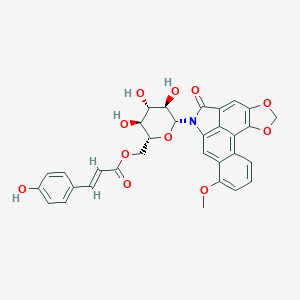
N-(Cglu)A
Description
Historical Context and Evolution of Research on N-Linked Glycoconjugates and Peptidomimetics
The journey to understanding compounds like N-(Cglu)A is deeply rooted in the historical and scientific evolution of two major classes of biomolecules: N-linked glycoconjugates and peptidomimetics.
The study of N-linked glycoconjugates , molecules where a carbohydrate (glycan) is attached to the nitrogen atom of an asparagine residue in a protein, has a rich history. Early research in glycobiology, dating back decades, laid the groundwork for identifying the fundamental roles of these modifications in protein folding, stability, and cell-cell recognition. nih.gov Key milestones include the elucidation of the dolichol phosphate (B84403) cycle for the biosynthesis of the precursor oligosaccharide and the discovery of the consensus sequence (Asn-X-Ser/Thr) required for N-glycosylation. wikipedia.org Initially, research focused on the structural characterization of these complex molecules, a formidable task that was gradually overcome with the advent of advanced analytical techniques like mass spectrometry. nih.gov
Concurrently, the field of peptidomimetics emerged from the desire to overcome the inherent limitations of using peptides as therapeutic agents. rroij.comlifechemicals.comnih.gov While peptides are crucial signaling molecules in a vast array of physiological processes, their application in medicine is often hampered by poor metabolic stability, rapid degradation by proteases, and low bioavailability. lifechemicals.comlongdom.orgacs.org Peptidomimetics are compounds designed to mimic the structure and function of natural peptides but with improved pharmacological properties. rroij.comlifechemicals.com The evolution of this field has seen a shift from simple modifications of the peptide backbone to the rational design of highly complex and novel scaffolds that can replicate the biological activity of the parent peptide with enhanced durability and specificity. rroij.comacs.org
The conceptual framework for a molecule like N-(Cglu)A, which combines features of both a glycan (Cglu, presumably a glucose derivative) and a peptide-like structure (A, likely an amino acid or a mimetic thereof), represents a convergence of these two historically distinct but intellectually complementary fields.
Contemporary Significance of N-(Cglu)A in Specialized Biochemical Pathways
While the specific pathways involving N-(Cglu)A are a subject of ongoing investigation, its structural characteristics suggest its involvement in several key biochemical processes. The contemporary significance of N-(Cglu)A is being explored in the context of pathways where protein glycosylation and peptide-mediated signaling are critical.
Research in the broader area of N-linked glycosylation has demonstrated its essential role in brain function and neuronal development. nih.gov Aberrant glycosylation is linked to a range of neurological disorders. nih.gov Given its nature as a glycoconjugate, N-(Cglu)A could potentially modulate such pathways. For instance, it might interact with lectins, a class of proteins that recognize specific carbohydrate structures, thereby influencing cell adhesion, signaling, and immune responses. mdpi.com
The peptidomimetic aspect of N-(Cglu)A suggests its potential to interact with receptors or enzymes that typically bind to endogenous peptides. longdom.org By mimicking a natural peptide ligand, N-(Cglu)A could act as an agonist or antagonist, thereby modulating cellular signaling cascades. The incorporation of a glucose moiety could influence its solubility, stability, and transport across cellular membranes, potentially targeting it to specific tissues or cellular compartments.
The table below summarizes some of the potential biochemical pathways and molecular interactions that are of interest in the study of N-(Cglu)A and related compounds.
| Potential Biochemical Pathway | Key Molecular Interactions | Potential Biological Significance |
| Cell Adhesion and Recognition | Interaction with cell-surface lectins | Modulation of cell-cell communication, immune response |
| Enzyme Inhibition | Binding to the active site of glycosidases or proteases | Regulation of metabolic processes, therapeutic intervention |
| Receptor Signaling | Acting as a ligand for peptide or growth factor receptors | Activation or inhibition of intracellular signaling cascades |
| Protein Quality Control | Involvement in the endoplasmic reticulum-associated degradation (ERAD) pathway | Influencing the folding and degradation of glycoproteins |
Interdisciplinary Methodologies Employed to Elucidate the Research Landscape of N-(Cglu)A
The study of a complex molecule like N-(Cglu)A necessitates a highly interdisciplinary approach, drawing on expertise from chemistry, biology, and computational sciences. apus.educsuci.eduamericananthropologist.org This convergence of disciplines allows for a comprehensive understanding of its synthesis, structure, and function. universiteitleiden.nl
Chemical Synthesis and Modification: The foundation of N-(Cglu)A research lies in its chemical synthesis. Organic chemists employ sophisticated techniques to create the molecule with precise control over its stereochemistry. nih.gov This often involves multi-step synthetic routes and the use of protecting groups. Furthermore, chemical methods are used to create libraries of N-(Cglu)A analogs with systematic variations, which are invaluable for structure-activity relationship (SAR) studies. acs.org
Biochemical and Biophysical Analysis: Once synthesized, a battery of biochemical and biophysical techniques is used to characterize the interactions of N-(Cglu)A with its biological targets. These methods include:
Nuclear Magnetic Resonance (NMR) Spectroscopy: To determine the three-dimensional structure of N-(Cglu)A and to map its binding interface with proteins.
X-ray Crystallography: To obtain high-resolution structural information of N-(Cglu)A in complex with its target protein.
Surface Plasmon Resonance (SPR) and Isothermal Titration Calorimetry (ITC): To quantify the binding affinity and thermodynamics of the interaction between N-(Cglu)A and its biological partners.
Cellular and Molecular Biology: To understand the function of N-(Cglu)A in a biological context, cell-based assays are crucial. researchgate.net Researchers introduce N-(Cglu)A to cultured cells and observe its effects on cellular processes such as proliferation, differentiation, and gene expression. Genetic techniques, such as gene knockout or knockdown of potential target proteins, can help to identify the specific pathways through which N-(Cglu)A exerts its effects. researchgate.net
Computational Modeling and Bioinformatics: In silico approaches play an increasingly important role in the study of molecules like N-(Cglu)A. rroij.com Molecular docking simulations can predict the binding mode of N-(Cglu)A to a target protein, guiding the design of more potent analogs. Bioinformatics tools are used to analyze large datasets from proteomics and transcriptomics experiments to identify cellular pathways affected by N-(Cglu)A.
The following table outlines the key interdisciplinary methodologies used in N-(Cglu)A research.
| Discipline | Methodologies | Research Goals |
| Chemistry | Organic synthesis, medicinal chemistry | Production of N-(Cglu)A and its analogs, SAR studies |
| Biochemistry | Enzyme kinetics, protein purification | Characterization of enzymatic targets, understanding metabolic effects |
| Biophysics | NMR, X-ray crystallography, SPR, ITC | Structural elucidation, quantification of molecular interactions |
| Cell Biology | Cell culture, microscopy, flow cytometry | Investigation of cellular effects and mechanisms of action |
| Molecular Biology | Gene cloning, siRNA, CRISPR/Cas9 | Identification of target proteins and pathways |
| Computational Science | Molecular modeling, bioinformatics | Prediction of binding modes, analysis of large-scale biological data |
Structure
3D Structure
Properties
CAS No. |
145613-84-9 |
|---|---|
Molecular Formula |
C32H27NO11 |
Molecular Weight |
601.6 g/mol |
IUPAC Name |
[(2R,3S,4S,5R,6R)-3,4,5-trihydroxy-6-(14-methoxy-9-oxo-3,5-dioxa-10-azapentacyclo[9.7.1.02,6.08,19.013,18]nonadeca-1(18),2(6),7,11(19),12,14,16-heptaen-10-yl)oxan-2-yl]methyl (E)-3-(4-hydroxyphenyl)prop-2-enoate |
InChI |
InChI=1S/C32H27NO11/c1-40-21-4-2-3-17-18(21)11-20-25-19(12-22-30(26(17)25)43-14-42-22)31(39)33(20)32-29(38)28(37)27(36)23(44-32)13-41-24(35)10-7-15-5-8-16(34)9-6-15/h2-12,23,27-29,32,34,36-38H,13-14H2,1H3/b10-7+/t23-,27-,28+,29-,32-/m1/s1 |
InChI Key |
POLMXRJPIMTBPO-DSPNEAMJSA-N |
SMILES |
COC1=CC=CC2=C3C4=C(C=C21)N(C(=O)C4=CC5=C3OCO5)C6C(C(C(C(O6)COC(=O)C=CC7=CC=C(C=C7)O)O)O)O |
Isomeric SMILES |
COC1=CC=CC2=C3C4=C(C=C21)N(C(=O)C4=CC5=C3OCO5)[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)COC(=O)/C=C/C7=CC=C(C=C7)O)O)O)O |
Canonical SMILES |
COC1=CC=CC2=C3C4=C(C=C21)N(C(=O)C4=CC5=C3OCO5)C6C(C(C(C(O6)COC(=O)C=CC7=CC=C(C=C7)O)O)O)O |
Synonyms |
aristolactam, N-((6'-p-coumaroyl)glucopyranosyl) aristolactam-N-(6'-trans-p-coumaroyl)-beta-D-glucopyranoside N-((6'-p-coumaroyl)glucopyranosyl)aristolactam N-((6'-trans-p-coumaroyl)-beta-D-glucopyranosyl)aristolactam N-(CGlu)A |
Origin of Product |
United States |
Advanced Synthetic Methodologies for N Cglu a and Its Structural Analogs
Design and Synthesis of N-(Cglu)A Analogues for Structure-Activity Relationship (SAR) Studies
Structure-Activity Relationship (SAR) studies are fundamental in medicinal chemistry and chemical biology, aiming to elucidate the relationship between a compound's chemical structure and its biological activity. For complex molecules like N-(Cglu)A, the design and synthesis of analogues are critical for identifying key pharmacophores, optimizing potency, selectivity, and pharmacokinetic properties.
Modification of the N-Linkage: The nature of the N-linkage is often a primary point of modification. For instance, in N-acyl-γ-glutamyldiaminopimelic acid derivatives, the N-acyl group on the D-glutamyl residue can be substituted with N-alkyl groups while largely preserving activity cenmed.com. Similarly, replacing an O-glycosidic linkage with an N-glycosidic linkage (glycosylamide) or a triazole-linkage can impact activity, as observed in glucosamine-based antitumor glycerolipids fishersci.ca.
Alterations to the "Cglu" Moiety:
Glucosyl Derivatives: If "Cglu" represents a glucosyl unit, modifications can include altering the stereochemistry of the sugar (e.g., converting a glucoconjugate to a galactoconjugate by inverting the chiral center at the sugar C-4 atom), introducing different sugar moieties, or modifying the hydroxyl groups mims.com. Such changes can significantly influence interactions with biological targets.
Glutamyl Derivatives: If "Cglu" represents a glutamyl unit, substitutions to the glutamic acid component itself, or its free carboxylates, can modulate activity. For example, replacing glutamic acid with glutaric or γ-aminobutyric acid in certain derivatives can lead to greatly attenuated agonistic activity cenmed.com. Esterification of free carboxylates can also yield more lipophilic, yet active, analogues cenmed.com.
Introduction of Functional Groups: Strategic incorporation of various functional groups can enhance specific interactions with biological targets, improve solubility, or facilitate membrane permeability. For instance, the presence of charged species, such as a quaternary ammonium (B1175870) group, has been shown to increase the bioavailability and transport of certain glycoconjugates across cell membranes mims.com.
Conformational Flexibility: Introducing flexible spacers between key moieties can reduce steric hindrance and allow the molecule to adopt more favorable conformations for binding to its target. A C2 spacer between glycon and heterocyclic moieties, for example, can increase molecular flexibility and improve accommodation within an active site mims.com.
Chirality: The stereochemistry at chiral centers is paramount for biological activity. Even subtle changes, such as the stereochemistry at the C2-position of a glycerol (B35011) backbone in diglycosylated analogs, can have a minimal yet discernible effect on anticancer activities fishersci.ca.
Combinatorial synthesis is a powerful strategy for rapidly generating diverse libraries of N-(Cglu)A derivatives, enabling high-throughput screening and efficient mapping of SAR. This approach allows for the simultaneous synthesis of numerous compounds by varying building blocks at different positions of the core scaffold.
Strategies for developing combinatorial libraries often involve:
Solid-Phase Synthesis: This method is highly effective for constructing libraries, particularly for peptide or glycopeptide-like structures. The growing molecule is tethered to a solid support, allowing for easy purification by washing and enabling the use of excess reagents to drive reactions to completion.
Solution-Phase Parallel Synthesis: For smaller to medium-sized libraries, parallel synthesis in solution can be employed. This involves conducting multiple reactions simultaneously in separate reaction vessels, each with different building blocks, followed by individual purification and characterization.
Building Block Approach: Pre-synthesized N-linked "Cglu" fragments can serve as central building blocks, around which diversity is introduced by coupling with various amines, carboxylic acids, or other functionalized molecules. This modular approach streamlines the synthesis of complex derivatives.
The application of combinatorial synthesis allows for the rapid exploration of chemical space around the N-(Cglu)A scaffold. For example, a hypothetical library of N-(Cglu)A derivatives might explore variations in the N-substituent (R1), the "Cglu" moiety (R2), and an additional side chain (R3), leading to a diverse set of compounds for biological evaluation.
Table 1: Hypothetical Combinatorial Library of N-(Cglu)A Derivatives and Their Bioactivity
| Compound ID | R1 (N-Substituent) | R2 ("Cglu" Moiety) | R3 (Side Chain) | Bioactivity (e.g., IC50, µM) |
| N-(Cglu)A-001 | Acetyl | Glucosyl | H | 15.2 |
| N-(Cglu)A-002 | Propionyl | Glucosyl | H | 12.8 |
| N-(Cglu)A-003 | Benzyl | Glucosyl | H | 8.5 |
| N-(Cglu)A-004 | Acetyl | Glutamyl | CH3 | 22.1 |
| N-(Cglu)A-005 | Acetyl | Glucosyl | CH2CH3 | 7.9 |
| N-(Cglu)A-006 | Benzyl | Glutamyl | H | 10.1 |
Note: This table presents hypothetical data for illustrative purposes of a combinatorial library.
Total Synthesis of Complex N-(Cglu)A Natural Product Variants
Total synthesis is the complete chemical synthesis of complex organic molecules from simpler, readily available precursors. For complex natural product variants of N-(Cglu)A, total synthesis serves multiple purposes, including confirming proposed structures, providing access to scarce compounds for biological evaluation, and enabling the synthesis of non-natural analogs that may possess improved properties nih.gov. The complexity of N-(Cglu)A, particularly if it incorporates multiple chiral centers, N-glycosidic bonds, or intricate polycyclic systems (as suggested by "aristolactam" derivatives wikipedia.org), necessitates sophisticated synthetic strategies.
Key strategies and challenges in the total synthesis of such complex natural product variants include:
Convergent Synthesis: This approach involves synthesizing several complex fragments independently and then joining them in a final few steps. This strategy is highly efficient for complex molecules, as it allows for the parallel development of synthetic routes to different parts of the molecule, as exemplified in the synthesis of limonoid natural products ctdbase.org.
Stereoselective Reactions: Given the potential for numerous chiral centers, achieving high stereoselectivity in each bond-forming step is critical. This often involves the use of chiral auxiliaries, asymmetric catalysis, or substrate-controlled reactions. For instance, the preparation of glycosides often requires specific stereochemical control at the anomeric carbon, and various glycosylation procedures have been developed to achieve this mims.com.
Protecting Group Strategies: Complex natural products typically possess multiple reactive functional groups that require selective protection and deprotection throughout the synthetic sequence. The judicious choice of protecting groups is essential to prevent unwanted side reactions and ensure high yields. Ester protecting groups, for example, are commonly used in sugar chemistry due to their role as neighboring participating groups in glycoside preparation mims.com.
Modern Synthetic Methodologies: Advances in organic chemistry continually provide new tools for complex molecule synthesis.
C-H Functionalization: This methodology allows for the direct functionalization of carbon-hydrogen bonds, significantly increasing synthetic efficiency by reducing the number of pre-functionalization steps metabolomicsworkbench.org. It is particularly valuable for constructing C-O and C-N bonds in natural product syntheses metabolomicsworkbench.org.
Enzymatic Synthesis: Enzymes offer highly selective and efficient routes to complex molecules, particularly those with multiple chiral centers or specific glycosidic linkages. For example, highly efficient one-pot multienzyme (OPME) sialylation systems have proven powerful for synthesizing N-glycolylneuraminic acid (Neu5Gc) and its derivatives nih.gov. Enzymatic DNA synthesis has also been explored for incorporating modified nucleoside triphosphates bearing various carbohydrate units nih.gov.
Computer-Guided Synthesis: Computational methods, such as density functional theory (DFT) calculations of NMR shifts, can guide synthetic efforts by suggesting the most likely structure of a natural product to be synthesized, thereby reducing time and resources researchgate.net.
The total synthesis of N-(Cglu)A natural product variants would likely involve a combination of these strategies, addressing the specific challenges posed by its N-linked nature and the glucosyl or glutamyl moiety.
Compound Names and PubChem CIDs
Sophisticated Analytical Techniques for N Cglu a Research
Advanced Chromatographic Separations for N-(Cglu)A Isolation and Quantification
Chromatographic methods are foundational in carbohydrate analysis, offering robust platforms for separating and quantifying target compounds from complex mixtures.
Gas Chromatography coupled with Mass Spectrometry (GC-MS) is a powerful technique for the selective and accurate quantification of N-acetylglucosamine (GlcNAc) and related hexosamines, particularly in highly complex and concentrated biological samples such as intracellular cell extracts, cell culture supernatants, and quenching/washing solutions acs.orgnih.gov. Due to the polar nature of carbohydrates, derivatization, often involving ethoximation and subsequent trimethylsilylation, is a prerequisite for their analysis by GC acs.orgnih.gov.
GC offers high sample capacity, exceptional separation efficiency, and precision, which are critical for distinguishing low-abundance stereoisomers of N-acetylhexosamines that possess identical exact masses and similar fragmentation patterns acs.orgnih.gov. A comparative study evaluating tandem mass spectrometric (GC-MS/MS) and time-of-flight mass spectrometric (GC-TOFMS) instrumentation for GlcNAc quantification demonstrated limits of detection in the lower femtomol range for both techniques acs.orgnih.gov. The results obtained from GC-MS/MS and GC-TOFMS for GlcNAc quantification in Penicillium chrysogenum samples showed excellent agreement, with an average deviation of 2.8 ± 5.5% across a concentration range of 0.5 to 23 µmol L⁻¹ nih.gov. Furthermore, GC-MS can confirm the presence of N-acetylglucosamine through characteristic fragmentation patterns (e.g., m/z = 43, 59, 72, and 130) and an approximate molecular mass of 221.1 g/mol rasayanjournal.co.in. This technique has also been successfully applied in metabolomic studies to identify changes in metabolite profiles in response to N-acetylglucosamine in fungal pathogens like Candida albicans mdpi.comresearchgate.net.
Table 1: Performance Metrics for N-Acetylglucosamine Quantification by GC-MS/MS and GC-TOFMS
| Analytical Technique | Sample Type | Limit of Detection (LOD) | Agreement (Average Deviation) |
| GC-MS/MS | Biotechnological Cell Samples | Lower femtomol range | 2.8 ± 5.5% nih.gov |
| GC-TOFMS | Biotechnological Cell Samples | Lower femtomol range | 2.8 ± 5.5% nih.gov |
| GC-MS | Enzymatic Degradation Products of Chitin | N/A | N/A |
High-Performance Liquid Chromatography (HPLC) is a versatile technique for the analysis of N-acetylglucosamine and its related substances, offering various modes of separation. Reverse-phase HPLC (RP-HPLC) methods are commonly employed, utilizing mobile phases composed of acetonitrile, water, and acidic modifiers such as phosphoric acid or formic acid (the latter for compatibility with mass spectrometry detection) sielc.com. Detection is often achieved using ultraviolet (UV) detectors, typically at wavelengths like 194 nm or 210 nm, to assess purity and quantify the compounds rasayanjournal.co.innih.gov.
Hydrophilic Interaction Liquid Chromatography (HILIC) coupled with UV detection is another established HPLC mode, particularly useful for polar compounds like N-acetylglucosamine. This method has been validated for determining N-acetylglucosamine in cosmetic formulations and skin test samples, employing a ZIC®-pHILIC column and a mobile phase of acetonitrile-aqueous KH2PO4 nih.gov. HPLC methods demonstrate excellent analytical performance, characterized by high linearity (correlation coefficients, R², typically >0.999), satisfactory precision (relative standard deviation, RSD%, generally ≤3.10%), and good accuracy (typically within 95-105% of expected concentrations) nih.govnih.gov. Furthermore, liquid chromatography-tandem mass spectrometry (LC-MS/MS) methods have been developed for the quantification of N-acetylglucosamine in human plasma, exhibiting a linear range from 20 to 1280 ng/ml nih.govresearchgate.netsci-hub.ru.
Table 2: Typical Performance Parameters for HPLC-UV and LC-MS/MS Methods for N-Acetylglucosamine
| Analytical Technique | Linearity (R²) | Precision (RSD%) | Accuracy (%) | Linear Range (LC-MS/MS) |
| HPLC-UV (RP-HPLC) | >0.999 nih.govnih.gov | <3.10% nih.govnih.gov | 95-105% nih.gov | N/A |
| LC-MS/MS | >0.9992 sci-hub.ru | <9.64% sci-hub.ru | 97.5-104% sci-hub.ru | 20-1280 ng/ml nih.govsci-hub.ru |
For the analysis of charge variants and highly efficient separations, Capillary Electrophoresis (CE) and Ion Exchange Chromatography (IEC) are indispensable.
Capillary Electrophoresis (CE): CE is a highly efficient separation technique in bioanalytical chemistry, particularly advantageous for carbohydrate analysis due to its ability to separate molecules based on their charge-to-size ratio with high resolution csic.esacs.org. CE-based enzyme assays, for instance, have been developed for enzymes like UDP-N-acetylglucosamine enolpyruvyl transferase (MurA), enabling baseline separation of reaction products from substrates using UV detection within minutes nih.gov. CE is also capable of resolving glycans that share the same monosaccharide sequence but differ in positional isomers, and can even assist in determining alpha or beta linkages acs.org. Methods have been established for separating N-acetylglucosamine and its oligomers, such as N,N',N''-triacetylchitotriose and N,N'-diacetylchitobiose, which are relevant in enzyme assays involving β-N-acetylhexosaminidase cuni.cz. Derivatives of chitosan, a polymer of N-acetylglucosamine, have also been explored as pseudostationary phases in CE for the separation of proteoforms of glycoproteins csic.es. The technique is valued for its rapid separations, high efficiency, and minimal consumption of reagents and samples csic.es.
Ion Exchange Chromatography (IEC): Ion Exchange Chromatography is widely applied for the separation and purification of N-acetylglucosamine, effectively removing charged organic molecules and inorganic salts google.com. A double-stage ion exchange chromatography process, utilizing ion exchange resins, can selectively adsorb impurities while allowing the target N-acetylglucosamine to pass through and be collected google.com. Ion-exclusion chromatography, specifically on cation-exchange resins (e.g., Dowex 50W-X2 in borate (B1201080) buffer), has been demonstrated for separating N-acetylglucosamine from N-acetylmannosamine, leveraging a combination of ion exclusion and gel permeation mechanisms nih.gov. This technique is also crucial in the purification of proteins that interact with N-acetylglucosamine polymers, such as lysozyme (B549824) iontosorb.cz. Furthermore, high-performance anion-exchange chromatography has been utilized for the quantification of meningococcal X polysaccharide, using synthetic N-acetylglucosamine-4-phosphate as a standard researchgate.net. Studies have also employed IEC to analyze (3H)N-acetylglucosamine labeled mucins nih.gov.
Mass Spectrometry-Based Characterization of N-(Cglu)A Structures
Mass spectrometry (MS) techniques are indispensable for the detailed structural characterization of N-(Cglu)A and related compounds, providing precise mass information and fragmentation data crucial for confirming molecular identity and determining structural linkages.
High-Resolution Mass Spectrometry (HRMS) is a critical tool for obtaining precise mass measurements, which are fundamental for confirming the elemental composition and exact structure of compounds like N-acetylglucosamine and its impurities researchgate.net. Advanced HRMS instruments, such as Fourier-Transform Ion Cyclotron Resonance (FT-ICR) and Orbitrap mass analyzers, can achieve mass resolutions exceeding 10^6 at m/z 200 Th acs.org. This exceptional resolution enables the differentiation of isobaric compounds and the precise determination of molecular formulas. HRMS is particularly valuable in complex matrices where selective detection is paramount, allowing for the distinction between bare ions and those adducted with common species like sodium or ammonium (B1175870), which can affect mass accuracy acs.orgnih.govacs.org. Beyond molecular identification, HRMS-based techniques like MALDI-Mass Spectrometry Imaging (MSI) are employed for spatial visualization. For instance, MALDI-MSI can map the distribution of O-GlcNAcylated proteins in tissue sections by detecting GlcNAc released through enzymatic hydrolysis, with detection limits as low as 5 ng/mL mdpi.com.
Tandem Mass Spectrometry (MS/MS), including Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS), is extensively used for both the quantification and detailed structural characterization of N-acetylglucosamine and its derivatives nih.govresearchgate.netsci-hub.ruresearchgate.netsielc.com. In quantification, LC-MS/MS often employs multiple reaction monitoring (MRM) mode, tracking specific mass transitions (e.g., m/z 220.3 → 118.9 for deprotonated N-acetylglucosamine) to achieve high sensitivity and selectivity in biological samples nih.govresearchgate.netsci-hub.ru.
For structural elucidation, MS/MS is crucial for analyzing N-acetylhexosamine stereoisomers, which pose a challenge due to their identical exact masses and similar fragmentation patterns acs.orgnih.gov. Collision-induced dissociation (CID) is a common fragmentation technique that yields diagnostic fragment ions. A key characteristic of N-acetylglucosamine modifications, such as O-GlcNAcylation, is the diagnostic loss of the GlcNAc moiety and the presence of the m/z 204.087 GlcNAc oxonium ion, which is specific to glycopeptides escholarship.org. Further analysis of fragment ion ratios can differentiate between GlcNAc and its isomer N-acetylgalactosamine (GalNAc); for O-GlcNAc, the m/z 138 ion is significantly more intense than the m/z 144 ion, whereas for O-GalNAc, these fragments exhibit similar intensities escholarship.org. Advanced fragmentation techniques like Electron-Transfer/Higher-Energy Collision Dissociation (EThcD) can provide even more comprehensive fragmentation data, enabling the precise identification of modification sites and differentiation between HexNAc isomers escholarship.org.
Compound Names and PubChem CIDs
This table lists the chemical compounds mentioned in the article, along with their corresponding PubChem Compound Identifiers (CIDs) where available.
Isotope-Labeling Strategies for Absolute Quantification in Biological Samples
Absolute quantification of N-(Cglu)A in complex biological samples is critical for understanding its physiological roles and pharmacokinetics. Isotope-labeling strategies, often coupled with mass spectrometry (MS), provide a highly accurate and sensitive approach to achieve this. The fundamental principle involves introducing stable isotopes (e.g., carbon-13 (¹³C), nitrogen-15 (B135050) (¹⁵N), or deuterium (B1214612) (²H)) into a synthetic version of N-(Cglu)A, creating an internal standard uni.lulibretexts.org.
This stable isotope-labeled internal standard (SIL-IS), which is chemically identical but isotopically distinct from the endogenous analyte, is spiked into the biological sample at a known concentration uni.lulibretexts.orgnih.gov. During mass spectrometric analysis, both the endogenous N-(Cglu)A and the SIL-IS are ionized and detected simultaneously. The ratio of the signal intensity of the unlabeled N-(Cglu)A to that of the labeled internal standard allows for the precise determination of the absolute concentration of N-(Cglu)A in the original sample uni.lunih.gov. This method effectively compensates for sample preparation variations, matrix effects, and ionization efficiencies, leading to highly reproducible and accurate quantification uni.lulibretexts.orgnih.gov. Such strategies are particularly valuable for molecules like N-(Cglu)A, which may be present in low concentrations within complex biological matrices nih.gov.
Nuclear Magnetic Resonance (NMR) Spectroscopy for Conformational and Linkage Analysis of N-(Cglu)A
Nuclear Magnetic Resonance (NMR) spectroscopy is an indispensable tool for the detailed structural elucidation, conformational analysis, and determination of glycosidic linkages in complex organic molecules, including glycoconjugates such as N-(Cglu)A. This non-destructive technique provides atomic-level information about the molecule's three-dimensional structure and dynamic behavior in solution.
Advanced 1D and 2D NMR Experiments (e.g., COSY, HSQC, HMBC, NOESY)
A suite of advanced 1D and 2D NMR experiments is employed to fully characterize N-(Cglu)A:
1D NMR (¹H and ¹³C NMR): These provide initial insights into the number and types of protons and carbons present, as well as their chemical environments. ¹H NMR spectra reveal proton multiplets and chemical shifts, while ¹³C NMR provides information on carbon backbone and functional groups.
COSY (Correlation Spectroscopy): This homonuclear 2D experiment identifies protons that are scalar-coupled (i.e., directly connected through 2 or 3 bonds). For N-(Cglu)A, COSY is crucial for tracing spin systems within the glucopyranosyl ring and the aliphatic/aromatic protons of the aristolactam and p-coumaroyl moieties, allowing for sequential assignment of interconnected protons.
HSQC (Heteronuclear Single Quantum Coherence): An essential heteronuclear 2D experiment, HSQC correlates directly bonded ¹H and ¹³C atoms. This technique provides a powerful means to assign proton and carbon signals simultaneously, particularly for the anomeric carbons of the glucose unit and the various sp2 and sp3 carbons throughout the molecule.
Investigation of Stereochemical Aspects and Glycosidic Linkages
NMR spectroscopy plays a pivotal role in resolving the stereochemical complexities and defining the glycosidic linkages within N-(Cglu)A. The diverse and complex roles of carbohydrates are often attributed to their structural diversity, including their stereoisomers and linkage types.
Anomeric Configuration: The anomeric configuration (α or β) of the glucopyranosyl unit, which defines the orientation of the anomeric carbon's substituent relative to the exocyclic oxygen, is critically determined by the chemical shift of the anomeric proton and carbon, as well as the magnitude of their coupling constants (e.g., ³J_H1-H2_ coupling). NOESY correlations between the anomeric proton and other protons on the sugar ring or the aglycone (aristolactam) are also diagnostic for assigning the anomeric configuration.
Glycosidic Linkage Positions: HMBC experiments are particularly effective in identifying the specific atoms involved in the glycosidic bonds. Long-range correlations from the anomeric proton of the glucose to the carbon atom of the aristolactam backbone, and from the protons of the p-coumaroyl group to the C6' carbon of the glucose, confirm the precise linkage positions (e.g., N-linkage to aristolactam, and 6'-O-linkage of p-coumaroyl to glucose).
Spectroscopic Methods for N-(Cglu)A Detection and Imaging
Spectroscopic methods offer sensitive and selective approaches for the detection, quantification, and even imaging of N-(Cglu)A, leveraging its inherent optical properties or those of its derivatives.
UV-Vis Spectroscopy for Absorption Characteristics of N-(Cglu)A Derivatives
Ultraviolet-Visible (UV-Vis) spectroscopy is a fundamental analytical technique that measures the absorption of light by molecules in the ultraviolet (100-400 nm) and visible (400-800 nm) regions of the electromagnetic spectrum. This absorption occurs when electrons in a molecule are promoted from lower to higher energy orbitals, typically involving π→π* and n→π* electronic transitions in conjugated systems and functional groups (chromophores).
N-((6'-p-Coumaroyl)glucopyranosyl)aristolactam contains significant chromophores, notably the p-coumaroyl group and the aristolactam backbone, both of which possess extended conjugated pi-electron systems ontosight.ai. These chromophores are expected to exhibit characteristic absorption maxima (λmax) in the UV-Vis region, making UV-Vis spectroscopy a valuable tool for:
Qualitative Identification: The unique absorption spectrum of N-(Cglu)A can serve as a fingerprint for its identification.
Quantitative Analysis: According to the Beer-Lambert Law, the absorbance is directly proportional to the concentration of the analyte and the path length of the light. This allows for the accurate quantification of N-(Cglu)A in solution, provided its molar absorptivity (ε) at a specific λmax is known.
Monitoring Reactions: Changes in the UV-Vis spectrum can be used to monitor chemical reactions involving N-(Cglu)A or the formation of its derivatives.
Computational and Theoretical Studies of N Cglu a
Quantum Mechanical (QM) Calculations for Electronic Structure and Reactivity of N-(Cglu)A
Quantum Mechanical (QM) calculations, rooted in the principles of quantum mechanics, are indispensable for investigating the electronic structure, bonding, and reactivity of molecules at an atomic level nih.govguidetopharmacology.org. These methods explicitly consider the behavior of electrons, providing highly accurate descriptions of molecular properties.
Density Functional Theory (DFT) is a widely utilized QM method due to its balance of accuracy and computational efficiency, making it suitable for larger molecular systems than more computationally intensive ab initio methods nih.govfishersci.at. In the context of N-(Cglu)A, DFT calculations would be employed to:
Elucidate Reaction Pathways: DFT can map potential energy surfaces, identifying stable intermediates and transition states along a reaction coordinate. This allows for a detailed understanding of the step-by-step mechanism of chemical transformations involving N-(Cglu)A, such as bond formation or cleavage. By calculating activation energies and reaction free energies, DFT can predict the feasibility and kinetics of different reaction pathways.
Gain Mechanistic Insights: Beyond identifying pathways, DFT provides insights into the electronic rearrangements during reactions. This includes analyzing charge distribution, orbital interactions, and the nature of transition states, which are crucial for rationalizing observed reactivity and designing new chemical processes. For instance, studies on reaction mechanisms often involve analyzing the electronic nature of intermediates and transition states to understand the driving forces behind a reaction.
QM calculations, including DFT, are instrumental in exploring the energetic and conformational landscapes of molecules. For N-(Cglu)A, this involves:
Identification of Isomers and Conformers: By systematically exploring different arrangements of atoms, QM calculations can identify various stable isomers and conformers of N-(Cglu)A. Each conformer represents a local minimum on the potential energy surface.
Relative Energies and Stability: The relative energies of these isomers and conformers can be calculated, providing insights into their thermodynamic stability. This helps in understanding which structures are most likely to be populated under specific conditions.
Mapping Potential Energy Surfaces: QM methods can be used to construct detailed potential energy surfaces, revealing the energy barriers between different conformational states and the pathways for interconversion. This is critical for understanding molecular flexibility and dynamics.
Molecular Dynamics (MD) Simulations for Conformational Analysis and Solvent Effects on N-(Cglu)A
Molecular Dynamics (MD) simulations provide a time-dependent view of molecular systems, allowing researchers to study the dynamic behavior of molecules and their interactions with the surrounding environment, such as solvent molecules. For N-(Cglu)A, MD simulations would be crucial for understanding its conformational flexibility and how it behaves in solution.
Many biological and chemical processes are highly sensitive to pH, as the protonation states of ionizable groups can significantly influence molecular structure, stability, and function. For a compound like N-(Cglu)A, which might contain titratable groups (e.g., the N-terminal amine and the C-terminal glutamate (B1630785) carboxylate), constant-pH MD simulations are particularly valuable.
This advanced MD technique allows the protonation states of titratable residues to dynamically change during the simulation, reflecting the local electrostatic environment and the bulk pH of the solution. Studies on related compounds, such as Glutathione (GSH), which contains N-terminal (Nter) and C-terminal glutamate (CGlu) moieties, have utilized constant-pH MD to determine the pKa values of these titratable sites and analyze how their protonation states influence conformational preferences.
Example of pKa Values from Analogous Studies (Glutathione): In studies involving Glutathione, which contains Nter and CGlu groups, constant-pH MD simulations have been used to determine the pKa values of its titratable sites. These values are crucial for understanding the molecule's behavior across different pH environments.
| Titratable Site (Analogous to N-(Cglu)A components) | pKa Value (Example from GSH) |
| N-terminus (Nter) | 7.46 |
| C-terminal Glutamate (CGlu) | 4.62 |
| C-terminus (Cter) | 3.19 |
| Cysteine (Cys) | 8.58 |
Note: These pKa values are illustrative examples from studies on Glutathione (GSH), a related tripeptide containing N-terminal and C-terminal glutamate-like components, and are presented to demonstrate the type of data obtainable from constant-pH MD simulations for titratable sites relevant to the hypothetical structure of N-(Cglu)A.
MD simulations generate a trajectory of atomic positions over time, from which a conformational ensemble can be derived. This ensemble represents the collection of accessible structures that a molecule adopts in solution. For N-(Cglu)A, analysis of these ensembles would provide:
Conformational Preferences: Identification of the most populated conformational states and their relative stabilities in solution. This reveals the preferred shapes the molecule adopts under specific solvent conditions.
Molecular Flexibility: Quantification of the molecule's flexibility, including the movement of specific bonds, angles, and dihedral angles. This is crucial for understanding how a molecule can adapt to different binding partners or environments.
Solvent Effects: Direct observation of how solvent molecules interact with N-(Cglu)A, including hydrogen bonding, electrostatic interactions, and hydrophobic effects. These interactions significantly influence the molecule's conformation and dynamics. Studies on peptides, for instance, show that their conformational space is significantly affected by solution pH and interactions with the solvent.
Molecular Mechanics (MM) and Force Field Development for N-(Cglu)A Systems
Molecular Mechanics (MM) methods are computationally less demanding than QM methods, making them suitable for simulating much larger systems and longer timescales guidetopharmacology.org. MM calculations approximate the potential energy of a system using classical physics, where atoms are treated as point masses connected by springs, and interactions are described by empirical force fields.
For N-(Cglu)A, the development or application of a suitable force field would be a prerequisite for MM simulations. This process typically involves:
Parameterization: Assigning parameters (e.g., bond lengths, angles, dihedral angles, partial charges, and non-bonded interaction parameters) to describe the interactions within the molecule and between the molecule and its environment. These parameters are often derived from high-level QM calculations or experimental data nih.gov.
Validation: Testing the developed force field against known experimental data or higher-level QM calculations to ensure its accuracy in reproducing molecular geometries, energies, and dynamic properties.
Application: Once a reliable force field is established, MM simulations can be used to explore the conformational space of N-(Cglu)A, study its interactions with other molecules (e.g., in docking or protein-ligand binding studies), and investigate its behavior in complex biological environments.
In Silico Prediction of N-(Cglu)A Biological Interactions
In silico prediction of biological interactions involves using computational methods to forecast how a chemical compound might interact with biological macromolecules, such as proteins, nucleic acids, or lipids [10 from first search]. This predictive capability is invaluable for elucidating mechanisms of action, identifying off-target effects, and discovering novel therapeutic candidates [11 from first search]. For N-(Cglu)A, these predictions would leverage its chemical structure to infer its binding affinity and functional modulation with various biological targets.
Virtual screening (VS) is a computational technique used to search large libraries of chemical compounds for potential hits that bind to a specific biological target, or conversely, to find potential targets for a given compound [22 from first search]. For N-(Cglu)A, virtual screening could be employed in two primary ways:
Structure-Based Virtual Screening (SBVS): If the three-dimensional structure of a putative protein target is known (e.g., from X-ray crystallography or cryo-electron microscopy), SBVS methods like molecular docking are used. In this approach, N-(Cglu)A would be computationally "docked" into the binding site of various target proteins. Docking algorithms predict the optimal binding pose and estimate the binding affinity using scoring functions [22 from first search], allowing for the ranking of potential binding partners. For instance, a study might dock N-(Cglu)A against a panel of enzymes or receptors to identify those with the most favorable binding scores.
Ligand-Based Virtual Screening (LBVS): When the structure of the biological target is unknown, or to complement SBVS, LBVS relies on the known chemical structures or molecular properties of compounds that exhibit a desired biological activity. Methods include pharmacophore modeling, 2D/3D similarity searches, and shape similarity methods [22 from first search]. For N-(Cglu)A, if a set of compounds with similar biological activity to N-(Cglu)A were known, LBVS could identify other compounds (or predict targets) based on shared structural features or physicochemical properties essential for that activity. Conversely, if N-(Cglu)A's activity is of interest, its structural features could be used to identify proteins that bind to similar ligands.
Illustrative Virtual Screening Results for N-(Cglu)A
While specific data for N-(Cglu)A are not available, a hypothetical virtual screening campaign might yield results similar to those shown in Table 1, where N-(Cglu)A demonstrates varying predicted binding affinities (represented by docking scores) to different hypothetical protein targets. Lower (more negative) docking scores typically indicate stronger predicted binding.
Table 1: Illustrative Virtual Screening Results for N-(Cglu)A Against Hypothetical Protein Targets
| Protein Target | PDB ID (Illustrative) | Predicted Docking Score (kcal/mol) | Predicted Binding Mode |
| Target A | 1XYZ | -8.5 | Hydrogen bonding, hydrophobic interactions |
| Target B | 2ABC | -7.2 | Pi-stacking, van der Waals forces |
| Target C | 3DEF | -5.1 | Weak electrostatic interactions |
| Target D | 4GHI | -9.1 | Multiple hydrogen bonds, strong hydrophobic contacts |
These predicted interactions would then guide experimental validation, focusing on the targets with the most promising scores and binding modes.
Quantitative Structure-Activity Relationship (QSAR) modeling aims to establish a mathematical relationship between the chemical structure of a series of compounds and their biological activity [18 from first search]. This relationship allows for the prediction of the activity of new, untested compounds and provides insights into the structural features critical for activity [25 from first search]. For N-(Cglu)A derivatives, QSAR models would be built using a dataset of N-(Cglu)A analogs with known biological activities.
The QSAR modeling process typically involves:
Data Collection: Gathering a series of N-(Cglu)A derivatives and their experimentally determined biological activities (e.g., IC50, Ki, EC50 values).
Molecular Descriptor Calculation: Computing numerical representations of the chemical structures, known as molecular descriptors. These can include physicochemical properties (e.g., logP, molecular weight, polar surface area), electronic properties (e.g., partial charges), and steric properties (e.g., molecular volume, shape descriptors) [16 from first search].
Model Building: Employing statistical or machine learning algorithms (e.g., multiple linear regression, partial least squares, support vector machines, neural networks) to correlate the molecular descriptors with the biological activity [16 from first search], [23 from first search].
Model Validation: Rigorously testing the predictive power and robustness of the QSAR model using internal (e.g., cross-validation) and external validation sets [16 from first search], [25 from first search].
Illustrative QSAR Findings for N-(Cglu)A Derivatives
A QSAR study on N-(Cglu)A derivatives might reveal specific structural modifications that enhance or diminish activity. For example, if "Cglu" refers to a glutamate moiety, changes to its side chain or the nature of the "N-" substitution could be explored.
Table 2: Illustrative QSAR Data for N-(Cglu)A Derivatives and Predicted Activity
| Derivative ID | R1 (N-substituent) | R2 (Cglu modification) | LogP (Illustrative) | Molecular Weight (Illustrative) | Predicted Activity (pIC50) |
| N-(Cglu)A-01 | -CH3 | -COOH | 1.2 | 250 | 6.8 |
| N-(Cglu)A-02 | -CH2CH3 | -COOH | 1.8 | 264 | 7.1 |
| N-(Cglu)A-03 | -CH3 | -CONH2 | 1.0 | 249 | 6.5 |
| N-(Cglu)A-04 | -C6H5 | -COOH | 2.5 | 312 | 7.5 |
| N-(Cglu)A-05 | -CH2CH3 | -CONH2 | 1.6 | 263 | 6.9 |
Detailed Research Findings (Illustrative): Analysis of such a QSAR model might indicate that increasing the lipophilicity (higher LogP) of the N-substituent (R1) generally leads to increased activity, while modifications to the R2 group (e.g., converting a carboxylic acid to an amide) might slightly reduce activity, possibly due to altered hydrogen bonding capabilities. The model could highlight the importance of specific functional groups or spatial arrangements for optimal interaction with a target. For example, a QSAR model might yield an equation like: pIC50 = C1 * LogP + C2 * (Number of H-bond Acceptors) + C3, where C1, C2, and C3 are coefficients indicating the weight of each descriptor. Such a model helps in rationally designing new N-(Cglu)A derivatives with improved predicted activity.
These computational studies, including virtual screening and QSAR modeling, provide powerful tools for exploring the chemical space around a compound like N-(Cglu)A, guiding the synthesis of new derivatives, and predicting their biological behavior, even when the exact identity of the compound is a subject of interpretation.
Future Research Directions and Translational Perspectives of N Cglu a Research
Development of Advanced N-(Cglu)A-Based Probes and Chemical Tools for Biochemical Investigations
The development of N-(Cglu)A-based probes and chemical tools is a critical avenue for elucidating its precise mechanisms of action and identifying its cellular targets. Such tools could involve the synthesis of fluorescently tagged N-(Cglu)A derivatives, enabling real-time visualization of its uptake, distribution, and interaction with biomolecules within living cells. Photoaffinity labeling (PAL) probes, incorporating a photoreactive group, could be designed to covalently bind to N-(Cglu)A's interacting proteins upon UV irradiation, allowing for subsequent identification of direct binding partners through mass spectrometry. ontosight.ai Furthermore, click chemistry-compatible N-(Cglu)A analogs could facilitate its conjugation to various reporter molecules or solid supports, aiding in pull-down assays for target identification or the creation of affinity chromatography resins for protein purification. These advanced chemical tools would significantly enhance the understanding of N-(Cglu)A's biochemical pathways and its influence on cellular processes.
Exploration of N-(Cglu)A as a Lead Compound for Novel Chemical Tool Discovery
N-(Cglu)A's inherent biological activities, such as its reported antioxidant, anti-inflammatory, and cytotoxic effects, underscore its potential as a lead compound for the discovery of novel chemical tools. ontosight.ai Structural modifications of N-(Cglu)A could lead to the development of more potent, selective, or stable derivatives with enhanced pharmacological profiles. For instance, medicinal chemistry efforts could focus on systematically altering the p-coumaroyl group, the glucopyranosyl moiety, or the aristolactam backbone to identify structure-activity relationships (SAR). This iterative process of synthesis and biological evaluation could yield compounds with optimized properties for specific biochemical interventions or therapeutic applications. High-throughput screening of N-(Cglu)A derivatives against various biological targets or pathways could uncover unexpected activities, expanding its utility beyond currently recognized effects. ontosight.ai
Bioengineering Approaches for Modulating N-(Cglu)A Production in Biological Systems
Given that N-(Cglu)A is a natural product, bioengineering approaches offer promising strategies for modulating its production in biological systems. This could involve metabolic engineering of the native plant sources to enhance N-(Cglu)A biosynthesis by overexpressing key enzymes in its biosynthetic pathway or downregulating competing pathways. Alternatively, synthetic biology techniques could be employed to reconstitute the entire N-(Cglu)A biosynthetic pathway in heterologous hosts, such as Escherichia coli or yeast. This would enable scalable and controlled production of N-(Cglu)A, overcoming limitations associated with extraction from natural sources, such as low yield or environmental variability. ontosight.ai CRISPR-Cas systems or other gene editing tools could be utilized to precisely engineer microbial or plant cell factories for optimized N-(Cglu)A production, facilitating its availability for research and potential industrial applications.
Emerging Analytical Technologies for Ultra-Trace Detection of N-(Cglu)A in Complex Biological Matrices
The accurate and sensitive detection of N-(Cglu)A in complex biological matrices, such as plasma, urine, or tissue samples, is crucial for pharmacokinetic studies, biomarker discovery, and monitoring its biological effects. Emerging analytical technologies are vital for achieving ultra-trace detection capabilities. Liquid chromatography-mass spectrometry (LC-MS/MS) remains a cornerstone, with advancements in sensitivity and specificity through techniques like ultra-high-performance liquid chromatography (UHPLC) coupled with high-resolution mass spectrometry (HRMS) or ion mobility-mass spectrometry (IM-MS). These methods allow for precise quantification and identification of N-(Cglu)A even at very low concentrations, while minimizing matrix interference. ontosight.ai
Furthermore, the development of biosensors, such as surface plasmon resonance (SPR) or electrochemical biosensors, tailored to specifically recognize N-(Cglu)A, could enable rapid, real-time, and label-free detection. Microfluidic devices integrating sample preparation and detection steps could further enhance throughput and reduce sample volume requirements. The application of nuclear magnetic resonance (NMR) spectroscopy, particularly advanced 2D and 3D NMR techniques, could provide detailed structural information of N-(Cglu)A and its metabolites in complex biological samples, complementing mass spectrometry data. ontosight.ai
Q & A
Basic: What experimental methodologies are recommended for synthesizing and characterizing N-(Cglu)A?
Methodological Answer:
Synthesis of N-(Cglu)A requires rigorous protocols to ensure purity and structural integrity. Key steps include:
- Chemical Synthesis : Use solid-phase peptide synthesis (SPPS) or recombinant expression systems, depending on the compound’s complexity. For post-synthesis purification, employ high-performance liquid chromatography (HPLC) with UV/Vis or mass spectrometry (MS) detection .
- Structural Characterization : Nuclear magnetic resonance (NMR) spectroscopy (1H, 13C, and 2D experiments) and Fourier-transform infrared spectroscopy (FTIR) are critical for confirming stereochemistry and functional groups. X-ray crystallography may be used if crystals are obtainable .
- Purity Validation : Quantify impurities via liquid chromatography-tandem mass spectrometry (LC-MS/MS) and ensure adherence to NIH guidelines for reporting preclinical data, including batch-to-batch variability .
Basic: How should researchers design assays to evaluate the biological activity of N-(Cglu)A?
Methodological Answer:
- In Vitro Assays : Use cell lines (e.g., Corynebacterium glutamicum for bacterial studies) to assess growth inhibition or metabolic modulation. Dose-response curves (IC50/EC50) should be generated with at least three biological replicates. Include controls for solvent effects and cytotoxicity .
- Enzyme Activity : For target-specific studies, employ fluorometric or colorimetric assays (e.g., NADH-coupled reactions) to measure kinetic parameters (Km, Vmax). Validate results with knockout strains or competitive inhibitors .
- Data Reporting : Follow FAIR principles (Findable, Accessible, Interoperable, Reusable) by documenting raw data, normalization methods, and statistical tests (e.g., ANOVA with post-hoc Tukey tests) .
Advanced: How can contradictions in gene essentiality data for N-(Cglu)A’s molecular targets be resolved?
Methodological Answer:
Discrepancies often arise from experimental conditions or organism-specific genetic redundancy. Strategies include:
- Comparative Genomics : Use tools like OrthoMCL or BLASTP to identify homologs of N-(Cglu)A’s targets across species. For example, ftsW is essential in Mycobacterium tuberculosis but dispensable in C. glutamicum due to structural variations in its C-terminal domain .
- Conditional Knockouts : Apply CRISPR-dCas9 or temperature-sensitive promoters to titrate gene expression. Monitor phenotype reversibility under varying conditions (e.g., nutrient stress) .
- Meta-Analysis : Aggregate transposon mutagenesis datasets (e.g., TraDIS) to identify conserved essential genes. Use Fisher’s exact test to assess statistical significance of insertion biases .
Advanced: What computational frameworks are suitable for modeling N-(Cglu)A’s interaction with bacterial membranes?
Methodological Answer:
- Molecular Dynamics (MD) Simulations : Use GROMACS or AMBER to simulate lipid bilayer interactions. Parameterize force fields with ab initio quantum mechanical calculations for accurate charge distribution .
- Docking Studies : Employ AutoDock Vina or Schrödinger Suite to predict binding affinities to membrane proteins (e.g., MmpL3 in C. glutamicum). Validate with mutagenesis data on key residues .
- Machine Learning : Train models on existing antimicrobial peptide datasets (e.g., CAMPR3) to predict N-(Cglu)A’s permeability and resistance mechanisms. Use SHAP values to interpret feature importance .
Basic: How to conduct a systematic literature review on N-(Cglu)A’s research landscape?
Methodological Answer:
- Keyword Strategy : Combine terms like “N-(Cglu)A synthesis,” “bacterial targets,” and “mechanism of action” with Boolean operators. Use Google Scholar’s “Cited by” feature to track recent papers .
- Database Searches : Query PubMed, Scopus, and Web of Science with filters for publication date (last 10 years) and study type (e.g., in vitro, in vivo). Export results to Zotero for deduplication .
- Critical Appraisal : Apply PRISMA guidelines to screen abstracts, assess bias (e.g., industry-funded studies), and synthesize findings in tabular format (e.g., compound efficacy across strains) .
Advanced: How to integrate multi-omics data to elucidate N-(Cglu)A’s mechanism of action?
Methodological Answer:
- Transcriptomics : Perform RNA-seq on treated vs. untreated C. glutamicum. Use DESeq2 for differential expression analysis and GSEA to identify enriched pathways (e.g., cell wall biosynthesis) .
- Proteomics : Apply tandem mass tag (TMT) labeling and LC-MS/MS to quantify protein abundance changes. Cross-reference with STRING database for protein interaction networks .
- Metabolomics : Conduct GC-MS or LC-MS to profile metabolic shifts (e.g., ATP depletion). Integrate omics layers using tools like MixOmics or Cytoscape for network visualization .
Basic: What are the best practices for replicating N-(Cglu)A-related experiments?
Methodological Answer:
- Protocol Standardization : Share step-by-step methods via protocols.io , including reagent lot numbers and equipment calibration details .
- Negative Controls : Include vehicle-only treatments and non-targeting siRNA in assays. For in vivo studies, use isogenic wild-type strains as comparators .
- Data Transparency : Publish raw microscopy images, flow cytometry files, and statistical code in repositories like Figshare or Zenodo .
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
