
-
Data Logging: Record your findings for every incorrect and uncerta in your error log (see Table 2).
-
Synthesize and Adapt: At the end of your review session, analyze your error log for patterns.[7][8] Adjust your study plan for the upcoming week to target your identified high-yield weaknesses.[8][11]
Visualizations
Caption: A workflow diagram illustrating the continuous cycle of practice, analysis, and strategic adjustment.
References
- 1. reddit.com [reddit.com]
- 2. This compound General Chemistry: Everything You Need to Know — Shemmassian Academic Consulting [shemmassianconsulting.com]
- 3. reddit.com [reddit.com]
- 4. youtube.com [youtube.com]
- 5. m.youtube.com [m.youtube.com]
- 6. medschoolbro.com [medschoolbro.com]
- 7. nucleustutoring.com [nucleustutoring.com]
- 8. m.youtube.com [m.youtube.com]
- 9. 5 Effective Strategies for this compound Practice Tests [varsitytutors.com]
- 10. Reddit - The heart of the internet [reddit.com]
- 11. m.youtube.com [m.youtube.com]
- 12. m.youtube.com [m.youtube.com]
- 13. google.com [google.com]
- 14. What's Tested on the this compound Chemistry â Strategies + Questions [inspiraadvantage.com]
- 15. Reddit - The heart of the internet [reddit.com]
common pitfalls in interpreting experimental results on the MCAT
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in navigating common pitfalls when interpreting experimental data, with a focus on scenarios commonly presented in MCAT passages.
Troubleshooting Guides
Issue: Misinterpretation of a Novel Drug's Efficacy Due to a Confounding Variable
Scenario: A study investigates the efficacy of a new drug, "Inhibitall," on the activity of Enzyme X, a key enzyme in a cancer-related signaling pathway. The researchers treat one group of cultured cancer cells with Inhibitall dissolved in DMSO and a control group with a saline solution. The results show a significant decrease in Enzyme X activity in the Inhibitall group.
Troubleshooting Steps:
-
Examine the Control Group: The control group should ideally isolate the effect of the independent variable (Inhibitall). In this case, the solvent used to dissolve Inhibitall, DMSO, is a known bioactive molecule that can affect cellular processes. A proper control would be to treat the control group with the vehicle (DMSO) alone.
-
Identify Potential Confounding Variables: A confounding variable is an unmeasured third variable that influences both the supposed cause and effect. Here, DMSO is a confounding variable because it was administered with the drug and could independently affect Enzyme X activity.
-
Consult Experimental Protocol for Details: Review the detailed methodology to understand how the solutions were prepared and administered.
Logical Relationship with a Confounding Variable
MCAT Science Sections: Critical Thinking Technical Support Center
Welcome to the Technical Support Center for enhancing critical thinking in the MCAT science sections. This resource is designed for researchers, scientists, and drug development professionals preparing for the this compound, providing targeted troubleshooting guides and frequently asked questions to address common challenges encountered during your preparation.
Troubleshooting Guides
This section provides structured approaches to common problems encountered in the this compound science sections.
Problem: Difficulty understanding and breaking down dense experimental passages.
Solution: Implement the "Passage Dissection Protocol." This involves a systematic approach to deconstruct complex scientific passages into manageable components.
Experimental Protocols: Passage Dissection Protocol
-
Initial Skim (1-2 minutes): Quickly read the passage to grasp the overall topic and purpose. Identify the main research question or hypothesis.[1][2]
-
Active Reading and Highlighting:
-
Analyze Figures and Tables: Before reading the results section in detail, examine the graphs and tables.
-
Summarize Paragraphs: Briefly jot down the main point of each paragraph in your own words. This creates a mental roadmap of the passage.[1]
-
Connect to Broader Concepts: Relate the specific experiment to foundational scientific principles. Ask yourself, "What larger biological or chemical concept is this experiment illustrating?"
Problem: Inability to accurately interpret graphical and tabular data.
Solution: Follow the "Data Interpretation Workflow." This structured method ensures a thorough analysis of all data presented.
Experimental Protocols: Data Interpretation Workflow
-
Identify the Variables: Determine the independent variable (typically on the x-axis) and the dependent variable (typically on the y-axis).[4][5][6][7]
-
Analyze the Axes and Units: Pay close attention to the units of measurement and the scale (linear or logarithmic).[5][9]
-
Look for Trends and Relationships: Determine if the relationship between variables is direct, inverse, or sigmoidal.[5][6] Note any maximums, minimums, or points of intersection.[9]
-
Evaluate Statistical Significance: Look for error bars or p-values to determine if the observed differences are statistically significant.[5][10]
Frequently Asked Questions (FAQs)
Q1: How do I approach questions that ask about the design of an experiment?
A1: To evaluate experimental design, focus on the core components of the scientific method.[11] Identify the research question, hypothesis, variables (independent, dependent, and controls), and the overall methodology.[6][11] Look for potential flaws in the design, such as confounding variables or the lack of a proper control group.[12]
Q2: What is the most effective way to improve my scientific reasoning skills?
A2: Consistent practice with this compound-style passages is crucial.[9] After completing a practice set, thoroughly review each question. For every question, explain why the correct answer is right and, just as importantly, why the incorrect answer choices are wrong.[13] This process of active review will help you internalize the logic of the test makers.
Q3: How much outside knowledge do I need for the science sections?
Q4: I'm having trouble with passages that describe complex signaling pathways. What should I do?
A4: When faced with a complex pathway, it's helpful to create a simple diagram on your scratch paper.[5][7] Use arrows to indicate activation or stimulation and blunted lines to represent inhibition.[5] This visual representation can simplify the relationships between the different molecules and make it easier to answer questions about the effects of up-regulation or down-regulation of components in the pathway.
Data Presentation
The AAMC emphasizes four key Scientific Inquiry and Reasoning Skills (SIRS) in the science sections. Understanding their distribution can help you focus your preparation.
| Scientific Inquiry & Reasoning Skill | C/P Section | B/B Section | P/S Section |
| Skill 1: Knowledge of Scientific Concepts and Principles | 35% | 35% | 40% |
| Skill 2: Scientific Reasoning and Problem-solving | 45% | 45% | 35% |
| Skill 3: Reasoning about the Design and Execution of Research | 10% | 10% | 15% |
| Skill 4: Data-based and Statistical Reasoning | 10% | 10% | 10% |
Note: Percentages are approximate and can vary slightly between exams.
Visualizations
The following diagrams illustrate key workflows and logical relationships for improving critical thinking in the this compound science sections.
Caption: Workflow for dissecting a complex this compound science passage.
Caption: A systematic approach to interpreting graphical and tabular data.
References
- 1. How to Read this compound Science Passages | 3 Effective Strategies [inspiraadvantage.com]
- 2. This compound Passage-Based Questions: The Best Approach to Answering Them — King of the Curve [kingofthecurve.org]
- 3. jackwestin.com [jackwestin.com]
- 4. forums.studentdoctor.net [forums.studentdoctor.net]
- 5. mcatselfprep.com [mcatselfprep.com]
- 6. m.youtube.com [m.youtube.com]
- 7. Reddit - The heart of the internet [reddit.com]
- 8. jackwestin.com [jackwestin.com]
- 9. blog.blueprintprep.com [blog.blueprintprep.com]
- 10. thepremedscene.com [thepremedscene.com]
- 11. mcatprep.org [mcatprep.org]
- 12. students-residents.aamc.org [students-residents.aamc.org]
- 13. Khan Academy [khanacademy.org]
- 14. elitemedicalprep.com [elitemedicalprep.com]
Validation & Comparative
A Comprehensive Guide to SN1 and SN2 Reactions for the MCAT
For researchers, scientists, and drug development professionals preparing for the MCAT, a thorough understanding of nucleophilic substitution reactions is paramount. This guide provides an in-depth comparison of the SN1 (Substitution Nucleophilic Unimolecular) and SN2 (Substitution Nucleophilic Bimolecular) reaction mechanisms, presenting key differentiating factors, quantitative data, and visual representations of the underlying principles.
Quantitative Comparison of SN1 and SN2 Reactions
The choice between an SN1 and SN2 pathway is dictated by a number of factors, from the nature of the substrate to the solvent used. The following table summarizes the key distinctions between these two reaction types.
| Feature | SN1 Reaction | SN2 Reaction |
| Rate Law | Rate = k[Substrate] (First-order)[1][2][3][4] | Rate = k[Substrate][Nucleophile] (Second-order)[2][3][5] |
| Mechanism | Two-step process[1][2][5] | Single-step (concerted) process[2][5][6] |
| Intermediate | Carbocation intermediate is formed[1][2][5][7] | No intermediate, only a transition state[2][6][8] |
| Substrate | Favored by tertiary > secondary substrates[1][5][9] | Favored by methyl > primary > secondary substrates[5][9] |
| Nucleophile | Favored by weak nucleophiles (e.g., H₂O, ROH)[10][11][12] | Favored by strong nucleophiles (e.g., OH⁻, CN⁻)[10][11][13] |
| Solvent | Favored by polar protic solvents (e.g., water, ethanol)[10][13][14][15] | Favored by polar aprotic solvents (e.g., acetone, DMSO)[5][10][13][14] |
| Stereochemistry | Results in a racemic mixture (both inversion and retention of configuration)[1][2][5][7] | Results in complete inversion of configuration (Walden inversion)[5][6][16][17] |
| Rearrangements | Carbocation rearrangements are possible to form a more stable carbocation[18] | No rearrangements occur |
| Leaving Group | Requires a good leaving group (a weak base)[11][15] | Requires a good leaving group (a weak base)[11] |
Experimental Methodologies
The determination of whether a reaction proceeds via an SN1 or SN2 mechanism relies on kinetic and stereochemical analyses.
Kinetics: The order of the reaction is a primary determinant. To ascertain this, experiments are designed where the concentration of the substrate and nucleophile are independently varied, and the initial reaction rate is measured.
-
For an SN1 reaction , doubling the concentration of the substrate will double the reaction rate, while changing the concentration of the nucleophile will have no effect on the rate.[1][2][5]
-
For an SN2 reaction , doubling the concentration of either the substrate or the nucleophile will double the reaction rate.[2][5]
Stereochemistry: The stereochemical outcome of the product is analyzed using techniques such as polarimetry.
-
If a chiral starting material yields a racemic mixture of products (optically inactive), it is indicative of an SN1 reaction due to the planar carbocation intermediate that can be attacked from either face.[1][2][5][7]
-
If a chiral starting material results in a product with the opposite stereochemical configuration (inversion), this points to an SN2 reaction , a consequence of the backside attack by the nucleophile.[5][6][16][17]
Visualizing the Mechanisms
The following diagrams illustrate the key differences in the reaction pathways and the factors influencing the choice of mechanism.
Caption: The two-step mechanism of an SN1 reaction.
Caption: The concerted, single-step mechanism of an SN2 reaction.
Caption: Factors influencing the SN1 vs. SN2 pathway.
References
- 1. masterorganicchemistry.com [masterorganicchemistry.com]
- 2. SN1 and SN2 reaction – Kinetics, Mechanism, Stereochemistry and Reactivity. [chemicalnote.com]
- 3. SN1 vs. SN2 Explained: Rate Laws, Reactivity, and Solvent Effects [eureka.patsnap.com]
- 4. quora.com [quora.com]
- 5. masterorganicchemistry.com [masterorganicchemistry.com]
- 6. SN2 Reaction Mechanism: Steps, Examples & Key Factors [vedantu.com]
- 7. chem.libretexts.org [chem.libretexts.org]
- 8. Ch 8 : SN2 mechanism [chem.ucalgary.ca]
- 9. medicalschoolhq.net [medicalschoolhq.net]
- 10. chem.libretexts.org [chem.libretexts.org]
- 11. Factors Affecting SN1 and SN2: Nature of the Substrate, Nucleophile, Solvent, Leaving Group Ability, Difference Between SN1 and SN2 in Chemistry: Definition, Types and Importance | AESL [aakash.ac.in]
- 12. SN1 versus SN2 Reactions, Factors Affecting SN1 and SN2 Reactions | Pharmaguideline [pharmaguideline.com]
- 13. 8.3. Factors affecting rate of nucleophilic substitution reactions | Organic Chemistry 1: An open textbook [courses.lumenlearning.com]
- 14. 7.5 SN1 vs SN2 – Organic Chemistry I [kpu.pressbooks.pub]
- 15. chem.libretexts.org [chem.libretexts.org]
- 16. byjus.com [byjus.com]
- 17. SN2 Reaction Mechanism [chemistrysteps.com]
- 18. Ch 8 : SN1 mechanism [chem.ucalgary.ca]
Differentiating Kinetic and Thermodynamic Control: A Guide for Researchers
In the realm of chemical synthesis and drug development, the ability to selectively obtain a desired product from a reaction that can yield multiple outcomes is paramount. This selectivity is often governed by the principles of kinetic and thermodynamic control. Understanding the interplay between these two controlling factors allows researchers to manipulate reaction conditions to favor the formation of either the most rapidly formed product (kinetic control) or the most stable product (thermodynamic control). This guide provides a comprehensive comparison of kinetic and thermodynamic control, supported by experimental data and detailed protocols for key reactions relevant to organic chemistry and the MCAT curriculum.
Core Concepts: Kinetic vs. Thermodynamic Control
A chemical reaction that can produce two or more different products from a single starting material is under either kinetic or thermodynamic control, depending on the reaction conditions.[1]
-
Kinetic Control: This prevails under conditions where the reaction is irreversible, typically at lower temperatures and for shorter reaction times.[2] The major product is the one that is formed the fastest, meaning it has the lowest activation energy (Ea). This product is referred to as the kinetic product.[3]
-
Thermodynamic Control: This is established when the reaction is reversible, usually at higher temperatures and for longer reaction times, allowing the system to reach equilibrium.[2] The major product is the most stable one, meaning it has the lowest Gibbs free energy (G). This product is known as the thermodynamic product.[3]
The key distinction lies in whether the product distribution is determined by the relative rates of formation or the relative stabilities of the products.[4]
Key Differentiating Factors
| Feature | Kinetic Control | Thermodynamic Control |
| Governing Principle | Rate of reaction | Stability of product |
| Product Formed | Fastest-forming product (lower activation energy) | Most stable product (lower Gibbs free energy) |
| Reaction Conditions | Lower temperatures, shorter reaction times | Higher temperatures, longer reaction times |
| Reversibility | Generally irreversible | Reversible, allows for equilibrium |
| Energy Profile | Favors the pathway with the lowest transition state energy | Favors the product with the lowest overall energy |
Experimental Examples and Data
To illustrate the practical application of these principles, we will examine three classic organic reactions that demonstrate the switch between kinetic and thermodynamic control.
Electrophilic Addition of HBr to 1,3-Butadiene
The reaction of 1,3-butadiene with hydrogen bromide can yield two different addition products: the 1,2-adduct and the 1,4-adduct. The distribution of these products is highly dependent on the reaction temperature.[5]
At lower temperatures, the 1,2-adduct is the major product, as it is formed more rapidly due to the proximity of the bromide ion to the initially formed carbocation.[6] This is the kinetic product. At higher temperatures, the reaction becomes reversible, and the more stable 1,4-adduct, which has a more substituted double bond, becomes the major product.[5] This is the thermodynamic product.
Data Presentation: Product Distribution in the Addition of HBr to 1,3-Butadiene
| Temperature (°C) | % 1,2-Adduct (Kinetic Product) | % 1,4-Adduct (Thermodynamic Product) | Predominant Control |
| -80 | 80 | 20 | Kinetic |
| 0 | 71 | 29 | Kinetic |
| 40 | 15 | 85 | Thermodynamic |
Enolate Formation from an Unsymmetrical Ketone
The deprotonation of an unsymmetrical ketone, such as 2-methylcyclohexanone, can result in the formation of two different enolates: the kinetic enolate and the thermodynamic enolate.
The kinetic enolate is formed by removing a proton from the less sterically hindered α-carbon.[7] This is achieved using a strong, bulky, non-nucleophilic base at low temperatures. The thermodynamic enolate is the more substituted and therefore more stable enolate, and its formation is favored by using a smaller, strong base at higher temperatures, which allows for equilibration.[7]
Data Presentation: Enolate Formation from 2-Methylcyclohexanone
| Conditions | Base | Temperature (°C) | % Kinetic Enolate | % Thermodynamic Enolate | Predominant Control |
| Irreversible | Lithium diisopropylamide (LDA) | -78 | >99 | <1 | Kinetic |
| Reversible | Sodium ethoxide | 25 | ~30 | ~70 | Thermodynamic |
Diels-Alder Reaction of Cyclopentadiene and Maleic Anhydride
The Diels-Alder reaction, a [4+2] cycloaddition, can also exhibit kinetic and thermodynamic control, particularly in the formation of endo and exo stereoisomers. In the reaction between cyclopentadiene and maleic anhydride, the endo product is formed faster and is therefore the kinetic product.[8] The exo product is sterically less hindered and more stable, making it the thermodynamic product.[9]
At lower temperatures, the reaction is under kinetic control and the endo product predominates.[9] At higher temperatures, the reverse Diels-Alder reaction becomes significant, allowing for equilibration to the more stable exo product.[9]
Data Presentation: Diels-Alder Reaction of Cyclopentadiene and Maleic Anhydride
| Temperature (°C) | % endo Adduct (Kinetic Product) | % exo Adduct (Thermodynamic Product) | Predominant Control |
| 25 (Room Temperature) | >95 | <5 | Kinetic |
| 140 (Reflux in xylene) | ~20 | ~80 | Thermodynamic |
Experimental Protocols
Protocol 1: Kinetic and Thermodynamic Control in the Addition of HBr to 1,3-Butadiene
Objective: To observe the effect of temperature on the product distribution of the addition of HBr to 1,3-butadiene.
Materials:
-
1,3-butadiene (liquefied gas)
-
Hydrogen bromide (gas or solution in acetic acid)
-
Dry ice/acetone bath (-78 °C)
-
Water bath (40 °C)
-
Reaction vessels (e.g., Schlenk tubes)
-
Gas chromatography-mass spectrometry (GC-MS) for product analysis
Procedure:
Kinetic Control (-78 °C):
-
Cool a reaction vessel containing a suitable solvent (e.g., dichloromethane) to -78 °C using a dry ice/acetone bath.
-
Bubble a known amount of 1,3-butadiene gas into the cold solvent.
-
Slowly bubble a stoichiometric equivalent of hydrogen bromide gas through the solution, or add a solution of HBr in acetic acid dropwise, while maintaining the temperature at -78 °C.
-
Allow the reaction to proceed for a short period (e.g., 30 minutes).
-
Quench the reaction by adding a cold, weak base (e.g., saturated sodium bicarbonate solution).
-
Extract the organic layer, dry it over anhydrous sodium sulfate, and analyze the product mixture by GC-MS to determine the ratio of 1,2- to 1,4-adducts.
Thermodynamic Control (40 °C):
-
In a separate reaction vessel, dissolve 1,3-butadiene in a suitable solvent.
-
Add a stoichiometric equivalent of hydrogen bromide (as a gas or solution).
-
Heat the reaction mixture in a water bath at 40 °C for an extended period (e.g., 2 hours) to allow the reaction to reach equilibrium.
-
Cool the reaction mixture and work up as described for the kinetic control experiment.
-
Analyze the product mixture by GC-MS to determine the ratio of 1,2- to 1,4-adducts.
Protocol 2: Regioselective Formation of Enolates from 2-Methylcyclohexanone
Objective: To selectively generate the kinetic and thermodynamic enolates of 2-methylcyclohexanone and trap them with an electrophile.
Materials:
-
2-methylcyclohexanone
-
Lithium diisopropylamide (LDA) solution in THF
-
Sodium ethoxide
-
Trimethylsilyl chloride (TMSCl) as a trapping agent
-
Anhydrous tetrahydrofuran (THF)
-
Dry ice/acetone bath (-78 °C)
-
NMR spectroscopy for product analysis
Procedure:
Kinetic Enolate Formation:
-
To a flame-dried, nitrogen-flushed flask, add anhydrous THF and cool to -78 °C.
-
Add a solution of LDA in THF dropwise to the cooled solvent.
-
Slowly add a solution of 2-methylcyclohexanone in THF to the LDA solution at -78 °C. Stir for 30 minutes.
-
Add TMSCl to the reaction mixture to trap the enolate as its silyl enol ether.
-
Allow the reaction to warm to room temperature, then quench with a saturated aqueous solution of sodium bicarbonate.
-
Extract the organic layer, dry, and concentrate. Analyze the product by NMR to determine the ratio of the kinetic and thermodynamic silyl enol ethers.
Thermodynamic Enolate Formation:
-
To a flask containing sodium ethoxide in ethanol at room temperature, add 2-methylcyclohexanone.
-
Stir the mixture at room temperature for several hours to allow for equilibration.
-
Add TMSCl to trap the enolate.
-
Work up the reaction as described for the kinetic enolate formation.
-
Analyze the product by NMR to determine the product ratio.
Protocol 3: The Diels-Alder Reaction - Kinetic and Thermodynamic Products
Objective: To synthesize and characterize the kinetic and thermodynamic products of the Diels-Alder reaction between cyclopentadiene and maleic anhydride.
Materials:
-
Dicyclopentadiene
-
Maleic anhydride
-
Ethyl acetate
-
Hexane
-
Xylene
-
Apparatus for fractional distillation
-
Reflux apparatus
-
Melting point apparatus
Procedure:
Preparation of Cyclopentadiene:
-
Set up a fractional distillation apparatus.
-
Gently heat dicyclopentadiene to "crack" it into cyclopentadiene monomers (retro-Diels-Alder).
-
Collect the freshly distilled cyclopentadiene and keep it on ice.
Kinetic Control (Room Temperature):
-
Dissolve maleic anhydride in ethyl acetate in a flask.
-
Add hexane to the solution.
-
Add the freshly prepared, cold cyclopentadiene to the maleic anhydride solution.
-
Allow the reaction to proceed at room temperature. The endo product should precipitate out of the solution.
-
Collect the crystals by vacuum filtration and determine their melting point.
Thermodynamic Control (High Temperature):
-
In a round-bottom flask equipped with a reflux condenser, dissolve the kinetically formed endo product in xylene.
-
Heat the solution to reflux for 1-2 hours. This will establish an equilibrium between the endo and exo products via a retro-Diels-Alder/Diels-Alder sequence.
-
Cool the solution slowly to allow the more stable exo product to crystallize.
-
Collect the crystals and determine their melting point. Compare it to the melting point of the kinetic product.
Visualizing Reaction Pathways
The energetic differences between kinetic and thermodynamic pathways can be visualized using reaction coordinate diagrams.
Caption: Reaction coordinate diagram for kinetic vs. thermodynamic control.
This diagram illustrates that the kinetic product has a lower activation energy (Ea), leading to a faster rate of formation. The thermodynamic product is at a lower overall energy level, indicating greater stability.
Caption: Decision workflow for determining reaction control.
This workflow provides a logical sequence for predicting whether a reaction will be under kinetic or thermodynamic control based on the reaction conditions.
By understanding and applying the principles outlined in this guide, researchers can effectively steer chemical reactions towards the desired outcomes, a critical skill in the fields of chemical synthesis and drug development.
References
- 1. 14.3 Kinetic versus Thermodynamic Control of Reactions - Organic Chemistry | OpenStax [openstax.org]
- 2. ochemacademy.com [ochemacademy.com]
- 3. masterorganicchemistry.com [masterorganicchemistry.com]
- 4. dalalinstitute.com [dalalinstitute.com]
- 5. chem.libretexts.org [chem.libretexts.org]
- 6. chem.libretexts.org [chem.libretexts.org]
- 7. researchgate.net [researchgate.net]
- 8. scribd.com [scribd.com]
- 9. masterorganicchemistry.com [masterorganicchemistry.com]
A Researcher's Guide to Enzyme Inhibition: A Comparative Analysis for the MCAT
For professionals in research, science, and drug development, a thorough understanding of enzyme kinetics and inhibition is paramount. This guide provides a comprehensive comparison of the different types of reversible enzyme inhibitors—competitive, non-competitive, uncompetitive, and mixed—with a focus on the concepts frequently tested on the MCAT. We will delve into their mechanisms of action, effects on kinetic parameters, and the experimental protocols used for their characterization.
Comparing the Four Major Types of Reversible Enzyme Inhibition
The four main types of reversible enzyme inhibition can be distinguished by how the inhibitor interacts with the enzyme and the enzyme-substrate complex. These differences lead to distinct effects on the enzyme's kinetic parameters, namely the maximum velocity (Vmax) and the Michaelis constant (Km).
Vmax represents the maximum rate of the reaction when the enzyme is saturated with substrate.[1] Km , the Michaelis constant, is the substrate concentration at which the reaction rate is half of Vmax and is an inverse measure of the substrate's affinity for the enzyme.[1][2]
The following table summarizes the key distinctions between the different inhibitor types:
| Inhibitor Type | Binding Site | Effect on Vmax | Effect on Km | Lineweaver-Burk Plot |
| Competitive | Active Site | Unchanged | Increases | Lines intersect at the y-axis |
| Non-competitive | Allosteric Site | Decreases | Unchanged | Lines intersect at the x-axis |
| Uncompetitive | Enzyme-Substrate (ES) Complex | Decreases | Decreases | Parallel lines |
| Mixed | Allosteric Site (binds to both E and ES) | Decreases | Increases or Decreases | Lines intersect at a point other than the axes |
Visualizing Inhibition Mechanisms
The interactions between enzymes, substrates, and inhibitors can be represented through logical diagrams. These visualizations help clarify the distinct mechanism of each inhibitor type.
In competitive inhibition, the inhibitor directly competes with the substrate for the active site of the enzyme.[3][4]
A non-competitive inhibitor binds to an allosteric site, a location other than the active site, and can bind to either the free enzyme or the enzyme-substrate complex.[3][4]
An uncompetitive inhibitor binds only to the enzyme-substrate complex, at a site distinct from the active site.[3][5]
Experimental Protocol: Determining the Type of Enzyme Inhibition
The following is a detailed protocol for a continuous spectrophotometric assay to determine the type of enzyme inhibition.
Objective: To determine the mode of inhibition of a test compound on a specific enzyme by measuring the initial reaction velocities at various substrate and inhibitor concentrations.
Materials:
-
Purified enzyme
-
Substrate
-
Test inhibitor compound
-
Assay buffer (optimized for pH and ionic strength for the specific enzyme)
-
Spectrophotometer (UV-Vis)
-
Cuvettes or 96-well microplates
-
Pipettes and tips
-
Reagent reservoirs
Procedure:
-
Preparation of Reagents:
-
Prepare a stock solution of the enzyme in the assay buffer. The final concentration should be such that a linear reaction rate is observed for a sufficient duration.
-
Prepare a stock solution of the substrate in the assay buffer. A series of dilutions will be made from this stock.
-
Prepare a stock solution of the inhibitor in a suitable solvent (e.g., DMSO), and then dilute it in the assay buffer to the desired concentrations. Ensure the final solvent concentration is constant across all assays and does not affect enzyme activity.
-
-
Determination of Optimal Enzyme Concentration:
-
Perform a preliminary assay with a fixed, saturating concentration of substrate and varying concentrations of the enzyme to determine an enzyme concentration that yields a robust and linear rate of product formation over a few minutes.
-
-
Enzyme Kinetics without Inhibitor:
-
Set up a series of reactions with a fixed enzyme concentration and varying substrate concentrations (e.g., 0.25x, 0.5x, 1x, 2x, 4x, 8x Km, if Km is known or estimated).
-
Initiate the reaction by adding the substrate.
-
Measure the change in absorbance over time at a wavelength specific for the product or a coupled reporter molecule.
-
Calculate the initial velocity (V₀) for each substrate concentration from the linear portion of the absorbance vs. time plot.
-
Plot V₀ versus substrate concentration ([S]) to generate a Michaelis-Menten curve.
-
Plot 1/V₀ versus 1/[S] to generate a Lineweaver-Burk plot and determine the Vmax and Km.
-
-
Enzyme Kinetics with Inhibitor:
-
Repeat the enzyme kinetics experiment (step 3) in the presence of a fixed concentration of the inhibitor. It is recommended to use at least two different inhibitor concentrations.
-
For each inhibitor concentration, measure the initial velocities at the same range of substrate concentrations used previously.
-
-
Data Analysis:
-
Plot the Michaelis-Menten and Lineweaver-Burk plots for the uninhibited reaction and for each inhibitor concentration on the same graphs.
-
Analyze the changes in the apparent Vmax and Km in the presence of the inhibitor to determine the type of inhibition, as summarized in the table above.
-
Case Study: Allosteric Inhibition of Phosphofructokinase in Glycolysis
A key regulatory point in the glycolytic pathway is the enzyme phosphofructokinase-1 (PFK-1) , which catalyzes the conversion of fructose-6-phosphate to fructose-1,6-bisphosphate.[4][5] PFK-1 is allosterically inhibited by high levels of ATP.[4][6][7] When ATP levels are high, it signifies that the cell has an abundance of energy, and thus, glycolysis can be slowed down. ATP binds to an allosteric site on PFK-1, inducing a conformational change that decreases the enzyme's affinity for its substrate, fructose-6-phosphate.[6][7] This is a classic example of non-competitive inhibition, as ATP does not bind to the active site.
This guide provides a foundational understanding of enzyme inhibition, crucial for both academic success on the this compound and practical applications in scientific research and drug development. The ability to design, execute, and interpret enzyme kinetic experiments is a fundamental skill for any scientist in the life sciences.
References
- 1. Experimental Enzyme Kinetics; Linear Plots and Enzyme Inhibition – BIOC*2580: Introduction to Biochemistry [ecampusontario.pressbooks.pub]
- 2. Mechanism of Action Assays for Enzymes - Assay Guidance Manual - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 3. quora.com [quora.com]
- 4. Phosphofructokinase 1 - Wikipedia [en.wikipedia.org]
- 5. jackwestin.com [jackwestin.com]
- 6. letstalkacademy.com [letstalkacademy.com]
- 7. letstalkacademy.com [letstalkacademy.com]
Validating Experimental Design: A Researcher's Guide to MCAT Passage Analysis
For researchers, scientists, and professionals in drug development, the ability to critically evaluate experimental design is paramount. The MCAT, a standardized test for aspiring medical students, rigorously assesses this skill through research-based passages. This guide provides a comparative analysis of two fictitious this compound-style research passages—one exemplifying a well-designed experiment and the other a flawed design—to highlight the key principles of experimental validation.
Passage 1: A Well-Designed Study on a Novel Kinase Inhibitor
Research Focus: A study investigating the efficacy of a novel small molecule, "Inhibitor-X," in blocking the signaling pathway of a receptor tyrosine kinase (RTK), "Kinase-A," which is implicated in uncontrolled cell proliferation in certain cancers.
Experimental Protocol:
Cell Culture and Treatment: Human colorectal cancer cells (HCT116) overexpressing Kinase-A were cultured. The cells were divided into four groups:
-
Vehicle Control: Treated with the solvent used to dissolve Inhibitor-X.
-
Inhibitor-X (10 µM): Treated with a 10 µM concentration of Inhibitor-X.
-
Positive Control (Ligand-A): Treated with Ligand-A, the known activator of Kinase-A.
-
Inhibitor-X + Ligand-A: Pre-treated with 10 µM Inhibitor-X for 1 hour, followed by stimulation with Ligand-A.
Western Blot Analysis: After 24 hours of treatment, cell lysates were collected to measure the phosphorylation of "Protein-B," a downstream target of Kinase-A. The total amount of Protein-B was also measured to ensure that changes in phosphorylation were not due to changes in the total amount of the protein.
Cell Proliferation Assay: HCT116 cells were seeded in 96-well plates and treated as described above. Cell proliferation was measured at 48 hours using a colorimetric assay.
Data Presentation:
| Treatment Group | Phosphorylated Protein-B (Relative Units) | Total Protein-B (Relative Units) | Cell Proliferation (Absorbance at 450 nm) |
| Vehicle Control | 1.0 ± 0.1 | 1.0 ± 0.05 | 0.25 ± 0.03 |
| Inhibitor-X (10 µM) | 0.9 ± 0.12 | 1.0 ± 0.06 | 0.24 ± 0.04 |
| Positive Control (Ligand-A) | 5.2 ± 0.4 | 1.0 ± 0.07 | 0.85 ± 0.05 |
| Inhibitor-X + Ligand-A | 1.5 ± 0.2 | 1.0 ± 0.05 | 0.30 ± 0.04 |
Signaling Pathway and Experimental Workflow:
Analysis of Experimental Design:
This study demonstrates a robust experimental design. The inclusion of a vehicle control is crucial to ensure that the solvent used to deliver Inhibitor-X has no effect on its own. The positive control (Ligand-A) confirms that the signaling pathway is active and can be stimulated, providing a baseline for the inhibitory effect. The use of a combination treatment (Inhibitor-X + Ligand-A) directly tests the hypothesis that Inhibitor-X can block the ligand-induced activation of the pathway. Furthermore, measuring both phosphorylated and total Protein-B is a critical control to ensure that the observed decrease in the phosphorylated form is due to the inhibitor's activity and not a general decrease in the protein's expression.
Passage 2: A Flawed Study on a New "Miracle" Weight-Loss Supplement
Research Focus: An investigation into the effectiveness of a new herbal supplement, "Slim-Fast-Herb," on weight loss in adults.
Experimental Protocol:
Participant Recruitment: Researchers recruited 100 volunteers who were interested in losing weight through a local newspaper advertisement. All participants were instructed to take one capsule of Slim-Fast-Herb daily for 30 days and to "try to eat healthier."
Data Collection: Participants' weight was measured at the beginning and end of the 30-day period. At the end of the study, participants also completed a survey about their general mood and energy levels.
Data Presentation:
| Time Point | Average Weight (lbs) |
| Day 1 | 185.4 ± 20.1 |
| Day 30 | 180.2 ± 19.5 |
Survey Results: 78% of participants reported feeling "more energetic" and having an "improved mood."
Logical Flaws in Experimental Design:
Analysis of Experimental Design:
-
Lack of a Control Group: The most significant flaw is the absence of a control group. Without a group that receives a placebo (an identical-looking capsule with no active ingredient), it is impossible to determine if the observed weight loss is due to the supplement or the placebo effect .
-
Confounding Variables: The instruction to "try to eat healthier" introduces a major confounding variable. The weight loss could be entirely attributable to changes in diet and not the supplement. A well-designed study would have standardized the diet for all participants or had a control group that also received the same dietary advice.
-
Selection Bias: Recruiting volunteers who are already motivated to lose weight introduces selection bias. This group is not representative of the general population and may be more likely to lose weight regardless of the intervention.
-
Subjective Measurements: The survey data on mood and energy levels are subjective and not quantifiable in a standardized way, making them unreliable measures of the supplement's effects.
Comparison and Conclusion
comparing the properties of different functional groups for the MCAT
For researchers, scientists, and drug development professionals preparing for the MCAT, a thorough understanding of functional groups is paramount. This guide provides a comprehensive comparison of the key properties of common functional groups, supported by quantitative data and detailed experimental protocols.
Properties of Common Functional Groups
The behavior of organic molecules is largely dictated by the functional groups they contain. These groups of atoms determine a molecule's polarity, acidity, basicity, and reactivity, which in turn influences its physical properties and biological activity.
Polarity and Boiling Point
The polarity of a functional group, arising from differences in electronegativity between atoms, significantly impacts a molecule's boiling point. More polar molecules exhibit stronger intermolecular forces, such as dipole-dipole interactions and hydrogen bonding, requiring more energy to transition into the gaseous phase.
Hydrogen bonding is a particularly strong type of dipole-dipole interaction that occurs when hydrogen is bonded to a highly electronegative atom like oxygen or nitrogen. Functional groups capable of hydrogen bonding, such as alcohols and carboxylic acids, have notably higher boiling points compared to those that cannot, like aldehydes, ketones, and ethers, even with similar molecular weights.[1][2][3][4][5]
Acidity and Basicity
The acidity or basicity of a functional group is a critical factor in its reactivity and is quantified by the pKa value. A lower pKa corresponds to a stronger acid.[6] The stability of the conjugate base is a key determinant of acidity; functional groups with more stable conjugate bases, often due to resonance stabilization, are more acidic.[7] For example, carboxylic acids are significantly more acidic than alcohols because the carboxylate conjugate base is resonance-stabilized.[7][8] Amines, on the other hand, are typically basic due to the lone pair of electrons on the nitrogen atom, which can accept a proton.
Data Presentation: Comparison of Functional Group Properties
The following table summarizes the key quantitative data for common functional groups encountered on the this compound.
| Functional Group | Structure | Polarity | Boiling Point (relative to alkanes of similar MW) | Approximate pKa | Characteristic IR Absorption (cm⁻¹) |
| Alkane | R-CH₃ | Nonpolar | Baseline | ~50 | 2850-2960 (C-H stretch) |
| Alkene | R₂C=CR₂ | Nonpolar | Similar to Alkanes | ~44 | 3020-3100 (C-H stretch), 1640-1680 (C=C stretch)[9][10] |
| Alkyne | RC≡CR | Nonpolar | Similar to Alkanes | ~25[11] | ~3300 (C-H stretch, terminal), 2100-2260 (C≡C stretch)[9] |
| Alcohol | R-OH | Polar (H-bonding) | Higher | ~15-18[6][8][11] | 3200-3600 (broad O-H stretch)[12] |
| Aldehyde | R-CHO | Polar | Higher | ~17 (α-hydrogen) | 1700-1740 (strong C=O stretch), 2700-2800 (C-H stretch)[10][13] |
| Ketone | R-CO-R | Polar | Higher | ~20 (α-hydrogen)[6][11] | 1700-1725 (strong C=O stretch)[13] |
| Carboxylic Acid | R-COOH | Very Polar (H-bonding) | Significantly Higher | ~4-5[6][11] | 2500-3300 (broad O-H stretch), 1700-1725 (C=O stretch)[9][12] |
| Ester | R-COOR' | Polar | Similar to Aldehydes/Ketones | ~25 (α-hydrogen)[11] | 1735-1750 (strong C=O stretch), 1000-1300 (C-O stretch)[13] |
| Ether | R-O-R' | Slightly Polar | Lower | - | 1000-1300 (C-O stretch)[13] |
| Amine | R-NH₂ | Polar (H-bonding) | Higher | ~38-40 (as acid), ~9-11 (protonated amine as acid)[11][14] | 3300-3500 (N-H stretch)[9] |
| Amide | R-CONH₂ | Very Polar (H-bonding) | Significantly Higher | ~17 (as acid) | 3100-3500 (N-H stretch), 1630-1690 (C=O stretch)[9] |
Experimental Protocols
Determining the pKa of a Weak Acid by Titration
This method involves titrating a weak acid with a strong base and monitoring the pH to determine the acid's dissociation constant (pKa).
Methodology:
-
Preparation: A known concentration of the weak acid is placed in a beaker. A standardized solution of a strong base (e.g., NaOH) is placed in a burette.[15]
-
Titration: The strong base is added to the weak acid in small increments. After each addition, the solution is stirred, and the pH is recorded using a calibrated pH meter.[15][16][17]
-
Data Analysis: A titration curve is generated by plotting the pH (y-axis) versus the volume of base added (x-axis).[15][17]
-
Equivalence Point Determination: The equivalence point is the point of inflection on the titration curve where the moles of added base equal the initial moles of the acid.
-
pKa Determination: The pKa is the pH at the half-equivalence point, where the concentrations of the weak acid and its conjugate base are equal.[17] This can be determined by finding the volume of base at the equivalence point and then finding the pH at half of that volume on the curve.[17]
Qualitative Tests for Aldehydes and Ketones
Simple chemical tests can be used to differentiate between aldehydes and ketones based on their differing reactivity, particularly their susceptibility to oxidation.
1. 2,4-Dinitrophenylhydrazine (2,4-DNP) Test for Carbonyls:
-
Principle: Both aldehydes and ketones react with 2,4-dinitrophenylhydrazine to form a yellow, orange, or red precipitate of a 2,4-dinitrophenylhydrazone. This test confirms the presence of a carbonyl group.[18][19][20]
-
Procedure:
2. Tollen's Test for Aldehydes:
-
Principle: Aldehydes are readily oxidized, while ketones are not. Tollen's reagent, an ammoniacal solution of silver nitrate, is a mild oxidizing agent. Aldehydes reduce the Ag⁺ ions to metallic silver, forming a characteristic silver mirror on the inside of the test tube.[18][20]
-
Procedure:
-
Prepare Tollen's reagent by adding a drop of dilute NaOH to silver nitrate solution to form a precipitate of silver oxide, then adding dilute ammonia solution dropwise until the precipitate dissolves.[18]
-
Add a few drops of the unknown compound to the freshly prepared Tollen's reagent.
-
Warm the mixture in a water bath.[18]
-
The formation of a silver mirror indicates the presence of an aldehyde.[18][19]
-
Visualizations
Caption: Relationship between functional group structure and its properties.
References
- 1. chem.libretexts.org [chem.libretexts.org]
- 2. Consider an alkane, alcohol, aldehyde, and a ketone with similar ... | Study Prep in Pearson+ [pearson.com]
- 3. 24.3 Physical Properties of Aldehydes and Ketones – Organic and Biochemistry Supplement to Enhanced Introductory College Chemistry [ecampusontario.pressbooks.pub]
- 4. scienceready.com.au [scienceready.com.au]
- 5. Physical properties of Aldehydes, Ketones and Carboxylic Acids - GeeksforGeeks [geeksforgeeks.org]
- 6. youtube.com [youtube.com]
- 7. jackwestin.com [jackwestin.com]
- 8. Important Functional Groups for the this compound: Everything You Need to Know — Shemmassian Academic Consulting [shemmassianconsulting.com]
- 9. IR Absorption Table [webspectra.chem.ucla.edu]
- 10. IR _2007 [uanlch.vscht.cz]
- 11. chem.indiana.edu [chem.indiana.edu]
- 12. Spectroscopy for the this compound: Everything You Need to Know — Shemmassian Academic Consulting [shemmassianconsulting.com]
- 13. eng.uc.edu [eng.uc.edu]
- 14. reddit.com [reddit.com]
- 15. egyankosh.ac.in [egyankosh.ac.in]
- 16. Protocol for Determining pKa Using Potentiometric Titration - Creative Bioarray | Creative Bioarray [creative-bioarray.com]
- 17. scribd.com [scribd.com]
- 18. byjus.com [byjus.com]
- 19. uomustansiriyah.edu.iq [uomustansiriyah.edu.iq]
- 20. Aldehydes and Ketones Tests: Simple Guide for Students [vedantu.com]
A Researcher's Guide to Differentiating Enzyme Inhibition: Competitive, Noncompetitive, and Uncompetitive Mechanisms
For researchers, scientists, and professionals in drug development, a thorough understanding of enzyme inhibition is fundamental. The ability to distinguish between competitive, noncompetitive, and uncompetitive inhibition is crucial for elucidating biological pathways, designing novel therapeutics, and interpreting experimental data accurately. This guide provides a comprehensive comparison of these three reversible inhibition mechanisms, supported by experimental data, detailed protocols, and visual representations to facilitate a deeper understanding.
Distinguishing Inhibition Mechanisms at a Glance
The three primary types of reversible enzyme inhibition—competitive, noncompetitive, and uncompetitive—are defined by how the inhibitor interacts with the enzyme and the enzyme-substrate complex. These distinct binding mechanisms lead to characteristic changes in the enzyme's kinetic parameters, namely the Michaelis constant (K_m) and the maximum velocity (V_max).
Competitive inhibition occurs when the inhibitor directly competes with the substrate for binding to the enzyme's active site.[1][2] This means the inhibitor and substrate cannot be bound to the enzyme simultaneously.[1] Consequently, the apparent K_m of the substrate is increased in the presence of a competitive inhibitor, as a higher substrate concentration is required to achieve half-maximal velocity. However, the V_max remains unchanged because, at sufficiently high substrate concentrations, the substrate can outcompete the inhibitor and the reaction can still reach its maximum rate.[1][3]
In noncompetitive inhibition , the inhibitor binds to a site on the enzyme other than the active site, known as an allosteric site.[3][4] This binding event can occur whether the substrate is bound to the enzyme or not.[4] The inhibitor's binding alters the enzyme's conformation, reducing its catalytic efficiency without affecting substrate binding.[3] As a result, noncompetitive inhibition leads to a decrease in V_max, but the K_m remains unchanged.[1][3]
Uncompetitive inhibition presents a unique scenario where the inhibitor binds exclusively to the enzyme-substrate (ES) complex, and not to the free enzyme.[1][2] This binding to the ES complex effectively sequesters it, leading to a decrease in both the apparent V_max and the apparent K_m.[1][3] The reduction in K_m might seem counterintuitive, but it is because the inhibitor binding to the ES complex shifts the equilibrium towards the formation of the ES complex, thereby increasing the enzyme's apparent affinity for the substrate.
Quantitative Comparison of Inhibition Types
The impact of each inhibitor type on the key kinetic parameters, K_m and V_max, can be summarized and quantified. The following table presents a hypothetical dataset for an enzyme-catalyzed reaction in the absence and presence of each type of inhibitor. This data illustrates the characteristic changes that can be experimentally observed.
| Condition | Inhibitor Concentration | Apparent K_m (μM) | Apparent V_max (μmol/min) |
| No Inhibitor | 0 | 10 | 100 |
| Competitive Inhibitor | [I] | 20 (Increased) | 100 (Unchanged) |
| Noncompetitive Inhibitor | [I] | 10 (Unchanged) | 50 (Decreased) |
| Uncompetitive Inhibitor | [I] | 5 (Decreased) | 50 (Decreased) |
These changes can be graphically represented using Michaelis-Menten and Lineweaver-Burk plots, which are indispensable tools for diagnosing the type of inhibition.
Visualizing Inhibition Mechanisms and Workflows
Visual diagrams can greatly aid in understanding the complex interactions in enzyme inhibition. The following diagrams, generated using Graphviz (DOT language), illustrate the binding mechanisms of each inhibitor and a typical experimental workflow for their characterization.
Experimental Protocols
To experimentally determine the type of inhibition, a series of enzyme assays must be performed. The following is a generalized protocol that can be adapted for various enzymes and inhibitors, with specific examples for acetylcholinesterase and trypsin inhibition assays.
General Protocol for Enzyme Inhibition Assay
This protocol outlines the fundamental steps for conducting an enzyme inhibition study.[5]
Materials and Reagents:
-
Purified enzyme
-
Substrate specific to the enzyme
-
Inhibitor compound
-
Appropriate buffer solution (e.g., phosphate buffer, pH 7.4)
-
Cofactors, if required by the enzyme
-
Spectrophotometer or microplate reader
-
Cuvettes or 96-well plates
-
Pipettes and tips
-
Distilled water
Procedure:
-
Preparation of Solutions: Prepare stock solutions of the enzyme, substrate, and inhibitor in the appropriate buffer. The buffer's pH should be optimal for enzyme activity.
-
Enzyme Concentration Determination: Perform a preliminary experiment to determine an enzyme concentration that yields a linear reaction rate for a convenient duration (e.g., 5-10 minutes).
-
Assay Setup:
-
No Inhibitor Control: In a series of tubes or wells, add a fixed amount of enzyme and varying concentrations of the substrate.
-
With Inhibitor: In separate series of tubes or wells, add the same fixed amount of enzyme, a fixed concentration of the inhibitor, and the same varying concentrations of the substrate. Repeat this for several different fixed inhibitor concentrations.
-
-
Reaction Initiation: Initiate the reaction by adding the substrate to the enzyme/inhibitor mixture (or enzyme to the substrate/inhibitor mixture).
-
Data Collection: Measure the initial reaction velocity (v₀) for each reaction. This is typically done by monitoring the change in absorbance of a product or substrate over time using a spectrophotometer.
-
Data Analysis:
-
Plot v₀ versus substrate concentration ([S]) to generate Michaelis-Menten plots for the uninhibited and inhibited reactions.
-
Transform the data into a double reciprocal plot (1/v₀ vs. 1/[S]) to create Lineweaver-Burk plots.
-
Determine the apparent K_m and V_max values from the intercepts of the Lineweaver-Burk plots.
-
Analyze the changes in K_m and V_max to identify the type of inhibition.
-
For a more detailed analysis, Dixon plots (1/v₀ vs. [I]) or Cornish-Bowden plots can be used to determine the inhibition constant (K_i).
-
Example Protocol: Acetylcholinesterase (AChE) Inhibition Assay
This assay is commonly used in drug discovery for Alzheimer's disease.[6]
Principle: AChE hydrolyzes acetylthiocholine to thiocholine, which then reacts with 5,5'-dithiobis-(2-nitrobenzoic acid) (DTNB, Ellman's reagent) to produce a yellow-colored product that can be measured spectrophotometrically at 412 nm.
Specific Reagents:
-
Acetylcholinesterase (AChE)
-
Acetylthiocholine iodide (substrate)
-
DTNB
-
Phosphate buffer (pH 8.0)
-
Test inhibitor
Procedure:
-
In a 96-well plate, add 140 µL of phosphate buffer, 10 µL of the test inhibitor solution (or buffer for control), and 10 µL of AChE solution to each well.[6]
-
Incubate the plate for 10 minutes at 25°C.[6]
-
Add 10 µL of 10 mM DTNB to each well.[6]
-
Initiate the reaction by adding 10 µL of 14 mM acetylthiocholine iodide.[6]
-
Shake the plate for 1 minute and then add 20 µL of 5% SDS to stop the reaction after a set time (e.g., 10 minutes).[6]
-
Measure the absorbance at 412 nm.
-
Calculate the percentage of inhibition and proceed with kinetic analysis as described in the general protocol.
Example Protocol: Trypsin Inhibition Assay
This assay is frequently used to screen for protease inhibitors.[7]
Principle: Trypsin, a serine protease, hydrolyzes Nα-Benzoyl-L-arginine 4-nitroanilide hydrochloride (L-BAPNA), releasing p-nitroaniline, which is yellow and can be quantified by measuring absorbance at 410 nm.
Specific Reagents:
-
Trypsin
-
L-BAPNA (substrate)
-
Tris-HCl buffer (pH 8.2) with CaCl₂
-
Test inhibitor
Procedure:
-
Prepare a trypsin solution and a stock solution of L-BAPNA.[7]
-
In microtubes, set up a "blank" (buffer and substrate), a "control" (buffer, enzyme, and substrate), and a "test" (buffer, enzyme, inhibitor, and substrate).[7]
-
For the test sample, pre-incubate the enzyme with the inhibitor for a defined period.
-
Initiate the reaction by adding the L-BAPNA solution.
-
After a specific incubation time, stop the reaction (e.g., by adding acetic acid).
-
Measure the absorbance at 410 nm.
-
Perform kinetic analysis by varying substrate and inhibitor concentrations as outlined in the general protocol.
By carefully designing and executing these experiments and analyzing the resulting data, researchers can confidently distinguish between competitive, noncompetitive, and uncompetitive inhibition, thereby gaining valuable insights into the mechanism of action of potential drug candidates and regulatory molecules.
References
- 1. Khan Academy [khanacademy.org]
- 2. labs.plb.ucdavis.edu [labs.plb.ucdavis.edu]
- 3. Physiology, Noncompetitive Inhibitor - StatPearls - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 4. Non-competitive inhibition - Wikipedia [en.wikipedia.org]
- 5. superchemistryclasses.com [superchemistryclasses.com]
- 6. 3.10. Acetylcholinesterase Inhibition Assay [bio-protocol.org]
- 7. protocols.io [protocols.io]
A Comparative Guide to the Structures and Functions of Carbohydrates and Lipids
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive comparison of the structural and functional characteristics of carbohydrates and lipids. It is designed to be a valuable resource for researchers, scientists, and professionals in drug development, offering objective comparisons supported by experimental data and detailed methodologies.
Structural Comparison
Carbohydrates and lipids are fundamental organic macromolecules essential for life, yet they possess distinct structural features that dictate their diverse functions. Both are primarily composed of carbon, hydrogen, and oxygen, though lipids have a significantly lower oxygen content.
Carbohydrates are polymers made up of monosaccharide monomers, which are simple sugars like glucose and fructose. These monomers can link together via glycosidic bonds to form disaccharides (e.g., sucrose), oligosaccharides, and polysaccharides (e.g., starch, glycogen, cellulose). Their general empirical formula is (CH₂)n.
Lipids are a more heterogeneous group of molecules, broadly defined by their hydrophobicity. They are not true polymers in the same sense as carbohydrates. The major classes of lipids include fatty acids, triglycerides, phospholipids, and steroids. Fatty acids are long hydrocarbon chains with a carboxyl group. Triglycerides, the primary form of fat storage, consist of a glycerol molecule esterified with three fatty acids. Phospholipids, the main components of cell membranes, are similar to triglycerides but have a phosphate group in place of one fatty acid, rendering them amphipathic.
Functional Comparison: Energy Storage
One of the primary functions of both carbohydrates and lipids is energy storage. However, they differ significantly in their efficiency and the duration for which they store energy.
Quantitative Comparison of Energy Content
Lipids are a more energy-dense form of storage compared to carbohydrates. The higher proportion of C-H bonds in lipids, which are in a more reduced state than the C-O bonds prevalent in carbohydrates, results in a greater energy yield upon oxidation.
| Molecule | Molar Mass ( g/mol ) | Standard Enthalpy of Combustion (kcal/mol) | Energy Yield (kcal/g) |
| Carbohydrate (Glucose) | 180.16 | -673 | ~3.74 |
| Lipid (Palmitic Acid) | 256.42 | -2380 | ~9.3 |
| Lipid (Tripalmitin) | 807.35 | -7510 | ~9.3 |
Note: The experimental values for the heat of combustion can vary slightly depending on the specific experimental conditions.
Experimental Protocol: Bomb Calorimetry
The energy content of carbohydrates and lipids is experimentally determined using a bomb calorimeter.
Principle: A known mass of the substance is completely combusted in a sealed container (the "bomb") filled with excess oxygen. The heat released by the combustion is absorbed by a surrounding water jacket of known volume. The temperature change of the water is measured to calculate the heat of combustion.
Methodology:
-
A pellet of a known mass of the sample (e.g., glucose or palmitic acid) is placed in the sample holder of the bomb calorimeter.
-
A fuse wire is positioned to be in contact with the sample.
-
The bomb is sealed and pressurized with pure oxygen to approximately 25-30 atm.
-
The bomb is submerged in a known volume of water in the calorimeter's insulated bucket.
-
The initial temperature of the water is recorded.
-
The sample is ignited by passing an electric current through the fuse wire.
-
The temperature of the water is monitored, and the maximum temperature reached is recorded.
-
The heat of combustion (q) is calculated using the formula: q = C_cal * ΔT where C_cal is the heat capacity of the calorimeter (determined by combusting a standard substance like benzoic acid) and ΔT is the change in temperature of the water.
-
Corrections are made for the heat released by the combustion of the fuse wire and for the formation of any acids (e.g., nitric acid from residual nitrogen in the air).
Functional Comparison: Role in Cell Structure
Carbohydrates and lipids are integral components of cell membranes, but they contribute to membrane structure and function in different ways.
The Lipid Bilayer: The Foundation of Cell Membranes
The fundamental structure of a cell membrane is the phospholipid bilayer. The amphipathic nature of phospholipids, with their hydrophilic heads and hydrophobic tails, drives their self-assembly into a bilayer in an aqueous environment, forming a selectively permeable barrier.
Glycolipids: Modulators of Membrane Properties and Cell Recognition
Glycolipids are lipids with a carbohydrate attached by a glycosidic bond. They are primarily found on the extracellular surface of the cell membrane and play crucial roles in cell-cell recognition, adhesion, and as receptors.
Quantitative Comparison of Membrane Fluidity
Membrane fluidity is a critical property that affects the function of membrane proteins and transport across the membrane. The composition of lipids, including the presence of cholesterol and glycolipids, significantly influences membrane fluidity. This can be quantified using fluorescence spectroscopy with probes like Laurdan.
| Membrane Composition | Laurdan Generalized Polarization (GP) Value | Interpretation |
| Pure Phospholipid Bilayer (DOPC) | ~ -0.3 | High fluidity (disordered state) |
| DOPC + 30% Cholesterol | ~ 0.1 | Reduced fluidity (more ordered state) |
| Phospholipid Bilayer + Ganglioside (GM1) | Increased GP value (more ordered) | Reduced fluidity |
Note: GP values are relative and can be influenced by temperature and the specific lipid composition of the bilayer.
Experimental Protocol: Measuring Membrane Fluidity with Laurdan
Principle: Laurdan is a fluorescent dye that exhibits a spectral shift depending on the polarity of its environment. In a more fluid, disordered membrane, water molecules can penetrate the bilayer, creating a more polar environment and causing Laurdan's emission to shift to a longer wavelength (red shift). In a more rigid, ordered membrane, water penetration is limited, resulting in a less polar environment and a blue shift in emission. The Generalized Polarization (GP) value is calculated from the intensities at these two wavelengths and provides a quantitative measure of membrane fluidity.
Methodology:
-
Prepare liposomes or isolate cell membranes with the desired lipid composition.
-
Incubate the membranes with a solution of Laurdan to allow the probe to incorporate into the lipid bilayer.
-
Measure the fluorescence emission spectrum of the Laurdan-labeled membranes using a fluorometer, with an excitation wavelength of around 350 nm.
-
Record the fluorescence intensities at 440 nm (I₄₄₀) and 490 nm (I₄₉₀).
-
Calculate the GP value using the following equation: GP = (I₄₄₀ - I₄₉₀) / (I₄₄₀ + I₄₉₀)
-
Higher GP values indicate lower membrane fluidity (a more ordered state), while lower GP values indicate higher membrane fluidity (a more disordered state).
Functional Comparison: Signaling Pathways
Both carbohydrates and lipids are involved in complex signaling pathways that regulate cellular metabolism and other processes.
Insulin Signaling Pathway: Regulating Glucose and Lipid Metabolism
The insulin signaling pathway is a primary example of how carbohydrate and lipid metabolism are interconnected. Insulin, released in response to high blood glucose, triggers a cascade of events that leads to the uptake and storage of glucose, as well as the synthesis of lipids.
Caption: A simplified diagram of the insulin signaling pathway, highlighting key proteins and outcomes.
Glycosphingolipid Signaling Pathway
Glycosphingolipids (GSLs) are not merely structural components but also active participants in signal transduction. They can cluster with other signaling molecules in membrane microdomains (lipid rafts) to initiate or modulate signaling cascades.
Caption: A generalized diagram of a glycosphingolipid-mediated signaling event at the cell membrane.
Experimental Workflows
Lipidomics and Glycomics: A Deeper Dive into Structure
To comprehensively analyze the lipid and carbohydrate components of cells and tissues, researchers employ "omics" approaches.
-
Lipidomics is the large-scale study of the pathways and networks of cellular lipids in biological systems.
-
Glycomics is the comprehensive study of all glycan structures in a cell or organism.
A common experimental workflow for lipidomics involves sample preparation, lipid extraction, separation by liquid chromatography (LC), and analysis by mass spectrometry (MS).
Caption: A typical experimental workflow for a lipidomics study using LC-MS.
This guide has highlighted the key structural and functional distinctions between carbohydrates and lipids, supported by quantitative data and detailed experimental protocols. This information is intended to serve as a valuable reference for researchers and professionals in the fields of biology, chemistry, and drug development.
A Researcher's Guide to Deconstructing MCAT Science Passages: Validating Data and Drawing Conclusions
I. Deconstructing the Experimental Narrative: A Systematic Approach
MCAT science passages are dense with information, often presenting a novel scientific scenario. The initial step is to systematically dissect the experimental design. This involves identifying the fundamental components of the research presented.
Key Experimental Components:
| Component | Description | Relevance to Data Validation |
| Hypothesis | The central question or proposed explanation the study aims to investigate. | All data must be evaluated in the context of supporting or refuting the stated hypothesis. |
| Independent Variable | The variable that is manipulated by the researchers. | Understanding what was changed is crucial to attributing causality to the observed effects. |
| Dependent Variable | The variable that is measured in response to the independent variable. | The validity of the data hinges on the accurate and appropriate measurement of this variable. |
| Controls (Positive and Negative) | Positive controls are expected to produce a known result, validating the experimental setup. Negative controls are expected to produce no result, ruling out confounding factors. | Controls are essential for validating the reliability and specificity of the experimental results.[1] |
| Methodology | The techniques used to conduct the experiment (e.g., Western blot, enzyme kinetics assays). | A critical understanding of the methodology is necessary to interpret the data correctly and recognize potential limitations. |
II. Case Study: Investigating a Novel Receptor Tyrosine Kinase Inhibitor
Experimental Workflow:
The researchers aim to characterize the efficacy and mechanism of a novel small molecule inhibitor, Compound A, on RTK-X activity.
References
Safety Operating Guide
Navigating the Disposal of 4-Methylthioamphetamine (MCAT): A Procedural Guide
For Researchers, Scientists, and Drug Development Professionals: Ensuring safety and compliance in the disposal of controlled substances is paramount. This guide provides essential logistical and safety information for the proper disposal of 4-Methylthioamphetamine (MCAT), a controlled psychoactive substance.
Given that 4-Methylthioamphetamine (this compound) is a controlled substance with hazardous properties, its disposal must be handled with strict adherence to safety protocols and regulatory requirements.[1][2][3] The following procedures are based on general best practices for hazardous chemical waste management and should be adapted to comply with all applicable local, state, and federal regulations.
Immediate Safety and Operational Plan
The disposal of this compound, like any hazardous chemical, requires a systematic approach to minimize risks to personnel and the environment.[4][5] The following steps provide a framework for its proper management as a hazardous waste.
1. Waste Identification and Segregation:
-
Identify as Hazardous Waste: All materials contaminated with this compound, including unused product, solutions, contaminated personal protective equipment (PPE), and labware, must be treated as hazardous waste.[4]
-
Segregate Waste Streams: Do not mix this compound waste with other chemical waste streams unless compatibility has been confirmed.[6][7] Incompatible wastes can lead to dangerous reactions.[7] Maintain separate, clearly labeled containers for solid and liquid this compound waste.[6][8]
2. Proper Containerization:
-
Use Appropriate Containers: Waste containers must be in good condition, free of leaks, and compatible with the chemical properties of this compound.[4][6] High-density polyethylene (HDPE) containers are often a suitable choice for chemical waste.[7]
-
Secure Closures: Containers must have leak-proof, screw-on caps.[6] Avoid using stoppers or parafilm as primary closures.[6] Keep containers closed except when adding waste.[4][6]
-
Secondary Containment: Always place waste containers in a secondary containment system, such as a lab tray or bin, to contain any potential leaks or spills.[6] The secondary container should be capable of holding 110% of the volume of the largest primary container.[6]
3. Labeling and Documentation:
-
Hazardous Waste Labeling: All containers of this compound waste must be clearly labeled with the words "Hazardous Waste."[4][5]
-
Complete Chemical Information: The label must include the full chemical name, "4-Methylthioamphetamine," and the concentration and quantity of the waste.[4][5] Avoid using abbreviations.[5]
Disposal Plan: Step-by-Step Guidance
The disposal of controlled substances is highly regulated and must be conducted through a licensed hazardous waste disposal service.
Step 1: Initial Collection and Storage
-
Collect all this compound-contaminated materials in the appropriately labeled containers as described above.
-
Store the waste in a designated, secure area away from general laboratory traffic.
Step 2: Arrange for Professional Disposal
-
Contact Environmental Health and Safety (EHS): Your institution's EHS department is the primary resource for arranging hazardous waste disposal.[4][5] They can provide specific guidance and schedule a pickup.
-
Licensed Waste Hauler: The disposal of controlled substances must be handled by a licensed and reputable hazardous waste hauler. Your EHS office will coordinate with such a vendor.
Step 3: Final Disposal
-
Incineration: Due to its nature as a potent psychoactive compound, incineration is the recommended method of destruction for this compound to ensure complete breakdown of the molecule. This is a common disposal method for pharmaceutical and controlled substance waste.
Under no circumstances should this compound or any hazardous chemical waste be disposed of down the drain or in the regular trash. [4][5]
Quantitative Data Management
To ensure proper tracking and compliance, maintain a detailed inventory of all this compound waste. The following table can be used as a template for your laboratory's waste management log.
| Waste Container ID | Waste Type (Solid/Liquid) | Composition and Concentration | Volume/Mass (g or mL) | Date Generated | Date of Disposal | Disposal Vendor |
Logical Workflow for this compound Disposal
The following diagram illustrates the decision-making process and workflow for the proper disposal of this compound.
Caption: Workflow for the proper disposal of this compound waste.
References
- 1. 4-Methylthioamphetamine - Wikipedia [en.wikipedia.org]
- 2. 4-Methylthioamphetamine - Expert Committee on Drug Dependence Information Repository [ecddrepository.org]
- 3. britannica.com [britannica.com]
- 4. campussafety.lehigh.edu [campussafety.lehigh.edu]
- 5. How to Dispose of Chemical Waste | Environmental Health and Safety | Case Western Reserve University [case.edu]
- 6. How to Store and Dispose of Hazardous Chemical Waste [blink.ucsd.edu]
- 7. How to Properly Dispose Chemical Hazardous Waste | NSTA [nsta.org]
- 8. google.com [google.com]
Essential Safety and Handling Protocols for Mephedrone (MCAT)
For Immediate Use by Laboratory Professionals
This guide provides critical safety and logistical information for researchers, scientists, and drug development professionals handling Mephedrone (4-methylmethcathinone or MCAT). Adherence to these procedures is essential for minimizing exposure risk and ensuring a safe laboratory environment.
Hazard Assessment and Engineering Controls
Mephedrone is a potent psychoactive substance. The primary routes of occupational exposure are inhalation of airborne particles and dermal contact. A thorough risk assessment should be conducted before any handling activities.
Engineering Controls are the first line of defense. Whenever possible, handle this compound within a certified chemical fume hood or a Class II Type B biosafety cabinet to control airborne particles. For operations with a high potential for aerosol generation, consider the use of containment systems like glove boxes or isolators.
Personal Protective Equipment (PPE)
A comprehensive PPE ensemble is mandatory for all personnel handling this compound. The following table summarizes the required PPE components.
| PPE Component | Specification | Rationale |
| Hand Protection | Double-gloving with nitrile gloves (minimum 4 mil thickness) is recommended.[1] | Provides a barrier against dermal absorption. Double-gloving offers additional protection in case of a tear or puncture in the outer glove. |
| Eye and Face Protection | ANSI Z87.1-compliant safety glasses with side shields are the minimum requirement. A full-face shield worn over safety glasses is recommended when there is a splash hazard.[2] | Protects against accidental splashes of solutions containing this compound or contact with airborne powder. |
| Respiratory Protection | For handling powders outside of a primary engineering control, a NIOSH-approved respirator is required. Options range from an N95 filtering facepiece respirator to a powered air-purifying respirator (PAPR) for higher-risk activities.[3][4] | Minimizes the risk of inhaling fine particles of the compound. The selection of respirator type depends on the quantity of material being handled and the potential for aerosolization. |
| Protective Clothing | A disposable, solid-front gown with long sleeves and tight-fitting cuffs or a lab coat is required.[1] | Prevents contamination of personal clothing and skin. |
| Shoe Covers | Disposable shoe covers should be worn when handling larger quantities of this compound or in the event of a spill.[1] | Prevents the tracking of contaminants out of the designated work area. |
Quantitative Data on PPE
| Parameter | Value/Recommendation | Notes |
| Glove Breakthrough Time (this compound) | Data not available. | In the absence of specific data, it is recommended to change gloves frequently, especially after any known contact. Nitrile gloves are generally preferred for their chemical resistance and tendency to show punctures.[5] |
| Occupational Exposure Band (OEB) for Potent Compounds | OEB 4 (1-10 µg/m³) or OEB 5 (<1 µg/m³) may be appropriate classifications for novel psychoactive substances pending toxicological data.[6] | These bands are used in the pharmaceutical industry to categorize compounds based on their potency and potential health effects, guiding the level of containment and PPE required. |
Experimental Protocols: Safe Handling Procedures
Preparation and Weighing of this compound Powder
-
Designated Area: All handling of this compound powder must occur in a designated area, such as a chemical fume hood.
-
Surface Protection: Line the work surface with absorbent, disposable bench paper.
-
Donning PPE: Follow the donning procedure outlined in section 4.
-
Weighing: Use a containment balance enclosure or perform weighing within a chemical fume hood. Use anti-static tools and weighing paper.
-
Aliquotting: If preparing solutions, add the diluent to the vial containing the pre-weighed this compound to avoid generating dust.
-
Cleaning: After handling, decontaminate all surfaces as described in section 5.
-
Doffing PPE: Carefully remove and dispose of PPE as outlined in section 4.
-
Hand Washing: Wash hands thoroughly with soap and water after removing gloves.
Handling of this compound Solutions
-
Donning PPE: Wear appropriate PPE, including gloves and eye protection.
-
Luer-Lock Syringes: Use syringes with Luer-Lok™ fittings to prevent accidental needle detachment and spraying of the solution.[1]
-
Spill Containment: Always work within a secondary container, such as a tray, to contain any potential spills.
-
Disposal: Dispose of all contaminated materials, including pipette tips and vials, in a designated hazardous waste container.
Donning and Doffing of PPE: A Step-by-Step Guide
Proper donning and doffing procedures are crucial to prevent cross-contamination.
Donning Sequence
-
Hand Hygiene: Wash hands with soap and water or use an alcohol-based hand sanitizer.[7]
-
Gown/Lab Coat: Put on the gown or lab coat, ensuring it is fully fastened.[7]
-
Mask/Respirator: If required, don the mask or respirator. Perform a seal check if using a tight-fitting respirator.[8]
-
Eye Protection: Put on safety glasses or a face shield.[7]
-
Gloves: Don the first pair of gloves, ensuring the cuffs of the gown are tucked inside. Don the second pair of gloves over the first.[7]
Doffing Sequence
-
Outer Gloves: Remove the outer pair of gloves using a glove-to-glove technique (peeling them off without touching the outside with bare skin). Dispose of them in the appropriate waste container.
-
Gown/Lab Coat: Remove the gown or lab coat by rolling it inside out and away from the body. Dispose of it in the appropriate waste container.[9]
-
Hand Hygiene: Perform hand hygiene.
-
Eye/Face Protection: Remove eye and face protection from the back by lifting the headband or earpieces.[9]
-
Mask/Respirator: Remove the mask or respirator without touching the front. Dispose of it appropriately.[9]
-
Inner Gloves: Remove the inner pair of gloves using the same glove-to-glove/skin-to-skin technique.[9]
-
Hand Hygiene: Wash hands thoroughly with soap and water.[9]
Decontamination and Disposal Plan
Surface Decontamination
In the event of a spill or for routine cleaning of work surfaces:
-
Alert Personnel: Notify others in the immediate area.
-
Don PPE: Wear appropriate PPE, including double gloves, a lab coat, eye protection, and a respirator if the spill involves powder.
-
Contain Spill: For liquid spills, cover with an absorbent material. For powder spills, gently cover with damp paper towels to avoid making the powder airborne.
-
Clean Area: Clean the spill area with soap and water.[10] Some sources suggest using a 10% bleach solution followed by a neutralizing agent like sodium thiosulfate for potent compounds, but the efficacy for this compound has not been established.[11]
-
Dispose of Waste: All cleaning materials must be disposed of as hazardous waste.
Disposal of this compound Waste
This compound is a controlled substance in many jurisdictions. All disposal must be in accordance with local, state, and federal regulations.
Recoverable Quantities (Unused or Expired this compound):
-
Must be disposed of through a licensed reverse distributor.[3]
-
The disposal process must be documented on a DEA Form 41 (Registrant Record of Controlled Substances Destroyed) or equivalent local documentation, and witnessed by at least two authorized individuals.[3][4]
-
Store unwanted this compound in a secure, clearly labeled container, segregated from active stock, until it can be transferred to the reverse distributor.[3]
Non-Recoverable Quantities (Empty Vials, Syringes):
-
Residual, non-recoverable amounts of this compound in empty containers can typically be disposed of in a biohazard sharps container.
-
It is best practice to document the "wasting" of any residual amounts on the corresponding usage log.
Workflow Diagrams
Caption: Workflow for the safe handling of powdered this compound in a laboratory setting.
Caption: Decision-making workflow for the proper disposal of this compound waste.
References
- 1. Chemical Resistance | Sempermed Gloves [sempermed.com]
- 2. Glove Selection Chart - Chemical Breakthrough Times | All Safety Products [allsafetyproducts.com]
- 3. cdn.mscdirect.com [cdn.mscdirect.com]
- 4. research.usu.edu [research.usu.edu]
- 5. fishersci.com [fishersci.com]
- 6. glovesbyweb.com [glovesbyweb.com]
- 7. Ansell 8th Edition Chemical Resistance Guide - All American Environmental Services Inc [aaesi.com]
- 8. Glove permeation of chemicals: The state of the art of current practice—Part 2. Research emphases on high boiling point compounds and simulating the donned glove environment - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Glove Selection Guide | Office of Environment, Health & Safety [ehs.berkeley.edu]
- 10. Understanding the EU Chemical Permeation Standard: A Guide to Glove Protection [shieldscientific.com]
- 11. researchgate.net [researchgate.net]
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
