
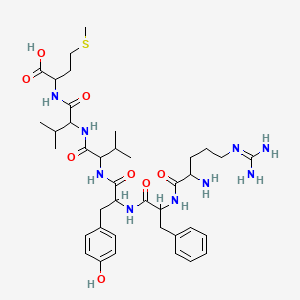
H-Arg-phe-tyr-val-val-met-oh
Description
Structure
2D Structure
Properties
IUPAC Name |
2-[[2-[[2-[[2-[[2-[[2-amino-5-(diaminomethylideneamino)pentanoyl]amino]-3-phenylpropanoyl]amino]-3-(4-hydroxyphenyl)propanoyl]amino]-3-methylbutanoyl]amino]-3-methylbutanoyl]amino]-4-methylsulfanylbutanoic acid |
Source


|
|---|---|---|
| Details | Computed by Lexichem TK 2.7.0 (PubChem release 2021.05.07) | |
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI |
InChI=1S/C39H59N9O8S/c1-22(2)31(36(53)44-28(38(55)56)17-19-57-5)48-37(54)32(23(3)4)47-35(52)30(21-25-13-15-26(49)16-14-25)46-34(51)29(20-24-10-7-6-8-11-24)45-33(50)27(40)12-9-18-43-39(41)42/h6-8,10-11,13-16,22-23,27-32,49H,9,12,17-21,40H2,1-5H3,(H,44,53)(H,45,50)(H,46,51)(H,47,52)(H,48,54)(H,55,56)(H4,41,42,43) |
Source
|
| Details | Computed by InChI 1.0.6 (PubChem release 2021.05.07) | |
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI Key |
CCHSWWYUHREZCY-UHFFFAOYSA-N |
Source
|
| Details | Computed by InChI 1.0.6 (PubChem release 2021.05.07) | |
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Canonical SMILES |
CC(C)C(C(=O)NC(C(C)C)C(=O)NC(CCSC)C(=O)O)NC(=O)C(CC1=CC=C(C=C1)O)NC(=O)C(CC2=CC=CC=C2)NC(=O)C(CCCN=C(N)N)N |
Source
|
| Details | Computed by OEChem 2.3.0 (PubChem release 2021.05.07) | |
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Formula |
C39H59N9O8S |
Source
|
| Details | Computed by PubChem 2.1 (PubChem release 2021.05.07) | |
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Weight |
814.0 g/mol |
Source
|
| Details | Computed by PubChem 2.1 (PubChem release 2021.05.07) | |
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Methodologies for the Synthesis of H Arg Phe Tyr Val Val Met Oh
Chemical Synthesis Approaches for Hexapeptides
Chemical peptide synthesis provides precise control over the peptide's composition and sequence, allowing for the incorporation of unnatural amino acids and various modifications. kbdna.com The primary strategies employed for synthesizing peptides like H-Arg-phe-tyr-val-val-met-oh are Solid-Phase Peptide Synthesis (SPPS) and Liquid-Phase Peptide Synthesis (LPPS). acs.orgnih.gov SPPS, in particular, has become the most widely used method due to its efficiency and suitability for automation. nih.gov LPPS remains a valuable technique, especially for large-scale production of shorter peptides. bachem.com Additionally, hybrid strategies that combine elements of both SPPS and LPPS have been developed to leverage the advantages of each method for the synthesis of more complex or lengthy peptides. kbdna.comcblpatras.gr
Liquid-Phase Peptide Synthesis (LPPS) Methodologies
Liquid-Phase Peptide Synthesis (LPPS), also known as solution-phase synthesis, is the classical method where peptide elongation is carried out entirely in a solution. bachem.comneulandlabs.com Unlike SPPS, the growing peptide chain is not attached to an insoluble resin. To facilitate purification after each step, LPPS often employs soluble tags (e.g., polyethylene glycol) that are attached to the C-terminus of the peptide. acs.orgbachem.com These tags alter the solubility properties of the peptide, allowing for its separation from excess reagents and byproducts through methods like precipitation or extraction. acs.orgbachem.com
LPPS avoids the use of large excesses of reagents often required in SPPS and is well-suited for the large-scale synthesis of shorter peptides. acs.orgbachem.com However, it is generally more labor-intensive than SPPS because it requires the isolation and purification of the peptide intermediate after each coupling step. neulandlabs.com
Comparison of SPPS and LPPS
| Feature | Solid-Phase Peptide Synthesis (SPPS) | Liquid-Phase Peptide Synthesis (LPPS) |
|---|---|---|
| Reaction Environment | Peptide is attached to an insoluble solid support (resin). jpt.com | All reactions occur in solution. acs.org |
| Purification | Excess reagents removed by simple filtration and washing. gyrosproteintechnologies.com | Intermediates purified after each step by precipitation, extraction, or crystallization. bachem.comneulandlabs.com |
| Reagent Usage | Large excess of reagents is typically used to drive reactions to completion. rsc.org | Uses near-stoichiometric amounts of reagents, reducing waste. acs.org |
| Automation | Easily automated. iris-biotech.de | More difficult to automate due to intermediate purification steps. |
| Scalability | Suitable for lab-scale and large-scale synthesis. | Often preferred for very large-scale (industrial) production of shorter peptides. bachem.com |
Hybrid Chemical Synthesis Approaches
Hybrid synthesis approaches combine the methodologies of SPPS and LPPS to leverage the strengths of both techniques. kbdna.com A common hybrid strategy is fragment condensation, where smaller peptide fragments are first synthesized using SPPS, which is efficient for producing peptides up to a certain length. cblpatras.gr These protected fragments are then cleaved from the resin and coupled together in solution (LPPS) to form the final, longer peptide. cblpatras.grambiopharm.com This approach can be more efficient than a continuous stepwise SPPS for very long peptides, as it reduces the potential for cumulative errors and allows for the purification of intermediate fragments, ensuring the final product's purity. cblpatras.gr
Enzymatic Peptide Synthesis Strategies
Enzymatic peptide synthesis offers a green and highly specific alternative to traditional chemical methods, operating under mild conditions and often without the need for extensive protecting group strategies.
Protease-Catalyzed Ligation for Hexapeptide Assembly
Proteases, enzymes that typically hydrolyze peptide bonds, can be used in reverse to catalyze the formation of peptide bonds under specific conditions. This process, known as protease-catalyzed ligation, can be applied to the assembly of this compound. The reaction equilibrium can be shifted towards synthesis by altering the reaction conditions, such as using organic solvents or aqueous-organic mixtures, which suppresses water-dependent hydrolysis.
For the synthesis of a hexapeptide, a combination of stepwise and fragment condensation approaches can be employed. For instance, di- or tripeptide fragments could be synthesized enzymatically and then ligated together. The choice of protease is critical and depends on its substrate specificity. For example, a protease with specificity for the C-terminal of an activated ester of a peptide fragment could be used to ligate it to the N-terminal of another fragment. Serine and cysteine proteases are particularly suitable for kinetically controlled synthesis as they can form acyl-enzyme intermediates.
| Enzyme Class | Example | Optimal pH Range for Ligation | Key Characteristics |
| Serine Proteases | Chymotrypsin, Trypsin | 5-9 | Form acyl-enzyme intermediates, favoring aminolysis over hydrolysis under kinetic control. |
| Cysteine Proteases | Papain, Subtilisin | 5-9 | Also form acyl-enzyme intermediates, with broad specificity in some cases. |
This table provides a general overview of enzyme classes applicable to protease-catalyzed ligation.
A potential enzymatic strategy for this compound could involve the synthesis of fragments like Arg-Phe-Tyr and Val-Val-Met, followed by a protease-catalyzed ligation of these two fragments.
Application of Engineered Ligase Enzymes
To overcome the inherent hydrolytic activity of natural proteases, enzymes have been engineered to function more effectively as ligases. nih.gov These engineered enzymes, often derived from proteases like subtilisin, have mutations that favor the aminolysis (ligation) reaction over hydrolysis. labome.com Subtiligase, a variant of subtilisin, is an example of such an engineered enzyme where the catalytic serine is replaced by a cysteine, significantly reducing hydrolytic activity. frontiersin.org
The use of engineered ligases offers several advantages for the synthesis of this compound:
High Efficiency: They can achieve high yields of the desired peptide.
Specificity: The ligation is highly specific, reducing the formation of byproducts.
Mild Conditions: The reactions are performed in aqueous solutions under physiological-like conditions. nih.gov
Other examples of engineered peptide ligases include sortases and butelases, which recognize specific peptide motifs for ligation. nih.govlabome.com While these often require the incorporation of their recognition sequences, variants with altered specificities are being developed. nih.gov
Recombinant Peptide Synthesis for Hexapeptide Production
Recombinant DNA technology provides a method for producing peptides and proteins by using living organisms, such as bacteria or yeast, as cellular factories. creative-peptides.com For the production of a short peptide like this compound, this method involves designing a synthetic gene that codes for the peptide. This gene is then inserted into an expression vector, which is introduced into a host organism. The host's cellular machinery then transcribes and translates the gene to produce the desired peptide. creative-peptides.com
This approach is particularly advantageous for large-scale production due to its cost-effectiveness. kbdna.com However, for very short peptides, it can be challenging. Often, the hexapeptide would be expressed as part of a larger fusion protein to ensure stability and prevent degradation by host cell proteases. creative-peptides.com A cleavage site is typically engineered between the fusion partner and the target peptide to allow for its release after purification.
| Advantages of Recombinant Synthesis | Challenges of Recombinant Synthesis |
| Cost-effective for large-scale production kbdna.com | Complex purification processes kbdna.com |
| Can produce peptides with complex structures | Potential for immunogenicity of the final product kbdna.com |
| More sustainable with reduced chemical waste kbdna.com | Long development cycles kbdna.com |
This interactive table summarizes the pros and cons of recombinant peptide synthesis.
Challenges and Innovations in Hexapeptide Synthesis Efficiency and Purity
While solid-phase peptide synthesis (SPPS) is a common method for producing peptides, it faces challenges related to efficiency and purity, especially for sequences prone to aggregation or side reactions.
Optimization of Coupling Chemistries and Protecting Groups
The efficiency of peptide bond formation in SPPS is highly dependent on the coupling reagents and the protecting groups used for the amino acid side chains.
Coupling Reagents: Highly efficient coupling reagents such as HATU, HCTU, and COMU are used to increase the speed and completeness of the coupling reaction, thereby minimizing the formation of deletion sequences (peptides missing one or more amino acids). creative-peptides.com These reagents activate the carboxylic acid group of the incoming amino acid, facilitating its reaction with the N-terminal amine of the growing peptide chain. jpt.com
Protecting Groups: The choice of protecting groups for the side chains of amino acids like Arginine (Arg) and Tyrosine (Tyr) is crucial to prevent unwanted side reactions. jpt.com For Fmoc-based SPPS, common protecting groups include Pbf (2,2,4,6,7-pentamethyldihydrobenzofuran-5-sulfonyl) for Arg and tBu (tert-butyl) for Tyr. The selection of these groups must ensure they remain stable throughout the synthesis and are cleanly removed during the final cleavage step without damaging the peptide. jpt.com
Advanced Analytical Characterization of H Arg Phe Tyr Val Val Met Oh
Chromatographic Techniques for Purity and Sequence Analysis
Chromatography is a cornerstone for assessing the purity of peptides by separating the target compound from impurities and by-products of synthesis, such as deletion sequences or incompletely deprotected species.
High-Performance Liquid Chromatography (HPLC) and its advanced iteration, Ultra-Performance Liquid Chromatography (UPLC), are fundamental for peptide separation and purity assessment. creative-proteomics.com These techniques primarily utilize reversed-phase chromatography, where peptides are separated based on their hydrophobicity. waters.com For H-Arg-phe-tyr-val-val-met-oh, the hydrophobic residues (Phe, Tyr, Val, Met) interact with the non-polar stationary phase (typically C18), while a gradient of increasing organic solvent (like acetonitrile) in the mobile phase elutes the peptides. UPLC, which uses columns with smaller particle sizes, offers significantly higher resolution, speed, and sensitivity compared to traditional HPLC, making it particularly valuable for resolving closely related impurities. creative-proteomics.comwaters.com
| Parameter | High-Performance Liquid Chromatography (HPLC) | Ultra-Performance Liquid Chromatography (UPLC) |
|---|---|---|
| Column Particle Size | 3.5 - 5 µm | < 2 µm (e.g., 1.7 µm) |
| Column Dimensions | 4.6 mm x 150 mm (Standard) | 2.1 mm x 50-100 mm |
| Flow Rate | ~1.0 mL/min | ~0.3 - 0.6 mL/min |
| System Pressure | Up to 6,000 psi (400 bar) | Up to 15,000 psi (1000 bar) chromatographytoday.com |
| Resolution | Good | Excellent, with sharper and narrower peaks waters.com |
| Analysis Time | Longer | Significantly shorter creative-proteomics.com |
Ion Exchange Chromatography (IEC) and Hydrophilic Interaction Liquid Chromatography (HILIC) provide alternative selectivity to reversed-phase methods and are often used as orthogonal techniques. waters.com
Ion Exchange Chromatography (IEC) separates molecules based on their net charge. phenomenex.com For the peptide this compound, the presence of the basic Arginine (Arg) residue gives it a net positive charge at an acidic pH. pepdd.com Therefore, cation-exchange chromatography is an effective method for its purification and analysis. The peptide binds to a negatively charged stationary phase and is eluted by increasing the ionic strength or pH of the mobile phase. phenomenex.compepdd.com
Hydrophilic Interaction Liquid Chromatography (HILIC) is a variant of normal-phase chromatography used for separating polar and hydrophilic compounds. chromatographyonline.com It utilizes a polar stationary phase and a mobile phase with a high concentration of organic solvent. polylc.com While this compound has significant hydrophobic character, it is also polar enough to be retained by HILIC columns, offering a separation mechanism that is complementary to reversed-phase chromatography. waters.comwaters.com This technique is particularly useful for separating peptides that are poorly retained in reversed-phase systems. waters.com
| Technique | Stationary Phase | Mobile Phase | Separation Principle | Application for this compound |
|---|---|---|---|---|
| Ion Exchange (IEC) | Charged (e.g., sulfopropyl for cation exchange) | Aqueous buffer with salt gradient | Based on net charge interactions phenomenex.com | Separates based on the positive charge of the Arginine residue. |
| Hydrophilic Interaction (HILIC) | Polar (e.g., amide, unbonded silica) waters.com | High organic solvent with aqueous buffer | Partitioning based on hydrophilicity nih.gov | Provides orthogonal selectivity to reversed-phase methods. |
Capillary Electrophoresis (CE) is a high-resolution analytical technique that separates molecules based on their charge-to-mass ratio. nih.gov In CE, peptides migrate through a narrow capillary filled with an electrolyte under the influence of an electric field. springernature.com Its high efficiency allows for the separation of peptides that may differ by only a single amino acid. bio-rad.com For this compound, CE can serve as a powerful tool to assess purity and detect subtle modifications, offering a separation mechanism that is orthogonal to liquid chromatography. springernature.com Different modes of CE, such as Capillary Zone Electrophoresis (CZE), can be employed for peptide analysis. ijpca.org
Mass Spectrometry for Molecular Weight and Sequence Confirmation
Mass Spectrometry (MS) is an indispensable tool for peptide characterization, providing precise molecular weight determination and definitive sequence confirmation.
Liquid Chromatography-Mass Spectrometry (LC-MS) combines the separation power of HPLC or UPLC with the detection capabilities of MS. chromatographytoday.com As peptides elute from the chromatography column, they are ionized (typically by electrospray ionization, ESI) and introduced into the mass spectrometer, which measures their mass-to-charge ratio (m/z). This provides the molecular weight of the peptide and any detected impurities with high accuracy. chromatographytoday.com
Matrix-Assisted Laser Desorption/Ionization Mass Spectrometry (MALDI-MS) is a soft ionization technique particularly well-suited for analyzing biomolecules like peptides. creative-proteomics.com The peptide is co-crystallized with a matrix, and a laser pulse desorbs and ionizes the analyte, typically producing singly charged ions. creative-proteomics.com MALDI combined with a Time-of-Flight (TOF) analyzer is frequently used for the rapid and accurate determination of a peptide's molecular weight. hawaii.edu
Tandem Mass Spectrometry (MS/MS) is used for definitive sequence confirmation. nih.gov In an MS/MS experiment, the precursor ion corresponding to the peptide of interest is isolated and then fragmented, usually through collision-induced dissociation (CID). nih.gov This fragmentation preferentially occurs along the peptide backbone, creating a series of characteristic "b" and "y" ions. By analyzing the mass differences between these fragment ions, the amino acid sequence can be reconstructed and confirmed. chromatographytoday.comnih.gov
| Peptide Property | Value | |
|---|---|---|
| Sequence | Arg-Phe-Tyr-Val-Val-Met | |
| Molecular Formula | C40H61N9O8S | |
| Monoisotopic Mass | 843.4388 Da | |
| b-ions (N-terminus) | b1 (Arg) | 157.1144 Da |
| b2 (Arg-Phe) | 304.1828 Da | |
| b3 (Arg-Phe-Tyr) | 467.2462 Da | |
| b4 (Arg-Phe-Tyr-Val) | 566.3146 Da | |
| b5 (Arg-Phe-Tyr-Val-Val) | 665.3830 Da | |
| b6 (Arg-Phe-Tyr-Val-Val-Met) | 796.4259 Da | |
| y-ions (C-terminus) | y1 (Met) | 150.0583 Da |
| y2 (Val-Met) | 249.1267 Da | |
| y3 (Val-Val-Met) | 348.1951 Da | |
| y4 (Tyr-Val-Val-Met) | 511.2585 Da | |
| y5 (Phe-Tyr-Val-Val-Met) | 658.3269 Da | |
| y6 (Arg-Phe-Tyr-Val-Val-Met) | 814.4281 Da |
While peptide mapping traditionally refers to the analysis of fragments from a larger digested protein, the principles are directly applied to the comprehensive characterization of synthetic peptides. creative-proteomics.com This process serves as a final verification of the peptide's primary structure. nih.gov It involves using high-resolution LC-MS/MS to generate a detailed "map" of the peptide. chromatographytoday.com The experimental data, including retention time, accurate mass of the precursor ion, and the fragmentation pattern from MS/MS analysis, are compared against the theoretical values for the target sequence this compound. This rigorous comparison confirms the correct amino acid sequence, identifies any unexpected modifications, and ensures the absence of sequence-related impurities. creative-proteomics.comnih.gov
Structural Analysis of Amino Acid Modifications and Impurities
During peptide synthesis and purification, several modifications to amino acid side chains can occur. For this compound, the methionine residue is particularly susceptible to oxidation, forming methionine sulfoxide. Other potential modifications include racemization of chiral centers and deamidation. Impurities often found in synthetic peptides include deletion sequences (where one or more amino acids are missing), truncated sequences, and residual reagents from the synthesis process, such as trifluoroacetic acid (TFA). novoprolabs.com Trifluoroacetic acid is commonly used in the purification of synthetic peptides and can form salts with basic amino acid residues like arginine. novoprolabs.com
These impurities and modifications are typically identified and characterized using a combination of high-performance liquid chromatography (HPLC) and mass spectrometry (MS).
Table 1: Potential Modifications and Impurities in Synthetic this compound
| Type | Example | Analytical Method |
|---|---|---|
| Amino Acid Modification | Oxidation of Methionine to Methionine Sulfoxide | HPLC, Mass Spectrometry |
| Racemization of amino acids | Chiral Amino Acid Analysis | |
| Process-Related Impurity | Deletion sequences (e.g., H-Arg-tyr-val-val-met-oh) | HPLC, Mass Spectrometry |
| Truncated sequences (e.g., H-Arg-phe-tyr-val-val-OH) | HPLC, Mass Spectrometry |
Spectroscopic Methods for Conformational and Structural Insights
Spectroscopic techniques are invaluable for providing detailed information about the secondary and tertiary structure of peptides, as well as their conformational dynamics.
Nuclear Magnetic Resonance (NMR) Spectroscopy (1D and 2D)
Nuclear Magnetic Resonance (NMR) spectroscopy is a powerful, non-destructive technique for elucidating the three-dimensional structure of peptides in solution. springernature.com One-dimensional (1D) NMR provides information about the chemical environment of individual protons, while two-dimensional (2D) NMR experiments can establish through-bond and through-space connectivities between atoms. researchgate.netemory.edu
For this compound, 2D NMR experiments such as COSY (Correlation Spectroscopy) would be used to identify spin systems of individual amino acid residues. researchgate.net TOCSY (Total Correlation Spectroscopy) would then be employed to connect the side-chain protons to the amide protons. The sequential assignment of amino acid residues can be achieved using NOESY (Nuclear Overhauser Effect Spectroscopy), which detects protons that are close in space (typically < 5 Å). The patterns of sequential and medium-range NOEs provide crucial information for defining the peptide's secondary structure.
Table 2: Hypothetical ¹H NMR Chemical Shift Assignments for this compound in H₂O/D₂O (90/10) at pH 5.0
| Residue | NH | αH | βH | Other |
|---|---|---|---|---|
| Arg | 8.35 | 4.30 | 1.90, 1.75 | γH: 1.65; δH: 3.20; NHε: 7.30 |
| Phe | 8.20 | 4.65 | 3.25, 3.10 | Aromatic: 7.20-7.35 |
| Tyr | 8.05 | 4.50 | 3.15, 3.00 | Aromatic: 6.85, 7.15 |
| Val-1 | 7.95 | 4.15 | 2.10 | γH: 0.95, 0.90 |
| Val-2 | 7.90 | 4.10 | 2.05 | γH: 0.90, 0.85 |
| Met | 8.10 | 4.40 | 2.15, 2.00 | γH: 2.55; εCH₃: 2.10 |
Circular Dichroism (CD) Spectroscopy for Secondary Structure Elucidation
Circular Dichroism (CD) spectroscopy is a rapid and sensitive technique for assessing the secondary structure of peptides in solution. nih.govyoutube.com The technique measures the differential absorption of left and right-handed circularly polarized light by chiral molecules. harvard.edu The peptide backbone's regular, repeating structure in α-helices and β-sheets gives rise to characteristic CD signals. libretexts.org
For this compound, the CD spectrum would reveal the predominant secondary structure adopted in a particular solvent system. A spectrum with negative bands at approximately 222 nm and 208 nm, and a positive band around 193 nm would indicate an α-helical conformation. libretexts.org Conversely, a negative band near 218 nm and a positive band around 195 nm would suggest a β-sheet structure. libretexts.org A lack of significant signal above 210 nm is indicative of a random coil or disordered conformation. libretexts.org
Table 3: Characteristic Far-UV CD Signals for Peptide Secondary Structures
| Secondary Structure | Positive Band (nm) | Negative Band(s) (nm) |
|---|---|---|
| α-Helix | ~193 | ~208, ~222 |
| β-Sheet | ~195 | ~218 |
| Random Coil | ~212 | ~195 |
Fourier Transform Infrared (FTIR) Spectroscopy for Peptide Bond Analysis
Fourier Transform Infrared (FTIR) spectroscopy is a valuable tool for investigating the secondary structure of peptides by analyzing the vibrational modes of the peptide backbone. nih.govspringernature.com The Amide I band (1600-1700 cm⁻¹), arising mainly from the C=O stretching vibration of the peptide bond, is particularly sensitive to the secondary structure. lew.rolongdom.org
The position of the Amide I band maximum can be correlated with specific secondary structural elements. For instance, α-helical structures typically show a band around 1655 cm⁻¹, while β-sheets exhibit a band in the region of 1620-1640 cm⁻¹. lew.ro β-turns and random coil conformations also have characteristic absorption frequencies.
Table 4: Correlation of Amide I Band Frequencies with Peptide Secondary Structure
| Secondary Structure | Amide I Frequency Range (cm⁻¹) |
|---|---|
| α-Helix | 1650 - 1658 |
| β-Sheet | 1620 - 1640 |
| β-Turn | 1660 - 1695 |
| Random Coil | 1640 - 1650 |
Electron Paramagnetic Resonance (EPR) Spectroscopy for Conformational Dynamics
Electron Paramagnetic Resonance (EPR) spectroscopy, in conjunction with site-directed spin labeling (SDSL), is a powerful technique for studying the conformational dynamics and structure of biomolecules. nih.govnih.gov This method involves introducing a paramagnetic spin label, typically a nitroxide radical, at a specific site in the peptide. uni-konstanz.de
For a small peptide like this compound, a spin-labeled analog could be synthesized to probe local dynamics or intermolecular interactions. The EPR spectrum of the spin label provides information about its mobility, which is influenced by the structure and dynamics of the peptide backbone in its vicinity. escholarship.org Pulsed EPR techniques, such as Double Electron-Electron Resonance (DEER), can be used to measure distances between two spin labels, providing valuable constraints for structural modeling. uni-konstanz.de
Quantitative Amino Acid Analysis for Peptide Content Determination
Quantitative Amino Acid Analysis (AAA) is a fundamental technique for accurately determining the total peptide content in a sample. nih.gov The method involves the complete hydrolysis of the peptide into its constituent amino acids, followed by their separation, identification, and quantification. nih.gov
The process begins with the acid hydrolysis of this compound, typically using 6 M HCl at elevated temperatures. nih.gov This breaks all the peptide bonds, releasing the individual amino acids. The resulting amino acid mixture is then separated using ion-exchange chromatography or reversed-phase liquid chromatography. nih.govresearchgate.net The separated amino acids are detected and quantified, often after post-column derivatization with a reagent like ninhydrin or pre-column derivatization. The molar amount of each amino acid is determined by comparing its peak area to that of a known standard. The total peptide content is then calculated based on the known amino acid sequence of the peptide.
Table 5: Expected Molar Ratios from Quantitative Amino Acid Analysis of this compound
| Amino Acid | Expected Molar Ratio |
|---|---|
| Arginine (Arg) | 1 |
| Phenylalanine (Phe) | 1 |
| Tyrosine (Tyr) | 1 |
| Valine (Val) | 2 |
Table of Compounds Mentioned
| Compound Name |
|---|
| This compound |
| Arginine |
| Phenylalanine |
| Tyrosine |
| Valine |
| Methionine |
| Methionine sulfoxide |
| Trifluoroacetic acid (TFA) |
| Ninhydrin |
Molecular Interactions of H Arg Phe Tyr Val Val Met Oh
Peptide-Protein Interactions
Mechanisms of Specific Molecular Recognition and Binding
No information is available in the scientific literature regarding the specific molecular recognition and binding mechanisms of H-Arg-phe-tyr-val-val-met-oh with any protein targets.
Influence of Hexapeptide Conformation on Binding Affinity
There are no studies describing the conformational properties of this compound or how its conformation might influence its binding affinity to proteins.
Characterization of Peptide-Protein Complex Formation
No data exists on the formation or characterization of any peptide-protein complexes involving this compound.
Peptide-Membrane Interactions
Physical Adsorption and Chemical Immobilization on Model Membranes
There is no research available on the physical adsorption or chemical immobilization of this compound onto model membranes.
Hexapeptide Effects on Membrane Bilayer Organization
The effects of this compound on the organization of membrane bilayers have not been investigated or reported in the available literature.
Interactions with Nanoparticles and Biomaterials
The interface between peptides and synthetic materials is a critical area of research in bionanotechnology and materials science. The specific amino acid sequence of this compound suggests it would engage in distinct interactions with nanoparticles and could be engineered into functional biomaterials.
When nanoparticles are introduced into a biological environment, they rapidly become coated with a layer of biomolecules, most notably proteins and peptides, forming what is known as a "protein corona" or "biomolecular corona." This corona dictates the biological identity and fate of the nanoparticle. The adsorption of the this compound hexapeptide onto a nanomaterial surface would be governed by the chemistry of both the peptide and the nanoparticle.
The interaction would be driven by a combination of forces:
Electrostatic Interactions: The N-terminal arginine residue confers a positive charge to the peptide at physiological pH wikipedia.org. This would lead to strong adsorption onto negatively charged nanoparticles, such as those made of silica, gold, or certain polymers.
Hydrophobic Interactions: The hydrophobic residues—phenylalanine, two valines, and methionine—would preferentially interact with hydrophobic nanomaterial surfaces, driving the adsorption process to minimize their exposure to the aqueous environment wikipedia.org.
Cation-π Interactions: A specific interaction can occur between the positively charged guanidinium (B1211019) group of arginine and the electron-rich aromatic rings of phenylalanine and tyrosine within the peptide itself or on a functionalized surface nih.govresearchgate.net.
The orientation of the adsorbed hexapeptide would depend on the balance of these forces and the surface characteristics of the nanomaterial. On a negatively charged hydrophilic surface, the peptide might anchor via its arginine residue, leaving the hydrophobic tail exposed. Conversely, on a hydrophobic surface, the peptide would likely adsorb via its hydrophobic face.
Peptides are valuable building blocks for creating functional biomaterials due to their biocompatibility and chemical specificity. The this compound sequence could be used to engineer biomaterials in several ways. Complex peptides are recognized for their potential in enhancing cellular signaling pathways and are explored for applications in drug delivery systems and the development of novel biomaterials chemimpex.com.
Functionalizing surfaces with this hexapeptide could be used to control subsequent biological interactions. For instance, immobilizing the peptide on a biomaterial scaffold could influence cell adhesion and proliferation, depending on whether the sequence contains a cryptic biorecognition motif. Furthermore, the inherent self-assembling properties of this amphiphilic peptide could be harnessed to form supramolecular hydrogels, which are highly hydrated, porous networks with applications in tissue engineering and controlled drug release.
Supramolecular Assembly and Self-Interactions of this compound
Self-assembly is a process where molecules spontaneously organize into ordered structures through non-covalent interactions. Peptides, particularly those with an amphiphilic design like this compound, are well-known for their ability to self-assemble into a variety of complex nanostructures mdpi.com.
The self-assembly of this compound into ordered supramolecular architectures is driven by a precise balance of several non-covalent forces.
Hydrogen Bonding: Hydrogen bonds are crucial for the formation of stable, ordered secondary structures. In this hexapeptide, hydrogen bonds would form between the amide (-CONH-) groups of the peptide backbone, leading to the formation of structures like β-sheets. The side chains of arginine (guanidinium group) and tyrosine (hydroxyl group) can also act as hydrogen bond donors and acceptors, further stabilizing the assembled structure nih.gov.
Hydrophobic Forces: The hydrophobic effect is likely the primary driving force for the initial assembly of this peptide. The side chains of phenylalanine, the two valine residues, and methionine are all hydrophobic technologynetworks.com. In an aqueous environment, these residues will aggregate to minimize their contact with water, leading to the formation of a hydrophobic core in the resulting nanostructure wikipedia.org.
Electrostatic Forces: The arginine residue carries a net positive charge at neutral pH wikipedia.org. This results in electrostatic repulsion between adjacent peptides. This repulsive force counteracts the attractive hydrophobic and hydrogen bonding forces, influencing the morphology, spacing, and stability of the final assembled structures.
| Amino Acid | Symbol | Property | Primary Contribution to Self-Assembly |
|---|---|---|---|
| Arginine | Arg | Positively Charged, Hydrophilic | Electrostatic Interactions, Hydrogen Bonding, Cation-π Interactions |
| Phenylalanine | Phe | Aromatic, Hydrophobic | Hydrophobic Interactions, π-π Stacking, Polar H-π Interactions |
| Tyrosine | Tyr | Aromatic, Polar, Hydrophobic | Hydrophobic Interactions, Hydrogen Bonding, π-π Stacking, Polar H-π Interactions |
| Valine | Val | Aliphatic, Hydrophobic | Hydrophobic Interactions |
| Methionine | Met | Hydrophobic | Hydrophobic Interactions |
The interplay of the forces described above leads to the formation of hierarchical structures. Short peptides containing both charged and hydrophobic amino acids can form well-defined nanostructures nih.gov.
Secondary Structure Formation: The process likely begins with the formation of β-strands, an extended conformation of the peptide backbone.
β-Sheet Assembly: These β-strands then assemble laterally, stabilized by a network of intermolecular hydrogen bonds between the backbones, to form β-sheets mdpi.com. In this arrangement, the amino acid side chains project alternately above and below the plane of the sheet, allowing the hydrophobic side chains to align on one face and the hydrophilic arginine side chains on the other.
Hierarchical Assembly: These amphiphilic β-sheets can then stack upon one another, burying the hydrophobic faces together and exposing the charged arginine residues to the water. This hierarchical process can lead to the formation of various higher-order structures, such as nanofibers, nanoribbons, or nanotubes. At sufficient concentrations, these nanofibers can entangle to form a three-dimensional network, resulting in a self-supporting hydrogel. Infrared and Raman spectroscopy have confirmed that peptides with alternating charged and hydrophobic residues can assume an antiparallel β-sheet conformation in their assembled state nih.gov.
Beyond classical hydrogen bonds and hydrophobic interactions, more nuanced forces like polar hydrogen-π (H-π) and cation-π interactions play a significant role in the structure and stability of peptide assemblies. These interactions involve the aromatic side chains of phenylalanine and tyrosine.
Polar Hydrogen-π (H-π) Interactions: This is a non-covalent interaction where a polar hydrogen atom (one bonded to an electronegative atom like oxygen or nitrogen) interacts with the electron cloud of a π-system. In the this compound peptide, the aromatic rings of Phe and Tyr can act as the π-system (acceptor). The polar hydrogen atoms from the peptide backbone amide groups (N-H) and the side chains of Tyr (-OH) and Arg (-NH2) can serve as donors. These interactions contribute to the stability of both secondary and tertiary protein structures.
Cation-π Interactions: This is a strong, non-covalent force between a cation and the face of an electron-rich π-system researchgate.net. A powerful cation-π interaction can occur between the positively charged guanidinium group of the arginine side chain and the aromatic rings of phenylalanine and tyrosine nih.govresearchgate.net. This interaction can be a key factor in stabilizing the folded or assembled state of the peptide, often orienting the arginine side chain over the face of an aromatic ring. Studies using model peptide systems have been employed to evaluate the energetic contribution of these interactions to protein and peptide stability nih.gov.
| Interaction Type | Donor/Cationic Group | Acceptor/π-System | Contributing Residues |
|---|---|---|---|
| Hydrogen Bond | Backbone N-H, Arg side chain, Tyr side chain | Backbone C=O, Tyr side chain | All (Backbone), Arg, Tyr |
| Hydrophobic Interaction | - | - | Phe, Val, Met, Tyr |
| Electrostatic Repulsion | Arg side chain | Arg side chain | Arg |
| π-π Stacking | Phe/Tyr side chain | Phe/Tyr side chain | Phe, Tyr |
| Cation-π Interaction | Arg side chain | Phe/Tyr side chain | Arg, Phe, Tyr |
| Polar Hydrogen-π Interaction | Backbone N-H, Arg/Tyr side chains | Phe/Tyr side chain | Arg, Phe, Tyr |
Computational and Theoretical Studies of H Arg Phe Tyr Val Val Met Oh
In Silico Design and Optimization Methodologies
In silico methodologies refer to computational techniques used to model and simulate biological systems. For a peptide like H-Arg-Phe-Tyr-Val-Val-Met-OH, these methods are crucial for designing variants with enhanced stability, affinity, or specific biological activity without the immediate need for costly and time-consuming synthesis. nih.gov
De novo design involves the creation of novel peptide sequences from scratch, tailored to bind to a specific molecular target or perform a certain function. researchgate.net This approach does not rely on existing natural peptide templates. For this compound, a de novo design process could be initiated to optimize its binding to a hypothetical protein target. Computational algorithms would explore vast sequence spaces, substituting amino acids to improve properties like binding energy and specificity. nih.gov For example, deep learning models can now generate and screen millions of potential sequences to identify candidates with high predicted affinity for a target before any are synthesized. biorxiv.orgacs.org The goal would be to refine the Arg-Phe-Tyr-Val-Val-Met sequence to create a new peptide with superior therapeutic or diagnostic potential.
Fragment assembly is a highly successful method for predicting the three-dimensional structure of proteins and peptides. researchgate.networldscientific.com This technique operates on the principle that the local structures of a peptide chain are often similar to short fragments found in experimentally determined protein structures in the Protein Data Bank (PDB). nih.gov
For this compound, the process would involve:
Dividing the hexapeptide sequence into overlapping short fragments (e.g., 3-residue fragments).
Searching a structural database for known protein segments that match the sequence of these fragments. nih.gov
Assembling these fragments computationally to generate a large number of possible full-length conformations of the hexapeptide. jkps.or.kr
Using a physics-based energy function to score and rank the assembled models, identifying the most energetically favorable structures.
This ab-initio (from the beginning) approach is particularly useful for short peptides that may not have a homologous template structure available for modeling. mdpi.com
Table 1: Illustrative Data from a Fragment Assembly Simulation This table provides a representative example of the output from a fragment assembly and energy minimization process for a hypothetical hexapeptide analysis.
| Model ID | Energy Score (REU) | RMSD from Lowest Energy Model (Å) | Predicted Secondary Structure |
| Model_01 | -25.8 | 0.00 | Turn |
| Model_02 | -23.1 | 1.25 | Coil |
| Model_03 | -22.5 | 1.89 | Turn-Coil |
| Model_04 | -20.9 | 2.54 | Coil |
| Model_05 | -19.7 | 3.11 | Extended |
Structure Prediction and Modeling
Predicting the three-dimensional structure of a peptide from its amino acid sequence is a fundamental challenge in computational biology. nih.govfrontiersin.org For a short and flexible hexapeptide like this compound, the goal is often not to find a single correct structure but to characterize the ensemble of conformations it adopts in solution. researchgate.net
Various computational tools are available for this purpose. Methods like PEP-FOLD are specifically designed for de novo peptide structure prediction. nih.gov More recently, deep learning-based methods like AlphaFold2, while primarily designed for larger proteins, have also shown considerable success in predicting the structures of smaller peptides, particularly those with defined secondary structures like helices or hairpins. nih.gov These methods provide high-quality structural models that can serve as starting points for more intensive computational studies, such as the MD simulations described above.
Table 3: Compound Names
| Full Name | Abbreviation |
| Arginine | Arg, R |
| Phenylalanine | Phe, F |
| Tyrosine | Tyr, Y |
| Valine | Val, V |
| Methionine | Met, M |
Homology Modeling and Template-Based Prediction
Homology modeling, or comparative modeling, is a technique used to construct an atomic-resolution model of a "target" protein or peptide from its amino acid sequence. wikipedia.org This method relies on the principle that proteins with similar sequences adopt similar three-dimensional structures. wikipedia.orguni-frankfurt.de The process involves identifying a related homologous protein with an experimentally determined structure to serve as a "template". wikipedia.org For a peptide like this compound, the initial step would be to search protein databases, such as the Protein Data Bank (PDB), for proteins or larger peptides containing this or a highly similar sequence fragment. nih.gov
The accuracy of a homology model is highly dependent on the sequence identity between the target and the template; higher identity generally results in a more reliable model. wikipedia.orgnih.gov Once a suitable template is found, the target sequence is aligned with the template sequence, and a 3D model is built by mapping the target's residues onto the template's backbone structure. wikipedia.orgbenthamdirect.com Programs like MODELLER are widely used to generate spatial constraints from the template to build the model. uni-frankfurt.de Other approaches, such as the SEGMOD program, utilize a library of fragments, including hexapeptide fragments, to construct the model structure. uni-frankfurt.de The final model is then refined through energy minimization to resolve any structural inconsistencies. benthamdirect.com
| Modeling Approach | Principle | Key Requirement | Application to this compound |
| Homology Modeling | Similar sequences fold into similar structures. wikipedia.orguni-frankfurt.de | An experimentally solved structure of a homologous protein (template). wikipedia.org | Building a 3D model by identifying a template in the PDB that contains a similar sequence. |
| Template-Based Modeling | Uses known structures as a starting point for prediction. plos.org | A suitable template structure from a database like the PDB. plos.org | Predicting the peptide's conformation based on solved structures of related peptide-protein complexes. nih.gov |
| Fragment Assembly | Assembles short, known structural fragments to build a larger structure. mdpi.com | A library of peptide fragments (e.g., hexapeptides). uni-frankfurt.de | Constructing the peptide's structure using a library of known hexapeptide conformations. |
Peptide-Protein Docking Algorithms
Peptide-protein docking is a computational method used to predict the binding mode and affinity of a peptide to a target protein. nih.govvietnamjournal.ru This is critical for understanding the function of this compound and for designing peptide-based therapeutics. nih.gov The process involves computationally placing the peptide (ligand) into the binding site of the protein (receptor) and evaluating the interaction energies of the resulting complex. nih.gov
A variety of docking algorithms are available, which can be broadly categorized. Some methods treat both the protein and peptide as rigid bodies, which is computationally fast but less accurate. nih.gov More advanced algorithms allow for flexibility in the peptide and sometimes in the protein's side chains, providing a more realistic prediction of the binding interaction. nih.gov The scoring functions used to rank the docked poses are typically based on factors like shape complementarity, electrostatic interactions, and desolvation energy. nih.gov
| Docking Algorithm | Approach | Key Features |
| ZDOCK | Rigid body docking based on Fast Fourier Transform (FFT). nih.gov | Combines shape complementarity, desolvation, and electrostatics for scoring. nih.gov |
| AutoDock | Flexible ligand docking using a Lamarckian genetic algorithm. nih.govresearchgate.net | Allows for peptide flexibility, enabling a more thorough search of conformational space. nih.gov |
| Hex | Rigid body docking using Spherical Polar Fourier (SPF) correlations. nih.gov | Utilizes shape and electrostatic correlations for rapid docking. nih.gov |
| PatchDock | Geometry-based rigid body docking. nih.gov | Focuses on geometric fit and atomic desolvation energy. nih.gov |
| ATTRACT | Flexible protein-protein docking. nih.gov | Employs a randomized search algorithm with a physics-based scoring function. nih.gov |
Machine Learning and Artificial Intelligence Applications
Predicting Hexapeptide Structures and In Vitro Functions
Predicting the three-dimensional structure of peptides, especially flexible ones like hexapeptides, is a significant challenge. nih.gov Machine learning models trained on data from molecular dynamics simulations have shown great promise in this area. rsc.org Research has demonstrated that for cyclic hexapeptides, simple linear regression models are often insufficient to capture the complex interactions that determine their structural preferences. nih.govacs.org However, more sophisticated models like convolutional neural networks (CNNs) and graph neural networks (GNNs) can predict structural ensembles with high accuracy, achieving R² values of up to 0.91 when compared to simulation data. nih.gov
| Machine Learning Model | Application to Hexapeptides | Reported Performance |
| Linear Regression | Predicting structural ensembles. | Poor (R² = 0.47 for cyclic hexapeptides). nih.gov |
| Convolutional Neural Networks (CNNs) | Predicting structural ensembles. | High (R² = 0.91 for cyclic hexapeptides). nih.gov |
| Graph Neural Networks (GNNs) | Predicting structural ensembles. | High (R² = 0.91 for cyclic hexapeptides). nih.govacs.org |
| ProtBERT (e.g., AggBERT) | Predicting amyloidogenesis (an in vitro function). | State-of-the-art performance. nih.gov |
Data Mining and Database Integration for Peptide Research
The power of machine learning in peptide research is contingent on the availability of large, high-quality datasets. oup.comoup.com Data mining and the integration of disparate databases are essential for creating the comprehensive resources needed to train robust predictive models. researchgate.net Numerous peptide databases exist, but they are often specialized and fragmented. nih.gov
Initiatives like Peptipedia have addressed this by integrating data from 30 different databases, creating the largest repository of peptides with reported activities, containing over 92,000 sequences. oup.com Such platforms often employ data mining strategies to extract and curate information. oup.comresearchgate.net Another approach, used by PepBank, involves text mining of scientific literature, such as MEDLINE abstracts, to extract peptide sequences and associated data. nih.gov The creation of integrated graph databases, like starPepDB, helps to unify data and metadata, enabling more comprehensive analysis of the relationships between peptide sequences, their properties, and their biological functions. oup.com
| Database Initiative | Methodology | Key Feature |
| Peptipedia | Integrates 30 existing peptide databases. oup.com | The most extensive collection of peptides with reported activities, supported by ML tools. oup.com |
| PepBank | Text mining of MEDLINE abstracts and compilation of public data. nih.gov | Extracts peptide data directly from scientific literature. nih.gov |
| starPepDB | Organizes web content from various databases into an integrated graph database. oup.com | Creates a unified, non-redundant view of peptide data and metadata. oup.com |
| PeptideDepot | Flexible relational database for quantitative proteomic data. nih.gov | Integrates external protein information databases and aids in false discovery rate estimation. nih.gov |
Protein Language Models (PLMs) in Hexapeptide Design
Protein Language Models (PLMs) are a class of deep learning models adapted from the field of natural language processing (NLP). frontiersin.org They treat amino acid sequences as a "protein language," where individual amino acids are like words and the entire peptide sequence is like a sentence. nih.govpipebio.com By training on millions of known protein sequences, PLMs learn the underlying "grammar" of protein structure and function without explicit labeling. frontiersin.orgpipebio.com
For hexapeptide design, PLMs are incredibly powerful. They can be used to generate entirely new peptide sequences that are likely to be functional. openreview.net Researchers can fine-tune these models on specific peptide families or condition them on desired properties to design novel hexapeptides with specific characteristics, such as binding to a particular target or possessing a certain enzymatic activity. frontiersin.org Models like ESM have been shown to encode detailed information about a protein's biochemical properties and evolutionary relationships from sequence alone. frontiersin.org This approach has been successfully applied to hexapeptides, with models like AggBERT (based on ProtBERT) being used to predict functions like amyloidogenesis. nih.gov
Graph Neural Networks for Interaction Prediction
Graph Neural Networks (GNNs) are a type of neural network specifically designed to work with data structured as graphs. emergentmind.com In the context of peptide research, molecules like this compound and its protein targets can be represented as graphs, where atoms are nodes and bonds are edges. unisi.it This representation allows GNNs to learn complex patterns related to the molecule's topology and chemical properties. nih.gov
GNNs have demonstrated promising results in predicting peptide-protein interactions (PPIs), which are crucial for cellular function. emergentmind.comresearchgate.net By learning from large datasets of known interacting and non-interacting protein pairs, GNNs can predict the likelihood of an interaction between a novel peptide and a protein. nih.gov Various GNN architectures, including Graph Convolutional Networks (GCN) and Graph Attention Networks (GAT), have been successfully applied to this problem. emergentmind.comnih.gov Furthermore, as noted previously, GNNs are also highly effective at predicting the structural ensembles of hexapeptides, providing the necessary conformational information for accurate interaction prediction. nih.govacs.org
| GNN-based Model | Application |
| Graph Convolutional Networks (GCN) | Predicting protein-protein interactions. nih.govresearchgate.net |
| Graph Attention Networks (GAT) | Predicting protein-protein interactions. nih.govresearchgate.net |
| Hyperbolic Graph Convolutions (HGCN) | Shown to have strong performance on protein-related datasets for interaction prediction. nih.gov |
| General GNNs | Predicting structural ensembles of cyclic hexapeptides. nih.govacs.org |
Quantitative Structure-Activity Relationship (QSAR) Modeling for Hexapeptides
Quantitative Structure-Activity Relationship (QSAR) is a computational modeling method used to establish a mathematical relationship between the chemical structure of a series of compounds and their biological activity. nih.gov For hexapeptides like this compound, QSAR studies are instrumental in predicting their biological activities and in designing new peptides with enhanced potency or specificity. acs.orgresearchgate.net
The fundamental principle of QSAR is that the biological activity of a compound is a function of its physicochemical properties, which are in turn determined by its molecular structure. nih.gov The general workflow of a QSAR study for hexapeptides involves several key steps:
Data Set Preparation : A dataset of hexapeptides with experimentally determined biological activities is compiled. This dataset is then divided into a training set, used to build the model, and a test set, used to validate the model's predictive power. acs.org
Descriptor Calculation : Numerical descriptors that quantify various aspects of the peptides' structure are calculated. For peptides, these descriptors can be categorized into several types:
0D-descriptors : Based on the elemental composition and molecular weight.
1D-descriptors : Based on the amino acid sequence, such as the count of specific amino acid types or the presence of certain motifs.
2D-descriptors : Based on the 2D representation of the molecule, including topological indices and connectivity indices.
3D-descriptors : Based on the 3D conformation of the peptide, such as molecular shape and volume.
Physicochemical descriptors : Properties of the individual amino acids, such as hydrophobicity, pKa, and steric parameters (e.g., van der Waals volume). nih.gov
Model Development : A mathematical model is developed to correlate the calculated descriptors with the biological activity. Various statistical methods can be employed, including Multiple Linear Regression (MLR), Partial Least Squares (PLS), and machine learning algorithms like Support Vector Machines (SVM) and Artificial Neural Networks (ANN). nih.gov
Model Validation : The predictive ability of the developed QSAR model is rigorously assessed using internal and external validation techniques. acs.org
A hypothetical QSAR study on a series of hexapeptides analogous to this compound might involve generating a variety of descriptors to predict a specific biological activity, for instance, inhibitory activity against a particular enzyme.
Table 1: Examples of Amino Acid Descriptors Used in Peptide QSAR
| Descriptor Class | Specific Descriptor | Description |
| Hydrophobicity | Kyte-Doolittle Scale | A value representing the hydropathic character of each amino acid. |
| Steric Properties | van der Waals Volume | The volume occupied by an amino acid residue. |
| Electronic Properties | pI (Isoelectric Point) | The pH at which an amino acid carries no net electrical charge. |
| Structural Features | Helical Propensity | The tendency of an amino acid to be found in an alpha-helical conformation. |
Table 2: Hypothetical Data for a QSAR Model of Hexapeptide Activity
| Hexapeptide Sequence | Experimental Activity (IC50, µM) | Average Hydrophobicity | Total van der Waals Volume (ų) | Predicted Activity (IC50, µM) |
| Arg-Phe-Tyr-Val-Val-Met | 15.2 | 0.85 | 650.8 | 14.8 |
| Ala-Phe-Tyr-Val-Val-Met | 22.5 | 1.12 | 620.5 | 23.1 |
| Arg-Leu-Tyr-Val-Val-Met | 12.8 | 1.05 | 665.2 | 13.5 |
| Arg-Phe-Trp-Val-Val-Met | 10.5 | 1.20 | 705.4 | 11.2 |
| Arg-Phe-Tyr-Ile-Val-Met | 18.9 | 0.95 | 665.2 | 19.5 |
| Arg-Phe-Tyr-Val-Leu-Met | 16.4 | 0.98 | 665.2 | 17.0 |
Note: The data in this table is purely hypothetical and for illustrative purposes only.
The resulting QSAR model, often expressed as an equation, can then be used to predict the activity of novel hexapeptides without the need for their synthesis and experimental testing, thereby accelerating the drug discovery and development process. nih.gov For example, a simplified hypothetical QSAR equation might look like:
log(1/IC50) = c0 + c1(Average Hydrophobicity) + c2(Total van der Waals Volume)
Where c0, c1, and c2 are coefficients determined from the regression analysis. Such a model could reveal, for instance, that higher hydrophobicity and a larger molecular volume are correlated with increased inhibitory activity for that particular series of hexapeptides. This knowledge can then guide the rational design of more potent peptide-based therapeutics.
Structure Activity Relationship Sar Studies of H Arg Phe Tyr Val Val Met Oh
Principles of Hexapeptide Structure-Activity Correlation
The biological function of a hexapeptide like H-Arg-Phe-Tyr-Val-Val-Met-OH is intrinsically linked to its primary, secondary, and tertiary structure. The specific arrangement of amino acids dictates how the peptide folds and interacts with its biological target.
Influence of Amino Acid Sequence and Composition on In Vitro Activity
The biological activity of peptides is heavily influenced by their amino acid composition. The presence of specific amino acids in a peptide's sequence has been found to be significantly correlated with its physiological benefits. For instance, the ratio of hydrophobic to hydrophilic residues and the presence of charged or aromatic amino acids can significantly impact a peptide's ability to interact with cell membranes or receptor binding pockets. Minor changes in the peptide sequence can significantly influence the self-assembly mechanism and thereby the biological activity.
Role of Specific Residues (Arginine, Phenylalanine, Tyrosine, Valine, Methionine) on In Vitro Biological Activities
Each amino acid in the this compound sequence contributes uniquely to its potential biological activity.
Arginine (Arg): As a positively charged amino acid, arginine is frequently involved in electrostatic interactions with negatively charged residues on target proteins or cell membranes. Its guanidinium (B1211019) group can form strong hydrogen bonds, which is crucial for stabilizing peptide-receptor complexes. Arginine-rich peptides are known for their ability to penetrate cellular membranes. The presence of arginine can enhance antimicrobial activity by facilitating interaction with the negatively charged bacterial membrane.
Phenylalanine (Phe): This aromatic and hydrophobic amino acid is often involved in π-π stacking and hydrophobic interactions within receptor binding sites. Phenylalanine's bulky side chain can also provide structural rigidity to the peptide backbone. Peptides containing phenylalanine may have a higher affinity for cancer cell membranes due to increased hydrophobicity.
Tyrosine (Tyr): Similar to phenylalanine, tyrosine is an aromatic amino acid, but it also possesses a hydroxyl group. This group can act as both a hydrogen bond donor and acceptor, contributing to the specificity of peptide-receptor interactions. The phenolic side chain of tyrosine is also redox-active and can be a site for post-translational modifications like phosphorylation, which can modulate biological activity.
Methionine (Met): This sulfur-containing amino acid has a nonpolar, aliphatic side chain. The thioether group in methionine can be susceptible to oxidation, which can either inactivate the peptide or, in some cases, modulate its activity. Methionine residues can play an antioxidant role by reacting with oxidizing species.
The collective properties of these amino acids in the specified sequence would result in a peptide with a cationic N-terminus (Arginine), a hydrophobic core (Phenylalanine, Tyrosine, Valine, Valine, Methionine), and the potential for a range of interactions including electrostatic, hydrophobic, and hydrogen bonding.
Conformation-Activity Relationships of this compound
The three-dimensional conformation of a peptide is a critical factor in its biological activity. For a short, linear peptide like this compound, it is likely to exist as an ensemble of conformations in solution. However, upon binding to its biological target, it is expected to adopt a specific, "bioactive" conformation.
The relationship between a peptide's conformation and its activity is a key area of study. For instance, some hexapeptides have been shown to be more active when they adopt a U-shaped conformation. The flexibility of the peptide backbone, influenced by the constituent amino acids, allows it to adapt to the topology of a binding site. Techniques such as Nuclear Magnetic Resonance (NMR) and molecular dynamics simulations are used to study the conformational preferences of peptides in solution. These studies can reveal the presence of secondary structures like β-turns or γ-turns, which can be crucial for positioning key residues for interaction with a receptor. The conformational flexibility of a peptide can be a double-edged sword; while it allows for adaptation to a binding site, excessive flexibility can lead to a loss of binding affinity due to the entropic cost of adopting a single bioactive conformation.
Methodologies for SAR Determination
To systematically investigate the structure-activity relationship of a peptide, several experimental techniques are employed. These methods help to identify which amino acid residues are critical for activity and which can be modified to enhance desired properties.
Alanine (B10760859) Scanning Mutagenesis
Alanine scanning is a widely used technique to determine the contribution of individual amino acid side chains to the function of a peptide. In this method, each amino acid residue in the peptide sequence is systematically replaced with alanine, one at a time. Alanine is chosen because its small, non-reactive methyl side chain removes the specific functionality of the original residue without significantly altering the peptide's backbone conformation.
The resulting alanine-substituted analogues are then tested for their biological activity. A significant decrease in activity upon substitution of a particular residue with alanine suggests that the original residue's side chain is important for the peptide's function. Conversely, if the substitution has little or no effect on activity, it indicates that the side chain of that residue is not critical.
Below is a hypothetical data table illustrating the results of an alanine scan on this compound. The "Relative Activity (%)" is a measure of the biological activity of the alanine-substituted peptide compared to the original peptide (defined as 100%).
| Original Peptide | Substituted Peptide | Relative Activity (%) | Interpretation |
|---|---|---|---|
| H-Arg-Phe-Tyr-Val-Val-Met-OH | H-Ala-Phe-Tyr-Val-Val-Met-OH | 5 | Arginine side chain is critical for activity, likely due to its positive charge and hydrogen bonding capacity. |
| H-Arg-Phe-Tyr-Val-Val-Met-OH | H-Arg-Ala-Tyr-Val-Val-Met-OH | 25 | Phenylalanine side chain is important for activity, possibly through hydrophobic or aromatic interactions. |
| H-Arg-Phe-Tyr-Val-Val-Met-OH | H-Arg-Phe-Ala-Val-Val-Met-OH | 30 | Tyrosine side chain contributes significantly to activity, likely via its aromatic ring and/or hydroxyl group. |
| H-Arg-Phe-Tyr-Val-Val-Met-OH | H-Arg-Phe-Tyr-Ala-Val-Met-OH | 85 | The first Valine side chain has a minor contribution to activity. |
| H-Arg-Phe-Tyr-Val-Val-Met-OH | H-Arg-Phe-Tyr-Val-Ala-Met-OH | 90 | The second Valine side chain has a minor contribution to activity. |
| H-Arg-Phe-Tyr-Val-Val-Met-OH | H-Arg-Phe-Tyr-Val-Val-Ala-OH | 60 | Methionine side chain has a moderate contribution to activity. |
Amino Acid Substitution Analysis (e.g., Aib-scanning)
Beyond alanine scanning, substituting residues with other natural or unnatural amino acids can provide more detailed insights into the specific requirements for activity at each position. For example, replacing a residue with amino acids of different properties (e.g., size, charge, hydrophobicity) can help to map the steric and electronic requirements of the receptor's binding pocket.
A specific example of this is Aib-scanning, where residues are replaced with α-aminoisobutyric acid (Aib). Aib is a non-proteinogenic amino acid that strongly promotes the formation of helical structures in peptides due to the steric hindrance imposed by its two methyl groups on the α-carbon. By introducing Aib at various positions, researchers can study the influence of conformational constraints on biological activity. An increase in activity upon Aib substitution may suggest that a helical conformation in that region of the peptide is favorable for binding.
The following table provides a hypothetical example of amino acid substitution analysis for the Phenylalanine residue in this compound.
| Original Peptide | Substituted Peptide | Nature of Substitution | Relative Activity (%) | Inference |
|---|---|---|---|---|
| H-Arg-Phe-Tyr-Val-Val-Met-OH | H-Arg-Ala-Tyr-Val-Val-Met-OH | Removal of aromatic side chain | 25 | Aromaticity is important. |
| H-Arg-Phe-Tyr-Val-Val-Met-OH | H-Arg-Trp-Tyr-Val-Val-Met-OH | Larger aromatic side chain | 110 | A larger aromatic ring is well-tolerated and may enhance binding. |
| H-Arg-Phe-Tyr-Val-Val-Met-OH | H-Arg-Leu-Tyr-Val-Val-Met-OH | Hydrophobic, non-aromatic | 40 | Hydrophobicity alone is not sufficient; aromaticity is preferred. |
| H-Arg-Phe-Tyr-Val-Val-Met-OH | H-Arg-Lys-Tyr-Val-Val-Met-OH | Positively charged | <1 | A positive charge at this position is detrimental to activity. |
| H-Arg-Phe-Tyr-Val-Val-Met-OH | H-Arg-Aib-Tyr-Val-Val-Met-OH | Conformationally restricted | 15 | Inducing a helical turn at this position reduces activity. |
Truncation and Designed Modification Strategies
The biological activity of RFYVVM is intrinsically linked to its amino acid sequence, and alterations through truncation or specific modifications have provided valuable insights into its function.
RFYVVM itself represents a critical active core sequence derived from longer peptides of the TSP-1 C-terminal domain. One such longer peptide is the octapeptide Arg-Phe-Tyr-Val-Val-Met-Trp-Lys (RFYVVMWK), also known as 4N1-1. google.com While the longer 4N1-1 peptide demonstrates significant cell-binding activity, the hexapeptide RFYVVM shows little to no activity in direct cell adhesion assays. google.com However, in competitive inhibition assays, RFYVVM effectively antagonizes the cell attachment mediated by the recombinant C-terminal binding domain (CBD) of TSP-1, indicating that it retains the essential binding motif. google.com This suggests that while the hexapeptide contains the necessary sequence for receptor interaction, the additional residues in the longer peptide may be crucial for stabilizing a conformation suitable for direct cell adhesion or for providing additional contact points.
Further studies on related peptides have highlighted the importance of specific residues within the RFYVVM sequence. The Val-Val-Met (VVM) tripeptide motif is particularly critical for receptor recognition. google.com Substitution of the two valine residues with glycine (B1666218) (as in the peptide KRFYGGMWKK) results in a loss of binding to its primary receptor, CD47. ucl.ac.uk This underscores the stringent structural requirement of the VVM sequence for biological activity.
Designed modifications of peptides containing the RFYVVM core have been explored to enhance their therapeutic potential. For instance, a derivative of the related 4N1K peptide (KRFYVVMWK) called PKHB1 was created by adding D-lysine residues to both termini (kRFYVVMWKk). researchgate.net This modification was designed to increase the peptide's stability in serum and was shown to enhance its ability to induce cell death in cancer cells. researchgate.net Such strategies demonstrate that while the RFYVVM core is essential for activity, targeted modifications can significantly improve its pharmacological properties.
| Peptide Sequence | Modification Strategy | Key Finding |
| Arg-Phe-Tyr-Val-Val-Met (RFYVVM) | Truncation of 4N1-1 | Retains inhibitory activity but loses direct cell adhesion capability. google.com |
| KRFYGG MWKK | Substitution of Val-Val with Gly-Gly | Abolishes binding to the CD47 receptor. ucl.ac.uk |
| k RFYVVMWKk (PKHB1) | Addition of terminal D-lysines | Increased stability and enhanced cell death-inducing activity. researchgate.net |
Mechanistic Insights into Hexapeptide Bioactivity (In Vitro)
In vitro studies have provided a foundational understanding of how RFYVVM and related peptides exert their biological effects at the molecular and cellular levels.
Receptor Binding and Ligand-Receptor Pharmacological Profiles (In Vitro)
The primary cell surface receptor for the RFYVVM sequence is the integrin-associated protein (IAP), also known as CD47. nih.govgoogle.com This 52 kDa membrane glycoprotein (B1211001) is the key mediator of the cellular responses initiated by the C-terminal domain of TSP-1. google.com The RFYVVM motif is specifically recognized by CD47, and this interaction is crucial for the subsequent signaling events. nih.govnih.govmdpi.com
The binding of RFYVVM-containing peptides to CD47 has been characterized as having a reasonably high affinity. google.com While a specific dissociation constant (Kd) for the hexapeptide RFYVVM has not been explicitly reported, its ability to act as a potent inhibitor in cell attachment assays at micromolar concentrations suggests a significant binding interaction. google.com The interaction between the RFYVVM sequence and CD47 is a key event that triggers downstream signaling cascades. ucl.ac.uk Furthermore, the effects mediated by the RFYVVM peptide have been shown to involve other cell surface receptors, such as the αvβ3 integrin, indicating a potential for receptor crosstalk. nactem.ac.uk
Enzymatic Activity Modulation (In Vitro Inhibition or Activation)
Current scientific literature does not provide direct evidence of this compound acting as a direct inhibitor or activator of specific enzymes in isolated in vitro enzymatic assays. The biological effects of this peptide are primarily attributed to its role as a ligand for cell surface receptors, which in turn initiates intracellular signaling pathways that can lead to the modulation of enzymatic activities within the cell. For example, the binding of a related peptide, 4N1K, to CD47 on platelets leads to the rapid phosphorylation of several downstream signaling proteins, including members of the Src kinase family, Syk, SLP-76, and phospholipase C gamma2. researchgate.net This indicates an indirect modulation of kinase activity as a consequence of receptor engagement.
Cell-Based Assay Readouts for Biological Response (In Vitro)
Cell-based assays have been instrumental in elucidating the biological responses elicited by the RFYVVM peptide. A key finding is its ability to act as an inhibitor of cell adhesion. In assays where cells are plated on surfaces coated with the recombinant C-terminal domain of TSP-1, the addition of soluble RFYVVM peptide can inhibit cell attachment in a dose-dependent manner. google.com Significant inhibitory effects have been observed at peptide concentrations below 0.2 mM. google.com
In addition to its inhibitory role in cell adhesion, the RFYVVM sequence has been shown to stimulate cell migration, a process known as chemotaxis. ucl.ac.uknih.gov Both endothelial and smooth muscle cells exhibit migratory responses towards peptides containing the RFYVVM motif. ucl.ac.uk This suggests that the interaction of RFYVVM with its receptor, CD47, can trigger cellular machinery responsible for cell motility. The chemotactic response to an RFYVVM-containing peptide in smooth muscle cells was found to be dependent on the presence of α2β1 integrin, further highlighting the interplay between CD47 and integrins in mediating the cellular effects of this peptide. nih.gov
| Assay Type | Biological Response | Effective Concentration | Cell Types |
| Cell Adhesion Inhibition | Inhibition of cell attachment to TSP-1 C-terminal domain | < 0.2 mM | G361 melanoma cells google.com |
| Chemotaxis | Stimulation of cell migration | Not specified | Endothelial cells, ucl.ac.uk Smooth muscle cells nih.gov |
| Platelet Aggregation | Stimulation of platelet aggregation (by longer peptides) | Not specified | Human platelets researchgate.net |
Q & A
Basic Research Questions
Q. What are the recommended methods for synthesizing H-Arg-Phe-Tyr-Val-Val-Met-OH and ensuring purity?
- Methodological Answer : Utilize solid-phase peptide synthesis (SPPS) with Fmoc/t-Bu chemistry for stepwise assembly. Purify via reverse-phase HPLC (C18 column, 0.1% TFA/acetonitrile gradient). Validate purity (>95%) using analytical HPLC and confirm identity via mass spectrometry (MALDI-TOF or ESI-MS). Protect oxidation-prone residues (e.g., methionine) under nitrogen atmosphere to prevent degradation .
Q. How can researchers characterize the secondary structure of this compound using spectroscopic techniques?
- Methodological Answer : Apply circular dichroism (CD) spectroscopy in the far-UV range (190–250 nm) to quantify α-helix, β-sheet, and random coil content. Complement with FTIR spectroscopy to analyze amide I bands (1600–1700 cm⁻¹). For dynamic structural insights, perform temperature-controlled CD experiments with thermal denaturation curves to assess stability .
Q. What in vitro assays are suitable for initial evaluation of the bioactivity of this compound?
- Methodological Answer : Conduct receptor-binding assays (e.g., surface plasmon resonance) to determine kinetic parameters (Kd, kon/koff). Use cell-based functional assays (cAMP accumulation, calcium flux) with dose-response curves (10⁻¹²–10⁻⁶ M) to calculate EC50. Include triplicate runs and statistical validation (ANOVA, p<0.05) .
Advanced Research Questions
Q. What experimental strategies can resolve discrepancies in reported binding affinities of this compound across studies?
- Methodological Answer : Standardize buffer conditions (pH 7.4, 150 mM NaCl) and temperature (25°C vs. 37°C). Compare orthogonal methods (e.g., isothermal titration calorimetry for ΔH/ΔS vs. SPR for kinetics). Validate using reference ligands and replicate experiments across independent labs. Perform meta-analysis of raw data from repositories like ChEMBL to identify methodological biases .
Q. How can molecular dynamics simulations be optimized to study the interaction mechanisms of this compound with target receptors?
- Methodological Answer : Employ explicit solvent models (TIP3P) with periodic boundary conditions. Use enhanced sampling (metadynamics) for free energy landscapes. Validate force fields (CHARMM36 vs. AMBER) against NMR-derived NOE constraints. Run simulations ≥200 ns in triplicate to ensure convergence. Analyze residue-specific energy contributions via MM-PBSA .
Q. What considerations are critical when designing long-term stability studies for this compound under physiological conditions?
- Methodological Answer : Incubate peptides in PBS (pH 7.4, 37°C) with protease inhibitors (e.g., PMSF) and antioxidants (0.1% ascorbate). Sample at intervals (0, 7, 14, 30 days) for HPLC purity checks and LC-MS/MS to detect oxidation/deamidation. Conduct accelerated stability testing (40°C/75% RH) with Arrhenius modeling to predict shelf-life .
Data Management & Experimental Design
Q. How should researchers document and manage spectral data for structural characterization of this compound?
- Methodological Answer : Archive raw CD/FTIR spectra in open repositories (e.g., Zenodo) with metadata (instrument settings, solvent conditions). Use standardized formats (e.g., JCAMP-DX for spectral data). Include baseline corrections and smoothing parameters in documentation. Cross-reference with synthetic protocols to ensure reproducibility .
Q. What statistical approaches are recommended for analyzing dose-response data in bioactivity assays?
- Methodological Answer : Fit data to a four-parameter logistic model (Hill equation) using nonlinear regression (e.g., GraphPad Prism). Report IC50/EC50 with 95% confidence intervals. Use outlier tests (Grubbs’ test) and assess goodness-of-fit (R² > 0.95). For multi-experiment studies, apply mixed-effects models to account for variability .
Featured Recommendations
| Most viewed |
|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
