DNA31
Description
BenchChem offers high-quality this compound suitable for many research applications. Different packaging options are available to accommodate customers' requirements. Please inquire for more information about this compound including the price, delivery time, and more detailed information at info@benchchem.com.
Properties
Molecular Formula |
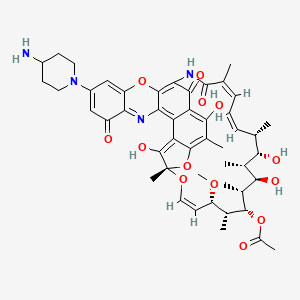
C48H58N4O13 |
|---|---|
Molecular Weight |
899.0 g/mol |
IUPAC Name |
[(7S,9Z,11S,12R,13S,14R,15R,16R,17S,18S,19Z,21Z)-30-(4-aminopiperidin-1-yl)-2,6,15,17-tetrahydroxy-11-methoxy-3,7,12,14,16,18,22-heptamethyl-23,32,37-trioxo-8,27,38-trioxa-24,34-diazahexacyclo[23.11.1.14,7.05,36.026,35.028,33]octatriaconta-1,3,5,9,19,21,25,28,30,33,35-undecaen-13-yl] acetate |
InChI |
InChI=1S/C48H58N4O13/c1-21-11-10-12-22(2)47(60)51-38-42(58)34-33(37-45(38)64-32-20-29(19-30(54)36(32)50-37)52-16-13-28(49)14-17-52)35-44(26(6)41(34)57)65-48(8,46(35)59)62-18-15-31(61-9)23(3)43(63-27(7)53)25(5)40(56)24(4)39(21)55/h10-12,15,18-21,23-25,28,31,39-40,43,55-57,59H,13-14,16-17,49H2,1-9H3,(H,51,60)/b11-10-,18-15-,22-12-/t21-,23+,24+,25+,31-,39-,40+,43+,48-/m0/s1 |
InChI Key |
CSVODQIZSSFFGA-QQSATCQASA-N |
Isomeric SMILES |
C[C@H]1/C=C\C=C(/C(=O)NC2=C3C(=C4C(=C(C(=C5C4=C([C@](O5)(O/C=C\[C@@H]([C@H]([C@H]([C@@H]([C@@H]([C@@H]([C@H]1O)C)O)C)OC(=O)C)C)OC)C)O)C)O)C2=O)N=C6C(=CC(=CC6=O)N7CCC(CC7)N)O3)\C |
Canonical SMILES |
CC1C=CC=C(C(=O)NC2=C3C(=C4C(=C(C(=C5C4=C(C(O5)(OC=CC(C(C(C(C(C(C1O)C)O)C)OC(=O)C)C)OC)C)O)C)O)C2=O)N=C6C(=CC(=CC6=O)N7CCC(CC7)N)O3)C |
Origin of Product |
United States |
Foundational & Exploratory
what are the basic principles of DNA computing
An In-depth Technical Guide to the Core Principles of DNA Computing
Introduction
DNA computing represents a paradigm shift from traditional silicon-based computation, leveraging the unique properties of deoxyribonucleic acid (DNA) to process and store information at a molecular scale.[1][2] Pioneered by Leonard Adleman in 1994 with his solution to a seven-node Hamiltonian Path Problem, this field merges computer science with molecular biology to create novel computational systems.[1][2][3] Unlike conventional computers that encode data in a binary format of 0s and 1s, DNA computing utilizes the four-base genetic alphabet: Adenine (A), Guanine (G), Cytosine (C), and Thymine (T).[4] The immense parallelism inherent in molecular interactions and the extraordinary data density of the DNA molecule offer tantalizing possibilities for solving complex combinatorial problems and developing advanced biomedical applications.[5] This guide details the fundamental principles, experimental methodologies, and applications of DNA computing, with a focus on its relevance to researchers in life sciences and drug development.
Core Principles of DNA Computing
The functionality of DNA computing is built upon several core principles that derive from the fundamental biochemical properties of nucleic acids.
2.1 DNA as an Information Storage Medium Information in DNA is encoded in the sequence of its nucleotide bases.[6] This four-letter alphabet allows for significantly higher information density than the binary system used in electronic computers.[7] A single gram of DNA can theoretically store up to 215 petabytes (215 million gigabytes) of data, making it an exceptionally compact and durable medium for long-term data archiving.[7][8]
2.2 Massive Parallelism A key advantage of DNA computing is its inherent parallelism.[6] A single test tube can contain trillions of DNA molecules, each of which can act as a processor.[9] This allows for a vast number of operations to be performed simultaneously, making this approach well-suited for tackling NP-complete problems, such as the Hamiltonian Path or Traveling Salesman problems, where a massive number of potential solutions must be explored.[4][10] Adleman's initial experiment, for instance, operated at a theoretical 100 Teraflops, a rate far exceeding the fastest supercomputers of its time.[9]
2.3 Fundamental Bio-molecular Operations Computation is performed not through electrical signals, but through a series of controlled biochemical reactions that manipulate the DNA strands.[11] Key operations include:
-
Hybridization and Denaturation : The process of single DNA strands binding to their Watson-Crick complements (A with T, C with G) to form a double helix, and the reverse process of separating them, typically with heat.[2] This is fundamental for molecular recognition.
-
Ligation : The joining of two separate DNA strands by a DNA ligase enzyme, used to form longer computational pathways.[9]
-
Enzymatic Cleavage : Using restriction enzymes to cut DNA at specific recognition sites, a key tool for manipulating and analyzing DNA strands.[12]
-
Polymerase Chain Reaction (PCR) : A technique to exponentially amplify specific DNA sequences, allowing for the detection and filtering of correct computational results.
-
Gel Electrophoresis : A method to separate DNA fragments based on their length, which is crucial for isolating solution strands from a complex mixture.[13]
Computational Models and Mechanisms
Several models have been developed to perform logical operations using DNA, primarily relying on strand displacement, enzymatic reactions, or self-assembly.
3.1 DNA Strand Displacement Toehold-mediated strand displacement is a central mechanism for programming dynamic molecular systems.[14][15] An input DNA strand binds to a short, single-stranded "toehold" region on a DNA duplex. This initiates a branch migration process where the input strand progressively displaces one of the original strands from the duplex, releasing it as an output.[14] This mechanism is highly programmable and can be used to construct logic gates, circuits, and molecular machines.[14][16]
References
- 1. DNA computing - Wikipedia [en.wikipedia.org]
- 2. tost.unise.org [tost.unise.org]
- 3. researchgate.net [researchgate.net]
- 4. britannica.com [britannica.com]
- 5. Unraveling the Potential of DNA Computing: A Revolutionary Leap in Information Processing | by Make Computer Science Great Again | Medium [medium.com]
- 6. neuroject.com [neuroject.com]
- 7. DNA's awesome potential to store the world's data | Micron Technology Inc. [micron.com]
- 8. DNA digital data storage - Wikipedia [en.wikipedia.org]
- 9. Computing with DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 10. medium.com [medium.com]
- 11. old.meritresearchjournals.org [old.meritresearchjournals.org]
- 12. mdpi.com [mdpi.com]
- 13. DNA Computing [cim.mcgill.ca]
- 14. Design of DNA Strand Displacement Reactions [arxiv.org]
- 15. DNA strand displacement based computational systems and their applications - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Frontiers | DNA strand displacement based computational systems and their applications [frontiersin.org]
An In-depth Technical Guide to the History and Evolution of Molecular Programming
For Researchers, Scientists, and Drug Development Professionals
Introduction: The Dawn of a New Computational Paradigm
Molecular programming represents a revolutionary shift in computation, moving from silicon-based hardware to the intricate world of biochemistry.[1] It harnesses the predictable and programmable nature of molecules—primarily DNA—to create nanoscale structures, devices, and circuits that can sense, compute, and act. This field merges computer science, molecular biology, and nanotechnology to build "smart" molecular systems for applications ranging from intelligent diagnostics and therapeutics to the fabrication of novel materials.[2][3] The core principle lies in the Watson-Crick base pairing of DNA (Adenine with Thymine, Guanine with Cytosine), a simple yet powerful rule that allows for the rational design and self-assembly of complex molecular architectures.[4][5][6] This guide provides a technical overview of the key historical milestones, foundational techniques, and evolutionary trajectory of this transformative field.
The Genesis: Dual Pillars of Molecular Programming
The origins of molecular programming can be traced back to two seminal, yet distinct, conceptual breakthroughs in the late 20th century.
Structural DNA Nanotechnology: Programming Matter
In the 1980s, Nadrian Seeman laid the conceptual groundwork for using DNA as a construction material rather than just a carrier of genetic information.[1][6] His vision was to exploit the specificity of DNA hybridization to create rigid, well-defined, three-dimensional lattices and structures from synthetic DNA strands. This marked the birth of structural DNA nanotechnology, a field dedicated to building arbitrary shapes and scaffolds at the nanoscale.[1][7] Seeman's work demonstrated that DNA could be designed to form stable, branched structures (junctions) that serve as vertices, connected by double-helical edges, fundamentally proving that molecules could be programmed to self-assemble into complex, non-biological forms.[1]
DNA Computing: Programming Information
While Seeman focused on structure, Leonard Adleman demonstrated the computational potential of DNA in 1994.[1][7] In a landmark experiment, he used DNA molecules to solve a seven-point instance of the Hamiltonian Path Problem, a classic NP-complete problem that is computationally intensive for conventional computers.[1][7][8] Adleman's work was a profound proof-of-concept: a test tube containing trillions of DNA molecules could act as a massively parallel processor, exploring all possible solutions simultaneously.[1][7][8][9] This experiment launched the field of DNA computing, establishing that molecular processes could execute algorithms.[1][10]
-
Encoding: Each of the seven "cities" (vertices) was encoded as a unique 20-nucleotide single strand of DNA. Each "road" (directed edge) between two cities was encoded as a complementary "linker" strand, designed to hybridize with the second half of the source city's sequence and the first half of the destination city's sequence.[8]
-
Ligation: All city and road strands were mixed in a test tube with DNA ligase, an enzyme that covalently bonds adjacent DNA strands.[4][8] This reaction generated trillions of DNA molecules representing all possible random paths through the graph.[8]
-
Amplification: Polymerase Chain Reaction (PCR) was used to selectively amplify only the paths that started with the designated start city and ended with the designated end city.
-
Length-Based Separation: Gel electrophoresis was used to isolate molecules of the correct length (representing paths that visited exactly seven cities).[4]
-
Affinity Purification: This step was performed iteratively for each of the seven cities. In each iteration, the DNA molecules were passed over magnetic beads coated with the sequence of a specific city. Only molecules containing that city's sequence would bind, ensuring that the final set of molecules represented paths that visited every city.
-
Detection: The remaining DNA molecules, if any, were sequenced to reveal the correct Hamiltonian path.[7] It took Adleman a week of lab work to extract the final solution from the initial mixture.[8]
Caption: Workflow of Adleman's DNA Computing Experiment.
The Evolution of Programmable Self-Assembly: DNA Origami
A major leap in structural DNA nanotechnology came in 2006 when Paul Rothemund at Caltech introduced DNA origami.[6][11] This technique enabled the creation of complex, arbitrary two- and three-dimensional shapes with unprecedented ease and precision.[6][12][13]
The core idea is to fold a long, single-stranded "scaffold" DNA (typically the 7,249-base genome of the M13 virus) into a desired shape using hundreds of short, synthetic "staple" strands.[5][6][11] Each staple is designed to bind to specific, distant regions of the scaffold, forcing it into a compact, predefined conformation.[6] DNA origami significantly improved the yield and reliability of self-assembled nanostructures, making the technology more accessible and powerful.[5][6]
-
Design: A target 2D or 3D shape is conceptualized. Software tools (like caDNAno) are used to determine the raster path of the scaffold strand to form the shape and to automatically generate the sequences for the hundreds of staple strands required to hold it in place.[14]
-
Synthesis: The long scaffold strand is typically harvested from viruses. The short staple strands are chemically synthesized.
-
Mixing: The scaffold strand and a stoichiometric excess of all staple strands are mixed in a buffered solution (typically containing magnesium, which is crucial for stabilizing the DNA double helix).[12]
-
Annealing: The mixture is subjected to a thermal annealing process. It is first heated to a high temperature (e.g., 90°C) to denature all DNA, ensuring the strands are unfolded. Then, the solution is slowly cooled over several hours to just below the melting temperature of the staple-scaffold duplexes (e.g., to ~50°C).[6][15] This slow cooling allows the staples to find their correct binding sites on the scaffold, guiding it into the target structure.
-
Characterization: The resulting nanostructures are typically visualized and confirmed using atomic force microscopy (AFM) or transmission electron microscopy (TEM).[6][14]
Caption: Conceptual Diagram of DNA Origami Assembly.
The Rise of Dynamic Systems: Toehold-Mediated Strand Displacement
While DNA origami perfected static structures, the next evolutionary step was to create dynamic molecular systems capable of computation and motion. The key enabling technology for this is toehold-mediated strand displacement (TMSD) .[16][17]
TMSD is a mechanism for triggering conformational changes in DNA complexes.[16][17] An "invader" strand binds to a short, single-stranded "toehold" region of a DNA duplex.[16][17] From this foothold, it can then progressively displace one of the strands in the duplex through a process called branch migration.[16][17] The rate of this reaction can be tuned over six orders of magnitude by altering the length and sequence of the toehold, making it a highly programmable and versatile tool.[18]
This simple mechanism is the foundation for building complex molecular circuits, including logic gates (AND, OR, NOT), amplifiers, and oscillators.[17][19] In these systems, the presence or absence of a specific DNA strand acts as a signal, and TMSD reactions process these signals, creating cascades that perform computation.[19]
An AND gate can be constructed from a multi-stranded DNA complex that releases an output strand only in the presence of two distinct input strands.
-
Initial State: A "gate" complex is formed where an output strand is partially hybridized to a substrate, leaving a segment of the substrate single-stranded. A "threshold" complex sequesters one of the inputs.
-
Input A: The first input strand (Input A) binds to a toehold on the threshold complex, releasing an intermediate strand.
-
Input B & Intermediate: The second input strand (Input B) and the intermediate strand from the previous step cooperate to displace the final output strand from the main gate complex.
-
Output: The output strand is released only when both Input A and Input B are present.
Caption: AND Gate Logic via DNA Strand Displacement.
Quantitative Benchmarks in Molecular Programming
The performance of molecular programming techniques can be evaluated across several key metrics. While direct comparisons are complex due to varying experimental goals, the following table summarizes typical quantitative data for the foundational methods.
| Technique | Primary Metric | Typical Value / Performance | Notes |
| DNA Computing (Adleman) | Computational Speed | ~100 Teraflops (10^14 operations/sec)[8][20] | Massively parallel but readout is extremely slow (days)[8]. Error-prone and resource-intensive for larger problems.[8] |
| Information Density | ~1 bit per cubic nanometer[20][21] | Far exceeds silicon-based storage.[8][20] | |
| DNA Origami | Assembly Yield | >90% for simple structures; varies with complexity[22] | Yield can be optimized by adjusting staple concentrations and annealing conditions.[12] Some complex assemblies have much lower yields (<2%).[14] |
| Structural Precision | Sub-nanometer resolution | Allows for precise positioning of attached molecules like proteins or nanoparticles.[12] | |
| Strand Displacement | Reaction Rate | Tunable from 10⁻³ M⁻¹s⁻¹ to >10⁶ M⁻¹s⁻¹[18] | Rate is exponentially dependent on toehold length (up to ~6-8 nucleotides).[16][23] |
| Error Rate (Leak) | Can be significant; various suppression strategies exist | Unintended "leak" reactions can release output strands without the correct input.[24] Error correction schemes can be implemented.[24] |
The Modern Era: Integration and Application
The principles of molecular programming are now being integrated to create increasingly sophisticated systems with real-world applications.
-
Molecular Robotics: DNA "walkers" have been designed to move along prescribed tracks on DNA origami surfaces, capable of carrying molecular cargo.
-
Diagnostics and Sensing: Molecular circuits are being developed to detect the presence of specific microRNAs or pathogens in biological samples, releasing a fluorescent signal upon detection.[18]
-
Drug Delivery: DNA nanostructures are being engineered as "smart" containers that can encapsulate a drug and release it only when a specific molecular trigger (e.g., a cancer cell marker) is detected.
-
Synthetic Biology: Strand displacement principles are being applied in vivo to create artificial gene regulatory networks inside living cells, offering new ways to control cellular behavior.[16][18]
The evolution continues, with researchers now exploring hybrid systems that combine DNA with proteins and other polymers, and developing high-level programming languages to abstract the complexity of designing molecular circuits, bringing the field closer to a true "chemistry as information technology."[1][2][3]
References
- 1. DNA computing - Wikipedia [en.wikipedia.org]
- 2. dna.caltech.edu [dna.caltech.edu]
- 3. dna.caltech.edu [dna.caltech.edu]
- 4. computingbiology.github.io [computingbiology.github.io]
- 5. nvlpubs.nist.gov [nvlpubs.nist.gov]
- 6. DNA origami - Wikipedia [en.wikipedia.org]
- 7. DNA computing | Algorithms, Applications & Benefits | Britannica [britannica.com]
- 8. Computing with DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. researchgate.net [researchgate.net]
- 11. Rothemund Lab - DNA Origami [rothemundlab.caltech.edu]
- 12. Concepts and Application of DNA Origami and DNA Self-Assembly: A Systematic Review - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Paul Rothemund's DNA origami: future and its application | Britannica [britannica.com]
- 14. dna.caltech.edu [dna.caltech.edu]
- 15. researchgate.net [researchgate.net]
- 16. Nucleic acid strand displacement – from DNA nanotechnology to translational regulation - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Design of DNA Strand Displacement Reactions [arxiv.org]
- 18. pubs.acs.org [pubs.acs.org]
- 19. Frontiers | DNA strand displacement based computational systems and their applications [frontiersin.org]
- 20. Evaluation [cs.stanford.edu]
- 21. illumin.usc.edu [illumin.usc.edu]
- 22. Co-self-assembly of multiple DNA origami nanostructures in a single pot - Chemical Communications (RSC Publishing) [pubs.rsc.org]
- 23. pnas.org [pnas.org]
- 24. pnas.org [pnas.org]
A Technical Guide to the Core Concepts of DNA Nanotechnology
For Researchers, Scientists, and Drug Development Professionals
Introduction
Deoxyribonucleic acid (DNA), the fundamental carrier of genetic information, has emerged as a powerful and versatile material for the construction of nanoscale structures and devices.[1][2] DNA nanotechnology leverages the molecule's inherent properties of self-assembly, programmability, and biocompatibility to create precisely engineered objects with applications spanning from targeted drug delivery to molecular diagnostics and computation.[3][4][5] This guide provides an in-depth exploration of the core principles, key techniques, and practical applications of this revolutionary field. The unique Watson-Crick base pairing (Adenine with Thymine, and Guanine with Cytosine) allows for the predictable and programmable assembly of DNA strands into a wide array of one-, two-, and three-dimensional nanostructures.[6][7] These structures can be designed with precise control over their size, shape, and functionality, making them ideal candidates for various biomedical and technological advancements.[8][9]
Core Principles of DNA Nanotechnology
The foundation of DNA nanotechnology rests on several key principles that distinguish it from other nanofabrication methods.
Programmable Self-Assembly
The specificity of Watson-Crick base pairing is the cornerstone of DNA nanotechnology, enabling the rational design of DNA sequences that spontaneously assemble into desired structures.[1][10] This bottom-up approach allows for the creation of complex architectures with molecular precision, a feat difficult to achieve with traditional top-down fabrication techniques.[11] The self-assembly process is highly predictable, reproducible, and scalable, making it a robust method for generating nanoscale materials.[4]
Addressability and Modularity
Each DNA strand within a nanostructure has a unique sequence and, therefore, a specific location. This "addressability" allows for the precise placement of functional components, such as therapeutic agents, targeting ligands, or reporter molecules, at specific sites on the DNA scaffold.[12] This modularity enables the construction of multifunctional devices with tailored properties for specific applications.[4]
Biocompatibility and Biodegradability
As a natural biological molecule, DNA is inherently biocompatible and biodegradable, minimizing concerns of toxicity and immunogenicity when used in biological systems.[4][9] This makes DNA nanostructures particularly well-suited for in vivo applications like drug delivery and diagnostics.[7][13]
Key Techniques and Structures
Several key techniques have been developed to harness the power of DNA self-assembly for the creation of a diverse range of nanostructures.
DNA Origami
DNA origami is a powerful technique for creating arbitrary two- and three-dimensional shapes.[11] It involves folding a long, single-stranded "scaffold" DNA (often from a viral genome) into a desired shape using hundreds of shorter "staple" strands.[11][14] The staple strands are designed to bind to specific regions of the scaffold, guiding its folding pathway.[14]
The general workflow for creating a DNA origami structure involves computational design, followed by self-assembly through thermal annealing, and subsequent purification and characterization.
References
- 1. DNA nanotechnology - Wikipedia [en.wikipedia.org]
- 2. news-medical.net [news-medical.net]
- 3. azolifesciences.com [azolifesciences.com]
- 4. Frontiers | Rationally Designed DNA Nanostructures for Drug Delivery [frontiersin.org]
- 5. mdpi.com [mdpi.com]
- 6. DNA-guided self-assembly in living cells - PMC [pmc.ncbi.nlm.nih.gov]
- 7. DNA Nanomaterials for Preclinical Imaging and Drug Delivery - PMC [pmc.ncbi.nlm.nih.gov]
- 8. pubs.acs.org [pubs.acs.org]
- 9. A Brief Introduction to DNA Nanotechnology | CUA [engineering.catholic.edu]
- 10. researchgate.net [researchgate.net]
- 11. DNA origami - Wikipedia [en.wikipedia.org]
- 12. DNA Nanodevice-Based Drug Delivery Systems - PMC [pmc.ncbi.nlm.nih.gov]
- 13. primescholars.com [primescholars.com]
- 14. A How To Guide for Creating DNA Origami | Technology Networks [technologynetworks.com]
The Molecular Architects of Computation: A Technical Guide to DNA and RNA Computing
For Researchers, Scientists, and Drug Development Professionals
In the quest for next-generation computing paradigms, the very blueprints of life—DNA and RNA—have emerged as powerful tools for computation at the molecular scale. This technical guide provides an in-depth exploration of the core differences between DNA and RNA computing, offering a comparative analysis of their fundamental principles, experimental underpinnings, and applications in the realm of drug discovery and development.
Core Principles: Stability and Versatility in Molecular Logic
DNA and RNA computing harness the predictable base-pairing of nucleic acids to encode information and perform logical operations.[1] However, the subtle yet significant chemical distinctions between deoxyribonucleic acid (DNA) and ribonucleic acid (RNA) give rise to profound differences in their computational capabilities and applications.
DNA (Deoxyribonucleic Acid): The Architect of Stability
DNA's double-stranded helical structure and the absence of a 2'-hydroxyl group on its deoxyribose sugar render it a remarkably stable molecule.[2] This inherent stability is a cornerstone of DNA computing, enabling the construction of robust and long-lasting molecular circuits and nanostructures.[3] The primary mechanism underpinning many DNA computing systems is strand displacement , a process where an input DNA strand binds to a complementary "toehold" region on a DNA duplex, subsequently displacing an incumbent strand. This predictable and programmable interaction allows for the creation of a complete set of Boolean logic gates (AND, OR, NOT), forming the foundation for complex computational circuits.[4]
RNA (Ribonucleic acid): The Master of Versatility
In contrast, RNA's single-stranded nature and the presence of a reactive 2'-hydroxyl group make it more conformationally flexible and chemically versatile, though less stable than DNA.[2] This flexibility allows RNA to fold into intricate three-dimensional structures, including catalytically active motifs known as ribozymes and ligand-binding structures called aptamers .[5] RNA computing often leverages these functional properties. For instance, toehold switches , a class of synthetic riboregulators, can be engineered to control gene expression in response to specific RNA inputs, effectively acting as molecular sensors and logic gates.[6] Furthermore, the enzymatic activity of ribozymes can be harnessed for computational tasks, and the diverse structures of RNA aptamers make them ideal for targeted molecular recognition.[5]
Quantitative Comparison of DNA and RNA Computing Modalities
The choice between DNA and RNA for a given computational application often depends on a trade-off between stability, speed, and functional complexity. The following tables summarize key quantitative data to facilitate this comparison.
| Parameter | DNA Computing | RNA Computing | Source(s) |
| Structural Stability | High | Low to Moderate | [2] |
| Information Carrier | Deoxyribonucleic Acid | Ribonucleic Acid | [2] |
| Primary Structure | Double Helix (typically) | Single Strand (typically) | [2] |
| Underlying Principle | Strand Displacement, Self-Assembly | Ribozyme Catalysis, Aptamer Binding, Toehold Switches | [4][5][6] |
| Performance Metric | DNA Computing | RNA Computing | Source(s) |
| In Vitro Half-life (unmodified) | ~60-90 minutes in plasma | Seconds in plasma | [7] |
| Binding Affinity (Kd of Aptamers) | Low nanomolar to picomolar range | Low nanomolar to picomolar range | [2] |
| Catalytic Rate (k_cat/K_M of DNAzymes vs. Ribozymes) | Can be significantly higher than ribozymes for certain reactions | Generally lower than comparable DNAzymes | [4][5] |
| Error Rates (Synthesis/Sequencing) | Lower | Higher | [8][9] |
| Computational Speed | Highly parallel, but individual gate operations can be slow (minutes to hours) | Potentially faster for certain in vivo applications due to co-transcriptional assembly | [10][11] |
Experimental Protocols: Building the Molecular Logic
The realization of DNA and RNA computers relies on a toolkit of precise molecular biology techniques. Below are detailed methodologies for key experiments central to each field.
DNA Computing: Strand Displacement-Based AND Gate
This protocol describes the in vitro implementation of a DNA AND logic gate based on toehold-mediated strand displacement. The gate produces a fluorescent output only in the presence of two specific DNA inputs.
Materials:
-
Gate-A strand (with fluorophore)
-
Gate-B strand (with quencher)
-
Input-A strand
-
Input-B strand
-
Fluorescence plate reader
-
Reaction buffer (e.g., TE buffer with 12.5 mM MgCl₂)
Methodology:
-
Gate Complex Formation: Anneal Gate-A and Gate-B strands by mixing them in a 1:1.2 molar ratio in reaction buffer. Heat the mixture to 95°C for 5 minutes and then slowly cool to room temperature over 1 hour to form the gate duplex.
-
Reaction Setup: In a 96-well plate, prepare four reaction conditions:
-
No inputs (gate complex only)
-
Input-A only
-
Input-B only
-
Input-A and Input-B
-
-
Initiate Reactions: Add the respective input strands to the wells containing the gate complex.
-
Fluorescence Measurement: Immediately place the plate in a fluorescence plate reader and monitor the fluorescence intensity over time. An increase in fluorescence indicates the displacement of the quencher-labeled strand from the fluorophore-labeled strand, signifying a "TRUE" output.
RNA Computing: In Vitro Selection of a Hammerhead Ribozyme
This protocol outlines the process of in vitro selection (SELEX) to isolate active hammerhead ribozymes from a random RNA library.
Materials:
-
DNA template with a randomized region flanked by constant regions and a T7 promoter
-
T7 RNA polymerase
-
DNase I
-
Reverse transcriptase
-
PCR amplification reagents
-
Polyacrylamide gel electrophoresis (PAGE) apparatus
-
Reaction buffer (e.g., 50 mM Tris-HCl, 10 mM MgCl₂)
Methodology:
-
RNA Pool Generation: Synthesize a pool of RNA molecules by in vitro transcription from the DNA template library using T7 RNA polymerase.
-
Selection Step: Incubate the RNA pool in the reaction buffer to allow for self-cleavage of active ribozymes.
-
Gel Electrophoresis: Separate the cleaved and uncleaved RNA molecules by denaturing PAGE.
-
Elution and Reverse Transcription: Excise the band corresponding to the cleaved RNA fragments from the gel and elute the RNA. Reverse transcribe the selected RNA back into cDNA.
-
PCR Amplification: Amplify the cDNA pool using PCR to enrich for the sequences of the active ribozymes.
-
Iterative Rounds: Repeat steps 1-5 for multiple rounds (typically 8-15) to progressively enrich the pool with the most active ribozyme sequences.
-
Cloning and Sequencing: Clone the final enriched cDNA pool into a plasmid vector and sequence individual clones to identify the active ribozyme sequences.
Integrated Workflow: Development of an Aptamer-Based Biosensor
This protocol details the integrated process of selecting a DNA aptamer and incorporating it into a fluorescent biosensor.
Materials:
-
ssDNA library
-
Target molecule
-
Streptavidin-coated magnetic beads
-
Biotinylated target
-
PCR reagents
-
Fluorophore and quencher-labeled DNA strands
-
Binding buffer
Methodology:
-
SELEX for Aptamer Selection:
-
Immobilize the biotinylated target on streptavidin-coated magnetic beads.
-
Incubate the ssDNA library with the target-coated beads.
-
Wash away unbound DNA strands.
-
Elute the bound DNA strands.
-
Amplify the eluted DNA by PCR.
-
Repeat this cycle for several rounds to enrich for high-affinity aptamers.
-
-
Aptamer Characterization: Sequence the enriched aptamer pool and characterize the binding affinity of individual aptamers to the target.
-
Biosensor Assembly: Design a biosensor construct where the selected aptamer is hybridized to a short, quencher-labeled DNA strand. In the absence of the target, the aptamer is in a conformation that brings a fluorophore (on the aptamer) and the quencher into close proximity, resulting in low fluorescence.
-
Validation:
-
Introduce the target molecule to the biosensor assembly.
-
Binding of the target to the aptamer induces a conformational change that separates the fluorophore and quencher, leading to an increase in fluorescence.
-
Measure the fluorescence intensity to quantify the concentration of the target molecule.[12]
-
Visualizing Molecular Logic: Signaling Pathways and Workflows
The following diagrams, rendered in Graphviz DOT language, illustrate key signaling pathways and experimental workflows in DNA and RNA computing.
DNA Computing Visualizations
Caption: A DNA AND logic gate workflow.
Caption: A DNA OR logic gate workflow.
RNA Computing Visualizations
Caption: An RNA toehold switch activation pathway.
Caption: The SELEX experimental workflow for aptamer selection.
Applications in Drug Development
The unique capabilities of DNA and RNA computing offer promising avenues for advancing drug discovery and development.
DNA Computing in Drug Development:
-
High-Throughput Screening: The massive parallelism of DNA computing can be leveraged to screen vast libraries of potential drug candidates against a target molecule simultaneously.[13]
-
Smart Drug Delivery: DNA-based nanostructures can be designed as "smart" drug delivery vehicles that release their therapeutic payload only in the presence of specific disease biomarkers, which act as the computational inputs.[14]
-
Molecular Diagnostics: DNA logic gates can be integrated into diagnostic platforms to detect the presence of multiple disease markers with high specificity, enabling more accurate and personalized diagnoses.[15]
RNA Computing in Drug Development:
-
Targeted Therapeutics: RNA interference (RNAi) pathways can be harnessed to design therapies that specifically silence disease-causing genes.[16]
-
Cellular Logic for Cancer Therapy: Multi-input RNA logic circuits can be engineered to identify cancer cells based on their unique miRNA expression profiles and trigger a therapeutic response, such as apoptosis, only in the diseased cells.[17]
-
Biosensors for In Vivo Monitoring: RNA-based biosensors can be designed to operate within living cells, providing real-time monitoring of drug efficacy and cellular responses.[18]
Conclusion and Future Outlook
DNA and RNA computing represent a paradigm shift from silicon-based computation, offering the potential to interface directly with biological systems and solve complex problems in massively parallel fashion. While DNA computing excels in the construction of stable, complex circuits for in vitro applications, RNA computing provides a versatile platform for in vivo sensing and actuation. The continued development of these molecular technologies, coupled with advances in synthetic biology and nanotechnology, promises to unlock new frontiers in drug discovery, diagnostics, and personalized medicine. The ability to program molecules to think and act within the human body is no longer the realm of science fiction, but an emerging reality poised to revolutionize healthcare.
References
- 1. High-resolution and programmable RNA-IN and RNA-OUT genetic circuit in living mammalian cells - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Thermostability, Tunability, and Tenacity of RNA as Rubbery Anionic Polymeric Materials in Nanotechnology and Nanomedicine—Specific Cancer Targeting with Undetectable Toxicity - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Quantitative Thermodynamic Characterization of Self-Assembling RNA Nanostructures - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. DNA Catalysis: The Chemical Repertoire of DNAzymes - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. Exploring the catalytic mechanism of the 10–23 DNAzyme: insights from pH–rate profiles - Organic & Biomolecular Chemistry (RSC Publishing) [pubs.rsc.org]
- 8. Simulation-based comprehensive benchmarking of RNA-seq aligners - PMC [pmc.ncbi.nlm.nih.gov]
- 9. RNAontheBENCH: computational and empirical resources for benchmarking RNAseq quantification and differential expression methods - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Fast and compact DNA logic circuits based on single-stranded gates using strand-displacing polymerase | Semantic Scholar [semanticscholar.org]
- 11. researchgate.net [researchgate.net]
- 12. researchgate.net [researchgate.net]
- 13. researchgate.net [researchgate.net]
- 14. Understanding the thermodynamics and kinetics of DNA- and RNA-based self-assembly with coarse-grained models [iris.uniroma1.it]
- 15. Complex cellular logic computation using ribocomputing devices - PMC [pmc.ncbi.nlm.nih.gov]
- 16. researchgate.net [researchgate.net]
- 17. DNA Strand-Displacement Temporal Logic Circuits - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Synthetic RNA-based logic computation in mammalian cells - PMC [pmc.ncbi.nlm.nih.gov]
Unraveling the Blueprint of Life: An In-depth Technical Guide to DNA Self-Assembly Mechanisms
For Researchers, Scientists, and Drug Development Professionals
This technical guide delves into the core mechanisms of DNA self-assembly, a revolutionary technology harnessing the inherent properties of deoxyribonucleic acid to construct nanoscale structures with unparalleled precision. This document provides a comprehensive overview of the fundamental principles, experimental methodologies, and quantitative data that underpin this rapidly evolving field. The programmability and biocompatibility of DNA make it an ideal material for a vast array of applications, from targeted drug delivery and diagnostics to the fabrication of nanoelectronic components.
Core Principles of DNA Self-Assembly
The remarkable ability of DNA to self-assemble into complex, predetermined structures is rooted in the specificity of Watson-Crick base pairing. Adenine (A) forms two hydrogen bonds with thymine (B56734) (T), while guanine (B1146940) (G) forms three hydrogen bonds with cytosine (C). This highly specific molecular recognition is the fundamental driving force behind the formation of the iconic double helix and more intricate, engineered nanostructures.[1] The self-assembly process is governed by the principles of thermodynamics and kinetics, where the final structure represents a state of minimal free energy.
Several key strategies have been developed to harness and control DNA self-assembly:
-
DNA Origami: This technique involves folding a long, single-stranded DNA "scaffold" (often from a viral genome) into a desired shape using hundreds of shorter "staple" strands.[2][3] Each staple strand is designed to bind to specific regions of the scaffold, acting as a molecular clamp to hold the structure in place.[4] This method allows for the creation of complex two- and three-dimensional shapes with high precision.[2][5]
-
Tile-Based Assembly: In this approach, smaller, rigid DNA motifs, known as "tiles," are designed to self-assemble into larger, often periodic, lattices.[6] These tiles typically consist of multiple DNA helices held together by crossover junctions and possess "sticky ends"—short single-stranded overhangs that are complementary to the sticky ends of other tiles, directing their assembly into larger arrays.[7]
-
Toehold-Mediated Strand Displacement: This dynamic process allows for the controlled assembly and disassembly of DNA structures. It involves a single-stranded "invader" strand binding to a short, single-stranded "toehold" domain on a duplex. This initial binding facilitates the displacement of the incumbent strand through a branch migration process.[8] The kinetics of this reaction can be precisely controlled by the length and sequence of the toehold.[8][9]
Quantitative Data in DNA Self-Assembly
The precise control over DNA self-assembly is underpinned by a quantitative understanding of its thermodynamics and kinetics. The following tables summarize key parameters for different self-assembly mechanisms.
Table 1: Thermodynamic Parameters of DNA Hybridization and Assembly
| Parameter | Value | Conditions | Reference |
| ΔG° (DNA Duplex Formation) | -22.4 kJ/mol | 37 °C, 1 M NaCl | [10] |
| ΔH° (DNA Duplex Formation) | Variable (sequence dependent) | 1 M NaCl | [10] |
| ΔS° (DNA Duplex Formation) | Variable (sequence dependent) | 1 M NaCl | [10] |
| ΔH° (DNA Nanotube Polymerization) | 87.9 ± 2.0 kcal/mol | - | [2][11] |
| ΔS° (DNA Nanotube Polymerization) | 0.252 ± 0.006 kcal/mol·K | - | [2][11] |
Table 2: Kinetic Parameters of DNA Self-Assembly
| Process | Rate Constant (k) | Conditions | Reference |
| DNA Hybridization (on-rate) | 2.3 x 10⁶ M⁻¹s⁻¹ | 600 mM NaCl | [12] |
| DNA Origami Dimerization (stacking) | (14.4 ± 0.1) x 10⁻² min⁻¹ | 30 °C | [13] |
| DNA Origami Dimerization (stacking) | (30 ± 4) x 10⁻² min⁻¹ | 30 °C | [13] |
| DNA Nanotube Association | (5.99 ± 0.15) x 10⁵ M⁻¹s⁻¹ | - | [2][11] |
| Toehold-Mediated Strand Displacement | Varies over 6 orders of magnitude | Dependent on toehold length | [14][15] |
Experimental Protocols
This section provides detailed methodologies for key experiments in the design, assembly, and characterization of DNA nanostructures.
DNA Origami Assembly Protocol
This protocol outlines the one-pot thermal annealing process for folding a DNA origami structure.
Materials:
-
Single-stranded scaffold DNA (e.g., M13mp18)
-
Staple strands (synthetic oligonucleotides)
-
Folding Buffer (e.g., 1x TE buffer with 12.5 mM MgCl₂)
-
Nuclease-free water
-
PCR tubes
-
Thermocycler
Procedure:
-
Prepare Staple Strand Mix: Combine equimolar amounts of all staple strands in a single tube to create a staple mix. The final concentration of each staple in the mix is typically 100-fold molar excess relative to the scaffold DNA.
-
Set up Annealing Reaction: In a PCR tube, combine:
-
Scaffold DNA (final concentration ~10 nM)
-
Staple strand mix (final concentration of each staple ~100 nM)
-
Folding Buffer (to the final desired concentration)
-
Nuclease-free water to reach the final volume.
-
-
Thermal Annealing: Place the PCR tube in a thermocycler and run the following program:
-
Heat to 90°C for 5 minutes (denaturation).
-
Cool down from 90°C to 65°C at a rate of 1°C per minute.
-
Cool down from 65°C to 25°C at a rate of 0.05°C per minute (slow annealing).
-
Hold at 25°C.
-
-
Purification (Optional): Excess staple strands can be removed using methods like agarose (B213101) gel electrophoresis or spin filtration.
-
Storage: Store the folded DNA origami structures at 4°C.
Atomic Force Microscopy (AFM) Imaging of DNA Nanostructures
AFM is a high-resolution imaging technique used to visualize the topography of DNA nanostructures.
Materials:
-
Folded and purified DNA origami sample
-
Deposition Buffer (e.g., 1x TE buffer with 10 mM MgCl₂)
-
Freshly cleaved mica discs
-
Ultrapure water
-
Compressed air or nitrogen
-
Atomic Force Microscope
Procedure:
-
Prepare Mica Surface: Secure a mica disc to a metal puck using double-sided tape. Cleave the top layer of the mica using adhesive tape to expose a fresh, atomically flat surface.
-
Sample Deposition:
-
Pipette a 20-50 µL drop of the DNA origami solution (diluted in deposition buffer to ~1-2 nM) onto the freshly cleaved mica surface.
-
Incubate for 2-5 minutes to allow the DNA structures to adsorb to the surface.
-
-
Rinsing and Drying:
-
Gently rinse the mica surface by adding a few drops of ultrapure water to the edge of the droplet and wicking it away with filter paper. Repeat this step 2-3 times.
-
Carefully dry the surface with a gentle stream of compressed air or nitrogen.
-
-
AFM Imaging:
-
Mount the sample in the AFM.
-
Engage the AFM tip with the surface in tapping mode (or other appropriate imaging mode).
-
Optimize imaging parameters (scan size, scan rate, setpoint) to obtain high-resolution images of the DNA nanostructures.
-
Visualizing Workflows and Pathways
The following diagrams, created using the DOT language, illustrate key workflows and logical relationships in DNA self-assembly.
DNA Origami Design and Assembly Workflow
Caption: Workflow for DNA origami design, assembly, and characterization.
Toehold-Mediated Strand Displacement Mechanism
References
- 1. DNA origami - Wikipedia [en.wikipedia.org]
- 2. dna.caltech.edu [dna.caltech.edu]
- 3. nvlpubs.nist.gov [nvlpubs.nist.gov]
- 4. m.youtube.com [m.youtube.com]
- 5. Overview of DNA Self-Assembling: Progresses in Biomedical Applications - PMC [pmc.ncbi.nlm.nih.gov]
- 6. biorxiv.org [biorxiv.org]
- 7. On the biophysics and kinetics of toehold-mediated DNA strand displacement - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Kinetics and Activation Strategies in Toehold-Mediated and Toehold-Free DNA Strand Displacement [mdpi.com]
- 9. pubs.acs.org [pubs.acs.org]
- 10. DOT Language | Graphviz [graphviz.org]
- 11. researchgate.net [researchgate.net]
- 12. pubs.acs.org [pubs.acs.org]
- 13. ocf.berkeley.edu [ocf.berkeley.edu]
- 14. researchgate.net [researchgate.net]
- 15. researchgate.net [researchgate.net]
The Ultimate Archive: A Technical Guide to the Theoretical Limits of Molecular Information Storage
For centuries, humanity has sought denser, more durable, and more efficient ways to store information. From clay tablets to silicon chips, each evolution has redefined the boundaries of data preservation. We now stand at the precipice of the next great leap: harnessing the very molecules of life and beyond to create storage media of unprecedented density and longevity. This guide delves into the theoretical and practical limits of molecular information storage, offering a comprehensive overview for researchers, scientists, and professionals in drug development and other data-intensive fields.
Executive Summary
The exponential growth of global data necessitates a paradigm shift in storage technology.[1] Molecular data storage, particularly using DNA, offers a solution with theoretical densities thousands of times greater than current state-of-the-art technologies.[2] DNA's inherent stability and the universality of its structure make it a compelling candidate for long-term archival.[3][4] However, significant challenges in write/read speeds, cost, and error correction remain.[5] This document explores the fundamental limits of DNA and other molecular systems, details the experimental protocols involved, and outlines the logical frameworks governing this nascent technology.
Theoretical Storage Density: Pushing the Boundaries of Physics
The allure of molecular storage lies in its extraordinary information density. At the atomic scale, the laws of physics and information theory dictate the ultimate storage capacity.
DNA: Nature's High-Density Hard Drive
Deoxyribonucleic acid (DNA) is the most studied molecular storage medium. Its structure, composed of four nucleotide bases—Adenine (A), Cytosine (C), Guanine (G), and Thymine (T)—provides a natural quaternary system for encoding data.
The theoretical maximum storage density of DNA is a subject of ongoing research, with estimates evolving as our understanding and techniques improve. Early calculations placed the upper limit at approximately 4.6 x 10^20 bytes per gram.[1] More recent work, such as the "DNA Fountain" method, has achieved practical densities of 215 petabytes per gram, which approaches 85-90% of the theoretical maximum for current methodologies.[3][5][6] This far surpasses conventional storage media, which are orders of magnitude less dense.[1][7]
Beyond DNA: The Promise of Synthetic Polymers and Small Molecules
While DNA is a frontrunner, other molecular systems offer unique advantages. Synthetic digital polymers, for instance, are not limited to the four bases of DNA and can be custom-designed for specific data storage needs.[8] This structural diversity can lead to even higher data densities and greater durability.[8][9][10] Additionally, researchers are exploring the use of mixtures of small, non-polymeric molecules, which could theoretically offer information densities two orders of magnitude greater than DNA.[11]
| Storage Medium | Theoretical Density | Achieved Density | Key Advantages | Key Challenges |
| DNA | ~10^21 bytes/gram (Zettabyte scale)[6] | 215 Petabytes/gram[5][6] | High density, proven longevity, easy replication (PCR).[3][7] | High cost of synthesis/sequencing, slow read/write speeds, error rates.[5] |
| Synthetic Polymers | Potentially higher than DNA[8][12] | N/A (emerging field) | High structural diversity, durability, custom design.[8][9] | Synthesis and sequencing (readout) methodologies are still in development.[8][9] |
| Small Molecules | Potentially 100x denser than DNA[11] | Kilobyte-scale demonstrated[11] | Very high theoretical density, circumvents polymer synthesis challenges.[11][13] | Complex readout (mass spectrometry), limited data capacity demonstrated so far.[11] |
| Single-Molecule Magnets | >200 Terabits/square inch[14] | N/A (proof-of-concept) | Extremely high areal density.[14] | Requires cryogenic temperatures for data stability.[14] |
The DNA Data Storage Workflow: From Bits to Bases and Back
The process of storing and retrieving data in DNA can be broken down into five key stages: Encoding, Synthesis, Storage, Retrieval, and Decoding.
A high-level overview of the DNA data storage and retrieval workflow.
Experimental Protocols
-
Binary Conversion: The source digital file is first converted into its binary representation (a sequence of 0s and 1s).
-
Data Segmentation: The binary stream is broken into smaller, manageable chunks.
-
Error Correction Coding: Redundancy is added to the data using error-correcting codes (ECCs) like Reed-Solomon or Fountain codes.[4][15][16] This is crucial to mitigate errors that occur during synthesis and sequencing.
-
Base Mapping: The binary data, now including ECCs, is converted into a sequence of DNA bases (A, T, C, G). A common approach is to map pairs of bits to one of the four bases (e.g., 00→A, 01→C, 10→G, 11→T).[17]
-
Indexing: Each DNA sequence is appended with an index to specify its position within the original file, enabling reassembly.[1][7]
-
Oligonucleotide Synthesis: The encoded DNA sequences, typically 150-200 nucleotides in length, are chemically synthesized.[18][19] Phosphoramidite chemistry is the current standard, although it is a primary bottleneck in terms of cost and speed.[18]
-
Pooling: The synthesized single-stranded DNA molecules (oligonucleotides or "oligos") are collected into a single pool.
-
Dehydration and Encapsulation: To ensure long-term stability, the DNA pool is often dehydrated.[4] Advanced techniques involve encapsulating the DNA in silica (B1680970) or other protective matrices to shield it from environmental degradation.[4]
-
Controlled Environment: The DNA is stored in a cool, dry, and dark environment to minimize chemical decay.[4][19] Under optimal conditions, DNA can preserve information for thousands of years.[2][4]
-
Random Access (Optional): To read a specific file without sequencing the entire pool, Polymerase Chain Reaction (PCR) is used.[17] Primers specific to the desired file's index sequences are introduced to selectively amplify only that data.[17]
-
Sequencing: The DNA (either the entire pool or the amplified subset) is read using next-generation sequencing (NGS) technologies (e.g., Illumina, Oxford Nanopore).[4][16][20] This process determines the sequence of bases for millions of DNA molecules in parallel.
-
Data Processing: The raw sequencing output is processed to generate digital sequence reads.
-
Sequence Assembly: The digital reads are clustered and aligned based on their indices to reconstruct the original DNA sequences.
-
Error Correction: The embedded ECCs are used to identify and correct errors (substitutions, insertions, deletions) that occurred during synthesis or sequencing.[15][20]
-
Binary Conversion: The corrected DNA sequences are converted back into binary code, and the original digital file is reassembled.
Error Correction: Ensuring Data Integrity
A significant hurdle in molecular storage is the inherent error rate of DNA synthesis and sequencing, which can range from 0.1% to 2% per nucleotide.[21] Without robust error correction, data would be quickly corrupted.
Logical flow of error correction in DNA data storage systems.
Error-correcting codes (ECCs) are essential for reliable data recovery.[15][21][22] These codes introduce mathematical redundancy into the data before it is written to DNA. During the decoding process, this redundancy allows the system to detect and repair errors, ensuring the faithful reconstruction of the original information.[15] The choice of ECC involves a trade-off between the level of redundancy (which impacts storage density) and the error-correcting capability.[15]
Future Outlook: Overcoming the Hurdles
While the theoretical limits of molecular storage are immense, several practical challenges must be addressed for widespread adoption:
-
Cost: The primary expense lies in DNA synthesis and sequencing.[5] Innovations in enzymatic DNA synthesis and alternative sequencing methods like nanopores are expected to drive down costs.[18]
-
Speed: Current write (synthesis) and read (sequencing) speeds are far slower than conventional storage technologies.[2][5]
-
Standardization: The development of universal encoding schemes, file formats, and operating systems for molecular storage is necessary for interoperability.
The field of molecular information storage is rapidly advancing, driven by interdisciplinary collaboration between computer science, chemistry, and biology. As we continue to refine our ability to write, store, and read information at the molecular level, we move closer to a future where the world's entire digital heritage can be preserved for millennia in a device no larger than a sugar cube.
References
- 1. DNA storage: research landscape and future prospects - PMC [pmc.ncbi.nlm.nih.gov]
- 2. youtube.com [youtube.com]
- 3. Pushing the Theoretical Limits of DNA Data Storage | Discover Magazine [discovermagazine.com]
- 4. perpova.com [perpova.com]
- 5. DNA digital data storage - Wikipedia [en.wikipedia.org]
- 6. twistbioscience.com [twistbioscience.com]
- 7. DNA Data Storage - PMC [pmc.ncbi.nlm.nih.gov]
- 8. chemistry.illinois.edu [chemistry.illinois.edu]
- 9. scitechdaily.com [scitechdaily.com]
- 10. sciencedaily.com [sciencedaily.com]
- 11. Principles of Information Storage in Small-Molecule Mixtures - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Digital synthetic polymers for information storage - Chemical Society Reviews (RSC Publishing) [pubs.rsc.org]
- 13. pubs.acs.org [pubs.acs.org]
- 14. Major leap towards storing data at the molecular level [manchester.ac.uk]
- 15. academic.oup.com [academic.oup.com]
- 16. researchgate.net [researchgate.net]
- 17. A DNA-Based Archival Storage System [cs.utexas.edu]
- 18. pubs.acs.org [pubs.acs.org]
- 19. biorxiv.org [biorxiv.org]
- 20. imt-atlantique.fr [imt-atlantique.fr]
- 21. Benchmarking Error-Correcting Codes For DNA Data Storage [eureka.patsnap.com]
- 22. Challenges for error-correction coding in DNA data storage: photolithographic synthesis and DNA decay - Digital Discovery (RSC Publishing) [pubs.rsc.org]
The Dawn of a New Computing Paradigm: A Technical Guide to Biomolecular Computing Systems
For Researchers, Scientists, and Drug Development Professionals
The relentless miniaturization of silicon-based computing is approaching its fundamental physical limits. In the quest for novel computational paradigms, scientists are turning to the very building blocks of life itself. Biomolecular computing, a revolutionary field at the intersection of computer science, biology, and nanotechnology, harnesses the unparalleled information processing capabilities of DNA, RNA, and proteins to perform complex computations. This in-depth technical guide provides a comprehensive overview of the core principles, experimental methodologies, and quantitative performance of biomolecular computing systems, offering a vital resource for researchers and professionals seeking to understand and leverage this transformative technology for applications ranging from advanced diagnostics to intelligent therapeutics.
Core Principles of Biomolecular Computing
Biomolecular computing leverages the inherent properties of biological molecules to execute logical operations.[1] The fundamental concept lies in the specific and programmable interactions between these molecules. For instance, the Watson-Crick base pairing of DNA (Adenine with Thymine, and Guanine with Cytosine) provides a robust and predictable framework for encoding information and designing computational components.[2] Similarly, the intricate folding of RNA and the specific binding of proteins to other molecules can be engineered to create sophisticated molecular machinery capable of computation.[3][4]
These systems can be broadly categorized into in vitro (in a test tube) and in vivo (within a living cell) systems. In vitro systems offer a controlled environment for complex computations, while in vivo systems hold the promise of creating "cellular computers" that can sense their environment and respond in a programmed manner, opening up unprecedented opportunities for targeted drug delivery and diagnostics.
Key Computational Strategies
The primary strategies in biomolecular computing involve the design and implementation of logic gates and gene circuits.
-
Logic Gates: Analogous to their electronic counterparts, biomolecular logic gates take molecular inputs and produce a specific molecular output based on a predefined logical rule (e.g., AND, OR, NOT). These gates can be constructed from DNA, RNA, proteins, and enzymes.
-
Gene Circuits: Within living cells, synthetic gene circuits are engineered networks of genes and regulatory elements designed to perform specific computations. These circuits can be designed to function as oscillators, toggle switches, and other complex computational modules, enabling sophisticated control over cellular behavior.
Quantitative Performance of Biomolecular Logic Gates
The performance of biomolecular logic gates can be quantified by various metrics, including fluorescence intensity of reporter molecules, which indicates the output state of the gate. The following tables summarize the performance of representative DNA, RNA, and protein-based logic gates.
DNA-Based Logic Gates: Fluorescence Output
| Logic Gate | Input 1 | Input 2 | Normalized Fluorescence Intensity (Output) |
| YES-1 | Absent | - | 1.00 |
| Present | - | 6.50[5] | |
| AND | Absent | Absent | 1.00 |
| Present | Absent | 1.20 | |
| Absent | Present | 1.15 | |
| Present | Present | 7.50[5] | |
| OR | Absent | Absent | 1.00 |
| Present | Absent | 5.80 | |
| Absent | Present | 6.20 | |
| Present | Present | 6.80[5] |
RNA-Based Logic Gates in Mammalian Cells: Apoptosis Regulation
| Logic Gate | miRNA Input 1 | miRNA Input 2 | Cell Viability (%) (Output) |
| AND | Absent | Absent | 100 |
| Present | Absent | 95 | |
| Absent | Present | 98 | |
| Present | Present | 40[6] |
De Novo Designed Protein Logic Gates: Assembly Quantification
| Logic Gate | Input 1 | Input 2 | Input 3 | Assembled Complex (%) (Output) |
| 3-Input AND | Absent | Absent | Absent | < 5 |
| Present | Absent | Absent | < 5 | |
| Absent | Present | Absent | < 5 | |
| Absent | Absent | Present | < 5 | |
| Present | Present | Absent | < 5 | |
| Present | Absent | Present | < 5 | |
| Absent | Present | Present | < 5 | |
| Present | Present | Present | > 80[7] |
Signaling Pathways and Experimental Workflows
Visualizing the intricate signaling pathways and experimental workflows is crucial for understanding the operational principles of biomolecular computing systems. The following diagrams, generated using the Graphviz DOT language, illustrate key processes.
De Novo Protein AND Gate Signaling Pathway
Caption: Signaling pathway of a 3-input de novo protein AND gate.
Synthetic Gene Oscillator Workflow in E. coli
Caption: Experimental workflow for a synthetic gene oscillator.
DNA Origami Functionalization Workflow
Caption: Workflow for DNA origami functionalization.
Detailed Experimental Protocols
A selection of key experimental protocols are provided below, offering a glimpse into the methodologies employed in biomolecular computing research.
Protocol 1: Construction of a Synthetic Gene Oscillator in E. coli
This protocol is adapted from Stricker et al. (2008).[8][9]
1. Plasmid Construction:
- The genes for the activator (AraC), repressor (LacI), and a yellow fluorescent protein reporter (YemGFP) are tagged with an ssrA degradation tag to decrease protein lifetime.
- These tagged genes are cloned into pZ modular plasmids under the transcriptional control of the Plac/ara-1 hybrid promoter. This promoter is activated by AraC in the presence of arabinose and repressed by LacI in the absence of IPTG.
- The activator araC and reporter yemGFP modules are placed on a ColE1 plasmid.
- The repressor lacI module is placed on a p15A plasmid.
2. Strain Construction:
- The two plasmids (ColE1 containing araC and yemGFP, and p15A containing lacI) are co-transformed into an appropriate E. coli strain.
3. Single-Cell Microscopy:
- The engineered E. coli cells are loaded into a microfluidic device tailored for single-cell microscopy.
- Environmental conditions, including the concentrations of inducers (arabinose and IPTG), temperature, and media source, are precisely controlled.
- Fluorescence oscillations in individual cells are monitored over multiple cycles using time-lapse microscopy.
Protocol 2: In Vitro Selection of RNA Aptamers (Capture-SELEX)
This protocol is a generalized method based on descriptions of SELEX (Systematic Evolution of Ligands by Exponential Enrichment).[10][11][12]
1. Library Preparation:
- A large, random library of RNA molecules is generated. This is typically done by in vitro transcription from a synthetic DNA template pool containing a randomized region flanked by constant primer binding sites.
2. Binding and Partitioning:
- The RNA library is incubated with the target molecule of interest (e.g., a protein or small molecule) that has been immobilized on a solid support (e.g., magnetic beads or a filter).
- RNA molecules that bind to the target are retained on the support, while non-binding sequences are washed away.
3. Elution and Amplification:
- The bound RNA molecules are eluted from the support.
- The eluted RNA is reverse transcribed into complementary DNA (cDNA).
- The cDNA is then amplified by Polymerase Chain Reaction (PCR) to generate a DNA pool enriched for sequences that bind to the target.
4. Iterative Rounds:
- The enriched DNA pool is used as a template for in vitro transcription to generate a new RNA pool for the next round of selection.
- Multiple rounds of this selection and amplification process are performed, progressively enriching the pool for high-affinity aptamers.
5. Sequencing and Characterization:
- After several rounds, the enriched pool is cloned and sequenced to identify individual aptamer candidates.
- The binding affinity and specificity of the selected aptamers are then characterized using various biochemical and biophysical techniques.
Protocol 3: DNA Origami Assembly and Functionalization
This protocol is based on typical workflows for creating and functionalizing DNA origami structures.[13]
1. Design:
- A long single-stranded DNA "scaffold" (often from a viral genome like M13mp18) is chosen.
- A set of short "staple" oligonucleotides are designed to bind to specific regions of the scaffold, folding it into the desired three-dimensional shape. Computational tools are often used for this design process.
2. Assembly (Annealing):
- The scaffold DNA and all staple strands are mixed in a buffered solution, typically containing magnesium ions which are crucial for shielding the negative charge of the DNA backbone.
- The mixture is heated to a high temperature (e.g., 90-95°C) to denature all DNA strands and then slowly cooled over several hours to a lower temperature (e.g., 20-25°C). This slow cooling process allows the staple strands to find their complementary binding sites on the scaffold and fold it into the target structure.
3. Pre-Assembly Functionalization:
- Individual staple strands can be chemically modified with a molecule of interest (e.g., a fluorescent dye, a protein, a nanoparticle) before the annealing step.
- These functionalized staples are then included in the annealing mixture to incorporate the molecule at a specific location on the DNA origami structure.
4. Post-Assembly Functionalization:
- Alternatively, the DNA origami structure can be assembled first with "addressable" staple strands that have a unique, unhybridized sequence extension (a "sticky end").
- A molecule of interest, conjugated to a complementary DNA strand, can then be attached to the origami structure by hybridization to the sticky end after the initial assembly.
5. Purification and Characterization:
- The assembled DNA origami structures are typically purified from excess staple strands using techniques like gel electrophoresis or size-exclusion chromatography.
- The final structures are visualized and characterized using Atomic Force Microscopy (AFM) or Transmission Electron Microscopy (TEM).
The Future of Biomolecular Computing
Biomolecular computing is still in its nascent stages, but its potential is vast. As our ability to design and engineer complex biological systems grows, we can envision a future with:
-
Smart Therapeutics: Cellular computers that can identify diseased cells based on multiple molecular markers and trigger a therapeutic response, such as the targeted release of a drug or the initiation of apoptosis.
-
Advanced Diagnostics: Highly sensitive and specific biosensors capable of detecting a wide range of analytes with high precision, enabling early disease diagnosis and environmental monitoring.
-
Biomanufacturing: Engineered microorganisms with sophisticated genetic circuits that can optimize the production of biofuels, pharmaceuticals, and other valuable chemicals.
The continued development of this field will require a multidisciplinary approach, combining the expertise of computer scientists, molecular biologists, chemists, and engineers. By unlocking the computational power of biomolecules, we are poised to revolutionize medicine, materials science, and information technology.
References
- 1. Biomolecular computing systems: principles, progress and potential - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. popovtzerlab.com [popovtzerlab.com]
- 3. De novo design of protein logic gates – Institute for Protein Design [ipd.uw.edu]
- 4. frontlinegenomics.com [frontlinegenomics.com]
- 5. Fluorescence-Based Multimodal DNA Logic Gates - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Synthetic RNA-based logic computation in mammalian cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. De novo design of protein logic gates - PMC [pmc.ncbi.nlm.nih.gov]
- 8. A fast, robust, and tunable synthetic gene oscillator - PMC [pmc.ncbi.nlm.nih.gov]
- 9. biocircuits.ucsd.edu [biocircuits.ucsd.edu]
- 10. pdfs.semanticscholar.org [pdfs.semanticscholar.org]
- 11. deepblue.lib.umich.edu [deepblue.lib.umich.edu]
- 12. In Vitro Selection of Aptamers from RNA Libraries | Springer Nature Experiments [experiments.springernature.com]
- 13. Functionalizing DNA origami to investigate and interact with biological systems - PMC [pmc.ncbi.nlm.nih.gov]
A Technical Guide to Foundational Research in Nucleic Acid Nanotechnology
For Researchers, Scientists, and Drug Development Professionals
This in-depth technical guide provides a comprehensive overview of the core principles, experimental methodologies, and key data in the field of nucleic acid nanotechnology. This document is intended to serve as a foundational resource for researchers, scientists, and professionals involved in drug development, offering detailed insights into the design, synthesis, characterization, and application of nucleic acid-based nanostructures.
Core Principles: Thermodynamic Stability of Nucleic Acid Structures
The predictable self-assembly of nucleic acid nanostructures is governed by thermodynamic principles, primarily the formation of Watson-Crick base pairs. The stability of these structures can be predicted using the nearest-neighbor model, which considers the identity of adjacent base pairs. The change in Gibbs free energy (ΔG°), enthalpy (ΔH°), and entropy (ΔS°) for the formation of a DNA or RNA duplex can be calculated by summing the thermodynamic parameters of its constituent nearest-neighbor pairs.[1][2][3][4]
Nearest-Neighbor Thermodynamic Parameters for DNA Duplexes
The following table summarizes the nearest-neighbor thermodynamic parameters for DNA duplex formation in 1 M NaCl solution. These values are crucial for the rational design of DNA nanostructures with desired stability.
| Nearest-Neighbor (5'-3'/3'-5') | ΔH° (kcal/mol) | ΔS° (cal/mol·K) | ΔG°₃₇ (kcal/mol) |
| AA/TT | -7.6 | -21.3 | -1.0 |
| AT/TA | -7.2 | -20.4 | -0.9 |
| TA/AT | -7.2 | -21.3 | -0.9 |
| CA/GT | -8.5 | -22.7 | -1.5 |
| GT/CA | -8.4 | -22.4 | -1.5 |
| CT/GA | -7.8 | -21.0 | -1.3 |
| GA/CT | -8.2 | -22.2 | -1.3 |
| CG/GC | -10.6 | -27.2 | -2.2 |
| GC/CG | -9.8 | -24.4 | -2.4 |
| GG/CC | -8.0 | -19.9 | -1.8 |
| Initiation | +0.2 | -5.7 | +2.2 |
Table 1: Nearest-neighbor thermodynamic parameters for DNA/DNA duplexes in 1 M NaCl. Data compiled from various sources.[5]
Nearest-Neighbor Thermodynamic Parameters for RNA Duplexes
Similarly, the stability of RNA nanostructures can be predicted using the following nearest-neighbor parameters.
| Nearest-Neighbor (5'-3'/3'-5') | ΔH° (kcal/mol) | ΔS° (cal/mol·K) | ΔG°₃₇ (kcal/mol) |
| AA/UU | -6.6 | -18.4 | -0.9 |
| AU/UA | -5.7 | -15.5 | -0.9 |
| UA/AU | -8.1 | -22.6 | -1.1 |
| CA/GU | -10.5 | -27.8 | -1.8 |
| GU/CA | -10.2 | -26.2 | -2.1 |
| CU/GA | -10.2 | -26.2 | -2.1 |
| GA/CU | -12.2 | -32.5 | -2.3 |
| CG/GC | -10.6 | -26.7 | -2.4 |
| GC/CG | -14.2 | -34.9 | -3.4 |
| GG/CC | -12.2 | -29.7 | -2.9 |
| Initiation | +3.6 | -1.5 | +4.1 |
Table 2: Nearest-neighbor thermodynamic parameters for RNA/RNA duplexes. Data compiled from various sources.[4]
Key Experimental Protocols
This section provides detailed methodologies for several key experiments in nucleic acid nanotechnology.
DNA Origami Self-Assembly
DNA origami is a powerful technique for creating complex 2D and 3D nanostructures.[6][7][8] The general protocol involves the folding of a long single-stranded scaffold DNA with the help of hundreds of short "staple" strands.[6][9]
Protocol:
-
Design: Design the desired DNA origami structure using software like caDNAno.[9] This involves routing the scaffold strand and designing the complementary staple strands.
-
Mixing: Combine the scaffold DNA (e.g., M13mp18 viral DNA) and all staple strands in a buffer solution (typically Tris-EDTA with magnesium chloride).[6] The typical molar ratio of staples to scaffold is 10:1.
-
Annealing: Heat the mixture to a denaturation temperature (e.g., 90°C) and then slowly cool it down to room temperature over several hours or days. This allows the staple strands to bind to the scaffold at their designated locations, folding it into the desired shape.
-
Purification: Remove excess staple strands using methods like agarose (B213101) gel electrophoresis or spin filtration.[7][10]
-
Characterization: Verify the successful formation of the origami structures using techniques such as Atomic Force Microscopy (AFM) or Transmission Electron Microscopy (TEM).[10]
Systematic Evolution of Ligands by Exponential Enrichment (SELEX)
SELEX is an in vitro selection process used to identify aptamers, which are short single-stranded DNA or RNA molecules that can bind to a specific target with high affinity and specificity.[11][12][13][14]
Protocol:
-
Library Preparation: Synthesize a large, random library of oligonucleotides (DNA or RNA), typically containing a central random region flanked by constant primer binding sites.[12]
-
Binding: Incubate the oligonucleotide library with the target molecule (e.g., a protein, small molecule, or even a whole cell).
-
Partitioning: Separate the target-bound oligonucleotides from the unbound sequences. This can be achieved using various methods such as nitrocellulose filter binding, affinity chromatography, or cell-based partitioning.[14]
-
Elution and Amplification: Elute the bound oligonucleotides and amplify them using the Polymerase Chain Reaction (PCR). For RNA libraries, a reverse transcription step is required before PCR.
-
Iteration: Repeat the binding, partitioning, and amplification steps for several rounds (typically 8-15 rounds) to enrich the pool of oligonucleotides with high affinity for the target.
-
Sequencing and Characterization: Sequence the enriched pool of oligonucleotides to identify individual aptamer candidates. The binding affinity and specificity of the identified aptamers are then characterized using techniques like surface plasmon resonance (SPR) or electrophoretic mobility shift assays (EMSA).
Lipid Nanoparticle (LNP) Formulation for Nucleic Acid Delivery
LNPs are a leading platform for the in vivo delivery of nucleic acid therapeutics, such as siRNA and mRNA.[15][16][17][18][19]
Protocol:
-
Lipid Mixture Preparation: Prepare a lipid mixture in an organic solvent (typically ethanol) containing an ionizable cationic lipid, a helper lipid (e.g., DSPC), cholesterol, and a PEG-lipid.[17]
-
Nucleic Acid Solution Preparation: Prepare an aqueous solution of the nucleic acid cargo (e.g., mRNA, siRNA) in an acidic buffer (e.g., citrate (B86180) buffer, pH 4).[15]
-
Mixing: Rapidly mix the lipid-ethanol solution with the aqueous nucleic acid solution.[15][16] This can be done using various techniques, including microfluidic mixing, which allows for precise control over nanoparticle size and uniformity.[16] The rapid change in polarity causes the lipids to self-assemble into nanoparticles, encapsulating the nucleic acids.
-
Dialysis and Concentration: Remove the organic solvent and raise the pH to a neutral level by dialyzing the LNP suspension against a buffer such as phosphate-buffered saline (PBS). The LNPs can then be concentrated using ultrafiltration.
-
Characterization: Characterize the LNPs for size, polydispersity, zeta potential, and encapsulation efficiency using techniques like Dynamic Light Scattering (DLS), Nanoparticle Tracking Analysis (NTA), and fluorescence-based assays.[17]
References
- 1. academic.oup.com [academic.oup.com]
- 2. pnas.org [pnas.org]
- 3. NNDB: the nearest neighbor parameter database for predicting stability of nucleic acid secondary structure - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Nearest-neighbor parameters for the prediction of RNA duplex stability in diverse in vitro and cellular-like crowding conditions - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Nucleic acid thermodynamics - Wikipedia [en.wikipedia.org]
- 6. dna.caltech.edu [dna.caltech.edu]
- 7. Protocols | I, Nanobot [inanobotdresden.github.io]
- 8. nvlpubs.nist.gov [nvlpubs.nist.gov]
- 9. Self-assembly of DNA into nanoscale three-dimensional shapes - PMC [pmc.ncbi.nlm.nih.gov]
- 10. pubs.acs.org [pubs.acs.org]
- 11. Capture-SELEX: Selection Strategy, Aptamer Identification, and Biosensing Application - PMC [pmc.ncbi.nlm.nih.gov]
- 12. tandfonline.com [tandfonline.com]
- 13. researchgate.net [researchgate.net]
- 14. Aptamer SELEX - Novaptech [novaptech.com]
- 15. biomol.com [biomol.com]
- 16. youtube.com [youtube.com]
- 17. Preparation and Optimization of Lipid-Like Nanoparticles for mRNA Delivery - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Advancing Delivery for Nucleic Acid Therapies | Technology Networks [technologynetworks.com]
- 19. sigmaaldrich.com [sigmaaldrich.com]
The Emergent Properties of DNA-Based Systems: A Technical Guide for Researchers and Drug Development Professionals
Introduction
Deoxyribonucleic acid (DNA), the fundamental carrier of genetic information, has transcended its biological role to become a premier engineering material for nanotechnology.[1] Its inherent properties of biocompatibility, stability, and predictable self-assembly through Watson-Crick base pairing make it an ideal building block for creating complex, functional systems at the nanoscale.[2][3] This guide explores the emergent properties of these systems, focusing on the sophisticated behaviors that arise from the programmed interaction of DNA strands. We delve into the core areas of DNA self-assembly, molecular computing, and advanced biosensing, providing a technical overview for researchers, scientists, and professionals in drug development.
DNA Self-Assembly: From Building Blocks to Complex Nanostructures
The cornerstone of DNA nanotechnology is the principle of self-assembly, where individual DNA strands spontaneously organize into stable, predetermined structures.[4] This bottom-up approach allows for the creation of a vast array of two- and three-dimensional objects with nanometer precision.[1][5] Two primary strategies dominate the field: tile-based assembly and DNA origami.
-
Tile-Based Assembly: This method uses smaller DNA motifs, or "tiles," composed of a few synthetic oligonucleotides that have "sticky ends"—short, single-stranded overhangs.[4] These sticky ends are programmed to bind to complementary ends on other tiles, allowing them to self-assemble into larger, often crystalline, lattices.[3]
-
DNA Origami: Pioneered by Paul Rothemund in 2006, DNA origami involves folding a long, single-stranded "scaffold" DNA (often from the M13 bacteriophage genome) into a desired shape using hundreds of shorter "staple" strands.[6][7] This technique enables the creation of complex, arbitrary, and non-periodic shapes with exceptional precision.[8][9]
The emergent property here is the formation of a complex, stable nanostructure from a solution of simple, linear DNA strands, purely dictated by the encoded sequence information. These structures serve as robust scaffolds for organizing other molecules, from nanoparticles to proteins, with unparalleled spatial control.[8]
Quantitative Analysis of DNA Nanostructure Assembly
The efficiency and yield of self-assembly are critical for practical applications. These parameters are influenced by factors such as cation concentration (which shields the electrostatic repulsion of the DNA backbone), staple-to-scaffold ratios, and annealing conditions.[10][11]
| DNA Nanostructure | Cation Type (10 mM) | Assembly Yield (%) | Reference |
| Double Crossover (DX) Motif | Mg²⁺ | ~95% | [12] |
| Double Crossover (DX) Motif | Ca²⁺ | ~95% | [12] |
| Double Crossover (DX) Motif | Ba²⁺ | ~95% | [12] |
| Double Crossover (DX) Motif | Na⁺ | ~75% | [12] |
| Double Crossover (DX) Motif | K⁺ | ~70% | [12] |
| DNA Tetrahedron | Mg²⁺ | High (not quantified) | [12] |
| DNA Origami (Triangle) | Mg²⁺ | High (not quantified) | [12] |
| DNA Origami (Triangle) | Ca²⁺ | High (not quantified) | [12] |
| DNA Origami (Triangle) | Ba²⁺ | High (not quantified) | [12] |
| DNA Origami (Rectangle) | Mg²⁺ (6-fold staple excess) | High (well-formed) | [11] |
| DNA Origami (Rectangle) | Mg²⁺ (2-fold staple excess) | Low (misfolded) | [11] |
Visualization of DNA Origami Assembly Workflow
The process of DNA origami folding is a carefully controlled thermal process.
DNA Computing: Logic and Information Processing at the Molecular Level
Beyond static structures, DNA systems can be designed to be dynamic and perform computations.[13] The primary mechanism enabling this is toehold-mediated strand displacement , a process where an "invader" DNA strand displaces an "incumbent" strand from a duplex.[14][15] This reaction is initiated at a short, single-stranded "toehold" domain, which provides a crucial kinetic and thermodynamic advantage to the invader strand.[6][16]
By programming the sequences of these interacting strands, researchers can construct molecular logic gates (e.g., AND, OR, NOT) that form the basis of DNA computers.[4][7][17] The emergent property in these systems is computation itself: the processing of molecular inputs to produce a predictable molecular output, analogous to electronic circuits but operating in a biocompatible, aqueous environment.[18][19]
Mechanism of Toehold-Mediated Strand Displacement
The strand displacement process is a cascade of molecular recognition and branch migration.
DNA-Based Logic Gates
DNA logic gates process input DNA strands to produce a specific output. The presence of an input strand is typically represented as a logical '1', and its absence as '0'. The output can be the release of another DNA strand or a change in a reporter molecule (e.g., fluorescence).[7][20]
References
- 1. researchgate.net [researchgate.net]
- 2. On the biophysics and kinetics of toehold-mediated DNA strand displacement - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. mdpi.com [mdpi.com]
- 5. cms-cdn.lmu.de [cms-cdn.lmu.de]
- 6. mdpi.com [mdpi.com]
- 7. researchgate.net [researchgate.net]
- 8. DNA origami | Springer Nature Experiments [experiments.springernature.com]
- 9. researchgate.net [researchgate.net]
- 10. Cost-efficient folding of functionalized DNA origami nanostructures via staple recycling - Nanoscale (RSC Publishing) DOI:10.1039/D5NR01435B [pubs.rsc.org]
- 11. Self-assembly of DNA nanostructures in different cations - PMC [pmc.ncbi.nlm.nih.gov]
- 12. par.nsf.gov [par.nsf.gov]
- 13. Fabrication of electrochemical-DNA biosensors for the reagentless detection of nucleic acids, proteins and small molecules - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. dna.caltech.edu [dna.caltech.edu]
- 15. [PDF] On the biophysics and kinetics of toehold-mediated DNA strand displacement | Semantic Scholar [semanticscholar.org]
- 16. neb.com [neb.com]
- 17. Folding (and then stapling) DNA Origami | Department of Chemistry [chem.ox.ac.uk]
- 18. mdpi.com [mdpi.com]
- 19. DNA-Based Biosensors for the Biochemical Analysis: A Review - PMC [pmc.ncbi.nlm.nih.gov]
- 20. Protocols | I, Nanobot [inanobotdresden.github.io]
Conceptual Frameworks for Molecular Robotics: An In-depth Technical Guide
Abstract
Molecular robotics is a rapidly advancing field at the intersection of nanotechnology, synthetic biology, and materials science. It endeavors to design and fabricate autonomous molecular machines capable of sensing, computation, and actuation at the nanoscale. These "molecular robots" hold immense potential for transformative applications, particularly in targeted drug delivery, in vitro diagnostics, and the precise assembly of nanoscale materials. This technical guide provides a comprehensive overview of the core conceptual frameworks that underpin the design and operation of molecular robots. We delve into the foundational principles of DNA nanotechnology, protein-based motor systems, and the integration of molecular sensing and computation. This document summarizes key quantitative performance data, details critical experimental protocols, and presents visual representations of fundamental concepts to serve as a resource for researchers and professionals in the field.
Core Conceptual Frameworks
The design of molecular robots is primarily guided by two powerful and complementary approaches: the programmability of nucleic acids and the diverse functionality of proteins.
DNA Nanotechnology: The Blueprint for Molecular Robotics
DNA's inherent properties of predictable self-assembly through Watson-Crick base pairing and its structural rigidity make it an exceptional material for constructing the foundational components of molecular robots.[1]
-
Structural Scaffolding: DNA origami is a powerful technique where a long, single-stranded DNA "scaffold" is folded into a predefined two- or three-dimensional shape by hundreds of shorter "staple" strands.[1] This allows for the creation of nanoscale breadboards upon which other molecular components, such as motors, sensors, and cargo, can be precisely positioned.
-
Molecular Actuation: DNA-based "walkers" are a class of molecular motors that can move along a predefined track, also constructed from DNA. Their movement is typically fueled by the hybridization of ATP or other oligonucleotide fuel strands, which induces conformational changes that result in a stepping motion.[2]
-
Molecular Computation: The predictable nature of DNA hybridization allows for the implementation of Boolean logic gates (e.g., AND, OR, NOT) at the molecular level.[3][4][5] These DNA-based circuits can process molecular signals and make decisions, forming the "brain" of a molecular robot.[6] For instance, a DNA logic gate could be designed to release a drug molecule only in the presence of two specific disease markers.
Protein-Based Systems: The Engines of Molecular Work
Nature has evolved a vast repertoire of protein-based molecular motors that convert chemical energy into mechanical work with remarkable efficiency. These biological machines are often incorporated into synthetic molecular robotic systems to provide powerful actuation.
-
Linear Motors: Kinesin and dynein are motor proteins that "walk" along microtubule tracks, while myosin motors move along actin filaments.[7] These motors are responsible for intracellular transport in living organisms and can be repurposed in synthetic systems to transport cargo over significant distances at the nanoscale.[8]
-
Rotary Motors: ATP synthase is a rotary motor that synthesizes ATP, the primary energy currency of the cell. Its rotary mechanism can be harnessed for tasks requiring rotational motion at the molecular level.[2]
Hybrid Systems: Integrating Logic and Motion
The most sophisticated molecular robots are hybrid systems that combine the strengths of both DNA nanotechnology and protein-based motors. In these systems, DNA-based computational circuits can be used to control the activity of protein motors, enabling complex, programmable behaviors.[9] For example, a DNA logic gate could be designed to activate a kinesin motor in response to a specific molecular signal, thereby initiating the transport of a therapeutic payload.
Quantitative Performance of Molecular Robots
The performance of molecular robots can be characterized by several key parameters, including their speed, the force they can generate, the size of the cargo they can transport, and their energy efficiency. The following table summarizes representative quantitative data for different classes of molecular robots.
| Molecular Robot Type | Motor Component | Fuel Source | Typical Speed | Stall Force | Maximum Cargo Size | Energy Efficiency | References |
| DNA Walker | DNAzymes/Toehold-mediated strand displacement | DNA/RNA fuel strands, ATP | 0.1 - 10 nm/s | ~1-5 pN | Small molecules, nanoparticles | Low | [2] |
| Kinesin-based Transporter | Kinesin-1 | ATP | ~800 nm/s | ~6-8 pN | ~1 µm diameter beads | Up to 50% | [8] |
| Dynein-based Transporter | Cytoplasmic Dynein | ATP | ~1 µm/s | ~1-2 pN | Vesicles, organelles | ~30-40% | [2] |
| Myosin-based Actuator | Myosin V | ATP | ~300-500 nm/s | ~1-3 pN | Actin filaments | ~20-30% | [10] |
| Light-activated Motor | Azobenzene derivatives | Light (UV/Visible) | Frequency dependent | N/A | Molecular switches | N/A | [11] |
Key Experimental Protocols
The successful design and implementation of molecular robots rely on a suite of precise experimental techniques. Below are detailed methodologies for two fundamental processes: the assembly of DNA origami structures and the in vitro motility assay for protein motors.
Protocol for DNA Origami Assembly
This protocol describes the self-assembly of a 2D DNA origami rectangle.
-
Design: Design the DNA origami structure using software like caDNAno. This will generate the sequences for the long scaffold strand and the short staple strands.
-
Materials:
-
M13mp18 single-stranded DNA scaffold (10 nM)
-
Staple strands (100 nM each)
-
Folding Buffer: 1x TAE buffer (40 mM Tris-acetate, 1 mM EDTA) supplemented with 12.5 mM MgCl₂.
-
-
Assembly:
-
In a PCR tube, mix 1 µL of the scaffold DNA with 1 µL of each staple strand solution.
-
Add 5 µL of 10x folding buffer and bring the total volume to 50 µL with nuclease-free water.
-
Perform thermal annealing in a PCR machine with the following program:
-
95°C for 5 minutes
-
Ramp down to 20°C over 90 minutes.
-
-
-
Purification:
-
Remove excess staple strands by spin-filtering the assembled origami through a 100 kDa molecular weight cutoff filter.
-
-
Characterization:
-
Visualize the assembled structures using Atomic Force Microscopy (AFM) or Transmission Electron Microscopy (TEM). Dilute the purified origami solution and deposit a small volume onto a freshly cleaved mica surface for AFM or a carbon-coated grid for TEM.
-
Protocol for In Vitro Motility Assay of Kinesin Motors
This protocol allows for the observation of microtubule movement driven by surface-adhered kinesin motors.
-
Flow Cell Preparation:
-
Construct a flow cell by sandwiching two pieces of double-sided tape between a glass slide and a coverslip.
-
-
Surface Passivation:
-
Introduce a solution of 1 mg/mL casein into the flow cell and incubate for 5 minutes to block non-specific protein binding.
-
Wash the flow cell with motility buffer (80 mM PIPES, 1 mM EGTA, 1 mM MgCl₂, pH 6.9).
-
-
Motor Immobilization:
-
Introduce a solution of kinesin motor proteins (e.g., 50 µg/mL) into the flow cell and incubate for 5 minutes.
-
Wash with motility buffer.
-
-
Microtubule Motility:
-
Prepare a solution of fluorescently labeled microtubules in motility buffer supplemented with 1 mM ATP and an oxygen scavenging system (e.g., glucose oxidase, catalase, and glucose) to prevent photobleaching.
-
Introduce the microtubule solution into the flow cell.
-
-
Imaging:
-
Observe the movement of the fluorescent microtubules using Total Internal Reflection Fluorescence (TIRF) microscopy.[12] Record time-lapse videos to analyze the velocity and processivity of the motor-driven movement.
-
Visualizing Molecular Robotics Concepts
Graphical representations are invaluable for understanding the complex interactions and workflows in molecular robotics. The following diagrams, generated using the DOT language, illustrate key conceptual frameworks.
General Workflow for Designing a Molecular Robot
Signaling Pathway for a Drug-Delivery Nanorobot
Logical Relationships in DNA-based Computation
Future Outlook
The field of molecular robotics is poised for significant advancements. Future research will likely focus on the development of more complex and robust molecular robots with enhanced capabilities, such as swarming behavior, multi-step synthesis, and in vivo applications. The integration of artificial intelligence and machine learning into the design process will accelerate the development of novel molecular robotic systems with unprecedented functionalities. As our ability to engineer at the molecular scale continues to improve, molecular robots will undoubtedly play an increasingly important role in medicine, materials science, and beyond.
References
- 1. Self-Assembly of DNA Molecules: Towards DNA Nanorobots for Biomedical Applications - PMC [pmc.ncbi.nlm.nih.gov]
- 2. pubs.acs.org [pubs.acs.org]
- 3. fiveable.me [fiveable.me]
- 4. DNA Logic Gates Integrated on DNA Substrates in Molecular Computing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Intelligent molecular logic computing toolkits: nucleic acid-based construction, functionality, and enhanced biosensing applications - Chemical Science (RSC Publishing) DOI:10.1039/D5SC06176H [pubs.rsc.org]
- 6. foglets.com [foglets.com]
- 7. Single molecule measurements and molecular motors - PMC [pmc.ncbi.nlm.nih.gov]
- 8. mdpi.com [mdpi.com]
- 9. pubs.acs.org [pubs.acs.org]
- 10. Thermodynamics and Kinetics of Molecular Motors - PMC [pmc.ncbi.nlm.nih.gov]
- 11. pubs.acs.org [pubs.acs.org]
- 12. researchgate.net [researchgate.net]
An In-depth Technical Guide to DNA Logic Gates and Circuits
For Researchers, Scientists, and Drug Development Professionals
Introduction
Deoxyribonucleic acid (DNA), the fundamental carrier of genetic information, has emerged as a remarkable building block for nanoscale engineering and molecular computation.[1] Its inherent properties of predictable Watson-Crick base pairing, self-assembly, and vast information storage capacity make it an ideal substrate for the development of sophisticated molecular devices.[2] This technical guide provides a comprehensive overview of DNA-based logic gates and circuits, delving into their core principles, design strategies, experimental implementation, and performance characteristics. The ability to perform computations at the molecular level opens up unprecedented opportunities in fields ranging from targeted drug delivery and diagnostics to advanced materials science.[3]
DNA logic gates are molecular-scale devices that perform Boolean logic operations, analogous to their electronic counterparts.[4] By designing specific DNA sequences, researchers can create gates that respond to molecular inputs (typically other DNA strands) to produce a defined output.[5] These gates can be interconnected to form complex circuits capable of sophisticated information processing.[6] The primary mechanism underpinning many DNA logic gates is the toehold-mediated strand displacement reaction, an enzyme-free process that allows for the controlled assembly and disassembly of DNA complexes.[7]
This guide will explore the foundational concepts of DNA logic, detail the construction and operation of various logic gates, provide quantitative performance data, and offer standardized experimental protocols for their realization and characterization.
Core Principles of DNA Logic Gates
The foundation of most DNA logic gates lies in the precise control of DNA hybridization and strand displacement reactions. These processes are highly programmable based on the nucleotide sequence of the interacting strands.
Toehold-Mediated Strand Displacement
Toehold-mediated strand displacement (TMSD) is a key process that enables dynamic DNA nanotechnology. It involves an input DNA strand binding to a short, single-stranded "toehold" region on a DNA duplex. This initial binding facilitates the displacement of an incumbent strand through a branch migration process, resulting in a new, more stable duplex. The rate of this reaction can be finely tuned by altering the length and sequence of the toehold, providing a mechanism for controlling the kinetics of DNA circuits.
The signaling pathway for a basic toehold-mediated strand displacement reaction can be visualized as follows:
References
- 1. academic.oup.com [academic.oup.com]
- 2. pubs.acs.org [pubs.acs.org]
- 3. Frontiers | Signal-to-Noise Ratio Measures Efficacy of Biological Computing Devices and Circuits [frontiersin.org]
- 4. researchgate.net [researchgate.net]
- 5. Constructing Controllable Logic Circuits Based on DNAzyme Activity - PMC [pmc.ncbi.nlm.nih.gov]
- 6. pubs.acs.org [pubs.acs.org]
- 7. mdpi.com [mdpi.com]
A Technical Guide to the Role of Thermodynamics in DNA Self-Assembly
Audience: Researchers, scientists, and drug development professionals.
Abstract: The precise and programmable nature of DNA self-assembly, a cornerstone of nanotechnology and modern drug delivery, is fundamentally governed by the principles of thermodynamics. Understanding the energetic contributions of enthalpy and entropy to the Gibbs free energy of hybridization allows for the rational design of complex nanostructures and therapeutic oligonucleotides. This guide provides an in-depth exploration of the core thermodynamic principles, predictive models, and key experimental protocols used to characterize and control DNA self-assembly. We present quantitative data in structured tables and detailed methodologies for crucial techniques such as UV-Vis thermal melting analysis and Isothermal Titration Calorimetry (ITC). Visual diagrams generated using Graphviz are provided to clarify experimental workflows and the interplay of thermodynamic forces.
Core Thermodynamic Principles Governing DNA Self-Assembly
The spontaneous formation of a DNA double helix or a more complex nanostructure from single-stranded DNA (ssDNA) is a process driven by a delicate balance of energetic factors. This process can be quantitatively described by the Gibbs free energy change (ΔG), which dictates the spontaneity of the assembly.
The Gibbs Free Energy Equation
The central equation in the thermodynamics of DNA self-assembly is:
ΔG = ΔH - TΔS
Where:
-
ΔG (Gibbs Free Energy): Represents the total energy available to do work. A negative ΔG indicates a spontaneous reaction (i.e., the assembled DNA structure is favored), while a positive ΔG indicates a non-spontaneous reaction.
-
ΔH (Enthalpy): Represents the change in heat of the system. In DNA assembly, this is primarily driven by the formation of hydrogen bonds between complementary base pairs and the favorable base-stacking interactions. The formation of these bonds is an exothermic process, resulting in a negative ΔH.
-
ΔS (Entropy): Represents the change in disorder or randomness of the system. The self-assembly of disordered single strands into a highly ordered duplex structure results in a decrease in conformational entropy, which is thermodynamically unfavorable (negative ΔS). However, this is counteracted by a favorable release of ordered water molecules from the surfaces of the bases, leading to a complex overall entropy change.[1][2]
-
T (Temperature): The absolute temperature in Kelvin.
DNA hybridization is primarily an enthalpy-driven process, where the favorable energy released from base pairing and stacking overcomes the unfavorable entropic cost of ordering the strands.[3]
Enthalpy (ΔH): Hydrogen Bonds and Base Stacking
The enthalpic contribution to DNA stability comes from two main sources:
-
Hydrogen Bonds: Watson-Crick base pairing involves the formation of two hydrogen bonds between Adenine (A) and Thymine (T) and three between Guanine (G) and Cytosine (C). The greater number of hydrogen bonds in a G-C pair makes it more thermally stable than an A-T pair.
-
Base Stacking: The van der Waals interactions between the flat, aromatic surfaces of adjacent base pairs in the helical structure are a major contributor to the stability of the duplex.[2] These stacking interactions are sequence-dependent and are responsible for almost all the enthalpy of DNA melting.[2]
Entropy (ΔS): The Cost of Ordering
The entropy change in DNA self-assembly has two opposing components:
-
Unfavorable Component: The transition from flexible, random-coil single strands to a rigid, ordered double helix results in a significant decrease in the conformational entropy of the DNA molecules themselves.
-
Favorable Component: The bases in single-stranded DNA organize water molecules around them. Upon duplex formation, these ordered water molecules are released into the bulk solvent, leading to a large increase in the overall entropy of the system. This entropy-driven base pairing is a crucial component of the overall Gibbs free energy.[2][4]
The Melting Temperature (Tm)
The melting temperature (Tm) is a critical parameter defined as the temperature at which 50% of the double-stranded DNA (dsDNA) has dissociated into single strands.[5] At the Tm, the folded and unfolded states are in equilibrium, and the ΔG of the system is zero. The Tm is highly dependent on the DNA sequence (especially its G-C content), the concentration of the DNA, and the salt concentration of the buffer.[6]
Predicting Duplex Stability: The Nearest-Neighbor Model
The thermodynamic stability of any DNA duplex can be accurately predicted using the nearest-neighbor (NN) model.[7] This model posits that the overall stability of a duplex is the sum of the thermodynamic contributions of individual "nearest-neighbor" dinucleotide pairs.
The total enthalpy and entropy for duplex formation can be calculated as follows:
ΔH°total = ΔH°initiation + Σi ni ΔH°i(NN) ΔS°total = ΔS°initiation + Σi ni ΔS°i(NN)
Once ΔH° and ΔS° are known, ΔG° at a specific temperature (e.g., 37 °C = 310.15 K) can be calculated. The following tables provide the unified nearest-neighbor parameters for DNA/DNA duplexes in 1 M NaCl.[8]
Table 1: Nearest-Neighbor Thermodynamic Parameters for Watson-Crick Pairs
| Sequence (5'-3'/3'-5') | ΔH° (kcal/mol) | ΔS° (cal/mol·K) | ΔG°37 (kcal/mol) |
| AA/TT | -7.6 | -21.3 | -1.0 |
| AT/TA | -7.2 | -20.4 | -0.9 |
| TA/AT | -7.2 | -21.3 | -0.6 |
| CA/GT | -8.5 | -22.7 | -1.5 |
| GT/CA | -8.4 | -22.4 | -1.5 |
| CT/GA | -7.8 | -21.0 | -1.3 |
| GA/CT | -8.2 | -22.2 | -1.3 |
| CG/GC | -10.6 | -27.2 | -2.2 |
| GC/CG | -9.8 | -24.4 | -2.2 |
| GG/CC | -8.0 | -19.9 | -1.8 |
| Data sourced from unified nearest-neighbor parameters.[8][9] |
Table 2: Initiation and Symmetry Correction Factors
| Factor | ΔH° (kcal/mol) | ΔS° (cal/mol·K) | ΔG°37 (kcal/mol) |
| Initiation with terminal G·C | 0.1 | -2.8 | 1.0 |
| Initiation with terminal A·T | 2.3 | 4.1 | 1.0 |
| Self-complementary duplex symmetry | 0 | -1.4 | 0.4 |
Experimental Determination of Thermodynamic Parameters
The thermodynamic parameters of DNA self-assembly are primarily determined using UV-Vis spectroscopy and Isothermal Titration Calorimetry (ITC).
UV-Vis Spectroscopy and Thermal Melting Analysis
This is the most common method for determining the Tm of a DNA duplex.[10][11] The technique relies on the hyperchromic effect : the absorbance of UV light at 260 nm is lower for dsDNA than for ssDNA because the base stacking in the duplex quenches the chromophores.[12][13] As the DNA is heated and denatures, the absorbance at 260 nm increases.
-
Sample Preparation:
-
Synthesize and purify the complementary single-stranded oligonucleotides.
-
Accurately determine the concentration of each strand using their extinction coefficients at 260 nm.
-
Prepare the final sample by mixing equimolar amounts of the complementary strands in a buffer solution (e.g., 1 M NaCl, 10 mM sodium phosphate, 1 mM EDTA, pH 7.0). Prepare a series of samples at different total strand concentrations (CT).[14]
-
-
Instrumentation Setup:
-
Data Acquisition:
-
Data Analysis:
-
Plot the absorbance versus temperature to generate a melting curve. The curve will be sigmoidal.
-
The Tm is the temperature at the midpoint of the transition, which can be determined by finding the peak of the first derivative of the melting curve.[12]
-
To determine ΔH° and ΔS°, plot 1/Tm (in Kelvin) versus ln(CT). The slope of this line is R/ΔH°, and the y-intercept is ΔS°/ΔH°.[14]
-
Caption: Experimental workflow for DNA thermal melting analysis using UV-Vis spectroscopy.
Table 3: Example UV-Melting Data and Calculated Parameters
| Duplex | Concentration (μM) | Tm (°C) | ΔH° (kcal/mol) | ΔS° (cal/mol·K) | ΔG°37 (kcal/mol) |
| Control Sequence | 10 | 58.4 | -55.2 | -150.1 | -10.5 |
| 3 Mismatches | 10 | 52.1 | -48.9 | -135.2 | -8.7 |
| 6 Mismatches | 10 | 44.5 | -41.5 | -118.9 | -6.2 |
| Hypothetical data based on trends observed in literature. Mismatches significantly decrease the stability of the duplex, lowering Tm and making ΔG less negative.[13][17] |
Isothermal Titration Calorimetry (ITC)
ITC provides a direct measurement of the heat change (ΔH) associated with a binding event, in this case, DNA hybridization. It is a powerful technique that can determine ΔH, the binding constant (Ka), and the stoichiometry (n) in a single experiment. From these, ΔG and ΔS can be calculated.
-
Sample Preparation:
-
Prepare highly pure and accurately concentrated solutions of the two complementary DNA strands in the same buffer dialysis batch to avoid heat artifacts from buffer mismatch.
-
One strand is placed in the sample cell, and the other is loaded into the injection syringe.
-
Degas both solutions thoroughly to prevent air bubbles.
-
-
Instrumentation Setup:
-
Set the desired experimental temperature in the ITC instrument.
-
Define the injection parameters: injection volume (e.g., 2-10 μL), number of injections (e.g., 20-30), and spacing between injections.
-
-
Data Acquisition:
-
The instrument injects small aliquots of the syringe solution into the sample cell.
-
The heat released or absorbed upon binding is measured by the power required to maintain a zero temperature difference between the sample and reference cells.
-
-
Data Analysis:
-
The raw data is a series of heat-flow peaks corresponding to each injection.
-
Integrate the area under each peak to determine the heat change per injection.
-
Plot the heat change per mole of injectant against the molar ratio of the two strands.
-
Fit this binding isotherm to a suitable model (e.g., a one-site binding model) to extract Ka, ΔH, and n.
-
Calculate ΔG and ΔS using the equations: ΔG = -RTln(Ka) and ΔS = (ΔH - ΔG)/T.
-
Caption: Experimental workflow for Isothermal Titration Calorimetry (ITC) of DNA hybridization.
Conclusion: Thermodynamics as a Design Tool
A thorough understanding of thermodynamics is indispensable for the rational design of DNA-based technologies. By leveraging the predictive power of the nearest-neighbor model and validating designs with empirical techniques like UV-melting and ITC, researchers can precisely control the self-assembly of DNA nanostructures.[10][18] This control is critical for applications ranging from the creation of complex DNA origami scaffolds for drug delivery to the optimization of probe hybridization in diagnostic assays and the development of potent antisense therapies. The principles outlined in this guide provide a foundational framework for professionals aiming to harness the power of DNA self-assembly in their research and development endeavors.
References
- 1. Thermodynamic basis of the α-helix and DNA duplex - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Forces maintaining the DNA double helix - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. youtube.com [youtube.com]
- 5. Nucleic acid thermodynamics - Wikipedia [en.wikipedia.org]
- 6. Melting curve analysis - Wikipedia [en.wikipedia.org]
- 7. pubs.acs.org [pubs.acs.org]
- 8. The thermodynamics of DNA structural motifs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. pnas.org [pnas.org]
- 10. pubs.acs.org [pubs.acs.org]
- 11. pubs.acs.org [pubs.acs.org]
- 12. DNA melting temperature analysis using UV-Vis spectroscopy | Cell And Molecular Biology [labroots.com]
- 13. documents.thermofisher.com [documents.thermofisher.com]
- 14. Measuring thermodynamic details of DNA hybridization using fluorescence - PMC [pmc.ncbi.nlm.nih.gov]
- 15. emeraldcloudlab.com [emeraldcloudlab.com]
- 16. Understanding DNA Melting Analysis Using UV-Visible Spectroscopy - Behind the Bench [thermofisher.com]
- 17. Nearest-neighbor thermodynamics and NMR of DNA sequences with internal A.A, C.C, G.G, and T.T mismatches - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. DNA nanotechnology - Wikipedia [en.wikipedia.org]
Methodological & Application
Application Notes and Protocols: Designing DNA Origami Structures for Drug Delivery
Audience: Researchers, scientists, and drug development professionals.
Introduction
DNA nanotechnology offers a powerful platform for creating precisely engineered drug delivery systems.[1][2] The DNA origami technique, in particular, allows for the self-assembly of a long single-stranded DNA scaffold into predefined two- and three-dimensional nanostructures with the help of shorter "staple" strands.[3][4] These structures offer unparalleled control over size, shape, and the spatial addressability of functional components, making them ideal candidates for advanced drug delivery vehicles.[1][5] Key advantages include excellent biocompatibility, biodegradability, and the ability to be extensively functionalized with targeting ligands, imaging agents, and therapeutic payloads.[1][6][7] This document provides a detailed guide to the design, fabrication, and evaluation of DNA origami nanostructures for therapeutic applications.
Design and Assembly of DNA Origami Nanostructures
The design of a DNA origami nanostructure is a critical first step that influences its stability, drug-loading capacity, and in vivo behavior.[5] The process involves computational modeling to create a blueprint of the desired shape, followed by the chemical synthesis of staple strands that will guide the folding of the scaffold DNA.
Workflow for DNA Origami Design and Assembly
The overall process from conceptual design to a purified drug-loaded nanostructure involves several key stages, as illustrated in the workflow below.
References
- 1. pubs.acs.org [pubs.acs.org]
- 2. Frontiers | Rationally Designed DNA Nanostructures for Drug Delivery [frontiersin.org]
- 3. Recent Developments of New DNA Origami Nanostructures for Drug Delivery - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. infoscience.epfl.ch [infoscience.epfl.ch]
- 6. Frontiers | Advanced applications of DNA nanostructures dominated by DNA origami in antitumor drug delivery [frontiersin.org]
- 7. Advanced applications of DNA nanostructures dominated by DNA origami in antitumor drug delivery - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for DNA Strand Displacement Reactions
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive overview of DNA strand displacement (DSD) reactions, a powerful tool in nucleic acid nanotechnology with broad applications in diagnostics, therapeutics, and synthetic biology. The accompanying protocols offer detailed methodologies for the design, execution, and analysis of key DSD experiments.
Introduction to DNA Strand Displacement
DNA strand displacement is a fundamental process in which a single-stranded DNA molecule (the "invader") displaces another strand (the "incumbent") from a double-stranded complex (the "substrate"). This process is typically initiated at a short, single-stranded overhang on the substrate known as a "toehold". The invader strand binds to the toehold and then, through a process of branch migration, progressively displaces the incumbent strand. The rate of this reaction can be precisely controlled by modulating the length and sequence of the toehold, making DSD a highly programmable and versatile mechanism for engineering dynamic molecular systems.
The simplicity and predictability of Watson-Crick base pairing allow for the rational design of complex DSD-based circuits and devices.[1][2] These enzyme-free systems can operate isothermally and have been used to construct logic gates, amplifiers, molecular motors, and biosensors.[3][4] In the context of drug development, DSD reactions are being explored for targeted drug delivery, diagnostics, and the controlled activation of therapeutic molecules.[5][6]
Key Concepts and Mechanisms
Toehold-Mediated Strand Displacement (TMSD)
The most common and well-characterized DSD mechanism is toehold-mediated strand displacement (TMSD).[2][7] The reaction proceeds in three main steps:
-
Toehold Binding: The invader strand recognizes and binds to the complementary toehold domain on the substrate-incumbent complex.
-
Branch Migration: A random walk-like process where base pairs between the invader and substrate form at the expense of base pairs between the incumbent and substrate.[8]
-
Displacement: The incumbent strand is fully displaced and released into the solution.
The kinetics of TMSD are highly dependent on the toehold length, with each additional nucleotide in the toehold increasing the reaction rate by approximately an order of magnitude, up to a saturation point.[9] Reaction rates can reach up to ~106 M-1s-1.[10]
Factors Influencing Reaction Kinetics
Several factors can be tuned to control the rate of DNA strand displacement reactions:
-
Toehold Length: The primary determinant of the reaction rate. Longer toeholds lead to faster displacement.[9][10]
-
Toehold Sequence: The GC content of the toehold affects its binding strength and, consequently, the reaction kinetics.[8]
-
Temperature: Higher temperatures generally increase the rate of both toehold binding and branch migration.[8]
-
Ionic Strength: The concentration of ions, particularly Mg2+, can influence the stability of the DNA duplexes and intermediates.[8]
-
Secondary Structure: Unwanted secondary structures in the invader or substrate strands can hinder the reaction.[9]
-
Leak Reactions: Spurious, toehold-independent displacement can occur, which can be minimized through careful sequence design.
Data Presentation: Quantitative Analysis of TMSD Kinetics
The following tables summarize the effect of toehold length and sequence on the rate constant of toehold-mediated DNA strand displacement reactions. The data is compiled from various studies and illustrates the programmability of DSD kinetics.
Table 1: Effect of Toehold Length on TMSD Rate Constant
| Toehold Length (nucleotides) | Approximate Second-Order Rate Constant (k) (M-1s-1) | Fold Increase per Nucleotide |
| 0 | < 10-2 | - |
| 1 | ~100 | ~100x |
| 2 | ~101 | ~10x |
| 3 | ~102 | ~10x |
| 4 | ~103 | ~10x |
| 5 | ~104 | ~10x |
| 6 | ~105 | ~10x |
| 7 | ~106 | ~10x |
| 8 | > 106 | Saturation |
Note: These are approximate values and can vary based on sequence, temperature, and buffer conditions.[9]
Table 2: Influence of Toehold Position on Reaction Rate
| Toehold Position | Relative Reaction Rate | Rationale |
| External (5' or 3' end) | 10-100x faster | Reduced entropic barrier and no topological constraints. |
| Internal (within a loop) | Slower | Increased entropic penalty for loop opening. |
Experimental Protocols
Protocol 1: Oligonucleotide Design and Preparation
This protocol outlines the steps for designing and preparing the DNA oligonucleotides required for a TMSD experiment.
1. Sequence Design:
- Define the functional domains: toehold, branch migration domain, and any recognition sequences.
- Use DNA design software (e.g., NUPACK) to design sequences with minimal secondary structure and to prevent unintended interactions.
- Ensure the branch migration domains of the invader and incumbent are identical.
- For fluorescence-based assays, design one strand (typically the incumbent) with a fluorophore and the substrate with a quencher at appropriate positions to monitor the displacement process.
2. Oligonucleotide Synthesis and Purification:
- Synthesize the designed DNA oligonucleotides.
- Purify the oligonucleotides to remove truncated products and other impurities. Common purification methods include:
- Desalting: Removes salts and very small organic molecules. Suitable for non-critical applications like PCR.
- Reverse-Phase Cartridge Purification: Removes many failure sequences.
- High-Performance Liquid Chromatography (HPLC): Provides high purity (>85%) and is recommended for kinetic studies.
- Polyacrylamide Gel Electrophoresis (PAGE): Offers the highest purity (>95%) and is ideal for applications requiring very pure oligonucleotides.
3. Quantification and Storage:
- Determine the concentration of the purified oligonucleotides using UV-Vis spectrophotometry at 260 nm.
- Store the oligonucleotides in a suitable buffer (e.g., TE buffer) at -20°C.
Protocol 2: Preparation of the Substrate-Incumbent Duplex
This protocol describes the annealing process to form the double-stranded substrate-incumbent complex.
1. Mixing:
- In a PCR tube, mix the substrate and incumbent strands in a 1:1 molar ratio in the desired reaction buffer (e.g., TE buffer with MgCl2). A slight excess of the substrate strand (e.g., 1.1:1) can be used to ensure all the incumbent strand is hybridized.
2. Annealing:
- Heat the mixture to 95°C for 5 minutes to denature any secondary structures.
- Slowly cool the mixture to room temperature (e.g., over 1-2 hours) to allow for proper annealing. This can be done using a thermocycler with a ramp-down program.
3. Verification (Optional):
- Run the annealed duplex on a native polyacrylamide gel to confirm the formation of the complex.
Protocol 3: Monitoring TMSD Kinetics using Fluorescence Spectroscopy
This protocol details the procedure for measuring the kinetics of a TMSD reaction using a fluorometer.
1. Instrument Setup:
- Set the fluorometer to the excitation and emission wavelengths of the chosen fluorophore-quencher pair.
- Set the temperature of the sample holder to the desired reaction temperature (e.g., 25°C).
2. Reaction Setup:
- In a fluorescence cuvette, add the reaction buffer.
- Add the pre-annealed substrate-incumbent duplex to the cuvette at the desired final concentration (e.g., 50 nM).
- Place the cuvette in the fluorometer and start recording the baseline fluorescence.
3. Initiation of the Reaction:
- Add the invader strand to the cuvette at the desired final concentration (e.g., 100 nM, typically in excess).
- Gently mix the solution without creating bubbles.
- Immediately start recording the fluorescence signal over time. Continue recording until the signal reaches a plateau, indicating the reaction has gone to completion.
4. Data Analysis:
- Normalize the fluorescence data.
- Fit the kinetic trace to a second-order reaction model to extract the observed rate constant (kobs).
- The second-order rate constant (k) can be calculated from kobs and the concentration of the excess reactant (the invader strand).
Mandatory Visualization: Diagrams of DSD Pathways and Workflows
The following diagrams, generated using the DOT language, illustrate key DSD mechanisms and experimental workflows.
Caption: Mechanism of Toehold-Mediated Strand Displacement (TMSD).
Caption: Experimental workflow for studying TMSD kinetics.
Caption: A simple catalytic DNA strand displacement circuit.
References
- 1. dna.caltech.edu [dna.caltech.edu]
- 2. Simultaneous and stoichiometric purification of hundreds of oligonucleotides - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Modelling Toehold-Mediated RNA Strand Displacement - PMC [pmc.ncbi.nlm.nih.gov]
- 4. m.youtube.com [m.youtube.com]
- 5. Design of DNA Strand Displacement Reactions [arxiv.org]
- 6. academic.oup.com [academic.oup.com]
- 7. mdpi.com [mdpi.com]
- 8. pubs.acs.org [pubs.acs.org]
- 9. bitesizebio.com [bitesizebio.com]
- 10. Oligonucleotide Purification Methods for Your Research | Thermo Fisher Scientific - US [thermofisher.com]
Application Notes and Protocols for the Synthesis and Purification of DNA Nanostructures
For Researchers, Scientists, and Drug Development Professionals
These application notes provide detailed protocols for the synthesis and purification of DNA nanostructures, critical for applications in drug delivery, biosensing, and nanotechnology. The following sections outline established methods, present quantitative data for comparison, and provide step-by-step experimental procedures.
I. Synthesis of DNA Nanostructures
The rational design and self-assembly of DNA strands enable the creation of intricate, programmable nanostructures. The two primary approaches for synthesis are scaffolded DNA origami and scaffold-free techniques.
A. Scaffolded DNA Origami
Scaffolded DNA origami is a widely used method for creating complex 2D and 3D nanostructures.[1][2] This technique involves folding a long, single-stranded DNA "scaffold" (typically from a viral genome like M13mp18) into a desired shape with the help of hundreds of shorter "staple" strands.[1][3] The staple strands are computationally designed to bind to specific regions of the scaffold, guiding its conformation.[1]
This protocol is adapted from established methods for DNA origami assembly.[4][5][6]
1. Materials:
-
Scaffold DNA: M13mp18 single-stranded DNA (ssDNA) is commonly used.[1]
-
Staple Strands: Custom-synthesized oligonucleotides, typically 20-60 nucleotides in length.[7] Gel-purified staples are often sufficient.[4]
-
Folding Buffer: 1x TAE buffer (40 mM Tris-acetate, 1 mM EDTA) supplemented with 10-20 mM MgCl₂.
-
Nuclease-free water.
-
Low-bind microtubes.
2. Procedure:
-
Staple Strand Preparation:
-
Resuspend lyophilized staple strands in nuclease-free water to a stock concentration of 100 µM.
-
Prepare a master mix of all staple strands at a final concentration typically 10-fold higher than the scaffold strand concentration.[6]
-
-
Folding Reaction Setup:
-
In a low-bind microtube, combine the scaffold DNA and the staple strand master mix. A common final concentration is 10 nM scaffold and 100 nM for each staple strand.
-
Add folding buffer to the desired final volume.
-
-
Thermal Annealing:
-
Place the reaction tube in a thermal cycler.
-
Heat the mixture to 80°C to denature any secondary structures.[5]
-
Gradually cool the mixture to allow for the staple strands to hybridize to the scaffold. A typical annealing ramp is from 65°C to 20°C at a rate of 1°C per 20 minutes.[5]
-
The folded origami structures can be stored at 4°C.[5]
-
B. Scaffold-Free DNA Nanostructures
Scaffold-free methods construct nanostructures solely from short, synthetic oligonucleotides.[8][9] These techniques, such as DNA bricks and single-stranded tiles (SSTs), offer greater design flexibility and are not limited by the size of a scaffold strand.[10][11]
Caption: Workflow for scaffold-free DNA nanostructure synthesis.
II. Purification of DNA Nanostructures
Purification is a critical step to remove excess staple strands, misfolded structures, and aggregates, which is essential for downstream applications.[12] Several techniques are available, with the choice depending on the scale of preparation, the size of the nanostructure, and the required purity.
A. Agarose (B213101) Gel Electrophoresis (AGE)
AGE separates DNA nanostructures based on their size and shape.[13] Well-folded structures typically migrate as a distinct band, which can be excised for extraction.[14] While effective for small-scale purification, recovery yields can be low.[15]
This protocol is based on standard procedures for purifying DNA origami.[5][13][16][17]
1. Materials:
-
Agarose
-
1x TAE buffer supplemented with MgCl₂ (typically 11 mM)
-
DNA stain (e.g., GelRed or SYBR Safe)
-
6x DNA loading dye
-
Gel electrophoresis system
-
UV transilluminator
-
Sterile scalpel or razor blade
-
Gel extraction kit
2. Procedure:
-
Gel Preparation:
-
Prepare a 0.7-1.5% agarose gel in 1x TAE-Mg²⁺ buffer.[5] Lower percentage gels are better for larger structures.
-
Add the DNA stain to the molten agarose before casting the gel.
-
-
Sample Loading and Electrophoresis:
-
Band Excision and Extraction:
-
Visualize the DNA bands on a UV transilluminator, minimizing UV exposure to prevent DNA damage.[16]
-
Carefully excise the band corresponding to the well-folded nanostructure using a clean scalpel.[16]
-
Extract the DNA from the agarose slice using a commercial gel extraction kit, following the manufacturer's instructions.
-
B. Size Exclusion Chromatography (SEC)
SEC separates molecules based on their size.[20] Larger DNA nanostructures elute first, while smaller impurities like staple strands are retained longer in the porous beads of the chromatography resin.[21] This method can be performed using gravity-driven columns for larger scales or with High-Performance Liquid Chromatography (HPLC) for higher resolution and analytical purposes.[15][22][23]
This protocol provides a robust method for purifying larger quantities of DNA nanostructures.[15][21][24]
1. Materials:
-
Size exclusion resin (e.g., Sepharose)
-
Chromatography column
-
Elution buffer (same as the folding buffer, e.g., 1x TAE-Mg²⁺)
-
Fraction collection tubes
2. Procedure:
-
Column Packing:
-
Pack the chromatography column with the size exclusion resin according to the manufacturer's instructions.
-
Equilibrate the column with at least three column volumes of elution buffer.[21]
-
-
Sample Loading and Elution:
-
Carefully load the crude DNA nanostructure sample onto the top of the resin bed.
-
Allow the sample to enter the resin.
-
Begin eluting the sample by adding elution buffer to the top of the column.
-
-
Fraction Collection:
-
Collect fractions as the buffer flows through the column. The larger DNA nanostructures will be in the initial fractions.
-
Analyze the fractions using AGE or UV-Vis spectroscopy to identify those containing the purified nanostructures.
-
Caption: Workflow for HPLC-based purification of DNA nanostructures.
C. Other Purification Methods
-
Ultrafiltration: Uses membranes with specific molecular weight cutoffs to retain large DNA nanostructures while allowing smaller contaminants to pass through.[12][25]
-
Rate-Zonal (Glycerol Gradient) Centrifugation: Separates structures based on their sedimentation rate through a density gradient (e.g., glycerol).[14][25] This method is effective for obtaining high-purity samples.[14]
III. Quantitative Data Summary
The efficiency of synthesis and purification methods can be evaluated based on yield and purity. The following tables summarize key quantitative data from the literature.
Table 1: Comparison of DNA Nanostructure Purification Methods
| Purification Method | Typical Recovery Yield | Scale | Advantages | Disadvantages |
| Agarose Gel Electrophoresis (AGE) | 20-30%[15] | < 1 µg[15][24] | High resolution | Laborious, low yield, potential for UV damage[14][15] |
| Gravity-Driven SEC | 50-70%[15][21][24] | 100-1000 µg[21][24] | Scalable, rapid, gentle[15][21] | Lower resolution than HPLC |
| Rate-Zonal Centrifugation | 40-80%[15] | 1-100 µg[15] | High purity, scalable[14] | Requires ultracentrifuge, time-consuming[21] |
| Ultrafiltration | Variable | Scalable | Rapid | Potential for sample loss and aggregation[25] |
IV. Characterization of DNA Nanostructures
After synthesis and purification, it is essential to characterize the nanostructures to confirm their integrity and purity.
-
Atomic Force Microscopy (AFM) and Transmission Electron Microscopy (TEM): These imaging techniques provide direct visualization of the size and shape of individual nanostructures.[26][27]
-
Dynamic Light Scattering (DLS) and Nanoparticle Tracking Analysis (NTA): These methods provide information about the size distribution and concentration of nanostructures in solution.[28][29]
-
Quantitative Polymerase Chain Reaction (qPCR): Can be used to quantify the concentration of DNA nanostructures, particularly for cellular uptake studies.[30][31]
References
- 1. DNA origami - Wikipedia [en.wikipedia.org]
- 2. DNA nanotechnology - Wikipedia [en.wikipedia.org]
- 3. Synthesis of DNA Origami Scaffolds: Current and Emerging Strategies - PMC [pmc.ncbi.nlm.nih.gov]
- 4. dna.caltech.edu [dna.caltech.edu]
- 5. Protocols | I, Nanobot [inanobotdresden.github.io]
- 6. cms-cdn.lmu.de [cms-cdn.lmu.de]
- 7. Versatile computer-aided design of free-form DNA nanostructures and assemblies - PMC [pmc.ncbi.nlm.nih.gov]
- 8. A General Design Method for Scaffold-Free DNA Wireframe Nanostructures | springerprofessional.de [springerprofessional.de]
- 9. Automated design of scaffold-free DNA wireframe nanostructures [ideas.repec.org]
- 10. researchgate.net [researchgate.net]
- 11. users.ics.aalto.fi [users.ics.aalto.fi]
- 12. Purification Techniques for Three-Dimensional DNA Nanostructures - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. "Agarose Gel Electrophoresis for Purification of DNA Origami Nanotubes " by Davis Daniel, William Hughes et al. [scholarworks.boisestate.edu]
- 14. Purification of DNA-origami nanostructures by rate-zonal centrifugation - PMC [pmc.ncbi.nlm.nih.gov]
- 15. pubs.acs.org [pubs.acs.org]
- 16. addgene.org [addgene.org]
- 17. addgene.org [addgene.org]
- 18. Purification of self-assembled DNA tetrahedra using gel electrophoresis - PMC [pmc.ncbi.nlm.nih.gov]
- 19. static1.squarespace.com [static1.squarespace.com]
- 20. harvardapparatus.com [harvardapparatus.com]
- 21. A Robust and Efficient Method to Purify DNA-Scaffolded Nanostructures by Gravity-Driven Size Exclusion Chromatography - PMC [pmc.ncbi.nlm.nih.gov]
- 22. Characterization of DNA nanostructure stability by size exclusion chromatography - Analytical Methods (RSC Publishing) [pubs.rsc.org]
- 23. Characterization of DNA nanostructure stability by size exclusion chromatography - PMC [pmc.ncbi.nlm.nih.gov]
- 24. pubs.acs.org [pubs.acs.org]
- 25. pubs.acs.org [pubs.acs.org]
- 26. pubs.acs.org [pubs.acs.org]
- 27. Assembly and microscopic characterization of DNA origami structures - PubMed [pubmed.ncbi.nlm.nih.gov]
- 28. chemrxiv.org [chemrxiv.org]
- 29. Characterization of DNA Origami Nanostructures for Size and Concentration by Dynamic Light Scattering and Nanoparticle Tracking Analysis | NSF Public Access Repository [par.nsf.gov]
- 30. Quantification of cellular uptake of DNA nanostructures by qPCR - PubMed [pubmed.ncbi.nlm.nih.gov]
- 31. researchgate.net [researchgate.net]
Applications of DNA Nanotechnology in Biosensing: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
Introduction
DNA, the blueprint of life, has transcended its biological role to become a versatile building material in the field of nanotechnology. Its inherent properties of programmability, predictability through Watson-Crick base pairing, and biocompatibility make it an exceptional candidate for the construction of nanoscale structures with unprecedented precision.[1][2] This has led to the emergence of DNA nanotechnology, a field dedicated to the design and fabrication of artificial DNA structures for various applications, most notably in biosensing.[3][4][5]
DNA nanotechnology-based biosensors offer remarkable advantages, including high sensitivity, specificity, and the potential for multiplexed detection of a wide range of analytes such as nucleic acids, proteins, small molecules, and ions.[6][7] This document provides detailed application notes and protocols for three prominent classes of DNA nanostructures used in biosensing: DNA origami, DNA walkers, and DNA hydrogels.
I. DNA Origami-Based Biosensors
DNA origami is a revolutionary technique that involves folding a long single-stranded DNA scaffold (typically from the M13 bacteriophage genome) into a predefined two- or three-dimensional shape using hundreds of shorter "staple" strands.[2][8] This method allows for the creation of nanostructures with complex geometries and the precise positioning of functional elements like aptamers, fluorophores, and nanoparticles, making them ideal platforms for biosensing.[1][9]
Application Note: Protein Detection using a Modular DNA Origami Biosensor
This application note describes an electrochemical biosensor based on a reconfigurable DNA origami platform for the detection of proteins, such as Platelet-Derived Growth Factor BB (PDGF-BB). The principle relies on a target-induced conformational change of the DNA origami structure, which brings redox reporters (Methylene Blue, MB) in proximity to a gold electrode surface, generating a detectable electrochemical signal.[5]
Signaling Pathway
Caption: Target protein binding induces a conformational change in the DNA origami, leading to signal generation.
Experimental Protocol: Fabrication of a DNA Origami Biosensor for PDGF-BB Detection
Materials:
-
M13mp18 single-stranded DNA scaffold
-
Staple strands (unmodified and modified with 5' extensions for MB reporters and aptamers)
-
Methylene Blue (MB)-modified oligonucleotides
-
PDGF-BB aptamer sequences
-
Gold electrodes
-
Tris-acetate-EDTA (TAE) buffer with MgCl₂
-
Square-wave voltammetry (SWV) instrument
Procedure:
-
DNA Origami Design: Design a flat, disk-shaped DNA origami structure with a central hole using a suitable software (e.g., caDNAno). Incorporate staple strands with 5' extensions at specific locations for attaching MB reporters and the PDGF-BB aptamer.
-
Origami Folding:
-
Mix the M13 scaffold DNA, staple strands (including those with extensions), and MB-modified oligos in TAE buffer containing 12.5 mM MgCl₂.
-
Anneal the mixture by heating to 95°C for 5 minutes and then slowly cooling to 20°C over 12-16 hours.
-
-
Electrode Functionalization:
-
Clean the gold electrode surface.
-
Immobilize a thiol-modified oligonucleotide containing the PDGF-BB aptamer sequence onto the gold surface through self-assembly.
-
-
Sensor Assembly:
-
Incubate the functionalized electrode with the folded DNA origami solution. The origami will attach to the electrode via hybridization of a linker strand.
-
-
Analyte Detection:
-
Introduce the sample containing PDGF-BB to the sensor surface.
-
Binding of the dimeric PDGF-BB to the aptamers on both the origami and the electrode surface induces a conformational change, bringing the MB reporters close to the electrode.
-
Measure the electrochemical signal using SWV. The increase in current is proportional to the concentration of PDGF-BB.[5]
-
II. DNA Walker-Based Biosensors
DNA walkers are dynamic nanodevices that can move along a predefined track on a DNA nanostructure.[3] Their movement is typically fueled by enzymatic reactions or strand displacement reactions, leading to signal amplification. This makes them highly sensitive biosensors for various targets, particularly nucleic acids like microRNAs (miRNAs).[10]
Application Note: miRNA Detection using a Target-Fueled DNA Walker
This application note details a fluorescent biosensor for the detection of a specific miRNA (e.g., let-7a) using a DNA walker. The target miRNA itself acts as the "fuel" to power the walker's movement along a track, leading to a significant amplification of the fluorescence signal.[10]
Experimental Workflow
Caption: Workflow for miRNA detection using a target-fueled DNA walker with signal amplification.
Experimental Protocol: miRNA-Responsive DNA Walker Biosensor
Materials:
-
Oligonucleotides for walker, track, and fuel strands (sequences specific to the target miRNA)
-
Target miRNA (e.g., let-7a)
-
Reaction buffer (e.g., Tris-acetate buffer with Mg²⁺)
-
T4 DNA ligase and buffer
-
Phi29 DNA polymerase and dNTPs (for Rolling Circle Amplification - RCA)
-
Fluorescent reporter (e.g., SYBR Green I)
-
Fluorescence spectrometer
Procedure:
-
DNA Walker and Track Assembly:
-
Mix the oligonucleotides for the walker and the track in the reaction buffer.
-
Anneal the mixture by heating to 90°C for 3 minutes, followed by slow cooling to 25°C to allow for proper hybridization and formation of the walker-track complex.[10]
-
-
Target-Induced Walking:
-
Introduce the sample containing the target miRNA to the assembled walker-track solution.
-
The miRNA will bind to a specific recognition site on the walker, initiating a strand displacement cascade that causes the walker to move along the track.[10]
-
-
Signal Amplification (RCA):
-
The movement of the walker can be designed to produce a circular DNA template.
-
Add T4 DNA ligase to circularize the template.
-
Add phi29 DNA polymerase and dNTPs to initiate RCA, which generates a long single-stranded DNA product containing multiple repeats of a specific sequence.[10]
-
-
Fluorescence Detection:
-
Add a fluorescent dye (e.g., SYBR Green I) that intercalates with the dsDNA product of RCA.
-
Measure the fluorescence intensity. The signal intensity is proportional to the initial concentration of the target miRNA.
-
III. DNA Hydrogel-Based Biosensors
DNA hydrogels are three-dimensional networks of crosslinked DNA chains that can swell in water.[11] These hydrogels can be designed to be responsive to specific stimuli, such as the presence of a target molecule, leading to a change in their physical properties (e.g., volume, color).[12][13] This makes them attractive materials for developing simple, often visual, biosensors.
Application Note: Small Molecule Detection using an Aptamer-Based DNA Hydrogel
This application note describes a colorimetric biosensor for the detection of a small molecule, adenosine (B11128), using a DNA hydrogel functionalized with an adenosine-binding aptamer. The binding of adenosine to the aptamer disrupts the hydrogel network, leading to the release of encapsulated gold nanoparticles (AuNPs) and a corresponding color change.[14]
Logical Relationship
Caption: Adenosine binding triggers hydrogel disassembly, AuNP release, and a visual color change.
Experimental Protocol: Aptamer-Based DNA Hydrogel for Adenosine Detection
Materials:
-
Acrydite-modified DNA aptamer for adenosine
-
Acrydite-modified complementary DNA strand
-
Acrylamide and N,N'-methylenebis(acrylamide) (BIS)
-
Ammonium persulfate (APS) and N,N,N',N'-tetramethylethylenediamine (TEMED)
-
Gold nanoparticles (AuNPs)
-
Adenosine standard solutions
-
UV-Vis spectrophotometer
Procedure:
-
Synthesis of DNA-Functionalized Polyacrylamide:
-
Prepare a solution containing the acrydite-modified adenosine aptamer and its complementary strand.
-
Add acrylamide, BIS, and APS to the DNA solution.
-
Initiate polymerization by adding TEMED. This will form a polyacrylamide backbone with incorporated DNA strands.
-
-
Hydrogel Formation and AuNP Encapsulation:
-
Mix the DNA-functionalized polyacrylamide solution with a solution of AuNPs.
-
The hybridization of the complementary DNA strands will crosslink the polymer chains, forming a hydrogel and entrapping the AuNPs within the network.
-
-
Analyte Detection:
-
Add the sample containing adenosine to the hydrogel.
-
Adenosine will bind to its aptamer, causing a conformational change that de-hybridizes the crosslinking strands.
-
This leads to the disassembly of the hydrogel and the release of the encapsulated AuNPs into the supernatant.
-
-
Signal Readout:
-
The released AuNPs will aggregate in the solution, causing a color change from red to blue.
-
Quantify the color change by measuring the absorbance spectrum using a UV-Vis spectrophotometer. The change in absorbance is proportional to the adenosine concentration.
-
IV. Applications in Cellular Imaging
DNA nanotechnology-based biosensors are also being developed for imaging and sensing applications within living cells. These intracellular biosensors can provide real-time information about the presence and localization of specific molecules, such as messenger RNA (mRNA), offering valuable insights into cellular processes.[15][16]
Application Note: mRNA Imaging in Living Cells using a DNA Walker
This application note describes the use of a DNA walker for the real-time imaging of a specific mRNA in living cells. The walker is designed to be activated by the target mRNA, leading to the generation of a fluorescent signal that can be monitored by microscopy.[3]
Experimental Workflow for Cellular Imaging
References
- 1. mdpi.com [mdpi.com]
- 2. pdfs.semanticscholar.org [pdfs.semanticscholar.org]
- 3. Programmed DNA walkers for biosensors [html.rhhz.net]
- 4. pnas.org [pnas.org]
- 5. Modular DNA origami–based electrochemical detection of DNA and proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. Recent Advances in DNA Nanotechnology-Enabled Biosensors for Virus Detection - PMC [pmc.ncbi.nlm.nih.gov]
- 8. mdpi.com [mdpi.com]
- 9. DNA Origami-Enabled Biosensors [mdpi.com]
- 10. Target-fueled DNA walker for highly selective miRNA detection - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Hydrogel-Based Biosensors for Effective Therapeutics - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. researchgate.net [researchgate.net]
- 14. Design, Bioanalytical, and Biomedical Applications of Aptamer-Based Hydrogels - PMC [pmc.ncbi.nlm.nih.gov]
- 15. dna.caltech.edu [dna.caltech.edu]
- 16. Dual Spatially Localized DNA Walker for Fast and Efficient RNA Detection - PubMed [pubmed.ncbi.nlm.nih.gov]
Application Notes and Protocols for Building Synthetic Gene Circuits for Metabolic Engineering
For Researchers, Scientists, and Drug Development Professionals
Introduction
Synthetic biology offers powerful tools to engineer cellular metabolism for the production of valuable chemicals, pharmaceuticals, and biofuels. At the heart of this discipline lies the construction of synthetic gene circuits, which are engineered regulatory networks designed to control gene expression in a predictable and programmable manner. These circuits enable precise and dynamic control over metabolic pathways, allowing researchers to optimize product yields, minimize toxic intermediates, and create robust microbial cell factories.[1][2][3][4]
This document provides detailed application notes and protocols for the design, assembly, and implementation of synthetic gene circuits in common microbial chassis such as Escherichia coli and Saccharomyces cerevisiae. It is intended for researchers, scientists, and drug development professionals who are looking to leverage synthetic biology for metabolic engineering applications.
Core Concepts in Synthetic Gene Circuit Design
A typical synthetic gene circuit consists of three main components: a sensor, a processor (or logic gate), and an actuator.[5]
-
Sensors: These components detect specific intracellular or extracellular signals, such as metabolites, metal ions, light, or temperature.[6] Biosensors are often based on transcription factors that change their activity in response to a specific molecule.[6]
-
Processors (Logic Gates): These elements process the input signals from the sensors and make a decision based on predefined rules.[7][8] They are analogous to electronic logic gates (e.g., AND, OR, NOT) and can be constructed using combinations of transcriptional activators and repressors.[9][10]
-
Actuators: These components execute the desired function based on the output from the processor. In metabolic engineering, actuators are typically enzymes or transporters that modulate the flux through a metabolic pathway.
The dynamic regulation of metabolic pathways is a key advantage of using synthetic gene circuits.[7][8][11] Unlike static engineering approaches that involve permanent gene knockouts or overexpression, dynamic control allows for the temporal regulation of gene expression, balancing the metabolic burden on the host cell with the production of the target compound.[2][4]
Experimental Workflows and Signaling Pathways
General Workflow for Building and Testing a Synthetic Gene Circuit
The construction and evaluation of a synthetic gene circuit for metabolic engineering generally follows a cyclical design-build-test-learn process.
Caption: A generalized workflow for the design, construction, testing, and optimization of synthetic gene circuits for metabolic engineering.
Example Signaling Pathway: A Metabolite-Responsive "ON" Switch
This diagram illustrates a simple genetic "ON" switch that activates the expression of a metabolic pathway in the presence of a specific metabolite.
Caption: A simple metabolite-responsive "ON" switch where a transcription factor activates a promoter upon binding to an inducer metabolite, leading to the expression of metabolic pathway genes.
Example Logic Gate: A CRISPRi-based NOT Gate for Dynamic Control
This diagram shows a CRISPR interference (CRISPRi) based NOT gate. An input signal (e.g., an inducer) triggers the expression of a single guide RNA (sgRNA), which then recruits a deactivated Cas9 (dCas9) protein to a target promoter, repressing the expression of a downstream gene.
Caption: A CRISPRi-based NOT gate where an inducer triggers sgRNA expression, leading to dCas9-mediated repression of an output gene.
Data Presentation: Quantitative Effects of Synthetic Gene Circuits
The following tables summarize quantitative data from studies that have successfully employed synthetic gene circuits to improve the production of various metabolites.
Table 1: Improvement of Isoprenoid Production in E. coli using CRISPRi-based Gene Repression
| Target Gene(s) Repressed | Host Strain | Pathway | Product | Titer (g/L) | Fold Increase | Reference |
| ldhA | E. coli DH1 | IPP-bypass | Isoprenol | 1.32 ± 0.31 | ~2.0 | [12] |
| adhE | E. coli DH1 | IPP-bypass | Isoprenol | 1.23 ± 0.23 | ~1.9 | [12] |
| fabH | E. coli DH1 | IPP-bypass | Isoprenol | 1.14 ± 0.17 | ~1.7 | [12] |
| yggV and accA | Engineered E. coli | Mevalonate | Isoprenol | 3.63 | - | [13] |
| - (Control) | E. coli DH1 | IPP-bypass | Isoprenol | ~0.66 | 1.0 | [12] |
Table 2: Dynamic Regulation of Fatty Acid Biosynthesis in E. coli
| Genetic Modification | Host Strain | Control Mechanism | Product | Titer (g/L) | Fold Increase | Reference |
| Overexpression of ACC pathway | E. coli BL21 | Static | Fatty Acids | ~0.68 | ~3.0 | [3] |
| Overexpression of FAS pathway | E. coli BL21 | Static | Fatty Acids | ~0.42 | ~1.8 | [3] |
| Controlled ACC and FAS pathways (n=1 fapO) | E. coli BL21 | Dynamic (FapR biosensor) | Fatty Acids | 3.86 | ~16.8 | [3] |
| Wild-type | E. coli BL21 | - | Fatty Acids | ~0.23 | 1.0 | [3] |
Table 3: Production of Isoprenoids in Engineered E. coli Strains
| Strain | Relevant Genotype/Plasmid | Product | Titer | Reference |
| Engineered E. coli BL21(DE3) | pTS-sPt-MVA and pS-NA | Isoprene (B109036) | 6.3 g/L | [1] |
| Engineered E. coli BL21 | Truncated ispS and ispG | Isoprene | 8.4 g/L | [1] |
| Engineered E. coli BL21 | ispS and archaeal mvk | Isoprene | 60 g/L | [1] |
Experimental Protocols
Protocol 1: Golden Gate Assembly of a Multi-Gene Construct
Golden Gate assembly is a powerful method for the seamless assembly of multiple DNA fragments in a single reaction.[5][7][14] It utilizes Type IIS restriction enzymes, which cleave outside of their recognition sequence, allowing for the creation of custom, non-palindromic overhangs.
Materials:
-
DNA fragments (e.g., promoters, coding sequences, terminators) flanked by BsaI or BsmBI recognition sites and unique 4 bp overhangs.
-
Destination vector with compatible BsaI/BsmBI sites.
-
T4 DNA Ligase and buffer.
-
BsaI or BsmBI restriction enzyme.
-
Nuclease-free water.
-
Chemically competent E. coli cells.
-
SOC medium.
-
LB agar (B569324) plates with appropriate antibiotic.
Procedure:
-
Design and Preparation of DNA Parts:
-
Design primers to amplify your DNA parts of interest (promoters, genes, terminators).
-
Incorporate BsaI restriction sites and unique 4 bp overhangs into the primers. The overhangs will direct the ordered assembly of the fragments.
-
Amplify the DNA parts using PCR and purify the products.
-
Quantify the concentration of each purified DNA fragment and the destination vector.
-
-
Assembly Reaction Setup:
-
In a sterile PCR tube, combine the following components on ice. It is recommended to use equimolar amounts of each insert and a 1:2 to 1:4 molar ratio of vector to total inserts.
-
Destination vector (e.g., 50-100 ng)
-
Each DNA insert (equimolar amounts)
-
1 µL T4 DNA Ligase Buffer (10X)
-
1 µL T4 DNA Ligase
-
Nuclease-free water to a final volume of 10-20 µL.
-
-
Mix gently by pipetting.
-
-
Thermocycling Program:
-
Incubate the reaction in a thermocycler using a program that cycles between the optimal temperatures for digestion and ligation. A typical program is:
-
30-60 cycles of:
-
37°C for 3-5 minutes (Digestion)
-
16°C for 4-5 minutes (Ligation)
-
-
Final digestion at 50-60°C for 5-10 minutes.
-
Heat inactivation at 80°C for 5-10 minutes.
-
-
-
Transformation into E. coli:
-
Thaw a 50 µL aliquot of chemically competent E. coli cells on ice.
-
Add 2-5 µL of the Golden Gate assembly reaction to the cells.
-
Incubate on ice for 30 minutes.
-
Heat shock at 42°C for 45 seconds.
-
Immediately return to ice for 2 minutes.
-
Add 250 µL of SOC medium and incubate at 37°C for 1 hour with shaking.
-
Plate 100 µL of the cell culture on an LB agar plate containing the appropriate antibiotic.
-
Incubate overnight at 37°C.
-
-
Verification of Assembly:
-
Pick several colonies and grow them overnight in liquid LB medium with the appropriate antibiotic.
-
Isolate the plasmid DNA using a miniprep kit.
-
Verify the correct assembly by restriction digest and/or Sanger sequencing.
-
Protocol 2: Construction of a CRISPRi-based Gene Circuit in S. cerevisiae
This protocol describes the construction of a CRISPRi system for repressing a target gene in yeast.[15]
Materials:
-
S. cerevisiae strain.
-
Plasmid expressing dCas9.
-
Plasmid for expressing the sgRNA, typically under the control of an inducible or constitutive promoter.
-
Lithium acetate/PEG transformation reagents.
-
Appropriate selective media.
Procedure:
-
sgRNA Design and Plasmid Construction:
-
Design a 20-nucleotide guide sequence that is complementary to the target sequence in the promoter region of the gene you wish to repress.
-
Clone this guide sequence into an sgRNA expression vector. This is often done using Golden Gate assembly or Gibson Assembly.
-
-
Yeast Transformation:
-
Prepare competent yeast cells using the lithium acetate/PEG method.
-
Co-transform the dCas9 expression plasmid and the sgRNA expression plasmid into the yeast cells.
-
Plate the transformed cells on selective media to isolate colonies that have taken up both plasmids.
-
-
Functional Characterization of the CRISPRi Circuit:
-
Grow the engineered yeast strain in liquid culture under both inducing and non-inducing conditions for the sgRNA expression.
-
Harvest the cells at different time points.
-
Quantify the repression of the target gene using RT-qPCR to measure mRNA levels or by assaying the activity of the protein product.
-
Protocol 3: Quantification of Metabolite Production
This protocol provides a general method for extracting and quantifying the production of a target metabolite from a microbial culture.
Materials:
-
Engineered microbial strain and appropriate culture medium.
-
Internal standard for quantification.
-
Extraction solvent (e.g., ethyl acetate, chloroform:methanol).
-
Gas chromatograph-mass spectrometer (GC-MS) or high-performance liquid chromatograph (HPLC).
Procedure:
-
Cultivation and Sampling:
-
Grow the engineered microbial strain in a suitable culture medium under conditions that induce the synthetic gene circuit.
-
At desired time points, collect culture samples.
-
-
Metabolite Extraction:
-
Separate the cells from the culture medium by centrifugation.
-
Extract the metabolite of interest from the cell pellet and/or the supernatant using an appropriate organic solvent. Add a known amount of an internal standard to the extraction solvent for accurate quantification.
-
-
Analysis by GC-MS or HPLC:
-
Analyze the extracted samples using GC-MS or HPLC.
-
Identify the peak corresponding to your target metabolite based on its retention time and mass spectrum (for GC-MS) or UV-Vis spectrum (for HPLC).
-
Quantify the amount of the metabolite by comparing its peak area to that of the internal standard and a standard curve generated with known concentrations of the pure compound.
-
-
Data Normalization:
-
Normalize the metabolite concentration to the cell density (e.g., optical density at 600 nm) to obtain the specific productivity.
-
Conclusion
The ability to design and construct synthetic gene circuits is a cornerstone of modern metabolic engineering. By providing precise and dynamic control over gene expression, these circuits enable the development of highly efficient and robust microbial cell factories for a wide range of applications. The protocols and data presented in this document offer a starting point for researchers to implement these powerful tools in their own work, paving the way for the next generation of bio-based products and therapies.
References
- 1. Engineered Escherichia coli strains as platforms for biological production of isoprene - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Protocols · Benchling [benchling.com]
- 3. Improving fatty acids production by engineering dynamic pathway regulation and metabolic control - PMC [pmc.ncbi.nlm.nih.gov]
- 4. mdpi.com [mdpi.com]
- 5. Golden Gate Assembly Protocol — NeoSynBio [neosynbio.com]
- 6. Advances in the dynamic control of metabolic pathways in Saccharomyces cerevisiae - PMC [pmc.ncbi.nlm.nih.gov]
- 7. coleman-lab.org [coleman-lab.org]
- 8. Multilayer Genetic Circuits for Dynamic Regulation of Metabolic Pathways - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. academic.oup.com [academic.oup.com]
- 10. From DNA-protein interactions to the genetic circuit design using CRISPR-dCas systems - PMC [pmc.ncbi.nlm.nih.gov]
- 11. neb.com [neb.com]
- 12. Enhancing isoprenol production by systematically tuning metabolic pathways using CRISPR interference in E. coli - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Improving isoprenol production via systematic CRISPRi screening in engineered Escherichia coli - Green Chemistry (RSC Publishing) [pubs.rsc.org]
- 14. neb.com [neb.com]
- 15. Synthetic Toolkit for Complex Genetic Circuit Engineering in Saccharomyces cerevisiae - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for DNA-Based Data Storage: Encoding and Decoding Strategies
Authored for: Researchers, Scientists, and Drug Development Professionals
Introduction
With the exponential growth of digital information, conventional storage technologies are approaching their physical limits in terms of capacity, energy consumption, and longevity. DNA, the molecule of life, has emerged as a revolutionary medium for digital data storage, offering unparalleled density, durability, and energy efficiency.[1][2][3] A single gram of DNA can theoretically store up to 215 petabytes (215 million gigabytes) of data, and when stored under proper conditions, it can preserve information for millennia.[4] This makes DNA an ideal candidate for long-term archival of vast datasets, including genomic data, clinical trial records, and extensive research libraries.
This document provides a detailed overview of the key strategies and protocols for encoding digital data into DNA and accurately decoding it back. It covers the entire workflow, from computational encoding and error correction to the wet-lab protocols for DNA synthesis, sequencing, and computational decoding.
The DNA Data Storage Workflow
The process of storing and retrieving data in DNA involves a series of distinct steps, bridging the digital and molecular worlds. The overall workflow begins with computationally encoding binary data into sequences of the four DNA bases (A, C, G, T), followed by the physical synthesis of these DNA molecules. After storage, specific data files can be retrieved, sequenced to read the base order, and finally, computationally decoded back into the original binary format.[1][5][6]
Caption: High-level workflow of the DNA-based digital data storage and retrieval process.
Encoding and Error Correction Strategies
Effective encoding is crucial for ensuring data integrity and maximizing storage density. The process must not only convert binary data into a DNA-compatible format but also incorporate mechanisms to prevent and correct errors that arise during synthesis and sequencing.[7][8]
Binary-to-Base Conversion
The fundamental step in encoding is mapping binary data (0s and 1s) to the four DNA bases (A, C, G, T). A simple scheme could map 00 to A, 01 to C, 10 to G, and 11 to T.[4] However, more sophisticated methods are used to avoid biochemical issues.
Biochemical Constraints: Encoding algorithms must account for the physical and chemical properties of DNA to ensure successful synthesis and sequencing.[9][10] Key constraints include:
-
Homopolymer Run Limit: Long repeats of the same base (e.g., 'AAAAA') are prone to errors during synthesis and sequencing.[10] Encoding schemes are designed to limit these runs.
-
GC Content: The percentage of Guanine (G) and Cytosine (C) bases should be balanced (around 50%) to ensure thermal stability and prevent issues during PCR and sequencing.[9][11]
-
Secondary Structures: Sequences that can fold back on themselves to form hairpins or other secondary structures can interfere with enzymatic processes like PCR.[11]
Error-Correcting Codes (ECC)
Errors in DNA data storage are inevitable and occur as substitutions (a base is replaced), insertions (a base is added), or deletions (a base is removed).[8] To combat this, logical redundancy is added to the data using Error-Correcting Codes (ECCs), a concept borrowed from communication and information theory.[7][12]
A common and robust strategy is to use a two-layered coding approach:
-
Inner Code: This code operates at the level of individual DNA sequences. It is designed to detect and correct substitution, insertion, and deletion errors that occur within a single DNA strand.[8]
-
Outer Code: This code operates across multiple DNA strands (oligonucleotides). Its primary function is to handle the complete loss of a DNA strand during storage or retrieval, treating the lost strand as an "erasure."[5][8] Reed-Solomon (RS) codes are frequently used for this purpose due to their high efficiency in correcting erasures.[12][13]
Caption: Structure of a typical DNA oligonucleotide for data storage.
Advanced Encoding Schemes
-
DNA Fountain: This approach is based on Luby Transform (LT) codes. The original data is broken into chunks, and a vast number of encoded "droplets" are generated through random XORing of these chunks. This scheme is highly efficient because it allows for perfect data recovery as long as a sufficient number of droplets (slightly more than the original number of chunks) are successfully read, regardless of which specific ones are lost.[7]
-
HEDGES Code: The Hash Encoded, Decoded by Greedy Exhaustive Search (HEDGES) code is an inner code designed specifically to correct insertion and deletion (indel) errors directly within a single strand, which simplifies the decoding process.[8]
Decoding Strategies
Decoding reverses the encoding process to faithfully retrieve the original digital file from the raw sequencing reads. This involves clustering reads, determining the correct sequence, correcting errors, and converting the base sequence back to binary.
The decoding workflow typically includes the following steps:
-
Clustering: Sequencing produces many noisy copies (reads) of each original DNA strand. The first step is to group or cluster all reads that originated from the same synthesized oligonucleotide.[14]
-
Consensus Generation: Within each cluster, the reads are aligned to generate a single consensus sequence. This process leverages the physical redundancy (multiple copies) to overcome random sequencing errors.[13]
-
Error Correction: The inner and outer ECCs are applied. The inner code corrects indel and substitution errors within the consensus sequence. The outer code then uses the address blocks to correctly order all the consensus sequences and recover any missing oligos (erasures).[8]
-
Base-to-Binary Conversion: The fully corrected and ordered DNA sequences are converted back into binary data, and the original file is reconstructed.
Caption: The computational workflow for decoding data from sequencing reads.
Quantitative Data Summary
The performance of a DNA data storage system can be evaluated by several key metrics. The table below summarizes typical quantitative data from various studies.
| Parameter | Value Range | Source Technology | Notes |
| Storage Density (Logical) | 2.2 - 215 PB/gram | Varies | Theoretical maximum is ~215 PB/g. Practical density is lower due to redundancy from ECCs.[4][15] |
| Information Density (Net) | 1.7 - 1.8 bits/nt | Various ECCs | Represents the actual data stored per nucleotide after accounting for all redundancy.[16] |
| Synthesis Error Rate | ~1% (Total) | Array-based Synthesis | Includes substitutions (~0.4%), deletions (~0.85%), and insertions (~0.05%).[7] Cheaper synthesis methods often have higher error rates.[17] |
| Sequencing Error Rate | 0.1% - 15% | Illumina, Nanopore | Illumina platforms generally have lower substitution error rates (~0.1-0.4%).[18] Nanopore sequencing has higher indel error rates (can be 10-15%) but offers long reads.[7][19] |
| Writing Throughput (Synthesis) | ~1 Mbps | Custom DNA Writer | This is an emerging capability; traditional methods are significantly slower.[20] |
| Reading Throughput (Sequencing) | Gigabases/day | Illumina NovaSeq | High-throughput sequencers can read massive amounts of DNA data in parallel. |
| Data Retrieval (Coverage) | 4.5x - 6.0x | Low Coverage Schemes | The number of times each unique oligo needs to be sequenced for error-free recovery. Efficient ECCs can significantly lower this requirement.[16] |
Experimental Protocols
Protocol 1: Computational Encoding of Digital Data
Objective: To convert a binary file into a set of DNA oligonucleotide sequences suitable for synthesis, incorporating addressing and error correction.
Materials:
-
Digital file to be encoded.
-
Python environment with libraries for bioinformatics (e.g., Biopython) and error correction (e.g., reedsolo).
-
Custom encoding script implementing a chosen strategy (e.g., Inner/Outer code).
Methodology:
-
File Segmentation: Read the binary file and divide it into smaller, equal-sized data chunks. The size depends on the desired payload per oligonucleotide.
-
Outer Code Application: For each data chunk, generate a unique address (index). Apply a Reed-Solomon outer code to the addresses across a block of chunks to create parity information.
-
Payload Encoding: a. For each data chunk, apply an inner error-correcting code to add redundancy for correcting base-level errors. b. Convert the combined data chunk (original data + inner code redundancy) into a DNA sequence using a mapping scheme that respects biochemical constraints (e.g., avoids homopolymers).
-
Oligonucleotide Assembly: Combine the encoded address, the encoded data payload, and universal primer sequences (for PCR amplification) into a final set of oligonucleotide sequences.
-
Constraint Verification: Screen all generated sequences to ensure they meet GC content and homopolymer constraints. Regenerate any sequences that fail.
-
Output: Generate a final file (e.g., FASTA format) containing all oligonucleotide sequences to be sent for synthesis.
Protocol 2: DNA Synthesis (Writing)
Objective: To physically synthesize the computationally designed DNA oligonucleotides.
Materials:
-
Oligonucleotide sequence file from Protocol 1.
-
Array-based DNA synthesizer.
-
Standard phosphoramidite (B1245037) chemistry reagents (A, C, G, T phosphoramidites, activators, etc.).
-
Cleavage and deprotection solutions.
-
DNA purification columns or beads.
Methodology:
-
Upload Sequences: Upload the design file to the DNA synthesizer's control software.
-
Synthesis: Initiate the synthesis process. The synthesizer uses photolithography or microfluidics to build each designed oligonucleotide base-by-base on a microarray.[17]
-
Cleavage and Deprotection: After synthesis, the oligonucleotides are chemically cleaved from the solid support (the array) and undergo deprotection to remove chemical protecting groups.
-
Pooling and Purification: All synthesized oligonucleotides are pooled into a single microtube. The pooled DNA is then purified to remove failed sequences and residual chemicals.
-
Quantification and QC: The final DNA pool is quantified (e.g., using a Qubit fluorometer) and quality-checked (e.g., via capillary electrophoresis) to confirm the length distribution of the synthesized oligos.
-
Storage: The purified DNA pool is desiccated or stored in a buffer solution at -20°C or colder for long-term preservation.
Protocol 3: Data Retrieval and Sequencing (Reading)
Objective: To selectively retrieve a specific file from the DNA pool and prepare it for next-generation sequencing.
Materials:
-
Stored DNA oligonucleotide pool.
-
PCR primers specific to the file of interest (matching the primer sequences designed in Protocol 1).
-
High-fidelity DNA polymerase and PCR master mix.
-
Thermal cycler.
-
DNA purification kit (e.g., PCR cleanup kit).
-
Next-Generation Sequencing (NGS) platform (e.g., Illumina MiSeq/NextSeq).
-
NGS library preparation kit.
Methodology:
-
PCR Amplification (Random Access): a. Set up a PCR reaction containing the pooled DNA library, the specific forward and reverse primers for the target file, and PCR master mix. b. Run the PCR in a thermal cycler for 20-25 cycles to selectively amplify only the oligonucleotides corresponding to the desired file.[21][22]
-
Purification: Purify the PCR product to remove primers and other reaction components.
-
Library Preparation: Prepare a sequencing library from the purified PCR product according to the manufacturer's protocol for the chosen NGS platform. This typically involves end-repair, A-tailing, and ligation of sequencing adapters.
-
Sequencing: Load the prepared library onto the NGS instrument and perform sequencing. The output will be a set of files (e.g., FASTQ format) containing the raw sequence reads.[23]
Protocol 4: Computational Decoding of Sequencing Data
Objective: To reconstruct the original digital file from the raw sequencing reads.
Materials:
-
Raw sequencing data (FASTQ files) from Protocol 3.
-
High-performance computing environment.
-
Custom decoding script that is the inverse of the encoding script from Protocol 1.
-
Bioinformatics tools for sequence clustering and alignment (e.g., STAR, CD-HIT).
Methodology:
-
Data Pre-processing: Filter the raw FASTQ reads to remove low-quality reads and trim adapter sequences.
-
Clustering: Cluster the reads based on sequence similarity. Each resulting cluster should represent the multiple copies of a single original oligonucleotide.
-
Consensus Generation: For each cluster, perform a multiple sequence alignment and generate a consensus sequence. This step corrects the majority of random sequencing errors.
-
Decoding and Error Correction: a. For each consensus sequence, identify the address block and the data payload. b. Apply the inner code's decoding algorithm to the data payload to correct any remaining substitution or indel errors. c. Collect the corrected address blocks and data payloads from all consensus sequences. d. Use the address information to place the data payloads in the correct order. e. Apply the outer code's (e.g., Reed-Solomon) decoding algorithm to identify and reconstruct any missing data chunks (oligos) using the parity information.
-
File Reconstruction: Convert the fully corrected and ordered DNA sequences back to binary and concatenate the data chunks to reconstruct the original digital file.
-
Verification: Compare the reconstructed file with the original file using a checksum (e.g., MD5 hash) to verify error-free recovery.
References
- 1. Recent progress in DNA data storage based on high-throughput DNA synthesis - PMC [pmc.ncbi.nlm.nih.gov]
- 2. ijpsjournal.com [ijpsjournal.com]
- 3. DNA Data Storage - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Using DNA for Data Storage - LubioScience [lubio.ch]
- 5. Emerging Approaches to DNA Data Storage: Challenges and Prospects - PMC [pmc.ncbi.nlm.nih.gov]
- 6. gwern.net [gwern.net]
- 7. shubhamchandak94.github.io [shubhamchandak94.github.io]
- 8. pnas.org [pnas.org]
- 9. Construction of Bio-Constrained Code for DNA Data Storage | IEEE Journals & Magazine | IEEE Xplore [ieeexplore.ieee.org]
- 10. ieeexplore.ieee.org [ieeexplore.ieee.org]
- 11. arxiv.org [arxiv.org]
- 12. mdpi.com [mdpi.com]
- 13. academic.oup.com [academic.oup.com]
- 14. par.nsf.gov [par.nsf.gov]
- 15. New Trends of Digital Data Storage in DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 16. High Information Density and Low Coverage Data Storage in DNA with Efficient Channel Coding Schemes [arxiv.org]
- 17. Challenges for error-correction coding in DNA data storage: photolithographic synthesis and DNA decay - Digital Discovery (RSC Publishing) [pubs.rsc.org]
- 18. A Characterization of the DNA Data Storage Channel - PMC [pmc.ncbi.nlm.nih.gov]
- 19. researchgate.net [researchgate.net]
- 20. DNA digital data storage - Wikipedia [en.wikipedia.org]
- 21. researchgate.net [researchgate.net]
- 22. High-throughput DNA synthesis for data storage - Chemical Society Reviews (RSC Publishing) DOI:10.1039/D3CS00469D [pubs.rsc.org]
- 23. researchgate.net [researchgate.net]
In Vitro Selection of Functional DNA Molecules: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
I. Application Notes
Introduction to In Vitro Selection
In vitro selection, also known as Systematic Evolution of Ligands by Exponential Enrichment (SELEX), is a powerful combinatorial chemistry technique used to isolate specific single-stranded DNA or RNA molecules (aptamers) or catalytic nucleic acids (DNAzymes or ribozymes) from a vast, random library. This process mimics natural evolution on a molecular level, allowing for the discovery of nucleic acids that can bind to a wide array of targets—from small molecules and proteins to whole cells—with high affinity and specificity. These functional nucleic acids are becoming increasingly important as therapeutic agents, diagnostic tools, and biosensors.
Core Technology: SELEX
The SELEX process is an iterative cycle involving three key steps: binding, partitioning, and amplification. A synthetic DNA library, which can contain upwards of 10¹⁵ unique sequences, is exposed to the target molecule. Sequences that bind to the target are separated from non-binding sequences. These selected sequences are then eluted and amplified, typically by Polymerase Chain Reaction (PCR), to create an enriched pool for the next round. By progressively increasing the selection stringency (e.g., by lowering the target concentration or increasing wash steps), sequences with the highest affinity and specificity are preferentially enriched over 8 to 20 cycles.
Key Applications of Functional DNA
-
DNA Aptamers in Diagnostics and Therapeutics: Aptamers are structured oligonucleotides that can bind to targets with affinities and specificities comparable to monoclonal antibodies. Their advantages include chemical stability, ease of synthesis and modification, and low immunogenicity. These properties make them excellent candidates for:
-
Diagnostic Assays: Aptamers are used as recognition elements in biosensors (aptasensors) for detecting biomarkers, pathogens, and small molecule contaminants.
-
Targeted Drug Delivery: Aptamers can be conjugated to nanoparticles or drugs to specifically deliver therapeutic payloads to diseased cells, such as cancer cells.
-
Therapeutics: Aptamers can act as antagonists by binding to and inhibiting the function of disease-related proteins. The first aptamer-based drug, Macugen®, targets vascular endothelial growth factor (VEGF) to treat macular degeneration.
-
-
DNAzymes (Deoxyribozymes) as Catalysts: DNAzymes are DNA molecules with catalytic activity. They are often selected to perform specific chemical reactions, with RNA-cleaving DNAzymes being one of the most studied classes. Their applications include:
-
Biosensing: DNAzymes can be designed to catalyze a signal-producing reaction (e.g., fluorescence generation) only in the presence of a specific cofactor, such as a metal ion or a small molecule, making them highly specific sensors.
-
Gene Silencing: RNA-cleaving DNAzymes can be engineered to specifically target and degrade messenger RNA (mRNA), thereby inhibiting the expression of a particular gene.
-
Advanced SELEX Methodologies
-
Cell-SELEX: This method uses whole living cells as the target to generate aptamers against cell-surface proteins in their native conformation. This is particularly valuable for identifying biomarkers for diseases like cancer without prior knowledge of the specific molecular targets. The process includes a negative selection step, where the DNA library is exposed to control cells to remove non-specific binders, thereby enriching for aptamers that are specific to the target cell type.
-
Capture-SELEX: This technique is optimized for selecting aptamers against small molecules, which can be challenging to immobilize. In Capture-SELEX, the DNA library is immobilized, and the small molecule target is introduced in the mobile phase. Aptamers that change their conformation upon binding to the target are eluted and amplified.
II. Data Presentation
Monitoring the enrichment of high-affinity sequences is crucial for a successful SELEX experiment. This is often tracked by measuring the binding affinity of the enriched pool after each round or by quantifying the amount of DNA that binds to the target.
Table 1: Example of Progressive Enrichment During a Typical SELEX Experiment
| SELEX Round | Target Concentration | % DNA Bound to Target | Enriched Pool Dissociation Constant (Kd) |
| 1 | 500 nM | 0.5% | > 1 µM |
| 3 | 250 nM | 2.5% | ~800 nM |
| 6 | 100 nM | 15% | ~350 nM |
| 9 | 50 nM | 40% | ~150 nM |
| 12 | 25 nM | 65% | ~50 nM |
This table presents hypothetical but representative data illustrating the typical progression of a SELEX experiment, where the percentage of bound DNA increases and the overall pool affinity improves with each round.
Table 2: Comparison of Binding Affinities (Kd) for Selected DNA Aptamers
| Aptamer Name | Target Molecule | Selection Method | Measurement Technique | Dissociation Constant (Kd) | Reference |
| AptHlyE97 | Salmonella Typhi HlyE | SELEX | ELONA | 83.6 nM | |
| V-Apt1 (DD) | VEGF₁₆₅ | ExSELEX | Biacore | < 1 pM | |
| I-Apt1 (DD) | IFNγ | ExSELEX | Biacore | 0.2 nM | |
| F27 | Furanyl Fentanyl | SELEX | ITC | 4 nM | |
| 5TR1 | MUC1 Glycopeptide | SELEX | Not Specified | 11 nM | |
| SPX7 | Spirolide G (SPXG) | SELEX | SPR | 0.0345 nM |
This table summarizes experimentally determined dissociation constants for various DNA aptamers, showcasing the range of affinities that can be achieved through in vitro selection.
III. Experimental Protocols & Visualizations
Protocol 1: Standard SELEX for DNA Aptamer Selection Against a Protein Target
This protocol outlines the fundamental steps for isolating DNA aptamers that bind to a purified protein target.
Workflow Diagram: The SELEX Cycle
Caption: Workflow of the Systematic Evolution of Ligands by Exponential Enrichment (SELEX).
Materials:
-
ssDNA Library: A synthetic oligonucleotide library with a central random region (e.g., 40 nucleotides) flanked by constant primer binding sites.
-
Target Protein: Highly purified protein of interest.
-
Binding Buffer: Buffer that maintains the target protein's native conformation (e.g., PBS with 5 mM MgCl₂).
-
Wash Buffer: Binding buffer, sometimes with slightly increased salt or detergent concentration.
-
Elution Buffer: e.g., High temperature (95°C) water, or a high pH buffer.
-
PCR Reagents: Taq polymerase, dNTPs, forward primer, and a biotinylated reverse primer.
-
Streptavidin-coated Magnetic Beads: For separating the biotinylated antisense strand.
-
Partitioning Matrix: Nitrocellulose membrane or magnetic beads coated with the target protein.
Methodology:
-
Library Preparation: Heat the ssDNA library to 95°C for 5 minutes and then cool on ice for 10 minutes to denature and then properly fold the DNA molecules.
-
Binding: Incubate the folded ssDNA library with the immobilized target protein in binding buffer for 30-60 minutes at room temperature.
-
Partitioning: Wash the matrix several times with wash buffer to remove unbound and weakly bound sequences.
-
Elution: Elute the tightly bound DNA sequences by heating the matrix to 95°C in elution buffer for 5 minutes.
-
PCR Amplification: Amplify the eluted ssDNA using PCR with the forward and biotinylated reverse primers. Optimize the number of PCR cycles to avoid over-amplification.
-
ssDNA Generation: Incubate the PCR product with streptavidin-coated magnetic beads to capture the biotinylated antisense strand. Elute the non-biotinylated sense strand (the new enriched ssDNA pool) using a mild alkaline solution (e.g., 0.1 M NaOH) and neutralize immediately.
-
Iterate: Use the enriched ssDNA pool as the input for the next round of selection (repeat steps 1-6). Gradually increase the selection stringency in subsequent rounds (e.g., decrease target concentration, increase wash steps).
-
Sequencing and Characterization: After 8-15 rounds, clone and sequence the final enriched pool to identify individual aptamer candidates. Synthesize promising candidates and characterize their binding affinity and specificity.
Protocol 2: Cell-SELEX for Aptamer Selection Against Cancer Cells
This protocol adapts the SELEX method to identify aptamers that bind to surface markers on a specific cell type.
Workflow Diagram: The Cell-SELEX Process
Caption: Workflow for generating cell-specific aptamers using Cell-SELEX.
Materials:
-
Target Cells: A cancer cell line of interest (e.g., CCRF-CEM, a human T-cell leukemia line).
-
Control Cells: A non-target cell line (e.g., Ramos, a B-cell line) for negative selection.
-
Cell Culture Medium and Reagents.
-
Buffers: Wash Buffer (e.g., PBS with MgCl₂), Binding Buffer.
-
All other reagents from Protocol 1 (ssDNA library, PCR reagents, etc.).
Methodology:
-
Library Preparation: Prepare the ssDNA library as described in Protocol 1.
-
Negative Selection: Incubate the ssDNA library with the control cells at 4°C to minimize internalization. Centrifuge the cell suspension and collect the supernatant, which contains sequences that did not bind to the control cells.
-
Positive Selection: Incubate the supernatant from the previous step with the target cancer cells at 4°C.
-
Partitioning: Wash the target cells several times with cold wash buffer to remove unbound sequences.
-
Elution: Resuspend the cells in an elution buffer and heat at 95°C for 5-10 minutes to release the bound DNA. Centrifuge to pellet the cell debris and collect the supernatant containing the eluted DNA.
-
Amplification and ssDNA Generation: Perform PCR and ssDNA generation as described in Protocol 1.
-
Iterate: Repeat the cycle, typically for 10-20 rounds, increasing stringency by reducing incubation times or increasing the number of washes.
-
Post-SELEX Analysis: Sequence the final pool and characterize individual aptamers for specific binding to the target cells, often using flow cytometry.
Protocol 3: Characterization of Aptamer Binding Affinity via Enzyme-Linked Oligonucleotide Assay (ELONA)
This protocol describes a method to quantify the binding affinity (Kd) of a selected aptamer to its protein target.
Application Notes & Protocols: Creating Dynamic Molecular Systems with DNA
For Researchers, Scientists, and Drug Development Professionals
The field of DNA nanotechnology has progressed from creating static structures to engineering complex, dynamic molecular systems capable of sensing, computation, and actuation.[1][2] The inherent programmability and predictable Watson-Crick base pairing of DNA make it an exceptional material for building nanoscale devices.[1][3][4] These systems are at the forefront of innovation in biosensing, targeted drug delivery, and molecular robotics.
This document provides an overview of the core technologies, key applications, and detailed protocols for designing and assembling dynamic DNA molecular systems.
Core Technologies and Mechanisms
Dynamic DNA systems are typically built upon a foundation of structural DNA nanotechnology, such as DNA origami or DNA tiles, and are actuated by mechanisms like strand displacement or environmental stimuli.[5]
DNA Strand Displacement (DSD)
Toehold-mediated strand displacement is a fundamental mechanism for programming dynamic behavior.[1] An incumbent strand in a DNA duplex is replaced by an invading strand. This process is initiated at a short, single-stranded "toehold" domain, which provides an initial binding site for the invading strand, dramatically accelerating the reaction.[6][7] The rate of displacement can be precisely controlled by modulating the length and sequence of the toehold.[6]
Table 1: Quantitative Impact of Toehold Length on DSD Rate
| Toehold Length (nucleotides) | Second-Order Rate Constant (M⁻¹s⁻¹) | Fold Increase (Approx.) |
|---|---|---|
| 0 | ~10⁰ - 10¹ | - |
| 3 | ~10³ | 100x |
| 5 | ~10⁵ | 10,000x |
| 7 | ~10⁶ - 10⁷ | 1,000,000x |
Note: Rates are approximate and sequence-dependent. Data synthesized from principles described in literature.[6]
DNA Origami
The DNA origami technique enables the self-assembly of complex 2D and 3D nanostructures by folding a long, single-stranded "scaffold" DNA (often from a viral genome) into a desired shape using hundreds of short "staple" strands.[8][9][10] These structures provide robust platforms for organizing dynamic components with nanoscale precision.[11]
Stimuli-Responsive Mechanisms
Dynamic behavior is triggered by integrating elements that respond to specific environmental cues.[5][12]
-
pH-Responsive: Cytosine-rich sequences (i-motifs) and triplex-forming oligonucleotides can induce conformational changes in acidic environments, common in tumor microenvironments or endosomes.[13][14][15]
-
Ion-Responsive: Guanine-rich sequences can form G-quadruplex structures in the presence of specific metal ions (e.g., K⁺), creating a molecular switch.[5][13]
-
Light-Responsive: Incorporating photosensitive molecules like azobenzene (B91143) into DNA strands allows for reversible conformational changes using UV/visible light.[12][16]
-
Small Molecule/Protein Responsive: DNA aptamers, which are short sequences that bind to specific targets (e.g., ATP, thrombin), can be used to trigger structural changes upon target recognition.[5][15]
Application Notes: Systems and Protocols
Application: Molecular Logic Gates for Biosensing
DNA strand displacement cascades can be engineered to perform Boolean logic operations (AND, OR, NOT), enabling the creation of "smart" diagnostic devices that can process multiple biological inputs.[17][18] For example, an AND gate can be designed to produce a fluorescent output only when two different miRNA biomarkers are present simultaneously.[19]
Protocol 1: Assembly and Testing of a Fluorescence-Based DNA AND Gate
This protocol describes the general steps to verify an AND gate where two input oligonucleotides trigger the release of a fluorophore-labeled reporter strand from a quencher-labeled strand.
-
Component Preparation:
-
Resuspend all DNA oligonucleotides (Input A, Input B, Gate Complexes, Reporter Complex) in a Tris-based buffer (e.g., 1x TE buffer with 12.5 mM MgCl₂).
-
Determine the concentration of each strand using UV-Vis spectrophotometry at 260 nm.[20]
-
Anneal the gate and reporter complexes by mixing stoichiometric amounts of the constituent strands, heating to 95°C for 5 minutes, and slowly cooling to room temperature over 2 hours.
-
-
Logic Gate Reaction:
-
In a microplate well, combine the annealed Gate A, Gate B, and Reporter complexes to a final concentration of 100 nM each in the reaction buffer.
-
Prepare four reaction conditions:
-
No Input (Buffer only)
-
Input A only (e.g., 150 nM)
-
Input B only (e.g., 150 nM)
-
Input A + Input B (e.g., 150 nM each)
-
-
Initiate the reactions by adding the inputs.
-
-
Data Acquisition:
-
Monitor the fluorescence intensity (e.g., using the appropriate excitation/emission wavelengths for your fluorophore, such as FAM) over time at a constant temperature (e.g., 25°C).
-
Record data every 5 minutes for at least 2 hours or until the reaction plateaus.
-
-
Analysis:
-
Plot fluorescence intensity versus time for all four conditions.
-
Calculate the signal-to-background ratio by dividing the final fluorescence of the (Input A + Input B) condition by the final fluorescence of the "No Input" condition. A successful AND gate will show a significant fluorescence increase only in the presence of both inputs.[19]
-
Table 2: Representative Performance of DNA Logic Gates
| Logic Gate Type | Inputs | Expected Output | Typical Signal-to-Background Ratio |
|---|---|---|---|
| YES | Input A Present | HIGH | 10 - 20 |
| AND | Input A & Input B | HIGH | 8 - 15 |
| AND | Input A only | LOW | ~1.2 |
| AND | Input B only | LOW | ~1.1 |
| OR | Input A or Input B | HIGH | 9 - 18 |
Note: Ratios are illustrative and depend on sequence design, purity, and experimental conditions.
Application: Stimuli-Responsive Drug Delivery
DNA nanostructures can act as "smart" carriers that encapsulate therapeutic agents and release them in response to specific triggers found in diseased environments.[12] A common strategy is a DNA origami "box" with a lid that opens in the acidic conditions of a tumor, releasing a chemotherapeutic drug like Doxorubicin (DOX).[13][14]
Protocol 2: Loading and pH-Triggered Release of Doxorubicin (DOX) from a DNA Nanostructure
-
Nanostructure Assembly:
-
Assemble the pH-sensitive DNA nanostructure via thermal annealing as described in the general protocol below (Protocol 3). The design should include C-rich sequences (for i-motif formation) as locking mechanisms.
-
-
Drug Loading:
-
Prepare a solution of the assembled DNA nanostructures (e.g., 50 nM) in a buffer at neutral pH (7.4).
-
Add Doxorubicin (DOX) to the solution at a molar ratio of ~100:1 (DOX:nanostructure) or as optimized. DOX will intercalate into the DNA duplexes.
-
Incubate the mixture for 4-6 hours at room temperature, protected from light.
-
Remove unloaded DOX using a purification method such as spin filtration until the filtrate is clear.
-
-
Release Study:
-
Divide the DOX-loaded nanostructure solution into two batches. Adjust the buffer of one batch to pH 7.4 (control) and the other to pH 6.0 (acidic trigger).
-
Incubate both samples at 37°C.
-
At various time points (e.g., 0, 1, 2, 4, 8, 12 hours), take aliquots from each sample.
-
Measure the fluorescence of DOX. The fluorescence of DOX is quenched when intercalated and increases upon release. An increase in fluorescence in the pH 6.0 sample relative to the pH 7.4 sample indicates triggered release.
-
-
Quantification:
-
Create a standard curve of free DOX fluorescence at known concentrations.
-
Use the standard curve to quantify the concentration of released DOX at each time point and plot the cumulative release percentage.
-
Table 3: Example Data for pH-Triggered DOX Release
| Time (hours) | Cumulative Release at pH 7.4 (%) | Cumulative Release at pH 6.0 (%) |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 5.2 | 25.1 |
| 4 | 9.8 | 55.6 |
| 8 | 14.5 | 78.3 |
| 12 | 18.1 | 85.4 |
Note: Data is representative and illustrates the differential release profile.
General Experimental Protocols
Protocol 3: Self-Assembly of DNA Nanostructures via Thermal Annealing
This is a fundamental protocol for the self-assembly of most DNA-based structures, including origami and logic gate components.[8][20]
-
Mixing Components:
-
In a PCR tube, mix the long scaffold strand (for origami) to a final concentration of 10-20 nM.
-
Add the short staple strands (or component strands for other structures) to a final concentration of 100-200 nM each (typically a 10-fold excess relative to the scaffold).
-
Add annealing buffer (e.g., 1x TE buffer containing 10-20 mM MgCl₂) to the final volume. The final volume is typically 50-100 µL.
-
Gently vortex and spin down the mixture.
-
-
Annealing Ramp:
-
Place the PCR tube in a thermocycler.
-
Run the following program:
-
Heat to 95°C and hold for 5 minutes (to denature all strands).
-
Slowly cool from 95°C to 20°C over a period of 12 to 48 hours. A slower ramp generally yields better-formed structures. A typical ramp is -1°C every 5 minutes.
-
Hold at 4°C for storage.
-
-
-
Storage:
-
Assembled nanostructures can be stored at 4°C for several weeks. For long-term storage, -20°C is recommended, but avoid repeated freeze-thaw cycles.
-
Protocol 4: Structural Verification by Agarose (B213101) Gel Electrophoresis
Gel electrophoresis separates molecules by size and shape, confirming the successful formation of a large nanostructure from its smaller components.[20]
-
Gel Preparation:
-
Prepare a 1.5-2.0% agarose gel in 1x TBE or TAE buffer.
-
Crucially, add MgCl₂ to the gel and the running buffer to a final concentration of 10-12.5 mM to maintain the stability of the DNA structure.
-
Allow the gel to fully solidify.
-
-
Sample Preparation:
-
In a separate tube, mix ~10 µL of your annealed DNA nanostructure solution with 2 µL of 6x loading dye. Do not heat the sample.
-
Prepare a lane with only the scaffold strand and another with only the staple strands as controls.
-
-
Electrophoresis:
-
Load the samples into the wells of the gel.
-
Run the gel at a low voltage (e.g., 70-80 V) in a cold room or an ice bath to prevent the structure from melting due to heat.
-
Run the gel until the dye front has migrated approximately 75% of the way down the gel.
-
-
Imaging:
-
Stain the gel with an intercalating dye (e.g., SYBR Safe or Ethidium Bromide) for 30 minutes.
-
Image the gel using a UV transilluminator. A successfully formed nanostructure will appear as a sharp, slow-migrating band, clearly distinct from the fast-migrating smear of excess staple strands and the scaffold strand.
-
Protocol 5: Structural Verification by Atomic Force Microscopy (AFM)
AFM provides direct visualization of the nanostructures, confirming their shape and integrity.[10][20]
-
Sample Preparation:
-
Cleave a fresh mica surface by peeling off the top layer with tape.
-
Immediately deposit 5-10 µL of your assembled nanostructure solution (diluted to 1-2 nM in annealing buffer) onto the mica surface.
-
Allow the sample to adsorb for 2-5 minutes.
-
-
Washing and Drying:
-
Gently rinse the mica surface with a drop of ultrapure water to remove excess salts and unbound staples.
-
Wick away the water with filter paper without touching the surface.
-
Allow the mica to air dry completely.
-
-
Imaging:
-
Mount the mica puck in the AFM.
-
Engage the AFM tip with the surface.
-
Image the surface using tapping mode (or contact mode) in air. Adjust imaging parameters (scan size, scan rate, gains) to obtain a high-resolution image.
-
-
Analysis:
-
Analyze the AFM images to confirm that a high yield of correctly folded structures is present. Measure the dimensions of the structures to ensure they match the design.
-
References
- 1. Dynamic DNA nanotechnology using strand-displacement reactions - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Dynamic DNA nanotechnology: toward functional nanoscale devices - Nanoscale Horizons (RSC Publishing) [pubs.rsc.org]
- 3. DNA-Based Molecular Machines: Controlling Mechanisms and Biosensing Applications - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. DNA-Based Molecular Machines - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Dynamic DNA Structures - PMC [pmc.ncbi.nlm.nih.gov]
- 6. dna.caltech.edu [dna.caltech.edu]
- 7. Design of DNA Strand Displacement Reactions [arxiv.org]
- 8. dna.caltech.edu [dna.caltech.edu]
- 9. DNA origami - Wikipedia [en.wikipedia.org]
- 10. Design, Assembly, and Verification of a 2D DNA Origami Nanostructure : 9 Steps (with Pictures) - Instructables [instructables.com]
- 11. DNA origami devices for molecular-scale precision measurements | MRS Bulletin | Cambridge Core [cambridge.org]
- 12. Recent Advances in Dynamic DNA Nanodevice | MDPI [mdpi.com]
- 13. Advances and prospects of dynamic DNA nanostructures in biomedical applications - RSC Advances (RSC Publishing) DOI:10.1039/D2RA05006D [pubs.rsc.org]
- 14. Construction of Dynamic DNA Structures for Drug Delivery [escholarship.org]
- 15. Prospects and challenges of dynamic DNA nanostructures in biomedical applications - PMC [pmc.ncbi.nlm.nih.gov]
- 16. mdpi.com [mdpi.com]
- 17. Molecular logic gate operations using one-dimensional DNA nanotechnology - Journal of Materials Chemistry C (RSC Publishing) [pubs.rsc.org]
- 18. fiveable.me [fiveable.me]
- 19. pubs.acs.org [pubs.acs.org]
- 20. Protocols for self-assembly and imaging of DNA nanostructures - PubMed [pubmed.ncbi.nlm.nih.gov]
Application Notes and Protocols for DNA Walker Design and Synthesis
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive overview and detailed protocols for the design, synthesis, and characterization of DNA walkers. DNA walkers are nanoscale machines capable of autonomous movement along a predefined track, with significant potential in targeted drug delivery, molecular diagnostics, and nanorobotics.[1][2]
Introduction to DNA Walkers
DNA walkers are synthetic molecular motors constructed from DNA that can "walk" along a track, also typically made of DNA.[1] This movement is powered by various mechanisms, including strand displacement reactions and enzymatic cleavage of the DNA track.[2][3] The programmable nature of DNA base pairing allows for the precise design and control of these walkers, enabling them to perform complex tasks such as cargo transport and delivery at the nanoscale.[4]
There are several designs of DNA walkers, primarily categorized by their number of "legs," such as unipedal, bipedal, and multipedal walkers. Bipedal walkers, for instance, can move with a hand-over-hand motion, which can offer improved processivity compared to their unipedal counterparts.[1][5] The track for the walker is often a DNA origami structure, which provides a stable and addressable platform for the walker's movement.[6][7]
Design Principles of DNA Walkers
The design of a DNA walker system involves two main components: the walker and the track. The interaction between these components dictates the walker's movement, speed, and processivity.
2.1. The Walker:
-
Legs: The walker's legs are single-stranded DNA sequences that bind to complementary strands on the track. The sequence and length of the legs are critical for stable binding and efficient detachment.
-
Body: The body of the walker provides a scaffold for the legs and any cargo that needs to be transported. For multipedal walkers, the body ensures the coordinated movement of the legs.
-
Propulsion Mechanism: The choice of propulsion mechanism is a key design consideration. Common mechanisms include:
-
Toehold-mediated strand displacement: A "fuel" strand binds to a short, single-stranded "toehold" on the walker-track complex, initiating a branch migration process that displaces the walker's leg, allowing it to move to the next binding site.[1][5]
-
Enzymatic cleavage: Enzymes such as DNAzymes or restriction enzymes are used to cleave the track at the walker's current position, destabilizing the binding and promoting forward movement. This is often referred to as a "burnt-bridge" mechanism.[3]
-
2.2. The Track:
-
DNA Origami: DNA origami is a powerful technique for creating nanoscale shapes and patterns.[4][8][9] A long, single-stranded DNA scaffold (often from a viral genome) is folded into a desired shape by hundreds of short "staple" strands.[4][9] This method allows for the precise positioning of binding sites for the DNA walker.
-
Stator Strands: These are the complementary DNA sequences on the track to which the walker's legs bind. The arrangement and spacing of these stator strands define the path of the walker.
Quantitative Performance of DNA Walkers
The performance of DNA walkers can be characterized by several key metrics. The choice of design and propulsion mechanism significantly impacts these parameters.
| Walker Type | Propulsion Mechanism | Speed | Processivity/Distance | Cargo | Reference |
| Bipedal DNA Walker | Strand Displacement | - | 64 nm | - | [1] |
| DNAzyme-based Walker | Enzymatic Cleavage (DNAzyme) | ~1 nm/s | ~5 µm | - | [3] |
| Quadruped DNA Walker | Enzymatic Cleavage (Nicking Enzyme) | Reaction time down to 20 min for detection | - | Ferrocene (Fc) | [10] |
| Gold Nanoparticle-based Multipedal Walker | Nicking Endonuclease-catalyzed Cleavage | Faster than single-pedal walkers | - | - | [11] |
| Dual Spatially Localized Bipedal Walker | Catalytic Hairpin Assembly | Accelerated reaction kinetics | - | - | [12] |
Experimental Protocols
This section provides detailed protocols for the synthesis and assembly of a DNA walker system based on a DNA origami track and a strand-displacement mechanism.
4.1. Protocol 1: Purification of Synthetic Oligonucleotides
High-purity oligonucleotides are essential for the successful assembly of DNA nanostructures. Commercially synthesized DNA often contains truncated sequences and other impurities that must be removed. Reversed-phase high-performance liquid chromatography (RP-HPLC) is a common and effective purification method.
Materials:
-
Crude synthetic DNA oligonucleotides (walker strands, staple strands, stator strands)
-
Triethylammonium acetate (B1210297) (TEAA) buffer
-
Acetonitrile (ACN)
-
RP-HPLC system with a C18 column
-
Lyophilizer
Procedure:
-
Resuspend the crude DNA pellets in nuclease-free water.
-
Set up the RP-HPLC system with a gradient of ACN in TEAA buffer. A typical gradient runs from a low to a high concentration of ACN to elute the DNA based on its hydrophobicity (the full-length product with the dimethoxytrityl group on will be more hydrophobic).
-
Inject the DNA sample onto the column.
-
Collect the fractions corresponding to the major peak, which represents the full-length oligonucleotide.
-
Lyophilize the collected fractions to remove the solvent.
-
Resuspend the purified DNA in nuclease-free water and quantify its concentration using a spectrophotometer.
4.2. Protocol 2: Self-Assembly of the DNA Origami Track
This protocol describes the one-pot self-assembly of a rectangular DNA origami track.
Materials:
-
M13mp18 single-stranded DNA scaffold
-
Purified staple strands and stator strands
-
Folding buffer (e.g., TE buffer with MgCl₂)
-
Thermal cycler or water bath
Procedure:
-
In a PCR tube, mix the M13mp18 scaffold DNA (final concentration ~10 nM) with a 10-fold molar excess of each staple and stator strand in the folding buffer.[7] The final concentration of MgCl₂ is typically between 10-20 mM.
-
Perform a thermal annealing ramp to fold the origami. A typical ramp involves:
-
Heating to 90-95°C for 5 minutes to denature all DNA strands.
-
Slowly cooling from 90°C to 65°C over 1-2 hours.
-
Slowly cooling from 65°C to 25°C over 12-16 hours.
-
Holding at 4°C.
-
-
The assembled DNA origami can be purified from excess staple strands using methods like agarose (B213101) gel electrophoresis or size exclusion chromatography.
4.3. Protocol 3: DNA Walker Assembly and Operation
This protocol describes the assembly of the DNA walker on the origami track and its operation using fuel strands.
Materials:
-
Purified DNA origami tracks
-
Purified DNA walker strands
-
Purified fuel and anti-fuel strands
-
Reaction buffer (similar to the origami folding buffer, but may require optimization)
Procedure:
-
Walker-Track Assembly:
-
Incubate the assembled DNA origami tracks with a stoichiometric amount of the DNA walker strands in the reaction buffer.
-
The incubation time and temperature will depend on the specific design of the walker and track, but a typical incubation is for 1-2 hours at room temperature.
-
-
Walker Operation:
-
Initiate the walking process by adding the first set of fuel strands to the reaction mixture. The concentration of fuel strands should be in molar excess to the walker-track complexes.
-
To stop or reverse the walker, add the corresponding anti-fuel strands, which will bind to and inactivate the fuel strands through strand displacement.
-
-
Characterization:
-
The assembly and movement of the DNA walker can be characterized using various techniques, including:
-
Atomic Force Microscopy (AFM): To visualize the DNA origami tracks and the position of the walker.[6]
-
Fluorescence Resonance Energy Transfer (FRET): By labeling the walker and track with a FRET pair of fluorophores, the movement of the walker can be monitored in real-time by changes in fluorescence.[11]
-
Gel Electrophoresis: To confirm the formation of the walker-track complex and to analyze the products of enzymatic cleavage if applicable.
-
-
Visualizations
5.1. Signaling Pathway: Toehold-Mediated Strand Displacement
Caption: Toehold-mediated strand displacement mechanism for DNA walker movement.
5.2. Experimental Workflow: DNA Walker Synthesis and Assembly
Caption: Experimental workflow for the synthesis and assembly of a DNA walker system.
5.3. Logical Relationship: Bipedal Walker Movement
Caption: State diagram illustrating the hand-over-hand movement of a bipedal DNA walker.
References
- 1. DNA Walkers for Biosensing Development - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Design Principles of DNA Enzyme-Based Walkers: Translocation Kinetics and Photoregulation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. dnananobots.com [dnananobots.com]
- 5. researchgate.net [researchgate.net]
- 6. researchgate.net [researchgate.net]
- 7. A plasmonic nanorod that walks on DNA origami - PMC [pmc.ncbi.nlm.nih.gov]
- 8. biocompare.com [biocompare.com]
- 9. dna.caltech.edu [dna.caltech.edu]
- 10. pubs.acs.org [pubs.acs.org]
- 11. mylens.ai [mylens.ai]
- 12. Dual Spatially Localized DNA Walker for Fast and Efficient RNA Detection - PubMed [pubmed.ncbi.nlm.nih.gov]
Application Notes & Protocols: DNA Scaffolds for Templating Nanomaterials
Introduction
DNA, the blueprint of life, has emerged as an exceptional programmable material in the field of nanotechnology.[1] Its inherent properties of molecular recognition through Watson-Crick base pairing, combined with its chemical stability and nanoscale dimensions, make it an ideal scaffold for the bottom-up fabrication of complex nanomaterials.[2][3] The technique known as DNA origami, developed in 2006, allows for the folding of a long single-stranded DNA "scaffold" (often from the M13mp18 viral genome) into prescribed two- and three-dimensional shapes using hundreds of short, synthetic "staple" strands.[4][5][6] This method provides unprecedented control over the size, shape, and spatial addressability of the resulting nanostructures, enabling the precise positioning of functional components like metallic nanoparticles, quantum dots, and proteins with nanometer accuracy.[7][8]
These DNA-templated nanomaterials have a wide array of applications, including targeted drug delivery, the construction of advanced plasmonic and nanophotonic devices, the fabrication of nanoelectronic components, and the development of high-strength, lightweight materials.[5][9][10] This document provides an overview of key applications and detailed protocols for the synthesis and functionalization of DNA-templated nanomaterials.
Key Applications
Targeted Drug Delivery
DNA nanostructures serve as highly effective carriers for therapeutic agents.[11] Their biocompatibility, programmability, and defined size allow for enhanced cellular uptake and targeted delivery.[12][13] For instance, tetrahedral DNA nanostructures have been used to carry anticancer drugs like Doxorubicin (DOX), effectively bypassing cellular efflux mechanisms that lead to drug resistance.[9][11] The surface of these scaffolds can be functionalized with targeting ligands, such as aptamers, to direct the nanocarrier specifically to cancer cells, minimizing side effects on healthy tissue.[1][12]
Caption: Workflow for targeted drug delivery using a DNA nanocarrier.
Plasmonics and Nanophotonics
DNA scaffolds, particularly DNA origami, offer a robust platform for assembling plasmonic nanoparticles (e.g., gold or silver) into precisely defined architectures.[7] When metallic nanoparticles are brought into close proximity, their surface plasmons can couple, leading to unique optical properties that are highly dependent on their spacing and arrangement.[7] By using DNA origami templates with specific binding sites, researchers can create complex clusters, helices, and arrays of nanoparticles.[8][14] These DNA-assembled plasmonic architectures can function as nanoantennas, waveguides, and chiral metamaterials with tailored optical responses in the visible spectrum.[10][14]
Caption: Assembly of plasmonic nanoparticles on a DNA origami scaffold.
Nanoelectronics
DNA molecules can serve as templates for the fabrication of conductive nanowires.[2] The process involves attaching DNA to a substrate and then using metallization techniques to deposit a layer of metal, such as silver or copper, onto the DNA backbone.[2][15] The negative charge of the DNA's phosphate (B84403) backbone can electrostatically attract positive metal ions from a solution.[15] A subsequent chemical reduction step converts these ions into metal atoms, forming a continuous or semi-continuous metallic sheath around the DNA template.[2][15] This bottom-up approach offers a pathway to creating nanoscale interconnects and components for future electronic circuits.
Experimental Protocols
Protocol 1: Synthesis of a 2D DNA Origami Sheet
This protocol describes the self-assembly of a rectangular DNA origami sheet using the M13mp18 scaffold.[4][16][17]
Materials:
-
M13mp18 single-stranded DNA scaffold (e.g., 10 nM concentration)
-
Staple oligonucleotides (custom synthesized, 100 nM each)
-
Folding Buffer (1x TE buffer with 10-18 mM MgCl₂)
-
Nuclease-free water
-
Thermocycler
Methodology:
-
Prepare the Folding Mixture: In a 0.5 mL PCR tube, combine the M13mp18 scaffold DNA, all staple strands, and the folding buffer. A typical reaction might include:
-
5 µL of 10 nM M13mp18 scaffold (final concentration: 1 nM)
-
5 µL of a mix of 100 nM each staple strand (final concentration: 10 nM each, a 10-fold excess)
-
10 µL of 2x Folding Buffer (final concentration: 1x with MgCl₂)
-
30 µL of nuclease-free water for a final volume of 50 µL.
-
-
Thermal Annealing: Place the PCR tube in a thermocycler and run the following program:
-
Purification (Optional but Recommended): To remove excess staple strands, the origami structures can be purified.
-
Add 450 µL of folding buffer to the 50 µL reaction mixture.
-
Use a spin filter (e.g., Amicon Ultra 100 kDa MWCO) and centrifuge according to the manufacturer's instructions.
-
Repeat the wash step 2-3 times, resuspending the pellet in 1x folding buffer each time.
-
-
Characterization: Verify the formation and integrity of the DNA origami sheets using Atomic Force Microscopy (AFM) or Transmission Electron Microscopy (TEM).[8][16]
References
- 1. Frontiers | Rationally Designed DNA Nanostructures for Drug Delivery [frontiersin.org]
- 2. Bottom-Up Fabrication of DNA-Templated Electronic Nanomaterials and Their Characterization - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Rationally Programming Nanomaterials with DNA for Biomedical Applications - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Synthesis of DNA Origami Scaffolds: Current and Emerging Strategies - PMC [pmc.ncbi.nlm.nih.gov]
- 5. ceramics.org [ceramics.org]
- 6. pubs.acs.org [pubs.acs.org]
- 7. DNA-assembled advanced plasmonic architectures - PMC [pmc.ncbi.nlm.nih.gov]
- 8. pubs.acs.org [pubs.acs.org]
- 9. mdpi.com [mdpi.com]
- 10. spiedigitallibrary.org [spiedigitallibrary.org]
- 11. DNA Nanodevice-Based Drug Delivery Systems - PMC [pmc.ncbi.nlm.nih.gov]
- 12. pubs.acs.org [pubs.acs.org]
- 13. azolifesciences.com [azolifesciences.com]
- 14. scilit.com [scilit.com]
- 15. pubs.acs.org [pubs.acs.org]
- 16. dna.caltech.edu [dna.caltech.edu]
- 17. DNA Origami Nano-Sheets and Nano-Rods Alter the Orientational Order in a Lyotropic Chromonic Liquid Crystal - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes & Protocols for Developing DNA-Powered Molecular Motors
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive overview of the principles, design, and operation of DNA-powered molecular motors. The accompanying protocols offer detailed methodologies for the assembly, characterization, and application of these nanoscale devices, which hold immense potential for targeted drug delivery, advanced diagnostics, and molecular computing.
Introduction to DNA-Powered Molecular Motors
DNA-based molecular machines are synthetic nanodevices that convert chemical energy into mechanical motion.[1][2][3] The remarkable programmability of DNA through Watson-Crick base pairing allows for the design of complex and sophisticated motors capable of performing tasks such as walking, rotating, and transporting cargo.[4][5] These motors operate on principles like toehold-mediated DNA strand displacement, enzymatic reactions, and conformational changes in response to stimuli like pH or light.[4][5][6][7] Recent advancements have led to the development of DNA motors with significantly improved speed and processivity, making them comparable to natural motor proteins.[1][2][3]
Key Performance Metrics of DNA Molecular Motors
The performance of DNA molecular motors is evaluated based on several quantitative parameters. The following table summarizes key metrics from recent studies, providing a comparative overview of the capabilities of different motor designs.
| Motor Type/Design | Speed | Processivity | Run-Length | Power Source | Reference |
| Engineered DNA-Nanoparticle Motor | 30 nm/s | 200 steps | 3 µm | Enzymatic RNA degradation (RNase H) | [1][2][3] |
| Conventional DNA-Nanoparticle Motor | < 1 nm/s | Lower | Shorter | Enzymatic RNA degradation (RNase H) | [2][8] |
| Autonomous Non-Bridge-Burning Motor | ~30 nm/min | High directionality | N/A | DNA strand displacement | [9][10] |
| Natural Motor Proteins (for comparison) | 10-1000 nm/s | High | Varies | ATP hydrolysis | [2][8] |
Mechanisms of DNA Motor Operation
Several mechanisms have been developed to power the movement of DNA molecular motors. Two prominent examples are the "burnt-bridge" Brownian ratchet and toehold-mediated strand displacement.
Burnt-Bridge Brownian Ratchet Mechanism
In this mechanism, a DNA motor moves along a track of RNA molecules. The motor's movement is driven by the enzymatic degradation of the RNA track by an enzyme like RNase H. This "burning of the bridge" prevents the motor from moving backward, thus biasing its random Brownian motion in a forward direction.[1][2][3]
Caption: Burnt-Bridge Brownian Ratchet Mechanism.
Toehold-Mediated Strand Displacement
This mechanism relies on a series of DNA strand displacement reactions to fuel the motor's movement. A "fuel" strand binds to a "toehold" region of a DNA duplex on the track, initiating a displacement reaction that frees up a new toehold for the next fuel strand. This process is highly programmable and does not require enzymes.[4][6]
Caption: Toehold-Mediated DNA Strand Displacement.
Experimental Protocols
Protocol 1: Assembly of a DNA Origami Track
This protocol describes the assembly of a DNA origami track, which serves as the substrate for the DNA motor.
Materials:
-
M13mp18 single-stranded DNA scaffold
-
Staple oligonucleotides (custom synthesized)
-
5X ISO buffer (50 mM Tris-HCl pH 7.5, 10 mM MgCl2, 0.2 mM each dNTP, 10 mM DTT, 5% PEG-8000, 1 mM NAD+)
-
Nuclease-free water
Procedure:
-
Design the DNA Origami Structure: Use software like caDNAno to design the desired 2D or 3D DNA origami structure. Design staple strands that will fold the M13mp18 scaffold into the target shape.
-
Prepare the Assembly Mixture: In a PCR tube, mix the M13mp18 scaffold DNA (final concentration 10 nM) and a stoichiometric excess of all staple oligonucleotides (final concentration 100 nM each) in 1X ISO buffer.
-
Thermal Annealing: Place the PCR tube in a thermocycler and run the following program:
-
95°C for 5 minutes (denaturation)
-
Ramp down to 25°C over 12-24 hours (folding)
-
-
Purification: Purify the assembled DNA origami structures from excess staple strands using agarose (B213101) gel electrophoresis or spin filtration.
Protocol 2: Characterization of DNA Motor Movement using Single-Particle Tracking
This protocol outlines the visualization and characterization of DNA motor movement along a DNA origami track using fluorescence microscopy.
Materials:
-
Assembled DNA origami tracks
-
Fluorescently labeled DNA motors
-
Microscope slides and coverslips
-
Total Internal Reflection Fluorescence (TIRF) microscope
-
Image analysis software (e.g., ImageJ)
Procedure:
-
Surface Preparation: Prepare a clean microscope slide and functionalize the surface to immobilize the DNA origami tracks.
-
Immobilization of Tracks: Incubate the functionalized slide with the purified DNA origami tracks to allow for their attachment to the surface.
-
Introduction of Motors: Introduce the fluorescently labeled DNA motors to the slide, along with the necessary fuel (e.g., ATP for enzymatic motors, fuel strands for displacement motors).
-
Data Acquisition: Using a TIRF microscope, record movies of the fluorescently labeled motors moving along the tracks.
-
Data Analysis: Use image analysis software to track the movement of individual motors over time. From these trajectories, calculate the speed, processivity, and run-length of the motors.
Applications in Drug Development
DNA-powered molecular motors offer exciting possibilities for advancing drug delivery and diagnostics.
-
Targeted Drug Delivery: DNA motors can be designed to carry drug cargo and release it at specific locations in response to disease-specific molecular cues.[6] This targeted approach can increase therapeutic efficacy while minimizing side effects.
-
Smart Diagnostics: The movement of DNA motors can be designed to be triggered by the presence of specific biomarkers, enabling the development of highly sensitive diagnostic devices.[1][2][3]
-
Molecular Computing: The logical operations performed by some DNA motors can be harnessed for in situ analysis of cellular environments, providing valuable data for drug development and personalized medicine.[11]
The continued development of DNA-powered molecular motors promises to revolutionize various aspects of biomedical research and clinical practice. By providing precise control over molecular-scale transport and actuation, these nanodevices are poised to become invaluable tools in the fight against disease.
References
- 1. scitechdaily.com [scitechdaily.com]
- 2. azonano.com [azonano.com]
- 3. sciencedaily.com [sciencedaily.com]
- 4. pubs.acs.org [pubs.acs.org]
- 5. DNA-Based Molecular Machines - PMC [pmc.ncbi.nlm.nih.gov]
- 6. pharmasalmanac.com [pharmasalmanac.com]
- 7. pubs.acs.org [pubs.acs.org]
- 8. bioengineer.org [bioengineer.org]
- 9. Autonomous DNA molecular motor tailor-designed to navigate DNA origami surface for fast complex motion and advanced nanorobotics - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. eurasiareview.com [eurasiareview.com]
Application Notes and Protocols for Single-Molecule Imaging of DNA Nanostructures
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive overview of single-molecule imaging techniques for the characterization and analysis of DNA nanostructures. Detailed protocols for key experimental methodologies are included to facilitate the adoption of these powerful techniques in academic and industrial research settings.
Introduction to Single-Molecule Imaging of DNA Nanostructures
DNA nanotechnology enables the design and self-assembly of complex, user-defined nanoscale structures with high precision.[1][2] These DNA nanostructures, including DNA origami, serve as versatile platforms for a wide range of applications, from targeted drug delivery and biosensing to the organization of molecular components in nanoelectronics and nanophotonics.[3] To ensure the structural integrity, functional performance, and stability of these intricate assemblies, it is crucial to characterize them at the single-molecule level. Single-molecule imaging techniques offer the necessary resolution to visualize individual nanostructures, assess their conformational dynamics, and quantify their interactions with other molecules.[1][2]
Key single-molecule imaging modalities for DNA nanostructures include:
-
Atomic Force Microscopy (AFM): Provides high-resolution topographical images of DNA nanostructures on a surface, revealing their size, shape, and structural integrity.[4][5]
-
Super-Resolution Microscopy (e.g., DNA-PAINT): Enables the visualization of DNA nanostructures with sub-diffraction-limit resolution by exploiting the transient binding of fluorescently labeled oligonucleotides.[6]
-
Single-Molecule Förster Resonance Energy Transfer (smFRET): A spectroscopic technique used to measure distances on the order of 1-10 nm within or between molecules, providing insights into the conformational dynamics of DNA nanostructures.[7][8]
Application Note 1: Assessing the Structural Fidelity of DNA Origami with Atomic Force Microscopy (AFM)
Application: Verifying the correct folding and assembly of DNA origami structures is a critical quality control step. AFM provides direct visualization of the topography of individual origami, allowing for the assessment of structural fidelity and the identification of malformed or aggregated structures.[5]
Workflow for AFM Imaging of DNA Nanostructures:
Caption: Experimental workflow for AFM imaging of DNA nanostructures.
Protocol: AFM Imaging of DNA Origami
Materials:
-
DNA origami solution
-
Freshly cleaved mica discs
-
(3-Aminopropyl)silatrane (APS) solution
-
TAE/Mg²⁺ buffer (e.g., 40 mM Tris, 20 mM acetic acid, 2 mM EDTA, 12.5 mM MgCl₂)
-
Ultrapure water
-
AFM with tapping mode capabilities
Procedure:
-
APS-Mica Surface Preparation:
-
Prepare a fresh solution of APS in ultrapure water.
-
Cleave a mica disc to expose a fresh, atomically flat surface.
-
Immediately apply the APS solution to the mica surface and incubate for 30 minutes.[9]
-
Rinse the APS-treated mica thoroughly with ultrapure water and dry with a gentle stream of nitrogen. This functionalized surface will bind the negatively charged DNA nanostructures.[9]
-
-
Sample Deposition:
-
Dilute the DNA origami sample to an appropriate concentration in TAE/Mg²⁺ buffer.
-
Deposit a small volume (e.g., 10-20 µL) of the diluted DNA origami solution onto the prepared APS-mica surface.
-
Incubate for 5-10 minutes to allow the DNA origami to adsorb to the surface.
-
Gently rinse the surface with ultrapure water to remove unbound structures and buffer salts.
-
Dry the sample under a gentle stream of nitrogen.
-
-
AFM Imaging:
-
Mount the sample on the AFM stage.
-
Engage the AFM cantilever with the surface in tapping mode.
-
Optimize the imaging parameters (scan rate, setpoint amplitude, integral and proportional gains) to obtain high-quality images with minimal sample damage.
-
Acquire topography and phase images over various scan sizes to locate and zoom in on individual DNA origami structures.
-
-
Data Analysis:
-
Use appropriate software to flatten the acquired images and remove imaging artifacts.[5]
-
Measure the dimensions (length, width, height) of individual, well-formed DNA origami structures.
-
Quantify the yield of correctly assembled structures versus malformed or aggregated structures.
-
Quantitative Data Presentation:
| DNA Nanostructure | Expected Dimensions (nm) | Measured Dimensions (AFM) (nm) | Reference |
| 2D Rectangular Origami | 291.5 x 23 | - | [10] |
| 60 nm Diameter Disk | 60 (diameter), 7 (height) | 11 ± 2 (height) | [11] |
| 4x4 Tile Lattice | 19.3 (lattice spacing) | 19.3 (lattice spacing) | [4] |
| Woven DNA Strands | ~5-6 (lattice spacing) | ~5-6 (lattice spacing) | [4] |
Application Note 2: Super-Resolution Imaging of Functionalized DNA Nanostructures with DNA-PAINT
Application: DNA-PAINT (Points Accumulation for Imaging in Nanoscale Topography) is a powerful super-resolution technique for visualizing DNA nanostructures and their functionalization with nanoscale precision.[6] It relies on the transient binding of short, fluorescently labeled "imager" strands to complementary "docking" strands on the DNA nanostructure.[6] This allows for the precise localization of individual binding events, leading to a reconstructed super-resolution image.
Signaling Pathway for DNA-PAINT:
Caption: The signaling pathway of DNA-PAINT super-resolution microscopy.
Protocol: DNA-PAINT Imaging
Materials:
-
Purified DNA nanostructures functionalized with docking strands.
-
Fluorescently labeled imager strands (complementary to the docking strands).
-
Imaging buffer (e.g., PBS with 500 mM NaCl).
-
Microscope coverslips and slides.
-
Surface passivation reagents (e.g., Biotin-BSA, NeutrAvidin).
-
Total Internal Reflection Fluorescence (TIRF) microscope equipped with a sensitive camera (e.g., EMCCD or sCMOS).
Procedure:
-
Surface Passivation and Sample Immobilization:
-
Clean microscope coverslips thoroughly.
-
Functionalize the coverslip surface for specific immobilization of the DNA nanostructures (e.g., using a biotin-neutravidin linkage).[11]
-
Incubate the functionalized coverslip with the DNA nanostructure solution to allow for surface immobilization.
-
Wash away unbound structures with imaging buffer.
-
-
Imaging:
-
Assemble the imaging chamber.
-
Add the imaging buffer containing a low concentration of imager strands to the chamber.
-
Mount the sample on the TIRF microscope.
-
Acquire a time-series of images, capturing the transient binding and unbinding of the imager strands. Thousands of frames are typically acquired.
-
-
Data Analysis:
-
Use single-molecule localization software to detect and localize the individual binding events in each frame with sub-pixel accuracy.
-
Correct for sample drift during the acquisition.
-
Reconstruct the super-resolution image by plotting the coordinates of all localized binding events.
-
Quantitative Data Presentation:
| Parameter | Value | Reference |
| DNA Origami Disk Pattern Spacing | ||
| Large Hexagon | 20.4 nm | [11] |
| Small Hexagon | 7.8 nm | [11] |
| Square | 15.7 nm | [11] |
| Triangle | 13.9 nm | [11] |
| DNA-PAINT Kinetic Rates | ||
| Association Rate (k_on) | 2.3 x 10⁶ M⁻¹s⁻¹ | [10] |
| Dissociation Rate (k_off) - Center | Increased by 30% compared to edge | [10] |
Application Note 3: Probing Conformational Dynamics with Single-Molecule FRET (smFRET)
Application: smFRET is a powerful tool for studying the dynamic conformational changes of DNA nanostructures, such as the operation of DNA-based molecular machines or the interaction with other biomolecules.[7][8] By labeling specific sites on the nanostructure with a donor and an acceptor fluorophore, changes in the distance between these sites can be monitored in real-time by observing the efficiency of energy transfer.[12]
Logical Relationship in smFRET Measurement:
Caption: Logical flow of an smFRET experiment to study DNA nanostructures.
Protocol: smFRET Imaging of DNA Nanostructures
Materials:
-
DNA nanostructures labeled with a suitable FRET pair (e.g., Cy3 and Cy5).
-
TIRF microscope with alternating laser excitation for the donor and acceptor dyes.
-
Imaging buffer with an oxygen scavenging system to reduce photobleaching.
-
Passivated microscope slides and coverslips.
Procedure:
-
Sample Preparation:
-
Synthesize or purchase DNA oligonucleotides labeled with the donor and acceptor fluorophores.
-
Incorporate these labeled strands at the desired positions during the self-assembly of the DNA nanostructure.
-
Purify the labeled nanostructures to remove excess free dyes.
-
Immobilize the labeled nanostructures on a passivated surface for observation.[7]
-
-
Data Acquisition:
-
Acquire time-series of fluorescence images, alternating between donor and acceptor excitation.
-
Use a sensitive camera to detect the emission from both fluorophores simultaneously (e.g., by splitting the emission onto two halves of the camera chip).
-
-
Data Analysis:
-
Identify single-molecule spots and extract the time-dependent fluorescence intensities of the donor and acceptor.
-
Calculate the FRET efficiency (E) for each time point using the formula: E = I_A / (I_A + I_D), where I_A and I_D are the acceptor and donor intensities, respectively.
-
Generate FRET efficiency histograms to identify different conformational states.
-
Analyze the time trajectories of the FRET efficiency to determine the kinetics of conformational transitions.
-
Quantitative Data Presentation:
| FRET Parameter | Description | Typical Value Range | Reference |
| R₀ (Förster Radius) | Distance at which FRET efficiency is 50% | 2 - 8 nm | [12] |
| Time Resolution | Limited by camera frame rate | ~1 ms (B15284909) (best case) | [12] |
| Detectable Distance Change | Smallest resolvable change in inter-dye distance | ~0.3 nm | [12] |
References
- 1. pubs.acs.org [pubs.acs.org]
- 2. researchgate.net [researchgate.net]
- 3. Quantizing single-molecule surface-enhanced Raman scattering with DNA origami metamolecules - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Application Note: High-Resolution Imaging of DNA Nanoarchitectures Using AFM | Bruker [bruker.com]
- 5. briefs.techconnect.org [briefs.techconnect.org]
- 6. Super-resolution Microscopy Protocols and Methods | Springer Nature Experiments [experiments.springernature.com]
- 7. Frontiers | Single-Molecule FRET: A Tool to Characterize DNA Nanostructures [frontiersin.org]
- 8. researchgate.net [researchgate.net]
- 9. Visualization of DNA and Protein-DNA Complexes with Atomic Force Microscopy - PMC [pmc.ncbi.nlm.nih.gov]
- 10. pubs.acs.org [pubs.acs.org]
- 11. Quantification of Strand Accessibility in Biostable DNA Origami with Single-Staple Resolution - PMC [pmc.ncbi.nlm.nih.gov]
- 12. A Practical Guide to Single Molecule FRET - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for Applying Machine Learning to DNA Sequence Design
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive overview and detailed protocols for the application of machine learning (ML) in the design of novel DNA sequences with desired functional properties. This technology is revolutionizing various fields, including drug development, gene therapy, and synthetic biology, by enabling the rapid and efficient engineering of genetic materials.
Introduction to Machine Learning-Guided DNA Sequence Design
Machine learning offers a powerful paradigm for navigating the vast and complex landscape of possible DNA sequences to identify those with specific functionalities. By learning the intricate relationships between DNA sequence and function from large-scale experimental data, ML models can predict the activity of novel sequences and even generate entirely new sequences with desired characteristics. This data-driven approach accelerates the design-build-test-learn cycle, a cornerstone of synthetic biology and genetic engineering.[1]
Generative models, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs), are at the forefront of this field.[2][3][4][5] These models can learn the underlying patterns in biological data to generate novel DNA sequences with properties like specific promoter strength, enhancer activity, or protein-binding affinity.
Key Applications
The applications of machine learning in DNA sequence design are rapidly expanding and include:
-
Promoter and Enhancer Design: Engineering regulatory elements with specific strengths and cell-type specificity is crucial for controlling gene expression in various therapeutic and biotechnological applications.[6][7][8][9] ML models can be trained on data from Massively Parallel Reporter Assays (MPRA) to design synthetic promoters and enhancers with predictable activity levels.[6][8]
-
Gene Therapy Vector Engineering: Designing viral vectors, such as Adeno-Associated Viruses (AAVs), with improved tissue targeting, transduction efficiency, and reduced immunogenicity is a major goal in gene therapy.[10][11][12][13] Machine learning is being used to engineer AAV capsids with enhanced properties.[10][11][12]
-
Transcription Factor Binding Site (TFBS) and Aptamer Design: Creating DNA sequences that bind with high affinity and specificity to target proteins is essential for developing novel diagnostics, therapeutics, and research tools.[13][14][15][16]
-
Synthetic Genetic Circuit Design: Building complex genetic circuits for sophisticated cellular programming requires finely tuned components. ML algorithms can aid in the design and optimization of these circuits.[1][12][17][18]
Quantitative Data Summary
The following tables summarize the performance of various machine learning models in designing and predicting the function of DNA sequences, as reported in recent literature.
Table 1: Performance of Machine Learning Models for Promoter Strength Prediction
| Model Type | Organism/Cell Line | Performance Metric | Value | Reference |
| XGBoost | Escherichia coli | R² (Predicted vs. Actual) | 0.88 | [6] |
| XGBoost | Escherichia coli | Pearson Correlation Coefficient | 0.94 | [6] |
| XGBoost | Escherichia coli | Mean Absolute Error | 0.15 | [6] |
| Convolutional Neural Network (CNN) | Human B-cell line | Pearson Correlation Coefficient | 0.63 | [8] |
| Pymaker (DNABERT-based) | Saccharomyces cerevisiae | Increase in Protein Expression | 3-fold | [19] |
Table 2: Performance of Machine Learning-Designed Enhancers
| Target Tissue (Drosophila) | Active Designed Enhancers | Tissue-Specific Enhancers | Reference |
| Central Nervous System | 8/8 (100%) | 8/8 (100%) | [6][9] |
| Muscle | 8/8 (100%) | 8/8 (100%) | [6][9] |
| Epidermis | 7/8 (87.5%) | 5/8 (62.5%) | [6][9] |
| Gut | 5/8 (62.5%) | 3/8 (37.5%) | [6][9] |
| Brain | 3/8 (37.5%) | 3/8 (37.5%) | [6][9] |
| Overall | 31/40 (78%) | 27/40 (68%) | [6][9] |
Table 3: Performance of Machine Learning Models for Transcription Factor Binding Site Prediction
| Model Type | Task | Performance Metric | Value | Reference |
| Convolutional Neural Network (CNN) | Predicting TF binding at motifs | Mean auROC | 0.94 | [20] |
| Random Forest | Predicting TFBS | Average Accuracy | >82% | [21] |
| Ensemble Method | Target gene identification | F1 Score Improvement | ~10% | [22] |
Table 4: Performance of Machine Learning-Designed AAV Capsids
| Design Goal | Validation Success Rate | Key Finding | Reference |
| Multi-trait (liver-targeted, manufacturable) | 89% of variants met 6 criteria | Models trained on mouse and human data accurately predicted performance in macaques. | [10] |
| Improved function over natural serotypes | Several hundred-fold improvement in design efficiency | Machine learning models significantly improve the probability of designing a variant with enhanced function. | [11] |
Experimental Protocols
This section provides detailed protocols for the experimental validation of machine learning-designed DNA sequences.
Protocol: High-Throughput Validation of Designed Regulatory Elements using Massively Parallel Reporter Assay (MPRA)
This protocol outlines the steps for quantifying the activity of thousands of designed promoter or enhancer sequences in parallel.
1. Library Synthesis and Cloning:
- Synthesize the designed DNA sequences as oligonucleotides.
- Amplify the oligonucleotide library using PCR, adding unique barcode sequences to each designed element.
- Clone the barcoded library into a reporter plasmid containing a minimal promoter (for enhancers) or replacing the native promoter (for promoters) and a reporter gene (e.g., GFP, Luciferase).
2. Cell Culture and Transfection:
- Culture the target cell line under standard conditions.
- Transfect the MPRA library into the cells. The choice of transfection method (e.g., lipofection, electroporation) should be optimized for the cell line.
3. Nucleic Acid Extraction:
- After a suitable incubation period (e.g., 24-48 hours), harvest the cells.
- Extract both DNA and RNA from the cell population.
4. Sequencing Library Preparation and High-Throughput Sequencing:
- For the RNA fraction, perform reverse transcription to generate cDNA.
- Amplify the barcode regions from both the DNA and cDNA samples using PCR with primers containing sequencing adapters.
- Perform high-throughput sequencing of the amplified barcode libraries.
5. Data Analysis:
- Count the occurrences of each barcode in both the DNA and RNA sequencing reads.
- Calculate the activity of each designed regulatory element by normalizing the RNA barcode counts to the DNA barcode counts. This ratio reflects the transcriptional activity of the sequence.
Protocol: Validation of Machine Learning-Designed AAV Capsids
This protocol describes the production and in vivo validation of a library of AAV capsids designed using machine learning.
1. AAV Library Production:
- Synthesize the designed capsid gene variants and clone them into an AAV packaging plasmid.
- Co-transfect HEK293T cells with the AAV capsid library plasmid, a helper plasmid, and a plasmid containing the gene of interest flanked by AAV inverted terminal repeats (ITRs).
- Harvest the viral particles from the cells and supernatant 48-72 hours post-transfection.
- Purify the AAV library using methods such as iodixanol (B1672021) gradient ultracentrifugation.
2. AAV Library Titer Determination:
- Extract viral DNA from the purified AAV library.
- Quantify the number of viral genomes using quantitative PCR (qPCR) with primers targeting the gene of interest.
3. In Vivo Administration and Tissue Harvesting:
- Administer the AAV library to model organisms (e.g., mice) via the desired route (e.g., intravenous, intramuscular).
- After a specified period to allow for gene expression, harvest the target organs and tissues.
4. Biodistribution and Transduction Efficiency Analysis:
- Extract genomic DNA and RNA from the harvested tissues.
- Use qPCR on the genomic DNA to determine the biodistribution of the different AAV variants.
- Use reverse transcription qPCR (RT-qPCR) on the RNA to quantify the expression of the delivered gene, indicating transduction efficiency.
- High-throughput sequencing of the capsid region from the tissue DNA can be used to determine the relative enrichment of different capsid variants in specific tissues.
Visualizing Workflows and Pathways
Machine Learning-Guided DNA Design Workflow
The following diagram illustrates a typical workflow for designing and validating DNA sequences using machine learning.
Modulating the NF-κB Signaling Pathway with Designed DNA Binders
This diagram depicts the canonical NF-κB signaling pathway and illustrates how machine learning-designed DNA binders can be used to modulate its activity. These synthetic molecules can be designed to bind to the κB sites in the promoters of NF-κB target genes, thereby inhibiting their transcription.
Conclusion
The integration of machine learning into DNA sequence design is a rapidly advancing field with the potential to significantly impact biomedical research and development. The protocols and data presented here provide a foundation for researchers to begin applying these powerful techniques in their own work. As more high-quality biological data becomes available and machine learning algorithms continue to improve, the ability to design novel DNA sequences with precise and predictable functions will only increase, opening up new avenues for therapeutic intervention and a deeper understanding of biological systems.
References
- 1. Quantitative modeling of transcription factor binding specificities using DNA shape - PMC [pmc.ncbi.nlm.nih.gov]
- 2. mlcb.github.io [mlcb.github.io]
- 3. A Comparison of Generative Models for Sequence Design [research.google]
- 4. researchgate.net [researchgate.net]
- 5. biorxiv.org [biorxiv.org]
- 6. Targeted design of synthetic enhancers for selected tissues in the Drosophila embryo - PMC [pmc.ncbi.nlm.nih.gov]
- 7. molecularpost.altervista.org [molecularpost.altervista.org]
- 8. researchgate.net [researchgate.net]
- 9. Targeted design of synthetic enhancers for selected tissues in the Drosophila embryo | Scilit [scilit.com]
- 10. researchgate.net [researchgate.net]
- 11. businesswire.com [businesswire.com]
- 12. Machine learning approach helps researchers design better gene-delivery vehicles for gene therapy | Broad Institute [broadinstitute.org]
- 13. academic.oup.com [academic.oup.com]
- 14. Generative and interpretable machine learning for aptamer design and analysis of in vitro sequence selection - PMC [pmc.ncbi.nlm.nih.gov]
- 15. biorxiv.org [biorxiv.org]
- 16. skysonginnovations.com [skysonginnovations.com]
- 17. Adapting machine-learning algorithms to design gene circuits - PMC [pmc.ncbi.nlm.nih.gov]
- 18. biorxiv.org [biorxiv.org]
- 19. Optimizing DNA Sequence Classification via a Deep Learning Hybrid of LSTM and CNN Architecture [mdpi.com]
- 20. researchgate.net [researchgate.net]
- 21. Predicting bacterial transcription factor binding sites through machine learning and structural characterization based on DNA duplex stability - PMC [pmc.ncbi.nlm.nih.gov]
- 22. Benchmarking DNA foundation models for genomic and genetic tasks - PMC [pmc.ncbi.nlm.nih.gov]
Troubleshooting & Optimization
DNA Origami Self-Assembly Technical Support Center
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in improving the yield of DNA origami self-assembly.
Frequently Asked Questions (FAQs)
Q1: What are the most critical factors influencing the yield of DNA origami self-assembly?
The yield of DNA origami is influenced by several factors, including the quality of the staple and scaffold DNA, the design of the staples, the concentration of magnesium ions in the folding buffer, and the thermal annealing protocol.[1][2] Optimizing the design of staple strands and the annealing conditions are particularly crucial once the salt concentration is optimized.[1]
Q2: How does the quality of staple strands affect the assembly process?
The integrity and purity of staple strands are paramount for successful DNA origami formation.[3] Over time, staple solutions can degrade, which may negatively impact the stability of the final structure, especially under harsh conditions.[3][4][5] While storage at -20°C for several years might not completely hinder self-assembly, it can lead to an accumulation of damaged nucleobases, resulting in weaker base-pairing and reduced duplex stability.[4][5]
Q3: What is the optimal ratio of staple strands to scaffold DNA?
A molar excess of staple strands to the scaffold is necessary to drive the folding reaction forward.[6] Typically, a 10-fold excess of each staple strand relative to the scaffold is used.[7][8] While higher concentrations might seem beneficial, ratios significantly above 10:1 are unlikely to substantially improve folding accuracy.[7][8] In some cases, for single-fold events, yield can even decrease at very high staple-to-scaffold ratios due to the formation of a "blocked state".[9]
Q4: What is the role of magnesium ions (Mg²⁺) in the folding buffer?
Magnesium ions are crucial for screening the electrostatic repulsion between the negatively charged phosphate (B84403) backbones of the DNA strands, thereby facilitating the close packing of DNA helices required for origami formation.[2] A typical concentration range for successful assembly is 5-20 mM Mg²⁺.[2] However, the optimal concentration can be structure-dependent, and some designs may fold accurately in MgCl₂ concentrations as low as 10 mM.[7] While essential for assembly, high concentrations are not always necessary for maintaining the stability of already folded structures.[10]
Q5: Can other cations be used instead of magnesium?
Yes, monovalent cations can substitute for Mg²⁺, but typically at much higher concentrations.[2] Spermidine is another molecule that can condense DNA and has been used in folding buffers, sometimes reducing or eliminating the need for MgCl₂.[11]
Q6: My DNA origami structures are aggregating. What could be the cause and how can I prevent it?
Aggregation can be caused by several factors, including base-stacking interactions between blunt-ended helices, improper drying during sample preparation for imaging, and high concentrations of the origami structures.[12][13] To mitigate aggregation, you can incorporate single-stranded DNA loops or poly-thymine brushes at the ends of helices.[13] For purification and concentration, methods like lyophilization have been shown to reduce aggregation compared to ultrafiltration or PEG precipitation, especially when starting with low concentrations in low-salt buffers.[14][15]
Troubleshooting Guides
Low Yield of DNA Origami Structures
This guide provides a structured approach to troubleshooting experiments with low yields of correctly folded DNA origami.
| Observation | Potential Cause | Suggested Solution | Key Parameters & Quantitative Data |
| Smearing or no distinct band on agarose (B213101) gel | Incomplete or failed folding reaction. | Verify the integrity and concentration of scaffold and staple strands. Optimize the annealing protocol (temperature ramp and incubation times).[1][7] | Scaffold:Staple Ratio: 1:10 (molar ratio)[7][8] MgCl₂ Concentration: 10-20 mM[2][7] Annealing Ramp: Start at 65°C for 10 min, then cool from 60°C to 40°C, decreasing by 1.0°C every hour.[7] |
| Multiple bands on agarose gel | Presence of misfolded structures, aggregates, or intermediates. | Optimize the annealing ramp to be slower to allow for proper kinetic trapping of the desired structure.[16] Adjust Mg²⁺ concentration as suboptimal levels can lead to misfolding.[7] | Annealing Time: Can range from hours to days depending on structural complexity.[17] |
| Faint band of the correct size | Low concentration of starting material or inefficient folding. | Ensure accurate quantification of scaffold and staple strands. Increase the initial concentration of reactants. Consider redesigning staples for improved thermodynamic stability.[18] | Scaffold Concentration: Typically 10 nM.[7][8] Staple Concentration: Typically 100 nM for each staple.[7][8] |
| Well-defined band, but low recovery after purification | Inefficient purification method leading to sample loss. | Consider alternative purification methods. Rate-zonal centrifugation can offer high recovery yields (40-80%).[19][20] SPRI beads are another option with good recovery.[21] | Rate-Zonal Centrifugation: Can yield 0.1–100 µg of purified product per tube.[19][20] |
Experimental Protocols
Agarose Gel Electrophoresis of DNA Origami
-
Gel Preparation: Prepare a 1-2% agarose gel in 1x Tris-borate-EDTA (TBE) buffer supplemented with 11 mM MgCl₂.[7]
-
Sample Loading: Mix your DNA origami sample with a 6x loading dye.
-
Electrophoresis: Run the gel at a constant voltage (e.g., 75 V) for an appropriate duration (e.g., 90 minutes).[22] For larger or more delicate structures, a lower voltage (e.g., 45 V) and lower percentage gel (e.g., 0.6%) for a longer duration (e.g., 2 hours) may be beneficial.[22]
-
Staining and Visualization: Stain the gel with a fluorescent dye like SYBR Safe or Ethidium Bromide and visualize it under UV light.[7] Correctly folded DNA origami structures should appear as a sharp, well-defined band with higher mobility than misfolded or aggregated species.[7]
Atomic Force Microscopy (AFM) Imaging of DNA Origami
-
Sample Preparation: Dilute the purified DNA origami sample to approximately 1-2 nM in a buffer compatible with AFM imaging (e.g., 1x TAE buffer with 10 mM MgCl₂).
-
Surface Deposition: Apply a small volume (e.g., 10 µL) of the diluted sample onto a freshly cleaved mica surface and let it adsorb for 5-7 minutes.[12]
-
Washing: Gently wash the mica surface with ultrapure water to remove excess salts.[12]
-
Drying: Dry the sample quickly using a gentle stream of inert gas to prevent aggregation and degradation that can occur with extended air drying.[12]
-
Imaging: Image the sample using an AFM in the appropriate mode (e.g., tapping mode in air or liquid).
Visualizations
Caption: A general workflow for DNA origami self-assembly.
Caption: A troubleshooting flowchart for low DNA origami yield.
References
- 1. biorxiv.org [biorxiv.org]
- 2. pubs.acs.org [pubs.acs.org]
- 3. hilarispublisher.com [hilarispublisher.com]
- 4. Effect of Staple Age on DNA Origami Nanostructure Assembly and Stability - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. academic.oup.com [academic.oup.com]
- 7. Design principles for accurate folding of DNA origami - PMC [pmc.ncbi.nlm.nih.gov]
- 8. pnas.org [pnas.org]
- 9. Failure Mechanisms in DNA Self-Assembly: Barriers to Single-Fold Yield - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Heavy Metal Stabilization of DNA Origami Nanostructures - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. researchgate.net [researchgate.net]
- 13. researchgate.net [researchgate.net]
- 14. Lyophilization Reduces Aggregation of Three-Dimensional DNA Origami at High Concentrations - PMC [pmc.ncbi.nlm.nih.gov]
- 15. pubs.acs.org [pubs.acs.org]
- 16. researchgate.net [researchgate.net]
- 17. DSpace [kb.osu.edu]
- 18. Design principles for accurate folding of DNA origami - PMC [pmc.ncbi.nlm.nih.gov]
- 19. ovid.com [ovid.com]
- 20. academic.oup.com [academic.oup.com]
- 21. biorxiv.org [biorxiv.org]
- 22. www2.eecs.berkeley.edu [www2.eecs.berkeley.edu]
Technical Support Center: Reducing Error Rates in DNA-Based Computations
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in mitigating error rates during DNA-based computations.
Frequently Asked Questions (FAQs)
What are the most common sources of errors in DNA-based computations?
Errors in DNA-based computations can arise from various biochemical operations. The primary sources include:
-
Polymerase Chain Reaction (PCR) Errors: DNA polymerases can introduce misincorporation errors, leading to incorrect base pairings.[1] Typical error rates are in the range of one misincorporation per one hundred thousand bases.[1] Thermally induced damage to DNA during PCR, such as depurination and cytosine deamination, also contributes to errors.
-
Ligation Errors: The enzymatic joining of DNA strands (ligation) can be imperfect. DNA ligases may ligate incorrect strands, especially if their structures are similar.[1] The choice of ligase is crucial, as some are more "promiscuous" than others.[1]
-
Hybridization/Annealing Errors: This process, where single-stranded DNA molecules bind to form a double strand, can result in imperfectly joined strands with bulges of unjoined bases. A molecule can also fold and bind to itself, creating unintended secondary structures.[1]
-
Affinity Purification Errors: This technique for filtering and selecting specific DNA strands has an accepted error rate of around 5%. This means it may fail to filter out incorrect strands or may erroneously filter out correct ones.[1]
-
Strand Loss: DNA strands can be lost during various experimental steps, particularly during purification and handling.[2] Studies have shown that DNA loss during purification can range from approximately 21% to over 60%, depending on the method and starting concentration.[3][4][5]
-
DNA Secondary Structures: Single-stranded DNA can fold back on itself to form secondary structures like hairpin loops, which can render the DNA inactive in the computational process.[6][7]
How can I minimize errors during the DNA sequence design phase?
Careful design of DNA sequences is a critical first step in reducing computational errors. Key strategies include:
-
Avoiding Secondary Structures: Design sequences that are unlikely to form stable hairpins or other secondary structures.[6][7] Computational tools can predict the secondary structure of DNA sequences.[8]
-
Maximizing Sequence Dissimilarity: To prevent unintended hybridization, ensure that non-complementary strands have minimal sequence similarity.
-
Codeword Design: Employ coding theory principles to design DNA "codewords" that are robust to certain types of errors.
-
Thermodynamic Uniformity: Design sequences with similar melting temperatures (Tm) to ensure they behave consistently under the same reaction conditions.
What are the key experimental parameters to control for reducing errors?
Precise control over experimental conditions is paramount for high-fidelity DNA computations. Important parameters include:
-
Temperature: Hybridization and enzyme activity are highly sensitive to temperature.[9] Optimal temperatures for ligation and annealing should be strictly maintained.
-
Buffer Composition: The pH and ionic strength of the reaction buffer can significantly impact the stability of DNA duplexes and the activity of enzymes.[9]
-
DNA Concentration: Using appropriate concentrations of DNA strands is crucial for minimizing unintended interactions and side reactions.[1]
-
Enzyme Selection: Choose high-fidelity DNA polymerases for PCR and specific DNA ligases to minimize errors during replication and ligation.[10][11][12][13]
Troubleshooting Guides
Issue 1: Inefficient or Failed DNA Ligation
Symptoms:
-
Few or no colonies after transformation of ligation product.
-
Gel electrophoresis of the ligation reaction shows no ligated product.
Possible Causes and Solutions:
| Cause | Recommended Solution |
| Inactive Ligase or Buffer | The ATP in ligase buffers is sensitive to freeze-thaw cycles. Use fresh buffer or aliquots that have not been repeatedly frozen and thawed. Ensure the ligase itself has been stored properly at -20°C.[14] |
| Incorrect Vector:Insert Molar Ratio | Optimize the molar ratio of vector to insert. A common starting point is a 1:3 ratio, but this can be varied from 1:1 to 1:10.[13][14] |
| Presence of Inhibitors | Purify DNA fragments to remove contaminants like salts (e.g., from restriction enzyme buffers) and EDTA, which can inhibit ligase activity.[14] |
| Lack of 5' Phosphate (B84403) | Ensure that at least one of the DNA ends to be ligated has a 5' phosphate group. This is essential for the ligase to form a phosphodiester bond. |
| Damaged DNA Ends | If excising DNA from an agarose (B213101) gel, minimize UV exposure to prevent DNA damage. Use long-wavelength UV (360 nm). |
Experimental Protocol: Optimizing DNA Ligation
-
Quantify DNA: Accurately determine the concentration of your vector and insert DNA using a fluorometer or spectrophotometer.
-
Calculate Molar Ratios: Use an online calculator or the following formula to determine the amount of insert needed for a desired molar ratio: ng of insert = (ng of vector × size of insert in bp) / size of vector in bp × (insert:vector molar ratio)
-
Set up Reactions: Prepare several ligation reactions with varying vector:insert molar ratios (e.g., 1:1, 1:3, 1:5). Include a "vector only" control to assess background ligation.[13][15]
-
Reaction Mixture (10 µL):
-
Vector DNA (e.g., 50 ng)
-
Insert DNA (calculated amount)
-
1 µL 10x T4 DNA Ligase Buffer
-
1 µL T4 DNA Ligase
-
Nuclease-free water to 10 µL[15]
-
-
Incubation: Incubate at room temperature for 1-2 hours or at 16°C overnight.[12][13]
-
Analysis: Transform competent cells with the ligation products and analyze the number of colonies. Run a small amount of the ligation reaction on an agarose gel to visualize the products.
Issue 2: Unintended Products or Errors in PCR Amplification
Symptoms:
-
Multiple bands on a gel when a single product is expected.
-
Sequencing results reveal a high rate of mutations.
Possible Causes and Solutions:
| Cause | Recommended Solution |
| Non-Specific Primer Annealing | Optimize the annealing temperature. Start with a temperature 5°C below the calculated melting temperature (Tm) of the primers and adjust as needed. |
| Primer-Dimers | Ensure primers are well-designed and do not have significant self-complementarity. |
| Low-Fidelity Polymerase | Use a high-fidelity DNA polymerase with proofreading activity (3'->5' exonuclease activity).[10][11][12][13] |
| Suboptimal Reaction Conditions | Optimize Mg²⁺ concentration (typically 1.5-2.0 mM) and dNTP concentrations. Ensure the pH of the buffer is optimal for the chosen polymerase.[12] |
| DNA Damage | Minimize the duration of high-temperature denaturation steps to reduce thermal damage to the DNA template. |
Quantitative Data: Error Rates of Common DNA Polymerases
| DNA Polymerase | Proofreading (3'→5' Exo) | Relative Fidelity vs. Taq | Error Rate (per 10⁵ bases) |
| Taq | No | 1x | ~10-20 |
| Pfu | Yes | ~6x | ~1.6 |
| Phusion® | Yes | ~52x | ~0.4 |
| Q5® High-Fidelity | Yes | >100x | ~0.1 |
Data compiled from various sources, including manufacturer's data and scientific literature. Error rates are approximate and can vary with reaction conditions.
Issue 3: DNA Strand Loss During Purification
Symptoms:
-
Low yield of DNA after purification steps.
-
Inconsistent results in downstream applications due to variable DNA concentrations.
Possible Causes and Solutions:
| Cause | Recommended Solution |
| Inefficient Binding to Silica (B1680970) Column | Ensure the buffer conditions (e.g., high salt, correct pH) are optimal for DNA binding to the silica membrane. Avoid overloading the column. |
| DNA Loss During Washing Steps | Follow the manufacturer's protocol carefully for wash steps. Ensure the correct wash buffers are used. |
| Incomplete Elution | Use the recommended elution buffer (often a low-salt buffer or nuclease-free water) and ensure it is applied directly to the center of the membrane. For higher concentrations, use a smaller elution volume. |
| Physical Loss | Be careful during pipetting and transfer steps to avoid losing the DNA pellet (in precipitation methods) or the eluate. |
Quantitative Data: DNA Loss with Purification Kits
| Purification Method | Average DNA Loss (%) | Key Considerations |
| Qiagen MinElute PCR Purification Kit | 21.75% - 60.56%[3][4][5] | Loss can be significant and may not correlate with DNA length or starting concentration.[3] |
| Magnetic Bead-Based Purification | Varies by kit | Generally offers high-quality DNA and is amenable to automation, which can improve consistency.[2][16] |
Visualizing Workflows and Pathways
Workflow for Enzymatic Mismatch Correction
This workflow describes a common method for removing errors from a pool of synthesized DNA fragments.
Signaling Pathway for a Toehold-Mediated Strand Displacement Cascade
This diagram illustrates a simple two-layer signaling cascade using toehold-mediated strand displacement, a fundamental process in dynamic DNA nanotechnology.
Logical Relationship of an AND Gate in DNA Computing
This diagram shows the logical operation of a simple DNA-based AND gate, where the presence of two specific input strands leads to the release of an output strand.
References
- 1. Sources of Error in DNA Computation [web.cs.dal.ca]
- 2. resources.revvity.com [resources.revvity.com]
- 3. How much DNA is lost? Measuring DNA loss of short-tandem-repeat length fragments targeted by the PowerPlex 16® system using the Qiagen MinElute Purification Kit - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. digitalcommons.wayne.edu [digitalcommons.wayne.edu]
- 5. researchgate.net [researchgate.net]
- 6. neb.com [neb.com]
- 7. A surface-based approach to DNA computation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Kinetic Characterization of Single Strand Break Ligation in Duplex DNA by T4 DNA Ligase - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. academic.oup.com [academic.oup.com]
- 11. agilent.com [agilent.com]
- 12. academic.oup.com [academic.oup.com]
- 13. Error Rate Comparison during Polymerase Chain Reaction by DNA Polymerase - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Nucleic acid strand displacement – from DNA nanotechnology to translational regulation - PMC [pmc.ncbi.nlm.nih.gov]
- 15. chem.uci.edu [chem.uci.edu]
- 16. documents.thermofisher.com [documents.thermofisher.com]
Technical Support Center: Troubleshooting Unexpected DNA Circuit Behavior
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals address common issues encountered during DNA circuit experimentation.
Section 1: Leaky Gene Expression
Leaky gene expression, the unintended expression of a gene in the "OFF" state, is a frequent challenge in synthetic biology that can confound experimental results and impact circuit performance. Below are common questions and troubleshooting strategies to identify and mitigate leaky expression.
FAQs: Leaky Gene Expression
Q1: My circuit is showing a high basal level of reporter gene expression in the absence of an inducer. What are the potential causes?
High background expression can stem from several factors:
-
Promoter Leakiness: The promoter controlling your gene of interest may have a basal level of activity even without its cognate activator.
-
Ineffective Repression: If your circuit uses a repressor, it might not be binding to its operator site with high enough affinity or its expression level may be insufficient.
-
Plasmid Copy Number: High plasmid copy numbers can lead to an accumulation of transcription factors that can titrate out repressors, leading to leaky expression.
-
Read-through Transcription: Transcription from an upstream promoter may not be effectively terminated, leading to unintended transcription of your gene of interest.
Q2: How can I quantify the leakiness of my promoter?
Promoter characterization is crucial for understanding and troubleshooting leaky expression. A common method involves measuring reporter gene expression over a range of inducer concentrations.
Experimental Protocol: Promoter Characterization Assay
Objective: To quantify the basal expression level (leakiness) and the dynamic range of an inducible promoter.
Methodology:
-
Construct Preparation: Clone the promoter of interest upstream of a reporter gene (e.g., GFP, RFP, Luciferase) in an appropriate expression vector. A negative control with no promoter and a positive control with a constitutive promoter of known strength should be included.
-
Transformation: Transform the constructs into the desired host organism (e.g., E. coli, mammalian cells).
-
Culture and Induction: Grow the cells under standard conditions. For inducible promoters, create a dilution series of the inducer molecule. A non-induced control (0 inducer) is essential to measure leakiness.
-
Reporter Gene Assay: After a defined induction period, measure the reporter gene expression. For fluorescent proteins, this is typically done using a plate reader or flow cytometer. For luciferase, a luminometer is used.
-
Data Analysis: Normalize the reporter signal to cell density (e.g., OD600 for bacteria). The leakiness is the normalized expression level in the absence of the inducer. The dynamic range is the ratio of the maximum induced expression to the leaky expression.
Q3: What strategies can I employ to reduce leaky gene expression?
Several strategies can be implemented to minimize basal expression:
-
Promoter Engineering: Mutate the promoter sequence to reduce its basal activity. This can involve altering the -10 and -35 regions in prokaryotic promoters.
-
Repressor Optimization: Increase the expression level of the repressor or use a repressor with higher binding affinity.
-
Operator Placement: Optimize the position of the operator sequence within the promoter to ensure efficient repression.
-
Insulator Elements: Flank your gene of interest with transcriptional terminators to prevent read-through from upstream promoters.
-
Antisense RNA (asRNA): Design an asRNA that is complementary to the 5' UTR of your target gene's mRNA. The asRNA can sequester the mRNA and prevent translation.[1][2][3]
-
Degradation Tags: Fuse a protein degradation tag to your output protein to ensure that any protein produced due to leaky expression is rapidly degraded.[4]
-
Coherent Feed-Forward Loop: Implement a circuit architecture, such as a coherent feed-forward loop with a suppressor tRNA, to dampen leaky expression.[5]
Troubleshooting Workflow for Leaky Expression
Caption: Troubleshooting workflow for addressing high basal gene expression.
Section 2: Failed or Low Circuit Output
Another common issue is the failure of a DNA circuit to produce the expected output or producing it at a very low level. This section provides guidance on diagnosing and resolving these problems.
FAQs: Failed or Low Circuit Output
Q1: My DNA circuit is not producing any detectable output. What should I check first?
A complete lack of output can be due to fundamental issues with the DNA construct or the experimental setup. Here's a checklist of initial troubleshooting steps:
-
Sequence Verification: The first and most critical step is to sequence your entire DNA construct.[6][7][8][9][10] Errors in the promoter, ribosome binding site (RBS), coding sequence, or terminator can all lead to a non-functional circuit.
-
Correct Assembly: Verify the correct assembly of your genetic parts. Restriction digests and gel electrophoresis can confirm the presence and size of your insert.
-
Transformation/Transfection Efficiency: Ensure that your host cells have successfully taken up the DNA construct. This can be checked by including a constitutively expressed fluorescent marker on your plasmid or by performing colony PCR.
-
Inducer Concentration and Activity: If your circuit is inducible, confirm that the inducer is at the correct concentration and has not degraded.
-
Reagent Integrity: Check the integrity of all reagents, including enzymes, buffers, and growth media.
Experimental Protocol: Sequence Verification of Synthetic DNA Constructs
Objective: To confirm the nucleotide sequence of a synthetic DNA construct.
Methodology:
-
Plasmid DNA Preparation: Isolate high-quality plasmid DNA from a bacterial culture using a miniprep kit.
-
Sequencing Reaction: Send the purified plasmid DNA and appropriate sequencing primers to a sequencing facility. Primers should be designed to bind upstream and downstream of the region of interest. For long constructs, internal primers may be necessary.
-
Sequence Analysis: Align the sequencing results with your expected reference sequence using sequence analysis software (e.g., SnapGene, Benchling). Pay close attention to potential mutations, deletions, or insertions in critical regions like promoters, RBS, start/stop codons, and operator sites.
Q2: My circuit is producing a very low output signal. How can I increase the expression level?
Low output can be addressed by optimizing various components of your circuit:
-
Promoter Strength: Use a stronger promoter to drive the expression of your gene of interest.
-
Ribosome Binding Site (RBS) Optimization: The RBS sequence significantly impacts translation initiation efficiency. Design and test a library of RBS sequences with varying predicted strengths to find one that maximizes protein expression.[1][2][3][11][12]
-
Codon Optimization: Ensure that the codon usage of your coding sequence is optimized for the host organism to prevent translational bottlenecks.
-
mRNA Stability: Modify the 5' and 3' untranslated regions (UTRs) of the mRNA to enhance its stability.
-
Protein Stability: If the expressed protein is unstable, consider fusing it to a stable protein partner or mutating residues that may be targeted for degradation.
-
Metabolic Burden: Overexpression of a gene can place a significant metabolic burden on the host cell, leading to reduced growth and lower protein yields.[13][14][15] Consider using a lower copy number plasmid or a weaker promoter to alleviate this.
Data Presentation: RBS Optimization for Increased Protein Expression
| RBS Sequence ID | Predicted Translation Initiation Rate (Arbitrary Units) | Observed Protein Expression (Relative Fluorescence Units) |
| RBS_weak | 10 | 150 ± 20 |
| RBS_medium | 100 | 1200 ± 80 |
| RBS_strong | 1000 | 9500 ± 500 |
| RBS_optimized | 850 | 15000 ± 750 |
Troubleshooting Workflow for Low/No Circuit Output
Caption: A systematic workflow for troubleshooting low or absent DNA circuit output.
Section 3: Inconsistent Circuit Performance
Variability in circuit behavior across experiments or within a cell population can be a significant hurdle. This section addresses the causes of and solutions for inconsistent performance.
FAQs: Inconsistent Circuit Performance
Q1: My DNA circuit shows high cell-to-cell variability in its output. What could be the cause?
High cell-to-cell variability, or noise, in gene expression can arise from:
-
Stochastic Gene Expression: Gene expression is an inherently noisy process, particularly for genes expressed at low levels.
-
Plasmid Copy Number Variation: The number of plasmids can vary significantly between individual cells, leading to different expression levels.
-
Uneven Distribution of Cellular Resources: Competition for cellular resources like RNA polymerases and ribosomes can lead to variability in the expression of synthetic genes.[12]
-
Cell Cycle Effects: Gene expression can be influenced by the cell cycle stage.
Q2: How can I reduce the noise in my DNA circuit?
Several strategies can help to make circuit performance more uniform:
-
Genomic Integration: Integrating your DNA circuit into the host genome at a single, defined locus can eliminate variability due to plasmid copy number.
-
Negative Feedback Loops: Introducing a negative feedback loop where the output of the circuit represses its own production can buffer against noise and stabilize expression.
-
Resource-Aware Design: Design circuits that are less sensitive to fluctuations in cellular resources. This might involve using orthogonal ribosomes or engineering components that are less burdensome on the cell.
Q3: My logic gate circuit is not behaving according to its truth table. How do I troubleshoot this?
Unexpected logic gate behavior can be due to several factors:
-
Signal Threshold Mismatches: The output of one gate may not be at the correct level to activate the next gate in a cascade.
-
Crosstalk: Components of your circuit may be unintentionally interacting with each other or with endogenous cellular components.
-
Timing Issues: In dynamic circuits, the timing of different signals can be critical. Delays in the expression of one component can lead to incorrect logical outcomes.
Troubleshooting Logic Gate Behavior
Caption: A workflow for diagnosing and correcting unexpected logic gate behavior.
References
- 1. pubs.acs.org [pubs.acs.org]
- 2. researchgate.net [researchgate.net]
- 3. hilarispublisher.com [hilarispublisher.com]
- 4. benchchem.com [benchchem.com]
- 5. A suppressor tRNA-mediated feedforward loop eliminates leaky gene expression in bacteria - PMC [pmc.ncbi.nlm.nih.gov]
- 6. academic.oup.com [academic.oup.com]
- 7. addgene.org [addgene.org]
- 8. blog.genewiz.com [blog.genewiz.com]
- 9. Sequence verification of synthetic DNA by assembly of sequencing reads - PMC [pmc.ncbi.nlm.nih.gov]
- 10. academic.oup.com [academic.oup.com]
- 11. Automated Design of Synthetic Ribosome Binding Sites to Precisely Control Protein Expression - PMC [pmc.ncbi.nlm.nih.gov]
- 12. [PDF] Automated Design of Synthetic Ribosome Binding Sites to Precisely Control Protein Expression | Semantic Scholar [semanticscholar.org]
- 13. Metabolic Burden: Cornerstones in Synthetic Biology and Metabolic Engineering Applications. | Semantic Scholar [semanticscholar.org]
- 14. researchgate.net [researchgate.net]
- 15. Synthetic biology and regulatory networks: where metabolic systems biology meets control engineering - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Optimizing DNA Strand Displacement Reaction Speed
This technical support center provides troubleshooting guidance and answers to frequently asked questions for researchers, scientists, and drug development professionals working with DNA strand displacement (DSD) reactions. Our goal is to help you diagnose and resolve common issues to enhance the speed and efficiency of your experiments.
Frequently Asked Questions (FAQs)
Q1: What are the primary factors that control the speed of a toehold-mediated DNA strand displacement reaction?
The kinetics of toehold-mediated strand displacement (TMSD) are influenced by several key factors:
-
Toehold Length: The length of the single-stranded toehold region is a critical determinant of the reaction rate. Longer toeholds generally lead to faster reaction kinetics up to a certain point (typically around 6-8 nucleotides), after which the rate plateaus.
-
Toehold Sequence and Composition: The base composition (GC vs. AT content) of the toehold affects the stability of the initial binding event. GC-rich toeholds tend to form more stable initial complexes, which can lead to faster strand displacement. The specific sequence can also influence the reaction rate by orders of magnitude.
-
Temperature: Temperature affects the stability of DNA duplexes and the kinetics of hybridization and branch migration. The optimal temperature will depend on the specific sequences and desired reaction outcome.
-
Buffer Composition: The ionic strength (salt concentration) and pH of the reaction buffer can significantly impact reaction rates by altering the stability of the DNA duplexes.
-
Concentration of Reactants: The rate of a bimolecular strand displacement reaction is dependent on the concentration of the invading strand and the substrate complex.
-
Secondary Structures: Unintended secondary structures within the DNA strands, such as hairpins, can hinder toehold binding and slow down the reaction.
Q2: How does the position of the toehold affect the reaction speed?
The location of the toehold significantly impacts the kinetics of the strand displacement reaction. External toeholds, located at the end of a duplex, generally result in reaction rates that are 10 to 100 times faster than those with internal toeholds (loops). This is because external toeholds have a lower entropic barrier for the invading strand to bind compared to internal toeholds, which are more topologically constrained.
Q3: Can enzymes be used to speed up DNA strand displacement?
Yes, certain enzymes can be used to facilitate or accelerate strand displacement. For instance, DNA polymerases with strand displacement activity can actively unwind a downstream duplex as they synthesize a new strand. This enzymatic action can be much faster than spontaneous branch migration. Nicking enzymes can also be used in isothermal amplification methods like Strand Displacement Amplification (SDA) to create initiation sites for a polymerase with strand displacement activity.
Troubleshooting Guide
This guide addresses common problems encountered during DNA strand displacement experiments and provides actionable solutions.
Problem 1: My DNA strand displacement reaction is much slower than expected.
Slow reaction kinetics can be a significant hurdle. The following steps can help you identify and address the root cause.
Logical Flow for Troubleshooting Slow Reactions
Caption: Troubleshooting workflow for slow DSD reactions.
Quantitative Impact of Key Parameters on Reaction Rate
| Parameter | Typical Effect on Rate | Notes |
| Toehold Length | Increases by an order of magnitude per nucleotide added (up to ~6 nt). | The effect plateaus for longer toeholds. |
| Temperature | Varies depending on the system; can increase or decrease rate. | Optimal temperature balances duplex stability and strand dynamics. |
| Mg²⁺ Concentration | Generally increases rate by stabilizing duplexes. | High concentrations can sometimes inhibit reactions or promote non-specific interactions. |
| Invading Strand Concentration | Higher concentration leads to a faster initial reaction rate. | Follows second-order reaction kinetics. |
Experimental Protocol: Optimizing Temperature
-
Preparation: Prepare your reaction mix with the substrate complex and invading strand at their final concentrations in the reaction buffer. Aliquot the mix into multiple tubes or wells of a PCR plate.
-
Temperature Gradient: Use a thermal cycler with a gradient function to incubate the reactions across a range of temperatures (e.g., 15°C to 45°C). The optimal range will depend on the melting temperature (Tm) of your DNA constructs.
-
Initiation and Measurement: Start the reaction by adding the invading strand. Monitor the reaction progress over time using a real-time fluorescence plate reader.
-
Data Analysis: For each temperature, plot the fluorescence signal versus time and fit the data to an appropriate kinetic model (e.g., single exponential) to extract the observed rate constant (k_obs).
-
Optimization: Identify the temperature that yields the highest reaction rate.
Problem 2: I am observing a high level of "leaky" or background signal in my reaction.
Leakage refers to the displacement reaction occurring in the absence of the intended input or trigger. This can be caused by the spontaneous dissociation of the incumbent strand or by unintended interactions between strands.
Strategies to Reduce Leakage
Caption: Strategies for reducing leakage in DSD reactions.
Experimental Protocol: Quantifying Leakage Rate
-
Reaction Setup: Prepare two sets of reactions.
-
Test Reaction: Substrate complex + Invading strand.
-
Leakage Control: Substrate complex only (no invading strand).
-
-
Incubation: Incubate both sets of reactions under the same experimental conditions (temperature, buffer).
-
Measurement: Monitor the fluorescence signal over an extended period (e.g., several hours to days) to capture the slow leakage kinetics.
-
Data Analysis:
-
Calculate the initial rate of the test reaction.
-
Calculate the rate of signal increase in the leakage control. This represents the leak rate.
-
The signal-to-noise ratio can be determined by comparing the endpoint signal of the test reaction to the signal generated by the leak reaction over the same time course.
-
Problem 3: My reaction is not going to completion, or the final signal is lower than expected.
Incomplete reactions can be due to several factors, including incorrect reactant ratios, degradation of oligonucleotides, or the presence of inhibitors.
Troubleshooting Incomplete Reactions
| Potential Cause | Suggested Solution |
| Incorrect Stoichiometry | Carefully re-quantify the concentration of all oligonucleotide stocks using a reliable method (e.g., NanoDrop, Qubit). Ensure accurate pipetting. |
| Oligonucleotide Degradation | Use freshly prepared or properly stored (at -20°C or -80°C) oligonucleotides. Consider running a denaturing PAGE gel to check the integrity of your strands. |
| Presence of Inhibitors | Ensure all reagents and water are nuclease-free. Some components from upstream purification steps can inhibit reactions; consider re-purifying your oligonucleotides. |
| Reversible Reaction | If the reverse reaction is significant, you may reach an equilibrium state before full completion. Consider redesigning the system to make the forward reaction more thermodynamically favorable (e.g., by creating a longer product duplex). |
| Photobleaching | If using a fluorescence readout, prolonged exposure to excitation light can cause photobleaching of the fluorophore, leading to a decrease in signal. Reduce the frequency of measurements or lower the excitation intensity if possible. |
Experimental Workflow for Verifying Strand Integrity and Concentration
Technical Support Center: Enhancing the Stability of DNA Nanostructures
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in overcoming challenges related to the stability of DNA nanostructures.
Troubleshooting Guides
This section offers step-by-step guidance to address common stability issues encountered during experiments with DNA nanostructures.
Issue 1: DNA Nanostructure Degradation in Biological Fluids (e.g., serum)
Symptoms:
-
Disappearance or smearing of the band corresponding to the DNA nanostructure on an agarose (B213101) or polyacrylamide gel after incubation in serum-containing media.
-
Loss of function (e.g., reduced binding affinity, compromised drug release profile).
-
Changes in particle size or aggregation state as measured by Dynamic Light Scattering (DLS).
Possible Causes:
-
Nuclease Activity: Serum and other biological fluids contain nucleases (e.g., DNase I) that digest DNA.[1]
-
Low Cation Concentration: Physiological fluids often have lower concentrations of divalent cations (like Mg²⁺) than are typically used for DNA nanostructure assembly and storage, leading to electrostatic repulsion and destabilization.[1][2]
Solutions:
-
Strategy 1: Protective Coatings
-
Poly(ethylene glycol) (PEG) Coating: PEGylation can shield the DNA nanostructure from nuclease attack and reduce aggregation.[1]
-
Oligolysine-PEG Copolymer Coating: This coating provides a positive charge to neutralize the negative phosphate (B84403) backbone, enhancing stability in low-salt conditions, while the PEG component prevents aggregation and offers nuclease resistance.[3] A 1,000-fold increase in nuclease resistance has been observed with this method.[3]
-
-
Strategy 2: Covalent Cross-linking
-
Glutaraldehyde Cross-linking: This method can be used to cross-link amine-modified DNA strands or to cross-link protective coatings like oligolysine, significantly enhancing stability.[4] Cross-linking oligolysine-coated structures can extend their survival by over 250-fold even in high concentrations of DNase I.[4]
-
Enzymatic Ligation: T4 DNA ligase can be used to seal nicks in the DNA backbone, creating a more robust, covalently closed structure.[5][6][7] Ligation can increase the thermal stability of DNA origami by as much as 20°C.[8]
-
-
Strategy 3: Buffer Optimization
Experimental Workflow for Nuclease Degradation Assay:
Issue 2: DNA Nanostructure Aggregation
Symptoms:
-
Visible precipitation in the sample tube.
-
Significant increase in hydrodynamic radius and polydispersity index (PDI) in DLS measurements.
-
Smearing or retention of the sample in the well of an agarose gel.
Possible Causes:
-
Hydrophobic Modifications: Modifications with hydrophobic moieties like cholesterol can lead to aggregation.
-
High N:P Ratios in Coatings: When using cationic coatings like oligolysine, a high ratio of nitrogen (N) in the coating to phosphate (P) in the DNA can cause aggregation.[3]
-
Inappropriate Buffer Conditions: Suboptimal salt concentrations can lead to aggregation.
Solutions:
-
For Hydrophobically Modified Nanostructures:
-
Shielding with ssDNA Overhangs: Introducing single-stranded DNA overhangs adjacent to hydrophobic modifications can sterically hinder aggregation.[9]
-
-
For Cationic Coatings:
-
Optimize N:P Ratio: Empirically determine the optimal N:P ratio that provides stability without causing aggregation. Ratios around 0.5:1 (N:P) for oligolysine have been shown to be effective.[3]
-
Use PEGylated Copolymers: Incorporating PEG into the cationic polymer (e.g., oligolysine-PEG) can prevent aggregation even at higher N:P ratios.[3]
-
Troubleshooting Logic for Aggregation Issues:
Quantitative Data on Stability Enhancement
The following tables summarize quantitative data on the stability of DNA nanostructures under various conditions and with different stabilization strategies. Note that direct comparison between studies should be made with caution due to variations in experimental setups.
Table 1: Half-life of DNA Nanostructures in Serum
| DNA Nanostructure | Serum Condition | Stabilization Method | Half-life | Reference |
| Tetrahedron (TDN) | 20% Human Serum | None | 23.9 hours | [10][11] |
| Tetrahedron (TDN) | 50% Human Serum | None | 10.1 hours | [10][11] |
| DNA Origami (DN1) | 10% Fetal Bovine Serum (FBS) | None | ~5 minutes | [3] |
| DNA Origami (DN1) | 10% FBS + 10 mM Mg²⁺ | None | ~55 minutes | [3] |
| DNA Origami (DN1) | 10% FBS | Oligolysine (K₁₀) coating | ~50 minutes | [3] |
Table 2: Nuclease Resistance with Different Stabilization Methods
| DNA Nanostructure | Nuclease Condition | Stabilization Method | Fold Increase in Resistance | Reference |
| DNA Origami (DN1) | DNase I | Oligolysine (K₁₀) coating | Up to 10-fold | [3] |
| DNA Origami (DN1) | DNase I | Oligolysine-PEG (K₁₀-PEG₅K) | ~1,000-fold | [3] |
| DNA Origami | DNase I | Glutaraldehyde cross-linked Oligolysine-PEG | ~250-fold (over non-cross-linked) | [4] |
Key Experimental Protocols
Protocol 1: Oligolysine-PEG Coating of DNA Nanostructures
-
Preparation of Solutions:
-
Prepare a stock solution of the DNA nanostructure at a known concentration in a suitable buffer (e.g., TE buffer with 10 mM MgCl₂).
-
Prepare a stock solution of Oligolysine-PEG copolymer.
-
-
Coating Procedure:
-
Mix the DNA nanostructure solution with the Oligolysine-PEG solution to achieve the desired N:P ratio. A common starting point is a 0.5:1 ratio of nitrogen in lysine (B10760008) to phosphorus in DNA.[3]
-
Incubate the mixture at room temperature for 30 minutes.
-
-
Purification (Optional but Recommended):
-
Characterization:
-
Confirm the integrity and dispersion of the coated nanostructures using agarose gel electrophoresis and DLS.
-
Protocol 2: Enzymatic Ligation of DNA Origami
-
Phosphorylation of Staples:
-
If not already 5'-phosphorylated, incubate the staple oligonucleotides with T4 Polynucleotide Kinase (PNK) in T4 DNA ligase buffer at 37°C for at least 1 hour.[6]
-
-
Origami Assembly:
-
Assemble the DNA origami with the phosphorylated staples and scaffold DNA using a standard thermal annealing protocol.
-
-
Ligation Reaction:
-
Purification:
-
Purify the ligated origami from excess staples and enzyme using methods like PEG precipitation or size exclusion chromatography.
-
-
Verification:
-
Confirm successful ligation by observing increased thermal stability (e.g., via a temperature-gradient gel) or resistance to denaturation.[7]
-
Frequently Asked Questions (FAQs)
Q1: My DNA origami structure is unstable even in the recommended storage buffer. What could be the problem?
A1: Several factors could be at play:
-
Incorrect Buffer Composition: Ensure your buffer (e.g., TAE) is supplemented with the correct concentration of MgCl₂, typically 10-15 mM.[14] The absence or low concentration of divalent cations is a primary cause of instability.[1]
-
pH Issues: The pH of your buffer should be around 8.0. Extreme pH values can lead to DNA denaturation.
-
Design Flaws: The design of the origami itself can influence its stability. Structures with fewer crossovers or a less compact design may be inherently less stable.[1] Consider redesigning for greater structural integrity if buffer optimization does not help.
-
Nuclease Contamination: Ensure all your solutions and labware are nuclease-free.
Q2: How can I assess the stability of my DNA nanostructures in a simple way?
A2: Agarose gel electrophoresis is a straightforward method.[15][16]
-
Incubate your nanostructure under the test condition (e.g., in 10% FBS) for various time points.
-
Run the samples on an agarose gel alongside a control sample (nanostructure in its optimal buffer).
-
Degradation is indicated by a decrease in the intensity of the band corresponding to the intact nanostructure and the appearance of a smear. By quantifying the band intensity at different time points, you can estimate the rate of degradation.[15]
Q3: Can I use heat inactivation to eliminate nucleases from fetal bovine serum (FBS)?
A3: While standard heat inactivation of FBS (56°C for 30 minutes) is common for inactivating complement proteins, it is not sufficient to completely eliminate nuclease activity that degrades DNA nanostructures.[2] More extreme heat treatment can damage other serum components essential for cell culture.[2] Therefore, relying on protective coatings or cross-linking is a more robust strategy for nuclease resistance.
Q4: What is the first step I should take to troubleshoot unexpected experimental results when working with DNA nanostructures in a biological context?
A4: Always verify the structural integrity of your nanostructures under the specific experimental conditions (e.g., cell culture medium, temperature) before proceeding with functional assays.[2] A simple stability check using agarose gel electrophoresis can save significant time and prevent misinterpretation of results. This is crucial because many standard biological buffers and media are not optimal for DNA nanostructure stability.[1][2]
References
- 1. Improving DNA Nanostructure Stability: A Review of the Biomedical Applications and Approaches - PMC [pmc.ncbi.nlm.nih.gov]
- 2. pubs.acs.org [pubs.acs.org]
- 3. Oligolysine-based coating protects DNA nanostructures from low-salt denaturation and nuclease degradation - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. Stabilization and structural changes of 2D DNA origami by enzymatic ligation - PMC [pmc.ncbi.nlm.nih.gov]
- 6. academic.oup.com [academic.oup.com]
- 7. Enhancing the stability of DNA origami nanostructures: staple strand redesign versus enzymatic ligation - Nanoscale (RSC Publishing) [pubs.rsc.org]
- 8. [PDF] Stabilization and structural changes of 2D DNA origami by enzymatic ligation | Semantic Scholar [semanticscholar.org]
- 9. academic.oup.com [academic.oup.com]
- 10. Characterization of DNA nanostructure stability by size exclusion chromatography - Analytical Methods (RSC Publishing) [pubs.rsc.org]
- 11. researchgate.net [researchgate.net]
- 12. researchgate.net [researchgate.net]
- 13. Facile and Scalable Preparation of Pure and Dense DNA Origami Solutions - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Structural stability of DNA origami nanostructures under application-specific conditions - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Nuclease degradation analysis of DNA nanostructures using gel electrophoresis - PMC [pmc.ncbi.nlm.nih.gov]
- 16. researchgate.net [researchgate.net]
Technical Support Center: Scaling Up DNA Computing
Welcome to the Technical Support Center for DNA Computing. This resource is designed for researchers, scientists, and drug development professionals to provide troubleshooting guidance and answers to frequently asked questions encountered when scaling up DNA computing experiments.
Frequently Asked Questions (FAQs)
Q1: My DNA logic gate is showing significant signal leakage, leading to incorrect outputs. What are the common causes and how can I troubleshoot this?
A1: Signal leakage in DNA logic gates, particularly those based on strand displacement reactions, is a common challenge. It often arises from non-specific strand displacement or "toehold exchange" reactions. Here are the primary causes and troubleshooting steps:
-
Spurious Toehold Binding: Unintended binding of DNA strands to short, complementary sequences outside of the designated toehold region.
-
Solution: Redesign your DNA sequences to minimize spurious toehold-like regions. Utilize sequence design software that screens for and eliminates such unintended binding sites.
-
-
Blunt-end Displacement: Slow, non-specific displacement of strands at the ends of duplexes.
-
Solution: Incorporate non-reactive "clamp" domains at the ends of your DNA constructs to prevent blunt-end exchanges.
-
-
Environmental Factors: Suboptimal temperature or buffer conditions can increase non-specific interactions.
-
Solution: Optimize the reaction temperature and buffer composition (e.g., salt concentration) to enhance the specificity of your strand displacement reactions.
-
Q2: I'm observing low yields of my desired DNA origami structures. What factors could be contributing to this and how can I improve the folding accuracy?
A2: Low yields in DNA origami self-assembly can be attributed to several factors, from design flaws to suboptimal experimental conditions. Here's a breakdown of potential issues and solutions:
-
Suboptimal Scaffold and Staple Strand Design: The routing of the scaffold strand and the design of staple strands are critical for proper folding.[1][2][3]
-
Incorrect Annealing Conditions: The temperature ramp during the annealing process is crucial for allowing the DNA strands to find their correct conformations.
-
Solution: Optimize the annealing protocol. This may involve adjusting the starting and ending temperatures, as well as the rate of cooling. A slower annealing ramp often leads to higher yields of correctly folded structures.
-
-
Impure or Degraded Oligonucleotides: The quality of the scaffold and staple strands is paramount.
-
Solution: Ensure the purity of your DNA oligonucleotides. Use purification methods like polyacrylamide gel electrophoresis (PAGE) to isolate full-length strands. Store DNA appropriately to prevent degradation.
-
Q3: My multi-stage DNA circuit is failing to propagate the signal effectively. What are the bottlenecks and how can I enhance signal amplification?
A3: Signal propagation failure in multi-stage DNA circuits is a significant hurdle in scaling up complexity. The primary bottleneck is often the loss of signal strength at each stage.
-
Concentration Mismatch: The output concentration from one stage may be insufficient to trigger the subsequent stage effectively.[4]
-
Solution: Integrate signal amplification modules between stages.[4] These can be enzymatic (e.g., using polymerases) or non-enzymatic (e.g., catalytic hairpin assembly).
-
-
Crosstalk Between Components: Unintended interactions between components of different stages can consume signal strands and inhibit the intended pathway.
-
Solution: Design orthogonal DNA sequences for each stage of the circuit. This minimizes the chance of unintended hybridization and strand displacement reactions between different parts of your circuit.
-
-
Incomplete Reactions: If the reactions in one stage do not go to completion, the output signal will be attenuated.
-
Solution: Optimize reaction times and concentrations of reactants to ensure each stage of the circuit reaches completion before the next is initiated.
-
Troubleshooting Guides
Issue: High Error Rates in DNA Data Storage and Retrieval
Symptoms:
-
Inaccurate data readout after sequencing.
-
Loss of stored information over time.
-
High frequency of insertions, deletions, or substitutions in sequenced DNA.
Possible Causes and Solutions:
| Cause | Solution |
| Synthesis Errors | Use high-fidelity synthesis methods. Incorporate error-correcting codes (ECCs) during the encoding process to detect and correct synthesis errors.[5][6] |
| Storage-induced DNA Damage | Store DNA in a dehydrated, anoxic environment at low temperatures to minimize degradation. Encapsulate DNA in silica (B1680970) or other protective materials. |
| Sequencing Errors | Use high-accuracy sequencing platforms. Employ redundant sequencing (i.e., sequence the same DNA multiple times) and use consensus calling to reduce sequencing errors.[7] |
| Strand Loss During Manipulation | Optimize DNA extraction and purification protocols to minimize physical loss of DNA strands.[8] Use PCR to amplify the retrieved DNA, but be mindful of potential amplification bias. |
Issue: Non-Specific Amplification in PCR-based DNA Computing Steps
Symptoms:
-
Multiple bands on a gel electrophoresis analysis where only one is expected.
-
Incorrect computational results due to the presence of unintended DNA products.
Possible Causes and Solutions:
| Cause | Solution |
| Suboptimal Primer Design | Design primers with appropriate melting temperatures (Tm) and avoid sequences prone to forming hairpins or self-dimers. Use primer design software to check for potential off-target binding sites.[9] |
| Incorrect Annealing Temperature | Optimize the annealing temperature in your PCR protocol. A temperature that is too low can lead to non-specific primer binding.[9] |
| High Primer Concentration | Use the lowest effective concentration of primers to reduce the likelihood of non-specific binding and primer-dimer formation.[10] |
| Contamination | Ensure a clean work environment and use aerosol-resistant pipette tips to prevent cross-contamination between samples.[10] |
Experimental Protocols
Protocol 1: High-Fidelity DNA Origami Annealing
This protocol is designed to maximize the yield of correctly folded DNA origami structures.
Materials:
-
Scaffold DNA (e.g., p7249)
-
Staple DNA strands (in excess)
-
Folding buffer (e.g., TE buffer with 12.5 mM MgCl2)
Procedure:
-
Mixing: In a PCR tube, combine the scaffold DNA and a 10-fold molar excess of each staple strand in the folding buffer.
-
Initial Denaturation: Heat the mixture to 95°C for 5 minutes to denature all DNA strands.
-
Annealing Ramp: Slowly cool the mixture from 95°C to 25°C over a period of 12-16 hours. A thermal cycler is ideal for this step. A typical ramp would be a decrease of 1°C every 5 minutes.
-
Analysis: Analyze the folded structures using agarose (B213101) gel electrophoresis or transmission electron microscopy (TEM) to confirm correct folding and yield.
Protocol 2: Error-Correction using Reed-Solomon Codes in DNA Data Storage
This protocol outlines the conceptual steps for implementing Reed-Solomon (RS) error correction in a DNA data storage workflow.
Methodology:
-
Encoding:
-
Convert your digital data into a binary stream.
-
Segment the binary data into blocks.
-
Apply a Reed-Solomon encoder to each block. This adds redundant parity bits to the data.
-
Convert the encoded binary data into DNA sequences (A, T, C, G).
-
-
Synthesis and Storage:
-
Synthesize the DNA sequences.
-
Store the DNA under appropriate conditions.
-
-
Retrieval and Sequencing:
-
Retrieve the DNA sample.
-
Sequence the DNA to read the stored information.
-
-
Decoding and Error Correction:
-
Convert the sequenced DNA back into binary format.
-
Apply the Reed-Solomon decoder to each data block. The decoder will use the parity bits to identify and correct errors (up to a certain limit) that occurred during synthesis, storage, or sequencing.
-
Convert the corrected binary data back to its original format.
-
Visualizations
Signaling Pathways and Workflows
Caption: A signal amplification cascade in a multi-stage DNA circuit.
Caption: The experimental workflow for creating DNA origami nanostructures.
Caption: The logical flow of error correction in DNA data storage.
References
- 1. mdpi.com [mdpi.com]
- 2. pnas.org [pnas.org]
- 3. Design principles for accurate folding of DNA origami - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. pubs.acs.org [pubs.acs.org]
- 5. academic.oup.com [academic.oup.com]
- 6. academic.oup.com [academic.oup.com]
- 7. project.inria.fr [project.inria.fr]
- 8. dna.caltech.edu [dna.caltech.edu]
- 9. bento.bio [bento.bio]
- 10. neb.com [neb.com]
Technical Support Center: Debugging Molecular Programming Simulations
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in debugging their molecular programming simulations.
I. Troubleshooting Guides
This section offers structured guidance for resolving common issues encountered during molecular programming simulations, categorized by simulation methodology.
Molecular Dynamics (MD) Simulations
Molecular dynamics simulations are powerful tools for understanding the behavior of molecular systems at an atomic level. However, their accuracy is highly dependent on proper setup and parameterization.
Issue: My simulation is unstable and crashing (e.g., "system blowing up").
This is a common problem, often indicating large, unphysical forces in the system.
-
Possible Causes & Solutions:
-
Poor Initial Structure: The starting coordinates of your molecular system may contain steric clashes, incorrect protonation states, or missing atoms.[1] It is crucial to properly prepare the initial structure by checking for and correcting these issues.[1]
-
Inadequate Energy Minimization: The system must be properly minimized to relieve any initial high-energy contacts before starting the simulation. A multi-stage minimization approach, where the solvent and ions are first minimized with the solute restrained, followed by a gradual release of restraints and minimization of the entire system, can be effective.[2]
-
Inappropriate Timestep: A timestep that is too large can lead to numerical instability.[2] For systems with high-frequency motions, such as bond vibrations involving hydrogen, a smaller timestep (e.g., 1-2 fs) is often necessary.
-
Incorrect Force Field Parameters: Using a force field that is not appropriate for your molecule or mixing incompatible force fields can lead to inaccurate energetics and instability.[1][3] Ensure the chosen force field is well-validated for the class of molecules you are simulating.[1]
-
Workflow for Diagnosing Unstable MD Simulations:
DNA Strand Displacement (DSD) Simulations
Simulations of DNA strand displacement cascades are crucial for designing and analyzing the kinetics of molecular circuits.
Issue: My simulated reaction kinetics do not match experimental results.
Discrepancies between simulated and experimental kinetics are common and can arise from several factors.
-
Possible Causes & Solutions:
-
Leak Reactions: Unintended, toehold-independent strand displacement reactions, known as "leaks," can significantly impact the overall kinetics.[4] These are often initiated by transient "breathing" at the ends of helices. Consider redesigning sequences to minimize fraying at duplex ends, for example, by using GC clamps.
-
Inaccurate Rate Constants: The rate constants used in the simulation may not accurately reflect the experimental conditions. Toehold-mediated strand displacement rates are highly dependent on toehold length and sequence.[5][6] Ensure your simulation's rate model accounts for these factors.
-
Secondary Structures: Unintended secondary structures in single-stranded species can sequester domains and inhibit reactions.[4] Use nucleic acid secondary structure prediction tools to check for and redesign problematic sequences.
-
Environmental Factors: The simulation may not accurately model the experimental buffer conditions (e.g., salt concentration, temperature), which can significantly affect hybridization kinetics.[7]
-
Logical Relationship for DSD Kinetic Mismatches:
Agent-Based Models (ABM) of Signaling Pathways
Agent-based models are valuable for simulating the emergent behavior of complex biological systems from the interactions of individual components.
Issue: My agent-based model produces unrealistic emergent behavior.
Unrealistic emergent behavior often points to issues with the agent rules or the environment definition.
-
Possible Causes & Solutions:
-
Incorrect Agent Rules: The rules governing agent behavior (e.g., movement, interaction, state changes) may not accurately reflect the underlying biology. A thorough review of the literature and experimental data is necessary to ensure the rules are well-founded.
-
Parameter Sensitivity: The model's output may be highly sensitive to certain parameters.[8] A sensitivity analysis, where parameters are systematically varied, can identify which ones have the most significant impact on the outcome.[9][10]
-
Spatial Abstraction: The way space is represented in the model (e.g., grid-based vs. continuous) can introduce artifacts.[11] The choice of spatial representation should be appropriate for the biological question being addressed.
-
Stochasticity: The role of randomness in the model should be carefully considered. While biological processes are inherently stochastic, the level and implementation of randomness in the model can significantly affect the results.
-
II. Frequently Asked Questions (FAQs)
Q1: How do I choose the right force field for my DNA simulation?
Choosing an appropriate force field is critical for the accuracy of your simulation.[1] Different force fields are parameterized for different types of molecules and conditions. For DNA, commonly used force fields include AMBER and CHARMM. Recent versions of these force fields have been specifically refined to better reproduce the structural properties of B-DNA.[4] It is important to consult recent benchmark studies to select a force field that has been well-validated for the specific properties you are interested in.[12]
Q2: My DNA origami simulation shows significant deviations from the target structure. What could be the cause?
Deviations from the target structure in DNA origami simulations can be due to several factors. The initial model generated from the design software may not be physically realistic. An equilibration period using molecular dynamics is often necessary to relax the structure.[13] The choice of force field and simulation parameters, such as the treatment of ions, can also significantly impact the final structure.[13][14] Comparing simulation results with experimental data from techniques like cryo-EM can help validate and refine the simulation protocol.[15]
Q3: How can I reduce leak reactions in my DNA strand displacement circuit?
Leakage, or the unintended reaction between components, is a common problem in DSD circuits.[4] Several strategies can be employed to reduce it:
-
Sequence Design: Avoid sequences prone to fraying at the ends of duplexes, such as AT-rich regions. Using GC-clamps can increase stability.
-
Structural Protection: Toeholds can be sequestered in hairpin loops or other secondary structures, making them inaccessible until a specific trigger is present.[16]
-
Redundancy: Implementing logical redundancy in the circuit design can create a higher energy barrier for leak reactions.[17]
Q4: What are common artifacts to watch out for in agent-based models of cellular signaling?
A common artifact in grid-based ABMs is the emergence of patterns that are aligned with the grid axes, which may not be biologically realistic. Using a different grid geometry (e.g., hexagonal) or an off-lattice model can help mitigate this. Another potential artifact arises from the order in which agents are updated, which can be addressed by using asynchronous updating schemes.
III. Data Presentation
Table 1: Comparison of DNA Force Fields
This table summarizes the performance of several common force fields in reproducing key structural parameters of B-DNA, as determined from molecular dynamics simulations. RMSD (Root Mean Square Deviation) values are in Ångstroms (Å) from experimental structures.
| Force Field | Average RMSD (Å) | Propensity for A-form DNA | BI/BII Population Ratio | Reference |
| AMBER (parmbsc0) | ~2.5 | Higher | Deviates from experiment | [1][4] |
| AMBER (parmbsc1) | ~2.0 | Moderate | Improved over parmbsc0 | [1] |
| CHARMM27 | ~3.8 (B to A transition) | High | - | [4] |
| CHARMM36 | ~1.8 | Low | Good agreement | [3][4] |
Table 2: Effect of Timestep on Simulation Stability
This table illustrates the relationship between the timestep size and the stability of a molecular dynamics simulation. The "Maximum Stable Timestep" is the largest timestep that can be used without the simulation crashing.
| System | Fastest Vibrational Period (fs) | Maximum Stable Timestep (fs) | Recommended Timestep (fs) | Reference |
| H₂ molecule | ~11 | < 1.823 | < 1.0 | [15][18] |
| CO₂ molecule | ~25 | < 3.808 | < 2.0 | [15] |
| Water (TIP3P) | ~10 | ~4 | 1-2 | [7] |
| DNA with hydrogens | ~10 | ~4 | 1-2 | [18] |
IV. Experimental Protocols
Detailed Methodology for Surface Plasmon Resonance (SPR) Analysis of DNA-Protein Interactions
This protocol describes the use of SPR to measure the binding kinetics of a protein to a DNA ligand.[19]
-
Immobilization of DNA Ligand:
-
A sensor chip (e.g., CM5) is activated with a mixture of N-hydroxysuccinimide (NHS) and 1-ethyl-3-(3-dimethylaminopropyl)carbodiimide (B157966) (EDC).
-
Streptavidin is injected over the activated surface for covalent immobilization.
-
The remaining active groups are deactivated with ethanolamine.
-
A biotinylated DNA oligo is injected over the streptavidin-coated surface for capture.
-
-
Binding Analysis:
-
A running buffer (e.g., HBS-EP) is continuously flowed over the sensor surface to establish a stable baseline.
-
The protein analyte is injected at various concentrations over the surface. The association phase is monitored in real-time.
-
After the injection, the running buffer is flowed over the surface to monitor the dissociation phase.
-
The surface is regenerated with a pulse of a suitable regeneration solution (e.g., a low pH buffer or high salt concentration) to remove the bound analyte.
-
-
Data Analysis:
-
The resulting sensorgrams are corrected for non-specific binding by subtracting the signal from a reference flow cell.
-
The association (k_a) and dissociation (k_d) rate constants are determined by fitting the sensorgram data to a suitable binding model (e.g., 1:1 Langmuir binding).
-
The equilibrium dissociation constant (K_D) is calculated as k_d / k_a.
-
Experimental Workflow for SPR:
Detailed Methodology for Atomic Force Microscopy (AFM) Imaging of DNA Origami
This protocol provides a method for imaging DNA origami structures using AFM in tapping mode.[20]
-
Sample Preparation:
-
DNA origami structures are self-assembled by mixing a long scaffold strand with an excess of short staple strands in a buffer containing Mg²⁺ and heating, followed by slow cooling.
-
The assembled origami is diluted to a final concentration of approximately 1 nM in an imaging buffer (e.g., 1x TAE buffer with MgCl₂).
-
-
Surface Preparation:
-
A fresh mica surface is prepared by cleaving the top layer with tape.
-
A small volume (e.g., 2 µL) of the diluted origami solution is deposited onto the mica surface and allowed to adsorb for 5-10 minutes.
-
The surface is gently rinsed with the imaging buffer to remove unbound origami.
-
-
AFM Imaging:
-
The AFM is operated in tapping mode in liquid, using a cantilever with a sharp tip.
-
The imaging parameters (scan size, scan rate, setpoint) are optimized to obtain high-resolution images without damaging the sample.
-
Images are collected and processed to remove noise and artifacts.
-
Detailed Methodology for Fluorescence Spectroscopy of DNA Hybridization
This protocol describes how to monitor DNA hybridization using a fluorescently labeled DNA probe.
-
Probe and Target Preparation:
-
A single-stranded DNA probe is synthesized with a fluorescent dye (e.g., FAM) at one end and a quencher (e.g., BHQ-1) at the other. In the unhybridized state, the probe forms a hairpin structure, bringing the dye and quencher into close proximity and quenching the fluorescence.
-
The target DNA or RNA is prepared in a hybridization buffer (e.g., saline-sodium citrate (B86180) buffer).
-
-
Fluorescence Measurement:
-
The fluorescent probe is added to the hybridization buffer in a quartz cuvette.
-
The baseline fluorescence is measured using a spectrofluorometer at an excitation wavelength appropriate for the dye.
-
The target DNA/RNA is added to the cuvette, and the fluorescence is monitored over time.
-
-
Data Analysis:
-
Hybridization of the probe to the target results in a conformational change that separates the dye and quencher, leading to an increase in fluorescence intensity.
-
The kinetics of hybridization can be determined by fitting the fluorescence increase over time to a kinetic model.
-
The final fluorescence intensity can be used to quantify the amount of target present.
-
Signaling Pathway for a Fluorogenic DNA Probe:
References
- 1. A Novel Computational Method to Reduce Leaky Reaction in DNA Strand Displacement - PMC [pmc.ncbi.nlm.nih.gov]
- 2. pubs.acs.org [pubs.acs.org]
- 3. tandfonline.com [tandfonline.com]
- 4. Availability: A Metric for Nucleic Acid Strand Displacement Systems - PMC [pmc.ncbi.nlm.nih.gov]
- 5. pnas.org [pnas.org]
- 6. Design of DNA Strand Displacement Reactions [arxiv.org]
- 7. mdpi.com [mdpi.com]
- 8. Facilitating Parameter Estimation and Sensitivity Analysis of Agent-Based Models [jasss.org]
- 9. Which Sensitivity Analysis Method Should I Use for My Agent-Based Model? [jasss.org]
- 10. researchgate.net [researchgate.net]
- 11. Methodological Issues of Spatial Agent-Based Models [jasss.org]
- 12. Methods That Support the Validation of Agent-Based Models [jasss.org]
- 13. pnas.org [pnas.org]
- 14. bionano.physics.illinois.edu [bionano.physics.illinois.edu]
- 15. academic.oup.com [academic.oup.com]
- 16. Toehold mediated strand displacement - Wikipedia [en.wikipedia.org]
- 17. pnas.org [pnas.org]
- 18. intranet.csc.liv.ac.uk [intranet.csc.liv.ac.uk]
- 19. Design and analysis of DNA strand displacement devices using probabilistic model checking - PMC [pmc.ncbi.nlm.nih.gov]
- 20. Design Approaches and Computational Tools for DNA Nanostructures - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Minimizing Crosstalk in Synthetic Biological Circuits
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals minimize crosstalk in their synthetic biological circuits.
Troubleshooting Guides
Unintended interactions, or crosstalk, between components of a synthetic biological circuit can lead to unpredictable behavior and circuit failure. This guide provides systematic troubleshooting for common issues.
Issue 1: Unexpected Gene Expression or Repression (Potential Direct Crosstalk)
Symptoms:
-
A reporter gene is expressed when its cognate activator is absent.
-
A gene is repressed when its specific repressor is not present.
-
The level of gene expression is significantly different from the expected output.
Troubleshooting Workflow:
Caption: Troubleshooting workflow for direct crosstalk issues.
Detailed Steps:
-
Verify Component Orthogonality: The first step is to determine if the transcription factors (TFs) used in your circuit are binding to non-cognate promoters.
-
Experiment: Perform a crosstalk characterization assay. For each TF in your system, co-transform a plasmid expressing the TF with a reporter plasmid where a fluorescent protein or luciferase is driven by each of the promoters in your system (both cognate and non-cognate).
-
Expected Outcome: Significant reporter expression should only be observed in the presence of the cognate TF.
-
Troubleshooting: If significant expression is seen with non-cognate TFs, the components are not orthogonal. You will need to select a different set of TFs and promoters with lower crosstalk.
-
-
Assess Promoter "Leakiness": A "leaky" promoter will have a basal level of transcription even in the absence of its cognate activator.
-
Experiment: Measure the output of your reporter construct in the absence of any activator protein.
-
Expected Outcome: The reporter signal should be at or near background levels.
-
Troubleshooting: If you observe significant basal expression, your promoter is leaky. Consider using a promoter with tighter regulation or incorporating a repressor to reduce basal activity.
-
-
Check Insulator Functionality: Insulators are genetic parts designed to prevent unintended transcriptional read-through or interference between adjacent genetic elements.
-
Experiment: If you are using insulators like RiboJ, compare the expression of your gene of interest with and without the insulator.[1]
-
Expected Outcome: The insulator should buffer the genetic component from its context, leading to more predictable expression levels. Note that some insulators, like RiboJ, have been shown to increase protein and transcript abundance.[1][2][3][4]
-
Troubleshooting: If the expression profile is highly variable and context-dependent even with an insulator, the insulator may not be functioning correctly in your specific construct. Consider testing different insulator sequences.
-
-
Sequence Verify Constructs: Errors in DNA synthesis or cloning can lead to mutated or incorrect genetic parts.
-
Action: Sequence-verify your entire plasmid construct.
-
Expected Outcome: The sequence should perfectly match your design.
-
Troubleshooting: Any mutations in promoters, ribosome binding sites (RBS), or terminators can drastically affect gene expression. If errors are found, the construct must be re-cloned.
-
Issue 2: Circuit Performance Varies with Cellular Growth Phase or Media Conditions (Potential Indirect Crosstalk)
Symptoms:
-
A genetic oscillator stalls or shows dampened oscillations as cell density increases.
-
A toggle switch flips to an unintended state at high cell densities.
-
The output of a circuit is significantly different when grown in minimal versus rich media.
Troubleshooting Workflow:
Caption: Troubleshooting workflow for indirect, resource-based crosstalk.
Detailed Steps:
-
Quantify Metabolic Burden: Overexpression of synthetic genes can place a significant metabolic load on the host cell, impacting its growth and the availability of resources for other cellular processes, including your circuit.[5]
-
Experiment: Measure the growth curves (OD600 over time) of your host cells with and without your synthetic circuit induced.
-
Expected Outcome: Ideally, the expression of your circuit should not significantly impair cell growth.
-
Troubleshooting: A significant decrease in growth rate upon induction indicates a high metabolic burden. To mitigate this, you can:
-
-
Assess Resource Competition: Synthetic genes compete with each other and with host genes for limited cellular resources like RNA polymerases and ribosomes.[6][7][8] This competition can create unintended couplings between otherwise independent genetic modules.
-
Experiment: Co-transform your cells with your synthetic circuit and a "resource sensor" plasmid. A resource sensor typically consists of a constitutively expressed fluorescent protein. Measure the fluorescence of the sensor with and without your circuit induced.[9]
-
Expected Outcome: The expression of the resource sensor should remain relatively constant.
-
Troubleshooting: A significant drop in the sensor's fluorescence upon induction of your circuit indicates that your circuit is sequestering a large amount of cellular resources.[7] To address this, you can:
-
Redesign the circuit to use components with lower resource demand.
-
Utilize orthogonal resources, such as a T7 RNA polymerase and its cognate promoters, to decouple your circuit from the host's transcriptional machinery.
-
-
-
Evaluate Host-Circuit Interactions: The genetic background of the host strain can influence the behavior of a synthetic circuit.
-
Experiment: Test your circuit in different E. coli strains. If your circuit is on a plasmid, compare its performance to a genome-integrated version.
-
Expected Outcome: The circuit's behavior should be consistent across different host contexts.
-
Troubleshooting: If performance varies significantly, it suggests interactions with the host's native regulatory network or instability of the plasmid. Genome integration can provide a more stable and predictable cellular environment.[5]
-
Frequently Asked Questions (FAQs)
Q1: What is crosstalk in synthetic biology?
A1: Crosstalk refers to any unintended interaction between components of a synthetic biological circuit or between the synthetic circuit and the host cell.[8] These interactions can be direct, such as a transcription factor binding to a non-cognate promoter, or indirect, such as competition for shared cellular resources like ribosomes and RNA polymerase.[6][7][8]
Q2: How can I design my circuit to minimize crosstalk from the start?
A2: Proactive design is key to minimizing crosstalk.
-
Use Orthogonal Parts: Select transcription factors and promoters that have been characterized to have minimal interaction with each other and with the host cell's native components.[10]
-
Insulate Genetic Elements: Use insulator sequences, such as self-cleaving ribozymes (e.g., RiboJ), to flank your genetic parts. This can prevent unintended interactions caused by the specific sequence context of a part.[1][4][11]
-
Balance Expression Levels: Avoid unnecessarily high expression of circuit components, as this increases metabolic burden and resource competition.[5] Use well-characterized promoters and RBSs to tune expression to the desired level.
-
Computational Modeling: Utilize computational tools to simulate your circuit's behavior before construction. These models can help predict potential crosstalk and guide the selection of components.[12][13][14][15]
Q3: What is a "crosstalk matrix" and how can I use it?
A3: A crosstalk matrix is a table that quantifies the interaction between a set of transcription factors and a set of promoters. The entry in each cell of the matrix represents the activity of a given promoter in the presence of a specific transcription factor. By examining this matrix, you can select pairs of TFs and promoters that are highly orthogonal (i.e., each TF only activates its cognate promoter).
Quantitative Data: Orthogonality of Synthetic Repressors
The following table provides a hypothetical example of a crosstalk matrix for three synthetic repressors and their cognate promoters. The values represent the fold-repression of the promoter in the presence of the repressor. Higher values along the diagonal and lower values off-diagonally indicate better orthogonality.
| Repressor | Promoter A | Promoter B | Promoter C |
| Repressor A | 150-fold | 1.2-fold | 1.5-fold |
| Repressor B | 1.1-fold | 180-fold | 2.0-fold |
| Repressor C | 1.3-fold | 1.8-fold | 160-fold |
Q4: My genetic toggle switch is not bistable. What are the common causes?
A4: A genetic toggle switch, composed of two mutually repressing genes, can fail to exhibit bistability for several reasons.[16][17][18][19][20]
-
Imbalanced Repressor Strengths: If one repressor is significantly stronger than the other, the switch will be monostable, always defaulting to the state where the weaker repressor is off.[21]
-
Leaky Promoters: If the promoters are "leaky," they will produce a small amount of repressor even when they are supposed to be "off." This can prevent the switch from fully committing to one state.
-
Slow Switching Dynamics: The time it takes for transcription and translation to occur can lead to slow switching, which may not be suitable for all applications. For faster switching, consider post-translational modifications.[17]
Signaling Pathway of a Genetic Toggle Switch:
Caption: A genetic toggle switch relies on mutual repression.
Q5: My genetic oscillator has inconsistent or dampened oscillations. How can I improve its robustness?
A5: Synthetic genetic oscillators are known to be sensitive to noise and cellular context.[5][22][23][24][25]
-
Insufficient Time Delay: Oscillations require a time delay in the negative feedback loop. If the degradation of proteins is too fast, the system may not oscillate.
-
Stochastic Noise: The inherent randomness of biochemical reactions (stochasticity) can disrupt regular oscillations, especially at low molecule numbers.
-
Metabolic Burden: As with other circuits, a high metabolic burden can dampen oscillations by affecting cellular physiology.[5]
-
Lack of Cooperativity: In many oscillator designs, cooperative binding of repressors is necessary for robust oscillations.
Signaling Pathway of a Repressilator (a type of genetic oscillator):
Caption: The repressilator creates oscillations through a three-gene negative feedback loop.
Experimental Protocols
Protocol 1: Dual-Luciferase Assay for Quantifying Crosstalk
This protocol allows for the sensitive quantification of promoter activity and can be used to measure crosstalk between different transcription factor-promoter pairs.
Materials:
-
Plasmids:
-
Effector plasmid expressing a transcription factor.
-
Reporter plasmid with a promoter of interest driving Firefly luciferase (lucF).
-
Control plasmid with a constitutive promoter driving Renilla luciferase (lucR).
-
-
Mammalian cells or plant protoplasts.
-
Transfection reagent.
-
Dual-Luciferase® Reporter Assay System (or equivalent).
-
Luminometer.
Procedure:
-
Cell Culture and Transfection:
-
Plate cells in a multi-well plate.
-
Co-transfect the cells with the effector, reporter, and control plasmids. For each promoter you are testing, you will have a set of wells where you transfect with its cognate TF and another set with a non-cognate TF.
-
-
Cell Lysis:
-
After 24-48 hours, remove the culture medium and wash the cells with PBS.
-
Add Passive Lysis Buffer and incubate to lyse the cells.
-
-
Luminometer Measurement:
-
Add Luciferase Assay Reagent II (LAR II) to the cell lysate to measure Firefly luciferase activity.
-
Add Stop & Glo® Reagent to quench the Firefly reaction and initiate the Renilla luciferase reaction. Measure the Renilla luminescence.
-
-
Data Analysis:
-
Calculate the ratio of Firefly to Renilla luciferase activity for each sample. This normalizes for transfection efficiency and cell number.
-
Compare the normalized activity of a promoter in the presence of its cognate TF versus non-cognate TFs. A high ratio for non-cognate pairs indicates significant crosstalk.
-
Protocol 2: Flow Cytometry for Characterizing Promoter Orthogonality
Flow cytometry allows for the analysis of gene expression at the single-cell level and is a powerful tool for characterizing the orthogonality of circuit components.[26][27][28]
Materials:
-
Plasmids:
-
Effector plasmid expressing a transcription factor.
-
Reporter plasmid with a promoter of interest driving a fluorescent protein (e.g., GFP).
-
Control plasmid expressing a different fluorescent protein (e.g., mCherry) from a constitutive promoter to identify transfected cells.
-
-
Host cells (e.g., E. coli or yeast).
-
Flow cytometer.
Procedure:
-
Cell Transformation and Culture:
-
Co-transform host cells with the effector, reporter, and control plasmids.
-
Culture the cells under inducing and non-inducing conditions.
-
-
Sample Preparation:
-
Harvest cells and resuspend them in PBS or an appropriate buffer.
-
-
Flow Cytometry Analysis:
-
Run the samples on a flow cytometer.
-
Gate on the population of cells expressing the control fluorescent protein to analyze only the transfected cells.
-
Measure the fluorescence intensity of the reporter protein in this population.
-
-
Data Analysis:
-
Plot the distribution of fluorescence intensity for each condition.
-
Calculate the mean fluorescence intensity for each sample.
-
Compare the mean fluorescence of a promoter in the presence of its cognate TF to its fluorescence with non-cognate TFs. A significant increase in fluorescence with a non-cognate TF indicates crosstalk.
-
References
- 1. The genetic insulator RiboJ increases expression of insulated genes - PMC [pmc.ncbi.nlm.nih.gov]
- 2. biorxiv.org [biorxiv.org]
- 3. biorxiv.org [biorxiv.org]
- 4. The genetic insulator RiboJ increases expression of insulated genes [authors.library.caltech.edu]
- 5. Addressing biological uncertainties in engineering gene circuits - PMC [pmc.ncbi.nlm.nih.gov]
- 6. s3.eu-central-1.amazonaws.com [s3.eu-central-1.amazonaws.com]
- 7. biorxiv.org [biorxiv.org]
- 8. Resource Competition Shapes the Response of Genetic Circuits - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. pubs.acs.org [pubs.acs.org]
- 11. Ribozyme-based insulator parts buffer synthetic circuits from genetic context - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Computational design tools for synthetic biology - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. Advances and Computational Tools towards Predictable Design in Biological Engineering - PMC [pmc.ncbi.nlm.nih.gov]
- 14. research.rug.nl [research.rug.nl]
- 15. Using Computational Modeling and Experimental Synthetic Perturbations to Probe Biological Circuits - PMC [pmc.ncbi.nlm.nih.gov]
- 16. dna.caltech.edu [dna.caltech.edu]
- 17. Synthetic biological toggle circuits that respond within seconds and teach us new biology - PMC [pmc.ncbi.nlm.nih.gov]
- 18. researchgate.net [researchgate.net]
- 19. researchgate.net [researchgate.net]
- 20. ccbb.pitt.edu [ccbb.pitt.edu]
- 21. Stability and Robustness of Unbalanced Genetic Toggle Switches in the Presence of Scarce Resources - PMC [pmc.ncbi.nlm.nih.gov]
- 22. A comparative analysis of synthetic genetic oscillators - PMC [pmc.ncbi.nlm.nih.gov]
- 23. Systems and synthetic biology approaches in understanding biological oscillators - PMC [pmc.ncbi.nlm.nih.gov]
- 24. researchgate.net [researchgate.net]
- 25. Synthetic Biology: How to make an oscillator | eLife [elifesciences.org]
- 26. Detection of promoter activity by flow cytometric analysis of GFP reporter expression - PMC [pmc.ncbi.nlm.nih.gov]
- 27. Monitoring Promoter Activity by Flow Cytometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 28. Standardized flow-cytometry-based protocol to simultaneously measure transcription factor levels - PMC [pmc.ncbi.nlm.nih.gov]
error correction codes for DNA data storage
This technical support center provides troubleshooting guidance and answers to frequently asked questions regarding the use of error correction codes (ECCs) in DNA data storage.
Troubleshooting Guide
This guide addresses common issues encountered during DNA data storage experiments involving error correction codes.
| Problem | Potential Cause | Suggested Solution |
| High error rates after sequencing | Issues with DNA synthesis, such as high indel rates. | - Verify the quality of synthesized DNA oligos. - Use a higher-fidelity synthesis method. - Increase the redundancy of the error correction code. |
| Failure to decode stored information | - Errors exceed the correction capability of the chosen ECC. - Systematic errors introduced during synthesis or sequencing. | - Implement a stronger ECC, such as one with a higher code rate or a concatenated code. - Analyze the error patterns to identify and mitigate systematic biases. - Re-sequence the DNA pool with a different sequencing technology. |
| Low data density | Inefficient error correction code design. | - Optimize the ECC to balance redundancy and data density. - Explore constrained coding techniques to avoid problematic DNA sequences. |
| File fails to reconstruct completely | Loss of DNA strands during storage or sequencing. | - Increase the physical copy number of each DNA oligo. <- Implement an outer code, such as a fountain code, to handle missing data packets (dropouts). |
Frequently Asked Questions (FAQs)
A list of common questions regarding the application of error correction codes in DNA data storage.
1. What are error correction codes (ECCs) and why are they essential for DNA data storage?
Error correction codes are algorithms that add redundancy to data to detect and correct errors that may occur during the DNA data storage and retrieval process. DNA is susceptible to various errors during synthesis, storage, and sequencing, including substitutions, insertions, and deletions (indels). ECCs are crucial for ensuring the integrity and accurate recovery of the stored information.
2. What are the common types of errors in DNA data storage?
The primary types of errors encountered in DNA data storage are:
-
Substitution errors: One nucleotide is replaced by another (e.g., A is replaced by C).
-
Insertion errors: An extra nucleotide is added to the sequence.
-
Deletion errors: A nucleotide is removed from the sequence.
-
Strand loss (dropout): Entire DNA strands are lost during storage or handling.
3. Which error correction codes are commonly used for DNA data storage?
Several classes of ECCs are employed in DNA data storage, each with its strengths:
-
Hamming codes: Effective for correcting single-bit substitution errors.
-
Reed-Solomon codes: Powerful codes that can correct burst errors (multiple errors in a short sequence) and are well-suited for handling a mix of error types.
-
Low-Density Parity-Check (LDPC) codes: Offer excellent performance close to the theoretical limits of error correction.
-
Fountain codes (e.g., Luby Transform codes): Primarily used as an "outer code" to address the issue of missing data packets or strand dropouts, allowing for reliable data recovery even if some DNA sequences are lost.
4. How do I choose the right error correction code for my experiment?
The choice of ECC depends on several factors:
-
Expected error rates: Higher anticipated error rates from your synthesis and sequencing methods will necessitate a more robust ECC with higher redundancy.
-
Types of errors: If indels are a significant concern, codes specifically designed to handle them, or combinations of inner and outer codes, are recommended.
-
Desired storage density: More powerful ECCs often require more redundancy, which can reduce the overall data density. A trade-off must be made between reliability and density.
-
Computational resources: The complexity of encoding and decoding algorithms can vary significantly between different ECCs.
5. What is the difference between an "inner code" and an "outer code"?
In many DNA data storage schemes, a concatenated coding strategy is used:
-
Inner code: This code operates at the level of individual DNA sequences to correct errors introduced during synthesis and sequencing (e.g., substitutions, indels). Reed-Solomon codes are often used as inner codes.
-
Outer code: This code works at a higher level to handle the loss of entire DNA strands (dropouts). Fountain codes are a common choice for the outer code.
Experimental Protocols & Workflows
This section provides a generalized workflow for DNA data storage incorporating error correction.
Caption: Overall workflow for DNA data storage with error correction.
The logical relationship for a concatenated coding scheme is illustrated below.
Caption: Concatenated error correction coding scheme.
improving the efficiency of enzymatic reactions in DNA computing
This guide provides troubleshooting advice and answers to frequently asked questions for researchers, scientists, and drug development professionals working to improve the efficiency of enzymatic reactions in DNA computing.
FAQs and Troubleshooting
This section addresses common problems encountered during DNA computing experiments, offering potential causes and solutions in a direct question-and-answer format.
Q1: My DNA logic gate or circuit shows a high level of "leakage" (output signal in the absence of the correct input). How can I reduce this?
A1: Leakage, or catalyst-independent reaction, is a primary barrier to creating complex, multi-layered DNA circuits. It often arises from non-specific enzyme activity or premature activation of components.
Potential Causes & Solutions:
-
Suboptimal DNA Sequence Design: Hairpin structures intended to sequester DNAzyme sequences or toeholds can "breathe," transiently exposing active sites.
-
Solution: Redesign DNA sequences to have higher melting temperatures (Tm) and more stable secondary structures. Ensure that toehold sequences are unique and have minimal off-target binding potential. Computational tools can help predict and minimize unwanted secondary structures.
-
-
Non-Specific Enzyme Activity: Enzymes like nickases or polymerases may exhibit low-level activity on unintended substrates.
-
Solution: Use high-fidelity or "hot-start" versions of enzymes, which are inactive at room temperature and only become active at higher temperatures, preventing reactions during setup.
-
-
Contamination: Contamination from previous experiments can act as an input, triggering the reaction.
-
Solution: Incorporate dUTP into amplification reactions and treat subsequent reaction setups with Uracil-DNA Glycosylase (UDG) to eliminate carryover amplicons.
-
-
Reaction Conditions: Suboptimal salt concentrations or temperatures can destabilize DNA complexes, promoting leakage.
-
Solution: Systematically optimize the concentration of Mg²⁺ and other salts, as well as the reaction temperature, to find a balance that maximizes specific activity while minimizing leakage.
-
Q2: The output signal from my enzymatic cascade is weak or absent. What are the likely causes?
A2: Low or no amplification is a frequent issue that can halt a DNA computing experiment. The problem can often be traced back to the enzyme, the DNA components, or the reaction buffer.
Potential Causes & Solutions:
-
Inactive Enzyme: The enzyme may have lost activity due to improper storage or handling, such as multiple freeze-thaw cycles.
-
Solution: Always store enzymes at -20°C in a non-frost-free freezer. Test enzyme activity with a known positive control substrate. If necessary, use a fresh aliquot of the enzyme.
-
-
Poor DNA Template/Substrate Quality: The DNA oligonucleotides may be degraded, contain impurities, or have been synthesized with errors.
-
Solution: Ensure high purity of all DNA strands using methods like PAGE purification. Verify the integrity of your templates and substrates via gel electrophoresis.
-
-
Suboptimal Buffer Conditions: The pH, salt concentration, or absence of a critical cofactor can inhibit enzyme activity.
-
Solution: Verify that you are using the recommended buffer for your specific enzyme. The concentration of MgCl₂, a critical cofactor for most polymerases and many nucleases, is often a key parameter to optimize. For long PCR products, high concentrations of KCl (>50 mM) can be inhibitory.
-
-
Insufficient Reaction Time or Temperature: The incubation time may be too short for the reaction to complete, or the temperature may be outside the optimal range for the enzyme.
-
Solution: Optimize incubation time and temperature. For polymerases, ensure the extension time is sufficient for the length of the product (a general rule is 1 min/kb).
-
Q3: My reaction kinetics are too slow for the intended application. How can I speed up the enzymatic reactions?
A3: The speed of DNA computing circuits is critical for many applications. Slow kinetics can be caused by diffusion limitations, low enzyme processivity, or inefficient strand displacement.
Potential Causes & Solutions:
-
Diffusion-Limited Reactions: On a solid surface or in a dilute solution, the rate at which molecules find each other can be the limiting factor.
-
Solution: Consider strategies to overcome diffusion limits, such as using microfluidic devices to increase local concentrations or employing "freezing-driven acceleration," where the formation of ice crystals concentrates reactants into micropockets.
-
-
Inefficient Strand Displacement: The rate of toehold-mediated strand displacement is highly dependent on the sequence and length of the toehold and displacement domains.
-
Solution: Redesign the toehold to be longer or more GC-rich to increase the initial binding affinity. The sequence of the displacement domain can also be altered to modulate reaction rates by orders of magnitude.
-
-
Low Enzyme Processivity: The enzyme may dissociate from the DNA template before completing its function.
-
Solution: Use engineered DNA polymerases with higher processivity. Adding accessory proteins like single-stranded binding proteins (SSBs) can also help by preventing secondary structure formation in the template.
-
-
Suboptimal Component Concentrations: The concentration of enzymes or substrates may not be optimal for maximum reaction velocity.
-
Solution: Titrate the concentration of the rate-limiting enzyme to find the optimal level. Be aware that excessively high enzyme concentrations can sometimes lead to inhibition or non-specific side reactions.
-
Q4: I'm seeing multiple unexpected bands on my analysis gel. What causes this non-specific amplification?
A4: The appearance of unexpected products indicates that the reaction is not specific to the intended target. This is often due to issues with primer/probe design or suboptimal reaction conditions.
Potential Causes & Solutions:
-
Primer-Dimer Formation: Primers can anneal to each other, creating a short template that is then amplified efficiently.
-
Solution: Redesign primers using established software to avoid complementarity, especially at the 3' ends. Reducing the primer concentration can also help.
-
-
Low Annealing Temperature: If the annealing temperature is too low, primers can bind to partially complementary sites on the template or other DNA strands, leading to non-specific amplification.
-
Solution: Increase the annealing temperature in increments. A gradient PCR can be used to quickly find the optimal temperature that allows for specific primer binding.
-
-
Excessive Mg²⁺ or Enzyme Concentration: High concentrations of Mg²⁺ can stabilize non-specific primer-template interactions, while too much polymerase can increase the amplification of low-level, non-specific products.
-
Solution: Perform a titration to find the lowest effective concentrations of both MgCl₂ and the DNA polymerase.
-
Data and Optimization Parameters
Optimizing enzymatic reactions requires careful tuning of multiple components. The following tables summarize key parameters for common enzymes used in DNA computing.
Table 1: General Buffer Optimization for DNA Polymerases & Nickases
| Component | Typical Concentration | Function | Troubleshooting Notes |
| Tris-HCl | 10-50 mM | Maintains stable pH (typically 8.0-9.5) for enzyme activity. | True reaction pH changes with temperature; a pKa of ~8.3 at 20°C is common. |
| KCl | 10-100 mM | Facilitates primer annealing by neutralizing negative charge on DNA backbone. | Concentrations >50 mM can inhibit Taq polymerase, especially for long templates. Higher concentrations (70-100 mM) may increase specificity for shorter products. |
| MgCl₂ | 1.5-3.5 mM | Critical cofactor for polymerase activity and stabilizes primer-template duplex. | This is the most critical component to optimize. Too low = no product; too high = non-specific product. |
| dNTPs | 200 µM (each) | Building blocks for DNA synthesis. | High concentrations can chelate Mg²⁺ and reduce fidelity. Use fresh aliquots to avoid degradation from freeze-thaw cycles. |
| Enzyme | 1-2.5 units / 50 µL | Catalyzes the reaction (polymerization, nicking, etc.). | Excess enzyme can lead to non-specific products. If activity is low, try a fresh batch. |
| Additives (Optional) | Varies | GC Enhancers, DMSO, Betaine help denature GC-rich templates. | May require re-optimization of annealing temperature. |
Table 2: Signal-to-Noise Ratio Enhancement Techniques
| Technique | Principle | Application in DNA Computing | Key Consideration |
| Signal Averaging | Reduces random noise by averaging multiple measurements of the same reaction. | Useful for improving the clarity of fluorescent kinetic readouts from logic gates. | The signal-to-noise ratio improves with the square root of the number of scans. |
| Circuit Design | Using cascaded amplifiers (e.g., catalyzed hairpin assembly) to increase signal gain. | Can achieve over 600,000-fold signal amplification for detecting low-concentration inputs. | Leakage from upstream components can be amplified, so low-leakage design is critical. |
| Optimized Dilution | For binary (yes/no) readouts, diluting to ~1.6 molecules per well maximizes statistical information. | In assays that count positive/negative wells, this improves accuracy and reduces the number of reactions needed. | This counterintuitive approach relies on quantifying the fraction of negative results. |
| Modulation | Shifting the signal to a higher frequency to avoid low-frequency noise (like 1/f flicker noise). | Can be applied in electronic detection systems to filter out baseline drift. | Requires hardware or software to modulate the signal before detection and demodulate it after. |
Key Experimental Protocols & Workflows
Protocol 1: Optimizing MgCl₂ Concentration for a Nicking/Polymerase Reaction
This protocol provides a systematic method for determining the optimal MgCl₂ concentration, a critical factor for the efficiency and specificity of many enzymatic DNA circuits.
Materials:
-
Nuclease-free water
-
10x PCR buffer (without MgCl₂)
-
50 mM MgCl₂ stock solution
-
10 mM dNTP mix
-
10 µM Forward and Reverse Primers/Substrates
-
DNA Template
-
DNA Polymerase/Nicking Enzyme
-
Nuclease-free PCR tubes
Procedure:
-
Prepare a Master Mix: In a single tube, prepare a master mix containing all components except MgCl₂. Calculate volumes for a series of reactions (e.g., 6 reactions) to test a range of MgCl₂ concentrations.
-
Example Master Mix for 6 reactions (50 µL each): 10x Buffer (30 µL), dNTPs (6 µL), Primers (6 µL each), Template (6 µL), Enzyme (3 µL), Water (to final volume).
-
-
Aliquot Master Mix: Dispense an equal volume of the master mix into each of the 6 PCR tubes.
-
Create MgCl₂ Gradient: Add a varying amount of the 50 mM MgCl₂ stock solution to each tube to achieve a range of final concentrations (e.g., 1.5, 2.0, 2.5, 3.0, 3.5 mM). Adjust the final volume of each reaction to 50 µL with nuclease-free water.
-
Run Reaction: Place the tubes in a thermocycler and run your standard protocol for the DNA computing circuit.
-
Analyze Results: Analyze the products on an agarose (B213101) or polyacrylamide gel. The optimal MgCl₂ concentration is the one that produces the highest yield of the desired product with the minimal amount of non-specific bands or primer-dimers.
Diagram: General Troubleshooting Workflow
The following diagram illustrates a systematic approach to diagnosing and solving common issues in enzymatic DNA computing experiments.
Caption: A decision tree for troubleshooting enzymatic DNA computing reactions.
Diagram: DNAzyme AND Gate Signaling Pathway
This diagram shows the mechanism of a simple DNAzyme-based AND logic gate, where two distinct input oligonucleotides are required to activate a catalytic DNA core that cleaves a fluorescently quenched substrate.
Caption: Logical workflow of a two-input DNAzyme AND gate.
Technical Support Center: Addressing Off-Target Effects in DNA-Based Therapies
Welcome to the technical support center for researchers, scientists, and drug development professionals. This resource provides in-depth troubleshooting guides and frequently asked questions (FAQs) to help you address and mitigate off-target effects in your DNA-based therapy experiments, including CRISPR-Cas9, siRNA, and Antisense Oligonucleotides (ASOs).
Frequently Asked Questions (FAQs)
This section addresses common questions regarding off-target effects in DNA-based therapies.
CRISPR-Cas9
Q1: What are off-target effects in the context of CRISPR-Cas9 gene editing?
Off-target effects refer to the unintended cleavage and subsequent modification of genomic loci that are not the intended on-target site.[1] These unintended edits occur when the Cas9 nuclease, guided by the single-guide RNA (sgRNA), recognizes and cuts DNA sequences that are similar but not identical to the intended target sequence.[2][3] This can lead to insertions, deletions (indels), and other mutations at these off-target sites, potentially disrupting gene function, causing cellular toxicity, or leading to inaccurate experimental outcomes.[1][3]
Q2: What are the primary causes of CRISPR-Cas9 off-target effects?
Several factors contribute to off-target effects in CRISPR-Cas9 experiments:
-
Guide RNA (sgRNA) Design: The specificity of the sgRNA is a critical determinant of off-target activity. Imperfectly designed sgRNAs can tolerate mismatches and bind to similar sequences elsewhere in the genome.[2][4]
-
Cas9 Nuclease Concentration and Activity Duration: High concentrations of the Cas9 protein and prolonged expression can increase the likelihood of off-target cleavage.[5]
-
Chromatin Accessibility: The structure of chromatin can influence the accessibility of genomic regions to the Cas9-sgRNA complex. More open and accessible chromatin regions may be more susceptible to off-target binding and cleavage.[2]
-
Sequence Homology: The presence of genomic sequences with high similarity to the on-target site increases the probability of off-target events.[2][4]
Q3: How can I minimize off-target effects during my CRISPR experiments?
Minimizing off-target effects is crucial for the reliability and safety of CRISPR-based therapies. Key strategies include:
-
Optimized sgRNA Design: Utilize bioinformatics tools to design sgRNAs with high on-target scores and minimal predicted off-target sites.[5]
-
High-Fidelity Cas9 Variants: Employ engineered Cas9 variants (e.g., SpCas9-HF1, eSpCas9, HypaCas9) that have been developed to exhibit reduced off-target activity while maintaining high on-target efficiency.[6][7]
-
RNP Delivery: Deliver the Cas9 protein and sgRNA as a ribonucleoprotein (RNP) complex instead of plasmid DNA. This limits the duration of Cas9 activity in the cell, thereby reducing the window for off-target events.[4]
-
Titration of Cas9/sgRNA Concentration: Use the lowest effective concentration of the Cas9-sgRNA complex to achieve the desired on-target editing while minimizing off-target cleavage.[5]
siRNA and ASOs
Q1: What are the primary mechanisms of off-target effects for siRNAs and ASOs?
Off-target effects for siRNAs and ASOs are primarily driven by unintended hybridization to partially complementary sequences in non-target messenger RNAs (mRNAs).[8][9][10]
-
siRNA Off-Target Effects: A major cause of siRNA off-target effects is the "miRNA-like" activity, where the seed region (nucleotides 2-8) of the siRNA guide strand binds to the 3' untranslated region (UTR) of unintended mRNAs, leading to their translational repression or degradation.[8][11]
-
ASO Off-Target Effects: For RNase H-dependent ASOs, off-target effects occur when the ASO binds to a non-target RNA with sufficient complementarity to recruit RNase H, leading to the cleavage of that unintended transcript.[12][13] Hybridization-dependent off-target effects can also occur with splice-switching oligonucleotides.[13]
Q2: How can I detect off-target effects of my siRNA or ASO?
The most common method for detecting off-target effects of siRNAs and ASOs is through transcriptome-wide analysis using RNA sequencing (RNA-seq). By comparing the gene expression profiles of cells treated with the therapeutic oligonucleotide to control-treated cells, you can identify unintended changes in mRNA levels.[14] For ASOs, in silico prediction tools can be used to identify potential off-target binding sites based on sequence complementarity, which can then be validated experimentally.[15]
Q3: What are the key strategies to reduce off-target effects for siRNA and ASO therapies?
Several strategies can be employed to mitigate off-target effects:
-
Bioinformatic Design: Utilize advanced algorithms to design siRNA and ASO sequences with minimal predicted off-target hybridization.[8]
-
Chemical Modifications: Introduce chemical modifications to the oligonucleotide backbone or sugar moieties to enhance specificity and reduce off-target binding.[8][11] For siRNAs, modifications in the seed region can be particularly effective.[11]
-
Pooling of siRNAs: Using a pool of multiple siRNAs targeting the same gene at lower individual concentrations can reduce the impact of off-target effects from any single siRNA.[15]
-
Dose Optimization: Use the lowest effective dose of the siRNA or ASO to achieve the desired on-target effect while minimizing off-target activity.[16]
-
Use of Controls: Always include appropriate negative controls, such as a scrambled sequence that does not target any known gene, to distinguish sequence-specific off-target effects from non-specific cellular responses.[16]
Troubleshooting Guides
This section provides solutions to common problems encountered during DNA-based therapy experiments.
CRISPR-Cas9 Troubleshooting
| Problem | Possible Causes | Recommended Solutions |
| High frequency of off-target mutations detected by NGS. | 1. Suboptimal sgRNA design with multiple potential off-target sites.[2] 2. High concentration or prolonged expression of Cas9/sgRNA.[5] 3. Use of wild-type Cas9 which has higher off-target propensity.[6] | 1. Redesign sgRNA using updated bioinformatics tools to select for higher specificity.[5] 2. Titrate down the concentration of Cas9 and sgRNA. If using plasmid delivery, consider switching to RNP delivery to limit expression time.[4] 3. Switch to a high-fidelity Cas9 variant.[6] |
| Low on-target editing efficiency. | 1. Inefficient sgRNA.[17] 2. Poor delivery of CRISPR components into the cells.[17] 3. Target site is in a region of condensed chromatin.[2] | 1. Test 2-3 different sgRNAs for the same target to identify the most efficient one.[17] 2. Optimize your transfection or electroporation protocol for your specific cell type. Use a positive control to verify delivery efficiency.[18] 3. Design sgRNAs targeting more accessible chromatin regions if possible. |
| Unexpected or severe cellular phenotype (e.g., toxicity, altered growth). | 1. Off-target cleavage in an essential gene.[3] 2. On-target effect of knocking out the gene of interest is more severe than anticipated. 3. Immune response to the delivery vehicle or CRISPR components. | 1. Perform an unbiased off-target analysis (e.g., GUIDE-seq, SITE-seq) to identify potential off-target sites and validate them.[19][20] 2. Perform a rescue experiment by re-introducing the wild-type gene to see if the phenotype is reversed. 3. Use a delivery method with lower immunogenicity (e.g., RNP electroporation). |
siRNA and ASO Troubleshooting
| Problem | Possible Causes | Recommended Solutions |
| Significant off-target gene downregulation observed in RNA-seq. | 1. "miRNA-like" seed-mediated off-target effects (siRNA).[8] 2. Hybridization to partially complementary sequences (ASO).[10] 3. High concentration of the oligonucleotide. | 1. Redesign the siRNA with a different seed sequence or introduce chemical modifications to the seed region.[8][11] 2. Perform a BLAST search or use specialized software to identify and avoid sequences with high homology to other transcripts.[15] 3. Perform a dose-response experiment to determine the lowest effective concentration.[16] |
| Low efficiency of on-target knockdown. | 1. Ineffective siRNA or ASO sequence. 2. Poor delivery into the cytoplasm (for siRNA) or nucleus (for some ASOs). 3. Rapid degradation of the oligonucleotide. | 1. Test multiple siRNA or ASO sequences targeting different regions of the target RNA.[16] 2. Optimize the transfection reagent and protocol for your cell type. 3. Use chemically modified oligonucleotides to increase stability.[8] |
| Inconsistent results between different siRNAs/ASOs targeting the same gene. | 1. One or more of the oligonucleotides has a strong off-target signature that is confounding the phenotype.[21] | 1. Validate the phenotype with at least two, and preferably three, different siRNAs/ASOs that show consistent on-target knockdown.[16] 2. Perform a rescue experiment by expressing a version of the target gene that is resistant to your siRNA/ASO. |
Quantitative Data Summary
The following tables provide a summary of quantitative data for comparing different high-fidelity Cas9 variants and off-target detection methods.
Table 1: Comparison of High-Fidelity SpCas9 Variants
| Cas9 Variant | Relative On-Target Activity (compared to WT SpCas9) | Reduction in Off-Target Events (compared to WT SpCas9) | Key Features |
| SpCas9-HF1 | >85% for most sgRNAs[22] | High reduction | Engineered to reduce non-specific DNA contacts.[22] |
| eSpCas9(1.1) | Can be lower than WT, ~20% in some studies[23] | High reduction | Rationally designed to decrease off-target activity. |
| HypaCas9 | Can be lower than WT, ~1.7% in some studies[23] | Very high reduction | A hyper-accurate Cas9 variant. |
| evoCas9 | Generally high | High reduction | Developed through directed evolution for increased specificity. |
| SuperFi-Cas9 | Reduced activity in mammalian cells | Exceptionally high fidelity | Described as a next-generation high-fidelity variant.[7] |
Note: On-target activity can be target site-dependent. Data is aggregated from multiple studies and may vary based on experimental conditions.
Table 2: Comparison of Off-Target Detection Methods
| Method | Principle | Advantages | Limitations | Typical Output |
| GUIDE-seq | Integration of a double-stranded oligodeoxynucleotide (dsODN) tag at DSB sites in living cells.[19] | Unbiased, genome-wide, performed in cells. | Can be influenced by the efficiency of dsODN integration. | Sequenced reads identify the locations of DSBs. |
| SITE-seq | In vitro Cas9 digestion of genomic DNA followed by sequencing of cleaved ends.[20][24] | Highly sensitive, cell-free system allows for control of Cas9 concentration.[24] | May identify sites not cleaved in a cellular context due to chromatin structure. | A list of potential off-target sites with cleavage scores. |
| rhAmpSeq | Targeted amplicon sequencing of predicted on- and off-target sites.[25][26] | Highly quantitative and sensitive for known or predicted sites. | Biased, will not detect novel off-target sites. | Precise quantification of editing efficiency at target loci. |
| WGS | Whole Genome Sequencing of edited and control cells. | Truly unbiased and comprehensive. | Requires high sequencing depth to detect low-frequency events, can be costly. | A complete map of all genomic alterations. |
Experimental Protocols
This section provides detailed methodologies for key experiments related to off-target effect analysis.
Protocol 1: GUIDE-seq (Genome-wide Unbiased Identification of DSBs Enabled by Sequencing)
Objective: To identify the genome-wide off-target cleavage sites of a CRISPR-Cas9 nuclease in living cells.
Materials:
-
Cells of interest
-
Plasmids encoding Cas9 and sgRNA, or purified Cas9 RNP
-
Double-stranded oligodeoxynucleotide (dsODN) tag
-
Transfection reagent or electroporation system
-
Genomic DNA isolation kit
-
Covaris sonicator
-
NEBNext Ultra II DNA Library Prep Kit for Illumina
-
Custom PCR primers for library amplification
-
AMPure XP beads
-
Next-generation sequencing platform (e.g., Illumina MiSeq)
Procedure:
-
Cell Transfection/Electroporation:
-
Co-transfect/electroporate the cells with the Cas9/sgRNA expression system and the dsODN tag.
-
Culture the cells for 3 days to allow for dsODN integration at DSB sites.[27]
-
-
Genomic DNA Isolation:
-
Harvest the cells and isolate high-molecular-weight genomic DNA using a commercial kit.
-
-
Library Preparation:
-
Quantify and shear the genomic DNA to an average size of 500 bp using a Covaris sonicator.[28]
-
Perform end-repair, A-tailing, and ligation of a Y-adapter containing a unique molecular index (UMI) using the NEBNext kit.[27]
-
Perform two rounds of nested PCR to enrich for dsODN-tagged genomic fragments. The first PCR uses a primer specific to the dsODN tag and a primer complementary to the ligated adapter. The second PCR adds sequencing indices.[27]
-
Purify the final library using AMPure XP beads.[28]
-
-
Sequencing and Data Analysis:
-
Quantify the library and sequence on an Illumina platform.
-
Analyze the sequencing data to map the integration sites of the dsODN tag to the reference genome. This identifies the on- and off-target cleavage sites.[29]
-
Protocol 2: SITE-seq (Selective Enrichment and Identification of Tagged DNA Ends by Sequencing)
Objective: To biochemically identify the genome-wide cleavage sites of a Cas9-sgRNA complex on purified genomic DNA.
Materials:
-
High-molecular-weight genomic DNA
-
Purified Cas9 protein and in vitro transcribed sgRNA
-
Biotinylated adapter
-
Restriction enzymes
-
Streptavidin magnetic beads
-
DNA library preparation kit for NGS
-
Next-generation sequencing platform
Procedure:
-
In Vitro Cleavage Reaction:
-
Assemble the Cas9-sgRNA RNP complex.
-
Incubate the RNP complex with high-molecular-weight genomic DNA to allow for cleavage.[20]
-
-
Adapter Ligation:
-
Perform end-repair and A-tailing on the cleaved DNA fragments.
-
Ligate a biotinylated adapter to the ends of the cleaved DNA.[20]
-
-
Enrichment of Cleaved Fragments:
-
Fragment the DNA using sonication.
-
Use streptavidin magnetic beads to capture the biotinylated fragments, thereby enriching for the Cas9-cleaved DNA.[20]
-
-
Library Preparation and Sequencing:
-
Perform library preparation on the enriched fragments, including the addition of sequencing adapters and indices.
-
Sequence the library on an NGS platform.[20]
-
-
Data Analysis:
-
Map the sequencing reads to the reference genome to identify the precise locations of Cas9 cleavage.
-
Protocol 3: RNA-seq for siRNA/ASO Off-Target Analysis
Objective: To identify transcriptome-wide changes in gene expression following treatment with an siRNA or ASO.
Materials:
-
Cells of interest
-
siRNA or ASO and appropriate controls (e.g., scrambled sequence)
-
Transfection reagent
-
RNA isolation kit
-
RNA-seq library preparation kit (e.g., TruSeq Stranded mRNA Library Prep Kit)
-
Next-generation sequencing platform
Procedure:
-
Cell Treatment:
-
Transfect the cells with the siRNA, ASO, or control oligonucleotide.
-
Incubate for the desired time period (e.g., 24-48 hours).
-
-
RNA Isolation:
-
Harvest the cells and isolate total RNA using a commercial kit. Ensure high quality RNA (RIN > 8).
-
-
Library Preparation:
-
Prepare RNA-seq libraries from the isolated RNA. This typically involves mRNA purification, fragmentation, reverse transcription to cDNA, and adapter ligation.
-
-
Sequencing:
-
Sequence the prepared libraries on an NGS platform.
-
-
Data Analysis:
-
Align the sequencing reads to the reference transcriptome and quantify gene expression levels.
-
Perform differential gene expression analysis to identify genes that are significantly up- or downregulated in the siRNA/ASO-treated cells compared to the control.
-
Further bioinformatic analysis can be performed to determine if downregulated genes contain seed match regions for the siRNA or complementary sequences for the ASO.
-
Visualizations
The following diagrams illustrate key concepts and workflows related to off-target effects.
Caption: Workflow for CRISPR off-target analysis.
Caption: Mechanism of siRNA off-target effects.
References
- 1. lifesciences.danaher.com [lifesciences.danaher.com]
- 2. What causes off-target effects in CRISPR? [synapse.patsnap.com]
- 3. synthego.com [synthego.com]
- 4. Off-target effects in CRISPR/Cas9 gene editing - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Troubleshooting Guide for Common CRISPR-Cas9 Editing Problems [synapse.patsnap.com]
- 6. High-fidelity CRISPR-Cas9 variants with undetectable genome-wide off-targets - PMC [pmc.ncbi.nlm.nih.gov]
- 7. biorxiv.org [biorxiv.org]
- 8. Methods for reducing siRNA off-target binding | Eclipsebio [eclipsebio.com]
- 9. Off Target Effects in small interfering RNA or siRNA [biosyn.com]
- 10. Evaluation of off‐target effects of gapmer antisense oligonucleotides using human cells - PMC [pmc.ncbi.nlm.nih.gov]
- 11. news-medical.net [news-medical.net]
- 12. Intronic off-target effects with antisense oligos | siTOOLs Biotech Blog [sitoolsbiotech.com]
- 13. researchgate.net [researchgate.net]
- 14. On-target/off-target effects (ASO) | omiics.com [omiics.com]
- 15. Design and off-target prediction for antisense oligomers targeting bacterial mRNAs with the MASON web server - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Guidelines for Experiments Using Antisense Oligonucleotides and Double-Stranded RNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Troubleshooting Low Knockout Efficiency in CRISPR Experiments - CD Biosynsis [biosynsis.com]
- 18. sg.idtdna.com [sg.idtdna.com]
- 19. Defining genome-wide CRISPR-Cas genome editing nuclease activity with GUIDE-seq - PMC [pmc.ncbi.nlm.nih.gov]
- 20. SITE-Seq: A Genome-wide Method to Measure Cas9 Cleavage [protocols.io]
- 21. horizondiscovery.com [horizondiscovery.com]
- 22. sfvideo.blob.core.windows.net [sfvideo.blob.core.windows.net]
- 23. researchgate.net [researchgate.net]
- 24. Mapping the genomic landscape of CRISPR–Cas9 cleavage | Springer Nature Experiments [experiments.springernature.com]
- 25. rhAmpSeq™ CRISPR Analysis System - LubioScience [lubio.ch]
- 26. sfvideo.blob.core.windows.net [sfvideo.blob.core.windows.net]
- 27. vedtopkar.com [vedtopkar.com]
- 28. syntezza.com [syntezza.com]
- 29. GUIDE-seq: The GUIDE-Seq Analysis Package — GUIDE-seq documentation [guide-seq.readthedocs.io]
Technical Support Center: Optimizing Buffer Conditions for DNA Self-Assembly
This technical support center provides troubleshooting guidance and frequently asked questions to assist researchers, scientists, and drug development professionals in optimizing buffer conditions for successful DNA self-assembly experiments.
Frequently Asked Questions (FAQs)
Q1: What is the optimal concentration of magnesium ions (Mg²⁺) for DNA self-assembly?
A1: Magnesium is a critical component in most DNA self-assembly buffers, as it screens the negative charges of the phosphate (B84403) backbone, reducing electrostatic repulsion between DNA helices.[1] While the optimal concentration can vary depending on the specific DNA nanostructure, a common starting concentration is 12.5 mM Mg²⁺ in a Tris-acetate-EDTA (TAE) buffer.[2] However, high concentrations of Mg²⁺ can sometimes lead to aggregation of DNA-nanoparticle complexes.[1]
Q2: Can I substitute Mg²⁺ with other cations for DNA self-assembly?
A2: Yes, successful assembly of DNA nanostructures has been demonstrated in the presence of other divalent cations such as Calcium (Ca²⁺) and Barium (Ba²⁺), as well as monovalent cations like Sodium (Na⁺), Potassium (K⁺), and Lithium (Li⁺).[1][3] In some cases, using monovalent ions can offer advantages, such as increasing the resistance of the DNA structures to nuclease degradation by up to 10-fold compared to structures assembled in divalent ions.[1][3]
Q3: What is the ideal pH range for DNA self-assembly and for the stability of pre-formed structures?
A3: The self-assembly of DNA origami is generally successful within a pH range of 6 to 9.[4] Pre-formed DNA origami structures are stable in a broader pH range, typically from 5 to 11.[4][5][6] Exposure to pH values below 4 or above 11 can lead to the degradation and denaturation of the DNA nanostructures due to hydrolysis of the phosphodiester backbone and disruption of hydrogen bonds.[5][6]
Q4: How does temperature influence the DNA self-assembly process?
A4: Temperature is a crucial parameter in DNA self-assembly, most commonly controlled through a process called thermal annealing.[7] This involves heating the solution to denature the DNA strands and then slowly cooling it to allow for proper hybridization and folding. The melting temperature of the DNA nanostructure, which is influenced by the buffer composition and DNA sequence, dictates the upper limit of its thermal stability.[5] Isothermal assembly at a constant temperature is also a viable method for forming DNA nanostructures.[7]
Troubleshooting Guide
Problem 1: Low yield of correctly folded DNA nanostructures.
-
Possible Cause: Suboptimal annealing protocol.
-
Solution: The rate of cooling during thermal annealing can significantly impact the folding yield. For complex structures, a slower cooling ramp is often beneficial.[8] Consider extending the annealing time to allow for proper hybridization of all components.
-
Possible Cause: Incorrect stoichiometry of staple strands to scaffold.
-
Solution: A 10-fold excess of staple strands is a common starting point for 2D DNA origami assembly.[2] However, an excessive staple-to-scaffold ratio can sometimes inhibit the formation of single folds.[9] Titrating the staple strand concentration can help optimize the yield.
-
Possible Cause: Inappropriate cation concentration.
-
Solution: Ensure the magnesium concentration is optimal. If using other cations, their concentrations may need to be adjusted. For example, when using Na⁺ and K⁺, the assembly yield of some structures increases with higher ion concentrations.[1]
Problem 2: Aggregation of DNA nanostructures.
-
Possible Cause: High concentration of divalent cations.
-
Solution: High levels of Mg²⁺ can sometimes cause aggregation.[1] Try reducing the Mg²⁺ concentration in the buffer. Alternatively, substituting Mg²⁺ with certain monovalent cations might mitigate aggregation.
-
Possible Cause: Unfavorable surface interactions during imaging or purification.
-
Solution: When immobilizing DNA nanostructures on surfaces like mica for imaging, the interplay between monovalent and divalent cations is crucial. The presence of competitive monovalent ions can enhance the mobility of DNA origami on the surface, preventing aggregation.[10][11]
Problem 3: Degradation of DNA nanostructures.
-
Possible Cause: Extreme pH of the buffer.
-
Solution: Verify that the pH of your buffer is within the stable range for your DNA nanostructures (typically pH 5-11).[5][6] Adjust the pH if necessary.
-
Possible Cause: Nuclease contamination.
-
Solution: If your experiments involve biological fluids or other potential sources of nucleases, consider using nuclease-free water and reagents. Assembling DNA structures in the presence of monovalent cations like Na⁺, K⁺, and Li⁺ has been shown to increase their resistance to nuclease degradation.[1][3]
Data Summary
Table 1: Stability of DNA Origami Under Various Chemical Conditions
| Condition | Stable Range/Observation | Reference(s) |
| pH | Stable between pH 5 and 11. Degradation occurs at pH below 4 and above 11. | [4][5][6] |
| Ionic Strength | High and low ionic strengths can lead to disintegration and detachment from surfaces. | [5] |
| Organic Solvents | Stable in common organic solvents like hexane, ethanol, and toluene (B28343) for at least 24 hours. | [6] |
| Temperature (in air) | Can withstand temperatures up to 150-200°C when adsorbed on a surface. | [6] |
Table 2: Effect of Different Cations on DNA Self-Assembly
| Cation | Typical Concentration Range | Key Effects on Assembly and Stability | Reference(s) |
| Magnesium (Mg²⁺) | 10-20 mM | Essential for screening electrostatic repulsion; high concentrations can cause aggregation. | [1] |
| Calcium (Ca²⁺) | 10-100 mM | Supports successful assembly with yields similar to Mg²⁺. | [1][7] |
| Barium (Ba²⁺) | >25 mM | Can induce the formation of higher-order structures. | [1] |
| Sodium (Na⁺) | 200-600 mM | Enables assembly and can increase nuclease resistance. Higher concentrations can increase mobility on surfaces. | [1][11] |
| Potassium (K⁺) | Varies | Supports assembly and enhances nuclease resistance. | [1][3] |
| Lithium (Li⁺) | Varies | Facilitates assembly and improves nuclease resistance. | [1][3] |
Experimental Protocols
Protocol 1: Standard Thermal Annealing for DNA Origami Assembly
-
Prepare the Annealing Mixture: In a PCR tube, combine the M13 scaffold DNA and staple oligonucleotides in a buffer solution. A typical buffer is Tris-acetate-EDTA (TAE) supplemented with 12.5 mM magnesium acetate.[2] The final volume is typically 50 µL.
-
Denaturation and Annealing: Place the PCR tube in a thermocycler.
-
Heat the mixture to 95°C for 5 minutes to denature the DNA strands.
-
Gradually cool the mixture to 20°C. A slow ramp of -0.1°C per 6-second cycle (approximately 1 hour and 15 minutes) is a common starting point.[2] For more complex structures, a slower ramp (e.g., over 5-6 hours) may be necessary.[2]
-
-
Storage: Once the annealing protocol is complete, the assembled DNA origami can be stored at 4°C.
Protocol 2: Characterization by Agarose (B213101) Gel Electrophoresis (AGE)
-
Prepare the Gel: Prepare a 1-2% agarose gel in 1x TAE buffer containing 12.5 mM Mg²⁺.
-
Load Samples: Mix a small volume of your annealed DNA origami solution with a loading dye. Load the mixture into the wells of the agarose gel. Also load a DNA ladder and a sample of the scaffold DNA as controls.
-
Run the Gel: Run the gel at a constant voltage (e.g., 110V) in a cold room (4°C) to prevent heating, which could denature the DNA nanostructures.[12]
-
Stain and Visualize: After electrophoresis, stain the gel with a DNA stain such as GelRed or SYBR Gold.[12] Visualize the DNA bands under UV light. Correctly folded DNA origami structures should migrate as a distinct band, separate from the scaffold and unincorporated staple strands.
Visualizations
Caption: General workflow for a DNA self-assembly experiment.
Caption: Decision-making flowchart for troubleshooting common issues.
Caption: Influence of cations and pH on DNA nanostructure stability.
References
- 1. Self-assembly of DNA nanostructures in different cations - PMC [pmc.ncbi.nlm.nih.gov]
- 2. biorxiv.org [biorxiv.org]
- 3. researchgate.net [researchgate.net]
- 4. researchgate.net [researchgate.net]
- 5. pubs.acs.org [pubs.acs.org]
- 6. Structural stability of DNA origami nanostructures under application-specific conditions - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. sg.idtdna.com [sg.idtdna.com]
- 9. Failure Mechanisms in DNA Self-Assembly: Barriers to Single-Fold Yield - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Reconfigurable pH-Responsive DNA Origami Lattices - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Cation-dependent assembly of hexagonal DNA origami lattices on SiO2 surfaces - Nanoscale (RSC Publishing) [pubs.rsc.org]
- 12. Purification of self-assembled DNA tetrahedra using gel electrophoresis - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: DNA Strand Displacement Cascades
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals prevent and troubleshoot leaks in DNA strand displacement cascades.
Troubleshooting Guides
Issue: High background signal or "leaky" reactions in the absence of input.
Possible Cause 1: Spurious toehold-mediated displacement due to transient duplex-end fraying.
Even in well-designed systems, the ends of DNA duplexes can "breathe" or fray, transiently exposing a few bases of the template strand. An invading strand with complementarity to this exposed region can initiate a slow, unwanted strand displacement reaction, leading to a "leaky" signal.
Solutions:
-
Introduce GC clamps: Terminate helices with one or more G-C base pairs. The stronger stacking interactions of G-C pairs compared to A-T pairs reduce the rate of fraying and, consequently, toeless displacement.
-
Add non-specific clamps: Extend the incumbent strand with a short sequence (1-3 bases) that is not complementary to the invader. This creates an energetic barrier for toeless displacement, as a larger fraying event is required for the invader to initiate branch migration.[1]
-
Incorporate mismatches: Introducing a mismatch between the invader and the substrate near the toehold binding site can significantly slow down the rate of spurious displacement.[2] The position of the mismatch is critical for its effectiveness.
Experimental Protocol: Quantifying Leak Reduction with Clamps
-
Design: Synthesize DNA complexes with and without clamps of varying lengths (e.g., 1, 2, 3 nucleotides). The core sequences of the invader, incumbent, and substrate should remain the same.
-
Reaction Setup: Prepare reaction mixtures containing the substrate-incumbent duplex and a fluorescent reporter system in a suitable buffer (e.g., TE buffer with 12.5 mM MgCl2).
-
Initiate Leak Reaction: Add the invader strand to the reaction mixture at a concentration that would be used in the actual experiment.
-
Monitor Fluorescence: Measure the fluorescence signal over time using a plate reader or fluorometer. The rate of increase in fluorescence in the absence of the intended input corresponds to the leak rate.
-
Data Analysis: Plot fluorescence intensity versus time and fit the initial linear portion of the curve to determine the leak rate. Compare the leak rates of the clamped and unclamped constructs.
Possible Cause 2: Non-specific binding and toehold-free displacement.
Invading strands may bind to partially unwound regions within the duplex, leading to toehold-free strand displacement. This is a slower process than toehold-mediated displacement but can be a significant source of leaks, especially at high concentrations or during long incubation times.
Solutions:
-
Optimize toehold length: The rate of toehold-mediated strand displacement increases by approximately an order of magnitude for each additional nucleotide in the toehold, up to about 6 nucleotides.[3] By using an optimal toehold length, the rate of the desired reaction can be maximized relative to the rate of toehold-free leakage.
-
Utilize Locked Nucleic Acids (LNAs): Incorporating LNA nucleotides into the DNA substrate can significantly reduce leakage. LNA-DNA base pairs have a higher binding affinity, which stabilizes the duplex and reduces fraying. This can lead to a more than 50-fold reduction in the leakage rate.[1][4]
-
Employ logical redundancy: Design cascades where the activation of a downstream component requires the cooperative binding of two or more signal molecules. This significantly increases the energetic penalty for spurious activation.
Experimental Protocol: Evaluating the Impact of LNA on Leakage
-
Design: Synthesize DNA substrates with and without LNA modifications at specific positions within the branch migration domain. The invader and incumbent strands are standard DNA.
-
Reaction Setup: Prepare reaction mixtures as described in the previous protocol.
-
Initiate and Monitor: Add the invader strand and monitor the fluorescence signal over time.
-
Data Analysis: Calculate and compare the leak rates of the LNA-modified and unmodified systems. The performance enhancement ratio (k_invading / k_leak) can also be calculated to quantify the improvement in signal-to-noise.[1]
Issue: Incomplete or slow desired reaction.
Possible Cause 1: Suboptimal toehold design.
The length and sequence of the toehold are critical for efficient strand displacement.
Solutions:
-
Adjust toehold length: As a general rule, a longer toehold (up to ~6 nt) leads to a faster reaction.[3]
-
Optimize toehold sequence: The sequence composition of the toehold can influence binding kinetics. Avoid long stretches of the same nucleotide and consider the thermodynamic stability of the toehold-invader interaction.
Possible Cause 2: Secondary structures in DNA strands.
Single-stranded DNA can form hairpins or other secondary structures that hinder their ability to participate in the strand displacement reaction.
Solutions:
-
Sequence Design Software: Use nucleic acid design software (e.g., NUPACK) to design sequences with minimal predicted secondary structure under experimental conditions.
-
Experimental Verification: Analyze the secondary structure of oligonucleotides using techniques like native PAGE or thermal melting analysis (Tm).
FAQs (Frequently Asked Questions)
Q1: What is the most common source of leaks in DNA strand displacement cascades?
A1: The most common source of leaks is often spontaneous, transient "breathing" or fraying at the ends of DNA duplexes. This exposes a few bases of the substrate strand, which can act as a toehold for an invading strand, initiating an unwanted displacement reaction. While slower than intended toehold-mediated displacement, this process can lead to significant background signal over time.
Q2: How can I reduce leaks without significantly slowing down my desired reaction?
A2: A powerful strategy is the incorporation of Locked Nucleic Acids (LNAs) into your DNA constructs. Site-specific LNA substitutions can reduce leakage by over 50-fold while maintaining the rate of the intended invasion.[1] This improves the signal-to-noise ratio of the system. Another approach is to use a "dynamically elongated associative toehold," where a hairpin lock design keeps the initial toehold short to minimize leaks, but elongates it upon target binding to accelerate the desired reaction.[5][6]
Q3: What is the role of mismatches in preventing leaks?
A3: A single base pair mismatch between the invading strand and the substrate can act as a kinetic barrier to strand displacement. Placing a mismatch near the toehold can dramatically slow down the rate of unwanted displacement.[2] However, the position of the mismatch is crucial; a mismatch further away from the toehold may have a less pronounced effect on the leak rate.
Q4: Can reaction conditions affect leakage?
A4: Yes, reaction conditions play a significant role. For instance, long incubation times and high concentrations of fuel strands can sometimes increase the likelihood of leaky reactions.[7] It is important to optimize these parameters for your specific system.
Q5: What is "logical redundancy" and how does it prevent leaks?
A5: Logical redundancy is a design principle where the activation of a downstream step in a cascade requires the presence of two or more distinct input signals. This creates a higher energetic barrier for spurious activation. For a leak to occur, multiple independent, low-probability leak events would need to happen simultaneously, making it a much rarer occurrence compared to a single leak event in a non-redundant system.
Data Presentation
Table 1: Effect of LNA Substitution on Leakage Rate
| Substrate Modification | Leakage Rate Constant (s⁻¹) | Invasion Rate Constant (M⁻¹s⁻¹) | Performance Enhancement Ratio (k_invasion / k_leak) | Fold Reduction in Leakage |
| All-DNA Control | ~1.0 x 10⁻⁵ | ~5.0 x 10⁵ | 5.0 x 10¹⁰ | 1x |
| Site-specific LNA | < 2.0 x 10⁻⁷ | ~5.0 x 10⁵ | > 2.5 x 10¹² | > 50x |
Data synthesized from concepts presented in[1][4]. Actual values are system-dependent.
Table 2: Effect of Mismatch Position in Invader on Displacement Rate
| Mismatch Position (from toehold) | Relative Mean First Passage Time (MFPT) | Fold Change in Displacement Rate (approx.) |
| Perfect Match | 1.0 | 1x (fastest) |
| Position 1 | ~10 | 10x slower |
| Position 5 | ~20 | 20x slower |
| Position 9 | ~70 | 70x slower |
Data synthesized from concepts presented in[2]. MFPT is inversely proportional to the displacement rate.
Table 3: Effect of Toehold Length on Displacement Rate
| Toehold Length (nt) | Approximate Increase in Reaction Rate |
| +1 | ~10-fold |
| +2 | ~100-fold |
| +3 | ~1000-fold |
| up to 6 | Continues to increase |
Data synthesized from concepts presented in[3].
Table 4: Qualitative Effect of Clamp Length on Leakage
| Clamp Length (nt) | Effect on Duplex Fraying | Impact on Leakage |
| 0 (none) | Normal fraying | Baseline leakage |
| 1-2 | Reduced fraying | Significant reduction |
| 3+ | Further reduced fraying | Diminishing returns, may slow desired reaction |
This table provides a qualitative summary based on principles described in[1].
Visualizations
Caption: Intended DNA strand displacement pathway.
Caption: Common leak pathway in strand displacement.
Caption: Key strategies for preventing leaks.
References
- 1. Kinetics of DNA Strand Displacement Systems with Locked Nucleic Acids - PMC [pmc.ncbi.nlm.nih.gov]
- 2. The Effect of Basepair Mismatch on DNA Strand Displacement - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Controlling DNA–RNA strand displacement kinetics with base distribution - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. academic.oup.com [academic.oup.com]
- 6. academic.oup.com [academic.oup.com]
- 7. A Novel Computational Method to Reduce Leaky Reaction in DNA Strand Displacement - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Enhancing the Programmability of DNA Logic Gates
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in their experiments with DNA logic gates.
Troubleshooting Guides
This section addresses specific issues that may arise during the design and execution of DNA logic gate experiments.
Issue 1: Low or No Output Signal
Question: My DNA logic gate is not producing the expected fluorescent output signal, or the signal is very weak. What are the potential causes and how can I troubleshoot this?
Answer:
Low or no signal is a common issue that can often be traced back to problems with the DNA components, their assembly, or the reaction conditions.
Potential Causes and Solutions:
| Potential Cause | Troubleshooting Steps |
| 1. Incorrect DNA Annealing | Ensure that the DNA strands forming the gate complex have been properly annealed. Improperly formed duplexes will not react as intended. Follow a reliable annealing protocol.[1] |
| 2. Low Template/Gate Concentration | Insufficient concentration of the DNA gate components is a primary reason for failed reactions.[2][3] Verify the concentration of your DNA stocks using a reliable method like a fluorometer. The working concentration for gates is often in the nanomolar range (e.g., 30 nM).[4][5] |
| 3. Inefficient Toehold-Mediated Strand Displacement (TMSD) | The kinetics of TMSD are highly dependent on the toehold length.[6][7] An 8-nucleotide toehold is often cited as optimal for efficient strand displacement.[8] If using shorter toeholds, the reaction rate may be too slow. Consider redesigning the strands with longer toeholds. |
| 4. Degraded or Poor-Quality DNA | DNA can degrade with repeated freeze-thaw cycles or nuclease contamination.[9] Run your DNA oligonucleotides on a gel to check their integrity. If degradation is suspected, re-order or re-purify the DNA. |
| 5. Suboptimal Buffer Conditions | The presence of divalent cations like Mg²⁺ is crucial for the stability of DNA duplexes and junctions.[4] Ensure your reaction buffer contains an adequate concentration of MgCl₂ (e.g., 10-12.5 mM).[4][10] |
| 6. Incorrect Primer/Input Design | The input DNA strand must be perfectly complementary to the toehold and the subsequent displacement domain. Verify your sequences for any potential mismatches or synthesis errors. |
| 7. Nuclease Contamination | If working with cell lysates or other biological samples, nucleases can degrade your DNA circuits. Consider using nuclease-resistant DNA modifications or adding nuclease inhibitors.[11] |
Issue 2: High Background Signal (Leakage)
Question: I'm observing a high fluorescence signal even in the absence of the input DNA strand. What causes this "leakage" and how can I minimize it?
Answer:
High background signal, or leakage, occurs when the output signal is generated without the intended input. This is often due to non-specific reactions or instability of the gate components.
Potential Causes and Solutions:
| Potential Cause | Troubleshooting Steps |
| 1. Unstable Gate Complex | The gate complex may be dissociating spontaneously, leading to the release of the output strand. For fluorophore-quencher pairs, this separation leads to a background signal.[5] Increasing the length of the hybridized regions can improve stability. |
| 2. Toehold-Free Strand Displacement | Strand displacement can occur even without a toehold, albeit at a much slower rate. This "leakage" reaction can become significant over long incubation times. Shortening the toehold length can help decrease the rate of fuel, TMSD, and reporter reactions, thereby reducing basal expression.[12] |
| 3. Non-Specific Interactions | Unintended hybridization between different DNA strands in the reaction can lead to the formation of incorrect structures and the release of signal.[13] Ensure that your DNA sequences have been designed to minimize such cross-reactivity. |
| 4. Contamination with Unbound Dyes | If using fluorescently labeled DNA, unincorporated dye molecules that were not removed during purification can contribute to background fluorescence.[14] Re-purify your labeled oligonucleotides. |
| 5. Suboptimal Strand Concentration Ratios | Using a significant excess of one component can sometimes drive unintended reactions. Optimize the concentration ratios of your gate components and inputs. A 1:1 or 1.2:1 ratio of complementary strands is often used for creating gate complexes.[15][16] |
Issue 3: Inconsistent or Unreliable Results
Question: My experiment works some of the time but fails on other occasions. What could be causing this lack of reproducibility?
Answer:
Inconsistent results often point to subtle variations in experimental setup and execution.
Potential Causes and Solutions:
| Potential Cause | Troubleshooting Steps |
| 1. Inaccurate Pipetting | Small volumes of concentrated DNA stocks can be difficult to pipette accurately. Ensure your pipettes are calibrated and use appropriate techniques for small volumes. |
| 2. Temperature Fluctuations | DNA hybridization and strand displacement kinetics are sensitive to temperature.[17] Use a thermocycler or a stable incubator to maintain a consistent reaction temperature. |
| 3. Variations in Buffer Preparation | Inconsistent pH or salt concentrations in your buffer can affect the stability and kinetics of DNA interactions.[17] Prepare a large batch of buffer to use across multiple experiments. |
| 4. Sample Contamination | Contamination from previous experiments or from the lab environment can interfere with your reactions.[2] Use filter tips and maintain a clean workspace. |
| 5. Repeated Freeze-Thaw Cycles | Repeatedly freezing and thawing your DNA stocks can lead to degradation.[1] Aliquot your DNA oligonucleotides into smaller, single-use tubes. |
Experimental Protocols & Data
Key Experimental Parameters
The following table summarizes key quantitative data for designing and troubleshooting DNA logic gate experiments.
| Parameter | Typical Value / Range | Notes |
| Toehold Length | 6 - 8 nucleotides | The rate of strand displacement increases exponentially with toehold length up to about 8 nt.[7] |
| Gate Component Concentration (Stock) | 1 µM - 20 µM | Used for the initial annealing of gate components.[4][10] |
| Gate Working Concentration | 30 nM - 100 nM | The final concentration of the assembled gate in the reaction.[4][15][18] |
| Input Strand Concentration | 1x to 2x relative to gate | Often used at a slight excess to ensure the reaction goes to completion.[15] |
| MgCl₂ Concentration in Buffer | 10 mM - 12.5 mM | Crucial for the stability of DNA structures.[4][10] |
| Annealing Temperature | 90°C - 95°C | Initial denaturation step before slow cooling.[1] |
| Reaction Time (in vitro) | 30 minutes to 12 hours | Highly dependent on the complexity of the circuit and component concentrations.[10] |
Protocol 1: Annealing of DNA Logic Gate Components
This protocol describes the formation of a double-stranded DNA gate complex from two complementary single-stranded oligonucleotides.
Materials:
-
Lyophilized DNA oligonucleotides
-
Nuclease-free water
-
Annealing Buffer (10x stock): 100 mM Tris (pH 7.5-8.0), 500 mM NaCl, 10 mM EDTA
-
Thermocycler
Methodology:
-
Resuspend Oligonucleotides: Dissolve the lyophilized DNA oligonucleotides in nuclease-free water to create stock solutions of a known concentration (e.g., 100 µM).
-
Mix Equimolar Amounts: In a PCR tube, mix equal molar amounts of the complementary DNA strands. For example, to create a 20 µM duplex solution, mix 40 µL of a 50 µM solution of each strand with 20 µL of 5x Annealing Buffer for a final volume of 100 µL.[1]
-
Thermal Cycling Program: Place the tube in a thermocycler and run the following program:[19]
-
Heat to 95°C for 2-5 minutes to denature any secondary structures.
-
Slowly cool to 25°C over a period of 45-60 minutes. This allows the complementary strands to anneal correctly.
-
Hold at 4°C for short-term storage.
-
-
Verification (Optional): The formation of the duplex can be verified by running the annealed product on a native polyacrylamide gel. The duplex will migrate slower than the single-stranded components.
Protocol 2: Functional Testing of a DNA 'AND' Gate using Fluorescence
This protocol outlines how to test the functionality of a simple 'AND' gate that produces a fluorescent signal only in the presence of two specific DNA inputs.
Materials:
-
Annealed 'AND' gate complex (with a fluorophore and quencher in proximity)
-
Input A DNA strand
-
Input B DNA strand
-
Reaction Buffer (e.g., 1x TAE-Mg buffer: 40 mM Tris, 20 mM acetic acid, 1 mM EDTA, and 10 mM Mg²⁺)[4]
-
384-well flat black plate
-
Fluorescence plate reader
Methodology:
-
Prepare Reactions: In separate wells of the 384-well plate, prepare the following reactions to a final volume of 50 µL in 1x Reaction Buffer:
-
Well 1 (Negative Control): 'AND' gate only
-
Well 2 (Input A only): 'AND' gate + Input A
-
Well 3 (Input B only): 'AND' gate + Input B
-
Well 4 (Positive Control): 'AND' gate + Input A + Input B
-
-
Concentrations: Use a final concentration of 30 nM for the 'AND' gate and a slight molar excess (e.g., 1.2x) for each input strand.
-
Incubation: Incubate the plate at a constant temperature (e.g., 25°C) for a set period (e.g., 2 hours).
-
Fluorescence Measurement: Measure the fluorescence intensity in each well using a plate reader with the appropriate excitation and emission wavelengths for your chosen fluorophore.
-
Data Analysis: Subtract the background fluorescence (Well 1) from the other wells. A successful 'AND' gate will show a significant increase in fluorescence only in Well 4, where both inputs were present.[5]
Visualizations
Signaling Pathways and Workflows
Caption: Troubleshooting workflow for a failing DNA logic gate experiment.
Caption: Mechanism of Toehold-Mediated Strand Displacement (TMSD).
Caption: Signaling pathway for a cascaded OR-AND DNA logic circuit.
References
- 1. metabion.com [metabion.com]
- 2. base4.co.uk [base4.co.uk]
- 3. Troubleshooting your sequencing results - The University of Nottingham [nottingham.ac.uk]
- 4. mdpi.com [mdpi.com]
- 5. Fluorescence-Based Multimodal DNA Logic Gates - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Kinetics and Activation Strategies in Toehold-Mediated and Toehold-Free DNA Strand Displacement - PMC [pmc.ncbi.nlm.nih.gov]
- 7. tandfonline.com [tandfonline.com]
- 8. academic.oup.com [academic.oup.com]
- 9. microsynth.com [microsynth.com]
- 10. pubs.acs.org [pubs.acs.org]
- 11. chembites.org [chembites.org]
- 12. researchgate.net [researchgate.net]
- 13. Logic Gates Based on DNA Aptamers - PMC [pmc.ncbi.nlm.nih.gov]
- 14. robarts.ca [robarts.ca]
- 15. researchgate.net [researchgate.net]
- 16. Constructing DNA logic circuits based on the toehold preemption mechanism - RSC Advances (RSC Publishing) DOI:10.1039/D1RA08687A [pubs.rsc.org]
- 17. Kinetics of the B-A transition of DNA: analysis of potential contributions to a reaction barrier - PMC [pmc.ncbi.nlm.nih.gov]
- 18. par.nsf.gov [par.nsf.gov]
- 19. static.igem.org [static.igem.org]
Technical Support Center: DNA Synthesis and Purification
Welcome to the technical support center for DNA synthesis and purification. This resource is designed for researchers, scientists, and drug development professionals to troubleshoot common issues encountered during experimental workflows.
Troubleshooting Guides & FAQs
This section provides answers to frequently asked questions and guidance on resolving specific problems that may arise during DNA synthesis and purification.
DNA Synthesis
Question: Why is my oligonucleotide synthesis yield consistently low?
Answer: Low yield in oligonucleotide synthesis can stem from several factors throughout the synthesis process. A primary reason is inefficient coupling at each step. The coupling efficiency should ideally be above 98.5% to obtain a reasonable yield of full-length product, especially for longer oligonucleotides.[1] Another common cause is the quality of the reagents. Ensure that all phosphoramidites, activators, and other reagents are fresh and have been stored under the recommended conditions to prevent degradation.[2] Moisture in the reagents or synthesis environment can significantly reduce coupling efficiency.[3]
Additionally, issues with the DNA synthesizer itself, such as improper calibration leading to incorrect reagent delivery volumes or clogged lines, can result in lower yields.[2] Finally, problems with the solid support, such as a low loading capacity, can also limit the total yield.
Question: What causes n-1 and other shortmer sequences in my synthetic DNA?
Answer: The presence of "shortmers" or failure sequences (n-1, n-2, etc.) is a common impurity in oligonucleotide synthesis.[1][4] These truncated sequences arise from incomplete coupling during a synthesis cycle.[1] If a nucleotide fails to couple to the growing chain, the unreacted 5'-hydroxyl group is typically "capped" in the subsequent step to prevent it from participating in future cycles.[5] However, if capping is inefficient, these truncated chains can continue to elongate, leading to a complex mixture of shorter products. The primary cause of poor coupling and subsequent shortmer formation is often related to reagent quality, particularly the phosphoramidites and activator, or the presence of moisture.[3]
Question: My purified oligonucleotide appears to be of poor quality. What are the likely causes?
Answer: Poor quality of a synthesized oligonucleotide can manifest as a low percentage of the full-length product, the presence of modified bases, or incomplete deprotection. Incomplete removal of protecting groups from the bases or the phosphate (B84403) backbone after synthesis can interfere with downstream applications.[6][7] This can be caused by using expired or improperly prepared deprotection reagents, or insufficient incubation time.[2]
Another factor could be the oxidation step. An inefficient oxidation step can lead to unstable phosphite (B83602) triesters which can be cleaved during subsequent steps, leading to chain cleavage and a lower yield of the full-length product.[6] Furthermore, some modified oligonucleotides are sensitive to standard deprotection conditions, which can lead to their degradation.[3]
DNA Purification
Question: My DNA yield after purification is very low. What are the common reasons for this?
Answer: Low DNA yield is a frequent issue in purification and can be attributed to several factors. Incomplete cell lysis is a primary cause, as DNA that is not released from the cells will be lost.[8][9][10] The starting material is also crucial; using too few cells or an old sample where DNA has degraded will naturally result in a lower yield.[11] For column-based methods, overloading the column with too much starting material can reduce lysis efficiency and clog the membrane, leading to decreased yield.[12][13]
During phenol-chloroform extraction, poor phase separation can lead to loss of the aqueous phase containing the DNA.[9] In spin-column methods, using incorrect binding or wash buffers, or not adding ethanol (B145695) to the wash buffer when required, can result in the DNA not binding to the silica (B1680970) membrane effectively.[12] Finally, the elution step is critical; using too little elution buffer, not applying it to the center of the membrane, or eluting at a suboptimal temperature can lead to incomplete recovery of the bound DNA.[12][14]
Question: The A260/A280 ratio of my purified DNA is below 1.8. What does this indicate and how can I fix it?
Answer: An A260/A280 ratio below the expected value of ~1.8 for pure DNA is typically indicative of protein contamination.[15] This is a common issue, particularly with methods like phenol-chloroform extraction where residual phenol (B47542) or incomplete separation of the aqueous and organic phases can carry over proteins.[8] To remedy this, you can perform an additional phenol-chloroform extraction or re-purify the DNA using a spin-column kit.[15] Ensuring complete lysis and including a proteinase K digestion step can help to degrade proteins before they are carried over.[10]
Question: My purified DNA has an A260/A230 ratio that is lower than expected. What is the cause?
Answer: A low A260/A230 ratio (generally expected to be in the range of 2.0-2.2) suggests the presence of contaminants that absorb at 230 nm. Common culprits include residual chaotropic salts (like guanidine (B92328) hydrochloride) from the binding buffer in spin-column kits, or residual phenol from a phenol-chloroform extraction.[15] To resolve this, ensure that the wash steps in your purification protocol are performed correctly and that no buffer from the previous step is carried over. An additional wash step may be beneficial. If using a spin column, make sure to perform the final centrifugation step to remove any residual ethanol from the wash buffer before eluting the DNA.[15]
Question: I am having trouble resuspending my DNA pellet after ethanol precipitation. What can I do?
Answer: Difficulty in resuspending a DNA pellet is often due to overdrying.[8][11] It is important not to dry the pellet for too long, especially when using a vacuum.[11] To aid in resuspension, you can gently heat the sample in the resuspension buffer (e.g., TE buffer) at 55-65°C for a short period.[11] Pipetting the solution up and down or gently vortexing can also help to dissolve the pellet. Be patient, as larger DNA pellets can take some time to fully resuspend.[8]
Quantitative Data Summary
| Parameter | Issue | Likely Cause(s) | Recommended Action(s) | Expected Value/Range |
| DNA Purity | A260/A280 ratio < 1.7 | Protein or phenol contamination | Re-purify the DNA; ensure complete removal of organic phase during extraction.[8][15] | ~1.8 |
| A260/A280 ratio > 1.9 | RNA contamination | Treat with RNase; ensure RNase is active.[15] | ~1.8 | |
| A260/A230 ratio < 2.0 | Chaotropic salt or phenol contamination | Repeat wash steps; ensure complete removal of wash buffers.[15] | 2.0 - 2.2 | |
| Oligonucleotide Synthesis | Coupling Efficiency | Low yield of full-length product | Check reagent quality and freshness; ensure anhydrous conditions.[2] | >98.5% |
| DNA Yield from Blood | Sample Age (stored at 2-8°C) | DNA degradation | Use fresh samples whenever possible.[11] | Expect 10-15% lower yield for samples stored >7 days.[11] |
Experimental Protocols
Phosphoramidite (B1245037) Oligonucleotide Synthesis Cycle
This protocol outlines the four main steps in one cycle of solid-phase DNA synthesis using the phosphoramidite method.
-
Detritylation: The 5'-dimethoxytrityl (DMT) protecting group is removed from the nucleotide attached to the solid support using a mild acid, typically trichloroacetic acid (TCA) in dichloromethane. This exposes the 5'-hydroxyl group for the next coupling step.[5][16]
-
Coupling: The next phosphoramidite monomer, activated by an activator like tetrazole, is added. The activated phosphoramidite couples with the free 5'-hydroxyl group of the growing oligonucleotide chain.[6][16] This reaction is carried out in an anhydrous solvent like acetonitrile.
-
Capping: To prevent unreacted 5'-hydroxyl groups from participating in subsequent cycles, they are "capped" by acetylation using reagents such as acetic anhydride (B1165640) and N-methylimidazole.[5]
-
Oxidation: The newly formed phosphite triester linkage is unstable and is oxidized to a more stable phosphate triester using an oxidizing agent, typically iodine in the presence of water and a weak base like pyridine.[6][16]
This cycle is repeated until the desired oligonucleotide sequence is synthesized.
Phenol-Chloroform DNA Extraction
This protocol is a standard method for purifying DNA from cellular lysates.
-
Cell Lysis: Resuspend the cell pellet in a suitable lysis buffer (e.g., containing SDS and proteinase K) and incubate to ensure complete cell lysis and protein digestion.[3][11]
-
Phenol-Chloroform Extraction: Add an equal volume of phenol:chloroform (B151607):isoamyl alcohol (25:24:1) to the lysate.[3][17] Mix thoroughly by vortexing to create an emulsion.
-
Phase Separation: Centrifuge the mixture to separate the phases. The upper aqueous phase contains the DNA, the interface contains precipitated proteins, and the lower organic phase contains lipids and other cellular debris.[3][11]
-
Aqueous Phase Transfer: Carefully transfer the upper aqueous phase to a new tube, avoiding the protein interface.[11]
-
Chloroform Extraction (Optional but Recommended): Add an equal volume of chloroform to the aqueous phase, mix, and centrifuge. This step removes any residual phenol. Transfer the upper aqueous phase to a new tube.[2]
-
DNA Precipitation: Add 2-2.5 volumes of cold 100% ethanol and 1/10 volume of sodium acetate (B1210297) to precipitate the DNA.[11]
-
Pelleting and Washing: Centrifuge to pellet the DNA. Wash the pellet with 70% ethanol to remove salts.[17]
-
Drying and Resuspension: Air-dry the pellet and resuspend in a suitable buffer like TE buffer or nuclease-free water.[11]
Silica Spin-Column DNA Purification
This is a common and rapid method for DNA purification.
-
Lysis: Lyse the cells using the provided lysis buffer, which often contains a chaotropic agent.
-
Binding: Add ethanol to the lysate to promote DNA binding to the silica membrane.[18] Transfer the mixture to the spin column and centrifuge. The DNA will bind to the silica membrane in the presence of the chaotropic salt and ethanol.[18]
-
Washing: Discard the flow-through and wash the membrane with the provided wash buffers. This typically involves one or two wash steps to remove proteins, salts, and other impurities.[18] Ensure that ethanol has been added to the wash buffer concentrate as indicated in the kit protocol.[19]
-
Dry Spin: After the final wash, centrifuge the empty column to remove any residual ethanol, which can inhibit downstream enzymatic reactions.[18]
-
Elution: Place the spin column in a clean collection tube. Add the elution buffer (often a low-salt buffer or nuclease-free water) directly to the center of the silica membrane and incubate for a few minutes.[18] Centrifuge to elute the purified DNA.
Visualizations
DNA Synthesis Workflow
References
- 1. labcluster.com [labcluster.com]
- 2. carlroth.com [carlroth.com]
- 3. How to Use Phenol-Chloroform for DNA Purification | Thermo Fisher Scientific - JP [thermofisher.com]
- 4. 2024.sci-hub.cat [2024.sci-hub.cat]
- 5. atdbio.com [atdbio.com]
- 6. Standard Protocol for Solid-Phase Oligonucleotide Synthesis using Unmodified Phosphoramidites | LGC, Biosearch Technologies [biosearchtech.com]
- 7. Manual Oligonucleotide Synthesis Using the Phosphoramidite Method | Springer Nature Experiments [experiments.springernature.com]
- 8. Purification of DNA Oligos by denaturing polyacrylamide gel electrophoresis (PAGE) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. RP-HPLC Purification of Oligonucleotides | Mass Spectrometry Research Facility [massspec.chem.ox.ac.uk]
- 10. stemcell.com [stemcell.com]
- 11. microbenotes.com [microbenotes.com]
- 12. How do you purify oligonucleotide conjugates by HPLC? | AAT Bioquest [aatbio.com]
- 13. DNA/RNA Purification from PAGE Gels - National Diagnostics [nationaldiagnostics.com]
- 14. geneticeducation.co.in [geneticeducation.co.in]
- 15. hplcchina.com [hplcchina.com]
- 16. DNA Oligonucleotide Synthesis [sigmaaldrich.com]
- 17. mpbio.com [mpbio.com]
- 18. Spin column-based nucleic acid purification - Wikipedia [en.wikipedia.org]
- 19. neb.com [neb.com]
Validation & Comparative
A Comparative Analysis of DNA and Silicon-Based Computing: Unveiling the Future of Information Processing
For researchers, scientists, and drug development professionals, the quest for more powerful and efficient computing paradigms is relentless. While silicon-based computing has been the bedrock of technological advancement for decades, its physical limitations are becoming increasingly apparent. In contrast, DNA-based computing, a field that harnesses the inherent information-carrying capacity of biological molecules, presents a revolutionary alternative. This guide provides an objective comparison of the efficiency of DNA versus silicon-based computing, supported by experimental data, detailed protocols, and visualizations to illuminate the fundamental principles and workflows of this emerging technology.
The core advantage of DNA computing lies in its massive parallelism. Unlike the sequential processing of traditional silicon computers, DNA computers can perform billions of calculations simultaneously in a single test tube.[1][2][3] This intrinsic parallelism makes them exceptionally well-suited for tackling complex combinatorial problems that are intractable for even the most powerful supercomputers.[1][4]
Quantitative Performance Metrics: A Head-to-Head Comparison
The following table summarizes the key performance metrics of DNA and silicon-based computing, drawing from various experimental findings and theoretical estimations.
| Performance Metric | DNA-Based Computing | Silicon-Based Computing | Supporting Evidence |
| Processing Speed | 10¹⁴ to 10²⁰ operations per second (in parallel) | 10⁸ to 10¹² operations per second | [1][2][5] |
| Data Storage Density | ~1 bit/nm³ (up to 10¹⁸ bytes/cm³) | ~1 bit/10¹² nm³ | [5][6][7] |
| Energy Consumption | ~5 x 10⁻²⁰ Joules per operation | ~10⁻⁹ Joules per operation | [5][8] |
| Error Rates | ~0.1% to 1% per base sequenced (can be reduced) | Extremely low (highly reliable) | [9][10][11] |
| Cost | High for synthesis and sequencing ($3,500/MB for synthesis) | Relatively low and continuously decreasing | [12][13][14] |
Experimental Protocols: A Look Under the Hood
To provide a practical understanding of DNA computing, this section details the methodologies for two key experimental concepts: Leonard Adleman's pioneering experiment on the Hamiltonian Path Problem and the fundamental mechanism of DNA strand displacement.
Experimental Protocol 1: Solving the Hamiltonian Path Problem
Leonard Adleman's 1994 experiment was the first successful demonstration of DNA computing.[1][15] He solved a seven-city instance of the "traveling salesman" problem, which is a classic NP-complete problem.
Objective: To find a path that starts at a designated city, ends at another, and passes through each of the other cities exactly once.
Methodology:
-
Encoding:
-
Each of the seven cities is represented by a unique 20-nucleotide single-stranded DNA molecule (an oligonucleotide).
-
Each possible path between two cities is represented by an oligonucleotide that is complementary to the second half of the origin city's DNA and the first half of the destination city's DNA.
-
-
Ligation:
-
The DNA strands representing the cities and the paths are mixed in a test tube with DNA ligase, an enzyme that joins DNA fragments.
-
This process results in the formation of all possible random paths through the cities, represented by longer DNA molecules.
-
-
Amplification:
-
Polymerase Chain Reaction (PCR) is used to selectively amplify the DNA molecules that represent paths starting with the designated start city and ending with the designated end city.
-
-
Length-Based Separation:
-
Gel electrophoresis is used to separate the amplified DNA molecules by length. Only the molecules with a length corresponding to a path that visits all seven cities are retained.
-
-
Affinity Purification:
-
This step ensures that the remaining DNA molecules represent paths that visit each of the seven cities. This is achieved by sequentially isolating the DNA strands that contain the sequence for each city.
-
-
Detection:
-
The final remaining DNA molecules, if any, represent the solution to the Hamiltonian Path Problem. Their sequence can be determined using standard DNA sequencing methods.
-
Experimental Protocol 2: Toehold-Mediated DNA Strand Displacement
DNA strand displacement is a fundamental process in many DNA computing and nanotechnology applications. It allows for the controlled release of an output DNA strand by an input DNA strand.
Objective: To design and execute a simple toehold-mediated strand displacement reaction.
Methodology:
-
Component Design:
-
Gate Complex: A double-stranded DNA complex is formed by a "template" strand and an "incumbent" strand. The template strand has a short, single-stranded region at one end called a "toehold."
-
Input Strand: A single-stranded DNA molecule that is complementary to the template strand, including the toehold region.
-
Output Strand: The incumbent strand that will be displaced from the gate complex.
-
-
Reaction Setup:
-
The gate complex and the input strand are mixed in a suitable buffer solution at a controlled temperature.
-
-
Reaction Mechanism:
-
The input strand first binds to the single-stranded toehold on the gate complex.
-
This initial binding facilitates a "branch migration" process, where the input strand progressively displaces the incumbent strand from the template strand.
-
The reaction concludes when the incumbent strand is fully displaced and released into the solution as the output.
-
-
Analysis:
-
The progress of the reaction can be monitored in real-time using fluorescence spectroscopy. Typically, the incumbent strand is labeled with a fluorophore and a quencher. When the incumbent is part of the gate complex, the quencher suppresses the fluorophore's signal. Upon displacement, the fluorophore and quencher are separated, resulting in an increase in fluorescence.
-
Visualizing the Logic: Workflows and Pathways
To further clarify the processes described, the following diagrams have been generated using Graphviz.
The Road Ahead: Challenges and Opportunities
Despite its immense potential, DNA computing faces several significant hurdles that must be overcome before it can become a mainstream technology. High error rates during DNA synthesis and sequencing, the slow speed of individual biochemical reactions, and the substantial cost of materials are major challenges.[3][9][16]
However, the field is rapidly advancing. Novel error-correction techniques are being developed, and the costs of DNA synthesis and sequencing are continuously decreasing.[10][11][13] Furthermore, researchers are exploring hybrid systems that combine the strengths of both silicon and DNA-based computing.[7] For specific applications, such as high-density data storage and solving complex optimization problems in drug discovery and materials science, DNA computing holds the promise of revolutionizing research and development.[3][17] As our understanding of molecular biology deepens and the tools to manipulate DNA become more sophisticated, the era of practical biomolecular computing draws ever closer.
References
- 1. Computing with DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Evaluation [cs.stanford.edu]
- 3. medium.com [medium.com]
- 4. digital-library.theiet.org [digital-library.theiet.org]
- 5. Programmable Biomolecule-Mediated Processors - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. Is DNA-based Computing the Future of Our Digital World? - Sify [sify.com]
- 8. insideainews.com [insideainews.com]
- 9. Sources of Error in DNA Computation [web.cs.dal.ca]
- 10. High-throughput DNA sequencing errors are reduced by orders of magnitude using circle sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 11. academic.oup.com [academic.oup.com]
- 12. researchgate.net [researchgate.net]
- 13. tarashirvani.com [tarashirvani.com]
- 14. Reddit - The heart of the internet [reddit.com]
- 15. cs.princeton.edu [cs.princeton.edu]
- 16. Computing with DNA | EMBO Reports [link.springer.com]
- 17. researchgate.net [researchgate.net]
A Researcher's Guide to Benchmarking DNA Synthesis Methods
The ability to accurately and rapidly synthesize custom DNA sequences is a cornerstone of modern biological research, fueling advancements in drug discovery, synthetic biology, and personalized medicine.[1] As the demand for synthetic DNA soars, a variety of synthesis technologies have emerged, each with distinct advantages and limitations.[2][3] This guide provides an objective comparison of the primary DNA synthesis methods, supported by performance data and detailed experimental protocols to help researchers make informed decisions for their specific applications.
Overview of DNA Synthesis Technologies
Modern DNA synthesis can be broadly categorized into two main approaches: traditional chemical synthesis and newer enzymatic methods.[4]
-
Chemical Synthesis (Phosphoramidite Chemistry): For decades, phosphoramidite (B1245037) chemistry has been the gold standard for DNA synthesis.[2] This method builds single-stranded DNA (oligonucleotides) by sequentially adding nucleotide building blocks in a four-step cycle.[4] It is a mature technology available in two main formats:
-
Column-based Synthesis: The traditional method where synthesis occurs on controlled-porosity glass beads within individual columns. It is reliable but offers lower throughput.[5]
-
Chip-based (Microarray) Synthesis: A high-throughput method where thousands to millions of unique oligonucleotides are synthesized in parallel on a small chip.[6][7] This approach dramatically reduces the cost per base but typically produces smaller quantities of each oligo and has historically had higher error rates.[5][8]
-
-
Enzymatic Synthesis: An emerging alternative that uses enzymes, such as Terminal deoxynucleotidyl Transferase (TdT), to synthesize DNA.[2][9] This approach mimics natural processes and offers several key advantages, including faster synthesis times, the elimination of hazardous chemical waste, and the potential to create much longer DNA strands in a single run.[4][9] While initially more expensive, the costs for enzymatic synthesis are becoming competitive with chemical methods.[4]
Quantitative Performance Comparison
The choice of a DNA synthesis method often depends on a trade-off between speed, cost, accuracy, and scale. The following table summarizes key performance metrics for the different technologies.
| Feature | Column-Based (Chemical) | Chip-Based (Chemical) | Enzymatic Synthesis |
| Error Rate | ~1 in 600 bp (post-assembly)[10] | 1 in 200 to 1 in 600 bp[11][12] | Can be < 1 in 8,700 bp (with error correction)[2][11] |
| Max Length | ~200-250 bases[13][14] | ~120-200 bases[15][16] | >1,000 bases, potentially up to 3,000+[2][13] |
| Throughput | Low-to-Medium (96-768 oligos) | Very High (up to 1,000,000+ oligos)[6] | Potentially Ultra-High[17] |
| Cost per Base | High (~$0.05 - $0.20)[8][18] | Very Low (~$0.00001 - $0.001)[8][19] | Becoming cost-competitive with chemical methods[4] |
| Turnaround Time | Slower (minutes per base addition)[9] | Slower (minutes per base addition)[9] | Faster (seconds per base addition)[4] |
| Yield | High (nmol scale)[20] | Low (fmol to pmol scale)[5][6] | Variable, under active development |
| Hazardous Waste | Yes[4][9] | Yes[4][9] | No[4] |
| Modifications | Extensive catalog available[9] | Limited compared to column-based | Limited catalog currently available[9] |
Experimental Protocols and Methodologies
Objectively comparing DNA synthesis methods requires a standardized benchmarking workflow. This involves synthesizing a defined library of DNA sequences, followed by assembly (if required) and rigorous sequence verification.
General Benchmarking Workflow
The overall process for evaluating a DNA synthesis technology involves designing, synthesizing, assembling, and verifying a set of target DNA sequences.
Caption: General workflow for benchmarking DNA synthesis methods.
1. DNA Library Design and Synthesis:
-
Protocol: Design a library of DNA sequences (e.g., 500 bp to 5 kb) with varying complexity, including regions with high GC content, repetitive sequences, and homopolymers.
-
Synthesize the corresponding oligonucleotides using the methods being compared. For chip-based synthesis, this results in a complex pool of oligos.[12]
2. Gene Assembly (for Oligo-based Methods):
-
Protocol: Assemble the synthesized oligonucleotides into full-length genes. Common methods include Polymerase Cycling Assembly (PCA) or Gibson Assembly.[21][22]
-
PCA: A series of overlapping oligonucleotides are progressively extended in a polymerase chain reaction to build the final construct.[22]
-
Gibson Assembly: Fragments with overlapping ends are joined in a one-pot isothermal reaction using a mix of three enzymes: an exonuclease, a polymerase, and a DNA ligase.[22]
-
3. Sequence Verification:
-
Protocol: Clone the assembled DNA fragments into a plasmid vector and transform into E. coli.
-
Isolate plasmids from a statistically significant number of individual colonies.
-
Sequence the cloned inserts using Sanger sequencing for individual clones or Next-Generation Sequencing (NGS) for a high-throughput analysis of the entire library.[6][7]
4. Data Analysis:
-
Protocol: Align the resulting sequence data against the intended reference sequences.
-
Calculate the error rate by identifying the frequency of substitutions, insertions, and deletions. The yield of error-free clones is a critical metric.[10]
-
Analyze other parameters such as synthesis time, cost, and total DNA yield.
Core Synthesis Mechanisms: Chemical vs. Enzymatic
The fundamental difference between chemical and enzymatic synthesis lies in the iterative cycle used to add each base.
Caption: Comparison of chemical and enzymatic DNA synthesis cycles.
Chemical synthesis involves harsh chemicals and produces hazardous waste, whereas the enzymatic process occurs in mild, aqueous conditions.[2] The efficiency of each cycle is critical, as even small inefficiencies compound over the length of the oligo, leading to a higher error rate.[23]
High-Throughput Synthesis and Assembly Workflow
For large-scale projects, chip-based synthesis is combined with automated assembly and error correction to produce many genes in parallel at a low cost.
Caption: High-throughput workflow from chip synthesis to applications.
This highly parallelized approach is essential for applications in synthetic biology and drug development, such as building large variant libraries for antibody engineering or screening for improved protein function. Enzymatic error correction methods can significantly improve the fidelity of the final gene products, reducing the number of error-containing clones by over 16-fold.[11]
Applications in Drug Development
The choice of synthesis method directly impacts its suitability for various applications in research and drug development:
-
High-Throughput Screening: Chip-based synthesis is ideal for creating large DNA libraries to screen for drug targets or optimize protein therapeutics. Its low cost and high throughput enable the testing of thousands of genetic variants simultaneously.
-
Gene and Cell Therapy: Enzymatic synthesis is a promising technology for producing the long, high-fidelity DNA required for gene therapies and CAR-T cell engineering.[1][2] The absence of harsh chemicals is also an advantage for therapeutic applications.
-
Custom Plasmids and Constructs: For routine cloning and the creation of a smaller number of specific DNA constructs, traditional column-based synthesis provides high-quality oligonucleotides that can be reliably assembled into larger genes.
-
Diagnostics and Probes: When highly modified oligonucleotides are needed, such as for qPCR probes or FISH, column-based chemical synthesis remains the superior method due to its extensive catalog of available modifications.[9]
As DNA synthesis technologies continue to evolve, the trend is toward greater speed, lower cost, and higher accuracy.[15] Enzymatic methods, in particular, are poised to redefine the landscape, potentially enabling benchtop devices that could give researchers unprecedented control and speed for their experiments.[23] By understanding the quantitative trade-offs and underlying methodologies of each approach, researchers can better leverage the power of synthetic DNA to accelerate discovery.
References
- 1. Reimagining DNA Synthesis from chemistry to enzymes. | Drug Discovery News [drugdiscoverynews.com]
- 2. Infographic: Chemical Versus Enzymatic DNA Synthesis | The Scientist [the-scientist.com]
- 3. Advancing high-throughput gene synthesis technology - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. ansabio.com [ansabio.com]
- 5. Synthetic DNA Synthesis and Assembly: Putting the Synthetic in Synthetic Biology - PMC [pmc.ncbi.nlm.nih.gov]
- 6. gcatbio.com [gcatbio.com]
- 7. americanlaboratory.com [americanlaboratory.com]
- 8. Overview of DNA synthesis technology - CD Biosynsis [biosynsis.com]
- 9. Which DNA Synthesis Approach Is Right for You? | Technology Networks [technologynetworks.com]
- 10. researchgate.net [researchgate.net]
- 11. Error Correction in Gene Synthesis Technology - PMC [pmc.ncbi.nlm.nih.gov]
- 12. A Scalable Gene Synthesis Platform Using High-Fidelity DNA Microchips - PMC [pmc.ncbi.nlm.nih.gov]
- 13. difference between chemical synthesis and enzymatic synthesis [biosyn.com]
- 14. DNA synthesis technologies to close the gene writing gap - PMC [pmc.ncbi.nlm.nih.gov]
- 15. DNA Synthesis: Approaches, Advances and Applications | Technology Networks [technologynetworks.com]
- 16. academic.oup.com [academic.oup.com]
- 17. biorxiv.org [biorxiv.org]
- 18. lcsciences.com [lcsciences.com]
- 19. DNA Synthesis and Sequencing Costs and Productivity for 2025 — synthesis [synthesis.cc]
- 20. Methods for Single-Stranded DNA Synthesis - Amerigo Scientific [amerigoscientific.com]
- 21. Next generation gene synthesis: From microarrays to genomes - PMC [pmc.ncbi.nlm.nih.gov]
- 22. Artificial gene synthesis - Wikipedia [en.wikipedia.org]
- 23. DNA Synthesis Heads Back to the Bench with New Enzymatic Methods | Labcompare.com [labcompare.com]
Bridging the Gap: A Guide to Experimental Validation of Molecular Programming Simulations
For researchers, scientists, and drug development professionals, the synergy between in-silico models and real-world experiments is paramount. This guide provides a comparative overview of key experimental techniques used to validate molecular programming simulations, supported by experimental data and detailed protocols. By rigorously comparing simulation predictions with experimental outcomes, we can enhance the predictive power of computational models and accelerate advancements in molecular engineering and therapeutics.
Molecular programming harnesses the predictable interactions of nucleic acids and other biomolecules to create nanoscale devices and circuits. Computer simulations are indispensable tools for designing and predicting the behavior of these complex systems. However, the accuracy of these simulations must be rigorously validated through experimental measurements. This guide explores several state-of-the-art experimental techniques and presents a framework for comparing simulation data with empirical results.
Structural Validation: Visualizing the Nanoscale
The precise three-dimensional structure of a molecular program is critical to its function. Techniques such as Atomic Force Microscopy (AFM), Transmission Electron Microscopy (TEM), and Small-Angle X-ray Scattering (SAXS) provide invaluable data for validating the predicted shapes and dimensions of DNA nanostructures.
Atomic Force Microscopy (AFM) and Transmission Electron Microscopy (TEM)
AFM and TEM are powerful imaging techniques that allow for the direct visualization of single molecules. In the context of molecular programming, they are routinely used to confirm the successful assembly of DNA origami structures and to measure their dimensions.
Comparison of Simulated and Experimental Structural Parameters of DNA Origami
| Parameter | Simulation (oxDNA) | Experiment (AFM/TEM) | Reference |
| Inter-helical Distance (Honeycomb Lattice) | ~2.3-2.4 nm | ~2.25 nm (TEM) | [1][2] |
| Inter-helical Distance (Square Lattice) | ~2.3-2.4 nm | ~2.7 nm (SAXS) | [1][2] |
| Global Twist (10.44 bp/turn tile) | Varies with model | 180° over 120 nm (SAXS) | [3] |
| DNA Origami Width (in air) | Model-dependent | 2.33 ± 0.14 nm/helix (AFM) | [2] |
| DNA Origami Width (in liquid) | Model-dependent | 2.88 ± 0.29 nm/helix (AFM) | [2] |
Experimental Protocol: AFM Imaging of DNA Nanostructures
A common method for preparing DNA nanostructures for AFM imaging involves depositing the sample onto a mica surface.[4][5]
-
Mica Preparation: Freshly cleave a mica sheet to expose a clean, flat surface.[5]
-
Sample Deposition: Apply a small volume (e.g., 1-20 µL) of the DNA nanostructure solution (1–20 ng/µL) onto the mica surface. The deposition buffer should contain divalent cations, such as 10 mM MgCl₂, to facilitate the adhesion of the negatively charged DNA to the negatively charged mica.[4]
-
Incubation: Allow the sample to incubate on the surface for 1–3 minutes.[4]
-
Rinsing: Gently rinse the surface with deionized water to remove unbound molecules and excess salts.[4][5]
-
Drying: Dry the sample using a stream of inert gas (e.g., nitrogen or argon).[5]
-
Imaging: Image the sample using tapping mode AFM to minimize damage to the delicate DNA structures.[5]
Small-Angle X-ray Scattering (SAXS)
SAXS is a technique that provides information about the average size and shape of macromolecules in solution.[3][6] It is particularly useful for determining the overall dimensions and internal structure of DNA origami objects, offering a valuable complement to the single-molecule views provided by AFM and TEM.[3][7]
Experimental Protocol: SAXS Analysis of DNA Origami
-
Sample Preparation: Concentrate the purified DNA origami structures to a suitable concentration (e.g., ~250 nM).[6]
-
Data Acquisition: Expose the sample to a collimated X-ray beam and record the scattered X-rays at small angles.
-
Data Analysis:
-
Buffer Subtraction: Subtract the scattering profile of the buffer from the sample scattering profile.
-
Form Factor Analysis: Analyze the resulting scattering curve to determine the overall shape and dimensions of the nanostructure.[6]
-
Pair-Distance Distribution Function (P(r)): Calculate the P(r) function, which provides information about the distribution of distances between all pairs of atoms within the particle, revealing details about the internal structure.[8]
-
Dynamic Validation: Probing Molecular Interactions and Kinetics
Molecular programs often involve dynamic processes such as strand displacement reactions. Validating the kinetics of these processes is crucial for ensuring the correct temporal behavior of molecular circuits and devices.
DNA Strand Displacement Kinetics
DNA strand displacement is a fundamental process in dynamic DNA nanotechnology. The rate of these reactions can be simulated and then experimentally measured, often using fluorescence-based assays.[9]
Comparison of Simulated and Experimental DNA Strand Displacement Rates
| System | Simulation Method | Predicted Rate Constant | Experimental Rate Constant | Reference |
| All-DNA Strand Displacement | oxDNA (Coarse-grained MD) | Qualitatively matches experiment | Varies with sequence and toehold | [9] |
| DNA-RNA Hybrid Strand Displacement | oxNA (Coarse-grained MD) | Reproduces experimental trends | Spans over four orders of magnitude | [9][10] |
| Temporal AND Gate | Probabilistic Model Checking | Predicts robust ON-OFF separation | Clear ON-OFF separation observed | [11] |
Experimental Protocol: Fluorescence-Based DNA Strand Displacement Assay
-
Labeling: Label the incumbent strand with a fluorophore and the substrate strand with a quencher. When the incumbent is bound to the substrate, the fluorescence is quenched.
-
Reaction Initiation: Initiate the strand displacement reaction by adding the invading strand to a solution containing the substrate-incumbent duplex.
-
Fluorescence Monitoring: Monitor the increase in fluorescence over time as the fluorophore-labeled incumbent strand is displaced from the quencher-labeled substrate.
-
Kinetic Analysis: Fit the resulting fluorescence kinetic trace to a suitable kinetic model (e.g., second-order kinetics) to extract the reaction rate constant.[9]
Super-Resolution Microscopy: DNA-PAINT
DNA-PAINT (Points Accumulation for Imaging in Nanoscale Topography) is a super-resolution microscopy technique that utilizes the transient binding of fluorescently labeled DNA "imager" strands to complementary "docking" strands on a target molecule to achieve sub-diffraction-limit imaging.[12][13] This technique is particularly well-suited for validating the structure of DNA nanostructures with high precision.
Experimental Protocol: DNA-PAINT Imaging
-
Sample Preparation: Immobilize the DNA nanostructure containing docking strands on a microscope slide.
-
Imaging Buffer: Prepare an imaging buffer containing the fluorescently labeled imager strands at a low concentration (e.g., 1-20 nM).[13]
-
Image Acquisition: Use a fluorescence microscope to record a time-series of images. The transient binding of imager strands to docking strands appears as "blinking" events.
-
Image Reconstruction: Process the acquired images to localize the center of each blinking event with high precision. The final super-resolved image is constructed by accumulating all the localized positions.[12]
Conclusion
The experimental validation of molecular programming simulations is a critical step in the development of robust and reliable molecular technologies. The techniques outlined in this guide provide a powerful toolkit for researchers to rigorously test their computational models against real-world data. By combining the predictive power of simulations with the empirical evidence from these advanced experimental methods, the field of molecular programming is poised to make significant strides in areas ranging from fundamental research to novel therapeutic and diagnostic applications.
References
- 1. pnas.org [pnas.org]
- 2. DNA Origami Fiducial for Accurate 3D Atomic Force Microscopy Imaging - PMC [pmc.ncbi.nlm.nih.gov]
- 3. pubs.acs.org [pubs.acs.org]
- 4. Imaging of nucleic acids with atomic force microscopy - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. Shape and inter-helical spacing of DNA origami nanostructures studied by small angle X-ray scattering - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. researchgate.net [researchgate.net]
- 9. pnas.org [pnas.org]
- 10. biorxiv.org [biorxiv.org]
- 11. pubs.acs.org [pubs.acs.org]
- 12. Super-resolution microscopy with DNA-PAINT | Springer Nature Experiments [experiments.springernature.com]
- 13. researchgate.net [researchgate.net]
DNA Computing: A Comparative Guide to In Vitro and In Vivo Applications
For Researchers, Scientists, and Drug Development Professionals
The field of DNA computing, which harnesses the information-carrying capabilities of DNA for computation, has evolved from theoretical concepts to practical applications in both controlled laboratory settings (in vitro) and within living organisms (in vivo). This guide provides a comprehensive comparison of these two application domains, offering quantitative data, detailed experimental protocols, and visual representations of key processes to inform research and development in molecular programming and nanomedicine.
Performance Comparison: In Vitro vs. In Vivo
The choice between an in vitro or in vivo approach for DNA computing depends on the specific application, with each environment offering distinct advantages and disadvantages. In vitro systems provide a controlled environment, leading to faster and more predictable computations. In contrast, in vivo applications, while closer to real-world biological systems, face challenges such as biocompatibility, stability, and delivery.
| Feature | In Vitro (Test Tube) | In Vivo (Living Cells) |
| Environment | Controlled, user-defined buffer conditions | Complex, dynamic cellular milieu |
| Speed | Generally faster due to optimized conditions and higher concentrations | Slower due to cellular complexity and lower effective concentrations |
| Accuracy/Error Rate | Lower error rates due to fewer interfering substances. Typical error rates for DNA polymerase in PCR are around one misincorporation per 100,000 bases.[1] | Higher potential for errors due to interaction with cellular machinery and degradation.[2] |
| Scalability | More readily scalable for complex computations | Limited by cell viability and the complexity of introducing multiple components |
| Biocompatibility | Not a primary concern | A critical factor; DNA constructs must be non-toxic and evade immune responses |
| Stability | Relatively stable, but can be affected by nucleases if not protected | Prone to degradation by cellular nucleases; requires chemical modifications for stability |
| Delivery | Not applicable | A major challenge; requires methods like transfection or electroporation |
| Readout | Straightforward using techniques like gel electrophoresis and fluorescence spectroscopy | More complex, often relying on fluorescence microscopy or sequencing of cellular DNA[3][4] |
| Applications | Proof-of-concept computations, diagnostics, fundamental research | Smart diagnostics, targeted drug delivery, synthetic gene circuits |
Quantitative Performance Metrics
The following table summarizes quantitative performance data for DNA computing circuits from various studies. It is important to note that direct comparisons can be challenging due to variations in experimental setups.
| Parameter | In Vitro | In Vivo (in cellulo) | Reference |
| Reaction Time | Minutes to hours | Hours | [5] |
| Signal-to-Background Ratio | High | Lower, but can be improved with specific reporters | [5] |
| DNA Looping Efficiency (Persistence Length) | 50 nm | 27 nm (in chromatin, indicating increased flexibility at short distances) | [6][7] |
| Error Rate (PCR Amplification) | ~1% per base (chemistry synthesis and 2nd-gen sequencing) | Not directly comparable, but cellular repair mechanisms can influence mutation rates. | [8] |
Experimental Protocols
In Vitro DNA Logic Gate: An "AND" Gate Example
This protocol describes the assembly and testing of a simple DNA "AND" logic gate using strand displacement reactions with a fluorescence readout.
Materials:
-
Purified DNA oligonucleotides (Input A, Input B, Gate Strand, Reporter Strand with fluorophore and quencher)
-
Reaction buffer (e.g., TE buffer with MgCl2)
-
Fluorometer
Procedure:
-
Gate Assembly:
-
Anneal the Gate Strand and Reporter Strand by mixing them in the reaction buffer.
-
Heat the mixture to 95°C for 5 minutes and then slowly cool to room temperature to form the gate complex.
-
-
Logic Operation:
-
Prepare four reaction tubes: (1) No inputs, (2) Input A only, (3) Input B only, and (4) Input A and Input B.
-
Add the assembled gate complex to each tube.
-
Add the respective inputs to each tube at a defined concentration.
-
-
Incubation:
-
Incubate the reactions at a constant temperature (e.g., 25°C or 37°C) for a set period (e.g., 1-2 hours).
-
-
Readout:
-
Measure the fluorescence intensity of each reaction using a fluorometer. A significant increase in fluorescence indicates a "TRUE" output, which should only occur in the tube containing both Input A and Input B.
-
In Vivo DNA Logic Circuit: Cellular miRNA Detection
This protocol outlines a general procedure for transfecting a DNA logic circuit into mammalian cells to detect the presence of specific microRNAs (miRNAs).
Materials:
-
DNA logic gate constructs (e.g., designed to respond to specific miRNAs)
-
Mammalian cell line (e.g., HeLa or HEK293)
-
Cell culture medium and supplements
-
Transfection reagent (e.g., Lipofectamine) or electroporator
-
Fluorescence microscope
Procedure:
-
Cell Culture:
-
Culture the mammalian cells in a suitable format (e.g., 6-well plate or chamber slide) until they reach the desired confluency (typically 50-75%).[9]
-
-
Transfection:
-
Incubation:
-
Incubate the cells for a period (e.g., 24-48 hours) to allow for the DNA circuit to interact with the intracellular environment and any target miRNAs.
-
-
Readout:
Visualizing DNA Computing Concepts
Signaling Pathway: miRNA-Based Cancer Diagnosis
This diagram illustrates a conceptual signaling pathway for an in vivo DNA computing circuit designed to detect cancer-specific miRNAs and trigger a therapeutic response.
Caption: A DNA logic gate detects two oncogenic miRNAs, triggering targeted drug release and apoptosis.
Experimental Workflow: In Vitro DNA Logic Gate
This diagram outlines the typical experimental workflow for designing, synthesizing, and testing a DNA logic gate in a laboratory setting.
References
- 1. Sources of Error in DNA Computation [web.cs.dal.ca]
- 2. researchgate.net [researchgate.net]
- 3. Measuring DNA content in live cells by fluorescence microscopy - PMC [pmc.ncbi.nlm.nih.gov]
- 4. The intracellular visualization of exogenous DNA in fluorescence microscopy - PMC [pmc.ncbi.nlm.nih.gov]
- 5. pubs.acs.org [pubs.acs.org]
- 6. Quantitative comparison of DNA looping in vitro and in vivo: chromatin increases effective DNA flexibility at short distances - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Quantitative comparison of DNA looping in vitro and in vivo: chromatin increases effective DNA flexibility at short distances | The EMBO Journal [link.springer.com]
- 8. researchgate.net [researchgate.net]
- 9. Transfection of mammalian cell lines with plasmids and siRNAs [protocols.io]
- 10. promega.jp [promega.jp]
- 11. frederick.cancer.gov [frederick.cancer.gov]
- 12. Super-resolution fluorescence imaging of directly labelled DNA: from microscopy standards to living cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. youtube.com [youtube.com]
A Comparative Guide to DNA and RNA Aptamers for Sensing Applications
For Researchers, Scientists, and Drug Development Professionals
In the rapidly evolving landscape of molecular sensing, aptamers — single-stranded DNA or RNA oligonucleotides — have emerged as powerful recognition elements, rivaling and, in some cases, surpassing traditional antibodies. Their high affinity and specificity, coupled with the advantages of in vitro selection, chemical synthesis, and modification, make them ideal candidates for a wide array of biosensing applications. This guide provides an objective comparison of DNA and RNA aptamers for sensing, supported by experimental data and detailed methodologies, to aid researchers in selecting the optimal platform for their specific needs.
At a Glance: DNA vs. RNA Aptamers
| Feature | DNA Aptamers | RNA Aptamers |
| Stability | High inherent stability against nucleases and a wide range of pH and temperatures.[1] | Inherently less stable due to the 2'-hydroxyl group, making it susceptible to hydrolysis and degradation by ribonucleases (RNases).[2][3] |
| Binding Affinity (Kd) | Can achieve high affinity, with dissociation constants (Kd) in the picomolar to nanomolar range.[4][5] | Can also achieve very high affinity, often in the low picomolar to nanomolar range, sometimes outperforming DNA aptamers for specific targets due to greater structural flexibility. |
| Structural Diversity | Forms stable secondary structures like hairpins, bulge loops, and G-quadruplexes.[2] | Generally accepted to form more diverse and intricate three-dimensional structures, enabling recognition of a broader range of targets.[2][3] |
| SELEX Process | Simpler and less expensive, involving PCR for amplification.[1] | More complex and costly, requiring reverse transcription and in vitro transcription steps in each round of selection.[2][6] |
| Cost & Synthesis | Cheaper and easier to synthesize with well-established protocols.[3] | More expensive and complex to synthesize, especially with modifications needed for stability.[3] |
| Modifications | Can be readily modified to enhance stability and functionality. | Often require chemical modifications (e.g., 2'-fluoro or 2'-O-methyl) to improve stability for practical applications.[2][3] |
| Common Applications | Diagnostics, biosensors, environmental monitoring, and therapeutics where high stability is crucial.[4][7] | Intracellular sensing, therapeutics requiring complex structural recognition, and as components of riboswitches. |
Performance Data: A Quantitative Comparison
The performance of an aptamer in a sensing application is critically dependent on its binding affinity (dissociation constant, Kd) and its stability under experimental and physiological conditions. The following tables summarize representative data from the literature.
Table 1: Comparative Binding Affinities (Kd) of DNA and RNA Aptamers
| Target | Aptamer Type | Dissociation Constant (Kd) | Reference |
| Dopamine | DNA | 3.2 pM | Kim & Paeng (2013)[4] |
| Dopamine | RNA | >100 nM | Kim & Paeng (2013)[4] |
| Tetracycline | DNA | 0.5 - 7.6 µM | [2] |
| Tetracycline | RNA | 0.3 nM | [2] |
| Thrombin | DNA | 0.5 - 100 nM | [4] |
| Vascular Endothelial Growth Factor (VEGF) | DNA | ~20.5 nM | [8] |
| Flavin Mononucleotide (FMN) | RNA | 35 nM | [9] |
| Theophylline | RNA | 320 nM | [9] |
| Arginine | RNA | 76 µM | [9] |
Note: Direct comparison of Kd values should be made with caution as they can be influenced by the specific experimental conditions.
Table 2: Comparative Stability of DNA and RNA Aptamers in Serum
| Aptamer Type | Modification | Half-life in Human Serum | Reference |
| Unmodified DNA | None | ~30-60 minutes | [2][6][10] |
| DNA with 3' inverted dT cap | 3' modification | Several hours | [11] |
| Unmodified RNA | None | Seconds to minutes | [2][6] |
| 2'-Fluoro (2'-F) modified RNA | Ribose modification | ~10 hours | [12] |
| 2'-O-Methyl (2'-OMe) modified RNA | Ribose modification | >240 hours | [12] |
Experimental Protocols
Detailed and robust experimental protocols are crucial for the successful development and application of aptamer-based sensors. Below are outlines of key methodologies.
Systematic Evolution of Ligands by Exponential Enrichment (SELEX)
SELEX is the cornerstone of aptamer discovery. The process involves iterative rounds of selection and amplification to isolate high-affinity aptamers from a large, random oligonucleotide library.
DNA SELEX Protocol (for a protein target):
-
Library Preparation: A single-stranded DNA (ssDNA) library, typically containing a central random region of 20-60 nucleotides flanked by constant primer binding sites, is synthesized.
-
Incubation: The ssDNA library is incubated with the target protein, which is often immobilized on a solid support (e.g., magnetic beads, nitrocellulose membrane) to facilitate separation.
-
Partitioning: Unbound sequences are washed away. The stringency of the washing steps is typically increased in subsequent rounds to select for higher affinity binders.
-
Elution: The bound ssDNA sequences are eluted from the target, often by heat denaturation or a change in pH.
-
Amplification: The eluted ssDNA is amplified by Polymerase Chain Reaction (PCR) using primers complementary to the constant regions.
-
ssDNA Generation: The double-stranded PCR product is converted to ssDNA for the next round of selection. This can be achieved by methods such as asymmetric PCR or enzymatic digestion of one strand.
-
Iteration: Steps 2-6 are repeated for multiple rounds (typically 8-15), with increasing selection pressure.
-
Sequencing and Characterization: The enriched pool of aptamers is sequenced, and individual candidates are characterized for their binding affinity and specificity.
RNA SELEX Protocol:
The RNA SELEX process is similar to DNA SELEX but includes additional enzymatic steps:
-
Initial Library: The process starts with a synthetic DNA library that includes a T7 RNA polymerase promoter.
-
In Vitro Transcription: The DNA library is transcribed into an RNA library.
-
Selection and Elution: The RNA library is incubated with the target, and bound sequences are partitioned and eluted, similar to DNA SELEX.
-
Reverse Transcription: The eluted RNA is reverse transcribed into complementary DNA (cDNA).
-
PCR Amplification: The cDNA is amplified by PCR.
-
Iteration: The amplified DNA is used as a template for the next round of in vitro transcription, and the cycle is repeated.
Aptamer Stability Assay (Serum Half-life Determination)
-
Incubation: The aptamer (DNA or RNA) is incubated in human serum (e.g., 50% v/v) at 37°C.
-
Time Points: Aliquots are taken at various time points (e.g., 0, 5, 30, 60 minutes for unmodified aptamers; longer for modified aptamers).
-
Analysis: The integrity of the aptamer at each time point is analyzed by denaturing polyacrylamide gel electrophoresis (PAGE).
-
Quantification: The intensity of the full-length aptamer band is quantified using densitometry software.
-
Half-life Calculation: The half-life is determined by plotting the percentage of intact aptamer against time and fitting the data to a one-phase decay model.[10]
Signaling Pathways and Experimental Workflows
Visualizing the mechanisms of aptamer-based sensing and the experimental procedures is essential for understanding and implementation.
Caption: Workflow for DNA and RNA SELEX.
Caption: Common fluorescence-based aptasensor signaling mechanisms.
Caption: Principle of an electrochemical aptasensor.
Conclusion: Making the Right Choice
The selection between DNA and RNA aptamers for a sensing application is a nuanced decision that depends on the specific requirements of the assay.
Choose DNA aptamers when:
-
High stability is paramount, especially for applications in complex biological fluids or under harsh environmental conditions.
-
Cost-effectiveness and ease of synthesis are important considerations.
-
The selection process needs to be simpler and faster .
Choose RNA aptamers when:
-
The target molecule is challenging and may require the greater structural flexibility of RNA for effective binding.
-
Intracellular applications are intended, where RNA's natural presence can be an advantage.
-
Chemical modifications to enhance stability are feasible and justifiable for the application.
Ultimately, the inherent trade-offs between the stability and structural versatility of DNA and RNA aptamers must be carefully weighed. With ongoing advancements in nucleic acid chemistry and selection methodologies, the lines between these two powerful classes of molecules are increasingly blurring, offering an expanding toolkit for the development of next-generation sensing technologies.
References
- 1. blog.alphalifetech.com [blog.alphalifetech.com]
- 2. Aptamer-Based Biosensors for Antibiotic Detection: A Review - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Development of an Efficient Targeted Cell-SELEX Procedure for DNA Aptamer Reagents - PMC [pmc.ncbi.nlm.nih.gov]
- 4. pentabind.com [pentabind.com]
- 5. Molecular affinity rulers: systematic evaluation of DNA aptamers for their applicabilities in ELISA - PMC [pmc.ncbi.nlm.nih.gov]
- 6. mdpi.com [mdpi.com]
- 7. A Detailed Protein-SELEX Protocol Allowing Visual Assessments of Individual Steps for a High Success Rate - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. pnas.org [pnas.org]
- 9. pubs.acs.org [pubs.acs.org]
- 10. researchgate.net [researchgate.net]
- 11. Effect of Chemical Modifications on Aptamer Stability in Serum - PMC [pmc.ncbi.nlm.nih.gov]
- 12. basepairbio.com [basepairbio.com]
A Researcher's Guide to Validating Synthetic Biological Circuits
The successful engineering of synthetic biological circuits hinges on the rigorous validation of their function. As circuit complexity increases, so does the need for precise and multi-faceted analytical techniques to confirm that their in vivo performance aligns with in silico design. This guide provides a comparative overview of common methodologies used to validate synthetic circuits, offering researchers, scientists, and drug development professionals a framework for selecting the appropriate tools. We present quantitative comparisons, detailed experimental protocols, and standardized visualizations to facilitate informed decision-making.
Key Performance Metrics for Circuit Validation
Before comparing validation methods, it is crucial to understand the key performance characteristics of a synthetic circuit that require quantification:
-
Transfer Function: The relationship between the input concentration (e.g., an inducer molecule) and the output level (e.g., reporter protein expression). This defines the circuit's input-output behavior, including its threshold, saturation point, and linearity.
-
Dynamic Range: The ratio between the maximum and minimum output levels of the circuit. A wider dynamic range indicates a more discernible difference between the "ON" and "OFF" states.
-
Response Time: The time required for the circuit to switch from an "OFF" to an "ON" state (rise time) or vice versa (fall time) after a change in input signal.
-
Orthogonality: The degree of isolation between different circuits operating within the same cell. An ideal circuit only responds to its specific inputs and does not affect or is not affected by other cellular processes or synthetic networks.
-
Robustness: The consistency of a circuit's performance across different environmental conditions, cellular contexts, and genetic backgrounds.
-
Noise: The cell-to-cell variability in the output for a given input, which can be dissected into intrinsic (e.g., stochasticity of transcription/translation) and extrinsic (e.g., cellular environment) components.
Core Validation Methodologies: A Comparison
The choice of validation technique depends on the specific performance metric being investigated, the required throughput, and the nature of the circuit's output. The most common methods involve quantifying reporter gene expression at the protein or mRNA level.
Flow Cytometry: High-Throughput Single-Cell Analysis
Flow cytometry is a cornerstone technique in synthetic biology for its ability to rapidly measure fluorescence from individual cells within a large population. This allows for the characterization of population heterogeneity and the precise measurement of a circuit's transfer function across a range of input concentrations.
| Parameter | Flow Cytometry | Fluorescence Microscopy | RNA-Sequencing |
| Primary Output | Single-cell fluorescence intensity | Spatiotemporal protein localization & intensity | Transcript abundance (bulk or single-cell) |
| Throughput | Very High (1,000-50,000 cells/sec) | Low to Medium (10-1,000s of cells/exp) | Medium (Bulk) to High (scRNA-seq) |
| Resolution | Single-cell | Sub-cellular | Gene-level |
| Data Type | Quantitative fluorescence distribution | Quantitative, spatial, and temporal imaging | Quantitative transcript counts |
| Primary Use Case | Transfer functions, noise analysis, library screening | Dynamic response, protein localization, cell-cell interactions | Circuit debugging, orthogonality, host-circuit interactions |
| Relative Cost/Sample | Low | Medium | High |
-
Cell Culture and Induction: Culture cells containing the synthetic circuit to mid-log phase. Aliquot the culture into a 96-well plate or individual tubes.
-
Induction Gradient: Add the input signal (inducer) at varying concentrations to different wells/tubes. Include negative (no inducer) and positive (saturating inducer) controls.
-
Incubation: Incubate the cells for a predetermined period to allow the circuit to reach a steady state (typically 4-16 hours, depending on the organism and circuit).
-
Growth Arrest & Dilution: Stop cell growth and protein expression by placing samples on ice or adding a fixative like paraformaldehyde. Dilute samples in a sheath-like fluid (e.g., Phosphate-Buffered Saline) to an appropriate concentration for analysis (~10^5 to 10^6 cells/mL).
-
Data Acquisition: Run the samples on a flow cytometer. For each cell, record forward scatter (FSC, proxy for size), side scatter (SSC, proxy for granularity), and fluorescence from the relevant channels (e.g., GFP, RFP).
-
Gating and Analysis: Gate the data to select the live, single-cell population. Extract the mean and distribution of fluorescence intensity for each inducer concentration to plot the transfer function.
Time-Lapse Fluorescence Microscopy: Capturing Dynamics
While flow cytometry provides snapshots of populations, time-lapse fluorescence microscopy allows for the direct observation of a circuit's function in individual cells over time. This is essential for characterizing temporal dynamics, such as response time and oscillatory behavior, as well as spatial information like protein localization.
-
Sample Preparation: Seed cells containing the synthetic circuit onto a microscopy-compatible vessel (e.g., glass-bottom dish, microfluidic chamber).
-
Microscope Setup: Place the sample on an automated, environmentally controlled microscope stage (maintaining temperature, humidity, and CO2/O2 levels). Define multiple stage positions for imaging.
-
Baseline Imaging: Acquire images (brightfield and fluorescence channels) before adding the stimulus to establish a baseline "OFF" state.
-
Induction: Introduce the inducer molecule into the cell media. In microfluidic devices, this can be done rapidly to precisely define t=0.
-
Time-Lapse Acquisition: Begin automated image acquisition at regular intervals (e.g., every 5-10 minutes). The duration can range from hours to days depending on the circuit's expected response time.
-
Image Processing: After acquisition, perform image processing steps, including background subtraction and flat-field correction.
-
Cell Segmentation and Tracking: Use image analysis software to identify individual cells (segmentation) and track them from one frame to the next.
-
Data Extraction: Quantify the mean fluorescence intensity for each cell in each frame. Plot the intensity over time for individual cells or as a population average to determine dynamic properties.
RNA-Sequencing (RNA-Seq): A Systems-Level View
When a circuit fails to function as expected, the issue may lie in its interaction with the host cell. RNA-Sequencing provides a global view of the transcriptome, enabling researchers to debug circuits by quantifying the abundance of every transcript in the cell. This is invaluable for assessing orthogonality, identifying unexpected host responses, and verifying the expression levels of circuit components.
-
Cell Culture and Induction: Grow cells with and without the active circuit (e.g., induced vs. uninduced states, or cells with/without the circuit plasmid).
-
RNA Extraction: Harvest cells and perform total RNA extraction using a kit-based or Trizol method. Ensure high-quality, intact RNA is obtained.
-
Library Preparation:
-
Deplete ribosomal RNA (rRNA), as it constitutes the majority of total RNA.
-
Fragment the remaining RNA.
-
Synthesize cDNA from the RNA template.
-
Ligate sequencing adapters to the cDNA fragments.
-
Amplify the library via PCR.
-
-
Sequencing: Sequence the prepared libraries on a high-throughput platform (e.g., Illumina NovaSeq).
-
Data Analysis (Bioinformatics):
-
Perform quality control on the raw sequencing reads.
-
Align reads to a reference genome (including the synthetic circuit sequences).
-
Count the number of reads mapping to each gene.
-
Perform differential gene expression analysis to identify genes whose expression is significantly altered by the circuit's activity.
-
The Future of Data: A Comparative Guide to DNA and Traditional Storage Media
In an era defined by an exponential surge in data generation, the limitations of conventional storage technologies are becoming increasingly apparent. The global demand for data storage is projected to reach an astounding 175 zettabytes by 2025, a scale that challenges the capacity, durability, and energy consumption of current magnetic, optical, and solid-state systems.[1][2] Nature's own information carrier, DNA, presents a revolutionary alternative, promising unprecedented storage density, remarkable longevity, and exceptional energy efficiency.[2][3]
This guide provides an objective comparison of DNA-based data storage with traditional media—Hard Disk Drives (HDDs), Solid-State Drives (SSDs), and Magnetic Tape—tailored for researchers, scientists, and professionals in drug development. We will delve into the quantitative performance metrics, experimental protocols, and the fundamental workflows that underpin these technologies.
Quantitative Performance Comparison
The most striking advantage of DNA as a storage medium is its extraordinary information density. Theoretically, a single gram of DNA can store up to 455 exabytes of data, a capacity millions of times greater than the most advanced traditional media.[4][5] This density, combined with its proven stability over millennia, positions DNA as a compelling solution for long-term archival storage.[5][6] However, the technology is nascent, with significant challenges in speed and cost that currently limit its practical application.[6][7]
The following table summarizes the key performance indicators for DNA and traditional storage media.
| Parameter | DNA Storage | Hard Disk Drives (HDD) | Solid-State Drives (SSD) | Magnetic Tape |
| Storage Density | ~215 PB/gram to 455 EB/gram[4][5][6] | ~10⁷ - 10⁸ bits/gram[8] | ~10⁸ - 10⁹ bits/gram[8] | ~10⁶ - 10⁷ bits/gram[8] |
| Longevity / Durability | Thousands to millions of years[6][9][10] | 3-5 years | 5-10 years | 10-30 years[10] |
| Write Speed | Very Slow (e.g., ~20 GB/day)[7] | ~50-250 MB/s | ~200-5500 MB/s | ~120-400 MB/s |
| Read Speed | Very Slow (e.g., 100MB in 10 mins with AI)[11] | ~50-250 MB/s | ~250-7000 MB/s | ~120-400 MB/s |
| Cost to Store 1 PB (10 Yrs) | Extremely High (~$3,500/MB for R/W)[3] | ~$480,000[12] | ~$3,900,000[12] | ~$30,000[12] |
| Energy Consumption | Near-zero for storage, high for R/W[6][13] | Continuous power required | Continuous power required | Zero power when idle[12] |
Experimental Protocols and Methodologies
The processes for writing and reading data differ fundamentally between DNA and traditional media. Traditional methods rely on manipulating the physical properties of materials, such as magnetic orientation or electrical charge, whereas DNA storage involves complex biochemical processes.
DNA Data Storage Protocol
The workflow for storing and retrieving digital data in DNA is a multi-step process involving encoding, synthesis, storage, sequencing, and decoding.[14]
-
Encoding: The process begins with the conversion of a digital file's binary code (0s and 1s) into a quaternary code corresponding to the four nucleotide bases of DNA: Adenine (A), Cytosine (C), Guanine (G), and Thymine (T).[1] To enhance data robustness and prevent errors during synthesis and sequencing, sophisticated algorithms are employed. These algorithms often add redundancy through error-correcting codes, such as Reed-Solomon codes, and break the data into smaller, indexed segments to facilitate reassembly.[14][15]
-
Writing (DNA Synthesis): The encoded DNA sequences are then physically created using a process called oligonucleotide synthesis.[6] A DNA synthesizer chemically constructs strands of DNA, base by base, according to the specified sequences. This is currently the most significant bottleneck in terms of both speed and cost.[3][7]
-
Storage: The synthesized DNA molecules are preserved for long-term storage. To ensure stability and prevent degradation, the DNA is typically stored in a dehydrated state in a cool, dark, and dry environment.[4][6] Encapsulation or the addition of stabilizing salts can further enhance longevity.[4]
-
Reading (DNA Sequencing): To retrieve the data, the specific DNA strands containing the desired information are first identified and often amplified using Polymerase Chain Reaction (PCR).[6] A DNA sequencer is then used to read the precise order of the nucleotide bases on these strands. Next-generation sequencing (NGS) technologies enable the parallel reading of millions of DNA fragments.[15]
-
Decoding: The final step involves computational processing. The raw sequence data is converted back into the digital binary code.[16] The embedded indexes are used to reassemble the data segments in the correct order, and the error-correction codes are applied to identify and rectify any discrepancies that may have occurred during the process, ensuring the integrity of the original file.[14]
Traditional Storage Media Methodology
-
Hard Disk Drives (HDDs): Data is stored by magnetizing and demagnetizing tiny sections of a ferromagnetic material on a spinning platter. A read/write head moves across the platter to access or modify the magnetic patterns representing binary data.
-
Solid-State Drives (SSDs): SSDs use flash memory, trapping electrons in floating-gate transistors to store data. The presence or absence of a charge in these cells represents binary 1s and 0s. Data access is electronic and thus significantly faster than the mechanical process of HDDs.
-
Magnetic Tape: Similar to HDDs, magnetic tape stores data on a thin, magnetizable film. Data is written and read sequentially as the tape moves past a read/write head, making it ideal for archival purposes where data is accessed infrequently.[12]
Visualizing the Processes and Comparisons
Diagrams are essential for conceptualizing complex workflows and relationships. The following visualizations, created using the DOT language, illustrate the DNA data storage process and compare its storage density to traditional media.
References
- 1. DNA Data Storage - PMC [pmc.ncbi.nlm.nih.gov]
- 2. DNA storage: research landscape and future prospects - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Uncertainties in synthetic DNA-based data storage - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Stabilizing synthetic DNA for long-term data storage with earth alkaline salts - Chemical Communications (RSC Publishing) DOI:10.1039/D0CC00222D [pubs.rsc.org]
- 5. researchgate.net [researchgate.net]
- 6. sg.idtdna.com [sg.idtdna.com]
- 7. The Outlook for DNA Data Storage - Horizon Technology [horizontechnology.com]
- 8. perpova.com [perpova.com]
- 9. molecular biology - How realistic is to use DNA for long term storage? - Biology Stack Exchange [biology.stackexchange.com]
- 10. DNA's awesome potential to store the world's data | Micron Technology Inc. [micron.com]
- 11. tomshardware.com [tomshardware.com]
- 12. webuyuseditequipment.net [webuyuseditequipment.net]
- 13. DNA hard drives: the data storage solution was inside us all along - Interface [interface.media]
- 14. researchgate.net [researchgate.net]
- 15. gwern.net [gwern.net]
- 16. scholarworks.boisestate.edu [scholarworks.boisestate.edu]
Assessing the Biocompatibility of DNA Nanostructures: A Comparative Guide
The burgeoning field of DNA nanotechnology offers unprecedented control over the design and fabrication of nanoscale structures, opening up new avenues for drug delivery, biosensing, and therapeutics.[1] The inherent biological nature of DNA suggests a high degree of biocompatibility; however, arranging it into synthetic, nanoscale architectures introduces complexities that require rigorous evaluation.[2] This guide provides a comparative assessment of the biocompatibility of different DNA nanostructures, supported by experimental data, to aid researchers and drug development professionals in selecting and designing structures for biomedical applications.
Cytotoxicity Assessment
A primary concern for any nanomaterial intended for biomedical use is its potential to induce cellular toxicity. DNA nanostructures are generally considered to have low cytotoxicity, but this can be influenced by their design, concentration, and the specific cell type being studied.[2] The most common method for assessing cytotoxicity is the MTT assay, which measures the metabolic activity of cells as an indicator of their viability.
Comparative Cytotoxicity Data
The following table summarizes results from various studies on the cytotoxicity of different DNA nanostructures.
| DNA Nanostructure | Cell Line | Concentration | Assay | Result (Cell Viability %) | Reference |
| Tetrahedral DNA (Td) | HTB-38 (Colon Cancer) | 500 nM | MTT | ~55% (with FdU modification) | [3] |
| DNA Origami (Rectangle) | HTB-38 (Colon Cancer) | 2 nM | MTT | ~80% (with FdU modification) | [3] |
| Tetrahedral DNA (Td) | RAW 264.7 (Macrophage) | Not specified | CCK-8 | High viability observed | [4] |
| Wireframe DNA Origami | In vivo (Mice) | 4 mg/kg | Biochemistry Panel | No signs of liver or kidney toxicity | [5] |
Note: Cytotoxicity can be significantly altered by the conjugation of therapeutic agents (e.g., 5-fluoro-2'-deoxyuridine, FdU) to the DNA nanostructure.[3] Unmodified DNA nanostructures generally exhibit higher cell viability.
Experimental Protocol: MTT Cytotoxicity Assay
The MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) assay is a colorimetric assay for assessing cell metabolic activity.
-
Cell Seeding: Plate cells in a 96-well plate at a density of 5,000-10,000 cells/well and incubate for 24 hours to allow for cell attachment.
-
Treatment: Aspirate the culture medium and add fresh medium containing various concentrations of the DNA nanostructures. Incubate for a specified period (e.g., 24, 48, or 72 hours). Include untreated cells as a negative control.
-
MTT Addition: After the incubation period, add 20 µL of MTT solution (5 mg/mL in PBS) to each well and incubate for 4 hours at 37°C. During this time, mitochondrial dehydrogenases in viable cells will cleave the tetrazolium ring of MTT, yielding purple formazan (B1609692) crystals.
-
Solubilization: Aspirate the medium containing MTT and add 150 µL of a solubilizing agent, such as dimethyl sulfoxide (B87167) (DMSO), to each well to dissolve the formazan crystals.
-
Absorbance Measurement: Shake the plate for 10 minutes to ensure complete dissolution and measure the absorbance at a wavelength of 570 nm using a microplate reader.
-
Data Analysis: Calculate the percentage of cell viability by comparing the absorbance of treated cells to that of the untreated control cells: (Absorbance of treated cells / Absorbance of control cells) x 100%.
Immunogenicity
While DNA itself can be an immune trigger, the immunogenicity of DNA nanostructures is complex and appears to be dose- and structure-dependent.[6] Key considerations include the activation of innate immune pathways, such as Toll-like receptor 9 (TLR9) which recognizes foreign DNA, and the production of inflammatory cytokines and antibodies.[6][7]
Comparative Immunogenicity Data
| DNA Nanostructure | Model | Dose | Key Findings | Reference |
| DNA Origami (Triangle & Rod) | In vivo (Mice) | 12.0 mg/kg | Modest, transient pro-inflammatory response; no cytokine storm. | [8] |
| DNA Origami | In vitro (Immune cells) | Not specified | Mild inflammatory response. | [6] |
| DNA Tetrahedron | In vivo (Mice) | Not specified | Can be used to present antigens and adjuvants to boost immune cell activation. | [9][10] |
| DNA Barrels | In vitro (Human blood) | Concentration-dependent | Elevated production of pro-inflammatory cytokines (TNF-alpha, IL-6) in the presence of serum. | [11] |
Experimental Protocol: Cytokine Secretion Assay (ELISA)
The Enzyme-Linked Immunosorbent Assay (ELISA) is a widely used method for quantifying the concentration of a specific cytokine secreted by cells in response to a stimulus.[12]
-
Coating: Coat the wells of a 96-well plate with a capture antibody specific for the cytokine of interest (e.g., anti-TNF-alpha). Incubate overnight at 4°C.
-
Blocking: Wash the plate to remove unbound antibody and add a blocking buffer (e.g., 1% BSA in PBS) to prevent non-specific binding. Incubate for 1-2 hours at room temperature.
-
Sample Addition: While the plate is blocking, treat immune cells (e.g., peripheral blood mononuclear cells or macrophages) with the DNA nanostructures for a desired time period. Centrifuge the cell suspension to pellet the cells and collect the supernatant, which contains the secreted cytokines.
-
Incubation: Add the collected supernatants (and cytokine standards for the calibration curve) to the coated and blocked wells. Incubate for 2 hours at room temperature.
-
Detection Antibody: Wash the plate and add a biotinylated detection antibody that recognizes a different epitope on the target cytokine. Incubate for 1-2 hours at room temperature.
-
Enzyme Conjugate: Wash the plate and add an enzyme-linked conjugate, such as streptavidin-horseradish peroxidase (HRP). Incubate for 20-30 minutes at room temperature.
-
Substrate Addition: Wash the plate and add a chromogenic substrate (e.g., TMB). The enzyme will convert the substrate into a colored product.
-
Stop Reaction & Read: Stop the reaction by adding a stop solution (e.g., sulfuric acid) and measure the absorbance at the appropriate wavelength. The concentration of the cytokine in the samples is determined by comparison to the standard curve.[8]
Complement Activation
The complement system is a part of the innate immune system that helps clear pathogens.[13] Nanoparticles can sometimes activate this system, leading to opsonization and, in some cases, adverse reactions.[14] Studies have shown that DNA nanostructures can activate the classical complement pathway, especially when functionalized to template antibody complexes.[15][16] The degree of activation can be influenced by the spacing and valency of antigens presented on the nanostructure.[15]
Cellular Uptake, Biodistribution, and Stability
The efficacy of DNA nanostructures in drug delivery and other intracellular applications depends on their ability to enter cells and reach their target location. Their in vivo fate, including distribution to various organs and clearance from the body, is also a critical aspect of their biocompatibility.
Cellular Uptake Mechanisms
DNA nanostructures can enter mammalian cells without the need for transfection agents, a significant advantage over free nucleic acids.[17] The primary mechanism of uptake is endocytosis, which can be dependent on the nanostructure's size, shape, and surface chemistry.[18][19]
-
Caveolin-dependent endocytosis: This pathway has been identified for tetrahedral DNA nanostructures.[17][20]
-
Clathrin-dependent endocytosis: Some DNA origami shapes are internalized via this pathway.[21]
-
Scavenger receptors: These receptors, such as LOX-1, have been shown to play a role in the uptake of certain DNA nanostructures.[17][22]
The shape of the nanostructure significantly influences its interaction with the cell membrane and subsequent uptake efficiency. For instance, compact structures with low aspect ratios tend to have higher uptake rates.[22]
In Vivo Biodistribution and Stability
Once administered in vivo, DNA nanostructures face several biological barriers. Studies in animal models, primarily mice, have provided insights into their distribution and persistence.
-
Organ Accumulation: Following intravenous injection, DNA nanostructures, including DNA origami and tetrahedra, show primary accumulation in the liver and kidneys.[5][9]
-
Clearance: Most DNA nanostructures are cleared relatively quickly from circulation, often within a few hours, primarily through renal excretion.[9]
-
Stability: A major challenge is the susceptibility of DNA nanostructures to degradation by nucleases present in the blood and within cells.[1] Their structural integrity in serum can be limited, sometimes lasting only for about an hour.[21] However, stability can be significantly enhanced through various strategies, such as chemical modifications to the DNA backbone (e.g., using L-DNA or 2'-fluoro-RNA), coating with polymers or lipids, or cross-linking the component strands.[21][23]
Conclusion
DNA nanostructures hold immense promise for a wide range of biomedical applications due to their programmability, precision, and inherent biocompatibility.[18][24] Experimental evidence largely supports the view that they are well-tolerated, exhibiting low cytotoxicity and manageable, often transient, immunogenicity.[2][8] However, their biocompatibility is not absolute and is intricately linked to their specific physicochemical properties, including size, shape, surface modifications, and dose.
Key challenges remain, particularly concerning in vivo stability and controlling their interaction with the immune system. Future research focused on chemical modifications and surface engineering will be crucial to enhance nuclease resistance, tune immune responses, and improve targeted delivery, ultimately paving the way for the clinical translation of these versatile nanodevices.
References
- 1. The Growing Development of DNA Nanostructures for Potential Healthcare‐Related Applications - PMC [pmc.ncbi.nlm.nih.gov]
- 2. The interactions between DNA nanostructures and cells: A critical overview from a cell biology perspective - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. researchgate.net [researchgate.net]
- 5. researchgate.net [researchgate.net]
- 6. DNA Origami Nanostructures Elicit Dose-Dependent Immunogenicity and are Non-toxic up to High Doses in vivo - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Evaluation of non-modified wireframe DNA origami for acute toxicity and biodistribution in mice - PMC [pmc.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. tandfonline.com [tandfonline.com]
- 10. researchgate.net [researchgate.net]
- 11. discovery.ucl.ac.uk [discovery.ucl.ac.uk]
- 12. mdpi.com [mdpi.com]
- 13. Analysis of Complement Activation by Nanoparticles | Springer Nature Experiments [experiments.springernature.com]
- 14. Frontiers | Nanoparticle-Induced Complement Activation: Implications for Cancer Nanomedicine [frontiersin.org]
- 15. DNA Nanostructure-Templated Antibody Complexes Provide Insights into the Geometric Requirements of Human Complement Cascade Activation - PMC [pmc.ncbi.nlm.nih.gov]
- 16. pubs.acs.org [pubs.acs.org]
- 17. researchgate.net [researchgate.net]
- 18. DNA Nanostructures as Drug Carriers for Cellular Delivery [crcu.jlu.edu.cn]
- 19. Uptake and stability of DNA nanostructures in cells: a cross-sectional overview of the current state of the art - PMC [pmc.ncbi.nlm.nih.gov]
- 20. academic.oup.com [academic.oup.com]
- 21. pubs.rsc.org [pubs.rsc.org]
- 22. pubs.acs.org [pubs.acs.org]
- 23. pubs.acs.org [pubs.acs.org]
- 24. Engineering in vivo behavior of DNA nanostructures toward organ-targeted drug delivery - PubMed [pubmed.ncbi.nlm.nih.gov]
A Researcher's Guide to the Validation of DNA-Based Diagnostic Assays
For researchers, scientists, and drug development professionals, the rigorous validation of DNA-based diagnostic assays is paramount to ensure the accuracy, reliability, and reproducibility of results. This guide provides a comprehensive framework for comparing the performance of a novel or laboratory-developed DNA-based diagnostic assay against established alternatives, complete with supporting experimental data protocols and visualizations.
The validation process establishes the performance characteristics of an assay, ensuring it is fit for its intended purpose.[1][2] Key performance indicators include accuracy, precision, analytical sensitivity, analytical specificity, and robustness. This guide will delve into the experimental methodologies required to assess these parameters and present the data in a clear, comparative format.
Core Performance Metrics: A Comparative Overview
A critical aspect of assay validation is the direct comparison of its performance metrics with those of an existing or "gold-standard" method. The following tables provide a template for summarizing the quantitative data obtained during validation studies.
Table 1: Accuracy and Precision
| Assay | Sample Type | No. of Replicates | Concordance with Reference Method (%) | Intra-Assay %CV | Inter-Assay %CV |
| New Assay | Whole Blood | 20 | |||
| Plasma | 20 | ||||
| Saliva | 20 | ||||
| Alternative Assay A | Whole Blood | 20 | |||
| Plasma | 20 | ||||
| Saliva | 20 | ||||
| Alternative Assay B | Whole Blood | 20 | |||
| Plasma | 20 | ||||
| Saliva | 20 |
%CV: Percent Coefficient of Variation
Table 2: Analytical Sensitivity and Specificity
| Assay | Limit of Detection (LOD) | Analytical Specificity (Cross-Reactivity) | Diagnostic Sensitivity (%) | Diagnostic Specificity (%) |
| New Assay | ||||
| Alternative Assay A | ||||
| Alternative Assay B |
Experimental Protocols for Key Validation Experiments
Detailed and standardized protocols are essential for generating reliable and comparable data. The following sections outline the methodologies for the principal validation experiments.
Accuracy Assessment
Objective: To determine the agreement between the results obtained from the new assay and a well-established reference or "gold-standard" method.[3][4][5]
Methodology:
-
Select a panel of well-characterized clinical samples with known positive and negative statuses for the target DNA sequence.
-
If available, include certified reference materials in the sample set.
-
Process and analyze each sample using both the new assay and the reference method according to their respective standard operating procedures.
-
Calculate the percentage of concordant results (both positive and negative) between the two assays.
Precision (Reproducibility) Evaluation
Objective: To assess the consistency and reproducibility of the assay's results. This is typically evaluated under two conditions: repeatability (intra-assay precision) and intermediate precision (inter-assay precision).[3][4][5]
Methodology:
-
Repeatability (Intra-Assay Precision):
-
Prepare three samples representing high-positive, low-positive, and negative concentrations of the target analyte.
-
Analyze each sample in multiple replicates (e.g., 5-10) within the same analytical run.[6]
-
Calculate the mean, standard deviation, and percent coefficient of variation (%CV) for the results of each sample.
-
-
Intermediate Precision (Inter-Assay Precision):
-
Using the same three samples, perform the analysis on different days, with different operators, and ideally, on different instruments.
-
Calculate the mean, standard deviation, and %CV for the results of each sample across all runs.
-
Analytical Sensitivity (Limit of Detection)
Objective: To determine the lowest concentration of the target DNA that can be reliably detected by the assay at least 95% of the time.[1]
Methodology:
-
Prepare a dilution series of a quantified DNA standard (e.g., plasmid DNA or a commercial standard) in a relevant matrix (e.g., plasma, buffer).
-
The dilution series should span a range expected to include the limit of detection (LOD).
-
Test each dilution in a high number of replicates (e.g., 20-24) to obtain statistically significant results.
-
The LOD is determined as the lowest concentration at which at least 95% of the replicates are positive.
Analytical Specificity (Cross-Reactivity)
Objective: To ensure the assay specifically detects the target DNA sequence without cross-reacting with other related or non-related organisms or sequences that may be present in the sample.[1]
Methodology:
-
Select a panel of genomic DNA from closely related organisms, common commensal microbes, or sequences with high homology to the target.
-
Test these non-target DNA samples at high concentrations using the new assay.
-
The assay should yield negative results for all non-target samples to be considered highly specific.
Visualizing the Validation Workflow
Understanding the logical flow of the validation process is crucial for effective planning and execution. The following diagram illustrates a typical workflow for validating a DNA-based diagnostic assay.
Caption: Workflow for the validation of a DNA-based diagnostic assay.
This structured approach to validation, combining rigorous experimental protocols with clear data presentation and logical workflow visualization, provides a robust framework for objectively comparing and documenting the performance of DNA-based diagnostic assays.
References
- 1. amp.org [amp.org]
- 2. Validation of Laboratory-Developed Molecular Assays for Infectious Diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Design and analytical validation of clinical DNA sequencing assays - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. cap.objects.frb.io [cap.objects.frb.io]
- 5. meridian.allenpress.com [meridian.allenpress.com]
- 6. enfsi.eu [enfsi.eu]
comparative study of DNA walkers and molecular motors
A Comparative Guide to DNA Walkers and Molecular Motors
For researchers and professionals in drug development and nanotechnology, the choice between synthetic DNA walkers and biological molecular motors is pivotal for designing nanoscale systems. This guide provides an objective comparison of their performance, supported by experimental data, and details the methodologies for key experiments.
Performance Comparison
DNA walkers and molecular motors, such as kinesin and dynein, are both nanoscale machines capable of directional movement and cargo transport. However, they differ significantly in their origin, composition, and operational characteristics. Molecular motors are proteins that have evolved over billions of years for efficient intracellular transport, while DNA walkers are artificial constructs designed with the programmability of nucleic acids.
The following table summarizes the key quantitative performance metrics for DNA walkers, kinesin, and dynein, providing a clear comparison for researchers to select the appropriate system for their specific application.
| Feature | DNA Walker | Kinesin-1 | Dynein |
| Composition | Synthetic DNA strands | Protein complex | Protein complex |
| Track | DNA origami, carbon nanotubes | Microtubules | Microtubules |
| Fuel | DNA/RNA strands, enzymes (e.g., nucleases), light | ATP | ATP |
| Speed | 0.05 - 1.67 nm/s (up to 40 nm/min)[1][2] | 600 - 800 nm/s (in vitro)[3] | 125 - 670 nm/s[4][5] |
| Processivity | 32 - 50 steps[2] | ~100 steps[6] | Variable, can be less processive than kinesin |
| Step Size | ~7 - 12 nm (programmable)[7] | 8 nm[6] | 8 - 32 nm (variable) |
| Stall Force | Not typically measured; operates on different principles | 5 - 7 pN[6][8] | 1 - 7 pN[4][9] |
| Fuel Efficiency | Approaching one fuel molecule per step[1] | One ATP molecule per 8 nm step[6][10] | One ATP molecule per step |
| Key Advantages | High programmability, customizability, works in artificial environments. | High speed and processivity, highly efficient. | Can move towards the microtubule minus-end. |
| Key Disadvantages | Slower speed, lower processivity, potential for nuclease degradation. | Less programmable, requires specific biological conditions. | Complex regulation, can be less processive. |
Experimental Protocols
Detailed methodologies are crucial for reproducing and building upon existing research. Below are outlines of key experimental protocols for the fabrication, characterization, and analysis of DNA walkers and molecular motors.
DNA Walker Fabrication and Motility Assay
Objective: To construct a DNA origami-based track and observe the movement of a fluorescently labeled DNA walker.
Methodology: This process involves the design and self-assembly of a DNA origami track, followed by the observation of walker motility using Total Internal Reflection Fluorescence (TIRF) microscopy.
Detailed Steps:
-
Design: The DNA origami track is designed using software like caDNAno or vHelix to create a specific pathway for the walker.[11]
-
Assembly: A long scaffold DNA strand is mixed with shorter "staple" strands that are designed to bind to specific regions of the scaffold, folding it into the desired shape.[11][12]
-
Annealing: The mixture is heated to denature the DNA and then slowly cooled to allow the staples to bind to the scaffold, forming the origami structure.[11][13]
-
Purification: The correctly folded origami structures are separated from excess staple strands and misfolded structures using agarose (B213101) gel electrophoresis or filtration methods.[11][13]
-
Immobilization: The purified DNA origami tracks are immobilized on a passivated glass slide for microscopy.
-
Motility Assay: The fluorescently labeled DNA walker and the necessary fuel strands (e.g., DNA or RNA) are added to the slide.[12]
-
Observation: The movement of the DNA walker along the track is observed in real-time using TIRF microscopy, which selectively excites fluorophores near the surface, reducing background noise.[14]
-
Tracking: The position of the walker over time is recorded and analyzed to determine its speed and processivity.[15]
Recombinant Kinesin Expression and Motility Assay
Objective: To produce recombinant kinesin motor proteins and measure their motility along microtubules.
Methodology: This protocol involves the expression and purification of a recombinant kinesin construct, followed by a single-molecule motility assay using TIRF microscopy.
Detailed Steps:
-
Expression: A plasmid containing the gene for a kinesin construct (often a truncated, constitutively active version) is transformed into E. coli. Protein expression is then induced.[16][17]
-
Purification: The bacterial cells are lysed, and the kinesin protein is purified using a multi-step chromatography process, typically involving affinity chromatography (e.g., His-tag) followed by size-exclusion chromatography.[16][18][19]
-
Microtubule Preparation: Tubulin is polymerized to form microtubules, which are stabilized and fluorescently labeled.
-
Motility Assay Setup: The stabilized, fluorescent microtubules are immobilized on a glass slide.
-
Observation: The purified kinesin and ATP are added to the chamber, and the movement of individual kinesin motors along the microtubules is observed using TIRF microscopy.[20]
-
Analysis: The velocity and run length (a measure of processivity) of the kinesin motors are determined from the recorded videos.[20]
Optical Tweezers Assay for Measuring Molecular Motor Force
Objective: To measure the stall force of a single molecular motor.
Methodology: An optical tweezers setup is used to trap a bead coated with motor proteins. The force exerted by a single motor as it moves a microtubule is measured until it stalls.
Detailed Steps:
-
Bead Preparation: Polystyrene beads are coated with the motor protein of interest (e.g., kinesin).[21]
-
Flow Cell Assembly: A flow cell is constructed with microtubules immobilized on the surface.
-
Trapping: A motor-coated bead is trapped using a highly focused laser beam. The stiffness of the optical trap is calibrated.[21][22][23][24]
-
Motility and Force Measurement: The trapped bead is brought into contact with a microtubule, and ATP is introduced to initiate motor movement. As the motor moves, it pulls the bead from the center of the optical trap. The displacement of the bead is precisely measured, and the force is calculated by multiplying the displacement by the trap stiffness.[21][25]
-
Stall Force Determination: The force increases as the bead is pulled further from the trap center until the motor can no longer move against the load and stalls. This maximum force is the stall force.[25]
Conclusion
Both DNA walkers and molecular motors offer unique advantages for nanoscale applications. Molecular motors provide unparalleled speed and efficiency, making them ideal for tasks requiring rapid transport. In contrast, the strength of DNA walkers lies in their programmability, allowing for the design of complex behaviors and responses to specific molecular cues. The choice between these two powerful systems will ultimately depend on the specific requirements of the research or application, balancing the need for speed and efficiency with the desire for customizability and logical control.
References
- 1. Tiny DNA Nano Walker Walk with Record Fuel Efficiency [techexplorist.com]
- 2. Tunable DNA Origami Motors Translocate Ballistically Over μm Distances at nm/s Speeds - PMC [pmc.ncbi.nlm.nih.gov]
- 3. rupress.org [rupress.org]
- 4. Control of cytoplasmic dynein force production and processivity by its C-terminal domain - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Dynein achieves processive motion using both stochastic and coordinated stepping - PMC [pmc.ncbi.nlm.nih.gov]
- 6. » How fast do molecular motors move on cytoskeletal filaments? [book.bionumbers.org]
- 7. researchgate.net [researchgate.net]
- 8. Kinesin and Dynein Mechanics: Measurement Methods and Research Applications - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. Pathway of processive ATP hydrolysis by kinesin - PMC [pmc.ncbi.nlm.nih.gov]
- 11. terra-docs.s3.us-east-2.amazonaws.com [terra-docs.s3.us-east-2.amazonaws.com]
- 12. m.youtube.com [m.youtube.com]
- 13. Protocols | I, Nanobot [inanobotdresden.github.io]
- 14. Single-Molecule Total Internal Reflection Fluorescence Microscopy - PMC [pmc.ncbi.nlm.nih.gov]
- 15. researchgate.net [researchgate.net]
- 16. electronicsandbooks.com [electronicsandbooks.com]
- 17. Expression, purification, and characterization of the Drosophila kinesin motor domain produced in Escherichia coli - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. researchgate.net [researchgate.net]
- 19. researchgate.net [researchgate.net]
- 20. Total Internal Reflection Fluorescence (TIRF) Single-Molecule Assay to Analyze the Motility of Kinesin - PMC [pmc.ncbi.nlm.nih.gov]
- 21. An Improved Optical Tweezers Assay for Measuring the Force Generation of Single Kinesin Molecules - PMC [pmc.ncbi.nlm.nih.gov]
- 22. An improved optical tweezers assay for measuring the force generation of single kinesin molecules - PubMed [pubmed.ncbi.nlm.nih.gov]
- 23. Measuring Molecular Forces Using Calibrated Optical Tweezers in Living Cells | Springer Nature Experiments [experiments.springernature.com]
- 24. Measuring Molecular Forces Using Calibrated Optical Tweezers in Living Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 25. The forward and backward stepping processes of kinesin are gated by ATP binding - PMC [pmc.ncbi.nlm.nih.gov]
evaluating the performance of different DNA logic gate designs
The field of DNA nanotechnology has seen remarkable progress in the design and implementation of molecular logic gates, laying the groundwork for sophisticated biochemical circuits with applications in diagnostics, smart therapeutics, and biocomputing.[1][2] These gates, analogous to their electronic counterparts, perform logical operations based on molecular inputs, typically specific DNA or RNA strands.[3][4] This guide provides a comparative evaluation of common DNA logic gate designs—AND, OR, NOT, and XOR—focusing on their performance metrics and the experimental protocols used for their characterization.
Performance Evaluation of DNA Logic Gates
The performance of DNA logic gates is crucial for the construction of reliable and scalable circuits. Key metrics include the speed of computation, signal-to-noise ratio, scalability, and biocompatibility. The following tables summarize the performance of different DNA logic gate designs based on experimental data from recent studies.
AND Gate Designs
An AND gate produces a high output only when all inputs are present.[3] DNA-based AND gates are fundamental for creating complex circuits that require multiple conditions to be met for activation.[5]
| Design Principle | Inputs | Output Signal | Reaction Time | Signal-to-Noise Ratio | Key Features | Reference |
| Toehold-mediated Strand Displacement | Two DNA strands | Fluorescence | Minutes to hours | High | Enzyme-free, programmable | [6][7] |
| DNAzyme-based | Metal ion and DNA strand | Cleavage of substrate, fluorescence | ~1 hour | Moderate | Catalytic activity, signal amplification | [8] |
| Aptamer-based | Two small molecules | Conformational change, fluorescence | Minutes | High | High specificity for non-DNA targets | [9] |
| Single-stranded gates with polymerase | Two DNA strands | Fluorescence | < 10 mins for 2 layers | High | Fast computation, reduced leakage | [10][11] |
OR Gate Designs
An OR gate produces a high output if at least one of its inputs is present.[3] These are essential for creating circuits that can be triggered by multiple independent signals.
| Design Principle | Inputs | Output Signal | Reaction Time | Signal-to-Noise Ratio | Key Features | Reference |
| Toehold-mediated Strand Displacement | Two DNA strands | Fluorescence | Minutes to hours | High | Modular, enzyme-free | [7][12] |
| DNAzyme-based | Two different DNA strands | Fluorescence | ~30 minutes | High | Connectable for complex circuits | [13] |
| Single-stranded gates with polymerase | Two DNA strands | Fluorescence | < 10 mins for 2 layers | High | Fast, compact design | [10][11] |
| Four-way Junction (4WJ) | Two DNA strands | Fluorescence | < 2 minutes | High | Rapid response | [14] |
NOT and XOR Gate Designs
The NOT gate inverts the input signal, while the XOR (exclusive OR) gate produces a high output only when the inputs are different.[3] These gates are crucial for building more complex logic circuits, though the NOT gate's inherent "off-to-on" nature presents design challenges.[15][16]
| Gate Type | Design Principle | Inputs | Output Signal | Reaction Time | Signal-to-Noise Ratio | Key Features | Reference |
| NOT | Photochemical control | DNA strand and light | Fluorescence | N/A | High | Temporal control, prevents premature execution | [15][16] |
| NOT | Four-way Junction (4WJ) | DNA strand | Fluorescence | ~2 minutes | High | Fast, integrated into circuits | [14][17] |
| XOR | Toehold-mediated Strand Displacement | Two DNA strands | Fluorescence | Hours | Moderate to High | Enzyme-free, avoids explicit NOT gate | [18] |
| XOR | Layered AND, NOT, and OR gates | Two DNA strands | Fluorescence | N/A | Moderate | Modular design, complex assembly | [19][20] |
Experimental Protocols
Detailed methodologies are critical for the replication and validation of experimental results. Below are generalized protocols for key experiments cited in the performance evaluation.
General Protocol for Fluorescence-Based Logic Gate Assay
This protocol outlines the typical steps for evaluating the performance of DNA logic gates that produce a fluorescent output signal.
-
Oligonucleotide Preparation : All DNA strands (gate components, inputs, and reporter probes) are synthesized and purified. Their concentrations are determined by UV-Vis spectrophotometry.
-
Gate Assembly : The component DNA strands of the logic gate are mixed in a reaction buffer (e.g., TE buffer with NaCl and MgCl2) at specified concentrations (e.g., 100 nM).[7][12] The mixture is annealed by heating to 95°C for 5 minutes and then slowly cooling to room temperature to ensure proper hybridization.
-
Fluorescence Measurement : The gate solution is placed in a fluorometer. The baseline fluorescence is recorded.
-
Input Addition : The input DNA strands are added to the gate solution at the desired concentration (e.g., 1x or 2x relative to the gate concentration).[7][10]
-
Signal Monitoring : The fluorescence intensity is monitored over time at the appropriate excitation and emission wavelengths for the chosen fluorophore-quencher pair. The reaction is typically allowed to proceed for a set duration (e.g., several hours) or until a plateau is reached.
-
Data Analysis : The change in fluorescence intensity is calculated to determine the output state of the logic gate. The signal-to-noise ratio is often calculated as the ratio of the fluorescence intensity in the "ON" state to that in the "OFF" state.[21]
Protocol for Toehold-Mediated Strand Displacement Reactions
Toehold-mediated strand displacement is a common mechanism for implementing DNA logic gates.
-
Design : DNA sequences are designed with specific domains: toeholds (short, single-stranded regions) and branch migration domains (longer, double-stranded regions).
-
Reaction Setup : The gate complex, typically a double-stranded DNA with an exposed toehold, is mixed with a reporter complex (e.g., a fluorophore-quencher pair).
-
Initiation : The input strand, which is complementary to the toehold and a portion of the gate's incumbent strand, is introduced to the solution.
-
Strand Displacement : The input strand binds to the toehold and initiates a branch migration process, displacing the pre-hybridized strand.
-
Output Generation : The displaced strand can then act as an input for a downstream gate or interact with a reporter to produce a signal.[22]
Signaling Pathways and Logical Relationships
The following diagrams, generated using Graphviz, illustrate the conceptual signaling pathways and logical relationships of the discussed DNA logic gates.
References
- 1. Advances in Applications of Molecular Logic Gates - PMC [pmc.ncbi.nlm.nih.gov]
- 2. chembites.org [chembites.org]
- 3. fiveable.me [fiveable.me]
- 4. Logic Gates Based on DNA Aptamers - PMC [pmc.ncbi.nlm.nih.gov]
- 5. chemrxiv.org [chemrxiv.org]
- 6. A Localized Scalable DNA Logic Circuit System Based on the DNA Origami Surface [mdpi.com]
- 7. researchgate.net [researchgate.net]
- 8. researchgate.net [researchgate.net]
- 9. [PDF] Logic Gates Based on DNA Aptamers | Semantic Scholar [semanticscholar.org]
- 10. researchgate.net [researchgate.net]
- 11. par.nsf.gov [par.nsf.gov]
- 12. researchgate.net [researchgate.net]
- 13. sciengpub.ir [sciengpub.ir]
- 14. Our progress in the design of a DNA computer - The Kolpashchikov Lab [sciences.ucf.edu]
- 15. biorxiv.org [biorxiv.org]
- 16. researchgate.net [researchgate.net]
- 17. Singleton {NOT} and Doubleton {YES; NOT} Gates Act as Functionally Complete Sets in DNA-Integrated Computational Circuits - PMC [pmc.ncbi.nlm.nih.gov]
- 18. kyutech.repo.nii.ac.jp [kyutech.repo.nii.ac.jp]
- 19. researchgate.net [researchgate.net]
- 20. Recent advances and opportunities in synthetic logic gates engineering in living cells - PMC [pmc.ncbi.nlm.nih.gov]
- 21. Signal-to-Noise Ratio Measures Efficacy of Biological Computing Devices and Circuits - PMC [pmc.ncbi.nlm.nih.gov]
- 22. dna.caltech.edu [dna.caltech.edu]
A Comparative Guide to Theoretical Models for DNA Hybridization
For Researchers, Scientists, and Drug Development Professionals
The accurate prediction of DNA hybridization is fundamental to a vast array of applications, from the design of PCR primers and molecular probes to the development of novel DNA-based therapeutics and nanostructures. Theoretical models that can reliably forecast the thermodynamics of DNA duplex formation are invaluable tools in this endeavor. This guide provides an objective comparison of two prominent theoretical models for DNA hybridization: the Nearest-Neighbor (NN) model and the Langmuir model. We will delve into their core principles, compare their predictive performance against experimental data, and provide detailed experimental protocols for their validation.
Core Theoretical Models: A Snapshot
The Nearest-Neighbor (NN) Model
The Nearest-Neighbor (NN) model is one of the most widely used methods for predicting the thermodynamic stability of DNA duplexes.[1] Its fundamental assumption is that the stability of a given base pair is influenced by the identity of its adjacent, or "nearest," base pairs.[1][2] The total free energy change (ΔG°), enthalpy (ΔH°), and entropy (ΔS°) of a DNA duplex formation are calculated by summing the thermodynamic parameters of its constituent dinucleotide steps, along with initiation factors.[1][3]
The Langmuir Model
The Langmuir model, originally developed to describe the adsorption of gas molecules onto a solid surface, has been adapted to model DNA hybridization on microarrays.[4][5] It treats the hybridization process as a reversible binding reaction between target DNA in solution and probe DNA immobilized on a surface. The model assumes that probes are identical, each can bind a single target, and there are no interactions between neighboring probes.[4]
Performance Comparison: Theoretical Predictions vs. Experimental Reality
The true measure of a theoretical model lies in its ability to accurately reflect experimental observations. The following table summarizes the performance of the Nearest-Neighbor and Langmuir models in predicting key hybridization parameters, based on data from various experimental studies.
| Performance Metric | Nearest-Neighbor (NN) Model | Langmuir Model | Supporting Experimental Data |
| Melting Temperature (Tm) Prediction Accuracy | High correlation with experimental Tm values (Pearson's r ≈ 0.98).[6][7] Average error can be as low as 1.31°C.[7] | Primarily used for isotherm analysis on surfaces, not direct Tm prediction in solution. | UV-Vis spectroscopy, High-Resolution Melting (HRM) analysis, and single-molecule unzipping experiments.[1][3][8] |
| Gibbs Free Energy (ΔG°) Prediction | Generally good agreement with experimental ΔG° values, though it can be less accurate for duplexes with mismatches.[9][10] | Provides dissociation constants (Kd), from which ΔG° can be derived for surface hybridization.[4] | Isothermal Titration Calorimetry (ITC) and microarray hybridization intensity analysis.[2][11] |
| Mismatch Discrimination | The model includes parameters for single mismatches, but accuracy can decrease with multiple or tandem mismatches.[2][9][12] | Can distinguish between perfect match and mismatch targets based on differences in hybridization intensity.[9] | Microarray experiments and differential scanning calorimetry (DSC).[9] |
| Influence of Salt Concentration | Salt correction factors are incorporated to account for the stabilizing effect of cations on the DNA backbone.[3] | The model's parameters (e.g., Kd) are dependent on the ionic strength of the hybridization buffer. | Single-molecule unzipping experiments and thermal denaturation studies at varying salt concentrations.[3][13] |
Experimental Protocols for Model Validation
Accurate cross-validation of theoretical models relies on robust experimental methodologies. Below are detailed protocols for key experiments used to generate the data for comparing DNA hybridization models.
UV-Vis Spectrophotometry for Thermal Denaturation (Melting Curve Analysis)
Objective: To determine the melting temperature (Tm) of a DNA duplex.
Methodology:
-
Sample Preparation: Prepare a solution of the DNA oligonucleotide in a buffer of known ionic strength and pH (e.g., 0.1 M NaCl, 10 mM Sodium Phosphate, pH 7.0). The DNA concentration is typically in the micromolar range.
-
Instrumentation: Use a UV-Vis spectrophotometer equipped with a temperature controller.
-
Data Acquisition: Monitor the absorbance of the DNA solution at 260 nm as the temperature is increased at a controlled rate (e.g., 1°C/minute).
-
Analysis: The absorbance will increase as the duplex denatures into single strands (hyperchromic effect). The Tm is determined as the temperature at which 50% of the DNA is denatured, which corresponds to the midpoint of the transition in the melting curve.[14]
Isothermal Titration Calorimetry (ITC)
Objective: To directly measure the thermodynamic parameters (ΔH°, ΔS°, and binding constant Kb) of DNA hybridization.
Methodology:
-
Sample Preparation: Prepare solutions of the single-stranded DNA and its complementary strand in a degassed buffer.
-
Instrumentation: Use an isothermal titration calorimeter.
-
Experiment: Load one DNA strand into the sample cell and the complementary strand into the injection syringe. A series of small injections of the titrant (from the syringe) into the sample cell are performed.
-
Data Acquisition: The instrument measures the heat released or absorbed during the binding reaction after each injection.
-
Analysis: The resulting data is a plot of heat change versus the molar ratio of the interacting molecules. This binding isotherm can be fitted to a suitable binding model to determine the binding constant (Kb), enthalpy change (ΔH°), and stoichiometry of the interaction. The Gibbs free energy (ΔG°) and entropy change (ΔS°) can then be calculated using the equation: ΔG° = -RTln(Kb) = ΔH° - TΔS°.[11]
DNA Microarray Hybridization
Objective: To measure the extent of hybridization of a target DNA sequence to a library of immobilized probes.
Methodology:
-
Probe Immobilization: DNA probes of known sequences are synthesized and spotted or synthesized in situ onto a solid support (e.g., a glass slide).
-
Target Labeling: The target DNA or RNA sample is labeled with a fluorescent dye.
-
Hybridization: The labeled target solution is incubated with the microarray slide under specific conditions of temperature, buffer composition, and time to allow for hybridization to occur.
-
Washing: The slide is washed to remove non-specifically bound target molecules.
-
Scanning: The microarray is scanned using a laser to excite the fluorescent labels, and the intensity of the fluorescence at each probe spot is measured.
-
Analysis: The fluorescence intensity is proportional to the amount of target hybridized to each probe. This data can be fitted to models like the Langmuir isotherm to determine binding affinities.[2][4]
Visualizing the Cross-Validation Workflow and Model Relationships
To better understand the process of model validation and the conceptual relationship between the discussed models, the following diagrams are provided.
Caption: Workflow for the cross-validation of a theoretical DNA hybridization model.
Caption: Conceptual relationship between DNA hybridization models.
References
- 1. Validation of the nearest-neighbor model for Watson–Crick self-complementary DNA duplexes in molecular crowding condition - PMC [pmc.ncbi.nlm.nih.gov]
- 2. academic.oup.com [academic.oup.com]
- 3. Derivation of nearest-neighbor DNA parameters in magnesium from single molecule experiments - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. researchgate.net [researchgate.net]
- 6. researchgate.net [researchgate.net]
- 7. A Phenomenological Model for Predicting Melting Temperatures of DNA Sequences - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Establishment of a simple prediction method for DNA melting temperature: high-resolution melting curve analysis of PCR products - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. helsinki.fi [helsinki.fi]
- 11. academic.oup.com [academic.oup.com]
- 12. biorxiv.org [biorxiv.org]
- 13. pubs.acs.org [pubs.acs.org]
- 14. Analysis of a DNA simulation model through hairpin melting experiments - PMC [pmc.ncbi.nlm.nih.gov]
Stability of DNA Origami Nanostructures: A Comparative Guide for Researchers
The remarkable programmability of DNA origami has positioned it as a key enabling technology in fields ranging from targeted drug delivery to nanoelectronics. However, the successful application of these intricate nanostructures is fundamentally dependent on their stability in diverse and often harsh environments. This guide provides a comprehensive comparison of DNA origami stability under various conditions, supported by experimental data, to aid researchers, scientists, and drug development professionals in optimizing their experimental designs and applications.
Temperature Stability
The thermal stability of DNA origami is a critical parameter, particularly for applications in biology and materials science that may involve temperature fluctuations. In solution, the structural integrity of DNA origami is typically limited by the melting temperature (dehybridization) of its constituent double-stranded DNA, which generally falls within the range of 40–100 °C.[1] However, when deposited on a solid substrate, the stability profile changes dramatically.
Several studies have demonstrated that DNA origami structures adsorbed on surfaces like mica or SiO2 can withstand significantly higher temperatures.[1][2] For instance, DNA origami has been shown to remain intact after being heated to 150 °C for at least 45 minutes and even up to 200 °C for 10 minutes.[1][2] Decomposition is typically observed at temperatures around 250 °C.[1][2] This enhanced stability on surfaces is attributed to the immobilization of the DNA strands, which restricts their movement and prevents dehybridization.[1]
| Condition | DNA Origami Structure | Substrate | Temperature (°C) | Incubation Time | Outcome | Reference |
| In Solution | Generic | - | 40-100 | - | Melting/Dehybridization | [1] |
| On Surface | Triangular Origami | Mica | 150 | 45 min | Intact | [2] |
| On Surface | Triangular Origami | SiO2 | 200 | 10 min | Intact | [1] |
| On Surface | Triangular Origami | Mica | 250 | - | Decomposition | [2] |
| In Solution | 3D Cross-linked | - | 90 | - | Intact | [2] |
| In Solution with 6M Urea (B33335) | Triangular Origami | - | 37-42 | - | Heavily Damaged | [3] |
| In Solution with 6M GdmCl | Triangular Origami | - | 23 | - | Stable | [3] |
pH Stability
The pH of the surrounding environment can significantly impact the stability of DNA origami by altering the charge of the DNA backbone and affecting the hydrogen bonds between base pairs. Generally, DNA origami structures exhibit good stability within a pH range of 5.5 to 9.5.[4] One study found that triangular DNA origami structures remained stable in a pH range of 7 to 11.[1] More extensive testing has shown that both triangular and rectangular origami structures can maintain their integrity for at least 12 hours in a pH range of 5 to 10.[5]
However, extreme pH conditions can lead to degradation. At pH values below 5, depurination of the DNA can occur, while pH values above 10 can disrupt the hydrogen bonds holding the double helices together.[4] For example, at pH 4, triangular origami structures have been observed to be broken, and at pH 2, they disintegrate into distinct pieces.[1][5] Similarly, at pH 11, slight compression and deformation can be observed, and at higher pH values, the structures are completely destroyed.[5]
| pH | DNA Origami Structure | Incubation Time | Outcome | Reference |
| 2 | Triangular Origami | - | Disintegrated into 6 pieces | [1] |
| 4 | Triangular Origami | 2 hours | Broken structures | [5] |
| 5-10 | Triangular & Rectangular Origami | 12 hours | Stable | [5] |
| 11 | Triangular Origami | - | Slight compression/deformation | [1][5] |
| >11 | Triangular Origami | - | Completely destroyed | [5] |
Cation Concentration
Cations, particularly divalent cations like magnesium (Mg²⁺), play a crucial role in stabilizing DNA origami structures by screening the electrostatic repulsion between the negatively charged phosphate (B84403) backbones of adjacent DNA helices.[6][7] Most DNA origami folding protocols utilize buffers supplemented with millimolar concentrations of Mg²⁺.[2]
Low cation concentrations can lead to the denaturation or "melting" of DNA origami.[8] However, this process can be reversible if the exposure to low cation concentrations is brief (e.g., less than 10 minutes).[8] Interestingly, the stability in low-magnesium buffers is highly dependent on the specific DNA origami design, with some structures like 6-helix bundles showing more resilience than 24-helix bundles.[2] While monovalent cations like Na⁺ can also stabilize DNA origami, they are much less efficient and require significantly higher concentrations compared to Mg²⁺.[9] In the presence of denaturing agents like urea, Mg²⁺ ions are about ten times more effective at stabilizing DNA origami than Na⁺ ions.[9]
| Cation Condition | DNA Origami Structure | Outcome | Reference |
| Low Cation Concentration (<10 min) | Triangular & Rectangular Origami | Reversible melting | [8] |
| Low Cation Concentration (>10 min) | Triangular & Rectangular Origami | Irreversible melting | [8] |
| Low-μM Mg²⁺ | Various | Integrity maintained post-assembly | [2] |
| High Na⁺/K⁺ | Various | Can counterbalance absence of Mg²⁺ | [9] |
Nuclease Stability
For in vivo applications such as drug delivery, the stability of DNA origami in the presence of nucleases is of paramount importance. Nucleases are enzymes that degrade nucleic acids, and DNA origami structures are susceptible to their activity, particularly from endonucleases like DNase I.[10][11]
Unprotected DNA origami can have varying half-lives in biological fluids. For instance, wireframe DNA origami was found to be stable for over 24 hours in fetal bovine serum and human serum but degraded within 3 hours in mouse serum, indicating species-specific nuclease activity.[10][12] Several strategies have been developed to enhance nuclease resistance, including coating the origami with minor groove binders (MGBs), PEGylation, or chemical cross-linking.[10][12] Incubation with diamidine-class MGBs has been shown to increase the half-life of DNA origami in mouse serum by more than 12 hours.[10][12]
| Environment | DNA Origami Structure | Protection Strategy | Half-life / Stability | Reference |
| Fetal Bovine Serum (10%) | Wireframe Origami | None | > 24 hours | [10][12] |
| Human Serum | Wireframe Origami | None | 24 hours | [10][12] |
| Mouse Serum | Wireframe Origami | None | < 3 hours | [10][12] |
| Mouse Serum | Wireframe Origami | Minor Groove Binders | > 12 hours | [10][12] |
| Cell Lysate | Various Origami | None | Stable for at least 12 hours | [13] |
| Lysosomes (in breast cancer cells) | Nanotubes | None | Intact up to 24 hours, degraded by 60 hours | [2] |
Stability in Organic Solvents and Denaturants
The stability of DNA origami in organic solvents and in the presence of chaotropic agents is relevant for nanofabrication processes and biophysical studies. DNA origami structures have been shown to maintain their shape after being immersed in a variety of organic solvents, including hexane, ethanol, and toluene, for up to 24 hours.[1] A systematic study on polar, water-miscible solvents found that DNA origami stability is superstructure-dependent and solvent-dependent, with the highest stability observed in acetone (B3395972).[6] Stability can be maintained in up to 25–40% DMF or DMSO and up to 70–90% acetone or ethanol.[14]
In the presence of strong denaturants like urea and guanidinium (B1211019) chloride (GdmCl), DNA origami can remain stable at room temperature in concentrations as high as 6 M for at least 24 hours.[15] However, at elevated temperatures, their stability is compromised.[15] Interestingly, increasing cation concentrations can stabilize DNA origami against urea denaturation but promotes denaturation by GdmCl.[9]
| Environment | DNA Origami Structure | Concentration | Temperature | Outcome | Reference |
| Hexane, Ethanol, Toluene | Triangular Origami | - | Room Temp | Stable for 24 hours | [1] |
| Acetone | Various | 70-90% | Room Temp | Stable | [14] |
| Ethanol | Various | 70-90% | Room Temp | Stable | [14] |
| DMF | Various | 25-40% | Room Temp | Stable | [14] |
| DMSO | Various | 25-40% | Room Temp | Stable | [14] |
| 6 M Urea | Triangular Origami | 6 M | Room Temp | Stable for 24 hours | [15] |
| 6 M GdmCl | Triangular Origami | 6 M | Room Temp | Stable for 24 hours | [15] |
| 6 M Urea | Triangular Origami | 6 M | 37-42 °C | Heavily Damaged | [3] |
Experimental Protocols
Atomic Force Microscopy (AFM) for Structural Integrity Assessment
A common method to assess the structural integrity of DNA origami is Atomic Force Microscopy (AFM).
-
Sample Preparation: A 5 µL aliquot of the DNA origami sample (typically 5 nM) is mixed with a buffer solution (e.g., 1x TAE/Mg²⁺).
-
Surface Adsorption: The mixture is deposited onto a freshly cleaved mica surface and incubated for approximately 15 minutes to allow the origami structures to adsorb.[3]
-
Washing: The surface is gently washed with deionized water to remove unbound structures and buffer salts.
-
Drying: The mica substrate is dried under a gentle stream of air or nitrogen.
-
Imaging: The sample is then imaged using an AFM in tapping mode. The resulting images provide information on the shape, size, and integrity of the DNA origami structures.
Agarose (B213101) Gel Electrophoresis (AGE) for Stability Analysis
Agarose Gel Electrophoresis (AGE) is another widely used technique to assess the stability and integrity of DNA origami structures.
-
Sample Incubation: DNA origami samples are incubated under the desired experimental conditions (e.g., different temperatures, pH values, or in the presence of nucleases).
-
Gel Preparation: An agarose gel (typically 0.5-2%) is prepared in a running buffer (e.g., 1x TAE) containing an intercalating dye like ethidium (B1194527) bromide or SYBR Safe.
-
Loading: The incubated DNA origami samples, mixed with a loading dye, are loaded into the wells of the agarose gel. A DNA ladder is also loaded for size reference.
-
Electrophoresis: The gel is run in an electrophoresis chamber filled with the running buffer at a constant voltage until the dye front has migrated a sufficient distance.
-
Visualization: The gel is visualized under UV light. Intact DNA origami structures will migrate as a distinct band, while degraded or denatured structures will result in smears or bands with altered mobility.
References
- 1. pubs.acs.org [pubs.acs.org]
- 2. Structural stability of DNA origami nanostructures under application-specific conditions - PMC [pmc.ncbi.nlm.nih.gov]
- 3. scispace.com [scispace.com]
- 4. pubs.acs.org [pubs.acs.org]
- 5. researchgate.net [researchgate.net]
- 6. Structural stability of DNA origami nanostructures in organic solvents - PMC [pmc.ncbi.nlm.nih.gov]
- 7. pubs.acs.org [pubs.acs.org]
- 8. Stability and recovery of DNA origami structure with cation concentration - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. Controlling Nuclease Degradation of Wireframe DNA Origami with Minor Groove Binders - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. pubs.acs.org [pubs.acs.org]
- 12. Controlling Nuclease Degradation of Wireframe DNA Origami with Minor Groove Binders [dspace.mit.edu]
- 13. Stability of DNA Origami Nanoarrays in Cell Lysate - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Structural stability of DNA origami nanostructures in organic solvents - Nanoscale (RSC Publishing) DOI:10.1039/D4NR02185A [pubs.rsc.org]
- 15. Structural stability of DNA origami nanostructures in the presence of chaotropic agents - Nanoscale (RSC Publishing) DOI:10.1039/C6NR00835F [pubs.rsc.org]
A Researcher's Guide to Force Field Validation for DNA Molecular Dynamics
For Researchers, Scientists, and Drug Development Professionals
The accurate computational modeling of DNA is paramount for understanding its biological functions and for the rational design of therapeutics. Molecular dynamics (MD) simulations have emerged as a powerful tool to probe the structure, dynamics, and interactions of DNA at an atomic level. The reliability of these simulations, however, is critically dependent on the underlying force field—a set of parameters that define the potential energy of the system. This guide provides an objective comparison of commonly used force fields for DNA MD simulations, supported by experimental data, to aid researchers in selecting the most appropriate model for their studies.
Comparing the Titans: AMBER vs. CHARMM and the Rise of Polarizable Models
The AMBER and CHARMM force fields have historically been the workhorses for biomolecular simulations. Both have undergone continuous refinement, leading to numerous versions with improved accuracy for DNA. More recently, polarizable force fields have been developed to offer a more physically realistic treatment of electrostatic interactions.
Key Findings from Benchmark Studies:
-
AMBER Force Fields: The AMBER suite of force fields, particularly the more recent versions like parmbsc1 and the OL15/OL21 modifications, have shown significant improvements over their predecessors (e.g., parmbsc0).[1][2][3][4] These newer force fields generally provide a better description of B-DNA helical parameters and sugar pucker populations, bringing simulation results into closer agreement with experimental NMR and X-ray data.[5][6]
-
CHARMM Force Fields: The CHARMM force fields, such as CHARMM27 and CHARMM36 , are also widely used for DNA simulations.[7][8] While they perform well for many aspects of DNA structure, some studies have reported instabilities in long-timescale simulations of B-DNA with CHARMM36, leading to deviations from the canonical structure.[7]
-
Polarizable Force Fields: Force fields like Drude and AMOEBA explicitly account for electronic polarizability, offering a more sophisticated representation of electrostatic interactions.[9][10][11] These models have shown promise in improving the accuracy of simulations, particularly in systems where electrostatic effects are dominant, such as those involving ion-DNA interactions.[9][10] However, they are computationally more expensive than their non-polarizable counterparts.
Quantitative Performance of DNA Force Fields
The following tables summarize the performance of various force fields in reproducing key experimental observables for DNA.
Table 1: Helical Parameter Deviations from Experimental Data
| Force Field | Average RMSD (Å) from Experimental Structure | Key Observations |
| AMBER parmbsc0 | ~1.5 - 2.0 | An older standard, shows some deviations in helical twist and sugar pucker over long simulations.[7] |
| AMBER parmbsc1 | ~1.0 - 1.5 | Improved over parmbsc0, with better representation of backbone parameters.[1][4] |
| AMBER OL15/OL21 | < 1.0 | Considered among the most accurate non-polarizable force fields for B-DNA, showing excellent agreement with NMR data.[1][2][5] |
| CHARMM27 | ~1.5 - 2.0 | Generally stable and provides a good description of B-DNA.[7][8] |
| CHARMM36 | Variable | Can show larger deviations and instabilities in multi-microsecond simulations of B-DNA.[7] |
| Drude (Polarizable) | ~1.0 | Shows improved agreement with experimental base stacking and conformational energetics.[10] |
Table 2: Sugar Pucker Population (% C2'-endo)
| Force Field | Simulated % C2'-endo | Experimental % C2'-endo (NMR) |
| AMBER parmbsc0 | Often overestimates C2'-endo | Sequence-dependent |
| AMBER parmbsc1 | Improved balance of C2'-endo/C3'-endo | Sequence-dependent |
| AMBER OL24 | Good agreement with NMR data for A/B equilibrium.[5] | Sequence-dependent |
| CHARMM27 | Generally reasonable pucker populations | Sequence-dependent |
| CHARMM36 | Can show deviations in sugar pucker dynamics | Sequence-dependent |
Experimental Protocols for Force Field Validation
Accurate experimental data is the bedrock of force field validation. The following are key experimental techniques and their protocols for generating benchmark data for DNA simulations.
Nuclear Magnetic Resonance (NMR) Spectroscopy
NMR spectroscopy provides a wealth of information on the structure and dynamics of DNA in solution.[12]
Experimental Protocol for 3J-Coupling Constant Measurement:
-
Sample Preparation: Dissolve the synthesized and purified DNA oligonucleotide in a suitable buffer (e.g., 10 mM sodium phosphate, 100 mM NaCl, 0.1 mM EDTA, pH 7.0) in D₂O.
-
NMR Data Acquisition: Acquire a high-resolution 2D DQF-COSY or E.COSY spectrum on a high-field NMR spectrometer (e.g., 600 MHz or higher).
-
Data Processing: Process the acquired data using appropriate software (e.g., TopSpin, NMRPipe).
-
J-Coupling Extraction: Measure the scalar coupling constants (e.g., ³J(H1'-H2'), ³J(H2''-H3')) from the cross-peak fine structure in the processed spectra. These couplings are sensitive to the sugar pucker conformation.[13][14][15][16]
X-Ray Crystallography
X-ray crystallography provides high-resolution static snapshots of DNA structure.[17][18][19]
Experimental Protocol for DNA Crystal Structure Determination:
-
Crystallization: Crystallize the DNA oligonucleotide using techniques like vapor diffusion. This involves screening a wide range of precipitants, buffers, and salt concentrations to find conditions that yield diffraction-quality crystals.
-
X-ray Diffraction Data Collection: Mount a single crystal and expose it to a monochromatic X-ray beam.[20][21] The diffracted X-rays are recorded on a detector.[20][21]
-
Data Processing: Integrate the diffraction spot intensities and scale the data.
-
Structure Solution and Refinement: Determine the initial phases of the structure factors (e.g., by molecular replacement) and build an initial model of the DNA. Refine the atomic coordinates and thermal parameters against the experimental diffraction data to obtain the final high-resolution structure.
UV-Vis Spectroscopy for DNA Melting Temperature (Tm) Measurement
The melting temperature (Tm) is a key thermodynamic parameter that reflects the stability of the DNA duplex.
Experimental Protocol for Tm Measurement:
-
Sample Preparation: Prepare a solution of the DNA duplex in a buffered solution (e.g., 10 mM sodium phosphate, 1 M NaCl, pH 7.0).[22][23]
-
UV-Vis Measurement: Place the DNA solution in a quartz cuvette in a UV-Vis spectrophotometer equipped with a temperature controller.
-
Thermal Denaturation: Monitor the absorbance at 260 nm as the temperature is slowly increased (e.g., 1°C/minute) from a low temperature (e.g., 20°C) to a high temperature (e.g., 95°C).[24][25]
-
Data Analysis: Plot the absorbance as a function of temperature. The Tm is the temperature at which the absorbance is halfway between the initial (double-stranded) and final (single-stranded) values.[26]
Single-Molecule Förster Resonance Energy Transfer (smFRET)
smFRET is a powerful technique to probe the conformational dynamics of individual DNA molecules.[1][2][27][28][29]
Experimental Protocol for smFRET:
-
DNA Labeling: Synthesize DNA strands with a donor and an acceptor fluorophore attached at specific locations.
-
Surface Immobilization: Immobilize the labeled DNA on a passivated microscope slide.
-
TIRF Microscopy: Use Total Internal Reflection Fluorescence (TIRF) microscopy to excite the donor fluorophore and detect the emission from both the donor and acceptor fluorophores of individual molecules.
-
Data Analysis: Calculate the FRET efficiency for each molecule over time. Changes in FRET efficiency reflect changes in the distance between the donor and acceptor, providing insights into DNA conformational dynamics.[1]
Visualizing the Validation Workflow and Force Field Landscape
The following diagrams illustrate the general workflow for validating a DNA force field and the relationship between different force field families.
Caption: Workflow for DNA force field validation.
Caption: Major families of DNA force fields.
Conclusion
The choice of force field is a critical decision in planning MD simulations of DNA. While newer versions of the AMBER force field, such as OL15 and OL21, currently show excellent agreement with a wide range of experimental data for canonical B-DNA, the best choice of force field will always be system-dependent. For studies involving significant electrostatic perturbations, such as high salt concentrations or interactions with highly charged proteins, polarizable force fields may offer a more accurate description. Researchers are encouraged to consult recent benchmark studies and carefully consider the specific biological question being addressed when selecting a force field. As computational power continues to increase and force fields are further refined, MD simulations will undoubtedly provide even deeper insights into the complex world of DNA.
References
- 1. Single-Molecule FRET to Measure Conformational Dynamics of DNA Mismatch Repair Proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 2. edepot.wur.nl [edepot.wur.nl]
- 3. researchgate.net [researchgate.net]
- 4. pubs.acs.org [pubs.acs.org]
- 5. Refinement of the Sugar Puckering Torsion Potential in the AMBER DNA Force Field - PMC [pmc.ncbi.nlm.nih.gov]
- 6. How accurate are accurate force-fields for B-DNA? - PMC [pmc.ncbi.nlm.nih.gov]
- 7. pubs.acs.org [pubs.acs.org]
- 8. DNA Polymorphism: A Comparison of Force Fields for Nucleic Acids - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Polarizable force fields for biomolecular simulations: Recent advances and applications - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Polarizable Force Field for DNA Based on the Classical Drude Oscillator: I. Refinement using Quantum Mechanical Base Stacking and Conformational Energetics - PMC [pmc.ncbi.nlm.nih.gov]
- 11. pubs.acs.org [pubs.acs.org]
- 12. pubs.acs.org [pubs.acs.org]
- 13. pubs.acs.org [pubs.acs.org]
- 14. Collection - Direct Comparison of Experimental and Calculated NMR Scalar Coupling Constants for Force Field Validation and Adaptation - Journal of Chemical Theory and Computation - Figshare [figshare.com]
- 15. Using J-coupling constants for force field validation: application to hepta-alanine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. pubs.acs.org [pubs.acs.org]
- 17. X-ray crystallography and the elucidation of the structure of DNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. researchgate.net [researchgate.net]
- 19. Protein Structure Validation and Analysis with X-Ray Crystallography | Springer Nature Experiments [experiments.springernature.com]
- 20. X-ray diffraction “fingerprinting” of DNA structure in solution for quantitative evaluation of molecular dynamics simulation - PMC [pmc.ncbi.nlm.nih.gov]
- 21. Structural Biochemistry/Nucleic Acid/DNA/Franklin's DNA X-ray Crystallography - Wikibooks, open books for an open world [en.wikibooks.org]
- 22. chem.sites.mtu.edu [chem.sites.mtu.edu]
- 23. rsc.org [rsc.org]
- 24. emeraldcloudlab.com [emeraldcloudlab.com]
- 25. agilent.com [agilent.com]
- 26. pendidikankimia.walisongo.ac.id [pendidikankimia.walisongo.ac.id]
- 27. Single Molecule FRET Analysis of DNA Binding Proteins | Springer Nature Experiments [experiments.springernature.com]
- 28. courses.physics.illinois.edu [courses.physics.illinois.edu]
- 29. Scholarly Article or Book Chapter | Single-Molecule FRET to Measure Conformational Dynamics of DNA Mismatch Repair Proteins | ID: d504rr08v | Carolina Digital Repository [cdr.lib.unc.edu]
Safety Operating Guide
Safeguarding Your Research: Proper Disposal Procedures for DNA31
The integrity of your research and the safety of your laboratory environment hinge on the meticulous management of all materials, including the proper disposal of DNA-based reagents, referred to here as DNA31. Adherence to established disposal protocols is not merely a regulatory requirement but a cornerstone of responsible scientific practice, minimizing the risk of environmental contamination and ensuring a secure research setting. This guide provides essential, step-by-step information for researchers, scientists, and drug development professionals on the proper disposal of this compound waste.
While DNA itself is a naturally occurring biological molecule and not inherently hazardous from a chemical standpoint, the waste generated during molecular biology workflows is often a complex mixture.[1] This waste can contain buffers, reagents, and other potentially hazardous chemicals, which dictate the specific disposal procedures required.[1] Therefore, the entire waste stream must be considered when determining the appropriate disposal method.
Personal Protective Equipment (PPE)
Before initiating any waste disposal procedures, it is imperative to be outfitted with the appropriate Personal Protective Equipment (PPE). This is a critical step for personal safety and to prevent the cross-contamination of samples and the laboratory environment.[1]
| PPE Item | Specification | Purpose |
| Gloves | Nitrile or latex | To protect hands from chemical and biological contamination.[1] |
| Lab Coat | Standard laboratory coat | To protect skin and clothing from spills.[1] |
| Safety Glasses | ANSI Z87.1 approved | To protect eyes from splashes and aerosols.[1] |
This compound Waste Segregation and Disposal Workflow
The systematic segregation and decontamination of DNA-containing waste are fundamental to a safe disposal process. The following workflow provides a decision-making framework for handling different forms of this compound waste.
Detailed Experimental Protocols for Waste Disposal
The following protocols provide step-by-step guidance for the disposal of common types of this compound waste.
Protocol 1: Decontamination of Liquid this compound Waste (Non-Hazardous)
This protocol is suitable for aqueous solutions containing DNA, such as buffers and supernatants from centrifugation, that do not contain hazardous chemicals.
Methodology:
-
Assessment : Confirm that the liquid waste does not contain any hazardous chemicals (e.g., phenol, chloroform).
-
Chemical Disinfection : Add fresh bleach to the liquid waste to achieve a final concentration of 10%.[2]
-
Contact Time : Gently mix the solution and allow it to sit for a minimum of 30 minutes to ensure complete decontamination.[2]
-
Disposal : After the contact time, the decontaminated liquid can be poured down the sink with a copious amount of water.[2]
Protocol 2: Decontamination of Solid this compound Waste (Non-Hazardous)
This protocol applies to solid laboratory waste contaminated with non-hazardous DNA, such as pipette tips, microfuge tubes, and gloves.
Methodology:
-
Collection : Discard contaminated solid waste directly into a waste container lined with a red or orange biohazard bag.[2]
-
Storage : Keep the biohazard container lid closed when not in use.
-
Decontamination : When the bag is approximately three-quarters full, loosely tie or tape it closed.[3] The bag should then be placed in a secondary, leak-proof, and puncture-resistant container for transport to an autoclave.
-
Autoclaving : Decontaminate the waste by autoclaving at 121°C for a minimum of 30 minutes.[1] The specific cycle parameters may need to be validated for your institution's autoclave.
-
Final Disposal : Once the autoclave cycle is complete and the waste has cooled, the biohazard bag can be placed in the regular municipal trash.
Protocol 3: Disposal of this compound Waste Containing Hazardous Chemicals
For this compound waste mixed with hazardous chemicals, such as ethidium (B1194527) bromide-stained gels or solutions containing phenol-chloroform, the disposal protocol is dictated by the chemical hazard.
Methodology:
-
Segregation : This waste must be segregated from the general and biohazardous waste streams.
-
Labeling : The waste container must be clearly labeled as hazardous chemical waste, listing all chemical constituents.
-
Disposal : The disposal of this waste must be handled by the institution's Environmental Health and Safety (EH&S) department or a licensed hazardous waste disposal company.[2] Do not attempt to decontaminate this waste with bleach, as it can react with certain chemicals to produce hazardous gases.
Protocol 4: Disposal of Sharps Contaminated with this compound
Sharps, including needles, scalpels, and Pasteur pipettes, require special handling to prevent injuries.
Methodology:
-
Collection : Immediately after use, dispose of all sharps into a designated, puncture-resistant, and leak-proof sharps container.[3]
-
Container Management : Do not overfill sharps containers. When the container is three-quarters full, it should be sealed.
-
Disposal : The sealed sharps container should be disposed of as regulated medical waste, which is typically collected by a specialized waste management service for incineration.[2]
It is crucial to consult your institution's specific safety guidelines and disposal protocols, as they may have additional requirements based on local regulations. By following these procedures, you contribute to a safer research environment for yourself and your colleagues.
References
Essential Safety Protocols for Handling DNA in a Laboratory Setting
A Note on "DNA31": The designation "this compound" does not correspond to a recognized chemical or biological substance in standard laboratory safety databases. It may refer to an internal nomenclature or the 31st International Conference on DNA Computing and Molecular Programming.[1][2] The following guidance pertains to the general handling of deoxyribonucleic acid (DNA) in a research and drug development context.
For researchers, scientists, and drug development professionals, ensuring the integrity of DNA samples and maintaining a safe laboratory environment are paramount.[3] This guide provides essential safety and logistical information for handling DNA, including personal protective equipment (PPE), operational workflows, and disposal plans. Adherence to these protocols is critical to prevent sample contamination and protect personnel from potential exposure to hazardous materials used in nucleic acid research.[3][4]
Personal Protective Equipment (PPE)
The primary objectives of using PPE when handling DNA are to protect the sample from contamination by the handler and to shield the handler from chemical and biological hazards.[3] The requisite level of PPE varies with the specific procedures being performed.[3]
Table 1: Personal Protective Equipment Levels for DNA Handling
| PPE Level | Equipment | Purpose |
| Level 1: Basic Handling | Disposable gloves, Lab coat, Safety glasses.[3] | Prevents direct contact with skin and eyes and protects clothing. Essential for preventing sample contamination.[3] |
| Level 2: Amplification/Sensitive Procedures | Disposable gloves (changed frequently), Lab coat, Face mask, Hair cap, Safety goggles.[3] | Minimizes the risk of introducing contaminants (e.g., from breath or hair) into sensitive reactions like PCR.[3] |
| Level 3: Handling Hazardous Materials | Chemical-resistant gloves, Chemical-resistant apron or gown, Safety goggles or face shield.[3] | Required when working with hazardous chemicals used in DNA extraction and analysis (e.g., phenol, chloroform).[3] |
Operational Plan: Aseptic DNA Handling and PCR Workflow
To prevent contamination, it is crucial to maintain a unidirectional workflow, moving from pre-PCR to post-PCR areas.[5] Each area should have its own dedicated set of equipment, reagents, and PPE.[5]
Experimental Protocol: Polymerase Chain Reaction (PCR)
Polymerase Chain Reaction (PCR) is a technique used to amplify a segment of DNA. The following is a generalized protocol:
-
Master Mix Preparation (in Pre-PCR area):
-
In a sterile, DNA-free environment (e.g., a laminar flow hood), prepare a master mix containing DNA polymerase, dNTPs, primers, and reaction buffer.
-
Aliquot the master mix into individual PCR tubes.
-
-
Template Addition (in Pre-PCR area):
-
Add the DNA template to the respective PCR tubes containing the master mix.
-
Include positive and negative controls to ensure the reaction is working correctly and to test for contamination.
-
-
Amplification (in Post-PCR area):
-
Place the reaction tubes in a thermal cycler.
-
The thermal cycler will cycle through the following temperatures:
-
-
Analysis:
-
The amplified DNA can be visualized using gel electrophoresis.
-
Below is a diagram illustrating the unidirectional workflow for PCR to minimize contamination.
Caption: Unidirectional workflow for PCR to prevent contamination.
Disposal Plan
Proper disposal of materials used in DNA handling is essential to prevent the release of hazardous chemicals and biological materials into the environment.
Table 2: Disposal Guidelines for DNA Handling Waste
| Waste Type | Disposal Method |
| Non-Hazardous Waste | Paper towels, packaging, and other non-contaminated items can be disposed of in the regular trash.[3] |
| Biohazardous Waste | Items contaminated with biological materials (e.g., cell cultures, tissues) should be placed in designated biohazard bags and autoclaved before disposal. |
| Chemical Waste | Solutions containing hazardous chemicals (e.g., phenol, chloroform, ethidium (B1194527) bromide) must be collected in labeled, leak-proof containers for disposal by the institution's environmental health and safety office. |
| Sharps Waste | Needles, scalpels, and other sharp objects must be disposed of in a designated sharps container. |
Spill Response
In the event of a spill of nucleic acids, the following steps should be taken:
-
Alert personnel in the immediate area.
-
Don appropriate PPE , including a lab coat, safety glasses, and disposable gloves.[6]
-
Contain the spill by covering it with absorbent material.[6]
-
Disinfect the area. For spills of nucleic acids, a 10% v/v sodium hypochlorite (B82951) solution is often recommended. Pour the disinfectant over the absorbent material and let it sit for at least 30 minutes.[6]
-
Clean up the absorbent material and dispose of it as hazardous waste.
-
Wipe down the area with soap and water.
References
- 1. 31st International Conference on DNA Computing and Molecular Programming - Sciencesconf.org [this compound.sciencesconf.org]
- 2. isnsce.org [isnsce.org]
- 3. benchchem.com [benchchem.com]
- 4. juniperpublishers.com [juniperpublishers.com]
- 5. Global Malaria Programme [who.int]
- 6. culturecollections.org.uk [culturecollections.org.uk]
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
